
Submitted:
02 May 2023
Posted:
03 May 2023
You are already at the latest version
Abstract
Unmanned Aerial Vehicles (UAV) are increasingly being used in a variety of domains and precision agriculture is no exception. Precision agriculture is the future of agriculture and will play a key role in long-term sustainability of agricultural practices. This paper presents a survey of how image data collected using UAVs has been used in conjunction with ma-chine learning techniques to support precision agriculture. Numerous agricultural applications including classification of crop types and trees, crops detection, weed detection, cropland cover, and segmentation of farming fields are discussed. A variety of supervised, semi-supervised and unsupervised machine learning techniques for image-based preci-sion agriculture are compared. The survey showed that for traditional machine learning approaches, Random Forests performed better than Support Vector Machines (SVM) and K-Nearest Neighbor Algorithm (KNN) for crop/weed classification. And, while Convolutional Neural Networks (CNN) have been used extensively, the U-Net-based models out-performed conventional CNN models for classification and segmentation tasks. Among the Single Stage Detectors (SSD), YOLO series performed relatively well. Two-Stage Detectors like R-CNN, FPN, and Mask R-CNN generally tended to outperform SSDs. Vision Trans-formers (ViT) showed promising results amongst transformer-based models which did not generally perform better than CNNs. Finally, Generative Adversarial Networks (GANs) have been used to address the problem of smaller datasets and unbalanced data
Keywords:
Precision Farming
; UAVs
; Agriculture
; Machine Learning
; Deep Learning
; CNN
; Transformers
; GANs.
1. Introduction
The rapid growth of the world’s population is putting growing demands on food production. A large percentage of world’s population is facing food insecurity today [1]. According to the Food and Agriculture Organization of United Nations (FAO), the demand for food production will continue to rise, reaching a staggering 70% increase by the year 2050 [2]. Such high demand cannot be sustained using conventional farming practices today. The problem is exacerbated by continuously diminishing natural resources used as inputs for farming. Use of traditional farming practices have also played a significant role in environmental degradation, including spread of water and atmospheric pollutants [3], degradation and erosion of soil [4], evolution of pesticide-resistant pests, and endangerment of human health due to excessive use of pesticides and agricultural chemicals [5]. Hence, new sustainable food production methods that maximize yield and minimize environmental impact must be developed. Using technology to support agricultural processes can potentially help reach this goal [6].
Precision agriculture, as defined by the International Society of Precision Agriculture (ISPA), is an agricultural management strategy that relies on the use of technology and agricultural data to improve the quality, sustainability, and yield of agricultural production [7]. Precision agriculture uses a wide array of sensors and monitoring devices to measure farming parameters like vegetation greenness, water content, nutrient status, and soil health [8]. These metrics help farmers make better decisions on how to manage their fields, reduce resource waste, and increase yield and production [9]. The use of precision agriculture also conserves farmers' time and reduces manual labor. For example, precision agriculture can replace farmers manually surveying and assessing vegetation in their fields which is a tiresome, time-consuming, and an error-prone task [10].
The use of Unmanned Aerial Vehicles (UAVs) in precision agriculture has grown rapidly in the last few years. This growth is a result of a UAVs’ ability to gather large amounts of information quickly, which can then be used to guide and enhance agronomic decision-making. In the early days of precision agriculture, most image data from fields was collected using ground cameras either mounted on unmanned ground vehicles (UGVs), or fixed next to vegetation patches. Later, satellites were used for image capturing. More recently, UAVs are being used in precision agriculture because of their ability to capture images at lower altitudes, at different angles, and at a higher speed than that of satellites [10]. Finally, recently, agricultural datasets to have become available and hence it is now possible to build a variety of machine learning models using these datasets [12].
This paper provides a survey of current research on applying machine learning to UAV image data for precision agriculture. While precision agriculture can use a variety of sensors [13], this paper limits itself to those studies that primarily used UAV image data. There are many previous survey papers related to this topic. For example, Kamilais et al. [14] covered various topics including disease detection, landcover classification, crop type classification, plant recognition, and fruit counting. The solutions discussed included various types of Convolutional Neural Networks (CNN) backbones like AlexNet and variations of VGG16. Since this paper appeared in 2018, many new deep learning models and architectures introduced after 2018 are not covered in this paper. Ren et al. [15] contained comparable material but also discussed newer models and backbones like YOLO detectors and fine-tuned AlexNet models. This paper classified models based on the backbone being used but did not cover a wider variety of problems requiring newer architectures. Meshram et al. [16] only focused on problems regarding disease and pest detection. Radoglou-Grammatikis et al. [17] provided a broad, non-technical overview of UAVs for precision agriculture with an emphasis on applications. Finally, Aslan et al. [18] is a recent survey paper that covered the use of UAV in both indoor and outdoor spaces but did so primarily in a non-technical manner.
The contributions of this paper are as follow:
- The paper discusses a wide variety of precision agriculture problems that can be addressed by using image data acquired from UAVs.
- The paper provides a technical discussion of the most recent papers using image data from UAVs to address agricultural problems.
- The paper evaluates the effectiveness of the various machine learning and deep learning techniques using image data to address agricultural problems using UAV data.
- The paper points out some fruitful future research directions based on the work done to date.
Rest of the paper is organized as follows. Key challenges with respect to precision agriculture are discussed first. Background on the types of images being collected using UAVs and evaluation techniques for models built using these techniques is then presented. Survey design is described next followed by a detailed presentation of the survey results. The paper ends with a discussion and a conclusion.
2. Challenges in Agriculture
Farmers face a variety of challenges many of which may be addressed using precision agriculture. This section briefly describes some agricultural challenges that can be addressed using precision agriculture utilizing image data from UAVs.
2.1. Plant Disease Detection and Diagnosis
The spread of plant diseases and the resulting loss in crop yields is a key problem for many farmers. According to the Food and Agriculture Organization of the United Nations (FAO), plant diseases have been the cause of around $220 billion annual loss to the global economy [19]. To control the spread of diseases, and hence the yield loss, farmers must detect plant diseases at an early stage and then take appropriate remedial measures. To detect diseases, farmers survey their fields to find obvious signs of infection. Once found, samples are taken from the infected plants to be observed under a microscope or similar instruments in the laboratory for a more reliable diagnosis [20]. Various laboratory assessments can also be performed for disease identification including Polymerase Chain Reaction (PCR) and Fluorescence in-situ Hybridization (FISH). Using such methods is laborious and time-consuming and requires access to experts in plant pathology. In addition, since these methods require plant sampling, they are damaging in nature [21].
2.2. Pest Detection and Control
Pests like insects and weeds can result in significant crop yield loss. Insects cause yield loss by feeding on plants or by spreading plant diseases [22]. Weeds cause yield loss by consuming crop-growth resources including water and nutrients [23]. Detecting and curbing the spread of pests by applying pest control mechanisms is essential for ensuring a good yield. Like plant disease detection, traditional pest detection is a manual time-consuming and expert-reliant process. Once detected, a control mechanism must be applied to halt the spread of pests. One popular method of pest control is spraying a field with agrochemicals where herbicides are sprayed to eradicate weeds, and insecticides are sprayed to control insects. Traditionally, agrochemicals are not sprayed on the affected areas of the fields only. Rather, chemicals are applied across a field because detecting specific areas requiring agrochemicals is time-consuming [24]. As a result, current pest control methods are wasteful and unnecessarily expensive. Moreover, research has shown dangers of agrochemical use on the environment and human health. For example, pesticides have been found to pollute water and air and cause significant changes to soil ecosystems by causing harm to soil microorganisms. In addition, pesticide use has been found to cause adverse health effects, including weakening immunity and causing cancer [25]. Excessive use of pesticides also results in the cultivation of pesticide-resistant populations of pests. Currently, more than 500 species of insects are resistant to insecticides and around 270 species of weeds are resistant to herbicides [26]. Use of pesticides will become an ineffective pest control mechanism if the farmers continue to use traditional pesticide application methods. Excessive use, however, is not the only problem that makes traditional methods of pesticide use inefficient and ineffective. For pesticides to be most effective, correct identification of pests must be done to select the right type of pesticides. Subsequently, an accurate estimation of pests’ vulnerability phase timings must be made to apply pesticides. Accuracy in time estimation is also required because early or late application of pesticides has little to no effect on the mitigation of pest spread. In order to choose the correct pesticides to use, and to determine the timing of application, an entomologist must survey the field, identify the pest types in the field, and predict the timing of their vulnerability phase [27]. Hence, for traditional pesticide-reliant pest control mechanisms to work, farmers also require expert help. Taking everything into account, traditional pest detection and control methods are not sustainable, especially with the growing demand for crop production.
2.3. Urban Vegetation Classification
Urban vegetation plays a vital role in facing global climate change challenges. The dominance of a single type of tree results in rapid temporal changes in the ecosystem functions like carbon storage [28]. Machine learning can be used to classify different tree species within heterogeneous urban environments. UAV imagery with spectral information allows more accurate classification results that can be used later to create a better distribution of plants on the landscape. Further, improving the mapping capacities in spatial, spectral, and geometric domains in agriculture enables better analysis of urban landscapes and efficient resolutions to encounter the increasing thermal changes [29].
2.4. Crop Yield Estimation
Accurate crop yield estimation helps create realistic plans for labor employment and agricultural produce storage [30]. Yield estimation is also important for making changes to crop management practices to improve the final crop yield [31]. Traditionally, crop yield is estimated by finding the yield in a small sample area of a field and then generalizing the results to the entire field’s area [32]. While seeming simple enough, in addition to being inaccurate, this method requires time-consuming manual work [33]. Manual crop counting is also an inefficient method of crop yield estimation with larger fields and more varied crop types. In addition, an obvious drawback of this method is that the estimation inaccuracies can lead to suboptimal plans for crop yield, labor, and storage.
2.5. Over and Under Irrigation
Postharvest quality of crops depends on preharvest practices [34]. Appropriate irrigation is one of these preharvest practices that plays a crucial role in determining crop quality. Several crops are not drought resistant and, therefore, yields decrease considerably after short periods of water deficiency during production. For example, a study conducted by Mitchell et al. [35] found that deficit irrigation reduced fruit water accumulation and fresh fruit yield. In addition, Atay et al. [36] hypothesized that over-irrigation could have a negative impact on total yield and fruit quality. Finally, with water being a scarce resource in most production areas, efficient water management scheme that maintains crop yield but has a moderate and controlled level of moisture stress on their crops is required [29]. Multispectral images acquired from a UAV for water irrigation level recognition can potentially be used to help address over and under irrigation [37].
2.6. Seed Quality and Germination
In crop planting, the germination rate and germination potential of seeds are important measures of their quality. Seed germination is the most critical stage of crop growth, and includes complex interactions such as water absorption, membrane reorganization, metabolic reorganization, and cell expansion. Selecting seeds with high germination rate can increase crop yields and help mitigate the risk of poor seed germination. However, during seedling stage, real-time monitoring, and detection of seed germination crucial for testing the quality of seeds, crop field management, and yield estimation. Owing to the low efficiency of traditional manual seedling rate monitoring, survey methods must gradually be replaced by UAVs and real-time video counting models.
2.7. Soil Quality and Composition
Soil quality and composition are critical for maximizing the crops output and for increasing yield. The potential root zone in the soil should be will-tilled and fertilized with the needed minerals [34]. Balanced levels of nitrogen, water, and calcium improves the crops quality and reduce the post-harvest decay and vice versa. UAVs equipped with multispectral cameras may detect useful geospatial data such as water stress, nitrogen level, and other existing supplements [38]. Appropriate soil treatments can then be performed at the right time through foliar sprays.
2.8. Fertilizer Usage
Use of fertilizers increases the yield of crops by providing plants the nutrients necessary accelerate growth. The type of fertilizer used depends on many factors including the crop type, the quality required, the purpose of use, and the diseases prevalent among the crop type. Under-use of fertilizers usually results in a reducing the quality of the crop because it may lower the sugar content and reduce the crops firmness. Meanwhile, over-fertilizing may result in multiple quality traits impairments such as total soluble solids, glucose, fructose, and pH issues [39]. Hence, a balanced fertilization level is necessary for crops. UAVs can be used to spray crops leaves or root soil with different combinations of nutrients needed in an effective and controlled manner to enhance the crops quality and its resistance to bacterial infections.
2.9. Quality of the Crop Output
Farmers aspire to produce crops with the highest possible quality by designing quality-ensuring pre-harvesting, harvesting, and post-harvesting plans tailored to the crop. In the pre-harvest stage, farmers are concerned with designing irrigation, fertilization, pesticide mitigation, and crop drainage plans that produce crops with required quality traits [40]. With these plans, crops are watered with a proper irrigation schedule, fertilized with the correct type of fertilizer and with the correct amount, and sprayed with the right kind and amount of pesticides [39], [40]. The harvesting stage also plays a role in the quality of the crop output. Farmers must harvest their crops during the correct time window to ensure that they adhere to their expected color, size, taste, and maturity characteristics. Traditionally, this is done using a variety of tests, including color, size, firmness, and acidity measurement. Lastly, in the post-harvest stage, farmers must design storage plans that ensure the quality of their harvest. Such plans must regard such important crop-specific factors as the harvested crops' storage time, and temperature and humidity requirements. Two examples of quality-ensuring storage plans include Dynamic Controlled Atmosphere (DCA) Storage and Heat Treatments [34]. Since crop pre-harvesting, harvesting, and post-harvesting plans require attention to crop types and careful assessment of their needs, farmers can leverage computer vision technology to perform these assessments and produce optimal plans, thereby reducing the need for manual labor and increasing the quality of the yield.
Table 1 below shows a summary of challenges in agriculture that potentially lend themselves to being addressed using image data from UAVs. As the table shows, UAVs can be potentially used to address all stages of the agriculture cycle.
3. Survey Design
Journal articles and conference papers were collected using IEEE Xplore, arXiv, MDPI, ResearchGate, and ScienceDirect. "Deep learning," "Precision Farming," and "Agriculture” were the primary search terms utilized. The keywords "crops" and "segmentation" were added to other searches. From the search results, only articles published between 2017 and 2023 were included, and when applicable, the results were sorted by relevance and citation count. Figure 1 shows the distribution of resulting publications. The exclusion and inclusion of research articles was decided first by a preliminary abstract analysis, then by a full review of the article. The research papers which did not utilize UAV/aerial image datasets were excluded. In addition, the primary inclusion criteria for our research were as follows:
- The study must include a clear report on the performance of the models.
- The study must present an in-depth description of the model architecture.
- The study carries out detection/classification/segmentation tasks or a combination of these using UAV image datasets.
The exclusion criteria of our research were as follows:
- The study is not indexed in a reputable database.
- The study does not propose any significant addition or change to previously existing deep learning or machine learning solutions in its domain.
- The study presents vague descriptions of the experimentation and classification results.
- The study proposes irrelevant or unsatisfactory results.
Based on these criteria, 70 papers were chosen for the survey. The papers were studied carefully to address the following major research questions:
- What data sources and image datasets were used in the paper?
- What type of pre-processing, data cleaning and augmentation methods were utilized?
- What type of machine learning or deep learning architectures were used?
- What overall performance was achieved, and which metrics were used to report the performance?
- Which architectures and techniques performed best for a class of agricultural problems?
4. Background
4.1. Image Data from UAVs
Raw images from a UAV are typically first corrected for displacements and distortions caused by terrain relief, camera tilt, etc. to create orthophoto images. The resulting images can be normal RGB images that define red, green, and blue color components for each individual pixel in an image. The RGB images are acquired using the standard visible light-sensitive cameras that usually only give surface-level information about the target data [41]. In addition to traditional imaging, UAVs for agricultural applications use multispectral images that capture different wavelength ranges across the electromagnetic spectrum. Multispectral data can be used to assess variations in plant/crop health that may be useful information for early treatment. Deep learning models using multispectral imaging have been developed [42]. The Near Infrared (NIR) spectral band images are acquired at 750-900 nm wavelength band and are primarily used for vegetation applications. NIR imaging provides additional beyond surface level information about the target data [43]. In such images, the red edge refers to the region in NIR range where rapid change in reflectance of vegetation is observed [44]. Similarly, Color-infrared (CIR) imagery also uses a portion from the NIR range. The invisible NIR light of CIR can be seen by the human eye by shifting it and the primary colors over. On CIR imagery vegetation appears red, water generally appears black and urban structures like buildings and roads show as a light blue-green tint [45]. Finally, Normalized Difference Vegetation Index (NDVI) quantifies vegetation by measuring the difference between near-infrared (which vegetation strongly reflects) and red light (which vegetation absorbs). The NDVI value ranges between -1 and 1 [46]. The NIR and Red channels are used for NDVI calculation as shown in Eq (1).
4.2. Image Features Used in UAV Data
Many machine learning models used derived features from images acquired from a UAV. Examples of commonly used features include Hue-Saturation-Value (HSV) channels, Vegetation Indices (VI)s from RGBs such as Excess Green Index (ExG), excess green minus (ExGR), and the color index of vegetation extraction (CIVE). Other VIs are crop sensitive and can be derived from NIR spectrums such as NDVI, Ratio vegetation index (RVI), and Perpendicular vegetation index (PVI). Edge detectors could also be useful and are commonly used such as Gaussian, Laplacian, and Canny Filters [47], Gabor Filters, Gray Level Co-occurrence Matrix (GLCM) [48], geometric and statistical features [49] are among other useful features used in precision farming.
4.3. Vision Tasks Using UAV Data
Precision agriculture applications using UAV image data are based on several computer vision tasks [50]. Image classification is the task of identifying which class the image of an object belongs to. Identification of weeds, for example, can be treated as an image classification task; given the image of a weed, identifying the image as a weed or non-weed. Another example is using image classification to identify different crops [51]. Image classification generally does not require isolating a particular object (e.g., a weed), but is based on observing general features in an image.
Object detection [52] is a related vision task that consists of identifying the location and labels of objects in an image. This task involves creating bounding boxes around objects and then labelling them. For example, for weed counting, one can detect all the weeds in an image and draw bounding boxes around them.
Another vision task is semantic segmentation that tries to identify objects that look similar or different from each other (e.g., weeds, ground, crop) at the pixel level [53]. For example, Zhang et al. [54] used segmentation to label pixels corresponding to purple rapeseeds to detect Nitrogen stress using UAV RGB data.
Finally, the instance segmentation task combines semantics segmentation and object detection to not only create a bounding box around an object, but to also then label each of the pixels of the object to belong to that specific instance. For example, in addition to identifying a weed, instance segmentation would also label each of the pixels of the weed and hence identifying shape of the weed as well.
4.4. Evaluation Metrics
Several evaluation metrics have been used to assess and compare the machine learning methods used for the various vision tasks described earlier. This section provides a brief explanation of the most used metrics. Any additional metrics used by a paper’s author/s are explained in the summary of the respective paper.
- Accuracy as shown in Eq (2) is a measure of an algorithm's ability to make correct predictions. Accuracy is described as the ratio of the sum of True Positive ( and True Negative (predictions to the algorithm's total number of predictions including false predictions (.
- Precision as shown in Eq(3) is a measure of an algorithm’s ability to make correct positive predictions. Precision is described as the ratio of True Positive (predictions to the sum of True Positive (and False Positive (predictions.
- Recall as shown in Eq(4) measures an algorithm’s ability to identify positive samples. Recall is the ratio of True Positive ( predictions made by the algorithm to the sum of its True Positive ( and False Negative ( predictions.
- F1-score as shown in Eq(5) is the harmonic mean of precision and recall. A high algorithm F1-score value indicates high accuracy. F1-score is calculated as follows:
- Area Under the Curve (AUC) is the area under an ROC curve which is a plot of an algorithm’s True Positive rate (TPR) Eq(6) Vs. its False Positive rate (FPR) Eq(7). An algorithm’s True Positive Rate can be defined as the ratio of positive samples an algorithm correctly classifies to the total actual positive samples. The false positive rate, on the other hand, can be defined as the ratio of an algorithm’s false positive sample classifications to the total actual negative samples.
- Intersection over Union (IoU) as shown in Eq(8) is an evaluation metric used to assess how accurate a detection algorithm's output bounding boxes around an object of interest in an image (e.g., a weed) are compared to the ground truth boxes. IoU is the ratio of the intersection area between a bounding box and its associated ground truth box to their area of union.
- Mean Average Precision (mAP) as shown in Eq (9) is used to assess the quality of object detection models. This metric requires finding a model’s average AP across its classes. The calculation of AP requires calculating a model’s Precision and Recall, followed by drawing its precision-recall curve, and finally, finding the area under the curve.
- Average residual as shown in Eq(10) is used to assess how erroneous a model is. Average residual displays the average difference between a model’s predictions and ground truth values.
- Root Mean Square Error (RMSE) as shown in Eq (11) is used to assess an algorithm’s ability to produce numeric predictions that are close to ground truth values. RMSE is calculated by finding the square root of the average distance between an algorithm’s predictions and their associated truth values.
- Mean Absolute Error (MAE) as shown in Eq (12) is an error metric used to assess how far off an algorithm’s numeric predictions are from truth values. MAE is calculated by finding the average value of the absolute difference between predictions and truth values.
- Frames Per Second (FPS) is a measure used to assess how fast a machine learning model is at analyzing and processing images.
5. Survey Results
70 papers were shortlisted based on the filtering methodology described earlier. These papers used a variety of cameras to capture images from UAVs. The cameras used ranged from low-end cameras like the Raspberry Pi NoIR Camera Module to commercial UAV cameras like the DJI FC6310 with high resolution imaging capabilities. In addition, consumer cameras like the 36.4-megapixel Sony A7R (RGB) camera were also deployed on larger UAVs. As Figure 2 shows, a wide image resolution was used in the papers reviewed here. The size of images ranged from 64x64 pixels to 7000x5000 pixels.
Figure 3 shows the percentage of papers addressing the various precision agricultural issues using the taxonomy of Liliane and Charles [55]. As Figure 3 shows, spatial segmentation and pesticide and disease treatment were the primary areas of interest in the reviewed papers.
Results of the filtered papers are organized according to the various machine learning techniques used. Papers using traditional machine learning techniques are discussed first followed by those utilizing neural networks and deep learning methods.
5.1. Traditional Machine Learning
5.1.1. Support Vector Machines (SVM)
Support Vector Machines (SVM) were used for classifying vegetation by health status [47], classifying trees by type [56], identifying and classifying weeds to generate weed maps [57], and lastly, to segment crop rows [48].
Tendolkar et al. [47] proposed the use of Agrocopter, a multipurpose farming drone to assess and evaluate plant health status, and for taking corrective actions. The system assessed plant health based on the NVDI index, texture, and color features of the individual pixels. These features were extracted utilizing a filter bank of 17 Gaussian and Laplacian filters. SVM was then used to perform semantic segmentation on the image pixels, and to classify the pixels as healthy or unhealthy. Finally, a segmented mask was generated and used to find the health ratio of the images based on the ratio of the area of healthy pixels to the total area of the image. The health ratio was then used to classify images into healthy, moderately healthy, and unhealthy. The trained model had 85% precision, 81% recall, and an F1-score of 79%.
Natividade et al. [56] proposed a pattern recognition system (PRS) to identify and classify vegetation using NDVI scale as a segmentation threshold. An SVM was trained on two data sets: a tree dataset with five classes and a vineyard dataset with three classes. The best models achieved an accuracy of around 72% on the two data sets.
Pérez-Ortiz et al. [57] introduced a UAV-based weed mapping system for the early detection of weeds in crop fields. They used a semi-supervised SVM (SSVM). The system used crop-row detection, vegetation indices, and spectral features to classify pixels in field images as belonging to one of three classes of crop, weed, or soil. Crop row detection was introduced to improve classifier performance in differentiating crops and weeds because their spectral features were similar. The proposed system took UAV-captured images, partitioned them into 1000x1000 pixel images, and then calculated the vegetation index of all image pixels. NDVI was used for multispectral images and the Excess Green index (ExG) was employed for visible images. The Otsu thresholding procedure was then applied to the vegetation indices to create thresholds that divided the indices into three classes where the highest Vegetation Index (VI) pertaining to crops, lower values to weeds, and the lowest values to soil. The image was then binarized by taking crop pixels as 1’s and weed and soil pixels as 0’s. The binarized image was then fed into the Hough Transform (HT) method to detect crop rows in the images. Finally, a crop row data feature, along with VI and spectral features, was used to train different machine learning models to classify pixels as soil, crop, or weed. The SSVM returned a MAE of 12.68%.
César Pereira et al. [48] compared the performance of multiple machine learning algorithms for the problem of crop row segmentation. Their study used a single image of a sugar cane field as its dataset and compared the segmentation results of running this image through different classifiers to a manually labelled image. The manually segmented image's pixels were classified into the two classes of crop row and the background. Spectral features were extracted using ExG and VI, and textural features were extracted through a four-filter Gabor filter bank and a Gray Level Co-Occurrence Matrix (GLCM). The feature vectors and color features (RGB) were used to train SVM models. For the Linear SVM model, the best combination of features was RGB, EXG, and Gabor filters. This combination yielded an F1-Score of 88.01% and an IoU percentage of 78.86%. The worst feature combination was RGB and GLCM. This combination yielded an F1-Score of 62.48% and an IoU percentage of 46.08%.
Table 2 shows a summary of the use of SVM with drone image data. Some similarities can be observed. Many (e.g., [47],[56],[57]) used the NDVI scale to perform pixel-wise classification. While others (e.g., [57] and [48]) used the ExG index for classification. Both [56] and [48] used a Radial Basis Function kernel to find the optimal hyperplane for separating the dataset classes.
5.1.2. K-Nearest Neighbors (KNN)
The K-nearest neighbor algorithm (KNN) has been used extensively in precision agriculture in land cover classification [58], sugarcane planting lines detection/fault study [59], and crop row segmentation [48].
Rodríguez-Garlito and Paz-Gallardo [58] proposed a KNN based land cover classification system. This system classified land cover into olive trees, soil, weeds, and shadow. In this system, high-resolution, multi-spectral images of the studied field were first captured using a UAV. These images went through spatial partitioning to reduce memory costs of the machine learning algorithm. As a result, processing windows were formed, with each window holding the spectral information of a row of image pixels. The KNN algorithm was then applied to one processing window at a time to perform land cover classification, and to classify individual pixels into the classes to which they belonged. The trained KNN model had a precision of 95.5%, an accuracy of 91.8%, and a balanced accuracy score of 90.9%. Similarly, Rocha et al. [59] used KNN to detect gaps in curved sugarcane planting lines from aerial images. The training and test sets were created using RGB images and classified based on Decision Tree, Linear Discriminant Analysis, and KNN. KNN had the best results with a relative error of 1.65% and effectively evaluated the planting conditions.
Pereira Júnior et al. [48] studied the use of the KNN algorithm in crop row segmentation. Two KNN models with two different K values of 3 and 11 were used. Constructing a KNN model with a K value of either 3 or 11 yielded similar results. The models used the Euclidean distance and using RGB, ExG, and Gabor filters as features, both models achieved an IoU score of about 76% and an F1-score of about 86%. Results for applying K-NN are summarized in Table 3.
5.1.3. Decision Trees (DT) and Random Forests (RF)
Decision tree classifiers were used in precision agriculture to classify vegetation like trees and vineyards, [56]. Similarly, the random forest algorithm was used to classify sugar beet crops and weeds [49].
Natividade et al. [56] used decision trees to detect and classify trees and vineyards in a field, where trees were classified into five distinct types, and vineyards into three types. On the tree data set, the best model resulted in 87% precision, 88% recall, and 74% accuracy. On the vineyard data, 87% precision, 90% recall and 79% accuracy were achieved.
Lottes et al. [49] proposed a crop and weed detection, feature extraction, and classification system that could identify and classify sugar beets and several types of weeds. NDVI, and ExG were used as features. A segmented mask based on the VI threshold was then used to extract a spectral feature vector per segmented object in the image and a feature vector per key point in the image. These feature vectors, along with geometric and statistical features, were used to train a Random Forest model. PHANTOM and MATRICE-graining data sets contained UAV-captured images of crops and weeds while JAI training dataset contained ground-captured images. The PHANTOM dataset was used to test how well the model could classify vegetation into sugar beet crops, saltbush weeds, chamomile weeds, and other weeds. The model yielded a precision of 85% for both saltbush and chamomile weeds. The recall values were 95% and 87% for saltbush weeds and chamomile weeds, respectively. Lastly, a recall of only 45% was attained for other weeds. The overall accuracy of the model was 86%. When weed-type classification was ignored, and vegetation was classified into two classes, 99% recall and 97% precision was achieved. Table 4 summarized the two studies using decision trees.
5.2. Neural Networks and Deep Learning
5.2.1. Convolutional Neural Networks (CNN)
Convolutional neural networks (CNN) have been used extensively in analyzing images for precision agriculture. In specific, transfer learning has been often used successfully using a variety of pre-trained models including Inception V3, VGG, etc. For example, Crimaldi et al. [60] used Inception V3 model and achieved 78.1% accuracy for classifying a crop into one of 14 crop types using data consisting of 54,309 images. Milioto et al. [61] built a CNN model using RGB and NIR camera images. The model had 97.3% accuracy for images of early crop growth and 89.2% accuracy for images of crops in later stages. However, both models had the same recall percentage, with the early stage scoring 98% and the later stage scoring 99%. Similarly, Bah et al. [62] used the AlexNet model on spinach, beet, and beans datasets, and got a precision of 93%, 81%, and 69%, respectively. The authors claimed that the bad results were primarily due to leaves overlapping between crops and weeds. Reddy et al. [63] used a customized CNN model for their work on plant species identification and achieved 99.5% precision for Flavia, Swedish leaf, and UCI leaf datasets. Sembiring et al. [64] focused on tomato plant disease detection. Their proposed model achieved 97.15% validation accuracy using the tomato leaf dataset from Plant village. However, their model did not achieve the highest validation accuracy among all four trained models. The highest accuracy score of 98.28% was achieved by the VGG16 model. Geetharamani et al. [65] achieved a classification accuracy of 96.46% using a customized nine-layer CNN model. R. et al., [66] used a residual learning CNN with an attention mechanism. The goal was to perform real-time corn leaf disease recognition. They also used the Plant Village Disease Classification challenge dataset. An overall accuracy of 98% was achieved. Nanni et al. [67] used different combinations of CNNs, including ResNet50, GoogleNet, ShuffleNet, MobileNetv2, and DenseNet201, with different Adam optimization methods. These CNN models were trained on three datasets of insect images: The Deng dataset, the IP102 dataset, and the Xie2 dataset. The best performing CNN achieved state-of-the-art accuracy on both insect datasets: 95.52% on Deng, a score that competed with human expert classifications, and 73.46% on IP102.
Atila et al. [68] proposed using the EfficientNet architecture for plant disease classification on the plant village dataset and achieved 99.91% and 99.97% accuracy on original and augmented datasets, respectively. Prasad et al. [69] proposed a two-step machine learning approach that analyzed low-fidelity and high-fidelity images from drones in sequence, preserving efficiency as well as the accuracy of plant diagnosis. The pathology 2020 dataset and a set of synthetically generated images were used. A semi-supervised model derived from EfficientNet called EfficientDet was used. The end goal was to perform segmentation and classification. The model scored 75.5% for the average accuracy of the identifier model. Albattah et al. [70] proposed a customized model of using EfficientNet called EfficientNetV2-B4 backbones to address plant disease classification. The Plant Village dataset and additional UAV images were used to train the model. The results were 99.63%, 99.93%, 99.99%, 99.78% for precision, recall, accuracy, and F1-score, respectively.
Mishra et al. [71] developed a standard CNN model to detect corn plant diseases in real-time. The model was deployed on an Intel Movidius NCS and a Raspberry Pi 3b+ module. The authors used the Plant-Village Disease Classification Challenge dataset and divided the images into three classes: Rust, Northern leaf blight, and Healthy. The system achieved an accuracy of 98.40% using a GPU and 88.56% on the NCS chip. Bah et al. [72] used unsupervised data labeling for weed detection from UAV images. The dataset consisted of two fields: Beans and Spinach. Each dataset was divided into the two classes or crop and weed. Two-thirds of the data was labelled in a supervised manner, while the third was labelled using unsupervised methods. The ResNet-18 model was used to perform the classification. The ResNet18 significantly outperformed SVM and RF methods in the bean field as it achieved an average AUC of 91.7% on both supervised and unsupervised labelled data in comparison to 52.68% using SVM and 66.7% using RF. On the other hand, RF resulted in a slightly better average AUC% in the Spinach field to that achieved using ResNet-18.
Zheng et al. [73] proposed multiple CNN models to estimate percent canopy cover as well as vineyard leaf area index in each field. The authors compared the estimation performance of five different models, including a CNN-ConvLSTM model, a Vision Transformer model, a Joint Model, an Xception model, and a ResNet-50 model. The five models were trained on a dataset containing approximately 840 images extracted from UAV videos taken of vineyard fields at Alcorn State University. The five models were evaluated using the RMSE of both leaf area index (LAI) and Percent Canopy Cover. For the prediction of leaf area index, Xception, CNN-ConvLSTM, Vision Transformer, ResNet-50, and Joint model had RMSE of 0.28, 0.32, 0.34, 0.41 and 0.43 respectively. For predicting percent canopy cover, Xception, CNN-ConvLSTM, Vision Transformer, ResNet-50, and Joint model had RMSE of the 4.01, 4.50, 4.56, 5.98, and 6.08 respectively. Clearly, Xception performed best for both LAI estimation and percent canopy cover estimation.
Yang et al. [74] proposed a method of multi-source data fusion for disease and pest detection of grape foliage using the ShuffleNet V2 model. The dataset consisted of 834 groups of grape foliage images. Each group contained three types of images of grape foliage: RGB Image (RGBI) (2592 × 1944, 3 channels), Multispectral Image (MSI) (409 × 216, 25 channels), and Thermal Infrared Image (TIRI) (640 × 512, 3 channels). The accuracy of MSI was 82.4%, RGB was 93.41%, and the TIRI was 68.26%.
Briechle et al. [75] used multispectral images to classify tree species and standing dead trees. They used the PointNet++ model. The data used was UAV-based Light Detection and Ranging including Laser Echo Pulse Width (LIDAR) data and five-channel MS imagery. They also applied segmentation to the images during the preprocessing of the data. Their model achieved an accuracy of 90.2%.
Aiger et al. [76] proposed a method of image classification based on multi-view image projections. Their method’s used projections of multiple images at multiple depth planes near the reconstructed surface. This enabled the classification of categories whose most noticeable aspect was appearance change under different viewpoints, such as water, trees, and other materials with complex reflection/light response properties. They obtained the best accuracy of 96.3% on their proposed 3D CNN.

Table 5.
Convolutional Neural Networks Summary.
| Paper | CNN | |||
|---|---|---|---|---|
| Model/ Architecture | Strengths | Comments | Best Results | |
| Crimaldi et al. [60] |
Inception V3 |
The identification time is 200ms which is good for real-time applications | Low accuracy | Accuracy of 78.1% |
| Milioto et al. [61] | CNN model fed with RGB+NIR camera images | High accuracy for early growth stage | Low accuracy for the later growth stage | Early growth stage Accuracy: 97.3% Recall: 98% Later growth stage Accuracy: 89.2% Recall: 99% |
| Bah et al. [62] | AlexNet | Less images with high resolution from a drone | Overlapping of the leaves between crops and weeds | Best precision was for the Spinach dataset with 93% |
| Reddy et al. [63] | Customized CNN | The results had a high precision and recall | Large dataset | Precision of 99.5% for the leaf snap dataset. The flavia, Swedish leaf, UCI leaf datasets had a recall of 98%. |
| Sembiring et al. [64] | Customized CNN | Low training time compared to other models compared in the paper | Not the highest performing model compared in the paper | Accuracy of 97.15% |
| Geetharamani et al. [65] | Deep CNN | Can classify 38 distinct classes of healthy and diseased plants | Large dataset | Classification accuracy of 96.46% |
| R. et al. [66] | Residual learning CNN with attention mechanism | Prominent level of accuracy and only 600k parameters which is lower than the other papers compared in this paper | Large dataset | Overall Accuracy of 98% |
| Nanni et al. [67] | ensembles of CNNs based on different topologies (ResNet50, GoogleNet, ShuffleNet, MobileNetv2, and DenseNet201) | Using Adam helps in decreasing the learning rate of parameters whose gradient changes more frequently | IP102 is a large dataset | 95.52% on Deng and 73.46% on IP102 datasets |
| Bah et al. [77] | CrowNet | Able to detect rows in images of several types of crops | Not a single CNN model | Accuracy: 93.58% IoU: 70% |
| Atila et al. [68] | EfficientNet | Reduces the calculations by the square of the kernel size | Did not have the lowest training time compared to the other models in the paper | Plant village dataset Accuracy: 99.91% Precision: 98.42% Original and augmented datasets Accuracy: 99.97% Precision: 99.39% |
| Prasad et al. [69] | EfficientDet | Scaling ability and FLOP reduction | Performs well for limited labelled datasets however, the accuracy is still low | Identifier model average accuracy: 75.5% |
| Albattah et al. [70] | EffecientNetV2-B4 | Really reliable results and has low time complexity | Large dataset | Precision: 99.63% Recall: 99.93% Accuracy: 99.99% F1: 99.78% |
| Mishra et al. [71] | Standard CNN | Can run on devices like raspberry-pi or smartphones and drones. Works in real-time with no internet. | NCS recognition accuracy is not good and can be improved according to the authors | Accuracy GPU: 98.40% NCS chip: 88.56% |
| Bah et al. [72] | ResNet18 | Outperformed SVM and RF methods and uses unsupervised training dataset | Results of the ResNet18 are lower than SVM and RF in the spinach field | AUC: 91.7% on both supervised and unsupervised labelled data |
| Zheng et al. [73] | Multiple CNN models including: CNN- Joint Model, Xception model, and ResNet-50 model. | Compares multiple models | Joint Model had trouble with LAI estimation, and the vision transformer had trouble with percent canopy cover estimation. |
Xception model: 0.28 CNN-ConvLSTM: 0.32 ResNet-50: 0.41 |
| Yang et al. [74] | ShuffleNet V2 | The total params were 3.785 M which makes it portable and easy to apply | Not the least number of params when compared to the models in the paper | Accuracy MSI: 82.4% RGB: 93.41% TIRI: 68.26% |
| Briechleet et al. [75] | PointNet++ | Good score compared to the models mentioned in the paper | Not yet tested for practical use | Accuracy: 90.2% |
| Aiger et al. [76] | CNN | Large-Scale, Robust, and high accuracy | Low accuracy for 2D CNN. | 96.3% Accuracy |
5.2.2. U-Net Architecture
The U-Net architecture was originally introduced in the medical domain by Ronneberger et al. [78] and is commonly used for image segmentation. U-Net follows an encoder-decoder architecture. Many factors like density of the crops, flight height of the drone, and the growth stage have an impact on how well U-Net will perform. According to Kitano et al. [79] U-Net did not perform well when the plants were remarkably close together. However, some techniques could be used to solve this problem, such as using the opening morphological operator.
Lin et al. [80] used U-Net to achieve an accuracy of 95.5% and a RMSE of 2.5% with 1000 manually labelled training images. Arun et al. [24] achieved an accuracy of 95.34% and an RMSE of 7.45 using reduced U-Net by designing an efficient pixel-wise for weeds and crops in agricultural field images. Hoummaidi et al. [81] used the U-Net model to perform vegetarian extraction and achieved an overall accuracy of 89.7%. However, Palm trees and Ghaf trees had higher detection rates of 96.03% and 94.54%, respectively. The authors justified their results with the fact that trees were obstructed by other trees. Palm trees also caused some errors due to their physical characteristics and the small crown sizes of some trees. The authors suggested that including young Palms in the training data could improve the crown size error rate. Doha et al. [82] used the U-Net architecture to detect crop rows by performing semantic segmentation on vertical aerial images. Zhang et al. [83] used the Dual flow U-Net (DF-U-Net) to detect yellow rust severity in farmlands. The dataset was from the Yangling experiment field, which used a RedEdge camera on board a DJI M100 UAV with a sensor size of 1336 × 2991. The F1-score, accuracy, and precision scores were 94.13%, 96.93%, and 94.02%, respectively. Sparse Channel Attention (SCA) was designed to increase the receptive field of the network and improve the ability to distinguish each category. Using U-Net, Lin et al. [80] achieved high accuracy with a small dataset. Similarly, with only 48 images, Tsuichihara et al. [84] achieved an accuracy of about 80% for detecting broad-leaved weeds. Table 6 provides a summary of studies using the U-Net architecture.
5.2.3. Other Segmentation Models
Efficient Dense modules of Asymmetric Convolution (EDANet) is another model that works well for real-time semantic segmentation. Therefore, EDANet can be useful for real-time applications like UAVs. Yang et al. [85] proposed an EDANet that does semantic segmentation for detecting rice lodging. Lodging occurs when the stem weakens, and the plant falls over. EDANet outperformed many systems because of its efficiency, low computational cost, and model size. The model identified normal rice at 95.28% and lodging at 86.17% accuracy. The model accuracy was improved to 99.25% when less than 2.5% of rice lodging was neglected.
Weyler et al. [86] proposed ERFNet-based instance segmentation model that segments individual crop leaves in plant imagery to extract relevant phenotyping information and then groups the instances that belong to one crop together. This model made use of two decoders, one of which was used to predict the offset of image pixels from leaf regions, while the other was used to predict the offset of image pixels from plant regions. The two decoder outputs were then used to generate one image with leaf clusters and another with plant clusters. The model was trained on a dataset of 1,316 RGB images of sugar beet fields captured by a camera onboard a UAV. The model was evaluated on its ability to perform crop leaf segmentation as well as full crop segmentation. In crop leaf segmentation, the model was able to achieve an average precision of 48.7% and an average recall of 57.3%. The model achieved an average precision of 60.4% and an average recall of 68% for crop segmentation.
Guo et al. [87] developed a three stages model to perform plant disease identification for smart farming. The model located the diseased leaves using a Region Proposal Network (RPN) algorithm trained on a leaf dataset in complex environments, after which regression and classification neural networks were used to locate and retrieve the diseased leaves. Later, the Chan-Vese algorithm was used to perform segmentation based on the set zero level set and minimum energy function. Finally, the diseases were identified using a pre-trained transfer learning model. The proposed model outperformed the traditional ResNet-101 model significantly with an accuracy of 83.75% in comparison to 42.5% by the latter.
Sanchez et al. [88] used a multilayer perception (MLP) neural network for the early detection of broad-leaved weeds and grass weeds in wide-row crops from UAV imagery. The data was manually collected using a UAV quadcopter equipped with a low-cost RGB camera. Image segmentation was done using the multiresolution segmentation algorithm (MRSA). The model achieved an average overall accuracy of 80.9% on two classes of crops.
Zhang et al. [89] proposed a unified CNN called UniStemNet for joint crop recognition and stem detection in real-time. The architecture of UniStemNet is like Mask R-CNN. The architecture consists of a backbone and two subnets in which the first performs crop recognition, and the other performs stem detection simultaneously. The backbone consists of five convolutional stages, where the first is a standard CNN with batch normalization while the other four contain two MobileNet2 inverted residual modules (IRMs). The subnets follow a varied-span feature fusion structure as each has different detection targets. The evaluation was performed on the open-source CWF-788 dataset, and labels were manually annotated. The model obtained an F1-score of 97.4% and an IoU score of 94.5 in segmentation which was slightly lower than that achieved by CR-DSS [90]. Nonetheless, the model achieved the best-known results in stem detection with an SDR of 97.8%. Summary of other segmentation models is presented in Table 7 below.
5.2.4. YOLO ONLY LOOK ONCE (YOLO)
You Only Look Once (YOLO) is a real-time object detection neural network model where a single stage neural network is applied to the full image. The network divides the image into regions and predicts bounding boxes along with probabilities for each region. YOLO has been gaining popularity lately in for agricultural disease and crop detection. For example, Chen et al. [91] proposed a UAV to photograph and detect pests and employed a Tiny-YOLOv3 model built on NVIDIA Jetson TX2 to recognize their position in real-time. The detected pest positions could later be used to plan optimal pesticide spraying routes, which agricultural UAVs would later follow. The model attained the best mAP score of 95.33% and 89.72% on 640*640 pixels test images.
Similarly, Qin et al. [92] proposed a solution for precision crop protection based on a light deep neural network (DNN) called Ag-YOLO consisting of a modified version of ShuffleNet-v2 backbone, a ResBlock neck, and a YOLOv3 head. This model enabled the crop protection UAV to perform embedded real-time pest detection and autonomous spraying of pesticides. The model was tested on the Intel NCS2 hardware accelerator owing to its low weight and low power consumption. The detection system achieved an average F1-score of 92.05%.
Parico et al. [93] proposed YOLO-WEED, a weed detection system trained with 720 annotated UAV images to detect instances of weeds, based on YOLOv3 using NVIDIA GeForce GTX 1060 for green onion crops. They obtained a mAP score of 93.81% and an F1-score of 94%.
Rui et al. [94] proposed a novel comprehensive approach that combined transfer learning based on simulation data and adaptive fusion using YOLOv5 for improved detection of small objects. Their transfer learning and adaptive fusion mechanism led to a 7.1% improvement as compared to the original YOLOv5 model.
Parico et al. [95] proposed a robust real-time pear fruit counter for mobile applications using only RGB data. Various variants of YOLOv4 (YOLOv4, YOLOv4-tiny, and YOLOv4-CSP) were compared. In terms of accuracy, YOLOv4-CSP was the best model with an AP of 98%. In terms of speed and computational cost, YOLOv4-tiny showed a promising performance at a comparable rate with YOLOv4 at lower network resolutions. If considering the balance in terms of accuracy, speed, and computational cost, YOLOv4 was found to be the most suitable with AP > 96%, inference speed of 37.3 FPS, and FN Rate of 6%. Thus, YOLOv4-512 was chosen as the detection model for the pear counting system with Deep SORT.
Jintasuttisak et al. [96] exploited the effective use of YOLO-V5 in detecting date palm trees in images captured by a UAV flying above farmlands in the Northern Emirates of the United Arab Emirates (UAE). The results of using YOLO-V5 for date palm tree detection in drone imagery were compared with those obtainable with other popular CNN architectures, YOLOv3, YOLOv4, and SSD300, both quantitatively and qualitatively. The results showed that for the training data used, the YOLO-V5m (medium depth) model had the highest accuracy, resulting in a mAP of 92.34%. Further, it provided the ability to detect and localize date palm trees of varied sizes in crowded, overlapped environments and areas where the date palm tree distribution was sparse.
Tian et al. [97] proposed an anthracnose lesion detection method based on deep learning. Cycle GAN was used for data augmentation. DenseNet was then utilized to optimize feature layers of the YOLO-V3 model, which had lower resolution. The improved model exceeded Faster R-CNN with VGG16 and the original YOLO-V3 model and could realize real-time detection. The model obtained an F1-score of 81.6% and 91.7% IoU on the entire dataset.
Table 8 presents a summary of methods using YOLO. As the Table shows, it is possible to get above 90% results from most YOLO models in a variety of domains.
5.2.5. Single Shot Detector (SSD)
The Single Shot Detector (SSD) is a one-stage object detection network that can detect objects in one feed-forward pass with low-resolution input images [98]. The model consists of 3 different modules. The first is a feature extraction module. This module is made up of a truncated base CNN model that is followed by convolutional layers used for the extraction of features at various scales. The second module is the object detection module which takes in feature maps and runs a set of default bounding boxes on their cells. The result is a defined number of box predictions, all of which have a shape offset and a class confidence score associated with them. The last module is the non-maximal suppression module which chooses the best predictions out of the set presented by the detection module using a specific value of IoU and confidence score as a threshold. Lately, SSDs have made an appearance in precision agriculture for their ability to perform fast inference and work with low-resolution input images. These two features of SSDs make them desirable in real-time precision agriculture applications.
Veeranampalayam Sivakumar et al. [99] proposed using a single shot detector to detect mid-to-late season weeds in soybean fields for weed-spread suppression. The authors used a feature extractor from the Inception V2 network and a stack of four extra convolutional layers to extract features at varying scales. The output of this feature extraction module were six feature maps that were then fed into the SSD’s detection module. A set of bounding boxes with five different aspect ratios and six different scales were used on all locations in all six feature maps, resulting in several box-bounded detection predictions, each prediction with its own shape offset and class confidence score. An RMS prop optimizer was used. After training the model over 25,000 epochs, the model achieved a precision of 66%, a recall of 68%, an F1-score of 67%, a mean IoU of 84%, and an inference time of 21s over 1152 x1152 image test data.
Ridho and Irwan [100] proposed a Strawberry picking robot that could detect strawberries of different health states in real-time. The robot ran an SSD-MobileNet architecture on a single board computer (SBC) to perform real-time inference. The network used a feature extraction module built with a MobileNet backbone. The choice of MobileNet was prompted by computational power and time restrictions associated with running a real-time inference model on a low-computational power single-board computer. Using transfer learning, the SSD-MobileNet V1 model was previously trained on 91 classes from the COCO dataset. The model was then re-trained on two new datasets containing a total of 250 training images of strawberries in good and bad condition. The result of the training returned an accuracy of 90% in detecting good and bad strawberries on image input extracted from a real-time-streamed video. Table 9 presents a summary of SSD methods.
| Paper | SSD | |||
|---|---|---|---|---|
| Model/ Architecture | Strengths | Comments | Best Results | |
| Veeranampalayam Sivakumar et al. [99] | SSD with a feature extraction module made of an Inception v2 network and 4 convolutional layers | Model is scale and translation invariant | Low optimal confidence threshold value of 0.1 Failure to detect weeds at the borders of images |
Precision: 0.66, Recall: 0.68, F1 score: 0.67, Mean IoU: 0.84, Inference Time: 0.21s |
| Ridho and Irwan. [100] | SSD with MobileNet as a base for the feature extraction module | Fast detection and image processing | Detection was not performed on a UAV Model did not yield the best accuracy in the paper | Accuracy: 90% |
5.2.6. Region-Based Convolutional Neural Networks
The Region-Based Convolutional Neural Network (R-CNN) is a two-stage object detection system that extracts many region proposals from input images, uses a CNN to perform forward propagation on each region proposal to extract its features, and then uses these features to predict the class and bounding box of this region proposal.
Sivakumar et al. [99] proposed an approach where object detection-based CNN models were trained and evaluated using low-altitude UAV images to detect weeds in mid and late seasons in soybean fields. Faster RCNN and SSD were both evaluated and compared in terms of weed detection performance. When Faster RCNN was configured with 200 box proposals, its weed detection performance was like the SSD model. The Faster RCNN model with 200 box proposals returned a precision of 0.65, a recall of 0.68, an F1-score of 0.66 and IoU of 0.85. On the other hand, the SSD model returned 0.66, 0.68, 0.67 and 0.84, for precision, recall, F1-score, and IoU, respectively. The performance of a patch-based CNN model was also evaluated and compared to the previous models. Faster RCNN model performed better than the patch-based CNN model. In conclusion Faster RCNN was found to be the best model in terms of weed detection performance and inference time among the different models compared in this study.
Ammar et al. [101] proposed an original deep learning framework for the automated counting and geolocation of palm trees from aerial images. They applied several recent convolutional neural network models (Faster R-CNN, YOLOv3, YOLOv4, and EfficientDet) to detect palm trees and other trees and conducted a complete comparative evaluation in terms of average precision and inference speed. YOLOv4 and EfficientDet-D5 yielded the best trade-off between accuracy and speed (up to 99% mAP and 7.4 FPS).
Su et al. [102] used the Mask-RCNN model for identifying Fusarium head blight disease in wheat spikes and its degree of severity. To perform this task, two Mask-RCNNs performed instance segmentation on the input images, one of which segments individual spikes in the images, and the other segments diseased areas of spikes. Thereafter, the severity of infection of spikes was evaluated by calculating the ratio of infected spike pixels in the images to the total number of spike pixels. The backbone of this model, for feature map extraction was composed of a combination of a ResNet-101 model and an FPN model. The model returned a prediction accuracy of 77.19% after comparing the results to a set of manually labelled images.
Yang et al. [103] used an FCN-AlexNet model to perform real-time crop classification using edge computing. The authors collected 224 images using a UAV during the growing period of rice and corn. The quantitative analysis showed that the SegNet model slightly outperformed FCN-AlexNet by 1% in the overall recall rate of object classification.
Menshchikov et al. [104] proposed an approach for fast and accurate detection of hogweed. The approach includes a UAV with an embedded system on board running various Fully Convolutional Neural Networks (FCNN). They proposed an optimal architecture of FCNN for the embedded system relying on the trade-off between the detection quality and frame rate. In their pilot study, they determined that different architectures could successfully solve the semantic segmentation task for the aerial hogweed detection of two classes. The SegNet model achieved the best ROC AUC with 96.9%. This model could detect hogweed, which was not initially labeled. The Modified U-Net architecture was characterized by a high frame rate (up to 0.7 FPS) and a reasonable recognition quality (ROC AUC > 0.938). Along with the low power consumption, the U-Net architecture demonstrated its applicability for real-time scenarios and running on edge-computing devices. One of the U-Net modifications could achieve 0.46 FPS on the NVIDIA Jetson Nano platform with the ROC AUC of 0.958.
Bah et al. [77] proposed a model that combined CNN and the Hough transform to detect crop rows in images taken by a UAV. The model called CRowNet was a combination of SegNet (S-SegNet) and a CNN Hough transform (HoughCNet). The model achieved an accuracy of 93.58% and IoU of 70%, respectively.
Hosseiny et al. [10] proposed a model with the framework’s core based on a faster Regional CNN (R-CNN) model with a backbone of ResNet-101 for object detection. The proposed framework’s primary idea was to generate unlimited simulated training data from an input image automatically. The authors proposed a fully unsupervised model for plant detection in UAV-acquired pictures of agricultural fields. Two datasets were used with 442 and 328 field patches, respectively. The precision, recall, and F1-score were 0.868, 0.849, and 0.855, respectively. Table 10 shows a summary of papers using two stage detectors.
5.2.7. Autoencoders
Weyner et al. [105] addressed the problem of automated, instance-level plant monitoring in agricultural fields and breeding plots. They proposed a vision-based approach to perform a joint instance segmentation of crop plants and leaves in breeding plots. They developed a CNN-based encoder-decoder network with lateral skip connections that follows a two-branch architecture with two task-specific decoders to determine the position of specific plant key points and group pixels to detect individual leaf and plant instances. Finally, they did pixel-wise instance segmentation of each crop and its associated leaves based on orthorectified RGB images captured by UAVs. Their method outperformed state-of-the-art instance segmentation approaches such as Mask-RCNN on this task. They achieved the highest score of 0.94 for AP50 at intermediate growth stages compared to 0.71 by Mask R-CNN with respect to the instance segmentation of sugar beet plants.
Lottes et al. [106] presented a novel approach for joint stem detection and crop-weed segmentation using a Fully Convolutional Network (FCN) integrating sequential information. Their proposed architecture enables the sharing of feature computations in the encoder while using two distinct task-specific decoder networks for stem detection and pixel-wise semantic segmentation of the input images. All their experiments were conducted using different generations of the BoniRob platform. BoniRob was built by BOSCH DeepField Robotics as a multi-purpose field robot for research and development applications in precision agriculture such as weed control, plant phenotyping, and soil monitoring. The system achieved the best mAP scores of 85.4%, 66.9%, 42.9%, and 50.1% for Bonn, Stuttgart, Ancona, and Eschikon datasets, respectively for stem detection and 69.7%, 58.9%, 52.9% and 44.2% mAP scores for Bonn, Stuttgart, Ancona, and Eschikon datasets, respectively for segmentation.
Su et al. [107] proposed a Deep Neural Network (DNN) that exploits the geometric location of ryegrass for the real-time segmentation of inter-row ryegrass weeds in a wheat field. Their proposed method introduced two subnets in a conventional encoder-decoder style DNN to improve segmentation accuracy. The two subnets treat inter-row and intra-row pixels differently and provide corrections to preliminary segmentation results of the conventional encoder-decoder DNN. A dataset captured in a wheat farm by an agricultural robot at different time instances was used to evaluate the segmentation performance, and the proposed method performed the best among various popular semantic segmentation algorithms (Bonnet, SegNet, PSPNet, DeepLabV3, U-Net). The proposed method ran at 48.95 FPS with a consumer-level graphics processing unit and thus is real-time deployable at camera frame rate. Their proposed model achieved the best mean accuracy and IoU scores of 96.22% and 64.21%, respectively.
Table 11.
Autoencoder Summary.
| Paper | Autoencoder | |||
|---|---|---|---|---|
| Model/ Architecture | Strengths | Comments | Best Results | |
| [105] | CNN-Autoencoder | Performed joint instance segmentation of crop plants and leaves using a two-step approach of detecting individual instances of plants and leaves followed by pixel-wise segmentation of the identified instances. | Low segmentation precision for smaller plants. (Outperformed by Mask R-CNN) | 0.94 for AP50 |
| [106] | FCN-Autoencoder | Performed joint stem detection and crop-weed segmentation using an autoencoder with two task-specific decoders, one for stem detection and the other for pixel-wise semantic segmentation. | Did not achieve best mean recall across all tested datasets. + false detections of stems in soil regions | Achieved mAP scores of 85.4%, 66.9%,42.9%, and 50.1% for Bonn, Stuttgart, Ancona, and Eschikon datasets, respectively for stem detection and 69.7%, 58.9%, 52.9% and 44.2% mAP scores for Bonn, Stuttgart, Ancona, and Eschikon datasets, respectively for segmentation. |
| [107] | Autoencoder | Utilized two position-aware encoder-decoder subnets in their DNN architecture to perform segmentation of inter-row and intra-row Rygrass with higher segmentation accuracy. | Low pixel-wise semantic segmentation accuracy for early-stage wheat. | mean accuracy and IoU scores of 96.22% and 64.21%, respectively. |
5.2.8. Transformers
Vaswani et al. [108] proposed the transformer architecture based on the attention mechanism. A transformer is a sequence transduction model initially designed to tackle natural language processing (NLP) problems. Using transformers for computer vision tasks was limited initially due to the high computational cost of training. To address this issue, Dosovitskiy et al. [109] proposed the Vision Transformer (ViT) that requires fewer resources while out-performing convolutional networks (CNN). Other notable contributions include utilizing Detection Transformers (DETR) targeting the same problem. [110].
Thai et al. [111] used ViTs for the early detection of infected cassava leaves and the classification of their diseases. Initially, they used the ImageNet pre-trained ViT model published by the Google Research Team [112]. The model was then tuned using Cassava Leaf Disease Dataset [113]. Later, the model was quantized to reduce its size and accelerate the inference step (FPS) before deploying it on a Raspberry Pi 4 Model B. Their model achieved a 90.3% F1-score in comparison to the best CNN score of 89.2% achieved by the Resnet50 model. Further, they proposed a smart solution powered by the Internet of Things (IoT) that can be used in the agriculture industry for real-time detection of leaf diseases. The system consists of a drone that captures the leaf images, including the exact position of the spot in the field. The ViT model installed on the Drones Pi classifies the images and clusters the infected leaves. The results are then combined with the spot’s position and sent to a server via a 4G network to create a survey map of the field. Farmers and rescue agencies can obtain the map on their mobile phones and prevent the loss of crops beforehand.
Reedha et al. [23] used two different models of ViT for plant classification of UAV images. Images were collected using a drone mounted with a high-resolution camera and deployed in a crop field of beet, parsley, and spinach located in France. The camera captured RGB orthorectified images at regular intervals in the field. The data was manually labelled into five classes: Weeds, Beet, Parsley, Spinach, and Off-type green leaves. They also employed data augmentation to help improve the robustness of the model and the generalization capabilities of the training dataset. Later, they used ViT-B32 and ViTB16 models. They also tested the training data on EfficientNet and ResNet CNN architectures for comparison purposes. The results showed that ViT models outperformed the CNN models as an F1-score of 99.4% and 99.2% were obtained from ViT-B16 and ViT-B32, respectively. In comparison, CNN models achieved slightly lower scores of 98.7% for EfficientNet B0, 98.9% for B1, and a close 99.2% using ResNet50. The authors pointed out that although all techniques obtained high accuracy and F1-scores, the classification of crops and weed images using ViTs yielded the best prediction performance. However, the inefficiency of ViT as compared with CNNs is another consideration if the model is to be deployed for real-time processing on a UAV.
Karila et al. [114] used ViT models to estimate grass sward (i.e., short grass) quality and quantity in a field. The datasets were captured in the spring “primary growth phase,” and the same dataset was captured again in the summer “regrowth phase” using a quadcopter drone equipped with two cameras. The first captured RGB images, while the second captured Fabry Perot (FPI) images. The results showed that ViT RGB models performed the best on different datasets. Similarly, VGG CNN models provided equally satisfactory results in most cases.
Dersch et al. [115] used a detection transformer (DETR) to detect single trees in high-resolution RGB true orthophotos (TDOPs) and compared it to a YOLOv4 single-stage detector. The multispectral images were collected by a ten channels camera system with a horizontal field of view. Later, the images were post-processed using structure-from-motion (SFM) software. The data was later manually labelled with a split of 80% training and 20% for validation. DETR outperformed YOLOv4 in mixed and deciduous plots with a 20% difference in F1-score in mixed plots and 4% in the latter plots; 86% to 65% and 71% to 67%, respectively. Across all three test plots, both methods had problems with over-segmentation. Furthermore, DETR failed to detect smaller trees far worse than YOLOv4 in multiple cases. The authors justified these poor results by the fact that DETR uses lower resolution feature maps than that of YOLOv4.
Chen et al. [116] proposed a new efficient deep learning model called the Density Transformer (DENT) for automatic tree counting from aerial images. The model’s architecture contains four stages: a Multi-Receptive Field CNN (Multi-RF CNN) to compute a feature map over the input images, followed by a standard transformer encoder, and a Density Map Generator (DMG) to predict the density distribution over the input images. They also introduced a benchmark dataset that contains aerial images for tree counting called Yosemite Tree dataset and released it to the public [116]. The model outperformed most state-of-the-art methods with a MAE of 10.7 and a RMSE of 13.7 in comparison to 17.3 and 22.6, respectively, using YOLOv3. It is worth mentioning that the CANNet model [117] achieved the closest values with 10.8 and 13.8, respectively, and achieved a better MAE score in one of four regions than the DENT models.
Finally, Zhang et al. [118] developed a spectral-spatial attention-based transformer (SSVT) to estimate crop nitrogen status from UAV imagery. The model is an improved version of the standard Vision Transformer (ViT) that can extract the spatial information of images. The newly proposed model can predict the spectral information which contains most of the features in agricultural applications. The model also tackles the computational complexity of large images that ViT suffers from by adopting a self-supervised learning (SSL) technology to allow models to train with unlabeled data. The results showed that the model with 96.2% accuracy outperformed the ViT model with 94.4% accuracy. However, this model required 4 million additional parameters to those required for a ViT model. Table 12 presents a summary of methods using transformers.
5.2.9. Active Learning
Coletta et al. [119] used a semi-supervised classification algorithm that can aggregate information from clusters with those provided by a supervised algorithm like SVM to discover new classes in an active learning manner. According to the authors, such an ability is largely convenient for inconsistent agricultural environments. The data was collected through a SenseFly eBee equipped with an RGB camera. The model consisted of two blocks; a classification block (ClaB) representing an area of 0.16m2 to be classified and a contextual block (ConB) providing supplementary context information. Both blocks formed a concentric pair that generates feature vectors to be classified. These vectors were manually labeled as belonging to one of three classes. Then a semi-supervised classifier was used to quantify the uncertainty of classification, and a density measure evaluated the importance of a classified feature vector. If the instances resulted in high uncertain labels, they were denoted as novelties to be learned, which was labelled later by an Entropy and Density-based Selection (EDS) domain expert and incorporated into the training set. The results showed that the all-class accuracy and recall improved iteratively.
5.2.10. Light Detection and Ranging Algorithm (LiDAR)
for individual tree detection from UAV imagery. The model used an existing LIDAR algorithm to generate RGB trees that could be used for training as a starting point. The model was then retained using a small number of manual labels to correct errors from the unsupervised detection. Then a pre-trained ResNet50 backbone was used to classify the images. The model was tested on the NEON public dataset and achieved the best performance among existing LIDAR-based models (+2%) in comparison to that achieved by Silva et al. [120].
5.2.10. Semi-supervised Convolutional Neural Networks
Bosilj et al. [121] used the fundamental SegNet architecture to perform pixel-level classification and segmentation of three classes of soil. The input comprises RGB and near-infrared (NIR) images. The authors used a median frequency weighting to avoid unbalanced labelling as soil pixels are dominant in any given field with respect to crops or weeds. The input data was taken in the form of RGB and NIR channels directly because NDVI preprocessing typically results in minimal differences. The model was trained on three different datasets of sugar beets, carrots, and onions (SB16, CA17, ON17) in which there were fully labelled examples in one, and partially labelled examples in the other and on both pixel-level and object-level training. Object-based detection performed better than pixel-based detection precision-wise. However, pixel-based detection performed better in recall. It is worth noting that the partially labelled ON17 dataset with SB16 weights outperformed the fully labelled dataset. The partially labelled CO17 dataset performed significantly worse than the fully labelled dataset, with a difference of almost 20% on weeds and 5% on crops.
6. Discussion and Future Work
6.1. Machine Learning Techniques
In general, SVMs did not work well in comparison to deep learning approaches. References [47], [48], [56], [57], [122] used SVMs to classify crops/weeds in agricultural fields. Most of the results showed low accuracies. This can be because SVMs underperform when there is no clear margin of difference between the different classes, which is usually the case in agricultural imagery even with the images being preprocessed. In addition, SVMs are more likely to fail when classes are noisy and overlapping. KNN suffered from similar limitations. References [48], [58], [59] showed that KNNs performed slightly better than SVMs. Nonetheless, they were still sensitive to noisy data. Random Forests (RF) were used in [49], [56] and performed better than SVM and KNN in this limited context. However, RF require higher computational cost as the algorithm involves multiple decision trees within, which makes it challenging to implement on a UAV for real-time predictions. Decision trees and RF also have the problem of overfitting. It is worth mentioning that Coletta et al. [119] used active learning to discover new classes through an SVM technique on semi-labelled data, and the results were promising and reliable. The Light Detection and Learning algorithm was used by Weinstein [123] with a ResNet backbone and achieved decent results as well.
CNNs represent a good candidate for solving image-based classification and detection problems in precision agriculture. U-Net models performed well with fewer training samples and provided better performance for segmentation tasks [124]. References [24], [80]–[84], [89] showed that U-Net outperformed other CNN models. In addition, Arun et al. [24] showed that U-Net can be further optimized without compromising on performance. Other architectures included ResNet, ShuffleNet, ShuffleNetV2, and MobileNet, which all require larger computational costs and are less suitable for real-time UAV applications.
Single Stage Detectors like the YOLO series, CornerNet, and CenterNet improved the detection speed while maintaining high accuracy. Tiny-YOLOv3 worked well in real-time applications due to a small number of parameters, high speed, and efficient computation. References [91]–[93], [97] showed that YOLOv3 performed the best among all YOLO models. Using Tiny-YOLOv3 resulted in a slight trade-off with accuracy, especially with detecting smaller objects. Nonetheless, the overall accuracy remained high. Two-Stage Detectors such as R-CNN, FPN, and Mask R-CNN performed better than Single-Stage detectors. References [76], [99], [100], [102], [105]–[107] showed that these models outperformed single-stage detectors in terms of recall and accuracy. However, many authors argued that region proposal modules required higher computation and run-time memory footprint, thus making detection slow even on high-end GPUs [92].
Transformers represent a viable approach in agricultural classification tasks using UAV image data. In specific, the ViT model showed promising results. References [23], [111], [114] compared ViT models with current CNN architectures and showed that both approaches achieved similar results, with ViTs enjoying a slight edge. The DETR model [115] was compared to the YOLO series of models and both approaches achieved similar results as well. However, it was evident that DETR models fell short in detecting smaller trees and crops due to their encoder-decoder nature. DENT was used in [116] and outperformed most current methods. However, the CNN model CANNet achieved better results on the same data.
Generative Adversarial Networks (GANs) were primarily used to enhance the training process by adding to the manually labelled data in a semi-supervised manner. References [125], [126] used semi-supervised GANs (SGAN) and cGAN, respectively. In both works, GAN architectures were outperformed by CNNs for higher labelling rates.
6.2. Best Techniques for Agricultural Problems
Table 13 shows the current best solutions for each problem and the respective type of learning architecture used. Because of the unavailability of appropriate benchmarks, it is difficult to compare the proposed approaches. However, Table XIII represents the best results achieved using specific data sets. The results generally show that machine learning and deep learning can yield reasonable results for a variety of problems. There is clearly room for improvement in most cases as the results are sometimes in the range of 80% accuracy.
Figure 4 shows an overall summary of machine learning techniques using UAV image data for precision agriculture. As the Figure shows, supervised, semi-supervised and unsupervised techniques have been used for a variety of problems.
6.3. Future Work
The current state of practice in deploying UAVs in an agricultural field typically consists of using multiple UAVs or stages. One smaller UAV is used to collect images from the field. Once the images are collected, machine learning algorithms are applied, and the results are used to program another typically larger delivery UAV that applies pesticides, fertilizer or similar in a smarter fashion. A future vision is to have autonomous agricultural UAVs that can process images on-board and take appropriate actions as necessary. However, current UAVs are resource-constrained, and their performance is limited by energy consumption, memory size, and latency. As a result, it is not practical to use high-resource algorithms to perform detection and classification tasks. Such issues can be addressed by using low-bit architectures, by compressing a dense model, by using an effective model with a small number of parameters, or by using a hardware accelerator that can be deployed on an embedded System-on-Chip (SoC) that includes graphic processing units (GPUs) or Field-programmable gate arrays (FPGAs) [127].
As the survey showed, many generic CNN backbones (e.g., ResNet18) have been used to address various agricultural problems. However, these backbones are typically pre-trained on non-agricultural data and are only finetuned on agricultural data. Availability of agricultural benchmarking data sets will help make progress towards creating pre-trained backbones for agricultural problems.
Many agricultural problems require semantic segmentation, object recognition, and instance segmentation. As Table XII shows, single stage detectors like YOLOv3 have performed well for object recognition. In addition, two stage detectors like FRCNN and specialized architectures like DENT have relatively better performance. Transformers like ViT have been used. However, one issue with transformer-based architectures is the higher computational inefficiency as compared to CNNs. Many new approached to optimize transformers for a more efficient footprint have been proposed [128]. This work is highly relevant for autonomous UAVs that need to perform the inference onboard the UAV. In addition, entirely new architectures like Hyena [129] that claim sub-quadratic performance when compared with transformers have been proposed. Such new architectures also carry promise with combined with the current object recognition and instance segmentation approaches.
Many surveyed UAV studies used multispectral data as opposed to using just the RGB data. Multispectral data represents a special challenge for UAVs because using higher number of channels in the input significantly increases the memory requirements which is not ideal for autonomous UAVs. Building efficient CNNs for multispectral data is a well-researched problem [130]. Transformers are also being used with multispectral data (e.g., [131]). Approaches for segmentation using multispectral data (e.g., [132], [133]) have been recently proposed as well. Efficient handling of multispectral data when using transformers represents another important research problem for the UAV image data.
Finally, a significant amount of work has been done in agriculture using satellite imagery [134]. The appearance of multimodal agricultural data including synced and UAV images (e.g., [135]) raises the interesting possibility of multimodal systems on a UAV utilizing ground, UAV and satellite data in tandem to solve the various agricultural problems more effectively.
From the agricultural problem perspective, many of the problems identified in Table I have been addressed using image data from UAVs. However, some problems in the post-harvesting stage like fruit grading, quality retention, storage environments, etc. may require additional attention.
7. Conclusion
In this survey, over 70 recent papers using UAV agricultural imagery to classify, detect, and segment crops and trees using machine learning algorithms and deep learning models were discussed. Deep learning models like U-Net, YOLOv3, and ViT performed the best among state-of-the-art approaches. The primary challenges include detecting small trees, interleaved crops, and the high-power consumption of complex models. Future work includes developing low power consuming and less expensive models that could be deployed on the UAVs to perform real time or on edge tasks that can provide faster and more sufficient solutions in the field of precision farming.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Global Report on Food Crises. p. 277.
- Shaikh, T.A.; Rasool, T.; Lone, F.R. Towards leveraging the role of machine learning and artificial intelligence in precision agriculture and smart farming. Comput. Electron. Agric. 2022, 198. [Google Scholar] [CrossRef]
- Mylonas, D. Stavrakoudis, D. Katsantonis, and E. Korpetis, “Better farming practices to combat climate,” Academic Press, pp. 1–29, 2020. [CrossRef]
- Wolińska, “Metagenomic Achievements in Microbial Diversity Determination in Croplands: A Review,” in Microbial Diversity in the Genomic Era, S. Das and H. R. Dash, Eds., Academic Press, 2019, pp. 15–35. [CrossRef]
- Mohamed, Z.; Terano, R.; Sharifuddin, J.; Rezai, G. Determinants of Paddy Farmer's Unsustainability Farm Practices. Agric. Agric. Sci. Procedia 2016, 9, 191–196. [Google Scholar] [CrossRef]
- K. R. Krishna, Push button agriculture: Robotics, drones, satellite-guided soil and crop management. CRC Press, 2017.
- ISPA (International Society of Precision Agriculture). Precison Ag Definition. 2019. Available online: https://www.ispag.org/about/definition (accessed on 14 July 2021).
- Singh, P.; Pandey, P.C.; Petropoulos, G.P.; Pavlides, A.; Srivastava, P.K.; Koutsias, N.; Deng, K.A.K.; Bao, Y. Hyperspectral remote sensing in precision agriculture: Present status, challenges, and future trends. In Hyperspectral Remote Sensing; Elsevier: Amsterdam, The Netherlands, 2020; pp. 121–146. [Google Scholar]
- Cisternas, I.; Velásquez, I.; Caro, A.; Rodríguez, A. Systematic literature review of implementations of precision agriculture. Comput. Electron. Agric. 2020, 176, 105626. [Google Scholar] [CrossRef]
- Hosseiny, B.; Rastiveis, H.; Homayouni, S. An Automated Framework for Plant Detection Based on Deep Simulated Learning from Drone Imagery. Remote. Sens. 2020, 12, 3521. [Google Scholar] [CrossRef]
- Aburasain, R.Y.; Edirisinghe, E.A.; Albatay, A. Palm Tree Detection in Drone Images Using Deep Convolutional Neural Networks: Investigating the Effective Use of YOLO V3. Conference on Multimedia, Interaction, Design and Innovation. LOCATION OF CONFERENCE, COUNTRYDATE OF CONFERENCE; pp. 21–36.
- Lu, Y.; Young, S. A survey of public datasets for computer vision tasks in precision agriculture. Comput. Electron. Agric. 2020, 178, 105760. [Google Scholar] [CrossRef]
- Shafi, U.; Mumtaz, R.; García-Nieto, J.; Hassan, S.A.; Zaidi, S.A.R.; Iqbal, N. Precision Agriculture Techniques and Practices: From Considerations to Applications. Sensors 2019, 19, 3796. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. A review of the use of convolutional neural networks in agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef]
- D.-K. K. Chengjuan Ren and Dongwon Jeong, “A Survey of Deep Learning in Agriculture: Techniques and Their Applications,” Journal of Information Processing Systems, vol. 16, no. 5, pp. 1015–1033, Oct. 2020. [CrossRef]
- V. Meshram, K. Patil, V. Meshram, D. Hanchate, and S. Ramkteke D., “Machine learning in agriculture domain: A state-of-art survey | Elsevier Enhanced Reader.”. Available online: https://reader.elsevier.com/reader/sd/pii/S2667318521000106?token=634DCBF0EC91ABEE41DEF3AF831054DC77F10DB01949D5414FBFDEC54E71CE2F2127753BEBEF4695C760D0F00D992D14&originRegion=eu-west-1&originCreation=20220719054056 (accessed on 19 July 2022).
- Radoglou-Grammatikis, P.; Sarigiannidis, P.; Lagkas, T.; Moscholios, I. A compilation of UAV applications for precision agriculture. Comput. Netw. 2020, 172, 107148. [Google Scholar] [CrossRef]
- Aslan, M.F.; Durdu, A.; Sabanci, K.; Ropelewska, E.; Gültekin, S.S. A Comprehensive Survey of the Recent Studies with UAV for Precision Agriculture in Open Fields and Greenhouses. Appl. Sci. 2022, 12, 1047. [Google Scholar] [CrossRef]
- Food and Agriculture Organization of the United Nations. Available online: http://www.fao.org/news/story/en/item/1187738/icode/ (accessed on 9 September 2020).
- Khakimov, I. Salakhutdinov, A. Omonlikov, and S. Utagnov, “Traditional and current-prospective methods of agricultural plant diseases detection: A review.”. Available online: https://www.researchgate.net/publication/357714060_Traditional_and_current-prospective_methods_of_agricultural_plant_diseases_detection_A_review (accessed on 21 July 2022).
- Fang, Y.; Ramasamy, R.P. Current and Prospective Methods for Plant Disease Detection. Biosensors 2015, 5, 537–561. [Google Scholar] [CrossRef]
- Ecological Understanding of Insects in Organic Farming Systems: How Insects Damage Plants | eOrganic.”. Available online: https://eorganic.org/node/3151 (accessed on 21 July 2022).
- Reedha, R.; Dericquebourg, E.; Canals, R.; Hafiane, A. Transformer Neural Network for Weed and Crop Classification of High Resolution UAV Images. Remote. Sens. 2022, 14, 592. [Google Scholar] [CrossRef]
- Arun, R.A.; Umamaheswari, S.; Jain, A.V. Reduced U-Net Architecture for Classifying Crop and Weed using Pixel-wise Segmentation. 2020 IEEE International Conference for Innovation in Technology (INOCON). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 1–6.
- Sharma, A.; Kumar, V.; Shahzad, B.; Tanveer, M.; Sidhu, G.P.S.; Handa, N.; Kohli, S.K.; Yadav, P.; Bali, A.S.; Parihar, R.D.; et al. Worldwide pesticide usage and its impacts on ecosystem. SN Appl. Sci. 2019, 1, 1446. [Google Scholar] [CrossRef]
- Rai, M.; Ingle, A. Role of nanotechnology in agriculture with special reference to management of insect pests. Appl. Microbiol. Biotechnol. 2012, 94, 287–293. [Google Scholar] [CrossRef]
- Pest control efficiency in Agriculture - Futurcrop. Available online: https://futurcrop.com/en/blog/post/pest-control-efficiency-in-agriculture (accessed on 28 July 2022).
- Urban vegetation classification: Benefits of multitemporal RapidEye satellite data | Elsevier Enhanced Reader. Available online: https://reader.elsevier.com/reader/sd/pii/S0034425713001429?token=8C76FFADC2BF1E1A573FBD896D61E55BF50B5D27C5866C1CBB6B247EC2328C2170337BF8AF4B02F0D77FBB9520D68A30&originRegion=us-east-1&originCreation=20220722111257 (accessed on 22 July 2022).
- Remote sensing of urban environments: Special issue | Elsevier Enhanced Reader. Available online: https://reader.elsevier.com/reader/sd/pii/S0034425711002781?token=418370169508BB5AAFF98E8B53A3FB30990D7886B72D5D22A007F023EBF3BF79DCFCC674C589CA16CD7EBA979A63F179&originRegion=us-east-1&originCreation=20220722111729 (accessed on 22 July 2022).
- IOWAAGLITERACY, “Why do they do that? – Estimating Yields,” Iowa Agriculture Literacy, Sep. 18, 2019. Available online: https://iowaagliteracy.wordpress.com/2019/09/18/why-do-they-do-that-estimating-yields/ (accessed on 21 July 2022).
- Horie, T.; Yajima, M.; Nakagawa, H. Yield forecasting. Agric. Syst. 1992, 40, 211–236. [Google Scholar] [CrossRef]
- Crop Yield,” Investopedia. Available online: https://www.investopedia.com/terms/c/crop-yield.asp (accessed on 21 July 2022).
- Altalak, M.; Uddin, M.A.; Alajmi, A.; Rizg, A. Smart Agriculture Applications Using Deep Learning Technologies: A Survey. Appl. Sci. 2022, 12, 5919. [Google Scholar] [CrossRef]
- R. K. Prange, “Pre-harvest, harvest and post-harvest strategies for organic production of fruits and vegetables.”. Available online: https://www.researchgate.net/publication/284871289_Pre-harvest_harvest_and_post-harvest_strategies_for_organic_production_of_fruits_and_vegetables (accessed on 25 July 2022).
- PDF) Tomato Fruit Yields and Quality under Water Deficit and Salinity. Available online: https://www.researchgate.net/publication/279642090_Tomato_Fruit_Yields_and_Quality_under_Water_Deficit_and_Salinity (accessed on 30 July 2022).
- Atay, E.; Hucbourg, B.; Drevet, A.; Lauri, P.-E. INVESTIGATING EFFECTS OF OVER-IRRIGATION AND DEFICIT IRRIGATION ON YIELD AND FRUIT QUALITY IN PINK LADYTM ‘ROSY GLOW’ APPLE. Acta Sci. Pol. Hortorum Cultus 2017, 16, 45–51. [Google Scholar] [CrossRef]
- Li, X.; Ba, Y.; Zhang, M.; Nong, M.; Yang, C.; Zhang, S. Sugarcane Nitrogen Concentration and Irrigation Level Prediction Based on UAV Multispectral Imagery. Sensors 2022, 22, 2711. [Google Scholar] [CrossRef]
- Aden, S.T.; Bialas, J.P.; Champion, Z.; Levin, E.; McCarty, J.L. Low cost infrared and near infrared sensors for UAVs. ISPRS - Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2014, XL-1, 1–7. [CrossRef]
- Arah, I.K.; Amaglo, H.; Kumah, E.K.; Ofori, H. Preharvest and Postharvest Factors Affecting the Quality and Shelf Life of Harvested Tomatoes: A Mini Review. Int. J. Agron. 2015, 2015, 478041. [Google Scholar] [CrossRef]
- What methods can improve crop performance? | Royal Society. Available online: https://royalsociety.org/topics-policy/projects/gm-plants/what-methods-other-than-genetic-improvement-can-improve-crop-performance/ (accessed on 29 July 2022).
- Takamatsu, T.; Kitagawa, Y.; Akimoto, K.; Iwanami, R.; Endo, Y.; Takashima, K.; Okubo, K.; Umezawa, M.; Kuwata, T.; Sato, D.; et al. Over 1000 nm Near-Infrared Multispectral Imaging System for Laparoscopic In Vivo Imaging. Sensors 2021, 21, 2649. [Google Scholar] [CrossRef]
- Sellami, A.; Tabbone, S. Deep neural networks-based relevant latent representation learning for hyperspectral image classification. Pattern Recognit. 2021, 121, 108224. [Google Scholar] [CrossRef]
- Multispectral Image - an overview | ScienceDirect Topics. Available online: https://www.sciencedirect.com/topics/earth-and-planetary-sciences/multispectral-image (accessed on 13 December 2022).
- Turner, E.L.; Schafer, J.; Ford, E.; O'Malley-James, J.T.; Kaltenegger, L.; Kite, E.S.; Gaidos, E.; Onstott, T.C.; Lingam, M.; Loeb, A.; et al. Vegetation's Red Edge: A Possible Spectroscopic Biosignature of Extraterrestrial Plants. Astrobiology 2005, 5, 372–390. [Google Scholar] [CrossRef]
- Land Management Information Center - Minnesota Land Ownership,” MN IT Services. Available online: https://www.mngeo.state.mn.us/chouse/airphoto/cir.html (accessed on 13 December 2022).
- GISGeography, “What is NDVI (Normalized Difference Vegetation Index)?,” GIS Geography, , 2017. 09 May. Available online: https://gisgeography.com/ndvi-normalized-difference-vegetation-index/ (accessed on 13 December 2022).
- Tendolkar, A.; Choraria, A.; Pai, M.M.M.; Girisha, S.; Dsouza, G.; Adithya, K. Modified crop health monitoring and pesticide spraying system using NDVI and Semantic Segmentation: An AGROCOPTER based approach. 2021 IEEE International Conference on Autonomous Systems (ICAS). LOCATION OF CONFERENCE, CanadaDATE OF CONFERENCE; pp. 1–5.
- Júnior, P.C.P.; Monteiro, A.; Ribeiro, R.D.L.; Sobieranski, A.C.; Von Wangenheim, A. Comparison of Supervised Classifiers and Image Features for Crop Rows Segmentation on Aerial Images. Appl. Artif. Intell. 2020, 34, 271–291. [Google Scholar] [CrossRef]
- Lottes, P.; Khanna, R.; Pfeifer, J.; Siegwart, R.; Stachniss, C. UAV-based crop and weed classification for smart farming. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3024–3031. [Google Scholar]
- V. Lakshmanan, M. V. Lakshmanan, M. Görner, and R. Gillard, Practical Machine Learning for Computer Vision. O’Reilly Media, Inc., 2021.
- Bouguettaya, A.; Zarzour, H.; Kechida, A.; Taberkit, A.M. Deep learning techniques to classify agricultural crops through UAV imagery: a review. Neural Comput. Appl. 2022, 34, 9511–9536. [Google Scholar] [CrossRef] [PubMed]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126. [Google Scholar] [CrossRef]
- Tian, D.; Han, Y.; Wang, B.; Guan, T.; Gu, H.; Wei, W. Review of object instance segmentation based on deep learning. J. Electron. Imaging 2021, 31, 041205. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, T.; Yang, C.; Song, H.; Jiang, Z.; Zhou, G.; Zhang, D.; Feng, H.; Xie, J. Segmenting Purple Rapeseed Leaves in the Field from UAV RGB Imagery Using Deep Learning as an Auxiliary Means for Nitrogen Stress Detection. Remote. Sens. 2020, 12, 1403. [Google Scholar] [CrossRef]
- Liliane, T.N.; MutwCharlengas, M.S.C. Factors Affecting Yield of Crops. In Agronomy-Climate Change & Food Security; Amanullah, IntechOpen: London, UK, 2020; Volume 9, pp. 1–16. [Google Scholar] [CrossRef]
- Natividade, J.; Prado, J.; Marques, L. Low-cost multi-spectral vegetation classification using an Unmanned Aerial Vehicle. 2017 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC). LOCATION OF CONFERENCE, PortugalDATE OF CONFERENCE; pp. 336–342.
- Pérez-Ortiz, M.; Peña, J.; Gutiérrez, P.; Torres-Sánchez, J.; Hervás-Martínez, C.; López-Granados, F. A semi-supervised system for weed mapping in sunflower crops using unmanned aerial vehicles and a crop row detection method. Appl. Soft Comput. 2015, 37, 533–544. [Google Scholar] [CrossRef]
- Rodriguez-Garlito, E.C.; Paz-Gallardo, A. Efficiently Mapping Large Areas of Olive Trees Using Drones in Extremadura, Spain. 2021, 2, 148–156. [CrossRef]
- Rocha, B.M.; Vieira, G.d.S.; Fonseca, A.U.; Pedrini, H.; de Sousa, N.M.; Soares, F. Evaluation and Detection of Gaps in Curved Sugarcane Planting Lines in Aerial Images. 2020 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE). LOCATION OF CONFERENCE, CanadaDATE OF CONFERENCE; pp. 1–4.
- Crimaldi, M.; Cristiano, V.; De Vivo, A.; Isernia, M.; Ivanov, P.; Sarghini, F. Neural Network Algorithms for Real Time Plant Diseases Detection Using UAVs. International Mid-Term Conference of the Italian Association of Agricultural Engineering. LOCATION OF CONFERENCE, ItalyDATE OF CONFERENCE; pp. 827–835.
- Milioto, A.; Lottes, P.; Stachniss, C. Real-time blob-wise sugar beets vs weeds classification for monitoring fields using convolutional neural networks. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 41–48. [Google Scholar] [CrossRef]
- Bah, M.D.; Dericquebourg, E.; Hafiane, A.; Canals, R. Deep learning based classification system for identifying weeds using high-resolution UAV imagery. Science and Information Conference:Springer, 2018,176-87.
- Reddy, S.R.G.; Varma, G.P.S.; Davuluri, R.L. Optimized convolutional neural network model for plant species identification from leaf images using computer vision. Int. J. Speech Technol. 2021, 26, 23–50. [Google Scholar] [CrossRef]
- Sembiring, A.; Away, Y.; Arnia, F.; Muharar, R. Development of Concise Convolutional Neural Network for Tomato Plant Disease Classification Based on Leaf Images. J. Physics: Conf. Ser. 2021, 1845. [Google Scholar] [CrossRef]
- Geetharamani, G. and Arun Pandian J, “Identification of plant leaf diseases using a nine-layer deep convolutional neural network | Elsevier Enhanced Reader.”. Available online: https://reader.elsevier.com/reader/sd/pii/S0045790619300023?token=2C657881C2D2EDBB85C23044E8BFCA69B649314432597FA9D45A48392FD1B10F49E30D04D95706CA328CD1A114A7E17E&originRegion=eu-west-1&originCreation=20220615171346 (accessed on 15 June 2022).
- R. , K.; M., H.; Anand, S.; Mathikshara, P.; Johnson, A.; R., M. Attention embedded residual CNN for disease detection in tomato leaves. Appl. Soft Comput. 2019, 86, 105933. [Google Scholar] [CrossRef]
- Nanni, L.; Manfè, A.; Maguolo, G.; Lumini, A.; Brahnam, S. High performing ensemble of convolutional neural networks for insect pest image detection. Ecol. Informatics 2021, 67, 101515. [Google Scholar] [CrossRef]
- Atila, M. Uçar, K. Akyol, and E. Uçar, “Plant leaf disease classification using EfficientNet deep learning model | Elsevier Enhanced Reader.”. Available online: https://reader.elsevier.com/reader/sd/pii/S1574954120301321?token=6A5F2FC8AE4A263722309CBE19B195E31EB4D614A298D3B3DAD91C75A971E4A88E7545F453E28200C3D2E11D49D8C189&originRegion=us-east-1&originCreation=20220616151758 (accessed on 16 June 2022).
- Prasad, N. Mehta, M. Horak, and W. D. Bae, “A two-step machine learning approach for crop disease detection: an application of GAN and UAV technology.” arXiv, Sep. 18, 2021. Accessed: Jun. 19, 2022. [Online]. 1106. Available online: http://arxiv.org/abs/2109.
- Albattah, W.; Javed, A.; Nawaz, M.; Masood, M.; Albahli, S. Artificial Intelligence-Based Drone System for Multiclass Plant Disease Detection Using an Improved Efficient Convolutional Neural Network. Front. Plant Sci. 2022, 13, 808380. [Google Scholar] [CrossRef]
- Mishra, S.; Sachan, R.; Rajpal, D. Deep Convolutional Neural Network based Detection System for Real-time Corn Plant Disease Recognition. Procedia Comput. Sci. 2020, 167, 2003–2010. [Google Scholar] [CrossRef]
- Bah, M.D.; Hafiane, A.; Canals, R. Deep Learning with Unsupervised Data Labeling for Weed Detection in Line Crops in UAV Images. Remote. Sens. 2018, 10, 1690. [Google Scholar] [CrossRef]
- Zheng, Y.; Sarigul, E.; Panicker, G.; Stott, D. Vineyard LAI and canopy coverage estimation with convolutional neural network models and drone pictures. Sensing for Agriculture and Food Quality and Safety XIV. LOCATION OF CONFERENCE, United StatesDATE OF CONFERENCE; pp. 29–38.
- Yang, R.; Lu, X.; Huang, J.; Zhou, J.; Jiao, J.; Liu, Y.; Liu, F.; Su, B.; Gu, P. A Multi-Source Data Fusion Decision-Making Method for Disease and Pest Detection of Grape Foliage Based on ShuffleNet V2. Remote. Sens. 2021, 13, 5102. [Google Scholar] [CrossRef]
- Briechle, S.; Krzystek, P.; Vosselman, G. CLASSIFICATION OF TREE SPECIES AND STANDING DEAD TREES BY FUSING UAV-BASED LIDAR DATA AND MULTISPECTRAL IMAGERY IN THE 3D DEEP NEURAL NETWORK POINTNET++. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. 2020, V-2-2020, 203–210. [CrossRef]
- Aiger, D.; Allen, B.; Golovinskiy, A. Large-Scale 3D Scene Classification with Multi-View Volumetric CNN. Computer Vision and Pattern Recognition. arXiv 2017, arXiv:1712.09216. Available online: https://arxiv.org/abs/1712.09216 (accessed on 25 December 2021). [Google Scholar]
- Bah, M.D.; Hafiane, A.; Canals, R. CRowNet: Deep Network for Crop Row Detection in UAV Images. IEEE Access 2019, 8, 5189–5200. [Google Scholar] [CrossRef]
- Ronneberger, P. Fischer, and T. Brox, "U-Net: Convolutional Networks for Biomedical Image Segmentation," arXiv.org, May 18, 2015. Available online: https://arxiv.org/abs/1505.04597.
- Kitano, B.T.; Mendes, C.C.T.; Geus, A.R.; Oliveira, H.C.; Souza, J.R. Corn Plant Counting Using Deep Learning and UAV Images. IEEE Geosci. Remote. Sens. Lett. 2019, 1–5. [Google Scholar] [CrossRef]
- Lin, Z.; Guo, W. Sorghum Panicle Detection and Counting Using Unmanned Aerial System Images and Deep Learning. Front. Plant Sci. 2020, 11. [Google Scholar] [CrossRef]
- L. El Hoummaidi, A. L. El Hoummaidi, A. Larabi, and K. Alam, “Using unmanned aerial systems and deep learning for agriculture mapping in Dubai | Elsevier Enhanced Reader.”. Available online: https://reader.elsevier.com/reader/sd/pii/S240584402102257X?token=08CBD9EDFD77D8950813E1351450D76E494A52920C53A724FFC4763B2D03C6A459F63D6C1C254EF04EBB26AA5515DACC&originRegion=eu-west-1&originCreation=20220601233300 (accessed on 2 June 2022).
- Doha, R.; Al Hasan, M.; Anwar, S.; Rajendran, V. Deep Learning based Crop Row Detection with Online Domain Adaptation. KDD '21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. LOCATION OF CONFERENCE, SingaporeDATE OF CONFERENCE;
- Zhang, T.; Yang, Z.; Xu, Z.; Li, J. Wheat Yellow Rust Severity Detection by Efficient DF-UNet and UAV Multispectral Imagery. IEEE Sensors J. 2022, 22, 9057–9068. [Google Scholar] [CrossRef]
- Tsuichihara, S.; Akita, S.; Ike, R.; Shigeta, M.; Takemura, H.; Natori, T.; Aikawa, N.; Shindo, K.; Ide, Y.; Tejima, S. Drone and GPS Sensors-Based Grassland Management Using Deep-Learning Image Segmentation. 2019 Third IEEE International Conference on Robotic Computing (IRC). LOCATION OF CONFERENCE, ItalyDATE OF CONFERENCE; pp. 608–611.
- Yang, M.-D.; Boubin, J.G.; Tsai, H.P.; Tseng, H.-H.; Hsu, Y.-C.; Stewart, C.C. Adaptive autonomous UAV scouting for rice lodging assessment using edge computing with deep learning EDANet. Comput. Electron. Agric. 2020, 179. [Google Scholar] [CrossRef]
- Weyler, J.; Magistri, F.; Seitz, P.; Behley, J.; Stachniss, C. In-Field Phenotyping Based on Crop Leaf and Plant Instance Segmentation. 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). LOCATION OF CONFERENCE, United StatesDATE OF CONFERENCE; pp. 2968–2977.
- Guo, Y.; Zhang, J.; Yin, C.; Hu, X.; Zou, Y.; Xue, Z.; Wang, W. Plant Disease Identification Based on Deep Learning Algorithm in Smart Farming. Discret. Dyn. Nat. Soc. 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Torres-Sánchez, J.; Mesas-Carrascosa, F.J.; Jiménez-Brenes, F.M.; de Castro, A.I.; López-Granados, F. Early Detection of Broad-Leaved and Grass Weeds in Wide Row Crops Using Artificial Neural Networks and UAV Imagery. Agronomy 2021, 11, 749. [Google Scholar] [CrossRef]
- Zhang, X.; Li, N.; Ge, L.; Xia, X.; Ding, N. A Unified Model for Real-Time Crop Recognition and Stem Localization Exploiting Cross-Task Feature Fusion. 2020 IEEE International Conference on Real-time Computing and Robotics (RCAR). LOCATION OF CONFERENCE, JapanDATE OF CONFERENCE; pp. 327–332.
- Li, N.; Zhang, X.; Zhang, C.; Guo, H.; Sun, Z.; Wu, X. Real-Time Crop Recognition in Transplanted Fields With Prominent Weed Growth: A Visual-Attention-Based Approach. IEEE Access 2019, 7, 185310–185321. [Google Scholar] [CrossRef]
- Chen, C.-J.; Huang, Y.-Y.; Li, Y.-S.; Chen, Y.-C.; Chang, C.-Y.; Huang, Y.-M. Identification of Fruit Tree Pests With Deep Learning on Embedded Drone to Achieve Accurate Pesticide Spraying. IEEE Access 2021, 9, 21986–21997. [Google Scholar] [CrossRef]
- Z. Qin, W. Z. Qin, W. Wang, K.-H. Dammer, L. Guo, and Z. Cao, “A Real-time Low-cost Artificial Intelligence System for Autonomous Spraying in Palm Plantations.” arXiv, Mar. 06, 2021. Accessed: Jun. 15, 2022. [Online]. Available online: http://arxiv.org/abs/2103.04132.
- Parico, A.I.B.; Ahamed, T. An Aerial Weed Detection System for Green Onion Crops Using the You Only Look Once (YOLOv3) Deep Learning Algorithm. Eng. Agric. Environ. Food 2020, 13, 42–48. [Google Scholar] [CrossRef]
- C. Rui, G. C. Rui, G. Youwei, Z. Huafei, and J. Hongyu, “A Comprehensive Approach for UAV Small Object Detection with Simulation-based Transfer Learning and Adaptive Fusion.” arXiv, Sep. 04, 2021. Accessed: Jun. 15, 2022. [Online]. 0180. Available online: http://arxiv.org/abs/2109.01800.
- Parico, A.I.B.; Ahamed, T. Real Time Pear Fruit Detection and Counting Using YOLOv4 Models and Deep SORT. Sensors 2021, 21, 4803. [Google Scholar] [CrossRef] [PubMed]
- Jintasuttisak, T.; Edirisinghe, E.; Elbattay, A. Deep neural network based date palm tree detection in drone imagery. Comput. Electron. Agric. 2021, 192, 106560. [Google Scholar] [CrossRef]
- Y. Tian, G. Y. Tian, G. Yang, Z. Wang, E. Li, and Z. Liang, “Detection of Apple Lesions in Orchards Based on Deep Learning Methods of CycleGAN and YOLOV3-Dense.”. Available online: https://www.researchgate.net/publication/355887041_Detection_of_Apple_Lesions_in_Orchards_Based_on_Deep_Learning_Methods_of_CycleGAN_and_YOLOV3-Dense (accessed on 20 June 2022).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar] [CrossRef]
- Veeranampalayam Sivakumar, A.N.; Li, J.; Scott, S.; Psota, E.; Jhala, A.J.; Luck, J.D.; Shi, Y. Comparison of Object Detection and Patch-Based Classification Deep Learning Models on Mid- to Late-Season Weed Detection in UAV Imagery. Remote Sens. 2020, 12, 2136. [Google Scholar] [CrossRef]
- Ridho, M.F. ; Irwan Strawberry Fruit Quality Assessment for Harvesting Robot using SSD Convolutional Neural Network. 2021 8th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI). LOCATION OF CONFERENCE, IndonesiaDATE OF CONFERENCE;
- Ammar, A.; Koubaa, A.; Benjdira, B. Deep-Learning-Based Automated Palm Tree Counting and Geolocation in Large Farms from Aerial Geotagged Images. Agronomy 2021, 11, 1458. [Google Scholar] [CrossRef]
- W.-H. Su et al., “Automatic Evaluation of Wheat Resistance to Fusarium Head Blight Using Dual Mask-RCNN Deep Learning Frameworks in Computer Vision.”. Available online: https://www.researchgate.net/publication/347793558_Automatic_Evaluation_of_Wheat_Resistance_to_Fusarium_Head_Blight_Using_Dual_Mask-RCNN_Deep_Learning_Frameworks_in_Computer_Vision (accessed on 20 June 2022).
- Der Yang, M.; Tseng, H.H.; Hsu, Y.C.; Tseng, W.C. Real-time Crop Classification Using Edge Computing and Deep Learning. 2020 IEEE 17th Annual Consumer Communications & Networking Conference (CCNC). LOCATION OF CONFERENCE, United StatesDATE OF CONFERENCE; pp. 1–4.
- Menshchikov, A.; Shadrin, D.; Prutyanov, V.; Lopatkin, D.; Sosnin, S.; Tsykunov, E.; Iakovlev, E.; Somov, A. Real-Time Detection of Hogweed: UAV Platform Empowered by Deep Learning. IEEE Trans. Comput. 2021, 70, 1175–1188. [Google Scholar] [CrossRef]
- Weyler, J.; Quakernack, J.; Lottes, P.; Behley, J.; Stachniss, C. Joint Plant and Leaf Instance Segmentation on Field-Scale UAV Imagery. IEEE Robot. Autom. Lett. 2022, 7, 3787–3794. [Google Scholar] [CrossRef]
- P. Lottes, J. P. Lottes, J. Behley, N. Chebrolu, A. Milioto, and C. Stachniss, “Robust joint stem detection and crop-weed classification using image sequences for plant-specific treatment in precision farming.”. Available online: https://www.researchgate.net/publication/335117645_Robust_joint_stem_detection_and_crop-weed_classification_using_image_sequences_for_plant-specific_treatment_in_precision_farming (accessed on 7 June 2022).
- Su, D.; Qiao, Y.; Kong, H.; Sukkarieh, S. Real time detection of inter-row ryegrass in wheat farms using deep learning. Biosyst. Eng. 2021, 204, 198–211. [Google Scholar] [CrossRef]
- et al. , “Attention is All you Need,” in Advances in Neural Information Processing Systems, Curran Associates, Inc., 2017. Accessed: Jun. 18, 2022. [Online]. Available online: https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html.
- et al. , “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” arXiv, Jun. 03, 2021. [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics) LNCS; Volume 12346, pp. 213–229. [Google Scholar] [CrossRef]
- Thai, H.-T.; Tran-Van, N.-Y.; Le, K.-H. Artificial Cognition for Early Leaf Disease Detection using Vision Transformers. 2021 International Conference on Advanced Technologies for Communications (ATC). LOCATION OF CONFERENCE, VietnamDATE OF CONFERENCE; pp. 33–38.
- J. Deng, W. J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A Large-Scale Hierarchical Image Database,” p. 8.
- Cassava Leaf Disease Classification. Available online: https://kaggle.com/competitions/cassava-leaf-disease-classification (accessed on 18 June 2022).
- Karila, K.; Oliveira, R.A.; Ek, J.; Kaivosoja, J.; Koivumäki, N.; Korhonen, P.; Niemeläinen, O.; Nyholm, L.; Näsi, R.; Pölönen, I.; et al. Estimating Grass Sward Quality and Quantity Parameters Using Drone Remote Sensing with Deep Neural Networks. Remote. Sens. 2022, 14, 2692. [Google Scholar] [CrossRef]
- S. Dersch, A. S. Dersch, A. Schottl, P. Krzystek, and M. Heurich, “NOVEL SINGLE TREE DETECTION BY TRANSFORMERS USING UAV-BASED MULTISPECTRAL IMAGERY - ProQuest.”. Available online: https://www.proquest.com/openview/228f8f292353d30b26ebcdd38372d40d/1?pq-origsite=gscholar&cbl=2037674 (accessed on 15 June 2022).
- Chen, G.; Shang, Y. Transformer for Tree Counting in Aerial Images. Remote. Sens. 2022, 14, 476. [Google Scholar] [CrossRef]
- Liu, W.; Salzmann, M.; Fua, P. Context-Aware Crowd Counting. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5094–5103. [Google Scholar]
- X. Zhang et al., “The self-supervised spectral-spatial attention-based transformer network for automated, accurate prediction of crop nitrogen status from UAV imagery,” arXiv, arXiv:2111.06839, Feb. 2022. arXiv:2111.06839, Feb. 2022. [CrossRef]
- Coletta, L.F.; de Almeida, D.C.; Souza, J.R.; Manzione, R.L. Novelty detection in UAV images to identify emerging threats in eucalyptus crops. Comput. Electron. Agric. 2022, 196. [Google Scholar] [CrossRef]
- Silva, C.A.; Hudak, A.T.; Vierling, L.A.; Loudermilk, E.L.; O’brien, J.J.; Hiers, J.K.; Jack, S.B.; Gonzalez-Benecke, C.; Lee, H.; Falkowski, M.J.; et al. Imputation of Individual Longleaf Pine (Pinus palustrisMill.) Tree Attributes from Field and LiDAR Data. Can. J. Remote. Sens. 2016, 42, 554–573. [Google Scholar] [CrossRef]
- Bosilj, P.; Aptoula, E.; Duckett, T.; Cielniak, G. Transfer learning between crop types for semantic segmentation of crops versus weeds in precision agriculture. J. Field Robot. 2019, 37, 7–19. [Google Scholar] [CrossRef]
- Khan, S.; Tufail, M.; Khan, M.T.; Khan, Z.A.; Iqbal, J.; Alam, M. A novel semi-supervised framework for UAV based crop/weed classification. PLOS ONE 2021, 16, e0251008. [Google Scholar] [CrossRef]
- Weinstein, B.G.; Marconi, S.; Bohlman, S.; Zare, A.; White, E. Individual Tree-Crown Detection in RGB Imagery Using Semi-Supervised Deep Learning Neural Networks. Remote. Sens. 2019, 11, 1309. [Google Scholar] [CrossRef]
- Z. Alom, T. M. Z. Alom, T. M. Taha, and V. K. Asari, “Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation,” p. 12.
- Fawakherji, M.; Potena, C.; Prevedello, I.; Pretto, A.; Bloisi, D.D.; Nardi, D. Data Augmentation Using GANs for Crop/Weed Segmentation in Precision Farming. 2020 IEEE Conference on Control Technology and Applications (CCTA). LOCATION OF CONFERENCE, CanadaDATE OF CONFERENCE; pp. 279–284.
- Fawakherji, M.; Potena, C.; Pretto, A.; Bloisi, D.D.; Nardi, D. Multi-Spectral Image Synthesis for Crop/Weed Segmentation in Precision Farming. Robot. Auton. Syst. 2021, 146, 103861. [Google Scholar] [CrossRef]
- Mazzia, V.; Khaliq, A.; Salvetti, F.; Chiaberge, M. Real-Time Apple Detection System Using Embedded Systems With Hardware Accelerators: An Edge AI Application. IEEE Access 2020, 8, 9102–9114. [Google Scholar] [CrossRef]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient Transformers: A Survey. ACM Comput. Surv. 2022, 55, 1–28. [Google Scholar] [CrossRef]
- M. Poli et al., “Hyena Hierarchy: Towards Larger Convolutional Language Models.” arXiv, Mar. 05, 2023. [CrossRef]
- Senecal, J.J.; Sheppard, J.W.; Shaw, J.A. Efficient Convolutional Neural Networks for Multi-Spectral Image Classification. 2019 International Joint Conference on Neural Networks (IJCNN). LOCATION OF CONFERENCE, HungaryDATE OF CONFERENCE; pp. 1–8.
- Yang, Z.; Li, J.; Shi, X.; Xu, Z. Dual flow transformer network for multispectral image segmentation of wheat yellow rust. International Conference on Computer, Artificial Intelligence, and Control Engineering (CAICE 2022). LOCATION OF CONFERENCE, ChinaDATE OF CONFERENCE; pp. 119–125.
- Tao, C.; Meng, Y.; Li, J.; Yang, B.; Hu, F.; Li, Y.; Cui, C.; Zhang, W. MSNet: multispectral semantic segmentation network for remote sensing images. GIScience Remote. Sens. 2022, 59, 1177–1198. [Google Scholar] [CrossRef]
- M. López and J. Alberto, “The use of multispectral images and deep learning models for agriculture: the application on Agave,” Dec. 2022, Accessed: Mar. 12, 2023. [Online]. 1128. Available online: https://repositorio.tec.mx/handle/11285/650159.
- Victor, Z. He, and A. Nibali, “A systematic review of the use of Deep Learning in Satellite Imagery for Agriculture.” arXiv, Oct. 03, 2022. [CrossRef]
- P. Sarigiannidis, “Peach Tree Disease Detection Dataset.” IEEE, Nov. 23, 2022. Accessed: Mar. 12, 2023. [Online]. Available online: https://ieee-dataport.org/documents/peach-tree-disease-detection-dataset.
Figure 1.
Sources Distribution of this Survey Paper.
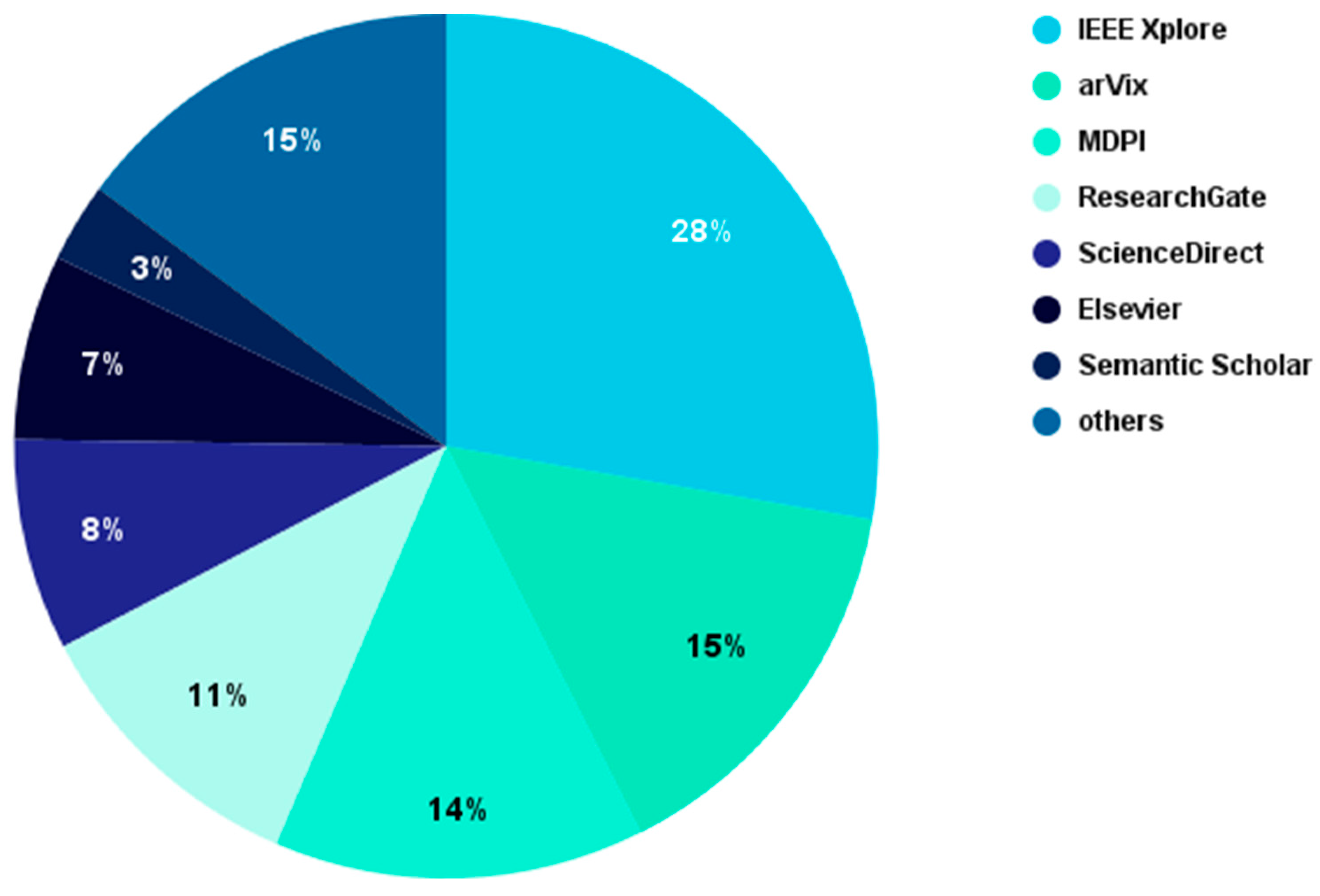
Figure 2.
Image size (pixels) Used for Vision Tasks using UAV Data.
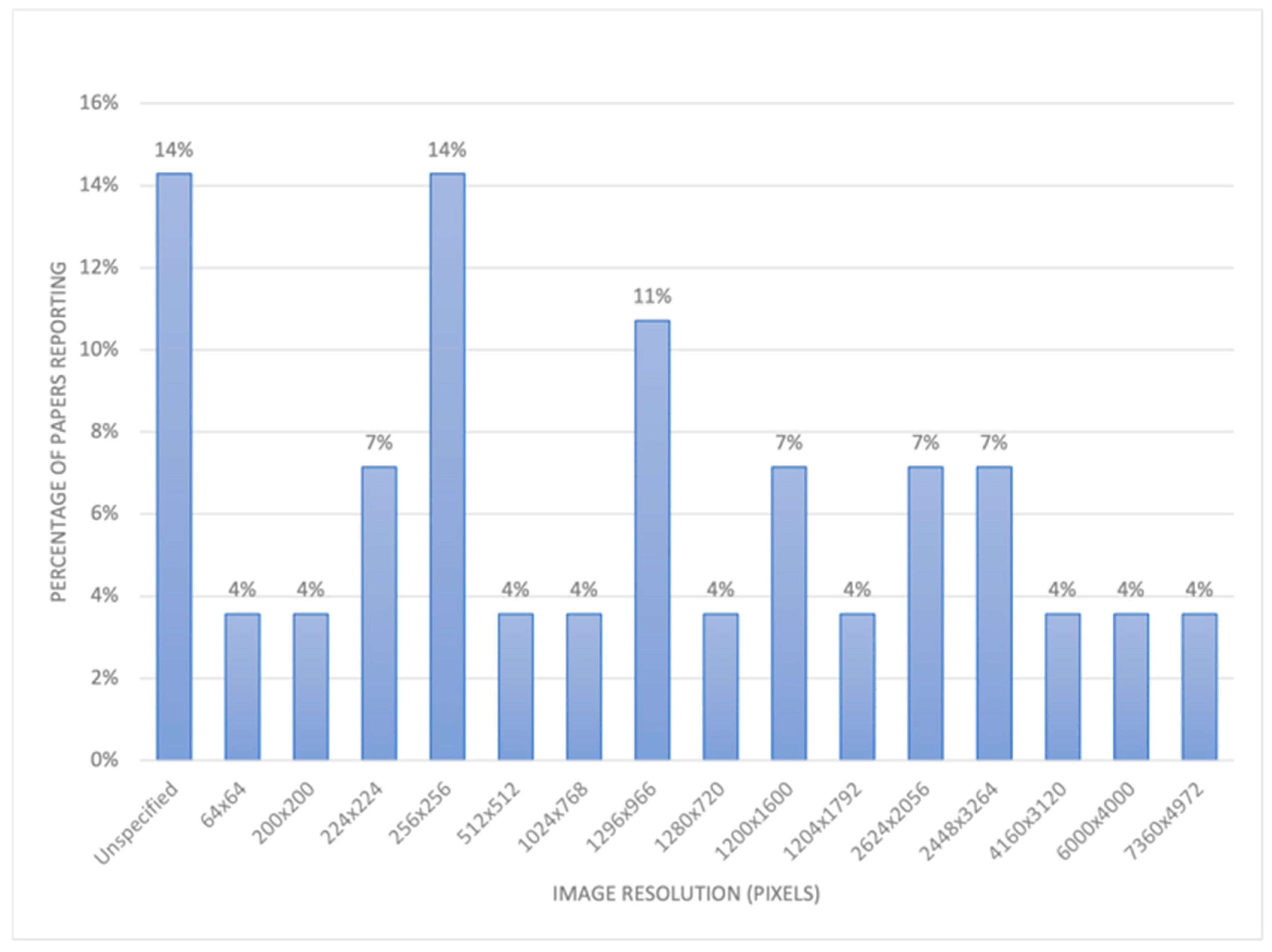
Figure 3.
Various Precision Agricultural Issues Addressed in the Papers.
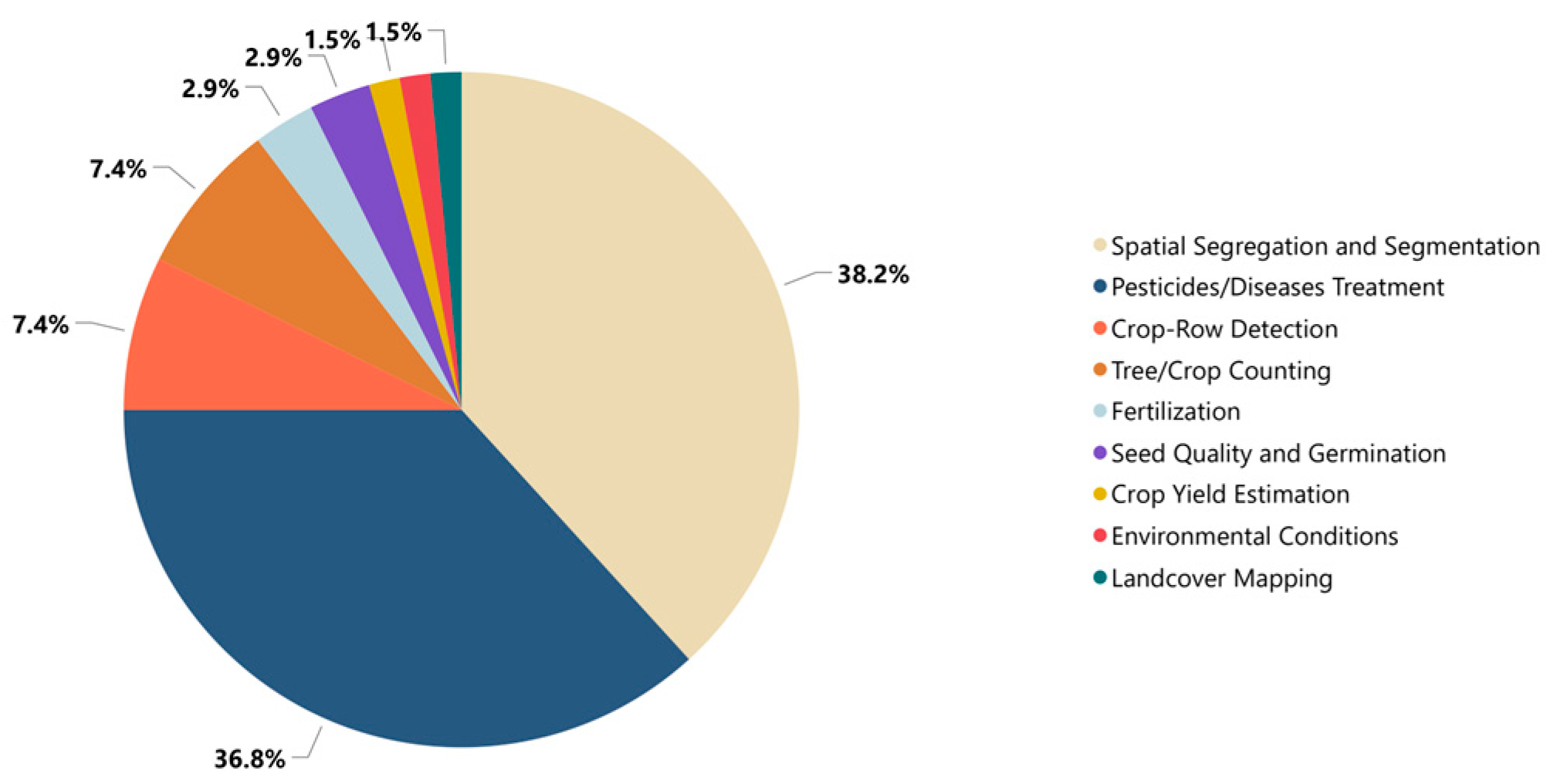
Figure 4.
A Summary of the papers surveyed based on the agricultural problem and technique used.
Table 1.
Summary of Challenges in Agriculture.
| Stage | Challenges |
|---|---|
| Pre-Harvesting | Disease Detection and Diagnosis, Seed Quality, Fertilisers Application, Field Segmentation, Urban Vegetation Classification |
| Harvesting | Crops Detection and Classification, Pest Detection and Control, Crop Yield Estimation, Tree counting, Maturity Level, Cropland Extent |
| Post-Harvesting | Fruit Grading, Quality retaining processes, Storage Environmental Conditions, Chemicals Usage detection |
Table 2.
Support Vector Machine Summary.
| Paper | SVM | |||
|---|---|---|---|---|
| Model / Architecture | Approach | Comments | Best Results | |
| Tendolkar et al. [47] |
SVM |
Dual-step based approach of pixel-wise NDVI calculation and semantic segmentation helps in overcoming NDVI issues. | Model was not compared to any other. | Precision: 85% Recall: 81% F1-score: 79% |
| Natividade et al. [56] | SVM | Pattern recognition system allows for classification of images taken by low-cost cameras. | Accuracy, precision, and recall values of model vary highly between datasets | Dataset #1 (1st configuration): [Accuracy: 78%, Precision: 93%, Recall: 86%, Accuracy: 72%] Dataset #2: [Accuracy: 83%, Precision: 97%, Recall: 94%, Accuracy: 73%] |
| Pérez-Ortiz et al. [57] | SVM | Able to detect weeds outside and within crop rows. Does not require a big training dataset |
Segmentation process produces salt and pepper noise effect on images. Training images are manually selected. Model inference is influenced by training image selection. |
Mean Average Error (MAE): 12.68% |
| César Pereira et al. [48] | LSVM | Model can be trained fast with a small training set | Image dataset is small and simple, containing images of sugarcane cultures only. | Using RGB + EXG + GABOR filters: IOU: 0.788654 F1: 0.880129 |
Table 3.
K-Nearest Neighbors Summary.
| Paper | KNN | |||
|---|---|---|---|---|
| Model/ Architecture | Strengths | Comments | Best Results | |
| César Pereira et al. [48] | KNN3, KNN11 |
Simplest algorithms to implement amongst implemented algorithms in the paper | Models did not achieve the best results in the paper | KNN3 and 11 with RGB+ EXG+GABOR filters: [IOU: 0.76, F1: 0.86] |
| Rodríguez-Garlito and Paz-Gallardo [58] | KNN | Uses an automatic window processing method that allows for the use of ML algorithms on large multispectral images. | Model did not achieve the best results in the paper | Approximate values: AP: 0.955 Accuracy score: 0.918 |
| Rocha et al. [59] | KNN | Best performing classifier | Model cannot perform sugarcane line detection and fault measurement on sugarcane fields of all growth stages | Relative Error: 1.65% |
Table 4.
Decision Trees and Random Forests Summary.
| Paper | DT & RF | |||
|---|---|---|---|---|
| Model/ Architecture | Strengths | Comments | Best Results | |
| Natividade et al. [56] | DT | Pattern recognition system allows for classification of images taken by low-cost cameras. | Model did not outperform SVM on all chosen metrics | Dataset #2: [Accuracy: 77%, Precision: 87%, Recall: 90%, Accuracy: 79%] |
| Lottes et al. [49] | RF | Model can detect plants relying only on its shape. | Low precision and recall for detecting weeds under the “other weeds” class | Saltbush class recall: 95%, Chamomile class recall: 87%, sugar beet class recall: 78%, recall of other weeds class: 45% Overall model accuracy for predicted objects: 86% |
Table 6.
U-Net Summary.
| Paper | U-Net | |||
|---|---|---|---|---|
| Model/ Architecture | Strengths | Comments | Best Results | |
| Lin et al. [80] | U-NET | Can detect overlapping sorghum panicles | The performance decreases with lower number of training images (<500) | Accuracy: 95.5% RMSE: 2.5% |
| Arun et al. [24] | Reduced U-NET | Reduces the total number of parameters and results in a lower error rate | The comparison was done with models that were used to problems not related to agriculture which is what this model was used for | Accuracy: 95.34% Error rate: 7.45% |
| Hoummaidi et al. [81] | U-NET | Real-time and the use of multispectral images | Trees obstruction and physical characteristics causes it to have errors, however it can be improved using a better dataset | Accuracy: 89.7% Palm trees Detection rate: 96.03% Ghaf trees Detection rate: 94.54% |
| Doha et al. [82] | U-NET | The method they used can refine the results of the U-Net to reduce errors as well as do frame interpolation of the input video stream | Not enough results were given | Variance: 0.0083 |
| Zhang et al. [83] | DF-U-Net | Reduces the computation load by more than half and had the highest accuracy among other models compared | Early-stage rust disease is difficult to recognize | F1: 94.13% OA: 96.93% Precision: 94.02% |
| Tsuichihara et al. [84] | U-Net | Accuracy is 80% for only 48 images trained | Low accuracy and that is due to the small number of images which is due to manually painting 6 colors on each image | Accuracy: ~80% |
Table 7.
Other Segmentation Models Summary.
| Paper | Other Segmentation Models | |||
|---|---|---|---|---|
| Model/ Architecture | Strengths | Comments | Best Results | |
| Yang et al. [85] | EDANet | Improved prior work on identifying and lodging by 2.51% and 8.26% respectively | Drone images taken from a greater height do not perform well, however, with the method they proposed it can have reliable results | Identify rice Accuracy: 95.28% Lodging Accuracy: 86.17% If less than 2.5% lodging is neglected, then the accuracy increases to 99.25%. |
| Weyler et al. [86] | ERFNet-based instance segmentation | Data was gathered from real agricultural fields | Comparison was made on different datasets | Crop leaf segmentation Average precision: 48.7% Average recall: 57.3% Crop segmentation Average precision: 60.4% Average recall: 68% |
| Guo et al. [87] | Three stage model with RPN, Chan-Vese algorithms and a transfer learning model | Outperformed the traditional ResNet-101 which had an accuracy of 42.5% and is unsupervised | The Chan-Vese algorithm runs for a long time | Accuracy 83.75% |
| Sanchez et al. [88] | MLP | Carried in commercial fields and not under controlled conditions | The dataset was captured noon to avoid shadow | Overall accuracy on two classes of crops: 80.09% |
| Zhang et al. [89] | UniSteamNet | Joint crop recognition and stem detection in real-time. Fast and can finish processing each image within 6ms. | The scores of this model were not always the best and the differences were small | Segmentation F1: 97.4% IoU: 94.5 Stem detection SDR: 97.8% |
Table 8.
YOLO Summary.
| Paper | YOLO | |||
|---|---|---|---|---|
| Model/ Architecture | Strengths | Comments | Best Results | |
| Chen et al. [91] | Tiny-YOLOv3 | Results in excellent outcomes in regard of FPS and mAP. In addition, reduces pesticide use. | Has a high false identification in adult T. papillosa |
mAP score of 95.33% |
| Qin et al. [92] | Ag-YOLO (v3-tiny) |
Tested Yolov3 with multiple backbones and achieved optimum results in terms of FPS and power consumption | Uses NCS2 that supports 16-bit float point values only | F1 Score of 92.05% |
| Parico et al. [93] | YOLO-Weed (v3) | High speed and mAP score | Limitations in detecting small objects | mAP score of 93.81% F1 score of 94% |
| Rui et al. [94] | YOLOv5 | Improves YOLOv5 ability to detect small objects | Was not tested on agricultural applications | +7.1% of the original model |
| Parico et al. [95] | YOLOv4 (multiple versions) |
Proves that YOLOv4-CSP has the lowest FPS with the highest mAP | Limitations in detecting small objects | AP score of 98% |
| Jintasuttisak et al. [96] | YOLOv5m | Compares different YOLO versions and proves that YOLOv5 with medium depth outperformers the rest even with overlapped trees. | YOLOv5x scored a higher detection average due to the increased number of layers. | mAP score of 92.34% |
| Tian et al. [97] | YOLOv3 (modified) | Tackles the lack of data by generating new images using CycleGAN | The model is weak without the images generated using CycleGAN | F1-score of 81.6% and IoU score of 91.7% |
Table 10.
Two-Stage Detectors Summary.
| Paper | DT & RF | |||
|---|---|---|---|---|
| Model/ Architecture | Strengths | Comments | Best Results | |
| Sivakumar et al. [99] | FRCNN | the optimal confidence threshold of the SSD model was found to be much lower than that of the Faster RCNN model. | Inference time of SSD is better than that of FRCNN, but it can be improved with a cost in performance. | 66% F1-score and 85% IoU. |
| Ammar et al. [101] | FRCNN | Large advantage in terms of speed | Very weak in detecting trees. Outperformed by Efficient-Det D5 and YOLOv3 | 87.13% and 49.41% IoU for Palm and Trees respectively |
| Su et al. [102] | Mask RCNN | Superior in comparison to CNN. | Inference time was not taken into consideration | 98.81% accuracy |
| Yang et al. [103] | FCN-AlexNet | Provides good comparison between SegNet and AlexNet | Outperformed by SegNet | 88.48% Recall Rate |
| Menshchikov et al. [104] | FCNN | Proposed method is applicable in real world scenario and the use of RGB cameras are cheaper than multi-spectral cameras | Complex algorithms compared to the multi-spectral approach |
ROC AUC in segmentation: 0.96 |
| Hosseiny et al. [10] | A model with the core of the framework based on the faster Regional CNN (R-CNN) with a backbone of ResNet-101 for object detection. | Results are good for an unsupervised method | Tested only on single object detection and automatic crop row estimation can fail due to dense plant distribution | Precision: 0.868 Recall: 0.849 F1: 0.855 |
Table 12.
Transformers Summary.
| Paper | Transformers | |||
|---|---|---|---|---|
| Model/ Architecture | Strengths | Comments | Best Results | |
| Reedha et al. [23] | ViT | The classification of crops and weed images using ViTs yields the best prediction performance. | Slightly overperformers existing CNN models | an F1-score of 99.4% and 99.2% were obtained from ViT-B16 and ViT-B32, respectively. |
| Karila et al. [114] | ViT | The ViT RGB models performed the best on several types of datasets. | VGG CNN models provided equally reliable results in most cases. |
Multiple results shown on several types of datasets |
| Dersch et al. [115] | DETR | DETR clearly outperformed YOLOv4 in mixed and deciduous plots | DETR failed to detect smaller trees far worse than YOLOv4 in multiple cases. | An F1-Score of 86% and 71% in mixed and deciduous plots respectively |
| Chen et al. [116] | DENT | The model outperformed most of the state-of-the-art methods | CANNet achieved better results | a Mean Absolute Error (MAE) of 10.7 and a Root Mean Squared Error (RMSE) of 13.7 |
| Coletta et al [119] | Active Learning | The model can classify unknown data. | Did not test the performance of different classification models other than their own. | An accuracy of 98% and a Recall of 97% |
Table 13.
Best Results Achieved in Different Agricultural Problems.
| Problem | Type of learning | Paper | Model/Architecture | Dataset | Best Results |
|---|---|---|---|---|---|
| Spatial Segregation and Segmentation | Supervised | Jintasuttisak et al. [96] | YOLOv5 | date palm trees collected using a drone | mAP score of 92.34% |
| Semi-Supervised | Fawakherji et al [118] | cGANs | of 5,400 RGB images of pears and strawberries of which 20% were labelled | An IoU score of 83.1% on mixed data including both original and synthesized. | |
| Unsupervised | Bah et al. [72] | ResNet18 | UAV images of spinach and bean fields | AUC: 91.7% | |
| Pesticides/ Diseases Treatment | Supervised | Zhang et al. [73] | DF-U-Net | Yangling UAV images | F1: 94.13% Accuracy: 96.93% Precision: 94.02% |
| Semi-Supervised | Coletta et al [119] | Active Learning: SVM | UAV images collected from Eucalyptus plantations | An accuracy of 98% and a Recall of 97% | |
| Unsupervised | Khan et al. [117] | SGAN | UAV images collected from strawberry and pea fields | Accuracy ~90% | |
| Fertilization | Supervised | Natividade et al. [56] | SVM | UAV images of vineyards and forests | Accuracy: 83%, Precision: 97%, Recall: 94% |
| Unsupervised | Zhang et al. [115] | SSVT | UAV images of a wheat field | 96.5% on 384x384-sized images | |
| Crop-Row Detection | Supervised | Cesar Pereira et al. [47] | SVM | Manually collected RGB images | 88.01% F1-Score |
| Semi-Supervised | Pérez-Ortiz et al. [57] | SVM | UAV images collected from a sunflower plot | MAE: 12.68% | |
| Tree/Crop Counting | Supervised | Ammar et al. [98] | FRCNN | Tree counting | 87.13% IoU om Palms and 49.41% on other trees |
| Semi- Supervised | Chen et al. [113] | DENT | Yosemite Tree dataset | 10.7 MAE score | |
| Others | Supervised | Aiger et al. [76] | CNN | UAV images of various types of landcover | 96.3% accuracy |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



