
Submitted:
09 July 2023
Posted:
11 July 2023
You are already at the latest version
Abstract
The increase and diversity of low-cost Air Quality (AQ) sensors, as well as their flexibility and low power consumption, offers us the opportunity to integrate them into a broad AQ wireless sensor networks with the aim of enabling real-time monitoring and higher spatial sampling density of pollution in all parts of the cities. Considering that the vast majority of the population lives in these cities and the increase in respiratory/allergic problems in a large part of the population, it is of great interest to offer services and applications to improve their quality of life. In the ECO4RUPA project we focus on this kind of service, proposing an inclusive and intelligent routing ecosystem carried out by using a network of low-cost AQ sensors with the support of 5G communications along with official AQ monitoring stations, assisted with artificial intelligence to improve the AQ monitoring data and by spatial interpolation techniques to enhance its spatial resolution. The goal of this service is to calculate healthy walking and/or cycling routes according to the particular citizen’s profile and needs. We provide and analyse the results of the proposed route planner under different scenarios (different time tables, congestion road traffic and routes) and different user’s profiles, with special interest on citizens with asthma and pregnant women, since both require special needs. In summary, our approach can lead to an approximately average reduction in pollution exposure of 17.82%, while experiencing an approximately average increase in distance travelled of 9.8 %.
Keywords:
air quality
; low cost sensors
; IoT network
; WSN
; deployment
1. Introduction
Urbanisation has meant that three-quarters of Europe’s population now lives in cities. Citizens are constantly confronted with levels of air pollution that violate the safe thresholds for human health defined by the World Health Organisation (WHO) [1], generally caused by the natural dynamics of the movement of people and the pollution associated with such transport.
According to Eurostat [2], in 2021, there were 369,000 deaths in the EU resulting from diseases of the respiratory system, equivalent to 7.9 % of all deaths in the EU-28. The BBC reported [3] that "around 422,000 people died prematurely in European countries in 2018 due to exposure to harmful levels of fine particulate matter PM2.5". Moreover, the problem is worse if we consider that a large part of the population has or may have some kind of allergy, respiratory, and skin problems [4]. And there is an increasing number of allergens that increase allergic problems, asthma, as well as other respiratory and skin problems [5].
In this scenario, Wireless Sensor Networks (WSN) for monitoring Air Quality (AQ) based on low-cost sensors and supported by 5G technologies, together with Artificial Intelligence (AI) techniques [6,7], along with official AQ monitoring stations, can help citizens in their day-to-day lives by means of a system that looks after their health when they are on the move, especially when they have respiratory and/or allergic problems.
To this end, the goal of this paper is to propose an inclusive and intelligent routing ecosystem with the objective of calculating healthy routes according to the profile and particular needs of each citizen (which include pathologies and clinical history) in their outdoor movements, assisted by a real-time AQ monitoring network within an Internet of Things (IoT) paradigm. These activities are carried out within the ECO4RUPA project.
Figure 1.
Official Air quality (AQ) monitoring network in Valencia city [8] and surroundings.
Figure 1.
Official Air quality (AQ) monitoring network in Valencia city [8] and surroundings.
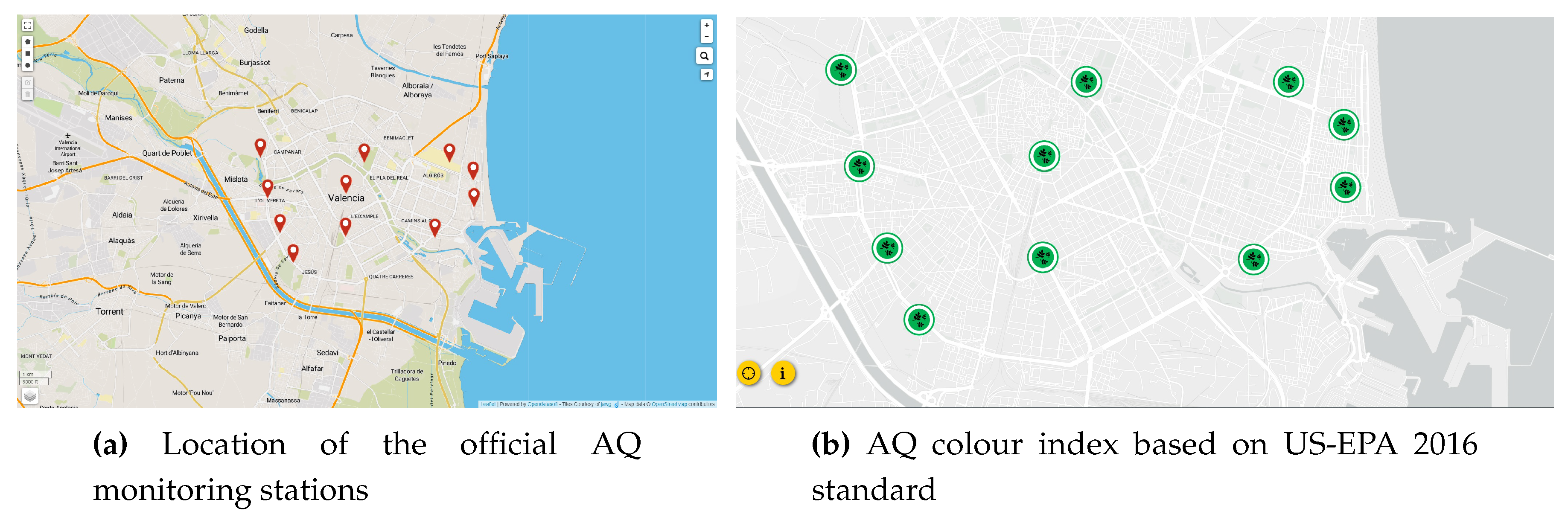
Notice that at the international level, the air quality is ruled by ISO 11771:2010 [10] and ISO 37122:2019 [11] according to the European Regulation Directive 2008/50/EC [12], cities with more than 2 million inhabitants must have at least one monitoring station for AQ. Thus, this monitoring network is supported by publicly available data from official AQ monitoring stations for polluting gases (the network of stations of the Generalitat Valenciana [9]) as well as other stations managed by the local councils, such as in Valencia city [8]. In Figure 2a, we shown an example of Official AQ monitoring station, in particular from Burjassot (outskirts of Valencia, Spain). All this information gathered is also improved with statistical techniques of spatial inference to enhance the spatial resolution of these pollutants over the city maps. Besides, in zone with poor official AQ coverage, we deploy additionally ECO4RUPA AQ monitoring nodes, as shown in Figure 2b,c, outdoor and indoor versions respectively.
The AQ Index scale is based on the US-EPA 2016 standard and it is classified into 6 categories, given by different ranges and colours, as follows: range [0 - 50] as good (green), [51 -100] as moderate (yellow), [101-150] as unhealthy for sensitive groups (orange), [151-200] as unhealthy (red), [201-300] as very unhealthy (purple) and more than 300 as hazardous (dark red). In Figure 1, we show a map with these official AQ monitoring stations, along with an indicator of the AQ index. In this case, all the different stations are reasonably good by the time they were queried. Also, in Figure 3, we show a at a higher scale the AQ index for the Valencia community region [13]. It must be stressed that in this Figure 3, the pollution is mainly due to ozone, , which is a secondary pollutant derived from the combustion of fossil fuels.
The rest of the paper is structured as follows. In Section 2, we show available AQ sensors and the related work. In Section 3, we analyse the different design alternatives to be used in the broad monitoring network and its architecture. In Section 4, we consider the options to integrate and merge the information obtained for the route planner. In Section 5, we present and discuss the results with different users’ profile. Finally, in Section 6, we summarise the main conclusions and future work.
2. State of the art
With regard to AQ monitoring, it should be noted that there are 3 distinct areas based on the different types of gases. That is, greenhouse gases (under control by emissions monitoring), chlorofluorinated gases (analysed in the upper layers of the atmosphere), and pollutants, which include Nitrogen Dioxide (), Sulfur Dioxide (), Carbon Monoxide (), Ozone (), as well as benzols and heavy metals (lead (), Arsenic , Cadmium ()). From these areas, the most relevant for citizens is the last one, the pollutants, most of which come from the combustion of fossil fuels in the city and for which there are regulations and standards for their control, such as Directive 2008/50/EC.
With concern to pollutants, the recent boom in low-cost AQ sensors, due to their ease of installation and low power consumption, makes them increasingly used and interesting to integrate into WSN. These sensors can measure pollutants, such as the ones mentioned before, as well as Volatile Organic Compounds (VOC, usually measured in totals, TVOC), Particulate Matter (PM) concentration or particle size distribution, along with Temperature (T), Atmospheric Pressure (AP) and Relative Humidity (RH). Depending on their operating principle, these sensors are available in different technologies to react to the presence of the pollutant such as electrochemical, metal oxide semiconductors, photo ionisation detectors, non-dispersive infrared, and light scattering, among others.
Manufacturers also integrate different sensors in the same module which makes them easier to be used and more attractive. A list of these types of sensors (or sensor modules) and their main characteristics, in particular the type of gases measured as well as the type of data connection, are shown in Table 1. From all of them, the one we consider to have the best performance, the largest number of gases, and the best quality/price ratio is ZPHS01B [17]. Besides, we can highlight different commercial initiatives [18,19] for AQ monitoring, also considered as low cost, based on a network system that auto-calibrates the AQ measurements.
However, with reference to the measuring ranges and measurement quality of low-cost AQ sensors, the recent CEN/TS 17660-1:2021 standard has set the criteria established by Directive 2008/50/EC for the equivalence of sensor systems used outdoors with the instruments for indicative measurements and objective estimations. In this scenario, these sensors have many limitations as they do not provide a reliable absolute measurement and therefore cannot be used as a substitute for a reliable absolute measurement, nor as a substitute for a reliable reference [20]. In practice, these sensors can be used to provide an order of magnitude and/or awareness of AQ and to allow the identification of pollution hotspots. Nevertheless, to increase the reliability of the readings, the measurements of these sensors can be used as input to the modeling procedure, assisted with AI techniques [6,7] and together with other data, typically measurements of other pollutants and ambient conditions (T and RH).
Furthermore, if we take into account the pollution information in the city, we can plan and influence the calculation of routes for citizens, also known as a route planner according to the particular citizen’s profile and needs. A route planner is a specialised search algorithm designed to find the optimal way to travel between two or more specific locations, trying to minimize a determined cost function. In [21], a routing application is introduced that calculates the least polluted route through the streets. The authors employ a modified version of the popular Ant Based Control routing algorithm as the basis for their routing algorithm. To incorporate pollution data and minimize travel time, the authors tackle a multi-parameter problem.
Similarly, in [22], the significant health risks associated with air pollution are emphasized, with AQ being influenced by factors such as time of day, location within the city, and traffic intensity. To forecast AQ over time, the authors devise a meteorological model integrated into the Healthy Urban Route Planner (HURP), specifically designed for cyclists and pedestrians in Amsterdam (Netherlands). HURP enables users to select and plan a route that promotes a healthier environment, utilizing information gathered from various systems. Traffic emissions are computed based on observed traffic intensities and emission factors. The authors utilize the WRF-Chem atmosphere and AQ model, which generates daily forecasts within a 48-hour, providing temperature and pollutant concentration forecast maps. These maps are then transformed into a unique metric that combines both factors. Hourly data of this metric is incorporated into the route planner, which employs the open source routing library pgRouting1 to identify healthier routes. Also, researchers from the National Institute for Public Health and the Environment in the Netherlands (RIVM) have developed the Atlas Living Environment [23]. By utilizing location-specific parameters, they generate maps displaying the local environment, particularly focusing on , , , and densities. These maps are derived from real-time measurements and prediction models. Additionally, the authors have developed an application that forecasts the AQ index for the next 48 hours.
In this line, in [24], it is introduced a monitoring system that utilizes a mobile network implemented on Android devices to provide real-time air pollution information to users. The pollution data collected from various sources is stored on a cloud-based server, facilitating real-time analysis and the development of an air pollution model. To measure air pollution levels, eco-sensors are deployed on public transport systems or bicycles. However, low-end sensors often suffer from reduced accuracy compared to more advanced sensors as mentioned above. In [25], a system for air pollution monitoring in Mauritius Island is shown, featuring a novel data aggregation algorithm specifically designed for air pollution monitoring systems. In [26], a dynamic routing was carried out using data from a set of pollutant particles of particulate pollutants considered PM10. The researchers used Open Source Routing Machine (OSRM) to perform the routing. Finally, in [27], the authors also explore the integration of air pollution data with route planning. But they propose alternative planning algorithms that aim to distribute traffic more evenly across urban areas. The authors demonstrate that such algorithms not only help alleviate traffic congestion but also contribute to reducing overall air pollution levels in urban environments.
Also, we can highlight several commercial applications known as route planners, such as Google maps [28], Ants Route [29], and Here [30] to name a few. Nevertheless, we must stress that these applications are focused mainly on driving and based on the shortest distance.
In summary from the related work, we can see that there are several initiatives to improve mobility and route planners with different strategies, but not focused on the user’s profiles and his/her needs for healthy routes. Thus, this is the goal of this paper.
3. Design alternatives and techniques for a broad AQ monitoring network and its architecture
For this purpose, the first step is to design and build the AQ monitoring network based on low-cost elements, adjusted with official AQ monitoring data. This network will be set up with IoT nodes based on a microcontroller that connects to different low-cost AQ sensors, seen in Section 2, with the option of different communication alternatives as shown in Figure 4. In case of failure, these IoT nodes incorporate a real-time clock, a memory card, and a watchdog mechanism for its recovery.
We have initially selected the ESP32 microcontroller [31], due to its performance and quality/price, as it offers in each model the possibility of having different antennas, as well as the possibility to implement different communication standards. The ESP32 is a series of low-cost, low-power system on a chip microcontrollers that embeds several communication modules. Based on this microcontroller, it is worth mentioning the Pycom’s 2 FiPy module [32], which includes technologies such as Lora/Sigfox, WiFi, Bluetooth, and cellular technologies such as Long Term Evolution (LTE) for machines (LTE-M) and Narrow Band IoT (NB-IoT). Notice that this FiPy module is flexible enough and permits building this type of IoT nodes, shown in Figure 4.
In particular, in Figure 5 it is depicted a hardware prototype of the implemented AQ IoT monitoring node, with the connection of the ESP32 microcontroller to the ZPHS01B AQ sensor module. Figure 2b,c show the indoor case (for tunnels and indoor environments) for this node that includes a tube and a fan to make air flow pass through the sensor board and also the outdoor version, where the air intake is at the bottom of the tube that sucks it in through also with a small fan. Notice as we mentioned before, that these IoT nodes are used as a coarse reference of the AQ, compared with the measurements provided by the official AQ monitoring stations. These direct measurements taken from these low-cost sensors, in order to be considered valid, are processed by AI-based algorithms to correct and adapt the measurements to reliable values [6]. This process is out of the scope of this paper since we focus only on how to calculate healthy routes according to the particular citizen’s profile and needs.
The communication scheme of the IoT node with the infrastructure is detailed in Figure 6. It is based on the IoT Message Queue Telemetry Transport (MQTT) protocol, which transmits information via messages between the nodes and the MQTT broker. It should be noted that MQTT allows 3 levels of Quality of Service (QoS) to verify the delivery of messages and also several security mechanisms regarding the transmitted data. We have chosen the highest QoS level, QoS-2, which guarantees the delivery of messages only once, without loss or duplication. In terms of security, we use username and password-based login, both at the broker and at the clients, and SSL-certified encryption for transmitted data. The data received is stored locally in a database. For the publishing process, nodes can create a new topic by simply publishing to it, so that more nodes can be added to the IoT system, which greatly facilitates the scalability of the system. This data can also be stored in the cloud, providing additional backup and security against data loss. To graphically visualise the data, the geographical positions of the nodes are indicated.
Notice that the placement of these ECO4RUPA low-cost AQ monitoring nodes will improve the coverage given by the official AQ monitoring stations as mentioned before, following a criteria explained in Section 4.2.
4. Data fusion, spatial interpolation, and route planner application
This section describes the core of the healthy router planner. The goal is to calculate healthy walking and/or cycling routes according to the particular citizen’s profile and needs. For the development of this service, its flowchart is shown in Figure 7. In this case, initially, the user launches a request for a route calculation. With this, his/her user profile is analysed, and based on it, the appropriate variables (specific pollutants) will be considered, performing a complete interpolation in the area of interest defined by the search using Kriging technique. Later, these values are superimposed on the geographical map and define the metric to be minimised in the route search.
4.1. Analysis of the user’s profile: weighting pollutants
Based on the users’ requirement (specified within his/her profile), we will estimate the pollution according to it, as a combination of the different parameters (pollutants) by weighting their different measurements in the area of user mobility. In particular, as a proof of concept, we have considered citizens with asthma and pregnant women without lack of generality. In this case, we will use the following weights for the different pollutants according to the literature.
In case of asthma, we assign 40% for ozone, , (), 10% for () and 50% for . These weights are assigned because is considered one of the most dangerous pollutants, as it can penetrate the lungs and cause various health problems [33]. Furthermore, is an oxidant known to irritate the airways and has a clearly defined effect on asthma exacerbation [34]. Also, according to [34,35], the results of a meta-analysis, there is evidence to support the link between increased ozone concentration and , worsening asthma.
In case of pregnant women, we assign 5% for (), 35% for (), 20% for , 30% for and 10% for . These gases are chosen because according to [36], exposure to , and , is associated with a reduction in neonatal weight and exposure to and has been related to an increased risk of premature birth. In addition, adds delay in the development of children’s attention span, according to a study conducted by [37]. We assign 30% for , because exposure to this gas can directly affect the fetus through oxygen deficiency [38], which can cause brain damage, developmental delay, and complications during pregnancy [39]. For and , we assign a weight of 20% for and 10% for , because it has been associated with complications during pregnancy, such as premature birth, low birth weight, and respiratory problems in the fetus. Finally, we assign only 5% for , because we have found studies that say that exposure increases the risk of premature birth, low birth weight, and respiratory problems in the fetus, but others do not confirm this relation [38].
Notice that in practice, these weights will be personalized based on the end user’s requirements, and even, they could be saved within his/her profile.
4.2. Kriging for spatial interpolation of pollution
Since the spatial sampling is still limited to the spots where the IoT nodes are deployed and/or the official AQ monitoring stations are installed for a real-time map of the pollutants, a spatial interpolation technique is required, because it is necessary accurate pollution measurements at the different points over the city map in order to analyse the different paths for the routes.
Kriging [40] is a spatial statistical technique that allows the analysis of geolocated information and is based on spatial autocorrelation, unlike other techniques such as Inverse distance weighting (IDW) and Splines [40,41]. The main idea with Kriging is that the estimated variable is given by a deterministic (without spatial influence) part and a random (with spatial influence) part. In this case, Kriging employs the spatial function from the random section in order to deliver the best linear unbiased estimator. Thus, the information gathered from the IoT nodes establishes a dataset associated to different locations with their coordinates, longitude, and latitude, as a first step to applying the Kriging technique
For Kriging, lets D denote a region of interest within a map, where . Within the region D, we want to measure some variable z. Let denote the random variable that can be measured at location s in the region. In practice, measurements are obtained at a finite number n of points:
In this case, for geostatistical data, the covariance functions for the response z at two different points and depend only on the difference in locations (distance and direction) between the two points, and it is given by Equation 1,
for some function c. The key of Kriging is to characterise the random section of the estimated variable via the variogram function, which represents an index of change of variable with respect to the distance. The function is called Variogram and function is the Semivariogram [42] given by:
Assuming and are constant throughout a specific region, that is considering a second-order and intrinsically stationary spatial process, then the variogram for an isotropic process in terms of auto-correlation function () between two spatial points can be written as
with h denote the distance (or lag) between the two points and . In terms of auto-covariance function, the variogram function becomes
From the previous expression, it is easy to see that when h becomes larger, and the variogram converges to . Figure 8 shows a theoretical variogram. As the distance h gets larger, the variogram values increase indicating that as points get farther apart, the expected difference between the measured values at those two points increases as well.
The variogram can be described based on the following attributes, as depicted in Figure 8:
- The Sill: corresponds to the maximum height of the variogram curve. As h gets large, the correlation (and hence covariance) between the measured values at two points separated by a distance h become independent.
- The Range: is the distance h such that pairs of sites further than this distance apart are negligibly correlated. The range of influence is sometimes defined as the point at which the curve is of the difference between the nugget and the sill.
- The Nugget Effect: is expected that , i.e. should be equal to zero if . However, this is usually not the case. As the distance h goes to zero, there is a nugget effect due to measurement error and micro-scale variation.
Thus, as a first approach, the variogram is estimated based on the measured values taken in different locations inside region D, and called empirical variogram. But, in order to be useful, this empirical variogram needs to be replaced later by a model. Some common models are spherical, exponential, gaussian, and power. It is worth mentioning that in this step we have room to move and improve the placement of the ECO4RUPA AQ monitoring nodes in order to enhance this variogram.
Notice that the classical method of estimating the variogram, which corresponds to the method of moments estimator, is given by [42]:
where is the set of all distinct pairs of points (, ) such that . Note that the data is smoothed to generate an estimate of the variogram. For instance, the data can be partitioned into groups, where observations in particular groups are within a certain range of distances, and then using the average squared difference of the points in each group are replaced in Equation 5.
Finally, using linear interpolation, we can estimate value at location based on N measurements as,
where are the weights applied to and is a constant. The estimation error is unknown but must be unbiased and its variance is derived from the input variogram model. Thus, the goal of Kriging is to find the weights for the linear estimator that minimizes the estimation variance. Kriging is a linear least square estimation algorithm, thus the weights of the sampled values are obtained through the minimisation of the estimation variance (error).
In addition, based on the treatment of the mean value of the stochastic field, there are different types of Kriging: Simple Kriging (SK), Ordinary Kriging (OK), Universal Kriging (UK), Lognormal Kriging, etc. In particular, the main ones are SK and OK. They differ mainly in the use of the samples’ mean. The mean value of the Simple Kriging is assumed to be known and constant for the entire domain. Unlike Simple Kriging, Ordinary Kriging considers the mean value unknown, constant, and equal to only for and the n points that enter into the estimation of , giving a more realistic approach to the estimation process.
4.3. Mapping of pollution over the grid on the city
Once we define the pollution for each user and it has been interpolated with OK over the city map on the area of the user mobility, we need to map this pollution over the grid of the city.
For this, the street network within a city is represented as a bidirectional graph, where nodes correspond to intersections and edges represent street segments. Each edge is associated with a parameter that signifies the cost of travelling along that particular segment. Common routing algorithms aim to minimise the total cost of a route by considering the cumulative costs along the edges, known as the cost function in this case given by the exposure to pollution for each user.
Notice that to do this, we have to assign the pollution at each point over the city map by using a grid of 0.0001 decimal degrees that corresponds to 11.5 meters (since 360º corresponds to the whole perimeter, 40075 km, of the Earth). It is necessary to find the match between each graph node and its corresponding grid point, and then assign the pollution value of the grid point to a new attribute of the graph node. In particular, the grid dataframe index is defined as a combination of the longitude and latitude coordinates, and a search over the grid for the corresponding point using these coordinates as indices.
For this, we have used OpenStreetMap (OSM) [43], which is a collaborative project for the creation of editable and free maps. We can find different libraries and tools such as OSMnx [44] for Python, which will allow us to analyse these maps in a coherent way.
Once the pollution values have been assigned to the nodes of the graph, the next step is to assign weights to the edges of the graph to convert it into a weighted graph. To determine the weights of the edges, the criterion based on the weighted average between the nodes that connect each edge will be used, considering both the pollution values, registered at that specific time and the distance between the nodes. This means that the weight of an edge will be the average of the pollution measurement values of the nodes connecting that edge, multiplied by the distance between the two nodes. This is because the travel time between two nodes is assumed to be directly proportional to the distance. In addition, the pollution to which people are exposed is proportional to the exposure time. Therefore, the pollution value and the length of the street segment are multiplied to obtain the cost function.
4.4. Healthy route planner
With the weighted graph in the area of user mobility with the pollution weights of the edges, we can proceed to find the path that minimises overall exposure to pollution.
To do this, we identify the node closest to our departure location and the node closest to our arrival location. The widely-used Dijkstra algorithm (or shortest path first) utilises the edge lengths as the cost function. Then, using the functions provided by the OSMnx library, we construct the optimal route to reach the destination.
5. Results and discussion
In this section, we provide and analyse the results of the proposed route planner under different scenarios (different timetables, congestion road traffic, and routes) and different user profiles, with a special interest on citizens with asthma and pregnant women, since both require special needs based on the weights defined in Section 4.1.
5.1. Analysis of the healthy route planner with different scenarios
In Figure 9, Figure 10 and Figure 11 are shown the resulting routes for users with asthma, pregnant women, and shortest path first respectively. Table 2 depicts the detail for each trial, in bold the ones plotted in Figure 9 to Figure 11. In this table, each column identifies: the trial number, source (src.), destination (dto.), day (DD) and hour (HH), total cost with asthma (C. Asthma) and total distance with asthma (D. Asthma), total cost for pregnancy (C. Preg.) and total distance for pregnancy (D. Preg.), cost with Shortest Path First (SPF) assuming asthma (C. SPF Asthma), cost with shortest path first assuming pregnancy (C. SPF Preg.) and finally distance with SPF (D. SPF).
It is important to highlight that the difference between the optimal healthy route and the shortest route is highly dependent on the selected origin and destination. In some cases, the difference between the shortest route and the optimal healthy route is minimal, for example, in trial number 3 in Table 2. While in other cases, there may be a significant difference, for example, in trial number 9 in the same table. Furthermore, the results suggest that there is a trade-off between reduced pollution exposure and journey length.
5.2. Statistical analysis for the different scenarios
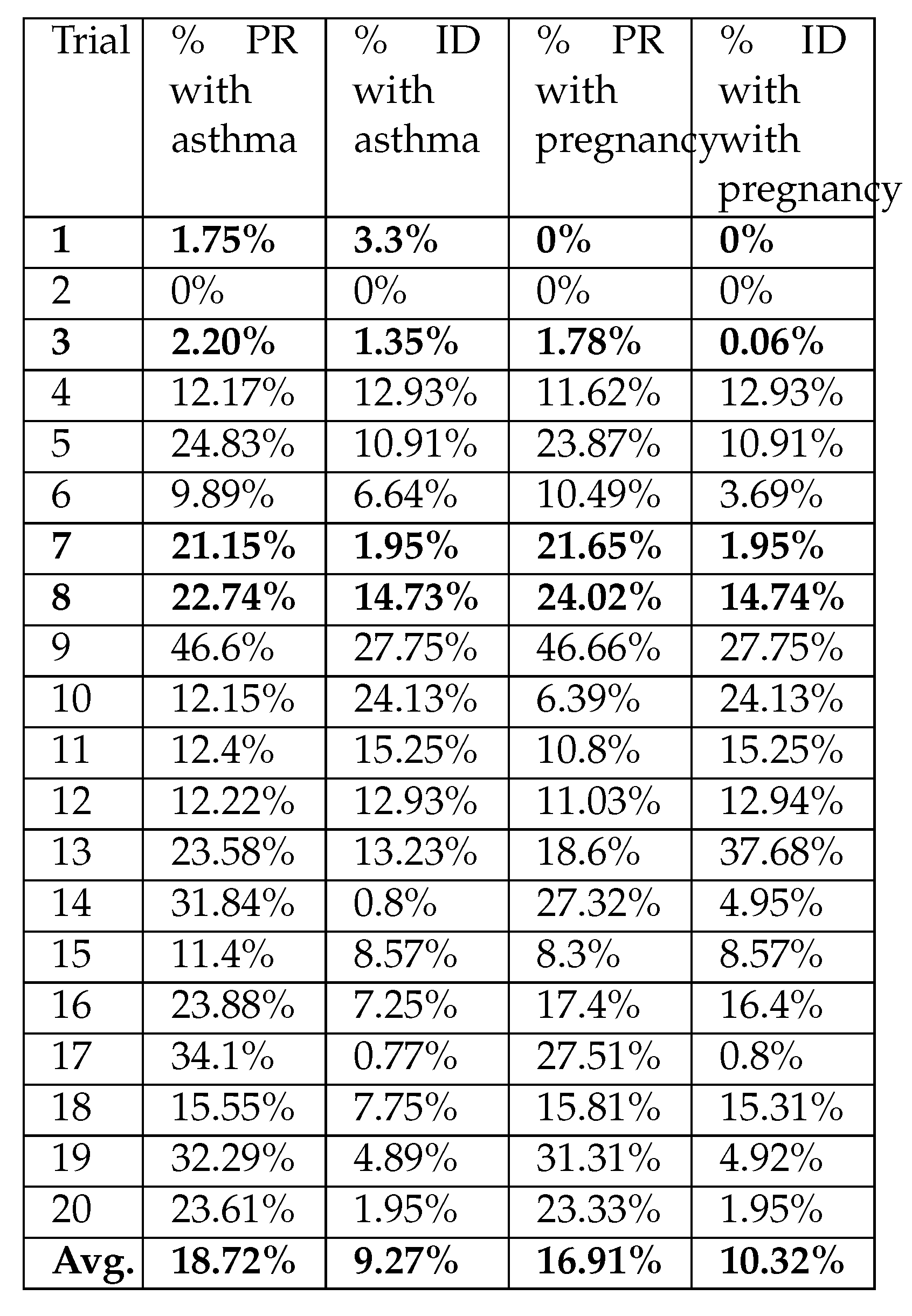
We will estimate the average pollution reduction percentages for each of the trials. Figure 12 shows % of pollution reduction (PR) and increased distance (ID) for each scenario, and in the last row is shown the average (avg.). In bold the trials plotted in Figure 9 to Figure 11.
Our main goal was to recommend optimal routes that ensure low exposure to air pollution during the journey. First, We have evaluated whether the algorithm recommends routes that have low exposure to air pollution compared to routes that recommend the shortest path (which is the one usually chosen). We are interested in determining whether our proposal excels at providing routes that minimise exposure to these types of pollutants. Also, we have examined whether routes with low exposure to pollution turn out to be longer compared to shorter routes. We are interested in whether, by prioritising health and reducing pollution exposure, there is a trade-off in terms of distance travelled.
With this evaluation, we validate the effectiveness of our algorithm.
Then, by analysing the trials performed, we can confirm that our algorithm succeeds in reducing exposure to polluted air by 18.72% in cases of asthma, which implies an increase of 9.27% in distance travelled. For pregnant women, our algorithm succeeds in reducing exposure to air pollution by 16.91%, increasing the distance travelled by 10.32%. On average, our approach can lead to an approximately average reduction in pollution exposure in Burjassot (Valencia) of 17.82%, while experiencing an approximately average increase in distance travelled of 9.8 %. Therefore, it is shown that the route planning system achieves the goal of reducing exposure to high air pollution. These results support the effectiveness of the method in providing healthier navigation options among users, without imposing a significant increase in distance. Also, there is evidence that the optimal route for health is consistent for both the pregnancy and asthma trials.
6. Conclusions and future work
Low-cost AQ sensors do not meet regulatory requirements for equivalent monitoring. Their sensitivity, time response and accuracy is very limited, but through AI techniques they can improve their measurements and together with spatial interpolation techniques and open data (for instance from governmental measurement stations), increase the accuracy of pollutant distribution on geographical maps. Thus, with a deployed WSN for AQ monitoring and its gathered information, we have seen that we can plan routes while minimising the impact and exposure of citizens to pollution. From our results, we achieve on average a reduction in pollution exposure of 17.82%, while experiencing an approximately average increase in distance travelled of 9.8 %.
In the same context, as future work, although it is not a pollutant gas, we could add pollen to this list. Pollen is of great concern to people with allergic pathologies. However, notice that, unlike the polluting gases, pollen, is controlled in a more complex way through health institutions using traditional and even legacy systems that require a posteriori analysis of the collection filters, analyzing the different particles one by one. Also, it must be noticed that there are other alternative and complementary metrics, such as subjective noise annoyance, which can be part of these route planning algorithms too [45].
Author Contributions
Conceptualization, J.S.G, S.F.C. and J.M.A.C.; methodology, R.F.J., J.M.A.C., J.S.G. and S.F.C.; software, R.A.C., R.F.J. and J.S.G.; validation, R.A.C., J.J.P.S., S.F.C.; investigation, J.J.P.S., S.F.C. and J.S.G,; resources, J.S.G. and S.F.C.; writing—original draft preparation, R.F.J., S.F.C and J.S.G.; writing—review and editing, J.J.P.S., R.A.C., and J.M.A.C. All authors have read and agreed to the published version of the manuscript.
Funding
Authors would like to thank the Spanish State Research Agency (AEI) and the European Regional Development Fund (ERDF) for partially funding this research within the projects with grant references PID2021-126823OB-I00 ("ECO4RUPA project") funded by MCIN/AEI/10.13039/501100011033 and by the “European Union NextGenerationEU/PRTR”. Also, to the Research vice-rectorship of Universitat de València for funding the grant with reference UV-INV-EPDI-2647726 for a research stay for S.F.C., and the Spanish Ministry of Education in the call for Senior Professors and Researchers to stay in foreign centers for the grant PRX22/00503 for J.S.G.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- H. Adair-Rohani. Air pollution responsible for 6.7 million deaths every year. https://www.who.int/teams/environment-climate-change-and-health/air-quality-and-health/health-impacts/types-of-pollutants, 2023. Accessed: 27/02/2023.
- Eurostat: Statistics Explained. Respiratory diseases statistics. https://ec.europa.eu/eurostat/statisticsexplained/ index.php?title=Respiratory_diseases_statistics#Deaths_from_diseases_of_the_respiratory_ system, September 2022. Accessed: 22/05/2023.
- BBC News. Air pollution news. https://www.bbc.co.uk/news/world-europe-46017339, 29 October 2018. Accessed: 23/05/2023.
- Molinari G, Colombo G, C. C. Respiratory allergies: a general overview of remedies, delivery systems, and the need to progress. International Scholarly Research Allergy. Hindawi 2014, 1, 1–16. [Google Scholar] [CrossRef]
- González-Díaz, S.; Arias-Cruz, A.; Macouzet-Sánchez, C.; Partida-Ortega, A. Impact of air pollution in respiratory allergic diseases. Medicina Universitaria 2016, 18, 212–215. [Google Scholar] [CrossRef]
- Zimmerman, N.; Presto, A.A.; Kumar, S.P.N.; Gu, J.; Hauryliuk, A.; Robinson, E.S.; Robinson, A.L.; Subramanian, R. A machine learning calibration model using random forests to improve sensor performance for lower-cost air quality monitoring. Atmospheric Measurement Techniques 2018, 11, 291–313. [Google Scholar] [CrossRef]
- Yadav, K.; Arora, V.; Kumar, M.; Tripathi, S.N.; Motghare, V.M.; Rajput, K.A. Few-Shot Calibration of Low-Cost Air Pollution (PM2.5) Sensors Using Meta Learning. IEEE Sensors Letters 2022, 6, 1–4. [Google Scholar] [CrossRef]
- Ajuntament de Valencia, minut a minut. Estaciones contaminación atmosféricas. https://valencia.opendatasoft.com/explore/dataset/estacions-contaminacio-atmosferiques-estaciones-contaminacion-atmosfericas/table/, 2023. Accessed: 21/05/2023.
- Conselleria d’Agricultura, Desenvolupament Rural, Emergència Climàtica i Transició Ecològica. RED VALENCIANA DE VIGILANCIA Y CONTROL DE LA CONTAMINACIÓN ATMOSFÉRICA. https://agroambient.gva.es/va/web/calidad-ambiental/datos-on-line, 2023. Accessed: 27/05/2023.
- ISO 11771:2010. Air quality -Determination of time-averaged mass emissions and emission factors -General approach. Technical report, ISO, 2010.
- ISO 37122:2019. Sustainable cities and communities -Indicators for smart cities. TC268 Sustainable cities and communities. Technical report, ISO, 2019.
- DIRECTIVE 2008/50/EC. OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL of 21 May 2008 on ambient air quality and cleaner air for Europe. Official Journal of the European Communities 2008, L 152, 1–44. [Google Scholar]
- aqicn.org project. World Air Quality Index project. https://aqicn.org/, 2023. Accessed: 27/02/2023.
- Nova Fitness Co., Ltd. . Air quality sensor SDS011. https://cdn-reichelt.de/documents/datenblatt/X200/SDS011-DATASHEET.pdf, 2023. Accessed: 27/04/2023.
- DecentLab, Ltd.. Air quality sensor DL-LP8P. https://www.catsensors.com/media/Decentlab/Productos/Decentlab-DL-LP8P-datasheet.pdf, 2023. Accessed: 27/04/2023.
- SGX, SensorTech. Air quality sensor MiCS-6814. https://www.sgxsensortech.com/content/uploads/2015/02/1143_Datasheet-MiCS-6814-rev-8.pdf, 2023. Accessed: 21/05/2023.
- Winsen, Ltd.. Air quality sensor zphs01b. https://www.winsen-sensor.com/d/files/zphs01b-english-version1_1-20200713.pdf, 2023. Accessed: 20/03/2023.
- S.L., K.T. Calidad del Aire Urbano: Información ambiental y parámetros meteorológicos en entornos urbanos. https://www.kunak.es/, 2023. Accessed: 28/2/2023.
- Ltd., O.I.P. Accurate and Affordable Air Quality Monitoring Solutions. https://oizom.com, 2023. Accessed: 28/2/2023.
- García, M.R.; Spinazzé, A.; Branco, P.T.; Borghi, F.; Villena, G.; Cattaneo, A.; Gilio, A.D.; Mihucz, V.G.; Álvarez, E.G.; Lopes, S.I.; Bergmans, B.; Orłowski, C.; Karatzas, K.; Marques, G.; Saffell, J.; Sousa, S.I. Review of low-cost sensors for indoor air quality: Features and applications. Applied Spectroscopy Reviews 2022, 57, 747–779. [Google Scholar] [CrossRef]
- Rothkrantz, L. Multi parameter routing in air polluted urban areas. 2020 Smart City Symposium Prague (SCSP), 2020, pp. 1–6. [CrossRef]
- Steeneveld, G.; Vreugdenhil, L.; van der Molen, M.; Ligtenberg, A. Towards a Healthy Urban Route Planner for cyclists and pedestrians in Amsterdam. EMS annual meeting abstracts 2017, 14. Annual Meeting European Meteorological Society, Dublin : EMS2017-305 ; Conference date: 04-09-2017 Through 08-09-2017.
- RIVM Institute. Environmental Health Atlas - Explore and discover your living environment. https://www.atlasleefomgeving.nl/en, 2023. Accessed: 27/05/2023.
- Alvear, O.; Zamora, W.; Calafate, C.T.; Cano, J.C.; Manzoni, P. EcoSensor: Monitoring environmental pollution using mobile sensors. 2016 IEEE 17th International Symposium on A World of Wireless, Mobile and Multimedia Networks (WoWMoM), 2016, pp. 1–6. [CrossRef]
- Khedo, K.; Rajiv, P.; Avinash, M. A Wireless Sensor Network Air Pollution Monitoring System. International Journal of Wireless and Mobile Networks 2010, 2. [Google Scholar] [CrossRef]
- Müller, S.; Voisard, A. Air Quality Adjusted Routing for Cyclists and Pedestrians. Proceedings of the 1st ACM SIGSPATIAL InternationalWorkshop on the Use of GIS in Emergency Management; Association for Computing Machinery: New York, NY, USA, 2015; EM-GIS ’15. [CrossRef]
- Vamshi, B.; Prasad, R.V. Dynamic route planning framework for minimal air pollution exposure in urban road transportation systems. 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), 2018, pp. 540–545. [CrossRef]
- Google. Google Maps. https://google.maps/, 2023. Accessed: 27/02/2023.
- AntsRoute. The solution for planning last-mile route of field workforce. https://antsroute.com/en, 2023. Accessed: 27/02/2023.
- Here. Our mission is to enable a digital representation of reality to radically improve the way the world moves, lives and interacts. https://www.here.com/, 2023. Accessed: 27/02/2023.
- Systems, E. ESP32 system-on-chip. https://www.espressif.com/en/products/socs/esp32, 2023. Accessed: 28/1/2023.
- Pycom.io. Fipy, five network development board for IoT. https://pycom.io/product/fipy/, 2022. Accessed: 28/12/2022.
- Kiesewetter, G.; Schoepp, W.; Heyes, C.; Amann, M. Modelling PM2. 5 impact indicators in Europe: health effects and legal compliance. Environmental Modelling & Software 2015, 74, 201–211. [Google Scholar]
- Ubilla, C.; Yohannessen, K. Contaminación atmosférica efectos en la salud respiratoria en el niño. Revista Médica Clínica Las Condes 2017, 28, 111–118. [Google Scholar] [CrossRef]
- Orellano, P.; Quaranta, N.; Reynoso, J.; Balbi, B.; Vasquez, J. Effect of outdoor air pollution on asthma exacerbations in children and adults: systematic review and multilevel meta-analysis. PloS one 2017, 12, e0174050. [Google Scholar] [CrossRef] [PubMed]
- Sanchez, P.B.C.; Macias, G.E.M.; Anchundia, Y.J.P.; Moreira, J.L.Z. Contaminación atmosférica y efectos respiratorios en niños, en mujeres embarazadas y en adultos mayores.
- Bienestar, O. La Exposición Al Dióxido de Nitrógeno Durante El Embarazo perjudica La Capacidad de Atención de los Niños. https://www.atresmedia.com/objetivo-bienestar/actualidad/exposicion-dioxido-nitrogeno-embarazo-perjudica-capacidad-atencion-ninos_20170803598433970cf2c0f4136d712c.html, 2017. Accessed on 15.06.2023.
- Vargas, S.; Onatra, W.; Osorno, L.; Páez, E.; Sáenz, O. Contaminación atmosférica y efectos respiratorios en niños, en mujeres embarazadas y en adultos mayores. Revista udca actualidad & divulgación científica 2008, 11, 31–45. [Google Scholar]
- ISGlobal. La exposición a la contaminación atmosférica durante el embarazo también perjudica a la capacidad de atención en la infancia. http://bit.ly/exposicion-a-contaminacion-atmosferica-durante-embarazo, 2017. Accessed on 15.06.2023.
- E.H., I.; R.M., S. An Introduction to Applied Geostatistics; Oxford University Press: New York, 1989.
- Cressie, N. Statistics for Spatial Data; John Wiley: New York, 1993. [Google Scholar]
- Matheron, G. Traite de geostatistique appliquee, Tome I. Memoires du Bureau de Recherches Geologiques et Minieres 1962, 1. [Google Scholar]
- OSM contributors. Open Street Map. https://www.openstreetmap.org/, 2023. Accessed: 27/05/2023.
- Boeing, G. OSMnx: New methods for acquiring, constructing, analyzing, and visualizing complex street networks. Computers, Environment and Urban Systems 2017, 65, 126–139. [Google Scholar] [CrossRef]
- Segura-Garcia, J.; Calero, J.M.A.; Pastor-Aparicio, A.; Marco-Alaez, R.; Felici-Castell, S.; Wang, Q. 5G IoT System for Real-Time Psycho-Acoustic Soundscape Monitoring in Smart Cities With Dynamic Computational Offloading to the Edge. IEEE Internet of Things Journal 2021, 8, 12467–12475. [Google Scholar] [CrossRef]
| 1 |
pgRouting extends the PostGIS / PostgreSQL geospatial database to provide geospatial routing functionality. |
| 2 | Pycom Ltd. went into bankruptcy in September 2022, but the newly created Pycom BV took over the company |
Figure 2.
Example of (a): Official Air Quality (AQ) monitoring station in Burjassot (outskirts of Valencia, Spain) [9], (b): ECO4RUPA outdoor AQ IoT node and (c): ECO4RUPA indoor AQ IoT node
Figure 2.
Example of (a): Official Air Quality (AQ) monitoring station in Burjassot (outskirts of Valencia, Spain) [9], (b): ECO4RUPA outdoor AQ IoT node and (c): ECO4RUPA indoor AQ IoT node


Figure 3.
Map of the air quality for the Valencia community region [13].
Figure 3.
Map of the air quality for the Valencia community region [13].
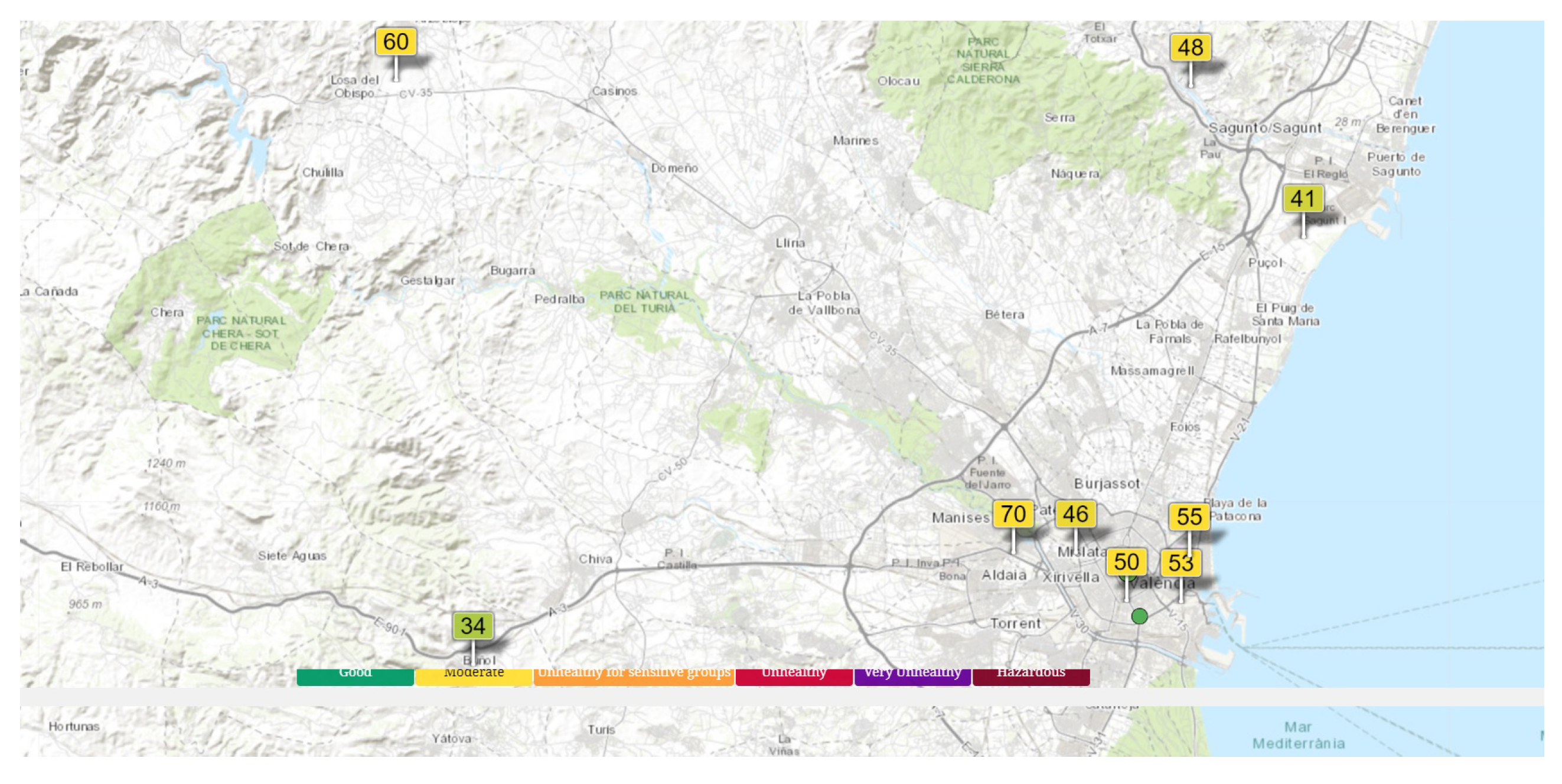
Figure 4.
Generic IoT node for air quality monitoring and communications schema.
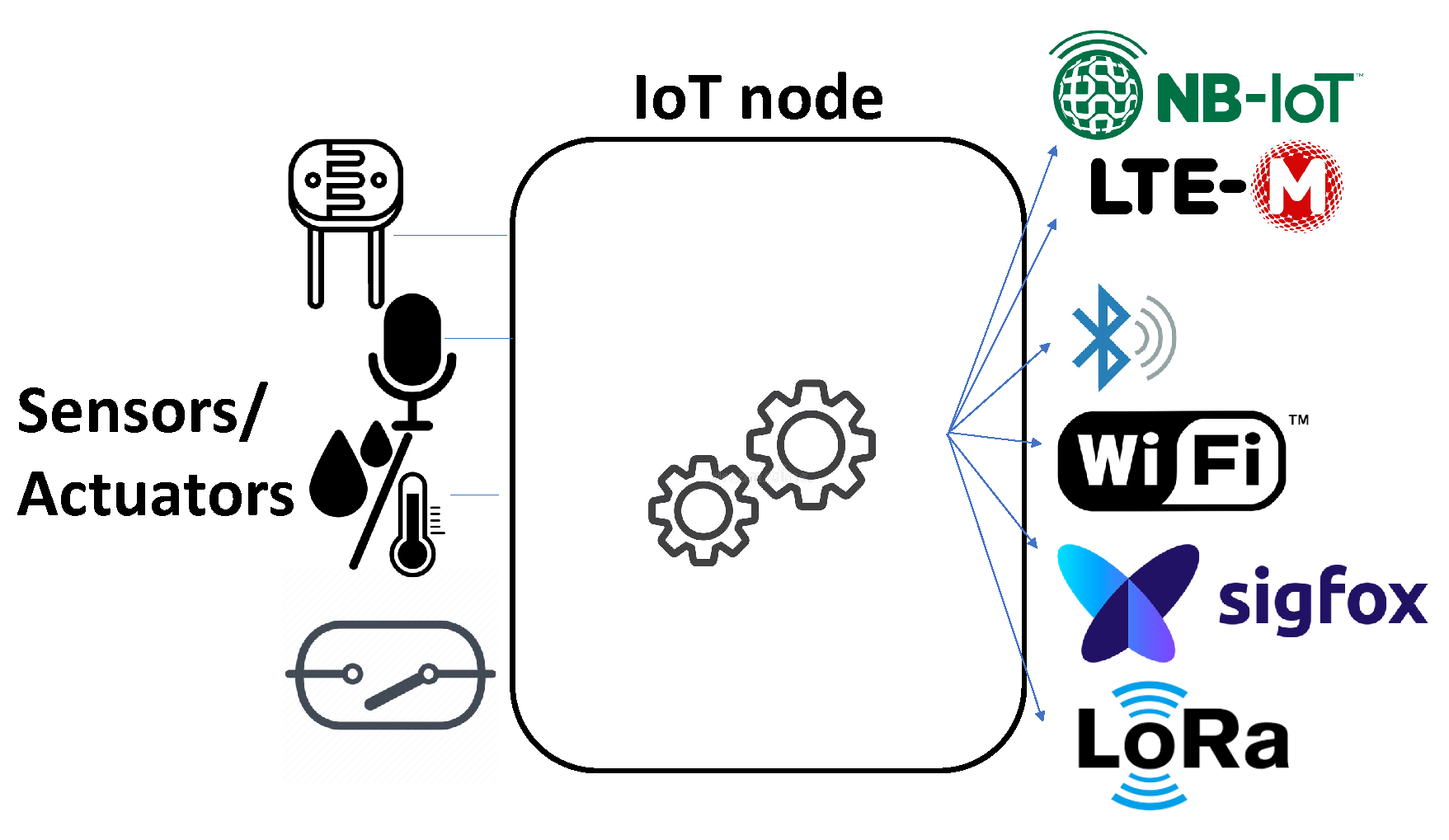
Figure 5.
Example of two ECO4RUPA IoT nodes with ESP32 microcontroller connected to module ZPHS01B with different air quality sensors [17].
Figure 5.
Example of two ECO4RUPA IoT nodes with ESP32 microcontroller connected to module ZPHS01B with different air quality sensors [17].

Figure 6.
Communication scheme of the ECO4RUPA AQ IoT node connection and communications protocol.
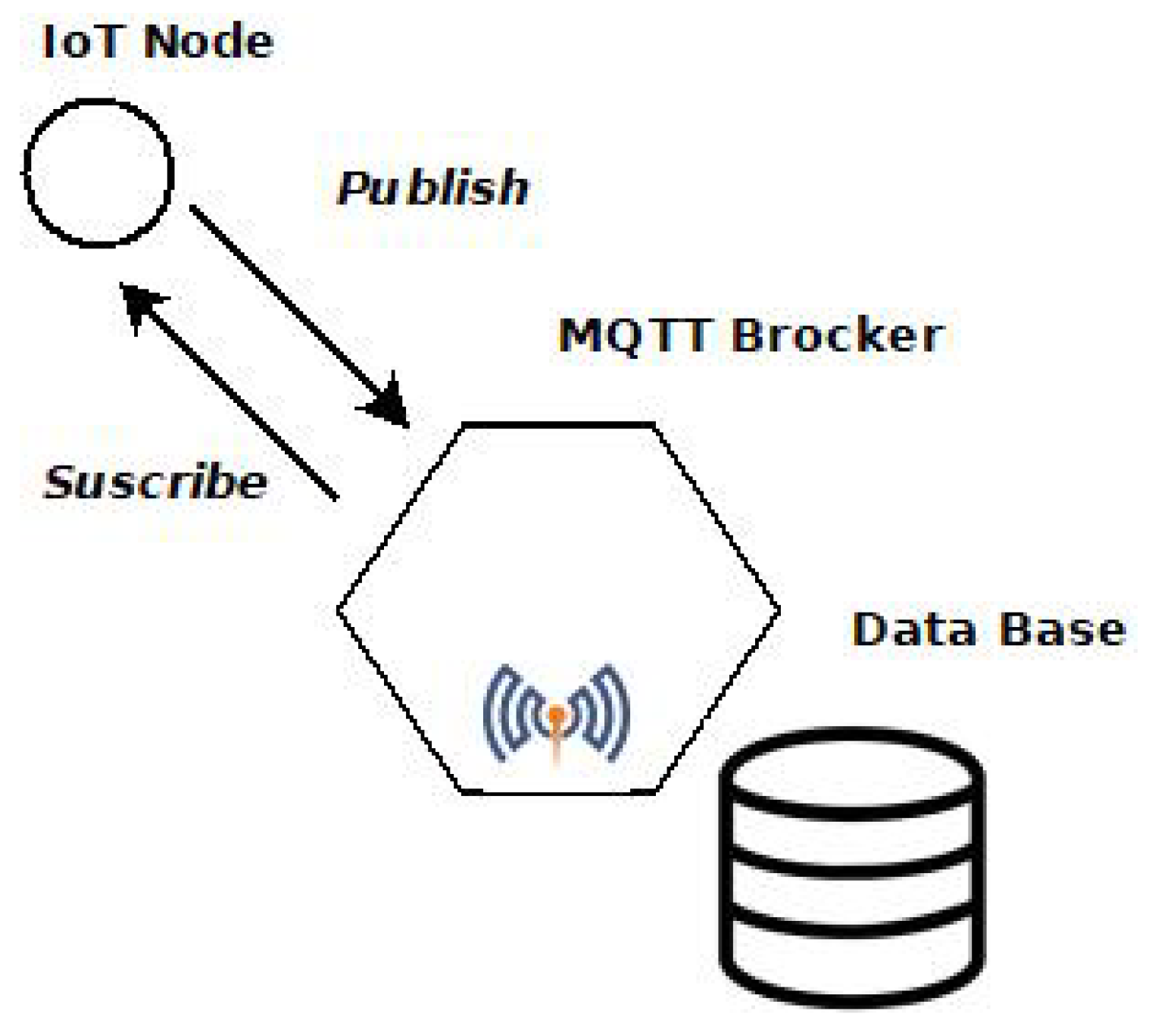
Figure 7.
Flowchart of the user application to request healthy routes
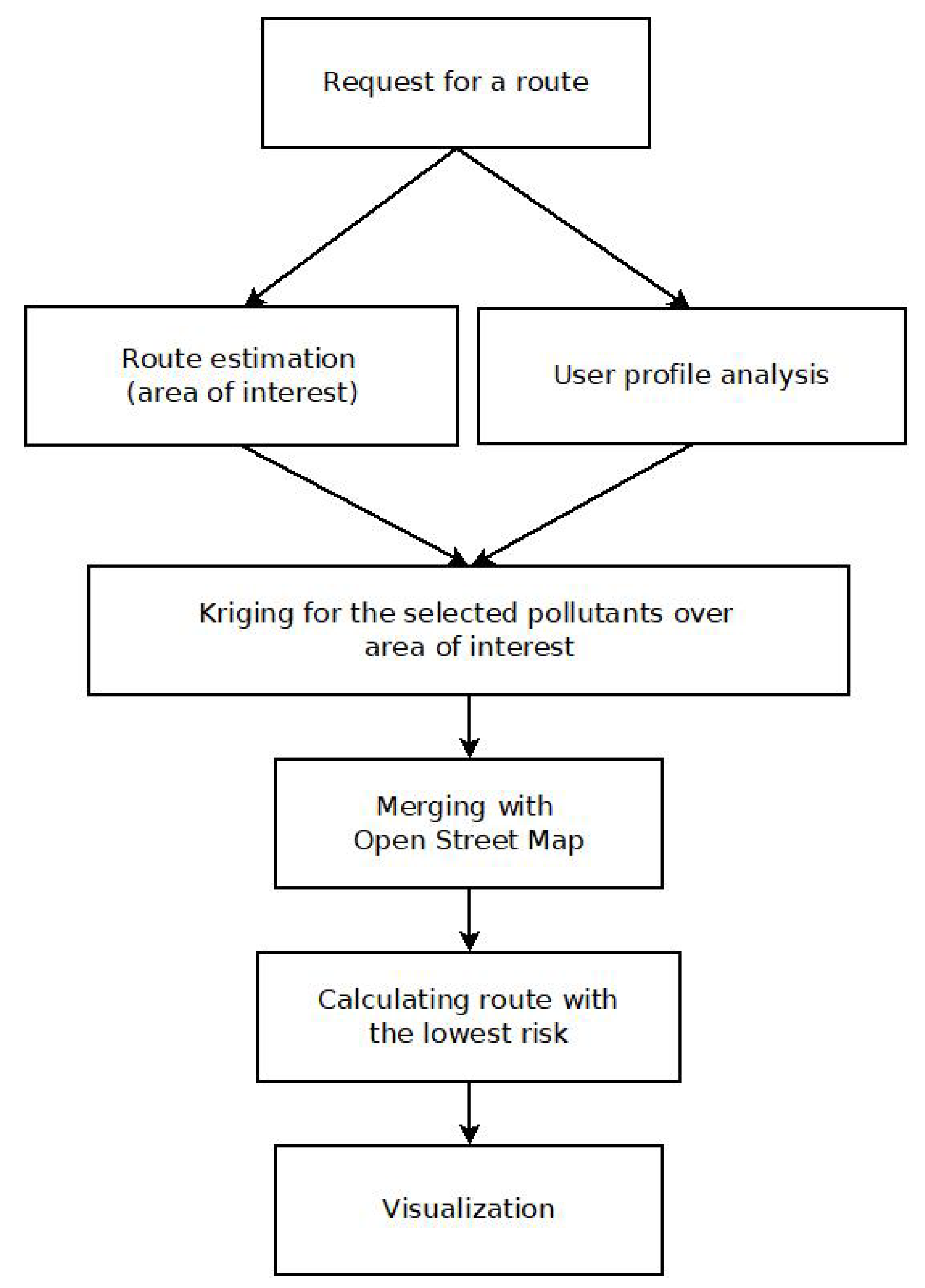
Figure 8.
A theoretical Gaussian model of variogram for Kriging technique.
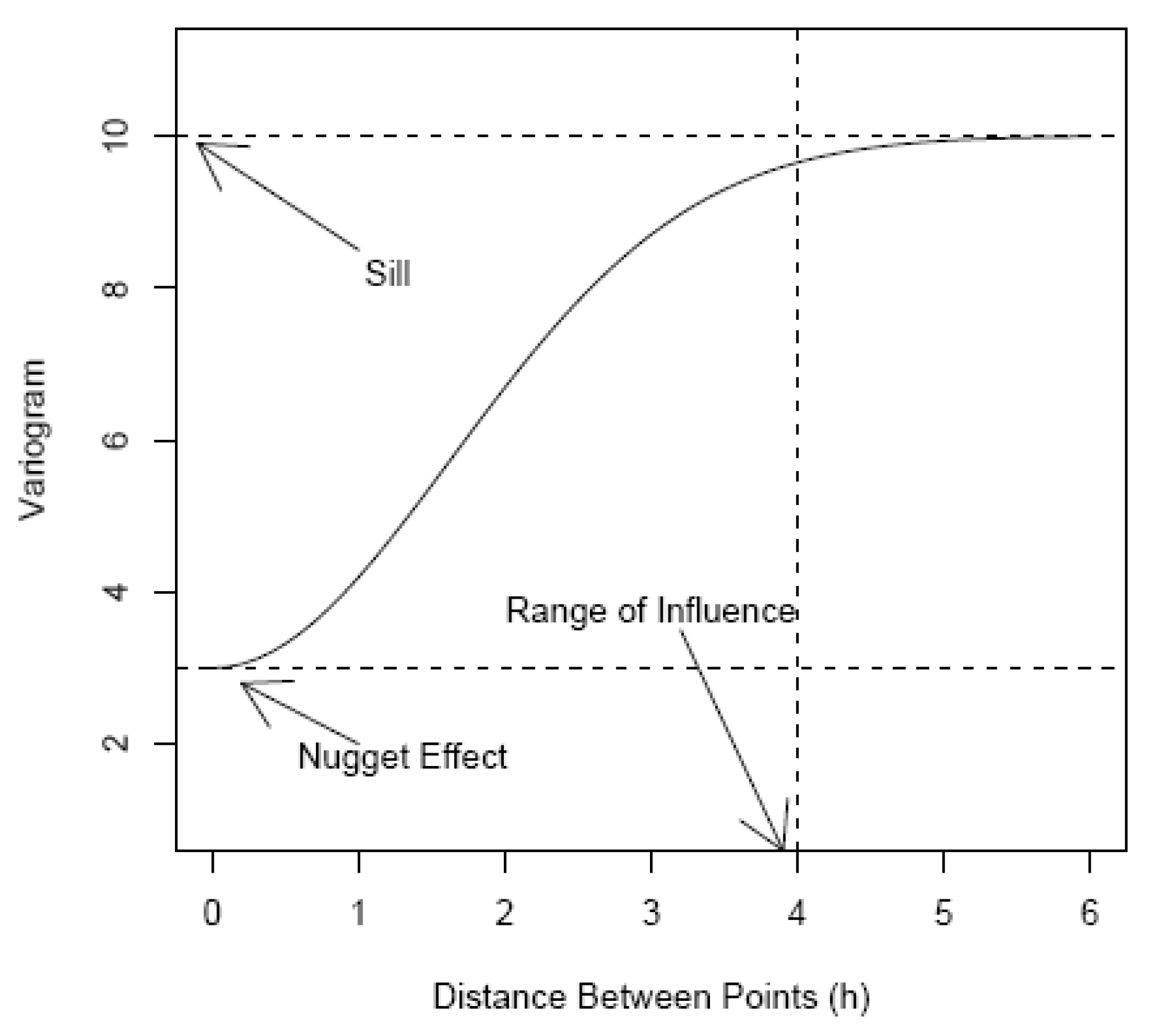
Figure 9.
Examples of several trials with asthma. See route details in Table 2
Figure 9.
Examples of several trials with asthma. See route details in Table 2
Figure 10.
Examples of several trials with pregnant women. See route details in Table 2.
Figure 10.
Examples of several trials with pregnant women. See route details in Table 2.
Figure 11.
Examples of several trials with Shortest Path First. See route details in Table 2.
Figure 11.
Examples of several trials with Shortest Path First. See route details in Table 2.
Figure 12.
% of Pollution Reduction (PR) and Increased Distance (ID) for each scenario. In bold the trials plotted in Figure 9 to Figure 11 and the average.
| Trial | % PR with asthma | % ID with asthma | % PR with pregnancy | % ID with with pregnancy |
| 1 | 1.75% | 3.3% | 0% | 0% |
| 2 | 0% | 0% | 0% | 0% |
| 3 | 2.20% | 1.35% | 1.78% | 0.06% |
| 4 | 12.17% | 12.93% | 11.62% | 12.93% |
| 5 | 24.83% | 10.91% | 23.87% | 10.91% |
| 6 | 9.89% | 6.64% | 10.49% | 3.69% |
| 7 | 21.15% | 1.95% | 21.65% | 1.95% |
| 8 | 22.74% | 14.73% | 24.02% | 14.74% |
| 9 | 46.6% | 27.75% | 46.66% | 27.75% |
| 10 | 12.15% | 24.13% | 6.39% | 24.13% |
| 11 | 12.4% | 15.25% | 10.8% | 15.25% |
| 12 | 12.22% | 12.93% | 11.03% | 12.94% |
| 13 | 23.58% | 13.23% | 18.6% | 37.68% |
| 14 | 31.84% | 0.8% | 27.32% | 4.95% |
| 15 | 11.4% | 8.57% | 8.3% | 8.57% |
| 16 | 23.88% | 7.25% | 17.4% | 16.4% |
| 17 | 34.1% | 0.77% | 27.51% | 0.8% |
| 18 | 15.55% | 7.75% | 15.81% | 15.31% |
| 19 | 32.29% | 4.89% | 31.31% | 4.92% |
| 20 | 23.61% | 1.95% | 23.33% | 1.95% |
| Avg. | 18.72% | 9.27% | 16.91% | 10.32% |

Table 1.
Example of different low-cost AQ sensors
| Module | Gas sensors | Connection type |
|---|---|---|
| SDS011 [14] | PM, T, HR, PA | UART |
| DL-LP8P [15] | , T, HR, PA | LoRAWAN |
| MiCS-6814 [16] | , , , , | I2C, SPI |
| ZPHS01B [17] | , , , , TVOC, T, HR | UART |
| Trial | Src. | Dto. | DD | HH | C. Asthma | D. Asthma | C. Preg. | D. Preg. | C. SPF Asthma | C. SPF Preg. | D. SPF |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | ETSE | Oficina de correos de Burjassot | Fri. 16/06/2023 | 10:13 | 42848.7 | 1728.1 | 17927.14 | 1671.05 | 43609.68 | 17927.14 | 1671.05 |
| 2 | ETSE | Residencia micampus Burjassot | Fri. 16/06/2023 | 12:21 | 28349.79 | 816.02 | 7679.55 | 816.02 | 28349.79 | 7679.55 | 816.02 |
| 3 | Residencia micampus Burjassot | Parque de la Granja | Fri. 16/06/2023 | 19:32 | 46232.2 | 1295.79 | 9822.41 | 1279.08 | 47273.17 | 10000.21 | 1278.33 |
| 4 | C/ Vista Alegre 2 | Polideportivo de Burjassot | Sat. 17/06/2023 | 9:21 | 432.97 | 850.25 | 191.17 | 850.25 | 492.98 | 216.3 | 740.34 |
| 5 | C/ Vista Alegre 2 | Hospital IMED | Sat. 17/06/2023 | 20:47 | 1290.39 | 2385.04 | 322.92 | 2385.04 | 1716.59 | 424.17 | 2124.88 |
| 6 | C/ Maestro Giner 32 | Restaurante Colonial buffet | Sun. 18/06/2023 | 14:09 | 954.03 | 1215.45 | 323.4 | 1178.19 | 1058.74 | 361.32 | 1134.74 |
| 7 | C/ Maestro Giner 32 | Restaurante Quitin | Sun. 18/06/2023 | 14:28 | 413.58 | 640.03 | 86.99 | 640.03 | 524.55 | 111.02 | 627.55 |
| 8 | C/ Vista Alegre 2 | Restaurante Quitin | Sun. 18/06/2023 | 14:31 | 1161.19 | 1996.87 | 249.01 | 1997.02 | 1502.93 | 327.74 | 1702.75 |
| 9 | C/ Vista Alegre 2 | ETSE | Mon. 19/06/2023 | 10:35 | 415.82 | 2281.57 | 893.67 | 2281.57 | 778.73 | 1675.34 | 1648.43 |
| 10 | ETSE | Residencia micampus Burjassot | Fri. 16/06/2023 | 12:21 | 28349.79 | 816.02 | 7679.55 | 816.02 | 28349.79 | 7679.55 | 816.02 |
| 11 | ETSE | C/ maestro Giner 32 | Mon. 19/06/2023 | 14:31 | 546.89 | 1928.15 | 156.95 | 1928.15 | 624.33 | 175.94 | 1928.15 |
| 12 | C/ Vista Alegre 2 | Consum 1 | Wed. 21/06/2023 | 9:32 | 433.32 | 850.26 | 139.79 | 850.41 | 493.63 | 157.11 | 740.34 |
| 13 | C/ Vista Alegre 2 | Consum 2 | Wed. 21/06/2023 | 9:41 | 513.38 | 663.54 | 159.03 | 923.98 | 671.82 | 159.03 | 575.77 |
| 14 | C/ Vista Alegre 2 | Mercadona | Wed. 21/06/2023 | 9:47 | 341.57 | 473.96 | 104.97 | 494.65 | 501.38 | 144.4 | 470.17 |
| 15 | C/ Lauri Volpi 12 | Druni | Wed. 21/06/2023 | 11:08 | 522.42 | 867.41 | 154.86 | 867.41 | 589.62 | 168.88 | 793.06 |
| 16 | C/ Lauri Volpi 15 | Mercadona | Wed. 21/06/2023 | 12:47 | 412.1 | 379.06 | 110.94 | 420.58 | 541.36 | 134.31 | 351.59 |
| 17 | C/ Vista Alegre 2 | Mercadona | Thurs. 22/06/2023 | 12:32 | 376.14 | 473.8 | 97.69 | 473.96 | 570.79 | 134.76 | 470.17 |
| 18 | Parada Burjassot-Godella | Centro de salud | Thurs. 22/06/2023 | 12:48 | 811.98 | 1380.04 | 196.48 | 1503.31 | 961.48 | 233.37 | 1273.13 |
| 19 | C/ Vista Alegre 2 | Parque de la granja | Sun. 25/06/2023 | 17:19 | 373.1 | 528.61 | 65.95 | 528.77 | 551.04 | 96 | 502.75 |
| 20 | C/ Maestro Giner 32 | Mercado | Mon. 26/06/2023 | 11:46 | 291.5 | 666.91 | 69.12 | 666.91 | 381.59 | 90.15 | 653.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



