Submitted:
19 April 2023
Posted:
20 April 2023
You are already at the latest version
Abstract
The study is based on the notion that big data predictive analytics is important for developing strategic alliances performance of companies. this study investigates the relationship between big data predictive analytics, big data culture, and competitive strategies 'techniques were adopted, such as descriptive statistics, correlation,regression, etc. using SPSS and SmartPLS statistical software. Hypotheses were tested with bootstrapped analysis using SEM (through SmartPLS). The study developed a structural equation model by using the SEM analysis. The results of the SEM analysis suggested the hypothesized model of the study was valid. The results supported all the hypotheses of the study.Through empirical analysis, demonstrated the conclusion is that the big data predictive analytics has a positive and significant relationship with strategic alliance performance
Keywords:
Big data predictive analytics
; big data culture
; competitive strategies
; Strategic alliance performance
; Pakistani Companies
1. Introduction
Digitalization has changed the world in a business context. Especially globally, a big data environment is the main phenomenon that has to reshape business activities in every business sector. Companies are increasingly challenged by “Big data,” which has emerged as an exciting frontier of productivity and opportunity in the last few years. Big data analytics capability (BDAC) is widely considered to transform how companies do business (Barton & Court, 2012; T. H. Davenport et al., 2007). a growing interest in, because of big data analytics is now allowing firms to collect, mine, and use very large volumes of data; big data predictive analytics (BDPA) has caught the attention of academics and industries due to its offering big data capabilities, which allow businesses to collect, analyze, and manage, larger data set (Aydiner, Tatoglu, Bayraktar, Zaim, & Delen, 2019; Malomo & Sena, 2017; Matthias, Fouweather, Gregory, & Vernon, 2017).
Recent literature regarding that BDPA has “the potential to transform management theory and practice” (Waller & Fawcett, 2013), it is the “next big thing in innovation” (Gobble, 2013); and “the fourth paradigm of science” (Mishra, Gunasekaran, Papadopoulos, & Childe, 2018); or the next “management revolution” (McAfee, Brynjolfsson, Davenport, Patil, & Barton, 2012). This drastic digital change has transformed different organization tactics and competitive strategies for business activities (D. Q. Chen, Preston, & Swink, 2015). Furthermore, a new trend also affects many types of businesses, like the nature and structure of organizational tasks, which are now very different from those of the last decade (Gale & Abraham, 2005). Businesspersons and scholars have mainly noticed these kinds of internet-based developments, the emergence of data analytics, information systems, cloud computing, and big data. Additionally, new concepts of the strategic alliance also provoke scholars, business people, and other practitioners in the context of competitive advantage in the market. This reshapes the business activities in big data environments like big data predictive analytics, competitive strategies, big data culture, and strategic alliances in the current era.
- Research Questions
- 1.
- What are the diverse dimensions of motives for strategic alliances in a big data environment for different companies involved in strategic alliances?
- 2.
- What are the various competitive outcomes for organizations through forming strategic alliances?
- 3.
- How can big data analytics, competitive strategies, and big data culture affect the companies’ strategic alliance performance?
- 4.
- What factors have a strong and positive impact on the strategic alliance, and how these factors can be promoted in the company’s environment?
- 5.
- What are the implications and potential challenges for the organizations for strategic alliances within the big data environment
- Research Hypothesis
H1.
Big data predictive analytics has a positive and significant relationship with strategic Alliance Performance.
H2.
There is a positive relationship between big data predictive analytics and competitive strategies.
H3.
There is a positive relationship between big data culture and strategic alliance performance.
H4.
There is a positive relationship between competitive strategies and strategic alliance performance.
H5.
Big data predictive analytics has a positive and significant relationship with big data culture.
H6.
A big data culture positively mediates the relationship between big data analytics and strategic alliance performance.
H7.
Competitive strategies positively mediate the relationship between big data predictive analytics and strategic alliance performance.
2. Literature Review
We have an overarching theoretical lens based on three additional theories: institutional theory (DiMaggio & Powell, 1983), resource-based theory (RBT) (Barney, 1991). Institutional theory illuminates BDPA adoption by examining the interconnections and collaboration between stakeholders and the focal agency. Resource based theory emphasizes internal resources’ role to influence organizations’ strategies and results (Barney, 1991). Previous studies have incorporated structural theory and RBV, explaining organizational decision-making as independent reasons for an organization (Oliver, 1991) and their various functions and connections of external pressures and internal resources (Tatoglu, Glaister, & Demirbag, 2016; Zheng, Chen, Huang, & Zhang, 2013). In the context of BDPA, however, it is not clear how external pressures and corporate culture will influence internal resources and the implementation of BDPA to improve operational efficiency. Braganza, Brooks, Nepelski, Ali, and Moro (2017) argue that the RB VRIN (value, rarity, imperfect imitability, and non-substitutability) criteria could be used to achieve competitiveness based on large-scale organization capital (Barney, 1991). (Tarofder, Marthandan, Mohan, & Tarofder, 2013) suggests that developments in the supply chain powered by the Internet are more driven by structural justification than technical thinking. We incorporate institutional theory, RBV, and Big Data culture to logically support our empirical outcomes, as no one viewpoint can justify BDPA’s direct success effects in organizational performance on its own.
Even though big data and other factors have been greatly studied in recent years, it still needs to be well understood in business and management to leverage the competition globally. Strategic management concepts need to be developed and adopted for this new form of business. An area that still needs further development in this aspect is the concept of strategic alliances concerning big data predictive analytics, big data culture, and competitive strategies (Capaldo and Giannoccaro, 2015).
The above discussion prevails in the globalization of the market. The rapid and expanded access to Internet technology has built up a rivalry. It has made it easy to find valuable goods and services for the customers, making it difficult to profit in the companies’ traditional competitive environment (Angrave, Charlwood, Kirkpatrick, Lawrence, & Stuart, 2016). Physical business models seemingly are not compatible in a virtual environment. Hence, competition needs to be taken care of more thoughtfully by adapting different strategic alliances in the big data environment to improve business and reduce business risk (Fatehi & Choi, 2019).
2.1. Big Data Predictive Analytics
The evolution of technology was significant since it allowed big data and analytics concepts to be carried out. Decades ago, it would have been impossible, for example, from the economic point of view, since they would have needed costly equipment to obtain and maintain (Kitchin, 2014b).
This evolution allowed us to analyze information from different perspectives, helping to make increasingly beneficial decisions. On the other hand, and according to authors mention, regarding the format of the data, the concept of data fiction arises, which refers to taking information of all existing things, such as the location of a person, the vibrations of a motor, or the stress that a bridge may have, and transform it into a data format that can be quantified (H. Hu, Wen, Chua, & Li, 2014; Mayer-Schönberger & Cukier, 2013). This allows us to use information in new ways, such as predictive analysis: detect the state of an engine from the vibrations it produces.
In addition to what was mentioned by these authors, a Big data definition emerged that would summarize the central idea of this new concept: “the ability of society to take advantage of the information in new ways, to produce useful ideas or goods and services of significant value”(Brown, Chui, & Manyika, 2011; Riggins & Wamba, 2015).
We can mention the author’s concept about big data along with these concepts (Marr 2015). Big data is everything we do incrementally by leaving a fingerprint (or data), which any individual can use and analyze to transform into more intelligent. The driving forces are characterized by an increase in the volume of data and the technological increase capacity to undermine what data can be recovered as ideas focused on business (M. Chen, Mao, & Liu, 2014). According to what this author mentions, the value is not in a large amount of information generated and stored but in what can be extracted (the value). The creation of information analysis techniques that allow the taking of unstructured data (which cannot be easily stored or indexed with conventional formats) contributes to making smarter decisions (Kitchin, 2014a; Verhoef, Kooge, & Walk, 2016).
On the other hand, and following the detail by T. Davenport (2014), big data can also be defined taking into account the criteria of the 3 V or dimensions: volume (increase in the amount of data), variety (range of increase in the number of the data type) and speed (increase in data processing speed). Other authors (Marr, 2015) have added other characteristics such as truthfulness (related to the disorder of data that is generated–for example, Twitter posts with hashtags, abbreviations, text language) and value (contribution in terms of value that data can offer for decision making) (Verhoef et al., 2016).
Big data can be defined in several ways, but all come together in the same idea: collect and store data, which can later be analyzed to improve decision making. As (T. Davenport, 2014) mentioned, Analytics can be defined as the focus given to the data using mathematical and statistical analysis for decision making. The following are the different types of analytics. Descriptive, Predictive, and Prescriptive
T. Davenport (2014) has mentioned their details as follows;
- ⮚
- Descriptive—In these dashboards, scorecards and alerts are included. They say what happened in the past, but not why they happened or what could change.
Predictive is more useful: past data is used to model future outputs and perhaps indicate how customers respond (Brouthers, Nakos, & Dimitratos, 2015).
- ⮚
- A marketing promotion or how sales will be affected by certain market conditions.
- ⮚
- Prescriptive: A use of optimization or the AB test to advise managers and workers on the best way to do their job.
In this aspect, according to H. Hu et al. (2014), Big data differs from traditional analysis in that it is mainly focused on unstructured data formats, leading them to generate a constant flow of data (Brown et al., 2011). Big data handles unstructured data, while the traditional approach manages data in row and column format. On the other hand, big data and Analytics data volume is much higher than those that characterize the traditional analysis. The same for big data is constant for the data flow, while it is static for traditional analysis (Wamba, Akter, Edwards, Chopin, & Gnanzou, 2015). The methods for big data is learning that employing mathematical models and complex algorithms lead to the machines to be able to “learn” and generate answers that a traditional analysis system, which is based on the hypothesis of the functioning of a system, do not believe (Brown et al., 2011).
Finally, the purpose for which big data is created is based on generating value from the data. At the same time, a traditional system, on the contrary, focuses on service and support for internal decisions. Also, justify this approach in the analysis techniques from which the volume of information has grown so much that the quantity to be examined could not be adjusted to the memories that the computers had to process; therefore, the engineers needed to modernize the tools to be able to analyze it (processing technologies such as Google’s Map Reduce, or Hadoop). These new analysis tools came out of rigid information hierarchies (M. Chen et al., 2014; Kitchin, 2014b).
That is to say, the different authors that were cited agree that the large volumes of information forced those who analyze them to create new techniques that adapt to the different types of data and the large volume that is collected, generating greater value added to the decision making (H. Hu et al., 2014). It is noteworthy that big data is a complement class and not a substitute, helping organizations understand the customer better and make better decisions. Big data analytics’ fundamental meaning is to generate value for that decision-making in organizations from the information collected and stored.
The first aspect to mention in this work is information. Based on the purpose of big data analytics, this chapter will delve into its role for companies (H. Chen, Chiang, & Storey, 2012; M. Chen et al., 2014). The value that information can generate for an organization can give it a dominant place, transforming itself into a fundamental stone for its actions. Reaching this position will depend on its approach to give to its processes and information processing for decision-making (Brown et al., 2011).
As T. Davenport (2014) says, what is necessary is the vision and determination of organizations to build and develop innovations. Imagination, courage, and commitment are required to embark on the journey of big data and Analytics. Each organization will collect a considerable amount of data collections, complemented by IT developments, data and systems integration, and an analytical model, allowing companies to be more productive by having new tools (H. Hu et al., 2014). More and more companies are looking for the value that information can provide them. Some discover the potential that big data and analytics can generate, including all organizations (Kitchin, 2014b).
Big data and Analytics are uniting concepts even more to the organization’s areas. That is taking them to a common goal: the business objective and being ahead of the competition. As T. Davenport (2014) comments, the impact of big data and analytics in the organization’s different sectors is variable. This constitutes an opportunity for the organization to exploit big data in all areas.
Further big data is also used according to the companies’ area. Furthermore, we seek to monitor employees’ communication and collaboration activities (Côrte-Real, Oliveira, & Ruivo, 2017). This also allows the relationship between the company and its employees to be even closer, since the channels in which the employees understand their role better within the organization will be enabled, and the latter will understand the importance of the role that each of your employees does (Wamba et al., 2015). Furthermore, big data help in the decision making of any organization (T. Davenport, 2014).
Further, the big data and analytics initiative can arise from the same, which is important to have a good sales strategy from IT to other sectors, focusing on the features and advantages that big data can offer the organization (cohesion of the different areas, which go towards a common business objective) (Burns, 2015).
Immersing yourself in big data and Analytics generates a culture of constant innovation and exploration. Innovation also goes hand in hand with technological change (Erevelles, Fukawa, & Swayne, 2016). In short, big data and predictive have importance in the area of technology, marketing, management, human resources management, and finance. Further, it helps the companies to decide based on big data, business strategy, generating greater performance, and integrating ideas to improve day-to-day operations (Kitchin, 2014a; Zhang & Dong, 2004).
This exploration is one of the big data and analytics pillars since it allows the organization, within its self-knowledge, to open new paths that they take to your business objective (Marr, 2015). Thus, the people who are part of the organization will also be part of the transformation, attracting new customers, and to enter a new market, and getting new business opportunities (Burns, 2015; Gandomi & Haider, 2015; Kitchin, 2014a; Reed & Dongarra, 2015).
Technology has reached the point where large amounts of information can often be captured and saved at cheaper costs. This, combined with the fact that the data value is much larger than the value extracted from its first use (Storey & Song, 2017). So there is a need and ways to generate value from the data and technology of the company. Many of these technologies or concepts are not new. Still, they fall under big data: like the traditional Business Intelligence (BI), Data Mining, Statistical applications (Ohlhorst, 2012; Zhang & Dong, 2004), Predictive analysis, Data modeling: These categories are only a portion of where Big data and Analytics points, and why it has a business (H. Chen et al., 2012; Stephens-Davidowitz & Pinker, 2017).
2.2. Big Data Culture
In today’s world, where the information is owned by those who have the power to make decisions, start a new business, concepts that challenge how to manage information arise. Big data is the trend generating changes in how this information is used, how it is stored, and how information can generate added value (H. Hu et al., 2014).
Considering the definition given by (T. Davenport, 2014), big data refers to data that is too large to fit on a single server, unstructured to fit a database of rows and columns, or data continuously flowing to be in a static data warehouse. The fact that the data volumes are too large is directly related to the origin of the data: social networks like Facebook, Pinterest, and Twitter, financial transactions, medical records, meteorological data, geographical location, voice, video, audio, generating non-conventional data formats (M. Chen et al., 2014). The generation of this type of information is constant. The data size also has relevance in the amount of hardware necessary to store and process the information.
2.3. Competitive Strategies
According to Herrmann (2005), the first strategy can be defined as “the company growth planning and executing.” According to (Feldman, 2014), cited in (Galbreath, 2011; Herman, Ostrander, Mueller, & Figueiredo, 2005) the firm objective is to maximize economic coming back. Ensuring the firm survival and prosperity is a strategy (Grant, 1991); therefore, the overall organizational goals meet through strategy guidance. “Strategic initiative” is defined by MacMillan (1983) as strategic behavior capture control capability in companies in which the industry competes. The above competitive advantage of its rivals is a strategy that an organization directs specifically (Porter, 1986). According to Schuler and Jackson (1987), competitive strategy has been classified into three types:
- (i)
- Cost reduction
- (ii)
- Modernization
- (iii)
- And quality improvement
Figure 3.1.
Conceptual Model.
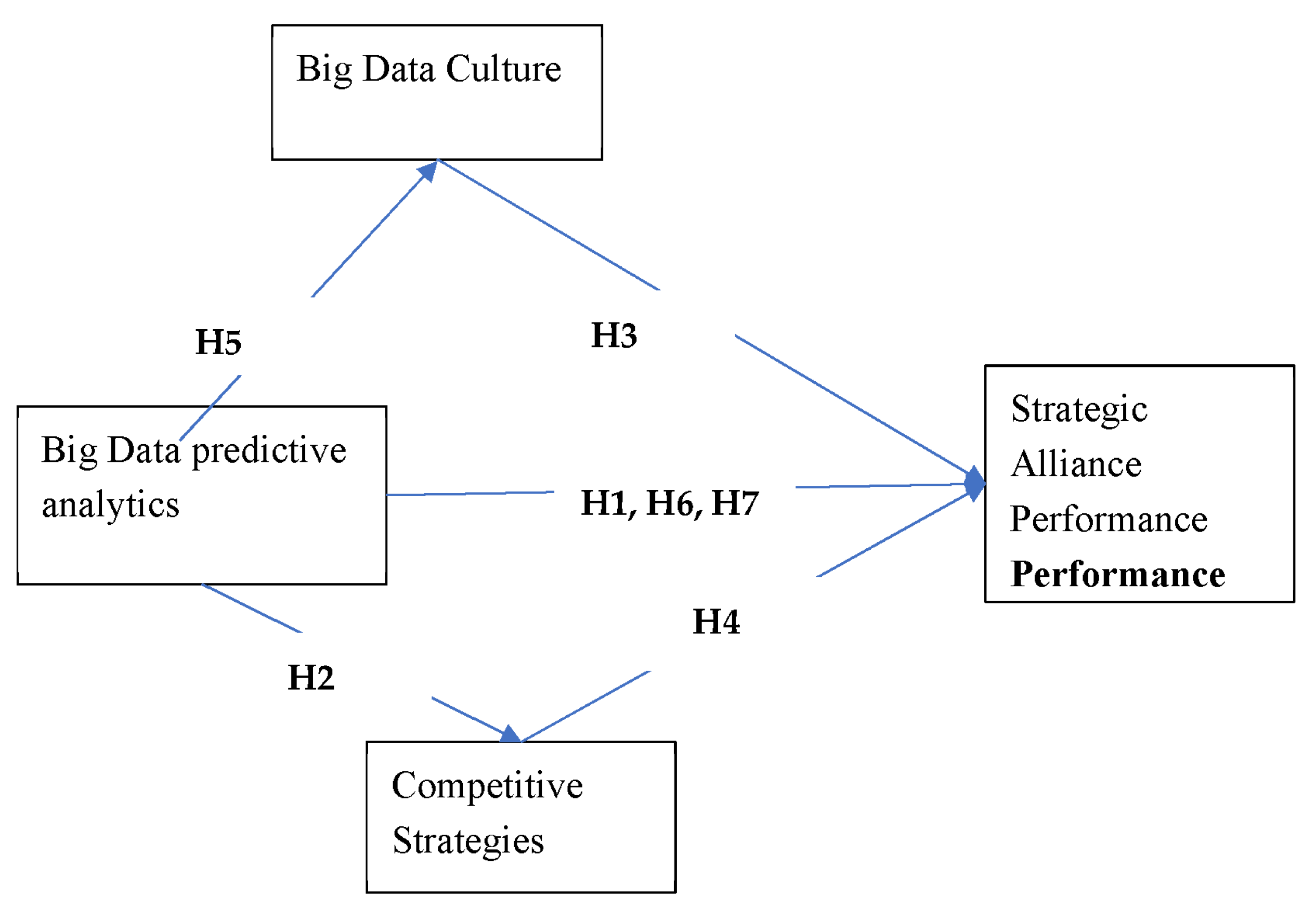
- Hypotheses Testing
Based on the findings of the relationship between big data predictive analytics, big data culture, competitive strategies, and strategic alliance performance, the following hypotheses were accepted. Table 5.12 shows the relationship between big data predictive analytics and strategic alliance performance was positive and significant; this relationship is accepted.
Secondly, Table 5.12 also shows that the positive and significant relationship between competitive strategies and strategic alliance performance. So, this hypothesis is also accepted.
Thirdly, the relationship between big data culture and strategic alliance performance is positive and significant. So, this hypothesis is also accepted.
Fourthly, competitive strategies play the mediator between big data predictive analytics and big data strategic analytics. Table 5.13 shows that competitive strategies play a mediator role between big data predictive analytics and strategic alliance performance. Results show that competitive strategies are a mediator between big data predictive analytics and strategic alliance performance. So, this hypothesis is also accepted.
Fifthly, big data culture strengthens the relationship between big data predictive analytics and strategic alliance performance. From the Table 12 results, it is cleared that big data culture is a mediator between big data predictive analytics and strategic alliance performance.
H1.
Big data predictive analytics has a positive and significant relationship with strategic alliance performance.
Table 12 results that big data predictive analytics has a positive and significant relationship with the strategic Alliance performance. So, this predicted hypothesis (H1) has been approved.
These results are in line with (Akter & Wamba, 2016) study findings.
H2.
Big data predictive analytics has a positive and significant relationship with competitive strategies.
Table 12 results that big data culture has a positive and significant relationship with the strategic Alliance performance. So, this predicted hypothesis (H2) has been approved.
H3.
Big data culture has a positive and significant relationship with strategic alliance performance.
Table 12 results that competitive strategies have a positive and significant relationship with the strategic Alliance performance. So, this predicted hypothesis (H3) has been approved.
H4.
Competitive strategies have a positive and significant relationship with strategic alliance performance.
Table 12 results that big data predictive analytics and strategic alliance performance have a positive and significant relationship with the strategic Alliance performance. So, this predicted hypothesis (H4) has been approved.
The results of this study are consistent with
H5.
Big data predictive analytics has a positive and significant relationship with the big data culture.
Table 12 results explain that big data predictive analytics positively and significantly relates to the big data culture.
H6.
Big data Culture has a mediating role between big data predictive analytics and strategic alliance performance.
From Table 13, p-value and Beta values explain that competitive strategies and strategic Alliance performance have a positive and significant relationship with the strategic alliance performance. Further, it strengthens the relationship between big data predictive analytics and strategic alliance performance. So, this predicted hypothesis (H6s) has been approved.
These results are in tune with the study’s (Goncalves & da Conceição, 2008; Schuler & Jackson, 1987) findings.
H7.
Competitive strategies have a mediating relationship between big data predictive analytics and strategic Alliance Performance.
Table 13 shows that big data culture is mediating between big data predictive analytics and strategic Alliance performance. p-value and B-values in these three tables explain that this variable has a positive and significant relationship with big data predictive analytics and strategic alliance performance. So, our study (H7) is accepted
The study results are consistent with the findings (Goncalves & da Conceição, 2008) study. From the above discussion, it is analyzed that all the relevant hypotheses of this study are accepted. Big data culture and competitive strategies mediate between big data predictive analytics and strategic alliance performance. Furthermore, interview results are in link with the quantitative analysis.
4. Research Methodology
This study questionnaire was based on the previous interviews and tested studies, but we also developed some measures. The questionnaire was developed in the English language. After developing a questionnaire, First, 90 were distributed in the respondents for the pilot study, 60 filled questionnaires were received. The Cronbach’s Alpha value was 0.08. After pilot testing the validity, some questionnaire was added while some things were corrected. After finalizing the questionnaire, we randomly selected 150 companies from five provinces of Pakistan, such as Punjab, Sindh, Baluchistan, Khyber Pakhtunkhwa, and Gilgit. Companies were selected from various high-tech and manufacturing industries in the sampling frame, such as chemicals, machinery, electronics, energy, and IT. To limit common method bias, we collected data for the variables from two respondents in each company (such as the CEO, director, HR manager, finance manager for alliance affairs). Carefully, we chose for their formal organizational positions and their knowledge about the core issues being studied. Both respondents were asked to choose the same partner that had been an ally for at least one year and answer the questionnaire independently. A pilot study was carried out to check further the reliability of the adapted questionnaires in Pakistani companies. The research experts checked a content and face validity analysis, and on the feedback of these experts, the questionnaire was finalized. Annexure B indicated the details of the questionnaire.
After matching key respondents and deleting missing data, the final sample included 331 partner companies (430 respondents). Inter-rater reliability was checked to find that the two respondents share similar views about key alliance characteristics such as alliance age and alliance scope. The main variables were measured with multi-items rated on a seven-point scale, from 1 (strongly agree) to 5 (strongly disagree).
In this study, all the questionnaires were adapted from the previous researcher’s studies. The study model compares big data analytics, big data culture, competitive strategies, and strategic performance alliance.
To research the answer to the research questions. A five-point Likert scale using 1 = strongly disagree, 2 = disagree, 3 = neutral, 4 = agree, and 5 = strongly agree were used. The researchers informed the respondents that gave their responses as again the five-point scale. Further, six control variables, as well as demographic information, were also garnered from the respondents. There are five items of demographic data that explain the personnel information of the respondents
4.1. Population
The present study population is composed of manufacturing companies in Pakistan. The details of manufacturing companies were collected from the Ministry of labor and Production Government of Pakistan website. Only those industries were selected, which have a strategic alliance with each other and have a big data culture and analytics know-how, and also, they are also working on this one. The participants of the companies were Chief executives and top-level managers out of 150 companies.
4.2. Sample Unit and Sample Frame
The present study sample unit was Pakistan’s companies, including chemicals, garments, banking sector, sport, and power sectors, which are part of the strategic alliance with other companies’ national and international companies.
4.3. Sampling Technique
A simple random sampling technique was used to collect the data from the participants. It is necessary for simple random sampling that each unit has an equal chance of being selected in the survey process.
4.4. Study Participants
The study participants have included CEO, marketing director, HR manager, operational manager and finance manager for the data collection through survey method and interviews.
4.5. Participants Eligibility Criteria
The participant’s eligibility criteria were established on behalf of the respondents who know about the strategic alliance in a big data environment. Firstly, participants should be employees of the companies. Secondly, they will be a full-time staff. Thirdly have an association with this company for a minimum period of one year.
4.6. Sample Size
Four hundred and thirty (430) questionnaires were distributed to the participants. A total of 331 useable responses were received. Sixteen responses were not suitable because of incomplete questionnaires obtained. The respondents were part of the companies, which have alliances with the other companies. Respondents were asked about their demographic characteristics big data Predictive analytics, competitive strategies, and big data culture and strategic alliance performance.

Table 4.2.
Response Rate.
| Questionnaire | Frequency | Percentage |
|---|---|---|
| Distributed | 430 | 100 |
| Received | 331 | 76.97 |
Source: Calculated by the author based on the questionnaire data of this study using SPSS 25.
4.7. Data Processing
After getting the participants’ responses, the next step is to enter the data on the computer. First, the coding process was done, and later on, the data screening. Data screening is the process of ensuring the data is clean and fit for statistical analysis. It is important to have data screened because it can get reliable and valid data for further statistical analysis. As this study’s data comes from self-administrated questionnaires, not all the responses may be filed completely in all aspects.
Table 4.3.
Questionnaire Summary.
| Variables | Dimensions of Variables | Numbers of Items | Total Items |
|---|---|---|---|
| Big data Predictive analytics | Performance, innovation, marketing, Skill development, Knowledge practices, Skills development both human and companies, efficiency, Prediction/progress | 1,2,3,4,5,6,7,8 | 8 |
| Big data Culture | Asset, Decision making, Improvement in business role, Employee’s training, learning. culture promotion, monitoring and evaluation, | 9,10,11,12,13,14,15,16 | 8 |
| Competitive Strategies | Product cost differentiation, push versus pull, Channel selection, competitive advantage, Product quality, Vertical integration, Price policy, Leverage Service differentiation, leadership | 17,18,19,20,21,22,23,24,25 | 9 |
| Strategic Alliance Performance | Economic performance, Competitive advantage, improve productivity, search for new knowledge, learning | 26,27,28,29,30,31 | 6 |
4.8. Analytical Procedure
The pilot study is a vital tool to make the questionnaire reliable and valid for further research. Reliability means that the study results must be reliable, as we used this technique to test the reliability and validity of the study’s constructs. For the data collection, a simple random sampling was employed. When the questionnaire gave to the respondents, it was requested them that fill according to their understanding. Respondents filled out demographic and other parts of the questionnaire. The response rate was about 77% that satisfied the minimum criteria to obtain data for the pilot study (Burgoon, Stern, & Dillman, 2007). Each variable’s reliability was checked; the value of Cronbach alpha (α = 0.72) is satisfactory according to the threshold values standard (Christmann & Van Aelst, 2006). In the data feeding process inclusion and exclusion, the process was also carried out; only filled questionnaires were included, and other incomplete questionnaires were discarded.
Above Table 4.9 shows the data’s reliability, which explains that overall, the entire variable’s reliability is greater than Cronbach’s threshold value (α). Therefore, the variables satisfied the need for reliability.
Table 4.9.
Reliability of the Variables.
| Variables | Total Items | Cronbach (α) |
|---|---|---|
| Big data Predictive analytic | 8 | 0.88 |
| Competitive Strategies | 9 | 0.782 |
| Big data Culture | 8 | 0.79 |
| Strategic Alliance Performance | 6 | 0.757 |
4.8.1. Assessment of Model Fitness
Model fitness is the last step before performing other statistical techniques such as correlation and regression to reject or accept the proposed hypothesis model to examine data’s fitness. The following criteria are mentioned in the literature to confirm whether the proposed model is fit or not (L. t. Hu & Bentler, 1999; Roh, Ahn, & Han, 2005):
In Table 4.9 one factor model analysis the values of χ2/df is 2334.52 and CFI = 0.91, NFI = 0.89, GFI = 0.97, and RMSEA = 0. 0.67, which shows a strong model. Moreover, the results explain that the model is statistically significant overall. All the values are around threshold values of χ2/df, CFI, NFI, GFI, and RMSEA.
Table 4.9 shows that all fitness index values had achieved the required level except for Parsimonious fit. Therefore, the model is good enough for the analysis.
Table 4.10.
Model Fit Summary.
| Name of Category | Name of Index | Index Value | Required Level |
|---|---|---|---|
| Absolute Fit | RMSEA | 0.067 | <0.08 |
| GFI | 0.97 | >0.90 | |
| Incremental Fit | CFI | 0.91 | >0.90 |
| Normal Fit Index | NFI | 0.89 | >0.90 |
| Parsimonious Fit | Chi-Square | 2334.52 | <5.0 |
5. Results and Findings
5.1. Difference Based on Gender
In this study, responses were recorded from both males and females. In the current research work, the ratio of males is higher than females. Table 5.1 explains that from 331 respondents, there were 225 males’ respondents and 106 females’ respondents. Table 5.1 explains that 225 (68%) males and 106 (32%) females participated in the study and gave their valuable feedback. Overall, the male ratio was higher than the females.
Table 5.1.
Differences Based on Gender.
| Frequency | Percent | Valid Percent | Cumulative Percent | ||
|---|---|---|---|---|---|
| Valid | Male | 225 | 68.0 | 68.0 | 68.0 |
| female | 106 | 32.0 | 32.0 | 100.0 | |
| Total | 331 | 100.0 | 100.0 | ||
Table 5.1 explains that 83% of males and 17% of females gave their feedback for this study.
5.2. Differences among Age Groups
Table 5.2 represents the respondents’ age who participated in the current study survey feedback. The highest response rate remained between 26 to 30 years of age. The minimum response was recorded between the ages of 41 and above years of respondents. So, it means that in this study, most of the participants were young and had work experience in companies.
Table 5.2.
Difference of Age of Respondents’.
| Frequency | Percent | Valid Percent | Cumulative Percent | ||
|---|---|---|---|---|---|
| Valid | 20–25 years | 61 | 18.4 | 18.4 | 18.4 |
| 26–30 years | 117 | 35.3 | 35.3 | 53.8 | |
| 31–35 years | 102 | 30.8 | 30.8 | 84.6 | |
| 36–40 years | 27 | 8.2 | 8.2 | 92.7 | |
| 41 and above years | 24 | 7.3 | 7.3 | 100.0 | |
| Total | 331 | 100.0 | 100.0 | ||
5.3. Difference Based on Education Level
Table 5.3 results elaborated on the education level of the participants. Most of the respondents were master’s degrees 166 (50.2%), 107 (32.3%) M.Phil./MS, 7 (2.1%), and 55 (22.6%) were bachelor degree. It means that the lowest rate of responses comes from Bachelor’s degree participants and higher responses recorded from master’s degree holders.
Table 5.3.
Difference based on Education Level.
| Frequency | Percent | Valid Percent | Cumulative Percent | ||
|---|---|---|---|---|---|
| Valid | BA | 51 | 15.4 | 15.4 | 15.4 |
| Master | 166 | 50.2 | 50.2 | 65.6 | |
| M.Phil./MS | 107 | 32.3 | 32.3 | 97.9 | |
| Ph.D./other | 7 | 2.1 | 2.1 | 100.0 | |
| Total | 331 | 100.0 | 100.0 | ||
5.4. Difference Based on Working Experience
Table 5.4 explains that 17 respondents were 1–5 years of experience, 158 were 6 to 10 years of experience, 90 were 11 to 15 years of experience, 55 were 16 to 20 years of experience, and 11 were 21 years of experience. Maximum respondents have experienced between 6–10 years.
Table 5.4.
Difference Based on Experience.
| Frequency | Percent | Valid Percent | Cumulative Percent | ||
|---|---|---|---|---|---|
| Valid | 1–5 years | 17 | 5.1 | 5.1 | 5.1 |
| 6–10 years | 158 | 47.7 | 47.7 | 52.9 | |
| 11–15 years | 90 | 27.2 | 27.2 | 80.1 | |
| 16–20 years | 55 | 16.6 | 16.6 | 96.7 | |
| 21 and above years | 11 | 3.3 | 3.3 | 100.0 | |
| Total | 331 | 100.0 | 100.0 | ||
5.5. Difference Based on Designation
Table 5.5 shows overall, 8 CEO, 75 directors, 93 HR managers, 100 operational managers and 55 finance managers gave their feedback for the current study. Overall, the operational managers response rate was higher than the other respondents.
Table 5.5.
Difference based on Designation.
| Frequency | Percent | Valid Percent | Cumulative Percent | ||
|---|---|---|---|---|---|
| Valid | CEO | 8 | 2.4 | 2.4 | 2.4 |
| Director | 75 | 22.7 | 22.7 | 25.1 | |
| HR manager | 93 | 28.1 | 28.1 | 53.2 | |
| Operational Manager | 100 | 30.2 | 30.2 | 83.4 | |
| Finance Manager | 55 | 16.6 | 16.6 | 100.0 | |
| Total | 331 | 100.0 | 100.0 | ||
5.6. Difference Based on Provinces
Table 4.5 clearly shows that Sindh (30.8 %), Punjab (41.1%), Baluchistan (6.6%), Khyber Pakhtunkhwa (43%), and 8.5% responses were recorded from Kashmir and Gilgit Baltistan, respectively. Maximum responses were received from Punjab and minimum from Baluchistan.
Table 5.6.
Difference based on Provinces Level.
| Frequency | Percent | Valid Percent | Cumulative Percent | ||
|---|---|---|---|---|---|
| Valid | Sindh | 102 | 30.8 | 30.8 | 30.8 |
| Punjab | 136 | 41.1 | 41.1 | 71.9 | |
| Baluchistan | 22 | 6.6 | 6.6 | 78.5 | |
| Khyber Pakhtunkhwa | 43 | 13.0 | 13.0 | 91.5 | |
| Kashmir/Gilgit Baltistan | 28 | 8.5 | 8.5 | 100.0 | |
| Total | 331 | 100.0 | 100.0 | ||
Table 5.7 illustrates that the KMO value is 0.956 and thus, explains that factor analysis can be carried out for underlying structure detection of all the variables. The statistically significant χ2 (df. = 465, N = 245) = 11916.269, p < 0.001 suggests the appropriateness of using factor analysis.
Table 5.7.
KMO and Bartlett’s Test.
| Kaiser-Meyer-Olkin Measure of Sampling Adequacy. | 0.956 | |
|---|---|---|
| Bartlett’s Test of Sphericity | Approx. Chi-Square | 11,916.269 |
| Df | 465 | |
| Sig. | 0.000 | |
The variables that are part of the study have factor loading above 0.60, and reliability values are also satisfactory, according to threshold values > 0.70). All variables whose factor loadings are above 0.60 were included in the table, and those with values less than 0.60 were excluded from the list.
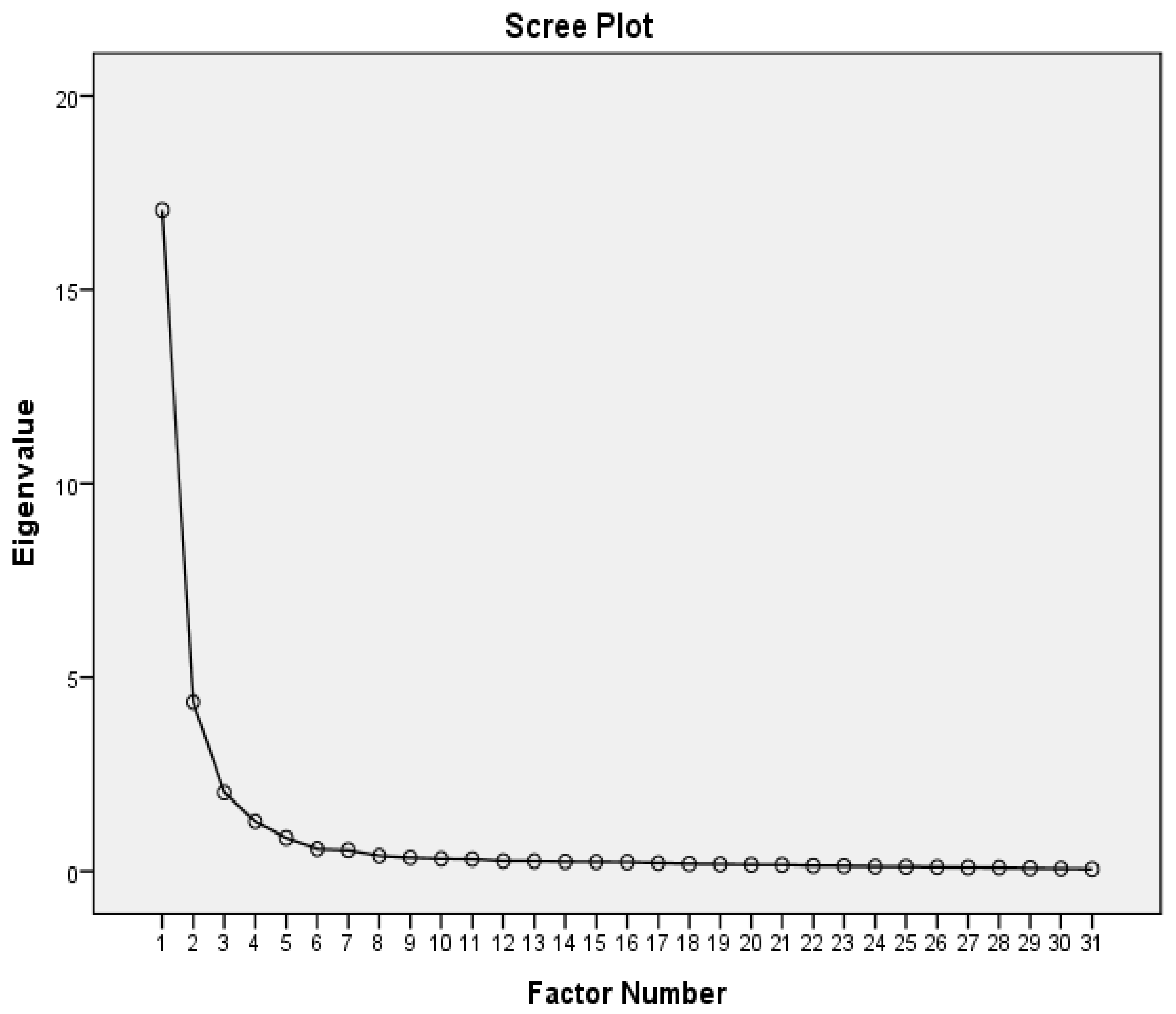
Table 5.8 shows that the Eigen value for factors 1; factor 2, factor 3, and factor 4 are 17.054, 4.352, and 1.278. The percentage of variance for factors 1, 2, 3, and 4 are 53.538, 66.453, 72.487, and 76.827. Although the Eigenvalue explained by four factors is greater than one is just 76.827.
Table 5.8.
Total Variance Explained.
| Factor | Initial Eigenvalues | Extraction Sums of Squared Loadings | Rotation Sums of Squared Loadings | ||||
|---|---|---|---|---|---|---|---|
| Total | % of Variance | Cumulative % | Total | % of Variance | Cumulative % | Total | |
| 1 | 17.054 | 55.013 | 55.013 | 16.597 | 53.538 | 53.538 | 13.233 |
| 2 | 4.352 | 14.037 | 69.050 | 4.004 | 12.915 | 66.453 | 9.813 |
| 3 | 2.020 | 6.516 | 75.566 | 1.871 | 6.034 | 72.487 | 13.596 |
| 4 | 1.278 | 4.123 | 79.689 | 1.345 | 4.340 | 76.827 | 12.591 |
| 5 | 0.848 | 2.737 | 82.426 | ||||
| 6 | 0.566 | 1.826 | 84.253 | ||||
| 7 | 0.535 | 1.726 | 85.978 | ||||
| 8 | 0.390 | 1.259 | 87.237 | ||||
| 9 | 0.343 | 1.108 | 88.345 | ||||
| 10 | 0.314 | 1.012 | 89.358 | ||||
| 11 | 0.305 | 0.984 | 90.342 | ||||
| 12 | 0.258 | 0.833 | 91.175 | ||||
| 13 | 0.253 | 0.817 | 91.992 | ||||
| 14 | 0.237 | 0.763 | 92.755 | ||||
| 15 | 0.229 | 0.739 | 93.494 | ||||
| 16 | 0.225 | 0.725 | 94.219 | ||||
| 17 | 0.200 | 0.646 | 94.865 | ||||
| 18 | 0.180 | 0.581 | 95.446 | ||||
| 19 | 0.170 | 0.548 | 95.994 | ||||
| 20 | 0.161 | 0.520 | 96.514 | ||||
| 21 | 0.156 | 0.504 | 97.018 | ||||
| 22 | 0.134 | 0.434 | 97.452 | ||||
| 23 | 0.128 | 0.414 | 97.866 | ||||
| 24 | 0.111 | 0.359 | 98.225 | ||||
| 25 | 0.106 | 0.342 | 98.567 | ||||
| 26 | 0.099 | 0.320 | 98.887 | ||||
| 27 | 0.088 | 0.285 | 99.172 | ||||
| 28 | 0.084 | 0.271 | 99.444 | ||||
| 29 | 0.068 | 0.219 | 99.663 | ||||
| 30 | 0.060 | 0.193 | 99.856 | ||||
| 31 | 0.045 | 0.144 | 100.000 | ||||
Figure 5.1 shows that the screw plot explains four factors identified for the complete questionnaire of big data analytics, competitive strategies, big data culture, and strategic alliance performance.
Figure 5.1.
Screw plot for the questionnaire.
5.7. Regression Analysis
Regression analysis shows how much change brings by independent variables.
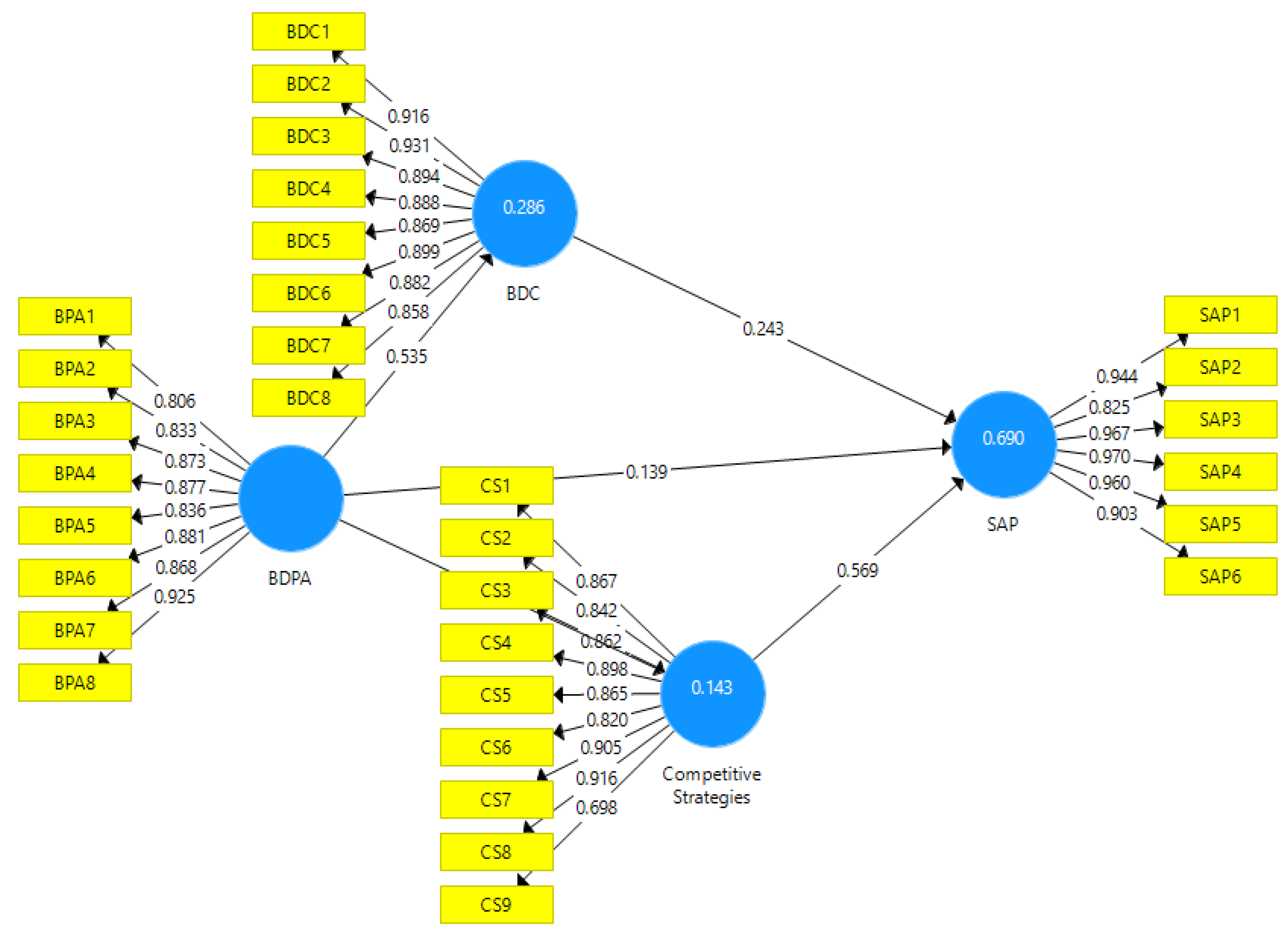
Table 5.11 shows that big data predictive analytics brings a change of 70% in strategic alliance performance. On the other hand, big data culture and competitive strategies change 28.6% and 14% in strategic alliance performance.
Table 5.10.
Regression Analysis Summary.
| R Square | R Square Adjusted | |
|---|---|---|
| BDC | 0.286 | 0.284 |
| Competitive Strategies | 0.143 | 0.144 |
| SAP | 0.690 | 0.687 |
Table 5.11 shows the discriminant validity based on Hetero-trait/Mono-trait (HTMT) Test of the model where the squared correlations were compared with the correlations from other latent constructs. Table 5.11 shows that all correlations were smaller relative to the squared root of average variance exerted along the diagonals, implying satisfactory discriminant validity. This proved that every construct’s observed variables indicated the given latent variable confirming the model’s discriminant validity. The inter-correlation among the variables explains a strong relationship between the variables; if the relationship and the variables are higher and significant. It explains the relatively same content. On the other hand, if the two factors’ inter-correlation is low, it explains two different content (Gordon, 2002).
Table 5.11.
Discriminant Validity based on Hetero-trait/Mono-trait (HTMT).
| BDC | BDPA | Competitive Strategies | SAP | |
|---|---|---|---|---|
| BDC | 0.892 | |||
| BDPA | 0.535 | 0.863 | ||
| Competitive Strategies | 0.696 | 0.378 | 0.855 | |
| SAP | 0.713 | 0.484 | 0.790 | 0.929 |
BDC, big data culture; BDPA, big data predictive analytics; CS, competitive strategies; SAP, strategic alliance performance.
In H1, we predicted that the big data culture factor would significantly influence strategic alliance performance. As predicted, the findings in Table 5.12 and Figure 5.2 confirmed that big data predictive analytics-related factors significantly influence strategic alliance performance (β = 0.053, T = 2.627, p < 0.000). Hence, H1 was robustly supported. Furthermore, observing the direct and positive influence of the big data predictive analytics on competitive strategies (H2), the findings from Table 5.12 and Figure 5.4 endorsed that the big data predictive analytics positively influenced competitive strategies (β = 0.058, T = 6.567, p < 0.000), and confirmed H2.
Figure 5.2.
Bootstrapping analysis.
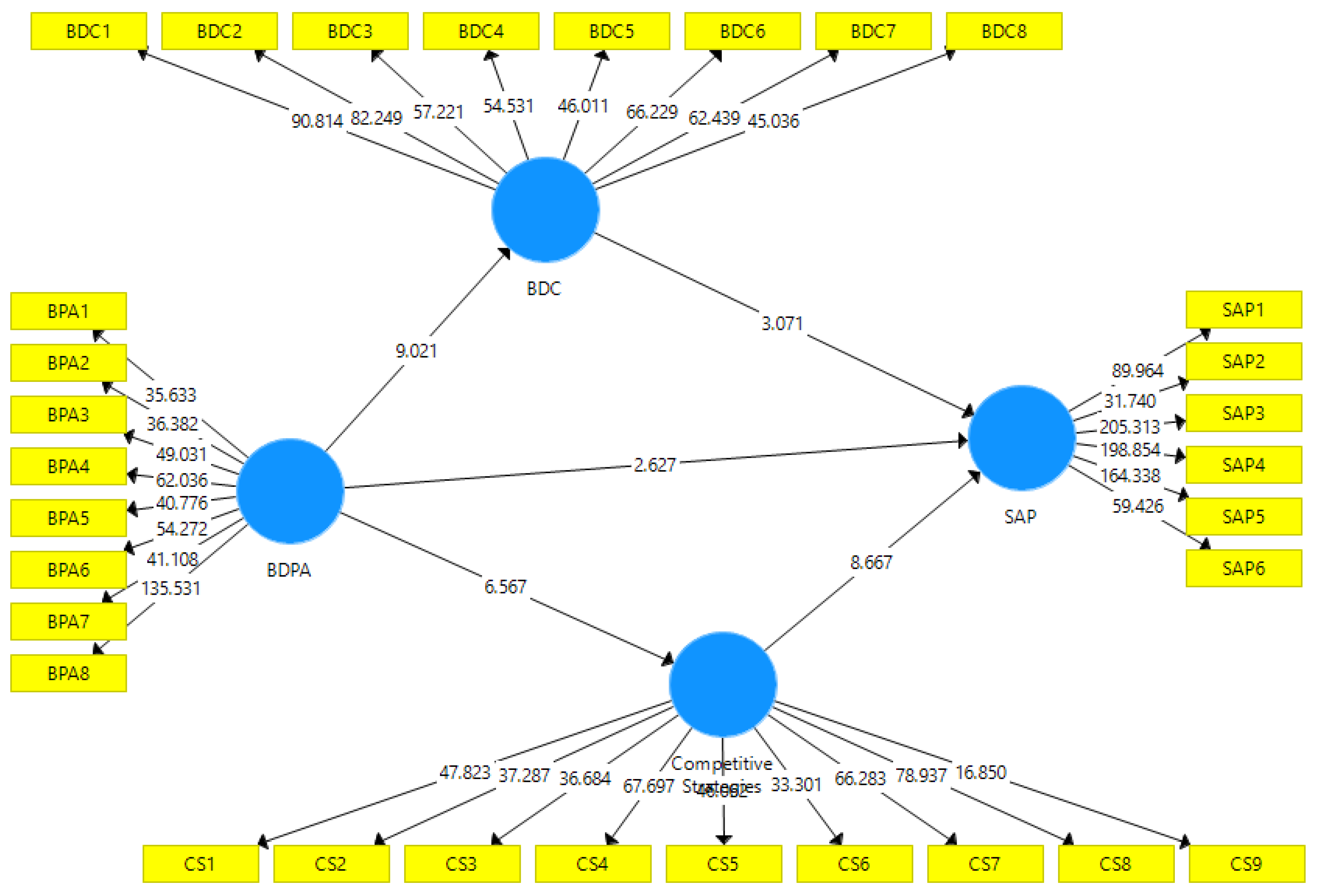
The big data culture’s influence on strategic alliance performance was positive and significant (β = 0.079, T = 3.071, p < 0.000), showing that H3 was supported.
The effect of competitive strategies on strategic alliance performance was significant (β = 0.066, T = 8.667, p < 0.000), therefore supporting H4. Similarly, the findings in Table 5.12 provided empirical support for H5, where big data predictive analytics has a positive and significant effect on big data culture. They significantly affected of the BDPA on big data culture (β = 0.079, T = 3.071, p < 0.000), confirming the hypothesis (H5).
Based on the result, we can conclude that all two mediations are significant at t-values > 1.96 and p-value < 0.05.
Table 5.12.
Path Coefficients and T-Statistics.
| Standard Deviation (STDEV) | T Statistics (|O/STDEV|) | p Values | Decision | |
|---|---|---|---|---|
| Big data Predictive Analytics -> Strategic Alliance Performance | 0.053 | 2.627 | 0.001 | H1 Accepted |
| Big data Predictive Analytics -> Competitive Strategies | 0.058 | 6.567 | 0.000 | H2 Accepted |
| Big data Culture -> Strategic Alliance Performance | 0.079 | 3.071 | 0.002 | H3 Accepted |
| Competitive Strategies -> Strategic Alliance Performance | 0.066 | 8.667 | 0.000 | H4 Accepted |
| Big data Predictive Analytics -> Big data Culture | 0.079 | 3.071 | 0.002 | H5 Accepted |
5.8. Mediation Test
The bootstrapping analysis has shown that all two indirect effects, β = 0.045, β = 0.043, and β = 0.136, are significant with t-values of 2.879 and 4.957. The indirect effects 95% Boot CI Bias Corrected: [LL = 0.249, UL = 0.440], and [LL = 0.074, UL = 0.334], do not straddle a 0 in between indicating there is mediation (Preacher and Hayes, 2004, 2008). Thus, we can conclude that mediation effects are statistically significant. The results of the mediation analysis are presented in Table 5.13.
Table 5.13 explains that a big data culture mediates big data predictive analytics and strategic alliance performance. Similarly, big data predictive and strategic alliance performance is positively and significantly mediated by competitive strategies.
Table 5.13.
Hypothesis Testing on Mediation.
| Standard Deviation (STDEV) | T Statistics (|O/STDEV|) | Confidence Interval LL UL |
p Values | Decision | |
|---|---|---|---|---|---|
| BDPA -> BDC -> SAP | 0.045 | 2.879 | 0.249 | 0.004 | H6. Supported |
| BDPA -> Competitive Strategies -> SAP | 0.043 | 4.957 | 0.074 | 0.000 | H7. Supported |
5.9. Goodness-of-Fit
Goodness-of-Fit (GOF) is applied as an index for the complete model fit to verify that the model sufficiently explains the empirical data. The GOF values lie between 0 and 1, where values of 0.10 (small), 0.25 (medium), and 0.36 (large) indicate the global validation of the path model. A good model fit shows that a model is parsimonious and plausible. The GOF is calculated by using the geometric mean value of the average communality (AVE values) and the average R2 value(s) and the equation for GOF index (1).
GOF = (Average R2 * Average communality) 1/2
It was calculated from Table 5.14 that the GOF index for this study model was measured as 0.745, which shows that empirical data fits the model satisfactory and has substantial predictive power in comparison with baseline values.
Table 5.14.
Goodness-of-Fit index calculation.
| Construct | AVE | R2 |
|---|---|---|
| Big data related construct | 0.796 | |
| Big data predictive related construct | 0.745 | |
| Competitive Strategies related construct | 0.731 | |
| Strategic Alliance related construct | 0.864 | |
| Average Values | 3.136 | 0.71 |
| AVE × R2 | 0.556 | 0.71 |
| GOF = (AVE × R2).5 | 0.745 |
Figure 5.3.
Figure Showing Correlation among study Variables.
6. Conclusion, Implications and Limitations of the Study
6.1. Conclusion
This research study focuses on exploring different issues related to forming strategic alliances within the big data environment, emphasizing different gaps and identifying the significance of strategic alliances in the big data environment. Moreover, this research study explores the implications for organizations to achieve a competitive advantage in the big data environment. The research aims to expand the exploration of companies’ cooperation and identify the challenges that may hinder gaining competitive advantage through strategic alliances in a big data environment. Emphasizing the approaches for gaining competitive advantage will help select strategic partners, specifically in a big data environment. That is one of the important aspects of achieving the full success of an alliance and exploring and identifying the implications associated with strategic alliance formation and implications related to achieving competitive advantage. This research study will also contribute to the advancement of knowledge by discussing cases of different organizations involved in strategic alliances in a big data environment to identify the approaches for creating better approaches for the formation of effective partnership. The study’s research objective was addressed by integrating diverse findings, critically analyzing the findings, and advancing the existing knowledge base with meaningful findings. To explore diverse dimensions of motives for strategic alliances in a big data environment concerning different variables of the study.
There are several strategic alliance challenges according to the big data environment, which should be minimized for the organization’s better performance. In Pakistan’s context, challenges faced by the different organizations in alliance with other companies. big data predictive analytics, competitive strategies, and big data culture are important variables for developing strategic alliance performance in Pakistan manufacturing and services companies.
6.2. Implications and Limitations of the Study
Integration into a single theoretical framework promises valuable opportunities for a multidisciplinary approach and such a way to better understand the performance process of strategic alliances.
In this sense, the first advantage that It is observed that research on the performance of associations will overcome the tendency to focus partially on only a few factors and that, besides, may benefit from an interdisciplinary theoretical framework to include in its content a series of constructs according to the precepts of the disciplines of organizational, economic, strategic and sociological behavior. The second advantage is that the results of the revision methodology. This study’s systematic nature will allow replication and generalization to other researchers in other contexts and may be used to produce reasonable predictions of future events regarding the empirical results obtained in this exploration. The proposed theoretical model describes the reality of the subjects of study since the propositions derived from the principles of the theory of resources and capabilities and corporate governance seem to have enough power to explain with greater precision and sufficiency the performance of strategic alliances.
First, it shows the utility for managers of the symbiotic connection between the company and the collaboration agreement and that both require an evaluation in parallel to achieve success. Both figures contribute to the success of the collaboration agreement. Besides, the sum of the resources and capacities of the two actors of the association (partners and alliance) and social networks of both constitute an advantage competition and, therefore, of opportunities for success for the strategic alliance. The partners’ commitment to the management of the strategic alliances and effective data governance aim is to improve the association’s results.
Also, interest in learning associations in different strategic options suggests an effective update of knowledge and its possible impact on the association’s performance. Besides, the results indicate that the performance of strategic alliances has a very important starting point, which is the definition of common objectives and strategies; the use of resources, capacities that allow them to achieve those objectives and strategies; and confronting different joint risks that must be solved so that the evolutionary cycle continues its march towards the best possible performance.
Some extensions could be beneficial to investigate and better understand this phenomenon. Some suggestions for studying and comparing the results on determinants of the success of the alliances could be the following: economic sectors where they participate, types of alliances, sizes, and many companies that make up the alliances, domestic and international geographic sectors where they are present and nature of the objectives for big data environment. Is it being convenient to point out the need to perform extrapolation work to other areas where it is considered that this model could be useful, for example, in non-profit associations or the application in social network structures?
This research also suggests that it is important for organizations to ally with data-providing organizations to focus on technical standards. This is a major source of competitive advantage for companies that have developed standards, and this is a comparative advantage compared to other companies (Demirkan et al. 2015).
Despite the contributions that this work-study has some limitations, which provides room for future research. Limitations are derived from applying the methodology. However, it is exhaustive in the bibliographic search. It is conceivable that some study is missing in the sample. Although these limitations are specific to the Meta-analysis, they should not be overlooked when interpreting the results.
The first limitation is that time and fund constraints data couldn’t get from the maximum responses.
Sample size of the study can be enlarged for future research. This is also a limitation of this research. In the future aspects data could be collected from the other sector for the analysis of the BDPA with other variables of the study. This study model can be included competitive strategies as a moderating variable.
- ANNEXURE A
- STUDY QUESTIONNAIRE
Welcome to this survey! in this questionnaire, you are asked to think about how big data predictive analytics, big data culture, competitive strategies affect the strategic alliance performance. There are two sections to this questionnaire. Please select those appropriate answers, which you think are best, in your opinion.
- Respondents’ Profile
- Gender: 1. Male 2. Female
- Age: 1. 20–25 years 2. 26–30 years, 3. 31–35 years, 4. 36–40 years and 5. 41 and above years.
- Qualification. 1. Bachelor 2. Master 3. M.Phil/MS. 4. PhD/other _____.
- Job Experience; 1. 1–5 yrs 2. 6–10 years 3. 11–15 years 4.16–20 years and 5. 21 and above years
- Designation: 1. CEO 2. HR Manager 3. Director 4. Operational manger 5. Finance Manager
- Province: 1. Sindh 2. Punjab 3. Baluchistan 4. KPK 5. Kashmir/Gilgit Baltistan
- Note. How far Do You Agree or Disagree with the Following Statements using the below-given 5-Point Scale of Preferences?
| Strongly Disagree | Disagree | Neutral | Agree | Strongly Agree |
| 1 | 2 | 3 | 4 | 5 |
| Big data Predictive Analytics | ||||||
| 1 | The infrastructure of the data is sufficient for organizational performance. | |||||
| 2 | BDPA helps the organization for further polishing the Intangible resources. | |||||
| 3 | It helps in the promotion of the product and its brand in the market. | |||||
| 4 | Big data predictive analytics helps in the development of managerial skills of the partners | |||||
| 5 | Big data predictive analytics promote data analytics knowledge practices | |||||
| 6 | Big data predictive analytics helps in the development of human skills at the companies’ level | |||||
| 7 | Big data predictive analytics provides the methodology in tapping intelligence from large data sets | |||||
| 8 | Big data predictive analytics predict the future progress of a company | |||||
| Big Data Culture | ||||||
| 9 | We consider data a tangible asset. | |||||
| 10 | Big data culture bases our decisions on data rather than on instinct. | |||||
| 11 | We are willing to override our intuition when data contradict our viewpoints | |||||
| 12 | We continuously assess and improve the business rules in response to insights extracted from data | |||||
| 13 | We continuously coach our employees to make decisions based on data | |||||
| 14 | We think that BDC helps in the cultural promotion of learning | |||||
| 15 | The big decision is made based on a big data culture climate in the organization | |||||
| 16 | Big data culture promotes a monitoring system of strategic alliance in the organization | |||||
| Competitive Strategies | ||||||
| 17 | In an alliance, the Company set its product cost slightly lower than other companies’ products. | |||||
| 18 | The companies concentrate on the provision of unique product different from its competitors. | |||||
| 19 | The companies differentiate their products/services on the customer value proposition. | |||||
| 20 | The company offers a wide range of differentiated products than its competitors. | |||||
| 21 | The company offers a wide range of differentiated supplementary services than its competitors, such as sports centers, new internet services, and the art library state. | |||||
| 22 | In Strategic alliance companies, research and development capabilities enhanced as a competitive advantage | |||||
| 23 | The company is committed to ensuring high discipline but freedom and responsibility. | |||||
| 24 | The company’s unique services with more effective equipment maintenance and replacement policies. | |||||
| 25 | The company offers unique services and maintains competitive pricing in strategic alliances. | |||||
| Strategic Alliance Performance | ||||||
| 26 | Strategic Alliance is more important for the Economic Performance of the company. | |||||
| 27 | Strategic Alliance is important for introducing new products or services into the market faster than our competitors | |||||
| 28 | Our success rate of new products or services has been higher than our competitor | |||||
| 29 | Our productivity has exceeded that of our competitors | |||||
| 30 | Strategic Alliance able to search for new and relevant knowledge | |||||
| 31 | Strategic Alliance is more important for the Economic Performance of the company. | |||||
References
- Akter, S.; Wamba, S.F. Big data analytics in E-commerce: A systematic review and agenda for future research. Electron. Mark. 2016, 26, 173–194. [Google Scholar] [CrossRef]
- Angrave, D.; Charlwood, A.; Kirkpatrick, I.; Lawrence, M.; Stuart, M. HR and analytics: Why HR is set to fail the big data challenge. Hum. Resour. Manag. J. 2016, 26, 1–11. [Google Scholar] [CrossRef]
- Aydiner, A.S.; Tatoglu, E.; Bayraktar, E.; Zaim, S.; Delen, D. Business analytics and firm performance: The mediating role of business process performance. J. Bus. Res. 2019, 96, 228–237. [Google Scholar] [CrossRef]
- Barney, J. Firm resources and sustained competitive advantage. J. Manag. 1991, 17, 99–120. [Google Scholar] [CrossRef]
- Barton, D.; Court, D. Making advanced analytics work for you. Harv. Bus. Rev. 2012, 90, 78–83. [Google Scholar]
- Braganza, A.; Brooks, L.; Nepelski, D.; Ali, M.; Moro, R. Resource management in big data initiatives: Processes and dynamic capabilities. J. Bus. Res. 2017, 70, 328–337. [Google Scholar] [CrossRef]
- Brouthers, K.D.; Nakos, G.; Dimitratos, P. SME entrepreneurial orientation, international performance, and the moderating role of strategic alliances. Entrep. Theory Pract. 2015, 39, 1161–1187. [Google Scholar] [CrossRef]
- Brown, B.; Chui, M.; Manyika, J. Are You Ready for the Era of “Big Data”? Report; McKinsey Global Institute: San Francisco, CA, USA, 2011. [Google Scholar]
- Burgoon, J.K.; Stern, L.A.; Dillman, L. Adaptation: Dyadic Interaction Patterns; Cambridge University Press, 2007. [Google Scholar]
- Burns, R. Rethinking big data in digital humanitarianism: Practices, epistemologies, and social relations. GeoJournal 2015, 80, 477–490. [Google Scholar] [CrossRef]
- Chen, D.Q.; Preston, D.S.; Swink, M. How the use of big data analytics affects value creation in supply chain management. J. Manag. Inf. Syst. 2015, 32, 4–39. [Google Scholar] [CrossRef]
- Chen, H.; Chiang, R.H.; Storey, V.C. Business intelligence and analytics: From big data to big impact. MIS Q. 2012, 1165–1188. [Google Scholar] [CrossRef]
- Chen, M.; Mao, S.; Liu, Y. Big data: A survey. Mob. Netw. Appl. 2014, 19, 171–209. [Google Scholar] [CrossRef]
- Christmann, A.; Van Aelst, S. Robust estimation of Cronbach’s alpha. J. Multivar. Anal. 2006, 97, 1660–1674. [Google Scholar] [CrossRef]
- Côrte-Real, N.; Oliveira, T.; Ruivo, P. Assessing business value of Big Data Analytics in European firms. J. Bus. Res. 2017, 70, 379–390. [Google Scholar] [CrossRef]
- Davenport, T. Big Data at Work: Dispelling the Myths, Uncovering the Opportunities; Harvard Business Review Press, 2014. [Google Scholar]
- Davenport, T.H.; Harris, J.G.; Jones, G.L.; Lemon, K.N.; Norton, D.; McCallister, M.B. The dark side of customer analytics. Harv. Bus. Rev. 2007, 85, 37. [Google Scholar]
- DiMaggio, P.J.; Powell, W.W. The iron cage revisited: Institutional isomorphism and collective rationality in organizational fields. Am. Sociol. Rev. 1983, 147–160. [Google Scholar] [CrossRef]
- Erevelles, S.; Fukawa, N.; Swayne, L. Big Data consumer analytics and the transformation of marketing. J. Bus. Res. 2016, 69, 897–904. [Google Scholar] [CrossRef]
- Fatehi, K.; Choi, J. International strategic alliance. In International Business Management; Springer, 2019; pp. 217–239. [Google Scholar]
- Feldman, M.P. The character of innovative places: Entrepreneurial strategy, economic development, and prosperity. Small Bus. Econ. 2014, 43, 9–20. [Google Scholar] [CrossRef]
- Galbreath, J. Strategy in a world of sustainability: A developmental framework. In Handbook of Corporate Sustainability: Frameworks, Strategies and Tools; 2011; pp. 37–56. [Google Scholar]
- Gale, J.; Abraham, D. Introduction: Toward understanding e-business transformation. J. Organ. Chang. Manag. 2005. [Google Scholar] [CrossRef]
- Gandomi, A.; Haider, M. Beyond the hype: Big data concepts, methods, and analytics. Int. J. Inf. Manag. 2015, 35, 137–144. [Google Scholar] [CrossRef]
- Gobble, M.M. Big data: The next big thing in innovation. Res. -Technol. Manag. 2013, 56, 64–67. [Google Scholar] [CrossRef]
- Goncalves, F.R.; da Conceição, V.G. Strategic alliances and competitive performance in the pharmaceutical industry. J. Med. Mark. 2008, 8, 69–76. [Google Scholar] [CrossRef]
- Gordon, S. Pattern recognition receptors: Doubling up for the innate immune response. Cell 2002, 111, 927–930. [Google Scholar] [CrossRef] [PubMed]
- Grant, R.M. The resource-based theory of competitive advantage: Implications for strategy formulation. Calif. Manag. Rev. 1991, 33, 114–135. [Google Scholar] [CrossRef]
- Herman, J.P.; Ostrander, M.M.; Mueller, N.K.; Figueiredo, H. Limbic system mechanisms of stress regulation: Hypothalamo-pituitary-adrenocortical axis. Prog. Neuro-Psychopharmacol. Biol. Psychiatry 2005, 29, 1201–1213. [Google Scholar] [CrossRef]
- Herrmann, P. Evolution of strategic management: The need for new dominant designs. Int. J. Manag. Rev. 2005, 7, 111–130. [Google Scholar] [CrossRef]
- Hu, H.; Wen, Y.; Chua, T.-S.; Li, X. Toward scalable systems for big data analytics: A technology tutorial. IEEE Access 2014, 2, 652–687. [Google Scholar] [CrossRef]
- Hu, L. t.; Bentler, P.M. Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Struct. Equ. Model. A Multidiscip. J. 1999, 6, 1–55. [Google Scholar] [CrossRef]
- Kitchin, R. Big Data, new epistemologies and paradigm shifts. Big Data Soc. 2014, 1, 2053951714528481. [Google Scholar] [CrossRef]
- Kitchin, R. The Data Revolution: Big Data, Open Data, Data Infrastructures and Their Consequences; Sage, 2014. [Google Scholar]
- Malomo, F.; Sena, V. Data intelligence for local government? Assessing the benefits and barriers to use of big data in the public sector. Policy Internet 2017, 9, 7–27. [Google Scholar] [CrossRef]
- Marr, B. Big Data: Using SMART Big Data, Analytics and Metrics to Make Better Decisions and Improve Performance; John Wiley & Sons, 2015. [Google Scholar]
- Matthias, O.; Fouweather, I.; Gregory, I.; Vernon, A. Making sense of big data–can it transform operations management? Int. J. Oper. Prod. Manag. 2017. [Google Scholar] [CrossRef]
- Mayer-Schönberger, V.; Cukier, K. Big Data: A Revolution That Will Transform How We Live, Work, and Think; Houghton Mifflin Harcourt, 2013. [Google Scholar]
- McAfee, A.; Brynjolfsson, E.; Davenport, T.H.; Patil, D.; Barton, D. Big data: The management revolution. Harv. Bus. Rev. 2012, 90, 60–68. [Google Scholar]
- Mishra, D.; Gunasekaran, A.; Papadopoulos, T.; Childe, S.J. Big Data and supply chain management: A review and bibliometric analysis. Ann. Oper. Res. 2018, 270, 313–336. [Google Scholar] [CrossRef]
- Ohlhorst, F.J. Big Data Analytics: Turning Big Data into Big Money; John Wiley & Sons, 2012; Volume 65. [Google Scholar]
- Oliver, C. Strategic responses to institutional processes. Acad. Manag. Rev. 1991, 16, 145–179. [Google Scholar] [CrossRef]
- Porter, M.E.P.M. Competition in Global Industries; Harvard Business Press, 1986. [Google Scholar]
- Reed, D.A.; Dongarra, J. Exascale computing and big data. Commun. ACM 2015, 58, 56–68. [Google Scholar] [CrossRef]
- Riggins, F.J.; Wamba, S.F. Research directions on the adoption, usage, and impact of the internet of things through the use of big data analytics. Presented at the 2015 48th Hawaii International Conference on System Sciences, 2015. [CrossRef]
- Roh, T.H.; Ahn, C.K.; Han, I. The priority factor model for customer relationship management system success. Expert Syst. Appl. 2005, 28, 641–654. [Google Scholar] [CrossRef]
- Schuler, R.S.; Jackson, S.E. Linking competitive strategies with human resource management practices. Acad. Manag. Perspect. 1987, 1, 207–219. [Google Scholar] [CrossRef]
- Stephens-Davidowitz, S.; Pinker, S. Everybody Lies: Big Data. New Data, and; 2017. [Google Scholar]
- Storey, V.C.; Song, I.-Y. Big data technologies and management: What conceptual modeling can do. Data Knowl. Eng. 2017, 108, 50–67. [Google Scholar] [CrossRef]
- Tarofder, A.K.; Marthandan, G.; Mohan, A.V.; Tarofder, P. Web technology in supply chain: An empirical investigation. Bus. Process Manag. J. 2013. [Google Scholar] [CrossRef]
- Tatoglu, E.; Glaister, A.J.; Demirbag, M. Talent management motives and practices in an emerging market: A comparison between MNEs and local firms. J. World Bus. 2016, 51, 278–293. [Google Scholar] [CrossRef]
- Verhoef, P.; Kooge, E.; Walk, N. Creating Value with Big Data Analytics: Making Smarter Marketing Decisions; Routledge, 2016. [Google Scholar]
- Waller, W.A.; Fawcett, S.E. Data science, predictive analytics, and big data: A revolution that will transform supply chain design and management. In Wiley Online Library; 2013. [Google Scholar]
- Wamba, S.F.; Akter, S.; Edwards, A.; Chopin, G.; Gnanzou, D. How ‘big data’can make big impact: Findings from a systematic review and a longitudinal case study. Int. J. Prod. Econ. 2015, 165, 234–246. [Google Scholar] [CrossRef]
- Zhang, L.H.; Dong, Y.H. Quorum sensing and signal interference: Diverse implications. Mol. Microbiol. 2004, 53, 1563–1571. [Google Scholar] [CrossRef] [PubMed]
- Zheng, D.; Chen, J.; Huang, L.; Zhang, C. E-government adoption in public administration organizations: Integrating institutional theory perspective and resource-based view. Eur. J. Inf. Syst. 2013, 22, 221–234. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



