Submitted:
27 September 2023
Posted:
28 September 2023
You are already at the latest version
Abstract
The work of this paper presents multiple novel findings from a comprehensive analysis of about 150,000 tweets about exoskeletons posted between May 2017 and May 2023. First, findings from content analysis and temporal analysis of these tweets reveal the specific months per year when a significantly higher volume of Tweets was posted and the time windows when the highest number of tweets, the lowest number of tweets, tweets with the highest number of hashtags, and tweets with the highest number of user mentions were posted. Second, the paper shows that there are statistically significant correlations between the number of tweets posted per hour and different characteristics of these tweets. Third, the paper presents a multiple linear regression model to predict the number of tweets posted per hour in terms of these characteristics of tweets. The R2 score of this model was observed to be 0.9540. Fourth, the paper reports that the 10 most popular hashtags were #exoskeleton, #robotics, #iot, #technology, #tech #innovation, #ai, #sci, #construction and #news. Fifth, sentiment analysis of these tweets was performed using VADER and the DistilRoBERTa-base library. The results show that the percentage of positive, neutral, and negative tweets were 46.8%, 33.1%, and 20.1%, respectively. The results also show that in the tweets that did not express a neutral sentiment, the sentiment of surprise was the most common sentiment. It was followed by the sentiments of joy, disgust, sadness, fear, and anger. Furthermore, analysis of hashtag-specific sentiments revealed several novel insights, for instance, for almost all the months in 2022, the usage of #ai in tweets about exoskeletons was mainly associated with a positive sentiment. Sixth, text processing-based approaches were used to detect possibly sarcastic tweets and tweets that contained news. Finally, a comparison of positive tweets, negative tweets, neutral tweets, possibly sarcastic tweets, and tweets that contained news, in terms of different characteristic properties of these tweets are presented. The findings reveal multiple novel insights, for instance, the average number of hashtags used in tweets that contained news has considerably increased since January 2022.
Keywords:
Twitter
; Data Analysis
; Big Data
; Exoskeletons
; Data Science
; Text Analysis
; Sentiment Analysis
; Content Analysis
; Natural Language Processing
1. Introduction
Social media platforms represent a category of web-based applications that rest upon the foundational concepts and technical frameworks of Web 2.0. They facilitate the creation and dissemination of user-generated content. These platforms offer users a seamless way to connect, communicate, and collaborate in a virtual manner. Social media platforms are inherently digital i.e. they reside entirely on the internet or on mediums or servers that are directly connected to the internet [1]. Social media encompasses various social networking platforms such as Twitter, Facebook, Instagram, TikTok, YouTube, Sina Weibo, and Snapchat [2]. Despite the emergence of numerous social networking platforms in recent times, they all share a common underlying structure rooted in Web 2.0 technologies. This implies that they are built upon an internet framework that enables numerous users to cooperate in producing and disseminating content. Users on such platforms are not merely consumers of digital content on the web; they actively participate in its creation and dissemination. Social media stands in stark contrast to traditional Web 1.0. Social networking platforms set themselves apart from previous online networks and interaction tools by being more open, inclusive, adaptable, resilient, and innovative [3,4].
The popularity of social media platforms has been on an exponential rise in recent times. On a daily basis, considerable volumes of user-generated content get uploaded on different social media platforms. This trend is projected to increase in the next few years. At present, approximately 4.9 billion people on a global scale are actively engaged with social media, and it has been predicted that this figure will rise to 5.85 billion by the year 2027. On average, a user of social media has approximately 8.4 social media accounts and dedicates roughly 145 minutes each day to various social media platforms. Out of different social media platforms, Twitter has been highly popular amongst users of different age groups [5,6]. At the same time, the ubiquitousness of Twitter makes it a rich resource for drawing insights related to multimodal components of conversations on emerging technologies such as exoskeletons.
1.1. An Overview of Twitter: a Globally Popular Social Media Platform
On a global scale, Twitter is the 7th most popular social media platform and has maintained its position since 2021, while other comparable platforms, such as WhatsApp and Instagram, have declined in popularity [7]. At the same time, Twitter is the 6th most popular social media platform in the United States. As of 2023, Twitter is the 4th most visited website in the world and had 7.1 billion visitors [8,9]. As of March 2023, there were 450 million active monthly Twitter users [9]. The United States has the most active Twitter users at 64.9 million, while Japan and Brazil have the second and third most active Twitter users at 51.8 million and 16.6 million, respectively. Regionally, North America has the largest number of active Twitter users at 71.7 million, while Central America follows closely at 14.4 million users [10]. Twitter also serves as a platform for people of a variety of age groups to connect with each other, and Gen Z is among the fastest-growing age groups of Twitter users [11].
In the United States, 42.3% of users use Twitter at least once a month [12]. On average, Twitter users spend around 5 hours a month on the social media platform. This is equivalent to approximately ten minutes per day. Twitter also serves as a source of information for many users. Approximately one-fifth of Twitter users under 30 years old use Twitter to stay up to date on their topics of choice. Moreover, 55% of Twitter users use the social media platform as a news source, and 96% use the platform monthly [8]. Of the Twitter users that utilize the platform as a source of news, 57% maintain that the platform has expanded their knowledge of current world events. In addition to using Twitter to stay informed on current events, people use the platform to discover new products and services. A staggering 89% of people consult Twitter when discovering new products and services, and 79% of users have purchased something based on their conversations on the platform [7]. Regarding advertisements on Twitter, content considered “relatable," or trendy material referencing recent culture and news, and educational content have the highest Return on Investment (ROI), and advertisements on Twitter also have a 40% higher ROI than advertisements posted on other social media platforms.
Therefore, mining and analysis of Tweets for understanding the underlying patterns of public disclosure have been very popular with researchers from different disciplines, as can be seen from recent works that focused on the analysis of Tweets related to emerging technologies, matters of global interest, and topics of global concern such as ChatGPT [13,14], the Russia–Ukraine war, [15,16] cryptocurrency markets [17,18], virtual assistants [19], abortions [20,21], loneliness [22,23], housing needs [24,25], fake news [26,27], religion [28,29], early detection of health-related problems [30,31], elections [32,33], education [34,35], pregnancy [36,37], food insufficiency [38,39], and virus outbreaks such as MPox [40,41], flu [42,43], H1N1 [44,45] and COVID-19 [46,47]. At the same time, researchers in this field have also focused on the analysis of tweets about various industries (discussed in Section 2.1). However, exoskeleton technology, an emerging industry and field of research, has not been the focus of any prior work in this field.
1.2. Exoskeleton Technology and its Emergence: A Brief Overview
A robotic exoskeleton can be broadly defined as a wearable electromechanical device, or a wearable robotics-based solution designed primarily to enhance the physical performance, endurance, and abilities of the person wearing it [48]. The specific design, functionality, operation, and maintenance of these exoskeletons vary depending on their intended application [49]. In a generic manner, exoskeletons can be categorized into upper-limb exoskeletons and lower-limb exoskeletons [50,51]. Lower limb exoskeletons represent mechatronic systems that aid in walking, standing, and performing similar movements. The Berkeley exoskeleton system (BLEEX) served as an early model, prioritizing safety and anthropomorphic design, albeit with simplified rotary joints [52]. Some recent examples of lower limb exoskeletons include the Hybrid Assistive Limb (HAL) exoskeleton, the EKSO exoskeleton [53], and the LOKOMAT exoskeleton [54]. Upper limb exoskeletons are electromechanical systems that are designed to interact with the user for the purpose of power amplification, assistance, or substitution of motor function [55]. A couple of examples of upper limb exoskeletons are Trackhold [56] and AmrmeoSpring [57], which have applications related to dynamic tracking and gravitational correction.
Exoskeletons have been developed for specific body parts or joints in recent years. These include exoskeletons for knee [58], shoulder [59], elbow [60], ankle [61], waist [62], hip [63], neck [64], spine [65], wrist [66], and index finger [67] exoskeletons. The rapid advancement of exoskeleton technology is driven by its diverse range of applications and use cases. Some of these applications include assisting older adults and individuals with disabilities in their daily tasks, enhancing productivity and reducing fatigue in the military, improving the quality of life for amputees or those with paralysis in healthcare, aiding firefighters in climbing and lifting heavy equipment, increasing labor productivity, and assisting in the transportation of heavy machinery in Industry 4.0 settings [68,69,70].
As of 2022, the exoskeleton market was valued at approximately USD 334.5 million and this market is expected to grow at a rate of 16.9% every year, at least until 2030 [71,72]. Looking at the exoskeleton market through the lens of mobility, the majority portion is occupied by mobile exoskeletons, which accounted for 61.4% of the market value in 2022. Mobile exoskeletons allow users to walk soon after neurological surgery, which would not be possible in general. It allows people to stand and walk around and simulate regular human movements, which a wheelchair does not permit. Mobile exoskeletons can also be used to assist reluctant walkers and runners in the form of a lower-body exoskeleton. It allows users to carry out day-to-day activities more easily and boosts confidence to move around [75,76]. Through the technology lens, on the other hand, the powered segment accounted for the highest portion of revenue – 73.9% in 2022. When it comes to extremities, the most common exoskeleton type is the lower-body exoskeleton, making up 42.7% of the revenue share in 2022. Based on the end-use segment, the healthcare segment was the principal sector, accounting for 50.6% of the revenue share in 2022. As for regions, North America dominated the market, accounting for 46.5% of revenue share in 2022. This can be attributed to the fact that North America has high investments in healthcare, both by private and government entities [71]. The healthcare sector remains the chief consumer of exoskeletons. Specifically, healthcare makes up 50.6% of the revenue, the largest share in end-use [71]. One of the most significant use cases of exoskeletons is to help with spinal cord injuries. Exoskeletons serve as better alternatives to wheelchairs for people with spinal cord injuries as they have a positive impact on several aspects of health [73,74].
Thus, to summarize, the wide range of emerging use cases of exoskeletons in different domains contributes to a significant buzz about this technology on social media platforms, such as Twitter. No prior work in this area of research has analyzed Tweets about exoskeletons to interpret the underlying patterns of information and communication exchange. Furthermore, there hasn’t been a study to infer the paradigms of user sentiments and trends of the same associated with exoskeleton technology. Addressing this research gap serves as the main motivation for this work. The rest of this paper is organized as follows. A comprehensive review of recent works in this field is presented in Section 2. Section 3 discusses the methodology that was followed for this work. The results and novel findings of this work are presented in Section 4, which is followed by the conclusion in Section 5.
2. Literature Review
This section is divided into two parts. In Section 2.1, an overview of the recent advances in the mining and analysis of Tweets that focused on different industries and interdisciplinary applications is presented. Section 2.2 discusses works in this area of research that specifically focused on the investigation and exploration of Tweets about robotics and wearable robotics-based solutions.
3.1. Review of Analysis of Tweets focusing on different Industries and Interdisciplinary Research
Kamiński et al. [78] performed sentiment analysis along with like count and retweets to follower ratio investigation of 33,890 tweets about COVID-19 and smoking. The findings showed that there was a less negative attitude associated with tweets about smoking in April 2020 compared to that of January 2020 through March 2020. This work suggested that blogs published regarding the advantages of smoking towards COVID-19 had influenced the responses of the Twitter community in a way that risks supporting smoking. Utilizing a similar method of analysis, the case study by Souza et al. [79] sought to find the relations between Twitter sentiments from specific retail brands and the associated market data. The results of this analysis indicated that social media platforms proved beneficial to the retail industry. The work by Pons et al. [80] studied the sentiment associated with the CSR (Corporate Social Responsibility) of the leather industry, which faced lashback due to the lack of communication about their CSR. The authors found that the overall attitude towards the leather industry was neutral. Leung et al.’s [81] study examined two social media platforms, Facebook and Twitter, to better understand the marketing strategies of the hotel industry and proposed a method for marketing on social media. Misopoulos et al. [82] identified various aspects of customer service in the airline industry that consumers found positive or negative by analyzing 67,953 tweets. Shukri et al. [83] performed sentiment analysis of Tweets about the automotive industry. The work focused on specific car brands: Mercedes, Audi, and BMW. The results indicated that the sentiment of joy was associated with BMW and the sentiment of sadness was associated with Audis and Mercedes.
By gathering over 10,000 posts from both Facebook and Twitter for two books, Criswell et al. [84] compared the social media activity for the two titles to Nielsen BookScan’s sales data. The analysis demonstrated that marketing through social media was beneficial to authors who already had a readership and was less effective for those authors who lacked one. Similarly, Parganas et al. [85] inspected how social media marketing was affected by Twitter engagement features. To understand the correlation between the engagement of top e-commerce organizations on Twitter and their financial ranking, Paredes-Corvalan et al. [86] analyzed 22,400 tweets. Despite the results not showing a direct relationship between the two, it was still evident that the social media platform could be used to effectively increase relations and sales with consumers. Garcia-Rivera et al. [87] examined various Twitter engagement features by studying 95,000 tweets during the Consumer Electronics Show 2020. The results indicated that user mentions impacted engagement in the electronics industry. Wonneberger et al. [88] applied automated network and content analysis methods in order to analyze the role of citizens for counter-publics. The study of two Twitter debates on animal welfare showed how the social media platform’s features, such as hashtags, retweets, and user mentions, drive online activism. Aleti et al. [89] collected data regarding Twitter features such as follower counts and retweets from the brewing industry in Australia. The results indicated that breweries must employ Maven-like behavior on social media to influence the community on Twitter. Komorowski et al. [90] discussed the role of Twitter in communities of practice by examining different communities within Brussels.
In order to combat iPhone mobile waste when phones are at EOL, Ghanadpour et al. [91] discussed how Twitter could be used to determine defects in phones by analyzing the opinions of consumers, emphasizing the importance of customer input. Based on the analysis of screened Twitter posts, Durand-Moreau et al. [92] presented a commentary discussing how the platform can be used to understand the opinions of the community regarding the meatpacking industry. To investigate the relationship between fashion and a given city, almost 100,000 tweets were inspected using text analysis methods by Casadei et al. [93]. This resulted in an understanding of how each city was represented by social media users during two fashion weeks in 2018, allowing the authors to argue that social media platforms allow for a more diverse view of fashion due to the diversity of the population of users. Furthermore, the collection of tweets from six different actors representing alcohol brands was analyzed by Sama et al. [94]. The results highlighted multiple common arguments among the tweets which included liberalizing the alcohol policy in Finland. To summarize, analysis of tweets focusing on different industries has attracted the attention of researchers from different disciplines. While there hasn’t been any study conducted in this field thus far where tweets about exoskeletons were analyzed, there have been a few studies where researchers analyzed tweets about robotics and wearable robotics-based solutions. As an exoskeleton can be considered to be a wearable robotics-based solution, so a review of these works is presented in Section 3.2.
3.2. Review of Analysis of Tweets focusing on Robotics and Wearable Robotics-based Technologies
Cramer et al. [95] studied two different effects of social media on human-robot interactions. The first approach examined how robots can use and share information on social media by applying a Nabaztag, a rabbit-shaped Wi-Fi-enabled electronic device. The second analysis examined tweets sent to a robot-twitter account. Their research supported existing concerns about human-robot interaction related to the storage of data and personal information. Salzmann-Erikson et al. [96] analyzed 5954 tweets to further understand public opinion towards robots in healthcare. The authors sorted the tweets under three themes: absorbability, applicability, and availability. Tweets categorized under “absorbability” showed that care robots are an integral part of everyday lives. Tweets categorized under “applicability” showed care robots can be employed in a variety of areas. Tweets categorized under “availability” showed concern about how care robots will impact the economy. Fraser et al. [97] studied the emotions and sentiments of tweets before and after the demolition of hitchBOT, a conversational and immobile robot that traveled across the USA to Germany and the Netherlands. The authors discovered that the emotions of tweets in the countries the robot visited did not differ, but strong negative emotions were associated with tweets about the robot after its demolition. Mubin et al. [98] sought to understand public opinion and tweeting trends about the Nao robot, a humanoid robot from Aldebaran Robotics, by analyzing 235 English tweets from Twitter. The analysis indicated that the robot is associated with human characteristics and is often utilized in topics about research and education. In [99], the authors predicted that humanoid robots would eventually be integrated into people’s everyday lives by studying relevant tweets. They also proposed that humanoid robots could be used as service robots by suggesting the framework of Pepper, a humanoid robot that can complete receptionist tasks.
Mahmud et al. [100] analyzed the personality characteristics of Twitter users to build computational models that would predict their opinions on different brands. Yamanoue et al. [101] work primarily focused on analyzing tweets about people’s perspectives towards wearable solutions. Tussyadiah et al. [102] deduced five potential motivations for wearing such devices: exploration, adventure tourism, travel documentation, travel reporting, and positive transformation by analyzing tweets. Saxena et al. [103] explored the involvement of people with cochlear implants on social media platforms such as Facebook, Twitter, Youtube, and other online forums. The findings suggested that people with cochlear implants interacted with Facebook groups for information and support the most often but were involved in a variety of social media platforms as a method of support, advocacy, and other information. After observing an increase in search trends of “breast implant illness” on Google, Adidharma et al. [103] performed a thematic analysis about the text of tweets with the #breastimplantillness and identified many tweets that referenced diseases such as cancer and lymphoma. In [104], researchers studied tweets related to birth control implants, such as Nexplanon. Semantic analysis of these tweets suggested there had been an increase in positive and negative perceptions towards birth control. The work also indicated that many tweets about Nexplanon discussed the side effects of the implant. Keane et al. [106] sought to understand the public perception of treatment plans for breast implant-associated anaplastic large cell lymphoma by identifying possible misconceptions between medical professionals and patients through related tweet analysis. The findings suggested that a disconnect exists in understanding treatment options for the disease.
The rise of artificial intelligence and other robotics has increased people's concerns about their future employment. Sinha et al. [107] performed semantic analysis and sentiment analysis to understand public opinion about accepting robots into the workplace. The research supported existing technophobia in the workplace. El-Gayar et al. [108] analyzed tweets to understand the characteristics that impacted whether people decided to use wearable devices to help improve their well-being and health. The findings revealed that people favored devices that worked easily with other systems. In [109], the authors aimed to understand the important factors to consider when developing smart watches. They performed sentiment analysis on Twitter data to discern the emotional associations of smart watches and public perception of smart watches in Korea. Niininen et al. [110] investigated opinions and concerns on human subcutaneous chip implants by performing text analysis of relevant tweets. Their results indicated that many people are open to the possibilities of implants for health tracking or payment options.
As can be seen from this comprehensive review of recent works in this field, analysis of tweets on different topics including a wide range of emerging technologies has been of keen interest to researchers from different disciplines. However, none of these prior works focused on the analysis of tweets about exoskeletons. Addressing this research gap serves as the main motivation for performing this work.
3. Methodology
This section describes the step-by-step methodology that was followed for this research work. First of all, a relevant data set had to be selected. So, the dataset proposed in [111] that contains about 120,000 Tweet IDs of Tweets about exoskeletons, posted from 21 May 2017 to 21 May 2022, was used. The dataset in [111] was developed by using the Search Twitter operator within RapidMiner [112] and utilizing the Twitter API's Advanced Search functionality. RapidMiner is a data science platform that allows the design, development, and implementation of different algorithms in Big Data, Data Mining, Data Science, Artificial Intelligence, Machine Learning, and related disciplines. The Search Twitter operator in RapidMiner operates by establishing a connection with the Twitter API while adhering to the rate limits for accessing Twitter data according to Twitter's Standard Search regulations. The Advanced Search characteristic of the Twitter API can be accessed by a user when they are logged into twitter.com. It allows users to search for Tweets based on time stamps, keywords, and a set of data filters such as Tweets containing an exact phrase(s), Tweets containing any of the specified keywords, Tweets that exclude specific keywords, Tweets featuring a distinct hashtag, and Tweets in a particular language. After the collection of the Tweets using both these methodologies driven by a keyword-based approach, the duplicate Tweets were removed in [111]. The dataset complies with the FAIR (Findability, Accessibility, Interoperability, and Reusability) principles for scientific data management [114]. The standard procedure for working with such Twitter datasets is to perform hydration of the Tweet IDs. However, this dataset was developed by the first author of this paper, so all the Tweets were already available for analysis. In addition to that, to include more recent Tweets for the analysis of this work, the same methodology for data collection as discussed in [111] was utilized to collect Tweets about exoskeletons from May 22, 2022, to May 13, 2023. May 13, 2023, was the most recent date at the time of data collection. Thereafter, the newly collected data was merged with the existing tweets to develop a merged dataset for analysis. This dataset comprised 153045 Tweets about exoskeletons, which were posted on Twitter between May 21, 2017, and May 13, 2023. These Tweets were posted by a total of 84,716 distinct users. In addition to the text of the Tweets, the data also contained characteristics associated with these Tweets present as different attributes. Table 1 summarizes the same.
Thereafter, the tweeting behavior per hour was analyzed. To perform this, the data present in the “created_at” attribute was analyzed. The data in this attribute contained both date and time information. By using the concept of binning, 24 bins representing the 24 hours in a day were created and each Tweet was assigned a bin by extracting only the time information from this attribute. The pseudocode of the program that was written in Python 3.11.5 is shown in Algorithm 1. Using a similar approach as shown in Algorithm 1, the number of Tweets posted per month per year between May 2017 and May 2023 were also extracted to analyze the Tweeting patterns about exoskeletons in the last six years.
 |
Thereafter, different characteristics associated with these tweets were computed. These characteristics included the mean value of the total number of characters used per hour, the median value of the total number of characters used per hour, the number of hashtags used per hour, and the number of user mentions included in the tweets per hour. After calculating these characteristics, these features were assigned to the bins. As a result of this assignment, for each hour for all the tweets posted, the mean value of the total number of characters used, the median value of the total number of characters used, the number of hashtags used, and the number of user mentions present were compiled. Algorithm 2 shows the pseudocode of the program that was written in Python 3.11.5 to compute the mean and median value of the Tweets per hour. The pseudocode of the program to calculate hashtags and user mentions per hour is shown in Algorithm 3.
 |
 |
The flowchart shown in Figure 1 summarizes the working of the above-mentioned algorithms. After obtaining this master dataset for analysis, as shown in Figure 1, the correlations between these characteristics and the number of Tweets per hour were evaluated to deduce if those characteristics were statistically significant (p<0.05). After analyzing these correlations (using Pearson’s correlation coefficient) it was observed that all these characteristics i.e. mean value of characters used in the Tweets per hour, median value of characters used in the Tweets per hour, number of hashtags used per hour, and number of user mentions used per hour, had statistically significant relationships with the number of Tweets per hour (results are discussed in detail in Section 4). Thereafter, a multiple linear regression model was developed where mean value characters used in the Tweets per hour, median value of characters used in the Tweets per hour, the number of hashtags used per hour, and the number of user mentions used per hour were considered as the independent variables and the number of Tweets per hour was considered as the dependent variable. Algorithm 4 shows the pseudocode of the program that was written in Python 3.11.5 to determine these correlations as well as to develop the multiple linear regression model.
Thereafter, the focus of the investigation shifted towards hashtag-specific sentiment analysis. This was considered relevant for investigation primarily because prior works that focused on the investigation of Tweets for sentiment analysis (Section 2) did not determine a list of popular hashtags and their associated sentiments. However, determining a list of popular hashtags and their associated sentiments has been popular in the area of Natural Language Processing as can be seen from multiple recent works in this field that focused on hashtag-specific sentiment analysis of Tweets about COVID-19 [115], politics [116], and movies [117], just to name a few. To perform the same, at first the list of top 10 hashtags (in terms of the number of tweets posted) was determined. Then, the number of Tweets per hashtag (out of these top 10 hashtags) per month between May 2017 to May 2023 was computed to understand the trends of the same. Algorithm 5 shows the pseudocode of the program that was written in Python 3.11.5 to determine the top 10 hashtags.
 |
 
|
After obtaining the results from Algorithm 5, the VADER sentiment analysis approach was applied to the tweets. The subject of Sentiment Analysis can be explored using various methods, including manual categorization, Linguistic Inquiry and Word Count (LIWC), Affective Norms for English Words (ANEW), the General Inquirer (GI), SentiWordNet, and machine learning-based approaches like Naive Bayes, Maximum Entropy, and Support Vector Machine (SVM). However, the specific approach chosen for this study was VADER, which stands for Valence Aware Dictionary for Sentiment Reasoning [118]. The decision to opt for VADER as the sentiment analysis method is based on multiple factors. First and foremost, VADER has demonstrated exceptional performance, surpassing human labeling in terms of accuracy and effectiveness. Furthermore, VADER has been proven to overcome the limitations faced by other similar sentiment analysis techniques. The following provides a comprehensive overview of the distinct characteristics and features of VADER.
VADER sets itself apart from LIWC by displaying heightened sensitivity to sentiment expressions that commonly appear in the analysis of social media posts.
The General Inquirer lacks the inclusion of sentiment-relevant lexical elements frequently encountered in social communication. However, VADER effectively addresses this issue.
The ANEW lexicon exhibits reduced responsiveness to lexical elements typically associated with sentiment in social media content. This is not a limitation of VADER.
The SentiWordNet lexicon contains a significant amount of noise since a notable proportion of its synsets lack either positive or negative polarity. However, this does not represent a constraint or drawback of VADER.
The Naïve Bayes classifier relies on the assumption of feature independence, which is a simplistic assumption. Nonetheless, VADER's more nuanced approach overcomes this weakness.
The Maximum Entropy technique incorporates information entropy by assigning feature weightings without assuming conditional independence between features.
Both machine learning classifiers and verified sentiment lexicons face the challenge of requiring a substantial amount of training data.
Additionally, machine learning models depend on the training set to accurately represent a wide range of characteristics. The VADER approach distinguishes itself through its concise rule-based framework, enabling the creation of a specialized sentiment analysis engine tailored specifically for language found on social media platforms. The system demonstrates remarkable adaptability, capable of adjusting to different domains without the need for specific training data. Instead, it relies on a flexible, valence-based sentiment dictionary that has been validated by humans to serve as a reliable standard. The VADER system is renowned for its high efficiency since it can immediately analyze streaming data. The VADER approach was applied to every Tweet to classify it as positive, negative, or neutral. Thereafter, the hashtag-specific sentiment analysis was performed for each of the top 10 hashtags, and the trends in the tweets (positive, negative, and neutral) were analyzed. Algorithm 6 shows the pseudocode of the program that was written in Python 3.11.5 to compute the number of tweets per sentiment per hashtag (top 10 hashtags).
 
|
As can be seen in Algorithm 5, it calls the algorithm for Data Preprocessing. The data processing algorithm represented a program that was written to perform the necessary preprocessing of the Tweets prior to assigning a sentiment label (positive, negative, and neutral) to each Tweet.
 |
As Algorithm 7 has been called in multiple Algorithms that are presented in this paper, a step-by-step working of this Algorithm is shown in Figure 2.
Thereafter, text processing and text analysis-based approaches were used to detect potentially sarcastic Tweets as well as Tweets that could contain news in the context of conversations about exoskeletons. For developing the methodology for sarcasm detection, prior works based on text-processing were reviewed. It was observed that several works (for example: [119], [120], [121]) detected potentially sarcastic Tweets by either searching for “sarcasm” or “sarcastic” present in the form of words or hashtags in Tweets as sarcasm appears to be a commonly recognized concept by many Twitter users, who explicitly mark their sarcastic messages by using hashtags [122]. In addition to these approaches, another study in this field [123] was reviewed to understand lexical-based approaches for detecting sarcasm in Tweets. So, in this work, a combination of keyword-based, hashtag-based, and lexical analysis-based methodologies was utilized for detecting potentially sarcastic Tweets. These included hashtags or keywords such as “sarcasm”, “sarcastic”, “irony”, and “cynicism”; interjections such as “gee” and “gosh”; lexical expressions such as “not sure if you know this”; formulaic expressions such as “thanks a lot”, and “good job”; foreign terms such as “au contraire”; rhetorical statements such as “tell us what you really think” and specific combination of keywords such as “perfect just perfect”. The approach in this context also accounted for different character case (upper case or lower case) combinations of these criteria to track potentially sarcastic Tweets. The pseudocode of the program that was written in Python 3.11.5 to detect potentially sarcastic Tweets from the dataset is shown in Algorithm 8.
 |
As can be seen from Algorithm 8, the output of this program produced a set of Tweets in a .CSV which were potentially sarcastic Tweets. Thereafter, a similar approach was used to detect Tweets that contained news. A review of prior works [124,125] related to the detection of Tweets showed that researchers in this field have tracked the presence of “news” in hashtag form or in keyword form in Tweets to detect news communicated in different Tweets. So, the methodology in this work involved searching for “news” in hashtag form or in keyword form in the Tweets present in this dataset. The methodology also accounted for different character case (upper case or lower case) combinations in the keyword as well as in the hashtag. Algorithm 9 represents the pseudocode of the program that was written in Python 3.11.5 to detect Tweets that contained news.
 |
As can be seen from Algorithm 9, the output of this program produced a set of Tweets in a .CSV which contained news about exoskeletons. Thereafter, Algorithms 2 and 3 were run on the master dataset (shown in Figure 1), .CSV file containing sentiment labels for each Tweet (one of the outputs of Algorithm 6), .CSV file representing potentially sarcastic Tweets (output of Algorithm 8) and the .CSV file representing Tweets that contained news (output of Algorithm 9). The objective of running these algorithms on these tweets was to compare the Positive tweets, Negative tweets, Neutral tweets, Possibly Sarcastic tweets, and Tweets that contained News in terms of mean length of the tweets per month, median length of the tweets per month, the average number of hashtags used per month, and the average number of user mentions used per month, to interpret the underlying trends of the same.
 |
After performing this analysis, a fine-grain analysis of sentiments associated with these tweets about exoskeletons was performed. This analysis was performed using the DistilRoBERTa-base library [127] of Python. This library can categorize a given text into one of seven distinct classes of sentiments - anger, disgust, fear, joy, neutral, sadness, and surprise. As shown in Algorithm 10, a program was written in Python 3.11.5 that provided a score for each Tweet for each of these sentiment classes. Thereafter, the sentiment class that received the highest score was used to obtain the label for that tweet in terms of anger, disgust, fear, joy, neutral, sadness, or surprise. The results of running all these Algorithms on the dataset are presented in Section 4.
4. Results and Discussions
This section presents the results of this work and the novel findings from this study. As stated in Section 3, the number of Tweets about exoskeletons per month between 2017 and 2023 was calculated. Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9 represent the same.
It is worth noting that the histograms presented in Figure 3 and Figure 9 do not represent all the Tweets that were posted in the month of May during those respective years. This is because the dataset contains Tweets starting from May 21, 2017, and for May 2023, the dataset contains Tweets up to May 13, 2023. As can be seen from Figures 3 to 9, the tweeting patterns about exoskeletons between May 2017 and May 2023 were diverse, and the general public posted a considerable number of Tweets about exoskeletons in almost all the months between May 2017 and May 2023. However, certain months stand out in some of these Figures to represent a significantly higher volume of Tweets posted during that time. For instance, in 2019, the most number of Tweets about exoskeletons were posted in October, and the same pattern was again observed in 2022. In 2022, the least number of Tweets were posted in September. However, in none of the prior years (2017 to 2021), September was the month when the least number of Tweets were posted. Similarly, other insights about the tweeting behavior about exoskeletons can be observed in Figures 3 to 9. As the number of Tweets posted about a topic represents the degree of public interest towards that topic [126], these results serve as a framework for indicating the specific and varied levels of public interest towards exoskeletons from May 2017 to May 2023.
In Figure 10, the analysis of the output from Algorithm 1 is presented. Specifically, a histogram-based approach was used to determine the specific timeslots of 1-hour duration during different times of the day (24-hour format) when the most and least number of Tweets about exoskeletons were posted. In addition to this, the varying trends of posting Tweets in other timeslots are also presented in Figure 10.
As can be seen from Figure 10, the timeslots of 17 (representing the time window 16:01 to 17:00 in a 24-hour format) and 16 (representing the time window 15:01 to 16:00 in a 24-hour format) represent time windows when the highest number of Tweets about exoskeletons have been posted. Furthermore, this figure also shows that the timeslot of 6 (representing the time window from 5:00 to 6:00 in a 24-hour format) represents the time window when the least number of Tweets about exoskeletons have been posted. It is worth noting that these timeslots were prepared based on the dataset that contains the timestamps in Eastern Standard Time (EST). The outputs from Algorithm 2 are presented in Figure 11 and Figure 12, respectively. These two figures show the mean character count of the Tweets posted per hour (in a 24-hour format) and the median character count of the Tweets posted per hour (in a 24-hour format), respectively.
The results shown in Figure 11 and Figure 12 also help to reveal patterns of public discourse about exoskeletons during different time instants of the day. For instance, from Figure 11 it can be concluded that the time slot of 1 (representing the time window 00:01 to 01:00 in a 24-hour format) is the time range when the general public has posted the shortest Tweets about exoskeletons.
The results shown in Figures 13 and 14 represent the output obtained from Algorithm 3. Specifically, these figures show the varying patterns of the usage of hashtags and user mentions in tweets about exoskeletons posted per hour (in a 24-hour format). These figures also help to reveal patterns of public discourse about exoskeletons during different time instants of the day. For instance, from Figure 13, it can be concluded that the time slot of 17 (representing the time window 16:01 to 17:00 in a 24-hour format) is the time range when the general public has used the highest number of hashtags in their Tweets about exoskeletons. Similarly, from Figure 14, it can be concluded that the time slot of 16 (representing the time window 15:01 to 16:00 in a 24-hour format) is the time range when the generic public has mentioned the highest number of users in their Tweets about exoskeletons.
The findings from Algorithm 4 are discussed next. This algorithm computed the correlation (using Pearson’s correlation) between the following:
- a)
- number of Tweets per hour and number of characters (mean value) in the Tweets per hour
- b)
- number of Tweets per hour and number of characters (median value) in the Tweets per hour
- c)
- number of Tweets per hour and number of hashtags in the Tweets per hour
- d)
- number of Tweets per hour and number of user mentions in the Tweets per hour
The coefficient of correlation between these parameters (Pearson’s r value) is shown in Figure 15, and Table 2 presents the p-values of these correlations.
Figure 14.
A tabular representation of the correlation between the number of Tweets posted per hour and specific characteristics of these Tweets.
Figure 14.
A tabular representation of the correlation between the number of Tweets posted per hour and specific characteristics of these Tweets.
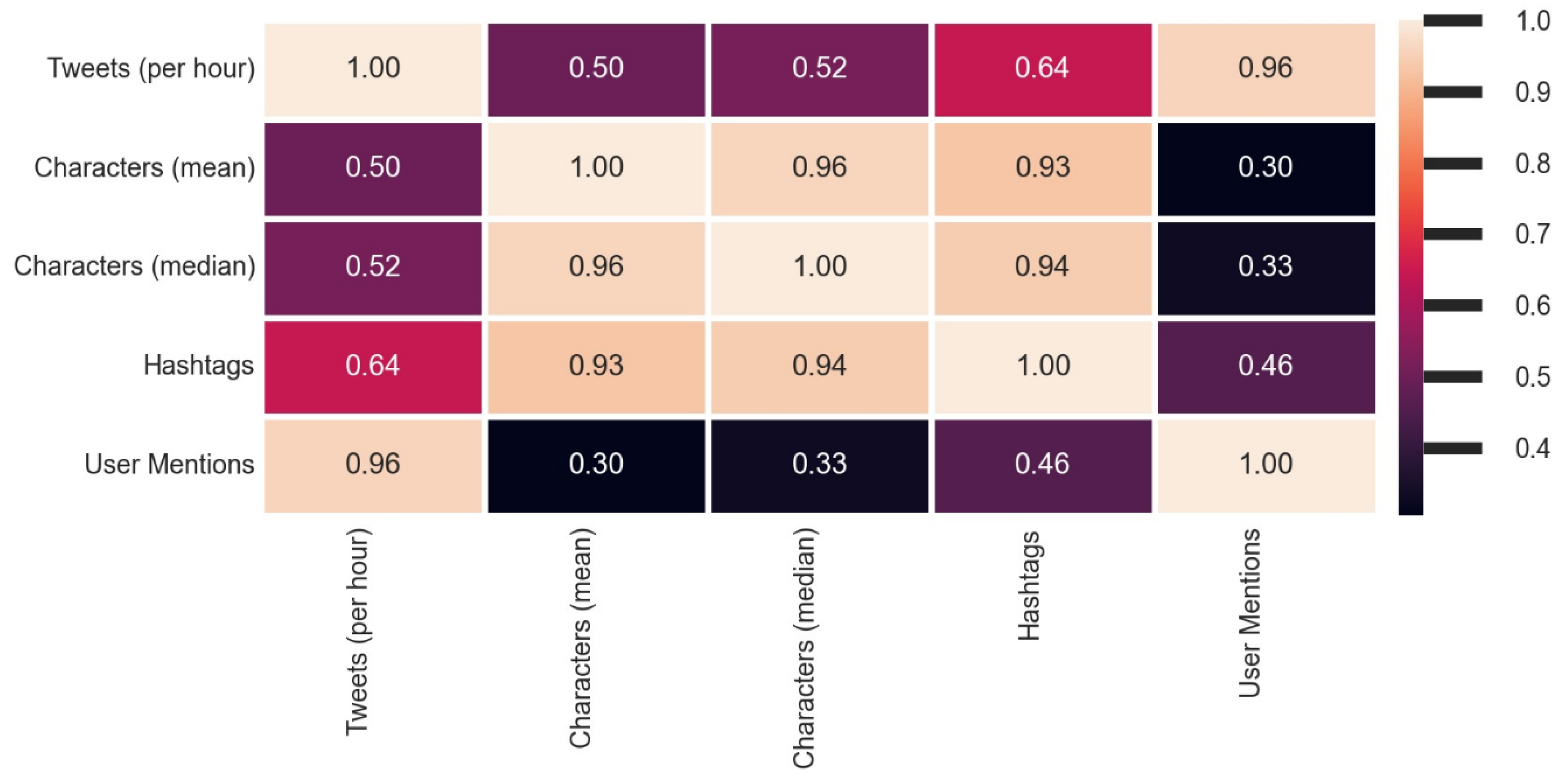
As can be seen from Figure 14 and Table 2, all these correlations were statistically significant. So, the multiple linear regression model (as shown in Algorithm 4) was developed by using the number of Tweets per month as the response variable and the other characteristics of these Tweets as predictor variables. The prediction equation is shown in Equation (1) and the characteristic features of this multiple linear regression model are represented in Table 3.
where,
TM = 2784.170988721279 + 11.78367763 (Cmean) -31.13336391 (Cmed) + 0.30537686 (Hc) + 0.96967955 (UMc)
TM = total number of Tweets per month
Cmean = mean value of the number of characters used in the Tweets per month
Cmed = median value of the number of characters used in the Tweets per month
Hc = number of hashtags used in the Tweets per month
UMc = number of user mentions used in the Tweets per month

Table 3.
Characteristic Features of the Multiple Linear Regression Model.
| Description | Value |
| Multiple Linear Regression Intercept | 2784.170988721279 |
| Multiple Linear Regression Coefficients | [11.78367763 -31.13336391 0.30537686 0.96967955] |
| R2 score | 0.9540953548345376 |
| Mean Squared Error (before cross-validation) | 54577.94142377716 |
| Root Mean Squared Error (before cross Validation) | 233.61922314693447 |
| Value of k for k-folds cross-validation | 10 |
| Mean Squared Error (after cross-validation) | 65260.27219328486 |
| Root Mean Squared Error (after cross-validation) | 255.46090149626588 |
The top 10 hashtags that were used in Tweets about exoskeletons from May 2017 to May 2023 were computed by Algorithm 5. This algorithm also computed the number of Tweets posted using each of these hashtags per month in this time range. The results of the same are shown in Figure 15. As can be seen from Figure 15, the top 10 hashtags were #exoskeleton, #robotics, #iot, #technology, #tech #innovation, #ai, #sci, #construction, and #news. Out of all these hashtags, #exoskeleton was by far the most used hashtag per month in this time range. Thereafter, Algorithm 6 was used to perform sentiment analysis of the Tweets. The output of Algorithm 6 showed that the number of positive, negative, and neutral Tweets were 71,596, 30,773, and 50,676, respectively. This distribution of positive, negative, and neutral Tweets is shown in the form of a pie chart in Figure 15. As can be seen from Figure 15, most of the tweets were positive. Furthermore, Algorithm 6 also computed the number of positive, negative, and neutral Tweets for each of the top 10 hashtags for every month in this time range. These results are presented in Figures 16 to 25, respectively.
The varying patterns of public sentiment towards exoskeletons can be inferred from these results. For instance, Figure 16 shows that most of the general public has expressed a positive sentiment in their tweets about exoskeletons. The patterns of sentiment associated with the top 10 hashtags also reveal novel insights associated with the paradigms of conversations regarding exoskeletons on Twitter. For instance, from Figure 22, it can be inferred that for almost all the months in 2022, the usage of #ai in tweets about exoskeletons was mainly associated with a positive sentiment. A similar pattern can be seen regarding the usage of #exoskeleton in the Tweets from Figure 16. As can be seen from this Figure, during 2022, the majority of the Tweets that were posted using #exoskeleton had a positive sentiment. In a similar manner, sentiment associated with the top 10 hashtags and the trends of the same on a monthly as well as on a yearly basis can be deduced from Figures 16 to 25.
Figure 14.
A graphical representation of the number of Tweets per month per hashtag for the top 10 hashtags.
Figure 14.
A graphical representation of the number of Tweets per month per hashtag for the top 10 hashtags.
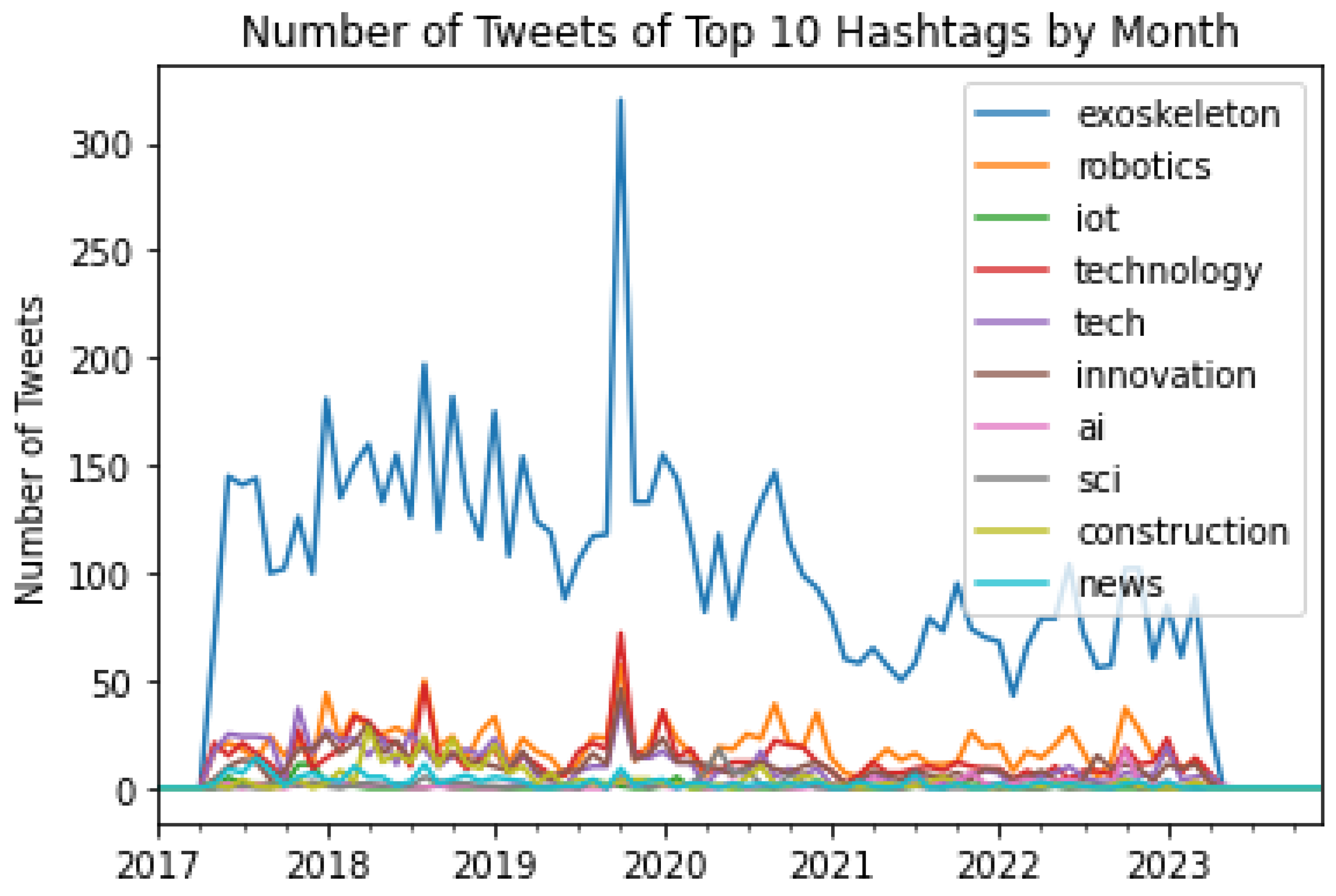
Figure 15.
A pie chart-based representation of the percentage of positive, negative, and neutral Tweets about exoskeletons.
Figure 15.
A pie chart-based representation of the percentage of positive, negative, and neutral Tweets about exoskeletons.
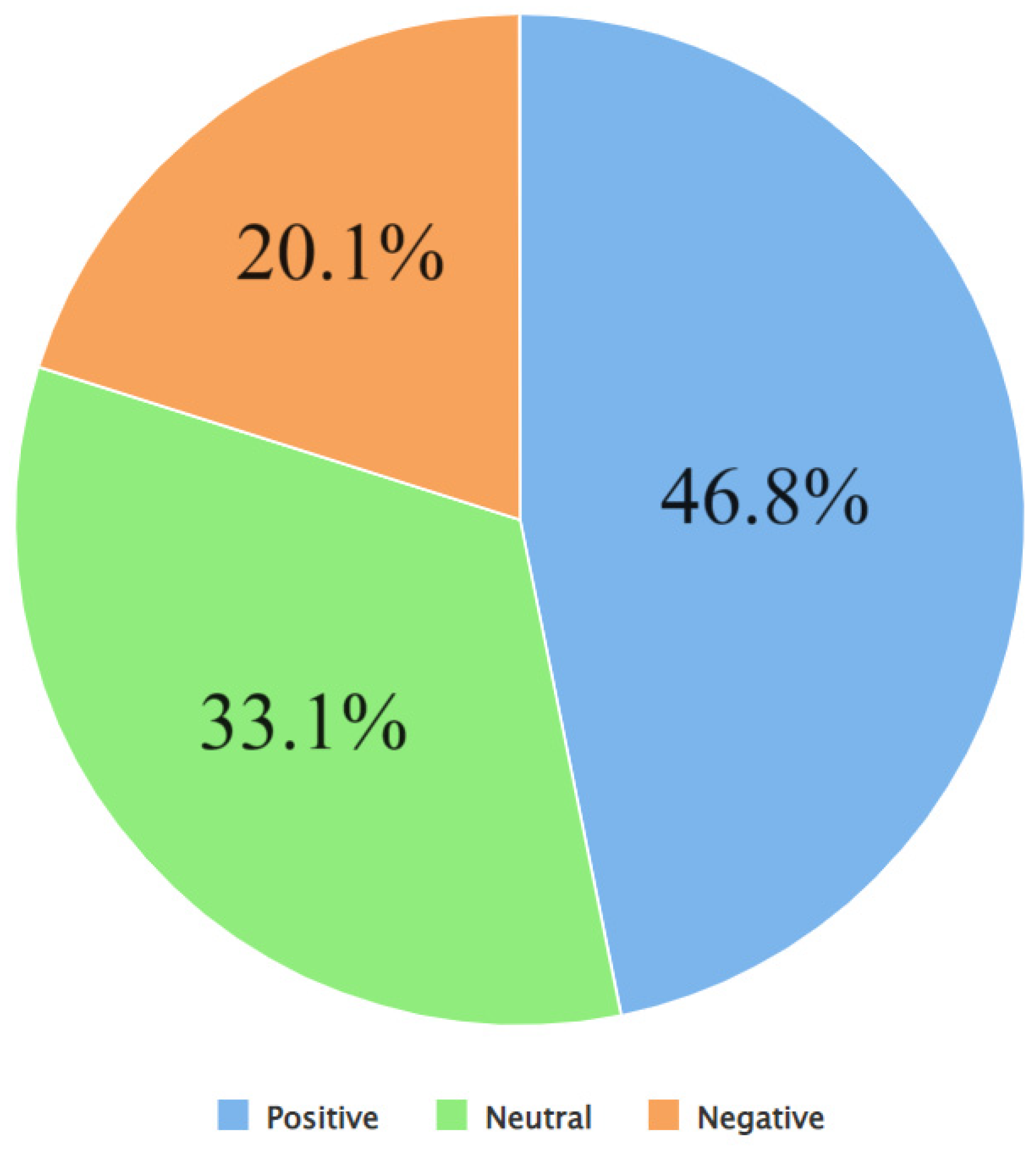
Figure 16.
A graphical representation of the number of Tweets per sentiment per month for #exoskeleton.
Figure 16.
A graphical representation of the number of Tweets per sentiment per month for #exoskeleton.
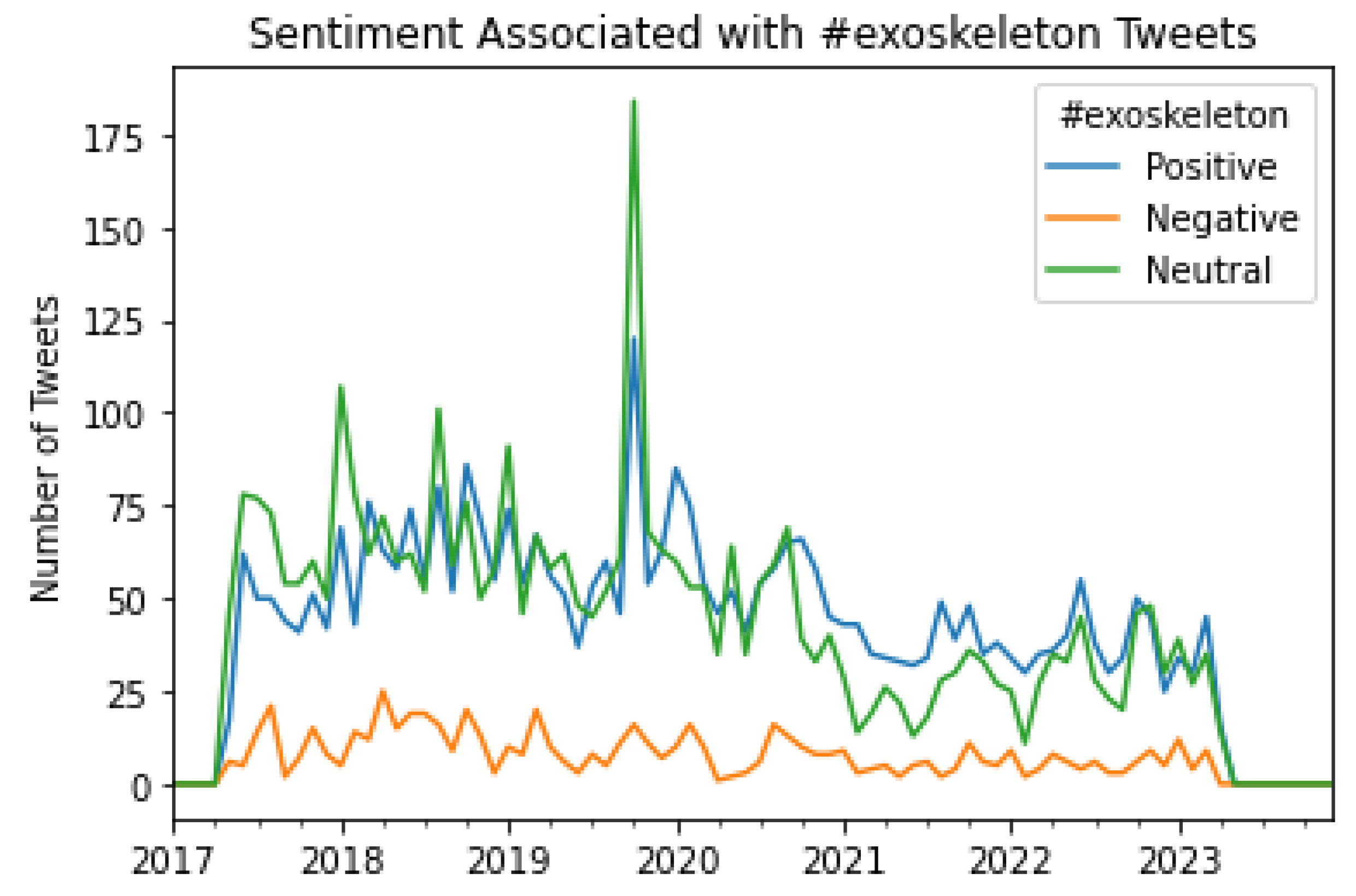
Figure 17.
A graphical representation of the number of Tweets per sentiment per month for #robotics.
Figure 17.
A graphical representation of the number of Tweets per sentiment per month for #robotics.
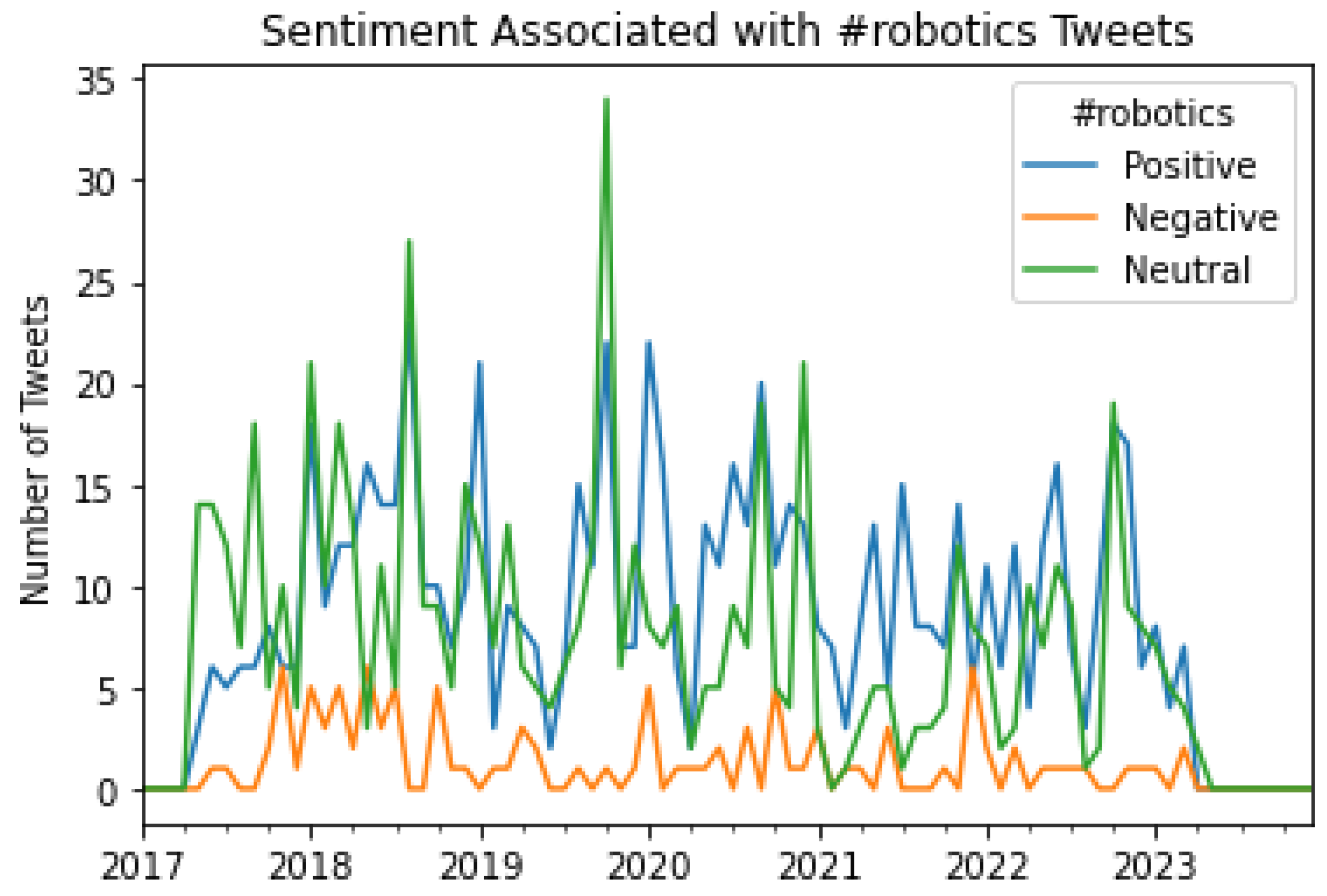
Figure 18.
A graphical representation of the number of Tweets per sentiment per month for #iot.
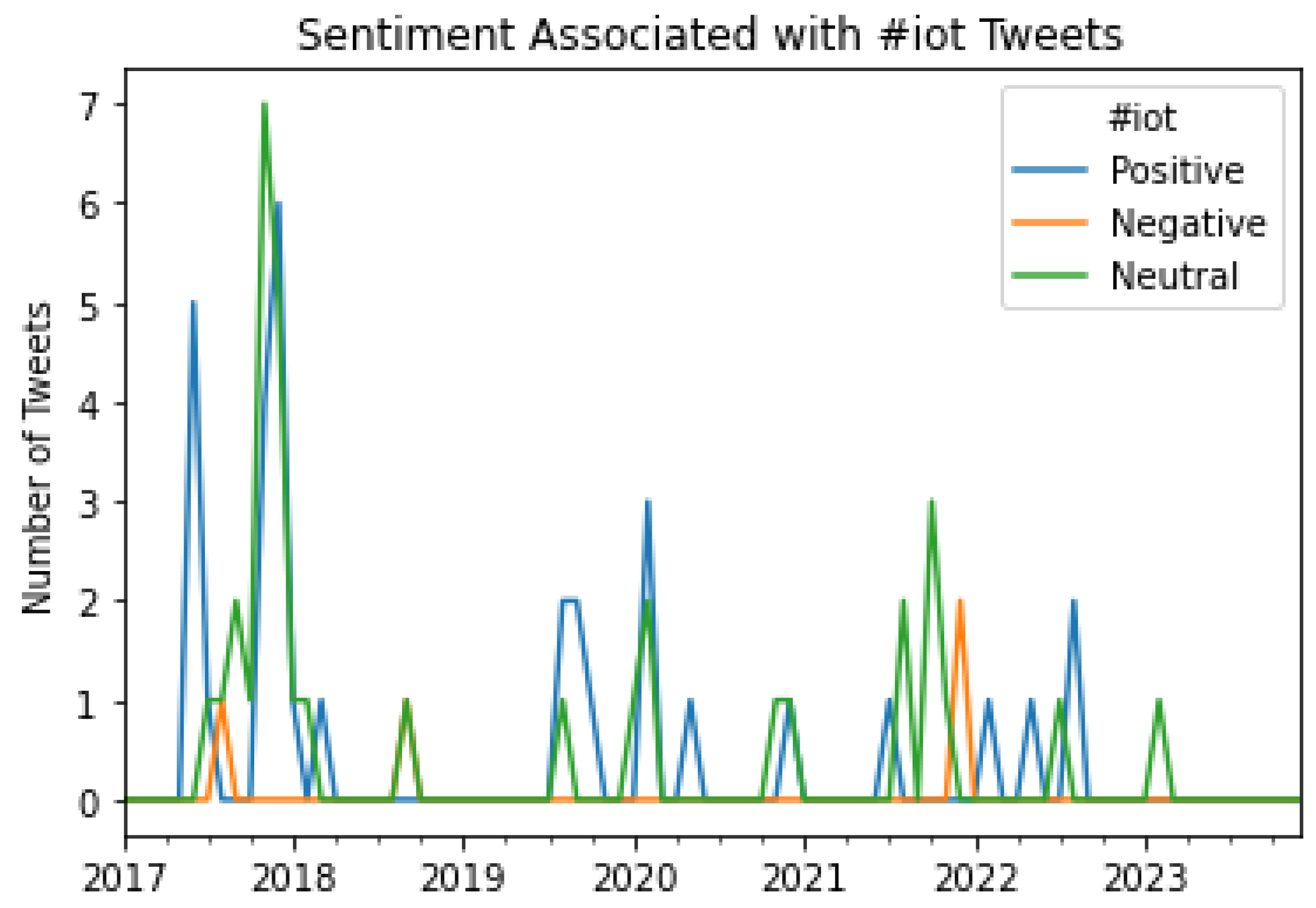
Figure 19.
A graphical representation of the number of Tweets per sentiment per month for #technology.
Figure 19.
A graphical representation of the number of Tweets per sentiment per month for #technology.
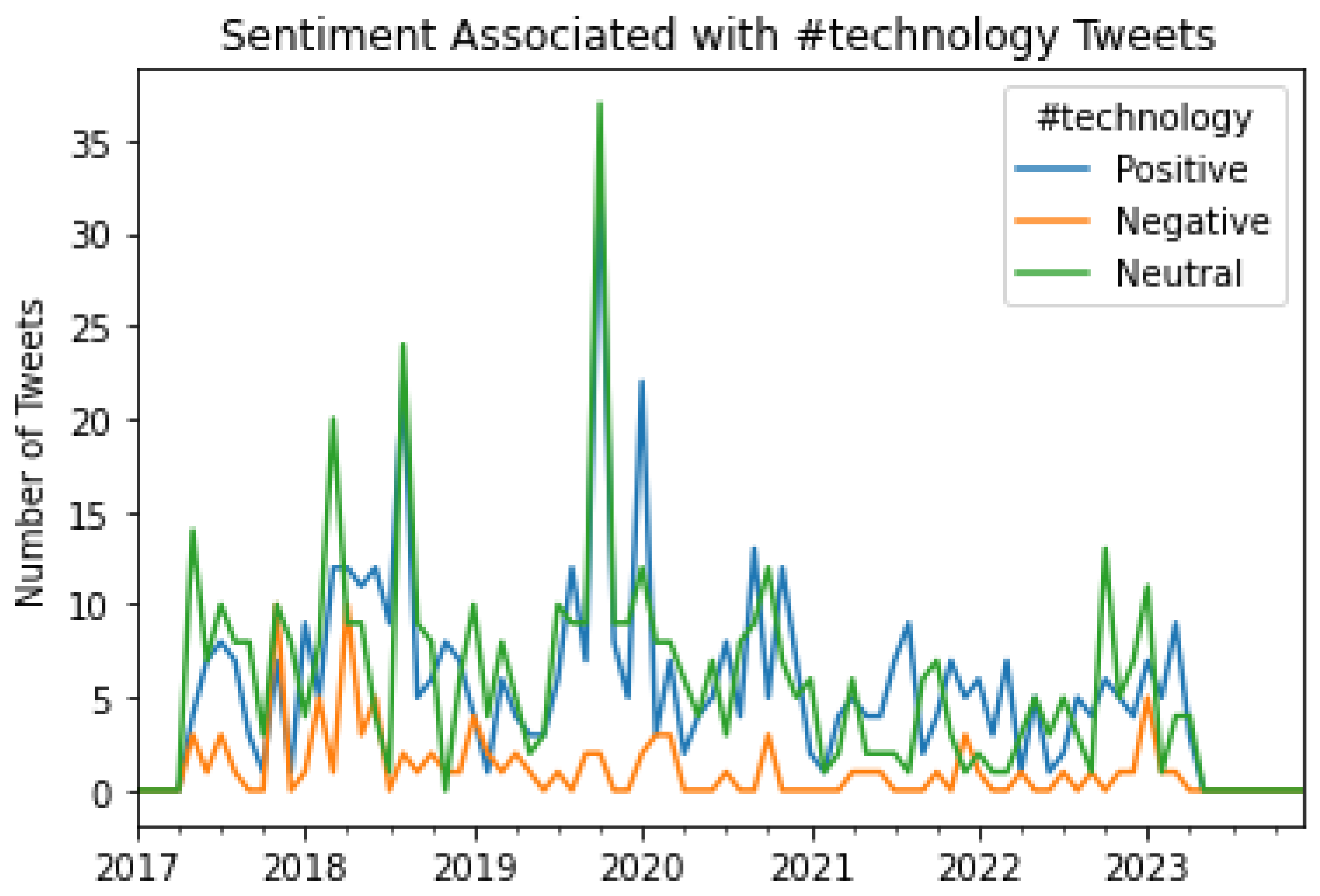
Figure 20.
A graphical representation of the number of Tweets per sentiment per month for #tech.
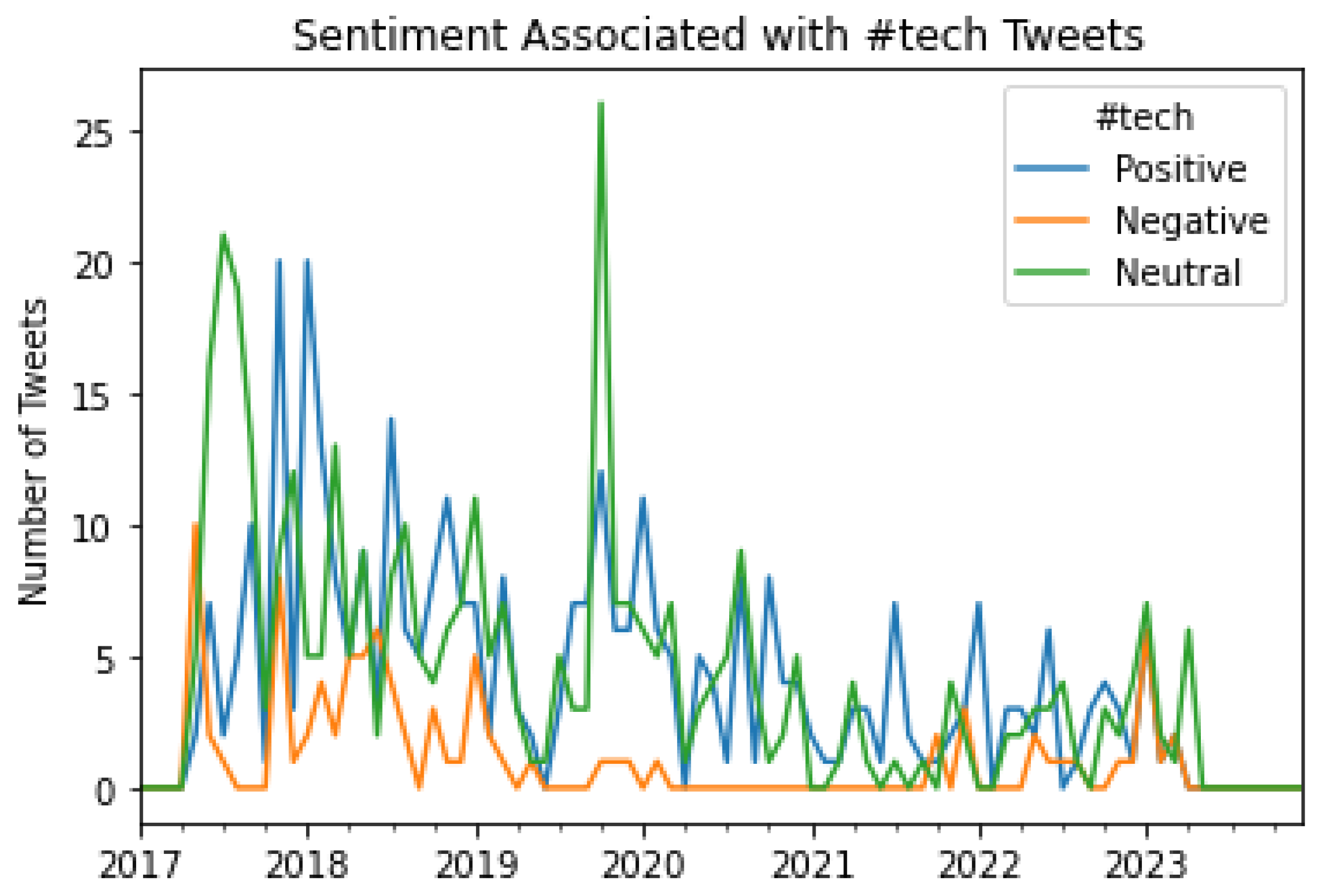
Figure 21.
A graphical representation of the number of Tweets per sentiment per month for #innovation.
Figure 21.
A graphical representation of the number of Tweets per sentiment per month for #innovation.
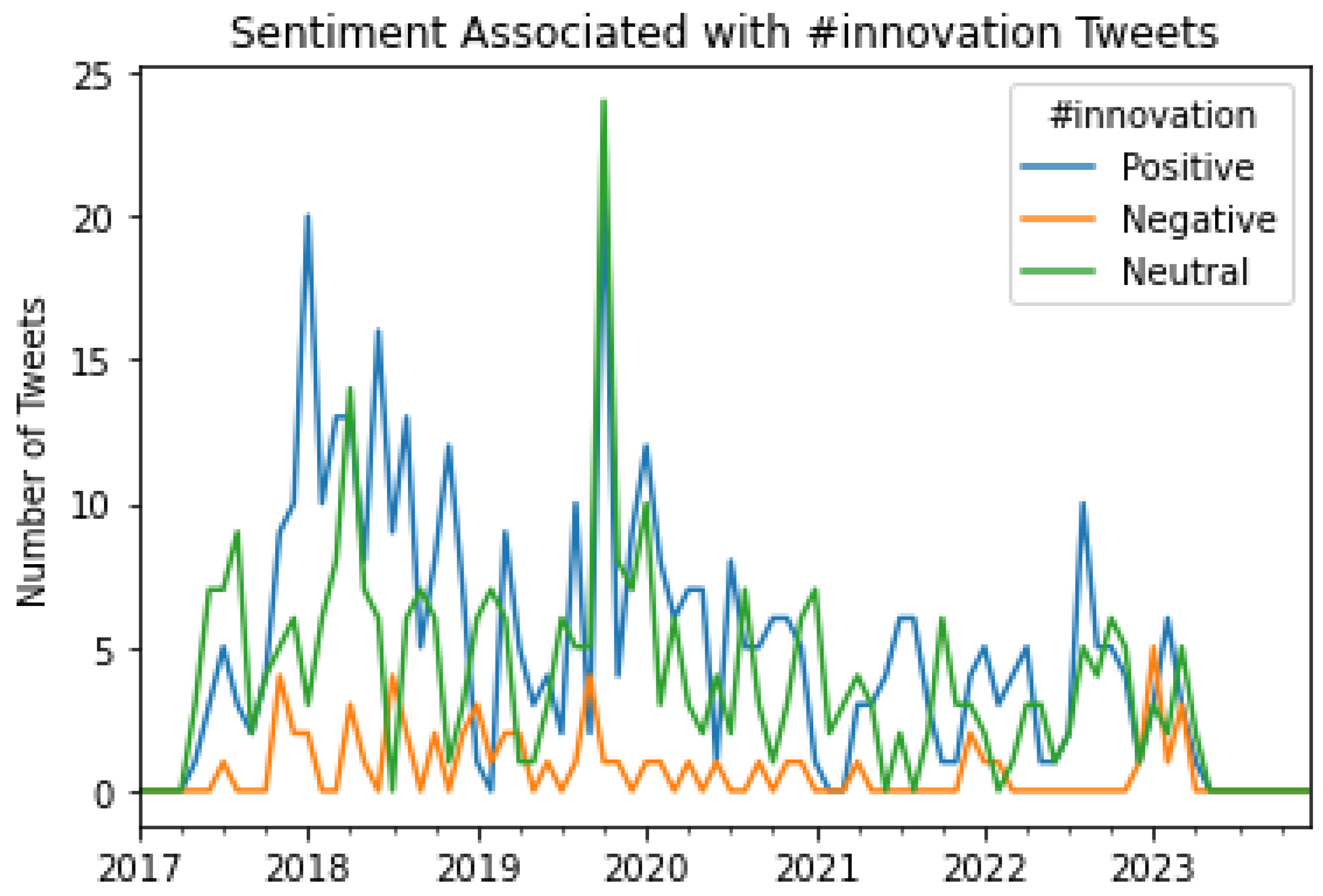
Figure 22.
A graphical representation of the number of Tweets per sentiment per month for #ai.
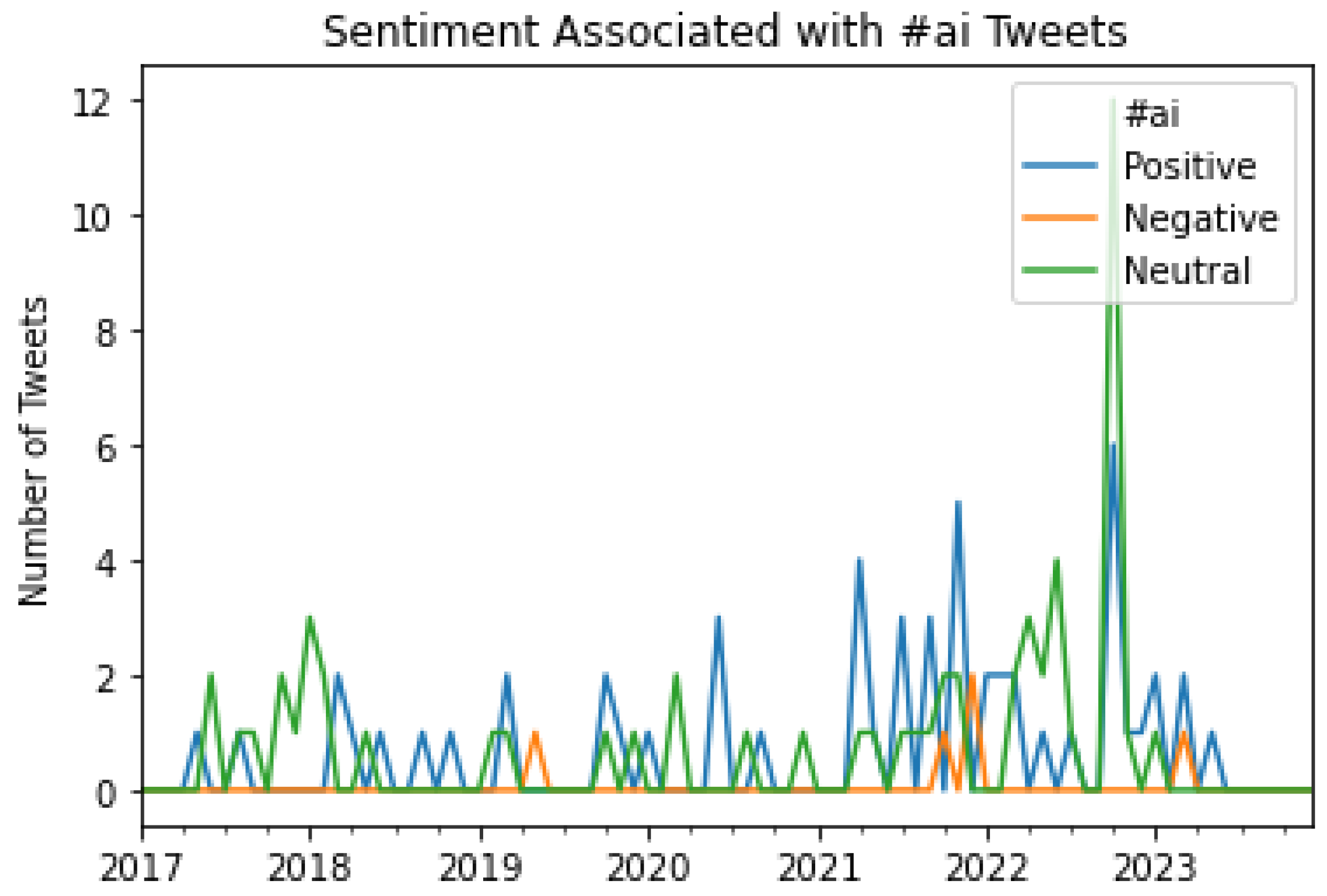
Figure 23.
A graphical representation of the number of Tweets per sentiment per month for #sci.
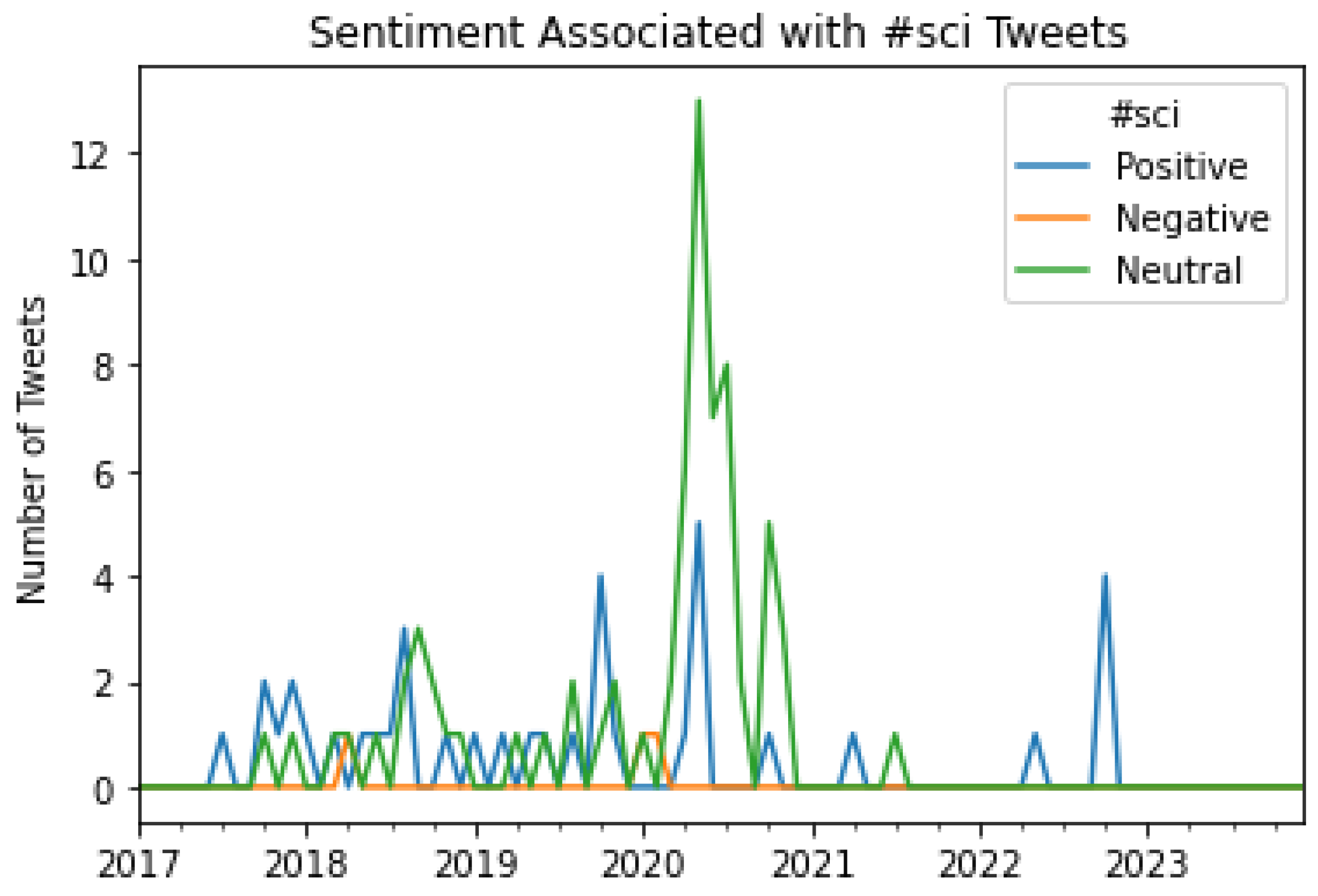
Figure 24.
A graphical representation of the number of Tweets per sentiment per month for #construction.
Figure 24.
A graphical representation of the number of Tweets per sentiment per month for #construction.
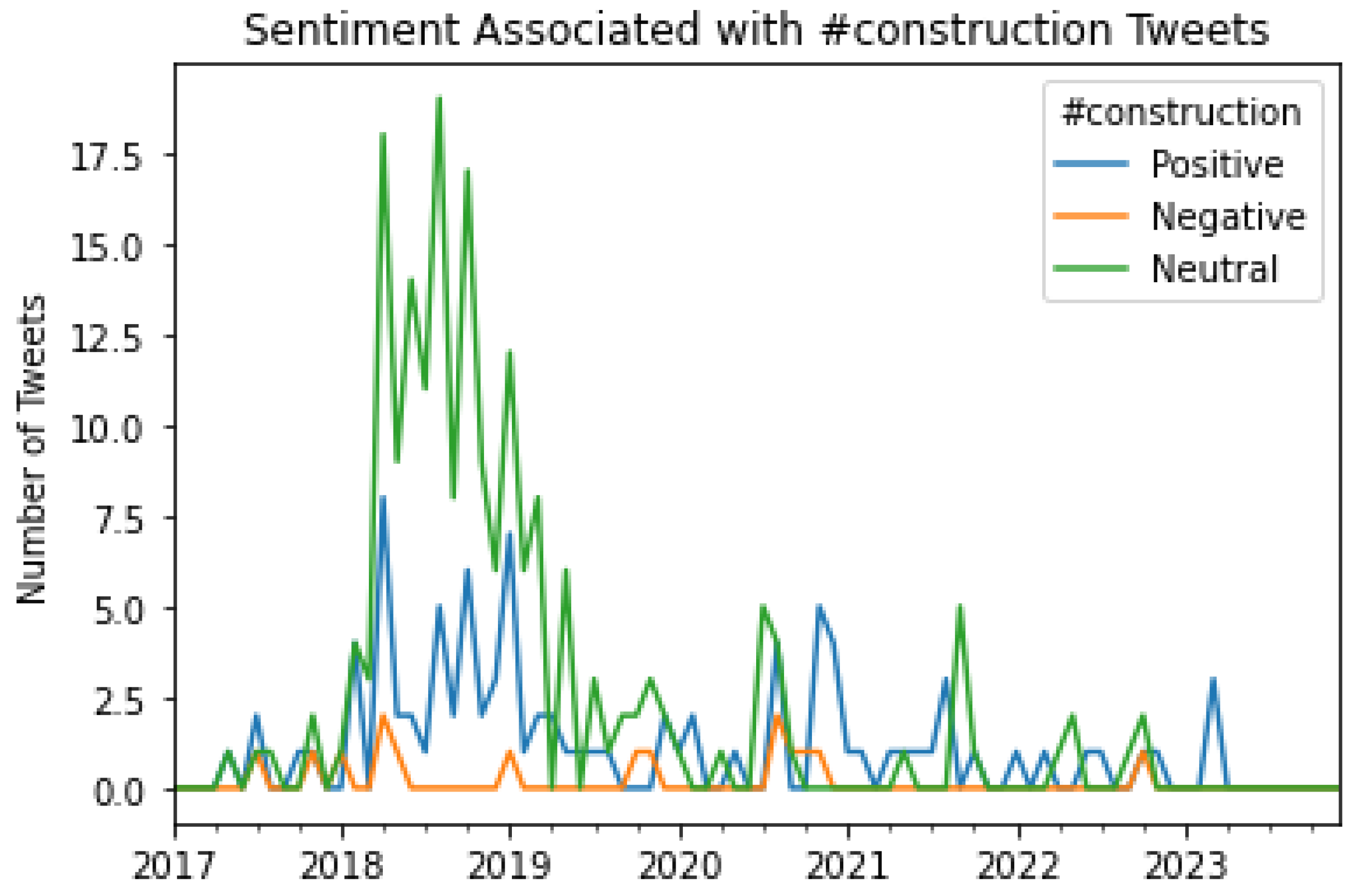
Figure 25.
A graphical representation of the number of Tweets per sentiment per month for #news.
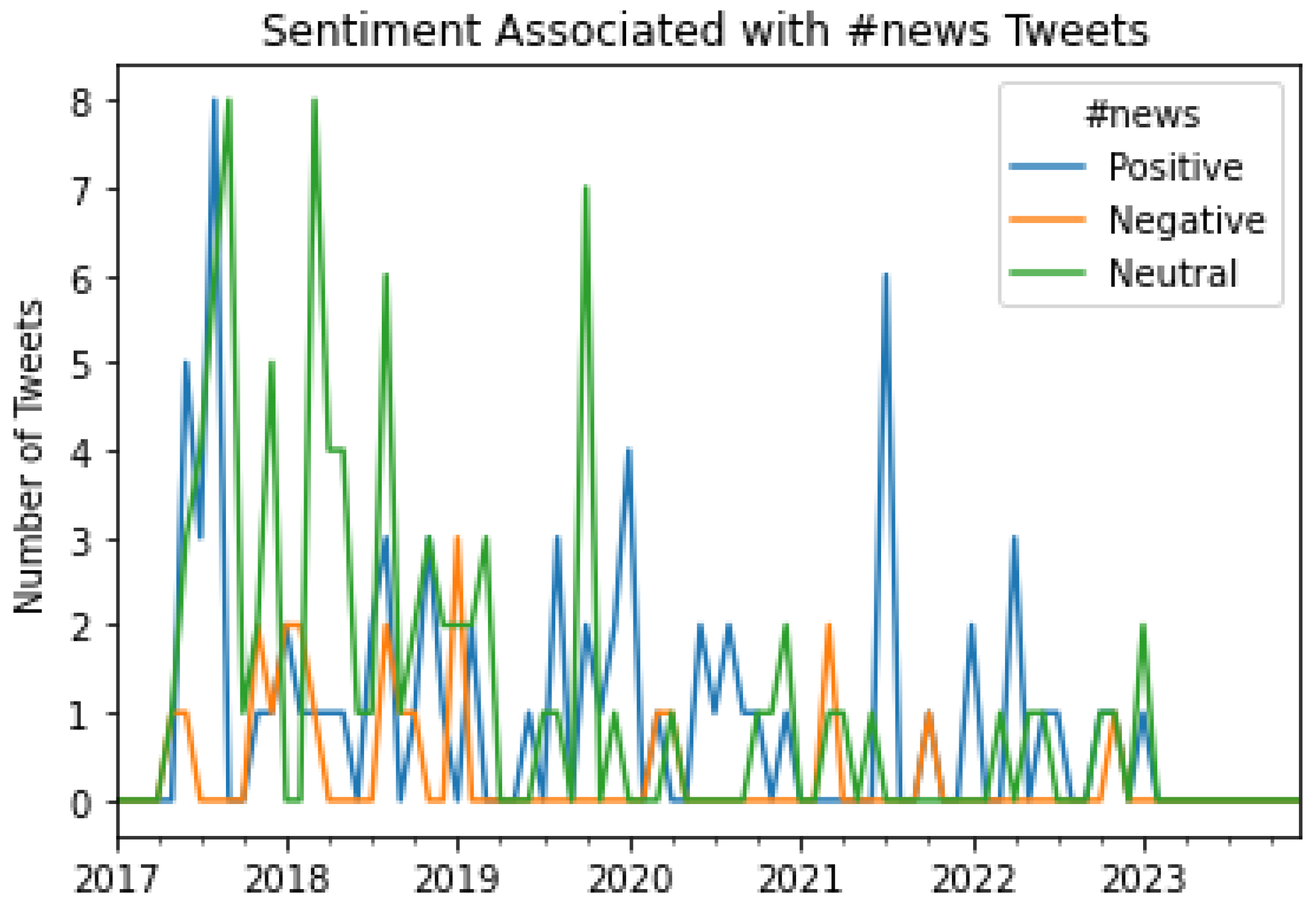
Next, Algorithms 2 and 3 were run on the master dataset (shown in Figure 1), .CSV file containing sentiment labels for each Tweet (one of the outputs of Algorithm 6), .CSV file representing potentially sarcastic Tweets (output of Algorithm 8) and the .CSV file representing Tweets that contained news (output of Algorithm 9). The objective of running these algorithms on these tweets was to compare the positive tweets, negative tweets, neutral tweets, possibly Sarcastic, and tweets that contained news in terms of the mean length of the tweets per month, the median length of the tweets per month, the average number of hashtags used per month, and the average number of user mentions used per month, to interpret the underlying trends of the same. The results of this analysis are shown in Figures 26 to 29, respectively. These results also reveal several novel insights related to the tweeting patterns of the general public in the context of Tweets about exoskeletons. For instance, from Figure 26 and Figure 27, it can be concluded that the average number of characters used in neutral tweets has been considerably lower as compared to positive tweets, negative tweets, possibly sarcastic tweets, as well as tweets that contained news. Figure 28 shows that the average number of hashtags used in tweets that contained news has considerably increased since the beginning of January 2022. Figure 29 shows that as far as possibly sarcastic Tweets are concerned, the number of user mentions has been significantly less (even zero on multiple occasions) as compared to positive tweets, negative tweets, neutral tweets, and tweets that contained news.
As discussed in Section 3, a fine-grain analysis of the sentiments was also performed to detect different sentiment classes such as anger, disgust, fear, joy, neutral, sadness, and surprise (pseudocode presented in Algorithm 10). As Figure 15 reports that 33.1% of the Tweets were neutral tweets, so the neutral tweets were removed prior to the data analysis to understand the distribution of sentiment classes such as anger, disgust, fear, joy, sadness, and surprise in the remainder of the tweets. The results of this analysis are shown in Figure 30. As can be seen from this Figure, the sentiment of surprise was the most common emotion. It was followed by joy, disgust, sadness, fear, and anger.
Next, a comparison of the work of this paper with prior works in this field in terms of the focus areas is presented in Table 3. As can be seen from Table 3, the work presented in this paper is the first paper in this area of research that focuses on multimodal forms of content analysis, text analysis, sentiment analysis, fine-grain sentiment analysis, hashtag-specific sentiment analysis in the context of tweets about exoskeletons. Furthermore, this work also presents a multiple linear regression model to predict tweets posted about exoskeletons on a monthly basis in terms of specific characteristics of the tweets.
Table 3.
Comparison of the focus areas of this research paper with the focus areas of prior works in this field.
Table 3.
Comparison of the focus areas of this research paper with the focus areas of prior works in this field.
| Work | CA of Tweets about Robots or Robotic Solutions |
CA of Tweets about Wearables (including Wearable Robotics) |
SA of Tweets about Robots or Robotic Solutions |
SA of Tweets about Robots (including Wearable Robotics) |
Fine Grain SA of Tweets about Wearable Robotics |
MLR Model to Predict Tweets about Wearable Robotics |
|---|---|---|---|---|---|---|
| Cramer et al. [18] | √ | |||||
| Salzmann-Erikson et al. [19] | √ | |||||
| Fraser et al. [20] | √ | |||||
| Mubin et al. [21] | √ | |||||
| Barakeh et al. [22] | √ | |||||
| Mahmud et al. [23] | √ | |||||
| Yamanoue et al. [24] | √ | |||||
| Tussyadiah et al. [25] | √ | |||||
| Saxena et al. [26] | √ | |||||
| Adidharma et al. [27] | √ | |||||
| Pillarisetti et al. [28] | √ | |||||
| Keane et al. [29] | √ | |||||
| Sinha et al. [30] | √ | |||||
| El-Gayar et al. [31] | √ | |||||
| Jeong et al. [32] | √ | |||||
| Niininen et al. [33] | √ | |||||
| Thakur et al. [this work] | √ | √ | √ | √ | √ | √ |
1 In this table. CA = Content Analysis, SA = Sentiment Analysis, MLR = Multiple Linear Regression Model
5. Conclusions
The popularity of social media platforms has been on an exponential rise in the last decade and a half as social media platforms provide a seamless means for users to connect, communicate, and collaborate with each other. Out of different social media platforms, analysis of conversations on Twitter has been of significant interest to researchers from different disciplines. This can be inferred from the fact that in the last few years, there have been several works that focused on the analysis of tweets about emerging technologies, matters of global interest, and topics of global concern such as ChatGPT, the Russia–Ukraine war, cryptocurrency markets, virtual assistants, abortions, loneliness, housing needs, fake news, religion, early detection of health-related problems, elections, education, pregnancy, food insufficiency, and virus outbreaks such as MPox, flu, H1N1, and COVID-19, just to name a few. Even though a wide range of topics and several emerging technologies have been investigated in recent works, there hasn’t been any prior work in this field thus far that has focused on the analysis of tweets about exoskeletons. The rapid advancement of exoskeleton technology is being propelled by its extensive range of applications. Some of these uses involve assisting elderly individuals and those with disabilities in their daily tasks, increasing productivity and alleviating fatigue in military personnel, enhancing the quality of life for amputees and individuals with paralysis in different body parts, aiding firefighters in climbing and lifting heavy equipment, bolstering labor efficiency, and facilitating the transportation of bulky machinery in different industrial settings. As a result of these expanding use cases of exoskeletons, the general public has shared their views, opinions, and perspectives about exoskeletons on Twitter in the last few years on social media platforms, such as Twitter. The work presented in this paper aims to address this research gap as well as it aims to contribute towards advancing research in the area of exoskeleton technology by presenting several novel findings from a comprehensive analysis of about 150,000 Tweets about exoskeletons posted between May 2017 and May 2023. First, findings from a comprehensive content analysis and temporal analysis of these tweets reveal the specific months when a significantly higher volume of Tweets was posted and the time windows when the highest number of Tweets, the lowest number of tweets, tweets with the highest number of hashtags, and tweets with the highest number of user mentions have been posted. Second, the paper shows that there are statistically significant correlations between the number of Tweets posted per hour and different characteristics of tweeting behavior, such as number of characters (mean value) in the Tweets per hour, number of characters (median value) in the Tweets per hour, number of hashtags used in the Tweets per hour, and number of user mentions used in the Tweets per hour. Third, the paper presents a multiple linear regression model to predict the number of Tweets posted per hour in terms of these characteristics of tweeting behavior. The R2 score of this model was observed to be 0.9540. Fourth, the paper reports that the 10 most popular hashtags were #exoskeleton, #robotics, #iot, #technology, #tech #innovation, #ai, #sci, #construction and #news. Fifth, an exploratory sentiment analysis of these tweets was performed using VADER and the DistilRoBERTa-base library in Python. The findings show that 46.8% of the Tweets were positive, 33.1% of the Tweets were neutral, and 20.1% of the tweets were neutral. The findings also show that in the tweets that did not express a neutral sentiment, the sentiment of surprise was the most common emotion. It was followed by joy, disgust, sadness, fear, and anger. Furthermore, analysis of hashtag-specific sentiments revealed several novel insights associated with the tweeting behavior of the general public in this regard. For instance, for almost all the months in 2022, the usage of #ai in tweets about exoskeletons was mainly associated with a positive sentiment. Sixth, text processing-based approaches were used to detect possibly sarcastic tweets and tweets that contained news. Thereafter, a comparison of positive tweets, negative tweets, neutral tweets, possibly sarcastic tweets, and tweets that contained news, in terms of different characteristic properties of these tweets are presented. The findings of this analysis reveal multiple insights related to the tweeting behavior of the general public about exoskeletons. For instance, the average number of characters used in neutral tweets has been considerably lower in neutral tweets as compared to positive tweets, negative tweets, possibly sarcastic tweets as well as tweets that contained news, and the average number of hashtags used in tweets that contained news has considerably increased since the beginning of January 2022. As per the best knowledge of the authors, no similar work has been done in this field thus far. Future work in this area would involve performing topic modeling of these tweets to interpret the specific topics represented in the tweets about exoskeletons.
Author Contributions
Conceptualization, N.T.; methodology, N.T., K.A.P., A.P., R.S., N.A., and C. H.; software, N.T., K.A.P., A.P., R.S.; validation, N.T., K.A.P., A.P., R.S., N.A., and C. H.; formal analysis, N.T., K.A.P, A.P. R.S., N.A. and C. H.; investigation, N.T., K.A.P., A.P., R.S., N.A. and C. H.; resources, N.T., K.A.P, A.P. R.S.; data curation, N.T.; writing—original draft preparation, N.T., K.A.P, A.P. R.S., N.A. and C. H.; writing—review and editing, N.T.; visualization, N.T., K.A.P, A.P. R.S.; supervision, N.T.; project administration, N.T.; funding acquisition, Not Applicable. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data analyzed in this study are publicly available at https://dx.doi.org/10.21227/r5mv-ax79.
Acknowledgment
The authors would like to thank Shuqi (Nicole) Cui from the Department of Computer Science at Emory University for her help with data cleaning during the expansion of this dataset.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gundecha, P.; Liu, H. Mining Social Media: A Brief Introduction. In 2012 TutORials in Operations Research; INFORMS, 2012; pp. 1–17.
- Messaoudi, C.; Guessoum, Z.; Ben Romdhane, L. Opinion Mining in Online Social Media: A Survey. Soc. Netw. Anal. Min. 2022, 12. [Google Scholar] [CrossRef]
- Van Looy, A. Definitions, Social Media Types, and Tools. In Social Media Management; Springer International Publishing: Cham, 2022; pp. 21–50. ISBN 9783030990930. [Google Scholar]
- Thakur, N. Social Media Mining and Analysis: A Brief Review of Recent Challenges. Information (Basel) 2023, 14, 484. [Google Scholar] [CrossRef]
- Belle Wong, J.D. Top Social Media Statistics and Trends of 2023. Available online: https://www.forbes.com/advisor/business/social-media-statistics/ (accessed on 23 September 2023).
- Morgan-Lopez, A.A.; Kim, A.E.; Chew, R.F.; Ruddle, P. Predicting Age Groups of Twitter Users Based on Language and Metadata Features. PLoS One 2017, 12, e0183537. [Google Scholar] [CrossRef] [PubMed]
- Martin, M. 29 Twitter Stats That Matter to Marketers in 2023. Available online: https://blog.hootsuite.com/twitter-statistics/ (accessed on 24 September 2023).
- Singh, C. 60+ Twitter Statistics to Skyrocket Your Branding in 2023. Available online: https://www.socialpilot.co/blog/twitter-statistics (accessed on 24 September 2023).
- Taylor, T. 30+ Remarkable Twitter Statistics to Be Aware of in 2023. Available online: https://blog.hubspot.com/marketing/twitter-stats-tips (accessed on 24 September 2023).
- Kemp, S. Twitter Users, Stats, Data, Trends, and More — DataReportal – Global Digital Insights. Available online: https://datareportal.com/essential-twitter-stats (accessed on 24 September 2023).
- Dinesh, S. 8 Facts about Americans and Twitter as It Rebrands to X. Available online: https://www.pewresearch.org/short-reads/2023/07/26/8-facts-about-americans-and-twitter-as-it-rebrands-to-x/ (accessed on 24 September 2023).
- Lin, Y. 10 Twitter Statistics Every Marketer Should Know in 2023 [Infographic]. Available online: https://www.oberlo.com/blog/twitter-statistics (accessed on 24 September 2023).
- Taecharungroj, V. “What Can ChatGPT Do?” Analyzing Early Reactions to the Innovative AI Chatbot on Twitter. Big Data Cogn. Comput. 2023, 7, 35. [Google Scholar] [CrossRef]
- Mujahid, M.; Kanwal, K.; Rustam, F.; Aljadani, W.; Ashraf, I. Arabic ChatGPT Tweets Classification Using RoBERTa and BERT Ensemble Model. ACM Trans. Asian Low-resour. Lang. Inf. Process. 2023, 22, 1–23. [Google Scholar] [CrossRef]
- Tao, W.; Peng, Y. Differentiation and Unity: A Cross-Platform Comparison Analysis of Online Posts’ Semantics of the Russian–Ukrainian War Based on Weibo and Twitter. Commun. Public 2023, 8, 105–124. [Google Scholar] [CrossRef]
- Chen, E.; Ferrara, E. Tweets in Time of Conflict: A Public Dataset Tracking the Twitter Discourse on the War between Ukraine and Russia. Proceedings of the International AAAI Conference on Web and Social Media 2023, 17, 1006–1013. [Google Scholar] [CrossRef]
- Ante, L. How Elon Musk’s Twitter Activity Moves Cryptocurrency Markets. Technol. Forecast. Soc. Change 2023, 186, 122112. [Google Scholar] [CrossRef]
- Kraaijeveld, O.; De Smedt, J. The Predictive Power of Public Twitter Sentiment for Forecasting Cryptocurrency Prices. J. Int. Financ. Mark. Inst. Money 2020, 65, 101188. [Google Scholar] [CrossRef]
- Acharya, S.; Jain, U.; Kumar, R.; Prajapat, S.; Suthar, S.; Ritesh, K. JARVIS: A Virtual Assistant for Smart Communication Available online: https://ijaem.net/issue_dcp/JARVIS%20A%20Virtual%20Assistant%20for%20Smart%20Communication.pdf.
- Cesare, N.; Oladeji, O.; Ferryman, K.; Wijaya, D.; Hendricks-Muñoz, K.D.; Ward, A.; Nsoesie, E.O. Discussions of Miscarriage and Preterm Births on Twitter. Paediatr. Perinat. Epidemiol. 2020, 34, 544–552. [Google Scholar] [CrossRef]
- Kosenko, K.; Winderman, E.; Pugh, A. The Hijacked Hashtag: The Constitutive Features of Abortion Stigma in the #ShoutYourAbortion Twitter Campaign. Int. J. Commun. 2019, 13, 21. [Google Scholar]
- Fox, B. Loneliness and Social Media: A Qualitative Investigation of Young People’s Motivations for Use, and Perceptions of Social Networking Sites. In Emotions and Loneliness in a Networked Society; Springer International Publishing: Cham, 2019; pp. 309–331. ISBN 9783030248819. [Google Scholar]
- Guntuku, S.C.; Schneider, R.; Pelullo, A.; Young, J.; Wong, V.; Ungar, L.; Polsky, D.; Volpp, K.G.; Merchant, R. Studying Expressions of Loneliness in Individuals Using Twitter: An Observational Study. BMJ Open 2019, 9, e030355. [Google Scholar] [CrossRef] [PubMed]
- Allen, J.D.; Hollander, J.; Gualtieri, L.; Alarcon Falconi, T.M.; Savir, S.; Agénor, M. Feasibility of a Twitter Campaign to Promote HPV Vaccine Uptake among Racially/Ethnically Diverse Young Adult Women Living in Public Housing. BMC Public Health 2020, 20. [Google Scholar] [CrossRef]
- Tan, M.J.; Guan, C. Are People Happier in Locations of High Property Value? Spatial Temporal Analytics of Activity Frequency, Public Sentiment and Housing Price Using Twitter Data. Appl. Geogr. 2021, 132, 102474. [Google Scholar] [CrossRef]
- Bovet, A.; Makse, H.A. Influence of Fake News in Twitter during the 2016 US Presidential Election. Nat. Commun. 2019, 10, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Ajao, O.; Bhowmik, D.; Zargari, S. Fake News Identification on Twitter with Hybrid CNN and RNN Models. In Proceedings of the Proceedings of the 9th International Conference on Social Media and Society; ACM: New York, NY, USA, 2018. [Google Scholar]
- Chandra, M.; Reddy, M.; Sehgal, S.; Gupta, S.; Buduru, A.B.; Kumaraguru, P. “A Virus Has No Religion”: Analyzing Islamophobia on Twitter during the COVID-19 Outbreak. In Proceedings of the Proceedings of the 32st ACM Conference on Hypertext and Social Media; ACM: New York, NY, USA, 2021. [Google Scholar]
- Bokányi, E.; Kondor, D.; Dobos, L.; Sebők, T.; Stéger, J.; Csabai, I.; Vattay, G. Race, Religion and the City: Twitter Word Frequency Patterns Reveal Dominant Demographic Dimensions in the United States. Palgrave Commun. 2016, 2, 1–9. [Google Scholar] [CrossRef]
- Amin, S.; Uddin, M.I.; alSaeed, D.H.; Khan, A.; Adnan, M. Early Detection of Seasonal Outbreaks from Twitter Data Using Machine Learning Approaches. Complexity 2021, 2021, 1–12. [Google Scholar] [CrossRef]
- Prieto, V.M.; Matos, S.; Álvarez, M.; Cacheda, F.; Oliveira, J.L. Twitter: A Good Place to Detect Health Conditions. PLoS One 2014, 9, e86191. [Google Scholar] [CrossRef]
- Buccoliero, L.; Bellio, E.; Crestini, G.; Arkoudas, A. Twitter and Politics: Evidence from the US Presidential Elections 2016. J. Mark. Commun. 2020, 26, 88–114. [Google Scholar] [CrossRef]
- Ali, H.; Farman, H.; Yar, H.; Khan, Z.; Habib, S.; Ammar, A. Deep Learning-Based Election Results Prediction Using Twitter Activity. Soft Comput. 2022, 26, 7535–7543. [Google Scholar] [CrossRef]
- Veletsianos, G.; Kimmons, R. Scholars in an Increasingly Open and Digital World: How Do Education Professors and Students Use Twitter? Internet High. Educ. 2016, 30, 1–10. [Google Scholar] [CrossRef]
- Carpenter, J.; Tani, T.; Morrison, S.; Keane, J. Exploring the Landscape of Educator Professional Activity on Twitter: An Analysis of 16 Education-Related Twitter Hashtags. Prof. Dev. Educ. 2022, 48, 784–805. [Google Scholar] [CrossRef]
- Rajabi, S. Grieving the Ambiguous Online: Pregnancy Loss, Meaning Making & Celebrity on Twitter. Fem. Media Stud. 2023, 1–17. [Google Scholar] [CrossRef]
- Moyer, C.A.; Compton, S.D.; Kaselitz, E.; Muzik, M. Pregnancy-Related Anxiety during COVID-19: A Nationwide Survey of 2740 Pregnant Women. Arch. Womens. Ment. Health 2020, 23, 757–765. [Google Scholar] [CrossRef] [PubMed]
- Goetz, S.J.; Heaton, C.; Imran, M.; Pan, Y.; Tian, Z.; Schmidt, C.; Qazi, U.; Ofli, F.; Mitra, P. Food Insufficiency and Twitter Emotions during a Pandemic. Appl. Econ. Perspect. Policy 2023, 45, 1189–1210. [Google Scholar] [CrossRef] [PubMed]
- Ahmad Kontar, N.A.; Mutalib, S.; Muhamed Hanum, H.F.; Abdul-Rahman, S. Exploratory Data Analysis: Food Security Risk among Twitter Users. J. Comput. Sci. Comput. Math. 2023, 13, 15–19. [Google Scholar] [CrossRef]
- Knudsen, B.; Høeg, T.B.; Prasad, V. Analysis of Tweets Discussing the Risk of Mpox among Children and Young People in School (May-Oct 2022): Public Health Experts on Twitter Consistently Exaggerated Risks and Infrequently Reported Accurate Information. bioRxiv 2023.
- Edinger, A.; Valdez, D.; Walsh-Buhi, E.; Trueblood, J.S.; Lorenzo-Luaces, L.; Rutter, L.A.; Bollen, J. Misinformation and Public Health Messaging in the Early Stages of the Mpox Outbreak: Mapping the Twitter Narrative with Deep Learning. J. Med. Internet Res. 2023, 25, e43841. [Google Scholar] [CrossRef]
- Wakamiya, S.; Kawai, Y.; Aramaki, E. Twitter-Based Influenza Detection after Flu Peak via Tweets with Indirect Information: Text Mining Study. JMIR Public Health Surveill. 2018, 4, e65. [Google Scholar] [CrossRef]
- Lee, K.; Agrawal, A.; Choudhary, A. Real-Time Disease Surveillance Using Twitter Data: Demonstration on Flu and Cancer. In Proceedings of the Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining; ACM: New York, NY, USA, 2013. [Google Scholar]
- Jain, V.K.; Kumar, S. An Effective Approach to Track Levels of Influenza-A (H1N1) Pandemic in India Using Twitter. Procedia Comput. Sci. 2015, 70, 801–807. [Google Scholar] [CrossRef]
- Ahmed, W.; Bath, P.A.; Sbaffi, L.; Demartini, G. Novel Insights into Views towards H1N1 during the 2009 Pandemic: A Thematic Analysis of Twitter Data. Health Info. Libr. J. 2019, 36, 60–72. [Google Scholar] [CrossRef] [PubMed]
- Ng, R.; Indran, N.; Liu, L. Ageism on Twitter during the COVID-19 Pandemic. J. Soc. Issues 2022, 78, 842–859. [Google Scholar] [CrossRef]
- Hua, Y.; Jiang, H.; Lin, S.; Yang, J.; Plasek, J.M.; Bates, D.W.; Zhou, L. Using Twitter Data to Understand Public Perceptions of Approved versus Off-Label Use for COVID-19-Related Medications. J. Am. Med. Inform. Assoc. 2022, 29, 1668–1678. [Google Scholar] [CrossRef] [PubMed]
- Olar, M.-L.; Leba, M.; Risteiu, M. Exoskeleton - Wearable Devices. Literature Review. MATEC Web Conf. 2021, 342, 05005. [Google Scholar] [CrossRef]
- Yang, C.-J.; Zhang, J.-F.; Chen, Y.; Dong, Y.-M.; Zhang, Y. A Review of Exoskeleton-Type Systems and Their Key Technologies. Proc Inst Mech Eng Part C 2008, 222, 1599–1612. [Google Scholar] [CrossRef]
- Palazzi, E.; Luzi, L.; Dimo, E.; Meneghetti, M.; Vicario, R.; Luzia, R.F.; Vertechy, R.; Calanca, A. An Affordable Upper-Limb Exoskeleton Concept for Rehabilitation Applications. Technologies (Basel) 2022, 10, 22. [Google Scholar] [CrossRef]
- Laubscher, C.A.; Goo, A.; Farris, R.J.; Sawicki, J.T. Hybrid Impedance-Sliding Mode Switching Control of the Indego Explorer Lower-Limb Exoskeleton in Able-Bodied Walking. J. Intell. Robot. Syst. 2022, 104. [Google Scholar] [CrossRef]
- Zoss, A.B.; Kazerooni, H.; Chu, A. Biomechanical Design of the Berkeley Lower Extremity Exoskeleton (BLEEX). IEEE ASME Trans. Mechatron. 2006, 11, 128–138. [Google Scholar] [CrossRef]
- Høyer, E.; Opheim, A.; Jørgensen, V. Implementing the Exoskeleton Ekso GTTM for Gait Rehabilitation in a Stroke Unit – Feasibility, Functional Benefits and Patient Experiences. Disabil. Rehabil. Assist. Technol. 2022, 17, 473–479. [Google Scholar] [CrossRef]
- van Kammen, K.; Boonstra, A.M.; van der Woude, L.H.V.; Reinders-Messelink, H.A.; den Otter, R. The Combined Effects of Guidance Force, Bodyweight Support and Gait Speed on Muscle Activity during Able-Bodied Walking in the Lokomat. Clin. Biomech. (Bristol, Avon) 2016, 36, 65–73. [Google Scholar] [CrossRef]
- Gull, M.A.; Bai, S.; Bak, T. A Review on Design of Upper Limb Exoskeletons. Robotics 2020, 9, 16. [Google Scholar] [CrossRef]
- Comani, S.; Velluto, L.; Schinaia, L.; Cerroni, G.; Serio, A.; Buzzelli, S.; Sorbi, S.; Guarnieri, B. Monitoring Neuro-Motor Recovery from Stroke with High-Resolution EEG, Robotics and Virtual Reality: A Proof of Concept. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 23, 1106–1116. [Google Scholar] [CrossRef]
- Grimm, F.; Walter, A.; Spüler, M.; Naros, G.; Rosenstiel, W.; Gharabaghi, A. Hybrid Neuroprosthesis for the Upper Limb: Combining Brain-Controlled Neuromuscular Stimulation with a Multi-Joint Arm Exoskeleton. Front. Neurosci. 2016, 10. [Google Scholar] [CrossRef] [PubMed]
- Sarkisian, S.V.; Ishmael, M.K.; Lenzi, T. Self-Aligning Mechanism Improves Comfort and Performance with a Powered Knee Exoskeleton. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 629–640. [Google Scholar] [CrossRef]
- van der Have, A.; Rossini, M.; Rodriguez-Guerrero, C.; Van Rossom, S.; Jonkers, I. The Exo4Work Shoulder Exoskeleton Effectively Reduces Muscle and Joint Loading during Simulated Occupational Tasks above Shoulder Height. Appl. Ergon. 2022, 103, 103800. [Google Scholar] [CrossRef] [PubMed]
- Zahedi, A.; Wang, Y.; Martinez-Hernandez, U.; Zhang, D. A Wearable Elbow Exoskeleton for Tremor Suppression Equipped with Rotational Semi-Active Actuator. Mech. Syst. Signal Process. 2021, 157, 107674. [Google Scholar] [CrossRef]
- Peng, X.; Acosta-Sojo, Y.; Wu, M.I.; Stirling, L. Actuation Timing Perception of a Powered Ankle Exoskeleton and Its Associated Ankle Angle Changes during Walking. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 869–877. [Google Scholar] [CrossRef]
- Liu, H.; Zeng, B.; Liu, X.; Zhu, X.; Song, H. Detection of Human Lifting State Based on Long Short-Term Memory for Wearable Waist Exoskeleton. In Lecture Notes in Electrical Engineering; Springer Singapore: Singapore, 2022; pp. 301–310. ISBN 9789811663277. [Google Scholar]
- Ishmael, M.K.; Archangeli, D.; Lenzi, T. A Powered Hip Exoskeleton with High Torque Density for Walking, Running, and Stair Ascent. IEEE ASME Trans. Mechatron. 2022, 27, 4561–4572. [Google Scholar] [CrossRef]
- Garosi, E.; Mazloumi, A.; Jafari, A.H.; Keihani, A.; Shamsipour, M.; Kordi, R.; Kazemi, Z. Design and Ergonomic Assessment of a Passive Head/Neck Supporting Exoskeleton for Overhead Work Use. Appl. Ergon. 2022, 101, 103699. [Google Scholar] [CrossRef]
- Song, J.; Zhu, A.; Tu, Y.; Zou, J. Multijoint Passive Elastic Spine Exoskeleton for Stoop Lifting Assistance. Int. J. Adv. Robot. Syst. 2021, 18, 172988142110620. [Google Scholar] [CrossRef]
- Dragusanu, M.; Iqbal, M.Z.; Baldi, T.L.; Prattichizzo, D.; Malvezzi, M. Design, Development, and Control of a Hand/Wrist Exoskeleton for Rehabilitation and Training. IEEE Trans. Robot. 2022, 38, 1472–1488. [Google Scholar] [CrossRef]
- Li, G.; Cheng, L.; Sun, N. Design, Manipulability Analysis and Optimization of an Index Finger Exoskeleton for Stroke Rehabilitation. Mech. Mach. Theory 2022, 167, 104526. [Google Scholar] [CrossRef]
- Bär, M.; Steinhilber, B.; Rieger, M.A.; Luger, T. The Influence of Using Exoskeletons during Occupational Tasks on Acute Physical Stress and Strain Compared to No Exoskeleton – A Systematic Review and Meta-Analysis. Appl. Ergon. 2021, 94, 103385. [Google Scholar] [CrossRef]
- Sawicki, G.S.; Beck, O.N.; Kang, I.; Young, A.J. The Exoskeleton Expansion: Improving Walking and Running Economy. J. Neuroeng. Rehabil. 2020, 17. [Google Scholar] [CrossRef] [PubMed]
- Massardi, S.; Rodriguez-Cianca, D.; Pinto-Fernandez, D.; Moreno, J.C.; Lancini, M.; Torricelli, D. Characterization and Evaluation of Human–Exoskeleton Interaction Dynamics: A Review. Sensors (Basel) 2022, 22, 3993. [Google Scholar] [CrossRef] [PubMed]
- Exoskeleton Market Size, Share & Trends Analysis Report, by Mobility, by Technology, by Extremity, by End-Use, by Region, and Segment Forecasts, 2023 - 2030. Available online: https://www.grandviewresearch.com/industry-analysis/exoskeleton-market (accessed on 24 September 2023).
- Bogue, R. Exoskeletons: A Review of Recent Progress. Ind. Rob. 2022, 49, 813–818. [Google Scholar] [CrossRef]
- Cardona, M.; Solanki, V.K.; García Cena, C.E. Exoskeleton Robots for Rehabilitation and Healthcare Devices; Springer Singapore: Singapore, 2020; ISBN 9789811547317. [Google Scholar]
- Tan, K.; Koyama, S.; Sakurai, H.; Teranishi, T.; Kanada, Y.; Tanabe, S. Wearable Robotic Exoskeleton for Gait Reconstruction in Patients with Spinal Cord Injury: A Literature Review. J. Orthop. Translat. 2021, 28, 55–64. [Google Scholar] [CrossRef]
- Kandilakis, C.; Sasso-Lance, E. Exoskeletons for Personal Use after Spinal Cord Injury. Arch. Phys. Med. Rehabil. 2021, 102, 331–337. [Google Scholar] [CrossRef] [PubMed]
- Jung, M.M.; Ludden, G.D.S. What Do Older Adults and Clinicians Think about Traditional Mobility Aids and Exoskeleton Technology? ACM Trans. Hum. Robot Interact. 2019, 8, 1–17. [Google Scholar] [CrossRef]
- Bunge, L.R.; Davidson, A.J.; Helmore, B.R.; Mavrandonis, A.D.; Page, T.D.; Schuster-Bayly, T.R.; Kumar, S. Effectiveness of Powered Exoskeleton Use on Gait in Individuals with Cerebral Palsy: A Systematic Review. PLoS One 2021, 16, e0252193. [Google Scholar] [CrossRef]
- Kamiński, M.; Muth, A.; Bogdański, P. Smoking, Vaping, and Tobacco Industry during COVID-19 Pandemic: Twitter Data Analysis. Cyberpsychol. Behav. Soc. Netw. 2020, 23, 811–817. [Google Scholar] [CrossRef]
- Souza, T.T.P.; Kolchyna, O.; Treleaven, P.C.; Aste, T. Twitter Sentiment Analysis Applied to Finance: A Case Study in the Retail Industry. arXiv [cs.CY] 2015. [Google Scholar]
- Pons, A.; Rius, J.; Vintró, C.; Gallart, A. Analysis of Twitter Posts for Evaluation of Corporate Social Responsibility in the Leather Industry. J. Eng. Fiber. Fabr. 2022, 17, 155892502211318. [Google Scholar] [CrossRef]
- Leung, X.Y.; Bai, B.; Stahura, K.A. The Marketing Effectiveness of Social Media in the Hotel Industry: A Comparison of Facebook and Twitter. J. Hosp. Tour. Res. 2015, 39, 147–169. [Google Scholar] [CrossRef]
- Misopoulos, F.; Mitic, M.; Kapoulas, A.; Karapiperis, C. Uncovering Customer Service Experiences with Twitter: The Case of Airline Industry. Manag. Decis. 2014, 52, 705–723. [Google Scholar] [CrossRef]
- Shukri, S.E.; Yaghi, R.I.; Aljarah, I.; Alsawalqah, H. Twitter Sentiment Analysis: A Case Study in the Automotive Industry. In Proceedings of the 2015 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies (AEECT); IEEE, 2015. [CrossRef]
- Criswell, J.; Canty, N. Deconstructing Social Media: An Analysis of Twitter and Facebook Use in the Publishing Industry. Publ. Res. Q. 2014, 30, 352–376. [Google Scholar] [CrossRef]
- Parganas, P.; Anagnostopoulos, C.; Chadwick, S. ‘You’Ll Never Tweet Alone’: Managing Sports Brands through Social Media. J. Brand Manag. 2015, 22, 551–568. [Google Scholar] [CrossRef]
- Paredes-Corvalan, D.; Pezoa-Fuentes, C.; Silva-Rojas, G.; Valenzuela Rojas, I.; Castillo-Vergara, M. Engagement of the E-Commerce Industry in the US, According to Twitter in the Period of the COVID-19 Pandemic. Heliyon 2023, 9, e16881. [Google Scholar] [CrossRef]
- Garcia-Rivera, D.; Matamoros-Rojas, S.; Pezoa-Fuentes, C.; Veas-González, I.; Vidal-Silva, C. Engagement on Twitter, a Closer Look from the Consumer Electronics Industry. J. Theor. Appl. Electron. Commer. Res. 2022, 17, 558–570. [Google Scholar] [CrossRef]
- Wonneberger, A.; Hellsten, I.R.; Jacobs, S.H.J. Hashtag Activism and the Configuration of Counterpublics: Dutch Animal Welfare Debates on Twitter. Inf. Commun. Soc. 2021, 24, 1694–1711. [Google Scholar] [CrossRef]
- Aleti, T.; Harrigan, P.; Cheong, M.; Turner, W. An Investigation of How the Australian Brewing Industry Influence Consumers on Twitter. Aust. J. Inf. Syst. 2016, 20. [Google Scholar] [CrossRef]
- Komorowski, M.; Huu, T.D.; Deligiannis, N. Twitter Data Analysis for Studying Communities of Practice in the Media Industry. Telemat. Inform. 2018, 35, 195–212. [Google Scholar] [CrossRef]
- Ghanadpour, S.H.; Shokouhyar, S.; Pourabbasi, M. Effective End of life (EOL) Products Management in Mobile Phone Industry with Using Twitter Data Analysis Perspective. Environ. Dev. Sustain. 2023, 25, 11337–11366. [Google Scholar] [CrossRef]
- Durand-Moreau, Q.; Mackenzie, G.; Adisesh, A.; Straube, S.; Chan, X.H.S.; Zelyas, N.; Greenhalgh, T. Twitter Analytics to Inform Provisional Guidance for COVID-19 Challenges in the Meatpacking Industry. Ann. Work Expo. Health 2021, 65, 373–376. [Google Scholar] [CrossRef]
- Casadei, P.; Lee, N. Global Cities, Creative Industries and Their Representation on Social Media: A Micro-Data Analysis of Twitter Data on the Fashion Industry. Environ. Plan. A 2020, 52, 1195–1220. [Google Scholar] [CrossRef]
- Sama, T.B.; Konttinen, I.; Hiilamo, H. Alcohol Industry Arguments for Liberalizing Alcohol Policy in Finland: Analysis of Twitter Data. J. Stud. Alcohol Drugs 2021, 82, 279–287. [Google Scholar] [CrossRef]
- Cramer, H.; Büttner, S. Things That Tweet, Check-in and Are Befriended: Two Explorations on Robotics & Social Media. In Proceedings of the Proceedings of the 6th international conference on Human-robot interaction; ACM: New York, NY, USA, 2011. [Google Scholar]
- Salzmann-Erikson, M.; Eriksson, H. Absorbability, Applicability and Availability in Nursing and Care Robots: A Thematic Analysis of Twitter Postings. Telemat. Inform. 2018, 35, 1553–1560. [Google Scholar] [CrossRef]
- Fraser, K.C.; Zeller, F.; Smith, D.H.; Mohammad, S.; Rudzicz, F. How Do We Feel When a Robot Dies? Emotions Expressed on Twitter before and after Hitch. In Proceedings of the Proceedings of the Tenth Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 62–71.
- Mubin, O.; Khan, A.; Obaid, M. #naorobot: Exploring Nao Discourse on Twitter. In Proceedings of the Proceedings of the 28th Australian Conference on Computer-Human Interaction - OzCHI ’16; ACM Press: New York, New York, USA, 2016. [Google Scholar]
- Barakeh, Z.A.; Alkork, S.; Karar, A.S.; Said, S.; Beyrouthy, T. Pepper Humanoid Robot as a Service Robot: A Customer Approach. In Proceedings of the 2019 3rd International Conference on Bio-engineering for Smart Technologies (BioSMART); IEEE, 2019. [CrossRef]
- Mahmud, J.; Fei, G.; Xu, A.; Pal, A.; Zhou, M. Predicting Attitude and Actions of Twitter Users. In Proceedings of the Proceedings of the 21st International Conference on Intelligent User Interfaces; ACM: New York, NY, USA, 2016. [Google Scholar]
- Yamanoue, T.; Yoshimura, K.; Oda, K.; Shimozono, K. A Wearable LED Matrix Sign System Which Shows a Tweet of Twitter and Its Application to Campus Guiding and Emergency Evacuation. In Proceedings of the Proceedings of the 2015 ACM SIGUCCS Annual Conference; ACM: New York, NY, USA, 2015.
- Tussyadiah, I. Expectation of Travel Experiences with Wearable Computing Devices. In Information and Communication Technologies in Tourism 2014; Springer International Publishing: Cham, 2013; pp. 539–552. ISBN 9783319039725. [Google Scholar]
- Saxena, R.C.; Lehmann, A.E.; Hight, A.E.; Darrow, K.; Remenschneider, A.; Kozin, E.D.; Lee, D.J. Social Media Utilization in the Cochlear Implant Community. J. Am. Acad. Audiol. 2015, 26, 197–204. [Google Scholar] [CrossRef]
- Adidharma, W.; Latack, K.R.; Colohan, S.M.; Morrison, S.D.; Cederna, P.S. Breast Implant Illness: Are Social Media and the Internet Worrying Patients Sick? Plast. Reconstr. Surg. 2020, 145, 225e–227e. [Google Scholar] [CrossRef]
- Pillarisetti, L.; Kerr, B.R.; Moreno, M. Exploring the Discussion of Nexplanon (Etonogestrel Birth Control Implant) on Twitter. Available online: https://digitalhealth.med.brown.edu/sites/default/files/Lekha%20P.pdf (accessed on 24 September 2023).
- Keane, G.; Chi, D.; Ha, A.Y.; Myckatyn, T.M. En Bloc Capsulectomy for Breast Implant Illness: A Social Media Phenomenon? Aesthet. Surg. J. 2021, 41, 448–459. [Google Scholar] [CrossRef]
- Sinha, N.; Singh, P.; Gupta, M.; Singh, P. Robotics at Workplace: An Integrated Twitter Analytics – SEM Based Approach for Behavioral Intention to Accept. Int. J. Inf. Manage. 2020, 55, 102210. [Google Scholar] [CrossRef]
- El-Gayar, O.; Nasralah, T.; Elnoshokaty, A. Wearable Devices for Health and Wellbeing: Design Insights from Twitter. In Proceedings of the Hawaii International Conference on System Sciences 2019 (HICSS-52); 2019.
- Jeong, W.-K.; Shin, D.-H. Analyzing Smart Watch Recognition and Response in Korea Using Text Mining Analysis Focusing on Twitter. J. Digit. Contents Soc. 2023, 24, 195–204. [Google Scholar] [CrossRef]
- Niininen, O.; Singaraju, S.; Arango, L. The Human RFID Implants Introduce a New Level of Human-Computer Interaction: Twitter Topic Detection Gauges Consumer Opinions; EasyChair, 2023. [Google Scholar]
- Thakur, N. Twitter Big Data as a Resource for Exoskeleton Research: A Large-Scale Dataset of about 140,000 Tweets from 2017–2022 and 100 Research Questions. Analytics 2022, 1, 72–97. [Google Scholar] [CrossRef]
- Mierswa, I.; Wurst, M.; Klinkenberg, R.; Scholz, M.; Euler, T. YALE: Rapid Prototyping for Complex Data Mining Tasks. In Proceedings of the Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining; ACM: New York, NY, USA, 2006. [Google Scholar]
- Twitter Advanced Search. Available online: https://twitter.com/search-advanced?lang=en (accessed on 24 September 2023).
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for Scientific Data Management and Stewardship. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Xue, J.; Chen, J.; Chen, C.; Zheng, C.; Li, S.; Zhu, T. Public Discourse and Sentiment during the COVID 19 Pandemic: Using Latent Dirichlet Allocation for Topic Modeling on Twitter. PLoS One 2020, 15, e0239441. [Google Scholar] [CrossRef] [PubMed]
- Rezapour, R.; Wang, L.; Abdar, O.; Diesner, J. Identifying the Overlap between Election Result and Candidates’ Ranking Based on Hashtag-Enhanced, Lexicon-Based Sentiment Analysis. In Proceedings of the 2017 IEEE 11th International Conference on Semantic Computing (ICSC); IEEE, 2017. [CrossRef]
- Qaseem, D.M.; Ali, N.; Akram, W.; Ullah, A.; Polat, K. Movie Success-Rate Prediction System through Optimal Sentiment Analysis Available online: https://iecscience.org/public/uploads/jpapers/202210/63jv6Sz1Y6sdsUtnflF9dmTy3XyB2JHLZ2IGClPo.pdf.
- Hutto, C.; Gilbert, E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. Proceedings of the International AAAI Conference on Web and Social Media 2014, 8, 216–225. [Google Scholar] [CrossRef]
- González-Ibáñez, R.; Muresan, S.; Wacholder, N. Identifying Sarcasm in Twitter: A Closer Look. Available online: https://aclanthology.org/P11-2102.pdf (accessed on 24 September 2023).
- Reyes, A.; Rosso, P.; Buscaldi, D. From Humor Recognition to Irony Detection: The Figurative Language of Social Media. Data Knowl. Eng. 2012, 74, 1–12. [Google Scholar] [CrossRef]
- Moores, B.; Mago, V. A Survey on Automated Sarcasm Detection on Twitter. arXiv [cs.CL] 2022. [Google Scholar]
- Kunneman, F.; Liebrecht, C.; van Mulken, M.; van den Bosch, A. Signaling Sarcasm: From Hyperbole to Hashtag. Inf. Process. Manag. 2015, 51, 500–509. [Google Scholar] [CrossRef]
- Kreuz, R.J.; Caucci, G.M. Lexical Influences on the Perception of Sarcasm. Available online: https://aclanthology.org/W07-0101.pdf (accessed on 24 September 2023).
- Phuvipadawat, S.; Murata, T. Breaking News Detection and Tracking in Twitter. In Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology; IEEE, 2010. [CrossRef]
- Bruns, A.; Burgess, J. RESEARCHING NEWS DISCUSSION ON TWITTER: New Methodologies. Journal. Stud. 2012, 13, 801–814. [Google Scholar] [CrossRef]
- Roberge, J.-M. Using Data from Online Social Networks in Conservation Science: Which Species Engage People the Most on Twitter? Biodivers. Conserv. 2014, 23, 715–726. [Google Scholar] [CrossRef]
- J-Hartmann/Emotion-English-Distilroberta-Base · Hugging Face. Available online: https://huggingface.co/j-hartmann/emotion-english-distilroberta-base? (accessed on 25 September 2023).
Figure 1.
A flowchart that represents the working of different algorithms to obtain the master dataset for analysis.
Figure 1.
A flowchart that represents the working of different algorithms to obtain the master dataset for analysis.
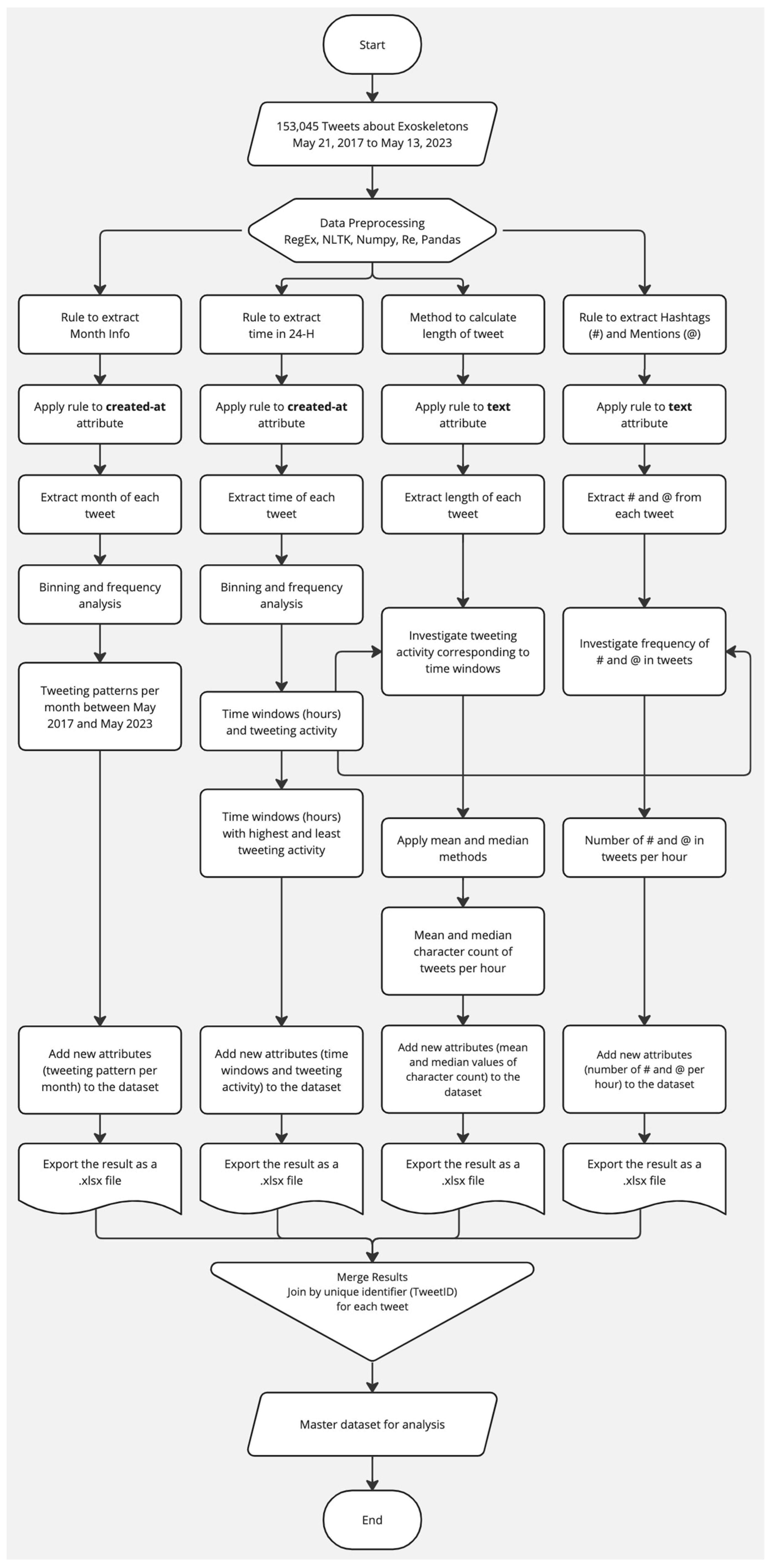
Figure 2.
A workflow diagram representing the working of Algorithm 7.
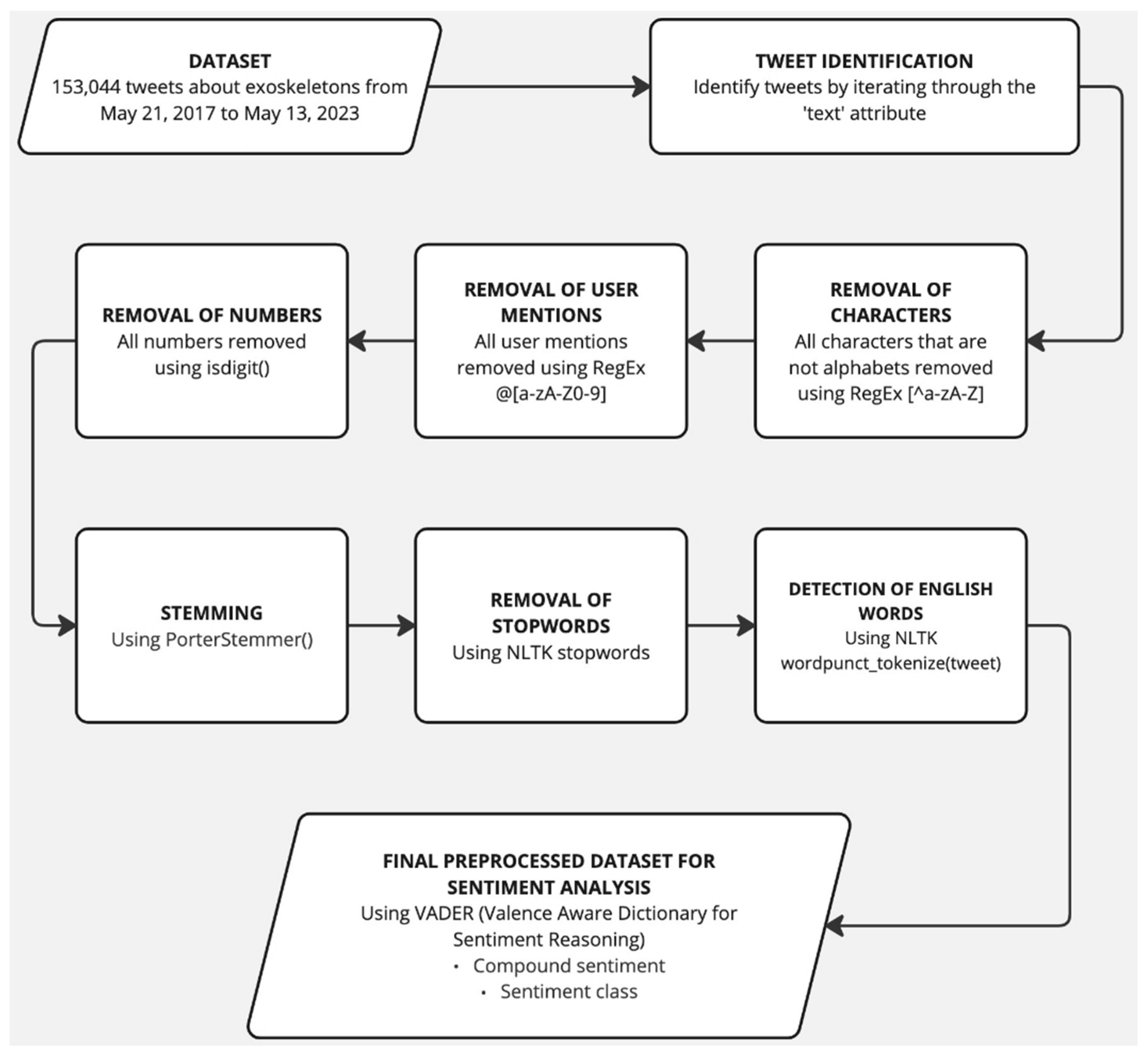
Figure 3.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2017.
Figure 3.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2017.
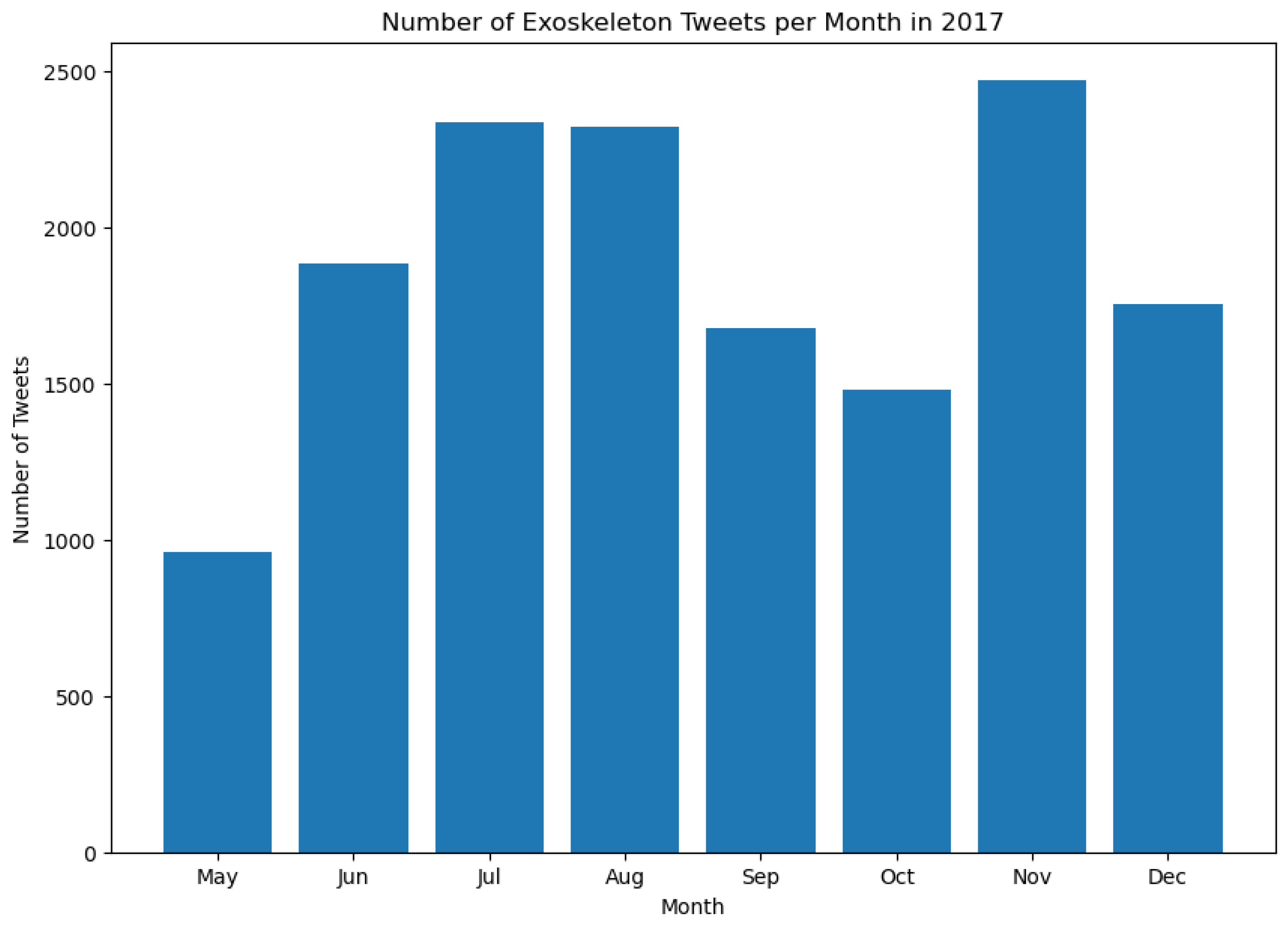
Figure 4.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2018.
Figure 4.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2018.
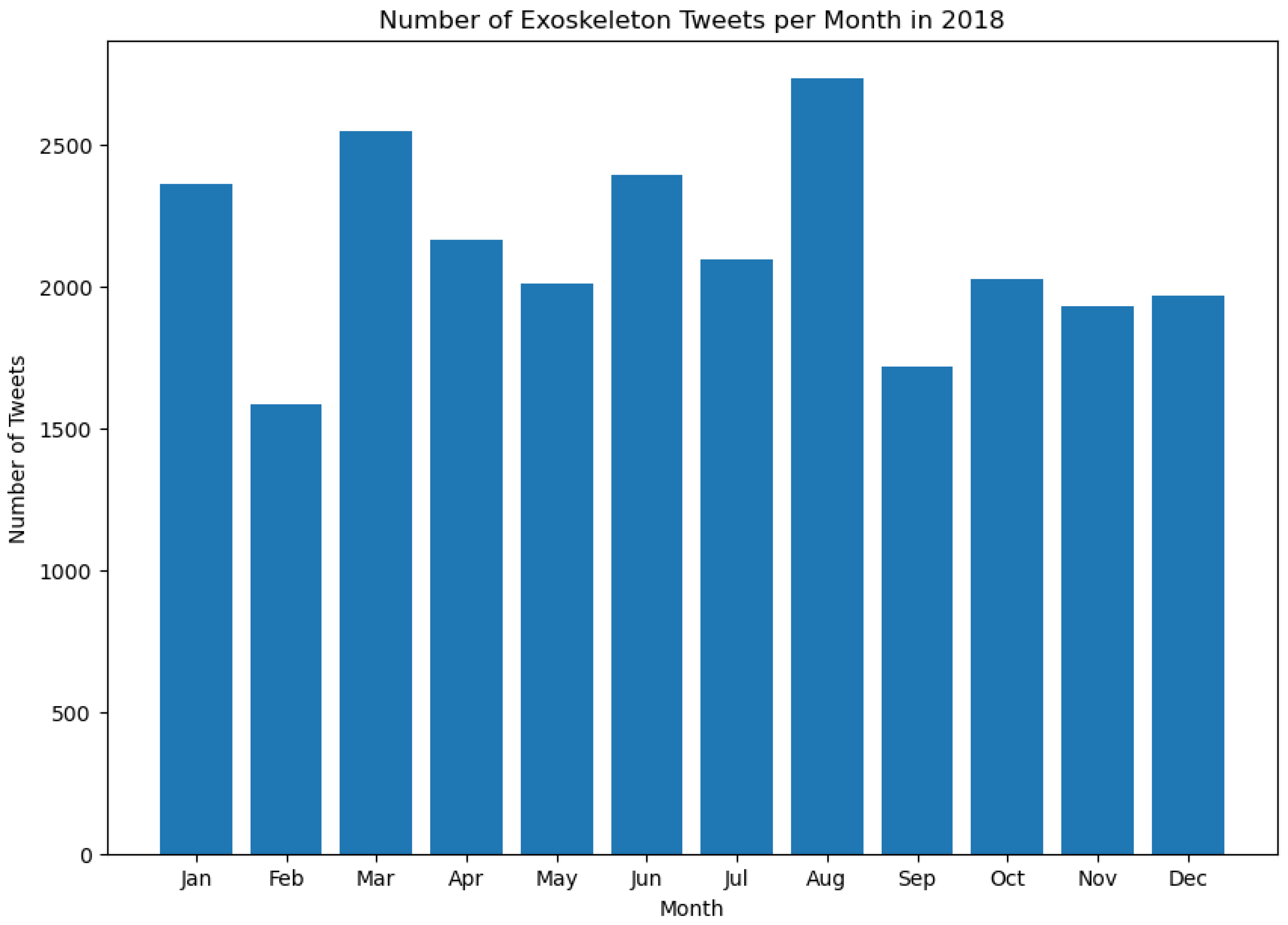
Figure 5.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2019.
Figure 5.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2019.
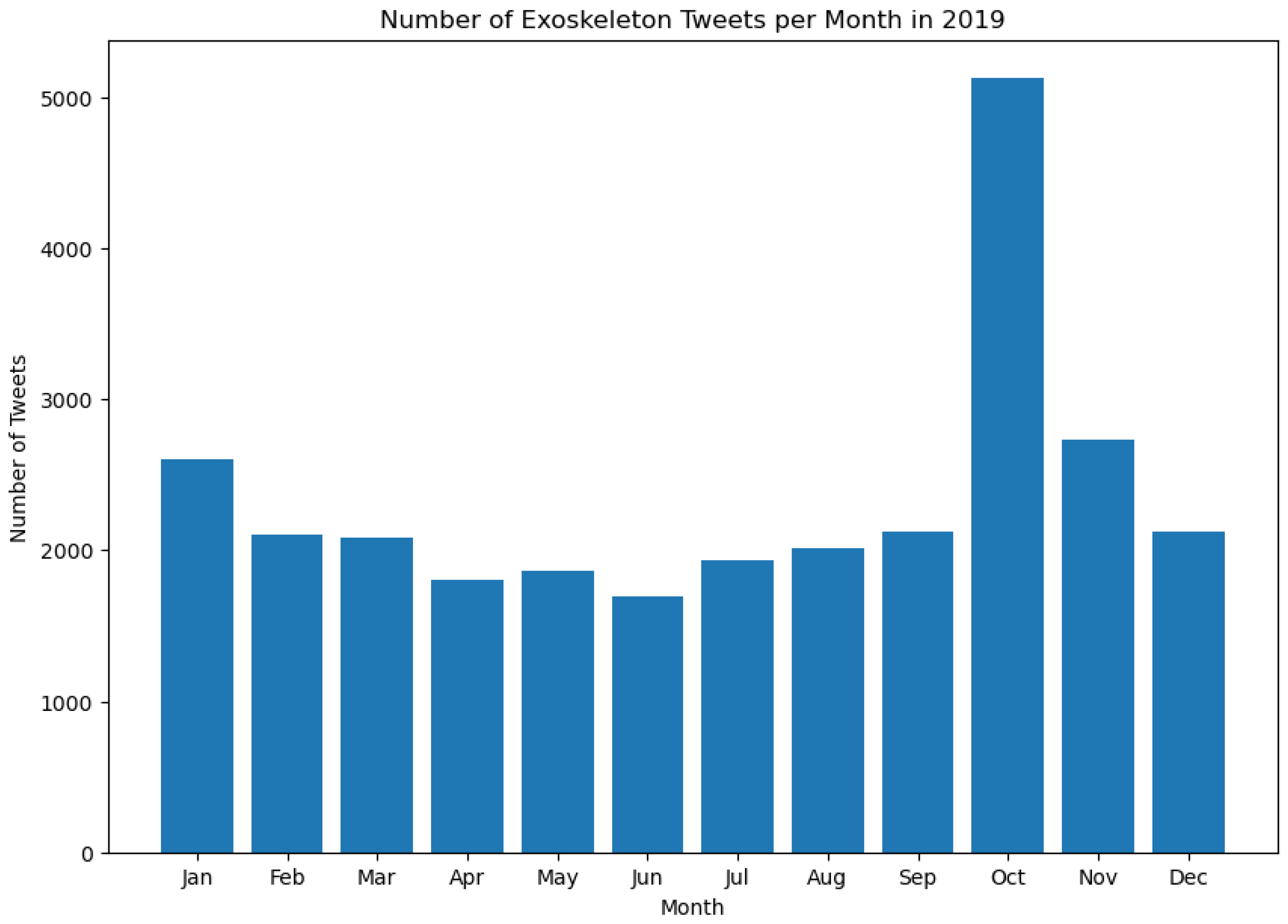
Figure 6.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2020.
Figure 6.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2020.
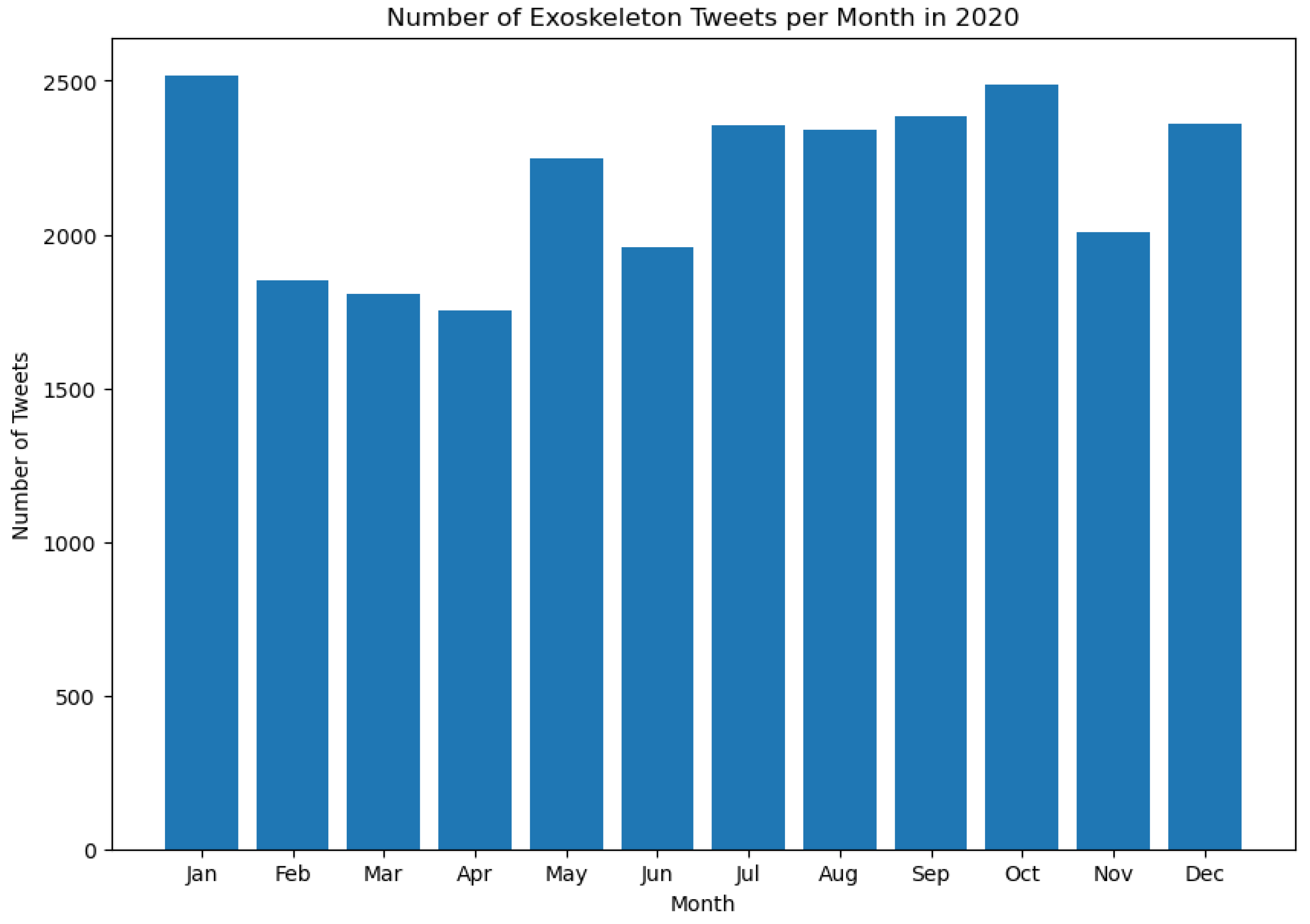
Figure 7.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2021.
Figure 7.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2021.
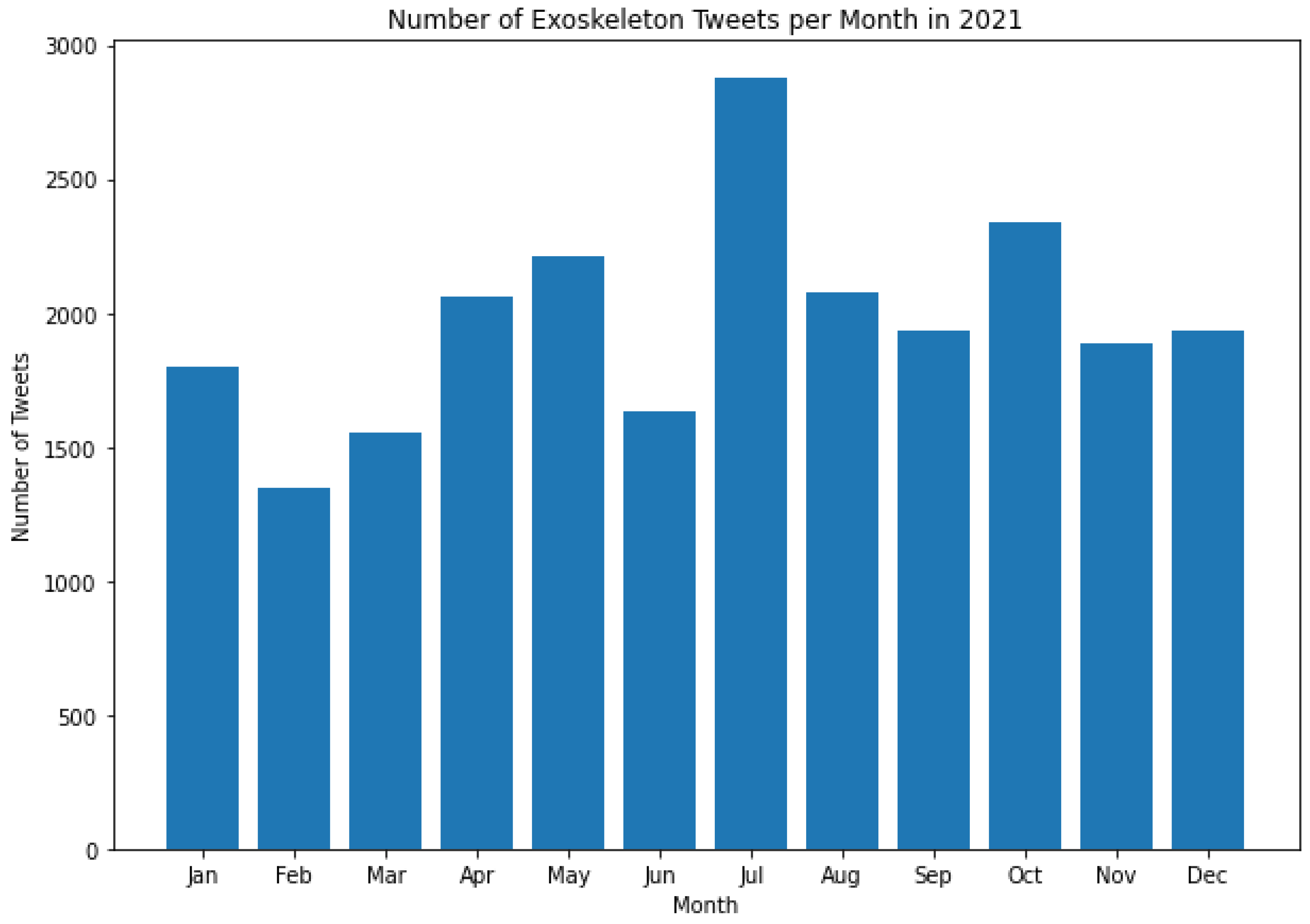
Figure 8.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2022.
Figure 8.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2022.
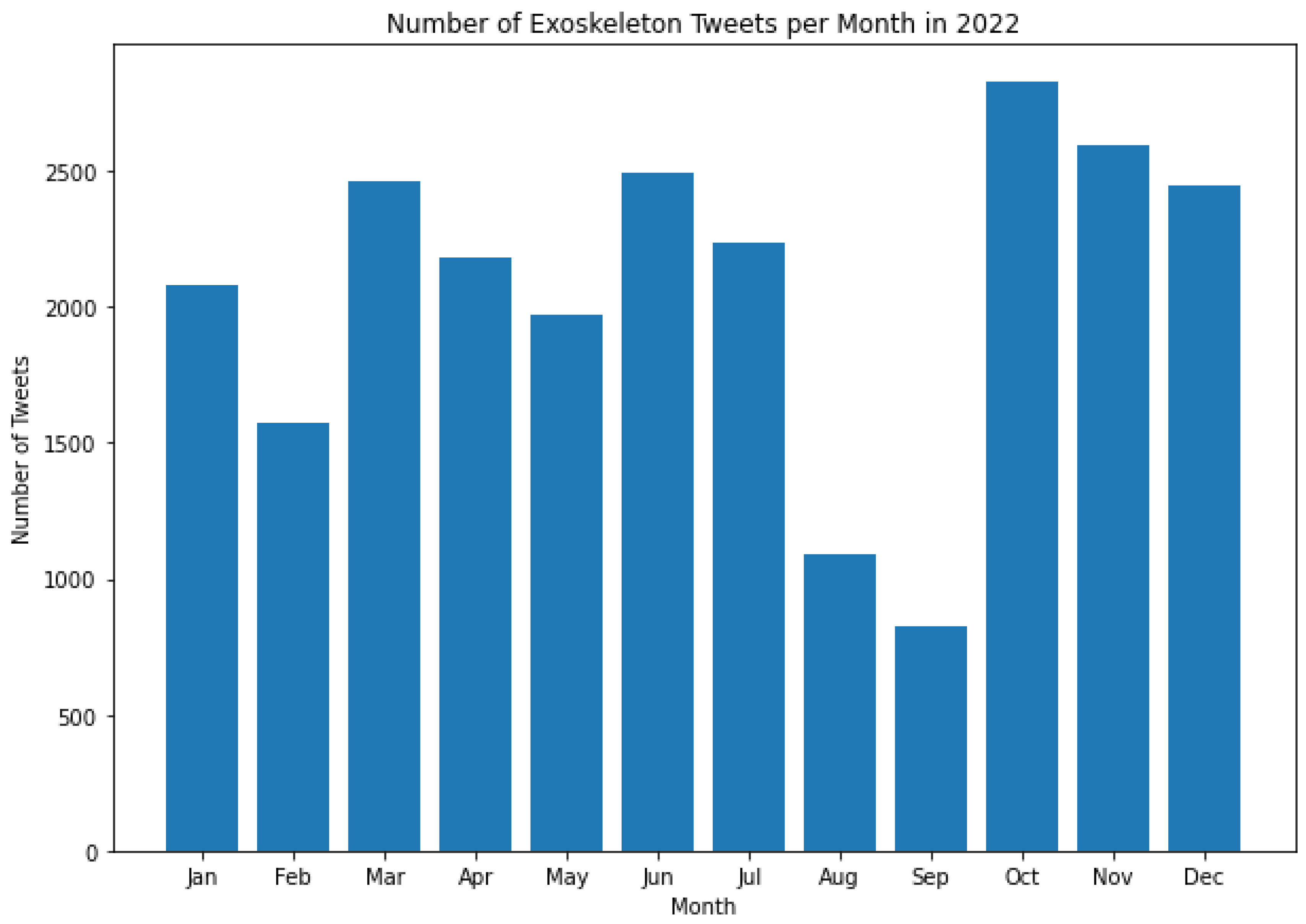
Figure 9.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2023.
Figure 9.
A histogram-based representation of the number of Tweets about exoskeletons per month in 2023.
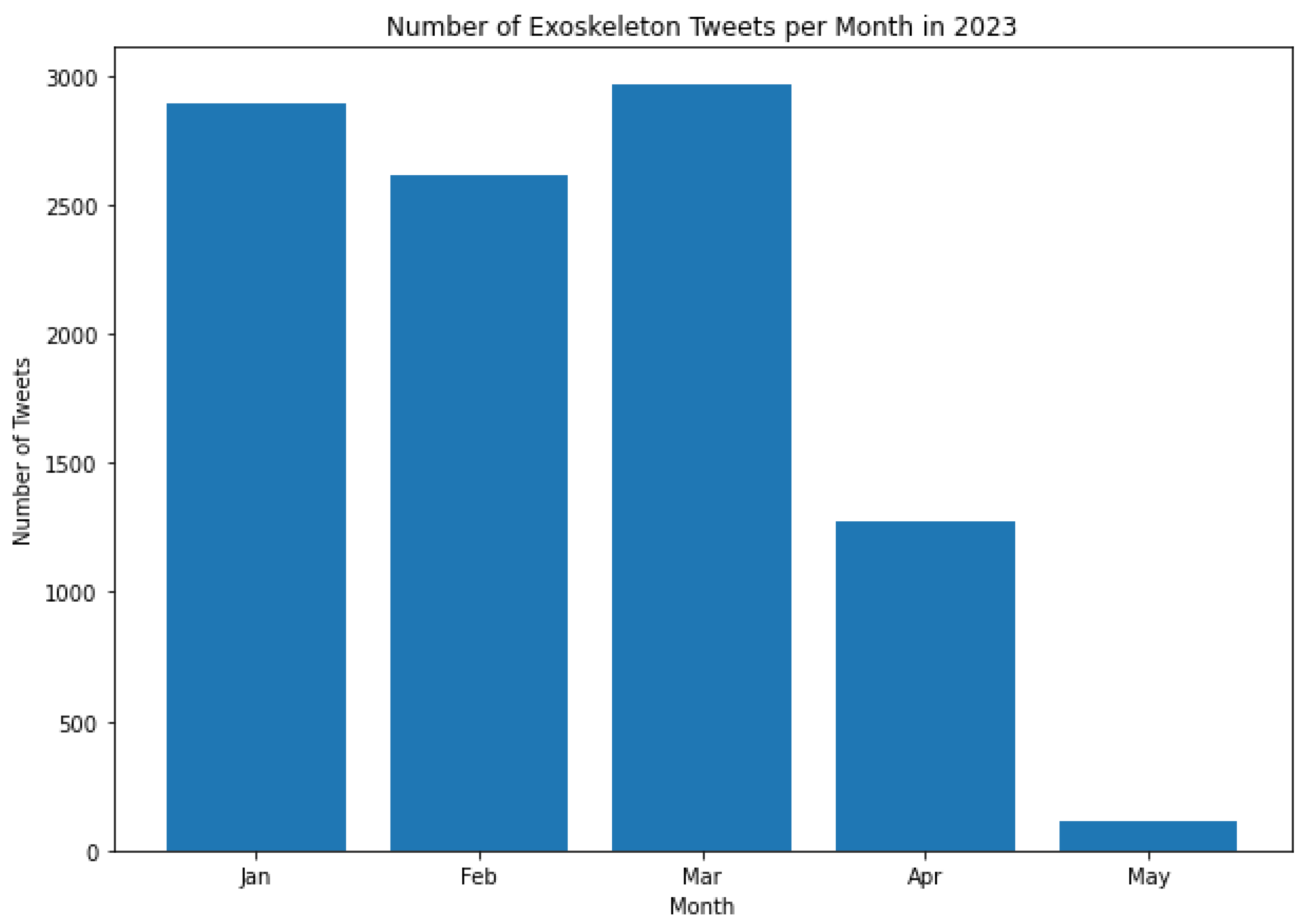
Figure 10.
A histogram-based representation of the number of Tweets in different time slots (of 1-hour duration) of a day (24-hour format).
Figure 10.
A histogram-based representation of the number of Tweets in different time slots (of 1-hour duration) of a day (24-hour format).
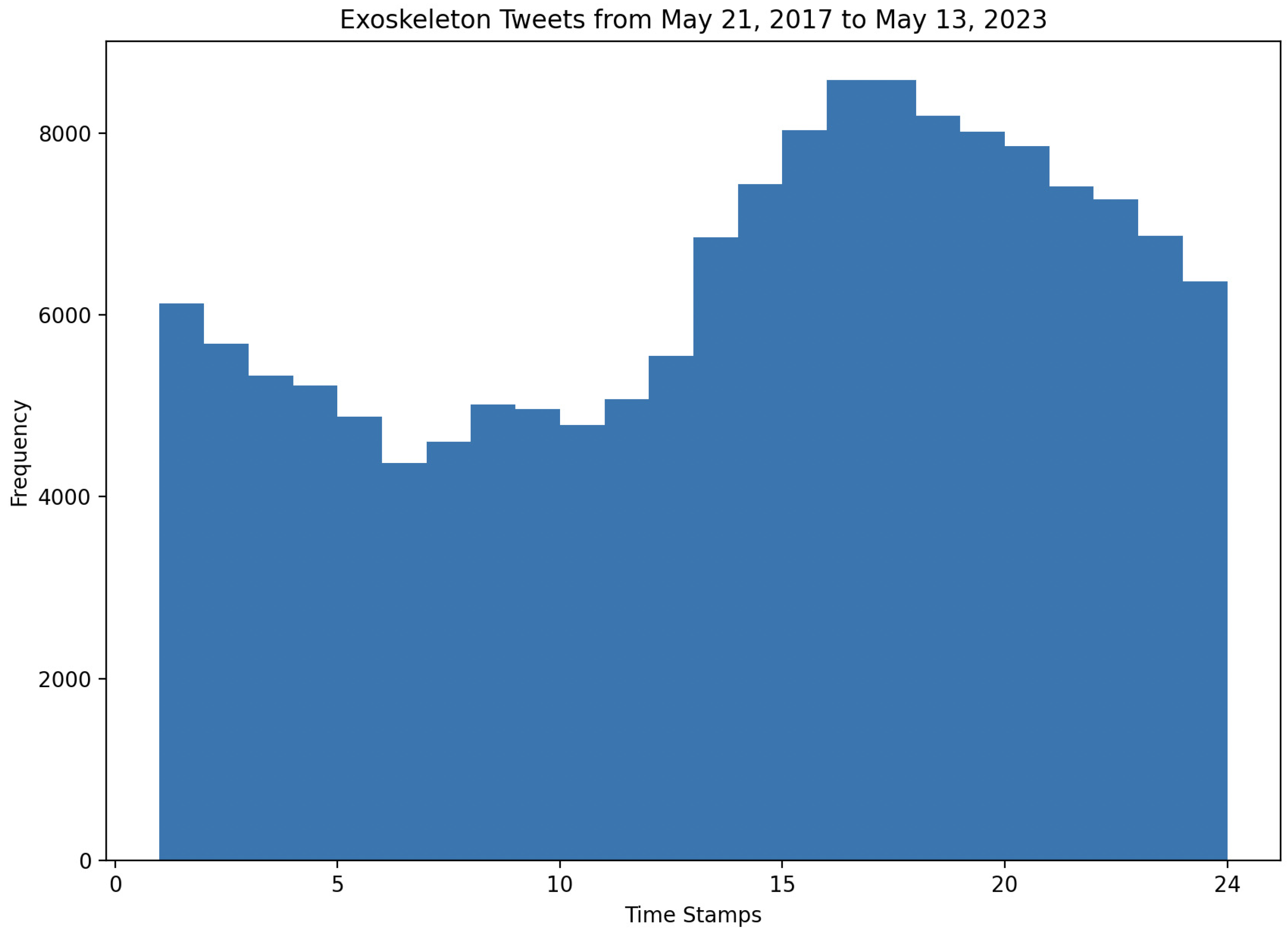
Figure 11.
A histogram-based representation of the number of characters (mean value) used in Tweets in different time slots (of 1-hour duration) of a day (24-hour format).
Figure 11.
A histogram-based representation of the number of characters (mean value) used in Tweets in different time slots (of 1-hour duration) of a day (24-hour format).
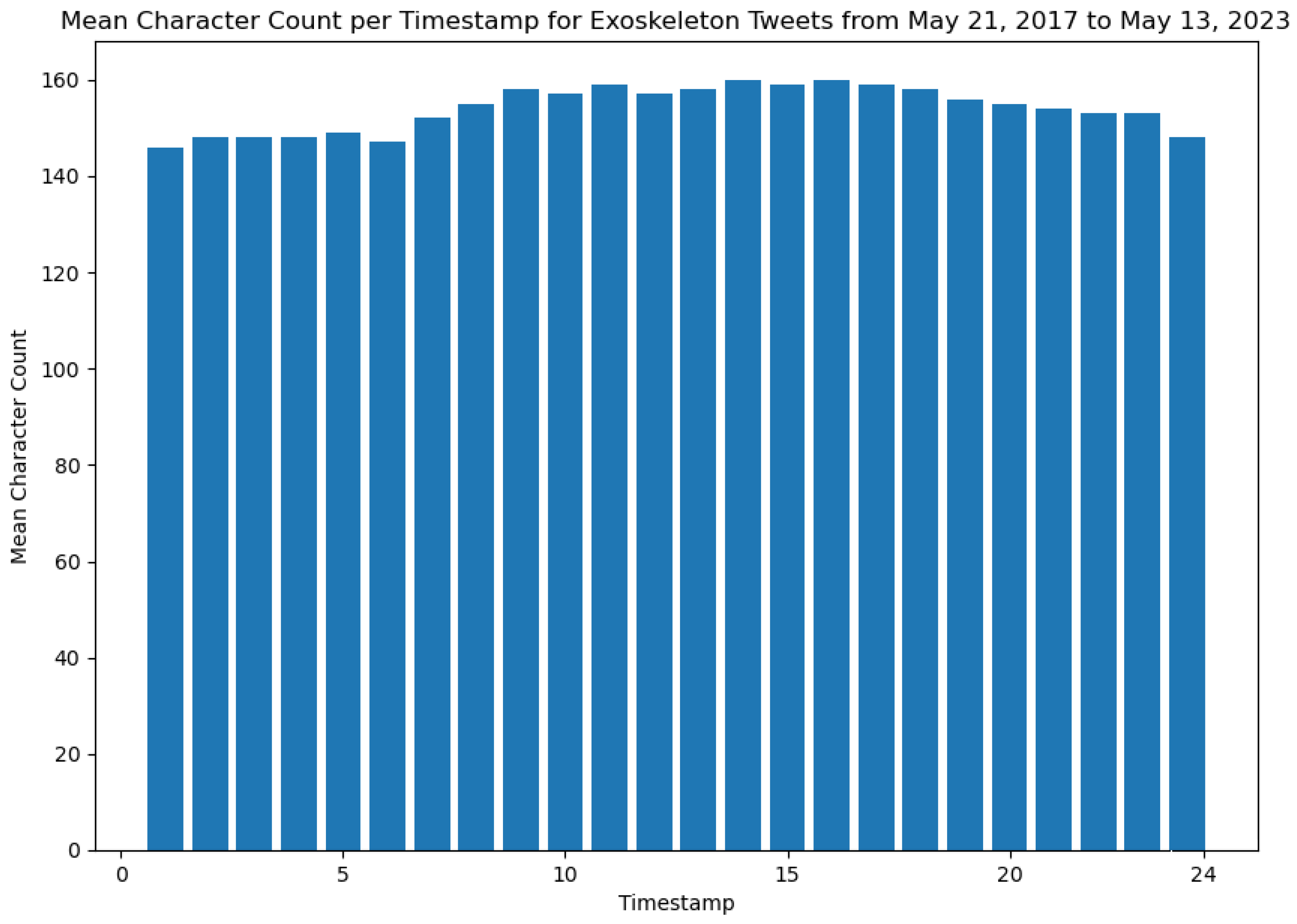
Figure 12.
A histogram-based representation of the number of characters (median value) used in Tweets in different time slots (of 1-hour duration) of a day (24-hour format).
Figure 12.
A histogram-based representation of the number of characters (median value) used in Tweets in different time slots (of 1-hour duration) of a day (24-hour format).
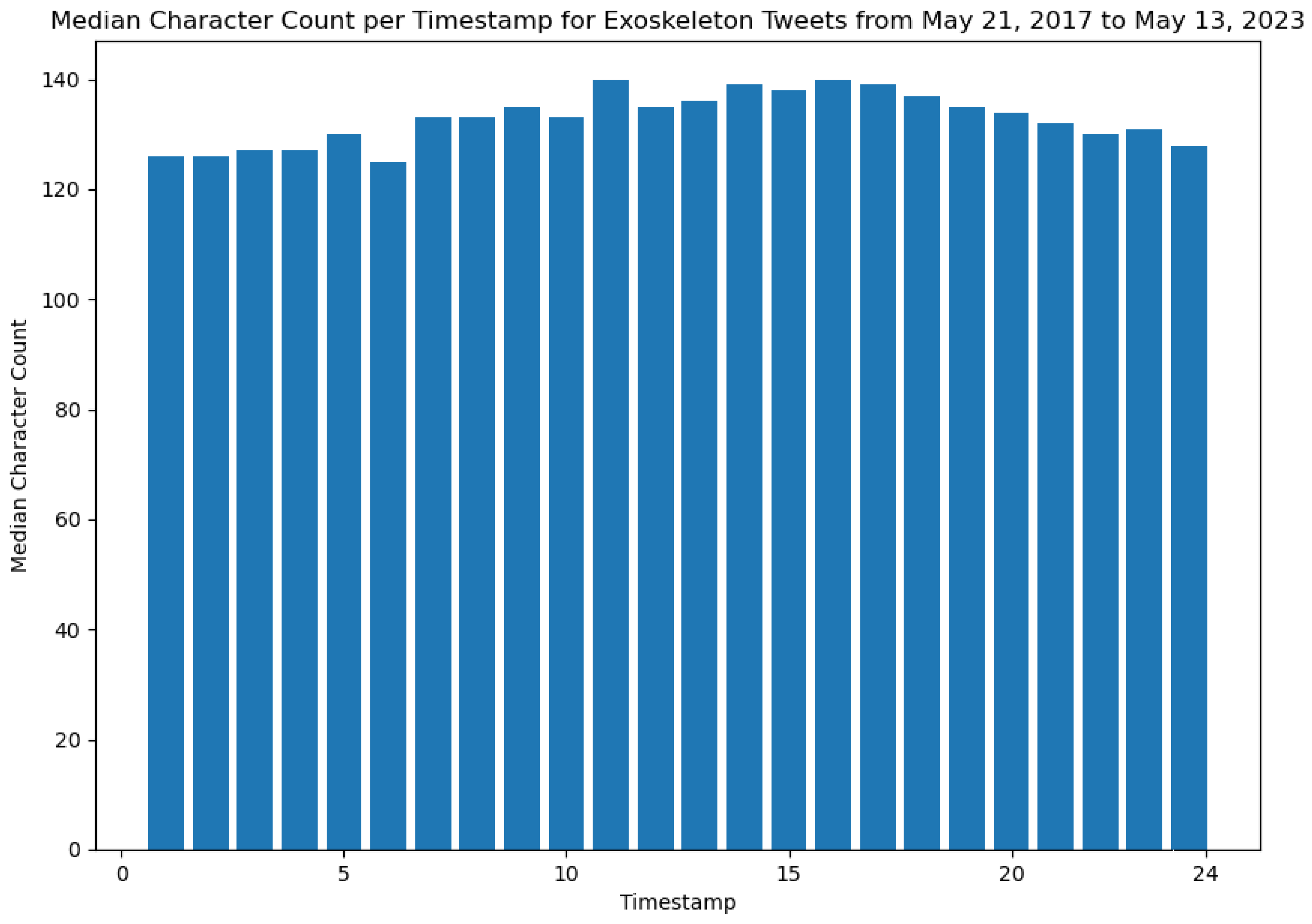
Figure 13.
A histogram-based representation of the number of hashtags used in Tweets in different time slots (of 1-hour duration) of a day (24-hour format).
Figure 13.
A histogram-based representation of the number of hashtags used in Tweets in different time slots (of 1-hour duration) of a day (24-hour format).
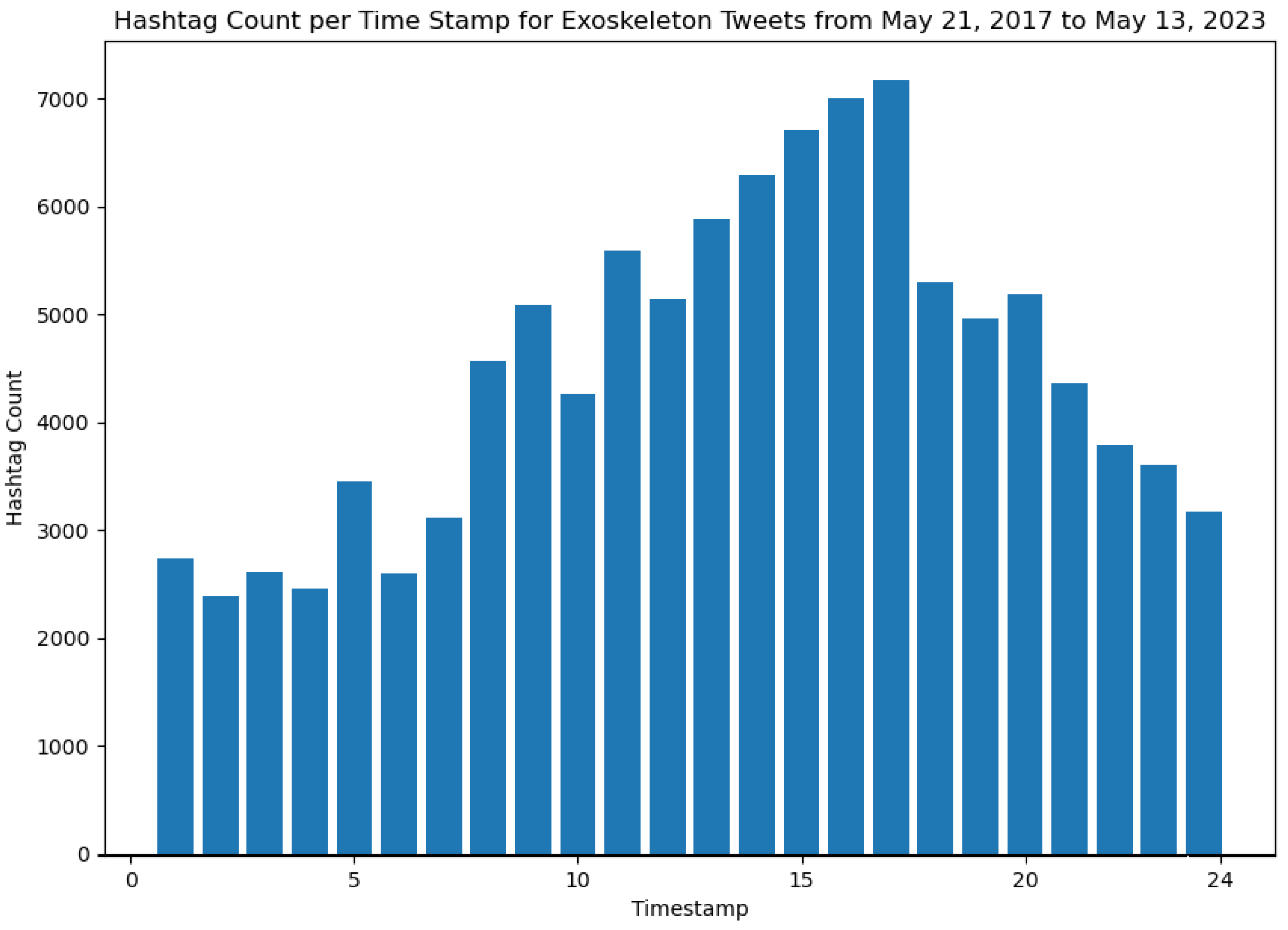
Figure 14.
A histogram-based representation of the number of user mentions used in Tweets in different time slots (of 1-hour duration) of a day (24-hour format).
Figure 14.
A histogram-based representation of the number of user mentions used in Tweets in different time slots (of 1-hour duration) of a day (24-hour format).
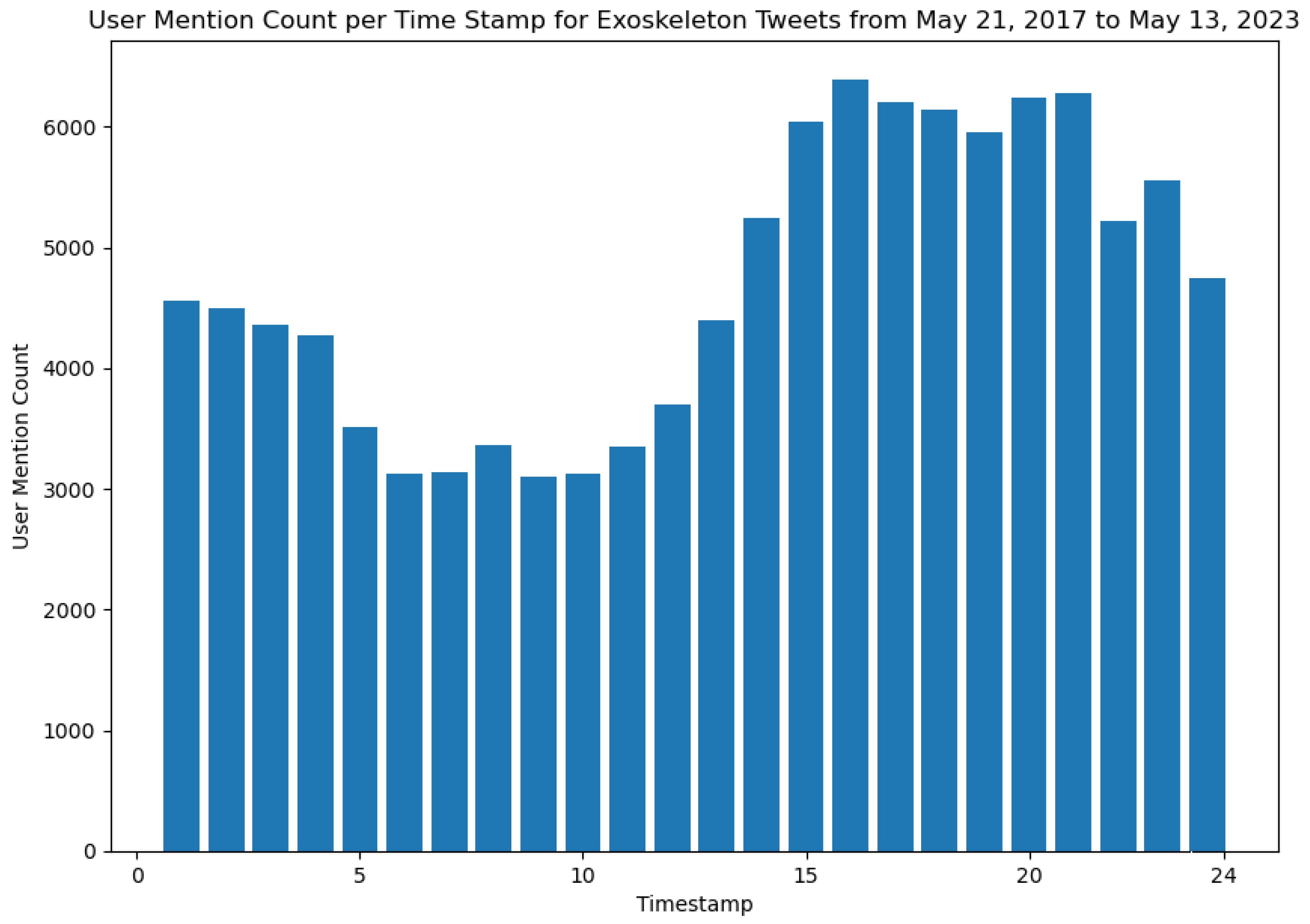
Figure 26.
A graphical representation to compare the positive tweets, negative tweets, possibly sarcastic tweets, and tweets that contained news, in terms of the mean value of the characters used, on a monthly basis.
Figure 26.
A graphical representation to compare the positive tweets, negative tweets, possibly sarcastic tweets, and tweets that contained news, in terms of the mean value of the characters used, on a monthly basis.
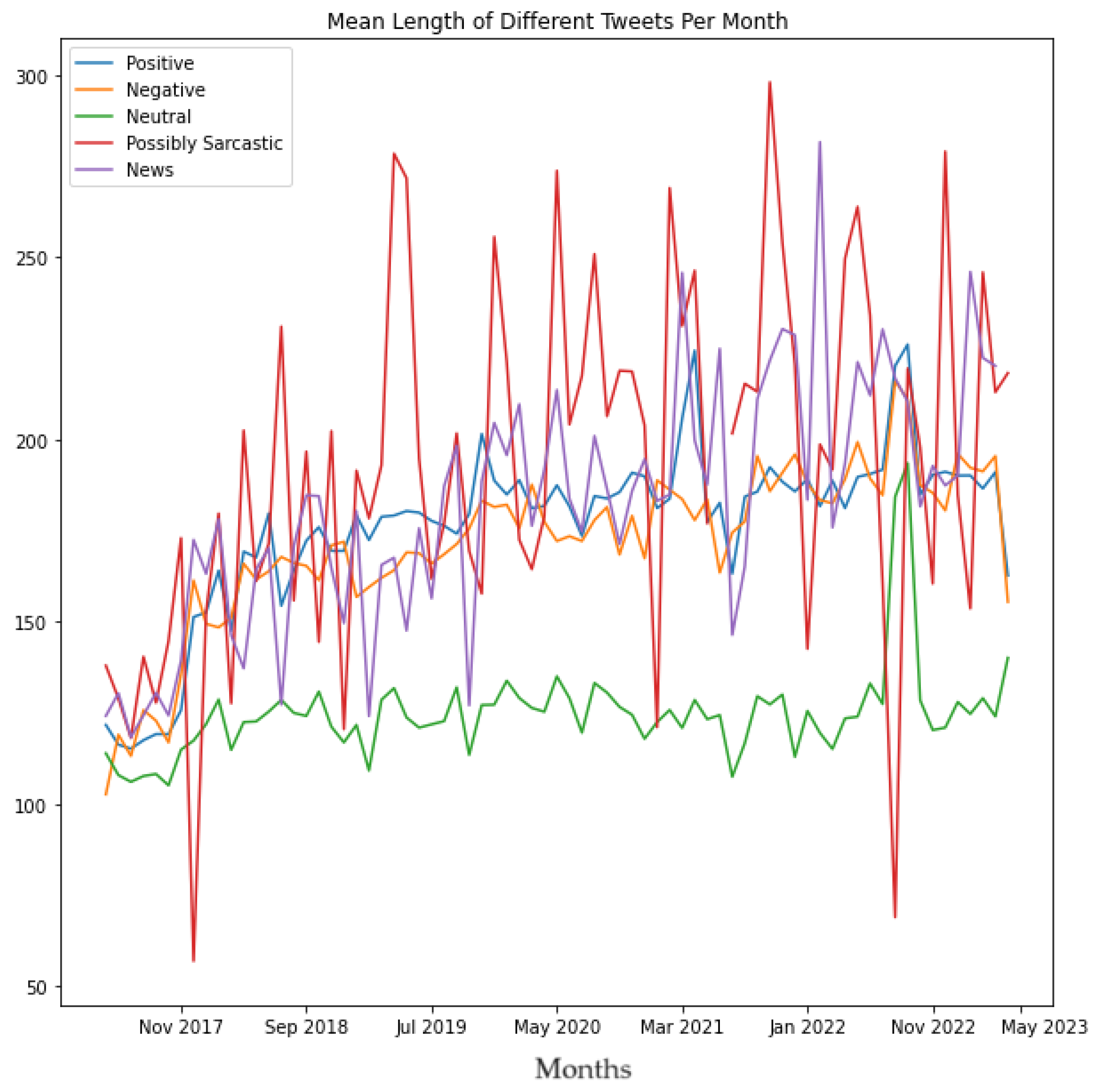
Figure 27.
A graphical representation to compare the positive tweets, negative tweets, possibly sarcastic tweets, and tweets that contained news, in terms of the median value of the characters used, on a monthly basis.
Figure 27.
A graphical representation to compare the positive tweets, negative tweets, possibly sarcastic tweets, and tweets that contained news, in terms of the median value of the characters used, on a monthly basis.
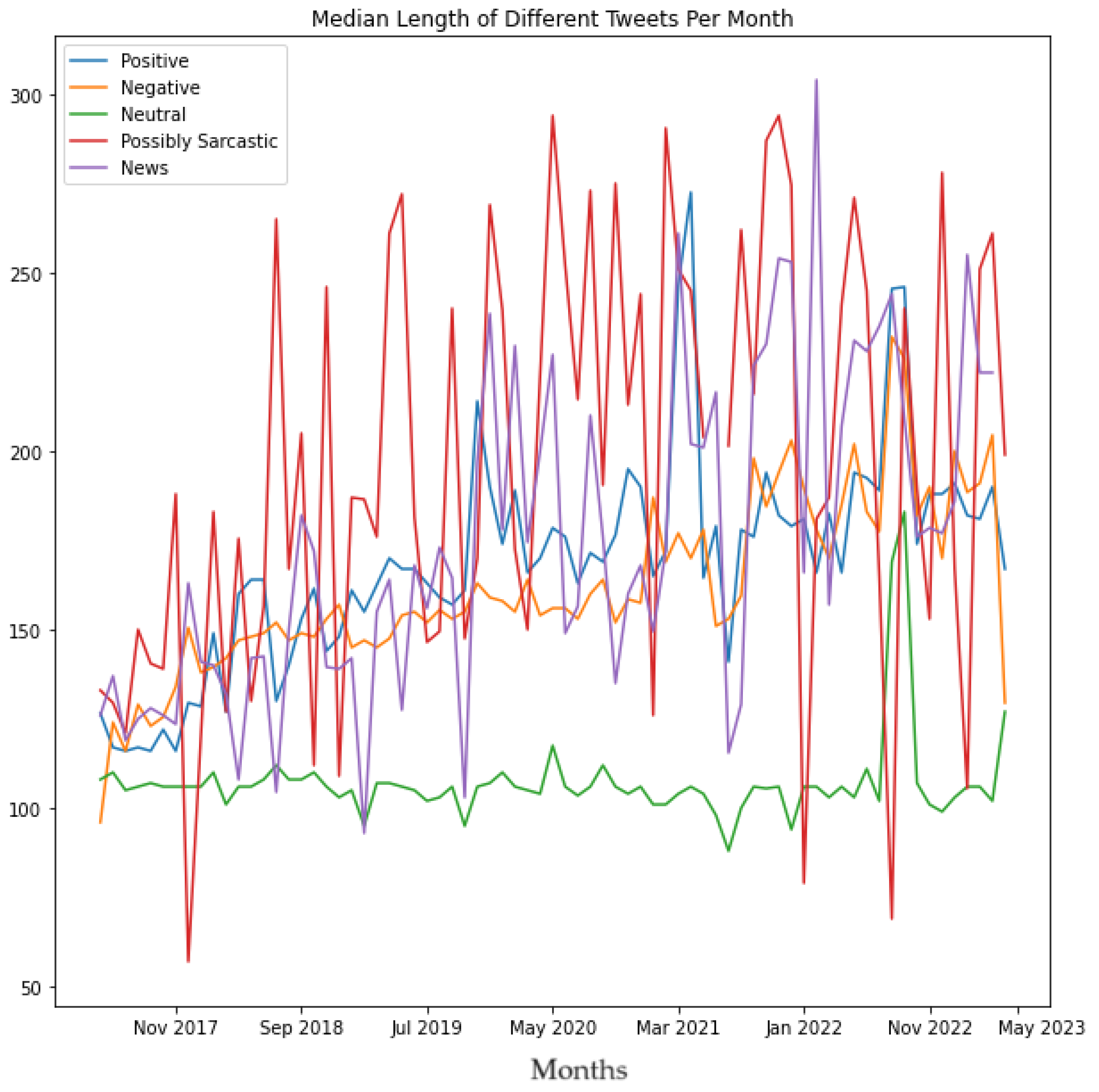
Figure 28.
A graphical representation to compare the positive tweets, negative tweets, possibly sarcastic tweets, and tweets that contained news, in terms of the average number of hashtags present in the tweets, on a monthly basis.
Figure 28.
A graphical representation to compare the positive tweets, negative tweets, possibly sarcastic tweets, and tweets that contained news, in terms of the average number of hashtags present in the tweets, on a monthly basis.
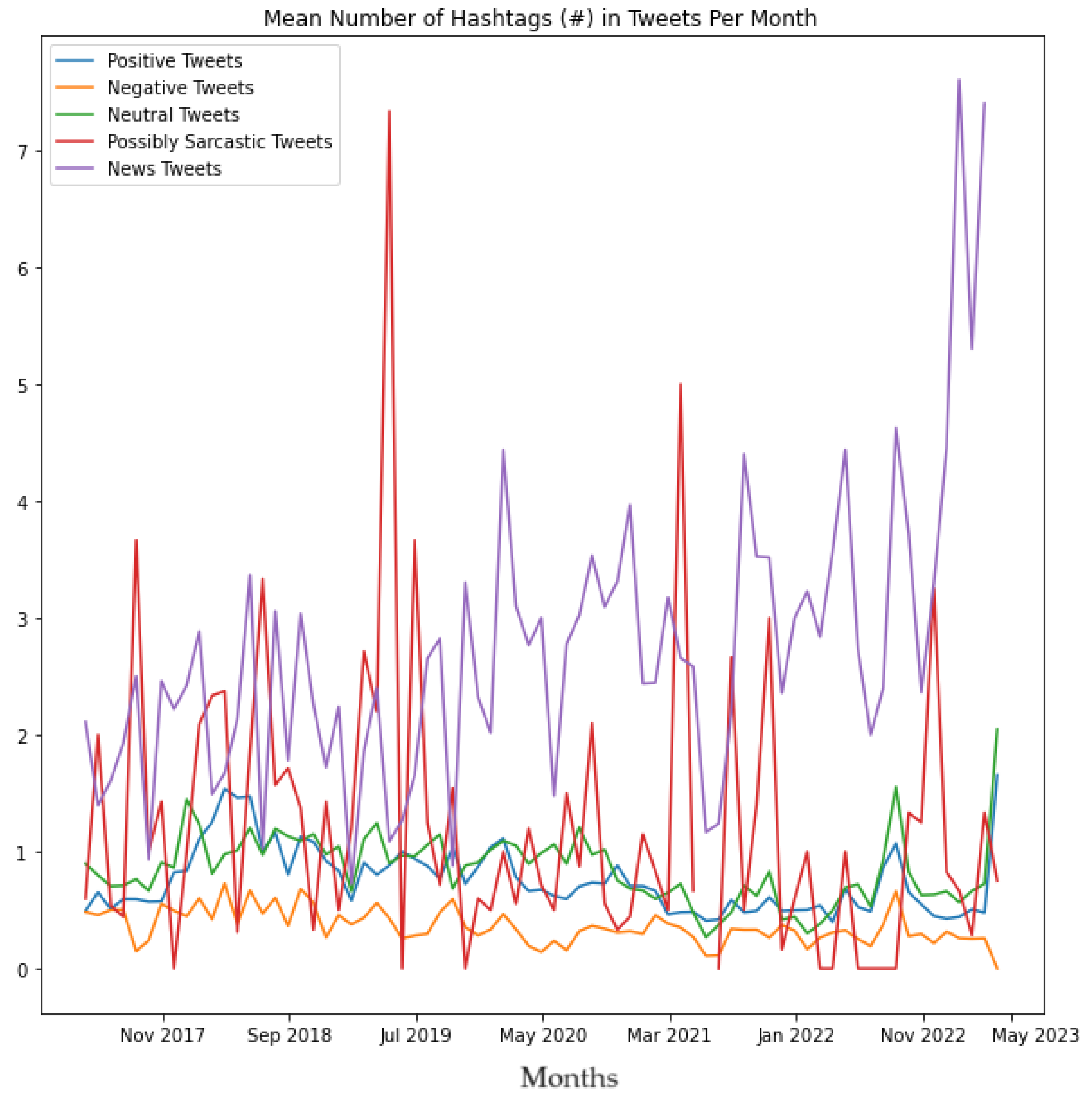
Figure 29.
A graphical representation to compare the positive tweets, negative tweets, possibly sarcastic tweets, and tweets that contained news, in terms of the average number of user mentions present in the tweets, on a monthly basis.
Figure 29.
A graphical representation to compare the positive tweets, negative tweets, possibly sarcastic tweets, and tweets that contained news, in terms of the average number of user mentions present in the tweets, on a monthly basis.
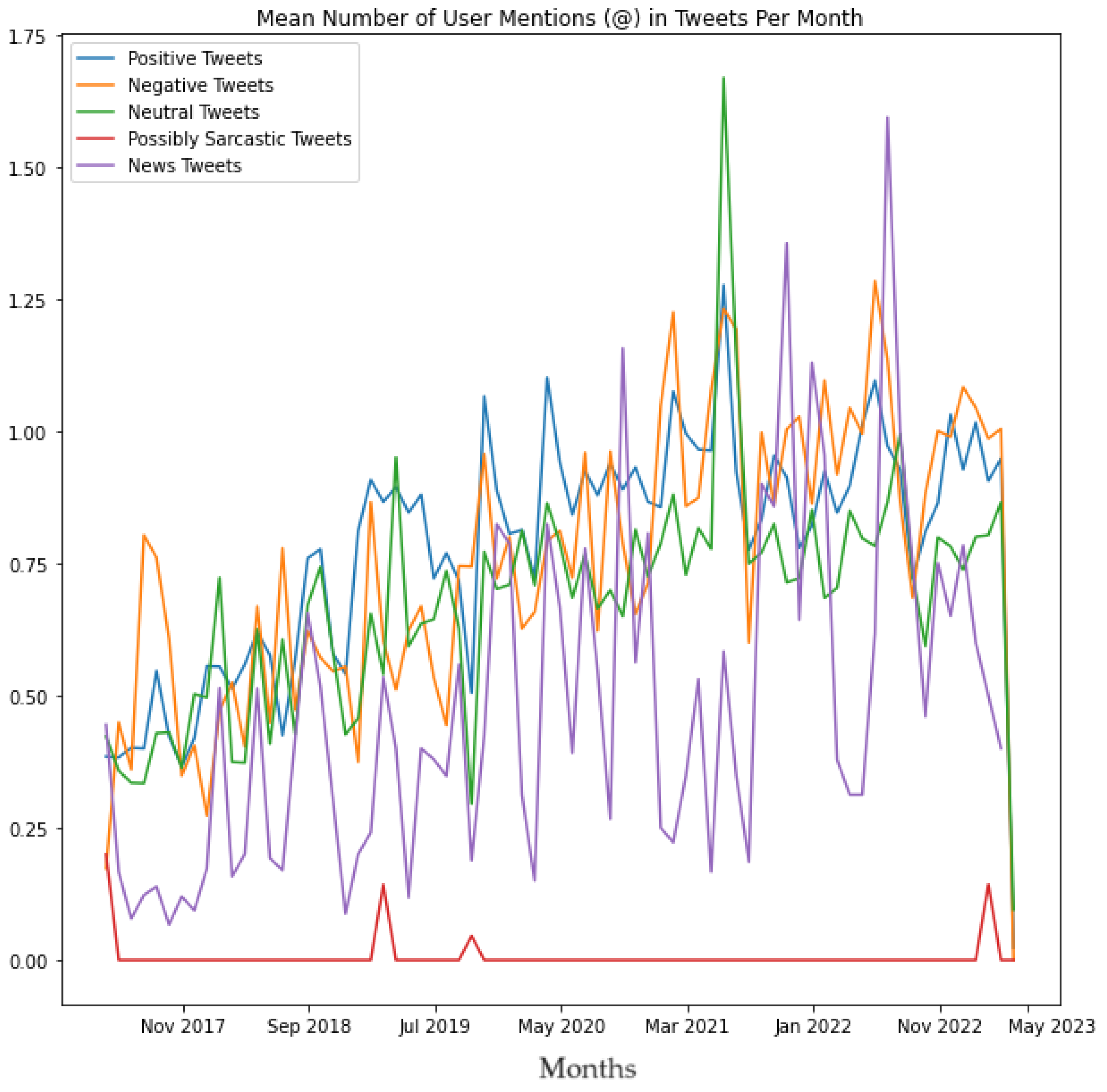
Figure 30.
A representation of the number of Tweets for each of the fine-grain sentiment classes - anger, disgust, fear, joy, sadness, and surprise.
Figure 30.
A representation of the number of Tweets for each of the fine-grain sentiment classes - anger, disgust, fear, joy, sadness, and surprise.
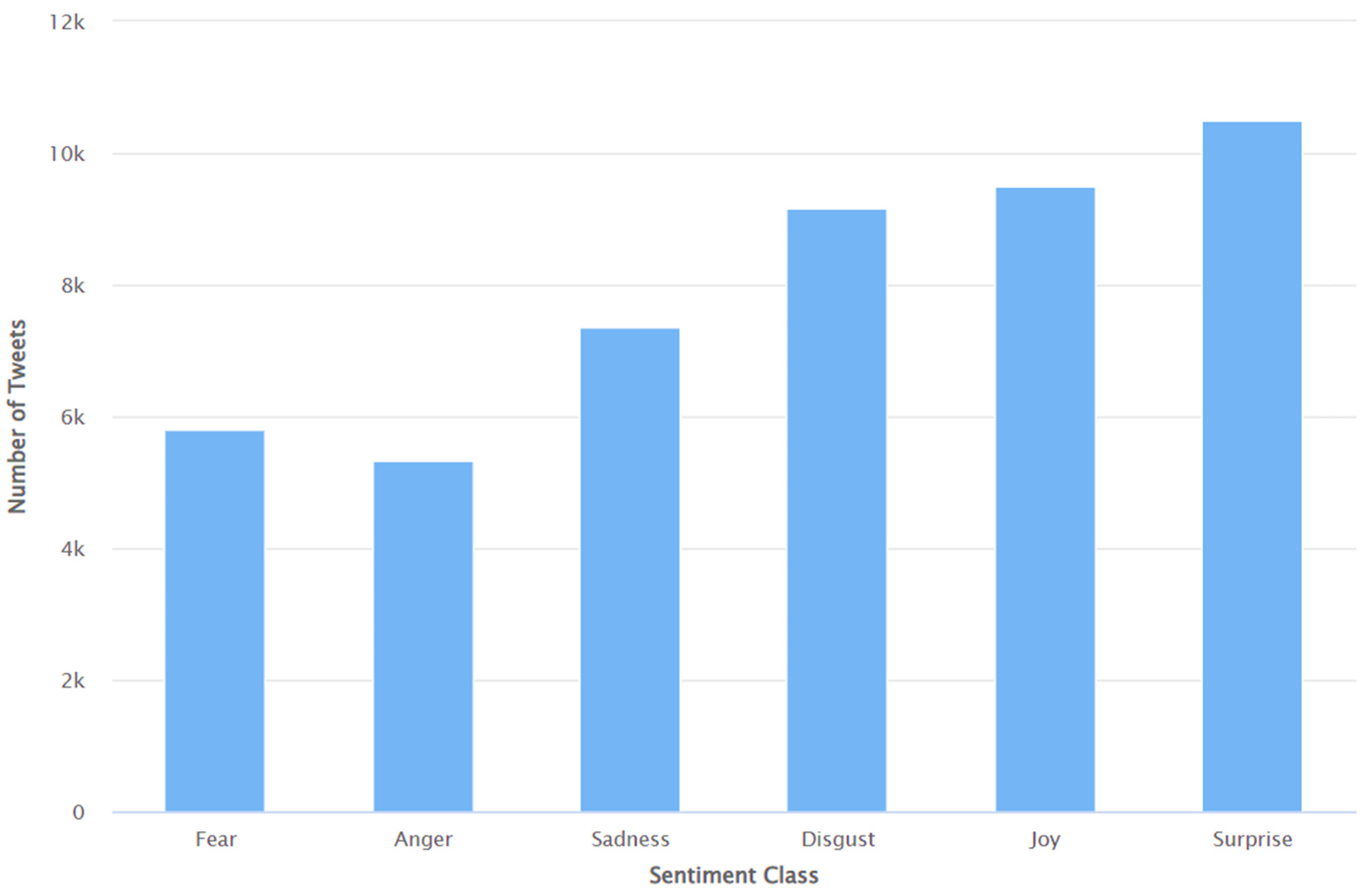
Table 1.
Description of the attributes in the dataset.
| Attribute Name | Description |
|---|---|
| Row no. | Row number of the data |
| Id | ID of the tweet |
| Created-At | Date and time when the tweet was posted |
| From-User | Twitter username of the user who posted the tweet |
| From-User-Id | Twitter User ID of the user who posted the tweet |
| To-User | Twitter username of the user whose tweet was replied to (if the tweet was a reply) in the current tweet |
| To-User-Id | Twitter user ID of the user whose tweet was replied to (if the tweet was a reply) in the current tweet |
| Language | Language of the tweet |
| Source | Source of the tweet to determine if the tweet was posted from an Android source, Twitter website, etc. |
| Text | Complete text of the tweet, including embedded URLs |
| Geo-Location-Latitude | Geo-Location (Latitude) of the user posting the tweet |
| Geo-Location-Longitude | Geo-Location (Longitude) of the user posting the tweet |
| Retweet Count | Retweet count of the tweet |
Table 2.
Representation of the p-values of the correlations that were investigated.
| Description | p-value |
|---|---|
| Number of Tweets per hour and the number of characters (mean) used in Tweets per hour | 0.0138 |
| Number of Tweets per hour and the number of characters (median) used in Tweets per hour | 0.0098 |
| Number of Tweets per hour and the number of hashtags used in Tweets per hour | 0.0006 |
| Number of Tweets per hour and the number of user mentions used in Tweets per hour | 2.44e-13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



