
Submitted:
17 March 2023
Posted:
20 March 2023
You are already at the latest version
Abstract
Is it possible to develop a meaningful measure for the complexity of a simulation model? Algorithmic information theory provides concepts that have been applied in other areas of research for the practical measurement of object complexity. This article offers an overview of complexity from a variety of perspectives and provides a body of knowledge with respect to the complexity of simulation models. Key terms of model detail, resolution, and scope are defined. An important concept from algorithmic information theory, Kolmogorov complexity, and an application of this concept, normalized compression distance, are used to indicate the possibility of measuring changes in model detail. Additional research in this area can advance the modeling and simulation body of knowledge toward the practical application of measuring simulation model complexity. Examples show that KC and NCD measurements of simulation models can detect changes in scope and detail.
Keywords:
simulation model
; complexity
; Kolmogorov complexity
; normalized compression distance
; resolution
; scope
; model families
1. Introduction
Modeling and simulation (M&S) has contributed greatly to the development of highly capable and reliable systems; it is a powerful tool for developing, understanding, and operating systems of both great simplicity and increasing complexity. As techniques progress and as system designers strive for more capability, M&S practitioners and stakeholders struggle to comprehend how systems operate and, often more importantly, how to protect against catastrophe when systems enter regimes of failure. Some stakeholders assume that M&S necessarily should be implemented with “high fidelity,” expecting that systems be represented in exquisite detail. Practitioners know that M&S is largely a software-intensive activity, and requires considerable resources be devoted to design, development, verification, and validation before M&S tools can be applied for experimentation, analysis, or training. Yet, limited resources require economical considerations to drive when and how much M&S to apply; stakeholders may be impatient to realize their expected return on investing in M&S. Through hard won experience, practitioners build up an intuitive sense of how much detail is required to address a given simulation problem. Is there a faster way to arrive at the insight provided by this intuition? The amount of complexity in a simulation model is driven by the amount of model detail, which is a function of the model’s resolution, scope, size, and interactions [1]. Measuring simulation model complexity would be useful for a number of purposes, driven by several foundational principles that M&S practitioners must consider.
The parsimony principle, often referred to as Occam’s razor after fourteenth century Franciscan philosopher, William of Occam, suggests an inherent bias towards more simple explanations of phenomena [2]. As George Box described of statistical models, “Since all models are wrong the scientist must be alert to what is importantly wrong. It is inappropriate to be concerned about mice when there are tigers abroad.” [3] The principle of representational parallelism (not computational parallelism) asserts that key components of systems should be decomposed to roughly equivalent levels of detail in order to make valid comparisons and inferences. Further, the M&S practitioner does not only have to contend with referential complexity (what in the source system to represent), but also methodological complexity (how that representation is implemented in software) [4]. Measuring complexity in some relative or absolute sense would assist with the simulation model selection problem—that is, which representation of a source system is the right one for answering the question at hand? Such a measure would help to locate a given representation within a multi-level approximation family or to compare across representations that purport to have similar referential complexity but different methodological complexity.
A number of complexity measures have been defined in other areas of research. The following section reviews key perspectives and terms and introduces the concept of Kolmogorov complexity as the most promising for simulation models. Section 4 introduces a set of simple models that incrementally increase explicitly modeled scope, and uses static source code analysis tools to investigate other source code complexity metrics. Then Section 5 demonstrates how Kolmogorov complexity could be a superior measure. Section 6 discusses limitations and challenges to calculating simulation model complexity and suggests future research before Section 7 emphasizes key points and conclusions.
2. Many facets of complexity
Complexity is a complicated word. Scientific rationalism and reductionism triumph when logical reasoning allows one to pick apart complicated systems and examine simple constituent parts as a means to understand a complicated whole.1 In the fields of computer science and information systems theory, and even more broadly in management or natural systems, researchers have proposed a number of uses, meanings, and measures for complexity, both broad and narrow. Examining these different meanings provides insight into the different ways one can regard a system, whether that system be simple, complicated, complex, chaotic, or disordered.
2.1. Defining Complexity
In the broadest sense, Rickels, et. al., give excellent definitions of the related terminology.
Constituent parts of a complicated system have much less interaction and fewer feedback mechanisms than with parts of a complex system.“System is simply the name given to an object studied in some field and might be abstract or concrete; elementary or composite; linear or non-linear; simple or complicated; complex or chaotic. Complex systems are highly composite ones, built up from very large numbers of mutually interacting subunits (that are often composites themselves) whose repeated interactions result in rich, collective behavior that feeds back into the behavior of the individual parts. Chaotic systems can have very few interacting subunits, but they interact in such a way as to produce very intricate dynamics. Simple systems have very few parts that behave according to very simple laws. Complicated systems can have very many parts too, but they play specific functional roles and are guided by very simple rules. Complex systems can survive the removal of parts by adapting to the change; to be robust, other systems must build redundancy into the system (e.g. by containing multiple copies of a part) [8].”
From a machine learning perspective, if a data set is merely complicated (that is, not complex), then one can often build a decision tree (a hierarchical data structure of multi-dimensional breakpoints; “is an input parameter higher or lower than X?”) to understand the data space. Sports broadcasters often share complicated statistics with their viewing audiences, perhaps ironically attempting to pass it off as giving insight into the complexity of sport. A representative example might go something like, “This pitcher has the best earned run average over the past seven years when starting a night game on a Thursday after having an extra day of rest between starts.” A savvy baseball fan will pick out the last of the four factors listed here (past seven years, night game, Thursday, extra day of rest) as the dominant factor, and the others having dubious influence on the pitcher’s success.
However, if a data set is complex, a decision tree alone is not sufficient; one must use a random forest (a probabilistic ensemble of decision trees) or a neural network, or some other algorithm with the capacity to account for the interaction and nonlinearity of the data. Complex systems often exhibit emergence, where individual agent-to-agent and agent-to-environment interactions develop into more complex behaviors in the aggregate—the whole is greater or unexplainable as the sum of the parts [9].
In thermodynamics and statistical mechanics, entropy quantifies the amount of order or disorder in a system and relates microstates to macrostates [10]. This approach was borrowed by Shannon, whose information theory definition of entropy is discussed below [11].
In management theory, Snowden and Boone defined the cynefin2 framework as a taxonomy of leadership approaches that map neatly into the definitions used by Rickels, et. al., and they discuss how understanding complexity can advance scientific management beyond the foundations laid by Taylor [12].
Another broad treatment of complexity comes from the field of cybernetics, the study of communications and automatic control systems in machines, living things, and organizations. Beer used the term variety to measure complexity in a system, defined as the number of possible states of the system [13]. Building on this, Ashby defined the Law of Requisite Variety, which states that for any system with a regulatory process, in order to obtain a desired outcome, the system must have at least as many states in the regulatory process as the number of possible input states [14,15].
The field of complex adaptive systems explores natural and engineered systems that have high levels of composition and interaction, and also learn and adapt to internal and external changes [16,17]. In this field, researchers sometimes use the term “holon,” coined by Koestler in 1968, to describe nodes in a hierarchy (or “holarchy”) that are at once a whole and a part, illustrating the potential for interaction and inter-dependency among and across levels [18].
2.2. Complexity in computer science
In a more narrow sense related to computer science, programmers aspire to write code that accomplishes useful tasks efficiently (programmer communicating to the machine typically via a compiler) and also is maintainable (programmer communicating to other programmers). Code complexity correlates with cost and difficulty in development and maintainability, thus there is great focus in software engineering on simplicity in design and construction [19,20], and several attempts to provide measures for code complexity. Computational complexity, sometimes called asymptotic computational complexity, aims at measuring the resource requirements for executing a given algorithm in terms of space and time—more precisely, memory use and the number of processor cycles [21]. Cyclomatic complexity (CyC), developed by McCabe in 1976, counts the number of linearly independent paths through a piece of code, however, its use in guiding programmers to more elegant and maintainable code has come into question [22]. Recently, Campbell developed an alternative metric called cognitive complexity (CoC) that assesses code complexity based on the following rules: “1. Ignore structures that allow multiple statements to be readably shorthanded into one; 2. Increment (add one) for each break in the linear flow of the code; 3. Increment when flow-breaking structures are nested.” [23] CoC also accounts for nesting and control flow structures. The chief aim is to make concrete which portions of code break the flow while reading it. 3
Early in the development of computer science, researchers recognized the need for methods to measure the runtime performance of software, and analyzing code with a software profiler is now a standard technique for software engineers. One such profiling technique is to keep track of which part of a program is running, and for how long—the GNU profiler gprof calls this the flat profile [24].
Software profiling is naturally an important consideration for M&S practitioners, as much of M&S involves implementing models and simulations in software. Control and Simulation Language (CSL), first described in 1962, allowed programmers to define a number of activities which would be invoked through simple or complex logical tests [25]. This approach enables activity scanning, counting the number of times an activity is activated [26]. Muzy, et al., tweaked the definition of activity to be, more generically, the number of events occurring during a simulation [27], and Capocchi, et al., employed this definition to develop a methodology for selecting the level of detail in a hierarchical simulation model [28].
2.3. Information theory views of complexity
In the field of information theory, three related concepts are Kolmogorov complexity (also referred to as algorithmic complexity), Shannon’s entropy and Bennett’s logical depth, and Lemberger & Morel give all three ideas excellent treatment [29]. These characterize complexity in terms of the description of a system, “assuming that we have a specific goal in mind” for the description. Shannon’s entropy considers the amount of randomness present in a system, often in the context of ensuring the error-free transmission of information through a communication channel. It relies on the fact that characters in a given language occur in words at a certain frequency, and the goal is to “encode strings of characters, whose probabilities are known, in such a way that their average encoded length is as short as possible” [29], and entropy is the average length of the optimal encoding. Logical depth, meanwhile, has the goal of finding “the description that requires as little computation as possible to reproduce the given string” [29]. This allows for a longer description, provided that it reduces computation. Contrast this with Kolmogorov complexity, which is more often thought of as the length of the most possible compression of a string, or as the minimum description length of an object. In all three ideas, the metric provides a useful estimate of optimality, but there is never a guarantee of finding the global optimum. Another key assertion of Lemberger & Morel is that there is no single concept of complexity relevant for all purposes. One must specify in what context or for what purpose one wants to consider a system’s complexity, reminiscent of how a wave function in quantum physics collapses when one makes an observation.
2.4. Kolmogorov complexity
A review of the precise definition of Kolmogorov complexity (KC) is useful here, as later sections will build on these ideas. In the 1960s, three scientists—Ray Solomonoff, Andrey Kolmogorov, and Gregory Chaitin—separately discovered very similar theoretical results in the fields of mathematics and computer science that together formed the foundation of the concept of Kolmogorov complexity and algorithmic information theory (AIT) [30,31,32,33,34]. Formally, the Kolmogorov complexity C of an object X is defined as
where p is a computer program that, when executed on a universal Turing machine U, produces X as an output. KC is also sometimes referred to as the minimum description length for an object, and is often expressed in bits, and scaled by log2.
Note that X as an “object” does not mean an instance of an object-oriented class loaded in the memory of a running computer program, but rather, is used in the generic sense of the word. A Wikipedia article about the Kamchatka Peninsula (selected to be mentioned here by choosing geographic coordinates using the website random.org), a password for user authentication on a computer network or website, the third coffee mug in your kitchen cabinet, the song Heat Waves by Glass Animals (number 1 streamed song on Spotify on 4 February 2022), and Andrew Wyeth’s painting Christina’s World are all objects, and each has a KC that can be calculated, at least in theory.
In practice, directly computing KC turns out to be impossible most of the time. Much as it is not possible to determine if an arbitrary computer program will run to completion (defined by Alan Turing as the “halting problem”), KC is uncomputable for non-trivial examples. This is so because there is no guarantee that a given p is the shortest program that will produce X. Despite the direct uncomputability of KC, there are methods to approximate its value, establish a bound, or otherwise employ the concept in useful ways. For example, suppose X is stored in a list in computer memory. To produce X, one needs only the index of X in that list, and the KC of X is its index. Cilibrasi & Vitányi used this approach to define the Google Similarity Distance [35], which uses the position of words and phrases in Google search results as a complexity measure and distance metric.
Another approach to approximate KC is through data compression. The information carried by an object is what remains when all redundancy is removed, or in other words, what is left over after maximal lossless compression. Cilibrasi & Vitányi describe how compression/decompression programs exhibit desirable properties that make them excellent choices as the program p in the definition of KC [36]. While their approach is robust to a number of compression algorithms, consider the Lempel-Ziv-Welch (LZW) compression algorithm [37], and the related Lempel-Ziv-Markov chain (LZMA) algorithm [38], which create a dictionary of the data to be compressed. The dictionary can be stored as a hash table and the compressed representation of the data stored as a sequence of keys. The concatenation of the hash values and the sequence of keys is in most cases smaller than the original data. The concatenation of the decompression algorithm and the compressed data takes the place of the program p in Equation 1, and the log2 of the size of the compressed data file is a suitable approximation of the KC of the original uncompressed data.
At the heart of the approach from Cilibrasi & Vitányi is their concept of normalized compression distance (NCD), which they demonstrated as a distance metric for clustering a wide variety of data types with no requirement for a priori knowledge of data features or subject matter.
Here, C(x) is the compressed size of data object x and C() is the compressed size of concatenated data objects x and y. When concatenated data objects have a high compression ratio and low NCD, this indicates the two objects share a significant amount of mutual information. Section 5 provides an example application of these concepts for measuring simulation model complexity, while the next section explores the established theory of simulation model complexity, proposes refined definitions of key terms, and illustrates these terms with a set of simulation model archetypes.
3. Simulation model complexity, abstraction, and model families
One turns to modeling and simulation (M&S) in a number of situations with the expectation that time invested in developing and executing simulation experiments will result in a sufficient return of knowledge to justify the investment. The economics of M&S drive a desire to maximize the return on investment by developing a model that, in the ideal, contains just enough detail to inform the problem at hand [39,40]. For many applications of M&S, models are necessarily simplifications of the source system they are intended to represent, implying that the cost to develop and experiment with the model is less than the cost to develop and experiment with the source system. Zeigler, et al., define model abstractions as valid simplifications of the source system [1]. For very complicated and complex systems-of-systems (SoS), a single representation is insufficient to inform all of the questions and decisions encountered through the SoS life cycle. A number of researchers have explored multi-perspective and multi-resolution modeling, and in the United States Department of Defense (DoD) and United States Air Force (USAF), it is common to categorize broad model families in terms of the size, scope, and resolution they provide to investigate the source system. These categories are often depicted in the shape of a triangle, with higher resolution models at the base and more abstracted but more broadly scoped models at the top [41,42,43,44,45,46].
3.1. Defining simulation model complexity
Even more narrowly than the above discussion in Section 2, with respect to simulation models, Zeigler, et al., distinguished between three kinds of complexity. A simulation model’s overall complexity is driven by the size/resolution/interaction product, which are illustrated in Figure 1 [1]. Quoting from Zeigler, “Scope refers to how much of the real world is represented, resolution refers to the number of variables in the model and their precision or granularity.” Further, Zeigler, et al., define size as “the number of components in a coupled model,” and is strongly determined by scope most of the time. Building on this foundation, the three kinds of complexity are analytic, simulation, and development complexity. Analytic complexity is the number of states that fully explore the global state space of a model. The simulation complexity is essentially the computational complexity of the simulation program, although they characterize it in more specific simulation terms, such as the number of interactions. Third, the exploratory complexity is the computational complexity of searching a modeling space.
Other foundational research into defining model resolution comes from Davis and several collaborators. Davis and Hillestad defined resolution as having many facets, including
- Entity: Modeled agents are individuals or aggregated as groups
- Attribute: Account for specific component performance or overall system performance/effectiveness
- Logical-dependency: Do (or do not) place constraints on attributes and their interdependence
- Process: State changes computed at different entity/attribute resolutions
- Spatial and Temporal: Finer or coarser scales of space and time [42]
Davis and Hillestad’s perspective seems to lump Zeigler’s concept of scope into the idea of attribute resolution and logical-dependency resolution. Merging the two approaches, the definitions in Table 1 frame the concept of simulation model complexity.
3.2. Model family archetypes
As introduced previously, when developing a complex SoS, such as future force designs for defense acquisition, it is often useful to conceptualize a hierarchy of simulation model representations and analysis of the SoS. The levels in this modeling, simulation, and analysis (MS&A) hierarchy, depicted in Figure 2, align to levels of key performance parameters of the SoS that provide insight into its capabilities, namely measures of performance (MoPs), measures of effectiveness (MoEs), and measures of objectives (MoOs) [46].
The following discussion and Figure 3 illustrate a number of simulation model archetypes for these levels of analysis.
- A performance model emphasizes resolution in a small area of scope, for example, a computational fluid dynamics model of airflow over a wing. While not true in all cases, simulations with performance models typically occur over a short duration (perhaps on the order of seconds or milliseconds), or may even be static in time.
- An effectiveness model trades away some of the resolution to consider broader scope. The flight dynamics models described below in Section 4.1 can be used for effectiveness analysis, in many cases, particularly when assessing the effectiveness of mission systems and payloads on an air vehicle. Effectiveness simulations typically span minutes to hours of simulated time.
- A utility model generally treats most components of a system with the lowest resolution in order to investigate the system in its most broad scope. For assessing an air vehicle’s utility to meet strategic and operational objectives, its movement may be characterized very simply, such as with an average cruising speed to compute the time it takes to travel to its destination. Utility simulations cover many hours, days, or even longer duration.
The final archetype in Figure 3 is that of a typical model, intended to convey that simulation models tend to have a particular focus area with higher resolution in support of the model’s intended use. A typical model does not match the resolution of the theoretical source system, nor does it cover the entire scope of the source system, as there will remain unknown and unobservable effects. In Figure 3, the darkly shaded areas of the figure depict the resolution and scope of each archetype, relative to the theoretical source system.
4. Investigating complexity measures
This section explores two of the source code complexity measures discussed above in Section 2, cyclomatic complexity (CyC), and cognitive complexity (CoC).
4.1. Flight dynamics simulation models
To illustrate the application of measuring the complexity of a family of related simulation models, consider a family of models that represent the motion of an air vehicle. The first model is the most detailed, inspired by a description of the equations of motion provided in a textbook for game developers by Grant Palmer, hereafter called the Palmer model. The Palmer model calculates the four primary forces of flight in three dimensions: lift, thrust, gravity, and drag [47]. The authors implemented this model in Rust4 and we use a fourth-order Runge-Kutta integration scheme to solve the differential equations of motion for a Cessna 172 Skyhawk. Note that the Palmer model does make several simplifying assumptions, such as modeling the aircraft as a point mass, not an extended rigid or flexing body. This level of abstraction is suitable for many applications, such as a virtual flight simulation where the goal of the flight dynamics model is to provide a user with a sufficiently realistic experience of piloting a specific aircraft under typical flight conditions.
At an even higher level of abstraction, consider three models implemented as individual Rust functions for simple kinematic equations of motion with two or three degrees of freedom: 2DOF, 2DOF-TRC, and 3DOF. The equations are based on a white paper by Weintraub [48]. The model 2DOF-TRC applies a turn rate constraint that limits the air vehicle’s ability to change its heading in a single time step. Each function updates an input state vector of 12 components consisting of the aircraft’s position, velocity, orientation, and orientation rates. The functions perform direct propagation (Euler’s method) and no more sophisticated numerical integration, requiring that the time step remains small. Together, they represent an incremental relaxing of assumptions about the aircraft’s motion and incremental addition of details that progressively better describe the motion of a true air vehicle. Even as simplistic as they may seem, such representations are used frequently in MS&A of future air vehicle concept exploration and requirements development.
4.1.1. Static Analysis Tools and Methodology
Members of the Rust community developed two static analysis tools that calculate relevant metrics. Clippy is an open source linter that at one time calculated CyC then switched to CoC, although not without dissenting voices about CoC’s usefulness.5 [49] Clippy does not report CoC by default, but can be forced to output CoC for any function that has non-zero CoC by setting the parameter cognitive-complexity-threshold to 1. The rust-code-analysis (RCA) library calculates CyC, CoC, and a number of other metrics [50].
The most appropriate comparisons with the simple models are with those in the Palmer file fdm.rs, as these are the equations directly involved in updating aircraft state. This analysis ignores other functions.
4.1.2. Results and Interpretation
Results are shown in Table 2. Clippy only provided CoC metrics for the three functions in fdm.rs of the Palmer model, not the simple models, indicating the simple model functions all have zero CoC. Clippy and RCA disagree on the reported value of CoC for the Palmer functions and for update_2dof_trc, although the trends are mostly consistent. The RCA CoC and RCA CyC values almost never match—one would not expect them to—yet there is general agreement in the trends between them.
Inspecting the code for the Palmer model, these functions account for various situations with logic checks in IF statements. In calculate_forces, there are logic checks for computing lift (below or above maximum angle of attack, flap position, and ground effects) and for modeling the ground by setting the gravitational force to zero if the altitude is zero. In plane_rhs, there is a loop to compute intermediate values of the state vector, as well as logic checks to avoid division by zero, and another check for zeroing the gravitational force if the altitude is zero. In eom_rk4, there are two FOR loops for updating the state vector. Conversely, the only simple model function to implement a logic check is 2DOF-TRC, which does so to enforce the maximum turn rate constraint. The RCA CoC and RCA CyC values are higher for the functions in fdm.rs of the Palmer model than for the simple model functions, indicating that these metrics picked up on the distinct increase in representation detail. There is no difference between the 2DOF and 3DOF models, though. The metrics are not able to detect the increase in information content because it does not require more complex code structure to implement. This analysis demonstrates that CoC and CyC are not sensitive to changes in size or scope for the Palmer or Simple models.
5. Measuring Kolmogorov complexity of simulation models
Previously in this article, Section 2.4 introduces the concept of Kolmogorov complexity and how researchers have used compression as a way to approximate KC. After exploring some alternative measures of source code complexity in Section 4, this Section describes how to measure KC of a simulation model, considering two case studies.
5.1. Case Study 1: Kolmogorov complexity of the simple air vehicle models
Each model introduced in Section 4.1 was separated into individual files and compressed using the 7zip program. Table 3 lists the KC of each model (log2 of the size of the compressed archive). The impact of incrementally adding scope to the equations of motion is seen in the incremental increase in KC.
5.2. Case Study 2: Normalized compression distance of a family of AFSIM models
The Air Force Research Laboratory maintains and distributes the Advanced Framework for Simulation, Integration, and Modeling (AFSIM) that supports a wide variety of MS&A [51,52]. AFSIM uses an object-oriented entity-component software design together with a run-time plugin capability to interface simulation models of components not supported by the core framework. This design allows AFSIM users to build simulations choosing from a variety of representations, including movement models of different scopes and resolutions. One of the built-in movement models is called AirMover, and is similar to the 3DOF simple air vehicle model described above. AirMover does not account for explicit aerodynamics, and vertical transitions are discontinuous, although it does produce continuous, smooth motion in the horizontal plane by enforcing maximums for linear acceleration, velocity, and radial acceleration. Users can define an entity and add an AirMover component using a domain-specific language of AFSIM commands and scripts.
Another air vehicle movement model option for AFSIM users is called P6dof, short for the pseudo six-degree-of-freedom model. This represents an air vehicle as a rigid body, and calculates aerodynamic forces and computes moments. The “pseudo” qualifier indicates abstraction in various modeling design choices—for example, assuming off-diagonal elements in the moment of inertia tensor are zero. P6dof is implemented as an AFSIM plugin and has little relationship to the core framework. Similar to AirMover, users define an entity and add a P6dof component using extensions of the AFSIM command and scripting language.
The AFSIM release comes with a number of examples and demos, several of which were selected for a demonstration of calculating NCD, listed in Table 4. Source code (C++) and model definitions (AFSIM command and script language) were extracted from the main folder structure and copied into separate directories. Using the 7zip program, these directories were compressed alone and in pairs and the size of the compressed archives inserted into Equation 2. Compressed archive file size and NCD values are reported in Table 5.
The relative simplicity of the AirMover model is seen in the order of magnitude difference in compressed archive size compared to the P6DOF models. The small NCD of FA-LGT and FA-LGT + external tanks demonstrates the large amount of mutual information in the two models, while FA-LGT and C-HVY have a slightly larger NCD. The NCD of FA-LGT and the AirMover model maximizes the theoretical value, indicating the two models share no detectable mutual information.
6. Challenges and future research
The approach introduced above suggests that the size of model source code and data after compression can be interpreted as a measure of the complexity of a simulation model. Before this approach can be widely adopted by M&S practitioners, additional research must be done to overcome limitations and to more precisely define the approach. Several are these challenges and opportunities for further work are described here.
- How far afield can this approach be used for valid comparison? It is well documented that there is a wide range in the complexity of source code written by different programmers, or written in different languages. The invariance theorem of Kolmogorov complexity (see Chapter 2 of Li & Vitányi [53]) implies that these differences can be accounted for with an additive constant, but how often does the constant dominate, washing out any observability of complexity differences due to changes in model detail?
- What gets measured? What gets included on the scale? To interpret an increase in KC as an increase in model detail and complexity, one would need confidence that all model details are included in the measurement, and irrelevant data are not included. But how does one draw a line to encapsulate a model? Formal modeling specifications like Discrete Event System Specification (DEVS) can provide a clear boundary. Research into M&S ontology can help to parse semantics. More work should be done to investigate tying these other areas of M&S research into model complexity.
- How does using KC compare to the approach defined by Cappochi, et al. [28], in using activity as the base metric for simulation complexity? Can KC of a DEVS model’s event transition functions be substituted for activity in Cappochi’s methodology?
- Is the textual representation of model source code and input data the right representation for this type of analysis? Other representations may be better, such as intermediate representations like LLVM used in the code compilation process [54]. This can take advantage of the automatic code optimization that compilers perform.
- How to measure? How should the compression program be configured? The 7zip program, used in the above demonstrations, allows a user to select from a number of parameters, including compression algorithm, level of compression, dictionary size, word size, and solid block size.
- How should the measurement be calculated? These demonstrations use the size of the compressed data, sometimes scaling by log2.
- How is complexity related to model accuracy and precision? Can complexity analysis be paired with verification, validation, and uncertainty quantification (VVUQ) approaches to inform model selection?
- How can resolution and scope be measured independently? Is it possible to treat them as separate dimensions of complexity?
7. Conclusion
Understanding a variety of perspectives on complexity can help M&S practitioners in developing and employing M&S tools. Using Kolmogorov complexity to interpret the size of a compressed archive containing a simulation model, it may be possible to measure the complexity of the simulation model and relate that directly to the model’s resolution and scope. This article investigates existing source code metrics that do not indicate changes in model detail, and also how KC and NCD may provide such an indication. Measurement of model complexity can assist M&S practitioners select a representation that is best suited for meeting requirements. Even if the selection is not a difficult one (choosing a utility model over a performance model when addressing questions of broad scope), a deeper understanding of complexity as being driven by resolution and scope can lead to better conceptual models in designing and implementing simulation models in software. Overall, expanding this area of research will advance the body of knowledge of M&S towards a practical means to measure simulation model complexity.
Disclaimer: The views expressed in this document are those of the authors and do not reflect the official policy or position of the United States Air Force, the United States Department of Defense or the United States Government.
Author Contributions
Conceptualization, writing—review and editing, J. S. Thompson, D. D. Hodson, M. R. Grimalia, N. Hanlon, R. Dill; software designs and implementations, J. S. Thompson and D. D. Hodson; methodology, formal analysis, and writing—original draft preparation, J. S. Thompson; supervision, D. D. Hodson. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The flight dynamics models described in Section 4.1 are available at https://github.com/jscott-thompson/se-models and https://github.com/jscott-thompson/gphys-palmer. The AFSIM models described in Section 5.2 are not available for public release.
Acknowledgments
The authors wish to acknowledge the Air Force Research Laboratory, Aerospace Systems Directorate, Strategic Analysis and Planning Division, Modeling, Simulation, and Analysis Branch, for supporting this research effort through shared duty assignment with the Air Force Institute of Technology, Department of Electrical and Computer Engineering. We also thank the academic reviewers for their constructive feedback that improved the quality of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| 2DOF | Two degree-of-freedom movement model |
| 2DOF-TRC | Two degree-of-freedom movement model with a turn rate constraint |
| 3DOF | Three degree-of-freedom movement model |
| AFSIM | Advanced Framework for Simulation, Integration, and Modeling |
| DoD | Department of Defense |
| CKC | Conditional Kolmogorov complexity |
| CoC | Cognitive complexity (of source code) |
| CyC | Cyclomatic complexity (of source code) |
| KC | Kolmogorov complexity |
| LZMA | Lempel-Ziv-Markov chain algorithm |
| LZW | Lempel-Ziv-Welch algorithm |
| MoE | Measure of effectiveness |
| MoO | Measure of objective |
| MoP | Measure of performance |
| MBSE | Model-based systems engineering |
| M&S | Modeling and simulation |
| MS&A | Modeling, simulation, and analysis |
| NCD | Normalized compression distance |
| P6DOF | Pseudo six degree-of-freedom movement model |
| RCA | Rust-code-analysis library |
| SoS | System-of-systems |
| TRC | Turn rate constraint |
| USAF | United States Air Force |
| VVUQ | Verification, validation, and uncertainty quantification |
References
- Zeigler, B.P.; Muzy, A.; Kofman, E. Chapter 16 - Abstraction: Constructing Model Families. In Theory of Modeling and Simulation (Third Edition); Zeigler, B.P.; Muzy, A.; Kofman, E., Eds.; Academic Press, 2019; pp. 405–443.
- Thorburn, W.M. Occam’s Razor. Mind 1915, 24, 287–288. [Google Scholar] [CrossRef]
- Box, G.E.P. Science and Statistics. J. Am. Stat. Assoc. 1976, 71, 791–799. [Google Scholar] [CrossRef]
- Hofmann, M.; Palii, J.; Mihelcic, G. Epistemic and normative aspects of ontologies in modelling and simulation. Journal of Simulation 2011, 5, 135–146. [Google Scholar] [CrossRef]
- Feher, J. "The Core Principles of Physiology". In Quantitative Human Physiology; Feher, J., Ed.; Academic Press: Boston, 2012; pp. 3–11. [Google Scholar]
- Hankey, A. The ontological status of western science and medicine. J. Ayurveda Integr. Med. 2012, 3, 119–123. [Google Scholar] [CrossRef]
- Moon, K.; Blackman, D. A guide to understanding social science research for natural scientists. Conserv. Biol. 2014, 28, 1167–1177. [Google Scholar] [CrossRef]
- Rickles, D.; Hawe, P.; Shiell, A. A simple guide to chaos and complexity. J. Epidemiol. Community Health 2007, 61, 933–937. [Google Scholar] [CrossRef] [PubMed]
- King, D.W.; Peterson, G.L. Classifying Emergence. Unpublished manuscript.
- Wehrl, A. General properties of entropy. Rev. Mod. Phys. 1978, 50, 221–260. [Google Scholar] [CrossRef]
- Ebeling, W.; Molgedey, L.; Kurths, J.; Schwarz, U. Entropy, Complexity, Predictability, and Data Analysis of Time Series and Letter Sequences. In The Science of Disasters: Climate Disruptions, Heart Attacks, and Market Crashes; Bunde, A., Kropp, J., Schellnhuber, H.J., Eds.; Springer Berlin Heidelberg: Berlin, Heidelberg, 2002; pp. 2–25. [Google Scholar]
- Snowden, D.J.; Boone, M.E. A Leader’s Framework for Decision Making. Harvard Business Review 2007. [Google Scholar]
- Beer, S. The Heart of Enterprise; John Wiley & Sons Ltd.: Bath, 1979. [Google Scholar]
- Raadt, J.D.R.d. Ashby’s Law of Requisite Variety: An Empirical Study. Cybern. Syst. 1987, 18, 517–536. [Google Scholar] [CrossRef]
- Ashby, W.R.; Goldstein, J. Variety, Constraint, And The Law Of Requisite Variety. Emergence: Complexity and Organization 2011, 13. [Google Scholar]
- Valckenaers, P.; Van Brussel, H. Chapter Two - On the Design of Complex Systems. In Design for the Unexpected; Valckenaers, P.; Van Brussel, H., Eds.; Butterworth-Heinemann, 2016; pp. 9–18.
- Johnson, B.; Hernandez, A. Exploring Engineered Complex Adaptive Systems of Systems. Procedia Comput. Sci. 2016, 95, 58–65. [Google Scholar] [CrossRef]
- Koestler, A. The ghost in the machine; Vol. 384, Macmillan: Oxford, England, 1968. [Google Scholar]
- Boehm, B.W. Software Engineering Economics. IEEE Trans. Software Eng. 1984, SE-10, 4–21.
- McConnell, S. Code Complete: A Practical Handbook of Software Construction, Second Ed.; Microsoft Press, 2004.
- Arora, S.; Barak, B. Computational Complexity: A Modern Approach; Cambridge University Press, 2007.
- Ebert, C.; Cain, J.; Antoniol, G.; Counsell, S.; Laplante, P. Cyclomatic Complexity. IEEE Softw. 2016, 33, 27–29. [Google Scholar] [CrossRef]
- Campbell, G.A. A new way of measuring understandability. Technical report, SonarSource, 2021.
- Graham, S.L.; Kessler, P.B.; McKusick, M.K. gprof: a call graph execution profiler. SIGPLAN Not. 2004, 39, 49–57. [Google Scholar] [CrossRef]
- Buxton, J.N.; Laski, J.G. Control and Simulation Language. Comput. J. 1962, 5, 194–199. [Google Scholar] [CrossRef]
- Balci, O. The implementation of four conceptual frameworks for simulation modeling in high-level languages. In Proceedings of the 1988 Winter Simulation Conference Proceedings; 1988; pp. 287–295. [Google Scholar]
- Muzy, A.; Touraille, L.; Vangheluwe, H.; Michel, O.; Traoré, M.K.; Hill, D.R.C. Activity regions for the specification of discrete event systems. In Proceedings of the Proceedings of the 2010 Spring Simulation Multiconference; Society for Computer Simulation International: San Diego, CA, USA, 2010; Number Article 136 in SpringSim ’10, pp. 1–7.
- Capocchi, L.; Santucci, J.F.; Pawletta, T.; Folkerts, H.; Zeigler, B.P. Discrete-Event Simulation Model Generation based on Activity Metrics. Simulation Modelling Practice and Theory 2020, 103, 102122. [Google Scholar] [CrossRef]
- Lemberger, P.; Morel, M. Complexity, Simplicity, and Abstraction. In Managing complexity of information systems: The value of simplicity; Iste, ISTE Ltd and JohnWiley & Sons: London, England, 2011; pp. 18–75. [Google Scholar]
- Solomonoff, R.J. A formal theory of inductive inference. Part I. Information and Control 1964, 7, 1–22. [Google Scholar] [CrossRef]
- Solomonoff, R.J. A formal theory of inductive inference. Part II. Information and Control 1964, 7, 224–254. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Three approaches to the definition of the concept `quantity of information’ [in Russian]. Probl. Peredachi Inf. 1965, 1, 3–11. [Google Scholar]
- Kolmogorov, A.N. Three approaches to the quantitative definition of information. Int. J. Comput. Math. 1968, 2, 157–168. [Google Scholar] [CrossRef]
- Chaitin, G.J. On the Length of Programs for Computing Finite Binary Sequences. J. ACM 1966, 13, 547–569. [Google Scholar] [CrossRef]
- Cilibrasi, R.L.; Vitányi, P.M.B. The Google Similarity Distance. IEEE Trans. Knowl. Data Eng. 2007, 19, 370–383. [Google Scholar] [CrossRef]
- Cilibrasi, R.L.; Vitányi, P.M.B. Clustering by compression. IEEE Trans. Inf. Theory 2005, 51, 1523–1545. [Google Scholar] [CrossRef]
- Welch, T.A. A Technique for High-Performance Data Compression. IEEE Comp 1984, 17, 8–19. [Google Scholar] [CrossRef]
- Pavlov, I. LZMA Software Development Kit. https://www.7-zip.org/sdk.html, 2022. Accessed: Nov 9, 2022.
- Nutaro, J.; Zeigler, B.P. Towards a theory of economic value for modeling and simulation: incremental cost of parallel simulation (wip). In Proceedings of the Proceedings of the 4th ACM International Conference of Computing for Engineering and Sciences; Association for Computing Machinery: New York, NY, USA, 2018; Number Article 9 in ICCES’18, pp. 1–11.
- Kobren, E.; Oswalt, I.; Cooley, T.; Waite, W.; Waite, E.; Gordon, S.; Severinghaus, R.; Feinberg, J.; Lightner, G. Calculating return on investment for U.S. Department of Defense modeling and simulation. https://apps.dtic.mil/sti/pdfs/ADA539717.pdf, 2011. Accessed: Oct 27, 2022.
- Friel, J. Air Battle Models. In Military Modeling; Hughes, Jr, W.P., Ed.; The Military Operations Research Society, 1984; pp. 127–145.
- Davis, P.K.; Hillestad, R. Aggregation, disaggregation, and the challenge of crossing levels of resolution when designing and connecting models. In Proceedings of the 1993 4th Annual Conference on AI, Simulation and Planning in High Autonomy Systems; 1993; pp. 180–188. [Google Scholar]
- Davis, P.K.; Hillestad, R. Families of Models that Cross Levels of Resolution: Issues for Design, Calibration and Management. In Proceedings of the Proceedings of 1993 Winter Simulation Conference - (WSC ’93), 1993; pp. 1003–1012.
- Trevisani, D.A.; Sisti, A.F. Air Force hierarchy of models: a look inside the great pyramid. In Proceedings of the Enabling Technology for Simulation Science IV; Sisti, A.F., Ed. SPIE; 2000. [Google Scholar]
- Gallagher, M.A.; Caswell, D.J.; Hanlon, B.; Hill, J.M. Rethinking the Hierarchy of Analytic Models and Simulations for Conflicts. Military Operations Research 2014, 19, 15–24. [Google Scholar] [CrossRef]
- LiCausi, A. MS&A of MOPs, MOEs, and MOOs: The Analysis Pyramid Reimagined. Phalanx 2019, 52, 46–51. [Google Scholar]
- Palmer, G. Physics for Game Programmers; Apress, 2005.
- Weintraub, I.E. Various Air Platform Models. Technical report, Air Force Research Laboratory, Aerospace Systems Directorate, 2019.
- rust-lang. rust-clippy: A bunch of lints to catch common mistakes and improve your Rust code. https://github.com/rust-lang/rust-clippy, 2022. Accessed: Apr 26, 2022.
- Ardito, L.; Barbato, L.; Castelluccio, M.; Coppola, R.; Denizet, C.; Ledru, S.; Valsesia, M. rust-code-analysis: A Rust library to analyze and extract maintainability information from source codes. SoftwareX 2020, 12, 100635. [Google Scholar] [CrossRef]
- Clive, P.D.; Johnson, J.A.; Moss, M.J.; Zeh, J.M.; Birkmire, B.M.; Hodson, D.D. Advanced Framework for simulation, integration and modeling (AFSIM). In Proceedings of the The 2015 WorldComp International Conference Proceedings; Arabnia, H.R.; Deligiannidis, L.; Jandieri, G.; Tinetti, F.G.; Gravvanis, G.A.; Grimaila, M.R.; Hodson, D.D.; Solo, A.M.G., Eds. CSREA; 2015; pp. 73–77. [Google Scholar]
- AFSIM Product Management Team. Advanced Framework for Simulation, Integration, and Modeling (AFSIM) v2.7.1 Basic User Training Presentation. Air Force Research Laboratory, 2020.
- Li, M.; Vitányi, P. An Introduction to Kolmogorov Complexity and Its Applications; Texts in Computer Science, Springer: Switzerland, 2019. [Google Scholar]
- Lattner, C.A. LLVM: An Infrastructure for Multi-Stage Optimization. Master’s thesis, University of Illinois at Urbana-Champaign, 2002.
| 1 | However, one should be cautious in applying too much reductionism to complex systems [5,6], and we have the likes of Heisenberg and Gödel to thank for helping us understand some critical limits. Moon and Blackman describe how a healthy dose of pragmatism helps keep the rationalist house of cards from tumbling down [7]. |
| 2 | Cynefin is pronounced kə-nev-in, Welsh for neighborhood or environment. |
| 3 | However, this metric does not appear to have any empirical support from experiments by cognitive scientists, so the use of the term cognitive is potentially problematic. |
| 4 | |
| 5 |
Figure 1.
Zeigler, et al., define a simulation model’s complexity as driven by its level of detail, which is the product of the model’s size and scope, resolution, and interactions [1].
Figure 1.
Zeigler, et al., define a simulation model’s complexity as driven by its level of detail, which is the product of the model’s size and scope, resolution, and interactions [1].
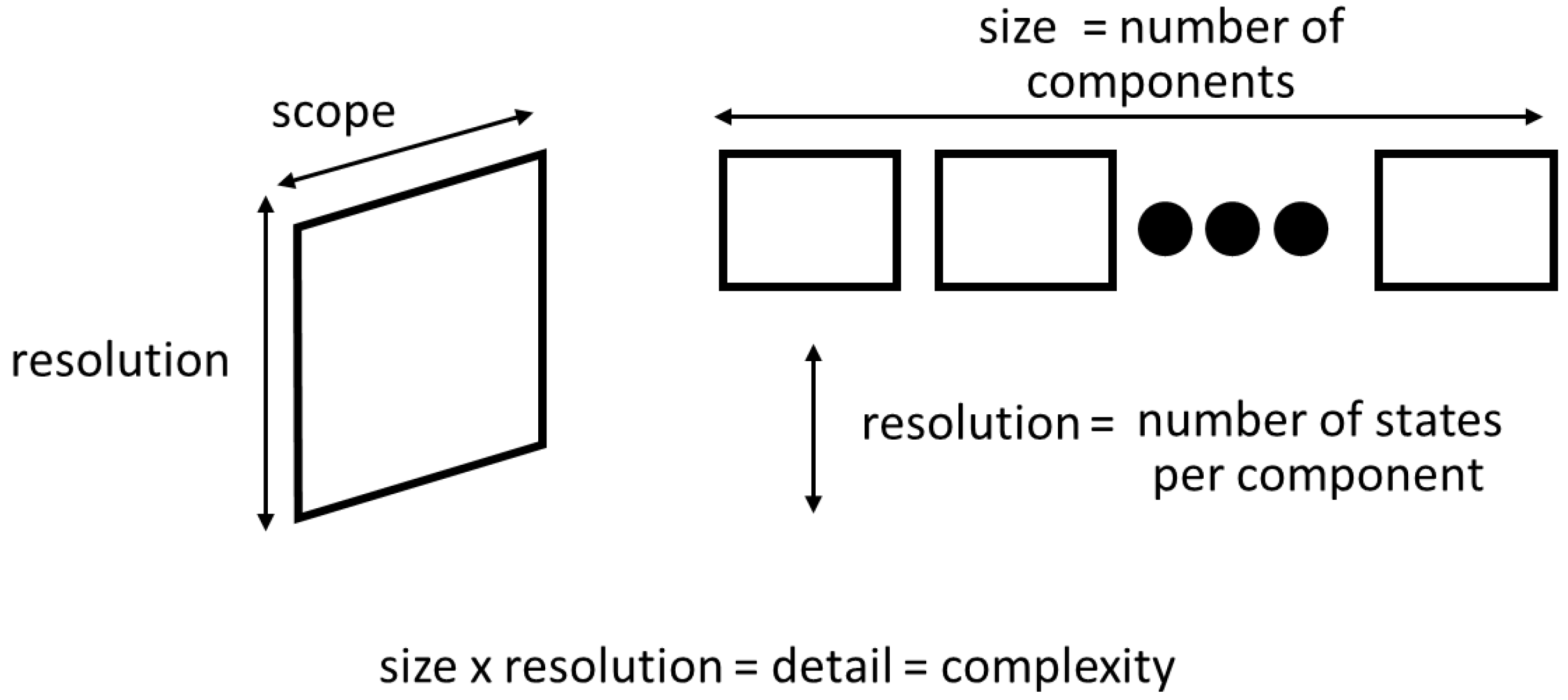
Figure 2.
In LiCausi’s depiction of the MS&A hierarchy, there are three levels of analysis: performance analysis, effectiveness analysis, and utility analysis. Simulation models typically support analysis at one of these levels, and a family of models are needed for multiple levels of analysis [46].
Figure 2.
In LiCausi’s depiction of the MS&A hierarchy, there are three levels of analysis: performance analysis, effectiveness analysis, and utility analysis. Simulation models typically support analysis at one of these levels, and a family of models are needed for multiple levels of analysis [46].
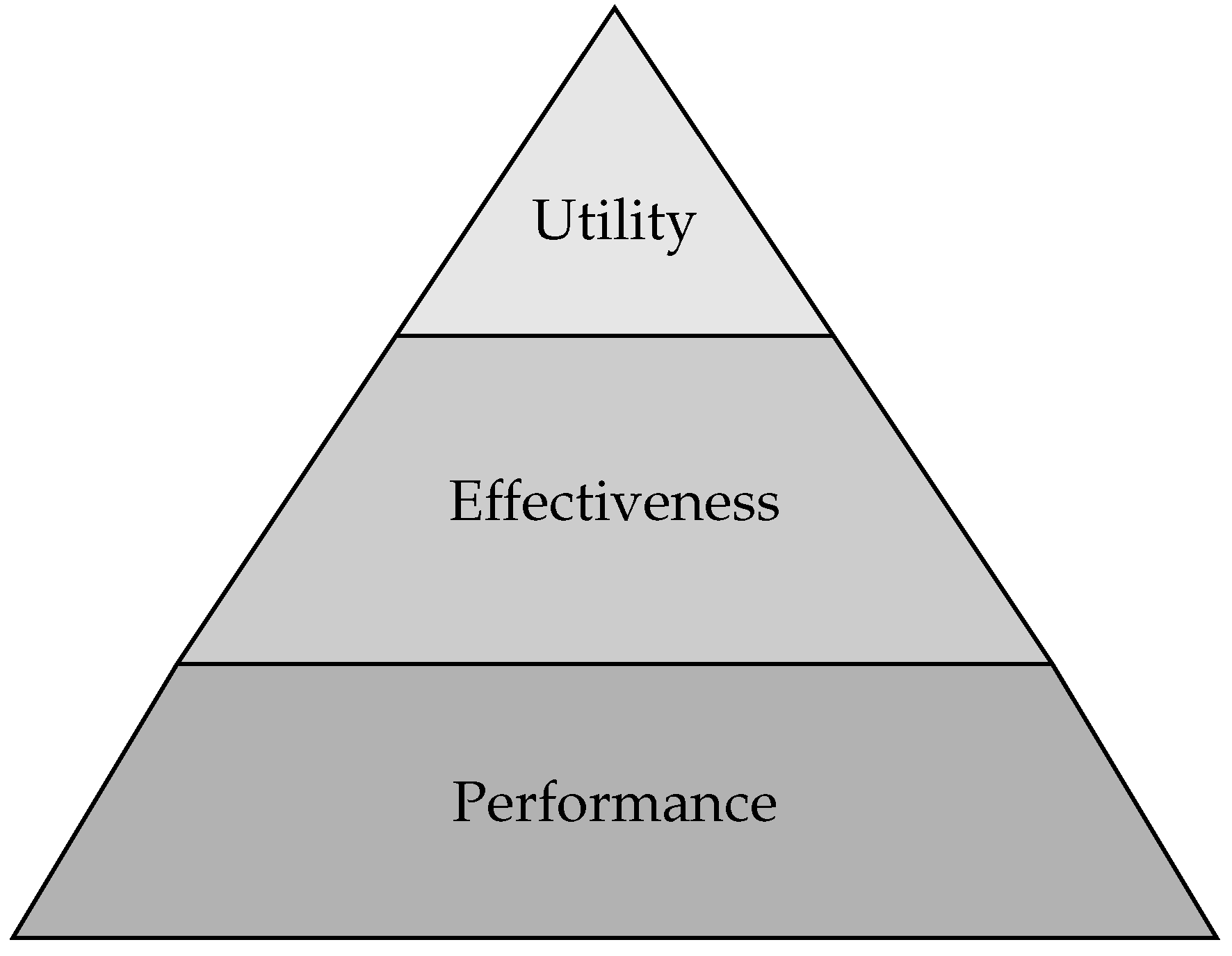
Figure 3.
An archetypal performance model has high resolution and limited scope, whereas an archetypal utility model has wide scope and low resolution. A typical simulation model often emphasizes resolution in a particular area of concern, makes simplifying assumptions and implements sufficient abstractions for other areas still within scope, and assumes away other areas as out of scope.
Figure 3.
An archetypal performance model has high resolution and limited scope, whereas an archetypal utility model has wide scope and low resolution. A typical simulation model often emphasizes resolution in a particular area of concern, makes simplifying assumptions and implements sufficient abstractions for other areas still within scope, and assumes away other areas as out of scope.
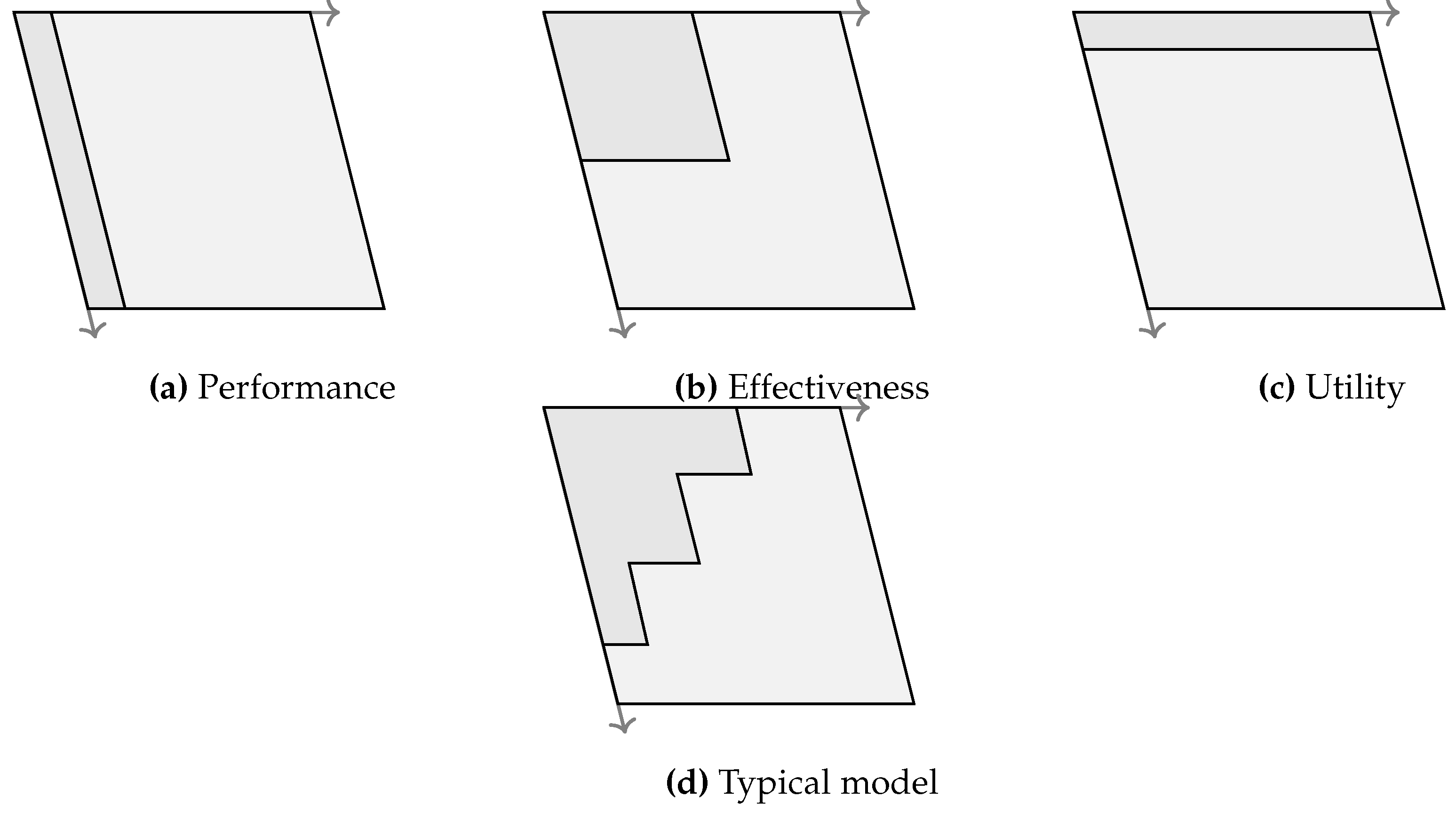

Table 1.
New definitions of simulation model complexity and related terms synthesized from Zeigler, Davis, and others
Table 1.
New definitions of simulation model complexity and related terms synthesized from Zeigler, Davis, and others
| Term | Definition |
|---|---|
| Scope | The breadth of the model; how much of reality is represented, particularly the number of components and parameters encoded as model variables to represent those components |
| Resolution | The depth of the model; the precision, granularity, quantization, and/or discretization of model parameters and structure, including internal interactions and logical dependencies |
| Detail | The product or integration of the model’s scope and resolution |
| Complexity | The aggregation of a model’s detail, external interactions and logical dependencies, and in many contexts its instantiation (input parameter settings) in a specific simulation scenario execution |
Table 2.
The static analysis tools Clippy and rust-code-analysis generated metrics for cognitive complexity (CoC) and cyclomatic complexity (CyC) for each of the functions in the Palmer and the simple models.
Table 2.
The static analysis tools Clippy and rust-code-analysis generated metrics for cognitive complexity (CoC) and cyclomatic complexity (CyC) for each of the functions in the Palmer and the simple models.
| Model | Function | Clippy CoC | RCA CoC | RCA CyC |
|---|---|---|---|---|
| Palmer | calculate_forces | 6 | 7 | 7 |
| Palmer | plane_rhs | 5 | 7 | 6 |
| Palmer | eom_rk4 | 3 | 2 | 3 |
| 2DOF | update_2dof | 0 | 0 | 1 |
| 2DOF-TRC | update_2dof_trc | 0 | 2 | 2 |
| 3DOF | update_3dof | 0 | 0 | 1 |
Table 3.
Compressed archive file size and KC values of the simple air vehicle models.
| Model | Compressed Size (Bytes) | Kolmogorov Complexity |
|---|---|---|
| 2DOF | 375 | 8.551 |
| 2DOF-TRC | 448 | 8.807 |
| 3DOF | 477 | 8.898 |
Table 4.
Select examples from the AFSIM release.
| Name | Description | Modeled Components |
|---|---|---|
| AirMover | Single-engine light fighter aircraft | • 3DOF movement |
| FA-LGT | Single-engine light fighter aircraft | • Aero for fixed surfaces and each flight control surface • Flight controls • Mass • Propulsion - Centerline engine - Fuel tank capacity - Throttle and fuel flow rates |
| FA-LGT + Ext Tanks | Extends FA-LGT, adds external fuel tanks | • All from FA-LGT • 2 wing-mounted fuel tanks - Aero - Mass - Fuel capacity |
| C-HVY | Four-engine heavy airlift cargo aircraft | • Aero for fixed surfaces and each flight control surface • Flight controls • Mass • Propulsion - 4 under-wing engines - Fuel tank - Throttle and fuel flow rates |
Table 5.
Compressed archive file size and normalized compression distance values.
| Model | Compressed Size (Bytes) | KC | NCD |
|---|---|---|---|
| AirMover | 63,421 | 15.9527 | N/A |
| FA-LGT | 21,258,004 | 24.3415 | N/A |
| FA-LGT + ext tanks | 22,078,546 | 24.3961 | N/A |
| C-HVY | 20,867,455 | 24.3078 | N/A |
| FA-LGT & FA-LGT + ext tanks | 22,114,939 | 24.3985 | 0.038813 |
| FA-LGT & C-HVY | 23,697,162 | 24.4982 | 0.128165 |
| FA-LGT & AirMover | 21,322,768 | 24.3459 | 1.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



