
Submitted:
07 August 2023
Posted:
09 August 2023
You are already at the latest version
Abstract
Self-adaptive systems are capable of reconfiguring themselves while in use to reduce the risks forced by environments for which they may not have been specifically designed. Run-time validation techniques are required because complex Self-adaptive systems must consistently offer acceptable behavior for important services. The run-time testing can offer further confidence that a Self-adaptive system will continue to act as intended even when operating in unknowable circumstances. This article introduces an evolutionary framework that supports adaptive testing for Self-adaptive systems. To ensure that the adaptive systems continue to operate following its requirements and that both test plans and test cases continuously stay relevant to shifting operational conditions. The proposed approach using the SPEA2 algorithm facilitates both the execution and adaptation of run-time testing operations.
Keywords:
search-based software engineering
; adaptive systems
; configurable systems
; multiobjective evolutionary algorithms
1. Introduction
When software systems are subjected to changing environments, the open-loop structure that traditionally guides software development necessitates human monitoring [1]. Software systems are designed with feedback loops so they may adjust on their own to changing environments, reducing the need for human supervision. These closed-loop systems are known as self-adaptive software systems [2] and they are frequently divided into two components: an adaptation engine that realizes the feedback loops and controls the adaptable software [1]. Such systems will be crucial for safety-critical applications, where they must meet stringent criteria, as mentioned by Calinescu [3].
Some strategies cover Self-adaptive system testing, but only for later development phases [4] through [5], after the systems have been put into use. It is not recommended to test the feedback loop in its entirety. Contrarily, we view the testing of a Self adaptive system components as a prerequisite to early validation because a system with fully integrated adaptive software and a feedback loop are only available in the most advanced stages of development [6].
There are two major obstacles to utilizing search algorithms to optimize the Self-adaptive system at runtime: First of all, it is challenging to successfully adapt with suitable feature encoding in the representation of optimization, the SAS design may be applied to the context of a search algorithm. Managing the dependencies between the features is very challenging; for instance, changing Cache Mode requires that the Cache feature be
turned on. The introduction of numerical features might make dependencies even more complex; for instance, in the Tomcat server, the number of maximum Threads should not be smaller than the size of the minimum Spare Threads [7]. Because of SAS's complex design and the inability of most search algorithms to handle dependency restrictions in nature. Secondly, it is difficult and complex to manage the tradeoffs between several competing objectives, particularly for SAS dynamically. This is explained by the abundance of potential adaption strategies and the requirement that the chosen strategy work. The contradictory relationships between objectives are further complicated by the dynamic and variable character of SAS, making it challenging to investigate the tradeoff relationship. If these issues are not properly resolved, the quality of the SAS runtime optimization may be degraded, the running overhead may be undesirable, and the tradeoffs may be unbalanced [8].
Regarding the first challenge as mentioned above, the conversion of the SAS design into the context of the search algorithm was done manually [2,9,10], which makes the process costly. Furthermore, feature dependencies are frequently disregarded, wasting important function evaluation time on incorrect solutions during SAS runtime with little assurance of finding accurate solutions. Researchers [11,12] have integrated the feature model [13] with search algorithms to improve SAS during runtime while taking category relationships into account. The use of search techniques to solve issues with the Software Product Line would be the inspiration for this study. [14]. The method frequently uses a straightforward binary format to encode all the features. This could result from the diverse dimension and add needless complexity to the SAS at a dynamic level. For the second problem, SAS runtime efficiency has been achieved by utilizing exact search [11,15] and objectives aggregation as a weighted sum methodology. Modern SAS, however, frequently demonstrates considerable variability, expanding the search space of all potential solutions and making the unmanageable issue. From this point on, the precise search may runtime fail to scale. Stochastic search, particularly the evolutionary algorithms that are frequently used in Search-Based Software Engineering (SBSE), on the other hand, tends to be inherently reliable when it comes to tackling issues with extremely huge numbers of different solutions [16].
When designed correctly, those algorithms can produce approximatively and almost optimum solutions for challenging software engineering issues in a manageable amount of time [17]. Stochastic search has also been shown to be successful for several real-time systems [10,18,19,20]. Existing methods frequently convert a multi-objective problem into an aggregated single-objective problem and then use a single-objective evolutionary algorithm to optimize SAS [9,20]. Somehow objective aggregation may be advantageous in some situations, it has been demonstrated that there are some situations where software developers find it difficult to assign weights to various objectives, making it difficult for the aggregate to retain a wide variety of solutions [16].
NSGA-II [20], a well-known Multi-Objective Evolutionary Algorithm (MOEA), has been used in studies [2,10,19] to optimize SAS without utilizing weighted aggregation. They demonstrated that MOEA is capable of discovering convergent and varied solutions as alternatives to optimizing via objective aggregation emerge in the tradeoff space.
However, the coarse diversity preservation method of the NSGA-II prevents it from offering well-distributed solutions in some circumstances [21]. As a result, it would be ideal to have an optimized framework that can easily be used with many MOEAs to optimize SAS without being constrained by a single algorithm. Additionally, because MOEAs generate a variety of non-dominated solutions, the SAS is at risk of making unfair compromises because there is no proven technique for selecting the best one for adaptation at runtime [8].
2. Background
Some state of artworks has been discussed in this section which becomes a motivation for our proposed approach.
By storing copies on servers at physically distant locations, remote data mirroring (RDM) is a data security approach to ensure data availability and reduce data loss [22,23]. The RDM network must also efficiently replicate and disseminate data by minimizing bandwidth consumption and offering assurance that dispersed data is not lost or corrupted. In reaction to uncertainties, such as dropped or delayed messages and network link failures, the RDM can be reconfigured in real-time. Each network link also has a measurable throughput, latency, and loss rate, as well as operational costs that have an impact on a controlling budget. These indicators are used to assess the overall effectiveness and dependability of the RDM. The RDM can change its network topology and data mirroring algorithms to address unforeseen problems. The RDM application can be described and executed as a SAS because of its sophisticated and adaptable nature [24].
Another approach is adopted by [8] where using the elitist chromosomal representation to encode a problem into MOEA can improve quality and reduce runtime overhead for SAS optimization, such a gain is more likely to be modest when there are few viable solutions. The search may be adequately guided by the dependency-aware operators, who will discover solutions with greater convergence and diversity, producing better SAS optimization. Nevertheless, using dependency-aware operators without making sure the selected adaptation method is balanced may reduce its efficacy. The FEMOSAA approach uses different MOEAs to generate better quality for SAS runtime optimization compared to the leading frameworks from the literature. Comparing FEMOSAA to modern frameworks, it has a very low runtime overhead overall. Additionally, the additional work required for knee selection and dependency-aware operators is minimal; on occasion, they can even marginally shorten MOEA runtime [8].
Proteus methodology is a run-time testing management based on requirements. Proteus is a framework specifically designed to execute testing tasks at runtime, such as test execution and online adaptation. Proteus offers two layers of test adaptation to achieve this: test case parameter value adaptation and test suite adaptation. The management of run-time testing activities, such as the modification and execution of test cases and test suites, is handled by the Proteus framework. Proteus carries out two primary jobs to aid in this strategy. Each SAS configuration has an adaptive test plan specified at design time, where each adaptive test plan consists of numerous test suites and each SAS configuration corresponds to a specific operational scenario. Second, each time a new SAS configuration is run, Proteus conducts a testing cycle that may include numerous iterations that each run a distinct test suite. Next, each task is outlined individually [25].
Our proposed approach can affect SAS and evolutionary algorithms, incorporating the best aspects of both disciplines Researchers can use MOEAs to handle SAS optimization without having substantial prior MOEA experience, especially with the SPEA2 method. The automatic conversion of the feature model into an MOEA context can establish a systematic and understandable domain knowledge for evolutionary computation researchers, who would be able to generate more novel results in terms of the SAS domain. As opposed to many search-based software engineering problems, our comprehensive methodology extends the internal structure of MOEA by automatically and dynamically retrieving the SAS domain knowledge. Future work will expand SPEA2-SAS to manage additional competing objectives and apply it to other SAS domains.
3. Proposed Approach-SPEA2-SAS
3.1. Optimizing Test Cases Generation for Large Adaptive Systems
SPEA2-SAS approach based on feature model for handling run-time testing. SPEA2-SAS is a framework specifically designed for running testing operations. A framework for handling run-time testing activities, such as the adaption in terms of SAS feature model configuration and execution of test cases and test suites, is called SPEA2-SAS. SPEA2-SAS carries out two primary jobs to aid in this strategy. Each SAS configuration has an adaptive test strategy specified at design time, where each adaptive test strategy consists of numerous test suites and each SAS configuration corresponds to a specific operational scenario. Second, each time a new SAS configuration is run, SPEA2-SAS conducts a testing cycle that may include numerous iterations that each run a distinct test suite. Adaptive test strategy includes every test suite that might be created for a specific operating environment or set of system and environmental characteristics. To do this, For each SAS setup, SPEA2-SAS creates an adaptive test strategy that consists of a default test suite and several intermediate, automatically created test suites. We also need to discuss how the intermediate test suites are derived at run time as well as how the default test suites are derived at design time.
For illustration purposes, consider that a SAS test engineer is setting up an adaptive test strategy for a certain SAS configuration in response to a specific set of operational conditions. In our case two objectives need to be optimized 1) testing cost and 2) the number of test cases that need to be optimized using the SPEA2 algorithm. There will be considered two types of test cases Valid Tests and Invalid Tests depending on the valid and invalid configuration of the feature model as SAS configuration. To achieve optimized test adaption, the SPEA2-SAS approach dynamically develops test suites at runtime. A new optimized test suite is generated based on SAT solver methodology adopted in our research work.
If any fault occurs in terms of invalid test suits, the SAS infrastructure should reconfigure the feature model system and should launch a fresh testing cycle with the reactivation of the valid test cases. The SAS can change features at runtime to optimize for different nonfunctional quality parameters like response time and cost etc. SAS is frequently built to dynamically search for the feature combinations that lead to the best solutions to accomplish this aim and the adoption of search algorithms.
Figure 1 shows the SPEA2-SAS architecture with two main components 1) describes the configuration scenario which creates valid configurations 2) responsible for an adaptable scenario based on an evolutionary algorithm with the capacity to adapt features combination at runtime to optimize for various nonfunctional quality metrics, such as reaction time and cost.
3.2. Transforming Feature Model of SAS to Evolutionary Algorithm (SPEA2)
It is challenging to select the appropriate features and encode them into the representation of the search algorithm in a complicated SAS that has numerous features and settings. As a result, the encoding of features may have a favorable or unfavorable impact on a potential search algorithm's ability to search. To optimize the SAS during runtime, such a representation establishes the fundamental search space of the problem to be researched. Existing work [11,12] merely encodes each feature in binary form and is redundant since certain elements in the SAS design might reflect the same aspect of variability [26] or do not contribute to the SAS's variability.
3.3. SAS Design Dependencies and Conflicting Objectives
Numerous popular stochastic and exact search algorithms (like MOEA) are not built to handle dependence constraints. Because of this, handling dependencies can be challenging, especially when there are a variety of categorical relationships included in the SAS dataset. If the constraints are handled incorrectly way then there are chances of degradation in adaption quality [12]. Modern SAS frequently exhibits considerable unpredictability in the generation of a large number of configurations, which causes the search space to explode. To achieve numerous conflicting quality objectives in SAS at once, choices must frequently be made. The relative relevance of objectives may generally be accurately measured as numerical weights, which is challenging in some circumstances [16], according to several existing methodologies [9]. When such weights are improperly stated and represented, they invariably have a detrimental effect on the search process and lead to undesirable, subpar adaption quality. Establishing a balanced compromise between objectives is considerably harder. These issues serve as the driving force behind our proposed approach, which automatically combines a particular feature model with an MOEA.
3.4. SPEA2 Approach for Optimizing the Objectives
SPEA2 makes use of a near-one-neighborhood density estimate approach, allowing it to direct its search strategy. SPEA2 employs the fitness assignment method, which takes into account each individual and how they impact or control others and vice versa. [27]. In their research work, Gueorguiev et al. used the Multi-Objective Genetic Algorithm (MOGA) SPEA2 to solve time and robustness problems in software project planning with better Pareto fronts for positive results. [28].
Figure 2 explains the pseudocode of the SPEA2 algorithm, where fitness criteria for each individual is described in the population.
Figure 3 shows the SPEA2 algorithm workflow, according to our proposed problem with two objectives (cost and time) that need to be optimized.
4. Experiments and Results
4.1. Objective Functions
The objectives (fitness) function as input utilized in the optimization is also defined with assistance from the elitist chromosome representation as mentioned above in sections.
Since the framework itself does not rely on any assumptions regarding the internal organization of those objectives, it is important to note that SPEA2-SAS works with a variety of measurable quality objectives while being indifferent to how the actual objective operates. It is also feasible to take into account more than two objectives with SPEA2-SAS, but we only do so in this article for the sake of a more understandable explanation because the basic idea behind multi-objective optimization holds optimization regardless of the number of objectives. As long as they are consistent with the genes described by SPEA2-SAS, the actual goal functions used by SPEA2-SAS can be constructed using a variety of modeling methodologies from the literature (e.g., machine learning-based [18,30,31], analytical [32], and simulation-based [33]).
The elicited dependency chains and combination of the genes are smoothly fed into the mutation operation at runtime to stop the generation of invalid offspring while mutating the solutions. In this study, we base our analysis on the boundary mutation operator, in which each gene is concerned according to a mutation rate. A gene's optional values are assigned at random utilizing the mutation rate. The mutation operator was selected for experimentation because (a) widely used operator and (b) it deals with optimization problems to pick a random value from predefined values in the form of the tree for a SAS feature model, which is especially appropriate for our proposed optimization problem regarding SAS systems. However, because the breach of dependence is avoided anytime a gene is altered, SPEA2-SAS may easily be modified to work with any additional operators that change the genes similarly to the mutation operator.
When exchanging elements of the solutions, it is vital to eliminate invalid offspring, just like during the mutation process. To do this, the supplied crossover operator in the MOEA can be utilized with the extracted dependency chains and the merged value trees. In our study, there is also dependency on the crossover method, which involves two genes from different parents that are located in the same place on the chromosome and may be switched depending on the crossover rate. These uniform crossover operators were selected because it reduces the issue of gene position, which makes it easier to moderate other SAS design constraints by making it less sensitive to the proximity of highly reliant genes (features) in the encoding. It is simple to adapt SPEA2-SAS to operate with any other operators like mutation or crossover, provided that each pair of switched genes is always at the same place in the encoding. This is because whenever a pair of genes is switched, the violation of dependency is averted.
The violation of dependence is, however, avoided anytime a pair of genes is switched, hence it is simple to adapt the SPEA2-SAS approach to operate with any other operators such that every pair of replaced genes would always be in the same place in the encoding.
The following two objectives need to be optimized:
- Minimizing the Test Cases (OBJ1)
- Minimizing the Cost (OBJ2)
We performed extensive tests to assess the efficacy of the SPEA2-SAS approach by contrasting it with its variations and cutting-edge frameworks under various metrics utilizing the actual operating feature model SAS. We specifically employ the hypervolume and a population size of 500 for SPEA2. The volume of the goal space is presented using the hype volume measure, and Pareto front A dominates this space. To assess the quality of the spread and convergence of the non-dominated solutions set, a hyper-volume quality indicator is used. The greater the performance of an algorithm, the higher the HV value will be. This metric generates a single value that aids in estimating solutions that are not dominated [34].
For our real-time tests, we set up two Feature models SAS are adopted for experiments. The two separate SAS are intended to look at the universality and application of SPEA2-SAS across various parameters. The proposed approach assist in showing how SPEA2-SAS may be used to analyze various feature models, reliance design, environmental variables, aspects of quality targets, and levels of objective conflicts. In general, the large number of constraints means the feature model SAS is under more pressure, which lowers the number of viable solutions and makes the problem complex. The objective is to continuously decrease the following two incompatible quality criteria in the form of two objectives optimization.
We believe this is the case because, even though SPEA2-SAS can direct the search for better solutions, the advantages of avoiding the exploration of invalid solutions, which could be highly unbalanced for the competing objectives, have been overshadowed by randomly choosing a solution for adaptation from the final non-dominated options. In our experiments, the parameters have been customized for runtime efficiency concerning quality and overhead, or they are standard values. SPEA2 used in the experiments is extended from the MOEA Framework [21].
Table 1 shows the SAS feature models selected for the experimentation process.
The two feature models have been selected 1) SmartHome 2.2 and Coche Ecologico, their attributes have been mentioned in detail in Table 1, like the total number of features, configurations, and number of pairs.
Table 2 describes the number of parameters that have been adopted in our experiments. Before starting the experiments, parameter settings are adopted. To have a consistent outcome and to compare the effectiveness of the algorithms used in experiments, the fixed parameters have been decided upon at the beginning. The population size, the maximum number of assessments, the size of FM, crossover, and mutation rates are the selected parameter values. The number of evaluation iterations for each FM and method is the specified benchmark to determine whether to discontinue the experiment process.
Table 3 displays the feature models (FMs) chosen for the experiment in the first column, along with the methods, solutions, generation convergence, and elapsed time (in milliseconds) in the other columns. The duration of time that an algorithm takes to complete from beginning to end is known as the elapsed time. The amount of time is expressed in milliseconds.
The proposed approach generated such solutions that maintain a balanced trade-off between all objectives. This is especially intriguing since SPEA2-SAS targets situations where the relative relevance of SAS's competing objectives is uncertain and their quantification is too challenging. These balanced solutions are probably to occur around the obvious curve, showing a good compromise of solutions in terms of two objectives, as we can see in Figure 3, which offers options that minimize both the number of test cases and cost. These Pareto front solutions, also known as the extreme solutions, are often the ones that have the worst outcomes for each individual target. Finding these solutions in a non-dominated set is comparable to seeking the solution or solutions with the greatest general distance from the set's extreme solutions.
To accomplish this, we implement a SPEA2 technique for selecting just one solution from the MOEA results set. Given the final non-dominated set produced by the feature-guided MOEA, as illustrated in Figure 3. SPEA2-SAS may operate with a variety of MOEAs with no loss of generality. In this study, we use one MOEA to run SPEA2-SAS.
We pertained these feature models by keeping track of the SAS data under a random workload for 250 intervals to stabilize the objective functions in this study, and then the models are progressively and dynamically modified during runtime. On the feature model, we also included several categories and numerical relationships. We changed the throughput and cost of a few specific concrete services at each time step by altering their variety level following the Hypervolume measure, simulating dynamism and unpredictability under time-varying environmental circumstances. More varied concrete feature models typically indicate SAT solver adaptation solutions, which lowers the number of efficient solutions and hence makes the task more challenging. Here, we can evaluate maximizing and minimizing the following competing objectives for the total composition.
Additionally, for each interval, we compare the percentage of valid adaptation solutions found in the final population. It is unclear whether the elitist chromosome representation outperforms the traditional binary representation, as the aforementioned comparison only shows the elitist chromosome representation and dependency-aware operations provide good combinatorial performance. and SAT solver selection. The main reason why elitist chromosome representation outperforms traditional binary representation is that it fundamentally reduces the search space without affecting SAS's original variability, increasing the likelihood that MOEA will find the best solutions, producing more valid solutions and higher-quality results.
5. Discussion
This is since the quality of the searched valid solution is fundamentally what determines how effective the proposed approach is. As we demonstrated in the previous section, when the search process wastes time exploring invalid solutions, the quality of the solutions in the final population may suffer, which would have a negative impact on the benefit provided by our SPEA2-SAS method for the same reason.
5.1. State of Art Comparison
We contrast SPEA2-SAS with the following cutting-edge search-based frameworks from the literature to assess its efficacy further:
PLATO [9]—an optimization strategy that uses the famous single-objective evolutionary algorithm Genetic Algorithm together with a weighted sum of the objectives. Additionally, it does not take dependence into account while optimizing, thus we employ the same method as SPEA2-SAS. To identify the most effective solution, we assign the objectives equal weights. We chose elitist chromosome representations as PLATO relies on manual transposition to ensure fair comparison and remove bias in repeatability
FUSION [11]—is a framework that uses the SAS optimization as an integer programming issue using a model-based approach with an aggregate objective function that is solved using an exact algorithm (in the tests, we employ branch-and-bound). FUSION solely takes into account category dependence and employs binary representation of the solutions. As a result, when there is no viable option, we correct the numerical dependence violations.
SPEA2-SAS achieves competitive results on runtime overhead in comparison to state-of-the-art frameworks, but the actual time required by SPEA2-SAS depends on the underlying MOEA. Notably, FUSION has the highest overhead because its exact algorithm cannot scale with a large search space and the optimization runs are frequently forcibly returned. SPEA2-SAS's ability to develop the synergy between SAS software engineering and evolutionary computing is its most prominent advantage. Software programmers are given the freedom to modify an MOEA's behaviors in whatever way they are accustomed to (i.e., the feature) without in-depth knowledge of evolutionary algorithms in general.
SPEA2-SAS makes use of MOEA, which is particularly appropriate in situations when the relative weights of the objectives are uncertain or too challenging to define. We do admit that there are situations where the relative importance of competing goals is stated explicitly. In such instances, the strength of elitist chromosome representation and dependency-aware operators may still be utilized by the SAS. It's also important to note that MOEA does not ensure optimum solutions, but it is particularly effective at generating accurate approximations to difficult, nonlinear problems that would otherwise be impractical to solve by exact optimization. Therefore, we do not advocate utilizing the SPEA2-SAS approach for SAS that are straightforward, have a small search area, and can be resolved with an exact search that produces the best solutions.
To tackle our SAS optimization challenge, however, search-based software engineering methods, notably evolutionary algorithms, present a potential approach. This is because of the algorithms' dynamic nature, which allows them to undertake optimization without requiring in-depth knowledge of or presumptions about the issue at hand (such as the SAS's characteristics or the environment). Additionally, it is possible to develop roughly optimal solutions for even the most difficult situations because of the concepts of natural evolution and population.
5.2. Threats to Validity
The most frequently evaluated quality aspects of SAS from the literature [36,37] were chosen for our experiments in this work, including response time, throughput in terms of test cases, cost, etc. However, there are some questions about whether the metrics we used can truly reflect what we want to measure.
Threats to construct validity could also be related to the stochastic nature of the considered SPEA2-SAS in experiments which can influence the measurements. To accurately interpret the measurements for stochastic search-based optimization is a fact, representative measurements for the different quality metrics were evaluated using Hypervoulme and Space, which are often used metrics to assess the quality of solutions to multi-objective optimization problems [38,39]. Indeed, as noted in Acuri and Briand [40], numerous runs are required to meaningfully interpret the data for stochastic search-based optimization. By employing the design outlined in Acuri and Briand [40], which included carrying out 500 optimization runs for two feature models SAS, we were able to reduce this bias.
We also examined the commonly used but unique SPEA2 under two operating SAS and various parameter settings, which might vary the runtime behaviors of the SAS, to increase the universality of experimental evaluations. It is challenging to claim total generality even though our testing on the instances approximates real and industrial size; such a claim would require a considerably larger number of independent domain-specific examples and needs to be carried out by software developers or testers.
6. Conclusion
To optimize SAS at runtime, this article introduces SPEA2-SAS, a unique framework that automatically combines a SAS feature model with an MOEA in a systematic way. To build a chromosome representation, SPEA2-SAS identifies elitism characteristics at design time, including categorical and numerical ones. It then extracts gene dependencies, which are subsequently utilized to expand the underlying MOEA for runtime optimization. The engineers' domain expertise, the feature model, may narrow the search space and guide the search, boosting the likelihood of coming up with better solutions.
SPEA2-SAS further identifies optimal solutions that produce a balanced tradeoff between two objectives. We demonstrate also how SPEA2-SAS produces better and more balanced results for tradeoffs with reasonable overhead by thoroughly contrasting it with its variants and cutting-edge frameworks on two complex real-world SAS with different parameters like mutation, crossover values, etc. In particular, the most noteworthy findings of SPEA2-SAS are:
1) while using the elitist chromosome representation to encode an issue into MOEA can enhance quality and reduce runtime overhead for SAS optimization, such a gain is more likely to be modest when there are few viable options like when the workload is high in terms of a large number of features of a SAS, 2) the search may be adequately guided by the dependency-aware operators, who will discover solutions with greater convergence and diversity metrics like Hypervolume and Spacing as mentioned in above sections, producing superior SAS optimization. However, using dependency-aware operators without making sure the chosen adaptation method is balanced may reduce its efficacy, 3) the choice of SAT solver aids in locating a more sensible adaption strategy in terms of a valid test case suite, 4) SPEA2-SAS, with the tested SPEA2, delivers statistically and practically better quality for SAS runtime optimization than the state-of-the-art frameworks from the literature.
Our work influences and develops the synergy between evolutionary computing and software engineering for SAS, incorporating the best aspects of both disciplines. Software developers may use MOEAs to solve SAS optimization without having substantial prior MOEA experience, especially with SPEA2-SAS. On the other side, automating the feature model's conversion into an MOEA context can help to learn MOEA and create domain expertise understandably and systematically for academics studying MOEA, which can help in designing SAS algorithms that are more effective.
As opposed to many search-based software engineering (SBSE) problems, our deeper synergy extends the internal structure of MOEA by automatically and dynamically retrieving the SAS domain knowledge. In subsequent work, we want to enhance SPEA2-SAS to manage additional competing objectives by applying it to more SAS domains.
We believe that combining techniques like the one we've described with approaches from a different category will have a similar positive impact on quality assurance for SASS. According to what we understand, this is especially true for SASS, where runtime surprises may occur and need to be properly handled. However, testing must still be carried out before a system is put into use to guarantee at least a foundational level of SASS quality.
The proposed testing method can be developed in many ways in the future. Instead, we may utilize coverage criteria and a formal model to automatically generate test inputs and oracles taking SASS and its environment's unpredictability into account. In further work, we intend to assess SPEA2-SAS in other extreme situations with large SAS models with constrained computing resources. It is important to keep in mind that developing the tests and setting up the SAS are not simple tasks, and they may cost money.
Author Contributions
First Author contributed equally to the research and wrote the article. Methodology, M.K.N; Software, M.K.N.; Validation, S.S.A.,S.M.S.; Investigation, M.K.N; Resources, M.J.H.; Data curation, A.N.A. and M.A.J;Writing—original draft, M.A.J.;Writing—review & editing, M.A.J; Supervision, M.A.J.; Funding acquisition, S.S.A. All authors have read and agreed to the published version of the manuscript.
Funding
The authors extend their appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia for funding this research work through the project number: IFP22UQU4320619DSR113.
Institutional Board Review Statement
Not Applicable.
Informed Consent Statement
Not Applicable.
Data Availability Statement
Data will be available upon reasonable request.
Acknowledgment
The authors extend their appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia for funding this research work through the project number: IFP22UQU4320619DSR113.
Conflicts of Interest
The authors declare no conflict of interest.
References
- M. Salehie and L. Tahvildari, “Self-adaptive software: Landscape and research challenges,” ACM Trans. Auston. Adapt. Syst., 2009, vol. 4, no. 2, pp. 14:1–14:42. [CrossRef]
- Andrade, S.S.; Macedo, R.J.d.A. A Search-Based Approach for Architectural Design of Feedback Control Concerns in Self-Adaptive Systems. 2013; 70. [Google Scholar] [CrossRef]
- Calinescu, R. Emerging Techniques for the Engineering of Self-Adaptive High-Integrity Software. 7740. [CrossRef]
- Goldsby, H.J.; Cheng, B.H.C.; Zhang, J. AMOEBA-RT: Run-Time Verification of Adaptive Software. 2008. [Google Scholar] [CrossRef]
- E. M. Fredericks, B. E. M. Fredericks, B. DeVries, and B. H. Cheng, “Towards run-time adaptation of test cases for self-adaptive systems in the face of uncertainty,” in Proceedings of the 9th International Symposium on Software Engineering for Adaptive and Self-Managing Systems. ACM, 2014, pp. 17–26.
- Cámara, J.; de Lemos, R.; Laranjeiro, N.; Ventura, R.; Vieira, M. Testing the robustness of controllers for self-adaptive systems. J. Braz. Comput. Soc. 2014, 20, 1. [Google Scholar] [CrossRef]
- Apache Tomcat. Available online: http://tomcat.apache.org/ (accessed on 10 March 2020).
- Chen, T. , Li, K., Bahsoon, R. and Yao, X., FEMOSAA: Feature-guided and knee-driven multi-objective optimization for self-adaptive software. ACM Transactions on Software Engineering and Methodology (TOSEM), 2018, 27(2), pp.1-50.
- Ramirez, A.J.; Knoester, D.B.; Cheng, B.H.C.; McKinley, P.K. Plato: a genetic algorithm approach to run-time reconfiguration in autonomic computing systems. Clust. Comput. 2010, 14, 229–244. [Google Scholar] [CrossRef]
- Yusoh, Z.I.M.; Tang, M. Composite SaaS Placement and Resource Optimization in Cloud Computing Using Evolutionary Algorithms. 2012. [Google Scholar] [CrossRef]
- Esfahani, N.; Elkhodary, A.; Malek, S. A Learning-Based Framework for Engineering Feature-Oriented Self-Adaptive Software Systems. IEEE Trans. Softw. Eng. 2013, 39, 1467–1493. [Google Scholar] [CrossRef]
- Pascual, G.G.; Lopez-Herrejon, R.E.; Pinto, M.; Fuentes, L.; Egyed, A. Applying multiobjective evolutionary algorithms to dynamic software product lines for reconfiguring mobile applications. J. Syst. Softw. 2015, 103, 392–411. [Google Scholar] [CrossRef]
- Kang, K.C.; Cohen, S.G.; Hess, J.A.; Novak, W.E.; Peterson, A.S. Feature-Oriented Domain Analysis (FODA) Feasibility Study. 1990. [Google Scholar] [CrossRef]
- Abdel Salam Sayyad, Joseph Ingram, Tim Menzies, and Hany Ammar., Scalable product line configuration: A straw to break the camel’s back. In Proceedings of the 2013 IEEE/ACM 28th International Conference on Automated Software Engineering (ASE), ACM/IEEE, 2013, pp. 465–474.
- Cardellini, V.; Casalicchio, E.; Grassi, V.; Iannucci, S.; Presti, F.L.; Mirandola, R. MOSES: A Framework for QoS Driven Runtime Adaptation of Service-Oriented Systems. IEEE Trans. Softw. Eng. 2012, 38, 1138–1159. [Google Scholar] [CrossRef]
- Harman, M.; Burke, E.; Clark, J.; Yao, X. Dynamic adaptive search based software engineering. 2012; 8. [Google Scholar] [CrossRef]
- Robert, M. Hierons, Miqing Li, Xiaohui Liu, Sergio Segura, and Wei Zheng., SIP: Optimal product selection from feature models using many-objective evolutionary optimization. ACM Transactions on Software Engineering and Methodology (TOSEM) 25, 2016, 17. [CrossRef]
- Tao Chen and Rami Bahsoon., Self-adaptive trade-off decisionmaking for autoscaling cloud-based services. IEEE Transactions on Services Computing 10, 2017, pp. 618–632. [CrossRef]
- El Kateb, D.; Fouquet, F.; Nain, G.; Meira, J.A.; Ackerman, M.; Le Traon, Y. Generic cloud platform multi-objective optimization leveraging models@run. time. 2014, 343–350. [Google Scholar] [CrossRef]
- Fredericks, E.M. Automatically hardening a self-adaptive system against uncertainty. 2016; 27. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- M. Ji, A. M. Ji, A. Veitch, and J. Wilkes, “Seneca: Remote mirroring done write,” in USENIX 2003 Annual Technical Conference., USENIX Association, 2003, pp. 253–268.
- K. Keeton, C. K. Keeton, C. Santos, D. Beyer, J. Chase, and J. Wilkes, “Designing for disasters,” in Proc. of the 3rd USENIX Conference on File and Storage Technologies. USENIX Association, 2004, pp. 59–62.
- Ramirez, A.J.; Knoester, D.B.; Cheng, B.H.; McKinley, P.K. Applying genetic algorithms to decision making in autonomic computing systems. 2009. [Google Scholar] [CrossRef]
- Fredericks, E.M. and Cheng, B.H., May. Automated generation of adaptive test plans for self-adaptive systems. In 2015 IEEE/ACM 10th International Symposium on Software Engineering for Adaptive and Self-Managing Systems¸ IEEE, 2015, pp. 157-167.
- Benavides, D.; Segura, S.; Ruiz-Cortés, A. Automated analysis of feature models 20 years later: A literature review. Inf. Syst. 2010, 35, 615–636. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. 2001. [CrossRef]
- Gueorguiev, S.; Harman, M.; Antoniol, G. Software project planning for robustness and completion time in the presence of uncertainty using multi objective search based software engineering. 2009. [Google Scholar] [CrossRef]
- Coello CA, Lamont GB, Veldhuizen DAV., Evolutionary Algorithms for Solving Multi-Objective Problems (Genetic and Evolutionary Computation), Springer, 2006.
- Tao Chen, Rami Bahsoon, and Xin Yao., Online QoS modeling in the cloud: A hybrid and adaptive multi-learners approach. In Proceedings of the IEEE/ACM 7th International Conference on Utility and Cloud Computing. 2014, pp. 327–336.
- Chen, T.; Bahsoon, R. Self-Adaptive and Online QoS Modeling for Cloud-Based Software Services. IEEE Trans. Softw. Eng. 2016, 43, 453–475. [Google Scholar] [CrossRef]
- Roy, N.; Dubey, A.; Gokhale, A.; Dowdy, L. A capacity planning process for performance assurance of component-based distributed systems. 36, 41. [CrossRef]
- Florian Fittkau, Soren Frey, and Wilhelm Hasselbring., CDOSim: Simulating cloud deployment options for software migration support. In Proceedings of the 2012 IEEE 6th InternationalWorkshop on the Maintenance and Evolution of Service-Oriented and Cloud-Based Systems (MESOCA’12). IEEE, 2012, pp.37–46. Http://dx.doi.org/10.1109/MESOCA.2012. 6392.
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: a comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Hadka, D. (2014). MOEA framework user guide.
- Simon Mingay. Gartner RAS Research Note G 15 3703, 2007.
- Wada, H.; Suzuki, J.; Yamano, Y.; Oba, K. E³: A Multiobjective Optimization Framework for SLA-Aware Service Composition. IEEE Trans. Serv. Comput. 2011, 5, 358–372. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Miqing Li, Tao Chen, and Xin Yao., A critical review of a practical guide to select quality indicators for assessing pareto-based search algorithms in search-based software engineering: Essay on quality indicator selection for SBSE. In Proceedings of the 40th International Conference on Software Engineering, NIER Track. IEEE/ACM, 2018.
- Arcuri, A.; Briand, L. A practical guide for using statistical tests to assess randomized algorithms in software engineering. 2011; 10. [Google Scholar] [CrossRef]
- Kader, A.; Zamli, K.Z.; Alkazemi, B.Y. An Experimental Study of a Fuzzy Adaptive Emperor Penguin Optimizer for Global Optimization Problem. IEEE Access 2022, 10, 116344–116374. [Google Scholar] [CrossRef]
- Odili, J.B.; Noraziah, A.; Alkazemi, B.; Zarina, M. Stochastic process and tutorial of the African buffalo optimization. Sci. Rep. 2022, 12, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Alsewari, A.A.; Zamli, K.Z.; Al-Kazemi, B. Generating t-way test suite in the presence of constraints. Journal of Engineering and Technology (JET), 2015, Volume. 6(2), pp.52-66.
- Zamli, K.Z.; Alsewari, A.R.; Al-Kazemi, B. COMPARATIVE BENCHMARKING OF CONSTRAINTS T-WAY TEST GENERATION STRATEGY BASED ON LATE ACCEPTANCE HILL CLIMBING ALGORITHM. Int. J. Comput. Syst. Softw. Eng. 2015, 1, 15–27. [Google Scholar] [CrossRef]
- Zamli, K.Z.; Hassin, M.H.M.; Al-Kazemi, B. tReductSA – Test Redundancy Reduction Strategy Based on Simulated Annealing. 2015. [Google Scholar] [CrossRef]
- Wazirali, R.; Alasmary, W.; Mahmoud, M.M.E.A.; Alhindi, A. An Optimized Steganography Hiding Capacity and Imperceptibly Using Genetic Algorithms. IEEE Access 2019, 7, 133496–133508. [Google Scholar] [CrossRef]
- Alhindi, Ahmad. Optimizing Training Data Selection for Decision Trees using Genetic Algorithms. International Journal of Computer Science and Network Security (IJCSNS), 2020, Volume 20(4).
Figure 1.
SPEA2-SAS based Architecture.
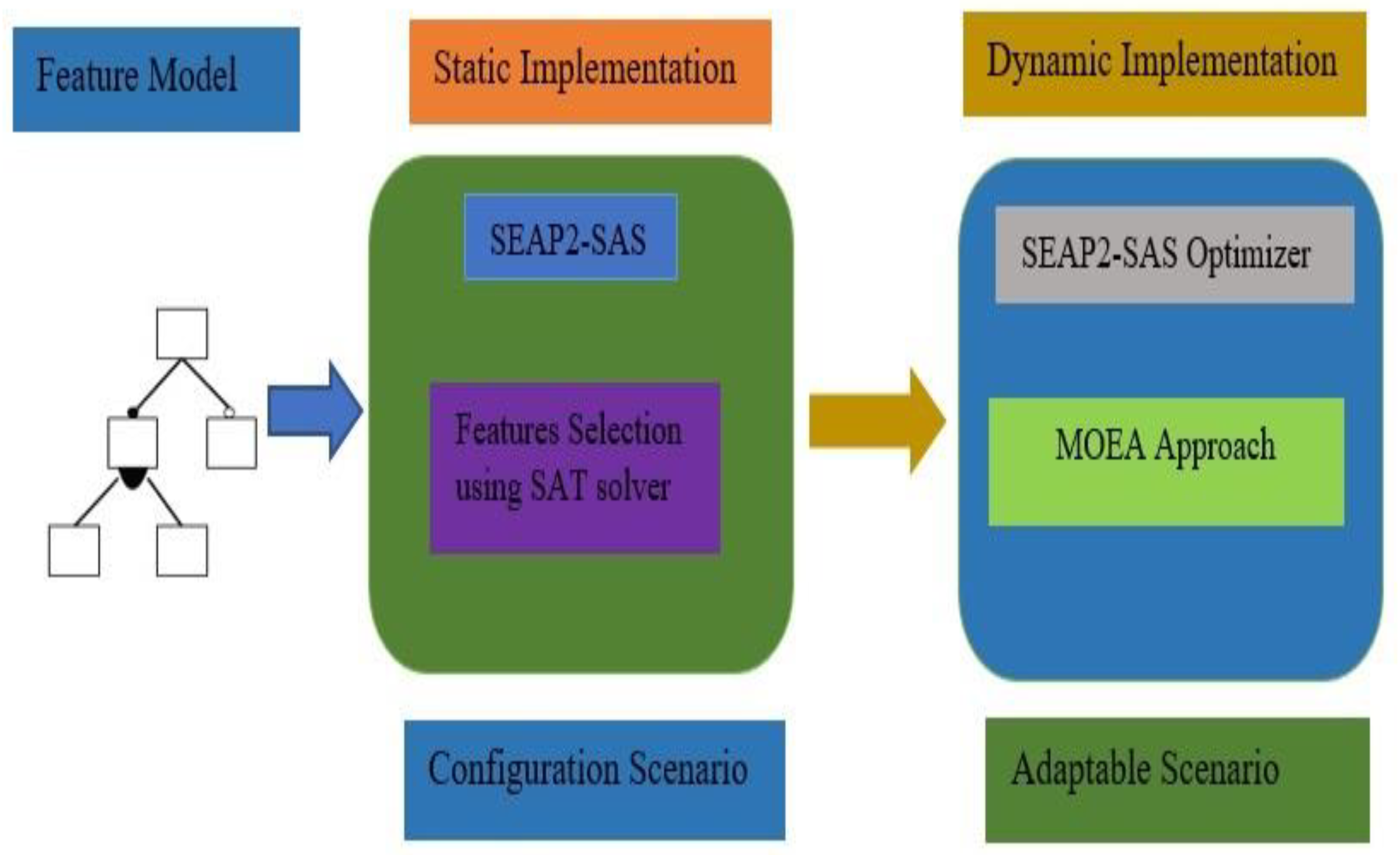
Figure 2.
Pseudocode of SPEA2 [29].
Figure 2.
Pseudocode of SPEA2 [29].

Figure 3.
SPEA2 Procedure WorkFlow.
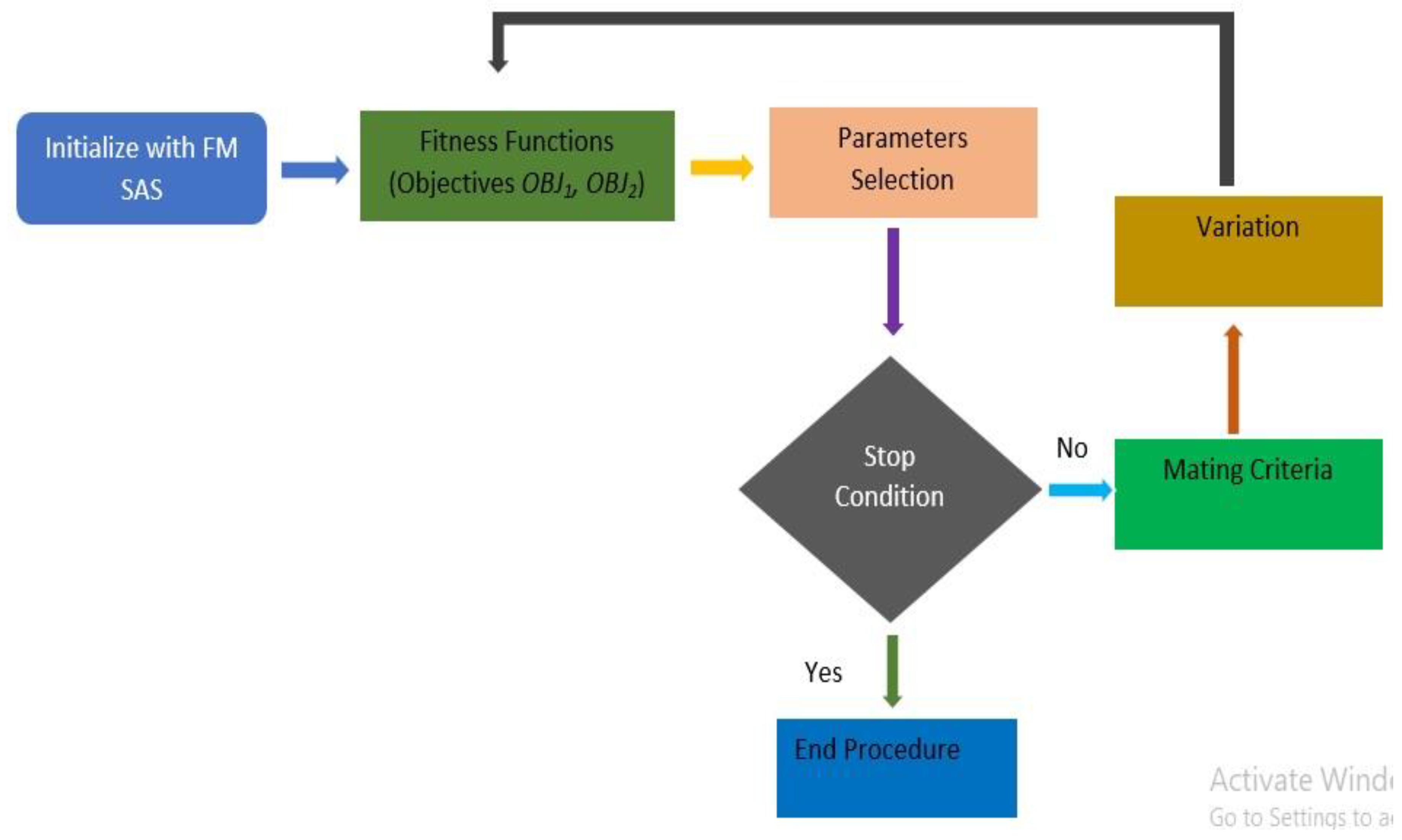
Figure 4.
Optimal Solutions Pareto Front.
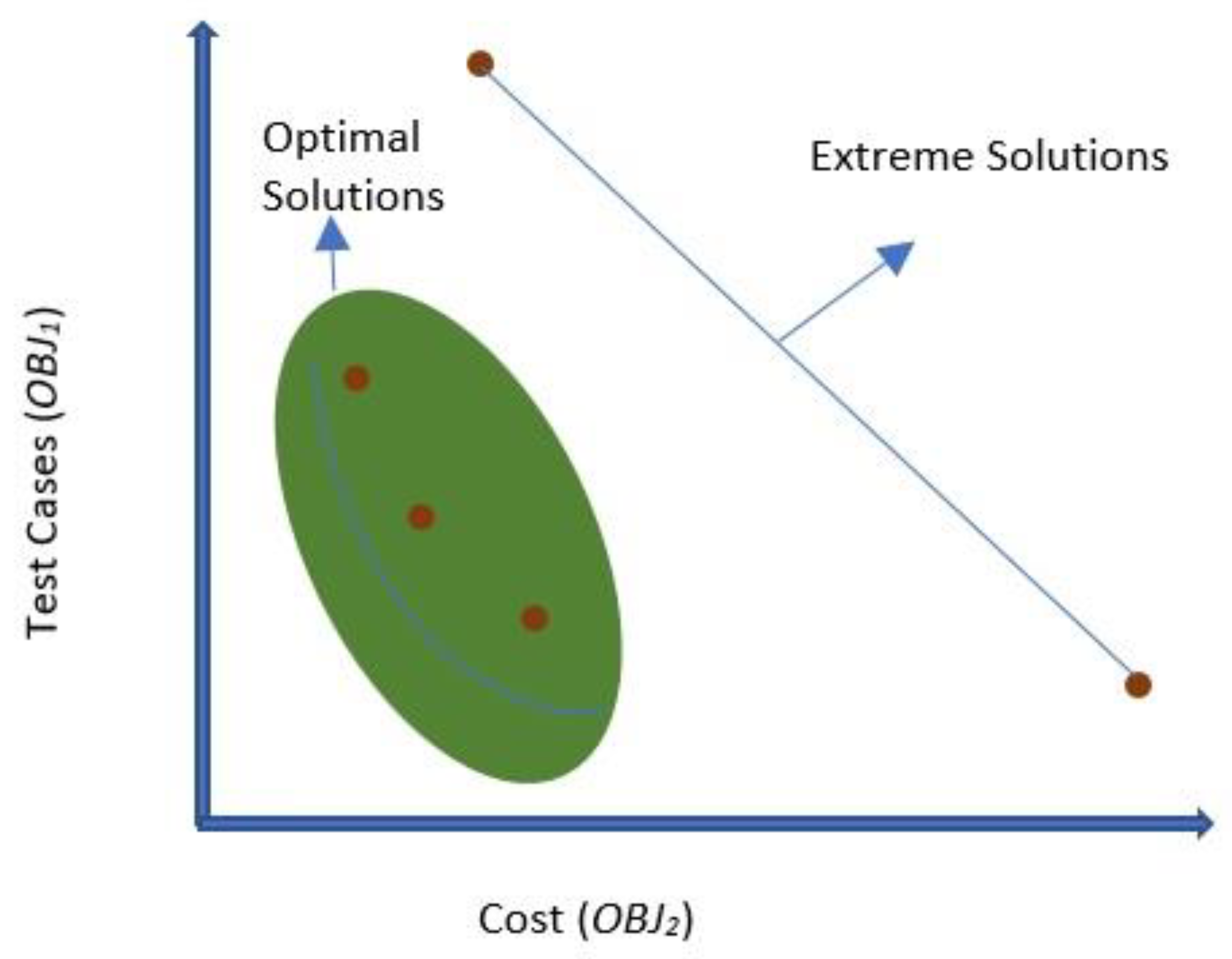

Table 1.
Feature Model SAS.
| Feature Models | Features | Configurations | Number of Pairs |
|---|---|---|---|
| Smart Homev2.2 | 60 | 3.87×109 | 6189 |
| Coche Ecologico | 94 | 2.32×107 | 11075 |
Table 2.
Parameters used for SPEA2 Algorithm.
| Parameter | Values |
|---|---|
| Population Size | 250 |
| Number of Generations | 500 |
| Crossover Rate | 60% |
| Mutation Rate | 40% |
Table 3.
Number of Solutions with Elapsed Time.
| Feature Model | Algorithm | Pareto Fronts Solutions | Generation Convergence | Elapsed Time (millisecond) |
|---|---|---|---|---|
| Smart Home v2.2 | SPEA2 | 200 | 16 | 25991 |
| Coche Ecologico | SPEA2 | 211 | 15 | 76827 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



