
Submitted:
15 September 2023
Posted:
20 September 2023
You are already at the latest version
Abstract
. In this paper, we introduce a series of definitions of generalized affine functions for vector-valued functions. We prove that our generalized affine functions have some similar properties with generalized convex functions. We present examples to show that our generalized affinenesses are different from one another, and also provide an example to show that our definition of presubaffinelikeness is non-trivial; presubaffinelikeness is the weakest generalized affineness introduced in this article. We work with optimization problems that are defined and taking values in linear topological spaces. We devote to the study of constraint qualifications, and derive some optimality conditions as well as a strong duality theorem. Our optimization problems have inequality constraints, equality constrains and abstract constraints; our inequality constraints are generalized convex functions and equality constraints are generalized affine functions.
Keywords:
real linear topological spaces
; affine functions
; generalized affine functions
; convex functions
; generalized convex functions
; constraint qualifications
MSC: 90C26; 90C29; 90C48
1. Introduction and Preliminary
The theory of vector optimization is at the
crossroads of many subjects. The terms “minimum,” “maximum,” and “optimum” are
in line with a mathematical tradition while words such as “efficient” or
“non-dominated” find a larger use in business-related topics.
Historically, linear programs were the focus in the optimization community, and
initially, it was thought that the major divide was between linear and
nonlinear optimization problems; later people discovered that some nonlinear
problems were much harder than others, and the “right” divide was between
convex and nonconvex problems. The author finds out that the affineness and
generalized affinenesses are also very useful for the subject “optimization”.
Suppose X, Y are a real linear
topological space [1].
A subset is called a linear set if B is a vector
subspace of X (i.e., B is nonempty, and whenever and ).
A subset is called an affine set if the line passing
through any two points of B is entirely contained in B (i.e., whenever and );
A subset is called a convex set if any segment with
endpoints in B is contained in B (i.e., whenever and ).
Each linear set is affine, and each affine set is
convex. Moreover, any translate of an affine (convex, respectively) set is
affine (convex, resp.). It is known that a set B is linear if and only
if B is affine and contains the zero point of X; a set B is affine if and only
if B is a translate of a linear set.
A subset Y+ of Y is said
to be a cone if for all and. We denote by the zero element in the topological vector space Y
and simply by 0 if there is no confusion. A convex cone is one for which for all and. A pointed cone is one for which. Let Y be a real topological vector space
with pointed convex cone Y+. We denote the partial order
induced by Y+ as follows:
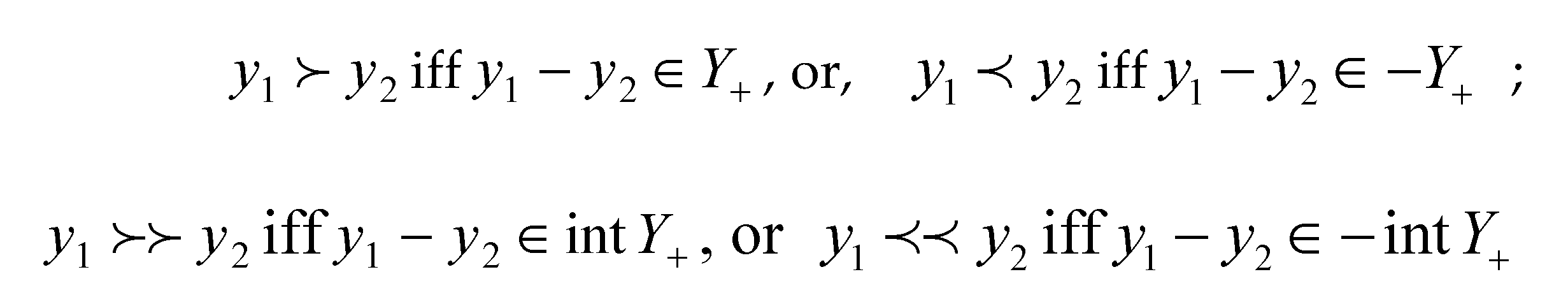 where intY+
denotes the topological interior of a set Y+.
where intY+
denotes the topological interior of a set Y+.
A function f: is said to be linear if
whenever and ; f is said to be affine if
whenever ; and f is said to
be convex if
whenever .
In the next section, we generalize
the definition of affine function, prove that our generalized affine functions
have some similar properties with generalized convex functions, and present
some examples which show that our generalized affinenesses are not equivalent
to one another.
In Section 3,
we recall some existing definitions of generalized convexities, which are very
comparable with the definitions of generalized affinenesses introduced in this
article.
Section 4 works
with optimization problems that are defined and taking values in linear
topological spaces, devotes to the study of constraint qualifications, and
derive some optimality conditions as well as a strong duality theorem.
2. Generalized Affinenesses
A function f:
is said to be affine on D
if
, there holds
We introduce here the following definitions of generalized affine functions.
Definition 2.1 A function f
:
is said to be affinelike on D
if
such that
Definition
2.2
A
function f:
is said to be preaffinelike on D
if
such that
In the
following Definition 2.3 and 2.4, we assume that
is any given linear set.
Definition 2.3 A function f
: is said to be B-subaffinelike
on D if , such that
Definition
2.4
A
function f : is said to be B-presubaffinelike
on D if , such that
For any linear
set
B, since
, we may take u = 0. So,
affinelikeness implies subaffinelikeness, and preaffinelikeness implies
presubaffinelikeness.
It is obviously that affineness
implies preaffineness, and the following Example 2.1 shows that the converse is
not true.
Example 2.1
An example of an affinelike function
which is not an affine function.
It is known that, a function is an
affine function if and only it is in the form of
, therefore
is not an
affine function.
However, f is affinelike.
taking
then
Similarly,
affinelikesness implies preaffinelikeness (
), presubaffinelikeness implies
subaffinelikeness. The following Example 1.2 shows that a preaffinelike
function is not necessary to be an affinelike function.
Example 2.2
An example of preaffinelike function
which is not an affinelike function.
Consider the function.
Take , then ; but
therefore
So
f
is not affinelike.
But f is an preaffinelike
function. For taking if , if , then
where
.
Example 2.3
An example of subaffinelike function which is not an affinelike
function.
Consider the function and the linear set
.
take then
therefore
is B-subaffinelike on
.
is not affinelike on
Actually, for
one has
, but
hence
Example 2.4
An example of presubaffinelike function which is not a
preaffinelike function.
Actually, the function in Example
2.3 is subaffinelike, therefore it is presubaffinelike on D.
However, for one has
but
Hence
This shows
that the function
f
is
not preaffinelike on D.
Example 2.5
An example of presubaffinelike function which is not a
subaffinelike function.
Consider the function.
Take the 2-dimensional linear set
.
Take , then
Either
or
must be negative; but
,, therefore
And so,
is not B-subaffinelike.
However, is B-presubaffinelike.
Case
1
. If both of are positive, we take , , , then
Case 2
. If both of are negative, we take , , , then
Case 3
. If one of is negative, and the other is
non-negative, we take
Then
And so
are both non-negative or both
negative, take
or , respectively, one has
Where
Therefore
is B-presubaffinelike.
Example 2.6
An example of subaffinelike function which is not a preaffinelike
function.
Consider the function.
Take the 2-dimensional linear set
.
Take, then
In the above
inequality, we note that either
or , .
Therefore, is not preaffinelike.
However, is B-subaffinelike.
In fact, we may choose
with x large enough such
that
Then,
where
Example 2.7
An example preaffinelike function which is not a subaffinelike
function.
Consider the function.
Take the 2-dimensional linear set
.
Take , then
So,
,
However, for
,
Actually, if
x
= 0, it is obviously that
; if , the right side of (1) implies
that
, and the left side of (1) is
. This proves that the inequality
(1) must be true. Consequently,
So
is not B-subaffinelike.
On the other hand, we may take
if or if , then
where
.
Therefore, is preaffinelike.
So far, we have showed the
following relationships (where subaffinelikeness and presubaffinelikeness are
related to “a given linear set B”).
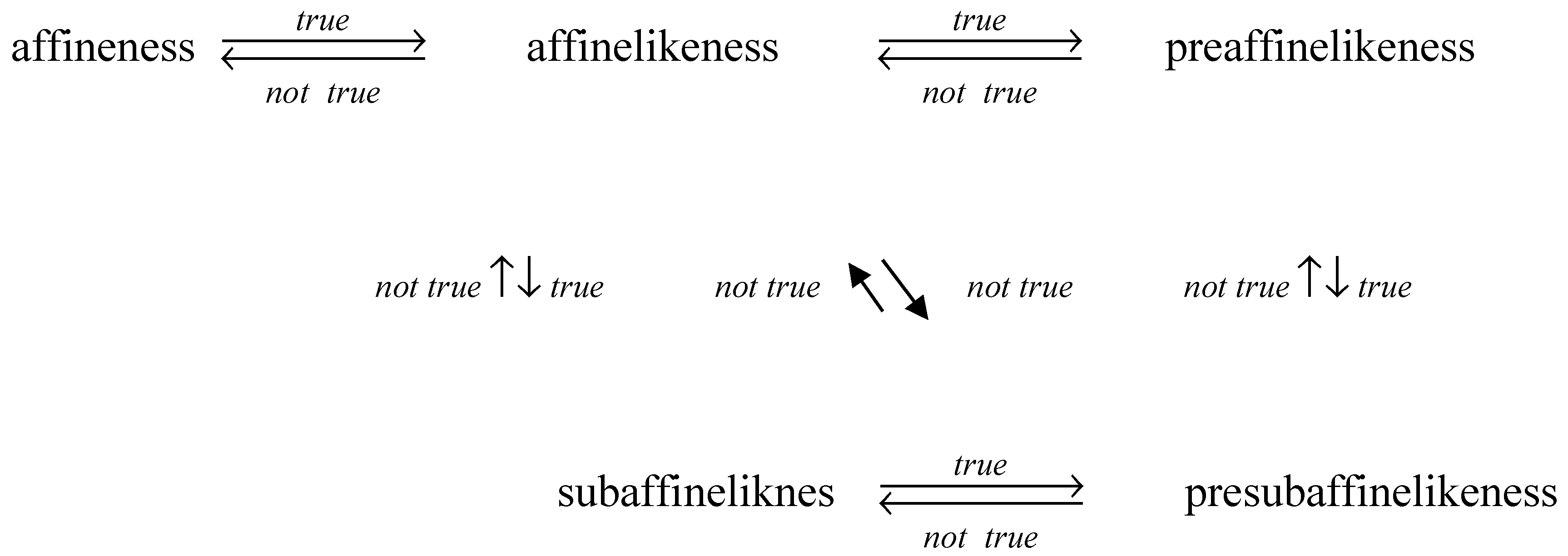
The following
Proposition 2.1 is very similar to the corresponding results for generalized
convexities (see Proposition 3.1).
Proposition 2.1 Suppose f: is a function, given linear set, and t
is any real scalar.
a) f is affinelike on D if and only
if f (D) is an affine set;
b) f is
preaffinelike on D if and only if is an affine set;
c) f is B-subaffinelike on D
if and only if f (D) + B is an affine set;
d) f is B-presubaffinelike on D if
and only if + B is an affine
set.
Proof.
a) If f is affinelike on D,
,
such that
Therefore f (D)
is an affine set.
On the other hand, assume that f
(D) is an affine set. we have
Therefore
such that
And hence f
is affinelike on D.
b) Assume f is a
preaffinelike function.
for
such that
Since
f
is preaffinelike, such that
Therefore
where . Consequently, is an affine set.
On the other hand, suppose that is an affine set. Then since ,
Therefore
such that
Then f
is an affinelike function.
c) Assume that f is B-subaffinelike.
, , such that
and . The subaffinelikeness of f
implies that
, and such that
i.e.,
Therefore
Where Then, f (D) + B is an affine
set.
On the other hand, assume that f
(D) + B is an affine set.
, such that
,
i.e.,
u
+,
where. And hence f is
B-subaffinelike.
d) Suppose f is a B-presubaffinelike
function.
, similar to the proof of (b),, , for which and
where . This proves that + B is an affine set.
On the other hand, assume that + B is an affine
set.
,since , , such that
.
Therefore
,
i.e.,
,
where . And so f is B-presubaffinelike.
The presubaffineness is the weakest one in the
series of the generalized affinenesses introduced here. The following example
shows that our definition of presubaffinelikeness is not trivial.
Example 2.8
An example of
non-presubaffinelike function.
Consider the function.
Take the linear set
.
Take , then
.
Either or must be negative, but
hold for
, therefore, for any scalar
(Actually, , one has
; and either or , then, either
or ).
And so, is not B-presubaffinelike.
3. Generalized Convexities
In this section, we recall some existing
definitions of generalized convexities, which are very comparable with the
definitions of generalized affinenesses introduced in this article.
Let Y be a topological vector space and be a nonempty set and Y+ be a
convex cone in Y and .
It is known that, a function f :is said to be Y+-convex on D
if for all , , there holds
The following Definition 3.1 was introduced in Fan [2].
Definition 3.1
A
function f :is said to be Y+-convexlike on D
if ,
, such that
We may define Y+-preconvexlike
functions as follows.
Definition 3.2 A function
f :is said to be Y+-preconvexlike
on D if , , , such that
Definition 3.3 was introduced by Jeyakumar [3].
Definition 3.3 A function f
:is said to be Y+-subconvexlike
on D if ,, , such that
In fact, in Jeyakumar [3],
the definition of subconvexlike was introduced as the following form Definition
3.3*.
Definition 3.3* A function f :is said to be Y+-subconvexlike on D if ,,, , such that
Li and Wang ([4], Lemma 2.3) proved that: A function f :is Y+-subconvexlike on D by Definition 3.3* if and only if ,, , such that
From the definitions above, one may introduce the following definition of presubconvexlike functions.
Definition 3.4 A function f :is said to be Y+-presubconvexlike on D if , , , , such that
And, similar to ([4], Lemma 2.3), one can prove that, a function f :is Y+-presubconvexlike on D if and only if ,, , , , such that
Our Definitions 3.3 and 3.4 are more comparable with our definitions of generalized affineness.
Similar to the proof of the above Proposition 2.1, one has the following Proposition 3.1.
Proposition 3.1 Let f : X be function, and t > 0 be any positive scalar, then
a) f is Y+-convexlike on D if and only ifis convex;
b) f is Y+-subconvexlike on D if and only if is convex;
c) f is Y+-preconvexlike on D if and only if is convex;
d) f is Y+-presubconvexlike on D if and only if is convex.
4. Constraint Qualifications
Consider the following vector optimization problem:
where f :, , , Y+, Zi+ are closed convex cones in Y and Zi, respectively, and D is a nonempty subset of X.
Throughout this paper, the following assumptions will be used (are real scalars).
(A1)such that
(A2), (j = 1, 2, …, n);
(A3)Wj (j = 1, 2, …, n) are finite dimensional spaces.
Remark 4.1 We note that the condition (A1) says that f and are presubconvexlike, and (j = 1, 2, …, n) are preaffinelike.
Let F be the feasible set of (VP), i.e.
The following is the well-known definition of weakly efficient solution.
Definition 4.1 A point
is said to be a weakly efficient solution of (VP) with a weakly efficient value if for every, there exists no satisfying.
We first introduce the following constraint qualification which is similar to the constraint qualification in the differentiate form from nonlinear programming (see e.g. [9]).
Definition 4.2 Let. We say that (VP) satisfies the No Nonzero Abnormal Multiplier Constraint Qualification (NNAMCQ) at if there is no nonzero vector satisfying the system
where is some neighborhood of .
It is obvious that NNAMCQ holds at with being the whole space X if and only if for all satisfying , there exists such that
Hence NNAMCQ is weaker than ([7], (CQ1)) (in [7], CQ1 was for set-valued optimization problems) in the constraint , which means that only the binding constraints are considered. Under the NNAMCQ, the following Kuhn-Tucker type necessary optimality condition holds.
Theorem 4.1 Assume that the generalized convexity assumption (A1) is satisfied and either (A2) or (A3) holds. If is a weakly efficient solution of (VP) with, then exists a vector withsuch that
for a neighbourhoodof .
Proof. Since is a weakly efficient solution of (VP) with there exists a nonzero vector such that (2) holds. Since NNAMCQ holds at, must be nonzero. Otherwise if = 0 then must be a nonzero solution of
But this is impossible since the NNAMCQ holds at .
Similar to ([7], (CQ2)) which is slightly stronger than ([7], (CQ1)), we define the following constraint qualification which is stronger than the NNAMCQ.
Definition 4.2 (SNNAMCQ) Let.We say that (VP) satisfies the No Nonzero Abnormal Multiplier Constraint Qualification (NNAMCQ) at provided that
satisfying,
, s.t. ;
, , s.t. for all .
We now quote the Slater condition introduced in ([10], (CQ3)).
Definition 4.3 (Slater Condition CQ) Let. We say that (VP) satisfies the Slater condition at if the following conditions hold:
, s.t. ;
for all j.
Similar to ([7], Proposition 2) (again, in [7], discussions are made for set-valued optimization problems), we have the following relationship between the constraint qualifications.
Proposition 4.1 The following statements are true:
(i) Slater CQ SNNAMCQ NNAMCQ with being the whole space X;
(ii) Assume that (A1) and (A2) (or (A1) and (A3)) hold and the NNAMCQ with being the whole space X without the restriction of at, Then the Slater condition (CQ) holds.
Proof. The proof of (i) is similar to ([7], Proposition 2). Now we prove (ii). By the assumption (A1), the following sets C1 and C2 are convex:
Suppose to the contrary that Slater condition does not hold. Then or. If the former holds, then by the separation theorem [1], there exists a nonzero vector such that
for all . Since are convex cones, consequently we have
for all and take in (3), we have
which contradicts the NNAMCQ. Similarly if the latter holds then there exists such that, which contradicts NNAMCQ.
Definition 4.4 (Calmness Condition) Let . Let and . We say that (VP) satisfies the calmness condition at provided that there exist, a neighborhood of, and a map with such that for each
Satisfying
there is no such that
Theorem 4.2 Assume that (A1) is satisfied and either (A2) or (A3) holds. If is a weakly efficient solution of (VP) with, and the calmness condition holds at , then there exists, a neighborhood of and a vector with such that
Proof. It is easy to see that under the calmness condition, being a weakly efficient solution of (VP) implies that is a weakly efficient solution of the perturbed problem:
VP(p,q) By assumption, the above optimization problem satisfies the generalized convexity assumption (A1). Now we prove that the NNAMCQ holds naturally at. Suppose that satisfies the system:
If , then there exists small enough such that. Since, and there exists which implies that and hence
which contradicts (5). Hence and (5) becomes
If then there exists p small enough such that. Let, then
and hence
which is impossible. Consequently,as well. Hence there exists with such that
It is obvious that (6) implies (4) and hence the proof of the theorem is complete.
Definition 4.5 Let be normed spaces. We say that (VP) satisfies the error bound constraint qualification at a feasible point if there exist positive constants andsuch that
where BX is the unit ball of X, and
Remark 4.2 Note that the error bound constraint qualification is satisfied at a feasible point if and only if the function is pseudo upper-Lipschitz continuous aroundin the terminology of ([8], Definition 2.8) (which is referred to as being calm at in [9]). Hence being either pseudo-Lipschitz continuous around in the terminology of [10] or upper-Lipschitz continuous at in the terminology of [11] implies that the error bound constraint qualification holds at. Recall that a function is called a polyhedral multifunction if its graph is a union of finitely many polyhedral convex sets. This class of function is closed under (finite) addition, scalar multiplication, and (finite) composition. By ([12], Proposition 1), a polyhedral multifunction is upper-Lipschitz. Hence the following result provides a sufficient condition for the error bound constraint qualification.
Proposition 4.2 Let X = Rn and W = Rm. Suppose that D is polyhedral and h is a polyhedral multifunction. Then the error bound constraint qualification always holds at any feasible point.
Proof. Since D is polyhedral and h is a polyhedral multifunction, its inverse map is a polyhedral multifunction. That is, the graph of S is a union of polyhedral convex sets. Since
which is also a union of polyhedral convex sets, is also a polyhedral multifunction and hence upper-Lipschitz at any point of by ([12], Proposition 1). Therefore the error bound constraint qualification holds at.
Definition 4.6 Let X be a normed space, be a function and. f is said to be Lipschitz near if there exist , a neighbourhood of and a constant L f > 0 such that for all ,
Where BY is the unit ball of Y.
Definition 4.7 Let X be a normed space, be a function and . f is said to be strongly Lipschitz on if there exist a constant Lf > 0 such that for all ,and ,
The following result generalizes the exact penalization ([9], Theorem 2.4.5).
Proposition 4.3 Let X be a normed space, be a function which is strongly Lipschitz of rank Lf on a set. Let and suppose that is a weakly efficient solution of
with. Then for all, is a weakly efficient solution of the exact penalized optimization problem
where .
Proof. Let us prove the assertion by supposing the contrary. Then there is a point, and satisfying. Let and be a point such that. Then for any,
Since is arbitrary it contradicts the fact that is a weakly efficient solution of
Proposition 4.4 Suppose is a normed space and f is strongly Lipschitz on D. If is a weakly efficient solution of (VP) and the error bound constraint qualification is satisfied at, then (VP) satisfies the calmness condition at.
Proof. By the exact penalization principle in Proposition 3.3, is a weakly efficient solution of the penalized problem
The results then follow from the definitions of the calmness and the error bound constraint qualification.
Theorem 4.3 Assume that the generalized convexity assumption (A1) is satisfied with f replaced by and either (A2) or (A3) holds. Suppose is a normed space and f is strongly Lipschitz on D. If is a weakly efficient solution of (VP) and the error bound constraint qualification is satisfied at, then there exist, a neighborhood of and a vector with such that (4) holds.
Using Proposition 4.2, Theorem 4.3 has the following easy corollary.
Corollary 4.1 Suppose Y is a normed space, X = Rn, W = Rm and D is polyhedral and f is strongly Lipschitz on D. Assume that the generalized convexity assumption (A1) is satisfied with f replaced by and either (A2) or (A3) holds. If is a weakly efficient solution of (VP) without the inequality constraint; and h is a polyhedral multifunction, then there exist, a neighborhood of a vector with such that
Our last result Theorem 4.4 is a strong duality theorem, which generalizes a result in Fang, Li, and Ng [13].
For two topological vector spaces Z and Y, let B(Z; Y ) be the set of continuous linear transformations from Z to Y and
The Lagrangian map for (VP) is the function
defined by
Given, consider the vector minimization problem induced by (VP):
and denote by the set of weakly efficient value of the problem (VPST). The Lagrange dual problem associated with the primal problem (VP) is
The following strong duality result holds which extends the strong duality theorem in ([7], Theorem 7) (which was for set-valued optimization problems), to allow weaker convexity assumptions. We omit the proof since it is similar to [7].
Theorem 4.4 Assume that (A1) is satisfied, either (A2) or (A3) is satisfied, and a constraint qualification such as NNAMCQ is satisfied. If is a weakly efficient solution of (VP), then there exists
such that
5. Conclusions
We introduce the following definitions of generalized affine functions: affinelikeness, preaffinelikeness, subaffinelikeness, and presubaffinelikeness. Examples 2.1 to 2.7 show that definitions of affine, affinelike, preaffinelike, subaffinelike, and presubaffinelike functions are all different. Example 2.8 is an example of non-presubaffinelike function; presubaffineness is the weakest one in the series. Proposition 2.1 demonstrates that our generalized affine functions have some similar properties with generalized convex functions.
And then, we work with vector optimization problems in real linear topological spaces, and obtain necessary conditions, sufficient conditions, or necessary and sufficient conditions for weakly efficient solutions, which generalize the corresponding classical results in [14,15] and some recent results in [7,9,16,17,18]. We note that the constraint qualifications in [15,17,18] are in the differentiation form. Comparing with the results in [19] and ([20], pp.297) in discussions of convex constraints, we only required weakened convexities for constraint qualifications in this article. We note that, [17] works with semi-definite programming. In [17], two groups of functions gi(x) ≥ 0, iI and hj(x) = 0, jJ can be just considered as two topological spaces (I and J do not have to be finite sets). We also note that f is supposed to be “proper convex” in [18]; and in [18], functions are required to be “quasiconvex”.
Generalized affine functions and generalized convex functions can be used for other discussions of optimization problems, e.g., dualities, scalarizations, as well as saddle points, etc.
References
- Deimling, K., Nonlinear Functional Analysis, Springer-Verlag, Berlin, 1985.
- Fan, K. Minimax Theorems. Proceedings of the National Academy of Sciences of the USA 1953, 39, 42–47. [Google Scholar] [CrossRef]
- Jeyakumar, V. Convexlike Alternative Theorems and Mathematical Programming. Optimization 1985, 16, 643–652. [Google Scholar] [CrossRef]
- Li, Z. F., and Wang S. Y., Lagrange Multipliers and Saddle Points in Multiobjective Programming. J. Optim. Theo. Appl. 1994, 1, 63–80.
- Zeng, R. Generalized Gordan Alternative Theorem with Weakened Convexity and its Applications. Optimization 2002, 51, 709–717. [Google Scholar] [CrossRef]
- Zeng, R., and Caron, R. J., Generalized Motzkin Theorem of the Alternative and Vector Optimization Problems. J. Optim. Theo. Appl. 2006, 131, 281–299. [CrossRef]
- Li, Z.-F., and Chen, G.-Y., Lagrangian Multipliers, Saddle Points and Duality in Vector Optimization of Set-Valued Maps. J. of Math. Anal. Appl. 1997, 215, 297–315. [CrossRef]
- Ye, J. J., and Ye, X. Y., Necessary Optimality Conditions for Optimization Problems with Variational Inequality Constriants. Math. Oper. Res. 1997, 22, 977–997. [CrossRef]
- Rockafellar, R. T., and Wets, R. J.-B., Variational Analysis, Springer-Verlag, Berlin, 1998.
- Aubin, J.-P. Lipschitz Behavior of Solutions to Convex Minimization Problems. Math. Oper. Res. 1984, 9, 87–111. [Google Scholar] [CrossRef]
- Robinson, S. M. Stability Theory for Systems of Inequalities. Part I: Linear Systems. SIAM J. Numer. Anal., 1975, 12, 754–769. [Google Scholar] [CrossRef]
- Robinson, S. M. , Some Continuity Properties of Polyhedral Multifunctions, Math. Programming Stud. 1981, 14, 206–214. [Google Scholar]
- Fang, D. H., Li, C., and Ng, K. F., Constraint Qualifications for Optimality Conditions and Total Lagrange Dualities in Convex Infinite Programming. Nonlinear Analysis 2010, 73, 1143–1159. [CrossRef]
- Luc, D. T., Theory of Vector Optimization. Springer-Verlag, Berlin, 1989.
- Clarke, F. H., Optimization and Nonsmooth Analysis, Wiley-Interscience, New York, 1983.
- Nguyen, M.-H., and Luu, D. V., On Constraint Qualifications with Generalized Convexity and Optimality Conditions, Cahiers de la Maison des Sciences Economiques 2006.20 - ISSN 1624-0340. 2006.
- Kanzi, N., and Nobakhtian, S., Nonsmooth Semi-Infinite Programming Problems with Mixed Constraints. J. Math. Anal. Appl. 2009, 351, 170–181. [CrossRef]
- Zhao, X. P. Constraint Qualification for Quasiconvex Inequality System with Applications in Constraint Optimization. J. Nonlinear. Convex Anal. 2016, 17, 879–889. [Google Scholar]
- Khazayel, B., Farajzadeh A. On the Optimality Conditions for DC Vector Optimization Problems. Optimization 2022, 71, 2033–2045. [CrossRef]
- Ansari, Q. H.; Yao J.-C., Recent Developments in Vector Optimization, Springer Link, 2012.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



