
Submitted:
04 May 2023
Posted:
05 May 2023
You are already at the latest version
Abstract
Malicious apps specifically aimed at the Android platform have increased in tandem with the proliferation of mobile devices. Malware is now so carefully written that it is difficult to detect. Due to the exponential growth in malware, manual methods of malware are increasingly ineffec-tive. Although prior writers have proposed numerous high-quality approaches, static and dy-namic assessments inherently necessitate intricate procedures. The obfuscation methods used by modern malware are incredibly complex and clever. As a result, it cannot be detected using only static malware analysis. As a result, this work presents a hybrid analysis approach, partially tai-lored for multiple-feature data, for identifying Android malware and classifying malware families to improve Android malware detection and classification. This paper offers a hybrid method that combines static and dynamic malware analysis to give a full view of the threat. Three distinct phases make up the framework proposed in this research. Normalization and feature extraction procedures are used in the first phase of pre-processing. Both static and dynamic features undergo feature selection in the second phase. Two feature selection strategies are proposed to choose the best subset of features to use for both static and dynamic features. The third phase involves ap-plying a newly proposed detection model to classify android apps; this model uses a neural net-work optimized with an improved version of HHO. Application of binary and multi-class classi-fication is used, with binary classification for benign and malware apps and multi-class classifica-tion for detecting malware categories and families. By utilizing the features gleaned from static and dynamic malware analysis, several machine-learning methods are used for malware classifi-cation. According to the results of the experiments, the hybrid approach improves the accuracy of detection and classification of Android malware compared to the scenario when considering static and dynamic information separately.
Keywords:
malware
; harris hawks optimization
; feature selection
; benign
; multiclass classification
; multi-verse optimization
; moth-flame optimization
; machine learning.
1. Introduction
Smartphones have rapidly grown in popularity over the past decade, with billions of users, according to an analysis of Statista in 2021[1]. The reason is that smartphones are so handy and convenient [2]. Sending emails, playing games, taking photographs and videos, searching the web, using GPS, and more are just some of the many uses for smartphones. Applications are being developed and improved daily, making it possible to achieve this, particularly on Android’s operating system, which first appeared as a hacked Linux kernel optimized for touchscreen mobile gadgets.
Moreover, last year Android OS apps extended to more than 3 million apps [3]. Banking, social media, healthcare, education, and entertainment are just some of the many possible uses for these Android apps [4]. As a result, most of these apps are employed to benefit their end consumers. Some of them, however, are used maliciously by hackers and exploiters. Malware refers to these harmful applications, defined as invasive software that steals data or causes damage to another user’s computer [5].
Cybercriminals create malware to function in many ways, including adware, worms, ransomware, and Trojan viruses [6]. Because malicious software is always evolving, it is increasingly challenging to foil security breaches [7]. For instance, in 2021, Cybersecurity Check Point warned Android users that millions of mobile smartphones were vulnerable to Agent Smith malware [8]. The spyware also uses WhatsApp as a cover to attack Android systems. In 2021, coccus reported that more than a billion Android smartphones would be vulnerable to hacking because they lacked the latest security upgrades [9]. Additionally, experts from Kaspersky Lab in 2020 found that numerous hackers had used the Google Play app store to spread complex malware [10] for years. Recently, many Facebook accounts were hacked using the android malware “FlyTrap” app [11].
The Android operating system has a built-in authorization module that checks whether or not a security policy has been breached before granting the permissions requested by an Android app. The four categories of Android permissions correspond to the four levels of security outlined in [12]. Also, the dataset includes four types of malware that may be labeled as such: ransomware [13] adware [14], SMS malware, and scareware [15]. The ever-expanding and changing nature of malware has prompted numerous proposals for detecting and avoiding it. The research community has revealed two methods for spotting malware. Static, dynamic, and hybrid malware analysis are three types of analyzing android malware. Static malware analysis is where applications are inspected without being run, while dynamic analysis evaluates the behavior of malware in a sandbox after it has been run [16]. Despite the role of current technologies in improving quality of life and expanding the cyber world, cyber-threats have reached a new level and are increasing at a scary rate [17]. More importantly, new attacks that can breach a smartphone’s defenses are constantly being developed and released.
Violating the security policy might take various forms, depending on the mobile device’s OS. This paper focuses on the Android operating system and new threats that threaten its security. The presence of malware in a mobile app has been investigated by several previous research [18,19,20,21,22], some of which made use of API calls and permissions. According to their findings, Dynamic analysis is also necessary since Static analysis is insufficient for detecting malware in obfuscated apps. It has been found in some research [23] that deep learning can be utilized to detect malware in mobile apps. This paper aims to provide a highly effective method for discovering and naming novel forms of malware, thus overcoming all these restrictions.
This is why we have put time and effort into Android malware detection and family classification. Here, “malware” and “benign” represent two classes in a binary classification problem, whereas “family classification” represents 13 classes in a multi-class classification problem. Android malware family refers to a collection of malicious apps that act similarly and are based on the same code. To identify and categorize malicious Android apps, we propose a hybrid classification. It depends on combining dynamic static malware analysis. At first, we run a static malware analysis to pull out static features like command strings, API calls, intents, and permissions. Then, we used CuckooDroid [24]to analyze dynamic malware to extract features. To do the automated analysis of suspicious Android files, CuckooDroid is an add-on to the cuckoo sandbox [25].
A standard method for malware detection using static and dynamic features, feature selection has received considerable attention [26]. Managing these massive datasets is no easy feat due to their complexity. It could hinder one’s learning ability or even lengthen the time. Feature reduction methods are essential to reduce the dimensionality of data because some attributes in datasets are unnecessary and redundant [27,28,29].
Accordingly, one of the most critical steps in developing a pattern classifier system is the feature selection phase, during which an appropriate feature subset is selected by analyzing possible feature subsets. For this reason, two feature selection strategies, static and dynamic, are proposed for the best possible malware classification in the used dataset. Using fuzzy logic [30,31] in conjunction with metaheuristic optimization, a two-stage feature selection strategy is proposed for selecting dynamic features. To detect and categorize An-droid malware applications, a hybrid model based on fuzzy optimization mixed with meta-heuristic optimization methods, hybrid of enhanced MFO [32] and MVO [33] is evaluated as wrappers. Three feature selection methods, fisher score, chi-square, and information gain, are applied to static features, eliminating more irrelevant features. Then, a subset of candidate features from both static and dynamic features was fed to several machine learning algorithms to produce the best detection results.
Several researchers have proposed artificial neural network (ANN) based models to replace more conventional approaches to malware detection and classification [34]. It has been shown that ANNs can model the relationships between inputs and outputs more accurately than other methods [34,35]. Additional restrictions on ANN use include difficulties in extrapolating beyond training data and overtraining the network due to extensive iterations during the training process. Therefore, the primary goals of this research are to (1) develop a better ANN model using the enhanced version of Harris Hawks optimizer (EHHO) and (2) check the accuracy of this model. The EHHO’s primary goal is to establish the optimal parameters for the ANN.
The following are the original contributions made by us in this paper:
- DroidDetectMW is proposed as a functional and systematic model for detecting and identifying Android malware and its family and category based on a combination of Dynamic and Static attributes.
- Methods are proposed for selecting features, either statically or dynamically, to use.
- A hybrid fuzzy-metaheuristics-optimization approach is proposed for selecting the optimal dynamic feature subset.
- An enhanced version of the HHO algorithm is proposed to optimize the parameters of ANN for malware detection.
- A Comparison is applied between the results of the proposed Deep learning method with those of more traditional machine learning classifiers in determining how well DroidDetectMW works.
- Evaluate the performance of DroidDetectMW in comparison to seven traditional machine learning methods: the Decision Tree (DT), the support vector machine (SVM), the K-Nearest Neighbor, the Multilayer Perceptron (MLP), the Sequential Minimal Optimization (SMO), Random Forest (RF) and the Naive Bayesian (NB).
- Compared to traditional machine learning algorithms and state-of-the-art studies, DroidDetectMW significantly improves detection performance and achieves good accuracy on both Static and Dynamic attributes.
In the remaining sections of the study, the following structure is used: understanding the fundamentals of Harris Hawks Optimization is covered in Section 2. In Section 3, we detail the methodology we’ll be using. Section 4 focuses on the experiments and findings, while Section 5 discusses the conclusion and directions for the future.
2. Preliminary
2.1. Harris Hawks optimization (HHO)
HHO was developed by [36], and it is a population-based optimization method with inspiration drawn from the natural world. Harris’ hawks’ cooperative chasing of prey, known as the surprise pounce, is an inspiration for HHO. Hawks use this strategy by swooping in from all sides to catch their prey off guard. The HHO consists of two primary phases: exploitation and exploration and a transition between exploitative actions. The hawks in the desert are the potential solutions, and the prey they’re waiting for is the best at each stage. Harris’ hawks begin their haunting by randomly picking areas and waiting to see whether they can detect any prey during the exploring phase. The first method relies on the locations of other hawks also involved in haunting the prey, whereas the second relies on the absence or presence of tall trees within the haunt range.
In both cases, the decision is based on the first strategy being chosen if q ≥ 0.5 and the second strategy being chosen if q <0.5. The vector of hawk positions in the next cycle is defined as X(t+1). The current iteration’s prey position is denoted by Xrabbit (t), a hawk’s position is chosen at random using Xrand (t), and the hawks’ positions are represented by X(t). Lower and upper bounds LB and UB are iteratively updated for the random values r4, r2, r1, r3, and q in the interval (0,1) as shown in Equation 1.
Equation 2 can be used to determine the mean position of the current population of hawks, denoted by the symbol Xm(t). Where Xi(t) defines the position of the hawk i in recent iteration, and N is the whole number of hawks.
During the exploitation stage, Harris’ hawks initiate attacks on victims using the surprise pounce. In response to repeated attempts at evasion by their victim, hawks modify their pursuit strategies. As a result, hawks employ four distinct chasing strategies: the Soft Besiege, the Hard Besiege, the Hard Besiege with progressive rapid dives, and the Soft Besiege with progressive quick dives.
As the victim expends energy to flee the haunt, its remaining reserve determines which of the four strategies it will employ. This means that the individual can switch between several forms of exploitation. Equation 3 is a valid modeling of the energy of the prey, where T is the highest number of iterations with E0 is the initial energy of the prey.
The soft besiege takes place when |E|≥0.5 and if the prey has a probability of r ≥ 0.5 of being able to leak from the hawks. If r <0.5, then the soft besiege strategy with progressive rapid dives is employed. Both approaches are shown in Equations 4 and 5, respectively. The instruction to assess the hawks’ next move during a soft besiege is denoted by Y, where ΔX(t) represents the difference between the rabbit’s position vector and the location stored in the current iteration t. Only if the Y rule isn’t successful may the misleading zigzag motion shown in the Levy Flight LF move be used. Readers can find Z, Y, and LF in the original literature.
If |E|<0.5, then the Hard besiege strategy is used, provided that r ≥0.5. In that case, a hard be-siege with progressive quick dives will be applied. For hard besiege with advanced rapid dives, the same Equation 5 is employed, except that Y considers the average locations of the hawks instead, as shown in Equation 6.
2.2. Dataset and malware categories
We determined that the Canadian Institute for Cybersecurity (CIC) [37] offers a competent real-world dataset named CICAndMal2017 after examining the most comprehensive and coherent set of related papers. First, the CIC amassed around 4,000 malware apps from various sources as Contagiodumpst [38] and VirusTotal [39]. In addition, nearly 6,000 benign apps from 2015 to 2017 that were uploaded to the Google Play market were collected. CIC has only been able to install 5,000 (benign 5,065 and malware 429) on actual An-droid smartphones to undertake real-world scenario testing. Several articles make use of the Drebin dataset. A total of 5,560 apps from 179 distinct malware families are included in this data collection. The MobileSandbox project generously provided us with samples gathered between August 2010 and October 2012. A total of 4890 recent Android apps were downloaded from virusshare and apkmirror and selected from DREBIN, CICInvesAndMal2017, datasets of them there are 1910 samples of malware and 2980 samples of benign. The used dataset consisted of static and dynamic features to evaluate the proposed model.
In this data set, labels can be found at various depths. Beginning with a binary classification system, files are either malware or benign. There are four broad classes of malware in the second level:
- Adware: To generate as much revenue as possible from unsolicited banner ads, the ad-ware will display these ads automatically [40].
- Ransomware: One goal of malicious software is to prevent apps from accessing system resources. To extort money from users, it can encrypt their files and demand payment before allowing them to access their files or recover their devices [41].
- Scareware: This malware software uses scare tactics to convince users to buy bogus security updates [42].
- SMS malware: A malicious malware that makes sms calls and sends text messages with-out the user’s permission. The malware operator can use the compromised handsets as a high-end SMS distribution channel [43].
3. Proposed Framework
Here, we’ll review the recommended process for locating and categorizing Android apps by family. Data preprocessing, feature selection, detection, and family categorization are its three main phases. The feature values are normalized in the first phase, and duplicate apps are removed from the dataset. Then, feature extraction of both static and dynamic malware features is applied. In this phase’s end stage, the extracted features are vectorized and put in binary vectors for further processing. He pulled static characteristics, including Command strings, API calls, intents, and permissions. Extracted elements from dynamic malware analysis include cryptographic activities, dynamic approvals, system calls, and information leakage. In the second phase, feature selection is employed for static and dynamic features extracted from the feature extraction stage. Three filter approaches are applied for static attributes, and the optimum feature subgroup is selected. For dynamic features, a two-stage fuzzy-metaheuristic method is applied to attain the best set of dynamic features. In the third phase, a proposed deep learning approach based on enhanced HHO is used to categorize the categories of malware and families. Then, the Android apps are identified and classified using the proposed detection approach against several distinct classifiers based on machine learning and deep learning, such as SMO, RF, DT, K-NN, NB, SVM, SMO, and MLP. The process flow of the proposed approach is pro-posed in Figure 1.
3.1. Data Pre-processing
The best results from a machine learning or deep learning model can only be achieved after extensive preprocessing. Duplicate instance cleanup, NaN removal, and normalization/scaling are all examples of everyday preprocessing operations. We use MinMax scaling to normalize the features because the given dataset has minimal variance and ambiguity. The term normalizing describes the operation of rescaling values with a fundamental number component to a speci-fied interval (e.g., 0 and 1). If your model depends on the absolute values of inputs, you must ensure that they are appropriately scaled. Data is normalized by applying the formula presented in for MixMax scaling using Eq. 7:
Where Xi is the feature’s initial value, the denominator represents the difference between the feature’s new normalized maximum and minimum values.
To filter out duplicates, the gathered Android apps are hashed using the MD5 method. There are now only 3514 unique Android apps after the copies have been removed, which consists of 1479 samples of malware and 2035 samples of benign.
Features can be extracted from malware using both dynamic and static analysis. According to the analysis of static features, we have collected intents, API calls, command strings, and permissions using a custom-written python script that uses the Apktool tool. According to the analysis of dynamic features, we have used CuckooDroid to extract dynamic permissions, cryptographic operations, system calls, and information leakage.
3.2. Feature Selection
It’s a tool for reducing the number of dimensions in a problem, which aids in selecting the most critical aspects—lowering the quality and accuracy of a classification model, and irrelevant and redundant features might have. More processing time and storage were needed for higher-dimensional datasets [44]. The time and space complexity can be reduced and the accuracy improved by selecting the necessary features. We have used feature selection methods that consider both static and dynamic features in this paper. The features that are generated as a byproduct are the most helpful set of features for the subsequent classification and detection processes. The results demonstrated that combining static and dynamic attributes is superior to using either alone. To eliminate and decrease the unnecessary static features, three filter techniques were employed to generate three candidate subsets; the best of these was then used for static feature selection. To select the optimal feature subset of dynamic features, a two-stage hybrid metaheuristic optimization algorithm using a fuzzy approach is proposed. More specific instructions for doing so are provided below.
To rationally evaluate the static features and improve the algorithm’s performance, feature selection is required. We use a filter-based methodology to ensure that feature selection does not rely on the underlying detection technique. See Algorithm 1 for further explanation. Three potential feature subsets were obtained using the chi-square test, the Fisher score, and the mutual information gain. The detection models are further compared in terms of their performance on the three feature subsets to determine which one is the most effective. The optimal detection model is chosen by averaging the results of various algorithmic models applied to the feature subset. The optimal feature subset is then selected by examining the effects of the chosen optimal model applied to the different feature subsets. Using experimental results, the chi-square test is the superior technique for determining features using the random forest anomalies detection model. The above methods were implemented using scikit-learn [45] a Python machine-learning package.
This study proposes combining fuzzy and meta-heuristic optimization to eliminate redundant information and improve performance. Both fuzzy benchmarking and meta-heuristic optimization techniques, such as Multi-Verse Optimization (MVO) and Enhanced Moth Flame Optimized (EMFO), executed within Machine Learning (ML) wrappers, are utilized to discover the best features.
In Figure 2, we see a schematic of the proposed dynamic feature selection framework. This phase generates fuzzy sets for each feature retrieved in the previous phase [23]. To get the fuzzy optimal feature set, each feature’s standard deviation (SD) is computed and compared to a threshold value. Fuzzification filters feature before sending them on to metaheuristic swarm optimization methods [46]. Following classification, the reduced feature set is sent into machine learning algorithms for testing their ability to categorize Android API calls into benign and malicious categories. While there are various feature optimization techniques to choose from, we have focused on MVO and MFO due to their lack of attention in the mal-ware detection literature. Following is a breakdown of the proposed hybrid method:
3.3. Detection and Family Classification
This section introduces the proposed detection approach and the comparative results with other machine learning models.
As mentioned in section two, the HHO algorithm is based on observations of how different Harris hawks approach prey. A solution’s efficacy determines how quickly HHO moves between exploitation and exploration. When it comes time to exploit the catch, Hawk swoops in for the kill.
Despite the remarkable performance of basic HHO, through simulations, we learn that improving both the exploration and exploitation processes improves the original HHO. Incorporating a QRL technique has been shown to improve both intensification and diversification.
To improve upon both the worst Xworst and best solution Xbest, the proposed method employs the QRL at each iteration. In this method, the following expression is used to get quasi-reflective solutions:
Where, generates random numbers from a uniform distribution in the range and, calculates the average of the upper and lower bound for every parameter j. Finally, Xbest and Xworst are replaced by and respectively, if and only if ’s fitness is greater than the previous best solution.
The proposed method for the malware families and categories detection phase using EHHO-ANN is depicted in Figure 3.
In this classification, models for identifying and categorizing Android malware are construct-ed using a wide range of ML techniques (including RF, SVM, DT, SMO, K-NN, MLP and NB). To gauge the efficacy of our proposed method, we employ these models for analysis. To train these models, the entire dataset is split into five sections called “folds.” Every part of the model is run, four pieces are utilized for training, and the remaining two are used for testing. Brief descriptions of ML algorithms and the criteria by which they are judged are provided here.
In this work, we used the following machine-learning algorithms:
- K-Nearest Neighbors (K-NN) is a simple supervised learning technique. This concept shares terminology with the lazy learner [47]. This technique does not care about the underlying data structure when a new instance appears. Instead, it uses distance measurements (e.g., Euclidean distance, Manhattan distance) to determine which training samples are most similar to the incoming instance. Majority voting notions ultimately determine this new instance’s class.
- Sequential Minimal Optimization (SMO) takes a set of points as its input. The method generates a hyperplane that separates points within the same class by analyzing the gaps between them. Kernel functions fill in the blanks in SMO by revealing data about the distance between two spots.
- SVM is a technique [48] that uses a hyperplane to partition the information. In a nutshell, it’s a dividing line from which to choose. Distances between the nearest data points are called support vectors, and the hyperplane is calculated randomly after the hyperplane is drawn. It searches for the optimal hyperplane that maximizes the profit.
- Random Forest (RF): A considerable number of independent decision trees are used in RF to form a unified whole [49]. Each decision tree generates an output classification for the input data, then compiled by RF and represented graphically based on a majority vote.
- A Decision Tree (DT) is organized in the form of a tree, where each node (whether internal, leaf, terminal) represents a test on an attribute, and each branch (whether internal, leaf, or terminal) carries a class name and the results of the test. The C4.5 algorithm has been utilized in this work to categorize Android malware [50].
- Bayes’ theorem provides the theoretical foundation for the NB idea. The program predicts the probabilities of class membership or the likelihood that a set of tuples belongs to a specific class. Multi-class and binary classification problems [51] both benefit from their application.
- Multilayer Perceptron (MLP): There are the hidden and output layers and the input layer. It can produce results in several different measurement systems. The hidden layer’s output units are fed into the subsequent layer as input. [52] applied deep learning approaches like ANNs classifiers to various classification challenges. The authors use MLP to identify and categorize Android malware when classifying and predicting gait data. The MLP is executed using a hidden layer of h=3 and sigmoid activation function for the binary classification and h=5 and softmax activation function for the multi-class classification. Learning is assumed to occur at a rate of 0.35. For a high-level overview of how backpropagation works in a neural network, see Figure 4.
4. Experiments
Specifically, we conduct three primary experiments to measure the efficacy of the proposed DroidDetectMW: The first experiment, detection, and identification, is to determine whether or not a specific app is a malware; the second experiment seeks to identify the family of malware, and the last one is the impact of feature selection proposed approach for both static and dynamic features. In the previous experiment, a comparison between with and without feature selection approaches is applied over different models, including the proposed detection approach. To begin, we divide the dataset into two classes: malware and benign apps. Ransomware, SMS malware, scareware, and adware samples comprise the four subcategories of malware used in the second stage of classification of the dataset. The data set is further annotated with labels for 13 families of malware.
4.1. Evaluation measures and experimental setup
Several measures are used to evaluate the classifiers’ efficacy, such as Matthews correlation coefficient (MCC), precision, F-measure, true positive rate (TPR), Area under curve (AUC), and false positive rate (FPR). The evaluation measures are based on false positive (FP), true negative (TN), true positive (TP), and false negative (FN). We used 20% of the data during the experiment for testing, while 80% was for training. The following Equations provide further information. The experimental computing setup is listed in Table 1.
- TPR - Recall: It is calculated by dividing the number of confirmed positive results by the total number of positive results. As illustrated in Eq., it can be estimated by Eq. 9:
- FPR: This metric represents the proportion of false positive cases relative to the total number of true negative cases. The calculation is described by the following Eq. 10:
- Precision is calculated by dividing the number of correct predictions by the total number of correct predictions. It can be calculated by Eq. 11:
- F-measure: It indicates the harmonic mean of precision and recall. Eq. 12 is used to deter-mine this is:
- Accuracy: It is calculated by dividing the number of cases by the sum of the instances that are both true negatives and true positives. Eq. 13 used to determine this is:
- MCC: It is a standard for evaluating the efficacy of binary classifiers. Its numerical value ranges from +1 to -1. Here, a value of +1 indicates an exact prediction, while a value of -1 indicates an opposite forecast. Eq. 14 used to determine this is:
- AUC curve: The F-measure is a crucial indicator of a classification model’s efficacy. It is a quantitative indicator of how easily things can be separated.
Where, True Positives (TP) are cases that were expected to be in the “Yes” category and were found there. False positives (FP) occur when a case is incorrectly labeled as belonging to the YES category. True Negative (TN) means the case was not included in the YES list but was expected to be. When a case is predicted to not be in the YES column but is, this is called a False Negative (FN).
4.2. Malware binary detection based on Static features
The results for the binary detection using static features are shown in Table 2. With DroidDetectMW, accuracy is maximized to 96.9%. The accuracy of some other standard meth-ods, including KNN, SMO, SVM, RF, DT, NB, and MLP, ranges from 92.3% to 93.5.0%, 92.3%, 95.8%, 95%, 94.2%, and 93.5%, respectively. Since NB’s accuracy relies on the probability distribution, additional data examples would have helped it perform better. The mentioned models work reasonably well on binary classification with static features and feature selection. The MCC of DroidDetectMW is recorded at 93.8%. When compared to other standard models, DroidDetectMW demonstrates a substantial performance gain. When tested, DroidDetectMW achieves a maximum accuracy of 96.9% at the 7th epoch. Accuracy in training ranges from 0.811% to 0.987%. This leads to a consistent convergence of training accuracy. The passing accuracy of a test might be anywhere from 0.795% to 0.951%.
4.3. Malware category detection based on Static features
The results of the static features selection on the detection of malware category can be shown in Table 3. Using DroidDetectMW, the highest accuracy possible is 94.2%. The accuracy of some other standard methods, including KNN, SMO, SVM, RF, DT, NB, and MLP, is 86.5%, 89.6%, 87.3%, 92.3%, 92.3%, 90.4%, and 88.80%. To improve the probability distribution, NB requires more data examples.
In this analysis, we look at category as a feature in the malware dataset, and we find that its ROC AUC curve is 92.4%. When compared to conventional approaches, DroidDetectMW demonstrates a noticeable performance gain. With an improved f-score of 93.6%, DroidDetectMW is an intelligent solution.
4.4. Malware family classification and detection based on Static features selection
The result of the malware family classification using the static feature selection is shown in Table 4. DroidDetectMW ‘s accuracy of 91.5% is the best for identifying malware belonging to the same family. The accuracy of other standard methods, including KNN, SMO, SVM, RF, DT, NB, and MLP, is 85.8%, 85.4%, 85%, 86.9%, 86.2%, 83.5%, and 84.6%. Due to its focus on probability distribution, Naive Bayes obtains a minimum accuracy of 83.5% in this scenario and requires more data examples to improve. This analysis determines that family is a significant feature in the malware dataset, with an MCC of 83% and an Area Under the Curve (AUC) of 90.1%.
4.5. Malware binary detection based on dynamic features selection
The result of the binary classification using the dynamic feature selection is shown in Table 5.
DroidDetectMW ‘s accuracy of 97.3% is the best. The accuracy of some other standard meth-ods, including KNN, SMO, SVM, RF, DT, NB, and MLP, is 92.7%, 93.8%, 93.5%, 94.2%, 93.5%, 93.5%, and 93.1. The MCC of DroidDetectMW is at 94.6%. The proposed approach is superior to other models in evaluation metrics for dynamic feature selection as it obtains high accuracy and f-measure.
4.6. Malware category detection based on dynamic features selection
The result of the malware category classification based on dynamic feature selection is displayed in Table 6. By utilizing DroidDetectMW, we can improve accuracy to 89.2%. Accuracy levels of 79.6%, 80.8%, 93.5%, 84.6%, 81.2%, 81.2%, 83.5%, and 80.8% are attained using the alternative traditional methods of KNN, SMO, SVM, RF, DT, NB, and MLP, respectively. When compared to conventional approaches, DroidDetectMW demonstrates a noticeable performance gain. Regarding f-score, accuracy, precision, and recall, DroidDetectMW displays a competent growth of 88.2%, 89.2%, 87.5%, and 89%, respectively. This work finds that the MCC is 78.3%, and the ROC AUC curve is 88.5%.
4.7. Malware family classification and detection based on Dynamic feature selection
In Table 7, we see that DroidDetectMW achieves the highest accuracy, 82.7% when applied to Malware Family classification using dynamic feature selection.
Accuracy rates of 78.8%, 80.4%, 81.2%, 81.2%, 80.4%, 80%, and 80.8% are attained by the traditional methods of KNN, SMO, SVM, RF, DT, NB, and MLP, respectively. When compared to standard models, DroidDetectMW demonstrates a substantial performance gain. According to this check of the family as a feature in the malware dataset, the ROC AUC curve is 77.8%.
4.8. Classification Results Based on hybrid Features
The malware’s execution stalling and obfuscation make a single static or dynamic technique insufficient for correct classification. As a result, we employ a hybrid method of analysis to address this issue. We integrated the dynamic and static malware analysis results to get a complete picture. Along with the proposed model, seven ML algorithms are used for both detection and classification of binary malware. Binary classification evaluation results using ML approaches on integrated features are shown in Table 8. The proposed DroidDetectMW model is superior and more accurate than the classifiers mentioned earlier. DroidDetectMW’s accuracy is 98.1%, whereas RF and DT only manage 96.9% and 96.2%, respectively. The results of a comparison of ML methods using integrated features for classification are shown in Table 9. Compared to the rest of these classifiers, DroidDetectMW is superior in terms of performance and precision. DroidDetectMW’s detection accuracy is 96.9%, with RF and K-NN each achieving 94.6 percent. DroidDetectMW achieves superior outcomes than other classifiers in terms of precision (95%) as well as TPR (98.3%) and F-measure (96.6%). In Figure 5, we compare seven different classifiers to the proposed model and other methods we tested for binary classification to see which one yielded the best results in terms of MCC and accuracy.Integrated with the results in Table 10, it is evident that combining static and dynamic information leads to gains in accuracy and MCC for all classifiers. This suggests that greater identification and classification of Android malware is possible when dynamic and static features are used together.
Figure 6 compares seven classifiers to the proposed model in terms of accuracy concerning different approaches in our tests for malware category classification.
It demonstrates that the integrated approach outperforms the dynamic and static features separately for all classifiers.
4.9. Comparative analysis
Precision and recall are evaluated between the two dataset versions in Table 10 and Table 11. Taheri et al. [21] conducted the study, calculating the dataset’s precision and recall with the help of the random forest algorithm. Using the DroidDetectMW algorithm, our method delivers the best results. Our research improves upon previous studies’ findings in Static and Dynamic feature analysis. Table 10 shows that our approach has a maximum precision of 96.7% when classifying malware binaries. Compared to the state-of-the-art, binary malware classification performance is enhanced by Static and dynamic classification performance.
Table 10 shows that with static feature selection malware binary classification, DroidDetectMW achieves the maximum precision of 96.7%. Other investigations’ highest levels of precision are 93%, 89%, and 85%. Table 11 shows that when applied to the dynamic feature selection for the malware category classification problem, DroidDetectMW ‘s 87.5% precision utilising optimized ANN is the best. For comparison, the highest levels of precision were found in other research.
4.10. Feature selection effect on static and dynamic features
The proposed two approaches for feature selection for static and dynamic features significantly impact the number of features. When the number of features is reduced, the evaluation metrics are improved. The filter approaches for feature selection in static features select the optimal subset of features to participate in the detection phase. The feature selection approach with the proposed model for malware detection improves the detection ability and reduces the false negatives and positives of malware apps.
5. Conclusion and future work
For Android malware detection and classification, this research suggested a hybrid analysis-based process, enhancing both static and dynamic features gleaned from network traffic. The proposed mode can be broken down into three distinct phases. The features are then sent into the selection phase after being extracted. There are two primary stages within the feature selection process: dynamic feature selection and static feature selection. We will work to lower the total amount of static and dynamic features throughout the two phases. Static feature selection employs a variety of filtering methods to zero in on the best static features. Fuzzy and metaheuristic optimization techniques are used in the second stage of the dynamic feature selection process. When the feature selection process is complete, the resulting subset of features is used in the detection stage. Within the scope of the detection process, we introduced a novel detection technique that uses an artificial neural network. The best architecture of ANN may be chosen with the help of a revised version of HHO, which is presented here. The detection method and the feature selection procedure are assessed by comparing the improved ANN to other ML models. Experiments are run utilizing a variety of binary, malware category, and malware family samples to gauge effectiveness. The results validated the proposed model’s ad-vantage over competing methods. Overall performance is measured using a variety of assessment criteria.
There is a significant risk that the use of code obfuscation and encryption will invalidate the results of this experiment. Some dynamic analysis features, such as traffic files, may not be enough to effectively detect malware that is not primarily network-based because they are employed in isolation from other features like memory device and logs information logs. The reliability of the experiment is also significantly affected by this. There is also a lack of transparency in interpreting dynamic analytic techniques. Our future efforts will center on these concerns.
References
- ODea,S. Smartphone users worldwide.”https://www.statista.com/statistics/330695/number-of-smartphone-users-worldwide/ (accessed 2016-2023).
- Mosa, A. S. M.Yoo, I. and Sheets, L. A systematic review of healthcare applications for smartphones. BMC medical informatics and decision making, 2021, vol. 12, no. 1, pp. 1-31. [CrossRef]
- Taher, F. Elhoseny, M., Hassan, M., brahim, I. and El-Hasnony.V. A Novel Tunicate Swarm Algorithm with Hybrid Deep Learning Enabled Attack Detection for Secure IoT Environment. Published in IEEE Access, 2022, vol. 10, pp. 127192 – 127204. [CrossRef]
- Alzaylaee, M. K. Yerima, S. Y. and Sezer, S. DL-Droid: Deep learning based android malware detection using real devices. Computers & Security, 2020, vol. 89, p. 101663. [CrossRef]
- Dhalaria M. and Gandotra, E. Android malware detection techniques: A literature review. Recent Patents on Engineering,2021, vol. 15, no. 2, pp. 225-245. [CrossRef]
- Wang, X. and Li, . Android malware detection through machine learning on kernel task structures. Neurocomputing,2021, vol. 435, pp. 126-150. [CrossRef]
- Agrawal, P. and Trivedi, B. Machine learning classifiers for Android malware detection. Data Management, Analytics and Innovation: Springer, 2021, pp. 311-322.
- Rajagopal, A. Incident of the week: Malware infects 25m android phone.”https://www.cshub.com/malware/articles/incident-of-the-week-malware-infects-25m-android phones (accessed 2019).
- BBC. “One billion android devices at risk of hacking. https://www.bbc.com/news/technology-51751950 (accessed 2021).
- D. GOODIN. Google play has been spreading advanced android malware for years, 2021.
- Vaas. L. Android malware flytrap hijacks facebook accounts. https://threatpost.com/android-malware-flytrap-facebook/168463/ (accessed 2022).
- Wang, C., Xu, Q., Lin, X., and Liu, S. Research on data mining of permissions mode for Android malware detection. Cluster Computing,2019, vol. 22, no. 6, pp. 13337-13350. [CrossRef]
- Ko, J.-S. , J.-S. Jo, Kim, D.-H., Choi, S.-K. and Kwak, J. Real time android ransomware detection by analyzed android applications. International Conference on Electronics, Information, and Communication (ICEIC), IEEE,2019, pp. 1-5.
- Ideses, I. and Neuberger, A.(2014).Adware detection and privacy control in mobile devices. IEEE 28th Convention of Electrical & Electronics Engineers in Israel, 2014, pp. 1-5.
- Faghihi, F. ,Abadi, M. and Tajoddin, A. Smsbothunter: A novel anomaly detection technique to detect sms botnets. 15th International ISC (Iranian Society of Cryptology) Conference on Information Security and Cryptology (ISCISC), IEEE, 2018, pp. 1-6.
- Sikorski,M. and Honig, A. Practical malware analysis: the hands-on guide to dissecting malicious software. no starch press, 2012.
- Iwendi., C. Keysplitwatermark: Zero watermarking algorithm for software protection against cyber-attacks. IEEE Access, vol. 8, 2020, pp. 72650-72660. [CrossRef]
- Yu, J. and Yamauchi, T. Access control to prevent attacks exploiting vulnerabilities of webview in android OS. IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, 2013: IEEE, pp. 1628-1633.
- Nishimoto, Y., Kajiwara, N., Matsumoto, S., Hori, Y.and Sakurai, K. Detection of android api call using logging mechanism within android framework. International Conference on Security and Privacy in Communication Systems, 2013: Springer, pp. 393-404.
- Song, S., Kim, B. and Lee, S. The effective ransomware prevention technique using process monitoring on android platform. Mobile Information Systems, 2016. [CrossRef]
- Taheri, L., Kadir, A. F. A. and Lashkari, A. H. Extensible android malware detection and family classification using network-flows and API-calls. International Carnahan Conference on Security Technology (ICCST), 2019: IEEE, pp. 1-8.
- Tchakounté, F., Djakene Wandala, A.,and Tiguiane, Y. Detection of android malware based on sequence alignment of permissions. Int. J. Comput.(IJC), 2019, vol. 35, no. 1, pp. 26-36.
- Yuan, Z., Lu, Y.and Xue, Y. Droiddetector: android malware characterization and detection using deep learning. Tsinghua Science and Technology, 2016, vol. 21, no. 1, pp. 114-123.
- “CuckooDroid.” https://cuckoo-droid.readthedocs.io/en/latest/installation/. (accessed).
- Gandotra, E., Bansal, D., and Sofat, S. Malware intelligence: beyond malware analysis. International Journal of Advanced Intelligence Paradigms, 2019, vol. 13, no. 1-2, pp. 80-100.
- Abid, R. Rizwan, M., Veselý, P. , Basharat, A., Tariq, U. and Javed, A. R. Social Networking Security during COVID-19: A Systematic Literature Review. Wireless Communications and Mobile Computing, 2022.
- Lakovic, V. Crisis management of android botnet detection using adaptive neuro-fuzzy inference system. Annals of Data Science, 2020,vol. 7, no. 2, pp. 347-355. [CrossRef]
- Saridou, B. , Rose, J. R. , Shiaeles, S. and Papadopoulos, B. SAGMAD—A Signature Agnostic Malware Detection System Based on Binary Visualisation and Fuzzy Sets. Electronics, 2022, vol. 11, no. 7, p. 1044. [CrossRef]
- Gupta, D. , Ahlawat, A. K. , Sharma, A., and Rodrigues, J. J. Feature selection and evaluation for software usability model using modified moth-flame optimization. Computing, 2020, vol. 102, no. 6, pp. 1503-1520. [CrossRef]
- Sahu, P. C. , Bhoi, S. K. , Jena, N. K. , Sahu, B. K.,and Prusty, R. C. A robust Multi Verse Optimized fuzzy aided tilt Controller for AGC of hybrid Power System. 1st Odisha International Conference on Electrical Power Engineering, Communication and Computing Technology (ODICON), 2021: IEEE, pp. 1-5.
- Rahnamayan, S., Tizhoosh, H. R. , and Salama, M. M. Quasi-oppositional differential evolution. IEEE congress on evolutionary computation, 2007, pp. 2229-2236.
- Strumberger, I. , Bacanin, N., Tuba, M., and Tuba, E. Resource scheduling in cloud computing based on a hybridized whale optimization algorithm. Applied Sciences, 2019, vol. 9, no. 22, p. 4893. [CrossRef]
- Strumberger, I. , Minovic, M., Tuba, M. and Bacanin,N. Performance of elephant herding optimization and tree growth algorithm adapted for node localization in wireless sensor networks. Sensors, vol. 19, no. 11, pp. 2515. [CrossRef]
- Heidari, A. A. , Mirjalili, S. , Faris, H., Aljarah, I., Mafarja, M., and Chen, H. Harris hawks optimization: Algorithm and applications. Future generation computer systems, 2019, vol. 97, pp. 849-872. [CrossRef]
- Lashkari, A. H. , Kadir, A. F. A. , Taheri, L. and Ghorbani, A. A. Toward developing a systematic approach to generate benchmark android malware datasets and classification. International Carnahan Conference on Security Technology (ICCST), 2018: IEEE, pp. 1-7, 2018.
- Parkour, M. Contagio malware database. contagiodump. 2013.
- Virustotal: Virustotal Free Antivirus Scanners. https://support.virustotal.com/hc/en-us/categories/360000160117-About-us (accessed.
- Ahvanooey, M. T. , Li, Q., Rabbani, M. and Rajput, A. R. A survey on smartphones security: software vulnerabilities, malware, and attacks. arXiv preprint arXiv:2001.09406, 2020.
- Liao, Q. Ransomware: a growing threat to SMEs. Conference Southwest Decision Science Institutes,: Southwest Decision Science Institutes USA, pp. 1-7. 2008.
- Gupta, S.(2013). Types of Malware and its Analysis. International Journal of Scientific and Engineering Research, vol. 4, no. 1, 2013, pp. 1-13.
- Hamandi, K. , Chehab, A. , Elhajj, I. H. and Kayssi, A. (2013). Android SMS malware: Vulnerability and mitigation. 27th International Conference on Advanced Information Networking and Applications Workshops, 2013: IEEE, pp. 1004-1009.
- Chizi, B. and Maimon, O. Dimension reduction and feature selection. Data mining and knowledge discovery handbook: Springer, 2009, pp. 83-100.
- Pedregosa, F.. Scikit-learn: Machine learning in Python. the Journal of machine Learning research, vol. 12, 2011, pp. 2825-2830.
- Sapre, S. and Mini, S. Emulous mechanism based multi-objective moth–flame optimization algorithm. Journal of Parallel and Distributed Computing, 2021, vol. 150, pp. 15-33.
- Darrell, T. , Indyk, P. and Shakhnarovich, G. Nearest-neighbor Methods in Learning and Vision: Theory and Practice. MIT Press, 2005.
- Keerthi, S. S. and Gilbert, E. G. (2002). Convergence of a generalized SMO algorithm for SVM classifier design. Machine Learning, vol. 46, no. 1, 2002, pp. 351-360, 2002. [CrossRef]
- Liaw, A. and Wiener, M. Classification and regression by randomForest. R news, vol. 2, no. 3, 2002, pp. 18-22.
- Quinlan, J. R.. Program for machine learning. C4. 5, 1993.
- Domingos, P. and Pazzani, M.(1997).On the optimality of the simple Bayesian classifier under zero-one loss. Machine learning, vol. 29, no. 2, 1997, pp. 103-130. [CrossRef]
- Jiang, J. Android malware family classification based on sensitive opcode sequence. Symposium on Computers and Communications (ISCC), 2019: IEEE, pp. 1-7.
- Abuthawabeh, M. K. A. and Mahmoud, K. W. Android malware detection and categorization based on conversation-level network traffic features. International Arab Conference on Information Technology (ACIT), 2019: IEEE, pp. 42-47.
- Semwal, V. B, Mondal, K. and Nandi, G. C. Robust and accurate feature selection for humanoid push recovery and classification: deep learning approach. Neural Computing and Applications, vol. 28, no. 3,2017, pp. 565-574. [CrossRef]
Figure 1.
The proposed model.
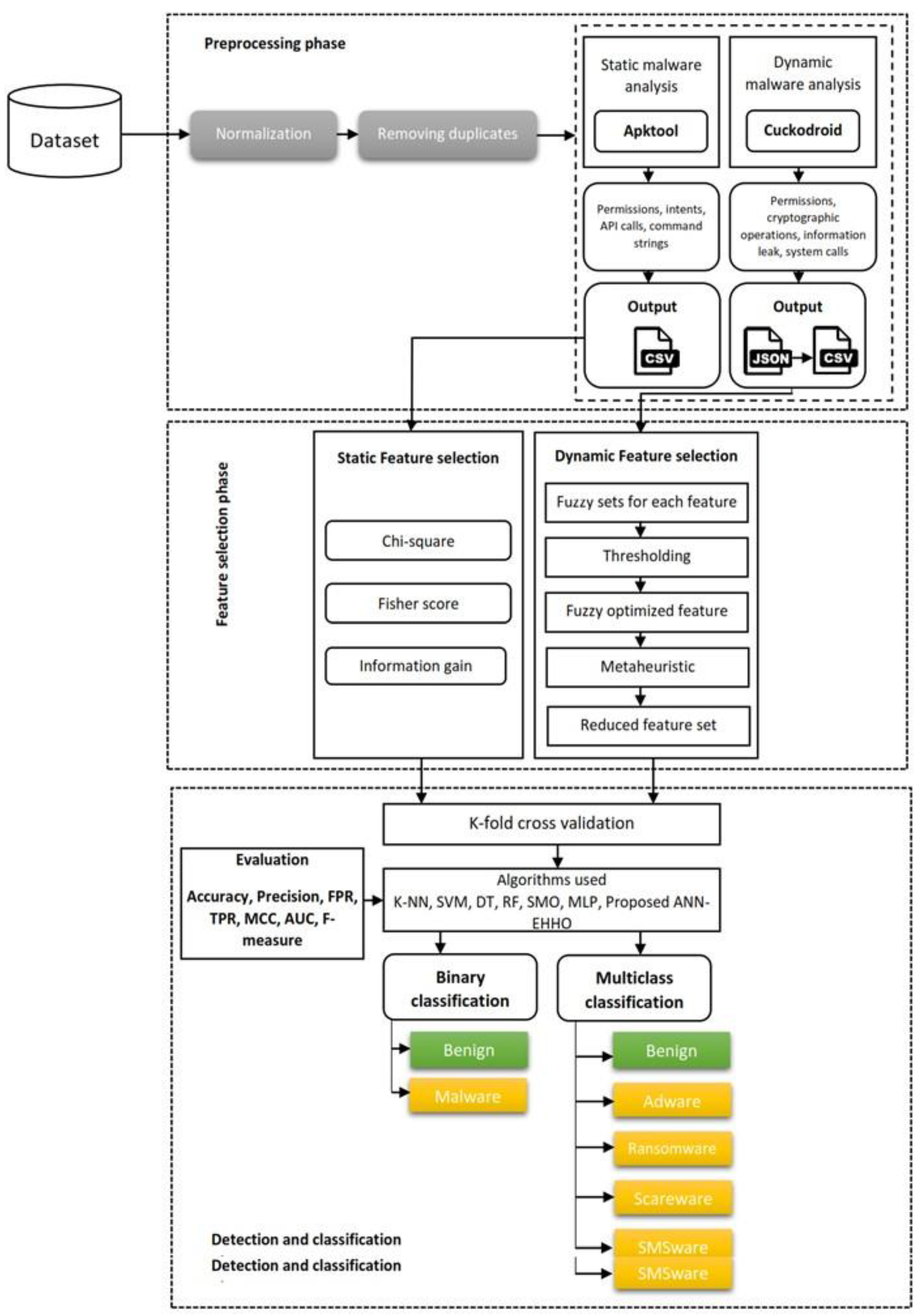
Figure 2.
The proposed dynamic feature selection approach.

Figure 3.
The flowchart of the proposed EHHO-ANN.
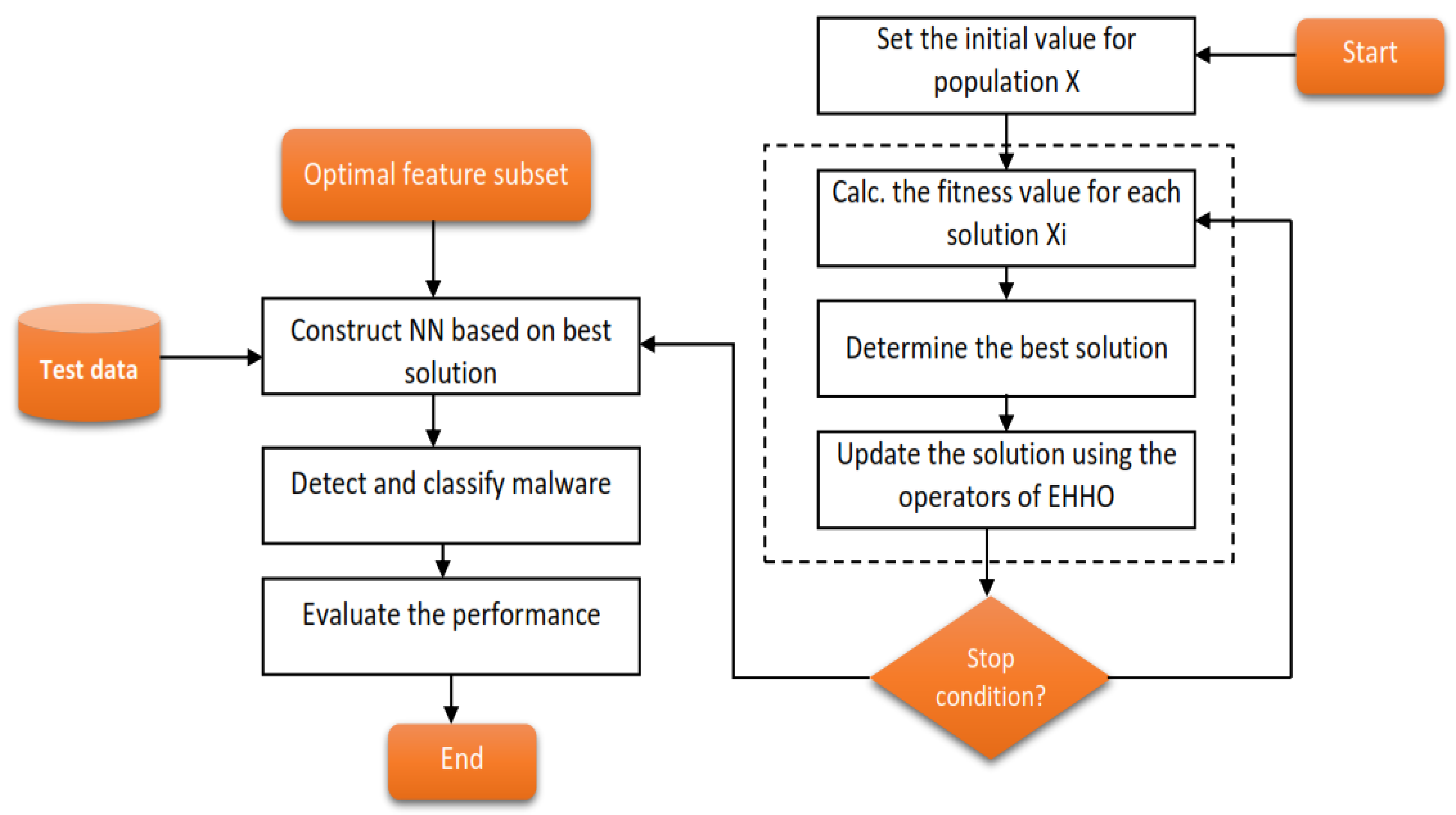
Figure 4.
Methodology of backpropagation in neural network.
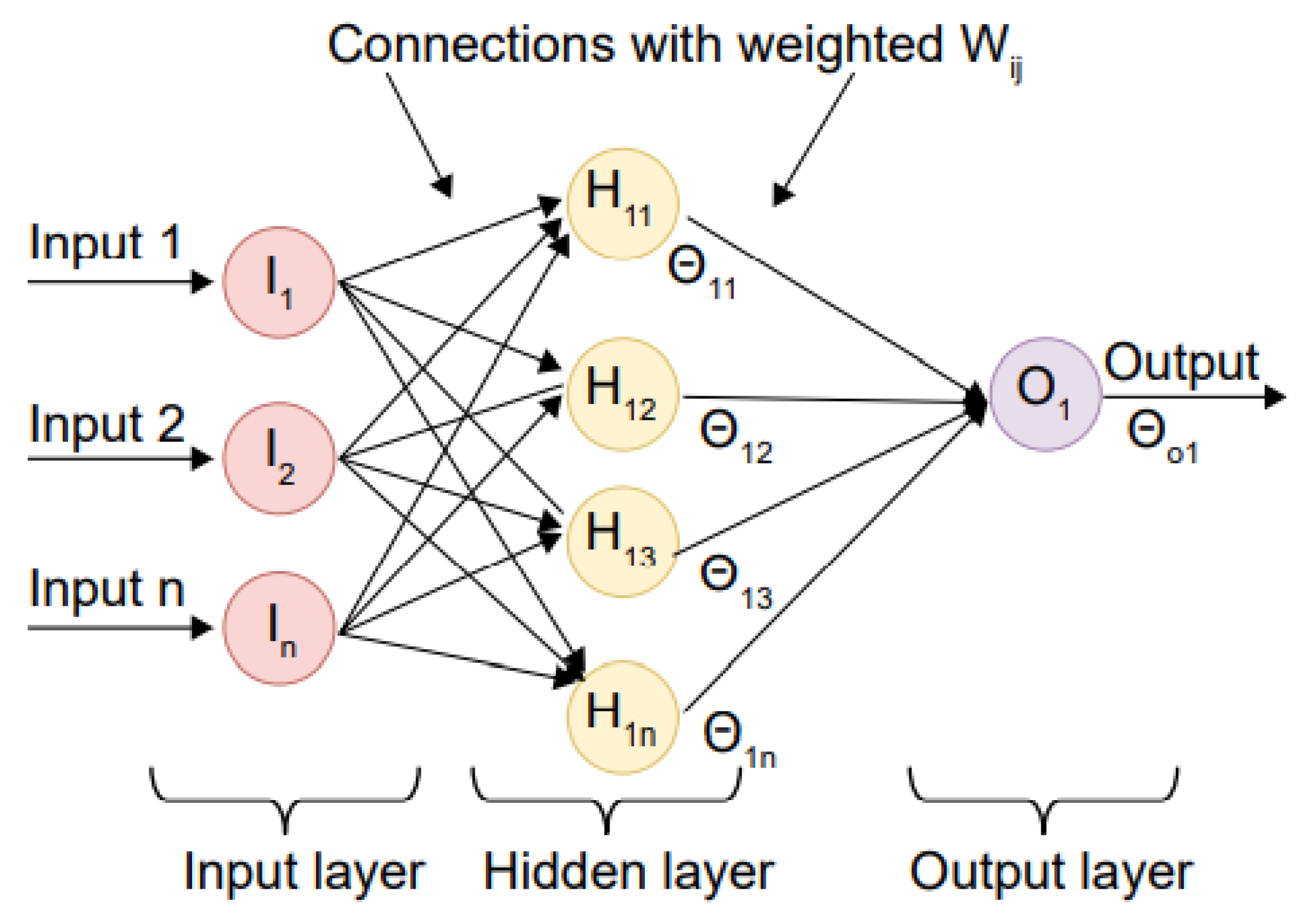
Figure 5.
Classifiers for binary malware classification were compared based on (a) Accuracy and (b) MCC with dynamic, static, and integrated features.
Figure 5.
Classifiers for binary malware classification were compared based on (a) Accuracy and (b) MCC with dynamic, static, and integrated features.
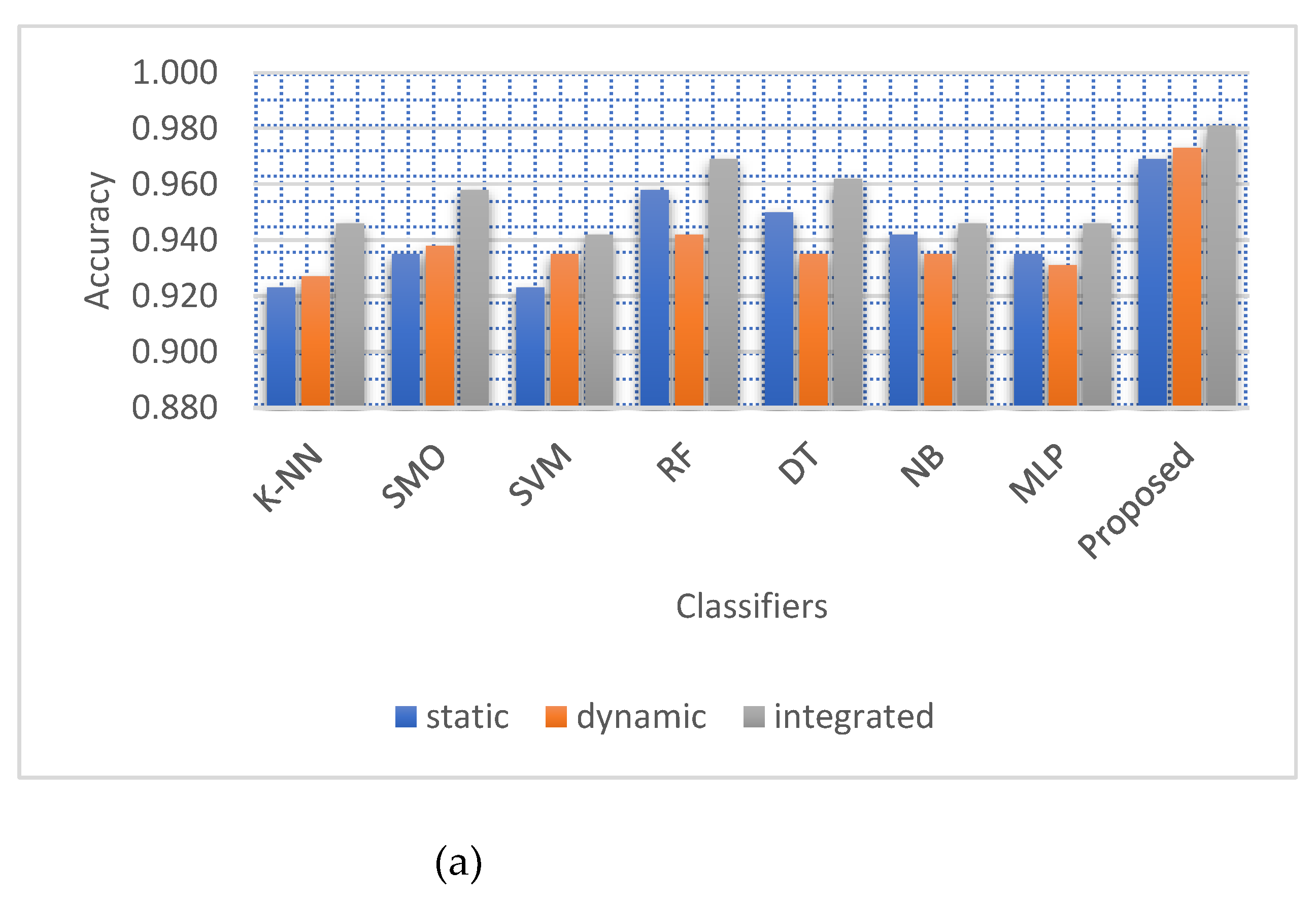
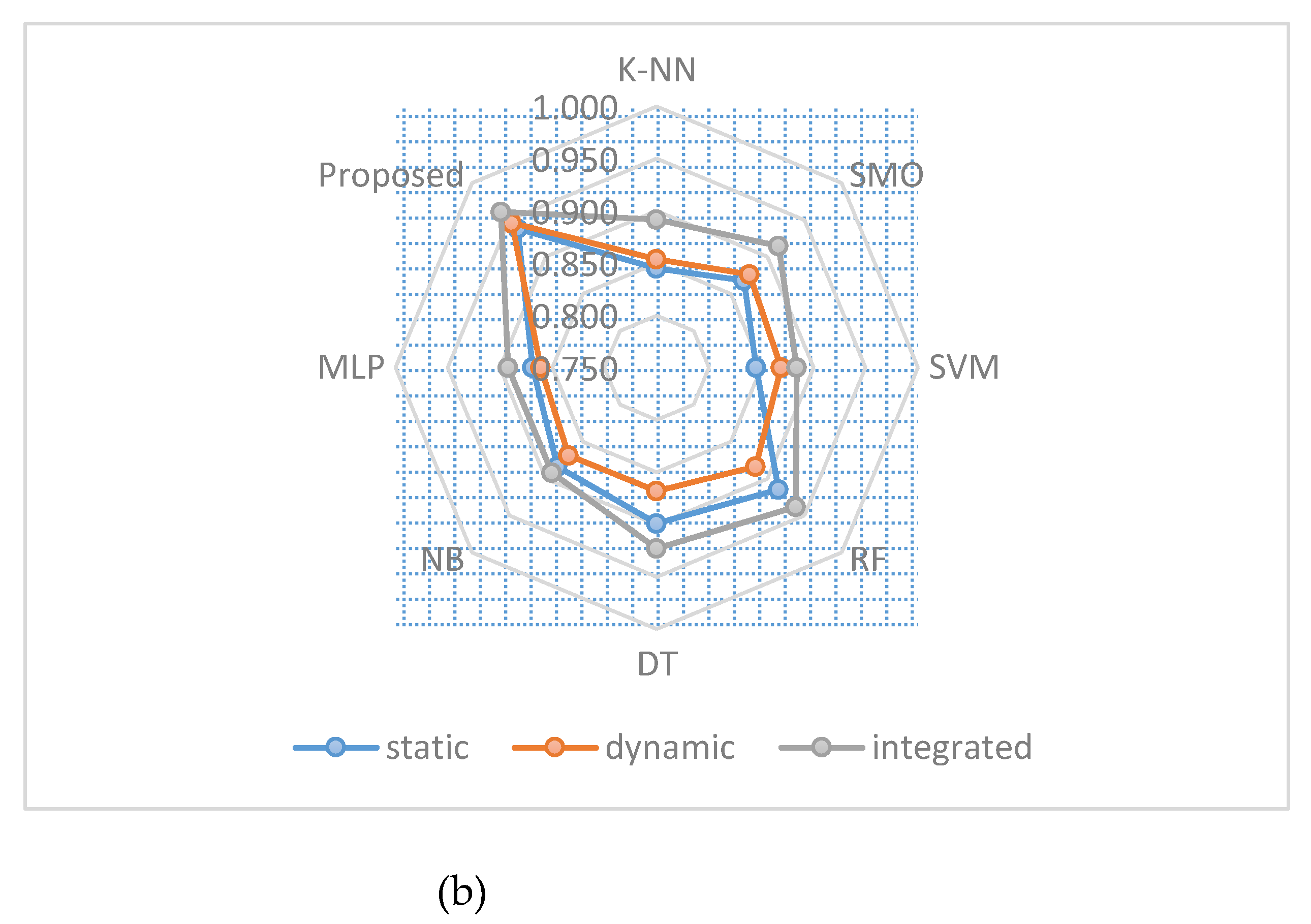
Figure 6.
Accuracy and precision of different classifiers using static, dynamic and integrated features in malware category classification.
Figure 6.
Accuracy and precision of different classifiers using static, dynamic and integrated features in malware category classification.
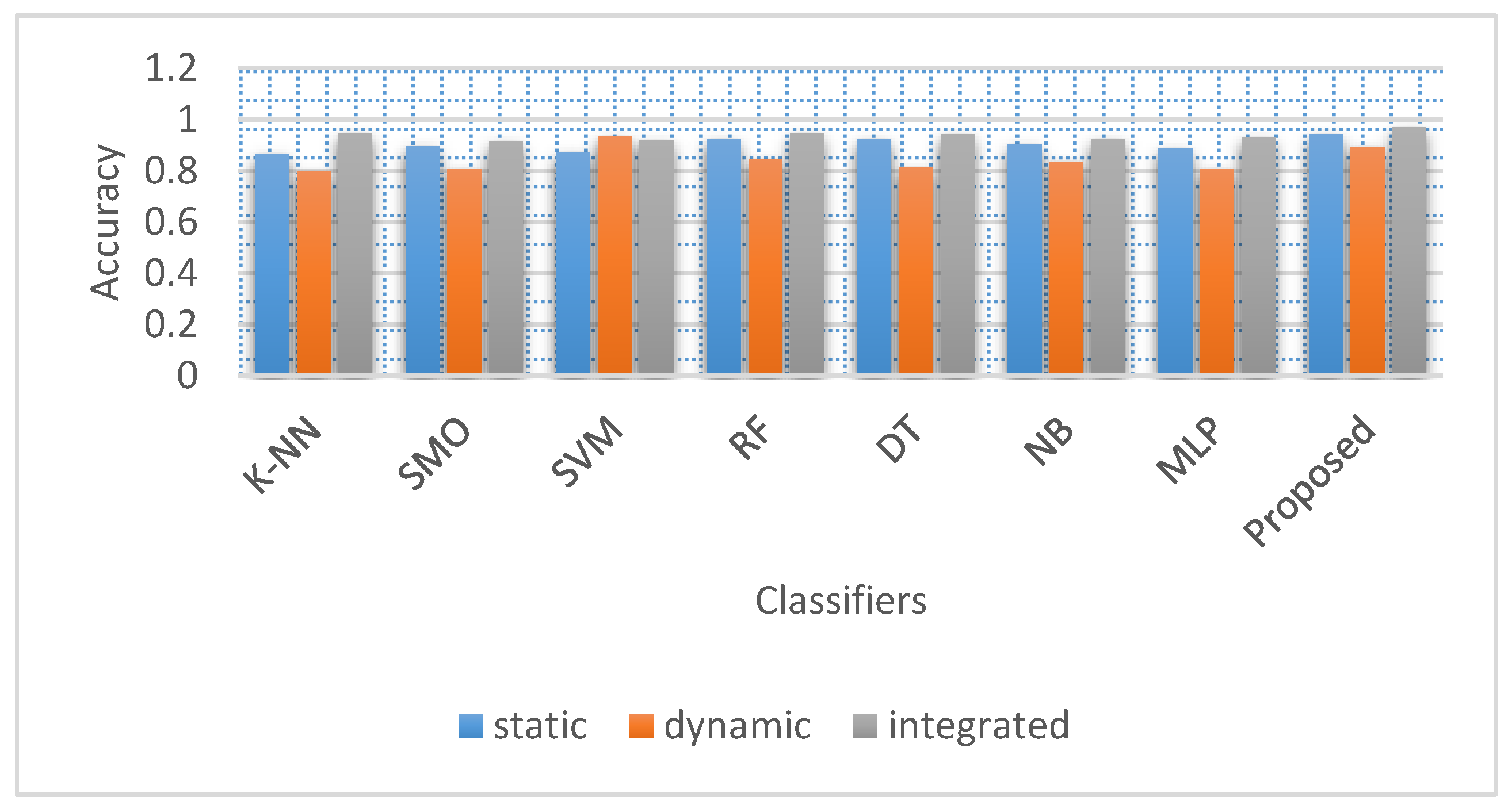

Table 1.
The experimental environment settings.
| PU | Intel(R) Core(TM)i7-2.40 GHz |
| Operating System | Windows 10 Home Single |
| GPU | NVIDIA 1060 |
| RAM | 32 GB |
| Python Version | 3.8 |
Table 2.
The effectiveness of static feature selection for binary malware classification.
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.923 | 0.935 | 0.923 | 0.958 | 0.950 | 0.942 | 0.935 | 0.969 |
| FPR (%) | 0.071 | 0.064 | 0.077 | 0.049 | 0.056 | 0.069 | 0.058 | 0.029 |
| TPR (%) | 0.917 | 0.933 | 0.924 | 0.966 | 0.957 | 0.957 | 0.926 | 0.967 |
| Precision (%) | 0.917 | 0.925 | 0.908 | 0.942 | 0.933 | 0.917 | 0.933 | 0.967 |
| F-measure (%) | 0.917 | 0.929 | 0.916 | 0.954 | 0.945 | 0.936 | 0.929 | 0.967 |
| MCC (%) | 0.845 | 0.868 | 0.845 | 0.915 | 0.899 | 0.884 | 0.869 | 0.938 |
| AUC (%) | 0.923 | 0.931 | 0.915 | 0.946 | 0.939 | 0.924 | 0.938 | 0.969 |
Table 3.
The effectiveness of static feature selection for malware category classification.
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.865 | 0.896 | 0.873 | 0.923 | 0.923 | 0.904 | 0.888 | 0.942 |
| FPR (%) | 0.138 | 0.105 | 0.126 | 0.083 | 0.071 | 0.092 | 0.117 | 0.069 |
| TPR (%) | 0.87 | 0.897 | 0.872 | 0.931 | 0.917 | 0.899 | 0.896 | 0.957 |
| Precision (%) | 0.833 | 0.875 | 0.85 | 0.9 | 0.917 | 0.892 | 0.858 | 0.917 |
| F-measure (%) | 0.851 | 0.886 | 0.861 | 0.915 | 0.917 | 0.895 | 0.877 | 0.936 |
| MCC (%) | - | - | - | - | - | - | - | - |
| AUC (%) | 0.848 | 0.885 | 0.862 | 0.908 | 0.923 | 0.900 | 0.871 | 0.924 |
Table 4.
The effectiveness of static feature selection for malware family classification.
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.858 | 0.854 | 0.850 | 0.869 | 0.862 | 0.835 | 0.846 | 0.915 |
| FPR (%) | 0.129 | 0.155 | 0.142 | 0.132 | 0.134 | 0.170 | 0.158 | 0.090 |
| TPR (%) | 0.843 | 0.866 | 0.840 | 0.871 | 0.856 | 0.841 | 0.851 | 0.922 |
| Precision (%) | 0.850 | 0.808 | 0.833 | 0.842 | 0.842 | 0.792 | 0.808 | 0.892 |
| F-measure (%) | 0.846 | 0.836 | 0.837 | 0.856 | 0.849 | 0.815 | 0.829 | 0.907 |
| MCC (%) | - | - | - | - | - | - | - | - |
| AUC (%) | 0.860 | 0.826 | 0.846 | 0.855 | 0.854 | 0.811 | 0.825 | 0.901 |
Table 5.
The effectiveness of dynamic feature selection for binary classification.
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.927 | 0.938 | 0.935 | 0.942 | 0.935 | 0.935 | 0.931 | 0.973 |
| FPR (%) | 0.094 | 0.069 | 0.082 | 0.050 | 0.064 | 0.051 | 0.076 | 0.028 |
| TPR (%) | 0.955 | 0.948 | 0.956 | 0.934 | 0.933 | 0.919 | 0.940 | 0.975 |
| Precision (%) | 0.883 | 0.917 | 0.900 | 0.942 | 0.925 | 0.942 | 0.908 | 0.967 |
| F-measure (%) | 0.918 | 0.932 | 0.927 | 0.938 | 0.929 | 0.930 | 0.924 | 0.971 |
| MCC (%) | 0.854 | 0.876 | 0.869 | 0.884 | 0.868 | 0.869 | 0.861 | 0.946 |
| AUC (%) | 0.895 | 0.924 | 0.909 | 0.946 | 0.931 | 0.945 | 0.916 | 0.969 |
Table 6.
The effectiveness of dynamic feature selection for malware category classification.
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.796 | 0.808 | 0.935 | 0.846 | 0.812 | 0.835 | 0.808 | 0.892 |
| FPR (%) | 0.204 | 0.179 | 0.082 | 0.143 | 0.173 | 0.183 | 0.188 | 0.106 |
| TPR (%) | 0.796 | 0.792 | 0.956 | 0.833 | 0.793 | 0.860 | 0.802 | 0.890 |
| Precision (%) | 0.750 | 0.792 | 0.900 | 0.833 | 0.800 | 0.767 | 0.775 | 0.875 |
| F-measure (%) | 0.773 | 0.792 | 0.927 | 0.833 | 0.797 | 0.811 | 0.788 | 0.882 |
| MCC (%) | - | - | - | - | - | - | - | - |
| AUC (%) | 0.773 | 0.807 | 0.909 | 0.845 | 0.814 | 0.792 | 0.794 | 0.885 |
Table 7.
The effectiveness of dynamic feature selection for malware family classification.
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.788 | 0.804 | 0.812 | 0.812 | 0.804 | 0.800 | 0.808 | 0.827 |
| FPR (%) | 0.229 | 0.209 | 0.210 | 0.206 | 0.213 | 0.222 | 0.204 | 0.194 |
| TPR (%) | 0.816 | 0.822 | 0.845 | 0.838 | 0.829 | 0.833 | 0.824 | 0.857 |
| Precision (%) | 0.700 | 0.733 | 0.725 | 0.733 | 0.725 | 0.708 | 0.742 | 0.750 |
| F-measure (%) | 0.753 | 0.775 | 0.780 | 0.782 | 0.773 | 0.766 | 0.781 | 0.800 |
| MCC (%) | - | - | - | - | - | - | - | - |
| AUC (%) | 0.735 | 0.762 | 0.757 | 0.763 | 0.756 | 0.743 | 0.769 | 0.778 |
Table 8.
The effectiveness of integrated feature selection for malware binary classification.
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.946 | 0.958 | 0.942 | 0.969 | 0.962 | 0.946 | 0.946 | 0.981 |
| FPR (%) | 0.068 | 0.049 | 0.063 | 0.035 | 0.042 | 0.056 | 0.056 | 0.021 |
| TPR (%) | 0.965 | 0.966 | 0.949 | 0.975 | 0.966 | 0.949 | 0.949 | 0.983 |
| Precision (%) | 0.917 | 0.942 | 0.925 | 0.958 | 0.950 | 0.933 | 0.933 | 0.975 |
| F-measure (%) | 0.940 | 0.954 | 0.937 | 0.966 | 0.958 | 0.941 | 0.941 | 0.979 |
| MCC (%) | 0.892 | 0.915 | 0.884 | 0.938 | 0.923 | 0.892 | 0.892 | 0.961 |
| AUC (%) | 0.924 | 0.946 | 0.931 | 0.962 | 0.954 | 0.938 | 0.938 | 0.977 |
Table 9.
The effectiveness of integrated feature selection for malware category classification.
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.946 | 0.915 | 0.919 | 0.946 | 0.942 | 0.923 | 0.931 | 0.969 |
| FPR (%) | 0.068 | 0.096 | 0.101 | 0.063 | 0.063 | 0.095 | 0.082 | 0.042 |
| TPR (%) | 0.965 | 0.930 | 0.946 | 0.957 | 0.949 | 0.946 | 0.947 | 0.983 |
| Precision (%) | 0.917 | 0.883 | 0.875 | 0.925 | 0.925 | 0.883 | 0.900 | 0.950 |
| F-measure (%) | 0.940 | 0.906 | 0.909 | 0.941 | 0.937 | 0.914 | 0.923 | 0.966 |
| MCC (%) | - | - | - | - | - | - | - | - |
| AUC (%) | 0.924 | 0.894 | 0.887 | 0.931 | 0.931 | 0.894 | 0.909 | 0.954 |
Table 10.
Binary malware classification using static features selection: a comparison of results.
| Related work | Precision | Recall |
|---|---|---|
| Abuthawabeh et al. [49] | ||
| Taheri et al. [21] | ||
| Lashkari et al. [45] | ||
| Lashkari et al. [45] | ||
| Abuthawabeh et al. [49] | ||
| DroidDetectMW |
Table 11.
Malware category classification using dynamic features selection: a comparison of results.
Table 11.
Malware category classification using dynamic features selection: a comparison of results.
| Related work | Precision | Recall |
|---|---|---|
| Abuthawabeh et al. [49] | 80.2%(RF) | 79.6%(RF) |
| Taheri et al. [21] | 49.9%(RF) | 48.5%(RF) |
| Lashkari et al. [45] | 47.8%(DT) | 45.9%(DN) |
| Lashkari et al. [45] | 49.5%(KNN) | 48%(KNN) |
| Abuthawabeh et al. [49] | 77%(DT) | 77%(DT) |
| DroidDetectMW | 87.5% | 89% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



