
Submitted:
12 August 2023
Posted:
14 August 2023
You are already at the latest version
Preprints on COVID-19 and SARS-CoV-2
Abstract
In bioinformatics research, traditional machine learning methods have demonstrated efficacy in addressing Euclidean data. However, real-world data often encompasses non-Euclidean forms, such as graph data, which contain intricate structural patterns or high-order relationships that elude conventional machine-learning approaches. Representation learning seeks to derive valuable data representations from enhancing predictive or analytic tasks, capturing vital patterns and structures. This method has proven particularly beneficial in bioinformatics and biomedicine, as it effectively handles high-dimensional, sparse data, detects complex biological patterns, and optimizes predictive performance. In recent years, graph representation learning has become a popular research direction. It embeds graphs into a low-dimensional space while preserving the structural and attribute information of the graph, enabling better feature extraction for downstream tasks. This study extensively reviews representation learning advancements, particularly in the research of representation methods since the emergence of COVID-19. We begin with an analysis and classification of neural network-based language model representation learning techniques as well as graph representation learning methods. Subsequently, we explore their methodological innovations in the context of COVID-19, with a focus on the domains of drugs, public health, and healthcare. Furthermore, we discuss the challenges and opportunities associated with graph representation learning. This comprehensive review presents invaluable insights for researchers as it documents the development of COVID-19 and offers experiential lessons to preempt future infectious diseases. Moreover, this study guides future bioinformatics and biomedicine research methodologies.
Keywords:
representation learning
; graph embedding
; graph neural network
; deep learning
; COVID-19
; healthcare
1. Introduction
After COVID-19 appeared at the end of 2019, the virus went through an 11-month phase of relative evolutionary stagnation [1]. Since the end of 2020, COVID-19 has experienced approximately two mutations per month, causing the emergence of new variants of concern (VOCs). Various organizations worldwide have sequenced the COVID-19 genome, finding many mutant variants of the virus. The phylogenetic tree depicted in Figure 1 [2] demonstrates the evolutionary relationships of COVID-19 in time and space. Due to low vaccination rates in many countries, the classical herd immunization goal of eradicating or eliminating COVID-19 has not been achieved [3]. While COVID-19 is unlikely to cause death at present, elderly people with cancer or underlying metabolic illnesses are at a higher risk of serious illness and death [4,5,6]. The mechanisms underlying this disease still remain unknown. The virus is widely distributed in humans and other mammals [7], as confirmed by a study utilizing machine learning unsupervised clustering methods [8]. Figure 2 demonstrates the structure of the SARS-CoV-2 [9]. Four significant structural proteins are encoded by the SARS-CoV-2 genome: spike (S) protein, envelope (E) protein, membrane (M) glycoprotein, and nucleocapsid (N) protein, as well as 16 nonstructural proteins and five to eight accessory proteins [10]. According to recent research, the S protein has undergone notable mutations in its amino acid sequence since 2020, which have resulted in changes to its distinct functions [11]. The D614G mutation (amino acid change from aspartate to glycine at position 614) has been found to increase viral infectivity [12], while other mutations, such as K417N, G446S, E484A, Q493R, and N440K, lead to immune escape [13]. In addition, N501Y enhances the binding of the S protein to ACE2, N679K increases viral transmission, and P681H enhances the binding affinity of the S protein [14]. Natural selection can drive the emergence of advantageous mutations in COVID-19 that confer higher fitness benefits, such as pathogenicity, infectivity, transmissibility, ACE2 binding affinity, and antigenicity [15]. Another variant of concern in the ongoing evolution of COVID-19 is XBB, a mutant strain of BA.2 whose prevalence is increasing globally [16]. The availability of publicly accessible and diverse COVID-19 genome sequence data is essential for analyzing the virus’s evolutionary trends, which, in turn, can inform drug discovery, vaccine development, and treatment guidance.
Representation learning, a subfield of machine learning, has gained significant attention in various domains due to its ability to extract meaningful high-level representations from raw data. In the fields of bioinformatics and biomedicine, representation learning techniques have been widely employed to address complex problems and uncover hidden patterns in biological and biomedical data. In representation learning, neural network-based methods capture intricate relationships and hierarchical structures in data, performing nonlinear transformations on high-dimensional data to solve classification and regression problems [17]. Deep learning models are a prevalent neural network architecture for representation learning, and they have been successfully applied to tasks such as gene expression analysis [18], drug discovery [19], and disease diagnosis [20]. Recent years have seen significant advancements in representation learning, and its application in bioinformatics and biomedicine is growing rapidly. Graph representation learning techniques, in particular, have advanced rapidly and excel at handling unstructured data [21]. They have made breakthroughs in areas such as drug design [22], protein interaction[23], and disease prediction[24]. Graphs are powerful structures for modeling complex relationships between entities. In bioinformatics and biomedical research, biological networks such as gene regulatory networks and disease networks provide valuable insights into the functionality of biological systems and the mechanisms of diseases [25]. Methods based on graph representation offer effective means of utilizing this network information for representation learning. Among them, graph embedding is a method of mapping nodes, links, and subgraphs in a graph to low-dimensional representations that capture the nodes’ topological structure and intrinsic properties [26]. When solving downstream graph tasks like node classification, link prediction, and visualization, these low-dimensional representations can be used as inputs [27]. However, graph neural networks (GNNs) update the node representations using message aggregation and propagation, integrating contextual information of the nodes. This is typically end-to-end and can directly learn low-dimensional representations of nodes and links from the raw graph data without relying on handcrafted features [28,29]. GNNs have emerged as a promising approach for representation learning on graph-structured data. GNNs can capture the structural and topological properties of biological networks, enabling them to learn representations of both nodes and the entire graph. By propagating information along graph edges and utilizing graph convolutional operations, GNNs can extract hidden features and patterns from biological networks [30]. GNNs have a broad range of applications in bioinformatics and biomedicine, including drug discovery [22], prediction of drug-target interactions [31], prioritization of disease-associated genes [32], and prediction of molecular properties [33]. By integrating network information and leveraging the power of graph representation learning, GNNs have demonstrated significant performance in these tasks, contributing to discovering new biological insights and potential therapeutic targets.
According to the World Health Organization, COVID-19 is no longer a public health emergency of global significance [34]. However, experts maintain that it remains an ongoing health threat. The COVID-19 pandemic has provided valuable insights and lessons for humanity. In order to effectively mitigate the impact of potential future outbreaks, it is crucial to make significant advancements in technological capabilities, bolster global vaccine research and production capacities, and optimize the speed and efficiency of our response to emerging viruses. Despite the urgent need for these developments, the complexity and diversity of COVID-19 data make it challenging to handle. Furthermore, the rapid progress of representation learning, particularly graph representation learning, requires a comprehensive and systematic summary of its application in COVID-19.
In this work, a comprehensive review of the advancements in representation learning methods is provided. Firstly, the related methods of neural network-based language model representation learning are introduced. This is followed by a detailed summary and discussion of graph representation methods, particularly graph neural network-related methods. The representative applications of representation learning in COVID-19 are also introduced. Furthermore, the challenges and opportunities of graph representation methods in the fields of bioinformatics and biomedicine are discussed. This work comprehensively reviews the research on representation learning methods since the emergence of COVID-19 and presents future applications in bioinformatics and biomedicine.
Figure 1.
Modified on a phylogenetic tree built on Nextstarin (2023-3-27) [2], consisting of 2775 SARS-CoV-2 genomes from the GISAID database evolving in chronological order, with bright colors representing the most noteworthy variants of the moment, such as red dots.
Figure 1.
Modified on a phylogenetic tree built on Nextstarin (2023-3-27) [2], consisting of 2775 SARS-CoV-2 genomes from the GISAID database evolving in chronological order, with bright colors representing the most noteworthy variants of the moment, such as red dots.
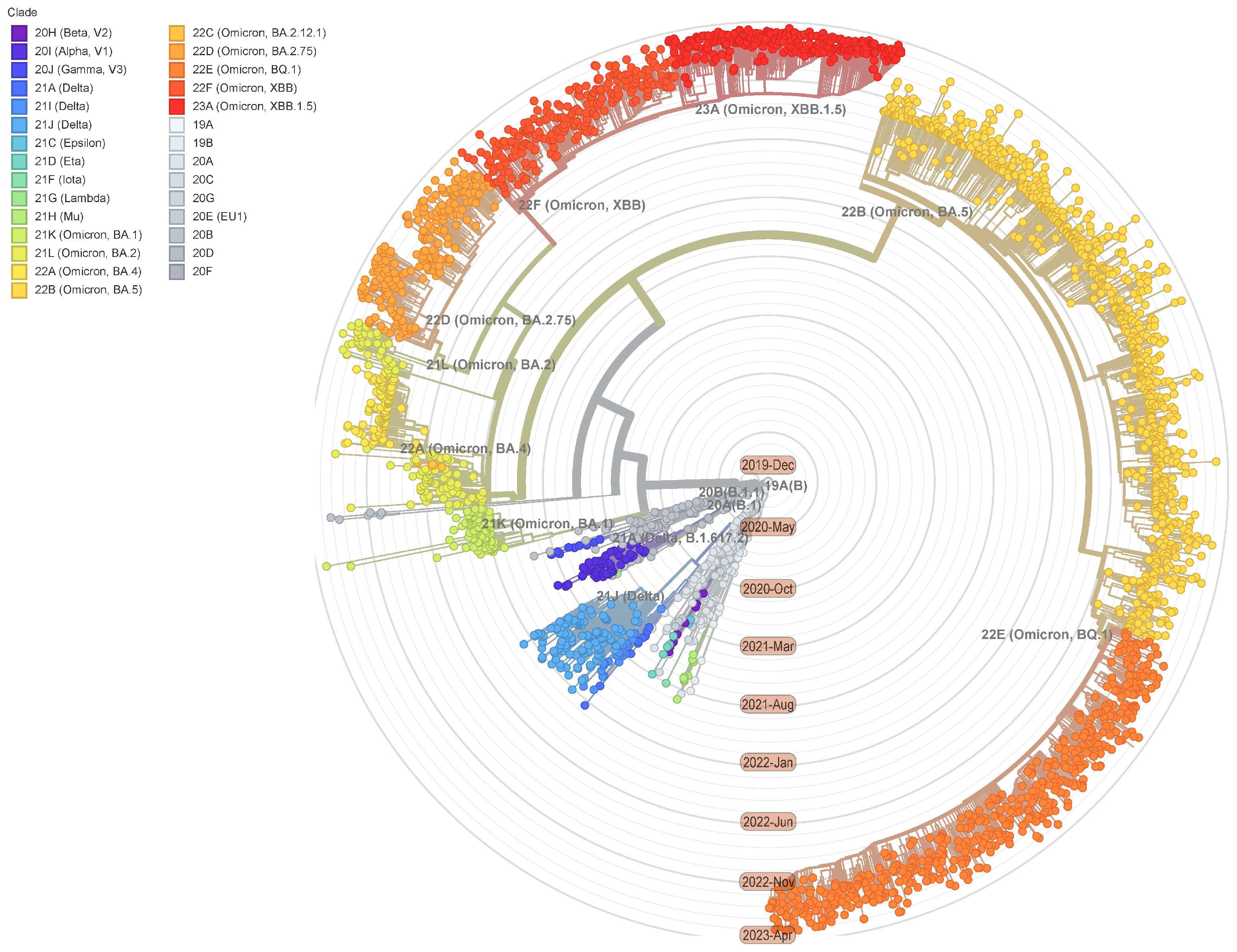
Figure 2.
SARS-CoV-2 Structure [9].
Figure 2.
SARS-CoV-2 Structure [9].

2. Representation Learning
Representation learning has facilitated many discoveries in the fields of bioinformatics and biomedicine, ranging from disease interactions to drug discovery. Traditional feature engineering methods require manually preset features to be input into machine learning models, and crafting optimal predictive features for complex networks is a daunting task. In contrast, representation learning learns network features in an automated manner. For instance, network embedding is a common representation learning method that maps nodes or edges in the network to a low-dimensional vector space, capturing the topological structure and node relationships of the network. This method does not require predetermined features, but generates features by learning the structural information of the network.
In addition, deep learning has provided new possibilities for representation learning. The emergence of graph representation learning has laid the foundation for processing and understanding graphical data. It generates useful features by automatically learning hidden patterns in the structure of graphs, thereby being able to directly handle complex graphical data. Graph Neural Networks (GNNs) have become a leading method for graph representation learning. They can automatically learn complex patterns in networks and generate high-quality feature representations. When dealing with biological data, such as gene expression networks and protein interaction networks, GNNs can capture complex relationships, automatically learn useful features, and eliminate the need for laborious manual feature engineering.
In the aforementioned methods, we can utilize some basic concepts of graph theory. For instance, biological networks can be viewed as a graph , where V is the set of nodes representing genes or proteins, and E is the set of edges representing interactions between genes or proteins. These networks are typically heterogeneous as they contain multiple types of nodes and edges, each type representing different information. For example, nodes can represent genes, edges can represent interactions between genes, and attributes of nodes and edges can represent gene expression levels or interaction strengths. In this case, GNNs can be considered as a multimodal graph representation learning method. They can handle graphs with multiple types of nodes and edges, enabling them to capture rich information in the network. Furthermore, GNNs can also handle dynamic graphs, where nodes and edges can be added, deleted, or modified over time. This is particularly useful for handling biological networks that change over time, such as time-varying gene expression networks.
GNNs work by applying neural networks on the nodes of the graph to learn the vector representation of the nodes. These representations can capture the characteristics of the nodes (through the feature vector of the nodes), as well as the position of the nodes in the graph (through the adjacency matrix A). In this way, GNNs can learn higher-order neighborhood information of the nodes, which is achieved by considering both the direct neighbors (first-order neighborhood) and more distant neighbors (higher-order neighborhoods) of the nodes. This can be represented by the higher-order adjacency matrix , where is the weight matrix of the edges, and t is the maximum order of the neighborhood considered. Furthermore, GNNs can also utilize meta-paths to capture complex relationships between different types of nodes and edges in heterogeneous graphs. A meta-path is a tool that can describe complex relationships between nodes, revealing relationships between different types of nodes in biological systems, thereby providing a deeper understanding of the complexity of biological systems. A meta-path can be represented as , where indicates that the ith node belongs to the tth type of node, and represents the ith type of edge. When learning node representations, GNNs consider not only the topological structure of the graph but also the semantic similarity of the nodes. This is achieved by measuring the similarity or correlation of the node vector representations in a low-dimensional vector space. This semantic similarity can be measured based on the labels of the nodes, the edges between the nodes, or other characteristics.
In precision medicine, the application of GNNs has also made significant progress. For instance, the study in [35] was the first to use GNNs to explore drug response prediction based on gene constraint multi-omics integration. Another study [36], utilized deep feature fusion graph convolutional neural network for cerebral arteriovenous malformation. These studies demonstrate that GNNs have tremendous potential in handling complex biological networks, predicting new gene functions, discovering potential drug targets, and understanding disease mechanisms. Although deep learning models are often viewed as "black boxes", the design of GNNs allows us to understand how the model works. For example, we can understand how the model comprehends the characteristics and positions of nodes by examining the vector representations of nodes. This is particularly important for precision medicine research, as it can help us understand the complexity of biological systems and provide powerful tools for the prevention and treatment of diseases.
3. Overview of Representation Learning Methods
In this section, we provide a brief overview of representation learning methods. Representation learning aims to uncover the underlying representations of raw data and project high-dimensional data onto a lower-dimensional space. This space captures the fundamental characteristics of the raw data while retaining the important information that better supports downstream tasks. Representation learning can aid researchers in extracting meaningful information and features to attain a more comprehensive representation of biological data. On this basis, we provided a summary of neural network-based language model representation learning methods and graph representation learning methods and extended other techniques. All the methods reviewed in this section are summarized in Figure 3.
3.1. Neural Network-Based Language Model Representation Learning
Neural network-based language model representation learning methods use distributed word vector representations learned through neural networks, especially context-dependent word vectors, which can effectively encode the semantic and syntactic information of words, providing useful language understanding capabilities for downstream NLP tasks. In this section, we categorize all methods into three major categories: word embedding methods, LSTM-based methods and attention mechanism-based methods.
Word embedding methods. A neural network-based method called word2vec [37] is used for natural language processing tasks such as sentiment analysis, language modeling, and text classification. Word2vec uses a neural network to learn a high-dimensional vector representation of each word in the corpus, with similar vectors used to represent words with similar meanings. The method uses a neural network architecture that consists of two learning models: a continues bag-of-words (CBOW) model that predicts target words using contextual words and a skip-gram model that predicts target words using target words. As a word2vec extension, doc2vec [38] can take sentences of various lengths as training samples. distributed memory (DM) and distributed bag-of-words are the two models that doc2vec uses to learn paragraph and document embeddings. The DM model predicts words by using vectors associated with passages as well as contextual words. The DBOW model ignores contextual words and predicts words in paragraphs directly using vectors associated with paragraphs. Global vectors for word representation (GloVe) [39] is a word representation tool based on global word frequency statistics that aims to capture semantic relationships between words through global word-word co-occurrence statistics information. The algorithm first creates a word-word co-occurrence matrix from the corpus, which is used to record the number of times each word appears in the context of other words. The matrix is then decomposed to obtain a low-dimensional representation of the words while retaining the co-occurrence statistics information. GloVe is similar to word2vec in that they both learn word embeddings from co-occurrence statistics, but it takes a different approach to capture word meaning. FastText [40] is used to learn vector representations of words and phrases. Unlike word2vec, which operates at the word level, FastText operates at the character n-gram level. By providing embeddings, FastText can represent words outside the vocabulary as the sum of their character n-grams. This enables FastText to perform better when dealing with uncommon or unknown words. Furthermore, FastText can infer the meaning of unseen words from their subwords.
The ability of word2vec to capture semantic features is a significant advancement in the field of representation learning, but it is unable to represent the semantic polysemy of words. In biological sequences, the position of a word in a sentence is equivalent to a specific amino acid or a string containing k bases divided by k-mer. For instance, the same amino acid can be encoded by various codons in a DNA sequence, and the same amino acid residue can have different interpretations depending on the context. Therefore, polysemy in biological sequences is significant. Here, we have introduced two methods to deal with contextual associations: one method makes use of long short-term memory (LSTM) [41], and the other method does so by using the attentional mechanism.
LSTM-based methods.Bidirectional long and short-term memory (Bi-LSTM) [42] is made up of two independent LSTM modules, one of which handles forward sequences and the other reverse sequences. The parameters of the two LSTM modules are independent of one another, and they only share the word embeddings of the input sequences. Bi-LSTM can capture long-term dependencies between elements in a sequence and is frequently used to model contextual information. In Bi-LSTM, the hidden state of the subsequent time step is also a factor that affects the output of each time step in addition to the current time step and the hidden state of the previous time step. This makes it possible to take into account how the forward and reverse information in the sequence depend on one another and better capture contextual information within the sequence. Embeddings from language models (ELMo) [43] is a pre-trained language model for creating word vectors that add a dynamic weight of the pre-trained language model to the output of Bi-LSTM. When using its word vector for a word, the entire text should be input, and the word vector is dynamically generated based on the entirety of contextual information, resulting in different word vector values for the same word in various contexts. To obtain richer feature information, ELMo uses not only the contextual information in Bi-LSTM but also the contextual information in the pre-trained language model.
Attention mechanism-based methods. The attention mechanism quantifies the degree of dependency between words and obtains a weighted representation by calculating the weights of each input position and weighting the inputs to sum [44,45]. The forward propagation-based model has a strong representation learning capability, which can naturally introduce attention weights into the model, dynamically calculate the attention weights, and apply the weights to various parts of the input to obtain a more accurate representation. Instead of relying on traditional context-aware architectures when processing sequence data, Transformer [46] achieves a significant improvement in model performance by implementing the attention mechanism and positional encoding [47] via key-value memory neural networks [48,49]. BERT [50] is a model with multiple stacks of transformers. The transformer model is further enhanced by the introduction of two new mechanisms, MLM and NSP. In the pre-training of BERT, [CLS] and [SEP] tokens are added to the start and end of each input sentence, respectively, and then long sequences are spliced together. In the MLM mechanism, some words are masked at random, and the model is asked to predict the words that have been masked to train the model’s capacity to model contextual information. In the NSP mechanism, BERT takes two sentences as input and asks the model to determine whether two sentences are adjacent to each other to train the model’s ability to model sentence relationships. BERT is more effective at capturing distal word associations than conventional recursive models such as RNN and LSTM [44,51]. Due to the implicit layer state of each word in the recursive model being determined solely by the implicit layer state of neighboring words, the contribution of other words distant from the word diminishes or disappears. By contrast, the attentional mechanism is effective for such problems. For different tasks, the architecture of the BERT pre-trained model can be solved directly without complex retraining or modification of the model architecture. This significantly simplifies the process of migration learning, allowing the model to be applied to new tasks more quickly. From a bioinformatics point of view, the advantages of BERT are clear, as distal interactions are significant for DNA sequence classification, gene expression prediction, and other tasks.
3.2. Graph Representation Learning
Graph representation learning is a technique that aims to learn low-dimensional vector representations of nodes and edges in graph data. Its overarching objective is to encode the structural and semantic information of graph data in a compact form that can be used for various downstream tasks. In this section, we introduce graph embedding methods and graph neural network methods. In the end, some other methods were introduced in an expanded manner.
3.2.1. Graph Embedding
The objective of graph embedding is to find a low-dimensional vector representation of a high-dimensional graph while preserving the connectivity and interactions between nodes in the graph, which typically retains some key information about the nodes in the original graph. We categorize these graph embedding methods into four major types: matrix factorization-based methods, manifold learning-based methods, random walk-based methods and deep learning-based methods.
Matrix factorization-based methods. A common graph embedding method is matrix factorization, which learns the low-dimensional representation of nodes by dissecting the adjacency matrix or laplacian matrix of the graph. The graph factorization (GF) [52] learns the low-dimensional representation of nodes in a graph by decomposing the graph’s adjacency matrix or Laplacian matrix. While maintaining the advantages of unsupervised text embedding, Predictive Text Embedding (PTE) [53] learns features from labeled data while using both labeled and unlabeled data for representation learning. Matrix factorization is used by both GraRep [54] and HOPE [55] to extract the higher-order neighborhood information from the graph. However, GraRep constructs the higher-order proximity matrix by concatenating k-hop transition probability matrices, while HOPE constructs the higher-order proximity matrix by measuring the pairwise similarity between nodes in subgraphs of varying sizes and orders. By generating edge representations and learning heterogeneous metrics, HEER [56] decomposes the network into low-dimensional embeddings and captures both structural and semantic information. A joint embedding matrix can be constructed by HERec [57] using meta-path-guided sampling to capture semantic and structural similarities between nodes of different types, which can then be factorized into low-dimensional embeddings.
Manifold learning-based methods. In high-dimensional spaces, the sparsity and noise of graph data can pose challenges for model training and lead to overfitting. Manifold learning methods address this issue by mapping high-dimensional graph data to a lower-dimensional manifold space, which preserves the local properties and structural information of the original data while reducing its dimensionality. The main idea of isometric mapping (IsoMap) [58] is to preserve the shortest path between data points to maintain the manifold structure. Both locally linear embedding (LLE) [59] and local tangent space alignment (LTSA) [60] are local information manifold learning methods. A local linear reconstruction is carried out in the neighborhood of each data point by LLE to maintain the flow structure. LTSA preserves the manifold structure by aligning the data in each point’s local tangent space. Laplacian eigenmaps (LE) [61] and hessian eigenmaps (HE) [62] are both manifold learning methods based on spectral analysis. Specifically, LE utilizes the Laplacian matrix to perform local weight assignment on the data’s neighborhood for preserving the manifold structure, while HE models the curvature and geometry of the data by leveraging the Hessian matrix. t-Distributed stochastic neighbor embedding (t-SNE) [63] uses a probabilistic approach to model the similarity between points in high-dimensional space and maps them to low-dimensional space while preserving pairwise similarities. Both uniform manifold approximation and projection (UMAP) [64] and t-SNE use graph layout algorithms to arrange data in low-dimensional space, which makes them very similar. The distinction is that UMAP builds a low-dimensional representation using an optimization technique based on the nearest neighbor graph.
Random walk-based methods. Inspired by the word vector model in the field of NLP, the researchers consider that the nodes on the graph can be analogized to words and the node sequences to sentences, and then the node sequences can be generated by random walk sampling on the graph to learn the representation vectors of the nodes using the Skip-gram model. DeepWalk [65] is the origin of the random walk approach, employing a simple, unbiased random walk followed by skip-gram representation learning of the walk sequences. Similarly, node2vec [66] is a biased random walk that introduces two parameters to regulate the search strategy of random walks, aiming to achieve a better balance between capturing graph structural features and node similarity features and improving the quality of node representations. By maximizing the likelihood functions of first-order proximity and second-order proximity, large-scale information network embedding (LINE) [67] learns the embedding of nodes. Additionally, LINE employs negative sampling strategies to boost training effectiveness. Walklets [68], which concentrates on higher-order structural information, splits joint random walk sequences of various lengths to obtain structural data on nodes at various scales. The similarity of the structural roles of nodes in the network is taken into account by struct2vec [69], not just the probability of contribution between nodes. Traditional node embedding techniques typically employ a co-occurrence probability-based methodology, which makes it difficult to adequately capture the semantic and structural information between nodes in heterogeneous information networks. By limiting the direction of random walk, meta-paths direct the generation of node sequences related to particular meta-paths, thereby capturing semantic and structural information between nodes. Metapath2vec [70] uses skip-gram to learn node embeddings after defining meta-paths to describe the semantic relationships between nodes and create heterogeneous neighborhoods of nodes. Using the defined meta-paths, HIN2vec [71] also creates diverse node neighborhoods. The crucial distinction is that it reconstructs the neighborhood using a self-encoder model and learns the embedding vector of the nodes by minimizing the reconstruction error. GATNE [72] combines the ideas of graph attention network (GAN) and neighborhood aggregation embedding (NAE). It employs the GAT model for node representation learning in heterogeneous graphs and the NAE method for node neighborhood aggregation. Setting the proper number of walks and walk lengths is crucial when learning node embedding in various heterogeneous networks.
Deep learning-based methods. Traditional machine learning techniques rely heavily on manually created feature representations, which have a priori knowledge restrictions and limit the expressiveness of the models. Deep learning techniques can enhance data representation by learning multi-level feature representations and reducing the need for manual features. To encode and decode the nodes and obtain the details of the graph structure, SDNE [73] employs a deep self-encoder architecture. First- and second-order proximity are simultaneously optimized, and overfitting is prevented by sparse regularization. The advantage of SDNE is that it learns the relationships between the nodes while retaining the graph’s structural information, improving the graph’s representation. DNGR [74] directly obtains graph structural information using a random walk model and learns node representations using stacked denoising autoencoders. The nonlinear features of the graph can be learned using these two techniques, but they do not perform well on non-Euclidean graphs. To encode the text, HNE [75] employs recursive neural networks, which can model the hierarchical structure of the text. Both image and text encoders are optimized using a joint training approach to learn better matching. A deep-aligned autoencoder-based embedding method for heterogeneous graphs was introduced by BL-MNE [76] to embed different types of nodes into the same low-dimensional space. TADW [77] learns low-dimensional embedding representations of network nodes using DeepWalk and latent dirichlet allocation (LDA) methods, and it introduces the attention mechanism to weigh the nodes’ textual information. Three different attention mechanisms—node attention, attribute attention, and neighbor attention—are introduced by the LANE [78] method, which adaptively adjusts the weights on different embedding layers to better capture the similarities and differences between nodes and improve the quality of embedding. ASNE [79] creates supernodes by combining the structural and attribute information of the nodes, employs an attention-based framework to regulate the weights between the different supernodes in the embedding space, and employs adaptive sparse methods to learn the representation of the nodes. DANE [80] can simultaneously capture highly nonlinear node attributes and topological relationships while preserving their proximity. The expressiveness and generalization performance of the node representation are improved by ANRL [81], which uses adaptive neighborhood regularization to dynamically adjust the weights of each node’s neighbors using the relationships between neighboring nodes.
3.2.2. Graph Neural Network-Based Methods
Currently, GNNs have emerged as a prominent research field in graph representation learning, especially in handling non-Euclidean data. Their capacity to effectively process such data makes them a suitable choice for various real-world applications. GNNs differ from traditional neural network methods in that they can effectively model the interactions between nodes and edges, thereby exhibiting superior performance in tasks related to the analysis and prediction of graph-structured data. Drawing upon prior research [82,83], we present a taxonomy of graph neural networks in this section, organized into five distinct categories based on their architectural design and unique approaches to processing structured graph data: GCNs, GATs, GAEs, GGANs, and GPNs.
GCNs. GCNs define a convolution operation on a graph that aggregates the features of a node’s neighboring nodes and the node itself to generate a new node feature. Graph convolution methods can be classified into spectral methods and spatial methods. In graph data, the relationships between nodes are irregular. GCN [84] introduces learnable convolutional parameters to extract and learn features from graph data. By stacking multiple graph convolutional layers, GCN obtains more abundant and complex node feature representations. DGCN [85] employs distinct graph convolution operations on the primal and dual graphs to obtain node representations on both graphs. To address the issue of traditional graph neural networks requiring the definition of static adjacency matrices in advance, AGCN [86] introduces adaptive adjacency matrices and gate mechanisms, avoiding the computational burden brought by multiple convolutional operations. LGCN [87] utilizes a learnable graph convolutional layer (LGCL) and a subgraph training technique for handling large-scale graph data, thereby circumventing the computational limitations of traditional graph convolutional operations that necessitate computing the entire graph. In addition, FastGCN [88] was proposed to address the issue of high computational and memory overheads in traditional graph convolutional methods by introducing importance sampling and mini-batch training. The GraphSAGE [89] approach is considered a significant milestone in the field of graph neural networks. It uses a sampler to randomly sample subgraphs from the graph data that contain the target node, enabling inductive representation learning and prediction on unseen nodes. GIN [90] incorporates a global sorted pooling operation in its aggregation process, endowing the GIN method with a certain degree of graph isomorphism invariance, thereby avoiding the mapping of isomorphic graphs to different vector representations. APPNP [91] uses the personalized PageRank algorithm to achieve personalized propagation and prediction of nodes and utilizes a larger receptive field for node classification tasks.
GATs. To address the issue of information aggregation in traditional graph neural networks, GATs introduced attention mechanisms [46] that enable different weighting of neighboring nodes around each node, thus better capturing the relationships between nodes. The attention mechanism in GAT [92] adaptively calculates the weights between nodes and further incorporates multi-head attention mechanisms to better capture the structural information of graphs and effectively handle large-scale graph data. AGNN [93] utilizes an attention mechanism to dynamically learn the relationships between each node and its neighboring nodes, thereby enhancing the model’s performance. DySAT [94] computes node representations through joint self-attention along the two dimensions of the structural neighborhood and temporal dynamics, more effectively capturing the relationships and features in dynamic graph data. GaAN [95] introduced an adaptive receptive field mechanism to dynamically adjust the neighborhood size of each node, enabling the receptive field size to adaptively fit the density and distribution of its surrounding nodes, thus enhancing the model’s flexibility and adaptability to different graph structures. HAN [96] utilizes distinct attention mechanisms to model different types of nodes and edges, learning complex relationships between nodes and the structural information of heterogeneous graphs by adaptively computing weights and representations of nodes. MAGNA [97] adopts a multi-hop attention mechanism that utilizes diffusive priors on attention values to consider all paths between non-connected node pairs, enabling the dynamic capture of complex relationships between nodes. High-order attention mechanisms and adversarial regularization constraints are employed by GCAN [98] to fully utilize both low-order and high-order information of nodes for representation learning.
GAEs. The encoder-decoder architecture has also been widely applied in graph generation and reconstruction tasks. GAE [99] initially employs this architecture by utilizing an encoder to compress the raw graph data into low-dimensional vectors and a decoder to decode these low-dimensional vectors back into the original graph. The structures of both the encoder and decoder are composed of multiple layers of GCN. VGAE [99] is an extension of GAE that introduces a variational inference method on top of GAE, enabling VGAE to learn more robust and interpretable low-dimensional representations. GraphVAE [100] adopts a similar structure to VAE, where the encoder transforms the graph information into a vector that approximates a normal distribution, and the decoder then transforms this vector back into a new graph. Graphite [101] utilizes graph neural networks to parameterize a variational autoencoder and employs a novel iterative graph refinement strategy for decoding. Graph2Gauss [102] builds upon VGAE by modeling node representations using Gaussian distributions and improving the distance metric to better capture complex category structures. In addition, DNVE [103] introduces deep generative models into graph autoencoders, embedding the network through deep encoders and decoders. Contrastive learning has also been applied to graph embedding methods. For example, DGI [104] uses a mutual information maximization method to learn node representations, which can learn high-order relationships between nodes without reconstructing the input graph. Another approach, InfoGraph [105], learns graph-level representations by maximizing the mutual information between the graph-level representation and representations of substructures at different scales within the graph. There is also a novel approach called MaskGAE [106], which combines the Masked Graph Model (MGM) with the graph autoencoder to achieve self-supervised graph representation learning and capture node features and structural information in the graph.
GGANs. GGANs are a type of generative model based on adversarial training that extends conventional generative adversarial networks (GANs) [107] and can be used for generating and learning embedded representations of graph data. The generator network can generate realistic graph data, while the discriminator network can evaluate the quality of the generated graph data. Through adversarial training between the two networks, GGANs can continuously optimize their ability to generate and learn graph data. An earlier method, GraphGAN [108], uses GAN to learn graph embedding representations and employs a loss function based on pairwise similarity to preserve the continuity of the embedding space. ARVGA [109] uses adversarial regularization to regularize node embeddings in the embedding space, thereby improving the continuity and robustness of embedding representations. By introducing an additional regularization term in adversarial training, ANE [110] enhances existing graph embedding methods by treating the prior distribution as real data and embedding vectors as generated samples. NetRA [111] is a network representation learning method based on an encoder-decoder framework and adversarial training. It encodes and decodes random walks on nodes, utilizes adversarial training to regularize embeddings, and introduces a prior distribution to improve the model’s generalization performance. In addition, there is an implicit generative model called NetGAN [112], which is used to simulate real-world networks. It uses GAN to train a generator and utilizes random walk loss in the graph to learn node-level representations. MolGAN [113] is an implicit generative model used for generating small molecule graphs. It combines GAN and policy gradient reinforcement learning methods to improve the quality and diversity of generated molecular graphs.
GPNs. GPNs use two operations, graph pooling and graph convolution, to process input graph data, with the main goal of reducing the size of the graph data and extracting global features. A general differentiable pooling operation called DiffPool [114] has been proposed, which can optimize node representations and pooling matrices through backpropagation to better capture the hierarchical structure of graph data. Zhang et al. [115] proposed a novel SortPooling operation that sorts each node’s feature vector along with the node’s degree and then uses the sorted result as the pooling result to better capture the global features of graph data. A method different from other graph pooling methods is SAGPool [116], which dynamically selects a subset of nodes using self-attention scores without the need to specify a fixed-size node subset. This approach enables more accurate learned graph representations that can adapt to different graph structures. Diehl et al. [117] proposed a pooling method called EdgePool, which relies on the edge contraction concept to learn localized and sparse hard pooling transformations. This method calculates importance scores for each edge to select representative edges and compress them together to form new nodes.
In addition, research on embedding methods for non-Euclidean spaces, contrastive learning for graph neural networks, and feature processing is worth noting. Corso et al. [118] proposed a neural distance embedding model, NeuroSEED, which embeds biological sequences into hyperbolic space for improved capture of hierarchical structure. A simple graph contrastive learning framework called SimGRACE [119] was proposed, which does not require data augmentation and enhances the robustness of graph contrastive learning using an adversarial scheme. Tang et al. [120] proposed a novel unsupervised feature selection method, MGF²WL, which combines multiple image fusion and feature weight learning to address poor-quality similarity graphs and designed an effective feature reconstruction model. Sun et al. Sun et al. [121] proposed a feature expanded graph neural network model FE-GNN that utilizes feature subspace flattening and structural principal components to expand the feature space and improve model performance.
We also summarize the representation learning method implementations reviewed in the paper in Table 1, most of which are official implementations.

Table 1.
Summary of Representation Learning Methods.
| Category | Method Name | Code Link |
|---|---|---|
|
Neural network-based language model representation learning |
Word2vec [37] | https://code.google.com/archive/p/word2vec/ |
| Doc2vec [38] | https://nbviewer.org/github/danielfrg/ word2vec/blob/main/examples/doc2vec.ipynb |
|
| GloVe [39] | https://nlp.stanford.edu/projects/glove/ | |
| FastText [40] | https://github.com/facebookresearch/fastText | |
| Bi-LSTM [42] | - | |
| ELMo [43] | https://allenai.org/allennlp/software/elmo | |
| Transformer [46] | https://github.com/tensorflow/tensorflow | |
| BERT [50] | https://github.com/google-research/bert | |
|
Graph representation learning |
||
| Graph embedding | GF [52] | - |
| PTE [53] | https://github.com/mnqu/PTE | |
| GraRep [54] | https://github.com/ShelsonCao/GraRep | |
| HOPE [55] | http://git.thumedia.org/embedding/HOPE | |
| HEER [56] | https://github.com/GentleZhu/HEER | |
| HERec [57] | https://github.com/librahu/HERec | |
| IsoMap [58] | https://github.com/scikit-learn/scikit-learn/blob/ main/sklearn/manifold/_isomap.py |
|
| LLE [59] | - | |
| LTSA [60] | - | |
| LE [61] | - | |
| HE [62] | - | |
| t-SNE [63] | https://lvdmaaten.github.io/tsne/ | |
| UMAP [64] | https://github.com/lmcinnes/umap | |
| DeepWalk [65] | https://github.com/phanein/deepwalk | |
| node2vec [66] | https://github.com/aditya-grover/node2vec | |
| LINE [67] | https://github.com/tangjianpku/LINE | |
| Walklets [68] | https://github.com/benedekrozemberczki/ walklets |
|
| struct2vec [69] | https://github.com/leoribeiro/struc2vec | |
| Metapath2vec [70] | https://ericdongyx.github.io/metapath2vec/ m2v.html |
|
| HIN2vec [71] | https://github.com/csiesheep/hin2vec | |
| GATNE [72] | https://github.com/THUDM/GATNE | |
| SDNE [73] | https://github.com/suanrong/SDNE | |
| DNGR [74] | https://github.com/ShelsonCao/DNGR | |
| HNE [75] | - | |
| BL-MNE [76] | - | |
| TADW [77] | https://github.com/thunlp/tadw | |
| LANE [78] | https://github.com/xhuang31/LANE | |
| ASNE [79] | https://github.com/lizi-git/ASNE | |
| DANE [80] | https://github.com/gaoghc/DANE | |
| ANRL [81] | https://github.com/cszhangzhen/ANRL | |
| Graph neural network | GCN [84] | https://github.com/tkipf/gcn |
| DGCN [85] | https://github.com/ZhuangCY/DGCN | |
| AGCN [86] | https://github.com/yimutianyang/AGCN | |
| LGCN [87] | https://github.com/divelab/lgcn | |
| FastGCN [88] | https://github.com/matenure/FastGCN | |
| GraphSAGE [89] | https://github.com/williamleif/GraphSAGE | |
| GIN [90] | https://github.com/weihua916/powerful-gnns | |
| APPNP [91] | https://github.com/gasteigerjo/ppnp | |
| GAT [92] | https://github.com/PetarV-/GAT | |
| AGNN [93] | - | |
| DySAT [94] | https://github.com/aravindsankar28/DySAT | |
| GaAN [95] | https://github.com/jennyzhang0215/GaAN | |
| HAN [96] | https://github.com/Jhy1993/HAN | |
| MAGNA [97] | https://github.com/xjtuwgt/GNN-MAGNA | |
| GCAN [98] | - | |
| GAE [99] | https://github.com/tkipf/gae | |
| VGAE [99] | https://github.com/tkipf/gae | |
| Graph neural network | GraphVAE [100] | https://github.com/snap-stanford/GraphRNN/ tree/master/baselines/graphvae |
| Graphite [101] | https://github.com/ermongroup/graphite | |
| Graph2Gauss [102] | https://github.com/abojchevski/gra ph2gauss |
|
| DNVE [103] | - | |
| DGI [104] | https://github.com/PetarV-/DGI | |
| InfoGraph [105] | https://github.com/fanyun-sun/Info Graph |
|
| MaskGAE [106] | https://github.com/EdisonLeeeee/Mas kGAE |
|
| GraphGAN [108] | https://github.com/hwwang55/GraphGAN | |
| ARVGA [109] | - | |
| ANE [110] | - | |
| NetRA [111] | https://github.com/chengw07/NetRA | |
| NetGAN [112] | https://github.com/danielzuegner/ne tgan |
|
| MolGAN [113] | https://github.com/nicola-decao/Mol GAN |
|
| DiffPool [114] | https://github.com/RexYing/diffpool | |
| SortPooling [115] | https://github.com/muhanzhang/DGCNN | |
| SAGPool [116] | https://github.com/inyeoplee77/SAG Pool |
|
| EdgePool [117] | - | |
| Others | NeuroSEED [118] | https://github.com/gcorso/NeuroSEED |
| SimGRACE [119] | https://github.com/mpanpan/SimGRACE | |
| MGF²WL [120] | - | |
| FE-GNN [121] | https://github.com/sajqavril/Featur e-Extension-Graph-Neural-Networks |
4. Representation Learning Methods for COVID-19
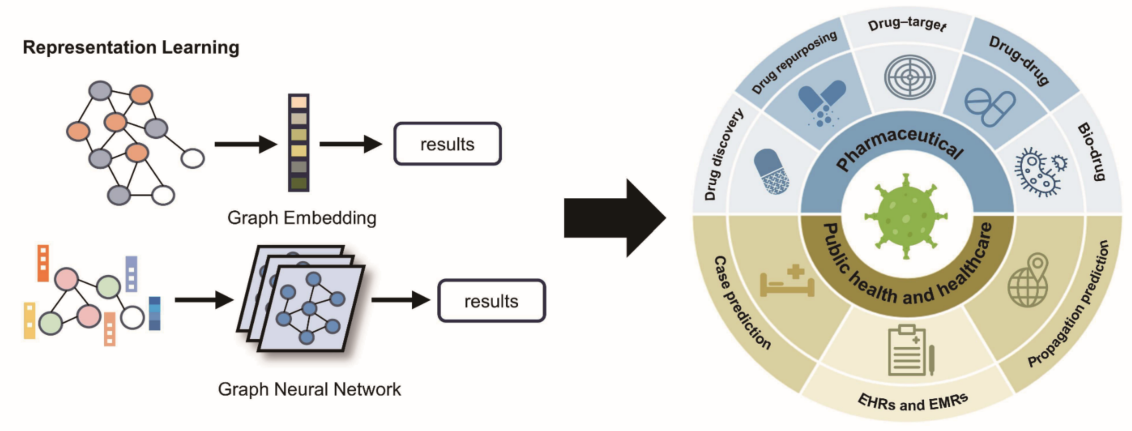
From drug omics to clinical outcomes, representation learning has been widely applied for the representation and modeling of multimodal biological and medical systems. This section summarizes a series of representative methods in the field of representation learning for COVID-19-related domains such as pharmaceuticals, public health, and healthcare. As shown in Figure 4.
4.1. Pharmaceutical
Traditional drug development is not only characterized by lengthy cycles and exorbitant costs but also by low success rates. Artificial intelligence methods offer advantages such as large-scale data processing, end-to-end learning, handling complex molecular structures, and adaptive learning, which have accelerated drug discovery and drug repurposing. On the other hand, graph representation methods are better suited to handle high-dimensional, non-linear data structures and intuitively display the structural features of drug molecules, making it easier to understand and interpret prediction results.
4.1.1. Drug Discovery
Ton et al. [122] utilized a deep learning platform called Deep Docking to screen over 1.3 billion compounds for inhibitors targeting the SARS-CoV-2 main protease, providing candidate drugs for drug development. Saravanan et al. [123] employed deep learning to predictively screen known compounds, enabling rapid and accurate identification of potential antiviral drugs.
Zhou et al. [124] proposed a nonlinear end-to-end method for predicting interactions between compounds and COVID-19 based on GCN and attention mechanisms in heterogeneous graph representation learning, accelerating drug development. To predict molecular properties and find new drugs, Wang et al. [125] developed a machine learning tool called AdvProp. AdvProp consists of four modules, including two graph-based and two sequence-based methods. Li et al. [126] integrated chemical, biological, and physical information to propose a multi-physics molecular graph representation and characterization method that can more accurately describe the interactions between drug molecules and proteins, making it better suited for COVID-19 drug discovery. Pi et al. [127]integrated node attention mechanisms and edge attention mechanisms into GCN for predicting the activity of microbial drugs and successfully predicted two drugs related to SARS-CoV-2.
4.1.2. Drug Repurposing
Ge et al. [128] developed a data-driven drug repurposing machine learning and statistical analysis framework to discover potential drug candidates against SARS-CoV-2. Mall et al. [129] proposed a data-driven drug repurposing strategy that successfully screened potential therapeutic drugs against COVID-19. Hooshmand et al. [130] used a multimodal restricted Boltzmann machine approach to connect multimodal information for drug repurposing to treat COVID-19. Anwaar et al. proposed a drug repurposing approach based on deep learning and molecular docking simulations.
Aghdam et al. [131] repurposed existing drugs to treat COVID-19 by utilizing biological network graphs and key proteins to propose multiple informative features for finding potential candidate drugs for COVID-19 treatment. Hsieh et al. [132] constructed a drug repurposing method based on a SARS-CoV-2 knowledge graph and used deep graph neural networks to determine the priority of repurposable drugs. Pham et al. [133] proposed a drug screening method utilizing graph neural networks and multi-head attention mechanisms for high-throughput mechanism-based phenotypic screening and applied it to COVID-19 drug repurposing. By integrating multiple lines of evidence to infer potential COVID-19 treatments, Hsieh et al. [134] used a graph neural network-based model to predict the potential therapeutic effects of existing compounds. Doshi et al. [135] proposed an end-to-end model based on graph neural networks for drug repurposing.
4.1.3. Drug–Target Interaction Prediction
Beck et al. [136] proposed a deep learning-based drug-target interaction model that can predict the interactions between drugs and specific protein targets for the discovery of commercially available antiviral drugs that can treat SARS-CoV-2. Saha et al. [137] employed a machine learning-based approach to predict the interactions between the COVID-19 virus and human proteins, identifying key proteins and metabolic pathways relevant to COVID-19 as well as potential drug targets and drug combinations.
To predict the affinity between COVID-19 ion channel targets and drugs, Wang et al. [138] proposed a hybrid graph network model that uses an attention mechanism and GCN to connect drugs and targets. Zhang et al. [139] incorporated multi-layer graph information into transformer networks to explore the molecular structure of drug compounds in drug-target interaction prediction. To alleviate the sparsity of bipartite graphs and obtain better node representations, Li et al. [140] proposed a novel prediction model based on a variational graph autoencoder combined with a dual Wasserstein generative adversarial network gradient penalty strategy according to the prior knowledge graph. This enhances the representation of edge information for better drug-target interaction.
4.1.4. Drug–Drug Interaction Prediction
Tang et al. [141] introduced domain-invariant learning to address the issue of domain shift between different datasets. They improved the generalization performance of drug-drug interaction prediction methods by minimizing the distributional discrepancy between the source and target domains. Sefidgarhoseini et al. [142] effectively improved the accuracy and robustness of drug-drug interaction extraction by combining multiple pre-trained Transformer models, entity tagging strategies, and a voting-based ensemble strategy.
Ren et al. [143] proposed a drug-drug interaction prediction method based on a biomedical knowledge graph, which utilizes a combination of local and global features to enhance predictive performance. Chen et al. [144] designed a multi-scale feature fusion approach and a bi-level cross strategy to optimize the feature fusion method, thereby enhancing the performance of drug-drug interaction prediction. This method also fully utilizes the features extracted from drug molecular structure graphs and biomedical knowledge graphs and can be applied to different types of DDI prediction tasks. Pan et al. [145] integrated the self-attention mechanism, cross-attention mechanism, and graph attention network to construct a multi-source feature fusion network, which enables the model to better capture drug-drug interaction information and further predict drug-drug interaction-related events. Li et al. [146] proposed a novel multi-view substructure learning method that fuses multiple views, such as chemical structures, pharmacophores, and targets, to learn key substructure information for drug-drug interaction. An improved and more precise model for predicting drug-drug interactions was proposed by Ma et al. [147] using a dual graph neural network model that takes into account both molecular-level and substructure-level data.
4.1.5. Bio-Drug Interaction Prediction
Dey et al. [148] constructed a dataset with rich sequence features and utilized machine learning techniques to predict the virus-host interactions between SARS-CoV-2 and human proteins. To predict virus-host interactions at the protein and organism levels using machine learning techniques, Du et al. [149] constructed a complex network with rich biological information.
Yang et al. [150] proposed a graph convolutional network-based method to uncover potential associations between human microbiota and drugs. The method employed a multi-kernel fusion strategy to integrate biological information from different sources, thereby enhancing prediction capability. Das et al. [151] proposed an innovative geometric deep learning model that effectively predicts and displays potential drug-virus interactions against SARS-CoV-2 by utilizing message passing neural networks (MPNN) and graph-structured features.
4.2. Public Health and Healthcare
Representation learning has also been applied to case prediction, propagation prediction, and analysis of multi-modal medical system data, such as electronic health records (EHRs) and electronic medical records (EMRs). The first two are important for predicting epidemic trends and guiding public health decisions, while EHRs and EMRs are crucial for improving clinical decision-making and optimizing medical resources.
4.2.1. Case Prediction
Shahid et al. [152] evaluated multiple predictive models and demonstrated the superior performance of the Bi-LSTM model in COVID-19 case forecasting. Abbasimehr et al. [153] employed a combination of multi-head attention, LSTM, and CNN, along with the Bayesian optimization algorithm, to forecast the number of confirmed COVID-19 cases soon. Sinha et al. [154] compared the performance of multiple deep learning models for analyzing and forecasting confirmed cases of COVID-19 and investigated the impact of data preprocessing and model tuning on predictive performance.
Gao et al. [155] proposed a spatiotemporal attention network based on real-world evidence for predicting the number of cases in a fixed number of days in the future. They also designed a dynamic loss term to enhance long-term forecasting. To effectively capture potential information about virus transmission and capture the linearity and non-linearity present in time series, Ntemi et al. [156] proposed a hybrid model composed of a GCN, a LSTM, and an autoregressive filter to more accurately predict the number of cases. Li et al. [157] proposed a prediction model that combines the lioness optimization algorithm with the graph convolutional network, which can capture spatiotemporal information from feature data to achieve accurate predictions of COVID-19 case numbers. Skianis et al. [158] developed a multi-scale graph model utilizing demographic data, medical facilities, socio-economic indicators, and other related information to improve the prediction accuracy of COVID-19 positive cases and hospitalizations. The model is capable of automatically learning the interrelationships between different features, thereby enhancing its predictive capability.
4.2.2. Propagation Prediction
Malki et al. [159] utilized multiple machine learning models, including random forest, support vector machine, and artificial neural network, to predict the transmission trend of COVID-19. Liu et al. [160] employed the Deep Neural Network (DNN) to predict the impact of social distancing on the transmission of COVID-19. They developed the Improved Particle Swarm Optimization (IPSO) algorithm, which introduced a generalized opposition-based learning strategy and an adaptive strategy to optimize the hyperparameters of the DNN. Ayris et al. [161] proposed a deep sequential prediction model and a machine learning-based nonparametric regression model to predict the transmission of COVID-19.
La et al. [162] proposed an epidemiological model based on graph neural networks that effectively predicted and analyzed the transmission of the COVID-19 epidemic using dynamic graph-structured data. Hy et al. [163] proposed a method that captures multiscale patterns in spatiotemporal data and combines multiscale neighborhood aggregation, temporal convolutions, and multi-task learning to efficiently predict the transmission of COVID-19. To detect spatiotemporal patterns in the transmission of COVID-19, Geng et al. [164] introduced the spectral graph wavelet transform (SGWT) to deeply mine the characteristics of infection data and process COVID-19 data on dynamic graphs. Shan et al. [165] introduced graph neural networks and topological data analysis to propose a Graph Topology Learning method that effectively solves the prediction problem of virus transmission on spatial and temporal scales.
4.2.3. Analysis of Ehrs and Emrs
An examination of EHRs and EMRs is integral to the healthcare industry and scientific community, as it enables a comprehensive comprehension of patients’ medical conditions and healthcare service utilization. In turn, this facilitates the optimization of medical resources, an enhancement of healthcare service quality, a support system for clinical decision-making, and a catalyst for medical research and innovation. To investigate the clinical characteristics and prognostic factors of COVID-19 patients, Izquierdo et al. [166] employed natural language processing techniques to extract clinical information from patients’ EHRs and utilized machine learning methods for modeling. Landi et al. [167] used deep learning techniques for feature extraction from EHRs, enabling effective stratification and classification of patient data, thereby providing robust support for precision medicine and treatment plan development. Wagner et al. [168] proposed an effective method for analyzing clinical records in large-scale EHR systems using deep neural networks, enabling early disease diagnosis based on EHR data. Wanyan et al. [169] developed a deep learning model based on contrastive loss to predict critical events such as severe illness, mortality, and intubation that demonstrates promising performance on imbalanced EHR data. They further proposed a unique EHR data heterogeneous feature design training algorithm and combined it with contrastive positive sampling to predict COVID-19 patient mortality [170]. To better perform prognostic analysis on COVID-19 patients, Ma et al. [171] proposed a distillation transfer learning framework that extracts knowledge from publicly available online EMR data through knowledge distillation.
Wanyan et al. [172] proposed a relationship learning framework based on heterogeneous graph models to predict the mortality rate of COVID-19 patients in intensive care units over different time windows. To address the challenges posed by data heterogeneity and semantic inconsistencies when integrating and analyzing electronic medical record data across institutions, Zhou et al. [173] proposed an integration method based on a multi-view incomplete knowledge graph, which takes into account the relationships between multiple data sources and the connecting information within each view. Gao et al. [174] proposed a new machine learning framework that uses electronic health records to predict hospitalization status and severity of illness in children and fuses clinical domain knowledge via graph neural networks, outperforming data-driven methods in terms of predictability and interpretability.
5. Challenges and Prospects
The method of graph representation has demonstrated excellent outcomes in various bioinformatics tasks, indicating huge potential for processing biological data. It can convert biological data into low-dimensional embeddings before using them for downstream tasks. However, there are challenges to the process of broadly employing graph representation methods on real-world data. Because graph data is non-Euclidean, its structure is very irregular in general. In the direction of the future, there are both opportunities and uncertainties.
5.1. Data Quality
As researchers delve deeper into the field of GNNs, the quality of graph data emerges as a critical factor that significantly influences the performance and reliability of our models. However, ensuring high-quality graph data is a challenging task due to the potential presence of redundant, erroneous, or missing features and connections, which can adversely impact the performance of GNNs [175]. In bioinformatics and biomedical research, graph data often represents intricate biological entities and their interactions, such as gene regulatory networks, protein-protein interaction networks, and patient similarity networks. The quality of this graph data is of paramount importance, as it directly impacts the accuracy and reliability of downstream analyses and predictions. The variability in the quality of gene sequence data produced by high-throughput sequencing can lead to noise in the sequencing data, causing GNNs to learn incorrect patterns. Sequencing data for COVID-19 is facing such issues. Several studies have employed training strategies such as decoupled training, joint training, and two-level optimization to address the challenges of graph data augmentation. Therefore, developing reliable methods for graph data representation is a challenging problem. Furthermore, it is crucial to establish benchmarks and metrics for assessing the quality of biological graph data, which can guide the development and evaluation of methods aimed at improving data quality.
5.2. Hyperparameters and Labels
When employing graph representation models on large datasets, numerous hyperparameters need to be adjusted, and data must be accurately labeled prior to training. The quality of labels and uncertainties in biological data can influence the outcomes of training graph embedding models [176]. In most cases, the quality of labels generated directly by the model is inferior to those manually annotated. In many practical applications, manual label creation remains an indispensable method, albeit time-consuming and requiring some prior knowledge of model hyperparameter settings. Particularly for COVID-19 genomic data, as COVID-19 continues to mutate to produce new variants, it undergoes insertions, deletions, and base substitutions in the genomic sequence, making it challenging to discern patterns and manually create labels. An intriguing area of research is how to enable models in unsupervised learning to generate labels by automatically extracting features of nodes and edges in graph data.
5.3. Interpretability and Extensibility
The graph neural network approach has developed quickly, but it has some limitations. Graph neural networks are still a "black box" with limited interpretability, but many real-world tasks require higher interpretability and scalability of the model. Interpretability is essential in bioinformatics, where there is a desire to better understand the mechanisms underlying biological processes, to provide accurate guidance for downstream analysis, and to apply them in bioinformatics [177,178]. It has also become a challenge to develop a highly scalable and generic framework for different biological sequence data in order to handle larger and more complex data, adapt to various application scenarios, and better meet practical needs.
6. Conclusions
Representation learning, especially graph representation learning, provides the ability to handle complex data, integrate multi-modal data, and process large-scale datasets in bioinformatics and biomedical research. It has been successfully applied to identifying gene mutations for complex traits, assisting in disease diagnosis and treatment, and developing safe and effective drugs. In this work, we conducted a comprehensive survey of the applications of representation learning in bioinformatics and biomedical. We summarized neural network-based language model representation learning and graph representation learning, and discussed the relevant graph neural network methods in detail. Additionally, we introduced applications in pharmaceuticals, public health, and healthcare for COVID-19 based on these two categories of approaches. Finally, we summarized the challenges faced by the popular research field of graph representation learning. It is anticipated that this work could promote the research of graph representation learning in the fields of bioinformatics and biomedical, provide guidance for researchers to review the entire development process of COVID-19, and prepare preventive measures for potential highly contagious epidemics in the future.
Author Contributions
Conception, P.L.; investigation, P.L., C.Z. and S.G.; writing—original draft preparation, P.L. and M.M.P.; writing—review and editing, P.L., M.M.P. and J.Z.; visualization, P.L., C.Z. and S.G. supervision, J.Z.; funding acquisition, J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by (1) 2021–2023 National Natural Science Foundation of China under Grant (Youth) No. 52001039; (2) 2022–2025 National Natural Science Foundation of China under Grant No. 52171310; (3) 2020–2022 Funding of the Shandong Natural Science Foundation in China under Grant No. ZR2019LZH005; (4) 2022–2023 Research fund from Science and Technology on Underwater Vehicle Technology Laboratory under Grant 2021JCJQ-SYSJJ-LB06903.
Acknowledgments
The authors would like to thank Microsoft Office Home and Student 2019 and the OfficePLUS plugin for providing the tools and materials that aided in the creation of Figure 3 and 4 in this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- William T Harvey, Alessandro M Carabelli, Ben Jackson, Ravindra K Gupta, Emma C Thomson, Ewan M Harrison, Catherine Ludden, Richard Reeve, Andrew Rambaut, COVID-19 Genomics UK (COG-UK) Consortium, et al. Sars-cov-2 variants, spike mutations and immune escape. Nature Reviews Microbiology, 19(7):409–424, 2021.
- James Hadfield, Colin Megill, Sidney M Bell, John Huddleston, Barney Potter, Charlton Callender, Pavel Sagulenko, Trevor Bedford, and Richard A Neher. Nextstrain: real-time tracking of pathogen evolution. Bioinformatics, 34(23):4121–4123, 2018. [CrossRef]
- David M Morens, Gregory K Folkers, and Anthony S Fauci. The concept of classical herd immunity may not apply to covid-19. The Journal of infectious diseases, 226(2):195–198, 2022. [CrossRef]
- Leiwen Fu, Bingyi Wang, Tanwei Yuan, Xiaoting Chen, Yunlong Ao, Thomas Fitzpatrick, Peiyang Li, Yiguo Zhou, Yi-fan Lin, Qibin Duan, et al. Clinical characteristics of coronavirus disease 2019 (covid-19) in china: a systematic review and meta-analysis. Journal of Infection, 80(6):656–665, 2020. [CrossRef]
- Elizabeth J Williamson, Alex J Walker, Krishnan Bhaskaran, Seb Bacon, Chris Bates, Caroline E Morton, Helen J Curtis, Amir Mehrkar, David Evans, Peter Inglesby, et al. Opensafely: factors associated with covid-19 death in 17 million patients. Nature, 584(7821):430, 2020.
- Yan-Rong Guo, Qing-Dong Cao, Zhong-Si Hong, Yuan-Yang Tan, Shou-Deng Chen, Hong-Jun Jin, Kai-Sen Tan, De-Yun Wang, and Yan Yan. The origin, transmission and clinical therapies on coronavirus disease 2019 (covid-19) outbreak–an update on the status. Military medical research, 7:1–10, 2020.
- Chaolin Huang, Yeming Wang, Xingwang Li, Lili Ren, Jianping Zhao, Yi Hu, Li Zhang, Guohui Fan, Jiuyang Xu, Xiaoying Gu, et al. Clinical features of patients infected with 2019 novel coronavirus in wuhan, china. The lancet, 395(10223):497–506, 2020.
- Thanh Thi Nguyen, Mohamed Abdelrazek, Dung Tien Nguyen, Sunil Aryal, Duc Thanh Nguyen, Sandeep Reddy, Quoc Viet Hung Nguyen, Amin Khatami, Edbert B Hsu, and Samuel Yang. Origin of novel coronavirus (covid-19): a computational biology study using artificial intelligence. BioRxiv, pages 2020–05, 2020. [CrossRef]
- Marco Cascella, Michael Rajnik, Abdul Aleem, Scott C Dulebohn, and Raffaela Di Napoli. Features, evaluation, and treatment of coronavirus (covid-19). Statpearls [internet], 2022.
- Shibo Jiang, Christopher Hillyer, and Lanying Du. Neutralizing antibodies against sars-cov-2 and other human coronaviruses. Trends in immunology, 41(5):355–359, 2020.
- Lok Bahadur Shrestha, Charles Foster, William Rawlinson, Nicodemus Tedla, and Rowena A Bull. Evolution of the sars-cov-2 omicron variants ba. 1 to ba. 5: Implications for immune escape and transmission. Reviews in Medical Virology, 32(5):e2381, 2022. [CrossRef]
- Bette Korber, Will M Fischer, Sandrasegaram Gnanakaran, Hyejin Yoon, James Theiler, Werner Abfalterer, Nick Hengartner, Elena E Giorgi, Tanmoy Bhattacharya, Brian Foley, et al. Tracking changes in sars-cov-2 spike: evidence that d614g increases infectivity of the covid-19 virus. Cell, 182(4):812–827, 2020.
- Yunlong Cao, Jing Wang, Fanchong Jian, Tianhe Xiao, Weiliang Song, Ayijiang Yisimayi, Weijin Huang, Qianqian Li, Peng Wang, Ran An, et al. Omicron escapes the majority of existing sars-cov-2 neutralizing antibodies. Nature, 602(7898):657–663, 2022.
- Manojit Bhattacharya, Ashish Ranjan Sharma, Kuldeep Dhama, Govindasamy Agoramoorthy, and Chiranjib Chakraborty. Omicron variant (b. 1.1. 529) of sars-cov-2: understanding mutations in the genome, s-glycoprotein, and antibody-binding regions. GeroScience, 44(2):619–637, 2022.
- Dhiraj Mannar, James W Saville, Xing Zhu, Shanti S Srivastava, Alison M Berezuk, Katharine S Tuttle, Ana Citlali Marquez, Inna Sekirov, and Sriram Subramaniam. Sars-cov-2 omicron variant: Antibody evasion and cryo-em structure of spike protein–ace2 complex. Science, 375(6582):760–764, 2022.
- Dinah V Parums. The xbb. 1.5 (‘kraken’) subvariant of omicron sars-cov-2 and its rapid global spread. Medical Science Monitor, 29, 2023.
- Imad A Basheer and Maha Hajmeer. Artificial neural networks: fundamentals, computing, design, and application. Journal of microbiological methods, 43(1):3–31, 2000. [CrossRef]
- Yifei Chen, Yi Li, Rajiv Narayan, Aravind Subramanian, and Xiaohui Xie. Gene expression inference with deep learning. Bioinformatics, 32(12):1832–1839, 2016. [CrossRef]
- Hongming Chen, Ola Engkvist, Yinhai Wang, Marcus Olivecrona, and Thomas Blaschke. The rise of deep learning in drug discovery. Drug discovery today, 23(6):1241–1250, 2018. [CrossRef]
- Mihalj Bakator and Dragica Radosav. Deep learning and medical diagnosis: A review of literature. Multimodal Technologies and Interaction, 2(3):47, 2018. [CrossRef]
- Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, and Maosong Sun. Graph neural networks: A review of methods and applications. AI open, 1:57–81, 2020. [CrossRef]
- Jiacheng Xiong, Zhaoping Xiong, Kaixian Chen, Hualiang Jiang, and Mingyue Zheng. Graph neural networks for automated de novo drug design. Drug Discovery Today, 26(6):1382–1393, 2021. [CrossRef]
- Fang Yang, Kunjie Fan, Dandan Song, and Huakang Lin. Graph-based prediction of protein-protein interactions with attributed signed graph embedding. BMC bioinformatics, 21(1):1–16, 2020. [CrossRef]
- Xiao-Meng Zhang, Li Liang, Lin Liu, and Ming-Jing Tang. Graph neural networks and their current applications in bioinformatics. Frontiers in genetics, 12:690049, 2021. [CrossRef]
- Daniele Mercatelli, Laura Scalambra, Luca Triboli, Forest Ray, and Federico M Giorgi. Gene regulatory network inference resources: A practical overview. Biochimica et Biophysica Acta (BBA)-Gene Regulatory Mechanisms, 1863(6):194430, 2020. [CrossRef]
- Hongyun Cai, Vincent W Zheng, and Kevin Chen-Chuan Chang. A comprehensive survey of graph embedding: Problems, techniques, and applications. IEEE transactions on knowledge and data engineering, 30(9):1616–1637, 2018. [CrossRef]
- Mengjia Xu. Understanding graph embedding methods and their applications. SIAM Review, 63(4):825–853, 2021. [CrossRef]
- James Kotary, Ferdinando Fioretto, Pascal Van Hentenryck, and Bryan Wilder. End-to-end constrained optimization learning: A survey. arXiv preprint arXiv:2103.16378, 2021. [CrossRef]
- Xiao Wang, Deyu Bo, Chuan Shi, Shaohua Fan, Yanfang Ye, and S Yu Philip. A survey on heterogeneous graph embedding: methods, techniques, applications and sources. IEEE Transactions on Big Data, 2022. [CrossRef]
- Giulia Muzio, Leslie O’Bray, and Karsten Borgwardt. Biological network analysis with deep learning. Briefings in bioinformatics, 22(2):1515–1530, 2021.
- Zehong Zhang, Lifan Chen, Feisheng Zhong, Dingyan Wang, Jiaxin Jiang, Sulin Zhang, Hualiang Jiang, Mingyue Zheng, and Xutong Li. Graph neural network approaches for drug-target interactions. Current Opinion in Structural Biology, 73:102327, 2022. [CrossRef]
- Sezin Kircali Ata, Min Wu, Yuan Fang, Le Ou-Yang, Chee Keong Kwoh, and Xiao-Li Li. Recent advances in network-based methods for disease gene prediction. Briefings in bioinformatics, 22(4):bbaa303, 2021. [CrossRef]
- Oliver Wieder, Stefan Kohlbacher, Mélaine Kuenemann, Arthur Garon, Pierre Ducrot, Thomas Seidel, and Thierry Langer. A compact review of molecular property prediction with graph neural networks. Drug Discovery Today: Technologies, 37:1–12, 2020. [CrossRef]
- World. Statement on the fifteenth meeting of the ihr (2005) emergency committee on the covid-19 pandemic, May 2023.
- Ruiwei Feng, Yufeng Xie, Minshan Lai, Danny Z Chen, Ji Cao, and Jian Wu. Agmi: Attention-guided multi-omics integration for drug response prediction with graph neural networks. In 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pages 1295–1298. IEEE, 2021. [CrossRef]
- Yaxin Zhu, Peisheng Qian, Ziyuan Zhao, and Zeng Zeng. Deep feature fusion via graph convolutional network for intracranial artery labeling. In 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), pages 467–470. IEEE, 2022.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26, 2013.
- Quoc Le and Tomas Mikolov. Distributed representations of sentences and documents. In International conference on machine learning, pages 1188–1196. PMLR, 2014.
- Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543, 2014.
- Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. Enriching word vectors with subword information. Transactions of the association for computational linguistics, 5:135–146, 2017.
- Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- Zhiheng Huang, Wei Xu, and Kai Yu. Bidirectional lstm-crf models for sequence tagging. arXiv preprint arXiv:1508.01991, 2015.
- Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations, 2018.
- Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
- Yoon Kim, Carl Denton, Luong Hoang, and Alexander M Rush. Structured attention networks. arXiv preprint arXiv:1702.00887, 2017.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N Dauphin. Convolutional sequence to sequence learning. In International conference on machine learning, pages 1243–1252. PMLR, 2017.
- Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. End-to-end memory networks. Advances in neural information processing systems, 28, 2015.
- Alexander Miller, Adam Fisch, Jesse Dodge, Amir-Hossein Karimi, Antoine Bordes, and Jason Weston. Key-value memory networks for directly reading documents. arXiv preprint arXiv:1606.03126, 2016.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Minh-Thang Luong, Hieu Pham, and Christopher D Manning. Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025, 2015.
- Amr Ahmed, Nino Shervashidze, Shravan Narayanamurthy, Vanja Josifovski, and Alexander J Smola. Distributed large-scale natural graph factorization. In Proceedings of the 22nd international conference on World Wide Web, pages 37–48, 2013.
- Jian Tang, Meng Qu, and Qiaozhu Mei. Pte: Predictive text embedding through large-scale heterogeneous text networks. In Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining, pages 1165–1174, 2015.
- Shaosheng Cao, Wei Lu, and Qiongkai Xu. Grarep: Learning graph representations with global structural information. In Proceedings of the 24th ACM international on conference on information and knowledge management, pages 891–900, 2015.
- Mingdong Ou, Peng Cui, Jian Pei, Ziwei Zhang, and Wenwu Zhu. Asymmetric transitivity preserving graph embedding. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, pages 1105–1114, 2016.
- Yu Shi, Qi Zhu, Fang Guo, Chao Zhang, and Jiawei Han. Easing embedding learning by comprehensive transcription of heterogeneous information networks. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2190–2199, 2018.
- Chuan Shi, Binbin Hu, Wayne Xin Zhao, and S Yu Philip. Heterogeneous information network embedding for recommendation. IEEE Transactions on Knowledge and Data Engineering, 31(2):357–370, 2018. [CrossRef]
- Joshua B Tenenbaum, Vin de Silva, and John C Langford. A global geometric framework for nonlinear dimensionality reduction. science, 290(5500):2319–2323, 2000. [CrossRef]
- Sam T Roweis and Lawrence K Saul. Nonlinear dimensionality reduction by locally linear embedding. science, 290(5500):2323–2326, 2000. [CrossRef]
- Zhenyue Zhang and Hongyuan Zha. Principal manifolds and nonlinear dimensionality reduction via tangent space alignment. SIAM journal on scientific computing, 26(1):313–338, 2004. [CrossRef]
- Mikhail Belkin and Partha Niyogi. Laplacian eigenmaps for dimensionality reduction and data representation. Neural computation, 15(6):1373–1396, 2003. [CrossRef]
- David L Donoho and Carrie Grimes. Hessian eigenmaps: Locally linear embedding techniques for high-dimensional data. Proceedings of the National Academy of Sciences, 100(10):5591–5596, 2003. [CrossRef]
- Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of machine learning research, 9(11), 2008.
- Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426, 2018.
- Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 701–710, 2014.
- Aditya Grover and Jure Leskovec. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, pages 855–864, 2016.
- Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, and Qiaozhu Mei. Line: Large-scale information network embedding. In Proceedings of the 24th international conference on world wide web, pages 1067–1077, 2015.
- Bryan Perozzi, Vivek Kulkarni, Haochen Chen, and Steven Skiena. Don’t walk, skip! online learning of multi-scale network embeddings. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2017, pages 258–265, 2017.
- Leonardo FR Ribeiro, Pedro HP Saverese, and Daniel R Figueiredo. struc2vec: Learning node representations from structural identity. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pages 385–394, 2017.
- Yuxiao Dong, Nitesh V Chawla, and Ananthram Swami. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pages 135–144, 2017.
- Tao-yang Fu, Wang-Chien Lee, and Zhen Lei. Hin2vec: Explore meta-paths in heterogeneous information networks for representation learning. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, pages 1797–1806, 2017.
- Yukuo Cen, Xu Zou, Jianwei Zhang, Hongxia Yang, Jingren Zhou, and Jie Tang. Representation learning for attributed multiplex heterogeneous network. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1358–1368, 2019.
- Daixin Wang, Peng Cui, and Wenwu Zhu. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, pages 1225–1234, 2016.
- Shaosheng Cao, Wei Lu, and Qiongkai Xu. Deep neural networks for learning graph representations. In Proceedings of the AAAI conference on artificial intelligence, volume 30, 2016.
- Shiyu Chang, Wei Han, Jiliang Tang, Guo-Jun Qi, Charu C Aggarwal, and Thomas S Huang. Heterogeneous network embedding via deep architectures. In Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining, pages 119–128, 2015.
- Jiawei Zhang, Congying Xia, Chenwei Zhang, Limeng Cui, Yanjie Fu, and S Yu Philip. Bl-mne: emerging heterogeneous social network embedding through broad learning with aligned autoencoder. In 2017 IEEE International Conference on Data Mining (ICDM), pages 605–614. IEEE, 2017. [CrossRef]
- Cheng Yang, Zhiyuan Liu, Deli Zhao, Maosong Sun, and Edward Y Chang. Network representation learning with rich text information. In IJCAI, volume 2015, pages 2111–2117, 2015.
- Xiao Huang, Jundong Li, and Xia Hu. Label informed attributed network embedding. In Proceedings of the tenth ACM international conference on web search and data mining, pages 731–739, 2017.
- Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua. Attributed social network embedding. IEEE Transactions on Knowledge and Data Engineering, 30(12):2257–2270, 2018.
- Hongchang Gao and Heng Huang. Deep attributed network embedding. In Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI)), 2018.
- Zhen Zhang, Hongxia Yang, Jiajun Bu, Sheng Zhou, Pinggang Yu, Jianwei Zhang, Martin Ester, and Can Wang. Anrl: attributed network representation learning via deep neural networks. In Ijcai, volume 18, pages 3155–3161, 2018. [CrossRef]
- Hitoshi Iuchi, Taro Matsutani, Keisuke Yamada, Natsuki Iwano, Shunsuke Sumi, Shion Hosoda, Shitao Zhao, Tsukasa Fukunaga, and Michiaki Hamada. Representation learning applications in biological sequence analysis. Computational and Structural Biotechnology Journal, 19:3198–3208, 2021. [CrossRef]
- Hai-Cheng Yi, Zhu-Hong You, De-Shuang Huang, and Chee Keong Kwoh. Graph representation learning in bioinformatics: trends, methods and applications. Briefings in Bioinformatics, 23(1):bbab340, 2022. [CrossRef]
- Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
- Chenyi Zhuang and Qiang Ma. Dual graph convolutional networks for graph-based semi-supervised classification. In Proceedings of the 2018 world wide web conference, pages 499–508, 2018. [CrossRef]
- Ruoyu Li, Sheng Wang, Feiyun Zhu, and Junzhou Huang. Adaptive graph convolutional neural networks. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
- Hongyang Gao, Zhengyang Wang, and Shuiwang Ji. Large-scale learnable graph convolutional networks. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1416–1424, 2018.
- Jie Chen, Tengfei Ma, and Cao Xiao. Fastgcn: fast learning with graph convolutional networks via importance sampling. arXiv preprint arXiv:1801.10247, 2018.
- Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. Advances in neural information processing systems, 30, 2017.
- Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? arXiv preprint arXiv:1810.00826, 2018.
- Johannes Gasteiger, Aleksandar Bojchevski, and Stephan Günnemann. Predict then propagate: Graph neural networks meet personalized pagerank. arXiv preprint arXiv:1810.05997, 2018.
- Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, Yoshua Bengio, et al. Graph attention networks. stat, 1050(20):10–48550, 2017.
- Kiran K Thekumparampil, Chong Wang, Sewoong Oh, and Li-Jia Li. Attention-based graph neural network for semi-supervised learning. arXiv preprint arXiv:1803.03735, 2018.
- Aravind Sankar, Yanhong Wu, Liang Gou, Wei Zhang, and Hao Yang. Dynamic graph representation learning via self-attention networks. arXiv preprint arXiv:1812.09430, 2018.
- Jiani Zhang, Xingjian Shi, Junyuan Xie, Hao Ma, Irwin King, and Dit-Yan Yeung. Gaan: Gated attention networks for learning on large and spatiotemporal graphs. arXiv preprint arXiv:1803.07294, 2018.
- Xiao Wang, Houye Ji, Chuan Shi, Bai Wang, Yanfang Ye, Peng Cui, and Philip S Yu. Heterogeneous graph attention network. In The world wide web conference, pages 2022–2032, 2019. [CrossRef]
- Guangtao Wang, Rex Ying, Jing Huang, and Jure Leskovec. Multi-hop attention graph neural network. arXiv preprint arXiv:2009.14332, 2020. [CrossRef]
- Haiyun Xu, Shaojie Zhang, Bo Jiang, and Jin Tang. Graph context-attention network via low and high order aggregation. Neurocomputing, 2023. [CrossRef]
- Thomas N Kipf and Max Welling. Variational graph auto-encoders. arXiv preprint arXiv:1611.07308, 2016.
- Martin Simonovsky and Nikos Komodakis. Graphvae: Towards generation of small graphs using variational autoencoders. In Artificial Neural Networks and Machine Learning–ICANN 2018: 27th International Conference on Artificial Neural Networks, Rhodes, Greece, October 4-7, 2018, Proceedings, Part I 27, pages 412–422. Springer, 2018.
- Aditya Grover, Aaron Zweig, and Stefano Ermon. Graphite: Iterative generative modeling of graphs. In International conference on machine learning, pages 2434–2444. PMLR, 2019.
- Aleksandar Bojchevski and Stephan Günnemann. Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking. arXiv preprint arXiv:1707.03815, 2017.
- Dingyuan Zhu, Peng Cui, Daixin Wang, and Wenwu Zhu. Deep variational network embedding in wasserstein space. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2827–2836, 2018.
- Petar Velickovic, William Fedus, William L Hamilton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm. Deep graph infomax. ICLR (Poster), 2(3):4, 2019.
- Fan-Yun Sun, Jordan Hoffmann, Vikas Verma, and Jian Tang. Infograph: Unsupervised and semi-supervised graph-level representation learning via mutual information maximization. arXiv preprint arXiv:1908.01000, 2019.
- Jintang Li, Ruofan Wu, Wangbin Sun, Liang Chen, Sheng Tian, Liang Zhu, Changhua Meng, Zibin Zheng, and Weiqiang Wang. Maskgae: masked graph modeling meets graph autoencoders. arXiv preprint arXiv:2205.10053, 2022.
- Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. Communications of the ACM, 63(11):139–144, 2020.
- Hongwei Wang, Jia Wang, Jialin Wang, Miao Zhao, Weinan Zhang, Fuzheng Zhang, Xing Xie, and Minyi Guo. Graphgan: Graph representation learning with generative adversarial nets. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018. [CrossRef]
- Shirui Pan, Ruiqi Hu, Sai-fu Fung, Guodong Long, Jing Jiang, and Chengqi Zhang. Learning graph embedding with adversarial training methods. IEEE transactions on cybernetics, 50(6):2475–2487, 2019. [CrossRef]
- Quanyu Dai, Qiang Li, Jian Tang, and Dan Wang. Adversarial network embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- Wenchao Yu, Cheng Zheng, Wei Cheng, Charu C Aggarwal, Dongjin Song, Bo Zong, Haifeng Chen, and Wei Wang. Learning deep network representations with adversarially regularized autoencoders. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2663–2671, 2018.
- Aleksandar Bojchevski, Oleksandr Shchur, Daniel Zügner, and Stephan Günnemann. Netgan: Generating graphs via random walks. In International conference on machine learning, pages 610–619. PMLR, 2018.
- Nicola De Cao and Thomas Kipf. Molgan: An implicit generative model for small molecular graphs. arXiv preprint arXiv:1805.11973, 2018.
- Zhitao Ying, Jiaxuan You, Christopher Morris, Xiang Ren, Will Hamilton, and Jure Leskovec. Hierarchical graph representation learning with differentiable pooling. Advances in neural information processing systems, 31, 2018.
- Muhan Zhang, Zhicheng Cui, Marion Neumann, and Yixin Chen. An end-to-end deep learning architecture for graph classification. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018. [CrossRef]
- Junhyun Lee, Inyeop Lee, and Jaewoo Kang. Self-attention graph pooling. In International conference on machine learning, pages 3734–3743. PMLR, 2019.
- Frederik Diehl, Thomas Brunner, Michael Truong Le, and Alois Knoll. Towards graph pooling by edge contraction. In ICML 2019 workshop on learning and reasoning with graph-structured data, 2019.
- Gabriele Corso, Zhitao Ying, Michal Pándy, Petar Veličković, Jure Leskovec, and Pietro Liò. Neural distance embeddings for biological sequences. Advances in Neural Information Processing Systems, 34:18539–18551, 2021.
- Jun Xia, Lirong Wu, Jintao Chen, Bozhen Hu, and Stan Z Li. Simgrace: A simple framework for graph contrastive learning without data augmentation. In Proceedings of the ACM Web Conference 2022, pages 1070–1079, 2022. [CrossRef]
- Chang Tang, Xiao Zheng, Wei Zhang, Xinwang Liu, Xinzhong Zhu, and En Zhu. Unsupervised feature selection via multiple graph fusion and feature weight learning. Science China Information Sciences, 66(5):1–17, 2023. [CrossRef]
- Jiaqi Sun, Lin Zhang, Guangyi Chen, Kun Zhang, Peng XU, and Yujiu Yang. Feature expansion for graph neural networks. arXiv preprint arXiv:2305.06142, 2023.
- Anh-Tien Ton, Francesco Gentile, Michael Hsing, Fuqiang Ban, and Artem Cherkasov. Rapid identification of potential inhibitors of sars-cov-2 main protease by deep docking of 1.3 billion compounds. Molecular informatics, 39(8):2000028, 2020.
- Konda Mani Saravanan, Haiping Zhang, Md Tofazzal Hossain, Md Selim Reza, and Yanjie Wei. Deep learning-based drug screening for covid-19 and case studies. In Silico Modeling of Drugs Against Coronaviruses: Computational Tools and Protocols, pages 631–660, 2021.
- Deshan Zhou, Shaoliang Peng, Dong-Qing Wei, Wu Zhong, Yutao Dou, and Xiaolan Xie. Lunar: drug screening for novel coronavirus based on representation learning graph convolutional network. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 18(4):1290–1298, 2021. [CrossRef]
- Zhengyang Wang, Meng Liu, Youzhi Luo, Zhao Xu, Yaochen Xie, Limei Wang, Lei Cai, Qi Qi, Zhuoning Yuan, Tianbao Yang, et al. Advanced graph and sequence neural networks for molecular property prediction and drug discovery. Bioinformatics, 38(9):2579–2586, 2022. [CrossRef]
- Xiao-Shuang Li, Xiang Liu, Le Lu, Xian-Sheng Hua, Ying Chi, and Kelin Xia. Multiphysical graph neural network (mp-gnn) for covid-19 drug design. Briefings in Bioinformatics, 23(4), 2022. [CrossRef]
- Jiangsheng Pi, Peishun Jiao, Yang Zhang, and Junyi Li. Mdgnn: Microbial drug prediction based on heterogeneous multi-attention graph neural network. Frontiers in Microbiology, 13, 2022. [CrossRef]
- Yiyue Ge, Tingzhong Tian, Suling Huang, Fangping Wan, Jingxin Li, Shuya Li, Hui Yang, Lixiang Hong, Nian Wu, Enming Yuan, et al. A data-driven drug repositioning framework discovered a potential therapeutic agent targeting covid-19. BioRxiv, pages 2020–03, 2020.
- Raghvendra Mall, Abdurrahman Elbasir, Hossam Al Meer, Sanjay Chawla, and Ehsan Ullah. Data-driven drug repurposing for covid-19. 2020.
- Seyed Aghil Hooshmand, Mohadeseh Zarei Ghobadi, Seyyed Emad Hooshmand, Sadegh Azimzadeh Jamalkandi, Seyed Mehdi Alavi, and Ali Masoudi-Nejad. A multimodal deep learning-based drug repurposing approach for treatment of covid-19. Molecular diversity, 25:1717–1730, 2021. [CrossRef]
- Rosa Aghdam, Mahnaz Habibi, and Golnaz Taheri. Using informative features in machine learning based method for covid-19 drug repurposing. Journal of cheminformatics, 13:1–14, 2021. [CrossRef]
- Kanglin Hsieh, Yinyin Wang, Luyao Chen, Zhongming Zhao, Sean Savitz, Xiaoqian Jiang, Jing Tang, and Yejin Kim. Drug repurposing for covid-19 using graph neural network with genetic, mechanistic, and epidemiological validation. Research Square, 2020.
- Thai-Hoang Pham, Yue Qiu, Jucheng Zeng, Lei Xie, and Ping Zhang. A deep learning framework for high-throughput mechanism-driven phenotype compound screening and its application to covid-19 drug repurposing. Nature machine intelligence, 3(3):247–257, 2021. [CrossRef]
- Kanglin Hsieh, Yinyin Wang, Luyao Chen, Zhongming Zhao, Sean Savitz, Xiaoqian Jiang, Jing Tang, and Yejin Kim. Drug repurposing for covid-19 using graph neural network and harmonizing multiple evidence. Scientific reports, 11(1):23179, 2021. [CrossRef]
- Siddhant Doshi and Sundeep Prabhakar Chepuri. A computational approach to drug repurposing using graph neural networks. Computers in Biology and Medicine, 150:105992, 2022. [CrossRef]
- Bo Ram Beck, Bonggun Shin, Yoonjung Choi, Sungsoo Park, and Keunsoo Kang. Predicting commercially available antiviral drugs that may act on the novel coronavirus (sars-cov-2) through a drug-target interaction deep learning model. Computational and structural biotechnology journal, 18:784–790, 2020.
- Sovan Saha, Piyali Chatterjee, Anup Kumar Halder, Mita Nasipuri, Subhadip Basu, and Dariusz Plewczynski. Ml-dtd: Machine learning-based drug target discovery for the potential treatment of covid-19. Vaccines, 10(10):1643, 2022. [CrossRef]
- Xianfang Wang, Qimeng Li, Yifeng Liu, Zhiyong Du, and Ruixia Jin. Drug repositioning of covid-19 based on mixed graph network and ion channel. Mathematical Biosciences and Engineering, 19(4):3269–3284, 2022. [CrossRef]
- Peiliang Zhang, Ziqi Wei, Chao Che, and Bo Jin. Deepmgt-dti: Transformer network incorporating multilayer graph information for drug–target interaction prediction. Computers in biology and medicine, 142:105214, 2022.
- Guodong Li, Weicheng Sun, Jinsheng Xu, Lun Hu, Weihan Zhang, and Ping Zhang. Ga-ens: A novel drug–target interactions prediction method by incorporating prior knowledge graph into dual wasserstein generative adversarial network with gradient penalty. Applied Soft Computing, 139:110151, 2023. [CrossRef]
- Zhenchao Tang, Guanxing Chen, Hualin Yang, Weihe Zhong, and Calvin Yu-Chian Chen. Dsil-ddi: A domain-invariant substructure interaction learning for generalizable drug–drug interaction prediction. IEEE Transactions on Neural Networks and Learning Systems, 2023. [CrossRef]
- Sarina Sefidgarhoseini, Leila Safari, and Zanyar Mohammady. Drug-drug interaction extraction using transformer-based ensemble model. 2023.
- Zhong-Hao Ren, Zhu-Hong You, Chang-Qing Yu, Li-Ping Li, Yong-Jian Guan, Lu-Xiang Guo, and Jie Pan. A biomedical knowledge graph-based method for drug–drug interactions prediction through combining local and global features with deep neural networks. Briefings in Bioinformatics, 23(5), 2022. [CrossRef]
- Yujie Chen, Tengfei Ma, Xixi Yang, Jianmin Wang, Bosheng Song, and Xiangxiang Zeng. Muffin: multi-scale feature fusion for drug–drug interaction prediction. Bioinformatics, 37(17):2651–2658, 2021. [CrossRef]
- Deng Pan, Lijun Quan, Zhi Jin, Taoning Chen, Xuejiao Wang, Jingxin Xie, Tingfang Wu, and Qiang Lyu. Multisource attention-mechanism-based encoder–decoder model for predicting drug–drug interaction events. Journal of Chemical Information and Modeling, 62(23):6258–6270, 2022. [CrossRef]
- Zimeng Li, Shichao Zhu, Bin Shao, Tie-Yan Liu, Xiangxiang Zeng, and Tong Wang. Multi-view substructure learning for drug-drug interaction prediction. arXiv preprint arXiv:2203.14513, 2022.
- Mei Ma and Xiujuan Lei. A dual graph neural network for drug–drug interactions prediction based on molecular structure and interactions. PLOS Computational Biology, 19(1):e1010812, 2023. [CrossRef]
- Lopamudra Dey, Sanjay Chakraborty, and Anirban Mukhopadhyay. Machine learning techniques for sequence-based prediction of viral–host interactions between sars-cov-2 and human proteins. Biomedical journal, 43(5):438–450, 2020.
- Hangyu Du, Feng Chen, Hongfu Liu, and Pengyu Hong. Network-based virus-host interaction prediction with application to sars-cov-2. Patterns, 2(5):100242, 2021.
- Hongpeng Yang, Yijie Ding, Jijun Tang, and Fei Guo. Inferring human microbe–drug associations via multiple kernel fusion on graph neural network. Knowledge-Based Systems, 238:107888, 2022. [CrossRef]
- Bihter Das, Mucahit Kutsal, and Resul Das. A geometric deep learning model for display and prediction of potential drug-virus interactions against sars-cov-2. Chemometrics and Intelligent Laboratory Systems, 229:104640, 2022.
- Farah Shahid, Aneela Zameer, and Muhammad Muneeb. Predictions for covid-19 with deep learning models of lstm, gru and bi-lstm. Chaos, Solitons & Fractals, 140:110212, 2020. [CrossRef]
- Hossein Abbasimehr and Reza Paki. Prediction of covid-19 confirmed cases combining deep learning methods and bayesian optimization. Chaos, Solitons & Fractals, 142:110511, 2021. [CrossRef]
- Trisha Sinha, Titash Chowdhury, Rabindra Nath Shaw, and Ankush Ghosh. Analysis and prediction of covid-19 confirmed cases using deep learning models: a comparative study. In Advanced Computing and Intelligent Technologies: Proceedings of ICACIT 2021, pages 207–218. Springer, 2022. [CrossRef]
- Junyi Gao, Rakshith Sharma, Cheng Qian, Lucas M Glass, Jeffrey Spaeder, Justin Romberg, Jimeng Sun, and Cao Xiao. Stan: spatio-temporal attention network for pandemic prediction using real-world evidence. Journal of the American Medical Informatics Association, 28(4):733–743, 2021. [CrossRef]
- Myrsini Ntemi, Ioannis Sarridis, and Constantine Kotropoulos. An autoregressive graph convolutional long short-term memory hybrid neural network for accurate prediction of covid-19 cases. IEEE Transactions on Computational Social Systems, 2022. [CrossRef]
- Dong Li, Xiaofei Ren, and Yunze Su. Predicting covid-19 using lioness optimization algorithm and graph convolution network. Soft Computing, pages 1–65, 2023. [CrossRef]
- Konstantinos Skianis, Giannis Nikolentzos, Benoit Gallix, Rodolphe Thiebaut, and Georgios Exarchakis. Predicting covid-19 positivity and hospitalization with multi-scale graph neural networks. Scientific Reports, 13(1):5235, 2023. [CrossRef]
- Zohair Malki, El-Sayed Atlam, Ashraf Ewis, Guesh Dagnew, Osama A Ghoneim, Abdallah A Mohamed, Mohamed M Abdel-Daim, and Ibrahim Gad. The covid-19 pandemic: prediction study based on machine learning models. Environmental science and pollution research, 28:40496–40506, 2021. [CrossRef]
- Dixizi Liu, Weiping Ding, Zhijie Sasha Dong, and Witold Pedrycz. Optimizing deep neural networks to predict the effect of social distancing on covid-19 spread. Computers & Industrial Engineering, 166:107970, 2022. [CrossRef]
- Devante Ayris, Maleeha Imtiaz, Kye Horbury, Blake Williams, Mitchell Blackney, Celine Shi Hui See, and Syed Afaq Ali Shah. Novel deep learning approach to model and predict the spread of covid-19. Intelligent Systems with Applications, 14:200068, 2022. [CrossRef]
- Valerio La Gatta, Vincenzo Moscato, Marco Postiglione, and Giancarlo Sperli. An epidemiological neural network exploiting dynamic graph structured data applied to the covid-19 outbreak. IEEE Transactions on Big Data, 7(1):45–55, 2020. [CrossRef]
- Truong Son Hy, Viet Bach Nguyen, Long Tran-Thanh, and Risi Kondor. Temporal multiresolution graph neural networks for epidemic prediction. In Workshop on Healthcare AI and COVID-19, pages 21–32. PMLR, 2022.
- Ru Geng, Yixian Gao, Hongkun Zhang, and Jian Zu. Analysis of the spatio-temporal dynamics of covid-19 in massachusetts via spectral graph wavelet theory. IEEE Transactions on Signal and Information Processing over Networks, 8:670–683, 2022. [CrossRef]
- Baoling Shan, Xin Yuan, Wei Ni, Xin Wang, and Ren Ping Liu. Novel graph topology learning for spatio-temporal analysis of covid-19 spread. IEEE Journal of Biomedical and Health Informatics, 2023. [CrossRef]
- Jose Luis Izquierdo, Julio Ancochea, Savana COVID-19 Research Group, and Joan B Soriano. Clinical characteristics and prognostic factors for intensive care unit admission of patients with covid-19: retrospective study using machine learning and natural language processing. Journal of medical Internet research, 22(10):e21801, 2020. [CrossRef]
- Isotta Landi, Benjamin S Glicksberg, Hao-Chih Lee, Sarah Cherng, Giulia Landi, Matteo Danieletto, Joel T Dudley, Cesare Furlanello, and Riccardo Miotto. Deep representation learning of electronic health records to unlock patient stratification at scale. NPJ digital medicine, 3(1):96, 2020. [CrossRef]
- Tyler Wagner, FNU Shweta, Karthik Murugadoss, Samir Awasthi, AJ Venkatakrishnan, Sairam Bade, Arjun Puranik, Martin Kang, Brian W Pickering, John C O’Horo, et al. Augmented curation of clinical notes from a massive ehr system reveals symptoms of impending covid-19 diagnosis. Elife, 9:e58227, 2020.
- Tingyi Wanyan, Hossein Honarvar, Suraj K Jaladanki, Chengxi Zang, Nidhi Naik, Sulaiman Somani, Jessica K De Freitas, Ishan Paranjpe, Akhil Vaid, Jing Zhang, et al. Contrastive learning improves critical event prediction in covid-19 patients. Patterns, 2(12):100389, 2021. [CrossRef]
- Tingyi Wanyan, Mingquan Lin, Eyal Klang, Kartikeya M Menon, Faris F Gulamali, Ariful Azad, Yiye Zhang, Ying Ding, Zhangyang Wang, Fei Wang, et al. Supervised pretraining through contrastive categorical positive samplings to improve covid-19 mortality prediction. In Proceedings of the 13th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, pages 1–9, 2022. [CrossRef]
- Liantao Ma, Xinyu Ma, Junyi Gao, Xianfeng Jiao, Zhihao Yu, Chaohe Zhang, Wenjie Ruan, Yasha Wang, Wen Tang, and Jiangtao Wang. Distilling knowledge from publicly available online emr data to emerging epidemic for prognosis. In Proceedings of the Web Conference 2021, pages 3558–3568, 2021. [CrossRef]
- Tingyi Wanyan, Akhil Vaid, Jessica K De Freitas, Sulaiman Somani, Riccardo Miotto, Girish N Nadkarni, Ariful Azad, Ying Ding, and Benjamin S Glicksberg. Relational learning improves prediction of mortality in covid-19 in the intensive care unit. IEEE transactions on big data, 7(1):38–44, 2020. [CrossRef]
- Doudou Zhou, Ziming Gan, Xu Shi, Alina Patwari, Everett Rush, Clara-Lea Bonzel, Vidul A Panickan, Chuan Hong, Yuk-Lam Ho, Tianrun Cai, et al. Multiview incomplete knowledge graph integration with application to cross-institutional ehr data harmonization. Journal of Biomedical Informatics, 133:104147, 2022. [CrossRef]
- Junyi Gao, Chaoqi Yang, Joerg Heintz, Scott Barrows, Elise Albers, Mary Stapel, Sara Warfield, Adam Cross, Jimeng Sun, et al. Medml: Fusing medical knowledge and machine learning models for early pediatric covid-19 hospitalization and severity prediction. Iscience, 25(9):104970, 2022. [CrossRef]
- Kaize Ding, Zhe Xu, Hanghang Tong, and Huan Liu. Data augmentation for deep graph learning: A survey. ACM SIGKDD Explorations Newsletter, 24(2):61–77, 2022. [CrossRef]
- Travers Ching, Daniel S Himmelstein, Brett K Beaulieu-Jones, Alexandr A Kalinin, Brian T Do, Gregory P Way, Enrico Ferrero, Paul-Michael Agapow, Michael Zietz, Michael M Hoffman, et al. Opportunities and obstacles for deep learning in biology and medicine. Journal of The Royal Society Interface, 15(141):20170387, 2018.
- Riccardo Miotto, Fei Wang, Shuang Wang, Xiaoqian Jiang, and Joel T Dudley. Deep learning for healthcare: review, opportunities and challenges. Briefings in bioinformatics, 19(6):1236–1246, 2018. [CrossRef]
- Guido Zampieri, Supreeta Vijayakumar, Elisabeth Yaneske, and Claudio Angione. Machine and deep learning meet genome-scale metabolic modeling. PLoS computational biology, 15(7):e1007084, 2019. [CrossRef]
Figure 3.
Comprehensive summary of the classification and representation methods of representation learning.
Figure 3.
Comprehensive summary of the classification and representation methods of representation learning.
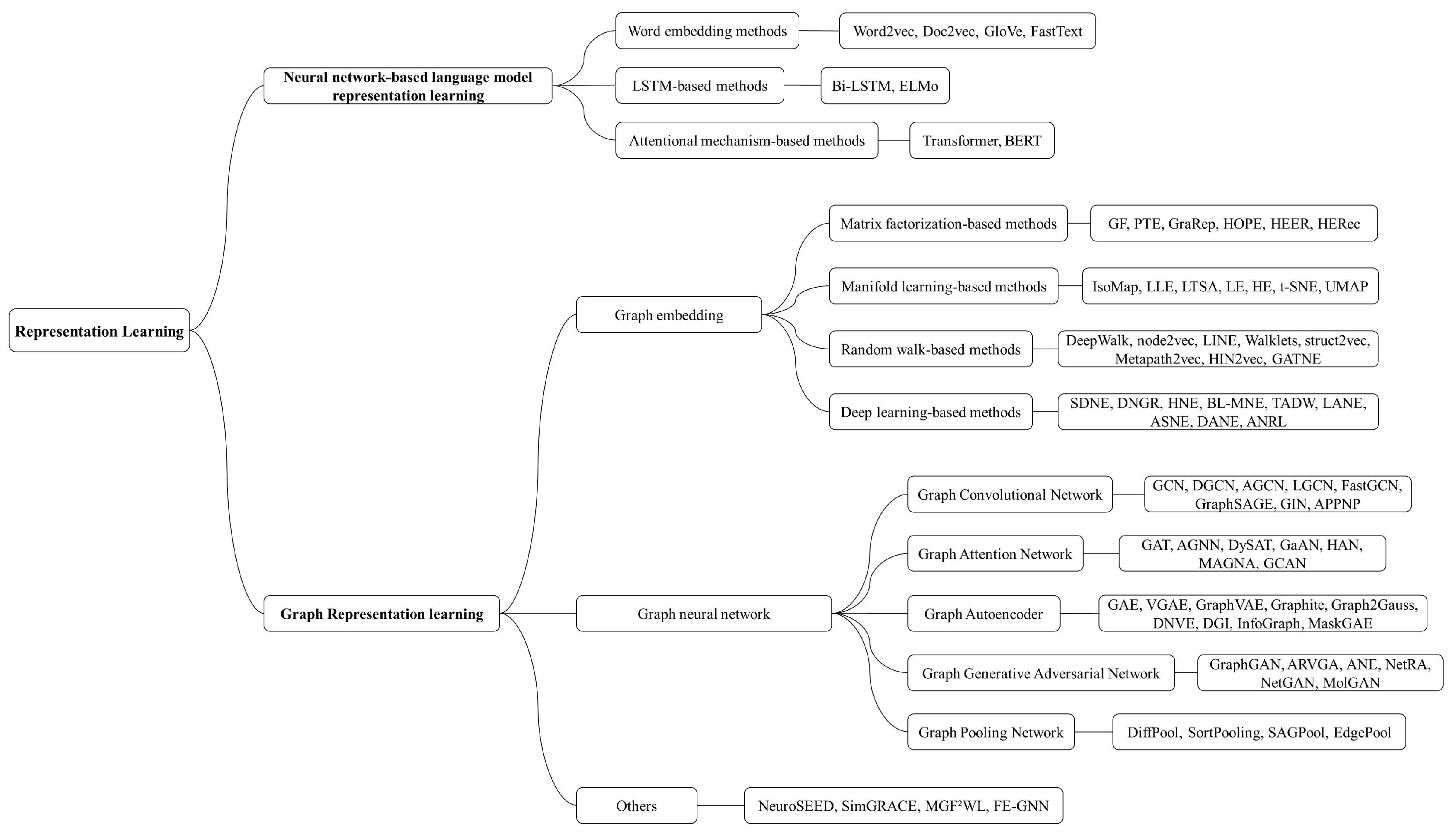
Figure 4.
An overview of graphs used in COVID-19 applications. From pharmaceuticals to healthcare, graphs exist in all aspects and influence each other. Drug discovery, repurposing, targets, microbes, and their interactions constitute the pharmaceutical graph. Propagation, cases, electronic health records, and electronic medical records constitute the healthcare knowledge graph. Pharmaceuticals can get feedback on the effectiveness of drugs through clinical trials, and healthcare can guide drug development by analyzing the obtained virus RNA or drug molecular structure. These multi-modal graphs are interconnected and need to be understood as a whole.
Figure 4.
An overview of graphs used in COVID-19 applications. From pharmaceuticals to healthcare, graphs exist in all aspects and influence each other. Drug discovery, repurposing, targets, microbes, and their interactions constitute the pharmaceutical graph. Propagation, cases, electronic health records, and electronic medical records constitute the healthcare knowledge graph. Pharmaceuticals can get feedback on the effectiveness of drugs through clinical trials, and healthcare can guide drug development by analyzing the obtained virus RNA or drug molecular structure. These multi-modal graphs are interconnected and need to be understood as a whole.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



