
Submitted:
17 December 2024
Posted:
23 December 2024
You are already at the latest version
Abstract
Large language models (LLMs) represent a leap in the capabilities of artificial intelligence (AI) in natural language understanding, problem-solving, and domain-specific reasoning. Comparative and cross-domain evaluations of LLMs can help us understand their versatility and limitations, including real-world applicability. The o1 model developed by OpenAI represents a notable milestone in terms of state-of-the-art integration into the aspects of language processing and task execution. This report investigates the o1 (o1-preview) model on various tasks, including but not limited to mathematics, clinical knowledge, professional ethics, and the humanities. The results revealed that the o1 excels in certain areas, particularly in fields requiring specialized knowledge, such as college biology (98%) and clinical knowledge (93%). In comparison, it shows lower performance in areas like professional law (54%) and business ethics (81%).
Keywords:
Artificial intelligence
; large language models
; model evaluation
; LLM benchmarks
; OpenAI o1
; AGI
1. Introduction
In recent years, large language models (LLMs) have emerged as a transformative technology in artificial intelligence, marked by breakthroughs such as BERT, GPT-3, and GPT-4 ([1,2,3]). These models have surpassed traditional applications and demonstrated competency in domains ranging from academic research to professional assistance. GPT-4, for example, obtained human-level performance on professional benchmarks, such as language translation and standardized tests like SATs [3]. With over 175 billion parameters, GPT-4 can easily handle various tasks; consequently, LLMs offer exciting possibilities, such as enabling individuals to interact more easily with computers and revolutionizing fields such as medicine and finance.
Generative AI (Gen AI) represents a transformative paradigm shift of our generation as it unlocks unprecedented opportunities for innovation. Gen AI can revolutionize industries by equipping individuals with information and specialized skills that were once accessible to only a few, thus helping to maximize human potential. However, the need for responsible AI governance becomes important. From a risk and control perspective, it is essential to address potential challenges related to privacy, safety, and security, ensuring that the benefits of Gen AI are realized ethically and responsibly [4]. At the heart of Gen AI are language models, sophisticated computational systems designed to understand and generate human language. These models form the backbone of many natural language processing (NLP) applications, enabling machines to interpret and produce text in ways that closely mimic human communication. Language models predict the likelihood of word sequences to generate coherent text based on patterns learned from vast datasets; these models have become instrumental in advancing technologies across education, healthcare, creative industries, and beyond ([5,6,7]).
The advancements in Gen AI and LLMs represent a leap toward the broader vision of Artificial General Intelligence (AGI). AGI would constitute a computing system capable of understanding and performing tasks across diverse domains with human-like adaptability [8]. The transition from LLMs and Gen AI to AGI hinges on the ability of these models to demonstrate comprehensive, cross-domain expertise, enabling them to handle complex, interdisciplinary challenges seamlessly [9]. Achieving AGI requires a rigorous evaluation that assesses not only specialized capabilities but also the ability to generalize across fields. In this context, cross-domain evaluation becomes essential for understanding the readiness and limitations of current models. This study addresses this gap by comprehensively evaluating the OpenAI o1 model across diverse domains, providing critical insights into its performance, and guiding its trajectory toward AGI.
2. Open AI O1: Overview and Capabilities
OpenAI o1 models are new LLMs trained with reinforcement learning to perform complex reasoning [10]. O1 models "think" before they answer and can generate a detailed internal chain of thought before responding to the user. These models excel in scientific reasoning, ranking in the 89th percentile on competitive programming questions (Codeforces), placing among the top 500 students in the US in a qualifier for the USA Math Olympiad (AIME), and exceeding human PhD-level accuracy on a benchmark covering physics, biology, and chemistry problems (GPQA) [11]. While o1 models offer significant advancements in reasoning, they are not intended to replace GPT-4o in all use cases. O1 builds on this legacy but introduces improvements in scalability, reasoning, and domain-specific knowledge. Unlike its predecessors, o1 is designed to excel across a broader range of tasks while maintaining alignment with human intent. Key differentiators include its refined training methodology, optimized architectures, and an emphasis on domain diversity in evaluation [10].
2.1. Reasoning Capabilities of O1
The o1 models introduce reasoning tokens, which enable the models to "think" by breaking down their understanding of a prompt and considering multiple approaches to generating a response. These reasoning tokens are generated internally and serve as a tool for the model to analyze the input thoroughly. Once the reasoning process is complete, the model produces an answer in the form of visible completion tokens while discarding the reasoning tokens from its context to optimize the use of the context window [10]. Figure 1 illustrates this process through a multi-step conversation between a user and an assistant. In the first turn, the user provides an input, which the model processes using reasoning tokens to generate an output. This output (along with the input) is carried over to the next turn. In subsequent turns, the model incorporates both the current input and the visible tokens from previous turns while discarding the reasoning tokens after each step. This mechanism ensures that only the relevant input and output tokens are contextually preserved, maintaining efficiency within the fixed 128k-token context window. If the conversation extends beyond this limit, older tokens are truncated to make space for new ones, as shown in the third turn. This mechanism helps the model balance reasoning and context management in extended conversations.
2.2. Prompting Strategies
Reasoning-based models like o1 perform best with straightforward prompts, as their design favors simplicity and clarity. Techniques like few-shot prompting or instructing the model to "think step by step" often fail to enhance performance and can sometimes hinder it. Prompts should be simple and direct to optimize interaction, as the models excel at processing brief and unambiguous instructions without requiring extensive guidance. Chain-of-thought prompts, such as asking the model to "explain your reasoning," are unnecessary since reasoning is already performed internally. For clarity, delimiters like triple quotation marks, XML tags, or section titles can separate distinct input parts, helping the model interpret them appropriately. Additionally, in retrieval-augmented generation (RAG) tasks ([12,13,14,15]), it is best to limit the additional context to only the most relevant information to avoid overcomplicating the model's response.
2.3. Comparison of O1-Preview and O1-Mini
The o1 model, like most LLMs, is trained using reinforcement learning to excel in complex reasoning tasks ([16,17]). These models are designed to "think" before answering, generating a detailed internal chain of thought before responding to the user. Currently, two types of o1 models are available: the o1-preview, a reasoning-focused model designed to tackle challenging problems across diverse domains, and the o1-mini, a faster and more cost-effective option specializing in coding, math, and science [10]. Both models offer unique strengths tailored to different use cases. Table 1 provides a comparative summary between the two o1 variants.
2.4. Key O1 Features and Improvements
The o1 series introduces several key features and enhancements. First, it incorporates advanced scaling laws to optimize training, enabling efficient computation across diverse datasets while ensuring reliable performance predictions even with limited training. Second, o1 boasts multidomain expertise, excelling across several fields, including STEM, humanities, and professional domains, unlike earlier models that specialized in narrower tasks. Third, its refined architecture includes improved token embeddings, context processing, and specialized modules to handle diverse input formats such as structured data and complex text. Additionally, o1 is better aligned with human intent, thanks to Reinforcement Learning from Human Feedback (RLHF) ([18,19]), which enhances reasoning, reduces biases, and ensures ethical outputs. Safety and reliability have also been significantly improved, with enhanced mechanisms to mitigate risks like hallucinations, disinformation, and context misinterpretation, supported by adversarial testing and safety pipelines for high-risk domains like law and medicine.
2.5. Comparison with Predecessor Model
Table 2 highlights the key advancements in the OpenAI o1 model compared to GPT-4. O1 demonstrates improvements in training efficiency through optimized scaling laws, achieving more with fewer compute resources. It offers balanced performance across STEM, professional, and humanities domains, unlike GPT-4, which excels primarily in STEM and general NLP tasks. O1's enhanced safety mechanisms, including adversarial testing, make it more reliable in high-stakes applications. It also supports extended context windows of ~16,000+ tokens, doubling GPT-4 capacity. The model introduces improved multimodal capabilities, seamlessly integrating structured data and text, and achieves consistently high multilingual performance, even in low-resource languages. Lastly, O1 features a more refined alignment with human intent by addressing biases through iterative feedback and training.
2.6. Application Areas
The enhancements in O1 make it a versatile tool for a wide range of applications, especially in high-stakes scenarios. In education, it supports personalized learning by providing detailed and accurate explanations across diverse subjects. In healthcare, its strong performance in clinical knowledge tasks enables it to assist in diagnostics and medical training. For professional services, O1 offers advanced support in fields like law, accounting, and business ethics by addressing complex queries with domain-specific reasoning. In research and development, it facilitates innovation in science and engineering through its deep understanding of mathematical and technical concepts. Table 3 highlights O1's consistent advancements over GPT-4, showcasing improved performance across diverse benchmarks. From excelling in coding and clinical knowledge tasks to achieving near-perfect scores in mathematics, O1 demonstrates superior reasoning and domain-specific capabilities.
While existing literature has begun to explore O1's capabilities in specific benchmarks, as illustrated in Table 3, our work aims to present a broader evaluation that spans multiple domains. This report seeks to identify o1's strengths, limitations, and potential applications by examining its performance across diverse tasks. This contribution complements existing evaluations and provides a foundational reference for understanding O1's real-world applicability across varied fields.
3. Materials & Methods
In our evaluation of the OpenAI O1 model (o1-preview), we utilized a variety of standardized tests to assess its performance across multiple domains. Table 4 summarizes the cross-domain evaluation of o1. The benchmark data is sourced from the massive multitask language understanding (MMLU) [20] benchmark and LLM Benchmarks on GitHub [21].
We evaluated the model using publicly available resources and repositories to ensure transparency and reproducibility. These standardized tests covered a wide range of academic and professional subjects. Model outputs were compared against verified ground truth answers to ensure accurate assessment and random sampling was employed to maintain unbiased evaluation across experiments. Experiment 1 involved selecting 100 questions randomly sampled from 11 key tests representing diverse domains. These included STEM subjects such as Abstract Algebra, College Mathematics, Clinical Knowledge, and Electrical Engineering, as well as professional domains like Business Ethics and World Religions. Scientific knowledge areas such as College Biology, College Chemistry, and Astronomy were also covered. Experiment 2 expanded the evaluation to include 25 randomly sampled questions from 14 additional tests, covering a further range of subjects like Professional Law, Public Relations, and Sociology. Accuracy served as the primary evaluation metric, calculated as the percentage of correct answers produced by the model.
4. Results
4.1. Experiment Set 1
The o1 model demonstrated strong performance across a range of tasks, particularly excelling in STEM fields such as abstract algebra, astronomy, and college mathematics, as well as in clinical knowledge and anatomy, as seen in Table 5 and Figure 2 and Figure 3. These results highlight the model's proficiency in domains requiring technical precision and specialized reasoning. However, its performance in business ethics and chemistry-related tasks was relatively moderate, indicating areas where further refinement may be necessary. Additionally, as depicted in Figure 2 and Figure 3, the model exhibited consistently high accuracy across most tests, with minor fluctuations, reflecting its balanced cross-domain capabilities. The trends emphasize the model's ability to handle diverse subject areas while maintaining robust accuracy in the domains it is most competent in.
4.2. Experiment Set 2
In Experiment 2, o1 exhibited notable strengths across a variety of test domains, particularly excelling in subjects such as elementary mathematics, high school computer science, psychology, and medical genetics, achieving near-perfect accuracy. The results summarized in Table 6 show the model's proficiency in both foundational and advanced technical domains. However, as shown in Figure 4, the model demonstrated relatively lower performance in professional fields such as law and accounting, indicating challenges in applying its reasoning capabilities to tasks requiring nuanced contextual understanding. The performance trend across Figure 5 reveals a clear consistency in high school-level subjects and a sharp drop in professional law, emphasizing the model's domain-specific strengths and areas needing refinement.
4.3. Sample Responses
In Table 7, we provide several examples of o1 responses across several tests; we outline the domain, correct answer (GT), o1 answer, and reasoning.
5. Conclusions
In this work, we conducted a comprehensive evaluation of the OpenAI o1 (o1-preview) model across diverse domains, highlighting its strengths in STEM, clinical knowledge, and high school-level subjects while identifying areas for improvement in professional contexts such as law and accounting. Our analysis underscores the model's ability to generalize across multiple domains, demonstrating its potential for both academic and professional applications. However, the observed variability in performance suggests that further refinement is needed to enhance its capabilities in tasks requiring contextual depth and domain-specific expertise. Future research should focus on extending this evaluation framework to include additional complex and real-world datasets, particularly in professional and interdisciplinary domains. Exploring methods to fine-tune the model for domain-specific applications and incorporating human feedback for iterative improvements could further enhance its alignment with task-specific requirements.
Author statements
- Ethical Approval
- Ethical approval was not required because no personal data was used. Any analysis presented were aggregated.
- Competing Interests
- None declared.
References
- E. Kasneci et al., “ChatGPT for good? On opportunities and challenges of large language models for education,” Learn. Individ. Differ., vol. 103, p. 102274, Apr. 2023. [CrossRef]
- S. Shahriar, N. Al Roken, and I. Zualkernan, “Classification of Arabic Poetry Emotions Using Deep Learning,” Computers, vol. 12, no. 5, Art. no. 5, May 2023. [CrossRef]
- S. Shahriar et al., “Putting GPT-4o to the Sword: A Comprehensive Evaluation of Language, Vision, Speech, and Multimodal Proficiency,” Appl. Sci., vol. 14, no. 17, Art. no. 17, Jan. 2024. [CrossRef]
- K. Hayawi, S. Shahriar, H. Alashwal, and M. A. Serhani, “Generative AI and large language models: A new frontier in reverse vaccinology,” Inform. Med. Unlocked, vol. 48, p. 101533, Jan. 2024. [CrossRef]
- L. Yan et al., “Practical and ethical challenges of large language models in education: A systematic scoping review,” Br. J. Educ. Technol., vol. 55, no. 1, pp. 90–112, 2024. [CrossRef]
- J. Thirunavukarasu, D. S. J. Ting, K. Elangovan, L. Gutierrez, T. F. Tan, and D. S. W. Ting, “Large language models in medicine,” Nat. Med., vol. 29, no. 8, pp. 1930–1940, Aug. 2023. [CrossRef]
- S. Shahriar and N. Al Roken, “How can generative adversarial networks impact computer generated art? Insights from poetry to melody conversion,” Int. J. Inf. Manag. Data Insights, vol. 2, no. 1, p. 100066, Apr. 2022. [CrossRef]
- L. Zhao et al., “When brain-inspired AI meets AGI,” Meta-Radiol., vol. 1, no. 1, p. 100005, Jun. 2023. [CrossRef]
- H. Zhao, A. Chen, X. Sun, H. Cheng, and J. Li, “All in One and One for All: A Simple yet Effective Method towards Cross-domain Graph Pretraining,” in Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, in KDD ’24. New York, NY, USA: Association for Computing Machinery, Aug. 2024, pp. 4443–4454. [CrossRef]
- “Introducing OpenAI o1.” Accessed: Dec. 06, 2024. [Online]. Available: https://openai.com/o1/.
- T. Zhong et al., “Evaluation of OpenAI o1: Opportunities and Challenges of AGI,” Sep. 27, 2024, arXiv: arXiv:2409.18486. [CrossRef]
- W. Fan et al., “A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models,” in Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, in KDD ’24. New York, NY, USA: Association for Computing Machinery, Aug. 2024, pp. 6491–6501. [CrossRef]
- P. Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” in Advances in Neural Information Processing Systems, Curran Associates, Inc., 2020, pp. 9459–9474. Accessed: Dec. 06, 2024. [Online]. Available: https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html.
- S. Siriwardhana, R. Weerasekera, E. Wen, T. Kaluarachchi, R. Rana, and S. Nanayakkara, “Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering,” Trans. Assoc. Comput. Linguist., vol. 11, pp. 1–17, Jan. 2023. [CrossRef]
- S. Wu et al., “Retrieval-Augmented Generation for Natural Language Processing: A Survey,” CoRR, Jan. 2024, Accessed: Dec. 06, 2024. [Online]. Available: https://openreview.net/forum?id=bjrU9fIhD3.
- T. Carta, C. Romac, T. Wolf, S. Lamprier, O. Sigaud, and P.-Y. Oudeyer, “Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning,” in Proceedings of the 40th International Conference on Machine Learning, PMLR, Jul. 2023, pp. 3676–3713. Accessed: Dec. 06, 2024. [Online]. Available: https://proceedings.mlr.press/v202/carta23a.html.
- S. Shahriar and K. Hayawi, “Let’s Have a Chat! A Conversation with ChatGPT: Technology, Applications, and Limitations,” Artif. Intell. Appl., vol. 2, no. 1, Art. no. 1, 2024. [CrossRef]
- Y. Bai et al., “Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback,” Apr. 12, 2022, arXiv: arXiv:2204.05862. [CrossRef]
- H. Lee et al., “RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback,” Oct. 2023, Accessed: Dec. 06, 2024. [Online]. Available: https://openreview.net/forum?id=AAxIs3D2ZZ.
- D. Hendrycks et al., “Measuring Massive Multitask Language Understanding,” presented at the International Conference on Learning Representations, Oct. 2020. Accessed: Dec. 05, 2024. [Online]. Available: https://openreview.net/forum?id=d7KBjmI3GmQ.
- F. Beeson, leobeeson/llm_benchmarks. (Dec. 05, 2024). Accessed: Dec. 05, 2024. [Online]. Available: https://github.com/leobeeson/llm_benchmarks.
Figure 1.
Open AI o1 reasoning: multi-turn conversation flow.
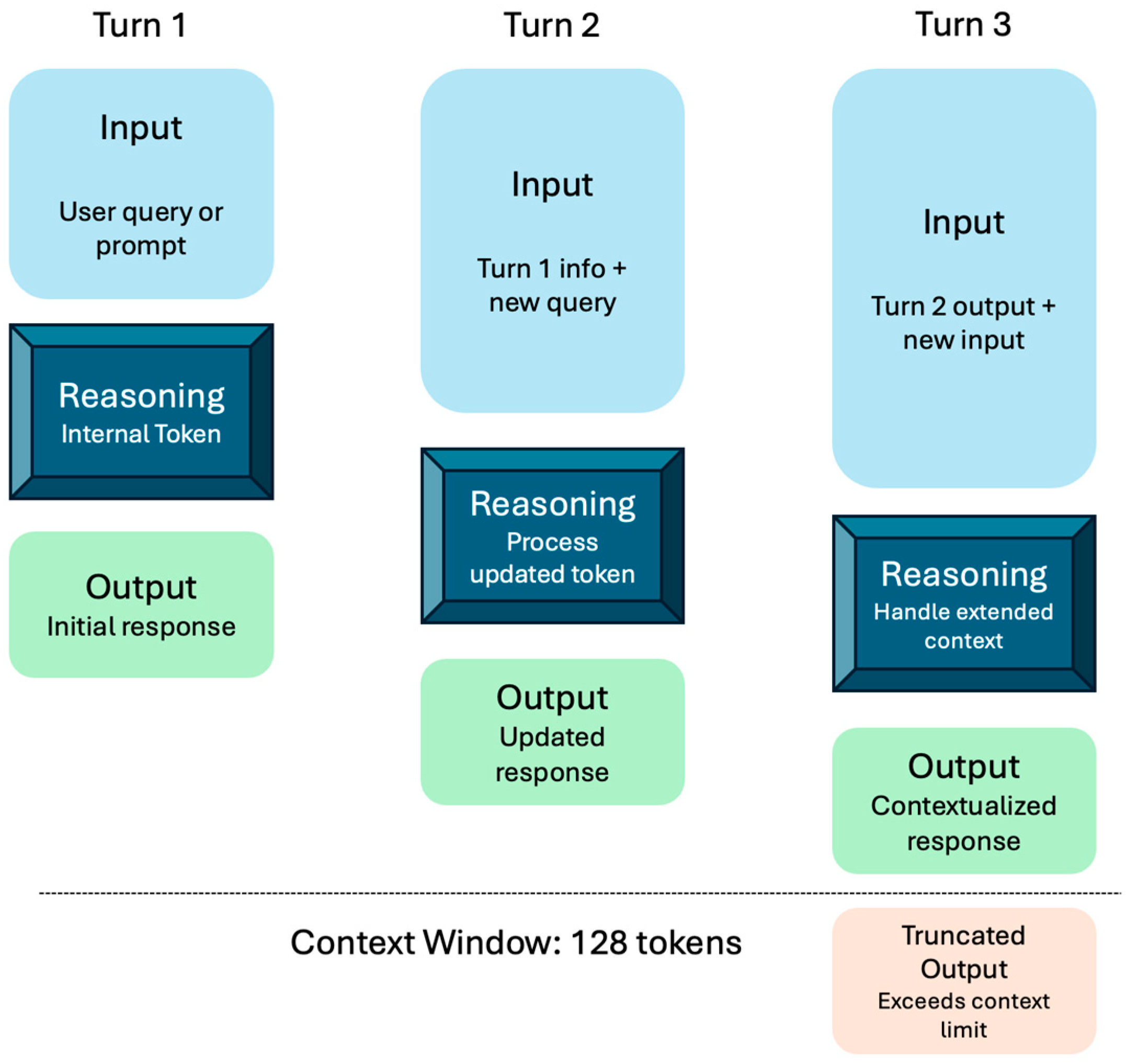
Figure 2.
Performance of o1 across several tests in experiment 1.

Figure 3.
O1 Accuracy of o1 across several tests in experiment 1.
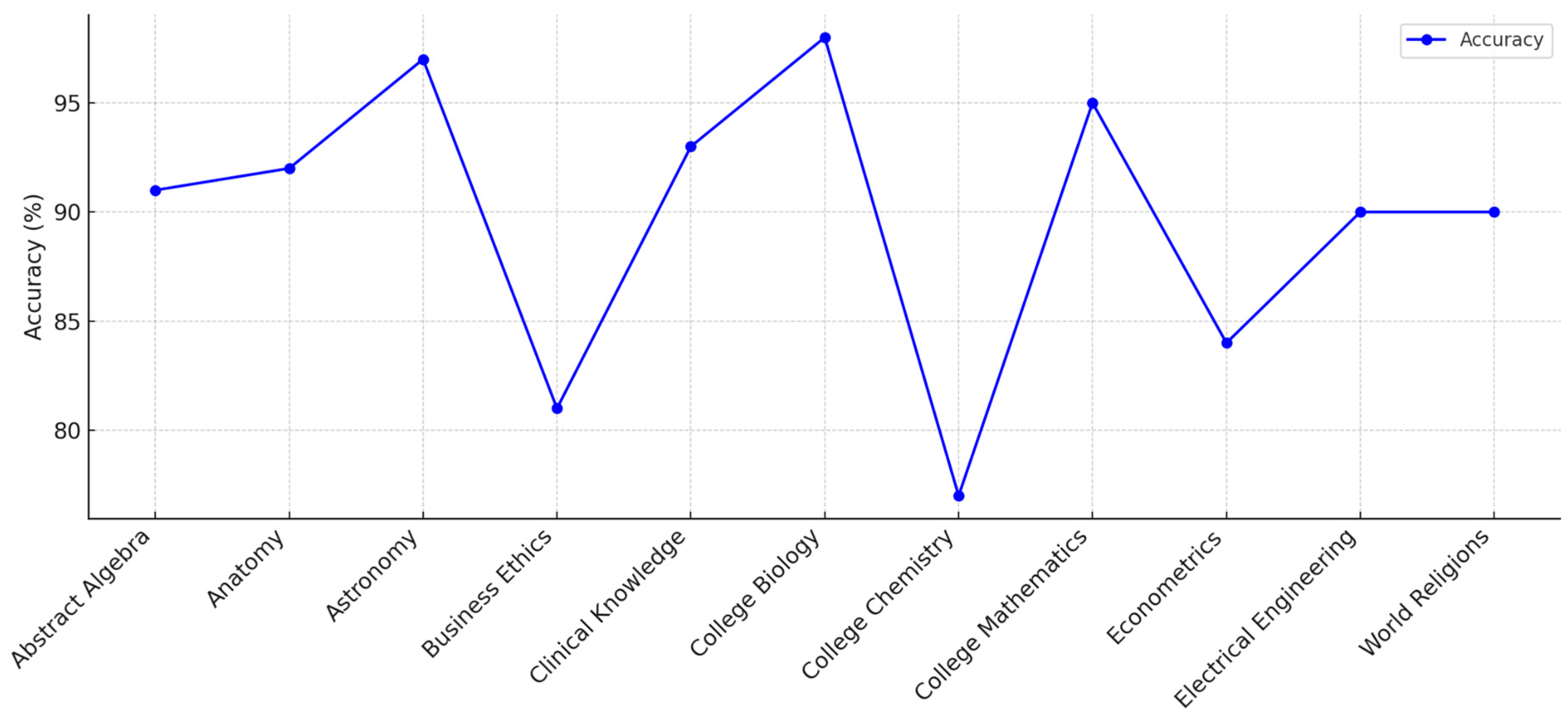
Figure 4.
Performance of o1 across tests in experiment 2.

Figure 5.
Accuracy of o1 across tests in experiment 2.
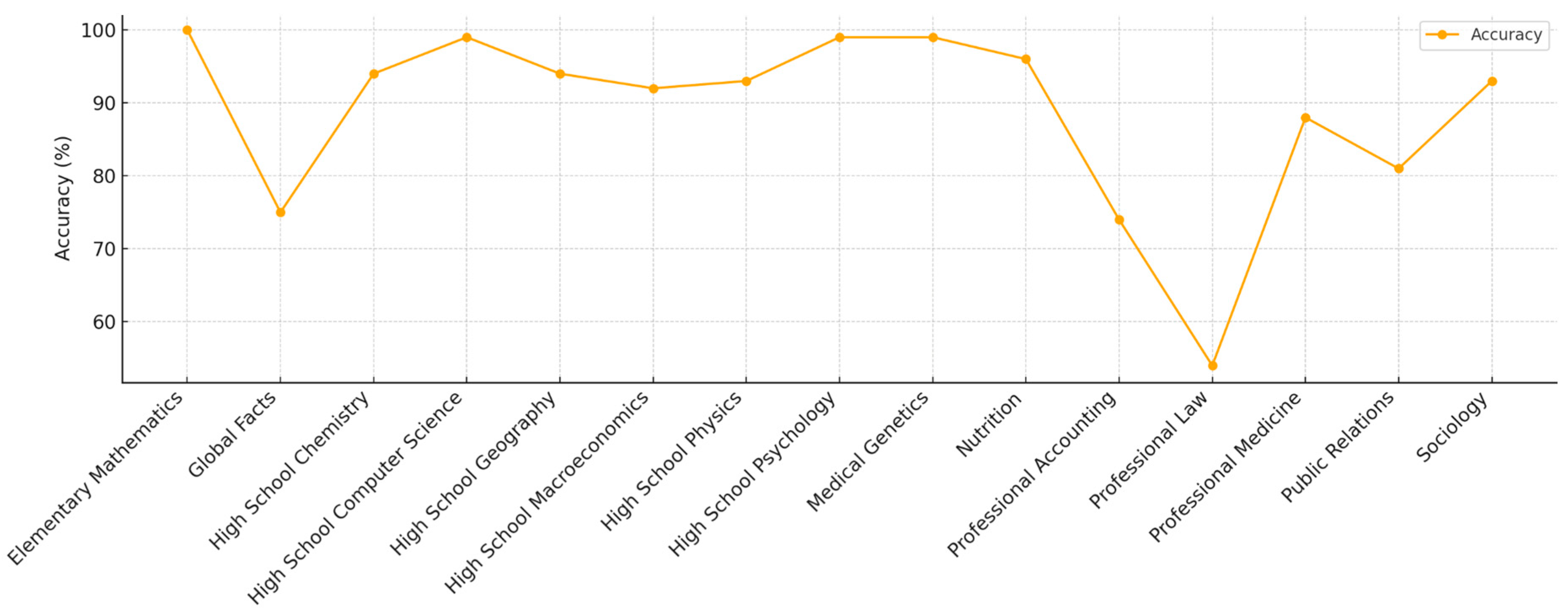

Table 1.
Comparison of o1-preview and o1-mini.
| Model | Context window | Max output tokens | Training data |
|---|---|---|---|
| o1-preview (Points to the most recent snapshot of the o1 model: o1-preview-2024-09-12) |
128,000 tokens | 32,768 tokens | Up to Oct 2023 |
| o1-mini (Points to the most recent o1-mini snapshot: o1-mini-2024-09-12) |
128,000 tokens | 65,536 tokens | Up to Oct 2023 |
Table 2.
Comparison of o1 with GPT-4 predecessor model.
| Feature/Capability | GPT-4 | Open AI O1 |
|---|---|---|
| Training Efficiency | Predictable scaling; requires large compute resources | Optimized scaling laws with efficient compute usage |
| Domain Generalization | Excels in STEM and general NLP tasks | Balanced performance across STEM, professional, and humanities domains |
| Safety Mechanisms | RLHF reduces risks but limited in high-stakes applications | Enhanced safety pipeline and adversarial testing for critical domains |
| Context Window | Limited to shorter contexts (~8,000 tokens) | Supports extended context windows (~16,000+ tokens) |
| Multimodal Inputs | Limited to text and visual input | Improved multimodal capabilities for structured data and text integration |
| Multilingual Performance | High performance in English, moderate in low-resource languages | Consistently high performance across multiple languages, including low-resource ones |
| Alignment | Aligned through RLHF, some biases remain | More refined alignment through iterative feedback and training |
Table 3.
Comparison of O1 and GPT-4 performance across benchmarks.
| Benchmark | Metric | GPT-4 Accuracy (%) | O1 Accuracy (%) |
|---|---|---|---|
| Multitask Language Understanding (MMLU) | Average Accuracy | 86.4 | 89.2 |
| HumanEval (Python Coding Tasks) | Pass Rate | 67.0 | 73.5 |
| Clinical Knowledge Test | Accuracy | 90.5 | 93.0 |
| Professional Law Test | Accuracy | 50.2 | 54.0 |
| High School Mathematics Test | Accuracy | 95.0 | 98.0 |
Table 4.
Summary of Evaluation Data.
| Domain | Test Description | Benchmark |
|---|---|---|
| Abstract Algebra | Evaluates the model's understanding of algebraic structures such as groups, rings, and fields, fundamental in advanced mathematics | MMLU |
| Anatomy | Assesses knowledge of human anatomical structures and systems, essential for medical and biological sciences | MMLU |
| Astronomy | Tests comprehension of celestial objects, phenomena, and the universe's structure, crucial for astrophysics studies | MMLU |
| Business Ethics | Evaluates understanding of moral principles in business contexts, important for corporate governance and ethical decision-making | MMLU |
| Clinical Knowledge | Measures proficiency in medical knowledge and clinical practices, vital for healthcare professionals. Included in the MMLU benchmark | MMLU |
| College Biology | Assesses understanding of biological concepts at the college level, covering topics like genetics, ecology, and physiology | MMLU |
| College Chemistry | Tests knowledge of chemical principles, reactions, and laboratory practices at the collegiate level | MMLU |
| College Mathematics | Evaluates proficiency in higher-level mathematics, including calculus, linear algebra, and differential equations | MMLU |
| Econometrics | Assesses the ability to apply statistical methods to economic data, essential for economic analysis and forecasting | MMLU |
| Electrical Engineering | Tests knowledge of electrical circuits, systems, and signal processing, fundamental for engineering disciplines | MMLU |
| World Religions | Evaluates understanding of major world religions, their histories, beliefs, and cultural impacts | MMLU |
| Elementary Mathematics | Assesses basic mathematical skills, including arithmetic and elementary problem-solving | LLM Benchmarks |
| Global Facts | Tests general knowledge about world geography, politics, and global events | LLM Benchmarks |
| High School Chemistry | Evaluates understanding of chemical principles taught at the high school level | LLM Benchmarks |
| High School Computer Science | Assesses knowledge of basic computer science concepts, including programming and algorithms | LLM Benchmarks |
| High School Geography | Tests understanding of physical and human geography topics covered in high school curricula | LLM Benchmarks |
| High School Macroeconomics | Evaluates knowledge of economic principles related to the economy, such as inflation and GDP | LLM Benchmarks |
| High School Physics | Assesses understanding of fundamental physics concepts taught at the high school level | LLM Benchmarks |
| High School Psychology | Tests knowledge of psychological theories and practices covered in high school courses | LLM Benchmarks |
| Medical Genetics | Evaluates understanding of genetic principles and their medical applications, crucial for healthcare and research | MMLU |
| Nutrition | Assesses knowledge of dietary principles, human nutrition, and health implications | MMLU |
| Professional Accounting | Tests proficiency in accounting principles, financial reporting, and auditing practices | MMLU |
| Professional Law | Evaluates understanding of legal concepts, case law, and legal reasoning, essential for legal professionals | MMLU |
| Professional Medicine | Assesses clinical knowledge and medical practices required for healthcare providers | MMLU |
| Public Relations | Tests understanding of communication strategies, media relations, and public perception management | MMLU |
Table 5.
Performance of o1 across several tests in experiment 1.
| Test | Accuracy (%) |
|---|---|
| Abstract Algebra | 91 |
| Anatomy | 92 |
| Astronomy | 97 |
| Business Ethics | 81 |
| Clinical Knowledge | 93 |
| College Biology | 98 |
| College Chemistry | 77 |
| College Mathematics | 95 |
| Econometrics | 84 |
| Electrical Engineering | 90 |
| World Religions | 90 |
Table 6.
Performance of o1 across tests in experiment 2.
| Test | Accuracy (%) |
|---|---|
| Elementary Mathematics | 100 |
| Global Facts | 75 |
| High School Chemistry | 94 |
| High School Computer Science | 99 |
| High School Geography | 94 |
| High School Macroeconomics | 92 |
| High School Physics | 93 |
| High School Psychology | 99 |
| Medical Genetics | 99 |
| Nutrition | 96 |
| Professional Accounting | 74 |
| Professional Law | 54 |
| Professional Medicine | 88 |
| Public Relations | 81 |
| Sociology | 93 |
Table 7.
Sample o1 responses.
 |
 |
 |
 |
 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



