
Submitted:
30 June 2023
Posted:
30 June 2023
You are already at the latest version
Abstract
Electroencephalography (EEG) signals are the primary source for discriminating the preictal from the interictal stage, enabling early warnings before the seizure onset. The epileptic seizure prediction models face significant challenges due to data scarcity, diversity, and privacy. This paper proposes a three-tier architecture for epileptic seizure prediction associated with the Federated Learning (FL) model that enhances the capability by utilizing the significant amount of seizure patterns from globally distributed patients with data privacy. The determination of the preictal state is influenced by global and local model-assisted decision-making by modeling the two-level edge layer. Integrating the Spiking Encoder (SE) with Graph Convolutional Neural Network (Spiking-GCNN) works as the local model trained using the bi-timescale approach. Each local model utilizes the aggregated seizure knowledge from the different medical centers through FL and determines the preictal probability in the coarse-grained personalization. The Adaptive Neuro-Fuzzy Inference System (ANFIS) is utilized in fine-grained personalization to recognize epileptic seizure patients by examining the outcomes of the FL model, heart rate variability features, and patient-specific clinical features. The proposed seizure prediction is evaluated using benchmark datasets by comparing them with the existing works to demonstrate the potential results.
Keywords:
Epilepsy
; Seizure Prediction
; Preictal
; Federated Learning (FL)
; Spiking Encoder
; Graph Convolutional Neural Network (GCNN)
; Patient-specific Personalization
1. Introduction
Epilepsy is a chronic neurological dysfunction syndrome characterized by repeated seizures induced due to irregular and excessive brain activity. Characteristics of seizure involve loss of consciousness, disruption of movement, and other cognitive malfunctions [1]. Epilepsy poses a severe disease burden; 70 million people are affected by epilepsy worldwide, according to the World Health Organization (WHO) survey and about 20 million new epileptic patients are recorded yearly [2]. Up to 70% of epileptic patients’ conditions are medically manageable by Anti-Epileptic Drugs (AED), whereas 30% of people with epilepsy are unmanageable due to the unpredictability of seizures [3]. Thus, epileptic seizure prediction becomes extremely important to save patients from seizures before they occur. Electroencephalogram (EEG) records the brain's electrical activity and serves as an analytical and diagnostic tool for epilepsy. EEG is a widely used signal in measuring the electrical, metabolic, or clinical changes in brain activity for observing the transition from the non-seizure state to the seizure state. EEG recordings of epileptic patients are categorized into multiple consecutive stages depending on the occurrence of seizures [4]. Preictal refers that the occurrence before the onset of a seizure, ictal stage refers to the phase during the occurrence of a seizure, postictal stage refers to a period after the seizure, and finally, the interictal stage denotes the seizure-free period between two seizure occurrences [5]. Seizure onset [6] implies the actual generation of clinical seizures in the cortex. Figure 1 illustrates the epilepsy stages.
Epilepsy is a life-threatening disorder due to unexpected seizure episodes, creating a high psychological and social impact on epileptic patients. To promote the quality of life, prediction is necessary to control impending seizures [7]. It is essential to device a potential seizure prediction method for patients who cannot be treated with medication. In the epileptic EEG signal processing, seizure detection and prediction are modeled as classification tasks. The small seizure duration in EEG recordings indicates that the interictal state is comparatively longer than the ictal state. Hence, the seizure detection task attempts to categorize the ictal state from the interictal state. In the preictal interval identification subsequence, the seizure onset prediction critically supports the early medical diagnosis of epileptic seizures in the patients.
Despite the abundant epilepsy research activities, researchers have envisioned the possibility of accurate seizure prediction by interceding before the onset of seizure indications [8]. Conventional works utilize the handcrafted features marked from the EEG signals to locate the preictal state before seizure onset. However, the manual feature extraction leads to inaccurate seizure prediction due to information loss and extends the warning time. Epileptic seizure prediction research works have employed various models, such as machine learning and signal processing [9]. Machine learning-based seizure prediction and medical diagnosis have been accompanied by privacy concerns due to the considerably sensitive health data. In addition to the patient characteristics in the health data, processing the diagnosis result is also sensitive; hence, privacy becomes a major constraint. Even though machine learning-based diagnosis researchers have investigated the different encryption methods, medical diagnosis systems confront low efficiency while achieving high privacy levels. The concept of Federated Learning (FL) [10] has emerged as the potential solution to overcome privacy issues that can train the machine learning models from the data of distributed edge devices worldwide.
Developing a high-performance model is crucial to provide a reliable, real-time medical diagnosis. The FL model protects the users’ data by transferring only model parameters trained locally on the client device instead of transferring the clients’ data to the cloud. Owing to the shortage of clinical experts and high-cost manual diagnosis, adopting FL improves the quality of healthcare service without an expensive diagnosis. In the FL, the local model learning and decision-making are leveraged from local data and global model knowledge, whereas the global shared model receives the updates from the distributed local models trained on various data. Hence, the main aim of the early epileptic seizure prediction system has been fulfilled by the privacy, minimal latency, and minimal power consumption-assured FL model.
Although most of the conventional epilepsy prediction research works [11] have increasingly applied Convolutional Neural Networks (CNN); however, the high diversity and complexity in the EEG signals deteriorate the prediction performance of its simple structure. Moreover, the epilepsy prediction system confronts the computation of optimal or personalized preictal period for the training set. Previous machine learning-based seizure prediction approaches have investigated a fixed preictal interval in the training samples. Patients have different preictal duration based on their characteristics before the seizure onset. Hence, examining a common preictal period becomes ineffective for accurate seizure prediction. Thus, as modeled in Figure 2, this work aims to build a patient-specific preictal period detection system to predict seizure onset quickly with high accuracy and privacy.
1.1. Contributions of this Work
This work proposes a three-tier architecture for a seizure prediction mechanism by applying federated learning and the hybrid deep learning model to detect the preictal class precisely. Notable contributions of this work are presented below:
-
Contribution 1: Design of Seizure Prediction System
- ▪
- Research Gap: Data Scarcity, Privacy, and Manual assistance in Real-time seizure prediction
- ▪
- Contribution: This work designs the preprocessing and classification stages in a two-level edge layer in the FL model instead of building the local models in the hospitals to ensure real-time prediction without manual interruption. Moreover, the postprocessing stage is also automated by the Adaptive Neuro-Fuzzy Inference System (ANFIS) model.
- ▪
- Achievement: As proof of principle in the FL, the data scarcity and privacy problems are resolved by utilizing the aggregated knowledge of seizure patterns from the distributed EEG signals, and the design of a two-level edge layer mitigates the manual interference.
-
Contribution 2: Preprocessing and Classification
- ▪
- Research Gap: Lack of Preictal-aware Learning Process
- ▪
- Contribution: To enhance the preictal state detection capability, this work generates the bi-timescale approach based on segment-aware training samples and models the layer-wise feature space of EEG signals. In particular, this work designed a learning model with the combination of a Spiking Encoder (SE) and Graph Convolutional Neural Network (GCNN) to handle the diversity and complexity of EEG signals. Furthermore, the local model utilizes global knowledge and distinguishes the preictal from the interictal state.
- ▪
- Achievement: Global preictal pattern-based coarse-grained personalization
-
Contribution 3: Postprocessing
- ▪
- Research Gap: Need for patient-specific seizure prediction
- ▪
- Contribution: This work employs the ANFIS-PSO model for fine-grained preictal personalization and adaptively integrates the Heart Rate Variability (HRV) features and clinical features, along with the seizure probability obtained from the FL-assisted coarse-grained personalization to strengthen the patient-specific seizure onset prediction ability in the edge server.
- ▪
- Achievement: Towards accurate seizure prediction
1.2. Paper Organization
This seizure prediction paper is structured as follows. Section 2 represents a literature review of previously developed epilepsy prediction research works. The system model and problem formulation contemplated in this epileptic seizure prediction work are described in Section 3. Section 4 contributes to the proposed epileptic seizure prediction methodology. Section 5 presents the experimental evaluation with the experimental setup and datasets used in the proposed model and compares previous works. At last, the conclusion and summary of the proposed approach are discussed in Section 6.
2. Literature Review
In recent decades, machine learning models have gained significant attention in predicting healthcare services' outcomes, including disease prediction, pattern extraction, and decision-making.
2.1. Deep-Learning based Epilepsy Prediction Approaches
A patient-specific seizure prediction approach [12] adopts the CNN model to categorize the preictal stage using EEG and iEEG signals. The short-time Fourier transform performs raw EEG data preprocesses with minimal effort in the feature engineering process. A seizure prediction framework [13] using Long Short-Term Memory Networks (LSTM) is developed to analyze the preictal state of EEG signals. This LSTM-based seizure prediction utilized a broad range of feature extraction, namely, frequency and time domain, graph theoretical measures, and EEG correlation, to impart a solid ictal prediction performance. A seizure prediction methodology [14] is designed to distinguish the preictal and interictal phases using CNN and conducted data equalization on conquering the trial imbalance problem. This model utilized common spatial patterns and wavelet packet decomposition feature extractors to extract temporal-frequency characteristics of EEG. The epileptic seizure occurrence prediction model [15] exploits the multi-view CNN model to attain a variety of views of EEG. This model acquires discriminative and adequate feature representations over EGG data using time and frequency domain methods. A seizure prediction approach [16] is developed by utilizing LSTM to recognize the preictal state from the interictal and ictal state of EEG. This approach builds a stacked Bi-LSTM network for better seizure prediction performance before seizure onset.
An end-to-end patient-specific model [17] employs CNN to predict seizures before seizures. This method implements the CNN network with one-dimensional (1D) and two-dimensional (2D) kernels in the initial and final stages of convolution and max-pooling layers to attain greater accuracy. The efficient seizure prediction approach [18] relies on CNN to extract features automatically and classify preictal and interictal segments of the EGG. This approach conducts EEG channel optimization with channel reduction technique to predict seizures of EEG signals. Patient-specific seizure prediction model [19] examines the Electrocardiogram (ECG) features, particularly time and frequency features from the RR series, through the recurrence quantification analysis. Furthermore, it exploits the Support Vector Machine (SVM) model to classify the preictal and interictal segments. To assess the preictal time in the EEG signals, the work in [20] investigates the HRV features of ECG signals with the contemplation of frequency and time domain features for the recognition of each seizure. The early changes in the EEG and HRV feature assist in characterizing the preictal and interictal states in drug-resistant epilepsy patients. The research work [21] develops the ANFIS-based seizure prediction system for patients affected by Parkinson's disease. By modeling the ANFIS for the EEG signal analysis, it detects the starting point of the seizure onset and supports real-time seizure prediction. However, a real-time medical diagnosis from examining a single modality of EEG input data alone becomes ineffective due to the lack of exploring the different inputs.
2.2. Hybrid Learning-based Epilepsy Prediction Approaches
A generalized deep learning framework [22] for seizure prediction employs CNN-LSTM architecture. At first, this framework applies Short-Time Fourier Transform (STFT) to carry out the preprocessing of EEG signals effectively. Then it captures the features of EEG sequential segments using spectral, spatial, and temporal methods and distinguishes it as the preictal EEG from interictal EEG with high prediction performance. Effective patient-specific seizure forecasting method [23] employs a Deep Convolutional Neural Network (DCNN) and Bidirectional LSTM (Bi-LSTM) models to analyze the temporal and spatial features of raw EEG. Subsequently, this method enables a Deep Convolutional Auto-encoder (DCAE) model-based supervised learning method with transfer learning and channel selection to diminish the training time and computation load while predicting the seizure events. The research work in [24] employed EMD and DWT methods for converting the raw EEG signals into the extracted features provided as the input to the classification models, particularly the decision tree, and evaluated their approach to the Bonn EEG dataset. The epilepsy prediction system in [25] proposed a method that combines LSTM and CNN and presented a Long-term Recurrent Convolutional Network (LRCN) model. Designing an LRCN determines the preictal segments from the analysis of spatial and temporal information of the EEG sequence from the CHB-MIT dataset. A novel epileptic seizure prediction approach [26] presents a hybrid DenseNet-LSTM model for forecasting patient-specific epileptic seizures. The hybrid DenseNet-LSTM model integrates DCNN and LSTM network. Furthermore, it applies Discrete Wavelet Transform (DWT) to EEG, transformed using CNN, and preictal and interictal states are classified using LSTM.
The epileptic seizure forecasting method [27] is developed to predict the preictal stage of seizure activity. This method encompasses a series of processes, including Empirical Mode Decomposition (EMD) for preprocessing EEG, Generative Adversarial Network (GAN) to overcome class imbalance issues, and CNN for automated optimal feature extraction and exploits LSTM to distinguish preictal and interictal segments robustly. An epileptic EEG recognition approach [28] utilizes the improved residual network architecture to diagnose epileptic EEG and automatically labels different states of epileptic EEG. This improved residual network is an independent convolutional recurrent neural network (RCNN) composed of a One-Dimensional CNN to preprocess the essential features of EEG and an Independent Recurrent Neural Network (indRNN) to learn the correlation between the EEG signal sequences and discriminate different ictal periods. Deep ensemble learning is proposed [29] for epileptic seizure forecasting, which encloses EMD to remove noise and GAN to generate synthetic preictal stages. Consecutively, it exploits three-layered customized CNN to extract a comprehensive feature set and SVM, CNN, LSTM enabled ensemble classifier using Model Agnostic Meta-Learning (MAML) to differentiate between preictal and interictal states. A new neuromorphic computing approach [30] employs the Gaussian random discrete encoder to create the spike sequences for the input EEG data. The combination of the energy-efficient SNN and CNN leverages the seizure prediction by the potential advantages of each model. The seizure prediction approach [31] mitigates the need for higher computation consumption in information fusion by adopting a Graph CNN (GCN) that explores the graph structure of EEG signals. Designing simple network architecture with node and edge features predicts the seizure from the scalp EEG signals. Despite this, the generalized graph structure misleads the medical diagnosis of each patient because the edge features in the graph are sensitive to the different patients.
The above literature analysis concludes that there are different models for epileptic seizure prediction, and new solutions are emerging. Although, several research directions in the patient-specific preictal state detection leveraging early diagnosis are not pioneering. Hence, several constraints still need to be resolved for reliable and real-time seizure prediction. For decision-making in the scarce data environment, extracting other patients’ preictal knowledge has not received adequate attention. Also, automated personalization for small EEG patterns without handcrafted features remains emerging in research. Fusion of multiple seizures indicating features, such as the EEG signals, ECG signals, and clinical records, needs further research for accurate seizure prediction. In deep learning, data scarcity handling and privacy-preserving in small sensitive medical data are not well studied. Hence, this work addresses these issues through the attempts modeled in the following task of epilepsy prediction.
3. Design of Epilepsy Prediction
In the real world, the healthcare system highly demands Cloud computing technologies to combat the massive generation of voluminous data from the revolution of smart technologies. To avert the uploading and to store a tremendous amount of raw data on a centralized server, smart healthcare systems adopt the Federated Learning technique in a decentralized manner, ensuring the privacy of sensitive local data.
3.1. System Model
This work presents the epilepsy prediction model that alerts patients and medical practitioners regarding the onset of epileptic seizures in distributed medical centers or hospitals.
From the reference of the work [32] that motivates the analysis of the ECG features, it is assumed that the (i) preictal interval search relies on state changes in EEG and ECG signals, and (ii) preictal state localization is influenced by ECG-related events, preceding the seizure onset on EEG. Preictal period initialization does not occur strictly near the seizure onset for each subject and varies over the patients; hence, the generalized consensus of the preictal period becomes infeasible. To furnish medical services in the distributed client environment, the federated learning model has adopted the advantage of a centralized global server, and clients update their knowledge by learning model parameters. The model-centric and cross-device FL model is considered for implementing the three-tier proposed system. In federated learning, the model-centric approach refers to the heterogeneous data stored in the different local hospitals when the learning model is fixed and centralized for training the different datasets. The cross-device refers to the data received from different edge devices belonging to a single organization like different hospitals only, which is contrast to various multiple organizations like data received from hospitals. To design the FL-assisted epileptic seizure prediction, three different hospitals’ data with the scenarios of the same feature space recorded from the EEG channels and different samples across three EEG datasets regardless of the dimensions, referred as the sample-based FL or horizontal FL. In the distributed hospitals, each dataset comprises the monitored observations of brain activity using different electrode placement systems at various sampling frequencies using different channels. In the FL design, the local model decision-making is interrelated with the global model by aggregating the local model parameters from the different clients for model building on the cloud server. By modeling the FedAvg algorithm for aggregating the local model weights of different clients at each iteration, the proposed epilepsy prediction system repeatedly aggregates the model weights until convergence on the centralized global server as well as the local model outcomes. In FedAvg, central server aggregates the parameters obtained from the distributed local models and then, distributes the global parameters to the clients. The federated learning greatly supports the medical clients of mobile healthcare, home healthcare, and hospital healthcare. This work predominantly intends to alert the patients or caretakers before the onset of epileptic seizures by identifying the potential signs that help distinguish between the preictal and interictal state from the EEG timeframes. Hence, the design of the proposed prediction model involves three major components in three-tier architecture: the hospital as the client, the local model as the edge server, and the cloud as the global server. The proposed three-tier architecture is illustrated in Figure 3.
Tier 1 focuses on gathering EEG signals from diversified patients in distributed hospitals in the three-tier architecture. In hospitals, EEG signals are recorded from the placement of non-invasive electrodes through a 10-20 electrode placement system and different mobile EEG systems like a headset, mobile EEG cap, saline-based electrodes, and so on. Tier 2 is responsible for utilizing the data collected from the hospitals and building the local model for each hospital at the edge server instead of building the local models in the hospital. Tier 3 remotely builds the global model from the knowledge of local models to discriminate states of EEG timeframes.
Client (Hospital): The proposed system contemplates the horizontal FL model that utilizes the distributed datasets with the same feature space across all the clients, implying that hospital1 and hospital 2 have the same feature model in different dimensions with a different number of channels as the columns. The hospital or medical center region is modeled as tier-1 in the three-tier epileptic seizure prediction system architecture.
Local Model (Edge Server): In the FL model, the edge server plays a critical role in providing the computations and data storage closer to the clients, enhancing network availability with minimal latency. By the potential advantage of edge server, the transmission time is comparatively minimal than transmitting to the cloud hence, request latency becomes minimal. Moreover, due to comparatively less number of minimal network traffic in each edge server within its coverage area, the network availability is high at the time of requests compared to the network availability in the cloud. Time-sensitive healthcare applications greatly benefit from edge computing capabilities over the huge data generation. From the distributed EEG signals observed in various hospitals, the FL model builds the local model for each hospital and builds a global model without transferring the local data to the cloud or other clients, referring to the ‘Model-Centric’ FL concept.
Global Model (Cloud): The Cloud computing infrastructure acts as the global model for the remote processing of distributed hospitals’ sensitive data in the horizontal FL, involving the global knowledge aggregation based on the different preictal patterns obtained from the different local models using FedAvg.
As discussed above, this work designs three-tier architecture from the perspective of architecture. Furthermore, this work divides an entire epileptic seizure prediction procedure into three stages: preprocessing, classification, and postprocessing, outlined in Figure 4. In the proposed system, preprocessing and classification processes are modeled in the edge server under the concept of FL. In the classification phase, FL-assisted coarse-grained personalization is a binary classification problem for discriminating preictal and interictal classes. As mentioned in Figure 5.3, for the postprocessing, the proposed approach only utilizes the preictal class probability after obtaining the outcome from the coarse-grained binary classification model. In particular, the postprocessing involves ANFIS-based decision-making, which is executed in the edge server's first layer to mitigate the client's computational burden.
3.2. Problem Formulation
In the biomedical field, disease diagnosis systems have often encountered challenges in predicting epileptic seizure patterns from the EEG signals over data scarcity, diversity, and data privacy. This work contemplates two major research constraints in the epilepsy seizure prediction system: model generalization and preictal state identification.
Definition 1 (Model Generalization):
Owing to the pattern diversity among the patients, the patient-specific epilepsy prediction models have been predominantly focused on the previous works. The model generalization is essential to overcome several shortcomings faced by epilepsy prediction research, involving the scarcity issue of preictal samples and the computational burden in frequently training the models for every patient.
During the epileptic seizure prediction, the generalized model-assisted prediction capability maximizes the first research objective by minimizing loss among the ‘S’ number of patients (i). In equation (1), refers the actual and predicted value parameters of the learning model for the loss computation.
Definition 2 (Preictal State Identification):
Besides numerous developments in EEG signal processing research, seizures are unpredictable due to the lack of medical theory in proving the prediction results. The epilepsy seizure prediction model intends to distinguish the preictal and interictal states, considered a binary classification problem, as the second research objective. In the sequence of time-series EEG signals, the preictal state is the period immediately before the seizure onset [1, 7]. In the preictal state, the predictive probability of seizure is the same as throughout the sample segments, which is not intuitively acceptable due to the lack of discrimination between the preictal and seizure state over a different period. Hence, the minimization of the loss across the ‘V’ number of EEG segments (r) within a patient ‘i’.
Quantifying the seizure pattern changes in the EEG signals and modeling the prediction system to determine the epileptogenic transient changes becomes challenging task. The preictal state of seizure onset varies over the patients from a few minutes to many hours. In addition, the selection of inaccurate preictal length drastically affects the prediction results. Hence, preictal period selection should be patient-specific to avert the increased false predictions and the decreased prediction sensitivity due to the fluctuations in the preictal period. Thus, this work targets to maintain the trade-off between the model generalization and patient-specific preictal period selection or Preictal probability identification without compromising the prediction performance in the epilepsy seizure prediction system.
4. Proposed Epileptic Seizure Prediction Methodology
With the target of predicting epileptic seizures, this work focuses on designing federated learning for local model building, generalized model building, global knowledge aggregation and global preictal knowledge unification, and distinct preictal period modeling.
Figure 5 depicts the proposed epileptic seizure prediction approach along with the FL-assisted process. The edge server is responsible for automating epilepsy prediction with the assistance of the cloud, involving EEG preprocessing, generalized and distinct feature extraction, and personalized federated learning-based seizure prediction. In other words, the proposed approach designs a two-level edge layer, incorporating the data-aware process in the level 1 that is the lower layer in the edge layer and the model-aware process in the level 2 that is the upper layer in the edge layer. In the two-level edge layer, the data-aware process involves filtering, correlative feature selection, segmentation, and patient-specific preictal modeling, whereas the model-aware process involves generalized model building and distinct preictal period modeling. The computational steps in the lower and upper layers are subsequently performed from the lower to upper layers. In contrast, even though patient-specific preictal modeling is designed at the lower level of the edge layer, it relies on the outcome of the distinct preictal period modeling from the upper level of the edge layer.
4.1. EEG-Signal based Distributed Local Model Building
This section describes the design of the distributed local models on edge servers for the EEG signals obtained from each hospital or medical center as the client by adopting the federated learning model.
4.1.1. EEG Signal Preprocessing
In seizure prediction, scalp EEG signals are paramount in recognizing the different ictal segments and are recorded by the electrodes on the individual's scalp. In the proposed system, EEG signal preprocessing is imperative to remove the artifacts and noises. Recently, signal processing techniques have enabled the system to automatically identify and remove the artifacts in the EEG-based seizure prediction system. To model the end-to-end automatic epileptic seizure prediction system, the proposed approach follows several preprocessing procedures alone without requiring human interference for feature extraction. As a result, it conducts the filtering, artifact removal, and correlative feature or channel selection in the preprocessing step.
- i)
- Filtering and Artifacts Removal: The proposed prediction model applies the window and Butterworth filter methods to filter out the noise. During the preprocessing of EEG recordings, the second-order Butterworth bandpass filter is critical in examining and removing the artifacts. With the significance of providing a linear frequency to bandpass, the Butterworth bandpass filter is employed as an EEG signal preprocessing filter. Moreover, preprocessing involves normalizing and chunking the signals by a fixed length. In high-dimensional data, the values in EEG signals largely vary from one channel to another channel, which becomes critical during model training. Hence, normalization is essential for the EEG signal processing as the structured data processing on the learning model. Moreover, input EEG signals are divided as the minimal time period of 1second samples as the sliding window length based on the sampling rate of EEG recordings to precisely normalize the EEG signals per second rather than normalizing it into entire timeframe.
- ii)
- Correlative Channel Selection: To accurately predict the seizures, the proposed approach aims to select a minimal number of channels because all channels have equal significance in epileptic seizure prediction. The investigation of the correlation between different channels measures that examining interaction across brain regions in modulating the epileptic seizure activity becomes the potentially more vital standard for seizure onset prediction. The channel reduction in the seizure prediction system ensures the potential advantages of minimal energy consumption, reduction in overfitting rate, and increased time efficiency. In this correlative channel reduction scheme, the proposed approach evaluates each channel's significance on the classification outcome through the wrapper feature selection method. If any channel does not influence the accuracy improvement, the proposed approach ignores that channel, which does not reduce performance in the future. To perform the correlative channel selection, the proposed system adopts the Taguchi method [33] based optimization that provides the potential information with a minimal number of experiments based on the concept of a Design of Experiment (DoE). In the channel reduction, the iteration continues until the model's accuracy is degraded when removing any channels from the final set. Thus, the proposed approach efficiently selects the EEG channels for epileptic seizure prediction.
4.2. Federated Learning-based Generalized Model Construction
In the biomedical community, resolving the data scarcity constraint becomes a major challenge in accurately diagnosing patients due to inadequate data about epileptic seizures for each patient. In contrast, the deep learning model requires a large amount of training data or patterns for decision-making. To overcome this obstacle, the proposed approach intends to adopt federated learning for the model generalization that supports the utilization of the influence from the diversified patients’ epileptic seizure patterns. In the edge environment, the model generalization is essential for predicting the seizure onset with the contemplation of segment-aware training sample generation and spike sequence-aware pattern modeling in addition to only utilizing the model parameters from multiple clients.
4.2.1. Segment-aware Training Sample Generation
The key factor in the proposed system is the discrimination between the preictal and interictal states. Hence, the segmentation process necessitates recognizing standard state transitions provided by clinical experts. The statistical features of the non-stationary EEG signals vary over a time interval. Accordingly, based on the data distribution, the proposed approach divides a long sequence into short-duration EEG segments with or without overlapping EEG signals. Thus, sensing EEG signals with a shorter duration benefits the minimal computational power, storage requirement, and low transmission bandwidth. In the proposed epilepsy prediction, segmentation is the process of dividing the input EEG samples into different timescale-based EEG samples. Segmentation is based on the timescales 1s, 2s, 4s, and 8s. Initially, the input EEG signals are segmented into four different timescales at the process of segmentation and then, the bi-timescale approach is performed for the decision-making. Bi-timescale approach is the process of selecting any two segments among four segments for each dataset and jointly making decisions in terms of binary classification in the coarse-grained decision-making.
Bi-Timescale Approach: EEG signals are time-dependent; hence, the proposed approach targeted the segmentation and learning of temporal signals with the aware of the bi-timescale modeling, which assists in contemplating the inherent relationship in the time domain. EEG signals are likely to comprise different potential information in various timescales. Hence, investigating four different timescales and selecting two optimal timescales enforces significant performance improvement for different EEG datasets. Finally, two timescale information are concatenated for decision-making in the GCNN model.
Due to the collection of long-period EEG signals, the segmentation of the signal is essential for the analysis by modeling representative forms of periodic and non-stationary EEG signals as smaller and mutually exclusive segments. Different EEG signals are gathered at different sampling rates in the distributed environment. Hence, signals' segmentation is critical for recognizing preictal patterns. Accordingly, the selection of optimal signal partition over the window length evaluates the 1s, 2s, 4s, and 8s EEG segments to determine any two different EEG segments that create the impact on the accurate preictal state detection in the corresponding dataset, referring to the bi-timescale based learning process, depicted in Figure 6. From the examination of previous EEG segmentation researches [34,35], the time duration of EEG segments is widely modeled as either 1s, 2s, 4s, or 8s; hence, this work considers all four segmentation lengths to optimally select the appropriate length for each dataset through the bi-timescale approach. The proposed system adaptively selects highly influencing EEG segment length for each dataset to uniquely examine the seizure patterns in the different distributed EEG datasets, which is determined by the ROC curve analysis. The significance of ROC curve-based examination is measuring the relationship between true positives and false positives in each dataset, facilitating the assigning of optimal segment duration for the corresponding dataset. Thus, the optimal EEG segment is found for a single dataset in which the segment is optimal in all the channels, which takes into account during the training of the learning model.
In the EEG signals, modeling the training samples enforces the learning behavior of deep learning to distinguish between preictal and interictal patterns. With the assistance of ROC analysis, the optimally selected EEG segments accomplished by the bi-timescale approach from the multiple timescales plays a vital role in the decision-making because each timescale conveys different potential information to the learning model. To generate the training samples, the segments are formed for both the preictal and interictal classes of the EEG signal using a sliding window, with and without overlap, respectively, based on the ratio of samples in classes for the balanced operation. Wherein, sliding window length is based on the segmentation timescales. Mentioned 1s, 2s, 4s, and 8s timescales-based EEG segmentation are performed under the sliding window concept. The interictal state belongs to the non-seizure EEG recordings, whereas the preictal state is sensitive to the duration before the seizure. Instead of modeling only one timescale of EEG data as one training sample, the research contemplates additional timescale signal duration as a single training sample to mitigate the noise effect in the training knowledge. As a result, the training set generation is influenced by the number of segments in the preictal and interictal parts with the balanced data modeling towards the recognition of seizure state transitions.
4.2.2. Spike Sequence-Aware Feature Space Modeling and Global Modeling
As stated in the neuroimaging concept of epilepsy [7], the interictal indicates the seizure-free period, and the preictal state implies the pre-seizure period in the time series of EEG signals. The length of the preictal period varies among the patients with different definitions; however, the reference standard is unavailable to conclude a particular preictal period. Hence, with the assistance of the FL, the proposed approach has the different Preictal patterns knowledge learned from different preictal datasets, which facilitates the conclusion about the generalized preictal pattern from the global model weights. The interictal period is the duration of neither the preictal nor ictal period in the sequence of EEG signals. Currently, epileptic seizure prediction research works have employed CNN and RNN models [36,37] for classifying the high dimensional preictal and interictal EEG patterns in the spatial and temporal aspects; however, the conversion of the EEG signals into a Euclidean grid structure suffers from the loss of adjacent spatial information. Hence, the proposed approach exploits the Graph Convolutional Neural Network (GCNN) with the succeeding of the spiking encoder, which results in the consumption of the minimal computational and storage resource across the channels after feature extraction. In the proposed epilepsy prediction system, the main objective of applying spiking encoder is to encode and represent the input EEG signals as the spike-aware sequence representation. Due to the matrix addition in the computation of Spike Neural Network (SNN) model instead of multiplication process, the Spike Encoder (SE) becomes energy efficient. Moreover, SE is able to model dynamical modes of network operations by encoding the temporal information in the signals. As a result, the SE is more computation and energy efficient.
- i)
- Spiking Encoder-based Feature Space Modeling
In the EEG signals, the proposed system intends to detect the spikes over the periods of the EEG timeframe for all the channels. Hence, the proposed system designs the deep neural network with the spike encoder, Graph Convolutional Neural Network model, and weight mapping to predict seizures. This approach builds the spiking-GCNN model for two sets of training samples generated from optimally selected EEG segment duration until the hidden layer representation of the GCNN model. To perform a bi-timescale approach, the proposed approach concatenates representation obtained from the optimally selected two timescales and provides them as the input to the dense layer of the spiking-GCNN model, as illustrated in Figure 6. Instead of extracting the statistical features by the time domain-based signal processing methods for the graph construction, the proposed approach automatically examines the features by adopting the spiking neural network that infers the reflection in the shape features in the time domain, involving the deviation in the signal amplitude, changes in the slopes, and the number of spikes. In the hybrid Spiking-GCNN model, the weights are trained for the CNN model associated with the energy and computation-efficient Spike Encoder model mapping in which the SE provides the representation of the EEG data as the spike sequences. To precisely generate the spike representation, the proposed system models the spike encoder with the surrogate gradient method that enables the backpropagation in the feed-forward neural network for the discrete nature of spikes. To build the spike encoder, the ‘up’ and ‘down’ threshold parameters are determined for each segmented timestep in the sequence of EEG signals. Instead of creating a random matrix for the input timesteps, the proposed approach builds a segment-aware matrix to model signal amplitude values for the segmented timesteps and channels. By generating a segment-aware matrix, the encoder model compares every signal value in the input data with the mean value obtained from the mean of ‘up’ and ‘down’ threshold points. If the mean value is greater, the spiked value of a particular signal will be ‘0’; otherwise, the spiked value will be ‘1’. Moreover, the encoding representation of the input sample in each segment relies on the number of spikes per sample and the spike average per sample duration.
The formulation of equation (3) is based on the strategy of the high number of spikes, and spikes with comparatively minimal duration indicate that the segmented timestep has a higher probability of seizure onset (). Consequently, the representation of the signals in the preictal class has higher weights of vector values than in the interictal class. In equation (3), and denotes the number of spikes at segmented timestep ‘t’ in qth channel and the duration of spikes at segmented timestep ‘t’ in qth channel, respectively. ‘m’ refers to the total number of channels and refers to the average duration of spikes occurring in each segment. By applying the ‘AND’ logic between the spikes computed from the spiking encoder and the seizure probability assigned by the equation (3), i.e. the proposed approach fine-tunes the spike sequences. encoded value of the input signal (S) at segmented timestep ‘t’, obtained from the spiking encoder. Thus, the spiking encoder generates the high-level abstraction of the input signals with the influence of the weight updation by the surrogate gradient descent-based backpropagation, and the GCNN discriminates the preictal and interictal from the modeling of the node and edge parameters in the graph structure.
To predict seizures from the signals, the proposed work trains the GCNN on the input data to get weights and maps the weights with the spike sequences transformed from the spike encoder. To provide the encoded knowledge to the GCNN model, the proposed approach builds a graph, in which referring to a set of ‘m’ channels and ‘E’ implies the connectivity between the channel electrodes located on the patients’ brain. In the proposed system, the node features are the vector representations obtained from the fine-tuned spike sequences. The adjacency matrix, comprises the edge features of the relationship between the channel values in the preprocessed EEG signals. To address the numerical instability, dispersion, and gradient explosion problems over the multiple iterations, the proposed approach applies the renormalization and generates the layer-wise propagation rule in the spiking-GCNN as referred from work [31]. The bi-timescale approach-based spiking-GCNN modeling achieves layer-wise propagation. Instead of examining the node and edge relations from the graph structure alone, modeling the spiking encoder-resultant representation matrix in each layer facilitates the accurate recognition of inherent relationships in each class.
In equation (4), , and refers to the activation matrix, representation matrix obtained from the spiking encoder, and layer-specific weight matrix in the Lth layer. ‘A’ and ‘’ denotes the adjacency matrix and renormalized degree matrix of the graphs, respectively. implies an activation function in the GCNN model.
- ii)
- Global Knowledge Aggregation
The deployment of intelligent models necessitates periodic training and updation, which burdens medical practitioners or experts to generate the annotated labels for the massive volume of patients at a particular time. Hence, federated learning mitigates this constraint across the hospitals during the peak volume season, enabling the medical centers to download and exploit the most up-to-date model for an epilepsy diagnosis. Accordingly, the adoption of federated learning leverages the proposed system to utilize other patients’ epileptic patterns to improve seizure prediction performance. Even though variations exist across the patients, the root-cause pattern of the epilepsy disease similarity appears between the patients. Accordingly, the proposed prediction system trains a model with the global model trained on other patients’ data and updates the local model with globally trained parameters. Adopting the global model parameters to each local model assists in predicting the epileptic seizure without jeopardizing the performance.
During the training stage in generalized federated learning, the proposed approach builds the global model based on the loss function of the prediction model () computed across all the patients or subjects (S). In the seizure prediction system, the different states (C) refer to the preictal and interictal states observed from the ‘S’ subjects in the different local medical centers. Let be a set of EEG samples from the subject ‘S’, where denotes the number of training samples. Let be a set of labels from the state ‘C’. To predict epileptic seizure, the proposed system maps the weights to the softmax-based probabilistic distribution, .
As formulated in equation (5), (.) results in one if there is equality between the actual and prediction outcomes and otherwise zero. In equation (5), i, j, and k refers the patient or subject, training sample, and class respectively. denotes the label of jth training sample of ith subject. Thus, the proposed approach aggregates the preictal segment-based knowledge with the appropriate global model parameters.
4.3. Coarse Grained-Personalization with Optimal Trade-off
In the proposed system, each local model receives the weights from the aggregated global server and updates its model for decision-making on its local EEG dataset. It is referred to as coarse-grained personalization, accomplished by the FL model. Furthermore, it maintains the optimal trade-off between the generalized and patient-specific personalized models. With this objective, to iteratively update the local model with the shared weights, the proposed approach measures the divergence between the probabilistic distribution of the generalized global model () and the personalized local model () using the Bregman divergence. In the proposed system, the Bregman divergence is computed based on the asymmetric measurement of the logistic loss. In equation (6), the proposed approach normalizes the probability of the global model () by analyzing the impact of the probability of the seizure computed from the outcome of the fine-tuned spiking encoder. The reason behind that is the personalized model needs to be updated for a higher probability of seizure onset in the number of ‘High-’ samples () for the corresponding local dataset, as formulated in equation (7).
The proposed approach computes the loss of the client data by contemplating the prediction loss () and divergence loss () with two constant weights (,), respectively. As modeled in equations (6) and (8), the loss divergence and loss are computed for the global-to-local and personalized local models, respectively.
Instead of sharing the sensitive raw medical information of the patients and network structure with the global model, the proposed approach shares the weights of the local model. A central hub in federated learning coordinates the learning process of all the clients through the global modeling and ensures better accuracy than the clients’ local models with the assumption of the data distribution of all clients is similar. In the proposed system, the training process of local models is held on the edge server for every hospital, and each client tests their samples while contributing to the global model and local model maintained by the cloud and edge server correspondingly. In consequence, each client utilizes the advantage of the knowledge from the global deep learning model to compensate for a learned knowledge from a minimal amount of training data in their hospitals. To decide the number of iterations in the federated learning, the proposed system adopts the early stopping method as the termination criteria that retains the model concerning the performance improvement on a fixed number of epochs. Consequently, the proposed approach discriminates against the preictal state from the interictal state and preserves the patients' privacy during the training process. Thus, the proposed approach significantly maintains the trade-off between model generalization and personalized preictal detection in the epileptic seizure prediction system.
4.4. Distinct Preictal State Modeling Seizure Prediction
In the proposed system, the postprocessing is the distinct preictal period modeling, which is highly correlated with the patient-specific clinical features, succeeded by the coarse-grained personalization obtained from the FL-assisted decision-making. The proposed approach utilizes several potential clinical features and Heart Rate Variability (HRV) of each epileptic patient with the assistance of the ANFIS-PSO in the edge server for fine-grained personalization. Figure 7 illustrates the ANFIS architecture used in the proposed epileptic seizure prediction system.
4.4.1. ANFIS-PSO based Fine-Grained Preictal Personalization.
The prediction of seizures and the diagnosis of epilepsy rely on both the electrophysiological and clinical data of each patient, in addition to the generalized global knowledge aggregated from the distributed medical centers. The correlation of the features from the clinical aspects of the seizure and electrical abnormalities from the input of EEG records along with the ECG signals facilitates the fine-grained personalization of the preictal state identification. The seizure onset time varies over the patients and is likely to be recognized by several seizure-related changes in the behaviors. To avert the confused state of the seizure onset identification in the EEG signals, the proposed approach exploits the additional clinical factors and enforces the precise determination of the seizure onset through the patient-specific modeling of the preictal duration. The actual start of the preictal duration varies from patient to patient. Hence, the proposed approach utilizes the ANFIS-PSO model and examines the clinical features, including the patient features of age, gender, family history, etiology, and Heart Rate Variability (HRV) features [38] on the time domain, frequency domain, and non-linear features.
For the testing purpose, this work synthetically modelled such HRV features from the reference of several previous research works. Even though inspired works [39,40] have different objectives, the range of several HRV features determined from the observations monitored from the normal and epileptic patient categories at different states. Hence, the ranges are combinedly analysed for the epileptic patients from the minimal and maximal changes in the observations of each feature and then, the observed ranges are divided to three classes for the proposed algorithm based on the HRV feature value transitions on two references at different states.
ANFIS model enforces the proposed system to build a set of fuzzy if-then rules based on the membership functions with the modeling of input-output pairs. The combination of fuzzy if-then rules, fuzzy inference system, adaptive structure, and adaptive learning rule in the ANFIS ensures improved outcome quality than the fuzzy logic. The integration of PSO with the ANFIS model facilitates the optimal selection of the learners and ensures computationally efficient and optimal decision-making motivated by the concept [41,42]. The design of fine-grained personalization of the preictal period towards the epileptic seizure prediction adopts the ANFIS modeling with nine input parameters obtained from three different inputs, such as the EEG, ECG, and patient's clinical records. The calculation of the membership function parameter is based on the embedded relation between the input data and the training datasets output.
In the ANFIS-PSO, tuning the membership function parameters relies on backpropagation. The learning process continues the evolution of membership functions until reaching the target error. To obtain the reduced output error of the fuzzy inference system, the optimization process involves adjusting the network parameters and weights along with the interpolation of the fuzzy membership function computation for a set of variables. In the proposed system, the Sugeno-type-based fuzzy inference system is modeled to examine the mapping relations between the input and output data values and optimally compute the membership function. The antecedent and consequent parameters perform fuzzy reasoning based on the linguistic variables and the outcome of the target variables based on if-then rules with logic ‘AND’ operations, respectively. The triangular membership logic-based membership function is modeled with each variable's reference. Thus, the initial fuzzy sets with input variables for the proposed ANFIS-PSO decision-making are presented in Table 1. In the proposed design, the consequent is modeled as the seizure risk level from the potential observation of preictal probability in EEG features, and HRV features.
In addition to the EEG analysis, by examining the HRV features of ECG signals and clinical features, the proposed approach computes the probability of epileptic seizure for all the samples with the preictal probability predicted from the FL-assisted coarse-grained personalization. To determine the predictability of epileptic seizures, the system customizes a set of patients (k) under the category of three preictal period intervals from the influence of the HRV and clinical features of the corresponding patient. In ECG signals, RR interval refers the time duration between two successive R waves in the QRS signal. Several HRV features of the ECG signals considered in this work are described in Table 2.
While analyzing the HRV features, this work additionally focuses on modeling the high, medium, and low-risk epileptic patients based on the criteria mentioned in equation (9) over the sequence of the ECG signals. The changes in the HRV () are recognized as the transition from the inherent examination of the triggering state of different preictal states.
Where,
- i)
- High-risk Preictal Period Criteria in HRV are formulated as,
- ii)
- Medium-risk Preictal Period Criteria in HRV are formulated as,
- iii)
- Low-risk Preictal Period Criteria in HRV are formulated as,
As modeled in equation (9), the proposed mechanism fine-tunes the preictal probability of every patient (i) towards predicting seizure onset, characterized by the changes in HRV features presented in Table 1. Adaptive learning and fuzzy inference-based membership functions and rules are generated from the knowledge of training data to determine the risk category of the epileptic seizure, and the ANFIS-PSO performs the final decision-making for the test data. In the subsequence of the first-level postprocessing stage by the ANFIS-PSO, the proposed approach elucidates the localization of the preictal interval in the second-level postprocessing stage instead of modeling the preictal duration alone. Accordingly, it models the optimal interval for separating the alarm onset from the seizure onset, Seizure Prediction Horizon (SPH), for , , and patient groups. As stated in condition that is high-risk preictal period criteria, observation of sudden or rapid changes in the HRV feature-values over the time () indicate that the patient is in high-risk who immediately suffer by the seizure onset. Similarly, in medium-risk preictal period criteria, observation of gradual changes in the HRV feature-values comparatively over the time () refer that the patient is in medium-risk who immediately suffer by the seizure onset. As stated in low-risk preictal period criteria, observation of marginal changes in the HRV feature-values comparatively over the time () indicate that the patient is in low-risk who immediately suffer by the seizure onset. As a result, the proposed approach initiates the alarm based on the risk level of the patients to ensure the accurate seizure diagnosis. In the proposed system, by considering the preictal state transition time, the alarm onset time is modelled before the seizure onset time. If only the preictal state duration is considered, the alarm onset modelling affects the SPH interval. SPH is the time interval between the alarm initialization time and the seizure occurrence time. The segment with two-succeeding much greater HRV features over the time (t) and the preceding one with greater HRV features is localized as the start time of the preictal interval before the SPH. Thus, this work ensures that the patient-specific preictal modeling system supports the preictal detection toward an accurate epileptic seizure prediction. The pseudocode of the proposed epilepsy prediction method is presented in Algorithm 1.
| Algorithm 1: Pseudocode of the Proposed Seizure Prediction Methodology |
| Input: Epileptic EEG Signals, {S×CH}Class |
| Output: Seizure Risk Levels {Low, Medium, High} |
| for all the hospitals and epileptic EEG samples do |
| //Preprocessing// |
| for all the samples, S do |
| Apply Butterworth filtering and normalize signals in 1s sliding window length |
| if a subset of channels obtains comparatively higher accuracy then |
| Select a subset as optimal channel |
| endif |
| endfor |
| //FL-based Generalized Model Construction// |
| for each hospital/ local EEG dataset do |
| Segment samples into four different timescales as 1s, 2s, 4s, and 8s |
| Validate each segment on each dataset through ROC curve analysis |
| //Bi-timescale approach// |
| if a segment has higher AUC score than others then |
| Select that first and second higher timescale as optimal timescales of that particular dataset |
| endif |
| for each timescale in selected bi-timescale do |
| Extract spike sequences using spiking encoder i.e. equation (3) |
| Build graphs for GCNN model |
| Implement GCNN until the representation obtained from hidden layers |
| endfor |
| Concatenate representations of two timescales at dense layer of GCNN |
| Classify the Preictal and Interictal Classes |
| endfor |
| for all three local models do |
| Perform FL-based global aggregation |
| Maintain trade-off between the global and local model using equations (5-8) |
| endfor |
| Update local GCNN model based on the global knowledge |
| Classify the Preictal and Interictal Classes |
| endfor |
| //Distinct Preictal State Modeling for Seizure Prediction// |
| for each hospital/ local EEG dataset do |
| Retain preictal probability of each sample |
| Obtain ECG-HRV features and Demographic features |
| for these three inputs do |
| Apply ANFIS for decision-making with the determination of three seizure risk levels using equation (9) |
| for the implementation of ANFIS do |
| Select the best learners using PSO algorithm |
| endfor |
| Determine the seizure risk levels as three classes |
| endfor |
| endfor |
| endfor |
4.5. Applicability in Real-time Medical System
Recently, medical devices have delivered healthcare services by connecting the medical system with patients and end users [43]. In the medical field, it is crucial to focus on the healthcare development from treatment process to prevention process to improve the quality of human life and alleviate the cost of care. Intelligent algorithms significantly ensure highly efficient prevention and decrease computational burden and time spent by medical practitioners in hospitals. With the rise of personalized and preventive care as the new treatment, medical instruments or tools can be used as a part of the treatment or disease recognition component in hospitals to handle the scenario of the absence of doctors or to mitigate the time spent on examining the patients’ health data.
The proposed epileptic seizure prediction system simplifies the client’s task at hospitals or medical centers by performing the core part of the system functions on the server, reducing the EEG database maintenance cost and seizure prediction system development cost on the client side. With the server interaction on the computer through internet access, the client, such as the hospital, operates the patient data for epilepsy prediction without needing maintenance. Clinicians or medical centers receive intelligence from the prediction system to assist in monitoring, and diagnosing epilepsy disease, while hospitals avoid the expensive clinical process. At the hospitals, the applicability of the proposed system in real-time disease prediction involves testing an individual patient’s sample on the designed system through the interface. The hospitals virtually perform their computations on the edge resources to combat the resource-constrained client environment. In a nutshell, in the proposed design, the outcome of preprocessing and classification stages, referring coarse-grained personalization model, act as the server with a huge database, and the postprocessing stage referring fine-grained personalization model that establishes the interaction between the application and the server at the hospitals.
Figure 8 depicts the proposed real-time prediction system using three components. Real-time prediction is the modeling of a predictive model, which is the deployment of a coarse-grained personalization model to enable real-time decision-making that is the postprocessing in which the predictive model is built on a huge amount of data. The coarse-grained personalization is a rigorous iterative experimentation using historical epileptic patient data. Then, to predict the epileptic seizures when a continuous stream of patient samples is fed to the system, the predictive model is built, thereby enhancing the end-user or client experience. Three major components [44] of real-time predictive analytics involve the i) prediction serving system, ii) trained model, and iii) feature inference. The prediction serving system utilizes a trained learning model for the recognition of seizure. It provides a prediction outcome for the new input data. In contrast, the trained model and features indicate the data structure comprising the weights obtained throughout the training process and relevant attributes of the data for the prediction.
5. Experiments
The effectiveness and performance of our proposed model are assessed for early epileptic seizure prediction, and the performance is compared with baseline models and several recently published works in the literature. The experimental model conducts the experiments of early epilepsy prediction models using Python programming language. The software environment of this experimental analysis is python running on a 64-bit Ubuntu operating system powered with a 3GHz Intel processing unit and 32GB memory.
Table 3 provides the configuration of the deep learning model of GCNN in the proposed epilepsy seizure prediction. During the implementation of the proposed epileptic seizure prediction algorithm, the number of preictal, interictal, and ictal samples for the training set and test set on CHB-MIT, Bonn, and NSC datasets are mentioned in Table 4.
5.1. Datasets
The experiments employ three EEG benchmark datasets, the CHB-MIT scalp EEG dataset, the Bonn EEG dataset, and New Delhi EEG dataset, to design the FL model for the proposed epileptic seizure prediction. The datasets are adjusted for the epileptic seizure prediction task by accurately discriminating the preictal class from either the interictal or ictal class. The main aim of this work is the seizure state prediction by determining the preictal state. Hence, accurately detecting the preictal state from the EEG signals (combination of preictal state with any other seizure states like interictal or ictal state). Due to the availability of the preictal and ictal classes alone in the benchmark CHB-MIT dataset, the experimentation performs for the discrimination of preictal and ictal classes in which the probability of preictal class detection only focused to further perform the postprocessing.
Preprocessed CHB-MIT scalp EEG database: It was originally gathered from the collaboration of Children's Hospital Boston and Massachusetts Institute of Technology (CHB-MIT) of patients with epileptic seizures, which were uncontrollable with medicament. This prediction model utilizes the Preprocessed CHB-MIT scalp EEG database [45], containing separate Comma Separated Value (CSV) files of preictal and ictal data for the performance evaluation. To fit the problem of epileptic seizure prediction, patients with adequate preictal and ictal samples are selected. Due to the availability of only preictal and ictal classes in the preprocessed CHB-MIT dataset, this work discriminates the preictal state from the ictal state during the evaluation of this dataset.
Bonn EEG dataset: The University of Bonn provides the Bonn EEG dataset [46], which comprises five distinct subsets of folders. There are 100 single-channel EEG epochs in each file, and they are digitized at a sampling rate of 173.61 Hz using 12-bit A/D resolution. Each EEG epoch contains 4097 samples with a duration of 23.6 seconds. Bonn dataset comprises the EEG observations from a 100 single-channel system. In this case, single channel refers the observations recorded from a single electrode only for each channel. As a conclusion, Bonn dataset has 100 channels that belongs to the recording type of single-channel. In the Bonn EEG dataset, sets C and D are EEG samples with interictal and preictal states, as referred from the research works [5,47].
New Delhi EEG dataset: The Neurology and Sleep Center (NSC) database [48] consists of 1024 EEG samples with a duration of 5.12 seconds, sampled at 200 Hz. Among three publicly available states of ictal, preictal, and interictal in the NSC dataset, this work considers the preictal and interictal classes for evaluating the seizure prediction algorithm.
Moreover, the experiments conducted on the patient's clinical records involving the demographic data and ECG signals-based HRV features to evaluate the ANFIS-based decision-making in the postprocessing stage of the proposed system. Owing to the lack of ECG data in the benchmark EEG datasets tested in this work, several HRV features for the ECG signals are modeled from the reference of the works [39,40] instead of extracting the features from the unknown ECG signals. Preprocessing and examining the ECG signals is the out of the research scope of this work. Hence, to prove the influence of the ECG features on epilepsy decision-making, standard ranges of HRV features were synthesized. Furthermore, these three epileptic EEG datasets lack to comprise clinical information about each patient. Thus, to test the influence of the clinical information on the epilepsy seizure prediction, patient-specific clinical information randomly modeled for each dataset.
5.2. Performance Metrics
The experiment utilizes the ensuing evaluation metrics: sensitivity, specificity, accuracy, and False Positive Rate (FPR) to demonstrate the reliability of the proposed model.
Sensitivity: It is the ratio between the number of correctly classified preictal samples and the total number of preictal samples to be classified in a particular class. The recall is also known as sensitivity.
Specificity: It is the ratio between the number of correctly classified interictal samples and the total number of interictal samples that are actually classified.
Accuracy: It measures the overall performance of the model in detecting both the preictal and interictal samples.
False Positive Rate: It measures the number of false positives over the total test period.
Area Under the Curve (AUC): AUC quantitatively measures the learning model in the discrimination of true positives and true negatives, and a higher AUC score shows better performance of the learning model.
5.3. Results
This experimental study investigates variation across several baseline models and Existing Epileptic Seizure Prediction (EESP) works. The comparative baseline models are K-Nearest Neighbor (KNN), Decision Tree, Support Vector Machine (SVM), CNN, and LSTM, whereas the EESP works are EESP1 [24], EESP2 [25], and EESP3 [27]. In this experiment, baseline algorithms were evaluated as classification models for the samples in three benchmark datasets. This section provides the results for the discrimination of the preictal state from the interictal as well as discrimination of the preictal state from the ictal state. In conclusion, the results from Bonn and NSC datasets tested on the preictal-interictal samples and results from the CHB-MIT dataset tested on the preictal-ictal samples.
Epileptic seizure prediction has been realized, and there is a different anticipation strategy. Thus, fixing the prediction time and considering the seizure onset time as a norm becomes ineffective. It is because the seizure prediction time varies from one patient to another patient and from period to another, even for the same epileptic patients. Hence, testing and evaluating the seizure prediction algorithm must be conducted on the medical cases in real-time to prove the performance of the seizure prediction. In conclusion, the classification problem is evaluated on the discrimination of preictal state samples from other states to qualify the seizure prediction performance in this research work.
Table 5 compares the epileptic seizure prediction performance of the proposed method and existing EESP1, EESP2, and EESP3 models. The evaluated metrics indicate the performance of discrimination between the preictal and interictal classes, exemplifying the seizure prediction performance. The proposed method outperformed the models in Table 5 and evaluated the prediction performance similar to the real-time scenario using the Leave-One-Out Cross Validation (LOOCV) method during training. The comparative baseline models and EESP research used k-fold cross-validation and train-test split to evaluate the CHB-MIT, Bonn, and NSC EEG datasets.
Figure 9 illustrates the comparative sensitivity and specificity of the proposed seizure prediction method with the existing EESP1, EESP2, and EESP3 works on both the CHB-MIT and Bonn EEG datasets. The distinguishing of the preictal state from the interictal state by the baseline classifiers of KNN, Decision tree, and SVM algorithms had a sensitivity of 54.16%, 82.19%, and 89.39%, respectively, while evaluating the CHB-MIT dataset. Under the scenario with the same number of patients and samples, our proposed method outperformed the deep learning models of CNN and LSTM by 11.46% and 6.8% higher accuracy, respectively. Compared to the EESP1 on the CHB-MIT dataset, the proposed method obtained a 10.54% higher sensitivity and 0.094 comparatively minimal false positive rate. The sensitivity and specificity of our method were comparatively higher than other models and works while testing on three EEG datasets.
As mentioned in Table 5, the proposed approach on the Bonn EEG dataset reaches an average of 93.94% sensitivity and 0.044 FPR. Overall sensitivity, specificity, and accuracy for the NSC dataset reach 91.11%, 94.24%, and 92.72%, respectively. Thus, the proposed model accurately categorizes preictal and interictal seizure states in the Bonn and NSC datasets and preictal and ictal seizure states in the CHB-MIT dataset. From Table 5, it is possible to notice the comparatively best results obtained by the proposed method than other methods. Eventhough the EESP3 accomplishes true negative rate as 95.23% which is comparatively higher than the proposed method, the accuracy of the proposed prediction model outperforms the existing researches by improving the true positive rate. All methods were evaluated on three publicly available EEG benchmark datasets of CHB-MIT, Bonn, and NSC locally and globally in the concept of FL. It is arduous to decide which model is better to predict epileptic seizure due to the testing of each method using the limited data of the different patients on different datasets. Hence, the generalizability of the proposed method is tested without the need for patient-specific clinical data and ECG data, referring to the proposed method without the ANFIS-PSO model that is the proposed method with SE, GCNN, and FL.
Furthermore, it is evident from Table 6 that the combination of SE, GCNN, FL, and ANFIS-PSO-based epileptic seizure prediction model provides higher sensitivity of 96.33% and a higher value of specificity of 96.14% for the CHB-MIT dataset. Also, the sensitivity and specificity in the Bonn and NSC datasets are 93.94% and 96.13%, and 91.11% and 94.24%, respectively. As a result, it is concluded that the recognition of the preictal state is accurate either from the discrimination of the ictal state in the CHB-MIT dataset or the interictal state in the Bonn and NSC datasets. However, there is a marginal variation in the performance measures on different EEG datasets even when the proposed method utilizes the global model parameters for the local model updation due to the variations in time definitions, patients, and epileptic patterns. From examining the performance of baseline models and existing works presented in Table 6, it is quite apparent that the proposed method comparatively yields better results towards the epileptic seizure prediction on three different datasets.
Compared to the accuracy and specificity, measuring the performance of detecting the preictal class is extremely important in this research, and sensitivity is a significant measure of validating the epileptic seizure prediction method. The results in Table 6 provide the comparative performance of the proposed method in the centralized and federated approaches. In this research, training in a centralized approach is the learning or processing one EEG dataset at a time, succeeding with gradient computation and weight updation. On the other hand, the federated approach is processing three EEG datasets at once, succeeding with averaging the weights of all the clients.
By introducing the FL in combination with the SE-GCNN model, this work found a 1.56% and 0.51% improvement in sensitivity and specificity while testing on the CHB-MIT dataset. This enhancement is due to the adoption of the global model by the FL model and the segment-aware training sample generation in the proposed system, facilitating the discrimination between the preictal and interictal states. As mentioned in Table 6, the centralized approach has the worst sensitivity, specificity, accuracy, and false positive rate among the proposed models. Consequently, the learning process in the epileptic seizure prediction system aims to adopt the FL model. Moreover, the proposed system used the ANFIS model in the postprocessing stage, and the results were influenced by the SE, GCNN, and FL models. As a result, the performance of the proposed model has increased in terms of sensitivity to 96.33%, specificity to 96.14%, and accuracy to 96.28% in the CHB-MIT dataset, as mentioned in Table 5. The false positive rate is also reduced to 0.032. During the postprocessing, the ANFIS-PSO model is tested with different combinations of input data such as i) EEG and ECG, ii) EEG and demographic, and iii) EEG, ECG, and demographic. Thus, the combination of EEG, ECG, and demographic outperforms the other two cases in terms of accomplishing 91.11% sensitivity and 94.24% specificity in the NSC dataset.
Moreover, Table 7 provides the performance of the proposed method and EESP2 for all the individual patients or subjects in the CHB-MIT dataset. Among all the patients in CHB-MIT dataset, few accomplish comparatively best results; for example, patient CHB03 achieves the highest performance with 98.27% sensitivity, 96.09% accuracy, and 0.071 FPR. In the seizure prediction system, improvement of all the metrics, such as sensitivity, specificity, FPR, and accuracy, are significant. From the analysis of Table 7, the proposed results of the average specificity range of 91.24% for the different patients. The proposed epileptic seizure prediction with the SE-GCNN and FL model enforces the yielding of the minimal false positive rate due to the spiking sequence-based graph construction and the influence of the generalized pattern-based local model updation. Moreover, the HRV features of the seizure activity accompanied by the EEG-based prediction probability greatly facilitates the achievement of higher sensitivity at 89.84% across all the patients. The performance presented in Table 7 illustrates that the proposed method ensures stability and maintains the trade-off between the accuracy of all the patients and the accuracy of a single patient.
ROC curves with the AUC score of the proposed model on three benchmark datasets are plotted in Figure 10. Figure 10 shows that the proposed model can discriminate the preictal samples from both the interictal and ictal samples in all three CHB-MIT, Bonn, and NSC datasets. The design of three-tier architecture for implementing the FL model in the epileptic seizure prediction system greatly assists the achievement of better AUC scores on different EEG datasets as 0.896, 0.932, and 0.923 by updating the local models with the influence of the global model parameters. As a result, the overall ROC-AUC analysis portrays the significance of the proposed method in ensuring the accurate real-time prediction of all the generalized seizure patients through the modeling of the FL-assisted coarse-grained personalization and ANFIS-assisted fine-grained personalization.
Figure 11 illustrates the ROC curve with the AUC score for each patient tested on five patients of CHB-MIT dataset. From the analysis of Figure 10 and Figure 11, it is determined that the proposed epilepsy prediction method accomplishes a higher AUC score in terms of providing accurate seizure prediction for all the patients and the patient-specific seizure prediction. Among five test epileptic patients, the proposed approach accurately predicted the epileptic seizure for a CHB03 patient as 0.961 AUC score through the preictal state discrimination from the ictal samples.
6. Conclusion:
This work designed a three-tier architecture for the FL-based epileptic seizure prediction and addressed the data scarcity, diversity, and privacy constraints without compromising the accuracy and computational cost by designing a two-level edge layer. As the modeling of the FL, the global model-based local model updation ensured the balance between the model generalization and coarse-grained personalization. The design of a hybrid model with SE and GCNN supported the accurate recognition of the preictal class from the interictal class through the segment-aware spike modeling and bi-timescale approach in coarse-grained personalization. Furthermore, the seizure risk-aware patient personalization is achieved by the ANFIS model, fine-tuning the coarse-grained results obtained from the FL model using the HRV features of ECG signals and patient-specific clinical features. As a result, the proposed system recognizes the risk level of the preictal state by examining the preictal probability determined from the EEG signals. Thus, the experimental results demonstrate that the proposed method outperforms several baseline models and previous research in epileptic seizure prediction, yielding 10.54% and 9.21% higher sensitivity than the EESP1 and EESP2, respectively. The proposed method can be extended to design the automatic early warning system with customized seizure prediction horizon time. In addition, the significance of the electrodes or channels' position on the scalp is to be contemplated for the real-time prediction of seizures using a deep learning algorithm.
References
- Beghi, E. The epidemiology of epilepsy. Neuroepidemiology 2020, 54(2), 185–191. [Google Scholar] [CrossRef] [PubMed]
- Thijs, R.D.; Surges, R.; O'Brien, T.J.; Sander, J.W. Epilepsy in adults. The Lancet 2019, 393(10172), 689–701. [Google Scholar] [CrossRef] [PubMed]
- Kuhlmann, L.; Lehnertz, K.; Richardson, M.P.; Schelter, B.; Zaveri, H.P. Seizure prediction—ready for a new era. Nature Reviews Neurology 2018, 14(10), 618–630. [Google Scholar] [CrossRef] [PubMed]
- Mula, M.; Monaco, F. Ictal and peri-ictal psychopathology. Behavioural neurology 2011, 24(1), 21–25. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Li, Z.; Feng, L.; Zheng, C.; Zhang, W. Automatic detection of epilepsy and seizure using multiclass sparse extreme learning machine classification. Computational and mathematical methods in medicine 2017, 2017. [Google Scholar] [CrossRef] [PubMed]
- Jehi, L. The epileptogenic zone: concept and definition. Epilepsy currents 2018, 18(1), 12–16. [Google Scholar] [CrossRef]
- Usman, S.M.; Khalid, S.; Akhtar, R.; Bortolotto, Z.; Bashir, Z.; Qiu, H. Using scalp EEG and intracranial EEG signals for predicting epileptic seizures: Review of available methodologies. Seizure 2019, 71, 258–269. [Google Scholar] [CrossRef] [PubMed]
- Assi, E.B.; Nguyen, D.K.; Rihana, S.; Sawan, M. Towards accurate prediction of epileptic seizures: A review. Biomedical Signal Processing and Control 2017, 34, 144–157. [Google Scholar] [CrossRef]
- Patel, V.; Tailor, J.; Ganatra, A. Essentials of Predicting Epileptic Seizures Based on EEG Using Machine Learning: A Review. The Open Biomedical Engineering Journal 2021, 15(1). [Google Scholar] [CrossRef]
- Aledhari, M.; Razzak, R.; Parizi, R.M.; Saeed, F. Federated learning: A survey on enabling technologies, protocols, and applications. IEEE Access 2020, 8, 140699–140725. [Google Scholar] [CrossRef]
- Natu, M.; Bachute, M.; Gite, S.; Kotecha, K.; Vidyarthi, A. Review on epileptic seizure prediction: machine learning and deep learning approaches. Computational and Mathematical Methods in Medicine 2022, 2022. [Google Scholar] [CrossRef] [PubMed]
- Truong, N.D.; Nguyen, A.D.; Kuhlmann, L.; Bonyadi, M.R.; Yang, J.; Ippolito, S.; Kavehei, O. Convolutional neural networks for seizure prediction using intracranial and scalp electroencephalogram. Neural Networks 2018, 105, 104–111. [PubMed]
- Tsiouris Κ, Μ.; Pezoulas, V.C.; Zervakis, M.; Konitsiotis, S.; Koutsouris, D.D.; Fotiadis, D.I. A long short-term memory deep learning network for the prediction of epileptic seizures using EEG signals. Computers in biology and medicine 2018, 99, 24–37. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Guo, Y.; Yang, P.; Chen, W.; Lo, B. Epilepsy seizure prediction on EEG using common spatial pattern and convolutional neural network. IEEE Journal of Biomedical and Health Informatics 2019, 24(2), 465–474. [Google Scholar] [CrossRef]
- Liu, C.L.; Xiao, B.; Hsaio, W.H.; Tseng, V.S. Epileptic seizure prediction with multi-view convolutional neural networks. IEEE access 2019, 7, 170352–170361. [Google Scholar] [CrossRef]
- Thara, D.K.; PremaSudha, B.G.; &Xiong, F. ; &Xiong, F. Epileptic seizure detection and prediction using stacked bidirectional long short term memory. Pattern Recognition Letters 2019, 128, 529–535. [Google Scholar]
- Xu, Y.; Yang, J.; Zhao, S.; Wu, H.; Sawan, M. (2020, August). An end-to-end deep learning approach for epileptic seizure prediction. 2020 2nd IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS); IEEE, 266; 270. [Google Scholar]
- Jana, R.; Mukherjee, I. Deep learning based efficient epileptic seizure prediction with EEG channel optimization. Biomedical Signal Processing and Control 2021, 68, 102767. [Google Scholar] [CrossRef]
- Billeci, L.; Marino, D.; Insana, L.; Vatti, G.; Varanini, M. Patient-specific seizure prediction based on heart rate variability and recurrence quantification analysis. PloS one 2018, 13(9), e0204339. [Google Scholar] [CrossRef]
- Leal, A.; Pinto, M.; Henriques, J.; da GraçaRuano, M.; de Carvalho, P.; Teixeira, C. (2019, July). Preictal Time Assessment using Heart Rate Variability Features in Drug-resistant Epilepsy Patients. In 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 6776; 6779. [Google Scholar]
- Daher, A.; Yassin, S.; Alsamra, H.; Abou Ali, H. (2021, December). Adaptive Neuro-Fuzzy Inference System As New Real-Time Approach For Parkinson Seizures Prediction. 2021 4th International Conference on Bio-Engineering for Smart Technologies (BioSMART); IEEE; pp. 1–4.
- Shahbazi, M.; Aghajan, H. (2018, November). A generalizable model for seizure prediction based on deep learning using CNN-LSTM architecture. 2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP); IEEE, 469; 473. [Google Scholar]
- Daoud, H.; Bayoumi, M.A. Efficient epileptic seizure prediction based on deep learning. IEEE transactions on biomedical circuits and systems 2019, 13(5), 804–813. [Google Scholar] [CrossRef]
- Bekbalanova, M.; Zhunis, A.; Duisebekov, Z. (2019, December). Epileptic seizure prediction in EEG signals using EMD and DWT. 2019 15th International Conference on Electronics, Computer and Computation (ICECCO); IEEE; pp. 1–4.
- Wei, X.; Zhou, L.; Zhang, Z.; Chen, Z.; Zhou, Y. Early prediction of epileptic seizures using a long-term recurrent convolutional network. Journal of neuroscience methods 2019, 327, 108395. [Google Scholar] [CrossRef]
- Ryu, S.; Joe, I. A Hybrid DenseNet-LSTM model for epileptic seizure prediction. Applied Sciences 2021, 11(16), 7661. [Google Scholar] [CrossRef]
- Usman, S.M.; Khalid, S.; Bashir, Z. Epileptic seizure prediction using scalp electroencephalogram signals. Biocybernetics and Biomedical Engineering 2021, 41(1), 211–220. [Google Scholar] [CrossRef]
- Ma, M.; Cheng, Y.; Wei, X.; Chen, Z.; Zhou, Y. Research on epileptic EEG recognition based on improved residual networks of 1-D CNN and indRNN. BMC Medical Informatics and Decision Making 2021, 21(2), 1–13. [Google Scholar] [CrossRef] [PubMed]
- Usman, S.M.; Khalid, S.; Bashir, S. A deep learning based ensemble learning method for epileptic seizure prediction. Computers in Biology and Medicine 2021, 136, 104710. [Google Scholar] [CrossRef] [PubMed]
- Tian, F.; Yang, J.; Zhao, S.; Sawan, M. (2021, May). A new neuromorphic computing approach for epileptic seizure prediction. 2021 IEEE International Symposium on Circuits and Systems (ISCAS); IEEE; pp. 1–5.
- Jia, M.; Liu, W.; Duan, J.; Chen, L.; Chen, C.P.; Wang, Q.; Zhou, Z. Efficient graph convolutional networks for seizure prediction using scalp EEG. Frontiers in Neuroscience 2022, 16, 967116–967116. [Google Scholar] [CrossRef] [PubMed]
- Leal, A.; Pinto, M.F.; Lopes, F.; Bianchi, A.M.; Henriques, J.; Ruano, M.G.; Teixeira, C.A. Heart rate variability analysis for the identification of the preictal interval in patients with drug-resistant epilepsy. Scientific reports 2021, 11(1), 1–11. [Google Scholar]
- Karna, S.K.; Sahai, R. An overview on Taguchi method. International journal of engineering and mathematical sciences 2012, 1(1), 1–7. [Google Scholar]
- Abdelhameed, A.; Bayoumi, M. A deep learning approach for automatic seizure detection in children with epilepsy. Frontiers in Computational Neuroscience 2021, 15, 650050. [Google Scholar] [CrossRef]
- Mir, W.A.; Anjum, M.; Shahab, S. Deep-EEG: An Optimized and Robust Framework and Method for EEG-Based Diagnosis of Epileptic Seizure. Diagnostics 2023, 13(4), 773. [Google Scholar] [CrossRef]
- Selim, S.; Elhinamy, E.; Othman, H.; Abouelsaadat, W.; Salem, M. A. M. (2019, December). A review of machine learning approaches for epileptic seizure prediction. 2019 14th International Conference on Computer Engineering and Systems (ICCES); IEEE; pp. 239–244.
- Soliman, S.; Fouad, A.M.; Mourad, E.; Hossam, S.; Ehab, M.; Selim, S.; Darweesh, M.S. (2022, October). Deep Learning Approaches for Epileptic Seizure Prediction: A Review. 2022 4th Novel Intelligent and Leading Emerging Sciences Conference (NILES); IEEE; pp. 01–06.
- Shaffer, F.; Ginsberg, J.P. An overview of heart rate variability metrics and norms. Frontiers in public health 2017, 258. [Google Scholar]
- Moridani, M.K.; Mahabadi, Z.; Javadi, N. Heart rate variability features for different stress classification. BratislavskeLekarskeListy 2020, 121(9), 619–627. [Google Scholar] [CrossRef] [PubMed]
- Hamdy, R.M.; Abdel-Tawab, H.; Abd Elaziz, O.H.; Sobhy El attar, R.; &Kotb, F.M.; &Kotb, F. M. Evaluation of Heart Rate Variability Parameters During Awake and Sleep in Refractory and Controlled Epileptic Patients. International Journal of General Medicine 2022, 3865–3877. [Google Scholar]
- Shoeibi, A.; Ghassemi, N.; Khodatars, M.; Moridian, P.; Alizadehsani, R.; Zare, A.; &Gorriz, J.M.; &Gorriz, J. M. Detection of epileptic seizures on EEG signals using ANFIS classifier, autoencoders and fuzzy entropies. Biomedical Signal Processing and Control 2022, 73, 103417. [Google Scholar]
- Multivariate Regression and Classification Using an Adaptive Neuro-Fuzzy Inference System (Takagi-Sugeno) and Particle Swarm Optimization. Available online: https://github.com/gabrielegilardi/ANFIS Accessed On October, 2022.
- van den Heuvel, R.; Kapadia, A.; Stirling, C.; Zhou, J. Medical devices 2030. KPMG International 2018. [Google Scholar]
- Gonzalez, J. Prediction Serving. 2017. [Google Scholar]
- Preprocessed CHB-MIT Scalp EEG Database. Available online: https://ieee-dataport.org/open-access/preprocessed-chb-mit-scalp-eeg-database Accessed On October, 2022.
- University of Bonn EEG seizure dataset, Nonlinear Time Series Analysis. Available online: https://www.upf.edu/web/ntsa/downloads/-/asset_publisher/xvT6E4pczrBw/content/2001-indications-of-nonlinear-deterministic-and-finite-dimensional-structures-in-time-series-of-brain-electrical-activity-dependence-on-recording-regi? Accessed On October, 2022.
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; &Adeli, H.; &Adeli, H. Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals. Computers in biology and medicine 2018, 100, 270–278. [Google Scholar]
- Neurology & Sleep Centre, Hauz Khas, New Delhi dataset. Available online: https://www.researchgate.net/publication/308719109_EEG_Epilepsy_Datasets Accessed On October, 2022.
Figure 1.
Epilepsy Stages Diagram.
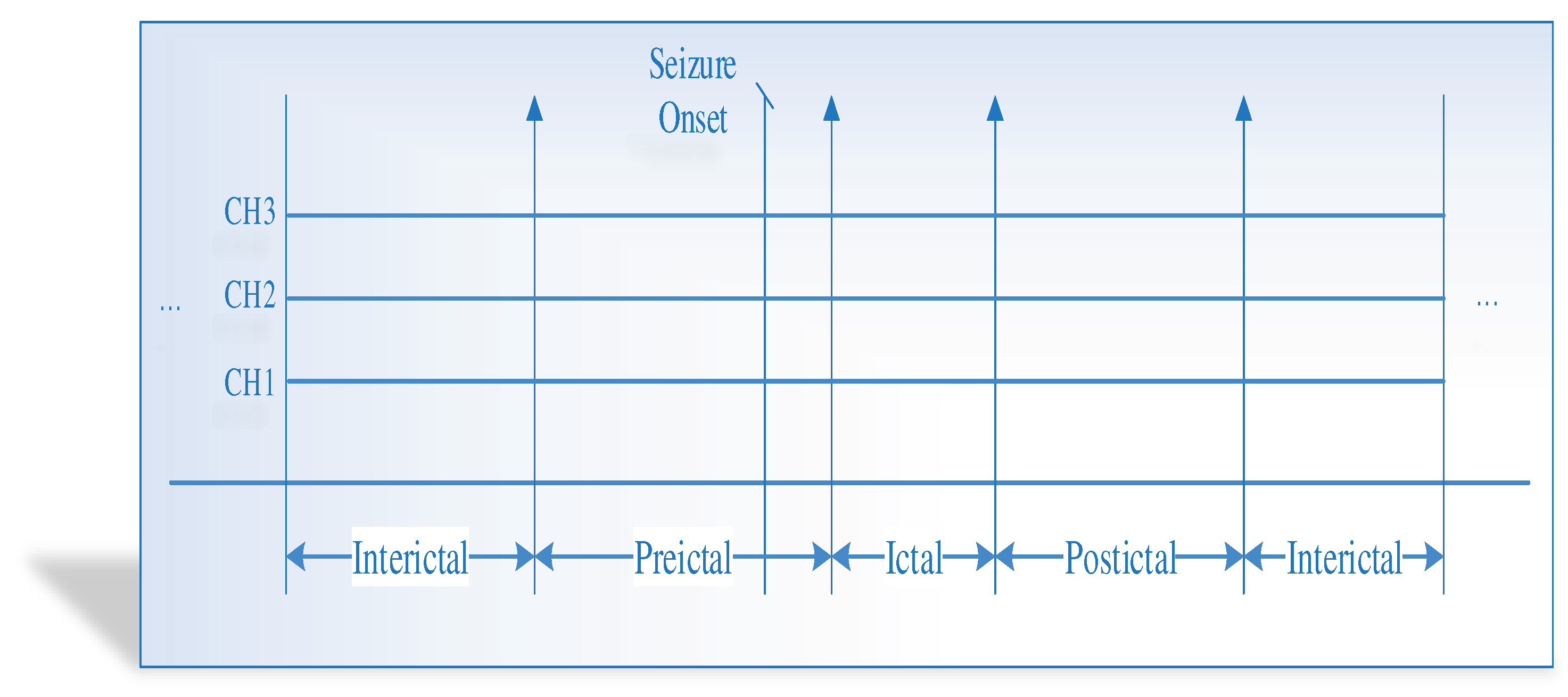
Figure 2.
A Pipeline of Proposed Epilepsy Prediction.
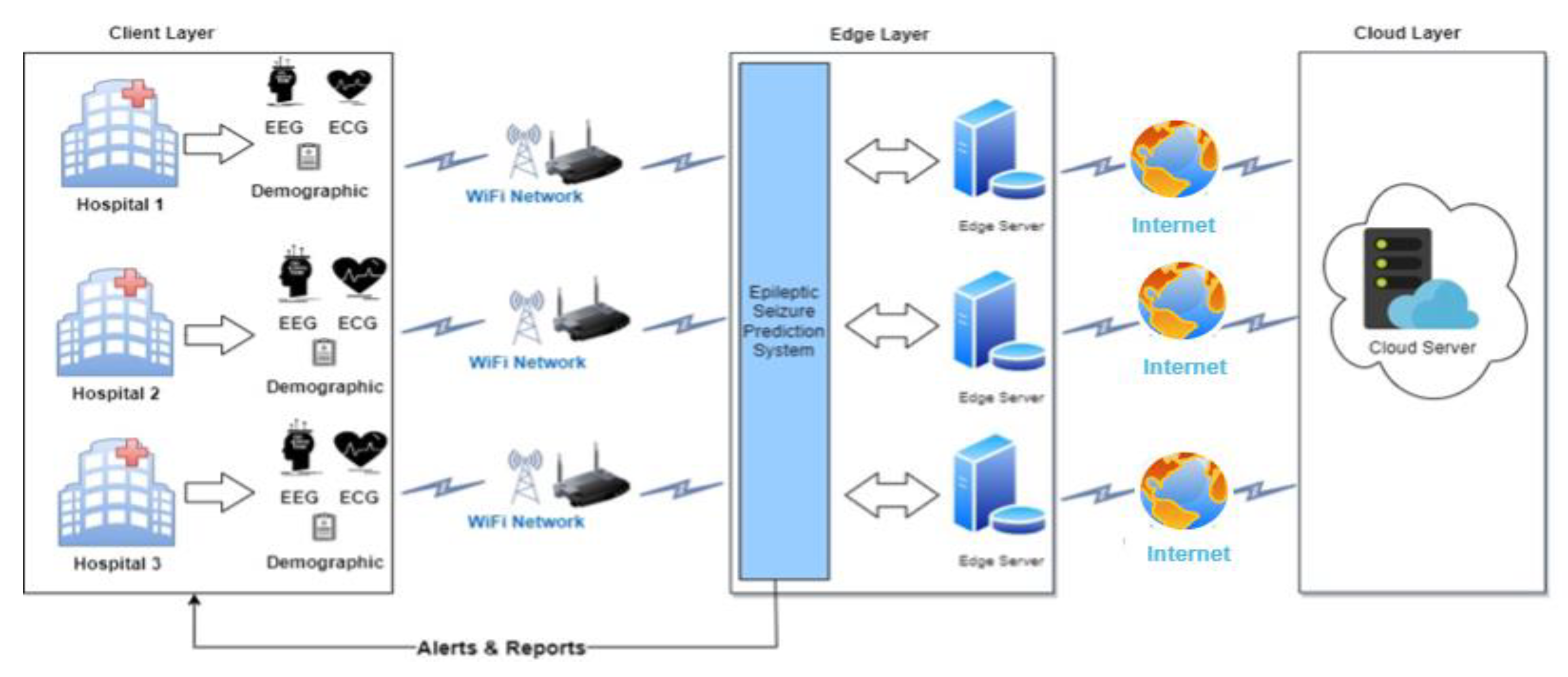
Figure 3.
Three-Tier Architecture of Federated Learning Model in the Proposed Epilepsy Prediction.
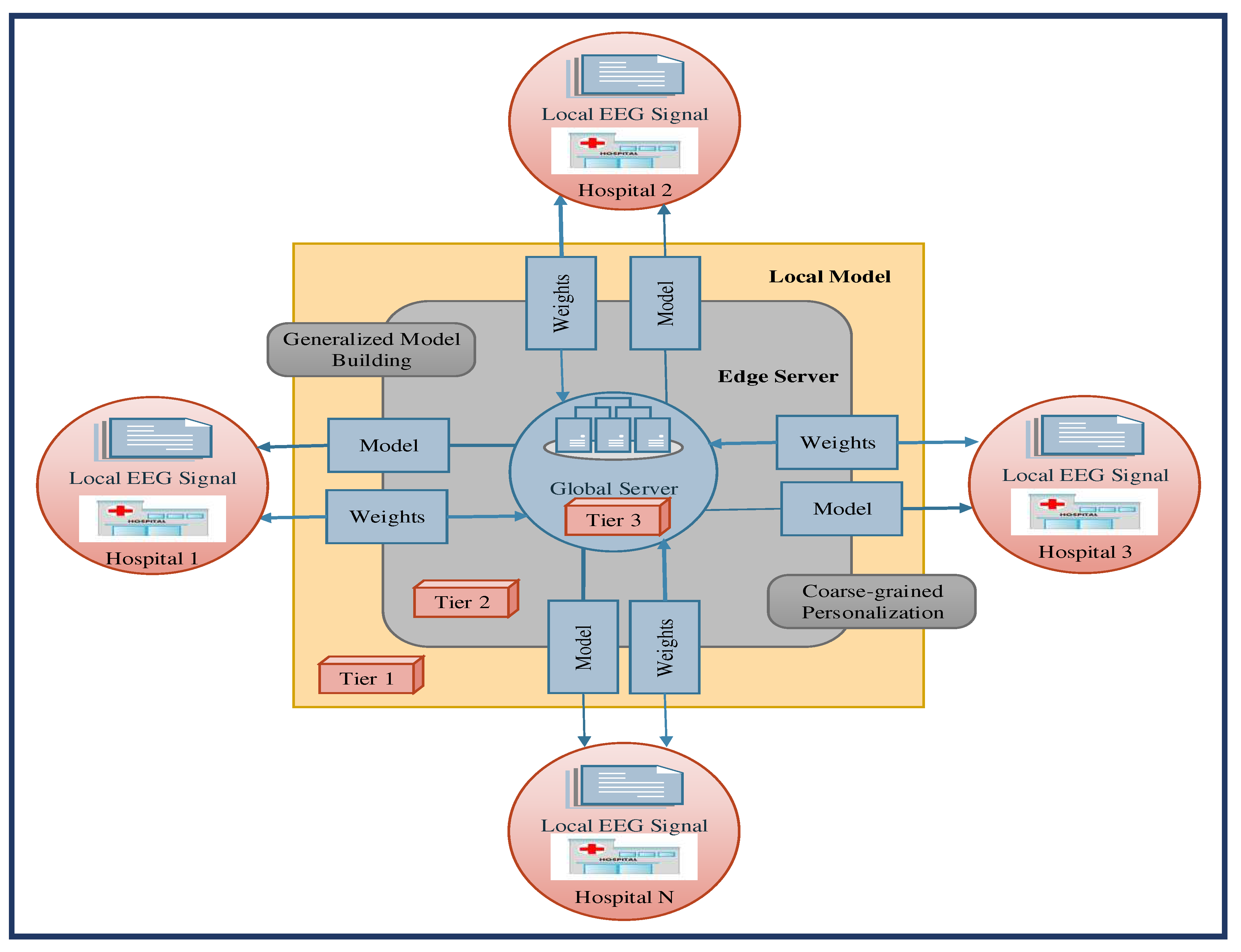
Figure 4.
Process Diagram of the Proposed Seizure Prediction.
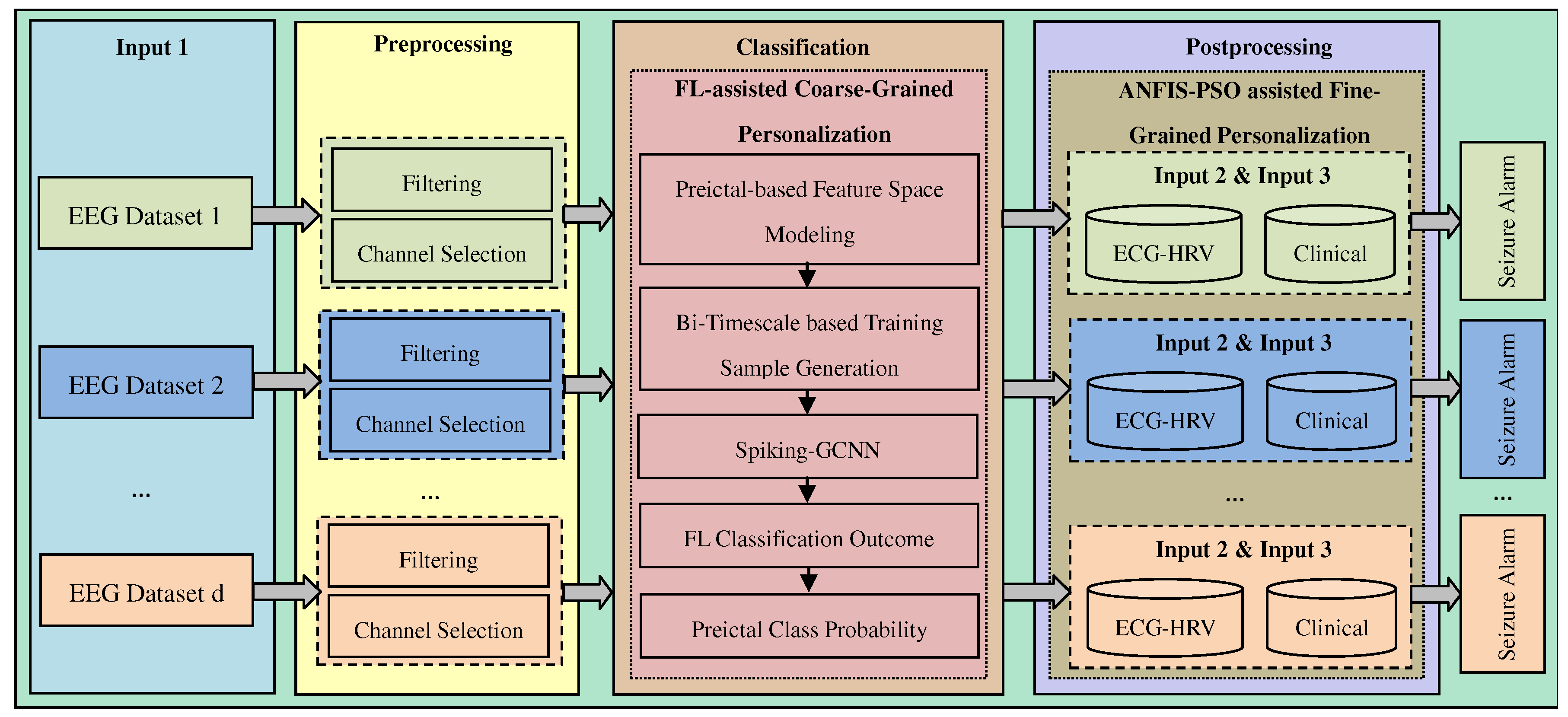
Figure 5.
The Proposed Epilepsy Seizure Prediction Methodology.
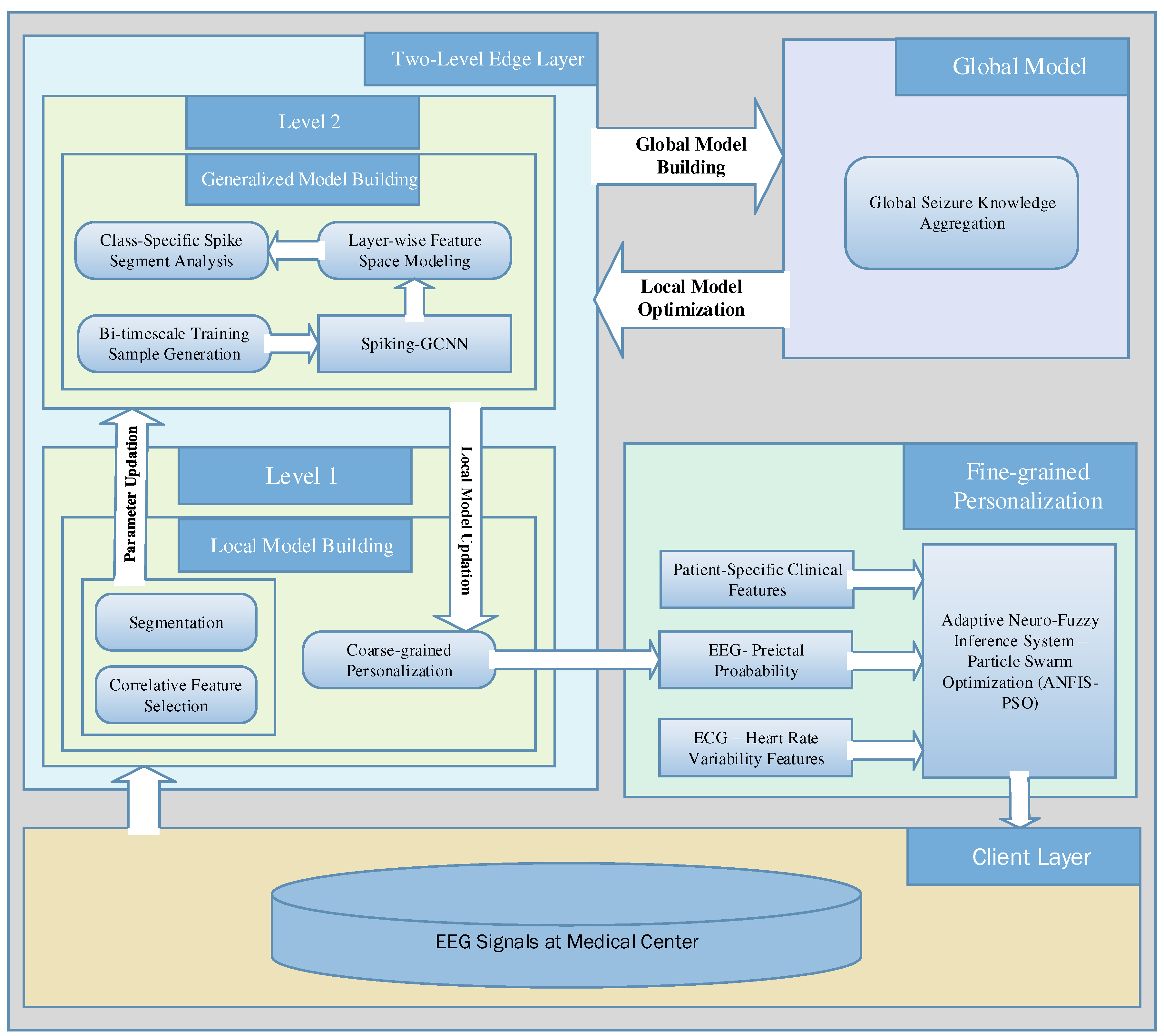
Figure 6.
Bi-timescale Approach based Segmented Samples Learning.
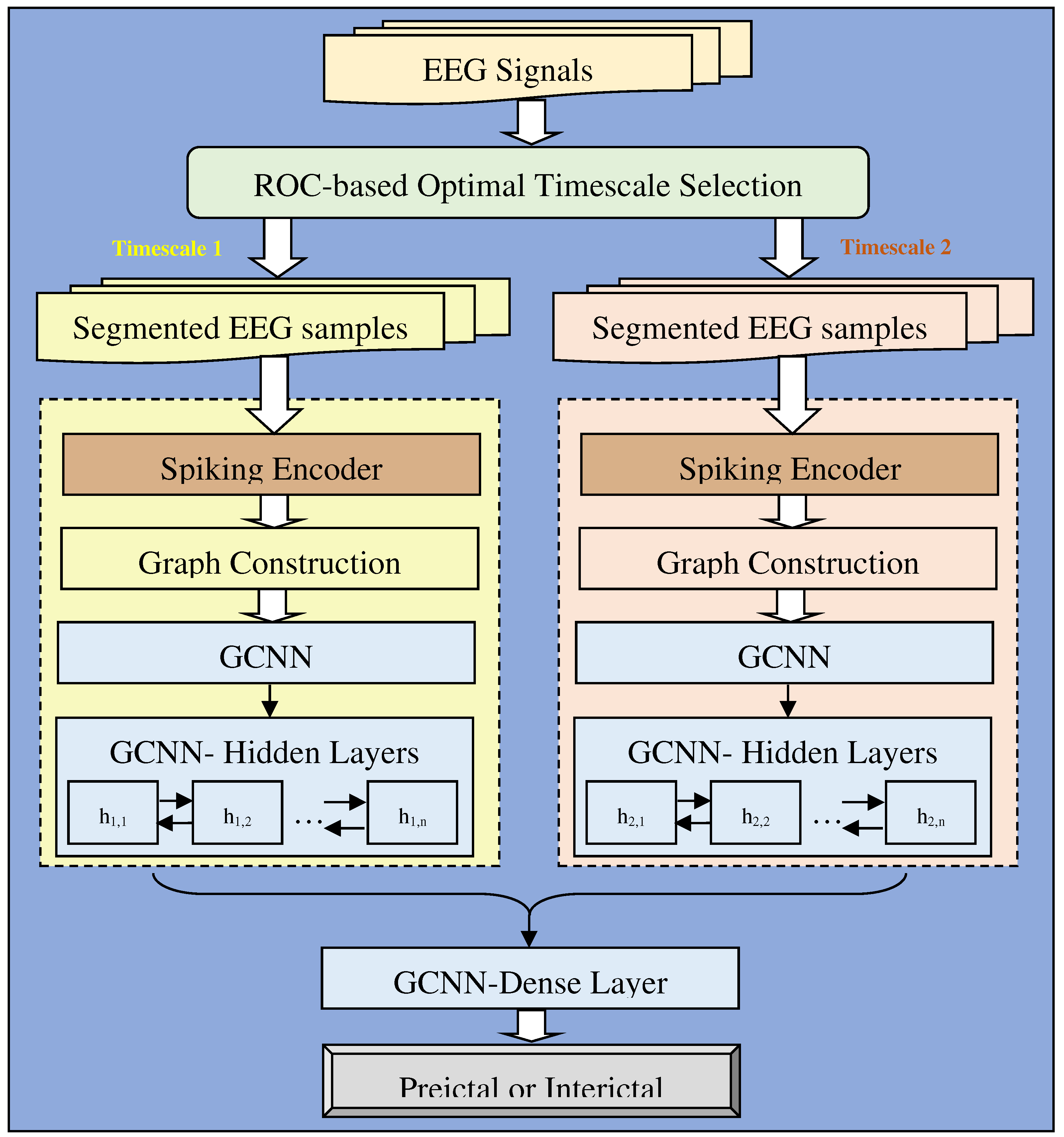
Figure 7.
Three Inputs with Three Membership Functions ANFIS architecture for Fine-grained Personalization.
Figure 7.
Three Inputs with Three Membership Functions ANFIS architecture for Fine-grained Personalization.
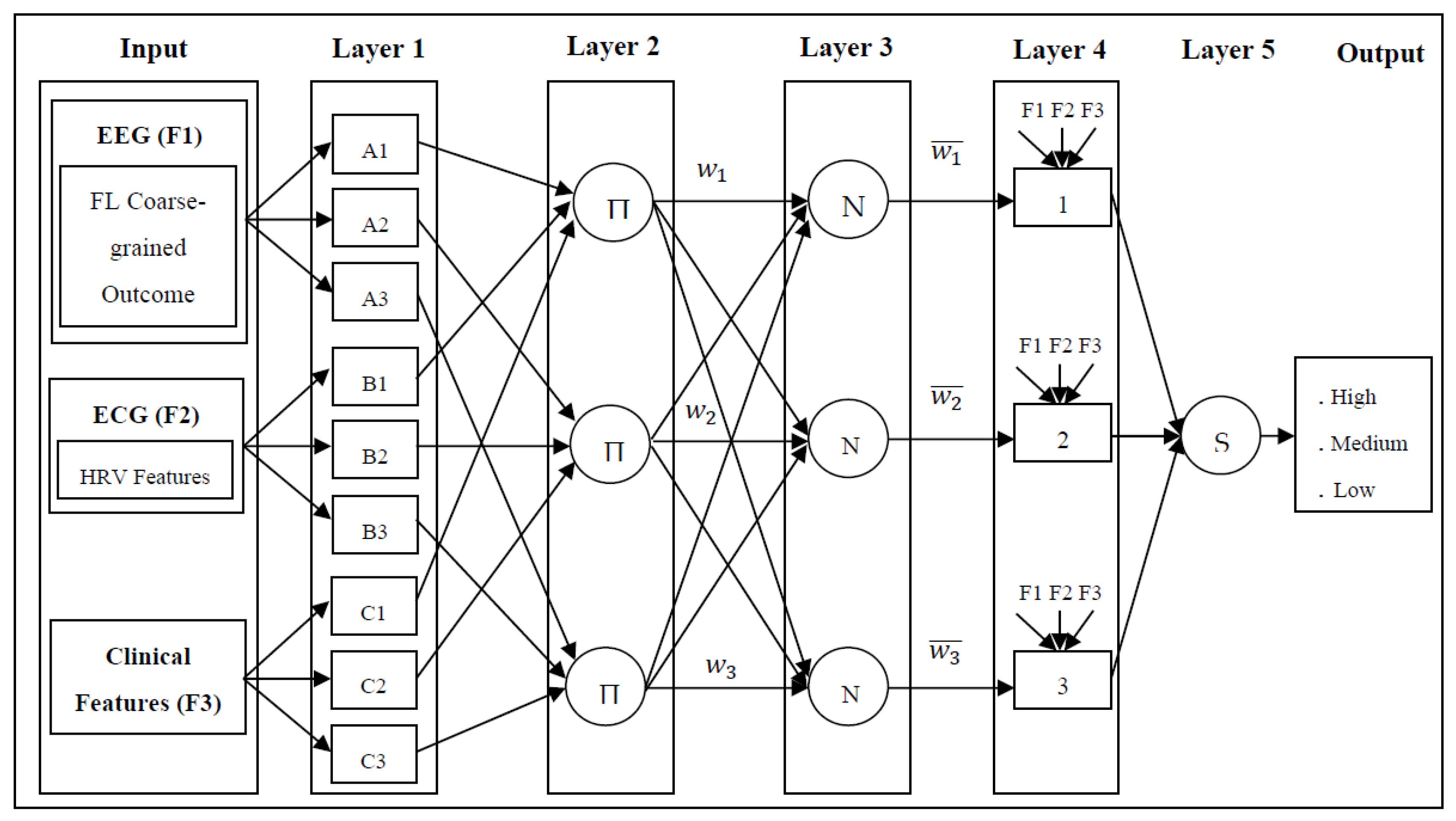
Figure 8.
Proposed Real-Time Epilepsy Prediction.
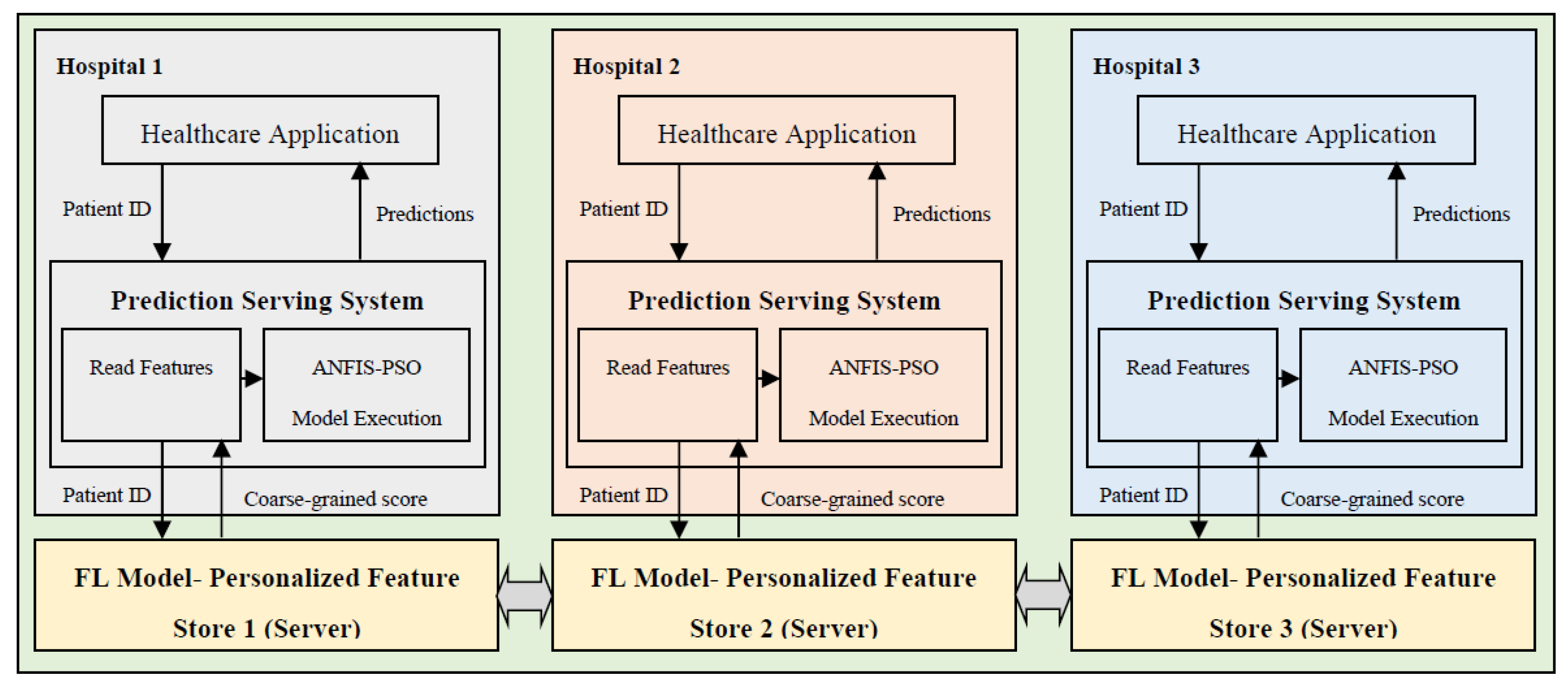
Figure 9.
Comparative Performance of Proposed Method.
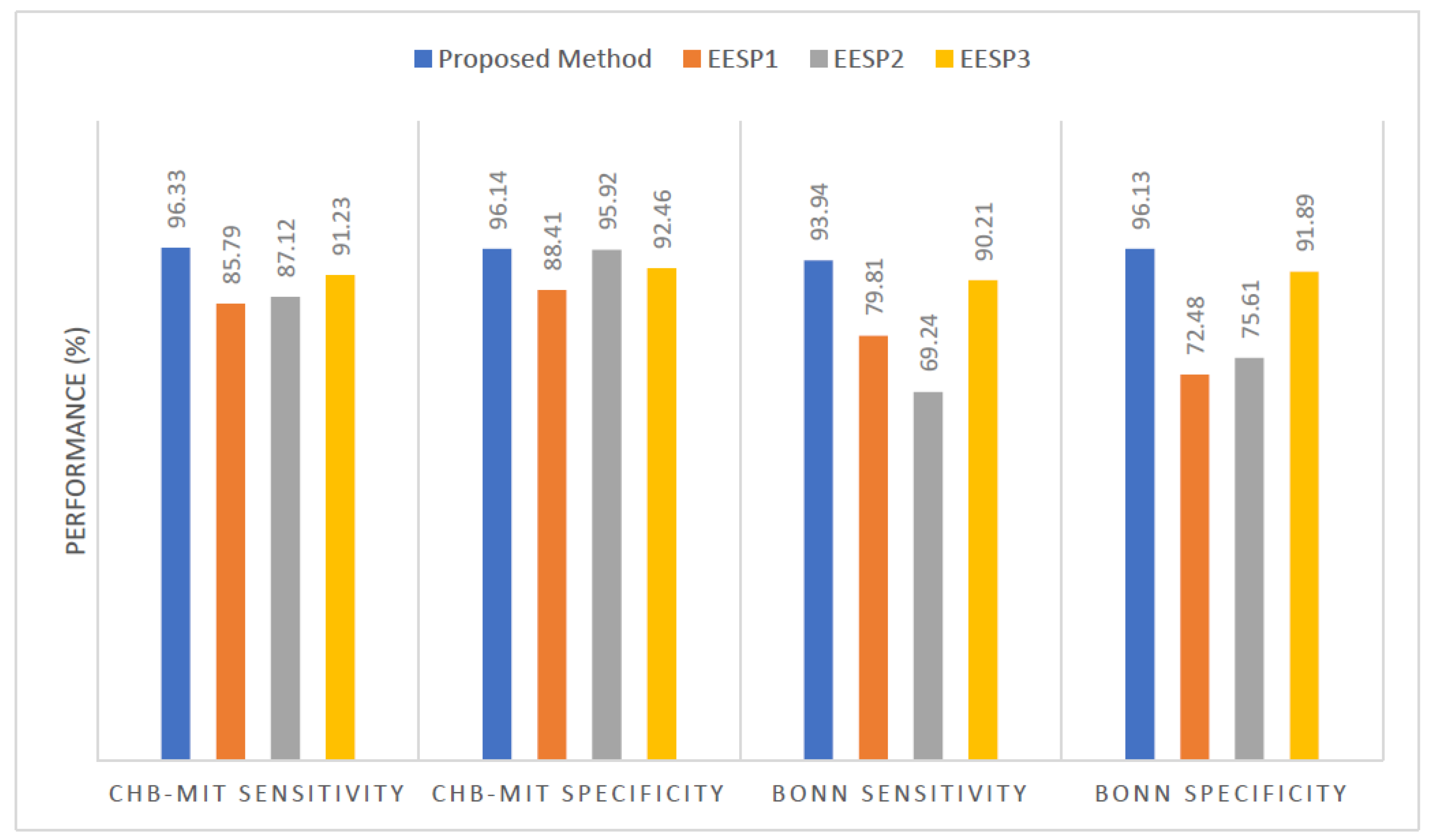
Figure 10.
a-c): ROC-AUC Curve for the Proposed Epilepsy Prediction (a) CHB-MIT dataset, (b) Bonn Dataset, and (c) NSC dataset.
Figure 10.
a-c): ROC-AUC Curve for the Proposed Epilepsy Prediction (a) CHB-MIT dataset, (b) Bonn Dataset, and (c) NSC dataset.
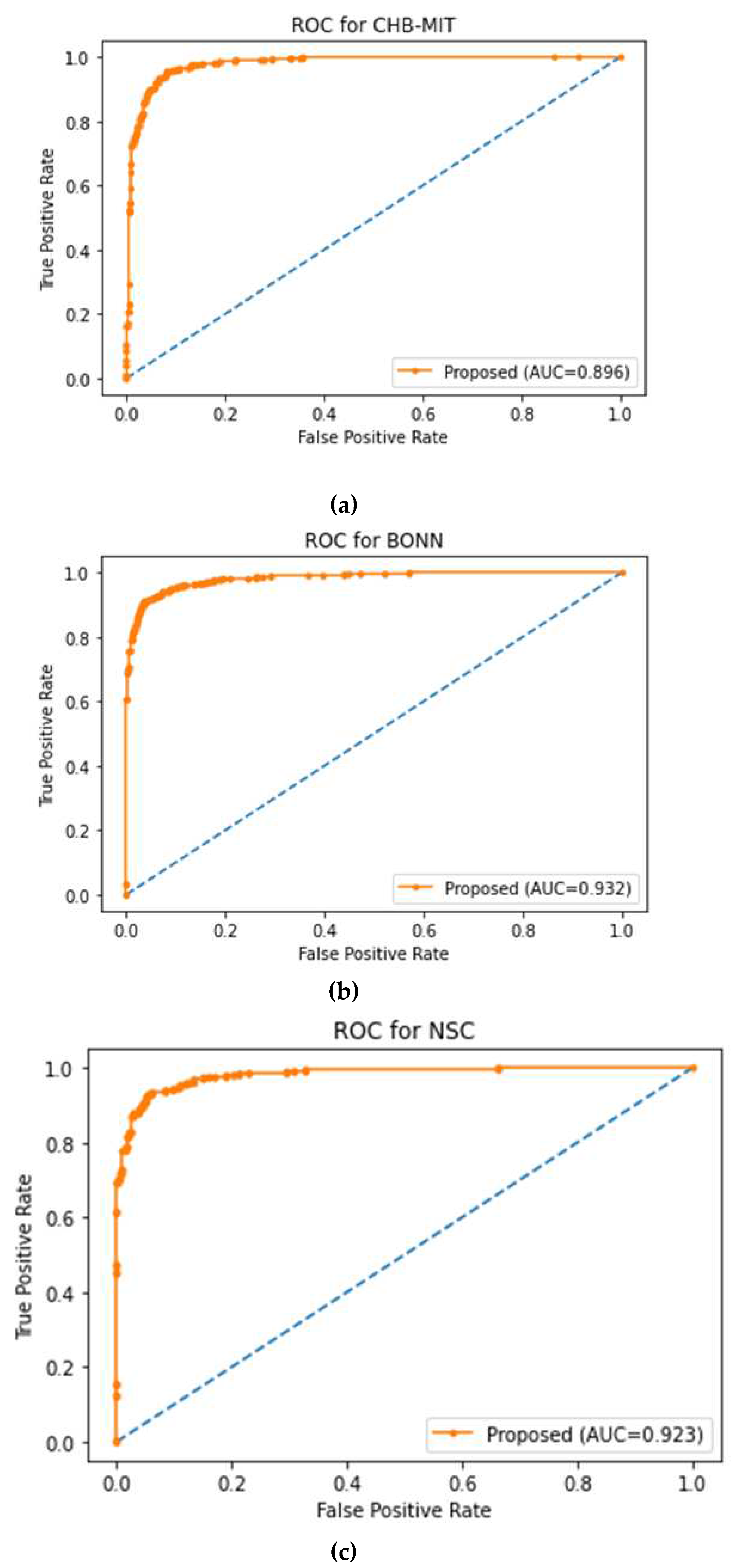
Figure 11.
ROC-AUC Curve of Patient-wise Epilepsy Prediction Performance in CHB-MIT dataset.
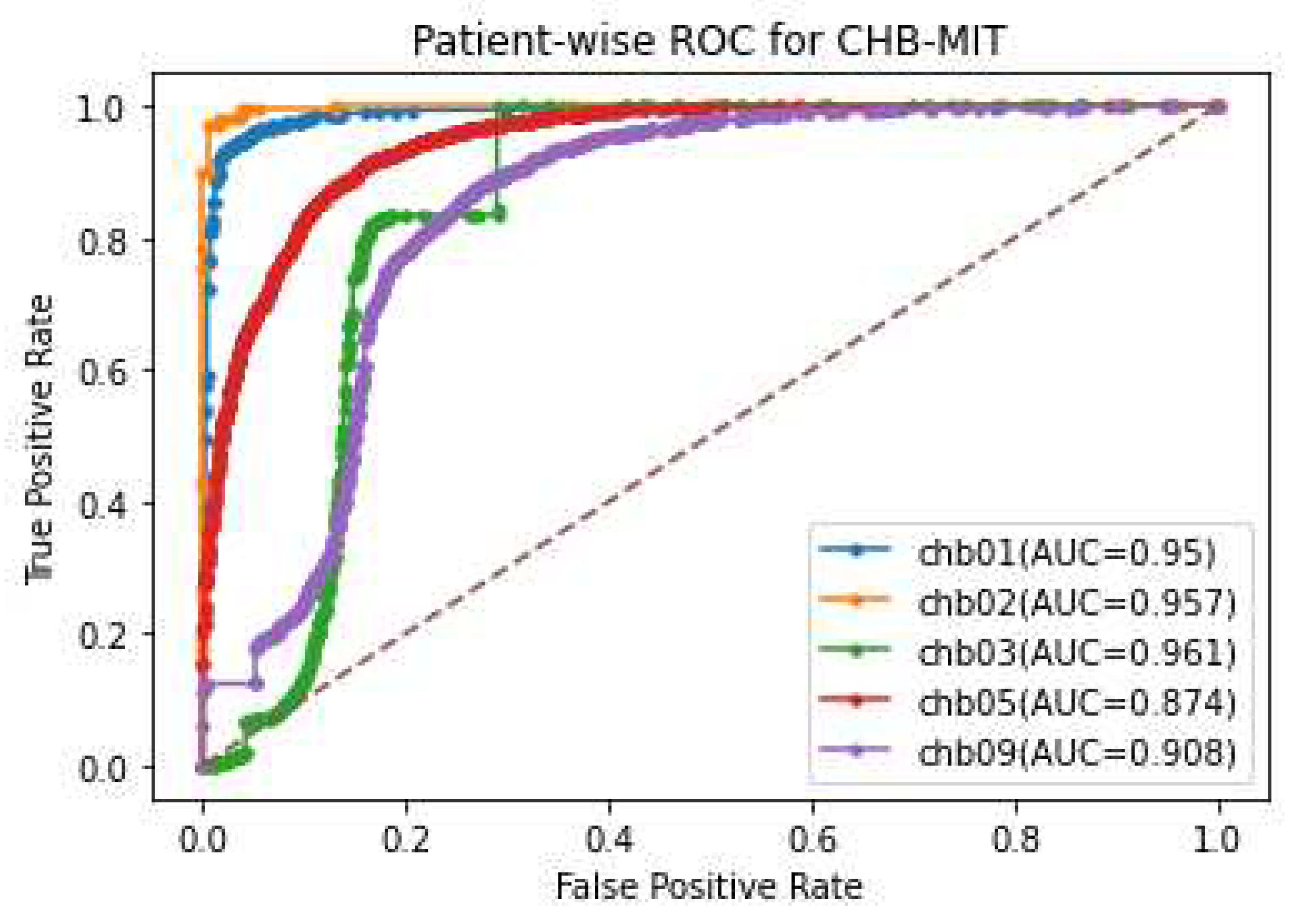

Table 1.
Fuzzy Input Variables.
| No. | Input | Features | Class 1(Low) | Class 2(Medium) | Class 3(High) |
|---|---|---|---|---|---|
| 1 | EEG | Coarse-grained Personalization | 0-0.3 | 0.31-0.6 | 0.61-1.0 |
| 2 | ECG (Heart Rate Variability) |
Lmax(beats) | 198-238 | 239-245 | 245-290 |
| LF/HF | 1.3-1.7 | 1.1-2.1 | 1.3-2.9 | ||
| SDNN (ms) | 109-141.6 | 85.4-165 | 83.7-159.1 | ||
| Mean HR(beats/min) | 65.2-76.2 | 71.6-81.4 | 72.1-92.5 | ||
| pNN50 (%) | 6.2-17.6 | 2.5-8.1 | 1.6-9.6 | ||
| 3 | Patients’ Clinical Records | Genetic | No | Yes | Yes |
| Metabolic | No | Yes | Yes | ||
| Number of seizure events | 0<Event<3 | 3≤Event≤5 | Greater than 5 |
Table 2.
HRV Features and its Description.
| HRV Features | Description |
| Lmax | Length of the longest diagonal line |
| SDNN | Standard deviation of R-R intervals in milliseconds |
| LF | Spectral density (computed through FFT) of the linear interpolated R-R tachogram between 0.04 and 0.3 Hz (low frequency) |
| HF | Spectral density (computed through FFT) of the linear interpolated R-R tachogram between 0.3 and 1.3 Hz (high frequency) |
| Mean HR | Average heart rate |
| pNN50 | Probability of R-R intervals > 50 ms e < −50 ms |
Table 3.
Model Parameters.
| Learning Parameters | Values |
| Dropout Rate | 0.2 |
| Hidden Units | [16, 16] |
| Learning Rate | 0.01 |
| Activation | GELU, Tanh, Sigmoid |
| Loss Function | Sparse Categorical Cross-Entropy |
| Epochs | 10 |
| Batch Size | 128 |
| Optimizer | Adam |
Table 4.
Samples used for the Implementation.
| Number of Samples | CHB-MIT | Bonn | NSC | |||
| Preictal | Ictal | Preictal | Interictal | Preictal | Interictal | |
| Training Set | 294 | 312 | 204 | 200 | 149 | 203 |
| Test Set | 756 | 738 | 746 | 750 | 436 | 382 |
Table 5.
The Result of Various Baseline Models and Works towards Epileptic Seizure Prediction.
| Comparative Works & Models | CHB-MIT | Bonn | NSC | |||||||||
| Sen (%) | Spec (%) | Acc (%) | FPR | Sen (%) | Spec (%) | Acc (%) | FPR | Sen (%) | Spec (%) | Acc (%) | FPR | |
| KNN | 54.16 | 77.47 | 66.15 | 0.253 | 46.85 | 89.26 | 68.13 | 0.11 | 78.10 | 59.02 | 68.78 | 0.412 |
| Decision Tree | 82.19 | 83.70 | 82.95 | 0.163 | 62.28 | 55.61 | 58.98 | 0.443 | 48.91 | 59.56 | 55.01 | 0.40 |
| SVM | 89.39 | 96.29 | 92.88 | 0.037 | 55.42 | 80.48 | 68.04 | 0.19 | 75.91 | 61.20 | 68.61 | 0.388 |
| CNN | 81.43 | 88.03 | 84.82 | 0.129 | 66.28 | 75.61 | 71.12 | 0.243 | 57.66 | 69.39 | 63.07 | 0.316 |
| LSTM | 88.63 | 90.03 | 89.48 | 0.105 | 78.85 | 77.56 | 78.25 | 0.224 | 69.34 | 66.12 | 67.75 | 0.348 |
| EESP1(EMD+DWT+Decision Tree) [22] | 85.79 | 88.41 | 87.26 | 0.126 | 79.81 | 72.48 | 76.59 | 0.285 | 76.85 | 90.10 | 83.48 | 0.098 |
| EESP2(LRCN) [23] | 87.12 | 95.92 | 91.57 | 0.051 | 69.24 | 75.61 | 72.55 | 0.243 | 78.51 | 56.89 | 67.82 | 0.43 |
| EESP3(GAN+CNN+LSTM) [25] | 91.23 | 92.46 | 91.91 | 0.084 | 90.21 | 91.89 | 91.14 | 0.097 | 89.94 | 95.23 | 92.61 | 0.061 |
| Proposed Method | 96.33 | 96.14 | 96.28 | 0.032 | 93.94 | 96.13 | 95.17 | 0.044 | 91.11 | 94.24 | 92.72 | 0.057 |
Table 6.
Performance Evaluation of the Proposed Method.
| Approach | Proposed Method | Input Data | Performance on Benchmark Datasets | |||||
| CHB-MIT | Bonn | NSC | ||||||
| Sen (%) | Spec (%) | Sen (%) | Spec (%) | Sen (%) | Spec (%) | |||
| Centralized | SE+GCNN | EEG | 89.07 | 91.53 | 92.27 | 94.28 | 88.18 | 92.22 |
| Federated | SE+GCNN+FL | EEG | 90.63 | 92.04 | 94.17 | 95.45 | 75.14 | 93.72 |
| Federated | SE+GCNN+FL+ANFIS-PSO | EEG+ECG | 91.78 | 92.31 | 92.42 | 94.59 | 91.08 | 92.82 |
| Federated | SE+GCNN+FL+ANFIS-PSO | EEG+Patients’ Demographic data | 91.10 | 92.52 | 93.87 | 92.28 | 90.79 | 93.65 |
| Federated | SE+GCNN+FL+ANFIS-PSO | EEG+ECG+Patients’ Demographic data | 96.33 | 96.14 | 93.94 | 96.13 | 91.11 | 94.24 |
Table 7.
Evaluation of CHB-MIT Dataset.
| Patient ID | Proposed Method | EESP2(LRCN) [23] | ||||||
| Sen (%) | Spec (%) | Acc (%) | FPR | Sen (%) | Spec (%) | Acc (%) | FPR | |
| CHB01 | 96.33 | 96.14 | 96.28 | 0.032 | 91.32 | 94.63 | 93.01 | 0.067 |
| CHB02 | 85.85 | 98.31 | 92.18 | 0.025 | 80.48 | 54.76 | 67.66 | 0.452 |
| CHB03 | 98.27 | 93.89 | 96.09 | 0.071 | 94.48 | 96.44 | 95.47 | 0.045 |
| CHB04 | 91.41 | 88.53 | 90.01 | 0.124 | 88.98 | 85.36 | 87.38 | 0.147 |
| CHB05 | 94.31 | 88.84 | 91.58 | 0.125 | 87.45 | 94.29 | 90.88 | 0.071 |
| CHB06 | 85.83 | 89.28 | 87.61 | 0.112 | 82.39 | 89.31 | 85.94 | 0.107 |
| CHB07 | 88.16 | 91.25 | 89.69 | 0.086 | 87.16 | 90.01 | 88.61 | 0.098 |
| CHB08 | 82.98 | 90.21 | 86.49 | 0.098 | 78.29 | 85.61 | 82.01 | 0.145 |
| CHB09 | 91.91 | 88.89 | 90.51 | 0.112 | 89.68 | 90.40 | 90.04 | 0.116 |
| CHB10 | 90.05 | 89.26 | 89.78 | 0.113 | 88.35 | 84.91 | 86.79 | 0.156 |
| CHB11 | 92.13 | 90.34 | 91.39 | 0.0953 | 89.63 | 90.31 | 89.85 | 0.097 |
| CHB12 | 89.02 | 88.91 | 88.89 | 0.1112 | 81.26 | 85.32 | 83.35 | 0.149 |
| CHB13 | 89.61 | 90.27 | 89.89 | 0.098 | 88.51 | 80.32 | 84.56 | 0.197 |
| CHB14 | 90.12 | 85.96 | 89.01 | 0.142 | 88.96 | 82.07 | 84.62 | 0.183 |
| CHB15 | 90.29 | 92.59 | 91.56 | 0.0756 | 87.31 | 90.01 | 88.75 | 0.098 |
| CHB16 | 88.20 | 89.97 | 89.98 | 0.112 | 80.12 | 78.31 | 80.02 | 0.218 |
| CHB17 | 87.05 | 90.28 | 89.12 | 0.098 | 76.31 | 88.04 | 82.23 | 0.118 |
| CHB18 | 92.36 | 91.64 | 92.05 | 0.085 | 90.53 | 89.31 | 89.87 | 0.107 |
| CHB19 | 87.89 | 93.58 | 91.01 | 0.0651 | 85.46 | 90.07 | 87.82 | 0.098 |
| CHB20 | 90.21 | 95.61 | 92.85 | 0.0443 | 89.43 | 92.67 | 91.12 | 0.074 |
| CHB21 | 89.31 | 93.14 | 91.34 | 0.069 | 88.91 | 90.71 | 89.93 | 0.094 |
| CHB22 | 90.54 | 89.04 | 89.85 | 0.114 | 89.34 | 87.05 | 88.23 | 0.132 |
| CHB23 | 85.31 | 90.16 | 87.89 | 0.099 | 82.67 | 89.67 | 86.29 | 0.112 |
| CHB24 | 89.19 | 93.57 | 91.45 | 0.0651 | 84.39 | 91.28 | 87.91 | 0.089 |
| Average | 89.84 | 91.24 | 90.69 | 0.090 | 86.31 | 87.12 | 86.76 | 0.132 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



