
Submitted:
14 September 2023
Posted:
15 September 2023
You are already at the latest version
Abstract
Data Extraction is a technique is called as clustering which is used to retrieve data either from the files or data bases or both. This paper focuses on the performance evaluation parameters of the clustering algorithms based on different parameters or conditions or constraints and parameters which are used to perform the clustering process to get the clusters on the data sets. Therefore best clusters are retrieved when best parameters or conditions or constraints or preferences which are applied on the data sources for the clustering process. These parameters or conditions or constraints are opted by the user called as user preferences.

Keywords:
clustering
; machine learning
; clustering algorithms
; conditions
; similarity functions
; clustering process
; types of learning
; data dimensions
I INTRODUCTION
Clustering technique is used for machine learning and data analysis and its purpose is group similar data points together into clusters or clusters of data points which share characteristics or patterns. Clustering process identifies the relationships within sources of data like Files and Data bases without the explicit labels or categories. The similarity Functions or dissimilarity Functions between data points is usually measured using distance metrics or similarity measures. After clustering we go for classification by assigning a class for each and every cluster [1].
Figure 1.
Clustering Stages.
Clustering is used in various applications such as, and more. It can help uncover hidden patterns in data, provide insights for decision-making, and aid in. Application areas of clustering are customer segmentation, Image Processing, document categorization, Artificial Intelligence, anomaly detection, Banks, Finance, Stock market, pharmacy, Health Care department, Telecom department, Military, World Wide Web, metrology, exploratory data analysis, and pharmacopoeia e.t.c [2].
The properties of data are identified using various data mining approaches from the data sources. The data properties are identify using a machine learning algorithmic approach. The data mining approaches are used to identify the data properties and are used for predictions on data.
Machine learning algorithms are computational methods which make the systems to acquire knowledge and make guess to make decisions based on data [3].

Table 1.
Classification of Machine learning algorithms.
| Algorithms of Machine Learning List | Machine Learning Techniques Sub Methods | Details |
|---|---|---|
| Supervised Learning | Regression | Its purpose is to predict continuous numeric value. Examples: Linear regression and support vector regression. Regression: It is a technique used to identify or guess the data set continuous values. Example: Its purpose is to predict the share market losses or profits and can be applicable in all the fields. |
| Classification | It assigns data points to predefined categories. Examples: decision trees, support vector machines (SVM), logistic regression, random forests. |
|
| Unsupervised Learning | Clustering | Its purpose is to group similar data points into clusters without predefined categories. Examples: hierarchical clustering, K-Means and DBSCAN. |
| Dimensionality Reduction [6] | It is technique applied on the dataset to remove the number of features by retaining important information. Examples: t-distributed Stochastic Neighbor Embedding and Principal Component Analysis. |
|
| Semi-Supervised Learning | It combines the aspects of labeled data (supervised) used along with the unlabeled data (unsupervised) [7]. | |
| Reinforcement Learning | It uses agent which interact with an environment and learn the best actions to maximize a reward. Examples: Q learning, deep reinforcement learning e.t.c [8]. | |
| Deep Learning | It is used to learn complex patterns and representations from data of neural networks. Examples: Recurrent Neural Networks (RNNs) for sequential data and Convolution Neural Networks (CNNs) for image analysis [9]. |
|
| Ensemble Methods | Ensemble Methods can be applied on multiple base models to increase its overall performance. Examples: boosting and bagging (Bootstrap Aggregating) [10]. |
|
| Natural Language Processing (NLP) | It is used for understanding and processing human language [11]. | |
| Time Series Analysis | Its purpose is to analyze the sequence of data point’s which is collected for a particular time interval. Examples: Long Short-Term Memory networks and Autoregressive Integrated Moving Average [12]. |
|
| Anomaly Detection Algorithms | It is used to identify outliers in data / unusual patterns. Examples: One-Class SVM and Isolation Forest [13]. |
Table 2.
Supervised verses unsupervised learning [14].
Table 2.
Supervised verses unsupervised learning [14].
| Types of Learning | ||
|---|---|---|
| Property | Supervised | Unsupervised Learning |
| Definition | Groups the input data. | Assigns Class labels |
| Depends On | Training Set | Prior Knowledge not required |
| No Of Classes | Known | Unknown |
| Training Data | Contains both input features and target labels (desired outputs). | Contains only input features |
| Learning Objective | Used to interpret input data | Based on the data source input and output it is used to develop predict model. |
| Training Process | Try to learn the relationship between input features and target labels for predictions or classifications. | Used to identify patterns using techniques like clustering and dimensionality reduction. |
| Examples | Classification and regression. | Clustering, anomaly detection, and topic modeling. |
| Purpose | Guess the upcoming observations | Used to develop, predicts model for the data understanding for knowing unknown properties of a data source. |
| Evaluation | Done using metrics like mean squared error, recall, F1-score, precision, Accuracy e.t.c | Done using internal measures (Silhouette score or domain-specific evaluations). |
| Applications | Spam detection, image recognition, medical diagnosis, and stock price prediction. | Customer segmentation, image compression, recommendation systems, and exploratory data analysis. |
Table 3.
Clustering Requirements for Data Extraction.
| Requirements | Details |
|---|---|
| Data Scalability | It’s capability to compact the Data [15]. |
| Deals With | Different types of Attributes, outliers and noise. |
| knowledge | Requires vertical knowledge. |
| Finds | Clusters |
| Orders Input Data | Orders Input Data in Ascending or Descending order |
| Dimensionality | Addresses dimensionality of the data [16]. |
II LITERATURE SURVEY
In the market Different types clustering methods were there proposed by different researcher’s persons. For each clustering method there will be one or more sub clustering Algorithms. Each sub clustering algorithm will have its own constraints. The major clustering methods available in the market were
Table 4.
Different Types of Clustering Algorithms and their sub Clustering Methods.
| Clustering Algorithm | Details | Sub Clustering Methods |
|---|---|---|
| Partitioning | It uses relocation technique for to group data by moves entities from one group to another group [17]. | 1. CLARA. 2. CLARANS. 3.EMCLUSTERING 4. FCM. 5. K MODES. 6. KMEANS. 7. KMEDOIDS. 8. PAM. 9. XMEANS |
| Hierarchical | Based on objects similarity Hierarchical clustering create clusters [18]. | 1. AGNES. 2. BIRCH. 3. CHAMELEON. 4. CURE. 5. DIANA. 6. ECHIDNA 7. ROCK. |
| Density Based | It is used to create clusters based on radius as a constraint. I.e. based on a particular radius the data points within the radius are considered as one group and remaining are considered as other group (noise) [19]. | 1. DBSCAN. 2. OPTICS. 3. DBCLASD 4. DENCLUE. |
| Grid Based | Density of cells calculated using grid used for the clustering process [20]. | 1. CLIQUE. 2. OPT GRID. 3. STING. 4. WAVE CLUSTER. |
| Model Based | Model Based Clustering of data uses statistical approach where weights (probability distribution) are assigned to individual objects, based on these weights data is clustered [21]. | 1. EM. 2. COBWEB. 3. SOMS. |
| Soft Clustering | Here more than one cluster the individual data points are assigned which will have minimum clusters similarity [22]. | 1. FCM. 2. GK. 3. SOM. 4. GA Clustering |
| Hard Clustering | Here for every one cluster the individual data points are assigned which will have the maximum clusters similarity [23]. | 1. KMEANS |
| Bi-clustering | It is used to cluster matrix rows and columns by using data mining technique [24]. | 1. OPSM. 2. Samba 3. JSa |
| Graph Based | Graph contains vertices or nodes collection. In the graph based Clustering nodes are assigned weights, based on these weights Clustering is done [25]. | 1. Graph based k-means algorithm |
Partitioning Based Clustering
It is used to divide the data from the data source into different sub clusters where every single data entity is present in each sub cluster. Every subset will contain a cluster centroid. Iterative relocation algorithm or Centroid based clustering are the other names for Partitioning Based Clustering.
Table 5.
Partitioning Clustering Algorithm Types:.
| Partitioning Clustering Algorithms | Details |
|---|---|
| K - Means | Its purpose is to split the data source data into k clusters [26]. |
| Parallel k / h-Means | It is a k-means version for big Data sources. It runs the k-means clustering algorithm in parallel on data sets to partition data into groups. Parallelization involves distributing the computation across multiple processors, cores, or machines to accelerate the clustering process and improve efficiency, especially for large datasets [27]. |
| Global k means | It is a K means incremental version of which finds a globally optimal solution by considering multiple initializations and avoiding convergence to local minima [28]. |
| K Means++ | It decreases the average squared distance between points for any cluster [29]. |
| PAM (Partition Around Mediods) | It begins by choosing K medoid after then objects of medoid are exchanged with non medoid objects. It is a robust clustering algorithm used to decrease the outliers and noise for the enhancement og quality of clusters. [30]. |
| CLARA (Clustering Large Applications) | CLARA uses the approach of sampling which contains large number of objects. CLARA used to decrease the storage space and computational time. [31]. |
| CLARANS (Clustering Large Applications based on RANdomized Search) | It is better than CLARA used by big clustering applications and uses search of randomization on the data source which contains huge number of objects [32]. |
| EMCLUSTERING | EM is same to K-means but in place of Euclidean distance EM clustering uses statistical methods which uses expectation (E) and maximization (M) between each of two data items [33]. |
| FCM(fuzzy c-means) | It is used group data set into sub clusters where all data point belongs all the clusters with a particular degree for the given data source [34]. |
| K MODES | Its purpose is to group a set of data entities into a number of clusters base on categorical attributes with uses modes or the most frequent values [35]. |
| KMEDOIDS | It is a version of K-means but instead of mean it uses cluster centrally located object with minimum sum of distances to other points [36]. |
| PAM (Partition Around Medoids) | It finds for k medoids from the data source and adds single each object to the nearest medoid in order to create clusters [37]. |
| XMEANS | XMEANS is a version of k-means which follow a condition Akaike information criterion (AIC) or Bayesian information to subdivision of clusters repeatedly for refining them [38]. |
Hierarchical Based Clustering or Hierarchical Cluster Analysis or HCA
It is a clustering method used to divide a data source into clusters or it combines sub cluster to form a big cluster until it meets user conditions for cluster tree creation. It is of two types. They were divisive and agglomerative.
Table 6.
Types of Hierarchical Based Clustering.
| Hierarchical Based Clustering Types | Details |
|---|---|
| Agglomerative Clustering | It is a bottom up approach where every entity is tried to merge with other clusters recursively until the user is constraints are satisfied. Or Agglomerative clustering clusters the data based on combining clusters up [39]. |
| Divisive Clustering | It is a bottom up approach begins with single cluster and then it splits into smaller recursively until the user is constraints are satisfied. Or Divisive clustering clusters the data based on merging clusters down [40]. |
Table 7.
Hierarchical Clustering Algorithms Types.
| Hierarchical Clustering Algorithms Types | Details |
|---|---|
| BIRCH (Balanced Iterative Reducing and Clustering Using Hierarchies ) | Its purpose is to cluster the big data sources. Its purpose is to utilize a memory efficient data structure and performing clustering in a single pass [41]. |
| CURE (Clustering Using REpresentavives) | It uses random sampling methods for merging the partitions. It reduces the running time, memory and creates good quality clusters [42]. |
| ROCK (Robust Clustering using links) | It understands the links for clustering the data [43]. |
| CACTUS (Clustering Categorical Data Using Summaries) | It is used on a data source which contains categorical data and it reduces the execution of clustering. It is applicable on any data source of any size [44]. |
| SNN (Shared Nearest Neighbor) | It is used on data sources which has high and have not stable density [45]. |
| AGNES(Agglomerative Nesting) | It is used to combine the each object of a singleton cluster recursively based on the objects similarity [46]. |
| CHAMELEON | It selects to merge clusters based on the connectivity and proximity of clusters objects similarity [47]. |
| DIANA (DIvisie ANAlysis clustering algorithm) | It is an up-down clustering and it begins with the data points split recursively to form sub clusters [48]. |
| ECHIDNA (Efficient Clustering of Hierarchical Data for Network Traffic Analysis) | It is applicable on attributes of mixed type comes from network traffic [49]. |
Density Based Clustering:
It uses radius as a constraint to group the data points until user threshold. Data points are grouped into a cluster and remaining is treated as noise.
Table 8.
Types of Density Clustering Algorithms:.
| Density Clustering Algorithms | Details |
|---|---|
| OPTICS(Ordering Points To Identify the Clustering Structure) | Its purpose is to generate clusters of different densities and shapes and is a variant of density-based clustering algorithm [50]. |
| DBSCAN (Density Based Clustering) | It is used to cluster data which is having huge outliers and noise [51] and is applicable for big data source. |
| SUBCLU (SUB space Clustering) | It is suggested clustering algorithm for subspace data and efficiency [52]. |
| DENCLU (Density Based Clustering) | It is suggested clustering algorithm for multimedia data and dataset which contains huge noise [52]. |
| DENCLU-IM (Density Based Clustering Improved) | Its purpose is to cluster multimedia data and dataset which contains huge noise and outliers [54]. |
| DBCLASD (Distribution-Based Clustering of LArge Spatial Databases) | It is suggested clustering algorithm for spatial [55]. |
Table 9.
The classification of data points.
| Data Point Type | Point Details |
|---|---|
| Core | Points of a specific cluster |
| Border | not core points |
| Noise | Not core and Border points |
Grid Based Clustering:
Grid contains limited number of cells. Cells are used to represent data and operations are done on the cells. Grid Based Clustering operates on spatial and non numeric data
Table 10.
Grid Based Clustering Algorithm Types.
| Density Clustering Algorithms | Details |
|---|---|
| CLIQUE(Clustering In QUEst) | It identifies subspaces of large dimensional data space for performing best clustering by using density and grid based concepts. Every dimension is divided into equal number of length intervals [56]. |
| OPT GRID | It is a based on grid clustering algorithm which finds optimal gird-size using the boundaries of the clusters [57]. |
| STING (Statistical Information Grid) | It is a similar on grid clustering Technique where the dataset is recursively split into a limited number of cells. It concentrates on value space near the data points but not only on data points [58]. |
| Wave Cluster | It is a based on multi resolution grid clustering algorithm, which is used to identify the borders between clusters using wavelet transform. Wavelet transform is used to process signals by dividing a signal into different frequency sub bands [59]. |
| MAFIA (Merging of Adaptive Finite IntervAls) | It is a down to up Adaptive calculation to cluster subspace data [60]. |
| BANG (BAtch Neural Gas) | Clustering is done by using neighbor search algorithm. Output of the neighbor search algorithm is pattern values [61]. |
| CLIQUE (Clustering IN QUEst) | Clustering focus of using the two algorithms density and grid [56]. |
Model Based Clustering
Clustering is based on the mean values similarity (low, medium and high). Here data are mapped with the models correctly. It is used to decrease the error function.
Table 11.
Types of Model Based Clustering Algorithms.
| Model Based Clustering Algorithms Types | Details |
|---|---|
| EM (Expectation maximization) | EM is a variant of K-means but instead of Euclidean distance EM clustering uses statistical methods which uses expectation (E) and maximization (M) between each of two data items [62]. |
| COBWEB | It uses hierarchical conceptual clustering which is used to guess missing attributes or the class of a new object by incremental system. It is proposed by Douglas H. Fisher [63]. |
| SOMS (Self Organizing Map) | SOM is a clustering technique which maps multidimensional data to lower dimensional data for understanding purpose [64]. |
Clustering Types:
Clustering process is the dataset is divided into two sub groups based on data point assignment to the clusters. The two sub groups of clustering are.
Table 12.
Hard and Soft based Clustering.
| Hard Clustering | Soft Clustering | |
|---|---|---|
| All Data Point Assigned to | single cluster | multiple clusters |
| Similarity Clustering | maximum | minimum |
Figure 2.
Soft and Hard Based Clustering.
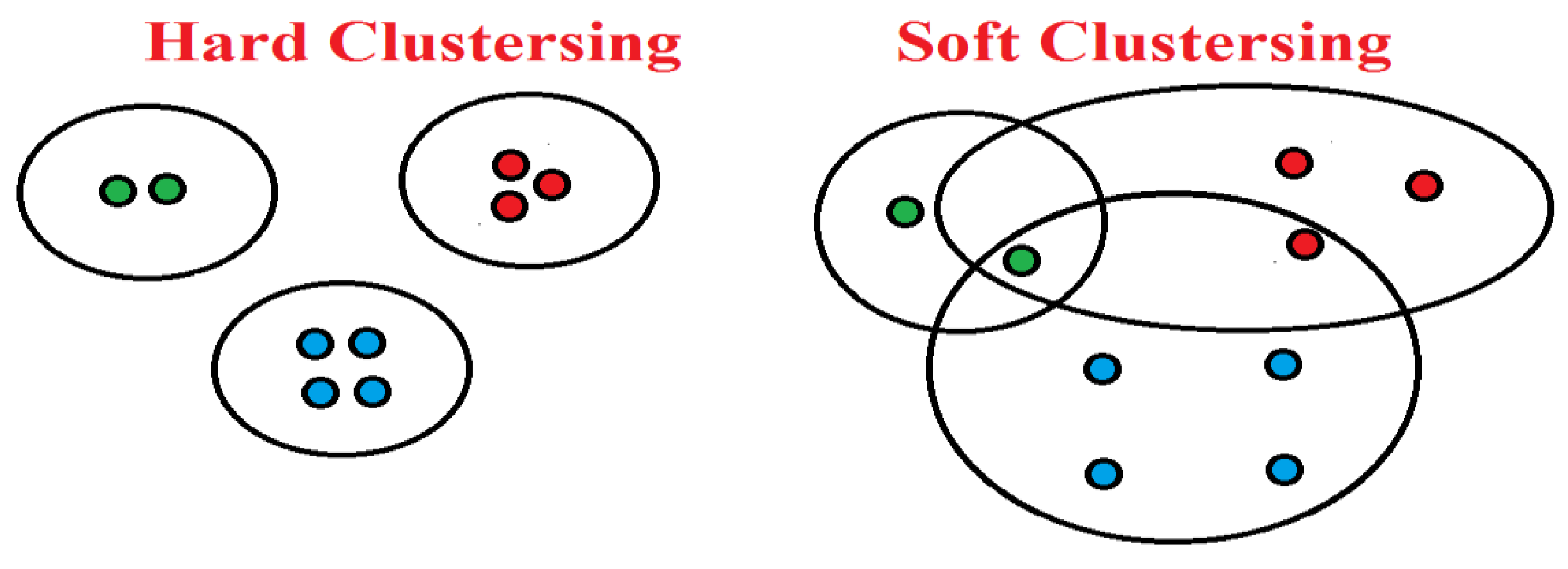
Table 13.
Types of Model Based Clustering Algorithms.
| Model Based Clustering Algorithms Types | Details |
|---|---|
| FCM | It is used group data set into sub clusters where all data point belongs all the clusters with a particular degree for the given data source. |
| GK (Gustafson-kessel) | It uses adaptive distance norm to identify clusters of dissimilar shapes from the data source and is a version of fuzzy c means algorithm. |
| SOMS (Self Organizing Map) | SOM is a clustering technique which maps multidimensional data to lower dimensional data for understanding purpose. |
| GA (Genetic algorithms) | It finds solutions by optimizing the search problems using the biological operators like selection, mutation and crossover [65]. |
Table 14.
Bi-clustering Based Clustering.
| Bi-clustering Based Clustering Algorithms | Details |
|---|---|
| FCM | It is used group data set into sub clusters where all data point belongs all the clusters with a particular degree for the given data source. |
| GK (Gustafson-kessel) | It uses adaptive distance norm to identify clusters of dissimilar shapes from the data source and is a version of fuzzy c means algorithm [66]. |
| SOMS (Self Organizing Map) | SOM is a clustering technique which maps multidimensional data to lower dimensional data for understanding purpose. |
| GA (Genetic algorithms) | It finds solutions by optimizing the search problems using the biological operators like selection, mutation and crossover. |
Table 15.
Graph Based Clustering.
| Graph Based Clustering Algorithms | Details |
|---|---|
| Graph based k-means algorithm | Its purpose is to split the graph into sub graphs based on the distance between the nodes. Graph is a collection of nodes. For calculating the distance between the nodes the following methods are used Chebyshev, Euclidean squared, Euclidean and manhattan distances [67]. |
Performance Evaluation of Clustering Algorithms:
The clustering algorithm performance every time is based on the following constraints, parameters and user preferences.
Table 16.
Performance Evaluation parameters of Clustering Algorithms with Constraints and User Preferences in clustering process.
Table 16.
Performance Evaluation parameters of Clustering Algorithms with Constraints and User Preferences in clustering process.
| Performance Evaluation of Clustering Algorithms | Details |
|---|---|
| Data Mining Tasks | It is of two types. They were Descriptive or Predictive. Clustering is Descriptive Data Mining Tasks. |
| Type of Learning / Knowledge | Unsupervised / Unsupervised / Reinforced learning |
| Dimensionality | If the clustering algorithm deals with more types of data then it is said to be multi dimensional. (High / Low / Medium). |
| Data Sources | Data Set / File / Data Base |
| Unstructured or Structured Data | Structured data is easily made into clusters but not Unstructured data. So algorithms are used to convert unstructured data to Structured data. So there is a requirement of unstructured data to be converted into unstructured data and it can discover new patterns. Clustering uses Structured in most cases. |
| Data Types used in Clustering | Clustering algorithm processes two types of data. They were (Qualitative / Categorical Data) and (Quantitative / Numerical Data). Qualitative type (Subjective) of data can be split into categories. Example: Persons Gender (male, female, or others). It is of three types. They were Nominal (sequenced), Ordinal (ordered) and binary (take true (1) / false (0)). Quantitative Data Type is measurable and is of two types. They were Discrete (countable, continuously, measurable). Example: Student height. 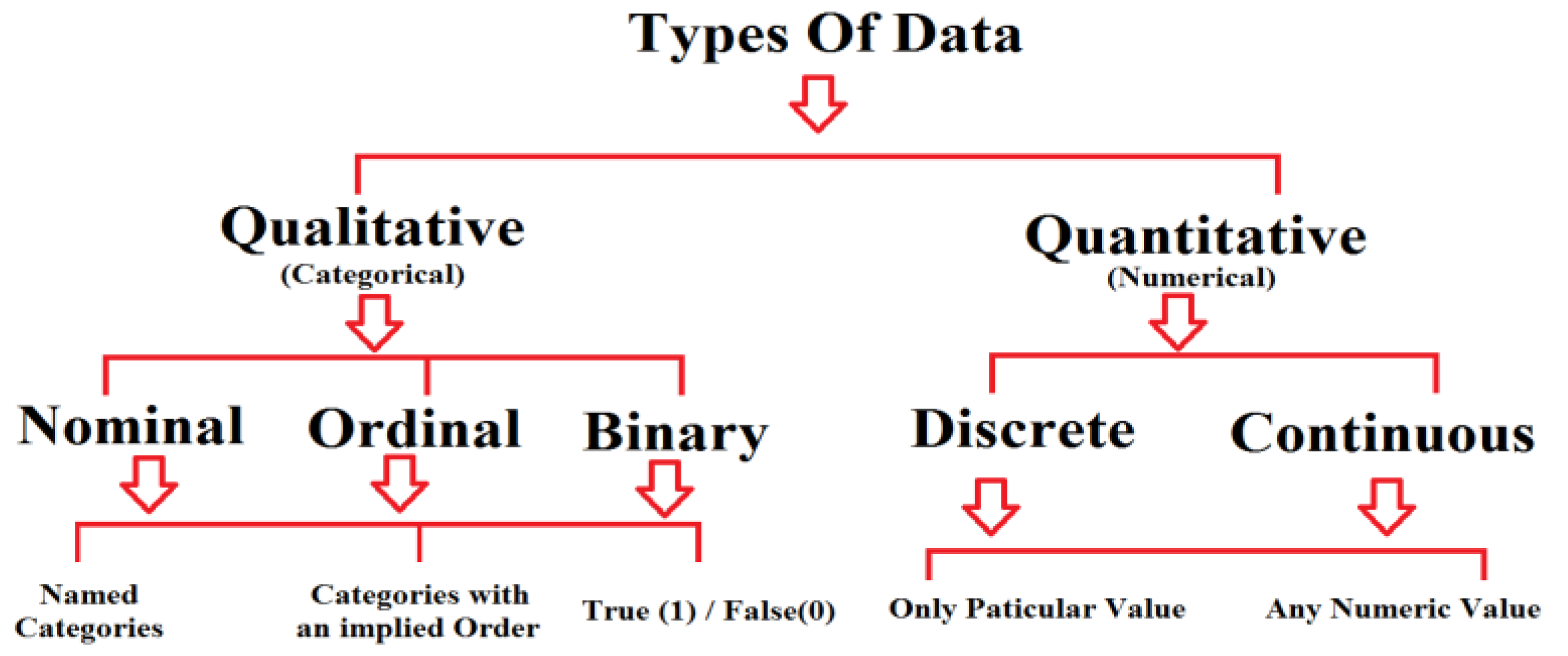 |
| ETL Operations used | Extraction, Transformation and loading operations are performed on the data source. |
| Data Preprocessed | It is used for data cleaning and data transforming to make it suitable for analysis. |
| Data Preprocessing Methods | Data Preprocessing Methods used in the market are cleaning, instance selection, normalization, scaling, feature selection, one-hot encoding, data transformation, feature extraction and feature selection and dimensionality reduction |
| Hierarchical Clustering Algorithms Type | It is two types Divisive (Top-Down) Or Agglomerative (Bottom-Up). |
| No Of Clustering Algorithms | It is the total count of two types of Clustering Algorithms (Main and sub).i.e. It is count of sum of total number of Main Clustering Algorithms and total number of Sub Clustering Algorithms |
| Algorithms Threshold / Stops At What Level | Hierarchical clustering algorithms Stops at a level defined by the user as his Preferences. |
| Algorithm Stability | It uses different clustering applications to determine the number of clusters. |
| Programming Language | It used For processing (Python, Java, .Net e.t.c) the clustering algorithm. |
| Number Of Inputs For The Clustering Process | Clustering Algorithm, Algorithm Constraints, Number of Levels and clusters per each level. |
| Number Of Levels | In Hierarchical clustering algorithms, divisive clustering (top-down) how many split it goes down is the number levels. Or Agglomerative (bottom-up) how many merges it goes up is he number of levels. |
| Level Wise Clusters | It is number of clusters at each level or stage |
| Data Points per Cluster | It is always depends on the type of cluster algorithm used and its preferences defined by the user. |
| Similarity Functions / Similarity Measure. | It is used to quantify how similar or dissimilar two clusters are in a clustering analysis. Similarity measures are used to identify the good clusters in the given data set. There are so many Similarity measures used in the current market. They were Weighted, Average, Chord , Mahalanobis, Mean Character Difference, Index of Association, Canberra Metric, Czekanowski Coefficient, Pearson coefficient, Minkowski Metric, Manhattan or City blocks distance, KullbackLeibler Divergence, Clustering coefficient, Cosine, Kmean e.t.c |
| Intra Cluster Distance | It says how near the data points in a cluster are to each other. If its value is low then the clusters are said to be tightly coupled other clusters are said to be loosely coupled. |
| Inter Cluster Distance | It is used to measures the separation or dissimilarity between different clusters. It quantifies how distinct or well-separated the clusters are from each other. |
| Sum Of Square Error (SSE) Or Other Errors | It is a measure of difference the actual to the expected result of the model. |
| Likelihood Of Clusters | It is the similarity of clusters in the data points |
| Unlikelihood Of Clusters | It is the dissimilarity of clusters in the data points. |
| Number Of Variable Parameters At Each Level | These are the input parameters which are changed during the running of the algorithm like threshold. |
| Outlier | In the clustering process any object doesn’t belong to any cluster it is called as an outlier. |
| Clusters Compactness | It deals with the inertia for better clustering. It means lower inertia indicates better clustering. Inertia means Within-Cluster Sum of Squares. |
| Purpose | Develop and predict model |
| Clustering Scalability | It is the increasing and decreasing abilities of every cluster as a part o whole. |
| Total Number of Clusters | It is total number clusters generated by the clustering algorithm after its execution. |
| Interpretability | Understandability , usability of clusters after is generation is called as Interpretability |
| Convergence | Convergence criterion is a condition by which controls the change in cluster centers. It should be always to be minimum. |
| Clusters Shape | Each clustering Algorithm handles the clustering in different shapes. Clustering Algorithm ------- Cluster Shape K Means ------- Hyper Spherical, Centroid Based Approach ------- Concave Shaped Clusters, Cure ------- Arbitrary, Partitional Clustering ------- Ellipsoidal, Clarans ------- Polygon Shaped, Dbscan ------- Concave E.t.c |
| Output | Clusters |
| Space Complexity | It of a clustering algorithm refers to the amount of memory or storage for storing input data, data structures or variables required by the algorithm to perform clustering on a given dataset. Space Complexity=Auxiliary Space + Space For Input Values. |
| Time Complexity | It is the time taken to run each and statements of a algorithm. Time Complexities of Clustering Algorithms Clustering Algorithm ---- Time Complexity BIRCH ---- O(n) CURE ---- O(sˆ2*s) ROCK ---- O(nˆ3) CLARANS ---- O(nˆ2) Chameleon ---- O(nˆ2) Sting ---- O(n) Clique ---- O(n) K -Means ---- O(n) K-medoids ---- O(nˆ2) PAM ---- O(nˆ2) CLARA ---- O(n) e.t.c |
| Clusters Visualization | It is a process used to representing clusters or groups of data points in a visual format. It gives the insights into patterns, relationships, and structures within the data. Techniques and tools for visualizing clusters: Scatter Plots, Dendrogram, Heatmaps, t-Distributed Stochastic Neighbor Embedding, Principal Component Analysis Plot, Silhouette Plots, K-Means Clustering Plot, Hierarchical Clustering Dendrogram, Density-Based Clustering Visualization, Interactive Visualization Tools: Matplotlib, Seaborn, Plotly, D3.js, and Tableau. |
Note:
- Every algorithm uses its own data type to get optimal clusters or results.
- Based on patterns, clusters, iterations and Levels Generated time and space Complexity of the clustering algorithm will varies.
- Clustering method performance based on Data source, Data source size, shape of clusters shape, objective function, similarity measurement functions.
- Clustering methods use different data types like Numerical, categorical, Textual data, Multimedia, Network, Uncertain, Time Series, Discrete data e.t.c.
- Similarity functions are used for recognize the similarities in between the clusters. Examples of distance functions are Euclidean Distance Function, Manhattan Distance Function, Chebyshev Distance Function, Davies Bould in Index e.t.c. Distance Function can affect the Performance of the clustering Algorithms.
- Clustering algorithm is one of the step in Knowledge Discovery in Databases (KDD) process.
- In the clustering process Uniqueness may or may not be present in the Inter and Intra clustering process.
- In any Clustering Algorithm used to differentiate between one cluster group with other cluster group.
- Every Clustering method will have its own advantages and disadvantages based on the constraints, metrics used in the clustering algorithm.
III CONCLUSION
This paper is about the comparison of various clustering algorithms and techniques which are used in the market for performance evaluation parameters. The comparison of clustering algorithms is based on different parameters or conditions or constraints are used on the data which are opted by the user called as user to perform the clustering process to identify the best clustering algorithm available in the market.
AUTHOR DETAILS:

References
- Archana Patel, K.M.; Thakral, P. The best clustering algorithms in data mining. In Proceedings of the 2016 International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 6–8 April 2016; pp. 2042–2046. [Google Scholar]
- Oyelade, J.; Isewon, I.; Oladipupo, O.; Emebo, O.; Omogbadegun, Z.; Aromolaran, O.; Uwoghiren, E.; Olaniyan, D.; Olawole, O. Data Clustering: Algorithms and Its Applications. 2019 19th International Conference on Computational Science and Its Applications (ICCSA). LOCATION OF CONFERENCE, RussiaDATE OF CONFERENCE; pp. 71–81.
- Hassan, C.A.U.; Khan, M.S.; Shah, M.A. Comparison of Machine Learning Algorithms in Data classification. 2018 24th International Conference on Automation and Computing (ICAC). LOCATION OF CONFERENCE, United KingdomDATE OF CONFERENCE;
- Krammer, P.; Habala, O.; Hluchy, L. Transformation regression technique for data mining. 2016 IEEE 20th Jubilee International Conference on Intelligent Engineering Systems (INES). LOCATION OF CONFERENCE, HungaryDATE OF CONFERENCE; pp. 273–278.
- Kesavaraj, G.; Sukumaran, S. A Study on classification techniques in data mining. In Proceedings of the 2013 fourth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Tiruchengode, India, 4–6 July 2013; pp. 1–7. [Google Scholar]
- Soni, A.; Rasool, A.; Dubey, A.; Khare, N. Data Mining based Dimensionality Reduction Techniques. 2022 International Conference for Advancement in Technology (ICONAT). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 1–8.
- Pise, N.N.; Kulkarni, P. A Survey of Semi-Supervised Learning Methods. 2008 International Conference on Computational Intelligence and Security (CIS). LOCATION OF CONFERENCE, ChinaDATE OF CONFERENCE; pp. 30–34.
- Vieira, D.C.d.L.; Adeodato, P.J.L.; Goncalves, P.M. Improving reinforcement learning algorithms by the use of data mining techniques for feature and action selection. 2010 IEEE International Conference on Systems, Man and Cybernetics - SMC. LOCATION OF CONFERENCE, TurkeyDATE OF CONFERENCE; pp. 1863–1870.
- Wlodarczak, P.; Soar, J.; Ally, M. Multimedia data mining using deep learning. 2015 Fifth International Conference on Digital Information Processing and Communications (ICDIPC). LOCATION OF CONFERENCE, SwitzerlandDATE OF CONFERENCE; pp. 190–196.
- Kumar, S.; Kaur, P.; Gosain, A. A Comprehensive Survey on Ensemble Methods. 2022 IEEE 7th International conference for Convergence in Technology (I2CT). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 1–7.
- Chen, Y. Natural Language Processing in Web data mining. 2010 IEEE 2nd Symposium on Web Society (SWS). LOCATION OF CONFERENCE, ChinaDATE OF CONFERENCE; pp. 388–391.
- Wang, F.; Li, M.; Mei, Y.; Li, W. Time Series Data Mining: A Case Study With Big Data Analytics Approach. IEEE Access 2020, 8, 14322–14328. [Google Scholar] [CrossRef]
- Wankhede, S.B. Anomaly Detection using Machine Learning Techniques. 2019 IEEE 5th International Conference for Convergence in Technology (I2CT). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 1–3.
- a: Sedkaoui, “Supervised versus Unsupervised Algorithms. [CrossRef]
- Uparkar, S.S.; Lanjewar, U.A. Scalability of Data Mining Algorithms for Non-Stationary Data. 2022 International Conference on Applied Artificial Intelligence and Computing (ICAAIC). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 737–743.
- Soni, A.; Rasool, A.; Dubey, A.; Khare, N. Data Mining based Dimensionality Reduction Techniques. 2022 International Conference for Advancement in Technology (ICONAT). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 1–8.
- Dharmarajan, A.; Velmurugan, T. Applications of partition based clustering algorithms: A survey. 2013 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 1–5.
- Nazari, Z.; Kang, D.; Asharif, M.R.; Sung, Y.; Ogawa, S. A new hierarchical clustering algorithm. 2015 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS). LOCATION OF CONFERENCE, JapanDATE OF CONFERENCE; pp. 148–152.
- Rahman, A.; Chowdhury, A.R.; Rahman, D.J.; Kamal, A.R.M. Density based clustering technique for efficient data mining. 2008 11th International Conference on Computer and Information Technology (ICCIT). LOCATION OF CONFERENCE, BangladeshDATE OF CONFERENCE; pp. 248–252.
- Brown, D.; Japa, A.; Shi, Y. A Fast Density-Grid Based Clustering Method. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; pp. 0048–0054. [Google Scholar]
- Zhong, S.; Ghosh, J. Model-based clustering with soft balancing. Third IEEE International Conference on Data Mining. LOCATION OF CONFERENCE, United StatesDATE OF CONFERENCE; pp. 459–466.
- Visalakshi, N.K.; Thangavel, K. Ensemble based distributed soft clustering. 2008 International Conference on Computing, Communication and Networking (ICCCN). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 1–6.
- Christina, J.; Komathy, K. Analysis of hard clustering algorithms applicable to regionalization. 2013 IEEE Conference on Information & Communication Technologies (ICT). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 606–610.
- Madeira, S.; Oliveira, A. Biclustering algorithms for biological data analysis: a survey. IEEE/ACM Trans. Comput. Biol. Bioinform. 2004, 1, 24–45. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Boubrahimi, S.F.; Hamdi, S.M. Graph-based Clustering for Time Series Data. 2021 IEEE International Conference on Big Data (Big Data). LOCATION OF CONFERENCE, United StatesDATE OF CONFERENCE; pp. 4464–4467.
- Na, S.; Xumin, L.; Yong, G. Research on k-means Clustering Algorithm: An Improved k-means Clustering Algorithm. 2010 Third International Symposium on Intelligent Information Technology and Security Informatics (IITSI). LOCATION OF CONFERENCE, ChinaDATE OF CONFERENCE; pp. 63–67.
- Zhang, J.; Wu, G.; Hu, X.; Li, S.; Hao, S. A Parallel K-Means Clustering Algorithm with MPI. 2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming (PAAP). LOCATION OF CONFERENCE, ChinaDATE OF CONFERENCE; pp. 60–64.
- Wang, J.; Su, X. An improved K-Means clustering algorithm. 2011 IEEE 3rd International Conference on Communication Software and Networks (ICCSN). LOCATION OF CONFERENCE, ChinaDATE OF CONFERENCE; pp. 44–46.
- Chi, D. Research on the Application of K-Means Clustering Algorithm in Student Achievement. 2021 IEEE International Conference on Consumer Electronics and Computer Engineering (ICCECE). LOCATION OF CONFERENCE, ChinaDATE OF CONFERENCE; pp. 435–438.
- Li, P.; Boubrahimi, S.F.; Hamdi, S.M. Graph-based Clustering for Time Series Data. 2021 IEEE International Conference on Big Data (Big Data). LOCATION OF CONFERENCE, United StatesDATE OF CONFERENCE; pp. 4464–4467.
- Li, P.; Boubrahimi, S.F.; Hamdi, S.M. Graph-based Clustering for Time Series Data. 2021 IEEE International Conference on Big Data (Big Data). LOCATION OF CONFERENCE, United StatesDATE OF CONFERENCE; pp. 4464–4467.
- Xu, Z.; Wang, L.; Luo, J.; Zhang, J. A modified clustering algorithm for data mining. 2005 IEEE International Geoscience and Remote Sensing Symposium, 2005. IGARSS '05.. LOCATION OF CONFERENCE, South KoreaDATE OF CONFERENCE;
- Gupta, M.; Rajpoot, V.; Chaturvedi, A.; Agrawal, R. A detailed Study of different Clustering Algorithms in Data Mining. 2022 International Conference on Intelligent Technologies (CONIT). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 1–6.
- Havens, T.C.; Bezdek, J.C.; Leckie, C.; Hall, L.O.; Palaniswami, M. Fuzzy c-Means Algorithms for Very Large Data. IEEE Trans. Fuzzy Syst. 2012, 20, 1130–1146. [Google Scholar] [CrossRef]
- Li, M.; Zhou, Y.; Tang, W.; Lu, L. K-modes Based Categorical Data Clustering Algorithms Satisfying Differential Privacy. 2020 International Conference on Networking and Network Applications (NaNA). LOCATION OF CONFERENCE, ChinaDATE OF CONFERENCE; pp. 86–91.
- Madbouly, M.M.; Darwish, S.M.; Bagi, N.A.; Osman, M.A. Clustering Big Data Based on Distributed Fuzzy K-Medoids: An Application to Geospatial Informatics. IEEE Access 2022, 10, 20926–20936. [Google Scholar] [CrossRef]
- Mohammed, N.N.; Abdulazeez, A.M. Evaluation of Partitioning Around Medoids Algorithm with Various Distances on Microarray Data. 2017 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData). LOCATION OF CONFERENCE, COUNTRYDATE OF CONFERENCE; pp. 1011–1016.
- Kumar, P.; Wasan, S.K. Analysis of X-means and global k-means USING TUMOR classification. 2nd International Conference on Computer and Automation Engineering (ICCAE 2010). LOCATION OF CONFERENCE, SingaporeDATE OF CONFERENCE; pp. 832–835.
- Abu Dalbouh, H.; Norwawi, N.M. Improvement on Agglomerative Hierarchical Clustering Algorithm Based on Tree Data Structure with Bidirectional Approach. 2012 3rd International Conference on Intelligent Systems, Modelling and Simulation (ISMS). LOCATION OF CONFERENCE, MalaysiaDATE OF CONFERENCE; pp. 25–30.
- Yuruk, N.; Mete, M.; Xu, X.; Schweiger, T.A.J. A Divisive Hierarchical Structural Clustering Algorithm for Networks. 2007 Seventh IEEE International Conference on Data Mining - Workshops (ICDM Workshops). LOCATION OF CONFERENCE, United StatesDATE OF CONFERENCE; pp. 441–448.
- Du, H.; Li, Y. An Improved BIRCH Clustering Algorithm and Application in Thermal Power. 2010 International Conference on Web Information Systems and Mining (WISM). LOCATION OF CONFERENCE, ChinaDATE OF CONFERENCE; pp. 53–56.
- Lathiya, P.; Rani, R. Improved CURE clustering for big data using Hadoop and Mapreduce. 2016 International Conference on Inventive Computation Technologies (ICICT). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 1–5.
- Patidar, A.; Joshi, R.; Mishra, S. Implementation of distributed ROCK algorithm for clustering of large categorical datasets and its performance analysis. 2011 3rd International Conference on Electronics Computer Technology (ICECT). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 79–83.
- Ali, A.; Bin Faheem, Z.; Waseem, M.; Draz, U.; Safdar, Z.; Hussain, S.; Yaseen, S. Systematic Review: A State of Art ML Based Clustering Algorithms for Data Mining. 2020 IEEE 23rd International Multitopic Conference (INMIC). LOCATION OF CONFERENCE, PakistanDATE OF CONFERENCE; pp. 1–6.
- Kumari, S.; Maurya, S.; Goyal, P.; Balasubramaniam, S.S.; Goyal, N. Scalable Parallel Algorithms for Shared Nearest Neighbor Clustering. 2016 IEEE 23rd International Conference on High Performance Computing (HiPC). LOCATION OF CONFERENCE, IndiaDATE OF CONFERENCE; pp. 72–81.
- Oyelade, J.; Isewon, I.; Oladipupo, O.; Emebo, O.; Omogbadegun, Z.; Aromolaran, O.; Uwoghiren, E.; Olaniyan, D.; Olawole, O. Data Clustering: Algorithms and Its Applications. 2019 19th International Conference on Computational Science and Its Applications (ICCSA). LOCATION OF CONFERENCE, RussiaDATE OF CONFERENCE; pp. 71–81.
- Karypis, G.; Han, E.-H.; Kumar, V. Chameleon: hierarchical clustering using dynamic modeling. Computer 1999, 32, 68–75. [Google Scholar] [CrossRef]
- Xiong, T.; Wang, S.; Mayers, A.; Monga, E. A New MCA-Based Divisive Hierarchical Algorithm for Clustering Categorical Data. 2009 Ninth IEEE International Conference on Data Mining (ICDM). LOCATION OF CONFERENCE, USADATE OF CONFERENCE; pp. 1058–1063.
- Mahmood, A.N.; Leckie, C.; Udaya, P. An Efficient Clustering Scheme to Exploit Hierarchical Data in Network Traffic Analysis. IEEE Trans. Knowl. Data Eng. 2008, 20, 752–767. [Google Scholar] [CrossRef]
- Babichev, S.; Durnyak, B.; Zhydetskyy, V.; Pikh, I.; Senkivskyy, V. Application of Optics Density-Based Clustering Algorithm Using Inductive Methods of Complex System Analysis. 2019 IEEE 14th International Scientific and Technical Conference on Computer Sciences and Information Technologies (CSIT). LOCATION OF CONFERENCE, UkraineDATE OF CONFERENCE; pp. 169–172.
- Deng, D. DBSCAN Clustering Algorithm Based on Density. 2020 7th International Forum on Electrical Engineering and Automation (IFEEA). LOCATION OF CONFERENCE, ChinaDATE OF CONFERENCE; pp. 949–953.
- Nagesh, H.; Goil, S.; Choudhary, A. A scalable parallel subspace clustering algorithm for massive data sets. 2000 International Conference on Parallel Processing. LOCATION OF CONFERENCE, CanadaDATE OF CONFERENCE; pp. 477–484.
- Idrissi, A.; Rehioui, H.; Laghrissi, A.; Retal, S. An improvement of DENCLUE algorithm for the data clustering. 2015 5th International Conference on Information & Communication Technology and Accessibility (ICTA). LOCATION OF CONFERENCE, COUNTRYDATE OF CONFERENCE; pp. 1–6.
- Rehioui, H.; Idrissi, A.; Abourezq, M.; Zegrari, F. DENCLUE-IM: A New Approach for Big Data Clustering. Procedia Comput. Sci. 2016, 83, 560–567. [Google Scholar] [CrossRef]
- Xu, X.; Ester, M.; Kriegel, H.-P.; Sander, J. A distribution-based clustering algorithm for mining in large spatial databases. In Proceedings of the 1998 IEEE International Conference on Data Engineering, Orlando, FL, USA, 23–27 February 1998; pp. 324–331. [Google Scholar]
- Boushaki, S.I.; Bendjeghaba, O.; Brakta, N. Accelerated Modified Sine Cosine Algorithm for Data Clustering. 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC). LOCATION OF CONFERENCE, United StatesDATE OF CONFERENCE; pp. 0715–0720.
- Fiolet, V.; Olejnik, R.; Lefait, G.; Toursel, B. Optimal Grid Exploitation Algorithms for Data Mining. 2006 Fifth International Symposium on Parallel and Distributed Computing. LOCATION OF CONFERENCE, RomaniaDATE OF CONFERENCE; pp. 246–252.
- Ali, A.; Bin Faheem, Z.; Waseem, M.; Draz, U.; Safdar, Z.; Hussain, S.; Yaseen, S. Systematic Review: A State of Art ML Based Clustering Algorithms for Data Mining. 2020 IEEE 23rd International Multitopic Conference (INMIC). LOCATION OF CONFERENCE, PakistanDATE OF CONFERENCE; pp. 1–6.
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamri, A.; Khalil, I.; Zomaya, A.Y.; Foufou, S.; Bouras, A. A Survey of Clustering Algorithms for Big Data: Taxonomy and Empirical Analysis. IEEE Trans. Emerg. Top. Comput. 2014, 2, 267–279. [Google Scholar] [CrossRef]
- Khaing, H.W. Data mining based fragmentation and prediction of medical data. 2011 3rd International Conference on Computer Research and Development (ICCRD). LOCATION OF CONFERENCE, ChinaDATE OF CONFERENCE; pp. 480–485.
- Ardilla, F.; Saputra, A.A.; Kubota, N. Batch Learning Growing Neural Gas for Sequential Point Cloud Processing. 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC). LOCATION OF CONFERENCE, Czech RepublicDATE OF CONFERENCE; pp. 1766–1771.
- Romero, O.; Chatterjee, S.; Pequito, S. Convergence of the Expectation-Maximization Algorithm Through Discrete-Time Lyapunov Stability Theory. 2019 American Control Conference (ACC). LOCATION OF CONFERENCE, USADATE OF CONFERENCE;
- Satyanarayana, A.; Acquaviva, V. Enhanced cobweb clustering for identifying analog galaxies in astrophysics. 2014 IEEE 27th Canadian Conference on Electrical and Computer Engineering (CCECE). LOCATION OF CONFERENCE, CanadaDATE OF CONFERENCE; pp. 1–4.
- Ahmed, R.F.M.; Salama, C.; Mahdi, H. Clustering Research Papers Using Genetic Algorithm Optimized Self-Organizing Maps. 2020 15th International Conference on Computer Engineering and Systems (ICCES). LOCATION OF CONFERENCE, EgyptDATE OF CONFERENCE; pp. 1–6.
- Ahmed, R.F.M.; Salama, C.; Mahdi, H. Clustering Research Papers Using Genetic Algorithm Optimized Self-Organizing Maps. 2020 15th International Conference on Computer Engineering and Systems (ICCES). LOCATION OF CONFERENCE, EgyptDATE OF CONFERENCE; pp. 1–6.
- Georgiev, G.; Gueorguieva, N.; Chiappa, M.; Krauza, A. Feature Selection Using Gustafson-Kessel Fuzzy Algorithm in High Dimension Data Clustering. 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA). LOCATION OF CONFERENCE, USADATE OF CONFERENCE; pp. 1–6.
- Muhlenbach, F.; Lallich, S. A New Clustering Algorithm Based on Regions of Influence with Self-Detection of the Best Number of Clusters. 2009 Ninth IEEE International Conference on Data Mining (ICDM). LOCATION OF CONFERENCE, USADATE OF CONFERENCE; pp. 884–889.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



