
Submitted:
05 May 2023
Posted:
06 May 2023
You are already at the latest version
Abstract
Ship detection using synthetic aperture radar (SAR) has been extensively utilized in both the military and civilian fields. On account of complex backgrounds, large scale variations, small-scale targets, and other challenges, it is difficult for current SAR ship detection methods to strike a balance between detection accuracy and computation efficiency. To overcome those challenges, ESarDet, an efficient SAR ship detection method based on context information and large effective receptive field (ERF) is proposed. We introduce the anchor-free object detection method YOLOX-tiny as a baseline model and make several improvements on it. First, the CAA-Net, which has a large ERF, is proposed to better merge the context and semantic information of ships in SAR images to improve ship detection, particularly for small-scale ships with complex backgrounds. Further, to prevent the loss of semantic information regarding ship targets in SAR images, we redesign a new spatial pyramid pooling network, namely A2SPPF. Finally, in consideration of the challenge posed by the large variation in ship scale in SAR images, we design a novel convolution block, called A2CSPlayer, to enhance the fusion of feature maps from different scales. Extensive experiments are conducted on three publicly available SAR ship datasets, DSSDD, SSDD, and HRSID, to validate the effectiveness of the proposed ESarDet. The experimental results demonstrate that ESarDet has distinct advantages over current state-of-the-art (SOTA) detectors in terms of detection accuracy, generalization capability, computational complexity, and detection speed.
Keywords:
ship detection
; synthetic aperture radar (SAR)
; context information
; effective receptive field
; you only look once (YOLO)
1. Introduction
Remote sensing technology is a method for acquiring remote sensing image data via satellite observation of the earth. It is an essential component of the remote sensing technology used for cartography, military reconnaissance, ocean surveillance, and other purposes, as it detects and classifies remote sensing images [1,2,3]. With the development of remote sensing technology, synthetic aperture radar (SAR) has been invented, which is an active earth observation system that can be installed on different flight platforms. SAR employs the principle of synthetic aperture to accomplish high-resolution microwave imaging, allowing it to monitor the Earth around the clock and in most conditions. In light of these technical benefits, SAR plays a critical role in ship monitoring. Nowadays, more and more scholars are conducting studies on ship monitoring using SAR to improve the detection accuracy of ships.
Initially, the constant false alarm rate (CFAR) algorithm was introduced for detecting targets in SAR images [4]. The CFAR-based detection methods can adaptively calculate the detection threshold by estimating the statistical arithmetic of background clutter. The CFAR algorithm has low computational complexity and is slightly robust to local uniform clutter. This algorithm, nevertheless, has poor generalization ability and low detection accuracy in complex scenes. In [5,6,7], to polish up the detection performance of CFAR, different statistical models were added to CFAR. The detection performance of the improved CFAR algorithm is robust in simple scenes. However, due to the difficulty of modeling, when small ships are present in SAR images or the scene is complex, these models perform poorly in detection accuracy.
Recently, methods for detecting targets based on deep learning have advanced significantly regarding detection efficiency and precision. Therefore, many researchers have introduced deep learning-based methods into the study of SAR ship detection. Current SAR ship detection methods based on deep learning can be broadly classified as either anchor-based or anchor-free. Refs. [8,9,10,11] introduced anchor-based target detection methods for SAR ship detection. These methods outperform traditional methods in detection precision. Nevertheless, anchor-based methods rely on fixed, manually designed anchors, resulting in a significant decrease in detection precision when the scale of ship targets varies significantly. To accommodate the extensive scale variation of ships in SAR images, [12,13,14,15,16] introduced anchor-free methods to detect ships. The anchor-free method overcomes the challenge of detecting ships in different scales and improves detection accuracy. Nevertheless, its high computational complexity makes efficient ship detection difficult. Methods for SAR ship detection based on deep learning significantly improved detection performance. However, existing SAR ship detection methods still have difficulty in striking a balance between detection precision and speed due to the following challenges [9,13,17]:
- The background in SAR images is complex. Due to the clutter caused by SAR imaging principles, land structures and other factors make it difficult for existing detection methods to differentiate the targets from the background.
- The scale of ships in SAR images, particularly small ships, is highly variable. Due to the varied scales of the ships in SAR images, it is challenging to extract efficient features from SAR images with existing methods.
- SAR is deployed on flight platforms, which have limited computational resources. Existing methods make it challenging to perform accurate ship detection in such conditions.
To overcome the aforementioned challenges, we propose an efficient SAR ship detection method ESarDet, which is based on the anchor-free object detection method YOLOX-tiny [18] with a number of improvements to expand the effective receptive field (ERF) and extract context information. The main contributions of this paper are shown below:
- For the characteristics of ships in SAR images, such as ships with a small scale and a complex background, we propose a novel context information extraction module, the context attention auxiliary network (CAA-Net). This module expands the ERF by introducing large kernel convolution to more efficiently extract the context information of SAR ships in the feature map. Then, by employing the proposed feature fusion module, the backbone’s extracted semantic information is combined with the context information extracted via CAA-Net. The proposed CAA-Net can effectively merge context and semantic information from SAR images, which improves detection performance.
- To expand the ERF and prevent the loss of ship-related semantic information in SAR images. An atrous attentive spatial pyramid network fast (A2SPPF) based on dilated convolution and attention mechanism is proposed to substitute for the spatial pyramid network (SPP) in YOLOX-tiny. The proposed A2SPPF is able to improve computational efficiency and more effectively extract multi-scale context information, thereby improving the detection accuracy of small-scale ships.
- In view of the fact that the scales of ship targets vary significantly in SAR images, a new convolution block is designed. To better fuse feature maps from different scales, we introduce the CSPlayer as the baseline model. A new convolution, named dynamic dilated depthwise separable convolution (), and channel attention module is added to the baseline model; it is referred to as the atrous attentive cross-stage partial layer (A2CSPlayer). The proposed A2CSPlayer can more effectively fuse the feature maps from different scales to enhance the detection performance of ships at different scales in SAR images.
- Extensive experiments are conducted on three challenging SAR ship datasets—DSSDD, SSDD, and HRSID—to verify the effectiveness of the proposed ESarDet. The experimental results prove that the ESarDet we proposed performs exceptionally well.
This paper contains six sections. In Section 2, we present recent advances in deep learning-based ship detection methods as well as techniques for detecting small targets. In Section 3, we elaborate on the proposed method in detail. In Section 4, evaluation metrics, experimental design, and experiment results are presented. In Section 5, we discuss the model’s capacity for generalization and the significance of large kernel convolution. The conclusion is presented in Section 6.
2. Related work
2.1. SAR Ship detection methods based on deep learning
In recent years, deep learning (DL) has risen to the forefront of computer vision. After the proposal of AlexNet [19], convolutional neural network (CNN)-based target detection methods generally outperformed traditional methods in many aspects. However, current DL-based methods generally had unperceived imbalance problems such as image sample imbalance, ship scale feature imbalance, ect. Therefore, how to handle those imbalances while improving the efficiency of ship detection without sacrificing accuracy is the latest research direction for DL-based methods. Lately, the DL-based methods for SAR ship detection have mainly been divided into anchor-based methods and anchor-free methods.
The anchor-based method generates prediction frames based on manually pre-designed anchors. Jiang et al.[8] refined the YOLOv4-light network with a multi-channel fusion SAR image processing method to extract features more effectively. As a result, the improved YOLOv4-light could not only make up for the loss of accuracy due to the original lightweight network but also implemented real-time ship detection. Based on the Cascade Mask R-CNN model, Xia et al. [9] innovatively integrated the merits of Swin Transformer and CNN, coming up with a brand-new backbone, CRbackbone. By taking great advantage of contextual information, the detection accuracy of ships at different scales was enhanced, while the training cost was also increased. For scatters and noises in SAR images and densely distributed small ships, Bai et al. [10] designed a feature enhanced pyramid and shallow feature reconstruction network (FEPS-Net). Although retaining shallow high-resolution features could effectively improve the detection performance, the computational cost was correspondingly multiplied. To directly apply the detection method with strong performance to SAR ship identification, Muhammad et al. [11] introduced an upgraded YOLOv5s using the C3 convolution and a new neck structure created by combining FPN and PAN. Though the network performance was further enhanced by the addition of an attention mechanism, it is still hard to achieve efficient detection of ships in SAR images in the face of complex situations such as azimuth ambiguity, wave measurement and sea state. Anchor-based detectors eliminate the need to scan images with sliding windows, which effectively raises detection efficiency. However, these anchor-based detectors still have shortcomings and problems in terms of detection accuracy. First, the detection performance of anchor-based detectors is dependent on the quantity of anchors, making it difficult to adjust parameters. Second, due to the fixed size of anchors, the robustness of the anchor-based method is not strong when encountering a significant deformation of the ship targets. Finally, anchor-based methods may cause sample imbalance and complex computation.
In contrast to anchor-based methods, anchor-free methods are based on point to predict frames. For the two difficulties of small ships with low resolution and complex overland background, Guo et al. [12] proposed an effective detector called CenterNet++. On the basis of CenterNet, three modules were added to address the above issues: the feature refinement module, the feature pyramid fusion module, and the head enhancement module. Yet it performed poorly on detecting the adjacent ships. In order to strike a balance between accuracy and speed without limiting the detection performance, Wan et al. [13] set YOLOX as the basic framework which redesigned the backbone into the lightweight MobileNetV2S. Moreover, channel and spatial attention mechanisms called CSEMPAN and a new target detection head ESPHead were brought up to mitigate the scattering characteristics of SAR images and extract features from different scales, respectively. Hu et al. [14] put forward an anchor-free method based on a balance attention network to enhance the generalization capability of multiscale ship detection. In this network, a local attention module was designed to further enhance the robustness of the network. A nonlocal attention module was also introduced to effectively derive nonlocal features from SAR images. While this is an approach to detecting ships of different sizes by extracting multiscale features, features from different scales may be not strictly aligned, which would interfere with the detection results. To deal with this problem, Xiao et al. [15] proposed an anchor-free model, namely power transformations and feature alignment guided network (Pow-FAN). Li et al. [16] improved YOLOX to tackle the challenges in SAR ship detection and achieve high detection accuracy. The application of high frequency sub-band channel fusion mitigates the issues of speckle noise and blurred ship contour. In addition, an ultra-lightweight backbone, including GhostCSP and a lightweight spatial dilation convolution pyramid, was designed to improve detection performance. Compared to anchor-based methods, anchor-free methods better locate the scattered and sparse ships in SAR images. Nevertheless, anchor-free methods require strong semantic information to be extracted from the backbone, resulting in its high computational complexity. Therefore, it is still a struggle for existing anchor-free methods to effectively detect ships from SAR images.
2.2. Small object detection methods
One of the biggest challenges of ship detection in SAR images is detecting small-scale ships in clutter and complex backgrounds. In recent years, considerable work has taken place concerning the development of a better small object detection method, which can be separated into three main categories: increasing the resolution of input images, data augmentation, and optimizing network structure. However, the first two methods significantly increase parameters and lead to computation inefficiency. Therefore, this subsection will concentrate on several foundational optimization network-based approaches in small object detection.
Yu et al. [20] developed a new convolution block that applied dilated convolutions to process multi-scale prediction by aggregating contextual information in different scales. Dilated convolution increased the respective field and avoided the loss of context information. Lin et al. [21] designed the feature pyramid network (FPN), a top-down feature fusion network, to fuse feature maps from different scales. The fusion factor in the FPN was implemented to regulate the transmission of information from deep to shallow layers, which made the FPN adaptive to small object detection. To avoid the intensive computational cost in image pyramids, Singh et al. [22] developed the algorithm SNIPER for efficient multi-scale training, which processes context regions around ground-truth instances in appropriate proportions. This method adaptively adjusts the number of chips according to the complexity of the scene in the image. Lim et al. [23] proposed FA-SSD, which combines feature fusion and the attention mechanism in a conventional SSD. In this method, several high-level feature maps which contain context information of small objects were fused via a one-stage attention module with low levels. On the basis of U-Net Wu et al. [24] innovatively nested two U-Nets to obtain a novel framework, namely UIU-Net, which could effectively prevent the loss of tiny objects and acquire more object contrast information. In detail, UIU-Net was separated into two modules, RM-DS and IC-A, to generate multi-scale features while learning global context information and encoding the local context information from different levels, respectively. The aforementioned methods for optimizing the network structure can achieve more precise detection of small targets without increasing the number of parameters or the computation cost, thereby enabling real-time detection of small objects.
3. Methodology
Aiming to achieve efficient ship detection in SAR images, we innovatively design an efficient anchor-free detector, namely ESarDet. Figure 1 depicts the working flow of the proposed ESarDet. Due to complicated computation and sample imbalance caused by anchor-based methods, we chose the latest lightweight, universal anchor-free object detection model YOLOX-tiny [18] as the baseline model. Taking into account the complex backgrounds, large scale variation, small-scale targets, and limited computational resources, three modules are proposed for the baseline model to optimize ship detection performance. First, to improve the detection of small ships in SAR images, we propose CAA-Net, which can effectively fuse context and semantic information. Second, to prevent losing the semantic information of ship targets at the bottom layer and improve detection efficiency, A2SPPF is designed to replace the SPP in YOLOX-tiny. Lastly, aiming to better detect multi-scale ships, we propose a new convolution block named A2CSPlayer, to better fuse feature maps of different scales. In the section that follows, the main components of the ESarDet will be described in detail.
3.1. CAA-Net
YOLOX-tiny applies cross-stage partial network (CSPNet) as the backbone, which can enhance the networks’ capacity for learning and reduce memory costs. However, due to the stacking of multiple small kernel convolutions, the ERF of CSPNet is small, which makes it challenging to capture context information of ships. In addition, the network extracts more semantic information but retains less context information as the layer’s number of network increases. To address these problems with CSPNet, a context attention auxiliary network (CAA-Net) is proposed to enhance the network’s ability to extract context information and expand ERF. Figure 2 depicts the working process of the proposed CAA-Net.
The proposed CAA-Net contains the two path network to process the input feature map . In the proposed CAA-Net, path A contains the depthwise separable convolution (DSConv) block [25]. Path B contains three parts that are convolution block, coordinate attention (CA) module [26], and convolution block. Subsequently, the results of the two paths will be concatenated and reshaped via convolution and SoftPool[27] to obtain the output of CAA-Net.
Most networks expand the receptive field by stacking convolutions with small kernel sizes. However, stacking small convolutions does not effectively increase the effective receptive field [28,29]. The large ERF can help the network better extract the context information of ships, especially small ones. The equation of the ERF is:
where is a standard deviation which indicates the size of ERF, is roughly a Gaussian with mean and variance, denotes the Gaussian model of . Moreover, m represents the pixel point in the kernel, k represents kernel size, and n denotes the convolution layers.
The ERF of a convolution is proportional to its kernel size and the square root of the number of layers, as demonstrated by the equation. It can be concluded that using a large kernel convolution expands the ERF more effectively than increasing the depth of small convolution layers. The use of large kernel convolution not only expands the effective receptive field, but also enhances its ability to extract context information of ships. Therefore, a convolution is added to the proposed CAA-Net, expanding the ERF and increasing the extraction of small ship context information from SAR images.
Nevertheless, convolution with a large kernel size has low computational efficiency. In addition, large kernel convolution makes it challenging to extract local features, which play a crucial role in ship detection. We introduce DSConv to increase the computational efficiency and performance of large convolutions to mitigate the aforementioned issues, and the equation of DSConv is as follows:
where denotes the pointwise convolution operation, and denotes depthwise convolution. Moreover, represents the feature map’s concatenate operation.
Different from conventional convolution, DSConv decouples the spatial information and cross-channel information of the input feature map. DSConv employs depthwise convolution (DWC) to process the input channel by channel and then concatenates these feature maps, merging them into an output. However, using only DWC to process feature maps may cause a loss of cross-channel information. Thus, the pointwise convolution (PWC) is designed, in which convolution is introduced to cope with the cross-channel information. After the whole process mentioned above, a new feature map is generated. Compared to conventional convolution, DSConv significantly reduces the model’s computational cost.
Aiming to balance the context information extracted by the large kernel convolution in path A, we add a shortcut path, path B, to CAA-Net. In path B, the input is first processed via a convolution block, which can prevent the network’s overfitting and increases the generalization ability. Additionally, the convolution block can deepen the neural network and add more nonlinear information to help extract more features. Moreover, We introduce the CA module, a lightweight attention module, to path B of CAA-Net to better balance the context information extracted in path A and enhance the network’s capacity to extract ship location data from SAR images. Figure 3 depicts the working process of the CA module.
In particular, the CA module contains two main steps, coordinate information embedding and coordinate attention generation, which can encode channel relations and long-range relations. The input X is first compressed by X and Y global average pooling to and , respectively. After that, the two feature maps are concatenated together. The concatenated results are reshaped to via a convolution block (r = 16 in this paper). The reshaped result is subsequently divided into two distinct feature maps. The two feature maps are transformed into and via two additional convolution and sigmoid functions. Finally, combining the output feature maps into a weighting matrix, the input feature map X is multiplied by two weighting matrices to refine the weights. The CA module’s operational flow can be summarized as follows:
where W and H are the width and height of the input feature map, and denote the results of X Avg Pool and Y Avg Pool, respectively. , represents convolution with kernel size , denotes the sigmoid activation function, and represents the batch normalization operation.
Paths A and B’s processed feature maps will be concatenated into a new feature map whose size is . The feature maps, respectively, from path A and path B, will be concatenated into a new feature map whose size is . Then the feature map will be reshaped by a convolution to .
To fuse with the feature map extracted from CSPNet, SoftPool is introduced to downsample the feature map to , and its operation flow is depicted in Figure 4. Conventional pooling operations, such as maximum and average pooling, result in the loss of semantic information of the feature map, which affects the precision of SAR ship detection. Unlike conventional pooling operation, SoftPool downsamples the feature map by using softmax of regions, producing normalized results that preserve more semantic information. The forward process of SoftPool can be summarized as follows:
where R denotes the kernel size of the SoftPool, e represents the natural exponent, denotes the input feature map, is the weights of , and is the final output activation map.
Finally, in order to fuse the context information extracted by CAA-Net with the semantic information extracted by backbone, an efficient feature fusion module is proposed. Its structure is depicted in Figure 5. The process of the proposed feature fusion module can be summarized as follows:
where denotes the CBAM attention module, represents a convolution block, which is consists of a dilated convolution with a kernel size of , batch normalization, and the SiLu activation function.
The feature maps extracted via CAA-Net and the backbone will first be concatenated in the feature fusion module. Then, the concatenated result will be reshaped via a DSConv block. To better merge semantic information with contextual information, the convolutional block attention module (CBAM) [30], a mixed attention module, is subsequently applied to refine the feature map. The CBAM module’s operating principle can be summarized as follows:
where and are spatial attention and channel attention modules. is multilayer perceptron. and denote global average pooling (GAPool) and global max pooling (GMPool), respectively. Meanwhile, and stand for average pooling (APool) and max pooling (MPool), respectively.
In CBAM, the input feature map will first be calculated via the channel attention submodule. In this submodule, two attention maps are obtained via GAPool and GMPool, respectively. After that, two attention maps are refined independently via a two-layer multilayer perceptron (MLP) and merged by summing the refined feature map. In addition, to normalize the merged results, the sigmoid activation function is also introduced. Finally, to obtain the results of the channel attention submodule, the input is multiplied with the attention map. Then the spatial attention submodule processes the refined feature map. The feature map, which is processed by the channel attention submodule, is first processed by APool and MPool, respectively. After that, the two feature maps are concatenated and reshaped via a convolution. As with the channel attention submodule, sigmoid activation functions are also applied to normalize the attention map. The CBAM module’s final result is generated by multiplying the feature map with the attention map extracted by the spatial attention submodule.
3.2. A2SPPF
YOLOX-tiny introduces SPP [31] in the backbone to remove the fixed-size constraint of the network. As shown in Figure 6(a), in SPP, the input feature map is parallel processed via the three max pooling operation. The three independently processed feature maps are concatenated with a residual feature map and then reshaped via a convolution block. However, the pooling operations in SPP result in the loss of the ship’s semantic information in SAR images. In addition, the parallel processing of three feature maps in SPP leads to low computational efficiency. Moreover, SPP cannot extract the information in different channels well.
Inspired by [32,33,34], we propose atrous attentive spatial pyramid pooling fast (A2SPPF), and its working flow is depicted in Figure 6(b). In comparison to SPP, the designed A2SPPF employs a serial operation to improve computational efficiency. Moreover, the proposed A2SPPF replaces the max pooling operation with dilated convolutions with different dilate rates and kernel sizes to expand the ERF and prevent the loss of detailed information in the feature map. Dilation rates of these three dilated convolutions are , and their kernel sizes are . We also introduce the efficient channel attention (ECA) module, a lightweight attention module [35], to refine the weights. The structure diagram of the ECA module is depicted in Figure 7. The ECA operating principle can be summarized as follows:
where denotes a 1D convolution with kernel k, and in this paper . represents the sigmoid activation function. The ECA module obtains a feature map via GAPool. A 1D convolution and a sigmoid function are subsequently applied to obtain the attention map. Lastly, feature maps will be refined by multiplying them with the relevant channels of the input.
Three feature maps, which are processed via the ECA module, will be concatenated with the residual feature map. At the end of the proposed A2SPPF, the results will be reshaped via a convolution to obtain the final output.
3.3. A2CSPlayer
How to efficiently merge the different scale features extracted from the backbone is an important issue for detecting multi-scale ships in SAR images. YOLOX-tiny introduces PAFPN, in which CSPlayer can effectively merge the feature maps from different scales. The CSPlayer increases the network’s depth by stacking convolutions, and the bottleneck structure raises the network’s computational efficiency. However, CSPlayer has a small ERF. In addition, it is also challenging for CSPlayer to effectively extract the features of small ships that are scattered in different channels. To achieve a more effective fusion of features from different scales, we propose the A2CSPlayer to process the concatenated feature maps. The architecture of the proposed A2CSPlayer is depicted in Figure 8.
The proposed A2CSPlayer contains two branches. In path A, a convolution block and an ECA module will refine the input feature map to extract the small ship features scattered in multiple channels. Then the feature map will be split into two parts. In one part, two convolutions with respective kernel sizes of and will be applied to process the input feature map. Then, the feature map of this part will be added to the residual part to generate the final result of path A. The convolution operation of path A can be formulated as:
In path B, the input feature map is processed via the proposed dynamic dilated depthwise separable convolution (), which has a larger ERF than conventional convolution, and the convolution operation can be expressed as:
The designed is shown in Figure 9. To expand ERF and raise the computational efficiency, we first combine DSConv with dilated convolution. To expand the ERF, we substitute the PWC convolution process in DSConv with a dilated convolution. However, feature maps of varying scales have varying widths and heights, and the context information they contain varies in scale. To improve the extraction of context information, we establish a mapping relationship between the dilation rate of and the width and height of the input image and the width and height of the current feature map.
The proposed mapping relationship should meet both of the following conditions. (1) The dilation rate increases proportionally with the size of the feature map; (2) to prevent the loss of long-range information due to the large dilation rate, the dilation rate of the proposed should be constrained. The proposed mapping relationship is shown below:
where is floor operation. In this paper, to meet the two previous conditions above, k and b are set to 3 and 0.2, respectively. Table 1 shows the relationship after calculation between input image size and current feature map size and dilation rate.
After the operation above, the two feature maps obtained from paths A and B will be concatenated first. Finally, to obtain output of A2CSPlayer a convolution block is used to process the feature map. The operation is as follows:
4. Experiments
To validate the validity of the proposed ESarDet, extensive experiments are conducted on DSSDD[36], SSDD[37], and HRSID[38], three challenging public datasets. This section will initially describe the experimental environment, dataset, evaluation metrics, and training details. Following that, detailed ablation experiments are carried out to validate the efficacy of each proposed module. Finally, we performed comparative experiments, comparing the proposed ESarDet to present state-of-the-art (SOTA) detectors.
4.1. Experimental Environment
All experiments in this paper are conducted in the same environment. The configuration of the environment is shown in Table 2.
4.2. Dataset Description
4.2.1. DSSDD
The dual-polarimetric SAR ship detection dataset (DSSDD) is a unique public dataset that contains dual-polarization images [36]. The DSSDD dataset includes 1236 images collected from Sentinel-1 satellites, containing 3540 ship targets in total. Moreover, the image size in DSSDD is fixed at 256 pixels by 256 pixels. Among these images, 856 are trainable, and the remaining 380 are testing data.
4.2.2. SSDD
The SAR ship detection dataset (SSDD) is the most widely used public dataset in SAR ship detection [37]. The SSDD dataset includes 1160 images collected from three different satellites, totaling 2456 ship targets. In SSDD, 928 of these images are used for training, while the remaining 232 are used for testing. The image size of the SSDD dataset is not fixed. The edge of the images in SSDD varies from 256 pixels to 608 pixels, and the distance resolution is 1∼15m.
4.2.3. HRSID
The high-resolution SAR images dataset (HRSID) is one of the most utilized datasets for ship detection tasks in high-resolution SAR images [38]. HRSID contains a total of 5604 images and 16,965 ship targets in the dataset, which is gathered from the Sentinel-1 and TerraSAR-X satellites. Among these 5604 images, the training set has 3642 images and the test set has 1962. The size of images in the HRSID dataset is fixed at 800 pixels by 800 pixels, and distance resolutions are 0.5 m, 1 m, and 3 m.
4.3. Training Details
This paper’s training parameters are established with reference to [18]. The optimization algorithm of the experiments used stochastic gradient descent (SGD) with a learning rate set to 0.01, momentum set to 0.937, and weight decay set to 0.0005. Furthermore, the unfreeze training batch size is 16. To obtain a pre-trained model, we first initialize all models with weights by random parameters. These models are then trained on the DSSDD dataset by unfreeze training for 30 epochs. Finally, the training results are applied as pre-trained models for subsequent training. Based on the pre-trained model, we trained 300 epochs by unfreeze training. The input image sizes are in DSSDD, in SSDD, and in HRSID. Mosaic[39] and MixUp[40] data augmentation is also included in the training pipeline.
4.4. Evaluation Metrics
To measure the performance of the proposed ESarDet model, we introduce average precision () and as evaluation indicators. The and are calculated by:
where P represents precision, and R represents recall, and they are calculated by:
where , , and denote the number of true positives, false positives, and false negatives, respectively.
In addition, parameters (), floating-point operations per second (), and frames per second () are also applied to measure the computational complexity and efficiency of the proposed model. The FPS is calculated as follows:
where T denotes the average time for the detector to detect an image.
4.5. Ablation Experiments
To verify the validation of each proposed module in ESarDet, we conduct three sets of ablation experiments on DSSDD, SSDD, and HRSID. Each set of ablation experiments contains five sub-experiments, containing fifteen sub-experiments in total.
In each set of ablation experiments, the first experiment is the YOLOX-tiny without any improvement as a baseline to provide a basis for comparison in subsequent experiments. The second experiment is the introduction of the proposed CAA-Net in the backbone of YOLOX-tiny to verify the effectiveness of the context attention auxiliary network (CAA-Net). In the third experiment, to validate the effectiveness of the proposed atrous attention spatial pyramid pooling fast (A2SPPF), we use the A2SPPF to replace the SPP in YOLOX-tiny. In the fourth experiment, we replace the CSPlayer in YOLOX-tiny’s PAFPN with the A2CSPlayer to verify the performance of the proposed atrous attentive cross-stage partial layer (A2CSPlayer) in feature fusion. Finally, in the fifth experiment, we superimposed the second experiment, the third experiment, and the fourth experiment in order to verify the validity of the proposed ESarDet. In addition, the training environment, parameters, and dataset used in each set of ablation experiments are kept consistent. The results of the three sets of ablation experiments are shown in Table 3, Table 4 and Table 5, and visual ablation experiment results are shown in Figure 10.
In the first experiment, the baseline YOLOX-tiny had an AP of 96.30%, 95.08%, and 90.65%, respectively, for the DSSDD, SSDD, and HRSID datasets. In the second experiment, we added the proposed CAA-Net to the backbone of YOLOX-tiny, which raised the AP by 1.42% on DSSDD, 2.56% on SSDD, and 1.56% on HRSID. As is shown in the first row in Figure 10, after adding CAA-Net, the model detected all ships in the image, whereas the baseline model missed some small ships. In the third experiment, we substituted the SPP of YOLOX-tiny with the proposed A2SPPF, and the AP of DSSDD, SSDD, and HRSID increased by 0.48%, 1.67%, and 1.19%, respectively, compared to the baseline. Figure 10 demonstrates that when there are dense small ships in the image, the detection performance of A2SPPF is superior to that of the baseline model. In the fourth experiment, we replaced the CSPlayer with the A2CSPlayer in the neck of YOLOX-tiny, and the AP increased by 0.67% on DSSDD, 1.51% on SSDD, and 1.25% on HRSID, while the parameters increased by only 0.25%. As demonstrated in the third row of Figure 10, the designed A2CSPlayer is capable of detecting multi-scale ships in SAR images. In the last experiment, we conducted ablation experiments with the proposed ESarDet on three datasets. The proposed ESarDet achieves an AP of 97.93%, 97.96%, and 93.22% on DSSDD, SSDD, and HRSID datasets, respectively, with an increase of 1.63%, 2.88%, and 2.57% compared to the baseline, respectively. The parameters of ESarDet increased by 23.1% compared to baseline. As is shown in Figure 10, the proposed ESarDet accurately detects all ships in SAR images.
4.6. Comparison Experiments
4.6.1. Comparison with SOTA detectors
In this section, several SOTA detectors, including anchor-free detectors such as YOLOX-m [18], FCOS[41], and anchor-based detectors such as YOLOv4 [42], YOLOv5-l [43], YOLOv7 [44], and YOLOv8-l[45], are selected to verify the detection performance of the proposed ESarDet. We conduct comparative experiments on DSSDD, SSDD, and HRSID datasets, and experimental results are shown in Table 6, Table 7 and Table 8.
The proposed ESarDet exceeds all other SOTA detectors for in SSDD, DSSDD, and HRSID. In the DSSDD dataset, the proposed ESarDet has an of 97.93%, which is 2.22%, 5.53%, 2.1%, 3.35%, 2.24%, and 1.46% higher than FCOS, YOLOv4, YOLOv5-l, YOLOv7, YOLOv8-l, and YOLOX-m, respectively. In the SSDD dataset, the proposed ESarDet has an of 97.96%, which is 1.5%, 4.08%, 1.03%, 0.74%, 1.44%, and 0.99% higher than FCOS, YOLOv4, YOLOv5-l, YOLOv7, YOLOv8-l, and YOLOX-m, respectively. In the HRSID dataset, the proposed ESarDet has an of 93.22%, which is 4.79%, 11.48%, 1.19%, 0.37%, 1.04%, and 0.89% higher than FCOS, YOLOv4, YOLOv5-l, YOLOv7, YOLOv8-l, and YOLOX-m, respectively. In terms of metrics, the proposed ESarDet has of 6.2 M, which is 25.911 M, 57.738 M, 40.431 M, 30.995 M, 37.431 M, and 19.081 M lower than FCOS, YOLOv4, YOLOv5-l, YOLOv7, YOLOv8-l, and YOLOX-m, respectively, reflecting the high efficiency of ESarDet. When the input image size is , ESarDet’s FPS reaches 60.58, which is 41.67, 34.77, 46.36, 23.04, 46.09, and 30.15 frames faster than FCOS, YOLOv4, YOLOv5-l, YOLOv7, and YOLOX-m, respectively. Experiment results indicate that the proposed ESarDet outperforms these SOTA detectors in terms of detection precision, computational complexity, and detection speed.
Furthermore, two SAR images with complex backgrounds are selected to demonstrate the detection performance of the proposed ESarDet, and the detection results are depicted in Figure 11 and Figure 12, and the ground truth of two SAR images is also shown in those figures. Only the proposed ESarDet accurately detects all ships in two sample images.
In the sample image , FCOS missed the two in-shore small ships on the right side of the two image. YOLOv5-l mistook the buildings on the shore and the noise on the sea for ships. The other detectors also missed and had false results. In the sample image , only the proposed ESarDet, FCOS, and YOLOv7 accurately detect two ships docked together. Other detectors are less effective at identifying dense ship targets than the proposed ESarDet. In addition, YOLOv4 missed detecting a large quantity of ships in images. YOLOv5-l incorrectly identifies the structures on shore as ships. Moreover, three superior detectors, YOLOv7, YOLOv8-l, and YOLOX-m, missed detecting several ships as well.
4.6.2. Comparison with SAR ship detectors
To further validate the performance of the proposed ESarDet, a comparison experiment was conducted on the SSDD dataset. In this subsection, we selected several SOTA SAR ship detectors to compare with the proposed ESarDet. Due to the fact that the majority of SAR ship detectors do not release their source code, we cannot reproduce them and can only compare them based on the data they provide.
The results of the comparison experiments are shown in Table 9. When the input images are smaller than the other six SAR ship detectors, the proposed ESarDet still achieves an AP and F1 of 97.96% and 0.96, respectively, which are superior to the other detectors. Compared with CenterNet++, ESarDet improved AP and F1 by 2.86% and 0.08, respectively, while the detection speed improved by 35.45 FPS. In comparison with BL-Net, ESarDet improved AP and F1 by 2.71% and 0.03 respectively, while decreasing the parameters and FLOPs by 41.61 M, 34.254 G, respectively. In terms of detection speed, ESarDet improved by 60.73 FPS compared to BL-Net’s 5.02 FPS, reaching 65.75 FPS. In addition, ESarDet reduced the parameters by 31.11 M and increased the AP by 1.96 % when compared to FEPS-Net. In contrast to FEPS-Net, the detection speed of ESarDet increased by 34.21 FPS. The comparison experiments’ results demonstrate that the proposed ESarDet performs better than the existing SOTA SAR ship detector in a number of performance metrics.
5. Discussion
This section begins with a discussion of the model’s generalization capability. We trained the model on the HRSID training dataset before testing it directly on the DSSDD test dataset. Then, the function of large kernel convolution in SAR ship detection is also discussed. We modified the DBS convolution block’s kernel size in CAA-Net’s path A and tested the effectiveness of various kernel sizes on the HRSID dataset.
5.1. Generalization study
There are apparent variations between ships in different images due to distinctions in polarization, sensor models, and shooting locations; therefore, an efficient SAR ship detection method should have a high capacity for generalization. To verify the generalization capability of the proposed ESarDet, a generalization study was conducted. In this section, we train the model on the HRSID dataset and then directly test the trained model on the DSSDD test dataset, and the results of the experiments are shown in Table 10.
From the results of the generalization study, the performance of anchor-based detectors is dependent on the quality of the manually pre-designed anchors, so the generalization ability of anchor-based detectors is poor. In contrast, anchor-free detectors such as FCOS, YOLOX-m, and the proposed ESarDet have better generalization ability. In the generalization test, the AP of ESarDet reached 81.49%, which was 2.45%, 42.26%, 13.02%, 66.51%, 5.46%, and 5.46% higher than those of FCOS, YOLOv4, YOLOv5-l, YOLOv7, YOLOv8-l, and YOLOX-m, respectively, and the F1 of ESarDet reached 0.82 over several other detectors. According to the results of the generalization study, our proposed ESarDet has greater generalization capability than other SOTA detectors.
5.2. Effects of large kernel convolution
In this subsection we discuss the effect of large kernel convolution on SAR ship detection. We replace the kernel size of the convolution block in path A of CAA-Net with different sizes and test it on the HRSID dataset. The results are shown in Table 11. The AP of the model is 91.38% when the convolutional kernel size is . As the kernel size increases, the AP also increases. According to the conclusion of Ding et al. [29], the performance should reach its maximum level when the kernel size of the convolution is large enough to completely cover the input feature map. Nevertheless, the model achieves an AP of 92.21% on the HRSID dataset when the kernel size is . When we continue to increase the kernel size, the model’s performance does not significantly improve. We directly set the kernel size to , which can completely cover the input feature map, but its AP is only 92.17% while the number of parameters reaches 6,448 M. Moreover, the FPS of our model is greater than that of other kernel size models when the kernel size is . Combining the above experiments, the proposed ESarDet finally selects the kernel convolution.
6. Conclusions
In this paper, an efficient SAR ship detection method based on a large effective receptive field and context information called ESarDet was proposed. We redesigned YOLOX-tiny to overcome the challenges of SAR ship detection, such as complex backgrounds, large scale variation, small-scale targets, and constrained computational resources. The CAA-Net, A2SPPF, and A2CSPlayer modules are proposed to improve ship detection in SAR images. CAA-Net extracts contextual information from the shallow network and fuses it with semantic information to better detect ships in SAR images, which is small in scale and in complex backgrounds. For detecting small ships in SAR images efficiently, A2SPPF can prevent the loss of semantic information of the ship and improve detection efficacy. A2CSPlayer is proposed to better fuse feature maps of different scales to address the issue of large variation in ship scales in SAR images.
Extensive experiments were conducted on DSSDD, SSDD, and HRSID datasets, respectively, to validate the effectiveness of the proposed ESarDet. The proposed ESarDet achieves 97.93%, 97.96%, and 93.22% AP on DSSDD, SSDD, and HRSID datasets, respectively, which is higher than the baseline model and other SOTA methods. Regarding computational efficiency, the proposed ESarDet model has only 6.2 M parameters, significantly less than other SOTA models. The experimental results prove that the proposed ESarDet can achieve accurate and efficient ship detection in SAR images.
In our future work, we will investigate how to more effectively detect small-scale and in-shore ships in SAR images. Additionally, we will continue to investigate the function of large effective receptive field in SAR ship detection.
Author Contributions
Conceptualization, Y.Z. and C.C.; methodology, Y.Z. and C.C.; software, Y.Z. and C.C.; validation, Y.Z. and C.C; formal analysis, R.H. and Y.Y; investigation, R.H.; resources, R.H.; data curation, Y.Z. and C.C.; writing—original draft preparation, Y.Z. and C.C.; writing—review and editing, Y.Z., C.C., R.H. and Y.Y.; visualization, Y.Z.; supervision, R.H.; project administration, R.H.; funding acquisition, Y.Y All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China under grant 62076107 and the Natural Science Foundation of Jiangsu Province under grant BK20211365.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Our code is available at https://github.com/ZYMCCX/ESarDet.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wu, X.; Hong, D.; Tian, J.; Chanussot, J.; Li, W.; Tao, R. ORSIm detector: A novel object detection framework in optical remote sensing imagery using spatial-frequency channel features. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5146–5158. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More diverse means better: Multimodal deep learning meets remote-sensing imagery classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4340–4354. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph Convolutional Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5966–5978. [Google Scholar] [CrossRef]
- Kuttikkad, S.; Chellappa, R. Non-Gaussian CFAR techniques for target detection in high resolution SAR images. Proceedings of ICIP-94, Austin, TX, USA, –16, 1994; pp. 910–914. [CrossRef]
- Banerjee, A.; Burlina, P.; Chellappa, R. Adaptive target detection in foliage-penetrating SAR images using Alpha-Stable models. IEEE Trans. Image Process. 1999, 8, 1823–1831. [Google Scholar] [CrossRef] [PubMed]
- Qin, X.; Zhou, S.; Zou, H.; Gao, G. A CFAR detection algorithm for generalized gamma distributed background in high-resolution SAR images. IEEE Geosci. Remote Sens. Lett. 2012, 10, 806–810. [Google Scholar] [CrossRef]
- Ai, J.; Qi, X.; Yu, W.; Deng, Y.; Liu, F.; Shi, L. A new CFAR ship detection algorithm based on 2-D joint log-normal distribution in SAR images. IEEE Geosci. Remote Sens. Lett. 2010, 7, 806–810. [Google Scholar] [CrossRef]
- Jiang, J.; Fu, X.; Qin, R.; Wang, X.; Ma, Z. High-speed lightweight ship detection algorithm based on YOLO-v4 for three-channels RGB SAR image. Remote Sens. 2021, 13, 1909. [Google Scholar] [CrossRef]
- Xia, R.; Chen, J.; Huang, Z.; Wan, H.; Wu, B.; Sun, L.; Yao, B.; Xiang, H.; Xing, M. CRTransSar: A Visual Transformer Based on Contextual Joint Representation Learning for SAR Ship Detection. Remote Sens. 2022, 14, 1488. [Google Scholar] [CrossRef]
- Bai, L.; Yao, C.; Ye, Z.; Xue, D.; Lin, X.; Hui, M. Feature Enhancement Pyramid and Shallow Feature Reconstruction Network for SAR Ship Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1042–1056. [Google Scholar] [CrossRef]
- Yasir, M.; Shanwei, L.; Mingming, X.; Hui, S.; Hossain, S.; Colak, A.T.I.; Wang, D.; Jianhua, W.; Dang, K.B. Multi-scale ship target detection using SAR images based on improved Yolov5. Front. Mar. Sci. 2023, 9, 1086140. [Google Scholar] [CrossRef]
- Guo, H.; Yang, X.; Wang, N.; Gao, X. A Centernet++ model for ship detection in SAR images. Pattern Recognit. 2021, 112, 107787. [Google Scholar] [CrossRef]
- Wan, H.Y.; Chen, J.; Huang, Z.X.; Xia, R.F.; Wu, B.C.; Sun, L.; Yao, B.D.; Liu, X.P.; Xing, M.D. AFSar: An anchor-free SAR target detection algorithm based on multiscale enhancement representation learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Hu, Q.; Hu, S.; Liu, S. BANet: A Balance Attention Network for Anchor-Free Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Xiao, M.; He, Z.; Li, X.; Lou, A. Power Transformations and Feature Alignment Guided Network for SAR Ship Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, S.; Fu, X.; Dong, J. Improved Ship Detection Algorithm Based on YOLOX for SAR Outline Enhancement Image. Remote Sens. 2022, 14, 4070. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Liu, C.; Shi, J.; Wei, S.; Ahmad, I.; Zhan, X.; Zhou, Y.; Pan, D.; Li, J.; et al. Balance learning for ship detection from synthetic aperture radar remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 182, 190–207. [Google Scholar] [CrossRef]
- Zheng, G.; Songtao, L.; Feng, W.; Zeming, L.; Jian, S. YOLOX: Exceeding YOLO Series in 2021. arXiv arXiv:2107.08430, 2021.
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. COMMUN ACM. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv arXiv:1511.07122, 2015.
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. SNIPER: Efficient multi-scale training. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 3–8 December 2018; pp. 9310–9320. [Google Scholar]
- Lim, J.; Astrid, M.; Yoon, H.; Lee, S. Small Object Detection using Context and Attention. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Chanussot, J. UIU-Net: U-Net in U-Net for Infrared Small Object Detection. IEEE Trans. Image Process. 2022, 32, 364–376. [Google Scholar] [CrossRef] [PubMed]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Stergiou, A.; Poppe, R.; Kalliatakis, G. Refining activation downsampling with SoftPool. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10357–10366. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 11963–11975. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. arXiv arXiv:1701.04128, 2017.
- Woo, S.; Park, J.; Lee, J.Y. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2018; pp. 3–19. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; LLi, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv arXiv:2209.02976, 2022.
- Qiu, Y.; Liu, Y.; Chen, Y.; Zhang, J.; Zhu, J.; Xu, J. A2SPPNet: Attentive Atrous Spatial Pyramid Pooling Network for Salient Object Detection. IEEE Trans. Multimed. 2022, 1. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hu, Y.; Li, Y.; Pan, Z. A Dual-Polarimetric SAR Ship Detection Dataset and a Memory-Augmented Autoencoder-Based Detection Method. Sensors. 2021, 21, 8478. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access. 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv arXiv:2004.10934, 2020.
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully Convolutional One-Stage Object Detection. In Proceedings of the the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, M.H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv arXiv:2004.10934, 2020.
- ocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Michael, K.; Xie, T.; Fang, J. ultralytics/yolov5: v7.0-YOLOv5 SOTA Realtime Instance Segmentation. Zenodo 2022.
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv arXiv:2207.02696, 2022.
- (a).
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2020), Washington, DC, USA, 14–19 June 2020; pp. 390–391. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
Figure 1.
The proposed ESarDet consists of backbone, neck, and prediction head. In the figure, the modules proposed in this paper are indicated in red. The proposed CAA-Net and A2SPPF are integrated into the backbone, and A2CSPlayer is added to the neck.
Figure 1.
The proposed ESarDet consists of backbone, neck, and prediction head. In the figure, the modules proposed in this paper are indicated in red. The proposed CAA-Net and A2SPPF are integrated into the backbone, and A2CSPlayer is added to the neck.
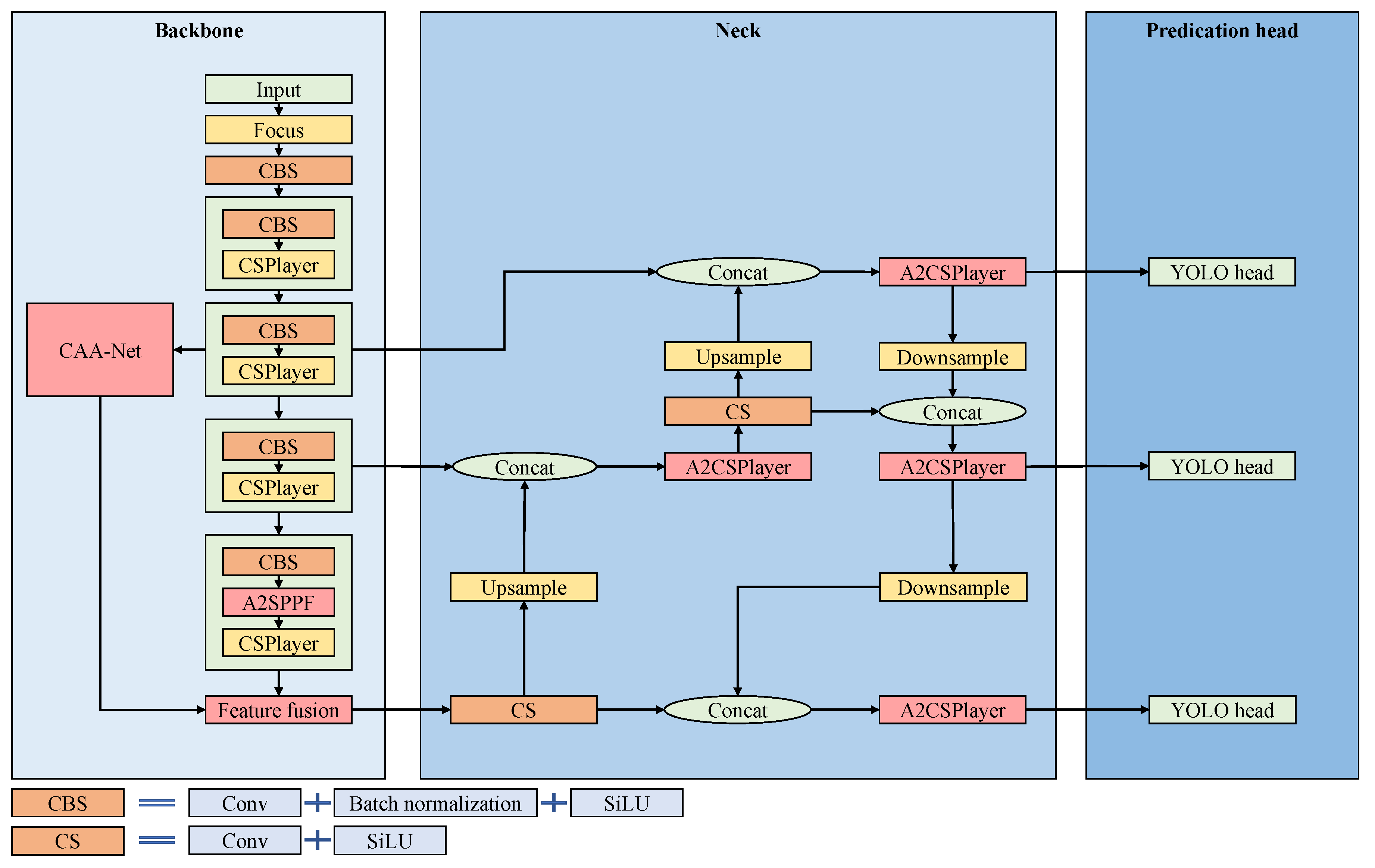
Figure 2.
The overall working process of the proposed CAA-Net. In the figure, CA stands for the coordinate attention module, and Ksize is the convolution block’s kernel size.
Figure 2.
The overall working process of the proposed CAA-Net. In the figure, CA stands for the coordinate attention module, and Ksize is the convolution block’s kernel size.
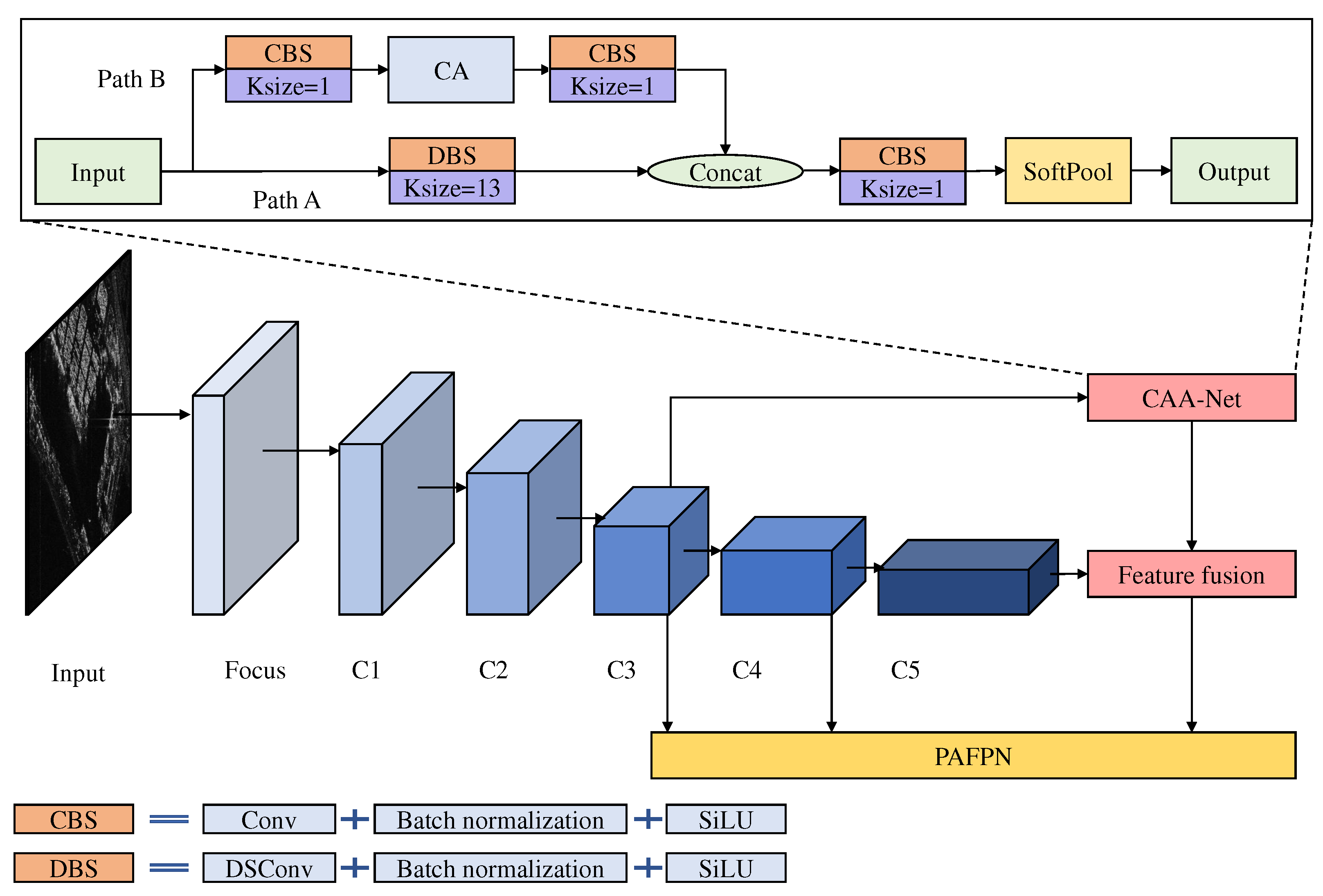
Figure 3.
The structure of the CA module; output size represents the size of the output feature map after the operation.
Figure 3.
The structure of the CA module; output size represents the size of the output feature map after the operation.
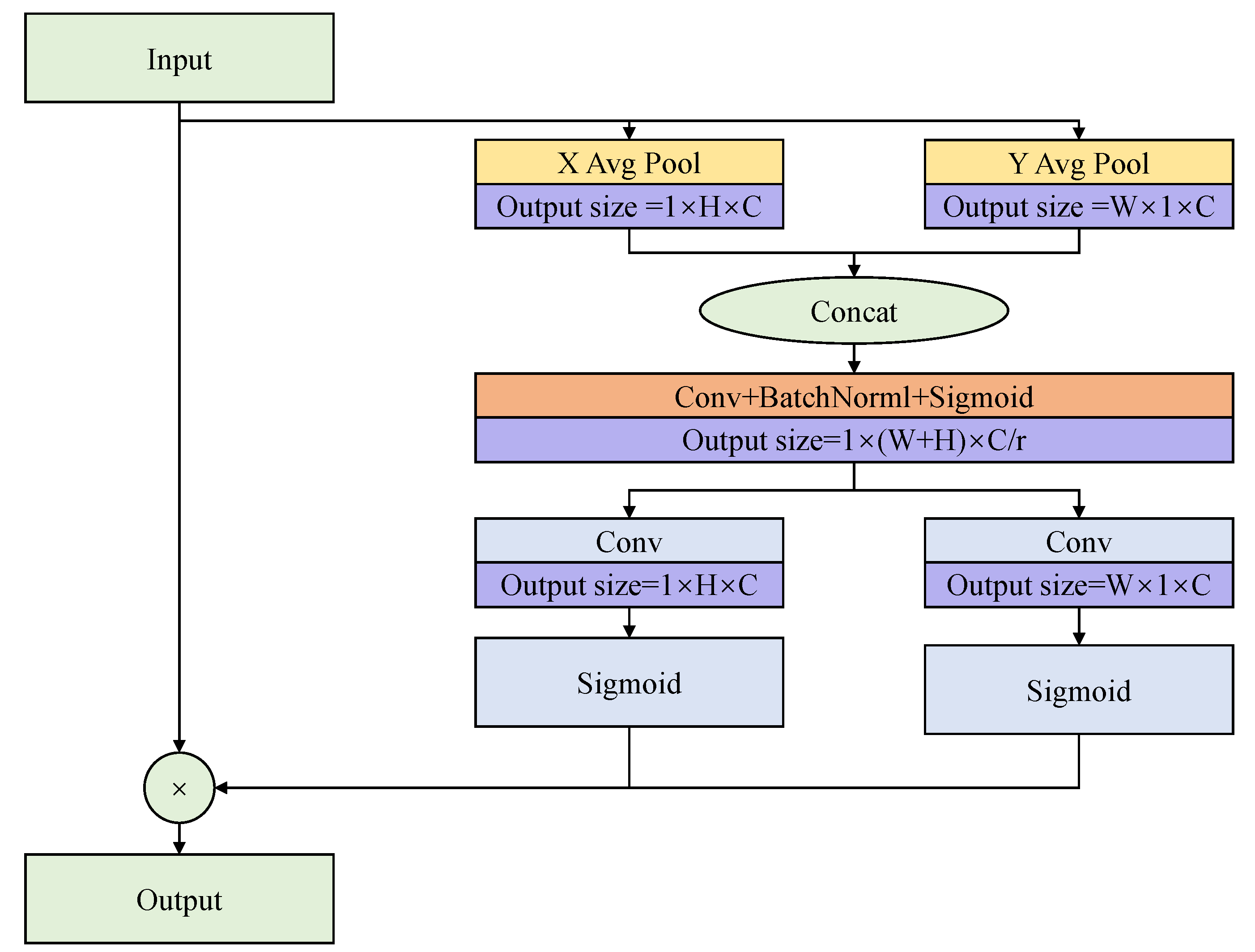
Figure 4.
The working flow of SoftPool.
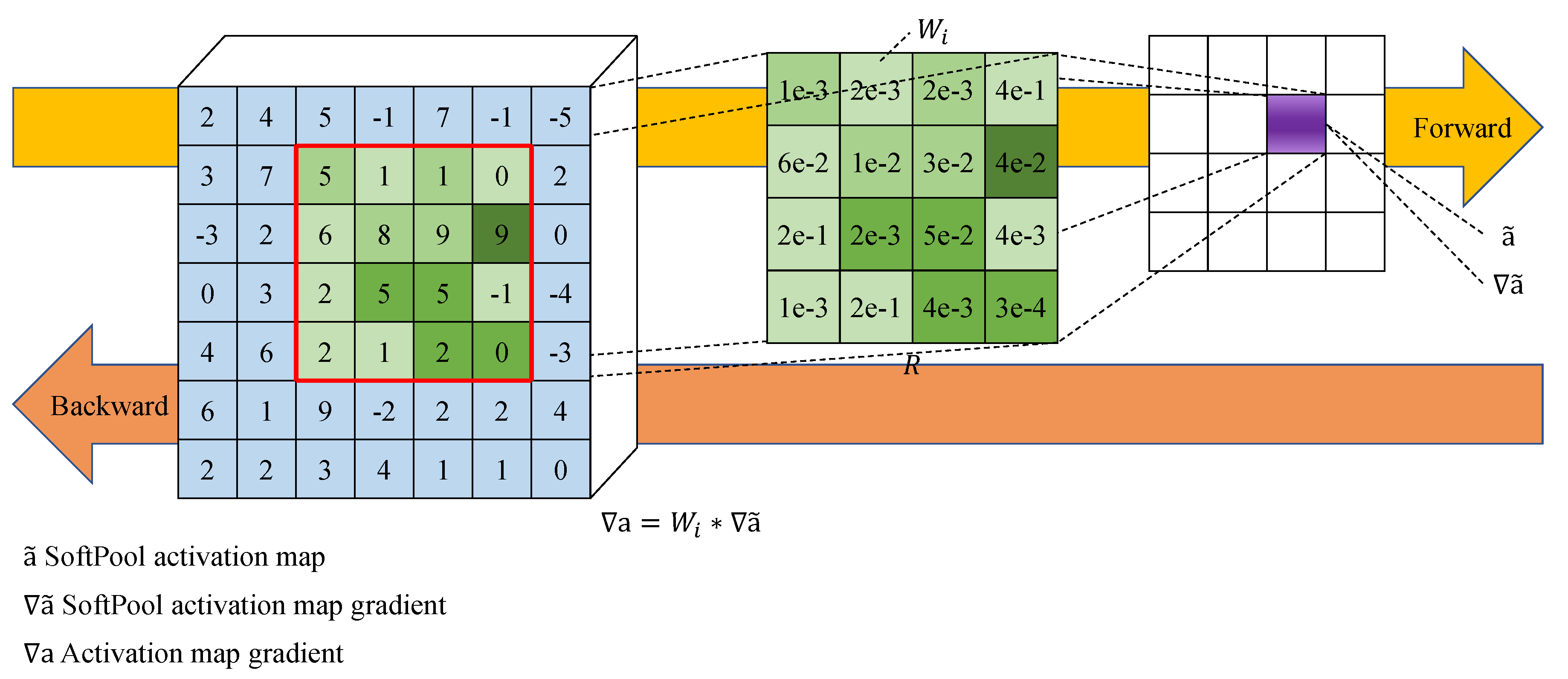
Figure 5.
The feature fusion module concatenates feature maps from CAA-Net and the backbone. Afterward, a DSConv is applied to reshape the concatenated results. Finally, CBAM will refine the reshaped feature map to obtain the feature fusion module’s output.
Figure 5.
The feature fusion module concatenates feature maps from CAA-Net and the backbone. Afterward, a DSConv is applied to reshape the concatenated results. Finally, CBAM will refine the reshaped feature map to obtain the feature fusion module’s output.
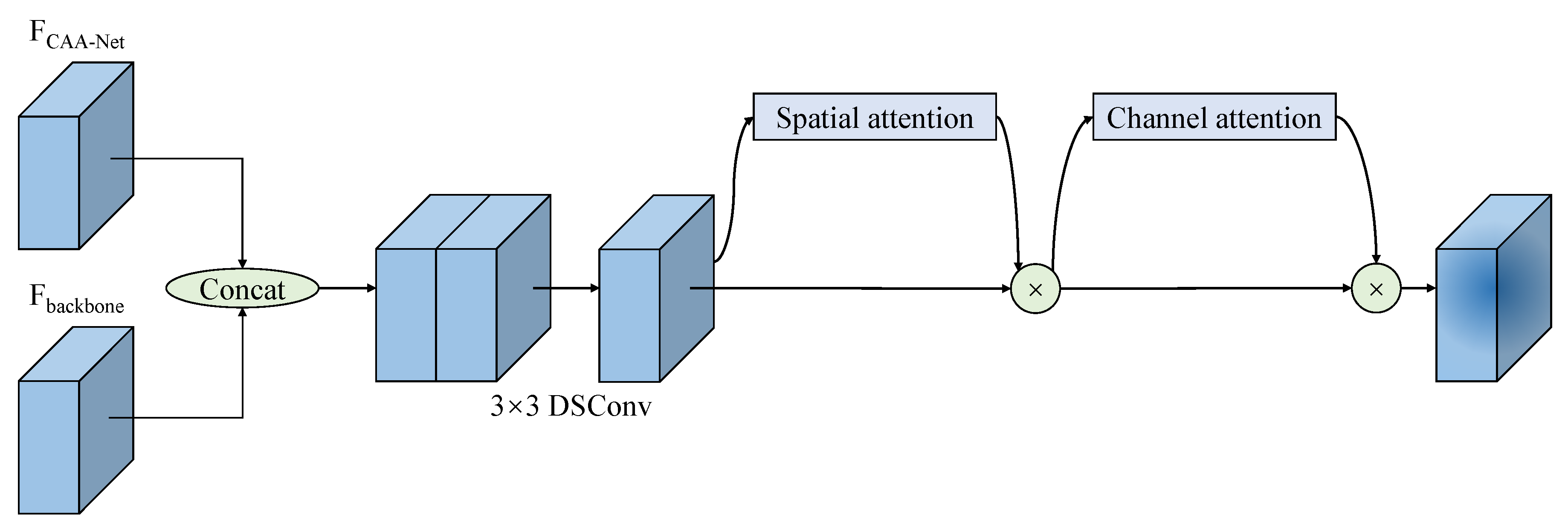
Figure 6.
The structure of the (a) SPP, and (b) proposed A2SPPF. Where ECA stands for efficient channel attention module, Ksize represents the kernel size of the operation, and rate represents the dilation rate of the dilated convolution. DCBS is the convolution operation of dilated convolution+batch normalization+silu.
Figure 6.
The structure of the (a) SPP, and (b) proposed A2SPPF. Where ECA stands for efficient channel attention module, Ksize represents the kernel size of the operation, and rate represents the dilation rate of the dilated convolution. DCBS is the convolution operation of dilated convolution+batch normalization+silu.
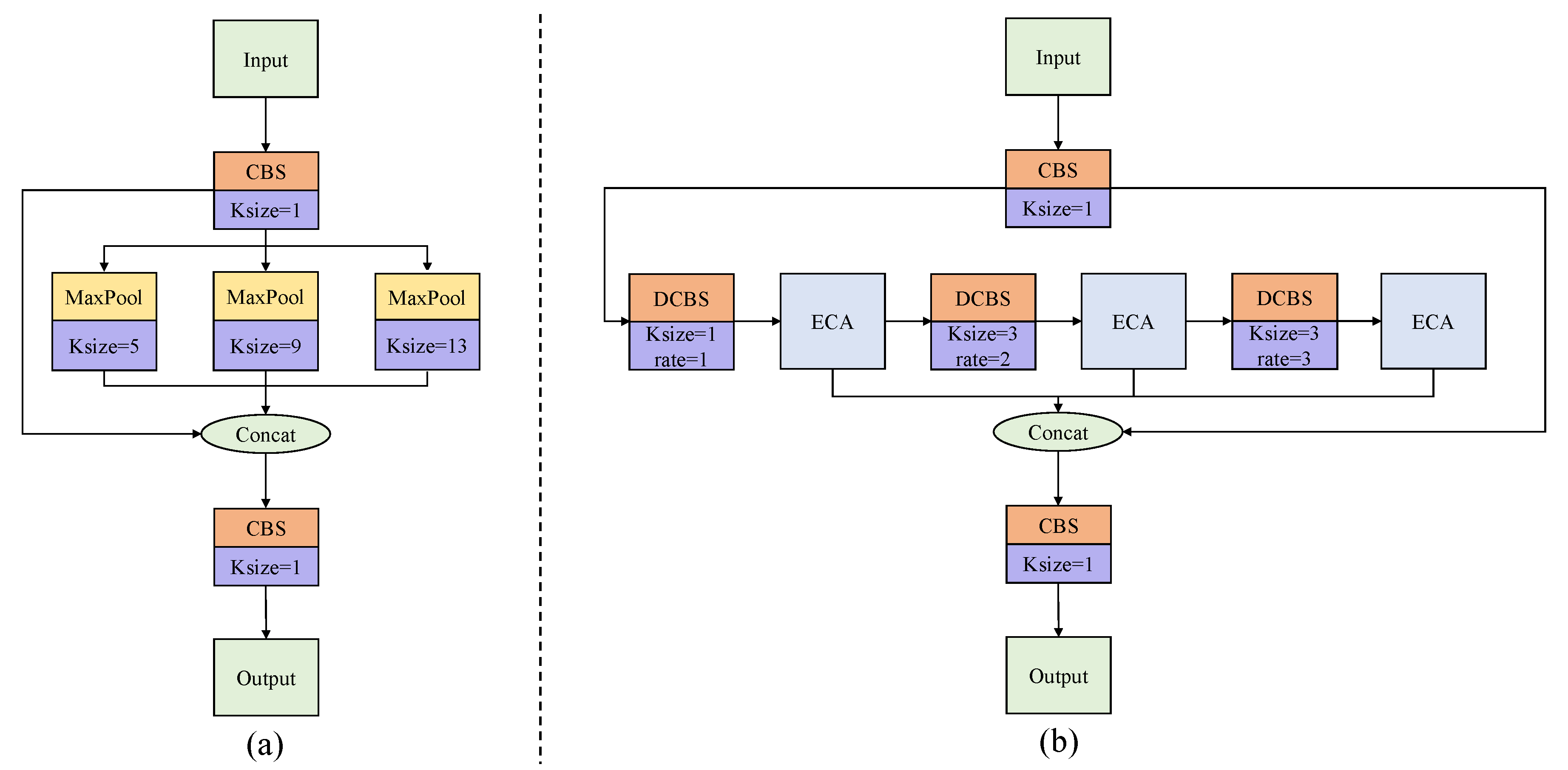
Figure 7.
The operation flow of the ECA module.
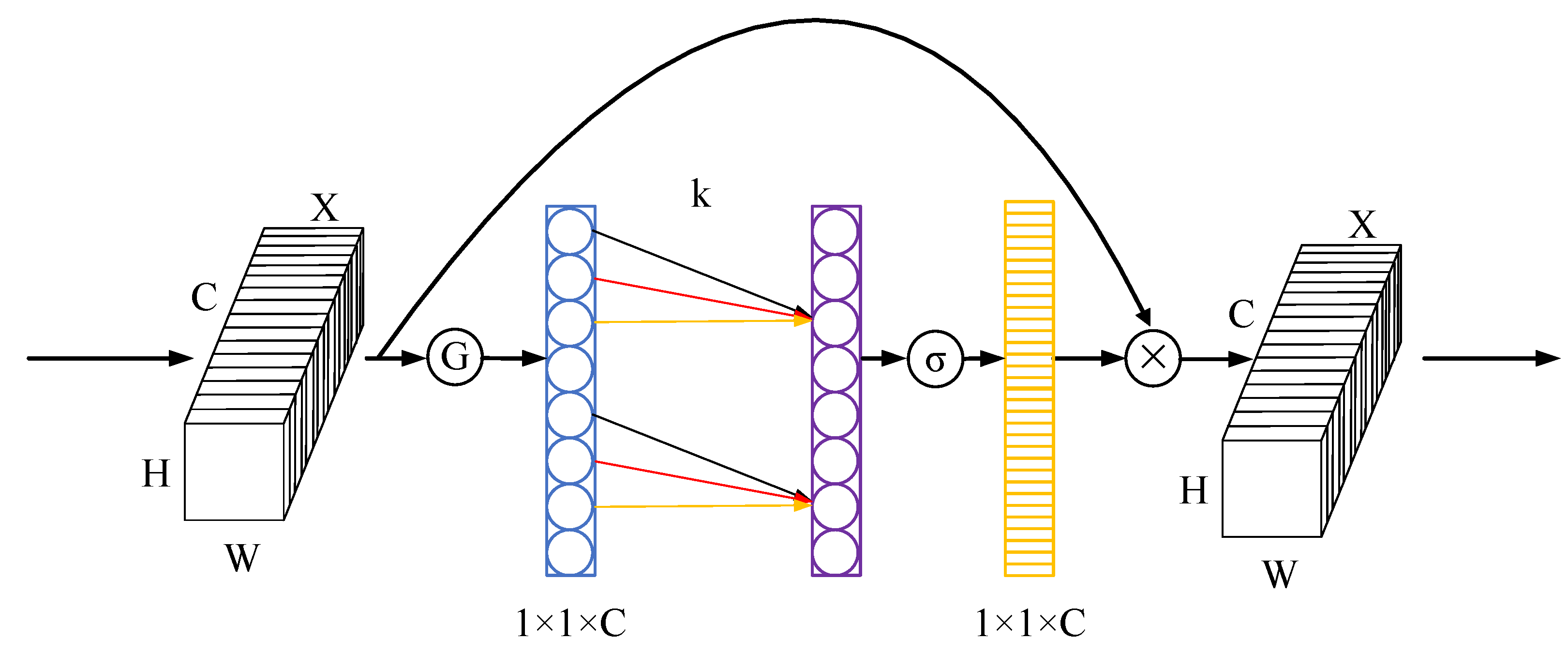
Figure 8.
The architecture of the proposed A2CSPlayer. represents the proposed dynamic dilated depthwise separable convolution, and ECA denotes the efficient channel attention module.
Figure 8.
The architecture of the proposed A2CSPlayer. represents the proposed dynamic dilated depthwise separable convolution, and ECA denotes the efficient channel attention module.
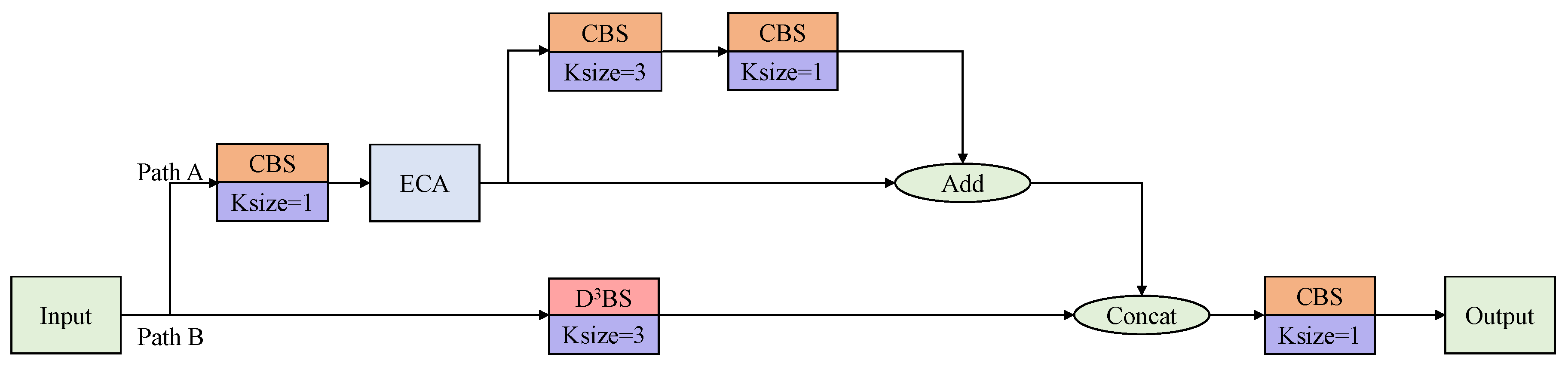
Figure 9.
The architecture of the proposed .
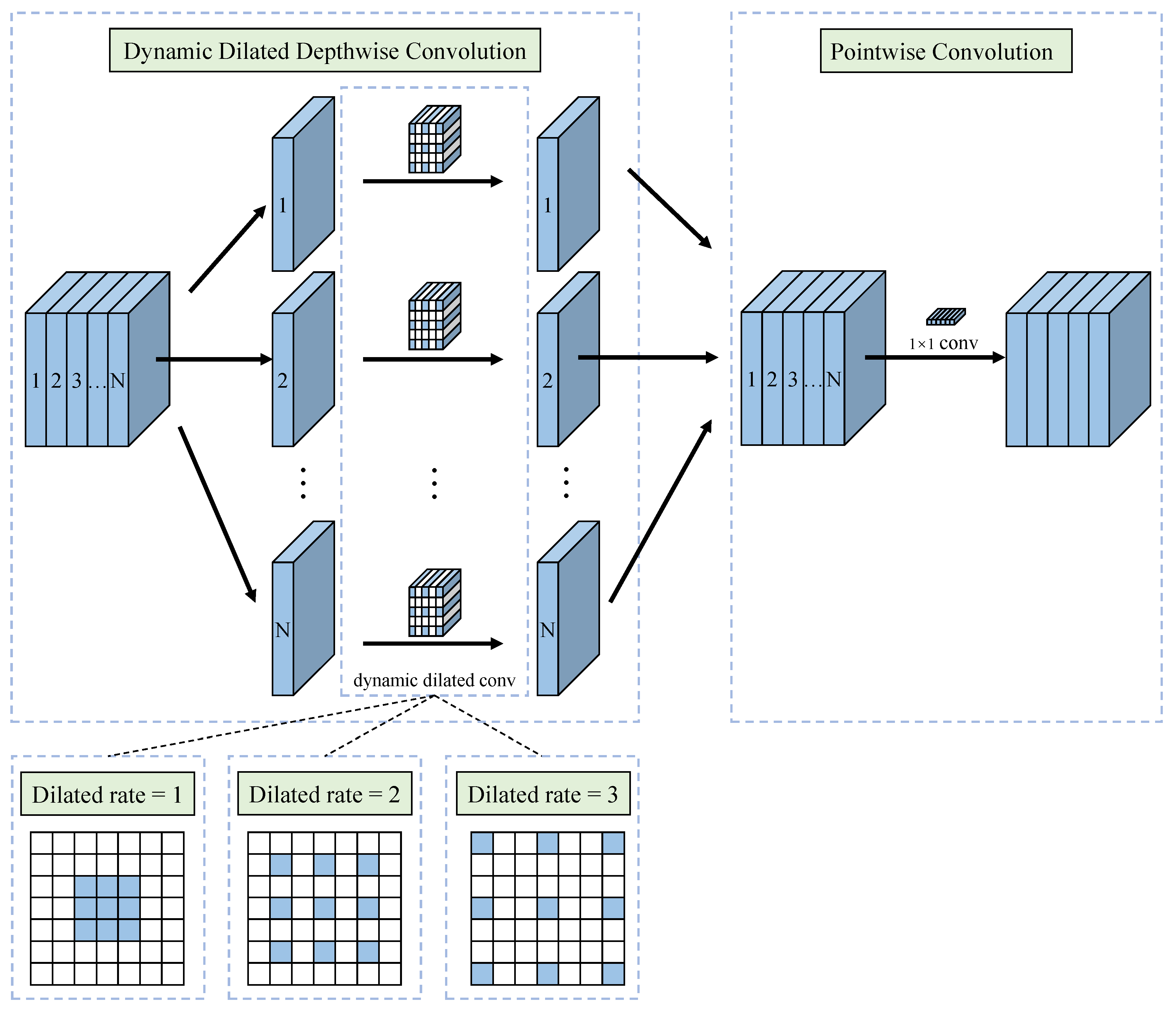
Figure 10.
Visual ablation experiment. GT represents ground truth; labels 1–5 correspond to the row ID 1–5 in Table 3, Table 4 and Table 5. The yellow circles represents the ships that missed detection, and the orange circles are the ships that are detected incorrectly.
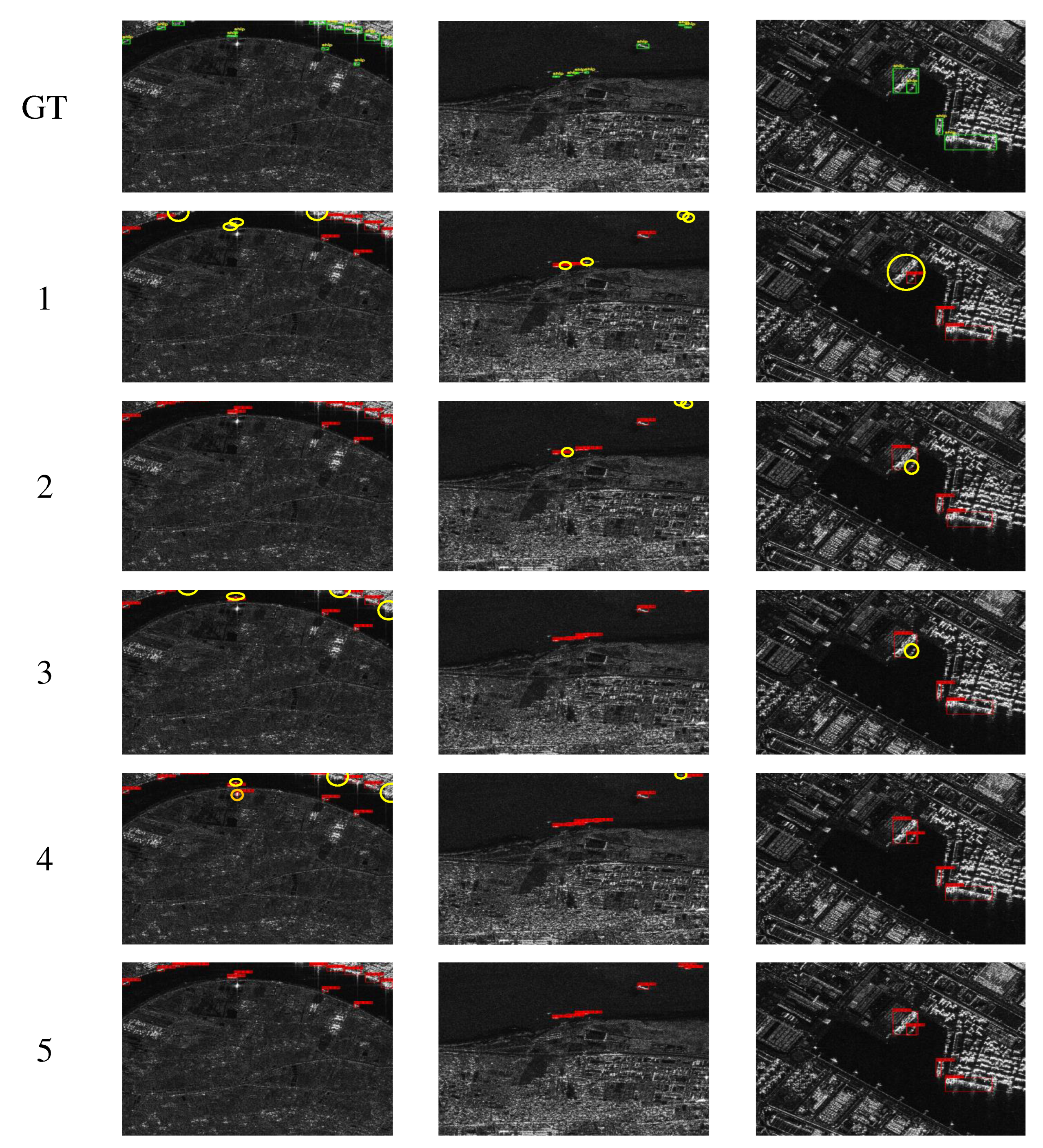
Figure 11.
Comparison of SAR ship detection of sample image . The yellow circles represents the ships that missed detection, and the orange circles are the ships that are detected incorrectly.
Figure 11.
Comparison of SAR ship detection of sample image . The yellow circles represents the ships that missed detection, and the orange circles are the ships that are detected incorrectly.

Figure 12.
Comparison of SAR ship detection of sample image . The yellow circles represents the ships that missed detection, and the orange circles are the ships that are detected incorrectly.
Figure 12.
Comparison of SAR ship detection of sample image . The yellow circles represents the ships that missed detection, and the orange circles are the ships that are detected incorrectly.
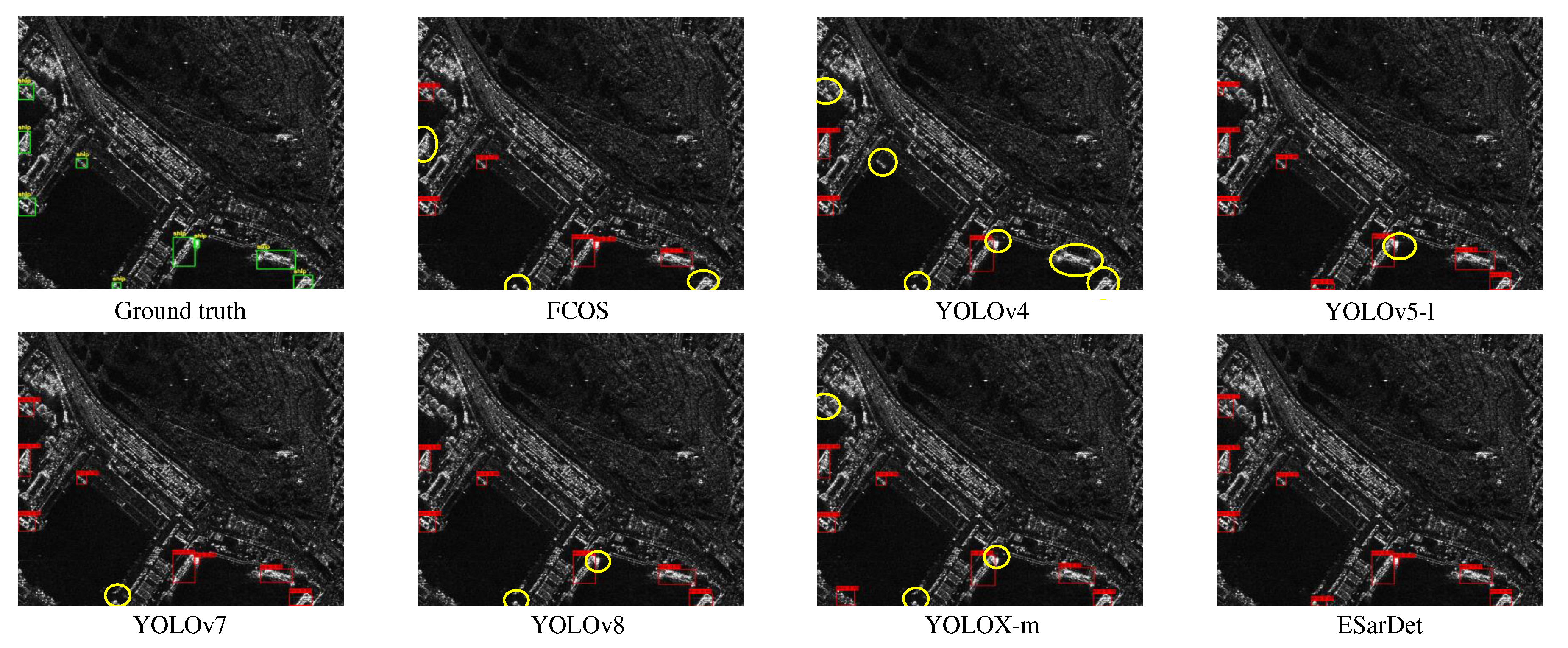

Table 1.
The relationship between input image size and current feature map size and dilation rate.
| Input image size | Current feature map size | Dilation rate |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 1 | ||
| 2 | ||
| 3 | ||
| 1 | ||
| 2 | ||
| 3 |
Table 2.
Configuration of the experimental environment.
| Configuration | Parameter |
|---|---|
| CPU | AMD Ryzen 7 5800X @3.8 GHz |
| RAM | 32GB RAM for DDR4 3200MHz |
| GPU | NVIDA GeForce RTX 3090 24GB GPU |
| Operating system | Ubuntu 18.04 |
| Developing tools | PyTorch 1.8.2; NumPy 1.21.6; OpenCV 4.6; SciPy 1.1.0; CUDA 11.1 |
Table 3.
Ablation experiment on DSSDD dataset.
| ID | CAA-Net | A2SPPF | A2CSPlayer | AP(%) | F1 | Parameters | FLOPs |
|---|---|---|---|---|---|---|---|
| 1 | F | F | F | 96.30 | 0.94 | 5.033 | 2.437 |
| 2 | T | F | F | 97.72 | 0.95 | 5.485 | 2.724 |
| 3 | F | T | F | 96.78 | 0.94 | 5.734 | 2.527 |
| 4 | F | F | T | 96.97 | 0.94 | 5.046 | 2.447 |
| 5 | T | T | T | 97.93 | 0.95 | 6.200 | 2.824 |
Table 4.
Ablation experiment on SSDD dataset.
| ID | CAA-Net | A2SPPF | A2CSPlayer | AP(%) | F1 | Parameters | FLOPs |
|---|---|---|---|---|---|---|---|
| 1 | F | F | F | 95.08 | 0.95 | 5.033 | 6.435 |
| 2 | T | F | F | 97.64 | 0.95 | 5.485 | 7.192 |
| 3 | F | T | F | 96.75 | 0.95 | 5.734 | 6.673 |
| 4 | F | F | T | 96.59 | 0.95 | 5.046 | 6.461 |
| 5 | T | T | T | 97.96 | 0.96 | 6.200 | 7.456 |
Table 5.
Ablation experiment on HRSID dataset.
| ID | CAA-Net | A2SPPF | A2CSPlayer | AP(%) | F1 | Parameters | FLOPs |
|---|---|---|---|---|---|---|---|
| 1 | F | F | F | 90.65 | 0.89 | 5.033 | 23.799 |
| 2 | T | F | F | 92.21 | 0.90 | 5.485 | 26.597 |
| 3 | F | T | F | 91.84 | 0.91 | 5.734 | 24.678 |
| 4 | F | F | T | 91.90 | 0.90 | 5.046 | 23.894 |
| 5 | T | T | T | 93.22 | 0.91 | 6.200 | 27.572 |
Table 6.
Comparison with the SOTA detectors on DSSDD dataset.
| Method | AP(%) | F1 | Parameters | FLOPs | FPS |
|---|---|---|---|---|---|
| YOLOX-m | 96.47 | 0.95 | 25.281 | 11.796 | 47.65 |
| FCOS | 95.71 | 0.87 | 32.111 | 25.782 | 69.01 |
| YOLOv4 | 92.40 | 0.93 | 63.938 | 22.704 | 56.83 |
| YOLOv5-l | 95.83 | 0.93 | 46.631 | 18.329 | 58.42 |
| YOLOv7 | 94.58 | 0.92 | 37.192 | 16.818 | 60.33 |
| YOLOv8-l | 95.69 | 0.93 | 43.631 | 26.464 | 66.61 |
| ESarDet | 97.93 | 0.95 | 6.200 | 2.824 | 71.36 |
Table 7.
Comparison with the SOTA detectors on SSDD dataset.
| Method | AP(%) | F1 | Parameters | FLOPs | FPS |
|---|---|---|---|---|---|
| YOLOX-m | 96.97 | 0.95 | 25.281 | 31.149 | 46.41 |
| FCOS | 96.46 | 0.92 | 32.111 | 68.209 | 62.32 |
| YOLOv4 | 93.88 | 0.90 | 63.938 | 59.953 | 52.11 |
| YOLOv5-l | 96.93 | 0.94 | 46.631 | 48.401 | 56.74 |
| YOLOv7 | 97.22 | 0.94 | 37.195 | 44.410 | 48.93 |
| YOLOv8-l | 96.52 | 0.94 | 43.631 | 69.883 | 46.09 |
| ESarDet | 97.96 | 0.96 | 6.200 | 7.456 | 65.75 |
Table 8.
Comparison with the SOTA detectors on HRSID dataset.
| Method | AP(%) | F1 | Parameters | FLOPs | FPS |
|---|---|---|---|---|---|
| YOLOX-m | 92.33 | 0.90 | 25.281 | 115.197 | 30.15 |
| FCOS | 88.43 | 0.83 | 32.111 | 252.015 | 41.67 |
| YOLOv4 | 81.74 | 0.78 | 63.938 | 221.719 | 34.77 |
| YOLOv5-l | 92.03 | 0.88 | 46.631 | 178.998 | 46.36 |
| YOLOv7 | 92.85 | 0.88 | 37.192 | 164.239 | 23.04 |
| YOLOv8-l | 92.18 | 0.90 | 43.631 | 258.442 | 46.09 |
| ESarDet | 93.22 | 0.91 | 6.200 | 27.572 | 60.58 |
Table 9.
Comparison with SOTA SAR ship detection methods on SSDD dataset.
| Method | input size | AP(%) | F1 | Parameters | FLOPs | FPS |
|---|---|---|---|---|---|---|
| CRTransSar[9] | 97.0 | 0.95 | 96 | - | 7.5 | |
| FEPS-Net[10] | 96.0 | - | 37.31 | - | 31.54 | |
| CenterNet++[12] | 95.1 | 0.88 | - | - | 30.30 | |
| AFSar[13] | 97.7 | 0.96 | - | 9.86 | - | |
| Pow-FAN[15] | 96.35 | 0.95 | - | - | 31 | |
| BL-Net[17] | 95.25 | 0.93 | 47.81 | 41.71 | 5.02 | |
| ESarDet | 97.96 | 0.96 | 6.200 | 7.456 | 65.75 |
Table 10.
Generalization experiment on DSSDD dataset.
| Method | AP(%) | F1 | Parameters | FLOPs | FPS |
|---|---|---|---|---|---|
| YOLOX-m | 76.03 | 0.80 | 25.281 | 11.796 | 47.65 |
| FCOS | 79.04 | 0.65 | 32.111 | 25.782 | 69.01 |
| YOLOv4 | 39.23 | 0.38 | 63.938 | 22.704 | 56.83 |
| YOLOv5-l | 68.47 | 0.72 | 46.631 | 18.329 | 58.42 |
| YOLOv7 | 14.98 | 0.31 | 37.192 | 16.818 | 60.33 |
| YOLOv8 | 70.96 | 0.74 | 43.631 | 69.883 | 66.61 |
| ESarDet | 81.49 | 0.82 | 6.200 | 2.824 | 71.36 |
Table 11.
Effects of large kernel convolution in HRSID.
| Kernel size | AP (%) | F1 | Parameters (M) | FPS |
|---|---|---|---|---|
| 91.38 | 0.90 | 5.469 | 72.57 | |
| 91.40 | 0.89 | 5.470 | 72.47 | |
| 91.59 | 0.90 | 5.474 | 70.78 | |
| 92.05 | 0.90 | 5.481 | 73.12 | |
| 92.21 | 0.90 | 5.485 | 74.89 | |
| 92.21 | 0.90 | 5.491 | 73.82 | |
| 92.14 | 0.90 | 5.504 | 73.44 | |
| 92.23 | 0.90 | 5.520 | 70.57 | |
| 92.17 | 0.91 | 6.448 | 53.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



