Submitted:
20 September 2023
Posted:
21 September 2023
You are already at the latest version
Abstract
To address the deficiency of existing relation extraction models in effectively extracting relational triplets pertaining to railway traffic knowledge in Tibet, this paper constructs a Tibet Railway Traffic text dataset and provides an enhanced relation extraction model. The proposed model incorporates subject feature enhancement and relational attention mechanisms. It leverages a pre-trained model as the embedding layer to obtain vector representations of text. Subsequently, the subject is extracted and its semantic information is augmented using an LSTM neural network. Furthermore, during object extraction, the multi-head attention mechanism enables the model to prioritize relations associated with the aforementioned features. Finally, objects are extracted based on the subjects and relations. The proposed method has been comprehensively evaluated on multiple datasets, including the Tibet Railway Traffic text dataset and two public datasets. The results on the Tibet dataset achieves an F1-score of 93.3\%, surpassing the baseline model CasRel by 0.8\%, indicating a superior applicability of the proposed model. On the other hand, the model achieves F1-scores of 91.1\% and 92.6\% on two public datasets, NYT and WebNLG, respectively, outperforming the baseline CasRel by 1.5\% and 0.8\%, which highlights the good generalization ability of the proposed model.
Keywords:
Relation extraction
; Subject feature
; Attention mechanism
; Railway traffic in Tibet
1. Introduction
As the highest average altitude region in the world, the construction of railways in Tibet differs significantly from that in plain areas. In recent years, the application of knowledge graph technology has emerged as a new research direction, particularly in constructing domain-specific knowledge graphs. By constructing a knowledge graph for railway traffic in Tibet, we can gain a deeper understanding of the railway development situation in this region. A knowledge graph typically comprises various relational triplets in the form of (subject, relation, object), with both the ’subject’ and ’object’ representing entities. These relational triplets are obtained through the task of relational extraction.
Relation extraction aims to extract potential relational triplets from textual data. The early methods generally adopt a pipeline model, which usually divides the extraction task into two subtasks: entity recognition and relation classification. Initially, potential entities within the text are identified to form entity pairs. Relation labels are then assigned to each entity pair through classification techniques. However, this model often exhibits three main limitations: 1) Error propagation: Errors generated during the entity extraction process tend to propagate and become more significant during the relation extraction phase [1]. 2) Lack of interaction between subtasks: The extraction of entities and relations is treated 32 as two independent components, overlooking the association between these subtasks [2]. 3) Presence of redundant entity pairs: In the entity extraction process, all entities in the text are extracted and paired, including those that might not be relevant. As a result, the relations between unrelated entities also require judgment, impacting efficiency [3].
In recent years, joint extraction models have partially overcome these limitations by employing a unified modeling approach for entity relation extraction. A cascaded end-to-end model, i.e., CasRel, proposed by Wei et al. (2020), has demonstrated significant improvements compared to previous pipelined models. In CasRel, relations are considered as functions that map subjects to objects, rather than being independent of entities. Consequently, the subject is extracted first, followed by the judgment of corresponding objects under each relation. However, the subject is extracted through two dense layers in CasRel, and its features are fused with the text. The fusion results are then directly used for subsequent object and relation extraction. Unfortunately, if the extraction of subject features is not accurate enough, it can lead to error propagation, thereby affecting the overall model performance. Furthermore, while CasRel has achieved promising results through training on general field datasets such as NYT and WebNLG, the availability of textual data specifically related to railway traffic knowledge in Tibet is severely limited. The scarcity of data hinders the adequate training of the CasRel model and poses challenges in adapting it to the specific context of Tibet’s railway transportation.
To address the issue of error propagation impacting model performance and the limitation of insufficient training data for CasRel, this paper proposes the Subject Features and Relational Attention-enhanced Relation Extraction (SFRARE) model. Our argument is that enhancing the semantic features of the subject can alleviate error propagation caused by inaccurate identification of subject features. Additionally, enhancing the model’s attention towards relations allows the model to focus more on relations relevant to the subject, reducing interference from irrelevant relations. As a result, the proposed model achieves better training performance even with limited datasets. The main contribution of this paper is as follows:
- We construct a small-scale Chinese dataset specifically focused on Tibet’s railway traffic texts, which has been manually annotated to ensure its suitability for training relation extraction models.
- In this paper, we propose a relation extraction model (SFRARE) that enhances subject features and relational attention. The model relies on Long Short Term Memory (LSTM) to enhance subject features and mitigate the effects of error propagation. Furthermore, we incorporate a multi-head attention mechanism to enable the fusion of relation-focused attention with the text vector. This allows the model to prioritize relations that are closely related to the subject.
- We evaluated SFRARE on the Tibet Railway Traffic text dataset and achieved a F1-score of 93.3%, which is 0.8% higher than the baseline model CasRel. To further assess the generalization ability of our model, we evaluated SFRARE on two widely-used English public datasets, namely NYT and WebNLG. The experimental results demonstrated that SFRARE outperforms mainstream models in terms of extraction performance.
2. Related Work
Knowledge graphs can be classified into two categories: general knowledge graphs and field knowledge graphs, depending on the breadth of knowledge they encompass. Field knowledge graphs, although narrower in scope, are more specialized and applicable to specific domains. The Tibet Railway Traffic Knowledge Graph that we intend to construct falls under the category of a Field Knowledge Graph. Our objective is to extract relational triplets containing relevant knowledge from textual data pertaining to Tibet Railway Traffic. In this regard, Zhang’s research [4] provides a comprehensive account of the history of railway construction in Tibet, while Rong’s analysis [5] delves into the role of the Qinghai-Tibet railway in shaping the spatio-temporal structure of transportation in Tibet. These research works serve as valuable resources for us to accumulate the necessary knowledge about railway traffic in Tibet, thereby facilitating our search for pertinent specialized texts.
Using a relation extraction model, it is possible to extract relational triplets containing field-specific knowledge from specialized textual data in the field. Early models for relational extraction typically employed a pipelined approach, which involved dividing the extraction process into two subtasks: named entity recognition and relation classification. However, this pipelined approach suffers from error propagation and a lack of interaction between the subtasks, leading to underutilization of information. In recent years, there has been a growing research trend towards joint extraction of entities and relations, which has shown improved model performance. This approach involves establishing a unified model that allows different subtasks to interact with each other, resulting in better overall performance [6]. Neural network-based joint entity-relation extraction has become the mainstream in research due to the excellent feature learning ability of neural networks. These models can be categorized into joint decoding based methods and shared parameter based methods, depending on the type of decoder used.
Joint extraction models based on shared parameters decompose joint extraction into different subtasks, where information is shared at the sequence coding layer. The SPTree model [7] was the first neural network-based joint extraction model for entities and relations. Tan et al. [8] and Liu et al. [9] proposed models that utilize Conditional Random Field (CRF) at the sequence coding layer to enhance entity recognition accuracy. The RIN (recurrent interaction network) model [10] employs bi-directional LSTM to capture dynamic interaction information at the shared parameter layer. Wei et al. took a novel perspective on Relation Extraction, defining relation as a function mapping the subject to the object. They introduced the cascading relation extraction framework called CasRel [11] for extracting relational triplets. Wang et al. [12] proposed a joint extraction model that achieves entity and relation extraction through a Handshaking Tagging method. Another model by Wang et al. [13] incorporates two encoders to separately encode entity information and relation type information, enabling internal interaction between them.
On the other hand, joint decoding based extraction models typically employ a unified decoder that is superimposed on the sequence coding layer. This decoder directly decodes the relational triplet information from the encoded sentence sequences. Zheng et al. [14] proposed a model that utilizes sequence annotation to achieve joint extraction for the first time. The model directly decodes the encoded sentence sequences to obtain sequence labeling information, which is then used to derive the relational triplets. Building upon Zheng’s work, Dai et al. [15] address the issue of overlapping relationships by incorporating a position-based attention approach and CRF to generate distinct sequence annotations. SPN (set prediction network) [16] employs a non-autoregressive decoder based on Transformer [17]. It also introduces an ensemble-based bisection matching loss function, enabling the generation of an ensemble containing all relational triplets simultaneously.
In general, the work by Zhang and Rong has significantly contributed to our understanding of railway traffic in Tibet. Their research has provided us with a more comprehensive knowledge base, enabling us to search for relevant textual data as better references. Additionally, the joint extraction model enhances the interaction between subtasks by constructing a unified model that fully leverages the information from each subtask. This approach presents a novel idea for extracting relational triplets. The CasRel model, in partic ular, considers relations as functions that map subjects to objects, challenging the traditional notion of separating relations from entity pairs. This method of extracting relational triplets serves as an inspiration for the development of the SFRARE model proposed in this paper.
3. The SFRARE Model
3.1. Relational triplet representation
Relational triplets can be used to represent relations between entities. The relational triplets present in the text can be obtained through the relation extraction task, as shown in Figure 1:
3.2. Overall framework of SFRARE model
SFRARE is a cascading end-to-end relation extraction model proposed in this paper. It consists of 5 key components, including a text embedding layer, a subject recognizer, a subject features enhancement module, a relational attention enhancement module, and a relation-object recognizer. The structure of the SFRARE model can be visualized in Figure 2.
3.3. Text Embedding Layer
The BERT pre-trained model [18] is employed as the text embedding layer due to its ability to incorporate contextual information and learn deep word representations. This model has demonstrated excellent performance in various natural language processing tasks since it was proposed. To facilitate convergence and mitigate issues such as gradient explosion or vanishing, a normalization layer is employed to process the vector representation of the text. This process can be represented by Equation (1):
where represents the word sequence of the text. Each represents a word that constitutes the text, and n represents the total number of words in the text. denotes the normalization layer, and H represents the resulting text vector representation obtained after passing the input text through the pre-trained model embedding and normalization layer processing. The dimension of H is b × l × d, where b represents the batch-size or the amount of data in one training iteration, l represents the length of the text, and d represents the dimension of the output from the last hidden layer of the pre-trained model.
3.4. Subject Recognizer
The subject recognizer is employed to extract potential subjects from the text. It takes the vector representation of the text after BERT embedding as input. The recognizer treats subject extraction as a binary classification task and utilizes two binary classifiers to label each word in the text. These classifiers determine whether a word is the head or tail of a subject. If a word is identified as the head or tail of a subject, it is marked as 1; otherwise, it is marked as 0. The specific details are illustrated in Equations (2) to (3):
where and represent the probabilities of each word in the text being the start and end of the subject, respectively. denotes the weight matrix used for determining the start of the subject, and is the corresponding bias term. Similarly, represents the weight matrix used for determining the end of the subject, and is its corresponding bias term. represents the vector representation of each word in the text.
3.5. Subject Features Enhancement Module
To mitigate the influence of error propagation on the model’s extraction performance caused by inaccurate subject feature recognition, we developed the subject features enhancement module. This module combines the text vectors with the subject features identified by the subject recognizer to generate new vectors. Subsequently, the LSTM neural network evaluates the semantic features embedded in these fused vectors. The process is demonstrated in Equations (4) to (5):
where H represents the text vector representation, represents the updated text vector representation obtained after subject feature fusion and enhancement. denotes the feature vector of the subject, and b represents the bias term of the LSTM neural network. The enhancement of subject semantic features enriches the vector representation by incorporating more detailed subject features and reinforcing the memory of these features. This helps mitigate the issue of error propagation resulting from inaccuracies in subject recognition.
3.6. Relational Attention Enhancement Module
To ensure that the model performs well in the relational extraction task even with limited training data, we developed the relational attention enhancement module. This module utilizes a multi-head attention mechanism to compute the weights of each relation based on the enhanced subject features and text vector representation. The attention weights assigned to each relation indicate the degree of association with the subject. Consequently, the model can focus more on relations that are relevant to the subject. This process is illustrated in Equations (6) to (9):
where , , and are obtained through linear transformations of the text vector representation enhanced by the semantic features of the subject. The represents the attention weights assigned to each relation for recognizing the start of the object, while represent the attention weights assigned to each relation for recognizing the end of the object. W is the output matrix. and are the text vector representations obtained after merging the relational attention. These representations are then utilized for the recognition of the start and end of the object, respectively.
3.7. Relation-object Recognizer
The relation-object recognizer is employed to extract the object that corresponds to the subject under a given relation. Similar to the subject recognizer, the object recognizer utilizes two binary classifiers for each relation. These classifiers determine whether each word in the text represents the start or end of the object corresponding to the subject under the current relation. The process is demonstrated in Equations (10) to (11):
where and represent the probabilities of each word in the text being the start and end of the object, respectively. These probabilities are calculated similarly to equations (2)-(3). represents the weight matrix used for determining the start of the object under relation r, while represents the weight matrix used for determining the end of the object under relation r. The terms and denote the corresponding bias terms. The vectors and are obtained from the relational attention enhancement module and are utilized for recognizing the start and end of the object, respectively.
3.8. Loss Function
In the SFRARE model, the extraction of both the subject and the object are treated as binary classification labeling tasks. Therefore, the binary cross-entropy loss function is employed. Since the model first extracts the subject and then proceeds to extract the corresponding object under the given relation, the losses during the extraction process are calculated separately and subsequently summed. The specific calculations are outlined in Equations (12) to (14):
where represents the loss incurred during the subject extraction, represents the loss incurred during the object extraction, and represents the overall loss of the entire model. L denotes the length of the text. The variables represent the ground truth start and end positions of the subject and object, as indicated in equations (12) and (13). On the other hand, represents the predicted start and end positions of the subject and object made by the model.
4. Experiments
4.1. Tibet Railway Traffic text Dataset
Due to the unavailability of a publicly accessible text dataset specifically focused on railway traffic in Tibet, we borrow ideas from Zhang and Rong’s works. Specifically, we utilized the history of railway construction in Tibet as an index to gather relevant textual data from the internet. For instance, we extracted texts containing knowledge related to railway traffic from the introduction of Qinghai-Tibet Railway on Baidu Baike (a Chinese online encyclopedia). Subsequently, we manually annotated the relational triplets present in these texts. These annotated textual data were then utilized to train our model, as illustrated in Figure 3.
In addition, we conducted searches using each railway station in Tibet as the departure and arrival stations to find train numbers. We then utilized the relevant information associated with these train numbers to create textual data. This portion of the text was also manually annotated with relational triplets for training the model in relation extraction tasks. We collected a total of 2056 textual data samples related to railway traffic in Tibet. These samples were used to construct a small Chinese text dataset specifically for the task of relation extraction in Tibet’s railway traffic domain. The constructed dataset was further divided into train set, validation set, and test set, with a ratio of 8:1:1 respectively. Details of the dataset division are presented in Table 1.

Table 1.
Data Statistics for Tibet Railway Traffic text Dataset.
| Dataset | Train | Valid | Test | ALL |
|---|---|---|---|---|
| Tibet Railway Traffic text Dataset | 1645 | 205 | 206 | 2056 |
Through the exploration of railway traffic knowledge in Tibet, we have identified a total of 16 types of relations. These relation types were defined in Chinese originally, and the translation in English is shown in Table 2.
Table 2.
Relation types of Tibet Railway Traffic text Dataset.
| Relation Type | The number of triplets | Relation Type | The number of triplets |
|---|---|---|---|
| railway station-be located in-location | 205 | railway station-cover an area of-area | 163 |
| railway-alternative name-name | 23 | railway-construction date-date | 35 |
| railway-finish date-date | 63 | railway-opening date-date | 32 |
| railway-length of railway-length | 22 | railway-width of railway-width | 17 |
| railway-height of railway-elevation | 26 | railway-belong to-railway | 46 |
| train-departure station-railway station | 54 | train-terminal station-railway station | 54 |
| train-departure time-time | 54 | train-journey time-time | 54 |
| constructors-construct-railway | 468 | passenger-take the train-train | 762 |
| The number of all triplets | 2078 | ||
As depicted in Table 2, we have defined 16 relation types for the dataset that we constructed. The table displays the format of the relational triplets formed by each relation type, along with their corresponding subject and object. For instance, the relation type ’railway-alternative name-name’ signifies that when the subject is a railway and the object is a name, there might exist an ’alternative name’ relation between them. Subsequently, we conducted a count of the number of relational triplets for each relation type and determined a total of 2078 relational triplets within the dataset.
4.2. Public Datasets
In this paper, English public datasets NYT[19] and WebNLG are used to verify the generalization ability of the proposed model. The NYT dataset is a publicly available English dataset constructed using a remote supervision method. It consists of 24 relations for relation extraction tasks. On the other hand, the WebNLG dataset was initially created for the natural language generation task but has been adapted for the relation extraction task. It contains a broader range of relation types, encompassing a total of 246 different relations. The relation types present in the two datasets are detailed in Table 3.
Table 3.
Data Statistics for NYT Dataset and WebNLG Dataset
| Category | NYT | WebNLG | ||||
|---|---|---|---|---|---|---|
| Train | Valid | Test | Train | Valid | Test | |
| All | 56195 | 4999 | 5000 | 5019 | 500 | 703 |
4.3. Experimental setup
The specific experimental settings of this paper are shown in Table 4.
Table 4.
Experimental details
| Items | Specific setting |
|---|---|
| Word embedding layer | bert_base&bert_chinese |
| Recognition threshold | 0.5 |
| Hidden layer dimension of LSTM | 768 |
| Number of heads of attention mechanism | num-rels |
| Learning rate | 1e-5 |
| Batch-size | 16 |
| Dropout | 0.2 |
| Experimental device | NVIDIA GeForce RTX 3090(24G) |
We employe the BERT model developed by Google as the word embedding layer. Specifically, for the experiment conducted on the Tibet Railway Traffic text Dataset, we utilize the bert_chinese version of BERT. For the experiments conducted on the NYT and WebNLG datasets, we use the bert_base version of BERT. The recognition thresholds for both the subject recognizer and the relation-object recognizer are set to 0.5. The hidden layer dimension of the LSTM is set to 768. Additionally, the number of heads in the two-layer multi-head attention mechanism is set to the number of relations defined by each respective dataset. During the training process, we employed the Adam optimizer with a learning rate of 1e-5 and a batch size of 16. A dropout rate of 0.5 was applied. The experimental device used was an NVIDIA GeForce RTX 3090 graphics card with 24GB of video memory. To evaluate the extraction results, we calculated the accuracy rate, recall rate, and F1-score, as shown in Equations (15) to (17).
where is the number of correct triplets predicted, is the number of all predicted triplets, and is the number of actually correct triplets.
4.4. Experimental result
4.4.1. Experimental results on Tibet Railway Traffic text Dataset
Due to the limitation of experimental equipment, we could not solve the problem that some models using bert_chinese as the word embedding layer exceeded the video memory during training. In this experimental part, we only chose the baseline model CasRel as the comparison model.
- CasRel : A novel cascade binary tagging framework for relational triplet extraction proposed by Wei et al.
The experimental results on Tibet Railway Traffic text Dataset are shown in Table 5.
Table 5.
Experimental results on Xizang Railway Traffic Dataset.
| Model | Tibet Railway Traffic text Dataset | ||
|---|---|---|---|
| Pre | Rec | F1 | |
| CasRel | 93.1% | 91.9% | 92.5% |
| SFRARE | 93.7% | 93.0% | 93.3% |
According to the experimental results presented in Table 5, the SFRARE model achieves a higher accuracy rate compared to CasRel, with an improvement of 0.6%. This suggests that the SFRARE model mitigates the impact of error propagation to some extent in comparison to CasRel. The recall rate of SFRARE is also 1.1% higher than CasRel, indicating that SFRARE better captures more relational triples in the Tibet Railway Traffic text Dataset. This implies that SFRARE performs better on this small dataset. Lastly, the F1-score achieved by SFRARE is 0.8% higher than CasRel, further supporting the conclusion that SFRARE outperforms CasRel on the Tibet Railway Traffic text Dataset.
4.4.2. Experimental results on public datasets
To assess the generalization capability of SFRARE, this paper includes several state-of-the-art relation extraction models that have previously published experimental results on two public datasets: NYT and WebNLG. In the experimental section, CasRel is selected as the baseline model for comparison against these representative models.
- CopyR[20] : An end-to-end relation extraction model with replication mechanism proposed by Zeng et al., a single decoder is used at the decoding layer.
- CopyR : An end-to-end relational extraction model with replication mechanism proposed by Zeng et al., multiple decoders are used at the decoding layer.
- GraphRel[21] : The first phase of relational extraction model based on relational graph structure proposed by Tsu-Jui Fu et al.
- GraphRel : The second phase of relational extraction model based on relational graph structure proposed by Tsu-Jui Fu et al.
- CopyR[22] : Zeng et al. proposed an end-to-end relation extraction model based on CopyR that applies reinforcement learning to the generation of relational triplets.
- CasRel : A novel cascade binary tagging framework for relational triplet extraction proposed by Wei et al.
The experimental results on the public dataset are shown in Table 6.
Table 6.
Experimental results on NYT and WebNLG
| Model | NYT | WebNLG | ||||
|---|---|---|---|---|---|---|
| Pre | Rec | F1 | Pre | Rec | F1 | |
| CopyR | 59.4% | 53.1% | 56.0% | 32.2% | 28.9% | 30.5% |
| CopyR | 61.0% | 56.6% | 58.7% | 37.7% | 36.4% | 37.1% |
| GraphRel | 62.9% | 57.3% | 60.0% | 42.3% | 39.2% | 40.7% |
| GraphRel | 63.9% | 60.0% | 61.9% | 44.7% | 41.1% | 42.9% |
| CopyR | 77.9% | 67.2% | 72.1% | 63.3% | 59.9% | 61.6% |
| CasRel | 89.7% | 89.5% | 89.6% | 93.4% | 90.1% | 91.8% |
| SFRARE | 90.5% | 91.7% | 91.1% | 92.6% | 92.7% | 92.6% |
Table 6 shows that SFRARE outperforms the baseline model on both the NYT and WebNLG datasets. On the NYT dataset, SFRARE achieves a precision rate of 90.5%, a recall rate of 91.7%, and an F1-score of 91.1%. These scores are 0.8%, 2.2%, and 1.5% higher than those of the baseline model CasRel. Similarly, on the WebNLG dataset, SFRARE achieves a precision rate of 92.6%, a recall rate of 92.7%, and an F1-score of 92.6%. Even the precision rate of SFRARE is slightly lower than that of CasRel, it improves the recall and F1-score by 2.6% and 0.8%, respectively. The experimental results demonstrate that the SFRARE model exhibits favorable generalization ability and surpasses mainstream models in terms of extraction performance.
4.4.3. Ablation experiment
To examine the influence of subject feature enhancement and relational attention enhancement on the extraction performance of the SFRARE model, we conducted ablation experiments on the NYT and WebNLG datasets. The results of these experiments are presented in Table 4. In the table, SFRARE represents the variant of the SFRARE model that only incorporates enhanced subject features, while SFRARE denotes the variant that solely incorporates enhanced relational attention. On the other hand, SFRARE refers to the complete model that combines both subject feature enhancement and relational attention enhancement.
Table 7.
The results of the ablation experiments on NYT and WebNLG.
| Methods | NYT | WebNLG | ||||
|---|---|---|---|---|---|---|
| Pre | Rec | F1 | Pre | Rec | F1 | |
| CasRel | 89.7% | 89.5% | 89.6% | 93.4% | 90.1% | 91.8% |
| SFRARE | 90.1% | 89.8% | 89.9% | 92.2% | 91.8% | 92.0% |
| SFRARE | 89.9% | 91.0% | 90.5% | 93.7% | 90.7% | 92.2% |
| SFRARE | 90.5% | 91.7% | 91.1% | 92.6% | 92.7% | 92.6% |
The experimental results indicate that enhancing subject features leads to an increase in the F1-scores achieved by SFRARE on both datasets. Specifically, compared to the baseline model, SFRARE achieves a 0.3% and 0.2% improvement in F1-score on the two datasets, respectively. Similarly, enhancing relational attention also contributes to improved performance. In comparison to the baseline model, SFRARE demonstrates an F1-score increase of 0.9% and 0.4% on the two datasets, respectively. When both subject features and relational attention are enhanced, the overall performance improvement is even more significant. SFRARE achieves an increase of 1.5% and 0.8% in F1-score on the two datasets, respectively. The results from the ablation experiments confirm that enhancing subject features and relational attention has a positive impact on the SFRARE model.
Based on the experimental results, it can be concluded that the SFRARE model surpasses the baseline CasRel and mainstream extraction models, on both the Chinese dataset (the Tibet Railway Traffic text Dataset) and two public English datasets (NYT and WebNLG). These findings demonstrate the effectiveness and generalization capability of the SFRARE model for knowledge graph construction in the field of railway traffic in Tibet. The improved performance of the SFRARE can be attributed to several factors. Firstly, the subject features enhancement module enhances the semantic features of the subject and the input text through LSTM. This provides more accurate information to the relation-object recognizer, thereby mitigating the effects of error propagation caused by inaccurate subject feature recognition. Furthermore, the relational attention enhancement module calculates the weight of each defined relation using two multi-attention mechanisms. This approach allows the model to focus more attention on relations related to the subject, thereby improving the performance of the model in extracting relation triplets. Moreover, this attention mechanism enables the model to achieve good performance even with small training datasets. Overall, the enhancements made in the SFRARE model contribute to its superior performance in relation extraction tasks, making it a suitable choice for knowledge graph construction in the field of railway traffic in Tibet.
5. Conclusions
The experimental results obtained by the model on two public datasets, NYT and WebNLG, are also better than the mainstream relation extraction models, indicating that the model proposed in this paper has the ability to generalize. In our follow-up work, we plan to continue to search for textual data about Tibetan railway traffic knowledge to expand our dataset, and continue to optimize the SFRARE model to make it more applicable to the relational triplet extraction task.
This paper introduces the SFRARE model, a relation extraction approach that enhances subject features and relational attention. Building upon CasRel, SFRARE addresses error propagation issues by improving the extracted subject features. It also tackles the challenge of limited training data in CasRel, specifically for extracting relational triplets related to Tibetan railway traffic knowledge, by enhancing relational attention to focus on subject-related relations within the text. The experimental results on the Tibet Railway Traffic textual Dataset demonstrate that the proposed model outperforms CasRel. This indicates that the SFRARE model is better suited for extracting relational triplets in the context of Tibetan railway traffic knowledge compared to CasRel. Furthermore, the experimental results on the NYT and WebNLG public datasets exhibit superior performance compared to mainstream relation extraction models, indicating the generalization capability of the proposed model.
In future work, one important aspect will be expanding the dataset by searching for additional textual data pertaining to Tibetan railway traffic knowledge. By incorporating more diverse and comprehensive data, the dataset can provide a richer training environment for the SFRARE model. This expansion will help improve the model’s performance and generalization ability. We will also continue to optimize the SFRARE model to make it more applicable to the relational triplet extraction task, e.g., by designing different architectures.
Author Contributions
Conceptualization, Weiqun Luo and Guiyuan Jiang; methodology, Weiqun Luo and Jiabao Wang; software, Jiabao Wang; investigation, Jiabao Wang and Xiangwei Yan; data curation, Jiabao Wang and Xiangwei Yan; writing—original draft preparation, Jiabao Wang; writing—review and editing, Weiqun Luo and Guiyuan Jiang; supervision, Weiqun Luo and Guiyuan Jiang. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been supported by National Natural Science Foundation of China (Grant No. 62372421), and Huangpu International Sci&Tech Cooperation Fundation of Guangzhou, China (Grant No. 2021GH12).
Data Availability Statement
The NYT dataset(https://drive.google.com/open?id=10f24s9gM7NdyO3z5OqQxJgYud4NnCJg3) and WebNLG dataset(https://drive.google.com/open?id=1zISxYa-8ROe2Zv8iRc82jY9QsQrfY1Vj) are two public English datasets. The Xizang Railway Traffic dataset is not made public due to the design of private road information in related areas.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Miller, S.; Fox, H.; Ramshaw, L. ; Weischedel, R A Novel Use of Statistical Parsing to Extract Information from Text. In Proceedings of the 6th Applied Natural Language Processing Conference, Seattle, Washington, USA, 29 April–4 May 2000; pp. 226–233. [Google Scholar]
- Chen, Y.; Zheng, D.; Zhao, T. Chinese relation extraction based on Deep Belief Nets. Journal of Software 2012, 23, 2572–2585. [Google Scholar] [CrossRef]
- E, H.; Zhang, W.; Xiao, S.; Cheng, R.; Hu, Y.; Zhou, X.; Niu, P. Joint entity relationship extraction based on deep learning. Journal of Software 2019, 30, 1793–1818. [Google Scholar]
- Zhang, Y. A historical survey of the construction of Xizang Railway. China’s Borderland History and Geography Studies 2015, 3, 32–43. [Google Scholar]
- Rong, Z. The role of Qinghai-Xizang Railway in the evolution of temporal and spatial structure of traffic in Xizang. China Tibetology 2016, 2, 62–71. [Google Scholar]
- Zhang, S.; Wang, X.; Chen, Z.; Wang, L.; Xu, D.; Jia, Y. Survey of Supervised Joint Entity Relation Extraction Methods. Journal of Frontiers of Computer Science and Technology 2022, 16, 713–733. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-end relation extraction using LSTMs on sequences and tree structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1105–1116. [Google Scholar]
- Tan, Z.; Zhao, X.; Wang, W.; Xiao, W. Jointly extracting multiple triplets with multilayer translation constraints. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, Hawaii, USA, 27 January–1 February 2019; pp. 7080–7087. [Google Scholar]
- Liu, J.; Chen, S.; Wang, B.; Zhang, J.; Xu, T. Attention as relation:learning supervised multi-head self-attention for relation extraction. In Proceedings of the 29th International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 3787–3793. [Google Scholar]
- Sun, K.; Zhang, R.; Mensah, S.; Mao, Y.; Liu, X. Recurrent interaction network for jointly extracting entities and classifying relations. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 3722–3732. [Google Scholar]
- Wei, Z.; Su, j.; Wang, Y.; Tian, Y.; Chang, Y. A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, Washington, USA, 5–10 July 2020; pp. 1476–1488. [Google Scholar]
- Wang, Y.; Yu, B.; Zhang, Y.; Liu, T.; Zhu, H.; Sun, L. TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain (Online), 8–13 December 2020; pp. 1572–1582. [Google Scholar]
- Wang, J.; Lu, W. Two are better than one: joint entity and relation extraction with table-sequence encoders. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 1706–1721. [Google Scholar]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Canada, 30 July-4 August 2017; pp. 1227–1236. [Google Scholar]
- Dai, D.; Xiao, X.; Lyu, Y.; Dou, S.; Wang, H. Joint extraction of entities and overlapping relations using position-attentive sequence labeling. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, Hawaii, USA, 27 January-1 February 2019; pp. 6300–6308. [Google Scholar]
- Sui, D.; Zeng, X.; Chen, Y.; Liu, K.; Zhao, J. Joint Entity and Relation Extraction With Set Prediction Networks. IEEE Transactions on Neural Networks and Learning Systems 2020, PP. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmer, N.; Uszkoreit, J.; Jones, L.; Gomez, N.A.; Kaiser, L.; Polosukhin, l. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, California, USA, 4-9 December 2017; pp. 5998–6008. [Google Scholar]
- Jacob, D.; Chang, M.W.; Kenton, L.; Kristina, T. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies Volume 1 (Long and Short Papers), Minneapolis, USA, 2-7 June 2019; pp. 4171–4186. [Google Scholar]
- Ren, X.; Wu, Z.; He, W.; Meng, Q.; Voss, R.C.; Ji, H.; Abdelzaher, F.T.; Han, J. CoType: joint extraction of typed entities and relations with knowledge bases. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3-7 April 2017; pp. 1015–1024. [Google Scholar]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting relational facts by an end-to-end neural model with copy mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume1: Long Papers), Melbourne, Australia, 15-20 July 2018; pp. 506–514. [Google Scholar]
- Fu, T.J.; Li, P.H.; Ma, W.Y. Modeling text as relational graphs for joint entity and relation extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 30 July-4 August; pp. 1409–1418.
- Zeng, X.; He, S.; Zeng, D.; Liu, K.; Liu, S.; Zhao, J. Learning the extraction order of multiple relational facts in a sentence with reinforcement learning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3-7 November 2019; pp. 367–377. [Google Scholar]
Figure 1.
There exists a relational triplet ( 青藏铁路(Qinghai-Tibet Railway), 别称(alternative name), 青藏线(Qinghai-Tibet Line)) in this example sentence. The subject of this triplet is ’Qinghai-Tibet Railway’, the object is ’Qinghai-Tibet Line’ and the relation between them is ’alternative name’. This relational triplet represents the information that the alternative name of ’Qinghai-Tibet Railway’ is ’Qinghai-Tibet Line’.
Figure 1.
There exists a relational triplet ( 青藏铁路(Qinghai-Tibet Railway), 别称(alternative name), 青藏线(Qinghai-Tibet Line)) in this example sentence. The subject of this triplet is ’Qinghai-Tibet Railway’, the object is ’Qinghai-Tibet Line’ and the relation between them is ’alternative name’. This relational triplet represents the information that the alternative name of ’Qinghai-Tibet Railway’ is ’Qinghai-Tibet Line’.
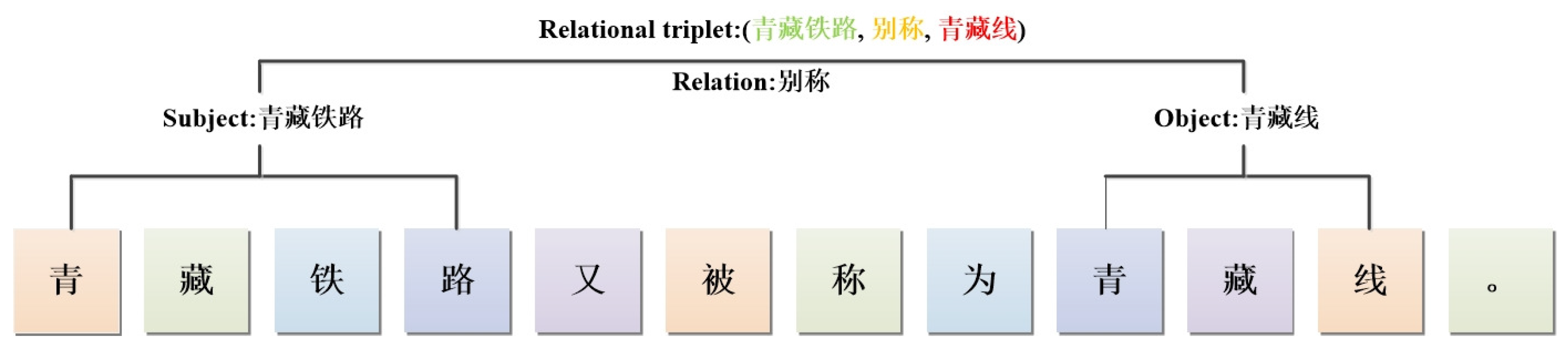
Figure 2.
The BERT embedding layer and normalization layer receive the input text depicted in Figure 2. The output of this process is the text vector denoted as H. The subject recognizer identifies and extracts the subject from the text, while also marking the start and end positions of the subject as 1. In this case, the extracted subject is ’ 青藏铁路(Qinghai-Tibet Railway)’. The subject features enhancement module takes the text vector H as input, which incorporates the subject features . The output of this module is the enhanced text vector . The relational attention enhancement module receives the enhanced text vector as input. It produces two text vectors with relational attention, namely and , as outputs. The relation-object recognizer takes the two text vectors with relational attention ( and ) as inputs. It extracts the start and end positions of the object. In this case, the extracted object is ’ 青藏线(Qinghai-Tibet Line)’corresponding to ’ 青藏铁路(Qinghai-Tibet Railway)’under the relation ’ 别称(alternative name)’, thereby forming a relational triplet (’ 青藏铁路(Qinghai-Tibet Railway)’, ’ 别称(alternative name)’, ’ 青藏线(Qinghai-Tibet Line)’).
Figure 2.
The BERT embedding layer and normalization layer receive the input text depicted in Figure 2. The output of this process is the text vector denoted as H. The subject recognizer identifies and extracts the subject from the text, while also marking the start and end positions of the subject as 1. In this case, the extracted subject is ’ 青藏铁路(Qinghai-Tibet Railway)’. The subject features enhancement module takes the text vector H as input, which incorporates the subject features . The output of this module is the enhanced text vector . The relational attention enhancement module receives the enhanced text vector as input. It produces two text vectors with relational attention, namely and , as outputs. The relation-object recognizer takes the two text vectors with relational attention ( and ) as inputs. It extracts the start and end positions of the object. In this case, the extracted object is ’ 青藏线(Qinghai-Tibet Line)’corresponding to ’ 青藏铁路(Qinghai-Tibet Railway)’under the relation ’ 别称(alternative name)’, thereby forming a relational triplet (’ 青藏铁路(Qinghai-Tibet Railway)’, ’ 别称(alternative name)’, ’ 青藏线(Qinghai-Tibet Line)’).
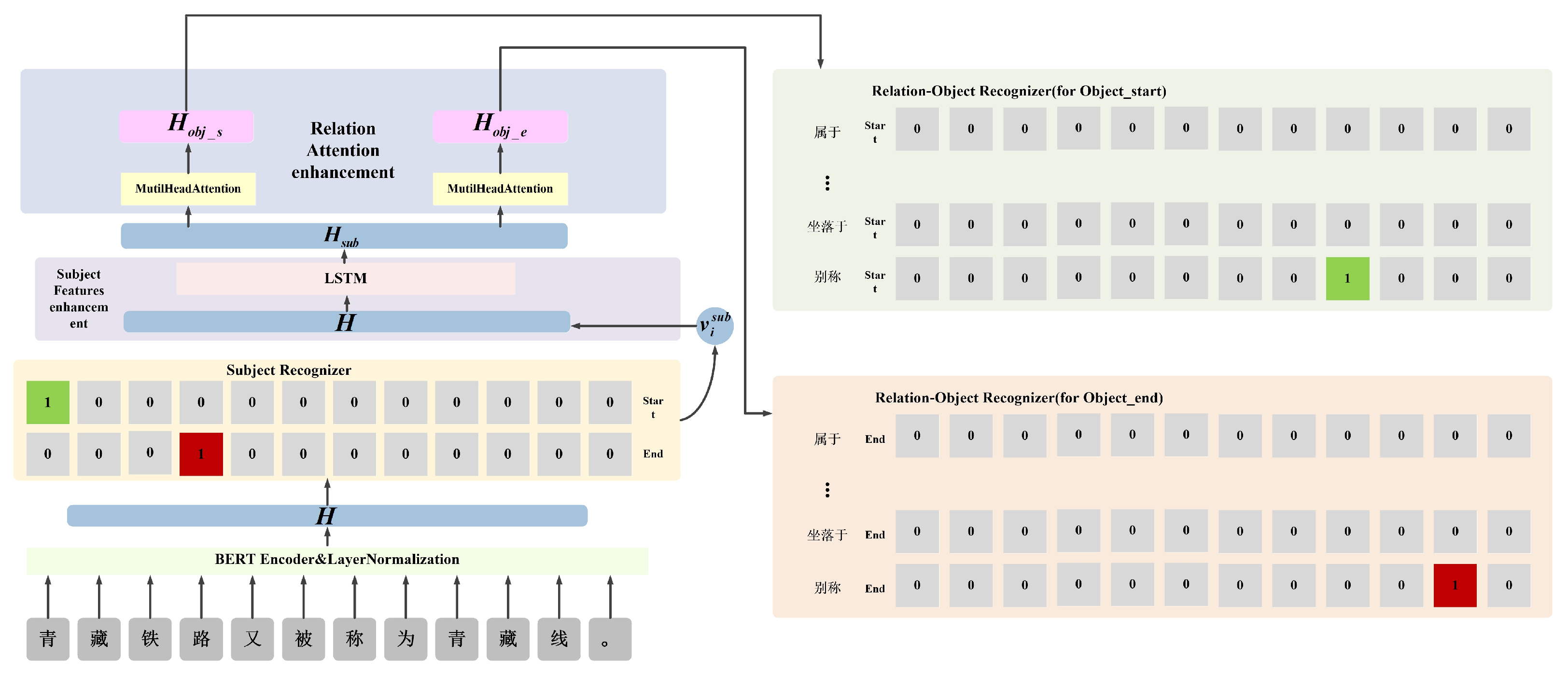
Figure 3.
Each piece of textual data is stored as a dictionary. The key ’text’ represents the text itself, and its corresponding value is the textual data that has been collected. The key ’spo_list’ represents the set of relational triplets present in the text, and the corresponding value is a list that records the relational triplets. Each relational triplet is stored as a dictionary within this list. Finally, all the annotated textual data is stored as a dataset in a JSON-formatted file.
Figure 3.
Each piece of textual data is stored as a dictionary. The key ’text’ represents the text itself, and its corresponding value is the textual data that has been collected. The key ’spo_list’ represents the set of relational triplets present in the text, and the corresponding value is a list that records the relational triplets. Each relational triplet is stored as a dictionary within this list. Finally, all the annotated textual data is stored as a dataset in a JSON-formatted file.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



