Submitted:
31 May 2023
Posted:
01 June 2023
You are already at the latest version
Abstract
In actuarial practice, the modeling of total losses tied to a certain policy is a non-trivial task. Traditional parametric models to predict total losses have limitations due to complex distributional features such as extreme skewness, zero inflation, multi-modality, etc., and the lack of explicit solutions for log-normal convolution. In the recent literature, the application of the Dirichlet process mixture for insurance loss has been proposed to eliminate the risk of model misspecification biases; however, the effect of covariates as well as missing covariates in the modeling framework is rarely studied. In this article, we propose novel connections among covariate-dependent Dirichlet process mixture, log-normal convolution, and missing covariate imputation. Assuming an individual loss is log-normally distributed, we develop a log skew-normal Dirichlet process to approximate the log-normal sum. As a generative approach, our framework models the joint of outcome and covariates, which allows to impute missing covariates under the assumption of missingness at random. The performance is assessed by applying our model to several insurance datasets, and the empirical results demonstrate the benefit of our model compared to the existing actuarial models such as the Tweedie-based generalized linear model, generalized additive model, or multivariate adaptive regression spline.
Keywords:
Bayesian nonparametric model
; heterogeneity
; missing at random
; log-normal sum approximation
; aggregate insurance claims
; clustering
; generative model
1. Introduction
In short-term insurance contracts, predicting accurate aggregate claims is essential for major actuarial decisions such as pricing or reserving. However, it is often not easy to model the aggregate loss due to its complex distributional features such as high skewness, zero inflation, hump shape, multi-modality, etc. With the advance of the modern Bayesian paradigm and computing power, the development of full distribution of aggregate claims has been studied and applied in actuarial practice. In particular, because of its considerable flexibility, a Bayesian nonparametric (BNP) approach has been gradually recognized to solve distributional conundrums in an insurance context. For instance, Hong and Martin (2018) [1] recently developed the Dirichlet process model as a BNP approach that maximizes the fitting flexibility of the full distribution for insurance loss, which obviates the chance of model misspecification bias. In this article, as an extension of their work, we aim to go beyond the search for the maximized fitting flexibility, focusing on the issues that arise from the presence of covariates and the aggregate outcome (total losses). The implication is that the predictive distribution for the expected aggregate claims developed under Hong and Martin’s Dirichlet process framework can be biased with the incorporation of covariate effects and log-normal convolution. For example, as covariates add new information that differentiates the data points of the outcome variable, a new structure can be introduced into the data space, and this increases the within-cluster heterogeneity [2]. Besides, the incorporation of missing covariates may exacerbate the existing heterogeneity. Additionally, assuming that the outcome variable describes the aggregate losses, rather than individual claim amounts, it is difficult to compute the log-normal convolution as it does not have a closed-form solution. In this regard, our study extends their work by addressing the following research questions:
- RQ1. If an additional unobservable heterogeneity is introduced by the inclusion of covariates, what is the best method to capture the within-cluster heterogeneity in modeling the total losses, comparing several conventional approaches?
- RQ2. If an additional estimation bias results from the use of the incomplete covariates under Missing At Random (MAR), what is the best way to increase the imputation efficiency, comparing several conventional approaches?
- RQ3. If an individual loss is distributed with log-normal densities, what is the best way to approximate the sum of log-normal outcome variables, comparing several conventional approaches?
2. Discussion on Research Questions and Related Work
Let be the independent claim amount (reported by each policyholder for a single policy) random variable, defined on a common probability space () from a certain loss distribution such as log-normal. Let be a vector of covariates, and be the total claim count denoting the number of individual claims for a single policy up to time t (policy period). The aggregate claim for a single policy, h, given time t can be expressed as a convolution: . At the end of the policy period t, let be the total aggregate claim amounts from the total policies received by an insurer, then: in which H is the total number of policies on the contracts. Note that both convolutions described so far are built upon the assumption that the summands - and - are mutually independent and identically distributed with log-normal densities (to maintain homogeneity of each loss).
However, the involvement of covariates and the lack of closed-form solutions for the log-normal sum bring about several challenges that violate the assumptions for an accurate estimation of the total aggregate loss . To begin with, the use of covariates gives rise to an additional within-cluster heterogeneity. Kass et al.(2008) [3] describes a standard aggregate loss modeling principle denoting that the expected aggregate claims is obtained by the product of the mean claim counts and severities: . With the inclusion of covariates , a new unknown structure or heterogeneity is introduced into the data space of , which means that within a single policy can still be independent, but cannot be identically distributed. Therefore, , and the total aggregate loss becomes difficult to compute with the conventional collective risk modeling approach. In addition, assuming that the severity follows a log-normal distribution, the computation of becomes quite difficult as its convolution is not known to have a closed-form [4]. Another challenge is the missing covariates in . As shown by Ungolo et al.(2020) [5], the missing covariates under the missingness at random (MAR) assumption lead to the biased parameter estimations because the uncertainty in the estimation results of the parameters describing the outcome Y is heavily affected by the quality of covariates . Again, in this case, cannot be computed properly.
Compounding all this, we propose the Dirichlet process log skew-normal mixture to model the . We consider the Dirichlet process framework to cope with the within-cluster heterogeneity as suggested by Hong and Martin (2018); Braun et al.(2016) [1,6] while employing the log skew-normal approximation studied by Li (2008) [7] to compute each , the sum of log-normal random variables . When it comes to the problem of missing covariates, we exploit the generative capability of the Dirichlet process to capture the latent structure of data, which allows for a rigorous statistical treatment of MAR covariates.
2.1. Can Dirichlet Process Capture the Heterogeneity and Bias?: RQ1, RQ2
In Figure 1, refers to individual claim amount and each represents a total claim amount defined by a unique policy (cluster h) as a homogeneous distribution. Although an insurer can collect the aggregate loss data for each policy cluster given policy period t, individual policyholders (in different risk classes) can raise more than one claim (i.e. random ) at any time over a fixed time horizon t, and their corresponding claim amounts (i.e. random ) will not be known in advance. Hence, the unsettled liability information of from certain policyholders always renders incomplete, which is often translated into the challenge of their inherent stochasticity. In addition, the new claims raised from unknown risk classes can trigger inherent heterogeneity across unique clusters as well. To make matters worse, if introducing covariates to better understand the different risk classes, one might introduce an additional source of heterogeneity into the scene, which prevents each cluster from being identically distributed.
With respect to this, Hong and Martin (2018) [1] propose the concept of the loss distribution mixture for each cluster based on the Dirichlet process framework. The main idea behind the Dirichlet process mixture (DPM) is to produce a single master distribution to model stochasticity in with the help of an infinite dimensional parametric structure and the probabilistic simulations of clustering scenarios. Braun et al.(2006) [6] articulates how the DPM automatically captures unobservable heterogeneity such as intracorrelation between claim amounts in the different risk classes without specifying the number of the classes upfront. In short, no matter how complex the distribution of the data is, the DPM is capable of accommodating any distributional properties - multi-modes, skewness, heavy tails, etc. - resulting from unobservable heterogeneity; and therefore, dramatically minimizes model misspecification biases.
With the inclusion of the covariates, the DPM offers a useful bedrock for a MAR treatment. As a generative modeling approach, the DPM models both outcomes and covariates jointly to produce cluster memberships. This is used as key knowledge to identify the latent structure of the data. For example, in the domain of medicine research, Roy et al. (2018) [8] develop a novel imputation strategy for the MAR covariate, using the latent structure unraveled by the DPM and the other covariate knowledge available. A further survey of imputation methods based on the Nonparametric Bayesian framework can be found in Si and Reiter (2013) [9] and references therein.
2.2. Can Log Skew-Normal Mixture Approximate the Log-Normal Convolution?: RQ3
The log-normal distribution has been considered a suitable claim amount distribution due to its non-negative support, right-skewed curve, and moderately heavy tail to accommodate some outliers. However, if generalizing the individual claim amount by introducing a log-normal distribution, the convolution computation for fails because the exact closed form for the log-normal sum is unknown.
Furman et al. (2020) [10] present several existing methods for the log-normal sum approximation that have been studied in the literature. This includes the moment matching approximation approaches such as Minimax approximation, Least squares approximation, Log shifted gamma approximation, and Log skew-normal approximation. The distance minimization approaches - Minimax approximation or Least squares approximation - described by Beaulieu and Xie (2003); Zhao and Ding (2007) [4,11] are conceptually simple, but they require to fit the entire cumulative densities to the sum of claim amounts, which can be computationally expensive and easy to fail when the number of the summands increases. The Log shifted gamma approximation suggested by Lam and Le-Ngoc (2007) [12] has less strict distributional assumptions, but it is not very accurate at the lower region of the distribution. In our study, special attention is paid to the possibility of the Log skew-normal approximation method for the sake of simplicity. A skew-normal distribution as an extension of a normal distribution has a third parameter to naturally explain skewness apart from the other parameters (for a location and spread). Li (2008) [7] points out that one can exploit the third parameter of the skew-normal distribution to capture different skewness levels of each summand. Taking the log of skew-normal densities, we can approximate , the sum of the log-normal . Using the log skew-normal as the underlying distribution for in the DPM framework, one can eliminate the need to compute the cumulative density curve, and its closed-form density and the optimal distribution parameters for can be easily obtained by the moment matching technique. For further details, see Li (2008) [7] and the references contained within.
2.3. Our Contribution and Paper Outline
The contribution of this study is as follows: first, using the Bayesian nonparametric framework, we propose solutions to the two major challenges of the aggregate claim computation - 1) heterogeneity in the log-normal random variable , 2) lack of closed-form of the sum of log-normal random variables - in a more unified fashion. Second, we introduce covariates into the aggregate claim modeling framework, taking into account the adverse impact triggered by the covariates . This includes the added heterogeneity across and the missing information fed by MAR covariates . To our knowledge, there have been no previous attempts to either estimate the log skew-normal mixture within the DPM framework or use the DPM to handle the MAR covariate in the insurance loss modeling.
The rest of the paper is structured as follows. In Section 3, we describe the proposed modeling framework for , assuming log-normal distributed and the inclusion of both continuous and discrete covariates . This section also presents our novel imputation approach for the MAR covariate within the DPM framework. Section 4 clarifies the final forms of the posterior and predictive densities accordingly. Section 5 presents our empirical results, and validates our approach by fitting to two different datasets with different sample sizes drawn from the R package CASdatasets and the Wisconsin Local Government Property Insurance Fund (LGPIF). This is followed by a discussion in Section 6.
3. Model: DP Log Skew-Normal Mixture for
3.1. Background
Consider that there are multiple unknown risk classes (clusters) across the claim information within each policy, and then the individual aggregate claims for the policy h would have diverse characteristics that cannot be explained by fitting a single log skew-normal distribution. In order to approximate the distribution that captures such diverse characteristics in , we seek to investigate diverse clustering scenarios. To this end, as suggested by Hong and Martin (2018) [1], we exploit the infinite mixture of log skew-normal clusters and their complex dependencies by employing a Dirichlet process. The Dirichlet process produces a distribution over clustering scenarios (with clustering parameters).
where G denotes the clustering scenarios, and the important components of G are
- : the parameters of the outcome variable defined with cluster j.
- : the parameter of the cluster weights defined with cluster j.
G, as a single realization of the joint cluster probability vector sampled from the DPM model, takes independent partitions of the sample space of the support of . By sufficient simulations of G, the Dirichlet process investigates all possible clustering scenarios rather than relying on a single best guess. The overall production of G is controlled with two parameters - a precision and a base measure . The precision controls a variance of sampling G in the sense that larger generates new clusters more often to account for the unknown risk classes. The base measure , as the mean of DP(), is a DP prior over the joint space of all parameters for the outcome model, covariate model, and the precision , as shown in Ghosal (2010) [13].
Note that the original research on DPM by Hong and Martin (2018) [1] mainly focuses on the random cluster weights independent of the covariates . On the other hand, in our model, the covariate effects are incorporated into the development of cluster weights . All calculations for the development of the DPM modeling components in this paper are based on the principles introduced by Ferguson (1973), Antoniak (1974), and Sethuraman (1994) [14,15,16].
3.2. Model Formulation with Discrete and Continuous Clusters
Let the outcome be denoting the H different aggregate claims (incurred by the H different policies). We assume that the covariate is binary, and the is Gaussian, and then our baseline DPM model can be expressed as:
where j is the risk class index; } describe the outcome model while explains the covariate model. is modeled as a mixture of a point mass at 0 and positive values distributed with log skew-normal density to address the complications of zero inflation in the loss data. models the probability of the outcome being zero using a multivariate logistic regression. Variable Definitions section has a brief description of all parameters used in this study.
Considering a Dirichlet process log skew-normal mixture to house the multiple unknown risk classes in , it is necessary to differentiate the forms of mixture components depending on the types of clusters it uses - the discrete and continuous. While keeping the inference of the cluster parameters to be data dominated, the DPM first develops discrete clusters based on the given claim information and then extrapolates certain unobservable clusters of claims by examining the heterogeneity (or hidden risk classes) of each cluster. In this process, the DPM develops new continuous clusters additionally and assesses them with some probabilistic decision-making algorithms, rendering the parameter estimations computationally efficient and asymptotically consistent [17].
The discrete mixture components (clusters) in the DPM framework have the standard form that is useful in accounting for the observed classes such as policy information for aggregate loss [18]. In calculating the discrete cluster probabilities, we assume that the non-zero outcome and covariates are distributed with the densities denoted by
where and are standard normal probability and cumulative density functions for the log skew-normal density. To model the outcome data for the policy h, the DPM takes the general form of the mixture
where J is the total number of mixture components (risk classes), and are the outcome and covariate parameters to explain the risk clusters, and , functions of covariates: , are the cluster components weights (mixing coefficient) satisfying .
However, when the DPM is extended as , the new continuous clusters are introduced by the (with its infinite-dimensional parametric structure) in order to address the additional unknown risk classes. This assesses the within-class heterogeneity in by confronting the current discrete clustering result and investigating the homogeneity more closely. As the new clusters are considered countably infinite, their corresponding forms of the outcome and covariate models to obtain the continuous cluster are given by
They are also known as a “parameter-free outcome model" and a “parameter-free covariate model" respectively to develop the new continuous cluster mixture. Given a collection of outcome-covariate data pairs , the DPM puts together the current discrete clusters and new continuous clusters to update the mixture form in Equation (3), with help of Monte Carlo Markov Chain (using sufficiently simulated samples of the major parameters ). Consequently, the sample G described in Equation (1) becomes where denotes both discrete and continuous cluster densities as point mass distributions at the random locations sampled from . Aligned with such flexible cluster development, the form of the predictive distribution can be molded based on the knowledge extracted from G, as follow:
and the finalized cluster weights in Equation (5) are secured through computing these two sub-models below for discrete and continuous cluster weights respectively which reflect the properties of the clusters and relevant covariates.
where is the precision parameter to control the acceptance chances of the new clusters, is the number of observations in cluster j, is the parameter-free covariate model in Equation (4b, 4c) to support the new continuous clusters, and is the covariate model to support the current discrete clusters. Note that instead of the popular stick-breaking scheme used by Hong and Martin (2018) [1], the cluster weights are obtained based on the covariate models of that explain the outcome .
The simulated outcome model and its predictive model in Equation (5) show that although the DPM framework allows infinite-dimensional modeling, the dimension of the sampling output G is adaptive as it is a mixture with at most finite components determined by data itself (e.g. its dimension cannot be greater than the total sample size H). This gives the model flexibility, and throughout such modeling flexibility, the G can become the comprehensive mixture distribution for , accommodating all distributional properties of the given claims as well as the additional unknown claims.
3.3. Modelling with Complete Case Covariate
The joint posterior update for the outcome and covariate parameters - - in Equation (5,6) can be made through a Gibbs Sampler. Using the conditional distribution of the unobservable variables given the observed data, the Gibbs sampler can obtain draws from the analytically intractable posterior distribution of the parameters [20]. Let the cluster-index for the observation h be . The parameter inference steps to ensure convergence are described below.
- Step.1
-
Initialize the cluster membership and the main parameters:
- (a)
- First the cluster membership is initialized by some clustering methods such as hierarchical clustering or k-means, etc. This step provides an initial clustering of the data ( as well as the initial number of clusters.
- (b)
- Next, after all observations have been assigned to a particular cluster , we can then update the parameters and () for each cluster. This is done using the posterior densities denoted by , and in which () represent all observations in cluster j.
- Step.2
-
Loop through the Gibbs sampler and new continuous cluster selection:Once the cluster memberships and parameters are initialized, we then loop through the Gibbs sampler many times (e.g. iterations) where the algorithm alternates between updating the cluster membership for each observation and updating the parameters given the cluster partitioning. Each iteration might give a slightly different selection of the new clusters based on the Polya Urn scheme [20], but the log-likelihood calculated at the end of each iteration can help keep track of the convergence of the selections. A detailed description of each iteration is given in Algorithm (A2) in Appendix B. The term on lines 6 and 9 in Algorithm (A2) is the Chinese Restaurant process [19] posterior value given bywhere c is a scaling constant to ensure that the probabilities sum to 1, and is the collection of cluster indices assigned to every observation without the cluster index of the observation h. As shown in Equation (7), the larger results in a higher chance of developing the new continuous cluster and adding to the collection of the existing discrete clusters. The forms of the prior and posterior densities used to simulate the main parameters on lines from 16 to 23 in Algorithm (A2) are presented in Appendix A.
There is a couple of points to note. The Gibbs sampler for the DPM described here can be characterized by the use of infinite clusters and covariates. Due to the infinite mixture capacity, the resulting clusters can be kept as homogeneous as possible. In this process, the within-class heterogeneity can be captured between parameters across the observations, and the DPM utilizes such dependencies within existing clusters to determine the rationale for the development of new clusters. The DPM harnesses the power of the covariate as well. For example, the DPM associates individual policies with the unobserved claim (in new clusters) and the observed claims (in old clusters), matching on the covariate information. The investigation of the infinite clusters, covariates, and the continuous cluster selection process in the DPM are briefly illustrated in the diagram in Figure 2. As a result, the unobserved claim problem mentioned in Figure 1 can be addressed by the new cluster introduction, which leads to a better approximation of .
3.4. Modelling with MAR Covariate
The DPM model for complete case data ( has been discussed in Section 3.3. In this Section, we present our novel imputation strategy for the MAR covariate in the DPM framework in which the missing values are explained by the observed data. We focus on the missingness in the binary type covariate. In addition, we specify here different prior distributions and the corresponding posterior distributions constructed for the Gibbs sampler, taking into account the MAR covariate. With the model definition in Equation (1), suppose the binary covariate has missingness within it. To handle this MAR covariate, we consider the following modifications in the DPM Gibbs sampler:
- a)
- Imputation: The missing covariate impacts on the parameter - - update. For , only the observations without the missing covariate are used to update. If the cluster does not have any observations with complete data for that covariate, then a draw from the prior distribution would be used to update. For , however, we must first impute values for the missing covariates for all observations within the cluster. Since having already defined a full joint model - - in Section 3.2, we can obtain draws for the MAR covariate from the imputation model such as at each iteration of the Gibbs sampler. The imputation process is briefly illustrated in Figure 3. Once all missing data in all covariates has been imputed, then we can sample from the posterior for and the parameters of each cluster are re-calculated. After this cycle is complete, the imputed data is discarded and the same imputation steps are repeated every iteration.
- b)
-
Re-clustering: To determine each cluster probability after the imputations, the algorithm re-defines the two main components for the cluster probability calculation - 1) covariate model, 2) outcome model. For the covariate model , we set this equal to the density functions of only those covariates with complete data for observation h. Assuming that , and the covariate is missing for observation h, then we drop and only use in the covariate model,This is the refined covariate model for the cluster j with the observation h where the data in is not available. For the outcome model , the algorithm simply takes the imputation model for each cluster and integrates them out the covariates with missing data. This reduces the degree of variances introduced by the imputations. In our case, as covariate is missing for observation h, this missing covariate can be removed from the term that is being conditioned on. Therefore, the refined outcome model isA similar process is conducted for each observation with missing data and each combination of missing covariates. Hence, using Equation (8,9), the cluster probabilities and the predictive distribution can be obtained as illustrated in Step III in Figure 4.
- c)
4. Bayesian Inference for with MAR Covariate
The efficient simulation for the model parameters - , and - requires the proper parameterization in the parameter models - prior parameter model and posterior parameter model. The accurate estimations of cluster probabilities rely on the legitimate development of data models - outcome model and covariate model - and the model parameter simulation results that govern the data model behaviors. This section is centered on the novel development of parameter and data models, providing the details of the DPM implementation integrated with the MAR imputation strategy.
4.1. Parameter Models and MAR Covariate
Our study is based on a three-level hierarchical structure: the first level regards the data models such as the log skew-normal outcome model and the Bernoulli, Gaussian covariate models, the second level involves the parameter models such as to explain the data, and the third level is developed from the generalized regression to explain the parameters or the related hyperparameters such as and to set a probabilistic distribution on the parameter vectors . See Variable Definition for further information on the variables. Given the model definition in Equation (1), we consider a set of conjugate parameter models due to its computational advantages [21]. For , , and , the prior models come in
and their corresponding kernels chosen in this study are listed in Appendix A.1. Accordingly, the Dirichlet process prior (probability measure) in our case can be defined as . With a feed of the observed data inputs - -, the prior models for each cluster j described above will be updated into the following posterior models analytically apart from .
and their corresponding parameterizations are elaborated in Appendix A.2. Note that the value of the precision parameter relies on the total cluster number J, thus does not vary by the cluster membership j, and its derivation of the posterior parameterization is not subject to the Bayesian conjugacy. Hence, we instead adapt the form of the posterior density for the suggested by Escobar and West (1995) [22], and its derivation is shown in Appendix C.1. As for , there are no conjugate priors available for log skew-normal likelihood, but their posterior samples can be secured by the conventional metropolis hastings described in Algorithm (A2) in Appendix A.
Considering that has missing data, although the parameterizations of the posterior densities for the covariate parameter model of and the precision listed in Equation (10) are not affected, any outcome data of with missingness should be dropped; therefore, and are defined with the only observations in cluster j that are not missing. This imputation example is provided in Appendix C.2. For the outcome parameter model of , the missing covariate must be imputed before its posterior computation shown in Algorithm (A2). Once the parameters are updated with the imputation, the data models can be constructed as described in Equation (8,9).
4.2. Data Models and MAR Covariate
Data models are the main components for cluster probability computations depicted in Figure 2. As with the development of parameter models, the covariate data model of ignores the observations with missingness while the outcome data model of requires to complete the covariates beforehand. However, the formulation of their densities can be more complex due to the marginalization process with respect to the missing covariate. In addition, as discussed in Section 3.2, the data model development is bound by the types of clusters such as discrete clusters and continuous clusters .
- a)
-
covariate model for the discrete cluster:Focusing on the scenario that is binary, is Gaussian, and the only covariate with missingness is , we simply drop the covariate to develop the covariate model for the discrete cluster. For instance, when computing the covariate probability term for hth observation in j cluster, the covariate model simply becomes due to the missingness of . As we have that is assumed to be normally distributed as defined in Equation (1), its probability term isinstead of
- b)
-
covariate model for the continuous cluster:If the binary covariate is missing, by the same logic, we drop the covariate for the continuous cluster; however, using Equation (4), the covariate model for the continuous cluster integrates out the relevant parameters simulated from the Dirichlet process prior as follows:instead ofThe derivation of the distributions above is provided in Appendix C.3.
- c)
-
outcome model for the discrete cluster:In developing the outcome model, as with the parameter model case discussed in Section 4.1 and Appendix C.2, it should be ensured that the covariate is complete beforehand. With all missing data in imputed, the outcome model for the discrete cluster is obtained by marginalizing the joint - - out the MAR covariate , which is a log skew-normal mixture as follows:instead of
- d)
-
outcome model for the continuous cluster:Once a missing covariate is fully imputed and the outcome model is marginalized out conditioned to the MAR covariate , the outcome model for the continuous cluster can also be computed by integrating out the relevant parameters, using Equation (4).However, it can be too complicated to compute its form analytically. Instead, we can integrate the joint model out the parameters, using Monte Carlo integration. For example, we can do the following for each .
- (i)
- Sample from the DP prior densities specified previously.
- (ii)
- Plug in these samples into .
- (iii)
- Repeat the above steps many times, recording each output.
- (iv)
- Divide the sum of all output values by the number of Monte Carlo samples, which will be the approximate integral.
4.3. Gibbs Sampler Modification for MAR Covariate
We have examined the parameter models and data models to update the parameters of the DPM based on probabilistically imputed values of the MAR covariate. Now we set out some modifications of the DPM and let the Gibbs sampler in Algorithm (A2) in Appendix B. address the MAR covariate of . The Gibbs sampler will alternate between imputing missing data and drawing parameters until it reaches a stationary distribution of the parameters. We elaborate below on the modifications that fit into Algorithm (A2) to update the clustering scenarios and the posterior cluster parameters properly.
- a)
- b)
- c)
- In line 22, with the presence of missing covariate , the imputation should be made before simulating the parameter as follows,
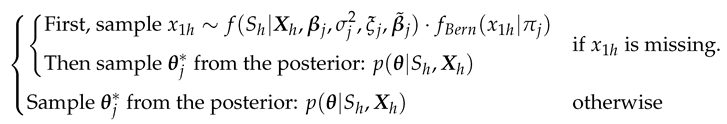
The imputation model formulation in the above has been discussed in Section 3.4.
Again, these modifications allow to draw missing covariate values from the conditional posterior density at each iteration, using the Metropolis-Hastings with a random walk.
5. Empirical Study
5.1. Data
The performance of our DPM framework is assessed based on two insurance datasets. They highlight data difficulties such as unobservable heterogeneity in an outcome variable and MAR covariates. For simplicity, in each dataset, we only consider two covariates - one binary and one continuous - to explain its loss information (outcome variable). In this study, all computations on these two datasets are performed in the same data format:
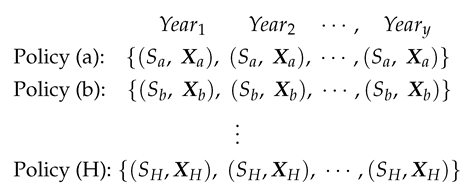
The first dataset is PnCdemand, which is about the international property and liability insurance demand of 22 countries over 7 years from 1987 to 1993. Secondly, we use a dataset drawn from the Wisconsin Local Government Property Insurance Fund (LGPIF) with information about the insurance coverage for government building units in Wisconsin for years from 2006 to 2010. The first one - PnCdemand - can be obtained from the R package CASdatasets. The dataset is relatively small as it has cases with an outcome variable GenLiab: the individual loss amount under the policies of general insurance for each case. As for covariates, we consider one indicator variable of the statutory law system (LegalSyst:1 or 0) and one continuous variable that measures a risk aversion rate (RiskAversion) for each area. For additional background on this dataset, see Browne et al. (2000) [23]. In the LGPIF dataset, the insurance coverage samples for the government properties from policies are provided. The outcome variable is the sum of all types of losses (Total Losses) for each policy. Only the covariates - LnCoverage, Fire5 - are considered in our study. Fire5 is a binary covariate that indicates fire-protection levels while LnCoverage is a continuous covariate that informs a total coverage amount in a logarithmic scale. For further details, see Quan et al. [24].
Histograms of the losses of the two datasets are exhibited in Figure 6. Due to the significant skewness, the loss data are log-transformed to attain Gaussianity. As shown in the histograms, each distribution displays different characteristics in regard to skewness, modality, excess of zeros, etc. Note that the zero-inflated outcome variable in LGPIF data (b1, b2 in Figure 6) requires a two-part modeling technique that distinguishes the probabilities of the outcome being zero and positive.
5.2. Three Competitor Models and Evaluation
Our DPM framework is compared to other commonly used actuarial models in practice. We employ three predictive models as benchmarks - namely, a generalized linear mixture model (GLM), multivariate adaptive regression spline (MARS), and generalized additive model (GAM). In each dataset, we assume different distributions for the outcome variables, and thus the three benchmark models are built upon the different outcome data models. For example, the PnCdemand dataset (a1,a2) that appeared in Figure 6, has a high frequency of small losses without zero values, hence it is safe to use a gamma mixture to explain the outcome data. As for the LGPIF data (b1,b2) in Figure 6, we consider the outcome data model based on a Tweedie distribution to accommodate the zero-inflated loss data. The benchmark models are implemented in R with the mgcv, splines, and mice packages.
All four models are trained, and investigations are performed in terms of model fit, prediction accuracy, and the conditional tail expectation (CTE) of the predictive distribution. Note that the goodness of fit value for a DPM is not available in Table 1,Table 2. Teh (2010) [25] argues that the goodness of fit evaluation for a DPM is unnecessary as underfitting is mitigated by the unbounded complexity of a DPM while overfitting is alleviated by the approximation of posterior densities over each parameter in a DPM. Gelman et al. (2007) [26] point out Posterior predictive check, which compares the simulated data under the fitted DPM to the observed data, can be useful in studying model adequacy, but its usage cannot be for model comparison. Therefore, the goodness of fit is only compared between the rival models. For the evaluation of prediction performance, the sum of square prediction error (SSPE) and sum of square absolute error (SAPE) are used.
5.3. Result 01. International General Insurance Liability Data
For this dataset, a training set of response and covariates pair with n = 160 records, and a test set of response and covariates pair with m = 80 records are constructed. We implement the following DPM:
A log-normal likelihood is chosen to accommodate the individual loss :GenLiab for a policy h. The covariate :RiskAversion is subject to missingness, and found to depend on (a MAR case). This is addressed by the internalized imputation process as discussed in Figure 3. The posterior parameters of are estimated with our DPM Gibbs sampler presented in Algorithm (A2). The algorithm runs 10,000 iterations until convergence, and the resulting scenarios of clustering mixture are shown in Figure 7. The plot reveals the overlays of predictive densities on the log scale from the last 100 iterations that are tied to convergence.
Figure 8 lists the classical data imputation process - Multivariate Imputation Chained Equation (MICE) - and predictive densities produced from our rival models - GLM, GAM, MARS. The MICE runs multiple imputation chains, and selects the imputation values from the final iteration. This process results in multiple candidate datasets. The trace plots (a1,a2) monitor the imputation mean and variance for the missing values in the dataset. In the covariate distribution plot (a3), the density of the observed covariate shown in blue is compared with the ones of the imputed covariate for each imputed dataset shown in red. The parameter inferences for the rival models are performed based on the imputed datasets tied to convergence [27]. The gamma distribution is chosen to fit the rival models as the is continuous and positively skewed with a constant coefficient of variation. The gamma-based predictive density plots (b1,b2,b3) estimated with GLM, GAM, MARS look similar, showing unusual bumps near the right tail.
In Figure 9, a histogram of the outcome data in the test set is displayed. The posterior mean densities for out-of-sample predictions produced with our DPM along with the rival models’ density estimates are overlaid on the histogram. Judging from the plot, one can say that our DPM model generates the best approximation. While the rival models generate smooth, mounded curves to make predictions, our DPM captures all possible peaks and bumps, which is closer to the actual situation. According to Table 1, the rival models produce slightly higher SAPEs, but lower SSPEs, compared to our proposed DPM. As SAPE weights all the individual differences equally, we can assume that the rival models tend to give too much focus on the most probable data points and miss some outliers. This is mainly due to the insufficient sample size. However, our DPM has good performance under small sample sizes when there is sufficient prior knowledge available. From the perspective of CTE, Table 1 shows that our DPM proposes a heavier tail than other rival models, which reflects that our DPM captures more uncertainties given the small sample size.
5.4. Result 02. LGPIF Data
For this dataset, a training set of response and covariates pair with n = 4529 records, and a test set of response and covariates pair with m = 1110 records are constructed. We implement the following DPM:
As the outcome :Total Losses for a policy h in this dataset is considered to be distributed with the sum of log-normal densities, a log skew-normal likelihood is chosen to approximate this convolution [7]. The covariate :Fire5 is subject to missingness under MAR, and the internalized imputation process illustrated in Figure 3 resolves this issue without creating imputed datasets. As the outcome exhibits zero inflation, we employ a two-part model, using a sigmoid and indicator function. Our DPM Gibbs sampler described in Algorithm (A2) produces the posterior parameters of with 10,000 iterations until convergence. Figure 10 reveals the resulting scenarios of clustering mixture. In the plot, there are 100 predictive densities suggested by our DPM, each of which stands for the convergence of the estimation results.
The output of the MICE and the resulting predictive densities from the rival models are displayed in Figure 11. The rival models are built upon a Tweedie distribution due to its ability to account for a large number of zero losses, and the flexibility to capture the unique loss patterns of the different classes of policyholders. According to the plot, all three rival models reasonably capture zero inflation, but the GAM tends to suggest more bumps that indicate a need for further assessment of the prediction uncertainty.
The overall out-of-sample prediction comparison is made in the histogram overlayed with predictive density curves generated from the four models in Figure 12. From the plot, it is apparent that the posterior predictive density proposed by our DPM best explains the new samples while other rival models keep producing multiple peaks. The prediction performance of our DPM is confirmed by the smallest SSPE and SAPE in Table 2. In terms of CTE, all three rival models suggest a similar level of tailedness, reflecting the knowledge obtained from the observed data. However, our DPM goes beyond this and proposes a much heavier tail. This is because our DPM accommodates the presence of outliers and shapes the tail behavior based on the combined knowledge of prior parameters and the observations available.
6. Discussion
This paper proposes a novel DPM framework for actuarial practice to model total losses with the incorporation of MAR covariates. Both log-normal and log skew-normal DPM present overall good empirical performances in capturing the shape of the distribution, out-of-sample prediction, and the estimation of the tailedness. This suggests that it is worth considering our DPM framework in order to avoid various model risks or biases in insurance claim analysis.
6.1. Research Questions
Regarding RQ1, we propose a DPM framework to address the within-cluster heterogeneity emerging from the inclusion of covariates. By allowing for an infinite number of clustering scenarios determined by the observations as well as prior knowledge, our DPM outperforms the rival methods in drawing the lines for the cluster membership. This can be assessed by examining the homogeneity of the resulting clusters. In our case, we fit cluster-wise GLMs (based on Gamma and Tweedie) to the data points within each resulting cluster to compare the goodness-of-fit, and the consistent AICs across all clusters endorse the benefits of the DPM. Similarly, our rival methods such as GAM or MARS can capture heterogeneity by using customized smooth functions across different subsets of the data, but we observe some statistically insignificant smooth terms, indicating the presence of heterogeneity in the cluster.
In terms of RQ2, we suggest incorporating the imputation steps into the parameter and cluster membership update process in the DPM Gibbs sampler by leveraging the joint distribution of the observed outcomes and missing covariates. This approach allows the imputed values to be consistent with the observed data, preserving the correlation structure within the dataset. In order to make a comparison of our approach with an existing alternative, we additionally employ a chained equation technique. The multiple sets of imputed values simulated from both approaches are investigated, and the result shows that our DPM Gibbs sampler does not represent a significant improvement over the chained equation because their average estimates of the imputed values are closer to each other. However, we feel that this result is mainly due to the relatively low dimensionality of the datasets we use and their simple data structure. The specific characteristics or dependencies in the data and the complexity of the missing patterns would give different results in practice.
As for RQ3, we fit a log skew-normal density to the aggregate loss outcomes. In order to assess its performance, one can consider Minimax approximation, Least squares approximation, Log shifted gamma approximation, etc. as the competitors. Li (2008) [7] provides a useful comparison between these competitors by overlaying the cumulative density curves for each technique, but its experiments are grounded on the simulated log-normal data with the pre-defined parameters and assumptions, which cannot be easily controlled in real-world scenarios. Therefore, we feel that the choice of the best approximation technique should be made based on the identification of the specific characteristics of the dataset. In our case, each summand in our dataset is significantly different from each other in magnitudes (the Minimax is inappropriate) and LGPIF data has a large volume of data smaller than 5 (the Log shifted gamma is inappropriate); therefore, we choose a log skew-normal density that is relatively simple while giving an accurate approximation at the lower region of the distribution.
6.2. Future Work
There are several concerns with our log skew-normal DPM framework.
- (a)
- Dimensionality: First, in our analysis, we only use two covariates (binary and continuous) for simplicity, hence more complex data should be considered. As the number of covariates grows, the likelihood components (covariate models) to describe the covariates grow, which results in the shrinking of the cluster weights. Therefore, using more covariates might enhance the level of sensitivity and accuracy in the creation of cluster memberships. However, it can also introduce more noise or hidden structures that render the resulting predictive distributions unstable. In this sense, further research on the problem of high dimensional covariates in the DPM framework would be worthwhile.
- (b)
- Measurement error: Second, although our focus in this article is MAR covariate, mismeasured covariate is an equally significant challenge that impairs the proper model development in insurance practice. For example, Aggarwal et al. (2016) [28] point out that “model risk" mainly arises due to missingness and measurement error in variables, leading to flawed risk assessments and decision-making. Thus, further investigation is necessary to explore the specialized construction of the DPM Gibbs sampler for mismeasured covariates, aiming to prevent the issue of model risk.
- (c)
- Sum of log skew-normal: Third, as an extension to the approximation of total losses (the sum of individual losses) for a policy, we recommend researching into ways to approximate the sum of total losses across entire policies. In other words, we pose the question of “how to approximate the sum of log skew-normal random variables". From the perspective of an executive or an entrepreneur whose concern is the total cash flow of the firm, nothing might be more important than the accurate estimation of the sum of total losses in order to identify the insolvency risk or to make important business decisions.
- (d)
- Scalability: Lastly, we suggest investigating the scalability of the posterior simulation by our DPM Gibbs sampler. As shown in our empirical study on the PnCdemand dataset, our DPM framework produces reliable estimates with relatively small sample sizes (). This is because our DPM framework actively utilizes significant prior knowledge in posterior inference rather than heavily relying on the actual features of the data. In the result from the LGPIF dataset, our DPM exhibits stable performance at sample size as well. However, a sample size of over 10000 is not explored in this paper. With increasing amounts of data, our DPM framework raises a question of computational efficiency due to the growing demand for computational resources or degradation in performance [29]. This is an important consideration, especially in scenarios where the insurance loss information is expected to grow over time.
7. Variable Definitions
The following variables and functions are used in this manuscript:
| observation index i in policy h. | |
| policy index h with sample (policy) size H. | |
| cluster index for J clusters. | |
| cluster index for observation h. | |
| number of observations in cluster j. | |
| number of observations in cluster j where observation h removed from. | |
| individual loss i in a policy observation h. | |
| outcome variable which is a in a policy observation h. | |
| outcome variable which is a across entire policies | |
| vector of covariates (including ) for observation h. | |
| vector of covariate (Fire5). | |
| vector of covariate (Ln(coverage)). | |
| individual value of covariate (Fire5). | |
| individual value of covariate (Ln(coverage)). | |
| parameter model (for prior). | |
| parameter model (for posterior). | |
| data model (for continuous cluster). | |
| data model (for discrete cluster). | |
| logistic sigmoid function - expit(·) - to allow for a positive probability of the zero outcome. | |
| set of parameters - - associated with the for j cluster. | |
| set of parameters - - associated with the for j cluster. | |
| cluster weights (mixing coefficient) for j cluster. | |
| vector of initial regression coefficients and variance-covariance matrix, i.e. obtained from the baseline multivariate Gamma regression of . | |
| regression coefficient vector for a mean outcome estimation. | |
| cluster-wise variation value for the outcome. | |
| skewness parameter for log skew-normal outcome. | |
| vector of initial regression coefficients and variance-covariance matrix obtained from the baseline multivariate logistic regression of . | |
| regression coefficient vector for a logistic function to handle zero outcomes. | |
| proportion parameter for Bernoulli covariate. | |
| location and spread parameter for Gaussian covariate. | |
| precision parameter that controls the variance of the clustering simulation. For instance, a larger allows to select more clusters. | |
| prior joint distribution for all parameters in the DPM - , and . It allows all continuous, integrable distributions to be supported while retaining theoretical properties and computational tractability such as asymptotic consistency, efficient posterior estimation, etc. | |
| hyperparameters for Inverse Gamma density of . | |
| hyperparameters for Beta density of . | |
| hyperparameters for Student’s t density of . | |
| hyperparameters for Gaussian density of . | |
| hyperparameters for Inverse Gamma density of . | |
| hyperparameters for Gamma density of . | |
| random probability value for Gamma mixture density of the posterior on . | |
| mixing coefficient for Gamma mixture density of the posterior on . |
Author Contributions
All authors contributed substantially to this work - Conceptualization, Kim.M.; Methodology, Kim.M., Lindberg.D., Bezbradica.M. and Crane.M.; Software, Kim.M., Lindberg.D.; Validation, Kim.M., Bezbradica.M and Crane.M.; Formal analysis, Kim.M.; Investigation, Kim.M., Bezbradica.M and Crane.M.; Resources, Kim.M.; Data curation, Kim.M.; Writing—original draft preparation, Kim.M.; Writing—review and editing, Kim.M., Bezbradica.M and Crane.M.; Visualization, Kim.M.; Supervision, Bezbradica.M and Crane.M.; Project administration, Bezbradica.M and Crane.M.; Funding acquisition, Crane.M. All authors have read and agreed to the published version of the manuscript.
Data Availability Statement
Data and implementation details are available at https://github.com/mainkoon81/Paper2-Nonparametric-Bayesian-Approach01 (accessed on 25 May 2023).
Acknowledgments
For this research, the authors wish to acknowledge the support from the Science Foundation Ireland under Grant Agreement No.13/RC/2106 P2 at the ADAPT SFI Research Centre at DCU. ADAPT, the SFI Research Centre for AI-Driven Digital Content Technology, is funded by the Science Foundation Ireland through the SFI Research Centres Programme.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A Parameter Knowledge
Appendix A.1. Prior Kernel for Distributions of Outcome, Covariates, and Precision
* Gamma regression, Logistic regression.
Appendix A.2. Posterior Inference for Outcome, Covariates, and Precision
| Algorithm A1:Posterior inference |
|
1 The outcome density is defined as: .
Appendix B Baseline Inference Algorithm for DPM
Once we obtain decent parameter samples from the posterior distributions, the posterior predictive density can be computed via the DPM Gipps sampling. The basic inference algorithm is described below. Note that the modification details for the missing data imputation are provided in Section 4.3. In every iteration, the algorithm updates the cluster memberships based on the parameter samples and observed data at hand, which leads to the re-calculation of the cluster parameters. In the sampler, the state is the collection of membership indices and parameters , where refers to the parameter associated with cluster j.
| Algorithm A2:DPM Gibbs Sampling for new cluster development |
|
Appendix C Development of the Distributional Components for DPM
Appendix C.1. Derivation of the Distribution of Precision α
In Section 4.1, the parameter model (posterior) of the precision term is defined as
To derive this, we first derive the distribution of the number of clusters given the precision parameter: . Consider a trivial example where we want to determine the number of clusters that observations fall into. One possible arrangement would be that observations 1, 2, and 5 form new clusters, while observations 3 and 4 join an existing cluster. (note, the order is important):
- observation 1 forms a new cluster, probability =
- observation 2 forms a new cluster, probability =
- observation 3 enters into an existing cluster, probability =
- observation 4 enters into an existing cluster, probability =
- observation 5 forms a new cluster, probability =
In this example, we have clusters. We want to find the probability of this arrangement. The probability is the following:
Hence the probability of observing J clusters amongst a sample size of n is given by
This is also considered the likelihood function. The posterior on is proportional to the likelihood times the prior, .
The beta function is defined as the following:
We can find the beta function of and n as follows:
Thus the posterior simplifies to the following:
Now, under the prior for , substituting with , then
Appendix C.2. Outcome Data Model of S h Development with MAR Covariate x 1 for the Discrete Clusters
Prior to the outcome parameter estimation, the missing covariates should be imputed first to obtain the complete covariate model beforehand. In this study, if the binary covariate is the only covariate with missingness, we develop the imputation model to impute the binary covariate , taking the following steps below, then update based on the posterior sampling detailed in Algorithm (A1) in Appendix (A.2). The imputation model for is approximated by the joint:
where
which serves as the joint density that we can use to sample the imputation values. For example,
Then, we can impute with the values sampled from where
Note that in R, the computation can be difficult when the numerator is too small. We suggest the following tricks.
Finally, the outcome model that is required to compute the parameter in Metropolis-Hastings in Algorithm (A1) is obtained by summing the joint of and (marginalize) out the MAR covariate , shown in Equation (9), as below.
Appendix C.3. Covariate Data Model of x 2 Development with MAR Covariate x 1 for the Continuous Clusters
The parameter-free distributions and as data models for continuous clusters are needed to calculate the probabilities of cluster membership and for the post-processing calculations for prediction in the DPM. However, when MAR covariates are present, it gives extra complexity in specifying distribution to integrate out the parameters. Recall the integrals we are attempting to find are the following:
If binary covariate is missing, then we will need to replace the distribution with the continuous distribution (Gaussian) of , which is . The derivation of the parameter-free distribution and for the continuous cluster is as below.
The first step is to integrate with respect to . First, we’ll simplify the exponent.
The integrand will have the kernel of a normal distribution for with mean and variance .
The integrand is the kernel of an inverse gamma distribution with shape parameter and scale parameter .
As shown above, a closed-form expression can be determined, but it is not always the case since it can be extremely complicated. To simplify, we instead might have to consider a Monte Carlo integral.
References
- Hong, L.; Martin, R. Dirichlet process mixture models for insurance loss data. Scandinavian Actuarial Journal 2018, 2018, 545–554. [Google Scholar] [CrossRef]
- Neuhaus, J.M.; McCulloch, C.E. Separating between-and within-cluster covariate effects by using conditional and partitioning methods. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2006, 68, 859–872. [Google Scholar] [CrossRef]
- Kaas, R.; Goovaerts, M.; Dhaene, J.; Denuit, M. Modern actuarial risk theory: using R; Vol. 128, Springer Science & Business Media, 2008.
- Beaulieu, N.C.; Xie, Q. In Proceedings of the Minimax approximation to lognormal sum distributions. The 57th IEEE Semiannual Vehicular Technology Conference, 2003. VTC 2003-Spring. IEEE, 2003, Vol. 2, pp. 1061–1065.
- Ungolo, F.; Kleinow, T.; Macdonald, A.S. A hierarchical model for the joint mortality analysis of pension scheme data with missing covariates. Insurance: Mathematics and Economics 2020, 91, 68–84. [Google Scholar] [CrossRef]
- Braun, M.; Fader, P.S.; Bradlow, E.T.; Kunreuther, H. Modeling the “pseudodeductible” in insurance claims decisions. Management Science 2006, 52, 1258–1272. [Google Scholar] [CrossRef]
- Li, X. A Novel Accurate Approximation Method of Lognormal Sum Random Variables. PhD thesis, Wright State University, 2008.
- Roy, J.; Lum, K.J.; Zeldow, B.; Dworkin, J.D.; Re III, V.L.; Daniels, M.J. Bayesian nonparametric generative models for causal inference with missing at random covariates. Biometrics 2018, 74, 1193–1202. [Google Scholar] [CrossRef] [PubMed]
- Si, Y.; Reiter, J.P. Nonparametric Bayesian multiple imputation for incomplete categorical variables in large-scale assessment surveys. Journal of educational and behavioral statistics 2013, 38, 499–521. [Google Scholar] [CrossRef]
- Furman, E.; Hackmann, D.; Kuznetsov, A. On log-normal convolutions: An analytical–numerical method with applications to economic capital determination. Insurance: Mathematics and Economics 2020, 90, 120–134. [Google Scholar] [CrossRef]
- Zhao, L.; Ding, J. Least squares approximations to lognormal sum distributions. IEEE Transactions on Vehicular Technology 2007, 56, 991–997. [Google Scholar] [CrossRef]
- Lam, C.L.J.; Le-Ngoc, T. Log-shifted gamma approximation to lognormal sum distributions. IEEE Transactions on Vehicular Technology 2007, 56, 2121–2129. [Google Scholar] [CrossRef]
- Ghosal, S. The Dirichlet process, related priors and posterior asymptotics. Bayesian nonparametrics 2010, 28, 35. [Google Scholar]
- Ferguson, T.S. A Bayesian analysis of some nonparametric problems. The annals of statistics. 1973, pp. 209–230.
- Antoniak, C.E. Mixtures of Dirichlet processes with applications to Bayesian nonparametric problems. The annals of statistics, 1152. [Google Scholar]
- Sethuraman, J. A constructive definition of Dirichlet priors. Statistica sinica.
- Hong, L.; Martin, R. A flexible Bayesian nonparametric model for predicting future insurance claims. North American Actuarial Journal 2017, 21, 228–241. [Google Scholar] [CrossRef]
- Diebolt, J.; Robert, C.P. Estimation of finite mixture distributions through Bayesian sampling. Journal of the Royal Statistical Society: Series B (Methodological) 1994, 56, 363–375. [Google Scholar] [CrossRef]
- Blei, D.M.; Frazier, P.I. Distance dependent Chinese restaurant processes. Journal of Machine Learning Research 2011, 12. [Google Scholar]
- Gershman, S.J.; Blei, D.M. A tutorial on Bayesian nonparametric models. Journal of Mathematical Psychology 2012, 56, 1–12. [Google Scholar] [CrossRef]
- Cairns, A.J.; Blake, D.; Dowd, K.; Coughlan, G.D.; Khalaf-Allah, M. Bayesian stochastic mortality modelling for two populations. ASTIN Bulletin: The Journal of the IAA 2011, 41, 29–59. [Google Scholar]
- Escobar, M.D.; West, M. Bayesian density estimation and inference using mixtures. Journal of the american statistical association 1995, 90, 577–588. [Google Scholar] [CrossRef]
- Browne, M.J.; Chung, J.; Frees, E.W. International Property-Liability Insurance Consumption. The Journal of Risk and Insurance 2000, 67, 73–90. [Google Scholar] [CrossRef]
- Quan, Z.; Valdez, E.A. Predictive analytics of insurance claims using multivariate decision trees. Dependence Modeling 2018, 6, 377–407. [Google Scholar] [CrossRef]
- Teh, Y.W. Dirichlet Process. 2010.
- Gelman, A.; Hill, J. Data analysis using regression and multilevel/hierarchical models; Cambridge university press, 2007.
- Shah, A.D.; Bartlett, J.W.; Carpenter, J.; Nicholas, O.; Hemingway, H. Comparison of random forest and parametric imputation models for imputing missing data using MICE: a CALIBER study. American journal of epidemiology 2014, 179, 764–774. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, A.; Beck, M.B.; Cann, M.; Ford, T.; Georgescu, D.; Morjaria, N.; Smith, A.; Taylor, Y.; Tsanakas, A.; Witts, L.; others. Model risk–daring to open up the black box. British Actuarial Journal 2016, 21, 229–296. [Google Scholar] [CrossRef]
- Ni, Y.; Ji, Y.; Müller, P. Consensus Monte Carlo for random subsets using shared anchors. Journal of Computational and Graphical Statistics 2020, 29, 703–714. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Independent and identically distributed aggregate losses (left) and a Dirichlet process mixture (DPM) to model the in every possible way (right). Given the unobserved loss incurred by the next policyholder (and added to a certain policy group), by how much (subject to stochasticity) and by which policy (subject to heterogeneity) will be left to the main concerns. A DPM addresses these concerns via the simulation of .
Figure 1.
Independent and identically distributed aggregate losses (left) and a Dirichlet process mixture (DPM) to model the in every possible way (right). Given the unobserved loss incurred by the next policyholder (and added to a certain policy group), by how much (subject to stochasticity) and by which policy (subject to heterogeneity) will be left to the main concerns. A DPM addresses these concerns via the simulation of .
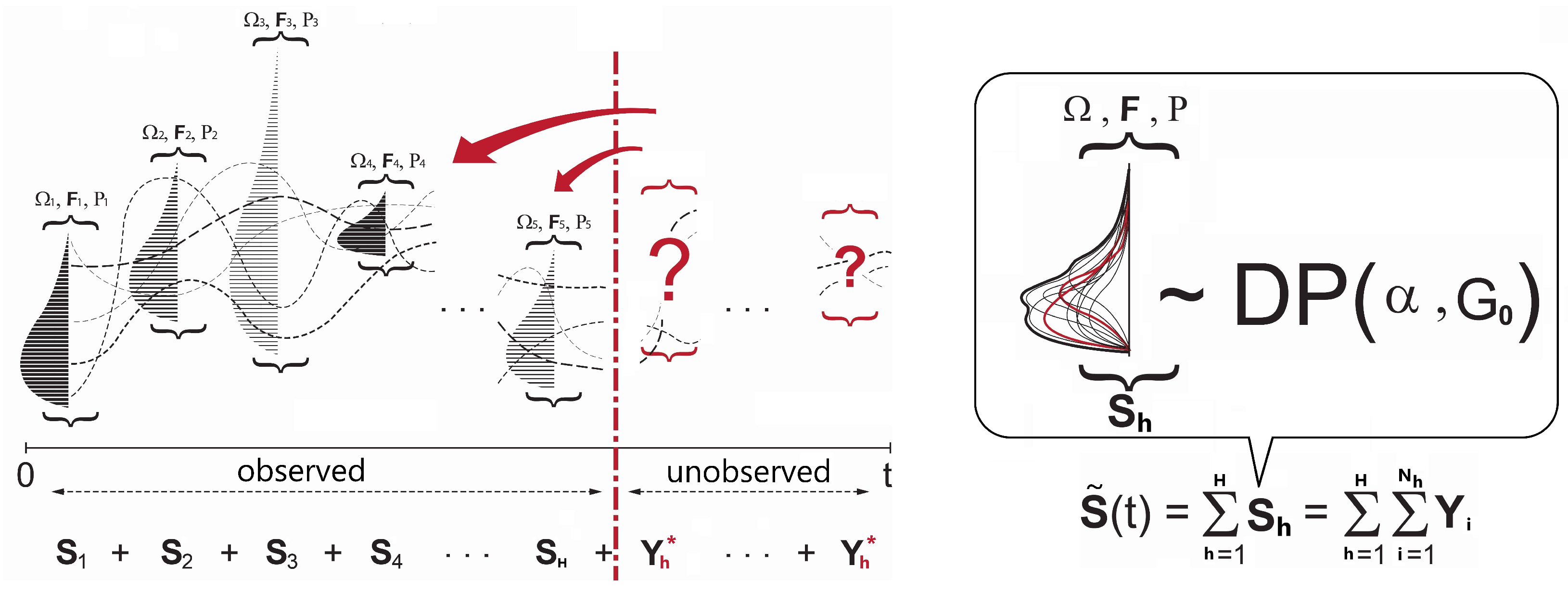
Figure 2.
An example of looping through the Gibbs sampler with complete data. In Step I, the algorithm requires the initial cluster memberships and parameters. In Step II.(A), based on the Chinese Restaurant scheme [19] with the DPM prior (), the probabilities of the selected observation h being in each current and the proposed new cluster are computed, which updates the cluster memberships. In Step II.(B), the new continuous cluster membership is determined by a multinomial distribution with a set of the resulting cluster probabilities from Step II.(A) randomly assigned based on the Polya Urn scheme. Once all observations have been assigned to clusters at a given iteration in the Gibbs sampler, then the parameters are updated, given cluster membership.
Figure 2.
An example of looping through the Gibbs sampler with complete data. In Step I, the algorithm requires the initial cluster memberships and parameters. In Step II.(A), based on the Chinese Restaurant scheme [19] with the DPM prior (), the probabilities of the selected observation h being in each current and the proposed new cluster are computed, which updates the cluster memberships. In Step II.(B), the new continuous cluster membership is determined by a multinomial distribution with a set of the resulting cluster probabilities from Step II.(A) randomly assigned based on the Polya Urn scheme. Once all observations have been assigned to clusters at a given iteration in the Gibbs sampler, then the parameters are updated, given cluster membership.
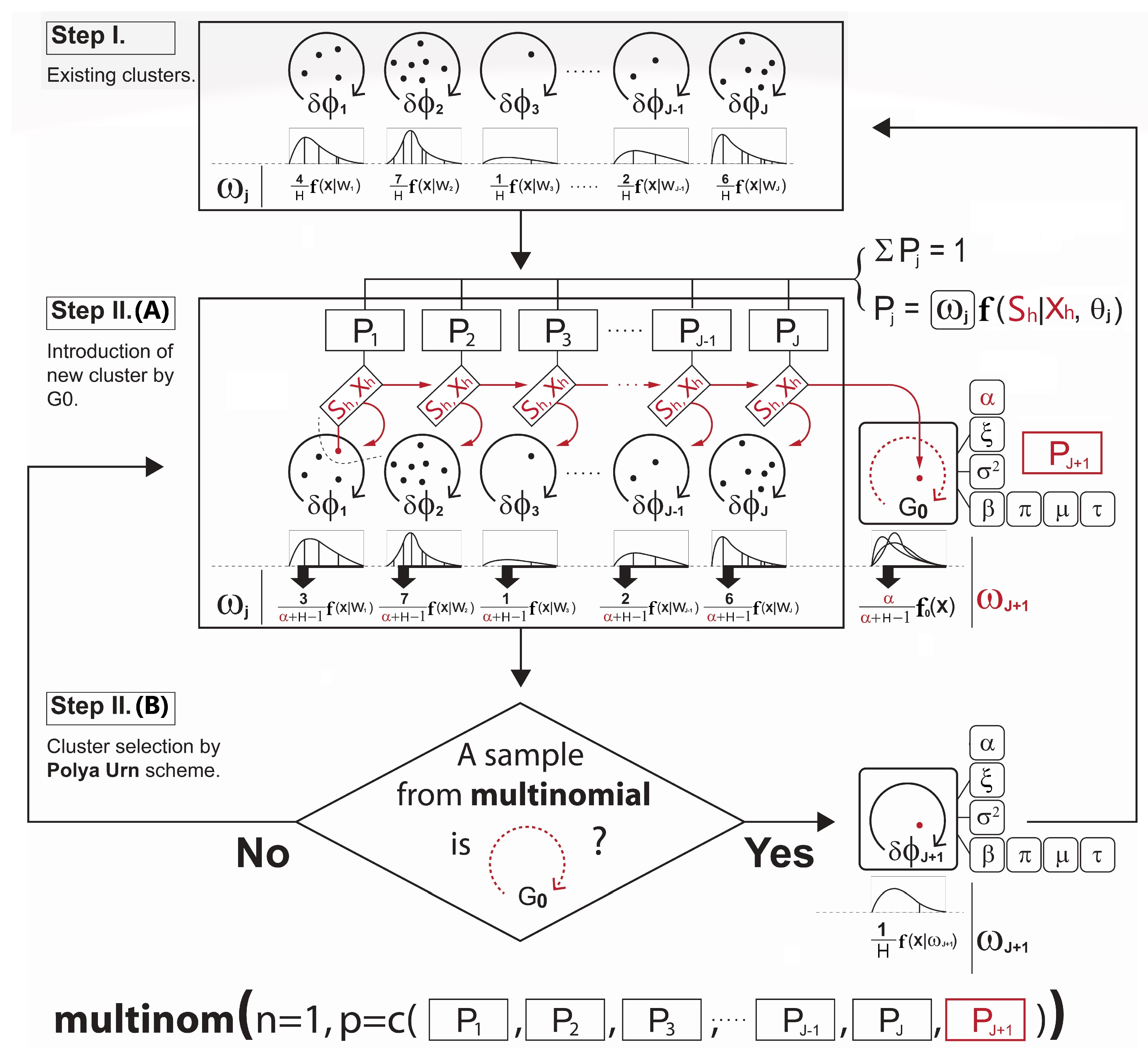
Figure 3.
An example of a re-clustering process with MAR imputation in the DPM Gibbs sampler: Step I and II. The imputations are made cluster membership-wise. Each imputation model as a joint distribution is the product of the outcome model and the covariate model that has missing data.
Figure 3.
An example of a re-clustering process with MAR imputation in the DPM Gibbs sampler: Step I and II. The imputations are made cluster membership-wise. Each imputation model as a joint distribution is the product of the outcome model and the covariate model that has missing data.
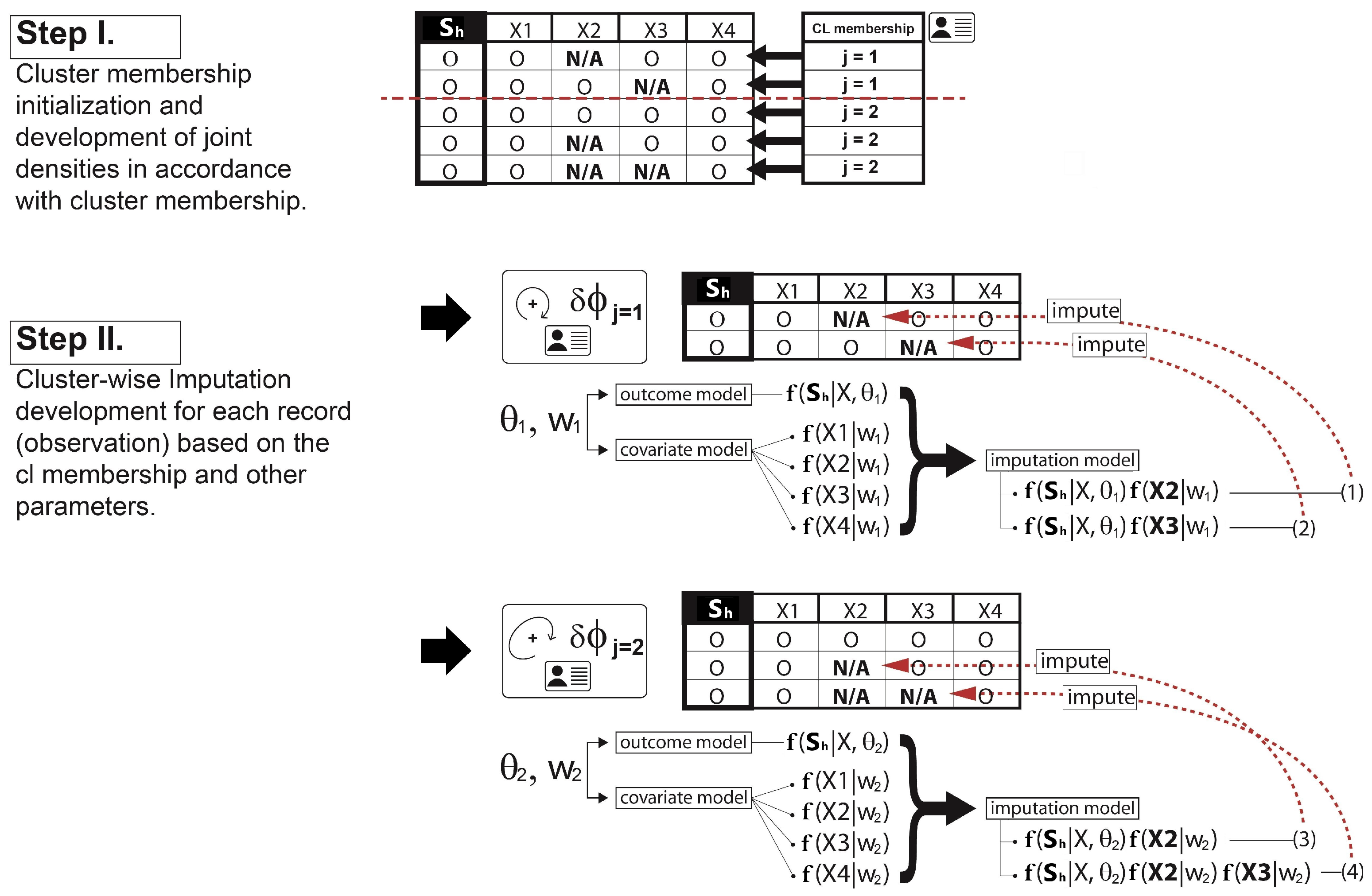
Figure 4.
An example of a re-clustering process with MAR imputation in the DPM Gibbs sampler: Step III. The DPM refines the outcome models for all possible configurations based on the types of missingness prior to running the Gibbs sampler. Using these outcome models, each cluster probability and the predictive density are updated.
Figure 4.
An example of a re-clustering process with MAR imputation in the DPM Gibbs sampler: Step III. The DPM refines the outcome models for all possible configurations based on the types of missingness prior to running the Gibbs sampler. Using these outcome models, each cluster probability and the predictive density are updated.
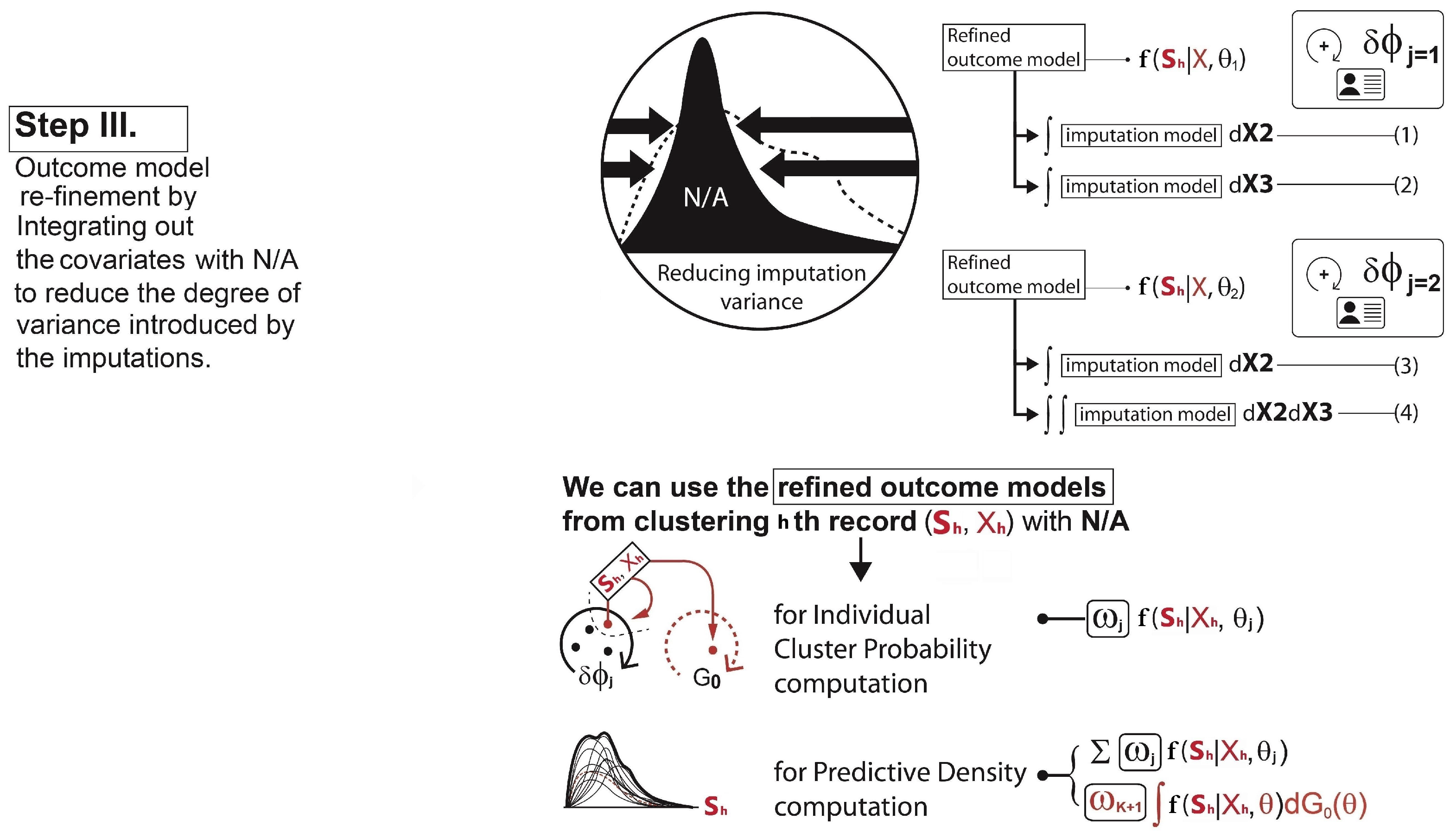
Figure 5.
Parameter re-estimation after the re-clustering with imputation in the Gibbs sampler. This diagram articulates flows of the parameter updates, using the acyclic graphical representation. The process cycles until achieving convergence.
Figure 5.
Parameter re-estimation after the re-clustering with imputation in the Gibbs sampler. This diagram articulates flows of the parameter updates, using the acyclic graphical representation. The process cycles until achieving convergence.
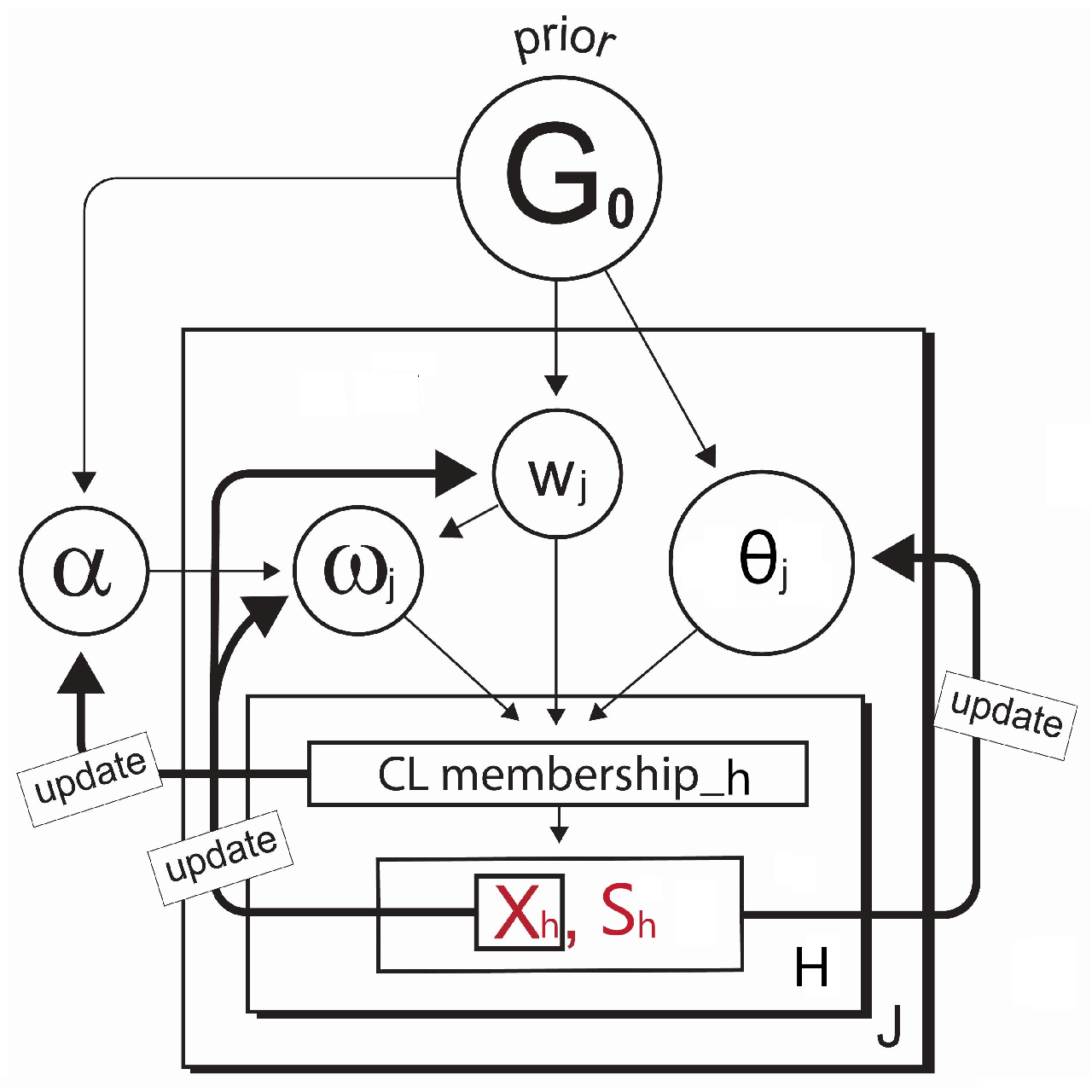
Figure 6.
Histograms of the outcomes and log-transformed outcomes for the two datasets: (a) PnCdemand, (b) LGPIF.
Figure 6.
Histograms of the outcomes and log-transformed outcomes for the two datasets: (a) PnCdemand, (b) LGPIF.
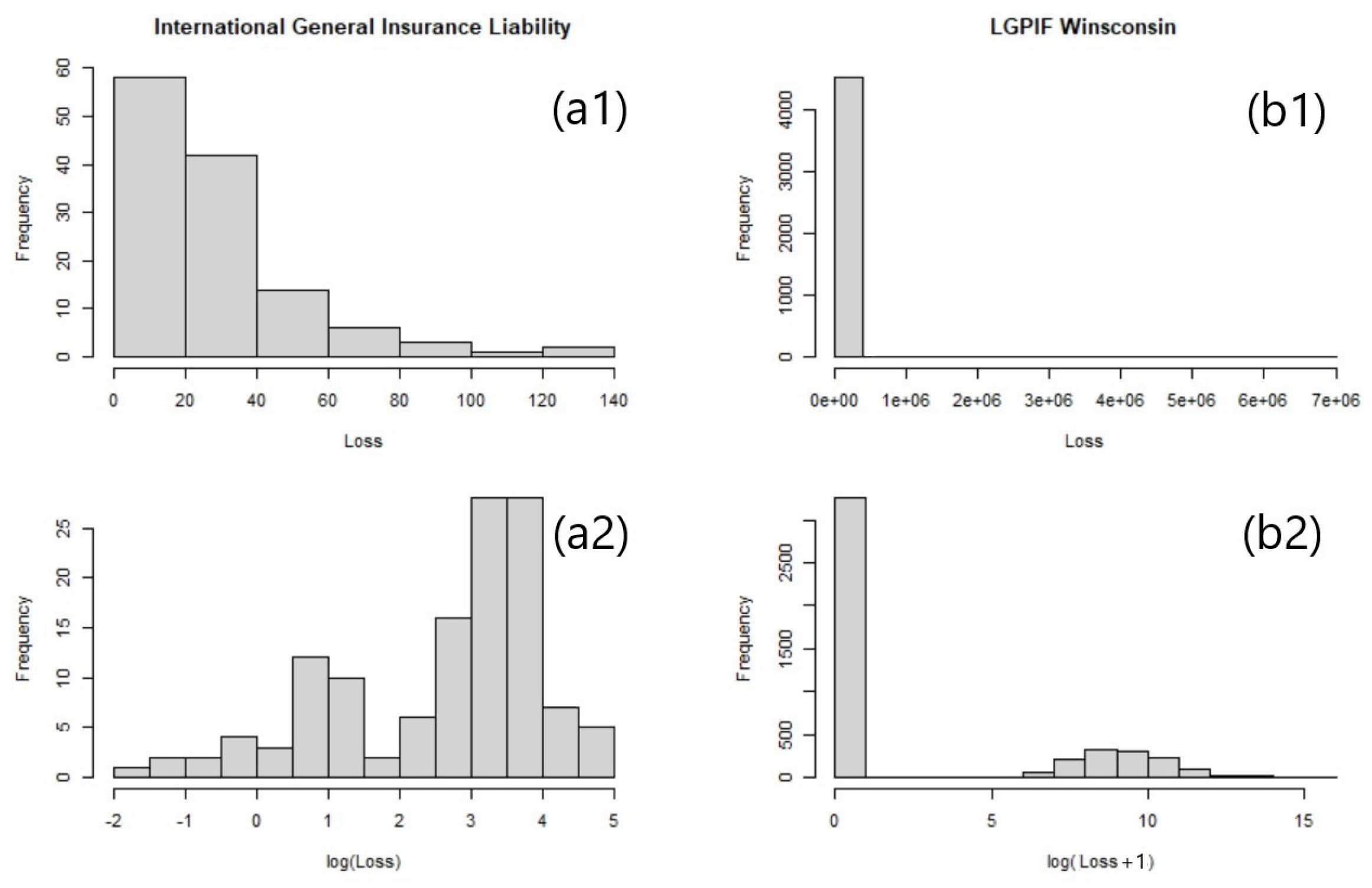
Figure 7.
LogN-DPM: The last 100 in-sample predictive densities (scenarios) overlaid together.
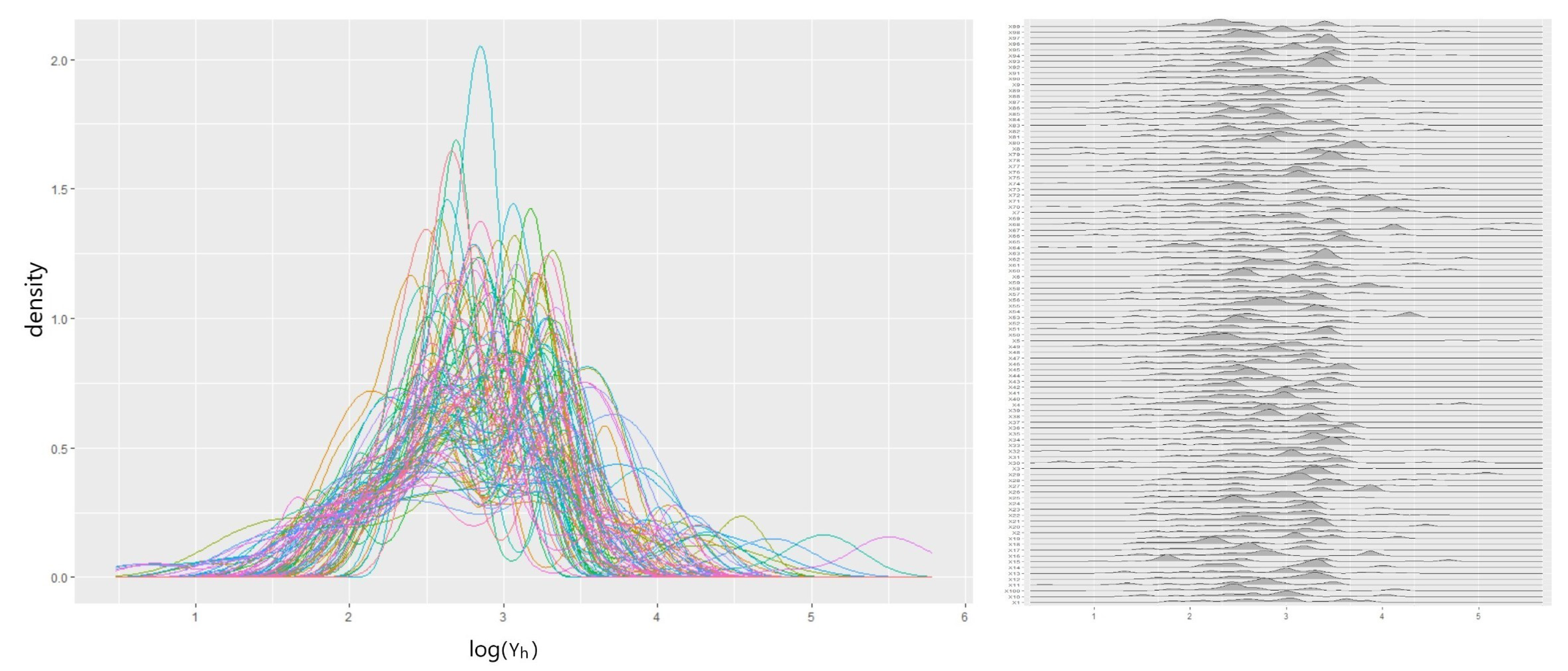
Figure 8.
MICE trace plots and in-sample predictive densities produced from GLM, GAM, MARS.
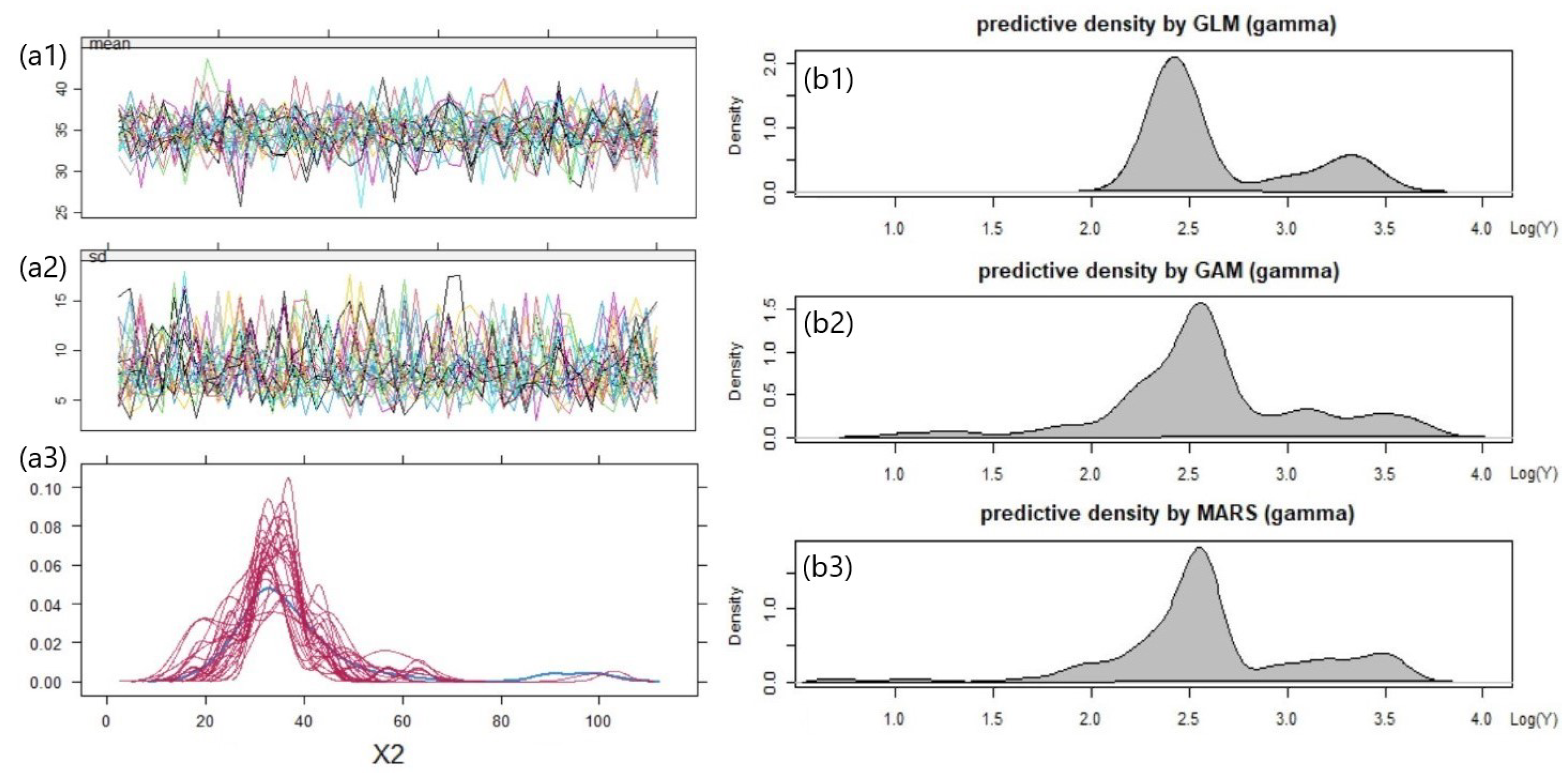
Figure 9.
A histogram of the observed loss on the log scale and the out-of-sample predictive densities for the typical class of a policy.
Figure 9.
A histogram of the observed loss on the log scale and the out-of-sample predictive densities for the typical class of a policy.
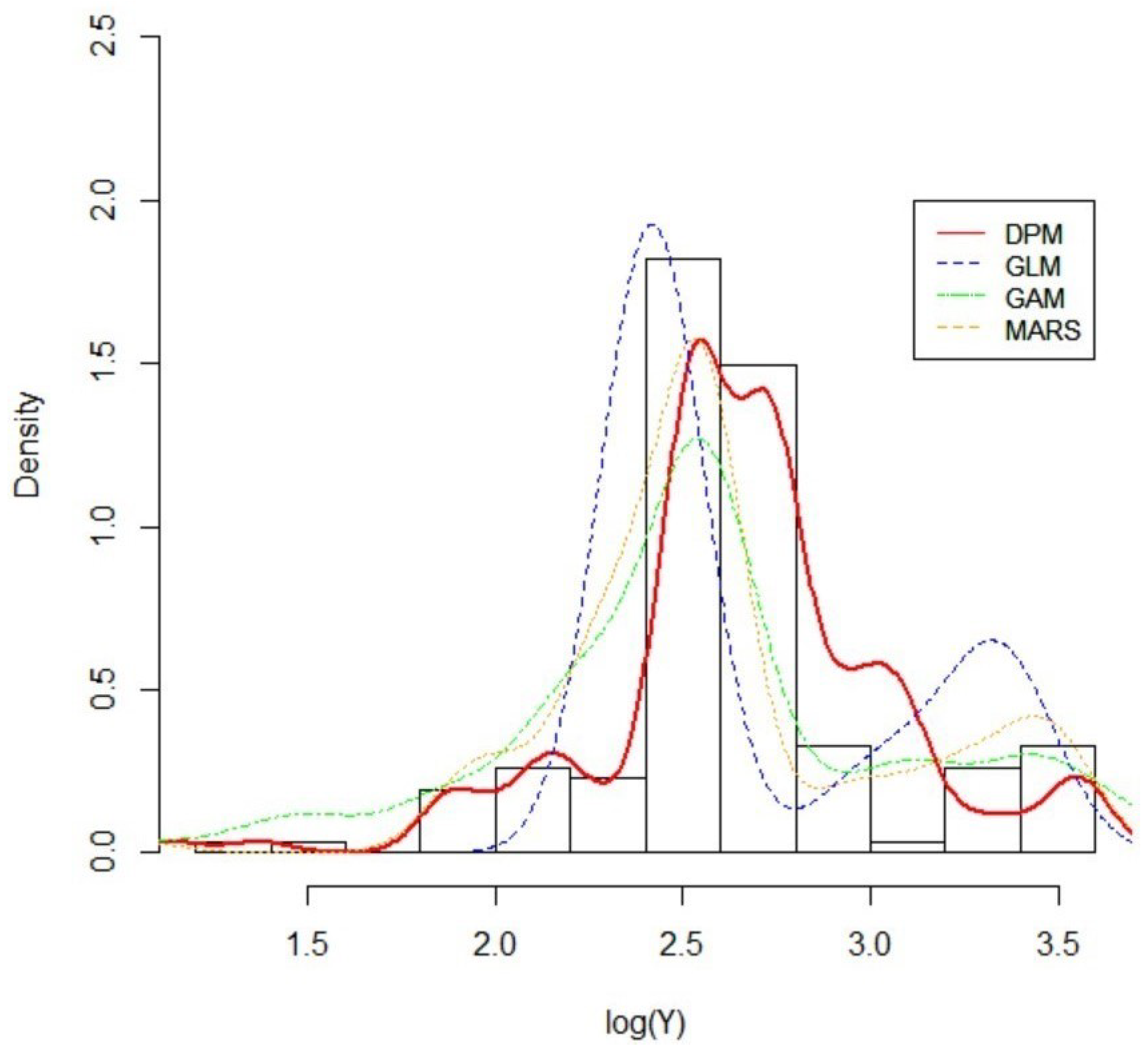
Figure 10.
LogSN-DPM: The last 100 in-sample predictive densities (scenarios) overlaid together.
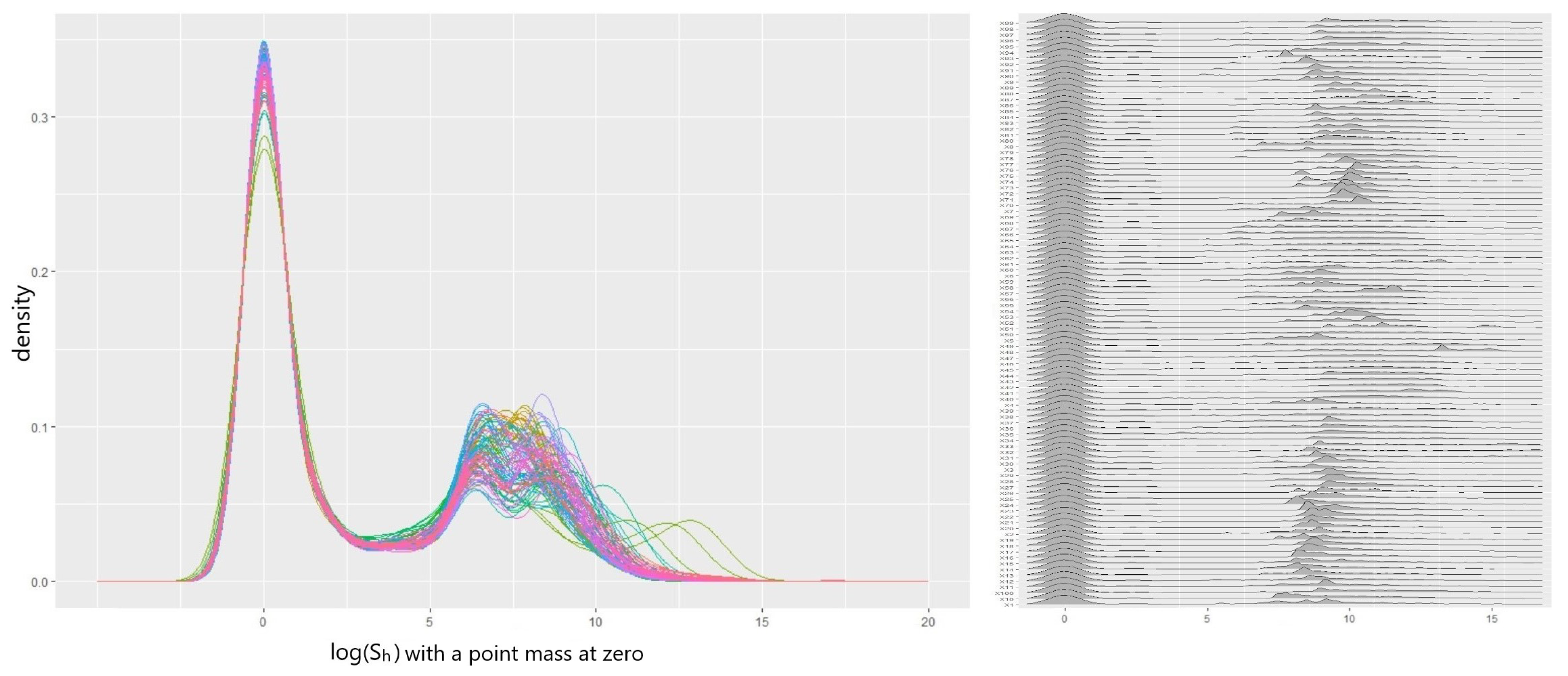
Figure 11.
MICE trace plots and in-sample predictive densities produced from GLM, GAM, MARS.
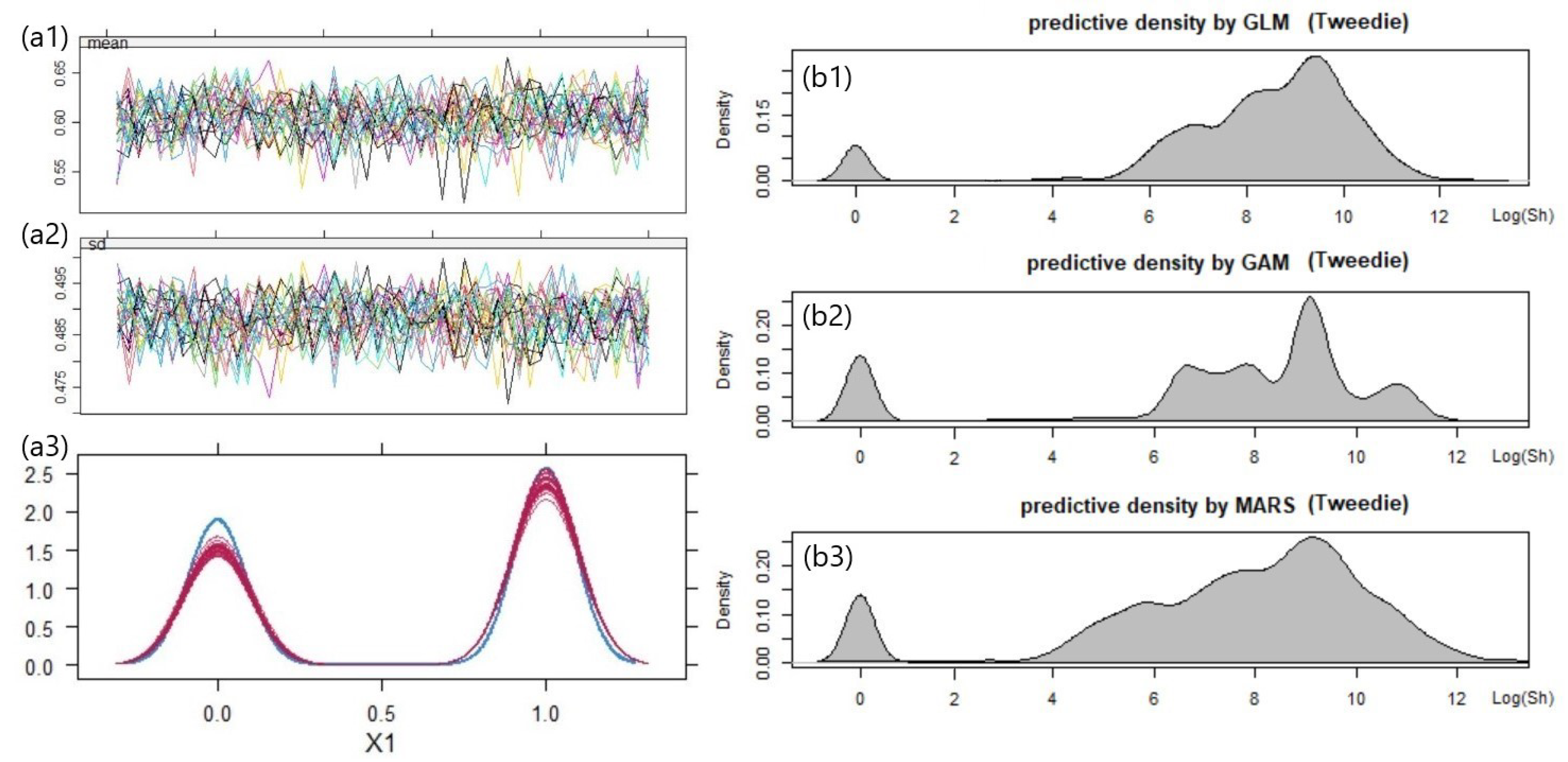
Figure 12.
A histogram of the observed total loss on the log scale and the out-of-sample predictive densities for the typical class of a policy.
Figure 12.
A histogram of the observed total loss on the log scale and the out-of-sample predictive densities for the typical class of a policy.
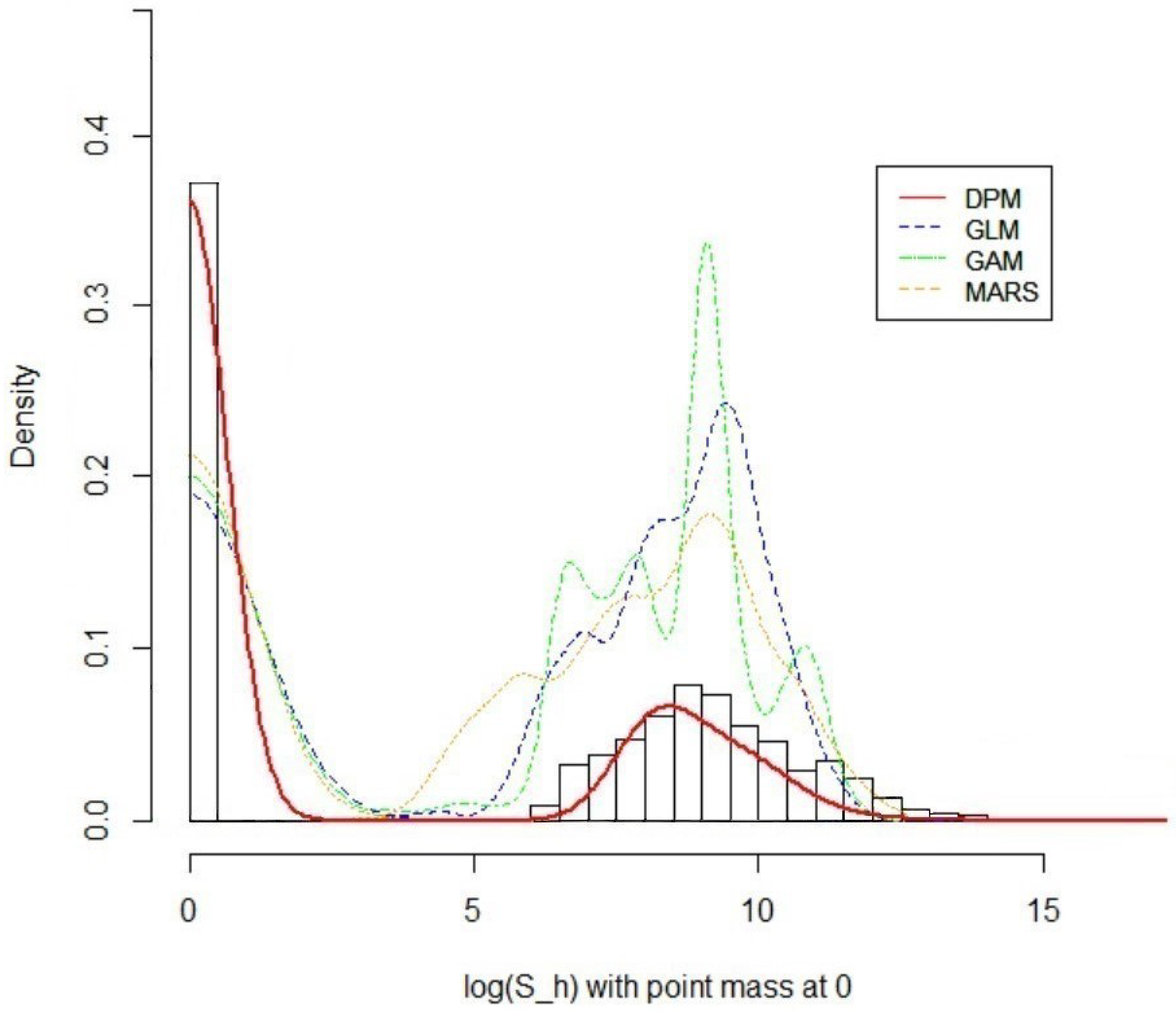

Table 1.
The comparison of out-of-sample modeling results based on the dataset PnCdemand.
| Model | AIC | SSPE | SAPE | 10% CTE | 50% CTE | 90% CTE | 95% CTE |
|---|---|---|---|---|---|---|---|
| Ga-GLM | 830.56 | 268.6 | 139.8 | 6.5 | 13.8 | 54.5 | 78.0 |
| Ga-MARS | 830.58 | 267.2 | 138.2 | 6.1 | 13.0 | 57.2 | 71.1 |
| Ga-GAM | 845.94 | 266.7 | 136.1 | 6.2 | 13.3 | 58.1 | 72.2 |
| LogN-DPM | - | 272.0 | 134.7 | 6.4 | 13.8 | 59.3 | 79.3 |
Table 2.
The comparison of out-of-sample modeling results based on the LGPIF dataset
| Model | AIC | SSPE | SAPE | 10% CTE | 50% CTE | 90% CTE | 95% CTE |
|---|---|---|---|---|---|---|---|
| Tweedie-GLM | 26270.3 | 2.04e+14 | 89380707 | 955.9 | 12977.2 | 133374.4 | 340713.1 |
| Tweedie-MARS | 24721.4 | 1.99e+14 | 88594850 | 961.7 | 10391.0 | 129409.2 | 355112.6 |
| Tweedie-GAM | 21948.9 | 1.95e+14 | 88213987 | 989.4 | 13026.2 | 140199.5 | 398263.1 |
| LogSN-DPM | - | 1.98e+14 | 83864890 | 975.3 | 13695.1 | 147486.6 | 425682.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



