
Submitted:
11 August 2023
Posted:
15 August 2023
You are already at the latest version
Abstract
Parametric form findings of free-form space structures and qualitative assessment of their aesthetics are among the concerns of architects. This study aims to evaluate the aesthetic aspect of these structures using ML algorithms based on the expert's experiences. First, various datasets of forms were produced using a parametric algorithm of free-form space structures written in Grasshopper. Then, three multilayer perceptron ANN models were adjusted in their most optimal modes using the results of the preference test based on the aesthetic criteria including simplicity, complexity, and practicality. The results indicate that the ANN models can quantitatively evaluate the aesthetic value of free-form space structures.
Keywords:
Free-form Space Structure
; Parametric Modelling
; Artificial Neural Network
; Aesthetics
1. Introduction
Free-form space structures, a new generation of space-frame structures, are surfaces with double curvature that have no dependence on conventional geometric forms and therefore have a high visual appeal. These structures usually cover large-scale areas without intermediate columns like museums, amphitheaters, mosques, and stadiums. In the last decades, free-form space structures, due to high flexibility, great variety, and beauty have been considered by architects and structural engineers. Since the function, structure, and form strongly influence each other, both structural engineers and architects must have some degree of communication with each other. Architects can take advantage of the form of these structures for both structural and architectural purposes, especially aesthetic criteria. Aesthetic is a qualitative criterion and various methods have been used to evaluate such qualitative criteria in architecture. Nowadays, artificial intelligence and machine learning techniques are used in the field of qualitative design. The core capability of machine learning is to discover and reconstruct complex relationships between input and output data from a relatively large data set [1]. Therefore, it can be very useful in both form-finding of spatial structures and evaluating their aesthetic criteria.
Mirra and Pugnale [2] investigated design spaces created by artificial intelligence and compared their outputs with human-designed spaces. A dataset of 800 maps obtained from 3D models of shell structures was used to train the system. The comparison shows that optimization based on design spaces created by artificial intelligence leads to a greater variety of design outputs than solutions provided by optimization based on human-designed spaces. Furthermore, AI solutions include structural configurations that would not be possible to find in a human-designed space. This indicates one of the main advantages of using artificial intelligence in structural design: the possibility of providing design options beyond those created by human intelligence [3]. Zheng et al. [4] produced a shell structure using graphic statics and then by dividing the force graph and its polyhedral cells using different rules achieved various new structures with different load-bearing capacities and the same boundary conditions. By training an artificial neural network, the model can predict the relationship between input data (subdivision rules) and structural performance and construction constraints. This alternative use of machine learning models to enable rapid exploration of design spaces is one of the important efforts to improve human-machine collaboration. Fuhrimann et al. [5] combined form-finding with machine learning techniques using combinatorial equilibrium modeling (CEM) and self-organizing maps (SOM). The objective of these studies is to locate a diverse and intricate range of solutions that can be handled more easily by designers. These investigations have emphasized the essential ability of machine learning to detect intricate connections between input and output data and identify correlations between the structure’s form and its performance. Once these correlations are established, structural optimization becomes simpler. [1]. In recent years, machine learning techniques in structural optimization have also increased due to overcoming long-term and complex computations. Aksöz and Preisinger [6] describe a method to optimize free-form spatial structures using machine learning. They designed arbitrary space frame structures and trained the artificial neural network to implement the optimal geometry for each structural node parallel to a given load. Koronaki et al. [7] used machine learning algorithms to determine the requirements of the fabrication process of space-frame structures and then optimize the structure geometrically. Es-Haghi et al. proposed a machine-learning algorithm for the optimization of large-scale space frames in real size with high speed and accuracy.
Machine learning algorithms can assist with the structural design process in more ways than just complex calculations. They can also be used to quantify subjective criteria, such as aesthetics, that are difficult to measure using traditional methods. Belém et al. [8] After discussing the important techniques and areas of machine learning that have been used successfully, finally concluded that aesthetic evaluation is culturally based on culture and changes over time, so it is difficult to achieve with current machine learning techniques. Zheng [9] proposed a method to evaluate polyhedral structures using machine learning and find the highest-scoring forms based on the results of architects’ preference tests. He produced polyhedral structures using the 3DGS method and then asked the architects to select their favorite form from the set of forms several times. After training the machine through the test result, the neural network evaluates the new input form and estimates how much the designers are interested in that form. Petrov et al. [10] employed machine learning methods to investigate how the geometric dimensions of free-form surfaces relate to their aesthetic properties. In addition to structures, researches have also been conducted in the field of using machine learning to evaluate the qualitative characteristics of various architectural designs. McCormack and Lomas [11] used Convolutional Neural Networks trained on an individual artist’s previous aesthetic evaluations to assist them in finding more appropriate phenotypes. Li and Chen [12] propose a feature extraction framework for evaluating the visual aesthetic quality of digital images of paintings. They trained the computer to make an identical decision on the visual aesthetic quality of a painting as that created by the bulk of people. Ciesielski et al. [13] found images with high aesthetic value using feature extraction methods from machine learning based on two image databases rated by humans. A number of research studies, referenced as [14,15,16,17,18,19], have been carried out concerning machine learning in relation to free-form surface structures. Some of these articles have emphasized aesthetics as their main area of interest. Although these studies are related to using machine learning for aesthetic evaluation and structural engineering exist due to the potential of integrating machine learning techniques in different fields of research and its importance, there has been no research on the commonality of these three issues. Therefore, the motivation for conducting this research is to develop a methodology for evaluating free-form space frame structures based on the subjective preferences of architectural experts. Free-form space frames are complex structures that require a balance between form and function, making it challenging to find an optimal design. The subjective nature of aesthetic preferences further complicates this process, as architects and designers must balance their personal preferences with functional requirements. The rationale for this research is to provide a data-driven approach to design free-form space frame structures that meet both functional requirements and aesthetic preferences. By collecting data on the subjective preferences of architectural experts, the study aims to develop a methodology for evaluating these structures and streamlining the form selection process. The use of machine learning techniques can further improve the efficiency of this process by predicting the scores that an expert would assign to a given form. Artificial Neural Networks (ANN) is one of the most well-known techniques of machine learning for different evaluations and it has been successfully employed in several pieces of research related to aesthetic evaluation based on human experiences [9,11]. But none of them provide sufficient information about the configuration and parameters of the ANN. Therefore, this study will present the procedure to set up an artificial neural network model and its parameters. This study, to the best of the authors’ knowledge, is the first to offer a comprehensive analysis of selecting ANN parameters for the purposes of form finding and evaluating free-form space structures. The study provides guidance on how to set these parameters.
This paper is prepared as takes after: section two presents the form-finding process of free-form space structures; in the following, the design of the questionnaire related to the preference test based on aesthetic criteria has been discussed; this section also details the sample and data collection; the third section introduces the ANN; in the fourth section, the detailed process of designing and configuring an ANN model is presented; Section five includes the discussion about testing the ANN; Section six contains the conclusion, the limitations of the study, and an exploration of possible subjects for future research.
2. Research Methodology
The research will utilize a survey methodology to investigate the aesthetic assessment of free-form space structures using machine learning based on experts’ experiences. The study will employ an exploratory approach to identify the parameters required for the machine learning algorithm to evaluate the aesthetic appeal of free-form space structures. Data will be collected through an online survey. The study will use a purposive sampling technique to recruit participants. The participants will be selected based on their expertise in architecture, structural engineering, and aesthetic evaluation. The information obtained from the questionnaire will be used as input data to train the artificial neural network. The artificial neural network will be trained in a step-by-step manner, and finally, it will be tested with the test data. Scheme 1 demonstrates the steps of the proposed method.
2.1. Form Finding of Free-form Space Structures
Space structures are a very important category of structural systems that have been technically developed in recent decades. One of the important features of spatial structures is their geometry. Typically, structures are designed with regular geometry, which offers advantages such as modularity, lower costs, and shorter construction periods. However, regular forms are not always intended. In the modern era, curved forms are more desirable. Therefore, as the order decreases, the cost and construction time increase. In such cases, the geometry of the structure usually becomes more complex, with the overall form containing smaller or free-form components [20]. These innovative forms are called "free form" and are created from the interaction of the structures’ functional requirements and the designers’ art and creativity [21]. In the definition of free forms, if there is no simple mathematical definition to draw the desired form, it is called free form. The new group of space structures possesses the following three characteristics:
- Great variety of ideals in terms of architecture.
- The novel behavioral concepts incorporated into these structures capture how uncertain forms affect the structure.
- The intricate and diverse connection geometry of these structures can create difficulties during their construction [22].
To overcome the complex and interesting geometry of free-form spatial structures, using a mathematical framework with graphic capabilities can be of great help. "Formex Algebra" [23] is a suitable mathematical framework for generating forms according to their geometric properties that are created by Professor Nooshin and Peter Disney in 1975 [24]. "Formian" software is used to design two-dimensional and three-dimensional forms based on Formex Algebra and Formian programming language [19].
The three articles published in the International Journal of Space Structures on "Formex Configuration Processing" [23,25,26] are the basic documents on Formex algebra and Formian software. These articles also provide useful information regarding methods of creating space structure configurations. Also, in his article Space Structures and Configuration Processing [27], Professor Nooshin provides useful information about space structures, their types, and their configuration in formex algebra. The main sources for the design of freeform structures are two papers on Formex Formulation of Freeform Structural Surfaces and Novational Transformations [21,28]. These studies introduce two Formex concepts of "novation" and "pellevation" that are important to produce free forms and then illustrate the design process of free forms using examples. Learning the Formian programming language is required to use Formex algebra, which can make it challenging to utilize. Nevertheless, the implementation of computer technologies in designing spatial structures enables architects and designers to use more accessible and user-friendly methods. Grasshopper is a parametric design tool and graphical algorithm editor that operates in conjunction with the Rhino 3D modeling program [29]. Due to its graphical interface, it does not need to learn more programming languages. Also, Grasshopper can interface with many other design software and plugins that have already been created [24]. For this reason, Grasshopper is a suitable environment for converting known coordinate systems from Formex algebra. The combination of Formex algebra and Grasshopper’s parametric workflow makes it possible to easily and quickly design free-form spatial structures in the most optimal state. The paper on Formex Algebra Adaptation into Parametric Design Tools and Rotational Grids describes the adaptation focusing on the applied mathematical solutions [31].
In this research, the parametric design of free-form space structures has been done using Grasshopper. Since most of the space structures can be obtained from a square-on-square grid space structure, first a two-layer square-on-square space structure with dimensions of 10×10 and 220 nodes was produced as the basic form. A parametric code was written that can assign a curve to each side of the upper and lower square perimeter to generate a new desired form (Figure 1).
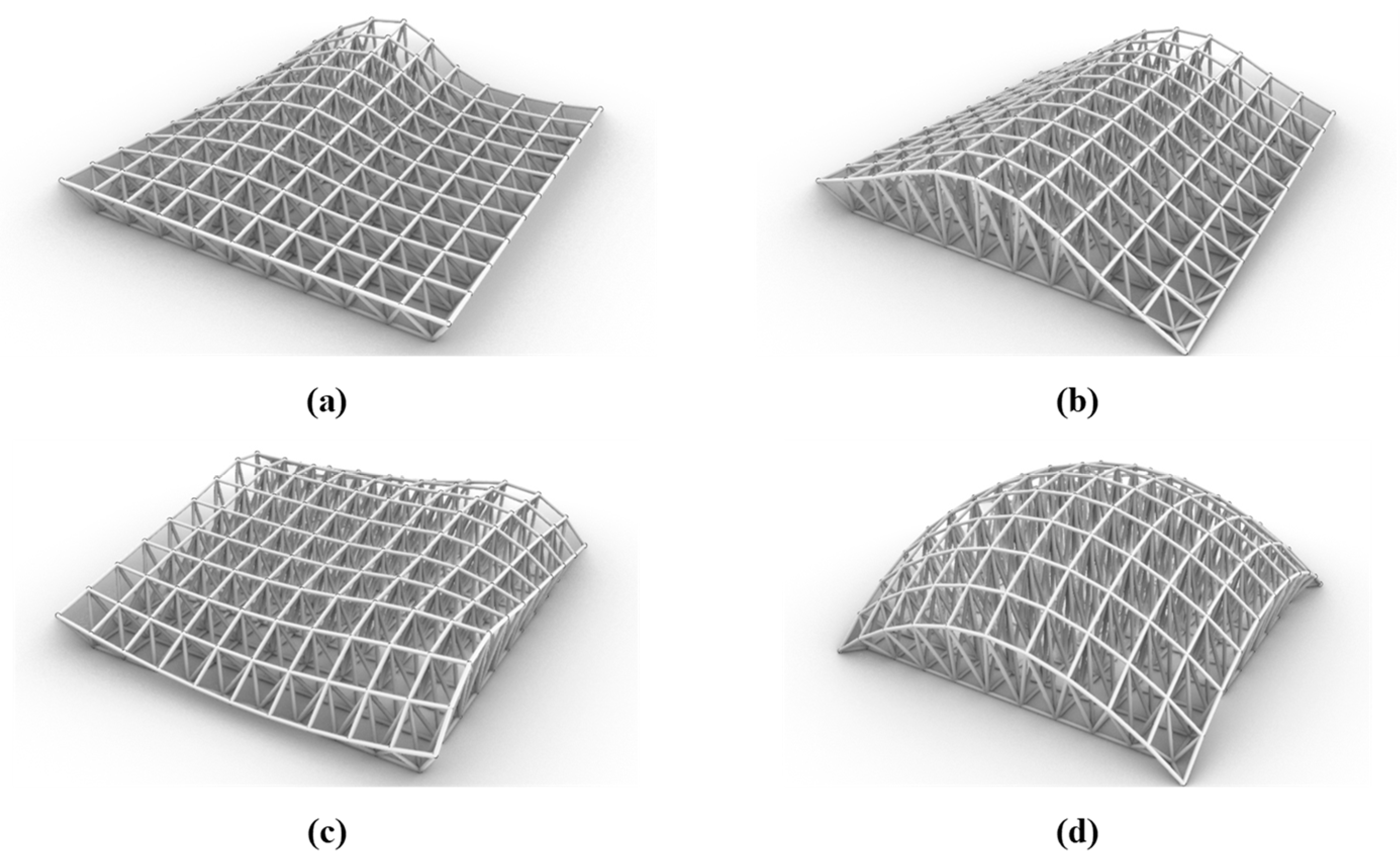
The next forms produced based on the basic form are created in two different general states: in the first state, only the square sides of the upper layer can be changed and the lower layer is fixed (Figure 2). In the second case, both layers change simultaneously and parallel to each other (Figure 3). These two categories are also divided into four categories: forms with one curved side, two curved sides, three curved sides, and finally four curved sides. In addition to changing forms by curves, it is possible to create various forms by removing nodes in different states or the deformation of nodes. The coding of these changes has also been done in the Launch Box plugin and applied to previously created forms (Figure 4 and Figure 5).
2.2. Visual Aesthetics and Preference Test
The term "aesthetics" has its roots in the Greek word "aesthesis," which means sensory perception [32]. As a branch of philosophy, aesthetics is concerned with the nature of beauty and its manifestation in art and the natural world. However, providing a precise and comprehensive definition of aesthetics is challenging. Aesthetic awareness encompasses various interests, feelings, ideals, tastes, perspectives, concepts, and theories. Generally speaking, aesthetics has two components: the "emotional component" and the "intellectual component." The emotional component is highly subjective, while the intellectual component is less so. The emotional component is the indefinable aspect of our personality that enables us to perceive an object emotionally, while the intellectual component, as a rational aspect, allows us to understand things through reasoning by considering their conditions, limitations, functions, characteristics, and so on [33].
Every day we judge and make decisions about aspects of the world around us based on our internal aesthetic responses [34]. However, Beauty is a relative concept. A phenomenon may be beautiful to some people and others may not see it as beautiful. But since the human tendency is always toward beauty, architects, and designers have always been trying to present an expression of beauty by using aesthetic criteria in their designs. Order, symmetry, balance, diversity and contrast, repetition, simplicity, complexity, etc. are considered to be aesthetic criteria. Also, because the matching of form and function is always of special importance in architecture, practicality is considered one of the criteria of aesthetics. Since space frame structures are discussed in this research, the criteria of simplicity, complexity, and practicality, which are most related to structures and are easier to evaluate with common sense, were selected. These criteria are defined as below:
- Simplicity: The simplicity of the structure means paying attention to the details of the structure and ensuring the efficiency of the structure as much as possible [35].
- Complexity: A complex structure is one that comprises a significant number of components that interact in a non-simple way [36].
- Practicality: The aspects of a situation that involve the actual doing or experience of something rather than theories or ideas.
Once a range of free-form space frame structures have been produced, it is necessary to assess them based on expert opinions. Architects take into account visual effects and subjective aesthetic qualities, which are challenging to quantify using a formula. However, machine learning techniques can be utilized to teach the computer to identify connections between various data sets, including the correlation between the forms and scores that reflect the architect’s personal preferences. To train the system and evaluate a form, a survey was created, and architectural experts were asked to complete it to gather training data sets for the artificial neural network.
To prepare the questionnaire, first, a set of 130 free-form space frame structures produced in the previous section were selected for evaluation. However, it can be a challenging and time-consuming task to ask an expert to rate every single one of them. Therefore, instead of asking the respondent to rate 130 forms, the forms were divided into sixty-five categories, each category containing 6 forms (Figure 6). This method allowed participants to focus on a smaller set of forms, reducing the cognitive load of rating a large number of designs. Since three components of aesthetics were considered, this questionnaire had also three categories of questions for each component. There were sixty-five groups consisting of six forms in each category. For each category, the person is asked to choose the desired form among six forms, and for each answer, a score of 0.33 is added to that form. Since each form is shown equally three times (65×6=390; 390÷130=3), after completing the test, each form will have a score of 0, 0.33, 0.66, or 1 which indicates the person’s preference. Each form was shown an equal number of times, ensuring that the rating process was fair and balanced.
To demonstrate the feasibility of machine learning in predicting scores at the following stage, a questionnaire in the form of three sets of questions is given to each respondent. In the first part, candidates are asked to choose the simplest form from their point of view, while in the second part, they are requested to select the most intricate form instead. Then, in the third part, the choice of the most practical form is questioned. The purpose of conducting these three comparative tests is to simplify personal preferences to a degree that makes them easier to evaluate using common sense. If the machine learning algorithm accurately assigns a higher score to simple forms in the first part, complex forms in the second part, and practical forms in the third part, it proves the feasibility of the approach.
2.3. Sample and Data Collection
One hundred forty-one architects and structural engineers answered the questionnaire, and this sample size is sufficient for this research. An examination of the participants’ profiles reveals that the proportion of women in the sample (80.86%) is significantly greater than that of men (19.14%). The participants had a range of educational backgrounds in architectural and structural engineering, with varying levels of familiarity with space structures. The field of study of all participants is architectural and structural engineering in different subfields. For the level of education, respondents with a master’s degree make up 68.10% of the total sample, followed by 21.27% of the total sample with a bachelor’s degree, and the remaining 10.63% have a doctorate. About 29.78% of the participants stated that they are entirely familiar with space structures, 51.08% of the total sample have a high amount of information about space structures, and 19.14% of them have moderate information in this field.
To collect data, the participants were asked to select their preferred form in each category using the method mentioned in the previous section. The participants had a time limit of 30 minutes to complete the questionnaire. After completing the questionnaire, each participant’s scores for each form regarding the criteria of simplicity, complexity, and practicality were calculated and recorded. Finally, the scores of all participants for the 130 designed structures were collected in an Excel file. These scores will be the input data for training the artificial neural network in the next stage.
3. Artificial Neural Networks (ANNs)
Taking inspiration from biological neural networks, ANNs are a commonly used artificial intelligence tool for modeling complex interactions between inputs and outputs. When compared to traditional linear techniques such as SEM, Binary Logistics Regression, MLR, and Multiple Discriminant Analysis, ANN has stronger predictive performance. Another advantage of the ANN technique is that it does not require the fulfillment of any multivariate assumptions (such as linearity, normality, and homoscedasticity) [37,38]. ANN can learn from and generalize from their past experiences. Forecasting is one of the most common uses of ANNs. Because of this; first, they learn from examples and catch delicate functional links between data, even when the underlying connections are unclear or difficult to express. Second, neural networks can generalize; they can infer the unknown part, such as forecasts of future behavior. Third, unlike traditional statistical approaches, ANNs are universal functional algorithms with more general and adaptable forms. Lastly, they can conduct nonlinear modeling without prior knowledge of the relationships between input and output data [39,40]. Artificial neurons, or simply neurons or nodes, are the primary components of neural network processing. In a simplified mathematical model of a neuron, the impact of synapses is conveyed through connection weights, which affect the associated input signals, while the nonlinear properties exhibited by neurons are represented by a transfer function. An artificial neuron’s learning ability is obtained by altering the weights in line with the specified learning algorithm [41]. As depicted in Figure 7, a neural network’s fundamental structure is composed of three types of neuron layers: an input layer, one or more hidden layers, and an output layer.
Neural networks come in various forms and can be classified into four groups: radial basis function networks, feedforward neural networks, recurrent networks, and multi-layer perceptron networks [41,43,44,45]. In line with the objectives of this study, as in Mr. Zheng’s research [9], a feedforward backpropagation multilayer perceptron was used as a model for the basal artificial neural network. Pixel-based CNN and voxel-based three-dimensional CNN, among other neural networks, are not well-suited for learning free-form space structures. A two-dimensional representation is inadequate for these structures, and only a three-dimensional representation can effectively describe them. Each network layer is made up of nodes (neurons) that communicate with neurons in the following layers via synaptic weights that can be adjusted. The signal flow in feed-forward networks is strictly in a feed-forward manner, from input to output nodes. The data processing can span many units, but there are no feedback relationships [39]. In supervised learning networks, like MLP, knowledge is acquired by training the system with specified input and output data [46]. The estimation error, which refers to the disparity between the actual and predicted output, is fed back into the network and employed to modify synaptic weights, thereby reducing and eliminating estimation errors [39].
To use a neural network, the first step is to convert the data into a digitally understandable format for the network. In this study, the coordinates of the points of the structure can be used to build an understandable free-form space structure for the network. Considering that the dimensions of the structures are chosen as 10×10, each structure consists of 220 nodes, and this means that for each structure, 660 coordinate numbers (3×220) will be entered into each network. The target output data related to each structure in each network only contains a real number that shows the score related to the desired component (simplicity, complexity, and practicality) for a form. Therefore, the input and target output of the network for each form will be according to Relation (1) as below:
Input (I) Output(O)
I = (x1, y1, z1, x2, y2, z2, …, x220, y220, z220)
O = (o1, o2, o3)
I = (x1, y1, z1, x2, y2, z2, …, x220, y220, z220)
O = (o1, o2, o3)
In relationship (1), x1 to z220 contains the coordinates of 220 points of each form, and o1 to o3 contains 3 aesthetic criteria. In network training, instead of one 220×3 network, three 220×1 networks have been used for ease of work. In fact, there is a network for each aesthetic component.
4. ANN Parameters Selection
The ANN model is complicated, and various parameters must be established for the model to be accurate. In general, there are no specific rules for determining and adjusting the parameters of the artificial neural network model. The crucial parameters in determining the effectiveness of an artificial neural network model include determining the number of hidden layers, the number of neurons within each hidden layer, and selecting the appropriate activation functions for the hidden and output layers. One of the paper’s key goals is to outline the process of choosing neural network parameters for these types of investigations and to make suggestions based on these criteria. The selected options of these parameters as well as how to select them for all three artificial neural networks will be analyzed in detail in the continuation of the research.
4.1. The Number of Hidden Layers
The number of hidden layers required in an artificial neural network is determined by the complexity of the problem being tackled. More complicated neural networks allow for more intricate problem modeling, but they come with a higher computing cost and require more data to train and test. Artificial neural networks can be classified as either shallow, with a single hidden layer, or deep, with two or more hidden layers, based on the number of hidden layers they contain [47]. Deep neural networks are particularly effective at addressing complex challenges that involve vast amounts of unstructured and intricate data. However, according to Negnevitsky’s 2011 research, each continuous function may be modeled just by one hidden layer, and discontinuous functions can be modeled by using two hidden layers [48]. Therefore, multilayer perceptron-based neural networks with more than two hidden layers are rarely utilized for typical structured datasets. This is because more complex models necessitate more data for the purpose of training and testing, and they do not necessarily produce superior outcomes [38]. Using the TensorFlow library, three artificial neural networks were created for each component, one with one hidden layer, the other with two hidden layers, and the last network with three hidden layers, following the study’s objectives and analysis of the number of hidden layers selected. For all three models, the other parameters were adjusted to the same level. To enhance the effectiveness of the training, all input and output data were normalized within the [1, 0] range. To prevent the issue of overfitting, a training set consisting of 90% of the sampled data and a testing set made up of the remaining 10% of the sampled data were employed. The mean square error (MSE) was determined to assess the performance of network models, and it is provided in Tables 1 to 3 along with the mean training time for all models. As can be easily seen in Table 1, for the neural network related to the simplicity component, the model with two hidden layers has lower MSE values for training, validation, and testing. Based on the sample size and complexity of the research model, it can be inferred that for a trained network based on data related to the simplicity component, the inclusion of two hidden layers leads to better network performance and is thus suggested. According to Table 2, it can be concluded that the neural network related to the complexity component has a lower error rate and better performance in the case where it has two hidden layers.
According to Table 3, it can be seen that this network, like the previous two networks, in a state with two hidden layers, despite the high training time, provides the lowest error and the best performance. The weakest performance of the network is related to the case where the network has a hidden layer. When the error rate of the testing and validation sets is higher than that of the training set, it is indicative of overfitting in this scenario.
4.2. The Number of Hidden Neurons
Selecting the number of neurons in the input and output layers is a straightforward task since these values correspond to the count of the independent and dependent variables (predictors and outputs). On the other hand, determining the appropriate number of neurons in the hidden layer can be difficult as there may be multiple factors to consider, such as the neural network architecture (including the number of hidden layers), sample size, neural network training algorithms, or the selected activation function [43]. As there is no universally accepted method for determining this parameter, the typical approach to assess the network’s performance is to modify the number of hidden neurons through trial and error. The number of neurons in the hidden layer typically has a significant impact on the predictive accuracy of the neural network model, but it may also influence the training speed of the artificial neural network model: In theory, a greater number of hidden neurons should result in more accurate models, but this is only true up to a certain point, beyond which the computational load may increase dramatically [48]. Overfitting is another significant concern. If there are too many hidden neurons, the ANN model may recall all of the training examples and lose its ability to generalize and generate accurate predictions when dealing with data that was not included in the training set. In 2021, Kalinić et al. [38] introduced a formula (Relation 2) to estimate the optimal number of hidden neurons in their study, which is as follows:
The appropriate number of hidden neurons = [Half of the input data] +1
In this study, we have 660 input data for each structure in each network. Therefore, according to the aforementioned formula, 331 hidden neurons may be an appropriate number for the current neural network. But since this relationship is only for approximate prediction, in addition to using the number obtained from this relationship, the trial-and-error method has also been used with other values so that we can compare the execution related to the predicted number with the rest of the executions. The number of hidden neurons ranged from 5 to 1000, while the other parameters of the neural network remained constant. Subsequently, ten runs were conducted for each neural network, employing a training set that comprised 90% of the sampled data and a test set consisting of the remaining 10% of the sampled data. Tables 4 to 6 and Figures 8 to 10 illustrate the average MSE values for training, validation, and testing, as well as the average training time, for each network. As shown in Figure 8, the average MSE values for all three training, validation, and testing sets have a minimum value for 331 hidden neurons. Also, all three sets are very close to each other, which prevents overfitting. As a result, this value was established as the ultimate parameter. Additionally, as depicted in Figure 8, it is apparent that the training time increases with the rise in the number of hidden neurons and, consequently, the model’s complexity.
According to Table 5, unlike the simplicity network, relation 2 does not apply. This network has the lowest error in the case where the number of hidden neurons is 15. As shown in Figure 9, with the increase of the number of hidden neurons up to 15, the training time of the network is high, then at the number of 15, the learning time is at a minimum and after that, it is increasing again. Therefore, based on the low values of the average MSE for all three sets (training, validation, and testing), as well as the training time, it can be inferred that the network performs optimally when it has 15 hidden neurons.
Figure 10 shows that the average MSE values for each training and testing set reach their minimum value when the network has 15 hidden neurons. Furthermore, all three sets are in close proximity to one another, which helps prevent overfitting. As a result, this value was established as the final parameter. Additionally, as demonstrated in Figure 10, the training time increases with the number of hidden neurons and, consequently, the model’s complexity. Additionally, a sudden increase is evident in both graphs when the number of neurons increases from 331 to 500. This leap indicates that a number of neurons above 500 are disproportionate for this network.
4.3. Activation Functions
In a neural network, every neuron computes the weighted sum of input signals, which is then transformed into an output signal via the activation function. While there are numerous types of activation functions in theory, only a limited number of them have practical applications [48]. The unit-step transfer activation function is the most basic and is frequently utilized in classification and pattern recognition problems, but it is not applicable to the issues investigated in this study. The sigmoid function is one of the most prevalent activation functions in feedforward networks, but this research also tested and compared two other activation functions: the ReLu function and the hyperbolic tangent function (Table 7). Since there are three computational layers for neurons (two hidden layers and one output layer), it is necessary to define a distinct activation function for all neurons within each layer. As the ReLu and hyperbolic tangent functions can only be applied in the hidden layers, while the sigmoid function is always employed in the output layer, there are 9 combinations of training, testing, and validation sets for each network. Ten runs were once again conducted for each combination, with 90% of the sampled data used for training the neural network and the remaining 10% for testing. In the following, we will examine the average MSE values for different combinations of activation functions for all three components. For the simplicity neural network, the average MSE values for diverse combinations of activation functions in the hidden and output layers are obtained, and only the test results are presented in Table 8. The training time for each combination is also included in Table 9. The minimum mean square error value for the test set is observed when the activation function of the first layer is ReLu and the second layer is hyperbolic tangent, and it is lower than the mean square error value for the test set of other combinations. Furthermore, the mean square error values for all three sets are close to one another, which helps prevent overfitting. As a result, in this network, the ReLu and hyperbolic tangent functions are used for the first and second hidden layers, respectively, while the sigmoid function is utilized for the output layer.
The average MSE values for various combinations of activation functions in the hidden and output layers for the complexity component neural network are shown in Table 10. The training time for each combination is also presented in Table 11. The minimum mean square error value for the test set is observed when the activation function of the first layer is ReLu and the second layer is sigmoid, and it is lower than the mean square error value for the test set of other combinations. Additionally, in this combination, the mean square error values for all three sets are close to one another, which helps prevent overfitting. As a result, in this study, the ReLu and sigmoid functions were employed for the first and second hidden layers, respectively, while the sigmoid function was utilized for the output layer.
The average MSE values for various combinations of activation functions in the hidden and output layers for the practicality neural network are shown in Table 12. The training time for each combination is also presented in Table 13. The minimum mean square error value for the test sets is observed when the activation function of both layers is sigmoid, and it is lower than the mean square error value for other combinations. Additionally, in this combination, the mean square error values for all three sets are close to one another, which helps prevent overfitting. Consequently, in this network, the sigmoid function is utilized for both the hidden layer and the output layer.
4.4. Other Parameters and Final Specification of Neural Networks
The neural network training process also necessitates the adjustment of several other parameters, which can have a significant impact on the speed and accuracy of the process. These parameters include the optimization method, loss function, learning rate, and the number of epochs [50]. In this research, Adam’s optimization algorithm, mean square error loss function, learning rate 0.001, and 50 epochs were used. Finally, after finding the most optimal state of each neural network, the final specifications of all networks are given in Table 14.

5. Discussion and Results
The primary and most critical objective of this study was to develop a method to assess the aesthetic aspect of free-form space structures utilizing machine learning algorithms and expert preference test results. This research method confirmed that quantitative evaluation of qualitative characteristics is possible. Regarding the second goal of the study, a comprehensive explanation of the parameter settings for all three artificial neural networks has been provided. This contributes to the significance of this article since such a detailed analysis has not been conducted in any previous research. The results indicate that shallow networks with only two hidden layers get the best results for all three networks. Also, after setting the networks, their performance is tested. Four new free-form space structures were created and inputted into the networks for evaluation. The outcomes of this assessment are presented in Table 15. Each network based on its learning from the preference test has assigned a score between 0 and 1 for each structure, which represents the average possible scores of experts for that structure. By using these scores, architecture can get an estimate regarding the aesthetic of the structure.
6. Conclusion, Limitations, and Future Works
This study presents a simple but powerful artificial intelligence model for evaluating the aesthetic value of free-form space frame structures. The well-defined data structure of these structures enables the artificial neural network to easily comprehend their features and evaluate their form. Conversely, the artificial neural network can learn the design priorities of experts through the preference test administered to them. As a result, this method enables the assessment of the aesthetic quality of designed forms in the three components of simplicity, complexity, and practicality based on the preferences of expert designers. The results indicate that the proposed model can evaluate the qualitative concept of aesthetics. Additionally, the current study presents the step-by-step setup method of an artificial neural network model and the selection of its parameters in the field of aesthetic evaluation. However, the research also has limitations. This research includes a limited number of aesthetic components (simplicity, complexity, practicality). In future works, more components such as order, symmetry, and coordination can be investigated. In addition, there are two other limitations regarding the artificial neural network. First, in this study, only a multilayer perceptron is used as an ANN model. In future works, other types of ANNs can be used and the final results can be compared with each other. Second, in this article, only three activation functions, which are the most important, have been used. Indeed, other well-known activation functions can be used in the hidden and output layers, and the outcomes can be compared to the results obtained in this study. This can help to determine which activation functions are most effective for assessing the aesthetic quality of free-form space structures. Finally, the effect of other parameters of the network such as epoch, learning rate, and optimization algorithm on the learning speed of the network and its accuracy could be investigated.
Author Contributions
All authors contributed equally to writing, editing, and reviewing the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Liu, F. , et al., Machine learning-based design and optimization of curved beams for multistable structures and metamaterials. Extreme Mechanics Letters, 2020. 41: p. 101002.
- Mirra, G. and A. Pugnale, Comparison between human-defined and AI-generated design spaces for the optimisation of shell structures. Structures, 2021. 34: p. 2950-2961.
- Mueller, C.T. , Computational exploration of the structural design space. 2014, Massachusetts Institute of Technology.
- Zheng, H., V. Moosavi, and M. Akbarzadeh, Machine learning assisted evaluations in structural design and construction. Automation in Construction, 2020. 119: p. 103346.
- Fuhrimann, L. , et al. Data-driven design: Exploring new structural forms using machine learning and graphic statics. in Proceedings of IASS Annual Symposia. 2018. International Association for Shell and Spatial Structures (IASS).
- Aksöz, Z. and C. Preisinger. An Interactive Structural Optimization of Space Frame Structures Using Machine Learning. in Impact: Design With All Senses. 2020. Cham: Springer International Publishing.
- KORONAKI, A., P. SHEPHERD, and M. EVERNDEN, Fabrication aware optimization of space-frame structures.
- Belém, C., L. Santos, and A. Leitão, On the Impact of Machine Learning: Architecture without Architects? 2019.
- Zheng, H. , Form Finding and Evaluating Through Machine Learning: The Prediction of Personal Design Preference in Polyhedral Structures. 2020. p. 169-178.
- Petrov, A. , et al., Understanding the relationships between aesthetic properties and geometric quantities of free-form surfaces using machine learning techniques. International Journal on Interactive Design and Manufacturing (IJIDeM), 2020. 14(2): p. 451-465.
- McCormack, J. and A. Lomas. Understanding Aesthetic Evaluation Using Deep Learning. in Artificial Intelligence in Music, Sound, Art and Design. 2020. Cham: Springer International Publishing.
- Li, C. and T. Chen, Aesthetic Visual Quality Assessment of Paintings. IEEE Journal of Selected Topics in Signal Processing, 2009. 3(2): p. 236-252.
- Ciesielski, V., P. Barile, and K. Trist. Finding Image Features Associated with High Aesthetic Value by Machine Learning. in Evolutionary and Biologically Inspired Music, Sound, Art and Design. 2013. Berlin, Heidelberg: Springer Berlin Heidelberg.
- Park, S.-W. , et al., Hull Form Optimization Study Based on Multiple Parametric Modification Curves and Free Surface Reynolds-Averaged Navier–Stokes (RANS) Solver. Applied Sciences, 2022. 12(5): p. 2428.
- Bakaev, M. and V. Khvorostov, Quality of Labeled Data in Machine Learning: Common Sense and the Controversial Effect for User Behavior Models. Engineering Proceedings, 2023. 33(1): p. 3.
- Bodini, M. , Will the Machine Like Your Image? Automatic Assessment of Beauty in Images with Machine Learning Techniques. Inventions, 2019. 4(3): p. 34.
- Paroiu, R. and S. Trausan-Matu, Measurement of Music Aesthetics Using Deep Neural Networks and Dissonances. Information, 2023. 14(7): p. 358.
- Peng, H. , et al., Multiple Visual Feature Integration Based Automatic Aesthetics Evaluation of Robotic Dance Motions. Information, 2021. 12(3): p. 95.
- Xu, L. , et al., Assessment of the Exterior Quality of Traditional Residences: A Genetic Algorithm–Backpropagation Approach. Buildings, 2022. 12(5): p. 559.
- Moghimi, M. , Formex configuration processing of compound and freeform structures. 2006: University of Surrey (United Kingdom).
- Nooshin, H. and M. Moghimi, FORMEX FORMULATION OF FREEFORM STRUCTURAL SURFACES. 2007.
- Chenaghlou, M.R., K. Abedi, and H. Esmailnejad. Connection geometry evaluation in free form space structures. in Proceedings of IASS Annual Symposia. 2020. International Association for Shell and Spatial Structures (IASS).
- Nooshin, H. and P. Disney, Formex Configuration Processing I. International Journal of Space Structures, 2000. 15: p. 1-52.
- Tedeschi, A. and D. Lombardi, The algorithms-aided design (AAD), in Informed Architecture. 2018, Springer. p. 33-38.
- Nooshin, H. and P. Disney, Formex Configuration Processing III. International Journal of Space Structures, 2002. 17: p. 1-50.
- Nooshin, H. and P. Disney, Formex Configuration Processing III. International Journal of Space Structures, 2002. 17(1): p. 1-50.
- Nooshin, H. , Space structures and configuration processing. Progress in Structural Engineering and Materials, 1998. 1(3): p. 329-336.
- Nooshin, H., F. Albermani, and P. Disney, Novational transformations, in An Anthology Of Structural Morphology. 2009, World Scientific. p. 63-81.
- McNeel, R. , Rhino 6 for Windows. 2019, Rhinoceros.
- Preisinger, C. , Linking structure and parametric geometry. Architectural Design, 2013. 83(2): p. 110-113.
- Sárközi, R., P. Iványi, and A.B. Széll, Formex algebra adaptation into parametric design tools and rotational grids. Pollack Periodica, 2020. 15(2): p. 152-165.
- Bhise, A.A. , Aesthetics in Architecture. International Journal of Engineering Research, 2018. 7(special3): p. 325-328.
- Kulasuriya, C. , Aesthetics in Structures. Engineer: Journal of the Institution of Engineers, Sri Lanka, 2005. 38(3).
- Palmer, S.E., K. B. Schloss, and J. Sammartino, Visual aesthetics and human preference. Annual review of psychology, 2013. 64: p. 77-107.
- Saliklis, E.P., M. Bauer, and D.P. Billington, Simplicity, scale, and surprise: evaluating structural form. ASCE Journal of Architectural Engineering, 2008. 14(1): p. 25.
- De Biagi, V. and B. Chiaia, Complexity of structures: A possible measure and the role for robustness. 2013: p. 726-734.
- Chong, A.Y.-L. , Predicting m-commerce adoption determinants: A neural network approach. Expert systems with applications, 2013. 40(2): p. 523-530.
- Kalinić, Z. , et al., Neural network modeling of consumer satisfaction in mobile commerce: an empirical analysis. Expert Systems with Applications, 2021. 175: p. 114803.
- Roman Cardell, J. , Python-based Deep-Learning methods for energy consumption forecasting. 2020, Universitat Politècnica de Catalunya.
- Zhang, G., B. E. Patuwo, and M.Y. Hu, Forecasting with artificial neural networks:: The state of the art. International journal of forecasting, 1998. 14(1): p. 35-62.
- Abraham, A. , Artificial neural networks. Handbook of measuring system design, 2005.
- Aghaei, S. , et al., A hybrid SEM-neural network method for modeling the academic satisfaction factors of architecture students. Computers and Education: Artificial Intelligence, 2023. 4: p. 100122.
- Sharma, S.K., H. Sharma, and Y.K. Dwivedi, A hybrid SEM-neural network model for predicting determinants of mobile payment services. Information Systems Management, 2019. 36(3): p. 243-261.
- Ramchoun, H. , et al. Multilayer Perceptron: Architecture Optimization and training with mixed activation functions. in Proceedings of the 2nd international Conference on Big Data, Cloud and Applications. 2017.
- Suzuki, K. , Artificial neural networks: methodological advances and biomedical applications. 2011: BoD–Books on Demand.
- Goodfellow, I. , et al., Deep learning, 1 MIT press. 2016, Cambridge.
- Orimoloye, L.O. , et al., Comparing the effectiveness of deep feedforward neural networks and shallow architectures for predicting stock price indices. Expert Systems with Applications, 2020. 139: p. 112828.
- Negnevitsky, M. , Artificial intelligence: a guide to intelligent systems. 2011: Pearson education.
- Sheela, K. and S.N. Deepa, Review on Methods to Fix Number of Hidden Neurons in Neural Networks. Mathematical Problems in Engineering, 2013. 2013.
- Yoo, Y. , Hyperparameter optimization of deep neural network using univariate dynamic encoding algorithm for searches. Knowledge-Based Systems, 2019. 178: p. 74-83.
Scheme 1.
The steps of the proposed method.

Figure 1.
The code for assigning curves to the sides of squares (Left), the basic form, square on square offset grid space structure (Right)
Figure 1.
The code for assigning curves to the sides of squares (Left), the basic form, square on square offset grid space structure (Right)
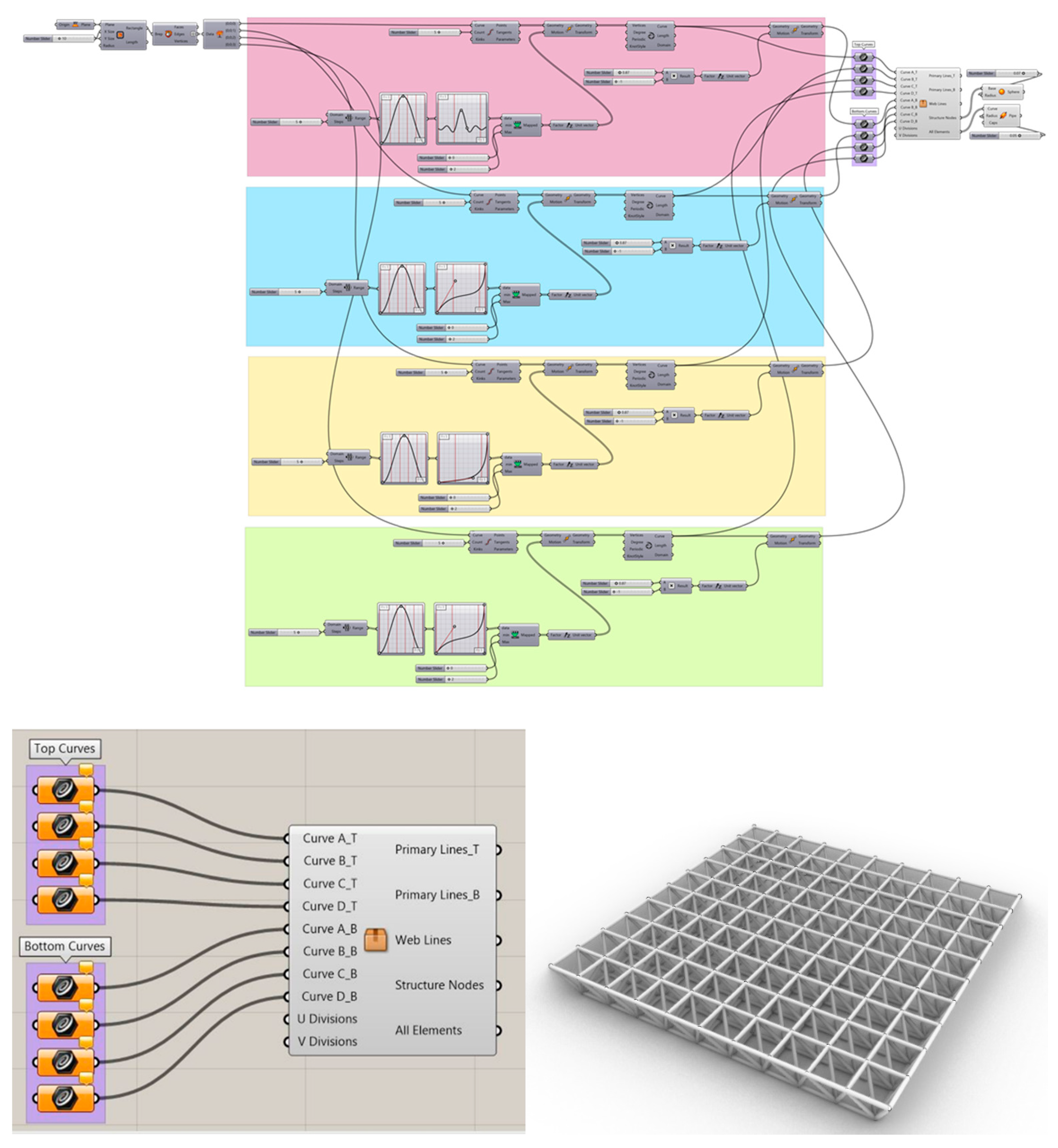
Figure 2.
Examples of forms obtained by changing the upper layer: (a) One curved side; (b) Two curved sides; (c) Three curved sides; (d) Four curved sides.
Figure 2.
Examples of forms obtained by changing the upper layer: (a) One curved side; (b) Two curved sides; (c) Three curved sides; (d) Four curved sides.
Figure 3.
Examples of forms obtained with the parallel movement of layers; (a) One curved side, (b) Two curved sides, (c) Three curved sides, (d) Four curved sides.
Figure 3.
Examples of forms obtained with the parallel movement of layers; (a) One curved side, (b) Two curved sides, (c) Three curved sides, (d) Four curved sides.
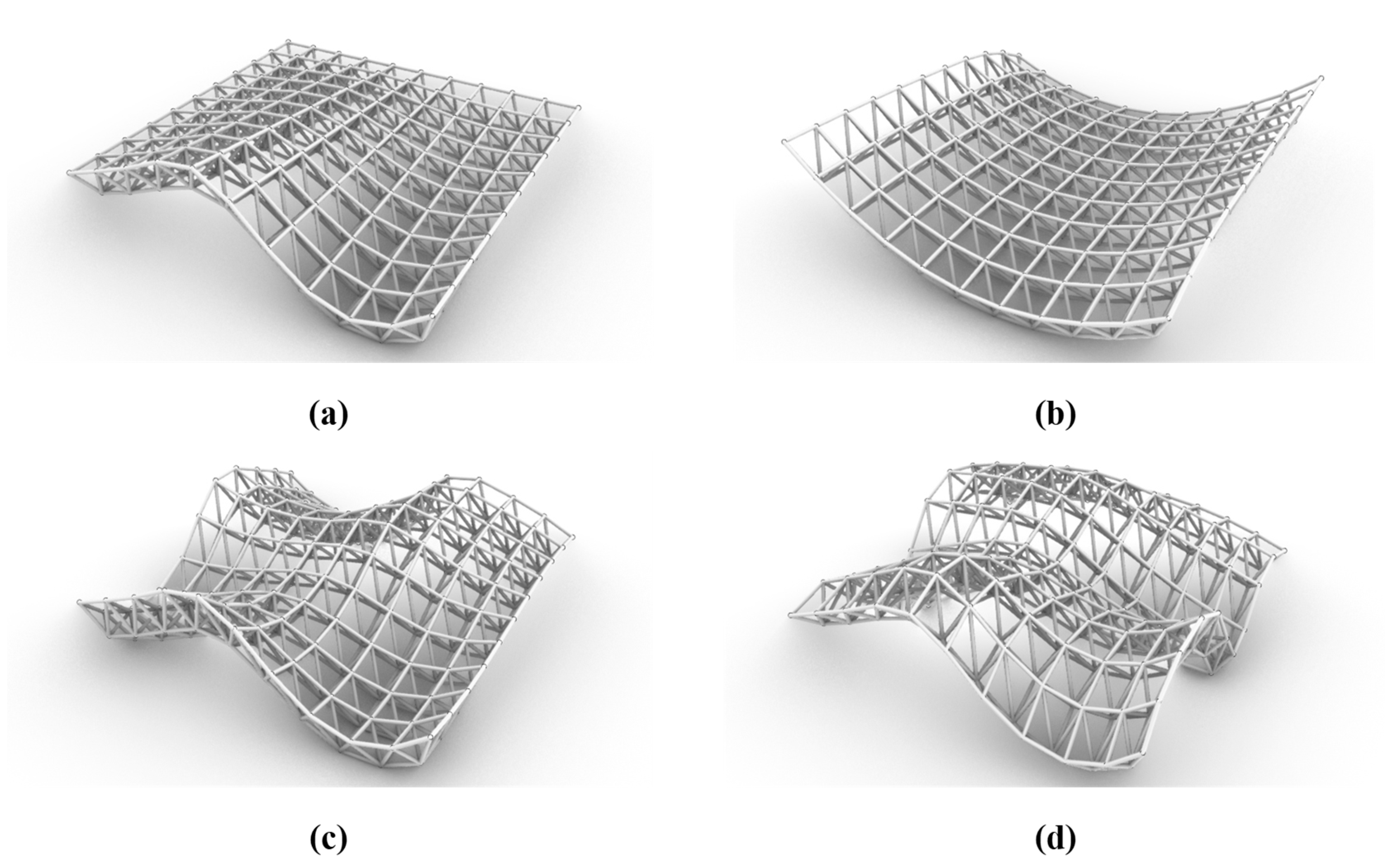
Figure 4.
The code and example of the form generated by the node removal code.
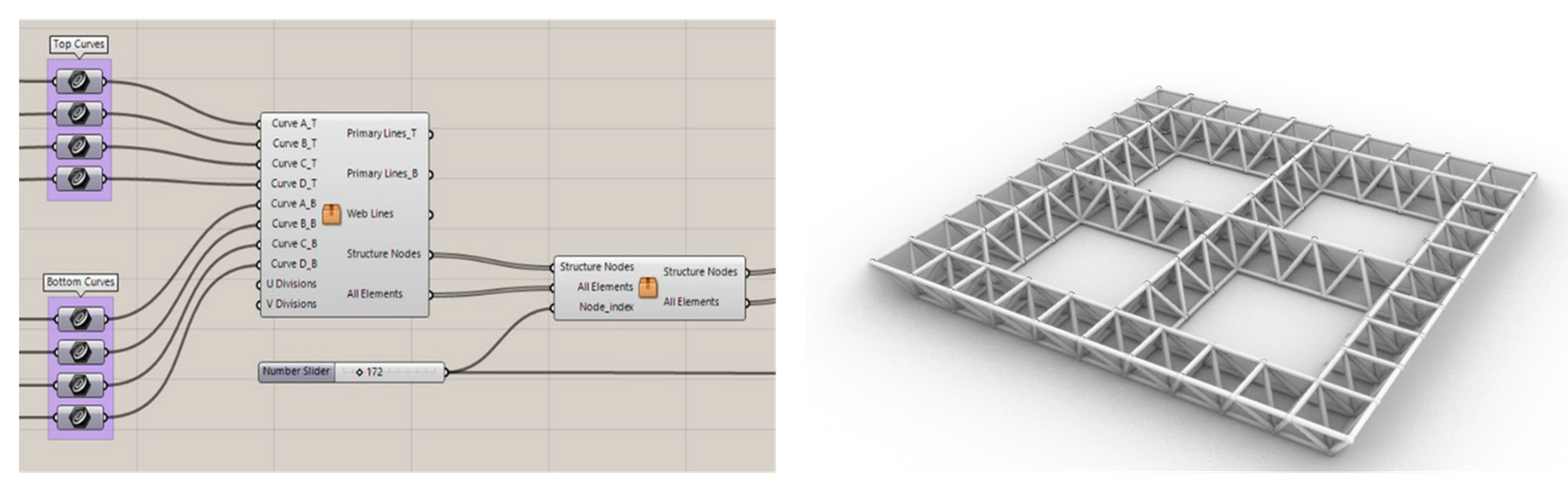
Figure 5.
The code and example of the form generated by the node deformation code.
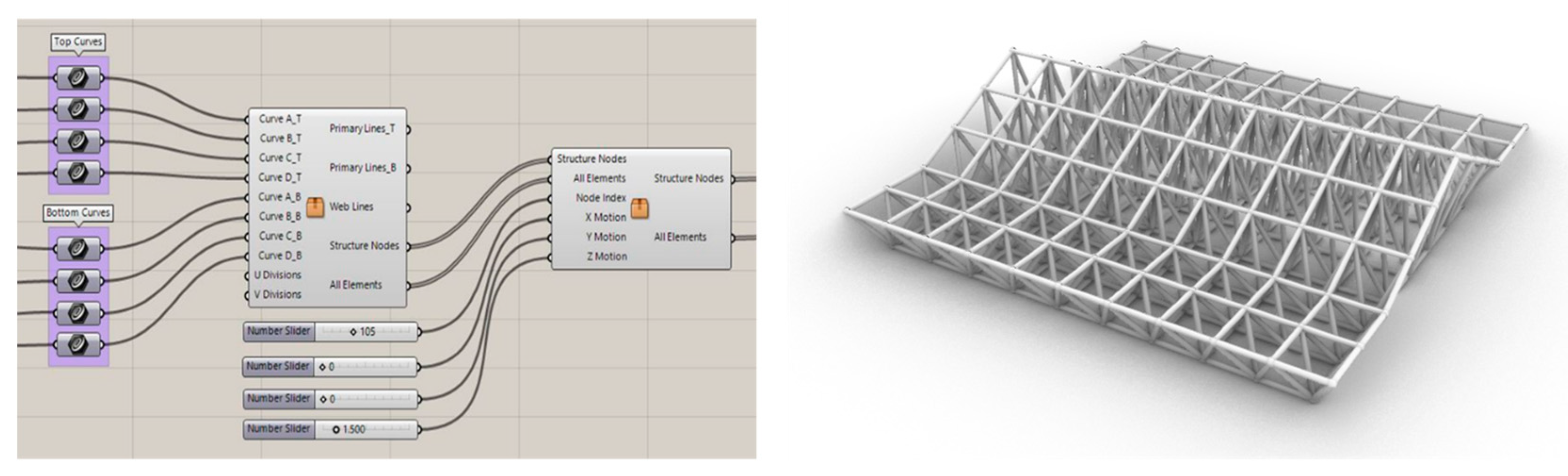
Figure 6.
Example of a category containing six forms in the questionnaire.

Figure 7.
Architecture of ANN: The input data is fed into the input layer nodes, processed by the hidden layer nodes, and the node in the output layer generates a recommendation [42].
Figure 7.
Architecture of ANN: The input data is fed into the input layer nodes, processed by the hidden layer nodes, and the node in the output layer generates a recommendation [42].
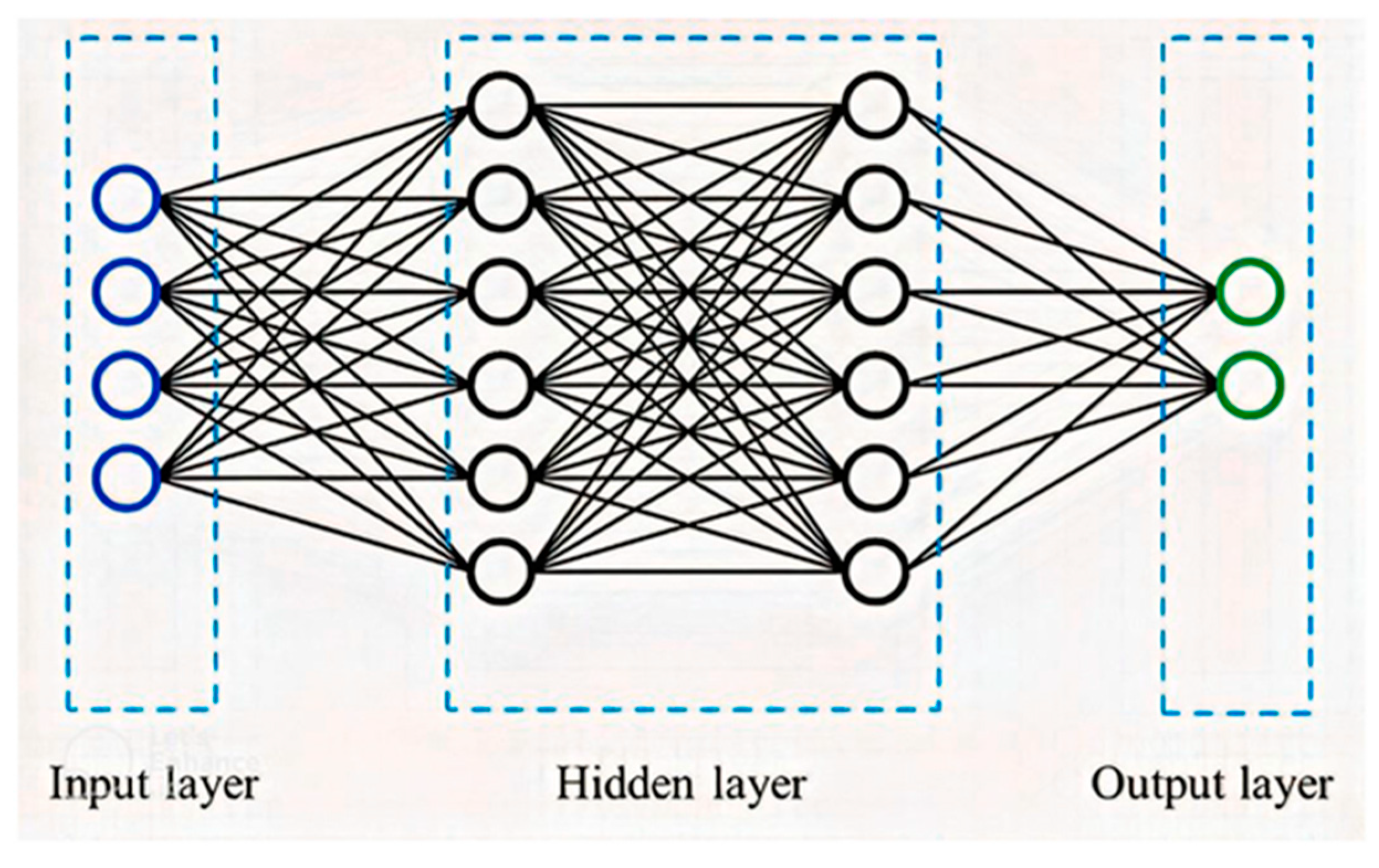
Figure 8.
Training time and mean square error of training, validation, and testing for different values of hidden neurons in the simplicity network.
Figure 8.
Training time and mean square error of training, validation, and testing for different values of hidden neurons in the simplicity network.
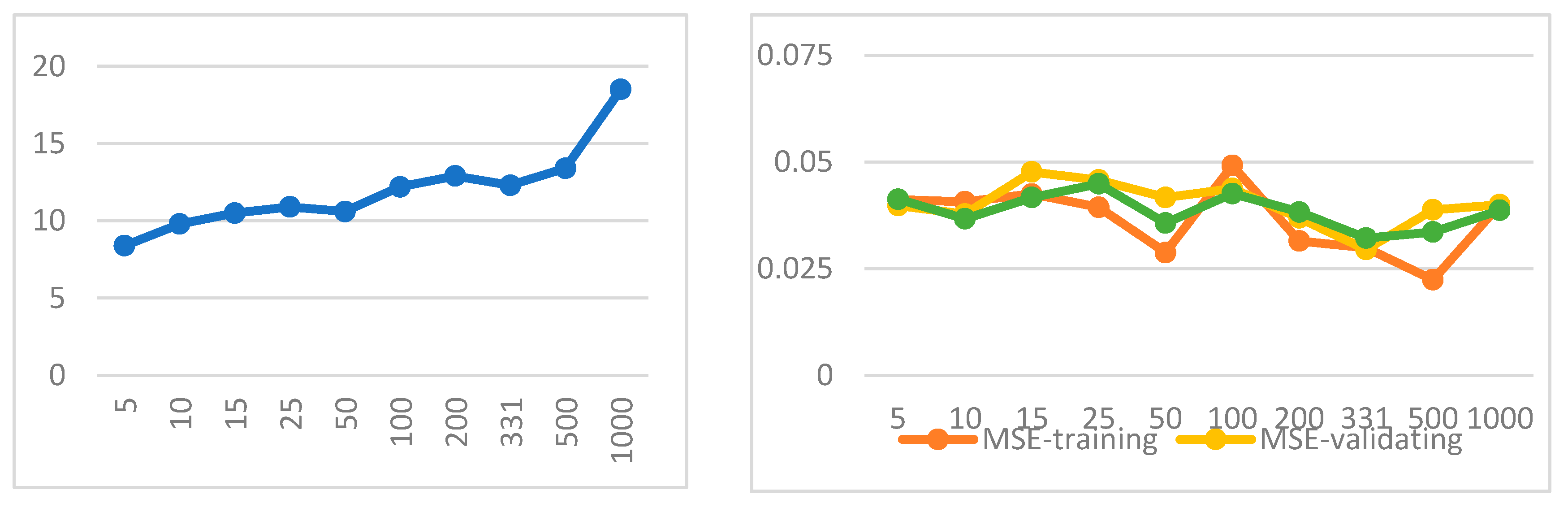
Figure 9.
Training time and mean square error of training, validation, and testing for different values of hidden neurons in the complexity network.
Figure 9.
Training time and mean square error of training, validation, and testing for different values of hidden neurons in the complexity network.
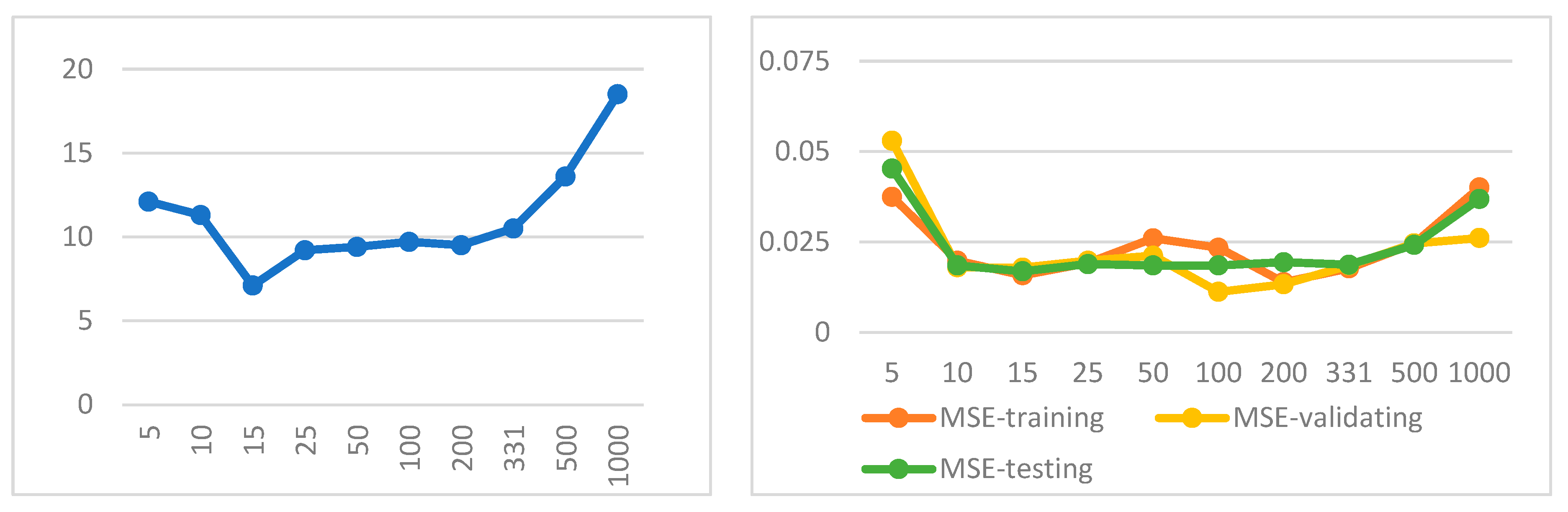
Figure 10.
Training time and mean square error of training, validation, and testing for different values of hidden neurons in the practicality network.
Figure 10.
Training time and mean square error of training, validation, and testing for different values of hidden neurons in the practicality network.
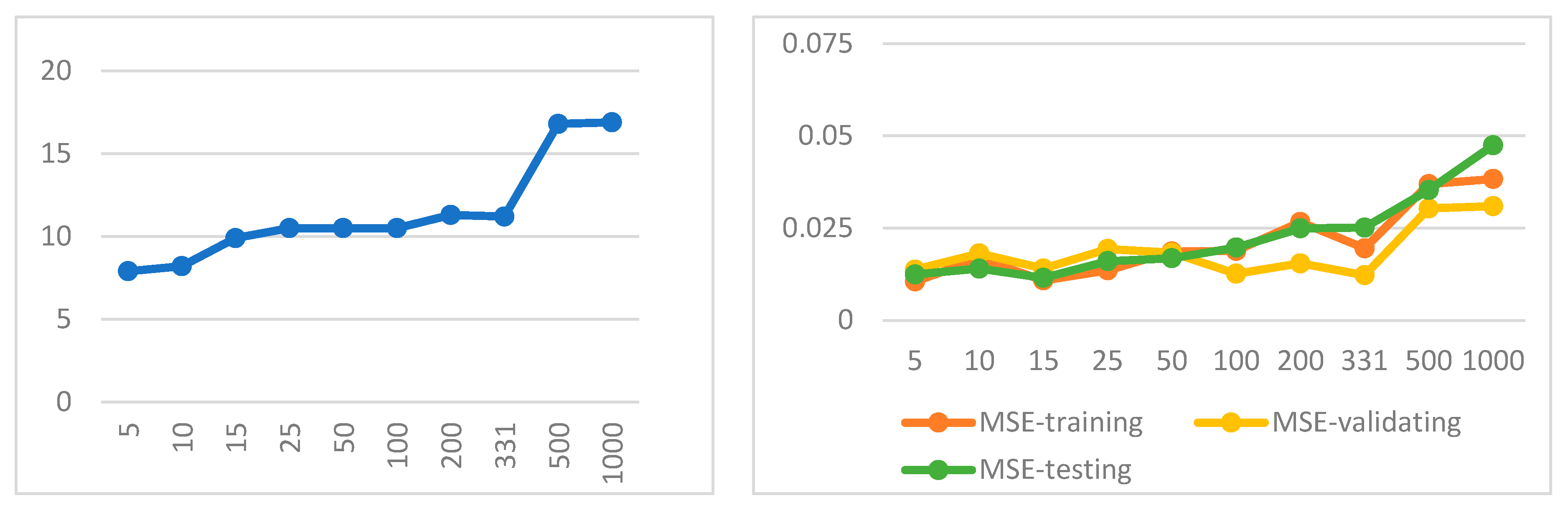

Table 1.
Mean square error values for the simplicity neural network for different values of hidden layers.
Table 1.
Mean square error values for the simplicity neural network for different values of hidden layers.
| ANN Model | MSE-Testing | MSE-Validating | MSE-Training | Training Time (s) |
|---|---|---|---|---|
| One hidden layer | 0.0740 | 0.0559 | 0.0665 | 12.5 |
| Two hidden layers | 0.0331 | 0.0380 | 0.0297 | 17.5 |
| Three hidden layers | 0.0740 | 0.0501 | 0.0665 | 30.8 |
Table 2.
Mean square error values for the complexity neural network for different values of hidden layers.
Table 2.
Mean square error values for the complexity neural network for different values of hidden layers.
| ANN Model | MSE-Testing | MSE-Validating | MSE-Training | Training Time (s) |
|---|---|---|---|---|
| One hidden layer | 0.0193 | 0.0193 | 0.0142 | 9.3 |
| Two hidden layers | 0.0191 | 0.0182 | 0.0189 | 11.2 |
| Three hidden layers | 0.0197 | 0.0171 | 0.0177 | 12.3 |
Table 3.
Mean square error values for the practicality neural network for different values of hidden layers.
Table 3.
Mean square error values for the practicality neural network for different values of hidden layers.
| ANN Model | MSE-Testing | MSE-Validating | MSE-Training | Training Time (s) |
|---|---|---|---|---|
| One hidden layer | 0.0158 | 0.0168 | 0.0060 | 9.8 |
| Two hidden layers | 0.0115 | 0.0140 | 0.0108 | 9.9 |
| Three hidden layers | 0.0117 | 0.0123 | 0.0106 | 8.5 |
Table 4.
Mean square error values for the simplicity neural network for different values of hidden neurons.
Table 4.
Mean square error values for the simplicity neural network for different values of hidden neurons.
| The Number of Hidden Neurons | 5 | 10 | 15 | 25 | 50 | 100 | 200 | 331 | 500 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|
| MSE-testing | 0.0413 | 0.0367 | 0.0417 | 0.0449 | 0.0357 | 0.0426 | 0.0383 | 0.0322 | 0.0336 | 0.0387 |
| MSE- validating | 0.0398 | 0.0378 | 0.0477 | 0.0458 | 0.0417 | 0.0438 | 0.0369 | 0.0295 | 0.0388 | 0.0400 |
| MSE-training | 0.0412 | 0.0407 | 0.0425 | 0.0394 | 0.0288 | 0.0492 | 0.0315 | 0.0299 | 0.0224 | 0.0400 |
| Training time | 8.4 | 9.8 | 10.5 | 10.9 | 10.6 | 12.2 | 12.9 | 12.3 | 13.4 | 18.5 |
Table 5.
Mean square error values for the complexity neural network for different values of hidden neurons.
Table 5.
Mean square error values for the complexity neural network for different values of hidden neurons.
| The Number of Hidden Neurons | 5 | 10 | 15 | 25 | 50 | 100 | 200 | 331 | 500 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|
| MSE-testing | 0.0453 | 0.0185 | 0.0169 | 0.0189 | 0.0185 | 0.0185 | 0.0194 | 0.0187 | 0.0242 | 0.0369 |
| MSE- validating | 0.0530 | 0.0180 | 0.0179 | 0.0198 | 0.0212 | 0.0112 | 0.0133 | 0.0185 | 0.0246 | 0.0261 |
| MSE-training | 0.0375 | 0.0198 | 0.0158 | 0.0192 | 0.0260 | 0.0234 | 0.0139 | 0.0177 | 0.0246 | 0.0401 |
| Training time | 12.1 | 11.3 | 7.1 | 9.2 | 9.4 | 9.7 | 9.5 | 10.5 | 13.6 | 16.1 |
Table 6.
Mean square error values for the practicality neural network for different values of hidden neurons.
Table 6.
Mean square error values for the practicality neural network for different values of hidden neurons.
| The Number of Hidden Neurons | 5 | 10 | 15 | 25 | 50 | 100 | 200 | 331 | 500 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|
| MSE-testing | 0.0124 | 0.0140 | 0.0115 | 0.0160 | 0.0168 | 0.0197 | 0.0249 | 0.0251 | 0.0353 | 0.0474 |
| MSE- validating | 0.0137 | 0.0181 | 0.0140 | 0.0193 | 0.0183 | 0.0126 | 0.0154 | 0.0122 | 0.0303 | 0.0309 |
| MSE-training | 0.0105 | 0.0167 | 0.0108 | 0.0135 | 0.0186 | 0.0188 | 0.0266 | 0.0195 | 0.0369 | 0.0383 |
| Training time | 7.9 | 8.2 | 9.9 | 10.5 | 10.5 | 10.5 | 11.3 | 11.2 | 16.8 | 16.9 |
Table 7.
Equations related to activation functions.
| Function | Equation |
| Sigmoid | 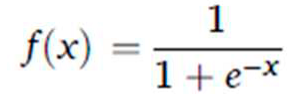 |
| ReLu | 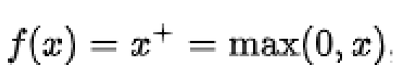 |
| Hyperbolic Tangent | 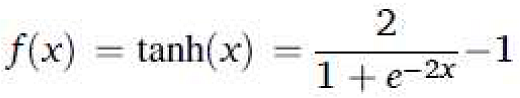 |
Table 8.
Mean MSE for the testing set of the simplicity network for different combinations of activation functions.
Table 8.
Mean MSE for the testing set of the simplicity network for different combinations of activation functions.
| Second Layer | Sigmoid | ReLu | Hyperbolic Tangent |
|---|---|---|---|
| First Layer | |||
| Sigmoid | 0.0377 | 0.0398 | 0.0443 |
| ReLu | 0.0298 | 0.0322 | 0.0216 |
| Hyperbolic Tangent | 0.0299 | 0.0297 | 0.0362 |
Table 9.
Training time for different combinations of Simplicity network activation functions.
| Second Layer | Sigmoid | ReLu | Hyperbolic Tangent |
|---|---|---|---|
| First Layer | |||
| Sigmoid | 10.1 | 10.1 | 10.9 |
| ReLu | 14.8 | 12.3 | 10.6 |
| Hyperbolic Tangent | 14.1 | 12.4 | 13.6 |
Table 10.
Mean MSE for the testing set of the complexity network for different combinations of activation functions.
Table 10.
Mean MSE for the testing set of the complexity network for different combinations of activation functions.
| Second Layer | Sigmoid | ReLu | Hyperbolic Tangent |
|---|---|---|---|
| First Layer | |||
| Sigmoid | 0.0169 | 0.0202 | 0.0181 |
| ReLu | 0.0160 | 0.0240 | 0.0179 |
| Hyperbolic Tangent | 0.0176 | 0.0201 | 0.0185 |
Table 11.
Training time for different combinations of complexity network activation functions.
| Second Layer | Sigmoid | ReLu | Hyperbolic Tangent |
|---|---|---|---|
| First Layer | |||
| Sigmoid | 7.1 | 8.7 | 8.7 |
| ReLu | 8.8 | 12.9 | 8.3 |
| Hyperbolic Tangent | 10.4 | 9.2 | 9.5 |
Table 12.
Mean MSE for the testing set of the practicality network for different combinations of activation functions.
Table 12.
Mean MSE for the testing set of the practicality network for different combinations of activation functions.
| Second Layer | Sigmoid | ReLu | Hyperbolic Tangent |
|---|---|---|---|
| First Layer | |||
| Sigmoid | 0.0115 | 0.0161 | 0.0150 |
| ReLu | 0.0183 | 0.0259 | 0.0258 |
| Hyperbolic Tangent | 0.0209 | 0.0300 | 0.0340 |
Table 13.
Training time for different combinations of practicality network activation functions.
| Second Layer | Sigmoid | ReLu | Hyperbolic Tangent |
|---|---|---|---|
| First Layer | |||
| Sigmoid | 9.9 | 9.1 | 13.5 |
| ReLu | 10.6 | 8.5 | 10.5 |
| Hyperbolic Tangent | 10.3 | 14.6 | 8.1 |
Table 15.
Artificial neural networks scores given to the new input structures.
| Free-Form Structures | Networks | ||
|---|---|---|---|
| SimplicityScore | ComplexityScore | PracticalityScore | |
 |
0.726 | 0.278 | 0.861 |
 |
0.335 | 0.652 | 0.874 |
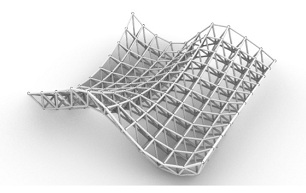 |
0.209 | 0.793 | 0.616 |
 |
0.183 | 0.847 | 0.543 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



