
Submitted:
13 September 2023
Posted:
14 September 2023
You are already at the latest version
Abstract
With the development of engineering technology, engineering has higher requirements for the accuracy and the scale of simulation calculation. The computational efficiency of traditional se-rial program can not meet the requirements of engineering。Therefore, reducing the calcula-tion time of temperature control simulation program has important engineering significance for real-time simulation of temperature field and stress field, and then adopting more reasona-ble temperature control and crack prevention measures. GPU parallel computing is introduced into the temperature control simulation program of massive concrete to solve this problem and the optimization is carried out. Considering factors such as GPU clock rate, number of cores, parallel overhead and Parallel Region, The improved GPU parallel algorithm analysis indicator formula is proposed. It makes up for the shortcomings of traditional formula that focus only on time. According to this formula, when there are enough threads, the parallel effect is limited by the size of the parallel domain, and when the parallel domain is large enough, the efficiency is limited by the parallel overhead and the clock rate. This paper studies the optimal Kernel execu-tion configuration. Shared Memory is utilized to improve memory access efficiency by 155%. After solving the problem of bank conflicts, an accelerate rate of 437.5x was realized in the sub-routine of the matrix transpose of the solver. The asynchronous parallel of data access and logi-cal operation is realized on GPU by using CUDA Stream , which can overlap part of the data access time. On the basis of GPU parallelism, asynchronous parallelism can double the compu-ting efficiency. Compared with the serial program, the accelerate rate of inner product matrix multiplication of the GPU asynchronous parallel program is 61.42x. This study further proposed a theoretical formula of data access overlap rate to guide the selection of the number of CUDA streams to achieve the optimal computing conditions. The GPU parallel program compiled and optimized by CUDA Fortran platform can effectively improve the computational efficiency of the simulation program for concrete temperature control, and better serve for engineering computing.
Keywords:
concrete
; simulation computing
; GPU
; parallel computing
; CUDA FORTRAN
; shared memory
; asynchronous parallel
1. Introduction
In the finite element calculation of temperature field and stress field of hydraulic concrete structure[1,2,3], especially the concrete structure with cooling water pipe[4], in order to get high accuracy[5,6], the calculators usually build a dense model, which leads to the increase of calculation scale[7]. In addition, reasonable temperature control calculation should be carried out in real time with the construction[8,9], so that the boundary conditions and parameters can be continuously adjusted and corrected with reference to the measured data, so as to obtain more reasonable results. Due to the low computational efficiency of the traditional serial program, it can not meet the actual needs of engineering under the condition of ensuring the calculation accuracy. All the above problems show that the existing serial simulation calculation method needs comprehensive improvement to improve the computational efficiency.
In recent years, the growth of CPU clock rate is slowing down year by year. In the field of engineering computing[10], the exploration of improving computing efficiency is gradually transferred to the parallelization implementation of programs[11]. Many explorations have been made for the implementation of multi-core CPU parallelism. Mao parallelized the joint optimization scheduling of multiple reservoirs in the upper reaches of Huaihe River, which took 5671.1s for 1 CPU core and 2104.6s for 6 CPU cores, with an accelerate rate of 2.704, and the efficiency is 45%[12]. Jia proposed a master-slave parallel MEC based on MPI, analyzed the effects of task allocation, communication overhead, sub-population size, individual evaluation time and the number of processors on the parallel speedup[13]. CPU parallelism relies on adding more CPU cores to achieve speedup. Whether you buying a multicore CPU or cluster parallelism[14], an order of magnitude increase in the number of CPU cores is definitely very expensive. The GPU of a home grade graphics card contains hundreds or thousands of processing cores[15,16].
The full name of GPU is Graphic Processing unit, which is designed for image computing, and the research in the field of image computing has been very mature. As a fine-grained parallel method, GPU was designed for compute-intensive, highly parallel computing, which enabled more transistors to be used for data processing, rather than data caching or flow control. GPU has an absolute advantage over CPU in the number of processors and threads. Therefore, GPU computing is very suitable for the field that requires large-scale parallel computing. In 2009, Portland Group(PGI) and NVDIA jointly launched the CUDA Fortran compiler platform, which greatly expanded the ication range of GPU general purpose computing. The release of this platform makes GPU computing widely used in medicine, meteorology, fluid calculation, hydrological prediction and other numerical computing fields[17,18,19,20]. T Mcgraw presented a Bayesian formulation of the fiber model which shown that the inversion method can be used to construct plausible connectivity[21]. An implementation of this fiber model on the graphics processing unit (GPU) is presented. Qin proposed a fast 3D registration technique based on CUDA architecture, which improves the speed by an order of magnitude while maintaining the registration accuracy, which is very suitable for medical clinical ications[22]. Takashi uses GPU to implement ASUCA, the next generation weather prediction model developed by Japan Meteorological Agency, and achieves significant performance speedup[23]. Taking pres-tack time migration and Gazdag depth migration in seismic data processing as a starting point, Liu introduced the idea, architecture and coding environment of GPU and CPU co-processing with CUDA[24]. GPU acceleration for OpenFMO, a fragment molecular orbital calculation program, has been implemented and its performance was examined.The GPU-accelerated program shows 3.3× speedups from CPU. MA Otaduy presented a parallel molecular dynamics algorithm for on-board multi-GPU architectures, parallelizing a state-of-the-art molecular dynamics algorithm at two levels[25]. Liang ied GPU platform and FDTD method to solve Maxwell equations with complex boundary conditions, large amount of data and low data correlation[26]. Wen presents a new particle-based SPH fluid simulation method based completely on GPU.By this method,hash-based uniform grid is constructed firstly on GPU to locate the neighbor particles faster in arbitrary scale scenes[27]. Lin presented a new node reordering method to optimize the bandwidth of sparse matrices, resulting in a reduction of the communication between GPUs[28]. JC Kalita present an optimization strategy for BiCGStab iterative solver on GPU for computing incompressible viscous flows governed by the unsteady N-S equations on a CUDA platform[29]. Tran harness the power of accelerators such as graphics processing units (GPUs) to accelerate numerical simulations up to 23x times faster [30].Cohen uses a GPU-based sparse matrix solver to improve the solving speed of the flood forecasting model, which is of great benefit to the early warning and operation management during the flood[31]. Ralf uses CUDA to numerically solve the equations of motion of a table tennis ball and performs statistical analysis of the data generated by the simulation[32].The Mike (Mike11, Mike21, and Mike3) series of commercial software developed by the Danish Institute of Hydraulics has also introduced GPUs to improve the computational efficiency of models[33,34,35]
GPU parallel computing is rarely used in the field of concrete temperature and stress field simulation. Concrete simulation calculation is to simulate the construction process[36], environmental conditions[37], material property changes and crack prevention measures and other factors as accurately as possible[38]. It is of great significance to y GPU parallel computing to concrete temperature control simulation calculation for real-time inversion of temperature field and stress field and shortening calculation time. In this paper, CUDA Fortran compiler platform is used to transform the large massive concrete temperature control simulation program into GPU parallel program. An improved analysis formula of GPU parallel algorithm is proposed. Aiming at the extra time consumption of GPU parallel in the indicators, two measures are proposed to optimize the GPU parallel program: One is to use shared memory to reduce the date access time, and the other is to hide the date access time through asynchronous parallelism.
2. Improved analytical formula for GPU parallel algorithms
The computation time of GPU parallel programs is affected by many factors. In order to better analyze and measure the advantages and disadvantages of parallel algorithms, a new analysis indicators based on the traditional parallel algorithm speedup is proposed. Through this theory, the relationship between the various elements of parallel computing can be better analyzed, so as to find the factors that restrict the improvement of parallel efficiency, and better serve for the optimization of efficient GPU parallel computing programs.
2.1. CUDA Fortran parallel experimental platform
2.2. The traditional analytical formula
The only indicators to evaluate the computational efficiency of traditional serial programs is the computation execution time. The formula for calculating the accelerate rate of the traditional parallel algorithm is as follows:
where is an accelerate rate, is the serial computation running time, n is the number of processors, is the parallel execution time using n processors.. The only index of the formula is time, although the formula can objectively reflect the acceleration effect of the calculation program, it can not reflect the various factors that affect the calculation time.
2.3. Improved analytical formula
During the execution of a program, not all processes and commands can be merged. The speedup of the code is limited by the proportion of the whole program that can be parallelized. In view of this, this paper divides the computation time of the program into serial domain and parallel domain.
where is parallel time for execution by n processors in parallel domain , is the serial time by single processor in serial domain. The total time the program takes to run is:
Insert Equation 3 into Equation 1, new parallel computing accelerate rate:
The execution of GPU parallel code also causes some other time consuming. Firstly, compared with the CPU parallel computing, it is also cost time to transfer data between the Host and the Device(H2D and D2H). Secondly, if the processors are not allocated the same amount of work, the load will be unbalanced, and some threads will be idle, which will affect the execution speed. Finally, there is a time penalty for calling the GPU Kernel subroutine. We define these extra time costs as
At present, the computing power of GPU single core is lower than that of CPU single core, so the attenuation coefficient λ of GPU computing power is used to represent the ratio of GPU and CPU computing power. The actual operation time of computing the parallel domain by GPU core is obtained as follows:
Insert Equation 5 into Equation 4, After collation, the parallel accelerate rate calculation formula considering computing power attenuation and extra time costs is as follows.
Formula 6 makes up for the shortcomings of the traditional calculation formula that only focuses on the calculation time, considering the accelerate rate of parallel computing, the core clock rate loss λ of GPU, the number of processors , the extra time cost and the proportion of serial domain .
In general, the speedup increases with the number of threads n participating in the computation for the same task, but the rate of increase slows down gradually due to the increase in communication overhead between threads. As approaches 0, which means that GPU computing power is infinite, . The speedup of the program is restricted by the serial duration and the extra time cost , and the value eventually tends to a constant . Similarly, as approaches 0, The speedup of the program is restricted by the serial duration and the extra time cost . The value of the speedup ratio is proportional to and inversely proportional to . In addition, the speedup will increase if the computational part of a task is larger. This is because the communication overhead at the device side and the host side is reduced in proportion to the computation time.
From the parallel algorithm analysis formula, it can be seen that in order to obtain better acceleration effect of GPU parallel program, we should pay attention to the following aspects: increasing the clock rate of GPU core, increasing the proportion of parallel operation of the program, increasing the number of GPU processors, and reducing the additional consumption.
3. Research on GPU Memory access optimization by using shared memory results
3.1. Selection of kernel execute parameter
The main program implements GPU parallel computing through ‘’call Kernel <<<Dg,Db >>> (parameter list)’’to write on the GPU device. Inside the <<< >>> operational character is the execution parameter of the kernel function. The parameter Dg is used to define the arrangement and number of Blocks. The parameter Db is used to define the arrangement and number of Threads in a Block. NVIDIA uses 32 threads to form a warp, and threads in a Warp must be in the same Block. Warp is the basic unit of scheduling and execution. If the number of threads in the block is not a multiple of the Warp size, the system will automatically fill the number of threads to a multiple of 32, and the extra threads are inactive threads.
Figure 1.
Calculation time for different number of threads
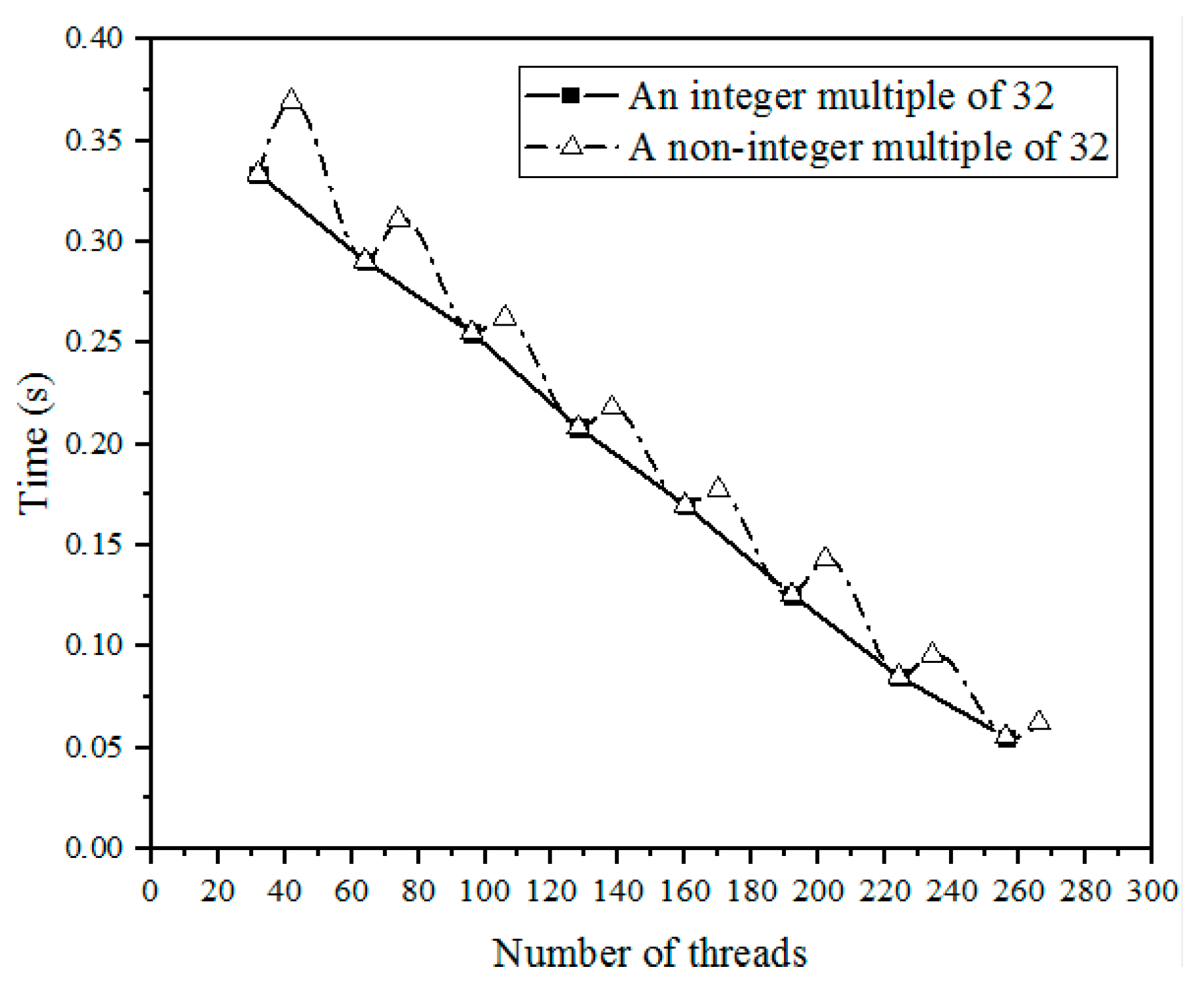
It can be seen from the figure that the increase of the total number of threads in the calculation process can effectively shorten the calculation time. When the thread increment is not an integer multiple of 32, the running time will first increase and then decrease. When the thread increment is too small, the number of parallel processes in a Warp increases less, and the number of inactive threads accounts for a large number. For example, when the total number of threads is increased by 1, the resource occupancy of 32 threads is actually increased, but only one active thread provided the actual computing power, and the inactive thread occupies many SM resources not to provide speedup. As the proportion of active threads increases, the speedup effect provided by the additional threads will outweigh the negative impact of inactive threads. The whole program presents a speedup effect. Therefore, we should set the number of threads to match the characteristics of Warp, to be an integer multiple of 32.
We take the GeForce GTX1050 graphics card as an example to study the data processing bandwidth under different execution parameters, Dg(blocks) and Db(Threads/block), with a consistent total number of threads, and the results are shown in Table 2:
For NVIDIA GeForce series graphics cards, max threads per multiprocessor is 2048. blocknumber= Max Threads per Multiprocessor/ Threadnumber. As the number of threads increases, the number of blocks decreases. From the table, the speedup effect first increases and then decreases with the increase of the number of thread per SM(Multiprocessor). When the number of threads is 32, the number of blocks is large, and the resources of SM are mainly used for the scheduling of blocks. Although this configuration can hide the scheduling delay of SM to a large extent, a block only dominates 32 threads for data operation, and there is a large gap between the data computing capacity and the peak capacity. Similarly, when the number of threads is 1024, SM only processes 2 blocks, although the computing capacity is sufficient, it cannot achieve the effect of hidden sm scheduling, and there will be a partial loss of computing capacity. The computing power of this configuration is not far from the peak capacity. The optimal number of threads is 256.
3.2. Features of Shared Memory
The architecture of GPU memory is similar to that of CPU memory. In order to adapt to graphics calculation, the graphics card has made a special design and partitioned the video memory in more detail. Include: local memory, global memory, Shared Memory, register, L1/L2 Cache and other memory. As following Figure 2 shows:
Different memory has different characteristics, you need to choose the appropriate memory according to the requirements of the program variables.The Register is the cache on the GPU chip, which is the fastest memory in the GPU. Same as registers,Shared Memory is located on the GPU chip. it is an efficient memory for thread collaboration. All threads in the same block can access variables in shared memory. The use of Shared Memory requires manual variable declarations in the Kernel: _device_,_shared_, for example: real(kind=8),shared::psum(*).The location and speed of L1/L2 cache and shared memory are very similar. The difference is that the use of L1/L2 cache is controlled by the system, and the use of shared memory is controlled by the user. The Local Memory is also the memory on the GPU chip, but is only retrieved by the thread. Global Memory is implemented by Dynamic Random Access Memory (DRAM). It is an independent off-chip memory, which is commonly referred to as video memory. It can be accessed by all threads on the device and shared globally.
According to the characteristics of each memory and combining Figure 2 and Table 3, we can see that the fastest Memory that a user can actively allocate is Shared Memory. Shared Memory is better for exchanging data between threads than Local Memory. For the data that needs to be read and written repeatedly, it can be stored on the Shared Memory. Compared with the Memory access in Global Memory, data access operations directly on Shared Memory can effectively improve the memory access efficiency of GPU.
3.3. Research on avoiding Bank Conflicts
Bank Conflict is a concept used for Shared Memory, which means that a thread has a conflict in accessing a Shared Memory Bank. For example, two or more threads access a Bank at the same time. Consider a two-dimensional B array of size 4*32. This array B is data processed by threads in one warp.
As can be seen from Figure 3-b, when threads in a warp access the first element of their own vector. The thread index is ThreadIdx.x. The access data address of each thread is: (ThreadIdx.x+0)*32. The address of Bank is: ThreadIdx.x/4+0. The thread index indicates that a bank conflict will occur. Multiple threads accessing different data in the same Bank, and the access of a thread to data needs to wait for the completion of the access of the previous thread. As shown in Figure 4-a.
In order to solve the bank conflict, we propose method of increasing the size of data stored in Shared Memory to solve it. The specific operation is to store one more column of empty data, as shown in Figure 5-a. This can realize the misalignment of data stored in the bank as shown in Figure 5-b. The code is shown in Line 6 of Code 1.
| List 1. Code of Shared Memory. |
 |
As can be seen from Figure 5-b, when threads in a warp access the first element of their own vector. The thread index is ThreadIdx.x. The access data address of each thread is: ThreadIdx.x*32+x. The address of Bank is: ThreadIdx.x/4+x. The data accessed by each thread is distributed in different banks, and the access of threads to banks is malposed. This method avoids Bank conflicts. The disadvantage of this method is that it takes up an extra column of Shared Memory. If a Kernel is overloaded with Shared Memory, this method is not available.
3.4. Time consumption analysis of shared memory
For a 1024*1024 matrix, the computation time for matrix addition and transpose is as follows:

Table 4.
Time consumption for matrix operations.
| Graphics card | Version | ||||
|---|---|---|---|---|---|
| Replication | Replication(Shared Memory) | Transposition | Transposition(Shared Memory) | Transposition(Non-Bank Conflict) | |
| Time(ms) | |||||
| Inteli7-6700 | 4974.03 | - | - | - | - |
| GTX 1050 | 91.23 | 88.31 | 336.38 | 180.26 | 89.24 |
| GTX 1070 | 44.86 | 42.12 | 102.37 | 54.29 | 41.64 |
| RTX 3080 | 12.61 | 11.41 | 40.93 | 16.04 | 11.37 |
| Bandwidth(GB/s) | |||||
| GTX 1050 | 85.64 | 88.47 | 23.23 | 43.34 | 87.54 |
| GTX 1070 | 174.39 | 185.45 | 76.31 | 143.93 | 187.61 |
| RTX 3080 | 619.62 | 864.82 | 190.89 | 487.07 | 687.09 |
From the table, we can see that the use of Shared Memory has a certain speed-up effect on both matrix replication and transpose operations. The operation speed of matrix replication is significantly faster than matrix transpose, this is because the data of matrix copy process is continuous, and the data corresponds to the matrix position one by one. Matrix replication can make full use of the advantages of coalescing access and reduce the number of access, so matrix replication can reach a very high bandwidth of 619.62 GB/s (RTX3080), and it is improved to 864.82 GB/s by using shared memory.
For transposition, the operation of the data is skip, so the data transfer cannot use coalescing access, which requires multiple fetching data from the Globle Memory, and the bandwidth of the program is 190.89 GB/s (RTX3080). After using shared memory, the GPU computing bandwidth of GTX 1050 can reach 43.34 GB/s, which is increased by 86%. For GTX 1070 , the bandwidth can increase by 88%, and for RTX 3080, the bandwidth can ncrease155%. The higher the clock rate of the graphics card, the more obvious the bandwidth improvement effect.
It can be seen from the data in the table that the rate of transpose operation is still lower than that of matrix replication after using Shared Memory for both 10 series graphics cards and 30 series graphics cards. This indicates that its performance is not fully utilized in the matrix transpose operation due to the existence of bank conflicts. After the optimization of matrix transpose without bank conflict, the bandwidth can reach 99% of the matrix copy using Shared Memory, which shows that the data transmission capacity between shared memory and Thread can be fully utilized.
This subsection shows that the computational efficiency of GPU parallelism is 122 times than that of CPU serial program. With Shared Memory, the ratio is increased to 310 times. At the same time this subsection studies the use of the augmented matrix method to avoid Bank Conflict which further improves the rate by 41%, reaching 437.5 times ,compared with serial calculation. Its advantages are easy to modify, easy to operate and good acceleration effect on kernel. Its advantage is that the optimization method is simple and the effect of kernel acceleration is good. The only disadvantage is that it will occupy more shared memory.
4. Research on asynchronous parallelism in GPU computing
An important concept in CUDA is a stream, which represents the execution queue of a series of instructions. GPU asynchronous parallelism is that the data and resources are divided into multiple parts, and the Host starts each execution sequence for CUDA stream to process separately. Thus, it has the effect of overlapping data transmission and device calculation. Compared with thread parallelism, asynchronous parallelism using CUDA stream is a higher level of parallelism. thread parallelism is a level of parallelism for data, and streams are a level of parallelism for instructions.
4.1. Comparison and analysis of different asynchronous parallel methods
For a subroutine that needs to be computed in parallel on the GPU, two types of operations (transfer of data between Host and Device and Kernel calculation) are required. Taking GTX 1050 as an example, this section visualizes the time of Memcpy D2H, Kernel kernel function and Memcpy H2D through Nvprof tool, so as to analysis the time of CUDA stream under different conditions.According to the different tasks divided, GPU computing is divided into three versions.
Versions 1: For computing tasks, one stream is used to realize the transmission of data from Host to Device, kernel execution, and then transferring data from Device to Host. The code is as follows:
| List 2. Code of Versions 1. |
 |
Figure 6.
Time analysis of Versions 1 (nstreams=1, RTX 3080)

Versions2:The whole computing tasks are divided into several subtask. Each CUDA stream completes the whole process of subtask. The code is as follows:
| List 3. Code of Versions 2. |
 |
As shown in Figure 7 and Figure 8 for versions 2, the object of stream is the whole process of sub-tasks. The CUDA stream operates on the whole process, so the Memcpy H2D and Memcpy D2H cannot be parallel as indicated by the red square in the Figure 7 and Figure 8. When nstreams is 4, the computation is split into 4 parts, we can see that Memcpy can overlap with the Kernel in three of the four parts, and the data transfer overlap rate is 75%. When nstreams is 10, the computation is split into 10 parts ,we can see that 9 parts of Memcpy H2D can overlap with the Kernel and 6.75 parts of Memcpy D2H can overlap with the Kernel. The total overlap of data transmission is 79%.
Versions3:The whole computing tasks are divided into three parts(Memcpy H2D,Kernel and Memcpy D2H). Then each part is divided into several sub-tasks to be executed by CUDA streams. The code is as follows:
| List 4. Code of Versions 3. |
 |
As shown in Figure 9 and Figure 10 for versions 3, The object of stream processing is the three parts(Memcpy H2D,Kernel and Memcpy D2H) that are divided.Thus, Memcpy D2H do not need to wait for all Memcpy H2D to complete before executing. For example, Memcpy D2H of Stream14 and Memcpy H2D of Stream16 in Figure 9 have a certain overlap time. When nstream is 4, although the overlap of memcpyD2H and Memcpy H2D saves some time, the time saved is wasted in waiting for kernel operation. Therefore versions 2 and versions 3 take almost the same amount of time. When nstream is 10, whether MemcpyD2H or MemcpyH2D, 9 parts can overlap. The overlap rate of the total data transmission is 90%. Therefore, the time consumption of version 3 is lower than that of version 2.
4.2. Overlap rate theory of Memcpy
In this paper, an asynchronous parallel overlap rate theory of Memcpy is proposed to explore the impact of different methods and different strean numbers on the overlap rate.The Memcpy version 1 cannot overlap, so it will not be discussed here.
- 1.
- Overlap rate formula of Memcpy of version 2
For version 2, time of Memcpy H2D and MemcpyD2H cannot overlap each other. Because the first and last Memcpy cannot be covered, when nstreams is n , the number of Memcpy that can be covered is 2(n-1). The overlap rate of Memcpy depends on whether the n kernel operations can cover the time of 2(n-1) Memcpy.The calculation time formula of version 2 is as follows:
where , is total time of kernel execution, is kernel time of subtask. is the time of Memcpy H2D, is the operation time of MemcpyD2H, is the number of CUDA streams. After extracting the common factor:
When is greater than 1, the computation time is constrained by the Kernel execution time, and vice versa, the computation time is constrained by the Memcpy time. It can be seen from Table 1, and are approximately equal, For the Memcpy time to be covered, must satisfy. Similarly, the number of fully covered Memcpy:
- 2.
- Overlap rate formula of Memcpy of version 3
For version 3, when the program executes the second kernel operation, the output value of the first kernel executes the MemcpyD2H command, and the input value of the third kernel executes the Memcpy H2D command at the same time. There are three commands going on at the same time. Similarly, for a task divided into n parts, the time of Memcpy H2D and MemcpyD2H can overlap except for the first and last Memcpy, so the computation time after overlapping is determined by the time of n kernels and (n-1) Memcpy. The calculation time formula of version 2 is as follows:
Similarly, for the Memcpy time to be covered, must satisfy. the number of fully covered Memcpy:
Comparing the calculation time formulas of version 2 and version 3, we find that when both of them are in the optimal condition, version 2 can overlap more than version 3, This can show that version 3 is better than version 2 in theory. In the actual calculation process, we should analyze the relationship between Kernel and Memcpy, select the appropriate number of CUDA streams according to to achieve the optimal working condition, as shown in Figure 11.
4.3. Analysis of theoretical operation time and practical operation time
Taking GTX 1050 as an example, it can be seen from nvprof that the execution time of the kernel function is 2.1325ms, the execution time of MemcpyH2D is 1.2633ms, and the ratio is 1.69. Figure 12 shows that version 2 can reach the optimal working condition when nstream is 7. As nstream becomes larger, cannot meet the requirements of the optimal operating condition, and Memcpy cannot achieve sufficient overlap. This is consistent with the phenomenon in Figure 12-a that the actual overlap rate reaches the highest at nstream=7. For version 3, is greater than 1, which meets the conditions of the optimal working condition. Figure 12-b shows that the actual overlap rate and the theoretical overlap rate are consistent for any nstream number.
Under the condition of array size 4*106, the total time of CUDA stream operation is 4.971ms, and the time of Memcpy(H2D) is 2.5266ms. Summing up formulas 000 and 001 we can calculate We can calculate the theoretical computation time of the program as follows. The theoretical computation time of the program can be calculated using fomula 8 and fomula 10,as shown in Figure 13.
As shown in Figure 13, either version 2 or 3, the actual computation time is more than the theoretical computation time. This is because the use of CUDA streams not only brings the gain of Memcpy time overlap to reduce the execution time, but also brings other extra time consumption. These include cuCtxDetach, cuMemcpyH2Dasync, launch kernel, etc., of which cuMemcpyH2Dasync and launch kernel will increase with the increase of the number of nstreams. Through the comparison of the actual calculation time and the theoretical calculation time, although we can see that there is a certain gap between the two, it is very small and the change trend is consistent. The overlap rate of Memcpy can analyze the influence of the number of streams on the calculation time to a certain extent, and can be used to predict the execution time of the task, which is of guiding significance for parallel compilation and optimization analysis of programs.
Despite the consumption of other extra time, asynchronous parallelism is better than traditional parallelism, and Version 3 takes the least time. The parallel accelerate rate of each version is shown in Table 5. Version 2 can improve the speed by 65% on the basis of ordinary GPU parallelism, and Version 3 can improve 100%. Compared with serial calculation, the accelerate rate is 50.90 and 61.42.
5. Conclusions
Aiming at the problem that the current conventional serial computing efficiency is low and cannot meet the engineering requirements, GPU parallel computing is introduced into the large massive concrete temperature control simulation calculation program. Improved analytical formula for GPU parallel algorithms is proposed, it makes up for the shortcomings of the traditional algorithms that only focuses on time. which is conducive to finding out the direction of program optimization. Optimization of parallel program is studied through two aspects: shared memory and CUDA stream. The optimized program obtains a better speedup ratio.
- From the improved analytical formula , GPU parallel programs should be optimized from the following aspects: Hardware level: replace the GPU with stronger performance to obtain more threads and higher clock rate. Algorithm level: modify the algorithm to increase the proportion of parallel operations, improve the running efficiency of kernel functions, and overlap more data transmission time.
- The data access mode of parallel programs is optimized by using shared memory, and the problem of bank conflicts is further solved. For matrix transpose operations of finite element operations, 437.5x acceleration is achieved.
- This paper implements asynchronous parallelism on the GPU through CUDA streams, which can hide the time of data access. Overlap rate theory of Memcpy is proposed to guide the optimization of asynchronous parallel programs. For GPU kernel subroutines of matrix inner product, compared with ordinary GPU parallel program that do not use asynchronous parallelism , it can achieve nearly twice the acceleration. Compared with serial programs, it can achieve 61.42x acceleration.
Author Contributions
Conceptualization, X.Z., J.J. and S.Q.; methodology, X.Z., Y.W. and S.Q.; software, X.Z., Y.W. and S.Q.; formal analysis, X.Z., Y.W. and S.Q.; investigation, X.Z. and M.Y.; resources, X.Z. and J.J.; data curation, X.Z., J.J. and M.Y.; writing—original draft preparation, X.Z. and J.J.; writing—review and editing, X.Z., Y.W. and S.Q.; visualization, X.Z., Y.W. and S.Q. supervision, Y.W. and S.Q.; project administration, Y.W. and S.Q.; funding acquisition, X.Z. and S.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China, grant number 52079049, Water Conservancy Science and Technology Project of Henan Province, China in 2022.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
The authors acknowledge the Fundamental Research Funds for the Central Universities and the Postgraduate Research & Practice Innovation Program of Jiangsu Province.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CUDA | Compute Unified Device Architecture |
| CPU | Central Processing Unit |
| GPU | Graphics Processing Unit |
| H2D | Host to Device |
| D2H | Device to Host |
| Dg/Db | Dim of Girde/Dim of Block |
| Memcpy | Memory Copy |
References
- Aniskin, N.; Nguyen, T.C. Influence factors on the temperature field in a mass concrete. E3S Web of Conferences, 2019, 97: 05021. [CrossRef]
- Briffaut, M.; Benboudjema, F.; Torrenti, J.M. Numerical analysis of the thermal active restrained shrinkage ring test to study the early age behavior of massive concrete structures. Engineering Structures, 2011, 33(4):1390-1401. [CrossRef]
- Silva, C.M.; Castro, L.M. Hybrid-mixed stress model for the nonlinear analysis of concrete structures. Computers & Structures, 2005, 83(28/30):2381-2394. [CrossRef]
- Yuan, M. ; Qiang, S; Xu, Y. Research on Cracking Mechanism of Early-Age Restrained Concrete under High-Temperature and Low-Humidity Environment. Materials, 2021, 14(15):4084. [CrossRef]
- Wang, H.B.; Qiang, S.; Sun, X. Dynamic Simulation Analysis of Temperature Field and Thermal Stress of Concrete Gravity Dam during Construction Period. ied Mechanics and Materials, 2011, 90-93. https://www.scientific.net/AMM.90-93.2677.
- Zhang, G.; Liu, Y.; Yang, P. Analysis on the causes of crack formation and the methods of temperature control and crack prevention during construction of super-high arch dams. Journal of Hydroelectric Engineering, 2010, 29(5):45-51. [CrossRef]
- Yin; Li; Hu. Coupled Thermo-Hydro-Mechanical Analysis of Valley Narrowing Deformation of High Arch Dam: A Case Study of the Xiluodu Project in China. ied Sciences, 2020, 10(2):524. [CrossRef]
- Zheng, X.; Shen, Z.; Wang, Z.; Qiang, S.; Yuan, M. Improvement and Verification of One-Dimensional Numerical Algorithm for Reservoir Water Temperature at the Front of Dams. . Sci. 2022, 12, 5870. [Google Scholar] [CrossRef]
- Chang, X.; Liu, X.; Wei, B. Temperature simulation of RCC gravity dam during construction considering solar radiation. Engineering Journal of Wuhan University, 2006, 39(1): 26-29. [CrossRef]
- Nishat, A.M. ; Mohamad,S.J. Efficient CPU Core Usage and Balanced Bandwidth Distribution using Smart Adaptive Arbitration[J]. Indian Journal of Science and Technology, 2016, 9(S1). [CrossRef]
- Lastovetsky, A.; Manumachu, R.R. Energy-Efficient Parallel Computing: Challenges to Scaling. Information 2023, 14, 248. [Google Scholar] [CrossRef]
- Mao, R.J. ; Huang,L.S.; Xu, D.J.; Chen, G.L. Joint optimization scheduling algorithm and parallel implementation of group Base in Middle and upper reaches of Huaihe River [J]. Small Microcomputer System, 2000, 21(6):5. https://CNKI:SUN:XXWX.0.2000-06-010.
- Jia, M. Master-slave Parallel Mind Evolutionary Computation Based on MPI [J]. Journal of North University of China: Natural Science Edition, 2007(S1):4. [CrossRef]
- Wencheng, W.; Xiaoru, W. Multi-Core CPU Parallel Power Flow Computation in AC/DC System Considering DC Control[J]. Electric Power Components and Systems,2017,45(9). [CrossRef]
- Bocci, Andrea.; CMS High Level Trigger performance comparison on CPUs and GPUs[J]. Journal of Physics: Conference Series,2023,2438(1). [CrossRef]
- Zhang, S.; Zhang, L.; Guo, H.; Zheng, Y.; Ma, S.; Chen, Y. Inference-Optimized High-Performance Photoelectric Target Detection Based on GPU Framework. Photonics 2023, 10, 459. [Google Scholar] [CrossRef]
- Wang, J.; Kuang, C.; Ou, L.; Zhang, Q.; Qin, R.; Fan, J.; Zou, Q. A Simple Model for a Fast Forewarning System of Brown Tide in the Coastal Waters of Qinhuangdao in the Bohai Sea, China. . Sci. 2022, 12, 6477. [Google Scholar] [CrossRef]
- Hu, H.; Zhang, J.; Li, T. Dam-Break Flows: Comparison between Flow-3D, MIKE 3 FM, and Analytical Solutions with Experimental Data. . Sci. 2018, 8, 2456. [Google Scholar] [CrossRef]
- Umeda, H.; Hanawa, T.; Shoji, M. Performance Benchmark of FMO Calculation with GPU-Accelerated Fock Matrix Preparation Routine[J]. Journal of Computer Chemistry Japan, 2015, 13(6):323-324. [CrossRef]
- Umeda, H.; Hanawa, T.; Shoji, M. GPU-accelerated FMO Calculation with OpenFMO: Four-Center Inter-Fragment Coulomb Interaction[J]. Journal of Computer Chemistry Japan, 2015, 14(3):69-70. [CrossRef]
- Mcgraw,T.; Nadar, M. Stochastic DT-MRI Connectivity Mapping on the GPU[J]. IEEE Transactions on Visualization & Computer Graphics, 2007, 13(6):1504-1511. [CrossRef]
- Qin, A.; Xu, J.; Feng, Q. Fast 3D medical image rigid registration Technology based on GPU [J]. ication Research of Computers, 2010(3):3. [CrossRef]
- Junichi, I.; Kohei, A.; Yuji, K.; Chiashi, M. ASUCA: The JMA Operational Non-hydrostatic Model [J]. Journal of the Meteorological Society of Japan. Ser.II。2022 Volume 100 Issue 5 Pages 825-846. [CrossRef]
- Guofeng, L. ; Qin,L.; Bo,L.I. GPU/CPU co-processing parallel computation for seismic data processing in oil and gas exploration [J]. Progress in Geophysics, 2009, 24(5):1671-1678. [CrossRef]
- Novalbos, M.; Gonzalez, J.; Otaduy, M.A.; Sanchez, A. (2013). On-Board Multi-GPU Molecular Dynamics. In: Wolf, F., Mohr, B., an Mey, D. (eds) Euro-Par 2013 Parallel Processing. Euro-Par 2013. Lecture Notes in Computer Science, vol 8097. Springer, Berlin, Heidelberg. [CrossRef]
- Liang, B.; Wang, S.; Huang, Y.; Liu, Y.; Ma, L. F-LSTM: FPGA-Based Heterogeneous Computing Framework for Deploying LSTM-Based Algorithms. Electronics 2023, 12, 1139. [Google Scholar] [CrossRef]
- Wen, C.; Ou, J. ; Jinyuan, A, J. GPGPU-based Smoothed Particle Hydrodynamic Fluid Simulation[J]. Journal of Computer-Aided Design & Computer Graphics, 2010, 22(3):406-411. [CrossRef]
- Lin, S.Z.; Zhi, Q. A Jacobi_PCG solver for sparse linear systems on multi-GPU cluster[J]. Journal of Supercomputing, 2016. [CrossRef]
- JC Kalita∗, P U∗.; GPU accelerated flow computation by the streamfunction-velocity (ψ-ν) formulation[J]. Aip Conference Proceedings, 2015, 1648(1). [CrossRef]
- Thi, K. T.; Huong, N.T.M.; Huy, N.D.Q.; Tai, P.A.; Hong, S.; Quan, T.M.; Bay, N.T.; Jeong, W.-K.; Phung, N.K. Assessment of the Impact of Sand Mining on Bottom Morphology in the Mekong River in An Giang Province, Vietnam, Using a Hydro-Morphological Model with GPU Computing. Water 2020, 12, 2912. [Google Scholar] [CrossRef]
- Nesti, A.; Mediero,L.; Garrote L. Probabilistic calibration of the distributed hydrological model RIBS ied to real-time flood forecasting: the Harod river basin case study (Israel)[J]. Egu General Assembly, 2010, 12(2):8028. [CrossRef]
- Schneider, R.; Lewerentz, L.; Lüskow, K.; Marschall, M.; Kemnitz, S. Statistical Analysis of Table-Tennis Ball Trajectories. . Sci. 2018, 8, 2595. [Google Scholar] [CrossRef]
- Lee, T. L. Prediction of Storm Surge and Surge Deviation Using a Neural Network[J]. Journal of Coastal Research, 2008, 24(s3):76-82. [CrossRef]
- Soares. Comparing the Performance of Spectral Wave Models for Coastal Areas[J]. Journal of Coastal Research, 2017. [CrossRef]
- Ganesh, R.; Gopaul, N. A predictive outlook of coastal erosion on a log-spiral bay (trinidad) by wave and sediment transport modelling[J]. Journal of Coastal Research, 2013, 65(Part 1, Sp. Iss. 65):488-493. [CrossRef]
- Zhu, Z.Y.; Qiang, S.; Liu, M.Z. Cracking Mechanism of RCC Dam Surface and Prevention Method. Advanced Materials Research, 2011, 295-297:2092-2096. [CrossRef]
- Zakonnova, A.V.; Litvinov, A.S. Analysis of Relation of Water Temperature in the Rubinsk Reservoir with Income of Solar Radiation. Hydrobiological Journal, 2017, 53(6). [CrossRef]
- Yuan, M. ; Qiang, S; Xu, Y. Research on Cracking Mechanism of Early-Age Restrained Concrete under High-Temperature and Low-Humidity Environment. Materials, 2021, 14(15):4084. [CrossRef]
- Windisch, D.; Kaever, C.; Juckeland, G.; Bieberle, A. Parallel Algorithm for Connected-Component Analysis Using CUDA. Algorithms 2023, 16, 80. [Google Scholar] [CrossRef]
Figure 2.
Simplified host and device memory architecture.
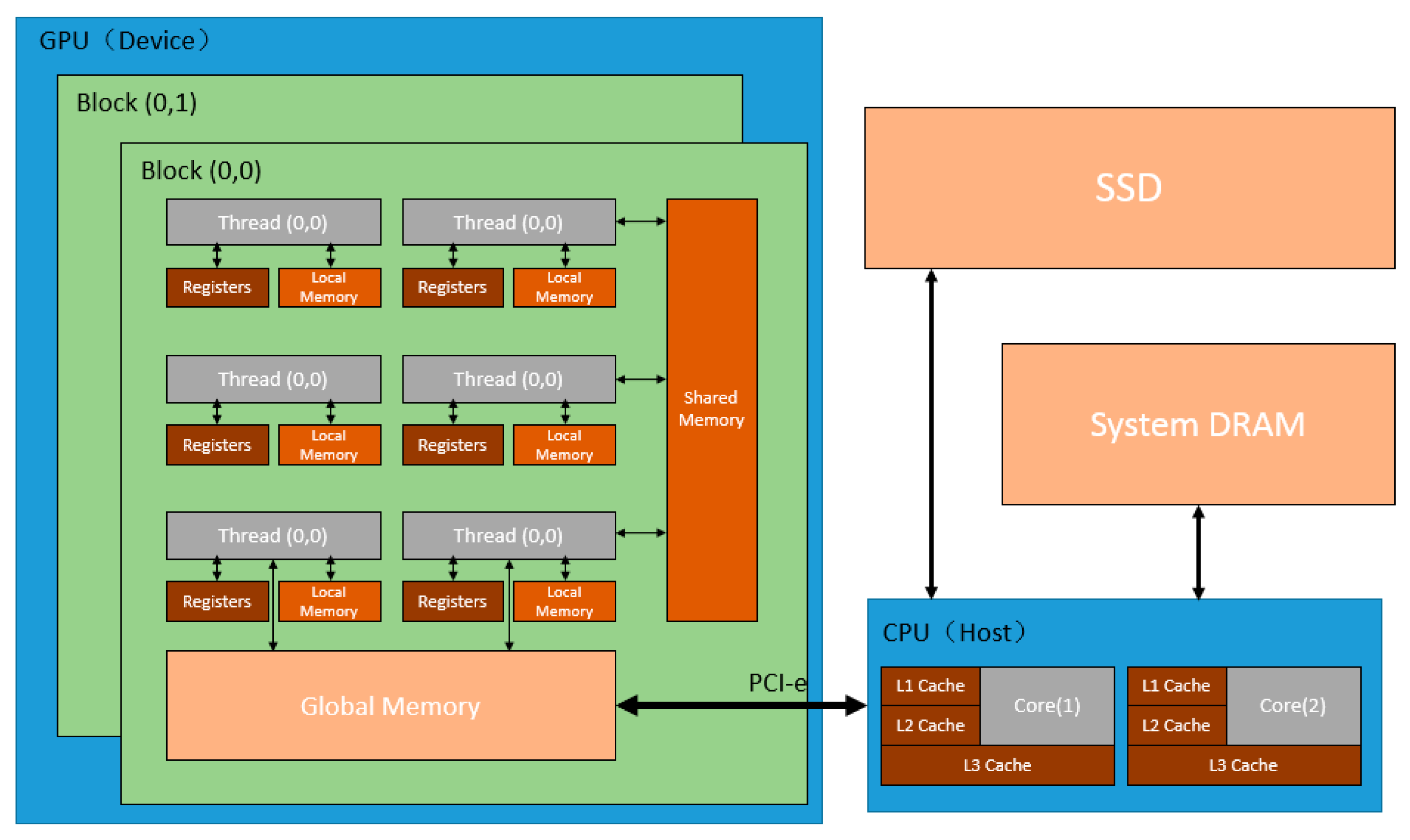
Figure 3.
The original arrangement of the data.

Figure 4.
Thread data access on Bank.
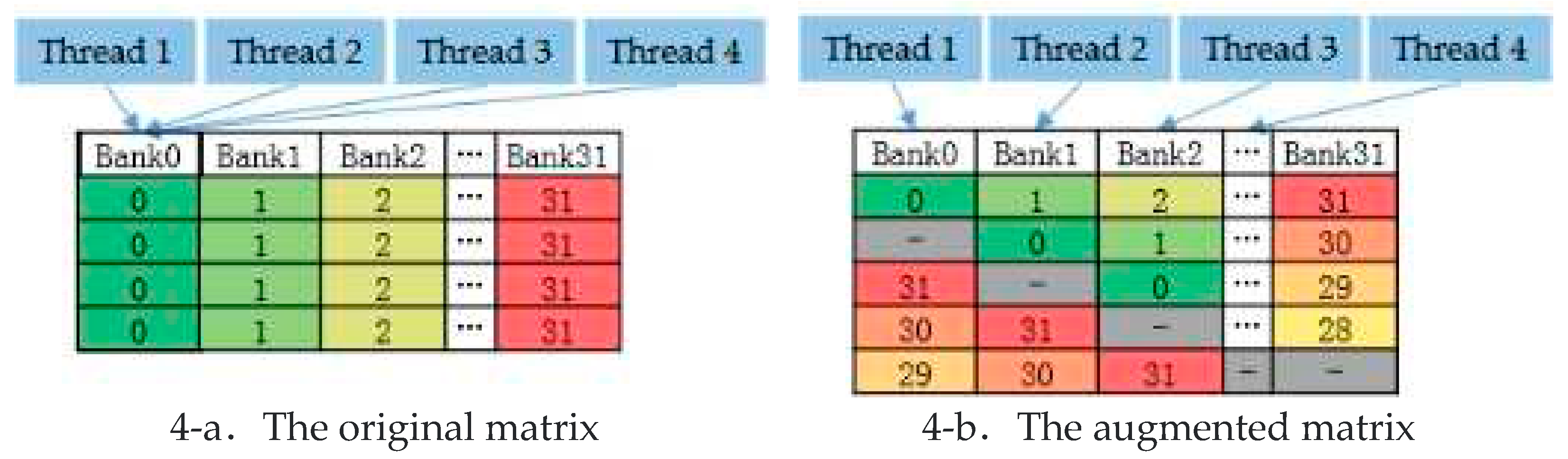
Figure 5.
The augmented arrangement of the data.
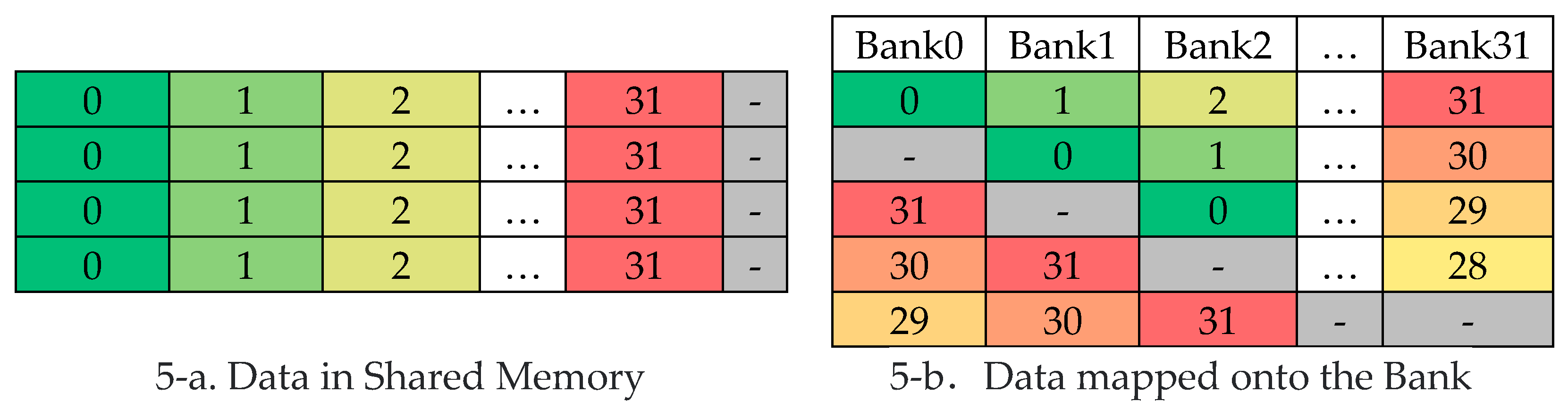
Figure 7.
Time analysis of Versions 2 (nstreams=4, RTX 3080).
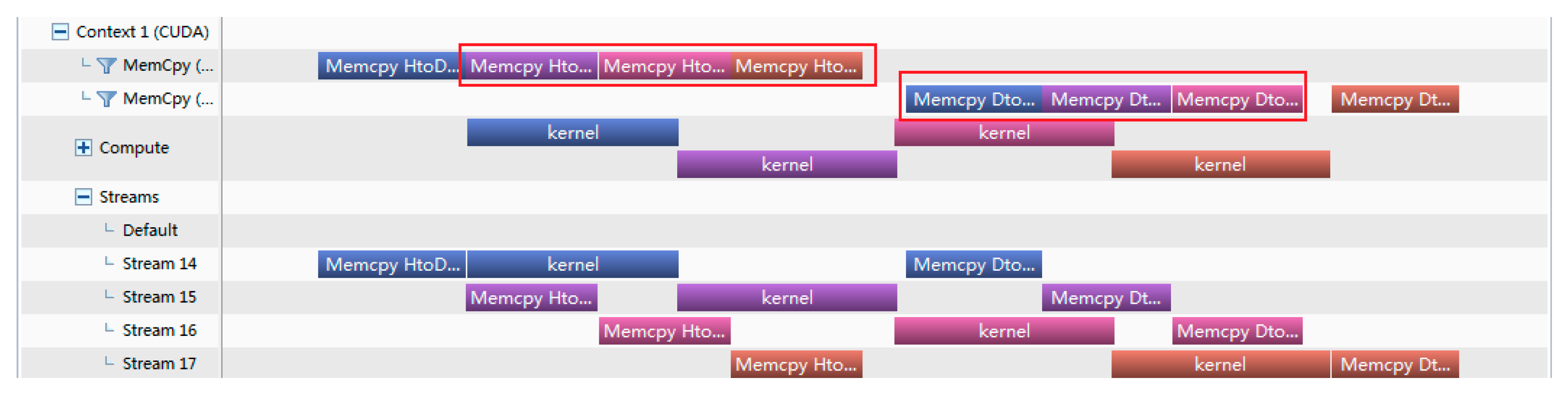
Figure 8.
Time analysis of Versions 2 (nstreams=10, RTX 3080).
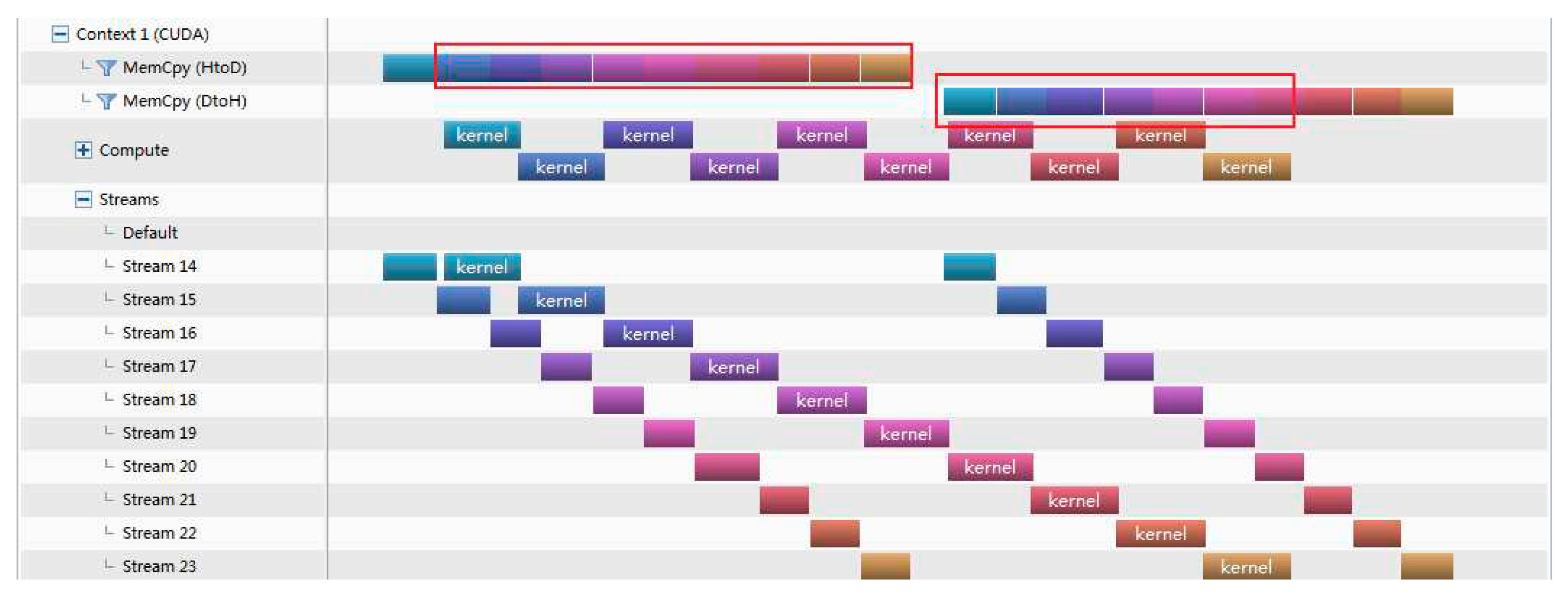
Figure 9.
Time analysis of Versions 3 (nstreams=4, RTX 3080).
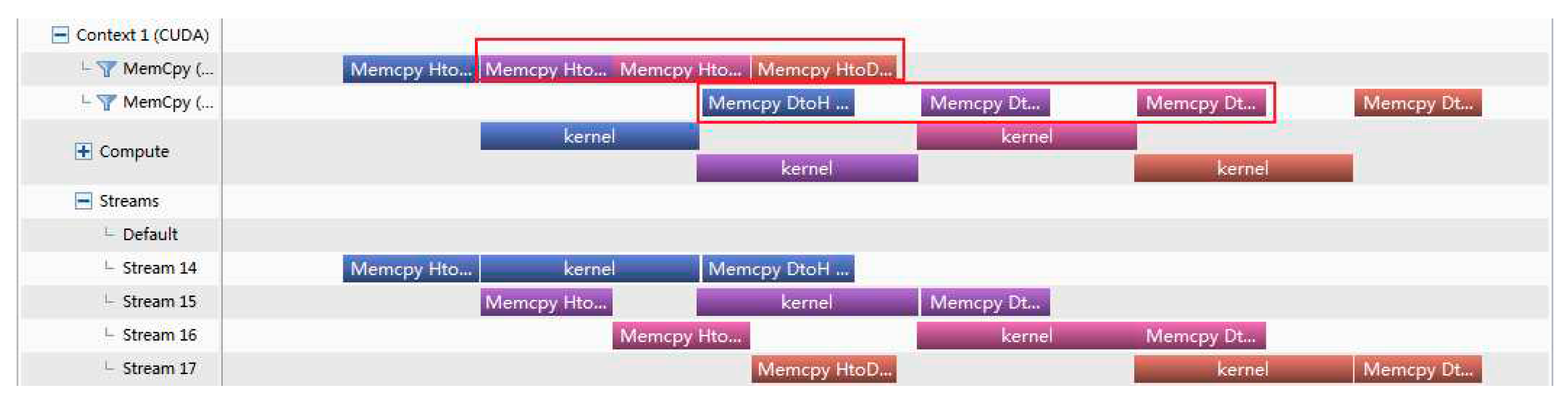
Figure 10.
Time analysis of Versions 3 (nstreams=10, RTX 3080).
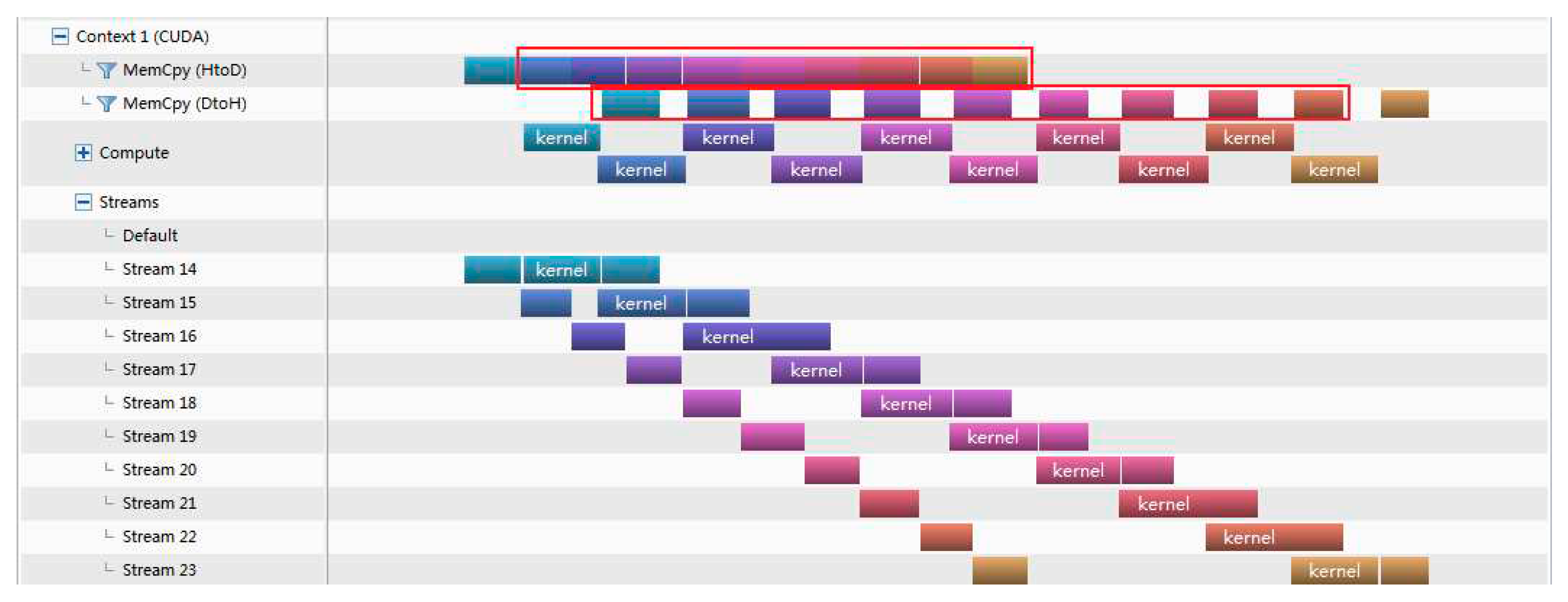
Figure 11.
The lowest in the optimal working condition.
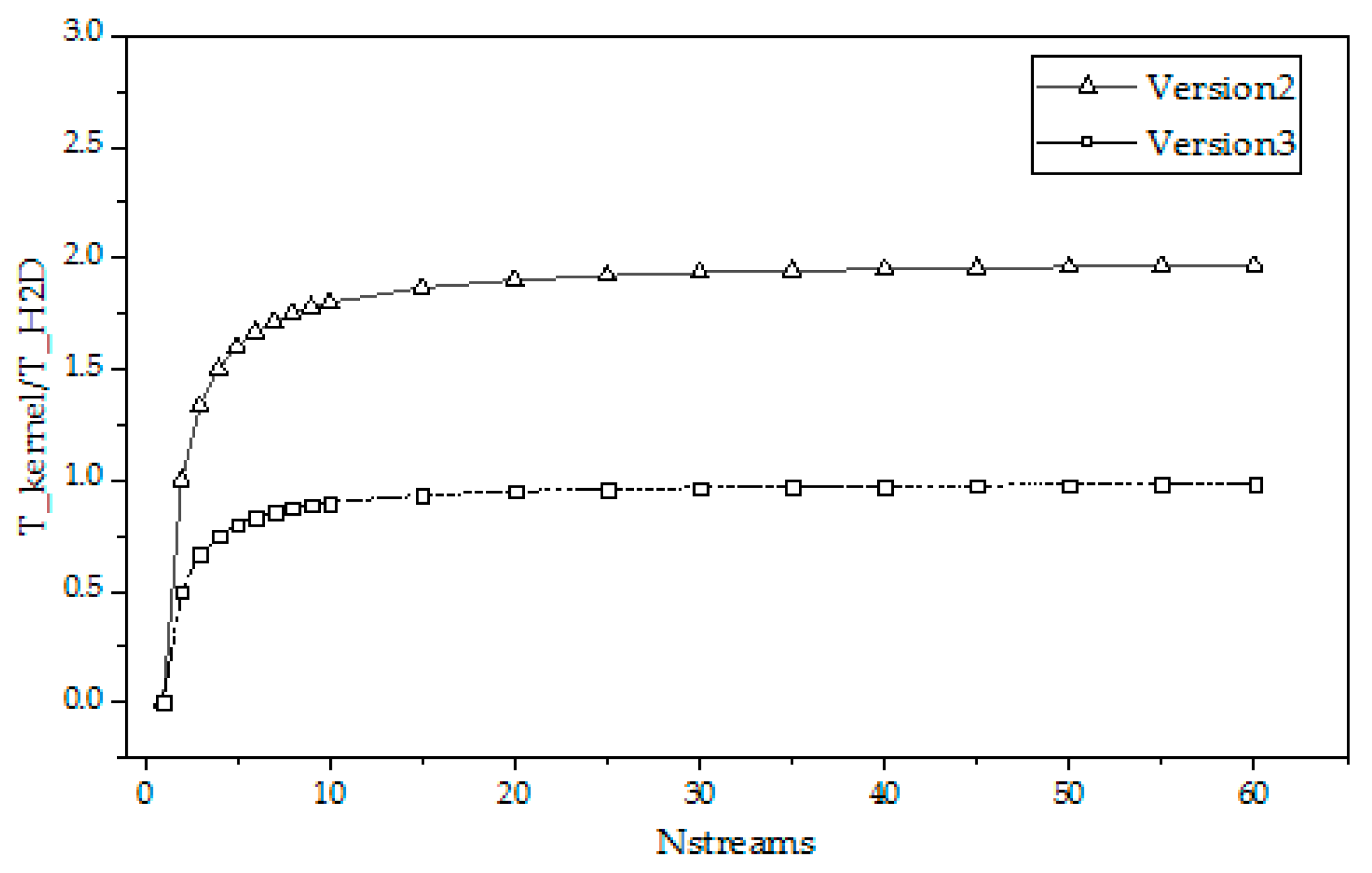
Figure 12.
Actual and theoretical overlap rates (RTX 3080).
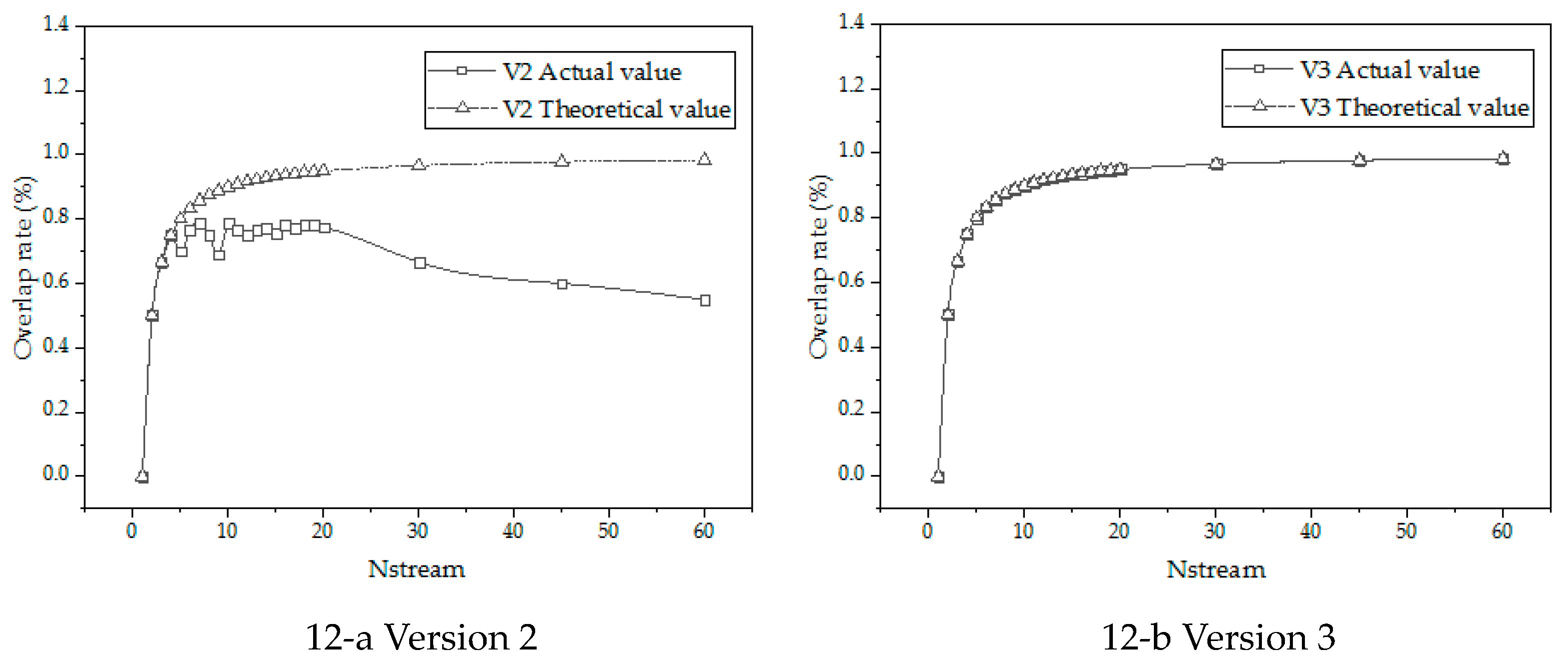
Figure 13.
Actual and theoretical execution time (RTX 3080).
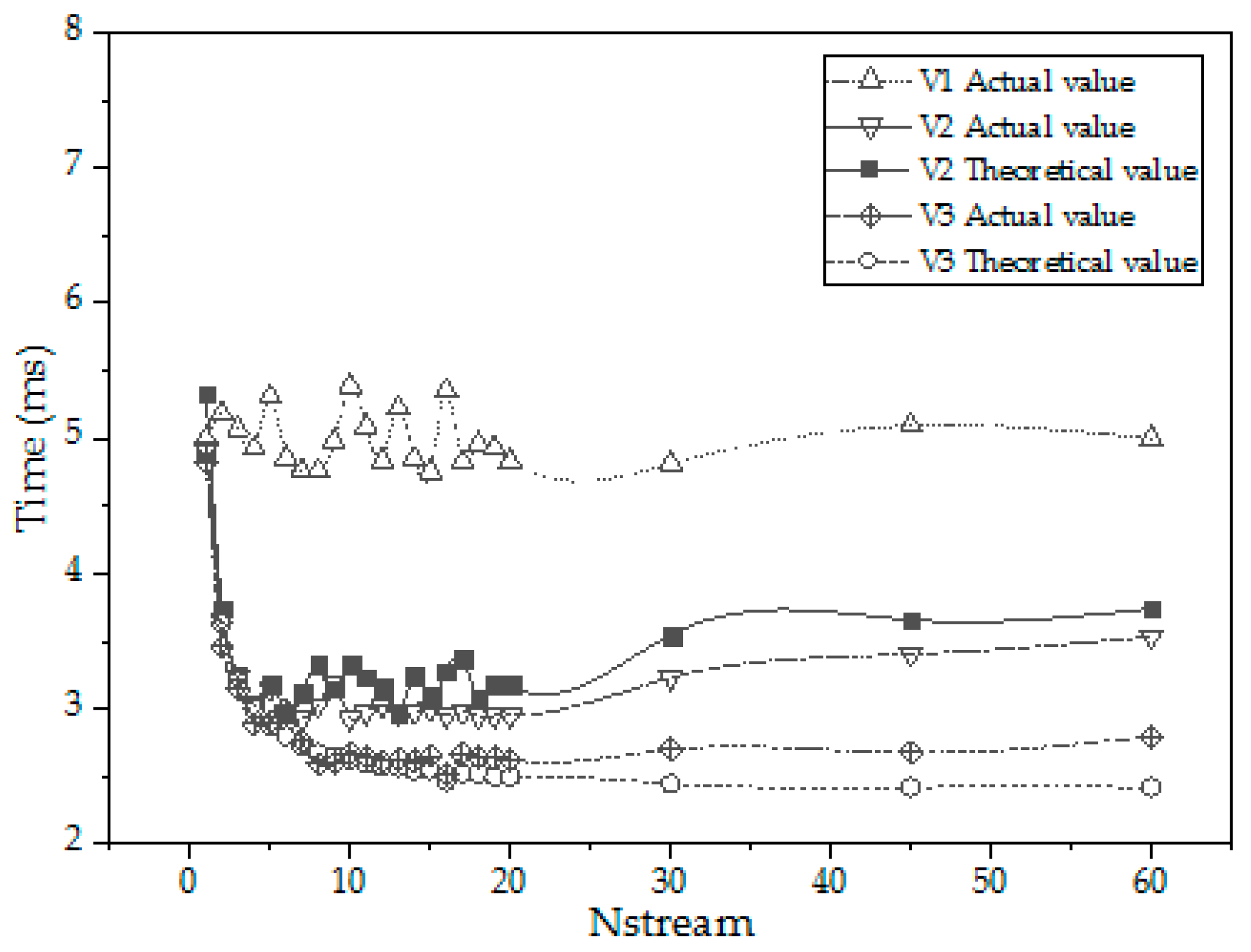
Table 1.
Parameters of experimental platform parameters.
| Platform No. | GPU | Clock Rate (MHz) | Processors | SM | Memory Copy | Rate (Gib/s) |
|---|---|---|---|---|---|---|
| 1 | GTX1050 | 1455 MHz | 640 | 5 | H2D | 11.33 |
| D2H | 11.32 | |||||
| 2 | GTX1070 | 1759 MHz | 1920 | 15 | H2D | 11.96 |
| D2H | 11.73 | |||||
| 3 | RTX3080 | 1770 MHz | 8960 | 70 | H2D | 23.97 |
| D2H | 23.71 |
Windows7 64x.Inteli7-6700.
Table 2.
Kernel bandwidth under different execution parameters.
| Blocks | Threads/Block | Bandwidth (GB/s) | Blocks | Threads/Block | Bandwidth (GB/s) |
|---|---|---|---|---|---|
| 64 | 32 | 67.52 | 8 | 256 | 90.83 |
| 32 | 64 | 87.69 | 4 | 512 | 89.23 |
| 16 | 128 | 89.76 | 2 | 1024 | 79.32 |
Table 3.
GPU Memory Characteristics.
| Memory | Sphere of action | Life cycle | Speed ordering | Control |
|---|---|---|---|---|
| Register | Thread | kernel | 1 | System |
| L1/L2 Cache | SM | kernel | 2 | System |
| Shared Memory | Block | kernel | 2 | User |
| Local Memory | Thread | kernel | 2 | User |
| Global Memory | Gride | Program | 3 | User |
Table 5.
Acccelerate ratio of each version.
| Version | Time(ms) | Accelerate rate | Cumulative accelerate rate |
|---|---|---|---|
| Serial | 148.63 | 1 | 1 |
| V1 | 4.83 | 30.77 | 30.77 |
| V2 | 2.92 | 1.65 | 50.90 |
| V3 | 2.42 | 2.00 | 61.42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



