
Submitted:
05 September 2023
Posted:
06 September 2023
You are already at the latest version
Abstract
The emergence of non-canonical amino acids (ncAAs) has enriched the functional pool inherent in canonical amino acids (cAAs). ncAAs are important building blocks in the production of various pharmaceuticals. The biosynthesis of ncAAs has emerged as an alternative to traditional chemical synthesis because of its environmental friendliness and high efficiency. The breakthrough genetic code expansion (GCE) technique developed in recent years has allowed for the incorporation of ncAAs into target proteins, giving them special functions and biological activities. Biosynthesis of ncAAs and their incorporation into target proteins within a single microbe has become an enticing application of such molecules. Based on that, in this study we first review the biosynthesis methods for ncAAs and analyze the difficulties in biosynthesis. We then summarize the GCE methods and analyze their advantages and disadvantages. Further, we review the application progress of ncAAs and anticipate the challenges and future development directions of ncAAs.
Keywords:
non-canonical amino acid
; genetic code expansion
; biosynthesis
; incorporation
; tailor-made protein
1. Introduction
Proteins are essential to life processes, playing important roles in transport, catalysis, and regulation. Most proteins are composed of only 20 canonical amino acids (cAAs). While the encoding of cAAs is sufficient for fundamental growth and metabolic functions, proteins require additional chemical group such as phosphate, methyl, hydroxyl, and acetyl group to perform more complicated and diverse biological functions [1,2,3]. The requirement for these extra functional groups demonstrates that the 20 cAAs severely restrict the types and functional applications of proteins, which are no longer sufficient to meet the research needs of fields such as biological science, chemistry, and medicine [4,5].
Non-canonical amino acids (ncAAs) are derivatives of cAAs, also known as non-standard amino acids (nsAAs), unnatural amino acids (unAAs or uAAs) or non-proteinogenic amino acids (npAAs). Some examples of ncAAs include L-homoserine, which serves as a precursor for the synthesis of essential amino acids and other chemical products [6,7]. 5-Aminolevulinic acid is an important precursor for the biosynthesis of heme, porphyrin, chlorophyll, and vitamin B12, which are biodegradable, non-toxic, and residue-free [8]. NcAAs contain various functional groups such as ketyl, alkynyl, azide, nitro, phosphate, sulfonate, among others, which allow them to modify proteins through various reactions. So far, more than 200 ncAAs can be inserted proteins by using genetic code expansion (GCE) technology [9,10], which offers new opportunities for theoretical research and applications for protein structures and functions.
Despite the growing diversity and range of applications of ncAAs, their synthesis remains challenging [11,12,13]. The traditional chemical synthesis methods are limited by harsh reaction conditions [14], highly volatile toxic substances [15,16], environmental pollution and high raw material costs [17]. Metabolic engineering is an emerging technique that could potentially solve these issues and enable green and efficient production of ncAAs. Based on that, this study reviews the methods, applications, difficulties, and solutions of metabolic engineering biosynthesis of ncAAs. The methods for incorporating ncAAs into proteins by using GCE methods are summarized as well. The potential applications of tailor-made proteins are also discussed and the future applications are prospected.
2. Biosynthesis of ncAAs
As mentioned above, the chemical synthesis of ncAAs has significant drawbacks. In addition, ncAAs have high technical barriers to synthesis due to the limitations of key technologies such as the screening and preparation of chemical catalysts, the construction of process routes, and the regulation of catalytic processes [18]. Development of a green and efficient synthesis method for ncAAs is crucial. Metabolic engineering offers promising solutions for synthesizing ncAAs by understanding the catalytic mechanisms of related enzymes. The key heterologous enzymes can be recombined, modified, and optimized in the engineered microbes. These create the possibility of establishing a production platform for ncAAs. The usage of metabolic engineering offers a promising path toward creating a sustainable and cost-effective method for producing ncAAs.
2.1. 5-Hydroxytryptophan
5-Hydroxytryptophan (5-HTP) is an important compound with medicinal value used to treat depression, insomnia, and other diseases. Wang et al. have successfully constructed a recombinant strain to biosynthesize 5-HTP [19]. The biosynthesis pathway was constructed on two plasmids containing three functional modules, substrate L-Trp biosynthesis modules, hydroxylation module, and cofactor regeneration module (Figure 1). Besides, the human tryptophan hydroxylase I (TPH I) was introduced into E. coli BL21ΔtnaA strain to hydroxylate L-Trp to produce 5-HTP. As a result, the engineered strain produced 5.1 g/L 5-HTP through fed-batch fermentation. By further inserting the tryptophan synthesis pathway into the genome, the yield of 5-HTP in shake-flask fermentation was increased to 1.61 g/L while reducing the accumulation of precursor L-Trp, which was beneficial for the subsequent separation and purification of 5-HTP [20]. After that, Lin et.al first engineered the phenylalanine-4-hydroxylase from Xanthomonas campestris (XcP4H) and introduced into a L-Trp-producing E. coli strain with co-factor regeneration pathway. The engineered strain produced 1.2 g/L 5-HTP [21]. Mora-Villalobos utilized sequence analysis, phylogenetic analysis and functional differential analysis tools to predict, screen and design the specific mutations of substrate-specific sites of aromatic amino acid hydroxylase from Cupriavidus taiwanensis (CtAAAH). The substrate preference of the CtAAAH was transferred from L-Phe to L-Trp, enabling the generation of 5-HTP with L-Trp as substrate [22,23]. These studies show that microbial-based metabolic engineering has achieved the green, efficient, and low-cost production of 5-HTP.
2.2. L-Homoserine
L-Homoserine (L-Hse), also known as 2-amino-4-hydroxybutyric acid, is a valuable platform chemical that has been widely used in various fields such as medicine, agriculture, cosmetics, and spices. The microbial fermentation method has great potential for large-scale production of L-Hse. Recent studies have focused on using E. coli and Corynebacterium glutamate (C. glutamate) to achieve the high-level production of L-Hse [24,25,26,27]. For example, Cai et al. enhanced the production of L-Hse by using a non-auxotrophic deficient and plasmid-free E. coli chassis [28]. They first constructed a E. coli chassis host strain via knock-down of the L-Hse degradation pathway [29]. Then, they optimized the metabolic flux of L-Hse biosynthesis by overexpressing the ppc, aspC, aspA , thrAfbr, and lysCfbrcgl (Figure 1). Additionally, they promoted L-Hse efflux by modifying the transport system and introduced a strategy of synergistic utilization of co-factors to promote the regeneration of NADPH and coordinated the level of redox co-factors by incorporating a heterologous dehydrogenase. As a result, the engineered strain was able to produce 85.29 g/L of L-Hse in 5-L fermenter, which was the highest titer of the plasmid-free and non-auxotrophic strains reported to date. This study demonstrates the effectiveness of optimizing L-Hse production using metabolic engineering strategies and the potential for microbial fermentation as a primary method for producing valuable platform chemicals. Although E. coli as an amino acid-producing chassis has achieved high-level production of L-Hse, large amounts of by-products such as acetate are also produced during the fermentation process [24,30]. To address this issue, C. glutamate which is known for its ability to synthesize useful compounds using cheap feedstock, was used to produce L-Hse. Through overexpressing key kinase genes, disrupting competing and degrading pathways and promoting the synthetic flux, the engineered C. glutamate produced 8.8 g/L L-Hse [26].
2.3. Trans-4-hydroxyproline
Trans-4-hydroxyproline (t4Hyp) as a value-added amino acid, has been widely used in medicine, food and cosmetics, especially in the field of chiral synthetic material. t4Hyp is Traditionally produced by the acidic hydrolysis of collagen, but the process has some drawbacks such as low productivity and complicated process. Metabolic engineering has been used to efficiently construct microbial cell factories of E. coli or C. glutamate in order to biosynthesize t4Hyp [31,32,33]. Introduction of a heterologous proline 4-hydroxylase from Alteromonas mediterranea (AlP4H) into E. coli enabled an accumulation of 45.83 g/L t4Hyp within 36 hours in a 5-L fermenter without the addition of proline [34]. Knockout of the genes of putA, proP, putP and aceA in competing pathway and mutation of ProB to D107N/E143A ProB in order to alleviate the feedback inhibition of L-Pro maximized the production of L-Pro, so as to enhance the biosynthesis of t4Hyp. Subsequently, Rao et.al. optimized the enzyme activity of L-Pro hydroxylase by using genome mining technology and rational design. After systematic modification, an engineered strain can use glycerol and glucose as carbon sources to produce 54.8 g/L t4Hyp in 60 hours [33]. The microbial metabolic network is large and complex. Genome modification methods such as gene knockout may lead to slow cell growth, stagnation or even death, which may not be suitable for blocking some competing pathways. So far, CRISPR interference (CRISPRi) that can reduce the transcription of target genes by up to 1000-fold inhibition without miss effect [35,36] has been appeared as an alternative to down-regulate the expression of enzymes, which may be employed to repress the expression of the putA gene to further increase t4Hyp production in the future.
2.4. Other ncAAs
L-Pyrrolysine (L-Pyl) is the 22nd amino acid that has been discovered so far to insert into proteins [37]. Krzycki et al. reported that L-Lys is the only precursor of L-Pyl. By providing isotopically labeled L-Lys to methanogenic Archaea with the pylTSBCD gene cluster, methylamine methyltransferase with L-Pyl incorporation was obtained by mass spectrometry analysis and purification. Further, the biosynthetic process of the converting two L-Lys molecules into one L-Pyl molecule were revealed [38]. The pylBCD genes are for L-Pyl synthesis with tRNA-independent [39], while the pylT gene can produce tRNACUA (also called tRNAPyl), and the pylS gene can encode pyrrolysyl-tRNA synthase [40]. Further, introduction of pylTSBCD genes into E. coli can enable the incorporation of endogenously biosynthesized pyrrolysine into proteins. The L-Pyl production capacity of E. coli was improved by Ho et al. via rational engineering and directed evolution of the whole biosynthetic pathway of L-Pyl. They also developed Alternating Phage Assisted Non-Continus Evolution (Alt-PANCE), alternating mutagenesis and selective phage growth, to accommodate the toxicity of L-Pyl biosynthetic genes [41]. The evolutionary pathway enabled a 32-fold increase in pyl-incorporating protein yield compared to rationally modified pathway. The evolved PylB mutant had a 4.5-fold increase in intracellular levels and a 2.2-fold increase in protease resistance.
Gamma-aminobutyric acid (GABA) which has high nutritional value, is produced by lactic acid bacteria [42,43,44]. The GABA production capacity of Lactiplantibacillus plantarum was improved by changing crucial fermentation parameters. Optimization of the inoculum percentage, initial pH, inorganic ions and nutrients concentration significantly improved the production of GABA [45].
Selenium is an essential micronutrient that can be incorporated into the active site of specific selenocysteine proteins in the organism through the form of selenocysteine. Selenium-containing proteins play an important role in the regulation of organisms and can be used as research targets for the treatment of some diseases. Normally, biosynthetic ncAAs are formed in the cytoplasmic matrix, which is then linked by aaRS to the corresponding tRNA, thereby completing the incorporation into protein. The biosynthetic pathway of selenocysteine is different from that of ordinary ncAAs. Selenocysteine has a homologous tRNASec, but there is no free selenocysteine in the cytoplasmic matrix and no corresponding selenocysteinyl-tRNA synthase. The synthesis of selenocysteine does not begin with the ligation of selenocysteine to homologous tRNASec, but rather the seryl-tRNA synthase first attaches L-Ser to non-homologous tRNASec to form seryl-tRNASec. In bacteria, selenocysteine synthase (SelA) acts directly on seryl-tRNASec and removes hydroxyl group from seryl group to generate an intermediate. The intermediate then receives the activated selenophosphate to eventually form selenocysteinyl-tRNASec. Subsequently, selenocysteinyl-tRNASec is paired with UGA codon to complete the incorporation of selenocysteine into the protein [46,47,48].
Enome-scale Models (GEMs) of metabolism as a new technology is composed of the full inventory of metabolic reactions encoded by the genome of an organism, and has been used to achieve the efficient production of ncAAs [49]. GEMs can explore trade-offs between growth rate and production, while computer simulations can be used to analyze metabolic pathways and identify strategies for improving production. For a specific example, the papBAC gene cluster from Pseudomonas fluorescens was introduced into E. coli strain EcNR2 to produce p-amino-phenylalanine (pAF), but there was a trade-off between pAF production and growth rate [50]. To increase pAF production, a GEM of E. coli metabolism with computer design was used to identify metabolic pathways and determine the recombinant strain metabolism. Upregulating the metabolic flux in the chorismate biosynthetic pathway by eliminating feedback inhibition was the most effective strategy for increasing pAF production [51]. This study demonstrates the power of GEMs and computational analysis for optimizing metabolic pathways and improving the production of valuable compounds.
The construction of efficient microbial cell factories for ncAAs has become popular in recent years. These cell factories are mainly created by reconstructing synthesis pathways, designing and modifying key enzymes, coordinating precursor regulation, knocking out competing bypass pathways, constructing cofactor regeneration systems, and intelligently regulating the fermentation process. So far, only a few biosynthetic pathways of ncAAs have been confirmed [11]. Advancements in synthetic and computational biology technologies, as well as multidisciplinary collaborations, have begun to shed light on ncAAs biosynthesis, both in the laboratory and industry. In the future, the precise design of ncAAs synthesis pathways may be accomplished with advanced bioinformatics or biosynthesis simulation tools. Additionally, more chassis with high tolerance to specific ncAAs must be engineered or screened to achieve compatibility between microbes and heterologous pathways, target ncAAs.
3. Methods for ncAAs incorporation into proteins
3.1. GCE methods for ncAAs incorporation into proteins
The biosynthesis of ncAAs and their incorporation into target proteins within a single microbe has become an attractive application of such molecules. This approach allows for the site-specific labeling or modification of proteins with ncAAs that have unique chemical properties, which can be used to improve the proteins properties and interactions. Recent advancements in genetic engineering techniques have enabled the production of the enzymes with incorporation of ncAAs by replacing cAAs with non-canonical ones at specific sites. In addition, optimization of the efficiency and selectivity of orthogonal reactions can enable the selective labeling of tailor-made proteins with fluorophores or other probes. The ability to produce and incorporate ncAAs into proteins within the same microbe provides significant advantages over traditional incorporation method based on chemical synthesis, enzyme conjugation and in vitro translation, as these methods are time-consuming and expensive, and often require post-translational modifications (PTMs) to proteins. The biosynthesis of ncAAs and the incorporation into target proteins within the same microbe relies on a technology of genetic code extension (GCE).
The process of GCE for integrating ncAAs into proteins requires a rigorous and efficient translation mechanism that resembles the natural translation process. For GCE to work, each amino acid is matched with its corresponding codon and an orthogonal translation system (OTS). This OTS contains exogenous tRNA and exogenous aminoacyl-tRNA synthetases (aaRS) that adhere to strict orthogonality criteria. There are two major routes to expand the amino acid repertoire: chemical aminoacylation of tRNA [52,53] and enzyme-mediated (aaRS) aminoacylation of tRNA, which can generate an aminoacyl-tRNA (aa-tRNA) that is active for protein synthesis on the ribosome. The aminoacylated tRNA carries the ncAA along with the reassigned and desired codons, thereby facilitating the incorporation of the ncAA into the extended peptide chain (Figure 2). It is important that orthogonal system do not cross-react with the endogenous translation system, as this will lead to confusion in the translation system. To prevent false cross-reactions, each orthogonal translation system must go through multiple rounds of positive and negative screening. The specific codons used in GCE are typically obtained from 'redundant' codons, reassigned stop codons, sense codons, quadruplet codons, and others.
3.1.1. GCE based on stop codon suppression (SCS)
In the natural translation system, there are three types of stop codons: UAG (amber codon), UAA (ochre codon), and UGA (opal codon). These codons do not encode any amino acids but mediate the termination of the translation process. Release factors (RFs) are proteins that recognize and bind to these stop codons, leading to the release of the synthesized protein. Interestingly, there is some redundancy in the genetic code when it comes to stop codons. For example, RF1 can recognize both UAA and UAG, while RF2 can recognize both UAA and UGA. This means that there is at least one ‘redundant’ codon that can potentially be repurposed to encode a different amino acid. In E. coli, Schultz and co-workers chemically acylated a suppressor tRNA to encode a ncAA in response to the ‘sense codons’ position which was replaced by a stop codon UAG [54]. This method known as stop codon suppression (SCS) takes advantage of the degeneracy of the three stop codons and the low abundance of the stop codon UAG (Figure 2, XYZ = Stop codon). As an example, Pastore et al. used GCE based on SCS to replace a single tryptophan residue in a copper protein amicyanin with ncAA 5-HTP. The incorporation of 5-HTP changed the fluorescence emission maximum of amicyanin from 318 to 331 nm. Besides, the fluorescence quantum yield of 5-HTP-containing amicyanin was much less than that of native amicyanin. The incorporation of ncAAs significantly alters protein properties [55].
Both RFs and suppressor tRNAs have the ability to recognize stop codons. However, competitive recognition between these factors can result in premature termination of translation, leading to protein truncation and reducing the incorporation efficiency of ncAAs, and protein yield and purity. To address this issue, Lajoie et al. utilized multiplex automated genome engineering (MAGE) and conjugative assembly genome engineering (CAGE) techniques to replace all 321 UAG codons with synonymous UAA codons in the E. coli genome [56]. Additionally, they deleted the prfA gene which encodes RF1 without affecting the strain growth. A genomically recoded organism (GRO) called E. coli C321.ΔA was created, which no longer recognized UAG as a stop codon. This strain has higher efficiency for incorporation of ncAAs as compared to wild-type strain [57,58]. So far, only genome-recoded E. coli was obtained and used as chassis. It is crucial to develop other chassis with modified genomes to expand the range of applicable hosts for incorporating ncAAs into proteins based on this principle. Overall, SCS allows for the introduction of ncAAs into specific positions in a protein, expanding the possibilities for protein engineering and modification.
3.1.2. GCE based on synonymous codon compression
Eighteen of the 20 cAAs have two or more codons. L-Leu, L-Arg and L-Ser are encoded by up to six synonymous codons, while only L-Met and L-Trp are encoded by one codon. Hence, utilizing the degeneracy of codons to replace synonymous codons with a different codon throughout the genome-wide scale and deleting the tRNAs that decode them, can release the replaced codons from the standard genetic code and reassign the replaced codons to ncAAs. This method is called synonymous codon compression [59]. By reducing the number of synonymous codons encoding cAAs, the recoded codons can be freed up for the incorporation of ncAAs or other non-amino acid molecules (Figure 2, XYZ = Sense codon). As an example, Fredens et al. replaced three L-Ser codons (UCG, UCA) and a stop codon (UAG) with their synonymous codons (AGC, AGU, UAA) and deleted the corresponding tRNA and the RF1 to construct an E. coli strain called Syn61 [60]. This allowed the incorporation of three ncAAs into a single protein in the engineered strain [61]. However, the reassignment of sense codons at the genome level is still a major technical challenge. Completely eliminating a large number of codons from the genome is not a straightforward task, and the replacement of synonymous codons can have various effects on gene expression, cell fitness [62], translation speed [63,64], and cellular homeostasis. Additionally, the current approach is primarily limited to bacterial hosts and not readily applicable to more complex eukaryotic systems.
3.1.3. GCE based on other approaches
Another method for incorporating ncAAs into proteins is to use quadruplet or quintuplet codons, which are called ‘frameshift suppression’. Unlike the redistribution or reassignment of codons, this method allows for the expansion of the genetic code without extensive modifications to the genome. ‘Frameshift suppression’ provides the potential to expand from the 64 codons of the natural genetic code to 44 = 256 [65] or 45 = 1024 [66] ‘blanking’ codons. The use of quadruplet codons offers more flexibility, as it allows for the incorporation of ncAAs without the need for large-scale genome modifications. This method also helps to reduce potential cross-decoding effects of endogenous triplet codons [67,68,69]. Quadruplet codons have been primarily used in single-celled systems such as the nematode Caenorhabditis elegans. The application range is currently limited and the efficiency is currently low. Efforts to improve the efficiency of quadruplet codon decoding have focused on directed evolution techniques, including the evolution of anticodon loops of tRNAs and the evolution of the ribosome decoding center in the chassis [70]. The use of quadruplet codons is an interesting and promising method for incorporating ncAAs into proteins. Further work needs to concentrate on expand its applicability and improve decoding efficiency.
Besides, unnatural base pairs (UBPs) provide another alternative for expanding the genetic codon library. For example, Bain et al. incorporated the ncAA L-iodotyrosine into proteins using an UBPs (iso-C)AG-tRNACU (iso-dG). The (iso-C)AG was called the 65th codon [71]. After that, several UBPs were also developed [72,73,74]. Malyshev created a synthetic base pair called X-Y, where X represents dNaM and Y represents d5SICS [72]. UBPs involve the introduction of new codon-anticodon interactions, enabling the site-specific incorporation of ncAAs into proteins through ribosomal-mediated translation. In a six-letter unnatural bases system, it is theoretically possible to generate 152 new codons for ncAAs [75]. The use of UBPs allows for the expansion of the genetic code in a novel form, providing additional opportunities for the incorporation of ncAAs into proteins. This technology holds promise for developing new functions and properties of proteins.
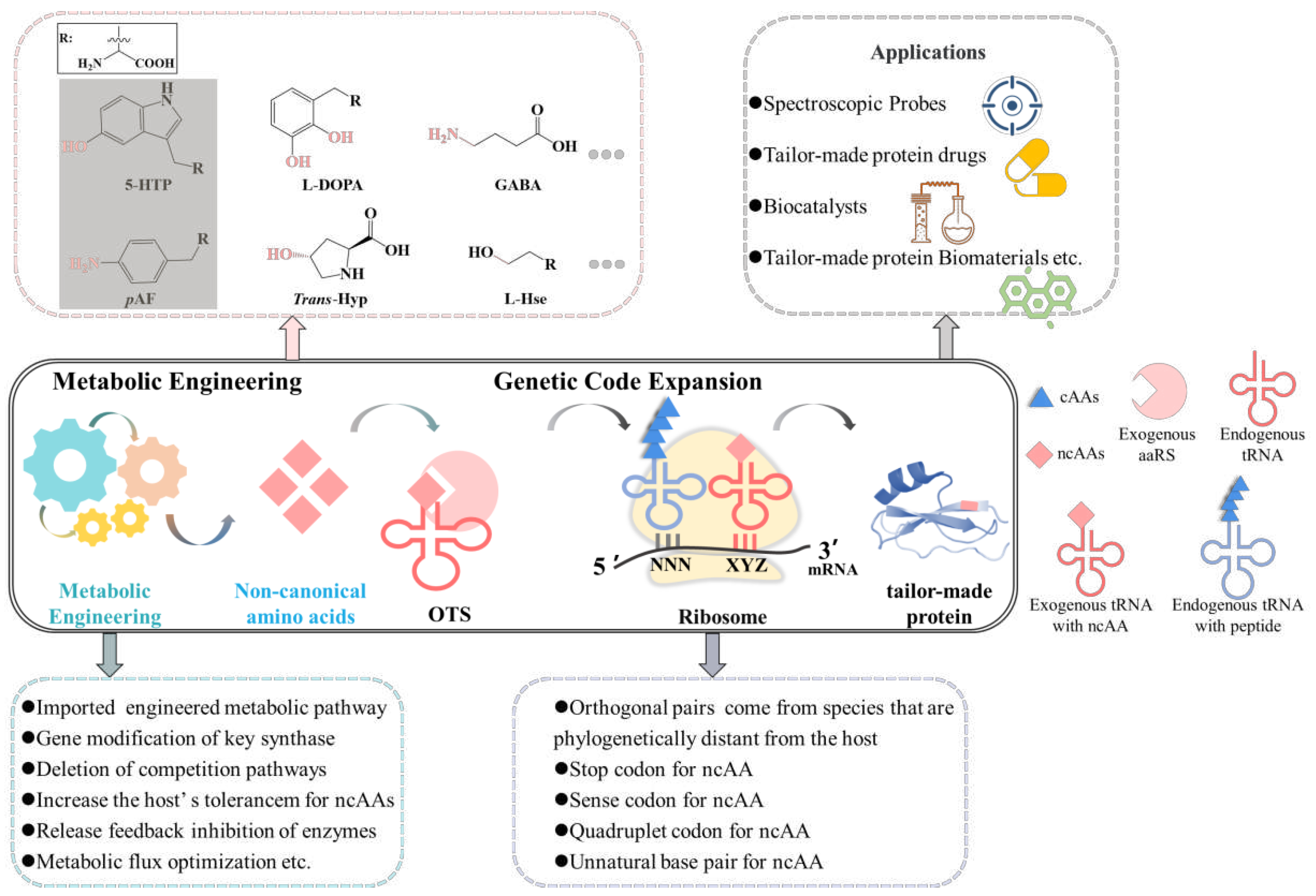
Figure 2.
A diagram of the combination of metabolic engineering and GCE. The diagram includes the metabolic biosynthesis of ncAAs, incorporation into proteins by GCE and applications of tailor-made proteins. 5-HTP [5] and pAF [76] has been biosynthesized in vivo, incorporated into proteins and implemented for applications.
Figure 2.
A diagram of the combination of metabolic engineering and GCE. The diagram includes the metabolic biosynthesis of ncAAs, incorporation into proteins by GCE and applications of tailor-made proteins. 5-HTP [5] and pAF [76] has been biosynthesized in vivo, incorporated into proteins and implemented for applications.
3.2. Selective pressure incorporation (SPI)
Selective pressure incorporation (SPI), also known as ‘residue-specific incorporation’, is a method that relies on auxotrophic hosts which are deficient in one or more specific cAAs [77]. This approach is based on the substrate tolerance of cellular systems [78]. Endogenous aaRS play a crucial role in replacing the cAAs in protein sequences with one or more amino acid analogs that have similar structure and chemistry [79]. The auxotrophic hosts are cultured in a medium that initially contains a limited amount of nAAs. As the cells grow and begin to express recombinant proteins, the cAAs are gradually depleted. At an appropriate growth state, exogenous ncAA analogs are supplemented in the medium. The expression of target protein gene is regulated by inducible promoter, ensuring that protein translation is dependent on the availability of ncAAs in the medium [80] (Figure 3). This method is commonly used to modify ribosomal synthetic and post-translationally modified peptides by incorporating ncAAs. Through adding ncAAs in the medium, unique functional polypeptides can be produced. SPI enables the specific modification of residues to generate novel functions and chemical diversity in peptides or proteins [81,82,83].
SPI allows for the incorporation of multiple ncAAs throughout the proteome. This can lead to a cumulative or synergistic effect of the ncAAs, resulting in more significant changes in the properties of the target proteins compared to a single substitution. However, SPI is more suitable for ncAAs that have similar properties to cAAs. This limitation restricts the application of SPI for ncAAs with distinct or unique properties. Additionally, SPI does not guarantee the specific incorporation of a single site, which is not conducive to study fine modification of protein sites or precise control of protein modification. Despite these limitations, SPI remains a valuable tool for introducing ncAAs into proteins and exploring their effects on protein structure and function. It offers a versatile approach for creating tailor-made proteins with expanded chemical diversity and potential applications in various fields.
3.3. Solid-phase peptide synthesis (SPPS)
In vitro methods can be used to incorporate ncAAs into proteins, which is advantageous when an endogenous expression system for tailor-made proteins is unavailable or impractical. One commonly used method for in vitro protein synthesis is solid-phase peptide synthesis (SPPS) (Figure 4). SPPS involves the stepwise assembly of peptide chains attached to an insoluble resin support. Multiple amino acids are linked together through peptide bonds to produce peptides. In SPPS, the C-terminal of the first amino acid which is protected by an amino-protecting group, is connected to the resin via a covalent bond. The protective group is then removed to expose a free amino group, which can be coupled with the next amino acid. This process is repeated, extending the length of the peptide chain. The general principle of SPPS involves a repeated cycle of coupling-flushing-deprotection-flushing-coupling. The polypeptide remains immobilized on the solid phase throughout the synthesis. After assembly, the polypeptide is separated from the resin using trifluoroacetic acid, and the protective group is also removed. Commonly used amino-protecting groups include 9-fluorenylmethoxycarbonyl (Fmoc) and t-butyloxycarbonyl (tBoc) [84,85]. SPPS has practical applications in the chemical synthesis of recombinant proteins using ncAAs [84,86,87]. It can be used to synthesize the peptides that are difficult to be endogenously expressed, such as those composed of D-amino acids. SPPS is also useful for modifying the main chain of peptides or proteins. It is particularly suitable for incorporating amino acid analogs that may be toxic to cells or incompatible with cellular translation mechanisms. The chemical synthesis of peptides is limited by the length of peptide (<50~60 amino acids) [88,89] and the speed of synthesis. Overall, SPPS is a valuable tool for incorporating ncAAs into proteins in vitro, allowing for the synthesis of peptides and proteins that are challenging or impossible to produce using traditional endogenous expression system.
3.4. Cell-free protein synthesis (CFPS)
Cell-free protein synthesis (CFPS) is another method to synthesize non-canonical proteins in vitro. CFPS is a rapid and high-throughput expression technique that allows the production of proteins using exogenous DNA or mRNA as a template [90,91] (Figure 5). This method requires the use of multiple enzymes provided by cell lysates to provide substrate and energy. CFPS systems are available based on different cell lysates, including E. coli lysate, yeast extract, rabbit reticulocyte lysate, or wheat germ extract [92,93,94]. Each system offers unique advantages and may be preferred depending on the specific requirements of the protein synthesis. The in vitro CFPS systems allow for flexibility and freedom in protein design, making it a powerful tool for protein engineering and biopharmaceutical production. CFPS has been successfully scaled up for manufacturing purpose. However, CFPS also have some limitations. For instance, the reaction duration is relatively short, which can result in low protein yields. The cost of CFPS is expensive due to the need of specialized reagents and enzymes. Despite these limitations, CFPS remains a valuable tool for the rapid synthesis of tailor-made proteins in vitro, offering advantages such as flexibility and high-throughput capability. Ongoing research continues to address the limitations of CFPS and improve its efficiency and scalability for broader applications.
3.5. Other methods for the incorporation of ncAAs
In addition to the above methods, post-translational mutagenesis and cysteine functionalization are also the methods for incorporating ncAAs into proteins. Natural PTMs form bonds with heteroatoms (non-carbon) at the γ (CysSγ, ThrOγ, SerOγ) or ω (LysNω, TyrOω) position of the side chain, while post-translational mutagenesis uses free radical chemistry to form carbon-carbon bonds between amino acid residues and selected functional groups, which can introduce functions or labels into a wide range of proteins [95]. Unpaired free cysteine often exhibits high nucleophilicity and is relatively rare among proteins, making it an ideal site for protein modifications. Cysteine residues can be easily introduced into proteins by site-specific mutagenesis [96]. Cysteine-specific modification is usually achieved via the reaction of sulfhydryl groups with electrophilic reagents such as iodoacetamides, pyridine disulfide, maleimides, and alkyl halides [97]. Cysteine modification is a practical method to produce functional proteins with a wide range of biomedical applications.
4. The applications of tailor-made proteins
4.1. Tailor-made protein materials
Due to the overproduction of special mussel adhesion proteins, marine mussels are able to firmly adhere to various wet surfaces. One of the key amino acids involved in special mussel foot proteins is L-3,4-dihydroxyphenylalanine (DOPA) containing a catechol group [98,99,100]. The adhesive property of these proteins relies on post-translational hydroxylation of L-DOPA. This modification can only be completed in eukaryotic cells. Therefore, recombinant production of these proteins in prokaryotic cells remains a significant challenge. Overcoming this challenge would have important implications for the engineering and design of new adhesives and coatings with improved underwater performance [101]. One approach to address this challenge is to develop an efficient orthogonal aaRS/tRNA pairs. Using the orthogonal aaRS/tRNA pairs to incorporate the photoactivatable ncAAs (O-nitrobenzyl DOPA) into proteins can achieve the production of mussel adhesion proteins in vivo [102]. Incorporation of DOPA-like ncAAs into proteins using an orthogonal system offers the possibility of developing bio-adhesives and coatings that mimic the adhesive properties of marine mussels.
4.2. Tailor-made protein probes
Proteomics presents challenges in analyzing protein-protein interactions within cells. Current methods often rely on affinity purification, but it is difficult to isolate and purify the complete protein complexes from cells. This can result in incomplete protein-protein interactions, as some proteins may dissociate during cell lysis or affinity purification. Alternative methods that utilize fluorescent protein photocrosslinking probes to target proteins of interest (POIs) have been developed [103,104,105,106,107]. These probes have become valuable tools for studying intracellular protein-protein interactions. By incorporating fluorescent ncAAs into proteins through site-specific incorporation, microorganisms can be modified to allow for live imaging and tracking [46]. For example, Praveschotinunt et al. incorporated p-azido-L-phenylalanine (pAzF) into E. coli in response to the UAG stop codon. They engineered the encoding gene of cell surface protein (CsgA) with a UAG codon. When pAzF was incorporated into CsgA, the strain could be covalently labeled with a Cy5 dye using a dibenzocyclooctyl (DBCO) group through a copper-free orthogonal reaction. This labeling strategy was also validated using a murine model for in vivo imaging. Fluorescent protein probes have also become powerful tools for exploring protein conformational changes, localization, and molecular interactions [108,109]. These probes have fluorescent properties that offer several advantages over traditional methods, including small size, ease of use, ability to provide various colors, and improved photochemical properties. The synthesis of fluorescent probes provides numerous benefits for in-depth study of protein properties and interactions.
4.3. Tailor-made protein drugs
The development of modern drugs mainly focuses on the screening of chemical compounds, with limited emphasis on the design and modification of protein drugs. So far, the tailor-made protein drugs have emerged, and the special functional groups of ncAAs have greatly expanded the design space for protein drugs, bringing new developments to the biomedical field [110,111]. One strategy for the development of covalent protein drugs is based on proximity-enabled reactivity (PERx) [112,113]. This approach needs to introduce an aromatic fluorosulfate group into the side chain of tyrosine and lysine residues in proteins, such as human programmed cell death protein-1 (PD-1). The ncAAs FSY (fluorosulfate-L-tyrosine) and FSK (fluorosulfonyloxy-benzoyl-L-lysine) are designed based on sulfur-fluorine replacement reactions with proximate lysine, histidine, and tyrosine residues. The covalent modification of PD-1 with FSY and FSK can result in stronger anti-tumor effects compared to wild-type PD-1 in immunized mice. This strategy highlights the potential of ncAAs in developing covalent protein drugs with enhanced therapeutic efficacy. Another important development in targeted anticancer drugs is the use of antibody-drug conjugates (ADCs) [114,115,116]. ADCs involve the site-specific conjugation of ncAAs, providing a new approach that overcomes the limitations of conventional modifications dependent on cysteine residues [117]. This site-specific conjugation of ncAAs allows ADCs to exhibit improved pharmacokinetics, higher titers, and enhanced antigen binding characteristics. These advancements have expanded the possibilities for the development of targeted therapies for cancer. Overall, the incorporation of ncAAs into protein drugs offers new avenues for drug design and modification, enabling the development of covalent protein drugs with enhanced therapeutic effects and the creation of more effective targeted therapies such as ADCs.
4.4. Applications of ncAAs in vaccine
GCE technology offers a groundbreaking solution for the development of therapeutic and prophylactic vaccines. For example, PTMs of L-tyrosine residues in proteins lead to the formation of nitrotyrosine and sulfonyl tyrosine, which have been found to be associated with the breaking of immune tolerance and the induction of autoimmune diseases. The nitro and sulfonyl groups possess strong immunogenicity, which is crucial for breaking self-immune tolerance [118]. Besides, Grünewald et al. utilized GCE to mutate the 11th L-Lys or the 86th L-Tyr residue in murine tumor necrosis factor-alpha (mTNF-α) into pNO2Phe [119]. These modifications introduced a new antigenic determinant in mTNF-α, effectively breaking autoimmune tolerance and generating high titers of antibodies that could recognize both the mutant and wild-type mTNF-α [120,121]. This demonstrates the potential of GCE in developing vaccines that target specific PTMs and break immune tolerance. GCE technology has also been applied in the development of preventive attenuated vaccines. For example, Zhou et al. incorporated the ncAA Nε-2-azidoxycarbonyl-L-lysine (NAEK) into the NP protein in influenza virus using the MbPylRS/tRNACUA pairs in transgenic 293T cells to construct a replication-incompetent influenza virus with a low escape rate [122]. This defective attenuated vaccine demonstrated stronger immunogenicity compared to commercial vaccines, eliciting a more robust and extensive immune response in the host immune system. These examples highlight the versatility and potential of ncAAs in vaccine development. GCE technology allows for the precise modification of proteins to generate novel antigenic determinants, enhancing immunogenicity and leading to effective vaccines. The broad application of ncAAs in vaccines holds promise for improving preventive and therapeutic strategies against various diseases.
5. Perspectives
Although NCAA shows exciting potential, there are still some challenges in its application and implementation. One challenge is the lack of clear biosynthesis pathways for some ncAAs and the limited knowledge of critical enzymes in the pathways. Enzymes are crucial for constructing microbial cell factories of ncAAs. Currently, the properties, structure, and interactions of enzymes with ncAA biosynthesis pathways or microbes are poorly understood [123]. Therefore, simulation prediction of enzyme structures and biosynthesis pathways is needed to reveal and elucidate the metabolic pathways and key enzymes of ncAAs biosynthesis. Understanding these pathways will help combine the production and incorporation of ncAAs to generate desired proteins. Another challenge is the development of a diverse set of codon-aaRS-tRNA orthogonal systems that exhibit sufficient efficiency and reading fidelity. The orthogonal systems are crucial for expanding the application of ncAAs. The design and modification of orthogonal systems are essential for achieving precise and reliable incorporation of ncAAs into proteins. The multiple strategies of GCE have challenged the ‘frozen accident hypothesis’ [124] of the genetic codon and demonstrated the plasticity and evolvability of the standard genetic code. This serves new possibilities for the design of the advanced life forms and the incorporation of ncAAs.
Due to the paucity of ncAAs biosynthetic pathways [125] and the frequent incompatibilities between GCE techniques and pathways [126], only a few ncAAs [5,76,127] are currently able to achieve biosynthesis and incorporation into proteins in vivo. By leveraging synthetic biology and evolutionary engineering, it is anticipated that more pathways for ncAAs production can be constructed in suitable chassis in the future. This will enable the biosynthesis and incorporation of desired ncAAs into target protein within the same microbe. We can expect the discovery of more ncAAs, synthesis pathways, physiochemical properties, and structures related to tailor-made proteins. Generally, addressing the challenges associated with ncAAs will require interdisciplinary efforts involving biochemistry, molecular biology, synthetic biology, and systems biology.
Funding
The authors acknowledge funding from the Construction of High-level Teachers in Beijing Municipal Colleges and Universities (2019)-Youth Talent-Chen Liang (CIT&TCD 201904047) and Research on national reference material and product development of natural products [SG030801]) for financial support.
References
- Wang, L. Genetically encoding new bioreactivity. N Biotechnol 2017, 38, 16–25. [Google Scholar] [CrossRef] [PubMed]
- Des Soye, B.J.; Patel, J.R.; Isaacs, F.J.; Jewett, M.C. Repurposing the translation apparatus for synthetic biology. Curr Opin Chem Biol 2015, 28, 83–90. [Google Scholar] [CrossRef] [PubMed]
- Macek, B.; Forchhammer, K.; Hardouin, J.; Weber-Ban, E.; Grangeasse, C.; Mijakovic, I. Protein post-translational modifications in bacteria. Nat Rev Microbiol 2019, 17, 651–664. [Google Scholar] [CrossRef] [PubMed]
- Gao, W.; Bu, N.; Lu, Y. Recent advances in cell-free unnatural protein synthesis. Sheng Wu Gong Cheng Xue Bao 2018, 34, 1371–1385. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Tang, J.; Wang, L.; Tian, Z.; Cardenas, A.; Fang, X.; Chatterjee, A.; Xiao, H. Creation of Bacterial cells with 5-Hydroxytryptophan as a 21st Amino Acid Building Block. Chem 2020, 6, 2717–2727. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.-F.; Liu, Z.-Q.; Jin, L.-Q.; Tang, X.-L.; Shen, Z.-Y.; Yin, H.-H.; Zheng, Y.-G. Metabolic engineering of Escherichia coli for microbial production of L-methionine. Biotechnol Bioeng 2017, 114, 843–851. [Google Scholar] [CrossRef] [PubMed]
- Hong, K.-K.; Kim, J.H.; Yoon, J.H.; Park, H.-M.; Choi, S.J.; Song, G.H.; Lee, J.C.; Yang, Y.-L.; Shin, H.K.; Kim, J.N.; et al. O-Succinyl-L-homoserine-based C4-chemical production: succinic acid, homoserine lactone, γ-butyrolactone, γ-butyrolactone derivatives, and 1,4-butanediol. J Ind Microbiol Biotechnol 2014, 41, 1517–1524. [Google Scholar] [CrossRef]
- Kang, Z.; Zhang, J.; Zhou, J.; Qi, Q.; Du, G.; Chen, J. Recent advances in microbial production of δ-aminolevulinic acid and vitamin B12. Biotechnol Adv 2012, 30, 1533–1542. [Google Scholar] [CrossRef]
- Zhu, H.Q.; Tang, X.L.; Zheng, R.C.; Zheng, Y.G. Recent advancements in enzyme engineering via site-specific incorporation of unnatural amino acids. World J Microbiol Biotechnol 2021, 37, 213. [Google Scholar] [CrossRef] [PubMed]
- Smolskaya, S.; Andreev, Y.A. Site-Specific Incorporation of Unnatural Amino Acids into Escherichia coli Recombinant Protein: Methodology Development and Recent Achievement. Biomolecules 2019, 9, 255. [Google Scholar] [CrossRef]
- Narancic, T.; Almahboub, S.A.; O’Connor, K.E. Unnatural amino acids: production and biotechnological potential. world j microbiol biotechnol 2019, 35, 1–11. [Google Scholar] [CrossRef]
- Zou, H.; Li, L.; Zhang, T.; Shi, M.; Zhang, N.; Huang, J.; Xian, M. Biosynthesis and biotechnological application of non-canonical amino acids: complex and unclear. Biotechnol Adv 2018, 36, 1917–1927. [Google Scholar] [CrossRef] [PubMed]
- Karbalaei-Heidari, H.R.; Budisa, N. Combating antimicrobial resistance with new-to-nature lanthipeptides created by genetic code expansion. Front Microbiol 2020, 11, 590522. [Google Scholar] [CrossRef]
- Tsubogo, T.; Kano, Y.; Ikemoto, K.; Yamashita, Y.; Kobayashi, S. Synthesis of optically active, unnatural α-substituted glutamic acid derivatives by a chiral calcium-catalyzed 1,4-addition reaction. Tetrahedron Asymmetry 2010, 21, 1221–1225. [Google Scholar] [CrossRef]
- Li, B.; Zhang, J.; Xu, Y.; Yang, X.; Li, L. Improved synthesis of unnatural amino acids for peptide stapling. Tetrahedron Lett 2017, 58, 2374–2377. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, D.; Xu, P.; Dong, X.; Wang, X.; Dai, Z. The asymmetric alkylation reaction of glycine derivatives catalyzed by the novel chiral phase transfer catalysts. Tetrahedron Lett 2015, 56, 1067–1071. [Google Scholar] [CrossRef]
- Anderhuber, N.; Fladischer, P.; Gruber-Khadjawi, M.; Mairhofer, J.; Striedner, G.; Wiltschi, B. High-level biosynthesis of norleucine in E. coli for the economic labeling of proteins. J Biotechnol 2016, 235, 100–111. [Google Scholar] [CrossRef] [PubMed]
- Bornscheuer, U.T.; Huisman, G.W.; Kazlauskas, R.J.; Lutz, S.; Moore, J.C.; Robins, K. Engineering the third wave of biocatalysis. Nature 2012, 485, 185–194. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Liu, W.; Shi, F.; Huang, L.; Lian, J.; Qu, L.; Cai, J.; Xu, Z. Metabolic pathway engineering for high-level production of 5-hydroxytryptophan in Escherichia coli. Metab Eng 2018, 48, 279–287. [Google Scholar] [CrossRef]
- Xu, D.; Fang, M.; Wang, H.; Huang, L.; Xu, Q.; Xu, Z. Enhanced production of 5-hydroxytryptophan through the regulation of L-tryptophan biosynthetic pathway. Appl Microbiol Biotechnol 2020, 104, 2481–2488. [Google Scholar] [CrossRef]
- Lin, Y.; Sun, X.; Yuan, Q.; Yan, Y. Engineering bacterial phenylalanine 4-hydroxylase for microbial synthesis of human neurotransmitter precursor 5-hydroxytryptophan. ACS Synth Biol 2014, 3, 497–505. [Google Scholar] [CrossRef] [PubMed]
- Mora-Villalobos, J.A.; Zeng, A.P. Synthetic pathways and processes for effective production of 5-hydroxytryptophan and serotonin from glucose in Escherichia coli. J Biol Eng 2018, 12, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Mora-Villalobos, J.A.; Zeng, A.P. Protein and pathway engineering for the biosynthesis of 5-hydroxytryptophan in Escherichia coli. Eng Life Sci 2017, 17, 892–899. [Google Scholar] [CrossRef] [PubMed]
- Mu, Q.; Zhang, S.; Mao, X.; Tao, Y.; Yu, B. Highly efficient production of L-homoserine in Escherichia coli by engineering a redox balance route. Metab Eng 2021, 67, 321–329. [Google Scholar] [CrossRef]
- Sun, B.Y.; Wang, F.Q.; Zhao, J.; Tao, X.Y.; Liu, M.; Wei, D.Z. Engineering Escherichia coli for L-homoserine production. J Basic Microbiol 2022. [CrossRef]
- Li, N.; Xu, S.; Du, G.; Chen, J.; Zhou, J. Efficient production of L-homoserine in Corynebacterium glutamicum ATCC 13032 by redistribution of metabolic flux. Biochem Eng J 2020, 161, 107665. [Google Scholar] [CrossRef]
- Li, N.; Zeng, W.; Zhou, J.; Xu, S. O-Acetyl-L-homoserine production enhanced by pathway strengthening and acetate supplementation in Corynebacterium glutamicum. Biotechnol Biofuels Bioprod 2022, 15, 27. [Google Scholar] [CrossRef]
- Cai, M.; Zhao, Z.; Li, X.; Xu, Y.; Xu, M.; Rao, Z. Development of a nonauxotrophic L-homoserine hyperproducer in Escherichia coli by systems metabolic engineering. Metab Eng 2022, 73, 270–279. [Google Scholar] [CrossRef]
- Huang, J.-F.; Zhang, B.; Shen, Z.-Y.; Liu, Z.-Q.; Zheng, Y.-G. Metabolic engineering of E. coli for the production of O-succinyl-L-homoserine with high yield. 3 Biotech 2018, 8, 310. [Google Scholar] [CrossRef]
- Li, H.; Wang, B.; Zhu, L.; Cheng, S.; Li, Y.; Zhang, L.; Ding, Z.Y.; Gu, Z.H.; Shi, G.Y. Metabolic engineering of Escherichia coli W3110 for L-homoserine production. Process Biochem 2016, 51, 1973–1983. [Google Scholar] [CrossRef]
- Yi, Y.; Sheng, H.; Li, Z.; Ye, Q. Biosynthesis of trans-4-hydroxyproline by recombinant strains of Corynebacterium glutamicum and Escherichia coli. BMC Biotechnol 2014, 14, 44. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Y.; Shang, X.; Wang, B.; Hu, Q.; Liu, S.; Wen, T. Reconstruction of tricarboxylic acid cycle in Corynebacterium glutamicum with a genome-scale metabolic network model for trans-4-hydroxyproline production. Biotechnol Bioeng 2019, 116, 99–109. [Google Scholar] [CrossRef]
- Long, M.; Xu, M.; Ma, Z.; Pan, X.; You, J.; Hu, M.; Shao, Y.; Yang, T.; Zhang, X.; Rao, Z. Significantly enhancing production of trans-4-hydroxy-l-proline by integrated system engineering in Escherichia coli. Sci Adv 2020, 6, eaba2383. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.-C.; Liu, J.; Zhao, J.; Ni, X.-M.; Zheng, P.; Guo, X.; Sun, C.-M.; Sun, J.-B.; Ma, Y.-H. Efficient production of trans-4-hydroxy-L-proline from glucose using a new trans-proline 4-hydroxylase in Escherichia coli. J Biosci 2018, 126, 470–477. [Google Scholar] [CrossRef] [PubMed]
- Qi, L.S.; Larson, M.H.; Gilbert, L.A.; Doudna, J.A.; Weissman, J.S.; Arkin, A.P.; Lim, W.A. Repurposing CRISPR as an RNA-guided platform for sequence-specific control of gene expression. Cell 2013, 152, 1173–1183. [Google Scholar] [CrossRef] [PubMed]
- Ghavami, S.; Pandi, A. CRISPR interference and its applications. Prog Mol Biol Transl Sci 2021, 180, 123–140. [Google Scholar] [CrossRef]
- James, C.M.; Ferguson, T.K.; Leykam, J.F.; Krzycki, J.A. The Amber Codon in the Gene Encoding the Monomethylamine Methyltransferase Isolated from Methanosarcina barkeri Is Translated as a Sense Codon*. J Biol Chem 2001, 276, 34252–34258. [Google Scholar] [CrossRef]
- Gaston, M.A.; Zhang, L.; Green-Church, K.B.; Krzycki, J.A. The complete biosynthesis of the genetically encoded amino acid pyrrolysine from lysine. Nature 2011, 471, 647–650. [Google Scholar] [CrossRef]
- Longstaff, D.G.; Larue, R.C.; Faust, J.E.; Mahapatra, A.; Zhang, L.; Green-Church, K.B.; Krzycki, J.A. A natural genetic code expansion cassette enables transmissible biosynthesis and genetic encoding of pyrrolysine. Proc Natl Acad Sci USA 2007, 104, 1021–1026. [Google Scholar] [CrossRef]
- Srinivasan, G.; James, C.M.; Krzycki, J.A. Pyrrolysine encoded by UAG in Archaea: charging of a UAG-decoding specialized tRNA. Science 2002, 296, 1459–1462. [Google Scholar] [CrossRef]
- Ho, J.M.L.; Miller, C.A.; Smith, K.A.; Mattia, J.R.; Bennett, M.R. Improved pyrrolysine biosynthesis through phage assisted non-continuous directed evolution of the complete pathway. Nat Commun 2021, 12, 3914. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Li, H.; Liu, L.; Ko, K.; Kim, I. Screening of gamma-aminobutyric acid-producing lactic acid bacteria and the characteristic of glutamate decarboxylase from Levilactobacillus brevis F109-MD3 isolated from kimchi. J Appl Microbiol 2022, 132, 1967–1977. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Chen, X.; Shu, G.; Ma, W. Screening of gamma-aminobutyric acid-producing lactic acid bacteria and its application in Monascus-fermented rice production. Acta Sci Pol Technol Aliment 2020, 19, 387–394. [Google Scholar] [CrossRef]
- Kim, N.Y.; Kim, S.K.; Ra, C.H. Evaluation of gamma-aminobutyric acid (GABA) production by Lactobacillus plantarum using two-step fermentation. Bioprocess Biosyst Eng 2021, 44, 2099–2108. [Google Scholar] [CrossRef] [PubMed]
- Diez-Gutiérrez, L.; Vicente, L.S.; Sáenz, J.; Esquivel, A.; Barron, L.J.R.; Chávarri, M. Biosynthesis of gamma-aminobutyric acid by Lactiplantibacillus plantarum K16 as an alternative to revalue agri-food by-products. Sci Rep 2022, 12, 18904. [Google Scholar] [CrossRef] [PubMed]
- Praveschotinunt, P.; Dorval Courchesne, N.-M.; den Hartog, I.; Lu, C.; Kim, J.J.; Nguyen, P.Q.; Joshi, N.S. Tracking of Engineered Bacteria In Vivo Using Nonstandard Amino Acid Incorporation. ACS Synth Biol 2018, 7, 1640–1650. [Google Scholar] [CrossRef] [PubMed]
- Hatfield, D.L.; Tsuji, P.A.; Carlson, B.A.; Gladyshev, V.N. Selenium and selenocysteine: roles in cancer, health, and development. Trends Biochem Sci 2014, 39, 112–120. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, R.L.; Simonović, M. Synthesis and decoding of selenocysteine and human health. Croat Med J 2012, 53, 535–550. [Google Scholar] [CrossRef]
- Long, M.R.; Ong, W.K.; Reed, J.L. Computational methods in metabolic engineering for strain design. Curr Opin Biotechnol 2015, 34, 135–141. [Google Scholar] [CrossRef]
- Masuo, S.; Zhou, S.; Kaneko, T.; Takaya, N. Bacterial fermentation platform for producing artificial aromatic amines. Sci Rep 2016, 6, 25764. [Google Scholar] [CrossRef]
- Zomorrodi, A.R.; Hemez, C.; Arranz-Gibert, P.; Wu, T.; Isaacs, F.J.; Segrè, D. Computational design and engineering of an Escherichia coli strain producing the nonstandard amino acid para-aminophenylalanine. iScience 2022, 25, 104562. [Google Scholar] [CrossRef]
- Hecht, S.M.; Alford, B.L.; Kuroda, Y.; Kitano, S. "Chemical aminoacylation" of tRNA's. J Biol Chem 1978, 253, 4517–4520. [Google Scholar] [CrossRef] [PubMed]
- Gamper, H.; Hou, Y.M. A Label-Free Assay for Aminoacylation of tRNA. Genes 2020, 11. [Google Scholar] [CrossRef]
- Noren, C.J.; Anthony-Cahill, S.J.; Griffith, M.C.; Schultz, P.G. A general method for site-specific incorporation of unnatural amino acids into proteins. Science 1989, 244, 182–188. [Google Scholar] [CrossRef]
- Pastore, A.J.; Ficaretta, E.; Chatterjee, A.; Davidson, V.L. Substitution of the sole tryptophan of the cupredoxin, amicyanin, with 5-hydroxytryptophan alters fluorescence properties and energy transfer to the type 1 copper site. J Inorg Biochem 2022, 234, 111895. [Google Scholar] [CrossRef]
- Lajoie, M.J.; Rovner, A.J.; Goodman, D.B.; Aerni, H.-R.; Haimovich, A.D.; Kuznetsov, G.; Mercer, J.A.; Wang, H.H.; Carr, P.A.; Mosberg, J.A.; et al. Genomically recoded organisms expand biological functions. Science 2013, 342, 357–360. [Google Scholar] [CrossRef]
- Yi, H.; Zhang, J.; Ke, F.; Guo, X.; Yang, J.; Xie, P.; Liu, L.; Wang, Q.; Gao, X. Comparative Analyses of the Transcriptome and Proteome of Escherichia coli C321.△A and Further Improving Its Noncanonical Amino Acids Containing Protein Expression Ability by Integration of T7 RNA Polymerase. Front Microbiol 2021, 12, 744284. [Google Scholar] [CrossRef] [PubMed]
- Costa, S.A.; Mozhdehi, D.; Dzuricky, M.J.; Isaacs, F.J.; Brustad, E.M.; Chilkoti, A. Active targeting of cancer cells by nanobody decorated polypeptide micelle with bio-orthogonally conjugated drug. Nano Lett 2019, 19, 247–254. [Google Scholar] [CrossRef]
- Wang, K.; Fredens, J.; Brunner, S.F.; Kim, S.H.; Chia, T.; Chin, J.W. Defining synonymous codon compression schemes by genome recoding. Nature 2016, 539, 59–64. [Google Scholar] [CrossRef]
- Fredens, J.; Wang, K.; de la Torre, D.; Funke, L.F.H.; Robertson, W.E.; Christova, Y.; Chia, T.; Schmied, W.H.; Dunkelmann, D.L.; Beránek, V.; et al. Total synthesis of Escherichia coli with a recoded genome. Nature 2019, 569, 514–518. [Google Scholar] [CrossRef] [PubMed]
- Robertson, W.E.; Funke, L.F.H.; de la Torre, D.; Fredens, J.; Elliott, T.S.; Spinck, M.; Christova, Y.; Cervettini, D.; Boge, F.L.; Liu, K.C.; et al. Sense codon reassignment enables viral resistance and encoded polymer synthesis. Science 2021, 372, 1057–1062. [Google Scholar] [CrossRef] [PubMed]
- Plotkin, J.B.; Kudla, G. Synonymous but not the same: the causes and consequences of codon bias. Nat Rev Genet 2011, 12, 32–42. [Google Scholar] [CrossRef] [PubMed]
- Brule, C.E.; Grayhack, E.J. Synonymous codons: choose wisely for expression. Trends Genet 2017, 33, 283–297. [Google Scholar] [CrossRef] [PubMed]
- Mitra, S.; Ray, S.K.; Banerjee, R. Synonymous codons influencing gene expression in organisms. Rese Rep Biochem 2016, 2016, 57–65. [Google Scholar] [CrossRef]
- Wang, N.; Shang, X.; Cerny, R.; Niu, W.; Guo, J. Systematic Evolution and Study of UAGN Decoding tRNAs in a Genomically Recoded Bacteria. Sci Rep 2016, 6, 21898. [Google Scholar] [CrossRef] [PubMed]
- Hohsaka, T.; Ashizuka, Y.; Murakami, H.; Sisido, M. Five-base codons for incorporation of nonnatural amino acids into proteins. Nucleic Acids Res 2001, 29, 3646–3651. [Google Scholar] [CrossRef] [PubMed]
- Xi, Z.; Davis, L.; Baxter, K.; Tynan, A.; Goutou, A.; Greiss, S. Using a quadruplet codon to expand the genetic code of an animal. Nucleic Acids Res 2022, 50, 4801–4812. [Google Scholar] [CrossRef]
- de la Torre, D.; Chin, J.W. Reprogramming the genetic code. Nat Rev Genet 2021, 22, 169–184. [Google Scholar] [CrossRef] [PubMed]
- Gamper, H.; Masuda, I.; Hou, Y.-M. Genome Expansion by tRNA +1 Frameshifting at Quadruplet Codons. J Mol Biol 2022, 434, 167440. [Google Scholar] [CrossRef]
- Guo, J.; Niu, W. Genetic Code Expansion Through Quadruplet Codon Decoding. J Mol Biol 2022, 434, 167346. [Google Scholar] [CrossRef]
- Bain, J.D.; Switzer, C.; Chamberlin, R.; Benner, S.A. Ribosome-mediated incorporation of a non-standard amino acid into a peptide through expansion of the genetic code. Nature 1992, 356, 537–539. [Google Scholar] [CrossRef]
- Malyshev, D.A.; Dhami, K.; Lavergne, T.; Chen, T.; Dai, N.; Foster, J.M.; Corrêa, I.R.; Romesberg, F.E. A semi-synthetic organism with an expanded genetic alphabet. Nature 2014, 509, 385–388. [Google Scholar] [CrossRef] [PubMed]
- Benner, S.A.; Karalkar, N.B.; Hoshika, S.; Laos, R.; Shaw, R.W.; Matsuura, M.; Fajardo, D.; Moussatche, P. Alternative Watson-Crick Synthetic Genetic Systems. Cold Spring Harb Perspect Biol 2016, 8, a023770. [Google Scholar] [CrossRef]
- Kimoto, M.; Hirao, I. Genetic alphabet expansion technology by creating unnatural base pairs. Chem Soc Rev 2020, 49, 7602–7626. [Google Scholar] [CrossRef] [PubMed]
- Kimoto, M.; Hirao, I. Genetic Code Engineering by Natural and Unnatural Base Pair Systems for the Site-Specific Incorporation of Non-Standard Amino Acids Into Proteins. Front Mol Biosci 2022, 9, 851646. [Google Scholar] [CrossRef] [PubMed]
- Mehl, R.A.; Anderson, J.C.; Santoro, S.W.; Wang, L.; Martin, A.B.; King, D.S.; Horn, D.M.; Schultz, P.G. Generation of a Bacterium with a 21 Amino Acid Genetic Code. J Am Chem Soc 2003, 125, 935–939. [Google Scholar] [CrossRef] [PubMed]
- Budisa, N. Prolegomena to Future Experimental Efforts on Genetic Code Engineering by Expanding Its Amino Acid Repertoire. Angew Chem Int Ed 2004, 43, 6426–6463. [Google Scholar] [CrossRef] [PubMed]
- Hoesl, M.G.; Budisa, N. In vivo incorporation of multiple noncanonical amino acids into proteins. Angew Chem Int Ed Engl 2011, 50, 2896–2902. [Google Scholar] [CrossRef]
- Baumann, T.; Schmitt, F.J.; Pelzer, A.; Spiering, V.J.; Freiherr von Sass, G.J.; Friedrich, T.; Budisa, N. Engineering 'Golden' Fluorescence by Selective Pressure Incorporation of Non-canonical Amino Acids and Protein Analysis by Mass Spectrometry and Fluorescence. J Vis Exp 2018. [CrossRef]
- Johnson, J.A.; Lu, Y.Y.; Van Deventer, J.A.; Tirrell, D.A. Residue-specific incorporation of non-canonical amino acids into proteins: recent developments and applications. Curr Opin Chem Biol 2010, 14, 774–780. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Viel, J.H.; Chen, J.; Kuipers, O.P. Synthesis and Characterization of Heterodimers and Fluorescent Nisin Species by Incorporation of Methionine Analogues and Subsequent Click Chemistry. ACS Synth Biol 2020, 9, 2525–2536. [Google Scholar] [CrossRef]
- Baumann, T.; Nickling, J.H.; Bartholomae, M.; Buivydas, A.; Kuipers, O.P.; Budisa, N. Prospects of In vivo Incorporation of Non-canonical Amino Acids for the Chemical Diversification of Antimicrobial Peptides. Front Microbiol 2017, 8, 124. [Google Scholar] [CrossRef]
- Nickling, J.H.; Baumann, T.; Schmitt, F.J.; Bartholomae, M.; Kuipers, O.P.; Friedrich, T.; Budisa, N. Antimicrobial Peptides Produced by Selective Pressure Incorporation of Non-canonical Amino Acids. J Vis Exp 2018. [CrossRef]
- Münzker, L.; Oddo, A.; Hansen, P.R. Chemical synthesis of antimicrobial peptides. Methods Mol Biol 2017, 1548, 35–49. [Google Scholar] [CrossRef] [PubMed]
- Wang, H. Comprehensive Organic Name Reactions; Wiley: 2010.
- Tsuchiya, K.; Numata, K. Chemoenzymatic synthesis of polypeptides containing the unnatural amino acid 2-aminoisobutyric acid. Chem Commun 2017, 53, 7318–7321. [Google Scholar] [CrossRef]
- Jakas, A.; Vlahoviček-Kahlina, K.; Ljolić-Bilić, V.; Horvat, L.; Kosalec, I. Design and synthesis of novel antimicrobial peptide scaffolds. Bioorg Chem 2020, 103, 104178. [Google Scholar] [CrossRef]
- Mueller, L.K.; Baumruck, A.C.; Zhdanova, H.; Tietze, A.A. Challenges and Perspectives in Chemical Synthesis of Highly Hydrophobic Peptides. Front Bioeng Biotechnol 2020, 8. [Google Scholar] [CrossRef] [PubMed]
- Behrendt, R.; White, P.; Offer, J. Advances in Fmoc solid-phase peptide synthesis. J Pept Sci 2016, 22, 4–27. [Google Scholar] [CrossRef] [PubMed]
- Yue, K.; Trung, T.N.; Zhu, Y.; Kaldenhoff, R.; Kai, L. Co-Translational Insertion of Aquaporins into Liposome for Functional Analysis via an E. coli Based Cell-Free Protein Synthesis System. Cells 2019, 8, 1325. [Google Scholar] [CrossRef] [PubMed]
- Levine, M.Z.; Gregorio, N.E.; Jewett, M.C.; Watts, K.R.; Oza, J.P. Escherichia coli-Based Cell-Free Protein Synthesis: Protocols for a robust, flexible, and accessible platform technology. J Vis Exp 2019. [CrossRef]
- Zemella, A.; Thoring, L.; Hoffmeister, C.; Kubick, S. Cell-Free Protein Synthesis: Pros and Cons of Prokaryotic and Eukaryotic Systems. Chembiochem 2015, 16, 2420–2431. [Google Scholar] [CrossRef]
- Purkayastha, A.; Iyappan, K.; Kang, T.J. Multiple Gene Expression in Cell-Free Protein Synthesis Systems for Reconstructing Bacteriophages and Metabolic Pathways. Microorganisms 2022, 10, 2477. [Google Scholar] [CrossRef]
- Anastasina, M.; Terenin, I.; Butcher, S.J.; Kainov, D.E. A technique to increase protein yield in a rabbit reticulocyte lysate translation system. Biotechniques 2014, 56, 36–39. [Google Scholar] [CrossRef] [PubMed]
- Wright, T.H.; Bower, B.J.; Chalker, J.M.; Bernardes, G.J.L.; Wiewiora, R.; Ng, W.-L.; Raj, R.; Faulkner, S.; Vallée, M.R.J.; Phanumartwiwath, A.; et al. Posttranslational mutagenesis: A chemical strategy for exploring protein side-chain diversity. Science 2016, 354, aag1465. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zang, C.; An, G.; Shang, M.; Cui, Z.; Chen, G.; Xi, Z.; Zhou, C. Cysteine-specific protein multi-functionalization and disulfide bridging using 3-bromo-5-methylene pyrrolones. Nat Commun 2020, 11, 1015. [Google Scholar] [CrossRef] [PubMed]
- Chalker, J.M.; Bernardes, G.J.L.; Lin, Y.A.; Davis, B.G. Chemical Modification of Proteins at Cysteine: Opportunities in Chemistry and Biology. Chemistry 2009, 4, 630–640. [Google Scholar] [CrossRef] [PubMed]
- Silverman, H.G.; Roberto, F.F. Understanding marine mussel adhesion. Mar Biotechnol 2007, 9, 661–681. [Google Scholar] [CrossRef] [PubMed]
- Wang, N.; Li, Y.; Zhang, Y.; Liao, Y.; Liu, W. High-strength photoresponsive hydrogels enable surface-mediated gene delivery and light-induced reversible cell adhesion/detachment. Langmuir 2014, 30, 11823–11832. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Kan, Y.; Rapp, M.; Danner, E.; Wei, W.; Das, S.; Miller, D.R.; Chen, Y.; Waite, J.H.; Israelachvili, J.N. Adaptive hydrophobic and hydrophilic interactions of mussel foot proteins with organic thin films. Proc Natl Acad Sci 2013, 110, 15680–15685. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Cao, Y. The molecular mechanisms underlying mussel adhesion. Nanoscale Adv 2019, 1, 4246–4257. [Google Scholar] [CrossRef] [PubMed]
- Hauf, M.; Richter, F.; Schneider, T.; Faidt, T.; Martins, B.M.; Baumann, T.; Durkin, P.; Dobbek, H.; Jacobs, K.; Möglich, A.; et al. Photoactivatable mussel-based underwater adhesive proteins by an expanded genetic code. ChemBioChem 2017, 18, 1819–1823. [Google Scholar] [CrossRef]
- Xiang, Z.; Ren, H.; Hu, Y.S.; Coin, I.; Wei, J.; Cang, H.; Wang, L. Adding an unnatural covalent bond to proteins through proximity-enhanced bioreactivity. Nat Methods 2013, 10, 885–888. [Google Scholar] [CrossRef]
- Zappala, F.; Tsourkas, A. Site-specific photocrosslinking to immunoglobulin G using photoreactive antibody-binding domains. In Bioconjugation, Springer: 2019; pp. 275–286.
- Elia, N. Using unnatural amino acids to selectively label proteins for cellular imaging: a cell biologist viewpoint. Febs J 2021, 288, 1107–1117. [Google Scholar] [CrossRef]
- Pagar, A.D.; Jeon, H.; Khobragade, T.P.; Sarak, S.; Giri, P.; Lim, S.; Yoo, T.H.; Ko, B.J.; Yun, H. Non-Canonical Amino Acid-Based Engineering of (R)-Amine Transaminase. Front Chem 2022, 10, 839636. [Google Scholar] [CrossRef]
- Miyazaki, R.; Akiyama, Y.; Mori, H. A photo-cross-linking approach to monitor protein dynamics in living cells. Biochim Biophys Acta Gen Subj 2020, 1864, 129317. [Google Scholar] [CrossRef] [PubMed]
- Jones, C.M.; Sungwienwong, I.; Petersson, E.J. The development of intrinsically fluorescent unnatural amino acids for in vivo incorporation into proteins. Biophys 2019, 116, 473a. [Google Scholar] [CrossRef]
- Curnew, L.J.F.; McNicholas, K.; Green, B.; Barry, J.; Wallace, H.L.; Wang, L.; Davidson, C.; Pezacki, J.P.; Russell, R.S. Visualizing HCV core protein via fluorescent unnatural amino acid incorporation. Proceedings 2020, 50, 129. [Google Scholar]
- Wang, Y.; Chen, X.; Cai, W.; Tan, L.; Yu, Y.; Han, B.; Li, Y.; Xie, Y.; Su, Y.; Luo, X.; et al. Expanding the structural diversity of protein building blocks with noncanonical amino acids biosynthesized from aromatic thiols. Angew Chem Int Ed Engl 2021, 60, 10040–10048. [Google Scholar] [CrossRef]
- Benedini, L. Advanced Protein Drugs and Formulations. Curr Protein Pept Sci 2022, 23, 2–5. [Google Scholar] [CrossRef]
- Li, Q.; Chen, Q.; Klauser, P.C.; Li, M.; Zheng, F.; Wang, N.; Li, X.; Zhang, Q.; Fu, X.; Wang, Q.; et al. Developing covalent protein drugs via proximity-enabled reactive therapeutics. Cell 2020, 182, 85–97. [Google Scholar] [CrossRef]
- Liu, J.; Cao, L.; Klauser, P.C.; Cheng, R.; Berdan, V.Y.; Sun, W.; Wang, N.; Ghelichkhani, F.; Yu, B.; Rozovsky, S.; et al. A Genetically Encoded Fluorosulfonyloxybenzoyl-L-lysine for Expansive Covalent Bonding of Proteins via SuFEx Chemistry. J Am Chem Soc 2021, 143, 10341–10351. [Google Scholar] [CrossRef]
- Lindberg, J.; Nilvebrant, J.; Nygren, P.; Lehmann, F. Progress and Future Directions with Peptide-Drug Conjugates for Targeted Cancer Therapy. Molecules 2021, 26, 6042. [Google Scholar] [CrossRef]
- Fu, Z.; Li, S.; Han, S.; Shi, C.; Zhang, Y. Antibody drug conjugate: the "biological missile" for targeted cancer therapy. Signal Transduct Target Ther 2022, 7, 93. [Google Scholar] [CrossRef]
- Jin, Y.; Schladetsch, M.A.; Huang, X.; Balunas, M.J.; Wiemer, A.J. Stepping forward in antibody-drug conjugate development. Pharmacol Ther 2022, 229, 107917. [Google Scholar] [CrossRef]
- Hallam, T.J.; Wold, E.; Wahl, A.; Smider, V.V. Antibody conjugates with unnatural amino acids. Mol Pharm 2015, 12, 1848–1862. [Google Scholar] [CrossRef]
- Grünewald, J.; Tsao, M.-L.; Perera, R.; Dong, L.; Niessen, F.; Wen, B.G.; Kubitz, D.M.; Smider, V.V.; Ruf, W.; Nasoff, M.; et al. Immunochemical termination of self-tolerance. Proc Natl Acad Sci USA 2008, 105, 11276–11280. [Google Scholar] [CrossRef] [PubMed]
- Grünewald, J.; Hunt, G.S.; Dong, L.; Niessen, F.; Wen, B.G.; Tsao, M.L.; Perera, R.; Kang, M.; Laffitte, B.A.; Azarian, S.; et al. Mechanistic studies of the immunochemical termination of self-tolerance with unnatural amino acids. Proc Natl Acad Sci U S A 2009, 106, 4337–4342. [Google Scholar] [CrossRef]
- Wang, N.; Li, Y.; Niu, W.; Sun, M.; Cerny, R.; Li, Q.; Guo, J. Construction of a live-attenuated HIV-1 vaccine through genetic code expansion. Angew Chem Int Ed Engl 2014, 53, 4867–4871. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Z.; Wang, N.; Kang, G.; Niu, W.; Li, Q.; Guo, J. Controlling Multicycle Replication of Live-Attenuated HIV-1 Using an Unnatural Genetic Switch. ACS Synth Biol 2017, 6, 721–731. [Google Scholar] [CrossRef]
- Si, L.; Xu, H.; Zhou, X.; Zhang, Z.; Tian, Z.; Wang, Y.; Wu, Y.; Zhang, B.; Niu, Z.; Zhang, C.; et al. Generation of influenza A viruses as live but replication-incompetent virus vaccines. Science 2016, 354, 1170–1173. [Google Scholar] [CrossRef]
- Chang, Z.; Liu, D.; Yang, Z.; Wu, J.; Zhuang, W.; Niu, H.; Ying, H. Efficient Xylitol Production from Cornstalk Hydrolysate Using Engineered Escherichia coli Whole Cells. J Agric Food Chem 2018, 66, 13209–13216. [Google Scholar] [CrossRef] [PubMed]
- Crick, F.H.C. The origin of the genetic code. J. Mol. Biol 1968, 38, 367–379. [Google Scholar] [CrossRef]
- Kim, S.; Sung, B.H.; Kim, S.C.; Lee, H.S. Genetic incorporation of l-dihydroxyphenylalanine (DOPA) biosynthesized by a tyrosine phenol-lyase. Chem Commun 2018, 54, 3002–3005. [Google Scholar] [CrossRef]
- Marchand, J.A.; Neugebauer, M.E.; Ing, M.C.; Lin, C.I.; Pelton, J.G.; Chang, M.C.Y. Discovery of a pathway for terminal-alkyne amino acid biosynthesis. Nature 2019, 567, 420–424. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.S.; Brunner, S.F.; Huguenin-Dezot, N.; Liang, A.D.; Schmied, W.H.; Rogerson, D.T.; Chin, J.W. Biosynthesis and genetic encoding of phosphothreonine through parallel selection and deep sequencing. Nat Methods 2017, 14, 729–736. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Biosynthetic pathways of some ncAAs derived from glucose. The blue color indicates the cAAs. The pink color indicates the ncAAs. Some key enzymes in the pathways: (1) Tryptophan hydroxylase or aromatic amino acid hydroxylase; (2) PapA, PapB and PapC; (3) Branched-chain amino acid transaminase; (4) Tyrosine phenol-lyase; (5) LeuABCD; (6) IlvCD; (7) Aspartate amino transferase; (8) Aspartokinase; (9) Aspartate-semialdehyde dehydrogenase; (10) Homoserine dehydrogenase; (11) Radical SAM enzyme PylB; (12) ATP-dependent PylC; (13) PylD for oxidation; (14) Glutamate dehydrogenase; (15) Theanine synthetase; (16) Glutamate decarboxylase; (17) Proline-4-hydroxylase (P4H). Abbreviation: 5-HTP: 5-Hydroxy tryptophan; p-AF: p-amino-phenylalanine; L-DOPA: Levodopa (3,4-dihydroxy-L-phenylalanine); L-Nva: L-norvaline; L-Nle: L-norleucine; L-Pyl: L-pyrrolysine; L-Hse: L-homoserine; GABA: Gamma-aminobutyric acid; t4Hyp: Trans-4-hydroxyproline.
Figure 1.
Biosynthetic pathways of some ncAAs derived from glucose. The blue color indicates the cAAs. The pink color indicates the ncAAs. Some key enzymes in the pathways: (1) Tryptophan hydroxylase or aromatic amino acid hydroxylase; (2) PapA, PapB and PapC; (3) Branched-chain amino acid transaminase; (4) Tyrosine phenol-lyase; (5) LeuABCD; (6) IlvCD; (7) Aspartate amino transferase; (8) Aspartokinase; (9) Aspartate-semialdehyde dehydrogenase; (10) Homoserine dehydrogenase; (11) Radical SAM enzyme PylB; (12) ATP-dependent PylC; (13) PylD for oxidation; (14) Glutamate dehydrogenase; (15) Theanine synthetase; (16) Glutamate decarboxylase; (17) Proline-4-hydroxylase (P4H). Abbreviation: 5-HTP: 5-Hydroxy tryptophan; p-AF: p-amino-phenylalanine; L-DOPA: Levodopa (3,4-dihydroxy-L-phenylalanine); L-Nva: L-norvaline; L-Nle: L-norleucine; L-Pyl: L-pyrrolysine; L-Hse: L-homoserine; GABA: Gamma-aminobutyric acid; t4Hyp: Trans-4-hydroxyproline.
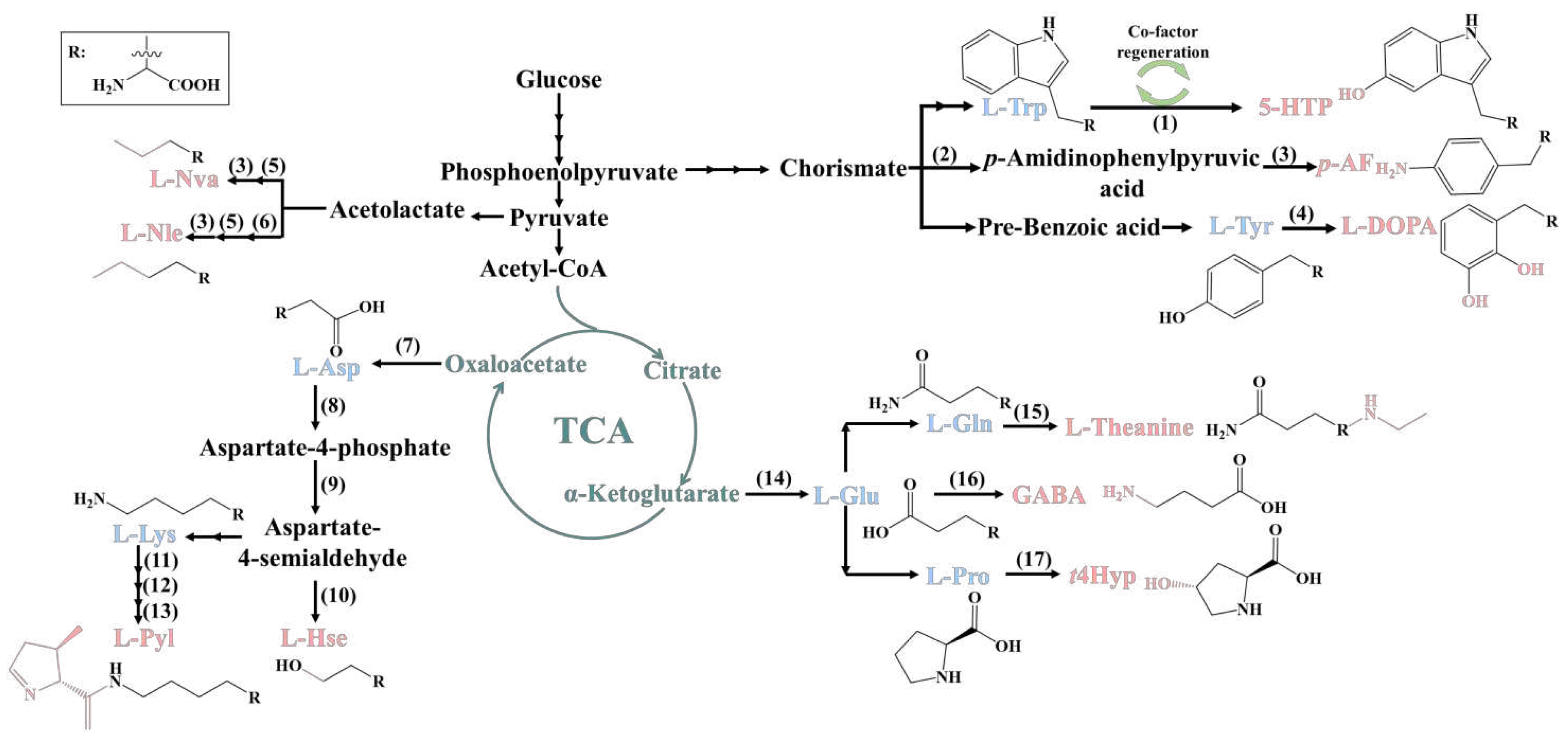
Figure 3.
SPI. The incorporation of ncAAs into proteins is realized by an endogenous orthogonal system. Exogenous ncAA analogs are supplemented in the medium to induce the protein translation based on the availability of ncAAs with assistance of the wild-type or mutated aaRS.
Figure 3.
SPI. The incorporation of ncAAs into proteins is realized by an endogenous orthogonal system. Exogenous ncAA analogs are supplemented in the medium to induce the protein translation based on the availability of ncAAs with assistance of the wild-type or mutated aaRS.
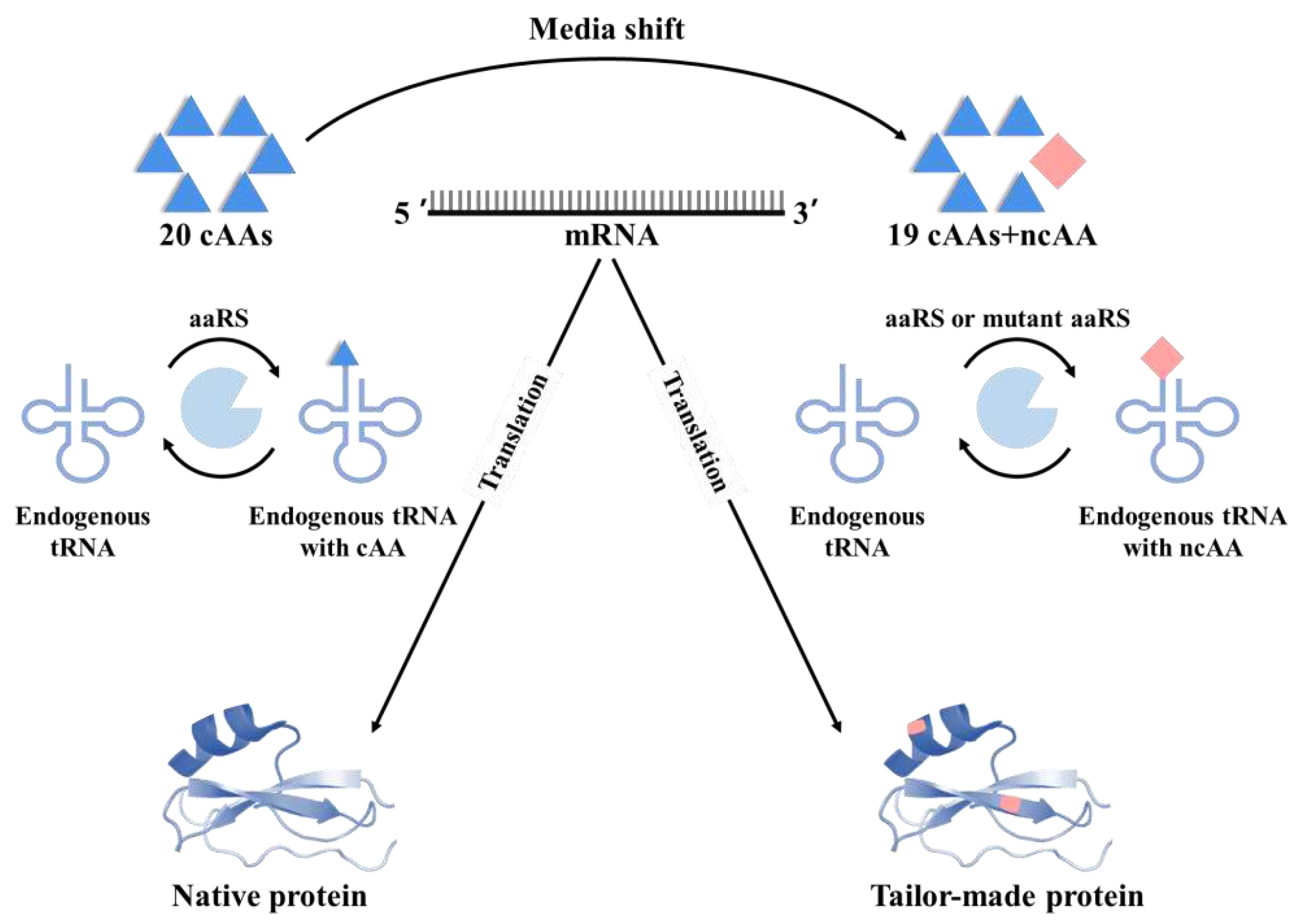
Figure 4.
SPPS. In SPPS, the C-terminal of the first amino acid protected by an amino-protecting group needs to connect to the resin via a covalent bond. After that, the protective group is removed to expose a free amino group, which can be coupled with the next amino acid. The general principle of SPPS consists of a repeated cycle of coupling-flushing-deprotection-flushing-coupling.
Figure 4.
SPPS. In SPPS, the C-terminal of the first amino acid protected by an amino-protecting group needs to connect to the resin via a covalent bond. After that, the protective group is removed to expose a free amino group, which can be coupled with the next amino acid. The general principle of SPPS consists of a repeated cycle of coupling-flushing-deprotection-flushing-coupling.
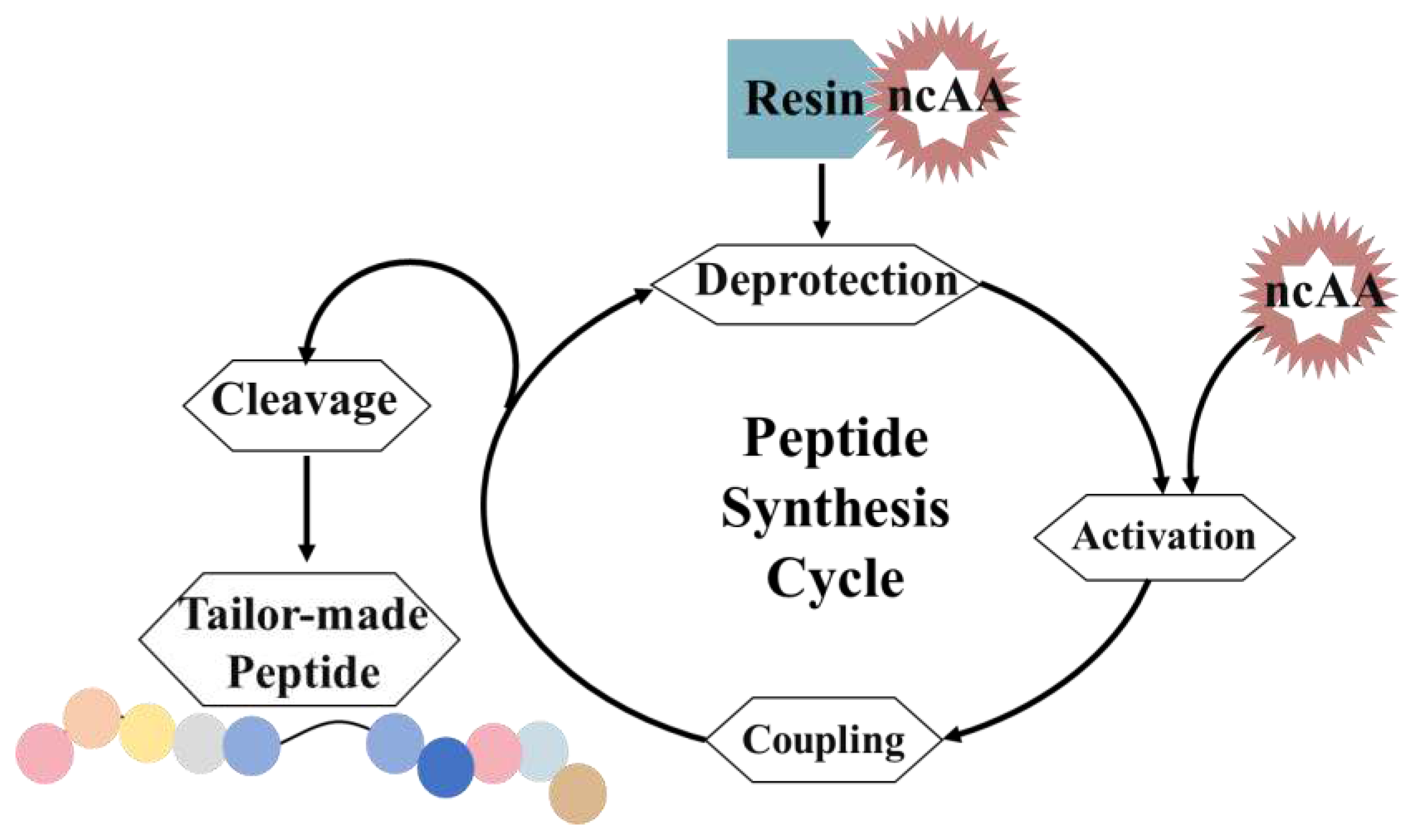
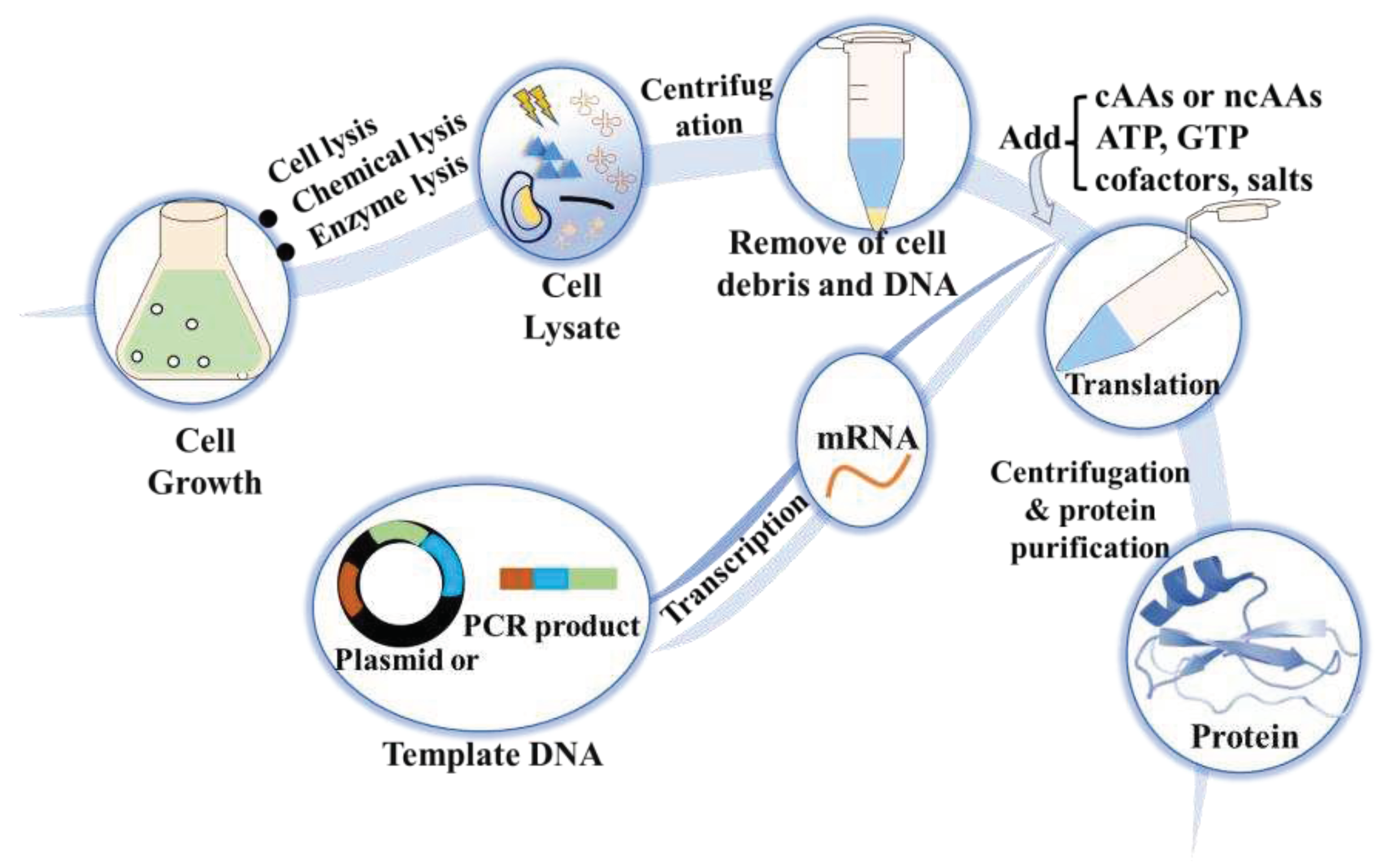
Figure 5.
CFPS. Mixing exogenous DNA or mRNA, cell lysate, ncAAs, ATP, cofactors salts could achieve the synthesis of tailor-made proteins with ncAAs incorporation.
Figure 5.
CFPS. Mixing exogenous DNA or mRNA, cell lysate, ncAAs, ATP, cofactors salts could achieve the synthesis of tailor-made proteins with ncAAs incorporation.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



