Submitted:
25 June 2023
Posted:
26 June 2023
You are already at the latest version
Abstract
The (numerical) solution of Ordinary Differential Equations (ODEs) problems is of paramount relevance, ODEs system being an ubiquitous mathematical formulation of many physical phenomena (such as those involved in fluid dynamics, chemistry, biology, evolutionary-anthropology, ...): almost every dynamici phenomenon can be modeled by means of an ODEs system. The present paper is the first manifesto of FOODIE, a library aimed to numerically solve ODEs problems by means of a clear, concise and efficient abstract interface. FOODIE, meaning Fortran Object oriented Ordinary Differential Equations integration library, has manifolds aims: to provide a set to built-in numerical schemes that are accurate, robust, validated and efficient and to allow easy application of these schemes to (almost) all ODEs problems by means of an effective Abstract Calculus Pattern. The key idea is to allow the same solver-implementation to be applied to all ODEs problems thus avoiding the re-implementation of the ODEs solver for each different ODEs problem: code re-usability is consequently maximized, FOODIE being a general robust framework. Besides, the same framework also allows rapid development of new ODEs solvers due to the high abstraction level of the library itself. The present paper is the first announcement of FOODIE project: the current implementation is extensively discussed and its capabilities are proved by means of tests and examples.
Keywords:
Ordinary Differential Equations (ODE)
; Partial Differential Equations (PDE)
; Object Oriented Programming (OOP)
; Abstract Calculus Pattern (ACP)
; Fortran
1. Introduction
1.1. Background
Initial Value Problem (IVP, or Cauchy problem, see [1]) constitutes a class of mathematical models of paramount relevance, it being applied to the modelling of a wide range of dynamic phenomena. Briefly, an IVP is an Ordinary Differential Equations system (ODE) coupled with specified initial values of the unknown state variables, the solution of which are searched at a given time after the initial time considered.
The prototype of IVP can be expressed as:
where is the vector of state variables being a function of the time-like independent variable t, is the (vectorial) residuals function and is the (vectorial) initial conditions, namely the state variables function evaluated at the initial time . In general, the residuals function R is a function of the state variable U through which it is a function of time, but it can be also a direct function of time, thus in general holds.
The problem prototype (1) is ubiquitous in the mathematical modelling of physical problems: essentially whenever an evolutionary (i.e. dyanamic) phenomenon is considered the prevision (simulation) of the future solutions involves the solution of an IVP. As a matter of facts, many physical problems (fluid dynamics, chemistry, biology, evolutionary-anthropology, ...) are described by means of an IVP.
It is worth noting that the state vector variables U and its corresponding residuals function are problem dependent: the number and the meaning of the state variables as well as the equations governing their evolution (that are embedded into the residuals function) are different for the Navier-Stokes conservation laws with respect the Burgers one, as an example. Nevertheless, the solvers used for the prediction of the Navier-Stokes equations evolution (hereafter the solution) are the same that are used for Burgers equations time-integration. As a consequence, the solution of the IVP model prototype can be generalized, allowing the application of the same solver to many different problems, thus eliminating the necessity to re-implement the same solver for each different problem.
In this work we presents the FOODIE library: it is designed for solving the generalized IVP (1), it being completely unaware of the actual problem’s definition. FOODIE library provides a high-level, well-documented, simple Application Program Interface (API) for many well-known ODE integration solvers, its aims being twofold:
- provide a robust set of ODE solvers ready to be applied to a wide range of different problems;
- provide a simple framework for the rapid development of new ODE solvers.
1.2. Related Works
There are many ODE solvers described in literature. In [2] SODES (Stepwise Ordinary Differential Equations Solver) is presented: the authors describe an ODE solver able to provide a step by step ODE solution exploiting a Computer Algebra System (CAS) written in Python programming language. In the framework of Computational Fluid Dynamics (CFD) and in particular for solving detailed chemical kinetics problems, in Owoyele and Pal [3] a novel neural ODE solver, ChemNODE, is presented: exploiting the neural networks, the chemical source terms are predicted and integrated and networks itself is adjusted during the training to minimize errors. In Nagy et al. [4] the problem of ODE solving is considered with respect of the computational efficiency point of view: the authors analyze the performance of three different solvers written in C++ and Julia programming languages on both CPU and GPU architectures with a special focus on the parallel optimization of the ODE solving algorithms. Finally, in Nascimento et al. [5] the Python framework TensorFlow is exploited to implement a neural network based ODE solver: their approach if hybrid in the sense that the neural model combines both physics-informed and data-driven kernel in order to improve the accuracy of ODE solutions.
The ODE framework solver presented in this work has different aims, as explained in the following subsection.
1.3. Motivations and Aims
FOODIE library is a free software1 and is designed with the following specifications:
- be written in modern Fortran (standard 2008 or newer);
- be written by means of Object Oriented Programming (OOP) paradigm;
- be well documented;
- be Tests Driven Developed (TDD);
- be collaboratively developed;
- be free.
FOODIE, meaning Fortran Object oriented Ordinary Differential Equations integration library, has been developed with the aim to satisfy the above specifications. The present paper is its first comprehensive presentation.
The Fortran (Formula Translator, [6,7]) programming language is the de facto standard into computer science field: it strongly facilitates the effective and efficient translation of (even complex) mathematical and numerical models into an operative software without compromise on computations speed and accuracy. Moreover, its simple syntax is suitable for scientific researchers that are interested (and skilled) in the physical aspects of the numerical computations rather than computer technicians. Consequently, we develop FOODIE using Fortran language: FOODIE is written by research scientists for research scientists.
One key-point of the FOODIE development is the problem generalization: the problem solved must be the IVP (1) rather than any of its actual definitions. Consequently, we must rely on a generic implementation of the solvers. To this aim, OOP is very useful (see [8]): it allows to express IVP (1) in a very concise and clear formulation that is really generic. In particular, our implementation is based on Abstract Calculus Pattern (ACP) concept.
The Abstract Calculus Pattern
The abstract calculus pattern provides a simple solution for the connection between the very high-level expression of IVP (1) and the eventual concrete (low-level) implementation of the ODE problem being solved. ACP essentially constitutes a contract based on an Abstract Data Type (ADT): we specify an ADT supporting a certain set of mathematical operators (differential and integral ones) and implement FOODIE solvers only on the basis of this ADT. FOODIE clients must formulate the ODE problem under integration defining their own concrete extensions of our ADT (implementing all the deferred operators). Such an approach defines the abstract calculus pattern: FOODIE solvers are aware of only the ADT, while FOODIE clients extend the ADT for defining the concrete ODE problem.
Is is worth noting that this ACP emancipates the solvers implementations from any low-level problem-dependent details: the ODE solvers developed with this pattern are extremely concise, clear, maintainable and less errors-prone with respect a low-level (non abstract) pattern. Moreover, the FOODIE clients can use solvers being extremely robust: as a matter of facts, FOODIE solvers are expressed in a formulation very close to the mathematical one and are tested on an extremely varying family of problems. As shown in the following, such a great flexibility does not compromise the computational efficiency.
The present paper is organized as following: in Section 2 a brief description of the mathematical and numerical methods currently implemented into FOODIE is presented; in Section 3 a detailed discussion on the implementation specifications is provided by means of an analytical code-listings review; in Section 4 a verification analysis on the results of FOODIE applications is presented; Section 5 provides an analysis of FOODIE performances under parallel frameworks scenario like the OpenMP and MPI paradigms; finally, in Section 6 concluding remarks and perspectives are depicted.
2. Mathematical and Numerical Models
In many (most) circumstances, the solution of equation (1) cannot be computed in a closed, exact form (even if it exists and is unique) due to the complexity and nature of the residuals functions, that is often non linear. Consequently, the problem is often solved relying on a numerical approach: the solution of system (1) at a time , namely , is approximated by a subsequent time-marching approximations where the relation implies a stepping, numerical integration from the time to time and N is the total number of numerical time steps necessary to evolve the initial conditions toward the searched solution . To this aim, many numerical schemes have been devised. Notably, the numerical schemes of practical usefulness must posses some necessary proprieties such as consistency and stability to ensure that the numerical approximation converges to the exact solution as the numerical time step tends to zero. A detailed discussion of these details is out the scope of the present work and is omitted. Here, we briefly recall some classifications necessary to introduce the schemes implemented into the FOODIE library.
A non comprehensive classification of the most widely used schemes could distinguish between multi-step versus one-step schemes and between explicit versus implicit schemes.
Essentially, the multi-step schemes have been developed to obtain an accurate approximation of the subsequent numerical steps using the informations contained into the previously computed steps, thus this approach relates the next step approximation to a set of the previously computed steps. On the contrary, a one-step scheme evolves the solution toward the next step using only the information coming from the current time approximation. In the framework of one-step schemes family an equivalent accurate approximation can be obtained by means of a multi-stage approach as the one due to Runge-Kutta. The current version of FOODIE provides schemes belonging to both these families.
The other ODE solvers classification concerns with explicit or implicit nature of the schemes employed. Briefly, an explicit scheme computes the next step approximation using the previously computed steps at most to the current time, whereas an implicit scheme uses also the next step approximation (that is the unknown), thus it requires extra computations. The implicit approach is of practical use for stiff systems where the usage of explicit schemes could require an extremely small time step to evolve in a stable way the solution. Mixing together explicit and implicit schemes it is possible to build a family of predictor-corrector methods: using an explicit scheme to predict a guess for the next step approximation it is possible to use an implicit method for correcting this guess. Currently, FOODIE provides explicit solvers and predictor-correct ones.
FOODIE currently implements the following ODE schemes:
-
one-step schemes:
- -
- explicit forward Euler scheme, it being 1st order accurate;
- -
-
- *
-
TVD/SSP Runge-Kutta schemes:
- 2-stages, it being 2nd order accurate;
- 3-stages, it being 3rd order accurate;
- 5-stages, it being 4th order accurate;
- *
-
low storage Runge-Kutta schemes:
- 5-stages 2N registers schemes, it being 4th order accurate;
- 6-stages 2N registers schemes, it being 4th order accurate;
- 7-stages 2N registers schemes, it being 4th order accurate;
- 12-stages 2N registers schemes, it being 4th order accurate;
- 13-stages 2N registers schemes, it being 4th order accurate;
- 14-stages 2N registers schemes, it being 4th order accurate;
-
multi-step schemes (see [11]):
- -
-
explicit Adams-Bashforth schemes:
- *
- 2-steps, it being 2nd order accurate;
- *
- 3-steps, it being 3rd order accurate;
- *
- 4-steps, it being 4th order accurate;
- -
-
implicit Adams-Moulton schemes:
- *
- 1-step, it being 2nd order accurate;
- *
- 2-steps, it being 3rd order accurate;
- *
- 3-steps, it being 4th order accurate;
- -
-
predictor-corrector Adams-Bashforth-Moulton schemes:
- *
- 1-step, it being 2nd order accurate;
- *
- 2-steps, it being 3rd order accurate;
- *
- 3-steps, it being 4th order accurate;
- -
-
explicit Leapfrog schemes2:
- *
- 2-steps unfiltered, it being 2nd order accurate, but mostly unstable;
- *
- 2-steps Robert-Asselin filtered, it being 1st order accurate (on amplitude error);
- *
- 2-steps Robert-Asselin-Williams filtered, it being 3rd order accurate (on amplitude error);
2.1. The explicit forward Euler scheme
The explicit forward Euler scheme for ODE integration is probably the simplest solver ever devised. Considering the system (1), the solution (approximation) of the state vector U at the time assuming to known the solution at time is:
where the solution at the new time step is computed by means of only the current time solution, thus this is an explicit scheme. The solution is an approximation of 1st order, the local truncation error being . As well known, this scheme has an absolute (linear) stability locus equals to where contains the eigenvalues of the linear (or linearized) Jacobian matrix of the system.
This scheme is Total Variation Diminishing (TVD), thus satisfies the maximum principle (or the equivalent positivity preserving property, see [12]).
2.2. The explicit TVD/SSP Runge-Kutta class of schemes
Runge-Kutta methods belong to the more general multi-stage family of schemes. This kind of schemes has been designed to achieve a more accurate solution than the 1st Euler scheme, but without increasing the number of time steps used, as it is done with the multi-step schemes, see [10]. Essentially, the high order of accuracy is obtained by means of intermediate values (the stages) of the solution and its derivative are generated and used within a single time step. This commonly implies the allocation of some auxiliary memory registers for storing the intermediate stages.
Notably, the multi-stage schemes class has the attractive property to be self-starting: the high order accurate solution can be obtained directly from the previous one, without the necessity to compute before a certain number of previous steps, as it happens for the multi-step schemes. Moreover, one-step multi-stage methods are suitable for adaptively-varying time-step size (that is also possible for multi-step schemes, but at a cost of more complexity) and for discontinuous solutions, namely discontinued solutions happening at a certain time (that in a multi-step framework can involve an overall accuracy degradation).
In general, the TVD/SSP Runge-Kutta schemes provided by FOODIE library are written by means of the following algorithm:
where is the number of Runge-Kutta stages used and is the stage defined as:
It is worth noting that the equations (3) and (4) contain also implicit schemes. A scheme belonging to this family is operative once the coefficients are provided. We represent these coefficients using the Butcher’s table, that for an explicit scheme where has the form reported in Table 1.
The equations (3) and (4) show that Runge-Kutta methods do not require any additional differentiations of the ODE system for achieving high order accuracy, rather they require additional evaluations of the residuals function R.
The nature of the scheme and the properties of the solutions obtained depend on the number of stages and on the value of the coefficients selected. Currently, FOODIE provides 3 Runge-Kutta schemes having TVD or Strong Stability Preserving (SSP) propriety (thus they being suitable for ODE systems involving rapidly changing non linear dynamics) the Butcher’s coefficients of which are reported in Table 2, Table 3 and Table 4.
The absolute stability locus depends on the coefficients selected, however, as a general principle, we can assume that greater is the stages number and wider is the stability locus on equal accuracy orders.
It is worth noting that FODDiE also provides a one-stage TVD Runge-Kutta solver that reverts back to the explicit forward Euler scheme: it can be used, for example, into a Recursive Order Reduction (ROR) framework that automatically checks some properties of the solution and, in case, reduces the order of the Runge-Kutta solver until those properties are obtained.
2.3. The explicit low storage Runge-Kutta class of schemes
As aforementioned, standard Runge-Kutta schemes have the drawback to require auxiliary memory registers to store the necessary stages data. In order to make an efficient use of the available limited computer memory, the class of low storage Runge-Kutta scheme was devised. Essentially, the standard Runge-Kutta class (under some specific conditions) can be reformulated allowing a more efficient memory management. Currently FOODIE provides a class of 2N registers storage Runge-Kutta schemes, meaning that the storage of all stages requires only 2 registers of memory with a word length N (namely the length of the state vector) in contrast to the standard formulation where registers of the same length N are required. This is a dramatic improvement of memory efficiency especially for schemes using a high number of stages () where the memory necessary is an half with respect the original formulation. Unfortunately, not all standard Runge-Kutta schemes can be reformulated as a low storage one.
Following the Williamson’s approach (see [13,14,15,16]) the standard coefficients are reformulated to the coefficients vectors A, B and C and the Runge-Kutta algorithm becomes:
Currently FOODIE provides 5/6/7/12/13/14 stages, all 4th order, 2N registers explicit schemes, the coefficients of which are listed in Table 5.

Table 5.
Williamson’s table of low storage Runge-Kutta schemes.
 |
Similarly to the TVD/SSP Runge-Kutta class, the low storage class also provides a fail-safe one-stage solver reverting back to the explicit forward Euler solver, that is useful for ROR-like frameworks.
2.4. The explicit Adams-Bashforth class of schemes
Adams-Bashforth methods belong to the more general (linear) explicit multi-step family of schemes. This kind of schemes has been designed to achieve a more accurate solution than the 1st Euler scheme using the information coming from the solutions already computed at previous time steps. Typically only one new residuals function R evaluation is required at each time step, whereas Runge-Kutta schemes require many of them.
In general, the Adams-Bashforth schemes provided by FOODIE library are written by means of the following algorithm (for only explicit schemes):
where is the number of time steps considered and are the linear coefficients selected.
Currently FOODIE provides 2, 3, and 4 steps schemes having 2nd, 3rd and 4th formal order of accuracy, respectively. The coefficients are reported in Table 6.
Similarly to the Runge-Kutta classes, the Adams-Bashforth class also provides a fail-safe one-step solver reverting back to the explicit forward Euler solver, that is useful for ROR-like frameworks.
It is worth noting that for the Adams-Bashforth class of solvers is not self-starting: the values of , , ..., must be provided. To this aim, a lower order multi-step scheme or an equivalent order one-step multi-stage scheme can be used.
2.5. The implicit Adams-Moulton class of schemes
Adams-Moulton methods belong to the more general (linear) implicit multi-step family of schemes. This kind of schemes has been designed to achieve a more accurate solution than the 1st Euler scheme using the information coming from the solutions already computed at previous time steps. Typically only one new residuals function R evaluation is required at each time step, whereas Runge-Kutta schemes require many of them.
In general, the Adams-Moulton schemes provided by FOODIE library are written by means of the following algorithm (for only implicit schemes):
where is the number of time steps considered and are the linear coefficients selected.
Currently FOODIE provides 1, 2, and 3 steps schemes having 2nd, 3rd and 4th formal order of accuracy, respectively. The coefficients are reported in Table 7.
Similarly to the Runge-Kutta and Adams-Bashforth classes, the Adams-Moulton class also provides a fail-safe zero-step solver reverting back to the implicit backward Euler solver, that is useful for ROR-like frameworks.
It is worth noting that for the Adams-Moulton class of solvers is not self-starting: the values of , , ..., must be provided. To this aim, a lower order multi-step scheme or an equivalent order one-step multi-stage scheme can be used.
2.6. The predictor-corrector Adams-Bashforth-Moulton class of schemes
Adams-Bashforth-Moulton methods belong to the more general (linear) predictor-corrector multi-step family of schemes. This kind of schemes has been designed to achieve a more accurate solution than the 1st Euler scheme using the information coming from the solutions already computed at previous time steps. Typically only one new residuals function R evaluation is required at each time step, whereas Runge-Kutta schemes require many of them.
In general, the Adams-Bashforth-Moulton schemes provided by FOODIE library are written by means of the following algorithm:
where is the number of time steps considered for the Adams-Bashforth predictor/Adams-Moulton corrector (respectively) and are the corresponding linear coefficients selected. Essentially, the Adams-Bashforth prediction is corrected by means of the Adams-Moulton correction resulting in . In order to preserve the formal order of accuracy the relation always holds.
2.7. The leapfrog solver
The leapfrog scheme belongs to the multi-step family, it being formally a centered second order approximation in time, see [17,18,19]. The leapfrog method (in its original formulation) is mostly unstable, however it is well suited for periodic-oscillatory problems providing a null error on the amplitude value and a formal second order error on the phase one, under the satisfaction of the time-step size stable limit. Commonly, the leapfrog methods are said to provide a computational mode that can generate unphysical, unstable solutions. As consequence, the original leapfrog scheme is generally filtered in order to suppress these computational modes.
The unfiltered leapfrog scheme provided by FOODIE is:
FOODIE provides, in a seamless API, also filtered leapfrog schemes. A widely used filter is due to Robert and Asselin, that suppress the computational modes at the cost of accuracy reduction resulting into a 1st order error in amplitude value. A more accurate filter, able to provide a 3rd order error on amplitude, is a modification of the Robert-Asselin filter due to Williams known as Robert-Asselin-Williams (RAW) filter, that filters the approximation of and by the following scalar coefficient:
The filter coefficients should be taken as and . If the filters of time and have the same amplitude and opposite sign thus allowing to the optimal 3rd order error on amplitude. The default values of the FOODIE provided scheme are , but they can be customized at runtime.
3. Application Program Interface
In this section we review the FOODIE API providing a detailed discussion of the implementation choices.
As aforementioned, the programming language used is the Fortran 2008 standard, that is a minor revision of the previous Fortran 2003 standard. Such a new Fortran idioms provide (among other useful features) an almost complete support for OOP, in particular for ADT concept. Fortran 2003 has introduced the abstract derived type: it is a derived type suitable to serve as contract for concrete type-extensions that has not any actual implementations, rather it provides a well-defined set of type bound procedures interfaces, that in Fortran nomenclature are called deferred procedures. Using such an abstract definition, we can implement algorithms operating on only this abstract type and on all its concrete extensions. This is the key feature of FOODIE library: all the above described ODE solvers are implemented on the knowledge of only one abstract type, allowing an implementation-style based on a very high-level syntax. In the meanwhile, client codes must implement their own IVPs extending only one simple abstract type.
In the subSection 3.1 a review of the FOODIE main ADT, the integrand type, is provided, while subSection 3.2, Section 3.3, Section 3.4, Section 3.5 and Section 3.8 cover the API of the currently implemented solvers.
It is worth noting that all FOODIE public entities (ADT and solvers) must be accessed by the FOODIE module, see Listing 1 for an example on how access to all public FOODIE entities.
| Listing 1. usage example importing all public entities of FOODIE main module |
 |
3.1. The main FOODIE Abstract Data Type: the integrand type
The implemented ACP is based on one main ADT, the integrand type, the definition of which is shown in Listing 2.
| Listing 2. integrand type definition |
 
|
The integrand type does not implement any actual integrand field, it being and abstract type. It only specifies which deferred procedures are necessary for implementing an actual concrete integrand type that can use a FOODIE solver.
As shown in listing 2, the number of the deferred type bound procedures that clients must implement into their own concrete extension of the integrand ADT is very limited: essentially, there are 1 ODE-specific procedure plus some operators definition constituted by symmetric operators between 2 integrand objects, asymmetric operators between integrand and real numbers (and viceversa) and an assignment statement for the creation of new integrand objects. These procedures are analyzed in the following paragraphs.
3.1.1. Time derivative procedure, the residuals function
The abstract interface of the time derivative procedure t is shown in Listing 3.
| Listing 3. time derivative procedure interface |
 |
This procedure-function takes two arguments, the first passed as a type bounded argument, while the latter is optional, and it returns an integrand object. The passed dummy argument, self, is a polymorphic argument that could be any extensions of the integrand ADT. The optional argument t is the time at which the residuals function must be computed: it can be omitted in the case the residuals function does not depend directly on time.
Commonly, into the concrete implementation of this deferred abstract procedure clients embed the actual ODE equations being solved. As an example, for the Burgers equation, that is a Partial Differential Equations (PDE) system involving also a boundary value problem, this procedure embeds the spatial operator that convert the PDE to a system of algebraic ODE. As a consequence, the eventual concrete implementation of this procedure can be very complex and errors-prone. Nevertheless, the FOODIE solvers are implemented only on the above abstract interface, thus emancipating the solvers implementation from any concrete complexity.
Add citations to Burgers, Adams-Bashfort, leapfrog references.
3.1.2. Symmetric operators procedures
The abstract interface of symmetric procedures is shown in Listing 4.
| Listing 4. symmetric operator procedure interface |
 |
This interface defines a class of procedures operating on 2 integrand objects, namely it is used for the definition of the operators multiplication, summation and subtraction of integrand objects. These operators are used into the above described ODE solvers, for example see equations (2), (3), (6) or (9). The implementation details of such a procedures class are strictly dependent on the concrete extension of the integrand type. From the FOODIE solvers point of view, we need to known only that first argument passed as bounded one, the left-hand-side of the operator, and the second argument, the right-hand-side of the operator, are two integrand object and the returned object is still an integrand one.
3.1.3. Integrand/real and real/integrand operators procedures
The abstract interfaces of Integrand/real and real/integrand operators procedures are shown in Listing 5.
| Listing 5. Integrand/real and real/integrand operators procedure interfaces |
 |
These two interfaces are necessary in order to complete the algebra operating on the integrand object class, allowing the multiplication of an integrand object for a real number, circumstance that happens in all solvers, see equations (2), (3), (6) or (9). The implementation details of these procedures are strictly dependent on the concrete extension of the integrand type. From the FOODIE solvers point of view, we need to known only that first argument passed as bounded one, the left-hand-side of the operator, and the second argument, the right-hand-side of the operator, are an integrand object and real number of viceversa and the returned object is still an integrand one.
3.1.4. Integrand assignment procedure
The abstract interface of integrand assignment procedure is shown in Listing 6.
| Listing 6. integrand assignment procedure interface |
 |
The assignment statement is necessary in order to complete the algebra operating on the integrand object class, allowing the assignment of an integrand object by another one, circumstance that happens in all solvers, see equations (2), (3), (6) or (9). The implementation details of this assignment is strictly dependent on the concrete extension of the integrand type. From the FOODIE solvers point of view, we need to known only that first argument passed as bounded one, the left-hand-side of the assignment, and the second argument, the right-hand-side of the assignment, are two integrand objects.
3.2. The explicit forward Euler solver
The explicit forward Euler solver is exposed (by the FOODIE main module that must imported, see Listing 1) as a single derived type (that is a standard convention for all FOODIE solvers) named euler_explicit_integrator. It provides the type bound procedure (also referred as method) integrate for integrating in time an integrand object, or any of its polymorphic concrete extensions. Consequently, for using such a solver it must be previously defined as an instance of the exposed FOODIE integrator type, see Listing 7.
| Listing 7. definition of an explicit forward Euler integrator |
 |
Once an integrator of this type has been instantiated, it can be directly used without any initialization, for example see Listing 8.
| Listing 8. example of usage of an explicit forward Euler integrator |
 |
where my_integrand is a concrete (valid) extension of integrand ADT.
The complete implementation of the integrate method of the explicit forward Euler solver is reported in Listing 9.
| Listing 9. implementation of the integrate method of Euler solver |
 |
This method takes three arguments, the first argument is an integrand class, it being the integrand field that must integrated one-step-over in time, the second is the time step used and the third, that is optional, is the current time value that is passed to the residuals function for taking into account the cases where the time derivative explicitly depends on time. The time step is not automatically computed (for example inspecting the passed integrand field), thus its value must be externally computed and passed to the integrate method.
3.3. The explicit TVD/SSP Runge-Kutta class of solvers
The TVD/SSP Runge-Kutta class of solvers is exposed as a single derived type named tvd_runge_kutta_integrator. This type provides three methods:
- init: initialize the integrator accordingly the possibilities offered by the class of solvers;
- destroy: destroy the integrator previously initialized, eventually freeing the allocated dynamic memory registers;
- integrate: integrate integrand field one-step-over in time.
As common for FOODIE solvers, for using such a solver it must be previously defined as an instance of the exposed FOODIE integrator type, see Listing 10.
| Listing 10: definition of an explicit TVD/SSP Runge-Kutta integrator |
 |
Once an integrator of this type has been instantiated, it must be initialized before used, for example see Listing 11.
| Listing 11: example of initialization of an explicit TVD/SSP Runge-Kutta integrator |
 |
In the Listing 11 a 3-stages solver has been initialized. As a matter of facts, from the equations (3) and (4) a solver belonging to this class is completely defined once the number of stages adopted has been chosen. The complete definition of the tvd_runge_kutta_integrator type is reported into Listing 12. As shown, the Butcher’s coefficients are stored as allocatable arrays the values of which are initialized by the init method.
| Listing 12: definition of tvd_runge_kutta_integrator type |
 
|
After the solver has been initialized it can be used for integrating an integrand field, as shown in Listing 13.
| Listing 13: example of usage of a TVD/SSP Runge-Kutta integrator |
 |
where my_integrand is a concrete (valid) extension of integrand ADT. Listing 13 shows that the memory registers necessary for storing the Runge-Kutta stages must be supplied by the client code.
The complete implementation of the integrate method of the explicit TVD/SSP Runge-Kutta class of solvers is reported in Listing 14.
| Listing 14: implementation of the integrate method of explicit TVD/SSP Runge-Kutta class |
 |
This method takes five arguments, the first argument is passed as bounded argument and it is the solver itself, the second is of an integrand class, it being the integrand field that must integrated one-step-over in time, the third is the stages array for storing the stages computations, the fourth is the time step used and the fifth, that is optional, is the current time value that is passed to the residuals function for taking into account the cases where the time derivative explicitly depends on time. The time step is not automatically computed (for example inspecting the passed integrand field), thus its value must be externally computed and passed to the integrate method.
It is worth noting that the stages memory registers, namely the array stage, must be passed as argument because it is defined as a not-passed polymorphic argument, thus we are not allowed to define it as an automatic array of the integrate method.
3.4. The explicit low storage Runge-Kutta class of solvers
The low storage variant of Runge-Kutta class of solvers is exposed as a single derived type named ls_runge_kutta_integrator. This type provides three methods:
- init: initialize the integrator accordingly the possibilities offered by the class of solvers;
- destroy: destroy the integrator previously initialized, eventually freeing the allocated dynamic memory registers;
- integrate: integrate integrand field one-step-over in time.
As common for FOODIE solvers, for using such a solver it must be previously defined as an instance of the exposed FOODIE integrator type, see Listing 15.
| Listing 15: definition of an explicit low storage Runge-Kutta integrator |
 |
Once an integrator of this type has been instantiated, it must be initialized before used, for example see Listing 16.
| Listing 6: example of initialization of an explicit low storage Runge-Kutta integrator |
 |
In the Listing 16 a 5-stages solver has been initialized. As a matter of facts, from the equation (5) a solver belonging to this class is completely defined once the number of stages adopted has been chosen. The complete definition of the ls_runge_kutta_integrator type is reported into Listing 17. As shown, the Williamson’s coefficients are stored as allocatable arrays the values of which are initialized by the init method.
| Listing 17: definition of ls_runge_kutta_integrator type |
 |
After the solver has been initialized it can be used for integrating an integrand field, as shown in Listing 18.
| Listing 18: example of usage of a low storage Runge-Kutta integrator |
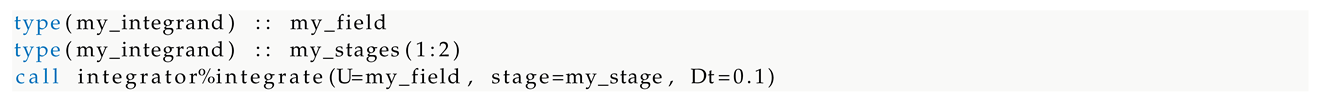 |
where my_integrand is a concrete (valid) extension of integrand ADT. Listing 18 shows that the memory registers necessary for storing the Runge-Kutta stages must be supplied by the client code, as it happens of the TVD/SSP Runge-Kutta class. However, now the registers necessary is always 2, independently on the number of stages used, that in the example considered are 5.
The complete implementation of the integrate method of the explicit low storage Runge-Kutta class of solvers is reported in Listing 19.
| Listing 19: implementation of the integrate method of explicit low storage Runge-Kutta class |
 
|
This method takes five arguments, the first argument is passed as bounded argument and it is the solver itself, the second is of an integrand class, it being the integrand field that must integrated one-step-over in time, the third is the stages array for storing the stages computations, the fourth is the time step used and the fifth, that is optional, is the current time value that is passed to the residuals function for taking into account the cases where the time derivative explicitly depends on time. The time step is not automatically computed (for example inspecting the passed integrand field), thus its value must be externally computed and passed to the integrate method.
It is worth noting that the stages memory registers, namely the array stage, must be passed as argument because it is defined as a not-passed polymorphic argument, thus we are not allowed to define it as an automatic array of the integrate method.
3.5. The explicit Adams-Bashforth class of solvers
The explicit Adams-Bashforth class of solvers is exposed as a single derived type named adams_bashforth_integrator. This type provides three methods:
- init: initialize the integrator accordingly the possibilities offered by the class of solvers;
- destroy: destroy the integrator previously initialized, eventually freeing the allocated dynamic memory registers;
- integrate: integrate integrand field one-step-over in time;
- update_previous: auto update (cyclically) previous time steps solutions.
As common for FOODIE solvers, for using such a solver it must be previously defined as an instance of the exposed FOODIE integrator type, see Listing 20.
| Listing 20: definition of an explicit Adams-Bashforth integrator |
 |
Once an integrator of this type has been instantiated, it must be initialized before used, for example see Listing 21.
| Listing 21: example of initialization of an explicit Adams-Bashforth integrator |
 |
In the Listing 21 a 4-steps solver has been initialized. As a matter of facts, from the equation (6) a solver belonging to this class is completely defined once the number of time steps adopted has been chosen. The complete definition of the adams_bashforth_integrator type is reported into Listing 22. As shown, the linear coefficients are stored as allocatable arrays the values of which are initialized by the init method.
| Listing 22 definition of adams_bashforth_integrator type |
 |
After the solver has been initialized it can be used for integrating an integrand field, as shown in Listing 23.
| Listing 23: example of usage of an Adams-Bashforth integrator |
 |
where my_integrand is a concrete (valid) extension of integrand ADT, times are the time at each 4 steps considered for the current one-step-over integration and previous are the memory registers where previous time steps solutions are saved.
The complete implementation of the integrate method of the explicit Adams-Bashforth class of solvers is reported in Listing 24.
| Listing 24: implementation of the integrate method of explicit Adams-Bashforth class |
 |
This method takes five arguments, the first argument is passed as bounded argument and it is the solver itself, the second is of an integrand class, it being the integrand field that must integrated one-step-over in time, the third are the previous time steps solutions, the fourth is the time step used, the fifth is an array of the time values of the steps considered for the current one-step-over integration that are passed to the residuals function for taking into account the cases where the time derivative explicitly depends on time and the sixth is a logical flag for enabling/disabling the cyclic update of previous time steps solutions. The time step is not automatically computed (for example inspecting the passed integrand field), thus its value must be externally computed and passed to the integrate method.
It is worth noting that the method also performs the cyclic update of the previous time steps solutions memory registers. This can be disable passing autoupdate=.false.: it is useful in the framework of predictor-corrector solvers.
3.6. The implicit Adams-Moulton class of solvers
The implicit Adams-Moulton class of solvers is exposed as a single derived type named adams_moulton_integrator. This type provides three methods:
- init: initialize the integrator accordingly the possibilities offered by the class of solvers;
- destroy: destroy the integrator previously initialized, eventually freeing the allocated dynamic memory registers;
- integrate: integrate integrand field one-step-over in time;
- update_previous: auto update (cyclically) previous time steps solutions.
As common for FOODIE solvers, for using such a solver it must be previously defined as an instance of the exposed FOODIE integrator type, see Listing 25.
| Listing 25 definition of an implicit Adams-Moulton integrator |
 |
Once an integrator of this type has been instantiated, it must be initialized before used, for example see Listing 26.
| Listing 26: example of initialization of an implicit Adams-Moulton integrator |
 |
In the Listing 26 a 3-steps solver has been initialized. As a matter of facts, from the equation (7) a solver belonging to this class is completely defined once the number of time steps adopted has been chosen. The complete definition of the adams_moulton_integrator type is reported into Listing 27. As shown, the linear coefficients are stored as allocatable arrays the values of which are initialized by the init method.
| Listing 27: definition of adams_moulton_integrator type |
 |
After the solver has been initialized it can be used for integrating an integrand field, as shown in Listing 28.
| Listing 28: example of usage of an Adams-Moulton integrator |
 |
where my_integrand is a concrete (valid) extension of integrand ADT, times are the time at each 4 steps considered for the current one-step-over integration and previous are the memory registers where previous time steps solutions are saved.
The complete implementation of the integrate method of the implicit Adams-Moulton class of solvers is reported in Listing 29.
| Listing 29: implementation of the integrate method of explicit Adams-Moulton class |
 |
This method takes six arguments, the first argument is passed as bounded argument and it is the solver itself, the second is of an integrand class, it being the integrand field that must integrated one-step-over in time, the third are the previous time steps solutions, the fourth is the time step used, the fifth is an array of the time values of the steps considered for the current one-step-over integration that are passed to the residuals function for taking into account the cases where the time derivative explicitly depends on time and the sixth is a logical flag for enabling/disabling the cyclic update of previous time steps solutions. The time step is not automatically computed (for example inspecting the passed integrand field), thus its value must be externally computed and passed to the integrate method.
It is worth noting that the method also performs the cyclic update of the previous time steps solutions memory registers. This can be disable passing autoupdate=.false.: it is useful in the framework of predictor-corrector solvers.
3.7. The predictor-corrector Adams-Bashforth-Moulton class of solvers
The predictor-corrector Adams-Bashforth-Moulton class of solvers is exposed as a single derived type named adams_bashforth_moulton_integrator. This type provides three methods:
- init: initialize the integrator accordingly the possibilities offered by the class of solvers;
- destroy: destroy the integrator previously initialized, eventually freeing the allocated dynamic memory registers;
- integrate: integrate integrand field one-step-over in time;
As common for FOODIE solvers, for using such a solver it must be previously defined as an instance of the exposed FOODIE integrator type, see Listing 30.
| Listing 30: definition of an implicit Adams-Moulton integrator |
 |
Once an integrator of this type has been instantiated, it must be initialized before used, for example see Listing 31.
| Listing 31: example of initialization of an implicit Adams-Moulton integrator |
 |
In the Listing 31 a 3-steps solver has been initialized. As a matter of facts, from the equation (8) a solver belonging to this class is completely defined once the number of time steps adopted has been chosen. The complete definition of the adams_moulton_integrator type is reported into Listing 32. As shown, the linear coefficients are stored as allocatable arrays the values of which are initialized by the init method.
| Listing 32: definition of adams_bashforth_moulton_integrator type |
 |
After the solver has been initialized it can be used for integrating an integrand field, as shown in Listing 33.
| Listing 33: example of usage of an Adams-Bashforth-Moulton integrator |
 |
where my_integrand is a concrete (valid) extension of integrand ADT, times are the time at each 4 steps considered for the current one-step-over integration and previous are the memory registers where previous time steps solutions are saved.
The complete implementation of the integrate method of the predictor-corrector Adams-Bashforth-Moulton class of solvers is reported in Listing 34.
| Listing 34: implementation of the integrate method of predictor-corrector Adams-Bashforth-Moulton class |
 |
This method takes four arguments, the first argument is passed as bounded argument and it is the solver itself, the second is of an integrand class, it being the integrand field that must integrated one-step-over in time, the third is the time step used, and the fourth is the current time. The time step is not automatically computed (for example inspecting the passed integrand field), thus its value must be externally computed and passed to the integrate method.
3.8. The leapfrog solver
The explicit Leapfrog class of solvers is exposed as a single derived type named leapfrog_integrator. This type provides three methods:
- init: initialize the integrator accordingly the possibilities offered by the class of solvers;
- integrate: integrate integrand field one-step-over in time.
As common for FOODIE solvers, for using such a solver it must be previously defined as an instance of the exposed FOODIE integrator type, see Listing 35.
| Listing 35: definition of an explicit Leapfrog integrator |
 |
Once an integrator of this type has been instantiated, it must be initialized before used, for example see Listing 36.
| Listing 36: example of initialization of an explicit Leapfrog integrator |
 |
The complete definition of the leapfrog_integrator type is reported into Listing 37. As shown, the filter coefficients are initialized to zero, suitable values are initialized by the init method.
| Listing 37: definition of leapfrog_integrator type |
 |
After the solver has been initialized it can be used for integrating an integrand field, as shown in Listing 38.
| Listing 38: example of usage of a Leapfrog integrator |
 |
where my_integrand is a concrete (valid) extension of integrand ADT, previous are the memory registers where previous time steps solutions are saved, filter_displacement is the register necessary for computing the eventual displacement of the applied filter and times are the time at each 2 steps considered for the current one-step-over integration.
The complete implementation of the integrate method of the explicit Leapfrog class of solvers is reported in Listing 39.
| Listing 39: implementation of the integrate method of explicit Leapfrog class |
 |
This method takes six arguments, the first argument is passed as bounded argument and it is the solver itself, the second is of an integrand class, it being the integrand field that must integrated one-step-over in time, the third are the previous time steps solutions, the fourth is the optional filter-displacement-register, the fifth is the time step used and the sixth is an array of the time values of the steps considered for the current one-step-over integration that are passed to the residuals function for taking into account the cases where the time derivative explicitly depends on time. The time step is not automatically computed (for example inspecting the passed integrand field), thus its value must be externally computed and passed to the integrate method. It is worth noting that if the filter displacement argument is not passed, the solver reverts back to the standard unfiltered Leapfrog method.
It is worth noting that the method also performs the cyclic update of the previous time steps solutions memory registers. In particular, if the filter displacement argument is passed the method performs the RAW filtering.
3.9. General Remarks
Table 8 presents a comparison of the relevant parts of equations (2), (3), (4), (5), (6) and (9) with the corresponding FOODIE implementations reported in Listings 9, 14, 19, 24 and 39, respectively. This comparison proves that the integrand ADT has allowed a very high-level implementation syntax. The Fortran implementation is almost equivalent to the rigorous mathematical formulation. This aspect directly implies that the implementation of a ODE solver into the FOODIE library is very clear, concise and less-errors-prone than an hard-coded implementation where the solvers must be implemented for each specific definition of the integrand type, it being not abstract.
4. Tests and Examples
For the assessment of FOODIE capabilities the oscillator test is considered:
4.1. Oscillation equations test
Let us consider the oscillator problem, it being a simple, yet interesting IVP. Briefly, the oscillator problem is a prototype problem of non dissipative, oscillatory phenomena. For example, let us consider a pendulum subjected to the Coriolis accelerations without dissipation, the motion equations of which can be described by the ODE system (11).
where the frequency is chosen as . The ODE system (11) is completed by the following initial conditions:
where is the initial time considered.
The IVP constituted by equations (11) and (12) is (apparently) simple and its exact solution is known:
where is an arbitrary time step. This problem is non-stiff meaning that the solution is constituted by only one time-scale, namely the single frequency f.
This problem is only apparently simple. As a matter of facts, in a non dissipative oscillatory problem the eventual errors in the amplitude approximation can rapidly drive the subsequent series of approximations to an unphysical solution. This is of particular relevance if the solution (that is numerically approximated) constitutes a prediction far from the initial conditions, that is the common case in weather forecasting.
Because the Oscillation system (11) posses a closed exact solution, the discussion on this test has twofolds aims: to assess the accuracy of the FOODIE’s built-in solvers comparing the numerical solutions with the exact one and to demonstrate how it is simple to solve this prototypical problem by means of FOODIE.
4.1.1. Errors Analysis
For the analysis of the accuracy of each solver, we have integrated the Oscillation equations (11) with different, decreasing time steps in the range . The error is estimated by the L2 norm of the difference between the exact () and the numerical () solutions for each time step:
where is the total number of time steps performed to reach the final integration time.
Using two pairs of subsequent-decreasing time steps solution is possible to estimate the order of accuracy of the solver employed computing the observed order of accuracy:
where .
4.1.2. FOODIE aware implementation of an oscillation numerical solver
The IVP (11) can be easily solved by means of FOODIE library. The first block of a FOODIE aware solution consists to define an oscillation integrand field defining a concrete extension of the FOODIE integrand type. Listing 40 reports the implementation of such an integrand field that is contained into the tests suite shipped within the FOODIE library.
| Listing 40: implementation of the oscillation integrand type |
 |
The oscillation field extends the integrand ADT making it a concrete type. This derived type is very simple: it has 5 data members for storing the state vector and some auxiliary variables, and it implements all the deferred methods necessary for defining a valid concrete extension of the integrand ADT (plus 2 auxiliary methods that are not relevant for our discussion). The key point is here constituted by the implementation of the deferred methods: the integrand ADT does not impose any structure for the data members, that are consequently free to be customized by the client code. In this example the data members have a very simple, clean and concise structure:
- is the number of space dimensions; in the case of equation (11) we have , however the test implementation has been kept more general parametrizing this dimension in order to easily allow future modification of the test-program itself;
- f stores the frequency of the oscillatory problem solved, that is here set to , but it can be changed at runtime in the test-program;
- U is the state vector corresponding directly to the state vector of equation (11);
As the Listing 40 shows, the FOODIE implementation strictly corresponds to the mathematical formulation embracing all the relevant mathematical aspects into one derived type, a single object. Here we not review the implementation of all deferred methods, this being out of the scope of the present work: the interested reader can see the tests suite sources shipped within the FOODIE library. However, some of these methods are relevant for our discussion, thus they are reviewed.
dOscillation_dt, the oscillation residuals function
Probably, the most important methods for an IVP solver is the residuals function. As a matter of facts, the ODE equations are implemented into the residuals function. However, the FOODIE ADT strongly alleviates the subtle problems that could arise when the ODE solver is hard-implemented within the specific ODE equations. As a matter of facts, the integrand ADT specifies the precise interface the residuals function must have: if the client code implements a compliant interface, the FOODIE solvers will work as expected, reducing the possible errors location into the ODE equations, having designed the solvers on the ADT and not on the concrete type.
Listing 41 reports the implementation of the oscillation residuals function: it is very clear and concise. Moreover, comparing this listing with the equation (11) the close correspondence between the mathematical formulation and Fortran implementation is evident.
| Listing 41: implementation of the oscillation integrand residuals function |
 |
Add method, an example of oscillation symmetric operator
As a prototype of the operators overloading let us consider the add operator, it being a prototype of symmetric operators, the implementation of which is presented in Listing 42.
| Listing 42: implementation of the oscillation integrand add operator |
 
|
It is very simple and clear: firstly all the auxiliary data are copied into the operator result, then the state vector of the result is populated with the addiction between the state vectors of the left-hand-side and right-hand-side. This is very intuitive from the mathematical point of view and it helps to reduce implementation errors. Similar implementations are possible for all the other operators necessary to define a valid intregrand ADT concrete extension.
assignment of an oscillation object
The assignment overloading of the oscillation type is the last key-method that enforces the conciseness of the FOODIE aware implementation. Listing 43 reports the implementation of the assignment overloading. Essentially, to all the data members of the left-hand-side are assigned the values of the corresponding right-hand-side. Notably, for the assignment of the state vector and of the previous time steps solution array we take advantage of the automatic re-allocation of the left-hand-side variables when they are not allocated or allocated differently from the right-hand-side, that is a Fortran 2003 feature. In spite its simplicity, the assignment overloading is a key-method enabling the usage of FOODIE solver: effectively, the assignment between two integrand ADT variables is ubiquitous into the solvers implementations, see equation (3) for example.
| Listing 43: implementation of the oscillation integrand assignment |
 |
FOODIE numerical integration
Using the above discussed oscillation type it is very easy to solve IVP (11) by means of FOODIE library. Listing 44 presents the numerical integration of system (11) by means of the Leapfrog RAW-filtered method. In the example, the integration is performed with steps with a fixed until the time is reached. The example shows also that for starting a multi-step scheme such as the Leapfrog one a lower-oder or equivalent order one-scheme is necessary: in the example the first 2 steps are computed by means of one-step TVD/SSP Runge-Kutta 2-stages schemes. Note that the memory registers for storing the Runge-Kutta stages and the RAW filter displacement must be handled by the client code. Listing 44 demonstrates how it is simple, clear and concise to solve a IVP by FOODIE solvers. Moreover, it proves how it is simple and effective to apply different solvers in a coupled algorithm, that greatly simplify the development of new hybrid solvers for self-adaptive time step size.
| Listing 44: numerical integration of the oscillation system by means of Leapfrog RAW-filtered method |
 
|
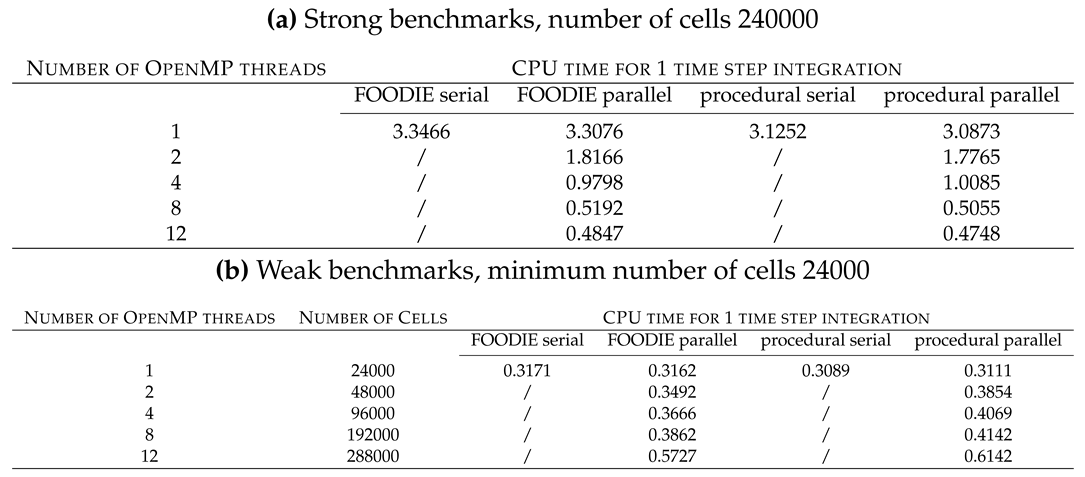
4.1.3. Adams-Bashforth
Table 9 summarizes the Adams-Bashforth error analysis. As expected, the Adams-Bashforth 1 step solution, that reverts back to the explicit forward Euler one, is unstable for all the exercised.
The expected observed orders of accuracy for the Adams-Bashforth solvers using 2, 3 and 4 time steps tend to 1.5, 2.5 and 3.5 that are in agreement with the expected formal order of 2, 3 and 4, respectively. Comparing the errors of the finest time resolution, i.e. , we find that the L2 norm decreases of the 2 orders of magnitude as the solver’s accuracy increases by 1 order. This also means that fixing a tolerance on the errors, the higher is the solver’s accuracy the larger is the time resolution available. As an example, assuming that admissible errors are of with the 4-steps solver we can use performing numerical integration steps, whereas using a 3-steps solvers we must adopt performing numerical integration steps instead of . Considering that the computational costs is only slightly affected by the number of previous time steps considered3, the accuracy order has strong impact on the overall numerical efficiency: to improve the numerical efficiency reducing the computational costs, the usage of high order Adams-Bashforth solvers with larger time steps should be preferred instead of low order solvers with smaller time steps.
Table 9.
Oscillation test: errors analysis of explicit Adams-Bashforth solvers
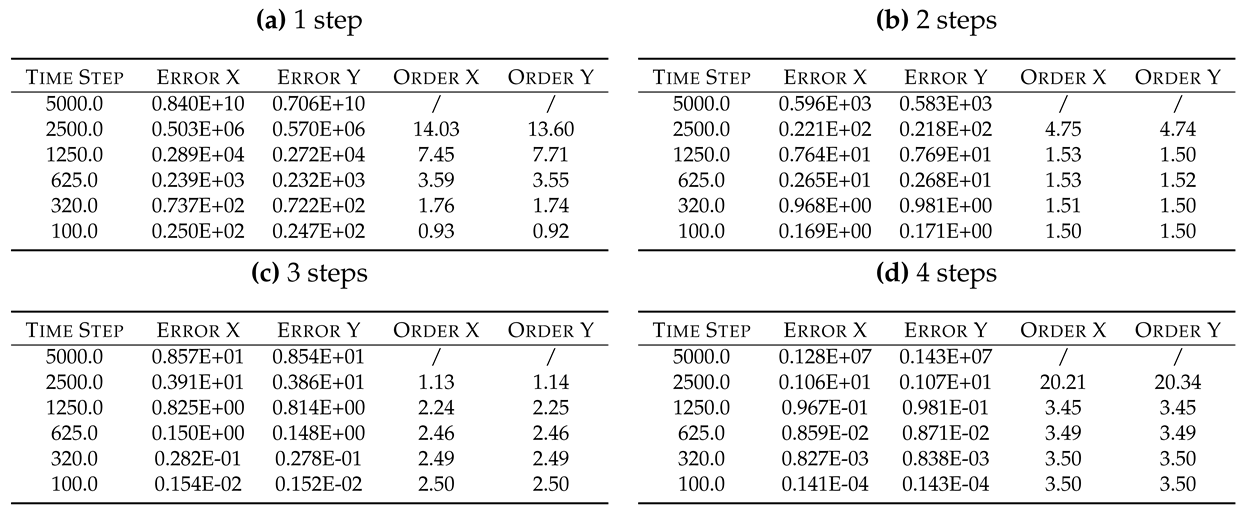 |
Figure 1 shows, for each solver exercised, the and solution for : the plots into the figure report a global overview of the solution for all the instants considered (left subplots) and a detailed zoom over the last instants of the integration (right subplots) for evaluating the numerical errors accumulation. For the sake of clarity, the strongly unstable solutions are omitted into the subplots concerning the final integration instants, namely the solutions for large . Figure 1 emphasizes the instability generation for some pairs steps number/. The 2 and 4 steps solutions are instable for . On the contrary, the 3 steps solution is stable, but the amplitude is dumped and the solution vanishes as the integration proceeds. The 2 and 4 steps solutions show a phase error that decreases as the time resolution increases, whereas 3 steps solution has null phase error.
4.1.4. Adams-Bashforth-Moulton
Table 10 summarizes the Adams-Bashforth-Moulton error analysis. The same considerations done for the Adams-Bashforth solutions can repeated for the Adams-Bashforth-Moulton ones, thus they are omitted for the sake of conciseness. An interesting result concerns the observed errors: the error is now obtained with for the 4-steps solver, thus it is 2 times faster than the corresponding Adams-Bashforth 4-step solver. Considering that the computational costs of a single Adams-Bashforth-Moulton step is only slightly greater than the corresponding Adamas-Bashforth step, the efficiency increasing is not negligible.
4.1.5. Adams-Moulton
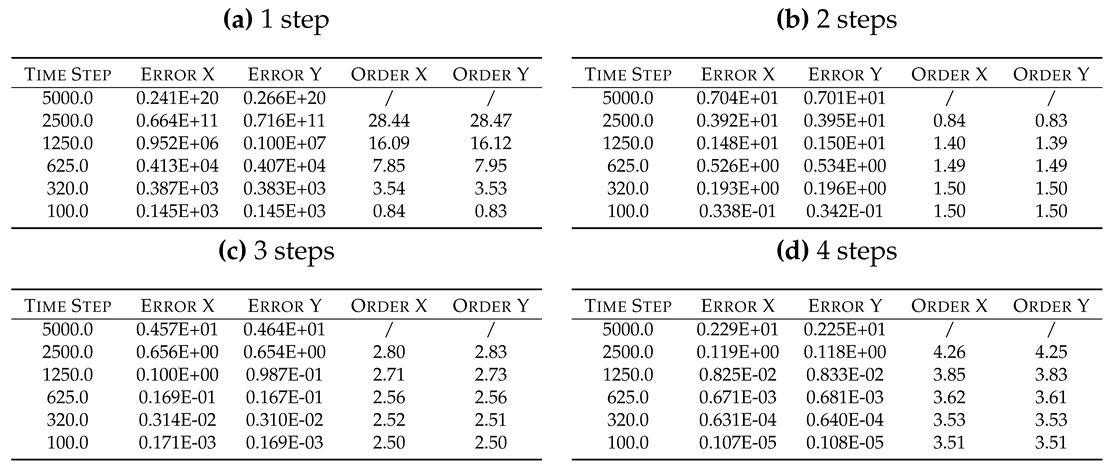
Table 11 summarizes the Adams-Moulton error analysis. The implicit Adams-Moulton solvers behave much like the Adams-Bashforth-Moulton ones: they have similar errors and observed orders for the same formal order considered. However, the implicit Adams-Moulton class uses one less step with respect the corresponding Adams-Bashforth-Moulton class: this could lead to the promise of higher computational efficiency. Notwithstanding, for solving the implicit non-linearity embedded into the Adams-Moulton solvers an iterative algorithm must be employed: for the results presented, a 5 iterations of fixed point algorithm have been computed. This strongly reduces the eventual gain of computational efficiency with respect the Adams-Bashforth-Moulton class.
Table 11.
Oscillation test: errors analysis of explicit Adams-Moulton solvers; the implicit non-linearity is solved by 5 iterations of fixed point algorithm
Table 11.
Oscillation test: errors analysis of explicit Adams-Moulton solvers; the implicit non-linearity is solved by 5 iterations of fixed point algorithm
 |
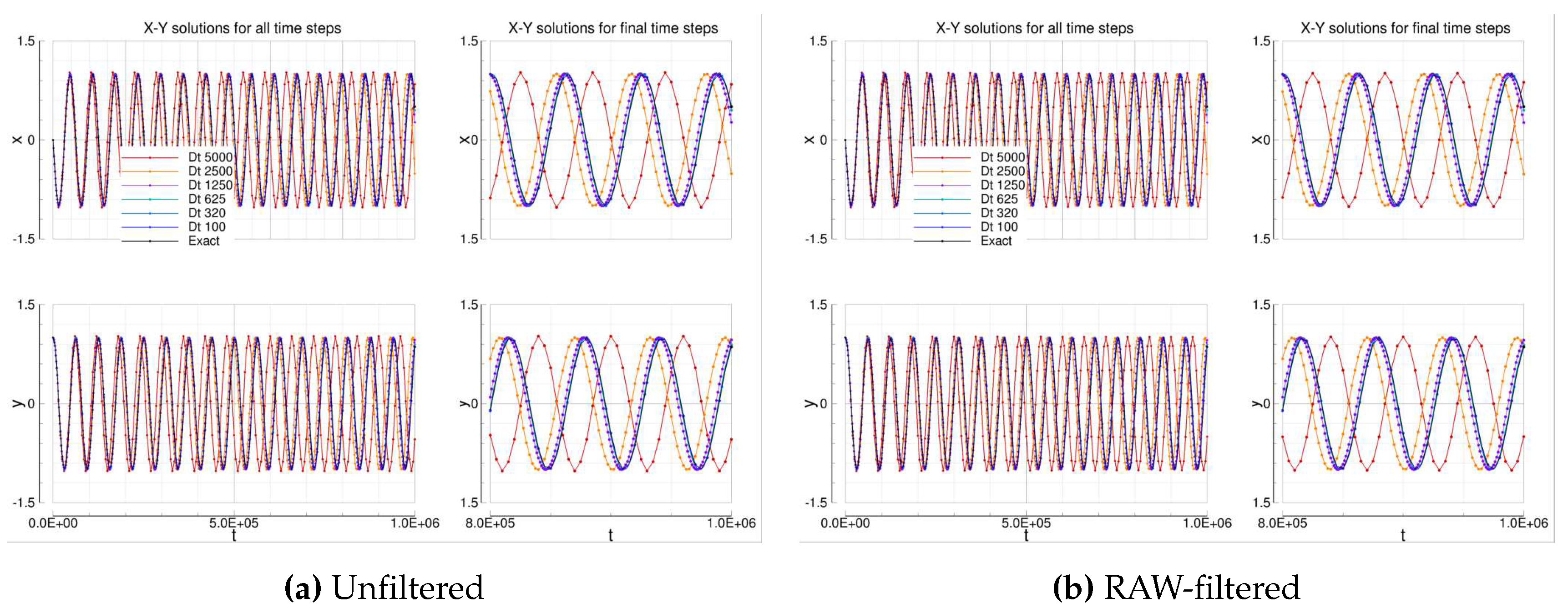
4.1.6. Leapfrog
The Leapfrog solutions are in agreement with the expected results: both unfiltered and RAW-filtered solutions show an observed order of accuracy that tends to the formal 2nd order. The two solutions are almost the same.
Table 12.
Oscillation test: errors analysis of explicit Leapfrog solvers.
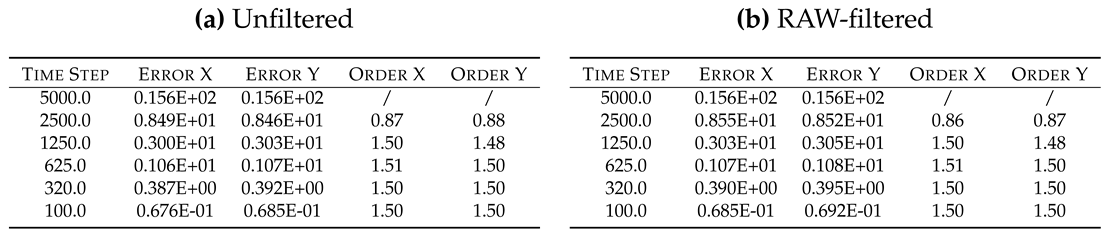 |
Figure 4.
Oscillation equations solutions computed by means of Leapfrog solvers.
4.1.7. Low Storage Runge-Kutta
Table 13.
Oscillationtest: errors analysis of explicit Low Storage Runge-Kutta solvers.
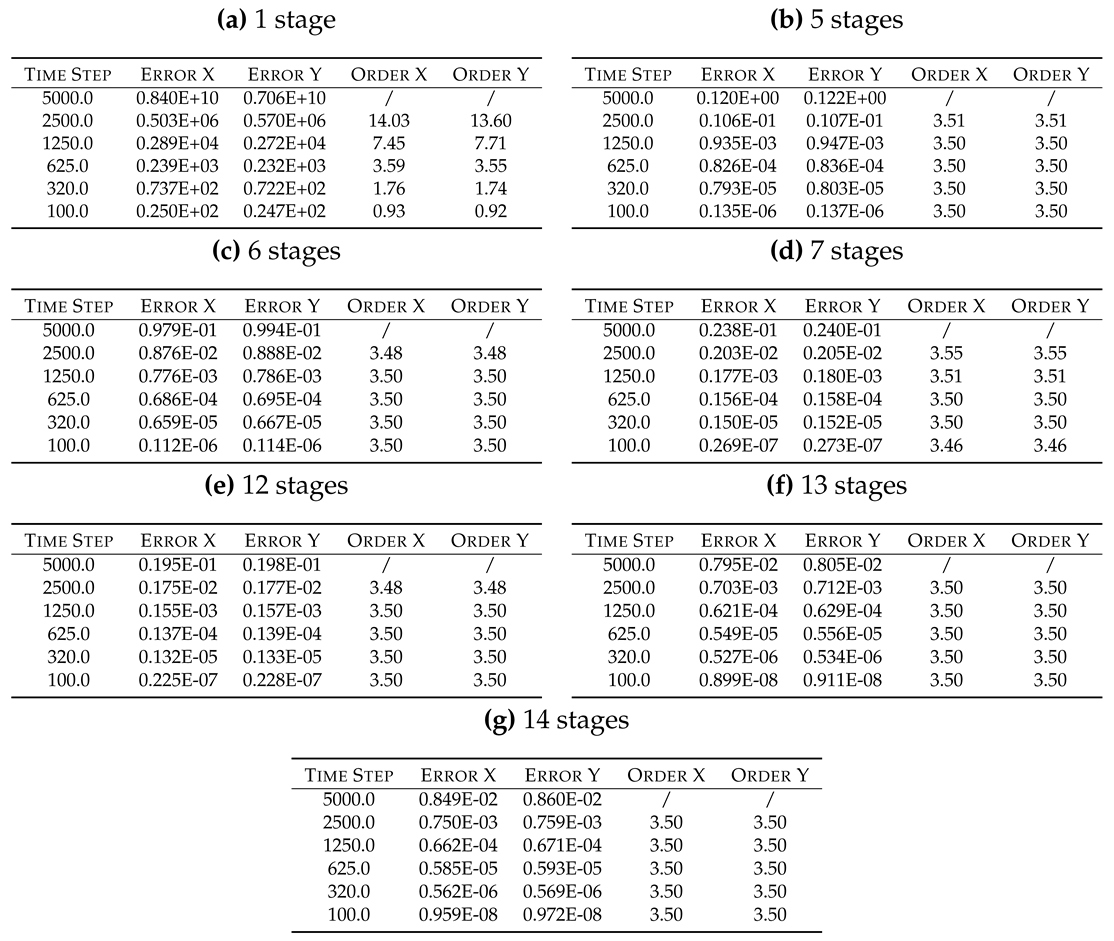 |
Figure 5.
Oscillation equations solutions computed by means of low storage Runge-Kutta solvers.
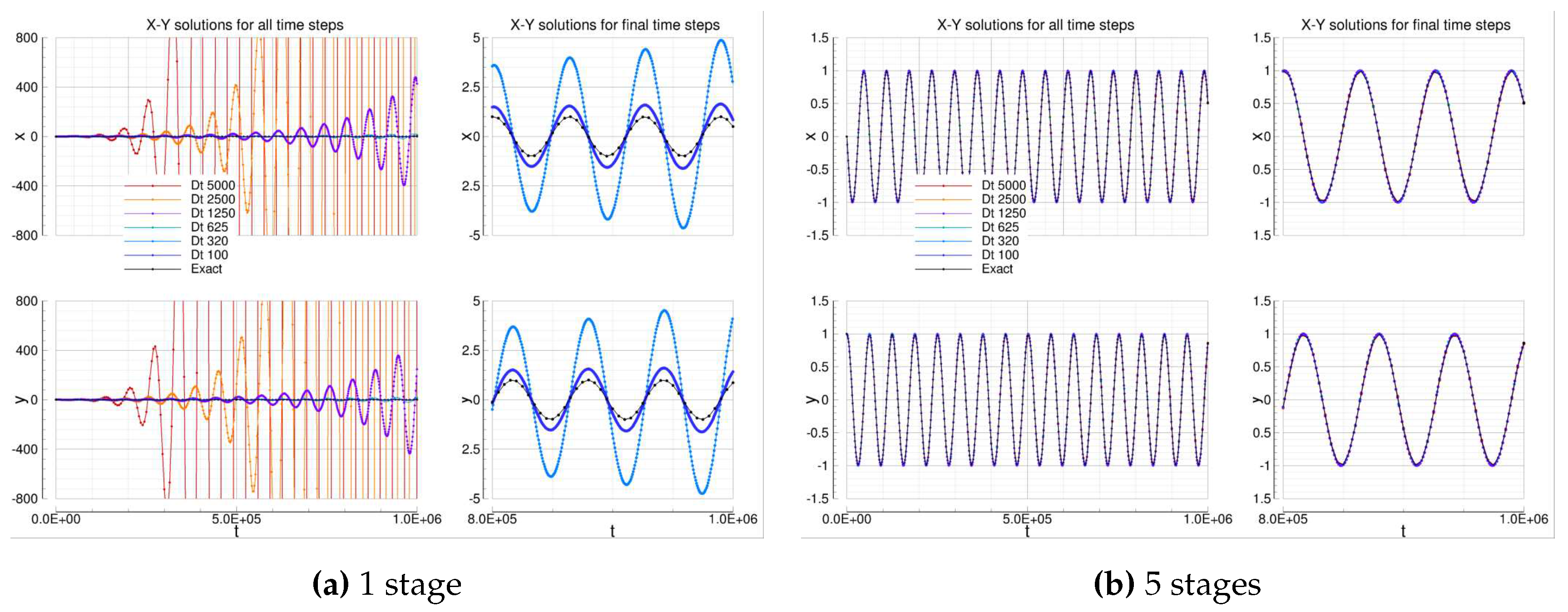
Figure 6.
Oscillation equations solutions computed by means of low storage Runge-Kutta solvers.
4.1.8. TVD/SSP Runge-Kutta
Table 14.
Oscillation test: errors analysis of explicit TVD/SSP Runge-Kutta.
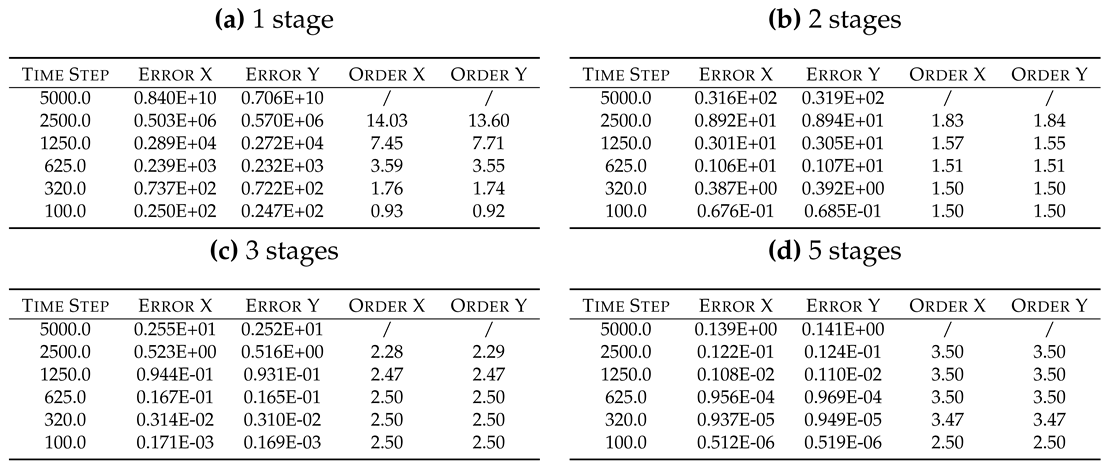 |
Figure 7.
Oscillation equations solutions computed by means of TVD/SSP Runge-Kutta solvers.
5. Benchmarks on parallel frameworks
As aforementioned, FOODIE is unaware of any parallel paradigms or programming models the client codes adopt. As a consequence, the parallel performances measurements presented into this section are aimed only to prove that FOODIE environment does not destroy the parallel scaling of the baseline code implemented without FOODIE.
To obtain such a prove, the 1D Euler PDE system described previously is numerically solved with FOODIE-aware test codes that in turn exploit parallel resources by means:
- CoArray Fortran (CAF) model, for shared and distributed memory architectures;
- OpenMP directive-based model, for only shared memory architectures;
In order to measure the performances of the parallel-enabled FOODIE tests, the strong and weak scaling have been considered. For the strong scaling the speedup has been computed:
where N is the problem size, K the number of parallel resources used (namely the physical cores), is the CPU time of the serial code and the one of the parallel code. The ideal speedup is linear with slop equals to 1. The efficiency correlated to the strong scaling measurement is defined as:
The maximum ideal efficiency is obviously the unity.
For the of weak scaling measurement the sizeup has been computed:
where is the minimum size considered and is the size used for the test computed with k parallel resources. If is scaled proportional to , the ideal sizeup is again linear and if the slope is again linear. The efficiency correlated to the weak scaling is defined as:
The maximum ideal efficiency is obviously the unity.
The same 1D Euler PDEs problem is also solved by parallel-enabled codes that are not based on FOODIE: their solutions provide a reference for measuring the effect of FOODIE abstraction on the parallel scaling.
5.1. CAF benchmark
This subsection reports the parallel scaling analysis of Euler 1D test programs (with and without FOODIE) being parallelized by means of CoArrays Fortran (CAF) model. This parallel model is based on the concept of coarray introduced into the Fortran 2008 standard: the array syntax is extended introducing the so called codimension that is a new arrays indexing. Essentially, a CAF enabled code is designed to be replicated a certain number of times and all copies, conventionally named images, are executed asynchronously. Each image has its own set of data (memory) and the codimension indexes are used to access to the (remote) memory of the other images. The CAF approach allows the implementation of Partitioned Global Address Space (PGAS) model following the SPMD (single program, multiple data) parallelization paradigm. The programmer must take care of defining the coarray variables and of synchronizing the images when necessary. This approach requires the refactoring of legacy serial codes, but it allows the exploitation of both shared and distributed memory architectures. Moreover, it is a standard feature of Fortran (2008), thus it is not chained to any particular compiler vendors extension.
The benchmarks shows in this section have been done on a dual Intel(R) Xeon(R) CPU X5650 exacores workstation for a total of 12 physical cores, coupled with 24GB of RAM. In order to perform an accurate analysis 4 different codes have considered:
-
FOODIE-aware codes:
- -
- serial code;
- -
- CAF-enabled code;
-
procedural codes without using FOODIE library:
- -
- serial code;
- -
- CAF-enabled code;
These codes (see A.1 for the implementation details) have been compiled by means of the GNU gfortran compiler v5.2.0 coupled with OpenCoarrays v1.1.04.
The Euler conservation laws are integrated for 30 time steps by means of the TVD RK(5,4) solver: the measured CPU time used for computing the scaling efficiencies is the average of the 30 integrations, thus representing the mean CPU time for computing one time step integration.
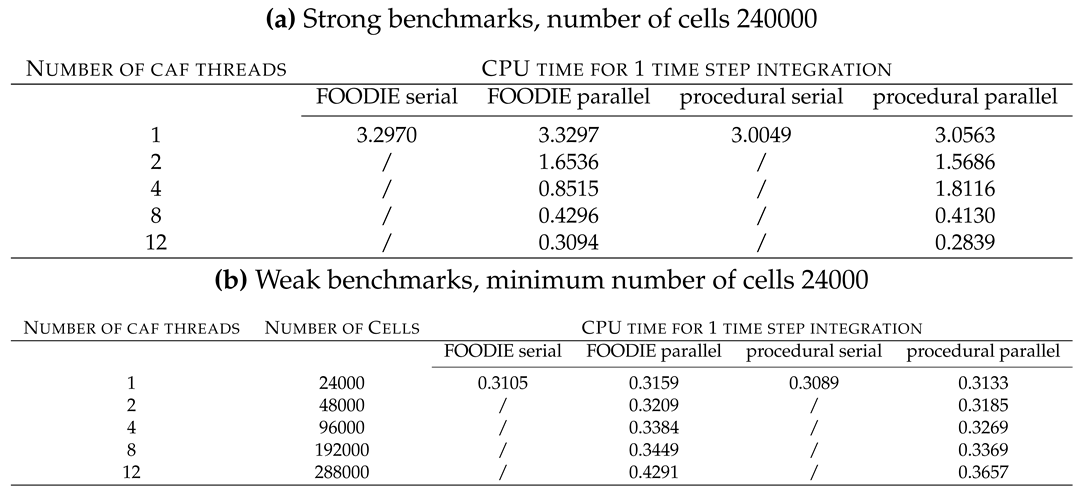
For the strong scaling, the benchmark has been conducted with 240000 finite volumes. Figure 8a summarizes the strong scaling analysis: it shows that FOODIE-based code scales similarly to the baseline code without FOODIE.
For the weak scaling the minimum size is 24000 finite volumes and the size is scaled linearly with the CAF images, thus cells. Figure 8b summarizes the weak scaling analysis and it essentially confirms that FOODIE-based code scales similarly to the baseline code without FOODIE.
Both strong and weak scaling analysis point out that for the computing architecture considered the parallel scaling is reasonable up to 12 cores, the efficiency being always satisfactory.
To complete the comparison, the absolute CPU-time consumed by the two families of codes (with and without FOODIE) must be considered. Table 15 summarizes the benchmarks results. As shown, procedural and FOODIE-aware codes consume a very similar CPU-time for both the strong and the weak benchmarks. The same results are shown in Figure 9. These results prove that the abstraction of FOODIE environment does not degrade the computational efficiency.
5.2. OpenMP benchmark
This subsection reports the parallel scaling analysis of Euler 1D test programs (with and without FOODIE) being parallelized by means of OpenMP directives-based paradigm. This parallel model is based on the concept of threads: an OpenMP enabled code start a single (master) threaded program and, at run-time, it is able to generate a team of (many) threads that work concurrently on the parallelized parts of the code, thus reducing the CPU time necessary for completing such parts. The parallelization is made by means of directives explicitly inserted by the programmer: the communications between threads are automatically handled by the compiler (through the provided OpenMP library used as back-end). OpenMP parallel paradigm is not a standard feature of Fortran, rather it is an extension provided by the compiler vendors. This parallel paradigm constitutes an effective and easy approach for parallelizing legacy serial codes, however its usage is limited to shared memory architectures because all threads must have access to the same memory.
The benchmarks shown in this section have been done on a dual Intel(R) Xeon(R) CPU X5650 exacores workstation for a total of 12 physical cores, coupled with 24GB of RAM. In order to perform an accurate analysis 4 different codes have considered:
-
FOODIE-aware codes:
- -
- serial code;
- -
- OpenMP-enabled code;
-
procedural codes without using FOODIE library:
- -
- serial code;
- -
- OpenMP-enabled code;
These codes (see A.1 for the implementation details) have been compiled by means of the GNU gfortran compiler v5.2.0 with -O2 -fopenmp compilation flags.
The Euler conservation laws are integrated for 30 time steps by means of the TVD RK(5,4) solver: the measured CPU time used for computing the scaling efficiencies is the average of the 30 integrations, thus representing the mean CPU time for computing one time step integration.
For the strong scaling, the benchmark has been conducted with 240000 finite volumes. Figure 10a summarizes the strong scaling analysis: it shows that FOODIE-based code scales similarly to the baseline code without FOODIE.
For the weak scaling the minimum size is 24000 finite volumes and the size is scaled linearly with the OpenMP threads, thus cells. Figure 10b summarizes the weak scaling analysis and it essentially confirms that FOODIE-based code scales similarly to the baseline code without FOODIE.
Both strong and weak scaling analysis point out that for the computing architecture considered the parallel scaling is reasonable up to 8 cores: using 12 cores the measured efficiencies become unsatisfactory, reducing below the 60%.
To complete the comparison, the absolute CPU-time consumed by the two families of codes (with and without FOODIE) must be considered. Table 16 summarizes the benchmarks results. As shown, procedural and FOODIE-aware codes consume a very similar CPU-time for both the strong and the weak benchmarks. The same results are shown in Figure 11. These results prove that the abstraction of FOODIE environment does not degrade the computational efficiency.
6. Concluding Remarks and Perspectives
The present manuscript provides detailed analysis of the implementation and tests of a software framework for the numerical solution of Ordinary Differential Equations (ODEs) for evolutionary (dynamic) problems. The numerical solution of general, non linear differential equations system of the form 5 is an ubiquitous mathematical representation for many dynamic phenomena. As a consequence, the development of new mathematical and numerical methods for solving ODEs is of paramount interest for mathematicians and physicists: in particular, it is crucial to minimize implementation errors, to maximize source code clearness and conciseness and to speed-up the rapid implementation of new ideas while preserving computational efficiency. Such goals are often in contrast with hard-coded ODEs solvers which implementations are often very different from the mathematical description of the solvers themselves. As demonstrated in this work, the exploitation of Fortran Object Oriented Programming capabilities had let us to implement a very powerful ODEs solver library, FOODIE framework, that allows mathematicians and physicists to implement novel solvers in a very clear, concise and less-errors-prone than the hard-coded way due to the high abstraction level of the library itself. In particular, by means of the Abstract Calculus Pattern (ACP), FOODIE library allows to express the solvers formulae with a very high-level language, it being close as much as possible to their natural mathematical formulations which scientists are familiar to, i.e. the presented approach allows the implementation of novels methods with the same low-efforts of Computer Algebra System (CAS). However, differently from common CAS, the presented approach is implemented in pure Fortran programming language, allowing also for High Performance Computing (HPC) problems. As a matter of facts, the presented tests and parallel benchmarks have proved that FOODIE (and ACP approach in general) does not decrease the parallel computing efficiency.
Future works on FOODIE will concern the implementation of new ODEs solvers as well as its applications to some non linear, dynamic PDEs system, in particular concerning the Computational Fluid Dynamics (CFD) field. Current exascale superpc are currently focused on GPU accelerators: the closest perspective of FOODIE extensions will concern the exploitation of parallel GPU computing power by means of OpenMP GPU offloading.
Appendix A. Euler 1D Parallel Tests API
In subSection 5.1 and Section 5.2 it has been proved that FOODIE usage does not penalize the parallel scaling of an equivalent procedural code implemented without FOODIE. To this aim, we have solved the Euler’s conservation laws (in one dimension) by means of FOODIE: as a matter of fact, Euler 1D PDEs constitutes a complex test retaining many difficulties of real applications, but it is still simple enough to serve as benchmark test. In this section we report the implementation details of the codes developed to solve (with serial and parallel models) the Euler 1D PDEs system.
Appendix A.1. Euler 1D baseline API
The 1D Euler PDEs system is a non linear, hyperbolic (inviscid) system of conservation laws for compressible gas dynamics, that reads
where is the density, u is the velocity, p the pressure, E the total internal specific energy and H the total specific enthalpy. The PDEs system must completed with the proper initial and boundary conditions. Moreover, an ideal (thermally and calorically perfect) gas is considered
where R is the gas constant, and are the specific heats at constant pressure and volume (respectively), e is the internal energy, h is the internal enthalpy and *T* is the temperature. The following addition equations of state hold:
An extension of the above Euler system is considered allowing the modelling of a multi-fluid mixture of different gas (with different physical characteristics). The well known Standard Thermodynamic Model is used to model the gas mixture replacing the density with the density fraction of each specie composing the mixture. This led to the following system:
where is the number of initial species composing the gas mixture.
Appendix A.1.1. Memory organization
The finite volume, Godunov’s like approach is employed. Essentially, the method of Lines is used to decouple the space operator from the time one. Firstly, the space operator (the residual function of equation (A1)) is numerically solved in order to reduce the original PDEs system to a system of ODEs that is then integrated over time by means of FOODIE solvers. Here we omit the details of the numerical models, interested readers can see [20,21]. On the contrary, some details on the memory organization is necessary to explaining the implemented API.
The conservative variables are co-located at the cell center. The cell and (inter)faces numeration is as shown in Listing 45.
| Listing 45: Numerical grid organization |
 |
In Listing 45 is the number of finite volumes (cells) used for discretizing the domain and is the number of ghost cells used for imposing the left and right boundary conditions (for a total of cells). For each cell the conservative variables must be stored: this is done by means of of rank 2 array where the first index refers to the conservative variables (densities, momentum or energy) while the second index refers to the space location, namely the cell index.
The most CPU time consuming part of a finite volume scheme is the fluxes computation across the cells interfaces. Such a computation corresponds to a loop over all the cells interfaces. Listing 46 shows a pseudo-code example of such a computation.
| Listing 46: Pseudo-code example of fluxes computation |
 |
In the pseudo-code of Listing 46 it has been emphasized that the fluxes across an interface depends on the cells at left and right of the interface itself. The key point for the parallelization of such an algorithm is to compute the fluxes concurrently using as much as possible the parallel resources provided by the running architecture. As a consequence, the above showed loop over the whole domain is split into sub-domains (explicitly or implicitly accordingly to the parallel model adopted) and the fluxes of each sub-domain are computed concurrently.
Appendix A.1.2. The integrand API
The conservative variables of 1D Euler’s system can be easily implemented as a FOODIE integrand field defining a concrete extension of the FOODIE integrand type. Listing 47 reports the implementation of such an integrand field that is contained into the tests suite shipped within the FOODIE library.
| Listing 47: implementation of the Euler 1D integrand type |
 |
Serial, CAF enabled and OpenMP versions of Euler test share the same integrand API. In the serial version the cells fluxes are computed serially, whereas in CAF and OpenMP versions they are computed in parallel by the number of CAF images or OpenMP threads used, respectively.
References
- Ince, E.L. Ordinary differential equations; Courier Corporation, 1956.
- Jose Luis Galan–García and Pedro Rodriguez–Cielos and Maria Ángeles Galan–Garcia and Morgan le Goff and Yolanda Padilla–Dominguez and Pablo Rodríguez–Padilla and Ivan Atencia and Gabriel Aguilera–Venegas. SODES: Solving ordinary differential equations step by step. Journal of Computational and Applied Mathematics 2023, 428, 115127. [Google Scholar] [CrossRef]
- Owoyele, O.; Pal, P. ChemNODE: A neural ordinary differential equations framework for efficient chemical kinetic solvers. Energy and AI 2022, 7, 100118. [Google Scholar] [CrossRef]
- Nagy, D.; Plavecz, L.; Hegedus, F. The art of solving a large number of non-stiff, low-dimensional ordinary differential equation systems on GPUs and CPUs. Communications in Nonlinear Science and Numerical Simulation 2022, 112, 106521. [Google Scholar] [CrossRef]
- Nascimento, R.G.; Fricke, K.; Viana, F.A. A tutorial on solving ordinary differential equations using Python and hybrid physics-informed neural network. Engineering Applications of Artificial Intelligence 2020, 96, 103996. [Google Scholar] [CrossRef]
- Backus, J.W.; Beeber, R.J.; Best, S.; Goldberg, R.; Haibt, L.M.; Herrick, H.L.; Nelson, R.A.; Sayre, D.; Sheridan, P.B.; Stern, H.; Ziller, I.; Hughes, R.A.; Nutt, R. The FORTRAN automatic coding system. Papers presented at the February 26-28, 1957, western joint computer conference: Techniques for reliability. ACM: New York, NY, USA, 1957; IRE-AIEE-ACM ’57 (Western), pp. 188–198. [CrossRef]
- Draft International Standard for Fortran 2003. Published by the International Fortran standards committee, ISO/IEC JTC1/SC22, 2004.
- Rouson, D.; Xia, J.; Xu, X. Scientific software design: the object-oriented way; Cambridge University Press, 2011.
- Butcher, J. Numerical Methods for Ordinary Differential Equations, 2 ed.; Wiley, 2008; p. 482.
- Gottlieb, S.; Ketcheson, D.I.; Shu, C.W. High order strong stability preserving time discretizations. Journal of Scientific Computing 2009, 38, 251–289. [Google Scholar] [CrossRef]
- Maury Jr, J.; Segal, G. Cowell type numerical integration as applied to satellite orbit computation. Technical report, 1969.
- Shu, C.W. Total-variation-diminishing time discretizations. SIAM Journal on Scientific and Statistical Computing 1988, 9, 1073–1084. [Google Scholar] [CrossRef]
- Williamson, J.H. Low-storage runge-kutta schemes. Journal of computational physics 1980, 35, 48–56. [Google Scholar] [CrossRef]
- Carpenter, M.H.; Kennedy, C.A. Fourth-order 2N-storage Runge-Kutta schemes. Technical report, 1994.
- Allampalli, V.; Hixon, R.; Nallasamy, M.; Sawyer, S.D. High-accuracy large-step explicit Runge–Kutta (HALE-RK) schemes for computational aeroacoustics. Journal of Computational Physics 2009, 228, 3837–3850. [Google Scholar] [CrossRef]
- Niegemann, J.; Diehl, R.; Busch, K. Efficient low-storage Runge–Kutta schemes with optimized stability regions. Journal of Computational Physics 2012, 231, 364–372. [Google Scholar] [CrossRef]
- Robert, A.J. The integration of a low order spectral form of the primitive meteorological equations. Journal of the Meteorological Society of Japan. Ser. II 1966, 44, 237–245. [Google Scholar] [CrossRef]
- Asselin, R. Frequency filter for time integrations. Monthly Weather Review 1972, 100, 487–490. [Google Scholar] [CrossRef]
- Williams, P.D. The RAW filter: An improvement to the Robert–Asselin filter in semi-implicit integrations. Monthly Weather Review 2011, 139, 1996–2007. [Google Scholar] [CrossRef]
- Zaghi, S.; Di Mascio, A.; Favini, B. Application of WENO-Positivity-Preserving Schemes to Highly Under-Expanded Jets. Journal of Scientific Computing 2016, 69, 1033–1057. [Google Scholar] [CrossRef]
- Zaghi, S. OFF, Open source Finite volume Fluid dynamics code: A free, high-order solver based on parallel, modular, object-oriented Fortran API. Computer Physics Communications 2014, pp. [Google Scholar] [CrossRef]
| 1 | FOODIE can be downloaded at https://github.com/Fortran-FOSS-Programmers/FOODIE. |
| 2 | Leapfrog method is a 2-steps solver being, in general 2nd order accurate, but mostly unstable. It is well suited for periodic/oscillatory problems, thus the error is generally categorized accordingly to the phase and amplitude errors: the unfiltered scheme provides a 2nd order error on phase approximation while the amplitude error is null. However, the unfiltered scheme is mostly unstable, thus many filters have been devised. In general, the filters retain the accuracy on the phase error, while affect the amplitude one. |
| 3 | Recalling equation (6) one can observe that there is only one new evaluation of the residuals function R independently of the previous time steps considered. Thus, the computational costs is affected only by the increasing number of residuals summations, the costs of which are typically negligible with respect the cost of R evaluation. |
| 4 | OpenCoarrays is an open-source software project for developing, porting and tuning transport layers that support coarray Fortran (CAF) compilers, see http://www.opencoarrays.org/. |
| 5 | Where U is the vector of state variables being a function of the time-like independent variable t, , R is the (vectorial) residual function, it could be a non linear function of the solution U itself and F is the (vectorial) initial conditions function. |
Figure 1.
Oscillation equations solutions computed by means of Adams-Bashforth solvers.
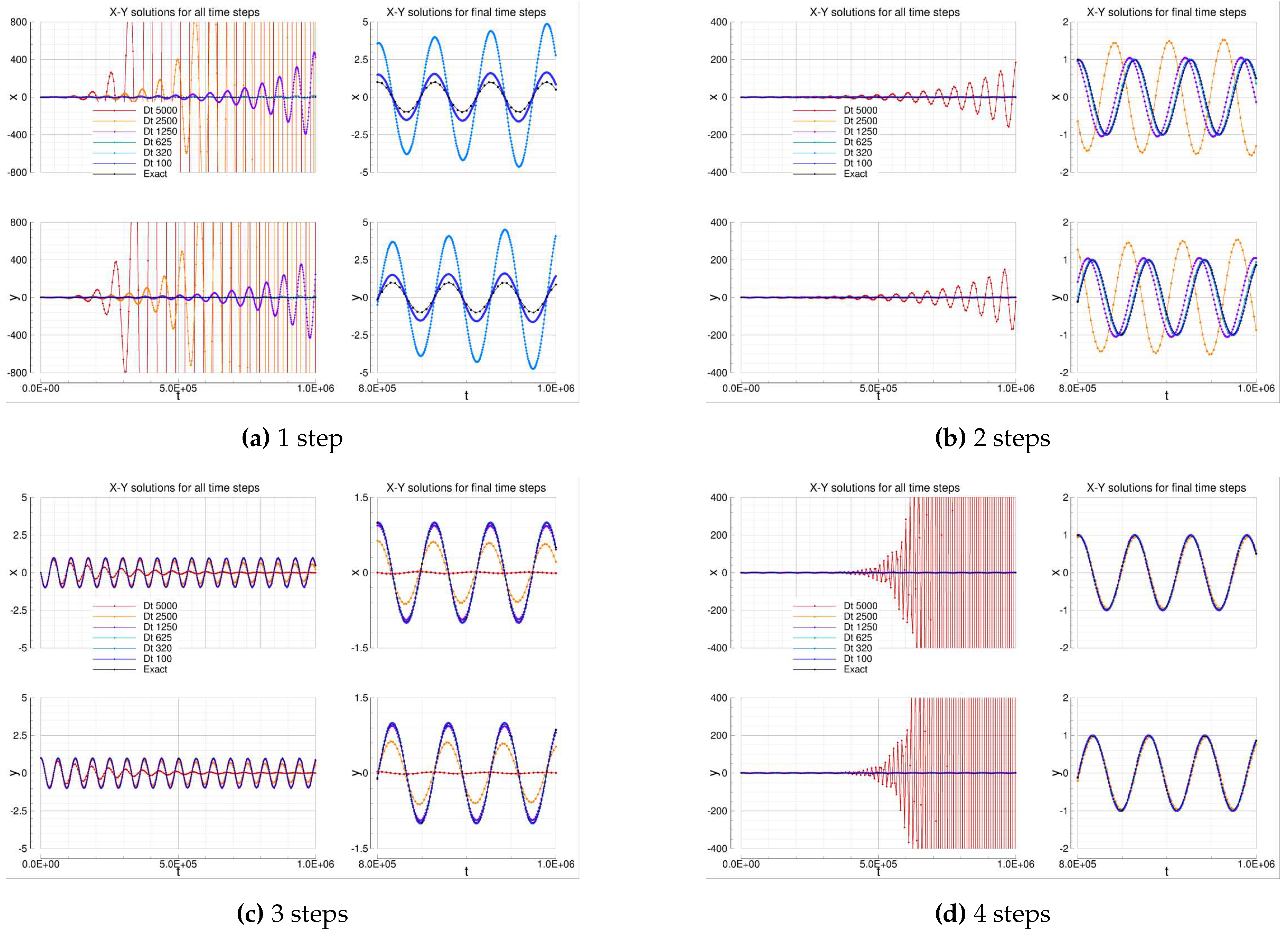
Figure 2.
Oscillation equations solutions computed by means of Adams-Bashforth-Moulton solvers
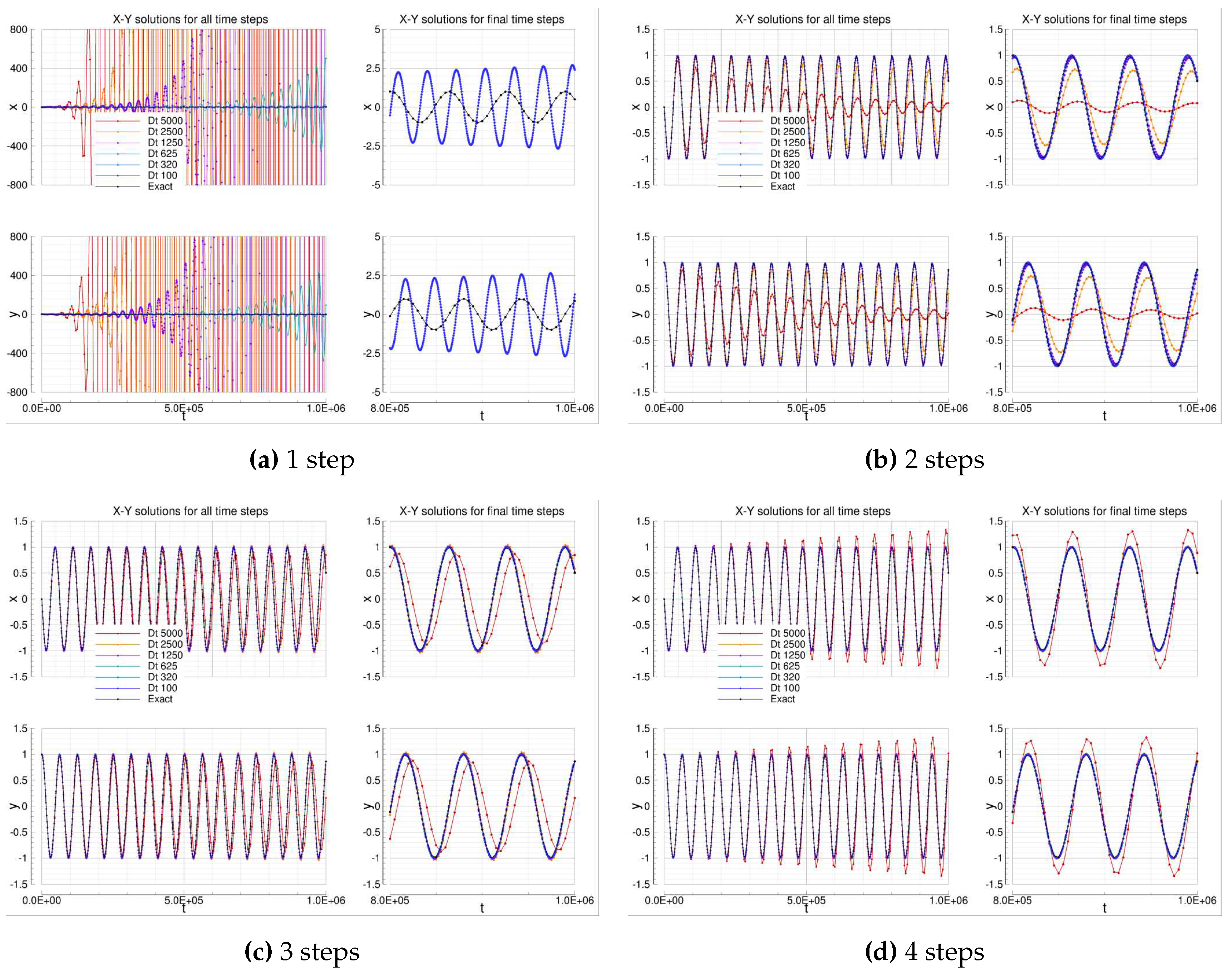
Figure 3.
Oscillation equations solutions computed by means of Adams-Moulton solvers
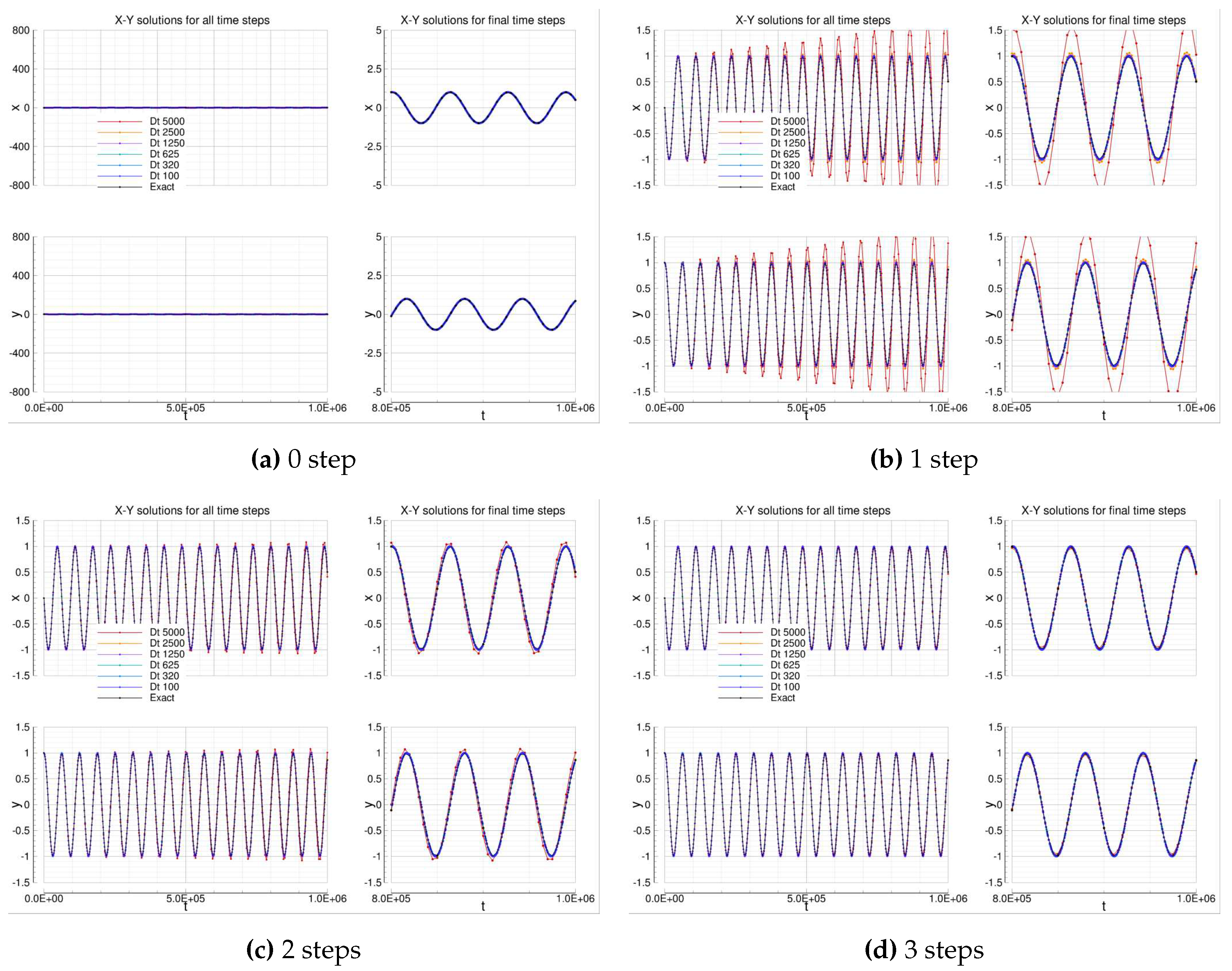
Figure 8.
Scaling efficiency with CAF programming model.

Figure 9.
CPU time consumed with caf programming model
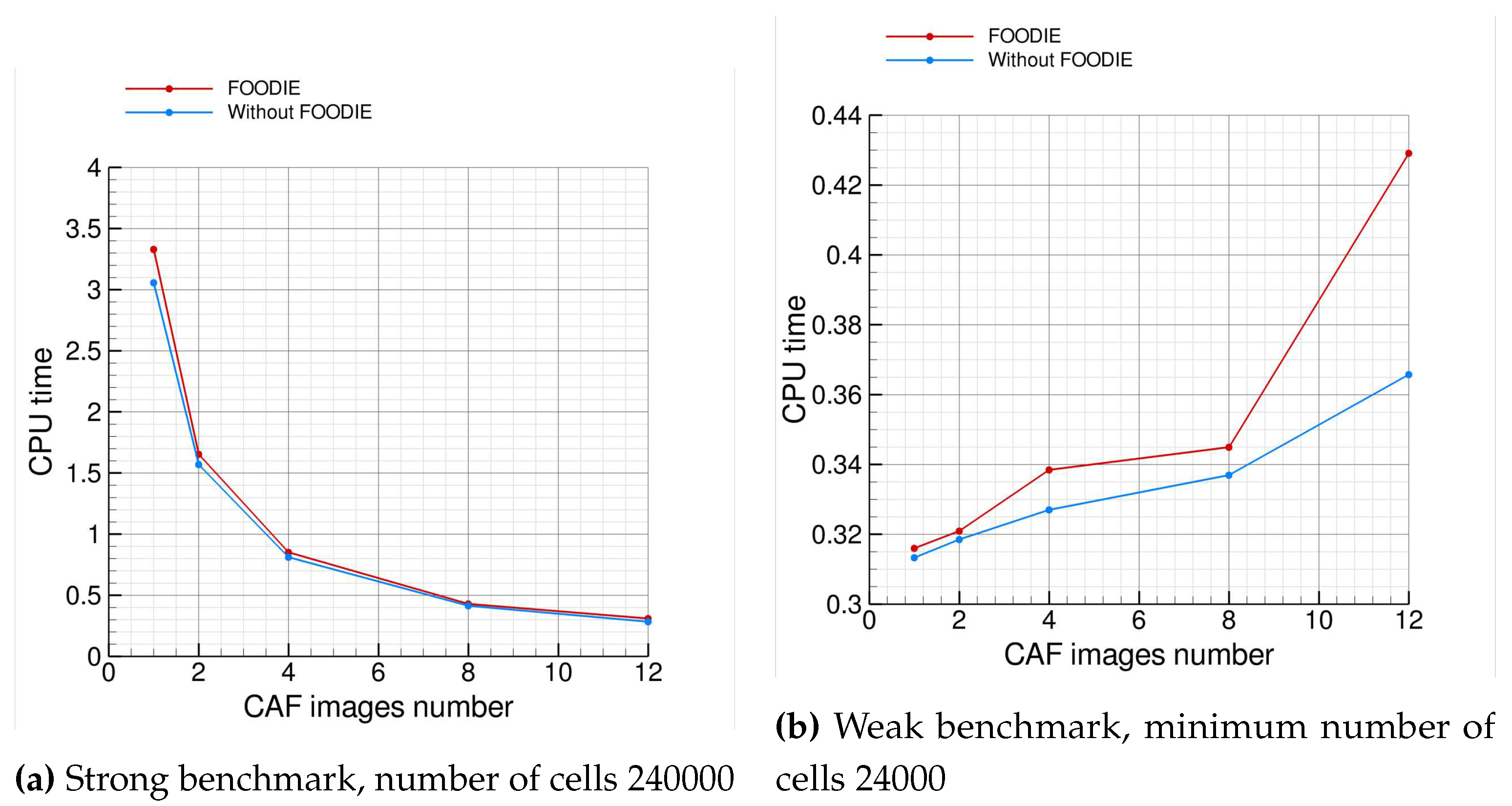
Figure 10.
Scaling efficiency with OpenMP programming model
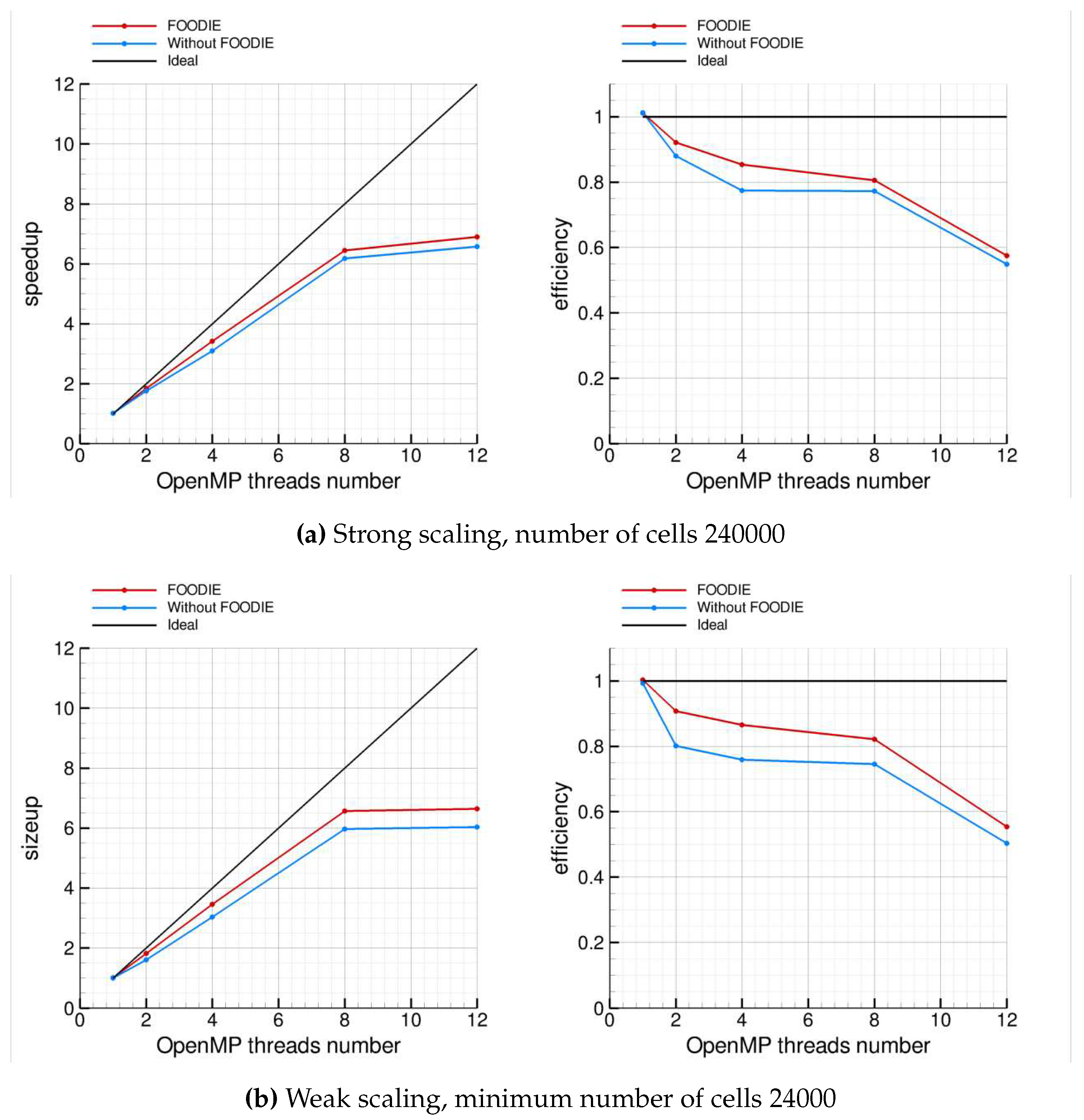
Figure 11.
CPU time consumed with OpenMP programming model.
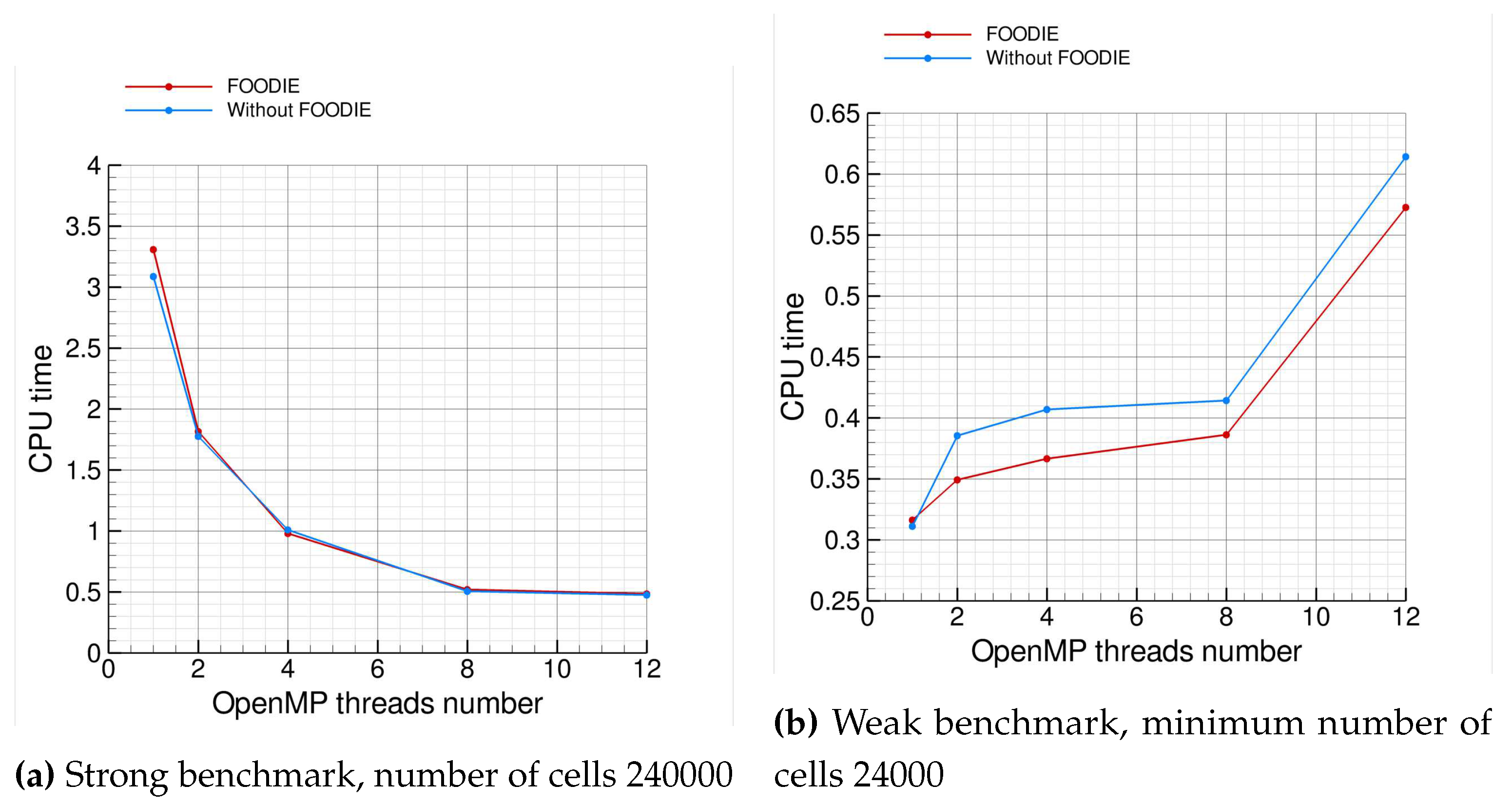
Table 1.
Butcher’s table for explicit Runge-Kutta schemes.
| ⋮ | ⋮ | ⋱ | |||
| ⋯ | |||||
| ⋯ |
Table 2.
Butcher’s table of 2 stages, 2nd order, Runge-Kutta TVD scheme.
| 1 | 1 | 0 |
| 1/2 | 1/2 |
Table 3.
Butcher’s table of 3 stages, 3rd order, Runge-Kutta SSP scheme.
| 1 | 1 | ||
| 1/2 | 1/4 | 1/4 | |
| 1/6 | 1/6 | 2/3 |
Table 4.
Butcher’s table of 5 stages, 4th order accurate, Runge-Kutta SSP scheme.
| 0.39175222700392 | 0.39175222700392 | ||||
| 0.58607968896779 | 0.21766909633821 | 0.36841059262959 | |||
| 0.47454236302687 | 0.08269208670950 | 0.13995850206999 | 0.25189177424738 | ||
| 0.93501063100924 | 0.06796628370320 | 0.11503469844438 | 0.20703489864929 | 0.54497475021237 | |
| 0.14681187618661 | 0.24848290924556 | 0.10425883036650 | 0.27443890091960 | 0.22600748319395 |
Table 6.
Explicit Adams-Bashforth coefficients.
| 2 | / | / | ||
| 3 | / | |||
| 4 |
Table 7.
Implicit Adams-Moulton coefficients
| 1 | / | / | ||
| 2 | / | |||
| 3 |
Table 8.
Comparison between rigorous mathematical formulation and FOODIE high-level implementation; the syntax "" and "" imply the summation operation
Table 8.
Comparison between rigorous mathematical formulation and FOODIE high-level implementation; the syntax "" and "" imply the summation operation
| Solver | Mathematical formulation | FOODIE implementation |
| explicit forward Euler | ||
| TVD/SSP Runge-Kutta | ||
| low storage Runge-Kutta | ||
| explicit Adams-Bashforth | ||
| explicit Leapfrog |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



