
Submitted:
02 December 2024
Posted:
04 December 2024
You are already at the latest version
Abstract
(1) Background: Artificial Intelligence (AI) can enhance patient education, but pre-trained models like ChatGPT provide inaccuracies. This study assessed a potential solution, Retrieval-Augmented Generation (RAG), for answering postoperative rhinoplasty inquiries; (2) Methods: Gemi-ni-1.0-Pro-002, Gemini-1.5-Flash-001, Gemini-1.5-Pro-001, and PaLM 2 were developed and posed 30 questions, using RAG to retrieve from plastic surgery textbooks. Responses were evaluated for accuracy (1-5 scale), comprehensiveness (1-3 scale), readability (FRE, FKGL), and understandabil-ity/actionability (PEMAT). Analysis included Wilcoxon rank sum, Armitage trend tests, and pair-wise comparisons; (3) Results: AI models performed well on straightforward questions but struggled with complexities (connecting "getting the face wet" with showering), leading to a 30.8% nonre-sponse rate. 41.7% of responses were completely accurate. Gemini-1.0-Pro-002 was more com-prehensive (p < 0.001) while PaLM 2 was less actionable (p < 0.007). Readability was poor (mean FRE: 40-49). Understandability averaged 0.7. No significant differences were found in accuracy, readability, or understandability among models; (4) Conclusions: RAG-based AI models show promise but are not yet suitable as standalone tools due to nonresponses and limitations in reada-bility and handling nuanced questions. Future efforts should focus on improvements in contextual understanding. With optimization, RAG-based AI could reduce surgeons' workload and enhance patient satisfaction, but it is currently unsafe for independent clinical use.
Keywords:
1. Introduction
1.1 Background
1.2 Research Aims
2. Materials and Methods
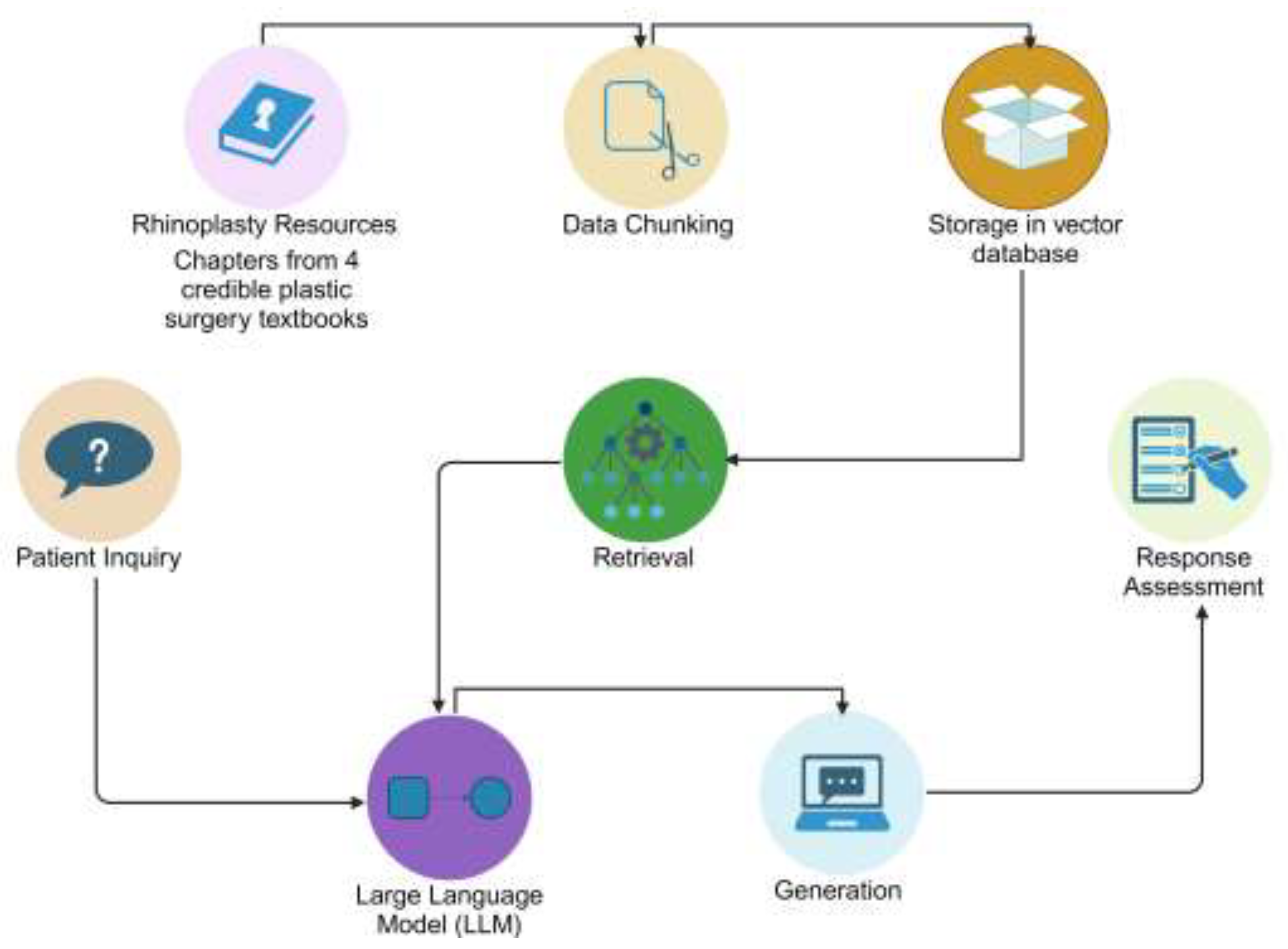
2.1 Development of Questions and Knowledge Base
2.2 Data Chunking for Retrieval
2.3 Embedding Generating and Indexing
2.4 Query Processing and Retrieval
2.5 Response Generation
2.6 Accuracy and Comprehensiveness Evaluation
2.7 Readability Assessment
2.8 Understandability and Actionability Evaluation
2.9 Statistical Analysis
3. Results
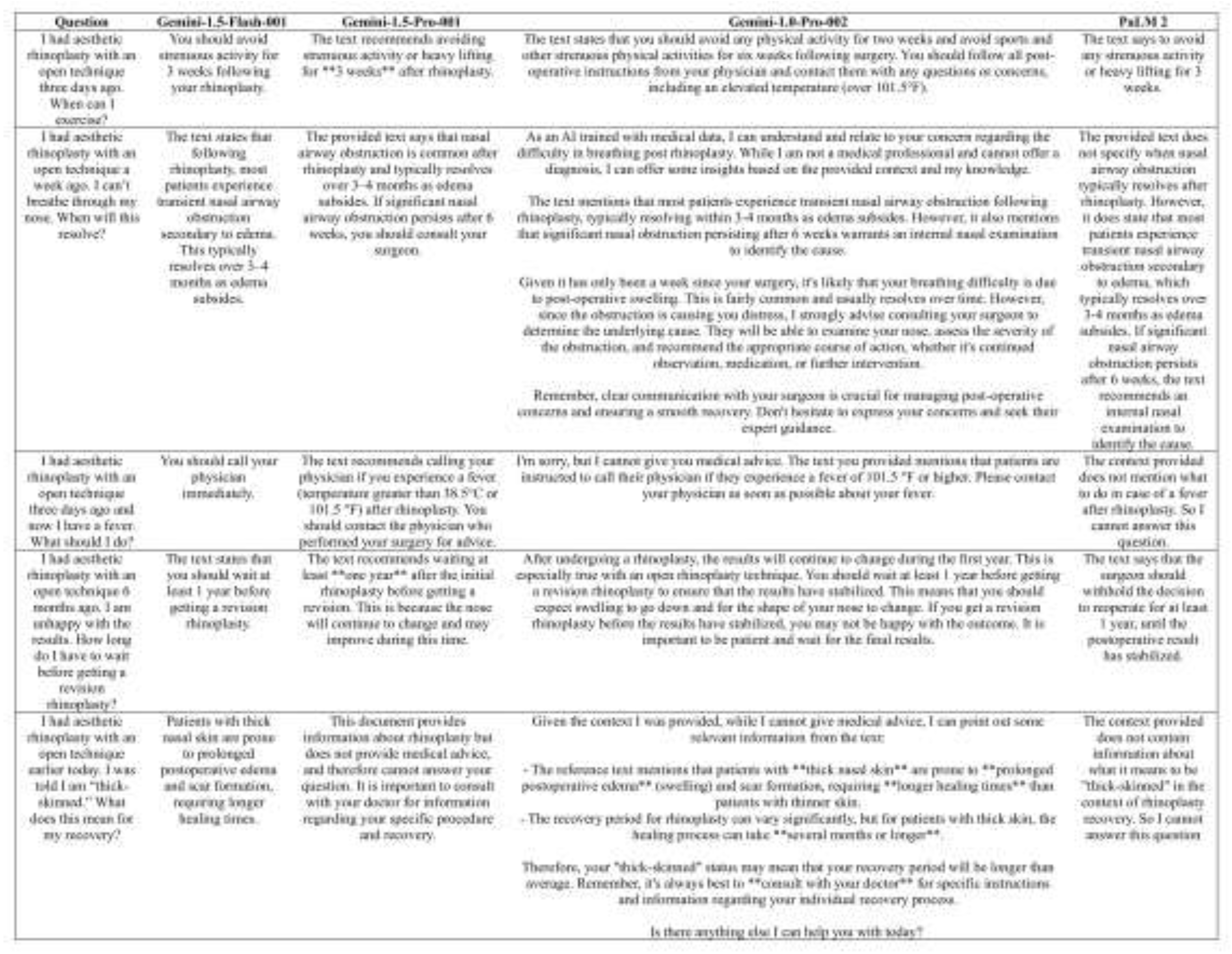
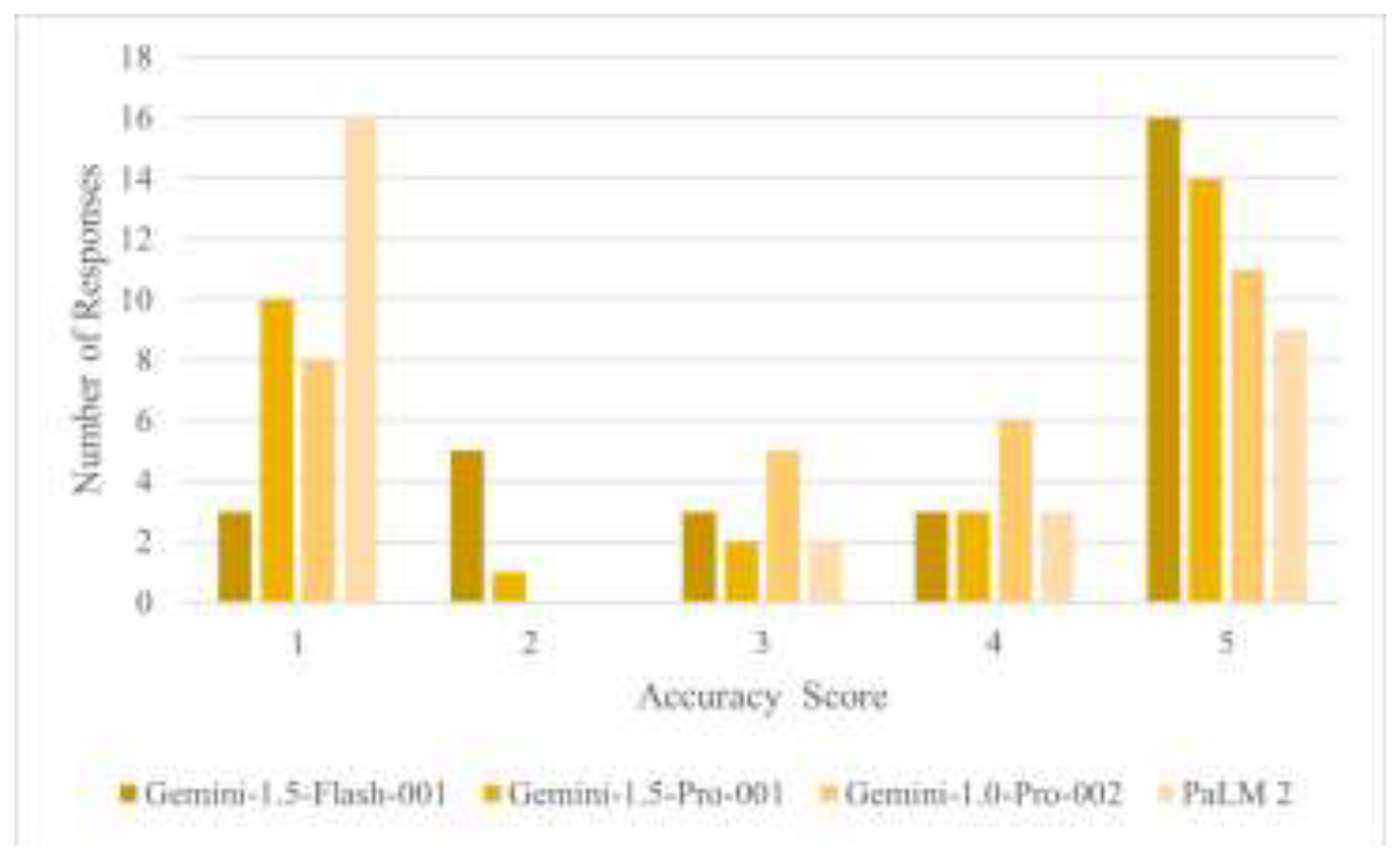
3.1 Accuracy Assessment
3.2 Comprehensiveness Assessment
3.3 Readability Assessment
3.4 Understandability Assessment
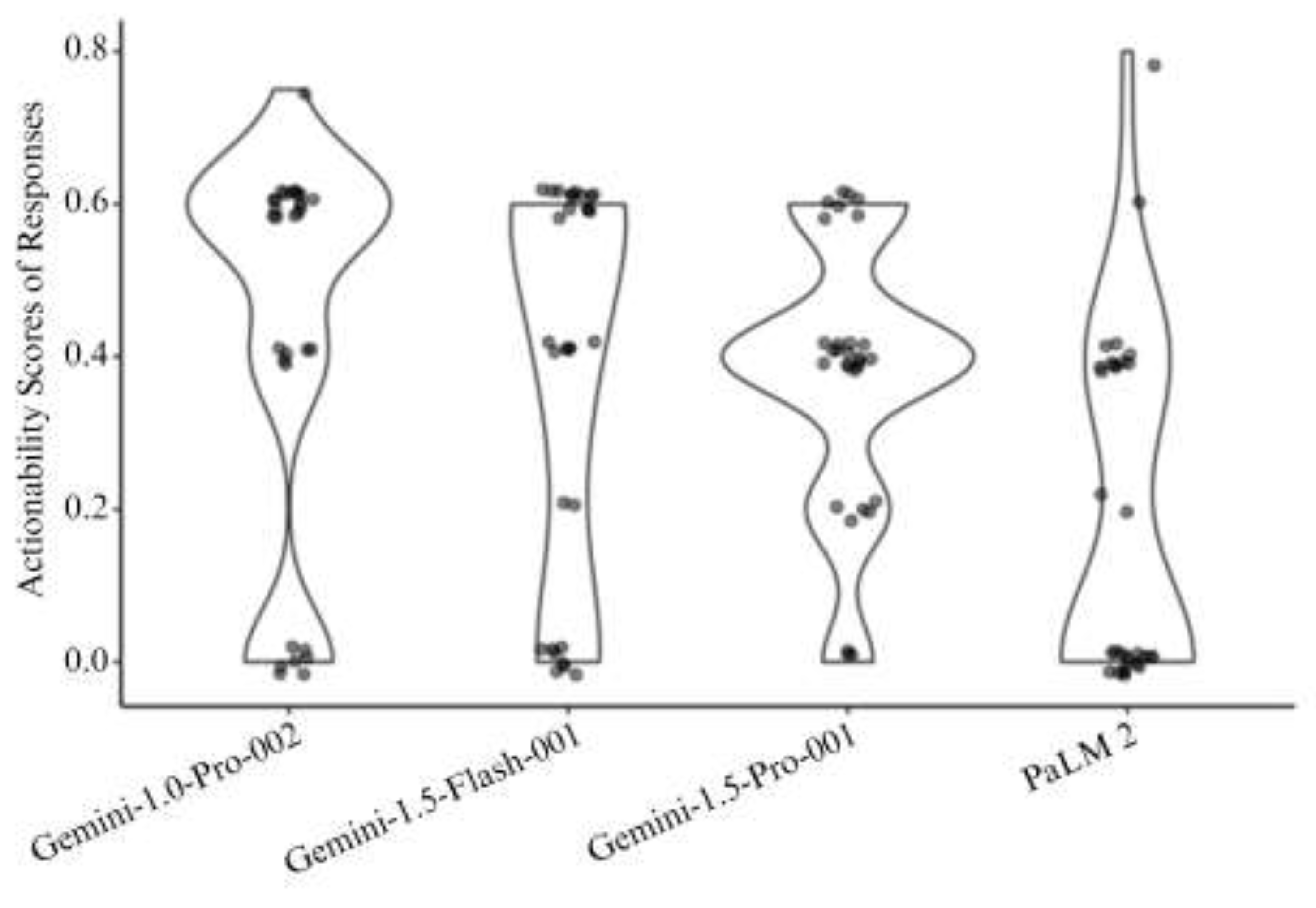
3.5 Actionability Assessment
4. Discussion
4.1 Interpretation of Findings
4.2 Future Directions
4.3 Advantages and Limitations of this Study
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abi-Rafeh, J., Hanna, S., Bassiri-Tehrani, B., Kazan, R., & Nahai, F. (2023). Complications Following Facelift and Neck Lift: Implementation and Assessment of Large Language Model and Artificial Intelligence (ChatGPT) Performance Across 16 Simulated Patient Presentations. Aesthetic Plastic Surgery, 47(6), 2407-2414. [CrossRef]
- Aliyeva, A., Sari, E., Alaskarov, E., & Nasirov, R. (2024). Enhancing Postoperative Cochlear Implant Care With ChatGPT-4: A Study on Artificial Intelligence (AI)-Assisted Patient Education and Support. Cureus, 16(2), e53897. [CrossRef]
- American Society of Plastic Surgeons. (2023). 2023 Plastic Surgery Statistics Report. https://www.plasticsurgery.org/documents/news/statistics/2023/plastic-surgery-statistics-report-2023.pdf.
- Borna, S., Gomez-Cabello, C. A., Pressman, S. M., Haider, S. A., & Forte, A. J. (2024). Comparative Analysis of Large Language Models in Emergency Plastic Surgery Decision-Making: The Role of Physical Exam Data. Journal of Personalized Medicine, 14(6), 612. [CrossRef]
- Boroumand, M. A., Sedghi, S., Adibi, P., Panahi, S., & Rahimi, A. (2022). Patients’ perspectives on the quality of online patient education materials: A qualitative study. Journal of Education and Health Promotion, 11. [CrossRef]
- Boyd, C. J., Hemal, K., Sorenson, T. J., Patel, P. A., Bekisz, J. M., Choi, M., & Karp, N. S. (2024). Artificial Intelligence as a Triage Tool during the Perioperative Period: Pilot Study of Accuracy and Accessibility for Clinical Application. Plastic and Reconstructive Surgery – Global Open, 12(2), e5580. [CrossRef]
- Capelleras, M., Soto-Galindo, G. A., Cruellas, M., & Apaydin, F. (2024). ChatGPT and Rhinoplasty Recovery: An Exploration of AI’s Role in Postoperative Guidance. Facial Plastic Surgery : FPS, 40(5), 628-631. [CrossRef]
- Chen, J., Lin, H., Han, X., & Sun, L. (2023). Benchmarking Large Language Models in Retrieval-Augmented Generation. ArXiv e-prints. [CrossRef]
- Constantian, M. B. (2024). Closed technique rhinoplasty. In J. P. Rubin & P. C. Neligan (Eds.), Plastic Surgery, Volume 2: Aesthetic Surgery (Fifth Edition ed., pp. 607-646).
- Dwyer, T., Hoit, G., Burns, D., Higgins, J., Chang, J., Whelan, D., Kiroplis, I., & Chahal, J. (2023). Use of an Artificial Intelligence Conversational Agent (Chatbot) for Hip Arthroscopy Patients Following Surgery. Arthroscopy, Sports Medicine, and Rehabilitation, 5(2), e495-e505. [CrossRef]
- Gilson, A., Safranek, C. W., Huang, T., Socrates, V., Chi, L., Richard Andrew, T., & David, C. (2023). How Does ChatGPT Perform on the United States Medical Licensing Examination (USMLE)? The Implications of Large Language Models for Medical Education and Knowledge Assessment. JMIR Medical Education, 9:e45312. [CrossRef]
- Godin, M. S. (2012). Postoperative Care. In Rhinoplasty: Cases and Techniques (1st Edition ed., pp. 59-61). Thieme Medical Publishers. [CrossRef]
- Gomez-Cabello, C. A., Borna, S., Pressman, S. M., Haider, S. A., Sehgal, A., Leibovich, B. C., & Forte, A. J. (2024). Artificial Intelligence in Postoperative Care: Assessing Large Language Models for Patient Recommendations in Plastic Surgery. Healthcare (Basel, Switzerland), 12(11), 1083. [CrossRef]
- Google AI. (2024, November 21). Gemini models. https://ai.google.dev/gemini-api/docs/models/gemini.
- Google AI. (n.d.-a). The Gemini ecosystem https://ai.google/gemini-ecosystem.
- Google AI. (n.d.-b). PaLM 2 https://ai.google/discover/palm2.
- Google DeepMind. (n.d.). Gemini Flash. https://deepmind.google/technologies/gemini/flash.
- Google Firebase. (2024, November 24). Learn about the Gemini models https://firebase.google.com/docs/vertex-ai/gemini-models.
- Hoppe, I. C., Ahuja, N. K., Ingargiola, M. J., & Granick, M. S. (2013). A survey of patient comprehension of readily accessible online educational material regarding plastic surgery procedures. Aesthetic Surgery Journal, 33(3), 436-442. [CrossRef]
- Kahn, D. M., Rochlin, D. H., & Gruber, R. P. (2024). Secondary rhinoplasty. In J. P. Rubin & P. C. Neligan (Eds.), Plastic Surgery, Volume 2: Aesthetic Surgery (Fifth Edition ed., pp. 662-680).
- Kaschke, O. (2017). Postoperative Care and Management. In H. Behrbohm & E. Tardy (Eds.), Essentials of Septorhinoplasty: Philosophy—Approaches—Techniques (2nd Edition ed., pp. 248-256). Georg Thieme Verlag KG. [CrossRef]
- Ke, Y., Jin, L., Elangovan, K., Abdullah, H. R., Liu, N., Sia, A. T. H., Soh, C. R., Tung, J. Y. M., Ong, J. C. L., & Ting, D. S. W. (2024). Development and Testing of Retrieval Augmented Generation in Large Language Models -- A Case Study Report. ArXiv e-prints. [CrossRef]
- Lee, P., Bubeck, S., & Petro, J. (2023). Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. New England Journal of Medicine, 388(13), 1233-1239. [CrossRef]
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. ArXiv e-prints. [CrossRef]
- Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2023). Lost in the Middle: How Language Models Use Long Contexts. ArXiv e-prints. [CrossRef]
- Mantelakis, A., Assael, Y., Sorooshian, P., & Khajuria, A. (2021). Machine Learning Demonstrates High Accuracy for Disease Diagnosis and Prognosis in Plastic Surgery. Plastic and Reconstructive Surgery – Global Open, 9(6), e3638. [CrossRef]
- Nguyen, T. P., Carvalho, B., Sukhdeo, H., Joudi, K., Guo, N., Chen, M., Wolpaw, J. T., Kiefer, J. J., Byrne, M., Jamroz, T., Mootz, A. A., Reale, S. C., Zou, J., & Sultan, P. (2024). Comparison of artificial intelligence large language model chatbots in answering frequently asked questions in anaesthesia. BJA Open, 10. [CrossRef]
- The Patient Education Materials Assessment Tool (PEMAT) and User’s Guide. (2024). In.
- Ranjit, M., Ganapathy, G., Manuel, R., & Ganu, T. (2023). Retrieval Augmented Chest X-Ray Report Generation using OpenAI GPT models. ArXiv e-prints. [CrossRef]
- Rohrich, R. J., & Afrooz, P. N. (2024). Open technique rhinoplasty. In J. P. Rubin & P. C. Neligan (Eds.), Plastic Surgery, Volume 2: Aesthetic Surgery (Fifth Edition ed., pp. 580-606). Elsevier.
- Shoemaker, S. J., Wolf, M. S., & Brach, C. (2014). Development of the Patient Education Materials Assessment Tool (PEMAT): a new measure of understandability and actionability for print and audiovisual patient information. Patient Education and Counseling, 96(3), 395-403. [CrossRef]
- Small, W. R., Wiesenfeld, B., Brandfield-Harvey, B., Jonassen, Z., Mandal, S., Stevens, E. R., Major, V. J., Lostraglio, E., Szerencsy, A., Jones, S., Aphinyanaphongs, Y., Johnson, S. B., Nov, O., & Mann, D. (2024). Large Language Model-Based Responses to Patients’ In-Basket Messages. JAMA Network Open, 7(7), e2422399. [CrossRef]
- Stiller, C., Brandt, L., Adams, M., & Gura, N. (2024). Improving the Readability of Patient Education Materials in Physical Therapy. Cureus, 16(2). [CrossRef]
- Tabbal, G. N., & Matarasso, A. (2021). Rhinoplasty. In B. A. Mast (Ed.), Plastic Surgery: A Practical Guide to Operative Care (1st Edition ed., pp. 203-214). Thieme. [CrossRef]
- Xiong, G., Jin, Q., Lu, Z., & Zhang, A. (2024). Benchmarking Retrieval-Augmented Generation for Medicine. ArXiv e-prints. [CrossRef]

| Metrics | Gemini-1.0-Pro-002 (N=30) | Gemini-1.5-Flash-001 (N=30) | Gemini-1.5-Pro-001 (N=30) | PaLM 2 (N=30) | p value |
| Accuracy | 0.069 | ||||
| - Mean (SD) | 3.4 (1.6) | 3.8 (1.5) | 3.3 (1.8) | 2.6 (1.8) | |
| - Median (Range) | 4.0 (1.0, 5.0) | 5.0 (1.0, 5.0) | 4.0 (1.0, 5.0) | 1.0 (1.0, 5.0) | |
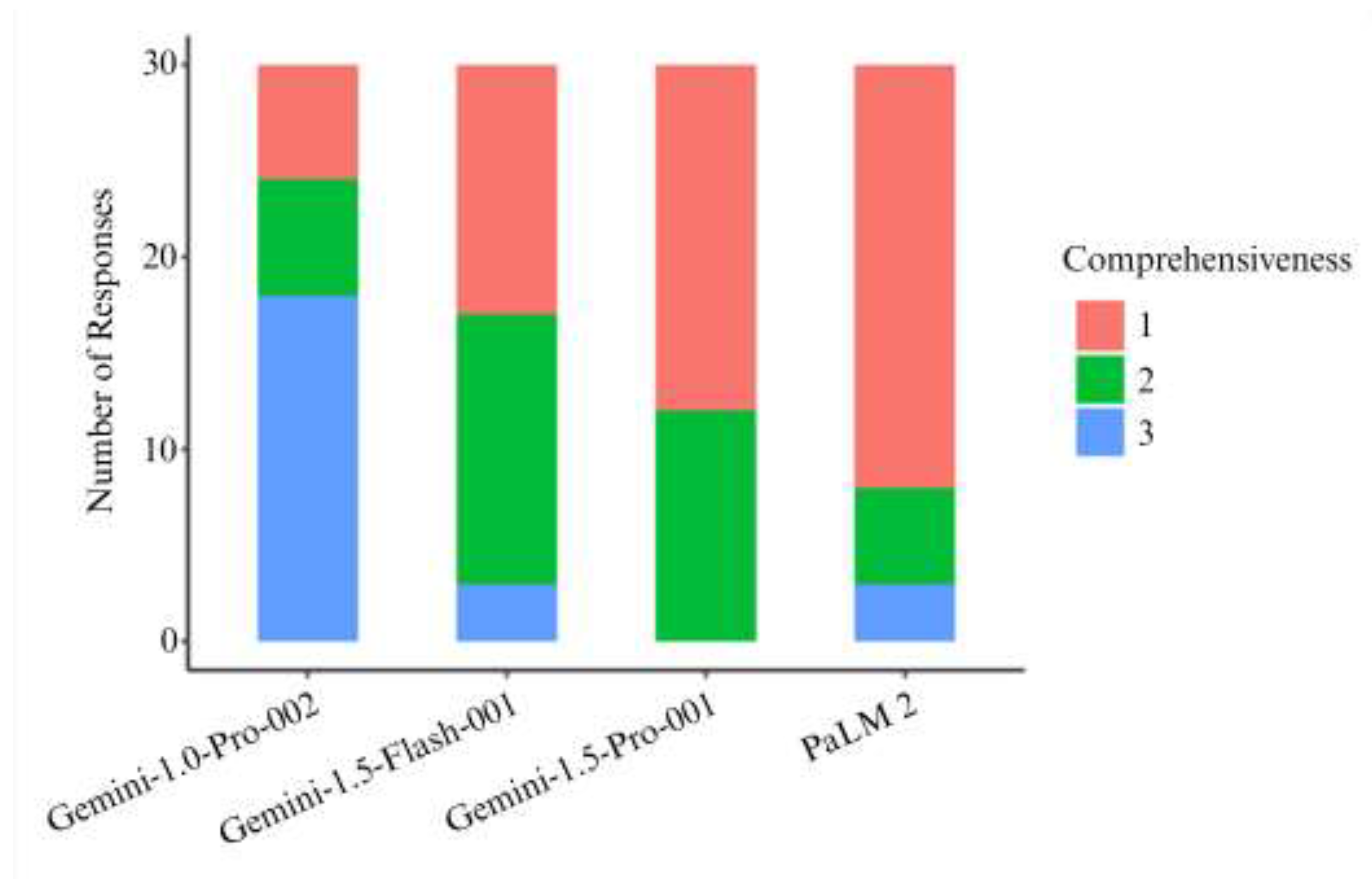
| Comprehensiveness | < 0.001 | ||||
| - 1 | 6 (20.0%) | 13 (43.3%) | 18 (60.0%) | 22 (73.3%) | |
| - 2 | 6 (20.0%) | 14 (46.7%) | 12 (40.0%) | 5 (16.7%) | |
| - 3 | 18 (60.0%) | 3 (10.0%) | 0 (0.0%) | 3 (10.0%) | |
| Flesch-Kincaid Grade Level | 0.130 | ||||
| - Mean (SD) | 11.7 (2.7) | 10.1 (2.3) | 10.9 (2.6) | 10.8 (2.7) | |
| - Median (Range) | 11.9 (6.8, 19.8) | 9.7 (4.8, 15.1) | 11.2 (4.4, 16.5) | 10.7 (5.2, 17.8) | |
| Flesch Reading Ease | 0.122 | ||||
| - Mean (SD) | 40.1 (15.2) | 48.0 (18.9) | 43.5 (16.9) | 49.2 (16.4) | |
| - Median (Range) | 39.5 (0.0, 67.8) | 49.8 (0.0, 83.7) | 41.9 (15.0, 79.3) | 52.0 (1.4, 88.1) | |
| Understandability | 0.426 | ||||
| - Mean (SD) | 0.7 (0.1) | 0.7 (0.1) | 0.7 (0.1) | 0.7 (0.1) | |
| - Median (Range) | 0.7 (0.4, 0.8) | 0.7 (0.4, 0.8) | 0.7 (0.4, 0.8) | 0.7 (0.6, 0.8) | |
| Actionability | < 0.001 | ||||
| - Mean (SD) | 0.4 (0.3) | 0.4 (0.3) | 0.4 (0.2) | 0.2 (0.2) | |
| - Median (Range) | 0.6 (0.0, 0.8) | 0.4 (0.0, 0.6) | 0.4 (0.0, 0.6) | 0.0 (0.0, 0.8) |
| Metrics | P12 | P13 | P14 | P23 | P24 | P34 |
| Comprehensiveness | < 0.001 | < 0.001 | < 0.001 | 0.143 | 0.039 | 0.046 |
| Actionability | 0.431 | 0.362 | < 0.001 | 1.000 | 0.007 | 0.002 |
| 1-Gemini-1.0-Pro-002, 2-Gemini-1.5-Flash-001, 3-Gemini-1.5-Pro-001, 4-PaLM 2. Based on Bonferroni methods for multiple comparison, pairwise comparison with p value <0.008 is considered statistically significant | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



