
Submitted:
28 July 2023
Posted:
31 July 2023
You are already at the latest version
Abstract
Stemming from the object overlap and undertraining from the few samples, the road dense object detection is confronted with the poor object identification performance and the inability to recognize edge objects. Based on this, one transfer learning-based YOLOv3 approach for identifying dense objects in the road has been proposed. Firstly, Darknet-53 network structure is adopted to obtain pre-trained YOLOv3 model, then the transfer training is introduced as the output layer for the special dataset of 2000 images containing vehicles; in the proposed model, one random function is adapted to intialize and optimize the weights of the transfer training model, which is seperately designed from the pre-trained YOLOv3; and the object detection classifier replaces the fully connected layer, which further improves the detection effect, the reduced size of the network model can further reduce the training and detection time, and can be better applied to actual scenarios. The experimental results demonstrate that the object detection accuracy of the presented approach is 87.75% for the Pascal VOC 2007 dataset, which is superior to the traditional YOLOv3 and the traditional YOLOv2 by 3.05% and 11.15%, respectively. Besides, the test was carried out using UA-DETRAC, a public road vehicle detection dataset, the object detection accuracy of the presented approach reaches 79.23% in detecting images, which is 4.13% better than the traditional YOLOv3, and compared with the existing relatively new object detection algorithm YOLOv5, the detection accuracy is 1.36% better. Moreover, the detection speed of the proposed YOLOv3 method reaches 31.2 Fps/s in detecting images, which is 7.6 Fps/s faster than the traditional YOLOv3, and compared with the existing relatively new object detection algorithm YOLOv5, the speed is 4.3 Fps/s faster; the proposed YOLOv3 performs 79.38Bn of floating point operations per second in detecting video, which obviously surpasses the traditional YOLOv3 and the newer object detection algorithm YOLOv5.
Keywords:
dense road
; object detection
; Darknet-53 network
; transfer learning
1. Introduction
The dense detection of objects such as vehicles and pedestrians in the road scenes faces the problems of object overlapping or occlusion, uneven distribution of objects, and difficulty in detecting edge objects. Traditional object detection techniques may be separated into the following two broad categories: R-CNN (Region-Convolutional Neural Network), which is based on candidate regions, including R-CNN[1], Fast R-CNN[2], Faster R-CNN[3], and other two-stage networks; and regression-based single-stage networks, like YOLO [4], SSD (Single Shot MultiBox Detector)[5]. R-CNN algorithms need extract the characteristics of the candidate regions before feeding them into a pre-trained CNN model in order to get a characteristic for classification. Due to the large amount of object overlapping in the candidate regions, the features from the overlapping regions will be repeatedly calculated when extracting features, thereby the real-time performance is poor; comparably, the YOLO model only requires one feed forward neural network to directly predict the classifications and positions of diverse objects for several independent candidate regions, which has the advantages of the simpler training, the better detection efficiency, etc[6]. YOLO has been widely used in object detection [7], and it has evolved to the YOLOv3 [8]. Compared with YOLOv2, the YOLOv3 model has the stronger self-learning ability and larger capacity, which can solve the problem of poor accuracy from the excessive high-resolution dataset and unbalanced positive and negative samples; besides, the YOLOv3 has more candidate frames and can improve the intersection ratio during detection. For matching the special road dense object detection scene, transfer learning[9] will be introduced to the YOLOv3 network to fine-tune and accelerate the original training model, which is embedded in the output layer of pre-trained YOLOv3 thereby one new transfer learning-based YOLOv3 model is shaped.
The key contributions can be described as
1) Based on the pre-trained YOLOv3 model, the transfer training is introduced as the output layer for the special dataset containing detecting objects; moreover, one random function is adapted to initialise and optimize the weights of the transfer training model, which is seperately designed from the pre-trained YOLOv3.
2) In the proposed YOLOv3, the object detection classifier replaces the full convolutional layer of the traditional YOLOv3, aiming to relieve the conflict distinguishing the edge target features and other background features caused by the excessive receptive field of the full connection layer, besides, the introduced classifier can avoid the excessive computation from the fully connected layer in the traditional YOLOv3.
2. Algorithm principle
Figure 1 shows the architecture of the dense road detection system based on YOLOv3, which include three parts: the YOLOv3 backbone network, transfer training unit, optimization of network parameters. Firstly, the VOC 2007, VOC 2012, and COCO datasets are selected for YOLOv3 network pre-training; then, the images containing vehicles are extracted from the VOC 2007 dataset and re-labeled to form the special vehicle dataset, and the transfer training-based YOLOv3 model is transferred and trained in this dataset; finally, the test dense road pictures or videos are input into the proposed model, and the output is obtained by feature extraction, multi-scale detection, and non-maximum suppression (NMS) processing. Performance evaluations are performed by confidence, mean precision (mAP, mean Average Precision), and precision-recall (P-R, Precision Recall) of object detection.
2.1. Feature extraction network
Compared with the YOLOv2 network, the backbone portion of the YOLOv3 network has evolved from Darknet-19 to Darknet-53, consequently expanding the number of network layers[10] and adding the cross-layer sum operation in the residual network; YOLOv3 network has fifty-three convolutional layers (ResNet, Residual Network). Darknet-53 is an entirely convolutional network comprised of 3x3 and 1x1 convolutional layers, including 23 residual modules and layers of detection channels that are completely interconnected. As depicted in Figure 2, the convolutional layers are interconnected by quick link[11] (that is, SC, Shortcut Connections). This SC structure can greatly enhance the computation performance of the network, enabling the network to obtain faster detection speed in a limited number of network layers. In the detection architecture, YOLOv3 separates three channels for feature detection into distinct grid sizes. These channels include feature maps with grid sizes of 52x52, 26x26, and 13x13, which correspond to the detection of large-scale(y1), medium-scale(y2), and small-scale(y3) picture features, respectively. thereby, The YOLOv3 can provide a higher detection accuracy with fewer network parameters and fewer superfluous network layers, enabling it to improve both the detection speed and the detection accuracy. By comparison, the conventional R-CNN relies on deepening the network structure to enhance the recognition rate.
2.2. Training strategy design
The traditional deep learning network generally improves the recognition accuracy by increasing the training set or deepening the network complexity. In the application of road dense object detection, the real-time detection is an important indicator[12]. Transfer learning is introduced in an effort to improve the training process of the traditional YOLOv3 network, as Figure 3.
In Figure 3, the YOLOv3 backbone network is combined with the transfer training model, during pre-training process, the YOLOv3 network is trained in the VOC 2007 and VOC 2012 dataset to obtain the pre-trained model for 20 object types in the VOC dataset, besides, the COCO dataset is trained to obtain 60 object types, totally 80 object types can be obtained; then, the transfer training unit substitutes the convolutional layer of the YOLOv3 backbone network, its parameters are not fixed, which can be randomly initialized and optimized[13], on the special vehicle dataset. During pre-training, the epoch is set to 300, and the average precision (AP, Average Precision) and mAP of the transfer training model are shown in Table 1.
In the transfer training model, the proposed YOLOv3 retains the convolutional layer in the traditional YOLOv3 after pre-training. When performing feature extraction, the pre-trained convolutional layers[14] are selected to be a feature extractor,which structure allows the input image to propagate forward. The convolutional layer parameters[15] retaind from the pre-trained model were frozen, and takes the output of convolutional layer L-1 as the proposed YOLOv3 extracted feature[16]. Such a convolutional layer can enable the network to better obtain the semantic information of the target and train it, thereby obtaining higher detection accuracy; then, the proposed YOLOv3 replaces the full convolutional layer of the traditional YOLOv3 with the object detection classifier[17], which can relieve the conflict distinguishing between the edge target features and other background features caused by the excessive receptive field of the full connection layer, besides, it can reduce the problem of excessive computation caused by the fully connected layer, so that the proposed YOLOv3 can train and detect objects faster; and the corresponding network parameters are accordingly optimized[18] to increase dense detection precision on the road while simultaneously reducing training complexity .
In Table 1, AP represents the mean precision of each object type in the test set. The term "correctly classifying a positive example as a positive example" (abbreviated "TP") refers to the degree of precision achieved when accurately identifying a positive example, while "falsely classifying a negative example as a positive example" refers to incorrectly identifying a negative example as a positive example (abbreviated as "FP")
During the transfer training, nearly 2000 images containing vehicles are screened and labeled. This is a special dataset built[19] for dense object detection in road situations. Included among the road objects in the dataset are car, people, bicycles, motorbikes, trucks, cats, and dogs. There are 7 types that appear frequently in the road scene, which is shown Table 2, and the remaining 13 types that are not common.
From Table 2, a total of 1434 labeled car images in the dataset are selected as special dense road sub-dataset. The images are then divided into a training set and a test set in a 4:1 ratio[20]. In addition, the classes of the special dense road sub-dataset must be modified to 7 and the file path of "train," "valid," "names," and "backup" must be modified correspondingly for the transfer training model to correspond with the extracted special dense road sub-dataset. This is necessary for the transfer training model to correspond with the special dense road sub-dataset. Meanwhile, parameters Batch, LEARN-RATE and IOU in config.py need to be optimized with the following consideration:
1) The Batch function is set to 8. It can make the network complete an epoch in a few iterations, and reach a local optimal state while finding the best gradient descent direction[21]. Increasing this value will prolong the training time, but will better find the gradient descent direction; decreasing this value may cause the training to fall into a local optimum, or not converge.
2) The LEARN-RATE function is set from 1e-4 to 1e-6. During the training procedure[22], the total number of training cycles generally determines a learning rate that continually adapts to new input. Ten rounds of training are setted. Experiments indicate that the learning rate is initially set at 0.0001 at the beginning of training and then gradually slows down after a certain number of rounds have been completed. As the training nears its conclusion, the learning rate is lowered until it hits 0.000001. The setting of the learning rate, which is based on ten training rounds, not only solves the problems of easy loss value explosion and easy oscillation caused by a learning rate that is too large at the beginning of training; if it is too small, it is easy to over fitting, resulting in slow network convergence.
3) The IOU function is allocated the value 0.65. In computer detection tasks, the IOU value is equal to one and the intersection is the same as the union if the actual bounding box and the predicted bounding box entirely overlap[23]. Generally, a value of 0.5 is utilized as the threshold to determine whether or not the predicted bounding box is correct. It is possible to increase the detection accuracy of tiny items and edge objects while dealing with the detection of dense road objects by setting IOU to 0.65. This will enable the gathering of higher-quality samples and enhance the identification of dense road objects.
2.3. Loss function selection
In the proposed YOLOv3, the error loss mainly comes from the misjudgment of prediction frame, confidence and category. The error in the prediction frame is determined by the rate of coincidence between the a priori frame and the prediction frame. If the rate at which the prediction frame and the a priori frame agree is large, this implies that the prediction is accurate and error margins are small; confidence error refers to the mistake induced by random sampling during testing in the test set, sampling the test set, and then estimating all test sets; category misjudgment error is the error caused by detecting one type into another. These three types of losses are expressed as lbox, lobj and lcls respectively.
Here, s is the grid size; B is amount of prediction frames;is the indicator function, which stand for if the prediction frame at i, j has a object, its value is 1, otherwise it is 0; is the indicator function, which stand for if The prediction box at i, j has no object and its value is 1, otherwise it is 0.
3. Experimental testing and evaluation
3.1. Required environment
The experimental configuration is shown in Table 3, using Tensorflow framework in deep learning and Opencv Python framework in computer vision.
3.2. Detection performance evaluation
In the existing object detection algorithms, map and P-R value are the common evaluation indicators of recognition accuracy. The P-R curve is composed of precision and recall[24].
here, "true positive" (TP) refers to the genuine example, "false positive" (FP) refers to a false positive example, and "false negative" (FN) refers to a false negative example. Besides, the index of mAP[25] is also adapted to show the Mean Average Precision.
Figure 4 displays the P-R curve generated by applying the proposed YOLOv3 to the data for the car object detection in road scene. If the classification results of all test samples are positive, the recall rate of the model will be 1 and the accuracy rate will be extremely low; if the classification results of almost all test samples are negative, the accuracy rate will be high and the recall rate will be very low. Precision and recall are two rather contradicting metrics. Figure 4 shows that the proposed YOLOv3 is capable of reaching a high accuracy rate, that the recall rate slope drops in a moderate and steady fashion, and that the accuracy rate and recall rate achieve a more balanced state.
In the special dense road sub-dataset, the training set and test set are divided into two sections with 4:1 ratio. AP statistics are performed on the 7 types as Table 2, and mAP is calculated. Table 4 and Table 5 show the object detection performance of the proposed YOLOv3 and the YOLOv2, respectively.
From Table 4 and Table 5, compared to the YOLOv2, the proposed YOLOv3 exhibits a obvious improvement in the detection accuracy of each category and average detection accuracy.
3.3. Comparative analysis of different algorithms
Using the UA-DETRAC dataset as the test set, for detecting static road pictures, Table 6 shows the detection accuracy of each algorithm, compared to the traditional YOLOv3 and YOLOv5, the proposed YOLOv3 approch exhibits a obvious improvement in the detection accuracy of each category and average detection accuracy.

Table 5.
Object detection performance of the YOLOv2.
| Algorithm mAP mAP |
Car | Bus | Van | Others | Average mAP |
| YOLOv3 | 79.61% | 80.29% | 76.21% | 70.32% | 75.1% |
| YOLOv5 | 83.32% | 82.26% | 79.64% | 72.11% | 77.87% |
| The proposed YOLOv3 | 82.73% | 81.37% | 80.36% | 74.53% | 79.23% |
Figure 5 shows the original object image in the top row, the detection result of YOLOv2 in the second row, and the proposed YOLOv3 detection result in the third row. It is evident that the proposed YOLOv3 is capable of accurately differentiating between different types of vehicles and pedestrians, as well as accurately detecting pedestrians at the edge of the image; it is also capable of using a confidence box to indicate the object type division probability, and to mark the object type division probability; besides, the confidence will not decrease as the density of road objects increasing.
When detecting the real-time collected videos, the test results of YOLOv2 and the proposed YOLOv3 utilizing of road dense objects are shown as Figure 6 and Figure 7, respectively.
Comparing Figure 6 and Figure 7, the proposed YOLOv3 can detect and divide vehicles and pedestrians in real-time, even the detection confidence for different types of objects can also be provided; while the YOLOv2 can only roughly divide the object types, and cannot provide confidence information.
Considering the the difference of object image resolutions, and for the YOLOv2, traditional YOLOv3 and the proposed YOLOv3, the detection time is shown in Table 7. Table 8 shows the corresponding detection time of selecting the length 42.6 seconds of video as the input.
Table 7 shows that the proposed YOLOv3 has the faster detection time, which changes proportionally with image resolution. The accordingly result can be taken from Table 7, which demonstrates that the proposed YOLOv3 can identify 87 frames per second, which is clearly superior to the 12frames/second of the traditional R-CNN and superior to the 9 frames/second of the traditional YOLOv3. In addition, the proposed YOLOv3 does 79.38 billion floating-point operations per second, which is three times more than the traditional R-CNN, and obviously surpasses the YOLOv2 and the traditional YOLOv3.
4. Conclusion
The application of YOLOv3 network in road dense object detection is studied in this paper, mainly including the deepening of Backbone network layers in YOLOv3 network structure and the cross-layer addition and operation in residual network. Different convolutional layers can realize image detection of small, medium and large scale features respectively. Thus, the traditional idea of deepening and improving the recognition rate by relying on network structure is fundamentally improved. It can provide higher recognition accuracy with fewer network parameters and network layers, and the detection speed is also taken into account. The proposed algorithm can accurately distinguish different types of vehicles and pedestrians, even pedestrians at the edge of the detection area. A confidence box can be used to mark the probability of object classification, and the confidence does not decrease with the increasing of road object density. By contrast, although YOLOv5 model has a good detection accuracy, the training and detection time is relatively low compared with the proposed algorithm, and it cannot be well applied to real life. In addition, the proposed training strategy of transfer training in a special dataset can also be extended to other dense object detection scenarios, which can achieve high target detection precision and is simple to train.
Funding
This research was financially supported by National Natural Science Foundation of China (61871176): Research of Abnormal Grain Conditions Detection using Radio Tomographic Imaging based on Channel State Information; Applied research plan of key scientific research projects in Henan colleges and Universities(22A510013): Research of Abnormal Grain Conditions Detection using Cone-beam CT based on Convolutional Neural Network; Open subject of Scientific research platform in Grain Information Processing Center(KFJJ2022011): Grain condition detection and classification-oriented semantic communication method in artificial intelligence of things; The Innovative Funds Plan of Henan University of Technology Plan(2020ZKCJ02): Data-Driven Intelligent Monitoring and Traceability Technique for Grain Reserves.
Data Availability Statement
The results/data/Figures in this manuscript have not been published elsewhere, nor are they under consideration (from you or one of your Contributing Authors) by another publisher.
Conflict Of Interest Disclosure
All authors declare have no competing interests as defined by BMC, or other interests that might be perceived to influence the results and/or discussion reported in this paper.
Ethics approval Statement
Not applicable' for that section.
Patient Consent Statement
All authors confirm that all authors understand IET Computer Vision is an open access journal that levies an article processing charge per articles accepted for publication. By submitting my article all authors agree to pay this charge in full if my article is accepted for publication.
Permission To Reproduce Material From Other Sources
The results/data/figures in this manuscript allow for the reproduction of the material from other sources.
Clinical Trial Registration
Not applicable' for that section.
About the authors
Zhu Chunhua (1976-), female, CCF member (81138M), professor, Doctoral supervisor, research direction: intelligent signal and information processing, advanced detection technology and abnormal recognition, etc, Email :zhuchunhua@haut.edu.cn; Liang Jiarui (1999-), male, master student, research direction: deep learning-based object detection, Email: liangjiarui@163.com.
References
- Girshick, R. , Donahue J., Darrell T., et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition 2014: 580-587.
- Oliveira, G. , Frazo X., Pimentel A., et al. Automatic graphic logo detection via Fast Region-based Convolutional Networks[C]. 2016 International Joint Conference on Neural Networks (IJCNN), 2016: 985-991. [CrossRef]
- Chen, Y. , Li W., Sakaridis C., et al. Domain Adaptive Faster R-CNN for Object Detection in the Wild[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 3339-3348.
- Redmon, J. , Divvala S., Girshick R., et al. You Only Look Once: Unified, Real-Time Object Detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016: 779-788.
- Liu W, Anguelov D, Erhan D, et al. SSD: Single Shot MultiBox Detector.[J]. Clinical orthopaedics and related research(CoRR), 2015: 01-09.
- Bell, S. , Zitnick C L., Bala K., et al. Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks[J]. Clinical orthopaedics and related research(CoRR), 2015: 2874-2883.
- Peng Y, H. , Zheng W H., Zhang J F. Deep learning-based on-road obstacle detection method[J]. Journal of Computer Applications, 2020, 40(8): 2428-2433. [CrossRef]
- Redmon, J. , Farhadi A. YOLOv3: An Incremental Improvement[J]. arXiv e-prints, 2018:01-06.
- Shao, L. , Zhu F., Li X. Transfer learning for visual categorization: A survey[J]. IEEE transactions on neural networks and learning systems, 2014, 26(5): 1019-1034. [CrossRef]
- K. Huang and W. Chang. A neural network method for prediction of 2006 World Cup Football Game[C]. The 2010 International Joint Conference on Neural Networks (IJCNN), 2010: 1-8. [CrossRef]
- Oyedotun, O. , Rahman Shabayek A., Aouada D., et al. Training very deep networks via residual learning with stochastic input shortcut connections[C]. International Conference on Neural Information Processing. Springer, Cham, 2017: 23-33.
- Zhu, B. , Huang M F., Tan D K. Pedestrian Detection Method Based on Neural Network and Data Fusion[J]. Automotive Engineering, 2020(11): 37-44.
- Thomee, B. , Shamma D A., Friedland G., et al. The new data and new challenges in multimedia research[J]. Communications of the ACM, 2015, 59(2):64-73.
- Wang, S. , Huang M., Deng Z. Densely connected CNN with multi-scale feature attention for text classification[C]. IJCAI. 2018, 2018: 4468-4474.
- Pan S, J. , Kwok J T., Yang Q. Transfer learning via dimensionality reduction[C], AAAI. 2008, 8: 677-682.
- Rezende, E. , Ruppert G., Carvalho T., et al. Malicious software classification using transfer learning of resnet-50 deep neural network[C]. 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA). IEEE, 2017: 1011-1014. [CrossRef]
- K. Huang and W. Chang. An Ground Cloud Image Recognition Method Using Alexnet Convolution Neural Network[J]. Chinese Journal of Electron Devices, 2010, 43(6): 1257-1261.
- Cetinic, E. , Lipic T., Grgic S. Fine-tuning convolutional neural networks for fine art classification[J]. Expert Systems with Applications, 2018, 114: 107-118. [CrossRef]
- Majee, A. , Agrawal K., Subramanian A. Few-shot learning for road object detection[C]. AAAI Workshop on Meta-Learning and MetaDL Challenge. PMLR, 2021: 115-126.
- Xu, R. , Xiang H., Xia X., et al. Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication[C]. 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022: 2583-2589. [CrossRef]
- Dogo, E. , Afolabi J., Nwulu N., et al. A comparative analysis of gradient descent-based optimization algorithms on convolutional neural networks[C]. 2018 international conference on computational techniques, electronics and mechanical systems (CTEMS). IEEE, 2018: 92-99. [CrossRef]
- Zhang, K. , Xu G., Chen L., et al. Instance transfer subject-dependent strategy for motor imagery signal classification using deep convolutional neural networks[J]. Computational and Mathematical Methods in Medicine, 2020, 2020. [CrossRef]
- Cai, Z. , Vasconcelos N. Cascade r-cnn: Delving into high quality object detection[C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 6154-6162.
- Wang, H. , Yu Y., Cai Y., et al. A comparative study of state-of-the-art deep learning algorithms for vehicle detection[J]. IEEE Intelligent Transportation Systems Magazine, 2019, 11(2): 82-95. [CrossRef]
- Mao, H. , Yang X., Dally W J. A delay metric for video object detection: What average precision fails to tell[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 573-582.
Figure 1.
Architecture of dense road object detection model.
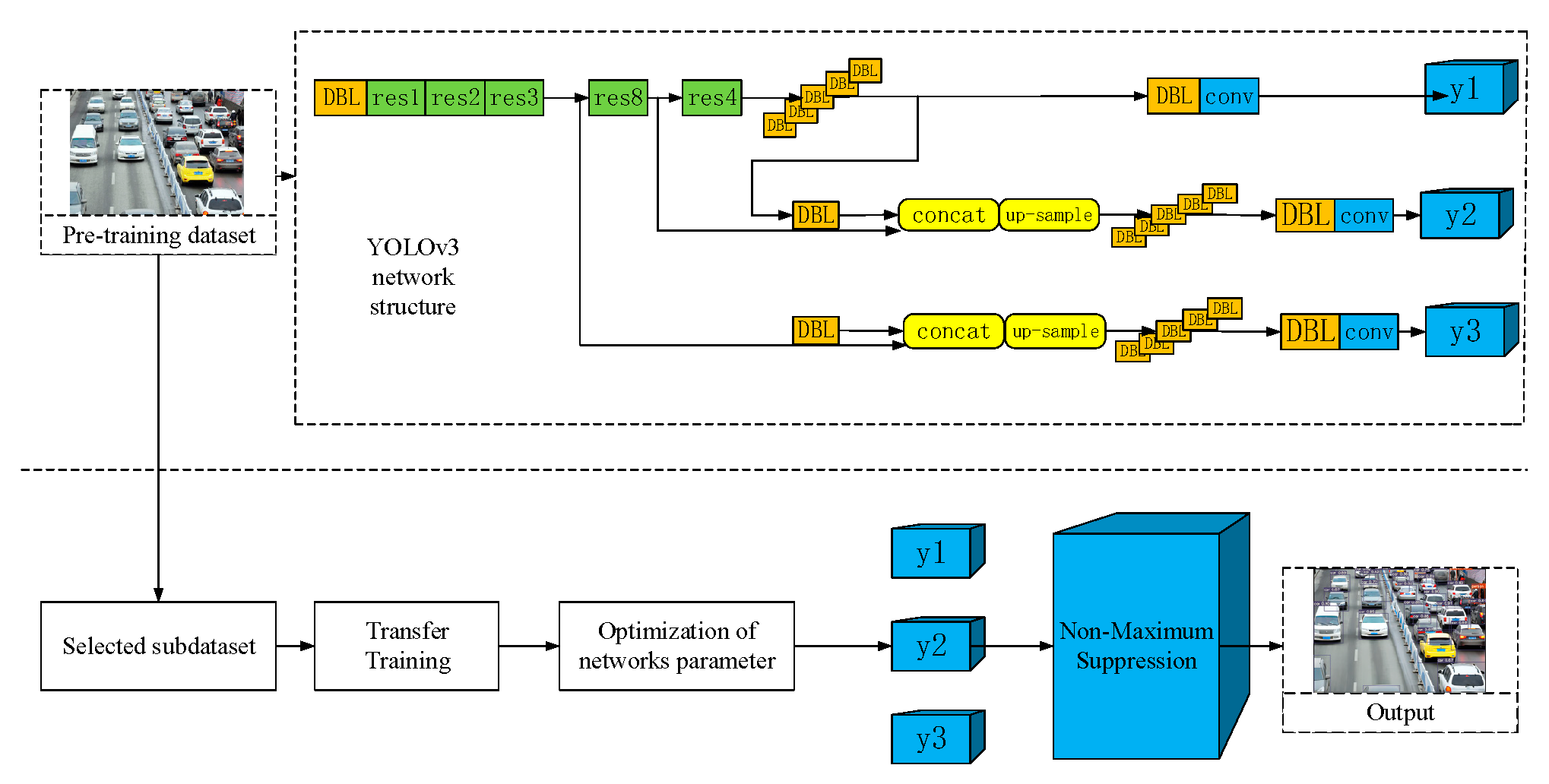
Figure 2.
Schematic diagram of quick link.
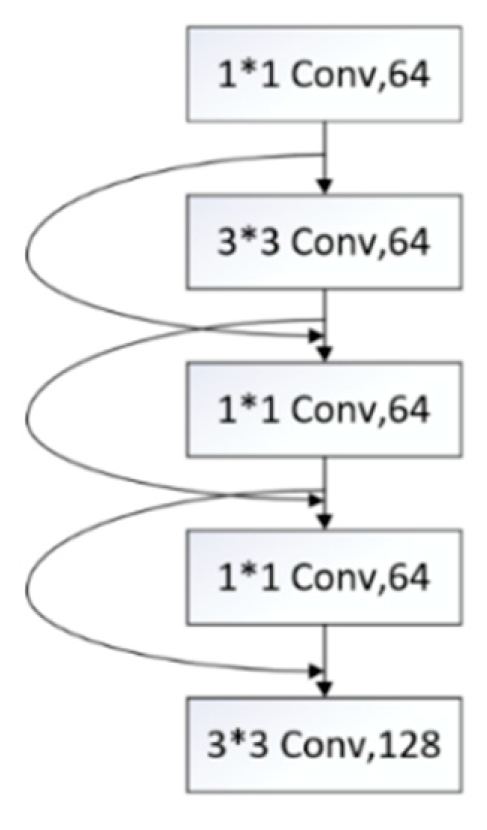
Figure 3.
Transfer training strategy.
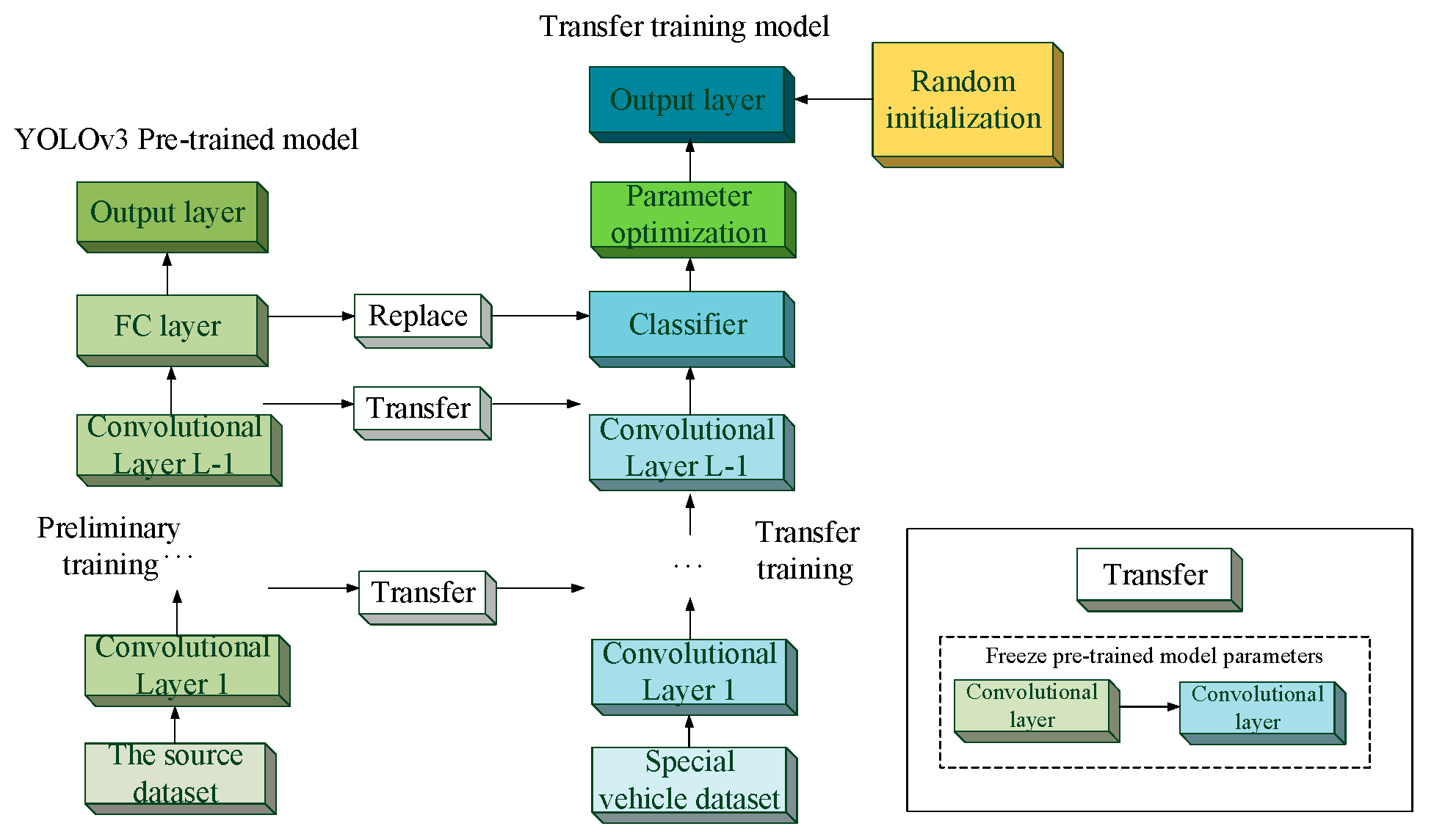
Figure 4.
P-R curve of vehicle object detection.
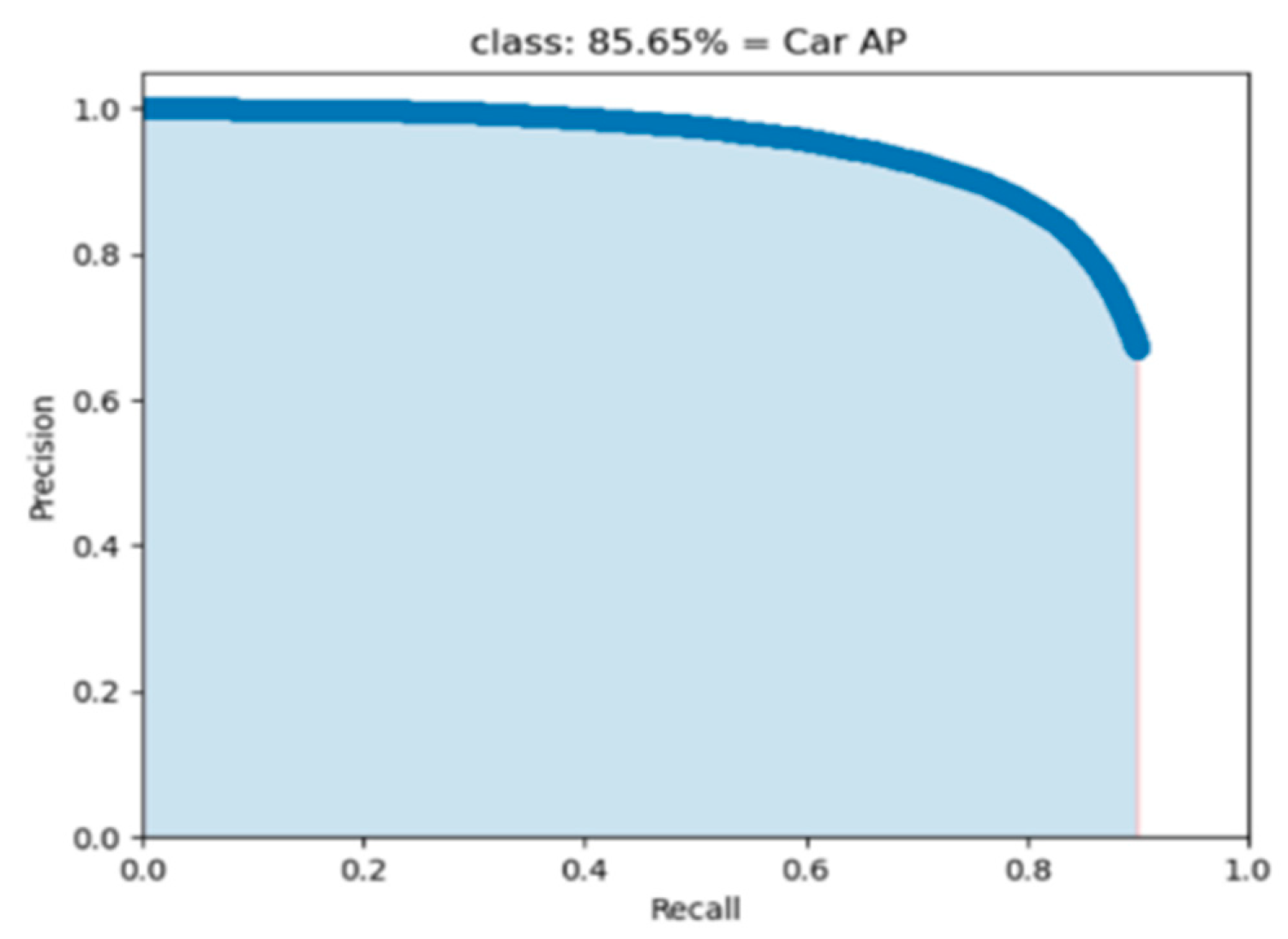
Figure 5.
Object detection results of a single picture.


Figure 6.
Real-time video detection based on YOLOv2.
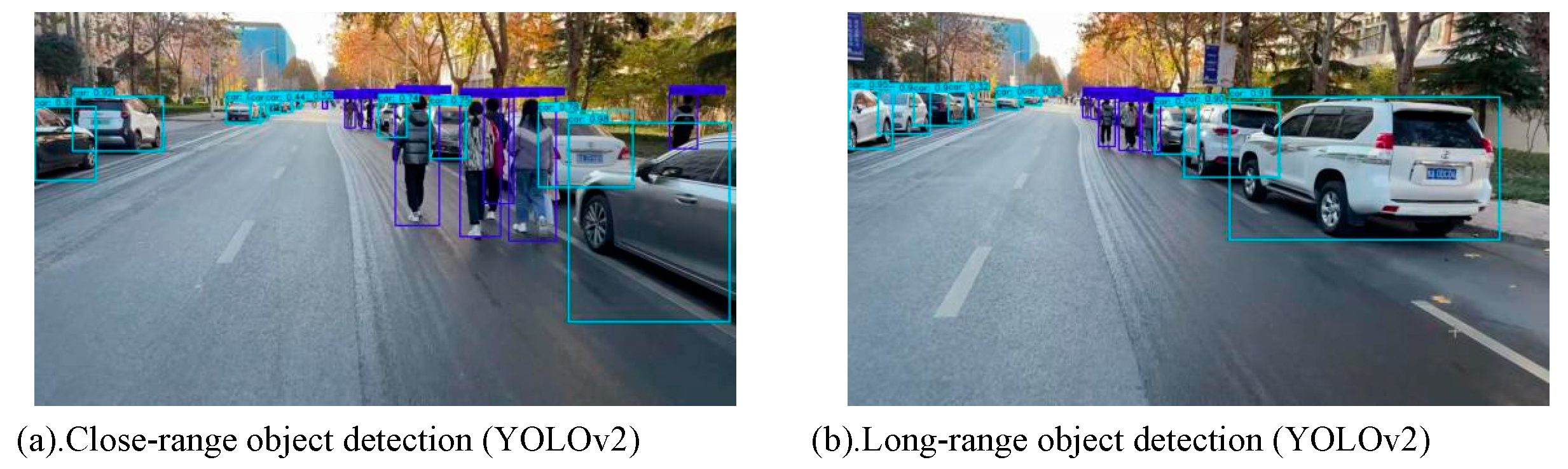
Figure 7.
Real-time video detection based on the proposed YOLOv3.
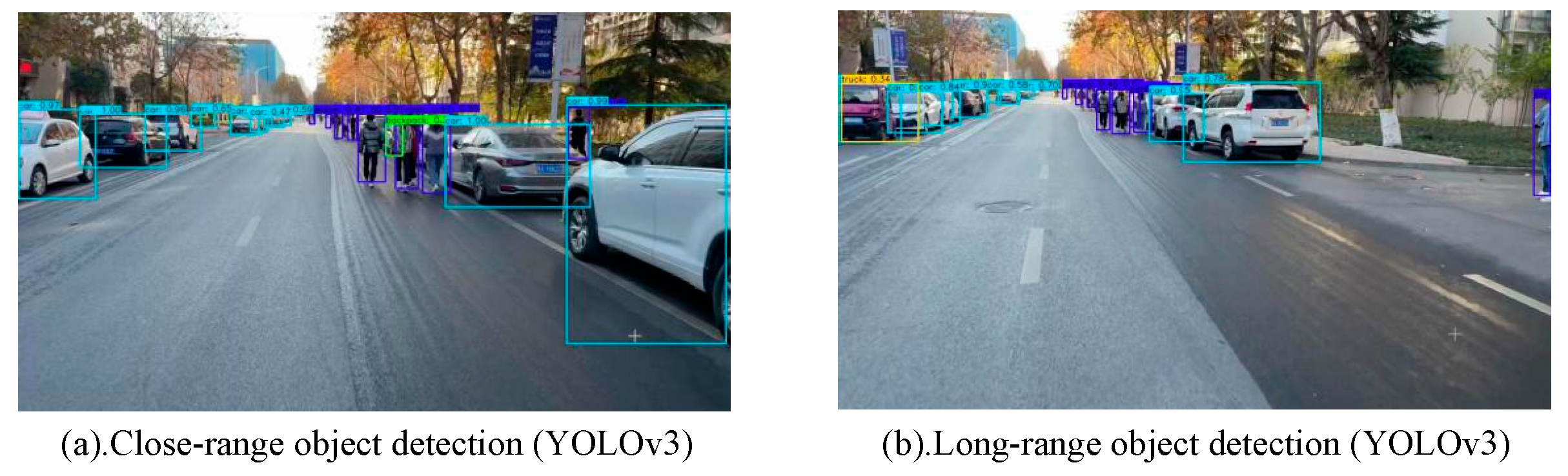
Table 1.
Performance of YOLOv3 transfer training model.
| Classes | AP | TP | FP | mAP |
| car | 81.25% | 79.65% | 20.34% | 83.85% |
| person | 76.43% | 60% | 40% | |
| bicycle | 74.12% | 82.81% | 17.18% | |
| motor cycle | 73.08% | 74.14% | 25.85% | |
| bus | 79.14% | 81.06% | 19.02% | |
| dog | 72.44% | 77.07 | 22.92% | |
| cat | 73.34% | 65.41% | 34.58% |
Table 2.
Selected special dataset.
| Class name | car | person | bicycle | motor cycle | bus | dog | cat |
| Total number | 1434 | 1360 | 860 | 430 | 300 | 220 | 180 |
Table 3.
Configuration environment.
| Operating System | CPU | Memory | GPU | CUDA | CUDNN |
| Windows 10 | Intel i5 | 8GB | NVIDIA GEFORCE RTX 745 | CUDA 10.04 | CUDNN 7.04 |
Table 4.
Object detection performance of the proposed YOLOv3.
| Classes | AP | TP | FP | AP |
| car | 89.25% | 86.5% | 13.4% | 87.85% |
| person | 83.43% | 73.2% | 26.8% | |
| bicycle | 82.12% | 88.9% | 11.0% | |
| motor cycle | 82.08% | 78.6% | 21.3% | |
| bus | 84.14% | 89.8% | 10.2% | |
| dog | 79.44% | 79.6% | 20.4% | |
| cat | 86.34% | 69.6% | 30.3% |
Table 5.
Object detection performance of the YOLOv2.
| Classes | AP | TP | FP | mAP |
| car | 78.25% | 79.65% | 20.34% | 76.7% |
| person | 75.43% | 60% | 40% | |
| bicycle | 72.12% | 82.81% | 17.18 | |
| motor cycle | 70.08% | 74.14% | 25.85 | |
| bus | 73.14% | 81.06% | 19.02% | |
| dog | 69.44% | 77.07% | 22.92% | |
| cat | 78.34% | 65.41% | 34.58% |
Table 7.
Detection time for the images with different resolutions.
| Algorithm | 320×320 Detection time/ms | 416×416 Detection time/ms | 608×608 Detection time/ms | FPS/frames per second |
| YOLOv2 | 31.6 | 37.9 | 64.6 | 19.3 |
| YOLOv3 | 22.8 | 29.4 | 51.9 | 23.6 |
| YOLOv5 | 20.3 | 26.1 | 43.1 | 26.9 |
| The proposed YOLOv3 | 19.2 | 24.4 | 39.7 | 31.2 |
Table 8.
Detection time for the video.
| Algorithm | Detection time/s | FPS/frames per second | FLOPS/floating point operations per second |
| YOLOv2 | 76.8 | 67 | 59.36Bn |
| YOLOv3 | 66.9 | 78 | 65.86Bn |
| YOLOv5 | 64.7 | 85 | 76.38Bn |
| The proposed YOLOv3 | 61.8 | 87 | 79.38Bn |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



