
Submitted:
24 March 2023
Posted:
27 March 2023
You are already at the latest version
Abstract
This article presents a review of current advances and future prospects in the field of forecasting renewable energy generation using machine learning (ML) and deep learning (DL) techniques. With the increasing penetration of renewable energy sources (RES) into the electricity grid, accurate forecasting of their generation becomes crucial for efficient grid operation and energy management. Traditional forecasting methods have limitations, and thus ML and DL algorithms have gained popularity due to their ability to learn complex relationships from data and provide accurate predictions. This paper reviews the different approaches and models that have been used for renewable energy forecasting and discusses their strengths and limitations. It also highlights the challenges and future research directions in the field, such as dealing with uncertainty and variability in renewable energy generation, data availability, and model interpretability. Finally, this paper emphasizes the importance of developing robust and accurate renewable energy forecasting models to enable the integration of RES into the electricity grid and facilitate the transition towards a sustainable energy future.
Keywords:
Accurate predictions
; Deep Learning
; Energy management
; Machine Learning
; Renewable En-ergy Forecasting
1. Introduction
Renewable energy research and development have gained significant attention due to a growing demand for clean and sustainable energy in recent years [1,2]. In the fight to cut greenhouse gas emissions and slow down climate change, renewable energy is essential [3,4,5]. In addition, RES offer several advantages, including a reduction in energy dependence on foreign countries, job creation, and the potential for cost savings [1,6]. However, the inherent variability and uncertainty of RES present a significant challenge for the widespread adoption of renewable energy [7,8]. For example, wind energy generation is heavily influenced by the weather, which can be unpredictable and difficult to forecast accurately [9,10]. Similarly, solar energy generation is influenced by factors such as cloud cover and seasonal changes in sunlight [11]. The high variability and uncertainty of renewable energy generation make it challenging to integrate RES into the power grid efficiently [12].
One approach to address this challenge is to develop accurate forecasting models for renewable energy generation. Accurate forecasting models can help to minimize the negative impact of the variability and uncertainty of renewable energy generation on the power grid. For decades, energy generation has been predicted using traditional forecasting models, such as statistical models [13]. However, these models have limitations in their ability to handle complex nonlinear relationships and the high-dimensional nature of renewable energy data [14]. Promising approaches to address the limitations of traditional forecasting models involve the utilization of ML and DL algorithms [14]. ML and DL algorithms can learn complex nonlinear relationships from immense quantities of information, making them suitable for handling the high-dimensional nature of renewable energy data. Moreover, they can handle a wide range of input data types, including time series data, meteorological data, and geographical data.
Many researchers have looked at the application of ML and DL algorithms for the forecasting of solar radiation, a significant element influencing the output power of solar systems [15]. For instance, Voyant et al. suggested the use of hybrid models (HMs) to enhance prediction performance after discovering that SVR, SVM, ARIMA and ANN are the superior approaches for forecasting solar radiation [16]. Huertas et al. demonstrated that the HM with SVM outperformed single predictor models in terms of improving forecasts of solar radiation [17]. In comparison to other models, Gürel et al. discovered that the ANN algorithm was the most effective model for assessing solar radiation [18]. Alizamir et al. found that when predicting solar radiation, the GBT model outperforms other models in terms of accuracy and precision [19]. Srivastava et al. suggest that the four ML algorithms (CART, MARS, RF, and M5) can be utilized for forecasting hourly solar radiation for up to six days in advance, with RF demonstrating the best performance while CART showing the weakest performance [20]. In their study, Agbulut et al., demonstrated that the various ML algorithms they tested were highly accurate in predicting daily global solar radiation data, with the best performance achieved by the ANN algorithm [21].
Similar to solar energy, the prediction of wind energy poses a challenge due to its nonlinearity and randomness, which results in inconsistent power generation. Consequently, there is a need for an effective model to forecast wind energy, as evidenced by research studies [22,23]. In light of the rising global population and increasing demand for energy, wind energy is viewed as a feasible alternative to depleting fossil fuels. Offshore wind farms are particularly advantageous compared to onshore wind farms since they offer higher capacity and access to more wind sources [24]. ML and DL models and algorithms are employed in wind energy development, utilizing wind speed data and other relevant information. Various researchers have proposed different models to increase prediction accuracy. For example, Zendehboud et al. suggested the SVM model as superior to other models and have introduced hybrid SVM models [25]. Wang et al. proposed an HM comprising a combination of models for short-term wind speed prediction [26]. Demolli et al. used five ML algorithms to predict long-term wind power, finding that the SVR algorithm is most effective when the standard deviation is removed from the dataset [27]. Xiaoetal suggested using a self-adaptive kernel extreme learning machine (KELM) as a means to enhance the precision of forecasting [28]. The ARIMA and Nonlinear Autoregressive Exogenous (NARX) models were evaluated by Cadenas et al., who came to the conclusion that the NARX model had less error [29]. Wind power and speed were predicted in other studies using a variety of models, including the Improved Dragonfly Algorithm (IDA) with SVM (IDA-SVM) model, Local Mean Decomposition (LMD), Firefly Algorithm (FA) models, and the CNN model [30,31,32].
ML and DL have significantly advanced the field of forecasting renewable energy, however there are still a number of issues that need to be resolved. For instance, the choice of ML and DL algorithms, the selection of input data, and the handling of missing data are essential factors that affect the precision of forecasting models for renewable energy. Additionally, there is a need to develop robust and interpretable models that can provide insights into the factors that influence renewable energy generation.
This review provides an overview of the current advances and future prospects of ML and DL algorithms for renewable energy forecasting. The paper highlights the advantages and limitations of different ML and DL algorithms and their applications to various renewable energy sources. In addition, the paper discusses the challenges facing renewable energy forecasting with ML and DL and provides recommendations for future research in the field.
2. Machine learning-based forecasting of Renewable energy
2.1. Overview of ML
ML is a subset of artificial intelligence that seeks to enable machines to learn from data and improve their ability to perform a particular task [33,34]. The process involves developing statistical models and algorithms that enable computers to identify patterns in data and utilize them to make decisions or predictions. In essence, ML involves teaching a computer to identify and react to specific types of data by presenting it with extensive examples, known as training data. This training procedure helps the computer to identify patterns and make predictions or decisions on fresh data that it has not encountered previously [35,36,37]. The applications of ML span across diverse industries such as healthcare, finance, e-commerce, and others [38,39,40,41,42,43]. In addition, ML techniques can be leveraged for predicting renewable energy generation, resulting in better management of renewable energy systems with improved efficiency and effectiveness.
2.2. ML types and algorithms used for Renewable energy forecasting
There are multiple ML algorithms available, each having distinct strengths and weaknesses. The algorithms can be categorized into three primary groups, namely supervised learning, unsupervised learning, and reinforcement learning [44].
2.2.1. Supervised Learning:
Supervised learning refers to a ML method that involves training a model using data that has been labeled. The labeled data comprises input-output pairs, where the input is the data on which the model is trained, and the output is the expected outcome [45,46]. The model learns to map inputs to outputs by reducing the error between the predicted and actual outputs during training. Once trained, the model can be applied to generate predictions on new, unlabeled data [47,48]. Regression and classification are the two basic sub-types of supervised learning algorithms (Figure 1) [45].
1. Regression: Regression is a supervised learning approach that forecasts a continuous output variable based on one or more input variables. Regression aims to identify a mathematical function that can correlate the input variables to a continuous output variable, which may represent a single value or a range of values [49]. Linear regression, Polynomial Regression, and Support Vector Regression (SVR) are the three main types of supervised learning algorithms in regression [50].
Linear and Polynomial Regression: Linear regression is a prevalent and straightforward approach used to forecast a continuous output variable utilizing one or multiple input variables. It uses a straight line to indicate the correlation between the input variables and the output variables [51]. On the other hand, Polynomial regression, a type of linear regression, employs nth-degree polynomial functions to depict the connection between input features and the outcome variable [52]. This can enhance the accuracy of predictions by enabling the model to capture more intricate correlations between the input data and the target variable. In renewable energy forecasting, both linear and polynomial regression can be used to predict the power output of RES such as solar and wind power [53,54]. Weather information like temperature, humidity, and wind speed are frequently included in the input characteristics, along with historical power output data. The target variable is the power output of the renewable energy source, which can be predicted using the input features.
For instance, Ibrahim et al. (2012) used data from a weather station collected over three years to create a linear regression model to predict solar radiation in Perlis. The model used three input variables and had a good fit with an R-squared value of 0.954. The authors concluded that their model could be a useful tool for estimating solar radiation in Perlis [55]. Another scholar Ekanayake et al. (2021), created artificial neural networks (ANNs), multiple linear regression, and power regression models to produce wind power prediction models for a Sri Lankan wind farm (ANN). The models were developed using power generation data over five years and showed acceptable accuracy with low RMSE, bias, and high correlation coefficient. The ANN model was the most precise, but the MLR and PR models provide insights for additional wind farms in the same area [56]. Mustafa et al. (2022) also compared four regression models, linear regression, logistic regression, Lasso regression, and elastic regression, for solar power prediction. The results showed that all four models are effective, but the Elastic regression outperformed the others in predicting maximum solar power output. Principal component analysis (PCA) was also applied, showing improved results in the elastic regression model. The paper focuses on the strengths and weaknesses of each solar power prediction model [57].
Support Vector Regression (SVR): SVR algorithm is utilized in regression analysis within the field of ML [58]. It works by finding the best hyperplane that can separate the data points in a high-dimensional space. The selection of the hyperplane aims to maximize the distance between the closest data points on each side of it. The approach involves constraining the margin while minimizing the discrepancy between the predicted and actual values. It is also a powerful model to predict renewable energy potentials for a specific location. For example, Yuan et al. (2022) proposed a Jellyfish Search algorithm optimization SVR (IJS-SVR) model to predict wind power output and address grid connection and power dispatching issues. The SVR was optimized using the IJS technique, and the model was tested in both the spring and winter. IJS-SVR outperformed other models in both seasons, providing an effective and economical method for wind power prediction [59]. In addition, Li et al. (2022) created ML-based algorithms for short-term solar irradiance prediction, incorporating Hidden Markov Model and SVM regression techniques. Bureau of Meteorology, they demonstrated that their algorithms can effectively forecast solar irradiance for 5-30 minute intervals in various weather conditions [60]. Another author Mwende et al. (2022) developed SVR and Random Forest Regression (RFR) models for real-time photovoltaic (PV) power output forecasting. On the validation dataset, SVR performed better than RFR with an RMSE of 43.16, adjusted R2 of 0.97, and MAE of 32.57, in contrast to RFR’s RMSE of 86, adjusted R2 of 0.90, and MAE of 69 [61].
Classification: Classification, a form of supervised learning, involves using one or more input variables to anticipate a categorical output variable [62]. Classification aims to find a function that can map the input variables to discrete output categories. The most widely used classification algorithms for predicting RES include logistic regression, decision trees, random forest, and support vector machines.
Logistic Regression: Logistic regression is a classification method that utilizes one or more input variables to forecast a binary output variable [63,64]. It models the probability of the output variable being true or false using a sigmoid function. In renewable energy forecasting, Logistic Regression can be used to predict whether or not a specific event will occur, such as a solar or wind farm reaching a certain level of power output. For instance, using ML, Jagadeesh et al. developed a forecasting method for solar power output in 2020. They used a logistic regression model with data from an 11-month period, including plant output, solar radiation, and local temperature. They found that the right choice of solar variables is essential for precise forecasting, and their study looked at the algorithm’s accuracy and the probability that a plant will produce on a specific day in the future [65].
Decision Trees: An alternative method for classification is decision trees, which involves dividing the input space into smaller sections based on input variable values and then assigning a label or value to each of these sections [64]. The different studies developed Decision Tree models to forecast power output from different renewable energy systems. Essama et al. (2018) developed a models to predict the power output of a photovoltaic (PV) system in Cocoa, Florida of USA using weather parameters obtained from United States’ National Renewable Energy Laboratory (NREL). By selecting the best performance among the ANN, RF, DT, extreme gradient boosting (XGB), and LSTM algorithms, they aim to fill a research gap in the area. They have come to the conclusion that even if all of the algorithms were good, ANN is the most accurate method for forecasting PV solar power generation.
Random Forest: An effective and reliable prediction is produced by the supervised ML method known as random forest, which creates several decision trees and merges them [66]. The bagging technique, which is employed by random forest, reduces the variance of the base algorithms. This technique is particularly useful for forecasting time series data [67]. Random forest mitigates correlation between trees by introducing randomization in two ways: sampling from the training set and selecting from the feature subset. The RF model creates a complete binary tree for each of the N trees in isolation, which enables parallel processing.
Vassallo et al. (2020) investigate optimal strategies for random forest (RF) modeling in wind speed/power forecasting. The investigation examines the utilization of random forest (RF) as a corrective measure, comparing direct versus recursive multi-step prediction, and assessing the impact of training data availability. Findings indicate that RF is more efficient when deployed as an error-correction tool for the persistence approach, and that the direct forecasting strategy performs slightly better than the recursive strategy. Increased data availability continually improves forecasting accuracy [68]. In addition, Shi et al. (2018) put forward a two-stage feature selection process, coupled with a supervised random forest model, for the purpose of addressing overfitting and weak reasoning and generalization in neural network models when forecasting short-term wind power. The proposed methodology removes redundant features, selects relevant samples and evaluates the performance of each decision tree. To address the inadequacies of the internal validation index, a new external validation index correlated with wind speed is introduced. Simulation examples and case studies demonstrate the model’s better performance than other models in accuracy, efficiency, and robustness, especially for noisy data and wind power curtailment [69]. Similarly, Natarajan and Kumar (2015) also compared wind power forecasting methods. Physical methods rely on meteorological data and Numerical Weather Prediction (NWP), while statistical methods like ANN and SVM depend on historical wind speed data. This study experiments with Random Forest Algorithm, finding it more accurate than ANN for predicting wind power at wind farms [70].
Support Vector Machines (SVM): SVM are a type of classification algorithm that identifies a hyperplane which maximizes the margin between the hyperplane and the data points, akin to SVR [71,72]. SVM has been utilized in renewable energy forecasting to estimate the power output of wind and solar farms by incorporating input features such as historical power output, weather data, and time of day. For instance, Zeng et al. (2022) propose a 2D least-square SVM (LS-SVM) model for short-term solar power prediction. The model uses atmospheric transmissivity and meteorological variables, and outperforms the reference autoregressive model and radial basis function neural network model in terms of prediction accuracy [73]. R. Meenal and A. I. Selvakumar (2018) conducted studies comparing the accuracy of SVM, ANN, and empirical solar radiation models in forecasting monthly mean daily global solar radiation (GSR) in several Indian cities using varying input parameters. Using WEKA software, the authors determine the most significant parameters and conclude that the SVM model with the most influential input parameters yields superior performance compared to the other models [74]. Generally, classification algorithms are used to predict categorical output variables and regression techniques are used to predict continuous output variables. The particular task at hand and the properties of the data will determine which method is being used.
2.2.2. Unsupervised Learning
Another form of ML is unsupervised learning, where an algorithm is trained on an unlabeled dataset lacking known output variables, with the objective of uncovering patterns, structures, or relationships within the data [75,76,77]. Unsupervised learning algorithms can be primarily classified into two types, namely clustering and dimensionality reduction [78].
Clustering: It is an unsupervised learning method that consists of clustering related data points depending on how close or similar they are to one another. Clustering algorithms, like K-means clustering, hierarchical clustering, and density-based clustering, are commonly used in energy systems to identify natural groupings or clusters within the data. The primary objective of clustering is to discover these inherent patterns or clusters [75,76]. K-Means Clustering is a widely used approach for dividing data into k clusters, where k is a user-defined number. Each data point is assigned to the nearest cluster centroid by the algorithm, and the centroids are updated over time using the average of the data points in the cluster [75,76]. Hierarchical Clustering is also a family of algorithms that recursively merge or split clusters based on their similarity or distance, to create a hierarchical tree-like structure of clusters. The other family of clustering algorithms that groups together data points that are within a certain density threshold, and separates them from areas with lower densities is density-based clustering algorithm [75,76,77].
Dimensionality Reduction: It is also an unsupervised learning technique utilized to decrease the quantity of input variables or features while retaining the significant information or structure in the data [75,76,77]. The purpose of dimensionality reduction is to find a lower-dimensional representation of data that captures the majority of the variation or variance in the data. Principal component analysis (PCA), t-SNE, and Autoencoders are some dimensionality reduction algorithms used in renewable energy forecasting [78]. Principal Component Analysis (PCA) is a commonly utilized method for decreasing the dimensionality of a dataset. It does so by identifying the primary components or directions that have the most variability in the data and then mapping the data onto these components [78]. t-SNE is a non-linear dimensionality reduction algorithm that is particularly useful for visualizing high-dimensional data in low-dimensional space. It uses a probabilistic approach to map similar data points to nearby points in the low-dimensional space. Autoencoders are a type of neural network that can learn to encode and decode high-dimensional data in a lower-dimensional space. The encoder network is trained to condense the input data into a representation with fewer dimensions, and the decoder network is trained to reconstruct the original data from this condensed representation [78].
In general, unsupervised learning algorithms are particularly useful when there is a large amount of unstructured data that needs to be analyzed, and when it is not clear what the specific target variable should be. Unsupervised learning has found various applications in the field of renewable energy forecasting, and one of its commonly used applications is the clustering of meteorological data [79]. For example, in a study by J. Varanasi and Tripathi, M. (2019), K-Means clustering was used to group days of the year, sunny days, cloudy days and rainy days into clusters based on similarity for short term PV power generation forecasting [80]. The resulting clusters were then used to train separate ML models for each cluster, which resulted in improved PV power forecasting accuracy. Unsupervised learning has also been used for anomaly detection in renewable energy forecasting. Anomaly detection refers to the task of pinpointing data points that exhibit notable deviations from the remaining dataset. In the context of renewable energy forecasting, anomaly detection can aid in identifying exceptional weather patterns or uncommon circumstances that may impact renewable energy generation. For example, in a study by Xu et al. (2015), the K-Means algorithm was used to identify anomalous wond power output data, which were then employed to improve the accuracy of the wind power forecasting model [81].
In the realm of renewable energy forecasting, unsupervised learning has been utilized for feature selection, which involves choosing a smaller set of pertinent features from a larger set of input variables. In renewable energy forecasting, feature selection can be used to reduce the computational complexity of ML models and to improve the accuracy of renewable energy output predictions. For example, in a study by Scolari et al. (2015), K-Means clustering was used to identify a representative subset of features for predicting solar power output [82].
Overall, unsupervised learning is a powerful tool for analyzing large amounts of unstructured data in renewable energy forecasting. Clustering, anomaly detection, and feature selection are just a few of the many applications of unsupervised learning in this field, and new techniques are continually being developed to address the unique challenges of renewable energy forecasting.
2.2.3. Reinforcement Learning Algorithms
Reinforcement learning (RL) is a branch of ML in which an agent learns to make decisions in an environment with the goal of maximizing a cumulative reward signal [83,84]. The agent interacts with its surroundings by taking actions and receiving responses in the form of rewards or penalties that are contingent on its actions. [85]. Some examples of RL algorithms are Q-learning, policy gradient, and actor-critic [86,87]. Q-learning is a RL algorithm used for learning optimal policies for decision-making tasks by iteratively updating the Q-values, which represent the expected future rewards for each action in each state [88]. Policy gradient is also a RL algorithm used for learning policies directly, without computing the Q-values [89]. Actor-critic is another RL algorithm that combines elements of both value-based and policy-based methods, by training an actor network to generate actions and a critic network to estimate the value of those actions [89].
Renewable energy forecasting is among the many tasks for which RL has been utilized [87,90]. One approach to applying RL to renewable energy forecasting is to use it to control the operation of energy systems [91]. For example, Sierra-García J. and S. Matilde (2020) developed an advanced yaw control strategy for wind turbines based on RL [92]. This approach uses a particle swarm optimization (PSO) and Pareto optimal front (PoF)-based algorithm to find optimal actions that balance power gain and mechanical loads, while the RL algorithm maximizes power generation and minimizes mechanical loads using an ANN. The strategy was validated with real wind data from Salt Lake, Utah, and the NREL 5-MW reference wind turbine through FAST simulations [92].
3. Renewable energy forecasting using Deep learning (DL)
DL is a type of ML that employs ANNs containing numerous layers to acquire intricate data representations with multiple layers of abstraction. The term “deep” refers to the large number of layers in these ANNs, which can range from a few layers to hundreds or even thousands of layers [93]. DL algorithms can learn to recognize patterns and relationships in data through a process known as training. During training, the weights of the links between neurons in an ANN are changed to reduce the disparity between the anticipated and actual output [94]. DL has brought about significant transformations in several domains, such as energy systems, computer vision, natural language processing, speech recognition, and autonomous systems. It has facilitated remarkable advancements in various fields, such as natural language processing, game playing, speech and image recognition [79].
3.1. DL algorithms used for Renewable energy forecasting
3.1.1. ANN for Renewable energy forecasting
Artificial Neural Networks (ANNs) belong to a category of ML models that imitate the arrangement and operation of the human brain [95]. They are devised to learn from data and utilize that knowledge to produce predictions or decisions. At a high level, ANNs consist of three main components: input layers, hidden layers, and output layers. The input layer receives the data, which is usually represented as a vector of numbers. The output layer produces the desired output of the network, which could be a classification (e.g., predicting the type of an object in an image) or a regression (e.g., predicting the price of a house based on its features). The hidden layers are where most of the “computation” happens in the network; they consist of one or more layers of neurons that perform nonlinear transformations on the input data [96]. Each neuron in an ANN receives input from other neurons or directly from the input layer. For each input, a weight is assigned that signifies the connection’s potency between two neurons (Figure 2). Then, the neuron processes an activation function on the weighted sum of its inputs, which generates an output. This output can serve as the input for another neuron, and this process repeats until the final output of the output layer is obtained [97].
The weights within the network are modified during training to ensure that the network generates the intended output for a given input. This process is usually executed through a technique known as back-propagation, which determines the gradient of the loss function concerning the weights and adjusts them correspondingly (Figure 2). [98,99]. The loss function quantifies the variance between the predicted output and the actual output, and the primary objective of training is to lessen this discrepancy. ANNs are versatile and can be employed for various purposes, such as predicting renewable energy, classifying images, recognizing speech, processing natural language, and conducting predictive analytics [100,101,102,103,104].
ANNs have been employed in renewable energy forecasting, such as solar energy, wind energy, and multi-renewable energy forecasting, for several years, demonstrating their efficacy in this application. S. Kumar and T. Kaur (2016) used ANN to predict solar radiation for solar energy applications in Himachal Pradesh. The ANN model used temperature, rainfall, sunshine hours, humidity, and barometric pressure as input variables. Three models with 3 to 5 input parameters were developed and tested, with the ANN-I5 model showing the best prediction accuracy with a mean absolute percentage error (MAPE) of 16.45%. This study showed the method can also be used to identify solar energy potential for any location worldwide without direct measuring instruments [105]. Another study by N. Premalathaa and Amirtham V. (2016) showed that an ANN model for accurately predicting solar radiation using meteorological data from five different locations across India over the last 10 years. The analysis evaluated two ANN models that incorporated four distinct algorithms, and the optimal algorithm and model were determined by the minimum MAE and RMSE, as well as the maximum R. The resulting ANN model exhibits a low MAPE, which renders it useful for designing or assessing solar energy systems in regions of India that lack meteorological data recording capabilities [106]. In their study, Woldegiyorgis et al. (2021) explored the viability of utilizing ANN for estimating the mean daily global solar radiation (GSR) and contrasted its effectiveness with empirical models founded on sunshine. The results demonstrated that the ANN model displayed favorable performance with a validation R value of 0.932, surpassing the empirical models [107].
Wind energy forecasting is another important area of research in renewable energy forecasting. For instance, Jamii et al. (2022) proposed an ANN-based paradigm to forecast wind power generation and load demand using meteorological parameters as inputs. Results showed that the ANN outperformed four other ML methods, providing high effectiveness and accuracy for power forecasting [108]. Q. Chen and K. Folly (2019) suggested an Artificial Neural Network (ANN) model for precise short-term wind power prediction in small wind farms. Their research examines how the input variables and sample size influence the forecasting efficiency and computational expense of the model. The study investigates the effect of input variables and sample size on the forecasting performance and computing cost of the model. Their findings suggest that the ANN model with all input features and a high training sample size performs the best in terms of forecasting [109].
2.1.2. CNN for Renewable energy forecasting
Convolutional Neural Networks (CNNs) are a class of ANN that exhibit exceptional performance in handling and interpreting data with a grid-like arrangement, such as videos or images [110]. CNNs derive inspiration from the organization and operation of the visual cortex in the brain, and employ convolutional layers to acquire localized characteristics from the input data [111]. A CNN is composed of several layers, which encompass convolutional layers, pooling layers, and fully connected layers (Figure 3). The convolutional layers are the principal building blocks of a CNN, which utilize filters (referred to as kernels) to extract localized characteristics from the input data [112]. Each filter is a small matrix that slides over the input data, performing a dot product between the filter and the corresponding input pixels. The output of this operation is a feature map, which highlights the areas of the input data that are most important for the task at hand [112,113]. Pooling layers are frequently added after convolutional layers to decrease the spatial dimensions of feature maps and enhance the computational efficiency of the network. Popular types of pooling include max pooling, which chooses the highest value within a small area of the feature map, and average pooling, which calculates the mean value within a small area of the feature map [114]. The fully connected layers are employed to generate the ultimate predictions based on the features acquired by the convolutional and pooling layers. These layers are similar to those in a traditional neural network and use the learned features to make predictions based on the task at hand. In the course of training, the CNN weights are modified to minimize the disparity between the predicted and actual output, akin to other types of neural network structures [115]. The back-propagation algorithm is utilized to compute the gradients of the loss function relative to the weights, and the weights are subsequently updated based on this information [116].
CNNs have demonstrated exceptional performance in various image and video recognition tasks, such as object detection, segmentation, and classification. To forecast time series, which is essential for forecasting renewable energy, CNNS can also be used in combination with the other algorithms [117,118,119,120]. For example, Lim et al. (2022) propose a CNN-LSTM hybrid model for stable power generation forecasting in photovoltaic (PV) systems, considering the impact of environmental factors like solar radiation and temperature. PV power output data from a plant located in Busan, Korea was used to train and test the model. The suggested model yielded a mean absolute percentage error of 4.58 on a clear day and 7.06 on a cloudy day, demonstrating its ability to enhance the efficiency of PV power plant operations [121]. Similarly, Gao et al. (2019) propose a CEEMDAN–CNN–LSTM model for hourly solar irradiance forecasting to manage electricity generation and smart grids. The model employs CEEMDAN to decompose data into constitutive series and a DL network based on CNN and LSTM to predict solar irradiance. The model outperforms other methods, achieving an average RMSE of 38.49 W/m2 and demonstrating stable performance in different climates [122]. Cannizzaro et al. (2021) presented a fresh approach to anticipate short- and long-term Global Horizontal Solar Irradiance (GHI) through machine learning techniques. Their methodology involves a combination of Variational Mode Decomposition (VMD) and CNN with either RF or LSTM. The approach is evaluated on a real-world dataset and achieves accurate results [123]. Furthermore, Wu et al. (2020) suggest a spatio-temporal correlation model (STCM) that utilizes CNN-LSTM to forecast ultra-short-term wind power. The model reconstructs meteorological factors at different sites into input data using CNN to extract spatial correlation features and LSTM to extract temporal correlation features. The STCM performs better than traditional models and accurately forecasts wind power using measured meteorological factors and wind power datasets from a wind farm in China [124].
2.1.3. RNN for Renewable energy forecasting
Recurrent Neural Networks (RNNs) are an artificial neural network category that is specifically engineered to manage sequential data by analyzing every element in a sequence while retaining an internal state or memory of previous elements [125,126,127]. RNNs are particularly useful for natural language processing, speech recognition, time series prediction, and other applications that involve sequential or temporal data. The key feature of RNNs is the use of recurrent connections, which allow information to be passed from one time step to the next. Recurrent connections are established in the network through the inclusion of loops, which permit the output of the prior time step to be utilized as input for the current time step. Like other neural networks, an RNN consists of layers of neurons with learnable weights. However, unlike other neural networks, the input and output of an RNN can be sequences of variable length, and the weights are shared across all time steps, allowing the network to learn patterns that are dependent on the sequence of input data (Figure 4) [128]. The internal state of an RNN at each time step is typically represented by a hidden vector or memory cell. The hidden vector is updated at each time step by combining the input at that time step with the previous hidden vector, using a set of learnable weights. This update is usually performed using an activation function, such as the hyperbolic tangent or the rectified linear unit (ReLU). One limitation of basic RNNs is that they can struggle to capture long-term dependencies in the input sequence, which can cause the gradient to vanish or explode during training. Recurrent connections are established in the network through the inclusion of loops, which permit the output of the prior time step to be utilized as input for the current time step. Different types of RNNs have been created to tackle this issue, like Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), which employ more intricate structures to effectively retain long-term correlations in the input sequence [129]. During the training process, the RNN weights are modified to reduce the difference between the predicted output and the actual output, similar to other neural network models. The back-propagation algorithm is employed to determine the gradients of the loss function in relation to the weights, and the weights are subsequently updated based on this information [130].
RNNs have shown remarkable success in tasks involving sequential data, such as speech recognition, sentiment analysis, machine translation, and even time series forecasting, including renewable energy forecasting. Several research studies have investigated the use of RNNs for predicting renewable energy. One such study by Kisvari et al. (2021) suggests a data-driven method for wind power prediction, which involves pre-processing, anomaly detection, feature engineering, and hyperparameter tuning using gated recurrent DL models [131]. They also compare a new DL neural network of GRU with LSTM. The approach achieves high accuracy at lower computational costs, and GRU outperforms LSTM in predictive accuracy [131]. Another work by M. Abdel-Nasser and K. Mahmoud (2017) proposes using LSTM-RNN to precisely estimate PV power output. Because of its recurrent architecture and memory units, LSTM networks can simulate temporal variations in PV output power. Utilizing hourly datasets, the proposed strategy is evaluated and found to reduce forecasting error more than three previous methods [132]. Yadav et al. (2013) also suggest a RNN model that utilizes an adaptive learning rate to predict daily, mean monthly, and hourly solar irradiation with the assistance of meteorological data. The outcomes demonstrate that the RNN performs better than the Multi-Layer Perceptron (MLP) method, and the proposed adaptive learning rate enhances performance in comparison to the traditional feed-forward network [133].
2.1.4. RBM for Renewable energy forecasting
Restricted Boltzmann Machines (RBM) is a type of unsupervised neural network that can learn complex probability distributions over input data. They are composed of two layers, a hidden layer and a visible layer, with each layer consisting of binary nodes that are either activated or deactivated [134]. The training process of RBM involves contrastive divergence, a technique that works towards reducing the dissimilarity between the input data and the model’s depiction of the data. Through training, the RBM adapts the weights connecting the visible and hidden layers to model the probability distribution of the input data. RBM’s have several unique features that make them useful for a variety of applications. Its capacity to learn high-level representations of input data without labels or supervision is one of their key strengths. This makes them ideal for unsupervised learning tasks like feature learning and dimensionality reduction [135]. Another strength of RBMs is their ability to model complex dependencies between input features, which makes them effective in modeling data with multiple interacting factors. They have been effectively employed in a wide range of fields, including image recognition, voice recognition, and natural language processing. Finally, RBMs have also been used as building blocks for more complex neural networks, such as deep belief networks and deep neural networks. In these architectures, RBMs are used to pre-train the network’s layers before fine-tuning them for a specific task (Figure 5) [136].
RBMs have found applications in various fields, including renewable energy forecasting. One such application involves using RBMs as a pre-processing step to extract features from renewable energy data before using them in other ML models such as neural networks for forecasting. Yang et al., for instance, proposed an unsupervised model for identifying irregularities in wind turbine monitoring systems that includes RBM [137].
2.1.5. Auto Encoder for Renewable energy forecasting
One of the most effective unsupervised learning models in recent decades is the autoencoder based on a deep neural network. The unsupervised model allows for the extraction of effective and discriminative features from a large unlabeled data set, making this approach extensively suitable for feature extraction and dimensionality reduction [138]. Essentially, an autoencoder can be described as a neural network consisting of three fully connected layers, with the encoder containing input and hidden layers, and the decoder containing hidden and output layers. The encoder converts higher-dimensional input data into a lower-dimensional feature vector [139]. The data is then converted back to the input dimension by the decoder. Building a complex nonlinear relationship between the input data is one of the deep neural network’s top priorities since it enables the autoencoder to successfully recreate the decoder’s output. As a result, throughout the entire training period, the reconstruction error will decrease simultaneously and important features will be stored in the hidden layer. Lastly, the output of the hidden layer will show how effectively the proposed autoencoder extracted features [140,141]. The basic autoencoder’s configuration is shown in Figure 6.
In renewable energy forecasting, autoencoder models have been used to extract features from input data such as weather data, historical energy production data, and other relevant variables. These features are then used to train ML models for energy forecasting. For example, Dairi et al., (2015) propose a Variational AutoEncoder (VAE) model for short-term solar power forecasting. The study compares the performance of the VAE-based method with seven DL methods and two ML methods using data from two PV systems. Results indicate that the VAE consistently outperforms the other methods in forecasting accuracy, highlighting the superiority of DL techniques over traditional ML methods [142]. Jaseena and Kovoor (2015) also presented a wind speed forecasting model that utilizes a hybrid approach of autoencoder and LSTM. The model incorporates an autoencoder to extract characteristics from the input data. The extracted features are then fed into an LSTM model for forecasting wind speed. Compared to other models, the proposed model attained superior accuracy in its forecasting [143].
2.1.6. Deep belief neural networks (DBN) for Renewable energy forecasting
DBNs are deep neural networks made up of several layers of RBMs. Like RBMs, DBNs are generative models, trained through unsupervised learning techniques to extract and represent features from input data [135]. The training process of DBNs follows a layer-wise unsupervised learning approach, where each layer is trained independently to extract features from input data (Figure 7) [144]. After training each layer, the output of the preceding layer is used as input to the subsequent layer until the entire network is trained. Once the network is fully trained, it can be fine-tuned using supervised learning methods for classification or regression tasks [145].
DBNs have found diverse applications in fields such as computer vision, speech recognition, and natural language processing, demonstrating remarkable performance in numerous use cases [146]. DBNs, for example, have been employed for image classification, where they achieved state-of-the-art accuracy on the MNIST dataset, which is a collection of handwritten digits. In natural language processing, DBNs have been used for sentiment analysis and language modeling, where they have shown to be effective in learning hierarchical representations of the input data. In the context of renewable energy forecasting, DBNs have been used for feature extraction and forecasting. For example, a study by Noe et al. (2017) proposed a forecasting method based on DL and the Deep Belief Network training algorithm. Their study found that the optimal number of input variables influences performance, and the proposed DBN accurately selected the parameters that best fit the data to achieve the lowest prediction error. The results were validated by comparing them to ELM, and actual evidence shows that DBN has better forecasting accuracy [147]. Similarly, Wang et al. (2018) introduced a deep belief network (DBN) model that employs clustered numerical weather prediction (NWP) data to enhance wind power forecasting, outperforming Back-propagation neural network (BP) and Morlet wavelet neural network (MWNN) by over 44% in accuracy when tested on Sotavento wind farm [148].
2.1.7. ANFIS for Renewable energy forecasting
ANFIS is a hybrid of ANN and fuzzy logic, designed in the early 1990s [149]. It uses a fuzzy inference system to approximate nonlinear functions, making it a powerful general estimator [150]. ANFIS is made up of five layers, which include the input layer, fuzzification layer, rule layer, normalization layer, and output layer. The fuzzification layer is the first layer and takes in input values to determine membership functions using the premise parameter set a, b, c. The second layer, the rule layer, generates firing strengths for the rules. The third layer normalizes the firing strengths by dividing each value by the total firing strength. In the fourth layer, the normalized values and result parameter set p, q, r are used as inputs to produce defuzzified values, which are then sent to the final layer to generate the ultimate output [151]. Figure 8 provides an illustration of ANFIS architecture.
ANFIS has been extensively utilized in renewable energy forecasting owing to its capacity to capture both linear and nonlinear connections in the data. For instance, Hussieny et al. (2018) developed a wind speed and temperature prediction system utilizing a combination of ANN, Genetic algorithm fused with ANN (GPANN), and ANFIS. The implementation of ANFIS with trapezoidal membership function yielded the best results, with an optimal mean square error of 7.2989 m/s for wind speed and 3.8364 C° for temperature [153]. Mellit et al. (2007) also proposed a new approach for estimating total solar radiation data with an ANFIS that is purely dependent on mean sunshine duration and air temperature. The model was trained and tested using a 10-year database of daily sunshine duration, ambient temperature, and total solar radiation data. The validation data set produced highly accurate estimate, with a mean relative error (REM) of less than 1% between the actual and predicted values and a correlation coefficient of 98%. They further claim that the proposed approach can be applied to any geographical location on the earth [154]. In order to enhance the accuracy of wind speed forecasting, ANFIS models have been utilized in conjunction with other machine learning models. For instance, Ahmed et al. (2017) conducted a study where they introduced a novel optimization algorithm called Krill Herd (KH) and combined it with ANFIS to develop a hybrid algorithm for wind speed forecasting, which is a critical factor for wind power generation. The Krill-ANFIS model, which was optimized using KH, outperformed the basic ANFIS, PSO-ANFIS, and GA-ANFIS models in terms of performance measures [153]. Yadav et al., (2019) also developed a hybrid model using a genetic algorithm and an adaptive network-based fuzzy inference system to forecast short-term solar photovoltaic (PV) power in the Indian electricity market. This model outperformed four other models, demonstrating higher accuracy in PV power forecasting [155].
2.1.8. Wavelet Neural Network (WNN) for Renewable energy forecasting
WNN is a kind of NN that combines the mathematical concept of wavelets with ANNs. Wavelets are mathematical functions that can be used to analyze and decompose complex signals or data into simpler components. They are particularly useful in analyzing signals with both time and frequency components, such as audio, images, and time-series data. Wavelets are employed as the activation functions for the hidden neurons in a WNN. The neurons are fed with input signals that have been broken down into wavelet coefficients. They then carry out linear transformations on these coefficients to extract characteristics or features from the input information [156]. The outcome of each hidden neuron is then passed through a wavelet activation function, which applies a wavelet function to the transformed coefficients to produce an output signal. The use of wavelet coefficients and activation functions in a network enables it to effectively capture the time and frequency features of the input data. As a result, this approach is highly advantageous for tasks that involve time series forecasting, signal processing, and image analysis [157]. WNNs have the capacity to capture non-linear correlations between input and output data, as well as manage noisy or missing data. They are also computationally efficient and can be trained using standard back-propagation techniques [158,159].
The application of WNN in renewable energy forecasting is attributed to its capability to capture the temporal and frequency characteristics of the input data. For example, a study by Shen et al. (2017) developed a WNN-based technique for wind power prediction. They optimized the forecasting model using EKMOABC, a new multi-objective artificial bee colony (MOABC) technique. They found that the proposed model and algorithm produced higher-quality prediction interval for wind power forecasting [160]. Sharma et al. (2016) created a mixed WNN using wavelet transform, which outperformed other methods for short-term solar irradiance forecasting in Singapore [161]. The use of WNN models in conjunction with other ML models has been implemented to enhance the precision of forecasting. For instance, Hamed H.H. Aly (2020) created a series of hybrid DL clustered models utilizing various AI systems such as RKF, FS, WNN, and ANN to predict wind speed and power with remarkable accuracy. They proposed and tested twelve distinct models, and it was found that the clustered model which combined WNN and RKF yielded the most optimal results [157].
2.1.9. RBNN for Renewable energy forecasting
The Radial Basis Function Neural Network (RBNN) is an ANN type that has gained extensive usage in different fields, including but not limited to pattern recognition, control systems, time-series prediction, and function approximation [162]. In RBNN, the neurons in the hidden layer are typically implemented using radial basis functions (RBFs). RBFs are a class of functions that have a center, which represents a prototype or a reference point, and a width, which controls the influence of the function on the input space [163,164]. In RBNN, the input vector is first transformed by the hidden layer using the RBFs, and the resulting outputs are then combined linearly to produce the final output. The weights of the linear combination are typically learned using a supervised learning algorithm such as backpropagation [163,164]. RBNN has the capability to approximate any continuous function with a high degree of accuracy, provided that an ample number of hidden neurons are available. Additionally, RBNN exhibits strong generalization performance when the RBF centers are thoughtfully selected to represent the input data distribution, particularly for unseen data [164].
RBNN has been applied in renewable energy forecasting due to its ability to capture the nonlinear relationships and temporal dependencies in the input data. In 2011, Wu et al. introduced a wind power prediction model based on RBNN that can forecast one hour ahead. They preprocessed the samples using the Grubbs test and evaluated the accuracy of their forecasting results by comparing them with the actual wind power outputs. The study demonstrated that the method proposed by the authors can provide reliable and consistent predictions [165]. M. Madhiarasan (2020) also developed a Recursive RBNN to predict wind speed reliably utilizing wind speed , temperature and wind direction inputs. According to the author, the model has the ability to improve the management, control, and protection of power systems, and the simulation results show more accuracy when compared to existing forecasting models [166]. RBNN models have also been used in combination with other ML models such as SVR to improve forecasting accuracy. For example, Ramedani et al. (2014) utilized four artificial intelligence models to predict global solar radiation in Tehran, Iran. They utilized SVR with polynomial and Radial Basis Neural Network (RBNN) kernel functions. The combination of SVR and RBNN yielded the most accurate predictions compared to the other models [167].
2.1.10. GRNN for Renewable energy forecasting
The Generalized Regression Neural Network (GRNN) is frequently utilized for regression tasks that require forecasting continuous quantities [168]. A GRNN’s fundamental structure comprises of four layers, namely the input layer, pattern layer, summation layer, and output layer (Figure 9). In the input layer, the network takes in the input data, which could be a vector or a set of vectors. The pattern layer is where the network compares the input data to stored prototypes and computes the similarity between them. The prototypes are essentially a set of reference vectors that the network uses to make predictions. After receiving the output from the pattern layer, the summation layer calculates a weighted sum of the values using similarity values determined by the former. Finally, the output layer generates a continuous prediction for the network. GRNNs are trained using a process called radial basis function (RBF) learning [158]. Throughout the training process, the network modifies the prototypes and their corresponding weights to decrease the disparity between the anticipated and factual values of the training dataset. GRNNs have several advantages over other types of neural networks [169]. They are relatively easy to train and can be trained on small datasets. They are also efficient at making predictions, and can handle noisy and incomplete data. However, they may not perform well on complex datasets with high-dimensional input spaces, and their predictions may be less accurate than other types of neural networks on such datasets.
GRNNs have been applied in renewable energy forecasting due to their ability to handle noisy and nonlinear data [170,171]. For example, Tu et al. (2022) propose a grey wolf optimization (GWO)-based GRNN for predicting energy output in solar power systems, which is affected by unpredictable external factors such as weather and cloud cover. A self-organizing map (SOM) is used for weather clustering and GRNN training with GWO. The proposed model achieves high prediction accuracy with shorter computational times and enhances the effective operation of solar power systems [172]. In 2021, M. Sridharan put forward a GRNN model that utilizes seasonal and meteorological factors as input parameters to forecast global solar irradiance. The outcomes demonstrate that this model offers precise predictions and is on par with other ML models like fuzzy logic and ANN models. The average percentage error for the proposed GRNN model stands at 3.55%, whereas for fuzzy logic and ANN models, it is 4.64% and 5.49%, respectively [173]. Likewise, G. Kumara and H. Malikb (2016) proposed wind speed prediction in 67 Indian cities employing GRNN and Multi-layer perceptron (MLP) models. Input variables included daily solar radiation, air temperature, and atmospheric pressure. In comparison to MLP, GRNN exhibited superior performance, achieving accuracy rates of 99.99% and 97.974% during training and 98.85% and 95.23% during testing, respectively [174].
2.1.11. ELM for Renewable energy forecasting
Extreme Learning Machines (ELM) was presented as a substitute for conventional gradient-based NN. ELM is designed to be computationally efficient and easy to implement, while still providing high accuracy in various applications, including regression, classification, and clustering. ELM is composed of a solitary layer of neurons that are hidden. In this layer, the connections between the input layer and the hidden layer are generated randomly and remain constant. The output layer in ELM is typically a layer that performs linear regression or classification, and the connections between the hidden layer and the output layer are determined through analytical means using matrix inversion [175]. During the training stage, the input information is fed through the randomly generated hidden layer weights to produce a set of outputs, which are then used to calculate the output layer weights using matrix inversion. Once the output layer weights are determined, the model becomes capable of making predictions for new input data. ELM has a significant benefit in its quick training time, attributed to the fact that the hidden layer weights are randomly generated and remain constant throughout the training process, thereby eliminating the need for any adjustments. This means that ELM can handle large datasets and complex problems with high-dimensional input spaces in a relatively short amount of time. Additionally, ELM is less prone to overfitting compared to traditional gradient-based neural networks, which can be beneficial in many applications. Overall, ELM is a simple and efficient NN model that can achieve high accuracy in a variety of applications, especially when dealing with large datasets and high-dimensional input spaces [176].
ELM models are utilized for forecasting renewable energy sources (RES), including wind and solar power [177]. For example, Li et al. (2016) suggested an ELM and error correction model to precisely predict short-term wind power. The addition of an error correction model enhanced the accuracy of ultra-short-term wind power forecasts [178]. Hou et al. (2018) suggest a forgetting factor (FOS)-ELM model with variable forgetting factor to predict solar radiation. Using Bayesian Information Criterion (BIC), they build and evaluate seven input combinations, with the FOS-ELM model showing improved RMSE and MAE compared to classical ELM model. The study confirms FOS-ELM’s effectiveness in daily global solar radiation simulation [179]. Likewise, Li et al., (2019) developed an ELM model to predict a wind power with kernel mean p-power error loss to overcome the limitations of traditional BP neural networks. The method eliminates redundant data components using PCA and achieves lower prediction error without compromising accuracy [180].
2.1.12. Ensemble Learning for Renewable energy forecasting
A ML approach called ensemble learning (EL) combines several models to provide predictions which are more accurate [181]. The idea is to train several models independently on the same data, and then combine their predictions to make a final prediction. EL is particularly useful when a single model is not able to achieve high accuracy, or when there is significant noise or variability in the data [182]. Bagging, boosting, and stacking are among the various types of EL techniques available [183,184]. Bagging involves training multiple models on various subsets of the training data with replacement. The final prediction is generated by combining the predictions of all the models. This technique is particularly useful when the base model is prone to overfitting [185]. Boosting involves training multiple models in a sequence where each subsequent model aims to correct the errors of its predecessor. The ensemble prediction is generated by aggregating the predictions of all the models. Boosting is particularly useful when the base model is prone to underfitting. Whereas in stacking, multiple models are trained and their predictions are used as input to a higher-level model that learns how to combine them [183]. Stacking is particularly useful when the base models have different strengths and weaknesses. EL has proven to be useful in a variety of applications, including image classification, natural language processing, and recommendation systems. However, it can be computationally expensive and requires careful tuning of the ensemble parameters to achieve optimal performance [186].
The Bagging technique is a popular EL method utilized in the prediction of renewable energy [185]. For example, Guia et Al. (2020) conducted a study where a Bagging-based EL technique was applied to forecast solar irradiance using weather patterns. The base learner in the ensemble was a pre-processed stacked LSTM model. The study showed that the Bagging-based ensemble learners outperformed individual learners in terms of accuracy, as evidenced by multiple metrics [187]. Another EL method used in renewable energy forecasting is the Boosting technique. P. Kumari and D. Toshniwal (2021) suggested an ensemble model for estimating hourly global horizontal irradiance that integrates extreme gradient boosting forest and deep neural networks (XGBF-DNN). They used a framework that incorporates feature selection and variety in base models, and the suggested model outperforms other models in prediction error with a forecast accuracy score range of 33%-40%, making it a reliable and appropriate model for solar energy system planning and design [188]. Al-Hajji et al. (2021) reported a comparative analysis of stacking-based ensembles for predicting solar radiation one day ahead using ML. They explored three stacking methods (feed-forward NN, SVR, and k-nearest neighbor) for merging base predictors, and assessed their performance over a year. Their findings revealed that stacking models, which combine heterogeneous models utilizing neural meta-models, outperformed recurrent models [189].
2.1.13. Transfer Learning (TL) for Renewable energy forecasting
TL is a ML approach in which a previously trained model is utilized as a reference point for a new task rather than developing a new model from scratch. Typically, the pre-trained model has been trained on a large dataset and has learnt useful features that can be applied to other related tasks. The TL process involves taking the pre-trained model and fine-tuning it on a new dataset for the new task. The fine-tuning process entails modifying the pre-trained model by adding new layers or modifying existing layers to fit the new data. This approach assists in enhancing the efficacy of the pre-trained model for the new task without the need to train a new model from the scratch (Figure 10) [190]. TL has numerous benefits, one of which is that it uses less data and computer resources while training new models. It also enables the use of pre-trained models that have already learned features that are relevant to the new task, which can lead to better performance than training a new model from scratch [191]. Several areas of ML have made extensive use of TL, including computer vision, natural language processing, and speech recognition. TL has been employed in computer vision to increase the performance of picture recognition tasks including object detection, classification, and segmentation. TL has been also employed in natural language processing to increase the performance of tasks like as sentiment analysis, language translation, and named entity recognition [192].
In renewable energy forecasting, TL has been utilized to enhance the accuracy of renewable energy forecasts by leveraging knowledge learned from related tasks. One common approach to TL in renewable energy forecasting is to use pre-trained models from other related forecasting tasks. For example, Sarmas et al., (2022) propose using TL with stacked LSTM models to accurately forecast solar plant production in situations where there is a lack of data. They compared three TL models against a non-TL model and a smart persistence model, with TL models achieving significant improvements in accuracy. They conclude that TL is an effective tool for power output forecasting, particularly for newly constructed solar plants, with a view to achieving energy balance and managing demand response [193]. Hu et al. (2016) also developed using deep neural networks trained on data-rich wind farms to extract wind speed patterns and transfer this information to newly-built farms, significantly reducing prediction errors [194].
2.1.14. Hybrid model (HM) for forecasting Renewable energy
HMs in renewable energy forecasting are ML models that combine multiple techniques, like ANN, SVM, and statistical models, to improve the accuracy of predictions [192]. HMs offer several advantages over individual models by leveraging the strengths of each technique while compensating for their limitations [195]. In renewable energy forecasting, HMsls can be employed to enhance prediction accuracy and overcome some of the limitations of classic ML models. For example, traditional models may struggle with capturing the complex and nonlinear relationships between RES and their influencing factors. HMs can address this challenge by combining multiple models and techniques to capture a wider range of features and enhance forecast accuracy [195].
One example of a HM used in renewable energy forecasting is the CNN and LSTM model. In a recent paper, Lim et. al. (2022) proposed a HM of a LSTM and CNN to accurately forecast power generation of photovoltaic (PV) systems [121]. The model classified weather conditions with CNN and learned power generation patterns with LSTM. The suggested model’s mean absolute percentage error was 4.58 on sunny days and 7.06 on cloudy days, indicating the possibility of precise power generation forecasting and optimization of PV power plant operations [121]. Another study by Mbah et al. 2013 employed a HM for short-term power prediction of a photovoltaic plant. The model combines SARIMA and SVM methods and is tested on a 20 kWp GCPV plant. Results show good accuracy and outperform both SVM and SARIMA models [196]. Eseye et al. (2018) employed an HMs to forecast power for a real microgrid PV system over the short term (one day in advance). In terms of predicting accuracy, the model, which integrates wavelet transform (WT), particle swarm optimization (PSO), and SVM approaches, surpasses seven other methods [197]. Likewise, H. Aly (2020) used HMs to improve wind speed forecasting for better renewable energy integration. The proposed models combine WNN and ANN, Time Series (TS), and Recurrent Kalman Filter (RKF) techniques. WNN, TS, and RKF in order, validated using unseen datasets, are the best-performing models [198].
4. Challenges and Future Prospects
For predicting the output of RES like solar and wind, there are several ML and DL algorithms. Each method has its own benefits as well as drawbacks. The best ML or DL method for predicting RES depends on the specific application and available data. Linear regression can be a good choice as a baseline model, while random forest, xgboost, and SVMs are suitable for handling non-linear relationships and complex data. The variant recurrent neural networks (RNNs) models in DL are particularly useful for time-series forecasting but can be computationally expensive to train relative to classical ML models. Classical ML models can also be used for forecasting, but they may not perform as well as specialized time-series forecasting methods such as autoregressive models, moving averages, and RNNs [199,200]. The main reason of this is that classical ML models frequently assume independent and uniformly distributed data points, which is often not the case with time series data. Time series data is characterized by temporal dependencies, meaning that the values at one time point are influenced by the values at previous time points. The assumption that the input variables are independent of each other makes it challenging for classical ML models to grasp the patterns and trends in the data. Furthermore, classical ML models are not optimized for handling time-varying features or unevenly spaced time series data, which are common in time-series forecasting. For example, a classical ML model may not be able to capture seasonality or trends in the data that occur over long periods of time.
For handling unevenly spaced time series data and identifying patterns and trends to produce precise forecasts, specialized time-series forecasting techniques like autoregressive models, moving average models, and RNNs are the best options [201]. Hybrid models are becoming increasingly popular for forecasting RESs, as they can combine traditional time-series analysis with ML algorithms to improve accuracy and reduce the risk of overfitting or underfitting. RNNs, in particular, are specifically designed to handle time-series data and can capture temporal dependencies to learn from long-term patterns and trends, making them a popular choice for forecasting renewable energy sources. These models have the potential to enhance the operation and development of renewable energy systems as well as their grid integration. However, forecasting RES remains challenging due to their variability and unpredictability, highlighting the need for ongoing research and development of advanced forecasting techniques.
ML and DL models offer promising prospects for forecasting renewable energy sources. These models can provide more accurate predictions by processing large amounts of data and detecting complex patterns that humans may miss. These models also enable real-time forecasting to adapt to changing weather conditions, improving grid stability and enabling better decision-making. Accurate predictions also support better resource planning, leading to more efficient operations and cost savings. Furthermore, improved predictions can facilitate the integration of RES into the grid, reducing instability and enhancing overall grid performance. With careful consideration of data quality, model complexity, and validation, the use of ML and DL models has significant prospects for optimizing renewable energy operations and improving grid stability.
5. Conclusion
There are several ML and DL methods that can be used for forecasting renewable energy sources, such as wind and solar. The choice of the most appropriate method depends on the specific application and available data. Classical machine learning models, such as linear regression, can be a good choice for a baseline model, while random forest, xgboost, and SVMs are suitable for handling non-linear relationships and complex data. However, specialized time-series forecasting methods such as autoregressive models, moving averages, and RNNs are ideal for handling unevenly spaced time series data and capturing patterns and trends to provide accurate predictions. Hybrid models that combine traditional time-series analysis with machine learning algorithms are also becoming increasingly popular. Despite the challenges posed by the variability and unpredictability of renewable energy sources, the use of machine learning and deep learning models has significant prospects for optimizing renewable energy operations and improving grid stability.
References
- D. Gielen, F. Boshell, D. Saygin, M.D. Bazilian, N. Wagner, R. Gorini, The role of renewable energy in the global energy transformation, Energy Strateg. Rev. 2019, 24, 38–50. [CrossRef]
- P.S.A. Review, W. Strielkowski, E. Tarkhanova, M. Tvaronaviˇ, Y. Petrenko, Renewable Energy in the Sustainable Development of Electrical Power Sector: A Review, Energies. 2021, 14, 8240.
- G.A. Tiruye, A.T. Besha, Y.S. Mekonnen, N.E. Benti, G.A. Gebreslase, R.A. Tufa, Opportunities and Challenges of Renewable Energy Production in Ethiopia, Sustain. 2021, 13, 10381.
- N. E. Benti, T.A. Woldegiyorgis, C.A. Geffe, G.S. Gurmesa, M.D. Chaka, Y.S. Mekonnen, Overview of Geothermal Resources Utilization in Ethiopia: Potentials, Opportunities, and Challenges, Sci. African 2023, 19, e01562. [Google Scholar] [CrossRef]
- N. Ermias, A. Berta, C. Amente, Y. Setarge, Biodiesel production in Ethiopia : Current status and future prospects, Sci. African 2023, 19, e01531. [Google Scholar] [CrossRef]
- N. E. Benti, Y.S. Mekonnen, A.A. Asfaw, Combining green energy technologies to electrify rural community of Wollega, Western Ethiopia, Sci. African 2023, 19, e01467. [Google Scholar] [CrossRef]
- C. R.K. J, M.A. Majid, Renewable energy for sustainable development in India: current status, future prospects, challenges, employment, and investment opportunities. Energy, Sustainability and Society, 10(1) | 10.1186/s13705-019-0232-1, Energy. Sustain. Soc. 2020, 10, 1–36. [Google Scholar] [CrossRef]
- P.Denholm, D.J. Arent, S.F. Baldwin, D.E. Bilello, G.L. Brinkman, J.M. Cochran, W.J. Cole, B. Frew, V. Gevorgian, J. Heeter, B.M.S. Hodge, B. Kroposki, T. Mai, M.J. O’Malley, B. Palmintier, D. Steinberg, Y. Zhang, The challenges of achieving a 100% renewable electricity system in the United States, Joule. 2021, 5, 1331–1352. [CrossRef]
- M.S. Nazir, F. Alturise, S. Alshmrany, H.M.J. Nazir, M. Bilal, A.N. Abdalla, P. Sanjeevikumar, Z.M. Ali, Wind generation forecasting methods and proliferation of artificial neural network: A review of five years research trend, Sustainability. 2020, 12, 3778. [CrossRef]
- L. Lledó, V. Torralba, A. Soret, J. Ramon, F.J. Doblas-Reyes, Seasonal forecasts of wind power generation, Renew. Energy. 2019, 143, 91–100. [Google Scholar] [CrossRef]
- E. Alhamer, A. Grigsby, R. Mulford, The Influence of Seasonal Cloud Cover, Ambient Temperature and Seasonal Variations in Daylight Hours on the Optimal PV Panel Tilt Angle in the United States, Energies. 2022, 15, 7516. [CrossRef]
- S. Impram, S. Varbak Nese, B. Oral, Challenges of renewable energy penetration on power system flexibility: A survey, Energy Strateg. Rev. 2020, 31, 100539. [Google Scholar] [CrossRef]
- Ghalehkhondabi, E. Ardjmand, G.R. Weckman, W.A. Young, An overview of article-title demand forecasting methods published in 2005–2015, Energy Syst. 2017, 8, 411–447. [Google Scholar] [CrossRef]
- Krechowicz, M. Krechowicz, K. Poczeta, Machine Learning Approaches to Predict Electricity Production from Renewable Energy Sources, Energies. 2022, 15, 1–41. [Google Scholar] [CrossRef]
- J. Fan, L. Wu, F. Zhang, H. Cai, W. Zeng, X. Wang, Empirical and machine learning models for predicting daily global solar radiation from sunshine duration : A review and case study in China, Renew. Sustain. Energy Rev. 2019, 100, 186–212. [Google Scholar] [CrossRef]
- C. Voyant, G. Notton, S. Kalogirou, M. Nivet, F. Motte, A. Fouilloy, Machine Learning methods for solar radiation forecasting: a review, Renew. Energy 2016, 105, 569–582. [Google Scholar] [CrossRef]
- J. Huertas-tato, R. Aler, I.M. Galván, F.J. Rodríguez-benítez, C. Arbizu-barrena, D. Pozo-vázquez, A short-term solar radiation forecasting system for the Iberian Peninsula. Part 2 : Model blending approaches based on machine learning, Sol. Energy 2020, 195, 685–696. [Google Scholar] [CrossRef]
- A. E. Gürel, Ü. Ağbulut, Y. Biçen, Assessment of machine learning, time series, response surface methodology and empirical models in prediction of global solar radiation, J. Clean. Prod. 2020, 277, 122353. [Google Scholar] [CrossRef]
- M. Alizamir, S. Kim, O. Kisi, M. Zounemat-kermani, A comparative study of several machine learning based non-linear regression methods in estimating solar radiation: Case studies of the USA and Turkey regions, Energy. 2020, 197, 117239. [CrossRef]
- R. Srivastava, A.N. Tiwari, V.K. Giri, Solar radiation forecasting using MARS, CART, M5, and random forest model : A case study for India, Heliyon. 2019, 5, e02692. [CrossRef]
- Khosravi, R.N.N. Koury, L. Machado, J.J.G. Pabon, Prediction of hourly solar radiation in Abu Musa Island using machine learning algorithms, J. Clean. Prod. 2018, 176, 63–75. [Google Scholar] [CrossRef]
- Li, S. Lin, F. Xu, D. Liu, J. Liu, Short-term wind power prediction based on data mining technology and improved support support vector machine method: A case study in Northwest China, J. Clean. Prod. 2018, 205, 909–922. [Google Scholar] [CrossRef]
- W. Yang, J. Wang, H. Lu, T. Niu, P. Du, Hybrid wind energy forecasting and analysis system based on divide and conquer scheme: a case study in China, J. Clean. Prod. 2019, 222, 942–959. [Google Scholar] [CrossRef]
- Z. Lin, X. Liu, Wind power forecasting of an offshore wind turbine based on high-frequency SCADA data and deep learning neural network, Energy. 2020, 201, 117693. [CrossRef]
- Zendehboudi, M.A. Baseer, R. Saidur, Application of support vector machine models for forecasting solar and wind energy resources : A review, J. Clean. Prod. 2018, 199, 272–285. [Google Scholar] [CrossRef]
- J. Wang, J. Hu, A robust combination approach for short-term wind speed forecasting and analysis e Combination of the ARIMA ( Autoregressive Integrated Moving Average ), ELM ( Extreme Learning Machine ), SVM ( Support Vector Machine ) and LSSVM ( Least Square SVM ) forec, Energy. 2015, 93, 41–56. [CrossRef]
- H. Demolli, A. Sakir, A. Ecemis, M. Gokcek, Wind power forecasting based on daily wind speed data using machine learning algorithms, Energy Convers. Manag. 2019, 198, 111823. [Google Scholar] [CrossRef]
- L. Xiao, W. Shao, F. Jin, Z. Wu, A self-adaptive kernel extreme learning machine for short-term wind speed forecasting, Appl. Soft Comput. J. 2020, 99, 106917. [Google Scholar] [CrossRef]
- E. Cadenas, W. Rivera, R. Campos-amezcua, C. Heard, Wind Speed Prediction Using a Univariate ARIMA Model and a Multivariate NARX Model, Energies. 2016, 9, 109. [CrossRef]
- L. Li, X. Zhao, M. Tseng, R.R. Tan, Short-term wind power forecasting based on support vector machine with improved dragon fl y algorithm, J. Clean. Prod. 2020, 242, 118447. [Google Scholar] [CrossRef]
- Z. Tian, Engineering Applications of Artificial Intelligence Short-term wind speed prediction based on LMD and improved FA optimized combined kernel function LSSVM ✩, Eng. Appl. Artif. Intell. 2020, 91, 103573. [Google Scholar] [CrossRef]
- Y. Hong, T. Rienda, A. Satriani, Day-ahead spatiotemporal wind speed forecasting using robust design-based deep learning neural network, Energy. 2020, 209, 118441. [CrossRef]
- M. I. Jordan, T.M. Mitchell, Machine learning: Trends, perspectives, and prospects, Science (80-. ). 2015, 349, 255–260.
- J.G. Carbonell, R.S. J.G. Carbonell, R.S. Michalski, T.M. Mitchell, AN OVERVIEW OF MACHINE LEARNING, Morgan Kaufmann., 1983. [CrossRef]
- W. Hua, A.R. W. Hua, A.R. Learning, A Brief Review of Machine Learning and its Application, in: 2009 Int. Conf. Inf. Eng. Comput. Sci., 2009: pp. 1–4.
- K. G. Liakos, P. Busato, D. Moshou, S. Pearson, Machine Learning in Agriculture : A Review, Sensors. 2018, 18, 2674. [CrossRef] [PubMed]
- K. Alanne, S. Sierla, An overview of machine learning applications for smart buildings, Sustain. Cities Soc. 2022, 76, 103445. [Google Scholar] [CrossRef]
- P.L.D. Atienza, J.D.-R.A. P.L.D. Atienza, J.D.-R.A. Ogbechie, C.P.-S.C. Bielza, Industrial Applications of Machine Learning, CRC Press, Taylor & Francis Group, New York, 2019.
- J. Schmidt, M.R.G. Marques, S. Botti, M.A.L. Marques, Recent advances and applications of machine learning in solid- state materials science, Npj Comput. Mater. 2019, 83, 1–36. [Google Scholar] [CrossRef]
- Y. Lei, B. Yang, X. Jiang, F. Jia, N. Li, A.K. Nandi, Applications of machine learning to machine fault diagnosis : A review and roadmap, Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- S. Kushwaha, S. Bahl, A.K. Bagha, K. Singh, M. Javaid, A. Haleem, R.P. Singh, Significant Applications of Machine Learning for COVID-19 Pandemic, J. Ind. Integr. Manag. Artic. 2020, 5, 453–479. [Google Scholar] [CrossRef]
- F. Recknagel, Applications of machine learning to ecological modelling, Ecol. Modell. 2001, 146, 303–310. [Google Scholar] [CrossRef]
- J. Joseph, C. Torney, M. Kings, A. Thornton, J. Madden, Applications of machine learning in animal behaviour studies, Anim. Behav. 2017, 124, 203–220. [Google Scholar] [CrossRef]
- I. H. Sarker, Machine Learning: Algorithms, Real-World Applications and Research Directions, SN Comput. Sci. 2021, 2, 1–21. [Google Scholar] [CrossRef] [PubMed]
- B. Liu, Exploring Hyperlinks, Contents, and Usage Data, Second Edi, Spinger Heidelberg, Dordrecht London New York, 2011.
- R. Miorelli, A. Kulakovskyi, B. Chapuis, O.D. Almeida, O. Mesnil, Supervised learning strategy for classification and regression tasks applied to aeronautical structural health monitoring problems, Ultrasonics. 2021, 113, 106372. [CrossRef] [PubMed]
- E. I. Knudsen, Supervised learning in the brain, J. Neurosci. 1994, 14, 3985–3997. [Google Scholar] [CrossRef] [PubMed]
- P.C. Sen, M. P.C. Sen, M. Hajra, M. Ghosh, Supervised Classification Algorithms in Machine Learning: A Survey and Review, in: Adv. Intell. Syst. Comput., Springer Nature, Singapore, 2020: pp. 99–111. [CrossRef]
- S. Xie, Y. Liu, Improving supervised learning for meeting summarization using sampling and regression, Comput. Speech Lang 2010, 24, 495–514. [Google Scholar] [CrossRef]
- R. Caruana, An Empirical Comparison of Supervised Learning Algorithms, in: 23rd Int. Con- Ference Mach. Learn., Pittsburgh, PA, 2006: pp. 161–168.
- D. H. Maulud, A.M. Abdulazeez, A Review on Linear Regression Comprehensive in Machine Learning, J. Appl. Sci. Technol. Trends 2020, 01, 140–147. [Google Scholar] [CrossRef]
- E.G. Tomer, R. E.G. Tomer, R. Jain;, A. Gupta;, Uma, Regression Analysis of COVID-19 using Machine Learning Algorithms, in: Proc. Int. Conf. Smart Electron. Commun., 2020: pp. 65–71.
- K. Mahmud, S. Azam, A. Karim, S.M. Zobaed, B. Shanmugam, D. Mathur, Machine Learning Based PV Power Generation Forecasting in Alice Springs, IEEE Access. 2021, 9, 46117–46128. [CrossRef]
- S. M. Learning, Prognosis of a Wind Turbine Gearbox Bearing Using Supervised Machine Learning, Sensors. 2019, 19, 3092.
- S. Ibrahim, I. Daut, Y.M. Irwan, M. Irwanto, N. Gomesh, Z. Farhana, Linear Regression Model in Estimating Solar Radiation in Perlis, Energy Procedia. 2012, 18, 1402–1412. [CrossRef]
- P. Ekanayake, A.T. Peiris, J.M.J.W. Jayasinghe, U. Rathnayake, Development of Wind Power Prediction Models for Pawan Danavi Wind Farm in Sri Lanka, Math. Probl. Eng. 2021, 2021, 4893713. [Google Scholar]
- M. Y. Erten, H. Aydilek, Solar Power Prediction using Regression Models, Int. J. Eng. Res. Dev. 2022, 14, s333–s342. [Google Scholar] [CrossRef]
- C. H. Ho, C.J. Lin, Large-scale linear support vector regression, J. Mach. Learn. Res. 2012, 13, 3323–3348. [Google Scholar]
- D. Yuan, M. Li, H.Y. Li, C.J. Lin, B.X. Ji, Wind Power Prediction Method: Support Vector Regression Optimized by Improved Jellyfish Search Algorithm, Energies. 2022, 15, 6404. [CrossRef]
- J. Li, J.K. Ward, J. Tong, L. Collins, G. Platt, Machine learning for solar irradiance forecasting of photovoltaic system, Renew. Energy 2016, 90, 542–553. [Google Scholar] [CrossRef]
- R. Mwende, S. R. Mwende, S. Waita, G. Okeng, Real time photovoltaic power forecasting and modelling using machine learning techniques., in: E3S Web Conf., 2022: p. 02004. [CrossRef]
- B. Mahesh, Machine Learning Algorithms - A Review, Int. J. Sci. Res. 2020, 9. [Google Scholar] [CrossRef]
- S. Ray, A Quick Review of Machine Learning Algorithms, in: 2019 Int. Conf. Mach. Learn. Big Data, Cloud Parallel Comput., IEEE, 2019: pp. 35–39.
- A. D. Kumari, J.P. Kumar, V.. Prakash, D. K.S, Supervised Learning Algorithms : A Comparison, Kristu Jayanti J. Comput. Sci. 2021, 1, 01–12. [Google Scholar]
- V. Jagadeesh, K.V. Subbaiah, J. Varanasi, Forecasting the probability of solar power output using logistic regression algorithm, J. Stat. Manag. Syst. ISSN 2020, 23, 1–16. [Google Scholar] [CrossRef]
- Leo Breiman, Random Forests, Mach. Learn. 2001, 45, 5–32. [CrossRef]
- E. Hillebrand, M.C. Medeiros, The benefits of bagging for forecast models of realized volatility, Econom. Rev. 2010, 29, 571–593. [Google Scholar] [CrossRef]
- D. Vassallo, R. Krishnamurthy, T. Sherman, H.J.S. Fernando, Analysis of random forest modeling strategies for multi-stepwind speed forecasting, Energies. 2020, 13, 1–19. [CrossRef]
- K. Shi, Y. Qiao, W. Zhao, Q. Wang, M. Liu, Z. Lu, An improved random forest model of short-term wind-power forecasting to enhance accuracy, efficiency, and robustness, Wind Energy. 2018, 21, 1383–1394. [CrossRef]
- V.A. Natarajan, K. N. V.A. Natarajan, K. N. Sandhya, Wind Power Forecasting Using Parallel Random Forest Algorithm, in: Hybrid Artif. Intell. Syst. Part II, Spinger, 2015: p. 570.
- W. S. Noble, What is a support vector machine?, Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- G. Mountrakis, J. Im, C. Ogole, Support vector machines in remote sensing: A review, ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- J. Zeng, W. Qiao, Short-term solar power prediction using a support vector machine, Renew. Energy 2013, 52, 118–127. [Google Scholar] [CrossRef]
- R. Meenal, A.I. Selvakumar, Assessment of SVM, Empirical and ANN based solar radiation prediction models with most influencing input parameters, Renew. Energy 2018, 121, 324–343. [Google Scholar] [CrossRef]
- H.U. Dike, Y. 75. H.U. Dike, Y. Zhou, K.K. Deveerasetty, Q. Wu, Unsupervised Learning Based On Artificial Neural Network: A Review, in: 2018 IEEE Int. Conf. Cyborg Bionic Syst. CBS, p: China, 2019, 2019. [Google Scholar] [CrossRef]
- Glielmo, B.E. Husic, A. Rodriguez, C. Clementi, F. Noé, A. Laio, Unsupervised Learning Methods for Molecular Simulation Data, Chem. Rev. 2021, 121, 9722–9758. [Google Scholar] [CrossRef] [PubMed]
- J. Karhunen, T. J. Karhunen, T. Raiko, K.H. Cho, Unsupervised deep learning: A short review, in: Adv. Indep. Compon. Anal. Learn. Mach., Elsevier Inc., 2015: pp. 125–142. [CrossRef]
- M. Usama, J. Qadir, A. Raza, H. Arif, K.L.A. Yau, Y. Elkhatib, A. Hussain, A. Al-Fuqaha, Unsupervised Machine Learning for Networking: Techniques, Applications and Research Challenges, IEEE Access. 2019, 7, 65579–65615. [CrossRef]
- J. P. Lai, Y.M. Chang, C.H. Chen, P.F. Pai, A survey of machine learning models in renewable energy predictions, Appl. Sci. 2020, 10, 5975. [Google Scholar] [CrossRef]
- J. Varanasi, M.M. Tripathi, K-means clustering based photo voltaic power forecasting using artificial neural network, particle swarm optimization and support vector regression, J. Inf. Optim. Sci. 2019, 40, 309–328. [Google Scholar] [CrossRef]
- Q. Xu, D. He, N. Zhang, C. Kang, Q. Xia, J. Bai, J. Huang, A short-term wind power forecasting approach with adjustment of numerical weather prediction input by data mining, IEEE Trans. Sustain. Energy. 2015, 6, 1283–1291. [Google Scholar] [CrossRef]
- E. Scolari, F. Sossan, M. Paolone, Irradiance prediction intervals for PV stochastic generation in microgrid applications, Sol. Energy 2016, 139, 116–129. [Google Scholar] [CrossRef]
- K. Arulkumaran, M.P. Deisenroth, M. Brundage, A.A. Bharath, Deep reinforcement learning: A brief survey, IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- M. Botvinick, S. Ritter, J.X. Wang, Z. Kurth-Nelson, C. Blundell, D. Hassabis, Reinforcement Learning, Fast and Slow, Trends Cogn. Sci. 2019, 23, 408–422. [Google Scholar] [CrossRef] [PubMed]
- L. Buşoniu, D. 85. L. Buşoniu, D. Ernst, B. De Schutter, R. Babuška, Approximate reinforcement learning: An overview, in: IEEE SSCI 2011 Symp. Ser. Comput. Intell. - ADPRL, p: Symp. Adapt. Dyn. Program. Reinf. Learn., 2011, 2011. [Google Scholar] [CrossRef]
- R. Nian, J. Liu, B. Huang, A review On reinforcement learning: Introduction and applications in industrial process control, Comput. Chem. Eng. 2020, 139, 106886. [Google Scholar] [CrossRef]
- A. T.D. Perera, P. Kamalaruban, Applications of reinforcement learning in energy systems, Renew. Sustain. Energy Rev. 2021, 137, 110618. [Google Scholar] [CrossRef]
- W. Shi, S. Song, C. Wu, C.L.P. Chen, Multi Pseudo Q-Learning-Based Deterministic Policy Gradient for Tracking Control of Autonomous Underwater Vehicles, IEEE Trans. Neural Networks Learn. Syst. 2019, 30, 3534–3546. [Google Scholar] [CrossRef] [PubMed]
- Grondman, L. Busoniu, G.A.D. Lopes, R. Babuška, A survey of actor-critic reinforcement learning: Standard and natural policy gradients, IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 1291–1307. [Google Scholar] [CrossRef]
- D. Zhang, X. Han, C. Deng, Review on the research and practice of deep learning and reinforcement learning in smart grids, CSEE J. Power Energy Syst. 2018, 4, 362–370. [Google Scholar] [CrossRef]
- D. Cao, W. Hu, J. Zhao, G. Zhang, B. Zhang, Z. Liu, Z. Chen, F. Blaabjerg, Reinforcement Learning and Its Applications in Modern Power and Energy Systems: A Review, J. Mod. Power Syst. Clean Energy. 2020, 8, 1029–1042. [Google Scholar] [CrossRef]
- J. E. Sierra-García, M. Santos, Exploring reward strategies for wind turbine pitch control by reinforcement learning, Appl. Sci. 2020, 10, 1–23. [Google Scholar] [CrossRef]
- H. Wang, Z. Lei, X. Zhang, B. Zhou, J. Peng, A review of deep learning for renewable energy forecasting, Energy Convers. Manag. 2019, 198, 111799. [Google Scholar] [CrossRef]
- M. Elsaraiti, A. Merabet, Solar Power Forecasting Using Deep Learning Techniques, IEEE Access. 2022, 10, 31692–31698. [CrossRef]
- M. Dougherty, A review of neural networks applied to transport, Transp. Res. Part C. 1995, 3, 247–260. [Google Scholar] [CrossRef]
- N. Shahid, T. Rappon, W. Berta, Applications of artificial neural networks in health care organizational decision-making: A scoping review, PLoS One. 2019, 14, 1–22. [CrossRef]
- M. W. Gardner, S.R. Dorling, Artificial neural networks (the multilayer perceptron) - a review of applications in the atmospheric sciences, Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- X. Yaot, A Review of Evolutionary Artificial Neural Networks, Int. J. Intell. Syst. 1993, 4, 203–222. [Google Scholar]
- M. R.G. Meireles, P.E.M. Almeida, M.G. Simões, A comprehensive review for industrial applicability of artificial neural networks, IEEE Trans. Ind. Electron. 2003, 50, 585–601. [Google Scholar] [CrossRef]
- E. Izgi, A. Öztopal, B. Yerli, M.K. Kaymak, A.D. Şahin, Short-mid-term solar power prediction by using artificial neural networks, Sol. Energy. 2012, 86, 725–733. [Google Scholar] [CrossRef]
- C. Chen, S. Duan, T. Cai, B. Liu, Online 24-h solar power forecasting based on weather type classification using artificial neural network, Sol. Energy. 2011, 85, 2856–2870. [Google Scholar] [CrossRef]
- J. 12 ( 2020. [CrossRef]
- T. Khatib, A. Mohamed, K. Sopian, M. Mahmoud, Solar energy prediction for Malaysia using artificial neural networks, Int. J. Photoenergy. [CrossRef]
- G. Perveen, M. Rizwan, N. Goel, P. Anand, Artificial neural network models for global solar energy and photovoltaic power forecasting over India, Energy Sources, Part A Recover. Util. Environ. Eff. 2020, 00, 1–26. [Google Scholar] [CrossRef]
- S. Kumar, T. Kaur, Development of ANN Based Model for Solar Potential Assessment Using Various Meteorological Parameters, Energy Procedia. 2016, 90, 587–592. [CrossRef]
- P. Neelamegam, V. Arasu, Prediction of solar radiation for solar systems by using ANN models with different back propagation algorithms, J. Appl. Res. Technol. 2016, 14, 206–214. [Google Scholar] [CrossRef]
- T. A. Woldegiyorgis, A. Admasu, N.E. Benti, A.A. Asfaw, A Comparative Evaluation of Artificial Neural Network and Sunshine Based models in prediction of Daily Global Solar Radiation of Lalibela, Ethiopia, Cogent Eng. 2022, 9, 0–12. [CrossRef]
- J. Jamii, M. Mansouri, M. Trabelsi, Effective arti fi cial neural network-based wind power generation and load demand forecasting for optimum energy management, Front. Energy Res. 2022, 10, 898413. [Google Scholar] [CrossRef]
- Q. Chen, K. Q. Chen, K. Folly, Effect of Input Features on the Performance of the ANN-based Wind Power Forecasting, in: 2019 South. African Univ. Power Eng. Conf. Mechatronics/Pattern Recognit. Assoc. South Africa, IEEE, 2019: pp. 673–678. [CrossRef]
- MuhaMohammad Mahdi Forootan;, L. Iman;, Z. Rahim;, AhmadiAbolfazl, Machine Learning and Deep Learning in Energy Systems: A Review, Sustain. 2022, 14, 4832. [CrossRef]
- G. Yao, T. Lei, J. Zhong, A review of Convolutional-Neural-Network-based action recognition, Pattern Recognit. Lett. 2019, 118, 14–22. [Google Scholar] [CrossRef]
- M.W. Akram, G. Li, Y. Jin, X. Chen, C. Zhu, X. Zhao, A. Khaliq, M. Faheem, A. Ahmad, CNN based automatic detection of photovoltaic cell defects in electroluminescence images, Energy. 2019, 189, 116319. [CrossRef]
- M.M. Bejani, M. M.M. Bejani, M. Ghatee, A systematic review on overfitting control in shallow and deep neural networks, Springer Netherlands, 2021. [CrossRef]
- M. T., McCann, K.H. Jin, M. Unser, Convolutional Neural Networks for Inverse problems in imaging, IEEE Signal Process. Mag. (2017) 85–95. [CrossRef]
- C. Qian, B. Xu, L. Chang, B. Sun, Q. Feng, D. Yang, Y. Ren, Z. Wang, Convolutional neural network based capacity estimation using random segments of the charging curves for lithium-ion batteries, Energy. 2021, 227, 120333. [CrossRef]
- Ajit, K. Acharya, A. Samanta, A Review of Convolutional Neural Networks, in: Int. Conf. Emerg. Trends Inf. Technol. Eng. Ic-ETITE. [CrossRef]
- Y. Lin, I. Y. Lin, I. Koprinska, M. Rana, Temporal Convolutional Neural Networks for Solar Power Forecasting, in: Proc. Int. Jt. Conf. Neural Networks, 2020: pp. 1–8. [CrossRef]
- W. Lee, K. Kim, J. Park, J. Kim, Y. Kim, Forecasting solar power using long-short term memory and convolutional neural networks, IEEE Access. 2018, 6, 73068–73080. [CrossRef]
- N. Dong, J.F. Chang, A.G. Wu, Z.K. Gao, A novel convolutional neural network framework based solar irradiance prediction method, Int. J. Electr. Power Energy Syst. 2020, 114, 105411. [Google Scholar] [CrossRef]
- K. Aurangzeb, S. Aslam, S.I. Haider, S.M. Mohsin, S. ul Islam, H.A. Khattak, S. Shah, Energy forecasting using multiheaded convolutional neural networks in efficient renewable energy resources equipped with energy storage system, Trans. Emerg. Telecommun. Technol. 2022, 33, 1–14. [Google Scholar] [CrossRef]
- S.C. Lim, J.H. Huh, S.H. Hong, C.Y. Park, J.C. Kim, Solar Power Forecasting Using CNN-LSTM Hybrid Model, Energies. 15 (2022). [CrossRef]
- B. Gao, X. Huang, J. Shi, Y. Tai, J. Zhang, Hourly forecasting of solar irradiance based on CEEMDAN and multi-strategy CNN-LSTM neural networks, Renew. Energy. 2020, 162, 1665–1683. [Google Scholar] [CrossRef]
- D. Cannizzaro, A. 123. D. Cannizzaro, A. Aliberti, L. Bottaccioli, E. Macii, A. Acquaviva, E. Patti, Solar radiation forecasting based on convolutional neural network and ensemble learning, Expert Syst. Appl. [CrossRef]
- Q. Wu, F. Guan, C. Lv, Y. Huang, Ultra-short-term multi-step wind power forecasting based on CNN-LSTM, IET Renew. Power Gener. 2020, 15, 1019–1029. [Google Scholar] [CrossRef]
- H. Hewamalage, C. Bergmeir, K. Bandara, Recurrent Neural Networks for Time Series Forecasting: Current status and future directions, Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- V.S. Lalapura, J. V.S. Lalapura, J. Amudha, H.S. Satheesh, Recurrent neural networks for edge intelligence: A survey, ACM Comput. Surv. 54 (2021). [CrossRef]
- J. Zhu, Q. Jiang, Y. Shen, C. Qian, F. Xu, Q. Zhu, Application of recurrent neural network to mechanical fault diagnosis: a review, J. Mech. Sci. Technol. 2022, 36, 527–542. [Google Scholar] [CrossRef]
- M. N. Fekri, H. Patel, K. Grolinger, V. Sharma, Deep learning for load forecasting with smart meter data: Online Adaptive Recurrent Neural Network, Appl. Energy. 2021, 282, 116177. [Google Scholar] [CrossRef]
- G. Yang, Y. Wang, X. Li, Prediction of the NOx emissions from thermal power plant using long-short term memory neural network, Energy. 2020, 192, 116597. [CrossRef]
- W. Zhang, X. Li, X. Li, Deep learning-based prognostic approach for lithium-ion batteries with adaptive time-series prediction and on-line validation, Meas. J. Int. Meas. Confed. 2020, 164, 108052. [Google Scholar] [CrossRef]
- Kisvari, Z. Lin, X. Liu, Wind power forecasting – A data-driven method along with gated recurrent neural network, Renew. Energy. 2021, 163, 1895–1909. [Google Scholar] [CrossRef]
- M. Abdel-Nasser, K. Mahmoud, Accurate photovoltaic power forecasting models using deep LSTM-RNN, Neural Comput. Appl. 2019, 31, 2727–2740. [Google Scholar] [CrossRef]
- A.K.& L.B. Ajay Pratap Yadav, RNN Based Solar Radiation Forecasting Using Adaptive Learning Rate, in: Swarm, Evol. Memetic Comput., Spinger, 2013: pp. 422–452.
- F. Harrou, A. Dairi, F. Kadri, Y. Sun, Effective forecasting of key features in hospital emergency department: Hybrid deep learning-driven methods, Mach. Learn. with Appl. 2022, 7, 100200. [Google Scholar] [CrossRef]
- Dedinec, S. Filiposka, A., Dedinec, L. Kocarev, Deep belief network based electricity load forecasting: An analysis of Macedonian case, Energy. 2016, 115, 1688–1700. [Google Scholar] [CrossRef]
- S. Hu, Y. Xiang, D. Huo, S. Jawad, J. Liu, An improved deep belief network based hybrid forecasting method for wind power, Energy. 2021, 224, 120185. [CrossRef]
- W. Yang, C. Liu, D. Jiang, An unsupervised spatiotemporal graphical modeling approach for wind turbine condition monitoring, Renew. Energy. 2018, 127, 230–241. [Google Scholar] [CrossRef]
- D. Yang, H.R. Karimi, K. Sun, Residual wide-kernel deep convolutional auto-encoder for intelligent rotating machinery fault diagnosis with limited samples, Neural Networks. 2021, 141, 133–144. [CrossRef] [PubMed]
- C.M.A. Roelofs, M.A. Lutz, S. Faulstich, S. Vogt, Autoencoder-based anomaly root cause analysis for wind turbines, Energy AI. 2021, 4, 100065. [CrossRef]
- S. Daneshgar, R. Zahedi, Optimization of power and heat dual generation cycle of gas microturbines through economic, exergy and environmental analysis by bee algorithm, Energy Reports. 2022, 8, 1388–1396. [CrossRef]
- N. Renström, P. Bangalore, E. Highcock, System-wide anomaly detection in wind turbines using deep autoencoders, Renew. Energy. 2020, 157, 647–659. [Google Scholar] [CrossRef]
- Dairi, F. Harrou, Y. Sun, S. Khadraoui, Short-term forecasting of photovoltaic solar power production using variational auto-encoder driven deep learning approach, Appl. Sci. 2020, 10, 1–20. [Google Scholar] [CrossRef]
- K.U. Jaseena, B.C. K.U. Jaseena, B.C. Kovoor, A hybrid wind speed forecasting model using stacked autoencoder and LSTM, J. Renew. Sustain. Energy. 12 (2020). [CrossRef]
- G. Fud, Deep belief network based ensemble approach for cooling load forecasting of air-conditioning system, Energy. 2018, 148, 269–282. [CrossRef]
- X. Hao, T. Guo, G. Huang, X. Shi, Y. Zhao, Y. Yang, Energy consumption prediction in cement calcination process: A method of deep belief network with sliding window, Energy. 2020, 207, 118256. [CrossRef]
- X. Sun, G. Wang, L. Xu, H. Yuan, N. Yousefi, Optimal estimation of the PEM fuel cells applying deep belief network optimized by improved archimedes optimization algorithm, Energy. 237 (2021). [CrossRef]
- Y.Q. Neo, T.T. 147. Y.Q. Neo, T.T. Teo, W.L. Woo, T. Logenthiran, A. Sharma, Forecasting of photovoltaic power using deep belief network, IEEE Reg. 10 Annu. Int. Conf. Proceedings/TENCON. 1189. [Google Scholar] [CrossRef]
- K. Wang, X. Qi, H. Liu, J. Song, Deep belief network based k-means cluster approach for short-term wind power forecasting, Energy. 2018, 165, 840–852. [CrossRef]
- C.T. Sun, J.S. C.T. Sun, J.S. Jang, Fuzzy modeling based on generalized neural networks and fuzzy clustering objective functions, in: Proc. IEEE Conf. Decis. Control, Brighton, England, 1991: pp. 2924–2929. [CrossRef]
- P. Tahmasebi, A. Hezarkhani, A hybrid neural networks-fuzzy logic-genetic algorithm for grade estimation, Comput. Geosci. 2012, 42, 18–27. [Google Scholar] [CrossRef]
- D. Karaboga, E. Kaya, Adaptive network based fuzzy inference system (ANFIS) training approaches: a comprehensive survey, Artif. Intell. Rev. 2019, 52, 2263–2293. [Google Scholar] [CrossRef]
- M. Nilashi, H. Ahmadi, L. Shahmoradi, O. Ibrahim, E. Akbari, A predictive method for hepatitis disease diagnosis using ensembles of neuro-fuzzy technique, J. Infect. Public Health. 2019, 12, 13–20. [Google Scholar] [CrossRef]
- Abd Al-Azeem Hussieny, M.A. El-Beltagy, S. El-Tantawy, Forecasting of renewable energy using ANN, GPANN and ANFIS (A comparative study and performance analysis), in: 2nd Nov. Intell. Lead. Emerg. Sci. Conf. NILES. [CrossRef]
- Mellit, A.H. Arab, N. Khorissi, H. Salhi, An ANFIS-based forecasting for solar radiation data from sunshine duration and ambient temperature, in: 2007 IEEE Power Eng. Soc. Gen. Meet. PES, 2007. [CrossRef]
- H. K. Yadav, Y. Pal, M.M. Tripathi, A novel GA-ANFIS hybrid model for short-term solar PV power forecasting in Indian electricity market, J. Inf. Optim. Sci. 2019, 40, 377–395. [Google Scholar] [CrossRef]
- R. M. Balabin, R.Z. Safieva, E.I. Lomakina, Wavelet neural network (WNN) approach for calibration model building based on gasoline near infrared (NIR) spectra, Chemom. Intell. Lab. Syst. 2008, 93, 58–62. [Google Scholar] [CrossRef]
- H.H. Aly, A novel deep learning intelligent clustered hybrid models for wind speed and power forecasting, Energy. 2020, 213, 118773. [CrossRef]
- Z. Yuan, W. Wang, H. Wang, S. Mizzi, Combination of cuckoo search and wavelet neural network for midterm building energy forecast, Energy. 2020, 202, 117728. [CrossRef]
- H. H.H. Aly, A novel approach for harmonic tidal currents constitutions forecasting using hybrid intelligent models based on clustering methodologies, Renew. Energy. 2020, 147, 1554–1564. [Google Scholar] [CrossRef]
- Y. Shen, X. Wang, J. Chen, Wind power forecasting using multi-objective evolutionary algorithms for wavelet neural network-optimized prediction intervals, Appl. Sci. 8 (2018). [CrossRef]
- V. Sharma, D. Yang, W. Walsh, T. Reindl, Short term solar irradiance forecasting using a mixed wavelet neural network, Renew. Energy. 2016, 90, 481–492. [Google Scholar] [CrossRef]
- Z. Q. Wu, W.J. Jia, L.R. Zhao, C.H. Wu, Maximum wind power tracking based on cloud RBF neural network, Renew. Energy. 2016, 86, 466–472. [Google Scholar] [CrossRef]
- Y. Han, C. Fan, Z. Geng, B. Ma, D. Cong, K. Chen, B. Yu, Energy efficient building envelope using novel RBF neural network integrated affinity propagation, Energy. 2020, 209, 118414. [CrossRef]
- H. Cherif, A. Benakcha, I. Laib, S.E. Chehaidia, A. Menacer, B. Soudan, A.G. Olabi, Early detection and localization of stator inter-turn faults based on discrete wavelet energy ratio and neural networks in induction motor, Energy. 2020, 212, 118684. [CrossRef]
- X. Wu, B. X. Wu, B. Hong, X. Peng, F. Wen, J. Huang, Radial basis function neural network based short-term wind power forecasting with Grubbs test, in: 2011 4th Int. Conf. Electr. Util. Deregul. Restruct. Power Technol., IEEE Xplore, Weihai, China, 2011: pp. 1879–1882. [CrossRef]
- M. Madhiarasan, Accurate prediction of different forecast horizons wind speed using a recursive radial basis function neural network, Prot. Control Mod. Power Syst. 5 (2020). [CrossRef]
- Z. Ramedani, M. Omid, A. Keyhani, S. Shamshirband, B. Khoshnevisan, Potential of radial basis function based support vector regression for global solar radiation prediction, Renew. Sustain. Energy Rev. 2014, 39, 1005–1011. [Google Scholar] [CrossRef]
- D. F. Specht, A general regression neural network, IEEE Int. Conf. Neural Networks - Conf. Proc. 1991, 2, 568–576. [Google Scholar] [CrossRef]
- H. B. Celikoglu, Application of radial basis function and generalized regression neural networks in non-linear utility function specification for travel mode choice modelling, Math. Comput. Model. 2006, 44, 640–658. [Google Scholar] [CrossRef]
- L. Wang, O. Kisi, M. Zounemat-Kermani, B. Hu, W. Gong, Modeling and comparison of hourly photosynthetically active radiation in different ecosystems, Renew. Sustain. Energy Rev. 2016, 56, 436–453. [Google Scholar] [CrossRef]
- P. Sakiewicz, K. Piotrowski, S. Kalisz, Neural network prediction of parameters of biomass ashes, reused within the circular economy frame, Renew. Energy. 2020, 162, 743–753. [Google Scholar] [CrossRef]
- Tu, W. Tsai, C., Hong, W. Lin, Short-Term Solar Power Forecasting via General Regression Neural Network with Grey Wolf Optimization, Energies. 2022, 15, 6624. [Google Scholar]
- M. Sridharan, Generalized Regression Neural Network Model Based Estimation of Global Solar Energy Using Meteorological Parameters, Ann. Data Sci. Data Sci. ( 2021. [CrossRef]
- G. Kumar, H. Malik, Generalized Regression Neural Network Based Wind Speed Prediction Model for Western Region of India, Procedia Comput. Sci. 2016, 93, 26–32. [Google Scholar] [CrossRef]
- G. Bin Huang, Q.Y. Zhu, C.K. Siew, Extreme learning machine: Theory and applications, Neurocomputing. 2006, 70, 489–501. [CrossRef]
- Y. Feng, W. Hao, H. Li, N. Cui, D. Gong, L. Gao, Machine learning models to quantify and map daily global solar radiation and photovoltaic power, Renew. Sustain. Energy Rev. 2020, 118, 109393. [Google Scholar] [CrossRef]
- S. Shamshirband, K. Mohammadi, P.L. Yee, D. Petković, A. Mostafaeipour, A comparative evaluation for identifying the suitability of extreme learning machine to predict horizontal global solar radiation, Renew. Sustain. Energy Rev. 2015, 52, 1031–1042. [Google Scholar] [CrossRef]
- Z. Li, L. Ye, Y. Zhao, X. Song, J. Teng, J. Jin, Short-term wind power prediction based on extreme learning machine with error correction, Prot. Control Mod. Power Syst. 2016, 1, 4–11. [Google Scholar] [CrossRef]
- M. Hou, T. Zhang, F. Weng, M. Ali, N. Al-Ansari, Z.M. Yaseen, Global solar radiation prediction using hybrid online sequential extreme learning machine model, Energies. 2018, 11, 3415. [CrossRef]
- N. Li, F. He, W. Ma, Wind power prediction based on extreme learning machine with kernel mean p-power error loss, Energies. 2019, 12, 673. [CrossRef]
- M. Zounemat-Kermani, O. Batelaan, M. Fadaee, R. Hinkelmann, Ensemble machine learning paradigms in hydrology: A review, J. Hydrol. 2021, 598, 126266. [Google Scholar] [CrossRef]
- S. K. Gunturi, D. Sarkar, Ensemble machine learning models for the detection of energy theft, Electr. Power Syst. Res. 2021, 192, 106904. [Google Scholar] [CrossRef]
- B. A. Tama, S. Lim, Ensemble learning for intrusion detection systems: A systematic mapping study and cross-benchmark evaluation, Comput. Sci. Rev. 2021, 39, 100357. [Google Scholar] [CrossRef]
- Dogan, D. Birant, Machine learning and data mining in manufacturing, Expert Syst. Appl. 2021, 166, 114060. [Google Scholar] [CrossRef]
- Y. Ren, P.N. Suganthan, N. Srikanth, Ensemble methods for wind and solar power forecasting - A state-of-the-art review, Renew. Sustain. Energy Rev. 2015, 50, 82–91. [Google Scholar] [CrossRef]
- J. S. Chou, C.F. Tsai, A.D. Pham, Y.H. Lu, Machine learning in concrete strength simulations: Multi-nation data analytics, Constr. Build. Mater. 2014, 73, 771–780. [Google Scholar] [CrossRef]
- J.D. de Guia;, R.S.C. II;, H.A. Calinao;, R.R. Tobias;, E.P. Dadios;, A.A. Bandala, Solar Irradiance Prediction Based on Weather Patterns Using Bagging-Based Ensemble Learners with Principal Component Analysis, in: 2020 IEEE 8th R10 Humanit. Technol. Conf., Kuching, Malaysia, 2020: pp. 1–6.
- P. Kumari, D. Toshniwal, Extreme gradient boosting and deep neural network based ensemble learning approach to forecast hourly solar irradiance, J. Clean. Prod. 2021, 279, 123285. [Google Scholar] [CrossRef]
- M. F. Rami Al-Hajj, Ali Assi, Short-Term Prediction of Global Solar Radiation Energy Using Weather Data and Machine Learning Ensembles: A Comparative Study, J. Sol. Energy Eng. 143 (664) 051003. [CrossRef]
- M. W. Akram, G. Li, Y. Jin, X. Chen, C. Zhu, A. Ahmad, Automatic detection of photovoltaic module defects in infrared images with isolated and develop-model transfer deep learning, Sol. Energy. 2020, 198, 175–186. [Google Scholar] [CrossRef]
- K. Weiss, T.M. K. Weiss, T.M. Khoshgoftaar, D.D. Wang, A survey of transfer learning, Springer International Publishing, 2016. [CrossRef]
- W. Chen, Y. Qiu, Y. Feng, Y. Li, A. Kusiak, Diagnosis of wind turbine faults with transfer learning algorithms, Renew. Energy. 2021, 163, 2053–2067. [Google Scholar] [CrossRef]
- E. Sarmas, N. Dimitropoulos, V. Marinakis, Z. Mylona, H. Doukas, Transfer learning strategies for solar power forecasting under data scarcity, Sci. Rep. 2022, 12, 1–13. [Google Scholar] [CrossRef]
- Q. Hu, R. Zhang, Y. Zhou, Transfer learning for short-term wind speed prediction with deep neural networks, Renew. Energy. 2016, 85, 83–95. [Google Scholar] [CrossRef]
- S. Zhang, Y. Chen, J. Xiao, W. Zhang, R. Feng, Hybrid wind speed forecasting model based on multivariate data secondary decomposition approach and deep learning algorithm with attention mechanism, Renew. Energy. 2021, 174, 688–704. [Google Scholar] [CrossRef]
- G. . Mbah, N.. Amulu, M.. Onyiah, Effects of Process Parameters on the Yield of oil from Castor Seed, Am. J. Eng. Res. 2014, 03, 179–186. [Google Scholar]
- A. T. Eseye, J. Zhang, D. Zheng, Short-term Photovoltaic Solar Power Forecasting Using a Hybrid Wavelet-PSO-SVM Model Based on SCADA and Meteorological Information, Renew. Energy. 2018, 118, 357–367. [Google Scholar] [CrossRef]
- H. H.H. Aly, An intelligent hybrid model of neuro Wavelet, time series and Recurrent Kalman Filter for wind speed forecasting, Sustain. Energy Technol. Assessments. 2020, 41, 100802. [Google Scholar] [CrossRef]
- G. N. Kariniotakis, G.S. Stavrakakis, E.F. Nogaret, Wind power forecasting using advanced neural networks models, IEEE Trans. Energy Convers. 1996, 11, 762–767. [Google Scholar] [CrossRef]
- G. Li, H. Wang, S. Zhang, J. Xin, H. Liu, Recurrent neural networks based photovoltaic power forecasting approach, Energies. 2019, 12, 1–17. [CrossRef]
- Kumar, H.D. Mathur, S. Bhanot, R.C. Bansal, Forecasting of solar and wind power using LSTM RNN for load frequency control in isolated microgrid, Int. J. Model. Simul. 2021, 41, 311–323. [Google Scholar] [CrossRef]
Figure 1.
ML types and algorithms.

Figure 2.
Artificial Neural Network Architecture.
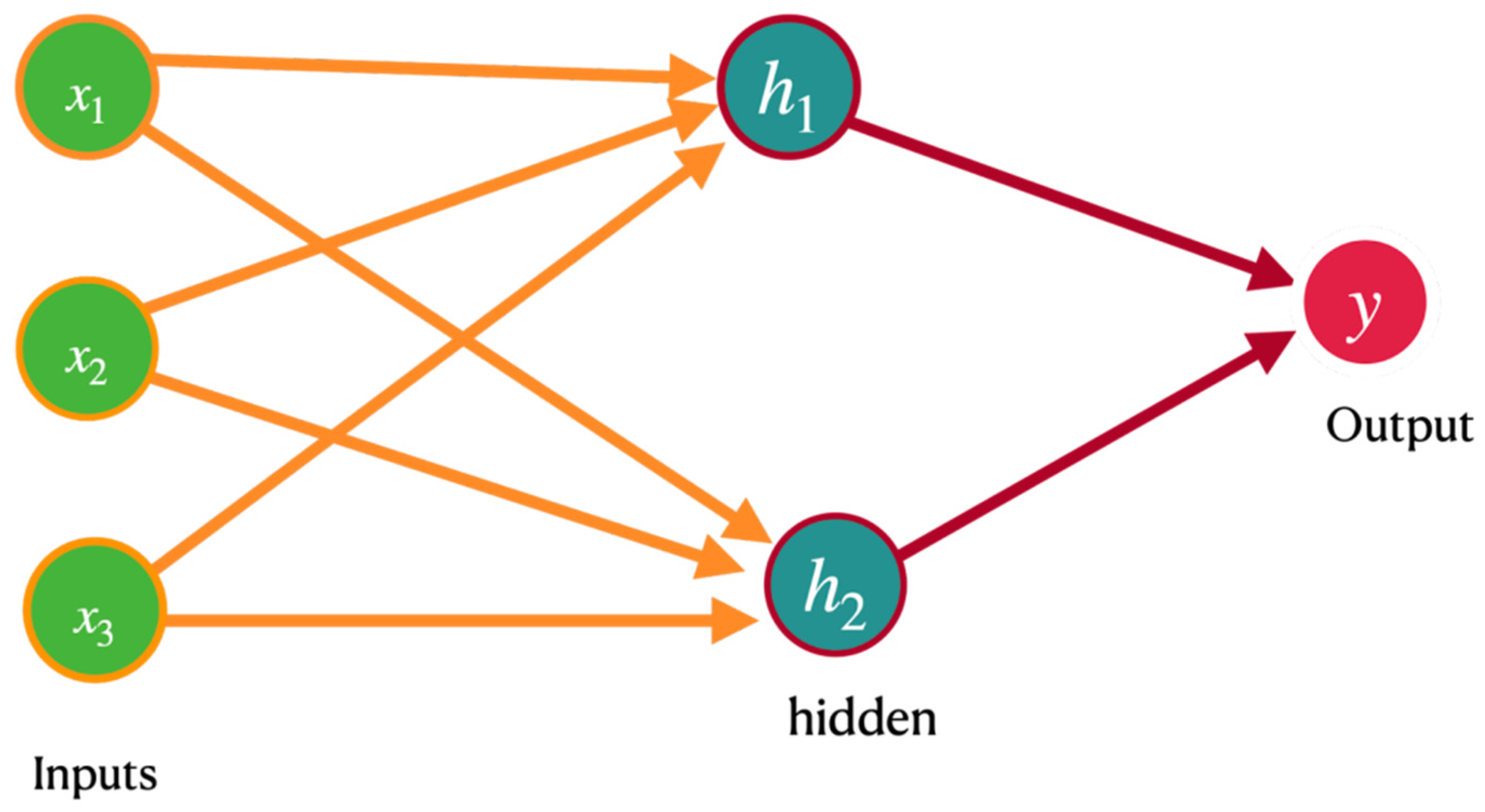
Figure 3.
Convolutional Neural Network Architecture [116].
Figure 3.
Convolutional Neural Network Architecture [116].
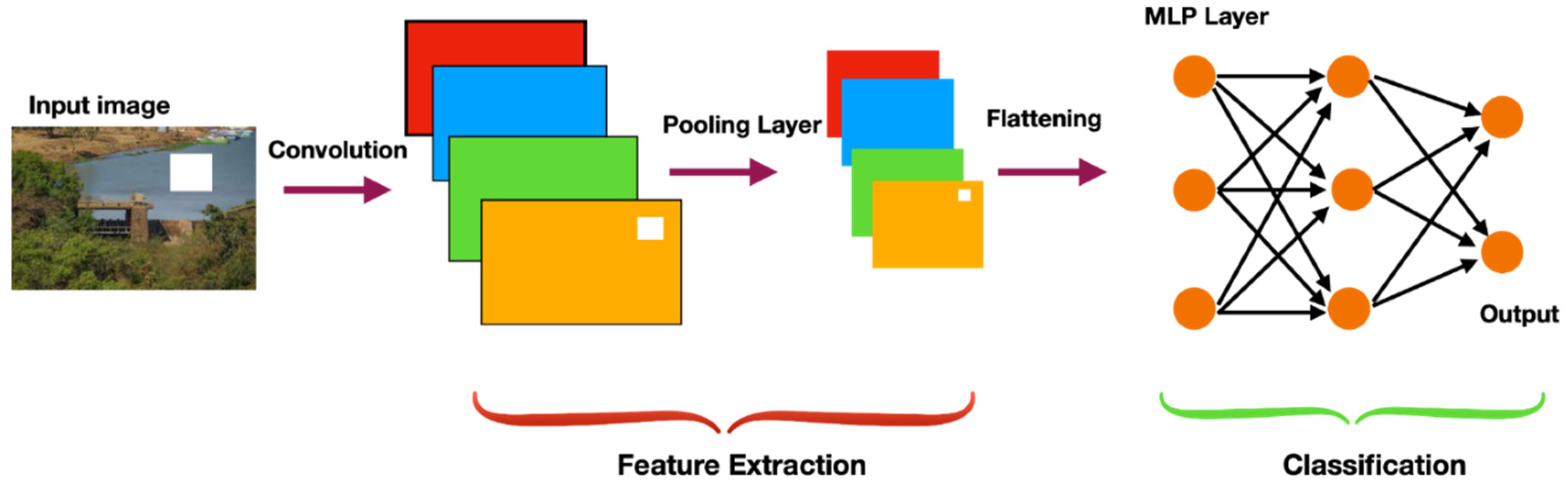
Figure 4.
Architecture of RNN.
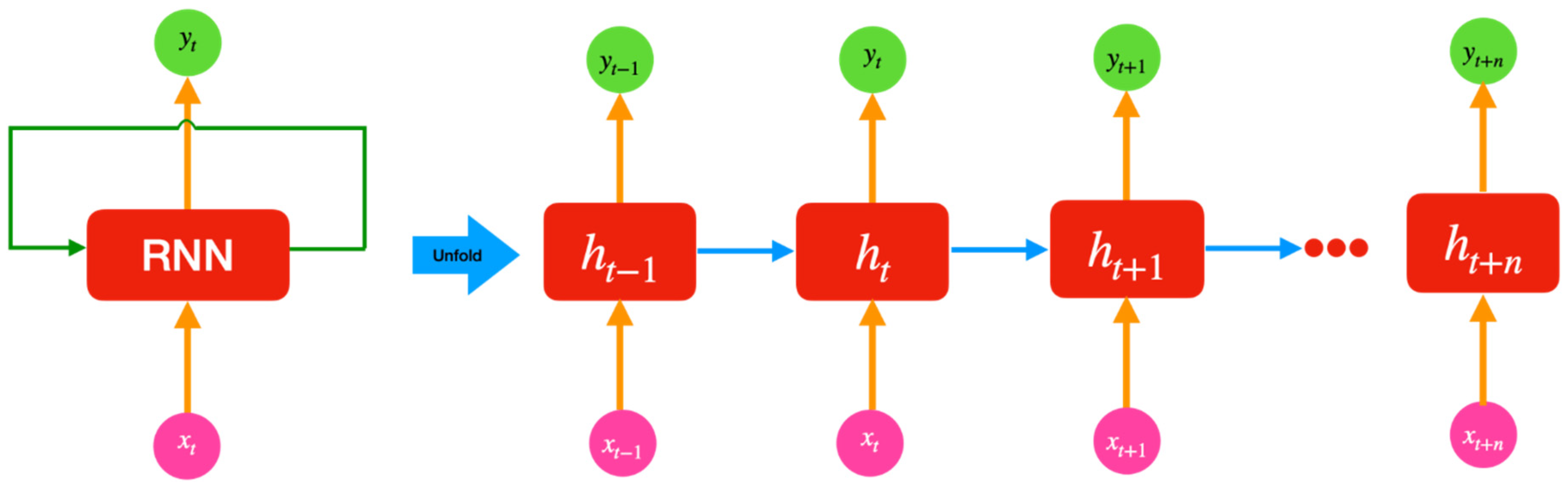
Figure 5.
RBM Forecasting architecture [134].
Figure 5.
RBM Forecasting architecture [134].
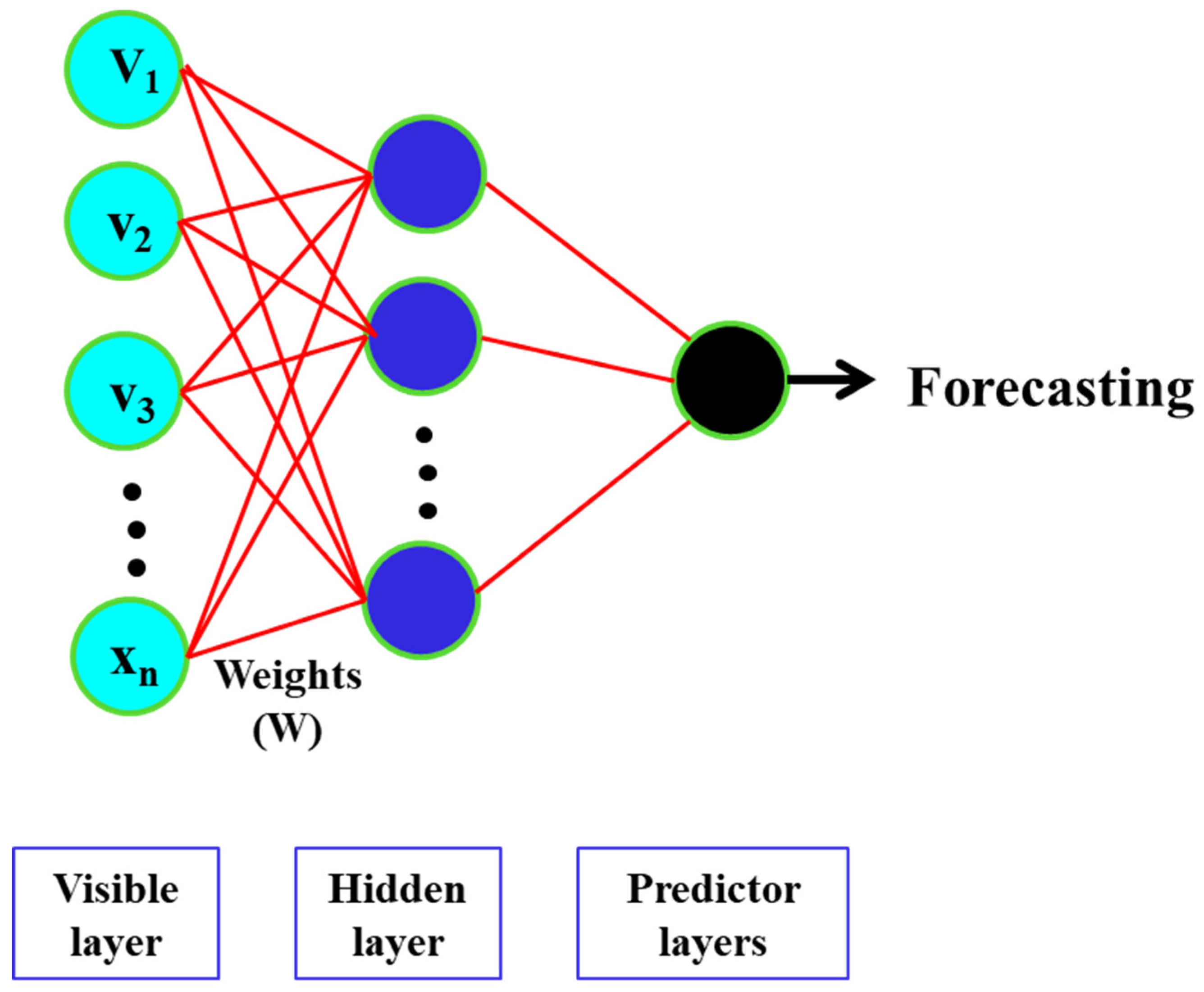
Figure 6.
The autoencoder’s basic design [141].
Figure 6.
The autoencoder’s basic design [141].
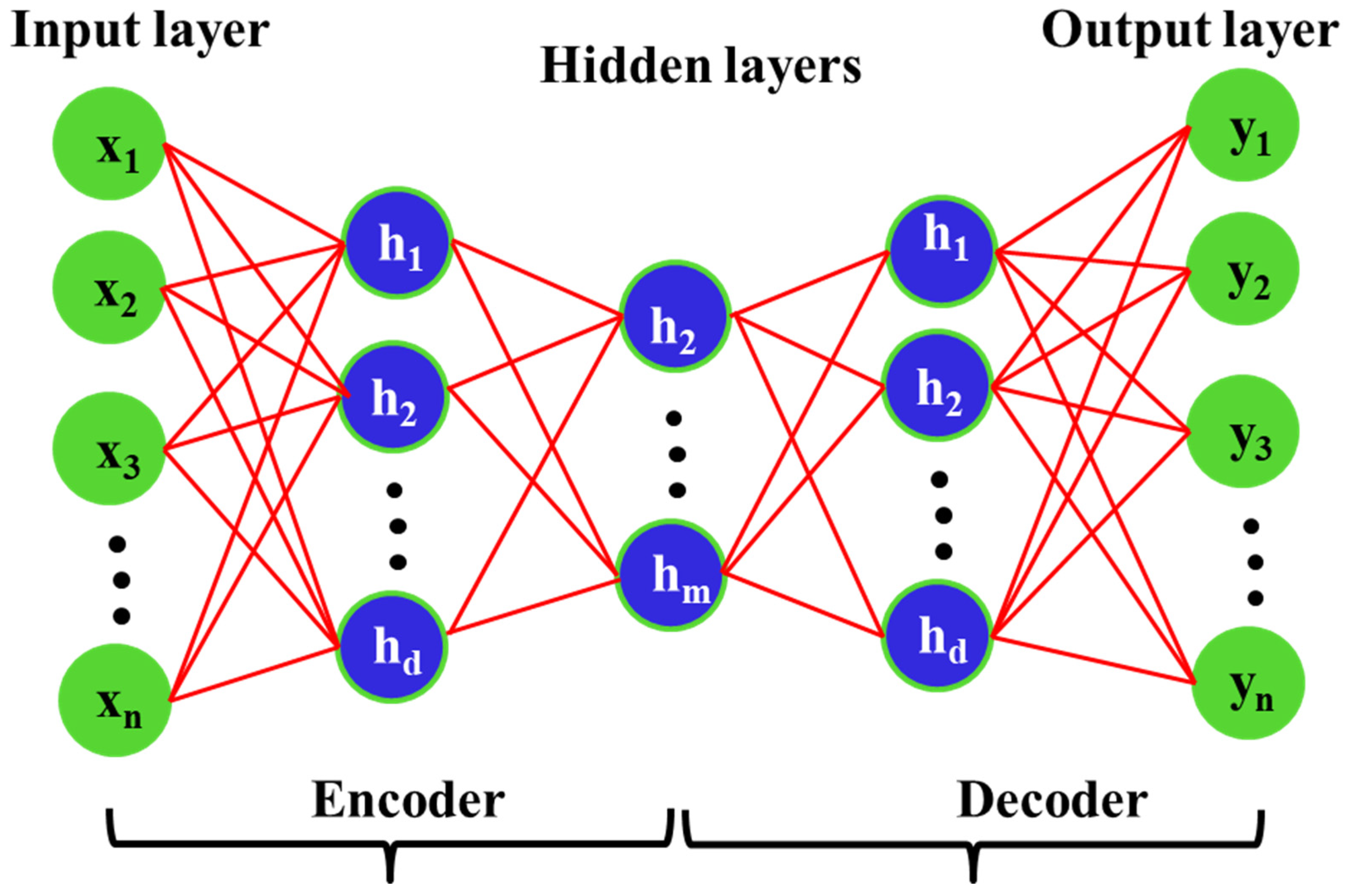
Figure 7.
Architecture of DBN [134].
Figure 7.
Architecture of DBN [134].
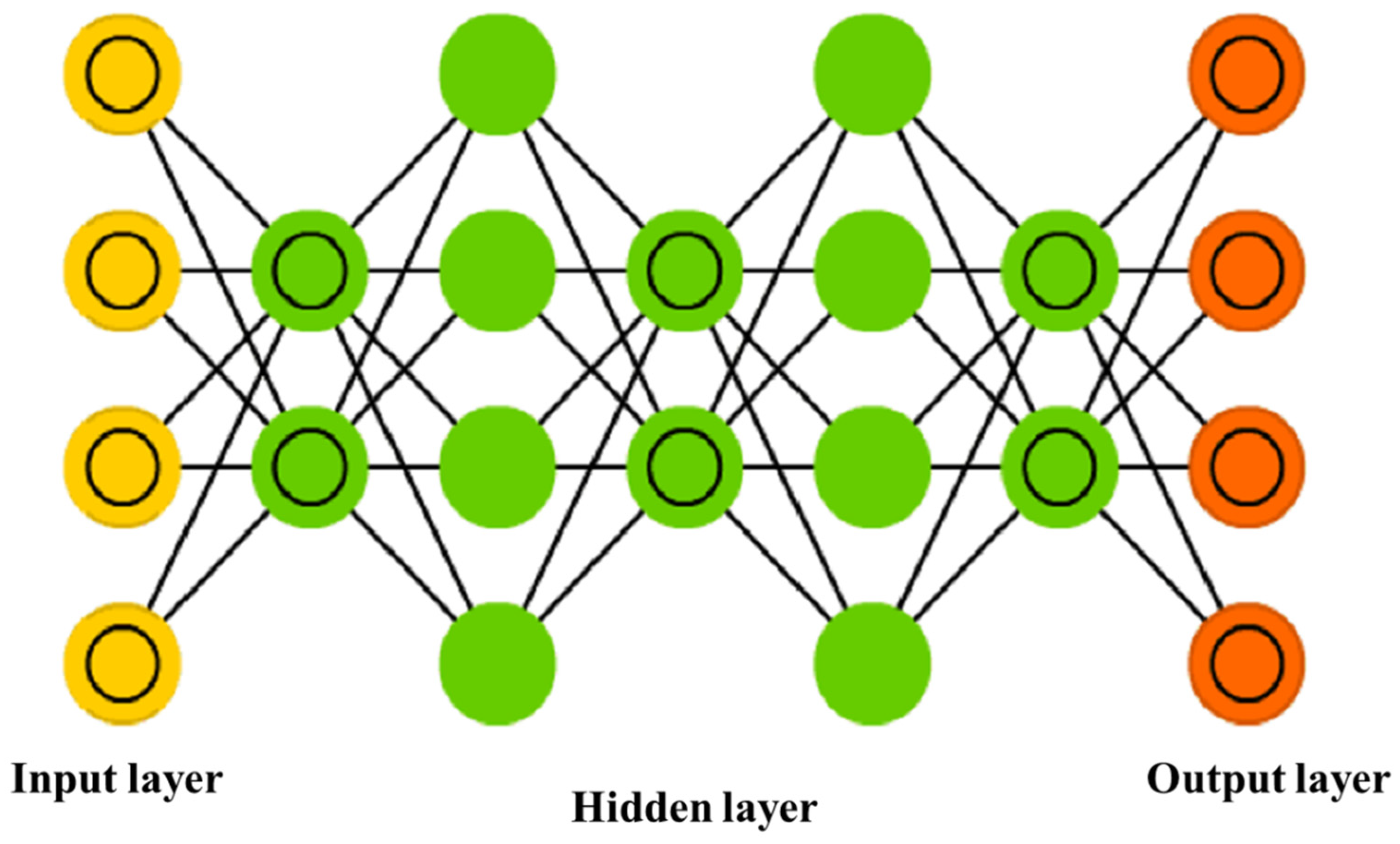
Figure 8.
ANFIS architecture [152].
Figure 8.
ANFIS architecture [152].
Figure 9.
The schematic representation of GRNN [170].
Figure 9.
The schematic representation of GRNN [170].
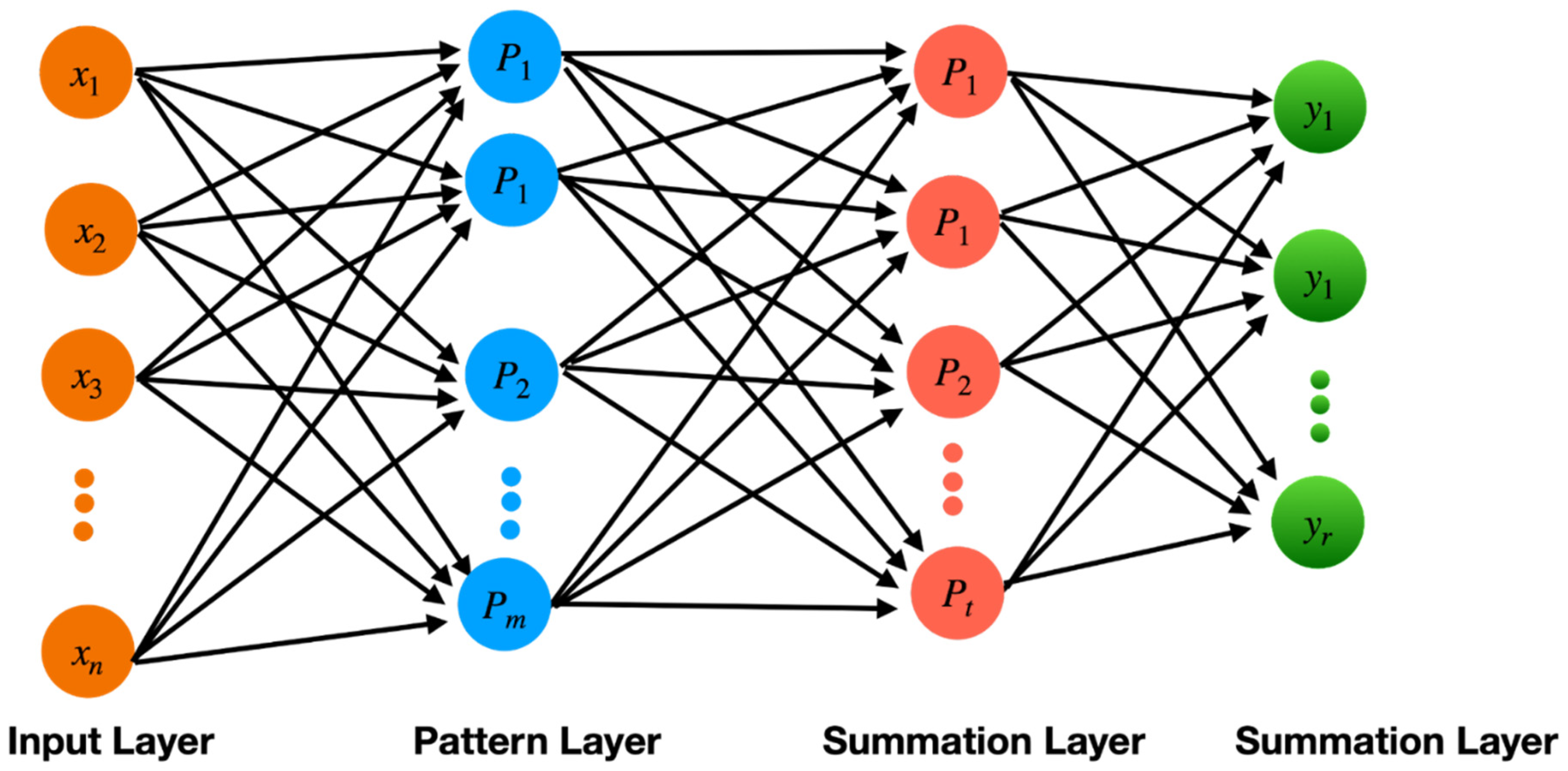
Figure 10.
The schematic representation of TL.
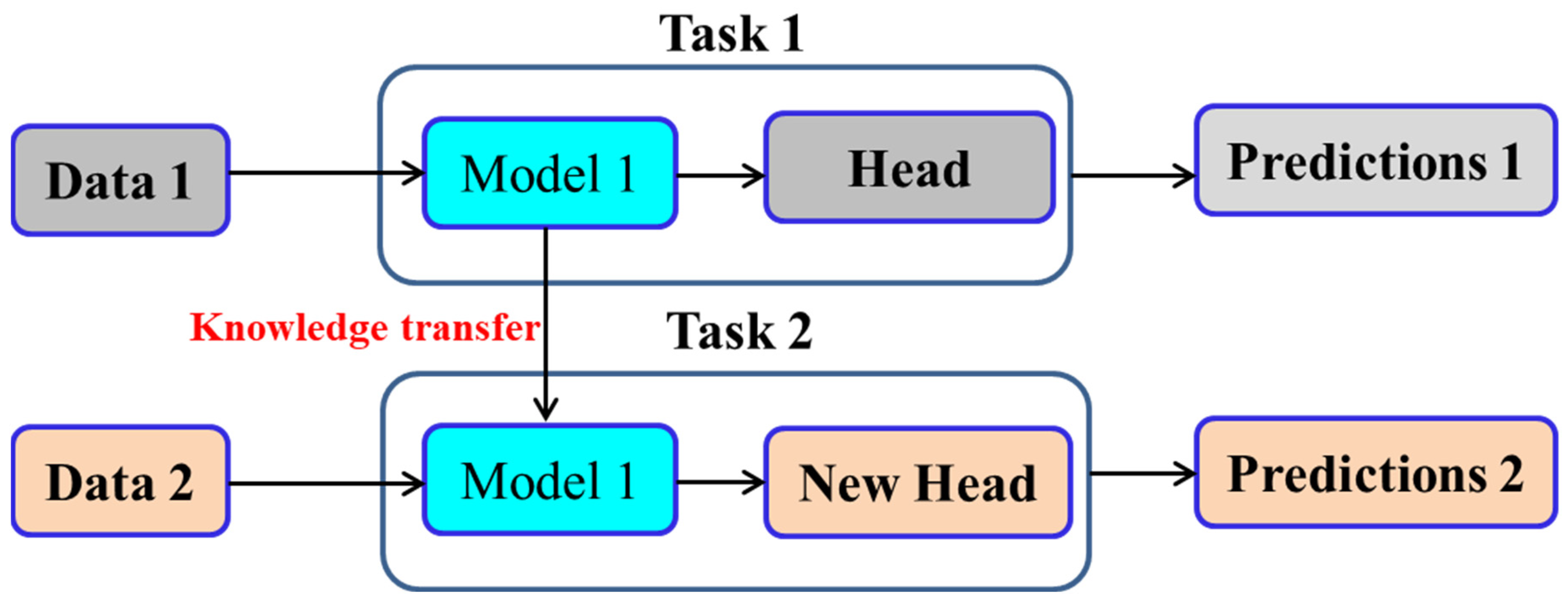
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



