
Submitted:
24 January 2023
Posted:
30 January 2023
You are already at the latest version
Abstract
Natural hazards threaten millions of people all over the world. To address the risk, exposure and vulnerability models with high resolution data are essential. However, in many areas of the world, exposure models are rather coarse and aggregated over large areas. Although OpenStreetMap (OSM) offers great potential to assess risk at a detailed building-by-building level, completeness of OSM building footprints is still heterogeneous. We present an approach to close this gap by means of crowdsourcing based on the mobile App MapSwipe, where volunteers swipe through satellite images of a region collecting user feedback on classification tasks. For our application, MapSwipe was extended by a completeness feature that allows to classify a tile as “no building”, “complete” or “incomplete”. To assess the quality of the produced data, the completeness feature was applied at four regions. Our results show that the crowdsourced approach yields a reasonable classification performance of the completeness of OSM building footprints. Nevertheless, this study also revealed that volunteers tend to classify nearly completely mapped tiles as “complete”, especially in areas with a high OSM building density. Another factor that influenced the classification performance was the level of alignment of the OSM layer with the satellite imagery.
Keywords:
OpenStreetMap
; MapSwipe
; data completeness
; disaster management
; exposure
; Volunteered Geographic Information
; data quality
1. Introduction
Natural hazards such as earthquakes, floods and tornadoes threaten millions of people all over the world [1]. The effects of these hazards on society and infrastructure depend on the vulnerability towards the hazards [2]. These vulnerabilities are highly dynamic as some are decreasing due to new building codes, preparedness actions and resilient planning, while others are increasing due to rapid urbanization, increased industrialization, aging infrastructure and stronger interdependencies in modern societies [3,4]. Regardless of the different hazards or even combinations of them, it is key for emergency planning, resilience building and first response to catastrophes to understand the risks a society is exposed to. Because risk is the combination of hazard, exposure and vulnerability, all three aspects of the risk chain need to be well understood for any measure to be taken to reduce it [5].
In this paper, we focus on the exposure part of the risk chain. Exposure models, describing the spatial distribution of assets (usually buildings and people) and the relative distribution of different building types show different levels of resolution and precision [6]. In well-regulated countries, such models may describe the location of each building. In high-resolution studies, each building may be individually described in all relevant parameters. However, in many areas of the world, exposure models are rather coarse and aggregated over large areas, sometimes even over entire countries. This results in them being only useful if the damage or losses are estimated at this aggregation level too. To address local planning or local emergency response, exposure models with high resolution down to the building scale are desired.
To create exposure models on the building scale, the location and additional parameters of the buildings such as the building footprint, building height, and building material need to be known. This information is usually provided by cadastral data. However, such data is not available everywhere, either because its use is restricted, expensive or it does not even exist [7].
The free and open geographic data community project OpenStreetMap (OSM) (https://www.openstreetmap.org/) is potentially able to fill this gap. Although OSM data have been used extensively in disaster mapping and management [8], their completeness is heterogeneous, with some areas very well mapped, whilst other areas lacking basic features [9,10,11]. For example, the completeness of highly populated urban areas is often higher than that of remote and rural areas [10,12]. There are also differences between developed and developing countries [11,13]. These disparities depend on social factors, such as population distribution and population density, as well as the location of contributing users [14].
Therefore, the assessment of the spatially heterogeneous data quality in OSM is of great importance. Current approaches can be distinguished mainly in extrinsic and intrinsic approaches. Extrinsic approaches use reference datasets as a benchmark to compare OSM against using indicators such as the length of the road network or the number of buildings or the positional accuracy of features such as buildings [10,15,16]. These approaches face the challenge that reference data of sufficient quality is missing especially for large parts of the global South. Even if reference data is available it might be less current than OSM and cover only a subset of the relevant features [17]. To overcome these issues, intrinsic approaches have been developed which address different aspects of data quality only based on the historical development of OSM [18,19,20,21]. Completeness of map features is thereby for example addressed by fitting saturation curves to the OSM contribution time series to assess the difference between fitted asymptote and current number of objects (e.g., [12]) or by deriving community activity stages [22,23]. The completeness assessment based on saturation curves can only be used for areas with a reasonably high number of OSM features. Other approaches have tried to estimate the expected number of objects based on covariates – such as building density or geometric indicators at street block level to estimate building completeness [24,25], socioeconomic indicators, population density or and urban-rural gradients [12,26,27]. Given large regional differences in both real-world features (such as building density) and mapping activity, the latter approaches are limited with respect to their transferability between regions, especially across urban-rural gradients or cultural boundaries.
The Humanitarian OpenStreetMap Team (HOT (https://www.hotosm.org/)) and other humanitarian organizations have been addressing this issue since 2010 by activating volunteers to map buildings and roads. HOT stimulated volunteers through mostly catastrophe-related activities in collaboration with first responders in need of good maps with building locations. This imminent benefit of the volunteers’ work for first responders has certainly drawn a lot of attention to humanitarian mapping activities in OSM. However, HOT and other organizations have not limited their activities to ongoing or imminent catastrophes but expanded them to mapping larger areas, a.k.a. putting them on the map [11,14].
While a lot of resources and tools are in place to ease mapping in OSM, still some learning effort is needed for newcomers wanting to contribute. To ease that initial hurdle, the smartphone application MapSwipe (https://mapswipe.org/) has been developed and is maintained by the Heidelberg Institute for Geoinformation Technology (HeiGIT) in cooperation with the British Red Cross (BRC), the Humanitarian OpenStreetMap Team (HOT), Médecins Sans Frontières (MSF) and volunteers. MapSwipe introduced the aspect of gamification to the detection of buildings by showing the user satellite imagery prompting for the selection of areas in which buildings can be identified by the user [28]. Once these areas are marked, the user swipes the satellite imagery aside to receive the next images, hence the name MapSwipe. As a result of these activities, areas containing no buildings are identified, making it much easier for other volunteers to draw their footprints from the satellite imagery as they do not have to intensely search for them over the total area of interest. This pre-selection of areas for mapping activities has proven useful as nearly 50,000 MapSwipe users have mapped more than 1,750,000 km2 and finished about 500 projects. The data are publicly available for further use (https://mapswipe.org/en/data.html). The HOT activities, together with MapSwipe as well as regular OSM volunteer mapping, have made data in OSM become a ubiquitous part of disaster planning, emergency management and first response [29].
MapSwipe conceptually extents desktop-based approaches such as Tomnod to the smartphone, thereby further lowering the bar for volunteers by enabling them to contribute easily during idle periods such as while riding a subway or waiting for a bus. Tomnod–a former project of the satellite company DigitalGlobe–was known for its campaigns such as searching for the missing Malaysian Airlines flight MH370 which attracted over eight million participants [30] before being discontinued in August 2019.
Because risk assessment models that use OSM data also have to address the spatially varying completeness, it is important to identify areas with complete OSM building footprints for which detailed exposure models can be provided. Furthermore, emergency groups can plan additional mapping efforts in unmapped areas that are particularly affected by natural catastrophes. In contrast to the previous MapSwipe project types that are used to provide information about the presence or absence of buildings on satellite imagery, we introduced a completeness project type that classifies areas with regard to the completeness of OSM building footprints. This is intended to support steering mapping activities of volunteers–for example in the HOT tasking manger–to areas where information is missing for activities such as disaster response or forecast based financing.
This study aims at investigating the robustness of the completeness data produced by this crowd-sourced approach and aims to examine the following specific research questions:
- What factors influence the performance of the OSM building completeness classification?
- How well can the completeness feature produce reliable results so that it can be used in applications of risk-assessment solutions, such as exposure modeling?
The new completeness feature in the MapSwipe application is part of a larger project. The Heidelberg University, the German Research Centre for Geosciences (GFZ) in Potsdam, the Karlsruhe Institute of Technology (KIT), Research Center for Information Technology (FZI) in Karlsruhe and the company Aeromey GmbH have teamed up in the project LOKI (Airborne Observation of Critical Infrastructures) to deliver a system based on OSM data for rapid damage assessment after earthquakes using a variety of technologies including unmanned aerial vehicles (UAV), machine learning, crowd-sourcing for recording the disaster scene, and exposure models at the building scale. LOKI combines in an interdisciplinary way new technologies with existing expertise in earthquake research and earthquake-engineering knowledge [31]. In this light, the completeness feature from MapSwipe aims to increase the resolution of existing exposure models from aggregated exposure information to a detailed building-by-building description, and to identify areas where further mapping effort is required.
This paper is divided into seven sections. The next section presents the MapSwipe data model, followed by a case-study description, covering the four test areas. The subsequent section assesses the robustness of the completeness feature and the derived data as well as a performance analysis of the classification result, which uses reference data that is presented in section five. In the last sections, the results are discussed and final remarks are presented to conclude this paper.
2. MapSwipe Data Model
MapSwipe is a mobile application that was developed within the Missing Maps project in 20142. Generally, the app comprises four important concepts: projects, groups, tasks and results. A project describes a region of interest. Based on the defined region, satellite imagery tiles are requested from a specific imagery provider. While creating the project, the project name, a project image, a zoom level (usually zoom level 18, extending approx. 150m in equatorial areas and about 100m in central Europe), and the number of users that are requested to verify a tile, can be defined. The MapSwipe tasks correspond to the satellite imagery at the specified zoom level. Other parameter such as metadata about the map provider can also be specified.
Regarding the completeness feature, each task is associated with a satellite imagery tile from Bing Maps with a semi-transparent overlay of the OSM building footprints. The mobile app, representing the client, can then request these tasks from the database. In order to enable a fast and efficient communication between the client and the database, groups have been introduced to reduce the amount of client requests. Each group consists of several tasks, which stands for one mapping session.
Results contain information on the user classification. A single classification result comprises information about the task ID, task geometry and tile classification. For the completeness feature project type, volunteers have to classify the completeness of each task into three categories: “no building”, “complete”, “incomplete”. The classification is conducted by tapping on each tile. The main screen of the app is divided into six tasks (c.f. Figure 1). A tile is considered complete, if the blue colored OSM building footprints cover all the buildings on the satellite imagery. Conversely, if the OSM building footprint does not cover all buildings visible in the imagery, the tile is regarded as incomplete. In case of no buildings being present on the satellite imagery, there is no need to tap and the user can swipe to the next screen, hereby indicating that the tile does not contain any buildings. Additionally, the users are aided in the tasks by a brief tutorial. The results of the volunteers can be obtained from the MapSwipeDev-API (https://dev.mapswipe.org/api/agg_results/).
3. Case Study
In our case study, we investigated building completeness at four study sites (c.f. Figure 2: Siros, Taipei, Tokyo and Medellin. These sites comprise heterogeneous OSM building coverage including fully complete areas, as well as incomplete areas. The four sites cover an overall area of 89.3 km2 subdivided into 4797 tasks (cf. Table 1). Multiple sites were selected as the varying building shapes, building sizes, building roof textures, as well as different land-cover settings (e.g. trees overlapping buildings) allow for the assessment of the classification behavior of the volunteers in different geographical settings.
In order to create a project in MapSwipe, all four sites were combined into one area of interest. After the project creation, a completeness mapping event was organized on 16 September 2020. Nine participants with different levels of experience took part in the project to evaluate the completeness of OSM building footprints. On average a participant required 0.38 seconds per task with an interquartile range of 0.1 seconds.
4. Methods and Data
4.1. Data
All participants collected completeness-classification data during our mapping event using MapSwipe on their smartphones. Each task was assessed by at least five of the nine volunteers. To validate the crowd-sourced classification results, the data has been compared to a reference dataset. For the reference data, three experts from the LOKI project classified each task carefully, resulting in three expert classification per task.
4.2. Data Pre-Processing
Based on the answers of the five users for each individual task (“no building”, “complete”, “incomplete”), we first computed the aggregated answer for each task by using majority voting. Thus, the aggregated answer was regarded as “complete”, if at least half of the volunteers classified the task as “complete”. The same applied to the other labels (“no building”, “incomplete”). For tasks with no clear majority, the final aggregated label was set to “incomplete”, as Table 2 shows. Since the study by Albuquerque, Herfort, and Eckle [32] has revealed that user tend to oversee small settlements on satellite imagery, we have chosen a pessimistic aggregation method, where a task was regarded as “incomplete” rather than “complete”, or “no building” in case of a tie (cf. Table 2). The same aggregation method has been applied on the raw reference dataset by the LOKI experts.
For the reference dataset and the crowd-sourced classification, 22 and 27 tasks out of 4797 tasks were considered as unclear majority tasks, respectively.
4.3. Analysis: Performance Evaluation
The aggregated results were used as the input for the performance analysis of the crowd-sourced classification using the usual metrics applied in information retrieval (accuracy, sensitivity, precision, F1 Score) as listed in Equations (1)–(4). The measure F1 represents the harmonic mean between the sensitivity and precision value. The results of the crowd-sourced classification were assessed in terms of their correspondance to the expert classification (true positives and true negatives vs. false positives and false negatives). The correspondence was checked for the three binary conditions: “complete” (true) vs. “not complete” (false), “incomplete” (true) vs. “not incomplete” (false) and “buildings” (true) vs. “no building” (false). Tasks where experts and volunteers agreed on the completeness condition were considered as “true positives” (TP), while tasks where both agreed on the absence of the condition were seen as “true negatives” (TN). Accordingly, tasks for which the experts assessed that the presence of a condition is present, but the volunteers chose absent, were regarded as “false negatives” (FN). Finally, tasks, where the experts chose ‘condition absent’ and the volunteers selected ‘condition present’ were considered as “false positives” (FP).
| Accuracy | (1) | |
| Sensitivity | (2) | |
| Precision | (3) | |
| F1 Score | (4) |
4.4. Analysis of Geographic Factors Influencing Crowd-Sourced Classification Performance
As factors influencing the crowd-sourced classification, we considered the share of the task area that was covered by OSM buildings or the number of OSM buildings per task. The analysis was guided by the assumption that it is easier to classify those tasks correctly as “incomplete” that comprise a lower OSM building coverage as shown in Figure 3a. It is presumably more difficult to assign those tasks as “incomplete”, where the OSM building footprints are almost complete (Figure 3b).
OSM data was extracted using the ohsome API [20]. Overlapping building areas were cleaned and resulting geometries intersected with the task boundaries. Afterwards the number of resulting OSM building parts with unique OSM ID and the area of the building parts per task were calculated. This step was performed in R [33] using the packages sf [34] tidyverse [35] and lwgeos [36]. As the tasks differ in their size in the different case study sites, we normalized numbers by the task areas. We compared the statistical distribution of the OSM building area for correctly and incorrectly classified tasks using histograms and conditional density plots. Furthermore, a predictive analysis of the crowd-sourced classification results for the class “incomplete” was conducted by using a logistic regression model. As the residuals of a logistic regression indicated a correlation between the errors of the different sites we applied a binomial generalized linear mixed model [37,38,39] using the logit link function and a random intercept model with the sites as grouping factor. Thereby, calculated fixed effects were corrected for the unaccounted differences between the four sites without limiting the analysis to the specifics of the four case studies as it would have been the case if we would have included the sites as a fixed effect [39]. In the calculations we did not consider tasks with 0 m2 OSM building footprint. The analysis was performed in R using the package lme4 (Bates et al., 2015). In addition to the likelihood-based information criteria AIC and BIC, we also calculated the pseudo-R² values from Nakagawa and Schielzeth (2013), which describe the explained deviance for fixed effects (R²GLMM(m)) and for fixed and random effects (R²GLMM(c)).
5. Results
5.1. Overall Classification Performance
Generally, the metrics for all classes regarding accuracy, sensitivity, precision and F1 score indicated a high agreement between the reference dataset and the majority votes of the participants (cf. Table 3 and Table 4). The highest accuracy value was obtained for the class “no building” (0.98), while the accuracy values of the label “complete” and “incomplete” showed a slightly lower accuracy (0.91, 0.90). The wrong classifications for the category “no building” were stronger affected by false positives (57) (e.g. Figure 4c), rather than by false negatives (34) (e.g. Figure 4d). For the class “complete”, a high sensitivity value was obtained (0.95). The precision value (0.80) was lowest compared to the other classes, due to a higher number of false positives (372). Volunteers wrongly classified 368 tasks as "complete", which should have been classified as label “incomplete” (cf. Table 4). Consequently, the class “incomplete” comprised more of false negatives (412) (e.g. Figure 4a), than false positives (89) (e.g. Figure 4b).
5.2. Classification Performance for Each Site
In general, the performance measures between all sites were relatively similar (cf. Table 5). However there were some interesting deviations between sites. Comparing the different sites together, as for the overall classification performance, the accuracy value for class “no building” was highest, followed by class “complete”. For all sites the class “complete” indicated a higher rate of false positives, rather than false negatives. For the class “incomplete” we observed the opposite characteristics. It seems that for some tasks volunteers tended to assign “incomplete” tasks as “complete”. Comparing all sites, Siros had the lowest sensitivity (0.60) value for the class “incomplete”. A closer inspection of the tasks at Siros showed that the OSM building footprint layer did not exactly align with the satellite imagery (Figure 5). Hence, a shifted OSM layer seems to have affected the performance of the crowdsourced classification.
The results of the classification performance indicate that volunteers achieved a high performance in general. However, for all sites the class “complete” faced a higher false-positive rate. For the class “incomplete”, we observed a higher rate of false negatives. We thus further investigated the effect of factors such as the OSM footprint area and the number of OSM buildings on the performance of crowd-sourced classifications.
5.3. Factors That Influenced the Crowd-Sourced Classification Performance
Tasks with a smaller OSM building area were more frequently classified correctly as “incomplete” (Figure 6), indicating that these tasks might have been easier. In contrast, “incomplete” tasks not classified as “incomplete” appeared more frequently for tasks with a larger OSM building-footprint area relative to the task area (conditional density plot in Figure 6). The same characteristics were observed for the number of OSM buildings per area of the task: incorrectly classified tasks occurred more frequently for sites with a high number of OSM buildings per area (Figure 6). The conditional density plots for the individual sites indicated that the functional relationships were similar across sites but with different offsets at the different sites, specifically for Siros, where the probability of correct classification of incomplete task was much lower at the same number or area of buildings. Furthermore, the plots indicate that the range of the two predictors differed across sites.
The fixed effects part of the logistic generalized linear mixed model (GLMM) for the OSM building area share explained 24% of the deviance in the crowdsourcing performance (cf. Table 6). For the GLMM with the number of OSM buildings per area the fixed effects part explained 26% of the variability in the crowdsourcing performance. AIC and BIC were in favor of the GLMM with the area of OSM buildings as the predictor. For this model, the variance of the normal distribution for the random intercept was higher, indicating a higher variability between sites captured in the random effect - this presumably explains the higher explained deviance (as well as the smaller AIC/BIC values) if both random and fixed effects are considered.
Regression coefficients for both predictors were negative, indicating that volunteers had more problems to correctly identify incompletely mapped areas that already had a relatively high number of buildings or a larger area covered by mapped building footprints.
Figure 6. Conditional density plots for the classification correctness of tasks classified as incomplete by the volunteers dependent on the part of the task area covered by buildings (left column) or the number of buildings per hectar (right column). In addition to the plots for all sites (first row, sub-figures a,b), site specific conditional density plots are shown (second row sub-figures c,d) in addition to the distribution of the explanatory variable by histograms (last row sub-figures e,f). The histograms show the two classes in a stacked way.
6. Discussion
In this study, we analyzed the quality of the crowd-sourced classification of the completeness of OSM building footprints. We showed that the completeness feature in MapSwipe has the potential to produce spatially explicit information about the completeness of OSM building footprints. Factors that influenced the OSM building completeness classification were tasks with a high OSM building density, expressed both by the number of buildings or their footprint area. More buildings or a larger share of the area covered by building footprints distracted the users from a correct “incomplete” classification. After correcting for the correlated error structure, the share of the footprint area lead to a slightly improved model compared to the model based on the number of buildings. Moreover, the classification performance was dependent on how exactly the OSM layer aligned with the satellite imagery. Presumably the currentness of the satellite imagery used in MapSwipe is of importance for the quality of the assessment as well. Unfortunately, image offsets often differ between imagery from different providers. The offset might even vary across the imagery, especially in hilly or mountainous terrain. Using recent imagery might therefore introduce a challenge for volunteers if this introduces an offset between OSM building footprints and imagery. Herfort et al. (2017) have shown that other factors, such as the resolution of the satellite imagery, missing images, as well as presence of clouds, might as well influence the quality of the classification. By successfully testing the approach at four different sites with different building textures, we suggest that the completeness feature in MapSwipe can be applied to most inhabited areas.
A main limitation of this study is the low number of volunteers taking part in the completeness mapping event. It is important to highlight that other authors have shown for OSM that a higher number of volunteers is positively related to the accuracy of the produced data [42]. Because the answer of each MapSwipe volunteer is also prone to errors, a larger group of volunteers would presumably reduce the overall uncertainty (“wisdom of the crowd”). The same applies to the number of experts. The quality of the classification task clearly depends not only on the properties of the task (such as building density, alignment of OSM and satellite imagery) but also on the experience of the volunteers with such pattern recognition tasks, on the knowledge of potential building types in the area as well as on factors influencing the concentration and motivation of the volunteers [43,44,45] These factors are by design not available for the researcher as MapSwipe does not request personal data from the user.
A further limitation of this study was that incomplete tasks did not provide qualitative information about the number of missing buildings. Therefore, the completeness feature does not provide information about the the share of missing buildings in the incomplete tasks. While it would be possible to extend the MapSwipe completeness tool with respect to additional classes—such as “mostly complete”, “up to 50% complete”, etc.—this would come at the cost of increasing complexity. MapSwipe was designed as a tool that requires only a minimum training effort and that uses a simple and easy-to-learn user interface. Extending the tool with more complex features might reduce its attractiveness for its intended users. The current idea is that MapSwipe is used to identify areas that demand more mapping and that the mapping itself is done in established OSM editors. The amount of missingness of buildings could later on be derived by an analysis of the newly mapped features by tools such as the ohsome [20].
[46] proposed a workflow combining deep-learning and crowd-sourcing methods to generate human settlement maps. An extension to this study could be used to perform an automated approach within the incomplete tiles in order to identify the share of missing human settlements automatically. Completely mapped tiles from nearby might be used in this context as a training dataset. As Pisl et al. (2021) have shown it is possible to fine tune pre-trained deep neural networks for building detection based on a relatively small set of additional training data. Furthermore, new products such as the World Settlement Footprint 2015 or similar datasets on the global distribution of built-up areas already relied on crowd-sourcing approaches to assess classification performance and completeness of built-up areas [48]. In this light, the completeness feature in MapSwipe could be used in future applications to complement automated approaches by generating training as well as validation datasets and could also address specific cases in which automated approaches do not perform well.
Despite the low number of volunteers taking part in the completeness mapping project, this study has shown the characteristics of the data produced by the completeness feature from MapSwipe, which can be useful for exposure models. The misclassifications mostly happened in nearly complete tasks. For exposure modeling, these are of minor importance, since results will only be affected marginally if a few buildings in nearly complete tiles are unmapped. It would have been more problematic, if actually incomplete tiles with a big share of unmapped buildings would have had been considered as “complete”.
In our study, we focused on the completeness of buildings. We can think of many other OSM classes such as land-use features or streets where a similar completeness-task design could be developed. In the domain of land-use and land-cover classification studies that underline the potential of crowd-sourcing approaches for better earth observation already exist [49,50]. Further studies are needed to fully comprehend which OSM classes perform well and which OSM classes are too complex. The use of MapSwipe to detect incompletely mapped regions at a small scale is limited to tasks that can be easily detected based on satellite imagery. It is not a silver bullet approach suitable for all types of OSM aspects but complements other approaches such as intrinsic and extrinsic data-quality assessments, incorporation of other Volunteered Geographic Information (VGI) sources such as Twitter [51] and awareness raising campaigns for mapathons [52].
7. Conclusions
Major natural disasters are expected to increase globally in the next centuries. Especially climate change will amplify the number of such disasters. They will likely hit an increasingly vulnerable population [53], increasing the demand for geospatial data for disaster response and preparedness actions. While commercial geospatial data is costly and far from being available worldwide, open geospatial data offer a valuable data source for the full cycle of disaster risk management. Volunteered geographic information (VGI), such as OpenStreetMap, shows great potential for applications in humanitarian aid, however there are still gaps in VGI data regarding completeness and accuracy [29]. The knowledge of incompletely mapped areas in especially hazardous regions can help volunteers to prioritize mapping efforts. An approach such as the presented completeness feature for MapSwipe, which requires little training and can be performed on the users smartphones, provides a huge potential to activate volunteers to help filling these gaps.
Author Contributions
Experimental design and set up of MapSwipe project: Tahira Ullah, Danijel Schorlemmer and Benjamin Herfort, data handling: Tahira Ullah, Benjamin Herfort and Sven Lautenbach, statistical analysis: Tahira Ullah and Sven Lautenbach, writing – original draft, Tahira Ullah; writing – review & editing, Sven Lautenbach, Benjamin Herfort and Danijel Schorlemmer.
Funding
This work was funded by the Federal Ministry for Education and Research (BMBF) in the frame of the research project LOKI (funding code: 03G0890A). Sven Lautenbach and Benjamin Herfort acknowledge funding by the Klaus-Tschira Stiftung.
Data Availability Statement
The data used for the analysis can be found in a pre-processed form at https://figshare.com/s/7f55a28b731d5e89cc72. Data supporting reported results as well as Python and R scripts can be found in the GIScience GitLab repository: https://gitlab.gistools.geog.uni-heidelberg.de/giscience/disaster-tools/loki-analysis.
Acknowledgments
We would like to thank the volunteers in participating during the validation session.
Conflicts of Interest
The authors declare no conflict of interest.
References
- McGlade, J.; Bankoff, G.; Abrahams, J.; Cooper-Knock, S.; Cotecchia, F.; Desanker, P.; Erian, W.; Gencer, E.; Gibson, L.; Girgin, S.; et al. Global Assessment Report on Disaster Risk Reduction 2019.
- Birkmann, J. Measuring Vulnerability to Promote Disaster-Resilient Societies: Conceptual Frameworks and Definitions. Measuring vulnerability to natural hazards: Towards disaster resilient societies 2006, 1, 9–54. [Google Scholar]
- Pittore, M.; Wieland, M.; Fleming, K. Perspectives on global dynamic exposure modelling for geo-risk assessment. Nat. Hazards 2016, 86, 7–30. [Google Scholar] [CrossRef]
- Shan, S.; Zhao, F.; Wei, Y.; Liu, M. Disaster management 2.0: A real-time disaster damage assessment model based on mobile social media data—A case study of Weibo (Chinese Twitter). Saf. Sci. 2019, 115, 393–413. [Google Scholar] [CrossRef]
- Peduzzi, P.; Dao, H.; Herold, C.; Mouton, F. Assessing global exposure and vulnerability towards natural hazards: the Disaster Risk Index. Nat. Hazards Earth Syst. Sci. 2009, 9, 1149–1159. [Google Scholar] [CrossRef]
- De Bono, A.; Mora, M.G. A global exposure model for disaster risk assessment. Int. J. Disaster Risk Reduct. 2014, 10, 442–451. [Google Scholar] [CrossRef]
- Gunasekera, R.; Ishizawa, O.; Aubrecht, C.; Blankespoor, B.; Murray, S.; Pomonis, A.; Daniell, J. Developing an adaptive global exposure model to support the generation of country disaster risk profiles. Earth-Science Rev. 2015, 150, 594–608. [Google Scholar] [CrossRef]
- Poiani, T.H.; Rocha, R.D.S.; Degrossi, L.C.; De Albuquerque, J.P. Potential of Collaborative Mapping for Disaster Relief: A Case Study of OpenStreetMap in the Nepal Earthquake 2015. 2016 49th Hawaii International Conference on System Sciences (HICSS). LOCATION OF CONFERENCE, COUNTRYDATE OF CONFERENCE; pp. 188–197.
- Goldblatt, R.; Jones, N.; Mannix, J. Assessing OpenStreetMap Completeness for Management of Natural Disaster by Means of Remote Sensing: A Case Study of Three Small Island States (Haiti, Dominica and St. Lucia). Remote. Sens. 2019, 12, 118. [Google Scholar] [CrossRef]
- Hecht, R.; Kunze, C.; Hahmann, S. Measuring Completeness of Building Footprints in OpenStreetMap over Space and Time. ISPRS Int. J. Geo-Information 2013, 2, 1066–1091. [Google Scholar] [CrossRef]
- Herfort, B.; Lautenbach, S.; de Albuquerque, J.P.; Anderson, J.; Zipf, A. The evolution of humanitarian mapping within the OpenStreetMap community. Sci. Rep. 2021, 11, 1–15. [Google Scholar] [CrossRef]
- Brückner, J.; Schott, M.; Zipf, A.; Lautenbach, S. Assessing shop completeness in OpenStreetMap for two federal states in Germany. Agil. GIScience Ser. 2021, 2, 1–7. [Google Scholar] [CrossRef]
- Quattrone, G.; Mashhadi, A.; Capra, L. Mind the Map: The Impact of Culture and Economic Affluence on Crowd-Mapping Behaviours. In Proceedings of the Proceedings of the 17th ACM conference on Computer supported cooperative work & social computing - CSCW ’14; ACM Press: Baltimore, Maryland, USA, 2014; pp. 934–944. In Proceedings of the Proceedings of the 17th ACM conference on Computer supported cooperative work & social computing - CSCW ’14; ACM Press: Baltimore, Maryland, USA.
- Haklay, M. How Good is Volunteered Geographical Information? A Comparative Study of OpenStreetMap and Ordnance Survey Datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Törnros, T.; Dorn, H.; Hahmann, S.; Zipf, A. UNCERTAINTIES OF COMPLETENESS MEASURES IN OPENSTREETMAP – A CASE STUDY FOR BUILDINGS IN A MEDIUM-SIZED GERMAN CITY. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. W5. [CrossRef]
- Zielstra, D.; Zipf, A. Quantitative Studies on the Data Quality of OpenStreetMap in Germany. In Proceedings of the Proceedings of GIScience. Vol. 2010. No. 3; 2010; p. 8.
- Barron, C.; Neis, P.; Zipf, A. A Comprehensive Framework for Intrinsic OpenStreetMap Quality Analysis. Trans. GIS 2013, 18, 877–895. [Google Scholar] [CrossRef]
- Minghini, M.; Brovelli, M.A.; Frassinelli, F. AN OPEN SOURCE APPROACH FOR THE INTRINSIC ASSESSMENT OF THE TEMPORAL ACCURACY, UP-TO-DATENESS AND LINEAGE OF OPENSTREETMAP. ISPRS - Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. W8. [CrossRef]
- Raifer, M.; Troilo, R.; Kowatsch, F.; Auer, M.; Loos, L.; Marx, S.; Przybill, K.; Fendrich, S.; Mocnik, F.-B.; Zipf, A. OSHDB: a framework for spatio-temporal analysis of OpenStreetMap history data. Open Geospat. Data Softw. Stand. 2019, 4, 3. [Google Scholar] [CrossRef]
- Senaratne, H.; Mobasheri, A.; Ali, A.L.; Capineri, C.; Haklay, M. (. A review of volunteered geographic information quality assessment methods. Int. J. Geogr. Inf. Sci. 2016, 31, 139–167. [Google Scholar] [CrossRef]
- Gröchenig, S.; Brunauer, R.; Rehrl, K. Estimating Completeness of VGI Datasets by Analyzing Community Activity Over Time Periods. In Connecting a Digital Europe Through Location and Place; Huerta, J., Schade, S., Granell, C., Eds.; Springer International Publishing: Cham, Swizterland, 2014; pp. 3–18, ISBN 978-3-319-03611-3.
- Yeboah, G.; de Albuquerque, J.P.; Troilo, R.; Tregonning, G.; Perera, S.; Ahmed, S.A.K.S.; Ajisola, M.; Alam, O.; Aujla, N.; Azam, S.I.; et al. Analysis of OpenStreetMap Data Quality at Different Stages of a Participatory Mapping Process: Evidence from Slums in Africa and Asia. ISPRS Int. J. Geo-Information 2021, 10, 265. [Google Scholar] [CrossRef]
- Zhou, Q. Exploring the relationship between density and completeness of urban building data in OpenStreetMap for quality estimation. Int. J. Geogr. Inf. Sci. 2017, 32, 257–281. [Google Scholar] [CrossRef]
- Zhou, Q.; Tian, Y. The use of geometric indicators to estimate the quantitative completeness of street blocks in OpenStreetMap. Trans. GIS 2018, 22, 1550–1572. [Google Scholar] [CrossRef]
- Camboim, S.P.; Bravo, J.V.M.; Sluter, C.R. An Investigation into the Completeness of, and the Updates to, OpenStreetMap Data in a Heterogeneous Area in Brazil. ISPRS Int. J. Geo-Information 2015, 4, 1366–1388. [Google Scholar] [CrossRef]
- Neis, P.; Zielstra, D.; Zipf, A. Comparison of Volunteered Geographic Information Data Contributions and Community Development for Selected World Regions. Futur. Internet 2013, 5, 282–300. [Google Scholar] [CrossRef]
- Herfort, B.; Reinmuth, M.; de, J.P.; Zipf, A. Towards Evaluating Crowdsourced Image Classification on Mobile Devices to Generate Geographic Information about Human Settlements. In Proceedings of the Bregt, A., Sarjakoski, T., Lammeren, R. van, Rip, posters and poster abstracts of the 20th AGILE Conference on Geographic Information Science. Wageningen University & Research 9-12 May 2017; 2017., F. (Eds.). Societal Geo-Innovation : short papers.
- Scholz, S.; Knight, P.; Eckle, M.; Marx, S.; Zipf, A. Volunteered Geographic Information for Disaster Risk Reduction—The Missing Maps Approach and Its Potential within the Red Cross and Red Crescent Movement. Remote. Sens. 2018, 10, 1239. [Google Scholar] [CrossRef]
- Baruch, A.; May, A.; Yu, D. The motivations, enablers and barriers for voluntary participation in an online crowdsourcing platform. Comput. Hum. Behav. 2016, 64, 923–931. [Google Scholar] [CrossRef]
- Kohns, J.; Zahs, V.; Ullah, T.; Schorlemmer, D.; Nievas, C.; Glock, K.; Meyer, F.; Mey, H.; Stempniewski, L.; Herfort, B. Innovative Methods for Earthquake Damage Detection and Classification Using Airborne Observation of Critical Infrastructures (Project LOKI); Copernicus Meetings, 2021.
- de Albuquerque, J.P.; Herfort, B.; Eckle, M. The Tasks of the Crowd: A Typology of Tasks in Geographic Information Crowdsourcing and a Case Study in Humanitarian Mapping. Remote. Sens. 2016, 8, 859. [Google Scholar] [CrossRef]
- R Core Team R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021.
- Pebesma, E. Simple Features for R: Standardized Support for Spatial Vector Data. R J. 2018, 10, 439–446. [Google Scholar] [CrossRef]
- Wickham, H.; Averick, M.; Bryan, J.; Chang, W.; McGowan, L.D.A.; François, R.; Grolemund, G.; Hayes, A.; Henry, L.; Hester, J.; et al. Welcome to the Tidyverse. J. Open Source Softw. 2019, 4, 1686. [Google Scholar] [CrossRef]
- Pebesma, E. Lwgeom: Bindings to Selected “liblwgeom” Functions for Simple Features 2020.
- Bolker, B.M.; Brooks, M.E.; Clark, C.J.; Geange, S.W.; Poulsen, J.R.; Stevens, M.H.H.; White, J.-S.S. Generalized linear mixed models: A practical guide for ecology and evolution. Trends Ecol. Evol. 2009, 24, 127–135. [Google Scholar] [CrossRef]
- Schielzeth, H.; Nakagawa, S. Nested by design: model fitting and interpretation in a mixed model era. Methods Ecol. Evol. 2012, 4, 14–24. [Google Scholar] [CrossRef]
- Instituto Adolfo Lutz Métodos físico-químicos para análise de alimentos; 2008; ISBN 9788578110796.
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 2015, 67, 48. [Google Scholar] [CrossRef]
- Nakagawa, S.; Schielzeth, H. A general and simple method for obtaining R2 from generalized linear mixed-effects models. Methods Ecol. Evol. 2012, 4, 133–142. [Google Scholar] [CrossRef]
- Haklay, M. (.; Basiouka, S.; Antoniou, V.; Ather, A. How Many Volunteers Does it Take to Map an Area Well? The Validity of Linus’ Law to Volunteered Geographic Information. Cartogr. J. 2010, 47, 315–322. [Google Scholar] [CrossRef]
- Antoniou, V.; Skopeliti, A. MEASURES AND INDICATORS OF VGI QUALITY: AN OVERVIEW. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. W5. [CrossRef]
- Comber, A.; Mooney, P.; Purves, R.S.; Rocchini, D.; Walz, A. Crowdsourcing: It Matters Who the Crowd Are. The Impacts of between Group Variations in Recording Land Cover. PLOS ONE 2016, 11, e0158329. [Google Scholar] [CrossRef]
- Eckle, M.; de Albuquerque, J.P. Quality Assessment of Remote Mapping in OpenStreetMap for Disaster Management Purposes. In Proceedings of the Geospatial Data and Geographical Information Science Proceedings of the ISCRAM 2015 Conference; p. 2015.
- Herfort, B.; Li, H.; Fendrich, S.; Lautenbach, S.; Zipf, A. Mapping Human Settlements with Higher Accuracy and Less Volunteer Efforts by Combining Crowdsourcing and Deep Learning. Remote. Sens. 2019, 11, 1799. [Google Scholar] [CrossRef]
- Pisl, J.; Li, H.; Lautenbach, S.; Herfort, B.; Zipf, A. Detecting OpenStreetMap missing buildings by transferring pre-trained deep neural networks. Agil. GIScience Ser. 2021, 2, 1–7. [Google Scholar] [CrossRef]
- Marconcini, M.; Metz-Marconcini, A.; Üreyen, S.; Palacios-Lopez, D.; Hanke, W.; Bachofer, F.; Zeidler, J.; Esch, T.; Gorelick, N.; Kakarla, A.; et al. Outlining where humans live, the World Settlement Footprint 2015. Sci. Data 2020, 7, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Fonte, C.C.; Minghini, M.; Patriarca, J.; Antoniou, V.; See, L.; Skopeliti, A. Generating Up-to-Date and Detailed Land Use and Land Cover Maps Using OpenStreetMap and GlobeLand30. ISPRS Int. J. Geo-Information 2017, 6, 125. [Google Scholar] [CrossRef]
- Vargas-Munoz, J.E.; Srivastava, S.; Tuia, D.; Falcao, A.X. OpenStreetMap: Challenges and Opportunities in Machine Learning and Remote Sensing. IEEE Geosci. Remote. Sens. Mag. 2020, 9, 184–199. [Google Scholar] [CrossRef]
- Li, H.; Herfort, B.; Huang, W.; Zia, M.; Zipf, A. Exploration of OpenStreetMap missing built-up areas using twitter hierarchical clustering and deep learning in Mozambique. ISPRS J. Photogramm. Remote. Sens. 2020, 166, 41–51. [Google Scholar] [CrossRef]
- Mobasheri, A.; Zipf, A.; Francis, L. OpenStreetMap data quality enrichment through awareness raising and collective action tools—experiences from a European project. Geo-spatial Inf. Sci. 2018, 21, 234–246. [Google Scholar] [CrossRef]
- Byers, E.; Gidden, M.; Leclère, D.; Balkovic, J.; Burek, P.; Ebi, K.; Greve, P.; Grey, D.; Havlik, P.; Hillers, A.; et al. Global exposure and vulnerability to multi-sector development and climate change hotspots. Environ. Res. Lett. 2018, 13, 055012. [Google Scholar] [CrossRef]
Figure 1.
(a) Green-colored tiles representing complete tiles, untapped tiles representing no building tiles; (b) All orange-colored tiles marked as incomplete.
Figure 1.
(a) Green-colored tiles representing complete tiles, untapped tiles representing no building tiles; (b) All orange-colored tiles marked as incomplete.

Figure 2.
Case study locations. The completeness of mapping in OSM differed across and inside the case studies. However, all four case studies contained a large number of OSM features as indicated by the detail maps which were limited here to the most relevant features. Data source: OpenStreetMap contributors under OdbL and Natural Earth (world map). Map tiles for detailed maps by Carto, under CC BY 3.0.
Figure 2.
Case study locations. The completeness of mapping in OSM differed across and inside the case studies. However, all four case studies contained a large number of OSM features as indicated by the detail maps which were limited here to the most relevant features. Data source: OpenStreetMap contributors under OdbL and Natural Earth (world map). Map tiles for detailed maps by Carto, under CC BY 3.0.
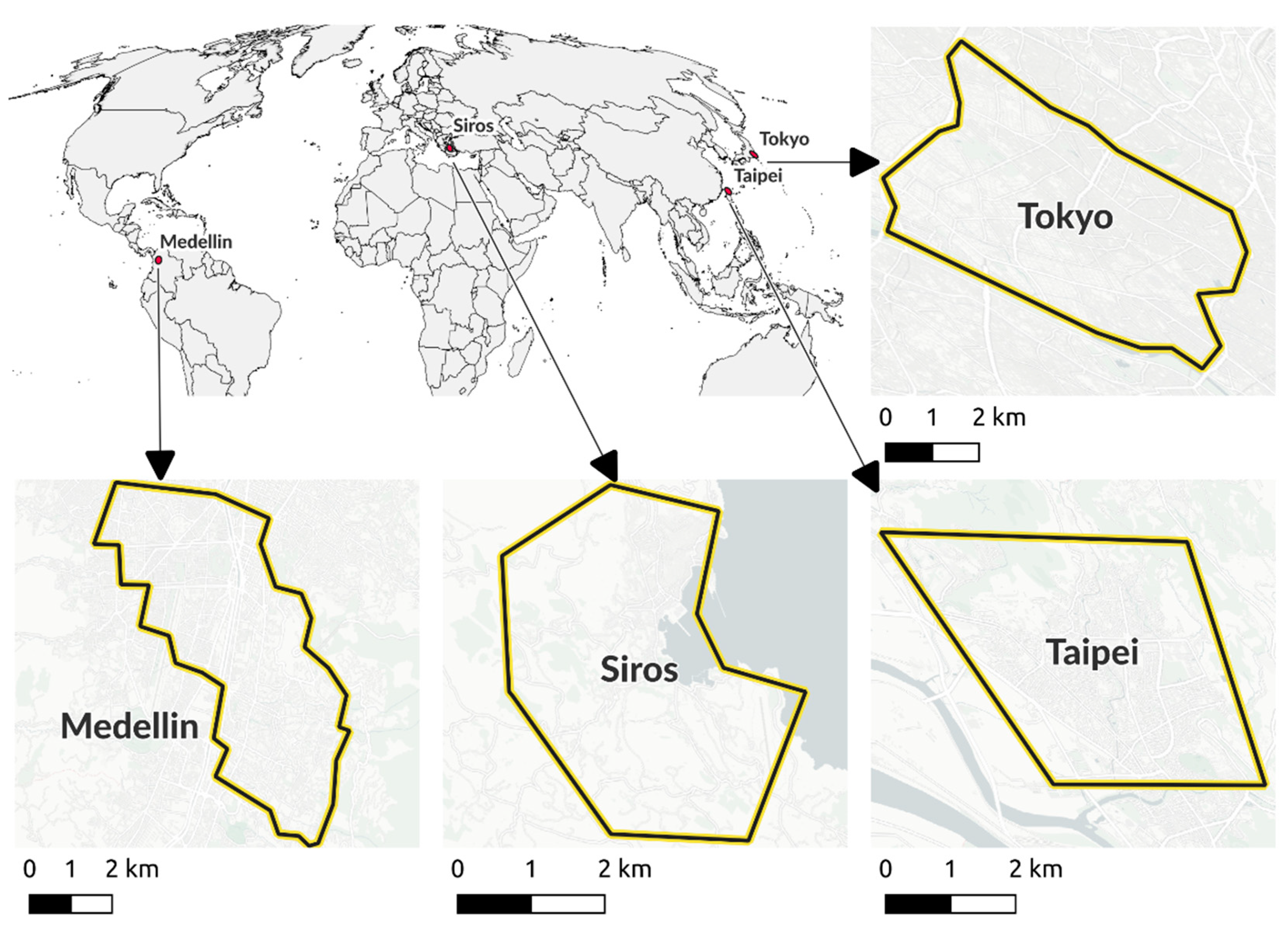
Figure 3.
(a) Example of a task with low OSM building coverage; (b) example of a task with almost complete OSM building coverage.
Figure 3.
(a) Example of a task with low OSM building coverage; (b) example of a task with almost complete OSM building coverage.

Figure 4.
Examples for mismatches between volunteer and expert assessment: (a) Tasks predicted as complete, true class is incomplete; (b) Tasks predicted as incomplete, true class is complete; (c) Tasks predicted as no building, true class is incomplete; (d) Tasks predicted as incomplete, true class is no building. Shown are MapSwipe tiles with the OSM building footprints (blue) overlaid.
Figure 4.
Examples for mismatches between volunteer and expert assessment: (a) Tasks predicted as complete, true class is incomplete; (b) Tasks predicted as incomplete, true class is complete; (c) Tasks predicted as no building, true class is incomplete; (d) Tasks predicted as incomplete, true class is no building. Shown are MapSwipe tiles with the OSM building footprints (blue) overlaid.
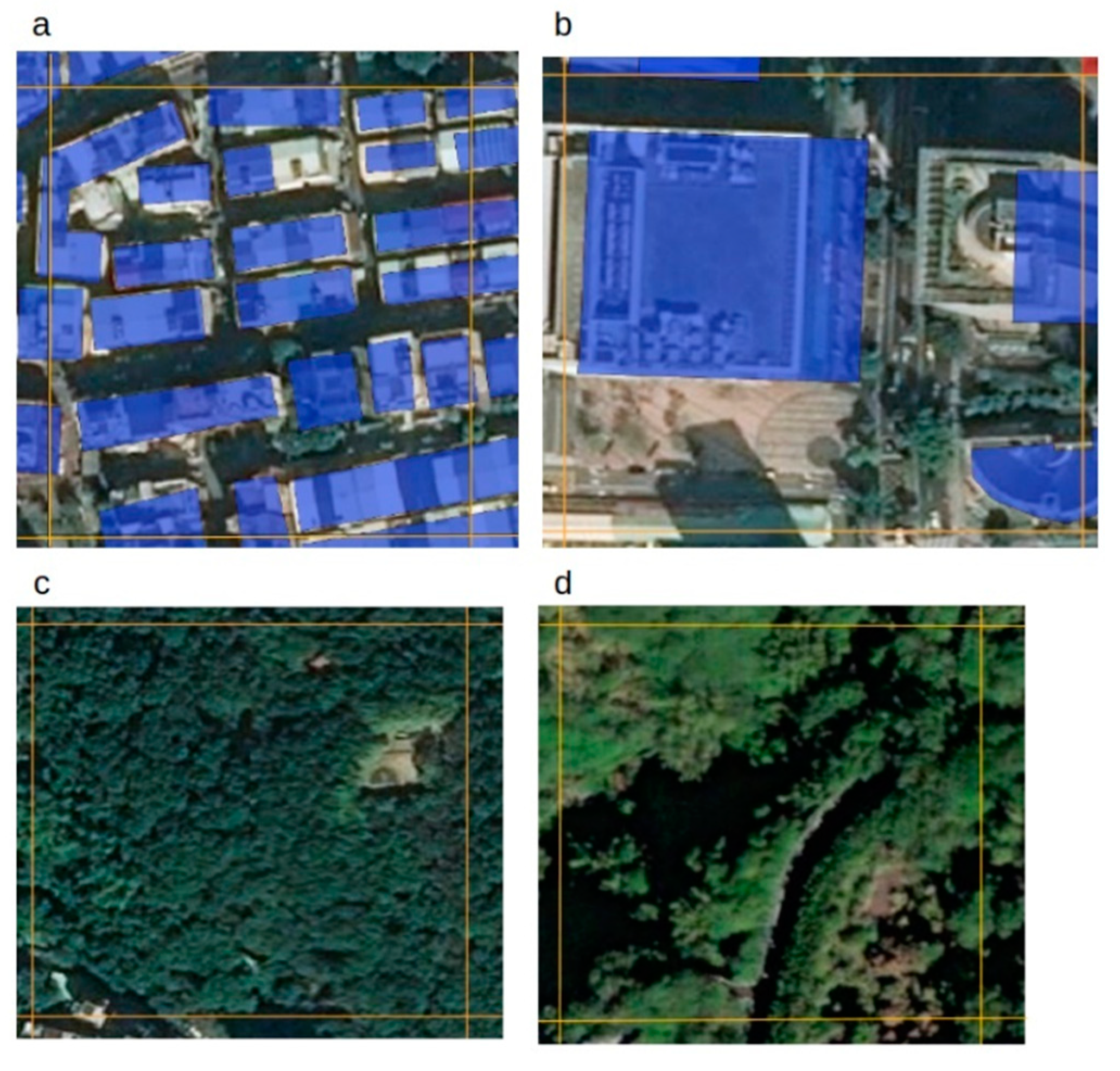
Figure 5.
Misalignment of the OSM building-footprint layer in Siros.
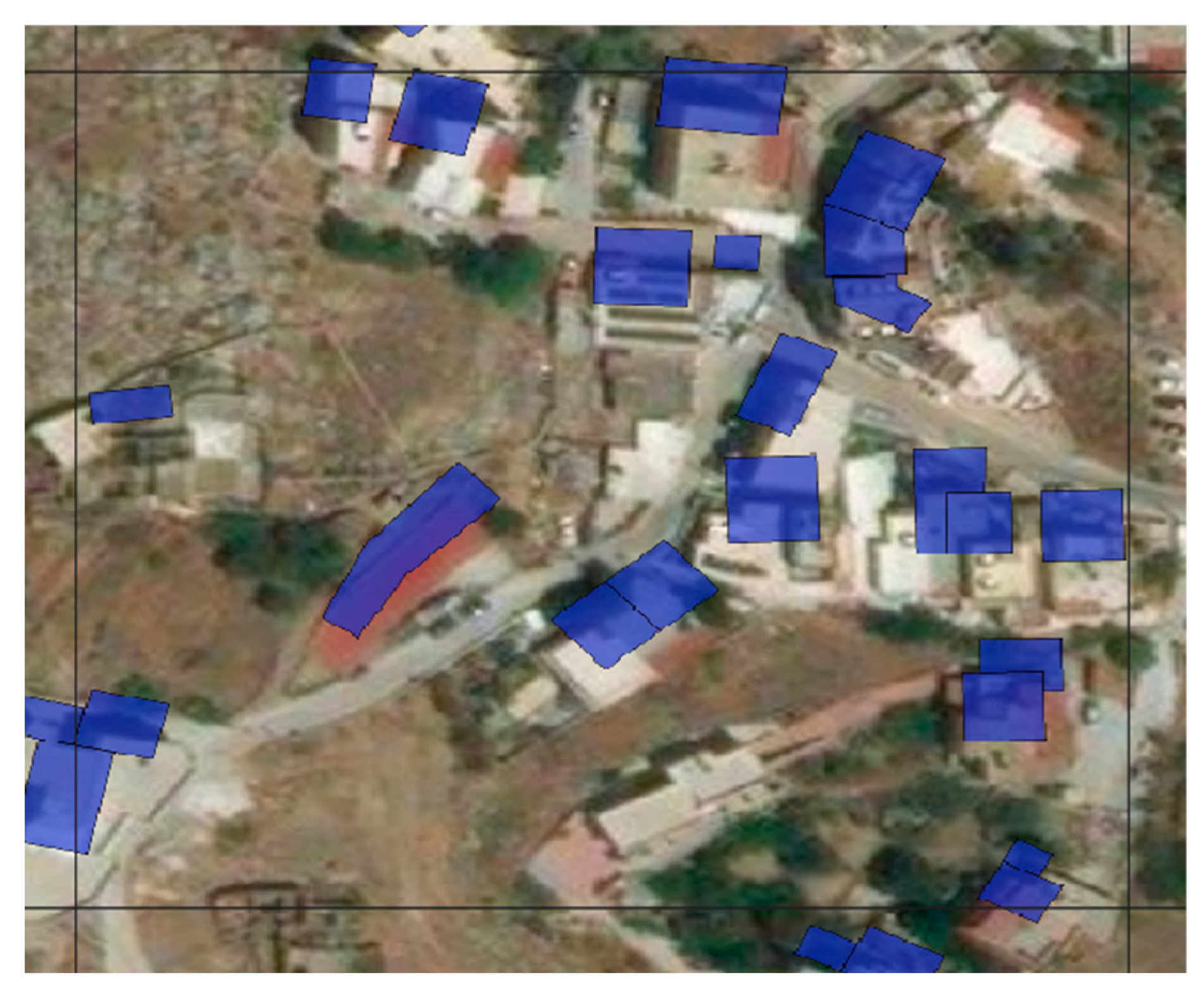

Table 1.
Characterization of the MapSwipe projects used as case-study sites for the assessment of building completeness. For the average number of buildings and the average building footprint area per task area the standard deviation is provided in parenthesis.
Table 1.
Characterization of the MapSwipe projects used as case-study sites for the assessment of building completeness. For the average number of buildings and the average building footprint area per task area the standard deviation is provided in parenthesis.
| Name | Area [km2] | Tasks | OSM Building Coverage | Number of OSM Buildings per Task [1/ha] | OSM Building Footprint Area per Task [%] |
|---|---|---|---|---|---|
| Tokyo | 27.5 | 1914 | Urban area including fully mapped, partly mapped and unmapped areas | 23.6 (24.4) | 21.0 (17.8) |
| Taipei | 13.7 | 792 | Urban area including fully mapped, partly mapped and unmapped areas | 3.6 (5.2) | 11.5 (15.2) |
| Siros | 25.0 | 981 | Island accompanied by smaller patches of agricultural land including fully mapped and partly mapped areas | 7.1 (15.3) | 5.7 (11.4) |
| Medellin | 23.1 | 1110 | Northern part including high building density with almost completely mapped areas, less densely populated southern part consisting of single-family homes with partly mapped areas | 4.8 (8.0) | 13.4 (16.3) |
| Total | 89.3 | 4797 |
Table 2.
Classification aggregation schema. Si (x=”no building”) describes the share of users that assigned the label “no building” to task i. Si (x=”incomplete”) and Si (x=”complete”) describe similar the share of users that assigned the label incomplete or complete to task i.
Table 2.
Classification aggregation schema. Si (x=”no building”) describes the share of users that assigned the label “no building” to task i. Si (x=”incomplete”) and Si (x=”complete”) describe similar the share of users that assigned the label incomplete or complete to task i.
| Majority Rule | Criteria | Aggregated Result |
|---|---|---|
| Clear majority | Si (x=“no building” ≥ 0.5) | “no building” |
| Si (x=“complete” ≥ 0.5) | “complete” | |
| Si (x=“incomplete” ≥ 0.5) | “incomplete” | |
| Unclear majority | Si (“no building”) == Si (“incomplete”) | “incomplete” |
| Si (x=“incomplete”) == Si (x=“complete” ) | “incomplete” | |
| Si (x=“no building”) == Si (x=“complete”) | “incomplete” | |
| Si (x=“incomplete”) == Si (x=“complete”) == Si (x=“no building”) | “incomplete” |
Table 3.
Classification performance metrics for the completeness classification task. TP – true positives, TN – true negatives, FN – false negatives, FP – false positives.
Table 3.
Classification performance metrics for the completeness classification task. TP – true positives, TN – true negatives, FN – false negatives, FP – false positives.
| TP | TN | FN | FP | Accuracy | Sensitivity | Precision | F1 Score | ||
|---|---|---|---|---|---|---|---|---|---|
| Overall performance | no building complete incomplete |
562 1516 2201 |
4144 2837 2095 |
34 72 412 |
57 372 89 |
0.98 0.91 0.90 |
0.94 0.95 0.84 |
0.91 0.80 0.96 |
0.93 0.87 0.90 |
Table 4.
Confusion matrix of the completeness classification task.
| Crowd Classification | |||||
|---|---|---|---|---|---|
| Reference dataset | “no building” | “complete” | “incomplete” | Total | |
| “no building” | 562 | 4 | 30 | 596 | |
| “complete” | 13 | 1516 | 59 | 1588 | |
| “incomplete” | 44 | 368 | 2201 | 2613 | |
| Total | 619 | 1888 | 2290 | ||
Table 5.
Quality measures of the crowd-sourced classification for each site. TP – true positives, TN – true negatives, FN – false negatives, FP – false positives.
Table 5.
Quality measures of the crowd-sourced classification for each site. TP – true positives, TN – true negatives, FN – false negatives, FP – false positives.
| TP | TN | FN | FP | Accuracy | Sensitivity | Precision | F1 Score | ||
|---|---|---|---|---|---|---|---|---|---|
| Siros | no buildings complete incomplete |
318 447 108 |
634 448 772 |
13 24 71 |
16 62 30 |
0.97 0.91 0.90 |
0.96 0.95 0.60 |
0.95 0.88 0.78 |
0.96 0.91 0.68 |
| Medellin | no building complete incomplete |
52 225 755 |
1049 813 280 |
3 15 60 |
6 57 15 |
0.99 0.94 0.93 |
0.95 0.94 0.93 |
0.90 0.80 0.98 |
0.92 0.86 0.95 |
| Taipei | no building complete incomplete |
117 219 373 |
644 517 340 |
15 11 57 |
16 45 22 |
0.96 0.93 0.90 |
0.89 0.95 0.87 |
0.88 0.83 0.94 |
0.88 0.89 0.90 |
| Tokyo | no building complete incomplete |
75 625 963 |
1815 1057 703 |
3 22 224 |
19 208 22 |
0.98 0.88 0.87 |
0.96 0.97 0.81 |
0.80 0.75 0.98 |
0.87 0.84 0.89 |
Table 6.
Fixed and random effects for the logistic GLMM regression model for the identification of factors influencing the correctness of the classification for “incomplete” tasks. The coefficients belong to two single predictor models. Coefficients, confidence intervals (CI) and standard errors are reported at the link scale.
Table 6.
Fixed and random effects for the logistic GLMM regression model for the identification of factors influencing the correctness of the classification for “incomplete” tasks. The coefficients belong to two single predictor models. Coefficients, confidence intervals (CI) and standard errors are reported at the link scale.
| Coefficient | Std. Error | 95% CI | z-value | p-value | |
|---|---|---|---|---|---|
| GLMM using building area share as predictor | |||||
| Intercept | 2.73 | 0.75 | [0.83, 4.65] | 3.62 | 0.00029 |
| OSM building area [%] | -9.11 | 0.54 | [-10.19, -8.07] | -16.83 | < 2*10-16 |
| AIC: 1341.0, BIC: 1357.6 Random intercept: σ2 = 2.20 (95% CI = [0.82–3.67])R²GLMM(m)= 0.24, R²GLMM(c)= 0.55 | |||||
| GLMM using buildings per area as predictor | |||||
| Intercept | 2.05 | 0.55 | [0.65, 3.45] | 3.71 | 0.00021 |
| OSM building count [1/sqm] | -744.9 | 42.4 | [-845.68, -649.57] | -17.57 | < 2*10-16 |
| AIC: 1398.1, BIC: 1414.6Random intercept: σ2 = 1.19 (95% CI = [0.60–2.70]) R²GLMM(m)= 0.26, R²GLMM(c)= 0.46 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



