
Submitted:
17 April 2025
Posted:
21 April 2025
You are already at the latest version
Abstract
We present a novel methodology for generating and filtering synthetic Unmanned Aerial Vehicle (UAV) flood imagery to enhance the generalization capabilities of segmentation models. Our framework combines text-to-image synthesis and image inpainting, using curated prompts and real-world segmentation masks to produce diverse and realistic flood scenes. To overcome the lack of human annotations, we employ an unsupervised pseudo-labeling method that generates segmentation masks based on floodwater appearance characteristics. We further introduce a filtering stage based on outlier detection in feature space to improve the realism of the synthetic dataset. Experimental results on three state-of-the-art flood segmentation models show that synthetic data can closely match real data in training performance, and combining both sources improves model robustness by 1 – 6%. Finally, we investigate the impact of prompt design on the visual fidelity of generated images and provide qualitative and quantitative evidence of distributional similarity between real and synthetic data.
Keywords:
unsupervised image segmentation
; deep learning
; pseudo-labels
; flood segmentation
; unmanned aerial vehicles
; image inpainting
; text-to-image synthesis
1. Introduction
Natural disasters have long affected humanity, with climate change intensifying their frequency and severity. These events cause significant loss of life, property damage, and service disruptions, such as electricity and transportation, while posing serious health risks. The economic and psychological toll is profound [1].
Technological advances such as Pattern Recognition (PR), Deep Learning (DL), Machine Learning (ML), and Artificial Intelligence (AI) provide powerful tools for disaster detection, risk reduction, and response management. As reviewed in [2,3,4], these technologies hold great promise for future disaster response, especially AI and ML in the domain of computer vision (CV), through the use of predictive models that analyze large datasets, identify patterns, forecast potential disasters and provide early warnings of hazardous events [4,5]. Deep learning (DL) is increasingly used for flood detection and segmentation, overcoming the limitations of traditional mapping [6]. However, DL models require extensive labeled data, which is difficult to obtain in disaster scenarios, requires multiple experts, is time-consuming, and is prone to human annotation.
To provide a comprehensive overview of the available resources in flood-related visual understanding from aerial imagery, we compiled a selection of ten publicly available datasets, namely AIDER [7], ISBDA [8,9], FloodNet [10], FAD [11], Spacenet-8 [12], FSSD [13], WaterBodies [14], Incidents1M [15], RescueNet [16], BlessemFlood21 [17], released between 2019 and 2024. These are illustrated in Figure 1, which depicts a bubble chart where each bubble represents a dataset. The horizontal axis indicates the year of publication, while the vertical axis corresponds to the dataset image size. The area of each bubble is scaled proportionally to the dataset size to emphasize the disparity in scale across datasets. Each bubble is also annotated with the dataset name, and a distinct color is used for visual separation. Gray bubbles indicate datasets without flood annotations (AIDER [7], ISBDA [8,9], Incidents1M [15]), and for AIDER [7] and Incidents1M [15] only the subset of flood-related aerial images is considered in the reported sizes.
The increasing trend in dataset size over recent years highlights the growing effort to support deep learning-based flood analysis and emergency response using aerial visual data. However, the creation of large-scale annotated datasets remains a significant challenge. Manual annotation is labor-intensive, often requiring expert interpretation of complex visual patterns. Furthermore, achieving scene diversity is difficult, as aerial imagery of floods is typically limited to specific geographical regions and events, which may reduce generalizability across diverse flood scenarios.
To overcome these challenges, one viable solution is the use of synthetic data generated through advanced generative methods, such as diffusion models or generative adversarial networks (GANs). Synthetic imagery enables the creation of diverse flooding scenarios, including rare or extreme cases, thereby improving the model’s generalizability and robustness. Moreover, in the absence of ground truth labels, pseudo-labeling through automated segmentation algorithms offers a promising alternative. These methods can generate approximate annotations at scale, significantly reducing the dependence on expert input and enabling effective training of deep learning models in a weakly- or unsupervised manner.
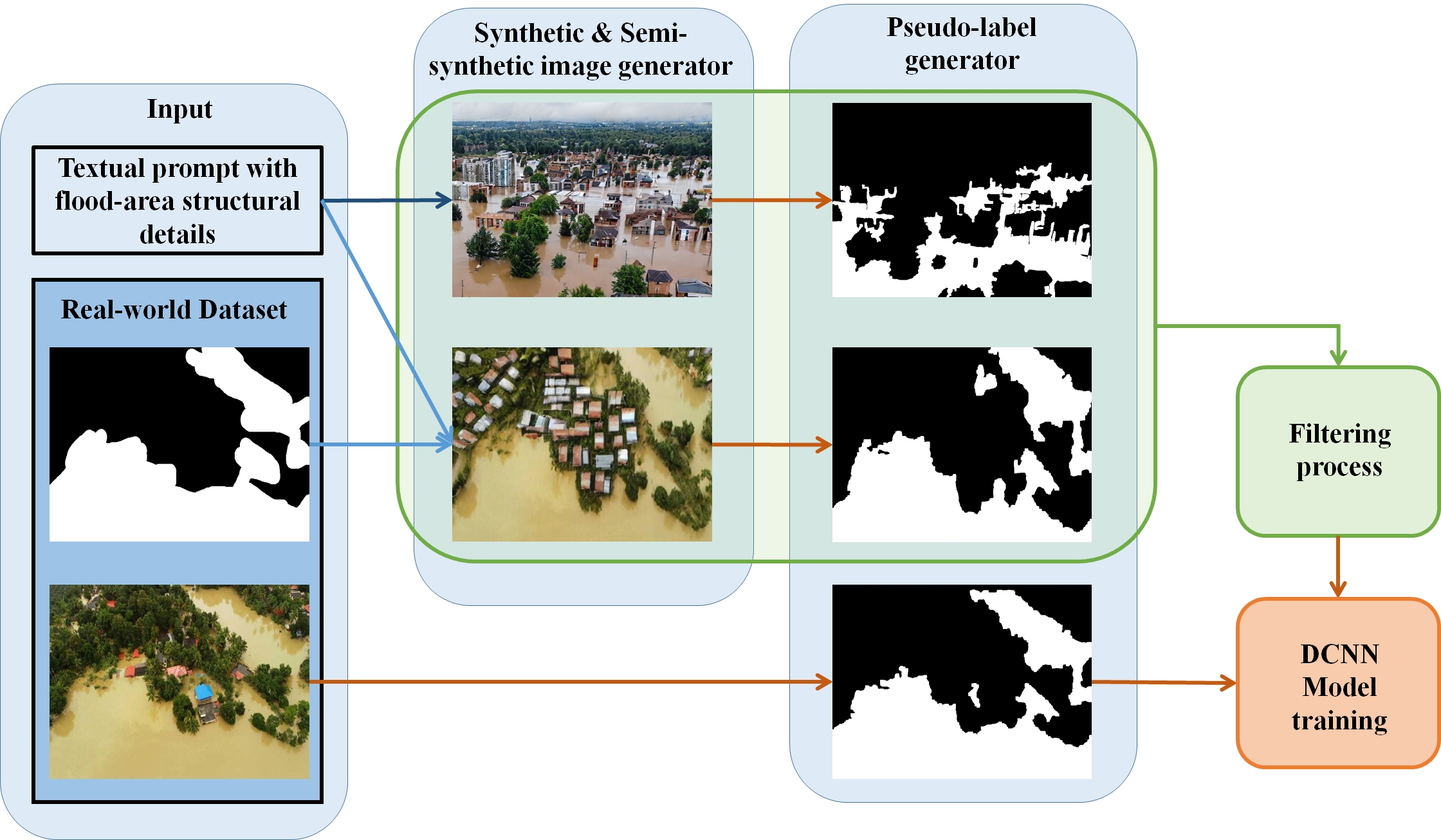
In this paper, we solve the problem of flood segmentation in UAV imagery using synthetic generated images of flooding events instead of real ones to answer the following open question: Can pseudo-labels from synthetic UAV data enable real-world flood segmentation? In our work, we propose a framework to create synthetic generated images of flooding events using two algorithms: (i) text-to-image synthesis and (ii) image inpainting based on real segmentation masks. The generated images undergo unsupervised pseudo-labeling for flood segmentation masks, and filtering using feature embeddings and clustering to refine the synthetic dataset. We train different popular Convolutional Neural Network (CNN) architectures for flood segmentation. Our results show that these models when trained on both synthetic and real images can achieve higher segmentation accuracy. We evaluate their performance on an unseen test set and compare the results to models trained with human-annotated labels and the unsupervised pseudo-labeling approach. A schematic overview of the proposed framework is shown in Figure 2.
The contributions of this work can be summarized as listed below.
- We introduce to the best of our knowledge, the first scalable pipeline for the unsupervised generation of synthetic aerial flood imagery, utilizing text-to-image diffusion models guided by semantically enriched prompts. To enable segmentation training without the need for manual annotation, we integrate an unsupervised pseudo-labeling approach [18], which automatically produces segmentation masks by exploiting the distinct color characteristics of floodwater and surrounding background elements.
- We demonstrate through extensive experiments with state-of-the-art flood segmentation models, that models trained solely on filtered synthetic data achieve performance close to real-data-trained models, with minor performance drops, and introduce an approach to combine real and synthetic data in order to boost performance.
- We systematically examine how the structure and semantics of text prompts affect the quality and realism of the generated flood imagery, identifying factors that influence scene consistency and visual fidelity.
The remainder of this paper is structured as follows: Section 2 provides a summary of related research. Our proposed unsupervised framework is described in Section 3. Section 4 outlines the experimental framework of this study. Section 5 presents the experimental results along with an in-depth discussion. Finally, Section 6 concludes the paper and outlines directions for future research.
2. Related Work
Flood Segmentation in UAV and Satelite Imagery: Deep learning techniques, particularly CNNs, are increasingly used for flood segmentation in remote sensing imagery, surpassing traditional methods by enabling more accurate and efficient delineation of flooded areas and enhancing decision-making processes [6]. CNNs have shown strong capabilities in flood detection from satellite imagery by leveraging temporal variations in synthetic aperture radar (SAR) and multispectral data to differentiate between permanent water bodies and flood-affected areas [19,20]. However, their effectiveness is often constrained by the reliance on pre-disaster imagery for accurate change detection. To address uncertainty in SAR-based water segmentation, Bayesian CNNs have been proposed due to their ability to estimate both the mean and variance of model parameters, providing a probabilistic understanding of predictions [21].
U-Net variants have been widely adopted for water body segmentation and flood extent mapping tasks. For instance, in [22], a modified U-Net architecture was proposed that incorporated geomorphic features and utilized pre-processed Sentinel-1 radar imagery to achieve three-class classification. This model successfully differentiated flood water from permanent water and background. Similarly, in [12,23] was demonstrated that lightweight U-Net configurations can offer an effective balance between accuracy, computational efficiency, and robustness. The use of transfer learning and targeted data augmentation proved essential in enabling the detection of flooded infrastructure, including roads and buildings. Furthermore, in [14], the performance of various CNN architectures for water body semantic segmentation was evaluated using high-resolution satellite and aerial imagery. The U-Net model with a MobileNet-V3 backbone, along with auxiliary features and data augmentation, achieved superior segmentation accuracy.
Benchmark experiments involving semantic segmentation, have validated state-of-the-art deep learning models including XceptionNet and ENet for distinguishing floodwaters from natural water bodies, and detecting inundated roads and buildings in UAV-acquired high-resolution post-disaster imagery [10]. Also, a CNN integrated into the Deep Earth Learning, Tools, and Analysis (DELTA) framework achieved high precision and recall for water segmentation across diverse datasets [24]. In [25], a multiscale attentive decoder network (ADNet) was proposed for automatic flood identification using Sentinel-1 images. When evaluated on the Sen1Floods11 benchmark dataset, ADNet outperformed recent deep learning and threshold-based approaches.
In [26], an enhanced version of the Efficient Neural Network (ENet) architecture was adopted for the semantic segmentation of UAV footage captured during flood events. The approach integrates atrous (dilated) separable convolutions in the encoder, enlarging the receptive field without increasing computational complexity [27], and depth-wise separable convolutions in the decoder, enabling efficient feature extraction with a reduced number of parameters. Atrous convolutions have been further utilized in disaster response scenarios to enhance the efficiency of search and rescue operations during events such as floods, high tides, and tsunamis. A notable example is FASegNet, a recently proposed CNN architecture designed for the semantic segmentation of flood and tsunami-affected areas [28].
Transformer-based architectures have also demonstrated strong performance in semantic segmentation of remote sensing imagery. In [29], a novel approach was introduced employing the Swin Transformer as the backbone to enhance contextual feature representation, coupled with a densely connected feature aggregation module as the decoder. Additionally, the Bitemporal Image Transformer (BiT) model proposed in [19] showed superior performance in change detection tasks by effectively identifying and localizing regions of change between image pairs.
In [30], an interactive semantic segmentation model for multi-source UAV flood images using four prompt types. A prompt encoder maps prompts into a three-channel space to lower labeling costs, while an image encoder, combining Mamba and convolution operations, extracts global features. The model further improves prompt utilization by incorporating a spatial and channel attention module with residual connections. This enables a multiscale fusion and filtering of prompt information and image features across both spatial and channel dimensions.
Several unsupervised flood segmentation methods have been developed using clustering and region-growing techniques. These include object-based K-means with region growing on SAR data [31] and UAV imagery [32], datacube-based flood mapping with probabilistic thresholds [33], tile-based histogram thresholding with contextual filters [34], and graph-based segmentation using Bayesian Markov random fields [35], all demonstrating effectiveness across various imaging sources and scenarios.
In [18], a fully unsupervised segmentation method, UFS-HT-REM, was introduced for fast and accurate flood area detection using UAV-acquired color imagery without requiring pre-disaster reference images. This framework addresses flood segmentation through a parameter-free, unsupervised image analysis pipeline that progressively eliminates non-flood regions using binary masks derived from color and edge information. Specifically, non-flood areas are excluded through mask calculations applied to each channel of the LAB color space, an RGB-based vegetation index, and edge maps from the original image. A probability map of flood presence is then generated using a weighted fusion strategy, followed by a modified hysteresis thresholding process to produce the final segmentation. The method demonstrates both high accuracy and computational efficiency, making it well suited for real-time, on-board processing during UAV operations. This methodology has been used as pseudo-label generator for an unsupervised DL approach [36], and also serves the same purpose as a module in this work.
Pseudo-Label-Based Methods for Semantic Segmentation: Pseudo-labels in image segmentation are a common strategy in semi-supervised and unsupervised learning. The idea is to use automatically generated labels, often produced by an initial model, unsupervised method, or rule-based system to train deep learning models without requiring large amounts of manually annotated data. This approach has been widely explored in general semantic segmentation tasks, such as urban scene understanding, medical imaging, and object detection.
A recent review and analysis of various PL methods and their applications in semi-supervised semantic segmentation (SSSS) underlined that training with limited labeled data by leveraging automatically generated labels can be effective [37]. Limitations of existing pseudo-label generation by leveraging enhanced class activation maps and dual attention mechanisms to produce semantically rich labels, achieving competitive or superior performance, has been addressed in [38]. Furthermore, self-supervised learning and pseudo-label refinement were integrated in a novel weakly-supervised semantic segmentation (WSSS) approach, achieving near fully-supervised performance by enhancing feature representation and mitigating label noise [39]. In [40], PseudoSeg was introduced, a method that generates structured pseudo-labels for training with unlabeled or weakly-labeled data, demonstrating effectiveness in both low-data and high-data regimes.
In the context of flood segmentation, pseudo-labeling is less established. A few recent studies have started exploring automatic label generation for SAR and optical imagery, particularly when annotated flood datasets are limited or unavailable. A semi-supervised learning method for flood segmentation using Sentinel-1 SAR imagery, employing a cyclical training process with an ensemble of U-Net models trained on both high-confidence hand-labeled data and generated pseudo-labels was introduced in [41]. Moreover, an unsupervised deep learning framework for water extraction from multispectral imagery, combining NDWI with a binarization algorithm to generate pseudo-labels for training was proposed [42]. A novel WSSS framework, TFCSD, has been introduced for efficient urban flood mapping, significantly reducing manual annotation by decoupling the generation of positive and negative samples [43]. The method enhances edge delineation and stability and maintains high performance even without pre-disaster data by incorporating SAM-assisted interactive labeling [44].
In our recent work [36], we have proposed a novel unsupervised deep learning approach for flood segmentation in Unmanned Aerial Vehicle (UAV) imagery, which leverages automatically generated pseudo-labels as training and validation masks, thereby eliminating the need for manually annotated ground truth data. Two widely used Convolutional Neural Network (CNN) architectures for semantic segmentation were trained under this framework. The results demonstrated that training with pseudo-labels alone can achieve performance levels comparable to those obtained using conventional ground truth annotations. Finally, in [45] a semi-supervised semantic segmentation algorithm for accurate flood delineation in SAR data was proposed. The method exhibited promising results utilizing a pseudo-label generation strategy and self-supervised teacher-student models.
Deep Generative Models and Diffusion-based Image Synthesis: The performance of modern DL models is fundamentally tied to the availability of large-scale datasets. In many real-world domains, such as disaster monitoring or remote sensing, data acquisition is costly. To address this bottleneck, a promising direction is the generation of synthetic data, which can serve as a scalable and controllable alternative to real-world data collection. Synthetic data can be created through simulation, procedural generation, or by leveraging deep generative models. Among generative approaches, models are typically grouped into four main categories: Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), auto-regressive models, and, more recently, diffusion models [46,47].
Diffusion models have emerged as the most widely adopted family of models, in a variety of domains such as image and text-to-image synthesis [48,49,50], image inpainting [47,51], and image-to-image translation [52,53]. These models operate by learning to denoise a sample starting from pure Gaussian noise, gradually transforming it into a realistic image. They exhibit greater training stability compared to GANs and offer fine-grained control over the generation process via conditioning mechanisms, such as textual prompts or image masks, and have proven to generate sharper images compared to VAEs, which often produce blurry outputs due to their reliance on approximate posterior inference [46]. The ability of diffusion-family models to learn strong latent representations that are aligned with textual prompts, and are able to generalize to unseen scenarios (textual prompts) generating high fidelity images, is asserted by the emergence of widely exploited models such as the DALL-E series [54,55], Stable Diffusion [56], and MidJourney, which generate high-quality, customizable images from textual descriptions. Their capacity to synthesize diverse, domain-specific imagery makes diffusion models particularly suitable for augmenting datasets in applications where labeled data is scarce or costly to produce.
3. Synthetic Dataset Generation Methodology
Our proposed approach is a framework that enables the construction of a synthetic dataset consisting of UAV images and corresponding segmentation masks for the task of flood segmentation. To achieve this, we employed two distinct generative strategies, subsequently integrating their outputs into a unified dataset. The first approach leverages a text-to-image generative model, enabling the synthesis of UAV imagery that encapsulates specific flood-related characteristics, explicitly defined through textual descriptions. The second approach employs an image-to-image translation paradigm, wherein segmentation masks derived from real data serve as structural constraints for synthesizing realistic UAV images via an inpainting method.
As a final step in the synthetic dataset creation pipeline, in order to ensure the fidelity and realism of the generated synthetic images, we apply a filtering process, based on outlier detection mechanisms, that aims to discard unrealistic synthetic images. An overview of the synthetic flood dataset generation method is shown in Figure 3.
3.1. Text-to-Image Synthesis Component
In the first direction, given a text-to-image synthesis models, noted as , which in our case was the Stable Diffusion [56], and a prompt from a predefined set , the output of the process is a generated synthetic image :
Stable Diffusion is a generative model that synthesizes high-quality images by reversing a gradual noising process through a series of denoising steps. Initially, an image is represented as pure noise, and the model iteratively refines it over a fixed number of steps, by progressively removing noise while conditioning on a text prompt or other guidance (e.g., semantic maps or class labels). At each step, the model predicts the noise component and subtracts it from the current image estimate, gradually revealing a coherent image that aligns with the input conditions. We have found out that 50 steps are enough to generate a visually realistic image that reflects the intended structure and content, in our case, a flooded environment, generated from an entirely random starting point, as depicted in Figure 4.
The quality of the generated outputs and the ability of the synthetic image dataset to adequately capture the variation inherent in UAV images depicting flooded areas are heavily influenced by the chosen input prompts. To ensure that the dataset encompasses a diverse range of scenarios, we systematically varied the prompts along three key attributes:
- Rural vs. Urban/Peri-urban Environment: The images were conditioned to represent either a rural or urban/peri-urban landscape.
- Sky Presence: The synthesized images either included or excluded visible sky regions.
- Flooded and Non-flooded Buildings: We controlled the number of flooded buildings in the generated images to ensure a diverse range of flooding scenarios.
The following are examples of prompts used for data generation:
- "Aerial view of a flooded urban area with high-rise buildings and streets underwater."
- "Drone footage of a rural landscape with scattered houses, some affected by flooding, others dry."
- "Low-altitude remotely sensed image depicting an urban neighborhood with partially submerged homes and roads."
- "UAV view of a countryside area with a river overflow flooding nearby fields and farmhouses."
Since the generated outputs lacked corresponding ground truth segmentation masks, we employed an unsupervised mask generation method to derive pseudo-labels (PL). Specifically, to generate the unsupervised pseudo-labels, we relied on the UFS-HT-REM method, as described in [18]. This method autonomously identifies flooded and non-flooded regions based on color and texture properties in aerial imagery. A hysteresis threshold is applied on a probabilistic map derived from color, intensity, and reflectance information :
where is the resulting pseudo-label binary mask of the synthetic image , with each pixel value defined as:
This process ensures robust segmentation by leveraging statistical color distributions and intensity variations to separate flood water from background, even in visually complex images. The final output of the process is a synthetic UAV image and its corresponding binary pseudo-label mask .
3.2. Image Inpainting from Segmentation Masks Component
An alternative approach to generating synthetic UAV images was image inpainting using real segmentation masks. This method involved using segmentation masks from a real dataset and applying an inpainting algorithm to synthesize realistic UAV imagery corresponding to the given segmentation structure. Using real flood segmentation masks as priors provides a more grounded structural context, ensuring that the generated images reflect plausible flood extents and spatial layouts as observed in real-world scenarios. This leads to synthetic data that are more representative and structurally aligned with actual flood patterns, thereby improving its utility for training segmentation models.
Overall, the process can be formulated as follows. Given a flood-related image, , selected from a real-world UAV flood segmentation dataset, and its corresponding ground truth segmentation mask , employ an image inpainting model , to generate a semi-synthetic UAV image with the real flood area untouched, thus inpainting the labeled background, conditioned on a textual context prompt, :
Following the previous approach, we again adopted Stable Diffusion [56] in our workflow as an image inpainting model in a text-guided image-to-image translation framework. The prompts were selected based on the image category, ensuring consistency with the expected scene semantics. Prompt context was similar to the previous process, to ensure a thematic consistency between both synthetic image generation schemes.
Since the generated image does not always exhibit a perfect one-to-one correspondence with the input ground truth , we apply the unsupervised pseudo-labeling method once again to derive a refined segmentation mask for the newly synthesized image:
We observed that this process better ensures that the final segmentation pseudo-labels reflect more accurately the flooded and non-flooded regions present in the semi-synthetic, inpainted images.
3.3. Post-Generation Filtering for Enhanced Dataset Fidelity
Following the generation of two synthetic image sets,
and
we merged both sets into a unified synthetic dataset:
To improve the unified synthetic dataset fidelity, we applied the FINCH [57,58] clustering algorithm to , retaining only images from the first partition and discarding those that formed singleton clusters. This choice ensures that filtering is applied early in the generation pipeline, where redundancy and noise are more prevalent, thereby preventing low-quality or outlier samples from propagating into later stages. Next, we encoded each synthetic image into a feature vector of size using a pre-trained ResNet50 model.
To further refine the dataset, we applied FINCH clustering to a real-world dataset and extracted cluster centers. We then computed pairwise Euclidean distances between the real cluster centers and the synthetic image feature vectors. Synthetic images were assigned to the closest cluster, and those failing to align with any real-world cluster were discarded:
where represents the feature embedding of a synthetic image and is the set of real-world cluster centers.
After applying the filtering process, where images failing to align with real-world cluster structures are discarded, the final filtered synthetic dataset is defined as:
where I is a synthetic or semi-synthetic image, and is its corresponding pseudo-label segmentation mask, represents the feature embedding of the image I, extracted using a pre-trained ResNet50, is the set of cluster centers obtained from the real-world dataset using the FINCH algorithm, denotes the Euclidean distance between the synthetic image embedding and the closest real-world cluster center, and is a distance threshold that determines the inclusion of synthetic images based on their proximity to the real-world data. The resulting set , has a size of 557 images (279 from SDs, 278 from SDip) and their corresponding pseudo-label masks, whereas pre-filtering size was 580 images (290 from SDs, 290 from SDip) and their corresponding pseudo-label masks. Synthetic image sets will be publicly available after paper acceptance1.
In Figure 5, representative examples of synthetic (a) and semi-synthetic (e) images, and their corresponding pseudo-label segmentation masks overlaid in blue, (b) and (f), are shown. For the inpainting process of the semi-synthetic images, ground truths (d) were used, derived from real-world images (c). The synthetic images exhibit a high degree of diversity in terms of environmental conditions, flood severity, and background complexity, as well as variation in camera angles and perspectives. This diversity is essential to enhance the model’s robustness and generalizability across a wide range of flooding scenarios. Moreover, the synthetic data were generated with particular attention to visual realism and structural similarity to real-world flood imagery, enabling more effective transfer of knowledge when such images are used in training. As previously mentioned, when inpainting is applied, the original ground truth annotations become invalid, as the generative process may not only modify the background but also extend or alter the spatial extent of the flooded regions, thereby introducing discrepancies between the modified image and its initial label.
Figure 6 presents examples of synthetic (a) and semi-synthetic (d) images which did not pass the filtering process. Also, the real-world images (b) and their respective ground truths (c), from which the semi-synthetic versions were generated, are also provided for reference. The discarded synthetic samples exhibit significant deviations from realistic flood scenes, including structural inconsistencies, unnatural repetition of patterns, excessive blurriness, or visual characteristics resembling stylized artwork (e.g., oil paintings). These artifacts resulted in the images to be classified as unrealistic according to our established outlier scoring scheme, thereby justifying their removal from the training set.
Outlier threshold, : we employ a z-score-based filtering mechanism grounded in the distribution of distances between synthetic features and real cluster centers. Specifically, for each synthetic feature vector, we computed its minimum Euclidean distance to the closest cluster center derived from FINCH clustering on real data. Let and denote the mean and standard deviation of these minimum distances, respectively. A synthetic sample i was retained if its distance satisfied:
where k is a hyperparameter controlling the strictness of the filtering (we set in our experiments). This statistical approach adapts the filtering threshold to the inherent distribution of the distances, avoiding arbitrary cutoffs and promoting a more robust selection of semantically similar synthetic samples.
4. Experimental Setup
To assess the generalization capability of a segmentation model trained on synthetic flood imagery, we conducted a series of controlled experiments using state-of-the-art deep learning architectures. Specifically, we selected three top-performing segmentation models, which were trained under six different data configurations: (a) exclusively on the real-world dataset with the actual ground truth , (b) on the real-world dataset with pseudo-labels assuming no ground truth is available , (c) on the synthetic dataset (see Equation 6) with corresponding pseudo-labels (), (d) on the semi-synthetic dataset (see Equation 7) with corresponding pseudo-labels (), (e) on the combination of real-world and both synthetic and semi-synthetic datasets ( as defined in Equation 8) with the actual ground truth and corresponding pseudo-labels (), and (f) on the combined real-world and filtered synthetic and semi-synthetic datasets ( as defined in Equation 10) with the actual ground truth and corresponding pseudo-labels (. The evaluation was performed on an independent real-world dataset with respective expert annotations, which was not used during training, to measure the effectiveness of the synthetic data in bridging the domain gap.
4.1. Datasets and Methods
Datasets: For the real-world dataset baselines, we employed two publicly available datasets that depict flood-affected regions, each accompanied by ground truth segmentation masks delineating flooded areas. These datasets consist of aerial imagery captured by UAVs and helicopters, encompassing a diverse range of environmental contexts, including urban, peri-urban, and rural landscapes. The images exhibit significant variability in scene composition, featuring elements such as vegetation, rivers, buildings, roads, mountainous terrain, and the sky. Additionally, they were acquired from multiple altitudes and viewing angles, ensuring a comprehensive representation of flood scenarios. Notably, both datasets maintain a similar balance between flood and background pixels, which mitigates potential class imbalance issues during model training.
As a baseline training set we opted to use the well-known Flood Area Dataset (FAD) [11]. This dataset comprises 290 RGB images, accompanied with manually annotated segmentation masks. The dataset exhibits variability in image resolution and dimensions. Contributing to the dataset’s heterogeneity is its diverse range of environmental contexts, including 203 urban and peri-urban scenes and 87 rural scenes. In terms of visual composition, 108 images contain full or partial views of the sky, while 182 images lack any visible sky. This diversity supports robust model training across varying landscape types and viewing conditions.
To assess the generalization capability of the segmentation models, we utilized only for inference the Flood Semantic Segmentation Dataset (FSSD) [13] as an independent test set, which consists of 663 RGB images and corresponding ground truth segmentation masks. Similarly to the FAD, this dataset comprises of images obtained from UAVs portraying diverse flooded scenes captured from various camera perspectives. The image sizes and resolutions also vary, but were all resized and, if necessary, zero-padded, to 512 × 512 by the dataset creator. All 663 images were used as our test set. Representative samples from both datasets, along with the corresponding ground truth masks, are illustrated in Figure 7.
Flood Segmentation Methods: We trained three well-established Convolutional Neural Networks (CNNs) for semantic segmentation tasks. The first model, the original U-Net architecture introduced in [59], is composed of a symmetric encoder–decoder structure. The encoder consists of repeated convolutional blocks followed by max pooling operations, progressively reducing spatial dimensions while enriching semantic abstraction. The decoder mirrors the encoder structure through transposed convolutions and skip connections, allowing precise localization by fusing high-resolution features from earlier layers. The model contains approximately 31 million trainable parameters.
The second architecture is the Fully Convolutional Network (FCN) integrated with a ResNet-50 backbone, following the design principles of [60]. FCNs are designed for pixel-wise classification by replacing fully connected layers with convolutional ones, preserving spatial resolution throughout the network. The ResNet-50 backbone introduces residual connections, which facilitate the training of deeper architectures by mitigating the vanishing gradient problem. In the FCN, skip connections from intermediate layers to the decoder enhance fine-grained segmentation by integrating both low-level and high-level features. The model contains approximately 33 million trainable parameters.
The third model is DeepLabV3, as proposed by Chen et al. in [61], which introduces atrous (dilated) convolution to expand the receptive field without loss of resolution. The architecture leverages Atrous Spatial Pyramid Pooling (ASPP), a module that captures multi-scale contextual information by applying parallel atrous convolutions with varying dilation rates. This enables the model to efficiently aggregate information at multiple spatial scales. DeepLabV3 is typically built on a ResNet backbone, where the final layers are adapted to maintain spatial resolution and support the ASPP module. The segmentation output is then upsampled to match the original input dimensions. This architecture is particularly effective in handling objects at multiple scales and segmenting fine structures in complex scenes. The DeepLabV3 model used in this study consists of approximately 41 million trainable parameters.
4.2. Training Protocol
Implementation Details: All models were implemented in PyTorch and trained for 100 epochs with a random generated batch of 8 images, using an initial learning rate of . A dynamic learning rate adjustment strategy was employed, whereby the learning rate was reduced by a factor of 0.5, if no improvement in validation performance was observed over five consecutive epochs. Optimization was conducted using the Adam optimizer with a weight decay of to prevent overfitting by penalizing large weights and encouraging model generalization. Adam was selected due to its adaptive learning rate strategy, which computes individual learning rates for each parameter based on estimates of first and second moments of the gradients. This facilitates efficient convergence and robustness in training deep neural networks, particularly in high-dimensional and non-convex optimization landscapes.
The model weights were initialized using the Kaiming normal initialization, which is specifically designed for layers with ReLU activations. This initialization strategy maintains the variance of activations across layers, thereby promoting stable gradient flow during training and preventing issues such as vanishing or exploding gradients. Each utilized dataset was randomly partitioned into 90% for training and 10% for validation. The Dice loss function was employed as the objective to address class imbalance, and model performance was evaluated using the accuracy on the validation set.
Notably, improved model convergence and higher validation accuracy were observed when training was performed on a combined dataset comprising real-world, synthetic, and semi-synthetic images (see also Section 5). In this setting, each training batch was composed of a fixed ratio of samples—specifically, two randomly selected images from the real-world dataset and three images each from the synthetic and semi-synthetic subsets. This sampling strategy enabled the model to benefit from the diversity and volume of synthetic data while maintaining grounding in real-world examples, effectively enhancing generalization and training stability.
Training was performed on a system equipped with an Intel i7 CPU (2.3 GHz), 40 GB of RAM, and two NVIDIA Quadro RTX 4000 GPUs. The total training times ranged from less than an hour to approximately four hours, depending on the deep learning architecture and the size of the training dataset.
Dataset Pre-processing: In the case of model training in real-word data, as previously stated, we utilized the FAD dataset. In the absence of ground truth, corresponding pseudo-label segmentation masks were automatically generated using an adapted UFS-HT-REM pipeline. All images were resized to pixels to speed up training, and normalized to zero mean and unit variance. These processes were also applied on the synthetic dataset, as well as on the FFSD dataset that is used for model performance evaluation.
Data Augmentation: To mitigate the limited training data, we applied on-the-fly augmentation with a per-transformation probability of 0.5. Augmentations included horizontal flipping, random rotations within degrees, and additive uniform noise in the range . Over 100 epochs, this strategy effectively expanded training variability.
5. Experimental Results
In this section, we present an evaluation of the proposed synthetic dataset generation method in the UAV flood segmentation task. First, we assess the effectiveness of training segmentation models using only synthetic data, comparing their performance against models trained on real-world datasets. Our experiments include three widely used architectures: DeepLabV3, FCN-ResNet50, and U-Net. In the second part of this section, we analyze the role of prompt structure and semantic context in the quality and utility of the generated synthetic images. Additionally, we evaluate the similarity between the synthetic and real image feature distributions by providing clustering statistics.
5.1. Impact of Synthetic Data on Model Performance
We evaluated the impact of the proposed synthetic dataset creation framework on the performance of three widely used semantic segmentation architectures: DeepLabV3 [61], FCN-ResNet50 [60], and U-Net [59]. For this, each model was trained exclusively on both intermediate synthetic datasets (text-to-image, , and image inpainting, ), on the combined real-world and synthetic dataset, before and after the filtering process , and was compared against its counterpart trained on the real-world dataset with the actual ground truth , and with pseudo-label segmentation masks instead of the ground truth. As reported in Table 1, Table 2, and Table 3, across all architectures, we observed that models trained solely on synthetic data achieved segmentation performance remarkably close to those trained on real-world data, and in case of the U-Net even better. On average, the observed performance was above in F1=-score, with a drop in the range of 2-5% compared to training with real-world data, and a raise of 1.08% in case of the U-Net, highlighting the high fidelity and generalizability of the generated synthetic samples.
Among the three evaluated architectures, we observed that DeepLabV3 exhibited the highest performance drop when trained solely on synthetic data, while U-Net consistently achieved a slight increase in performance—approximately 1% across all evaluation metrics—compared to its training on real-world data. This divergence in behavior can be attributed to architectural differences: DeepLabV3, with its atrous spatial pyramid pooling and deeper encoder, may rely more heavily on fine-grained real-world features and textures that the synthetic data only partially captures. In contrast, U-Net’s symmetric encoder-decoder structure with skip connections may better exploit the spatial coherence and regularity present in the synthetic masks and images, thus benefiting from the structured nature of the generated dataset.
A particularly noteworthy outcome of our experimental analysis is the consistent performance improvement observed across all examined segmentation models, DeepLabV3, FCN-ResNet50, and U-Net, when trained on the combined dataset comprising both real-world data (images and manually annotated masks) and synthetic data (generated images and pseudo-label masks). These gains range between 1% and 6% in the F1-score, underscoring the complementary nature of the synthetic dataset. The inclusion of synthetically generated samples, which capture diverse flood-affected scenarios and augment underrepresented visual patterns, likely aids in regularizing the models and enhancing their generalization capabilities. Additionally, the pseudo-label masks, though automatically generated, provide reasonably accurate supervision signals that help the models learn more robust decision boundaries. This result highlights the value of synthetic data as a scalable and effective means to enrich limited annotated datasets in domain-specific applications such as disaster response.
The introduction of our filtering strategy following the initial creation of the synthetic dataset (row 5 vs row 6 in Table 1, Table 2, Table 3) further enhances model performance across all segmentation architectures. Specifically, we observe improvements ranging from 1% to 4% in key evaluation metrics when the filtered synthetic dataset is used instead of the unfiltered one. Among the evaluated models, U-Net consistently exhibits the highest performance gain, suggesting that its architecture may be particularly sensitive to noisy or low-quality training examples. By eliminating synthetic samples with low semantic alignment to real data distributions, the filtering stage effectively increases the signal-to-noise ratio in the training set, leading to better convergence and generalization. This demonstrates the importance of curating synthetic data not only in terms of diversity, but also in maintaining fidelity to real-world distributions.
Overall, among the evaluated architectures, as observed in Figure 8, DeepLabV3 yielded the lowest performance when trained solely on synthetic data, though it was able to marginally surpass training on real-world data when a combined real and synthetic dataset was used. FCN-ResNet50 consistently achieved the highest performance in most scenarios, yet its performance declined slightly under synthetic-only training conditions. U-Net, in contrast, demonstrated notably stronger performance with synthetic data and significantly outperformed the other deep learning models when trained with a filtered combination of real and synthetic data. This can be attributed to U-Net’s encoder-decoder structure with skip connections, which excels at capturing both fine-grained local details and global spatial context. Such architectural characteristics are particularly well-suited for segmentation tasks involving structured patterns. Consequently, the U-Net architecture excels in our synthetic flood imagery that features regular shapes and consistent textural cues, as generated via stable diffusion. U-Net’s inductive biases align well with the spatial regularity present in the synthetic data, enhancing its ability to generalize effectively in this context. Statistcally, we have obtained 58.22% over all images better inferences with U-Net, 29.26% with FCN-ResNet50, and only 12.67% with DeepLabV3 indicating it is the worst performing model when trained with combined real and synthetic data. Note that inferences can excel in more than one model.
5.2. Real and Synthetic Dataset Similarity, Role of Prompt Semantics in Dataset Quality
Real and Synthetic Data Similarity: To quantitatively assess the distributional similarity between real and synthetic datasets, we computed the Maximum Mean Discrepancy (MMD) between their respective feature representations. Specifically, we extracted deep features using a pre-trained ResNet50 model and computed the MMD between the real dataset and two variants of the synthetic dataset. The resulting scores were and . Both scores indicate a reasonable alignment with the real data distribution, as MMD values below 0.1 are typically indicative of good distributional similarity in high-dimensional spaces. Notably, the second synthetic dataset demonstrates a significantly closer alignment to the real data, suggesting improvements in generation fidelity—possibly due to enhanced prompt structure, better context grounding, or more effective filtering. These results support the hypothesis that high-quality synthetic data, when properly curated, can closely mimic real-world distributions and serve as a valuable resource for training deep segmentation models.
Additionally, as a second way to assess the similarity between a real-world dataset (Dr) and two synthetic datasets (SDs and SDip), with a more direct and visual manner, we also used the feature embeddings from each image and applied Principal Component Analysis (PCA) for dimensionality reduction and visualization. The resulting 2D PCA plot, shown in Figure 9, demonstrates a substantial overlap between the three datasets in the feature space (best-fit ellipses overlap), indicating a high degree of visual similarity. Notably, the synthetic datasets exhibit significant alignment with the real-world distribution, suggesting that the synthetic data generation processes effectively capture the global visual characteristics of real imagery. Among them, SDip shows a tighter overlap with Dr, which can be attributed to the ground truth mask prior, while SDs exhibits a slightly broader spread, which may imply higher visual diversity or variability in synthesis quality. This kind of deviation may reflect that, while the synthetic dataset captures much of the variance of the real data (hence the overlap), it might also be exploring new areas or patterns in the feature space that are not fully represented in the real data. This is also suggested by the slight deviation in orientation of the fitted ellipses between the real and synthetic datasets. The novel pattern assumption appears to be verified by the model performance increase when training on the union of the real and synthetic datasets. These findings support the potential utility of synthetic datasets as substitutes or complements to real-world data for training DL models, especially in scenarios where labeled real data is limited or costly to obtain.
Prompt Structure and Semantics in Synthetic Image Quality: The structure and semantics of textual prompts play a critical role in guiding the fidelity of generated synthetic images. As shown in Figure 10, minor variations in phrasing, specificity, or contextual richness can substantially affect visual realism and alignment with the intended flood scenario. Detailed prompts that include spatial relationships, lighting conditions, environmental context (e.g., urban vs. rural), and object-level cues (e.g., “partially submerged tractors”, “muddy floodwater”, “sky reflections”) consistently result in higher quality images. Conversely, vague or semantically sparse prompts often lead to artifacts, inconsistencies in water boundaries, or unnatural object placements (e.g, "flooded city" or "flooded river").
For instance, as illustrated in Figure 10, the use of a vague or underspecified prompt in the text-to-image synthesis pipeline leads to the generation of semantically and structurally inconsistent elements, such as the appearance of building rooftops that were not explicitly requested and exhibit unrealistic geometries (highlighted with red boxes). Similarly, in the image-to-image generation approach conditioned on segmentation masks, employing a more generic prompt results in the synthesis of implausible structures—such as slanted apartment-like buildings—demonstrating that prompt specificity directly impacts the semantic and geometric fidelity of the generated content.
5.3. Ablation on Filtering Threshold
As a final task, we investigate the sensitivity of our filtering scheme to the choice of strictness parameter, we varied the k-value in the z-score threshold formulation, presented in Section 3.3. Specifically, we examined , , and , corresponding to progressively stricter inclusion criteria for synthetic images based on their distance to real data clusters in feature space. Our results, shown in Table 4, demonstrate that a stricter threshold (i.e., ) consistently yields better segmentation performance across the majority of evaluated models. This suggests that retaining only the most semantically aligned synthetic samples—those with the highest fidelity to real data distributions—is beneficial for generalization.
The performance gains are particularly evident for DeepLabV3 and FCN-ResNet50, which both benefit significantly from the more selective filtering. This is likely due to the fact that these architectures possess deep and complex feature extractors, which are more sensitive to domain discrepancies introduced by low-quality or semantically inconsistent synthetic data. By aggressively filtering out such samples, the learned representations remain more robust and transferable to real-world data. Interestingly, the intermediate threshold shows the greatest benefit for the U-Net architecture. Unlike the others, U-Net has a more symmetric and shallow encoder-decoder structure, which may allow it to benefit from a slightly larger, more diverse synthetic training set—so long as the noise introduced remains within tolerable bounds. The less favorable performance of DeepLabV3 and FCN-ResNet50 with may highlight their greater sensitivity to noisy or out-of-distribution synthetic examples.
5.4. Qualitative Segmentation Results
To evaluate the qualitative performance of the proposed framework, we present segmentation results from the best-performing model, namely U-Net trained on the combined real-world and filtered synthetic dataset. This configuration consistently achieved the highest F1-scores across validation and test sets, confirming its robustness and generalization capability under varying image conditions.
For interpretability and comprehensive assessment, representative segmentation outputs were selected based on percentile sampling of the F1-score distribution over the test set. Specifically, we used the best performing U-Net model variant, i.e. the variant trained with real and synthetic data, and sorted all segmented test images in descending order of F1-scores and extracted five representative cases corresponding to the 0th (best), 20th, 40th, 60th, and 80th percentiles. This approach enables a structured visualization of the model’s performance across different levels of difficulty, from highly accurate segmentations to more challenging scenarios.
As illustrated in Figure 11, the top-ranked examples, e.g. 0th and 20th percentiles (Figure 11 (c) and (h)), show high performance segmentation with near-precise delineation of flood boundaries and minimal false positives or negatives. These cases typically involve well-lit, high-contrast scenes with distinct flood regions and minimal occlusions. In contrast, lower percentile examples, e.g. 60th and 80th percentiles (Figure 11 (r) and (w)), demonstrate the model’s limitations, often corresponding to visual ambiguities such as flooded vegetation, low contrast between land and water surfaces, or significant reflections and shadow artifacts. Nonetheless, even in these more difficult cases, the U-Net generally preserves the structural integrity of the flooded regions, indicating resilience to challenging input conditions.
These results further substantiate the effectiveness of combining real-world data with selectively filtered synthetic images, which likely enhanced the diversity and coverage of the training set, enabling the U-Net to generalize well across both typical and edge-case scenarios. For comparative reasons, we also present in Figure 11 the segmentation results of the other two models, FCN-ResNet50 and DeepLabV3, trained with the same configuration as the U-Net, together with the respective F1-scores achieved. FCN-ResNet50 performed second best and produced in general better results than the DeepLabV3 architecture, as observed in Figure 11 (d), (i), and (s), respectively, compared to (e), (j), and (t).
In Figure 12, we showcase the effectiveness of synthetic and semi-synthetic data for flood segmentation presenting representative segmentation results from the same U-Net architecture trained under four distinct configurations: (i) using real-world images with manually annotated ground truth masks, (ii) using purely synthetic images generated via Stable Diffusion with automatically produced pseudo-labels, (iii) using semi-synthetic images created through image inpainting with corresponding pseudo-labels, and (iv) a combined dataset comprising real, synthetic, and semi-synthetic samples with their respective ground truth and pseudo-label masks. Five representative cases were chosen among the descending sorted differences of the F1-scores of the best and worst performing configurations, (iv) and (i), corresponding to the highest difference (first row), the differences of the 25th, 50th, 75th percentiles, and the lowest difference (last row).
Among the four cases, the combined dataset (case iv in the last column) achieved the highest performance in terms of segmentation accuracy, as measured by the F1-score. This indicates that the integration of real-world examples with synthetic and semi-synthetic data can significantly enhance the model’s generalization capability. The observed improvement is attributed to the increased variability and diversity introduced by the synthetic samples, which augment the training distribution and expose the model to a wider range of environmental conditions, textures, and structural layouts. This diversity appears to regularize the training and prevent overfitting to the limited real-world data.
Interestingly, both synthetic (case ii, third column) and semi-synthetic (case iii, fourth column) training independently produced segmentation results that were not only comparable to, but in some cases exceeded, the performance of models trained solely on real-world data (case i, second column), as observed in Figure 12 (c), (d), and (n) compared to (b) and (l). This highlights the capacity of U-Net to learn robust features even when trained exclusively on artificially generated data, provided that the pseudo-labels contain sufficient region of interest despite their inherent noise. It also underscores the model’s resilience to imperfect supervision and demonstrates the potential of unsupervised or weakly supervised learning approaches for remote sensing tasks where high-quality annotated datasets are often scarce. The synthetic data, generated entirely from random noise using a generative diffusion process, provided a broad distribution of flood-like appearances, while the semi-synthetic data retained structural realism from the real imagery due to inpainting guided by true segmentation masks. Of course, there are also failure cases where complex patterns could not be learned and synthetic generated data as well as their combination with real data seemingly confused the model (see Figure 12 (w), (x) and (y)).
These findings collectively suggest that in the absence of annotated datasets, the use of synthetic or semi-synthetic imagery in conjunction with automatic pseudo-labeling can offer a viable alternative for training deep segmentation models. Furthermore, combining such data with limited real-world samples results in a synergistic effect that further improves segmentation accuracy, advocating for hybrid training strategies in future work.
6. Conclusions
In this work, we presented a framework for constructing a synthetic dataset aimed at the task of flood segmentation in UAV imagery. Our approach integrates two distinct generative strategies: a text-to-image synthesis pipeline guided by flood-related textual prompts, and an image-to-image translation paradigm that leverages real segmentation masks as structural priors to generate realistic flood scenes via inpainting. These complementary approaches are unified to produce a diverse and semantically meaningful dataset.
To address the challenge of missing ground truth annotations for segmentation, we employ an unsupervised pseudo-labeling strategy to generate segmentation masks for the synthetic images. This allows us to construct paired image-mask samples without the need for manual annotation, significantly reducing the cost and effort typically associated with dataset curation. Furthermore, we incorporate a filtering stage based on outlier detection to ensure the realism and structural fidelity of the generated images, discarding samples that do not meet quality standards. To evaluate the effectiveness of the synthetic dataset, we conducted experiments with three top-performing flood segmentation models, assessing their performance on a real-world benchmark dataset. Our findings demonstrate that training with the synthetic data, even when annotated via unsupervised pseudo-labeling, not only leads to minor model performance drops, but the combination of synthetic and real-world data during training is able to improve model generalization and robustness. Our framework offers a scalable and low-cost solution for generating annotated flood segmentation datasets, with practical applications in disaster monitoring, remote sensing, and other vision-based environmental analysis tasks.
While our current framework provides a scalable solution for generating synthetic flood segmentation datasets, several promising directions remain open for future exploration. These include improving the accuracy of the unsupervised pseudo-labeling method by integrating stronger segmentation priors or combining multiple weak supervision signals. We also plan to explore domain adaptation techniques—such as adversarial training and feature alignment—to further reduce the gap between synthetic and real data. Lastly, we aim to extend the framework by considering multi-modal data synthesis for broader environmental monitoring applications.
Author Contributions
The contributions to this paper are as follows: Conceptualization, G.S., K.B., and C.P.; Funding acquisition, C.P.; Investigation, G.S., K.B., and C.P.; Methodology, G.S., K.B., and C.P.; Software, G.S. and K.B.; Validation, G.S.; Supervision, K.B. and C.P.; Data Curation, G.S. and K.B.; Writing—original draft, G.S., K.B., and C.P.; Writing—review and editing, G.S., K.B., and C.P.. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article; further inquiries or requests can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ADNet | Attentive Decoder Network |
| AI | Artificial Intelligence |
| ASPP | Atrous Spatial Pyramid Pooling |
| BiT | Bitemporal image Transformer |
| CNN | Convolutional Neural Network |
| CV | Computer Vision |
| DELTA | Deep Earth Learning, Tools, and Analysis |
| DL | Deep Learning |
| DNN | Deep Neural Network |
| ENet | Efficient Neural Network |
| FAD | Flood Area Dataset |
| FCN | Fully Convolutional Network |
| FSSD | Flood Semantic Segmentation Dataset |
| GAN | Generative Adversarial Network |
| IoU | Intersection over Union |
| ML | Machine Learning |
| MMD | Maximum Mean Discrepancy |
| MRF | Markov Random Field |
| NDWI | Normalized Difference Water Index |
| PCA | Principal Component Analysis |
| PR | Pattern Recognition |
| ResNet | Residual Network |
| SAM | Segment Anything Model |
| SAR | Synthetic Aperture Radar |
| SSSS | Semi-Supervised Semantic Segmentation |
| UAV | Unmanned Aerial Vehicle |
| WSSS | Weakly Supervised Semantic Segmentation |
References
- Ritchie, H.; Rosado, P. Natural Disasters. https://ourworldindata.org/natural-disasters, 2022. Accessed on April 2025.
- Algiriyage, N.; Prasanna, R.; Stock, K.; Doyle, E.E.; Johnston, D. Multi-source multimodal data and deep learning for disaster response: a systematic review. SN Computer Science 2022, 3, 1–29. [Google Scholar] [CrossRef] [PubMed]
- Linardos, V.; Drakaki, M.; Tzionas, P.; Karnavas, Y.L. Machine learning in disaster management: recent developments in methods and applications. Machine Learning and Knowledge Extraction 2022, 4. [Google Scholar] [CrossRef]
- Albahri, A.; Khaleel, Y.L.; Habeeb, M.A.; Ismael, R.D.; Hameed, Q.A.; Deveci, M.; Homod, R.Z.; Albahri, O.; Alamoodi, A.; Alzubaidi, L. A systematic review of trustworthy artificial intelligence applications in natural disasters. Computers and Electrical Engineering 2024, 118, 109409. [Google Scholar] [CrossRef]
- Bacharidis, K.; Moirogiorgou, K.; Koukiou, G.; Giakos, G.; Zervakis, M. Stereo System for Remote Monitoring of River Flows. Multimedia Tools and Applications 2018, 77, 9535–9566. [Google Scholar] [CrossRef]
- Bentivoglio, R.; Isufi, E.; Jonkman, S.N.; Taormina, R. Deep learning methods for flood mapping: a review of existing applications and future research directions. Hydrology and Earth System Sciences 2022, 26, 4345–4378. [Google Scholar] [CrossRef]
- Kyrkou, C.; Theocharides, T. Deep-Learning-Based Aerial Image Classification for Emergency Response Applications Using Unmanned Aerial Vehicles. In Proceedings of the CVPR workshops; 2019; pp. 517–525. [Google Scholar]
- Zhu, X.; Liang, J.; Hauptmann, A. MSNet: A Multilevel Instance Segmentation Network for Natural Disaster Damage Assessment in Aerial Videos. arXiv preprint arXiv:2006.16479, arXiv:2006.16479 2020.
- Zhu, X.; Liang, J.; Hauptmann, A. Msnet: A multilevel instance segmentation network for natural disaster damage assessment in aerial videos. In Proceedings of the Proceedings of the IEEE/CVF winter conference on applications of computer vision, 2021, pp. 2023–2032.
- Rahnemoonfar, M.; Chowdhury, T.; Sarkar, A.; Varshney, D.; Yari, M.; Murphy, R.R. Floodnet: A high resolution aerial imagery dataset for post flood scene understanding. IEEE Access 2021, 9, 89644–89654. [Google Scholar] [CrossRef]
- Karim, F.; Sharma, K.; Barman, N.R. Flood Area Segmentation. https://www.kaggle.com/datasets/faizalkarim/flood-area-segmentation. Accessed on January 2025.
- Hänsch, R.; Arndt, J.; Lunga, D.; Gibb, M.; Pedelose, T.; Boedihardjo, A.; Petrie, D.; Bacastow, T.M. Spacenet 8-the detection of flooded roads and buildings. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1472–1480.
- Yang, L. Flood Semantic Segmentation Dataset. https://www.kaggle.com/datasets/lihuayang111265/flood-semantic-segmentation-dataset. Accessed on January 2025.
- Wieland, M.; Martinis, S.; Kiefl, R.; Gstaiger, V. Semantic segmentation of water bodies in very high-resolution satellite and aerial images. Remote Sensing of Environment 2023, 287, 113452. [Google Scholar] [CrossRef]
- Weber, E.; Papadopoulos, D.P.; Lapedriza, A.; Ofli, F.; Imran, M.; Torralba, A. Incidents1M: a large-scale dataset of images with natural disasters, damage, and incidents. IEEE transactions on pattern analysis and machine intelligence 2023, 45, 4768–4781. [Google Scholar] [CrossRef]
- Rahnemoonfar, M.; Chowdhury, T.; Murphy, R. RescueNet: A high resolution UAV semantic segmentation dataset for natural disaster damage assessment. Scientific data 2023, 10, 913. [Google Scholar] [CrossRef]
- Polushko, V.; Jenal, A.; Bongartz, J.; Weber, I.; Hatic, D.; Rösch, R.; März, T.; Rauhut, M.; Weinmann, A. BlessemFlood21: A High-Resolution Georeferenced Dataset for Advanced Analysis of River Flood Scenarios. IEEE Access 2024. [Google Scholar] [CrossRef]
- Simantiris, G.; Panagiotakis, C. Unsupervised Color-Based Flood Segmentation in UAV Imagery. Remote Sensing 2024, 16. [Google Scholar] [CrossRef]
- Dong, Z.; Liang, Z.; Wang, G.; Amankwah, S.O.Y.; Feng, D.; Wei, X.; Duan, Z. Mapping inundation extents in Poyang Lake area using Sentinel-1 data and transformer-based change detection method. Journal of Hydrology 2023, 620, 129455. [Google Scholar] [CrossRef]
- Drakonakis, G.I.; Tsagkatakis, G.; Fotiadou, K.; Tsakalides, P. OmbriaNet—supervised flood mapping via convolutional neural networks using multitemporal sentinel-1 and sentinel-2 data fusion. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 2022, 15, 2341–2356. [Google Scholar] [CrossRef]
- Hertel, V.; Chow, C.; Wani, O.; Wieland, M.; Martinis, S. Probabilistic SAR-based water segmentation with adapted Bayesian convolutional neural network. Remote Sensing of Environment 2023, 285, 113388. [Google Scholar] [CrossRef]
- Li, Z.; Demir, I. U-net-based semantic classification for flood extent extraction using SAR imagery and GEE platform: A case study for 2019 central US flooding. Science of The Total Environment 2023, 869, 161757. [Google Scholar] [CrossRef]
- Hänsch, R.; Arndt, J.; Lunga, D.; Pedelose, T.; Boedihardjo, A.; Pfefferkorn, J.; Petrie, D.; Bacastow, T.M. SpaceNet 8: Winning Approaches to Multi-Class Feature Segmentation from Satellite Imagery for Flood Disasters. In Proceedings of the IGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium. IEEE; 2023; pp. 1241–1244. [Google Scholar]
- Shastry, A.; Carter, E.; Coltin, B.; Sleeter, R.; McMichael, S.; Eggleston, J. Mapping floods from remote sensing data and quantifying the effects of surface obstruction by clouds and vegetation. Remote Sensing of Environment 2023, 291, 113556. [Google Scholar] [CrossRef]
- Chouhan, A.; Chutia, D.; Aggarwal, S.P. Attentive decoder network for flood analysis using sentinel 1 images. In Proceedings of the 2023 International Conference on Communication, Circuits, and Systems (IC3S). IEEE, 2023, pp. 1–5.
- Inthizami, N.S.; Ma’sum, M.A.; Alhamidi, M.R.; Gamal, A.; Ardhianto, R.; Jatmiko, W.; et al. Flood video segmentation on remotely sensed UAV using improved Efficient Neural Network. ICT Express 2022, 8, 347–351. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions, 2016, [arXiv:cs.CV/1511.07122].
- Şener, A.; Doğan, G.; Ergen, B. A novel convolutional neural network model with hybrid attentional atrous convolution module for detecting the areas affected by the flood. Earth Science Informatics 2024, 17, 193–209. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images. IEEE Geoscience and Remote Sensing Letters 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Shi, L.; Yang, K.; Chen, Y.; Chen, G. An Interactive Prompt Based Network for Urban Floods Area Segmentation Using UAV Images. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 2024. [Google Scholar] [CrossRef]
- Landuyt, L.; Verhoest, N.E.; Van Coillie, F.M. Flood mapping in vegetated areas using an unsupervised clustering approach on sentinel-1 and-2 imagery. Remote Sensing 2020, 12, 3611. [Google Scholar] [CrossRef]
- Ibrahim, N.; Sharun, S.; Osman, M.; Mohamed, S.; Abdullah, S. The application of UAV images in flood detection using image segmentation techniques. Indones. J. Electr. Eng. Comput. Sci 2021, 23, 1219. [Google Scholar] [CrossRef]
- Bauer-Marschallinger, B.; Cao, S.; Tupas, M.E.; Roth, F.; Navacchi, C.; Melzer, T.; Freeman, V.; Wagner, W. Satellite-Based Flood Mapping through Bayesian Inference from a Sentinel-1 SAR Datacube. Remote Sensing 2022, 14, 3673. [Google Scholar] [CrossRef]
- McCormack, T.; Campanyà, J.; Naughton, O. A methodology for mapping annual flood extent using multi-temporal Sentinel-1 imagery. Remote Sensing of Environment 2022, 282, 113273. [Google Scholar] [CrossRef]
- Trombini, M.; Solarna, D.; Moser, G.; Dellepiane, S. A goal-driven unsupervised image segmentation method combining graph-based processing and Markov random fields. Pattern Recognition 2023, 134, 109082. [Google Scholar] [CrossRef]
- Simantiris, G.; Panagiotakis, C. Unsupervised Deep Learning for Flood Segmentation in UAV imagery. In Proceedings of the Proceedings of the 13th IAPR Workshop on Pattern Recognition in Remote Sensing, 2024.
- Ran, L.; Li, Y.; Liang, G.; Zhang, Y. Pseudo Labeling Methods for Semi-Supervised Semantic Segmentation: A Review and Future Perspectives. IEEE Transactions on Circuits and Systems for Video Technology 2025, 35, 3054–3080. [Google Scholar] [CrossRef]
- Qin, Z.; Chen, Y.; Zhu, G.; Zhou, E.; Zhou, Y.; Zhou, Y.; Zhu, C. Enhanced Pseudo-Label Generation With Self-Supervised Training for Weakly- Supervised Semantic Segmentation. IEEE Transactions on Circuits and Systems for Video Technology 2024, 34, 7017–7028. [Google Scholar] [CrossRef]
- Lu, X.; Jiang, Z.; Zhang, H. Weakly Supervised Remote Sensing Image Semantic Segmentation With Pseudo-Label Noise Suppression. IEEE Transactions on Geoscience and Remote Sensing 2024, 62, 1–12. [Google Scholar] [CrossRef]
- Zou, Y.; Zhang, Z.; Zhang, H.; Li, C.L.; Bian, X.; Huang, J.B.; Pfister, T. Pseudoseg: Designing pseudo labels for semantic segmentation. arXiv preprint arXiv:2010.09713, arXiv:2010.09713 2020.
- Paul, S.; Ganju, S. Flood segmentation on sentinel-1 SAR imagery with semi-supervised learning. arXiv preprint arXiv:2107.08369, arXiv:2107.08369 2021.
- Li, J.; Meng, Y.; Li, Y.; Cui, Q.; Yang, X.; Tao, C.; Wang, Z.; Li, L.; Zhang, W. Accurate water extraction using remote sensing imagery based on normalized difference water index and unsupervised deep learning. Journal of Hydrology 2022, 612, 128202. [Google Scholar] [CrossRef]
- He, Y.; Wang, J.; Zhang, Y.; Liao, C. An efficient urban flood mapping framework towards disaster response driven by weakly supervised semantic segmentation with decoupled training samples. ISPRS Journal of Photogrammetry and Remote Sensing 2024, 207, 338–358. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything, 2023. arXiv:cs.CV/2304.02643].
- Savitha, G.; Girisha, S.; Sughosh, P.; Shetty, D.K.; Mymbilly Balakrishnan, J.; Paul, R.; Naik, N. Consistency Regularization for Semi-Supervised Semantic Segmentation of Flood Regions From SAR Images. IEEE Access 2025, 13, 9642–9653. [Google Scholar] [CrossRef]
- Croitoru, F.A.; Hondru, V.; Ionescu, R.T.; Shah, M. Diffusion models in vision: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence 2023, 45, 10850–10869. [Google Scholar] [CrossRef] [PubMed]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10684–10695.
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Advances in neural information processing systems 2021, 34, 8780–8794. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, arXiv:2010.02502 2020.
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems 2022, 35, 36479–36494. [Google Scholar]
- Batzolis, G.; Stanczuk, J.; Schönlieb, C.B.; Etmann, C. Conditional image generation with score-based diffusion models. arXiv preprint arXiv:2111.13606, arXiv:2111.13606 2021.
- Saharia, C.; Chan, W.; Chang, H.; Lee, C.; Ho, J.; Salimans, T.; Fleet, D.; Norouzi, M. Palette: Image-to-image diffusion models. In Proceedings of the ACM SIGGRAPH 2022 conference proceedings; 2022; pp. 1–10. [Google Scholar]
- Wang, T.; Zhang, T.; Zhang, B.; Ouyang, H.; Chen, D.; Chen, Q.; Wen, F. Pretraining is all you need for image-to-image translation. arXiv preprint arXiv:2205.12952, arXiv:2205.12952 2022.
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International conference on machine learning. Pmlr; 2021; pp. 8821–8831. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 2022, arXiv:2204.06125 2022, 1, 31, 3. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 10684–10695.
- Sarfraz, S.; Sharma, V.; Stiefelhagen, R. Efficient parameter-free clustering using first neighbor relations. In Proceedings of the Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8934–8943.
- Zotou, P.; Bacharidis, K.; Argyros, A. Leveraging FINCH and K-means for Enhanced Cluster- Based Instance Selection, 2024. [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer, 2015, pp. 234–241.
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3431–3440.
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587, arXiv:1706.05587 2017.
| 1 |
Figure 1.
Flood-related aerial image datasets and their sizes (in images). Gray bubbles indicate absence of explicit flood annotations. Sizes for AIDER and Incidents1M reflect only flood-related images.
Figure 1.
Flood-related aerial image datasets and their sizes (in images). Gray bubbles indicate absence of explicit flood annotations. Sizes for AIDER and Incidents1M reflect only flood-related images.
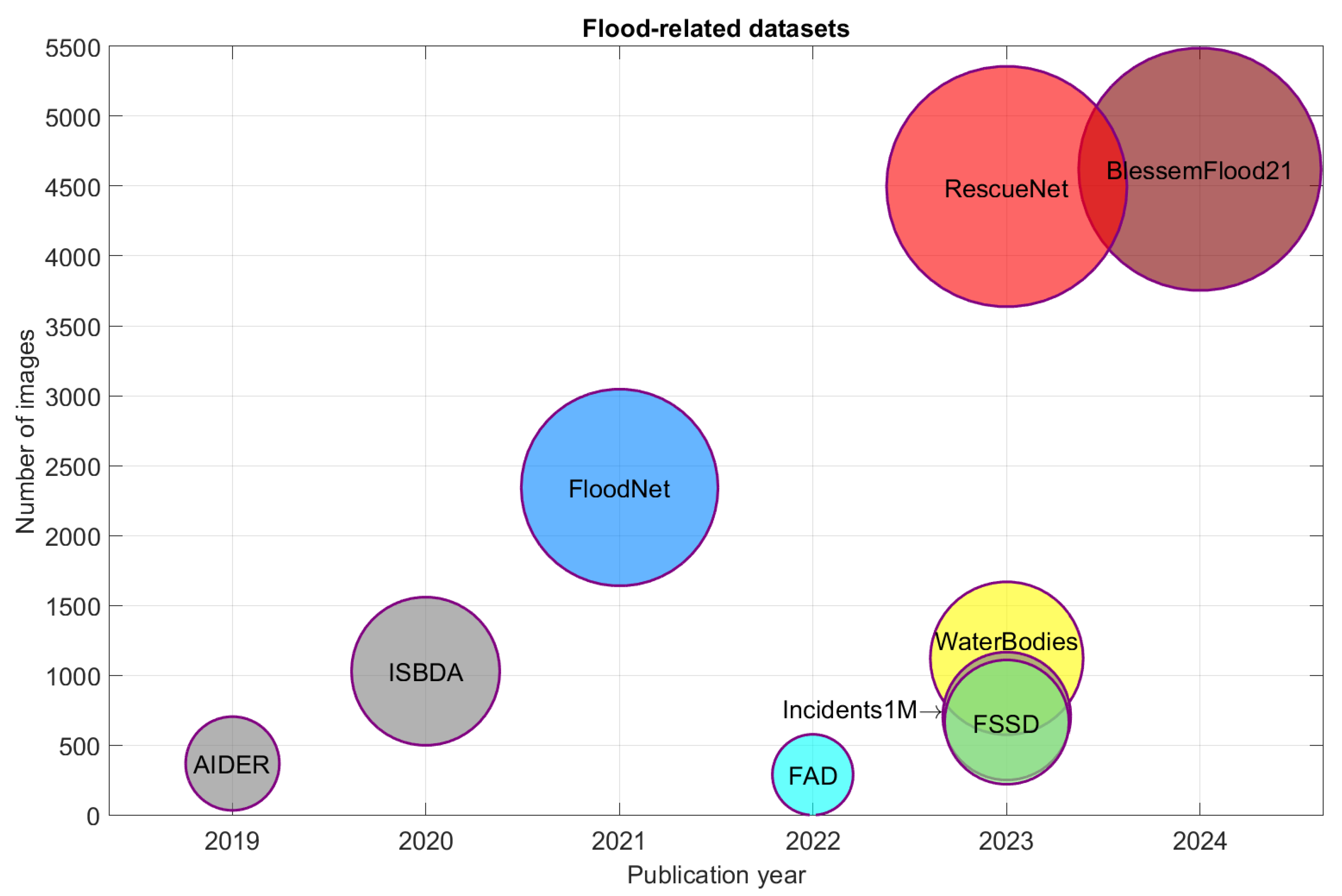
Figure 2.
Schematic overview of the proposed approach.
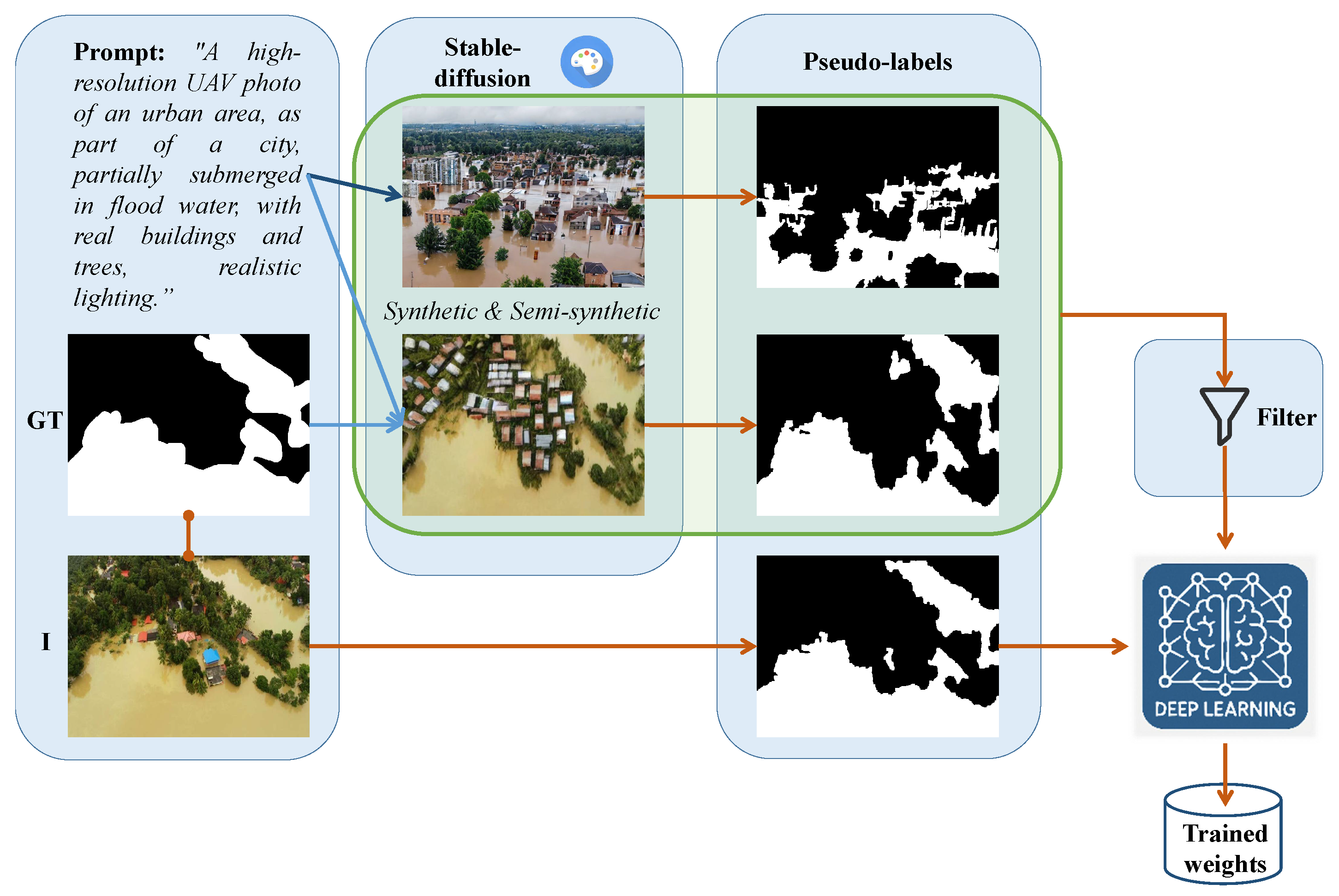
Figure 3.
Overview of synthetic dataset creation pipeline. The process begins with the generation of synthetic flood images using two methodologies: (i) text-to-image synthesis and (ii) image inpainting based on real segmentation masks. The generated images undergo an unsupervised pseudo-labeling process (PL Gen) to obtain corresponding segmentation masks. Next, a filtering stage is applied to refine the synthetic dataset by leveraging feature embeddings and clustering techniques.
Figure 3.
Overview of synthetic dataset creation pipeline. The process begins with the generation of synthetic flood images using two methodologies: (i) text-to-image synthesis and (ii) image inpainting based on real segmentation masks. The generated images undergo an unsupervised pseudo-labeling process (PL Gen) to obtain corresponding segmentation masks. Next, a filtering stage is applied to refine the synthetic dataset by leveraging feature embeddings and clustering techniques.
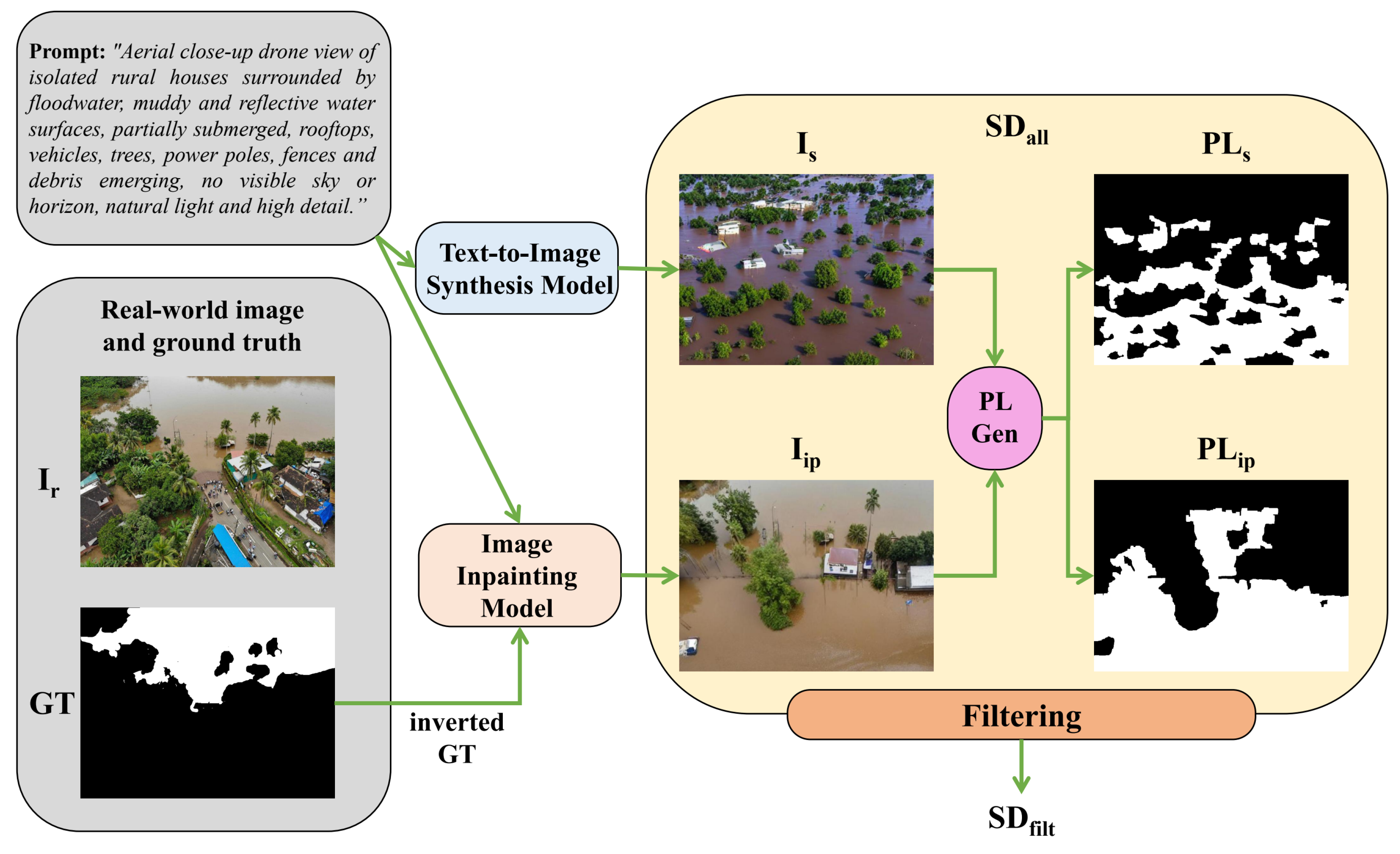
Figure 4.
Illustration of the image generation process using Stable Diffusion over 50 denoising steps. The sequence shows the initial random noise and intermediate outputs at every 10th step (t) until the final synthesized image. Diversity in the generated outputs is achieved through carefully constructed text prompts. The model successfully generates realistic flooded environments, including urban/peri-urban scenes (a), (b), and rural landscapes (c), (d). Variations in sky presence which can include sky (b), (d) or not (a), (c), simulate different camera viewpoints and orientations.
Figure 4.
Illustration of the image generation process using Stable Diffusion over 50 denoising steps. The sequence shows the initial random noise and intermediate outputs at every 10th step (t) until the final synthesized image. Diversity in the generated outputs is achieved through carefully constructed text prompts. The model successfully generates realistic flooded environments, including urban/peri-urban scenes (a), (b), and rural landscapes (c), (d). Variations in sky presence which can include sky (b), (d) or not (a), (c), simulate different camera viewpoints and orientations.

Figure 5.
Synthetic images (a) from Figure 4 representing flooded urban/peri-urban environments with sky absence and presence, and rural scenes also without and with sky. Real-world UAV captured flood-related images with the same scene diversity (c), along with their respective ground truths (d), which are used, as described in Section 3.2, to generate semi-synthetic images (e) via inpainting. Respective pseudo-labels, PLs and PLip, are overlaid in blue for the synthetic Is(b) and semi-synthetic images Iip (f).
Figure 5.
Synthetic images (a) from Figure 4 representing flooded urban/peri-urban environments with sky absence and presence, and rural scenes also without and with sky. Real-world UAV captured flood-related images with the same scene diversity (c), along with their respective ground truths (d), which are used, as described in Section 3.2, to generate semi-synthetic images (e) via inpainting. Respective pseudo-labels, PLs and PLip, are overlaid in blue for the synthetic Is(b) and semi-synthetic images Iip (f).

Figure 6.
Representative examples of synthetic (a) and semi-synthetic images (d) which were filtered with outlier threshold . Semi-synthetic images were generated as described in Section 3.2, with the ground truth (c) used for inpainting derived from the real-world UAV captured flood-related images (b).
Figure 6.
Representative examples of synthetic (a) and semi-synthetic images (d) which were filtered with outlier threshold . Semi-synthetic images were generated as described in Section 3.2, with the ground truth (c) used for inpainting derived from the real-world UAV captured flood-related images (b).

Figure 7.
Sample images from the training dataset FAD [11] (a) and the corresponding ground truths (b), which were used in Section 3.2 to generate semi-synthetic images, and from the test dataset FSSD [13] (c) together with their respective ground truths (d).
Figure 7.
Sample images from the training dataset FAD [11] (a) and the corresponding ground truths (b), which were used in Section 3.2 to generate semi-synthetic images, and from the test dataset FSSD [13] (c) together with their respective ground truths (d).

Figure 8.
The F1-score of DeepLabV3, FCN-ResNet50 and U-Net on the test dataset (FSSD) according to training with the real dataset (FAD), text-to-image synthetic dataset (), the semi-synthetic image inpainting dataset (), and their union, unfiltered () and filtered (), when its combined with the FAD dataset, with the usage of ground truth (GT) and pseudo-label (PL) masks.
Figure 8.
The F1-score of DeepLabV3, FCN-ResNet50 and U-Net on the test dataset (FSSD) according to training with the real dataset (FAD), text-to-image synthetic dataset (), the semi-synthetic image inpainting dataset (), and their union, unfiltered () and filtered (), when its combined with the FAD dataset, with the usage of ground truth (GT) and pseudo-label (PL) masks.
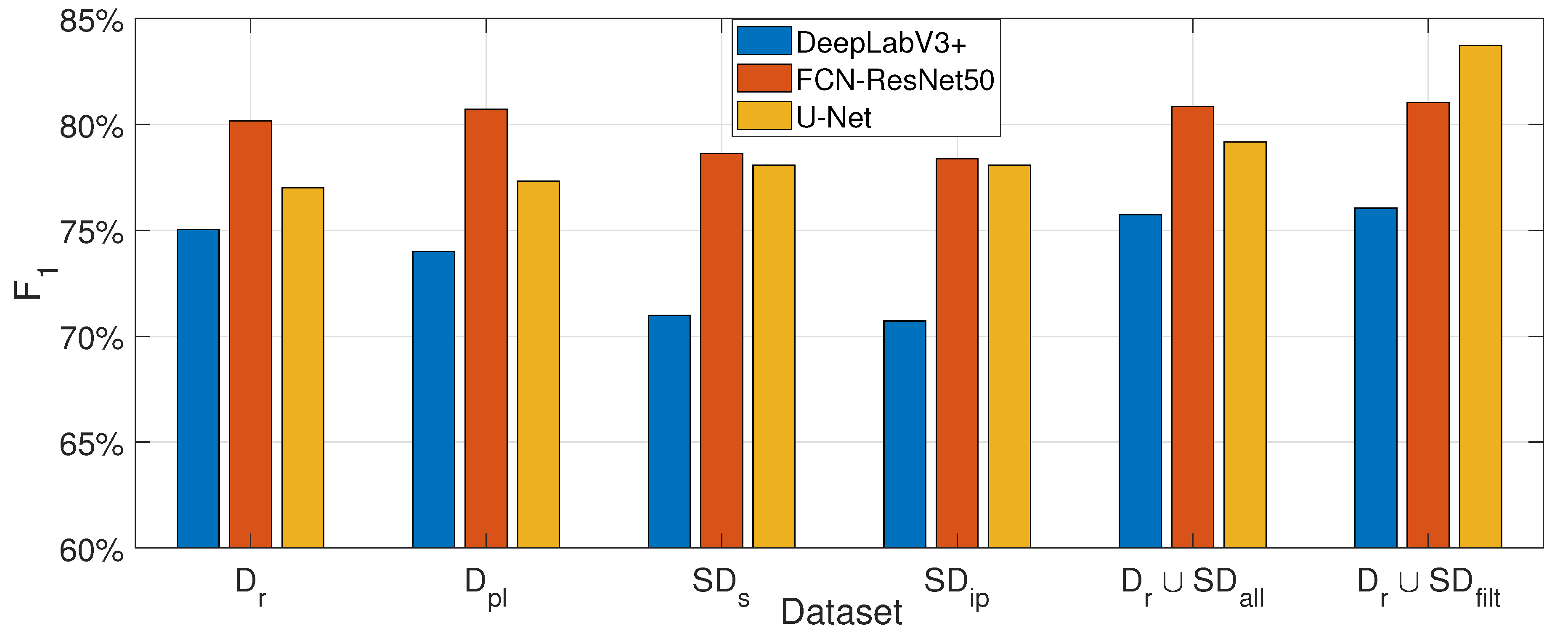
Figure 9.
2D PCA visualization of ResNet50 feature embeddings extracted from real (FAD) and synthetic (SDs, SDip) datasets with the best fit ellipses of each dataset calculated by 2D normal distribution fitting. Each point represents an image, colored by dataset. The substantial overlap suggests strong visual alignment between real and synthetic domains.
Figure 9.
2D PCA visualization of ResNet50 feature embeddings extracted from real (FAD) and synthetic (SDs, SDip) datasets with the best fit ellipses of each dataset calculated by 2D normal distribution fitting. Each point represents an image, colored by dataset. The substantial overlap suggests strong visual alignment between real and synthetic domains.
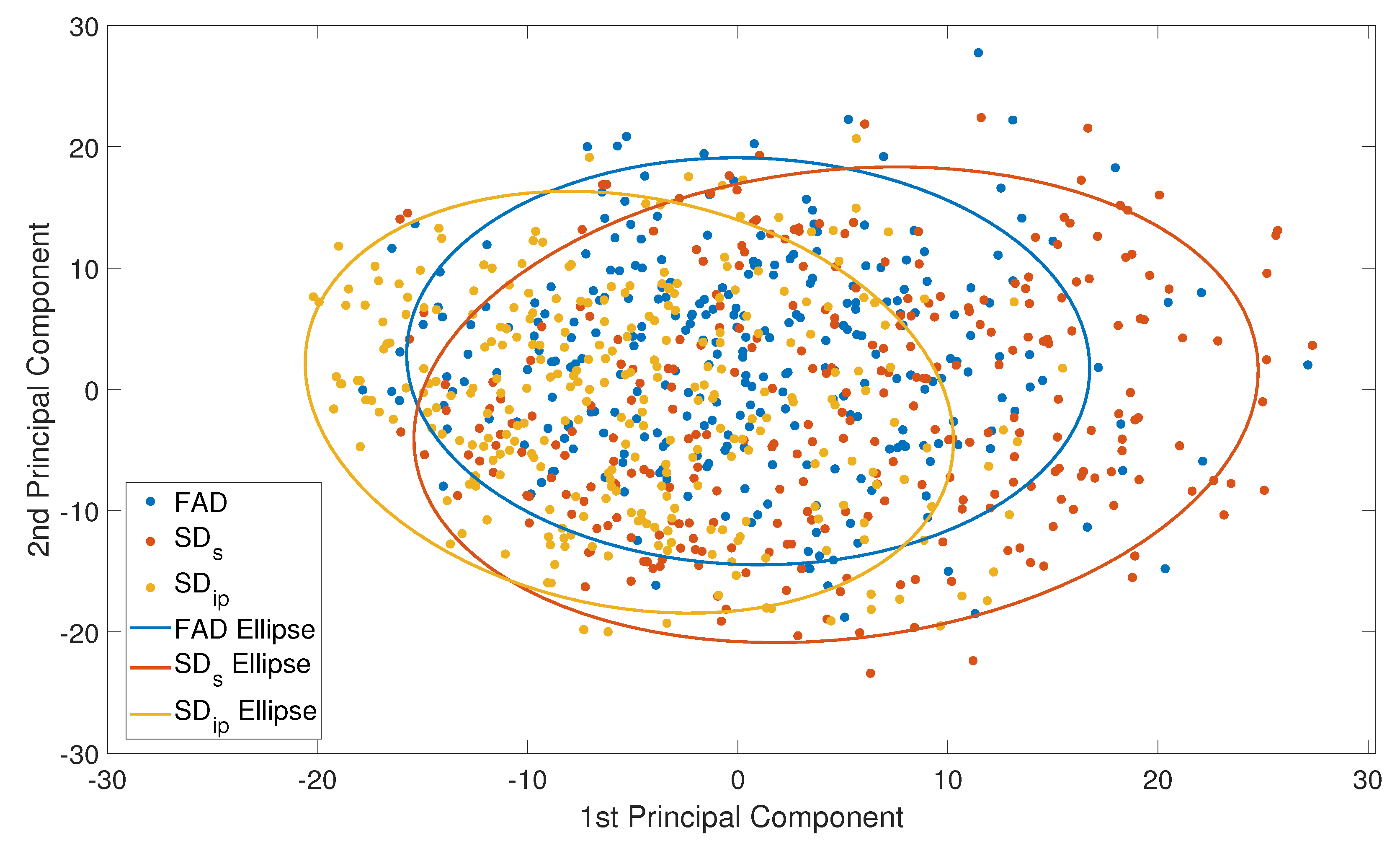
Figure 10.
Comparison of accepted (top) and rejected (bottom) synthetic flood images generated via prompt-to-image (left) and image-to image (right) translation. Problematic regions—including artifacts, erroneous configurations, and undesired objects—are highlighted with red bounding boxes.
Figure 10.
Comparison of accepted (top) and rejected (bottom) synthetic flood images generated via prompt-to-image (left) and image-to image (right) translation. Problematic regions—including artifacts, erroneous configurations, and undesired objects—are highlighted with red bounding boxes.
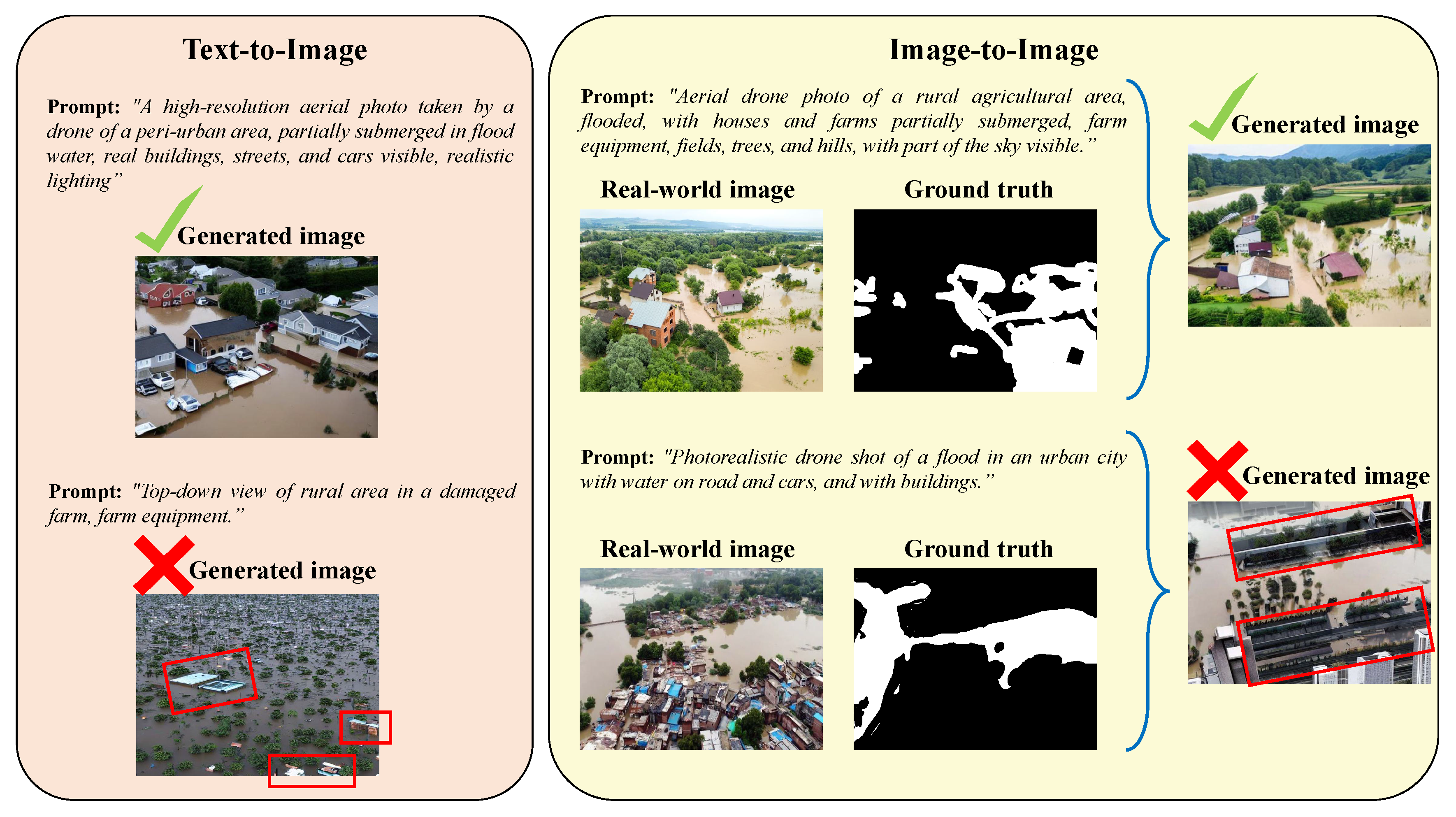
Figure 11.
Original images (first column), ground truth masks (second column) and representative segmentation results of the U-Net (third column), FCN-ResNet50 (fourth column), and DeepLabV3 (fifth column) from the FSSD test dataset. The masks are overlaid in blue. Rows correspond to the (best results), , , and percentile of the descending sorted F1-score values of the top performing U-Net architecture trained with real and synthetic data. FCN-ResNet50 and DeepLabV3 were also trained under the same conditions.
Figure 11.
Original images (first column), ground truth masks (second column) and representative segmentation results of the U-Net (third column), FCN-ResNet50 (fourth column), and DeepLabV3 (fifth column) from the FSSD test dataset. The masks are overlaid in blue. Rows correspond to the (best results), , , and percentile of the descending sorted F1-score values of the top performing U-Net architecture trained with real and synthetic data. FCN-ResNet50 and DeepLabV3 were also trained under the same conditions.

| Image | Ground truth | U-Net | FCN-ResNet50 | DeepLabV3 |
Figure 12.
Original images (first column), and representative segmentation results from the FSSD test dataset of the U-Net architecture trained with different datasets: real-world images and ground truths (second column), synthetic images and corresponding pseudo-label masks (third column), semi-synthetic images and corresponding pseudo-label masks (fourth column), and combined real-world data and filtered synthetic datasets and corresponding ground truth and pseudo-labels (fifth column). Segmentations are overlaid in blue. Rows correspond to the (best results), , , and (worst results) percentile of the descending sorted F1-score differences of the top performing U-Net architecture (last columns) and its counterpart trained with real-world images and ground truth (second column).
Figure 12.
Original images (first column), and representative segmentation results from the FSSD test dataset of the U-Net architecture trained with different datasets: real-world images and ground truths (second column), synthetic images and corresponding pseudo-label masks (third column), semi-synthetic images and corresponding pseudo-label masks (fourth column), and combined real-world data and filtered synthetic datasets and corresponding ground truth and pseudo-labels (fifth column). Segmentations are overlaid in blue. Rows correspond to the (best results), , , and (worst results) percentile of the descending sorted F1-score differences of the top performing U-Net architecture (last columns) and its counterpart trained with real-world images and ground truth (second column).

| U-Net | ||||
| U-Net | U-Net | U-Net | FAD ∪ SDfilt / | |
| Image | FAD / GT | SDs / PLs | SDip / PLip | GT ∪ PLfilt |

Table 1.
DeepLabV3 performance on the test dataset (FSSD) based on training with the real dataset and ground truths (), the real dataset and pseudo-labels (), the text-to-image synthetic dataset (), the semi-synthetic image inpainting dataset (), and their union, unfiltered () and filtered (), when it is combined with the real-world dataset .
Table 1.
DeepLabV3 performance on the test dataset (FSSD) based on training with the real dataset and ground truths (), the real dataset and pseudo-labels (), the text-to-image synthetic dataset (), the semi-synthetic image inpainting dataset (), and their union, unfiltered () and filtered (), when it is combined with the real-world dataset .
| Training | Test Metrics | ||||
|---|---|---|---|---|---|
| Dataset | Acc (%) | IoU (%) | Pr (%) | Rec (%) | F1 (%) |
| Dr | 79.48 | 60.03 | 67.39 | 84.62 | 75.03 |
| Dpl | 78.03 | 58.75 | 65.04 | 85.85 | 74.01 |
| SDs | 76.48 | 55.02 | 64.47 | 78.97 | 70.99 |
| SDip | 74.54 | 54.70 | 60.85 | 84.42 | 70.72 |
| Dr ∪ SDall | 79.21 | 60.94 | 65.89 | 89.02 | 75.73 |
| Dr ∪ SDfilt | 79.55 | 61.34 | 66.34 | 89.06 | 76.04 |
Table 2.
FCN-ResNet50 performance on the test dataset (FSSD) based on training with the real dataset and ground truths (), the real dataset and pseudo-labels (), the text-to-image synthetic dataset (), the semi-synthetic image inpainting dataset (), and their union, unfiltered () and filtered (), when it is combined with the real-world dataset .
Table 2.
FCN-ResNet50 performance on the test dataset (FSSD) based on training with the real dataset and ground truths (), the real dataset and pseudo-labels (), the text-to-image synthetic dataset (), the semi-synthetic image inpainting dataset (), and their union, unfiltered () and filtered (), when it is combined with the real-world dataset .
| Training | Test Metrics | ||||
|---|---|---|---|---|---|
| Dataset | Acc (%) | IoU (%) | Pr (%) | Rec (%) | F1 (%) |
| Dr | 83.60 | 66.90 | 71.65 | 90.98 | 80.16 |
| Dpl | 83.64 | 67.67 | 70.72 | 94.00 | 80.72 |
| SDs | 81.35 | 64.80 | 67.48 | 94.22 | 78.64 |
| SDip | 81.28 | 64.44 | 67.65 | 93.14 | 78.38 |
| Dr ∪ SDall | 83.74 | 67.82 | 70.84 | 94.09 | 80.83 |
| Dr ∪ SDfilt | 84.22 | 68.12 | 72.08 | 92.54 | 81.04 |
Table 3.
U-Net performance on the test dataset (FSSD) based on training with the real dataset and ground truths (), the real dataset and pseudo-labels (), the text-to-image synthetic dataset (), the semi-synthetic image inpainting dataset (), and their union, unfiltered () and filtered (), when it is combined with the real-world dataset .
Table 3.
U-Net performance on the test dataset (FSSD) based on training with the real dataset and ground truths (), the real dataset and pseudo-labels (), the text-to-image synthetic dataset (), the semi-synthetic image inpainting dataset (), and their union, unfiltered () and filtered (), when it is combined with the real-world dataset .
| Training | Test Metrics | ||||
|---|---|---|---|---|---|
| Dataset | Acc (%) | IoU (%) | Pr (%) | Rec (%) | F1 (%) |
| Dr | 81.03 | 62.62 | 68.95 | 87.21 | 77.01 |
| Dpl | 80.33 | 63.04 | 66.65 | 92.07 | 77.33 |
| SDs | 81.45 | 64.04 | 68.56 | 90.68 | 78.08 |
| SDip | 81.11 | 64.04 | 67.63 | 92.34 | 78.08 |
| Dr ∪ SDall | 81.91 | 65.52 | 68.21 | 94.32 | 79.17 |
| Dr ∪ SDfilt | 86.97 | 72.00 | 76.85 | 91.94 | 83.72 |
Table 4.
Impact of the z-score threshold parameter k on the segmentation performance of different architectures trained on the filtered synthetic dataset. A lower k value corresponds to stricter filtering of synthetic images.
Table 4.
Impact of the z-score threshold parameter k on the segmentation performance of different architectures trained on the filtered synthetic dataset. A lower k value corresponds to stricter filtering of synthetic images.
| Method | Thresh. Par. (k) |
Filt. Imgs |
Test Metrics | ||||
|---|---|---|---|---|---|---|---|
| Acc (%) | IoU (%) | Pr (%) | Rec (%) | F1 (%) | |||
| DeepLabV3 | - | 0/580 | 79.21 | 60.94 | 65.89 | 89.02 | 75.73 |
| DeepLabV3 | 3 | 3/580 | 79.11 | 60.76 | 65.82 | 88.77 | 75.59 |
| DeepLabV3 | 2 | 23/580 | 78.68 | 59.69 | 65.73 | 86.67 | 74.76 |
| DeepLabV3 | 1.5 | 53/580 | 79.55 | 61.34 | 66.34 | 89.06 | 76.04 |
| FCN-ResNet50 | - | 0/580 | 83.74 | 67.82 | 70.84 | 94.09 | 80.83 |
| FCN-ResNet50 | 3 | 3/580 | 83.56 | 67.64 | 70.51 | 94.32 | 80.70 |
| FCN-ResNet50 | 2 | 23/580 | 82.85 | 66.90 | 69.27 | 95.14 | 80.17 |
| FCN-ResNet50 | 1.5 | 53/580 | 84.22 | 68.12 | 72.08 | 92.54 | 81.04 |
| U-Net | - | 0/580 | 81.91 | 65.52 | 68.21 | 94.32 | 79.17 |
| U-Net | 3 | 3/580 | 84.67 | 68.82 | 72.67 | 92.85 | 81.53 |
| U-Net | 2 | 23/580 | 87.57 | 72.83 | 78.17 | 91.42 | 84.28 |
| U-Net | 1.5 | 53/580 | 86.97 | 72.00 | 76.85 | 91.94 | 83.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



