Submitted:
26 September 2023
Posted:
27 September 2023
You are already at the latest version
Abstract
Single image deraining (SID) has shown its importance in many advanced computer vision tasks. Though many CNN based image deraining methods have been proposed, how to effectively remove raindrops while maintaining background structure remains a challenge that needs to be overcome. Most of the deraining work focuses on removing rain streaks, but in heavy rain images, the dense accumulation of rainwater or the rain curtain effect significantly interferes with the effective removal of rain streaks, and often introduces some artifacts that make the scene more blurry. In this paper, we propose a new network structure R-PReNet for single image deraining with good background structure maintaining. This framework fully utilizes the cyclic recursive structure of PReNet. Moreover, we introduce residual channel prior (RCP) and feature fusion modules for better deraining performance by focusing on background feature information. Compared with the previous methods, our method has significantly improvement effect on the rainstorm image with the artifacts removing and good visual detail restoring.
Keywords:
single image deraining
; residual channel prior
; interactive fusion
1. Introduction
Rain is a common weather phenomenon which causes adverse effects on the visual quality of images and affecting the performance of subsequent image processing tasks, such as object recognition [1], object detection [2], autonomous driving and video surveillance [3,4,5], etc. Hence, removing rain streaks from images with rain has become an important and meaningful research topic, and has also received attention in recent years [6,7,8]. Single image deraining refers to restoring a clean and rainless image scene from a single image with rain. However, due to the complex combination of background information and raindrop information, how to simultaneously remove raindrops and protect the background remains a challenging issue. We found in the experiment that the PreNet deraining network model [6] can reconstruct a relatively clear rain free image, but in the test of rainstorm data set, the background structure of the reconstructed image corresponding to the rainstorm image has also been damaged to some extent, that is, the introduction of artifacts, and this destruction of the image background will sometimes lead to serious problems, such as fuzzy or missing traffic signs may lead to serious accidents in automatic driving. In order to address this problem, this paper introduce an additional image background prior to protect the background structure, so that a clearer and correct reconstruction of rainless images can be obtained in the case of rainstorm, as shown in Figure 1.
In this article, we explore the effective reconstruction problem of complex combinations of background and raindrops, and propose a new algorithm called R-PReNet that can effectively remove raindrops and protect background information. This algorithm fully utilizes the cyclic recursive structure and raindrop energy of PReNet. In addition, this article introduces residual channel prior (RCP) [9,10,11,12] in the model to achieve background structure protection. In addition, this article also proposes the use of the 'Squeeze Excitation' residual module (SE ResBlock) [13] to extract deep features of RCP, and the interactive fusion feature module (IFM) [12] to fully utilize RCP information, achieving high-quality rainless image reconstruction.
Our contributions are summarized as follows:
This article replicates and tests the PreNet deraining network on three popular image deraining datasets (Rain100H [15], Rain100L [15], Rain14000 [16]) and real datasets (Practical_by_Yang [15]), and studies the results of deraining.
This article explores the effectiveness of residual channel prior (RCP) for background protection and proposes an image deraining network structure based on RCP. Numerous experiments have shown that our method outperforms the original method on commonly used rainfall datasets, restoring visually clean images and good details.
We propose an RCP extraction module and an interactive fusion module (IFM) for RCP extraction and guidance, respectively, to obtain deep features of RCP and guide the network to recover more background details.
The rest of this article is as follows. In Section 2, we briefly reviewed the relevant research on image deraining methods. In Section 3, we proposed an overall R-PreNet deraining network based on image background prior, and elaborated on the RCP residual channel prior and IFM fusion methods in detail. In the fourth section, we presented our experimental results and comparisons. The conclusion is given in Section 5.
2. Related Works
The goal of the single image deraining task is to restore rainless images from images with rain. The video based deraining task can use video to obtain consecutive multiple frames of images, and use the temporal nature of the continuous images to obtain the position information of rain streaks and the background information of rain streaks occlusion position, thus achieving the video based deraining task. However, the task of removing rain from a single image lacks the assistance of the location information of rain streaks and the background information of occlusion positions, making it difficult to reconstruct a single rainless image.
The existing methods proposed for this task can be mainly divided into two categories: model driven methods and data driven methods.
2.1. Model-driven Methods
Generally speaking, early filter based methods and traditional prior based methods belong to the model driven type. We will introduce representative works of these two aspects as follows.
An image can be decomposed into low-frequency and high-frequency parts, with details and noise information mainly distributed in the high-frequency part of the image. So, it can be seen that the raindrops in the rain image are mainly distributed in the high-frequency part. Therefore, in the early stage of removing rain from a single image, a guided filter [17] is introduced as a general tool for image prior representation, decomposing the rain image into low-frequency part (LFP) and high-frequency part (HFP). Subsequently, Xu et al. [18], Zheng et al. [19], Ding et al. [20], Kim et al. [21] utilized the characteristics of rain streaks and different guided filtering methods to remove rain from a single rain image, achieving preliminary success. However, there are still issues such as leaving obvious rain streaks and missing background details, so there is room for further performance improvement in this method.
Broadly speaking, we consider an image with rain to be composed of clear background layers and rain layers:
B represents the background layer, which is the target image to be obtained; S represents the rainmark layer; O represents the input image with rain marks, so the problem of removing rain can be expressed as an image decomposition problem based on dictionary learning and sparse representation. Therefore, later scholars no longer only rely on different guided filtering methods to remove rain from a single rain image, but began to study the physical properties of rain streaks themselves (such as sparsity and Self-similarity), and introduced them into the deraining model as prior information, thus realizing the reconstruction of rainless images.
Kang et al. [22,23] first decomposed the image into high-frequency and low-frequency components using Bilateral filter, and then decomposed the high-frequency components into "rain component" and "no rain component" through dictionary learning and sparse coding, deleting the rain component from the image, and retaining most of the original image details. This algorithm focuses on training in the high frequency layer rather than the image domain, so it has the advantages of reducing computing resources and no interference in the low frequency layer. However, this method is very time-consuming, and because it relies too much on the preprocessing of Bilateral filter, the background is usually fuzzy, so there is still room for further optimization of performance.
In order to further obtain a clear background layer, we comprehensively explored more inherent properties of the background and raindrops, and regularized them to constrain the solution space. The classic methods include (1) low rank appearance induced by non local similarity of raindrops [24]; (2) Gaussian Mixture model (GMM) to calculate the distribution of rain streaks at different scales and directions [25,27]; (3) A sparse representation model based on some learning rain atoms [26]. Although these methods have modeled and referenced both rain streaks and background layers, they can only handle light rain streaks, making it difficult to handle heavy or sudden rain streaks, and there is still a problem of time-consuming processing.
We have studied these model driven methods and found that although incorporating physical prior information about rain patterns and background layers can help achieve rain image reconstruction, these prior information is usually subjective and incomplete, making it difficult to fully transfer existing prior knowledge in real rain images [27,28,29]. Especially, the rain maps obtained from real scenes are often complex and variable, so the performance of directly establishing models for removing rain is always unsatisfactory. Therefore, data-driven deep learning deraining algorithms have become the latest trend in deraining tasks.
2.2. Data-driven Methods
With the development of deep learning theory and technology, data-driven single image deraining methods are becoming increasingly popular. These methods automatically extract features from the dataset through network structures, thereby achieving mapping from rain images to deraining images.
Since 2013, Eigen et al. [30] trained a special CNN by minimizing the mean square deviation between predicted rain and no rain image blocks, and for the first time used deep learning methods to remove raindrops attached to images. To this day, many CNN based image denoising deep networks have been proposed [16,28,31]. Usually, in these deep neural networks, constraints related to rainfall, such as rainfall masks and background features, are added to the network to learn features more comprehensively. Later, some methods utilized cyclic networks and residual networks [6] to gradually remove raindrops, which streamlined the network structure and reduced network parameters.
However, due to the difficulty in obtaining paired real rain maps and rainless images, there are differences between synthetic rain maps and real rain maps. Previous deraining algorithms may result in certain performance deviations when directly applied to real rain maps. To address the above issues, experts have considered introducing unsupervised and semi supervised methods in image deraining networks.
Semi-Supervised Learning is to use both unlabeled data and labeled data for learning. For example, Wei et al. [27] proposed SIRR. The network simulates the real rain residue through the likelihood term applied to the Gaussian Mixture model, and minimizes the KullbackLerbler divergence between the synthetic rain and the real rain distribution; Yasala et al. [32] proposed Syn2real (GP), which uses Gaussian process to model the potential features of rain images and create false labels for unlabeled data; Huang et al. [8] proposed MOSS, which uses a memory oriented decoder encoder network to learn rainfall patterns and restore rainless background images. These methods improve the generalization ability of the deraining algorithm by jointly mining the features of rain streaks from real and synthetic data using different methods.
Unsupervised learning means that it does not rely on the marked data and directly models the input data. The unsupervised algorithm in the deraining algorithm is implemented by introducing the Generative adversarial network (GAN) Zhu et al. [34] proposed an unsupervised end-to-end adversarial deraining network, RainRemoval GAN (RR GAN), which can generate real rain free images using only unpaired images. The network mainly includes a multi-scale attention memory generator and a multi-scale attention discriminator, and its architecture is still similar to the supervised GAN method; Jin [33] proposed another unsupervised Generative adversarial network (UD-GAN), which introduced self supervision constraints into the internal statistical information of unpaired rain and clean images. It uses two mutually cooperative modules, namely, the background guidance module (BGM) and the rain guidance module (RGM), where RGM is used to distinguish between real rain free maps and fake rain free maps generated based on BGM, BGM uses a hierarchical Gaussian blur gradient error to ensure the background consistency between the rain map input and the deraining output.
Afterwards, there were also unsupervised algorithms such as DerainCycleGAN [7] which greatly solved the problems of difficulty in obtaining paired real rain images and rainless images, as well as poor generalization ability of algorithms based on synthetic images. However, there are still problems such as overly complex networks, time-consuming training, and insufficient rain pattern removal.
Although these data-driven methods can effectively remove some rain streaks, they cannot remove all rain streaks in complex situations such as rainstorm. At the same time, these methods are also difficult to fully protect the structural information of the image, and even introduce new artifacts in the reconstructed image. Therefore, a method that is simple and efficient, removes a large number of raindrops, protects object structures, and improves generalization ability is crucial.
3. Proposed Work
In this section, we introduce the overall network architecture of the algorithms in this paper. We first describe the proposed residue channel prior (RCP) implementation details. Then We show the structure of progressive recurrent network (PReNet) as a backbone network. Finally, we propose methods for fusing high-dimensional features of the RCP.
3.1. Residue-Progressive Recurrent Network
As shown in Figure 2, R-PReNet consists of two main parts: (i) the RCP feature extraction and fusion module, and (ii) the progressive recurrent network. We first extract and fuse image features and RCP features from the rainy image. Then we concatenate the fused features with image features. The components of our method are described in detail in the following sections.
3.2. Residue Channel Prior (RCP)
The occurrence of rain streaks is usually modeled as a linear combination of a background layer and a rain layer [16,24,36,37]. Based on this model, Li et al [9] demonstrated that subtracting the minimum color channel from the maximum color channel will generate a rain-free image. Rain streaks are colorless (white or grey) and appear at the same location in different RGB color channels. So subtracting the minimum color channel from the maximum color channel will cancel the appearance of rain streaks as in Figure 3.
The colored-image intensity of a rainy image is defined [9] as:
where L is the color vector of luminance and B is the color vector of background reflection.
In the model (Eq. (2)), the first term is the rain streak term and the second term is the background term. and are defined the chromaticities of L and B. T is the exposure time and τ is the time for the raindrop to pass through pixel x. consists of the refraction coefficients of the raindrop, the specular reflection coefficients, and the internal reflection coefficients. We assume that is wavelength independent, which implies that the raindrop is colorless.
As a consequence, we need to cancel the light chromaticity σ in the rain-streak term in Eq. (2) to generate a residual channel without rain streaks. To do so, we use any existing color constancy algorithm [38] to estimate σ, and then apply the following normalization step to the input image.
where, , , .
Vector division is done element-wise. Note that when we normalize the image, we cancel not only the light chromaticity but also the color effect of spectral sensitivity.Hence, according to the previous equation and a rainy image I, the residual channel is defined as:
where,
is the residual channel of the image I, which has no rain streaks.
3.3. RCP High-Dimensional Feature Extraction
Although the operation of subtracting a color channel from another color channel in the image space is useful and the structural information of the RCP is clearer than the rainy image, it can be destructive to the background image because of information loss. Therefore, we move the operation that utilizes the RCP structural information to the feature domain. We propose the RCP feature extraction module to extract the high dimensional features of RCP.
Based on the Squeeze-and-Excitation (SE) block proposed by Hu et al [14], which focuses on channel relationships to construct informative features, this residual block adaptively recalibrates the channel feature responses by explicitly modeling the interdependencies between channels. Since the RCP module is a module that uses color channels to interact with each other, in order to reduce the noise in the initial features and enrich the semantic information of the features, we use the SE-ResBlock structure shown in Figure 4 to extract the high dimensional features Fp of the RCP.
3.4. Interactive Fusion Features
We extract the high dimensional features of RCP, but it is still a challenging task that fully utilize the RCP features to guide the model.
A simple solution is directly concatenating RCP features with image features, but this is ineffective for guiding model deraining and may cause feature interference. To address this problem, we propose an interactive fusion module (IFM) [39] consisting of two branches (rainy image features and prior features) to progressively combine features. As shown in Figure 5, two 3 × 3 kernel-sized convolutions are performed to map the rainy image features Fo and RCP features Fp to and .
Next, the similarity map S between and is computed using element multiplication:
The background information of the rainy image corrupted by the rain streaks is enhanced using the similarity map S. In addition, since the background of the RCP is similar to the rainy image, the similarity map S can also highlight the feature information in the priori features, which further enhances the structure of the priori features.
3.5. Progressive Recurrent Network
The progressive recurrent network consists of the following four parts: (i) a convolutional layer receives network inputs, (ii) a recurrent layer propagates cross-stage feature dependencies, (iii) several residual blocks extracts the deep representation, and (ii) a convolutional layer outputs deconvolutional results. Where takes as input the current estimation , the rainy image y, and the concatenation of the background fusion prior features G. The recurrent layer we implement using convolutional Long Short-Term Memory (LSTM) because LSTM has experience advantages in image deraining, through which cross-stage feature dependencies can be propagated to facilitate rain streaks removal.
where , and are stage-invariant, the network parameters are reused in different stages. The recurrent layer takes and the recurrent state as inputs to stage t-1. By unfolding PreNet [6] with T recurrent stages, the deep representation of rain streak removal is favored by recurrent state propagation. The rain removal results from the intermediate stages of the network structure show that the accumulation of storm streaks can be gradually eliminated.
3.6. Loss Function
We employ negative SSIM loss [40] as our objective function. For a model with T stages, we have T outputs, , , …, , and we apply supervision only to the final output . The negative SSIM loss is:
where is the corresponding ground-truth clean image.
4. Experiments
Our model was trained on Ubuntu OS, NVIDIA GeForce GTX 3080Ti GPU using Pytorch framework in Python environment with 12GB of RAM. To validate the effectiveness of our model, we evaluated our method on three popular image-deraining synthetic datasets (Rain100H, Rain100L, Rain14000) and a real rainy images dataset (Practical_by_Yang) to evaluate our approach:
Figure 6.
Image deraining results tested in both synthetic and real datasets. The first column is the rainy image, the second column is the real rain-free image on the synthetic dataset (no example images on the real dataset), the third column is the deraining result of the PReNet algorithm, and the fourth column is the deraining result of the R-PReNet algorithm of this paper. It can be seen that R-PReNet can reconstruct the rain-free image with clearer background structure and reduce the introduction of artifacts.
Figure 6.
Image deraining results tested in both synthetic and real datasets. The first column is the rainy image, the second column is the real rain-free image on the synthetic dataset (no example images on the real dataset), the third column is the deraining result of the PReNet algorithm, and the fourth column is the deraining result of the R-PReNet algorithm of this paper. It can be seen that R-PReNet can reconstruct the rain-free image with clearer background structure and reduce the introduction of artifacts.



4.1. Experimental Setup
4.1.1. A Datasets
In this paper, we mainly use synthetic datasets and real datasets for evaluation. The synthetic image datasets include (1) Rain100L, where 200 pairs of images are used for training and 100 pairs of images are used for testing; (2) Rain100H has 200 synthetic images used for training and 100 images used for testing; and (3) Rain14000, which composed of training and test images with a ratio of 12600:1400 split. The real dataset consists of (1) the Practical_by_Yang dataset with 147 images without ground-truth; and (2) real rainy images from certain movie and television productions.
4.1.2. B Evaluation Indicators
In our experiments, for images with ground truth, we can evaluate each method by two commonly used quantitative metrics, the peak signal-to-noise ratio (PSNR) [41] and the structural similarity index (SSIM) [40]. For the images without ground truth (i.e., real dataset), we provide some visual results.
4.2. Ablation Study
4.2.1. A Effectiveness on RCP module
The first ablation study evaluates the performance of R-PReNet with experimental results with and without the RCP module, we train and test the networks with and without the RCP module and the baseline algorithms of JORDER [28] and RESCAN [31] on the datasets Rain100L, Rain100H, and Rain14000, respectively, and Table 1 shows the performance of the above algorithms on the quantitative results in PSNR and SSIM. Both quantitative and visual results show that the recurrent network with RCP module outperforms the network without RCP module and the baseline algorithm.
4.2.2. B Effectiveness on IFM module
To investigate the effectiveness of the feature fusion module, we compare two different network architectures: (a) with the RCP module, but the RCP high-dimensional features are directly connected with the rainy image features into the network, and (b) with the RCP module and the IFM module, which uses interactive fusion to combine the RCP high-dimensional features and the rainy image features together into the network. We train and test the networks with and without the IFM module and the baseline algorithms of JORDER [28], RESCAN [31], and PreNet [6] on the datasets Rain100L, Rain100H, and Rain14000, respectively, and Table 2 shows the quantitative results of the above algorithms in PSNR and SSIM. Both quantitative and visual results are that the recurrent network with IFM module outperforms the network without IFM module and the baseline network.
5. Conclusion
In this paper, we propose a progressive recurrent deraining network based on background protection. The experiments show that this algorithm can remove rain streaks and protect background information at the same time. In the pre-processing stage of the rainy image, we first extract the residual channel from the rainy image, and the extracted residual channel does not contain rain streaks, while the residual channel is used to extract high-dimensional features, and then we interactively fuse the extracted features with the rainy image features and then input into the progressive recurrent network. The input to the network of each generation is composed of the fused features, the reconstructed image of the previous generation, and the original rainy image. After generations of progressive recursion, the final rain-free image is produced. Comprehensive experimental evaluations show that our method outperforms the original algorithm on both synthetic and real rainy images.
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant 61305040 and the Higher Education Science Research Project of Shaanxi Higher Education Society of China under Grant XGH21062.
References
- Josi, M. Alehdaghi, R. M. O. Cruz and E. Granger, "Multimodal Data Augmentation for Visual-Infrared Person ReID with Corrupted Data," 2023 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 2023, pp. 1-10. [CrossRef]
- S. S. Chaturvedi, L. Zhang and X. Yuan, "Pay "Attention" to Adverse Weather: Weather-aware Attention-based Object Detection," 2022 26th International Conference on Streaks Recognition (ICPR), Montreal, QC, Canada, 2022, pp. 4573-4579. [CrossRef]
- J. Xiao, H. Long, R. Li and F. Li, "Research on Methods of Improving Robustness of Deep Learning Algorithms in Autonomous Driving," 2022 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 2022, pp. 644-647. [CrossRef]
- H. Tyagi, V. Kumar and G. Kumar, "A Review Paper on Real-Time Video Analysis in Dense Environment for Surveillance System," 2022 International Conference on Fourth Industrial Revolution Based Technology and Practices (ICFIRTP), Uttarakhand, India, 2022, pp. 171-183. [CrossRef]
- Z. Zhang, W. Lu, W. Sun, X. Min, T. Wang and G. Zhai, "Surveillance Video Quality Assessment Based on Quality Related Retraining," 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 2022, pp. 4278-4282. [CrossRef]
- D. Ren, W. Zuo, Q. Hu, P. Zhu and D. Meng, "Progressive Image Deraining Networks: A Better and Simpler Baseline," 2019 IEEE/CVF Conference on Computer Vision and Streaks Recognition (CVPR), Long Beach, CA, USA, 2019, pp. 3932-3941. [CrossRef]
- Y. Wei et al., "DerainCycleGAN: Rain Attentive CycleGAN for Single Image Deraining and Rainmaking," in IEEE Transactions on Image Processing, vol. 30, pp. 4788-4801, 2021. [CrossRef]
- H. Huang, A. Yu and R. He, "Memory Oriented Transfer Learning for Semi-Supervised Image Deraining," 2021 IEEE/CVF Conference on Computer Vision and Streaks Recognition (CVPR), Nashville, TN, USA, 2021, pp. 7728-7737. [CrossRef]
- Ruoteng Li, Robby T Tan, and Loong-Fah Cheong. Robust optical flow in rainy scenes. In Proceedings of the European Conference on Computer Vision (ECCV), pages 288–304, 2018. 2, 4.
- Ruoteng Li, Robby T Tan, and Loong-Fah Cheong. All in one bad weather removal using architectural search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Streaks Recognition, pages 3175–3185, 2020. 2.
- Ruoteng Li, Robby T Tan, Loong-Fah Cheong, Angelica I Aviles-Rivero, Qingnan Fan, and Carola-Bibiane Schonlieb.Rainflow: Optical flow under rain streaks and rain veiling effect. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7304–7313, 2019. 2.
- Q. Yi, J. Li, Q. Dai, F. Fang, G. Zhang and T. Zeng, "Structure-Preserving Deraining with Residue Channel Prior Guidance," 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 2021, pp. 4218-4227. [CrossRef]
- X. Zhong, O. Gong, W. Huang, L. Li and H. Xia, "Squeeze-and-Excitation Wide Residual Networks in Image Classification," 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 2019, pp. 395-399. [CrossRef]
- Hu, Jie et al. “Squeeze-and-Excitation Networks.” 2018 IEEE/CVF Conference on Computer Vision and Streaks Recognition (2017): 7132-7141.
- Yang W, Tan R T, Feng J, et al. Deep joint rain detection and removal from a single image[C]//Proceedings of the IEEE Conference on Computer Vision and Streaks Recognition. 2017: 1357-1366.
- Fu X , Huang J , Zeng D , et al. Removing Rain from Single Images via a Deep Detail Network[C]// 2017 IEEE Conference on Computer Vision and Streaks Recognition (CVPR). IEEE Computer Society, 2017.
- He K, Sun J, Tang X (2010) Guided image filtering. European Conf. on Comput. vision, pp 1–14.
- Xu J, Zhao W, Liu P, Tang X (2012) Removing rain and snow in a single image using guided filter. IEEE Int. Conf. on Comput. Sci. and Automation Eng, pp 304–307.
- Zheng X, Liao Y, Guo W, Fu X, Ding X (2013) Single-image-based rain and snow removal using multi-guided filter. Neural Inform. Process, pp. 258–265. [CrossRef]
- Ding X, Chen L, Zheng X, Huang Y, Zeng D (2016) Single image rain and snow removal via guided L0 smoothing filter. Multimed Tools Appl 75(5):2697–2712. [CrossRef]
- Kim JH, Lee C, Sim JY, Kim (2013) Single-image deraining using an adaptive nonlocal means filter. IEEE Int. Conf. on Image Process, pp 914–917.
- Kang L, Lin C, Fu Y (2012) Automatic single-image-based rain streaks removal via image decomposition. IEEE Trans Image Process 24(4):1742–1755. [CrossRef]
- Kang L, Lin C, Lin C, Lin Y (2012) Self-learning-based rain streak removal for image/video. IEEE Int Symp Circuits Syst 57(1):1871–1874. [CrossRef]
- Luo Y, Xu Y, Ji H (2015) Removing rain from a single image via discriminative sparse coding. IEEE Int. Conf. on Comput. Vision, pp 3397–3405.
- Li Y, Tan RT, Guo X, Lu J, Brown MS (2016) Rain streak removal using layer priors. IEEE Conf. on Comput. vision and streaks recognition.
- Gu S, Meng D, Zuo W, Zhang L (2017) Joint convolutional analysis and synthesis sparse representation for single image layer separation. IEEE Int. Conf. on Comput. Vision, pp 1717–1725.
- Wei W, Meng D, Zhao Q, Xu Z, Wu Y (2019) Semi-supervised transfer learning for image rain removal. In Proc. of the IEEE Conf. on Comput. vision and streaks recognition, pp 3877–3886.
- Yang W, Tan RT, Feng J, Liu J, Guo Z, Yan S (2017) Deep joint rain detection and removal from a single image. IEEE Conf. on Comput. vision and streaks recognition, pp 1685–1694.
- Mu P, Chen J, Liu R, Fan X, Luo Z (2018) Learning bilevel layer priors for single image rain streaks removal. IEEE Signal Process Lett 26(2):307–31. [CrossRef]
- Eigen D,Krishnan D,Fergus R.Restoring an image taken through a window covered with dirt or rain [C]//Proc of IEEE International Conference on Computer Vision.Washington DC:IEEE Computer Society, 2013: 633-640.
- Li Xia,Wu Jianlong,Lin Zhouchen, et al. Recurrent squeeze-and-excitation context aggregation net for single image deraining[C]//Proc of the 15th European Conference on Computer Vision. Cham: Springer, 2018: 262-277.
- Rajeev Yasarla, Vishwanath A Sindagi, and Vishal M Patel.Syn2real transfer learning for image deraining using gaussian processes. In IEEE/CVF Conference on Computer Vision and Streaks Recognition, pages 2726–2736, 2020.
- Jin Xin,Chen Zhibo,Lin Jianxin, et al. Unsupervised single image deraining with self-supervised constraints[C]//Proc of IEEE International Conference on Image Processing.Piscataway, NJ: IEEE Press,2019: 2761-2765.
- Zhu H , Peng X , Zhou J T , et al. Singe Image Rain Removal with Unpaired Information: A Differentiable Programming Perspective[C]// 2019:9332-9339.
- R. Li, R. T. Tan, and L.-F. Cheong. Robust optical flow in rainy scenes. In The European Conference on Computer Vision (ECCV), September 2018.
- W. Yang, R. T. Tan, J. Feng, J. Liu, S. Yan, and Z. Guo.Joint rain detection and removal from a single image with contextualized deep networks. IEEE transactions on streaks analysis and machine intelligence, 2019. [CrossRef]
- L. W. Kang, C. W. Lin, and Y . H. Fu. Automatic single-image-based rain streaks removal via image decomposition.IEEE Transactions on Image Processing, 21(4):1742–1755,April 2012. [CrossRef]
- Cheng, D., Prasad, D.K., Brown, M.S.: Illuminant estimation for color constancy: why spatial-domain methods work and the role of the color distribution. JOSA A 31(5), 1049–1058 ,2014.
- Yuchen Hu, Nana Hou, Chen Chen, Eng Siong Chng. Interactive Feature Fusion for End-to-End Noise-Robust Speech Recognition. ICASSP 2022: 6292-6296.
- Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P . Simoncelli.Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing,13(4):600–612, 2004. 3, 5. [CrossRef]
- Q. Huynh-Thu and M. Ghanbari. Scope of validity of psnr in image/video quality assessment. Electronics letters, 44(13):800–801, 2008. 6. [CrossRef]
Figure 1.
Image deraining in the real world. PReNet [6] and R-PReNet were trained on RainTrainH. This image shows that R-PReNet can effectively remove rain streaks while retaining better background textures and maintaining the basic tone of the original image.
Figure 1.
Image deraining in the real world. PReNet [6] and R-PReNet were trained on RainTrainH. This image shows that R-PReNet can effectively remove rain streaks while retaining better background textures and maintaining the basic tone of the original image.

Figure 2.
The overall structure of Residue-progressive recurrent network (R-PReNet), where (a) shows the overall network framework of R-PReNet; (b) shows progressive recurrent network composition in R-PReNet, where is a convolutional layer with ReLU, is a recursive ResBlocks, is a convolutional layer, is a convolutional LSTM, is a connectivity layer; (c) is the RCP fusion feature module.
Figure 2.
The overall structure of Residue-progressive recurrent network (R-PReNet), where (a) shows the overall network framework of R-PReNet; (b) shows progressive recurrent network composition in R-PReNet, where is a convolutional layer with ReLU, is a recursive ResBlocks, is a convolutional layer, is a convolutional LSTM, is a connectivity layer; (c) is the RCP fusion feature module.
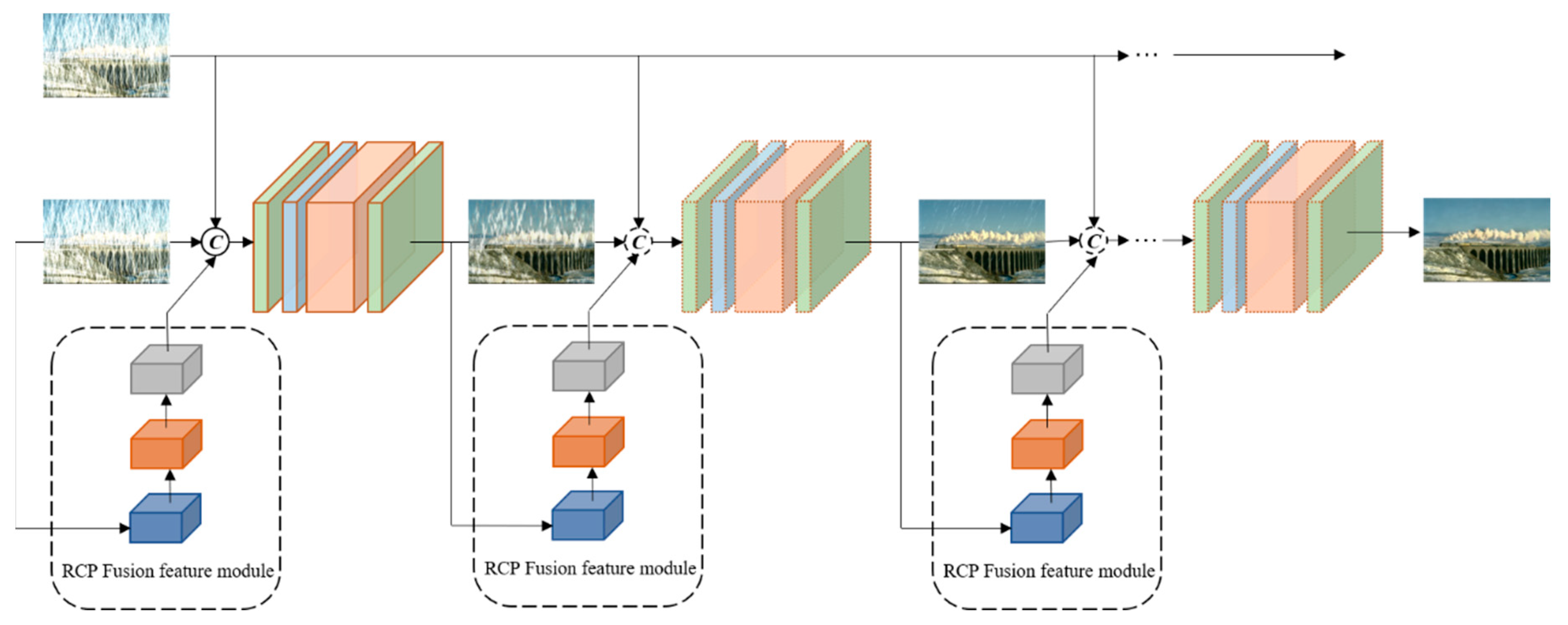
Figure 3.
RCP Extraction Module.
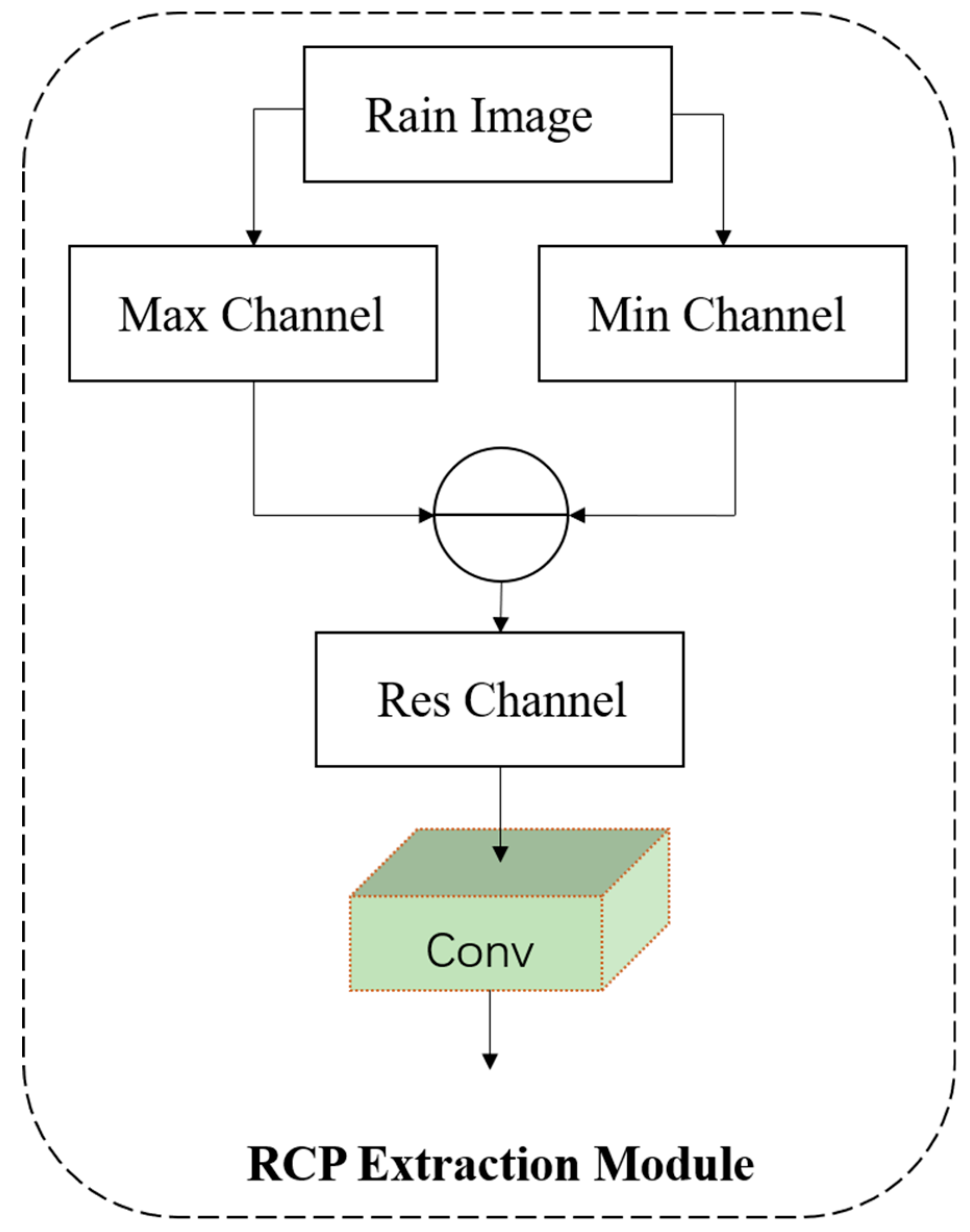
Figure 4.
SE-ResBlock Module.
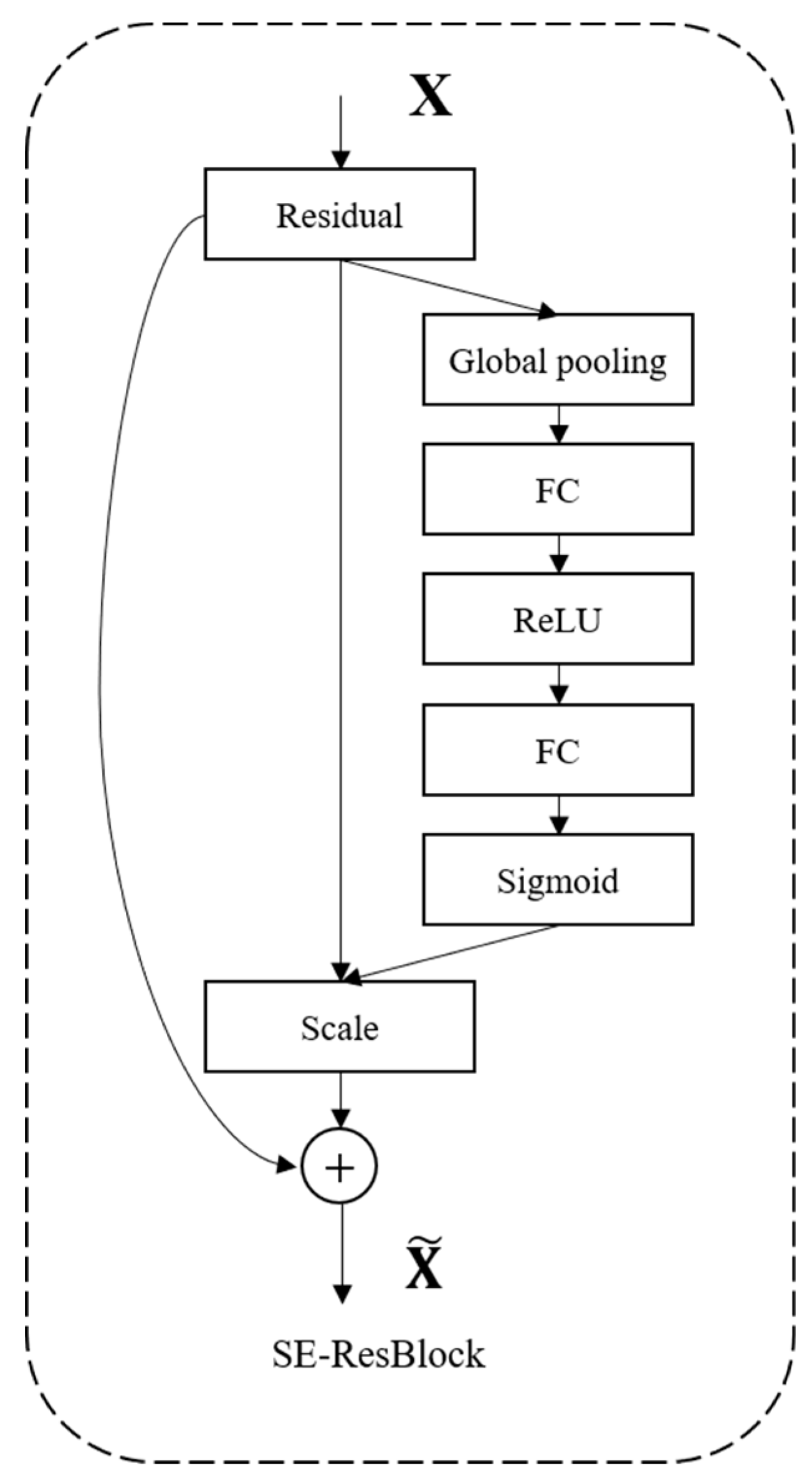
Figure 5.
Interactive Fusion Feature Module.
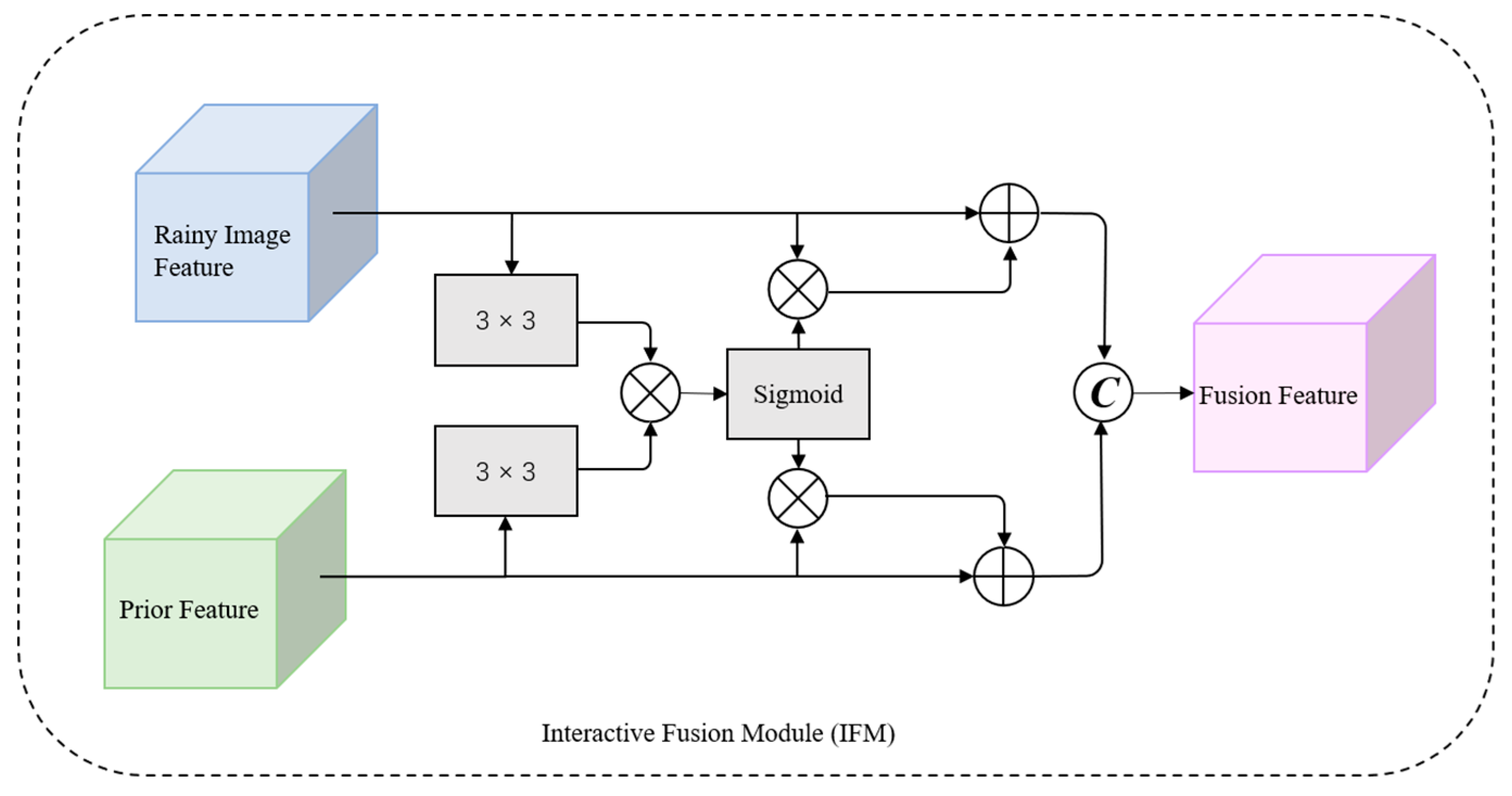

Table 1.
Performance comparison of synthetic datasets on network structure with and without RCP module.
Table 1.
Performance comparison of synthetic datasets on network structure with and without RCP module.
| Methods. | PReNet | R-PReNet | JORDER [28] | RESCAN [31] |
|---|---|---|---|---|
| Rain100H | 29.46/0.899 | 30.76/0.916 | 26.54/0.835 | 28.88/0.866 |
| Rain100L | 37.48/0.979 | 38.87/0.984 | 36.61/0.974 | --- |
| Rain14000 | 32.60/0.946 | 33.03/0.963 | --- | --- |
Table 2.
Performance comparison of synthetic datasets with and without IFM module network structure.
Table 2.
Performance comparison of synthetic datasets with and without IFM module network structure.
| Methods | PReNet | R-PreNet (no IFM) |
R-PreNet | JORDER [28] | RESCAN [31] |
|---|---|---|---|---|---|
| Rain100H | 29.46/0.899 | 29.86/0.901 | 30.76/0.916 | 26.54/0.835 | 28.88/0.866 |
| Rain100L | 37.48/0.979 | 37.67/0.967 | 38.87/0.984 | 36.61/0.974 | --- |
| Rain14000 | 32.60/0.946 | 32.89/0.954 | 33.03/0.963 | --- | --- |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



