
Submitted:
22 January 2025
Posted:
22 January 2025
You are already at the latest version
Abstract
In this era, digital images and videos are ubiquitous in people’s lives. Today, generative models can easily produce high-quality images and videos. These images and videos enrich people’s lives and play important roles in various fields. However, maliciously generated images and videos can mislead the public, manipulate public opinion, invade privacy, and even lead to illegal activities. Therefore, detecting AI-created visual content has become a significant research topic in the field of multimedia information security. In recent years, the rapid development of deep learning technology has greatly accelerated the progress of AI-created visual content detection. This survey introduces the detection technologies for AI-created visual content that have developed in recent years, divided into two parts: AI-generated images detection and deepfake detection. In the AI-generated images detection section, we introduce current generative models and basic detection frameworks, and overview existing detection methods from the perspectives of unimodal and multimodal. In the deepfake detection section, we provide an overview of existing deepfake generation technique classifications, commonly used datasets, and evaluation metrics. We also analyze the technical characteristics of existing methods based on the different feature information they utilize, summarizing and categorizing them. Finally, we propose future research directions and conclusions, offering suggestions for the development of AI-created visual content detection technologies.
Keywords:
AI-created visual content
; AI-generated images detection
; deepfake detection
; deep learning
1. Introduction
In recent years, the rapid development of technology has significantly improved AI-created visual content techniques in terms of visual quality, semantic complexity, and operational efficiency. People can easily obtain high-quality images and videos by simply clicking a mouse or entering a text description. However, this unprecedented technology has also raised concerns about the spread of false information. Therefore, developing effective tools for AI-created visual content detection has become increasingly important. In this survey, we focus on deep learning-based AI-generated images detection techniques and deepfake detection technologies. AI-created visual content detection techniques are categorized based on different methods, as shown in Figure 1.
The current AI-generated images detection methods can be primarily divided into two categories: image classification tasks and image attribution tasks. Image classification tasks treat AI-generated images detection as a binary classification problem, where the detector learns to differentiate between real and fake images by identifying distinct features, thus outputting different labels to detect fake images. Image attribution tasks, on the other hand, leverage unique fingerprints and other characteristics specific to different generative models, matching them with the input image features to identify the generating model of fake images. Some studies also explore which aspects are more beneficial for detecting AI-generated images. Currently, most AI-generated images detection methods are based on image classification tasks. Starting with the simplest classifiers, the field has progressed to using deep neural networks (DNNs), convolutional neural networks (CNNs), and other neural networks for AI-generated images detection by incorporating spatial, frequency, texture, and other features. Later advancements involved cross-domain feature fusion and the use of image-text methods. AI-generated images detection technology has rapidly developed in recent years. Even though high-quality generated images may be indistinguishable from real ones to the human eye, statistical characteristics of the images still exhibit differences from real images. These differences enable detectors to distinguish between real and fake images. With the development of deep learning techniques, computers are now capable of learning these differences and performing effective detection.
In AI-created visual content technologies, deepfake technology allows the amazingly accurate modification of faces, sounds, or whole scenarios. This includes modifying facial expressions, swapping faces, adjusting lip-syncing in films, and more [1]. In 2017, a Reddit user named "Deepfake" used deep learning techniques to create and spread a pornographic video of Gal Gadot, marking the beginning of this technology’s tremendous rise. In 2022, a video of Ukrainian President Zelensky urging soldiers to surrender went viral, with over 250,000 viewers. In 2024, South Korea experienced a surge in deepfake-related sexual crimes, with potentially up to 220,000 victims, including many adolescent students and even minors. According to a security report by QAX in 2024, AI-based deepfake frauds surged 30 times in 2023, and AI-driven phishing emails increased 10 times. While deepfake technology does have some positive applications, its abuse has posed significant threats to national security, social media, and public trust. To address these challenges, researchers have focused on deepfake detection tasks, improving robustness and generalizability, and developing advanced methods. Among these, deep learning-based approaches have shown clear superiority in detection performance, so this survey primarily focuses on deep learning-based methods.
In the past few years, several surveys on AI-generated images detection technologies have been published. Hu et al. [2] outlined the mainstream frameworks of neural networks, briefly introduced the applications of deep learning in generative image and natural image forensics, and finally pointed out the challenges and future prospects of deep learning in this field. Deng et al. [3] studied research on defending against AI-generated visual media attacks. They summarized existing attack methods and defense strategies, and within a unified passive and active framework, reviewed mainstream defense-related tasks, evaluating their robustness and fairness. Additionally, they summarized commonly used evaluation datasets, standards, and metrics, but noted that there is limited research on AI-generated images detection methods. Guo et al. [4] categorized AI-generated images into active forensics and passive forensics, discussing the superiority of active forensics over passive forensics. However, most generative models do not embed watermarks in generated images, making this method highly limited. Lin et al. [5] conducted an extensive survey on AI-generated content detection, but the AI-generated images detection methods they reviewed were all from 2023, without analyzing or reviewing earlier methods. This survey briefly introduces generative models used for image generation, provides a comprehensive review of AI-generated images detection methods, and compares their advantages and disadvantages.
Several recent reviews have systematically summarized the existing deepfake detection techniques. Rana et al. [6] analyzed 112 relevant papers and categorized their methods into four types: deep learning-based techniques, classical machine learning-based methods, statistical techniques, and blockchain-based techniques. However, this paper does not delve into future trends. Seow et al. [7] provided a detailed introduction to deepfake generation, including the types of deepfakes and some available forgery tools. They reviewed existing deepfake detection work from two perspectives: traditional methods and deep learning-based methods. Gong and Li [8] grouped the surveyed methods into four categories: traditional CNN-based detection, CNN backbone with semi-supervised detection, transformer-based detection, and biological signal detection, according to their feature extraction methods and network architectures. Heidari et al. [9] focused on deep learning-based detection methods, providing a detailed study of four applications: video detection, image detection, audio detection, and hybrid multimedia detection. They also highlighted several unresolved issues that require further attention. Sandotra and Arora [10] focused on the generation of deepfakes, covering topics such as face manipulation methods, open-source tools, and so on. It classified forgery detection methods from the perspectives of space, time, and frequency features. Kaur et al. [11] provided a detailed classification of detection methods while discussing some challenges in the field, which are summarized into three categories: data challenges, training challenges, and reliability challenges. They also highlighted some of the main differences between deepfake image detection and video detection. Finally, it offered an outlook on future opportunities. The above reviews have conducted an in-depth analysis of past work, but none of them summarize detection methods from the perspective of the features used. Therefore, this review will start with feature selection and provide a discussion and analysis of existing deepfake detection algorithms.
The remainder of this survey is organized as follows: Section 2 provides the fundamentals of AI-generated images detection and deepfake detection, including datasets, basic detection frameworks, evaluation metrics, and more. Section 3 presents the state-of-the-art methods in AI-generated images detection. Section 4 discusses the state-of-the-art deepfake detection technologies, with a focus on the differences in feature selection approaches. Section 5 offers future research directions of AI-created visual content detection and conclusions.
2. AI-Created Visual Content Detection Techniques
This section introduces common generative models, forgery methods, AI-generated image detection techniques and deepfake technology’s basic framework, along with commonly used datasets and performance metrics.
2.1. AI-Generated Images Detection
This section will be elaborated in the following three parts: generative models for images, basic framework of AI-generated images detection and datasets for AI-denerated images detection.
2.1.1. Generative Models for Images
The rapid development of technology has led to the emergence of many generative models capable of producing high-quality images, such as generative adversarial networks (GANs) and diffusion models (DMs). We provide a brief introduction to GANs and DMs used for image generation.
GANs for Images:
In 2014, Goodfellow et al. [12] introduced generative adversarial network, which became a very effective method for image generation. It consists of two components: the discriminator and the generator. The goal is for the discriminator and generator to compete against each other, where the generator tries to produce images that can deceive the discriminator, and the discriminator aims to identify images generated by the generator. Overall framework is shown in Figure 2.
The mathematical expression of the loss function L for the model can be written as Equation (1):
where the probabilities and represent the outputs of the discriminator and the generator, respectively. The discriminator aims to minimize the loss, while the generator seeks to maximize it, thus creating an adversarial process.
Due to the superiority of GANs in image generation, numerous variants of GANs have emerged in recent years, particularly for image-related applications. In 2017, Chollet et al. [13] introduced deepfake, which replaces the Inception module with depthwise separable convolutions, achieving better results with the same number of parameters. Following that, Zhu et al. [14] introduced CycleGAN, an unsupervised learning-based GAN that enables style transfer without requiring extensive data preparation. In 2018, Bellemare et al. [15] designed a unique loss function and introduced CramerGAN, a model capable of generating high-quality images. Karras et al. [16] introduced ProGAN, which learns to generate high-resolution images progressively, starting from low-resolution ones. To address the single-domain transfer issue seen in models like CycleGAN, Choi et al. [17] introduced StarGAN, a model capable of performing multi-domain transfer with a single network.
In 2019, Brock et al. [18] incorporated the idea of orthogonal regularization into GANs, leading to the introduction of BigGAN, which significantly improves the generative performance of GANs through timely truncation of the input prior distribution. He et al. [19] introduced AttGAN by incorporating an attribute classification constraint to enable more precise manipulation of image attributes. Wu et al. [20] proposed RelGAN, a GAN based on relative attributes, which allows for the modification of images by continuously altering specific attributes of interest. Park et al. [21] introduced GauGAN, a network capable of generating images from textual descriptions, marking a new era in image generation. Karras et al. [22] re-examined the limitations of ProGAN and, drawing inspiration from style transfer, proposed StyleGAN. Due to occasional artifacts in images generated by StyleGAN, Karras et al. [23]improved upon it, resulting in StyleGAN2, which generates higher-quality images. In 2021, Lee et al. [24] enhanced GANs by incorporating contrastive learning and mutual information maximization techniques, presenting InfoMaxGAN.
DMs for Images:
In 2020, Ho et al. [25] introduced the diffusion model, which involves both forward and reverse propagation processes. The quality of images generated by this model surpassed that of GANs, offering advantages such as greater diversity and more stable training. This marked the beginning of the growing popularity of diffusion models. In 2021, Ramesh et al. [26] proposed DALLE, a model capable of generating surrealistic images directly from textual descriptions. Dhariwal et al. [27] introduced ADM, which incorporated classifier guidance to improve the quality of generated images. In 2022, Nichol et al. [28] introduced Glide, which employed classifier-guided generation by training an additional classifier to continually refine the generated image at each timestep, ultimately generating images belonging to specific categories. Saharia et al. [29] proposed Imagen, which featured two super-resolution diffusion models for generating high-resolution images. Rombach et al. [30] introduced stable diffusion (SD), which transformed the diffusion process into a low-dimensional latent space, addressing the issue of large sampling spaces. Subsequently, a series of variants of SD were released. Gu et al. [31] introduced VQDM, which segmented images into patches and used VQ-VAE to model the relationship between patches and token indices, significantly improving computational efficiency. Then, commercial models such as Midjourney [32] and Wukong [33] emerged, greatly enhancing the quality and speed of image generation. The basic process of image generation using diffusion models is shown in Figure 3.
In 2024, Shirakawa and Uchida [34] proposed a novel layout-aware text-to-image diffusion model, NoiseCollage, which independently estimates the noise for each object and then crops and merges them into a single noise, helping to avoid conditional mismatches. Shiohara and Yamasaki [35] introduced the Face2Diffusion method for highly editable facial personalization. They remove identity-irrelevant information from the training process to prevent overfitting and improve the editability of facial encoding. Cao et al. [36] proposed LeftRefill, a model that effectively learns the structural and texture correspondence between the reference and target without the need for additional image encoders or adapters. Zhou et al. [37] introduced MIGC, a method that ensures the generated instances are accurately placed at specified locations based on a set of predefined coordinates and their corresponding descriptions. Hoe et al. [38] proposed an interactive control model called InteractDiffusion, which extends existing pre-trained T2I diffusion models to better condition on interactions. Höllein et al. [39] introduced ViewDiff, which leverages a pre-trained text-to-image model as a prior and learns to generate multi-view images through a single denoising process from real-world data.
2.1.2. Basic Framework of AI-Generated Images Detection
The rapid development of deep learning technology has led to its increasingly widespread application in various fields, achieving significant advantages in many areas, with AI-generated images detection being one of them. High-quality fake images can deceive the human eye and even mislead the public through media dissemination, causing panic. Therefore, there is an urgent need for detectors capable of identifying fake images. The basic framework for AI-generated images detection based on deep learning is shown in Figure 4.
2.1.3. Datasets for AI-Generated Images Detection
To validate the performance of AI-generated images detection technology, many studies have published relevant datasets. Table 1 describes eight public datasets used for AI-generated images detection technology, showing the types of generative models included and the number of images.
2.2. Deepfake Generation and Detection
Since the taking off of deep learning before 2012, deep learning architectures have rapidly evolved, driving significant advancements in deepfake research [46]. With the support of this technology, the types of synthetic fake faces have become diverse, and their quality continues to improve, making it impossible for the human eye to make judgments. Driven by this demand, detection technologies have progressed rapidly, and researchers have begun to leverage various feature information to enrich the body of research in this field. Therefore, in the following sections of this paper, a more in-depth discussion will be provided. Before that, this section will introduce some fundamental knowledge of this field, including deepfake generation technologies, existing deepfake detection datasets, and evaluation metrics.
2.2.1. Deepfake Generation
From traditional techniques, autoencoders (AE), and GANs to DMs, image generation architectures have continuously improved. In existing datasets, these techniques can generally be categorized into four types: identity swapping, face reenactment, attribute editing, and entire-face synthesis. Identity swapping involves directly replacing one person’s facial features with another’s, preserving all facial attributes. Face reenactment synchronizes one person’s facial expressions or actions onto another person to create a forgery. Attribute editing allows modifications to certain facial features, such as age, gender, hairstyle, or skin color, without altering the identity of the person. Entire-face synthesis generates a completely virtual facial image using GANs or other generative models. Finally, we provide the generation process or example forged faces for these techniques, as shown in Figure 5.
2.2.2. Existing Deepfake Datasets
The dataset is primarily used to train, validate, and evaluate the quality and performance of the model. The earliest deepfake detection datasets, such as UADFV [49] and Deepfake TIMIT [50], not only had a small quantity but also poor quality, to the extent that the authenticity could be easily discerned by the human eye. However, with the rise of deepfake detection and the increasing involvement of researchers, various high-quality and challenging datasets have been proposed. Datasets such as FaceForensics++ (FF++) [51], WildDeepfake (WDF) [52], and deepfake detection challenge (DFDC) [53] have become widely used in scientific research, and the forgery techniques used are diverse, significantly increasing the difficulty of detection. Among them, the FF++ dataset uses five deepfake techniques: DeepFakes, Face2Face, FaceSwap, NeuralTextures, and FaceShifter, with three different compression levels—c0, c23, and c40. It has been used for model training in nearly all related studies. Therefore, to assist future researchers in understanding this field, we have organized the existing datasets based on four aspects: modality, real/fake quantity, source, and generation technique, as shown in Table 2.
2.2.3. Evaluation Metrics
Deepfake detection is a binary classification task, where the input image is classified as either real (positive) or fake (negative). Therefore, in actual classification, four possible outcomes can occur, including true positive, false negative, false positive and true negative, which can be represented by a confusion matrix, as shown in Table 3.
In AI-created visual content detection field, commonly used evaluation metrics include accuracy, receiver operating characteristic curve, area under curve, equal error rate, and precision, which will be introduced below.
Accuracy (a) is the proportion of correctly predicted images out of all input images, a higher value indicates better model performance, which is expressed as Equation (2):
Receiver operating characteristic (ROC) curve is commonly used to evaluate the performance of binary classifiers. First, we define the following three concepts: True positive rate (TPR, ), true negative rate (TNR, ), false positive rate (FPR, ), and false negative rate (FNR, ), which are expressed as Equations (3)–(6):
The ROC curve plots the on the vertical axis and the on the horizontal axis. By setting different thresholds, diverse values of and are obtained. As the threshold decreases, more instances are classified as positive, but these positive instances also include some negatives, causing both and to increase simultaneously. When the threshold is at its maximum, the corresponding point on the ROC curve is (0, 0), and when the threshold is at its minimum, the corresponding point is (1, 1).
Area under curve (AUC) refers to the area under the ROC curve. Since the ROC curve typically lies above the diagonal line , the AUC value ranges from 0.5 to 1. A larger AUC indicates better model performance. Specifically, an AUC value of 0.5 suggests a model with no discriminative ability (equivalent to random guessing), while an AUC value of 1 indicates perfect classification performance.
Equal error rate (EER) is the point on the ROC curve where the and are equal. Since , EER occurs when on the ROC curve. This can be determined by drawing a line from (0, 1) to (1, 0) on the ROC curve. The lower the EER, the higher the classification accuracy of the model.
Precision (p), based on the prediction results, is the proportion of correctly predicted positive samples among those predicted as positive. The results predicted as positive can fall into two categories: either they are or . It can be expressed as Equation Equation(7):
Recall (r), based on the actual samples, is the proportion of correctly predicted positive samples among all actual positive samples. The actual positive samples can be either correctly predicted as or incorrectly predicted as . be expressed as Equation Equation(8):
3. AI-Generated Images Detection Methods Based on Deep Learning
The AI-generated images detection methods can be categorized based on modality into unimodal and multimodal approaches. When classified according to the required features, unimodal methods can be further divided into spatial domain-based, frequency domain-based, and cross-domain features fusion-based. Multimodal methods mainly focus on image-text combinations. This section introduces various AI-generated images detection methods. At the end of this section, a table is provided that compares the characteristics, advantages, and limitations of these methods. An overview of deep learning-based AI-generated images detection methods is shown in Figure 6.
3.1. Spatial Domain-Based
Most methods are based on the spatial domain, so this section will categorize spatial domain-based methods into spatial features-based, color features-based, texture features-based, and other methods.
3.1.1. Spatial Features
Marra et al. [63] conducted a comparison of several detectors for generated image detection, highlighting performance differences and finding that only deep learning-based detectors maintained high accuracy even on compressed data. Hsu et al. [64] employed contrastive loss to identify typical features of synthetic images generated by different GANs, followed by the connection of a classifier to detect these computer-generated images. Yu et al. [65] proposed the first study on learning GAN fingerprints for image attribution. They first reconstructed images through an autoencoder to obtain image fingerprints, then calculated the similarity between image fingerprints and GAN fingerprints to trace back to the image generation model. Zhuang et al. [66] focused on detecting generated images based on GAN noise residual similarity, proving the existence of GAN fingerprints and discovering that training the same architecture on different datasets produced distinct fingerprints. Marra et al. [67] utilized triplet loss to learn discriminative features between real and fake images, and then introduced a novel dual network that accurately captured both local and global features of forged or authentic images. Marra et al. [68] employed an incremental learning approach for generated image detection, which also showed good performance when detecting previously unseen GAN models.
In 2020, Wang et al. [69] incorporated data augmentation techniques into the training phase, which improved the model’s performance and generalization ability. The GAN dataset they proposed has also been widely used. Jeon et al. [70] introduced the transferable GAN-images detection framework (T-GD), which consists of a teacher model and a student model. These two models iteratively teach and evaluate each other, thereby enhancing detection performance. Chai et al. [71] divided images into multiple patches and employed a patch-based classifier for generated image detection, finding visible artifacts in some image patches. Mi et al. [72] applied a self-attention mechanism to extract global information for generated image detection. In 2021, He et al. [73] employed super-resolution, denoising, and colorization as reconstruction methods to obtain residuals by regenerating denoised images and used a binary classifier for detection. Li et al. [74] constructed reference features for both real and fake images from datasets, and performed generated image detection by calculating the similarity between the input image and the reference features. However, this method depends on the quality and category of the datasets. Girish et al. [75] employed an iterative algorithm to detect previously unseen GAN-generated images by leveraging the unique fingerprints left by GANs on the generated images.
In 2022, Liu et al. [76] identified distinct characteristics in the noise patterns of real and fake images and designed an LNP extraction block to extract noise features from the images. By exploiting the noise patterns unique to real images, they designed a simple classifier for detection. Jeong et al. [77] synthesized images from real images and used them to train a classifier. Zhang et al. [78] proposed an unsupervised domain adaptation strategy to improve the generalization capability of the model. Ju et al. [79] extracted global spatial information and local informative features from multiple image patches and utilized a multi-head attention mechanism to fuse the global and local features for image detection. Mandelli et al. [80] divided images into patches and input them into multiple CNNs to obtain various features, then used ensemble learning to detect generated images.
In 2023, previous methods mainly targeted GANs, and due to the superior image generation quality of diffusion models, these methods performed poorly on images generated by diffusion models. To address this issue and improve generalization across unknown generative models, many new approaches have emerged in recent years. Tan et al. [81] argued that the trend of pixel-level changes differs between real and generated images, and employed CNNs as a transformation model to convert images into gradients, using these gradients as input for image detection. Ojha et al. [82] used CLIP [83] for generative image detection and found that CLIP exhibited good generalization capability for detecting generated images. To address the challenges faced by existing detectors in detecting images generated by diffusion models, Wang et al. [84] utilized the residual differences (DIRE) between real and synthesized images before and after reconstruction to detect diffusion model-generated images. However, this approach showed a decline in performance when detecting GAN-generated images due to its focus on diffusion models. Xu et al. [85] developed a hybrid neural network based on attention-guided feature extraction (AGFE) and vision transformers-based feature extraction (ViTFE) modules, designed to capture both long-range and global features.
In 2024, Ju et al. [86], building on the work in [79], divided ResNet-50 into multiple layers to separately extract low-level and high-level features. They then constructed a Patch Selection Module to extract high-energy patches, followed by the fusion of global and local features for image detection. Zhang et al. [87] developed a three-branch network, which alternately trains between the backbone network and auxiliary networks. Tan et al. [88] proposed neighboring pixel relationships (NPR) for image detection, based on the observation that upsampling causes correlations between neighboring pixels. Lim et al. [89], building on the work in [84], introduced a lightweight diffusion-synthesized deepfake detector with faster computation. Yan et al. [90] expanded the forgery space by constructing and simulating internal and inter-feature variations in the latent space, improving the model’s generalization ability. Wang et al. [91] proposed a method to check if the examined images could be well-reconstructed using an inverted latent input to detect generated images. Chen et al. [92] reconstructed both real and fake images, and based on four categories of images-real, real-reconstructed, fake, and fake-reconstructed-they used contrastive learning loss to train a classifier, achieving a more accurate decision boundary. Sinitsa et al. [93] proposed the use of the deep image fingerprint method for generative image detection. He et al. [94] introduced RIGID, a model-agnostic, training-free method for detecting AI-generated images, which works by comparing the similarity between the original image and a slightly perturbed version in the visual model representation space. Liang et al. [95] repeatedly employed contrastive learning to extract common features from real images, concatenating them with fake image features, and feeding them into a detector. Chen et al. [96] proposed randomly cropping the image, selecting the simplest patch, resizing it, and feeding it into the detector. Zhang et al. [97] utilized a pre-trained diffusion model to extract universal image representations for generative image detection. Finally, Yang et al. [98] introduced the discrepancy deepfake detector framework, incorporating a parallel network branch that uses distorted images as additional discrepancy signals to supplement the original images, thereby learning general forgery features from multiple generators. The comparison of spatial features-based methods is shown in Table 4.
3.1.2. Color Features
Some studies have found that generative models fail to capture the color characteristics of real images and have proposed detection methods based on color features.
In 2019, He et al. [99] utilized residual signals from chroma components in multiple color spaces and employed CNNs to learn robust deep feature representations. These features were then input into a random forest classifier to obtain the final detection results. In 2022, Chandrasegaran et al. [100] analyzes transferable forensic features (T-FF) in universal detectors and proposes a novel forensic feature relevance statistic (FFRS) to quantify and discover T-FF in these detectors. Additionally, it was found that color is a key T-FF in the detectors. Uhlenbrock et al. [101] found that natural and synthetic images differ in their color statistics, and thus, they used simple handcrafted color functions combined with random forests for generative image detection. Qiao et al. [102] selected several color components that exhibited significant differences between real and synthetic images and employed the cross-color spatial co-occurrence matrix (CSCM) to extract color features for generative image detection. The comparison of color features-based methods is shown in Table 5.
3.1.3. Texture Features
AI-generated images (such as those generated by GANs) often exhibit differences from real images in aspects like texture consistency. Therefore, texture features can be helpful in distinguishing these images from authentic ones.
In these texture feature-based works, Liu et al. [103] identified significant differences in texture features between generative and real images, and proposed the use of the gram matrix to construct a gram-net for generative image detection. Yang et al. [104] introduced a novel multi-scale deep texture learning method, which captures multi-scale and deep texture features, incorporating an attention mechanism for feature fusion. Zhong et al. [105] observed that for existing generative models, synthesizing realistic and rich textured regions is more challenging. To address this, they leveraged the pixel-wise correlation between rich and sparse texture regions in images to distinguish generative images. Zhang et al. [106] proposed a deep local binary pattern network (DLBPNet), where each branch contains filters and LBP feature extraction, followed by a central difference convolution module to learn more advanced features. The comparison of texture features-based methods is shown in Table 6.
3.1.4. Others
Lorenz et al. [107] proposed using the lightweight multi local intrinsic dimensionality (MultiLID) method for detecting generated images, demonstrating strong performance in detecting images generated by diffusion models. Lin et al. [108] employed genetic programming for generative image detection, emphasizing the need for interpretability in the detection process. Sarkar et al. [109] discovered that generative models cannot perfectly replicate projective geometric shapes, and developed a detection method using newer cues, such as object-shadow cues, perspective field cues, and line segment cues, to detect generated images. In order to address the need for detection without relying on fake image training and to improve the ability to detect unknown generative models, Cozzolino et al. [110] found that generated images exhibit higher encoding costs and proposed a zero-shot detection method based on information entropy that utilizes encoding costs. To address the issue of detector bias towards training and testing sources, Tan et al. [111] employed invariant operators (such as the laplacian operator) alongside backbone networks for generative image detection, demonstrating a method that performs well without the need for training. The comparison of other methods is shown in Table 7.
3.2. Frequency Domain-Based
Zhang et al. [112] utilized unique artifacts in the frequency domain generated by GAN upsampling operations for generative image detection. Frank et al. [113] applied 2D-discrete cosine transform (DCT) to transform images into the frequency domain and performed generative image detection using ridge regression, optimizing parameters through grid search. Durall et al. [114] designed a spectral regularization term and incorporated it into the training optimization objective. This approach enables the training of spectral-consistent GANs that avoid high-frequency errors. Dzanic et al. [115] focused on high-frequency features for image detection and proposed a method to modify the high-frequency features of deep network-generated images to better mimic real images, also finding that spectral features are more easily distinguishable at high resolution and low compression rates. Bonettini et al. [116] used Benford’s Law to extract a compact feature vector from images, which could be input into a very simple classifier for generative image detection.
Chandrasegaran et al. [117] discovered that the high-frequency fourier spectral decay differences are not inherent features of existing CNN-based generative models and, therefore, cannot be used for robust generative image detection. Dong et al. [118] proposed a method to mitigate spectral artifacts, effectively reducing artifacts in the spectra of fake images, thus significantly improving the performance of frequency-based detectors. Corvi et al. [119] identified that diffusion models, like GANs, exhibit distinct fingerprints in the frequency domain, and incorporating a diffusion model during training helps detect images generated by diffusion-based models. Corvi et al. [120] further found significant differences between real and generated images in spatial autocorrelation functions, angular spectra, and radial spectra. Based on these differences, they designed high-performance detectors for generative image detection.
In 2024, Bammey et al. [121] used high-pass filtering to obtain image residuals, then applied Fourier transforms to generate spectral maps, which were subsequently fed into a classifier for detection. Pontorno et al. [122] conducted a detailed examination of the statistical distribution of discrete cosine transform coefficients, training machine learning classifiers on different combinations of coefficients. Their experiments revealed that traces left by generative models are more distinguishable and persistent under JPEG attacks. Tan et al. [123] proposed a novel frequency-aware method called FreqNet, which centers on frequency learning and focuses on the high-frequency components of images. The method employs both phase and magnitude spectra for classification. Their designed frequency-domain learning module is capable of learning features that are independent of generative models, thus improving the model’s generalization ability. To address the issue of model overfitting to training data, Doloriel et al. [124] introduced a frequency-domain masking approach. By applying random masks to the image’s frequency domain, their method prevents the detector from overfocusing on all the image information. Weng et al. [125] proposed an innovative local frequency analysis (LFA) method, which combines medium-scale frequency domain analysis using Krawchouk moments and fine-scale frequency domain analysis via discrete cosine transform. This method enables multi-scale frequency analysis of images, allowing for the extraction of more comprehensive features. The comparison of frequency features-based methods is shown in Table 8.
3.3. Cross-Domain Features Fusion-Based
As generative models continue to evolve, the quality of generated images has significantly improved, making them increasingly difficult for the human eye to distinguish. As a result, traditional detection methods have become less effective in identifying outputs from newer generative models. The performance of generators designed with only single-domain features is limited, and as a result, an increasing number of detectors are utilizing cross-domain feature fusion techniques for detecting generated images. Yu et al. [126] proposed a method based on channel difference image (CDI) and spectrum image (SI), employing octave convolution and an attention-based fusion module. This approach effectively extracts intrinsic features from these two domains to detect AI-generated images. To capture GAN fingerprints at different levels, Liu et al. [127] introduced a decoupling representation framework, which is designed to separate and extract two types of GAN fingerprints from different domains. This framework also incorporates an adversarial data augmentation strategy and a transformation-invariant loss to enhance the robustness of the fingerprints against image perturbations.
In 2024, The cross-domain features fusion method has been rapidly developing, with an increasing number of approaches leaning towards identifying distinguishing features between real and fake images from multiple domains. Luo et al. [128] proposed the latent reconstruction error (LaRE), the first feature based on reconstruction error in latent space. They also introduced an error-guided feature refinement module (EGRE) that refines image features guided by LaRE to improve their discriminability. The EGRE utilizes an alignment and refinement mechanism to effectively refine image features from both spatial and channel perspectives for generative image detection. Lanzino et al. [129] constructed a classifier using a combination of fast fourier transform (FFT) frequency-domain features, local binary pattern (LBP) texture features, and pixel-domain features. They also employed convolution to reduce the number of channels for detecting generated images. Wißmann et al. [130] trained a classifier using DCT, power spectral density (PSD), and autocorrelation coefficients, finding that DCT and PSD demonstrated excellent performance in robust detection and high-precision attribution. Gallagher et al. [131] proposed a dual-branch neural network architecture that takes both images and their Fourier frequency decompositions as inputs. The network uses CNNs for feature fusion to detect generated images. Meng et al. [132] introduced the artifact purification network (APN), separated and extracted artifact features from both the spectrum and spatial domain, and further aggregate the diluted artifact information in the features. Xu et al. [133] designed a global feature extraction module based on attention using MobileViT to learn deep representations of global tracking information. Additionally, multiple enhanced residual blocks are employed to extract distinctive multi-scale features. Leporoni et al. [134] argued that the generation of fake content introduces potential inconsistencies in the depth of generated images. They proposed a method that inputs both RGB and depth images into the backbone network, which utilizes an RGB attention mechanism to perform final feature fusion. Yan et al. [135] concatenated DCT high and low-frequency local image block features with CLIP global semantic features for classification. The comparison of cross-domain features fusion methods is shown in Table 9.
3.4. Image-Text
With the development of multimodal language models like CLIP and Flamingo, these models have demonstrated good generalization capabilities in AI-generated images detection. As text-to-image generation technology becomes more widespread, many studies have focused on utilizing multimodal models such as CLIP as the backbone network for detection. By combining the visual features of image content with the semantic features of text descriptions, detection is performed through the consistency, contrast, and alignment between the image and text, thus enabling the identification of generated images.
Based on the aforementioned multimodal language models, Sha et al. [136] investigated how the prompts used to generate fake images affect detection and attribution, and verified that fake images exhibit a higher correlation with text descriptions. To address the generalization issue of detectors, Wu et al. [137] designed textual labels to improve performance. Moreover, they transformed the synthetic image detection problem into a recognition task, fine-tuning CLIP’s image encoder and text encoder based on contrastive learning loss, bringing the features of fake images closer to the "fake photo" prompt text features. Liu et al. [138] proposed the forgery aware adaptive transformer approach (FatFormer). First, a forgery-aware adapter detects local forgery traces in both image and frequency domains. Then, FatFormer incorporates language-guided alignment, supervising forgery adaptation using both image and text prompts. Cazenavette et al. [139] mapped the original image to latent space using the VAE encoder from stable diffusion. They then used DDIM for inversion and reconstruction, relying on the CLIP embeddings of BLIP-generated image captions. Finally, they concatenated the original image, decoded noise image, and decoded reconstruction image for generative image detection. Khan et al. [140] built four detectors based on different strategies using CLIP, including prompt tuning, adapters, fine-tuning, and linear probing, for generative image detection. Keita et al. [141] proposed an innovative method called Bi-LORA, which combines visual-language models (VLMs) and low-rank adaptation (LoRA) tuning techniques to improve the detection accuracy of synthetic images generated by unseen models. Building on this approach, Keita et al. [142] further used Bi-LORA to learn text features that align with image features and then employed a large language model to output real or fake text. Sha et al. [143] first generated DDIM inversion noise through adversarial prompts. They then reconstructed the image from the generated noise and compared the reconstructed image with the original image to determine whether the image was real or fake. The comparison of image-text-based methods is shown in Table 10.
4. Deepfake Detection Based on Feature Selection
Deepfake detection methods can be broadly classified into four categories based on the feature information utilized, including methods based on spatial features, spatiotemporal features, biological features, and identity features. Among these, spatial features and spatio-temporal features can be considered general features, while biological features and identity features are considered special features, typically requiring specialized network architectures for extraction. Therefore, this section will present an article review in these four directions, and we have also summarized and organized the selected articles, as shown in Figure 7.
4.1. Spatial Features-Based
The initial deepfake detection methods primarily relied on spatial features, including texture features, tampering artifacts, etc. These methods focused on single-frame analysis, achieving simple and effective detection by extracting forgery clues from different domains. Based on the source of information, these methods can be categorized into space domain-based, frequency domain-based, and multi-domain fusion approaches.
4.1.1. Space Domain Information-Based
In the field of deepfake detection, the space domain is a commonly used source of information. Many researchers have improved model performance by designing network architectures, applying image preprocessing techniques, or leveraging specific spatial inconsistencies. As an earlier method, Afchar et al. [144] used a shallow convolutional network to extract mid-level features from images for forgery detection and achieved video-level detection through image aggregation. Li et al. [145] proposed Face X-ray, which detects the blending boundary in forged faces through synthetic data training. It performs classification while also locating the blending areas, but this approach does not apply to completely synthesized fake images. Bonettini et al. [146] used EfficientNetB4 as the backbone network and incorporated attention layers and siamese training mechanisms, highlighting the role of these mechanisms through ablation studies.
To address the issue of limited generalization due to the commonly used fake data, researchers have proposed the idea of synthetic data, which helps make the trained models more generalizable. Shiohara and Yamasaki [147] proposed self-blended images (SBI) to prevent the model from overfitting to specific forgery methods. By using a data synthesis strategy to reproduce general forgery artifacts, they improved the model’s generalization ability. The general synthesis process of SBI is shown in Figure 8. The basic idea is to generate the target image and the pseudo source image from the base image, and then blend the two images using a face mask, thereby creating general visual artifacts. Chen et al. [148] also employed data synthesis methods, but they enriched the diversity of synthetic data by introducing multi-configuration strategies and used adversarial training to enable the model to learn more robust feature representations. Lin et al. [149] designed self-shifted blending images to simply fuse temporal artifacts, searching for a suitable augmentation scheme during training. Their curriculum learning-based training strategy further enhanced model performance. Guan et al. [150] introduced a gradient regularization term into the original loss function to reduce the model’s sensitivity to texture features. The new loss function improved the model’s robustness to shallow feature statistical perturbations and could be combined with existing backbone networks or methods to further enhance detection performance.
Additionally, Gao et al. [151] proposed separating texture and artifact information in the features and performing face and background separation using estimated masks obtained through self-supervised learning strategies. This allowed for the extraction of more detailed texture information, which was then combined with artifacts for detection. Lu et al. [152] proposed a long-distance attention mechanism based on fine-grained classification and designed spatial and temporal attention modules to obtain local region attention maps from single and consecutive frames. To address the generalization issue, Zheng et al. [153] combined unsupervised-supervised contrastive learning for deepfake detection. They mined features from both original and data-augmented images, performed multi-scale fusion, and applied contrastive loss constraints between individual samples and diverse class features, achieving effective and stable detection. Since forgeries disrupt the consistency of regional noise, Bai et al. [154] proposed a method that leverages the noise pattern differences between the face and background regions. They performed noise enhancement and multi-scale integration to effectively detect forged images. Ma et al. [155] utilized incremental learning strategies to improve the model’s generalization performance with limited samples and combined human perception saliency with self-attention to highlight important regions. Lu et al. [156] designed a multi-scale texture feature extraction module using central difference convolution, effectively enhancing the quality of texture features. They also introduced region-specific separable self-consistency loss to constrain the representation learning of different regions and emphasize important areas. Table 11 summarizes these methods from three aspects: key idea, backbone, and dataset.
4.1.2. Frequency Domain Information-Based
Space domain-based detection methods can achieve good detection performance; however, when subjected to common attacks such as noise or compression, the forgery clues become harder to detect. Additionally, the traces left by different forgery methods vary, which limits further improvement in generalization performance. On the other hand, the frequency domain information of an image, especially high-frequency components, contains edges and other fine details that are more resilient to attacks. Furthermore, different forgery methods tend to generate unnatural artifacts in the frequency domain, which makes it possible to detect forgery traces that are difficult to identify in the space domain. Therefore, incorporating frequency domain information can enhance the robustness and generalization of the detection model.
In these methods, common frequency domain information extraction techniques include FFT, DCT, and discrete wavelet transform (DWT). Peng et al. [158] designed a high-frequency residual extraction module based on the Laplacian pyramid, utilizing the high-frequency components of shallow features to extract visual artifacts. Qian et al. [159] used DCT for domain transformation and integrated frequency-aware decomposition images and local frequency statistics through a dual-stream collaborative learning framework to mine forgery clues. Li et al. [160] restructured DCT coefficients across different frequency bands while preserving the original spatial relationships, allowing the use of convolutional networks for frequency feature extraction. They also employed a single-center loss to compress intra-class variations and expand inter-class differences. Gao et al. [161] addressed the difficulty of detecting compressed data by proposing a high-frequency enhancement framework that integrates comprehensive frequency-domain information from block-wise DCT and DWT. Using a two-stage cross-fusion strategy, they effectively merged information and achieved high accuracy on highly compressed data.To address the limitation of self-attention in capturing subtle clues, Miao et al. [162] introduced the central difference operators to extract fine-grained feature details and used DWT to supplement local high-frequency information, achieving strong accuracy and robustness. To supplement fine-grained information in transformer, Li et al. [163] embedded wavelet transforms into self-attention and designed down-sampling strategies for information enhancement across stages. Through optimal data augmentation, they effectively improved generalization performance. Hasanaath et al. [164] extracted discriminative generic features from self-blended images using DWT and fed them into a CNN for deepfake classification. Zhao et al. [165] introduced an adaptive fourier neural operator to learn frequency-domain forgery clues and applied an efficient attention mechanism to enhance detailed information while reducing the computation.
4.1.3. Multi-Domain Information Fusion-Based
To leverage complementary information from different domains, many researchers have fused multi-domain features to obtain more comprehensive feature representations. Table 13 compares the multi-domain information fusion-based methods in terms of information sources, fusion methods, backbone, and datasets.
Wang et al. [166] calculated the residual between the original grayscale image and the low-frequency components of the DWT to obtain the mid-high frequency image, which was then concatenated with the RGB image and fed into a convolution network for classification. Wang et al. [167] integrated deep-frequency domain information extracted from residual maps reflecting facial edge information with wavelet frequency domain and RGB domain information. Zhou et al. [168] fused multi-scale RGB features with frequency-domain-aware features based on FFT. Le and Woo [169] used attention distillation to transfer high-frequency components learned by a teacher model trained on high-quality data to a student model, enhancing feature discrimination under low-quality data conditions. To restore the model’s attention to compressed artifacts, Wang et al. [170] designed a spatial-frequency feature fusion architecture and also employed knowledge distillation to transfer feature representations from a teacher model to a student model. Most existing methods focus on improving traditional convolutional backbones, but Guo et al. [171] designed a new space-frequency interactive convolution module that integrates space domain information and high-frequency information through interaction, resulting in more refined feature representations.
High-pass filters in spatial rich model (SRM) can extract high-frequency noise from images, removing color textures and revealing the differences between the real and forgery regions. The three commonly used filtering kernels and their resulting noise residual images are shown in Figure 9. Based on this observation, Luo et al. [172] used SRM to extract multi-scale high-frequency residuals as an information branch and generated residual attention maps to highlight forgery clues in the RGB branch features. Their cross-modal fusion achieved efficient utilization of the dual-branch information. Zhang et al. [173] also fused high-frequency noise with spatial texture features and used local attention to enhance forgery traces. Fei et al. [174] supplemented noise features while calculating first and second order local anomaly maps in the RGB branch, magnifying and learning the local anomaly information of forged images for more generalizable detection. Dong et al. [175] treated SRM high-frequency noise as data augmentation and employed supervised contrastive learning to minimize the positive pair distance, improving the generalization performance of the model.
4.2. Spatio-Temporal Features-Based
The consecutive frames of an original video have natural consistency, but deepfake videos are composed of individual forged images linked together, which disrupts the original spatio-temporal consistency and introduces forgery traces in the temporal domain. Spatial feature-based detection methods fail to account for this disruption, making them unsuitable for video-level detection. As a result, some researchers have started designing frameworks for extracting spatio-temporal features. The backbone networks used in these methods mainly include CNN, recurrent neural networks (RNN), and transformer, so these methods can be divided into three categories: CNN-based, CNN+RNN-based, and transformer-based.
4.2.1. CNN-Based
CNN-based methods typically involve special designs for feature extraction or the use of 3D CNNs. Liu et al. [176] integrated RGB domain and frequency domain information, utilizing locally sensitive regions to enhance forgery features, and employed a 3D CNN to supplement temporal domain information. Concas et al. [177] proposed an innovative method for extracting forgery artifacts by performing facial quality estimation on the face region of single-frame or consecutive-frame images and generating a quality feature matrix that is input into a CNN for forgery detection. Existing methods tend to capture spatio-temporal information with fixed time steps, rarely focusing on the extraction of dynamic spatio-temporal inconsistencies. Pang et al. [178] designed a video sampling strategy, BGS, which used different sampling rates to obtain multiple video frame sets and extracted short-term and long-term spatio-temporal information in subsequent networks, enabling full utilization of forgery clues. Zhang et al. [179] proposed a frame sampling strategy with temporal diversification and used self-contrastive learning to extract short-term and long-term temporal artifacts, reducing the model’s sensitivity to binary labels. Yu et al. [180] applied multi-path dynamic inconsistency magnification to multiple groups of sampled frames to extract local-consecutive fine-grained features, used graph convolution network (GCN) to obtain global temporal views across multiple groups and designed a domain alignment module to improve generalization performance.
To fill the gap in frequency domain spatio-temporal information for deepfake detection, Wang et al. [181] proposed a frequency domain forgery clue augmentation strategy based on DCT. They first enhanced the high-frequency components of the DCT spectrum, then divided it into multiple blocks along the spatial dimension, replacing the original spectrum with the maximum response to reduce computational complexity. The attention map obtained from the frequency temporal attention module enhanced temporal clues. Wu et al. [182] designed patch-wise decomposable DCT to extract finer-grained high-frequency clues and extracted comprehensive spatio-temporal representations of both RGB and frequency branches in stages. An interaction module was used to eliminate cross-modality feature inconsistencies, achieving effective feature fusion.
4.2.2. CNN+RNN-Based
Since CNNs are primarily used for extracting spatial information from images and are not effective at capturing temporal dependencies, applying RNNs for temporal modeling of the features extracted by CNNs has become an effective solution. RNNs, especially long short-term memory (LSTM) networks, are well-suited for modeling sequential data and capturing the temporal relationships between frames in video, which helps improve the detection of temporal inconsistencies in deepfake videos. By combining CNNs for spatial feature extraction with RNNs for temporal sequence modeling, such hybrid approaches can better leverage both spatial and temporal information for more accurate and robust deepfake detection.
The general process of using a CNN and RNN hybrid model for detection is shown in Figure 10. In this process, the CNN extracts spatial features from the facial image, the RNN performs temporal modeling on the spatial features, and finally, classification is performed. Based on this process, Guera and Delp [183] used InceptionV3 to extract frame features and input them into an LSTM to learn inter-frame inconsistencies, achieving video-level classification. Saikia et al. [184] utilized optical flow from consecutive face frames and fed it into a hybrid model of CNN and LSTM to extract temporal information. Chen et al. [185] introduced a spatio-temporal attention mechanism to enhance the temporal correlation between frames, and the augmented frames were input into Xception and ConvLSTM to extract spatial and temporal inconsistencies. K and M [186] optimized network weights using the spotted hyena optimizer during the hybrid model training. Amerini and Caldelli [187] used image prediction errors as inputs to incorporate temporal information; however, the increase in complexity led to a decrease in generalization ability. Masi et al. [188] proposed a dual-stream network, with one branch extracting RGB features and the other using the laplacian of gaussian (LoG) operator to suppress facial visual content and extract high-frequency edge information. They also designed a new loss function based on the concept of one-class classifiers, which pulls positive samples closer while pushing negative samples further apart. Since deepfake videos often fail to preserve the inherent features left during the camera capture process, Ciamarra et al. [189] used UprightNet to estimate camera orientation and generate surface frames. They leveraged temporal anomalies in these frames to detect forgery.
4.2.3. Transformer-Based
Transformer was first applied to natural language processing (NLP) tasks and achieved significant improvements [190]. To extend their application to vision tasks, researchers designed the vision transformer (ViT) [191] and swin transformer (SwinT) [192], utilizing self-attention mechanisms to capture long-distance dependencies between different frames.
Given their powerful spatio-temporal modeling capabilities, many researchers have started applying these models to the field of deepfake detection. Yu et al. [193] designed a multi-view modeling strategy based on transformer, where for multiple groups of consecutive frames, they first establish local spatio-temporal fusion features for each set and then connect them along the temporal channel to create global spatio-temporal fusion features. Huang and Zhang [194] introduced an improved meta-learning approach to the spatio-temporal backbone, effectively enhancing generalization to unseen forgery methods. Zhao et al. [195] decomposed the computation of self-attention, using a self-subtract mechanism to make the model focus more on inter-frame distortions based on feature residuals, thus reducing redundant information. Inspired by correlation propagation algorithms, they also designed a visualization algorithm to improve the interpretability of the transformer. Liu et al. [196] used RGB images and motion flow to provide spatio-temporal information, modeling spatio-temporal feature connections with SwinT, and designed identity-decoupling attention to extract more general spatio-temporal feature representations that are independent of identity, thus effectively improving the model’s generalization ability. Yue et al. [197] used UniformerV2 as the backbone to extract global features and leveraged local frequency dynamic information, generated region-of-interest (ROI) attention maps by local region alignment, guided the global features to extract more refined forgery clues. Zhu et al. [198] employed knowledge distillation to transfer fine-grained spatial-frequency knowledge and spatio-temporal structural knowledge to the student model, effectively improving the model’s robustness to compression. Zhang et al. [199] proposed a self-supervised learning approach to learn the natural consistency representation of real face videos and used the fact that the consistency of deepfake videos is disrupted to distinguish authenticity, designing corresponding natural consistency enhancement strategies to improve detection accuracy.
In addition to the aforementioned methods, some studies detect deepfakes by preprocessing data or utilizing special information. Choi et al. [200] found temporal variations in the style latent vectors of generated facial videos, so they used a StyleGRU module to capture the style latent vector and established a style flow based on the differences for subsequent input. Tian et al. [201] extracted rich and robust forgery information by leveraging the temporal variation of local and global lighting information and the dynamic spatio-temporal inconsistencies of intra-frame/inter-frame forgery cues. Tu et al. [202] employed optical flow difference algorithms to locate key facial expression frames as input, which, compared to using the entire video sequence, improved accuracy while reducing training time by nearly 75%. To reduce computational requirements, Xu et al. [203] designed a thumbnail layout method that transforms consecutive frames into a predefined layout while preserving the original spatio-temporal relationships. After embedding modified positions, it effectively utilizes the transformer to learn spatio-temporal information.
Finally, we summarize the transformer-based methods, including three aspects: whether transformer network architecture design, whether input design, and datasets were performed, as shown in Table 15.
4.3. Biological Features-Based
The detection methods based on general features have achieved good performance, but they suffer from a significant lack of interpretability. In contrast, biological features, due to their inherent regularity, are much easier to interpret when subjected to forgery distortion. They provide a more intuitive understanding and align better with human cognition. Therefore, detection methods based on biological features represent a promising research direction.
Next, some methods based on biological features are introduced. Yang et al. [204] trained a classifier using the head pose differences between real and fake facial images for deepfake detection. Haliassos et al. [205] detected fakes by exploiting the high-level semantic irregularities of mouth movements in forged videos, and their method is robust to most data corruptions. Demir and Ciftci [206] extensively analyzed features related to eyes and gaze, integrating visual, geometric, and temporal information, achieving superior detection results compared to methods based on a single biological feature. Peng et al. [207] aggregated gaze direction, facial attributes, and texture information as spatio-temporal features to enhance the model’s ability to mine discriminative information. He et al. [208] proposed GazeForensics, which incorporates MSE and applies constraints on general spatial features using 3D gaze features, achieving an accuracy of 0.9942 on the CDF dataset. Qi et al. [209] introduced remote photoplethysmography (rPPG) into deepfake detection by observing the heart rate differences between real and fake facial videos, enhancing facial detail information with eulerian video magnification. Wu et al. [210] extracted multi-region rPPG maps and highlighted significant information using local attention, with adjacent features input into a transformer to extract temporal knowledge. Yang et al. [211] used CPPG signals to provide temporal information, supplementing spatial information through correlations between image pixels reflected by AR coefficients, extracting pixel-level discriminative features for forgery detection. Motion in deepfake videos often contains apparent errors; to capture this anomaly for forgery detection, Saif et al. [212] constructed spatio-temporal graphs from facial landmarks in both single frames and across frames, using GCNs for detection, which is parameter-efficient and computationally effective. Zhang et al. [213] used facial landmarks and face region information as nodes for GCNs, effectively identifying anomalous regions by analyzing both explicit and latent geometric relationships. Table 16 describes these methods from three aspects: biosignal type, backbone, and datasets.
4.4. Identity Features-Based
Certain forgery methods can cause identity discrepancies in video subjects. Therefore, using identity-aware frameworks to extract such identity features can help leverage this anomaly information for deepfake detection. Agarwal et al. [218] enabled the model to learn spatio-temporal biological behavioral features related to identity, distinguishing between different individuals and achieving face-swapping detection. Cozzolino et al. [219] introduced adversarial training to generate feature vectors consistent with the input individual’s identity information, using a temporal ID network as a discriminator for identity recognition. Ramachandran et al. [220] trained face recognition models with multiple loss functions to extract identity features. To address the identity representation bias in the extracted features, Fang et al. [221] designed a bias rectification module and implemented attention-based feature fusion, also utilizing the inconsistency between reference-query images. Additionally, Fang et al. [222] proposed a knowledge distillation framework, supervising the identity extractor with region-sensitive spatial features and cross-modality audio’s temporal representations to obtain rich spatio-temporal information. Attribute bias can cause errors in the extracted identity features, and Yu et al. [223] aligned reference and test images to the same attribute space to extract identity differences, quantifying pixel differences to discern authenticity. The key ideas of several methods and their AUC scores comparison on the FF++, CDF and DFDCp datasets are shown in Table 17.
5. Future Research Directions and Conclusions
5.1. Future Research Directions
The previous sections of this survey provide a comprehensive overview of AI-created visual content detection, including generation technologies, datasets, and related detection methods, along with a detailed classification of detection techniques, offering essential guidance for future researchers. Based on the study of existing challenges, this section will discuss the future directions for AI-created visual content detection.
Regarding AI-generated images detection algorithms, although there has been some development in this area, challenges such as low generalization ability and poor robustness still persist. The fundamental issue in AI-generated images detection is the design of a detector that can effectively identify the differences between real and fake images, while also maintaining strong generalization on unknown generative models. Since the performance of AI-generated images detection algorithms based on deep learning largely depends on the specific generative models in the training datasets, their performance typically drops significantly when tested on samples from different generative models. This necessitates a deeper analysis of the intrinsic relationships between different generated images and improvements in network architectures to learn more effective, generalized features. When images are subjected to certain post-processing attacks (such as scaling, rotation, or JPEG compression), the model’s ability to detect general features of generated images also diminishes. In the future, many methods are likely to focus on extracting universal features of generated images from multiple domain-specific features of images. Some methods aim to design detectors that do not require training on fake images, thus avoiding the reliance on specific generative data and offering higher generalization. With the development of image-text models such as CLIP, some research is inclined towards using both images and text for detecting generated images.
For deepfake detection, firstly, existing detection methods have achieved good performance within datasets, but due to the differences in datasets and various forgery techniques, the generalization performance remains insufficient. Therefore, it is necessary to explore methods to improve generalization, such as applying learning strategies like meta-learning and incremental learning, combining data augmentation techniques, or utilizing self-supervised learning to enhance generalization. These are promising directions for future research. Secondly, most current detection technologies are based on a single modality, limited to video and image data. However, many forgery techniques also involve multimodal data such as audio and text. Relying solely on single-modality information may limit detection performance. It is crucial to effectively integrate multimodal knowledge and perform multimodal collaborative learning to fully leverage forgery cues, thereby improving detection performance. Thirdly, with the widespread dissemination of deepfake content across social media, news reports, and live streaming, deepfake detection will move towards real-time online detection to meet practical demands. However, most current methods focus primarily on improving detection accuracy, with little attention given to model efficiency and lightweight design. This gap remains to be addressed in future research. Finally, in addition to passive detection of forged content, researchers are beginning to focus on active defense methods, such as adding watermarks or noise through preprocessing techniques to make images and videos resistant to forgeries or easily detectable when forged, fundamentally preventing the generation and spread of deepfake content.
5.2. Conclusions
In this review, we provide an overview of existing research on AI-created visual content detection, include AI-generated images detection techniques and deepfake image forensics based on deep learning.
For AI-generated images detection, the key approach is to train detectors to explore distinctive feature patterns between real and fake images. In this investigation, we analyze and review the latest techniques for AI-generated images detection based on deep learning. First, we introduce a deep learning-based framework for AI-generated images detection, which includes evaluation metrics and commonly used datasets. Based on the type of detection features, AI-generated images detection methods can be classified into three categories: spatial-domain-based detection methods, frequency-domain-based detection methods, cross-domain feature fusion detection methods, and image-text-based detection methods. Next, we compare and analyze the state-of-the-art algorithms from three aspects: detection methods, advantages, and limitations. Finally, we address the challenges in current AI-generated images detection algorithms and explore future research directions.
In deepfake detection, we conducted a comprehensive study of existing detection technologies and summarized these methods into four categories based on feature selection: spatial features-based, spatio-temporal features-based, biological features-based, and identity features-based. Methods based on spatial features focus on mining forgery cues within single-frame images, and they can be further subdivided into space domain-based, frequency domain-based, and multi-domain fusion methods. These approaches generally lack generalization ability and overlook temporal information between video frames, making them unsuitable for detecting dynamic content. Methods based on spatio-temporal features integrate temporal information to enable video-level detection. Depending on the backbone network used, these can be classified into CNN-based, CNN+RNN-based, and transformer-based methods. Among these, transformer-based methods have stronger spatio-temporal modeling capabilities, and most current spatio-temporal methods use transformer networks as the backbone. Both the aforementioned categories are based on general features. While they achieve good detection performance, they lack interpretability. To address this, biological features-based methods have been introduced. These methods leverage the biological regularities inherent in faces, such as mouth movement, gaze direction, and heart rate, to detect deepfakes. They are more interpretable and easier to understand. Additionally, some forgery techniques alter the identity features of the video subject, prompting researchers to use facial recognition models for identity consistency verification to detect deepfakes. Several improvements have been made in this area, but these methods rely on identity differences, so they are not suitable for detecting forgery techniques that do not change the identity. Finally, based on the existing challenges, a brief analysis of future directions for deepfake detection is provided.
Author Contributions
Y.Z., Z.P. and C.W. chose the topic and designed the structure of the paper. Z.P. and C.W. sorted out and analyzed AI-generated images detection techniques. Y.Z. and C.W. reviewed the deepfake detection methods. Y.Z., Z.P. and X.Z. classified the involved algorithms and analyzed the data. C.W., S.H. and X.Z. revised the manuscript. C.W. performed the project administration and supervision. C.W. and X.Z. is funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by Natural Science Foundation under Grant ZR2021MF060, in part by the National Key Research and Development Program of China under Grant 2023YFC3321601, in part by the Joint Fund of Shandong Provincial Natural Science Foundation under Grant ZR2021LZH003, in part by the National Natural Science Foundation of China under Grant 61702303, and in part by the 19th Student Research Training Program (SRTP) at Shandong University, Weihai, under Grant A23246.
Informed Consent Statement
Not applicable
Data Availability Statement
Not applicable.
Conflicts of Interest
The author declare no conflict of interest.
References
- Yadav, A.; Vishwakarma, D.K. Datasets, clues and state-of-the-arts for multimedia forensics: An extensive review. Expert Syst. Appl. 2024, 249, 123756. [Google Scholar] [CrossRef]
- Hu, B.; Wang, J. Deep learning for distinguishing computer generated images and natural images: A survey. J. Inf. Hiding Privacy Protection 2020, 2, 37–47. [Google Scholar] [CrossRef]
- Deng, J.; Lin, C.; Zhao, Z.; Liu, S.; Wang, Q.; Shen, C. A survey of defenses against AI-generated visual media: Detection, disruption, and authentication. arXiv 2023, arXiv:2407.10575. [Google Scholar]
- Guo, M.; Hu, Y.; Jiang, Z.; Li, Z. AI-generated image detection: Passive or watermark? arXiv 2024, arXiv:2411.13553. [Google Scholar]
- Lin, L.; Gupta, N.; Zhang, Y.; Ren, H.; Liu, C.H.; Ding, F.; Xin, W.; Xin, L.; Luisa, V.; Shu, H. Detecting multimedia generated by large AI models: A survey. arXiv 2024, arXiv:2402.00045. [Google Scholar]
- Rana, M. S.; Nobi, M.N.; Murali, B.; Sung, A.H. Deepfake detection: A systematic literature review. IEEE Access 2022, 10, 25494–25513. [Google Scholar] [CrossRef]
- Seow, J. W.; Lim, M.K.; Phan, R.C.W.; Liu, J.K. A comprehensive overview of deepfake: Generation, detection, datasets, and opportunities. Neurocomputing 2022, 513, 351–371. [Google Scholar] [CrossRef]
- Gong, L.Y.; Li, X.J. A contemporary survey on deepfake detection: Datasets, algorithms, and challenges. Electronics 2024, 13, 585. [Google Scholar] [CrossRef]
- Heidari, A.; Navimipour, N.J.; Dag, H.; Unal, M. Deepfake detection using deep learning methods: A systematic and comprehensive review. Wiley Interdiscip. Rev.-Data Mining Knowl. Discov. 2024, 14, 1–45. [Google Scholar] [CrossRef]
- Sandotra, N.; Arora, B. A comprehensive evaluation of feature-based AI techniques for deepfake detection. Neural Comput. Appl. 2024, 36, 3859–3887. [Google Scholar] [CrossRef]
- Kaur, A.; Hoshyar, A.N.; Saikrishna, V.; Firmin, S.; Xia, F. Deepfake video detection: Challenges and opportunities. Artif. Intell. Rev. 2024, 57, 159. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget, A.J.; Mirza, M.; Xu, B. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, Canada, 8–11 December 2014; pp. 2672–2680. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Bellemare, M.G.; Danihelka, I.; Dabney, W.; Mohamed, S.; Lakshminarayanan, B.; Hoyer, S.; Munos, R. The cramer distance as a solution to biased wasserstein. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–23. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of GANs for improved quality, stability, and variation. In Proceedings of the International Conference on Learning Representations, Vancouver, Canada, 30 April–3 May 2018; pp. 1–26. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. In Proceedings of the Inernational Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019; pp. 1–35. [Google Scholar]
- He, Z.; Zuo, W.; Kan, M.; Shan, S.; Chen, X. AttGAN: Facial attribute editing by only changing what you want. Trans. Img. Proc. 2019, 28, 5464–5478. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.W.; Lin, Y.J.; Chang, C.H.; Chang, E.Y.; Liao, S.W. RelGAN: Multi-domain image-to-image translation via relative attributes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 5914–5922. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2337–2346. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of styleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–20 June 2020; pp. 8110–8119. [Google Scholar]
- Lee, K.S.; Tran, N.T.; Cheung, N.M. Infomax-GAN: Improved adversarial image generation via information maximization and contrastive learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 3942–3952. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the Advances in Neural Information Processing Systems, Online, Canada, 6–12 December 2020; pp. 6840–6851. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat GANs on image synthesis. In Proceedings of the Advances in Neural Information Processing Systems, Online, Canada, 6–14 December 2021; pp. 8780–8794. [Google Scholar]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Sutskever, I.; Chen, M. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 16784–16804. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo, L.R.; Karagol, A.B.; Salimans, T.; Ho, J.; Fleet, D.J.; Norouzi, M. Photorealistic text-to-image diffusion models with deep language understanding. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; pp. 36479–36494. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Gu, S.; Chen, D.; Bao, J.; Wen, F.; Zhang, B.; Chen, D.D.; Yuan, L.; Guo, B. Vector quantized diffusion model for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 110696–10706. [Google Scholar]
- Midjourney. Available online: https://www.midjourney.com/home (accessed on 12 July 2022).
- Wukong. Available online: https://xihe.mindspore.cn/modelzoo/wukong (accessed on 14 September 2023).
- Shirakawa, T.; Uchida, S. NoiseCollage: A layout-aware text-to-image diffusion model based on noise cropping and merging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 8921–8930. [Google Scholar]
- Shiohara, K.; Yamasaki, T. Face2Diffusion for fast and editable face personalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 6850–6859. [Google Scholar]
- Cao, C.; Cai, Y.; Dong, Q.; Wang, Y.; Fu, Y. LeftRefill: Filling right canvas based on left reference through generalized text-to-image diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 7705–7715. [Google Scholar]
- Zhou, D.; Li, Y.; Ma, F.; Zhang, X.; Yang, Y. Migc: Multi-instance generation controller for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 6818–6828. [Google Scholar]
- Hoe, J.T.; Jiang, X.; Chan, C.S.; Tan, Y.P.; Hu, W. InteractDiffusion: Interaction Control in Text-to-Image Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 6180–6189. [Google Scholar]
- Höllein, L.; Božič, A.; Müller, N.; Novotny, D.; Tseng, H.Y.; Richardt, C.; Zollhöfer, M.; Nießner, M. Viewdiff: 3d-consistent image generation with text-to-image models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 5043–5052. [Google Scholar]
- Wang, Z.J.; Montoya, E.; Munechika, D.; Yang, H. Diffusiondb: A large-scale prompt gallery dataset for text-to-image generative models. arXiv 2022, arXiv:2210.14896. [Google Scholar]
- Rahman, M.A.; Paul, B.; Sarker, N.H.; Hakim, Z.I.A.; Fattah, S.A. Artifact: A large-scale dataset with artificial and factual images for generalizable and robust synthetic image detection. In Proceedings of the IEEE International Conference on Image Processing, Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 2200–2204. [Google Scholar]
- Bird, J.J.; Lotfi, A. Cifake: Image classification and explainable identification of AI-generated synthetic images. IEEE Access 2024, 12, 15642–15650. [Google Scholar] [CrossRef]
- Zhu, M.; Chen, H.; YAN, Q.; Huang, X.; Lin, G.; Li, W.; Tu, Z.; Hu, H.; Wang, Y. Genimage: A million-scale benchmark for detecting AI-generated image. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; pp. 77771–77782. [Google Scholar]
- Lu, Z.; Huang, D.; Bai, L.; Qu, J.; Wu, C.; Liu, X.; Ouyang, W. Seeing is not always believing: Benchmarking human and model perception of AI-generated images. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; pp. 25435–25447. [Google Scholar]
- Hong, Y.; Zhang, J. Wildfake: A large-scale challenging dataset for AI-generated images detection. arXiv 2024, arXiv:2402.11843. [Google Scholar]
- Edwards, P.; Nebel, J.-C.; Greenhill, D.; Liang, X. A review of deepfake techniques: Architecture, detection, and datasets. IEEE Access 2024, 12, 154718–154742. [Google Scholar] [CrossRef]
- Deepfakes github. Available online: https://github.com/deepfakes/faceswap (accessed on 29 October 2018).
- Thies, J.; Zollhöfer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of RGB videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? Assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Li, Y.; Chang, M.-C.; Lyu, S. In ictu oculi: Exposing AI created fake videos by detecting eye blinking. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Hong Kong, China, 10–13 December 2018; pp. 1–7. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Niessner, M. FaceForensics++: Learning to Detect Manipulated Facial Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2018; pp. 1–11. [Google Scholar]
- Zi, B.; Chang, M.; Chen, J.; Ma, X.; Jiang, Y.-G. Wilddeepfake: A challenging real-world dataset for deepfake detection. In Proceedings of thethe 18th ACM International Conference on Multimedia, Seattle, WA, USA, 12–26 October 2020; pp. 2382–2390. [Google Scholar]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The deepfake detection challenge (DFDC) dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Contributing Data to Deepfake Detection Research. Available online: https://research.google/blog/contributing-data-to-deepfake-detection-research (accessed on 24 September 2019).
- Jiang, L.; Li, R.; Wu, W.; Qian, C.; Loy, C.C. Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2886–2895. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-df: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3204–3213. [Google Scholar]
- Kwon, P.; You, J.; Nam, G.; Park, S.; Chae, G. Kodf: A large-scale korean deepfake detection dataset. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 10–17 October 2021; pp. 10724–10733. [Google Scholar]
- Trung-Nghia, L.; Nguyen, H. H.; Yamagishi, J.; Echizen, I. Openforensics: Large-scale challenging dataset for multi-face forgery detection and segmentation in-the-wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 10–17 October 2021; pp. 10097–10107. [Google Scholar]
- Zhou, T.; Wang, W.; Liang, Z.; Shen, J. Face forensics in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5774–5784. [Google Scholar]
- Jia, S.; Li, X.; Lyu, S. Model attribution of face-swap deepfake videos. In Proceedings of the IEEE International Conference on Image Processing, Bordeaux, France, 16–19 October 2022; pp. 2356–2360. [Google Scholar]
- Narayan, K.; Agarwal, H.; Thakral, K.; Mittal, S.; Vatsa, M.; Singh, R. Df-platter: Multi-face heterogeneous deepfake dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18–22 June 2023; pp. 9739–9748. [Google Scholar]
- Bhattacharyya, C.; Wang, H.; Zhang, F.; Kim, S.; Zhu, X. Diffusion deepfake. arXiv 2024, arXiv:2404.01579. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Cozzolino, D.; Verdoliva, L. Detection of GAN-generated fake images over social networks. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval, Miami, FL, USA, 10–12 April 2018; pp. 384–389. [Google Scholar]
- Hsu, C.C.; Lee, C.Y.; Zhuang, Y.X. Learning to detect fake face images in the wild. In Proceedings of the International Symposium on Computer, Consumer and Control, Taiwan, China, 6–8 December 2018; pp. 388–391. [Google Scholar]
- Yu, N.; Davis, L.S.; Fritz, M. Attributing fake images to GANs: Learning and analyzing GAN fingerprints. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 7556–7566. [Google Scholar]
- Zhuang, Y.X.; Hsu, C.C. Detecting generated image based on a coupled network with two-step pairwise learning. In Proceedings of the IEEE International Conference on Image Processing, Taiwan, China, 22–25 September 2019; pp. 3212–3216. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Verdoliva, L.; Poggi, G. Do GANs leave artificial fingerprints? In Proceedings of the IEEE conference on Multimedia Information Processing and Retrieval, San Jose, CA, USA, 28–30 March 2019; pp. 506–511. [Google Scholar]
- Marra, F.; Saltori, C.; Boato, G.; Verdoliva, L. Incremental learning for the detection and classification of GAN-generated images. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Delft, The Netherlands, USA, 9–12 December 2019; pp. 1–6. [Google Scholar]
- Wang, S.Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-generated images are surprisingly easy to spot... for now. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8695–8704. [Google Scholar]
- Jeon, H.; Bang, Y.; Kim, J.; Woo, S.S. T-GD: Transferable GAN-generated images detection framework. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 4746–4761. [Google Scholar]
- Chai, L.; Bau, D.; Lim, S.N.; Isola, P. What makes fake images detectable? Understanding properties that generalize. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 103–120. [Google Scholar]
- Mi, Z.; Jiang, X.; Sun, T.; Xu, K. GAN-generated image detection with self-attention mechanism against GAN generator defect. IEEE J. Sel. Top. Signal Process. 2020, 14, 969–981. [Google Scholar] [CrossRef]
- He, Y.; Yu, N.; Keuper, M.; Fritz, M. Beyond the spectrum: Detecting deepfakes via re-synthesis. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, Canada, 21–26 August 2021; pp. 2534–2541. [Google Scholar]
- Li, W.; He, P.; Li, H.; Wang, H.; Zhang, R. Detection of GAN-generated images by estimating artifact similarity. IEEE Signal Process. Lett. 2021, 29, 862–866. [Google Scholar] [CrossRef]
- Girish, S.; Suri, S.; Rambhatla, S.S.; Shrivastava, A. Towards discovery and attribution of open-world GAN generated images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 11–17 October 2021; pp. 14094–14103. [Google Scholar]
- Liu, B.; Yang, F.; Bi, X.; Xiao, B.; Li, W.; Gao, X. Detecting generated images by real images. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 95–110. [Google Scholar]
- Jeong, Y.; Kim, D.; Ro, Y.; Kim, P.; Choi, J. Fingerprintnet: Synthesized fingerprints for generated image detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 76–94. [Google Scholar]
- Zhang, M.; Wang, H.; He, P.; Malik, A.; Liu, H. Improving GAN-generated image detection generalization using unsupervised domain adaptation. In Proceedings of the IEEE International Conference on Multimedia and Expo, Taiwan, China, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Ju, Y.; Jia, S.; Ke, L.; Xue, H.; Nagano, K.; Lyu, S. Fusing global and local features for generalized AI-synthesized image detection. In Proceedings of the IEEE International Conference on Image Processing, Bordeaux, France, 16–19 October 2022; pp. 3465–3469. [Google Scholar]
- Mandelli, S.; Bonettini, N.; Bestagini, P.; Tubaro, S. Detecting GAN-generated images by orthogonal training of multiple CNNs. In Proceedings of the IEEE International Conference on Image Processing, Bordeaux, France, 16–19 October 2022; pp. 3091–3095. [Google Scholar]
- Tan, C.; Zhao, Y.; Wei, S.; Gu, G.; Wei, Y. Learning on gradients: Generalized artifacts representation for GAN-generated images detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 17–24 June 2023; pp. 12105–12114. [Google Scholar]
- Ojha, U.; Li, Y.; Lee, Y.J. Towards universal fake image detectors that generalize across generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 17–24 June 2023; pp. 24480–24489. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; Krueger, G.; Sutskever, I. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Wang, Z.; Bao, J.; Zhou, W.; Wang, W.; Hu, H.; Chen, H.; Li, H. Dire for diffusion-generated image detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 22445–22455. [Google Scholar]
- Xu, Q.; Wang, H.; Meng, L.; Mi, Z.; Yuan, J.; Yan, H. Exposing fake images generated by text-to-image diffusion models. Pattern Recognit. Lett. 2023, 176, 76–82. [Google Scholar] [CrossRef]
- Ju, Y.; Jia, S.; Cai, J.; Guan, H.; Lyu, S. GLFF: Global and local feature fusion for AI-synthesized image detection. IEEE Trans. Multimed. 2024, 26, 4073–4085. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, H.; Hu, S.; Zhu, B.; Lin, C.S.; Wu, X.; Hu, J.R.; Wang, X. X-Transfer: A transfer learning-based framework for GAN-generated fake image detection. In Proceedings of the International Joint Conference on Neural Networks, Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Tan, C.; Zhao, Y.; Wei, S.; Gu, G.; Liu, P.; Wei, Y. Rethinking the up-sampling operations in CNN-based generative network for generalizable deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 28130–28139. [Google Scholar]
- Lim, Y.; Lee, C.; Kim, A.; Etzioni, O. DistilDIRE: A small, fast, cheap and lightweight diffusion synthesized deepfake detection. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024; pp. 1–6. [Google Scholar]
- Yan, Z.; Luo, Y.; Lyu, S.; Liu, Q.; Wu, B. Transcending forgery specificity with latent space augmentation for generalizable deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 8984–8994. [Google Scholar]
- Wang, Z.; Sehwag, V.; Chen, C.; Lyu, L.; Metaxas, D.N.; Ma, S. How to trace latent generative model generated images without artificial watermark? In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024; pp. 51396–51414. [Google Scholar]
- Chen, B.; Zeng, J.; Yang, J.; Yang, R. DRCT: Diffusion reconstruction contrastive training towards universal detection of diffusion generated images. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024; pp. 7621–7639. [Google Scholar]
- Sinitsa, S.; Fried, O. Deep image fingerprint: Towards low budget synthetic image detection and model lineage analysis. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 4067–4076. [Google Scholar]
- He, Z.; Chen, P.Y.; Ho, T.Y. RIGID: A training-free and model-agnostic framework for robust AI-generated image detection. arXiv 2024, arXiv:2405.20112. [Google Scholar]
- Liang, Z.; Wang, R.; Liu, W.; Zhang, Y.; Yang, W.; Wang, L.; Wang, X. Let real images be as a judger, spotting fake images synthesized with generative models. arXiv 2024, arXiv:2403.16513. [Google Scholar]
- Chen, J.; Yao, J.; Niu, L. A single simple patch is all you need for AI-generated image detection. arXiv 2024, arXiv:2402.01123. [Google Scholar]
- Zhang, Y.; Xu, X. Diffusion noise feature: Accurate and fast generated image detection. arXiv 2023, arXiv:2312.02625. [Google Scholar]
- Yang, Y.; Qian, Z.; Zhu, Y.; Wu, Y.D. Scaling up deepfake detection by learning from discrepancy. arXiv 2024, arXiv:2404.04584. [Google Scholar]
- He, P.; Li, H.; Wang, H. Detection of fake images via the ensemble of deep representations from multi color spaces. In Proceedings of the IEEE International Conference on Image Processing, Taiwan, China, 22–25 September 2019; pp. 2299–2303. [Google Scholar]
- Chandrasegaran, K.; Tran, N.T.; Binder, A.; Cheung, N.M. Discovering transferable forensic features for CNN-generated images detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 671–689. [Google Scholar]
- Uhlenbrock, L.; Cozzolino, D.; Moussa, D.; Verdoliva, L.; Riess, C.; Cheung, N.M. Did you note my palette? Unveiling synthetic images through color statistics. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Baiona, Spain, 24–26 June 2024; pp. 47–52. [Google Scholar]
- Qiao, T.; Chen, Y.; Zhou, X.; Shi, R.; Shao, H.; Shen, K.; Luo, X. Csc-net: Cross-color spatial co-occurrence matrix network for detecting synthesized fake images. IEEE Trans. Cognit. Dev. Syst. 2024, 16, 369–379. [Google Scholar] [CrossRef]
- Liu, Z.; Qi, X.; Torr, P.H.S. Global texture enhancement for fake face detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8060–8069. [Google Scholar]
- Yang, J.; Li, A.; Xiao, S.; Lu, W.; Gao, X. MTD-Net: Learning to detect deepfakes images by multi-scale texture difference. IEEE Trans. Inf. Forensic Secur. 2021, 16, 4234–4245. [Google Scholar] [CrossRef]
- Zhong, N.; Xu, Y.; Qian, Z.; Zhang, X. Rich and poor texture contrast: A simple yet effective approach for AI-generated image detection. arXiv 2023, arXiv:2311.12397. [Google Scholar]
- Zhang, Y.; Zhu, N.; Zhang, X.; Wang, K. Computer-generated image detection based on deep LBP network. In Proceedings of the International Conference on Computer Application and Information Security, Wuhan, China, 20–22 December 2024; pp. 932–939. [Google Scholar]
- Lorenz, P.; Durall, R.L.; Keuper, J. Detecting images generated by deep diffusion models using their local intrinsic dimensionality. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 448–459. [Google Scholar]
- Lin, M.; Shang, L.; Gao, X. Enhancing interpretability in AI-generated image detection with genetic programming. In Proceedings of the IEEE International Conference on Data Mining Workshops, Shanghai, China, 1–4 December 2023; pp. 371–378. [Google Scholar]
- Sarkar, A.; Mai, H.; Mahapatra, A.; Lazebnik, S.; Forsyth, D.A.; Bhattad, A. Shadows don’t lie and lines can’t bend! Generative models don’t know projective geometry…for now. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 28140–28149. [Google Scholar]
- Cozzolino, D.; Poggi, G.; Nießner, M.; Verdoliva, L. Zero-shot detection of AI-generated images. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 54–72. [Google Scholar]
- Tan, C.; Liu, P.; Tao, R.; Liu, H.; Zhao, Y.; Wu, B.; Wei, Y. Data-independent operator: A training-free artifact representation extractor for generalizable deepfake detection. arXiv 2024, arXiv:2403.06803. [Google Scholar]
- Zhang, X.; Karaman, S.; Chang, S.F. Detecting and simulating artifacts in GAN fake images. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Delft, Netherlands, 9–12 December 2019; pp. 1–6. [Google Scholar]
- Frank, J.; Eisenhofer, T.; Schönherr, L.; Fischer, A.; Kolossa, D.; Holz, T. Leveraging frequency analysis for deep fake image recognition. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 3247–3258. [Google Scholar]
- Durall, R.; Keuper, M.; Keuper, J. Watch your up-convolution: CNN based generative deep neural networks are failing to reproduce spectral distributions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7890–7899. [Google Scholar]
- Dzanic, T.; Shah, K.; Witherden, F. Fourier spectrum discrepancies in deep network generated images. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Beijing, China, 6–12 December 2020; pp. 3022–3032. [Google Scholar]
- Bonettini, N.; Bestagini, P.; Milani, S.; Tubaro, S. On the use of Benford’s law to detect GAN-generated images. In Proceedings of the International Conference on Pattern Recognition, Taiwan, China, 18–21 July 2021; pp. 5495–5502. [Google Scholar]
- Chandrasegaran, K.; Tran, N.T.; Cheung, N.M. A closer look at fourier spectrum discrepancies for CNN-generated images detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7200–7209. [Google Scholar]
- Dong, C.; Kumar, A.; Liu, E. Think twice before detecting GAN-generated fake images from their spectral domain imprints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7865–7874. [Google Scholar]
- Corvi, R.; Cozzolino, D.; Zingarini, G.; Poggi, G.; Nagano, K.; Verdoliva, L. On the detection of synthetic images generated by diffusion models. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Corvi, R.; Cozzolino, D.; Poggi, G.; Nagano, K.; Verdoliva, L. Intriguing properties of synthetic images: from generative adversarial networks to diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Vancouver, Canada, 18–22 June 2023; pp. 973–982. [Google Scholar]
- Bammey, Q. Synthbuster: Towards detection of diffusion model generated images. IEEE Open J. Signal Process. 2024, 5, 1–9. [Google Scholar] [CrossRef]
- Pontorno, O.; Guarnera, L.; Battiato, S. On the exploitation of DCT-traces in the generative-AI domain. In Proceedings of the IEEE International Conference on Image Processing, Bordeaux, France, 27–30 October 2024; pp. 3806–3812. [Google Scholar]
- Tan, C.; Zhao, Y.; Wei, S.; Gu, G.; Liu, P.; Wei, Y. Frequency-aware deepfake detection: Improving generalizability through frequency space learning. In Proceedings of the AAAI Conference on Artifical Intelligence, 20–27 February 2024; Volume 38, pp. 5052–5060. [Google Scholar]
- Doloriel, C.T.; Cheung, N.-M. Frequency masking for universal deepfake detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Seoul, Korea (South), 14–19 April 2024; pp. 13466–13470. [Google Scholar]
- Weng, J. Local frequency analysis for diffusion-generated image detection. In Proceedings of the International Conference on Image Processing and Artificial Intelligence, Suzhou, China, 19–21 April 2024; pp. 66–73. [Google Scholar]
- Yu, Y.; Ni, R.; Li, W.; Zhao, Y. Detection of AI-manipulated fake faces via mining generalized features. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 94. [Google Scholar] [CrossRef]
- Liu, C.; Zhu, T.; Zhao, Y.; Zhang, J.; Zhou, W. Disentangling different levels of GAN fingerprints for task-specific forensics. Comput. Stand. Interfaces 2024, 89, 103825. [Google Scholar] [CrossRef]
- Luo, Y.; Du, J.; Yan, K.; Ding, S. LaRE2: Latent reconstruction error based method for diffusion-generated image detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 17006–17015. [Google Scholar]
- Lanzino, R.; Fontana, F.; Diko, A.; Marini, M.R.; Cinque, L. Faster than lies: real-time deepfake detection using binary neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 3771–3780. [Google Scholar]
- Wißmann, A.; Zeiler, S.; Nickel, R.M.; Kolossa, D. Whodunit: Detection and attribution of synthetic images by leveraging model-specific fingerprints. In Proceedings of the ACM International Workshop on Multimedia AI against Disinformation, Phuket, Thailand, 10–13 June 2024; pp. 65–72. [Google Scholar]
- Gallagher, J.; Pugsley, W. Development of a dual-input neural model for detecting AI-generated imagery. arXiv 2024, arXiv:2406.13688. [Google Scholar]
- Meng, Z.; Peng, B.; Dong, J.; Tan, T.; Cheng, H. Artifact feature purification for cross-domain detection of AI-generated images. Comput. Vis. Image Underst. 2024, 247, 104078. [Google Scholar] [CrossRef]
- Xu, Q.; Jiang, X.; Sun, T.; Wang, H.; Meng, L.; Yan, H. Detecting artificial intelligence-generated images via deep trace representations and interactive feature fusion. Inf. Fusion 2024, 112, 102578. [Google Scholar] [CrossRef]
- Leporoni, G.; Maiano, L.; Papa, L.; Amerini, I. A guided-based approach for deepfake detection: RGB-depth integration via features fusion. Pattern Recognit. Lett. 2024, 112, 99–105. [Google Scholar] [CrossRef]
- Yan, S.; Li, O.; Cai, J.; Hao, Y.; Jiang, X.; Hu, Y.; Xie, W. A sanity check for AI-generated image detection. arXiv 2024, arXiv:2406.19435. [Google Scholar]
- Sha, Z.; Li, Z.; Yu, N.; Zhang, Y. DE-FAKE: Detection and attribution of fake images generated by text-to-image generation models. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, Seattle, New York, NY, USA, 26–30 November 2024; pp. 3418–3432. [Google Scholar]
- Wu, H.; Zhou, J.; Zhang, S. Generalizable synthetic image detection via language-guided contrastive learning. arXiv 2023, arXiv:2305.13800. [Google Scholar]
- Liu, H.; Tan, Z.; Tan, C.; Wei, Y.; Wang, J.; Zhao, Y. Forgery-aware adaptive transformer for generalizable synthetic image detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 10770–10780. [Google Scholar]
- Cazenavette, G.; Sud, A.; Leung, T.; Usman, B. FakeInversion: Learning to detect images from unseen text-to-image models by inverting stable diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 10759–10769. [Google Scholar]
- Khan, S.A.; Dang-Nguyen, D.-T. CLIPping the deception: Adapting vision-language models for universal deepfake detection. In Proceedings of the International Conference on Multimedia Retrieval, New York, NY, USA, 10–14 June 2024; pp. 1006–1015. [Google Scholar]
- Keita, M.; Hamidouche, W.; Eutamene, H.B.; Hadid, A.; Taleb-Ahmed, A. Bi-LORA: A vision-language approach for synthetic image detection. arXiv 2024, arXiv:2404.01959. [Google Scholar] [CrossRef]
- Keita, M.; Hamidouche, W.; Bougueffa, H.; Hadid, A.; Taleb-Ahmed, A. Harnessing the power of large vision language models for synthetic image detection. arXiv 2024, arXiv:2404.02726. [Google Scholar]
- Sha, Z.; Tan, Y.; Li, M.; Backes, M.; Zhang, Y. ZeroFake: Zero-shot detection of fake images generated and edited by text-to-image generation models. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, Salt Lake City, UT, USA, 14–18 October 2024; pp. 4852–4866. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: a compact facial video forgery detection network. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Hong Kong, China, 10–13 December 2018; pp. 1–7. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face x-ray for more general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5000–5009. [Google Scholar]
- Bonettini, N.; Cannas, E.D.; Mandelli, S.; Bondi, L.; Bestagini, P.; Tubaro, S. Video face manipulation detection through ensemble of CNNs. In Proceedings of the 25th International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; pp. 5012–5019. [Google Scholar]
- Shiohara, K.; Yamasaki, T. Detecting deepfakes with self-blended images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18699–18708. [Google Scholar]
- Chen, L.; Zhang, Y.; Song, Y.; Liu, L.; Wang, J. Self-supervised learning of adversarial example: Towards good generalizations for deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18689–18698. [Google Scholar]
- Lin, Y.; Song, W.; Li, B.; Li, Y.; Ni, J.; Chen, H.; Li, Q. Fake it till you make it: Curricular dynamic forgery augmentations towards general deepfake detection. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 104–122. [Google Scholar]
- Guan, W.; Wang, W.; Dong, J.; Peng, B. Improving generalization of deepfake detectors by imposing gradient regularization. IEEE Trans. Inf. Forensic Secur. 2024, 19, 5345–5356. [Google Scholar] [CrossRef]
- Gao, J.; Micheletto, M.; Orru, G.; Concas, S.; Feng, X.; Marcialis, G.L.; Roli, F. Texture and artifact decomposition for improving generalization in deep-learning-based deepfake detection. Eng. Appl. Artif. Intell. 2024, 133, 108450. [Google Scholar] [CrossRef]
- Lu, W.; Liu, L.; Zhang, B.; Luo, J.; Zhao, X.; Zhou, Y.; Huang, J. Detection of deepfake videos using long-distance attention. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 9366–9379. [Google Scholar] [CrossRef] [PubMed]
- Zheng, J.; Zhou, Y.; Hu, X.; Tang, Z. Deepfake detection with combined unsupervised-supervised contrastive learning. In Proceedings of the IEEE International Conference on Image Processing, Bordeaux, France, 27–30 October 2024; pp. 787–793. [Google Scholar]
- Bai, W.; Liu, Y.; Zhang, Z.; Zhang, X.; Wang, B.; Peng, C.; Hu, W.; Li, B. Learn from noise: Detecting deepfakes via regional noise consistency. In Proceedings of the International Joint Conference on Neural Networks, Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Ma, X.; Tian, J.; Cai, Y.; Chai, Y.; Li, Z.; Dai, J.; Zang, L.; Han, J. HIDD: Human-perception-centric incremental deepfake detection. In Proceedings of the International Joint Conference on Neural Networks, Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Lu, L.; Wang, Y.; Zhuo, W.; Zhang, L.; Gao, G.; Guo, Y. Deepfake detection via separable self-consistency learning. In Proceedings of the IEEE International Conference on Image Processing, Abu Dhabi, UAE, 27–30 October 2024; pp. 3264–3270. [Google Scholar]
- Dolhansky, B.; Howes, R.; Pflaum, B.; Baram, N.; Ferrer, C.C. The deepfake detection challenge (DFDC) preview dataset. arXiv 2019, arXiv:1910.08854. [Google Scholar]
- Peng, S.; Cai, M.; Ma, R.; Liu, X. Deepfake detection algorithm for high-frequency components of shallow features. Laser Optoelectron. Prog. 2023, 60, 1015001. [Google Scholar]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 86–103. [Google Scholar]
- Li, J.; Xie, H.; Li, J.; Wang, Z.; Zhang, Y. Frequency-aware discriminative feature learning supervised by single-center loss for face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6454–6463. [Google Scholar]
- Gao, J.; Xia, Z.; Marcialis, G.L.; Dang, C.; Dai, J.; Feng, X. Deepfake detection based on high-frequency enhancement network for highly compressed content. Expert Syst. Appl. 2024, 249, 123732. [Google Scholar] [CrossRef]
- Miao, C.; Tan, Z.; Chu, Q.; Liu, H.; Hu, H.; Yu, N. F2Trans: High-frequency fine-grained transformer for face forgery detection. IEEE Trans. Inf. Forensic Secur. 2023, 18, 1039–1051. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Yang, H.; Chen, B.; Huang, D. SA3WT: Adaptive wavelet-based transformer with self-paced auto augmentation for face forgery detection. Int. J. Comput. Vis. 2024, 132, 4417–4439. [Google Scholar] [CrossRef]
- Hasanaath, A.A.; Luqman, H.; Katib, R.; Anwar, S. FSBI: Deepfakes detection with frequency enhanced self-blended images. arXiv 2024, arXiv:2406.08625. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, J.; Wang, L. Harmonizing dynamic frequency analysis with attention mechanisms for efficient facial image authenticity detection. In Proceedings of the International Conference on Computer Science and Automation Technology, Shanghai, China, 6–8 October 2023; pp. 348–352. [Google Scholar]
- Wang, B.; Wu, X.; Tang, Y.; Ma, Y.; Shan, Z.; Wei, F. Frequency domain filtered residual network for deepfake detection. Mathematics 2023, 11, 816. [Google Scholar] [CrossRef]
- Wang, F.; Chen, Q.; Jing, B.; Tang, Y.; Song, Z.; Wang, B. Deepfake detection based on the adaptive fusion of spatial-frequency featuress. Int. J. Intell. Syst. 2024, 2024, 7578036. [Google Scholar] [CrossRef]
- Zhou, J.; Zhao, X.; Xu, Q.; Zhang, P.; Zhou, Z. MDCF-Net: Multi-scale dual-branch network for compressed face forgery detection. IEEE Access 2024, 12, 58740–58749. [Google Scholar] [CrossRef]
- Le, M.B.; Woo, S. ADD: Frequency attention and multi-view based knowledge distillation to detect low-quality compressed deepfake images. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, Canada, 22 February–1 March, 202; pp. 122–130.
- Wang, B.; Wu, X.; Wang, F.; Zhang, Y.; Wei, F.; Song, Z. Spatial-frequency feature fusion based deepfake detection through knowledge distillation. Eng. Appl. Artif. Intell. 2024, 133, 108341. [Google Scholar] [CrossRef]
- Guo, Z.; Jia, Z.; Wang, L.; Wang, D.; Yang, G.; Kasabov, N. Constructing new backbone networks via space-frequency interactive convolution for deepfake detection. IEEE Trans. Inf. Forensic Secur. 2024, 19, 401–413. [Google Scholar] [CrossRef]
- Luo, Y.; Zhang, Y.; Yan, J.; Liu, W. Generalizing face forgery detection with high-frequency features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16312–16321. [Google Scholar]
- Zhang, D.; Chen, J.; Liao, X.; Li, F.; Chen, J.; Yang, G. Face forgery detection via multi-feature fusion and local enhancement. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 8972–8977. [Google Scholar] [CrossRef]
- Fei, J.; Dai, Y.; Yu, P.; Shen, T.; Xia, Z.; Weng, J. Learning second order local anomaly for general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20238–20248. [Google Scholar]
- Dong, F.; Zou, X.; Wang, J.; Liu, X. Contrastive learning-based general deepfake detection with multi-scale RGB frequency clues. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 90–99. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, H.; Wang, S. Cross-domain local characteristic enhanced deepfake video detection. In Proceedings of the 16th Asian Conference on Computer Vision, Macau SAR, China, 4–8 December 2023; pp. 196–214. [Google Scholar]
- Concas, S.; La Cava, S.M.; Casula, R.; Orrù, G.; Puglisi, G.; Marcialis, G. L. Quality-based artifact modeling for facial deepfake detection in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 17–21 June 2024; pp. 3845–3854. [Google Scholar]
- Pang, G.; Zhang, B.; Teng, Z.; Qi, Z.; Fan, J. MRE-Net: Multi-rate excitation network for deepfake video detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3663–3676. [Google Scholar] [CrossRef]
- Zhang, R.; He, P.; Li, H.; Wang, S.; Cao, Y. Temporal diversified self-contrastive learning for generalized face forgery detection. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 12782–12795. [Google Scholar] [CrossRef]
- Yu, Y.; Ni, R.; Yang, S.; Ni, Y.; Zhao, Y.; Kot, A.C. Mining generalized multi-timescale inconsistency for detecting deepfake videos. Int. J. Comput. Vis. 2024, 1–17. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, C.; Liu, D.; Wang, N.; Gao, X. Spatial-temporal frequency forgery clue for video forgery detection in VIS and NIR scenario. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7943–7956. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, B.; Li, Z.; Pang, G.; Teng, Z.; Fan, J. Interactive two-stream network across modalities for deepfake detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 6418–6430. [Google Scholar] [CrossRef]
- Guera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the 15th IEEE International Conference on Advanced Video and Signal Surveillance, Auckland, New Zealand, 27–30 November 2018; pp. 127–132. [Google Scholar]
- Saikia, P.; Dholaria, D.; Yadav, P.; Patel, V.; Roy, M. A hybrid CNN-LSTM model for video deepfake detection by leveraging optical flow features. In Proceedings of the International Joint Conference on Neural Networks, Padua, Italy, 18–23 July 2024; pp. 1–7. [Google Scholar]
- Chen, B.; Li, T.; Ding, W. Detecting deepfake videos based on spatiotemporal attention and convolutional LSTM. Inf. Sci. 2022, 601, 58–70. [Google Scholar] [CrossRef]
- K, J.; M, A. Safeguarding media integrity: A hybrid optimized deep feature fusion based deepfake detection in videos. Comput. Secur. 2024, 142, 103860. [Google Scholar] [CrossRef]
- Amerini, I.; Caldelli, R. Exploiting prediction error inconsistencies through LSTM-based classifiers to detect deepfake videos. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Denver, CO, USA, 22–24 June 2020; pp. 97–102. [Google Scholar]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P. ; Two-branch recurrent network for isolating deepfakes in videos. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 667–684. [Google Scholar]
- Ciamarra, A.; Caldelli, R.; Bimbo, A.D. Temporal surface frame anomalies for deepfake video detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 17–21 June 2024; pp. 3837–3844. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 1–11. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; Uszkoreit, J.; Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Yu, Y.; Ni, R.; Zhao, Y.; Yang, S.; Xia, F.; Jiang, N.; Zhao, G. MSVT: Multiple spatiotemporal views transformer for deepfake video detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4462–4471. [Google Scholar] [CrossRef]
- Huang, D.; Zhang, Y. Learning meta model for strong generalization deepfake detection. In Proceedings of the International Joint Conference on Neural Networks, Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Zhao, C.; Wang, C.; Hu, G.; Chen, H.; Liu, C.; Tang, J. ISTVT: Interpretable spatial-temporal video transformer for deepfake detection. IEEE Trans. Inf. Forensic Secur. 2023, 18, 1335–1348. [Google Scholar] [CrossRef]
- Liu, B.; Liu, B.; Ding, M.; Zhu, T. MeST-former: Motion-enhanced spatiotemporal transformer for generalizable deepfake detection. Neurocomputing 2024, 610, 128588. [Google Scholar] [CrossRef]
- Yue, P.; Chen, B.; Fu, Z. Local region frequency guided dynamic inconsistency network for deepfake video detection. Big Data Min. Anal. 2024, 7, 889–904. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, C.; Gao, J.; Sun, X.; Rui, Z.; Zhou, X. High-compressed deepfake video detection with contrastive spatiotemporal distillation. Neurocomputing 2024, 565, 126872. [Google Scholar] [CrossRef]
- Zhang, D.; Xiao, Z.; Li, S.; Lin, F.; Li, J.; Ge, S. Learning natural consistency representation for face forgery video detection. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 407–424. [Google Scholar]
- Choi, J.; Kim, T.; Jeong, Y.; Baek, S.; Choi, J. Exploiting style latent flows for generalizing deepfake video detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle,WA, USA, 17–21 July 2024; pp. 1133–1143. [Google Scholar]
- Tian, K.; Chen, C.; Zhou, Y.; Hu, X. Illumination enlightened spatial-temporal inconsistency for deepfake video detection. In Proceedings of the IEEE International Conference on Multimedia and Expo, Niagara Falls, ON, Canada, 15–19 July 2024; pp. 1–6. [Google Scholar]
- Tu, Y.; Wu, J.; Lu, L.; Gao, S.; Li, M. Face forgery video detection based on expression key sequences. J. King Saud Univ.-Comput. Inf. Sci. 2024, 36, 102142. [Google Scholar] [CrossRef]
- Xu, Y.; Liang, J.; Sheng, L.; Zhang, X.-Y. Learning spatiotemporal inconsistency via thumbnail layout for face deepfake detection. Int. J. Comput. Vis. 2024, 132, 5663–5680. [Google Scholar] [CrossRef]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Niagara Falls, Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar]
- Haliassos, A.; Vougioukas, K.; Petridis, S.; Pantic, M. Lips don’t lie: A generalisable and robust approach to face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5037–5047. [Google Scholar]
- Demir, I.; Ciftci, U.A. Where do deep fakes look? Synthetic face detection via gaze tracking. In Proceedings of the ACM Symposium on Eye Tracking Research and Applications, Stuttgart, Germany, 25–27 May 2021; pp. 1–6. [Google Scholar]
- Peng, C.; Miao, Z.; Liu, D.; Wang, N.; Hu, R.; Gao, X. Where deepfakes gaze at? Spatial–temporal gaze inconsistency analysis for video face forgery detection. IEEE Trans. Inf. Forensic Secur. 2024, 19, 4507–4517. [Google Scholar] [CrossRef]
- He, Q.; Peng, C.; Liu, D.; Wang, N.; Gao, X. GazeForensics: Deepfake detection via gaze-guided spatial inconsistency learning. Neural Networks 2024, 180, 106636. [Google Scholar] [CrossRef] [PubMed]
- Qi, H.; Guo, Q.; Juefei-Xu, F.; Xie, X.; Ma, L.; Feng, W.; Liu, Y.; Zhao, J. DeepRhythm: Exposing deepfakes with attentional visual heartbeat rhythms. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 4318–4327. [Google Scholar]
- Wu, J.; Zhu, Y.; Jiang, X.; Liu, Y.; Lin, J. Local attention and long-distance interaction of rPPG for deepfake detection. Visual Comput. 2024, 40, 1083–1094. [Google Scholar] [CrossRef]
- Yang, J.; Sun, Y.; Mao, M.; Bai, L.; Zhang, S.; Wang, F. Model-agnostic method: Exposing deepfake using pixel-wise spatial and temporal fingerprints. IEEE Trans. Big Data 2023, 9, 1496–1509. [Google Scholar] [CrossRef]
- Saif, S.; Tehseen, S.; Ali, S.S. Fake news or real? Detecting deepfake videos using geometric facial structure and graph neural network. Technol. Forecast. Soc. Chang. 2024, 205, 123471. [Google Scholar] [CrossRef]
- Zhang, R.; Wang, H.; Liu, H.; Zhou, Y.; Zeng, Q. Generalized face forgery detection with self-supervised face geometry information analysis network. Appl. Soft. Comput. 2024, 166, 112143. [Google Scholar] [CrossRef]
- Guan, H.; Kozak, M.; Robertson, E.; Lee, Y.; Yates, A.N.; Delgado, A.; Zhou, D.; Kheyrkhah, T.; Smith, J.; Fiscus, J. MFC datasets: Large-scale benchmark datasets for media forensic challenge evaluation. In Proceedings of the IEEE Winter Applications of Computer Vision Workshops, Waikoloa, HI, USA, 7–11 January 2019; pp. 63–72. [Google Scholar]
- Ciftci, U.A.; Demir, I.; Yin, L. FakeCatcher: Detection of synthetic portrait videos using biological signals. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1–17. [Google Scholar] [CrossRef]
- Kong, C.; Chen, B.; Yang, W.; Li, H.; Chen, P.; Wang, S. Appearance matters, so does audio: Revealing the hidden face via cross-modality transfer. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 423–436. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, C.; Liu, D.; Wang, N.; Gao, X. ForgeryNIR: Deep face forgery and detection in near-infrared scenario. IEEE Trans. Inf. Forensic Secur. 2022, 17, 500–515. [Google Scholar] [CrossRef]
- Agarwal, S.; Farid, H.; El-Gaaly, T.; Lim, S.-N. Detecting deep-fake videos from appearance and behavior. In Proceedings of the IEEE International Workshop on Information Forensics and Security, New York City, NY, USA, 6–11 December 2020; pp. 1–6. [Google Scholar]
- Cozzolino, D.; Rössler, A.; Thies, J.; Nießner, M.; Verdoliva, L. ID-Reveal: Identity-aware deepfake video detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 10–17 October 2021; pp. 15088–15097. [Google Scholar]
- Ramachandran, S.; Nadimpalli, A.V.; Rattani, A. An experimental evaluation on deepfake detection using deep face recognition. In Proceedings of the International Carnahan Conference on Security Technology, Pune, India, 11–15 October 2021; pp. 1–6. [Google Scholar]
- Fang, M.; Yu, L.; Song, Y.; Zhang, Y.; Xie, H. IEIRNet: Inconsistency exploiting based identity rectification for face forgery detection. IEEE Trans. Multimed. 2024, 26, 11232–11245. [Google Scholar] [CrossRef]
- Fang, M.; Yu, L.; Xie, H.; Tan, Q.; Tan, Z.; Hussain, A.; Wang, Z.; Li, J.; Tian, Z. STIDNet: Identity-aware face forgery detection with spatiotemporal knowledge distillation. IEEE Trans. Comput. Soc. Syst. 2024, 11, 5354–5366. [Google Scholar] [CrossRef]
- Yu, C.; Zhang, X.; Duan, Y.; Yan, S.; Wang, Z.; Xiang, Y.; Ji, S.; Chen, W. Diff-ID: An explainable identity difference quantification framework for deepfake detection. IEEE Trans. Dependable Secur. Comput. 2024, 21, 5029–5045. [Google Scholar] [CrossRef]
Figure 1.
The basic categories of AI-created visual content detection.
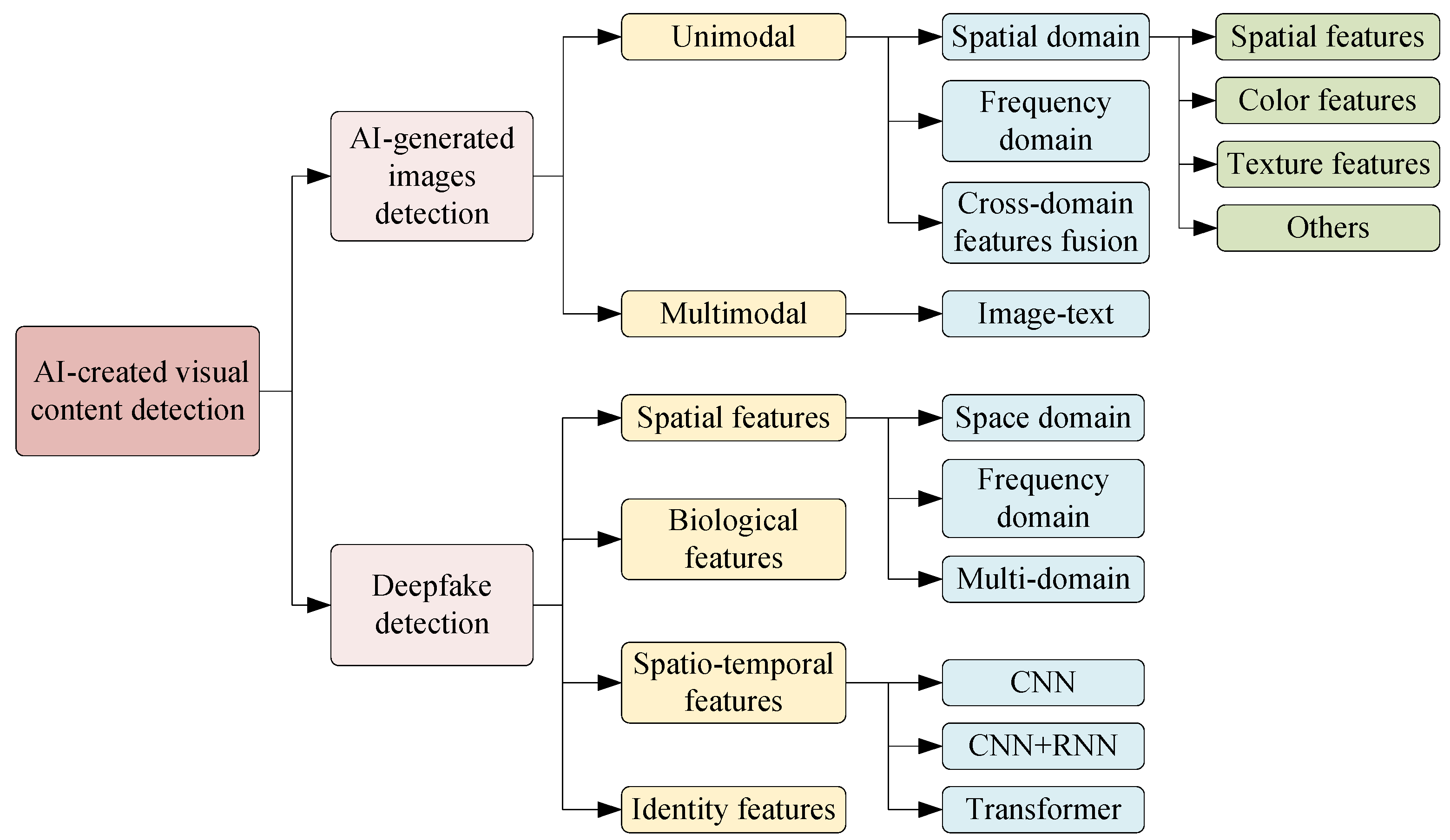
Figure 2.
Basic framework of generative adversarial network.
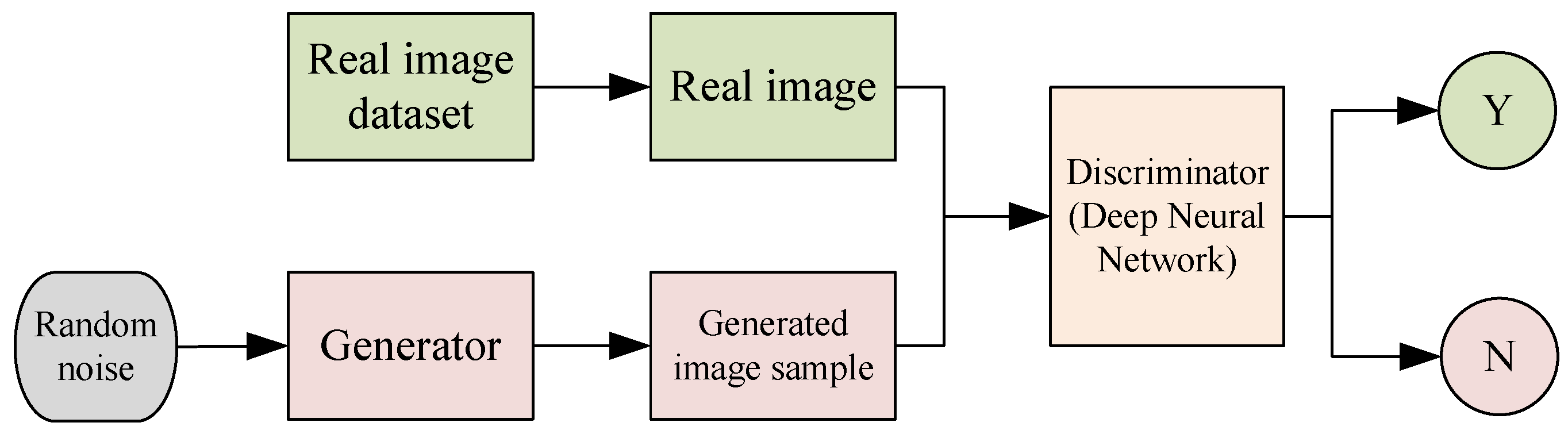
Figure 3.
Basic framework of diffusion model.
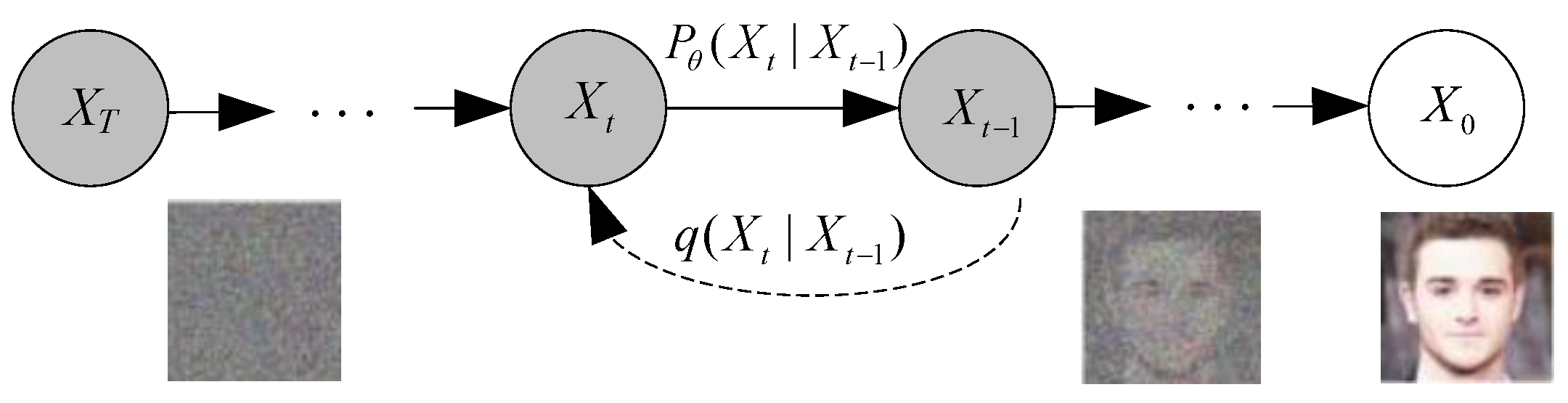
Figure 4.
Basic framework of AI-generated images detection on deep learning.
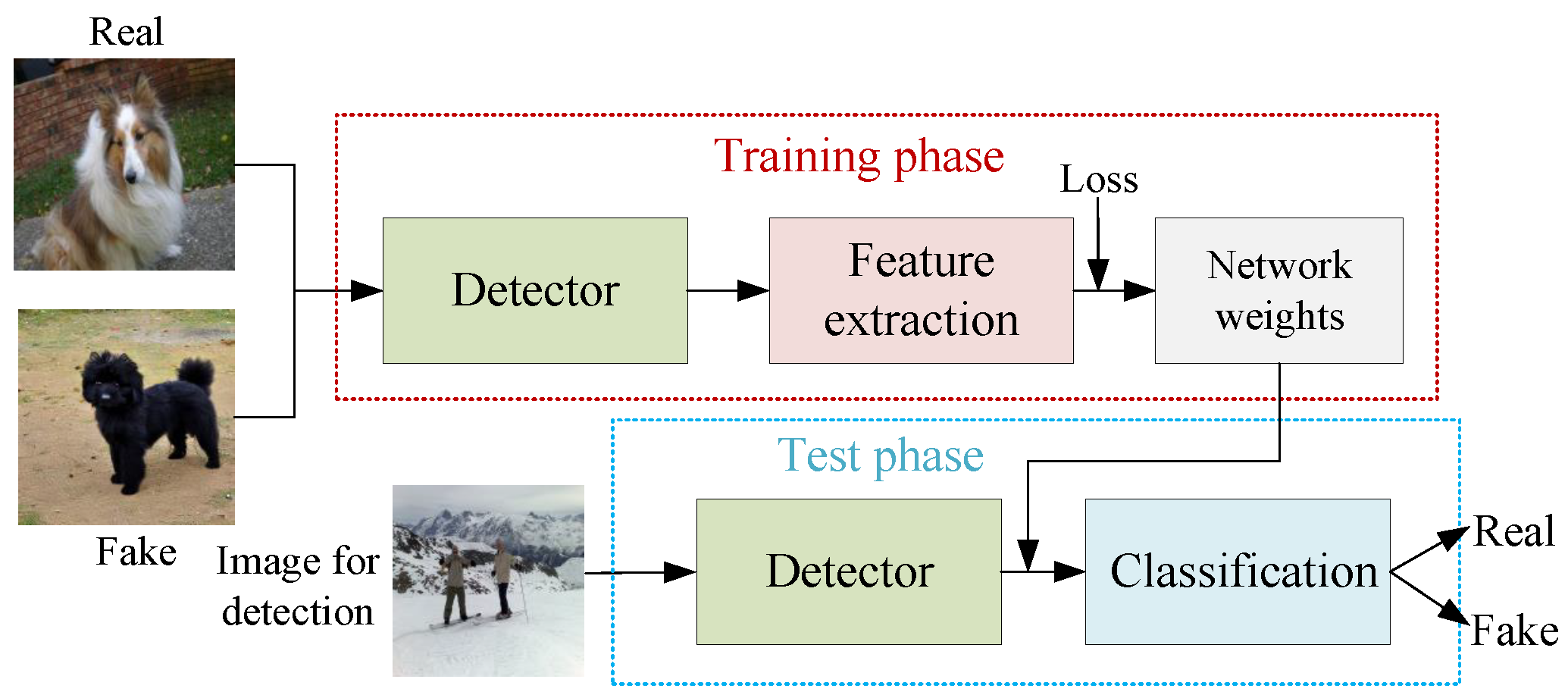
Figure 5.
Examples of the generation process or forged faces for the four forgery types: (a) Deepfakes [47] forgery technique based on encoder-decoder architecture, belongs to faceswap; (b) Synthesis framework for Face2Face [48] in face reenactment, where the expression of the source face is modified; (c) Some examples of fake faces with attribute editing, where the hairstyle, gender or age has been modified; (d) General architecture for virtual face generation.
Figure 5.
Examples of the generation process or forged faces for the four forgery types: (a) Deepfakes [47] forgery technique based on encoder-decoder architecture, belongs to faceswap; (b) Synthesis framework for Face2Face [48] in face reenactment, where the expression of the source face is modified; (c) Some examples of fake faces with attribute editing, where the hairstyle, gender or age has been modified; (d) General architecture for virtual face generation.
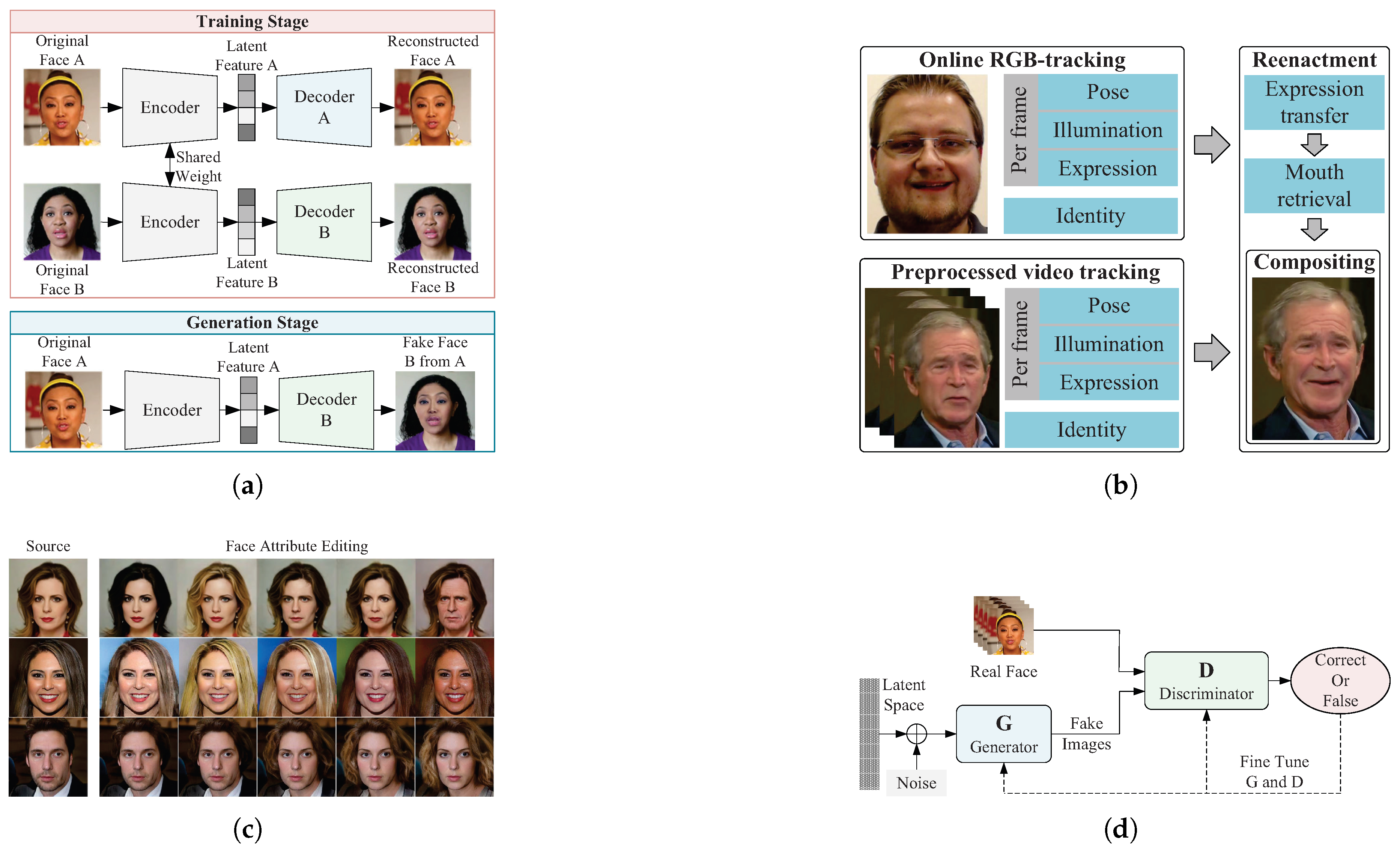
Figure 6.
Taxonomy of AI-generated images detection methods based on deep learning.
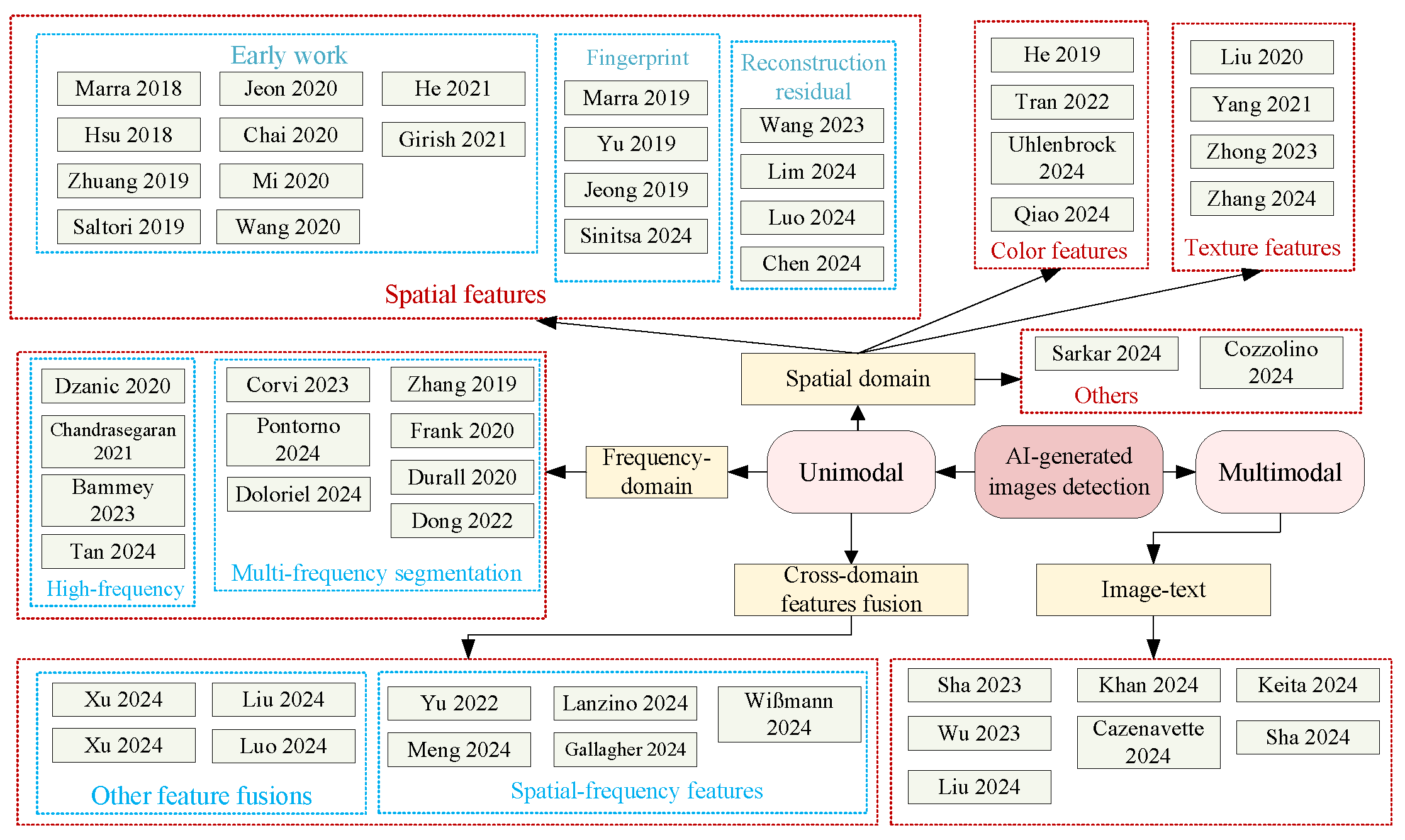
Figure 7.
Taxonomy of deepfake detection methods based on feature selection.
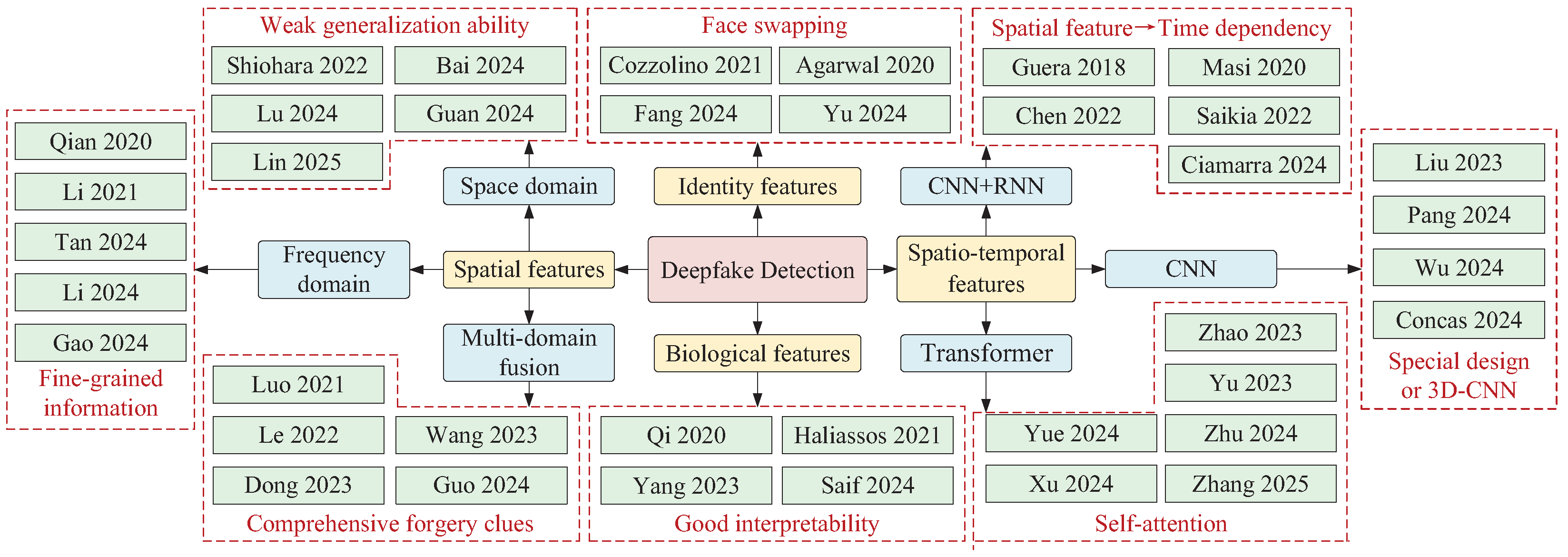
Figure 8.
The general synthesis process of SBI. ⨀ denote element-wise multiplication operation.
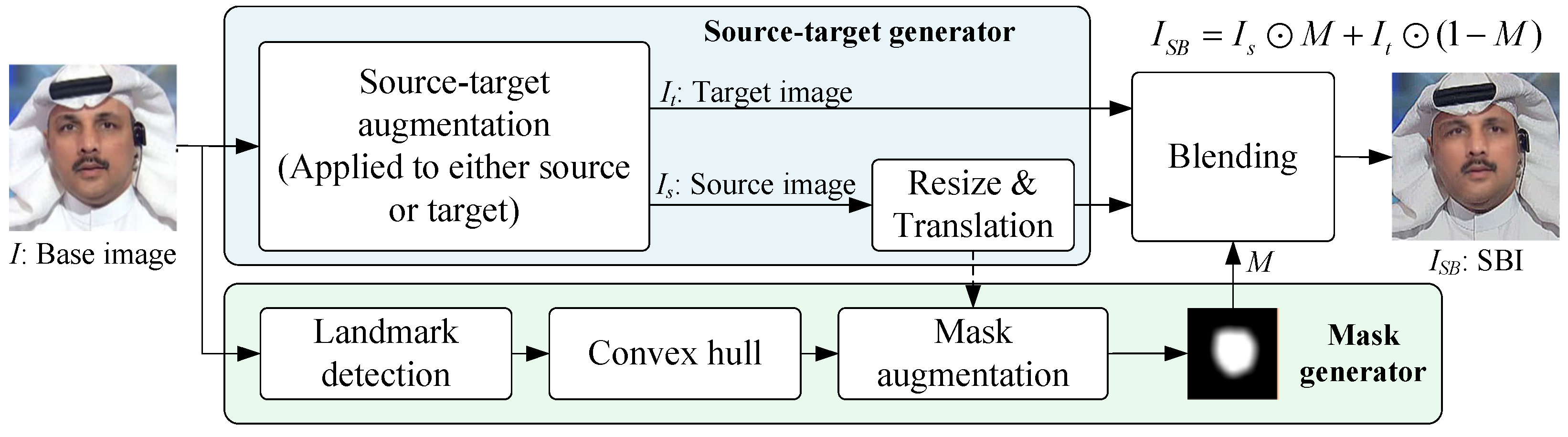
Figure 9.
Three commonly used high-pass filtering kernels in SRM and their resulting noise residual images.
Figure 9.
Three commonly used high-pass filtering kernels in SRM and their resulting noise residual images.
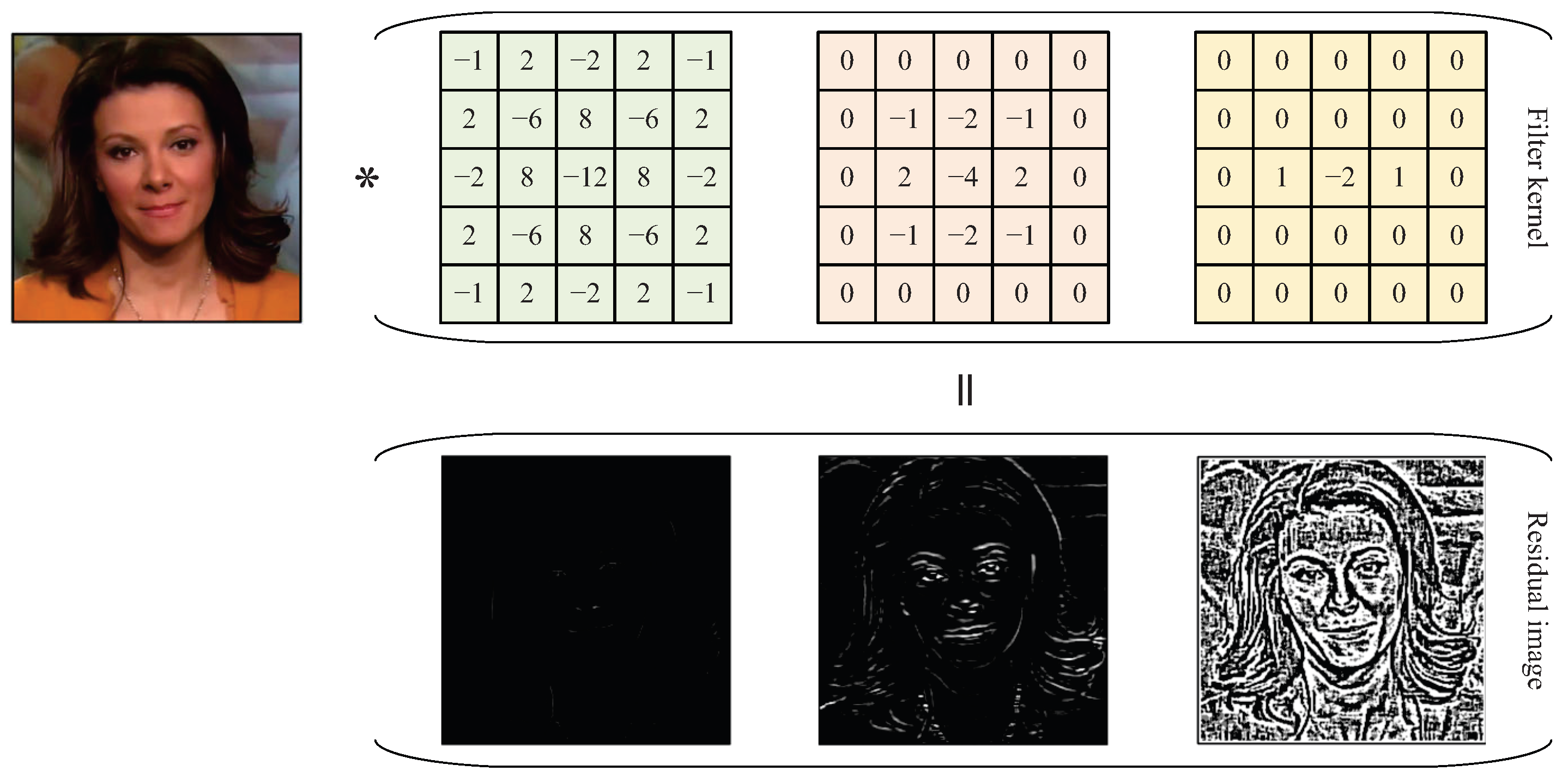
Figure 10.
The general detection process based on the CNN and RNN hybrid model.
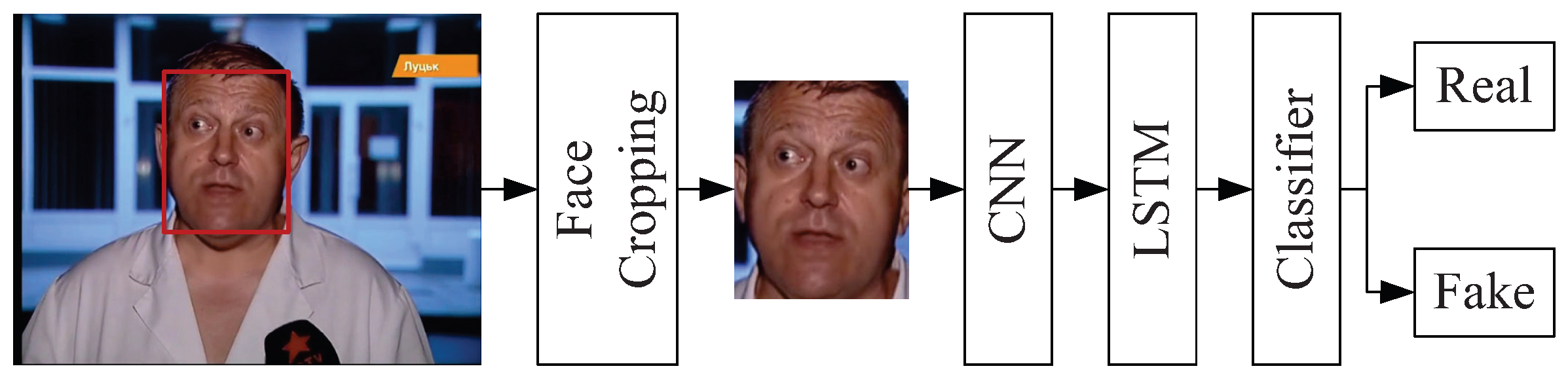

Table 1.
Datasets for AI-generated images detection.
| Datasets | Year | Generator | Number of images (k) | |
| Fake | Ture | |||
| CNNSpot [69] | 2020 | GANs | 362 | 262 |
| Diffusiondb [40] | 2022 | DMs | 14000 | 0 |
| DE-Fake [136] | 2023 | DMs | 20 | 60 |
| Artifact [41] | 2023 | GANs, DMs | 1522 | 962 |
| Cifake [42] | 2024 | DMs | 60 | 60 |
| Genimage [43] | 2024 | GANs, DMs, Others | 133 | 1350 |
| Fake2M [44] | 2024 | GANs, DMs, Others | 2000 | 0 |
| Wildfake [45] | 2024 | GANs, DMs, Others | 2577 | 1313 |
Table 2.
A summary of existing deepfake datasets, including their modality, real/fake numbers and generation techniques.
Table 2.
A summary of existing deepfake datasets, including their modality, real/fake numbers and generation techniques.
| Dataset | Year | Modality | Real/Fake | Source | Generation Technique |
|---|---|---|---|---|---|
| UADFV | 2018 | Video | 49 / 49 | YouTube | FakeAPP |
| Deepfake TIMIT | 2018 | Video | 320 / 640 | VidTIMIT | FaceSwap |
| FF++ | 2019 | Video | 1000 / 5000 | YouTube | Deepfakes, Face2Face, NeuralTextures, FaceSwap, FaceShifter |
| DFD [54] | 2019 | Video | 363 / 3068 | Live Action | Deepfakes |
| DFDC | 2020 | Video | 23,654 / 104,500 | Live Action | FaceSwap, NTH, FSGAN, StyleGAN |
| DFo [55] | 2020 | Video | 11,000 / 48,475 | YouTube | FaceSwap |
| CDF-(v1, v2) [56] | 2020 | Video | 590 / 5639 | YouTube | DeepFake |
| WDF | 2020 | Video | 3805 / 3509 | Internet | Internet |
| KoDF [57] | 2021 | Image | 175,776 / 62,166 | Live Action | FaceSwap, DeepFaceLab, FSGAN, FOMM, ATFHP, Wav2Lip |
| OpenForensics [58] | 2021 | Image | 45473 / 70325 | Google Open Images | GAN |
| FFIW10k [59] | 2021 | Video | 10,000 / 10,000 | Live Action | FaceSwap, FSGAN, DeepFaceLab |
| DFDM [60] | 2022 | Video | 590 / 6450 | YouTube | Facewap |
| DF-Platter [61] | 2023 | Video | 764 / 132,496 | YouTube | FSGAN, FaceSwap, FaceShifter |
| Diffusion Deepfake [62] | 2024 | Image | 94120 / 112,627 | DiffusionDB | Diffusion Model |
Table 3.
Confusion matrix.
| Prediction Label | Positive | Negative | |
|---|---|---|---|
| True Label | |||
| Positive | True Positive () | False Negative () | |
| Negative | False Positive () | True Negative () | |
Table 4.
A comparison of spatial features-based methods.
| Ref. | Year | Method | Advantage | Deficiency |
| Yu et al. [65] | 2019 | Fingerprint attribution | Trace the image back to the specific generative model | More complex computation when there are many models |
| Wang et al. [69] | 2020 | Data augmentation | The generalization ability of GAN-generated images is good | Poor generalization ability on diffusion models |
| Jeon et al. [70] | 2020 | Teacher-student model | Transferable model and good detection accuracy | Poor generalization ability on diffusion models |
| Chai et al. [71] | 2020 | Image patch | Extracting local features of the image | Ignoring global information |
| Mi et al. [72] | 2020 | Self-attention mechanism | Focus on the artifact regions of the features | Some generative models do not use upsampling operations |
| Girish et al. [75] | 2021 | Fingerprint attribution | Good generalization to unseen GANs | As the number of generative models increases, the computational cost grows |
| Liu et al. [76] | 2022 | Noise pattern | Good generalization | The noise information in the compressed image affect detection performance |
| Jeong et al. [77] | 2022 | Fingerprint recognition | Only real images are needed for training, avoiding data dependency | As the number of generative models increases, the computational load grows |
| Tan et al. [81] | 2023 | Gradient feature | Excellent detection performance on GAN-generated images | Poor detection performance on non-GAN generated images |
| Ojha et al. [82] | 2023 | CLIP model | CLIP demonstrates good generalization capability in detecting generated images | The method is simple, and the accuracy is not high |
| Wang et al. [84] | 2023 | Reconstruction error | Performs well in detecting on diffusion models | Performs poorly on non-diffusion models |
| Tan et al. [88] | 2024 | Pixel correlation | Simple to compute, with good generalization | Relies on upsampling operations, with limitations |
| Lim et al. [89] | 2024 | Reconstruction error | Lightweight network, faster computation | Has limitations for diffusion models |
| Yan et al. [90] | 2024 | Data augmentation | The method can be combined with other networks to improve generalization | It causes the computation time of other networks to increase |
| Chen et al. [92] | 2024 | Image reconstruction | The method can be combined with other detectors | Additional reconstruction dataset is required |
Table 5.
A comparison of color feature-based methods.
| Ref. | Year | Method | Advantage | Deficiency |
|---|---|---|---|---|
| He et al. [99] | 2019 | Chrominance components | Strong robustness | Limited generalization |
| Chandrasegaran et al. [100] | 2022 | Relevance statistic | Discover that color is a critical feature in universal detectors | Images generated by diffusion models are similar to real images in terms of color |
| Uhlenbrock et al. [101] | 2024 | Color statistics | High accuracy | Not tested on GAN datasets |
| Qiao et al. [102] | 2024 | Co-occurrence matrix | Exhibits strong robustness | The experiment is simple |
Table 6.
A comparison of texture features-based methods.
| Ref. | Year | Method | Advantage | Deficiency |
|---|---|---|---|---|
| Liu et al. [103] | 2019 | Texture differences | Using texture differences for generated image detection | Limited generalization |
| Yang et al. [104] | 2021 | Multi-scale texture | Extract multi-scale and deep texture information from the image | The network is complex and computationally intensive |
| Zhong et al. [105] | 2023 | Texture contrast | Good generalization ability | Dependent on the high-frequency components of the image |
| Zhang et al. [106] | 2024 | Deep LBP network | Extract depth texture information | The experiment is simple and unable to validate the performance of the method |
Table 7.
A comparison of other methods.
| Ref. | Year | Method | Advantage | Deficiency |
|---|---|---|---|---|
| Lorenz et al. [107] | 2023 | Local intrinsic dimensionality | Good performance in diffusion models | Dependent on data augmentation |
| Lin et al. [108] | 2023 | Genetic programming | Can improve accuracy to some extent | Limited generalization ability |
| Sarkar et al. [109] | 2024 | Projective geometry | Having some level of generalization | Lacks effective defense against some attacks |
| Cozzolino et al. [110] | 2024 | Coding cost | Good generalization ability | Weak robustness |
Table 8.
A comparison of frequency domain-based methods.
| Ref. | Year | Method | Advantage | Deficiency |
|---|---|---|---|---|
| Zhang et al. [112] | 2019 | Frequency artifacts | Detect frequency differences between real and fake images | Limited generalization |
| Frank et al. [113] | 2020 | 2D-DCT | Discover that color is a critical feature in universal detectors | Images generated by diffusion models are similar to real images in terms of color |
| Durall et al. [114] | 2020 | High-frequency fourier modes | Transferable model and good detection accuracy | Poor generalization ability on diffusion models |
| Corvi et al. [119] | 2023 | Training DM’s images | Enhancing the performance of detecting diffusion model images | With the emergence of new generative models, updates are continuous |
| Tan et al. [123] | 2024 | Frequency learning | It can learn features unrelated to the generative model, enhancing the model’s generalization ability | High computational cost and time-consuming |
| Doloriel et al. [124] | 2024 | Frequency mask | Less dependence on detector data | The mask size affects the performance of the detector |
Table 9.
A comparison of cross-domain features fusion methods.
| Ref. | Year | Method | Advantage | Deficiency |
|---|---|---|---|---|
| Yu et al. [126] | 2022 | Channel and spectrum difference | Effectively mine intrinsic features | Limited generalization ability |
| Luo et al. [128] | 2024 | Reconstruction error | Able to extract refined features from images | Poor performance on non-diffusion models |
| Lanzino et al. [129] | 2024 | Three types of feature fusion | Capture multiple features of the image with a simple network | Weak resistance to adversarial attacks |
| Xu et al. [133] | 2024 | Deep trace feature fusion | Good generalization performance | Complex network with long computation time |
| Leporoni et al. [134] | 2024 | RGB-depth integration | RGB features capable of extracting depth | Weak resistance to adversarial attacks |
Table 10.
A comparison of image-text-based methods.
| Ref. | Year | Method | Advantage | Deficiency |
|---|---|---|---|---|
| Wu et al. [137] | 2024 | Contrastive learning | Transform the synthetic image detection problem into a recognition problem | Text description affects the performance of the detector |
| Liu et al. [138] | 2024 | Forgery aware adaptive | Strong generalization ability | Computationally intensive and time-consuming |
| Cazenavette et al. [139] | 2024 | Inverting stable diffusion | Good detection accuracy | Limited in the context of stable diffusion |
| Keita et al. [141] | 2024 | Technical optimizations | Combining BLIP and LoRA to enhance accuracy | Computationally intensive and time-consuming |
| Sha et al. [143] | 2024 | Image reconstruction | Requires no large training data and has good robustness | Mainly focused on diffusion models, with certain limitations |
Table 11.
A comparison of space domain information-based deepfake detection methods.
| Ref. | Year | Key Idea | Backbone | Dataset |
|---|---|---|---|---|
| Shiohara et al.[147] | 2022 | Synthetic data | EfficientNetB4 | FF++, CDF, DFD, DFDCp [157], DFDC, FFIW10k |
| Bai et al.[154] | 2024 | Regional noise inconsistency | Xception | FF++, CDF, DFDC |
| Gao et al.[151] | 2024 | Feature decomposition | Convolution layer | FF++, WDF, CDF, DFDC |
| Lu et al.[152] | 2024 | Long-distance attention | Xception | FF++, CDF |
| Lin et al.[149] | 2024 | Synthetic data, curriculum learning | Transformer | FF++, CDF, DFDCp, DFDC, WDF |
Table 12.
A comparison of frequency domain information-based deepfake detection methods.
| Ref. | Year | Transform Type | Backbone | Dataset |
|---|---|---|---|---|
| Qian et al.[159] | 2020 | DCT | Xception | FF++ |
| Li et al.[160] | 2021 | DCT | Xception | FF++ |
| Miao et al.[162] | 2023 | DWT | Transformer | FF++, CDF, DFDC, Deepfake TIMIT |
| Zhao et al.[165] | 2023 | FFT | Convolution and attention layer | FF++-Deepfakes, FFHQ, CelebA |
| Gao et al.[161] | 2024 | DCT, DWT | Convolution and fusion layer | FF++, CDF, OpenForensics |
| Hasanaath et al.[164] | 2024 | DWT | EfficientNetB5 | FF++, CDF |
| Li et al.[163] | 2024 | DWT | Transformer | FF++, CDF, DFDC, Deepfake TIMIT, DFo |
Table 13.
A comparison of multi-domain information fusion-based deepfake detection methods.
| Ref. | Year | Information Source | Fusion Method | Backbone | Dataset |
|---|---|---|---|---|---|
| Luo et al. [172] | 2021 | RGB, SRM noise | Concatenation | Xception | FF++, DFD, DFDC, CDF, DFo |
| Fei et al. [174] | 2022 | RGB, SRM noise | Attention-guided | ResNet-18 | FF++, CDF, DFD |
| Wang et al. [166] | 2023 | RGB, DWT | Concatenation | Xception | FF++, CDF, UADFV |
| Guo et al. [171] | 2024 | RGB, High-frequency | Interaction, concatenation | ResNet-26 | HFF , FF++, DFDC, CDF |
| Wang et al. [170] | 2024 | RGB, DCT | Attention-guided | Xception | FF++, CDF |
| Wang et al. [167] | 2024 | RGB, DWT, Residual feature | Attention-guided | ResNet-34 | FF++, CDF, UADFV, DFD |
| Zhang et al. [173] | 2024 | RGB, SRM noise | Attention-guided | EfficientNet | FF++, DFDC, CDF, WDF |
| Zhou et al. [168] | 2024 | RGB, FFT | Multihead-attention | EfficientNetB4 | FF++, CDF, WDF |
Table 14.
Summary of methods for extracting spatio-temporal features using CNNs.
| Ref. | Year | Improved method | Backbone | Dataset |
|---|---|---|---|---|
| Liu et al.[176] | 2023 | Local attention augmentation | 3D ResNet-50 | FF++, CDF, DFDC |
| Pang et al.[178] | 2023 | Sampling strategy | ResNet-34 | FF++, CDF, DFDC, WDF |
| Wang et al.[181] | 2023 | Attention augmentation | ResNet-50 | FF++, CDF, WDF, DeepfakeNIR |
| Concas et al.[177] | 2024 | Quality feature | Convolution layer | FF++ |
| Yu et al.[180] | 2024 | Multilevel spatio-temporal features | ResNet-50, GCN | FF++, DFD, DFDC, CDF, DFo |
| Zhang et al.[179] | 2024 | Sampling strategy | EfficientNetB3 | FF++, CDF, DFDC, WDF |
Table 15.
A summary of Transformer-based methods.
| Ref. | Year | Network Architecture Design | Input Design | Dataset |
|---|---|---|---|---|
| Yu et al.[193] | 2023 | ✕ | ✔ | FF++, DFD, DFDC, DFo, CDF, WDF |
| Zhao et al.[195] | 2023 | ✔ | ✕ | FF++, CDF, DFDC |
| Choi et al.[200] | 2024 | ✕ | ✔ | FF++, DFo, CDF, DFD |
| Liu et al.[196] | 2024 | ✕ | ✔ | DFGC, FF++, DFo, CDF, DFD, UADFV |
| Tian et al.[201] | 2024 | ✕ | ✔ | FF++, CDF, DFDC |
| Tu et al.[202] | 2024 | ✕ | ✔ | FF++ |
| Xu et al.[203] | 2024 | ✔ | ✔ | FF++, CDF, DFDC, DFo, WDF, KoDF, DLB |
| Yue et al.[197] | 2024 | ✕ | ✔ | FF++, CDF, DFDC, DiffFace, DiffSwap |
Table 16.
A comparison of biological features-based deepfake detection methods.
| Ref. | Year | Biosignal Type | Backbone | Dataset |
|---|---|---|---|---|
| Yang et al. [204] | 2019 | Head poses | SVM | UADFV, DARPA GAN [214] |
| Qi et al. [209] | 2020 | rPPG | DNN, GRU | FF++, DFDCp |
| Demir and Ciftci [206] | 2021 | Eye, gaze | DNN | FF++, DF Datasets [215], CDF, DFo |
| Haliassos et al. [205] | 2021 | Mouth movements | ResNet-18, MS-TCN | FF++, CDF, DFDC |
| Yang et al. [211] | 2023 | CPPG | ACBlock-based DenseNet | FF++, FF, DFDC, CDF, FakeAVCeleb [216] |
| Peng et al. [207] | 2024 | Gaze | ResNet-34,ResNet-50, Res2Net-101 | FF++, WDF, CDF, DFDCp |
| He et al. [208] | 2024 | Gaze | ResNet-18 | FF++, WDF, CDF |
| Saif et al. [212] | 2024 | Facial landmarks | GCN | FF++, CDF, DFDC |
| Wu et al. [210] | 2024 | rPPG | MLA, Transformer | FF++, CDF |
| Zhang et al. [213] | 2024 | Facial landmarks, informative regions | GCN | FF++, CDF, WDF, DFDCp, DFD, DFo, ForgeryNIR [217] |
Table 17.
The AUC score comparison of identity-based methods on the FF++, CDF and DFDCp datasets.
| Ref. | Year | Key Idea | FF++ | CDF | DFDCp |
|---|---|---|---|---|---|
| Cozzolino et al. [219] | 2021 | Adversarial training | — | 0.840 | 0.910 |
| Fang et al. [221] | 2024 | Identity bias rectification | 0.996 | 0.945 | 0.983 |
| Fang et al. [222] | 2024 | Multi-modal knowledge distillation | 0.958 | 0.921 | 0.994 |
| Yu et al. [223] | 2024 | Attribute alignment | 0.991 | 0.911 | — |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



