Submitted:
22 March 2023
Posted:
24 March 2023
You are already at the latest version
Abstract
Federated Distillation (FD) has recently attracted increasing attention for its efficiency in aggregating multiple diverse local models trained from statistically heterogeneous data of distributed clients. Existing FD methods generally treat these models equally by merely computing the average of their output soft predictions for some given input distillation sample, which does not take the diversity across all local models into account, thus leading to degraded performance of the aggregated model, especially when some local models learn little knowledge about the sample. In this paper, we propose a new perspective that treats the local data in each client as a specific domain and design a novel domain knowledge aware federated distillation method, dubbed DaFKD, that can discern the importance of each model to the distillation sample, and thus is able to optimize the ensemble of soft predictions from diverse models. Specifically, we employ a domain discriminator for each client, which is trained to identify the correlation factor between the sample and the corresponding domain. Then, to facilitate the training of the domain discriminator while saving communication costs, we propose sharing its partial parameters with the classification model. Extensive experiments on various datasets and settings show that the proposed method can improve the model accuracy by up to $6.02\%$ compared to state-of-the-art baselines.
Keywords:
Federated Learning
; Knowledge Distillation
; Domain aware
1. Introduction
Federated learning (FL) has emerged as a prominent distributed machine learning framework to train a global model via the collaboration among users without sharing their original dataset [17,22,27]. Due to the benefits of preserving privacy and economic communication efficiency, FL has been widely adopted in various applications such as medical image processing [8,19,32] and recommendation [2,26].
The classic FL paradigm, FedAvg [22], iteratively optimize the global model by aggregating the parameters of local models trained from data resides on a number of remote devices or servers. However, these methods usually suffer from serious model performance degradation when the data is not independently and identically distributed (Non-IID) across clients, which is a common issue in FL scenarios. This is mainly because the model parameters on different clients are optimized towards diverse directions [14], leading to the overlarge variance of the aggregated model.
To tackle this challenge, federated distillation (FD) [13] proposes to distill the knowledge of multiple local models into the global model by aggregating only the output soft predictions, which recently attracts increasing attention. For instance, Tao et al. [18] leveraged the public dataset as the distillation data samples to obtain the soft predictions from multiple local models and then updated the global model with the average of these soft predictions. Based on [18], Zhu et al. [40] and Zhang et al. [37] improved the distillation by replacing the public dataset with data generated by the generative model. Although these methods achieve significant improvement over existing parameter-averaging methods, they still do not take the model diversity into account and may still limit the model performance. More specifically, only computing the average of soft predictions will inevitably bring errors when some local models make wrong predictions for the distillation sample.
To break the limitations of existing federated distillation methods, we in this paper propose a novel federated distillation method dubbed DaFKD that can discern the importance of each model to the given distillation sample, and thus is able to reduce the impact of wrong soft predictions. More specifically, we consider that the local data in each client constitutes as a specific domain and employ a domain discriminator for each client to identify the correlation factor between the sample and the domain. For a given distillation sample, we endow the local model with high importance when its correlation factor is significant and vice versa. The principle behind this is the fact that a model tends to make the correct prediction when the sample is contained in the domain for training the model. Furthermore, to facilitate the training of domain discriminator, we propose sharing its partial parameters with the target classification model. Through extensive experiments over various datasets (MNIST, EMNIST, FASHION MNIST, SVHN) and different settings (various models and data distributions), we show that the proposed method significantly improves the model accuracy as compared to state-of-the-art algorithms. The contributions of this paper are:
- We propose a new domain aware federated distillation method named DaFKD which endows the model with different importance according to the correlation between the distillation sample and the training domain.
- To adaptively discern the importance of multiple local models, we propose employing the domain discriminator for each client which identifies the correlation factors. To facilitate the training of the discriminator, we further propose sharing partial parameters between the discriminator and the target classification model.
- We establish the theories for the generalization bound of the proposed method. Different from existing methods, we theoretically show that DaFKD efficiently solves the Non-IID problem where the generalization bound of DaFKD does not increases with the growth of data heterogeneity.
- We conduct extensive experiments over various datasets and settings. The results demonstrate the effectiveness of the proposed method which improves the model accuracy by up to compared to state-of-the-art methods.
2. Related Work
Federated Learning with Parameters Aggregation The main problem incurred by Non-IID for the model parameters aggregation based methods is the huge diverse of the parameters of local models across clients [21,39], where the local models are optimized to different directions. To tackle this challenge, many prior works seek to to reduce the diverse across local model parameters for efficient model aggregation [1,36]. For instance, Tian et al. [16] proposed adding a regularization item in the local objective function such that the divergence of the local model is constrained by the global model. Sai et al. [14] proposed reducing the variance of local gradient to align the diverse local update. This paper applies the ensemble distillation over the obtained local models which is orthogonal to these methods.
Knowledge Distillation is to transfer the knowledge from one or more networks (teacher) to another (student) [12]. The key step in knowledge distillation is to align the soft prediction of the student model to that of the teacher model [5,25,30,33,38]. For example, some works leverage a proxy dataset to distill knowledge between networks [11,34]. Considering that the proxy dataset may not always exist, some recent works proposed distillation in a data-free manner including reconstructing samples used for training the teacher [20,23] or learning a generator [35]. By following this path forward, we in this paper particularly focus on the distillation in federated learning by tailoring the generative model and ensemble distillation techniques.
Federated Distillation Federated distillation is to distill the knowledge from multiple teacher models trained by different clients to the student model [3,9,28]. Lin et al. [18] first proposed leveraging the knowledge distillation in the server to transfer the knowledge from multiple local models to the global model based on an unlabeled proxy dataset. Chen et al. [4] proposed linearly aggregating multiple local models with weights generated by the Bayesian posterior to produce a series of combined models and then, distilling these models into one global model. Considering that these methods rely on an unlabeled auxiliary dataset in the server which may not exist in real-world settings, Zhu et al. [40] and Zhang et al. [37] proposed replacing the proxy dataset with data generated by the generative models and making ensemble federated distillation in a data-free way. However, most of these methods construct the ensemble knowledge by simply computing the average of soft predictions from multiple local models, which does not take model diversity into account and may limit the model performance. In this paper, we take the domain knowledge for training local models into account and endow the local models with different importance when ensembling these soft predictions.
3. Methodology
In this section, we specify the proposed method DaFKD. As illustrated in Figure 1, the key idea of the DaFKD is to leverage a domain discriminator to discern the importance of each local model to the given distillation sample such that the performance of ensemble distillation can be improved. Specifically, each client in DaFKD trains the local model with its private dataset and the domain discriminator with a global generator in an adversarial way. Then, the server aggregates local models from all participated clients and make ensemble distillation with the generator producing distillation samples and the discriminator producing importance. Besides, to facilitate the training of the discriminator, we further propose sharing partial parameters between the discriminator and the target classification model. The workflow of the proposed algorithm is shown in the Algorithm 1.
3.1. Problem Formulation
We aim to collaboratively train a global model for K total clients in FL. We consider each client k can only access to his local private dataset , where is the i-th input data sample and is the corresponding label of with C classes. We denote the number of data samples in dataset by . The global dataset is considered as the composition of all local datasets , . The objective of the FL learning system is to learn a global model w that minimizes the total empirical loss over the entire dataset :
where is the local loss in the k-th client and is the cross-entropy loss function that measures the difference between the prediction and the ground truth labels.
3.2. Domain Discriminator
To endow the model with suitable importance to the given distillation sample, an intuition is that the model has high probability in making the correct prediction when the sample is contained in the domain for training the model. As a consequence, quantifying the correlation between the domain and any given sample is necessary. Motivated by the adversarial training techniques [7] where the discriminator is trained to distinguish whether the generated data is sampled from the distribution of the target dataset, we in this paper proposes a domain discriminator which views the local dataset as the target and outputs the correlation between the distillation sample and the local domain.
More specifically, we assign a personalized discriminator for each client k and adopt a global generator shared by all clients. At each round t, each participated client k firstly pulls the generator from the server to produce pseudo dataset with samples by sampling noise from the distribution . Then, each client k labels the samples in local private dataset positive and the samples in pseudo dataset negative. Using these data samples with generated labels, each client k trains the domain discriminator with the following loss function:
where denotes the probability of being real data. Considering that there have been extensive works for training effective generators [37,40] which can be jointly used with our method, we in this paper simplify the training of generator and adopt the basic FedAvg [22] to train the generator, which still exhibits great effectiveness. Specifically, after obtaining the discriminator , the client k in turn leverages the discriminator to train the generator, which maximizes the loss function 2:
It is worthwhile to note that the client can also train the generator and the discriminator in an alternative way like [7]. After obtaining the updated local generator , the server receives them from all participated clients and aggregates them to get the new global generator:
From a global perspective, the adversarial loss function can be formulated as:
Discussion. One concern for this method may be that the local generator will lead to privacy leakage when it is uploaded from client to the server. In fact, there have been many prior works solving this problem. For example, to protect privacy, Zhu et al. [40] proposed generating feature maps instead of the original data and Xin et al. [31] proposed exploiting the differential privacy. Similarly, the privacy concern of the global generator can also be addressed by only allowing the generator to output intermediate features as specified in Zhu et al. [40]. The main method proposed in this paper supports various generators and thus can definitely achieve privacy protection as combined with these privacy-protecting methods together, of which more details can be found in Appendix A.
| Algorithm 1: Workflow of DaFKD Algorithm |
 |
3.3. Domain-aware Federated Distillation
To obtain the classification model, in each round t, each participated client k firstly locally trains the model and sends it as well as the domain discriminator to the server. After receiving the two models, the server aggregates multiple local models by computing their average as:
Then, the server uses the global generator to generate the pseudo dataset as the distillation data. After that, for every distillation sample , the server computes the importance of each local model with the domain discriminator as and then normalizes it into the probability:
which guarantees that . Finally, the server inputs the pseudo sample into each local model and the average model to obtain the soft predictions and , and applies ensemble knowledge distillation with the importance to obtain the global model :
where is to compute the Kullback-Leibler divergence (KL-divergence).
Discussion. In our method, the domain discriminator is not necessary to be uploaded to the server. Since the domain discriminator is mainly used to output the importance of each model to the distillation sample, it can definitely be used in each client when the distillation sample is generated locally. Naturally, considering that each client has access to the global generator which is used to train the domain discriminator, the shared distillation dataset can be generated in each local client when the random seed of noise is consistent. Besides, to further protect the privacy of importance, each client can directly upload the soft predictions weighted by importance to the server, which we defer the details to the Appendix B.
3.4. Partial Parameters Sharing
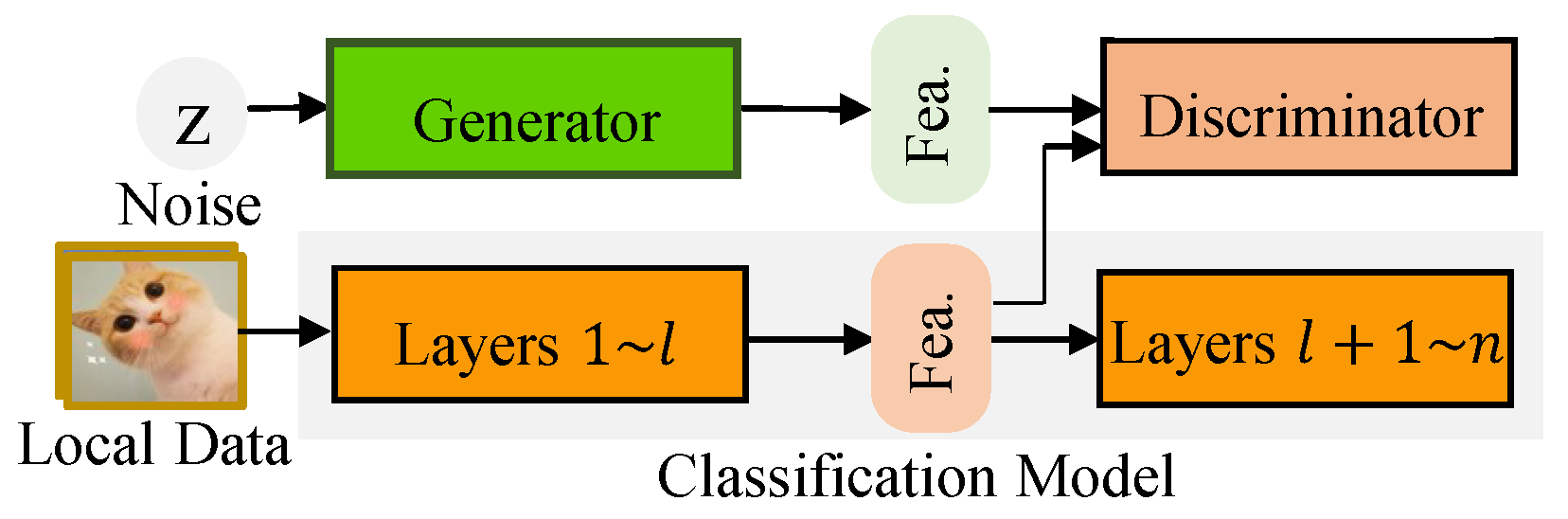
Considering that the domain discriminator is trained over the local dataset, its performance may be deteriorated when the size of local dataset is small. Motivated by the idea in the multi-task learning where sharing the encoder between different tasks can promote each other, we propose sharing partial parameters between the discriminator and the classification model to solve this problem. The intuition behind this is that both the discriminator and the classification model have to distinguish the sample from the extracted features. Besides, another benefit of sharing layers is that the communication cost can be reduced when the discriminator is also uploaded to the server.
To this end, we propose sharing the front model layers between the two models which are used to extract features, as illustrated in Figure 2. Specifically, by denoting the c-layer shared extractor by where is the i-th layer of the shared extractor, we can re-write the -layer discriminator by , and the n-layer classification model by with as the i-th layer of the classification model . With the shared layers, the discriminator and the classification model are trained in a joint way:
where refers to (2) and is defined in (1).
3.5. Theoretical Analysis
In this section, we prove that our method can solve the Non-IID problem of FD. To verify this, we first analyze the distribution learned by the generator and discriminator.
Theorem 1.
Denote the data distribution of each client k by , the data distribution of all clients by , and the pseudo data distribution of the generator by . If the Algorithm 1 trains the discriminator and the global generator to the optima for the loss function (5), then the pseudo data distribution of the generator is , and the discriminator outputs for each client .
The detailed proof is deferred to Appendix C. Theorem 1 exhibits that the global generator still learns the global data distribution even though there are multiple discriminators specialized for different clients. Besides, the discriminator can distinguish the samples either from the global distribution or the local distribution, and thus can generate efficient correlation factors with the collaboration of the generator that produces global distribution. For simplicity of notation, we denote the local model trained over the local dataset by and trained over global dataset by . Besides, without losing generality, we consider . Then, we can further derive the generalization bound of the proposed method.
Theorem 2.
Denote the empirical distribution of activation from each client k by and the empirical distribution of global dataset by . Then, given the constants and , with the probability at least , the expected generalization error of domain-aware ensemble model is:
The proof can be found in the Appendix D. For ease of comparison, we here present the bounds of state-of-the-art FD methods. Specifically, the bound of FEDFUSION [18] is
where and FEDGEN [40] is
The main differences between DaFKD and baselines are the items and which measure the distance between the local data distribution and the global distribution and are incurred by the Non-IID. DaFKD does not include the two items, which indicates that the Non-IID problem is efficiently solved.
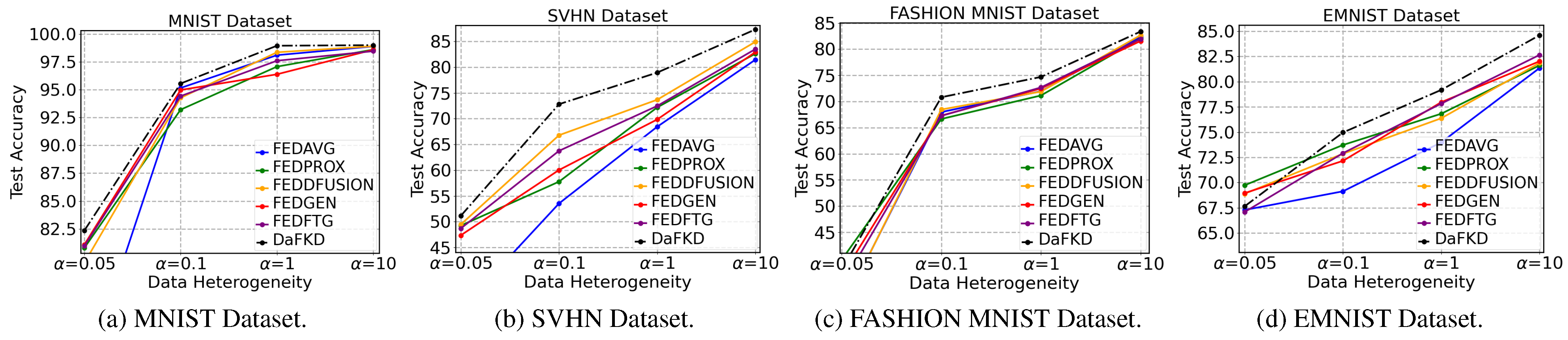
Figure 3.
Visualized performance w.r.t data heterogeneity.
4. Experiments
In this section, we compare the performance of our proposed approach with related works.
4.1. Setup
Baselines: In addition to FEDAVG [22], FEDPROX regularizes the local model training with a proximal term in the model objective [16]. FEDDFUSION is a data-based knowledge distillation method, which applies unlabeled training samples as the proxy dataset [18]. FEDGEN is a data-free knowledge distillation approach that each client can directly regulate the local model updating using the generated unlabeled samples in server [40]. FEDFTG learns a generator to ensemble knowledge of local models in a data-free manner and fine-tunes the global model in server instead of broadcasting the aggregated model back to each client directly [37].
Dataset: We conduct experiments on four image datasets with heterogeneous dataset partition: MNIST [15], EMNIST [6], FASHION MNIST [29] and SVHN [24]. Among them, MNIST, EMNIST and SVHN dataset is for digit and character image classifications, and FASHION MNIST is a fashion-product dataset which is used to learn a multi-class classification task.
Configurations: Unless otherwise mentioned, we set the number of local training epoch E = 20, communication round T = 60, the client number K = 20 with an active ratio r = 0.4. For local training, the batch size is 32 and the weight decay is . The learning rate is for distillation and for training the classifier, generator, and discriminator. Like FEDGEN [40], we use the Dirichlet distribution Dir() on labels to simulate the data heterogeneity. We apply all the training samples and distribute them to user models, and we use all the testing samples for the performance evaluation. For the classifier in all methods, we employ ResNet11 [10] as the basic backbone. For the generator in FEDGEN, FEDFTG and DaFKD, we apply the network composed of two embedding layers(for one-hot label vector and noise vector respectively) and the fully-connected layer with LeakyReLU and BatchNorm layers. For the multi-task learning structure in our DaFKD approach, we treat all previous layers before the last fully-connected layer as share layers, and we use two different fully-connected layers to get outputs as the classifier result and discriminator result.
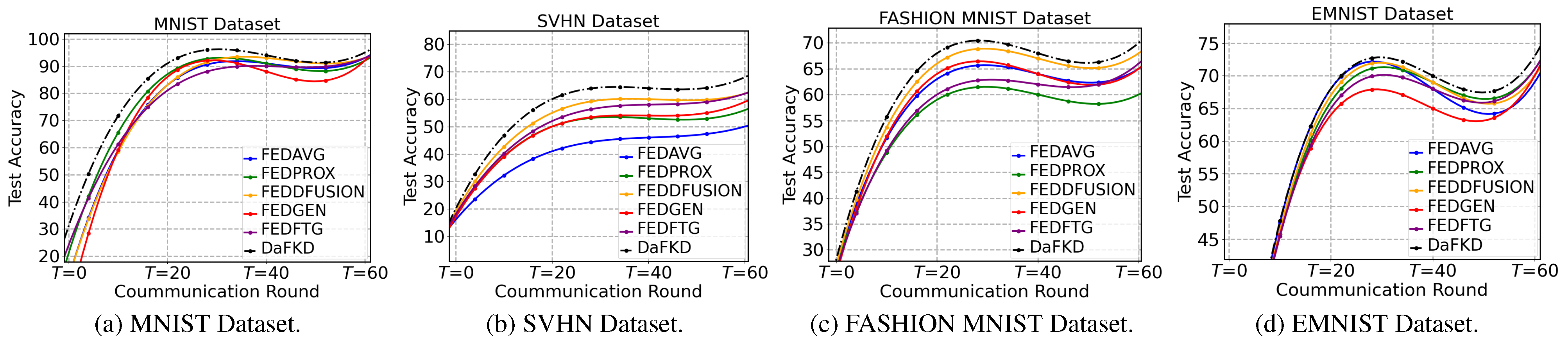
Figure 4.
Fitted learning curve of four image datasets in 60 communication rounds ( = 0.1).
4.2. Performance Overview
Test accuracy. Table 1 shows the performance of our DaFKD and other baseline methods on four image datasets. We carry out experiments against different levels of data heterogeneity on each dataset, and DaFKD achieves the best performance in most cases. Among all mentioned approaches, FEDDFUSION, FEDGEN, FEDFTG and DaFKD apply the knowledge distillation with extra data to improve the model training. As shown in Table 1, these KD based methods are notably excellent, and outperform FEDAVG and FEDPROX in most scenarios. Besides, DaFKD is the only KD-algorithm that is robust against different datasets while consistently performs well, especially surpassing the second by 2-6% with different data heterogeneity levels on SVHN dataset. These results verify our motivation that the domain discriminator can identify the correlation and thus solve the heterogeneity problem.
Data heterogeneity and Client participant. Figure 3 displays the test accuracy with different levels of data heterogeneity on four image datasets. As vividly shown in this figure, all methods achieve an improvement in test accuracy with the decreasing degree of data heterogeneity. Most notably, DaFKD gains a significant improvement in test accuracy in data heterogeneity = 0.1 and steadily outperforms all methods. Figure 5 provides the test accuracy under different ratios r between active clients and total clients. In this figure, DaFKD performs best with different ratios r and the higher accuracy is achieved as applying more active clients in each communication round.
Communication rounds. Table 2 shows evaluation of DaFKD and other baseline methods in terms of the communication rounds to reach the target test accuracy. Here we highlight the best and second-best results in bold. DaFKD reaches most best and the second-best evaluation results on all datasets. What is more, although FEDAVG reach the target accuracy with fewer communication rounds on EMNIST dataset, DaFKD finally can surpass it by significant 5% after all communication rounds. Meanwhile, Figure 4 displays the fitted learning curve of four image datasets in 60 communication rounds, where we adapt the test accuracy per five communication rounds to fit the learning curve. In the figure, each method rapidly increases at the beginning and slows down as training goes. DaFKD always keeps a leading tendency in the test accuracy.
Parameter sensitivity analysis. To figure out whether DaFKD is sensitive to some specific parameters, we select local training epoch E, sample batchsize B and dimension d of noise on SVHN with = 0.1 to carry out experiments. Figure 6 shows the performance of DaFKD under different configurations. DaFKD achieves the better result when we increase the local training epochs at the beginning. However, DaFKD has a comparable performance when the E is set to 20 and 40. In order to balance communication expense and test accuracy, we give priority to the local training epoch E = 20 here. In addition, DaFKD achieves a similar performance with different sample size B and dimension d of noise. This indicates that DaFKD is only sensitive to few parameters and still robust to most parameters in a large range.
The impact of sharing parameters. We share all front layers (ResNet11) before the last fully-connected layer as share layers between the generator and the discriminator in DaFKD. Table 3 shows the results. As can be seen, parameter sharing facilitates the training of DaFKD in two folds: 1) it enables higher accuracy in most cases; 2) it accelerates convergence where it consistently costs fewer rounds as reaching some given accuracy. Furthermore, parameter sharing can save communication costs by transmitting fewer parameters in each round. Besides, from Table 3.(a), we can find that DaFKD with correlations performs better in all cases (sharing or not). From the last two columns of Table 3.(b), we can find that parameter sharing can accelerate convergence faster than correlations.
5. Conclusion
In this paper, we seek to tackle the data heterogeneity challenge in the federated knowledge distillation. We propose a novel method dubbed domain-aware federated knowledge distillation, namely, DaFKD, which imposes an importance on each local model for some given distillation sample. To quantify the importance, we leverage a domain discriminator to compute the correlation between the distillation sample and the domain for training the local model. Furthermore, to facilitate the training of the domain discriminator, we propose sharing its partial parameters to the classification model. Extensive experiments conducted on various datasets and settings show that our method achieves significant improvement for the model accuracy.
A. DaFKD Without Uploading the Discriminator
The privacy of local generators can be protected by using secure aggregation. The privacy of the global generator can be protected by only outputting features instead of the original data, as shown in Figure 7, which is elaborated in FEDGEN[40] and mentioned in Section 3.2.
Figure 7.
Feature generator. The discriminator and the generator learn the feature map instead of the original dataset. Similarly, the distillation dataset also includes the feature map.
Figure 7.
Feature generator. The discriminator and the generator learn the feature map instead of the original dataset. Similarly, the distillation dataset also includes the feature map.
B. DaFKD Without Uploading the Discriminator
In fact, the discriminator and the correlation factors are not necessarily visible to the server to protect the privacy of clients. More specifically, all clients can use the same generator to produce pseudo distillation data locally. Then, each client k inputs the distillation data to the discriminator to produce correlation factors and input the distillation data to the classification model to produce soft predictions . To enable the domain-aware federated distillation, each client k multiplies the correlation factors to the corresponding soft predictions s obtaining and transmits it to the server. At the same time, the server aggregates from all clients in a privacy-preserving manner by using differential privacy or homomorphic encryption to obtain . After receiving multiplied soft predictions from all clients and the aggregated , the server normalizes the multiplied soft predictions getting . To enable distillation, the server uses the same random seed as each client is adopted to produce the pseudo data and inputs it to the global model obtaining . Finally, the server implements the ensemble distillation using (8), i.e.,
C. Proof of Theorem 1
Theorem 1.
Denote the data distribution of each client k by , the data distribution of all clients by , and the pseudo data distribution of the generator by . If the Algorithm 1 trains the discriminator and the global generator to the optima for the loss function (5), then the pseudo data distribution of the generator is , and the discriminator outputs for each client .
Proof:
To analyze the distribution fitted by the global generator and multiple discriminators, we formally present the overall adversarial loss function including the generator and all discriminators as:
where is the data distribution of client k. Given the fixed generator , considering the distribution of generated data as , we have
Obviously, the equation (14) achieves the minima when
Now, to solve the optimal generator, we bring (15) back to (13) and obtain
where JSD denotes the Jensen-Shannon Divergence. Since the centroid defined as the average sum of a finite set of probability distributions is the minimizer of Jensen-Shannon divergences between a probability distribution and the prescribed set of distributions, we can derive the formulation of optimal as , which completes the proof.
D. Proof of Theorem 2
Theorem 2.
Denote the empirical distribution of activation from each client k by and the empirical distribution of global dataset by . Then, given the constants and , with the probability at least , the expected generalization error of domain-aware ensemble model is:
Proof:
We seek to establish the relationship between and . Considering that the convexity of the loss function in terms of the prediction, we have
Considering the optimal discriminator where , we have
Bringing the bound of in (19) back to (18) derives:
Next, we bound the with its empirical counterpart through Hoeffding inequality. Without losing the generality, we consider the simplified case where the size of samples in all clients are equal, i.e., . Then, a simple application of the Hoeffding’s inequality gives:
where and are the constants. Thereby, with probability at least , we have:
For all K devices, we have
Putting (22) back to (20) derives:
Considering that minimizes the loss function over the distribution of training dataset , can be easily obtained. According to the definition that , we can derive
Thereby, the following inequality holds with probability at least :
References
- Acar, D.A.E.; Zhao, Y.; Navarro, R.M.; Mattina, M.; Whatmough, P.N.; Saligrama, V. Federated Learning Based on Dynamic Regularization. 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021.
- Ammad-ud-din, M.; Ivannikova, E.; Khan, S.A.; Oyomno, W.; Fu, Q.; Tan, K.E.; Flanagan, A. Federated Collaborative Filtering for Privacy-Preserving Personalized Recommendation System. CoRR, abs/1901.09888, 2019. [CrossRef]
- Bistritz, I.; Mann, A.; Bambos, N. Distributed Distillation for On-Device Learning. Proceedings of Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems, NeurIPS, 2020.
- Chen, H.; Chao, W. FedBE: Making Bayesian Model Ensemble Applicable to Federated Learning. 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021.
- Cho, J.H.; Hariharan, B. On the efficacy of knowledge distillation. Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, ICCV, 2019, pp. 4794–4802.
- Cohen, G.; Afshar, S.; Tapson, J.; Van Schaik, A. EMNIST: Extending MNIST to handwritten letters. 2017 international joint conference on neural networks (IJCNN). IEEE, 2017, pp. 2921–2926.
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, pp. 2672–2680.
- Guo, P.; Wang, P.; Zhou, J.; Jiang, S.; Patel, V.M. Multi-Institutional Collaborations for Improving Deep Learning-Based Magnetic Resonance Image Reconstruction Using Federated Learning. IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pp. 2423–2432.
- Guo, Q.; Wang, X.; Wu, Y.; Yu, Z.; Liang, D.; Hu, X.; Luo, P. Online knowledge distillation via collaborative learning. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, 2020, pp. 11020–11029.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- He, R.; Sun, S.; Yang, J.; Bai, S.; Qi, X. Knowledge Distillation as Efficient Pre-training: Faster Convergence, Higher Data-efficiency, and Better Transferability. IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pp. 9151–9161.
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv preprint 2015, arXiv:1503.02531. [Google Scholar]
- Jeong, E.; Oh, S.; Kim, H.; Park, J.; Bennis, M.; Kim, S. Communication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation under Non-IID Private Data. CoRR, abs/1811.11479, 2018. [CrossRef]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.J.; Stich, S.U.; Suresh, A.T. SCAFFOLD: Stochastic Controlled Averaging for Federated Learning. Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, pp. 5132–5143.
- LeCun, Y.; Cortes, C.; Burges, C. MNIST handwritten digit database, 2010.
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proceedings of Machine Learning and Systems 2020, 2, 429–450. [Google Scholar]
- Li, X.; Xu, Y.; Song, S.; Li, B.; Li, Y.; Shao, Y.; Zhan, D. Federated Learning with Position-Aware Neurons. IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pp. 10072–10081.
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Ensemble distillation for robust model fusion in federated learning. Advances in Neural Information Processing Systems 2020, 33, 2351–2363. [Google Scholar]
- Liu, Q.; Chen, C.; Qin, J.; Dou, Q.; Heng, P. FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space. IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pp. 1013–1023.
- Lopes, R.G.; Fenu, S.; Starner, T. Data-Free Knowledge Distillation for Deep Neural Networks. CoRR, abs/1710.07535, 2017. [CrossRef]
- Malinovskiy, G.; Kovalev, D.; Gasanov, E.; Condat, L.; Richtárik, P. From Local SGD to Local Fixed-Point Methods for Federated Learning. Proceedings of the 37th International Conference on Machine Learning, ICML, 13-18 July, Virtual Event, 2020, pp. 6692–6701.
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. Artificial intelligence and statistics. PMLR, 2017, pp. 1273–1282.
- Micaelli, P.; Storkey, A.J. Zero-shot Knowledge Transfer via Adversarial Belief Matching. Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pp. 9547–9557.
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning 2011.
- Phuong, M.; Lampert, C.H. Distillation-based training for multi-exit architectures. Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 1355–1364.
- Ramaswamy, S.; Mathews, R.; Rao, K.; Beaufays, F. Federated Learning for Emoji Prediction in a Mobile Keyboard. CoRR, abs/1906.04329, 2019. [CrossRef]
- Wang, C.; Chen, X.; Wang, J.; Wang, H. ATPFL: Automatic Trajectory Prediction Model Design under Federated Learning Framework. IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, New Orleans, LA, USA, June 18-24, 2022, pp. 6553–6562.
- Wu, G.; Gong, S. Peer Collaborative Learning for Online Knowledge Distillation. Proceedings of the AAAI Conference on Artificial Intelligence, AAAI, 2021.
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint 2017, arXiv:1708.07747. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, 2020, pp. 10687–10698.
- Xin, B.; Yang, W.; Geng, Y.; Chen, S.; Wang, S.; Huang, L. Private FL-GAN: Differential Privacy Synthetic Data Generation Based on Federated Learning. 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, May 4-8, 2020, pp. 2927–2931.
- Xu, A.; Li, W.; Guo, P.; Yang, D.; Roth, H.; Hatamizadeh, A.; Zhao, C.; Xu, D.; Huang, H.; Xu, Z. Closing the Generalization Gap of Cross-silo Federated Medical Image Segmentation. IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pp. 20834–20843.
- Yang, C.; Xie, L.; Qiao, S.; Yuille, A.L. Training deep neural networks in generations: A more tolerant teacher educates better students. Proceedings of the AAAI Conference on Artificial Intelligence, AAAI, 2019, Vol. 33, pp. 5628–5635.
- Yang, Z.; Li, Z.; Jiang, X.; Gong, Y.; Yuan, Z.; Zhao, D.; Yuan, C. Focal and Global Knowledge Distillation for Detectors. IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pp. 4633–4642.
- Yoo, J.; Cho, M.; Kim, T.; Kang, U. Knowledge Extraction with No Observable Data. Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pp. 2701–2710.
- Zhang, L.; Luo, Y.; Bai, Y.; Du, B.; Duan, L. Federated Learning for Non-IID Data via Unified Feature Learning and Optimization Objective Alignment. IEEE/CVF International Conference on Computer Vision, ICCV, Montreal, QC, Canada, October 10-17, 2021, 2021, pp. 4400–4408.
- Zhang, L.; Shen, L.; Ding, L.; Tao, D.; Duan, L. Fine-tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning. IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pp. 10164–10173.
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep mutual learning. Proceedings of 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2018, pp. 4320–4328.
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated Learning with Non-IID Data. CoRR, abs/1806.00582, 2018. [CrossRef]
- Zhu, Z.; Hong, J.; Zhou, J. Data-free knowledge distillation for heterogeneous federated learning. International Conference on Machine Learning. PMLR, 2021, pp. 12878–12889.
Figure 1.
Illustration of the DaFKD framework in the server. The distillation data samples are generated by the generator . By inputting the pseudo sample into the domain discriminator , the correlation factor of each domain is obtained. Then, the soft predictions are obtained by inputting the data into the local models and are scaled with the correlation factors . Finally, the server aggregates all scaled soft predictions and computes distillation loss .
Figure 1.
Illustration of the DaFKD framework in the server. The distillation data samples are generated by the generator . By inputting the pseudo sample into the domain discriminator , the correlation factor of each domain is obtained. Then, the soft predictions are obtained by inputting the data into the local models and are scaled with the correlation factors . Finally, the server aggregates all scaled soft predictions and computes distillation loss .
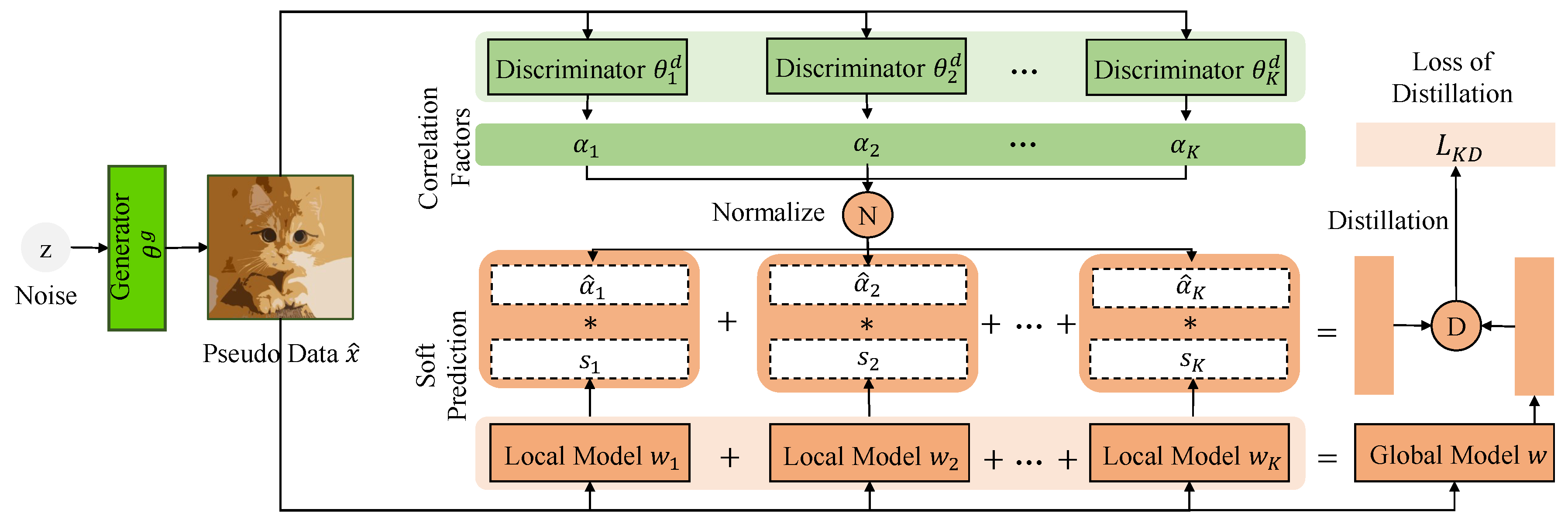
Figure 2.
Illustration of the Shared Learning between Discriminator and Classification Model.
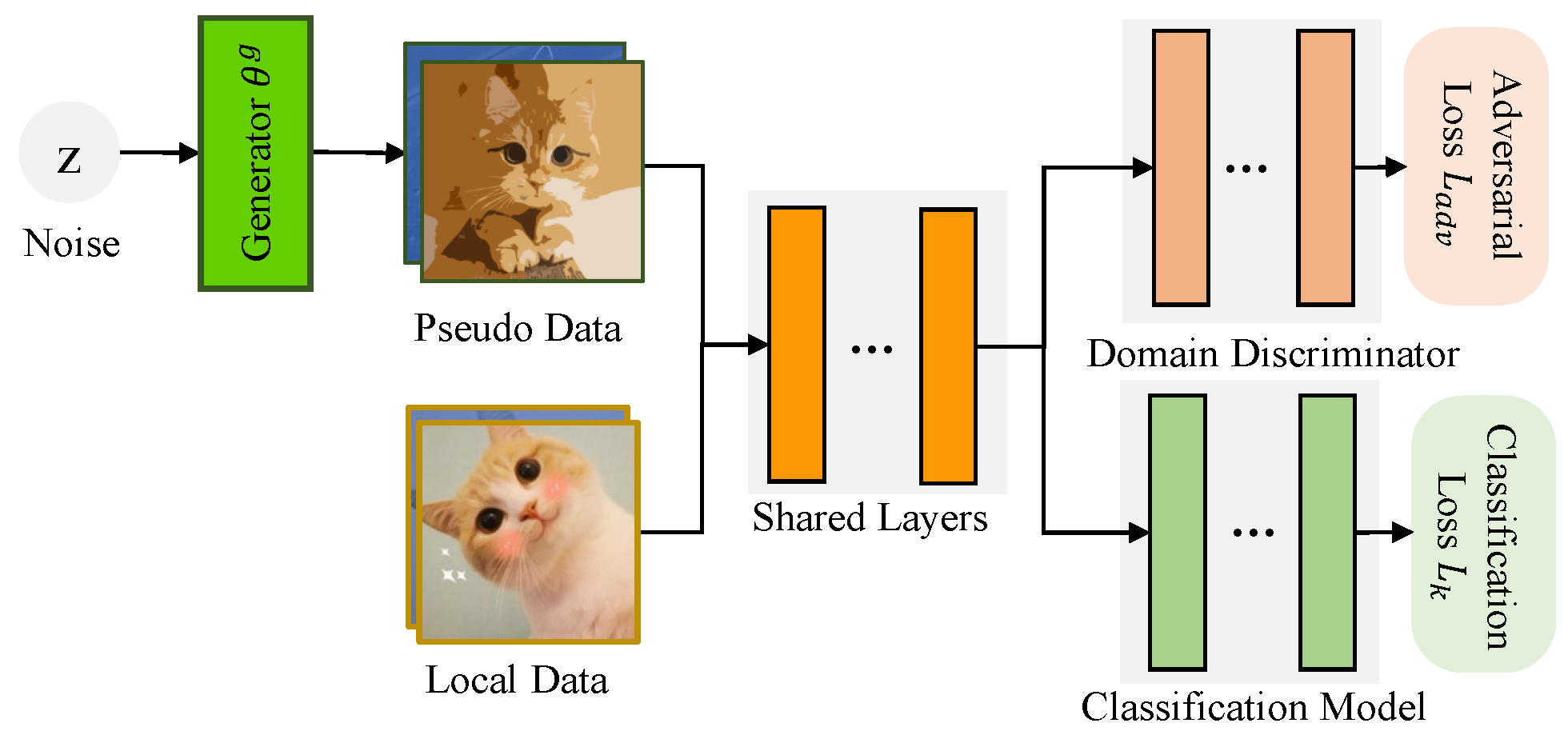
Figure 5.
Test accuracy w.r.t. ratio r between active clients and total clients in each round ( = 0.1).
Figure 5.
Test accuracy w.r.t. ratio r between active clients and total clients in each round ( = 0.1).
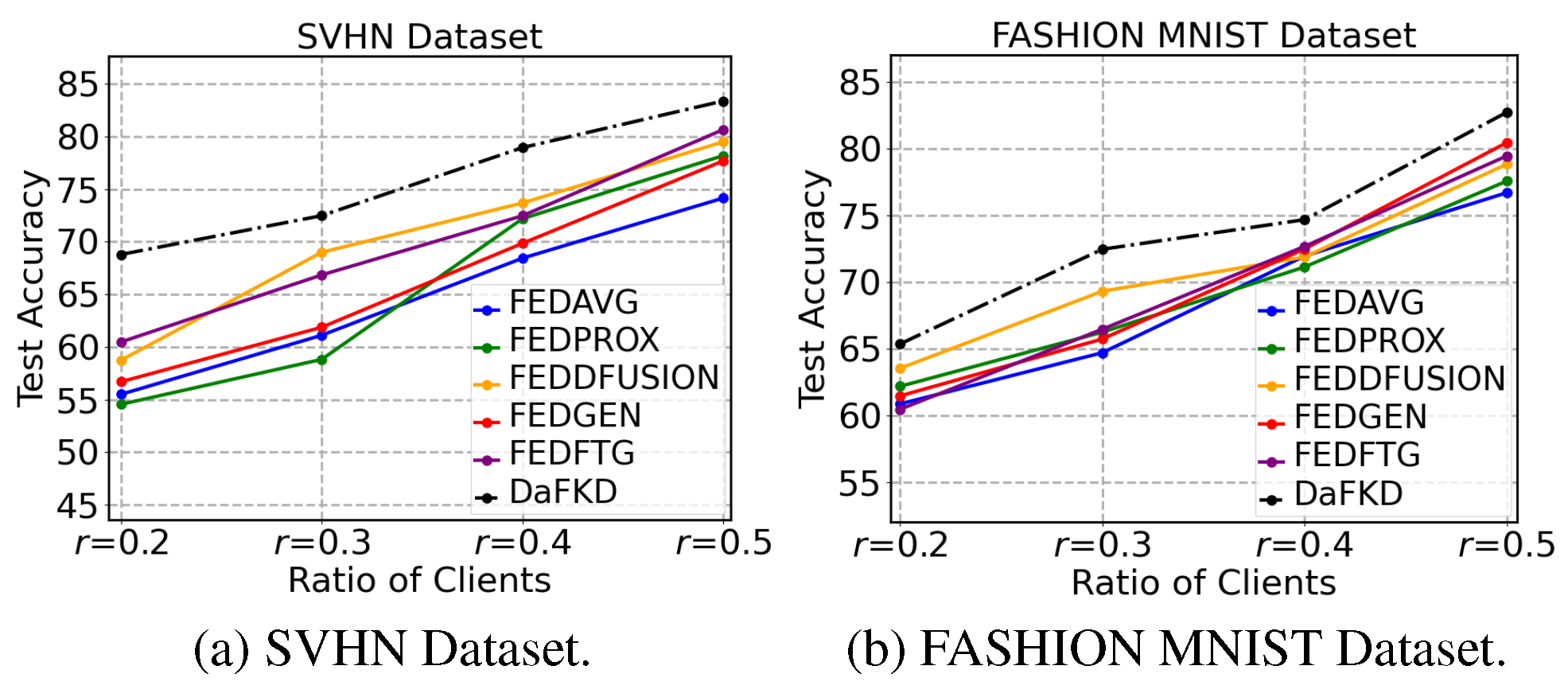
Figure 6.
Performance of DaFKD under different configurations (a) local training epoch E, (b) sample size B in classifier and generator, (c) dimension d of noise on SVHN with = 0.1.
Figure 6.
Performance of DaFKD under different configurations (a) local training epoch E, (b) sample size B in classifier and generator, (c) dimension d of noise on SVHN with = 0.1.

Table 1.
Performance of our DaFKD and other baseline methods on four image datasets. For all methods, a smaller indicates higher heterogeneity and E indicates the local training steps.
Table 1.
Performance of our DaFKD and other baseline methods on four image datasets. For all methods, a smaller indicates higher heterogeneity and E indicates the local training steps.
| Top-1 Test Accuracy | |||||||
|---|---|---|---|---|---|---|---|
| Dataset | Setting | FEDAVG | FEDPROX | FEDDFUSION | FEDGEN | FEDFTG | DaFKD |
| MNIST, E = 20 |
= 0.05 = 0.1 = 1 |
69.11± 1.39 95.16± 0.79 98.11± 0.14 |
80.77± 0.35 93.21± 0.55 97.08± 0.69 |
79.42± 0.57 94.27± 0.12 98.37± 0.40 |
81.06± 1.09 94.98± 0.47 96.39± 0.90 |
80.95±1.06 94.43±0.49 98.47±0.21 |
82.33±0.44 95.56±0.41 98.96±0.38 |
| SVHN, E = 20 |
= 0.05 = 0.1 = 10 |
33.01± 0.12 53.54± 0.21 81.44± 0.01 |
49.24± 0.16 57.77± 0.86 82.61± 0.34 |
49.46± 0.17 66.78± 0.33 84.91± 0.64 |
47.36± 0.42 60.03± 1.12 82.91± 0.73 |
48.69±1.87 63.75±0.11 83.49±1.32 |
51.14±0.16 72.80±0.11 87.31±0.85 |
| FASHION MNIST, E = 20 |
= 0.05 = 0.1 = 10 |
30.01± 0.54 67.97± 0.03 82.37± 0.82 |
39.71±0.23 66.65± 0.08 82.06± 0.53 |
30.08± 0.82 68.46± 0.14 82.67± 1.03 |
36.59± 0.98 67.29± 2.05 81.57± 1.96 |
34.84±0.77 67.25±0.14 81.96±1.86 |
37.85±0.24 70.81±0.21 83.37±0.06 |
| EMNIST, E = 40 |
= 0.05 = 0.1 = 10 |
67.28± 0.14 69.13± 0.23 81.35± 1.03 |
69.73± 0.17 73.72± 0.55 81.61± 0.71 |
68.89± 0.07 72.85± 0.93 81.85± 1.08 |
68.95±0.88 72.15± 2.04 82.02± 1.19 |
67.08±0.97 72.91±1.87 82.65±1.04 |
67.64±1.86 74.96±0.91 84.60±1.86 |
Table 2.
Evaluation of DaFKD and other baseline methods on four image datasets ( = 0.1), in terms of the communication rounds to reach the target test accuracy (). Here we highlight the best and second-best results in bold.
Table 2.
Evaluation of DaFKD and other baseline methods on four image datasets ( = 0.1), in terms of the communication rounds to reach the target test accuracy (). Here we highlight the best and second-best results in bold.
| Communication Round | |||||||
|---|---|---|---|---|---|---|---|
| Dataset | Accuracy | FEDAVG | FEDPROX | FEDDFUSION | FEDGEN | FEDFTG | DaFKD |
| MNIST |
= 85% = 90% |
22.67±2.33 33.33±1.00 |
18.33±3.67 40.00±3.33 |
19.67±8.33 46.33±2.33 |
21.67±2.00 39.00±3.67 |
20.67±1.33 43.67±3.67 |
19.00±2.67 38.33±1.67 |
| SVHN |
= 55% = 60% |
58.33±6.67 > 60 |
50.67±3.33 > 60 |
21.67±3.33 40.67±2.00 |
32.67±5.67 57.33±3.67 |
30.00±4.67 55.67±2.33 |
14.00±2.33 18.67±1.33 |
| FASHION MNIST |
= 60% = 65% |
21.00±1.33 35.67±3.67 |
22.67±5.67 38.33±4.00 |
20.67±3.33 34.33±0.67 |
25.00±3.33 39.67±2.67 |
27.67±4.67 43.33±6.66 |
18.67±2.33 33.67±3.00 |
| EMNIST |
= 65% = 70% |
16.33±6.33 57.66±1.33 |
18.00±3.33 44.67±2.67 |
21.33±5.67 42.67±4.67 |
23.33±1.67 50.67±2.33 |
22.67±3.67 41.33±0.67 |
20.00±3.33 40.67±4.33 |
Table 3.
Ablation studies.
| = 0.05 | = 0.1 | = 0.05 | = 0.1 | = 0.05 | = 0.1 | |
| MNIST | 82.33±0.44 | 95.56±0.41 | 84.67±0.92 | 95.23±0.16 | 80.57±1.67 | 94.14± 0.85 |
| SVHN | 51.14±0.16 | 72.80±0.11 | 50.78±0.03 | 74.01±1.08 | 50.33±2.08 | 72.51±0.98 |
| FASHION MNIST | 37.85±0.24 | 70.81±0.21 | 35.45±0.34 | 70.51±0.14 | 34.64±1.68 | 64.35±1.87 |
| EMNIST | 67.64±1.86 | 74.96±0.91 | 68.20±0.07 | 73.61±2.32 | 65.01±0.06 | 71.72±0.67 |
| (a) Test accuracy (%) of DaFKD with different techniques. | ||||||
| MNIST |
= 85% = 90% |
19.00±2.67 38.33±1.67 |
21.33±1.67 47.00±2.67 |
20.67±1.33 45.33±2.67 |
||
| SVHN |
= 55% = 60% |
14.00±2.33 18.67±1.33 |
22.33±2.67 35.33±5.67 |
20.67±1.33 31.00±3.67 |
||
| FASHION MNIST |
= 60% = 65% |
18.67±2.33 33.67±3.00 |
18.67±1.00 33.33±1.67 |
19.33±0.67 37.67±1.67 |
||
| EMNIST |
= 65% = 70% |
20.00±3.33 40.67±4.33 |
22.33±2.00 45.66±1.67 |
21.33±2.33 42.33±0.33 |
||
| (b) The number of communication rounds to reach the given accuracy. | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



