
Submitted:
20 October 2023
Posted:
23 October 2023
You are already at the latest version
Abstract
Abstract—Online learning platforms provide diverse course resources, but this often result in the issue of information overload. Learners always want to learn courses that are appropriate for their knowledge level and preferences quickly and accurately. Effective course recommendation plays a key role in helping learners select appropriate courses and improving the efficiency of online learning. However, when a user is enrolled in multiple courses, Existing course recommendation methods face the challenge in accurately recommending the target course that is most relevant to the user, because of the noise courses. In this paper, we propose a novel reinforcement learning model named Actor-Critic Hierarchical Reinforcement Learning (ACHRL). The model incorporates the Actor-Critic method to construct the profile reviser. This can remove noise courses and make personalized course recommendation effectively. Furthermore, we propose a policy gradient based on temporal difference error to reduce the variance in the training process, to speed up the convergence of the model, and improves the accuracy of the recommendation. We evaluate the proposed model on two real datasets, and the experimental results show that the proposed model is significantly outperforms the existing recommendation models (improving 3.77% to 13.66% in terms of HR@5).
Keywords:
course recommendation
; actor-critic method
; hierarchical reinforcement learning method
; policy gradient method
1. Introduction
With the reform of traditional education methods, online course education has been developing rapidly. Massive open online courses (MOOCs) have become the most important platform for online education [1]. Worldwide, various MOOC platforms such as Coursera and edX have emerged, extending access to courses from prestigious universities to millions of students. In China, XuetangX has risen as one of the largest MOOC platforms, offering thousands of courses and attracting a substantial user base [2]. The evolution of MOOC platforms has disrupted the conventional offline teaching approach of traditional education [3,4,5,6]. This transformation not only addresses the issue of unequal distribution of educational resources but also offers users the convenience of flexible learning. Nevertheless, this proliferation of online courses and the constant evolution of knowledge pose a new challenge in the form of information overload for MOOC platforms [7,8,9]. In a new domain, users are often confused when facing the massive content, and they cannot find the courses that are really suitable for them quickly. Now, The primary challenge is whether the learners' records of their learning can be analyzed and utilized effectively, recommend suitable target courses to them.
Course recommendation [10,11,12,13,14] is an effective approach to tackle this challenge [15]. The formalized definition of the course recommendation is: When presented with a set of historical courses that users enrolled in before time t, our goal is to recommend the most relevant courses that the user will enroll in at time t+1 [16]. Clearly, it is particularly important to describe and model the user profile accurately for the recommendation model. To this end, the factor item similarity model (FISM) [17] can be used to extract implicit feedback from the learning behaviors of users, or the neural attentive item similarity (NAIS) [18] can be used to distinguish the importance of different historical courses to target courses by assigning different weight coefficients to historical courses. However, different from many other recommendation domains [19,20,21,22,23], As users' improvement of cognition level and the change of interests , they will enroll diversified courses. Under the circumstances, the recommendation effect of courses with high contribution will be weakened by other courses with low contribution, which may result in recommending a course that do not align with the user's preferences. These low contribution courses are called noise courses.
In order to solve the problem of noise courses, Hierarchical Reinforcement Learning (HRL) algorithm [16]can be used, acting on the user profile to remove noise courses in the historical courses sequence through a two-level sequential decision process. Then, joint training with the recommendation model (NAIS).
While substantial advancements have been achieved in course recommendation using the HRL model, there are still some issues with the model. Specifically, The profile reviser of the model contains a high- level task and a low-level task, when the high-level task decides not to revise the user profile, even if there are some noise courses at this time, the model cannot remove them.
Inappropriate decisions will diminish the overall performance of the model and may converge to a local optimum state. For the low-level task, because the sampling of the policy function and the state transition function are both random probability values in the reinforcement learning (RL) method [24]. Removing some noise courses randomly will lead to instability of model prediction. When recommending target courses to users, some of the more relevant courses may be ignored. As shown in Figure 1, the HRL model recommended the target course "Monetary Finance" due to the noise course "Principles of Economics". But according to the historical courses, the user has studied "C++" and "Principles of Databases", so he or she should prefer the computer programming courses.
In the above case, The user profile reviser does not guarantee the accuracy of decisions. In this work, we aim to reconstruct the profile reviser to improve the accuracy of course recommendation. To this end, we propose the new course recommendation model: actor-critic hierarchical reinforcement learning (ACHRL) model. The Actor-Critic method (AC) embedded in the model can improve the accuracy of decision making efficiently in the process of revising user profile. In particular, we adopt the policy gradient method [25] based on temporal difference error [26].This can reduce variance and improves robustness. The profile reviser can be updated in a timely manner, improving the accuracy of decisions adaptively. In summary, the contributions of our research are as follows:
- We propose an actor-critic hierarchical reinforcement learning model (ACHRL) to optimize the user's profile reviser of HRL model and improve the accuracy of course recommendations.
- We propose a policy gradient method based on temporal difference error, which updating the policy adopted by agent of reinforcement learning model with rewards at the current moment and states of the moments before and after. This can speed up model convergence and improve the accuracy of the recommendation model.
- We performed experiments on two MOOC datasets, with the majority of users enrolling in courses from various categories, and our proposed model demonstrated a significant improvement over the baseline model on different evaluation metrics.
2. Related Work
- Course recommendation
The rapid development of Massive Open Online Course (MOOC) platforms has led to increased research and application of course recommendation systems. Traditional course recommendations often rely on feature engineering, where valuable insights are extracted from user characteristics and historical learning data. Existing course recommendation methods can be classified into four primary categories:
Course Recommendation Based on Collaborative Filtering. Collaborative filtering methods encompass user-based and item-based collaborative filtering. These methods typically recommend courses to users based on the preferences of users with similar interests or the characteristics of courses. For example, Ray et al. [27] extended the collaborative filtering approach to develop a course recommendation system that provides accurate grade predictions, which aids in elective course selection. Li et al. [28] designed a personalized online education platform based on collaborative filtering, resulting in more accurate and efficient course recommendations aligned with users' interests. Course Recommendation Based on Content. Content-based recommendation methods leverage information about the features of the courses to make recommendations. These methods are suitable for addressing cold start problems as they don't rely on user interaction data. Ghauth et al. [29] proposed an e-learning recommendation system based on content-based filtering, which enhanced users' course outcomes by increasing the accuracy of the learning system. Course Recommendation Based on Knowledge Graph. Knowledge graph-based recommendation methods utilize graph structures to represent the relationships between courses. They leverage domain knowledge and semantic relationships within the knowledge graph to model connections between a user's interests and courses, resulting in personalized recommendations. Xu et al. [30] applied knowledge graph representation learning to embed semantic information of items into a low-dimensional semantic space and calculated semantic similarity between recommended items. This approach enhanced recommendation performance at the semantic level. Course Recommendations Based on a Hybrid Approach. Hybrid recommendation methods combine multiple recommendation techniques, leveraging the strengths of each to provide a combined set of recommendations that aim to enhance accuracy and diversity. Hybrid approaches have become a popular solution for addressing various recommendation challenges simultaneously, offering greater adaptability compared to single-method approaches. Emon et al. [31] used a hybrid approach that combines association rule mining and user-based collaborative filtering to develop a recommendation system that identifies the unique interests of different students in learning materials more effectively, resulting in more personalized recommendations. Gulza ret al. [32] proposed a hybrid method that uses ontology in combination with ontology to retrieve valuable information and make accurate recommendations, with the potential to improve learners' performance and satisfaction.
- B.
- RL-based Course recommendation
In recent years, there have been significant breakthroughs in Reinforcement Learning (RL) within the field of recommendation systems [33]. RL has achieved remarkable success in various domains, including e-commerce, video, and gaming [34,35,36]. These advancements have also opened up new opportunities in the realm of course recommendations within the education sector. As an interactive recommendation approach, RL-based recommendation models can continuously update their recommendation policies by receiving real-time feedback from users. This dynamic approach aligns more closely with real-world recommendation scenarios compared to traditional static methods. Particularly, Deep Reinforcement Learning (DRL) [37,38,39,40] stands out for its capacity to process large-scale data, extract underlying features, and accurately achieve specific goals through end-to-end learning. One of the challenges in traditional reinforcement learning methods [41,42,43] is the issue of the "dimensional disaster." When the environment is complex or the task is intricate, the state space of the agent becomes too extensive. This results in a rapid increase in the number of parameters to be learned and the memory space required. Consequently, achieving the desired results becomes difficult. To address the dimensional disaster problem, researchers have introduced Hierarchical Reinforcement Learning (HRL) [44,45,46]. The objective is to break down complex problems into smaller, more manageable subproblems and solve the original task by addressing these subproblems individually. In complex recommendation tasks, optimizing the policy directly according to the final goal can be inefficient. Hierarchical methods offer an effective means of enhancing recommendation efficiency by breaking down complex tasks into more manageable components.
HRL has made great progress in MOOC course recommendation. The accurate construction of the user profile model is the foundation of a recommendation system. Zhang et al. [16] applied HRL technology to course recommendation for the first time. The author believed that the noise courses in the sequence of historical courses will affect the weight of the courses with real contributions. The noise courses are removed by the reinforcement learning method. Utilizing the revised data can indeed enhance the accuracy of course recommendations. On the basis of the above work, Yang et al. [47] focused on improving the performance of the profile reviser, making the agent to obtain the cumulative rewards of the context and adopt better policies Lin et al. [48] used a recommendation model can capture user preferences by historical course and improve the accuracy of course recommendation. Inspired by the above methods, we proposed the ACHRL model to optimized the profile reviser, which ensures more accurate decisions on whether to delete noise courses. Finally, the accuracy of the recommendation results is improved.
3. Preliminaries
- C.
- Policy gradient method
We need to learn a target policy explicitly to defining the policy-based method [49] in reinforcement learning. The policy gradient is the basis of the policy-based method. It can parameterize the policy. Our objective is to discover an optimal policy that maximizes the expected return in the given environment. Therefore, the update of the objective function approximates the gradient ascent in as follows:
where is the policy parameter at time t, is the learning rate, which controls the step size of parameter updates, is a random estimate, and its expected value can be approximated as the gradient of according to its parameter The method that follows Eq. (1) is referred to as the policy gradient method.
- D.
- Actor-critic method
In reinforcement learning, the policy-based method needs to learn a policy function, the value-based method needs to learn a value function explicitly. Actor-Critic(AC) method [50] combines both aspects, enabling the simultaneous learning of both the policy function and the value function. This combination allows the value function to assist in the more effective learning of the policy function. In the context of policy gradients, we can express the gradient formula in a more generalized form as follows:
where represents the expected value of a random variable based on the policy function , In this paper, is the temporal difference error to guide the learning of policy function. represents policy function, We could call it "Actor".
In this paper, we employ the actor-critic method, as illustrated in Figure 2. The value function in this method plays a crucial role in guiding the learning of the policy function and optimizing the agent's action selection. We update the value function using the Temporal Difference error (TD error). Notably, the actor-critic method is essentially a policy-based approach, because its goal is also to optimize a policy with parameters. In summary, we utilize a policy gradient method based on the temporal difference error to enhance the objective function.
4. Proposed ACHRL Framework
In this section we first present the overview of the proposed model. Then, we elaborate the two modules of the model and two separable components of ACHRL, Ultimately, we will provide a detailed description of the model's training process.
Overview. The ACHRL model is depicted in Figure 3. It consists of two parts: a profile reviser module optimized by AC method and a recommendation module based on attention mechanism. The profile reviser is a hierarchical reinforcement learning framework, consisting of a two-layer Markov decision process [51] (MDP). In this framework, the high-level task is responsible for determining whether to revise the user profile, while the low-level task is tasked with deciding which noise course should be removed. When the high-level task determines to revise the user profile, the delay reward can be obtained after removing the last noise course in the low-level task. Two temporal difference errors from the AC method: TD-ERROR_H and TD-ERROR_L can guide the updating of high-level policy and low-level policy respectively After completing the task of the profile reviser, the embedding vector of the courses is fed into the recommendation module generating the recommended probability value. In the ACHRL model, we optimize the two-layer tasks of the profile reviser so that the agent(ah, al) can take more accurate actions. This can provide more accurate data for recommendation modules.( The variables involved in the figure are explained in the introduction to the two modules of the model).
- E.
- Profile reviser module
In the profile reviser, the agent selects the high-level action decision according to the high-level policy and removes the noise course according to the low-level policy. The key challenge is how the two-level task can revise the user profile more accurately.
- 1)
- HRL for profile reviser module
The modification task of the user profile can be divided into a two-layer Markov decision process (MDP). The first layer is a high-level task that decides whether to revise the user profile, and the second layer is a low-level task responsible for determining which historical course to remove. They can be transformed into a 5-tuple Markov Decision Process (MDP) denoted as represent a set of states, and represent a set of actions. is the state transition function. That ×× converts to a probability value of [0,1] by mapping. is a function used to represent rewards. signifies the discount factor applied to the reward at each moment. The following paragraph describes the content come from [16].
State. In the high-level task, we define the state features, which is characterized as the average cosine similarity and the average element-wise product between the embedding vectors [52] of each historical course and the target course. In the low-level task, we define the state feature , which is characterized as the cosine similarity [53], the element-wise product and the average of the two previous features between the embedding vector of the current historical course and the target course .
Action. Action is a discrete variable. The action in the high-level task determines whether to revise the profile of a user or no, and the action in the low-level task represent whether to remove the historical course or not.
Reward. Reward is used to indicate whether the performed actions are reasonable or not. When deciding to revise the user profile, the reward can be obtained after the last action is executed in the low-level task. Before that, the reward is zero. Here is defined as the difference between the log-likelihood after and before the profile is revised. The reward for the high-level task is defined as follows:
where denotes the state of high-level task at time t, denotes the action of the high-level task at time t, and is the revised profile, which is a subset of .The is the original profile. denotes a target course, is an abbreviation of The logarithmic function is used in the formula to have better convergence for the training of the model.
For the reward in the lower-level task, aside from the common component shared with the high-level task reward, there is an internal reward in the low-level task, which is defined as the difference of the average cosine similarity between each historical course after and before the user profile is revised and the target course , Internal reward is used to optimize the efficiency of the policy execution of the agent in the low-level task. The reward of the low-level task is defined as follows:
where represents the state of the low-level task at time t, represents the action of low-level task at time t, represents the cosine similarity between the historical courses and the target course .
Policy. The policy function of the high-level task:
where and bias vector are the parameters to be learned in the neural network, is the size of the hidden layer, is the number of state features, is the size of the hidden layer of the neural network at time t in the high-level task, and is the non-linear activation function used to transform the state into a probability value. is a activation function. Therefore, the policy parameter of the high-level task can be defined as follows , Similarly, we can get the low-level task policy parameter as .
- 2)
- AC method optimize profile reviser
Different from the decision made by the agent relying on the policy function, the action selection of the agent in the AC method has higher accuracy. Based on this, we use the AC method in the hierarchical task of the profile reviser. In this case, instead of relying on the cumulative rewards obtained in each training round for policy updates, the agent performs policy updates through the temporal differential error The is estimated using the critic network of AC method. In the calculation process of , we use the rewards of the current moment and the states of the moments before and after. It is more instructive for the policy update. The formula is as follows:
where represents the state value network in reinforcement learning, is the parameter of the value network,and represent the state of the current moment and the next moment respectively, is the reward of the current moment. is a discount factor for cumulative rewards of the agent.
| Algorithm 1 Actor-Critic Method |
|
Input: a derivable policy parameterization , a derivable actor-value a derivable parameterization , a state-value parameterization Initialize:parameters , 1: 2: Generate a sampling sequence {s1,a1,r1,s2,a2,r2…} following 3: for data at each step do 4: 5: 6: 7: |
- 3)
- Policy gradient based on temporal differential error
The previous section illustrates that the value function in the AC method can guide the policy function enable the agent make more accurate decisions. We use the temporal difference error in the gradient update process, and the gradient formula is as follows:
Thein the formula represents the two sides of the formula are proportional, represents a policy distribution in the policy function, is temporal differential error ).
- 4)
- Objective function
The ACHRL model improves the accuracy of course recommendations. For the hierarchical tasks, the temporal difference error is used in the policy gradient method to optimize policy function. It is calculated by the value of rewards and states. For our model, the objective function is to maximize the expectation of expected rewards:
The represents the policy parameter: or t .τ represents the sampling sequence of the actions and transition states. For the high-level task, it can be represented as , for the low-level task, it can be represented as , is the probability of the state transition in the high-level task or the low-level task, is the temporal differential error .
The policy function for high-level task are as follows:
where represents the quantity of historical courses. is the real reward obtained by the high-level task at time t. is the representation of the state value network in the high-level task, is the updated parameter in the state value network is the temporal difference error.
In the low-level task, the delayed reward can be obtained after removing the last noise course. The temporal difference error can be obtained through the calculation of the rewards and states. The policy function of the low-level task as follows:
where is the real reward which obtained at the time t of the low-level task. is the representation of the state value network in the low-level task. The meanings of other terms in the formula can be analogous to the relevant definitions in the above high-level policy network.
- F.
- Attention-based recommendation module
In our model, the recommendation module is the NAIS model [18]. It is a recommendation model that relies on an attention mechanism, and it excels at efficiently converting the course embedding vectors obtained from the profile reviser into recommended probability values. Besides, this can ensure provide a fair and reasonable verification for our ACHRL model and the HRL model. The following is a basic introduction of the NAIS model.
where represents the embedding vector of profile, is a embedding vector of historical courses. is an embedding vector of target course , is an attention weight coefficient of the historical course , during the recommendation process. is an attention function . Its essence is one multi-layer perceptron (MLP) [54].
where is the attention weight vector mapped by the hidden layer of the neural network, is the weight matrix, is a bias vector. is an activation function.
According to and the attention-based recommendation module generates a recommendation probability .
If the value of y is 1, the recommendation is successful, is an activation function used to convert the input embedding to the probability value in the recommendation model.
- G.
- Separable two components of ACHRL
The model proposed in this paper is called ACHRL to indicate that we optimize the two-layer structure of the profile reviser by using the AC method. We use the term ACHRL_H to represent the optimization of the high-level task. The term ACHRL_L represents the optimization of the low-level task. Next, we will provide a comprehensive description of both of them. In the ablation experiment , we will compare both model methods with HRL and ACHRL.
- 1)
- High-level task optimization: ACHRL_H
As has been introduced above, a major problem of the HRL model is the action of agent is random. The high-level task cannot decide whether to revise the user profile accurately. The ACHRL_H model enhances the precision of decision-making for high-level task. To ensure a fair performance comparison with the HRL model, we employ the REINFORCE algorithm [55] to calculate the gradient of the low-level task policy function too:
where represents the cumulative delay reward of the low-level task obtained by each sampling sequence 𝜏.
- 2)
- Low-level task optimization: ACHRL_L
In the HRL model, the key to the low-level task is How to identify the noise course and remove it accurately. Due to the limitation of the policy function itself, the low-level task removes noise courses with randomness, which makes the execution of the policy less accurate, and may even remove the valid course mistakenly, affecting the recommendation performance. To solve this problem, we use ACHRL_L to assist low-level task to remove noise courses improving the accuracy of low-level action selection. While removing noise courses, we reserve the target course for each user as far as possible. We still use the REINFORCE algorithm to calculate the gradient of the high-level task policy function:
where represents the cumulative delay reward for each sampling sequence in the high-level task. Note here: Some element representations in formulas (9), (10), (14), and (15) are simplified, and we omit h and l representing high and low levels.
- D.
- Model training
The previous section outlines that the entire model can be split into two components. The training process involves three key steps: initially, pre-training the recommendation module [56], followed by pre-training the profiler reviser module, and finally, jointly train the two models together.
Next, we illustrate the details of its interaction by combining Figure 4 and Algorithm 2. First, pre-train our recommendation module (i.e., ) using the original dataset (). Then we conduct the pre-training of the profile reviser module (i.e., ), In this process, the update of the high -level policy and the low-level policy depend on the optimization of the temporal difference error (TD-ERROR_H and TD-ERROR_L ) calculated by the AC method. Finally, we conduct the joint training of the two models. If the output: of the recommendation model is greater than the threshold set in the experiment (e.g., 0.6) The recommendation model has got a reasonable recommendation result. At this time, the high-level task makes the decision corresponding to "0" in Figure 4, which means that the user's profile is not modified. No reward will be given in this case and the is zero(corresponding to the fifth line in Algorithm 2) The course embedding vector of the unrevised profile are input into the recommendation model directly. On the contrary, the high-level task takes the decision corresponding to "1" in Figure 4, which means revising the user's profile is required. At this time, noise courses need to be removed .In low-level task, "0" means remove the course, "1" means keep the course. When the low-level task is completed, both the high-level task and the low-level task obtain the reward. The corresponding values are also obtained for both and .Under the optimization of them, the removing work of all noise courses is completed, and the user profile is revised (lines 7-9 of Algorithm 2). The revised profile is input into the recommendation model as an embedding vector. The next round of joint training begins until the end of the training. The parameters are updated during the training process (lines 12-13 of Algorithm 2).
| Algorithm 2 Actor-Critic -Based Hierarchical Reinforcement Learning |
|
Input:training data:εu; pre-train recommendation model parameterized by:; pre-train profile reviser parameterized by:= {w1,w2,b}; Derivable state value functions: (s,w), (s,w) Initialize:, , (r,s)=0, (r,s)=0; 1: for sequence k=1 to k do 2: for each εu:=(eu1, … )and ci do 3: Sample a high-level action ah , in the high-level task; 4: if then 5: 6: else 7: Sample a sequence of states and actions with ,in the low-level task; 8: Calculate:, ; 9: Calculate the gradients by Eq. (9) and (10) according to Algorithm 1; 10: end if 11: end for 12: Update parameters ,,, by the gradients; 13: Update parameter by the recommendation module; 14: Output the recommendation probability by Eq. (13) 15: end for |
5. Experiment and Analyze
In this section, we'll begin by introducing two datasets and explaining the experimental setup. Subsequently, we'll delve into the results and findings of the experiment.
- E.
- Dataset
We conduct the experiment using the real-world datasets, MOOCCourse1 and MOOCCube. Both of these datasets are from the domestic MOOC platform "XuetangX2". Table 1 shows the details of the two datasets. Each user registered for at least three courses in the MOOCCourse dataset, and each user registered for at least two courses in the MOOCCube dataset. To ensure the fairness of the experiment, we adopted the same data preprocessing method as the HRL mode [16]. We structured the user enrollment behavior in such a way that the actions in the training phase, actions were taken in the training set before the test set. Each entry in both training and test sets includes a series of previous courses alongside the user's target courses. For training, we identified the final course in each sequence as the target course, with all the previous courses treated as historical. In the testing phase, every historical course in the test set was regarded as the target course, and the corresponding course from the training set for the same user was considered the historical course.
- F.
- Experimental setup
- 1)
- Compared method
To evaluate model performance, we compared the ACHRL model with some baseline models, as follows:
- MLP [54]: A powerful recommendation system model that leverages deep learning techniques to provide personalized recommendations based on complex user-item interactions.
- FISM [17]: An important model in the field of recommendation systems, particularly suitable for collaborative filtering recommendation problems where user historical behavior data is the primary input.
- NeuMF [57]: A model that combines matrix decomposition techniques and MLP methods to mine the potential information of user courses for modelling and recommend relevant courses to users.
- NAIS [18]: The model built by an item-based collaborative filtering method combined with an attention mechanism neural network that can distinguish between different historical course weights for course recommendation.
- HRRL [47]: An HRL-based method using time-context rewards can optimize strategy learning in reinforcement learning for course recommendation.
- DARL [48]: a novel course recommendation framework can capture user preferences by historical data improving the effectiveness of course recommendations.
We investigate recommendation performance of the HRL model and two variants of the ACHRL model (ACHRL_H and ACHRL_L).
- HRL [16]: Recommendation model and profile reviser joint training.
- ACHRL_H: A Simplified version of ACHRL model and profile reviser joint training, and only adopts optimization of AC method in the high-level task of profile reviser.
- ACHRL_L: A simplified version of ACHRL model and profile reviser joint training, and only adopts optimization of AC method in the low-level task of profile reviser.
- 2)
- Evaluation Metrics
We employ the most authoritative evaluation metrics used in the recommended field [59] :
- HR@K (Hit Ratio at K) : A measure of how many of the relevant items were successfully included in the top K recommendation.
The following formula represents a successful recommendation to the user
where represents the total number of items corresponding to users in all test sets, represents the count of items that users interact with or find relevant in the previous K recommendations.
- NDCG@K (Normalized Discounted Cumulative Gain) : An accumulative performance measure that takes into account both the relevance and position of ranked items It can be defined as follows:
- 3)
- Parameters and Environment
Experimental Environment: We implement the model by Tensorflow2 and deployed it on a Linux server equipped with an NVIDIA RTX 3090 GPU featuring 20 GB of video memory.
Parameter Settings: Recommendation module: The size of both course embedding vector De and the hidden layer Dh are configured as 16. The batch size is 256. The learning rate is 0.02. Profile reviser: The sampling times N is set to 3, the learning rate for the pre-training model and the joint training model is set to 0.001, 0.0005. For the policy network, the hidden layer (dh1,dh2) is configured as 8, the state size (dh2) of the high-level layer is 18, and the state size(dl2) of the low-level layer is 34. The discount factor of reward β is 0.5. ACHRL model parameter: the sampling times N is also 3, and the hiding layer size of the recommendation module is configured as 16. For the value network, the hidden layer size (dh1,dh2) is 20. The state (dh2) size of the high-level layer is 18, The state (dl2) size of the low-level layer is configured as 34
- G.
- Comparison of experimental results
Table 2 demonstrates that our three proposed models achieved better results in terms of recommendation performance compared to the baseline models. For the MOOCCourse dataset, the HR was improved of 0.13% to 6.35% and the NDCG was improved of 0.59% to 5.34%. For the MOOCCube dataset, the HR was improved of 5.58% to 6.35% and the NDCG was improved of 1.48% to 2.12%. In summary, the above results provide a proof of the effectiveness of ACHRL model.
In Table 2, of all the baseline models, namely NeuMF,FISM, and MLP, they exhibit worst performance. This is primarily due to their inability to account for the contribution of various historical courses when making recommendations for target courses. NARM and NAIS underperform in comparison to all HRL-based models This performance gap arises from their limited ability to differentiate the impact of historical courses when users are enrolled in a larger variety of courses. All models based on HRL surpassed the performance of other baseline models. The is because that the HRL-based models optimize the user profile. It makes the updated data represent the preferences of users more accurately and improves the accuracy of the recommendation. Comparing the performance of ACHRL model on the two datasets in Figure 5. It's clear that the ACHRL model performs better on the MOOCCourse dataset. Those users in MOOCCourse dataset enrolled in more courses. This proves that the ACHRL model has a good recommendation effect to those users who are interested in multiple courses. More courses help the model to train adequately and to removing noise courses accurately. This can recommend target courses to users more accurately.
In addition, to further verify the effectiveness of the ACHRL model, we compare it with the two newest models: HRRL and DARL in the past two years, that ACHRL model exhibits the highest performance. since the MOOCCube dataset of this thesis is slightly different from the MOOCCube dataset used by the two models mentioned above, the experimental data of the comparison is not given in the corresponding position in Table 2.
- H.
- Ablation experiment
Figure 6 and Figure 7 illustrate the performance of HRL-based models concerning different top N values on two datasets. Within the category of HRL-based models, the ACHRL, ACHRL_H, and ACHRL_L models demonstrated superior performance in HR on two datasets. This proves the effectiveness of our proposed model.
The ACHRL_H model outperforms the HRL model. This because the high-level task modified the user profile more accurately after being optimized by the AC method. The ACHRL_L model also outperforms the HRL model because the noise courses in the course sequence are removed more accurately in the lower-level task. To sum up, The AC method optimizes two layers of tasks well.
As can be seen from the two figures, the ACHRL model attains the highest level of performance. This superiority is observed when compared to the other two variations of the method. Clearly, the combination of ACHRL_H and ACHRL_L Maximize the accuracy of decision making for high -lever and low-level tasks. The ACHRL model, which optimizes both the two layers of tasks of the model, improves the accuracy of the decision task, and achieves a more accurate course recommendation task.
Figure 8 and Figure 9, showing the variation in reward values of ACHRL, ACHRL_H, ACHRL_L models during the course of the experiment. It can be seen from the change of reward value in the figures that the ACHRL model performed best, which further proves the effectiveness of the model for course recommendation.
- I.
- Influence of hyper-parameters
we examine the impact of two crucial hyperparameters. (the size of the hidden layer of the attention mechanism network and the course embedding layer) on the model performance.
Figure 10 and Figure 11 show the performance of the five models at various embedding layer sizes. In practice, The embedding layer size is specified as 8, 16, 32, 64, and 128. First of all, it can be seen from the two figures that The HRL-based model notably outperforms the NAIS model in HR. The ACHRL model achieves the best results on two datasets. The ACHRL model handles historical courses more accurately and improves recommendation performance. In addition, Our conclusion is that the recommendation performance of the five models in the experiment improves as the embedding layer size increases. This is because with an increase in the dimension of the embedding layer, the attention mechanism's capacity for representation is enhanced., and the model can provide more useful information for recommendation learning.
Figure 12 and Figure 13 display the performance of the five models across various hidden layer sizes. In our experiment, we empirically chose 4, 8, 16, 32, and 64 as the hidden layer sizes, respectively. As shown in the two figures, the ACHRL model performed best relative to the other models on two datasets. As can be seen from the figures that our model is robust.
- J.
- Performance analysis
To visually illustrate the effectiveness of the HRL model, we provide specific instances of course recommendations for qualitative analysis. Table 3 displays the performance of the ACHRL and HRL model. In the first case, the ACHRL model removes the noise course "Economics" accurately and recommends the target course correctly. In the second case the ACHRL model removes noise courses " Operating Systems ", and recommends the target course correctly. while the HRL model did not accurately remove the noise course.
This indicates the ACHRL model's capacity to effectively filter out irrelevant courses and offer recommendations that align better with the user's preferences.
6. Conclusions
In this paper, we introduce the ACHRL model for course recommendation. We are the first to apply the AC method to hierarchical reinforcement learning model, reconstructing the user profile effectively. We applied the AC method to hierarchical tasks of profile reviser, improving the accuracy of action selection at each layer respectively. In addition, the use of the policy gradient method, which relies on temporal difference error, leads to an enhancement in the recommendation performance. This gradient method can be applied not just in episodic scenarios but also the continuing situations. This allows the model to be used in more scenarios. The model with good expansibility. For example, it can be applied to music, film, radio and other fields. The historical data formed by the historical information of user interaction can be modelled well by the model method in this paper. Through the construction of user profile, users can be recommended to their favorite items.
While the ACHRL model aligns with the primary objectives of many existing recommendation models, which prioritize recommendation accuracy, the field of recommendation embraces a multitude of user satisfaction metrics. Users often appreciate diverse offerings. For example: ranging from popular courses at different universities to those from various majors. Consequently, a recommendation model that strikes a balance between precision and variety can significantly enhance user satisfaction.
In our future research, we plan to explore the ACHRL model's performance across multiple evaluation metrics, particularly focusing on recommendation accuracy and diversity. To achieve this, we intend to employ a multi-objective evolutionary approach for optimizing the evaluation process [60]. Moreover, we will focus on the interpretability of the model. This can help users get the best recommended courses and at the same time understand the motivation of learning the target course. In terms of methods, we learned the Advantage Actor-Critic(A2C) method [61] is an improvement of the Actor-Critic method designed to improve training efficiency and stability, we will consider embedding A2C method into our model to ensure the accuracy of model recommendations.
Author Contributions
Conceptualization, K.L.; Methodology and Writing, G.Z.; Formal analysis, J.G.; Data curation, W.L. All authors have read and agreed to the published version of the manuscript.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets generated during the current study are available from the corresponding author on reasonable request.
Acknowledgments
This work is supported by the National Natural Science Foundation of China (No.62377036, No.61807024) and Science and Technology Program of Tianjin (No. 22YDTPJC00940).
Conflict of Interest
The authors declare that they have no conflicts of interest.
| 1 | |
| 2 |
References
- Saadatdoost, R.; Sim, A.T.H.; Jafarkarimi, H.; Hee, J.M. Exploring MOOC from education and Information Systems perspectives: a short literature review. Educ. Rev. 2015, 67, 505–518. [Google Scholar] [CrossRef]
- Cheng, J.; Yuen, A.H.; Chiu, D.K. Systematic review of MOOC research in mainland China. Libr. Hi Tech 2022, 41, 1476–1497. [Google Scholar] [CrossRef]
- Tucker, S. Distance education: Better, worse, or as good as traditional education. Online journal of distance learning administration, 2001, 4, 1–6. [Google Scholar]
- He, L.; Yang, N.; Xu, L.; Ping, F.; Li, W.; Sun, Q.; Li, Y.; Zhu, H.; Zhang, H. Synchronous distance education vs traditional education for health science students: A systematic review and meta-analysis. Med. Educ. Rev. 2021, 55, 293–308. [Google Scholar] [CrossRef]
- Mazoue, J. G. The MOOC model: Challenging traditional education. EDUCAUSE review online 2013, 28. [Google Scholar]
- He, L.; Yang, N.; Xu, L.; Ping, F.; Li, W.; Sun, Q.; Li, Y.; Zhu, H.; Zhang, H. Synchronous distance education vs traditional education for health science students: A systematic review and meta-analysis. Med. Educ. Rev. 2021, 55, 293–308. [Google Scholar] [CrossRef] [PubMed]
- Atiaja, L. A.; Proenza, R. The MOOCs: origin, characterization, principal problems and challenges in Higher Education. Journal of e-learning and Knowledge Society 2016, 12. [Google Scholar]
- Laurillard, D. The educational problem that MOOCs could solve: professional development for teachers of disadvantaged students. Res. Learn. Technol. 2016, 24. [Google Scholar] [CrossRef]
- Xu, M.; Deng, J.; Zhao, T. On Status Quo, Problems, and Future Development of Translation and Interpreting MOOCs in China--A Mixed Methods Approach. Journal of Interactive Media in Education 2020, 2020. [Google Scholar] [CrossRef]
- Parameswaran, A.; Venetis, P.; Garcia-Molina, H. Recommendation systems with complex constraints: A course recommendation perspective. ACM Transactions on Information Systems (TOIS), 2011, 29, 1–33. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, T.; Lv, Z.; Liu, S.; Zhou, Z. MCRS: A course recommendation system for MOOCs. Multimedia Tools Appl. 2018, 77, 7051–7069. [Google Scholar] [CrossRef]
- Jiang, W.; Pardos, Z. A.; Wei, Q. Goal-based course recommendation. In Proceedings of the 9th international conference on learning analytics & knowledge; 2019; pp. 36–45. [Google Scholar]
- Ma, B.; Lu, M.; Taniguchi, Y.; Konomi, S. CourseQ: the impact of visual and interactive course recommendation in university environments. Res. Pr. Technol. Enhanc. Learn. 2021, 16, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Thanh-Nhan, H. L.; Nguyen, H. H.; Thai-Nghe, N. Methods for building course recommendation systems. In 2016 Eighth international conference on knowledge and systems engineering (KSE); IEEE, 2016; pp. 163–168. [Google Scholar]
- Khalid, A.; Lundqvist, K.; Yates, A. A literature review of implemented recommendation techniques used in Massive Open online Courses. Expert Syst. Appl. 2022, 187, 115926. [Google Scholar] [CrossRef]
- Zhang, J.; Hao, B.; Chen, B.; Li, C.; Chen, H.; Sun, J. Hierarchical Reinforcement Learning for Course Recommendation in MOOCs. Proc. AAAI Conf. Artif. Intell. 2019, 33, 435–442. [Google Scholar] [CrossRef]
- Kabbur, S.; Ning, X.; Karypis, G. Fism: factored item similarity models for top-n recommender systems. In Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining; 2013; pp. 659–667. [Google Scholar]
- He, X.; He, Z.; Song, J.; Liu, Z.; Jiang, Y.-G.; Chua, T.-S. NAIS: Neural Attentive Item Similarity Model for Recommendation. IEEE Trans. Knowl. Data Eng. 2018, 30, 2354–2366. [Google Scholar] [CrossRef]
- Zhang, L. Top-N recommendation algorithm integrated neural network. Neural Comput. Appl. 2021, 33, 3881–3889. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, Z.; Bi, X.; Sun, Y. A new point-of-interest group recommendation method in location-based social networks. Neural Comput. Appl. 2020, 35, 12945–12956. [Google Scholar] [CrossRef]
- Jiang, X.; Sun, H.; Zhang, B.; He, L.; Jia, X. A novel meta-graph-based attention model for event recommendation. Neural Comput. Appl. 2022, 34, 14659–14682. [Google Scholar] [CrossRef]
- Liu, H.; Wang, Y.; Lin, H.; Xu, B.; Zhao, N. Mitigating sensitive data exposure with adversarial learning for fairness recommendation systems. Neural Comput. Appl. 2022, 34, 18097–18111. [Google Scholar] [CrossRef]
- Ren, Y.; Liang, K.; Shang, Y.; Zhang, Y. MulOER-SAN: 2-layer multi-objective framework for exercise recommendation with self-attention networks. Knowledge-Based Systems, 2023, 260, 110117. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Sutton, R. S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Advances in neural information processing systems 1999, 12. [Google Scholar]
- O'Doherty, J.P.; Dayan, P.; Friston, K.; Critchley, H.; Dolan, R.J. Temporal Difference Models and Reward-Related Learning in the Human Brain. Neuron 2003, 38, 329–337. [Google Scholar] [CrossRef] [PubMed]
- Ray, S.; Sharma, A. A collaborative filtering based approach for recommending elective courses. In Information Intelligence, Systems, Technology and Management: 5th International Conference, ICISTM 2011, Gurgaon, India, March 10-12, 2011. Proceedings 5; Springer: Berlin Heidelberg, 2011; pp. 330–339. [Google Scholar]
- Li, J.; Ye, Z. Course Recommendations in Online Education Based on Collaborative Filtering Recommendation Algorithm. Complexity 2020, 2020, 1–10. [Google Scholar] [CrossRef]
- Ghauth, K. I.; Abdullah, N. A. The effect of incorporating good learners' ratings in e-Learning content-based recommender System. Journal of Educational Technology & Society, 2011, 14, 248–257. [Google Scholar]
- Xu, G.; Jia, G.; Shi, L.; Zhang, Z. Personalized Course Recommendation System Fusing with Knowledge Graph and Collaborative Filtering. Comput. Intell. Neurosci. 2021, 2021, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Emon, M.I.; Shahiduzzaman; Rakib, R.H.; Shathee, M.S.A.; Saha, S.; Kamran, N.; Fahim, J.H. Profile Based Course Recommendation System Using Association Rule Mining and Collaborative Filtering. In 2021 International Conference on Science & Contemporary Technologies (ICSCT); IEEE, 2021; pp. 1–5. [Google Scholar]
- Gulzar, Z.; Leema, A.A.; Deepak, G. PCRS: Personalized Course Recommender System Based on Hybrid Approach. Procedia Comput. Sci. 2018, 125, 518–524. [Google Scholar] [CrossRef]
- Moerland, T.M.; Broekens, J.; Plaat, A.; Jonker, C.M. Model-based Reinforcement Learning: A Survey. Found. Trends® Mach. Learn. 2023, 16, 1–118. [Google Scholar] [CrossRef]
- Rohde, D.; Bonner, S.; Dunlop, T.; Vasile, F.; Karatzoglou, A. Recogym: A reinforcement learning environment for the problem of product recommendation in online advertising. arXiv 2018, arXiv:1808.00720. [Google Scholar]
- Wang, X.; Chen, W.; Wu, J.; Wang, Y. F.; Wang, W. Y. Video captioning via hierarchical reinforcement learning. In Proceedings of the IEEE conference on computer vision and pattern recognition; 2018; pp. 4213–4222. [Google Scholar]
- Lanctot, M.; Zambaldi, V.; Gruslys, A.; Lazaridou, A.; Tuyls, K.; Pérolat, J.; Silver, D.; Graepel, T. A unified game-theoretic approach to multiagent reinforcement learning. Advances in neural information processing systems 2017, 30. [Google Scholar]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An introduction to deep reinforcement learning. Foundations and Trends® in Machine Learning 2018, arXiv:1811.1256011, 219–354. [Google Scholar]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep reinforcement learning that matters. In Proceedings of the AAAI conference on artificial intelligence; 2018; 32. [Google Scholar]
- Li, S. E. Deep reinforcement learning. In Reinforcement Learning for Sequential Decision and Optimal Control; Springer Nature Singapore: Singapore, 2023; pp. 365–402. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Wiering, M. A.; Van Otterlo, M. Reinforcement learning. Adaptation, learning, and optimization, 2012, 12, 729. [Google Scholar]
- Mo, S.; Pei, X.; Wu, C. Safe Reinforcement Learning for Autonomous Vehicle Using Monte Carlo Tree Search. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6766–6773. [Google Scholar] [CrossRef]
- Wang, J. X.; Kurth-Nelson, Z.; Tirumala, D.; Soyer, H.; Leibo, J. Z.; Munos, R.; Blundell, C.; Kumaran, D.; Botvinick, M. Learning to reinforcement learn. arXiv 2016, arXiv:1611.05763. [Google Scholar]
- Pateria, S.; Subagdja, B.; Tan, A. H.; Quek, C. Hierarchical reinforcement learning: A comprehensive survey. ACM Computing Surveys (CSUR), 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Nachum, O.; Gu, S. S.; Lee, H.; Levine, S. Data-efficient hierarchical reinforcement learning. Advances in neural information processing systems 2018, 31. [Google Scholar]
- Botvinick, M.M. Hierarchical reinforcement learning and decision making. Curr. Opin. Neurobiol. 2012, 22, 956–962. [Google Scholar] [CrossRef]
- Lin, Y.; Lin, F.; Yang, L.; Zeng, W.; Liu, Y.; Wu, P. Context-aware reinforcement learning for course recommendation. Appl. Soft Comput. 2022, 125. [Google Scholar] [CrossRef]
- Lin, Y.; Feng, S.; Lin, F.; Zeng, W.; Liu, Y.; Wu, P. Adaptive course recommendation in MOOCs. Knowledge-Based Syst. 2021, 224, 107085. [Google Scholar] [CrossRef]
- Nachum, O.; Norouzi, M.; Xu, K.; Schuurmans, D. Bridging the gap between value and policy based reinforcement learning. Advances in neural information processing systems 2017, 30. [Google Scholar]
- Howard, R. A. Dynamic programming and markov processes. 1960. [Google Scholar]
- Garcia, F.; Rachelson, E. Markov decision processes. Markov Decision Processes in Artificial Intelligence 2013, 1–38. [Google Scholar]
- Frome, A.; Corrado, G. S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M. A.; Mikolov, T. Devise: A deep visual-semantic embedding model. Advances in neural information processing systems 2013, 26. [Google Scholar]
- Lahitani, A.R.; Permanasari, A.E.; Setiawan, N.A. Cosine similarity to determine similarity measure: Study case in online essay assessment. In 2016 4th International Conference on Cyber and IT Service Management; 2016; pp. 1–6. [Google Scholar]
- Taud, H.; Mas, J. F. Multilayer perceptron (MLP). Geomatic approaches for modeling land change scenarios 2018, 451–455. [Google Scholar]
- Williams, R. J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Poth, C.; Pfeiffer, J.; Rücklé, A.; Gurevych, I. What to pre-train on efficient intermediate task selection. arXiv 2021, arXiv:2104.08247. [Google Scholar]
- Liu, H.; Yu, J.; Chen, X.; Zhang, L. NeuMF: Predicting Anti-cancer Drug Response Through a Neural Matrix Factorization Model. Curr. Bioinform. 2022, 17, 835–847. [Google Scholar] [CrossRef]
- Li, J.; Ren, P.; Chen, Z.; Ren, Z.; Lian, T.; Ma, J. Neural attentive session-based recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management; 2017; pp. 1419–1428. [Google Scholar]
- Dalianis, H.; Dalianis, H. Evaluation metrics and evaluation. Clinical text mining: secondary use of electronic patient records 2018, 45–53. [Google Scholar]
- von Lücken, C.; Barán, B.; Brizuela, C. A survey on multi-objective evolutionary algorithms for many-objective problems. Comput. Optim. Appl. 2014. [Google Scholar] [CrossRef]
- Alibabaei, K.; Gaspar, P.D.; Assunção, E.; Alirezazadeh, S.; Lima, T.M.; Soares, V.N.G.J.; Caldeira, J.M.L.P. Comparison of On-Policy Deep Reinforcement Learning A2C with Off-Policy DQN in Irrigation Optimization: A Case Study at a Site in Portugal. Computers 2022, 11, 104. [Google Scholar] [CrossRef]
Figure 1.
An example of HRL model for course recommendation.
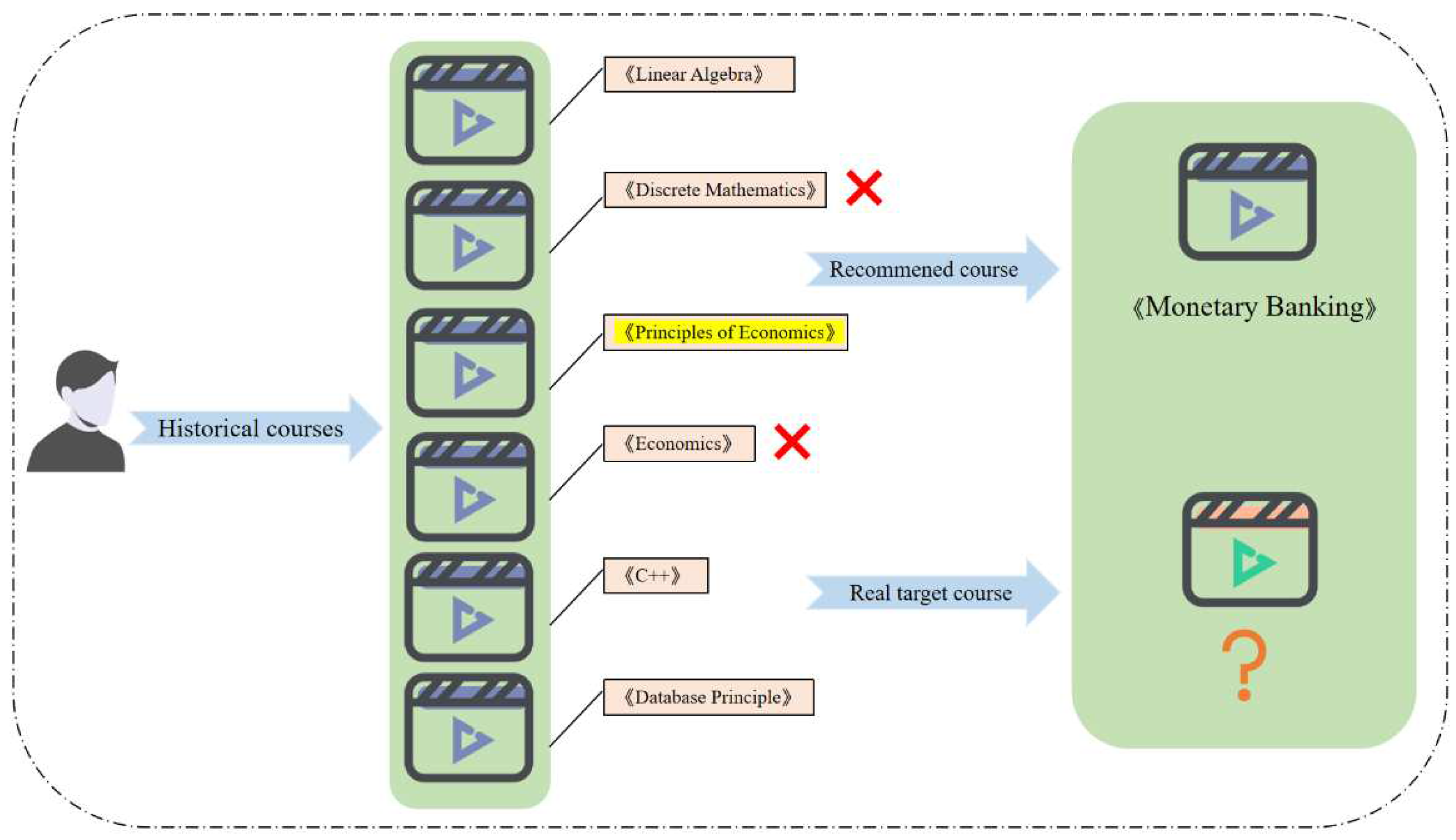
Figure 2.
The execution process of AC method.
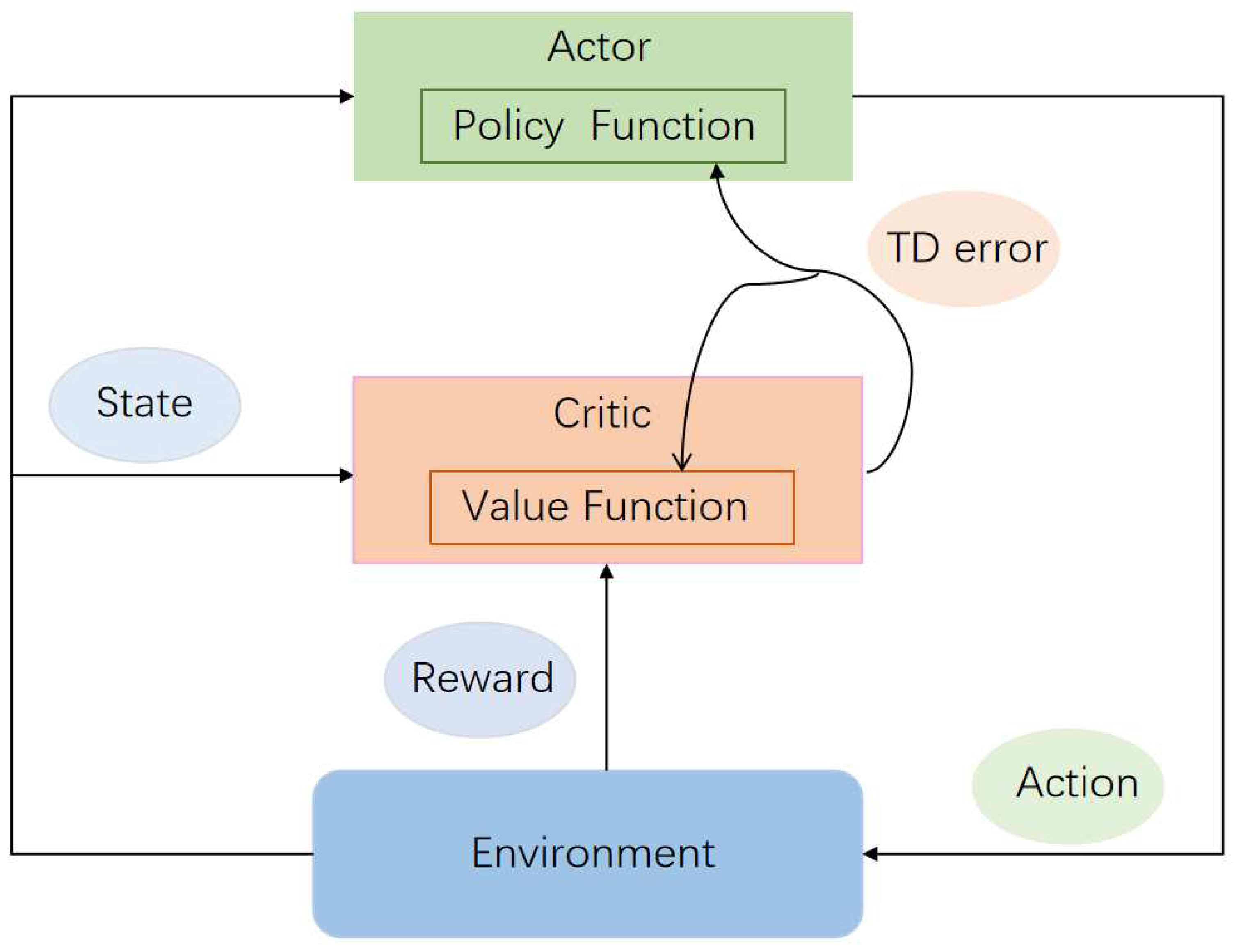
Figure 3.
The overall framework of the proposed model (ACHRL) We use AC method to optimize the HRL model to revise the user profile. Next, we will introduce the specific composition of the profile reviser based on HRL and its optimization by AC method in detail.
Figure 3.
The overall framework of the proposed model (ACHRL) We use AC method to optimize the HRL model to revise the user profile. Next, we will introduce the specific composition of the profile reviser based on HRL and its optimization by AC method in detail.
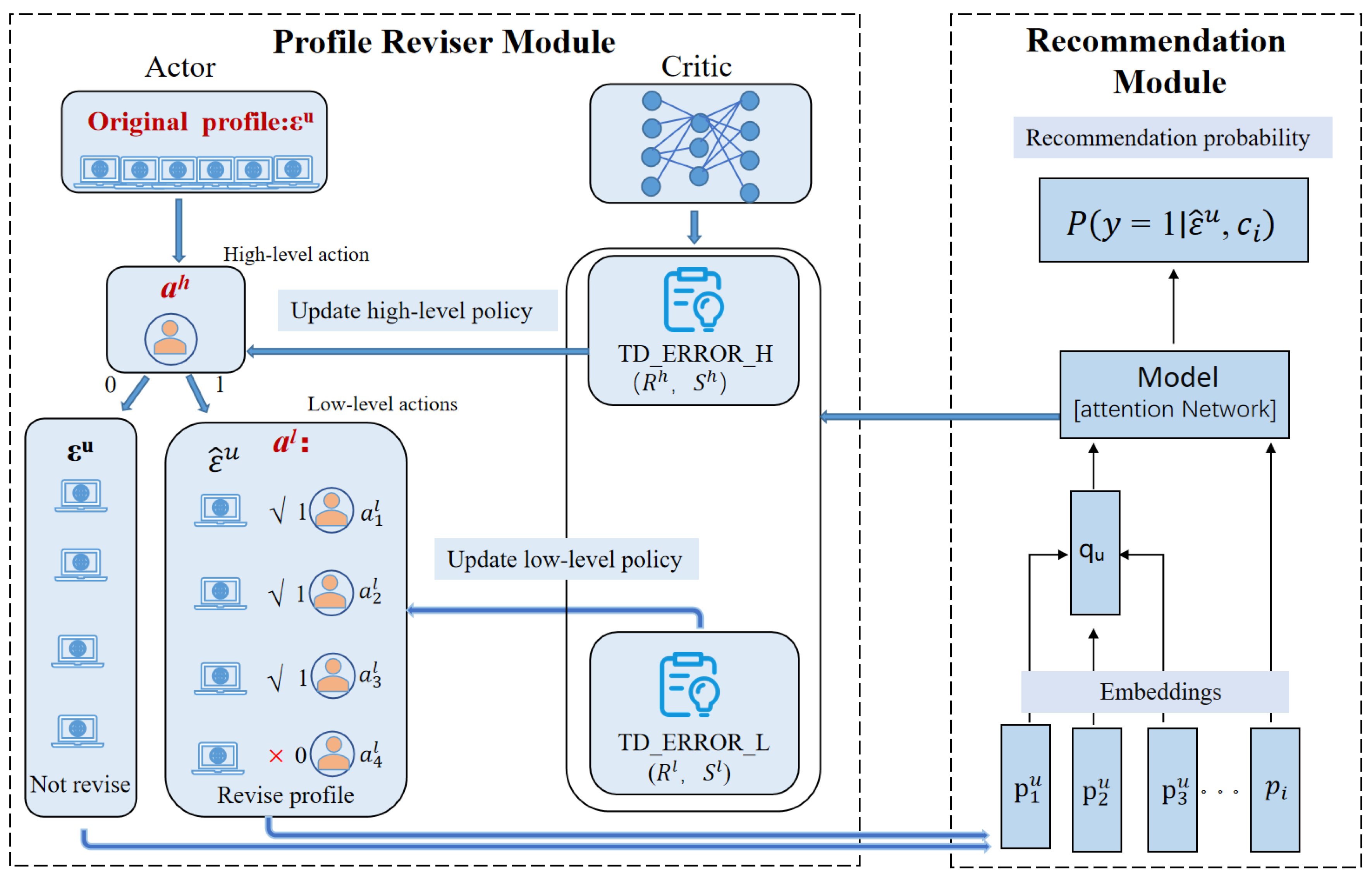
Figure 4.
Interaction details of recommendation module and profile reviser.
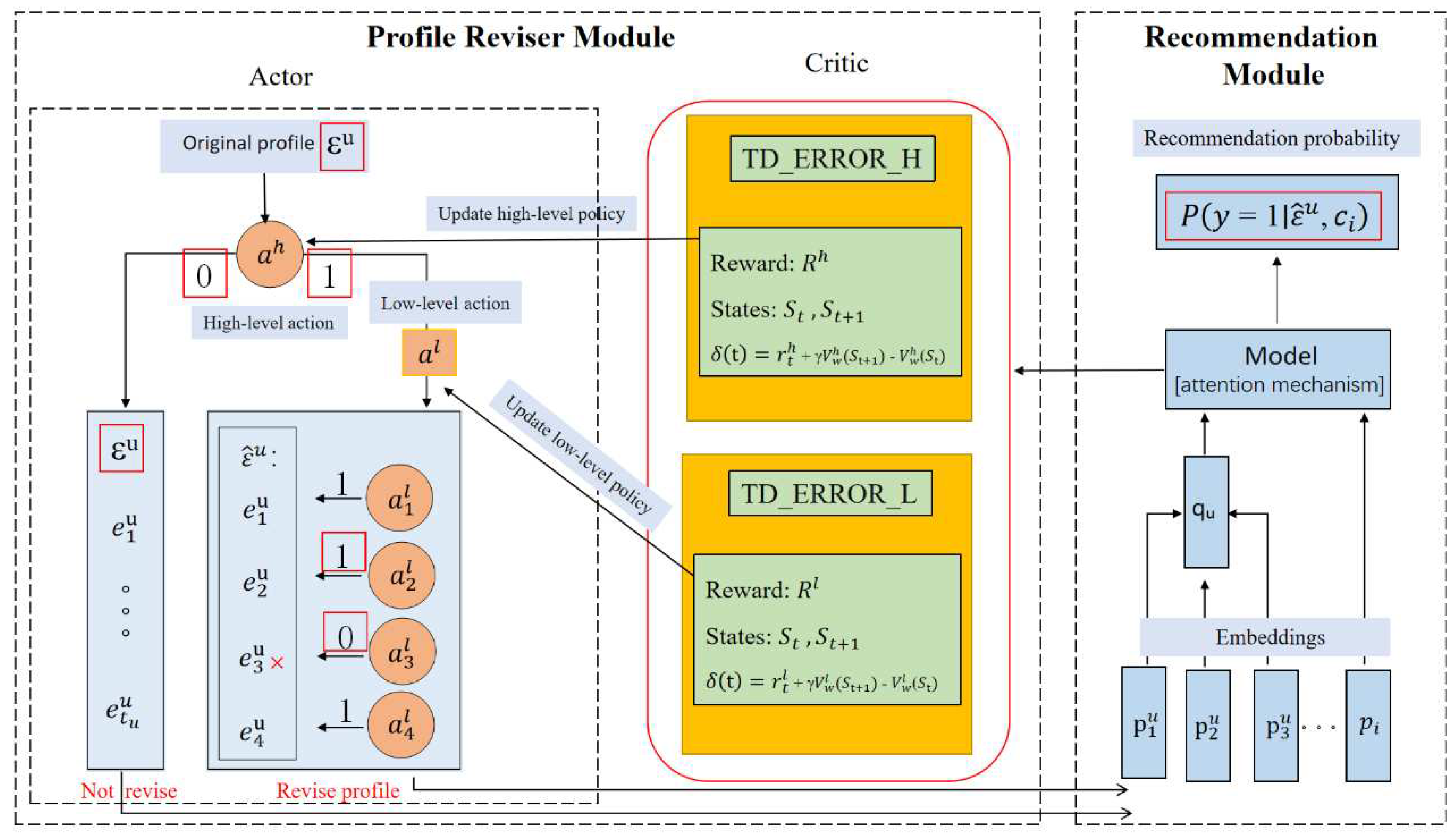
Figure 5.
Recommendation performance of ACHRL model on MOOCCourse and MOOCCube(HR,NDCG).
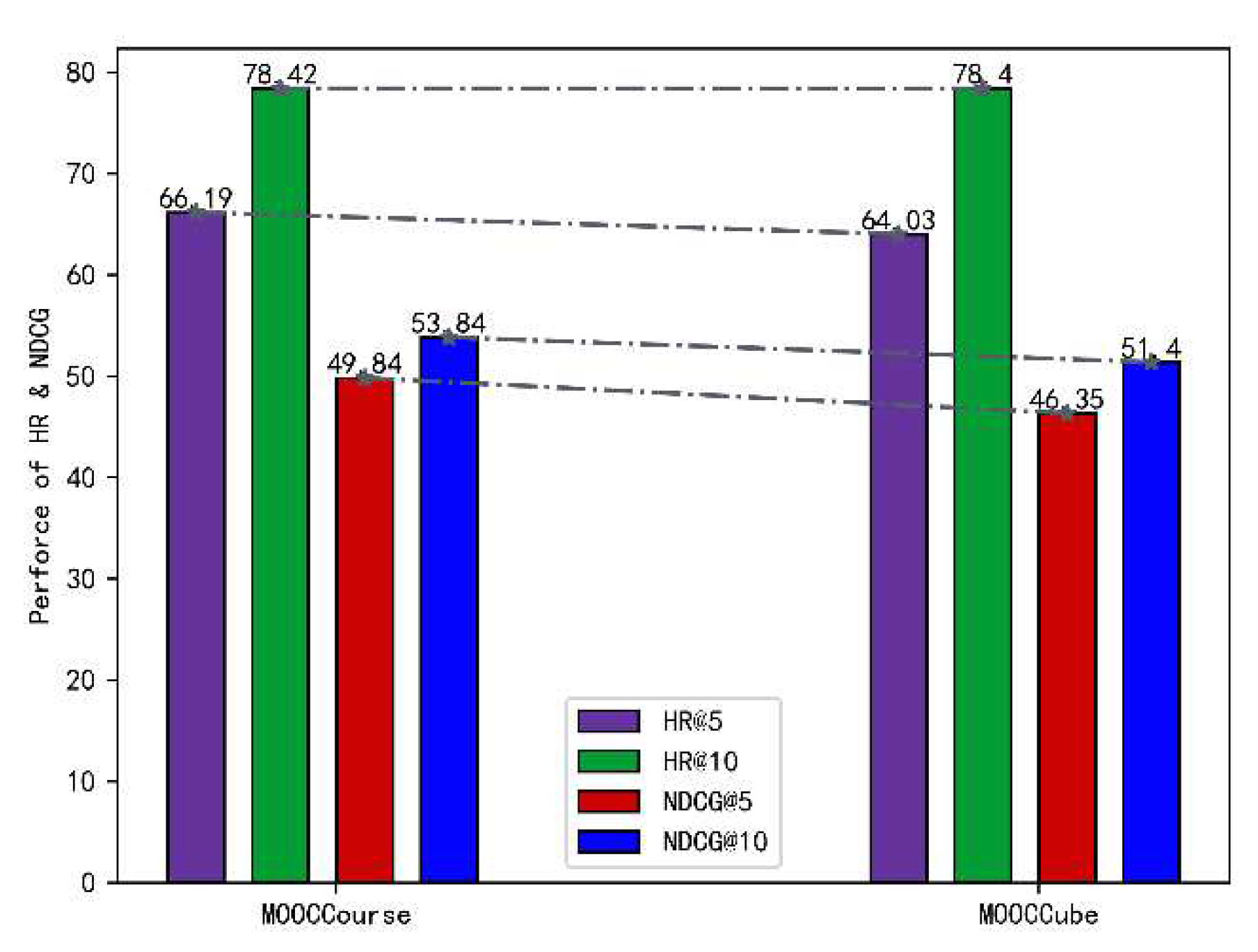
Figure 6.
The performance of HRL-based models, assessed in terms of HR (%) at different top N HR values, on MOOCCourse.
Figure 6.
The performance of HRL-based models, assessed in terms of HR (%) at different top N HR values, on MOOCCourse.
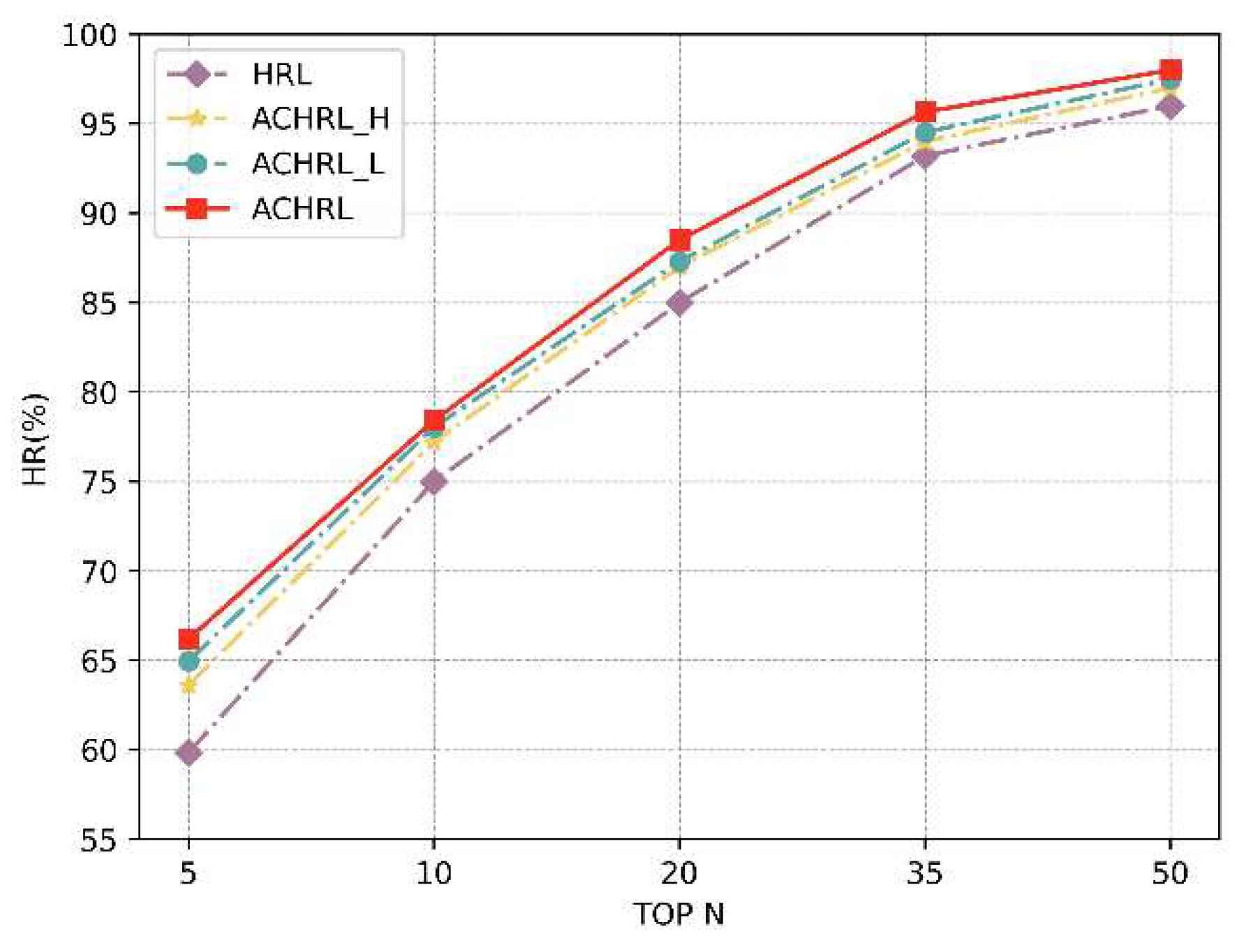
Figure 7.
The performance of HRL-based models, assessed in terms of HR (%) at different top N HR values, on the MOOCCube.
Figure 7.
The performance of HRL-based models, assessed in terms of HR (%) at different top N HR values, on the MOOCCube.
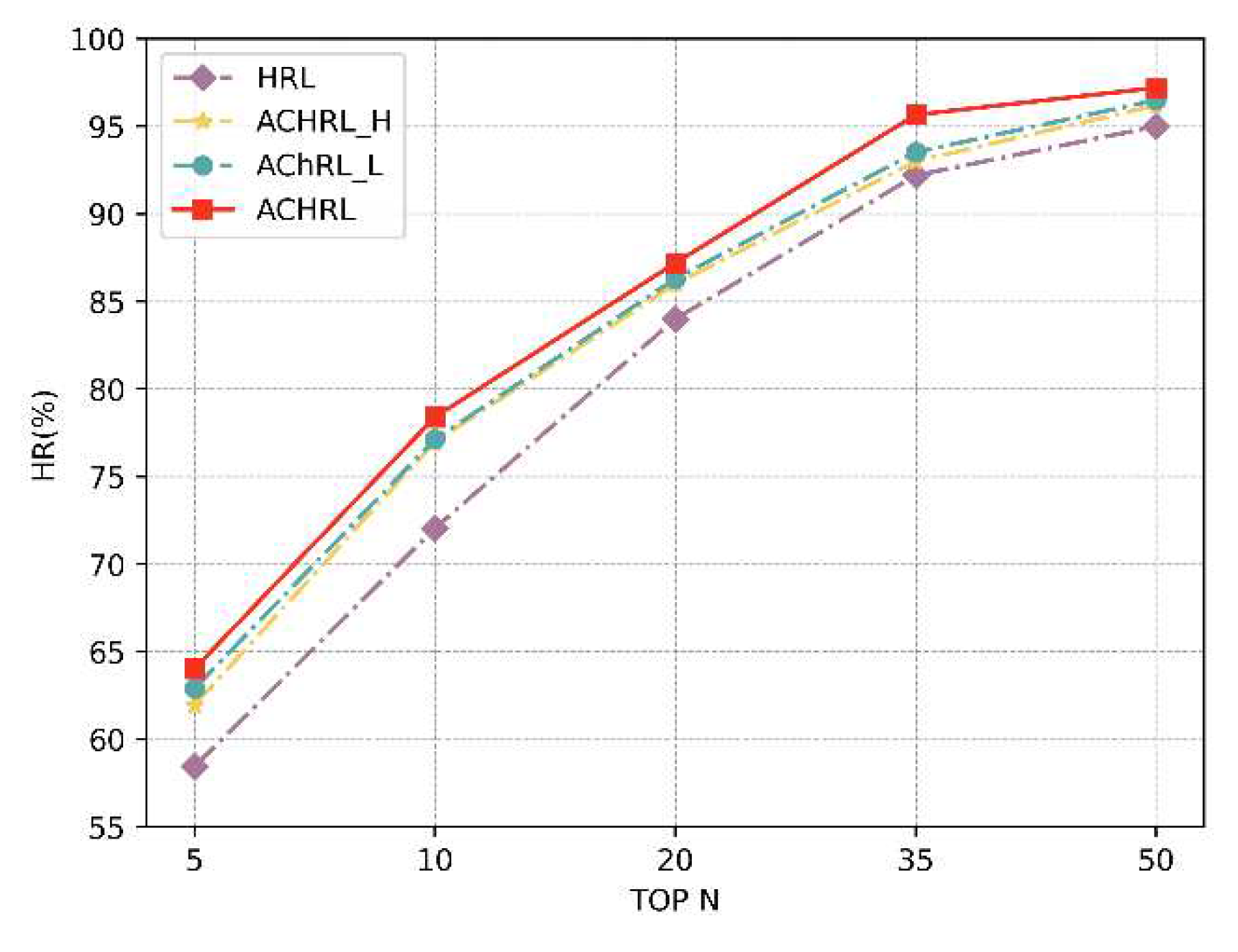
Figure 8.
Variation of reward value with epoch of ACHRL, ACHRL_H, ACHRL_L models on MOOCCourse.
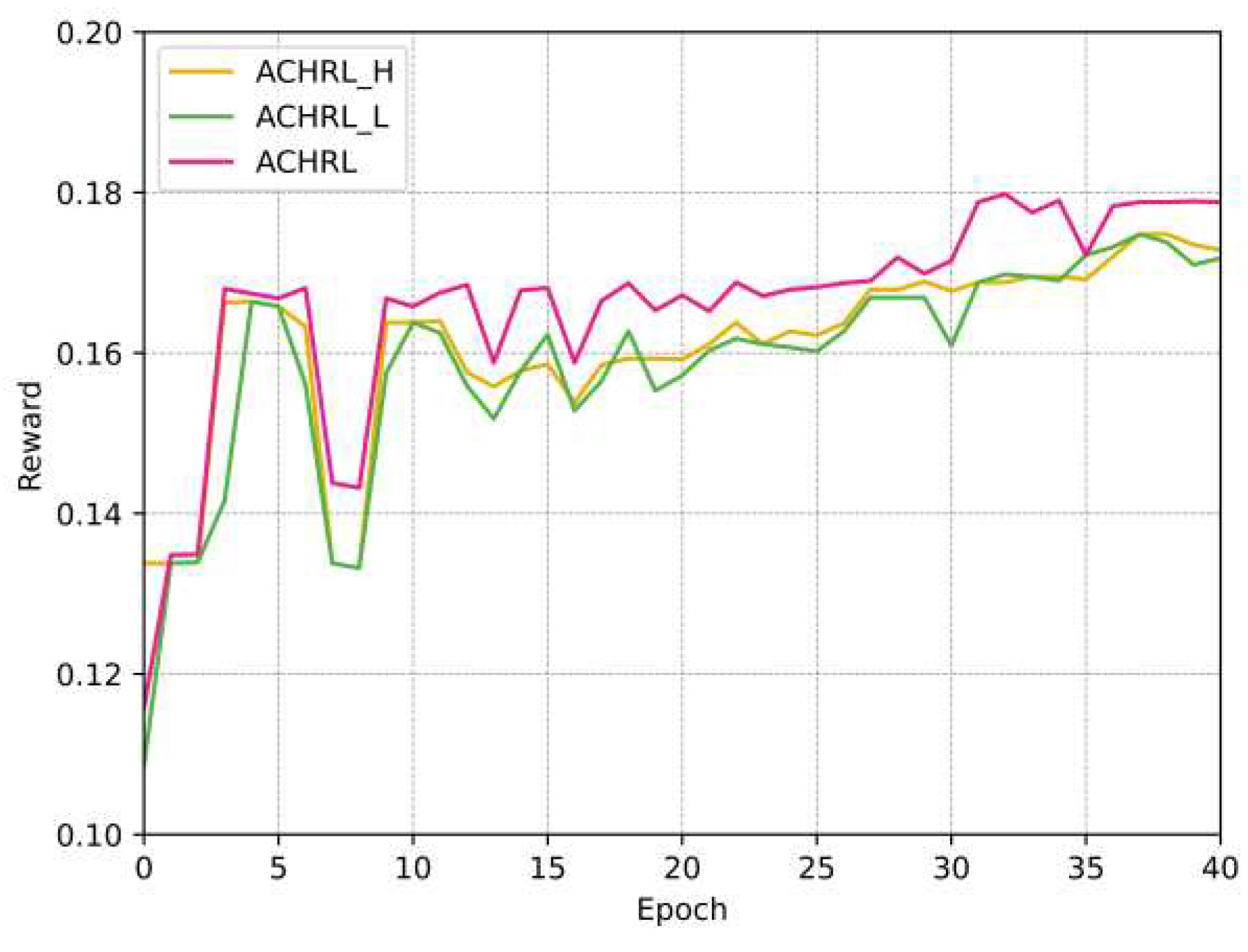
Figure 9.
Variation of reward value with epoch of ACHRL, ACHRL_H, ACHRL_L models on MOOCCube.
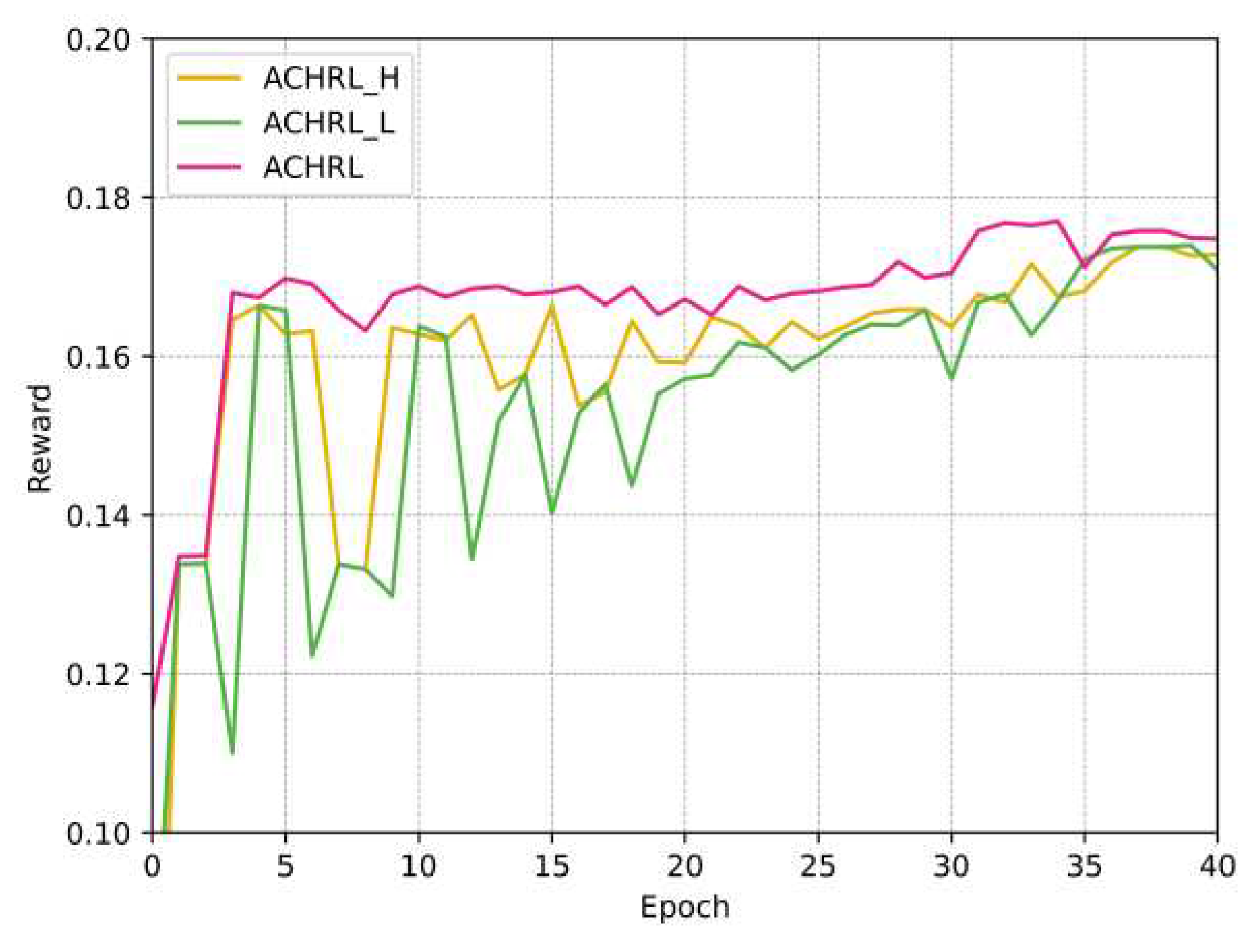
Figure 10.
The performance of ACHRL, ACHRL_H, ACHRL_L, HRL, and NAIS, concerning different embedding size 8/16/32/64/128, are evaluated with respect to HR@10, and NDCG@10 on MOOCCourse.
Figure 10.
The performance of ACHRL, ACHRL_H, ACHRL_L, HRL, and NAIS, concerning different embedding size 8/16/32/64/128, are evaluated with respect to HR@10, and NDCG@10 on MOOCCourse.
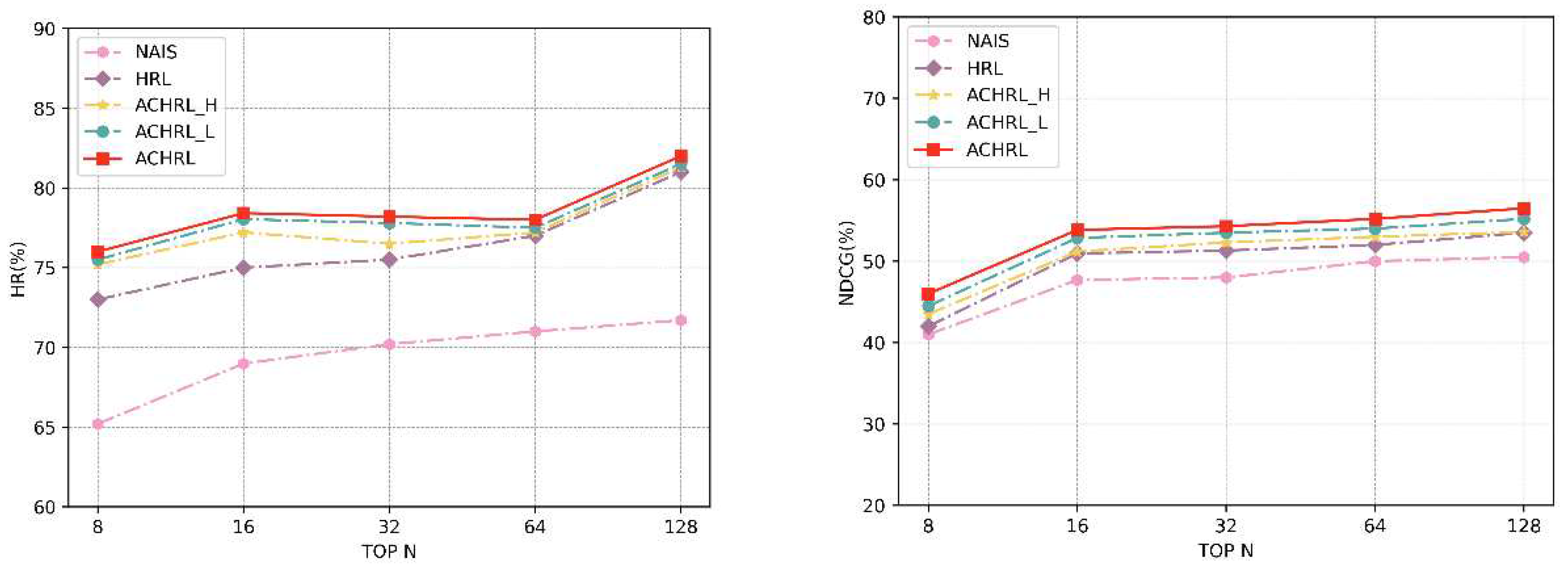
Figure 11.
The performance of ACHRL, ACHRL_H, ACHRL_L, HRL, and NAIS, concerning different embedding size 8/16/32/64/128, are evaluated with respect to HR@10, and NDCG@10 on MOOCCube.
Figure 11.
The performance of ACHRL, ACHRL_H, ACHRL_L, HRL, and NAIS, concerning different embedding size 8/16/32/64/128, are evaluated with respect to HR@10, and NDCG@10 on MOOCCube.
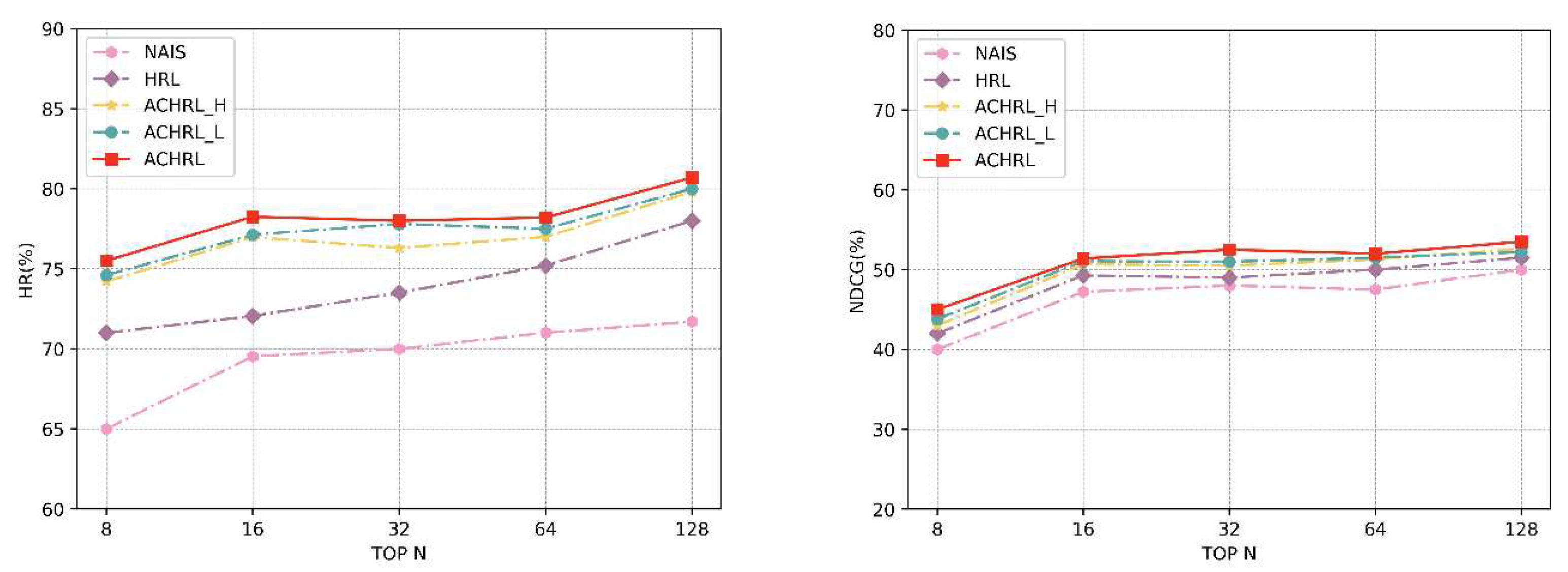
Figure 12.
The performance of ACHRL, ACHRL_H, ACHRL_L, HRL, and NAIS, concerning different hidden layer sizes (4/8/16/32/64) are evaluated with respect to HR@10, and NDCG@10 on MOOCCourse.
Figure 12.
The performance of ACHRL, ACHRL_H, ACHRL_L, HRL, and NAIS, concerning different hidden layer sizes (4/8/16/32/64) are evaluated with respect to HR@10, and NDCG@10 on MOOCCourse.
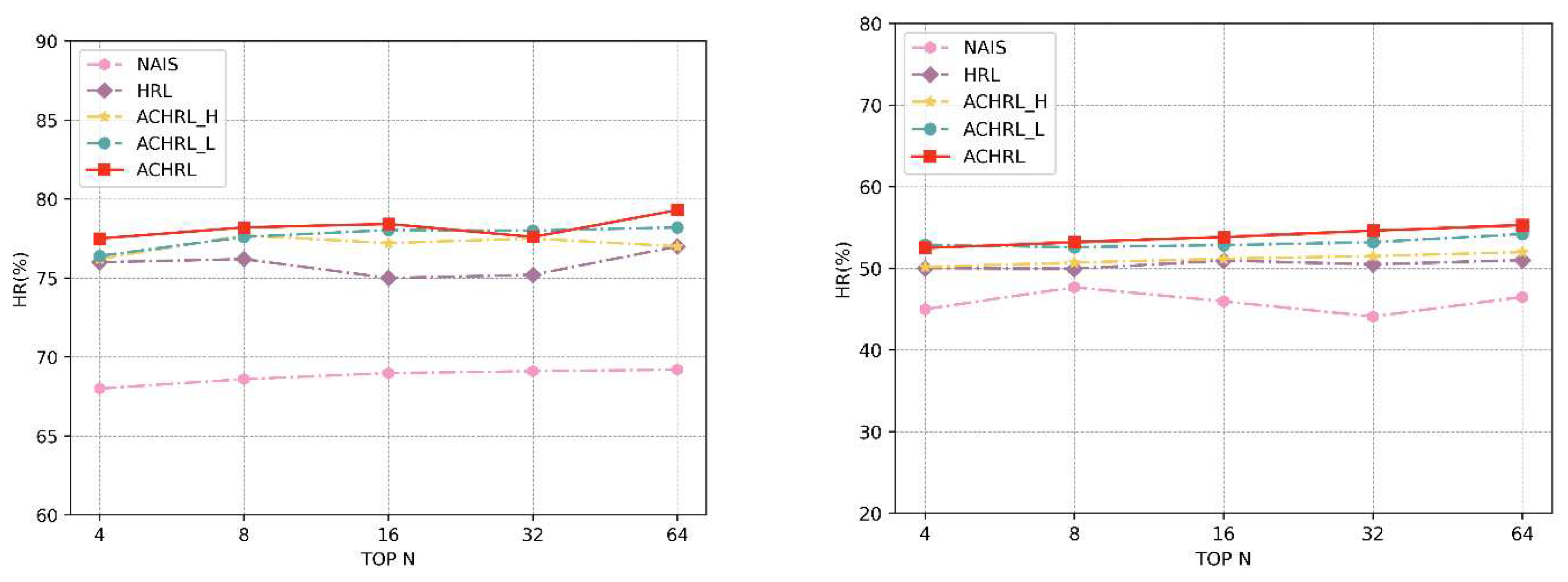
Figure 13.
The performance of ACHRL, ACHRL_H, ACHRL_L, HRL, and NAIS, concerning different hidden layer sizes (4/8/16/32/64) are evaluated with respect to HR@10, and NDCG@10 on MOOCCube.
Figure 13.
The performance of ACHRL, ACHRL_H, ACHRL_L, HRL, and NAIS, concerning different hidden layer sizes (4/8/16/32/64) are evaluated with respect to HR@10, and NDCG@10 on MOOCCube.
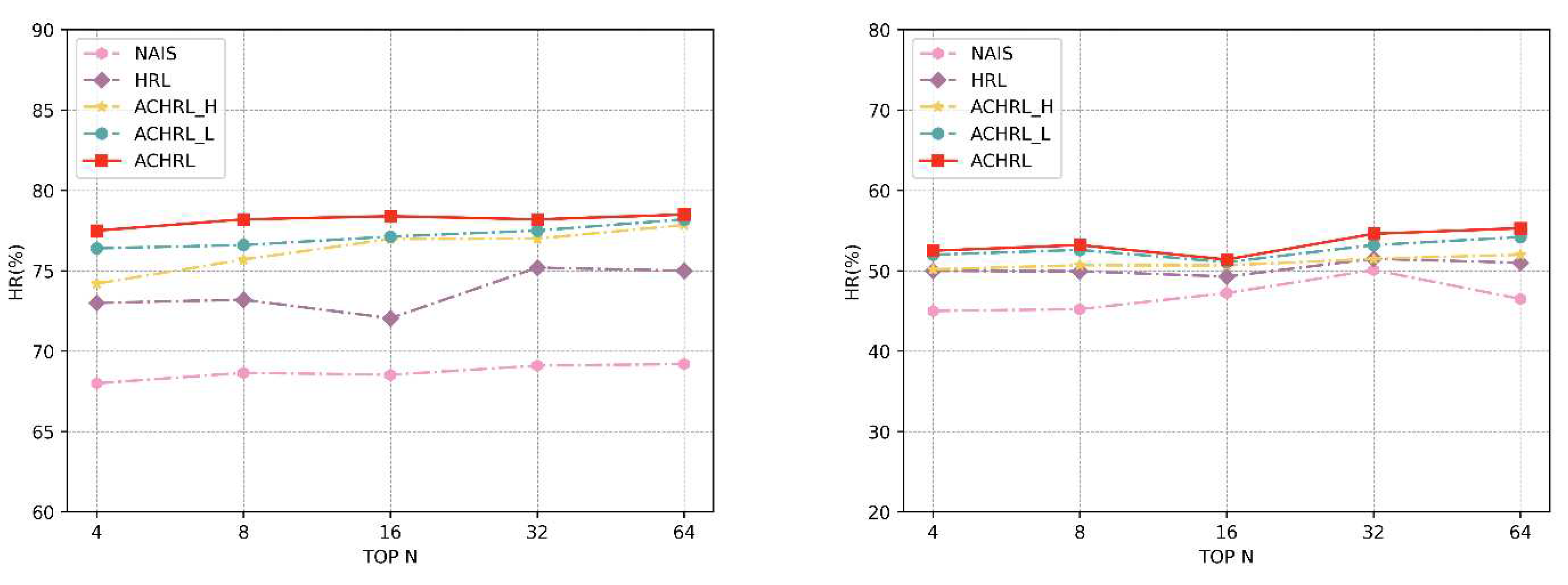

Table 1.
The experimental datasets.
| Dataset | #Courses | #Users | #Interactions |
|---|---|---|---|
| MOOCCourse | 1302 | 82535 | 458453 |
| MOOCCube | 706 | 55203 | 190049 |
Table 2.
Recommendation performance (%).
| MOOCCourse | MOOCCube | |||||||
|---|---|---|---|---|---|---|---|---|
| HR@5 | HR@10 | NDCG@5 | NDCG@10 | HR@5 | HR@10 | NDCG@5 | NDCG@10 | |
| MLP | 52.53 | 66.74 | 40.61 | 40.96 | 51.62 | 66.55 | 40.00 | 43.58 |
| FISM | 53.12 | 65.89 | 40.63 | 45.13 | 52.85 | 65.80 | 40.50 | 45.52 |
| NeuMF | 54.20 | 67.25 | 42.06 | 46.05 | 54.25 | 67.50 | 41.72 | 46.00 |
| NARM | 54.23 | 69.37 | 42.54 | 47.24 | 54.12 | 69.50 | 41.85 | 47.20 |
| NAIS | 56.05 | 68.98 | 43.58 | 47.69 | 56.02 | 69.53 | 43.50 | 47.23 |
| HRL HRRL DARL |
59.84 61.36 63.12 |
75.00 78.29 77.63 |
44.50 45.82 48.53 |
50.95 51.70 53.25 |
58.45 - - |
72.05 - - |
44.87 - - |
49.28 - - |
| ACHRL_H | 63.61 | 77.21 | 46.07 | 51.18 | 61.95 | 76.98 | 45.42 | 50.67 |
| ACHRL_L | 64.96 | 78.04 | 48.58 | 52.86 | 62.91 | 77.13 | 46.33 | 51.07 |
| ACHRL | 66.19 | 78.42 | 49.84 | 53.84 | 64.03 | 78.40 | 46.35 | 51.40 |
Table 3.
Two cases of the recommendation performance of ACHRL and HRL.
| Model | Performance | Recommended Result | |
|---|---|---|---|
| (1) | ACHRL | Data Structure, Java, Assembly Language, Software Engineering | Software Engineering(√) |
| HRL | Data Structure, Java, Economics, Data Structure, Software Engineering | Organic Chemistry(×) | |
| (2) | ACHRL | Monetary and Financial Studies, Investment Studies, Corporate Finance | Principles of Economics(√) |
| HRL | Operating Systems, Monetary and Financial Studies, Investment Studies | Software Engineering(×) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



