
Submitted:
02 April 2025
Posted:
07 April 2025
You are already at the latest version
Abstract
Customer churn poses a significant challenge across various sectors, resulting in considerable revenue losses and increased customer acquisition costs. Machine Learning (ML) and Deep Learning (DL) have emerged as transformative approaches in churn prediction, significantly outperforming traditional statistical methods by effectively analyzing high-dimensional and dynamic customer datasets. This literature review systematically examines recent advancements in churn prediction methodologies based on 240 peer-reviewed studies published between 2020 and 2024 across diverse domains such as telecommunications, retail, banking, healthcare, education, and insurance. It examines the evolution, strengths, and limitations of conventional ML techniques—such as Decision Trees, Random Forests, and boosting algorithms—and advanced DL methods, including convolutional neural networks (CNNs), long short-term memory (LSTM) networks, Transformers, and hybrid models. Key emerging trends identified are the increasing adoption of ensemble models, profit-driven frameworks, sophisticated DL architectures, and attention-based mechanisms, coupled with a stronger emphasis on Explainable AI (XAI) and adaptive learning strategies. Despite significant progress, the review highlights persistent challenges like class imbalance, interpretability issues associated with DL's black-box nature, and difficulties addressing concept drift in dynamic customer behaviors. This study categorizes predominant methodologies, compares model performances, and identifies critical gaps such as limited consideration of real-world deployment constraints and business-oriented metrics. By addressing these gaps, the review provides actionable insights to develop robust, interpretable, economically beneficial churn prediction models, emphasizing alignment with business goals and guiding future research toward improved accuracy, adaptability, and practical deployment.
Keywords:
customer churn prediction
; machine learning
; deep learning
; literature review
; customer retention
1. Introduction
Customer retention has become a critical challenge for businesses across various industries, including telecommunications, retail, banking, insurance, healthcare, education, and subscription-based services. Customer churn—customers discontinuing their relationship with a company—can significantly impact revenues, with annual churn rates ranging from 20% to 40% in some sectors (Ahn et al. 2006). Research indicates that acquiring a new customer is five to twenty-five times more expensive than retaining an existing one, making churn prevention a strategic priority for companies (Shu and Ye, 2023).
Machine Learning and Deep Learning have emerged as powerful tools for churn prediction due to their ability to analyze large, high-dimensional, and dynamic customer datasets effectively. Traditional churn prediction methods, such as rule-based systems and statistical modeling, often fail to capture customer behavior’s complexities adequately. Conversely, ML approaches like Decision Trees (DTs), Random Forests (RFs), Support Vector Machines (SVMs), and boosting algorithms (e.g., XGBoost, LightGBM, CatBoost) have demonstrated strong predictive capabilities with structured datasets (Imani et al. 2023, 2024, 2025). Furthermore, advanced DL architectures—including Artificial Neural Networks (ANNs), CNNs, LSTMs, and Transformer-based models—provide significant advantages for modeling sequential and unstructured data, such as customer interaction histories and textual feedback.
Despite these technological advancements, several critical challenges remain in churn prediction. Model interpretability remains a significant concern, especially with complex DL-based approaches often functioning as “black-box” models (Lemmens and Gupta 2020). Data imbalance is another prevalent issue, as churn datasets typically feature significantly fewer churners than non-churners, potentially biasing model predictions (Imani et al. 2025). Additionally, concept drift—the evolving nature of customer behavior over time—complicates the sustained accuracy of predictive models.
This literature review systematically explores advancements in customer churn prediction by analyzing peer-reviewed research published between 2020 and 2024 across diverse domains such as telecommunications, retail, banking, healthcare, education, and insurance. It aims to map the current landscape of ML and DL approaches, evaluating their strengths, limitations, and applicability to real-world scenarios. Given the broad adoption of predictive analytics across industries, this review seeks to clarify the evolution of these methodologies, the specific challenges they address, and the gaps that require further research.
A key objective of this study is to identify and categorize the most frequently employed ML and DL techniques used in churn prediction. Understanding the evolution of these methods over recent years provides insights into how businesses and researchers have refined approaches to enhance accuracy and adaptability. Additionally, this review evaluates the performance and interpretability of various predictive models, focusing specifically on their capacity to manage imbalanced datasets, dynamic customer behaviors, and practical deployment constraints. Considering that customer churn results from multiple factors—such as transaction histories, engagement patterns, and external market conditions—it is crucial to assess the effectiveness of models in capturing these complexities.
Another central goal is highlighting persistent challenges and limitations within churn prediction research. Despite substantial progress, issues such as the black-box nature of DL models, class imbalance, and difficulty adapting models to evolving customer behaviors impede real-world implementations. This review emphasizes these research gaps and suggests potential areas for future investigation, including improving model transparency, advancing feature engineering techniques, and developing adaptive learning methods to address shifting customer preferences.
To address these objectives, this study is guided by three fundamental research questions:
- What are the predominant ML and DL approaches used in customer churn prediction, and how have these methodologies evolved over time?
- How do different predictive models compare accuracy, adaptability, and interpretability when applied to churn prediction across various industries?
- What are the significant challenges and limitations in existing churn prediction research, and what future directions can be explored to enhance the effectiveness of predictive models?
This review comprehensively synthesizes recent research by addressing these questions, offering valuable insights into best practices and emerging methodologies in churn prediction. It also serves as a foundation for future research, enabling data scientists, industry practitioners, and academics to refine their approaches and develop more robust, scalable, and interpretable churn prediction models.
2. Purpose of the Study
Customer churn prediction is vital in modern Customer Relationship Management (CRM), helping businesses proactively retain at-risk customers and maximize customer lifetime value. With high churn rates leading to substantial revenue losses, businesses in subscription-based services, telecommunications (Ahn et al. 2006, Joudaki et al. 2011), retail (Matuszelański and Kopczewska 2022), banking (Al-Najjar et al. 2022), education (Christou et al. 2023), healthcare (Ajegbile et al. 2024), Insurance (Ahn et al. 2020), and other sectors increasingly rely on data-driven approaches to enhance customer retention strategies.
While businesses collect vast amounts of customer data, extracting actionable insights from these datasets is challenging. Data mining, a key discipline in ML and artificial intelligence enables organizations to uncover hidden patterns and trends in churn behaviors. However, the effectiveness of churn prediction models varies significantly based on the choice of methodology, dataset characteristics, and industry-specific factors.
This study systematically reviews 240 research articles published between 2020 and 2024, focusing on churn prediction using ML and DL methodologies across various sectors. The review:
- Examines different churn prediction approaches across multiple industries.
- Assesses the comparative performance of ML and DL techniques in churn prediction.
- Investigates common challenges, such as data imbalance, feature selection, interpretability, and concept drift.
- Highlights emerging trends in churn prediction, including profit-driven modeling, explainable AI (XAI), and adaptive learning approaches.
Churn prediction research is crucial for developing effective retention strategies, allowing businesses to anticipate customer attrition, personalize marketing efforts, and allocate retention budgets more efficiently. Studies suggest that businesses implementing advanced churn prediction techniques can improve retention rates by 5%–10%, leading to profit increases of 25%–95% (Reichheld and Teal 1996).
By synthesizing insights from recent research, this paper serves as a valuable resource for researchers, data scientists, and industry practitioners, helping them understand best practices, methodological advancements, and future directions in churn prediction.
For more information, readers can refer to several comprehensive review papers that explore various aspects of customer churn prediction. Imani and Arabnia (2023) provide a comparative analysis of hyperparameter optimization techniques and data sampling strategies in ML models for churn prediction, highlighting their impact on predictive performance. Imani et al. (2025) extend this analysis by evaluating the effectiveness of SMOTE, ADASYN, and GNUS upsampling techniques in conjunction with RF and XGBoost under different class imbalance levels. Geiler et al. (2022) offer a broad survey of ML approaches for churn prediction, discussing their strengths, limitations, and practical applications. Domingos et al. (2021) focus on hyperparameter tuning for DL-based churn prediction models, particularly within the banking sector, providing insights into optimizing deep neural networks for improved accuracy. These studies offer valuable perspectives on churn prediction research’s methodological advancements and challenges.
3. Search Strategies
A systematic literature search was conducted across six major academic publishers, including Springer, IEEE, Elsevier, MDPI, ACM, and Wiley, ensuring comprehensive coverage of recent advancements in customer churn prediction using ML and DL techniques. The search was executed via Lens.org, a scholarly research platform offering advanced filtering and indexing capabilities superior to generic search engines like Google Scholar.
To refine the search, the query “(churn prediction AND machine learning) OR (churn prediction AND deep learning) NOT (“survey” OR “review”)” was applied, focusing on original research contributions rather than survey or review articles. Additionally, results were restricted to journal and conference proceedings articles published between 2020 and 2024, ensuring relevance to recent developments. The KStem-based stemming approach was utilized to normalize variations of the term “churn,” such as “churned” and “churning,” to capture a broader range of relevant studies.
As illustrated in Figure 1, the initial search retrieved 837 articles. To ensure relevance and quality, a series of refinement steps were applied. First, filtering by document type to include only journal and conference articles while excluding pre-prints, technical reports, and other non-peer-reviewed documents reduced the count to 679 articles. Next, restricting the selection to high-quality publishers—as previously outlined—further refined the dataset to 368 articles. Finally, a domain-specific review was conducted to eliminate papers unrelated to customer churn prediction or those not utilizing ML and DL techniques. This resulted in a final selection of 240 articles for the first phase (shallow review phase). This exploratory phase analyzed broad research trends, methodological patterns, and key developments in customer churn prediction using ML and DL approaches. This phase focused on high-level bibliometric analysis, including publication trends across research domains, the distribution of ML and DL techniques, the average citation trends of publishers (Crossref citation), citation patterns, and the publications shared among different publishers over the past five years (2020–2024). By analyzing these broader trends, this phase provided a foundation for identifying the most influential studies, emerging research directions, and methodological advancements.
A second phase (deep review phase) was conducted to ensure a more focused and rigorous examination, in which 61 papers were selected based on relevance, citation impact, methodological novelty, and contribution to the field. This phase delved into the technical depth of the selected studies, focusing on critical aspects such as dataset characteristics, applied ML and DL techniques, evaluation metrics, and the key outcomes reported in the studies. By conducting this two-phase review strategy, the study captured broad research trends and provided a granular understanding of methodological advancements, dataset challenges, and performance benchmarks. This structured approach enhanced the literature review’s comprehensiveness, objectivity, and depth, ensuring both breadth and depth in assessing the state-of-the-art customer churn prediction research.
The inclusion criteria are outlined below:
Inclusion Criteria:
- Articles must focus on churn prediction using ML or DL techniques.
- Articles published between 2020 and 2024 in peer-reviewed, high-quality journals.
- Articles must be original research papers.
Exclusion Criteria:
- Articles unrelated to churn prediction.
- Articles unrelated to ML or DL.
- Non-peer-reviewed works (e.g., lecture notes, newsletters, dissertations).
- Low-quality publishers.
- Review papers, preprints, books, etc.
This systematic approach, following a well-documented filtering process and PRISMA guidelines, ensures the reproducibility of this literature review. All inclusion criteria, search strings, and filtering steps have been explicitly outlined to allow future researchers to replicate the results.
4. Trends in Churn Prediction Research
To comprehensively investigate the state of churn prediction research, we systematically reviewed 240 publications spanning the years 2020 to 2024. This five-year window was chosen to capture current trends and reflect the rapid advancements in ML and DL applications. The broad scope of this initial pool enabled us to analyze significant trends in publisher distribution, citation dynamics, average citation variations, research domain focus, and the adoption of various ML and DL techniques.
From this more extensive set, we selected 61 studies for deeper qualitative examination. This subset was identified based on multiple criteria, including methodological rigor, novelty of approach, domain diversity, and overall contribution to the field. By combining a wide-ranging quantitative overview with a focused, in-depth analysis of key studies, our methodology ensures an expansive mapping of churn prediction research and a thorough investigation of the most influential and innovative work. This dual-level strategy thus provides readers with a robust understanding of current practices, emerging challenges, and future directions in churn prediction using ML and DL techniques.
Figure 2 presents the overall distribution of publications by publishers. The pie chart illustrates that IEEE accounts for the largest share, with 60.4% of the total publications. Springer and Elsevier follow, at 12.9% and 11.2%, respectively, while MDPI comprises 7.1% of the dataset. ACM and Wiley comprise the remaining 5.8% and 2.5%, respectively. These percentages highlight the dominant position of IEEE among the publishers represented in this study.
Figure 3 further explores the temporal dimension of these publications from 2020 through 2024. IEEE exhibits a marked increase in published papers, peaking in 2023. In contrast, the other publishers remain relatively steady, though minor fluctuations can be observed from year to year. Notably, the apparent decline in publications for 2024 is likely attributable to incomplete indexing during data extraction (January 2025). Given that not all 2024 publications may have been processed and included in our study by that point, the downward trend for 2024 should be interpreted with caution. These figures suggest that IEEE consistently leads in publication output, while other publishers maintain comparatively smaller yet stable shares over the examined period.
Figure 4 and Figure 5 illustrate the number of citations and normalized impact factor trends for the selected publishers (Elsevier, IEEE, MDPI, Springer, Wiley, and ACM) from 2020 to 2024. Figure 4 shows that Elsevier exhibited the highest total citations in 2020, followed by a noticeable decline in subsequent years. Other publishers, including IEEE and MDPI, display smaller but still discernible peaks in earlier years, with a tendency toward reduced citation counts in 2023 and 2024. These observations align with the typical pattern in bibliometric analyses whereby earlier publications have a longer window to accumulate citations.
Figure 5 illustrates the normalized impact factor trends of the publishers from 2020 to 2024. To ensure a fair comparison of citation performance across publication years, we computed a normalized impact factor (IF) by dividing the total number of citations received by the number of published papers and the number of years since publication. This approach accounts for the varying time windows available for papers to accumulate citations, thus mitigating the bias that favors earlier publications. The formula used is as follows:
As shown in Figure 5, Elsevier and MDPI consistently outperform other publishers in terms of normalized impact across most years. Elsevier exhibits strong performance in 2020 (above 10 citations per paper per year), dips in 2022, and then peaks again in 2023, suggesting a combination of high-impact publications and efficient visibility. MDPI demonstrates a steep rise in 2021—reaching nearly 10 citations per paper per year—and a gradual decline in the following years, yet maintaining a relatively strong citation performance through 2023. Springer shows a downward trend from 2020 to 2022 but stabilizes around three citations per paper per year by 2023—Wiley peaks in 2021, similar to MDPI, followed by a moderate but steady decline. IEEE and ACM display lower and more stable citation patterns across the years, with values remaining primarily below 2, indicating more consistent but modest average citation rates.
While the normalized impact factor accounts for the time since publication, a general decline is still observed in 2024 across most publishers. This may reflect several factors, including recent shifts in publication strategies, article topics, quality changes, or early-stage visibility. Moreover, papers published in 2024 may not yet be fully indexed or cited at the time of data extraction (January 2025), especially for journals with delayed indexing pipelines. As such, citation-based metrics from the most recent year should be interpreted with caution, as they may underestimate the eventual long-term impact of these publications. Overall, the trends reveal significant year-to-year variation in normalized citation performance among publishers, underscoring the roles of editorial policy, topical focus, and dissemination strategies. By adjusting for publication age, the normalized impact factor offers a fairer and more time-independent comparison, particularly when analyzing performance across both recent and earlier publication years.
Figure 6 illustrates the overall distribution of citation counts for the collected publications, revealing a highly skewed pattern. Most papers receive only a few citations (fewer than five), while a relatively small number of publications accumulate notably higher citation counts. This right-skewed distribution is typical in bibliometric analyses, wherein most publications garner modest attention, whereas a limited subset gains substantial visibility and, consequently, higher citation impact.
Figure 7 presents the normalized impact factor trends—the average number of citations per paper per year—for Open Access (OA) and Non-Open Access (non-OA) publications from 2020 to 2024. Across all years, OA papers consistently outperform non-OA papers in terms of citation impact, with particularly strong performance in 2020 and 2021. This trend supports the notion that OA publishing may enhance the visibility and discoverability of research, thereby increasing its citation potential. While the normalized metric accounts for the time since publication, a noticeable decline is observed for both OA and non-OA papers in 2024. This may reflect limited early-stage visibility, indexing delays, or publication lags that hinder citation accumulation—particularly for papers published close to the data extraction date (January 2025), which may not yet be fully indexed or cited, especially in journals with slower indexing pipelines. As such, the lower values observed for the most recent year should be interpreted cautiously, as they may not accurately reflect the long-term influence of those publications.
Figure 8 presents the annual distribution of publications across six research domains—Telecom, Retail, Banking, Education, Healthcare, and Insurance—from 2020 to 2024. Across most domains, the overall trend is gradual growth from 2020 through 2023, followed by a slight decline in 2024. Telecom, in particular, shows a pronounced increase in publications up to 2023, indicating a sustained research focus on churn prediction within that sector. Healthcare and Education also exhibit steady upward trajectories, reflecting broader interest in applying churn-related methodologies to patient retention and student engagement. Retail and Banking maintain moderate but consistent growth, while Insurance remains comparatively lower throughout the observed period. The apparent drop in 2024 publications for all domains is likely influenced by the shorter window for indexing at the time of data extraction (January 2025), and it does not necessarily indicate a waning research interest.
Figure 9 presents the time series trends of ML and DL techniques in churn prediction from 2020 to 2024. ML methods exhibit a steady upward trend, indicating their widespread adoption. In contrast, DL publications remain relatively low but show gradual growth. The apparent decline in 2024 should be interpreted cautiously, as many papers from this year may not yet be fully indexed or have had sufficient time to gain citations and visibility.
Figure 10 depicts the annual usage of seven ML algorithms—Boosting Techniques (including XGBoost, LightGBM, and CatBoost), K-Nearest Neighbors, RF, DT, SVM, Naïve Bayes, and Logistic Regression—between 2020 and 2024. Boosting Techniques, RF, and Logistic Regression show notable growth through 2022–2023, suggesting increased research interest in ensemble-based methods and widely used baseline models. While most techniques experienced a slight dip in 2024, it is likely due to incomplete indexing and the relatively short time since publication at the time of data extraction (January 2025).
Figure 11 focuses on DL approaches—ANNs, LSTMs, CNNs, Recurrent Neural Networks (RNNs), Transformers, and Reinforcement Learning —over the same period. ANNs exhibit a pronounced surge in 2022, reflecting their broad applicability in diverse domains. LSTMs and CNNs also show moderate yet consistent usage, while Transformers and Reinforcement Learning remain less frequent but appear to have gained modest traction in recent years. Similar to the ML trends, the lower counts for 2024 likely do not capture the full extent of ongoing research activity, underscoring the need to interpret these recent-year values cautiously. Overall, the data reveal a continued shift toward advanced ML and DL techniques, albeit tempered by the time-dependent nature of publication and indexing cycles.
5. Paper’s Categorizations
In our review, we propose a comprehensive taxonomy that systematically organizes the literature on churn prediction into two primary methodological categories: Machine Learning Approaches and Deep Learning Approaches. Each category is further subdivided into specific subcategories, as illustrated in Figure 12. The ML Approaches encompass a range of techniques, including profit-centric models, which optimize retention strategies based on business impact, and ensemble and hybrid approaches, which combine multiple classifiers to improve predictive performance. Optimization and metaheuristic methods also focus on refining feature selection and hyperparameter tuning, while adaptive and resampling techniques address data imbalance and concept drift. The review also covers explainable and interpretable models, which enhance transparency in churn prediction, data-centric and augmentation strategies that leverage novel data sources and synthetic data generation, and traditional ML techniques, which continue to play a foundational role in churn modeling.
On the other hand, DL Approaches leverage advanced architectures to capture complex patterns in customer behavior. These include deep reinforcement learning, which enables adaptive decision-making, and temporal and sequential models, such as LSTMs, which capture evolving churn patterns over time. The taxonomy also highlights hybrid and ensemble DL approaches, which integrate multiple DL frameworks for improved generalization, and CNN-based models, which excel in feature extraction. Furthermore, feedforward deep neural networks, NLP-based models for text-based churn analysis, and representation and feature interaction techniques, which enhance predictive performance by capturing high-order dependencies, are explored.
By structuring the existing research into this hierarchical framework, our taxonomy provides a clear perspective on the evolution of churn prediction methodologies. It underscores how different approaches have been tailored to address the multifaceted challenges of churn modeling, from enhancing predictive accuracy and scalability to improving interpretability and data efficiency.
6. Machine Learning Approaches
Machine learning methodologies have significantly enhanced churn prediction through diverse approaches to address complex customer retention challenges across various sectors. Recent research encompasses profit-driven models, ensemble learning techniques, optimization-based methods, adaptive resampling strategies, explainable artificial intelligence (XAI), and traditional algorithms. Each methodology contributes distinct advantages such as improved predictive accuracy, enhanced interpretability, computational efficiency, and alignment with business objectives. This section reviews these innovative approaches, outlining their methodologies, data characteristics, and performance evaluations, thereby providing valuable guidance for selecting suitable ML techniques for specific churn prediction applications. Table 1 briefly summarizes each study by indicating the dataset types used (public, private, or synthetic), ML techniques employed, and performance metrics evaluated.
A. Profit-Centric Approaches
Recent developments in churn prediction research reflect a growing emphasis on aligning predictive models with business objectives, particularly profitability. Traditionally, churn models have been optimized for accuracy-based metrics like AUC. Still, a shift toward integrating financial considerations directly into model training has emerged as critical for more impactful customer retention strategies.
Höppner et al. (2020) exemplify this shift by introducing ProfTree, a profit-driven DT tailored explicitly for churn prediction. Rather than solely optimizing classification accuracy, ProfTree employs the Expected Maximum Profit for Customer Churn (EMPC) metric to construct DTs prioritizing profitability. The model systematically accounts for misclassification costs and customer-specific economic value through an evolutionary algorithm. Experiments on telecommunication datasets demonstrate that ProfTree significantly enhances profit compared to conventional accuracy-centric approaches, underscoring the importance of profit-centric predictive analytics.
Building on similar principles, Maldonado et al. (2020) propose a profit-oriented churn prediction model utilizing Minimax Probability Machines (MPM). Unlike traditional methods that often use profitability metrics only during post-model selection or threshold adjustments, this approach directly integrates profit maximization into the classifier’s training objective. Their framework includes a baseline model and two regularized variants incorporating LASSO and Tikhonov regularization to ensure robust generalization. Benchmark evaluations confirm that these profit-driven MPM extensions yield superior profitability outcomes relative to standard binary classifiers, emphasizing the necessity of embedding business objectives directly into predictive modeling.
Extending this perspective into the business-to-business (B2B) domain, Janssens et al. (2024) introduce B2Boost, an instance-dependent gradient boosting model explicitly designed for B2B churn scenarios. Recognizing customer heterogeneity in profitability, they propose the Expected Maximum Profit for B2B churn (EMPB) metric to guide model training. B2Boost directly optimizes customer-specific profit rather than traditional classification accuracy, yielding notable profit improvements over standard approaches. The successful application in B2B contexts highlights the broader potential of profit-centric methodologies beyond consumer markets.
These studies underscore the necessity of shifting predictive modeling practices toward profit-centric frameworks. By directly incorporating financial objectives, churn prediction models become more aligned with strategic business goals, facilitating more effective and economically beneficial customer retention efforts.
B. Ensemble and Hybrid ML Approaches
Ensemble and hybrid approaches have emerged as robust methodologies for enhancing customer churn prediction across various industries. By integrating multiple classifiers, clustering techniques, and advanced feature engineering methods, these approaches harness the strengths of individual models to mitigate the limitations of single-algorithm solutions. This section provides a comprehensive review of key studies that have demonstrated the effectiveness of ensemble and hybrid learning in churn prediction, highlighting their contributions to predictive accuracy, model robustness, and real-world applicability.
One notable study by Liu et al. (2022) introduces a hybrid approach that integrates clustering and classification algorithms to improve predictive accuracy in the telecom sector. Their model employs k-means, k-medoids, and random clustering techniques alongside classifiers such as Gradient Boosting Trees (GBT), DTs, RFs, DL, and Naïve Bayes (NB). The study reports significant performance improvements by leveraging stacking-based hybridization, with 96% and 93.6% accuracy on the Orange and Cell2Cell datasets. These results emphasize the benefits of ensemble learning and clustering-based feature enhancement in churn prediction. Similarly, Ramesh et al. (2022) propose a hybrid model combining ANNs and RFs to enhance churn prediction in telecommunications. Their ANN architecture, consisting of four hidden layers, achieved 90.34% accuracy, outperforming standalone RF and simpler ANN models. Integrating ANN’s predictive power with RF’s robustness effectively identifies churn factors, aiding telecom companies in proactive customer retention strategies.
Using hybrid approaches, Usman-Hamza et al. (2022) introduce Intelligent Decision Forest (DF) models to address scalability issues and class imbalance in telecom churn prediction. Their approach significantly enhances classification accuracy by incorporating Logistic Model Tree (LMT), RF, and Functional Trees (FT) within a weighted soft voting and stacking framework. The study underscores the potential of decision forest-based models in handling imbalanced datasets and improving churn detection across telecommunications.
Saias et al. (2022) focus on churn prediction within cloud service providers, emphasizing the importance of early detection in mitigating customer loss and optimizing resource allocation. Their ML framework evaluates multilayer neural networks, AdaBoost, and RF models, with RF emerging as the most effective, achieving an accuracy of 98.8% and an AUC score of 0.997. These findings reinforce the relevance of ensemble learning in dynamic service industries.
In the context of the webcasting industry, Fu et al. (2023) employ an ensemble learning-based churn prediction model optimized by the Nelder-Mead algorithm. Their approach extracts high-dimensional behavioral features from time-series data, introducing a novel churn indicator to enhance label accuracy. The study demonstrates superior operational efficiency and outperformance of traditional ensemble models, offering actionable insights for customer retention strategies.
Optimization techniques have also been explored to refine ensemble methods. Khoh et al. (2023) introduce an optimized weighted ensemble model tailored for the telecommunications industry, integrating Powell’s optimization algorithm to assign differential weights to base learners based on their predictive strength. This model achieves an accuracy of 84% and an F1-score of 83.42%, surpassing conventional ML approaches. Beeharry and Tsokizep Fokone (2022) further contribute to this domain by proposing a two-layer flexible voting ensemble, demonstrating the impact of data balancing on improving classification performance.
Boosted tree models have gained traction in various industries for their efficiency in churn prediction. Sagala and Permai (2021) explore the use of XGBoost, LightGBM, and CatBoost in banking churn prediction, finding LightGBM to be the most effective with 91.4% accuracy, 94.8% AUC, and 87.7% recall. Similarly, Xu et al. (2021) implement a stacking-based ensemble framework combining XGBoost, Logistic Regression, DTs, and Naïve Bayes, achieving 98.09% accuracy by incorporating feature grouping techniques.
A novel direction in ensemble learning is explored by Arshad et al. (2024), who introduce Q-Ensemble Learning, a quantum-enhanced ensemble approach incorporating Quantum Support Vector Machine (Q-SVM), Quantum k-Nearest Neighbors (Q-kNN), and Quantum Decision Tree (QDT). By integrating blockchain technology for data security and transparency, their model outperforms classical ensemble models, achieving 15% higher accuracy and 12% higher precision, demonstrating the transformative potential of quantum computing in churn prediction.
Ensemble methods have also been applied to e-commerce churn prediction. Jahan and Sanam (2022) present an AI-driven framework that combines model tuning, feature selection, and comparative analysis, achieving 100% accuracy and F1-score using CatBoost. Manohar et al. (2021) investigate a collective data mining approach integrating SVMs, Bayesian Classifiers, and RF, highlighting the benefits of combining multiple classifiers for improved accuracy and recall.
Other studies have focused on refining traditional ensemble techniques. Adiputra and Wanchai (2023) propose a weighted average ensemble combining XGBoost and RF, demonstrating superior predictive performance in the telecom and insurance sectors, with an F1-score of 0.850 and 0.947, respectively. Jain et al. (2020) explore Logistic Regression and Logit Boost for telecom churn prediction, confirming the efficacy of boosting techniques in outperforming conventional regression models.
Finally, Wang et al. (2020) provide a comparative analysis of widely used classification algorithms for churn prediction, reinforcing the importance of ensemble learning in enhancing model performance. Their benchmarking study offers valuable guidance for businesses seeking data-driven retention strategies.
These studies collectively illustrate ensemble and hybrid approaches’ diverse and practical applications in customer churn prediction. By integrating multiple ML models and leveraging sophisticated feature engineering techniques, these methodologies provide robust, scalable, and high-performing solutions to the complex challenge of customer retention across various industries.
C. Optimization and Metaheuristic Approaches
Optimization and metaheuristic approaches have gained prominence in churn prediction research as effective strategies for enhancing model performance and reducing computational complexity. These studies offer robust frameworks that improve predictive accuracy and provide greater interpretability and actionable insights by integrating advanced feature selection techniques, hyperparameter tuning, and metaheuristic algorithms. This section reviews key contributions that employ these techniques to optimize churn prediction models across various domains.
Feature selection plays a critical role in improving model efficiency and accuracy. Saheed and Hambali (2021) introduce an ML-based churn prediction framework for the telecommunications sector, leveraging Information Gain and Ranker-based feature selection to enhance model interpretability. Their approach, which incorporates SVM, Multi-Layer Perceptron (MLP), RF, and Naïve Bayes, achieves a 95.02% accuracy rate—surpassing the 92.92% obtained without feature selection. These results highlight the importance of selecting relevant churn-related attributes for improved classification performance.
Building on feature selection techniques, Al-Shourbaji et al. (2022) propose a novel hybrid method, ACO-RSA, which integrates Ant Colony Optimization (ACO) with the Reptile Search Algorithm (RSA) to enhance predictive performance. Evaluated across multiple open-source churn datasets, ACO-RSA outperforms Particle Swarm Optimization (PSO), Multi-Verse Optimizer (MVO), and Grey Wolf Optimizer (GWO), demonstrating its effectiveness in handling high-dimensional telecom data. This study underscores the potential of metaheuristic approaches in refining feature selection for improved churn detection.
Pustokhina et al. (2021) introduce the ISMOTE-OWELM model, which integrates Improved SMOTE (ISMOTE) for data balancing with an Optimal Weighted Extreme Learning Machine (OWELM) for classification. A Multi-objective Rain Optimization Algorithm (MOROA) optimizes sampling rates and model parameters, yielding 94%, 92%, and 90.9% accuracy across three telecom datasets—significantly surpassing traditional approaches. The study emphasizes the effectiveness of ISMOTE-OWELM in improving churn detection while maintaining computational efficiency, making it a valuable tool for telecom providers aiming to enhance customer retention efforts.
Incorporating hyperparameter tuning into feature selection, Sina Mirabdolbaghi and Amiri (2022) present a comprehensive model optimization framework integrating Principal Component Analysis (PCA), Autoencoders, Linear Discriminant Analysis (LDA), t-SNE, and XGBoost for feature reduction. Their approach employs Bayesian and genetic optimization to fine-tune LightGBM models, significantly outperforming AdaBoost, SVM, and DT classifiers. The study also utilizes SHAP for feature importance interpretation and introduces a Customer Lifetime Value (CLV) ranking system, offering actionable insights for prioritizing high-value customers at risk of churn.
Koçoğlu and Özcan (2023) present an Extreme Learning Machine approach for customer churn prediction, optimized using grid search for hyperparameter tuning. The study utilizes a churn dataset from the UCI Machine Learning Repository and compares ELM’s performance against Naïve Bayes, k-Nearest Neighbor, and SVM models. The results demonstrate that ELM achieves the highest accuracy of 93.1%, highlighting its efficiency in churn prediction due to minimal parameter tuning requirements and competitive performance. The study underscores ELM’s potential as a robust and effective technique for churn analysis.
Metaheuristic optimization has also been explored to enhance gradient boosting techniques. AlShourbaji et al. (2023) propose the Enhanced Gradient Boosting Model (EGBM), which integrates an SVM RBF base learner with PSO and Artificial Ecosystem Optimization (AEO) for hyperparameter tuning. Evaluated on seven telecom datasets, EGBM demonstrates superior predictive capabilities compared to traditional GBM and SVM models, effectively addressing premature convergence and enhancing customer retention strategies.
Hybrid optimization approaches further improve churn prediction efficiency. Durkaya Kurtcan and Ozcan (2023) introduce PCA-GWO-SVM, a model combining Principal Component Analysis (PCA) for feature selection, Grey Wolf Optimization for hyperparameter tuning, and SVM for classification. Compared to logistic regression, k-nearest neighbors, naïve Bayes, and DTs, PCA-GWO-SVM achieves higher accuracy, recall, and F1-score, reinforcing the value of combining optimization techniques with classification frameworks.
Ponnusamy et al. (2023) employ a PSO-SVM-based algorithm to enhance churn prediction performance in the banking sector. By optimizing hyperparameters using Particle Swarm Optimization, their approach significantly outperforms traditional SVM models, demonstrating the effectiveness of hybrid optimization strategies for financial institutions seeking to minimize customer attrition. Similarly, Venkatesh and Jeyakarthic (2020) propose an Optimal Genetic Algorithm (OGA) with SVM for cloud-based churn prediction. Their approach utilizes a double-chain quantum genetic algorithm to fine-tune SVM hyperparameters, achieving high sensitivity (94.50), accuracy (90.27), and an F-score of 94.30. These findings underscore the effectiveness of genetic optimization in enhancing predictive performance, making it a promising technique for large-scale cloud-based analytics.
These studies illustrate how optimization and metaheuristic approaches significantly improve churn prediction models’ accuracy, efficiency, and interpretability. By integrating advanced feature selection, hyperparameter tuning, and metaheuristic optimization, these methodologies provide scalable and high-performing solutions for industries grappling with complex customer data, ultimately enhancing retention strategies and business decision-making.
D. Adaptive and Resampling Approaches
In dynamic environments where customer behavior and data distributions continuously evolve, addressing class imbalance and adapting to concept drift are critical challenges in churn prediction. Researchers have increasingly turned to resampling and adaptive learning strategies to enhance model performance in real-time applications. This section reviews key studies that employ these techniques to mitigate imbalances and adapt predictive models to changing data patterns, ensuring more accurate and reliable churn detection.
Toor and Usman (2022) introduce the Optimized Two-Sided Cumulative Sum Churn Detector (OTCCD), a novel adaptive churn prediction framework for telecom data streams. By integrating the Synthetic Minority Over-sampling Technique (SMOTE) for data balancing and a cumulative sum control chart for drift detection, OTCCD efficiently identifies shifts in customer behavior within a sliding window framework. Experimental evaluations on real-world telecom datasets, such as Call Detail Records, demonstrate that OTCCD outperforms traditional methods by providing higher accuracy and faster drift detection. This study highlights the importance of real-time adaptability in churn prediction models, offering telecom companies a robust tool for proactive customer retention strategies.
Amin et al. (2023) propose an adaptive learning approach that integrates evolutionary computation with a Naïve Bayes classifier to address class imbalance in telecommunications churn prediction. By dynamically adjusting model parameters based on incoming data patterns, the hybrid method significantly improves precision, recall, and F1 scores compared to traditional approaches. Evaluations on real-world telecom datasets confirm the model’s effectiveness in proactively identifying at-risk customers, underscoring the potential of adaptive learning in minimizing revenue loss due to customer churn.
Complementing adaptive methodologies, Ouf et al. (2024) develop a hybrid churn prediction framework that combines XGBoost with SMOTE-ENN resampling to balance datasets and improve classification accuracy. This integration enhances precision, recall, and F1 scores, outperforming conventional ML techniques across three telecom datasets. By effectively addressing class imbalance and leveraging ensemble learning, the model facilitates proactive retention strategies, reinforcing the role of resampling techniques in churn prediction.
Incorporating a more customer-centric approach, Lee et al. (2023) propose a hybrid churn prediction framework that dynamically models churn probability based on customer lifetime value rather than fixed periods. By segmenting customers into groups such as new, short-term, high-value, and churn-prone users, their methodology applies tailored ML models to enhance predictive accuracy. Evaluations of datasets from a U.K. gift seller and Pakistan’s largest e-commerce platform show recall scores ranging from 0.56 to 0.72 in one case and 0.91 to 0.95 in another. The study highlights the advantages of integrating statistical modeling with ML techniques to refine customer retention strategies while reducing data requirements.
These studies illustrate how adaptive and resampling approaches effectively address class imbalance and concept drift, enabling more scalable and robust churn prediction solutions. By integrating real-time learning, resampling techniques, and evolutionary optimization, these methodologies provide powerful tools for businesses seeking to enhance customer retention strategies in evolving market conditions.
E. Explainable and Interpretable Approaches
Understanding the underlying decision processes in complex predictive tasks such as churn prediction is crucial for gaining stakeholder trust and facilitating actionable insights. Recent research has increasingly focused on integrating interpretability and explainable AI techniques into churn prediction models. This section reviews key contributions that enhance model transparency through rule-based formulations, SHAP analyses, and other XAI methodologies.
De Bock and De Caigny (2021) introduce Spline-Rule Ensemble classifiers with Structured Sparsity Regularization (SRE-SGL) as an interpretable approach to customer churn prediction. While traditional ML models often prioritize predictive accuracy, this study emphasizes the need for explainable models that provide actionable insights into customer behavior. The proposed spline-rule ensembles integrate tree-based ensemble methods with regression analysis, balancing model flexibility and simplicity. However, conventional rule-based ensembles can become excessively complex due to conflicting components. To address this, the authors incorporate Sparse Group Lasso regularization, which enhances interpretability by enforcing structured sparsity. Evaluations across fourteen real-world datasets demonstrate that SRE-SGL outperforms standard rule ensembles in AUC and top decile lift while maintaining competitive predictive performance. A case study in the telecommunications sector further illustrates the model’s interpretability, reinforcing the value of structured regularization in making churn prediction both effective and explainable.
Extending interpretability techniques to workforce analytics, Mitravinda and Shetty (2022) investigate employee attrition prediction using ML models and XAI methodologies. Their study applies SHAP to identify key factors driving attrition and visualize their impact. Additionally, the research introduces a recommendation system leveraging user-based collaborative filtering to propose personalized retention strategies. By combining predictive modeling with actionable insights, this study demonstrates how XAI techniques can inform more effective employee retention policies.
In digital entertainment, Wang et al. (2024) address the challenge of player churn prediction in online video games, where understanding social interaction dynamics is critical. While ML models are widely used for player behavior analysis, their black-box nature limits adoption by product managers and game designers. The study restructures model inputs into explicit and implicit features to bridge this gap, enhancing expert interpretability. Furthermore, the research highlights the necessity of XAI techniques that explain feature contributions and provide actionable recommendations for reducing churn. The proposed approach is validated through two case studies involving expert feedback and a within-subject user study, demonstrating its effectiveness in improving decision-making for player retention strategies.
Together, these studies illustrate the crucial role of interpretability in churn prediction models. By integrating advanced XAI techniques, researchers bridge the gap between high predictive performance and the need for transparent, actionable insights. This integration supports more informed and effective retention strategies across diverse industries, reinforcing the value of explainable AI in real-world predictive analytics.
F. Data-Centric and Augmentation Approaches
Beyond refining predictive models, recent research in churn prediction has increasingly emphasized enhancing the quality and diversity of training data. Data-centric and augmentation approaches seek to enrich traditional datasets by incorporating novel data sources, generating synthetic data, and leveraging advanced feature engineering techniques. These strategies are crucial for improving model robustness, addressing data imbalances, and achieving higher predictive accuracy. This section reviews key contributions that exemplify these efforts.
Vo et al. (2021) explore a novel churn prediction approach that integrates unstructured call log data with traditional structured data. While existing ML models primarily rely on demographic and account history data, this study highlights the untapped potential of analyzing spoken content from customer interactions. Using natural language processing techniques, the authors process a large-scale call center dataset containing two million calls from over 200,000 customers. Their findings demonstrate that incorporating unstructured call data significantly enhances prediction accuracy while providing deeper insights into customer behavior. Additionally, interpretable ML techniques extract personality traits and customer segmentation patterns, facilitating personalized retention strategies. This study underscores the importance of combining structured and unstructured data sources to develop more comprehensive churn prediction frameworks in the financial services industry.
De and Prabu (2023) address the challenge of optimizing training data quality through a representation-based query strategy for churn prediction. Given manual data annotation’s high cost and inefficiency, the authors propose Entropy-based Min-Max Similarity (E-MMSIM), an active learning algorithm inspired by protein sequencing techniques. This method selects the most informative and representative data points for annotation, reducing redundancy and improving model efficiency. The approach enhances topic classification accuracy in customer service messages, yielding significant improvements in F1-score, AUC, and overall model performance. Moreover, when these qualitative features are integrated with structured customer data, churn prediction models achieve a 5% performance gain. The study highlights the critical role of data selection strategies in optimizing ML workflows for customer retention management.
In the realm of synthetic data generation, Wang et al. (2023) explore the impact of data-centric AI on churn prediction. Unlike traditional model-centric AI, which focuses on hyperparameter tuning and algorithm modifications, data-centric AI enhances predictive performance by improving training data quality and distribution. This research evaluates various data synthesis algorithms, examining their effects on data balancing, augmentation, and substitution. The findings underscore the potential of resampling methods in mitigating class imbalance and improving model robustness, providing valuable insights for AI-driven churn prediction frameworks across industries.
Amiri and Hosseini (2024) introduce a social network-based churn prediction model, recognizing that social interactions and peer behavior often influence customer churn. The study develops a feature engineering approach incorporating influence and conformity indices derived from call network data. By integrating social connectivity metrics, the model significantly enhances the predictive power of standard ML classifiers, particularly gradient boosting models. This research demonstrates that churn is not solely an individual decision but is shaped by broader social dynamics. This perspective extends beyond telecommunications to various industries where peer influence affects customer behavior.
Collectively, these studies illustrate the transformative impact of data augmentation and quality improvement in churn prediction. Researchers are developing more comprehensive and robust predictive frameworks by incorporating novel data sources, employing active learning for data selection, generating synthetic data, and leveraging social network information. These advancements enhance model accuracy and provide deeper insights into customer behavior, enabling more effective and proactive retention strategies.
G. Traditional ML Approaches
Traditional machine learning approaches significantly influence churn prediction by leveraging established statistical and algorithmic techniques. These methods rely on classical models and feature engineering to derive actionable insights and achieve high predictive accuracy. This section highlights key studies that exemplify the application of conventional ML methodologies across diverse domains.
Zhang et al. (2022) present a data-driven approach to customer churn prediction in telecommunications, incorporating customer segmentation to enhance predictive accuracy. Using Fisher discriminant analysis and logistic regression, their model achieves a 93.94% accuracy rate on telecom datasets, effectively identifying potential churners. Tailoring predictions to specific customer groups enhances the precision of retention campaigns, providing telecom operators with a powerful tool to proactively reduce churn and improve profitability. The study underscores the significance of segmentation in refining churn prediction models.
Expanding on customer relationship management (CRM) applications, Šimović et al. (2023) explore churn prediction using big data analytics to analyze heterogeneous customer behaviors, such as self-care service usage, service duration, and responsiveness to marketing efforts. Their study introduces an enhanced logistic regression model with a mixed penalty term to mitigate overfitting and balance feature selection. Empirical evaluation on a large CRM dataset demonstrates high classification performance across standard metrics, reinforcing the potential of penalized logistic regression as a scalable and computationally efficient approach to churn modeling in big data environments.
Jakob et al. (2024) extend traditional ML techniques to the digital health sector, investigating early user churn in a weight loss app. By analyzing engagement data from 1,283 users and 310,845 event logs, the study employs an RF model to predict user dropout based on daily login counts. Achieving an F1 score of 0.87 on day 7 and identifying 93% of churned users, the study highlights how churn prediction can enable personalized retention strategies in digital health interventions, ultimately improving long-term user engagement and health outcomes.
Returning to the telecommunications industry, Sikri et al. (2024) developed an ML-based approach for improving customer retention. By analyzing customer demographics, usage patterns, and service details, the study applies DTs and SVM to identify customers at risk of churning. The results demonstrate high predictive accuracy, empowering telecom companies to implement targeted retention strategies effectively. This study reaffirms the value of conventional ML techniques in customer retention efforts.
Expanding on real-time prediction applications, Tamuka and Sibanda (2020) developed a churn prediction model tailored for the telecommunications industry, specifically focusing on pre-paid customers who frequently switch providers. Using Watson Studio, their study employs big data analytics within the CRISP-DM framework and evaluates three ML algorithms—Logistic Regression, RF, and DT. While Logistic Regression exhibited the lowest misclassification rate (2.2%), RF and DT achieved relatively high accuracy rates (78.3% and 79.2%, respectively) but suffered from misclassification rates above 20%. This research underscores the limitations of relying solely on accuracy metrics and advocates for more comprehensive evaluation techniques to enhance real-time churn prediction performance.
Beyond customer churn, AbdElminaam et al. (2023) introduce EmpTurnoverML, an AI-driven approach for predicting employee turnover and customer churn using ML algorithms. The study evaluates various classification techniques, including K-Nearest Neighbors, DTs, Logistic Regression, RF, SVM, AdaBoost, Naïve Bayes, and Gradient Boosted Machines (GBM), using an 80-20 train-test split. By identifying key patterns associated with employee departures, the study highlights how AI-powered prediction models can help organizations implement proactive retention strategies, reducing hiring and training costs while enhancing workforce stability. The findings demonstrate the broader applicability of churn prediction methodologies in workforce analytics and business efficiency.
These studies illustrate the continued relevance of conventional ML approaches in churn prediction. Through rigorous model development and strategic feature engineering, these methodologies provide potent tools for organizations seeking to mitigate churn, improve customer and employee retention, and drive sustainable business growth.
7. Deep Learning Approaches
Deep learning techniques have significantly advanced churn prediction by offering diverse methodologies that address complex user behavior patterns and industry retention challenges. Recent advancements include deep reinforcement learning, sequential modeling with architectures like LSTMs, hybrid and ensemble methods integrating multiple DL paradigms, CNNs tailored for structured data, efficient feedforward neural networks, and innovative representation learning and feature interaction models. Each category provides unique strengths, such as improved accuracy, enhanced interpretability, or computational efficiency, collectively supporting proactive and effective churn management strategies. This section explores these distinct approaches, highlighting their applications, advantages, and contributions to predictive analytics. Table 2 highlights the datasets used (public, private, simulation-based), DL techniques implemented, and performance metrics evaluated.
A. Deep Reinforcement Learning Approaches
Deep reinforcement learning approaches represent an emerging paradigm in churn prediction, particularly within dynamic environments such as digital entertainment. These methods go beyond traditional supervised learning by leveraging simulation-based techniques to model complex user behaviors and engagement dynamics. This section highlights a pioneering study that exemplifies the potential of deep reinforcement learning in addressing churn challenges in mobile gaming.
Roohi et al. (2020) introduce a novel simulation-based model for predicting churn in mobile gaming. Unlike traditional supervised ML models that rely on historical player data, this work integrates Deep Reinforcement Learning to simulate AI-driven gameplay behavior, capturing in-game difficulty and player skill evolution. A key strength of this approach is its ability to model player persistence and engagement dynamics without requiring extensive real-world behavioral data. The study demonstrates that incorporating a population-level simulation of player heterogeneity improves churn prediction accuracy, thereby reducing the dependency on expensive retraining of DRL agents. This framework offers a promising direction for churn analysis in digital entertainment, where player retention strategies are critical for revenue sustainability.
B. Temporal and Sequential DL Approaches
Temporal and sequential DL approaches have emerged as essential tools for capturing the dynamic nature of customer behavior in churn prediction. By leveraging temporal dependencies inherent in user engagement data, these models enable a more nuanced understanding of churn patterns, ultimately leading to more effective retention strategies. This section reviews recent studies that utilize deep sequential architectures, such as LSTM networks, to enhance churn prediction performance.
Joy et al. (2024) present a hybrid DL approach that integrates sequential modeling with explainable AI to improve churn prediction in streaming services. The proposed framework combines LSTM and Gated Recurrent Unit (GRU) networks to capture temporal trends in user engagement, complemented by LightGBM to refine predictive performance. A key contribution of this study is its emphasis on interpretability, employing Shapley Additive Explanations and Explainable Boosting Machines (EBM) to provide transparency in feature importance rankings. By ensuring that decision-makers understand the reasoning behind churn predictions, the model enhances actionable insights for business applications. The study reports state-of-the-art performance, achieving a 95.60% AUC and a 90.09% F1 score, reinforcing the effectiveness of hybrid architectures in churn analysis.
Expanding on sequential DL techniques, Zhu et al. (2020) introduce a trajectory-based LSTM framework (TR-LSTM) for churn prediction, which extracts three trajectory-based features from customer movement data. The model significantly outperforms traditional methods, demonstrating the utility of spatiotemporal behavior analysis in predicting churn. Similarly, Alboukaey et al. (2020) emphasize the importance of daily behavioral patterns by developing an LSTM-based dynamic churn prediction model for mobile telecom customers. Unlike conventional monthly-based models, this approach captures short-term fluctuations in customer activity, enhancing prediction accuracy and allowing for more timely interventions. These findings underscore the superiority of LSTM-based architectures in modeling evolving user engagement patterns, particularly in dynamic service industries.
Further validating the effectiveness of LSTMs, Beltozar-Clemente et al. (2024) demonstrate that deep sequential networks can overcome vanishing gradient issues and effectively model long-term dependencies in customer behavior sequences. Their study achieves 95% performance across multiple evaluation metrics, highlighting the potential of LSTM-based models to refine churn prediction by capturing complex behavioral trends.
Collectively, these studies establish sequential and temporal DL approaches as robust tools for churn prediction. By leveraging LSTM-based architectures, these models offer enhanced predictive accuracy, more profound insights into user behavior, and timely interventions, making them invaluable for developing proactive retention strategies across various industries.
C. Ensemble and Hybrid DL Approaches
Ensemble and Hybrid DL approaches have gained significant traction in churn prediction due to their ability to combine multiple models’ strengths and overcome individual architectures’ limitations. These approaches achieve enhanced predictive accuracy and improved generalization across diverse application domains by integrating DL techniques—such as RNNs, CNNs, and attention mechanisms with ensemble methods and optimization algorithms. This section highlights key studies that exemplify the effectiveness of hybrid and ensemble strategies in churn prediction.
Jajam et al. (2023) introduce an ensemble model that integrates Stacked Bidirectional LSTMs (SBLSTM) and RNNs with an arithmetic optimization algorithm (AOA). The framework is fine-tuned using an improved Gravitational Search Optimization Algorithm (IGSA), achieving a state-of-the-art accuracy of 97.89% in the insurance domain. These results highlight the potential of ensemble architectures to effectively merge multiple DL techniques, improving generalization and performance in churn prediction tasks.
Similarly, Liu et al. (2022) present a fused attentional DL model (AttnBLSTM-CNN) that integrates Bidirectional LSTMs (BiLSTM) and CNNs to address the limitations of standalone RNNs and CNNs. By incorporating an attention mechanism, the model enhances prediction accuracy by prioritizing critical customer behavior patterns. The study demonstrates that integrating attention layers into DL pipelines improves churn detection accuracy and enhances interpretability, providing valuable insights for financial institutions.
Expanding on hybrid architectures in the financial sector, Vu (2024) proposes a DL ensemble model for customer churn prediction in banking. The approach employs a stacked DL architecture where Level 0 integrates three distinct deep neural networks, and Level 1 utilizes a logistic regression model for final prediction. Tested on the Bank Customer Churn Prediction dataset, the framework achieves 96.60% accuracy, 90.26% precision, 91.91% recall, and an F1-score of 91.07%. These results highlight the robustness of combining DL models with logistic regression to improve churn prediction accuracy, reinforcing the value of ensemble methodologies in financial customer retention strategies.
Zhao et al. (2023) further enhance churn prediction by integrating unsupervised and supervised learning techniques. Their hybrid model incorporates K-means clustering, entropy-based methods, and customer portrait analysis for segmenting telecom customers. A multi-head self-attention-based nested LSTM classifier is then applied to evaluate customer behavior. Tested on China’s telecom market data, the model outperforms traditional classification methods by improving the accuracy of customer behavior recognition. Additionally, it effectively differentiates between medium-value and high-value customers, providing critical insights for precision marketing strategies and enabling telecom companies to tailor service offerings more effectively.
Collectively, these studies illustrate that hybrid and ensemble DL approaches enhance predictive accuracy and improve model interpretability and generalization across sectors. Their innovative integration of diverse methodologies offers promising avenues for developing robust, scalable churn prediction systems that effectively support targeted retention strategies.
D. CNN–Based Approaches
Convolutional Neural Networks have emerged as a powerful tool in churn prediction, particularly for tasks requiring complex feature extraction and hierarchical data representation. While traditionally applied to image and text processing, CNN-based approaches have proven effective in structured data scenarios, offering improved predictive accuracy and addressing challenges such as class imbalance and information loss. This section reviews key studies that leverage CNNs—often in combination with other techniques—to enhance churn prediction models.
Usman et al. (2021) compare DL architectures on benchmark datasets such as Cell2Cell and KDD Cup for churn prediction. Their findings identify CNNs as the most effective model based on multiple evaluation criteria, outperforming traditional ML algorithms and DL models. These results underscore the ability of convolutional architectures to capture hierarchical relationships within customer data, particularly in scenarios where feature extraction poses significant challenges.
Extending CNN applications to workforce analytics, Pekel Ozmen et al. (2022) introduce a hybrid model (ECDT-GRID) for employee churn prediction. This approach integrates Extended Convolutional Decision Trees (ECDT) with grid search optimization to enhance classification accuracy. Unlike conventional CNN applications in image and text processing, this study adapts CNNs for structured numerical data, addressing information loss through DT-based learning. The ECDT-GRID model outperforms CNN, ECDT, and traditional ML models, demonstrating the importance of hyperparameter tuning in improving predictive performance. The study highlights the potential of DL in workforce analytics, particularly in retail, where employee churn impacts operational stability. By combining CNNs with DT structures, this approach provides a robust predictive framework, showcasing the role of DL in optimizing employee retention strategies.
Saha et al. (2024) introduce ChurnNet, a novel DL-based churn prediction model tailored for the telecommunications industry (TCI). Recognizing the importance of customer retention in a competitive market, the study aims to enhance predictive accuracy beyond existing methods. ChurnNet integrates a 1D convolutional layer with residual blocks, squeeze-and-excitation blocks, and a spatial attention module, allowing the model to capture complex feature dependencies while mitigating the vanishing gradient problem. The model is evaluated using three public datasets, each exhibiting significant class imbalance, which is addressed through SMOTE, SMOTEEN, and SMOTETomek resampling techniques. Rigorous experimentation, including 10-fold cross-validation, demonstrates that ChurnNet outperforms state-of-the-art models, achieving accuracy scores of 95.59%, 96.94%, and 97.52% across the three datasets. These findings emphasize the potential of DL architectures with attention mechanisms in advancing churn prediction models, making them more effective and interpretable for telecom service providers.
These studies highlight the versatility and strength of CNN-based approaches in churn prediction. By addressing challenges such as feature extraction, information loss, and class imbalance, CNNs, and their hybrid variants provide robust frameworks that can be adapted to various applications—from customer retention in telecom to employee churn in retail—underscoring their critical role in modern predictive analytics.
E. Feedforward Deep Neural Network Approaches
Feedforward deep neural network approaches remain widely used in churn prediction because they can learn complex nonlinear relationships directly from data while maintaining relatively straightforward architectures. These methods, including Extreme Learning Machines, Multi-Layer Perceptrons, and Deep Neural Networks, balance predictive performance and computational efficiency. This section reviews key studies that have leveraged these architectures to achieve robust churn prediction outcomes.
Przybyła-Kasperek (2024) evaluates Multi-Layer Perceptron and Radial Basis Function (RBF) networks for churn prediction in mobile telecommunications. Their findings suggest that MLPs achieve near-perfect accuracy (0.999), significantly outperforming traditional fuzzy rule-based and rough-set systems. However, the study also acknowledges the black-box nature of neural networks, emphasizing the need for explainability in DL models to support real-world adoption. These insights highlight the trade-off between model performance and interpretability, an ongoing challenge in deploying DL solutions for churn prediction.
Arifin (2020) investigates churn prediction in the telecommunications sector using Deep Neural Networks, comparing their performance against RF and XGBoost. Recognizing the critical impact of customer attrition on business retention, the study incorporates feature selection techniques and evaluates model efficiency using Google Colaboratory with a TensorFlow backend. The results indicate that DNN achieves 80.62% accuracy in just 68 seconds, outperforming XGBoost (76.45% accuracy, 175 seconds) and RF (77.87% accuracy, 529 seconds). These findings highlight DNN’s ability to balance accuracy and computational efficiency, making it a promising alternative for real-time churn prediction in telecommunications.
These studies underscore the potential of feedforward and standard deep neural network approaches to provide robust and efficient churn prediction solutions. At the same time, they highlight the ongoing need to improve model interpretability to enhance adoption and usability in practical business applications.
F. NLP–Based DL Approaches
NLP-based deep learning approaches represent an innovative frontier in churn prediction by leveraging unstructured textual data to complement traditional numerical inputs. These methods harness advanced language models and RNNs to extract meaningful insights from customer communications, enriching predictive analytics and enhancing retention strategies. This section highlights a key study that exemplifies the potential of NLP-driven churn prediction.
Ozan (2021) offers a unique perspective by applying NLP techniques to CRM data for churn prediction. Utilizing word embeddings alongside RNNs, the study demonstrates that text data—such as customer feedback and service interactions—can be effectively harnessed to predict churn. This approach complements traditional structured data methods and provides deeper insights into customer sentiment and behavior. The findings suggest that NLP-driven churn prediction models could be particularly beneficial in industries where customer communication is critical in shaping retention strategies.
G. Representation and Feature Interaction Approaches
Representation and feature interaction approaches have emerged as promising strategies to enhance churn prediction by capturing complex relationships within customer data. These methods address limitations in traditional deep neural networks, particularly in handling high-order feature interactions and categorical variables. This section reviews key studies that leverage advanced embedding techniques to improve predictive accuracy and interpretability in churn modeling.
Tang (2020) introduces a Feature Interaction Network (FIN) designed to overcome challenges standard deep neural network-based churn models face. Traditional models often struggle to capture high-order feature interactions and effectively handle one-hot encoded categorical features. FIN integrates two key components to address this: an entity embedding network to capture meaningful feature representations and a factorization machine network with sliding windows to enhance feature interactions. Experimental evaluations on four public datasets demonstrate that FIN outperforms state-of-the-art models by effectively capturing complex dependencies in customer data. This study underscores the importance of feature interaction modeling in churn prediction, offering a robust framework for leveraging structured customer data in predictive analytics.
In a complementary approach, Cenggoro et al. (2021) develop a DL-based vector embedding model tailored for churn prediction in the telecommunications industry. This model not only emphasizes predictive accuracy but also enhances interpretability. The model enables precise differentiation between loyal and churn-prone customers by leveraging vector embeddings to represent customer behavior in a discriminative feature space. Experimental results indicate that the model achieves an F1 score of 81.16%, demonstrating strong predictive performance. Additionally, cluster similarity analysis and t-SNE visualizations confirm that the learned representations are highly separable, reinforcing the model’s effectiveness. This study highlights the potential of vector embeddings as a powerful tool for churn modeling, equipping telecom providers with actionable insights for customer re-engagement and retention.
These studies illustrate how embedding and feature interaction techniques can significantly improve churn prediction by capturing nuanced relationships within customer data. By enhancing both predictive performance and interpretability, these approaches offer valuable tools for developing proactive and targeted retention strategies in competitive industries.
8. Discussion
A. Challenges and Limitations
Despite significant advancements in ML and DL for churn prediction, several challenges hinder real-world implementation. One of the most persistent issues is class imbalance, where the number of churners in datasets is significantly smaller than non-churners. This imbalance often biases models toward the majority class, reducing their effectiveness in identifying at-risk customers. While resampling techniques and cost-sensitive learning have been proposed as solutions, they can lead to overfitting or increased computational costs.
Another major challenge lies in feature engineering and data representation. Many models rely on structured transactional data, yet customer interactions involve diverse data sources such as call logs, social media activity, and customer support interactions. Integrating and extracting meaningful features from such heterogeneous data remains a complex task. DL models can automate feature extraction but often require extensive data preprocessing and significant computational resources.
Model interpretability is another critical concern, especially with DL models. While traditional ML techniques such as DTs and logistic regression provide human-readable decision rules, neural networks and ensemble models function as black boxes, making it difficult for businesses to trust their predictions. Explainable AI techniques, such as SHAP and attention mechanisms, have been introduced to address this issue, but they are not yet widely adopted in real-world churn prediction systems.
Furthermore, customer behavior is dynamic, and many churn prediction models struggle to adapt to evolving patterns over time. Concept drift—where customer preferences, engagement levels, and churn risks change—challenges models trained on historical data. Adaptive learning techniques, such as online learning and reinforcement learning, offer potential solutions but require continuous retraining, making them resource-intensive.
Finally, there is a disconnect between academic evaluation metrics and business impact. Many studies assess model performance using accuracy, F1-score, and AUC-ROC, but these do not necessarily translate to actionable business decisions. Profit-driven evaluation metrics, which factor in the cost of retention efforts versus lost revenue from churners, are still underexplored in research. Bridging this gap is essential for developing models that provide tangible business value.
Addressing these challenges will require further advancements in adaptive modeling, explainability techniques, and profit-aware churn prediction. As businesses continue to invest in data-driven retention strategies, future research should focus on developing scalable, interpretable, and business-aligned solutions to improve churn prediction outcomes.
B. Identified Gaps in Reviewed Research
Despite the extensive advancements in ML and DL for customer churn prediction, several gaps persist in the reviewed research, highlighting areas that require further exploration. One of the most notable gaps is the limited emphasis on real-world deployment challenges. While many studies focus on improving model accuracy and robustness, fewer address the practical aspects of implementing these models in business environments. Issues such as scalability, computational efficiency, and integration with existing CRM systems remain underexplored. Research into lightweight, efficient, and real-time deployable solutions is essential since many organizations lack the computational infrastructure to support complex DL models.
Another significant gap is the lack of focus on model interpretability and explainability. While DL approaches, particularly RNNs, CNNs, and transformers, have shown improved predictive performance, their black-box nature limits their adoption in business settings where transparency is crucial. Although techniques like SHAP and Local Interpretable Model-Agnostic Explanations (LIME) have been introduced, they are not widely integrated into churn prediction models. Future research should prioritize the development of inherently interpretable models or hybrid approaches that balance accuracy with transparency to facilitate better decision-making in customer retention strategies.
Additionally, most existing studies rely on static datasets, which fail to account for the dynamic nature of customer behavior. Concept drift—where customer engagement patterns and churn drivers change over time—poses a significant challenge for model generalization. While some studies explore adaptive, reinforcement, or online learning techniques, their practical adoption remains limited. Future research should focus on developing adaptive and self-learning models that continuously update based on evolving customer data, ensuring sustained predictive performance over time.
Another gap is the lack of cross-domain generalization in churn prediction models. Many studies develop models tailored to specific industries, such as telecommunications or banking, but do not test their applicability across different sectors. Given that customer behavior varies significantly across domains, future research should explore domain adaptation techniques and transfer learning to improve model generalizability. This would enable businesses in different sectors to leverage churn prediction methodologies without extensive retraining.
Finally, profit-driven evaluation metrics remain underutilized in the reviewed literature. While traditional metrics such as accuracy, F1-score, and AUC-ROC are widely reported, they do not fully capture the business implications of churn prediction. Few studies incorporate profit-based metrics like Expected Maximum Profit for Customer Churn, which consider the financial impact of retention strategies. Further research is needed to develop models that align more closely with business goals, optimizing for predictive performance, cost-effectiveness, and revenue maximization.
Addressing these gaps will require a multi-faceted research approach, integrating interpretability, adaptive learning, cross-domain validation, and business-centric evaluation into future churn prediction models. By bridging these gaps, the field can advance toward more practical, transparent, and financially viable solutions for churn management in real-world applications.
C. Trends Direction
Analyzing publication trends in churn prediction research over 2020–2024 reveals a clear shift toward more advanced ML and DL techniques. IEEE has consistently led in publication volume, indicating a strong research focus within engineering and computational disciplines. While traditional ML techniques such as DTs and logistic regression remain widely used, boosting methods and ensemble learning have steadily grown, reflecting an industry preference for robust and interpretable models.
In recent years, DL approaches, particularly RNNs, CNNs, and transformers, have gained traction, especially in domains dealing with complex sequential and unstructured data, such as telecommunications and banking. Adopting hybrid ML-DL models also suggests an increasing interest in combining the strengths of multiple paradigms to improve predictive accuracy.
Another notable trend is the growing importance of explainability and business-aligned evaluation metrics. While early studies prioritized accuracy-based benchmarks, more recent research integrates profit-driven evaluation methods, addressing the gap between academic performance metrics and real-world applicability.
The field will likely see further advancements in adaptive learning techniques, reinforcement learning for churn management, and integration of multi-modal data sources. The continued evolution of ML and DL for churn prediction indicates a shift toward models that are more accurate, transparent, cost-effective, and dynamically adaptable to changing consumer behaviors.
9. Conclusions
Customer churn prediction has seen significant advancements in recent years, with ML and DL techniques being increasingly central in identifying at-risk customers and optimizing retention strategies. This review of 240 research articles published between 2020 and 2024 reveals a strong preference for ensemble learning, advanced ML techniques, and DL architectures, reflecting the growing complexity of churn modeling. While ML techniques such as gradient boosting (XGBoost, LightGBM, CatBoost), DTs, and RFs remain widely used, DL models, particularly LSTMs, CNNs, and attention-based architectures, are gaining momentum in capturing temporal and behavioral patterns in churn prediction.
Hybrid modeling approaches have also been explored, but they predominantly involve combinations of different ML techniques or various DL architectures rather than a fusion of ML with DL methods. While DL models offer superior predictive power, they often come at the cost of higher computational demands and reduced interpretability. In contrast, though more interpretable and computationally efficient, traditional ML models may struggle with high-dimensional and complex datasets. Some studies have attempted to bridge this gap using explainable AI techniques, such as SHAP, LIME, and attention mechanisms, but their integration into practical churn prediction frameworks remains limited.
Despite these advancements, several challenges persist. Class imbalance remains a significant issue, as churn datasets are often skewed toward non-churners, leading to biased model performance. Many existing models are also trained on static datasets, making them susceptible to concept drift as customer behaviors evolve over time. While some research has explored adaptive learning techniques, continuous model updating and real-time retraining have yet to be widely implemented. Additionally, most studies prioritize accuracy-based evaluation metrics, whereas relatively few focus on profit-driven approaches that align more closely with business decision-making.
To further improve churn prediction, future research should focus on developing adaptive models that can adjust to evolving customer behaviors, integrating more interpretable AI techniques, and incorporating business-oriented evaluation metrics. By addressing these gaps, the field can move toward more scalable, interpretable, and business-aligned churn prediction models, ultimately helping organizations optimize customer retention strategies and drive long-term profitability.
Author Contributions
M.I. conceptualized the manuscript. M.I. and M.J. conducted a literature review. M.I. drafted the manuscript. A.B. and H.R.A. provided comments and revised the manuscript. M.I. created and designed all the figures. All authors read and approved the final version of the manuscript. It should be noted that M.I. and A.B. are co-corresponding authors of this manuscript.
Funding
No funds, grants, or other support was received.
Data Availability
Not applicable.
Conflict of Interest
The authors declare no competing interests.
Open Access
This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
References
- AbdElminaam, D.S.; Maged, M.; Mousa, M.K.; Younis, A.O.; Abdelsalam, M.S.; Hisham, Y.; Talaat, T. EmpTurnoverML: An Efficient Model for Employee Turnover and Customer Churn Prediction Using Machine Learning Algorithms. 2023 International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC). Egypt; pp. 1–8.
- Adiputra, I.N.M. and Wanchai, P., 2023, June. Customer Churn Prediction Using Weight Average Ensemble Machine Learning Model. In 2023 20th International Joint Conference on Computer Science and Software Engineering (JCSSE) (pp. 90-94). IEEE.
- Ahn, J.-H.; Han, S.-P.; Lee, Y.-S. Customer churn analysis: Churn determinants and mediation effects of partial defection in the Korean mobile telecommunications service industry. Telecommun. Policy 2006, 30, 552–568. [CrossRef]
- Ahn, J.; Hwang, J.; Kim, D.; Choi, H.; Kang, S. A Survey on Churn Analysis in Various Business Domains. IEEE Access 2020, 8, 220816–220839. [CrossRef]
- Ajegbile, M.D.; Olaboye, J.A.; Maha, C.C.; Igwama, G.T.; Abdul, S. The role of data-driven initiatives in enhancing healthcare delivery and patient retention. World J. Biol. Pharm. Heal. Sci. 2024, 19, 234–242. [CrossRef]
- Al-Najjar, D.; Al-Rousan, N.; Al-Najjar, H. Machine Learning to Develop Credit Card Customer Churn Prediction. J. Theor. Appl. Electron. Commer. Res. 2022, 17, 1529–1542. [CrossRef]
- Al-Shourbaji, I.; Helian, N.; Sun, Y.; Alshathri, S.; Elaziz, M.A. Boosting Ant Colony Optimization with Reptile Search Algorithm for Churn Prediction. Mathematics 2022, 10, 1031. [CrossRef]
- AlShourbaji, I.; Helian, N.; Sun, Y.; Hussien, A.G.; Abualigah, L.; Elnaim, B. An efficient churn prediction model using gradient boosting machine and metaheuristic optimization. Sci. Rep. 2023, 13, 1–18. [CrossRef]
- Alboukaey, N.; Joukhadar, A.; Ghneim, N. Dynamic behavior based churn prediction in mobile telecom. Expert Syst. Appl. 2020, 162. [CrossRef]
- Amin, A.; Adnan, A.; Anwar, S. An adaptive learning approach for customer churn prediction in the telecommunication industry using evolutionary computation and Naïve Bayes. Appl. Soft Comput. 2023, 137. [CrossRef]
- Amiri, B.; Hosseini, S.H. Unveiling the Power of Social Influence: A Machine Learning Framework for Churn Prediction With Network Analysis. IEEE Access 2024, 12, 71271–71285. [CrossRef]
- H, N.P.O.; Arifin, A.S. Telecommunication Service Subscriber Churn Likelihood Prediction Analysis Using Diverse Machine Learning Model. 2020 3rd International Conference on Mechanical, Electronics, Computer, and Industrial Technology (MECnIT). Indonesia; pp. 24–29.
- Arshad, U.; Khan, G.; Alarfaj, F.K.; Halim, Z.; Anwar, S. Q-ensemble learning for customer churn prediction with blockchain-enabled data transparency. Ann. Oper. Res. 2024, 1–27. [CrossRef]
- Beeharry, Y.; Fokone, R.T. Hybrid approach using machine learning algorithms for customers' churn prediction in the telecommunications industry. Concurr. Comput. Pr. Exp. 2021, 34, e6627. [CrossRef]
- Beltozar-Clemente, S.; Iparraguirre-Villanueva, O.; Pucuhuayla-Revatta, F.; Zapata-Paulini, J.; Cabanillas-Carbonell, M. Predicting customer abandonment in recurrent neural networks using short-term memory. J. Open Innov. Technol. Mark. Complex. 2024, 10. [CrossRef]
- Cenggoro, T.W.; Wirastari, R.A.; Rudianto, E.; Mohadi, M.I.; Ratj, D.; Pardamean, B. Deep Learning as a Vector Embedding Model for Customer Churn. Procedia Comput. Sci. 2021, 179, 624–631. [CrossRef]
- Christou, V.; Tsoulos, I.; Loupas, V.; Tzallas, A.T.; Gogos, C.; Karvelis, P.S.; Antoniadis, N.; Glavas, E.; Giannakeas, N. Performance and early drop prediction for higher education students using machine learning. Expert Syst. Appl. 2023, 225. [CrossRef]
- De, S.; Prabu, P. A Representation-Based Query Strategy to Derive Qualitative Features for Improved Churn Prediction. IEEE Access 2023, 11, 1213–1223. [CrossRef]
- De Bock, K.W. and De Caigny, A., 2021. Spline-rule ensemble classifiers with structured sparsity regularization for interpretable customer churn modeling. Decision Support Systems, 150, p.113523.
- Domingos, E.; Ojeme, B.; Daramola, O. Experimental Analysis of Hyperparameters for Deep Learning-Based Churn Prediction in the Banking Sector. Computation 2021, 9, 34. [CrossRef]
- Kurtcan, B.D.; Ozcan, T. Predicting customer churn using grey wolf optimization-based support vector machine with principal component analysis. J. Forecast. 2023, 42, 1329–1340. [CrossRef]
- Fu, K.; Zheng, G.; Xie, W. Customer churn prediction for a webcast platform via a voting-based ensemble learning model with Nelder-Mead optimizer. J. Intell. Inf. Syst. 2023, 61, 859–879. [CrossRef]
- Geiler, L.; Affeldt, S.; Nadif, M. A survey on machine learning methods for churn prediction. Int. J. Data Sci. Anal. 2022, 14, 217–242. [CrossRef]
- Höppner, S.; Stripling, E.; Baesens, B.; Broucke, S.V.; Verdonck, T. Profit driven decision trees for churn prediction. Eur. J. Oper. Res. 2020, 284, 920–933. [CrossRef]
- Imani, M.; Arabnia, H.R. Hyperparameter Optimization and Combined Data Sampling Techniques in Machine Learning for Customer Churn Prediction: A Comparative Analysis. Technologies 2023, 11, 167. [CrossRef]
- Imani, M.; Ghaderpour, Z.; Joudaki, M.; Beikmohammadi, A. The Impact of SMOTE and ADASYN on Random Forest and Advanced Gradient Boosting Techniques in Telecom Customer Churn Prediction. 2024 10th International Conference on Web Research (ICWR). Iran; pp. 202–209.
- Imani, M.; Beikmohammadi, A.; Arabnia, H.R. Comprehensive Analysis of Random Forest and XGBoost Performance with SMOTE, ADASYN, and GNUS Under Varying Imbalance Levels. Technologies 2025, 13, 88. [CrossRef]
- Jahan, I.; Sanam, T.F. An Improved Machine Learning Based Customer Churn Prediction for Insight and Recommendation in E-commerce. 2022 25th International Conference on Computer and Information Technology (ICCIT). Bangladesh; pp. 1–6.
- Jain, H.; Khunteta, A.; Srivastava, S. Churn Prediction in Telecommunication using Logistic Regression and Logit Boost. Procedia Comput. Sci. 2020, 167, 101–112. [CrossRef]
- Jajam, N.; Challa, N.P.; Prasanna, K.S.L.; Deepthi, C.H.V.S. Arithmetic Optimization With Ensemble Deep Learning SBLSTM-RNN-IGSA Model for Customer Churn Prediction. IEEE Access 2023, 11, 93111–93128. [CrossRef]
- Jakob, R., Lepper, N., Fleisch, E. and Kowatsch, T., 2024, May. Predicting early user churn in a public digital weight loss intervention. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (pp. 1-16).
- Janssens, B.; Bogaert, M.; Bagué, A.; Poel, D.V.D. B2Boost: instance-dependent profit-driven modelling of B2B churn. Ann. Oper. Res. 2022, 341, 267–293. [CrossRef]
- Joudaki, M., Imani, M., Esmaeili, M., Mahmoodi, M. and Mazhari, N., 2011. Presenting a New Approach for Predicting and Preventing Active/Deliberate Customer Churn in Telecommunication Industry. In Proceedings of the International Conference on Security and Management (SAM) (p. 1). The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp).
- Joy, U.G.; Hoque, K.E.; Uddin, M.N.; Chowdhury, L.; Park, S.-B. A Big Data-Driven Hybrid Model for Enhancing Streaming Service Customer Retention Through Churn Prediction Integrated With Explainable AI. IEEE Access 2024, 12, 69130–69150. [CrossRef]
- Khoh, W.H.; Pang, Y.H.; Ooi, S.Y.; Wang, L.-Y.; Poh, Q.W. Predictive Churn Modeling for Sustainable Business in the Telecommunication Industry: Optimized Weighted Ensemble Machine Learning. Sustainability 2023, 15, 8631. [CrossRef]
- Koçoğlu, F.Ö.; Özcan, T. A grid search optimized extreme learning machine approach for customer churn prediction. J. Eng. Res. 2022. [CrossRef]
- Lee, N.-T.; Lee, H.-C.; Hsin, J.; Fang, S.-H. Prediction of Customer Behavior Changing via a Hybrid Approach. IEEE Open J. Comput. Soc. 2023, 5, 27–38. [CrossRef]
- Lemmens, A.; Gupta, S. Managing Churn to Maximize Profits. Mark. Sci. 2020, 39, 956–973. [CrossRef]
- Liu, R.; Ali, S.; Bilal, S.F.; Sakhawat, Z.; Imran, A.; Almuhaimeed, A.; Alzahrani, A.; Sun, G. An Intelligent Hybrid Scheme for Customer Churn Prediction Integrating Clustering and Classification Algorithms. Appl. Sci. 2022, 12, 9355. [CrossRef]
- Liu, Y.; Shengdong, M.; Jijian, G.; Nedjah, N. Intelligent Prediction of Customer Churn with a Fused Attentional Deep Learning Model. Mathematics 2022, 10, 4733. [CrossRef]
- Maldonado, S.; López, J.; Vairetti, C. Profit-based churn prediction based on Minimax Probability Machines. Eur. J. Oper. Res. 2020, 284, 273–284. [CrossRef]
- Manohar, E., Jenifer, P., Nisha, M.S. and Benita, B., 2021, February. A collective data mining approach to predict customer behaviour. In 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV) (pp. 1310-1316). IEEE.
- Matuszelański, K.; Kopczewska, K. Customer Churn in Retail E-Commerce Business: Spatial and Machine Learning Approach. J. Theor. Appl. Electron. Commer. Res. 2022, 17, 165–198. [CrossRef]
- Mitravinda, K.M.; Shetty, S. Employee Attrition: Prediction, Analysis Of Contributory Factors And Recommendations For Employee Retention. 2022 IEEE International Conference for Women in Innovation, Technology & Entrepreneurship (ICWITE). India; pp. 1–6.
- Ouf, S.; Mahmoud, K.T.; Abdel-Fattah, M.A. A proposed hybrid framework to improve the accuracy of customer churn prediction in telecom industry. J. Big Data 2024, 11, 1–27. [CrossRef]
- Ozan, Ş. Case studies on using natural language processing techniques in customer relationship management software. J. Intell. Inf. Syst. 2020, 56, 233–253. [CrossRef]
- Ozmen, E.P.; Ozcan, T. A novel deep learning model based on convolutional neural networks for employee churn prediction. J. Forecast. 2021, 41, 539–550. [CrossRef]
- Ponnusamy, R.R.A., Rana, M.E., Manickavasagam, S.A. and Hameed, V.A., 2023, July. PSO-SVM based algorithm for customer churn prediction in the banking industry. In 2023 IEEE 6th International Conference on Big Data and Artificial Intelligence (BDAI) (pp. 220-225). IEEE.
- Przybyła-Kasperek, M.; Marfo, K.F.; Sulikowski, P. Multi-Layer Perceptron and Radial Basis Function Networks in Predictive Modeling of Churn for Mobile Telecommunications Based on Usage Patterns. Appl. Sci. 2024, 14, 9226. [CrossRef]
- Pustokhina, I.V.; Pustokhin, D.A.; Nguyen, P.T.; Elhoseny, M.; Shankar, K. Multi-objective rain optimization algorithm with WELM model for customer churn prediction in telecommunication sector. Complex Intell. Syst. 2021, 9, 3473–3485. [CrossRef]
- Ramesh, P.; Emilyn, J.J.; Vijayakumar, V. Hybrid Artificial Neural Networks Using Customer Churn Prediction. Wirel. Pers. Commun. 2021, 124, 1695–1709. [CrossRef]
- Reichheld, F.F. and Teal, T., 1996. The Loyalty Effect: The Hidden Force Behind Growth, Profits, and Lasting. Harvard Business School Publications, Boston, pp.352-354.
- Roohi, S., Relas, A., Takatalo, J., Heiskanen, H. and Hämäläinen, P., 2020, November. Predicting game difficulty and churn without players. In Proceedings of the Annual Symposium on Computer-Human Interaction in Play (pp. 585-593).
- Sagala, N.T.M.; Permai, S.D. Enhanced Churn Prediction Model with Boosted Trees Algorithms in The Banking Sector. 2021 International Conference on Data Science and Its Applications (ICoDSA). Indonesia; pp. 240–245.
- Saha, S.; Saha, C.; Haque, M.; Alam, G.R.; Talukder, A. ChurnNet: Deep Learning Enhanced Customer Churn Prediction in Telecommunication Industry. IEEE Access 2024, 12, 4471–4484. [CrossRef]
- Saheed, Y.K.; Hambali, M.A. Customer Churn Prediction in Telecom Sector with Machine Learning and Information Gain Filter Feature Selection Algorithms. 2021 International Conference on Data Analytics for Business and Industry (ICDABI). Bahrain; pp. 208–213.
- Saias, J.; Rato, L.; Gonçalves, T. An Approach to Churn Prediction for Cloud Services Recommendation and User Retention. Information 2022, 13, 227. [CrossRef]
- Shu, X.; Ye, Y. Knowledge Discovery: Methods from data mining and machine learning. Soc. Sci. Res. 2022, 110, 102817. [CrossRef]
- Sikri, A.; Jameel, R.; Idrees, S.M.; Kaur, H. Enhancing customer retention in telecom industry with machine learning driven churn prediction. Sci. Rep. 2024, 14, 1–13. [CrossRef]
- Šimović, P.P.; Chen, C.Y.T.; Sun, E.W. Classifying the Variety of Customers’ Online Engagement for Churn Prediction with a Mixed-Penalty Logistic Regression. Comput. Econ. 2022, 61, 451–485. [CrossRef]
- Mirabdolbaghi, S.M.S.; Amiri, B. Model Optimization Analysis of Customer Churn Prediction Using Machine Learning Algorithms with Focus on Feature Reductions. Discret. Dyn. Nat. Soc. 2022, 2022. [CrossRef]
- Tamuka, N. and Sibanda, K., 2020, November. Real time customer churn scoring model for the telecommunications industry. In 2020 2nd International Multidisciplinary Information Technology and Engineering Conference (IMITEC) (pp. 1-9). IEEE.
- Tang, Q., Xia, G., Zhang, X. and Li, Y., 2020, February. A feature interaction network for customer churn prediction. In Proceedings of the 2020 12th International Conference on Machine Learning and Computing (pp. 242-248).
- Toor, A.A.; Usman, M. Adaptive telecom churn prediction for concept-sensitive imbalance data streams. J. Supercomput. 2021, 78, 3746–3774. [CrossRef]
- Usman, M.; Ahmad, W.; Fong, A. Design and Implementation of a System for Comparative Analysis of Learning Architectures for Churn Prediction. IEEE Commun. Mag. 2021, 59, 86–90. [CrossRef]
- Usman-Hamza, F.E.; Balogun, A.O.; Capretz, L.F.; Mojeed, H.A.; Mahamad, S.; Salihu, S.A.; Akintola, A.G.; Basri, S.; Amosa, R.T.; Salahdeen, N.K. Intelligent Decision Forest Models for Customer Churn Prediction. Appl. Sci. 2022, 12, 8270. [CrossRef]
- Venkatesh, S.; Jeyakarthic, M. An Optimal Genetic Algorithm with Support Vector Machine for Cloud Based Customer Churn Prediction. 2020 International Conference on System, Computation, Automation and Networking (ICSCAN). India; pp. 1–6.
- Vo, N.N.; Liu, S.; Li, X.; Xu, G. Leveraging unstructured call log data for customer churn prediction. Knowledge-Based Syst. 2021, 212. [CrossRef]
- Vu, V.-H. Predict customer churn using combination deep learning networks model. Neural Comput. Appl. 2023, 36, 4867–4883. [CrossRef]
- Wang, X., Nguyen, K. and Nguyen, B.P., 2020, January. Churn prediction using ensemble learning. In Proceedings of the 4th international conference on machine learning and soft computing (pp. 56-60).
- Wang, A.X.; Chukova, S.S.; Nguyen, B.P. Data-Centric AI to Improve Churn Prediction with Synthetic Data. 2023 3rd International Conference on Computer, Control and Robotics (ICCCR). China; pp. 409–413.
- Wang, X.; Xie, L.; Wang, H.; Xing, X.; Wan, W.; Wu, Z.; Ma, X.; Li, Q. Deciphering Explicit and Implicit Features for Reliable, Interpretable, and Actionable User Churn Prediction in Online Video Games. IEEE Trans. Vis. Comput. Graph. 2024, PP, 1–18. [CrossRef]
- Xu, T.; Ma, Y.; Kim, K. Telecom Churn Prediction System Based on Ensemble Learning Using Feature Grouping. Appl. Sci. 2021, 11, 4742. [CrossRef]
- Zhang, T.; Moro, S.; Ramos, R.F. A Data-Driven Approach to Improve Customer Churn Prediction Based on Telecom Customer Segmentation. Futur. Internet 2022, 14, 94. [CrossRef]
- Zhao, Y.; Shao, Z.; Zhao, W.; Han, J.; Zheng, Q.; Jing, R. Combining unsupervised and supervised classification for customer value discovery in the telecom industry: a deep learning approach. Computing 2023, 105, 1395–1417. [CrossRef]
- Zhu, B., Qian, C., Pan, X. and Chen, H., 2020, June. A trajectory-based deep sequential method for customer churn prediction. In Proceedings of the 2020 5th International Conference on Machine Learning Technologies (pp. 114-118).
Figure 1.
PRISMA Flowcahrt.
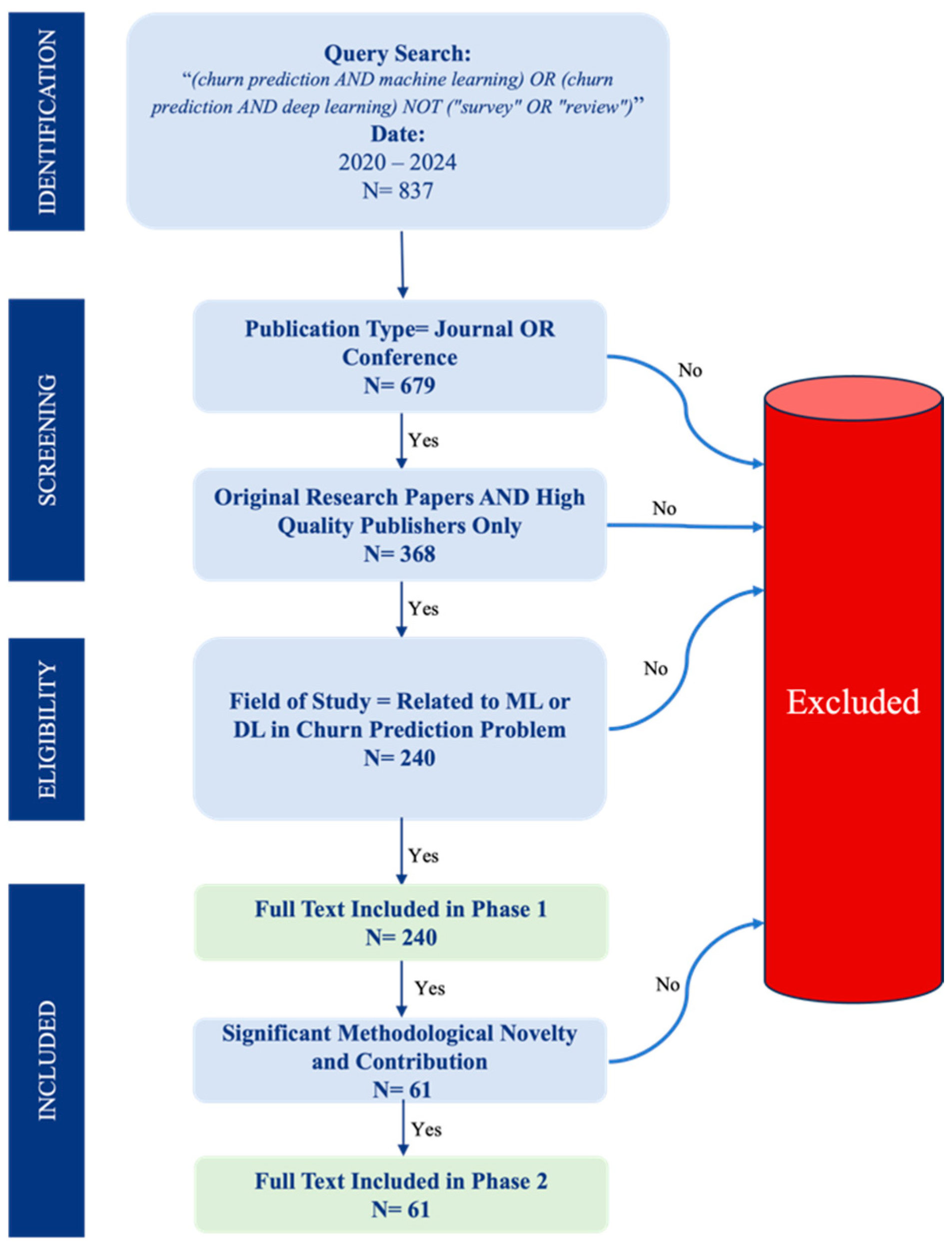
Figure 2.
Share of Publications by Publishers in Churn Prediction Research.
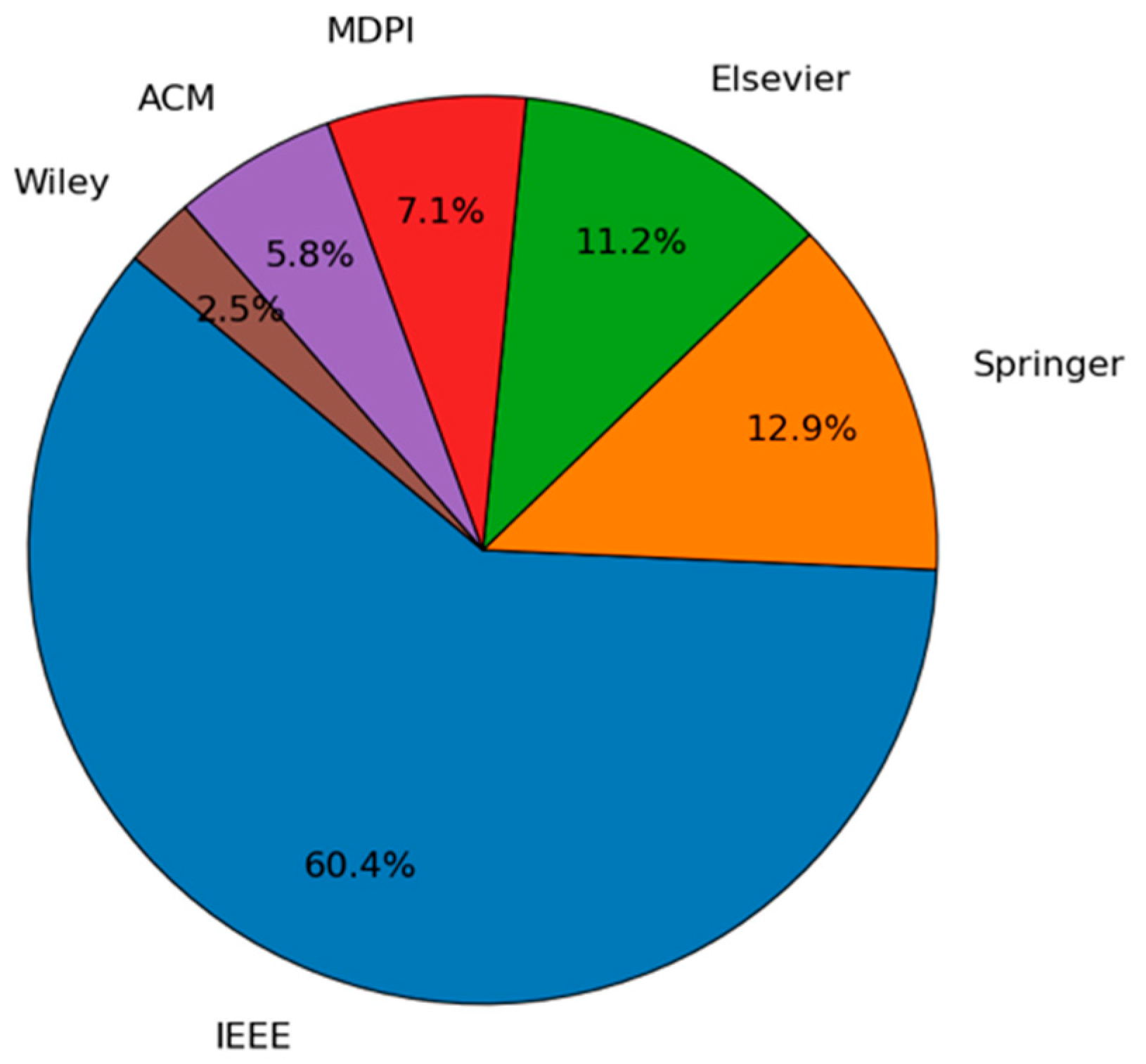
Figure 3.
Publication Trends of Publishers.
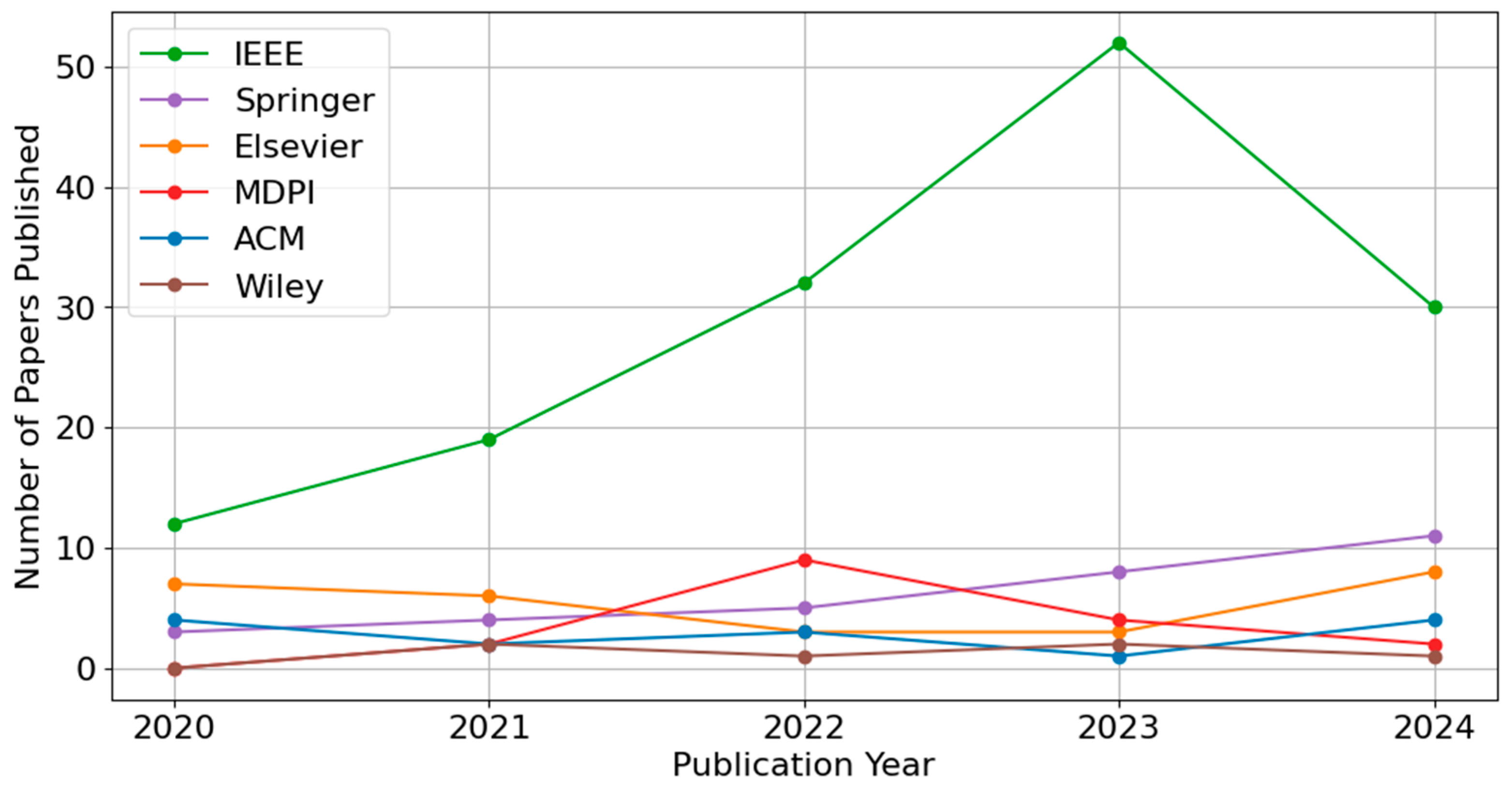
Figure 4.
Citations Received by Each Publisher.
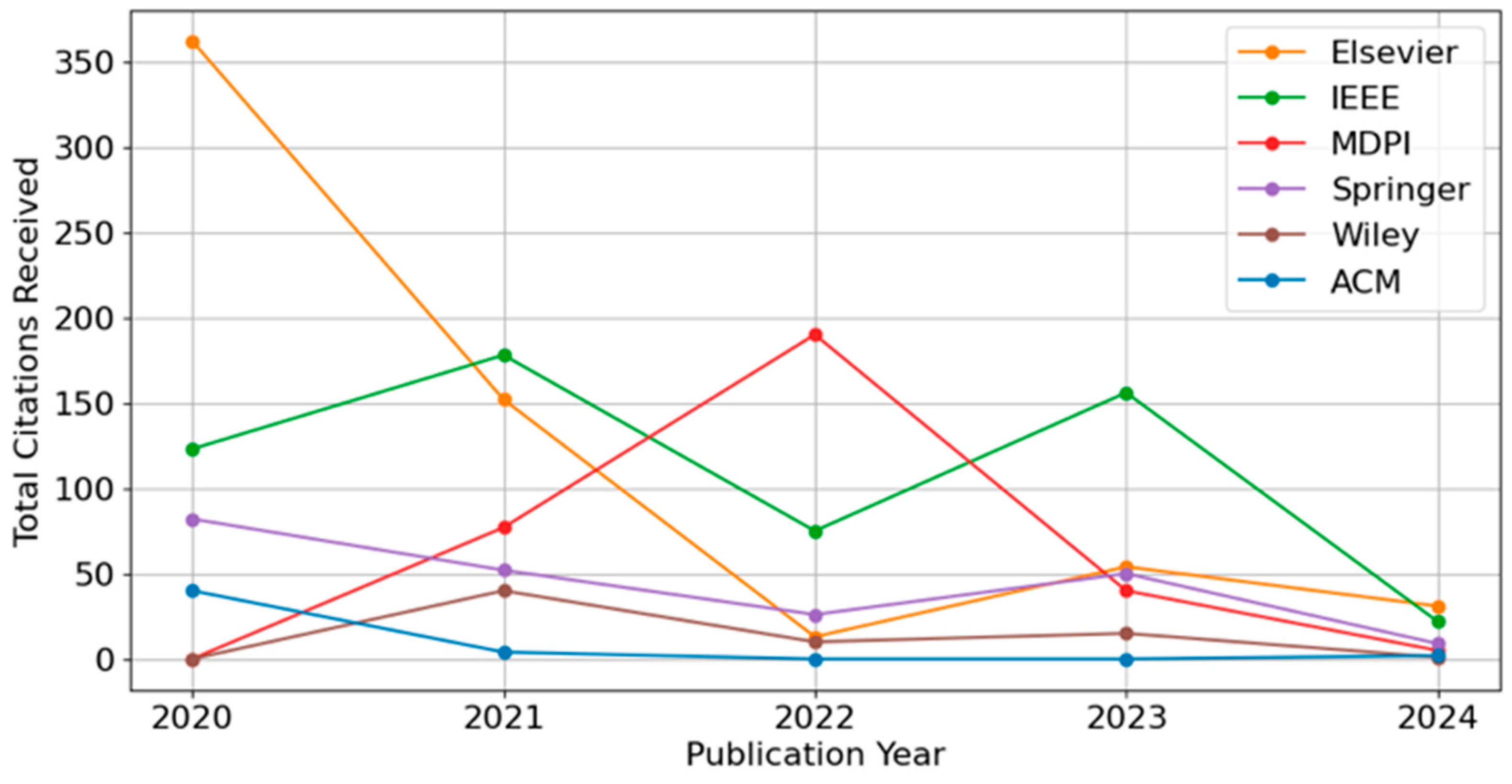
Figure 5.
Normalized IF Trends of Publishers.
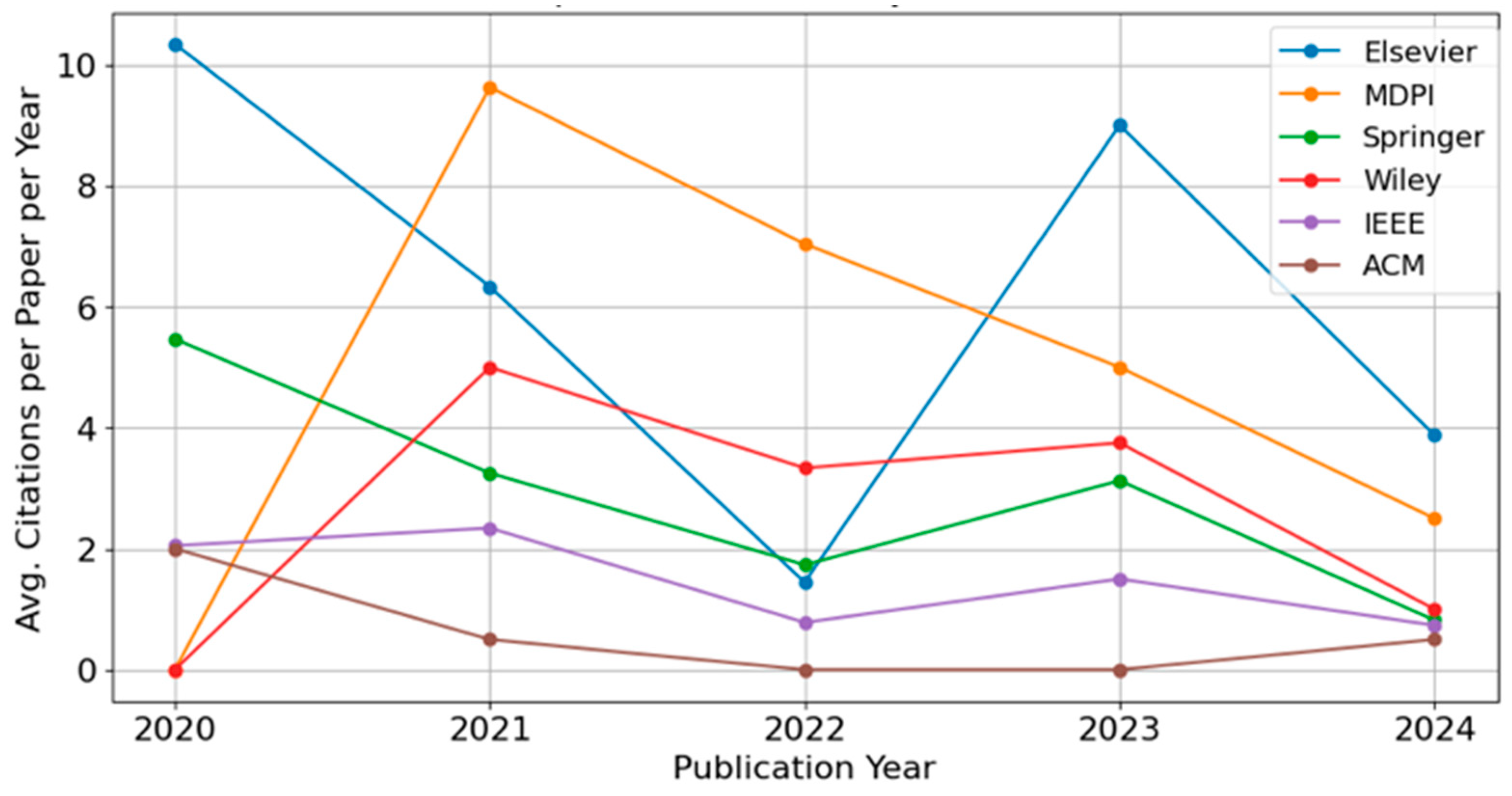
Figure 6.
Citation Count Distribution.
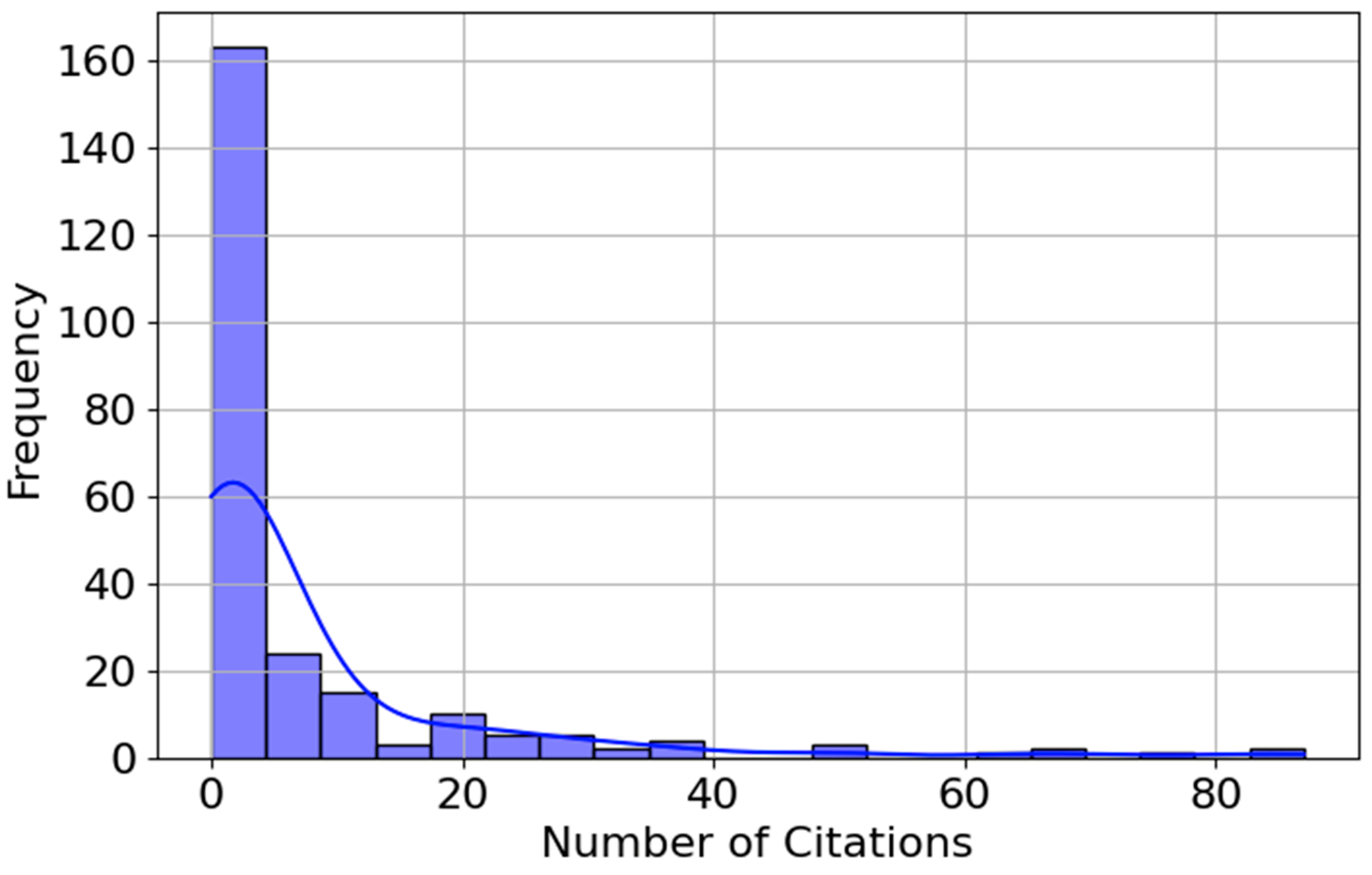
Figure 7.
Normalized IF Trends: OA vs. non-OA Papers.
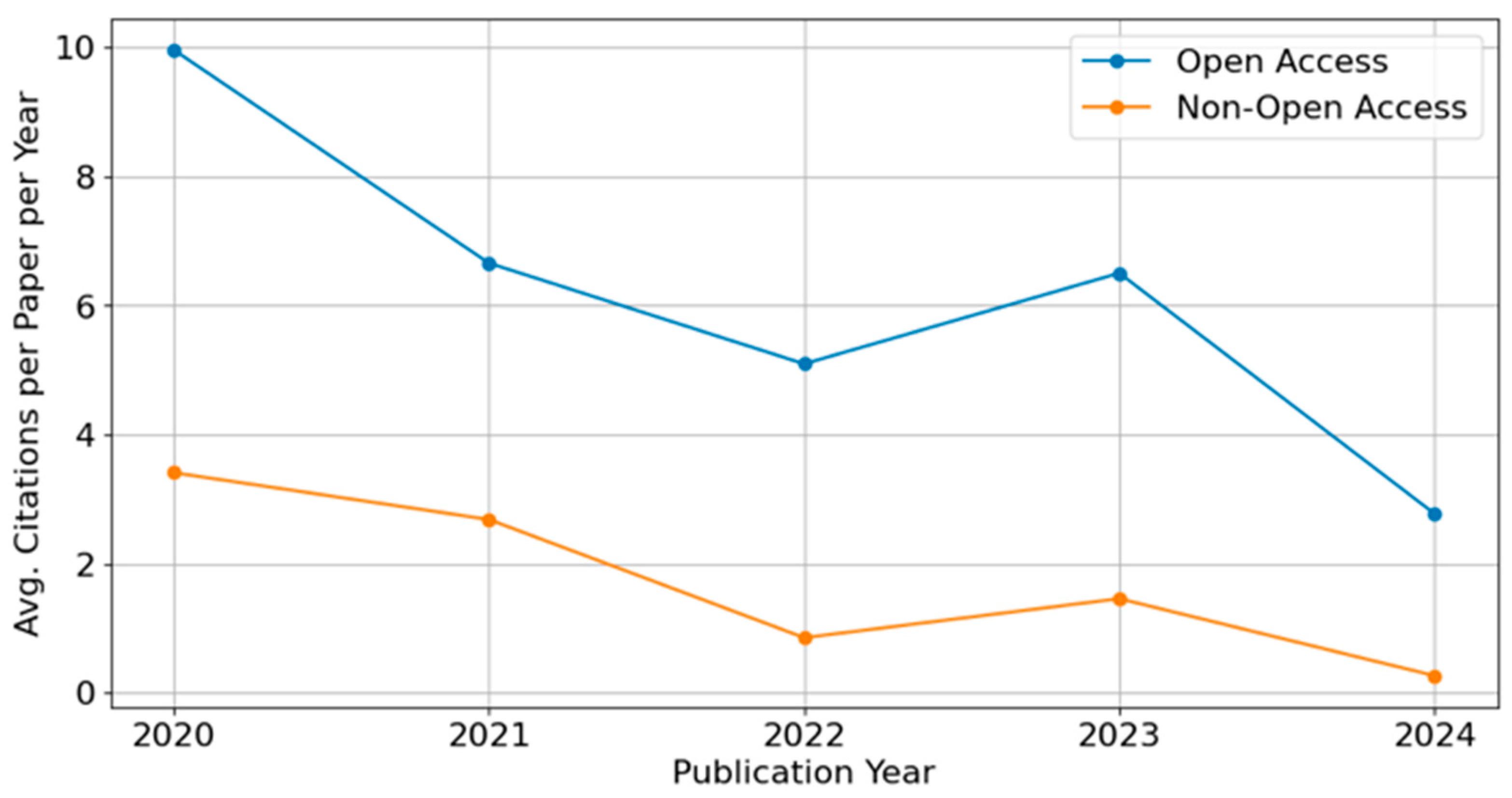
Figure 8.
Publication trends by research domains.
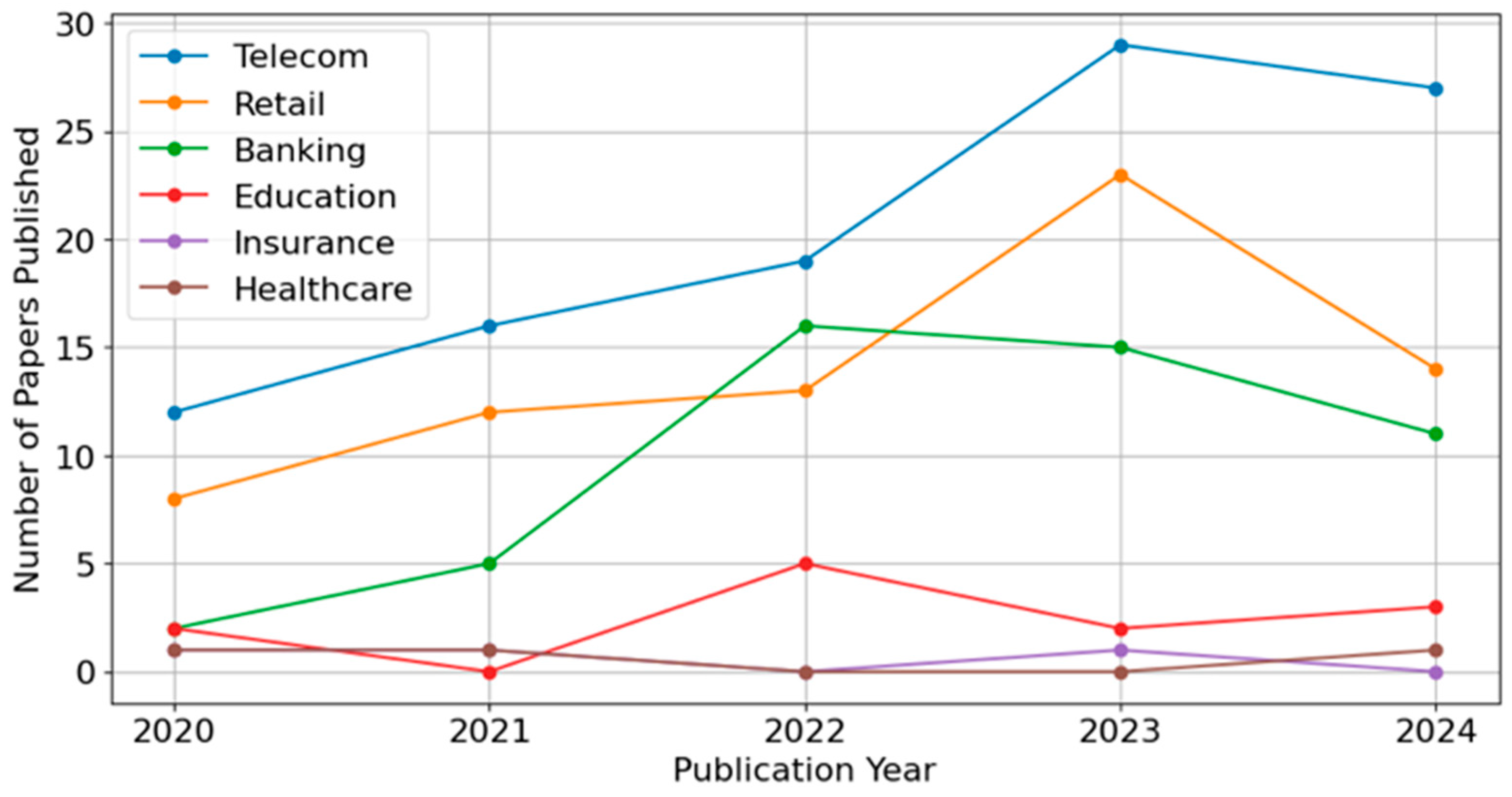
Figure 9.
The usage of different categories of techniques in churn prediction research.
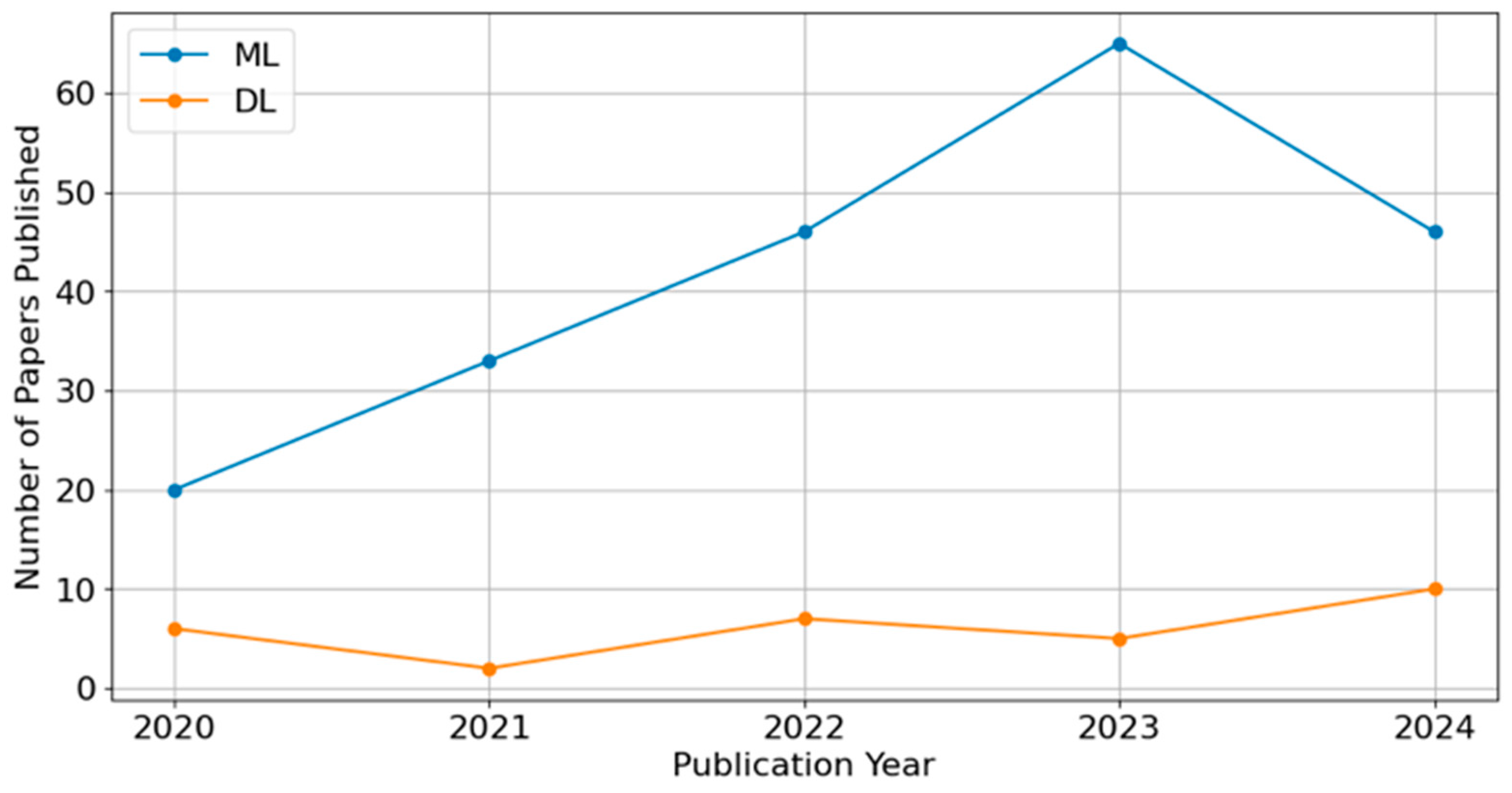
Figure 10.
The usage of different ML techniques in churn prediction research.
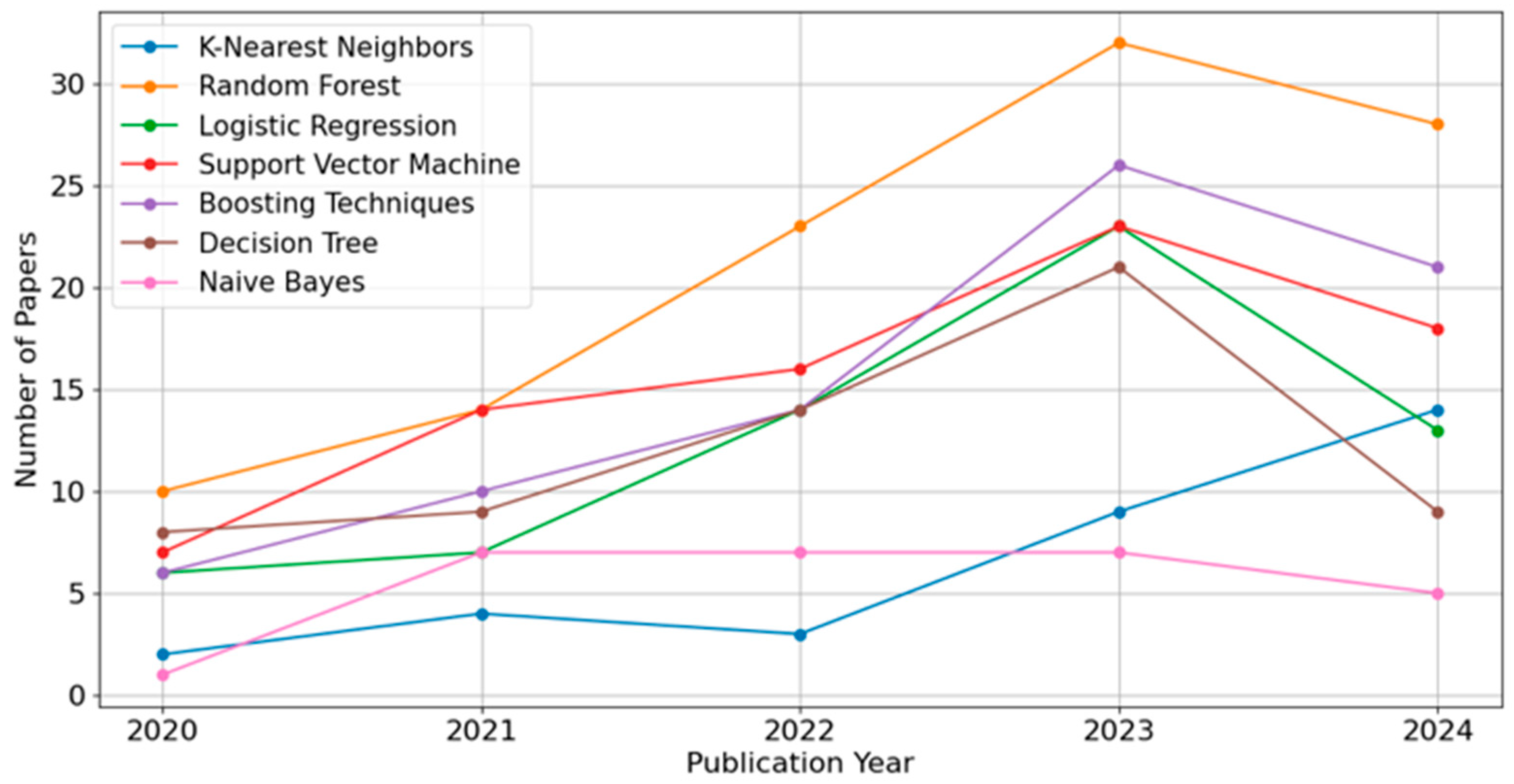
Figure 11.
The usage of different DL techniques in churn prediction research.
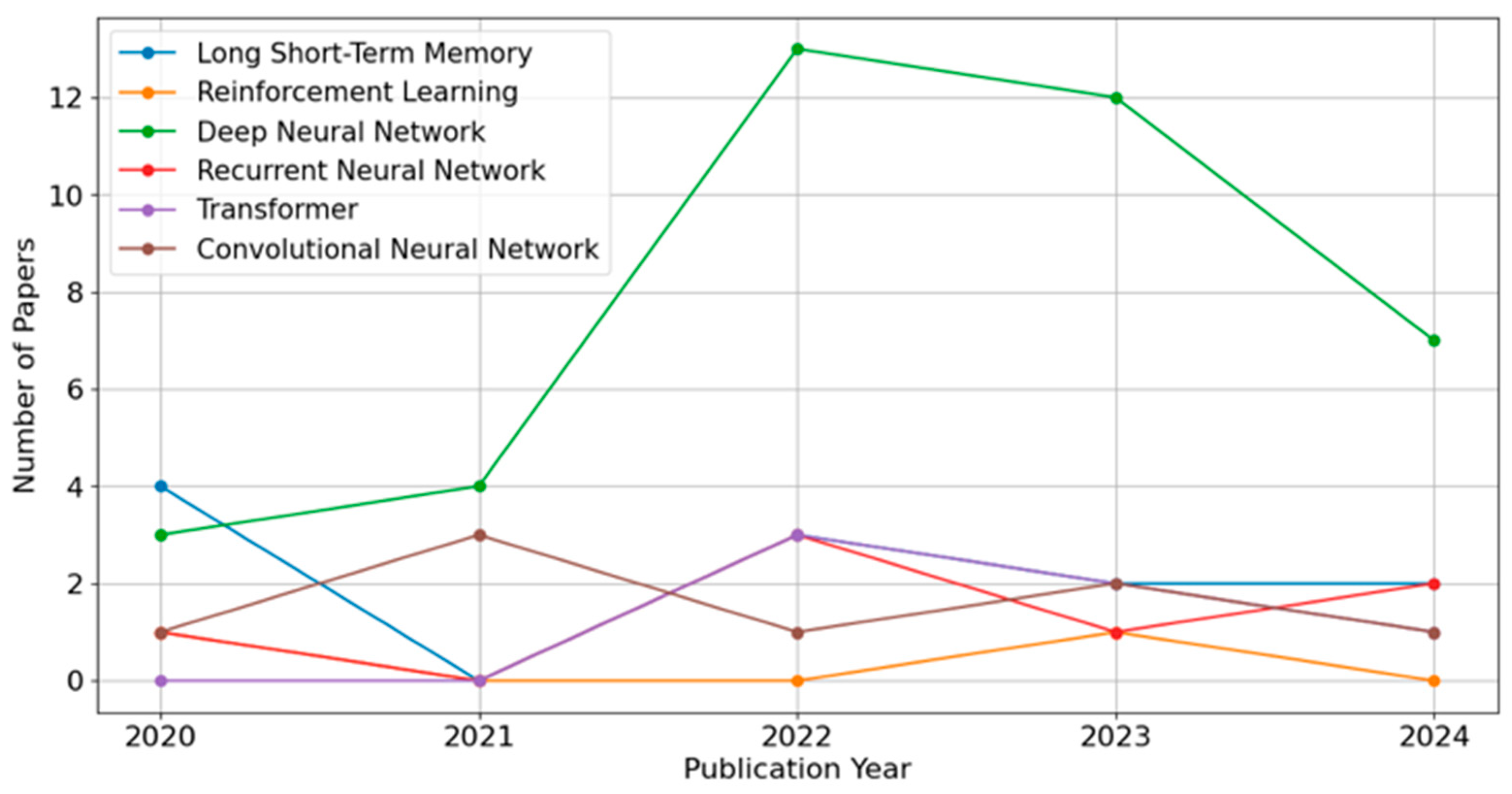
Figure 12.
Taxonomy of Churn Prediction Approaches.
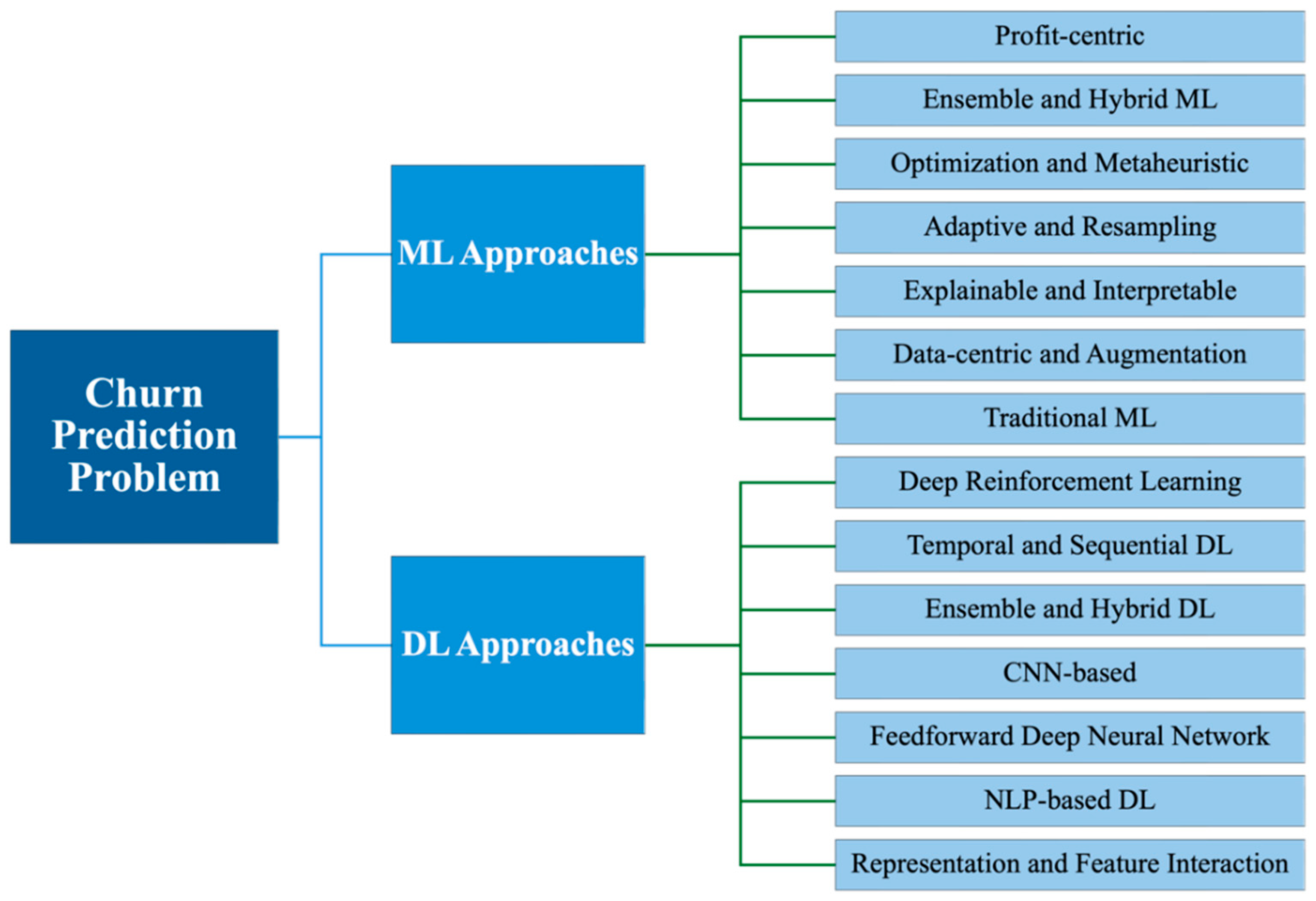

Table 1.
The summary of studies in the domain of conventional ML.
| Category | Reference | Dataset | Techniques Used | Metrics Used |
| Profit-centric | (Höppner et al. 2020) | Public | DT, Evolutionary Algorithm | AUC, Expected Maximum Profit for Customer Churn (EMPC) |
| (Maldonado et al. 2020) | Public | Minimax Probability Machines (MPM), LASSO, Tikhonov Regularization | Profit Maximization | |
| (Janssens et al. 2024) | Private | Gradient Boosting | Expected Maximum Profit for B2B (EMPB) | |
| Ensemble and Hybrid ML | (Wang et al. 2020) | Public | Ensemble Learning | Accuracy |
| (Jain et al. 2020) | Private | Logistic Regression, Logit Boost | Accuracy, ROC AUC, PR AUC, Precision, Recall, MCC | |
| (Sagala and Permai 2021) | Private | Boosted Tree Algorithms (XGBoost, LightGBM, CatBoost) | Accuracy, AUC, Precision, Recall | |
| (Xu et al. 2021) | Private | Stacking Model (XGBoost, Logistic Regression, DT, Naïve Bayes) | Accuracy | |
| (Manohar et al. 2021) | Public | SVMs, Bayesian Classifier, RF | Accuracy, Precision, Recall, F1-score | |
| (Ramesh et al. 2022) | Private | Atificial Neural Networks, RF | Accuracy | |
| (Usman-Hamza et al. 2022) | Public | Decision Forest, Weighted Soft Voting | Accuracy | |
| (Saias et al. 2022) | Private | Multilayer Neural Networks, AdaBoost, RF | Accuracy, ROC AUC | |
| (Jahan and Sanam 2022) | Private | CatBoost, Recursive Feature Elimination (RFE) | Accuracy, F1-score | |
| (Liu et al. 2022) | Public | Clustering (k-means, k-medoids), Gradient Boosying Trees, DT, RF, Deep Lerning, Naïve Bayes | Accuracy | |
| (Beeharry and Tsokizep Fokone 2022) | Public | Hybrid Ensemble Learning, Two-Layer Flexible Voting | Accuracy, F1-score | |
| (Fu et al. 2023) | Private | Ensemble Learning, Nelder-Mead Optimization | Accuracy | |
| (Adiputra and Wanchai 2023) | Public | Weighted Ensemble Model (XGBoost, RF) | F1-score, Execution Time | |
| (Khoh et al. 2023) | Private | Weighted Ensemble Model, Powell’s Optimization | Accuracy, F1-score | |
| (Arshad et al. 2024) | Public | Quantum Support Vector Machine, Quantum k-Nearest Neighbors, and Quantum Decision Tree | Accuracy, Precision, Recall | |
| Optimization and Metaheuristic ML | (Venkatesh and Jeyakarthic 2020) | Public | Optimal Genetic Algorithm (OGA) with SVM (OGA-SVM), Quantum-Genetic Algorithm | Accuracy, F-score, Sensitivity |
| (Saheed and Hambali 2021) | Public | SVMs, Multi Layer Perceptron, RF, Naïve Bayes, Feature Selection (Information Gain) | Accuracy | |
| (Pustokhina et al. 2021) | Public | Improved SMOTE (ISMOTE) with an Optimal Weighted Extreme Learning Machine (OWELM), Multi-objective Rain Optimization Algorithm (MOROA) | Accuracy, F-measure | |
| (Sina Mirabdolbaghi and Amiri 2022) | Public | Principal Component Analysis (PCA), Autoencoders, Linear Discriminant Analysis (LDA), t-SNE, XGBoost, LightGBM | AUC, MCC, F1-score, Kappa | |
| (Al-Shourbaji et al. 2022) | Public | Ant Colony Optimization with the Reptile Search Algorithm (ACO-RSA) | Accuracy | |
| (AlShourbaji et al. 2023) | Public | SVMs, Particle Swarm Optimization (PSO), Artificial Ecosystem Optimization (AEO) | Accuracy | |
| (Durkaya Kurtcan and Ozcan 2023) | Public | Principal Component Analysis (PCA), Grey Wolf Optimization (GWO), SVMs | Accuracy, Recall, F1-score | |
| (Ponnusamy et al. 2023) | Public | Particle Swarm Optimization, SVMs | Accuracy | |
| (Koçoğlu and Özcan 2023) | Public | Extreme Learning Machine, Grid Search Optimization | Accuracy, F1-score, Modified Accuracy | |
| Adaptive and Resampling | (Toor and Usman 2022) | Public | Adaptive Churn Prediction (OTCCD), SMOTE | Accuracy |
| (Amin et al. 2023) | Public | Naive Bayes, Evolutionary Computation | Precision, Recall, F1-score | |
| (Lee et al. 2023) | Public | Hybrid Statistical Modeling | Recall | |
| (Ouf et al. 2024) | Public | XGBoost, SMOTE-ENN Resampling | Accuracy, Precision, Recall, F1-score | |
| Explainable and Interpretable | (De Bock and De Caigny 2021) | Public | Spline-Rule Ensemble, Sparse Group Lasso (SGL) | AUC |
| (Mitravinda and Shetty 2022) | Public | Shapley Additive Explanations (SHAP) Explainable AI, Collaborative Filtering | Accuracy | |
| (Wang et al. 2024) | Other | Explainable AI, Social Interaction Analysis | Interpretability, Decision-Making | |
| Data-centric and Augmentation | (Vo et al. 2021) | Private | Natural Language Processing, Interpretable ML | Accuracy |
| (De and Prabu 2023) | Public | Entropy-based Min-Max Similarity (E-MMSIM), Topic Classification | F1-score, AUC, Accuracy | |
| (Wang et al. 2023) | Public | Synthetic Data Generation, Data-Centric AI | Accuracy | |
| (Amiri and Hosseini 2024) | Public | Network-Based Feature Engineering, Gradient Boosting | Accuracy | |
| Traditional ML | (Tamuka and Sibanda 2020) | Public | CRISP-DM, Logistic Regression, RF | Accuracy, Misclassification Rate |
| (Zhang et al. 2022) | Public | Fisher Discriminant Analysis, Logistic Regression | Accuracy | |
| (Šimović et al. 2023) | Private | Logistic Regression with Mixed Penalty | Accuracy, Precision, Recall | |
| (AbdElminaam et al. 2023) | Public | KNN, DTs, Logistic Regression, RF, SVM, AdaBoost, GBM | Accuracy | |
| (Jakob et al. 2024) | Private | RF | F1-score, Recall | |
| (Sikri et al. 2024) | Private | DTs, SVMs | Accuracy |
Table 2.
The summary of studies in the domain of DL.
| Category | Ref. | Dataset | Techniques Used | Metrics Used | |
| Deep Reinforcement Learning | (Roohi et al. 2020) | Simulation | Deep Reinforcement Learning | Accuracy | |
| Temporal and Sequential DL | (Zhu et al. 2020) | Public | Trajectory-based LSTM (TR-LSTM) | ROC AUC | |
| (Alboukaey et al. 2020) | Public | LSTM-based Dynamic Churn Model | AUC, F1-Score, Log Loss, Lift, EMPC | ||
| (Joy et al. 2024) | Private | LSTM and Gated Recurrent Unit (GRU) networks, LightGBM, SHAP, Explainable Boosting Machines (EBM) | AUC, F1-score | ||
| (Beltozar-Clemente et al. 2024) | Public | LSTM | Accuracy, Precision, Recall, F1-score | ||
| Ensemble and Hybrid DL | (Liu et al. 2022) | Private | Attentional DL model (AttnBLSTM-CNN) integrated with Bidirectional LSTMs (BiLSTM) and CNNs | F1-score, ROC AUC | |
| (Jajam et al. 2023) | Private | Stacked Bidirectional LSTMs (SBLSTM) and RNNs with an arithmetic optimization algorithm (AOA), Improved Gravitational Search Optimization Algorithm (IGSA) | Accuracy | ||
| (Zhao et al. 2023) | Public | K-Means Clustering, Self-Attention LSTM | AUC, F1-score | ||
| (Vu 2024) | Private | Stacked DNNs, Logistic Regression | Accuracy, Precision, Recall, F1-score | ||
| CNN–based | (Usman et al. 2021) | Public | Comparative CNNs, LSTMs | Accuracy, ROC AUC, G-Mean | |
| (Pekel Ozmen et al. 2022) | Private | CNNs, Extended Convolutional Decision Trees (ECDT) integrated with Grid Search Optimization | Accuracy | ||
| (Saha et al. 2024) | Public | 1D CNN, Residual Blocks, Attention | Accuracy | ||
| Feedforward Deep Neural Network | (Arifin 2020) | Public | DNN, RF, XGBoost | Accuracy | |
| (Przybyła-Kasperek 2024) | Public | Multi-Layer Perceptron, Radial Basis Function (RBF) Networks | Accuracy | ||
| NLP-based DL | (Ozan 2021) | Private | NLP, RNNs | F1-score | |
| Representation and Feature Interaction | (Tang 2020) | Public | Feature Interaction Network (FIN) | Accuracy | |
| (Cenggoro et al. 2021) | Public | Vector Embeddings for Churn | F1-score | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



