
Submitted:
14 November 2023
Posted:
27 November 2023
You are already at the latest version
Abstract
Appeals to governments for implementing basic income are contemporary. The theoretical backgrounds of the basic income notion, only prescribe transferring equal amounts to individuals irrespective of their specific attributes. However, the most recent basic income initiatives all around the world are attached to certain rules with regard to the attributes of the households. This approach is facing significant challenges to appropriately recognize the vulnerable groups. A possible alternative for setting rules with regard to the welfare attributes of the households is to employ artificial intelligent algorithms that can process unprecedented amounts of data. Can integrating machine learning change the future of basic income by perdition of vulnerable to future poverty households? In this paper, we utilize a multidimensional and longitudinal welfare data comprising one and a half million individual data and a Bayesian beliefs network approach to examine the feasibility of predicting households’ vulnerability to future poverty based on the existing households’ welfare attributes.
Keywords:
Basic income
; Poverty
; Machine learning
; Bayesian beliefs
1. Introduction
The idea of basic income, a minimum income transferred by state to each member of a society, is wide spreading. Appeals to governments for implementing basic income programs are all contemporary including the United Kingdom (Jordan , 2012; Mori, 2017), Germany (Scientific Advisory Board at the Federal Ministry, 2021; Coalition agreement SPD, The Greens and FDP, 2021) and Spain (Perkiö, 2013; De Durana & Rodrigu, 2021). In addition to the major programs and plans, there are a large number of small scale pilot projects, which are mostly revolving around several experiments in the United States (Yang et al., 2021) and serve as scientific controlled trials to capture the potential up and downs of performing this idea (Moffitt, 2003). A complete list of major implemented or ongoing basic income programs can be found in the world bank study (Gentilini et al., 2020). Basic income systems per definition do not attach any specific attributes such as age, marital status, gender, health status, social class and etc. to any individual as eligibility criteria (Bill, 1988; Van Parijs, 1991; Van der Veen, 1998; Pateman, 2004; Raventós , 2007; Widerquist, 2001). In addition, basic income shall be paid uniformly to each person of the society (Bill, 1988; Van Parijs, 1991; Van der Veen, 1998; Standing, 2012; Von Gliszczynski, 2017; Lovett, 2009; Raventós, 2007).
The idea of paying uniformly distributed basic income to all members of a society might improve the quality of life and reduce poverty, however, there are yet theoretical debates (Hoynes & Rothstein, 2019; Yang et al., 2021; Jackson, 2017; OECD, 2017; Zheng et al., 2020) regarding the financing a broad basic income program. Basically, if the equally transferred cash to all individuals is set too low, it becomes insufficient in reducing poverty. On the other hand, setting too high cash transfers payed to each individual can become extremely costly and infeasible in the face of the governments’ budget constraint (Fitzpatrick, 1999). The evidences of expansiveness’s of basic income come not only from theoretical perspective but also from empirical experiences. Hoynes & Rothstein (2019) estimate a broad basic income program not attached to social and demographic variables to be costly about twice the cost of all existing transfers in the United States. A universal no question asked public transfer to everyone would necessitate significant tax rises as well as reductions in essential existing benefits in (OECD, 2017). Jackson (2017) predicts that implementing a broad basic income program would increase tax rates for below median income workers up to 80 percent if the basic income level is set at one-half of Canada’s median income. Zheng et al., (2020) prognoses that if in China, in 2014, the government would have decided to pay every adult a monthly income of 336 yuan (if living in urban areas) or 231 yuan (if living in rural areas), this would have required a yearly government expenditure of 3.472 trillion yuan, equivalent to approximately 5.46% of overall Chinese GDP and almost half of the overall Chinese government expenditure.
Iran is known as the first country in the world to provide a de facto based on the definition of World bank (Gentilini et al., 2020) basic income system to all its citizens. In December 2010, Iran launched a cash transfer program that payed every Iranian residing in the country the equivalent of $40–45 a month, unconditionally. The program, while still continuing after thirteen years, has lost much of its desired effect as the purchasing power of the transfers has been largely receding through inflation. It is now witnessed as insufficient for the vulnerable households and simultaneously as of little value for the relatively wealthier households, while worsening the government’s budget considering its large aggregate size.
Subsequently, in the recent years, it became inevitable for the Iranian administration to pursue the idea of a basic income, which incorporates a households’ eligibility examination in its system. Apart from Iran’s experience, the most recent or currently ongoing basic income initiatives all around the world, are attached to certain socioeconomic conditions to select the eligible receivers (Yang et al., 2021).
Since the recent time the Iranian government has been aiming to consider a set of rules with regard to the welfare attributes of the households to let them become eligible. This approach is facing significant challenges with regard to appropriate recognition of the vulnerable groups. A possible alternative for setting rules with regard to the welfare attributes of the households is to employ machine learning algorithms that can process unprecedented amounts of data. Can integrating machine learning change the future of basic income by smart perdition of vulnerable to future poverty households? In light of the Iranian evident, this question is identified by us as a research gap in the context of the basic income’s existing literature as a counterfactual scenario for the future.
Prediction of the vulnerable households requires exact definition of the concept vulnerability.
The literature of poverty (Gallardo, 2018) highlights a basic distinction between the concepts of poverty and vulnerability. Measuring poverty can be done based on monetary poverty measurements or based on the multi-dimensional poverty measurements (Salecker et al., 2020). Monetary poverty comprises people at risk when e.g. their disposable income (, which is the money available for spending or saving after tax, social transfers and other deductions) is below than some certain threshold e.g. poverty line. The multi-dimensional poverty measurements consider multiple well-being measures i.e. educational, health services and etc. alongside with monetary measures to appropriate assessment of poverty. While a multidimensional definition of poverty appears to be more promising in a comprehensive sense (Bossert et al., 2013), however, in this paper we work, first with the more understandable version of definition i.e. the monetary poverty measurement.
Once we define the poverty, measuring vulnerability can be done based on the risk of non-poor people to fall below a certain welfare threshold e.g. the poverty line in the future time horizon or the risk that poor people remain poor in the future time horizon (Chaudhuri et al., 2002; Christiaensen and Subbarao, 2005). Hence, vulnerability must be distinguished from poverty as it measures the ex-ante risk of being poor, that is, before the uncertainty is resolved (Calvo and Dercon, 2005, 2007, 2013). In view of the above definitions, in this paper we aim at employing machine learning to predict the posterior probability of the not observable vulnerability to future poverty of a household by inputting a set of present observable welfare attributes of it.
We use a monetary parameter as the poverty line for the households to be the criterion for receiving basic income. The monetary criterion to be compared with the selected poverty line is the average cash accessibility of a household expressed in average account balance of a household. The average account balance of a household is equal to the remaining total amount of the accessible money, which exists on average in the bank accounts of the entire members of a household, after all deposits and credits have been balanced with any charges or debits. This parameter is presumed to be suitable to represent the cash accessibility of a household, which is under examination to receive further cash within a basic income program. Hence, we name this measure cash accessibility of a household throughout. To predict this parameter, the administration thinks through a complete set of the observable welfare attributes of that family within the recent years. The machine learning algorithm employed by the administration, will then support the administration by predicting the cash accessibility of that household within the upcoming future time. The decision regarding becoming eligible or not, then will be finalized based on the probabilistic outcome of the machine learning model together with a probability line set by the administration. For example, if the machine learning algorithm predicts a family to be 80% vulnerable to future poverty and 20% not, then it is up to the above mentioned government’s probability line whether households with 80% vulnerability probability are eligible or e.g. only households with 90% vulnerability probability are eligible. In this paper we design experiments to examine whether we achieve high accuracies in prediction of the vulnerable to future poverty households by changing the critical cash accessibility threshold value (i.e. the selected poverty line) as well as by changing the classification probability thresholds (the government’s probability line selected rule).
Several studies in the recent literature of poverty studies, propose setting links between the households’ observable welfare attributes and the probability of being vulnerable to future poverty. Gallardo (2020) and Feeny and McDonald (2016) obtain the conditional probability of being vulnerable in various welfare dimension by a Probit or Logit model. The approach of Feeny and McDonald (2016) measures vulnerability as the probability of being multidimensional poor as an aggregate by determining deprivation scores to a total set of vulnerabilities. The approach of Gallardo (2020) estimates the probabilities of being vulnerable in each one of the welfare indicators disaggregated by components. The approach of Feeny and McDonald (2016) outputs only one probability as a measure through a Probit model, regardless of the specific welfare dimensions. However, this estimation method does not account for the different qualities of the vulnerabilities in different dimensions of well-being. That is, it omits the fact that, in addition to the deprivation score e.g. a household has, the composition of the deprivation set that this score involves, also matters. The approach of Gallardo (2020) provides distinct evidence with regard to vulnerabilities in different dimensions of well-being. However, this estimation method might not manage to compute a flawless aggregate welfare estimation.
Gallardo (2022) propose Bayesian beliefs network to predict the probability of being multidimensional poor. In contrast to the Probit and logit models, Bayesian belief networks (Grover, 2012) incorporate the conditional connections of a set of multidimensional welfare attributes in a graphical network and the Bayes theorem (Bishop, 2006). The Bayesian networks are more appropriate to solve multidimensional welfare estimation in comparison to Logit and Probit models, which can only face a multidimensional problem through one or several one dimensional solutions (Gallardo, 2022).
In this paper, we proceed forward along with the developments of the recent vulnerability to future poverty studies by application of an explainable machine learning approach i.e. Bayesian belief networks BBNs. Thereby we extend the scarce research literature (Ceriani and Gigliarano, 2020) on Bayesian networks’ application to economic analysis and policy. In addition, while massive panel data are rarely available in developing countries, we design our experiments in this paper based on thirty welfare attributes of one and a half million individuals’ data from a first real basic income experiment of the world in Iran, which can enrich the robustness of the outcomes. Third, while, none of the existing literature of vulnerability to poverty, explores vulnerability across time using longitudinal data, our study investigates the feasibility of predicting the vulnerable households in a future time step by incorporating the existing set of the households’ welfare attributes in multiple preceding time steps.
The remainder of the paper is as follows. Section 2 explains the main welfare attributes of the individuals within the source data of the research. How the Bayesian model is constructed and analyzed, is explained in section 3. The results of the analysis are presented in section 4. Concluding remarks are highlighted in section 5.
2. Data
The anonymized welfare data of 1.5 million randomly chosen individual Iranian citizens provided by Iran’s ministry of cooperatives, labor, and social welfare are utilized in this paper. The 30 distinct registered information for each individual are shown in Table 1. The source data table’s each row belongs exactly to one person containing welfare information of that person in 30 distinct columns. We did not utilize this data table directly, as in line with existing literature we believe in a more meaningful parameter to evaluate each individuals’ welfare i.e. the aggregation of individuals’ welfare attributes within their corresponded household. Over the key identification Parent ID, we ascribed each of the 1.5 million individual persons to their corresponded unique household and came out with exactly five hundred thousand households in the total. We generated out of individual available data a new table named Household_welfare_data. In the aggregation process, we added the welfare values of individual persons (e.g. car numbers and car values) within a family together and averaged the sum over the number of family members. The aggregation carried out with the exception of person ID, parent ID, age, gender and the living place. These variables are not to be summed and hence are represented by the parent’s information in the Household_welfare_data. Finally, due to the existing of 8280 NaN values in a column related to the question of living in the city or not, we dropped the corresponded rows to come up with a data table consisting of 491,720 rows (households) × 30 columns (welfare attributes).
3. Bayesian Network model
A Bayesian belief network BBN model (Pearl, 1988) is an explainable machine learning approach comprising a graphical network that represents probabilistic relationships among a bundle of variables. It comprises a directed acyclic graph DAG with nodes representing the variables and arcs representing conditional dependencies between the connected nodes. Bayes theorem defines the relationships between variables (Puga et. al., 2015). The main objective of BBNs is to infer the posterior probability distribution of a set of presumably not completely observable variables after observing a set of observable variables. A clear explanation of what Bayesian Belief Networks are and how they are utilized is explained in Barbrook-Johnson and Penn (2022).
In our investigation, the total of the 30 variables in the Table 1 are selected to be the main components of the Bayesian network. The corresponded variable to the thirty’s row of the Table 1 i.e. the average balance of the entire family members’ accounts within the period of 20.032019-20.03.2020, is the key dependent variable of our study. In a certain year, this variable represents the averaged remaining total amount of the money, which is accessible in the bank accounts of the entire members of a family through that year, after all the debits and credits have been considered. This is presumed to be the criterion for a household to receive further cash in the form of a basic income transfer. If the administration decides e.g. on 20.03.2019 upon the eligibility of a household to be the receiver of the basic income within the time period 20.032019-20.03.2020, it uses the data of the aggregated values of the welfare attributes of the entire members of that family by means of their banking records from 20.03.2016 until 20.03.2019 (rows 18-29 at Table 1) as well as their non-banking welfare attributes of that household at the day of decision making (rows 3-17 at Table 1) to assess the household’s posterior probability of having access to cash within the upcoming time. As the individual banking records can be interpreted as sensitive information and might not be applicable in all circumstances, we design experiments in this paper, once with the existence of the banking records and once without the banking records.
Constructing a Bayesian belief network, requires performing of three steps. First, as the Bayesian networks conventionally use labeled variables, whose domain are a finite set of labels, we should discretize the space of the data for the entire variables. In our study, if a welfare variable is greater or equal than a certain threshold , it becomes labeled as negative (by assumption) and if it is smaller than it becomes labeled as positive (by assumption). To experiment the impact of setting different values of , we incorporate deciles. A decile is the result of splitting up the ranked data of each variable into 10 equally large subsections, so that each subsection represents 1/10 of the data of a variable. We set the splitting threshold in each experiment of our study to the 9 in-between threshold value of 10 identified deciles. Thus, the n’th decile splits the entire data related to a certain variable of the Table 1 to the negatives, which represent the data part with values greater or equal than the n/10 of the ranked data of that variable and the positives, which represent the data part with values smaller than the (10-n)/10 of the ranked data of that variable. For example, the splits the data of a variable into the values less than the median (positives) and the values greater than the median (negatives). In our study, each time we set the variables splitting threshold in line with a certain decile, we apply the same decile number n to split the data of all 30 variables. The splitting of variables is done with the exception of the gender and the living place, which are binary variables on their own.
In the second step of constructing a BBN, we estimate a DAG that reveals the dependencies between the variables given the labeled data (Neapolitan, 2003). In our study we are using the Hill Climbing Search algorithm (Tsamardinos et al., 2006). This algorithm undertakes a greedy local search that starts from a disconnected DAG consisting of the entire 30 variables and proceeds by iteratively performing single-edge manipulations that maximally increase the value of a score function. The score function maps DAGs to a numerical score, which measures how well DAGs fit to the given data table. We apply the pyAgrum 1.9.0 on Jupyter framework to compute the DAG as well as the subsequent Bayesian learning computations through this study.
In the third step, we must compute the conditional probability distributions CPTs of the individual variables, given the DAG and the labeled data.
By completion of the third step, the BNN is completed and can be used to make inferences with regard to the variables of concern’s posterior probabilities.
As above mentioned, in this paper we are pursuing the feasibility of obtaining reliable inferences regarding the cash accessibility of any household in an upcoming year of interest, by inputting a set of the household’s welfare attributes to the BBN.
We design experiments to split the variable average accounts balance within the period of 20.032019-20.03.2020 (, which is the key variable of our study) according to the 9 in-between threshold values of 10 deciles, each time to the corresponded negative and positive subsection and see how well the BBN can distinguish the households, who are positioned on the area larger or equal than the threshold (negatives), from the households, who are positioned on the area smaller than the threshold (positives). As the BBN model outputs probabilistic values linked to being negative or positive, we must decide upon a probability threshold upon which we (i.e. the administration) decide to classify a household as a positives type, if the predicted posterior probability of positives exceeds and classify a household as a negatives, if the predicted posterior probability of positives for that household through the BBN model does not exceed the . Obviously, the default for interpreting probabilities to class labels is 0.5. However, tuning of to increase the preciseness of predictions, necessitates observing the changes in the accuracy of the BBN model to predict each negative and positive value of the target variable while moving e.g. from 0.0 to 0.9 in small (e.g. 0.1) incremental step sizes. Thereby, to analyze the accuracies we apply the receiver operating characteristic (ROC) curve (Fawcett, 2006) as well as the precision and recall (PR) curve (Powers, 2011).
Before presenting the results in section 4, we explain the applied metrics to assess the feasibility of accurate eligible households’ classification by a special case in the experiment design of our paper.
3.1. Classification of households according to above and under median cash availability
In this subsection we examine the distinguishing of the population with under median average cash access from the population with above median average cash access. The threshold (n=5) is set to be the cash level larger than available for the lower n=5 deciles (positives) and less than available for the upper n=5 deciles (negatives). We split the data of the rest of the variables to the negatives and positives based on their median levels, accordingly, as described in the previous section. The BBN model is trained using the labeled data of 30 variables in line with (n=5) and the Hill Climbing Search algorithm over the 80% of the 491,720 rows × 30 columns of data. The BBN’s DAG is presented in Figure 1.
We use the rest of 20% of the entire data table as the test set. Left and right hand panels of the Figure 2 illustrate the ROC and PR metrics of the test set, respectively. To interpret these accuracy measures we should first note the definitions a-d, as well as the equations 1-8.
- True negative (TN): if the target value is negative and the predicted value is negative.
- True positive (TP): if the target value is positive and the predicted value is positive.
- False negative (FN): if the target value is positive and the predicted value is negative.
- False positive (FP): if the target value is negative and the predicted value is positive.
The ROC Curve depicts the contrast between the true positive rate and false positive rate by changing the probability thresholds . The PR curve depicts the possible trade-off between the recall and the precision by changing the probability thresholds . Note that the precision describes, how precise the model is, if it predicts a class to be e.g. positive, whereas the recall describes, how much the model has succeeded to cover the positives to be correctly predicted. The PR becomes more meaningful, when there are moderate to large imbalances between the number of data within the negatives and positives classes e.g. when we are seeking to distinguish the population with the lowest n=1 decile (positives) from the rest 9 deciles (negatives).
The AUC represents each time the integral of the area under ROC and PR curves, respectively and is a metrics for evaluating the accuracy of the model by considering the entire possible ranges of the . The f1_score represents the harmonic mean of the precision and recall metrics. Note that f1_score does not incorporate the True negative count. The accuracy_total represents the overall accurateness of the model without being detailed in the negatives and positives subsections.
The blue point in Figure 2 is the optimal PR threshold that results in the best balance between the precision and recall metrics expressed in the term f1_score. The red point in the Figure 2 is the optimal ROC threshold that result in the best balance between the true and the false positive rates. The ROC and PR curves in Figure 2 show a around 0.425-0.492 as the optimum threshold, which delivers a balanced accuracy and preciseness to predict the positive classes. In that , we will be able to cover between 80-90 percent precisely predicted positive i.e. below median level cash accessible households. Through, by setting non-optimal threshold values deviating from the optimal value, we can increase the recognition of the true positive households up to levels higher than e.g. 90%, however, then we should take extra added false positives (in ROC), as well as a reduced precision (in PR) into the account.
Note that the most of the indicators in our study are concerning regarding the possible fine-tuned detection of positives and not the negatives, per definition. This is presumed to be legitimate in our study, as the first concern of basic income programs is the detection of positives (i.e. the relatively vulnerable to future poverty people) and not the negatives.
Depending on the government budget constraints, the political administrations might be interested (beside the optimal thresholds) in the range of non-optimal threshold values as well, as they can choose threshold values encompassing higher than e.g. 90% recognition of True positives (, which promises a higher recognition rate of lower income groups compared to the level corresponded to optimal threshold) at the cost of accepting to allocate extra budget to be distributed to False positives. This trade-off between recognition of negatives and positives in the test set of the Household_welfare_data through altering the threshold from 0.0 to 0.9 in small (0.1) incremental step sizes and its relationship with the accuracy_total is represented in Figure 3.
As the individual banking records can be interpreted as sensitive information and might not be applicable, we replicate the classification of households in the test set according to above and under median cash availability without their recent years banking records (with the exception of the average balance of the entire family members’ accounts, which is incorporated only in the training step). Note that, banking records of the recent years play a crucial role to predict the households’ cash access. This is evident from depiction of importance of welfare attributes in Figure 4.
Each panel in Figure 4 describes the change in the posterior probability of the dependent variable of our study (household cash accessibility) to be classified as negative or positive (in the vertical axis) by providing evidences from a single explanatory variable in form of probability x for being that variable negative and 1-x for being that variable positive and incrementing x along the horizontal axis from 0.0 to 1.0 in small (0.01) incremental step sizes. The absolute difference of the maximum and the minimum of the posterior probability of negatives cash access by changing the value of the explanatory variable in the horizontal axis is depicted in the parenthesis above each explanatory variable’s panel and is a criterion for assessing how important that variable is in the shaping of a prediction for the dependent variable. The panels are sorted from the left to the right and above to below based on increasing in the importance values. As it is evident from the Figure 4, the entire banking records (rows 18-29 at Table 1 and in the lower 4 rows in Figure 4) play the greater role to predict the posteriors in comparison with the non-banking welfare attributes of that household (rows 3-17 at Table 1 and the first 4 rows in Figure 4). Hence, it can be rationally expected that erasing banking records will reduce the model accuracy metrics.
The reduced BBN (BBN_2) model through subtraction of banking records of the recent years is trained using the labeled data of 14 variables in line with (n=5) and the Hill Climbing Search algorithm over the 80% of the 491,720 rows × 14 columns of data. The BBN_2′s DAG is presented in Figure 5.
The PR and ROC curves together with AUC and f_score values in Figure 6 indicate the feasibility of obtaining relatively precise predictions through erasing the banking records by (n=5) and by setting the to optimal values. The indicators, of Figure 6, however imply lower preciseness compared to the Figure 2 as it is expected.
The trade-off between recognition of negatives and positives (in the case of cutting the banking records from the households’ eligibility question in the test set of the Household_welfare_data) through altering the threshold from 0.0 to 0.9 in small (0.1) incremental step sizes and its relationship with the accuracy_total is represented in Figure 7. It is evident that, in this case, the administration will have less play room in the range of non-optimal threshold values, as in contrast to Figure 3 the represented True and the False positive rates curves are not drifting that much from each other. If the government e.g. decide to choose threshold values to achieve higher than 90% recognition of True positives, in this case (, which promises a higher recognition rate of lower income groups), it must be accepting to allocate extra budget to be distributed to more than 60% False positives, who are not be deserved to be receivers of the basic income, indeed.
4. Results
The results of examining the feasibility of distinguishing lower cash accessible groups (positives) form higher cash accessible groups (negatives) by setting various cash accessibility thresholds th(n) and various distinguishing probability thresholds tp(n), are presented in Table 2 (where banking and non-banking welfare records of households are incorporated) and Table 3 (where only non-banking welfare records of households are incorporated). Each column represents one distinct percentile number , which can be the possible poverty boundary with regard to cash accessibility to define the negatives and positives. Each of the first nine rows, represent one distinct percentile number , upon which the government can decide to classify a household as a positives type if the predicted posterior probability of positives exceeds . Each cell within the first 9 rows and 9 columns, represents the result of the BNN models’ predictions regarding 1000 randomly chosen persons from the test set in a confusion matrix depicted in the explanatory Table 2.
The tp_ROC, tp_PR, AUC_ROC, AUC_PR, f1_score_ROC, f1_score_PR and max_accuracy represent the optimal indicators of accuracy corresponded to the entire test set within each column. The max_accuracy describes the maximum of the overall accuracy (accuracy_total) we can achieve to deliver correct predictions within each .
The applied evaluation metrics reveal that, first of all, the probability of proper recognition of the entire vulnerable households without error by using the BBN is infinitely low. This is especially a matter of concern due to emergence of false negative counts, i.e. vulnerable households, that mistakenly are detected as wealthy classes almost among all experiments. The rare results, without false negatives being involved, comprise corner solutions consisting of e.g. tp(n=1) and th(n=9), which describe the situation, where the administration is almost next to the point approximating a basic income system based on the definition for the entire population of the society.
In the both tables 3 and 4, the minimum level of max_accuracy appears when the thresholds for distinguishing positives from negatives are set at the median cash accessibility level e.g. th(n=5) or next to it. The max_accuracy increases when we move towards deciding to distinguish the extreme high cash accessible groups e.g. th(n=9) from the rest of the society or to distinguish the extra low cash accessible groups e.g. th(n=1) from the rest of the society. This relatively higher overall feasibility of appropriate predictions to distinguish extreme groups from the rest is also evident form the parameter AUC_ROC in tables 3 and 4. However, the obtained high total accuracies by detection of extreme groups does not mean equal preciseness with regard to positives and negatives. This is revealed through observing at f1_scores obtained at optimal threshold levels. f1_score_ROC and f1_score_PR decrease if we move from the th(n=9) to th(n=1). This mainly goes back to the increase in False negative counts and can be made evident by means of looking at the False negative counts within each row. That is, although by setting the threshold at the left hand side of the deciles range e.g. th(n=1) we are capable to recognize a relative high number of negative marked households, however, due to imbalance in the data (through higher proportion of negatives), some predictions regarding real positive household, which are the main targets of the basic income turns to be false. The problem of False negative counts becomes less severe when setting the threshold at the right hand side of the deciles range e.g. th(n=9). In this case all indicators i.e AUC_ROC, AUC_PR, f1_score_ROC, f1_score_PR and max_accuracy, are indicating satisfactory predictions. Regardless of the question of the optimum decile number , the question, which probability threshold , should we set to achieve the maximum accuracy of detection, can be answered to some extent by deviating from the optimal tp_ROC and tp_PR levels. A government can deviate from the optimal levels, which often occur to be around 0.4 i.e. tp(n=4) in our research and set extremely soft classification probability thresholds by reducing the thresholds to the levels lower than the optimum one e.g. to the tp(n=1 or 2 or 3), to achieve the minimum possible number of e.g. False negative counts. However, this tolerance often happens at the cost of accepting to allocate extra budget to be distributed to the False positives. The play room, the administrations have to move back and forth in the range of non-optimal tp_ROC and tp_PR threshold values, in the cases of the availability of high resolution welfare attributes of the households (e.g. through including the households’ bank records) is wider, compared to the cases of working with relatively limited number of welfare attributes of the households (e.g. through excluding the households’ bank records). This is evident from the slopes of the true positive and false positive count curves in figures 3 (through the curves’ relative sharp style) and 5 (through the curves’ relative mild style).
5. Further discussion and conclusion
The theoretical notion of the basic income notion prescribes transferring equal amounts to individuals irrespective of their specific attributes, per definition. However, practical implementation of the basic income proposals can necessitate setting smart criteria to be attached to specific attributes of households to become eligible receivers. In this paper, we proposed the question whether machine learning can resolve the inconsistency problem between theory and practice. Can integrating machine learning change the future of basic income by confidently excluding the societies’ relative wealthy groups from a basic income program and simultaneously let the basic income program running broadly for the rest of the society?
We analyzed this question by utilizing a multidimensional and longitudinal welfare data comprising one and a half million individuals and a Bayesian beliefs network approach to examine the feasibility of predicting households’ vulnerability to future poverty based on the existing households’ welfare attributes.
We first converted the individual household data to household level and set the cash availability level of a household as the criterion, upon which, the governments can decide, whether a household can be included in the receivers’ list of cash transfers within the context of a basic income program. We designed experiments to observe how precise one administration can distinguish the relative vulnerable groups of the society from the relative wealthier groups by employing a Bayesian beliefs model. To figure out optimal feasible solutions, we changed the cash accessibility thresholds as well as the classification probability thresholds in small increments. The experiments are carried out once with incorporation of a comprehensive set of households’ welfare attributes especially with considering their records of banking data and once with incorporation of a limited set of the households’ welfare attributes i.e. without considering their records of banking data. Thereby, we utilized standard machine learning metrics to evaluate the results of the experiments. The main emphasis of the metrics is put on the recognition of the relative vulnerable groups, which are marked as positives through the study. The metrics reveal that, the probability of proper recognition of the entire vulnerable households without error by using Bayesian networks is infinitely low. The rare results, without false negatives being involved, comprise merely corner solutions, which are equivalent to a solution, where the administration is almost next to the point of approximating a basic income system by distributing uniform cash values to all households.
However, different metrics applied in our study shows that the opportunity to converge toward a balanced solution between a highly precise prediction of relative wealthier groups and lowest possible error regarding false negative counts are to some extent possible. 3 experimental set-ups in our study grant near to optimal solutions. First, when we set the cash accessibility threshold criteria possibly close to the deciles at the right hand side of the median level. Second, when we set the minimal classification probability threshold possibly lower than the optimal classification probability thresholds. Third, when we incorporate more data to the welfare attributes profile of the households e.g. by consideration of the households’ banking records. There might exist further caveats for each of these experimental setups. First, low precision by recognition of vulnerable groups by setting the threshold at the left hand side of the deciles ranges, can have been triggered in our study through the imbalance in the training sample. This issue might be theoretically resolved by incorporating extra data of the societies’ vulnerable groups to be represented in the machine learning model’s training procedure or by using the resampling or penalizing learning techniques. Yet, note that as the main goal of the most basic income systems is to cover a broad range of the society, setting the practical cash accessibility threshold close to the deciles at the right hand side of the median level, makes sense if we assume that the real poverty line in various countries lies somewhere not far from the median levels people.
Then, setting the minimal classification probability threshold possibly lower than the optimal classification probability thresholds seems to be essential to obtain maximal recognition levels of truly vulnerable groups at the cost of accepting extra government budget allocated to the basic income program. Furthermore, incorporating of individual (or household level) banking records in a machine learning algorithm to increase its preciseness is a subject of discussion outside of our paper’s scope, as the individual banking records can be interpreted as sensitive information and might not be applicable in all circumstances. All in all, the solution achieved in our study might be interpreted as a preliminary step, which still is not satisfactory due to the existence of small percentage of false negatives, who can be falsely recognized and be disadvantaged through the households’ eligibility application within a basic income system. Indeed, not recognition of even extremely small number of vulnerable to poverty persons can give a misleading impression with regard to feasibility of integrating machine learning in the notion of basic income as a guaranty against the existence of vulnerability to poverty in the society. However, this does not mean that reaching an optimized solution by incorporating machine learning is not obtainable. We merely utilized one method i.e. Bayesian networks in our application, with the advantage of achieving interpretable results in a graphical grace. Using the application of several other machine learning methods especially deep neural network models can come out with outcomes with high accuracies as well. Achieving a high degree of preciseness by using the data set of this paper together with high interpretability by using other machine learning models remains a further step of our research. There are furthermore some other limits in the designing our study’s model e.g. by modelling the time factor. While we incorporated the information regarding the previous years’ welfare profiles to predict the future welfare levels, we did not explicitly model the consequence time points as influencing factors in the Bayesian networks. Capturing the dynamics of the welfare dimensions through the time can be done by applying other machine learning models e.g. recurrent deep learning approaches and or dynamic Bayesian belief networks, which are capable to relate variables to each other over adjacent time steps. In addition, while we used a monetary poverty measurement as the dependent variable of our study i.e. a poverty line, applying a broader range of welfare variables to be predicted in a multidimensional vulnerability to future poverty concept can be considered as another frontier of research to be accomplished.
6. Supplementary material
You can find further material related to this paper consisting of code, data, results and figures in the GitLab account corresponded to this paper, which is provided by University of.
References
- Barbrook-Johnson, P., Penn, A.S. (2022). Bayesian Belief Networks. In: Systems Mapping. Palgrave Macmillan, Cham. [CrossRef]
- Bossert, W., Chakravarty, S., D’Ambrosio, C., 2013. Multidimensional poverty and material deprivation with discrete data. Rev. Income Wealth 59 (1), 29–43.
- Koller & Friedman, Probabilistic Graphical Models - Principles and Techniques, MIT Press, 2009. http://mitp-content-server.mit.edu:18180/books/content/sectbyfn?collid=books_pres_0&id=7953&fn=9780262013192_sch_0001.pdf.
- Richard E. Neapolitan, Learning Bayesian Networks. Northeastern Illinois University Chicago, Illinois, 2003. http://www.cs.technion.ac.il/~dang/books/Learning%20Bayesian%20Networks(Neapolitan,%20Richard).pdf.
- Ioannis Tsamardinos, Laura E. Brown, Constantin F. Aliferis. The max-min hill-climbing Bayesian network structure learning algorithm, Mach Learn (2006) 65:31–78. [CrossRef]
- Fawcett, Tom (2006). “An Introduction to ROC Analysis” (PDF). Pattern Recognition Letters. 27 (8): 861–874. [CrossRef]
- Powers, David M. W. (2011). “Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation”. Journal of Machine Learning Technologies. 2 (1): 37–63.
- Puga, J., Krzywinski, M. & Altman, N. Bayes’ theorem. Nat Methods 12, 277–278 (2015). [CrossRef]
- Baker , J. (1992). An egalitarian case for basic income. In: Van Parijs P (ed) Arguing for basic income: ethical foundations for a radical reform. New York: Verso.
- Banerjee , A., Niehaus, P., & Suri , T. (2019). Universal Basic Income in the Developing World. Annual Review of Economics11(1), 959-983.
- Bartscher, A., Kuhn, M., chularick, M., & Wachtel, P. (2021). Monetary policy and racial inequality. NBER working paper.
- Bill , J. (1988). The prospects for basic income. Soc Policy Adm 22(2), 115–123.
- Bobkov V., C. E. (2020). Unconditional Basic Income: Criterial Bases, Transitional Forms and Experimental Implementation . Sotsiologicheskie issledovaniya;10 C, 84-94.
- Calvo, C., Dercon, S., 2005. Measuring Individual Vulnerability. Discussion Paper Series 229, University of Oxford, Department of Economics.
- Calvo, C., Dercon, S., 2007. Vulnerability to Poverty. CSAE Working Paper 2007-03.
- Calvo, C., Dercon, S., 2013. Vulnerability to individual and aggregate poverty. Soc. Choice Welf. 41, 721–740.
- Cappelen, A., Nielsen, U., Tungodden, B., Tyran, J., & Wengström, E. (2015). Fairness is intuitive. Experimental Economics volume 19, 727-740.
- Caterina, C., & Flamand, S. (2019). A Review on Basic Income: A Radical Proposal for a Free Society and a Sane Economy by Philippe Van Parijs and Yannick Vanderborght. Journal of Economic Literature, 57 (3), 644-58.
- Chaudhuri, S., Jalan, J., Suryahadi, A., 2002. Assessing Household Vulnerability to Poverty from Cross-Sectional Data: A Methodology and Estimates from Indonesia. Department of Economics Discussion Paper Series (vol. 102), Columbia University.
- Ceriani, L., Gigliarano, C., 2020. Multidimensional well-being: A Bayesian networks approach. Soc. Indic. Res. 152, 237–263.
- Christiaensen, L., Subbarao, K., 2005. Towards an understanding of household vulnerability in rural Kenya. J. Afr. Econ. 14 (4), 520–558. Clark, Robert, 2016. Chapter 2: anatomy of a pandemic. business continuity and the pandemic threat. It Governance Publishing. United Kingdom, pp. 1–298.
- Coalition agreement SPD, The Greens and FDP. (2021). Mehr Fortschritt wagen. https://www.spd.de/fileadmin/Dokumente/Koalitionsvertrag/Koalitionsvertrag_2021-2025.pdf: SPD.
- Davis, A., Hirsch, D., Padley, M., & Shepherd, C. (2021). A Minimum Income Standard for the United Kingdom in 2021. www.jrf.org.uk: Joseph Rowntree foundation.
- De Durana, A., & Rodrigu, G. (2021). New developments in the national guaranteed minimum income scheme in Spain. EUROPEAN SOCIAL POLICY NETWORK.
- De Wispelaere , J., & Stirton , L. (2004). The many faces of universal basic income. Polit Q 75(3), 266–274.
- Delsen, L. (2019). Empirical Research on an Unconditional Basic Income in Europe. Springer.
- Feeny, S., McDonald, L., 2016. Vulnerability to multidimensional poverty: Findings from households in Melanesia. J. Dev. Stud. 52 (3), 447–464.
- Fitzpatrick, T. (1999). Freedom and Security: An Introduction to the Basic Income Debate. London: Macmillan Press.
- Gallardo, M., 2018. Identifying vulnerability to poverty: A critical survey. J. Econ. Surv. 32 (4), 1074–1105.
- Gallardo, M., 2020. Measuring vulnerability to multidimensional poverty. Soc. Indic. Res. 148, 67–103.
- Gallardo, M., 2022. Measuring vulnerability to multidimensional poverty with Bayesian network classifiers. Economic Analysis and Policy, 73, 492-512.
- Gentilini, U., Grosh, M., Rigolini, J., & Yemtsov, R. (2020). Exploring Universal Basic Income; A Guide to Navigating Concepts, Evidence, and Practices. World Bank.
- Grover, J. (2012). A Literature Review of Bayes’ Theorem and Bayesian Belief Networks (BBN). Strategic Economic Decision-Making, 11-27.
- Hoynes , H., & Rothstein, J. (2019). Universal Basic Income in the United States and Advanced Countries. Annual Review of Economics, 929-58.
- Jackson, A. (2017). Basic income: a social democratic perspective. Glob Soc Policy 17(1), 101–104.
- Jenson, F. V. (1996). An introduction to Bayesian networks. Newyork: Springer.
- Johnson, R., & Orme, B. (1996). How Many Questions Should You Ask in Choice-Based Conjoint Studies? Sawtooth Software, Inc.
- Jordan , B. (2012). The low road to basic income? Tax-beneft integration in the UK. J Soc Policy 41, 1–17.
- Kangas, O., Signe, J., Miska, S., & Minna, Y. (2021). Experimenting with Unconditional Basic Income: Lessons from the Finnish BI Experiment 2017-2018. Edward Elgar Publishing.
- King, J., & Marangos, J. (2006). TWO ARGUMENTS FOR BASIC INCOME: THOMAS PAINE (1737-1809) AND THOMAS SPENCE (1750-1814). History of Economic Ideas, 14(1), 55–71.
- Kulshreshtha, K., Sharma, G., & Bajpai, N. (2021). Conjoint analysis: the assumptions, applications, concerns, remedies and future research direction. International Journal of Quality & Reliability Management.
- Lister, A. (2020). Reconsidering the reciprocity objection to unconditional basic income. Politics, Philosophy & Economics, 19(3), 209–228.
- Louivere, J. (1998). Conjoint Analysis Modelling of Stated Preferences: A Review of Methods Recent Developments and External Validity. Journal of transport Economics 22(1), 93-119.
- Louviere , J., & Woodworth, G. (1983). Design and analysis of simulated consumer choice experiments: an approach based on aggregate data. Journal of Marketing Research;20(4), 350–67.
- Lovett , F. (2009). Domination and distributive justice. J Polit 71(3), 817–830.
- Luce, R., & Tukey, J. (1964). Simultaneous conjoint measurement: A new type of fundamental measurement. Journal of Mathematical Psychology;1(1), 1-27.
- Marshall, D., Bridges, J., & Hauber, B. (2010). Conjoint Analysis Applications in Health — How are Studies being Designed and Reported? Patient-Patient-Centered-Outcome-Res 3, 249–256.
- McFadden. (1974). Conditional logit analysis of qualitative choice behavior. In e. Zarembka P, Frontiers in Econometrics (pp. 105–142). New York: Academic Press.
- Moffitt, R. (2003). The Positive Income Tax and the Evolution of U.S. Welfare Policy. https://www.nber.org/: National Bureau of Economic Research, Cambridge, MA.
- Mori, I. (2017). Half of UK Adults Would Support Universal Basic Income in Principle. https://www.ipsos.com/ipsos-mori/en-uk/half-uk-adults-wouldsupport-: Polling commissioned by the Institute for Policy Research, University of Bath.
- Nguyen, L. (2021). On the implementation of the universal basic income as a response to technological unemployment . International Journal of Management Research and Economics 1(3), 1-6.
- Nooteboom , B. (1987). Basic income as a basis for small business. Int Small Bus J 5(3), 10–18.
- OECD. (2017). Basic income as a policy option: Can it add up?
- OECD. (2019). A data-driven public sector. Paris, https://www.oecd-ilibrary.org/docserver/09ab162c-en.pdf?expires=1644620690&id=id&accname=guest&checksum=08C311E2ACEE5A054D350727AC3A4873: OECD.
- Pateman , C. (2004). Democratizing citizenship: some advantages of a basic income. Polit Soc 32(1), 89–105.
- Pearl, J. (1988). Probabilistic reasoning in intelligent systems: networks of plausible inferencee, first ed. in: Representation and Reasoning. California: Morgan Kaufmann.
- Peduzzi , P., Concato , J., Kemper , E., Holford , T., & Feinstein , A. (1996). A simulation study of the number of events per variable in logistic regression analysis. Journal of Clinical Epidemiology 49, 1373-1379.
- Perkiö, J. (2013). Basic income proposals in Finland, Germany and Spain. https://www.transform-network.net/fileadmin/_migrated/news_uploads/paper__2_13.pdf: european network for alternative thinking and political dialogue.
- Pulkka , V. (2017). A free lunch with robots - can a basic income stabilise the digital economy? Transf-Eur Rev Labor Res 23(3), 295–311.
- Raventós , D. (2007). Basic income: the material conditions of freedom. London: Pluto Press.
- Rawls, J. (2009). A theory of justice. Cambridge: Harvard University Press.
- Salecker, L., Ahmadov, A.K. & Karimli, L. Contrasting Monetary and Multidimensional Poverty Measures in a Low-Income Sub-Saharan African Country. Soc Indic Res 151, 547–574 (2020). [CrossRef]
- Scientific Advisory Board at the Federal Ministry. (2021). Unconditional basic income. bmf-wissenschaftlicher-beirat.de.
- Standing , G. (2012). The precariat: from denizens to citizens? Polity 44(4), 588–608.
- Thomas, A. (2020). Full Employment, Unconditional Basic Income and the Keynesian Critique of Rentier Capitalism. Basic Income Studies;15(1), 2019-0015.
- Van der Veen , R. (1998). Real freedom versus reciprocity: competing views on the justice of unconditional basic income. Polit Stud 46(1), 140–163.
- Van Parijs , P. (1991). Why surfers should be fed: the liberal case for an unconditional basic income. Philos Public Af 20(2), 101–131.
- Von Gliszczynski , M. (2017). Social protection and basic income in global policy. Glob Soc Policy17(1), 98–100.
- Widerquist, K. (2001). Perspectives on the guaranteed income, part I. J Econ Issues 35(3), 749–757.
- Yang, J., Mohan, G., Pipil, S., & Fukushi, K. (2021). Review on basic income (BI): its theories and empirical cases. Journal of Social and Economic Development (23), 203–239.
- Ypma , T. (1995). Historical development of the Newton-Raphson method. SIAM Review;37(4), 531–551.
- Zheng, Y., Guerriero, M., Lopez, E., & Haverman, P. (2020). Universal Basic income; a working paper. UNDP China Office.
Figure 1.
The Bayesian belief network’s directed acyclic graph incorporating 30 welfare variables.
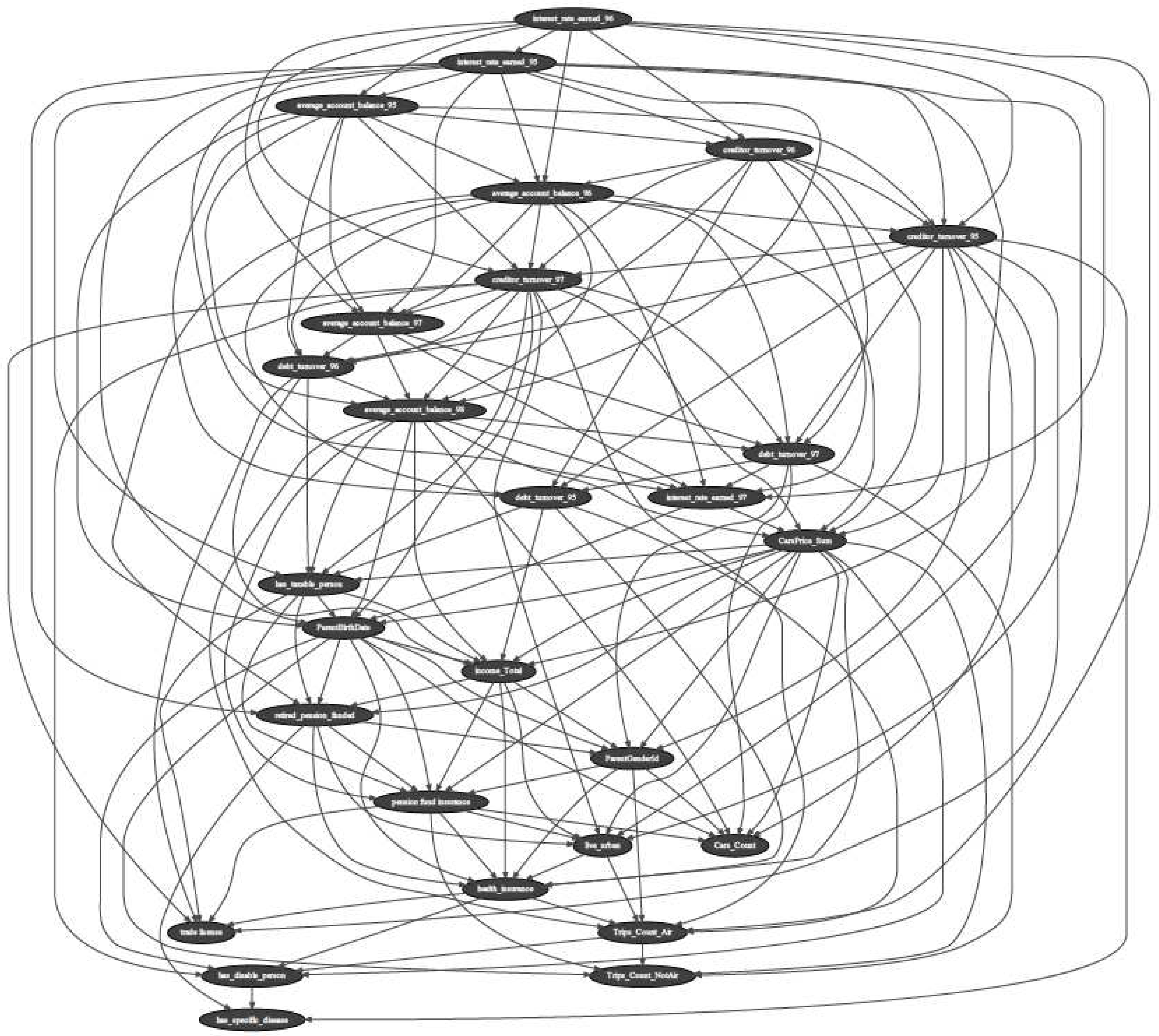
Figure 2.
The test set’s ROC and PR metrics.
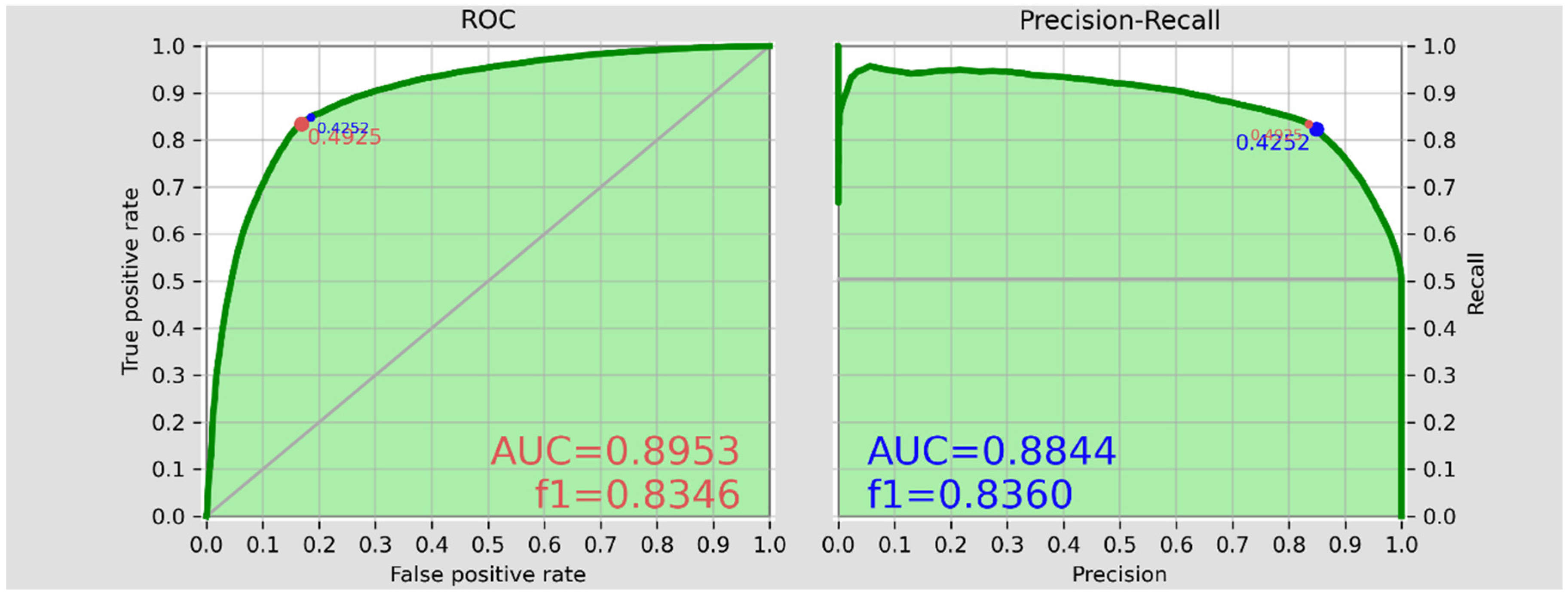
Figure 3.
Government’s play room to recognize higher True positive rates.
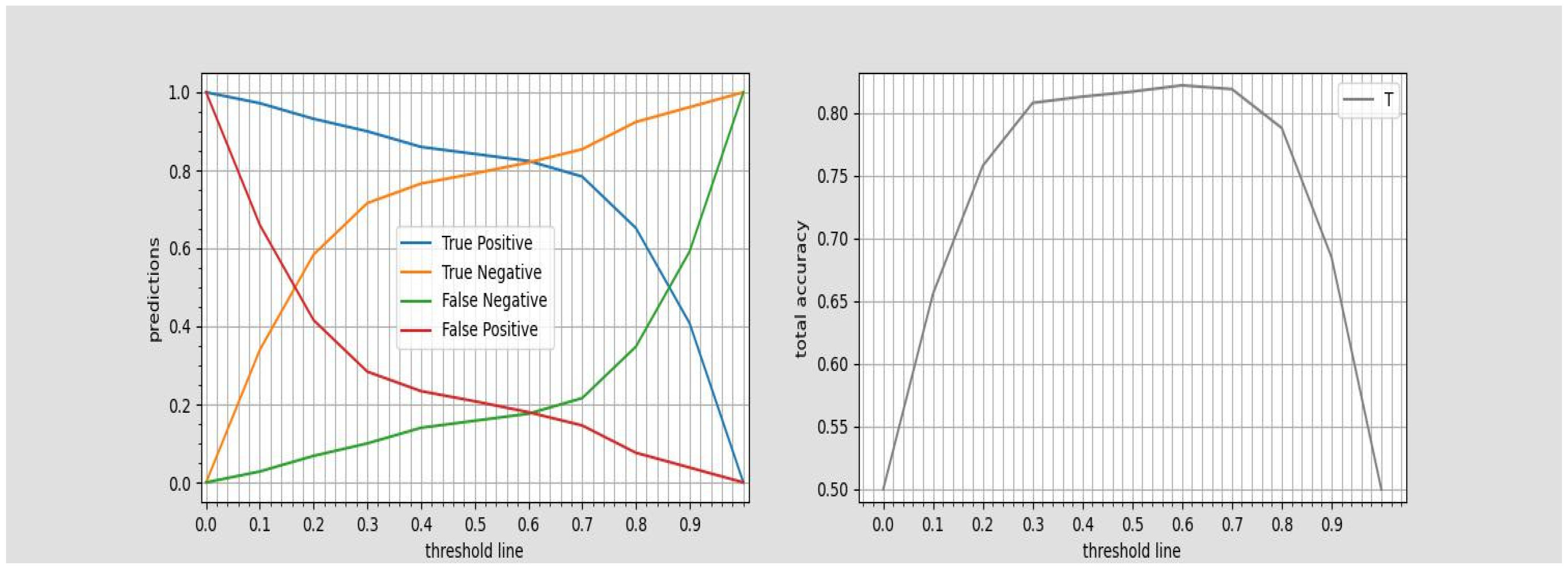
Figure 4.
Welfare attributes importance to provide evidence regarding negative and positives.
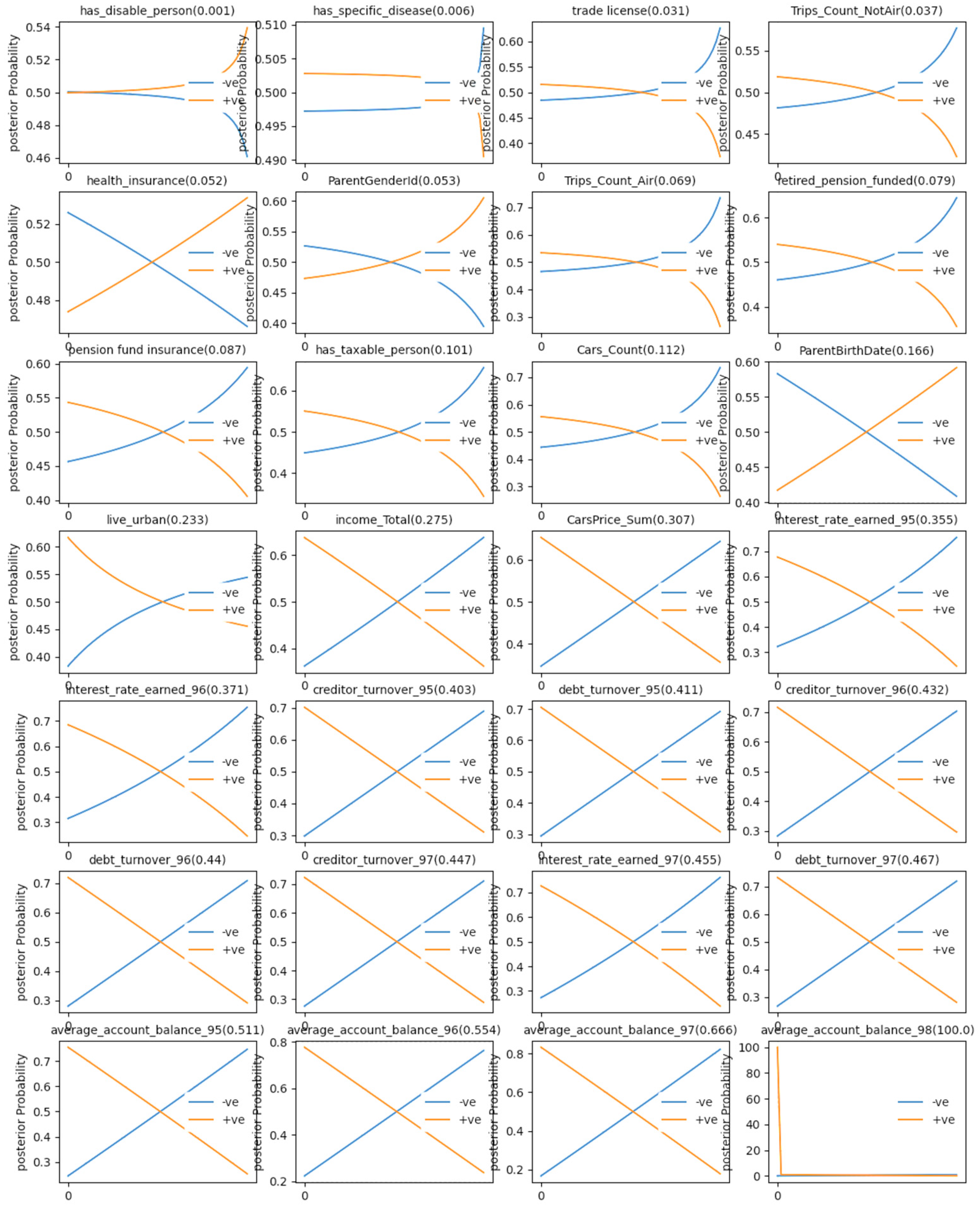
Figure 5.
The Bayesian belief network’s directed acyclic graph incorporating non-banking welfare variables.
Figure 5.
The Bayesian belief network’s directed acyclic graph incorporating non-banking welfare variables.
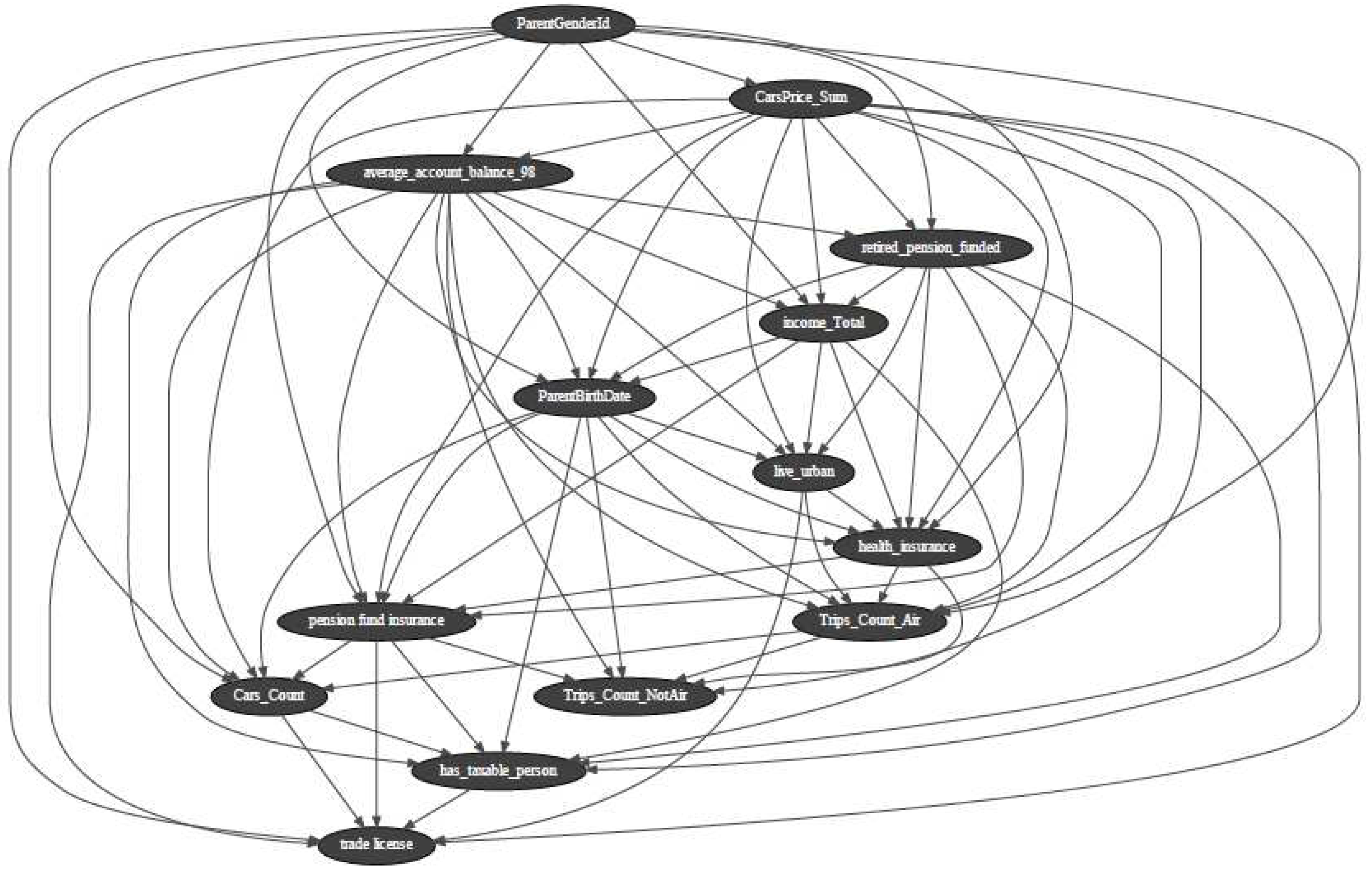
Figure 6.
The test set’s ROC and PR metrics by incorporating non-banking welfare variables.
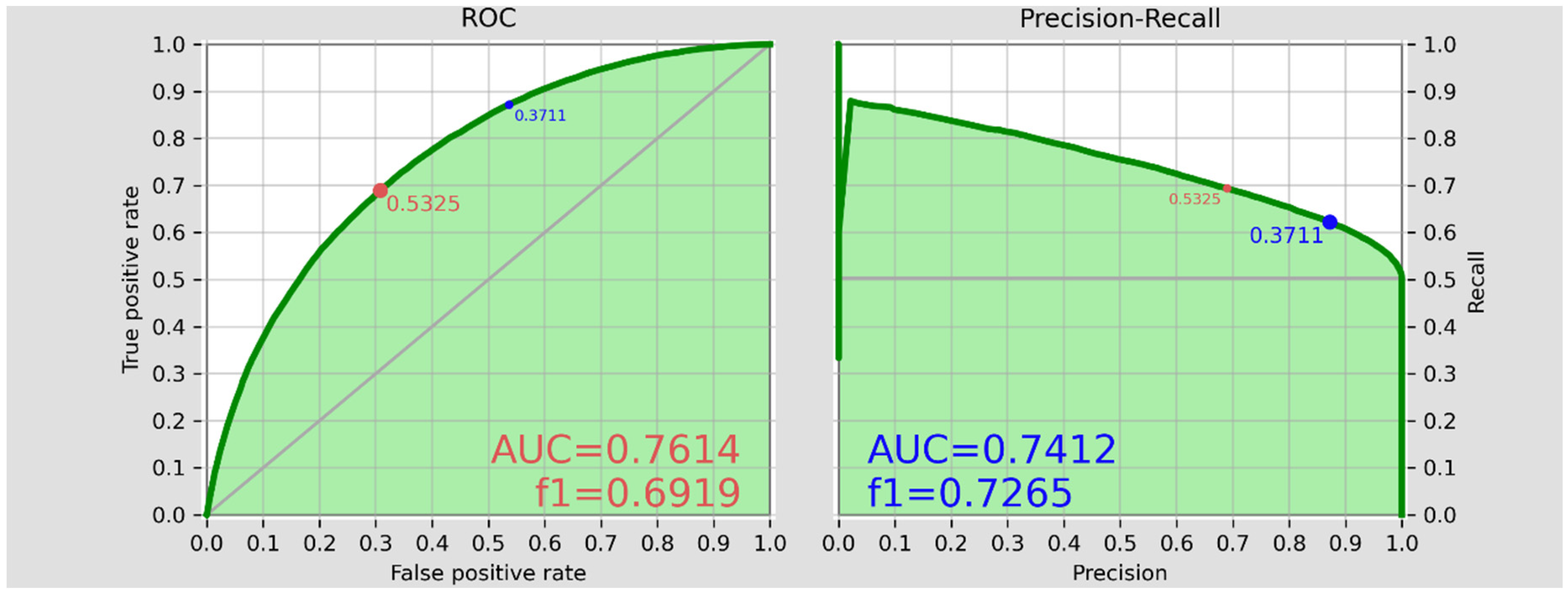
Figure 7.
Government’s play room to recognize higher True positive rates by incorporating non-banking welfare variables.
Figure 7.
Government’s play room to recognize higher True positive rates by incorporating non-banking welfare variables.
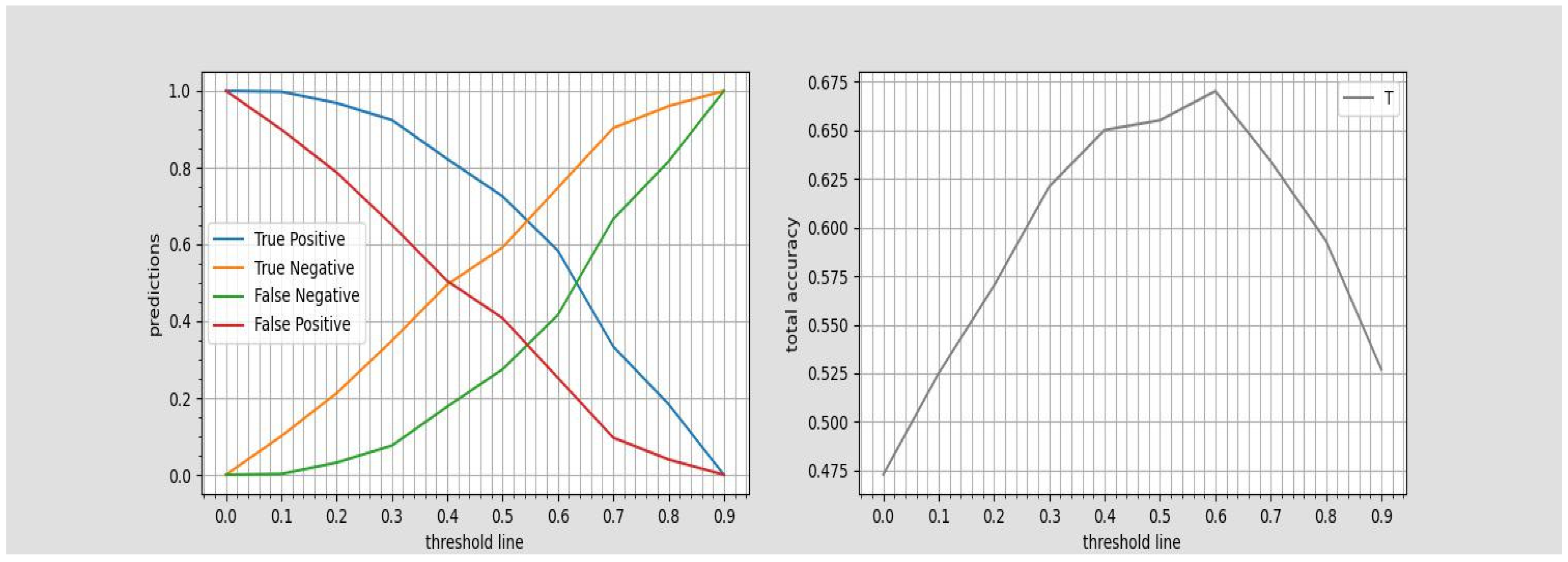

Table 1.
The types of 30 distinct registered information from each individual. Note that the dates are Iranian calendar dates corresponded to the beginning and the end of each Iranian years 1395, 1396, 1397, 1398 converted to European equivalents 2016-2017, 2017-2018, 2018-2019, 2019-2020, respectively.
Table 1.
The types of 30 distinct registered information from each individual. Note that the dates are Iranian calendar dates corresponded to the beginning and the end of each Iranian years 1395, 1396, 1397, 1398 converted to European equivalents 2016-2017, 2017-2018, 2018-2019, 2019-2020, respectively.
| Person’s family profile and gender | 1. Person ID |
| 2. Parent ID | |
| 3. Age | |
| 4. Gender | |
| Person’s living place | 5. live in the city or not? |
| Person’s income | 6. Total annual salary |
| 7. Has a trade union license? | |
| 8. Is an employed taxable person? | |
| Person’s insurance and retirement status | 9. Has health insurance? |
| 10. Is a pension fund insurer? | |
| 11. Is a pension fund retiree? | |
| Person’s transport and trips | 12. Number of foreign air trips |
| 13. Number of foreign land trips | |
| 14. Total number of cars | |
| 15. Total value of cars | |
| Person’s special health issues | 16. Is a special patient? |
| 17. Is a disabled person? | |
| Person’s bank account records of the recent years | 18. Total income from bank interest within 20.03.2016-20.03.2017 |
| 19. Total creditor turnover within 20.03.2016-20.03.2017 | |
| 20. Total debt within 20.032016-20.03.2017 | |
| 21. Average accounts balance within 20.03.2016-20.03.2017 | |
| 22. Total income from bank interest in within 20.03.2017-20.03.2018 | |
| 23. Total creditor turnover within 20.03.2017-20.03.2018 | |
| 24. Total debt within 20.03.2017-20.03.2018 | |
| 25. Average accounts balance within 20.03.2017-20.03.2018 | |
| 26. Total income from bank interest within 20.03.2018-20.03.2019 | |
| 27. Total creditor turnover within 20.03.2018-20.03.2019 | |
| 28. Total debt within 20.03.2018-20.03.2019 | |
| 29. Average accounts balance within 20.03.2018-20.03.2019 | |
| 30. Average accounts balance within 20.03.2019-20.03.2020 |
| Column: th(n=i) | ||
|---|---|---|
| Row: tp(n=i) | TP count out of 1000 | FP count out of 1000 |
| FN count out of 1000 | TN count out of 1000 | |
Table 3.
feasibility of distinguishing lower cash accessible groups (positives) form higher cash accessible groups(negatives) by setting various cash accessibility thresholds th(n) and various distinguishing probability thresholds tp(n) if bank records incorporated.
Table 3.
feasibility of distinguishing lower cash accessible groups (positives) form higher cash accessible groups(negatives) by setting various cash accessibility thresholds th(n) and various distinguishing probability thresholds tp(n) if bank records incorporated.
| index | th(n=1) | th(n=2) | th(n=3) | th(n=4) | th(n=5) | th(n=6) | th(n=7) | th(n=8) | th(n=9) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tp(n=1) | 110 | 109 | 204 | 247 | 299 | 293 | 382 | 321 | 475 | 342 | 592 | 319 | 695 | 245 | 816 | 164 | 907 | 87 |
| 29 | 752 | 20 | 529 | 22 | 386 | 17 | 280 | 11 | 172 | 2 | 87 | 6 | 54 | 2 | 18 | 0 | 6 | |
| tp(n=2) | 96 | 45 | 187 | 103 | 271 | 133 | 362 | 199 | 461 | 190 | 561 | 197 | 687 | 182 | 812 | 129 | 902 | 73 |
| 43 | 816 | 37 | 673 | 50 | 546 | 37 | 402 | 25 | 324 | 33 | 209 | 14 | 117 | 6 | 53 | 5 | 20 | |
| tp(n=3) | 93 | 38 | 171 | 68 | 248 | 79 | 325 | 122 | 448 | 119 | 541 | 136 | 667 | 120 | 800 | 93 | 897 | 56 |
| 46 | 823 | 53 | 708 | 73 | 600 | 74 | 479 | 38 | 395 | 53 | 270 | 34 | 179 | 18 | 89 | 10 | 37 | |
| tp(n=4) | 87 | 32 | 162 | 62 | 244 | 69 | 315 | 101 | 429 | 88 | 528 | 99 | 655 | 89 | 787 | 75 | 889 | 34 |
| 52 | 829 | 62 | 714 | 77 | 610 | 84 | 500 | 57 | 426 | 66 | 307 | 46 | 210 | 31 | 107 | 18 | 59 | |
| tp(n=5) | 78 | 27 | 156 | 54 | 239 | 62 | 304 | 92 | 416 | 72 | 516 | 84 | 642 | 76 | 782 | 62 | 885 | 28 |
| 61 | 834 | 68 | 722 | 82 | 617 | 95 | 509 | 70 | 442 | 78 | 322 | 59 | 223 | 36 | 120 | 22 | 65 | |
| tp(n=6) | 60 | 21 | 146 | 42 | 229 | 52 | 289 | 82 | 398 | 62 | 506 | 330 | 626 | 69 | 775 | 58 | 876 | 24 |
| 79 | 840 | 78 | 734 | 92 | 627 | 110 | 519 | 88 | 452 | 76 | 88 | 75 | 230 | 43 | 124 | 31 | 69 | |
| tp(n=7) | 43 | 12 | 117 | 26 | 192 | 29 | 257 | 58 | 368 | 50 | 480 | 55 | 605 | 64 | 760 | 53 | 866 | 21 |
| 96 | 849 | 107 | 750 | 129 | 650 | 142 | 543 | 118 | 464 | 114 | 351 | 96 | 235 | 58 | 129 | 41 | 72 | |
| tp(n=8) | 39 | 12 | 66 | 8 | 140 | 17 | 193 | 40 | 304 | 28 | 414 | 44 | 551 | 43 | 728 | 37 | 844 | 19 |
| 100 | 849 | 158 | 768 | 181 | 662 | 206 | 561 | 182 | 486 | 180 | 362 | 150 | 256 | 90 | 145 | 63 | 74 | |
| tp(n=9) | 0 | 0 | 0 | 0 | 94 | 6 | 108 | 10 | 199 | 14 | 293 | 20 | 446 | 24 | 643 | 24 | 803 | 11 |
| 139 | 861 | 224 | 776 | 227 | 673 | 291 | 591 | 287 | 500 | 301 | 386 | 255 | 275 | 175 | 158 | 104 | 82 | |
| tp_ROC | 0.074 | 0.185 | 0.265 | 0.366 | 0.474 | 0.627 | 0.740 | 0.821 | 0.910 | |||||||||
| tp_PR | 0.378 | 0.379 | 0.397 | 0.405 | 0.430 | 0.486 | 0.463 | 0.491 | 0.429 | |||||||||
| AUC_ROC | 0.907 | 0.897 | 0.897 | 0.897 | 0.894 | 0.897 | 0.900 | 0.909 | 0.918 | |||||||||
| AUC_PR | 0.653 | 0.760 | 0.804 | 0.852 | 0.885 | 0.917 | 0.924 | 0.968 | 0.985 | |||||||||
| f1_score_ROC | 0.557 | 0.686 | 0.763 | 0.804 | 0.835 | 0.864 | 0.881 | 0.903 | 0.924 | |||||||||
| f1_score_PR | 0.668 | 0.73 | 0.77 | 0.805 | 0.836 | 0.871 | 0.901 | 0.935 | 0.967 | |||||||||
| max_accurcy | 0.916 | 0.88 | 0.856 | 0.815 | 0.858 | 0.838 | 0.865 | 0.902 | 0.95 | |||||||||
Table 4.
feasibility of distinguishing lower cash accessible groups (positives) form higher cash accessible groups(negatives) by setting various cash accessibility thresholds th(n) and various distinguishing probability thresholds tp(n) if bank records not incorporated.
Table 4.
feasibility of distinguishing lower cash accessible groups (positives) form higher cash accessible groups(negatives) by setting various cash accessibility thresholds th(n) and various distinguishing probability thresholds tp(n) if bank records not incorporated.
| index | th(n=1) | th(n=2) | th(n=3) | th(n=4) | th(n=5) | th(n=6) | th(n=7) | th(n=8) | th(n=9) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tp(n=1) | 98 | 274 | 188 | 496 | 302 | 534 | 386 | 514 | 521 | 430 | 596 | 383 | 707 | 284 | 808 | 192 | 904 | 86 |
| 27 | 601 | 16 | 327 | 3 | 161 | 5 | 95 | 4 | 45 | 1 | 20 | 1 | 8 | 0 | 0 | 0 | 0 | |
| tp(n=2) | 81 | 129 | 161 | 288 | 270 | 341 | 369 | 406 | 509 | 384 | 585 | 339 | 701 | 263 | 806 | 187 | 904 | 0 |
| 44 | 746 | 43 | 508 | 35 | 354 | 22 | 203 | 16 | 91 | 12 | 64 | 7 | 29 | 2 | 5 | 96 | 0 | |
| tp(n=3) | 45 | 58 | 119 | 126 | 239 | 239 | 323 | 290 | 476 | 305 | 568 | 275 | 688 | 239 | 803 | 175 | 902 | 94 |
| 80 | 817 | 85 | 670 | 66 | 456 | 68 | 319 | 49 | 170 | 29 | 128 | 20 | 53 | 5 | 17 | 2 | 2 | |
| tp(n=4) | 33 | 47 | 112 | 101 | 188 | 163 | 260 | 203 | 453 | 235 | 540 | 232 | 668 | 222 | 797 | 165 | 901 | 89 |
| 92 | 828 | 92 | 695 | 117 | 532 | 131 | 406 | 72 | 240 | 57 | 171 | 40 | 70 | 11 | 27 | 3 | 7 | |
| tp(n=5) | 0 | 0 | 103 | 85 | 141 | 85 | 222 | 130 | 379 | 149 | 491 | 182 | 624 | 171 | 778 | 145 | 896 | 84 |
| 125 | 875 | 101 | 711 | 164 | 610 | 169 | 479 | 146 | 326 | 106 | 221 | 84 | 121 | 30 | 47 | 8 | 12 | |
| tp(n=6) | 0 | 0 | 0 | 0 | 121 | 66 | 140 | 64 | 307 | 99 | 400 | 119 | 581 | 133 | 753 | 124 | 888 | 80 |
| 125 | 875 | 204 | 796 | 184 | 629 | 251 | 545 | 218 | 376 | 197 | 284 | 127 | 159 | 55 | 68 | 16 | 16 | |
| tp(n=7) | 0 | 0 | 0 | 0 | 36 | 13 | 92 | 38 | 186 | 48 | 326 | 77 | 486 | 84 | 696 | 95 | 859 | 69 |
| 125 | 875 | 204 | 796 | 296 | 682 | 299 | 571 | 339 | 427 | 271 | 326 | 222 | 208 | 112 | 97 | 45 | 27 | |
| tp(n=8) | 0 | 0 | 0 | 0 | 0 | 0 | 12 | 5 | 129 | 27 | 162 | 27 | 357 | 53 | 607 | 61 | 812 | 45 |
| 125 | 875 | 204 | 796 | 305 | 695 | 379 | 604 | 396 | 448 | 435 | 376 | 351 | 239 | 201 | 131 | 92 | 51 | |
| tp(n=9) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 3 | 122 | 5 | 335 | 19 | 720 | 35 |
| 125 | 875 | 204 | 796 | 305 | 695 | 391 | 609 | 525 | 475 | 587 | 400 | 586 | 287 | 473 | 173 | 184 | 61 | |
| tp_ROC | 0.127 | 0.255 | 0.338 | 0.408 | 0.524 | 0.609 | 0.720 | 0.793 | 0.933 | |||||||||
| tp_PR | 0.251 | 0.255 | 0.311 | 0.338 | 0.363 | 0.370 | 0.416 | 0.447 | 0.480 | |||||||||
| AUC_ROC | 0.826 | 0.794 | 0.777 | 0.766 | 0.761 | 0.758 | 0.765 | 0.775 | 0.783 | |||||||||
| AUC_PR | 0.367 | 0.504 | 0.584 | 0.669 | 0.743 | 0.798 | 0.867 | 0.921 | 0.963 | |||||||||
| f1_score_ROC | 0.412 | 0.538 | 0.604 | 0.65 | 0.693 | 0.735 | 0.766 | 0.813 | 0.863 | |||||||||
| f1_score_PR | 0.441 | 0.538 | 0.605 | 0.662 | 0.726 | 0.785 | 0.841 | 0.897 | 0.948 | |||||||||
| max_accurcy | 0.875 | 0.814 | 0.751 | 0.701 | 0.705 | 0.712 | 0.745 | 0.825 | 0.908 | |||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



