
Submitted:
22 July 2023
Posted:
25 July 2023
You are already at the latest version
Abstract
In many research fields, statistical probability models are often used to analyze real-world data. However, data from many fields, such as the environment, economics, and health care, do not necessarily fit traditional models. New empirical models need to be developed to improve their fit. In this paper, we explore a further extension of the quasi-Lindley model. Maximum likelihood, least square error, Anderson-Darling algorithm, and expectation-maximization algorithm are four techniques for estimating the parameters under study. All techniques provide accurate and reliable estimates of the parameters. However, the mean square error of the expectation maximization approach was lower. The usefulness of the proposed model was demonstrated by analyzing a dynamical systems data set, and the analysis shows that it outperforms the other models in all statistical models considered.
Keywords:
Quasi Lindley model
; maximum likelihood estimator
; expectation maximization algorithm
1. Introduction
A Lindley model that is simple and remarkably flexible in application was proposed by [1]. It is characterized by the probability density function (pdf)
which is a mixture of two gamma models and with weights, and respectively. Numerous studies have been conducted on the Lindley model. For example, many properties, extensions, and applications of the model have been studied in [2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21]. A scale-invariant version of the Lindley model, namely the quasi Lindley (QL), with the pdf
which is a mixture of two gamma models and with weights and respectively proposed by [22].
A family of models characterized by is said to be scale-invariant if the transformation from to lies within the family pdf times a Jacobi associated with that transformation. Thus, if you change the scale of measurement or the unit of, the fit remains invariant. For instance, a lifetime can be measured in days, hours, or minutes, and the unit of measurement does not affect inferences about lifetimes. Since scale invariance is an essential property of lifetime models, this model has attracted considerable interest. A comparison of the maximum likelihood estimator (MLE) and the expectation-maximization (EM) algorithm for estimating the parameters of the QL model studied by [23] and a new scale-invariant extension of the Lindley model proposed by [24].
Many data sets are composed of multiple populations or sources, and the subpopulation associated with each data is usually unknown or recorded. For example, the lifetime of a device or system may be available, but the manufacturer or an event associated with a living being without its geographic location may not be. Such data sets are mixtures because information about some covariates, such as the manufacturer or geographic location, that significantly affect the observations is unknown. For detailed information on mixture models, see [26,27]. The Lindley model and its extensions are examples of mixture models of the gamma distribution that can be useful for describing many real-world applications.
This study proposes a new extension of the scaled invariant QL model, a mixture of three gamma models, and is investigated. Some statistical and reliability properties, such as failure rate (FR), mean residual life (MRL), and p-quantile residual life (p-QRL) functions, are discussed. Four methods for estimating the model parameters are then discussed. It is examined that all methods provide consistent and efficient estimates of the parameters. However, the algorithm for maximizing expected values yields a lower mean square error.
The rest of the article is organized as follows. The scaled-invariant extended quasi-Lindley (EQL) model is explained in Section 2 along with some of its basic properties. Section 3 estimates the parameters of the model using the maximum likelihood (ML) method, the least squares error (LSE) method, the weighted LSE method, and the algorithm EM. A simulation study is then conducted in Section 4 to investigate and compare the behavior of the estimators. The proposed model is fitted to a dataset of intervals between successive air conditioning failures in a Boeing 720 aircraft to show how useful it could be in practice.
2. Scaled-invariant extended QL model
A random variable follows from if its PDF equals
It shows a mixture of , and with weights , and respectively. When , it reduces to the exponential model. The reliability function is an important yet very simple measure in reliability theory and survival analysis. For the EQL model it is
The distribution function is simply related to the reliability function by and the quantile function which is in fact the inverse of the distribution function equals
The quantile function could be used for simulation random samples, estimating the parameters, and computing skewness of the model.
In addition, for the EQL the k-th moment is finite and equal to
2.1. Statistics and Reliability Properties
The FR function at a time expresses the instantaneous risk of fail at given survival up to . For EQL model we have
Using simple algebra, we can see that the FR function increases from to .
Figure 1 shows the shape of the pdf and the FR function for some parameter values. Two other useful and well-known measures in the reliability theory and survival analysis are MRL and -QRL functions. At time , they describe the mean and -quantile of the remaining life for survival to . For EQL, the MRL is obtained by
Since the FR function is increasing, it follows that the MRL function decreases from to at infinity.
The -QRL reads
which can be calculated numerically. Like the MRL, this measure is a decreasing function of . When , it is called the median residual life, which is a good alternative to the MRL. In Figure 2, the MRL and the median residual lifetime are plotted for some parameter values and show their similar behavior.
An important concept in reliability theory and survival analysis is orderings between lifetimes. For two lifetimes and following reliability functions and respectively, we say that, is greater than , , in stochastic if for every . Equivalently we may write in stochastic. There are other useful orderings, e.g., by means of the FR function, , in FR if for every . Moreover, , in MRL and -QRL if and respectively for every . The following result shows that EQL is internally ordered in terms of .
Proposition 1.
Let
,
follows from
and
, then in stochastic, FR, MRL and -QRL.
Proof.
To show the FR ordering, the derivative of the FR function in terms of is proportional to
So, the FR ordering follows. The stochastic, MRL and -QRL orderings follows from FR ordering. See Lai and Xie [28] for relationship between orderings.
3. Estimation
This section discusses some methods for estimating the parameters of the EQL model. In particular, the parameters are estimated using ML, LSE, weighted LSE methods, and an advanced EM algorithm.
3.1. ML method
Let represent independent and identically distributed (iid) instances from. Then, the log-likelihood function is
The ML estimator of denoted by maximizes the log-likelihood function and can be computed directly by numerical methods or by solving the following likelihood equations.
and
The observed Fisher information matrix can be calculated by replacing and for and in the following Fisher information matrix.
Then the asymptotic distribution of is approximately the bivariate normal distribution with mean and variance-covariance matrix .
3.2. LSE method
In this approach, we search for parameter values which minimize the sum of squared distances between the empirical distribution and the estimated distribution functions. More precisely, we minimize the following expression in terms of the parameters.
By substituting the distribution function, we have
Then, the estimates could be computed as in the following.
3.3. Weighted LSE method
A well-known weight which could improve the LSE estimate is . With this idea, the weighted LSE estimate are computed by minimizing the following expression in terms of the parameters.
This method is well-known as the Anderson Darling (AD) method.
3.2. EM algorithm
Suppose that , is an iid sample from . For a short exposition, take . Since EQL is a mixture of three gamma models , , we consider a latent random variable such that , when comes from . Thus, and , . However, the latent variable will not be observed, but applying it helps to improve the estimation of the parameters in an iterative process. With the evidences and , , the likelihood function can be written as follows.
where equals when and otherwise, and represents the PDF of gamma . Then, the log-likelihood function is
Since this function depends on the unobserved random variable , we cannot estimate the parameters by maximizing them directly. One approach is to implement an iterative process with expectation (E) and maximization (M) steps. In the E step, the expected log-likelihood function is constructed with respect to the conditional latent variable. In the M step, the expected log-likelihood function is maximized to estimate the parameters.
E step:
Assume that the estimate of the parameters at iteration , is known. Then, by the well-known Bayes formula, the conditional probabilities of is
So,
and
Now, applying these probabilities, we can write the expected log-likelihood function at iteration .
Clearly, consists of three expressions
depending solely on and respectively and which does not depend on or .
M step:
To estimate the parameters at iteration, we should maximize in terms of . Thus, for estimating at iteration , we could simply solve the likelihood equation which gives as in the following.
Similarly, by solving the likelihood equation , we could check that is the positive solution of the following quadratic equation in terms of
where . The sequence converges to and we could stop the iterations when does not improve significantly, i.e. for a predefined small value , , see Wu [29] for more information about convergence of the EM algorithm.
4. Simulations
The behavior of the estimators is examined and compared in a simulation study. We were able to generate a random sample of by the following steps:
- First, drive one random instance from multinomial model with parameters where , and . Assume the derived instance be .
- Generate and mix three identical and independent (iid) random samples from , and with sizes , and respectively.
In each simulation run, samples are generated with a size of or . Then, the parameters are estimated for each instance using the ML, LSE, AD methods or EM algorithm. For the calculation of the optimum values of the parameters, the integrated function "optim" of R is used. The initial values needed for computing all estimators are randomly generated from a uniform distribution, e.g., the initial values for are randomly and uniformly derived from the interval (, ). Table 1 shows the bias (B) and mean square error (MSE) for estimators and for some parameter values calculated by the following relations:
and
and similarly, for . Small values of MSE reported in Table 1 show that all estimators are consistent and sufficiently efficient but EM algorithm outperforms others for all selected parameters.
5. Application
Table 2 shows 29-time intervals between successive air conditioning failures in a Boeing 720 aircraft. For more details about the experiment and the data, see Proschan [30].
Total time on test time (TTT) is plotted in Figure 3 with an increasing FR function (left). The histogram of the data and the calculated PDF of the EQL are shown on the right.
The dataset was fitted to the EQL and some alternative models as a comparative analysis. The parameters of the EQL are estimated using the MLE and EM methods. The estimates from EM and ML are approximately the same. The alternative models include the gamma, exponentiated gamma (EG), Lehmann gamma (LG), Marshal-Olkin gamma (MOG), and QL. For each model, the Akaike information criterion (AIC), Cramer-von Mises (CVM) statistics, Anderson-Darling (AD) statistics, and Kolmogorov-Smirnov (KS) statistics are calculated and summarized in Table 3.
The analysis shows that the EQL performs better than the other models in all the statistics considered. In Figure 4, the empirical and fitted distribution function for EQL and some alternatives are plotted and provides a graphical investigation.
6. Conclusions
For data modeling and analysis, the right statistical model must be used to draw more accurate conclusions. The EQL model, which combines three gamma distributions, is an extension of QL, which can be used in various scientific disciplines. The model can be useful in practice, as shown by the analysis of a data set consisting of the intervals between successive air conditioning failures of a Boeing 720 aircraft. The ML approach and the EM algorithm provide accurate and consistent parameter estimates based on simulation results. However, the EM algorithm provides a more accurate approximation than the MLE.
Acknowledgments
This work is supported by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2023R226), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lindley, D.V. Fiducial distributions and Bayes’ theorem. J. R. Stat. Soc. Ser. (Methodol.) 1958, 20, 102–107. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Atieh, B.; Nadarajah, S. Lindley distribution and its application. Math. Comput. Simul. 2008, 78, 493–506. [Google Scholar] [CrossRef]
- Shanker, R.; Ghebretsadik, A.H. A New Quasi Lindley Distribution. Int. J. Stat. Syst. 2013, 8, 143–156. [Google Scholar]
- Zakerzadeh, H.; Dolati, A. Generalized Lindley distribution. J. Math. Ext. 2009, 3, 13–25. [Google Scholar]
- Shanker, R.; Shukla, K.K.; Shanker, R.; Leonida, T.A. A Three-Parameter Lindley Distribution. Am. J. Math. Stat. 2017, 7, 15–26. [Google Scholar]
- Merovci, F.; Sharma, V.K. The Beta-Lindley Distribution: Properties and Applications. J. Appl. Math. 2014, 2014, 198951. [Google Scholar] [CrossRef]
- Ibrahim, E.; Merovci, F.; Elgarhy, M. A new generalized Lindley distribution. Math. Theory Model. 2013, 3, 30–47. [Google Scholar]
- Sankaran, M. The discrete poisson-Lindley distribution. Biometrics 1970, 26, 145–149. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Mutairi, D.K.; Balakrishnan, N.; Al-Enezi, L.J. Power Lindley distribution and associated inference. Comput. Stat. Data Anal. 2013, 64, 20–33. [Google Scholar] [CrossRef]
- Al-Mutairi, D.K.; Ghitany, M.E.; Kundu, D. Inferences on stress-strength reliability from Lindley distribution. Commun. Stat.-Theory Methods 2013, 42, 1443–1463. [Google Scholar] [CrossRef]
- Zamani, H.; Ismail, N. Negative Binomial-Lindley Distribution and Its Application. J. Math. Stat. 2010, 6, 4–9. [Google Scholar] [CrossRef]
- Al-babtain, A.A.; Eid, H.A.; A-Hadi, N.A.; Merovci, F. The five parameter Lindley distribution. Pak. J. Stat. 2014, 31, 363–384. [Google Scholar]
- Ghitany, M.E.; Al-Mutairi, D.K.; Aboukhamseen, S.M. Estimation of the reliability of a stress-strength system from power Lindley distributions. Commun. Stat.-Simul. Comput. 2015, 44, 118–136. [Google Scholar] [CrossRef]
- Abouammoh, A.M.; Alshangiti Arwa, M.; Ragab, I.E. A new generalized Lindley distribution. J. Stat. Comput. Simul. 2015, 85, 3662–3678. [Google Scholar] [CrossRef]
- Ibrahim, M.; Singh Yadav, A.; Yousof, H.M.; Goual, H.; Hamedani, G.G. A new extension of Lindley distribution: modified validation test, characterizations and different methods of estimation. Commun. Stat. Appl. Methods. 2019, 26, 473–495. [Google Scholar] [CrossRef]
- Marthin, P.; Rao, G.S. Generalized Weibull-Lindley (GWL) distribution in modeling lifetime Data. J. Math 2020, 2020, 1–15. [Google Scholar] [CrossRef]
- Al-Babtain, A.A.; Ahmed, A.H.N.; Afify, A.Z. A new discrete analog of the continuous Lindley distribution, with reliability applications. Entropy 2020, 22, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Joshi, R.K.; Kumar, V. Lindley Gompertz distribution with properties and applications. Int. J. Appl. Math. Stat. 2020, 5, 28–37. [Google Scholar] [CrossRef]
- Afify, A.Z.; Nassar, M.; Cordeiro, G.M.; Kumar, D. The Weibull Marshall and Olkin Lindley distribution: properties and estimation. J. Taibah Univ. Sci. 2020, 14, 192–204. [Google Scholar] [CrossRef]
- Chesneau, C.; Tomy, L.; Gillariose, J.; Jamal, F. The Inverted Modified Lindley Distribution. J Stat. Theory Pract. 2020, 14. [Google Scholar] [CrossRef]
- Algarni, A. On a new generalized lindley distribution: Properties, estimation and applications. PLoS ONE 2021, 16, 1–18. [Google Scholar] [CrossRef]
- Shanker, R.; Mishra, A. A quasi Lindley distribution. Afr. J. Math. Comput. Sci. Res. 2013, 6, 64–71. [Google Scholar]
- Kayid, M.; Nassr, S. Al-Maflehi, EM Algorithm for Estimating the Parameters of Quasi-Lindley Model with Application. Journal of Mathematics 2022, 2022, 1–9. [Google Scholar]
- Kayid, M.; Alskhabrah, R.; Alshangiti, A.M. A New Scale-Invariant Lindley Extension Distribution and Its Applications. Mathematical Problems in Engineering 2021, 3747753. [Google Scholar] [CrossRef]
- Alrasheedi, A. , Abouammoh, A. and Kayid, M. A new flexible extension of the Lindley distribution with applications. Journal of King Saud University – Science 2022, 34, 1–9. [Google Scholar] [CrossRef]
- Titterington, D.M.; Smith, A.F.M.; Makov, U.E. Statistical analysis of finite mixture distributions; John Wiley and Sons: Chichester, U.K., 1985. [Google Scholar]
- Ord, J.K. Families of frequency distributions; Charles Griffin: London, U.K., 1972. [Google Scholar]
- Lai, C.D.; Xie, M. Stochastic Aging and Dependence for Reliability; Springer, 2006; ISBN 978-0-387-29742-2. [Google Scholar]
- Wu, C.F.J. On the convergence properties of the EM algorithm. Ann. Stat. 1983, 11, 95–103. [Google Scholar] [CrossRef]
- Proschan, F. Theoretical Explanation of Observed Decreasing Failure Rate. Technometrics 1963, 5, 375–383. [Google Scholar] [CrossRef]
Figure 1.
The PDF (left) and FR (right) of EQL for some parameter values.
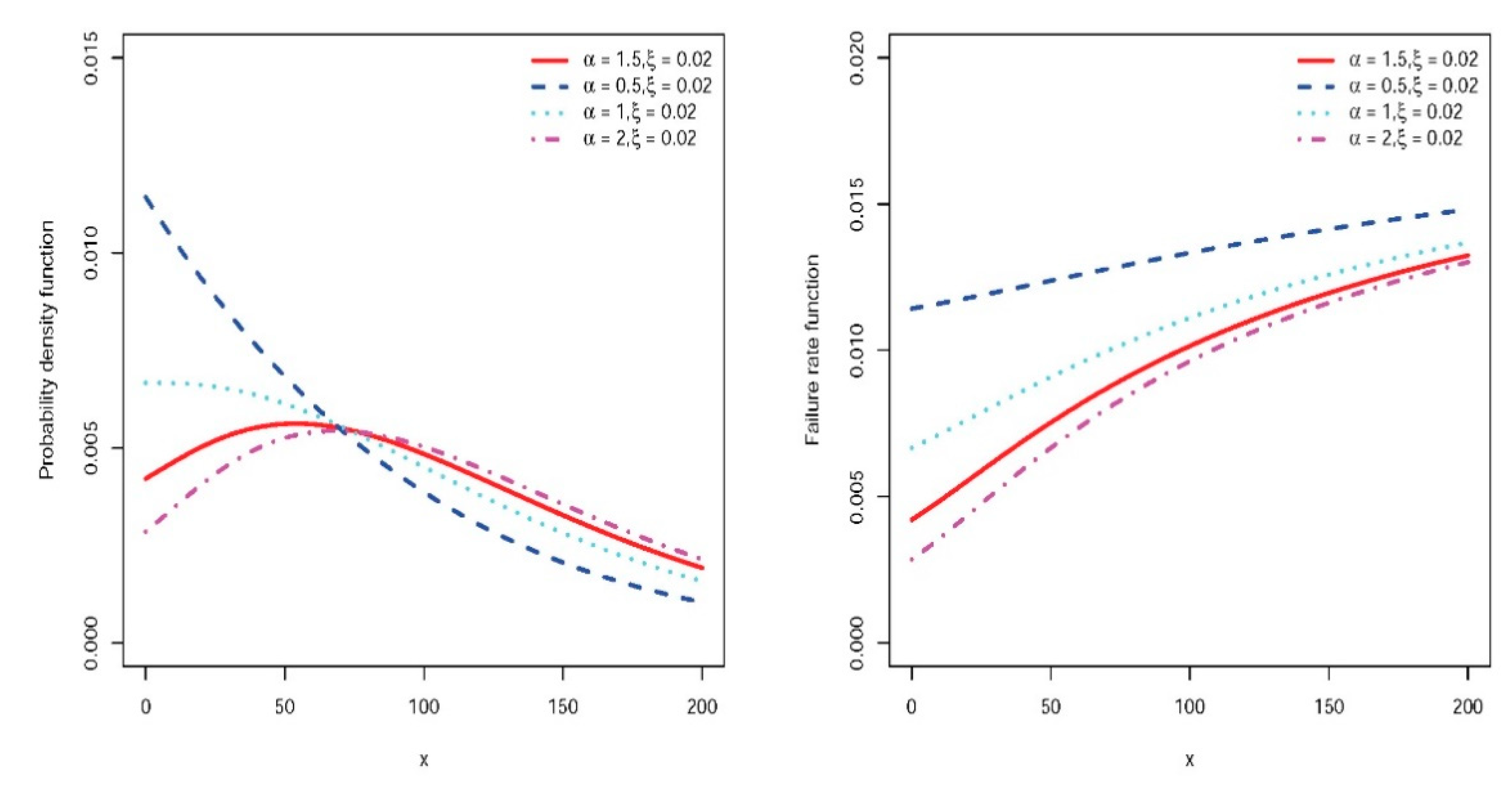
Figure 2.
The MRL (left) and median residual life (right) of EQL for some parameter values.
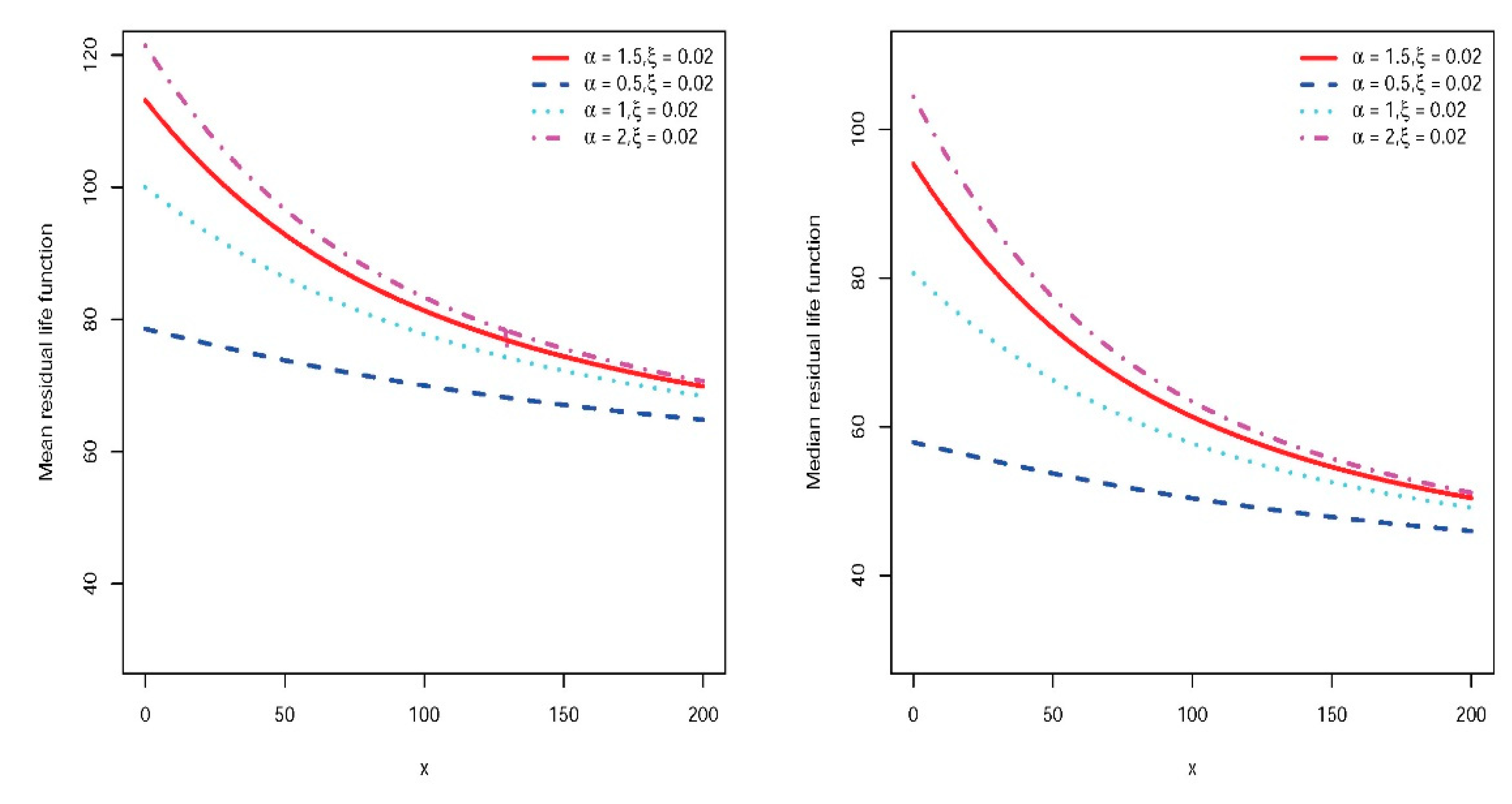
Figure 3.
The TTT plot (left) and histogram along with estimated PDF (right) of times between failures of air conditioning system.
Figure 3.
The TTT plot (left) and histogram along with estimated PDF (right) of times between failures of air conditioning system.
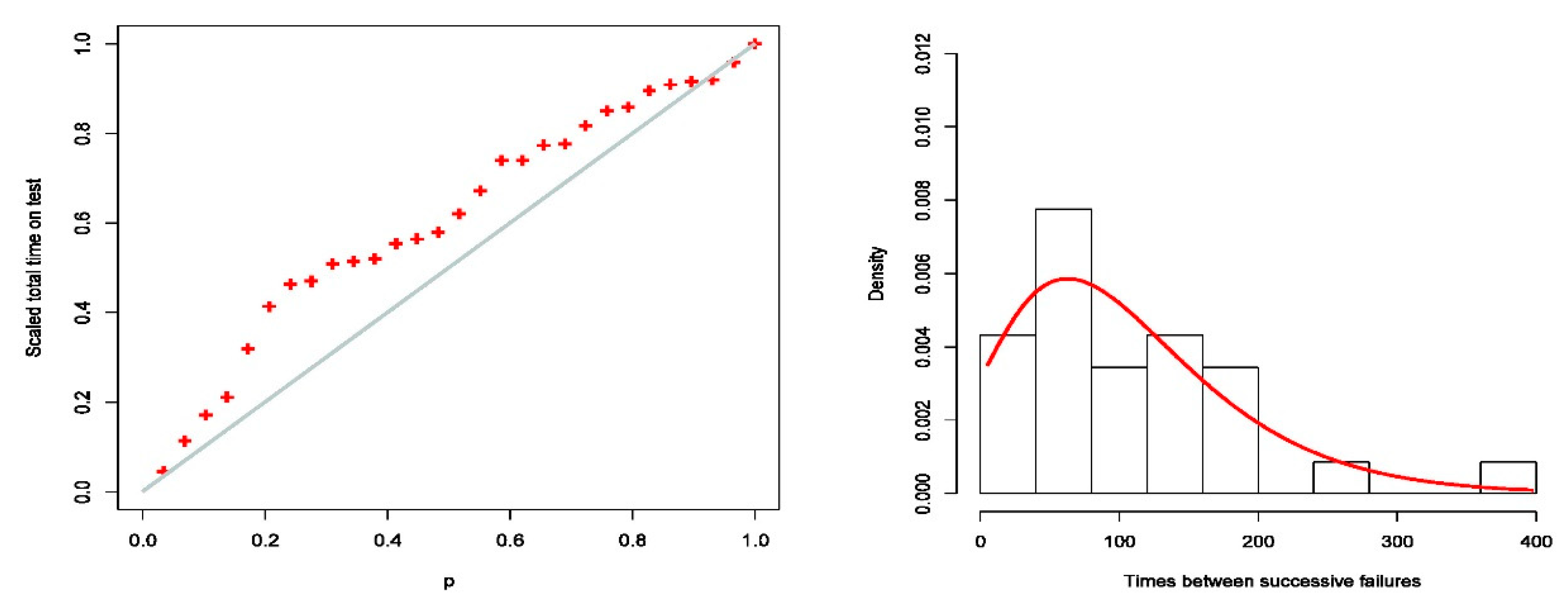
Figure 4.
The empirical and estimated CDF for QL and some alternative models of times between failures of air conditioning system.
Figure 4.
The empirical and estimated CDF for QL and some alternative models of times between failures of air conditioning system.
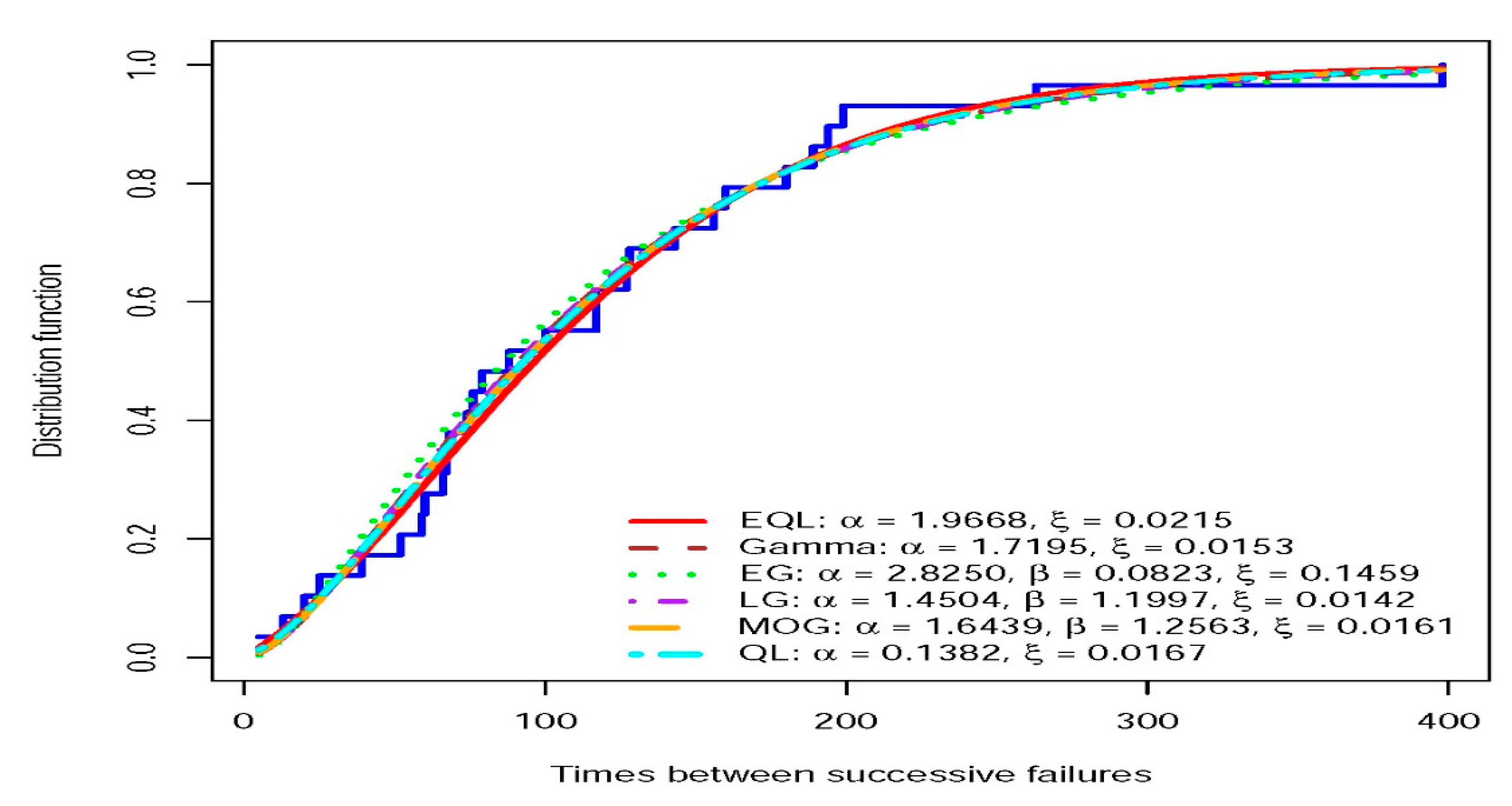

Table 1.
Simulation results for ML, LSE, AD and EM algorithm. The first and second lines of every cell corresponds to and respectively.
Table 1.
Simulation results for ML, LSE, AD and EM algorithm. The first and second lines of every cell corresponds to and respectively.
| Method | 80 | 150 | |||
| B | MSE | B | MSE | ||
| MLE | 0.1, 0.1 | 0.2093 0.0221 |
0.1413 0.0015 |
0.1486 0.0166 |
0.0853 0.0010 |
| 0.3, 0.5 | 0.1009 0.0415 |
0.1222 0.0209 |
0.0466 0.0168 |
0.0771 0.0133 |
|
| 0.8, 1 | 0.0598 0.0029 |
0.1716 0.0326 |
0.0273 -0.0043 |
0.0948 0.0201 |
|
| EM | 0.1, 0.1 | 0.0833 0.0097 |
0.0377 0.0004 |
0.0463 0.0054 |
0.0126 0.0002 |
| 0.3, 0.5 | 0.1346 0.0530 |
0.1095 0.0181 |
0.0807 0.0329 |
0.0554 0.0100 |
|
| 0.8,1 | 0.1023 0.0223 |
0.1856 0.0299 |
0.0281 0.0015 |
0.0728 0.0156 |
|
| LSE | 0.1, 0.1 | 0.2350 0.0306 |
0.1970 0.0026 |
0.1734 0.0230 |
0.1185 0.0016 |
| 0.3, 0.5 | 0.0906 0.0523 |
0.1726 0.0315 |
0.0466 0.0287 |
0.1083 0.0206 |
|
| 0.8,1 | 0.0609 0.0075 |
0.2960 0.0500 |
0.0143 -0.0038 |
0.1085 0.0270 |
|
| Weighted LSE (AD) | 0.1, 0.1 | 0.0283 0.0097 |
0.0592 0.0009 |
0.0249 0.0084 |
0.0392 0.0006 |
| 0.3, 0.5 | -0.1116 -0.0233 |
0.1157 0.0211 |
-0.1373 -0.0367 |
0.0778 0.0121 |
|
| 0.8,1 | -0.3220 -0.1497 |
0.2795 0.0700 |
-0.2426 -0.1230 |
0.1963 0.0466 |
|
Table 2.
Time interval between successive failures of air conditioner system of Boeing 720 aircraft.
Table 2.
Time interval between successive failures of air conditioner system of Boeing 720 aircraft.
| 10 | 60 | 186 | 61 | 49 | 14 | 24 | 56 | 20 |
| 84 | 44 | 59 | 29 | 118 | 25 | 156 | 310 | 76 |
| 44 | 23 | 62 | 130 | 208 | 70 | 101 | 208 |
Table 3.
Fitting the successive times between failures.
| Model | AIC | CVM | AD | KS | |||
| p-value | p-value | p-value | |||||
| EQL | 1.9668 | — | 0.0215 | 331.22 | 0.0278 0.9843 |
0.1833 0.9944 |
0.0801 0.9923 |
| Gamma | 1.7195 | — | 0.0153 | 331.55 | 0.0363 0.9539 |
0.2399 0.9754 |
0.1028 0.9190 |
| EG | 2.8250 | 0.0823 | 0.1459 | 334.57 | 0.0647 0.7882 |
0.3836 0.8638 |
0.1308 0.7037 |
| LG | 1.4504 | 1.1997 | 0.0142 | 333.59 | 0.0373 0.9682 |
0.2454 0.9727 |
0.1041 0.9120 |
| MOG | 1.6439 | 1.2563 | 0.0161 | 333.37 | 0.0322 0.9705 |
0.2169 0.9851 |
0.0965 0.9498 |
| QL | 0.1382 | — | 0.0167 | 331.35 | 0.0320 0.9712 |
0.2057 0.9888 |
0.0965 0.9499 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



