Submitted:
06 June 2023
Posted:
06 June 2023
You are already at the latest version
Abstract
Personalized recommendation is an important part of ecommerce platform. In the recommendation system, the neural network is used to enhance collaborative filtering to accurately capture user preferences, so as to obtain better recommendation performance. Traditional recommendation methods focused on the results of a single user behavior, ignoring the modeling of multiple interactive behaviors of users, such as click, add to cart and purchase. Although many studies had also focused on Multi-Behavior modeling, two important challenges remained. 1)Since multiple behavioral context information was ignored, it was still a challenge to identify the multimodal relationships of behaviors. 2) Surveillance signals were still sparse. In order to solve this problem, this paper proposes Two-path Multi-behavior Sequence Modeling(TP_MB). First, a two-path learning strategy is introduced to maximize the multiple interaction information of user items learned by the two paths, which effectively enhances the robustness of the model. Second, a multi-behavior dependent encoder is designed. Contextual information is obtained through behavior dependencies in the interaction of different user. In addition, three contrastive learning methods are designed, which not only obtain additional auxiliary supervision signals, but also alleviate the problem of sparse supervision signals. Extensive experiments on two real datasets demonstrate that our method outperforms state-of-the-art multi-behavior recommendation methods.
Keywords:
Two-path 1
; Multi-Behavior Dependence 2
; Contrast Learning 3
; Sparse Data 4
0. Introduction
With the rapid development of the Internet, recommendation systems have also emerged. As the number of users grows dramatically, e-commerce platforms continue to offer a wide variety of products to meet the needs of the ever-increasing number of users, and this is where recommendation systems play a key role to help e-commerce platforms solve this problem. The recommendation system is to recommend to the user items that he may be interested in even if he does not know his preferences. To achieve this, the recommendation system needs a large amount of user data for analysis, which can be product information, user personal information, user interaction behavior, etc. Effective modeling of user information is to provide more satisfactory services to users. Nowadays, recommendation systems had been widely used in various E-Commerce platforms [1]. Personalize recommendations captures user interests by model users’ information. With the continuous development of deep learning, more methods had improved collaborative filtering, modeling more complex user-items interactions. For example, NCF [2] made collaborative filtering to have the ability to learn the non-linear interaction of users by referring to multi-layer perceptron. Compared with models that modeled single behaviors. Methods for modeling multiple behaviors had achieved great success in recent years. GHCF was divided into lightGCN according to the type of User-Item interaction behavior. Used lightGCN to convey information about various behaviors of users to represent users [1]. However, the actual purchase behavior data of users was extremely sparse.
Based on the above challenges, this work proposes Self-supervised Learning Method for Multi-behavior Attention Based on two paths Parallel Computational. Here is an introduction to two path parallel computational. Compared to a single path that operates in an end-to-end way, two paths operate in parallel and can greatly improve the performance of the model. Specifically, this work first proposes a multi-behavior relational learning framework—a self-supervised learning method based on two-path multi-behavior attention. It Learns behavioral dependence by combining specific types of behavioral representations in different types of user-item interactions. Then the Two-path Multi-Behavior Self-Supervised learning endows the TP_MB framework to solve the data sparsity problem. In order to model multiple types of behavioral pattern dependencies, we design a two path Multi-Behavior dependent Self-Supervised learning model. That is parameterize each type of User-Item interaction into a separate embed space to learn the dependent representation of the type of user personalization behavior. That is a Self-Supervised learning paradigm between paths is used to enhance data supervision signals. Contribution of this paper:
- In order to distinguish the ability of different users’ behavioral perception preferences, we propose a new Multi-Behavioral attention Two-path Self-Supervised learning framework. The strategy of Multi-Behavior interaction sequence path and Multi-Behavior interaction graph path based on attention is proposed. It emphasizes the necessity of modeling the dependency relationship between different behaviors of users.
- In order to capture the commonality of multiple behaviors of users, we design three contrastive learning methods. It not only enhances the representation results of two paths, but also enables the model to obtain more auxiliary supervision signals in the Self-Supervised learning within paths and between paths. It effectively alleviates the problem of sparse supervisory signals.
- We conduct extensive experiments on two real world user behavior datasets. Experiments show that the recommendation performance of TP_MB outperforms many current popular baseline models.
1. Related Work
1.1. Self-Supervised Representation Learning
The purpose of self-supervised learning was to learn useful representations by maximizing the mutual information between the inputs and outputs of the encoder [11]. With respect to visual representation learning multiple graphs were generated by multiple data augmentation, which maximized the mutual information of these graph features[12]. Figure characterization was based on self-supervised learning to extract features [3]. Regarding sequence recommendations, self-supervised signals were obtained by feature masks. With sparse data on the session, the mask generated sparse self-supervised signals and therefore was not applicable to sequence behavior recommendation [6].
1.2. Ggeneral Recommendation
Collaborative filtering algorithm was used as a recommendation system to predict similar users based on the interests of similar users, and to recommend interested projects to them[13]. Factorization was one of the most popular methods among collaborative filtering methods, which mapped user interactions to a representation space. Hadamard product of feature vectors of users-items was used to represent user preferences[14]. The other methods aimed to be different from the collaborative filtering method and had the same goals as the results of this method. For example, user preferences were predicted by using neural collaborative filtering[2] through multiple MLPS.
1.3. Multi-Behavior Recommendation System
In recent years, various studies had been proposed to deal with multiple user interactions [5,6]. Specifically, MBGCN effectively transmitted heterogeneous behavior information and obtained user characteristics due to the effectiveness of graph neural network [5]. MGNN-SPred proposed to learn global Item-Item relations via GNN, and integrated target embedding and current session through a gating mechanism [6].
2. Materials and Methods
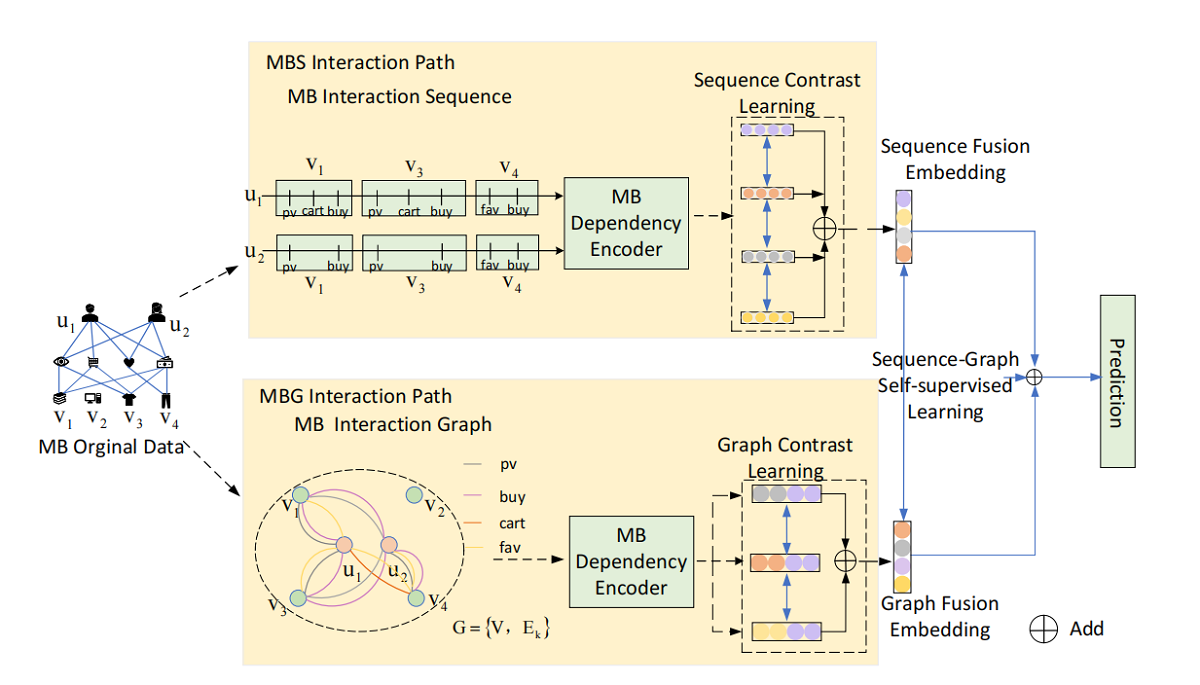
In order to distinguish different user behavior perception preferences, we propose an Self-supervised Learning Method for Multi-behavior Attention Based on two paths parallel computational(TP_MB), and the model framework is shown in Figure 1. The model consists of a Multi-behavior interaction sequence path, a multi-behavior interaction graph path and path-path self-supervised learning. Each path consists of three parts: (1) Multi-Behavior initial embedding. (2) Multi-Behavior interaction dependencies. (3) Multi-Behavior Self-Supervised learning paradigm for paths. The sequence path is based on the BERT approach to model user behavior sequences capable of capturing individual user characteristics. The graph path models all users to form a user-item behavior graph, where the behavior graph contains extracted behavior subgraphs by behavior categories, and the behavior graph contains all user characteristics. Individual user features in the sequence path are not sufficient to provide enough data for the model, while all user features in the graphics path can be effectively modeled as user features. Therefore, parallel computation of sequence and graph paths can complement each other and effectively help extract user feature information. TP_MB first learns embeddings containing user behavior features through a two-path (sequence path, graph path) framework. Embeddings are learned by TP_MB that contains user behavior features through a two-path (sequence path (MBS Interaction path), graph path (MBG Interaction path)) framework. Where ’pv’ means click, ’buy’ means purchase, ’cart’ means shopping cart and ’fav’ means favorite. Then, the multi-behavior dependencies between the auxiliary behavior (click, add to cart) and the target behavior (purchase) is captured in the calculation of user multi-behavior including the calculation of the behavior of the sequence path and the calculation of the behavior of the graph path. Finally, the consistency of user interests is maximized by contrast learning between multi-behavior graph path and sequential path, which is in order to predict items that users will interact with through certain behaviors.
2.1. Problem Formulation
User multi-behavior interaction items are used as input, and the dependencies between different behaviors is analyzed from a fine-grained perspective by considering the interaction between different behaviors. Defined to represent the set of users, represents the set of items and represents the set of user behavior types. User interaction behaviors such as click, shopping cart, favorite and purchase.
2.2. Multi-Behavior Interactive Sequence Path
2.2.1. Multi-Behavior Interaction Sequence Embedding(MBS Embedding)
We designed a multi-behavior attention network to help users collaborate on different behaviors. In order to make the behavior interaction context as the input of the sequence path, the embedding layer of the behavior context sequence path is designed. Multi Behavioral Interaction Sequence (MB Sequence) is used as the input to the sequence path, and we design the embedding layer for the behavioral contextual sequence path. Joint embedding of individual user, project information and corresponding interactive behavior context information. Given , we set each element in the sequence of user interaction as a triple , which indicates that user q interacts with item x with the k-th behavior. The multi-behavior sequence of a user contains the interaction information of a single user. Thus, the multi-behavior interaction sequence of the user is mapped to the initial embedding matrix as shown in Figure 2.
2.2.2. Multi-Behavior Interaction Sequence Attention Representation(Attention Fusion)
In order to better extract user preferences and simulate the dependence between different types of behaviors, we use attention in user behavior interaction to obtain the commonality of individual behaviors and the relationship of different behaviors. Considering the correlation between different behaviors of users, this correlation will help e-commerce platforms to combine the correlation of behaviors to more accurately recommend products to users, and the attention can capture which behavior has a greater relationship with the purchase behavior, hence the name "multi-behavior attention". The relationship between multiple user behaviors is used to model the fine-grained interaction between users and items, as shown in Figure 2. We propose a Multi-Behavior Interaction Sequence-Dependent Encoder(MB Dependency Encoder), which is an implicit or explicit user interest about items that users interact with by using within behaviors and between behaviors. Different behaviors of users differently contribute to items that users may be interested in. Therefore, we propose to capture the different modal relationships using user behaviors in attention. Based on self-attention mechanism capture fine-grained correlations between different types of auxiliary behaviors and target behaviors, modeling multi-behavior dependencies. Multiple behaviors are put into attention can make behaviors no longer independent behaviors, and form a vector of features related to the purchase behavior. Specifically, is a sequence of historical interactions of each user. The input of attention is an auxiliary behavior feature vector and the target behavior feature vector of the same user, , where represents the first item i in the item collection I. The feature vector is an element in the sequence . In addition, we calculate the weight matrix of each auxiliary behavior feature vector and target behavior feature vector , which is to understand the correlation between behaviors from users’ historical behaviors:
where ,, are weight matrices of learnable behavior vectors. As represents an correlation matrix between the auxiliary behavior k and the target behavior . This correlation matrix represents the correlation between the auxiliary and target behaviors. represents the attention score. represents calculated by function in order to find auxiliary behavior that is closer to the target behavior. To prevent overfitting problems, we use dropout method to obtain . The sequence contain the closer relationship between the auxiliary behavior and the target behavior ,which is obtained by multiplying the attention fraction with the behavior feature vector .
2.2.3. Multi-Behavior Interaction Sequence Modeling
The history of multiple user interactions in the real world contains a wealth of information. Past studies have modeled user interactions chronologically to predict the next item that a user will interact with. However, due to the existence of many external uncertain factors, it is impossible for users to interact according to the strict sequence of interactive behaviors. We developed a multi-behavior Attention Fusion to extract different user behavior characteristics, which is to capture personalized user interests by modeling the underlying relationships of different types of behavior. We develop an Attention Fusion to extract different user behavior features. Inspired by BERT4Rec [7] in terms of text, we introduce a semantic encoder of behavior to capture personalized user interests:
where we use (GELU) activation function. W represents the weight matrix of the GELU activation , b means bias. represents the user partial long-term interest captured by k behaviors in the user long-term history. Softmax, as the activation function of output, normalizes the results of the concatenation of various behavior sequences:
For different users, users have different behavioral interaction sequences leading to different encoding results.
2.2.4. Multi-Behavior Interaction Sequence Contrast Loss(Sequence Contrast Learning)
In TP_MB, it is our goal to captures the commonality of multiple behaviors of the same user, the differences of multiple behaviors of different users. Inspired by EHCF, users’ multi-behavioral relationships reflect their implicit intentions[13]. Self-supervised learning is a kind of contrast learning in machine learning. Therefore, we design intra-path self-supervised learning of multi-behavior interaction sequences to enhance supervision signals of multiple behavioral data through self-supervised learning. Specifically, we regard the different behaviors of the same user as positive sample pairs, and the different behaviors of different users as negative sample pairs. We define the TP_MB objective according to InfoNCE:
2.3. Multi-Behavior Interaction Graph Path
2.3.1. Multi-Behavior Interaction Graph Embedding
In general, using a single information of the user cannot obtain enough available information. Since users have multiple behaviors, including clicking, shopping cart, favorate and purchase. In addition, for the user’s purchase behavior, other behaviors have great value in helping extract user interest. Therefore, we set the purchase behavior as the target behavior, and other behaviors as auxiliary behaviors. Learning user interests with the help of auxiliary behaviors is to predict user purchasing behavior. Here we build a user-item graph of different interaction behaviors through all items that users interact with in different behaviors. Multi-behavior interaction graph(MB Interaction Graph) contain all information about user interactions. First, we define , V means that the node set includes user set and item set , namely . E represents different interaction behaviors between user nodes and item nodes. Furthermore, the embedding of a multi-behavior graph is composed of multiple behavior subgraph embeddings, so our behavior subgraph embedding can be expressed as . For example, the behavior subgraph composed of the items clicked by the user, , represents the item graph representation that the user interacts with by clicking. represents the user and item node connected with the click behavior, and represents the user’s click behavior.
2.3.2. Attention Representation of Multi-Behavior Interaction Graph in Two-path(Graph-inner Attention)
We design Multi-Behavior Interaction Graph Information Aggregation. Research results on graph convolution showed that general research focused on node characterization of simple undirected graphs[8]. The above work ignored edges between nodes that also had multiple properties, such as behavior. Inspired by graph neural network processing user multi-relational data GHCF [2]. We propose a multi-behavior interaction graph path, and use neural networks to obtain the global representation of user interaction, as shown in Figure 3. Specifically, it first focuses on the node representation of the learning graph. For each behavior subgraph, it is embedded into the adjacency matrix , which is composed of the matrix :
where represents the degree matrix of k behavior, and represents the identity matrix of k behavior. is the normalized Laplacian matrix of k behavior. For the multi-behavior interaction graph of users, GCN can be used to better obtain the global representation of all users. We follow LightGCN:
where is the node feature matrix of layer l of nodes in the figure, and is the transformation matrix of behavior graph information transfer. is the activation . GCN has a total of L layers, and l represents the order of neighbors we obtain. By obtaining the features of nodes with k behaviors in the graph. We design a multi-behavior interaction sequence attention encoder. The encoder constructs with the graph node representation under different behaviors. The influence coefficient of the corresponding auxiliary behavior graph with respect to the target behavior graph can be obtained. Therefore, we introduce a cross-behavior interaction graph attention encoder, auxiliary behavior graph and target behavior graph as input:
where ,, is the weight matrix of the learnable behavior matrix. g is the attention correlation coefficient, which is regarded as the weight added to the auxiliary behavior . is calculated in the same way as we mentioned in section 3.2. By taking the Attention-Correlation matrix as the input, it is obtained by Multi-Classification. is the auxiliary behavior feature matrix about the target behavior as the final output of the cross-behavior interaction graph attention encoder.
2.3.3. Multi-Behavior Interaction Graph Contrast Loss(Graph Contrast Learning)
As we all known, the sparsity problem of user interaction behavior in the recommendation system was widespread[15]. There is also a long tail problem among behaviors. For example, users click too many times and make few purchases. Therefore, to alleviate this problem, in TP_MB we capture user interests by capturing complex dependencies among behaviors through unsupervised signals of multi-behavior interaction graphs, instead of utilizing a single behavior to capture user interests. Specifically, the output of our multi-behavior interaction graph attention encoder and the embedding of the graph of the target behavior are taken as input. That is to say, the embedding of the graph of the auxiliary behavior and the embedding of the graph of the target behavior are used as input. Contrastive learning is one of the method in self-supervised learning. Thus, features are learned by constructing positive and negative examples and establishing a contrastive loss. Therefore, intra-path multi-behavior interaction graph self-supervised learning is designed to enhance multiple behavioral data supervision signals through self-supervised learning. Graph self-supervised learning based on InfoNCE can effectively alleviate the long-tail distribution problem of different behaviors among users. In TP_MB, different behavior graph of the same user are regarded as positive sample pairs, and different behaviors of different users are regarded as negative sample pairs. Maximize mutual information between users by comparing positive and negative sample pairs:
The consistency of two behavioral graph is maximized via the self-supervised loss defined above. And maximize the difference between different user behaviors to get behavior data enhancement.
2.4. Contrast Loss for Two-Path Enhancement
Since the problem of user interaction data sparsity has always existed, even the sequence self-supervision proposed in Section 3.2.4 and the graph self-supervision proposed in Section 3.3.3 can effectively alleviate this problem. However, using only these two self-supervision modalities will not perform better than combining the two supervision modalities to complement each other. Specifically, multi-behavior interactions between different multi-behavior paths is based on use InfoNCE loss. We regard the sequence path and graph path of the same user as positive samples, expressed by . The sequence path and graph path of different users are regarded as negative samples expressed by . Self-supervised Losses for InfoNCE -based sequences and Graphs :
is the temperature coefficient that balances the intensity of learning between the two paths. is the sequence self-supervised learning of multi-behavior interactions within two paths we mentioned in Section 4.2.4. is the self-supervised learning of multi-behavior interaction graphs within two paths we mentioned in Section 4.3.3. Therefore, We propose the two contrastive learning losses as the supplement. The final loss function list is composed of sequence loss function , graph loss function and sequence graph loss function for each pair of behaviors.
3. Results
We conduct experiments on two public datasets to verify the effectiveness of TP_MB. Our aim is to study the following questions:
- RQ1: Whether TP_MB can achieve better performance compared to the State-Of-The-Art model?
- RQ2: In our designed TP_MB, analyze the influence of each component on each other.
- RQ3: How different hyperparameters affect model performance?
3.1. Experimental Results and Analysis
Experiments on two real datasets in the real world demonstrate the effectiveness of our proposed TP_MB. And compare it with other baseline models and mainstream models. We evaluated TP_MB using a series of parameterization and ablation studies.
3.2. Datasets
We evaluate the effectiveness of our model on two different types of datasets, as shown in Table 1. Tmall: One of the largest E-Commerce platforms in China. This data set contains user interaction data: click, add to cart, purchase. We follow the method in [2] for data processing. CIKM2019 EComm AI: It is the E-Commerce data provided by CIKM2019 E-Commerce Artificial Intelligence Challenge. Each piece of data consists of a user, an item, and an interaction. Among them, user interaction includes (click, add to shopping cart, purchase), and various user interaction behaviors reflect the user’s intention for the item.
3.3. Implementation Details and Environment
We choose pytorch as the deep learning framework. The Adam optimizer is used to optimize the parameters during the training process, and the maximum sequence length is set to 100. The adjustment range of learning rate is . The size of each batch entered from the dataset is 256. The decay rate at each epoch in the training phase is . The adjustment range of the number of layers for the information transmission of the graph is 1-4. In addition, due to the small number of behavior types, Over-Fitting problems are prone to occur during the experiment. We use dropout in the graph convolutional network to solve this problem. In our evaluation, four evaluation indicators are selected, which are hit rate (Hit), normalized loss cumulative gain (NDCG), mean reciprocal rank (MRR), and area under the metric (AUC). The first three are used to measure the accuracy of our recommendation model. The area under the metric (AUC) is a performance indicator to measure the pros and cons of the learner.
3.4. Baseline
In order to fully verify the validity of the model in this paper, we selected three different types of push line system models as the baseline models for comparative experiments. These include: Single-behavior recommender system approaches, sequential recommender methods, and Multi-behavior recommender system approaches.
Single-behavior Recommended Methods:
- LightGCN [9]:A simplified method of traditional GCN. This model removed the feature transformation and Non-Linear activation operations of the aggregation layer and propagation layer in the standard GCN, and only consisted of neighborhood aggregation, making it more concise and more suitable for recommendation systems.
- BERT4Rec [7]: To Modeled user behavior through Self-Attention mechanism, and fused project neighbor information for recommendation.
General Sequence Recommendations:
- Caser [9]:For the most recent project, graph convolution was embedded in time and space to model the dynamic change of user interest over time.
Multi-behavior Recommendation Methods:
- GHCF [2]:The model encoded the behavior of users interacting with products, and the behavior pattern was embedded into the overall heterogeneous graph as a node when composing the graph. At the same time, LightGCN was used to realize aggregation and propagation between nodes.
- DHSL-GM [10]:Similar users and similar items constituted hypergraphs respectively. The gated neural network was used to predict less popular items in a more balanced manner. It was the latest use of Self-Supervised learning to model the representation of users and products on the dual hypergraph. This model was a relatively advanced method at present, and was also the main comparison object of this paper.
3.5. Performance Comparison
In order to fully verify the validity of the model in this paper, we select three different types of recommendation system models as the baseline models for comparative experiments. These include: Single-behavior recommendation system approaches, sequential recommendation methods, and Multi-behavior recommendation system approaches. We summarize the detailed evaluation results of all methods on different dataset in Table 2, where TP_MB results are compared with baseline as well as State-Of-The-Art models. The results of the State-Of-The-Art model and TP_MB comparison are underlined and bold.
The main observations are two main reasons for TP_MBs outperforms other baselines on two datasets:
1) Multi-behavior recommendation methods (such as GHCF, DHSL-GM) perform better than Single-behavior recommendation methods (such as LightGCN, BERT4Rec, Caser). This demonstrates the effectiveness of modeling user preferences by exploring Multi-behavior information.
2) The improvement of TP_MB is due to the exploration of multi-behavior dependencies that are ignored by existing methods. This suggests that modeling different behavioral dependencies can make the model better. It is verified that our two-path comparison method gives the model the ability to deal with behavioral dependence. Unlike the Graph-Based Self-Supervised method GHCF. The two-path contrastive learning paradigm included in TP_MB incorporates auxiliary Self-Supervised signals from different types of behavioral dimensions.
3) Unlike the Graph-Based Self-Supervised method GHCF. The two-path contrastive learning paradigm included in TP_MB incorporates auxiliary Self-Supervised signals from different types of behavioral dimensions. The direction of parameter optimization is provided for the model.
These models not only do not extract the interactions between multiple behaviors but also none of the other models have parallel computation methods, except for DHSL_GM which is a dual hypergraph convolution model. And our model outperforms DHSL_GM because our two path parallel computational is in the form of sequence path and graph path contrast, and the possibility of overfitting is less than that of DHSL_GM. The superiority of our model can be demonstrated compared to these baseline models. As shown in Figure 4(a) and Figure 4(b), TP_MB outperforms the other models both on the Tmall and CIKM datasets.
3.6. Ablation Study
We performed ablation studies on the model to justify the key components. The analysis details are summarized as follows. In particular, we describe the model variables in the experiment:
- Remove path attention -Att: Different modal relationships between multiple behaviors are not captured using attention in the two paths.
- Remove two-path Self-Supervision -DCL: No two-path contrastive learning strategy is used to supplement sparse data.
Table 3 shows the results of TP_MB ablation study. We summarize the following findings:
1)TP_MB compared with w/o-Att. Combining interdependencies between different types of interactions on all items can greatly improve performance. It demonstrates the legitimacy of our Self-Attention structures for learning explicit paired relationships between different types of behavior.
2)The effect of TP_MB after the removal of two path Self-Supervision (w/o-DCL) decreased significantly. Thus illustrating the importance of considering dense contextual data across multiple behavior types when analyzing user preferences.
3.7. Hyper-Parameters Analysis
In this section of the experiment, we investigate the effects of different hyperparameter settings in our designed TP_MB framework. The experimental results are shown in Figure 5(a) and Figure 5(b). We study the effect of one hyperparameter at a time and keep the other parameters at their default settings.
hyperparameter. It controls the importance of comparing learning tasks and recommendation tasks between paths as shown in Figure 5(a). When the value of is low, the model pays less attention to the recommendation task. The model cannot obtain enough supervisory signals from the training data to update the parameters. With the increase of , the performance of the model also improves. When =0.3, the performance is the best. When is larger than a certain value ( = 0.4), the performance of the model decreases slightly in both datasets.
Embedding dimension d. When the embedding dimension is 256 on the Tmall dataset, the dimension on the CIKM dataset is 128, The model has good performance as shown in Figure 5(b). When the embedding dimension is set too high, it will cause the tensor dimension to be too large. While further increasing the amount of calculation, it will also lead to non-discriminative characterization results. So the embedding dimension is also crucial. Experimental results show that this model can improve learning performance in a higher dimension. This shows that the model is capable of learning from User-Item multiple interactions.
4. Conclusion
In this paper, we propose a new Multi-Behavior Self-Supervised attention learning method based on two paths. It explicitly captures multiple behavioral dependencies. Due to the many types of interactions between users and items are easily overlooked. TP_MB designs a two-path multi-behavior dependent encoder to encode relational context signals from different types of user behaviors. In addition, we propose a framework for incorporating Self-Supervised learning. Multi-behavior model modeling in a customized way, capture different Multi-behavior modes of users for recommendation.
Funding
This research was funded by National Key R&D Program of under Grant (No.2020YFB1710200), Heilongjiang Provincial Natural Science Foundation of China(No.LH2021F047)
Author Contributions: Mingyue Qu
: methodology,software, writing—original draft. Nan Wang:supervision, writing—review; Editing, Jinbao Li: funding acquisition.
Institutional Review Board Statement
“Not applicable” for studies not involving humans or animals.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Acknowledgments
In this section you can acknowledge any support given which is not covered by the author contribution or funding sections. This may include administrative and technical support, or donations in kind (e.g., materials used for experiments).
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Sample Availability
Samples of the compounds are available from the authors.
Abbreviations
The following abbreviations are used in this manuscript:
| TP_MB | Two-path Multi-behavior Sequence Modeling |
References
- Wang J, Huang P, Zhao H, et al. Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba[J]. ACM, 2018. [CrossRef]
- Chen, Chong, et al. "Graph heterogeneous multi-relational recommendation." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 35. No. 5. 2021. [CrossRef]
- Velikovi P, Fedus W, Hamilton W L, et al. Deep Graph Infomax[J]. 2018. [CrossRef]
- Wu J, Wang X, Feng F, et al. Self-supervised Graph Learning for Recommendation[J]. ACM, 2021. [CrossRef]
- Jin B, Gao C, He X, et al. Multi-behavior Recommendation with Graph Convolutional Networks[C]// SIGIR ’20: The 43rd International ACM SIGIR conference on research and development in Information Retrieval. ACM, 2020. [CrossRef]
- Wang W, Zhang W, Liu S, et al. Beyond Clicks: Modeling Multi-Relational Item Graph for Session-Based Target Behavior Prediction[J]. 2020. [CrossRef]
- Sun F, Liu J, Wu J, et al. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer[J]. 2019. [CrossRef]
- Velikovi P, Cucurull G, Casanova A, et al. Graph Attention Networks[J]. 2017.
- He X, Deng K, Wang X, et al. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation[J]. ACM, 2020. [CrossRef]
- Gao, Rong, et al. "Gated Dual Hypergraph Convolutional Networks for Recommendation with Self-supervised Learning." 2022 International Joint Conference on Neural Networks (IJCNN). IEEE, 2022. [CrossRef]
- Hjelm R D, Fedorov A, Lavoie-Marchildon S, et al. Learning deep representations by mutual information estimation and maximization[J]. 2018. [CrossRef]
- Bachman P, Hjelm R D, Buchwalter W. Learning Representations by Maximizing Mutual Information Across Views[J]. 2019.
- Chen C, Zhang M, Zhang Y, et al. Efficient Heterogeneous Collaborative Filtering without Negative Sampling for Recommendation[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(1):19-26. [CrossRef]
- Koren Y, Rendle S, Bell R. Advances in collaborative filtering[J]. Recommender systems handbook, 2021: 91-142. [CrossRef]
- Huang C, Wu X, Zhang X, et al. Online purchase prediction via multi-scale modeling of behavior dynamics[C]//Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 2019: 2613-2622. [CrossRef]
Figure 1.
TP_MB Framework
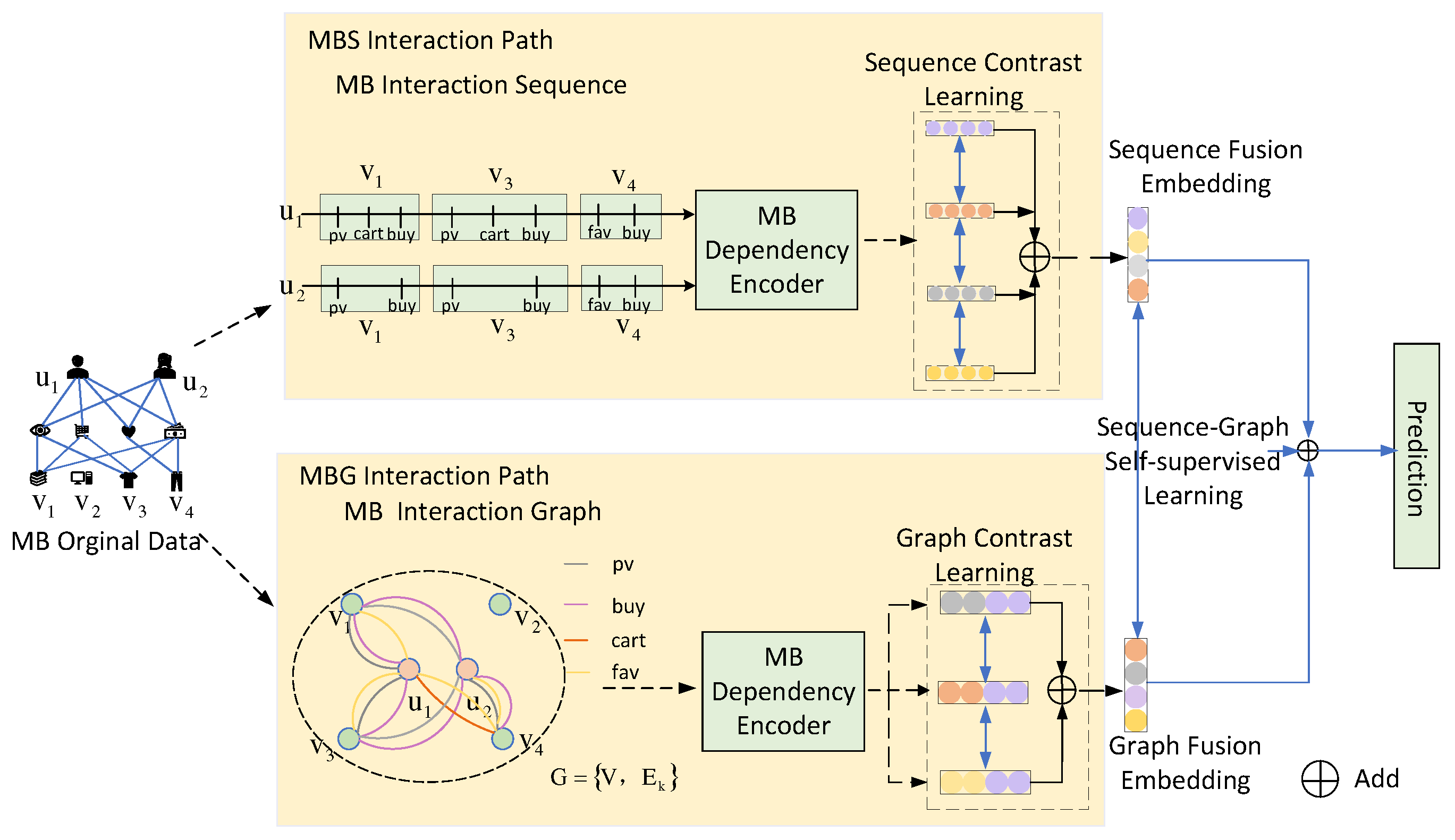
Figure 2.
Multi-Behavior Interaction Sequence Path
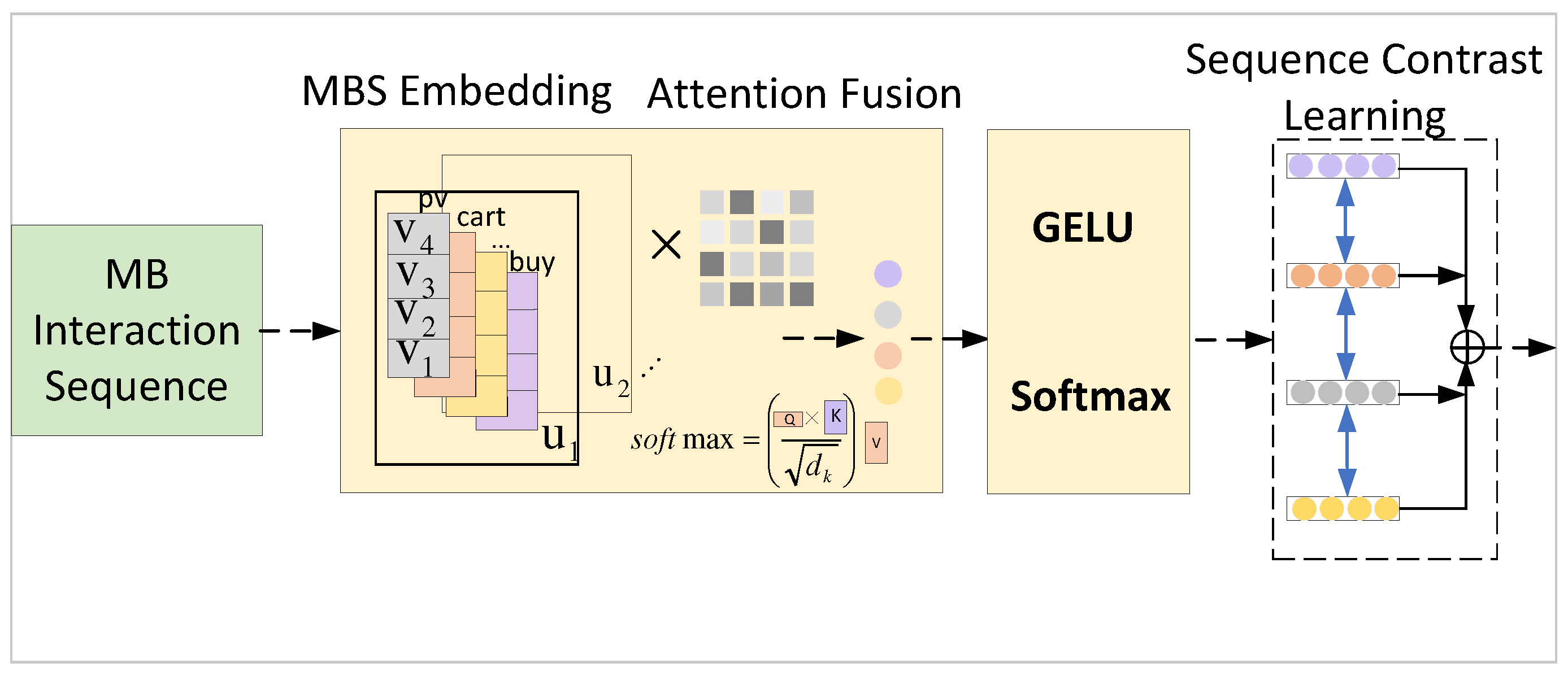
Figure 3.
Multi-Behavior Interaction Graph Path
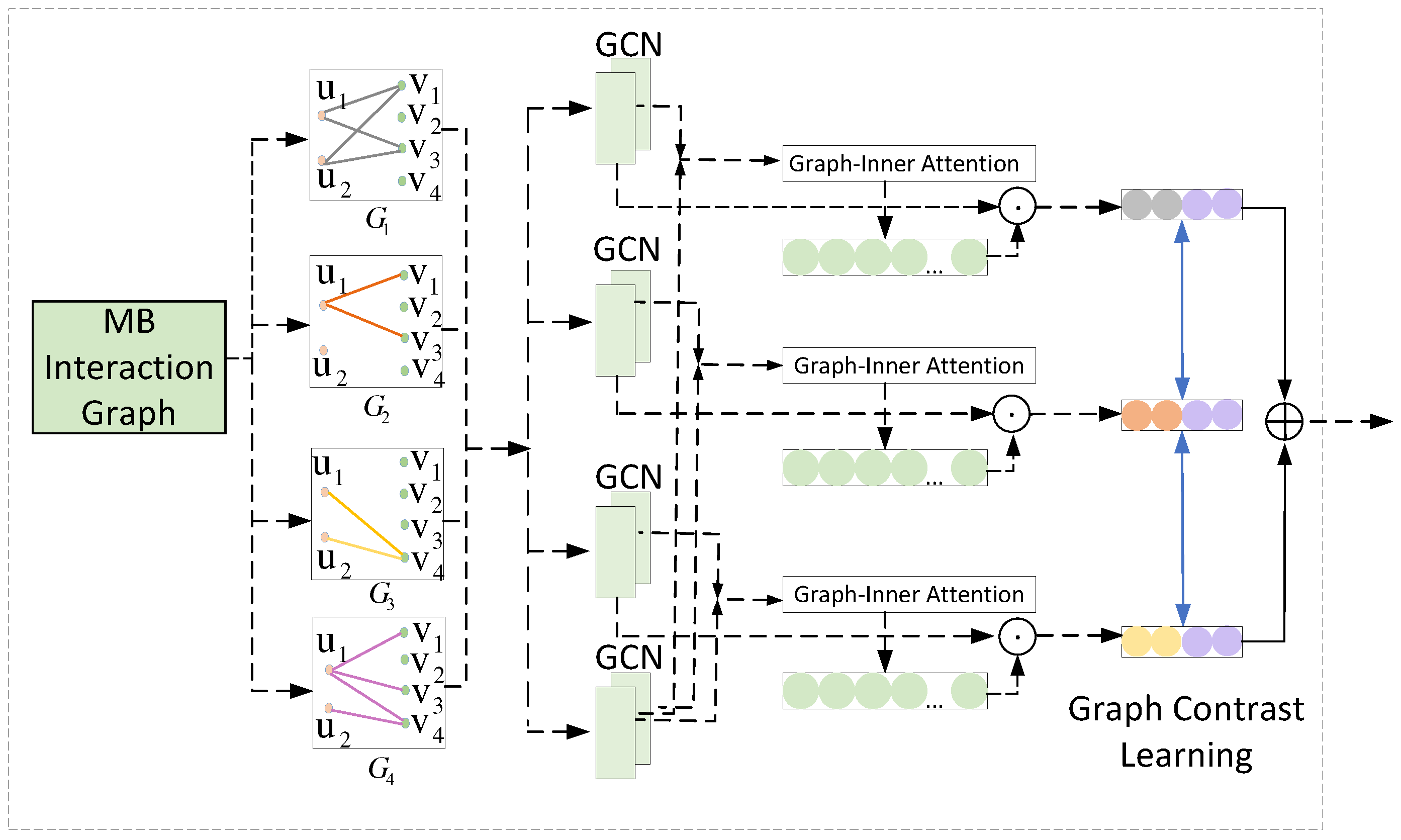
Figure 4.
Various baseline models in the Tmall and CIKM dataset compare with TP_MB.
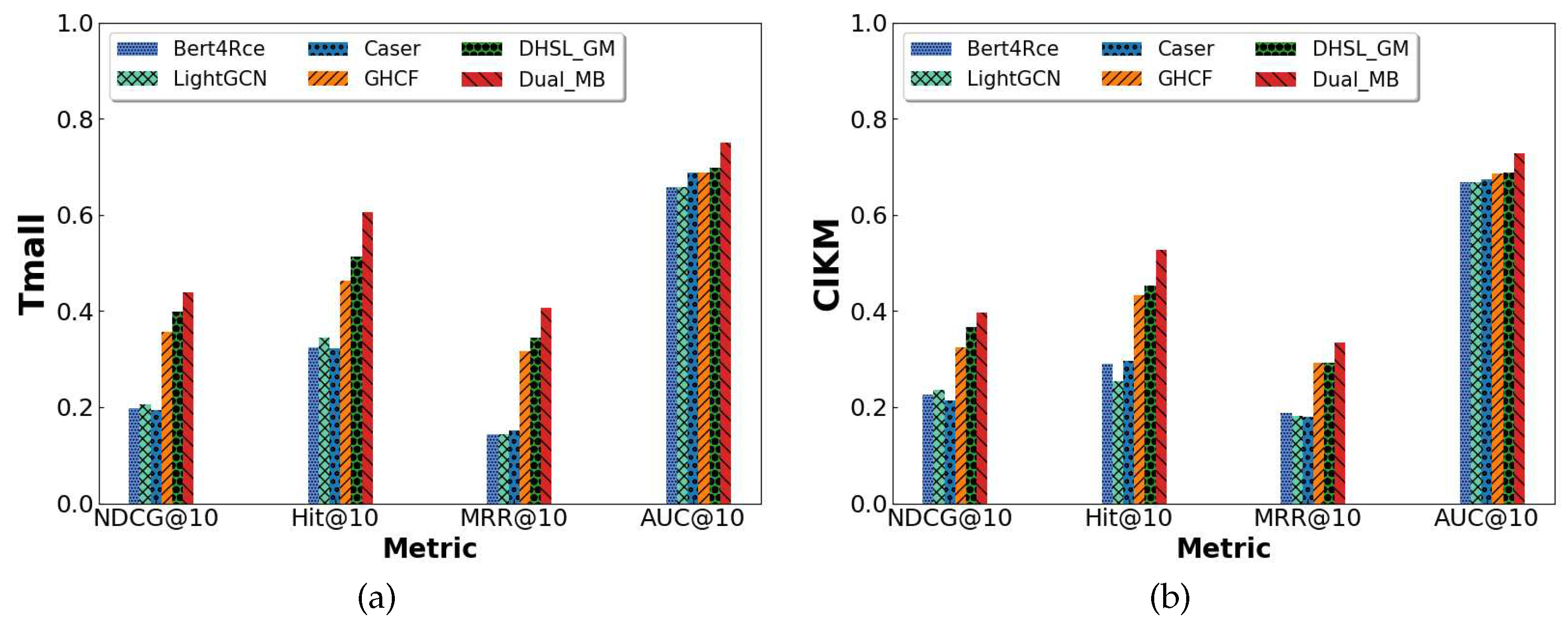
Figure 5.
Different hyperparameter and different dimension d, changes in NDCG@10
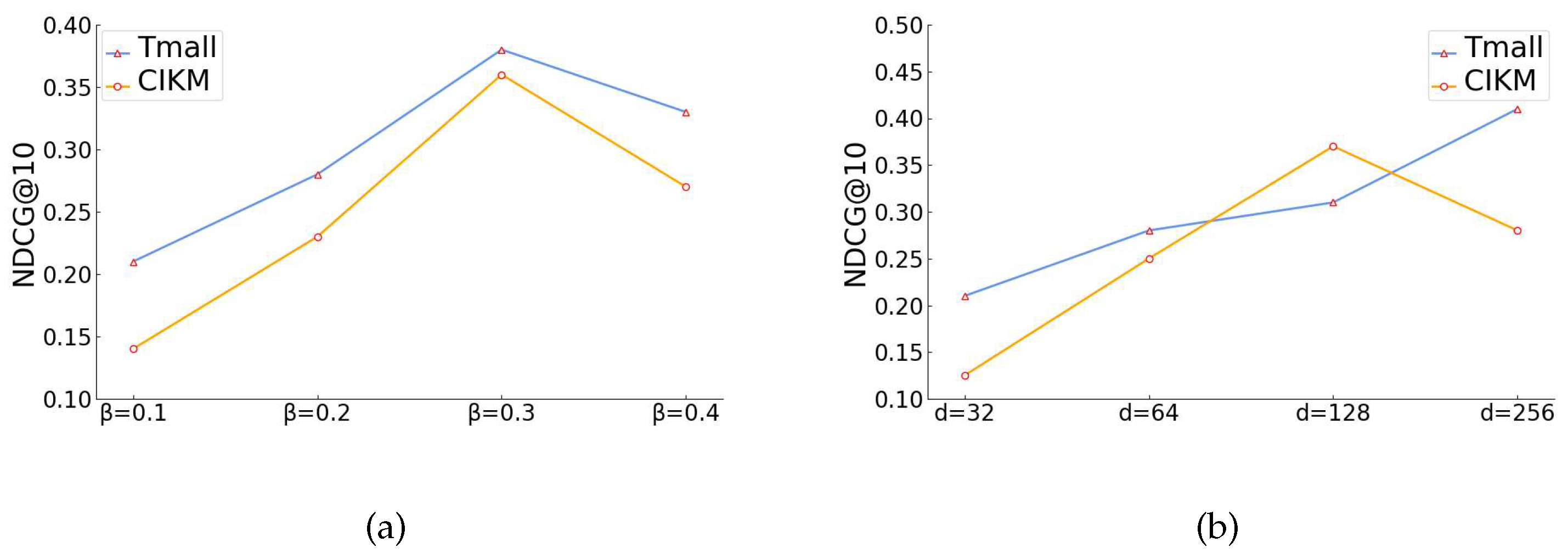

Table 1.
Statistics Of Experimental Dataset
| Dataset | User | Item | Interaction | Interaction Behavior Types |
|---|---|---|---|---|
| Tmall | 27155 | 22014 | 613978 | {click,add_to_cart,buy} |
| CIKM2019EComm AI | 23023 | 25054 | 41526 | {click,add_to_cart,buy} |
Table 2.
Overall Performance Comparison Of All methods
| Data | Metric | Bert4Rec | LightGCN | Caser | GHCF | DHSL_GM | TP_MB | Improvement |
|---|---|---|---|---|---|---|---|---|
| Tmall | NDCG@10 | 0.1985 | 0.2051 | 0.1933 | 0.3754 | 0.3983 | 0.4393 | 10.3% |
| Hit@10 | 0.3274 | 0.3447 | 0.3231 | 0.4635 | 0.5126 | 0.6053 | 18.1% | |
| MRR@10 | 0.1447 | 0.1447 | 0.1522 | 0.3164 | 0.3437 | 0.4066 | 8.2% | |
| AUC@10 | 0.6583 | 0.6583 | 0.6876 | 0.6873 | 0.6981 | 0.7505 | 7.5% | |
| CIKM | NDCG@10 | 0.2264 | 0.2352 | 0.2139 | 0.3244 | 0.3662 | 0.3970 | 8.4% |
| HiT@10 | 0.2896 | 0.2534 | 0.2962 | 0.4337 | 0.4537 | 0.5277 | 16.3% | |
| MRR@10 | 0.1878 | 0.1811 | 0.1790 | 0.2926 | 0.3108 | 0.3344 | 7.6% | |
| AUC@10 | 0.6686 | 0.6671 | 0.6731 | 0.6866 | 0.6874 | 0.7273 | 5.8% |
Table 3.
Ablation Study Of TP_MB
| Data | Tmall | CIKM | ||
|---|---|---|---|---|
| Metric | Hit@10 | NDCG@10 | Hit@10 | NDCG@10 |
| w/o-Att | 0.3431 | 0.1863 | 0.2581 | 0.1264 |
| w/o-DCL | 0.3108 | 0.1773 | 0.3630 | 0.1973 |
| MB_gsCL | 0.6053 | 0.4393 | 0.5277 | 0.3970 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



