
Submitted:
02 October 2023
Posted:
03 October 2023
You are already at the latest version
Preprints on COVID-19 and SARS-CoV-2
Abstract
The work presented in this paper presents several novel findings from a comprehensive analysis of about 50,000 Tweets about online learning during COVID-19, posted on Twitter between November 9, 2021, and July 13, 2022. First, the results of sentiment analysis from VADER, Afinn, and TextBlob show that a higher percentage of these tweets were positive. The results of gender-specific sentiment analysis indicate that for positive tweets, negative tweets, and neutral tweets, between males and females, males posted a higher percentage of the tweets. Second, the results from subjectivity analysis show that the percentage of least opinionated, neutral opinionated, and highly opinionated tweets were 56.568%, 30.898%, and 12.534%, respectively. The gender-specific results for subjectivity analysis indicate that for each subjectivity class, males posted a higher percentage of tweets as compared to females. Third, toxicity detection was performed on the tweets to detect different categories of toxic content - toxicity, obscene, identity attack, insult, threat, and sexually explicit. The gender-specific analysis of the percentage of tweets posted by each gender in each of these categories revealed several novel insights. For instance, for the sexually explicit category, females posted a higher percentage of tweets as compared to males. Fourth, gender-specific tweeting patterns for each of these categories of toxic content were analyzed to understand the trends of the same. The results unraveled multiple paradigms of tweeting behavior, for instance, the intensity of obscene content in tweets about online learning by males and females has decreased since May 2022. Fifth, the average activity of males and females per month was calculated. The findings indicate that the average activity of females has been higher in all months as compared to males other than March 2022. Finally, country-specific tweeting patterns of males and females were also performed which presented multiple novel insights, for instance, in India a higher percentage of the tweets about online learning during COVID-19 were posted by males as compared to females.
Keywords:
online learning
; COVID-19
; Twitter
; Data Analysis
; Natural Language Processing
; Sentiment Analysis
; Subjectivity Analysis
; Toxicity Analysis
; Diversity Analysis
1. Introduction
In December 2019, the world was challenged by the outbreak of COVID-19. COVID-19 is a coronavirus (CoV), specifically or otherwise known as SARS-CoV-2, that causes severe respiratory illness [1]. For some individuals, this respiratory illness may even cause acute respiratory distress syndrome or extra-pulmonary organ failure due to the extreme inflammatory response of the virus [2]. The dangers of COVID-19 resulted in a global search for understanding as to how this virus works and is contracted. SARS-CoV-2, named such because of its similarities with SARS-CoV, is believed to initially be contracted by humans through animal-human contact and thereafter spread through human-human contact [3]. This is not unusual, as other CoVs, like MERS-CoV, were transmitted through animal-human contact [4]. While COVID-19 is believed to have originated in a seafood market in Wuhan, China, the exact animal that may have infected the first identified patients remains unclear [3]. However, genome sequencing between SARS-CoV-2 and SARS-CoV in a bat from Yunnan Province, China suggests that bats may have been the originators of SARS-CoV-2 due to the CoVs having a 93.1% identity with the RaTG12 virus found in the bat [1].
After the initial outbreak, COVID-19 soon spread to different parts of the world and on March 11, 2020, the World Health Organization (WHO) declared COVID-19 an emergency [5]. As no treatments or vaccines for COVID-19 were available at that time, the virus rampaged unopposed across different countries, infecting and leading to the demise of people the likes of which the world had not witnessed in centuries. As of September 21, 2023, there have been a total of 770,778,396 cases and 6,958,499 deaths due to COVID-19 [6]. As an attempt to mitigate the spread of the virus, several countries across the world went on partial to complete lockdowns [7]. Such lockdowns affected the educational sector immensely. Universities, colleges, and schools across the world were left searching for solutions to best deliver course content online, engage learners, and conduct assessments during the lockdowns. During this time, online learning was considered a feasible solution. Online learning platforms are applications (web-based or software) that are used for designing, delivering, managing, monitoring, and accessing courses online [8]. This switch to online learning took place in more than 100 countries [9] and led to an incredible increase in the need to familiarize, utilize, and adopt online learning platforms by educators, students, administrators, and staff at universities, colleges, and schools across the world [10].
In today’s Internet of Everything era [11], the usage of social media platforms has skyrocketed as such platforms serve as virtual communities [12] for people to seamlessly connect with each other. Currently, around 4.9 billion individuals worldwide actively participate in social media, and it is projected that this number will reach 5.85 billion by 2027. On average, a social media user maintains approximately 8.4 social media profiles and allocates roughly 145 minutes each day to engage with various social media platforms. Among the various social media platforms available, Twitter has gained substantial popularity across diverse age groups [13,14]. This rapid transition to online learning resulted in a tremendous increase in the usage of social media platforms, such as Twitter, where individuals communicated their views, perspectives, and concerns towards online learning, leading to the generation of Big Data of social media conversations. This Big Data of conversations holds the potential to provide insights about these paradigms of information and seeking behavior about online learning during COVID-19.
1.1. COVID-19: A Brief Overview
COVID-19 is a type of coronavirus (CoVs). CoVs are a type of RNA virus consisting of four proteins: spike (S) protein, membrane (M) protein, envelope (E) protein, and nucleocapsid (N) protein. The S protein is involved with the attachment and recognition of the host cell (infection); the M protein is involved with shaping virions; the E protein is responsible for packaging and reproduction, and the N protein packages RNA into a nucleocapsid. The virions also have polyproteins that are translated after entry into the host or target cell. These polyproteins include 1a and b (pp1a, pp1b) [15,16]. The SARS-CoV-2 virus particle measures between 60 to 140 nanometers in diameter and boasts a positive-sense, single-stranded RNA genome spanning a length of 29891 base pairs [15].
Infection by SARS-CoV-2 occurs when the S protein binds to the surface receptor, angiotensin-converting enzyme 2 (ACE2), and enters type II pneumocytes, which are found in human lungs. The S protein is critical to transmission and infection by SARS-CoV-2, as the S protein has two domains, S1 and S2, where S1 involves binding of ACE2 and S2 involves fusion to the host cell at its membrane. Similarly important is the cleavage of the S protein. Having two cleavage sites, the S protein must be cleaved by nuclear proteases so that viral entry, and subsequent infection, of the host cell can happen. Previous research suggests that the S protein of SARS-CoV-2 has a higher binding efficiency and may explain its high rate of transmissibility. The high transmissibility is also explained by four amino acids found during insertion, P681, R682, R683, and A684, that have not been found in other CoVs before, nor was it found in the RaTG12 virus observed in the bat thought to have infected the first human patients of COVID-19 [17,18].
While infections involving various organs have been documented in different cases, the typical effect of the SARS-CoV-2 virus on patients is centered around their respiratory systems. Investigation of the infections caused in Wuhan in December 2019 has shown that patients suffer from a range of symptoms during the initial days of contracting this virus. These symptoms encompass fever, a dry cough, breathing difficulties, headaches, dizziness, fatigue, nausea, and diarrhea. It’s important to note that the symptoms of COVID-19 can vary from person to person both in terms of the nature of the symptoms as well as the intensity of one or more symptoms [19,20].
1.2. Twitter: A Globally Popular Social Media Platform
Twitter ranks as the sixth most popular social platform in the United States and the seventh globally [21,22]. Notably, 42% of Americans between the ages of 12 and 34 are active Twitter users, marking a substantial 36.6% surge over the span of two years. The frequency of posting on the platform appears to correlate with the number of accounts followed, as users who post more than five Tweets per month tend to follow an average of 405 accounts, in contrast to those who post less frequently and follow an average of 105 accounts [22]. Furthermore, users spend an average of 1.1 hours per week on Twitter, which equates to 4.4 hours per month on the platform [23].
In 2023, Twitter boasts 353.9 million monthly active users, constituting 9.4% of the global social media user base [24]. The majority of Twitter users, accounting for 52.9%, fall within the age range of 25 to 49 years. Notably, 17.1% of users belong to the 14-18 age group, 6.6% to the 13-17 age group, and the remaining 17% are aged 50 and above [25]. On average, U.S. adults spend approximately 34.1 minutes per day on Twitter [26]. Impressively, a staggering 500 million tweets are published each day, equivalent to 5,787 tweets per second. An encouraging statistic reveals that 42.3% of U.S. users utilize Twitter at least once a month and it is currently the ninth most visited website globally. The countries with the highest number of Twitter users include the United States with 95.4 million users, Japan with 67.45 million, India with 27.25 million, Brazil with 24.3 million, Indonesia with 24 million, the UK with 23.15 million, Turkey with 18.55 million, and Mexico with 17.2 million [28,29]. On average, a Twitter user spends 5.1 hours per month on the platform, translating to approximately 10 minutes daily. A fifth of users under 30 visit frequently, and 25% use the platform every week, with 71% visiting at least weekly. Twitter is a significant source of news, with 55% of users accessing it regularly for this purpose. Ninety-six percent of U.S. Twitter users report monthly usage. Additionally, 82% engage with Twitter for entertainment. In terms of activity, 6,000 tweets are sent per second. Mobile usage is dominant, with 80% of active users accessing Twitter via smartphones [30,31].
Due to this ubiquitousness of Twitter, studying the multimodal components of information-seeking and sharing behavior has been of keen interest to scientists from different disciplines as can be seen from recent works in this field that focused on the analysis of tweets about various emerging technologies [32,33,34,35], global affairs [36,37,38], humanitarian issues [39,40,41], and societal problems [42,43,44]. Since the outbreak of COVID-19, there have been several research works conducted in this field (Section 2) where researchers analyzed different components and characteristics of the tweets to interpret the varying degrees of public perceptions, attitudes, views, and responses towards this pandemic. However, the tweeting patterns about online learning during COVID-19, with respect to the gender of twitter users, have not been investigated in any prior work in this field.
1.3. Gender Diversity on Social Media Platforms
Gender differences in content creation online have been comprehensively studied by researchers from different disciplines [45] as such differences have been considered important in the investigation of digital divides that produce inequalities of experience and opportunity [46,47]. Analysis of gender diversity and the underlying patterns of content creation on social media platforms has also been widely investigated [48]. However, the findings are mixed. Some studies have concluded that males are more likely to express themselves on social media as compared to females [49,50,51], while others found no such difference between genders [52,53,54]. The gender diversity related to the usage of social media platforms has varied over the years in different geographic regions [55]. For instance, Figure 1 shows the variation in social media use by gender from the findings of a survey conducted by the Pew Research Center from 2005 to 2021 [56].
In general, most social media platforms tend to exhibit a notable preponderance of male users over their female counterparts, for example – WhatsApp [57], Sina Weibo [58], QQ [59], Telegram [60], Quora [61], Tumblr [62], Facebook, LinkedIn, Instagram [63], and WeChat [64]. Nevertheless, there do exist exceptions to this prevailing trend. Snapchat has male and female users accounting for 48.2% and 51%, respectively [65]. These statistics about the percentage of male and female users in different social media platforms are summarized in Table 1. As can be seen from Table 1, Twitter has the highest gender gap as compared to several social media platforms such as Instagram, Tumblr, WhatsApp, WeChat, Quora, Facebook, LinkedIn, Telegram, Sina Weibo, QQ, and SnapChat. Therefore, the work presented in this paper focuses on the analysis of user diversity-based (with a specific focus on gender) patterns of public discourse on Twitter in the context of online learning during COVID-19.
The rest of this paper is organized as follows. In Section 2, a comprehensive review of recent works in this field is presented. Section 3 discusses the methodology that was followed for this work. The results and scientific contributions of this study are presented and discussed in Section 4. It is followed by Section 5, which summarizes the contributions of this study and outlines the scope of future research in this area.
2. Literature Review
This section is divided into two parts. Section 2.1 presents an overview of the recent works related to sentiment analysis of tweets about COVID-19. In Section 2.2, a review of emerging works in this field is presented where the primary focus was the analysis of tweets about online learning during COVID-19.
2.1. A Brief Review of Recent Works related to Sentiment Analysis of Tweets about COVID-19
Villavicencio et al. [66] analyzed tweets to determine the sentiment of people towards the Philippines government, regarding their response to COVID-19. They used the Naïve Bayes model to classify the tweets as positive, negative, and neutral. Their model achieved an accuracy of 81.77%. Boon-Itt et al. [67] conducted a study using Twitter data to gain insights into public awareness and concerns related to the COVID-19 pandemic. They conducted sentiment analysis and topic modeling on a dataset of over 100,000 tweets related to COVID-19. Taking a slightly different angle, Marcec et al. [68] analyzed 701,891 tweets mentioning the COVID-19 vaccines, specifically AstraZeneca/Oxford, Pfizer/BioNTech, and Moderna. They used the AFINN lexicon to calculate the daily average sentiment. The findings of this work showed that Pfizer and Moderna remained consistently positive as opposed to AstraZeneca which showed a declining trend. Machuca et al. [69] focused on evaluating the general public sentiment towards COVID-19. They used a Logistic Regression-based approach to classify the tweets as positive or negative. The methodology achieved 78.5% accuracy. Kruspe et al. [70] performed sentiment analysis of Tweets about COVID-19 from Europe and their approach used a neural network for performing sentiment analysis. Similarly, the works of Vijay et al. [71], Shofiya et al. [72], and Sontayasara et al. [73] focused on sentiment analysis of tweets about COVID-19 from India, Canada, and Thailand, respectively. Nemes et al. [74] used a Recurrent Neural Network for sentiment classification of the tweets about COVID-19.
Okango et al. [75] employed a dictionary-based method for detecting sentiments in tweets about COVID-19. Their work indicated that mental health issues and lack of supplies were a direct result of the pandemic. The work of Singh et al. [76] focused on a deep-learning approach for sentiment analysis of tweets about COVID-19. Their algorithm was based on an LSTM-RNN-based network and enhanced featured weighting by attention layers. Kaur et al. [77] developed an algorithm, the Hybrid Heterogeneous Support Vector Machine (H-SVM), for sentiment classification. The algorithm was able to categorize tweets as positive, negative, and neutral as well as detect the intensity of sentiments. In [78], Vernikou et al. implemented sentiment analysis through seven different deep-learning models based on LSTM neural networks. Sharma et al. [79] studied the sentiments of people towards COVID-19 from the USA and India using text mining-based approaches. The authors also discussed how their findings could provide guidance to authorities in healthcare to tailor their support policies in response to the emotional state of their people. Sanders et al. [80] took a slightly different approach to also aid policy makers, by analyzing over one million tweets to illustrate public attitudes towards mask-wearing during the pandemic. They observed both the volume and polarity of tweets relating to mask-wearing increased over time. Alabid et al. [81] used two machine learning classification models - SVM and Naïve Bayes classifier to perform sentiment analysis of tweets related to COVID-19 vaccines. Mansoor et al. [82] used Long Short-Term Memory (LSTM) and Artificial Neural Networks (ANN) to perform sentiment analysis of the public discourse on Twitter about COVID-19. Singh et al. [83] studied two datasets, one of tweets from people all over the world and the second restricted to tweets only by Indians. They conducted sentiment analysis using the BERT model and achieved a classification accuracy of 94%. Imamah et al. [84] conducted a sentiment classification of 355384 tweets using Logistic Regression. The objective of their work was to study the negative effects of ‘stay at home’ on people’s mental health. Their model achieved a sentiment classification accuracy of 94.71%. As can be seen from this review, a considerable number of works in this field have focused on the sentiment analysis of tweets about COVID-19. In the context of online learning during COVID-19, understanding the underlying patterns of public emotions becomes crucial and this has been investigated in multiple prior works in this field. A review of the same is presented in Section 2.2.
2.2. Review of Recent Works in Twitter Data Mining and Analysis related to Online Learning during COVID-19
Sahir et al. [85] used the Naïve Bayes classifier to perform sentiment analysis of tweets about online learning posted in October 2020 from individuals in Indonesia. The results showed that the percentage of negative, positive, and neutral tweets were 74%, 25%, and 1%, respectively. Althagafi et al. [86] analyzed tweets about online learning during COVID-19 posted by individuals from Saudi Arabia. They used the Random Forest approach and the K-Nearest Neighbor (KNN) classifier alongside Naïve Bayes and found that most tweets were neutral about online learning. Ali [87] used Naïve Bayes, Multinomial Naïve Bayes, KNN, Logistic Regression, and SVM to analyze the public opinion towards online learning during COVID-19. The results showed that the SVM classifier achieved the highest accuracy of 89.6%. Alcober et al. [88] reported the results of multiple machine learning approaches such as Naïve Bayes, Logistic Regression, and Random Forest for performing sentiment analysis of tweets about online learning.
While Remali et al. [89] also used Naïve Bayes and Random Forest, their research additionally utilized the Support Vector Machine (SVM) approach and a Decision Tree-based modeling. The classifiers evaluated tweets posted between July 2020 and August 2020. The results showed that the SVM classifier using the VADER lexicon achieved the highest accuracy of 90.41% [89]. The work of Senadhira et al. [90] showed that an Artificial Neural Network (ANN)-based approach outperformed an SVM-based approach for sentiment analysis of tweets about online learning. Lubis et al. [91] used a KNN-based method for sentiment analysis of tweets about online learning. The model achieved a performance accuracy of 88.5% and showed that a higher number of tweets were positive. These findings are consistent with another study [92] which reported that for tweets posted between July 2020 and August 2020, 54% were positive tweets. The findings of the work by Isnain et al. [93] indicated that the public opinion towards online learning between February 2020 and September 2020 was positive. These results were computed with a KNN-based approach that reported an accuracy of 84.65%.
Aljabri et al. [94] analyzed results at different education stages. Using Term Frequency-Inverse Document Frequency (TF-IDF) as a feature extraction to a Logistic Regression classifier, the model developed by the authors achieved an accuracy of 89.9%. The results indicated positive sentiment from elementary through high school, but negative sentiment for universities. The work by Asare et al. [95] aimed to cluster the most commonly used words into general topics or themes. The analysis of different topics found 48.9% of positive tweets, with “learning,” “COVID,” “online,” and “distance” being the most used words. Mujahid et al. [96] used TF-IDF alongside Bag of Words (BoW) for analyzing tweets about online learning. They also used SMOTE to balance the data. The results demonstrated that the Random Forest and SVM classifier achieved an accuracy of 95% when used with the BoW features. Al-Obeidat [97] also used TF-IDF to classify sentiments related to online education during the pandemic. The study reported that students had generally negative feelings towards online learning. In view of the propagation of misinformation on Twitter during the pandemic, Waheeb et al. [98] proposed eliminating noise using AutoEncoder in their work. The results found that their approach yielded a higher accuracy for sentiment analysis, with an F1-score value of 0.945. Rijal et al. [99] aimed to remove bias from sentiment analysis using concepts of feature selection. Their methodology involved the usage of the AdaBoost approach on the C4.5 method. The results found that the accuracy of C4.5 and Random Forest went up from 48.21% and 50.35% to 94.47% for detecting sentiments in tweets about online learning. Martinez [101] investigated negative sentiments about “teaching and schools” and “teaching and online” using multiple concepts of Natural Language Processing. Their study reported negativity towards both topics. At the same time, a higher negative sentiment along with expressions of anger, distrust, or stress towards “teaching and school,” was observed.
As can be seen from this review of works related to the analysis of public discourse on Twitter about online learning during COVID-19, such works have multiple limitations centered around lack of reporting from multiple sentiment analysis approaches to explain the trends of sentiments, lack of focus on subjectivity analysis, lack of focus on toxicity analysis, and lack of focus on gender-specific tweeting patterns. Addressing these research gaps serves as the main motivation for this work.
3. Methodology
This section presents the methodology that was followed for this research work. This section is divided into 2 parts. In Section 3.1 a description of the dataset that was used for this research work is presented. Section 3.2 discusses the procedure and the methods that were followed for this research work.
3.1. Data Description
The dataset used for this research was proposed in [102]. The dataset consists of about 50,000 unique Tweet IDs of Tweets about online learning during COVID-19. The dataset covers tweets posted on Twitter between November 9, 2021, and July 13, 2022. The dataset includes tweets in 34 different languages, with English being the most common. The dataset spans 237 different days, with the highest tweet count recorded on January 5, 2022. These tweets were posted by 17,950 distinct Twitter users, with a combined follower count of 4,345,192,697. The dataset includes 3,273,263 favorites and 556,980 retweets. Furthermore, 5,722 tweets in the dataset were posted by verified Twitter accounts, while the rest came from unverified accounts. There are a total of 7,869 distinct URLs embedded in these tweets. The Tweets IDs present in this dataset are organized into nine .txt files based on the date range of the tweets. The dataset was developed by mining tweets that referred to COVID-19 and online learning at the same time. To perform the same, a collection of synonyms of COVID-19 such as COVID, COVID19, coronavirus, Omicron, etc., and a collection of synonyms of online learning such as online education, remote education, remote learning, e-learning etc. were used. Thereafter, duplicate tweets were removed to obtain a collection of about 50,000 Tweet IDs. The standard procedure for working with such a dataset is the hydration of the Tweet IDs. However, this dataset was developed by the first author of this paper. So, the tweets were already available, and hydration was not necessary. In addition to the Tweet IDs, the dataset file that was used comprised several characteristic properties of Tweets and Twitter users who posted these Tweets, such as the Tweet Source, Tweet Text, Retweet count, user location, username, user favorites count, user follower count, user friends, count, user screen name, and user status count.
The dataset complies with the FAIR principles (Findability, Accessibility, Interoperability, and Reusability) of scientific data management. It is designed to be findable through a unique and permanent DOI. It is accessible online for users to locate and download. The dataset is interoperable as it uses .txt files, enabling compatibility across various computer systems and applications. Finally, it is reusable because researchers can obtain tweet-related information, such as user ID, username, and retweet count, for all Tweet IDs through a hydration process, facilitating data analysis and interpretation while adhering to Twitter policies.
3.2. System Design and Development
At first, the data preprocessing of these Tweets was performed by writing a program in Python 3.11.5. The data preprocessing involved the following steps. The pseudocode of this program is shown in Algorithm 1.
- a)
- Removal of characters that are not alphabets.
- b)
- Removal of URLs
- c)
- Removal of hashtags
- d)
- Removal of user mentions
- e)
- Detection of English words using tokenization.
- f)
- Stemming and Lemmatization.
- g)
- Removal of stop words.
- h)
- Removal of numbers
| Algorithm 1: Data Preprocessing |
 |
After performing data preprocessing, the GenderPerformr package in Python developed by Wang et al. [104,105] was applied to the usernames to detect their gender. GenderPerformr uses an LSTM model built in PyTorch to analyze usernames and detect genders in terms of male or female. The working of this algorithm was extended to classify usernames into 4 categories – male, female, none, and maybe. The algorithm classified a username as 'male' if that username matched a male name from the list of male names accessible to this Python package. Similarly, the algorithm classified a username as 'female' if that username matched a female name from the list of female names accessible to this Python package. The algorithm classified a username as 'none' if that username was a word in the English dictionary that cannot be a person's name. Finally, the algorithm classified a username as 'maybe' if the username was a word absent in the list of male and female names accessible to this Python package and the username was also not an English word. The classification performed by this algorithm was manually verified. Furthermore, all the usernames that were classified as ‘maybe’ were manually classified as male, female, or none. The pseudocode that was written in Python 3.11.5 to detect genders from Twitter usernames is presented as Algorithm 2.
| Algorithm 2: Detect Gender from Twitter Usernames |
 |
Thereafter, three different models for sentiment analysis – VADER, Afinn, and TextBlob were applied to the Tweets. VADER (Valence Aware Dictionary and sEntiment Reasoner), developed by Hutto et al. [106] is a lexicon and rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media. The VADER approach can analyze a text and classify it as positive, negative, or neutral. Furthermore, it can also detect the compound sentiment score and the intensity of the sentiment (0 to +4 for positive sentiment and 0 to -4 for negative sentiment) expressed in a given text. The AFINN lexicon developed by Nielsen is also used to analyze Twitter sentiment [107]. The AFINN lexicon is a list of English terms manually rated for valence with an integer between -5 (negative) and +5 (positive). Finally, TextBlob, developed by Lauria [108] is a lexicon-based sentiment analyzer that also uses a set of predefined rules to perform sentiment analysis and subjectivity analysis. The sentiment score lies between (-1 to 1) where -1 identifies the most negative words such as ‘disgusting’, ‘awful’, and ‘pathetic’, and 1 identifies the most positive words like ‘excellent’, and ‘best’. The subjectivity score lies between (0 and 1), It shows the amount of personal opinion, if a sentence has high subjectivity i.e., close to 1, it resembles that the text contains more personal opinion than factual information. These three approaches for performing sentiment analysis of tweets have been very popular as can be seen from several recent works in this field which used VADER [109,110,111,112], Afinn [113,114,115,116], and TextBlob [117,118,119,120]. The pseudocodes of the programs that were written in Python 3.11.5 to apply VADER, Afinn, and TextBlob to these Tweets are shown in Algorithms 3, 4, and 5, respectively.
| Algorithm 3: Detect Sentiment of Tweets Using VADER |
 |
| Algorithm 4: Detect Sentiment of Tweets Using Afinn |
 |
| Algorithm 5: Detect Polarity and Subjectivity of Tweets Using TextBlob |
 |
Thereafter, toxicity analysis of these Tweets was performed using the Detoxify package [121]. It includes three different trained models and outputs different toxicity categories. These models are trained on data from the three Kaggle jigsaw toxic comment classification challenges [122,123,124]. Using this package, each Tweet received a score in terms of the degree of toxicity, obscene content, identity attack, insult, threat, and sexually explicit content. The pseudocode of the program that was written in Python 3.11.5 to apply the Detoxify package to these Tweets is shown in Algorithm 6.
| Algorithm 6: Perform Toxicity Analysis of the Tweets Using Detoxify |
 |
Figure 2 represents a flowchart summarizing the working of Algorithms 1 to 6. In addition to the above, average activity analysis of different genders (male, female, and none) was also performed. The pseudocode of the program that was written in Python 3.11.5 to compute and analyze the average activity of different genders is shown in Algorithm 7. This program uses the formula for the total activity calculation of a twitter user which was proposed in an earlier work in this field [125]. This formula is shown in Equation (1):
Activity of a Twitter User = Author Tweets count + Author favorites count
| Algorithm 7: Compute Average Activity of different Genders on a monthly basis |
 |
Finally, the trends in tweeting patterns related to online learning from different geographic regions were also analyzed to understand the gender-specific tweeting patterns from different geographic regions. To perform this analysis, the PyCountry [127] package was used. Specifically, the program that was written in Python applied the fuzzy search function available in this package to detect the country of a twitter user based on the publicly listed city, county, state, or region on their Twitter profile. Algorithm 8 shows the pseudocode of the Python program that was written to perform this task. The results of applying all these algorithms on the dataset are discussed in Section 4.
| Algorithm 8: Detect Locations of Twitter Users, Visualize Gender-Specific Tweeting Patterns |
 |
4. Results and Discussion
This section presents and discusses the results of this study. As stated in Section 3, Algorithm 2 was run on the dataset to detect the gender of each Twitter user. After obtaining the output from this algorithm, the classifications were manually verified as well and the ‘maybe’ labels were manually classified as either male, female, or none. Thereafter, the dataset contained only three labels for the “Gender” attribute – male, female, and none. Figure 3 shows a pie chart-based representation of the same. As can be seen from Figure 3, out of the tweets posted by males and females, males posted a higher percentage of the tweets.
The results obtained from Algorithm 3 are presented next. Figure 4 presents a pie chart to show the percentage of tweets in each of the sentiment classes (positive, negative, and neutral) by taking all the genders together. As can be seen from this Figure, the percentages of positive, negative, and neutral tweets as per VADER were 41.704%, 29.932%, and 28.364%, respectively.
Next, for each sentiment class (positive, negative, and neutral) the distribution in terms of tweets posted by males, females, and twitter accounts assigned a none gender was calculated. The results of the same are shown in Figure 5, Figure 6 and Figure 7.
As can be seen from Figure 5, Figure 6 and Figure 7, for each sentiment label (positive, negative, and neutral) between males and females, males posted a higher percentage of tweets. A similar analysis was performed by applying Algorithm 4 and 5 on the dataset. The results of applying Algorithm 4 are presented in Figure 8, Figure 9, Figure 10 and Figure 11.
As can be seen from Figure 8, the percentage of positive tweets (as per the Afinn approach for sentiment analysis) was higher than the percentage of negative and neutral tweets. This is consistent with the findings from VADER (presented in 4). Furthermore, Figure 9, Figure 10 and Figure 11 show that for each sentiment label (positive, negative, and neutral) between males and females, males posted a higher percentage of the tweets. This finding is also consistent with the results obtained from VADER as shown in Figure 5, Figure 6 and Figure 7. The results of applying TextBlob for performing sentiment analysis are shown in Figure 12, Figure 13, Figure 14 and Figure 15.
From Figure 12, it can be inferred that, as per Afinn, the percentage of positive tweets was higher as compared to the percentage of negative and neutral tweets. This is consistent with the results of VADER (Figure 4) and Afinn (Figure 8). Furthermore, Figure 13, Figure 14 and Figure 15 show that for each sentiment class (positive, negative, and neutral), between males and females, males posted a higher percentage of the tweets. Once again, the results are consistent with the observations from VADER (Figure 5, Figure 6 and Figure 7) and Afinn (Figure 9, Figure 10 and Figure 11). In addition to sentiment analysis, TextBlob also computed the subjectivity of each tweet and categorized each tweet as highly opinionated, least opinionated, or neutral. The results of the same are shown in Figure 16, Figure 17, Figure 18 and Figure 19.
As can be seen from Figure 16, more than a majority of the tweets were least opinionated. To add to this, Figure 17, Figure 18 and Figure 19 show that for each subjectivity class (i.e. highly opinionated, least opinionated, and neutral), between males and females, males posted a higher percentage of the tweets. The results obtained from Algorithm 6 are discussed next. This algorithm analyzed all the tweets and categorized them into one of toxicity classes - toxicity, obscene, identity attack, insult, threat, and sexually explicit. The number of tweets that were classified into each of these classes was 36081, 8729, 3411, 1165, 18, and 4, respectively. This is shown in Figure 20. Thereafter, the percentage of tweets posted by each gender for each of these categories of toxic content was analyzed and the results are presented in Figure 21, Figure 22, Figure 23, Figure 24, Figure 25 and Figure 26.
From Figure 21, Figure 22, Figure 23 and Figure 24, it can be seen that for the classes – toxicity, obscene, identity attack, and insult, between males and females, males posted a higher percentage of the tweets. Furthermore, Figure 25 shows that there wasn’t any tweet from females that was assigned a threat label. Figure 26 shows that for those tweets that were categorized as sexually explicit, between males and females, females posted a higher percentage of those tweets. It is worth mentioning here that the results of Figure 25 and Figure 26 are based on data that constitutes less than 1% of the tweets present in the dataset. So, in a real-world scenario, these percentages could vary when a greater number of tweets are posted for each of the two categories – threat and sexually explicit.
In addition to analyzing the varying trends in sentiments and toxicity, the content of the underlying tweets was also analyzed using word clouds. For generation of these word clouds the top 100 words (in terms of frequency were considered). To perform the same, a consensus of sentiment labels from the three different sentiment analysis approaches was considered. For instance, to prepare a word cloud of positive tweets, all those tweets that were labeled as positive by VADER, Afinn, and TextBlob were considered. A word cloud was developed to represent the same. Thereafter, for all the positive tweets, gender-specific tweeting patterns were also analyzed to compute the top 100 words used by males for positive tweets, the top 100 words used by females for positive tweets, and the top 100 words used by twitter accounts associated with a none gender label. A high degree of overlap in terms of the 100 words for all these scenarios was observed. More specifically, a total of 79 words were common amongst the lists of the top 100 words for positive tweets, the top 100 words used by males for positive tweets, the top 100 words used by females for positive tweets, and the top 100 words used by Twitter accounts associated with a none gender label. So, to avoid redundancy, Figure 27 shows a word cloud-based representation of the top 100 words used in positive tweets. Similarly, a high degree of overlap in terms of the 100 words was also observed for the analysis of different lists for negative tweets and neutral tweets. So, to avoid redundancy, Figure 28 and Figure 29 show word cloud-based representations of the top 100 words used in negative tweets and neutral tweets, respectively. In a similar manner, the top 100 frequently used words for the different subjectivity classes were also computed and word cloud-based representations of the same are shown in Figure 30, Figure 31 and Figure 32.
After performing this analysis, a similar word frequency-based analysis was performed for the different categories of toxic content that were detected in the tweets using Algorithm 6. These classes were toxicity, obscene, identity attack, insult, threat, and sexually explicit. As explained in Algorithm 6, each tweet was assigned a score for each of these classes and whichever class received the highest score, the label of the tweet was decided accordingly. For instance, if the toxicity score for a tweet was higher than the scores that the tweet received for the classes - obscene, identity attack, insult, threat, and sexually explicit, then the label of that tweet was assigned as toxicity. Similarly, if the obscene score for a tweet was higher than the scores that the tweet received for the classes - toxicity, identity attack, insult, threat, and sexually explicit, then the label of that tweet was assigned as obscene. The results of this word cloud-based analysis for the top 100 words (in terms of frequency) for each of these classes are shown in Figure 33, Figure 34, Figure 35, Figure 36, Figure 37 and Figure 38.
As can be seen from Figure 33, Figure 34, Figure 35, Figure 36, Figure 37 and Figure 38 the patterns of communication were diverse for each of the categories of toxic content designated by the classes - toxicity, identity attack, insult, threat, and sexually explicit. At the same time, Figure 37 and Figure 38 appear significantly different in terms of the top 100 words used. This also shows that for tweets that were categorized as threat (Figure 37) and as containing sexually explicit content (Figure 38) the paradigms of communication and information exchange in those tweets were very different as compared to tweets categorized into any of the remaining classes representing toxic content. In addition to performing this word cloud-based analysis, the scores each of these classes received were analyzed to infer the trends of their intensities over time. To perform this analysis, the mean value of each of these classes was computed per month and the results were plotted in a graphical manner as shown in Figure 39.
From Figure 39, several insights related to the tweeting patterns of the general public can be inferred. For instance, the intensity of toxicity was higher than the intensity of obscene, identity attack, insult, threat, and sexually explicit content. Similarly, the intensity of insult was higher than the intensity of obscene, identity attack, threat, and sexually explicit content. Next, gender-specific tweeting patterns for each of these categories of toxic content were analyzed to understand the trends of the same. These results are shown in Figure 40, Figure 41, Figure 42, Figure 43, Figure 44 and Figure 45. This analysis also helped to unravel multiple paradigms of tweeting behavior of different genders in the context of online learning during COVID-19. For instance, Figure 40 and Figure 44 show that the intensity of toxicity and threat in tweets by males and females has increased since July 2022. The analysis shown in Figure 41, shows that the intensity of obscene content in tweets by males and females has decreased since May 2022.
The result of Algorithm 7 is shown in Figure 46. As can be seen from this Figure, between males and females, the average activity of females has been higher in all months other than March 2022. The results from Algorithm 7 are presented in Figure 47 and Figure 48, respectively. Figure 47 shows the trends in tweets about online learning during COVID-19 posted by males from different countries of the world. Similarly, Figure 48 shows the trends in tweets about online learning during COVID-19 posted by females from different countries of the world.
Figure 47 and Figure 48 reveal the patterns of posting tweets by males and females about online learning during COVID-19. These patterns include similarities as well as differences. For instance, from these two figures, it can be inferred that in India a higher percentage of the tweets were posted by males as compared to females. However, in Australia, a higher percentage of the tweets were posted by females as compared to males. Finally, a comparative study is presented in Table 2 where the focus area of this work is compared with the focus areas of prior areas in this field to highlight its novelty and relevance. As can be seen from this Table, the work presented in this paper is the first work in this area of research where the focus area has included text analysis, sentiment analysis, analysis of toxic content, and subjectivity analysis of tweets about online learning during COVID-19. It is worth mentioning here that the work by Martinez et al. [101] considered only two types of toxic content – insults and threats whereas the work presented in this paper performs the detection of six types of toxic content - toxicity, obscene, identity attack, insult, threat, and sexually explicit. Furthermore, no prior work in this field has performed a gender-specific analysis of tweets about online learning during COVID-19. As this paper analyzes the tweeting patterns in terms of gender, the authors would like to clarify three aspects. First, the results presented and discussed in this paper aim to address the research gaps in this field (as discussed in Section 2). These results are not presented with the intention to comment on any gender directly or indirectly. Second, the authors respect the gender identity of every individual and do not intend to comment on the same in any manner by presenting these results. Third, the authors respect every gender identity and associated pronouns [126]. The results presented in this paper take into account only three gender categories – male, female, and none as the GenderPerformr package (the current state-of-the-art method that predicts gender from usernames) has limitations.
5. Conclusions
To reduce the rapid spread of the SARS-CoV-2 virus, several universities, colleges, and schools across the world transitioned to online learning. This was associated with a range of emotions in students, educators, and the general public who used social media platforms such as Twitter during this time to share and exchange information, views, and perspectives related to online learning leading to the generation of Big Data. Twitter has been popular amongst researchers from different domains for the investigation of patterns of public discourse related to different topics. Furthermore, out of several social media platforms, Twitter has the highest gender gap as of 2023. There have been a few works published in the last few months where sentiment analysis of tweets about online learning during COVID-19 was performed. However, those works have multiple limitations centered around a lack of reporting from multiple sentiment analysis approaches, a lack of focus on subjectivity analysis, a lack of focus on toxicity analysis, and a lack of focus on gender-specific tweeting patterns. The work presented in this paper aims to address these research gaps as well as aims to contribute towards advancing research and development in this field. A dataset comprising about 50,000 Tweets about online learning during COVID-19, posted on Twitter between November 9, 2021, and July 13, 2022, was analyzed for this study. This work reports multiple novel findings. First, the results of sentiment analysis from VADER, Afinn, and TextBlob show that a higher percentage of the tweets were positive. The results of gender-specific sentiment analysis indicate that for positive tweets, negative tweets, and neutral tweets, between males and females, males posted a higher percentage of the tweets. Second, the results from subjectivity analysis show that the percentage of least opinionated, neutral opinionated, and highly opinionated tweets were 56.568%, 30.898%, and 12.534%, respectively. The gender-specific results for subjectivity analysis show that for each subjectivity class (least opinionated, neutral opinionated, and highly opinionated) males posted a higher percentage of tweets as compared to females. Third, toxicity detection was applied to the tweets to detect different categories of toxic content - toxicity, obscene, identity attack, insult, threat, and sexually explicit. The gender-specific analysis of the percentage of tweets posted by each gender in each of these categories revealed several novel insights. For instance, males posted a higher percentage of tweets that were categorized as toxicity, obscene, identity attack, insult, and threat, as compared to females. However, for the sexually explicit category, females posted a higher percentage of tweets as compared to males. Fourth, gender-specific tweeting patterns for each of these categories of toxic content were analyzed to understand the trends of the same. These results unraveled multiple paradigms of tweeting behavior of different genders in the context of online learning during COVID-19. For instance, the results show that the intensity of toxicity and threat in tweets by males and females has increased since July 2022. To add to this, the intensity of obscene content in tweets by males and females has decreased since May 2022. Fifth, the average activity of males and females per month in this time range was also investigated. The findings indicate that the average activity of females has been higher in all months as compared to males other than March 2022. Finally, country-specific tweeting patterns of males and females were also investigated which presented multiple novel insights. For instance, in India, a higher percentage of tweets about online learning during COVID-19 were posted by males as compared to females. However, in Australia, a higher percentage of such tweets were posted by females as compared to males. As per the best knowledge of the authors, no similar work has been done in this field thus far. Future work in this area would involve performing gender-specific topic modeling to investigate the similarities and differences in terms of the topics that have been represented in the tweets posted by males and females.
Author Contributions
Conceptualization, N.T.; methodology, N.T., S.C, K.K, Y.N.D.; software, N.T., S.C, K.K, Y.N.D., M.S.; validation, N.T.; formal analysis, N.T., K.K, S.C, Y.N.D., V.K.; investigation, N.T., K.K, S.C, Y.N.D.; resources, N.T., K.K, S.C, Y.N.D.; data curation, N.T and S.Q.; writing—original draft preparation, N.T., V.K., K.K, M.S., Y.N.D, S.C; writing—review and editing, N.T.; visualization, N.T., S.C, K.K, Y.N.D.; supervision, N.T.; project administration, N.T.; funding acquisition, Not Applicable.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data analyzed in this study are publicly available at https://doi.org/10.5281/zenodo.6837118.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shi, Y.; Wang, G.; Cai, X.-P.; Deng, J.-W.; Zheng, L.; Zhu, H.-H.; Zheng, M.; Yang, B.; Chen, Z. An Overview of COVID-19. J. Zhejiang Univ. Sci. B 2020, 21, 343–360. [Google Scholar] [CrossRef] [PubMed]
- Fauci, A.S.; Lane, H.C.; Redfield, R.R. Covid-19 — Navigating the Uncharted. N. Engl. J. Med. 2020, 382, 1268–1269. [Google Scholar] [CrossRef] [PubMed]
- Alanagreh, L.; Alzoughool, F.; Atoum, M. The Human Coronavirus Disease COVID-19: Its Origin, Characteristics, and Insights into Potential Drugs and Its Mechanisms. Pathogens 2020, 9, 331. [Google Scholar] [CrossRef] [PubMed]
- Ciotti, M.; Ciccozzi, M.; Terrinoni, A.; Jiang, W.-C.; Wang, C.-B.; Bernardini, S. The COVID-19 Pandemic. Crit. Rev. Clin. Lab. Sci. 2020, 57, 365–388. [Google Scholar] [CrossRef]
- Cucinotta, D.; Vanelli, M. WHO Declares COVID-19 a Pandemic. Acta Bio Medica : Atenei Parmensis 2020, 91, 157. [Google Scholar] [CrossRef]
- WHO Coronavirus (COVID-19) Dashboard. Available online: https://covid19.who.int/ (accessed on 26 September 2023).
- Allen, D.W. Covid-19 Lockdown Cost/Benefits: A Critical Assessment of the Literature. Int. J. Econ. Bus. 2022, 29, 1–32. [Google Scholar] [CrossRef]
- Kumar, V.; Sharma, D. E-Learning Theories, Components, and Cloud Computing-Based Learning Platforms. Int. J. Web-based Learn. Teach. Technol. 2021, 16, 1–16. [Google Scholar] [CrossRef]
- Muñoz-Najar, A.; Gilberto, A.; Hasan, A.; Cobo, C.; Azevedo, J.P.; Akmal, M. Remote Learning during COVID-19: Lessons from Today, Principles for Tomorrow. World Bank 2021. [Google Scholar]
- Simamora, R.M.; De Fretes, D.; Purba, E.D.; Pasaribu, D. Practices, Challenges, and Prospects of Online Learning during Covid-19 Pandemic in Higher Education: Lecturer Perspectives. Stud. Learn. Teach. 2020, 1, 185–208. [Google Scholar] [CrossRef]
- DeNardis, L. The Internet in Everything; Yale University Press: New Haven, CT, 2020; ISBN 9780300233070. [Google Scholar]
- Gruzd, A.; Haythornthwaite, C. Enabling Community through Social Media. J. Med. Internet Res. 2013, 15, e248. [Google Scholar] [CrossRef]
- Belle Wong, J.D. Top Social Media Statistics and Trends of 2023. Available online: https://www.forbes.com/advisor/business/social-media-statistics/ (accessed on 26 September 2023).
- Morgan-Lopez, A.A.; Kim, A.E.; Chew, R.F.; Ruddle, P. Predicting Age Groups of Twitter Users Based on Language and Metadata Features. PLoS One 2017, 12, e0183537. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Yang, X.-L.; Wang, X.-G.; Hu, B.; Zhang, L.; Zhang, W.; Si, H.-R.; Zhu, Y.; Li, B.; Huang, C.-L.; et al. A Pneumonia Outbreak Associated with a New Coronavirus of Probable Bat Origin. Nature 2020, 579, 270–273. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Yang, X.-L.; Wang, X.-G.; Hu, B.; Zhang, L.; Zhang, W.; Si, H.-R.; Zhu, Y.; Li, B.; Huang, C.-L.; et al. Discovery of a Novel Coronavirus Associated with the Recent Pneumonia Outbreak in Humans and Its Potential Bat Origin. bioRxiv 2020.
- Wrapp, D.; Wang, N.; Corbett, K.S.; Goldsmith, J.A.; Hsieh, C.-L.; Abiona, O.; Graham, B.S.; McLellan, J.S. Cryo-EM Structure of the 2019-NCoV Spike in the Prefusion Conformation. Science 2020, 367, 1260–1263. [Google Scholar] [CrossRef]
- Huang, Q.; Herrmann, A. Fast Assessment of Human Receptor-Binding Capability of 2019 Novel Coronavirus (2019-NCoV). bioRxiv 2020.
- Çalıca Utku, A.; Budak, G.; Karabay, O.; Güçlü, E.; Okan, H.D.; Vatan, A. Main Symptoms in Patients Presenting in the COVID-19 Period. Scott. Med. J. 2020, 65, 127–132. [Google Scholar] [CrossRef]
- Larsen, J.R.; Martin, M.R.; Martin, J.D.; Kuhn, P.; Hicks, J.B. Modeling the Onset of Symptoms of COVID-19. Front. Public Health 2020, 8. [Google Scholar] [CrossRef]
- Dial, #infinite The Infinite Dial 2022. Available online: http://www.edisonresearch.com/wp-content/uploads/2022/03/Infinite-Dial-2022-Webinar-revised.pdf (accessed on 26 September 2023).
- Twitter ‘Lurkers’ Follow – and Are Followed by – Fewer Accounts. Available online: https://www.pewresearch.org/short-reads/2022/03/16/5-facts-about-twitter-lurkers/ft_2022-03-16_twitterlurkers_03/ (accessed on 26 September 2023).
- Shewale, R. Twitter Statistics in 2023 — (Facts after “X” Rebranding). Available online: https://www.demandsage.com/twitter-statistics/ (accessed on 26 September 2023).
- Lin, Y. Number of Twitter Users in the US [Aug 2023 Update]. Available online: https://www.oberlo.com/statistics/number-of-twitter-users-in-the-us (accessed on 26 September 2023).
- Twitter: Distribution of Global Audiences 2021, by Age Group. Available online: https://www.statista.com/statistics/283119/age-distribution-of-global-twitter-users/ (accessed on 26 September 2023).
- Feger, A. TikTok Screen Time Will Approach 60 Minutes a Day for US Adult Users. Available online: https://www.insiderintelligence.com/content/tiktok-screen-time-will-approach-60-minutes-day-us-adult-users/ (accessed on 26 September 2023).
- Hootsuite Inc Digital Trends - Digital Marketing Trends 2022. Available online: https://www.hootsuite.com/resources/digital-trends (accessed on 26 September 2023).
- Demographic Profiles and Party of Regular Social Media News Users in the U.S. Available online: https://www.pewresearch.org/journalism/2021/01/12/news-use-across-social-media-platforms-in-2020/pj_2021-01-12_news-social-media_0-04/ (accessed on 26 September 2023).
- Countries with Most X/Twitter Users 2023. Available online: https://www.statista.com/statistics/242606/number-of-active-twitter-users-in-selected-countries/ (accessed on 26 September 2023).
- Kemp, S. Twitter Users, Stats, Data, Trends, and More — DataReportal – Global Digital Insights. Available online: https://datareportal.com/essential-twitter-stats (accessed on 26 September 2023).
- Singh, C. 60+ Twitter Statistics to Skyrocket Your Branding in 2023. Available online: https://www.socialpilot.co/blog/twitter-statistics (accessed on 26 September 2023).
- Albrecht, S.; Lutz, B.; Neumann, D. The Behavior of Blockchain Ventures on Twitter as a Determinant for Funding Success. Electron. Mark. 2020, 30, 241–257. [Google Scholar] [CrossRef]
- Kraaijeveld, O.; De Smedt, J. The Predictive Power of Public Twitter Sentiment for Forecasting Cryptocurrency Prices. J. Int. Financ. Mark. Inst. Money 2020, 65, 101188. [Google Scholar] [CrossRef]
- Saura, J.R.; Palacios-Marqués, D.; Ribeiro-Soriano, D. Using Data Mining Techniques to Explore Security Issues in Smart Living Environments in Twitter. Comput. Commun. 2021, 179, 285–295. [Google Scholar] [CrossRef]
- Mubin, O.; Khan, A.; Obaid, M. #naorobot: Exploring Nao Discourse on Twitter. In Proceedings of the Proceedings of the 28th Australian Conference on Computer-Human Interaction - OzCHI ’16; ACM Press: New York, New York, USA, 2016.
- Siapera, E.; Hunt, G.; Lynn, T. #GazaUnderAttack: Twitter, Palestine and Diffused War. Inf. Commun. Soc. 2015, 18, 1297–1319. [Google Scholar] [CrossRef]
- Chen, E.; Ferrara, E. Tweets in Time of Conflict: A Public Dataset Tracking the Twitter Discourse on the War between Ukraine and Russia. Proceedings of the International AAAI Conference on Web and Social Media 2023, 17, 1006–1013. [Google Scholar] [CrossRef]
- Tao, W.; Peng, Y. Differentiation and Unity: A Cross-Platform Comparison Analysis of Online Posts’ Semantics of the Russian–Ukrainian War Based on Weibo and Twitter. Commun. Public 2023, 8, 105–124. [Google Scholar] [CrossRef]
- Jongman, B.; Wagemaker, J.; Romero, B.; de Perez, E. Early Flood Detection for Rapid Humanitarian Response: Harnessing near Real-Time Satellite and Twitter Signals. ISPRS Int. J. Geoinf. 2015, 4, 2246–2266. [Google Scholar] [CrossRef]
- Madichetty, S.; Muthukumarasamy, S.; Jayadev, P. Multi-Modal Classification of Twitter Data during Disasters for Humanitarian Response. J. Ambient Intell. Humaniz. Comput. 2021, 12, 10223–10237. [Google Scholar] [CrossRef]
- Dimitrova, D.; Heidenreich, T.; Georgiev, T.A. The Relationship between Humanitarian NGO Communication and User Engagement on Twitter. New Media Soc. 2022, 146144482210889. [Google Scholar] [CrossRef]
- Weller, K.; Bruns, A.; Burgess, J.; Mahrt, M.; Twitter, C.P.T. Pages, 447 Twitter and Society. Available online: https://journals.uio.no/TJMI/article/download/825/746/3768 (accessed on 26 September 2023).
- Olza, I.; Koller, V.; Ibarretxe-Antuñano, I.; Pérez-Sobrino, P.; Semino, E. The #ReframeCovid Initiative: From Twitter to Society via Metaphor. Metaphor Soc. World 2021, 11, 98–120. [Google Scholar] [CrossRef]
- Li, M.; Turki, N.; Izaguirre, C.R.; DeMahy, C.; Thibodeaux, B.L.; Gage, T. Twitter as a Tool for Social Movement: An Analysis of Feminist Activism on Social Media Communities. J. Community Psychol. 2021, 49, 854–868. [Google Scholar] [CrossRef]
- Hargittai, E.; Walejko, G. THE PARTICIPATION DIVIDE: Content Creation and Sharing in the Digital Age1. Inf. Commun. Soc. 2008, 11, 239–256. [Google Scholar] [CrossRef]
- Trevor, M.C. Political Socialization, Party Identification, and the Gender Gap. Public Opin. Q. 1999, 63, 62–89. [Google Scholar] [CrossRef]
- Verba, S.; Schlozman, K.L.; Brady, H.E. Voice and Equality: Civic Voluntarism in American Politics; Harvard University Press: London, England, 1995; ISBN 9780674942936. [Google Scholar]
- Bode, L. Closing the Gap: Gender Parity in Political Engagement on Social Media. Inf. Commun. Soc. 2017, 20, 587–603. [Google Scholar] [CrossRef]
- Lutz, C.; Hoffmann, C.P.; Meckel, M. Beyond Just Politics: A Systematic Literature Review of Online Participation. First Monday 2014. [Google Scholar] [CrossRef]
- Strandberg, K. A Social Media Revolution or Just a Case of History Repeating Itself? The Use of Social Media in the 2011 Finnish Parliamentary Elections. New Media Soc. 2013, 15, 1329–1347. [Google Scholar] [CrossRef]
- Vochocová, L.; Štětka, V.; Mazák, J. Good Girls Don’t Comment on Politics? Gendered Character of Online Political Participation in the Czech Republic. Inf. Commun. Soc. 2016, 19, 1321–1339. [Google Scholar] [CrossRef]
- Gil de Zúñiga, H.; Veenstra, A.; Vraga, E.; Shah, D. Digital Democracy: Reimagining Pathways to Political Participation. J. Inf. Technol. Politics 2010, 7, 36–51. [Google Scholar] [CrossRef]
- Vissers, S.; Stolle, D. The Internet and New Modes of Political Participation: Online versus Offline Participation. Inf. Commun. Soc. 2014, 17, 937–955. [Google Scholar] [CrossRef]
- Vesnic-Alujevic, L. Political Participation and Web 2.0 in Europe: A Case Study of Facebook. Public Relat. Rev. 2012, 38, 466–470. [Google Scholar] [CrossRef]
- Krasnova, H.; Veltri, N.F.; Eling, N.; Buxmann, P. Why Men and Women Continue to Use Social Networking Sites: The Role of Gender Differences. J. Strat. Inf. Syst. 2017, 26, 261–284. [Google Scholar] [CrossRef]
- Social Media Fact Sheet. Available online: https://www.pewresearch.org/internet/fact-sheet/social-media/?tabId=tab-45b45364-d5e4-4f53-bf01-b77106560d4c (accessed on 26 September 2023).
- Global WhatsApp User Distribution by Gender 2023. Available online: https://www.statista.com/statistics/1305750/distribution-whatsapp-users-by-gender/ (accessed on 26 September 2023).
- Sina Weibo: User Gender Distribution 2022. Available online: https://www.statista.com/statistics/1287809/sina-weibo-user-gender-distibution-worldwide/ (accessed on 26 September 2023).
- QQ: User Gender Distribution 2022. Available online: https://www.statista.com/statistics/1287794/qq-user-gender-distibution-worldwide/ (accessed on 26 September 2023).
- Samanta, O. Telegram Revenue & User Statistics 2023. Available online: https://prioridata.com/data/telegram-statistics/ (accessed on 26 September 2023).
- Shewale, R. 36 Quora Statistics: All-Time Stats & Data (2023). Available online: https://www.demandsage.com/quora-statistics/ (accessed on 26 September 2023).
- Gitnux The Most Surprising Tumblr Statistics and Trends in 2023. Available online: https://blog.gitnux.com/tumblr-statistics/ (accessed on 26 September 2023).
- Social Media User Diversity Statistics. Available online: https://blog.hootsuite.com/wp-content/uploads/2023/03/twitter-stats-4.jpg (accessed on 26 September 2023).
- WeChat: User Gender Distribution 2022. Available online: https://www.statista.com/statistics/1287786/wechat-user-gender-distibution-worldwide/ (accessed on 26 September 2023).
- Global Snapchat User Distribution by Gender 2023. Available online: https://www.statista.com/statistics/326460/snapchat-global-gender-group/ (accessed on 26 September 2023).
- Villavicencio, C.; Macrohon, J.J.; Inbaraj, X.A.; Jeng, J.-H.; Hsieh, J.-G. Twitter Sentiment Analysis towards COVID-19 Vaccines in the Philippines Using Naïve Bayes. Information (Basel) 2021, 12, 204. [Google Scholar] [CrossRef]
- Boon-Itt, S.; Skunkan, Y. Public Perception of the COVID-19 Pandemic on Twitter: Sentiment Analysis and Topic Modeling Study. JMIR Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef]
- Marcec, R.; Likic, R. Using Twitter for Sentiment Analysis towards AstraZeneca/Oxford, Pfizer/BioNTech and Moderna COVID-19 Vaccines. Postgrad. Med. J. 2022, 98, 544–550. [Google Scholar] [CrossRef] [PubMed]
- Machuca, C.R.; Gallardo, C.; Toasa, R.M. Twitter Sentiment Analysis on Coronavirus: Machine Learning Approach. J. Phys. Conf. Ser. 2021, 1828, 012104. [Google Scholar] [CrossRef]
- Kruspe, A.; Häberle, M.; Kuhn, I.; Zhu, X.X. Cross-Language Sentiment Analysis of European Twitter Messages Duringthe COVID-19 Pandemic. arXiv [cs.SI], 2020. [Google Scholar]
- Vijay, T.; Chawla, A.; Dhanka, B.; Karmakar, P. Sentiment Analysis on COVID-19 Twitter Data. In Proceedings of the 2020 5th IEEE International Conference on Recent Advances and Innovations in Engineering (ICRAIE); IEEE, 2020.
- Shofiya, C.; Abidi, S. Sentiment Analysis on COVID-19-Related Social Distancing in Canada Using Twitter Data. Int. J. Environ. Res. Public Health 2021, 18, 5993. [Google Scholar] [CrossRef] [PubMed]
- Sontayasara, T.; Jariyapongpaiboon, S.; Promjun, A.; Seelpipat, N.; Saengtabtim, K.; Tang, J.; Leelawat, N.; Department of Industrial Engineering, Faculty of Engineering, Chulalongkorn University 254 Phayathai Road, Pathumwan, Bangkok 10330, Thailand; International School of Engineering, Faculty of Engineering, Chulalongkorn University, Bangkok, Thailand; Disaster and Risk Management Information Systems Research Group, Chulalongkorn University, Bangkok, Thailand Twitter Sentiment Analysis of Bangkok Tourism during COVID-19 Pandemic Using Support Vector Machine Algorithm. J. Disaster Res. 2021, 16, 24–30. [CrossRef]
- Nemes, L.; Kiss, A. Social Media Sentiment Analysis Based on COVID-19. J. Inf. Telecommun. 2021, 5, 1–15. [Google Scholar] [CrossRef]
- Okango, E.; Mwambi, H. Dictionary Based Global Twitter Sentiment Analysis of Coronavirus (COVID-19) Effects and Response. Ann. Data Sci. 2022, 9, 175–186. [Google Scholar] [CrossRef]
- Singh, C.; Imam, T.; Wibowo, S.; Grandhi, S. A Deep Learning Approach for Sentiment Analysis of COVID-19 Reviews. Appl. Sci. (Basel) 2022, 12, 3709. [Google Scholar] [CrossRef]
- Kaur, H.; Ahsaan, S.U.; Alankar, B.; Chang, V. A Proposed Sentiment Analysis Deep Learning Algorithm for Analyzing COVID-19 Tweets. Inf. Syst. Front. 2021, 23, 1417–1429. [Google Scholar] [CrossRef]
- Vernikou, S.; Lyras, A.; Kanavos, A. Multiclass Sentiment Analysis on COVID-19-Related Tweets Using Deep Learning Models. Neural Comput. Appl. 2022, 34, 19615–19627. [Google Scholar] [CrossRef]
- Sharma, S.; Sharma, A. Twitter Sentiment Analysis during Unlock Period of COVID-19. In Proceedings of the 2020 Sixth International Conference on Parallel, Distributed and Grid Computing (PDGC); IEEE, 2020; pp. 221–224.
- Sanders, A.C.; White, R.C.; Severson, L.S.; Ma, R.; McQueen, R.; Alcântara Paulo, H.C.; Zhang, Y.; Erickson, J.S.; Bennett, K.P. Unmasking the Conversation on Masks: Natural Language Processing for Topical Sentiment Analysis of COVID-19 Twitter Discourse. AMIA Summits on Translational Science Proceedings 2021, 2021, 555. [Google Scholar]
- Alabid, N.N.; Katheeth, Z.D. Sentiment Analysis of Twitter Posts Related to the COVID-19 Vaccines. Indones. J. Electr. Eng. Comput. Sci. 2021, 24, 1727. [Google Scholar] [CrossRef]
- Mansoor, M.; Gurumurthy, K.; U, Anantharam R; Prasad, V.R.B. Global Sentiment Analysis of COVID-19 Tweets over Time. arXiv [cs.CL] 2020.
- Singh, M.; Jakhar, A.K.; Pandey, S. Sentiment Analysis on the Impact of Coronavirus in Social Life Using the BERT Model. Soc. Netw. Anal. Min. 2021, 11. [Google Scholar] [CrossRef] [PubMed]
- Imamah; Rachman, F.H. Twitter Sentiment Analysis of Covid-19 Using Term Weighting TF-IDF and Logistic Regresion. In Proceedings of the 2020 6th Information Technology International Seminar (ITIS); IEEE, 2020; pp. 238–242.
- Sahir, S.H.; Ayu Ramadhana, R.S.; Romadhon Marpaung, M.F.; Munthe, S.R.; Watrianthos, R. Online Learning Sentiment Analysis during the Covid-19 Indonesia Pandemic Using Twitter Data. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1156, 012011. [Google Scholar] [CrossRef]
- Althagafi, A.; Althobaiti, G.; Alhakami, H.; Alsubait, T. Arabic Tweets Sentiment Analysis about Online Learning during COVID-19 in Saudi Arabia. Int. J. Adv. Comput. Sci. Appl. 2021, 12. [Google Scholar] [CrossRef]
- Ali, M.M. Arabic Sentiment Analysis about Online Learning to Mitigate Covid-19. J. Intell. Syst. 2021, 30, 524–540. [Google Scholar] [CrossRef]
- Alcober, G.M.I.; Revano, T.F. Twitter Sentiment Analysis towards Online Learning during COVID-19 in the Philippines. In Proceedings of the 2021 IEEE 13th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM); IEEE, 2021.
- Remali, N.A.S.; Shamsuddin, M.R.; Abdul-Rahman, S. Sentiment Analysis on Online Learning for Higher Education during Covid-19. In Proceedings of the 2022 3rd International Conference on Artificial Intelligence and Data Sciences (AiDAS); IEEE, 2022; pp. 142–147.
- Senadhira, K.I.; Rupasingha, R.A.H.M.; Kumara, B.T.G.S. Sentiment Analysis on Twitter Data Related to Online Learning during the Covid-19 Pandemic. Available online: http://repository.kln.ac.lk/handle/123456789/25416 (accessed on 27 September 2023).
- Lubis, A.R.; Prayudani, S.; Lubis, M.; Nugroho, O. Sentiment Analysis on Online Learning during the Covid-19 Pandemic Based on Opinions on Twitter Using KNN Method. In Proceedings of the 2022 1st International Conference on Information System & Information Technology (ICISIT); IEEE, 2022; pp. 106–111.
- Arambepola, N. Analysing the Tweets about Distance Learning during COVID-19 Pandemic Using Sentiment Analysis. Available online: https://fct.kln.ac.lk/media/pdf/proceedings/ICACT-2020/F-7.pdf (accessed on 27 September 2023).
- Isnain, A.R.; Supriyanto, J.; Kharisma, M.P. Implementation of K-Nearest Neighbor (K-NN) Algorithm for Public Sentiment Analysis of Online Learning. IJCCS 2021, 15, 121. [Google Scholar] [CrossRef]
- Aljabri, M.; Chrouf, S.M.B.; Alzahrani, N.A.; Alghamdi, L.; Alfehaid, R.; Alqarawi, R.; Alhuthayfi, J.; Alduhailan, N. Sentiment Analysis of Arabic Tweets Regarding Distance Learning in Saudi Arabia during the COVID-19 Pandemic. Sensors (Basel) 2021, 21, 5431. [Google Scholar] [CrossRef]
- Asare, A.O.; Yap, R.; Truong, N.; Sarpong, E.O. The Pandemic Semesters: Examining Public Opinion Regarding Online Learning amidst COVID-19. J. Comput. Assist. Learn. 2021, 37, 1591–1605. [Google Scholar] [CrossRef]
- Mujahid, M.; Lee, E.; Rustam, F.; Washington, P.B.; Ullah, S.; Reshi, A.A.; Ashraf, I. Sentiment Analysis and Topic Modeling on Tweets about Online Education during COVID-19. Appl. Sci. (Basel) 2021, 11, 8438. [Google Scholar] [CrossRef]
- Al-Obeidat, F.; Ishaq, M.; Shuhaiber, A.; Amin, A. Twitter Sentiment Analysis to Understand Students’ Perceptions about Online Learning during the Covid’19. In Proceedings of the 2022 International Conference on Computer and Applications (ICCA); IEEE, 2022; Vol. 00, p. 1.
- Waheeb, S.A.; Khan, N.A.; Shang, X. Topic Modeling and Sentiment Analysis of Online Education in the COVID-19 Era Using Social Networks Based Datasets. Electronics (Basel) 2022, 11, 715. [Google Scholar] [CrossRef]
- Integrating Information Gain Methods for Feature Selection in Distance Education Sentiment Analysis during Covid-19. TEM J. 2023, 12, 285–290.
- Fauzan, M.; Setiawan, T. Acts of Hate Speech in News on Twitter Related to Covid-19. Available online: http://icollate.uny.ac.id/sites/icollate.uny.ac.id/files/download-file/PROCEEDING%20ICOLLATE-4%202021-Muhammad%20Fauzan1%2C.pdf (accessed on 27 September 2023).
- Martinez, M.A. What Do People Write about COVID-19 and Teaching, Publicly? Insulators and Threats to Newly Habituated and Institutionalized Practices for Instruction. PLoS One 2022, 17, e0276511. [Google Scholar] [CrossRef] [PubMed]
- Thakur, N. A Large-Scale Dataset of Twitter Chatter about Online Learning during the Current COVID-19 Omicron Wave. Data (Basel) 2022, 7, 109. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for Scientific Data Management and Stewardship. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef]
- Genderperformr. Available online: https://pypi.org/project/genderperformr/ (accessed on 27 September 2023).
- Wang, Z.; Jurgens, D. It’s Going to Be Okay: Measuring Access to Support in Online Communities. In Proceedings of the Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA; pp. 33–45.
- Hutto, C.; Gilbert, E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. Proceedings of the International AAAI Conference on Web and Social Media 2014, 8, 216–225. [Google Scholar] [CrossRef]
- Nielsen, F.Å. A New ANEW: Evaluation of a Word List for Sentiment Analysis in Microblogs. arXiv [cs.IR] 2011.
- TextBlob. Available online: https://media.readthedocs.org/pdf/textblob/latest/textblob.pdf (accessed on 27 September 2023).
- Jumanto, J.; Muslim, M.A.; Dasril, Y.; Mustaqim, T. Accuracy of Malaysia Public Response to Economic Factors during the Covid-19 Pandemic Using Vader and Random Forest. J. Inf. Syst. Explor. Res. 2022, 1, 49–70. [Google Scholar] [CrossRef]
- Bose, D.R.; Aithal, P.S.; Roy, S. Survey of Twitter Viewpoint on Application of Drugs by VADER Sentiment Analysis among Distinct Countries 2021.
- Borg, A.; Boldt, M. Using VADER Sentiment and SVM for Predicting Customer Response Sentiment. Expert Syst. Appl. 2020, 162, 113746. [Google Scholar] [CrossRef]
- Newman, H.; Joyner, D. Sentiment Analysis of Student Evaluations of Teaching. In Lecture Notes in Computer Science; Springer International Publishing: Cham, 2018; pp. 246–250. ISBN 9783319938455. [Google Scholar]
- Gan, Q.; Yu, Y. Restaurant Rating: Industrial Standard and Word-of-Mouth -- A Text Mining and Multi-Dimensional Sentiment Analysis. In Proceedings of the 2015 48th Hawaii International Conference on System Sciences; IEEE, 2015.
- Gabarron, E.; Dechsling, A.; Skafle, I.; Nordahl-Hansen, A. Discussions of Asperger Syndrome on Social Media: Content and Sentiment Analysis on Twitter. JMIR Form. Res. 2022, 6, e32752. [Google Scholar] [CrossRef]
- Lee, I.T.-L.; Juang, S.-E.; Chen, S.T.; Ko, C.; Ma, K.S.-K. Sentiment Analysis of Tweets on Alopecia Areata, Hidradenitis Suppurativa, and Psoriasis: Revealing the Patient Experience. Front. Med. (Lausanne) 2022, 9. [Google Scholar] [CrossRef]
- Nalisnick, E.T.; Baird, H.S. Character-to-Character Sentiment Analysis in Shakespeare’s Plays. Available online: https://aclanthology.org/P13-2085.pdf (accessed on 27 September 2023).
- Hazarika, D.; Konwar, G.; Deb, S.; Bora, D.J. Sentiment Analysis on Twitter by Using TextBlob for Natural Language Processing. In Proceedings of the Annals of Computer Science and Information Systems; PTI, 2020; Vol. 24.
- Mas Diyasa, I.G.S.; Marini Mandenni, N.M.I.; Fachrurrozi, M.I.; Pradika, S.I.; Nur Manab, K.R.; Sasmita, N.R. Twitter Sentiment Analysis as an Evaluation and Service Base On Python Textblob. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1125, 012034. [Google Scholar] [CrossRef]
- Mansouri, N.; Soui, M.; Alhassan, I.; Abed, M. TextBlob and BiLSTM for Sentiment Analysis toward COVID-19 Vaccines. In Proceedings of the 2022 7th International Conference on Data Science and Machine Learning Applications (CDMA); IEEE, 2022.
- Hermansyah, R.; Sarno, R. Sentiment Analysis about Product and Service Evaluation of PT Telekomunikasi Indonesia Tbk from Tweets Using TextBlob, Naive Bayes & K-NN Method. In Proceedings of the 2020 International Seminar on Application for Technology of Information and Communication (iSemantic); IEEE, 2020.
- Detoxify. Available online: https://pypi.org/project/detoxify/ (accessed on 27 September 2023).
- Jigsaw Unintended Bias in Toxicity Classification. Available online: https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification (accessed on 27 September 2023).
- Jigsaw Multilingual Toxic Comment Classification. Available online: https://www.kaggle.com/c/jigsaw-multilingual-toxic-comment-classification (accessed on 27 September 2023).
- Toxic Comment Classification Challenge. Available online: https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge (accessed on 27 September 2023).
- Sharma, S.; Gupta, V. Role of Twitter User Profile Features in Retweet Prediction for Big Data Streams. Multimed. Tools Appl. 2022, 81, 27309–27338. [Google Scholar] [CrossRef]
- Zambon, V. Gender Identity. Available online: https://www.medicalnewstoday.com/articles/types-of-gender-identity (accessed on 28 September 2023).
- Pycountry. Available online: https://pypi.org/project/pycountry/ (accessed on 28 September 2023).
Figure 1.
The variation of social media use by gender from the findings of a survey conducted by the Pew Research Center from 2005 to 2021.
Figure 1.
The variation of social media use by gender from the findings of a survey conducted by the Pew Research Center from 2005 to 2021.
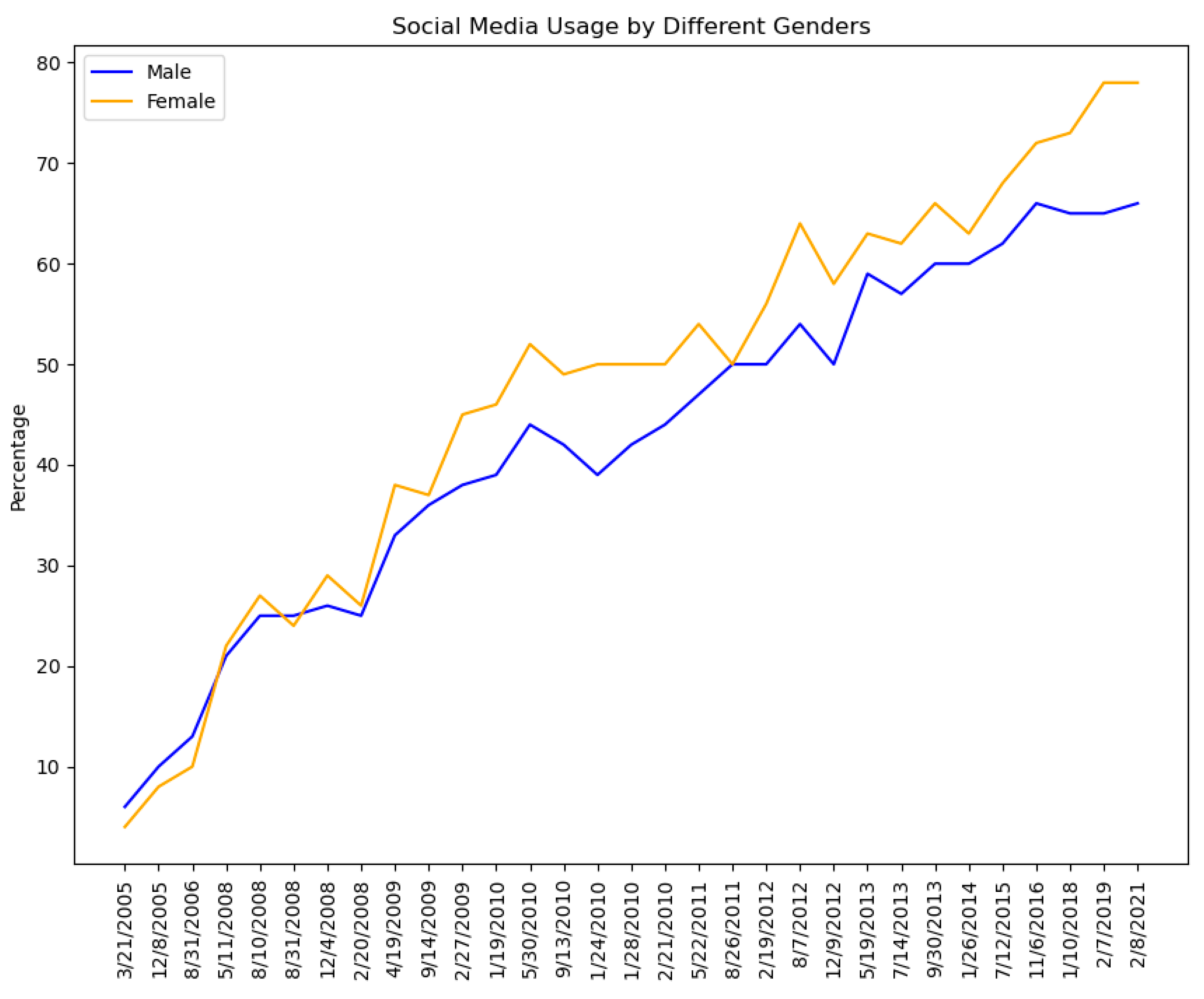
Figure 2.
A flowchart representing the working of Algorithm 1 to Algorithm 6 for the development of the master dataset.
Figure 2.
A flowchart representing the working of Algorithm 1 to Algorithm 6 for the development of the master dataset.
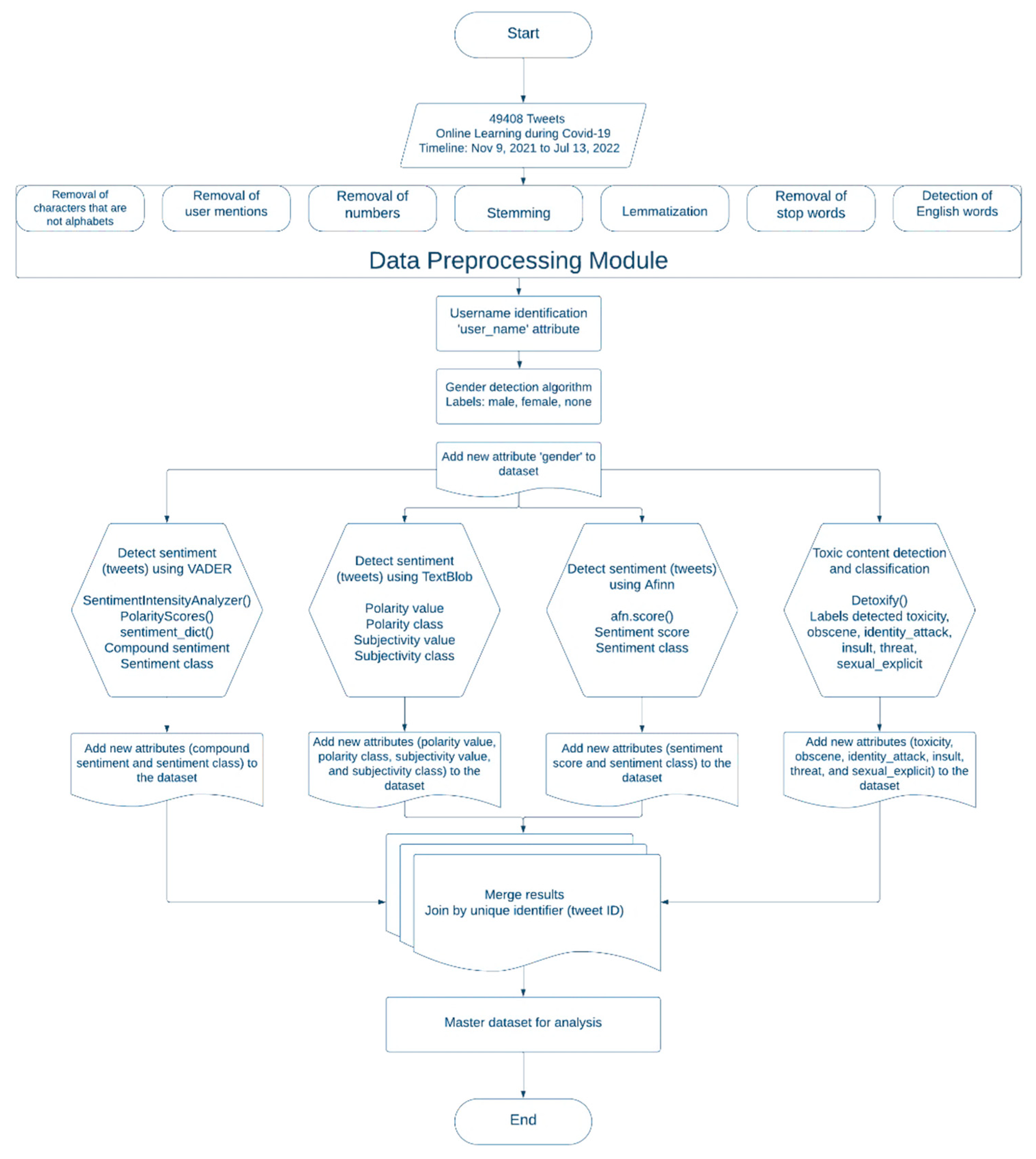
Figure 3.
A pie chart to represent different genders from the “Gender” attribute.
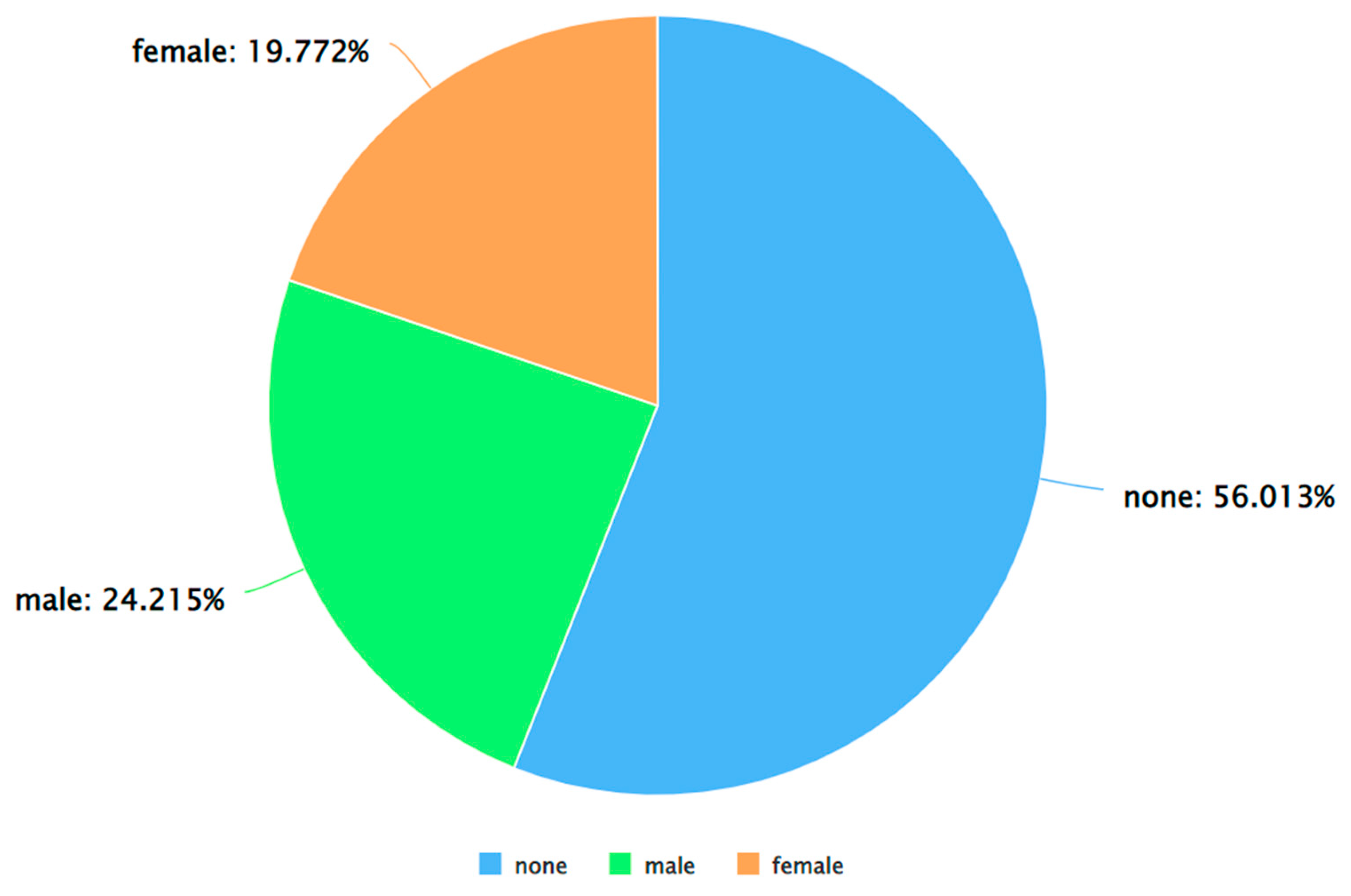
Figure 4.
A pie chart to represent the distribution of positive, negative, and neutral sentiments (as per VADER) in the tweets.
Figure 4.
A pie chart to represent the distribution of positive, negative, and neutral sentiments (as per VADER) in the tweets.
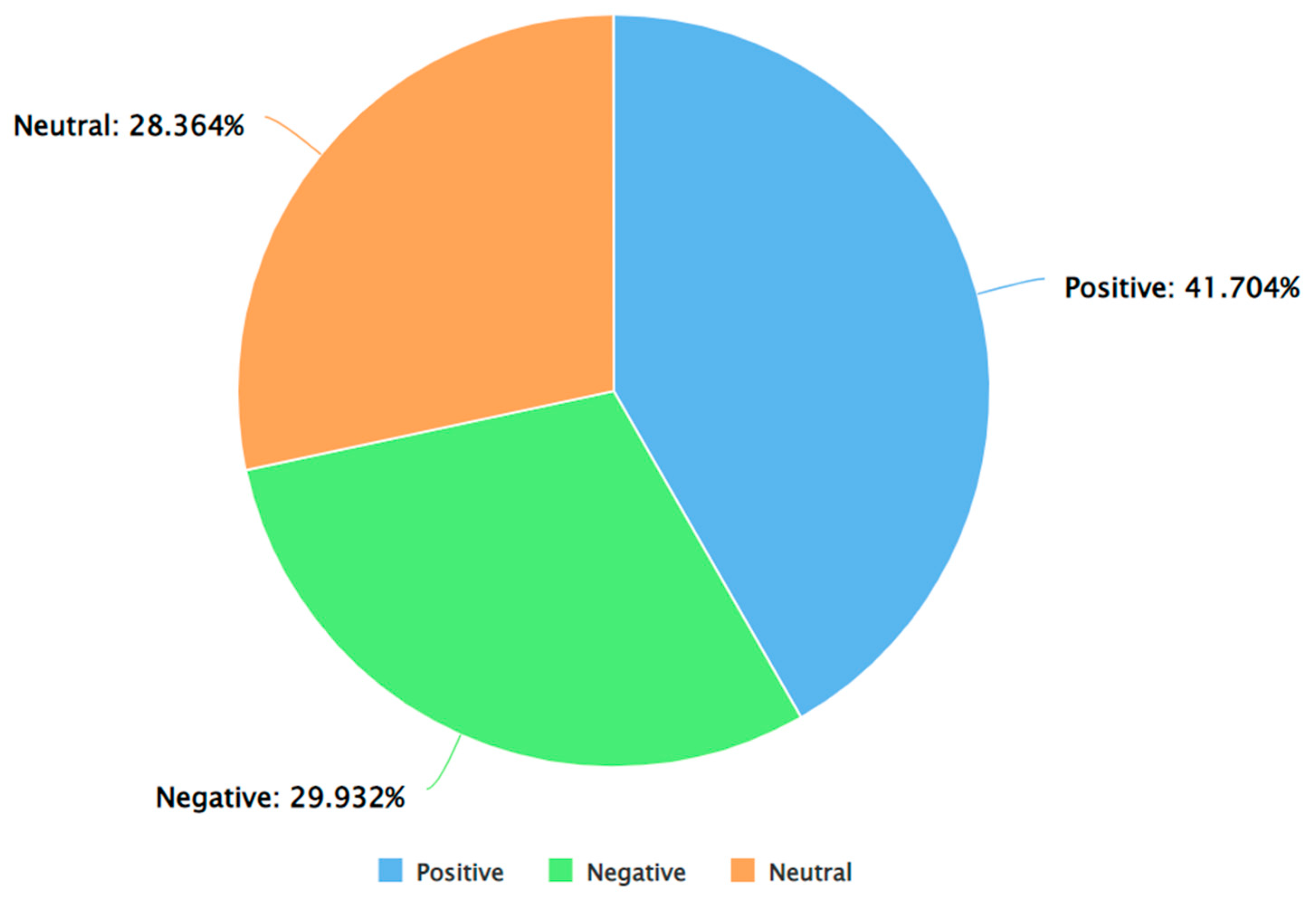
Figure 5.
A pie chart to represent the percentage of positive tweets (as per VADER) posted by each gender.
Figure 5.
A pie chart to represent the percentage of positive tweets (as per VADER) posted by each gender.
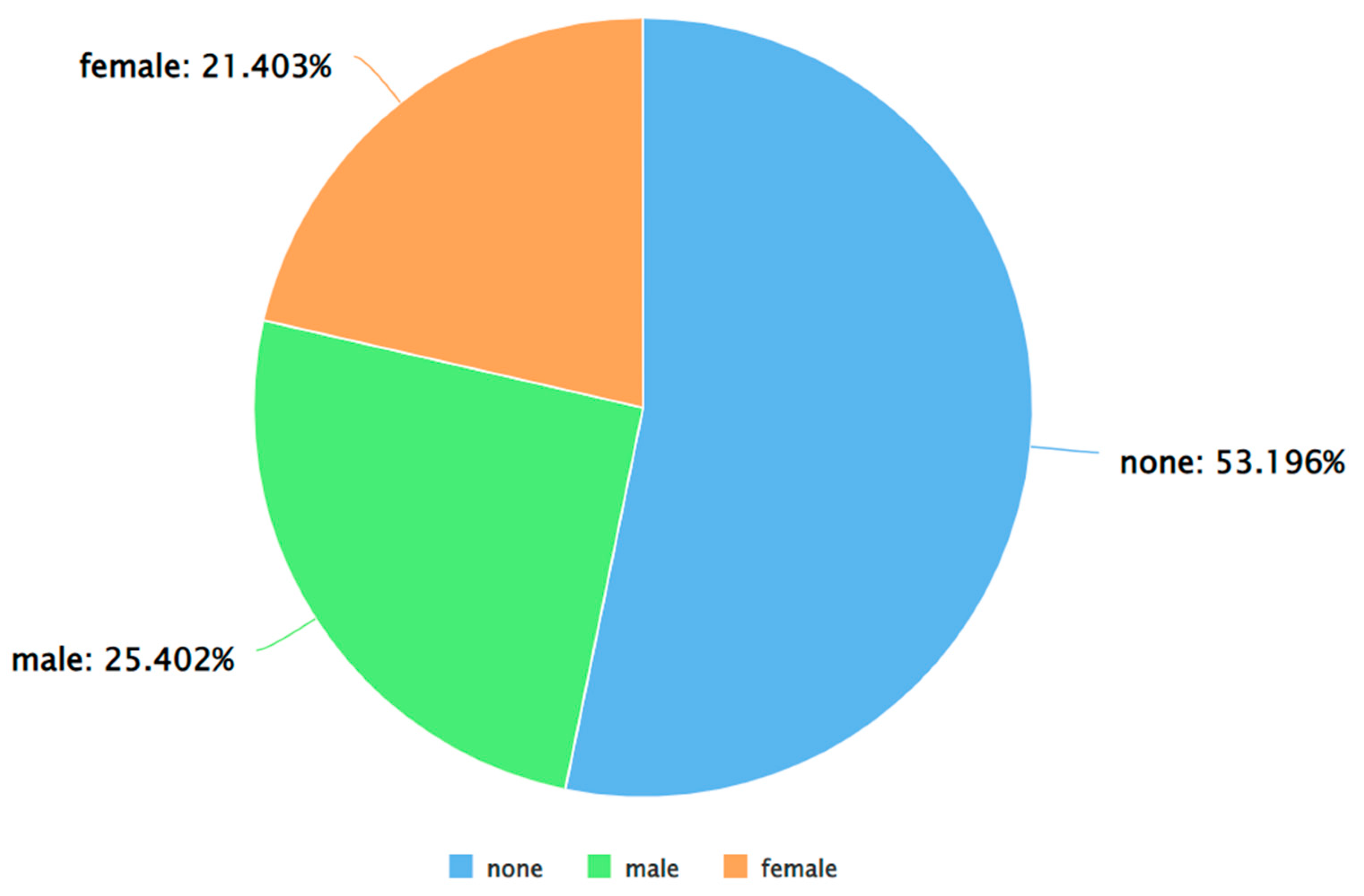
Figure 6.
A pie chart to represent the percentage of negative tweets (as per VADER) posted by each gender.
Figure 6.
A pie chart to represent the percentage of negative tweets (as per VADER) posted by each gender.
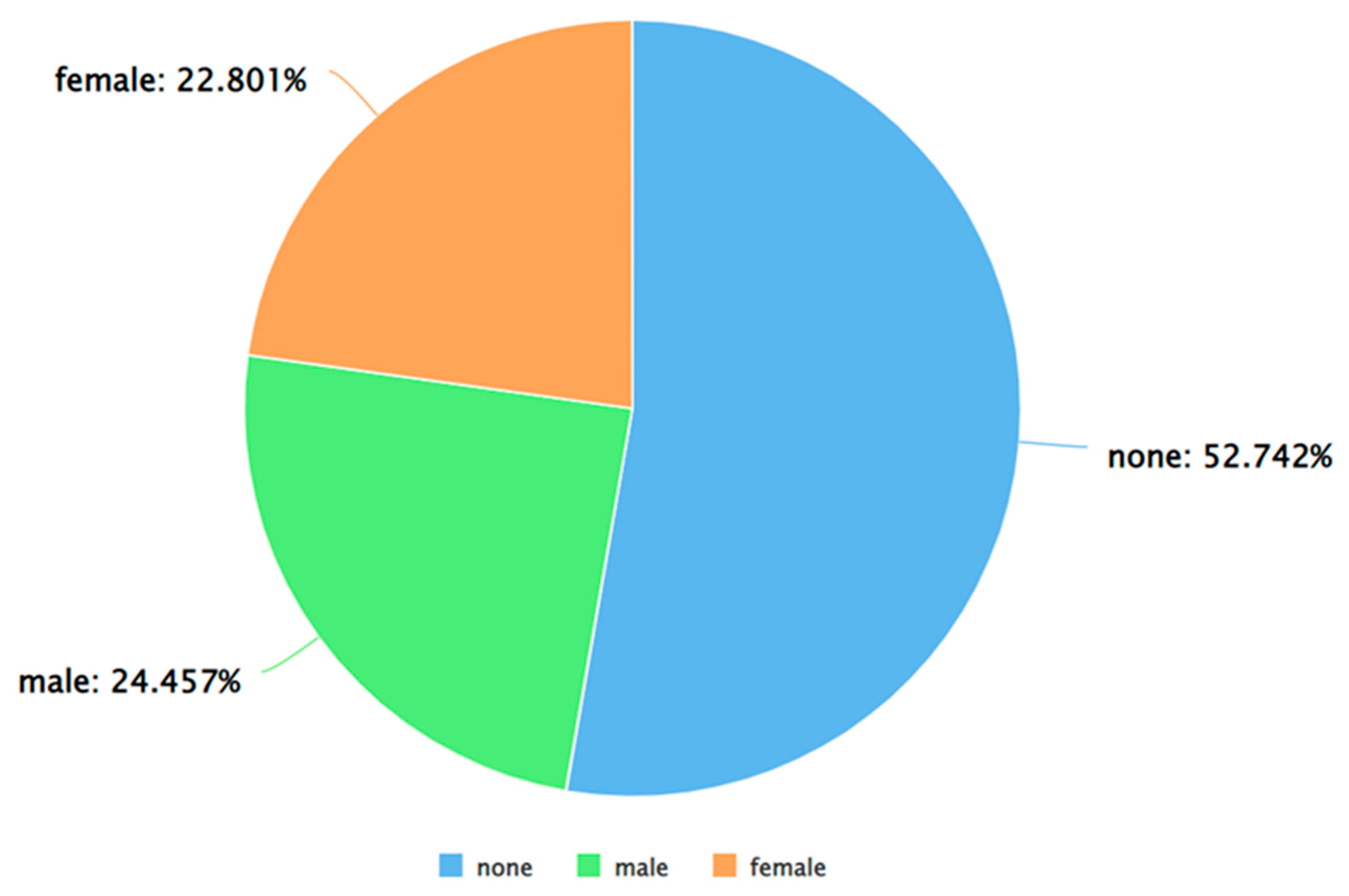
Figure 7.
A pie chart to represent the percentage of neutral tweets (as per VADER) posted by each gender.
Figure 7.
A pie chart to represent the percentage of neutral tweets (as per VADER) posted by each gender.
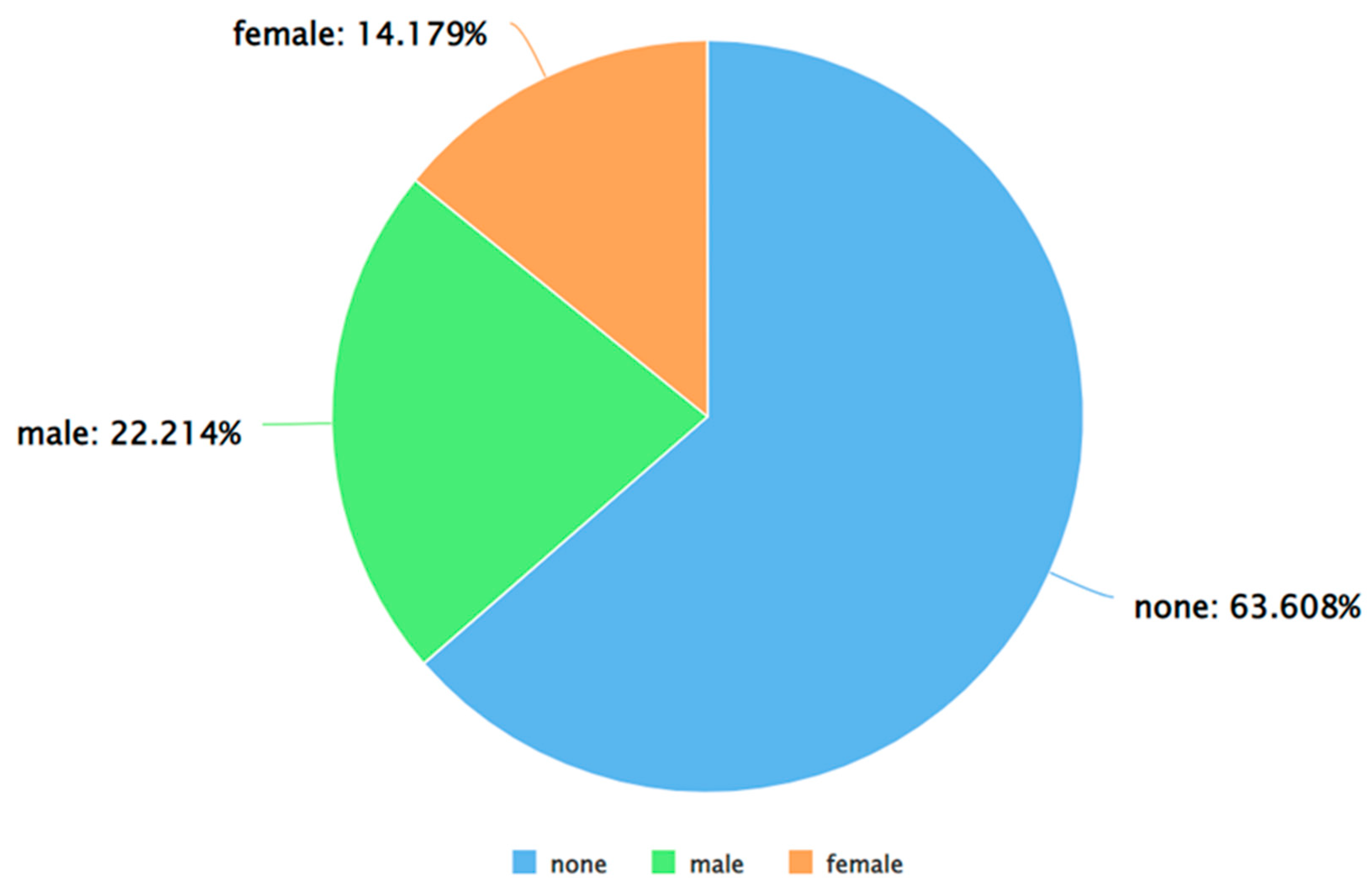
Figure 8.
A pie chart to represent the distribution of positive, negative, and neutral sentiments (as per Afinn) in the tweets.
Figure 8.
A pie chart to represent the distribution of positive, negative, and neutral sentiments (as per Afinn) in the tweets.
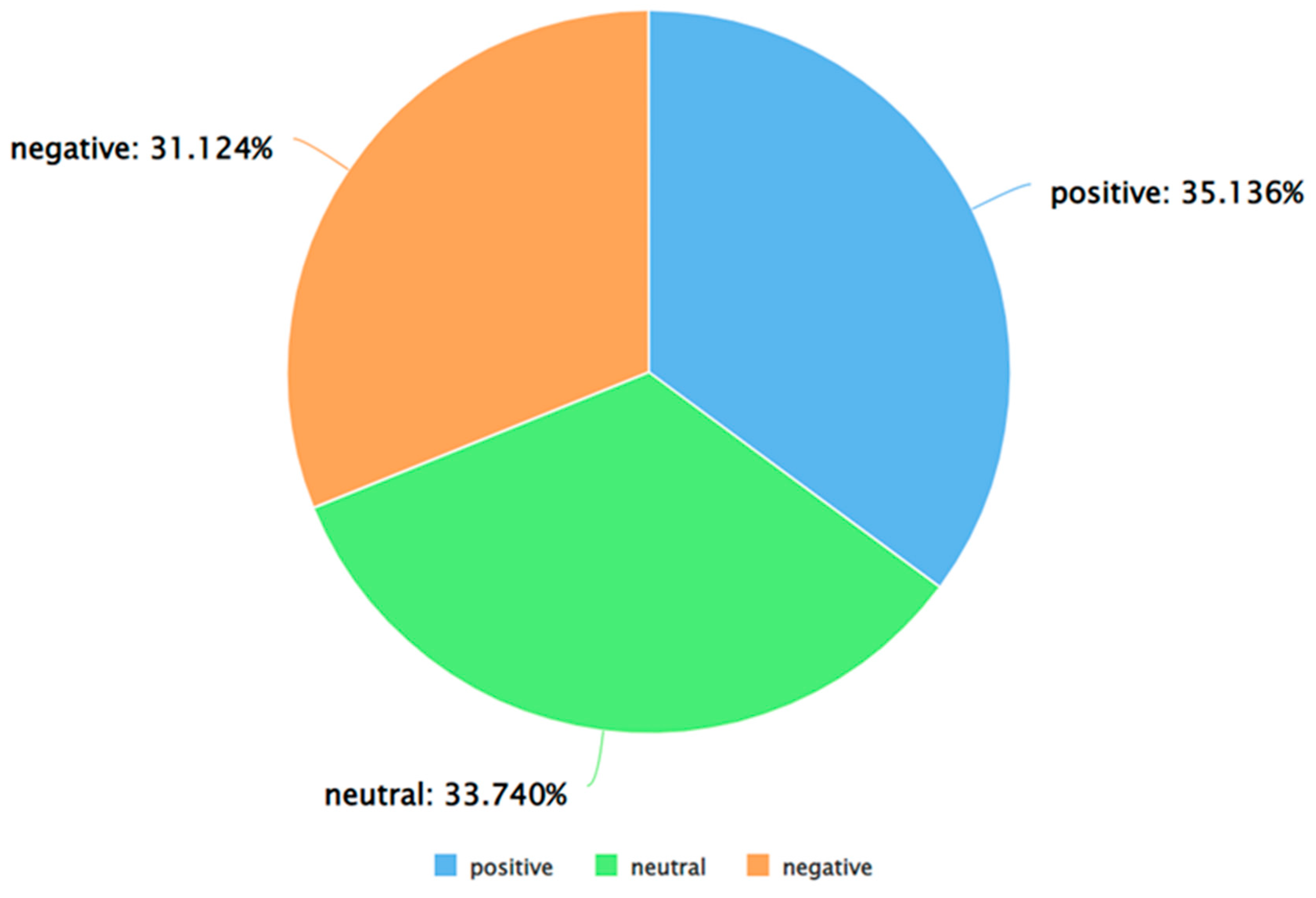
Figure 9.
A pie chart to represent the percentage of positive tweets (as per Afinn) posted by each gender.
Figure 9.
A pie chart to represent the percentage of positive tweets (as per Afinn) posted by each gender.
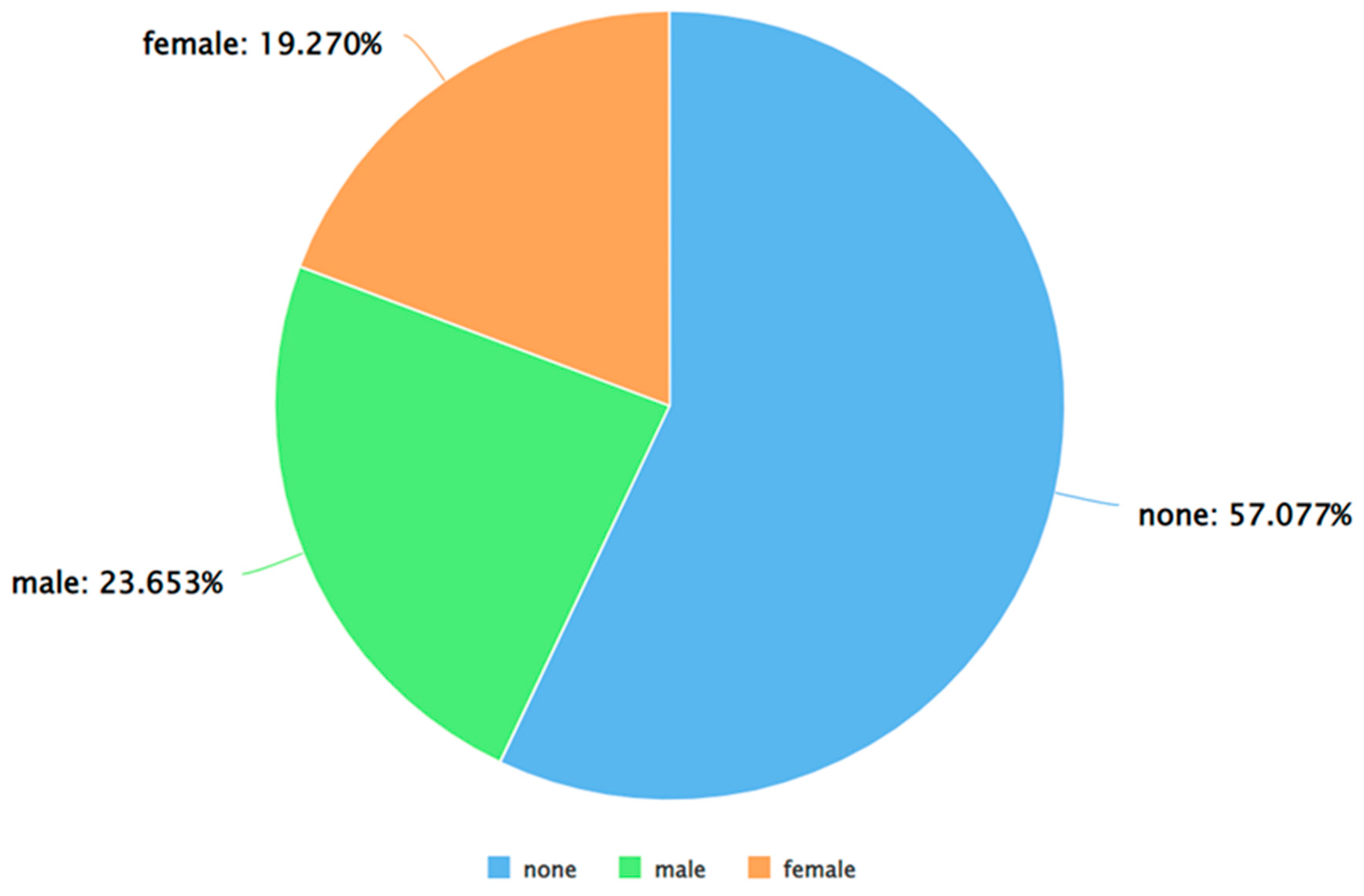
Figure 10.
A pie chart to represent the percentage of negative tweets (as per Afinn) posted by each gender.
Figure 10.
A pie chart to represent the percentage of negative tweets (as per Afinn) posted by each gender.
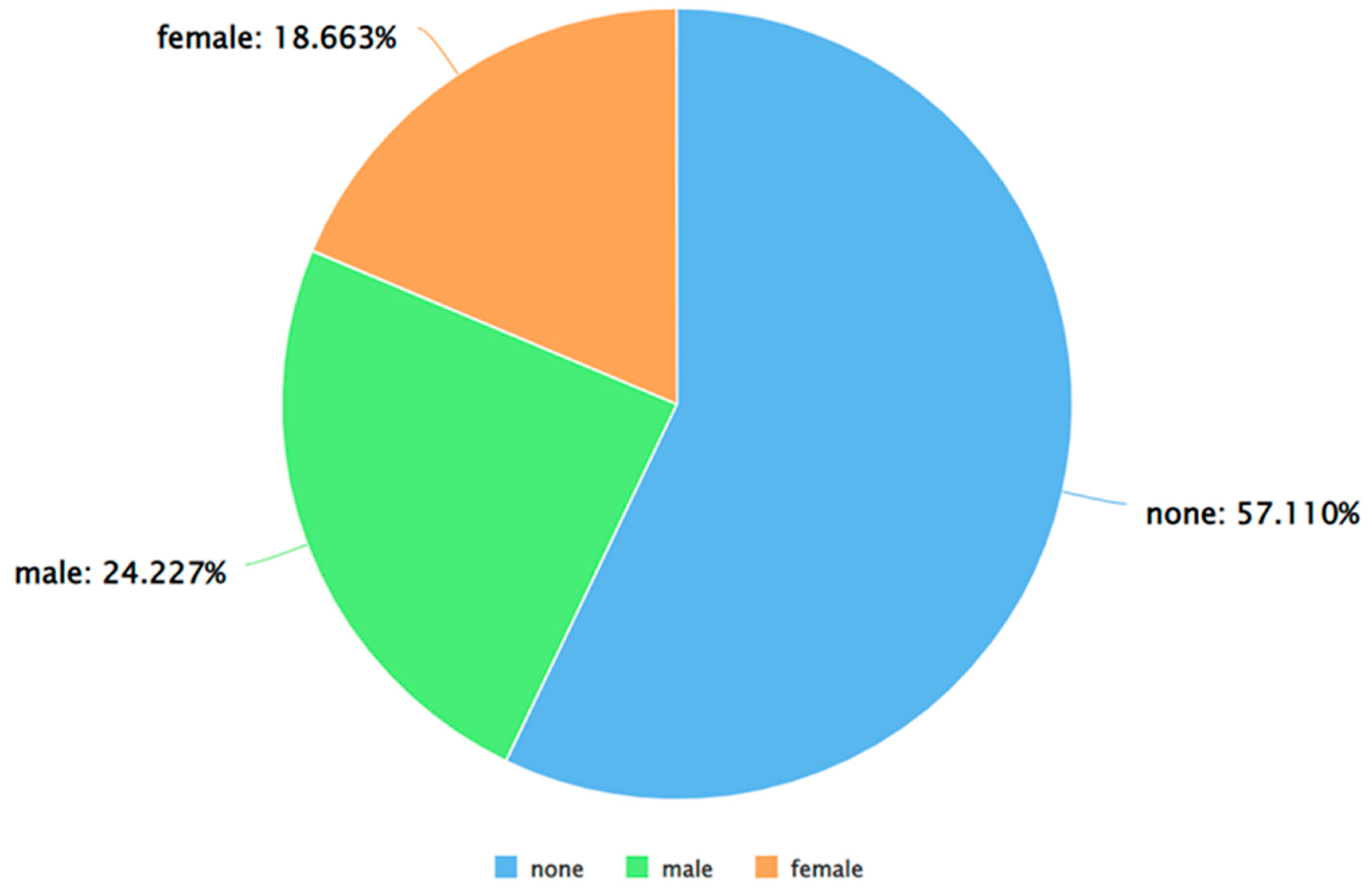
Figure 11.
A pie chart to represent the percentage of neutral tweets (as per Afinn) posted by each gender.
Figure 11.
A pie chart to represent the percentage of neutral tweets (as per Afinn) posted by each gender.
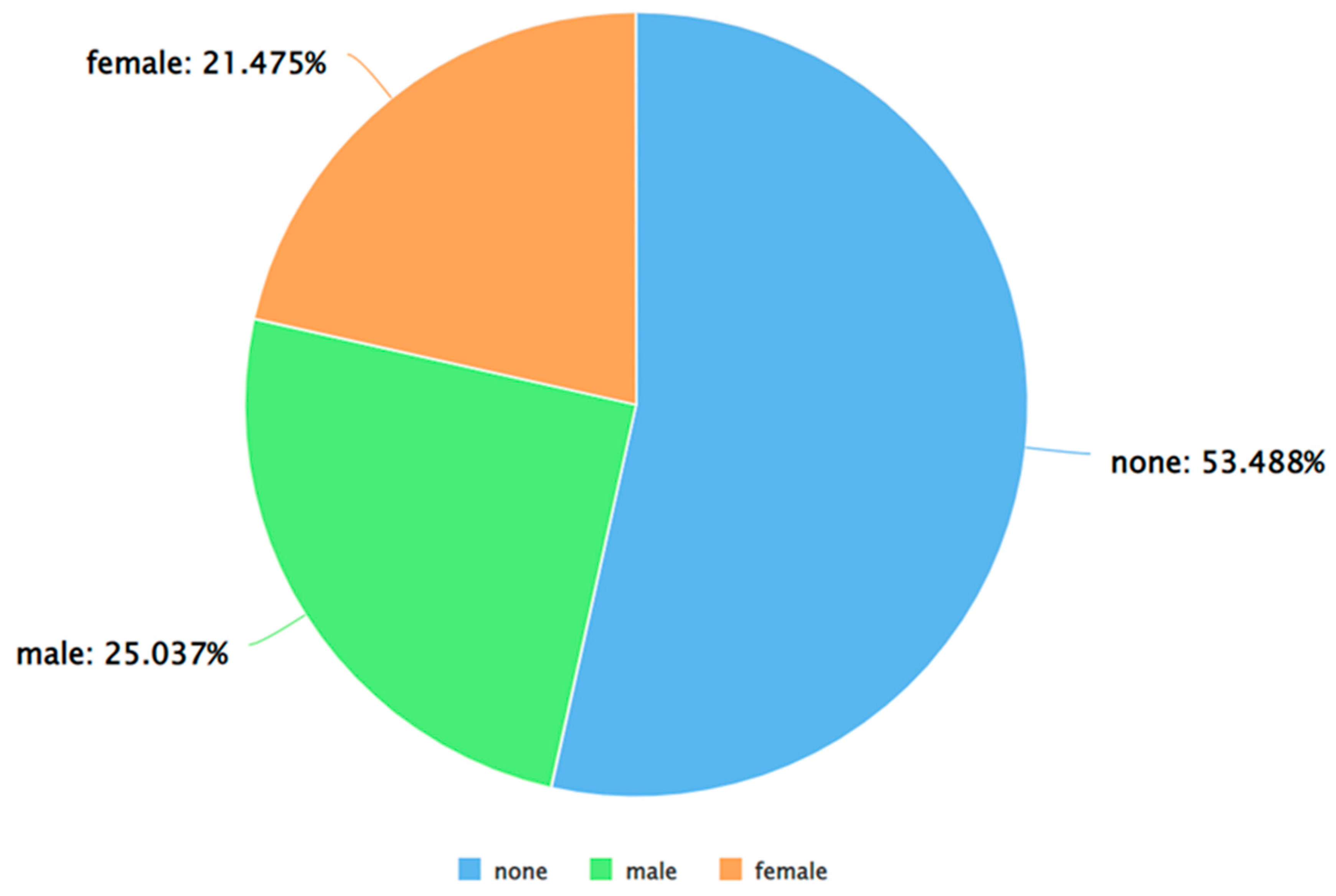
Figure 12.
A pie chart to represent the distribution of positive, negative, and neutral sentiments (as per TextBlob) in the tweets.
Figure 12.
A pie chart to represent the distribution of positive, negative, and neutral sentiments (as per TextBlob) in the tweets.
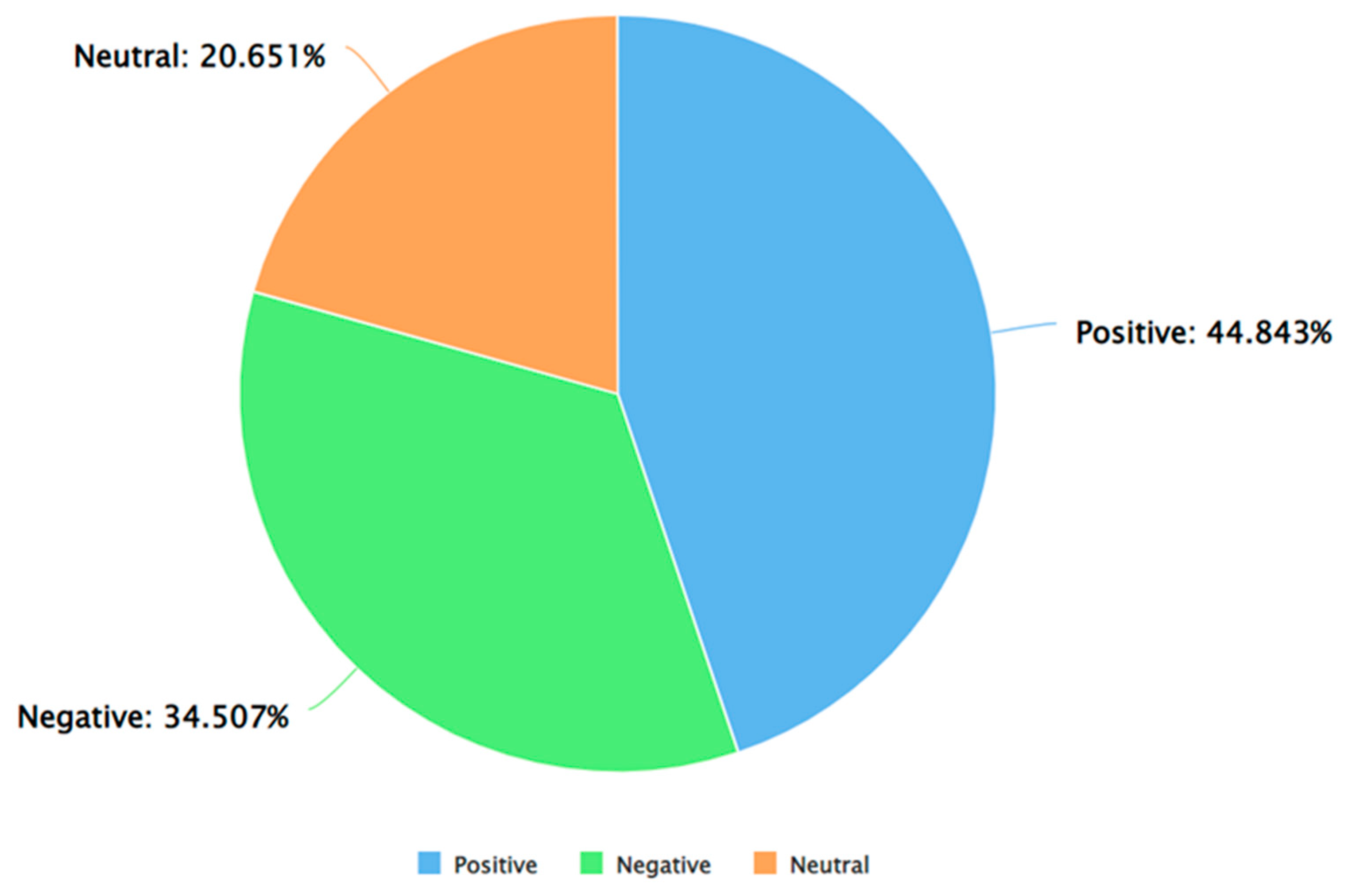
Figure 13.
A pie chart to represent the percentage of positive tweets (as per TextBlob) posted by each gender.
Figure 13.
A pie chart to represent the percentage of positive tweets (as per TextBlob) posted by each gender.
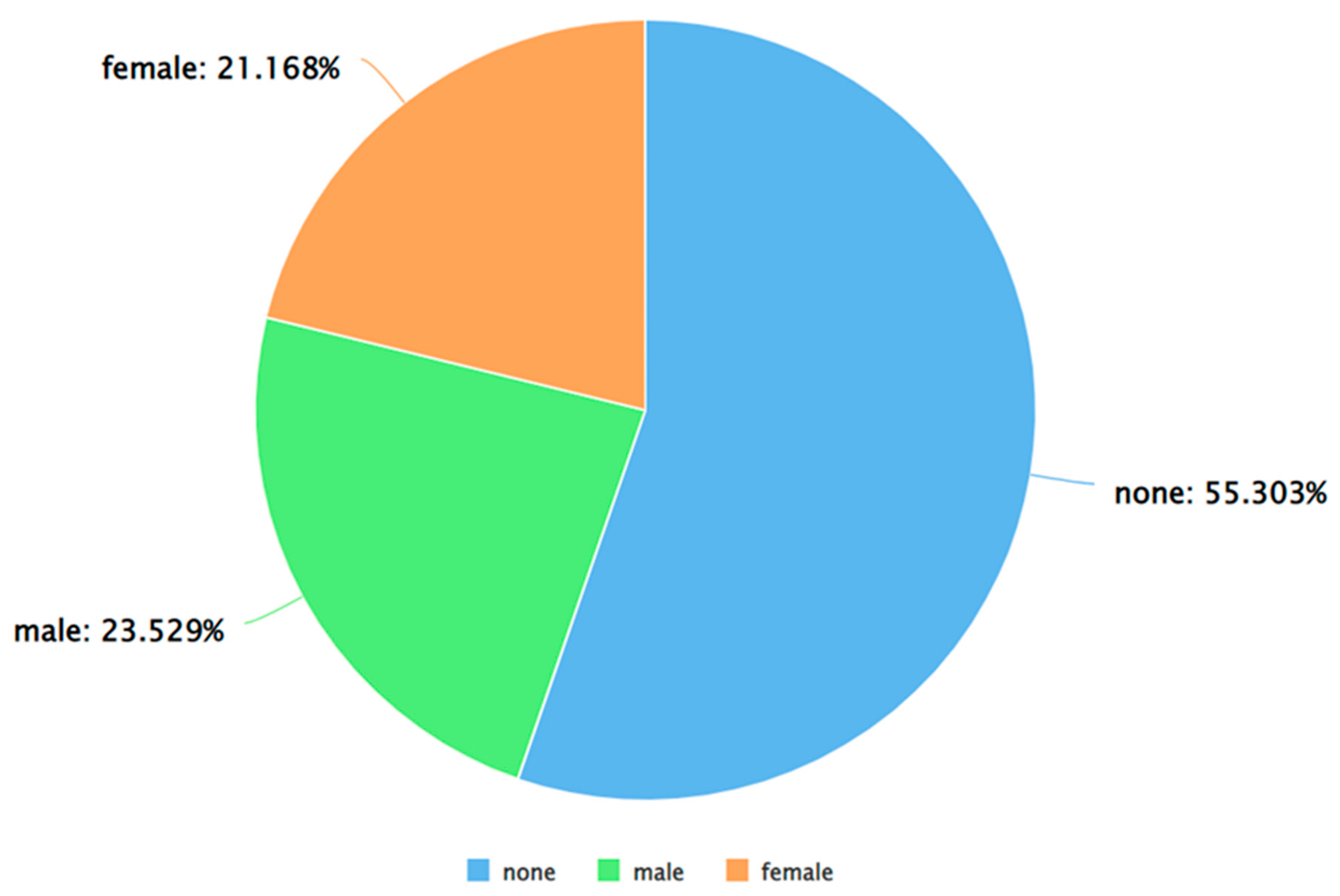
Figure 14.
A pie chart to represent the percentage of negative tweets (as per TextBlob) posted by each gender.
Figure 14.
A pie chart to represent the percentage of negative tweets (as per TextBlob) posted by each gender.
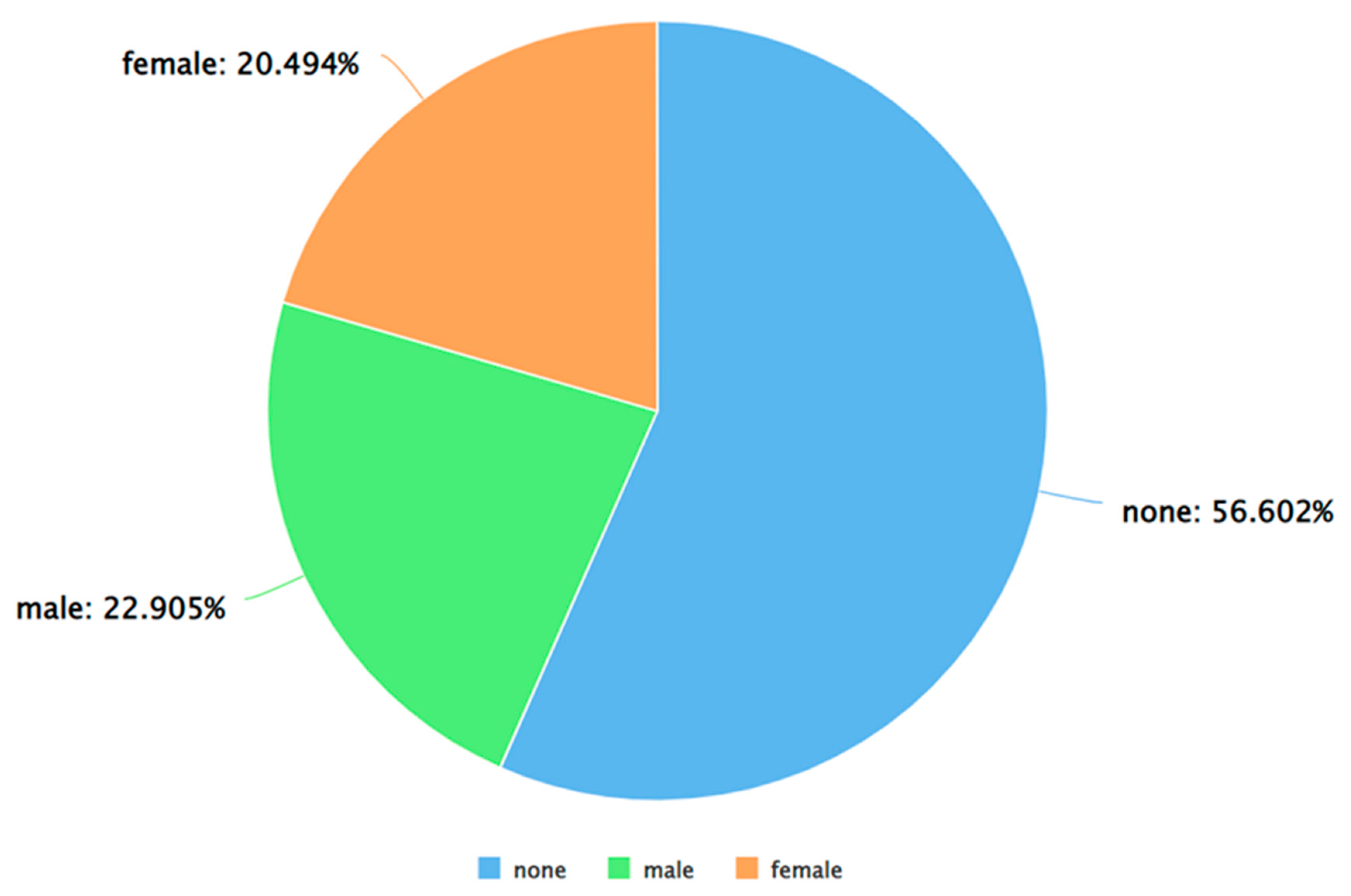
Figure 15.
A pie chart to represent the percentage of neutral tweets (as per TextBlob) posted by each gender.
Figure 15.
A pie chart to represent the percentage of neutral tweets (as per TextBlob) posted by each gender.
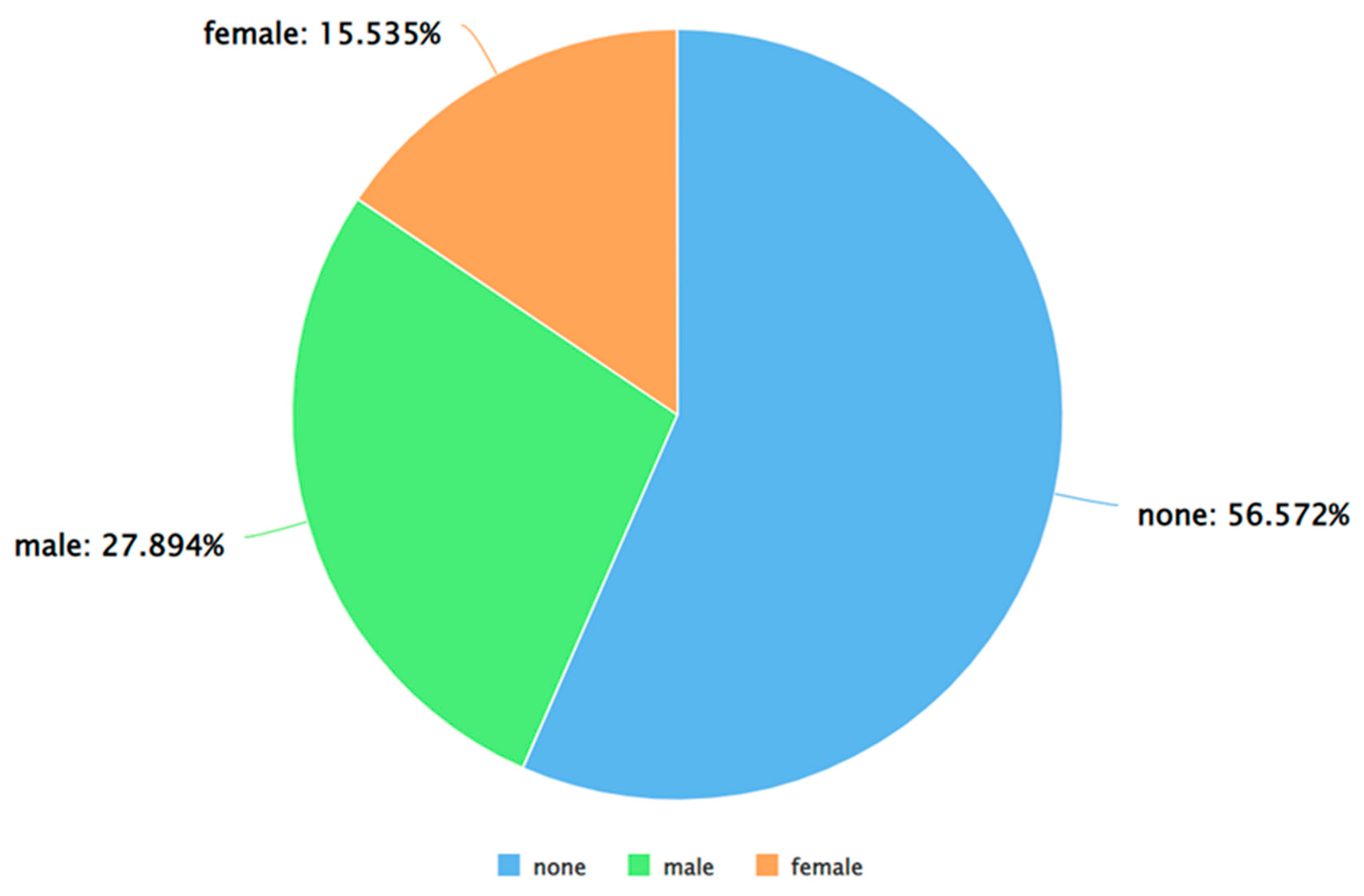
Figure 16.
A pie chart to represent the results of subjectivity analysis using TextBlob.
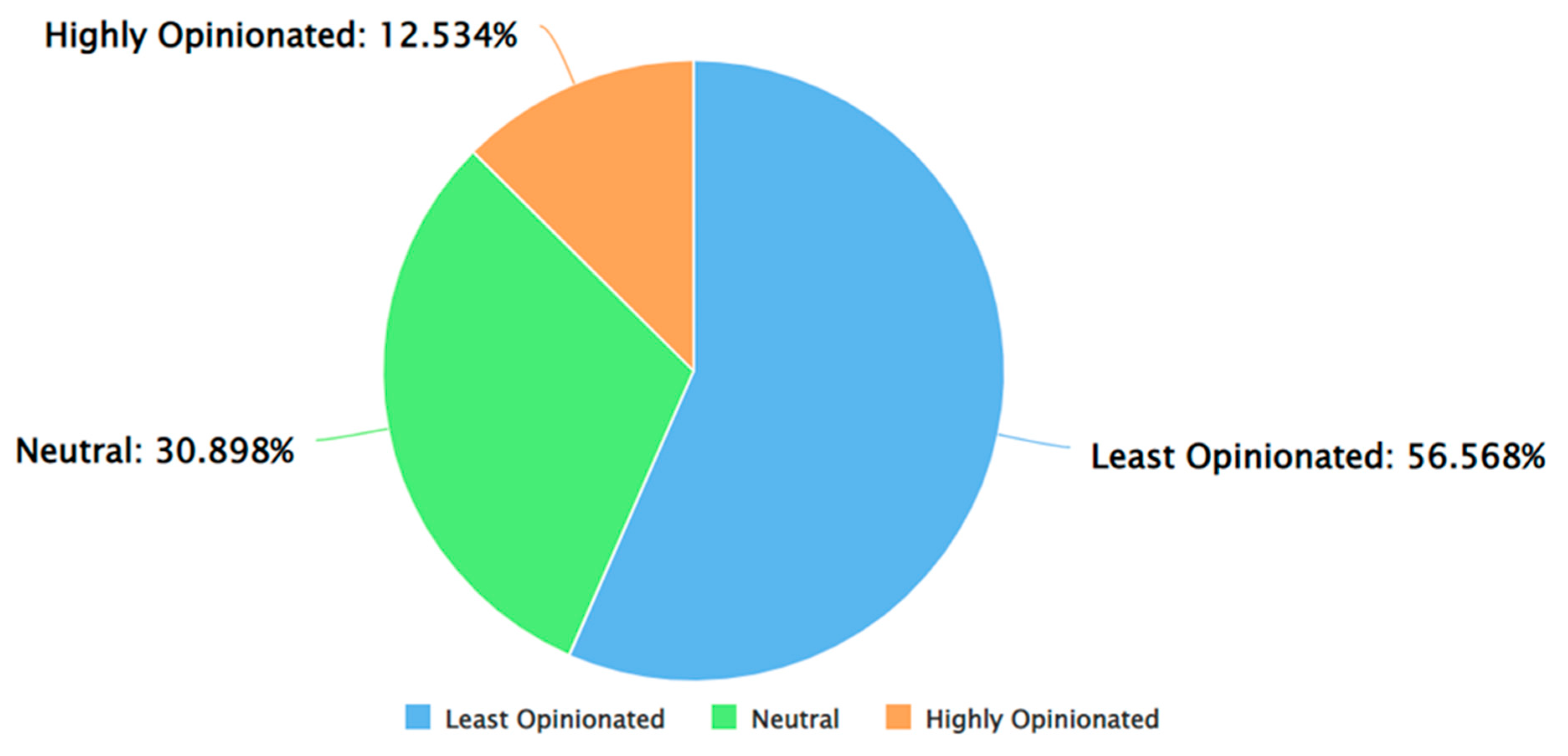
Figure 17.
A pie chart to represent the percentage of highly opinionated tweets (as per TextBlob) posted by each gender.
Figure 17.
A pie chart to represent the percentage of highly opinionated tweets (as per TextBlob) posted by each gender.
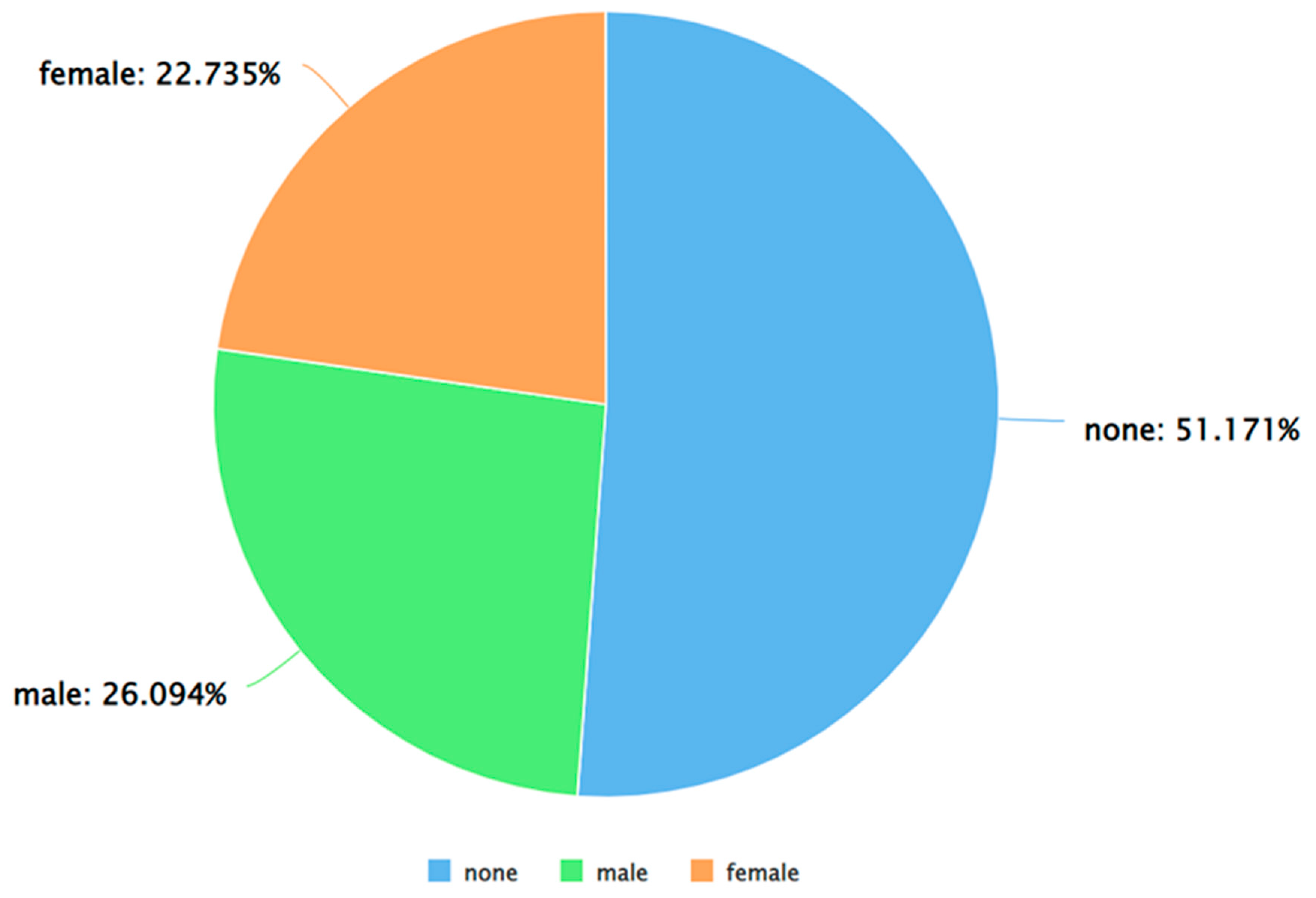
Figure 18.
A pie chart to represent the percentage of least opinionated tweets (as per TextBlob) posted by each gender.
Figure 18.
A pie chart to represent the percentage of least opinionated tweets (as per TextBlob) posted by each gender.
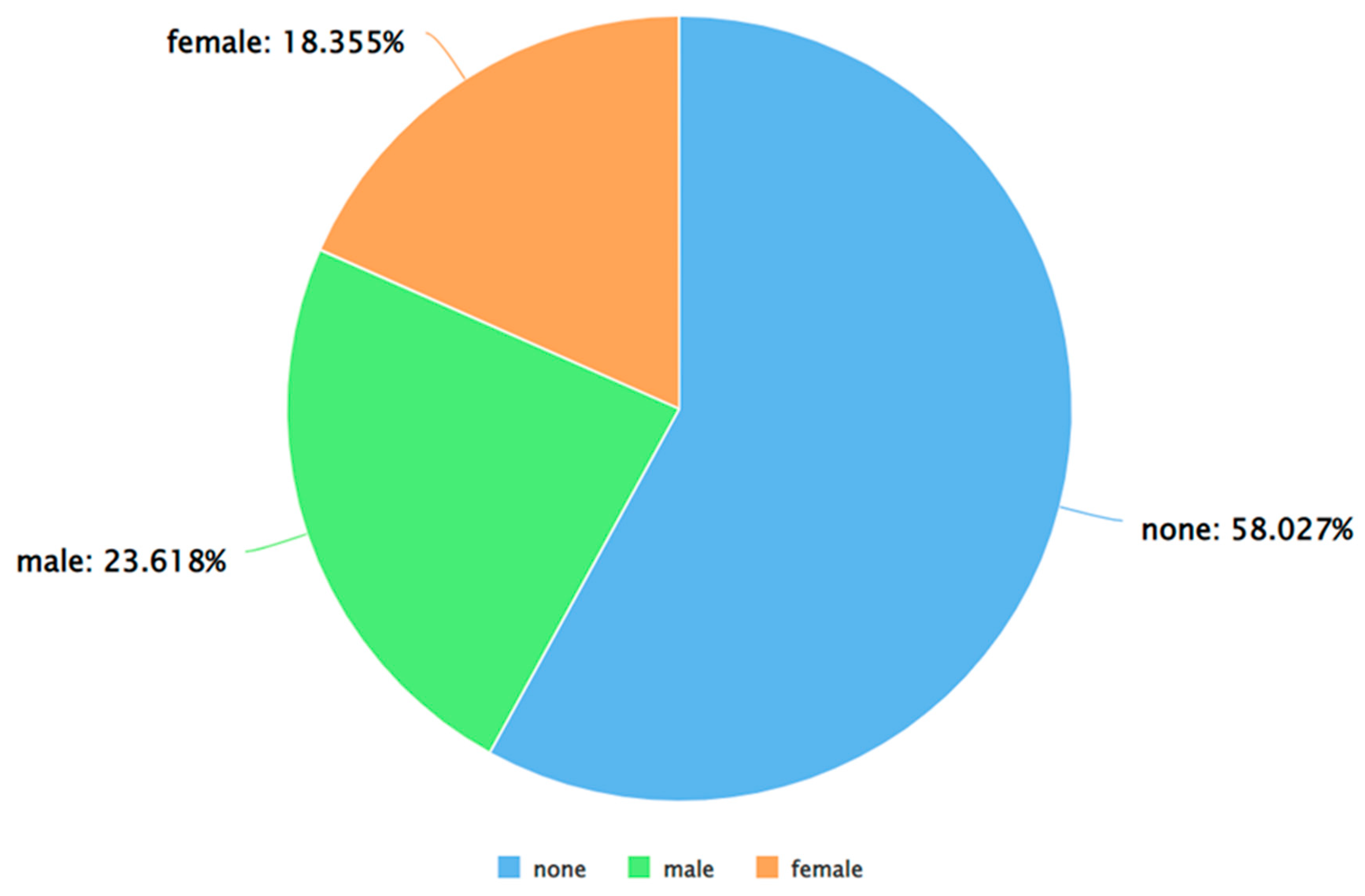
Figure 19.
A pie chart to represent the percentage of tweets for the neutral subjectivity class (as per TextBlob) posted by each gender.
Figure 19.
A pie chart to represent the percentage of tweets for the neutral subjectivity class (as per TextBlob) posted by each gender.
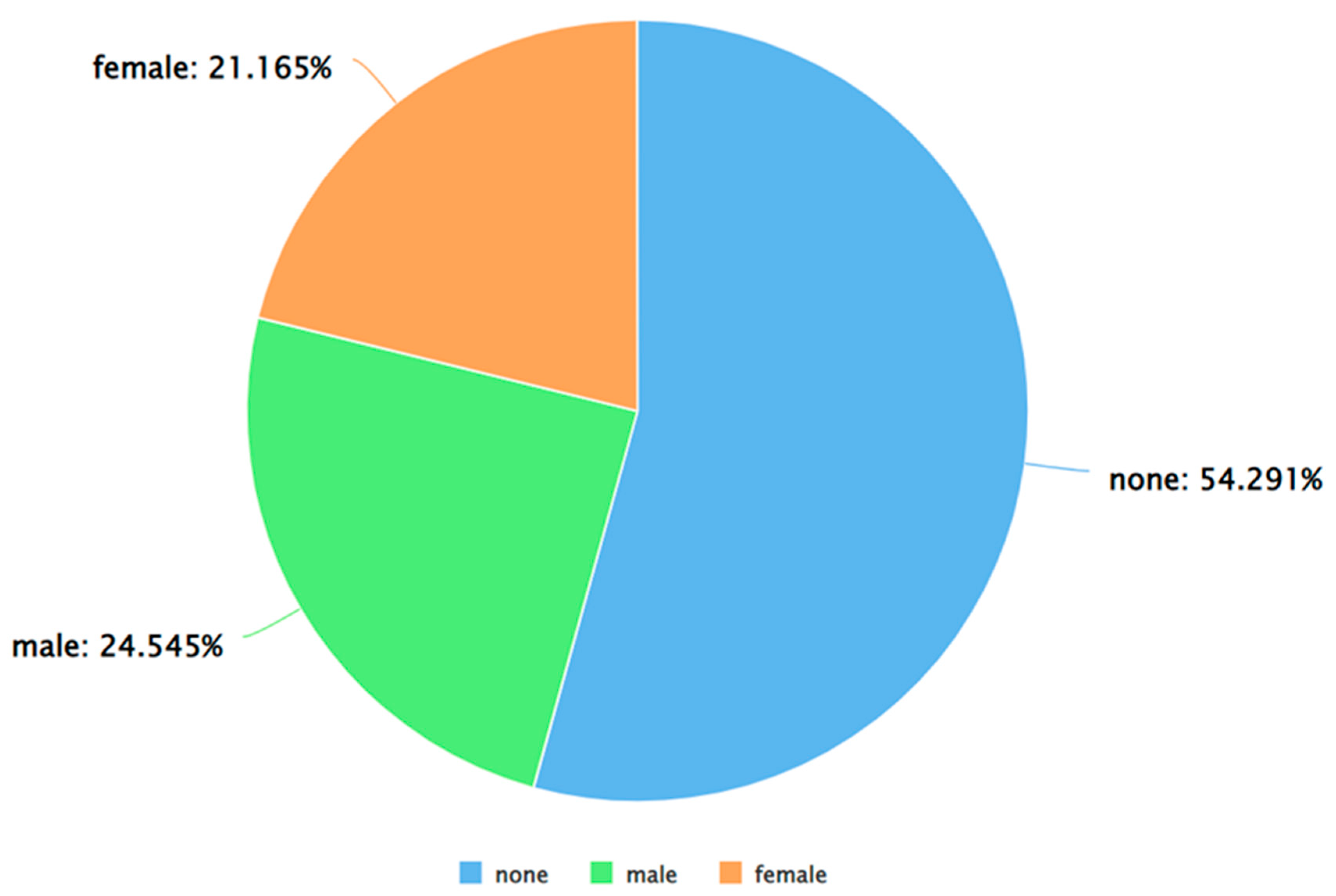
Figure 20.
Representation of the variation of different categories of toxic content present in the tweets.
Figure 20.
Representation of the variation of different categories of toxic content present in the tweets.
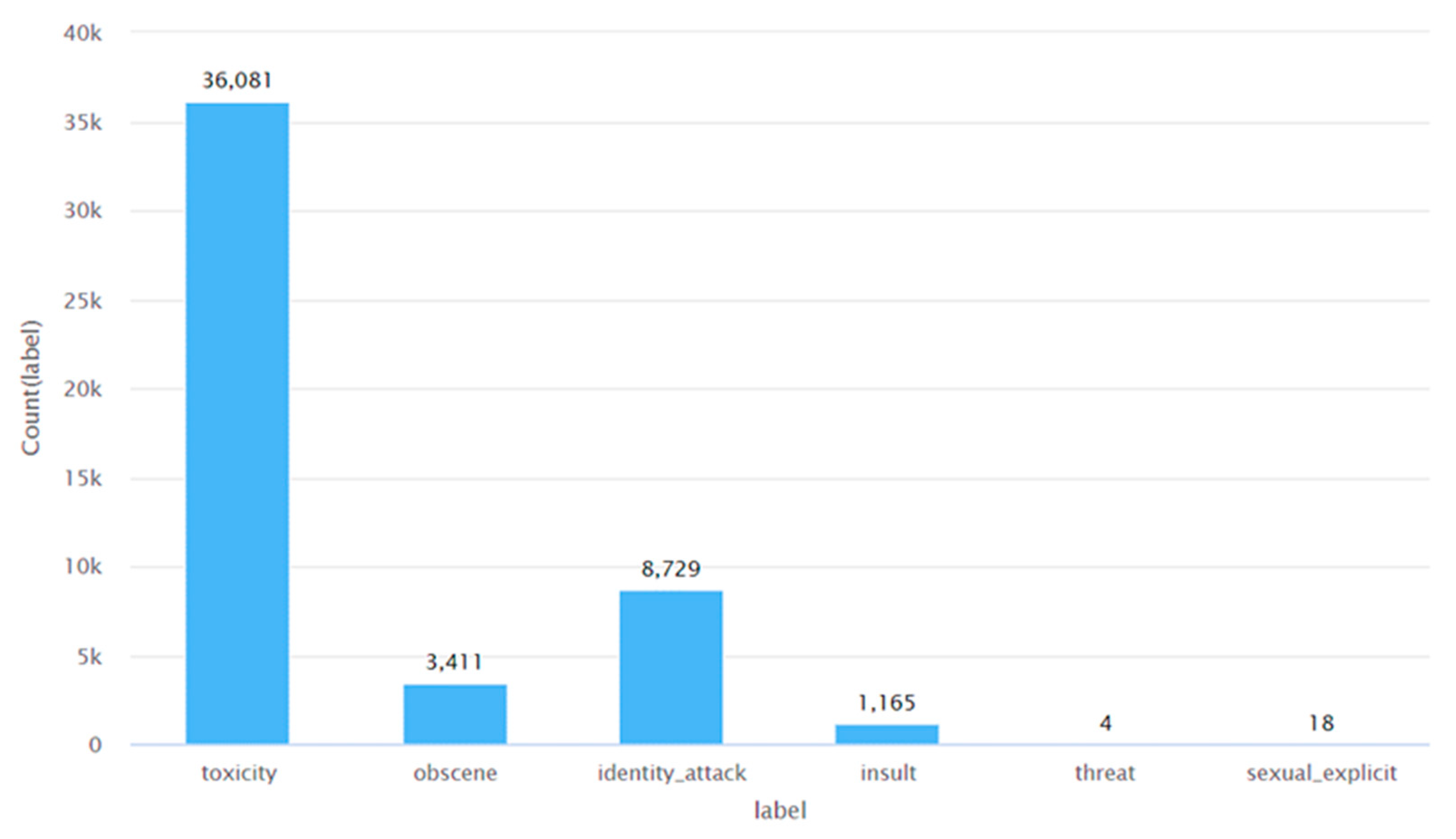
Figure 21.
A pie chart to represent the percentage of tweets for the toxicity class (as per Detoxify) posted by each gender.
Figure 21.
A pie chart to represent the percentage of tweets for the toxicity class (as per Detoxify) posted by each gender.
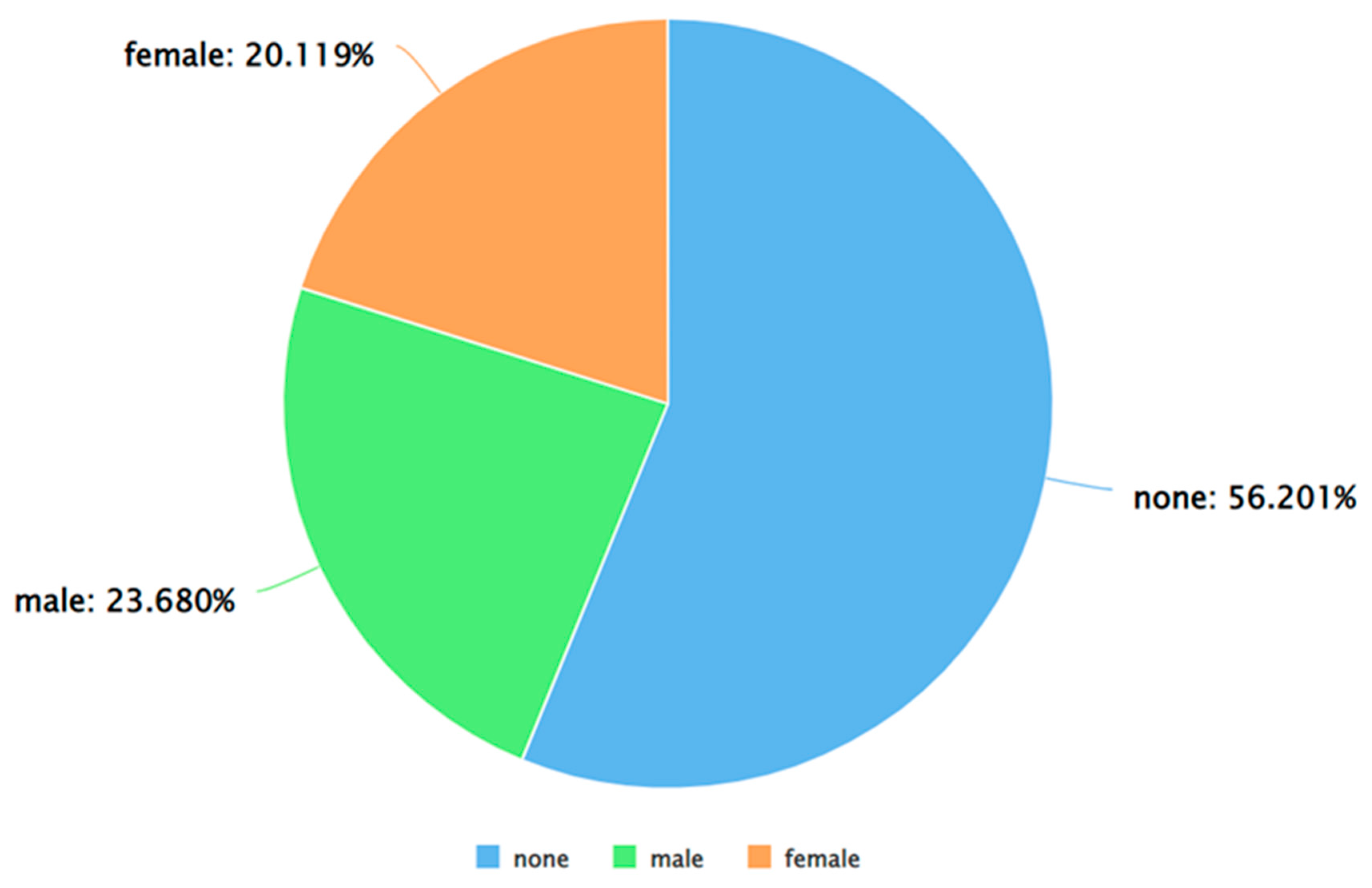
Figure 22.
A pie chart to represent the percentage of tweets for the obscene class (as per Detoxify) posted by each gender.
Figure 22.
A pie chart to represent the percentage of tweets for the obscene class (as per Detoxify) posted by each gender.
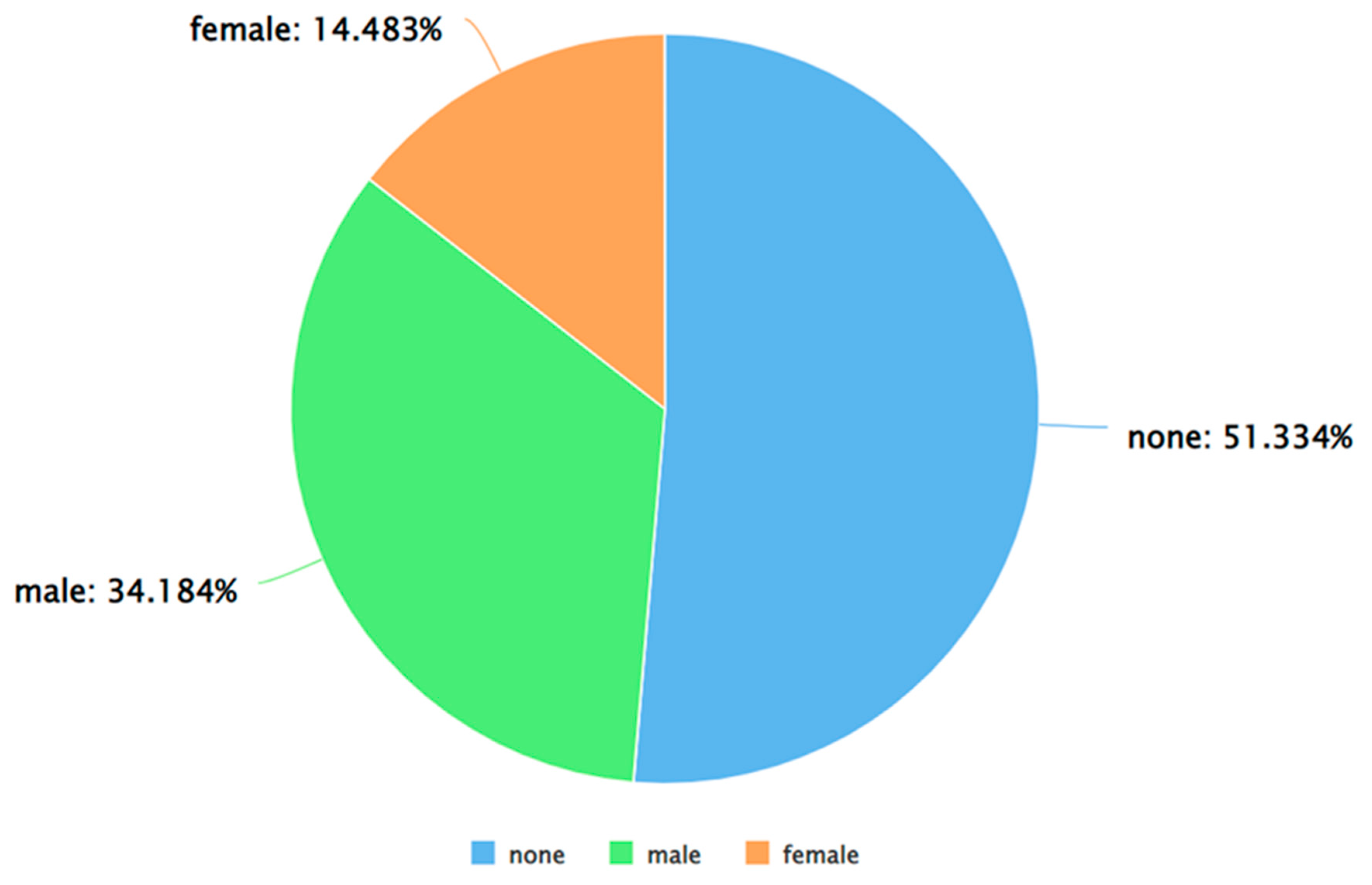
Figure 23.
A pie chart to represent the percentage of tweets for the identity attack class (as per Detoxify) posted by each gender.
Figure 23.
A pie chart to represent the percentage of tweets for the identity attack class (as per Detoxify) posted by each gender.
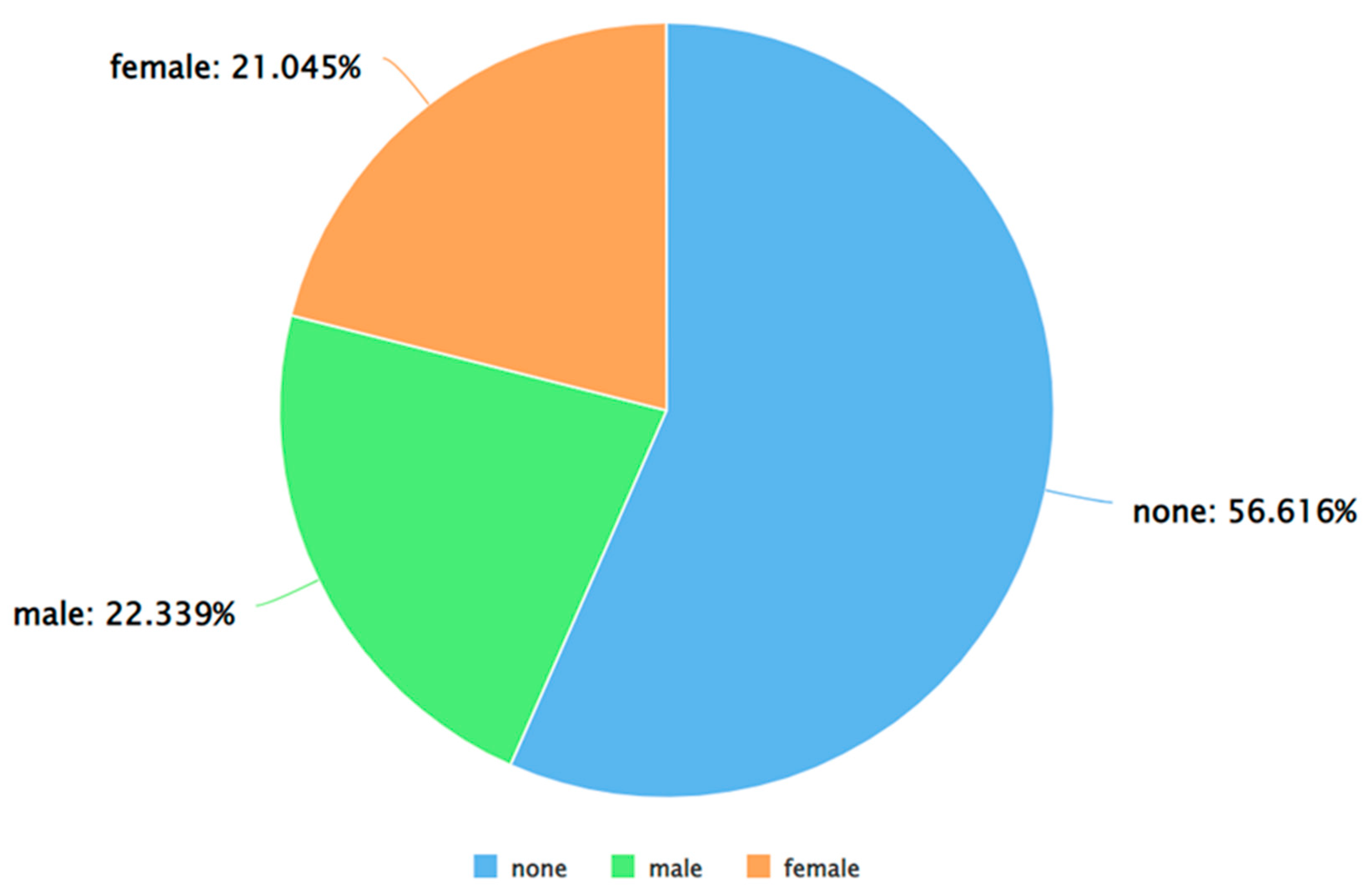
Figure 24.
A pie chart to represent the percentage of tweets for the insult class (as per Detoxify) posted by each gender.
Figure 24.
A pie chart to represent the percentage of tweets for the insult class (as per Detoxify) posted by each gender.
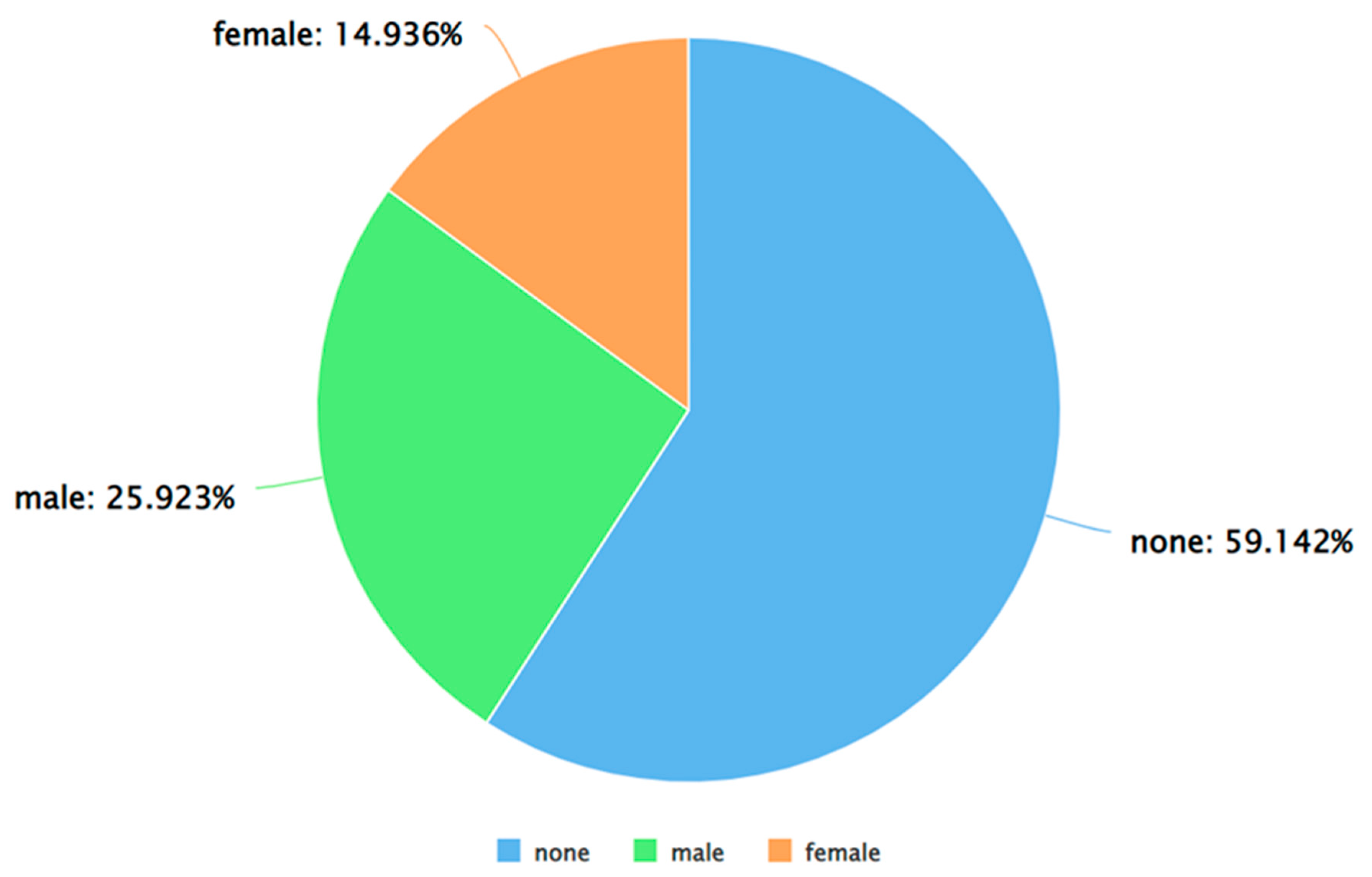
Figure 25.
A pie chart to represent the percentage of tweets for the threat class (as per Detoxify) posted by each gender.
Figure 25.
A pie chart to represent the percentage of tweets for the threat class (as per Detoxify) posted by each gender.
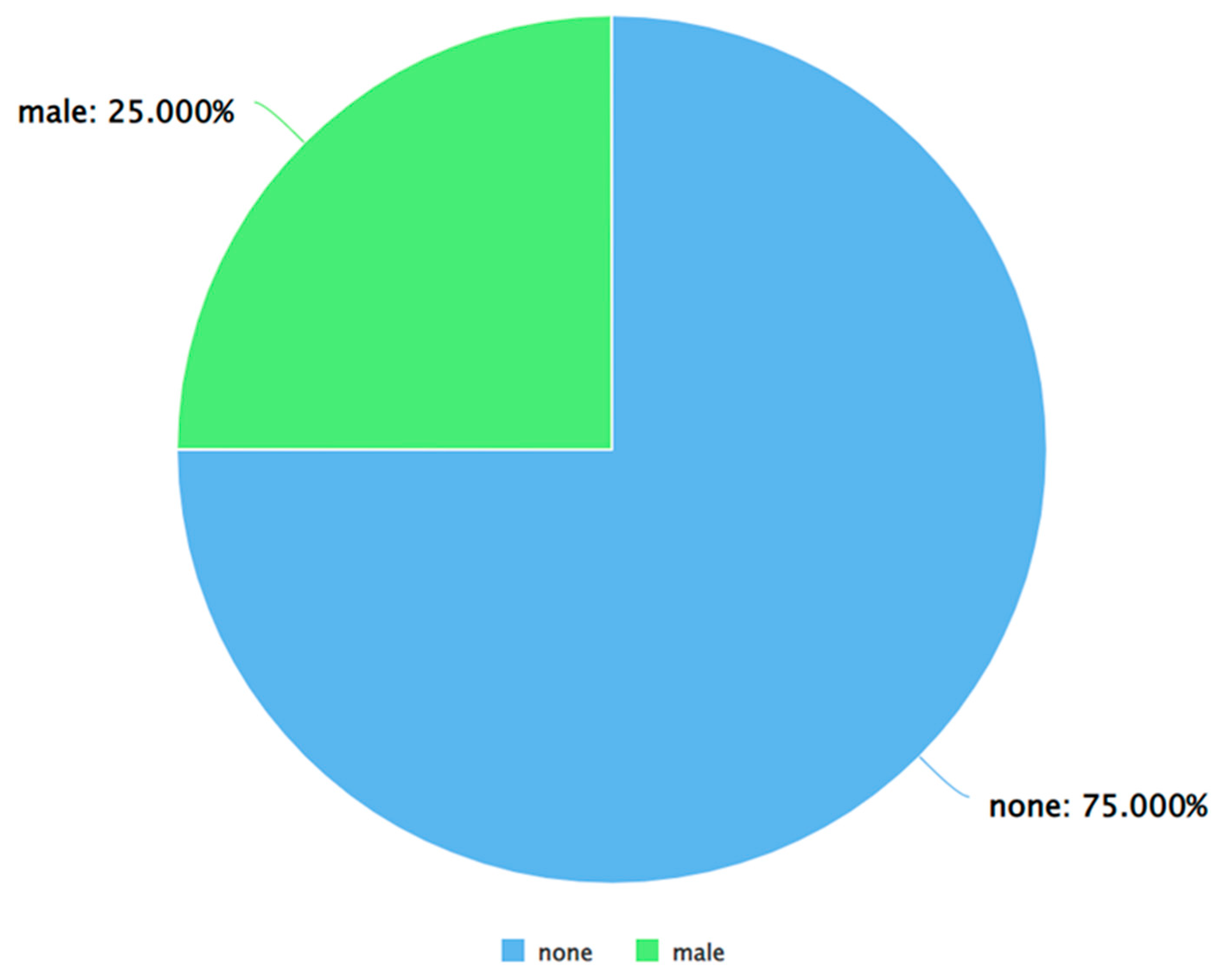
Figure 26.
A pie chart to represent the percentage of tweets for the sexually explicit class (as per Detoxify) posted by each gender.
Figure 26.
A pie chart to represent the percentage of tweets for the sexually explicit class (as per Detoxify) posted by each gender.
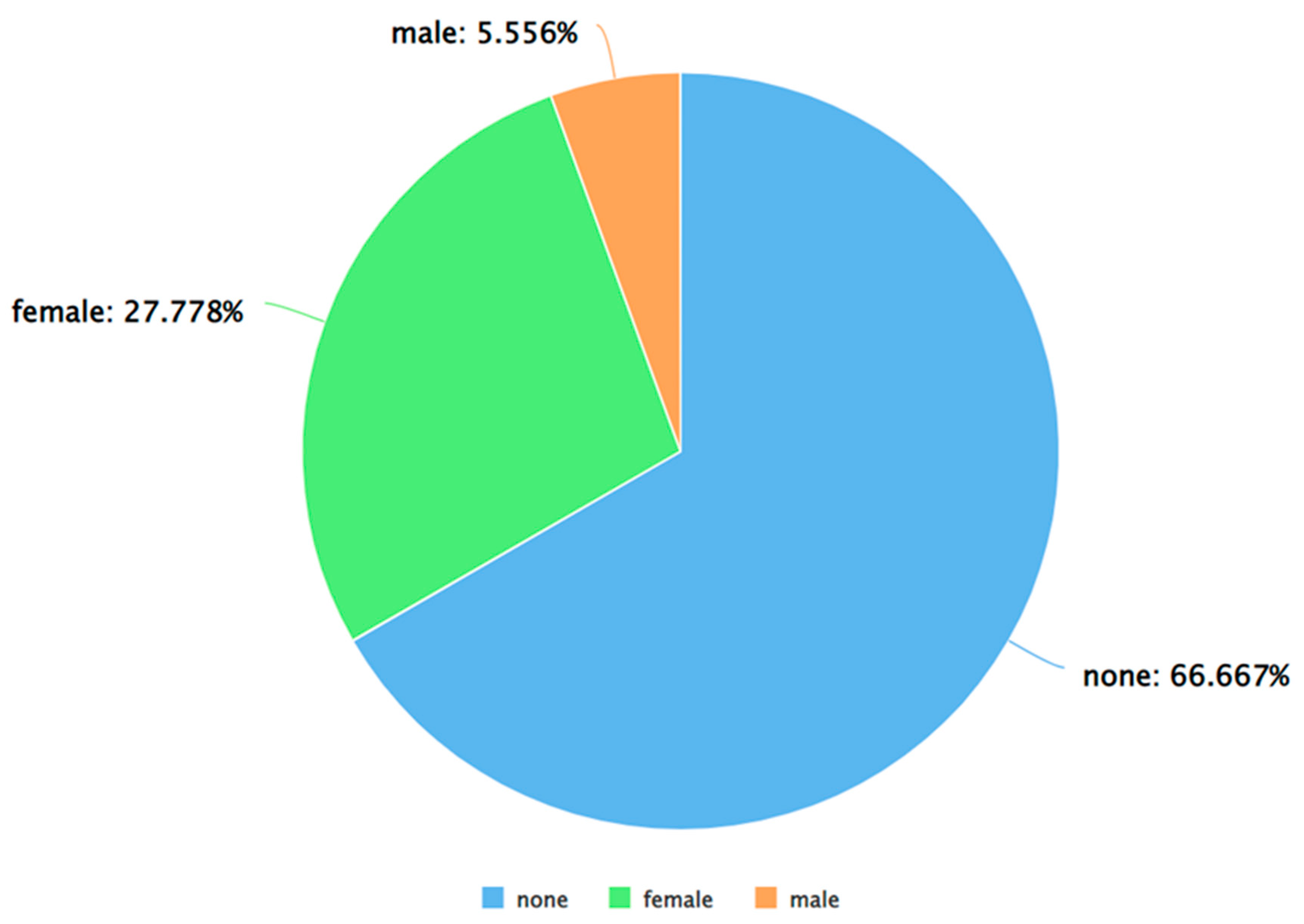
Figure 27.
A word cloud-based representation of the 100 most frequently used in positive tweets.

Figure 28.
A word cloud-based representation of the 100 most frequently used in negative tweets.
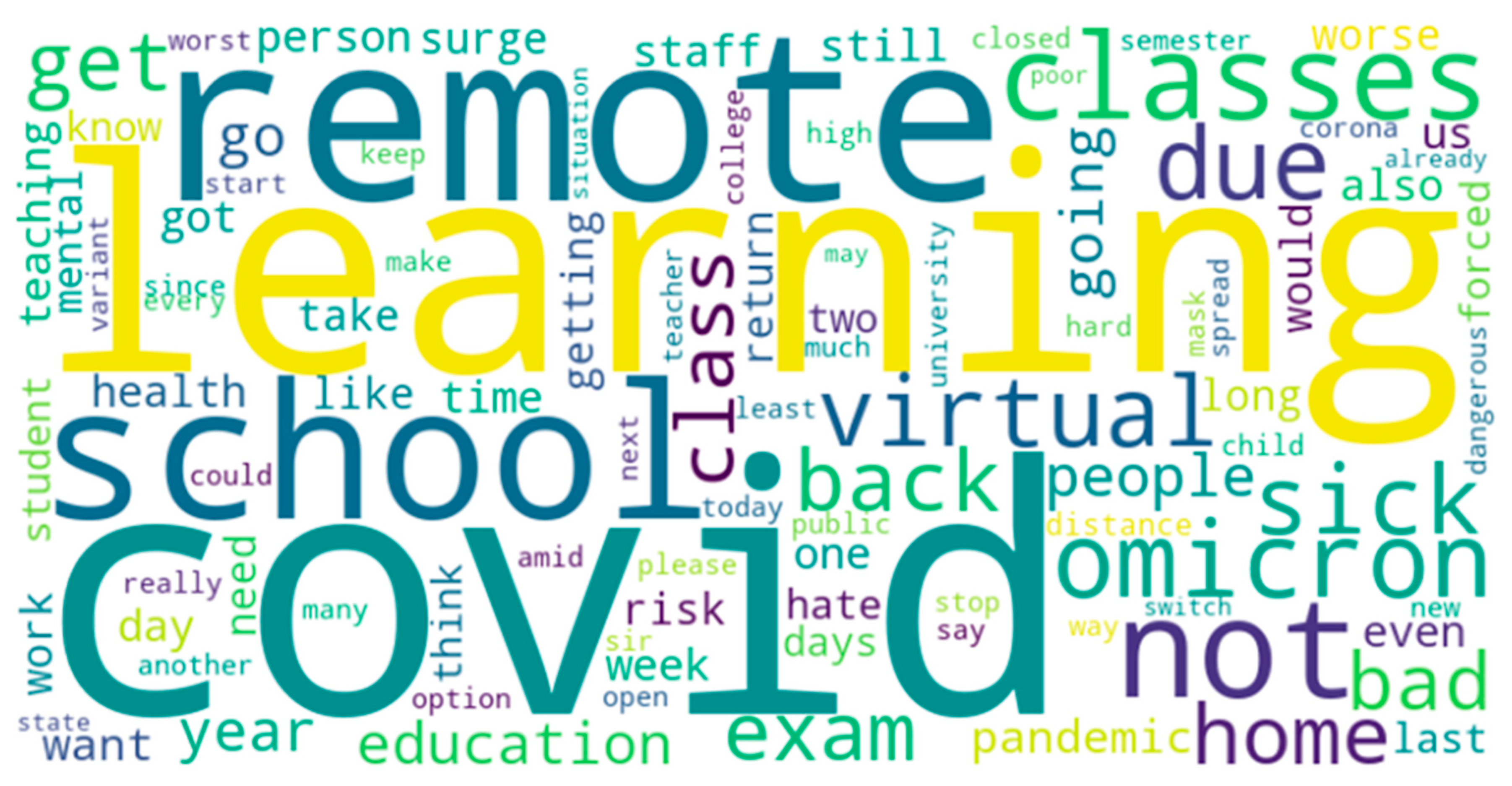
Figure 29.
A word cloud-based representation of the 100 most frequently used in neutral tweets.
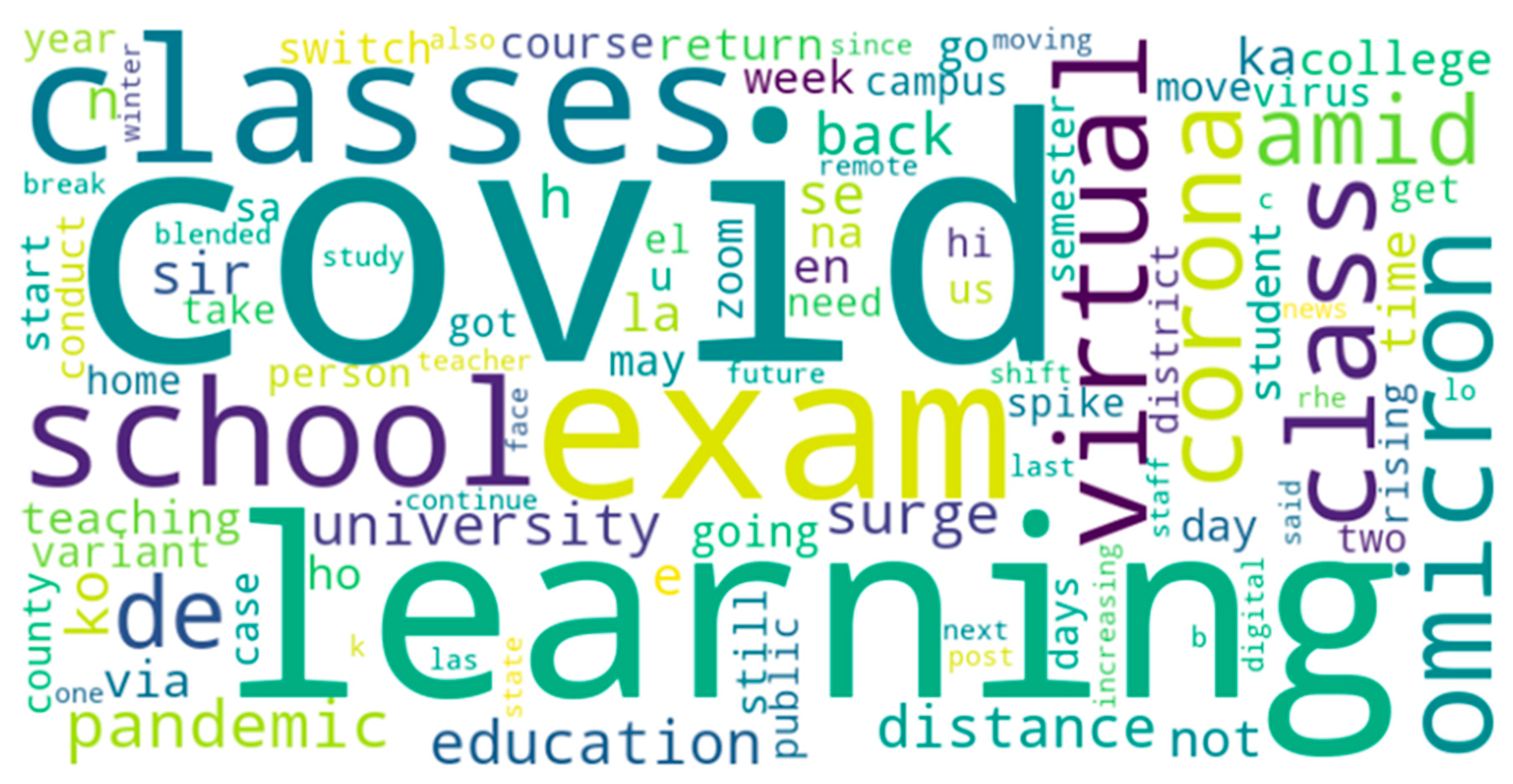
Figure 30.
A word cloud-based representation of the 100 most frequently used words in tweets that were highly opinionated.
Figure 30.
A word cloud-based representation of the 100 most frequently used words in tweets that were highly opinionated.
Figure 31.
A word cloud-based representation of the 100 most frequently used words in tweets that were least opinionated.
Figure 31.
A word cloud-based representation of the 100 most frequently used words in tweets that were least opinionated.
Figure 32.
A word cloud-based representation of the 100 most frequently used words in tweets that were categorized as having a neutral opinion.
Figure 32.
A word cloud-based representation of the 100 most frequently used words in tweets that were categorized as having a neutral opinion.

Figure 33.
A word cloud-based representation of the 100 most frequently used words in tweets that belonged to the toxicity category.
Figure 33.
A word cloud-based representation of the 100 most frequently used words in tweets that belonged to the toxicity category.

Figure 34.
A word cloud-based representation of the 100 most frequently used words in tweets that belonged to the obscene category.
Figure 34.
A word cloud-based representation of the 100 most frequently used words in tweets that belonged to the obscene category.

Figure 35.
A word cloud-based representation of the 100 most frequently used words in tweets that belonged to the identity attack category.
Figure 35.
A word cloud-based representation of the 100 most frequently used words in tweets that belonged to the identity attack category.

Figure 36.
A word cloud-based representation of the 100 most frequently used words in tweets that belonged to the insult category.
Figure 36.
A word cloud-based representation of the 100 most frequently used words in tweets that belonged to the insult category.
Figure 37.
A word cloud-based representation of the 100 most frequently used words in tweets that belonged to the threat category.
Figure 37.
A word cloud-based representation of the 100 most frequently used words in tweets that belonged to the threat category.

Figure 38.
A word cloud-based representation of the 100 most frequently used words in tweets that belonged to the threat category.
Figure 38.
A word cloud-based representation of the 100 most frequently used words in tweets that belonged to the threat category.

Figure 39.
A graphical representation of the variation of the intensities of different categories of toxic content on a monthly basis.
Figure 39.
A graphical representation of the variation of the intensities of different categories of toxic content on a monthly basis.
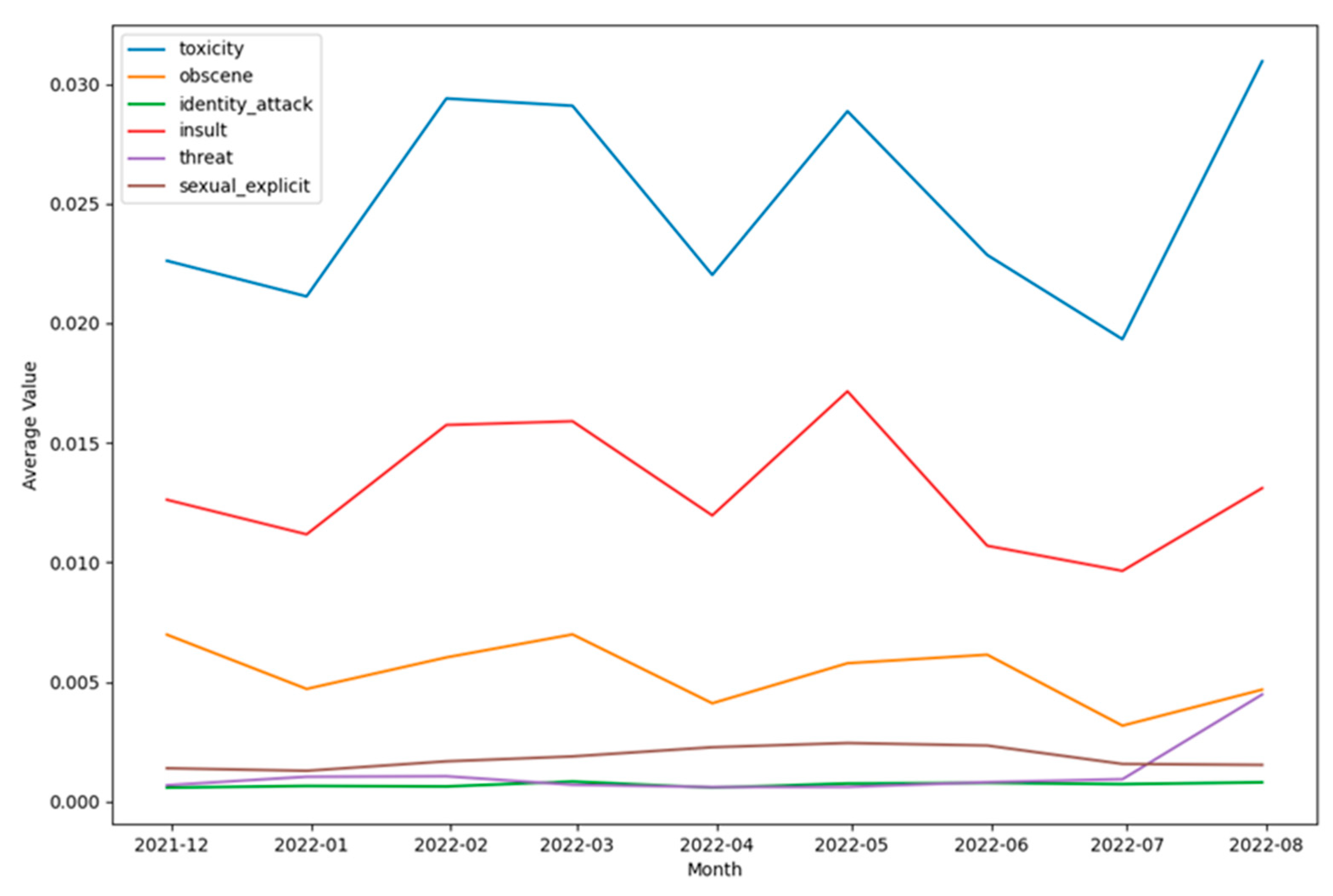
Figure 40.
A graphical representation of the variation of the intensity of toxicity on a monthly basis by different genders.
Figure 40.
A graphical representation of the variation of the intensity of toxicity on a monthly basis by different genders.
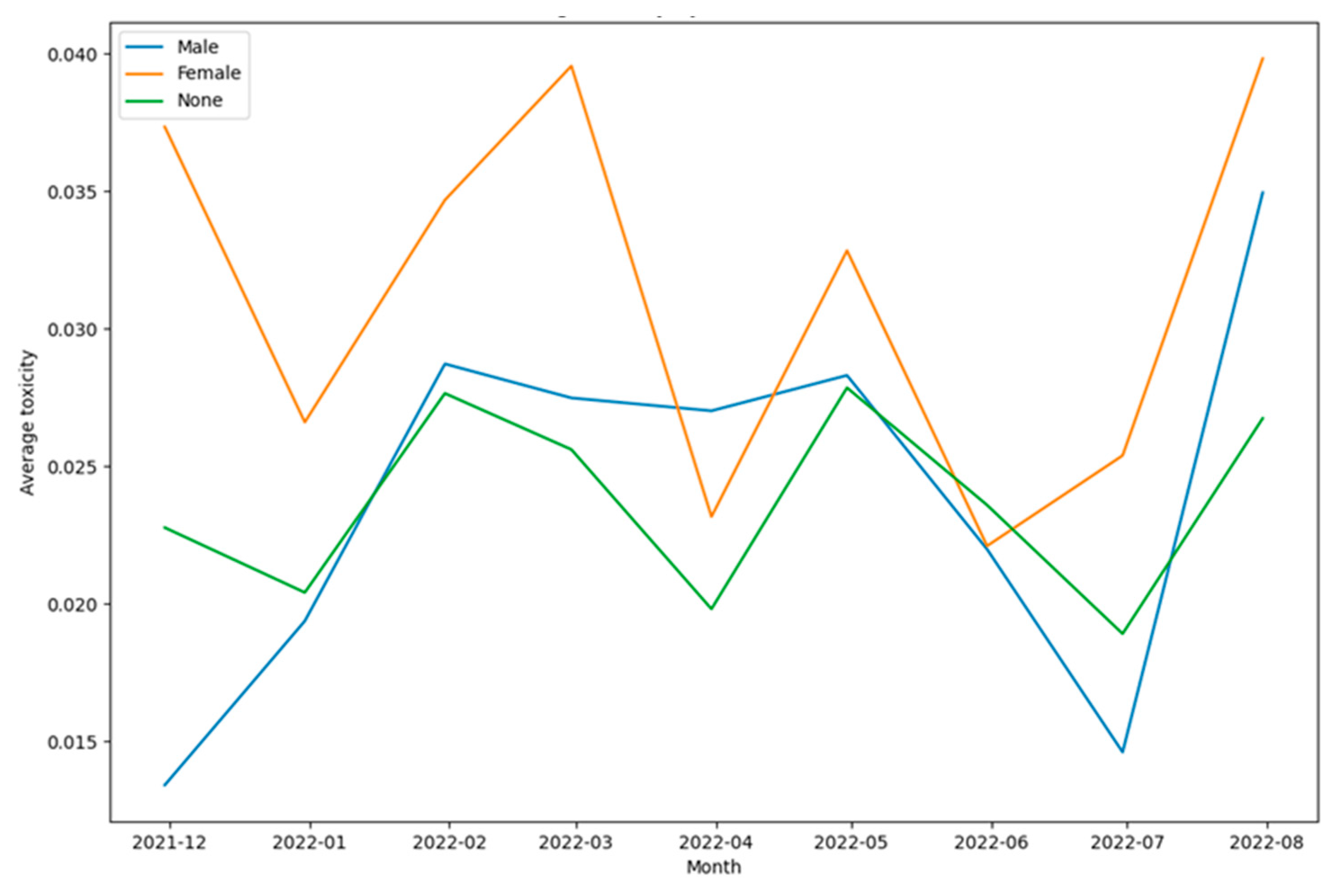
Figure 41.
A graphical representation of the variation of the intensity of obscene content on a monthly basis by different genders.
Figure 41.
A graphical representation of the variation of the intensity of obscene content on a monthly basis by different genders.
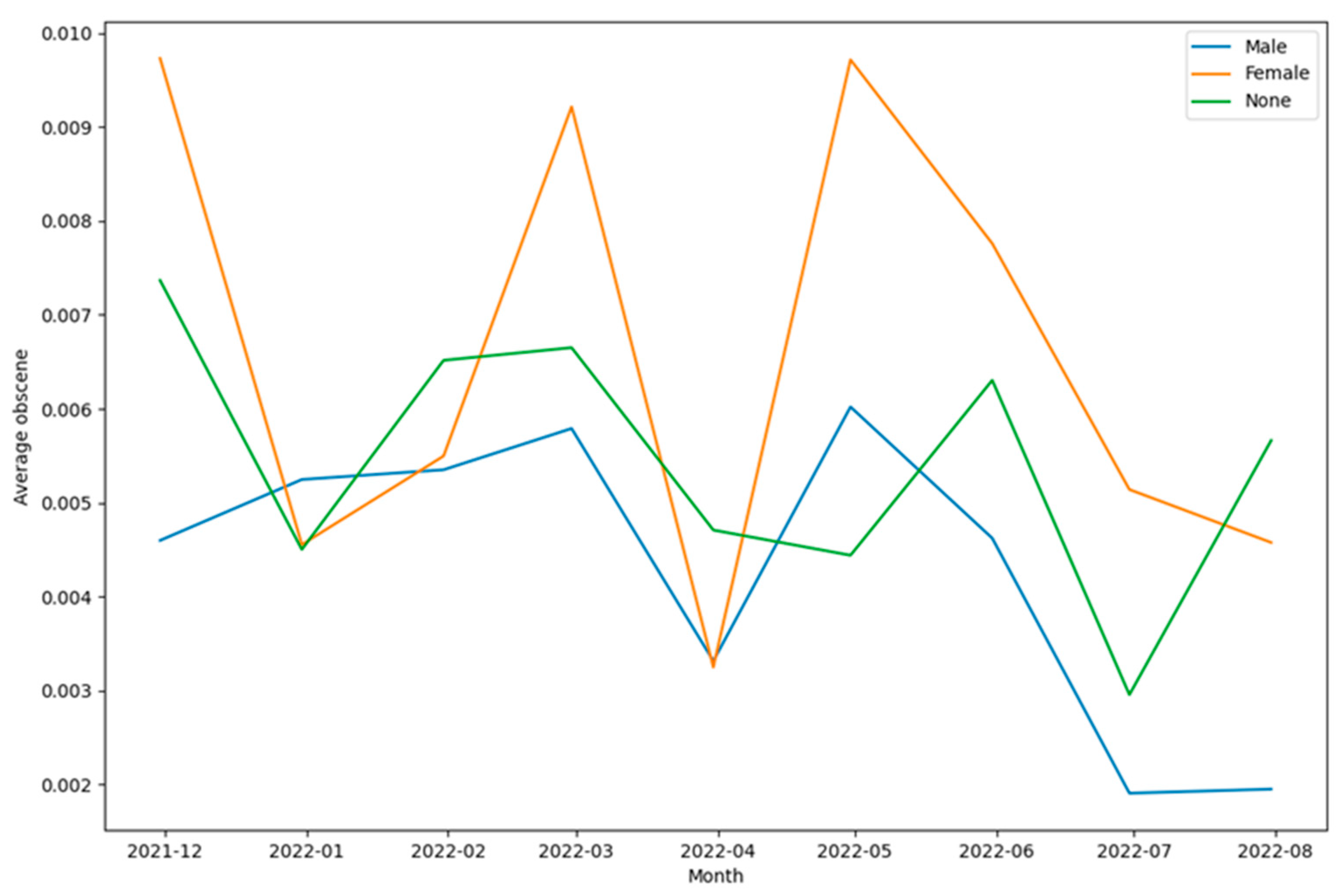
Figure 42.
A graphical representation of the variation of the intensity of identity attacks on a monthly basis by different genders.
Figure 42.
A graphical representation of the variation of the intensity of identity attacks on a monthly basis by different genders.
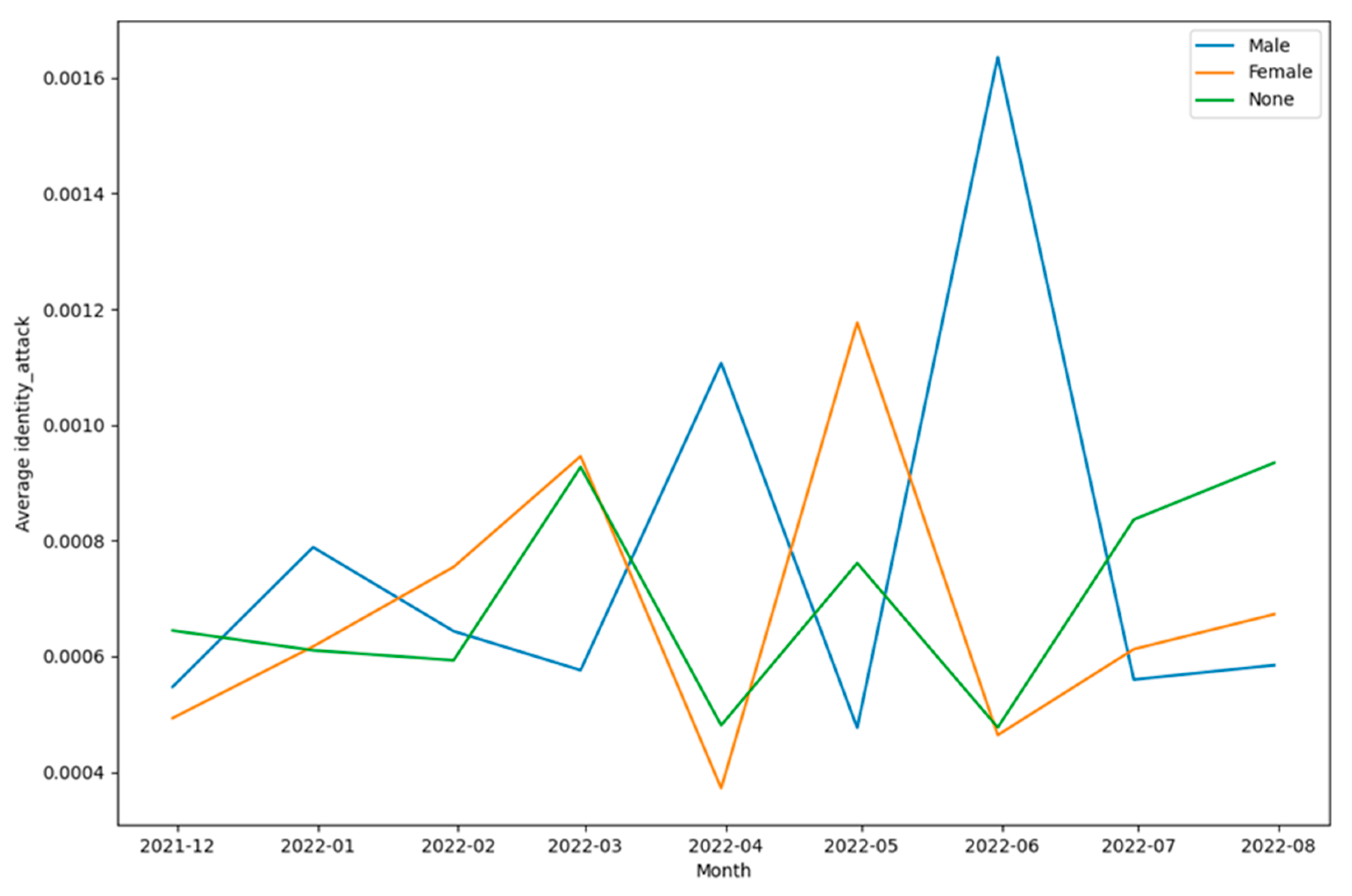
Figure 43.
A graphical representation of the variation of the intensity of insult on a monthly basis by different genders.
Figure 43.
A graphical representation of the variation of the intensity of insult on a monthly basis by different genders.
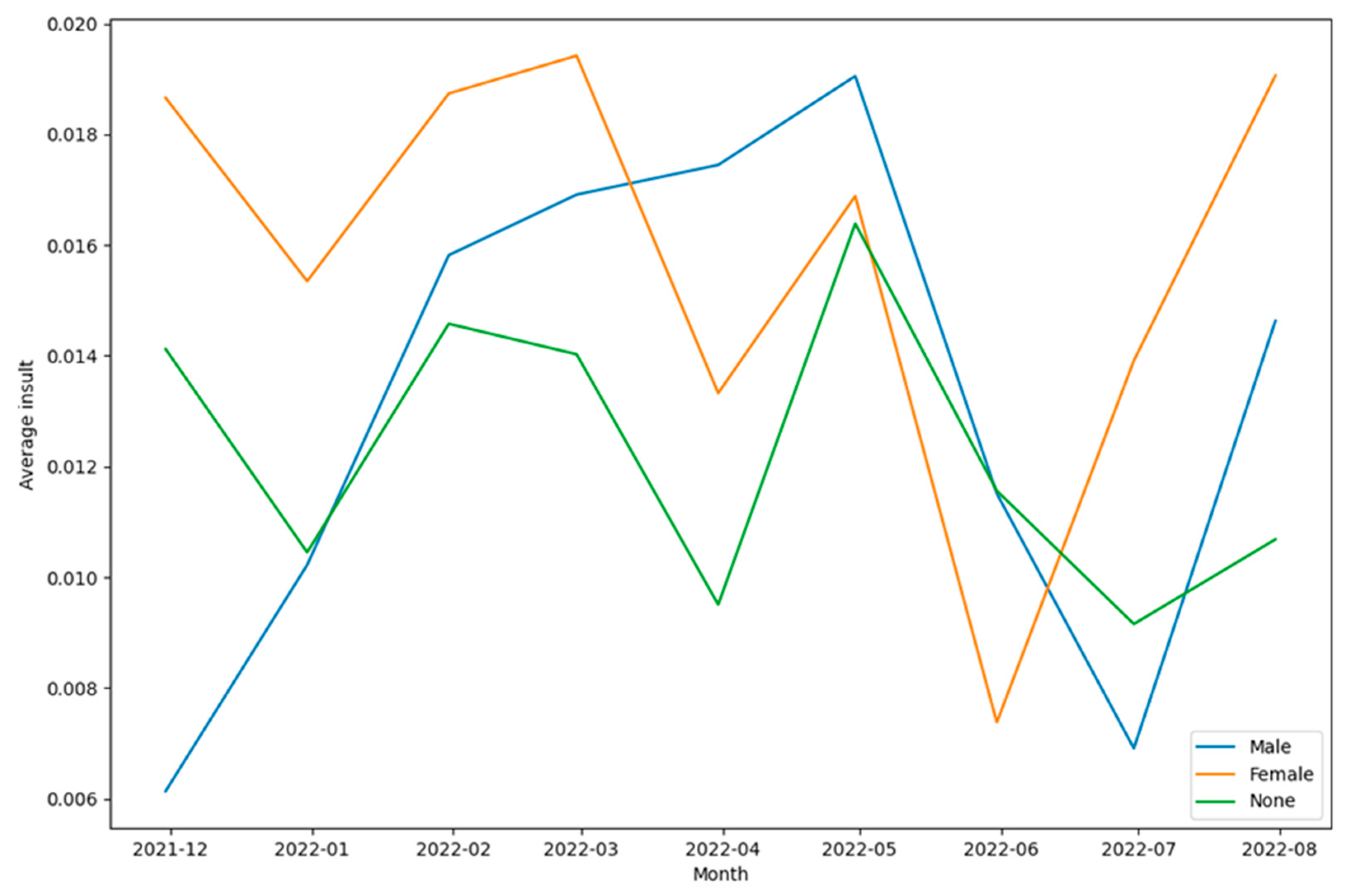
Figure 44.
A graphical representation of the variation of the intensity of threat on a monthly basis by different genders.
Figure 44.
A graphical representation of the variation of the intensity of threat on a monthly basis by different genders.
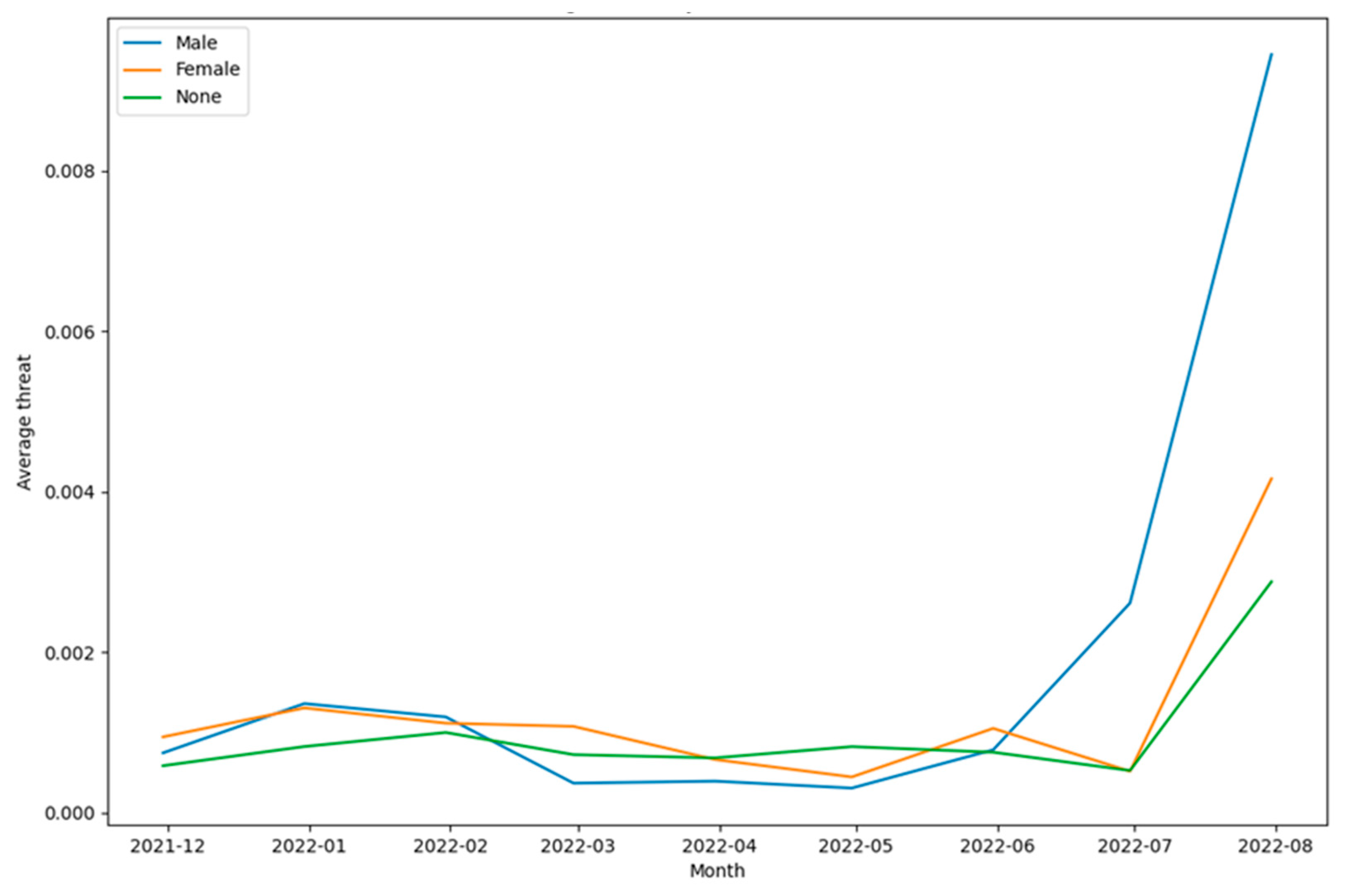
Figure 45.
A graphical representation of the variation of the intensity of sexually explicit content on a monthly basis by different genders.
Figure 45.
A graphical representation of the variation of the intensity of sexually explicit content on a monthly basis by different genders.
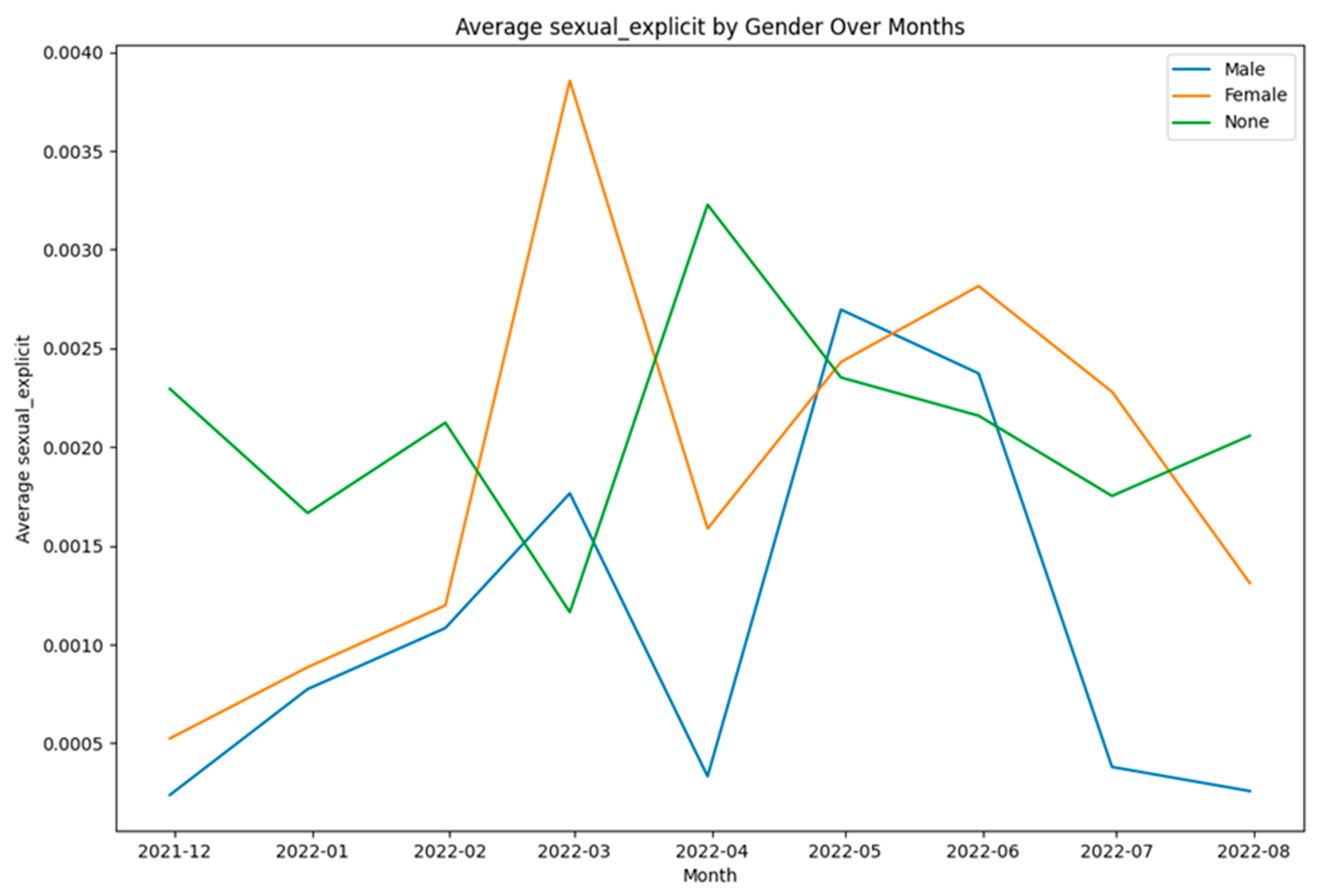
Figure 46.
A graphical representation of the variation of the average activity on twitter (in the context of tweeting about online learning during COVID-19) on a monthly basis.
Figure 46.
A graphical representation of the variation of the average activity on twitter (in the context of tweeting about online learning during COVID-19) on a monthly basis.
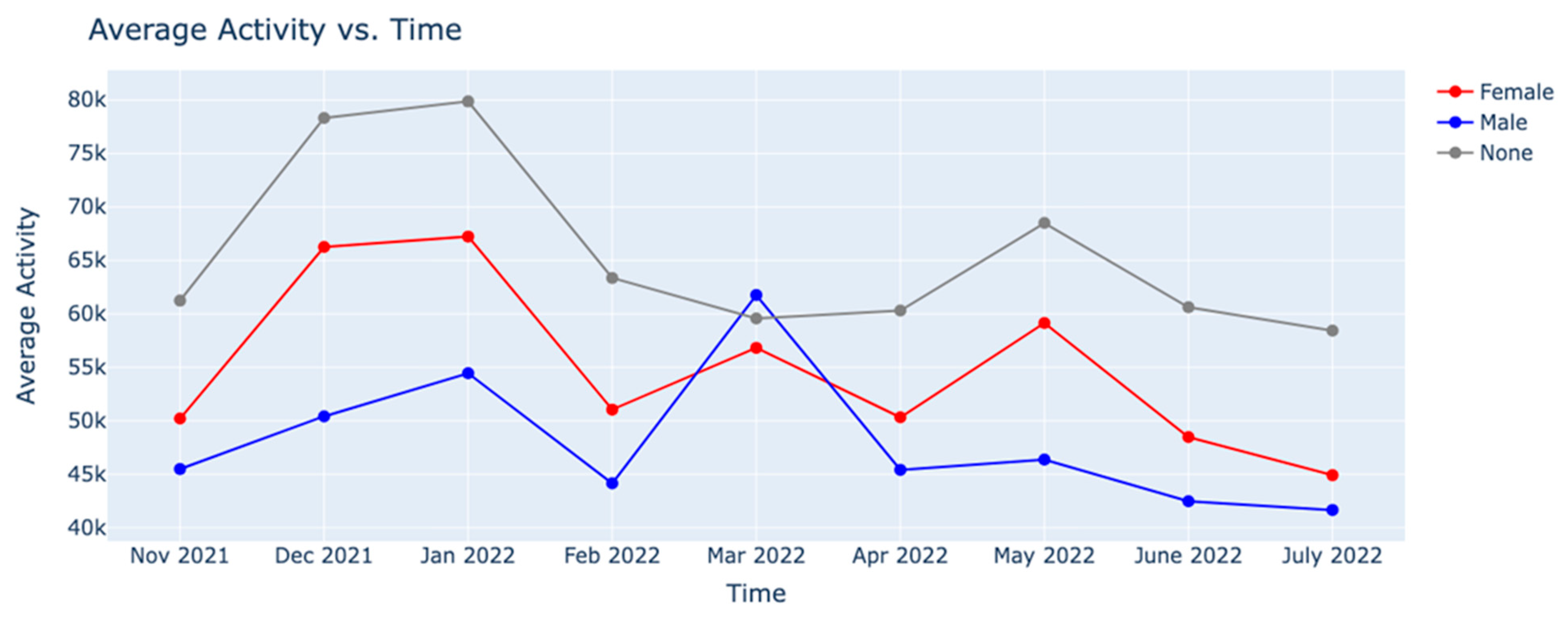
Figure 47.
Representation of the trends in tweets about online learning during COVID-19 posted by males from different countries of the world.
Figure 47.
Representation of the trends in tweets about online learning during COVID-19 posted by males from different countries of the world.
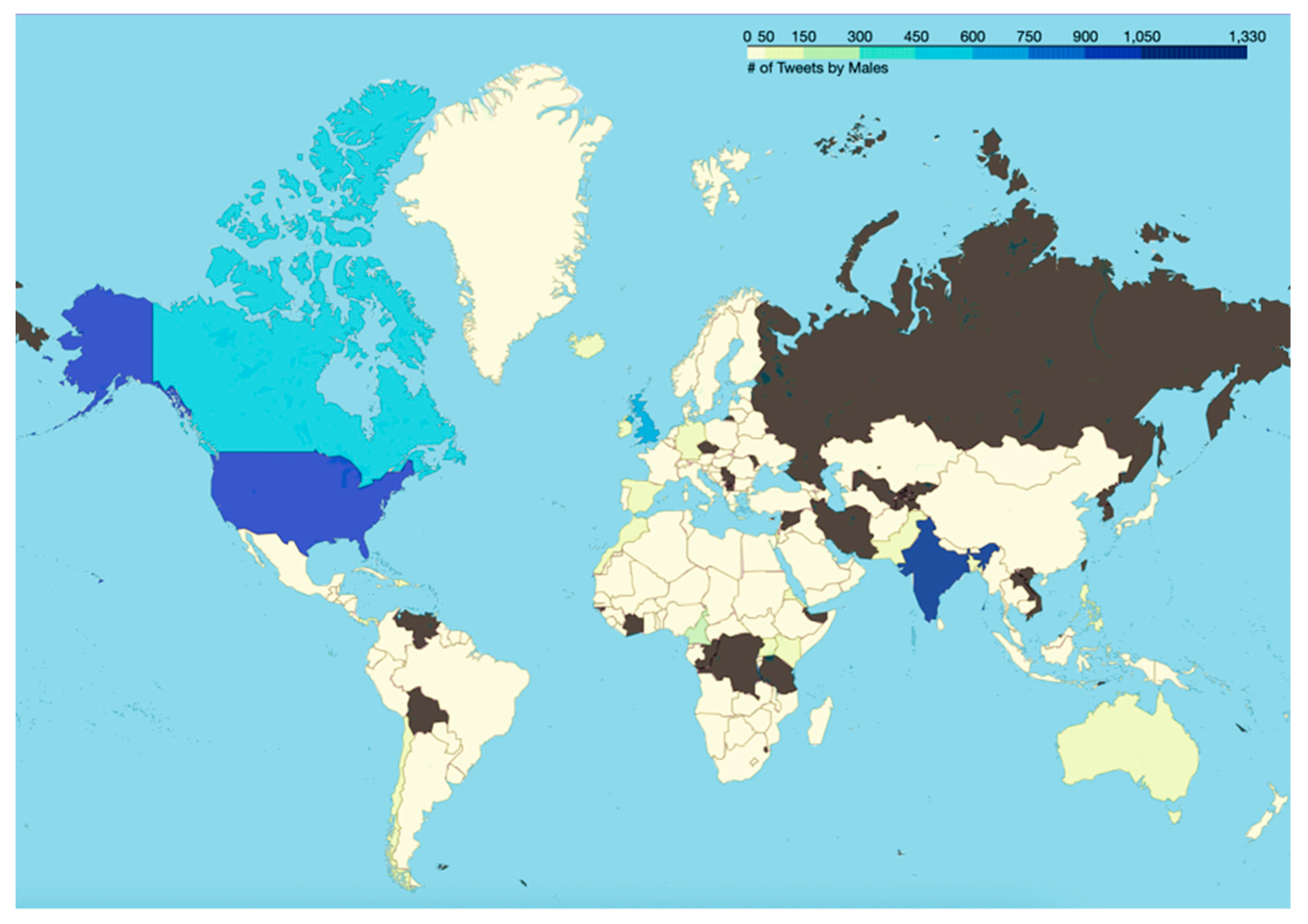
Figure 48.
Representation of the trends in tweets about online learning during COVID-19 posted by females from different countries of the world.
Figure 48.
Representation of the trends in tweets about online learning during COVID-19 posted by females from different countries of the world.
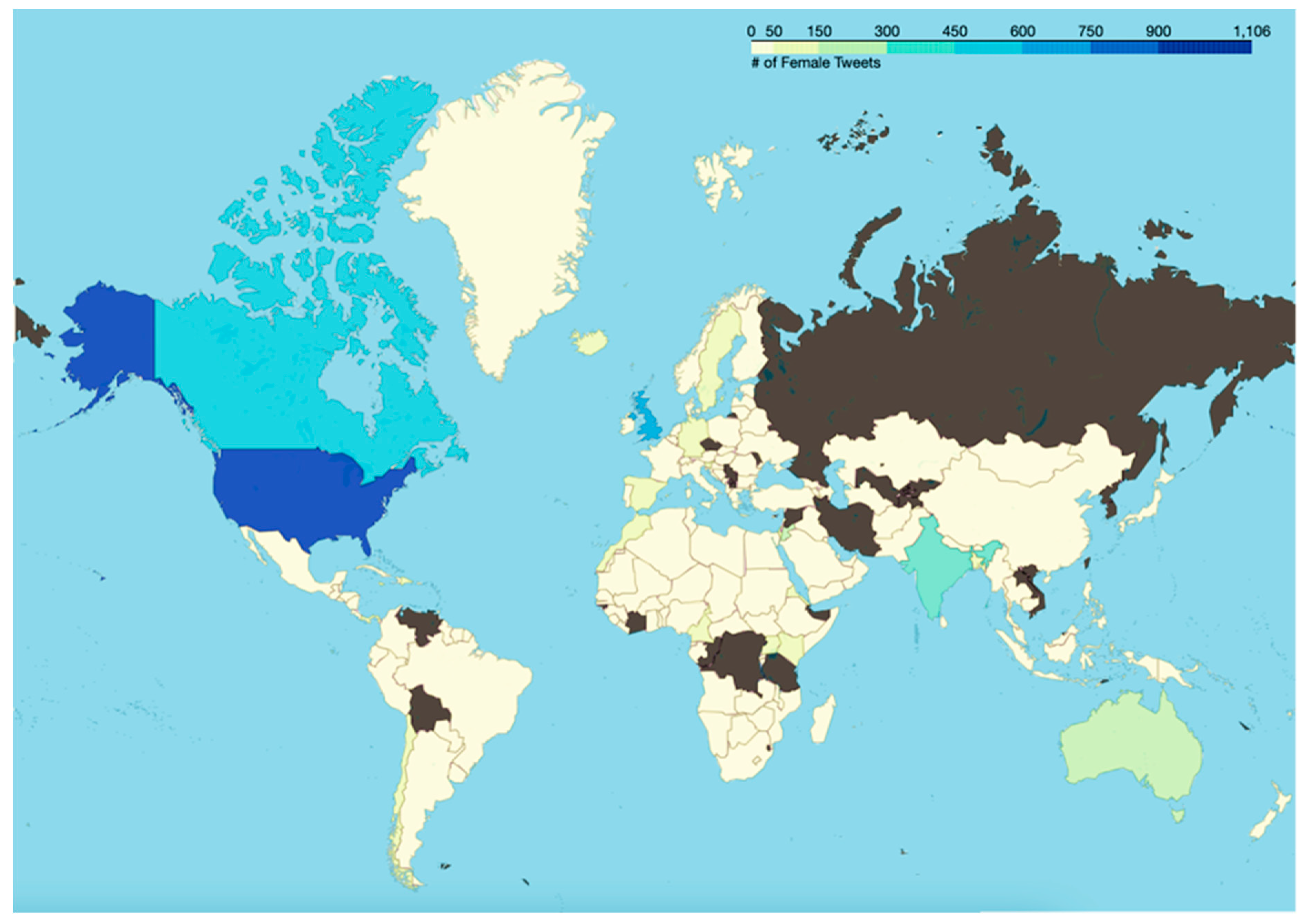

Table 1.
Gender Diversity in Different Social Media Platforms.
| Social Media Platform | Percentage of Male Users | Percentage of Female Users |
|---|---|---|
| 63 | 37 | |
| Instagram Tumblr Quora Telegram Sina Weibo SnapChat |
51.8 52 53.2 53.5 55 56.3 57.2 58.6 51 51.7 48.2 |
48.2 48 46.7 46.5 45 43.7 42.8 41.4 49 48.3 51 |
Table 2.
A comparative study of this work with prior works in this field in terms of focus areas.
| Work | Text Analysis of Tweets about Online Learning during COVID-19 | Sentiment Analysis of Tweets about Online Learning during COVID-19 | Analysis of types of toxic content in Tweets about Online Learning during COVID-19 | Subjectivity Analysis of Tweets about Online Learning during COVID-19 |
|---|---|---|---|---|
| Sahir et al. [20] | ✓ | |||
| Althagafi et al. [21] | ✓ | |||
| Ali et al. [22] | ✓ | ✓ | ||
| Alcober et al. [23] | ✓ | |||
| Remali et al. [24] | ✓ | |||
| Senadhira et al. [25] | ✓ | ✓ | ||
| Lubis et al. [26] | ✓ | ✓ | ||
| Arambepola [27] | ✓ | ✓ | ||
| Isnain et al. [28] | ✓ | ✓ | ||
| Aljabri et al. [29] | ✓ | ✓ | ||
| Asare et al. [30] | ✓ | ✓ | ✓ | |
| Mujahid et al. [31] | ✓ | ✓ | ||
| Al-Obeidat et al. [32] | ✓ | |||
| Waheeb et al. [33] | ✓ | ✓ | ||
| Rijal et al. [34] | ✓ | |||
| Martinez [36] | ✓ | |||
|
Thakur et al. [this work] |
✓ | ✓ | ✓ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



