
Submitted:
25 April 2023
Posted:
26 April 2023
You are already at the latest version
Abstract
In this paper, we will extend the expected value of the function w.r.t the uniform probability measure on sets measurable in the Caratheodory sense to be finite for a larger class of functions, since the set of all measurable functions with infinite or undefined expected values forms a prevalent subset of the set of all measurable functions, which means "almost all" measurable functions have infinite or undefined expected values. Before we define the specific problem in section 2, we will outline some preliminary definitions. We'll then define the specific problem (along with a partial solution in section 3) to visualize the complete solution. Along the way, we will ask a series of questions to clarify our understanding of the paper.
Keywords:
Prevalence
; Expected Value
; Uniform Measure
; Measure theory
; Uniform Cover
; Entropy
; Sample
; Linear
; Superlinear
; Choice Function
; Bernard's Paradox
; Pseudo-random
0. Background
I am an undergraduate from Indiana University despite being the age of a grad student. I should have graduated by now, but my obsession with research prevents me from moving forward. There is a chance that I might have a learning disability since writing isn’t very easy for me.
As I’ve been in and out of college, I never got the chance to rigorously learn the subjects I’m researching. Most of what I learned was from Wikipedia, blogs and random research articles. I know little of what I read but learn what I can from asking questions on math stack exchange.
What I truly want, however; is for someone to take my ideas and publish them.
I warn that the definitions may not be rigorous so try to go easy on me. (I recommend using programming such as Mathematica, Python, JavaScript or Matlab to understand later sections).
1. Preliminaries
1.1. Motivation
It seems the set of measurable functions with infinite or undefined expected values (def. 1), using the uniform measure ([17], pp. 32-37), may be a prevalent subset [11,14] of the set of all measurable functions, meaning "almost every" measurable function has infinite or undefined expected values. Furthermore, when the Lebesgue measure of A, measurable in the Caratheodory sense, has zero or infinite volume (or undefined measure), there may be multiple, conflicting ways of defining a "natural" uniform measure on A.
Below I will attempt to define a question regarding an extension of the expected value (when it’s undefined or infinite) which allows for finite values instead (def. 3).
Note the reason the question will be so long is there are plenty of “meaningless” extensions of the expected value (e.g. if the expected value is infinite or undefined we can just replace it with zero).
Therefore we must be more specific about what is meant by “meaningful” extension but there are some preliminary definitions we must clarify.
1.2. Preliminary Definitions
Definition 1
(Expected value w.r.t the Uniform Probability Measure). From an answer to a question in cross validated (a website for statistical questions) [10] , let denote a uniform random variable on set and denote the probability density function from the radon-nikodym derivative ([2], pp. 419-427) of the uniform probability measure on A measurable in the Carathèodory sense. If denotes the indicator function on :
then the radon-nikodym derivative of uniform probability measure must have the form . (Note is not the derivative of U in the sense of calculus but rather the denominator of the probability density function derived from the uniform probability measure U.)
Therefore, by using the law of the unconscious statistician, we should get
such the expected value is undefined when A does not have a uniform probability distribution or f is not integrable w.r.t the measure .
Definition 2
(Defining the pre-structure). Since there’s a chance that does not exist or f is not integrable w.r.t to , using def. 1 we define a sequence of sets where if:
- (a)
- (b)
then we have:
- For all , exists (when A is countable infinite, then for every , must be finite since would be a discrete uniform distribution of ; otherwise, when A is uncountable, is the normalized Lebesgue measure or some other uniform measure on (e.g. [8]) where for every , either measure on exists and is finite.
- For all , is positive and finite such that is intrinsic. (For countably infinite A, would be the counting measure where is positive and finite since is finite. For uncountable A, would either be the Lebesgue measure or the radon-nikodym derivative of some other uniform measure on (e.g. [8]), where either of the measures on are positive and finite.)
where is apre-structureof A, since for every the sequence does not equal A, but "converges" to A as r increases (see (a) & (b) of this definition).
Example 1.
Suppose . One pre-structure of is since:
- For every , set is finite, meaning each term of the pre-structure has a discrete uniform distribution. Therefore, exists.
- For every , is finite; meaning is the counting measure. Furthermore, since and for all , is positive and finite, criteria (3) of def. 2 is satisfied.
Example 2.
Suppose . Another pre-structure of is
where we note the following:
- For every , set is finite, meaning each term of the pre-structure has a discrete uniform distribution. Therefore, exists.
- For every , is finite; meaning is the counting measure, since (when is the Euler’s totient function [15], pp.239-249) we have , and if correct, is greater than zero and positive for all . Therefore, criteria (3) of def. 2 is satisfied.
There are plenty of pre-structures of . Infact, there may be countably infinite many of these pre-structures.
Example 3.
We need additional examples, where is not the counting measure. Perhaps one example of (where ) is:
It’s obvious that:
Note that the uniform random variable of doesn’t exist but for every , the uniform density of is .
Furthermore, for every , is the 1-d Lebesgue measure where , such where is positive and finite (since ).
Definition 3
(Expected value of f on Pre-Structure). If is a pre-structure of A (def. 2), then for , if
we then have that the expected value of f on the pre-structure could be described as where:
Example 4.
Suppose where such that:
Using the pre-structure in example 1 or , we presume (and prove) using def. 3 is 1.
And using the pre-structure in example 2 or
we presume (but must prove) , using def. 3 is .
This shows different pre-structures give different expected values; therefore, we must choose a unique set of equivelant pre-structures (def. 8) which gives the same & finite expected value.
Definition 4
(Uniform coverings of each term of the pre-structure). We define the uniform ε coverings of each term of the pre-structure (i.e., ) as a group of pair-wise disjoint sets that cover for every , such the measure of each of the sets that cover have the same value of , where and the total sum of of the coverings is minimized. In shorter notation, if
- The element
- The set is arbitrary and uncountable.
and set Ω is defined as:
then for every , the set of uniform ε coverings is defined using where ω “enumerates" all possible uniform ε coverings of for every .
Example 5.
Suppose
Inorder to calculate , note that:
and; since and is the counting measure, one example of is
Note (in this case the counting measure) of each set in the uniform ε covering is 2 where we’re "over-covering" by one element (i.e. ) as we are minimizing the total sum of of the coverings (which for is ).
If , then
and e.g.
Also note, for counting measure , where and (i.e. ), we have that .
Definition 5
(Sample of the uniform coverings of each term of the pre-structure). The sample of uniform ε coverings of each term of the pre-structure or is the set of points, such for every and , we take a point from each pair-wise disjoint set in the uniform ε coverings of (def. 4). In shorter notation, if
- The element
- The set is arbitrary and uncountable.
and set is defined as:
then for every , the set of all samples of the set of uniform ε coverings is defined using , where ψ “enumerates" all possible samples of .
Example 6.
From example 5 where:
Then one sample of is:
and another sample of is:
Definition 6
(Entropy on the sample of uniform coverings of each term of the pre-structure). Since there are finitely many points in the sample of the uniform ε coverings of each term of pre-structure (def. 5), we:
- Arrange the x-value of the points in the sample of uniform ε coverings from least to greatest. This is defined as:
- Take the multi-set of the absolute differences between all consecutive pairs of elements in (1). This is defined as:
- Normalize (2) into a probability distribution. This is defined as:
where (4) is the entropy on the sample of uniform coverings of .
Example 7.
From example 6:
Then
- which organizes elements in from least to greatest.
- Since we use this to normalize (2) into a probability distribution
- Hence we take the entropy of or:
Definition 7
(Pre-Structure Converging Uniformly to A). For every (using def. 4, 5, and 6)if set A is finite and for , we have , we then want:
and if set A is non-finite:
we say the pre-structure converges uniformlyto A (or in shorter notation):
(Note we wish to define a uniform convergence of a sequence of sets to A since the definition is analogous to a uniform measure.)
Theorem 1.
Show every pre-structure of A converges uniformly to A.
Example 8.
I assume, using example 5, if
then . I need to prove this.
Definition 8
(Equivalent Pre-Structures). The pre-structures and of A areequivalentif for all , where from def. 3, or such that:
Definition 9 (Equivelant Pre-Structures The pre-structures and of A areequivalentif we have:
is the r-value (for every ) where is minimized
is the r-value (for every ) where is maximized
is the j-value (for every ) where is minimized and:
is the j-value (for every ) where is maximized such that:
means the pre-structures and are equivelant.
Example 9.
From example 3, if where , the cantor set is and . Since with either pre-structure, is the 1-d dimensional Lebesgue measure and (using equation 12) we get:
Definition 10
(Non-Equivalent Pre-Structures). The pre-structures and of A arenon-equivalentif there exists an , where from def. 3, or where:
Definition 11 (Non-Equivelant Pre-Structures The pre-structures and of A arenon-equivalentif we have:
is the r-value (for every ) where is minimized
is the r-value (for every ) where is maximized
is the j-value (for every ) where is minimized and:
is the j-value (for every ) where is maximized such that:
means the pre-structures and are non-equivelant.
Example 10.
From example 4, if , pre-structures and are non-equivelant since for where:
we have (i.e. the expected value of f on ) and (i.e. the expected value of f on ), which means
hence from def. 10, the pre-structures and are non-equivelant.
Example 11.
Suppose , where , and
is undefined (i.e. the expected value of f on ) and (i.e. the expected value of f on ). Since at least one of the pre-structure i.e. has a defined expected value and (i.e. undefined values do not equal 1), we can say that and are non-equivelant.
Definition 12
(Pre-Structures converging Sublinearly, Linearly, or Superlinearly to A compared to that of another Sequence).Suppose pre-structures and are non-equivalent and converge uniformly to A; and suppose for every , where and :
- (a)
-
From def. 5 and 6, suppose we have:then (using 14) we have
- (b)
-
From def. 5 and 6, suppose we have:then (using 16) we get
-
If using equations 15 and 17 we have that:we say converges uniformly to A at asuperlinear rateto that of .
-
If using equations 15 and 17 we have either:
- (a)
-
- (b)
-
- (c)
-
- (d)
-
we then say converges uniformly to A at alinear rateto that of .
-
If using equations 15 and 17 we have that:we say converges uniformly to A at asublinear rateto that of .
Note 2. Since def. 12 is difficult to apply, we make assumptions (without proofs) for the examples below:
Example 12
(Example of pre-structure converging super-linearly to A compared to that of another pre-structure). From example 5:
we assume that converges uniformly to A, at asuperlinearrate, compared to that of .
Example 13
(Obvious Example of pre-structure converging linearly to A compared to that of another pre-structure). Consider the following:
we assume that converges uniformly to A, at alinearrate, compared to that of , since using programming we assume:
Example 14
(Non-Obvious Example of pre-structure converging linearly to A compared to another pre-structure). If is the nearest integer function and is the floor function, consider the following:
- (we choose this pre-structure since if is the highest entropy (def. 6) that could be for every , we say has ahigher entropy per elementthan that of if there exists a , such for all , ).
despite having a higher entropy per element, converges uniformly to A at alinearrate, compared to that of , since using programming we assume:
which should satisfy criteria (2a) in def. 12.
Theorem 2.
If converges super-linearly to A compared to that of then converges sub-linearly to A compared to that of
Example 15
(Example of pre-structure converging sub-linearly to A compared to another pre-structure). In example 12, if we swap for where:
we assume that converges to A at asublinearrate to that of .
1.3. Question on Preliminary Definitions
- Are there “simpler" alternatives to either of the preliminary definitions? (Keep this in mind as we continue reading).
2. Main Question
Does there exist a unique extension (or a method that constructively defines a unique extension) of the expected value of f when the value’s finite, using the uniform probability measure [17] on sets measurable in the Carathèodory sense, such we replace f with infinite or undefined expected values with f defined on a chosen pre-structure which depends on A where:
- The expected value of f on each term of the pre-structure is finite
- The pre-structure converges uniformly to A
- The pre-structure converges uniformly to A at a linear or superlinear rate to that of other non-equivalent pre-structures of A which satisfies (1) and (2).
- The generalized expected value of f on a pre-structure (i.e. an extension of def.3 to answer the full question) has a unique & finite value, such the pre-structure satisfies (1), (2), and (3).
- A choice function is defined which chooses a pre-structure from A where the following satisfies (1), (2), (3), and (4) for the largest possible subset of .
- If there is more than one choice function that satisfies (1), (2), (3), (4) and (5), we choose the choice function with the “simplest form", meaning for a general pre-structure of A, when each choice function is fully expanded, we take the choice function with the fewest variables/numbers (excluding those with quantifiers).
How do we answer this question? (See Section 3.1, Section 3.2 and Section 3.4 for a partial answer.)
3. Informal Attempt to Answer Main Question
(I advise using computer programmings such as Mathematica, Python, JavaScript, or Matlab to understand the definitions of the answer below.)
3.1. Generalized Expected Values
If the image of f under A is , such from def. 2 and 7, we take the pre-structure of where:
and take the pre-image under f of (defined as ) such that:
However, note the expected value of (def. 3) may be infinite (e.g. unbounded f). Hence, for every , we take the pre-structure of where:
Thus, the generalized expected value or is:
and (similar to def. 2 & 3) if
we describe the process of the generalized expected value as .
3.2. Choice Function
Suppose is the set of all pre-structures of A which satisfies criteria (1) and (2) of the main question where the generalized expected value of the pre-structures, as they converge uniformly to A, is unique and finite such the pre-structure should be a sequence of sets that satisfies criteria (1), (2), (3) and (4) of the main question where (using the end of ):
and pre-structure is an element of such (using the end of ):
but is not an element of the set of equivelant pre-structures of (i.e. def. 8).
Further note from (a), with equation 14 in def. 12, if we take:
and from (b), with equation 16 in def. 12, we take:
Then, using def. 5 with equations 22 and 23, if:
where, using absolute value function , we have:
such that
and, using equations 24, 25, 26, 27, 28 with the nearest integer function , we want:
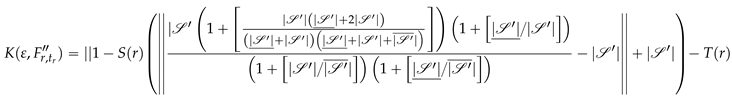 such, using equation 29, if set and is the power-set, then set is the largest element of:
w.r.t to inclusion, such the choice function is if the following contains just one element.
such, using equation 29, if set and is the power-set, then set is the largest element of:
w.r.t to inclusion, such the choice function is if the following contains just one element.
Otherwise, for , suppose we say represents the k-th iteration of the choice function of A, e.g. , where the infinite iteration of (if it exists) is . Therefore, when taking the following:
we say is the choice function and the expected value, using def. 20, is .
3.3. Questions on Choice Function
-
Suppose we define function . What unique pre-structure would contain (if it exists) for:
- where if and , we want
- where if and , we want
- where we’re not sure what would be if . What would be if it’s unique?
3.4. Increasing Chances of an Unique and Finite Expected Value
In case , in equation 31, does not exist; if there exists a unique and finite (see ) where:
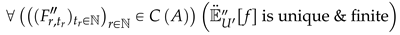
Then is the generalized expected value w.r.t choice function C, which answers criteria (1), (2), (3), (4), (perhaps (5)) of the question in ; however, there is still a chance that the equation 32 fails to give an unique . Hence; if , we take the k-th iteration of the choice function C in 30, such there exists a , where for all , if is unique and finite then the following is the generalized expected value w.r.t finitely iterated C.
In other words, if the k-th iteration of C is represented as (where e.g. ), we want a unique and finite where:
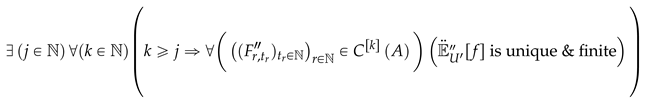
If this still does not give a unique and finite expected value, we then take the most generalized expected value w.r.t an infinitely iterated C where if the infinite iteration of C is stated as , we then want a unique where:
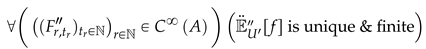
However, in such cases, should only be used for functions where the expected value is infinite or undefined or for worst-case functions—badly behaved (where for , , and f is a function) defined on infinite points covering an infinite expanse of space. For example:
- For a worst-case f defined on countably infinite A (e.g. countably infinite "pseudo-random points" non-uniformly scattered across the real plane), one may need just one iteration of C (since most function on countable sets need just one iteration of C for to be unique); otherwise, one may use equation 33 for finite iterations of C.
- For a worst-case f defined on uncountable A, we might have to use equation 34 as averaging such a function might be nearly impossible. We can imagine this function as an uncountable number of "pseudo-random" points non-uniformly generated on a subset of the real plane (see Section 4.1 for a visualization.)
Note, however, that no matter how generalized and “meaningful" the extension of an expected value is, there will always be an f where the expected value does not exist.
3.5. Questions Regarding The Answer
-
Using prevalence and shyness [11,14], can we say the set of f where either equations 32, 33 and 34 have an unique and finite which forms either a prevalent or neither prevalent nor shy subset of ? (If the subset is prevalent, this implies either one of the generalized expected values can be unique and finite for a “large" subset of ; however, if the subset is neither prevalent nor shy we need more precise definitions of “size" which takes “an exact probability that the expected values are unique & finite"—some examples (which are shown in this answer [9]) being:
- (a)
- Fractal Dimension notions
- (b)
- Kolmogorov Entropy
- (c)
- Baire Category and Porosity
- There may be a total of 292 variables in the choice function C (excluding quantifiers). Is there a choice function (ignoring quantifiers) which answers criteria (1), (2), (3) & (4) of the main question in Section 2 for a "larger" subset of ? (This might be impossible to answer since such a solution cannot be shown with prevalence or shyness [11,14])—therefore, we need a more precise version of “size" with some examples, again, shown in [9].
- If question (2) is correct, what is the choice function C using either equations 32, 33 and 34 fully answers the question in Section 2?
- Can either equations 32, 33 and 34 (when A is the set of all Liouville numbers [6] and ) give a finite value? What would the value be?
- Similar to how definition 13 in §4 approximates the expected value in definition 1, how do approximate equations 32, 33 and 34?
- Can programming be used to estimate equations 32, 33 and 34 respectively (if an unique/finite result of either of the expected values exist)?
3.6. Applications
-
In Quanta magazine [3], Wood writes on Feynman Path Integrals: “No known mathematical procedure can meaningfully average1 an infinite number of objects covering an infinite expanse of space in general. The path integral is more of a physics philosophy than an exact mathematical recipe."—despite Wood’s statement, mathematicians Bottazzi E. and Eskew M. [5] found a constructive solution to the statement using integrals defined on filters over families of finite sets; however, the solution was not unique as one has to choose a value in a partially ordered ring of infinite and infinitesimal elements.
- (a)
- Perhaps, if Botazzi’s and Eskew’s Filter integral [5] is not enough to solve Wood’s statement, could we replace the path integral with expected values from equations 32, 33 and 34 respectively (or a complete solution to Section 2)? (See, again, Section 4.1 for a visualization of Wood’s statement.)
-
As stated in Section 1.1, “when the Lebesgue measure of A, measurable in the Caratheodory sense, has zero or infinite volume (or undefined measure), there may be multiple, conflicting ways of defining a "natural" uniform measure on A." This is an example of Bertand’s Paradox which shows, "the principle of indifference (that allows equal probability among all possible outcomes when no other information is given) may not produce definite, well-defined results for probabilities if applied uncritically, when the domain of possibilities is infinite [16].Then might serve as a solution to Bertand’s Paradox (unless there’s a better and which completely solves the main question in ).Now consider the following:
- (a)
-
How do we apply (or a better solution) to the usual example which demonstrates the Bertand’s Paradox as follows: for an equilateral triangle (inscribed in a circle), suppose a chord of the circle is chosen at random—what is the probability that the chord is longer than a side of the triangle? [4] (According to Bertand’s Paradox there are three arguments which correctly use the principle of indifference yet give different solutions to this problem [4]:
- The “random endpoints" method: Choose two random points on the circumference of the circle and draw the chord joining them. To calculate the probability in question imagine the triangle rotated so its vertex coincides with one of the chord endpoints. Observe that if the other chord endpoint lies on the arc between the endpoints of the triangle side opposite the first point, the chord is longer than a side of the triangle. The length of the arc is one-third of the circumference of the circle, therefore the probability that a random chord is longer than a side of the inscribed triangle is .
- The "random radial point" method: Choose a radius of the circle, choose a point on the radius, and construct the chord through this point and perpendicular to the radius. To calculate the probability in question imagine the triangle rotated so a side is perpendicular to the radius. The chord is longer than a side of the triangle if the chosen point is nearer the center of the circle than the point where the side of the triangle intersects the radius. The side of the triangle bisects the radius, therefore the probability a random chord is longer than a side of the inscribed triangle is .
- The "random midpoint" method: Choose a point anywhere within the circle and construct a chord with the chosen point as its midpoint. The chord is longer than a side of the inscribed triangle if the chosen point falls within a concentric circle of radius the radius of the larger circle. The area of the smaller circle is one-fourth the area of the larger circle, therefore the probability a random chord is longer than a side of the inscribed triangle is .
4. Glossary
4.1. Example of Case (2) of Worst Case Functions
(If the explanation below is difficult to understand, see the code in [1] to accompany the explanation.)
We wish to create a function that has uncountable points which are non-uniform (i.e. without complete spatial randomness [13]) in the sub-space of , , such a countable collection of non pseudo-randomy-values in the range of the function "almost surely" or never "almost unsurely" has corresponding pseudo-random x-values, where the expected value or integral of the function w.r.t uniform probability measure [17][ p.32-37] is non-obvious (i.e. not equivalent to the arithmetic mean of the output of the function on the uniform sample of domain). For the sake of simplicity, I shall say the function is made of uncountable "nearly" pseudo-random points, even though that’s technically impossible.
Suppose for real numbers and , we generate an uncountable number of "nearly pseudo-random" points that are non-uniform in the subspace .
We therefore define the function as .
Now suppose where the base-b expansion of real numbers, in interval , have infinite decimals that approach x from the right side so when we get .
Furthermore, for , if and is a function where takes the digit in the -th decimal fraction of the base-b expansion of x (e.g. ), then is a sequence of functions such that is defined to be:
then for some large and , the intermediate function (before f) or is defined to be
where the points in are "almost pseudo-randomly" and non-uniformly distributed on . What we did was convert every digit of the base-b expansion of x to a pseudo-random number that is non-equally likely to be an integer, including and in-between, 0 and . Furthermore, we also make the function appear truly “pseudo-random", by adding the -th decimal fraction with the next k decimal fractions; however, we want to control the end-points of such if , we convert to by manipulating equation 37 to get:
such the larger k is, the more pseudo-random the distribution of points in f in the space , but unlike most distributions of such points, f is uncountable.
4.2. Question Regarding Section 4.1
Let us give a specific example, suppose for the function in equation 38 of Section 4.1, we have:
(one can try simpler parameters); what is the expected value using either equations 33 and 34 (or a more complete solution to Section 2) if the answer is finite and unique?
What about for f in general (i.e. in terms of b, , , , and k)?
(Note if and , then the function is an explicit example of the function that Wood2 describes in Quanta Magazine)
4.3. Approximating the Expected Value
Definition 13
(Approximating the Expected Value). In practice, the computation of this expected value may be complicated if the set A is complicated. If analytic integration does not give a closed-form solution then a general and relatively simple way to compute the expected value (up to high accuracy) is with importance sampling. To do this, we produce values for some density function g with support (hopefully with support fairly close to A) and we use the estimator:
From the law of large numbers, we can establish that so if we take M to be large then we should get a reasonably good computation of the expected value of interest.
Note importance sampling requires three things:
- We need to know when point x is in set A or not
- We need to be able to generate points from a density g that is on a support that covers A but is not too much bigger than A
- We have to be able to compute and for each point
References
- Krishnan B. Finding expected value over uncountable number of pseudo-random points, non-uniformly distributed over the sub-space of R2, 2023. https://mathematica.stackexchange.com/questions/283525/finding-expected-value-over-uncountable-number-of-pseudo-random-points-non-unif.
- Patrick B. John Wiley & Sons, New York, 3 edition, 1995. https://www.colorado.edu/amath/sites/default/files/attached-files/billingsley.pdf.
- Wood C. Mathematicians prove 2d version of quantum gravity really works. Quanta Magazine. https://www.quantamagazine.org/mathematicians-prove-2d-version-of-quantum-gravity-really-works-20210617.
- Alon Drory. Failure and uses of jaynes’ principle of transformation groups. Foundations of Physics, 45(4):439–460, feb 2015. https://arxiv.org/pdf/1503.09072.pdf.
- Bottazi E. and Eskew M. Integration with filters. https://arxiv.org/pdf/2004.09103.pdf.
- Adam Grabowski and Artur Kornilowicz. Introduction to liouville numbers. Formalized Mathematics, 25, 01 2017. https://sciendo.com/article/10.1515/forma-2017-0003.
- Michael Greinecker (https://mathoverflow.net/users/35357/michael greinecker). Demystifying the caratheodory approach to measurability. MathOverflow. https://mathoverflow.net/q/34007.
- Mark McClure (https://mathoverflow.net/users/46214/mark mcclure). Integral over the cantor set hausdorff dimension. MathOverflow. https://mathoverflow.net/q/235609 (version: 2016-04-07).
- Dave L. Renfro (https://math.stackexchange.com/users/13130/dave-l renfro). Proof that neither “almost none” nor “almost all” functions which are lebesgue measurable are non-integrable. Mathematics Stack Exchange. https://math.stackexchange.com/q/4623168 (version: 2023-01-21).
- Ben (https://stats.stackexchange.com/users/173082/ben). In statistics how does one find the mean of a function w.r.t the uniform probability measure? Cross Validated. https://stats.stackexchange.com/q/602939 (version: 2023-01-24).
- Brian R. Hunt. Prevalence: a translation-invariant “almost every” on infinite-dimensional spaces. 1992. https://arxiv.org/abs/math/9210220.
- Gray M. Springer New York, New York [America];, 2 edition, 2011. https://ee.stanford.edu/~gray/it.pdf.
- Rokach L. Maimon O. Springer New York, New York [America];, 2 edition, 2010. [CrossRef]
- William Ott and James A. Yorke. Prevelance. Bulletin of the American Mathematical Society, 42(3):263–290, 2005. https://www.ams.org/journals/bull/2005-42-03/S0273-0979-05-01060-8/S0273-0979-05-01060-8.pdf.
- Kenneth H. Rosen. Elementary number theory and its applications (6. ed.). Addison-Wesley, 1993. https://www.bibsonomy.org/bibtex/2bdf609bd9cb49ba96ef69ca99540db82/dblp.
- Nicholas Shackel. Bertrand’s paradox and the principle of indifference. Philosophy of Science, 74(2):150–175, 2007. https://orca.cardiff.ac.uk/id/eprint/3803/1/Shackel%20Bertrand’s%20paradox%205.pdf.
- Leinster T. and Roff E. The maximum entropy of a metric space. https://arxiv.org/pdf/1908.11184.pdf.
| 1 | Meaningful Average—The average answers the main question in §2. |
| 2 | Wood wrote on Feynman Path Integrals: “No known mathematical procedure can meaningfully average 1 an infinite number of objects covering an infinite expanse of space in general." |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



