
Submitted:
07 February 2023
Posted:
07 February 2023
You are already at the latest version
Abstract
With the advent of Neural Machine Translation, the more the achievement of human-machine parity is claimed at WMT, the more we come to ask ourselves if their evaluation environment can be trusted. In this paper, we argue that the low quality of the source test set of the news track at WMT may lead to an overrated human parity claim. First of all, we report nine types of so-called technical contaminants in the data set, originated from an absence of meticulous inspection after web-crawling. Our empirical findings show that when they are corrected, about 5% of the segments that have previously achieved a human parity claim turn out to be statistically invalid. Such a tendency gets evident when the contaminated sentences are solely concerned. To the best of our knowledge, it is the first attempt to question the “source” side of the test set as a potential cause of the overclaim of human parity. We cast evidence for such phenomenon that according to sentence-level TER scores, those trivial errors change a good part of system translations. We conclude that to overlook it would be a mistake, especially when it comes to an NMT evaluation.
Keywords:
human parity
; NMT evaluation
; WMT
1. Introduction
Since the astonishing performance of neural machine translation (NMT) [1,2,3] has caused a sensation in the MT research community, winning back the state-of-the-art position from Statistical Machine Translation [4], it did not take more than two years for the newcomer to reach a human-level translation quality in public. As a front runner, a group of researchers at Microsoft claimed that their models were at human parity in a Chinese→English test set distributed by Conference on Machine Translation (WMT) 2017 [5]. In detail, their three NMT models were evaluated via a source-based direct assessment against three levels of human translations (HT) and were positioned at the top rank where the HT of the highest quality was situated. Subsequently, [6] claimed another human parity in the English→Czech translation at WMT 18, and [7] even declared superhuman performance in the German→English and English→Russian translation at WMT 19.1
The fact that such results were acquired from the best practices of WMT evaluation protocol should make these claims more trustworthy, considering the authority of the campaign mentioned above as one of the most active gatherings in terms of MT evaluation since 2006. Despite their glory, however, these claims were regarded as a “hyperbolic” move and received with skepticism by many in the relevant field, who at once revisited some of the most representative exercises [8,9,10,11,12,13]. The gist of their work was that the current evaluation standards of WMT were insufficient to fairly assess the high performance of NMT models for the following motives:
- Sentence-level assessment without context information
- Assessment by an inexpert group
- Reference translation of low quality
- Adverse effect of translationese
They proved that when the evaluation surroundings were improved, the gap between HT and MT was noticeably widened and, therefore, such human parity claims were premature.
In a like manner, we cast doubt on the human parity claims by suggesting another erroneous evaluation environment of WMT: contamination of the source text of the test sets. Our primary interest lies in the influence of the polluted test set on assessing the human parity level. We, therefore, formulate a hypothesis as such:
Albeit minor, contaminants in a source text of a test set will bring out a false human parity claim.
To this aim, characteristics of the contaminants are identified from two perspectives: technical (Section 3.2) and topical (Section 3.3). We manually detect 101 technical contaminants and raise a question about topical diversity by evaluating the theme of the test samples with a BERT-based news topic classifier. While a perfect scenario of “a clean test set” would be to remove both contaminants, we confine ourselves to the technical contaminants in this study. To verify their adverse effect on an NMT evaluation, we conduct a pairwise relative ranking (RR) human evaluation comparing two online NMT models and reference translation on the English→Korean translation with 15 researchers (Section 4). We report that some of the human parity claims become invalidated when the contaminants are eliminated.2
2. Related Works
It is not a new discovery that the test sets released by WMT contain errors, but it is unusual to expect that they will have an adverse effect on the evaluation. The most relevant work is found concerning a translationese issue in the test set of WMT 18. The term translationese refers to a particular feature found in a translated text. As [12] summarize, these features are mainly characterized as simplified use of language and perfect grammaticality. [9] and [13] demonstrate that the construction pipeline of WMT test sets posed the inherent dangers of containing translationese, which led to a more favorable judgment for MT. They conducted a RR evaluation comparing two MT models and one HT on three type of texts — i) a complete set, ii) source-language-sourced set (Chinese), and iii) target-language-sourced (English) set— provided by [5] of Microsoft. Results proved that when translationese was removed from the test set (type iii), Microsoft’s NMT model that had previously achieved human parity was significantly below the human level. Since then, many reconfirmed its critical influence on NMT evaluations [10,12,14]. WMT also acknowledged that translationese should be omitted from all test sets, and it has been avoided since WMT 2019.
As a matter of fact, the quality issue of their dataset had been discussed indeed in terms of human reference translation of WMT. [5] admitted that they had to reconstruct a new reference translation of higher quality for their experiment, because WMT-provided HT created from crowdsourcing seemed to be of inadequate quality. [9] criticized the quality of WMT’s Chinese-English translations, informing on their grammatical as well as syntactic errors. They commented that the reference must have been created by “in-experienced” translators or by post-editing. [13] ran a pairwise RR evaluation on Adequacy and Fluency apart, in a binary way: (MT, HT) and (HT, HT). HT was obtained from [5], known to be of high quality, and HT was provided by a vendor. Results showed that HT was significantly preferred to HT. Therefore, although MT achieved human parity over HT, such a claim could be on a false basis. In this respect, [9] stressed the importance of a discriminative test set in an evaluation for robust models like NMT.
We deviate from those studies in that our focal point is the original source text of a test set. From our understanding, it is the first study to raise a quality issue of the source side of the test sets of WMT. While consulting the experimental setups of the aforementioned studies, we demonstrate that the contaminants in the original text harm the whole environment, inducing an overclaim of the human-machine parity. We strongly argue that such an issue should not be taken for granted when it comes to an NMT evaluation.
3. Contaminants
3.1. WMT 20 Test Set
In the WMT’s news track, source texts of the test set were prepared in eight languages, inclusive of English. In 2020, three types of English source texts were constructed, each of which served as a basis for a test set of different language pairs [15]. While our experiment employs English III, we offer a holistic view of all English source texts at WMT in Table 1.
Technically speaking, the number of sentences with paragraph-split is counted with the Moses sentence parser [16]. The tokenized texts are lowercased with the Moses tokenizer and the number of distinct words was counted. As Table 1 displays, English III covers a broader range of data with more varied vocabularies and a larger scale.
3.2. Technical Contaminants
We detect contaminants, as we call them, on a surface level. We report that out of 130 documents, 42 documents are contaminated either slightly or considerably. Half of the cases are a single presence (), while the rest are multiple appearances () in one document when examined on a sentence basis.
It is speculated that the majority of the technical contaminants is originated from an incorrect web-crawling, or more explicitly, the absence of meticulous posterior inspection of the web-crawled texts. As in Table 2, we have spotted a total of 101 contaminants in the data set and classified them into nine types. It is noticeable that about 63.4% of the contaminants stem from a misuse of quotation marks. Some of the most intriguing categories are discussed in this section.
Quotation Marks It accumulates 63.4% of the total contaminants. In detail, the end quotes are mostly omitted (78%). 22% are incorrectly used as an apostrophe. In addition, we have revised 15 pairs of single quotes () to double quotes as in the American manner (Category: Cultural difference) in an effort to see their impact on the result, but we notice that such case is not considered as a contaminant in the statistics.
Spacing In most cases, two words are mistakenly attached without spacing.
Typo It includes simple typos such as: monitorigin →monitoring, he→He, n→in, Laszlo Trocsanyi→László Trócsányi. Other cases seem more influential to the content when translating: though→through, other→another, the→ they.
Missing Headlines Unlike other documents that always start with a headline, four documents do not have it. In order to provide an equal evaluation environment, we take this case as a contaminant. By appending their headlines through a manual web search, we assure a balance in our after-test-set.
Caption Either captions for photos or a leaflet are inserted in the middle of the documents. As they interrupt the context, they are considered as a contaminant in this paper.
Irrelevance It refers to an irrelevant segment to the context, such as a journal’s date, name or city. Not only is their existence useless in an evaluation, but some of them are separated as one segment by mistake, to make matters worse.
Out-of-Context Extraction Unlike other documents extracted from the beginning of an original article, two cases in the test set start from the middle. It is problematic for humans in that it hinders the translators’ understanding of the context. While it is a contaminant, we omit it from the final count.
3.3. Topical Contaminants
Together with the technical contaminants, we argue that the test set is topically imbalanced. We observe that the documents repeatedly cover similar events or deal with a limited group of figures. We denominate such phenomena as topical contaminants and confirm their existence with the help of a Topic Classification algorithm. Under the assumption that the aim of the news track at WMT is to evaluate MT models on a diversified testbed, we point out that a good test set should represent the training set distribution proportionally. Their statistical impact on NMT evaluation, however, is out of the scope of this study and should be further verified in a more detailed setup.
We train a classifier by fine-tuning BERT [17] on a News Category Data Set [18,18] from Kaggle that consists of around 200,000 news headlines and short descriptions collected from HuffPost during 2012-2018. The original data set contains 41 topic categories, but we have merged some of the overlapped categories such as “worldpost” and “the worldpost” or “art” and “art & culture” under the category of “Representatives.” The bottom 20 categories are also combined to the category of “Others.” On such criteria, we compare the WMT 20 English news-crawl training set containing 1,600,000 documents and the given test set.
When the distribution of the topics in both texts is compared, the result shows that the test set (b) is markedly disproportional to the distribution of the training set (a) of Figure 1. Moreover, it turns out that the given test set is considerably biased toward a few categories, including “world,” “politics” or “crime.” The least popular topic, on the other hand, would be “parenting,” “wellness,” or “art & culture.”
4. Evaluation Setup
We hypothesize that contaminants of an original source text make the human parity claim more reachable, especially in terms of NMT models. We test the given hypothesis by conducting RR on two different test sets: an originally-WMT-distributed test set and its revised version. They are named after “Before Test Set (BTS)” and “After Test Set (ATS),” respectively. We believe that this type of data set construction allows us to demonstrate that the contaminants are the sole factor of the outcome.
Language Pair The translation direction is English → Korean.
Data set We use a source text of English-III-typed WMT 20 test set built for German, Czech, and Chinese [15]. The 21 documents (437 sentences) with two or more contaminants described in Section 3.2 are selected and provide a foundation for constructing BTS and ATS, totaling 874 sentences.
System translations of the two NMT models are created on July 21, 2021, all on the same day to avoid a possible temporal influence on the result. For the experiment, a mixture of BTS and ATS are shuffled document-wise to create HITs of around 100 segments each, a portion for one annotator, containing both versions as evenly as possible. Such a mixture is intended for every annotator to judge both of the data set in the assessment. In total, 10 HITs are prepared, and each HIT is assigned to two annotators. Evaluation data collected from this experiment are displayed in Table 3. In summary, we have collected 5,244 pairwise judgments.
NMT Models We employ two online NMT models, anonymously denominated as MT and MT. We make a special effort to select the best-performing engines for this language pair via a preliminary test, as this evaluation focuses on human parity.3 Their translations are contrasted to a Korean reference translation created initially by a vendor and manually revised afterward by one of our researchers who has been working as a professional translator. We have endeavored to build a reference of the highest quality.
RR For each source sentence, annotators are asked to perform a pairwise ranking of three candidate translations —HT and two system translations (MT, MT)— from best () to worst (), with ties allowed. A sentence is displayed in the order of articles along with one previous/following sentence. The task is prepared on TAUS DQF 4.
Computation The result is extracted from the two-sided Sign Tests suggested by [8] or [11], where MT is better, HT is better, and their ties are calculated. Their method is designed for a binary comparison of two candidates; we iterate two independent rounds, such that (MT, HT) and (MT, HT) can be contrasted on the same scenario. At the end, the statistical significance is verified by a two-sided binomial test. More details in terms of the given methodology are referred to [8].
We also take a look at the trend of an absolute score of each model as guided by TAUS5. The score is computed by weighing each rank with different points and normalizing them by the total number of rankings, as in Equation (1). The best absolute result, therefore, is .
Human Parity According to [8], human parity is represented as a tie to HT, and superhuman performance, to MT-better. We are concerned, however, that a tied rank can also be interpreted as a personal characteristic of indecisiveness. In that sense, we regard human parity as a sum of MT-better and tie ranks. It is to note that such a definition is only valid in the current study.
Annotator We collect judgments from 15 in-house researchers in the field of MT. They are native Koreans with good English proficiency. Some of them have previous experience in NMT evaluation. The participants are not previously informed of the involvement of HT in the task. Each is assigned to 1 - 2 HITs.
5. Result
5.1. RR: Significance Test
Figure 2 displays a range of score variations from BTS to ATS of RR between MT and MT. The exact score is provided in Appendix A. A consistent tendency is that the proportion of HT-better is slightly increased in ATS (, ) while that of MT-better and Tie decreases. When MT-better and Tie scores are combined, 3.09 and 5.38 percentage points of the judgments on human parity in MT and MT respectively turn out to be invalid. When narrowing down the scope to the contaminated sentences (), to our surprise, the tendency gets more intensified, as in Figure 2 (b). The loss of human parity claims reaches more than double in MT (→). We also notice that the percentage of Ties in both systems remains almost identical (, ).
The fact that the score difference per category is more apparent in MT than in MT is also intriguing in that there is a definite possibility that a final ranking of the candidate systems can change. Such chance, however, is scarce in our case because more significant drop of MT-better or Tie occurs with MT, which has seemingly lower performance than its counterpart.We confirm our hypothesis from the given result that the current test set of WMT 20 is more favorable to MT and leads to a false human parity achievement.
Meanwhile, the absolute RR scores of the three candidates are given in Table A3 and Table A4 in Appendix A. Figure 3 shows a score variation of the absolute ranking score of the three candidates when in BTS and ATS. Although the comparative rank is maintained identically in the order of [HT-MT-MT], the absolute score of HT increases up to 3.3% while that of MT descreases up to 4.67% (in MT). Consequently, the gap between the two NMT models becomes more prominent. From such findings, we assume that systems behave differently with the contaminants of the test set. In our case, MT is more vulnerable to them.
5.2. IAA
Figure 4 shows the IAA scores per group computed by Cohen’s K. Each group is composed of two annotators who have been assigned to the same HIT. The average K score is .
6. Additional Work
6.1. Automatic Evaluation
While the influence of the contaminants on human parity is clarified, we get curious whether it is also observable in an automatic MT evaluation despite the small size of the data set (). BLEU [21], TER, and chrF2 [22] are computed on BTS and ATS with Sacrebleu [23]. The sentences are tokenized with MeCab [24] before the computation. We compare the result to Google Translate (GT) as a benchmark model to guarantee the compatible performance of the two anonymous models.6 Table 4 shows that such changes barely affect the suggested metrics except for GT. The overall scores for GT have degraded in all three metrics.
All in all, more investigation is required in this regard based on the following observations: i) different from the outcome of RR (Section 5.1), MT obtains a better result; its correlation with human evaluation, thus, is uncertain, ii) the reliability of the automatic metrics in the Korean language is still dubious [25], and iii) such marginal gap between BTS and ATS cannot be a shred of valid evidence.
6.2. Qualitative Analysis
We suppose that sentence-level TER scores between BTS and ATS would hint at our interest in finding cases that have been critically influenced by the technical contaminants. Three sentences have scored above 0.8 in either MT or MT, two of which have had contaminants in the source text. Taking a look at one of those examples () in Figure 5 with back-translations of Google Translate (KO→EN), the contaminant in BTS-ST is an absence of an end quote. Just by adding it, we have obtained quite different system translations (in ATS-Y and ATS-Z). As expressed in the back-translations, ATS-Z’s translation has lost a good deal of the source content, such as "oh my" and "it’s a lot of work." A more interesting finding is their ranking scores. In BTS, the ranking of [HT, MT, MT] is either [] or []. In ATS, however, the score is converted into either [] or []. It is still unclear why such phenomenon happens, but we confirm that such minor changes in the source sentence can produce a very different translation, which affects to the human evaluation.
7. Conclusion
Many of us probably agree that a test set can have errors. Some would even say that it represents a real-world scenario and that it is acceptable. We, however, give proof that it is not satisfactory anymore if the human-machine parity of high-performing MT models is involved.
Technically, we identify nine types of contaminants and point out quotation marks as a primary culprit of the error. While doing so, we also confirm with the help of topic classification that the topic of the WMT 20 test set is heavily tilted toward world news and politics, while art is hardly visible. We show that such topical imbalance ignores the composition of its training set and disqualifies itself as a testbed. The in-depth study in this regard is left for a future work.
To verify the influence of technical contaminants on human-machine parity, we conduct an RR evaluation on two test sets (BTS and ATS) comparing two NMT systems and HT. We report that when Sign Test is concerned, the two MTs have lost about 5% of human parity claims in the clean test set (ATS) and that such tendency gets much more substantial when contaminated sentences are tested only. The sentence-wise TER scores show that system translations could be edited up to 86% when the contaminants are revised. When qualitatively approached, we confirm that ranking judgments on that sentence become unfavorable. In the meantime, the side-effects of the contaminants on automatic evaluation metrics are questioned as an additional work, but it seems minor at this moment.
The current study is limited to a single language pair that has not been employed in WMT. We also acknowledge that such findings should be further examined on a larger scale with more resourceful language pairs and with publicly available NMT models. However, we believe that the WMT evaluation surroundings should be consistent at all times. With the results at hand, we cannot help but question the true goal of the news track at WMT. Is the real-world scenario what we want indeed? If we are to assess the maximum performance of NMT in comparison with human performance, we insist that the test set be technically impeccable and topically multifaceted to secure an unbiased evaluation experiment.
Acknowledgments
We would like to thank each and every one of our in-house researchers who put their time and efforts on our evaluation. We also appreciate Graham Neubig and Samuel Läubli for their valuable comments.
Appendix A

Table A1.
Sign test of MT and MT (, p-value ≤).
| MT | MT | |||
|---|---|---|---|---|
| BTS | ATS | BTS | ATS | |
| MT better | 117 | 115 | 116 | 89 |
| Tie | 246 | 221 | 180 | 160 |
| HT better | 511 | 538 | 578 | 625 |
Table A2.
Sign test of MT and MT (, p-value ≤).
| MT | MT | |||
|---|---|---|---|---|
| BTS | ATS | BTS | ATS | |
| MT better | 38 | 30 | 32 | 20 |
| Tie | 40 | 42 | 36 | 36 |
| HT better | 106 | 112 | 116 | 128 |
Table A3.
Absolute score of RR. The total score is 3 (n=874).
| HT | MT | MT | |
|---|---|---|---|
| BTS | 2.77 | 2.23 | 2.08 |
| ATS | 2.80 | 2.14 | 1.94 |
Table A4.
Absolute score of RR. The total score is 3 (n=184).
| HT | MT | MT | |
|---|---|---|---|
| BTS | 2.68 | 2.20 | 2.14 |
| ATS | 2.78 | 2.20 | 2.00 |
References
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, arXiv:1409.0473 2014.
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. CoRR, 1406. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. CoRR, 1706. [Google Scholar]
- Bentivogli, L.; Bisazza, A.; Cettolo, M.; Federico, M. Neural versus Phrase-Based Machine Translation Quality: a Case Study. CoRR, 1608. [Google Scholar]
- Hassan, H.; Aue, A.; Chen, C.; Chowdhary, V.; Clark, J.; Federmann, C.; Huang, X.; Junczys-Dowmunt, M.; Lewis, W.; Li, M.; Liu, S.; Liu, T.; Luo, R.; Menezes, A.; Qin, T.; Seide, F.; Tan, X.; Tian, F.; Wu, L.; Wu, S.; Xia, Y.; Zhang, D.; Zhang, Z.; Zhou, M. Achieving Human Parity on Automatic Chinese to English News Translation. CoRR, 1803. [Google Scholar]
- Bojar, O.; Federmann, C.; Fishel, M.; Graham, Y.; Haddow, B.; Koehn, P.; Monz, C. Findings of the 2018 Conference on Machine Translation (WMT18). Proceedings of the Third Conference on Machine Translation: Shared Task Papers; Association for Computational Linguistics: Belgium, Brussels, 2018; pp. 272–303. [Google Scholar] [CrossRef]
- Barrault, L.; Bojar, O.; Costa-jussà, M.R.; Federmann, C.; Fishel, M.; Graham, Y.; Haddow, B.; Huck, M.; Koehn, P.; Malmasi, S.; Monz, C.; Müller, M.; Pal, S.; Post, M.; Zampieri, M. Findings of the 2019 Conference on Machine Translation (WMT19). Proceedings of the Fourth Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1); Association for Computational Linguistics: Florence, Italy, 2019; pp. 1–61. [Google Scholar] [CrossRef]
- Läubli, S.; Sennrich, R.; Volk, M. Has Machine Translation Achieved Human Parity? A Case for Document-level Evaluation. CoRR, 1808. [Google Scholar]
- Toral, A.; Castilho, S.; Hu, K.; Way, A. Attaining the Unattainable? Reassessing Claims of Human Parity in Neural Machine Translation. CoRR, 1808. [Google Scholar]
- Graham, Y.; Haddow, B.; Koehn, P. Translationese in Machine Translation Evaluation. CoRR, 1906. [Google Scholar]
- Toral, A. Reassessing Claims of Human Parity and Super-Human Performance in Machine Translation at WMT 2019. CoRR, 2005. [Google Scholar]
- Graham, Y.; Haddow, B.; Koehn, P. Statistical Power and Translationese in Machine Translation Evaluation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Online, 2020; pp. 72–81. [Google Scholar] [CrossRef]
- Läubli, S.; Castilho, S.; Neubig, G.; Sennrich, R.; Shen, Q.; Toral, A. A Set of Recommendations for Assessing Human-Machine Parity in Language Translation. CoRR, 2004. [Google Scholar]
- Edunov, S.; Ott, M.; Ranzato, M.; Auli, M. On The Evaluation of Machine Translation Systems Trained With Back-Translation. CoRR, 1908. [Google Scholar]
- Barrault, L.; Biesialska, M.; Bojar, O.; Costa-jussà, M.R.; Federmann, C.; Graham, Y.; Grundkiewicz, R.; Haddow, B.; Huck, M.; Joanis, E.; Kocmi, T.; Koehn, P.; Lo, C.k.; Ljubešić, N.; Monz, C.; Morishita, M.; Nagata, M.; Nakazawa, T.; Pal, S.; Post, M.; Zampieri, M. Findings of the 2020 Conference on Machine Translation (WMT20). Proceedings of the Fifth Conference on Machine Translation; Association for Computational Linguistics: Online, 2020; pp. 1–55. [Google Scholar]
- Koehn, P.; Hoang, H.; Birch, A.; Callison-Burch, C.; Federico, M.; Bertoldi, N.; Cowan, B.; Shen, W.; Moran, C.; Zens, R.; Dyer, C.; Bojar, O.; Constantin, A.; Herbst, E. Moses: Open Source Toolkit for Statistical Machine Translation. ACL 2007, Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, -30, 2007, Prague, Czech Republic; Carroll, J.A.; van den Bosch, A.; Zaenen, A., Eds. The Association for Computational Linguistics, 2007. 23 June.
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. CoRR, 1810. [Google Scholar]
- Misra, R.; Grover, J. Sculpting Data for ML: The first act of Machine Learning; 2021.
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educational and Psychological Measurement 1960, 20, 37. [Google Scholar] [CrossRef]
- Bojar, O.; Chatterjee, R.; Federmann, C.; Graham, Y.; Haddow, B.; Huck, M.; Jimeno Yepes, A.; Koehn, P.; Logacheva, V.; Monz, C.; Negri, M.; Névéol, A.; Neves, M.; Popel, M.; Post, M.; Rubino, R.; Scarton, C.; Specia, L.; Turchi, M.; Verspoor, K.; Zampieri, M. Findings of the 2016 Conference on Machine Translation. Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 131–198. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Philadelphia, Pennsylvania, USA, 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Popović, M. chrF: character n-gram F-score for automatic MT evaluation. Proceedings of the Tenth Workshop on Statistical Machine Translation; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 392–395. [Google Scholar] [CrossRef]
- Post, M. A Call for Clarity in Reporting BLEU Scores. CoRR, 1804. [Google Scholar]
- Park, E.L.; Cho, S. KoNLPy: Korean natural language processing in Python. Proceedings of the 26th Annual Conference on Human & Cognitive Language Technology;, 2014.
- Kim, A.; Ventura, C.C. Human Evaluation of NMT & Annual Progress Report: A Case Study on Spanish to Korean. Revista Tradumàtica: tecnologies de la traducció 2020, 18. [Google Scholar]
| 1 | *Work done during the author’s internship at Kakao Enterprise. |
| 2 | Link to our code is available at https://github.com/ahrii-kim/suboptimal_test_set
|
| 3 | Note that the purpose of our evaluation does not involve clarification of what a better MT model is. In that context, we anonymize the models. |
| 4 | |
| 5 | |
| 6 | Google Translate is known to be one of the most robust online translation models in many language pairs. Despite its fame, is was not employed in our experiment after having tested that it’s false positive ratio of sentence-wise TER scores reached 88.69%, which meant that the contaminants were not a sole factor of the variation. |
Figure 1.
Topic classification of (a) training set and (b) test set of WMT 20.
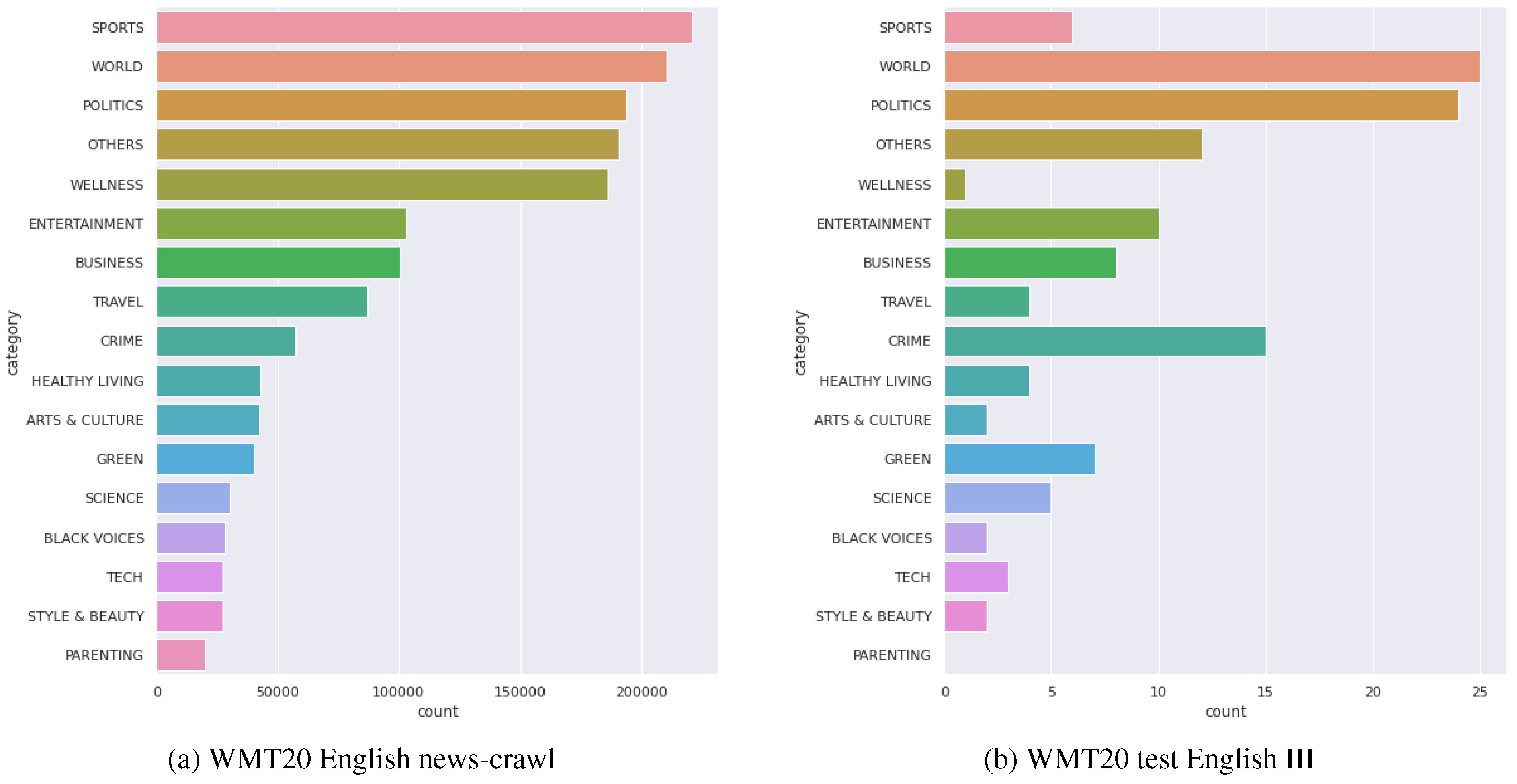
Figure 2.
Score variation of Sign Test (BTS→ATS) for MT and MT.
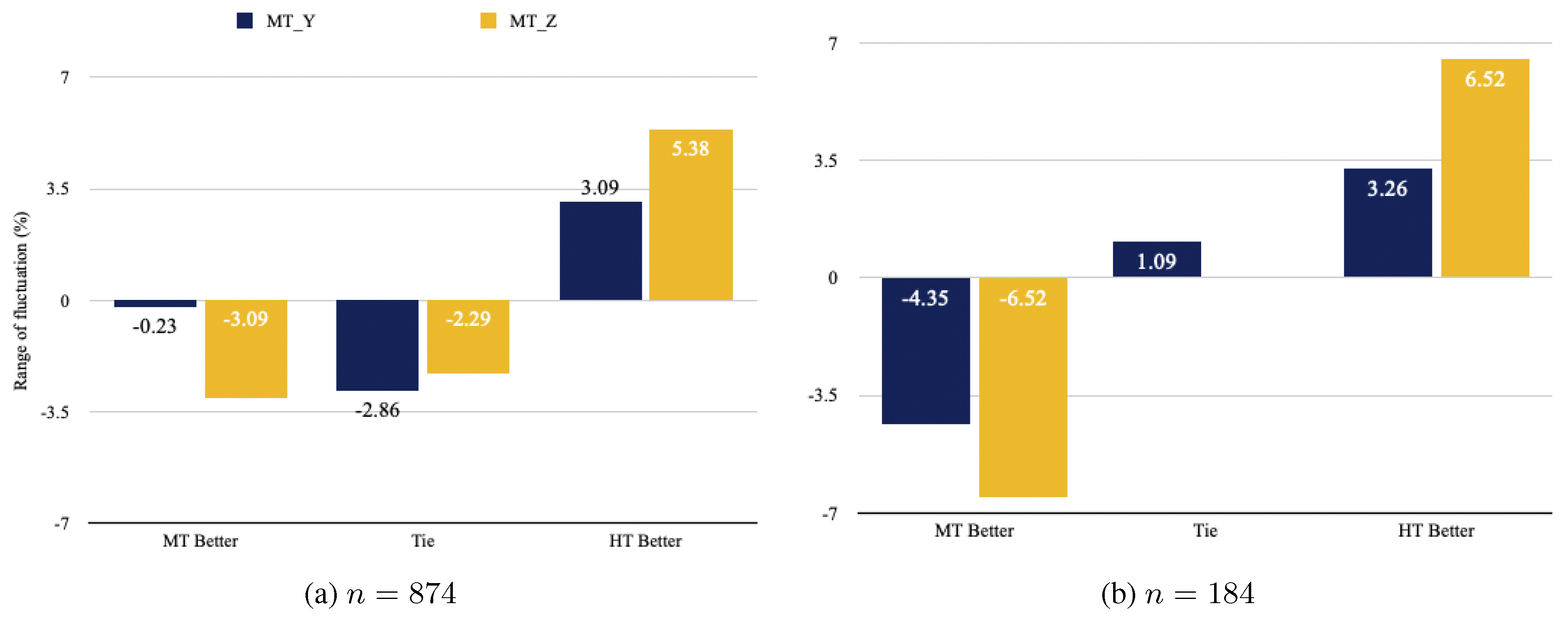
Figure 3.
Absolute score variation of RR (BTS→ATS) in two volumes of the data set.
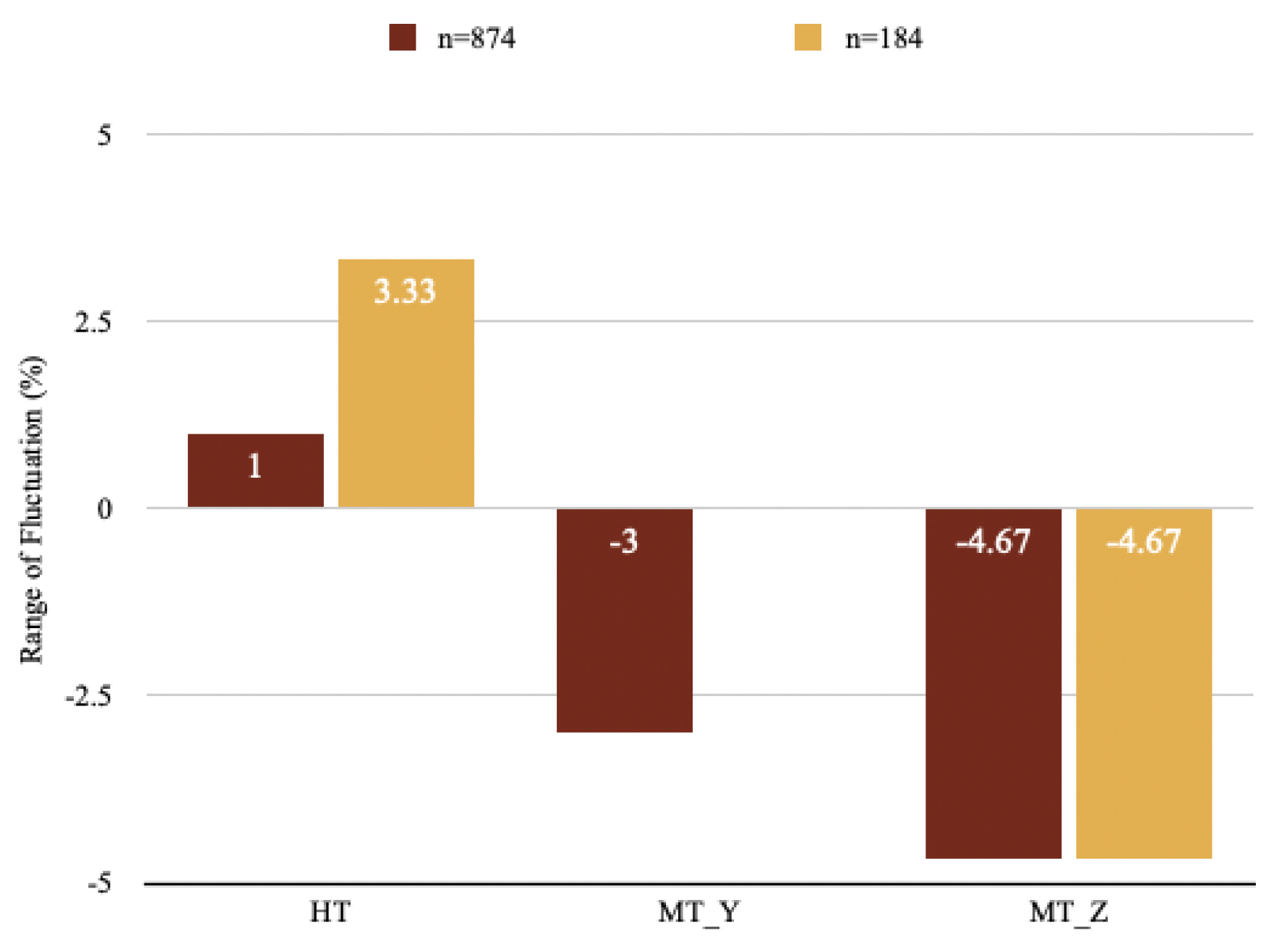
Figure 4.
Inter-annotator agreement measured by 11 groups(A-K) by Cohen K. The scores are in ascending order.
Figure 4.
Inter-annotator agreement measured by 11 groups(A-K) by Cohen K. The scores are in ascending order.
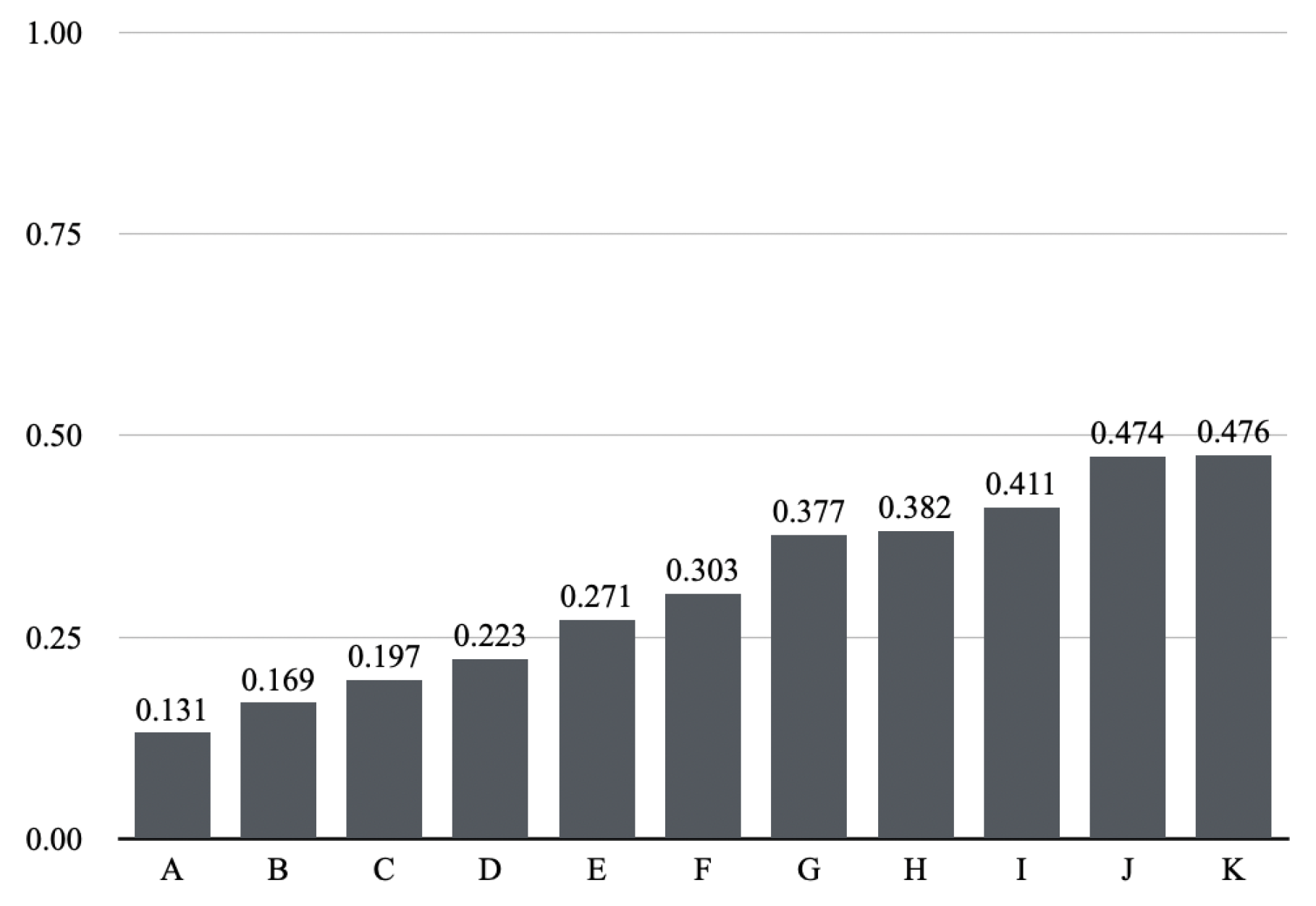
Figure 5.
MT’s exemplary sentence of . The contaminant is an absence of end quote (Category: Quotation marks). Back-translations are created from Google Translate. The source texts of BTS and ATS are brifed as BTS-ST and ATS-ST.
Figure 5.
MT’s exemplary sentence of . The contaminant is an absence of end quote (Category: Quotation marks). Back-translations are created from Google Translate. The source texts of BTS and ATS are brifed as BTS-ST and ATS-ST.
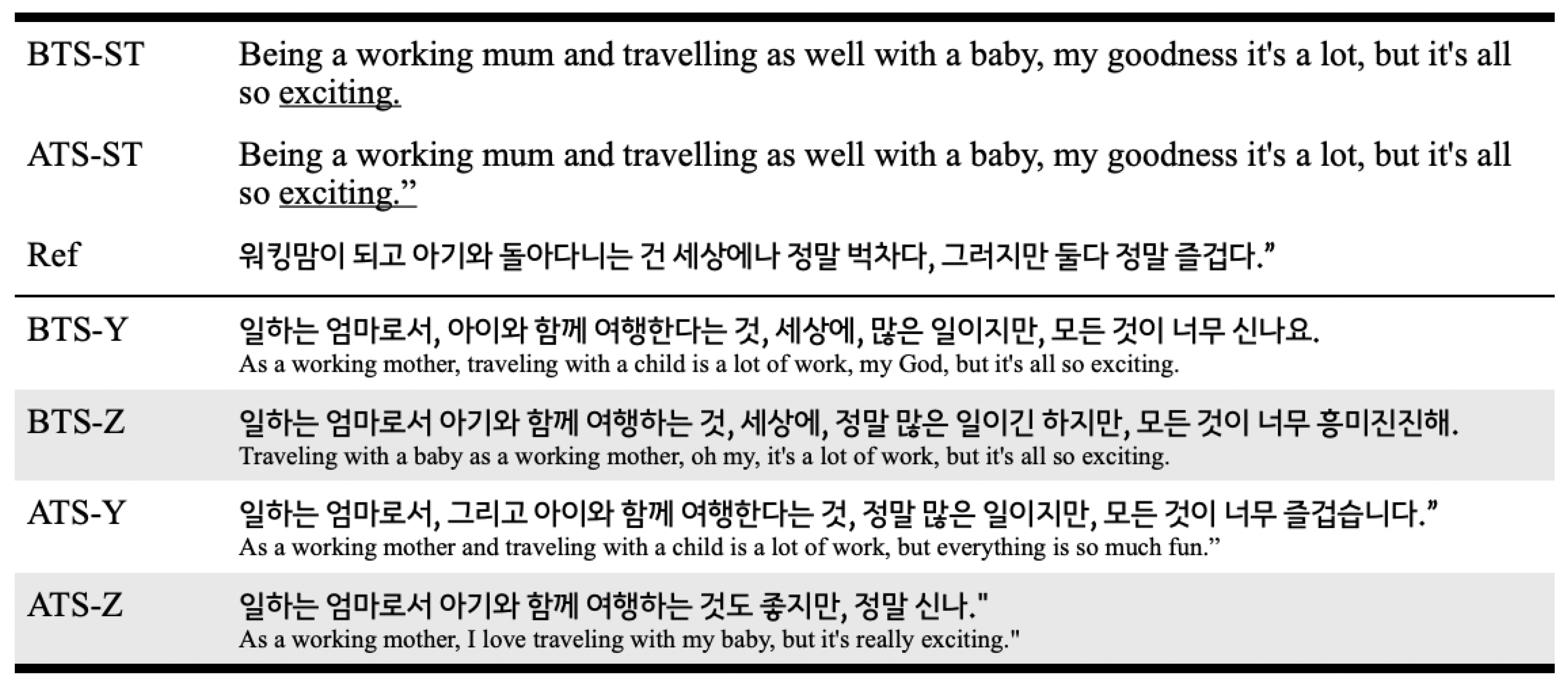
Table 1.
Statistics of English source texts of WMT 20 test set. The paragraph-related information is only given in English III.
Table 1.
Statistics of English source texts of WMT 20 test set. The paragraph-related information is only given in English III.
| Document | Sentence | Distinct Word | Paragraph | Sentence/Paragraph | ||
|---|---|---|---|---|---|---|
| Mean | Max | |||||
| English I | 63 | 1,000 | 4,970 | - | - | - |
| English II | 61 | 1,002 | 5,040 | - | - | - |
| English III | 130 | 2,048 | 7,892 | 1,418 | 1.44 | 9 |
Table 2.
Type of contaminants in the English III test set of WMT 20. Asterisks(*) are excluded from the total counts.
Table 2.
Type of contaminants in the English III test set of WMT 20. Asterisks(*) are excluded from the total counts.
| Error Category | Count |
|---|---|
| Quotation marks | 64 |
| Apostrophe | 14 |
| Omission | 50 |
| Cultural difference* | 30 |
| Spacing | 9 |
| Typo | 9 |
| Omission of period | 8 |
| Missing headlines | 4 |
| Caption | 3 |
| Irrelevant content | 3 |
| Grammar | 1 |
| Out-of-context extraction* | 18 |
| Total | 101 |
Table 3.
Amount of collected assessment data per system (sys) and sentences (sent).
| Pair | Sys | Assess | Assess/Sys | Assess/Sent |
|---|---|---|---|---|
| en→ko | 3 | 5,244 | 1,748 | 2 |
Table 4.
Result of automatic metrics for MT, MT, and Google Translate (GT) in BTS and ATS.
| BTS | ATS | |||||
|---|---|---|---|---|---|---|
| MT | MT | GT | MT | MT | GT | |
| BLEU | 19.78 | 20.19 | 13.12 | 19.78 | 20.24 | 9.49 |
| TER | 0.65 | 0.66 | 0.76 | 0.65 | 0.66 | 0.82 |
| chrF2 | 0.27 | 0.27 | 0.19 | 0.27 | 0.27 | 0.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



