
Submitted:
21 April 2023
Posted:
23 April 2023
You are already at the latest version
Abstract
Next Generation IoT systems will allow sustainable performance in long-term monitoring systems. This sustainability concept is applicable to soundscape description, as it allows monitoring in urban environments. In this work, the implementation of psycho-acoustic annoyance models in a 5G-enabled IoT system is proposed applying two Edge Computing approaches. A modified Zwicker’s model is adopted in this research, introducing a term that takes into account the tonal component of the captured sound. These implementations have been validated in a measurement campaign where several IoT devices have been deployed to evaluate different sound environments of a University Campus. Then, the analysis of the sound quality metrics is done in different location showing that if tonality is present in a noisy environment, it results in greater subjective annoyance. Moreover, the Just Noticeable Difference of these results are derived for the Zwicker’s psycho-acoustic annoyance to establish a limitation for this metric.
Keywords:
5G-enabled IoT
; Sound Quality Metrics
; Psycho-acoustic Annoyance
; JND
1. Introduction
The concept of Soundscape inside the Smart City has taken a main role in the urban environment. According to ISO 12913-1:2014, it is referred as the "acoustic environment as perceived or experienced and/or understood by a person or people, in context" [1,2]. In this way, soundscape means a paradigm change from noise control policies towards a new multidisciplinary approach as it involves not only physical measurements, but also subjective assessment coming from humans and social sciences which establish the focus on how people actually experience an acoustic environment in context [3]. The taxonomy of sounds in the soundscape description, which is defined in ISO 12913-2:2018 [2], can be highly advantageous when implementing deep learning methods for automatic sound classification, as stated in a study by Lopez et al. [4].
Several authors have taken different perspectives on soundscape monitoring and psycho-acoustic annoyance, as evidenced by studies by Mont et al. [5], Castrillon et al. [6], and Yang et al. [7]. These studies have explored the use of various parameters based on psycho-acoustic models, with a focus on Loudness [8], denoted as L, as the most relevant parameter. Other parameters such as Sharpness, Roughness, and Fluctuation Strength [9,10], denoted as S, R and F respectively, have also been considered. Moreover, in [11], authors offered a thoughtful study of different researches using psycho-acoustic metrics. More recently, alternative variations of the equivalent sound pressure level [12,13,14] have been proposed to describe the soundscape in different environments.
In the traditional vision, the soundscape description is focused on measurements for mappings which are usually based on the Equivalent Sound Level (named ). However, is not enough for this description when evaluating subjective annoyance or pleasantness, since similar values for can lead to different feelings of the noise, perceived by different people, failing to provide information related to the environmental noise annoyance [15] and their psycho-acoustic properties. This is due to the information from regarding the frequency characteristics. In addition, there are many sources of noise with low levels of that produce an uncomfortable annoyance and even worse than the ones with high values of , for instance, an isolated tone from a mechanic vibration. To define metrics based on the human hearing system, different studies and techniques have been carried out and different methods have been defined in order to estimate the subjective annoyance (such as Zwicker’s [16] model or Moore’s [17] model). Nevertheless, all of them require high computational costs due to the complexity of the analysis and required signal processing.
In the case of the psycho-acoustic parameters, the subjective response produced by tonal sound is more annoying [18] and some authors proposed penalty parameters. In [19], the authors proposed a modification of the psycho-acoustic annoyance model by Zwicker’s in order to weigh the effect of tonal sounds in the subjective evaluation. The purpose in the current work is to modify the basic implementation established in [10] by adding the Tonality as a weighting parameter. Moreover, a validation of this advanced implementation is carried out by several measurement campaigns in different sound environments and comparing with results of the basic model, i.e. without Tonality.
This paper is organized as follows. After the introduction in which the motivation and aim of this work is presented, the methodology and materials used in the proposed system setup is described in Section 2, together with the Zwicker’s model and the modifications introduced in this work. In Section 3, the implementation of this advanced model is explained using two different approaches. Then, the use of these approaches in different environments is studied in Section 4, discussing the obtained results. Last section, concludes the study summarizing the discussion and focusing the main outputs.
2. Materials and Methods
The development of the algorithms involved in the Psycho-acoustic Annoyance (PA) model, based on the Zwicker’s model, was mainly focused in [10]. In this work, a modification of the basic implementation of this model is created, in order to introduce Tonality as a parameter, that can be involved with higher nuisance environments.
2.1. Zwicker’s model and Tonality
As previously mentioned, the Zwicker’s annoyance model [16] traditionally proposes the evaluation of four parameters (i.e. N, S, R and F) to determine the as a non-linear combination of the aforementioned parameters.
1) Loudness (N): This magnitude describes the perceptual value of perceived loudness by the human ear. It is measured in on a linear scale and represents the subjective loudness of a sound. It does not take into account any perceptual distinction between "pleasant" or "annoying" sounds. The calculation procedure is standardised in the DIN45631/A1 [20] or ISO 532-1:2017 [8] standards.
2) Sharpness (S): This metric assesses the level of unpleasant sensory perception that a sound produces in humans, and considers the high-frequency components of the sound. It is often viewed as a representation of the centre of the spectrum and is measured in on a linear scale. Standardization for this metric is provided by DIN 45692 [21].
In our implementation, it is used the method defined by Zwicker and Fastl which is the one on which the standard is based [10].
3) Roughness (R): This metric describes the perceived fluctuation of a sound even when L or remain unchanged. It analyses the effects with different degrees of frequency modulations (around 70 Hz) in each critical band (CB). The basic unit of R is . In our implementation, the model used for R is the one defined by Jourdes [22] based on the optimised model of Daniel [23].
4) Fluctuation Strength (F): Describes how strongly or weakly sounds fluctuate. It depends on the frequency and depth of loudness fluctuations, around 4 Hz in each equivalent rectangular bandwidth (ERB). It is measured in .
The traditional Zwicker’s model takes into account the S contribution as long as it is greater than 1.75 . Equations (1) describe the determination of psycho-acoustic annoyance according to this model. In case equation (1b) has a S lower than 1.75 , is 0. Also, in the case of N, it takes into account the contribution of the 5th percentile (), which indicates, after sorting the data from lowest to highest, the value of N below which the 5th percentile of loudness observations is found.
where
The modified Zwicker model, shown in [19], introduces a new term in the equation (1a) that takes into account the tonal component of the evaluated sounds. This term is seen in the equation (2a), where the term in the equation (2b) takes into account the tonality (T). This component extraction has been implemented using the Aures tonality model [24], from Terhardt’s algorithm [25] for the extraction of the pitch of complex tonal signals.
where
5) Tonality (T): According to [26], for the application of the Aures tonality model, after the spectrum analysis, the calculations are divided into two ways. One is the calculation based on the tonal components which involves the calculation of the excess sound pressure level (SPL) for each tonal component and its tonal weighting function, and the other is the calculation of the total loudness of the whole spectrum and the loudness of the noise spectrum, where noise spectrum means the spectrum that removes the tonal components or narrowband components. Finally, the tonal loudness weighting is obtained, and the tonal weighting is calculated for all components with positive SPL excess levels. It is important to note that the Aures tonality model considers the level of dependence of the human auditory system through N [27]. It also shows a way to extract a single value combining the tonal weighting and the tonal weighting of loudness.
2.2. Study of JNDs in sound quality metrics
Just Noticeable Difference (JND) is an important concept in psycho-acoustics. JNDs refer to the smallest change in a stimulus that a person can detect. This can be related to physical properties of sound such as loudness, pitch, and timbre, as well as more subjective qualities like attractiveness and emotion.
JNDs are important in understanding the way people perceive sound. They are used to measure how sensitive people are to changes in sound, which is valuable for applications such as designing audio equipment, creating soundtracks for movies, or understanding how different types of music affect people.
The magnitude of a JND is determined by several factors, including the intensity of the sound, the duration of the sound, and the context of the sound. For example, a small change in a sound may be much more noticeable when it is played at a higher volume or when it is in a noisy environment. JNDs can also be used to compare different people’s sensitivity to sound. People with lower JND are more sensitive to sound changes, while people with higher JND require greater sound changes in order to perceive differences. In this work, attending to the definition of JND provided by Ernst H. Weber [28], the JND is a statistical quantity, rather than an exact one. So, from trial to trial, the difference that a given person notices will vary somewhat, and it is, therefore necessary to conduct many trials in order to determine the threshold. For the purpose of this research, this statistical nature can be considered similar to the computation of a standard deviation, taking into account a reference sample instead of the mean value of the set of samples.
According to the study exposed in [29], the JNDs for the main psycho-acoustic metrics for a refrigerator are 0.5 for loudness (), 0.08 for sharpness (), 0.04 for roughness (), and 0.012 for fluctuation strength (). These values were obtained after doing auditory experiments which were designed to determine the difference between the reference and comparing with the stimulus in terms of each sound quality characteristic. The duration of each pair of experiments was 10.5 seconds (5.0 s reference stimuli + 0.5 s silence + 5.0 s comparison stimuli). They had 40 participants, between 20 and 35 years old and with normal hearing. The stimuli were presented with a headphone system in a semi-anechoic chamber.
As the Zwicker’s PA is a complex magnitude composed by all the previous metrics, we can get the JND by deriving the composed metric (in this case PA) and propagating the error with the related metrics, shown in equation (3), of the JNDs of the previous metrics within equation (1a).
Where the different partial derivatives are
According to equation (4) the JND of Zwicker’s psycho-acoustic annoyance depends on N, S, R and F, but the most complex value is N and it will have a major contribution to JND.
3. Architecture implementation
The methodology used in this work to design the system followed a double strategy: a) acquisition and sample of the sound signal, together with the computation of the psycho-acoustic metrics is performed in the Edge node of the network, and b) acquisition and sample of the sound signal in an external device, e.g. implementation in a Fipy node [30], and then transmission of the audio file to the Edge node through the Message Queuing Telemetry Transport (MQTT) protocol for the computation of the metrics.
The different algorithms of the psycho-acoustic metrics N, S, R, F and T have been implemented in Matlab, from [31,32]. Similarly, these algorithms have been integrated in Simulink models that allow their conversion to C/C++ code using the Matlab "coder" tool and their direct installation in Single Board Computer (SBC) type platforms. In our case, it has been integrated on a Raspberry Pi 4B+ with 4GB of RAM (RPi4). This platform acts as the Edge node of the system, which allows calculating the psycho-acoustic metrics from the recorded audios.
Figure 1 (considering Fipy with a microphone and sending the audio to the Edge) and Figure 2 (integrating the microphone in the Edge) show the Simulink schematic of the complete algorithm that determines the different psycho-acoustic metrics, as well as the modified psycho-acoustic annoyance [19], taking into account the two strategies explained in this section, both options have been implemented.
In Figure 1, the option with Fipy (MCU+modems) from Pycom, where an ESP32 MCU node with various wireless connectivity options (i.e. Wifi, BLE, Lora, Sigfox and LTE-M/NB-IoT) connected to an INMP441 MEMS microphone, samples audio, performs windowing and sends the audio to the Rpi4, which allows the calculation of the different metrics, is shown. Figure 2 shows the option in which the RPi4 itself, which acts as an Edge, has a USB microphone connected.
In both options, the output, which is an array with different metrics, is sent to an online Cloud. In this work, Thingspeak platform [33] is used, with MQTT protocol for data communication, because of its quick integration in Matlab.
3.1. Calibration procedure
The calibration is done using a file with sinusoidal tone at 1kHz in the scheme of Figure 1. The result of the loudness with this file is N 40 sones, measuring a sound pressure level of 40 dB (as it is stated in the definition of loudness). Also, the other parameters are fixed accordingly to its definition in the Matlab-generated code.
4. Results and discussion
4.1. Application of the system to compare models’ results
After the calibration procedure, the values of the psycho-acoustic parameter values of a pneumatic hammer from a digital recording1 were measured during 17 minutes. This sound source was rendered using a Behringer MS16 loudspeaker and sound was captured with the RPi4, sending values in the cloud every 1s.
The produced PA by this sound source has been calculated using both the basic Zwicker model, Eq. 1, and the modified model with tonality, Eq. 2. Figure 3 shows the values calculated with these two models (Zwicker’s PA and modified PA with tonality), showing that the appearance of tonal sounds in a noisy environment produces greater subjective annoyance. The calculation of the annoyance model with the tonality was launched, and it can be seen in this figure with increased values. It is also observed that this noise, although annoying at certain levels, is not very tonal so a large percentage of the measurements of the two models coincide.
4.2. Application of the system to a specific site: UCAM Campus
In the application of the proposed system to a real scenario, a set of Single Board Computers (SBC), in particular Raspberry Pi 4B+, was used to deploy a wireless acoustic sensor network across the campus of the Universidad Católica de Murcia (UCAM) located in Murcia, Spain. Figure 4 shows the location of the 7 nodes distributed in three different soundscapes, both indoors, a canteen and a monastery cloister, and outdoors, a square called pergolas.
Figure 5 shows the results of a 10s measurement (one shot) in the three devices located at the canteen (Figure 5a–c). Moreover, results from a long recording (700s) in an intermediate location within the canteen are shown in Figure 5d. This zone is one of the busiest areas of the campus, therefore it is observed that the psycho-acoustic annoyance is higher at specific moments due to a higher concentration of people.
Also, Figure 6 shows the plots of in 10s measurement two devices located at the cloister of the monastery of the UCAM (Figure 6a,b). The low annoyance is one of the main characteristics in this location, as it is shown in the long recording (630s) (Figure 6c).
Third environment, pergolas square, is an outdoor zone that can be both crowded and quite place depending in the period of time, where staffs and students can use in break times. Figure 7 shows the psycho-acoustic annoyance of a 10s measurement of two deployed devices in this square (Figure 7a,b). At the moment when the measurement was done, the outdoor environment was quite calm, the nuisance is not too high, as it is shown in the long recording (640s) (Figure 7c).
4.3. JND in the UCAM Campus
With the values obtained in the error propagation considered in section 2.2, the application of produces a range of JNDs for the Zwicker’s psycho-acoustic annoyance in the canteen of the campus with an average value for of 0.3553 and a variance value of 0.1012, which determines a mean percentage of 4.2% of relative variation for the PA () to have perceptual a change in this environment. In the cloister area of the campus the mean value for the PA JND is 0.7489 and the variance is 0.0044 , which determines a mean percentage of 38.7% of relative variation for the PA () to have perceptual a change in this environment. This value means that silent places can have a higher variation in the perception of annoyance. And in the case of the outdoor pergolas the PA JND has a mean value of 0.5008 and a variation value of 0.0289, which determines a percentage of 6.6% of relative variation for the PA () to have perceptual a change in this environment.
5. Conclusions
This paper presents different implementation options for a modified psycho-acoustic annoyance algorithm and compares it with Zwicker’s psycho-acoustic annoyance, introducing a term that weights the tonality of sounds. The implementation of these algorithms was done in different Raspberry Pi 4B+ and applied to different locations in the UCAM Campus in Murcia (Spain). According to reference [29], the JNDs of PA values computed from sound quality metrics obtained in these measurements are kept in a range between 4% and 38% depending on the environment. According to our experience in this study silent places can have a higher variation in the perception of annoyance.
The model exported to an SBC (RPi4B) has been applied to measure noise generated by a recorded pneumatic hammer and different locations in the campus. It has been observed that from the values calculated with the two models, the occurrence of tonal sounds in a noisy environment produces greater subjective annoyance. The MATLAB implementation to integrate in the RPI4B+ with the codegen command ave been have published in https://github.com/jausegar/urbauramon/tree/master/URPAA_Rasp_simulink h.
Both implementations, the one from Figure 1 and the one from Figure 2, showed a good performance in computing all the metrics in real-time, but the offloading in the first case allowed a better performance as the computing load in the sampling and windowing was done in the external node.
For future work, it is intended to extend this study to a larger number of noisy environments to describe other soundscapes for classification purposes.
Author Contributions
Conceptualization, J.S.G. and J.M.N.; methodology, J.S.G. and S.F.C.; software, J.S.G. and J.L.B.; validation, J.J.P.S., S.F.C. and J.M.N.; investigation, J.M.N. and J.M.B.; resources, J.S.G.; writing—original draft preparation, J.S.G.; writing—review and editing, J.M.N. and J.J.P.S. All authors have read and agreed to the published version of the manuscript.
Funding
This paper was supported by Ministerio de Innovación y Economía with the grant number BIA2016-76957-C3-1-R, co-funded FEDER funds and the grant number PID2021-126823OB-I00 and PID2020-112827GB-I00, funded by MCIN/AEI/10.13039/501100011033 and also by ERDF, a way of making Europe and the grant BES-2017-082340. Finally, by the Universitat de València which contributed with the grant named "acciones especiales" reference: UV-INV-AE-1544281.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
| 1 |
https://www.youtube.com/watch?v=_MDzFgznDxg&t=34s (pneumatic hammer recording) (accessed on 13/04/2023) |
References
- ISO 12913-1:2014. Acoustics — Soundscape — Part 1: Definition and Conceptual Framework, 2014.
- ISO 12913-2:2018. Acoustics — Soundscape — Part 2: Data collection and reporting requirements, 2018.
- Dunbavin, P. ISO/TS 12913-2:2018 – Soundscape – Part 2: Data collection and reporting requirements – what’s it all about? Acoustics Bulletin 2018, 43, 55–57. [Google Scholar]
- Lopez-Ballester, J.; Pastor-Aparicio, A.; Felici-Castell, S.; Segura-Garcia, J.; Cobos, M. Enabling Real-Time Computation of Psycho-Acoustic Parameters in Acoustic Sensors Using Convolutional Neural Networks. IEEE Sensors Journal 2020, 20, 11429–11438. [Google Scholar] [CrossRef]
- Montoya-Belmonte, J.; Navarro, J.M. Long-Term Temporal Analysis of Psychoacoustic Parameters of the Acoustic Environment in a University Campus Using a Wireless Acoustic Sensor Network. Sustainability 2020, 12. [Google Scholar] [CrossRef]
- Castro, F.L.; Brambilla, G.; Iarossi, S.; Fredianelli, L. The LIFE NEREiDE project: psychoacoustic parameters and annoyance of road traffic noise in an urban area . In Proceedings of the Proceedings of the Euronoise Conference (Euronoise 2018); , 2018.area. In Proceedings of the Proceedings of the Euronoise Conference (Euronoise 2018); p. 2018.
- Yang, X.; Wang, Y.; Zhang, R.; Zhang, Y. Physical and Psychoacoustic Characteristics of Typical Noise on Construction Site: “How Does Noise Impact Construction Workers’ Experience?”. Frontiers in Psychology 2021, 12, 3143. [Google Scholar] [CrossRef]
- ISO 532:2017. Acoustics — Methods for Calculating Loudness — Part 1: Zwicker Method; Part 2: Moore-Glasberg Method, 2017. [Google Scholar]
- Pastor-Aparicio, A.; Segura-Garcia, J.; Lopez-Ballester, J.; Felici-Castell, S.; García-Pineda, M.; Pérez-Solano, J.J. Psychoacoustic Annoyance Implementation With Wireless Acoustic Sensor Networks for Monitoring in Smart Cities. IEEE Internet of Things Journal 2020, 7, 128–136. [Google Scholar] [CrossRef]
- Pastor-Aparicio, A.; Segura-Garcia, J.; Lopez-Ballester, J.; Felici-Castell, S.; García-Pineda, M.; Pérez-Solano, J.J. Psychoacoustic Annoyance Implementation With Wireless Acoustic Sensor Networks for Monitoring in Smart Cities. IEEE Internet of Things Journal 2020, 7, 128–136. [Google Scholar] [CrossRef]
- Engel, M.; Fiebig, A.; Pfaffenbach, C.; Fels, J. A Review of the Use of Psychoacoustic Indicators on Soundscape Studies. Curr Pollution Rep 2021, 7, 359–378. [Google Scholar] [CrossRef]
- Arce, P.; Salvo, D.; Piñero, G.; Gonzalez, A. FIWARE based low-cost wireless acoustic sensor network for monitoring and classification of urban soundscape. Computer Networks 2021, 196, 108199. [Google Scholar] [CrossRef]
- Chen, C.Y. Monitoring time-varying noise levels and perceived noisiness in hospital lobbies. Building Acoustics 2021, 28, 35–55. [Google Scholar] [CrossRef]
- Bonet-Solà, D.; Martínez-Suquía, C.; Alsina-Pagès, R.M.; Bergadà, P. The Soundscape of the COVID-19 Lockdown: Barcelona Noise Monitoring Network Case Study. International Journal of Environmental Research and Public Health 2021, 18. [Google Scholar] [CrossRef]
- Raimbault, M.; Dubois, D. Urban Soundscapes: Experiences and Knowledge. Cities 2005, 22, 339–350. [Google Scholar] [CrossRef]
- Fastl, H.; Zwicker, E. Psychoacoustics: Facts and Models; Springer series in information sciences, Springer, 2007.
- Moore, B.C.J.; Glasberg, B.R.; Baer, T. A Model for the Prediction of Thresholds, Loudness, and Partial Loudness. J. Audio Eng. Soc 1997, 45, 224–240. [Google Scholar]
- Yonemura, M.; Lee, H.; Sakamoto, S. Subjective Evaluation on the Annoyance of Environmental Noise Containing Low-Frequency Tonal Components. International Journal of Environmental Research and Public Health 2021, 18. [Google Scholar] [CrossRef] [PubMed]
- Di, G.Q.; Chen, X.W.; Song, K.; Zhou, B.; Pei, C.M. Improvement of Zwicker’s psychoacoustic annoyance model aiming at tonal noises. Applied Acoustics 2016, 105, 164–170. [Google Scholar] [CrossRef]
- DIN45631/A1:2010. Calculation of loudness level and loudness from the sound spectrum - Zwicker method - Amendment 1: Calculation of the loudness of time-variant sound. Standard, Deutsches Institut Fur Normung E.V. (German National Standard), Beuth Verlag GmbH, D, 2010.
- DIN45692/A1:2009. Measurement technique for the simulation of the auditory sensation of sharpness. Standard, Deutsches Institut Fur Normung E.V. (German National Standard), Beuth Verlag GmbH, D, 2009.
- Jourdes, V. Estimation of Perceived Roughness. Student Thesis: Master, 2004.
- P. Daniel, R.W. Psychoacustical Roughness: Implementation of an Optimized Model. Acustica 1997, 83, 113–123.
- Aures, W. Procedure for Calculating the Sensory Euphony of Arbitrary Sound Signals. Acustica 1985, 59, 130–141. [Google Scholar]
- Terhardt, E.; Stoll, G.; Seewann, M. Algorithm for extraction of pitch and pitch salience from complex tonal signals. The Journal of the Acoustical Society of America 1982, 71, 679–688. [Google Scholar] [CrossRef]
- Zhong Zhang, M.S. Sound Quality User-defined Cursor Reading Control -Tonality Metric. Student Thesis, : Master, IMM, DTU Brüel & Kjær, 2003. [Google Scholar]
- Estreder, J.; Piñero, G.; de Diego, M.; Rämö, J.; Välimäki, V. Improved Aures tonality metric for complex sounds. Applied Acoustics 2023, 204, 109238. [Google Scholar] [CrossRef]
- Just Noticeable Difference. https://en.wikipedia.org/wiki/Just-noticeable_difference. (Accessed: 18/04/2023).
- You, J.; Jeon, J.Y. Just noticeable differences in sound quality metrics for refrigerator noise. Noise Control Engineering Journal 2008, 56, 414. [Google Scholar] [CrossRef]
- Pycom.io. Fipy, five network development board for IoT. https://pycom.io/product/fipy/, 2022. (Accessed: 28/12/2022).
- Pastor-Aparicio, A.; Lopez-Ballester, J.; Segura-Garcia, J.; Felici-Castell, S.; Cobos-Serrano, M.; Fayos-Jordán, R.; Pérez-Solano, J. Zwicker’s Annoyance model implementation in a WASN node. In Proceedings of the INTERNOISE 2019, 48th International Congress and Exhibition on Noise Control Engineering, 2019. [Google Scholar]
- Segura-Garcia, J.; Lopez-Ballester, J.; Pastor-Aparicio, A.; Felici-Castell, S.; Cobos-Serrano, M.; Pérez-Solano, J.; Soriano-Asensi, A.; Garcia-Pineda, M. Visualization of nuisance information in acoustic environments using an IoT system. In Proceedings of the INTERNOISE 2019, 48th International Congress and Exhibition on Noise Control Engineering, 2019. [Google Scholar]
- ThingSpeak. IoT Analytics - ThingSpeak Internet of Things. https://thingspeak.com/, 2023. (Accessed: 13/04/2023).
Figure 1.
Simulink model for the determination of psycho-acoustic annoyance from an audio file in the Edge. Sampling is performed by the Fipy node.
Figure 1.
Simulink model for the determination of psycho-acoustic annoyance from an audio file in the Edge. Sampling is performed by the Fipy node.
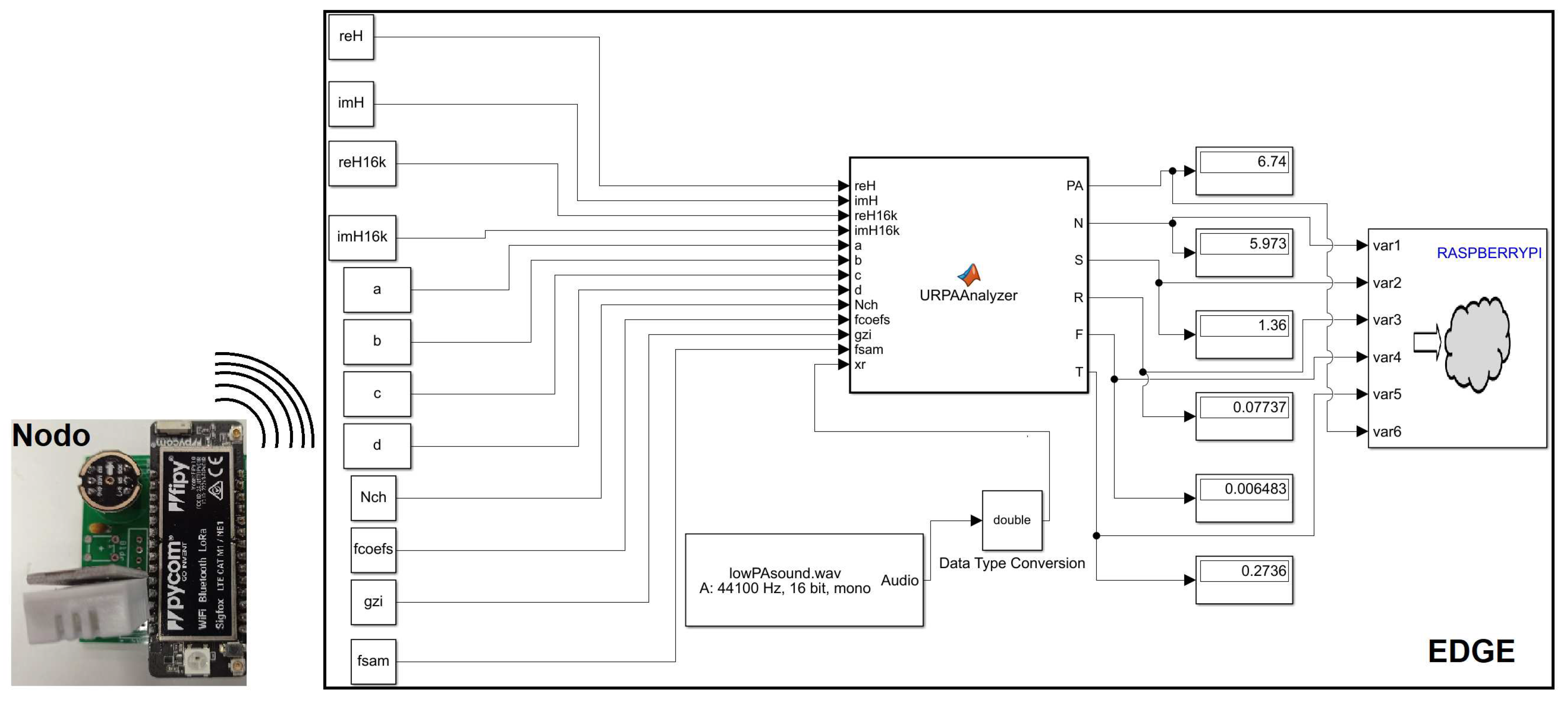
Figure 2.
Simulink model for the determination of psycho-acoustic annoyance from a microphone connected to the Edge. Sampling is performed by the Edge itself.
Figure 2.
Simulink model for the determination of psycho-acoustic annoyance from a microphone connected to the Edge. Sampling is performed by the Edge itself.
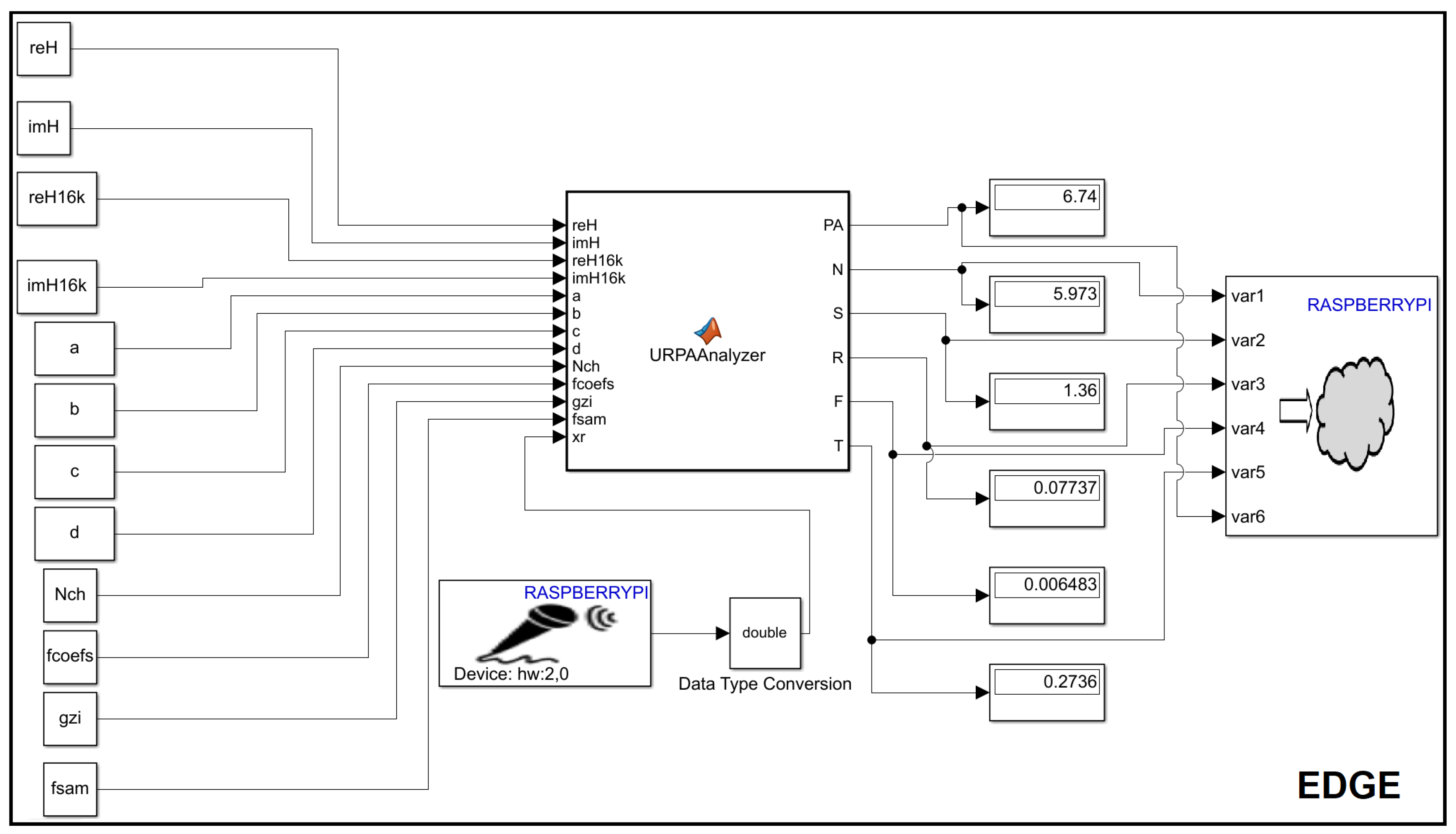
Figure 3.
Representation of psycho-acoustic annoyance (PA) measurements with the Zwicker model (blue) and with the modified model (orange) of a pneumatic hammer.
Figure 3.
Representation of psycho-acoustic annoyance (PA) measurements with the Zwicker model (blue) and with the modified model (orange) of a pneumatic hammer.
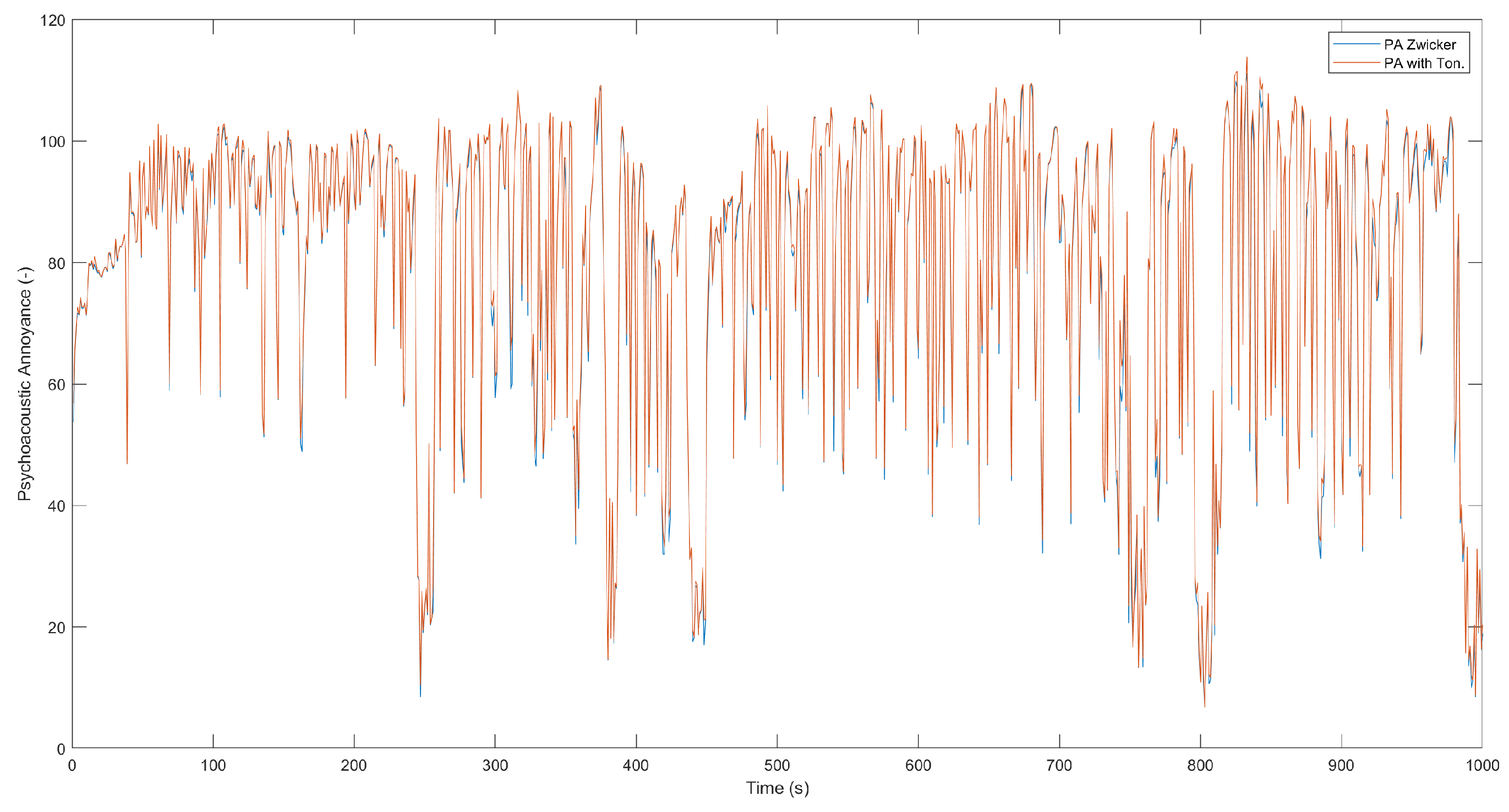
Figure 4.
Location of the nodes for the measurement campaign in UCAM Campus - Murcia.
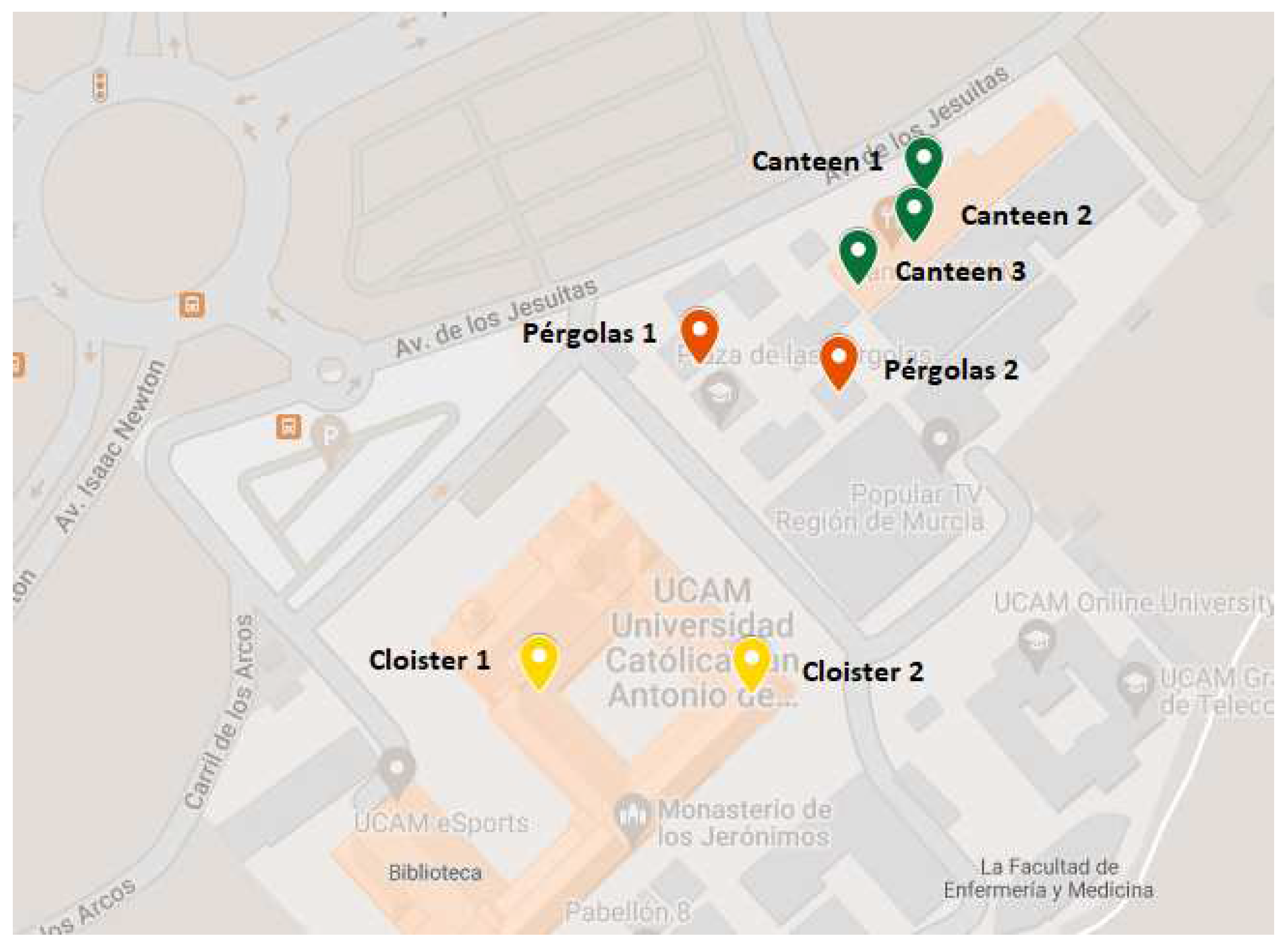
Figure 5.
Recording of psycho-acoustic annoyance (PA) measurements with the Zwicker model (blue) and with the modified model (orange) in the canteen in UCAM Campus - Murcia.
Figure 5.
Recording of psycho-acoustic annoyance (PA) measurements with the Zwicker model (blue) and with the modified model (orange) in the canteen in UCAM Campus - Murcia.
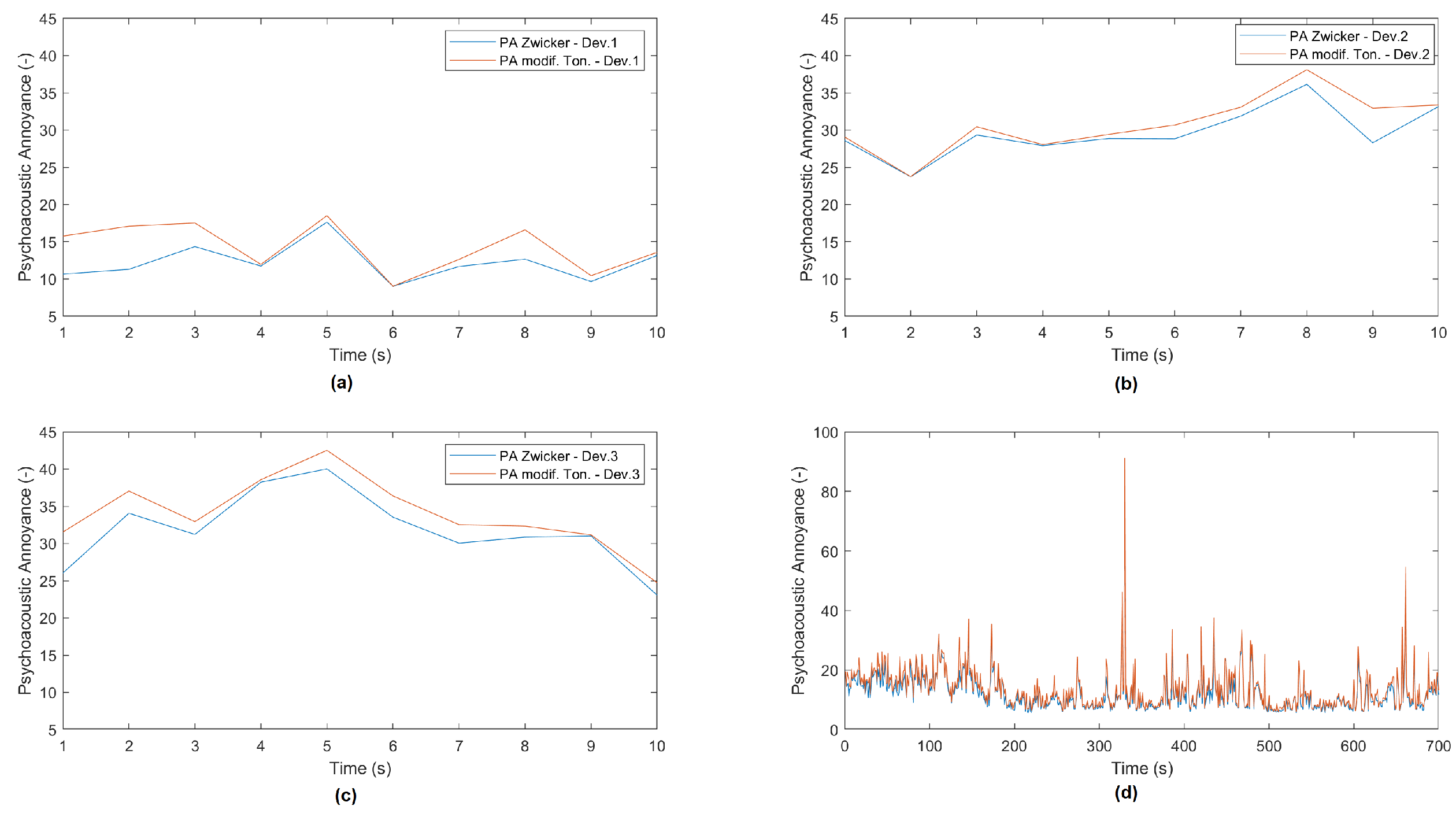
Figure 6.
Recording of psycho-acoustic annoyance (PA) measurements with the Zwicker model (blue) and with the modified model (orange) in the cloister in UCAM Campus - Murcia.
Figure 6.
Recording of psycho-acoustic annoyance (PA) measurements with the Zwicker model (blue) and with the modified model (orange) in the cloister in UCAM Campus - Murcia.
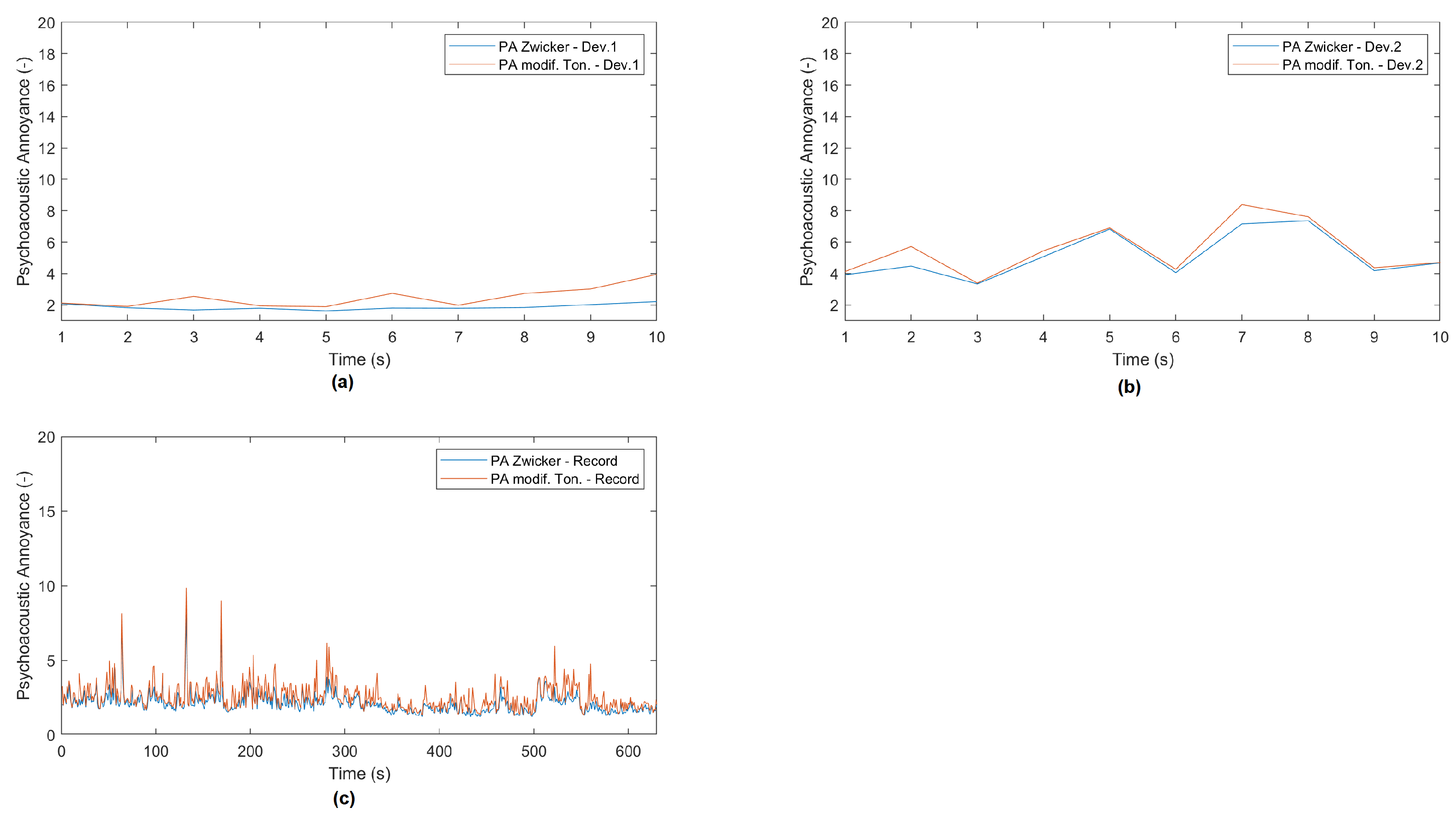
Figure 7.
Recording of psycho-acoustic (PA) annoyance measurements with the Zwicker model (blue) and with the modified model (orange) in the outdoor pergola in UCAM Campus - Murcia.
Figure 7.
Recording of psycho-acoustic (PA) annoyance measurements with the Zwicker model (blue) and with the modified model (orange) in the outdoor pergola in UCAM Campus - Murcia.
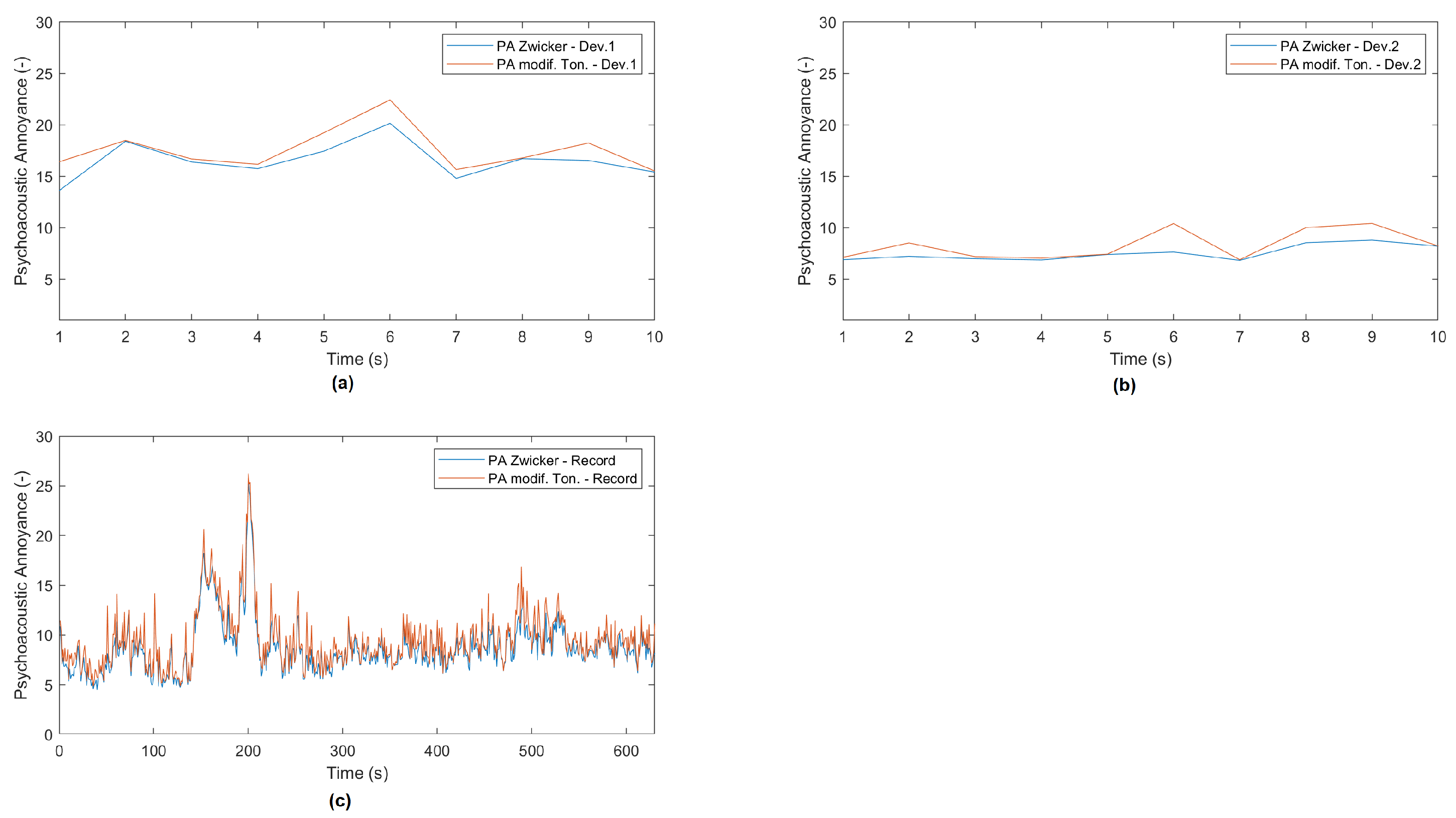
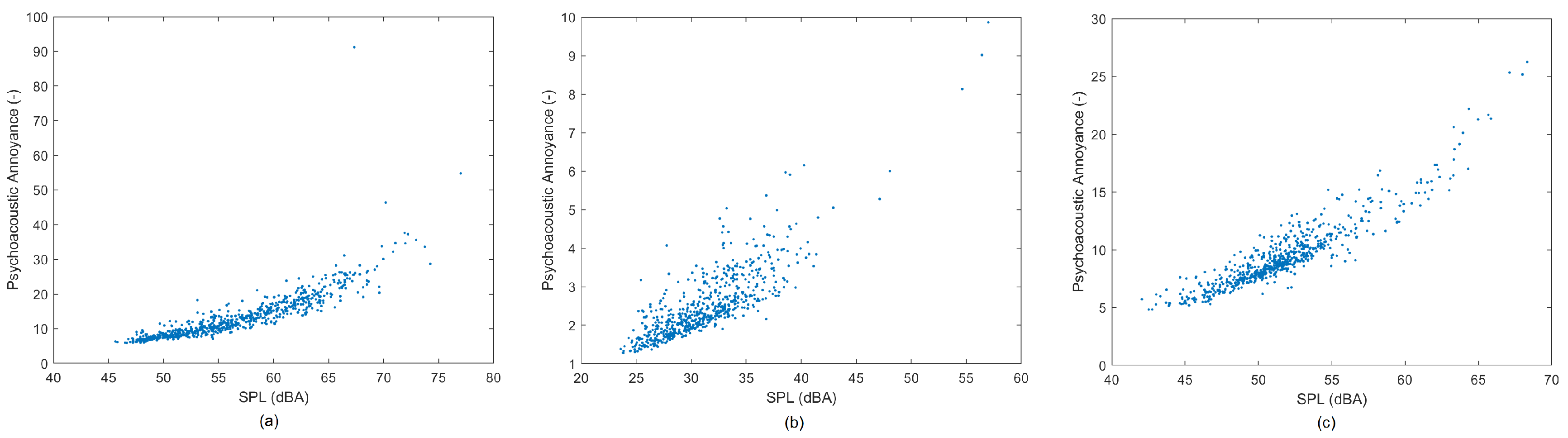
Figure 8.
Graphics of the relationship of Sound Pressure Level versus psycho-acoustic annoyance.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



