
Submitted:
31 August 2023
Posted:
01 September 2023
You are already at the latest version
Abstract
Landsat and Sentinel-2 data archives provide ever-increasing amounts of satellite data for studying land cover and land use change (LCLUC) over the past four decades. However, the availability of cloud-, shadow-, and snow-free observations varies spatially and temporally due to climate and satellite data acquisition schemes. Spatio-temporal heterogeneity poses a major issue for some time-series analysis approaches, but can be addressed with pixel-based compositing that generates temporally equidistant cloud-free or near-cloud free synthetic images. Although much consideration is given to methods identifying the ‘best’ pixel value for each composite, determining the aggregation period receives less attention and is often done arbitrary, or based on expert intuition. Here, we evaluated data compositing windows ranging from five days to one year for 1984-2021 Landsat and 2015-2021 Sentinel‑2 time series across Europe. We considered separate and joint use of both data archives and analyzed spatio-temporal availability of composites during each calendar year and pixel-specific growing season. We reported mean annual composites’ availability investigating differences among biogeographical regions, checked feasibility of pan‑European analyses for three LCLUC applications based on annual, monthly and 10-day composites, and analyzed the shortest feasible compositing window ensuring ≥50% temporal data availability and interpolation of the remaining composites for individual years and across a variety of medium- and long‑term time windows. Our results highlighted low data coverage in the 1980s, 1990s, and in 2012, as well as spatial variability in data availability driven by climate and orbit overlaps, which altogether impact spatio-temporal consistency of medium- and long-term time series, limiting feasibility of some LCLUC analyses. We demonstrated that prior to 2011 monthly composites ensured overall 50-62% data coverage for each calendar year, and ~75% afterwards, with further increase to ~82% when Landsat and Sentinel-2 were combined. Temporal consistency of monthly composites was overall low and temporal interpolation augmenting up to 50% missing data each year and across a time window of interest, ensured feasibility of analyses. Applications based on shorter than monthly composites were challenging without joining Landsat and Sentinel‑2 archives after 2015, and beyond the Mediterranean biogeographical region. Using pixel-specific growing season data typically boosted data availability in most geographies and diminished most of the latitudinal differences, but feasibility of complete time series with sub-monthly compositing windows was still restricted to the most recent years, and required data interpolation. Overall, our analyses provided a detailed assessment of Landsat and Sentinel-2 data availability over Europe, and based on selected application examples, highlighted often lacking spatio-temporal consistency of time series with sub-monthly compositing windows and long-time periods, which might hinder feasibility of some LCLUC applications.
Keywords:
Time-series
; data availability
; aggregation
; long-term analyses
Highlights
- Spatio-temporal variability in data availability over Europe is substantial
- Data availability in 1980s-90s throttles compositing windows for long-term analyses
- For most geographies, data availability is greater during the growing season
- Joint use of Landsat and Sentinel-2 data reduces temporal granularity of composites
- Data interpolation is often essential to ensure temporally consistent time series
1. Introduction
Remote sensing is an irreplaceable source of information on Earth’s systems [1,2]. A broad and constantly increasing portfolio of Earth observation missions enables near real-time monitoring capabilities [3,4], whereas rich data archives provide the baseline for long-term analyses [5,6]. Land cover and land use change monitoring is among research and application domains frequently employing remote sensing [7,8]. Multi-spectral medium-resolution satellite data are commonly used when studying land cover and land use processes because they provide a well-balanced trade-off between spectral sensitivity to changes, spatial resolution, and revisit frequency.
Among optical medium-resolution sensors (i.e., 10-30 m), the Landsat missions are the longest, continuously running Earth observation program. Comparability of acquisition schemes and technical characteristics of the consecutive Landsat missions, especially since the launch of Landsat 4 in 1982, make the Landsat data record a unique source of information for numerous land cover and land use applications [1,2,9]. With a maximum revisit time of 8 days when two satellites are in operation, Landsat can capture subtle long-term and more dynamic land surface processes [5,6,10] relevant for, but not limited to, forestry [11,12], agriculture [13,14,15], fresh water [16,17,18] and urban monitoring [19,20,21].
The Sentinel-2 mission of the European Commission’s Copernicus program is another prominent source of medium-resolution Earth observation data for land cover and land use monitoring [22]. With two satellites in operation phase since December 2015 (Sentinel-2A) and June 2017 (Sentinel-2B), the mission provides multi-spectral observations at 10-20-m resolution [23] under a ‘free, full and open data policy’ [24]. Thanks to the constellation design and a wide observation swath, the revisit time is reduced to 5 days at the equator, and to 2-3 days at mid-latitudes. Despite relatively short operation history, Sentinel-2 has already been extensively used in analyses including agricultural [25,26,27], forest [28,29], aquatic [30,31] and urban ecosystems [32,33]. Higher revisit time of Sentinel-2, as compared with Landsat, facilitates using Sentinel-2 data for detection of key management and phenological events [27,34,35].
The technological advancements in data preprocessing, processing and storage, combined with free and open data distribution have facilitated a shift from mono- and bi-temporal analyses to studies based on dense time series of satellite observations [36,37,38]. Moreover, because spectral and spatial consistency is a fundamental prerequisite for time series analyses, past studies have been typically confined to acquisitions from a single sensor system. However, increasing computing capabilities have eased this limitation, allowing for harmonization of vast volumes of data. Consequently, it has become feasible to integrate acquisitions across sensor families with different spatial and spectral resolutions, in order to fill data gaps [39,40] and to improve temporal resolution [41,42,43]. Synergetic use of Landsat and Sentinel-2 data has become especially recognized and resulted in various harmonization workflows and datasets [44] such as the Harmonized Landsat Sentinel-2 (HLS) data [45], the harmonization workflow available in the Framework for Operational Radiometric Correction for Environmental monitoring (FORCE; Frantz, 2019), and Sen2Like toolbox [47].
Despite all technological advances, valid observations are always less frequent than the nominal data acquisition frequency due to clouds, cloud shadows, snow, and other disturbances [48,49,50]. Depending on the geographical location of the study area and targeted time period, data availability varies vastly owing to, among others, long-term and seasonal variability of meteorological conditions [51,52], as well as historic data acquisition and archiving schemes [53]. While analyses based on, for example, spectral-temporal metrics [54,55,56] and per-pixel function fitting [38,57] are somewhat insensitive to irregular temporal resolution of a time series, analysis approaches such as Fourier and wavelet transforms, trend analyses, and some machine learning implementations require temporally equidistant data distribution (Griffiths et al., 2019; Testa et al., 2018; Udelhoven, 2011).
Pixel-based temporal compositing, also broadly referred to as temporal binning [58], generates temporally equidistant cloud-free or near-cloud free synthetic images by deriving the ‘best’ per-pixel value within a desired time window. The approach has a long heritage in satellite remote sensing and has been used to derive cloud-free datasets such as the AVHRR GIMMS [59,60], MODIS multi-day data products [61,62], Landsat WELD [63], WorldCover Sentinel-2 annual mosaics [64], and Planet base maps. Temporal composites typically require a minimum of one valid observation per pixel within a time window, although more data generally improve the composites’ quality [65,66]. While multiple algorithms exist to select or calculate the ‘best’ pixel value for each time step [65,67,68,69], a length of the time window tends to be selected arbitrary based on the operator’s intuition and experience, to match the temporal granularity of a studied process (Table 1). The data availability in time and space over the studied area is rarely explored thoroughly a-priori, making the selection of an appropriate time window a difficult decision, especially for less experienced users. Yet, spatio-temporal inconsistency in data availability combined with the use of a sub-optimal compositing window width may lead to data gaps and lower quality of derived composites and time series, which in turn may impact credibility of subsequent analyses. Composite-based long-term studies of land-cover and land use dynamics are particularly vulnerable to changes in data availability over time, especially when aimed at dynamic ecosystems [6,70]. Concomitantly, spatial disparity of data availability is expected over vast regions [50,71].
In this study we analyzed how data availability of Landsat and Sentinel-2 over Europe varies in space and time and how these variations translate into feasible lengths of compositing windows, thereupon to support the informed selection of compositing windows for land use and land cover analyses. We calculated per-pixel availability of usable data at 20-km point-grid throughout the complete 1984-2021 Landsat and 2015-2021 Sentinel-2 data records considering their separate and conjoint use, and focused on compositing windows of: five, 10, 15, 20, and 25 days; one, two, three, four, six and 12 months. Specifically, our research objective (RO) were to analyze: i) how composites’ availability changed in Europe altogether and within biogeographical regions across the temporal depth of the archives for both the full calendar year and the growing seasons; ii) spatio-temporal data availability of annual, monthly and 10-day composites commonly used in forest disturbances, land cover, and agricultural monitoring studies, respectively, to determine where and when research could be facilitated or hampered by data availability; iii) the shortest feasible compositing windows over Europe on a yearly basis and across a variety of medium- and long-term time windows, assuming a minimum of 50% of data each year and interpolation of the missing composites; iiii) spatio-temporal capability to capture observations acquired on a specific day, here 15th June or 15th July, that correspond with key phenological states and management events. Altogether, our results aim to support informed decisions on the selection of compositing windows for land cover and land use change analyses.
2. Materials and methods
2.1. Study area
Our study area covers Europe spanning between 25°W and 45°E, and 71°N and 35°N. The area comprises 32 EEA member states (as of September 2022), six Balkan states, the United Kingdom, Ukraine, Belarus and Kaliningrad Oblast. Owing to great latitudinal and longitudinal extend the study area encompasses 17 climate zones [101] and 10 biogeographical regions (EEA, 2016; Figure 1). Environmental conditions follow a latitudinal gradient with arctic and cold climate in the northmost regions and hot Mediterranean climate in the south, and longitudinal gradient with humid Atlantic climate in the west that changes to continental and dry climate to the east. Mountain ranges are characterized by alpine conditions.
Variability of environmental conditions in Europe is reflected in land cover and land use. Forests dominate land cover (>40% or the area) with boreal coniferous forests in the north and in the high mountains, and more fragmented mixed and broadleaved stands at lower altitudes and to the south. Approximately 40% of the land in Europe is used for agriculture, which comprises perennial crops, permanent crops and grasslands. Management intensity and landscape complexity vary greatly across the area with highly-managed systems common in Western Europe and Turkey [103,104,105].
Compared to other regions, Europe is characterized by relatively high Landsat and Sentinel-2 data availability [49,50,53]. Furthermore, a discrepancy between higher Sentinel-2 observation frequencies over Europe and other geographical regions is particularly clear for the ramp-up phase of the mission before 2018. High Landsat data availability over Europe in the 1980s and 1990s arises from the extended network of historical ground receiving stations and ESA’s archiving efforts that preserved over 1.2 million unique TM and ETM+ scenes [53,106], though only half of these scenes met Level 1 Tier-1 requirements [107].
2.2. Landsat and Sentinel-2 time series and their preprocessing
We used all Landsat surface reflectance Level 2, Tier 1 (Collection 2) scenes from 1984 through 2021 and Sentinel-2 TOA reflectance Level-1C (pre-Collection-1; European Space Agency, 2021) scenes from 2016 through 2021 acquired over Europe, as available in Google Earth Engine (data accessed in June 2022; Gorelick et al., 2017). We utilized Seninel-2 Level-1C data instead of Level-2A because the Level-2A inherent quality data lack the desired scope and accuracy [110,111]. Yet, the Level-1C products are accompanied by cloud probabilities [112] facilitating improved cloud screening. Furthermore, for cloud screening we also used Band 10 (Cirrus), which is not available as Level-2A. Since we performed data availability analyses, the disparity between Landsat and Sentinel-2 reflectance values was negligible. The difference in processing levels, however, played out in cloud, shadow and snow masking accuracy, where the Sentinel-2 workflow assemble several approaches with known accuracies [113], but has not been evaluated as the whole. We, however, acknowledge that for real-life applications, data from corresponding processing levels should be used. We recommend thus either preprocessing Sentinel-2 TOA data to achieve desired quality of masks, or linking Sentinel-2 Level-A2 data with Level-1C band 10 and relevant Cloud Probability scenes for more rigorous cloud screening.
To ensure only pixels with the highest quality entered the analysis we applied conservative pixel-quality screening. For Landsat scenes we excluded all pixels flagged as cloud, shadow or snow using the inherent pixel quality bands [114,115] and discarded saturated pixels(Zhang et al., 2022). Owing to Landsat 7′s orbit drift [116], we excluded all ETM+ scenes acquired after 31st December 2020. We applied the following screening steps to Sentinel-2 Level-1C data: we excluded all pixels flagged as clouds and cirrus in the inherent ‘QA60′ cloud mask band; we excluded all pixels with cloud probability higher than 50% as defined in the corresponding Cloud Probability product; we excluded cirrus clouds (B10 reflectance >0.01); we run Cloud Displacement Analyses (CDI<-0.5; Frantz et al., 2018); and finally we excluded dark pixels (B8 reflectance <0.16) by using scene-specific sun parameters within modeled shadows casted by the clouds identified in the previous steps, assuming a cloud height of 2,000 m. We further masked a buffer of 40 m (two pixels at 20-m resolution) around each identified cloud and shadow object. Finally, we excluded snow pixels by applying thresholds from snow mask branch of the Sen2Cor processor [118].
2.3. Auxiliary data
To identify the pixel-specific growing season we used 2001-2019 time series of the yearly 500-m MODIS land cover dynamics product (MCD12Q2; Collection 6) available in Google Earth Engine (data accessed June 2022). We used only ‘best’ quality per-pixel dates of start and end of the growing season. For pixels with two growing cycles per year, we defined the growing season as a period between the onset of the first growing cycle and the end of the second growing cycle. Because both the start of the season and the end of the season showed considerable variability during the studied period, but without overall significant trends (P=0.227 and P=0.983 for start and end of season, respectively, with accounting for temporal autocorrelation following Ives et al. (2021)), we derived the pixel-based key phenological dates as 25th and 75th percentiles of the 2001-2019 distribution for the start of season and end of season, respectively (Figures S1 and S2). This approach provided a good approximation allowing us to account for intra-annual variability and to extend the use of derived dates to the entire study period of 1984-2021. Phenological information in the northern- and southern-most parts of Europe was restricted owing to low quality of data and insufficiently pronounced seasonality [120].
2.4. Data availability analysis
We used a 20-km grid of 16,642 equidistant points to analyze the availability of useable Landsat and Sentinel-2 observations over Europe. We distributed points according to the Lambert azimuthal equal-area projection (LAEA, EPSG:3035), which is the preferred projection for EU-wide products. Despite LAEA being the equal-area projection, the distance distortion within our study area was mostly below 10 m, which is less than one pixel in high-resolution Sentinel-2 bands. The systematic gridded sampling design ensured good representation of the West-East and South-North climatic and phenological gradients, and facilitated graphical presentation of results.
We intersected the point grid with each cloud-, shadow, and snow-masked Landsat and Sentinel-2 scene retrieving the date of the valid acquisition. In the process, we kept all datasets in their original resolution and assumed each point to be a probabilistic sample of the surrounding 20x20-km area. We excluded duplicated data entries coming from the vertical overlaps among Landsat tiles in the same row, and vertical and horizontal overlaps among Sentinel-2 granules from the same swath. This resulted in daily data availability for 1984-2021 (1 – valid observation; 0 – no data or unsuitable), which we used to derive data availability information for composites with aggregation periods of five, 10, 15, 20, and 25 days; one, two, three, four, six and 12 months. The non-overlapping compositing windows compartmentalized daily information for each year into 73, 37, 24, 18, 15, 12, six, four, three, two, and one composites for each calendar year, respectively. We used January 1st as the starting date for the compositing window sequence for each year. When the last compositing window was shorter than half its window width, we merged it with the penultimate composite. For each data point and every considered aggregation period we recorded the amount of available observations and considered the composite as ‘successful’ if at least one valid observation was available.
We summarized data availability for each grid point and each compositing window as the percentage of ‘successful’ composites available per year (hereafter ‘data availability’) (RO i). To reflect upon regional diversity of geographical and meteorological conditions we compiled annual mean of composites’ availability (± one standard deviation) within each biogeographical region. We considered Landsat and Sentinel-2 data records jointly and individually, and ran the analyses for the complete calendar year and pixel-specific growing season period as derived from MODIS land cover dynamics products. We included a composite into the growing season period if their timings overlapped at least one day, and reported the rate of ‘successful’ composites during the growing season only. For pixels with the growing season extending across two calendar years (e.g., in the Mediterranean region where the green vegetation peak is typically observed in December), we assigned respective statistics to the year comprising the major part of the growing season in question. Owing to the Sentinel-2 data record starting in mid-2015, we calculated Sentinel-2-only results starting from 2016.
To illustrate how data availability can affect specific LCLUC applications (RO ii), we analyzed the availability of growing season annual and monthly composites, and calendar year 10-day composites, which are commonly used in studies on forest, land cover, and agricultural monitoring, respectively (Table 1). We evaluated data availability for different land cover classes reporting the overall number of years in the time series with 100% and >50% of the composites derived successfully. To better understand spatio-temporal differences in composites availability, we summarized data availability along the latitudinal and longitudinal gradients. Furthermore, to obtain a detailed insight into the availability of single composites we used selected points across different biogeographical regions across Europe. In Germany and Spain, we intentionally placed two points not further than 35 km away of each other to compare data availability within and outside vertical overlaps among Landsat orbits.
We analyzed the length of the shortest feasible per-pixel compositing window ensuring a minimum of 50% of data availability each year, assuming temporal interpolation of the missing composites (RO iii). We selected the 50% threshold (allowing for temporal clustering of missing composites) as a liberal maximum for a hypothetical data interpolation yielding a complete data record, apprehending that the chosen data reconstruction approach, desired accuracy, and specific application may well lead to different interpolation strategies [124,125]. We extended the analyses to a variety of medium- and long-term time periods comprising calendar year and growing season observations, and used two scenarios requiring a minimum 50% of data i) across all the years, and ii) for each year in the time series.
Finally, we examined how data availability can support detection of management practices and key phenological phases (RO iiii). We derived relevant spatial patterns of temporal granularity through identifying a successful composite with the shortest possible compositing window comprising the target dates 15th June and 15th July. We selected both dates owing to their rough coincidence with timing of key phenological phases and management practices in European ecosystems and being relevant for agricultural management practices [35,126].
3. Results
3.1. Overall 1984-2021 data availability per calendar year
Availability of Landsat and Sentinel-2 composites over Europe varied over time (Figure 2). In 1984 and 1985, 15-day composites ensured only ~25% spatial data coverage, with >50% coverage assured by minimum 2-monthly composites. From 1986 through 1998, 15-day composites provided ~37% data coverage, whereas >50% data coverage was ensured by composites with a minimum monthly aggregation period, although 25-day composites also exceeded the 50% threshold in some years. 1999-2002 marked improved data availability with ~25%, ~50% and >62% data coverage achieved by 5-day, 20-day, and one-month composites, respectively. Between 2003 and 2011 data availability decreased slightly, but was still higher than before 1999 and allowed for >50% data coverage when using composites comprising minimum 25 days. 2012 marked an overall drop in data availability with monthly and 20-day composites providing data coverage of almost 50% and ~37%, respectively. Since 2013, the overall composites’ availability was the highest during the analyzed period with Landsat-derived 10-day composites ensuring close to 50%, and monthly composites providing almost 75% spatial data coverage each year. Synergetic use of Landsat and Sentinel-2 data beyond 2018 allowed us to achieve >50% and >75% data coverage using 5-day and 15-day composites, respectively, whereas Sentinel-2 time series alone ensured ~62% data coverage already with 10-day composites (Figure 2).
3.2. Data availability across biogeographical regions per calendar year
Data availability varied among biogeographical regions of Europe (Figure 2). The Mediterranean region had the greatest spatial data availability per calendar year with 15-day and monthly composites ensuring >50% and >75% data coverage, respectively, during the 1990s and 2000s. Beyond 2014, Landsat-based 10-day composites ensured >62% data coverage in the Mediterranean region (Figure S4), whereas combining Landsat and Sentinel-2 data allowed for >62% data coverage already with 5-day composites (Figure 2). Using Sentinel-2 only resulted in ~75% data coverage with 10-day composites (Figure S5). Anatolian and Pannonian regions had slightly lower data coverage, with 15-day composites frequently providing >50% spatial data coverage before 2012. From 2013 onwards, Landsat data ensured >50% data coverage in both regions based on composites aggregated over minimum 10 days (Figure S4). Synergetic use of Landsat and Sentinel-2 data resulted in >62% and ~60% data coverage in Anatolian and Pannonian regions, respectively, when we used 5-day composites, and >82% data coverage in both regions with 15-day composites. Relying on Sentinel-2 based 10-day composites ensured ~75% and ~62% data coverage in Anatolian and Pannonian regions, respectively (Figure S5).
The Steppic and Black Sea regions shared similar data availability with 20-day composites ensuring ~50% data coverage before 2012 and >62% afterwards when relying on Landsat data only (Figure S4). Sentinel-2 20-day composites provided ~75% and 75-82% data coverage for the Steppic and Black Sea regions, respectively (Figure S5). When we jointly used Landsat and Sentinel-2 time series data coverage for 20-day composites increased to >75% and >82%, respectively (Figure 2).
Continental and Atlantic biogeographical regions had moderate data availability, with the Continental region always a few more percentage points (Figure 2). While prior to 2012 10-day composites ensured >25%, or even ~32% data coverage in the Continental region, the same aggregation period provided only ~25% coverage in the Altantic region. Similarly, monthly composites assured >50% and >62% data coverage in the Continental region for 1986-1998 and 1999-2011, respectively, but only ~50% and between 50 and 62% data coverage in the Altlantic region during the same periods. Data coverage in both regions increased after 2013. When using Landsat in the Atlantic region we achieved ~50% and ~75% data coverage with 15-day and monthly composites, respectively (Figure S4). A similar data coverage was possible in the Continental biogeographical region using 10-day and 25-day composites. Combined use of Landsat and Sentinel-2 data further reduced aggregation periods ensuring >75% data coverage with minimum 20-day and 15-day composites for Atlantic and Continental regions, respectively. Concurrently, Sentinel-2 time series secured minimum 75% data coverage in the Altlantic region with 25-day composites, whereas in the Continental region the same data coverage was met with 20-day composites (Figure S5).
In the Alpine and Boreal biogeographical regions monthly composites provided ~32% data coverage priori to 1998 and between 32% and 50% during 1999-2011. After 2013 >50% data coverage was achieved with minimum 25-day composites when using only Landsat data, 10-day composites relying on Sentinel-2, and minimum 10-day composites when combining Landsat and Sentinel-2 archives (Figure 2, S5). We noted the lowest data availability in the Arctic areas where prior to 2016 using two-month composites resulted in 25-32% data coverage. Relying on Landsat data alone after 2016 ensured >32% data coverage for two-month composites, whereas combining Landsat and Sentinel-2 boosted coverage to >75%. This increase was driven by Sentinel-2 data availability securing ~50% data coverage with composites aggregated over a minimum of 15 days (Figure S5). Summarizing, six-month and annual composites ensured ~100% data coverage throughout the analysis period with the exception of the Alpine and Arctic biogeographical regions.
3.3. Overall 1984-2021 data availability per growing season
Data coverage during the growing season was higher than during the calendar year when comparing monthly or sub-monthly composites (Figure 3). While two-month composites ensured comparable data coverage, three-, four-, six-month and annual composites provided lower data coverage for the growing season as compared with the results for the calendar year (Figure 2). Furthermore, in 1993, 2003, 2011 and after 2019 six-month composites yielded lower data availability for growing season period than four-month composites. During the 1986-1998 period, 15-day composites ensured 32-50% data coverage and composites of minimum 25-day length yielded >50% data coverage for the growing season. Between 1999 and 2011 we achieved >50% data coverage with composites of minimum 20 days, and >60% data coverage with composites aggregated over minimum 25 days. After 2016 using Landsat data alone guaranteed >50% and >75% spatial data coverage for 10-day and 25-day composites, respectively. Synergetic use of Landsat and Sentinel-2 data further boosted data coverage resulting in >75% and ~82% for 10-day and 25-day composites, respectively, which was driven by Sentinel-2 ensuring >62% and ~80% data coverage, respectively.
3.4. Data availability across biogeographical regions per growing season
Narrowing the analysis scope to the pixel-specific growing season improved spatial data availability in the majority of European biogeographical regions (Figure 3). The greatest improvement occurred in the Boreal region where monthly composites ensured >50% and even >62% data coverage in some years prior to 1998, and ~75% coverage since 1999 for Landsat data alone (Figure S7). Combining Landsat and Sentinel-2 archives improved data availability after 2016 up to ~82% and >62% data coverage for minimum monthly and 5-day composites, respectively. Sentinel-2 time series assured ~82% and ~50% data coverage for those compositing periods, respectively (Figure S8). Data coverage in the Arctic region also improved, allowing for 32-50% spatial data coverage with monthly composites prior to 2016 and >75% afterwards, when Landsat and Sentinel-2 were used together. Restricting analyses to the growing season boosted data coverage also in the Alpine biogeographical region, where monthly composites ensured spatial coverage of ~50% prior to 1998, ~62% for 1999-2011 and ~75% after 2013 for Landsat data alone. Including Sentinel-2 observations further enhanced data coverage after 2016 to ~82% and ~75% for monthly and 10-day composites, respectively, which arose from 75-82% and ~62% data coverage for the said compositing period for Sentinel-2 only (Figure S8). The use of growing season observations resulted in a small increase of data coverage in the Continental region, where monthly composites ensured ~62% data coverage before 1998 and 62-75% between 1999 and 2011. Including Sentinel-2 data after 2016 further enhanced spatial data coverage for monthly composites from ~80% (Landsat only) up to ~90%. In the Pannonian and Steppic biogeographical regions gain in data coverage for growing season observations was limited only to a few percentage points in most of the years.
Restricting the compositing to the growing season had no impact on data coverage in the Atlantic, Anatolian, and Black Sea regions for monthly composites, but restricted data coverage for all composites with longer compositing period as compared to the calendar year results (Figure 3). We, however, observed an overall small decrease in data availability in the Mediterranean region when using growing season observations. 10-day composites yield there ~50% data coverage prior to 2011 and ~82% after 2013 for combined Landsat and Sentinel-2 data, and a bit less than 75% for Sentinel-2 time series (Figure S8).
Interestingly, composites spanning more than three months showed nonlinear, or even reversed relationships between compositing time window and achieved data coverage. For example, in all biogeographical regions but Mediterranean and Steppic, six-months composites tended to yield lower data availability than four-month composites (Figure 3).
3.5. Growing season annual composites for forest monitoring
Spatio-temporal availability of Landsat and Sentinel-2 data for growing season annual composites over forests was high in Europe (Figure 4). The highest temporal data availability occurred in southern Scandinavia, Central Europa, and in Greece and Turkey (>30 out of 38 years). We recorded the lowest rate of successful composites in northern Scandinavia, the British Isles, and in mountainous regions. Furthermore, we noted vertical stripes with greater temporal data availability following orbit overlaps. Overall, we observed lower success rate of composites in the early years of the data record, in the mid-1990s, early 2000s, and mid-2010s. Northern and western Europe was characterized by lower data availability, especially during the aforementioned periods. Since 2016, data coverage of growing season annual composites over forest in Europe was complete.
3.6. Growing season monthly composites for land cover monitoring
Availability of growing season monthly composites derived from Landsat and Sentinel-2 data hinged on latitude, longitude, orography, and orbit overlaps (Figure 5A). The British Isles and Iceland had the lowest number of years with a complete record of monthly composites during the growing season (<10 out of 38 years). They were followed closely by France, Germany, Scandinavia, and main mountain regions. The best data availability was in northern Italy, southern Ukraine and in the Balkans (>25). Different data availability originating from overlapping Landsat orbits were clearly visible. The lowest data availability occurred in the 1980s, mid-1990s, and in 2012-2013, with the northern and western parts of Europe affected the most. Since 2016 the availability of monthly composites increased across the board, reaching almost complete temporal coverage each year. Availability of growing season monthly composites improved greatly when we assumed that up to 50% of composites each year could be interpolated (Figure S12).
A more detailed look at availability of monthly composites across 12 sites confirmed often prolonged periods of missing data in the UK and Ireland (Figure 6 top). In France, Germany 1, Norway and Spain 2 sites missing data were less often temporally clustered, whereas in Germany 2, Spain 1, Turkey, and Ukraine months with no data occurred only sporadically. We marked substantial differences between time series recorded for two pairs of adjacent sites in Germany and Spain, where data availability for sites located within Landsat orbit overlaps (Germany 2 and Spain 1) was much greater than for the sites outside of overlap areas. The differences were especially strong in the early years of the data record.
3.7. 10-day composites for agricultural monitoring
Complete annual 10-day composite time series based on joined Landsat and Sentinel-2 archives were extremely rare over agricultural areas, and were only achieved for maximum five years in a few isolated areas in the Mediterranean region (Figure 5B). Data availability for this relatively short compositing window rarely exceeded 50% each year prior to 2016, with a clearly lower availability in northern Europe and overall lower data availability in western Europe. We again noted benefits of the overlaps across Landsat orbits. Since 2016 the overall availability of 10-day composites increased to >75%, but was still lower in the northern latitudes. Assuming that up to 50% of composites each year could be interpolated improved the overall temporal consistency of data availability in southern Europe (Figure S9).
Among all the inspected sites, the lowest availability of 10-day composites occurred in Ireland, Norway, and in the UK (Figure 6 center), with often prolonged periods of no data. Contrastingly, the highest rate of successful 10-day composites occurred in Turkey, Greece and Spain 1 sites. We observed higher success rates for 10-day composites for sites located within overlaps across Landsat orbits (i.e., Spain 1 and Germany 2). For many sites, data availability followed seasonality, with fewer successful composites in winter. Finally, since mid-2010s we marked a clear increase in the overall data availability of 10-day composites with many more successful composites even in Ireland, Norway or the UK.
3.8. Feasible compositing windows for single-year analyses
Complex data availability patterns over Europe drove complex spatial pattern of the shortest feasible compositing window with ≥50% temporal data coverage and up to 50% of data interpolated each year (Figure 7). The latitudinal variability was clear with the northern-most regions requiring longer compositing windows to satisfy the data availability criterium, and the Mediterranean area characterized by greater data availability, thus shorter compositing windows. Notably, prior 2012 meeting the 50% threshold often required two- to six-month compositing period in Scandinavia, Western, and Central Europe when using all data acquired during a given calendar year. Simultaneously, we found compositing periods of 10- to 25-days sufficient to meet the same data availability requirement in Southern Europe. Since 2014, 10-day and 15-day composites successfully provided ≥50% temporal data coverage each year for the majority of Western and Central Europe, with Scandinavia requiring at least monthly and the Mediterranean only 5-day composites. Joint use of Landsat and Sentinel-2 data after 2016 allowed on shorter compositing periods of no more than 10 days for the vast majority of the continent (Figure 7). Spatial variability in compositing periods arising from overlaps-driven data availability was obvious in all years.
Limiting data to the growing season reduced the latitudinal discrepancies in the shortest feasible compositing window. When requiring ≥50% of data each year and assuming interpolation of the remaining <50%, for most of the years prior to 2012 monthly or shorter composites were sufficient (Figure S14). Composites covering periods longer than one month were, however, typically necessary for the British Isles. From 2014 onward, 15- to 25-day Landsat-only based composites were sufficient to meet the ≥50% data availability criterium in the Mediterranean, Western and Central Europe. Combining Landsat with Sentinel-2 data allowed us to further push the shortest feasible compositing window to only 10-days (Figure S15).
3.9. Feasible compositing windows for medium- and long-term analyses
The length of the shortest feasible compositing window meeting the overall ≥50% temporal data availability threshold across all the years within medium- to long-term time periods was governed by geographical location and the time range of the analyses. For Landsat observations acquired during the calendar year the overall ≥50% temporal availability threshold was met in the northern latitudes only by composites comprising two or more months (Figure 8). Combining Landsat and Sentinel-2 data reduced the required length of the compositing window over Scandinavia to maximum one month for 2000-2021 and even to 10 days for 2017-2021. For the rest of Europe, 25-day Landsat composites were essential to meet the ≥50% temporal availability criterium for 1984-1989, and minimum 10-day composites for 1990-1999 and 2000-2009. Joint use of Landsat and Sentinel-2 time series allowed to further reduce the minimum compositing period to five days for 2000-2021 and 2017-2021, proving the added value of Sentinel-2 observations. For the complete 1984-2021 time window, ≥50% data availability was ensured by six-month composites in northern Scandinavia, monthly composites in Central Europe, and five- to 10-day composites in the Mediterranean region. Combining Landsat and Sentinel-2 data had limited benefits for the 1984-2021 time window and mostly allowed to increase feasibility of 15-day composites in Southern Europe.
Requiring ≥50% data each year and assuming interpolation of the remaining missing composites, highlighted the limited data availability especially before 2000, leading to longer compositing windows, or even incomplete time series (Figure S16). We found monthly composites to be sufficient for decadal time windows, but for the 1984-2021 and 2000-2021 range even annual composites were not always adequate. Overlaps among Landsat orbits provided a clear advantage allowing for 10-day composites in the Mediterranean region. Joint use of Landsat and Sentinel-2 shortened feasible compositing windows in the most recent years to only five days in the southern and 15 to 20 days in central and northern Europe.
Focusing our analyses on the growing season resulted in more homogeneous pattern of the shortest feasible compositing window for all considered medium- and long-term time periods when requiring ≥50% of data across all considered years (Figure 9). The latitudinal differences in the length of compositing windows were less apparent in our results, but the overlaps across orbits were still clearly visible. Although for the 1984-1989 time period, monthly to 6-monthly composites were needed, maximum monthly compositing periods were sufficient to meet the temporal data availability requirement for the 1990-1999, 2000-2009, and 2010-2021 time periods. We found that for most of Europe monthly composites were sufficient in securing ≥50% of data for the complete 1984-2021 time period too. A notable exception were the British Isles where two-monthly composites were necessary. Interestingly, for Sentinel-2 time series alone, monthly composites were the shortest compositing window that ensured ≥50% data availability for the 2017-2021 time period, with 10-day composites being adequate for the orbit overlaps.
Requiring ≥50% data for each growing season and assuming interpolation of the remaining <50% across each considered medium- and long-term time period resulted in prevalent use of monthly composites (Figure S17). Comparing with the results requiring ≥50% data for each calendar year (Figure S16) we noted shorter compositing windows in the 1980s and 2010s, but longer compositing windows in the 2000s, which altogether throttled results for all medium- and long-term analyses. While combining Landsat and Sentinel-2 shortened the required compositing window to less than 20 days, using Sentinel-2 data alone required 10-day to monthly composites to meet the 50% temporal availability threshold.
3.10. Spatial patterns of temporal granularity
The capacity to provide observations for a specific day, or its close proximity, varied greatly over Europe across the past four decades (Figure 10). Using the example of 15th June, which approximates timing of some key phenological phases and management practices (i.e., ongoing leaf unfolding in the northern latitudes, harvest of winter cereals and first mowing in Central European grasslands), we identified variable temporal granularity of composites comprising the desired day at the shortest possible aggregation period. We saw limited latitudinal difference between northern and southern Europe with cloud presence and the acquisition schedule and revisit time playing the most important role in shaping temporal granularity, along with orbit patterns. For Landsat data alone, we noted the best temporal granularity in the early 2000s and from the mid-2010s onwards, when the majority of the continent was depicted with composites comprising 10 or less days. In the remaining years temporal granularity of composites was lower and at times exceeded one month, or even several months in the North-West Europe. With the exception of 2016, Sentinel-2 time series typically ensured data granularity of less than 14 days (Figure S18). Synergetic use of Landsat and Sentinel-2 data improved temporal granularity of composites ensuring maximum 11-day temporal granularity for most of the continent, and reducing areas where granularity exceeded 20 days. We observed very similar results for 15th July (Figure S19 and S20), however with improved granularity in early 1990s and late 2000s.
4. Discussion
Compositing is among the data processing approaches facilitating land cover and land use related analyses through providing time series of cloud-free synthetic, temporally equidistant images. Although a lot of consideration is given to the methods identifying the ‘best’ pixel value for each time step, identification of the aggregation period recognizing temporal granularity of the process of interest and data availability over time and space receives less attention. Here, we analyzed lengths of data compositing periods feasible for Landsat and Sentinel-2 time series across Europe, considering minimum data availability requirements, and showcased the implications of data availability on selected applications.
We found that the Landsat data record ensured >50% overall spatial data coverage with monthly composites each year prior to 2011, and ~75% data coverage after 2014. Combining Landsat and Sentinel-2 archives from 2015 onward resulted in ~82% spatial data coverage for monthly composites each year, and between 62% and 75% coverage for 10-day composites. Temporal data coverage across a selection of medium- and long-term time periods was, however, limited in the northern latitudes, which necessitated compositing windows of minimum one month even when liberal ≥50% data availability threshold hence extensive data interpolation were imposed. As expected, data availability varied among biogeographical regions with the highest overall data coverage in Mediterranean and the lowest in Arctic, Alpine, and Boreal regions, hampering the feasibility of using short compositing windows for some applications in those regions. Limiting the annual data window to the growing season typically improved data coverage for composites with temporal granularity of less than one month, and reduced latitudinal diversity of feasible compositing windows, though consistency of data availability across medium- and long-term time periods remained mostly insufficient.
4.1. Data availability over Europe
Predictably, overall data coverage over Europe followed the timeline of the different phases of the Landsat and Sentinel-2 missions (Figure 6 bottom). The difference in overall data coverage provided by a single Landsat 5 satellite in mid- to late-1990s was only a few percentage points lower compared to times of synergetic operation of Landsat 4 and 5 (1984-1994) and Landsat 5 and 7 (1999-2013) (Figure 2 vs. Figure 6), which is due to low acquisition load of Landsat 4, reduced Landsat 5 acquisitions during 1999-2003, and limited capacity of Landsat 7 after 2003. Notably, the Landsat 7 SLC failure in 2003 (Andréfouët et al., 2003) and technical issues of Landsat 5 since November 2011 that led to its decommissioning, had a clear negative impact on data availability, which is visible in spatial and temporal patterns. The first two years of our Landsat record were also characterized by low data coverage due to low acquisition load and potentially also preparations for a commercial phase of the mission operations in 1985 [37]. We observed relatively high data coverage during the commercialization era of the Landsat Program (1985-2001), which stems from ESA’s archiving efforts and data consolidated [53,106], though notably only half of the preserved scenes were successfully processed to Level 1 [107]. Overall, this distinguishes Europe from other geographical regions that typically have much lower Landsat data availability prior to 2010 [50], but is far from data density available for this time period for the USA, Australia, and East China.
Since the launch of Landsat 8 in 2013, the overall data availability in Europe has greatly improved. The commence of Landsat 8 mission boosted Landsat-based data coverage providing ~75% annual spatial data coverage with monthly composites. The 2021 decline in data coverage arises from the exclusion of Landsat 7 data acquired after 31st December 2020 [116], but with Landsat 9 being operational since 2022 [2] the data availability will further increase. Furthermore, the Sentinel-2 constellation provided a remarkable source of data since 2016. With only 5-day revisit time, Sentinel-2 ensured much higher data frequency, thus typically supported shorter aggregation periods and higher temporal granularity comparing with Landsat. Combining Landsat and Sentinel-2 observations further improved spatial and temporal data coverage for most compositing windows and geographies, allowing much higher temporal granularity and time series consistency, and thus a better monitoring of land cover and land use.
Geographical location was the second factor driving differences in data coverage across Europe. As expected, regions in higher latitudes, and thus characterized by longer winters, and areas under maritime climate prone to higher cloud cover probability [51], exhibited lower and more irregular data availability, thus required longer aggregation periods even when assuming interpolation of <50% of data. Similarly, mountain ranges also showed lower data coverage arising from cloud formation [128] and snow cover (Notarnicola, 2020). When restricting our analyses to the per-pixel growing season, data coverage improved in the Alpine, Arctic and Boreal regions. On the contrary, in the Mediterranean region growing season analyses yielded lower data availability than analyses for the calendar year, which is due to growing season being governed by precipitation in the hot climate with dry summers. Finally, focus on the growing season lead to no improvements in the Atlantic biogeographical region, which is characterized by high cloud probability throughout the year. Notably, compositing windows comprising between three and 12 months sometimes yielded lower than expected temporal data availability for the growing season. This steams from our inclusive rules on including a composite as a growing-season-specific, which in some regions introduced composites with very low data availability. Altogether, we found the use of growing season data favorable in some geographies and conditions, while we caution for its general use, recognizing further that many approaches require or benefit from all-year acquisitions [28,130].
Finally, orbit overlaps systematically impact data availability At least two times higher average number of acquisitions in the areas of orbit overlaps as compared to the non-overlapping areas also translate into, on average, shorter compositing windows. This inconsistency is further convoluted for the high latitudes where the overlaps are increasingly greater, ultimately leading to multiple overlaps between more than the two neighboring orbits in the northernmost regions of Europe, as well as when more than one data source is used (Figure S21). Although the greatest difference in number of acquisitions occurs along the latitudinal gradient, the absolute data availability in the northern regions is depleted due to meteorological conditions. Nevertheless, data availability infers heterogeneous quality of per-pixel compositing and different temporal granularity across regions and times, with sometimes startling differences within very close range. Acknowledging this heterogeneity is crucial when selecting the length of a compositing period, and when deriving and discussing results’ quality [126,131].
4.2. Impact of the processing workflow on the results
Data preprocessing and processing play a significant role in shaping availability and quality of data in the time series. Here we used all Landsat surface reflectance and Sentinel-2 TOA data available in Google Earth Engine (as of June 2022) and relied on cloud, cloud shadow, and snow masking functionality available in this environment. Including all scenes, regardless their scene-specific cloud cover metadata property, in theory, allowed us to incorporate all usable observations. This presents an advantage over using only acquisitions with scene-specific cloud cover below a certain user-defined threshold (e.g., <75% in Hemmerling et al. (2021) and <70% in Nill et al. (2022) and Frantz et al. (2022)). However, inclusion of the most cloudy scenes may increase the probability of introducing lower quality observations into the time series due to higher geolocation errors and omission errors in cloud and cloud shadow masking, as well as adjacency effects [113,114]. In our analyses we relied on Fmask version 3.3.1 for cloud, cloud shadow, and snow masking for Landsat [114,115], and expanded cloud and shadow identification for Sentinel-2 beyond the Cloud Probability product. The latter combined with Sen2Cor-based snow detection and the Sentinel-2 B10 cirrus-related threshold likely increased the commission error of cloud masking by excluding bright surfaces, such as rock and sand surfaces [110], but also boosted detection of cirrus clouds and thus reduced low-quality observations in the time series. Moreover, simplified assumptions about uniform clouds’ height may translate into higher omission of cloud shadows. We acknowledge that performing the same analysis using alternative processing workflows will lead to different results due to the application of different cloud, cloud shadows, and snow masking approaches with often largely different properties in cloud detection user’s and producer’s accuracies [113] that will affect the number of usable observation. Last but not least, all currently available cloud detection algorithms come with some level of omission error (see Skakun et al., 2022 – note that cloud shadow detection does not reach the same accuracy as cloud detection, see e.g., Zhu and Woodcock, 2012), which means that the ‘successfully’ generated composite may not always be factually cloud-free. This is principally important to acknowledge when data are processed using conceptually simpler cloud, shadow and snow detection approaches. Hence, our analyses are rather conservative with regard to their practical use. Overall, we are hence convinced that our results provide a valid generic overview of availability of usable Landsat and Sentinel-2 data over Europe since 1984.
Finally, our relatively sparse 20-km grid captured environmental gradients and orbit overlaps across Europe well. Although some local variability in data availability arising from cloud formation or snow cover duration may be omitted in our results, the broad data availability across Europe is appropriately represented adequately.
4.3. Implications for time-series analyses
Variability in Landsat and Sentinel-2 availability in time and space translated directly into the feasibility of creating continuous time series of spatially homogeneous composites for different aggregation windows over desired time periods. Despite relative data abundance in the most recent years, especially after 2015 for combined Landsat and Sentinel-2 archives, availability of usable data was often sparse for medium- and long-term applications and analyses. Data scarcity in the first 20 years of the Landsat record combined with occasional low data availability thereafter throttled spatial and temporal consistency of composite-based time series even for annual composites, affecting feasibility of some long-term LCLUC applications or leading to potential inaccuracies in, for example, labeling the time of land cover change.
Big improvement in spatial and temporal consistency of data was secured assuming interpolation of up to 50% of the composites each year (Figures S13-S17), or across a complete time series of interest (Figure 8 and Figure 9). Data enhancement granted long-term analyses based on sub-annual composites, though complete 1984-2021 data coverage for monthly composites, and even more so for shorter compositing windows was still problematic. While reliability of interpolation depends on availability and distribution of the data [124,125] and used interpolation algorithms [133,134], any data interpolation provides only a simplified representation of the actual temporal variability. Consequently, interpolated data give only a generalized approximation of intra- and inter-annual variability, which is appropriate for some analyses and application areas (e.g., most of the forest disturbance monitoring and overall vegetation productivity studies) but may be problematic for the others (e.g., management intensity and mowing detection analyses).
Importantly, in our analyses we assumed that a single observation within each aggregation period will result in a successful composite. However, the quality of compositing depends on data availability for each compositing window [65,66] with some compositing algorithms requiring more than one observation for each aggregation period. Consequently, more conservative compositing approaches may require longer aggregation periods (Figures S22–S27), with depleted temporal and spatial consistency of the resulting time series.
Overall, our results highlighted challenges in time series analyses based on Landsat and Sentinel-2 arising from highly variable data availability over Europe. Data availability may present a major limitation depending on the application, time frame of the analysis, compositing approach, additional postprocessing, and data interpolation. Time series of composites based on shorter aggregation windows and spanning longer time periods, especially before 2015, are most likely to be affected and comprise data gaps, which, depending on the application, may lend lower credibility of the subsequent analyses. As such, our analysis offers a readily available first assessment of 1984-2021 data availability for local to continental LCLUC analyses, informing thus on potential challenges and uncertainties, therefore allowing for a better understanding of downstream error budgets.
5. Conclusions
Here we demonstrated that the availability of usable 1984-2021 Landsat and Sentinel-2 observations over Europe varies greatly over time and space. This heterogeneity may result in inconsistent composited time series, which directly translates into feasibility and quality of some land cover and land use analyses and applications. This is particularly critical when expanding the temporal domain across different sensors and larger regions, where analyses at all spatial level should take these heterogeneities into account.
Our results indicated that achieving consistent availability of monthly 1984-2021 data over Europe requires extensive data interpolation, which may not be appropriate for all land cover and land use-related analyses and applications. Feasibility of consistent time series based on composites with shorter than monthly aggregation periods is mostly limited to the combined Landsat and Sentinel-2 archives after 2015, yet still may require extensive data interpolation in some geographies. In the Mediterranean biogeographical region, where overall data availability is the best, sub-monthly composites are most achievable. Among others, lower data availability may limit capability for rigorous Landsat-only-based, multi-decadal agricultural monitoring in some regions. However, the current Landsat and Sentinel-2 setups, and the planned Landsat Next and Sentinel Next Generation secure archives of dense data acquisitions that satisfy most requirements of most of the LCLUC applications for the upcoming years.
Overall, our results provide a detailed assessment of Landsat and Sentinel-2 data availability for compositing over Europe, suggesting concrete compositing windows feasible under selected analysis assumptions, time periods, and for exemplified application. Because these results represent only a fraction of possible analysis setups, we acknowledge that, while providing a general guideline for selecting suitable aggregation windows for composite-based studies, our results cannot accommodate all application-specific needs. To support informed decisions on application- and region-specific analyses, we refer users to the interactive, GEE-based interface (see “Data availability”) to use their respective settings for simulating compositing opportunities.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org.
Data Availability Statement
The data presented in this study are available in Dryads as (tba). Furthermore, they can be interactively browsed through a GEE App: https://katarzynaelewinska.users.earthengine.app/view/europedataval.
Acknowledgments
The research presented in this paper was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Project-ID 414984028 – SFB 1404 FONDA. This research contributed to the Landsat Science Team 2018–2023. We express our gratitude to three anonymous reviewers whose comments markedly improved the quality of the paper.
References
- Roy, D.P.; Wulder, M.A.; Loveland, T.R.; C.E., W.; Allen, R.G.; Anderson, M.C.; Helder, D.; Irons, J.R.; Johnson, D.M.; Kennedy, R.; et al. Landsat-8: Science and product vision for terrestrial global change research. Remote Sensing of Environment 2014, 145, 154–172. [CrossRef]
- Wulder, M.A.; Roy, D.P.; Radeloff, V.C.; Loveland, T.R.; Anderson, M.C.; Johnson, D.M.; Healey, S.; Zhu, Z.; Scambos, T.A.; Pahlevan, N.; et al. Fifty years of Landsat science and impacts. Remote Sensing of Environment 2022, 280, 113195. [Google Scholar] [CrossRef]
- Shang, R.; Zhu, Z.; Zhang, J.; Qiu, S.; Yang, Z.; Li, T.; Yang, X. Near-real-time monitoring of land disturbance with harmonized Landsats 7–8 and Sentinel-2 data. Remote Sensing of Environment 2022, 278, 113073. [Google Scholar] [CrossRef]
- Tang, X.; Bullock, E.L.; Olofsson, P.; Woodcock, C.E. Can VIIRS continue the legacy of MODIS for near real-time monitoring of tropical forest disturbance? Remote Sensing of Environment 2020, 249, 112024. [Google Scholar] [CrossRef]
- Chen, S.; Woodcock, C.E.; Bullock, E.L.; Arévalo, P.; Torchinava, P.; Peng, S.; Olofsson, P. Monitoring temperate forest degradation on Google Earth Engine using Landsat time series analysis. Remote Sensing of Environment 2021, 265, 112648. [Google Scholar] [CrossRef]
- Lewińska, K.E.; Buchner, J.; Bleyhl, B.; Hostert, P.; Yin, H.; Kuemmerle, T.; Radeloff, V.C. Changes in the grasslands of the Caucasus based on Cumulative Endmember Fractions from the full 1987–2019 Landsat record. Science of Remote Sensing 2021, 4, 100035. [Google Scholar] [CrossRef]
- Potapov, P.; Hansen, M.C.; Pickens, A.; Hernandez-Serna, A.; Tyukavina, A.; Turubanova, S.; Zalles, V.; Li, X.; Khan, A.; Stolle, F.; et al. The Global 2000-2020 Land Cover and Land Use Change Dataset Derived From the Landsat Archive: First Results. Front. Remote Sens. 2022, 3, 856903. [Google Scholar] [CrossRef]
- Zhu, Z.; Qiu, S.; Ye, S. Remote sensing of land change: A multifaceted perspective. Remote Sensing of Environment 2022, 282, 113266. [Google Scholar] [CrossRef]
- Potapov, P.; Hansen, M.C.; Kommareddy, I.; Kommareddy, A.; Turubanova, S.; Pickens, A.; Adusei, B.; Tyukavina, A.; Ying, Q. Landsat Analysis Ready Data for Global Land Cover and Land Cover Change Mapping. Remote Sensing 2020, 12, 426. [Google Scholar] [CrossRef]
- Vogelmann, J.E.; Gallant, A.L.; Shi, H.; Zhu, Z. Perspectives on monitoring gradual change across the continuity of Landsat sensors using time-series data. Remote Sensing of Environment 2016, 185, 258–270. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Yang, Z.; Cohen, W.B. Detecting trends in forest disturbance and recovery using yearly Landsat time series: 1. LandTrendr — Temporal segmentation algorithms. Remote Sensing of Environment 2010, 114, 2897–2910. [Google Scholar] [CrossRef]
- Homer, C.; Dewitz, J.; Jin, S.; Xian, G.; Costello, C.; Danielson, P.; Gass, L.; Funk, M.; Wickham, J.; Stehman, S.; et al. Conterminous United States land cover change patterns 2001–2016 from the 2016 National Land Cover Database. ISPRS Journal of Photogrammetry and Remote Sensing 2020, 162, 184–199. [Google Scholar] [CrossRef]
- Xie, Y.; Lark, T.J. Mapping annual irrigation from Landsat imagery and environmental variables across the conterminous United States. Remote Sensing of Environment 2021, 260, 112445. [Google Scholar] [CrossRef]
- Yin, H.; Brandão, A.; Buchner, J.; Helmers, D.; Iuliano, B.G.; Kimambo, N.E.; Lewińska, K.E.; Razenkova, E.; Rizayeva, A.; Rogova, N.; et al. Monitoring cropland abandonment with Landsat time series. Remote Sensing of Environment 2020, 246, 111873. [Google Scholar] [CrossRef]
- Halabisky, M.; Moskal, L.M.; Gillespie, A.; Hannam, M. Reconstructing semi-arid wetland surface water dynamics through spectral mixture analysis of a time series of Landsat satellite images (1984–2011). Remote Sensing of Environment 2016, 177, 171–183. [Google Scholar] [CrossRef]
- Pekel, J.-F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-resolution mapping of global surface water and its long-term changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef]
- Yao, F.; Wang, J.; Wang, C.; Crétaux, J.-F. Constructing long-term high-frequency time series of global lake and reservoir areas using Landsat imagery. Remote Sensing of Environment 2019, 232, 111210. [Google Scholar] [CrossRef]
- Goldblatt, R.; Stuhlmacher, M.F.; Tellman, B.; Clinton, N.; Hanson, G.; Georgescu, M.; Wang, C.; Serrano-Candela, F.; Khandelwal, A.K.; Cheng, W.-H.; et al. Using Landsat and nighttime lights for supervised pixel-based image classification of urban land cover. Remote Sensing of Environment 2018, 205, 253–275. [Google Scholar] [CrossRef]
- Li, X.; Zhou, Y.; Zhu, Z.; Liang, L.; Yu, B.; Cao, W. Mapping annual urban dynamics (1985–2015) using time series of Landsat data. Remote Sensing of Environment 2018, 216, 674–683. [Google Scholar] [CrossRef]
- Schug, F.; Frantz, D.; Wiedenhofer, D.; Haberl, H.; Virág, D.; van der Linden, S.; Hostert, P. High-resolution mapping of 33 years of material stock and population growth in Germany using Earth Observation data. J of Industrial Ecology 2022, jiec.13343. [Google Scholar] [CrossRef]
- Phiri, D.; Simwanda, M.; Salekin, S.; Nyirenda, V.R.; Murayama, Y.; Ranagalage, M. Sentinel-2 Data for Land Cover/Use Mapping: A Review. REMOTE SENSING 2020, 12. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sensing of Environment 2012, 120, 25–36. [Google Scholar] [CrossRef]
- European Commission COM (2011) 152 final; European Comission: Brussels, 2011.
- Hunt, M.L.; Blackburn, G.A.; Carrasco, L.; Redhead, J.W.; Rowland, C.S. High resolution wheat yield mapping using Sentinel-2. Remote Sensing of Environment 2019, 233, 111410. [Google Scholar] [CrossRef]
- Kowalski, K.; Okujeni, A.; Brell, M.; Hostert, P. Quantifying drought effects in Central European grasslands through regression-based unmixing of intra-annual Sentinel-2 time series. Remote Sensing of Environment 2022, 268, 112781. [Google Scholar] [CrossRef]
- Schwieder, M.; Buddeberg, M.; Kowalski, K.; Pfoch, K.; Bartsch, J.; Bach, H.; Pickert, J.; Hostert, P. Estimating Grassland Parameters from Sentinel-2: A Model Comparison Study. PFG 2020, 88, 379–390. [Google Scholar] [CrossRef]
- Hemmerling, J.; Pflugmacher, D.; Hostert, P. Mapping temperate forest tree species using dense Sentinel-2 time series. Remote Sensing of Environment 2021, 267, 112743. [Google Scholar] [CrossRef]
- Lang, N.; Schindler, K.; Wegner, J.D. Country-wide high-resolution vegetation height mapping with Sentinel-2. Remote Sensing of Environment 2019, 233, 111347. [Google Scholar] [CrossRef]
- Pahlevan, N.; Sarkar, S.; Franz, B.A.; Balasubramanian, S.V.; He, J. Sentinel-2 MultiSpectral Instrument (MSI) data processing for aquatic science applications: Demonstrations and validations. Remote Sensing of Environment 2017, 201, 47–56. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, J.; Li, J.; Meng, Y.; Pokhrel, Y.; Zhang, H. Basin-scale high-resolution extraction of drainage networks using 10-m Sentinel-2 imagery. Remote Sensing of Environment 2021, 255, 112281. [Google Scholar] [CrossRef]
- Schug, F.; Frantz, D.; Okujeni, A.; van der Linden, S.; Hostert, P. Mapping urban-rural gradients of settlements and vegetation at national scale using Sentinel-2 spectral-temporal metrics and regression-based unmixing with synthetic training data. Remote Sensing of Environment 2020, 246, 111810. [Google Scholar] [CrossRef]
- Yang, X.; Qin, Q.; Grussenmeyer, P.; Koehl, M. Urban surface water body detection with suppressed built-up noise based on water indices from Sentinel-2 MSI imagery. Remote Sensing of Environment 2018, 219, 259–270. [Google Scholar] [CrossRef]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sensing of Environment 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Tian, F.; Cai, Z.; Jin, H.; Hufkens, K.; Scheifinger, H.; Tagesson, T.; Smets, B.; Van Hoolst, R.; Bonte, K.; Ivits, E.; et al. Calibrating vegetation phenology from Sentinel-2 using eddy covariance, PhenoCam, and PEP725 networks across Europe. Remote Sensing of Environment 2021, 260, 112456. [Google Scholar] [CrossRef]
- Woodcock, C.E.; Loveland, T.R.; Herold, M.; Bauer, M.E. Transitioning from change detection to monitoring with remote sensing: A paradigm shift. Remote Sensing of Environment 2020, 238, 111558. [Google Scholar] [CrossRef]
- Wulder, M.A.; Masek, J.G.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Opening the archive: How free data has enabled the science and monitoring promise of Landsat. Remote Sensing of Environment 2012, 122, 2–10. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Continuous change detection and classification of land cover using all available Landsat data. Remote Sensing of Environment 2014, 144, 152–171. [Google Scholar] [CrossRef]
- Feng Gao; Masek, J. ; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sensing 2006, 44, 2207–2218. [Google Scholar] [CrossRef]
- Yan, L.; Roy, D. Large-Area Gap Filling of Landsat Reflectance Time Series by Spectral-Angle-Mapper Based Spatio-Temporal Similarity (SAMSTS). Remote Sensing 2018, 10, 609. [Google Scholar] [CrossRef]
- Houborg, R.; McCabe, M.F. A Cubesat enabled Spatio-Temporal Enhancement Method (CESTEM) utilizing Planet, Landsat and MODIS data. Remote Sensing of Environment 2018, 209, 211–226. [Google Scholar] [CrossRef]
- Li, J.; Chen, B. Global Revisit Interval Analysis of Landsat-8 -9 and Sentinel-2A -2B Data for Terrestrial Monitoring. Sensors 2020, 20, 6631. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Atkinson, P.M. Spatio-temporal fusion for daily Sentinel-2 images. Remote Sensing of Environment 2018, 204, 31–42. [Google Scholar] [CrossRef]
- Wulder, M.A.; Hilker, T.; White, J.C.; Coops, N.C.; Masek, J.G.; Pflugmacher, D.; Crevier, Y. Virtual constellations for global terrestrial monitoring. Remote Sensing of Environment 2015, 170, 62–76. [Google Scholar] [CrossRef]
- Claverie, M.; Ju, J.; Masek, J.G.; Dungan, J.L.; Vermote, E.F.; Roger, J.-C.; Skakun, S.V.; Justice, C. The Harmonized Landsat and Sentinel-2 surface reflectance data set. REMOTE SENSING OF ENVIRONMENT 2018, 219, 145–161. [Google Scholar] [CrossRef]
- Frantz, D. FORCE—Landsat + Sentinel-2 Analysis Ready Data and Beyond. Remote Sensing 2019, 11, 1124. [Google Scholar] [CrossRef]
- Saunier, S.; Louis, J.; Debaecker, V.; Beaton, T.; Cadau, E.G.; Boccia, V.; Gascon, F. Sen2like, A Tool To Generate Sentinel-2 Harmonised Surface Reflectance Products - First Results with Landsat-8. In Proceedings of the IGARSS 2019 - 2019 IEEE International Geoscience and Remote Sensing Symposium; IEEE: Yokohama, Japan, 2019; pp. 5650–5653. [Google Scholar]
- Kovalskyy, V.; Roy, D.P. The global availability of Landsat 5 TM and Landsat 7 ETM+ land surface observations and implications for global 30m Landsat data product generation. Remote Sensing of Environment 2013, 130, 280–293. [Google Scholar] [CrossRef]
- Sudmanns, M.; Tiede, D.; Augustin, H.; Lang, S. Assessing global Sentinel-2 coverage dynamics and data availability for operational Earth observation (EO) applications using the EO-Compass. International Journal of Digital Earth 2020, 13, 768–784. [Google Scholar] [CrossRef]
- Zhang, Y.; Woodcock, C.E.; Arévalo, P.; Olofsson, P.; Tang, X.; Stanimirova, R.; Bullock, E.; Tarrio, K.R.; Zhu, Z.; Friedl, M.A. A Global Analysis of the Spatial and Temporal Variability of Usable Landsat Observations at the Pixel Scale. Front. Remote Sens. 2022, 3, 894618. [Google Scholar] [CrossRef]
- Sfîcă, L.; Beck, C.; Nita, A.; Voiculescu, M.; Birsan, M.; Philipp, A. Cloud cover changes driven by atmospheric circulation in Europe during the last decades. Int J Climatol 2021, 41. [Google Scholar] [CrossRef]
- Tzallas, V.; Hatzianastassiou, N.; Benas, N.; Meirink, J.; Matsoukas, C.; Stackhouse, P.; Vardavas, I. Evaluation of CLARA-A2 and ISCCP-H Cloud Cover Climate Data Records over Europe with ECA&D Ground-Based Measurements. Remote Sensing 2019, 11, 212. [Google Scholar] [CrossRef]
- Wulder, M.A.; White, J.C.; Loveland, T.R.; Woodcock, C.E.; Belward, A.S.; Cohen, W.B.; Fosnight, E.A.; Shaw, J.; Masek, J.G.; Roy, D.P. The global Landsat archive: Status, consolidation, and direction. Remote Sensing of Environment 2016, 185, 271–283. [Google Scholar] [CrossRef]
- Azzari, G.; Lobell, D.B. Landsat-based classification in the cloud: An opportunity for a paradigm shift in land cover monitoring. Remote Sensing of Environment 2017, 202, 64–74. [Google Scholar] [CrossRef]
- Pflugmacher, D.; Rabe, A.; Peters, M.; Hostert, P. Mapping pan-European land cover using Landsat spectral-temporal metrics and the European LUCAS survey. REMOTE SENSING OF ENVIRONMENT 2019, 221, 583–595. [Google Scholar] [CrossRef]
- Potapov, P.V.; Turubanova, S.A.; Tyukavina, A.; Krylov, A.M.; McCarty, J.L.; Radeloff, V.C.; Hansen, M.C. Eastern Europe’s forest cover dynamics from 1985 to 2012 quantified from the full Landsat archive. Remote Sensing of Environment 2015, 159, 28–43. [Google Scholar] [CrossRef]
- Bullock, E.L.; Woodcock, C.E.; Olofsson, P. Monitoring tropical forest degradation using spectral unmixing and Landsat time series analysis. Remote Sensing of Environment 2020, 238, 110968. [Google Scholar] [CrossRef]
- Rufin, P.; Frantz, D.; Ernst, S.; Rabe, A.; Griffiths, P.; Özdoğan, M.; Hostert, P. Mapping Cropping Practices on a National Scale Using Intra-Annual Landsat Time Series Binning. Remote Sensing 2019, 11, 232. [Google Scholar] [CrossRef]
- Cihlar, J.; Manak, D.; D’Iorio, M. Evaluation of compositing algorithms for AVHRR data over land. IEEE Trans. Geosci. Remote Sensing 1994, 32, 427–437. [Google Scholar] [CrossRef]
- Tucker, C.J.; Pinzon, J.E.; Brown, M.E.; Slayback, D.A.; Pak, E.W.; Mahoney, R.; Vermote, E.F.; El Saleous, N. An extended AVHRR 8-km NDVI dataset compatible with MODIS and SPOT vegetation NDVI data. International Journal of Remote Sensing 2005, 26, 4485–4498. [Google Scholar] [CrossRef]
- Vermote, E. MODIS/Terra Surface Reflectance 8-Day L3 Global 250m SIN Grid V061. NASA EOSDIS Land Processes DAAC. 2021. [Google Scholar] [CrossRef]
- Wolfe, R.E.; Roy, D.P.; Vermote, E. MODIS land data storage, gridding, and compositing methodology: Level 2 grid. IEEE Trans. Geosci. Remote Sensing 1998, 36, 1324–1338. [Google Scholar] [CrossRef]
- Roy, D.P.; Ju, J.; Kline, K.; Scaramuzza, P.L.; Kovalskyy, V.; Hansen, M.; Loveland, T.R.; Vermote, E.; Zhang, C. Web-enabled Landsat Data (WELD): Landsat ETM+ composited mosaics of the conterminous United States. Remote Sensing of Environment 2010, 114, 35–49. [Google Scholar] [CrossRef]
- Zanaga, Daniele; Van De Kerchove, Ruben; Daems, Dirk; De Keersmaecker, Wanda; Brockmann, Carsten; Kirches, Grit; Wevers, Jan; Cartus, Oliver; Santoro, Maurizio; Fritz, Steffen; et al. ESA WorldCover 10 m 2021 v200 2022. [CrossRef]
- Francini, S.; Hermosilla, T.; Coops, N.C.; Wulder, M.A.; White, J.C.; Chirici, G. An assessment approach for pixel-based image composites. ISPRS Journal of Photogrammetry and Remote Sensing 2023, 202, 1–12. [Google Scholar] [CrossRef]
- Van doninck, J.; Tuomisto, H. Influence of Compositing Criterion and Data Availability on Pixel-Based Landsat TM/ETM+ Image Compositing Over Amazonian Forests. IEEE J. Sel. Top. Appl. Earth Observations Remote Sensing 2017, 10, 857–867. [Google Scholar] [CrossRef]
- Dennison, P.E.; Roberts, D.A.; Peterson, S.H. Spectral shape-based temporal compositing algorithms for MODIS surface reflectance data. Remote Sensing of Environment 2007, 109, 510–522. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; Olofsson, P.; Woodcock, C.E.; Jin, S. Evaluation of Landsat image compositing algorithms. Remote Sensing of Environment 2023, 285, 113375. [Google Scholar] [CrossRef]
- Ruefenacht, B. Comparison of Three Landsat TM Compositing Methods: A Case Study Using Modeled Tree Canopy Cover. Photogram Engng Rem Sens 2016, 82, 199–211. [Google Scholar] [CrossRef]
- Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W.; Campbell, L.B. Mass data processing of time series Landsat imagery: pixels to data products for forest monitoring. International Journal of Digital Earth 2016, 9, 1035–1054. [Google Scholar] [CrossRef]
- Griffiths, P.; Nendel, C.; Hostert, P. Intra-annual reflectance composites from Sentinel-2 and Landsat for national-scale crop and land cover mapping. Remote Sensing of Environment 2019, 220, 135–151. [Google Scholar] [CrossRef]
- Kottek, M.; Grieser, J.; Beck, C.; Rudolf, B.; Rubel, F. World Map of the Köppen-Geiger climate classification updated. metz 2006, 15, 259–263. [Google Scholar] [CrossRef] [PubMed]
- EEA Biogeographical regions Available online: https://www.eea.europa.eu/data-and-maps/data/biogeographical-regions-europe-3.
- Estel, S.; Mader, S.; Levers, C.; Verburg, P.H.; Baumann, M.; Kuemmerle, T. Combining satellite data and agricultural statistics to map grassland management intensity in Europe. Environ. Res. Lett. 2018, 13, 074020. [Google Scholar] [CrossRef]
- Rega, C.; Short, C.; Pérez-Soba, M.; Luisa Paracchini, M. A classification of European agricultural land using an energy-based intensity indicator and detailed crop description. Landscape and Urban Planning 2020, 198, 103793. [Google Scholar] [CrossRef]
- Zillmann, E.; Gonzalez, A.; Montero Herrero, E.J.; van Wolvelaer, J.; Esch, T.; Keil, M.; Weichelt, H.; Garzon, A.M. Pan-European Grassland Mapping Using Seasonal Statistics From Multisensor Image Time Series. IEEE J. Sel. Top. Appl. Earth Observations Remote Sensing 2014, 7, 3461–3472. [Google Scholar] [CrossRef]
- Gascon, F.; Biasutti, R.; Ferrara, R.; Fischer, P.; Galli, L.; Hoersch, B.; Hopkins, S.; Jackson, J.; Lavender, S.; Mica, S.; et al. European Space Agency (ESA) Landsat MSS/TM/ETM+ Archive Bulk-Processing: processor improvements and data quality.; Butler, J.J., Xiong, X. (Jack), Gu, X., Eds.; San Diego, California, United States, 2014; p. 92181C.
- USGS Landsat Thematic Mapper No-Payload Correction Data | U.S. Geological Survey. Available online: https://www.usgs.gov/landsat-missions/landsat-thematic-mapper-no-payload-correction-data (accessed on Dec 2, 2022).
- European Space Agency Sentinel-2 MSI Level-1C TOA Reflectance, Collection 0 2021. [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sensing of Environment 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Baetens, L.; Desjardins, C.; Hagolle, O. Validation of Copernicus Sentinel-2 Cloud Masks Obtained from MAJA, Sen2Cor, and FMask Processors Using Reference Cloud Masks Generated with a Supervised Active Learning Procedure. Remote Sensing 2019, 11, 433. [Google Scholar] [CrossRef]
- Coluzzi, R.; Imbrenda, V.; Lanfredi, M.; Simoniello, T. A first assessment of the Sentinel-2 Level 1-C cloud mask product to support informed surface analyses. Remote Sensing of Environment 2018, 217, 426–443. [Google Scholar] [CrossRef]
- Zupanc, A. Improving cloud detection with machine learning 2017.
- Skakun, S.; Wevers, J.; Brockmann, C.; Doxani, G.; Aleksandrov, M.; Batič, M.; Frantz, D.; Gascon, F.; Gómez-Chova, L.; Hagolle, O.; et al. Cloud Mask Intercomparison eXercise (CMIX): An evaluation of cloud masking algorithms for Landsat 8 and Sentinel-2. Remote Sensing of Environment 2022, 274, 112990. [Google Scholar] [CrossRef]
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Joseph Hughes, M.; Laue, B. Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sensing of Environment 2017, 194, 379–390. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sensing of Environment 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; Shang, R.; Crawford, C.J. Can Landsat 7 preserve its science capability with a drifting orbit? Science of Remote Sensing 2021, 4, 100026. [Google Scholar] [CrossRef]
- Frantz, D.; Haß, E.; Uhl, A.; Stoffels, J.; Hill, J. Improvement of the Fmask algorithm for Sentinel-2 images: Separating clouds from bright surfaces based on parallax effects. Remote Sensing of Environment 2018, 215, 471–481. [Google Scholar] [CrossRef]
- Main-Knorn, M.; Pflug, B.; Louis, J.; Debaecker, V.; Müller-Wilm, U.; Gascon, F. Sen2Cor for Sentinel-2. In Proceedings of the Image and Signal Processing for Remote Sensing XXIII; Bruzzone, L., Bovolo, F., Benediktsson, J.A., Eds.; SPIE: Warsaw, Poland, 2017; p. 3. [Google Scholar]
- Ives, A.R.; Zhu, L.; Wang, F.; Zhu, J.; Morrow, C.J.; Radeloff, V.C. Statistical inference for trends in spatiotemporal data. Remote Sensing of Environment 2021, 266, 112678. [Google Scholar] [CrossRef]
- Friedl, M.; Josh, G.; Sulla-Menashe, D. MCD12Q2 MODIS/Terra+Aqua Land Cover Dynamics Yearly L3 Global 500m SIN Grid V006 2019. [CrossRef]
- Friedl, M.; Sulla-Menashe, D. MCD12Q1 MODIS/Terra+Aqua Land Cover Type Yearly L3 Global 500m SIN Grid V006 2019. [CrossRef]
- Sulla-Menashe, D.; Gray, J.M.; Abercrombie, S.P.; Friedl, M.A. Hierarchical mapping of annual global land cover 2001 to present: The MODIS Collection 6 Land Cover product. Remote Sensing of Environment 2019, 222, 183–194. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Friedl, M.A. User Guide to Collection 6 MODIS Land Cover (MCD12Q1 and MCD12C1) Product. 2018, 18.
- Chu, D.; Shen, H.; Guan, X.; Chen, J.M.; Li, X.; Li, J.; Zhang, L. Long time-series NDVI reconstruction in cloud-prone regions via spatio-temporal tensor completion. Remote Sensing of Environment 2021, 264, 112632. [Google Scholar] [CrossRef]
- Huamin, T.; Qiuqun, D.; Shanzhu, X. Reconstruction of time series with missing value using 2D representation-based denoising autoencoder. J. of Syst. Eng. Electron. 2020, 31, 1087–1096. [Google Scholar] [CrossRef]
- Schwieder, M.; Wesemeyer, M.; Frantz, D.; Pfoch, K.; Erasmi, S.; Pickert, J.; Nendel, C.; Hostert, P. Mapping grassland mowing events across Germany based on combined Sentinel-2 and Landsat 8 time series. Remote Sensing of Environment 2022, 269, 112795. [Google Scholar] [CrossRef]
- Andrefouet, S.; E, B. de C.; Brown de Colstoun, E.; E.C., C. Preliminary Assessment of the Value of Landsat 7 ETM+ Data following Scan Line Corrector Malfunction; USGS, 2003.
- Wilson, A.M.; Jetz, W. Remotely Sensed High-Resolution Global Cloud Dynamics for Predicting Ecosystem and Biodiversity Distributions. PLoS Biol 2016, 14, e1002415. [Google Scholar] [CrossRef] [PubMed]
- Notarnicola, C. Hotspots of snow cover changes in global mountain regions over 2000–2018. Remote Sensing of Environment 2020, 243. [Google Scholar] [CrossRef]
- Frantz, D.; Hostert, P.; Rufin, P.; Ernst, S.; Röder, A.; van der Linden, S. Revisiting the Past: Replicability of a Historic Long-Term Vegetation Dynamics Assessment in the Era of Big Data Analytics. Remote Sensing 2022, 14, 597. [Google Scholar] [CrossRef]
- Kowalski, K.; Senf, C.; Hostert, P.; Pflugmacher, D. Characterizing spring phenology of temperate broadleaf forests using Landsat and Sentinel-2 time series. International Journal of Applied Earth Observation and Geoinformation 2020, 92, 102172. [Google Scholar] [CrossRef]
- Nill, L.; Grünberg, I.; Ullmann, T.; Gessner, M.; Boike, J.; Hostert, P. Arctic shrub expansion revealed by Landsat-derived multitemporal vegetation cover fractions in the Western Canadian Arctic. Remote Sensing of Environment 2022, 281, 113228. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Jeganathan, C.; Dash, J.; Atzberger, C. Inter-comparison of four models for smoothing satellite sensor time-series data to estimate vegetation phenology. Remote Sensing of Environment 2012, 123, 400–417. [Google Scholar] [CrossRef]
- Kandasamy, S.; Baret, F.; Verger, A.; Neveux, P.; Weiss, M. A comparison of methods for smoothing and gap filling time series of remote sensing observations – application to MODIS LAI products. Biogeosciences 2013, 10, 4055–4071. [Google Scholar] [CrossRef]
- Zhang, Z.; Wei, M.; Pu, D.; He, G.; Wang, G.; Long, T. Assessment of Annual Composite Images Obtained by Google Earth Engine for Urban Areas Mapping Using Random Forest. Remote Sensing 2021, 13, 748. [Google Scholar] [CrossRef]
- Zhang, Y.; Ling, F.; Wang, X.; Foody, G.M.; Boyd, D.S.; Li, X.; Du, Y.; Atkinson, P.M. Tracking small-scale tropical forest disturbances: Fusing the Landsat and Sentinel-2 data record. Remote Sensing of Environment 2021, 261, 112470. [Google Scholar] [CrossRef]
- Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C. Land cover classification in an era of big and open data: Optimizing localized implementation and training data selection to improve mapping outcomes. Remote Sensing of Environment 2022, 268, 112780. [Google Scholar] [CrossRef]
- Senf, C.; Seidl, R.; Poulter, B. Post-disturbance canopy recovery and the resilience of Europe’s forests. Global Ecol. Biogeogr. 2022, 31, 25–36. [Google Scholar] [CrossRef]
- Senf, C.; Seidl, R. Mapping the coupled human and natural disturbance regimes of Europe’s forests. Nature Sustainability 2021, 4, 26. [Google Scholar] [CrossRef]
- Coops, N.C.; Shang, C.; Wulder, M.A.; White, J.C.; Hermosilla, T. Change in forest condition: Characterizing non-stand replacing disturbances using time series satellite imagery. Forest Ecology and Management 2020, 474, 118370. [Google Scholar] [CrossRef]
- Franklin, S.; Robitaille, S. Forest insect defoliation and mortality classification using annual Landsat time series composites: a case study in northwestern Ontario, Canada. Remote Sensing Letters 2020, 11, 1175–1180. [Google Scholar] [CrossRef]
- Suess, S.; van der Linden, S.; Okujeni, A.; Griffiths, P.; Leitão, P.J.; Schwieder, M.; Hostert, P. Characterizing 32 years of shrub cover dynamics in southern Portugal using annual Landsat composites and machine learning regression modeling. Remote Sensing of Environment 2018, 219, 353–364. [Google Scholar] [CrossRef]
- Nasiri, V.; Deljouei, A.; Moradi, F.; Sadeghi, S.M.M.; Borz, S.A. Land Use and Land Cover Mapping Using Sentinel-2, Landsat-8 Satellite Images, and Google Earth Engine: A Comparison of Two Composition Methods. Remote Sensing 2022, 14, 1977. [Google Scholar] [CrossRef]
- Okujeni, A.; Jänicke, C.; Cooper, S.; Frantz, D.; Hostert, P.; Clark, M.; Segl, K.; van der Linden, S. Multi-season unmixing of vegetation class fractions across diverse Californian ecoregions using simulated spaceborne imaging spectroscopy data. Remote Sensing of Environment 2021, 264, 112558. [Google Scholar] [CrossRef]
- Thieme, A.; Yadav, S.; Oddo, P.C.; Fitz, J.M.; McCartney, S.; King, L.; Keppler, J.; McCarty, G.W.; Hively, W.D. Using NASA Earth observations and Google Earth Engine to map winter cover crop conservation performance in the Chesapeake Bay watershed. Remote Sensing of Environment 2020, 248, 111943. [Google Scholar] [CrossRef]
- Filippelli, S.K.; Vogeler, J.C.; Falkowski, M.J.; Meneguzzo, D.M. Monitoring conifer cover: Leaf-off lidar and image-based tracking of eastern redcedar encroachment in central Nebraska. Remote Sensing of Environment 2020, 248, 111961. [Google Scholar] [CrossRef]
- De Marzo, T.; Pflugmacher, D.; Baumann, M.; Lambin, E.F.; Gasparri, I.; Kuemmerle, T. Characterizing forest disturbances across the Argentine Dry Chaco based on Landsat time series. International Journal of Applied Earth Observation and Geoinformation 2021, 98, 102310. [Google Scholar] [CrossRef]
- Zhai, Y.; Roy, D.P.; Martins, V.S.; Zhang, H.K.; Yan, L.; Li, Z. Conterminous United States Landsat-8 top of atmosphere and surface reflectance tasseled cap transformation coefficients. Remote Sensing of Environment 2022, 274, 112992. [Google Scholar] [CrossRef]
- Yang, X.; Qin, Q.; Yésou, H.; Ledauphin, T.; Koehl, M.; Grussenmeyer, P.; Zhu, Z. Monthly estimation of the surface water extent in France at a 10-m resolution using Sentinel-2 data. Remote Sensing of Environment 2020, 244, 111803. [Google Scholar] [CrossRef]
- Johnson, D.M.; Mueller, R. Pre- and within-season crop type classification trained with archival land cover information. Remote Sensing of Environment 2021, 264, 112576. [Google Scholar] [CrossRef]
- Kearney, S.P.; Porensky, L.M.; Augustine, D.J.; Gaffney, R.; Derner, J.D. Monitoring standing herbaceous biomass and thresholds in semiarid rangelands from harmonized Landsat 8 and Sentinel-2 imagery to support within-season adaptive management. Remote Sensing of Environment 2022, 271, 112907. [Google Scholar] [CrossRef]
- Xu, F.; Li, Z.; Zhang, S.; Huang, N.; Quan, Z.; Zhang, W.; Liu, X.; Jiang, X.; Pan, J.; Prishchepov, A.V. Mapping Winter Wheat with Combinations of Temporally Aggregated Sentinel-2 and Landsat-8 Data in Shandong Province, China. Remote Sensing 2020, 12, 2065. [Google Scholar] [CrossRef]
- Kato, A.; Thau, D.; Hudak, A.T.; Meigs, G.W.; Moskal, L.M. Quantifying fire trends in boreal forests with Landsat time series and self-organized criticality. Remote Sensing of Environment 2020, 237, 111525. [Google Scholar] [CrossRef]
- Ghassemi, B.; Dujakovic, A.; Żółtak, M.; Immitzer, M.; Atzberger, C.; Vuolo, F. Designing a European-Wide Crop Type Mapping Approach Based on Machine Learning Algorithms Using LUCAS Field Survey and Sentinel-2 Data. Remote Sensing 2022, 14, 541. [Google Scholar] [CrossRef]
- Phan, T.N.; Kuch, V.; Lehnert, L.W. Land Cover Classification using Google Earth Engine and Random Forest Classifier—The Role of Image Composition. Remote Sensing 2020, 12, 2411. [Google Scholar] [CrossRef]
- Kim, S.; Eun, J. Reflectance composites from multispectral satellite imagery for crop monitoring. In Proceedings of the Remote Sensing for Agriculture, Ecosystems, and Hydrology XXIII; Neale, C.M., Maltese, A., Eds.; SPIE: Online Only, Spain, 2021; p. 53. [Google Scholar]
- Defourny, P.; Bontemps, S.; Bellemans, N.; Cara, C.; Dedieu, G.; Guzzonato, E.; Hagolle, O.; Inglada, J.; Nicola, L.; Rabaute, T.; et al. Near real-time agriculture monitoring at national scale at parcel resolution: Performance assessment of the Sen2-Agri automated system in various cropping systems around the world. Remote Sensing of Environment 2019, 221, 551–568. [Google Scholar] [CrossRef]
- Silveira, E.M.O.; Pidgeon, A.M.; Farwell, L.S.; Hobi, M.L.; Razenkova, E.; Zuckerberg, B.; Coops, N.C.; Radeloff, V.C. Multi-grain habitat models that combine satellite sensors with different resolutions explain bird species richness patterns best. Remote Sensing of Environment 2023, 295, 113661. [Google Scholar] [CrossRef]
- Griffiths, P.; Nendel, C.; Pickert, J.; Hostert, P. Towards national-scale characterization of grassland use intensity from integrated Sentinel-2 and Landsat time series. Remote Sensing of Environment 2020, 238, 111124. [Google Scholar] [CrossRef]
- Liu, L.; Xiao, X.; Qin, Y.; Wang, J.; Xu, X.; Hu, Y.; Qiao, Z. Mapping cropping intensity in China using time series Landsat and Sentinel-2 images and Google Earth Engine. Remote Sensing of Environment 2020, 239, 111624. [Google Scholar] [CrossRef]
- Mardian, J.; Berg, A.; Daneshfar, B. Evaluating the temporal accuracy of grassland to cropland change detection using multitemporal image analysis. Remote Sensing of Environment 2021, 255, 112292. [Google Scholar] [CrossRef]
- Blickensdörfer, L.; Schwieder, M.; Pflugmacher, D.; Nendel, C.; Erasmi, S.; Hostert, P. Mapping of crop types and crop sequences with combined time series of Sentinel-1, Sentinel-2 and Landsat 8 data for Germany. Remote Sensing of Environment 2022, 269, 112831. [Google Scholar] [CrossRef]
- Bolton, D.K.; Gray, J.M.; Melaas, E.K.; Moon, M.; Eklundh, L.; Friedl, M.A. Continental-scale land surface phenology from harmonized Landsat 8 and Sentinel-2 imagery. Remote Sensing of Environment 2020, 240, 111685. [Google Scholar] [CrossRef]
Figure 1.
Biogeographical regions of Europe with marked main mountain chains.
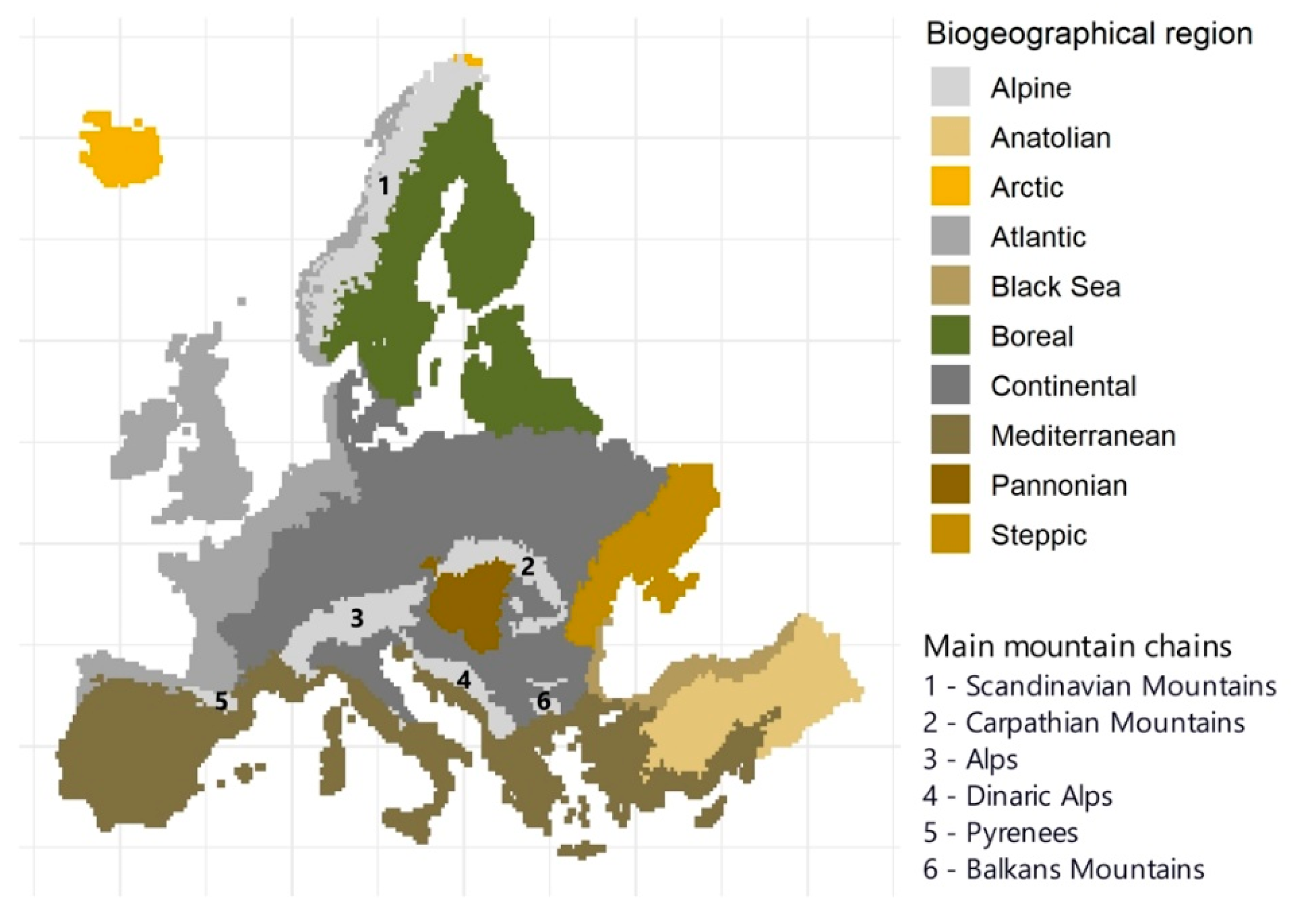
Figure 2.
Overall mean annual data availability across Europe (top) for composites based on combined Landsat and Sentinel-2, Landsat, and Sentinel-2 time series (left to right) and within biogeographical regions of Europe (bottom) for composites of different aggregation periods based on combined Landsat and Sentinel-2 data. Corresponding standard deviation in Figure S3. Landsat and Sentinel-2 based results in Figures S4 and S5, respectively.
Figure 2.
Overall mean annual data availability across Europe (top) for composites based on combined Landsat and Sentinel-2, Landsat, and Sentinel-2 time series (left to right) and within biogeographical regions of Europe (bottom) for composites of different aggregation periods based on combined Landsat and Sentinel-2 data. Corresponding standard deviation in Figure S3. Landsat and Sentinel-2 based results in Figures S4 and S5, respectively.
Figure 3.
Overall mean annual data availability during the growing season across Europe (top) based on combined Landsat and Sentinel-2, Landsat and Sentinel-2 time series (left to right) and within biogeographical regions of Europe (bottom) for composites derived for different aggregation periods based on combined Landsat and Sentinel-2 data. Corresponding standard deviation in Figure S6. Landsat and Sentinel-2 based results in Figures S7 and S8, respectively.
Figure 3.
Overall mean annual data availability during the growing season across Europe (top) based on combined Landsat and Sentinel-2, Landsat and Sentinel-2 time series (left to right) and within biogeographical regions of Europe (bottom) for composites derived for different aggregation periods based on combined Landsat and Sentinel-2 data. Corresponding standard deviation in Figure S6. Landsat and Sentinel-2 based results in Figures S7 and S8, respectively.
Figure 4.
Number of years within the 1984-2021 time series (Landsat and Sentinel-2 data) with a successful growing season annual composite for the forest land cover class. Spatio-temporal variability of data availability along latitude and longitude in side panels. Annual standard deviation per biogeographical region in Figure S9.
Figure 4.
Number of years within the 1984-2021 time series (Landsat and Sentinel-2 data) with a successful growing season annual composite for the forest land cover class. Spatio-temporal variability of data availability along latitude and longitude in side panels. Annual standard deviation per biogeographical region in Figure S9.
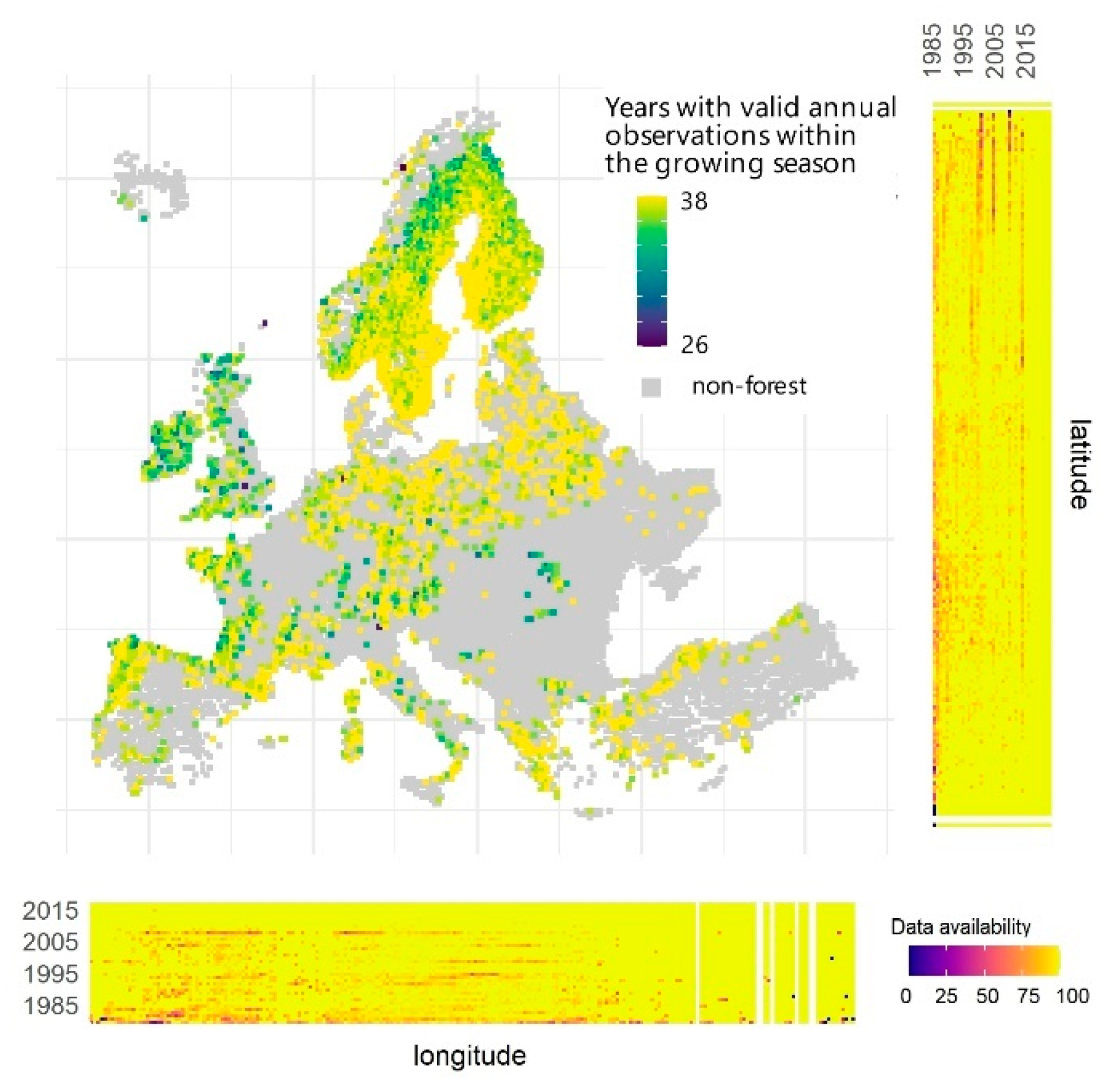
Figure 5.
Number of years within the 1984-2021 time series (Landsat and Sentinel-2 data) with (A) all growing season monthly composites for all land cover classes and (B) calendar year 10-day composites for agricultural land together with location of sites from Figure 6. Spatio-temporal variability of data availability along latitude and longitude in respective side panels. Annual summaries on data availability per biogeographical region in Figures S10 and S11. Results fulfilling minimum >50% data availability each year in Figure S12.
Figure 5.
Number of years within the 1984-2021 time series (Landsat and Sentinel-2 data) with (A) all growing season monthly composites for all land cover classes and (B) calendar year 10-day composites for agricultural land together with location of sites from Figure 6. Spatio-temporal variability of data availability along latitude and longitude in respective side panels. Annual summaries on data availability per biogeographical region in Figures S10 and S11. Results fulfilling minimum >50% data availability each year in Figure S12.
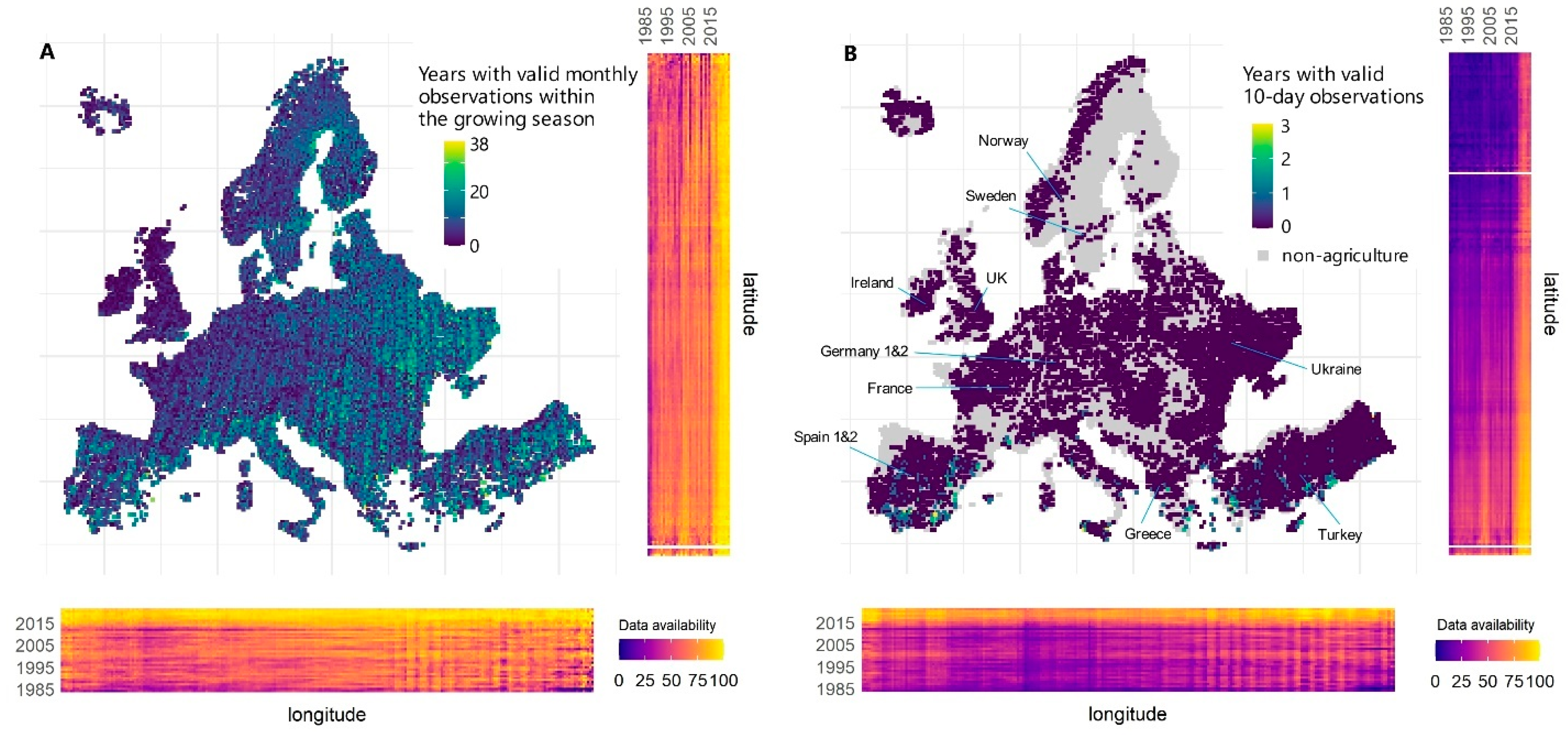
Figure 6.
Data availability (Landsat and Sentinel-2 together) for (top) monthly composites across a growing period and (center) 10-day composites across calendar years for 12 selected sites, compared to (bottom) the operational phases of Landsat and Sentinel-2 satellite missions. Location of the sites in Figure 5B.
Figure 6.
Data availability (Landsat and Sentinel-2 together) for (top) monthly composites across a growing period and (center) 10-day composites across calendar years for 12 selected sites, compared to (bottom) the operational phases of Landsat and Sentinel-2 satellite missions. Location of the sites in Figure 5B.
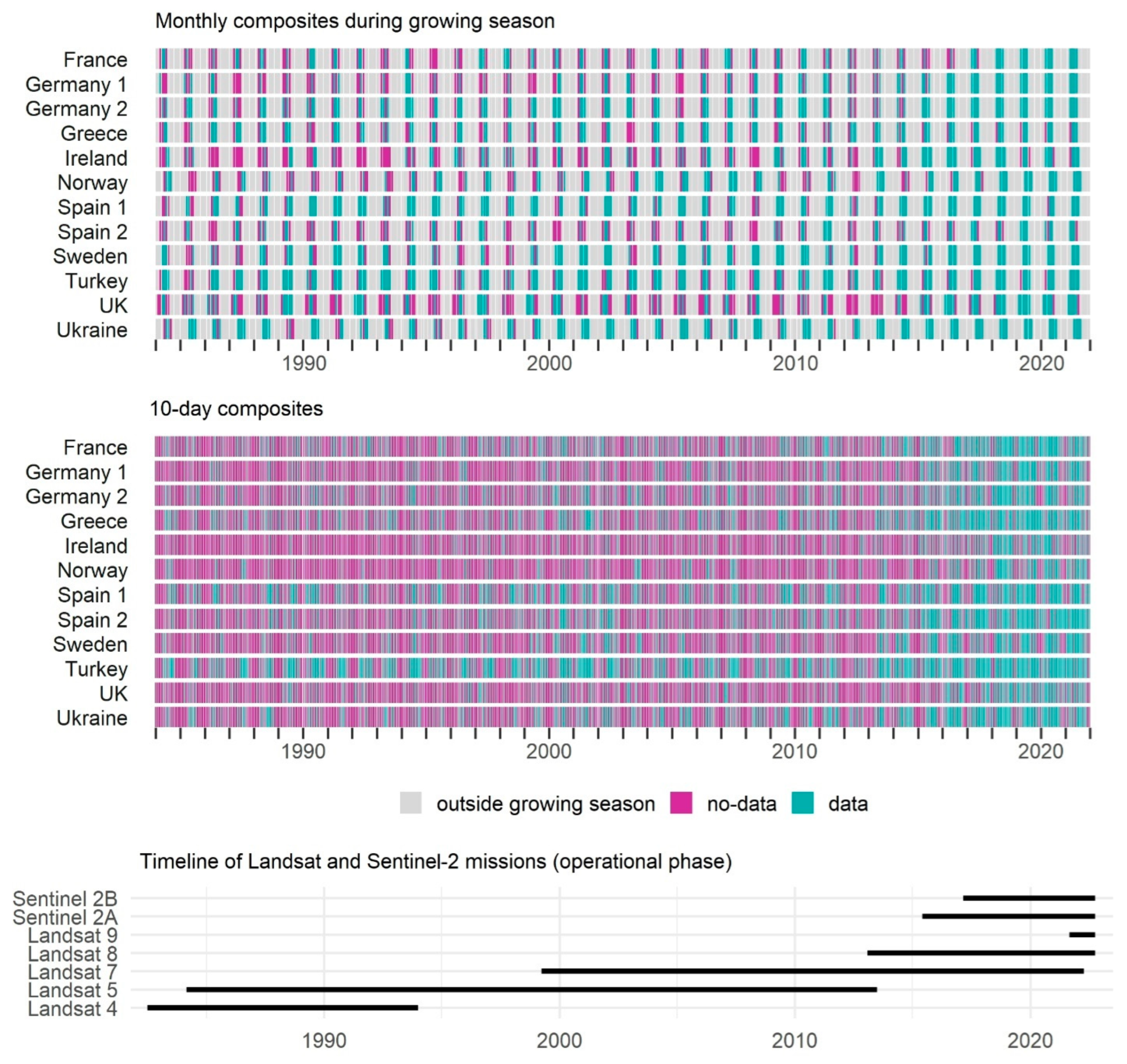
Figure 7.
The shortest feasible compositing window assuming interpolation of up to 50% of data each calendar year. Results for Sentinel-2 in Figure S13.
Figure 7.
The shortest feasible compositing window assuming interpolation of up to 50% of data each calendar year. Results for Sentinel-2 in Figure S13.
Figure 8.
Feasible shortest compositing window assuming ≥50% temporal data coverage across all years for a selection of medium- and long-term time periods. Results showing 50% data coverage for each year in the time series in Figure S16.
Figure 8.
Feasible shortest compositing window assuming ≥50% temporal data coverage across all years for a selection of medium- and long-term time periods. Results showing 50% data coverage for each year in the time series in Figure S16.
Figure 9.
Feasible shortest aggregation window providing 50% temporal data coverage across all respective growing seasons for a selection of medium- and long-term time periods. Results showing minimum 50% temporal coverage each year in the time series in Figure S17.
Figure 9.
Feasible shortest aggregation window providing 50% temporal data coverage across all respective growing seasons for a selection of medium- and long-term time periods. Results showing minimum 50% temporal coverage each year in the time series in Figure S17.
Figure 10.
Temporal granularity of composites comprising 15th June. Sentinel-2 results in Figure S18.
Figure 10.
Temporal granularity of composites comprising 15th June. Sentinel-2 results in Figure S18.

Table 1.
Selected examples of recent analyses based on data composited using different length of a compositing window.
Table 1.
Selected examples of recent analyses based on data composited using different length of a compositing window.
| Temporal resolution | Enhancement | Application | References | Dataset |
|---|---|---|---|---|
| Annual | Land cover classification: urban areas | [72] | Landsat 8 | |
| Land cover monitoring: forest disturbance | [73] | Landsat 7, 8, Sentinel-2 | ||
| Annual with target period/day | Land cover classification | [74] | Landsat time series | |
| Land cover monitoring: forest disturbance | [75] [76] |
Landsat time series | ||
| Infill interpolation | [77] | Landsat time series | ||
| Land cover monitoring: forest health | [78] | Landsat time series | ||
| Land cover monitoring: shrub dynamics | [79] | Landsat time series | ||
| Seasonal | Land cover classification | [80] | Landsat 8, Sentinel-2 | |
| Land cover monitoring: land cover composition | [81] | Landsat 7, 8 | ||
| Land cover monitoring: cover crops | [82] | Landsat time series, HLS Seninel-2 | ||
| Land cover monitoring: forest encroachment | [83] | Landsat time series | ||
| Land cover monitoring: forest disturbance | [84] | Landsat time series | ||
| Derivation of updated Tasseled cap transformation coefficients | [85] | Landsat 8 | ||
| Seasonal and monthly | Land cover monitoring: surface water extend | [86] | Sentinel-2 | |
| 48-day | Land cover classification: crop type | [87] | Landsat 7, 8 | |
| 31-day | Savitzky–Golay | Land cover monitoring: biomass of herbaceous vegetation | [88] | HLS: Landsat 8, Sentinel 2 |
| (six) phenological periods | Land cover classification: crop classification | [89] | Landsat 8, Sentinel-2 | |
| Varied pre- and post-event composites | Land cover monitoring: forest fire disturbances | [90] | Landsat time series | |
| Monthly and annual | Land cover classification: crop type | [91] | Sentinel-2 | |
| Monthly | Land cover classification | [92] | Landsat 8 | |
| Land cover monitoring: crop monitoring | [93] | Sentinel-2 | ||
| Land cover monitoring: agriculture | [94] | Landsat 8, Sentinel-2 | ||
| Whittaker | Land cover monitoring: grasslands | [6] | Landsat time series | |
| Habitat modeling: bird species richness | [95] | Landsat 8, Sentinel-2 | ||
| 16-day | Land cover and land use dynamism | [7] | Landsat time series | |
| 10-day | linear interpolation | Land cover monitoring: mowing detection | [96] | HLS: Landsat 8, Sentinel-2 |
| linear interpolation and Savitzky–Golay | Land cover monitoring: croplands | [97] | Landsat 5, 7, 8, Seninel-2 | |
| 10-day, monthly, seasonal | linear interpolation | Land cover classification: crop and land cover mapping | [71] | HLS: Landsat 8, Sentinel-2 |
| 8-day | Whittaker | Land cover monitoring: change detection in grasslands | [98] | Landsat time series |
| 5-day | Radial Basis Function | Land cover classification: tree species | [28] | Sentinel-2 |
| Radial Basis Function | Land cover classification: crop types mapping | [99] | Landsat 8, Sentinel-2, Sentinel-1 | |
| 1-day | penalized cubic smoothing splines | Land cover phenology | [100] | HLS: Landsat 8, Sentinel-2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



