
Submitted:
09 May 2023
Posted:
10 May 2023
You are already at the latest version
Abstract
The rapid development of Deep Learning brought novel methodologies for 3D Object Detection using LiDAR sensing technology. These improvements in precision and inference speed performances lead to notable high performance and real-time inference, which is especially important for self-driving purposes. However, the developments carried by these approaches overwhelm the research process in this area since new methods, new technologies, and software versions lead to different project necessities, specifications and requirements. Moreover, the improvements brought by the new methods may be due to improvements in newer versions of deep learning frameworks and not just the novelty and innovation of the model architecture.
Thus, it became crucial to create a framework with the same software versions, specifications and requirements that accommodate all these methodologies and allow the easy introduction of new methods and models.
A framework is proposed that abstracts the implementation, reusing and building of novel methods and models. The main idea is to facilitate the representation of state-of-the-art (SoA) approaches and simultaneously encourage the implementation of new approaches by reusing, improving and innovating modules in the proposed framework, which has the same software specifications to allow a fair comparison. This makes it possible to determine if the key innovation approach outperforms the current SoA by comparing models in a framework with the same software specifications and requirements.
Keywords:
Autonomous Driving
; Deep learning Methods
; LiDAR Sensing Technology
; 3D Object Detection
1. Introduction
The field of computer vision has seen significant advancements in recent years, particularly in the area of 3D object detection from point cloud data. However, there is still a need for a general representation framework that can be applied to a wide range of 3D object detection tasks, regardless of the specific sensor or application domain. The development verified in recent years of the computational power offered by cutting-edge GPUs allowed the application of deep learning algorithms to detect objects in several domains. One such domain is autonomous driving using Light Detection And Ranging (LiDAR) data, representing a considerable gain in detection efficiency, precision, and inference speed [1].
In recent years, there has been significant progress in 3D object detection models based on LIDAR data for self-driving applications. A multitude of frameworks and projects have been proposed, each with its own unique approach to addressing the challenges of detecting and tracking objects in a 3D environment. However, this diversity also poses a challenge when it comes to deploying these models for onboard inference in a self-driving vehicle [4,17].
One major issue is the enormous variation in software versions, libraries, and supported platforms, making it difficult to assemble and deploy these models correctly. Additionally, self-driving requirements must be taken into consideration, such as the need for operationalisation with different modules and the limited computational resources available in onboard systems.
Regardless, the 3D object detection models discussed in the literature take point clouds as input and are known to be more complex. These models have a deeper pipeline and process a more significant amount of data. For example, a point cloud usually comprises between 100k-120k [4], where each point holds data related to the Euclidean distance and signal reflection, that is, 128 bits to translate each information of each point.
The literature includes recent research such as [1,2,3,4], it has been suggested that the minimum operating requirements for self-driving applications should include an overall class classification of at least 60 mAP and an inference time of less than 100 ms.
In this context, the need for a standardized and optimized framework for 3D object detection based on LIDAR data becomes even more important. Such a framework could simplify the deployment process, enable better interoperability across different systems, and facilitate the development of more efficient and effective self-driving systems.
1.1. Our Contribution
This paper aims to propose a general SoA representation framework for 3D object detection from the point cloud. It supports multiple SoA 3D object detection methods with highly refactored codes for both one-stage and two-stage methods. Also, it enables the implementation and reusing of different approaches with less manual engineering efforts by proposing an abstract way of building object detectors. At the same time, it facilitates the implementation of new methods in each module of the framework. By implementing different SoA we are trying to facilitate a new approach for the scientific community. In this way, it will be possible to offer a framework for real-time testing inference and measure the trade-off between metrics (mAPvs inference time) in one single framework 3D model objects applying for self-driving applications. Therefore, the contributions proposed in this paper are as follows:
- An abstract framework for the implementation/representation of edge for 3D object detection models using LIDAR data.
- Less engineer effort to implement new methods in different framework models.
- A simpler way to change hyperparameters and retrain models using YML files.
- An easily represented model using these YML files automatically.
The organisation of this paper is as follows: In the next Section 2, some of the state-of-the-art works related to 3D object detection systems and hardware platforms for their implementation are presented. Section 3 shows a four-step methods used to select, train, and tune a deep learning model for deployment on a hardware device. The following section, Section 4, presents the selected 3D object detection model, as well as its deep learning components, specifying the details about the architecture of the target hardware device and the implementation of the hardware components and software. The presentation of performance evaluation results, comparison of results and discussion of these results occur in Section 7. Finally, Section 8 presents the main results achieved in this paper and future work.
2. Related Work
In recent years, object detection models in point cloud presented in the literature have been highly improved, and more and more detection performance has been achieved. Based on the literature, the most discussed models are divided into two broad categories: approaches based on CNN 3D and approaches based on CNN 2D, where different data representations, backbone networks and multiscale resource learning techniques can be adopted [4].
When it comes to 3D object detection approaches, they can be classified into three types. The first category is based on volumetric representation. The second is based on Pillars. Finally, the third is based on raw points. Furthermore, they are novel models recognised by the scientific community that provide innovation in the diverse architecture pipeline, high accuracy and performance in 3D object detection.
The first category, which can be divided into one-stage or two-stage, is usually based on the volumetric representation to discretize the point cloud. The one-stage representation only has a single stage, and SECOND [8] is an example. This 3D convolution-based technique produces item class prediction, bounding box regression, and orientation classification. The two-stage representation got the same results as the single stage but fine-tuned the bounding box. Examples of two-stage are P-RCNN [9], VoxelRCNN [7] and [10]. Usually, these methods require more resources in terms of computing power because they either use the costly volumetric representation of the point cloud or rely on computationally intensive 3D convolutions.
The second category of models fall under one-stage methods and use 2D convolutions in place of the computationally intensive 3D convolutions. PointPillar [18] is an example of this approach. To decrease the high computational cost of handling 3D LiDAR data, these models usually compress the data into a 2D projection or organize it into Pillars [18]. While these methods are quicker and suitable for real-time applications, they sacrifice detection capabilities by losing some information. This highlights the trade-off between inference time and accuracy.
The third category of methods, such as Point RCNN [12], utilizes a two-stage approach based on raw point data and voxel representation to take advantage of their respective benefits. In the first stage, the network uses voxel representation as input and performs light convolutional operations, which results in a small number of high-quality initial predictions. An attention mechanism effectively combines coordinate and indexed convolutional features of each point in the initial forecast, maintaining both accurate localization and contextual information. The second stage uses the fused feature of interior points to refine the prediction [13].
3. Methodology
To implement/represent the 3D Object Detection models based on Deep Learning in the framework, we employed a three-step methodology, which is depicted in Figure 1. (1) Firstly, a set of model architecture and hyper-parameter specifications are defined in different configuration files. These files define the specifications of the components of each module in the framework (described in Section 4) as well as the training and test specifications that are then used to build, train and test the object detectors. We chose the models for 3D Object Detection based on a review of existing literature, which is outlined in Section 2 and elaborated further in [4]. The framework, described in the Section 4 section, was developed to facilitate the representation of any Object Detection model.
Once the object detector is built, it is subjected to a training and evaluation pipeline (2), where various optimizations can be performed to enhance the accuracy metrics and fulfill the inference time requirements. In our project, since different components need to operate simultaneously, such as the SLAM algorithm and object detector, we define an overall mAP of 60% and an inference time of less than 100ms (metrics are always subject to trade-offs). The training and evaluation step can be done by changing the training specification in the respective model configuration. The concept behind defining the training and testing parameters in these configuration files is to make it easier to modify them and subsequently submit the object detector to the same training and evaluation pipeline. The pipeline was executed on a server-side node with an Intel Core i9 processor, 64GB of RAM, and a Quadro RTX 8000 GPU. Therefore, the proposed workflow follows an iterative process, where the model is fine-tuned. The training and evaluation steps are repeated whenever necessary until it meets the requirements and satisfies the application requirements. The evaluation and comparison process is carried out using KITTI benchmarks using the validation set on the aforementioned server node. In conclusion, this workflow guarantees that the models meet the application requirements and attain the highest possible accuracy. This procedure identifies a group of potential Object Detection models for the subsequent step.
After completing step (2) workflow, a comparison phase of the resulting models (step 3) is conducted to select the model that can ensure a better balance between precision and inference time. The subsequent section presents information on the architecture of the framework, the chosen Deep Learning models, and the parameters used in the fine-tuning process.
4. Framework for Representing 3D Object Detection Models
Our framework’s key innovation is that it facilitates the representation of any object detector through YML configuration files that define their module specifications in each framework component. Moreover, this framework, shown in Figure 2, aims to facilitate the implementation and integration of new modules in each framework component to allow the comprehensive representation of the different state-of-the-art 3D object detectors.
The first component, (1) Data Representation, receives the set of points and discretises them in a set o data structures, such as Pillars or Voxels or only passes the set of points to be used by the Middle Extractor module (3). (2) The local feature encoder receives as input these data structures, more specifically, the set of Pillars or Voxels and encodes and concatenates their features. Then, in the Middle Extractor (3), 3D and/or 2D Backbones extract features from local encoded features, which are used by the (4) Detection Head to predict object class, bounding box offsets and direction (5). (4.1) This Detection Head based on RPN can be assisted by two modules, a (4.2) Point Head module and (4.3) Region of Interest (RoI) Head module, which refines the predicted bounding box offsets and orientation. (4.2) Point Head module is composed of three networks: a Point Intra Part Offset Head [10], a point-based segmentation head for keypoint segmentation [14], and another point-based segmentation head based on [12]. The (4.3) RoiHead module is defined for each state-of-the-art model based on their specificities, but typically it is composed of a Proposal Layer, which proposes a set of RoIs, a RoI Feature Extraction that pooled the RoI features and a RoI Head that predicts RoI class and bounding box offsets.
4.1. Point Cloud Data Representation
We receive an unordered set of points , where and each point p is represented as , where and correspond to coordinates in the three-dimension cartesian axis and is the reflectance value provided by the LiDAR sensor. A point cloud range is a tuple , where L consists of , H consists of , and W consists of . We denote a point cloud subset with respect to as .
4.1.1. Pillar Representation
The framework receives the points in and discretises them in the X-Y axis thus creating a set of pillars , where , is the max number of Pillars and . Each has a fixed size in , and it is represented by a tuple , where w is the width of the Pillar along the x axis, and h is the height of the Pillar along the y axis. The points are grouped accordingly with the Pillar that resides.
To deal with the sparsity problem and save computation, a max number of points per pillar is defined. The points are randomly sampled if the number of points in each pillar is higher than . On the other hand, zero padding is added in case of less than points.
4.1.2. Voxel-based Representation
The voxelisation process assumes a similar way as proposed in Pillar discretisation; however, the received points are discretised in the X-Y-Z axis. It allows the creation of a set of voxels , where , means the max number of Voxels and and each assumes a fixed size in , and a tuple represents it . w is the width of the voxel along the x axis, h is the height of the voxel along the y axis, and d is the depth of the voxel along the z axis.
A Random Sampling strategy is also applied to save computation, and a max number of points per voxel is also used. The strategy to sample points or apply zero padding is the same as the Pillar Representation.
4.1.3. Point-based
The idea in the point-based strategy is to pass the cropped point cloud, herein denoted as , to the Middle Feature Encoder.
4.2. Local Feature Encoder
The Local Feature Encoder receives the data representation structures , such as Pillars denoted as , Voxels or just the set of points of cropped area . Then, a set of methods are applied to obtain features and produce dense tensors in the case of Pillar Feature Network (PFN) and Voxel Feature Encoder (VFE) or calculate these features by simply calculating the mean values of point coordinates within each voxel using Mean VFE method.
4.2.1. Pillar Feature Network
The features of each Pillar, , are augmented in a tensor
, where c describes the distance to the arithmetic mean of all points in , and is the offset distance from the center.
For this purpose, (1) Pillar Feature Network (PFN) receives the Pillar augmented features as input and applies linear transformations to each point, herein described as , where corresponds to the initial tensor , and to the output tensor. In , all but the last dimension are the same shape as the input. Dimension results from the linear transformation of , thus producing . Then, Batch-Norm and ReLU are applied to this tensor. Afterwards, all resulting features are aggregated. This process allows generating a dense tensor to represent the Pillar as a tuple , where D is the above-mentioned augmented point, P is the number of non-empty pillars per batch, and N is the number of points per Pillar. Next, max pooling operations over the channels are used to generate a tensor of size .
4.2.2. Voxel Feature Encoder
Similar to PFN, the points in each Voxel, , are augmented by calculating offset distance of the point to the center herein denoted as , which generates the tensor , where as mentioned before is the max number of points per Voxel. Afterwards, each is subject VFE Layers , where . Each is composed by a set of transformations, where linear transformation, Batch-Norm, and ReLU are applied. Then, all points features of , resulting from the above-mentioned transformations, herein described as , are aggregated. Each can be described as , where is the output dimension that results from the linear transformation of all points . The output size resulting from the linear transformation can be described as , where means the output features of a specific index l. After, all point features are subject to a max pooling operation over the channels. The output tensor is described as where . Afterwards, a repeat process of the above tensor is performed in , which means the repeat point feature resulted from max pooling k times, where . Each is augmented with to generate and . The set of features for each voxel can be described by the tuple , where , , and applies linear, Batch-Norm, ReLU and max pooling to each . Thus, , means that has output dimension F, the output feature of the last VFE layer.
Finally, it generates a list of obtained voxel features , , where is the above-mentioned augmented features of all voxels.
4.2.3. Mean Voxel Feature Encoder
Mean VFE receives a set of Voxels , sums all points residing in each Voxel in a specific axis, and divides by the number of points of each one. This operation can be described as
. corresponds to the total number of points of the Voxel in a given axis, the max number of Voxels and corresponds to a resulting point. This strategy considers the voxel-wise features a new Voxel center and approximately equivalent to raw point cloud data. The idea herein is to process the voxel-wise features in Middle Feature Encoder more efficiently, especially by the 3D sparse convolutions since it generates (max number of voxels as described in Section 4.1) number of non-empty Voxels.
4.3. Middle Feature Extractor
The (3) Middle Feature Extractor is responsible for extracting more features from the (2) Local Feature Encoders to provide more context for the shape description of objects for the networks of the Detection Head module. Various methods are used; herein, we separated into 3D Backbones and 2D Backbones, which will be described in more detail above.
4.3.1. Backbone 3D
A variety of methods resort to 3D backbones based on sparse convolutions (sparse CNN), such as SECOND (Figure 4), PV-RCNN (Figure 6), PartA² (Figure 7) and Voxel-RCNN (Figure 8). In particular, PV-RCNN uses a Voxel Set Abstraction 3D backbone, which is used to encode the multiscale semantic features obtained by sparse CNN to keypoints. PointRCNN (Figure 5) uses PointNet++ [9] with multiscale grouping for feature extraction and gets more context to the shape of objects and then passes these features to (4) Detection Head module.
3D Sparse Convolution
The 3D Sparse Convolution method receives the voxel-wise features of VFE, or Mean VFE, .
This backbone is represented as a set of blocks , in the form , where . Each block can be defined by a set of Sparse Sequential operations denoted as . Each is described by , where means Submanifold Sparse Convolution 3D [12], Spatially-sparse Convolution 3D [16], 1D Batch Normalisation operation, and represents ReLU method. The last method assumes the standard procedure as mentioned in [17].
In our framework, the set of blocks assumes the following configurations:
- The input block can be described by ;
- The next block is represented in the form ;
- The block 3 is represent as ;
- The block 4 is denoted as ;
- The block 5 is denoted as ;
- The last block is defined by .
The Batch Normalisation element is defined by , which represents the formula in [18]. represents the input features, which are the output features of Submanifold Sparse or Spatially-sparse Convolutions 3D, so that . represents the eps, and the momentum values. These values are defined in the following Table 1.
The element can be represented as . represents the input features of and it is denoted as where represents the output features of Submanifold Sparse Conv3D. The element represents the output features resulting from applying . means kernel size of a Spatially-sparse Convolution 3D and it is denoted as where , and . The stride can be described as a set and . designates padding, and a set can define it . means dilation and can be defined as a set . The output padding is represented as a in the form and . The configurations used in our framework are represented in Table 2.
is represented by [12]. represents the input features passed by (2) Local Feature Encoder or by the last Sparse Sequential block , and the output features of . Thus, in the case of the Local Encoder be Mean VFE, otherwise , where F are the output features of the VFE network. Also, can be represented by and , where represents the output features of a . The element represents the kernel size that can be defined as where , and . means stride and can be defined as a set and . represents padding, and a set can describe it in the form . means dilation and can be described as a set . represents the output padding, and a set describes it in the form and . The configurations used in our framework are represented in Table 3.
The hyperparameters used in each are defined in Table 7.
Finally, the output spatial features is defined by , where SP is defined by a tuple (B, C, D, H, W). B represents the batch size, C the output features of represented in as , D depth, H height and W width.
PointNet++
We use a modified version of PointNet++ [9] based on [12] to learn undiscretised raw point cloud data (herein denoted as ) features in multi-scale grouping fashion. The objective is to learn to segment the foreground points and contextual information about them. For this purpose, a Set Abstraction module herein denoted as is used to sub-sampling points at a continuing increase rate, and a Feature Proposal module, described as , is used to capture feature map per point with the objective of point segmentation and proposal generation. A is composed by , where means PointNet Set Abstraction module operations. Each is represented by , where corresponds to Query and Grouping operations to learn multi-scale patterns from points, and are the set of specifications of the PointNet before the global pooling for each scale.
means ball query operation followed by a grouping operation . It can be defined by the set where and correspond to two query and group operations. A ball query is represented as , where R means the radius within all points will be searched from the query point with an upper limit , in a process called ball query, P means the coordinates of the point features in the form that are used to gather the point features, represents the coordinates of the centers of the ball query in the form , where , , and are center coordinates of a ball query. Thus, this ball query algorithm search for point features P in a radius R with an upper limit of query points from the centroids (or ball query centers) . This operation generates a list of indices in the form , where corresponds to the number of . represents the indices of point features that form the query balls. After, a grouping operation is performed to group point features and can be described by , in which and correspond to point features and indices of the features to group with, respectively. In each of a , the number of centroids will decrease, so that , and due to the relation of the centroids in ball query search, the number of indices and corresponding point features will also decrease. Thus, in each the number of points features is defined by . The number of centroids defined in QGL during operations is defined in Table 4.
Afterwards, a is performed, defined by a set of specifications of the PointNet before the operations. The idea herein is to capture point-to-point relations of the point features in each local region. The point features coordinates translation to the local region relative to the centroid point is performed by the operation . , , and are coordinates of point features as mentioned before, and , , and are coordinates of the centroid center. can be defined by a set that represent two sequential methods. Each is represented by the set of operations , where means Convolution 2D, 2D Batch Normalisation, and represents the ReLU method. is defined by . , where , represents the input features that can be received by or by the output features of the , the kernel size, and the stride of the Convolution 2D. The kernel size is defined by the set and . Also, the stride is represented by a set , and with . The set of specifications used in our models regarding are summarised in Table 5. can be defined as:
, where denotes max pooling, denotes random sampling of features, multi-layer perceptron network to encode features and relative locations.
Finally, a Feature Proposal is applied employing a set of feature proposal modules . Each is defined by the element as defined above. Also, the element assumes a set and each has the same operations with the only difference in the element s that describes the number of operations, assuming instead of . The configurations used in our models are summarised in Table 6.
Voxel Set Abstraction
This method aims to generate a set of keypoints from given point cloud and use a keypoint sampling strategy based on Farthest Point Sampling. This method generates a small number of keypoints that can be represented by , where is the number of points features that have the largest minimum distance, and B the batch size. The Farthest Point Sampling method is defined according to a given subset , where M is the maximum number of features to sample, and subset , where N is the total number of points features of , the point distance metric is calculated based on . Based on D a operation is performed, which calculates the smallest value distance between and . and represents the list of the last known largest minimum distance of point features. Assuming , it returns the index . Based on , thus . Finally, this operation generates a set of indexes in the form , and , where B corresponds to the batch size and M the maximum number of features to sample. The keypoints K are given by
These keypoints K are subject to an interpolation process utilising the semantic features encoded by the 3D Sparse Convolution as . In this interpolation process, these semantic features are mapped with the keypoints to the voxel features that reside. Firstly, this process defines the local relative coordinates of keypoints with Voxels by means . Then, a bilinear interpolation is carried out to map the point features from 3D Sparse Convolution in a radius R with the , the local relative coordinates of keypoints. This is perform . Afterwards, indexes of points are defined according to in the form and another . The expression that gives the features from the BEV perspective based on and is the following:
Thus, the weights between these indexes , and are calculated, as follows:
- ;
Finally, the bilinear expression that gives the features from the BEV perspective is , where , , , . Also, , , , , and .
The local features of is indicated by and aggregated using PointNet++ according with their specification defined above. It will generate that are voxel-wise features within the neighbouring voxel set of , transforming using PointNet++ specifications. This generates according and each are aggregate features of 3D Sparse Convolution with from different levels according to Table 4.
Backbone 2D
PointPillars (Figure 3) uses only a 2D Backbone since they require fewer computational resources when compared to 3D Backbones. However, they introduce information loss that can be mitigated by readjusting the objects back to LiDAR’s Cartesian 3D system with minimal information loss. For this purpose, the features resulting from the PFN are used by the Backbone Scatter component, which scatters them back into a 2D pseudo-image. The next component, the Detection Head, then uses this 2D pseudo-image.
Other models, such as SECOND (Figure 4), PV-RCNN (Figure 6), PartA² (Figure 7) and Voxel-RCNN (Figure 8) compress the information into Bird’s-eye view (BEV) after using a 3D Backbone for feature extraction. After, they perform feature encoding and concatenation using an Encoder Conv2D. After this process, the resulting features are passed to the Detection Head module.
Backbone Scatter
The features resulting from the PFN are used by the PointPillars Scatter component, which scatters them back to a 2D pseudo-image of size , where H and W denote height and width, respectively.
BEV Backbone
BEV Backbone module receives 3D feature maps from 3D Sparse Convolution and reshapes them to BEV feature map. Admitting the given sparse features , the new sparse features are . The BEV Backbone is represented as a set of blocks , in the form , where . Each block , is represented by . The element n represents the number of convolutional layers in . The set of convolutional layers C in is described as a set , where . F represents the number of filters of each , U is the number of upsample filters of . Each of the upsample filters has the same characteristics, and their outputs are combined through concatenation. S denotes the stride in . If , we have a downsampled convolutional layer (). There are a certain convolutional layers (, such that ) that follow this layer. BatchNorm and ReLU layers are applied after each convolutional layer.
The input for this set of blocks is spatial features extracted by 3D Sparse Convolution or Voxel Set Abstraction modules and reshaped to BEV feature map.

Table 7.
The different block configuration () used. N.A. - Not Applicable.
| Models | |||
|---|---|---|---|
| PointPillars | (3, 64, 128, 2) | (5, 128, 128, 2) | (5, 128, 128, 2) |
| SECOND | (5, 64, 128, 1) | (5, 128, 256, 2) | N.A. |
| PV-RCNN | (5, 64, 128, 1) | (5, 128, 256, 2) | N.A. |
| PointRCNN | N.A. | N.A. | N.A. |
| PartA² | (5, 128, 256, 2) | (5, 128, 256, 2) | N.A. |
| VoxelRCNN | (5, 128, 256, 2) | (5, 128, 256, 2) | N.A |
Encoder Conv2D
Based on features extract in each block and after upsampled based on , where D means downsample factor of the convolution layer C, upsample features are concatenate, such that , where cat means .
4.4. Detection Head
After that, the (4) Detection Head component receives the 2D encoded features as input and performs operations based on three modules: RPN Head, Point Head, and RoI Head.
4.4.1. RPN Head
Based on 2D encoded features, a set of convolutions to predict class labels, regression offsets, and direction are performed. Thus, a set of 1x1 convolutions , where , is applied. Each can be represented by , where mean Convolution 2D, input channels, output channels and kernel size. is the class prediction convolution and can be described by , where means number of anchor per location and number of target classes to predict. is the convolution for bounding box offset regression and can be defined by where it generates 2 anchors for each class and 7 are the number of bounding box offsets. Finally, is performed based on where represent the same number of anchor per location as previously mentioned, the number of bins per anchor location and kernel size.
4.4.2. Point Head
Different implementations of Point Head have been proposed to refine RPN predictions or generate class labels, bounding box regression offsets, and direction. It can be composed of a class layer regression in the form and bounding box layer described as . The point class layer provides the segmentation score of foreground points, and gives the relative location of foreground points as and calculated based on a foreground point using , where , , are center coordinates of the bounding box, h, w, and l means height, width, length of bounding box respectively, and is the box orientation in bird-view.
Firstly, bounding box targets are normalised in a canonical coordinate system by first checking if the given points are within the Bounding box by performing where if the given statement is true the local and are calculated. The operation is and . After, we determine the local relative coordinate of concerning bounding box in X-Y by means and then determine if a point belongs and returning respective index to bounding box by . After getting the points indexes within the bounding Boxes, all inside points are aggregated with PointNet++.
Point Intra Part Offset
It is both and to predicted point class labels and point bounding box offsets.
Point Head Simple
It is only composed of . However, it has modifications to its architecture where each is represented by a tuple where means linear regression, batch normalisation, and ReLU method. can be defined by where means the number of features and typically assumes the same value as .
Point Head Box
It is composed of and with architecture modifications. where where means linear regression, batch normalisation, and ReLU method. is composed of , where each is defined by the same tuple .
4.4.3. RoI Head
The Regions of Interest (RoI) Head is responsible for taking the RoI features of each box proposal of the RPN Head and then optimising the imperfect bounding box proposals by predicting and fixing the size and location (centre and orientation) residuals relative to the input bounding box predictions. Besides each model’s specificities, any RoI Head is composed of a proposal layer that generates/refines a set of RoIs based on RPN RoIs, denoted as , an RoI feature extraction method , and Head module that can be composed but not restricted to Shared Fully Connected Layer , up-down layer and , class layer , regression layer , RoI Point Pool 3D layer (), RoI Grid Pool layer (), RoI-aware Pool 3D layer (), and a convolution part () and convolution RPN ().
are responsible for feature extraction and can be defined by a set , , and and is represented by a tuple , where means convolution 1D, means batch normalisation 1D, ReLU, and means dropout. can be defined by the set and each by . produces box predictions and is composed by the set , where each is defined by . and mean bottom-up box generation proposal layers from foreground points. A sequence of Convolution 2D and ReLU methods can define the . A is represented as and each by the same sequence of Convolution 2D and ReLU methods.
specifically pool 3D points and their corresponding point features according to the location of each 3D proposal of . Admitting the given output of bounding boxes and a specific bounding box , where , where x, y, z are center coordinates of the predicted bounding box, h, w, and l denotes the height, width, and length of the bounding box, and the orientation of bounding box. Herein the produces an enlarged set of that can be defined by , where represents a constant value to resize the bounding box. The depth information loss for each bounding box proposal is compensated by including the distance information to the LiDAR sensor to the that are BEV spatial features. Each is augmented with , where , , and correspond to coordinates of point features of Local Encoder module and , , and center coordinates of LiDAR sensor. Thus, it generates a tensor in the form that is fed to PointNet++ as described in Section 4.3.1 to encode the augmented tensor with local features with global semantic BEV features . This generates a feature vector for confidence classification and box refinement.
The idea of is to aggregate the keypoint features to the RoI-grid points with multiple receptive fields. Grid points are uniform sampling and can be described by , which means that a grid are usually adopted. Firstly, the identification of neighbouring keypoints to grid in a radius R is performed by means . After all, a PointNet block is used to aggregate neighbouring keypoint set in the same way of Equation 2:
Then, the two MLP layers, and , are performed.
aims to provide bounding box score confidence and refinement by aggregating the local feature information () with global semantic BEV features () within the proposals. Two operations are performed within the point features of bounding boxes , such that and scattered to the voxel data structures where , , are encoded in canonical coordinates using Point Head module, m are the number of inside points within bounding box . The objective is to solve the problem of different proposals generating the same pooled points. For this purpose, average pooling for pooled part features operation denoted as , and max pooling for pooled RPN features defined as are adopted and can be described as and where , , are the resolution of Voxels spatial shape. The operations RoIMax and RoIAvg can be described more specifically:
5. 3D Object Detection Model Specifications
Herein, we will specify each model in the different module frameworks. These models were selected based on the requirements established and defined in Section 1, since they are the models that best guarantee the trade-off between metrics (mAP and inference time). The set of models and their specificities concerning the developed framework is illustrated in Figure 3, Figure 4, Figure 5, Figure 6, Figure 7 and Figure 8. The modules of each model are represented in the figures as green boxes, and the flow of the tensors occurs in the direction of the orange arrows.
Figure 3.
Structure of the PointPillars model represented in the developed framework.
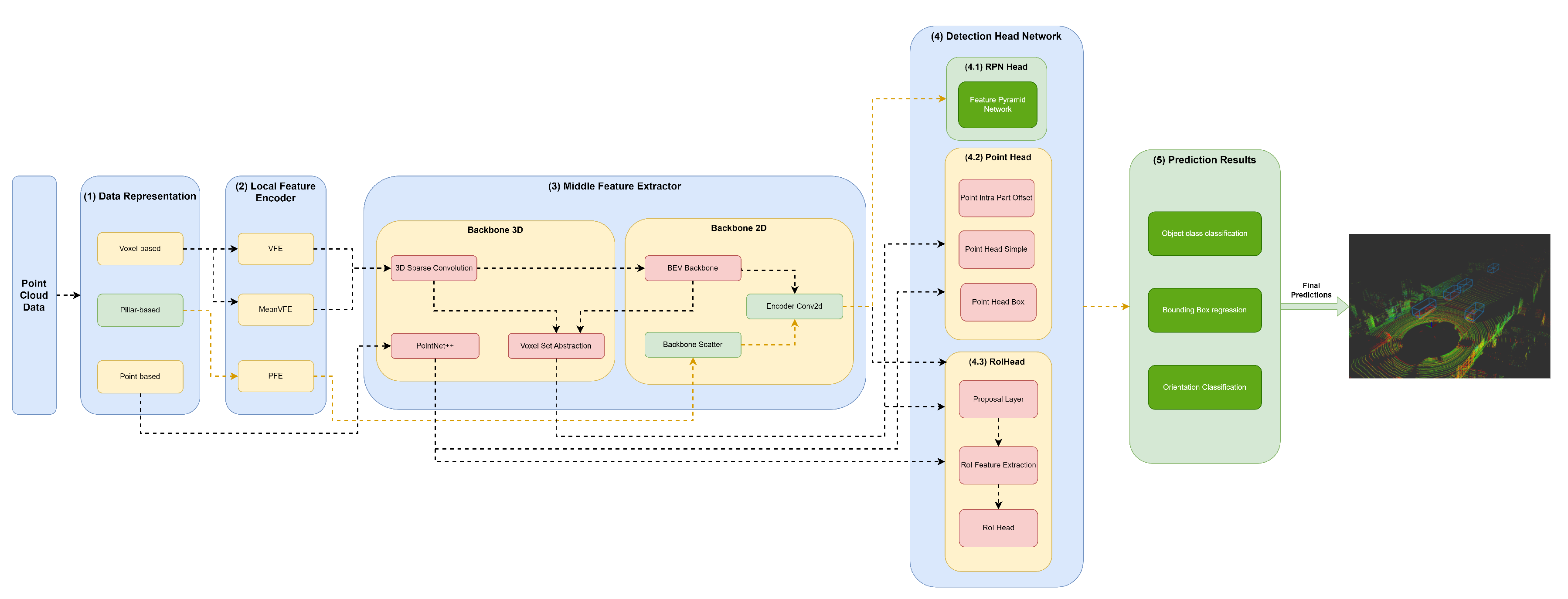
Figure 4.
Structure of the SECOND model represented in the developed framework.
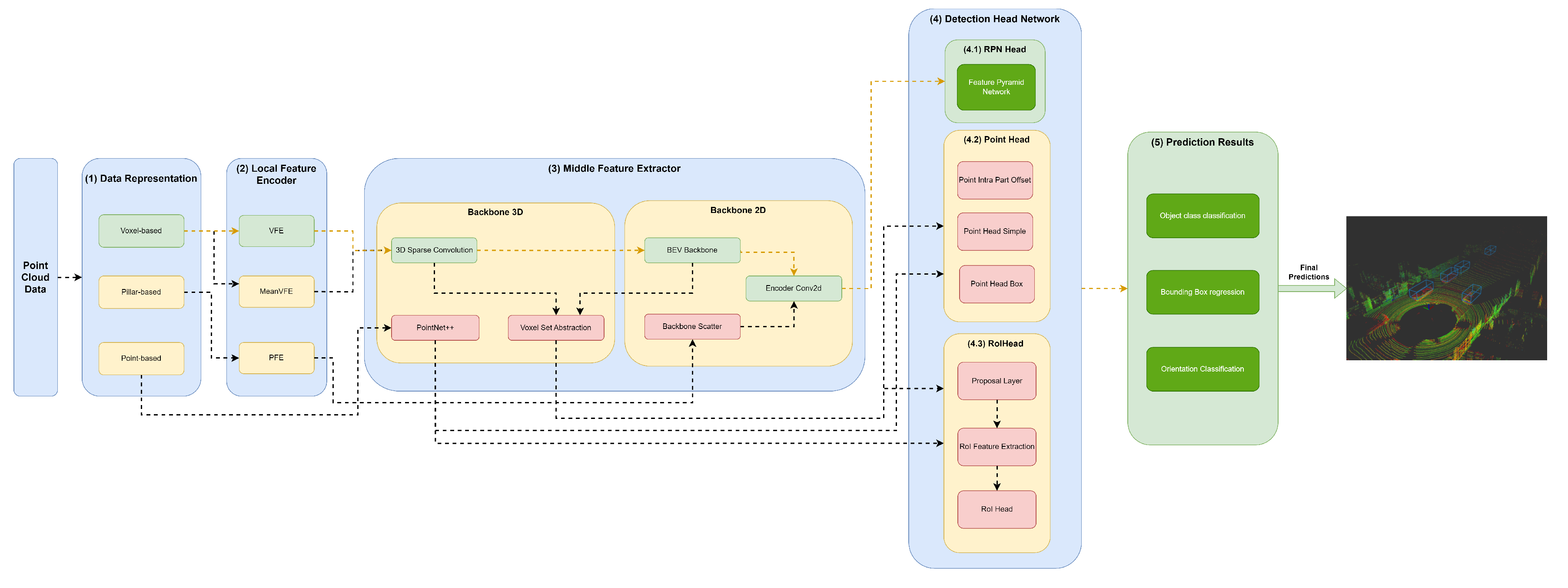
Figure 5.
Structure of the PointRCNN model represented in the developed framework..
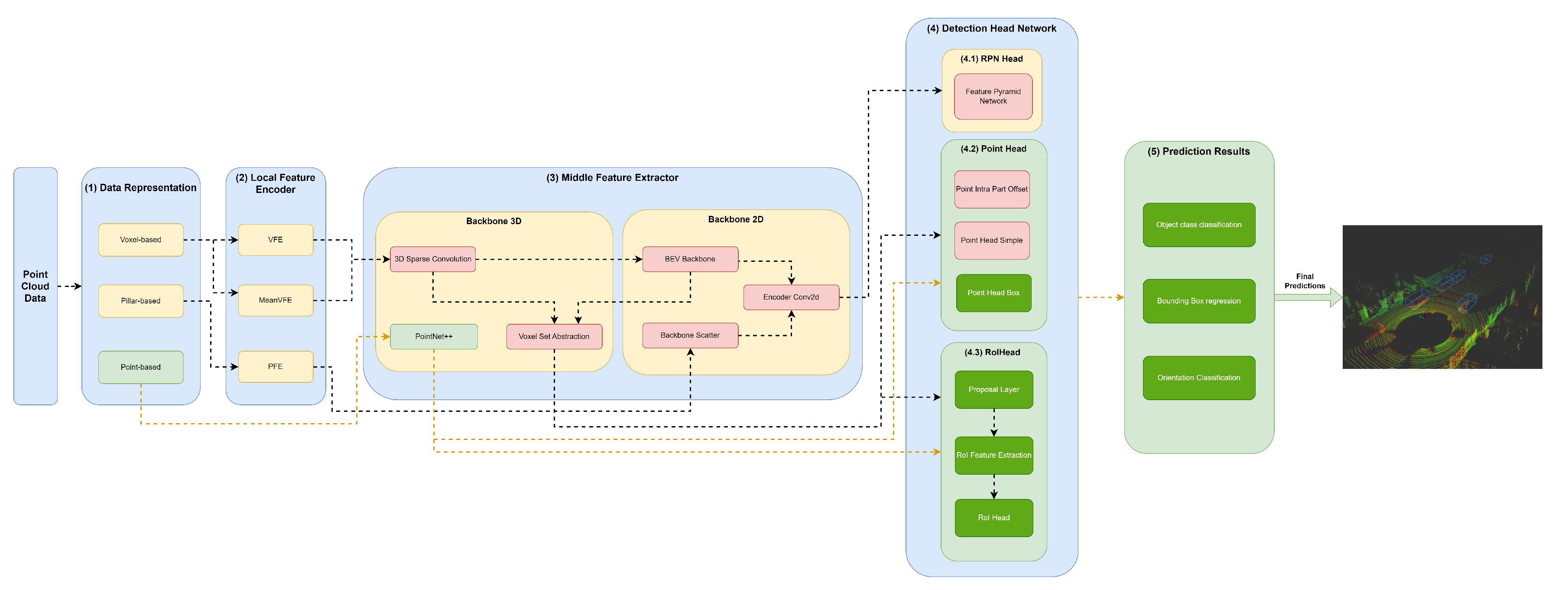
Figure 6.
Structure of the PV RCNN model represented in the developed framework.
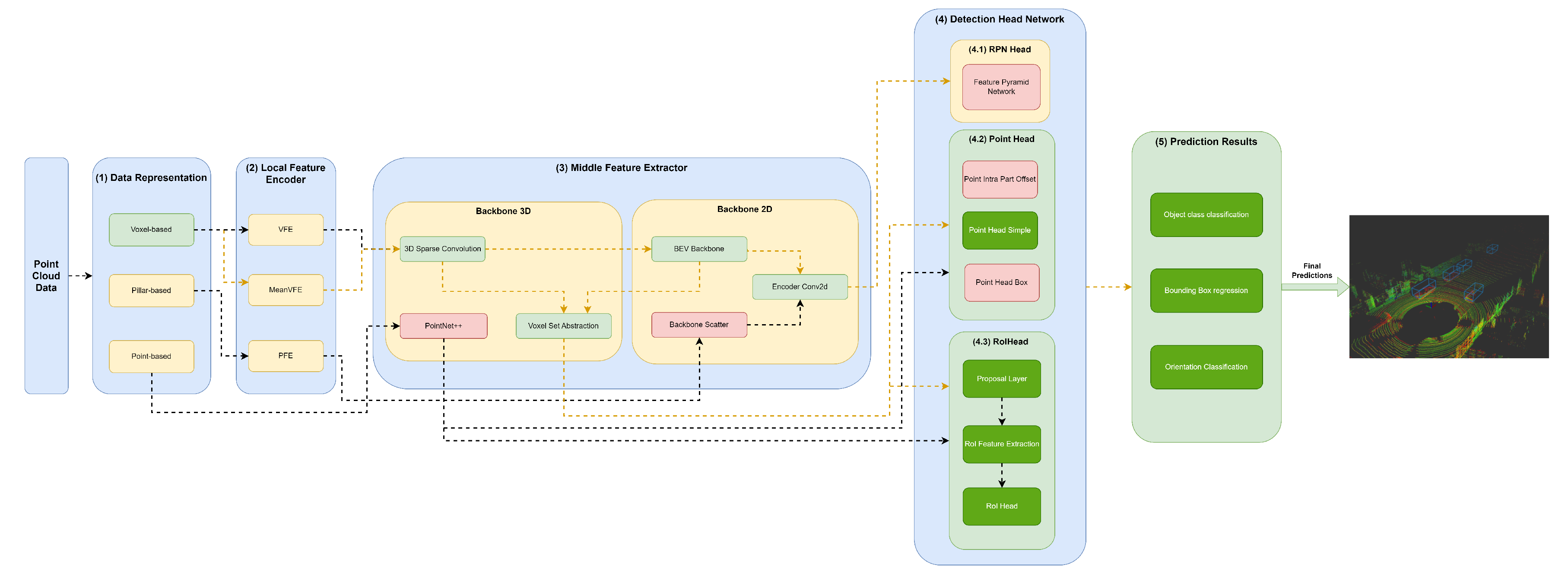
Figure 7.
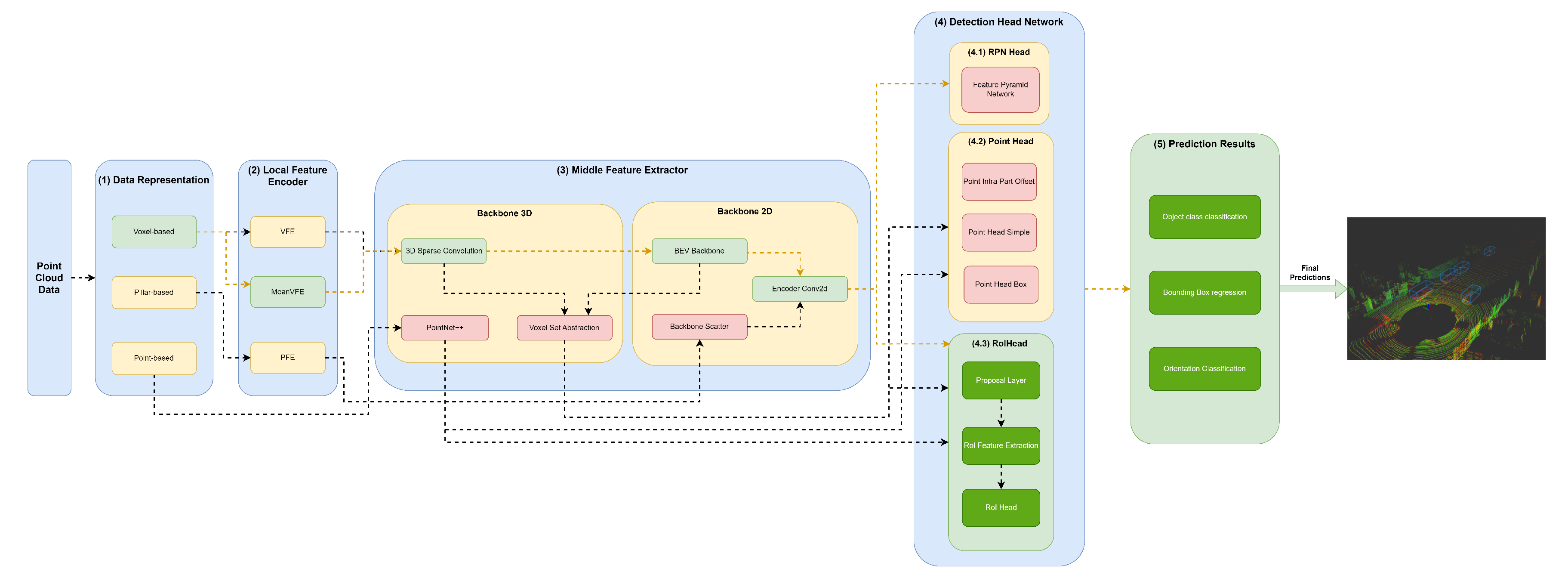
Structure of the model represented in the developed framework.
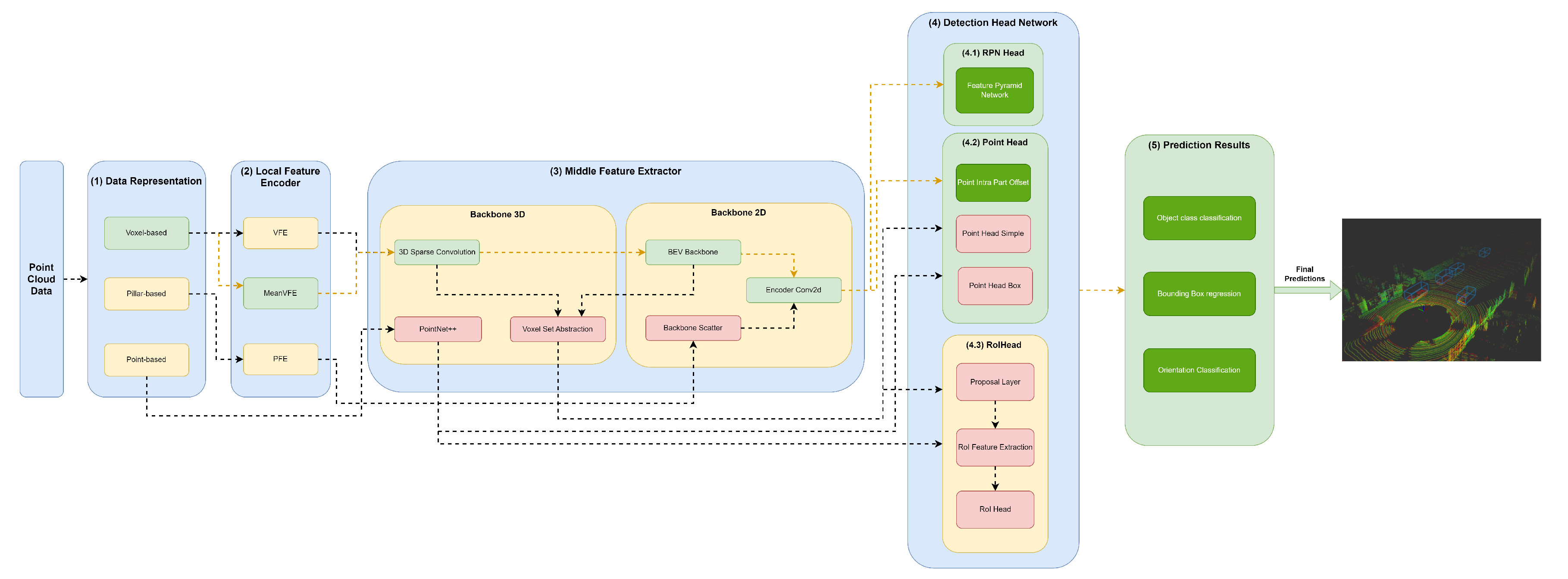
Figure 8.
Structure of the VoxelRCNN model represented in the developed framework.
5.1. Data Representation
Typically the models of Figure 4, Figure 6, Figure 7 and Figure 8 choose to represent the point cloud in Voxels. In this data structure, the point cloud is delimited (using the cropping technique), and a grid is produced where the data is discretised along the X-Y-Z axis.
Only PointPillars, illustrated in Figure 3, discretises this delimited space of the point cloud on the X-Y axis, creating a set of Pillars.
In the case of the PointRCNN model (Figure 5), it provides the delimited point cloud without any data discretisation and structuring process for the Middle Feature Encoder.
5.2. Local Feature Encoders
As illustrated in the Figures, three strategies are used by the models to improve the efficiency of the object detectors in the feature extraction of the data structures. Typically, these modules are responsible for the local feature extraction and then, via concatenation, aggregate these features. Three networks are used: VFE for SECOND (Figure 4), PFE for PointPillars (Figure 3) and Mean VFE for PV RCNN (Figure 6), (Figure 7), and VoxelRCNN (Figure 8).
5.3. Middle Feature Extractor
A variety of methods use 3D Backbones based on sparse and sub-manifold convolutions, such as SECOND (Figure 4), PV-RCNN (Figure 6), (Figure 7 ) and Voxel-RCNN (Figure 8). In the case of PV-RCNN, the 3D Voxel Set Abstraction backbone encodes the multiscale semantic features obtained by the 3D sparse CNN for keypoints. PointRCNN (Figure 5) uses PointNet++ [9] with multiscale clustering for feature extraction and get more context to the shape of objects and then passes these features to the Detection Head module.
Only PointPillars (Figure 3) uses 2D Backbones since they require fewer computational resources when compared to 3D Backbones. However, they introduce a loss in the information that is easily mitigated since it is possible to readjust the objects again to the Cartesian 3D system of LiDAR with fewer loss of information. For this purpose, the resulting PFE features are used by the Backbone Scatter component, which scatters them back into a 2D pseudo-image. The next Detection Head component then uses this 2D pseudo-image.
Other models, such as SECOND (Figure 4), PV RCNN (Figure 6), (Figure 7) and Voxel-RCNN (Figure 8) compress the information in Bird’s-eye view (BEV) using the BEV Backbone for feature extraction then encode and concatenate the features using the Encoder Conv2D component. After this process, the resulting features are passed to the Detection Head.
5.4. Detection Head
As mentioned earlier, this module comprises three networks: RPN Head, Point Head and RoI Head.
All models except PointRCNN use the RPN Head to generate RoIs using a low-level algorithm called Selective Search [19] to produce proposed regions per frame of the point cloud. Selective Search generates sub-segments to generate many candidate regions and, following bottom-up grouping, recursively combines similar regions into larger regions to provide more accurate final candidate proposals. Each of these regions is submitted independently to the CNN module. The output feature map is then fed to an SVM classifier to predict the object class within the candidate RoI. Along with object class prediction, the algorithm also predicts four Bounding Box offset values.
The Point Head is used to assist the RPN Head, as illustrated in Figure 6 and Figure 7, or generate predictions of object classes and predict four values that are the Bounding Box offsets, as shown in Figure 5 and Figure 8. Point Head generates various masks of objects or parts of objects in a multiscale way, followed by a simple bounding box inference to generate proposals, also called point proposals, using each point to contribute to the reconstruction of the 3D geometry of the object.
The RoI Head used by the PointRCNN (Figure 5), PV-RCNN (Figure 6), (Figure 7) and Voxel-RCNN ( Figure 8), naturally uses the RoI features of each bounding box proposed in the RPN, and then optimises the imperfect bounding boxes from previous stages, predicting and correcting the size and location (center and orientation) in relation to the predictions of the input bounding boxes.
6. Network Training and Fine-Tuning
The models described in this document were trained using the KITTI data sets. In addition, the models were evaluated based on the KITTY benchmarks, namely for detecting 3D objects and BEV, considering a validation set. Regarding the number of epochs used in the training phase, a methodology spread by the literature was considered. Thus we use 200 epochs, considering the data described in Table 13. Considering training hyperparameters, We define the initial learning rate of 0.01, learning rate decay of 0.1, decay epoch methodology, weight decay of 0.01, gradient clipping normalisation with a max value of 10, beta1 of 0.95 and beta2 of 0.85. We use learning rate decay, weight decay, and gradient clipping normalisation as regularisation procedures to prevent overfitting. The evaluation metrics in the results were based on the official KITTY evaluation detection metrics. Hence, the metrics used were mAP for a BEV and 3D Object Detection. The partition of the training data used in this work consisted of a division discussed in [17]. This approach divides the 7481 training examples that are provided, into a training set of 3712 samples, with the remaining 3769 samples belonging to the evaluation set. Moreover, the benchmarks presented in this article are based on the evaluation set only.
We select three target classes in all experiments: car, pedestrian and cyclist. Typically, all the models described herein generate two separate networks. One network is optimised for predicting cars and another for pedestrians and cyclists. However, this approach can be improper in self-driving car applications since low-edge devices with few resources must cope with two parallel models. For this reason, we trained all classes in a one-single model for all 3D Object Detectors.
For the fine-tuning process, we save the results of the mAP for each epoch to understand when models converge. Herein, we provide a study with the consequences of the number of samplings and min points per class sampling compared with the study made in [20]. In [20], we used different class sampling strategies but without changing the number of min points for class sampling.
Sampling Instance Strategy. We focus on optimising the number of sampling instances and min points per class sampling. The main objective of the sampling strategy is to soften the KITTI dataset imbalance issue. During training, the point cloud is randomly fed with these instances, which means they are placed into the current point cloud. Although this is true, the min points affect whether or not a certain instance can be used for sampling. If we increase the min number of points in the training process, instances such as pedestrians and cyclists are less sample because few points exist to describe their shape. On the other hand, if we decrease too many min points, the model suffers in distinguishing between the foreground and the background points. In our experiments, we use the configurations described in Table 9. The min point for class sampling was fixed per class as 5 instead of 10 points for pedestrian and cyclist classes and 5 points for the car.
Point Cloud Range. The point cloud range affects any Object Detector’s detection range, limiting its detection range. Our research uses the original point cloud range for all models to represent the location of ground truth objects for all frames in the KITTI dataset frame. For example, in cars, it is possible to verify in terms of depth information that most ground truth instances are between the 0 and 70 meters. After 70 meters from the LiDAR sensor centre, the number of instances drastically decreases. This can be explained by the fact that after this range, the number of points to describe an object’s shape is very few, making detecting objects difficult. Thus, this experiment compares the point cloud range of PointPillars and the other models where the detection range is not compromised. The point cloud ranges are depicted in Table 10. Also, we analyse the number of data structures (max number of Pillars or Voxels) compared with the study in [20].
Data structure sizes. The object detection model receives the points in and discretises them in the X-Y axis, thus creating a set of pillars, or discretises in X-Y-Z and creates a set of Voxels. Each data structure has a fixed size in . The data structure size directly impacts model accuracy and inference time. Increasing the data structure size can result in too much data being encoded and consequently randomly sampled, leading to information loss (the maximum number of points per data structure is set for computational saving purposes). On the other hand, reducing the data structure size can increase the number of non-empty data structures, increasing memory usage and inference time. Two configurations were used in our fine-tuning process, as shown in Table 11.
Number of Data Structures. Max number of data structures is defined to explore the KITTI dataset sparsity problem since most data structures will be empty. Using a large number of Data Structures can result in most of them being filled with zeros (to create a dense tensor), making it inefficient for inference time purposes. Based on the distribution of the number of points per data structure in the KITTI dataset, a max number of points is also defined, as shown in Table 12.
7. Performance Evaluation, Comparison, and Discussion
This section reports the set of experiments, which results from the random search methodology, used to achieve a better trade-off between accuracy and inference time performance metrics. Table 13 depicts the experiments and corresponding network configurations and models. PointPillars settings and their results are also provided to understand the impact of producing a model optimised to produce three-class output rather than separating into two distinct networks (one for cars and another for pedestrians and cyclists).
Table 13.
The set of experiments conducted and respective network configurations.
| Experiment | Model | Config. | SI Config. | No. Output | Config. | P Config. |
|---|---|---|---|---|---|---|
| Config. | Classes | |||||
| 1 | PointPillars | 3 | ||||
| 2 | SECOND | 3 | ||||
| 3 | PV-RCNN | 3 | ||||
| 4 | PointRCNN | 3 | ||||
| 5 | Part A² | 3 | ||||
| 6 | VoxelRCNN | 3 | ||||
| 7 | PointPillars | 3 | ||||
| 8 | SECOND | 3 | ||||
| 9 | PV-RCNN | 3 | ||||
| 10 | PointRCNN | 3 | ||||
| 11 | Part A² | 3 | ||||
| 12 | VoxelRCNN | 3 |
The following Table 14, Table 15, Table 16, and Table 17 provide the results of experiments of Table 13 in terms of AP for three difficulty levels (Easy, Moderate and Hard) and different Intersection over Union (IOU) thresholds, according to KITTI benchmarks. For cars, IOU is 70%, while for pedestrians and cyclists, it is required IOU of 50%. Table 18 presents the comparative results of the experiments carried out in this study with the original results in the literature. The comparison considers the overall three identified classes, both for 3D and BEV. The results presented for the developed experiments consider the overall values per class for the best detection metric.
As demonstrated in the before-mentioned results, the improvements introduced for three-class trained models produced better mAP and very close inference time results (Table 19 and Table 20). However, it is clear that there is always a cost in terms of mAP for producing three-class inference models and our results are for the KITTI validation set, and the original results are for the KITTI test set. Regarding the point cloud range in our networks, we reproduced original configurations for all models, with fewer when compared with the study in [20] since most will be empty. This improvement drastically decreases the inference time when comparing PointPillars with the same research. Although the original model inference times are better when compared with our results (Table 19 and Table 20), this can be explained by the fact that original models obtained their results by training separated networks, one for cars and another for pedestrians and cyclist (a standard literature practice on KITTI benchmarks). By training three-class models, gradients are affected by all those instances, which leads our models to lose the specialisation for prediction. However, as mentioned in [20], producing separate networks is impractical for self-driving applications.
Reducing the minimum points to consider a sample instance brought gains in terms of mAP and for the same model architecture since more instances can be used for data augmentation. This allows for expanding the diversity of the training data and our models to learn more patterns from data.
8. Conclusions
The research about deep learning methods for 3D Object Detection on LiDAR data has increased tremendously in recent years, with many models, repositories, and different technologies being developed. Although this benefits scientific development in this area, the various technologies, software, repositories and models are a bottleneck for testing and improving the current methods.
To cope with this limitation, we develop a framework for representing multiple SoA 3D object detectors with highly refactored codes for both one-stage and two-stage methods. The main idea of this framework is to facilitate the implementation, reusing and implementation of new techniques in each framework module with less manual engineering effort. In conclusion, it enables the abstract implementation, reusing and building of any object detector in one single 3D object detector framework.
Nonetheless, it is evident that creating three-class inference models comes with a trade-off in terms of mAP. Our study’s results are based on the KITTI validation set, while the original findings were obtained using the KITTI test set. We replicated the original network configurations for all models concerning the point cloud range, but with fewer DS and than the research mentioned in previous section. The improvement mentioned earlier leads to a considerable reduction in the inference time when PointPillars is compared to the same research.
Author Contributions
Conceptualization, A.S., P.O., and D.D.; methodology, A.S., P.O., and D.D.; software, A.S., and P.O; validation, P.M.P., J.Mac., P.N., A.S, P.O., D.D., D.F. R.N., and J.M.; formal analysis, A.S., P.O., D.D., J.Mac., P.N., D.F., R.N., P.M.P, J.M.; investigation, A.S., P.O., and D.D.; resources, J.Mac, P.N., P.M.P., and J.M.; data curation, A.S., P.O. and R.N.; writing—original draft preparation, A.S., P.O., and D.D.; writing—review and editing, A.S., P.O., D.D, R.N., D.F., J.Mac., P.N., J.M. and P.M.P.; visualization, A.S., P.O., D.D., D.F., J.Mac., P.N., P.M.P. and J.M.; supervision, J.Mac., P.N., P.M.P., and J.M.; project administration, J.Mac., P.N., J.M., and P.M.P.; funding acquisition, J.Mac., P.N., J.M. and P.M.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been supported by FCT—Fundação para a Ciência e Tecnologia within the R&D Units Project Scope: UIDB/00319/2020 and the project “Integrated and Innovative Solutions for the well-being of people in complex urban centers” within the Project Scope NORTE-01-0145-FEDER-000086. The work of Pedro Oliveira was supported by the doctoral Grant PRT/BD/154311/2022 financed by the Portuguese Foundation for Science and Technology (FCT), and with funds from European Union, under MIT Portugal Program.
Institutional Review Board Statement
x.
Informed Consent Statement
x.
Data Availability Statement
x.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Cosmas, K.; Kenichi, A. Utilization of FPGA for onboard inference of landmark localization in CNN-Based spacecraft pose estimation. Aerospace 2020, 7, 159. [Google Scholar] [CrossRef]
- Ngadiuba, J.; Loncar, V.; Pierini, M.; Summers, S.; Di Guglielmo, G.; Duarte, J.; Harris, P.; Rankin, D.; Jindariani, S.; Liu, M.; et al. Compressing deep neural networks on FPGAs to binary and ternary precision with hls4ml. Mach. Learn. Sci. Technol. 2020, 2, 015001. [Google Scholar] [CrossRef]
- Sharma, H.; Park, J.; Amaro, E.; Thwaites, B.; Kotha, P.; Gupta, A.; Kim, J.K.; Mishra, A.; Esmaeilzadeh, H. Dnnweaver: From high-level deep network models to fpga acceleration. In Proceedings of the Workshop on Cognitive Architectures; 2016. [Google Scholar]
- Fernandes, D.; Silva, A.; Névoa, R.; Simões, C.; Gonzalez, D.; Guevara, M.; Novais, P.; Monteiro, J.; Melo-Pinto, P. Point-cloud based 3D object detection and classification methods for self-driving applications: A survey and taxonomy. Inf. Fusion 2021, 68, 161–191. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Zhou, X.; Tao, Y.; Liu, L.; Yu, X.; Kumar, N. Intelligent Security Performance Prediction for IoT-Enabled Healthcare Networks Using Improved CNN. IEEE Trans. Ind. Inform. 2021, 1. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. arXiv 2017, arXiv:cs.CV/1711.06396. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2647–2664. [Google Scholar] [CrossRef] [PubMed]
- Ye, M.; Xu, S.; Cao, T. Hvnet: Hybrid voxel network for lidar based 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1631–1640. [Google Scholar]
- Graham, B.; van der Maaten, L. Submanifold Sparse Convolutional Networks. [1706.01307].
- Graham, B. Sparse 3D convolutional neural networks. [1505.02890].
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Meyer, G.P.; Laddha, A.; Kee, E.; Vallespi-Gonzalez, C.; Wellington, C.K. Lasernet: An efficient probabilistic 3d object detector for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 12677–12686. [Google Scholar]
- Li, B.; Zhang, T.; Xia, T. Vehicle detection from 3d lidar using fully convolutional network. arXiv 2016, arXiv:1608.07916. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 12697–12705. [Google Scholar]
- Jo, J.; Kim, S.; Park, I.C. Energy-Efficient Convolution Architecture Based on Rescheduled Dataflow. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 4196–4207. [Google Scholar] [CrossRef]
- George, A.D.; Wilson, C.M. Onboard Processing With Hybrid and Reconfigurable Computing on Small Satellites. Proc. IEEE 2018, 106, 458–470. [Google Scholar] [CrossRef]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; Wang, Y.; Yang, H. Going Deeper with Embedded FPGA Platform for Convolutional Neural Network. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016; pp. 26–35. [Google Scholar] [CrossRef]
- Yang, Z.; Yan, L.; Yuan, J. Design and Implementation of Driverless Perceptual System Based on CPU + FPGA. In Proceedings of the 2020 5th International Conference on Control, Robotics and Cybernetics (CRC), Wuhan, China, 16–18 October 2020; pp. 261–265. [Google Scholar] [CrossRef]
- Chen, Y., Liu, S., Shen, X., Jia, J. . Fast point r-cnn. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 9775-9784).
- Abdelouahab, K.; Pelcat, M.; Serot, J.; Bourrasset, C.; Berry, F. Tactics to directly map CNN graphs on embedded FPGAs. IEEE Embed. Syst. Lett. 2017, 9, 113–116. [Google Scholar] [CrossRef]
- Kathail, V. Xilinx Vitis unified software platform. In Proceedings of the 2020 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 23–25 February 2020; pp. 173–174. [Google Scholar]
- Duarte, J.; Han, S.; Harris, P.; Jindariani, S.; Kreinar, E.; Kreis, B.; Ngadiuba, J.; Pierini, M.; Rivera, R.; Tran, N.; et al. Fast inference of deep neural networks in FPGAs for particle physics. J. Instrum. 2018, 13, P07027. [Google Scholar] [CrossRef]
- Xilinx. DPUCZDX8G for Zynq UltraScale+ MPSoCs. Product Guide. Xilinx. 2021. Available online: http://aiweb.techfak.uni-bielefeld.de/content/bworld-robot-control-software/ (accessed on).
- Afonso, T.; Girão, P.; Simões, Cláudia Fernandes, D.; Silva, A.; Névoa, R.; Gonzalez, D.; Guevara, M.; Novais, P.; Monteiro, J.; Melo-Pinto, P. Real-time object detection and SLAM in a Low-Cost LiDAR Test Vehicle Setup. Sensors submitted.
- Krishnamoorthi, R. Quantizing deep Convolutional Networks for Efficient Inference: A Whitepaper. arXiv 2018, arXiv:cs.LG/1806.08342. [Google Scholar]
- Nagel, M.; van Baalen, M.; Blankevoort, T.; Welling, M. Data-Free Quantization Through Weight Equalization and Bias Correction. arXiv 2019, arXiv:cs.LG/1906.04721. [Google Scholar]
Figure 1.
Methodology for object detection model fine-tuning.
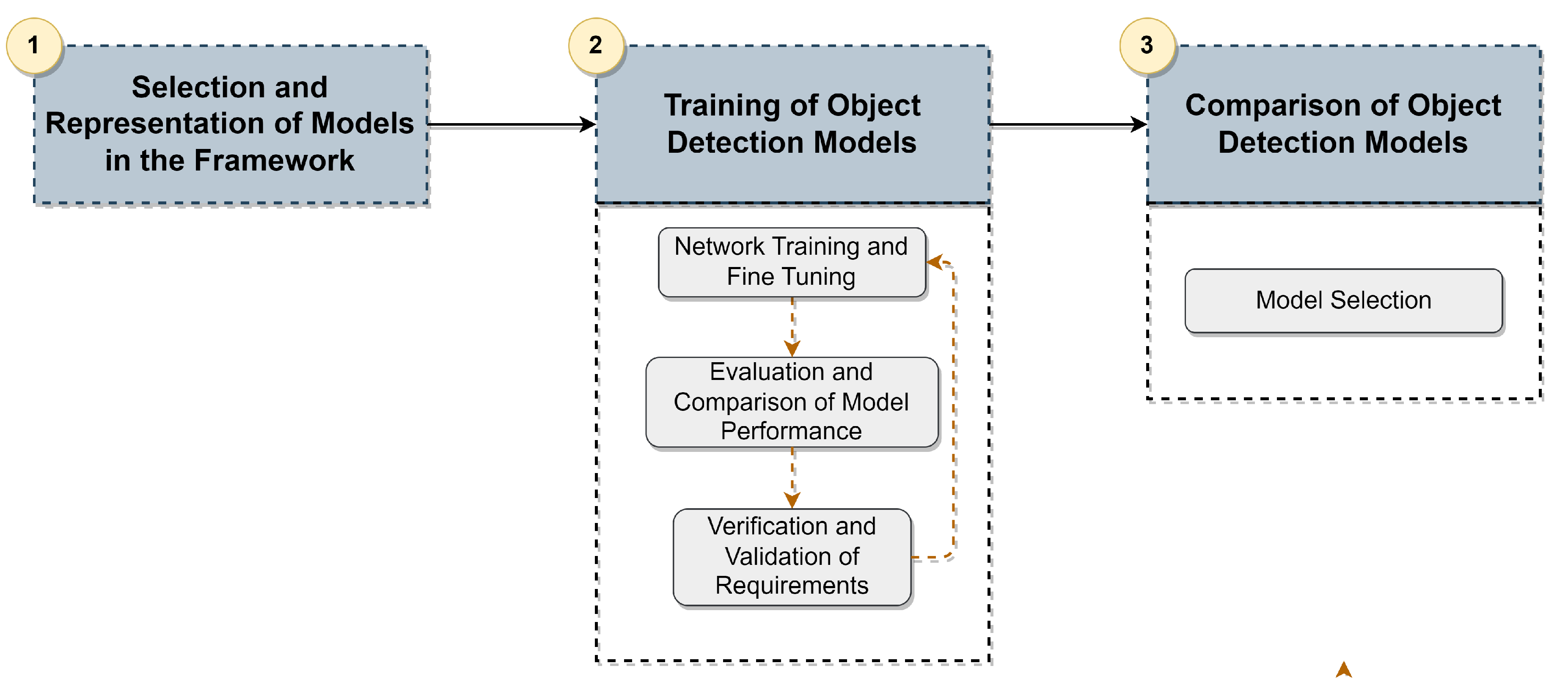
Figure 2.
Framework used for the implementation/representation of Object Detection models.
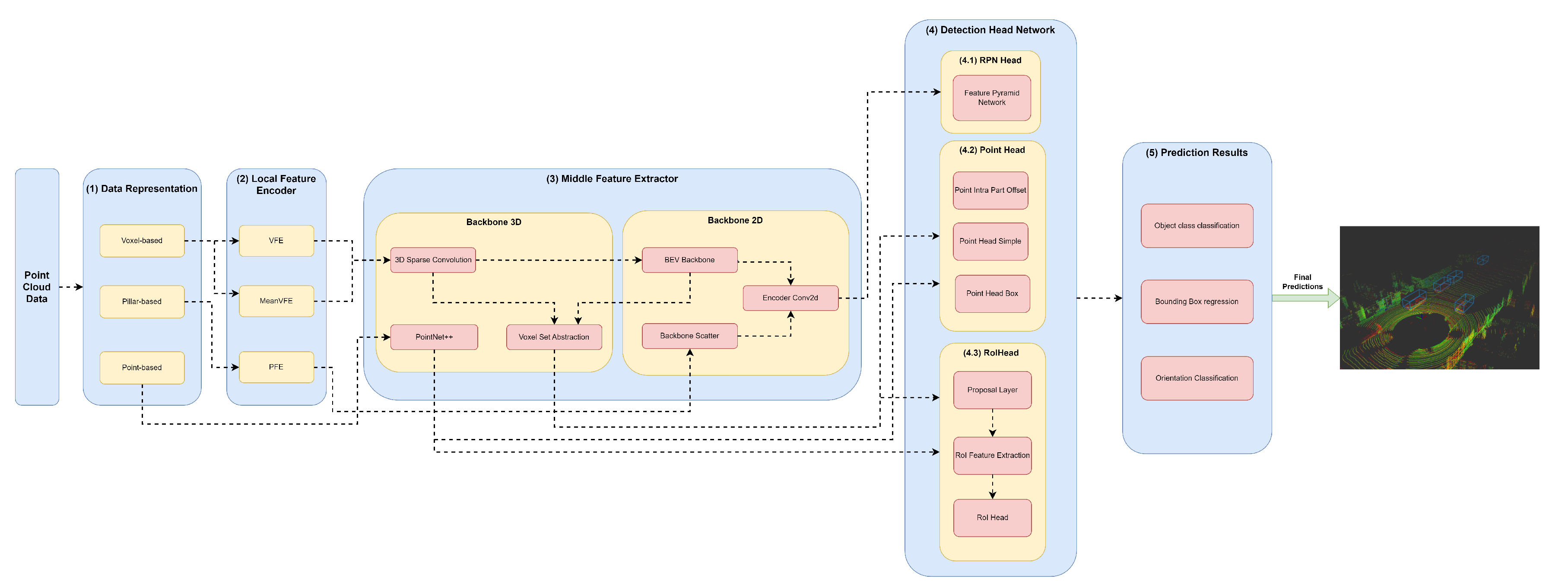
Table 1.
Values used in .
| Bn Element | Value |
|---|---|
| 0.001 | |
| 0.01 |
Table 2.
Configurations used in for each element.
| SpC Element | Value |
|---|---|
| 3 | |
| 1 | |
| 1 | |
| 1 | |
| 0 |
Table 3.
Configurations used in and for each block. N.A. - Not applicable.
| SuM Element | InS | OutS | InM | OutM | Ks | St | Pd | Dl | Op |
|---|---|---|---|---|---|---|---|---|---|
| N.A | N.A | 4 | 16 | 3 | 1 | 1 | 1 | 0 | |
| N.A. | N.A. | 16 | 16 | 3 | 1 | 0 | 1 | 0 | |
| 16 | 32 | N.A. | N.A. | 3 | 2 | 1 | 1 | 0 | |
| N.A. | N.A. | 32 | 32 | 3 | 1 | 0 | 1 | 0 | |
| N.A. | N.A. | 32 | 32 | 3 | 1 | 0 | 1 | 0 | |
| 32 | 64 | N.A. | N.A. | 3 | 2 | 1 | 1 | 0 | |
| N.A. | N.A | 64 | 64 | 3 | 1 | 0 | 1 | 0 | |
| N.the A. | N.A. | 64 | 64 | 3 | 1 | 0 | 1 | 0 | |
| 64 | 64 | N.A. | N.A. | 3 | 2 | 0 | 1 | 0 | |
| N.A. | N.A. | 64 | 64 | 3 | 1 | 0 | 1 | 0 | |
| N.A. | N.A. | 64 | 64 | 3 | 1 | 0 | 1 | 0 | |
| 64 | 128 | N.A. | N.A. | 3 | 2 | 0 | 1 | 0 |
Table 4.
Configurations used in for each element.
| NCP Element | Value |
|---|---|
| 4096 | |
| 1024 | |
| 256 | |
| 64 |
Table 5.
Set of configurations used in of a specific of the element in a specific .
| NCP Element | InC2D | OutC2D |
|---|---|---|
| 4 | 16 | |
| 16 | 16 | |
| 16 | 32 | |
| 4 | 32 | |
| 32 | 32 | |
| 32 | 64 | |
| 99 | 64 | |
| 64 | 64 | |
| 64 | 128 | |
| 99 | 64 | |
| 64 | 96 | |
| 96 | 128 | |
| 259 | 128 | |
| 128 | 196 | |
| 196 | 256 | |
| 259 | 128 | |
| 128 | 196 | |
| 196 | 256 | |
| 515 | 256 | |
| 256 | 256 | |
| 256 | 512 | |
| 515 | 256 | |
| 256 | 384 | |
| 384 | 512 |
Table 6.
Set of configurations used in of a specific in a specific .
| NCP Element | InC2D | OutC2D |
|---|---|---|
| 257 | 128 | |
| 128 | 128 | |
| 608 | 256 | |
| 256 | 256 | |
| 768 | 512 | |
| 512 | 512 | |
| 1536 | 512 | |
| 512 | 512 |
Table 8.
The different RPN configurations () used. N.A. - Not Applicable.
| Models | |||
|---|---|---|---|
| PointPillars | (512, 18, 1) | (5, 128, 128, 2) | (5, 128, 128, 2) |
| SECOND | (512, 18, 1) | (512, 42, 1) | N.A. |
| PV-RCNN | (512, 18, 1) | (512, 42, 1) | N.A. |
| PartA² | (512, 18, 1) | (512, 42, 1) | N.A. |
| VoxelRCNN | (5, 128, 256, 2) | (5, 128, 256, 2) | N.A |
Table 9.
Number of sampling instances (SI) per class.
| SI Configuration | Car | Pedestrian | Cyclist |
|---|---|---|---|
| 15 | 10 | 10 | |
| 25 | 20 | 20 |
Table 10.
The different point cloud ranges () configurations used in fine-tuning.
| Configuration | ||||||
|---|---|---|---|---|---|---|
| 0 | 69.12 | -39.68 | 39.68 | -3 | 1 | |
| 0 | 70 | -40 | 40 | -3 | 1 |
Table 11.
Pillar size () configurations used in fine-tuning.
| Configuration | |||
|---|---|---|---|
| 0.16 | 0.16 | 1 | |
| 0.05 | 0.05 | 0.1 |
Table 12.
Total number of data structures used in fine-tuning.
| P Configuration | Total Number of | Max Number of Points Per |
|---|---|---|
| 12K | 100 | |
| 16K | 5 |
Table 14.
Results in validation set for BEV detection metric for experiment 1-6.
| Model | Epoch | Experiment | Car | Cyclist | Pedestrian | Overall | ||||||
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | ||||
| Voxel R-CNN | 197 | 6 | 96.9 | 94.89 | 95.08 | 73.03 | 77.68 | 80.3 | 85.03 | 85.54 | 85.97 | 87.12 |
| Part A² | 187 | 5 | 97.64 | 96.72 | 96.6 | 81.37 | 83.02 | 83.38 | 90.21 | 90.81 | 90.95 | 90.31 |
| PointPillars | 160 | 1 | 76.29 | 79.05 | 80.80 | 57.52 | 58.01 | 58.10 | 77.75 | 72.52 | 73.62 | 70.84 |
| PointRCNN | 24 | 4 | 92.83 | 88.64 | 88.55 | 80.71 | 79.85 | 80.9 | 89.35 | 89.03 | 88.67 | 86.04 |
| PV-RCNN | 92 | 3 | 94.52 | 93.91 | 93.58 | 78.65 | 79.46 | 80.65 | 80.83 | 80.32 | 80.59 | 84.94 |
| SECOND | 154 | 2 | 87.97 | 83.75 | 84.43 | 71.29 | 76.0 | 78.23 | 77.99 | 78.96 | 79.55 | 80.74 |
Table 15.
Results in validation set for 3D detection metric for experiment 1-6.
| Model | Epoch | Experiment | Car | Cyclist | Pedestrian | Overall | ||||||
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | ||||
| Voxel R-CNN | 140 | 6 | 89.55 | 83.37 | 82.63 | 69.72 | 72.7 | 73.53 | 72.16 | 71.38 | 72.71 | 76.29 |
| Part A² | 182 | 5 | 79.15 | 77.31 | 77.25 | 73.6 | 74.84 | 76.11 | 72.63 | 74.94 | 76.01 | 76.46 |
| PointPillars | 179 | 1 | 63.49 | 58.98 | 59.27 | 52.27 | 60.16 | 63.0 | 41.06 | 40.38 | 38.99 | 53.75 |
| PointRCNN | 89 | 4 | 84.87 | 79.86 | 79.37 | 68.96 | 71.11 | 71.35 | 76.55 | 75.01 | 74.36 | 75.03 |
| PV-RCNN | 139 | 3 | 88.86 | 83.57 | 82.89 | 71.52 | 73.21 | 74.39 | 64.34 | 64.53 | 64.28 | 73.86 |
| SECOND | 147 | 2 | 75.55 | 72.19 | 72.43 | 55.23 | 62.36 | 65.06 | 61.77 | 62.05 | 61.34 | 66.28 |
Table 16.
Results in validation set for BEV detection metric for experiment 7-12.
| Model | Epoch | Experiment | Car | Cyclist | Pedestrian | Overall | ||||||
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | ||||
| Voxel R-CNN | 199 | 12 | 97.19 | 96.11 | 96.32 | 74.43 | 77.55 | 79.92 | 88.53 | 88.29 | 88.42 | 88.22 |
| Part A² | 195 | 11 | 97.75 | 96.71 | 96.61 | 78.23 | 80.9 | 82.74 | 89.99 | 90.41 | 90.76 | 90.04 |
| PointPillars | 21 | 7 | 85.76 | 81.04 | 82.87 | 67.04 | 73.04 | 75.8 | 55.39 | 57.19 | 58.58 | 72.42 |
| PointRCNN | 16 | 10 | 96.3 | 90.84 | 90.83 | 78.31 | 78.51 | 79.01 | 85.88 | 85.24 | 85.32 | 85.05 |
| PV-RCNN | 190 | 9 | 96.4 | 93.45 | 94.08 | 69.05 | 72.34 | 74.74 | 78.77 | 80.17 | 80.7 | 83.17 |
| SECOND | 162 | 8 | 90.61 | 86.51 | 86.05 | 78.66 | 79.76 | 79.91 | 66.27 | 73.66 | 76.79 | 80.92 |
Table 17.
Results in validation set for 3D detection metric for experiment 7-12.
| Model | Epoch | Experiment | Car | Cyclist | Pedestrian | Overall | ||||||
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | ||||
| Voxel R-CNN | 186 | 12 | 83.72 | 81.21 | 81.33 | 68.44 | 71.01 | 73.69 | 67.62 | 69.28 | 70.42 | 75.15 |
| Part A² | 187 | 11 | 83.29 | 82.53 | 82.87 | 74.13 | 75.38 | 76.2 | 69.46 | 70.95 | 70.82 | 76.63 |
| PointPillars | 21 | 7 | 69.49 | 66.31 | 66.94 | 47.58 | 52.72 | 56.98 | 37.4 | 36.91 | 39.48 | 54.57 |
| PointRCNN | 39 | 10 | 89.96 | 83.36 | 81.59 | 68.66 | 71.26 | 71.32 | 73.52 | 74.04 | 72.66 | 75.19 |
| PV-RCNN | 44 | 9 | 83.42 | 80.46 | 80.61 | 63.75 | 67.41 | 70.22 | 63.18 | 63.38 | 63.45 | 71.42 |
| SECOND | 162 | 8 | 76.02 | 70.24 | 72.77 | 56.1 | 63.59 | 65.77 | 56.2 | 58.87 | 58.14 | 65.56 |
Table 18.
Our results in KITTI validation set vs Original results in KITTI test set for 3D and BEV detection metrics.
Table 18.
Our results in KITTI validation set vs Original results in KITTI test set for 3D and BEV detection metrics.
| Model | Our results (Overall per Class) | Original results (Overall per Class) | ||||||||||
| 3D | BEV | 3D | BEV | |||||||||
| Car | Cyc. | Ped. | Car | Cyc. | Ped. | Car | Cyc. | Ped. | Car | Cyc. | Ped. | |
| Voxel R-CNN | 85.18 | 71.98 | 72.08 | 96.54 | 77.3 | 88.41 | 83.19 | - | - | 89.94 | - | - |
| Part A² | 82.9 | 75.24 | 70.41 | 96.99 | 82.59 | 90.66 | 79.94 | 66.54 | 45.50 | 88.03 | 71.34 | 34.92 |
| PointPillars | 67.58 | 52.43 | 37.93 | 83.22 | 71.96 | 57.05 | 75.29 | 62.56 | 44.09 | 86.48 | 66.07 | 50.67 |
| PointRCNN | 84.97 | 70.41 | 73.41 | 90.01 | 80.49 | 89.02 | 77.77 | 62.10 | 41.12 | 87.41 | 70.03 | 47.91 |
| PV-RCNN | 85.11 | 73.04 | 64.38 | 94.0 | 79.59 | 80.58 | 82.83 | 66.65 | 45.25 | 90.59 | 71.26 | 52.39 |
| SECOND | 73.39 | 60.88 | 61.72 | 87.72 | 79.44 | 72.24 | 79.20 | 62.56 | 44.09 | 88.4 | 68.36 | 47.63 |
Table 19.
Our inference time metric results.
| Model | Total (ms) ~ | Speed (Hz) ~ |
|---|---|---|
| PointPillars | 17.25 | 57.97 |
| SECOND | 34.1 | 29.33 |
| PV-RCNN | 118.03 | 8.47 |
| PointRCNN | 97.83 | 10.22 |
| Part A² | 82.66 | 12.10 |
| VoxelRCNN | 59 | 16.95 |
Table 20.
Original model inference time metric results.
| Model | Total (ms) ~ | Speed (Hz) ~ |
|---|---|---|
| PointPillars | 16 | 62.5 |
| SECOND | 110 | 9.09 |
| PV-RCNN | 80 | 12.5 |
| PointRCNN | 100 | 10 |
| Part A² | 80 | 12.5 |
| VoxelRCNN | 40 | 25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



