
Submitted:
22 October 2023
Posted:
23 October 2023
You are already at the latest version
Abstract
As the oil industry increasingly turns to unconventional low-permeability and low-porosity reservoirs, precise post-fracture production prediction is a pivotal instrument in investment de-cision-making, formulation of energy policies, and promotion of environmental assessments. Nevertheless, despite extensive research spanning decades, the precise post-fracture production prediction based on logging parameters remains an intricate task. In this study, we gathered ex-tensive logging data and segmented the post-frac gas production during well testing on the first day to enrich the dataset. Nine pipelines were then architected using various techniques of data preprocessing, feature extraction, and advanced machine learning models. Hyperparameter op-timization was executed via the GridsearchCV. To assess the efficacy of diverse models, metrics including the coefficient of determination (R2), standard deviation (SD), and root mean square error (RMSE) were invoked. Among the several pipelines explored, the PS-NN exhibited excellent predictive capability in specific reservoir contexts (an R2 value of 0.94 and an RMSE of 48.15). In essence, integrating machine learning with logging parameters effectively assesses reservoir productivity at multi-meter formation scales. This strategy not only mitigates uncertainties en-demic to reservoir exploration but also equips petroleum engineers with monitoring on reservoir dynamics, thereby facilitating reservoir development. Additionally, this approach provides res-ervoir engineers with an efficient way of reservoir performance oversight.
Keywords:
Post-fracture production prediction
; Production segmentation
; well logging
; Pipelines
; GridSearchCV
; Machine learning
1. Introduction
Oil production plays a pivotal role in national economic progression, energy assurance, and global geopolitical equilibrium [1]. As the energy demand continues to rise, the industry has turned to unconventional reservoirs, particularly those with low-permeability and low-porosity formations. Recent advancements in hydraulic fracturing have introduced innovative methodologies to optimize the exploration and production of these challenging reservoirs. An integrated geological-engineering design, such as volume fracturing with a fan-shaped well pattern, has been proposed to enhance hydrocarbon recovery by optimizing well placement [2]. This approach, backed by in-depth studies into the dynamics of hydraulic fractures in multi-layered formations, offers insights into fracture propagation and its subsequent impact on reservoir performance [3].
However, with the introduction of hydraulic fracturing and other advanced extraction techniques, predicting post-fracture oil production capacity becomes an intricate endeavor fraught with multifaceted challenges [4]. Accurate post-fracture production prediction is paramount in enhancing well operations, mitigating operational hiatuses, and ensuring a higher return on petroleum investment. The integration of machine learning with advanced numerical techniques, like the 3-D lattice method, has emerged as a promising solution for understanding fracture dynamics in various shale fabric facies, as evidenced by a case study from the Bohai Bay basin, China [5]. Moreover, the advent of physics-informed methods for evaluating feasibility emphasizes the need to comprehend the intrinsic properties of shale reservoirs for efficient production [6]. When combined with sustainable extraction techniques, accurate production prediction can lead to more effective oil development, minimizing environmental degradation [7]. This approach provides a pathway toward a more sustainable and environmentally friendly energy economy. Nonetheless, predicting oil production capacity is an intricate endeavor with multifaceted challenges [8,9,10].
The oil and gas field typically employs several ways to predict production. There are numerous methods for production prediction. One prevalent strategy involves forecasting oil production metrics for a specific well by extrapolating anticipated oil yield. This extrapolation leans heavily on historical production metrics and pertinent reservoir data [8,11,12]. Another strategy is based on the production potentialities of adjacent wells [13,14], representing the extant geological and geophysical data on the target reservoir. This approach evaluates the economic viability of implementing new drillings and finding the sweet spots within the reservoir's geological and engineering landscape [15,16].
Reservoir simulation is a widely used technique that employs physics-based models to predict oil production under different scenarios. However, the simulation requires extensive reservoir geological and engineering data, which may not always be available. A deep understanding of the geology and engineering aspects of the complex reservoir is also challenging for people without professional knowledge [17]. Moreover, the assumptions made in the simulation model can impact the predictive accuracy. Reservoirs with low permeability and porosity are distinct due to their constrained pore spaces and fluid flow capabilities [18,19,20,21]. This nature inherently complicates numerical computations for production rates [22]. The reduced permeability demands a more detailed grid division, amplifying computational intricacy and extending calculation durations [23]. Such environments can also generate numerical dispersion, causing potential mismatches between simulated outcomes and actual field data [24]. Additionally, fluid flow in these settings might not always adhere to Darcy's law, requiring more nuanced modeling approaches [23]. The limited permeability further complicates the flow dynamics of oil, gas, and water, and obtaining precise rock and fluid properties becomes a challenge, introducing more significant model uncertainties [25]. Therefore, numerical calculations for these reservoirs demand a particularly cautious and accurate approach [26].
Machine learning has recently gained popularity in production prediction [13,14]. The estimated ultimate recovery (EUR) prediction model for shale gas wells is established based on the multiple linear regression method. The key factors controlling productivity are analyzed using the Pearson correlation coefficient and maximum mutual information coefficient analysis method [9]. In contrast, The EUR prediction model for fractured horizontal wells in tight oil reservoirs employs a deep neural network (DNN) and demonstrates significantly higher prediction accuracy than the traditional multiple linear regression model [10].
The present study provides a novel method to predict each sample's production in different depths, exclusively using well logging parameters. This approach is applied to find the relationship between rock physics, geo-mechanics, and production performance. Specifically, our research focuses on forecasting the post-fracture yield of the developed wells. In these wells, fracturing has already induced multi-fractures and facilitates the migration of hydrocarbons into production conduits. By harnessing well logging parameters, we make our efforts to focus on predicting the post-fracture yield of the designated stratum. Given that each well has a unique productivity, collecting productivity data for hundreds of wells can be challenging for most researchers. To address this, we propose a method of segmenting productivity. We divide the gas production during well testing on the first day based on the formation coefficient, which is the product of permeability, gas saturation, and porosity. Building on the foundations laid by previous studies, this study incorporates machine learning techniques to predict hydrocarbon production potential [27,28].
Utilizing the Sci-kit learn approach, we employ pipelines with GridSearchCV for production prediction. It is paramount to emphasize that a singular machine learning algorithm might not yield the optimal training model. Therefore, the pipelines are adopted to simplify the intricate workflow consolidate data preprocessing, feature selection and transformation, and algorithmic modeling. This method not only facilitates code development for researchers but also prevents model data leakage, ensuring the integrity of the modeling process [29,30,31]. Subsequently, the integration of GridSearchCV provides a robust framework for hyperparameter optimization within the pipeline, significantly enhancing the workflow's efficiency [32,33,34,35]. Integrating pipelines and GridSearchCV can simplify the modeling process, making it possible to identify the most favorable production sweet spots by utilizing multi-class parameters (reservoir properties, rock mechanics parameters, well logging parameters, and other oilfield data).
This paper is structured as follows: In Section 2, we outline the technical path for production prediction, providing some details on the process of pipeline establishment and the techniques used for model evaluation. Section 3 introduces our proposed production subdivision algorithm, presenting both the actual logging parameters and the subsequent data distribution for a specified block. In Section 4, we present and discuss the comparative analysis between predicted outcomes and actual results from three pipelines, all using consistent data preprocessing and feature extraction methods. Additionally, we delve into an analysis of potential correlations between logging parameters and productivity. Finally, Section 5 wraps up our findings, offering key conclusions and recommendations geared towards enhancing the forecasting efficiency for sustainable capacity development.
2. Material and Method
The overall technical approach for predicting post-fracturing production involves ten steps, which is shown in Figure 1:
2.1. Data collection and processing
Two data types need to be collected: the well logging data based on the depth range of perforated wells that have undergone hydraulic fracturing and the gas production during well testing on the first day. Since the sample size provided by the perforated segment is too small to carry out reliable and stable production prediction, the gas production during well testing is divided into ‘production segmentation’ at each logging sample.
2.2. Sample preparation
The data collected from the fractured wells are organized samples for machine learning-based production prediction. The features of the samples include nine logging parameters (depth, p-wave velocity, density, natural gamma, neutron porosity, resistivity, porosity, permeability, and water saturation).
2.3. Data Splitting
To ensure that the machine learning model is able to generalize the unseen data, the collected data is divided into a training set and a testing set. Usually, 80% of the data is used for training the model, and the remaining 20% is reserved for final testing to assess the model's performance. The basic process, including data collection, sample preparation, and data splitting, is shown in Figure 2.
2.4. Data Scaling and feature extraction
Effective data preprocessing involves handling variations in data scales and units. This is usually performed through data standardization and normalization. Our study incorporates two scaling techniques: StandardScaler, which normalizes data to have a mean of zero and a standard deviation of one, and RobustScaler, which uses the median and interquartile range, making it less prone to outliers.
For the StandardScaler, it follows the function [36]:
where, x is the original dataset, μ represents the mean of the dataset, σ denotes the standard deviation of the dataset, and z is the processed dataset.
For the RobustScaler, it follows the function [37]:
where, v' is the processed value, v is a value from the original dataset, median represents the median of the dataset, and IQR denotes the interquartile range of the dataset.
We employ Principal Component Analysis (PCA) for feature extraction to reduce the data dimension while preserving critical information. The Polynomial Features is also used to generate complex polynomial combinations of features. We comparatively analyze three preprocessing combinations (StandardScaler with PCA, RobustScaler with PCA, and StandardScaler with Polynomial Features), aiming to discern the optimal preprocessing strategy for our dataset.
2.5. Machine Learning Algorithm
We employ a combined approach of three robust models: XGBoost, Random Forest, and Neural Networks. XGBoost is a sequential model that iteratively corrects errors from previous predictions, thus enhancing the predictive accuracy. Random Forest, containing multiple decision trees, excels in handling intricate datasets, offers resistance to overfitting, and highlights essential features. Neural Networks are adept at deciphering complex patterns using interconnected layers of neurons, making them suitable for high-dimensional datasets. Our ensemble approach taps into the distinct strengths of each model, ensuring a comprehensive and efficient prediction mechanism.
2.5.1. XGBoost
XGBoost is an ensemble gradient boosting algorithm abbreviated from eXtreme Gradient Boosting. The method has been proven effective in handling geophysical data, especially with small sample sizes. We use XGBoost to build a regression model for the production prediction in this paper. The algorithm begins by training a weak learner, typically a decision tree. This tree starts with a root node encompassing all training data, then optimally splits the dataset based on features. The dataset partitioning continues until the data is correctly classified. Successive learners iteratively refine prediction errors from their predecessors using gradient descent on the loss function's second-order Taylor expansion. The final model aggregates these weak learners' results. For in-depth mathematical insights, we have provided a brief introduction based on Chen et al. [38].
Given a dataset , the tree ensemble model in XGBoost is represented by a set of functions from an input space to the output space. Each corresponds to a tree structure that maps an instance to the corresponding leaf index, yielding a predictive value from the set of leaf weights . Specifically, an instance is mapped as:
The objective function to be minimized during the training of XGBoost is given by the sum of a differentiable convex loss function and a regularization term . Formally:
For the loss function, a second-order Taylor expansion provides an approximation:
where, and represent the first and second-order gradients, respectively.
The regularization term, which penalizes the complexity of the tree ensemble, is defined as:
where, denotes the number of leaves in the tree; is the L2 regularization term on the leaf weights.
2.5.2. Random Forest
The Random Forest algorithm, introduced by Leo Breiman in 2001, is a robust machine learning technique that leverages the power of multiple decision trees for making predictions [39]. This ensemble method operates by constructing a multitude of decision trees at training time and outputs the classes (classification) or mean prediction (regression) of the individual trees1. Random decision forests can correct the habit of overfitting to the training set caused by decision trees. The algorithm's name comes from the fact that it introduces randomness into the tree building to ensure each tree is different. This randomness originates from two main aspects. Firstly, whenever a tree split is considered, a random sample of 'm' predictors is selected from the full set of 'p' predictors. Secondly, each tree is constructed using a bootstrap sample instead of the entire original dataset.
The application of Random Forest in petroleum exploration has been gaining traction in recent years. For instance, Roubícková et al. [40] utilized Random Forest to reduce ensembles of geological models for oil and gas exploration. They found that the Random Forest algorithm effectively identifies the critical grouping of models based on the most essential feature. This work highlights the potential of Random Forest in handling large datasets and complex geological models.
2.5.3. Neural network models(MLP Regressor)
The Multi-layer Perceptron (MLP), a foundational element in neural network architectures, has witnessed substantial advancements across various applications due to rigorous research efforts. Recent studies [41,42] highlight the adaptability of MLPs in varied tasks, from phishing URL detection to pinpointing functionals' extrema. Newer innovations, such as the MC-MLP [43], have broadened the scope of MLP applications, particularly in computer vision. Moreover, research into heterogeneous multilayer networks [44] and the exploration of the universality of equivariant MLPs [45] have further deepened the comprehension and application potential of MLPs across multiple sectors. This study establishes nine distinct pipelines by integrating the methodologies from sections 2.4 and 2.5. A flow chart detailing these pipelines will be provided in Table 1.
2.6. GridsearchCV
To enhance code maintainability, we've developed nine distinct pipelines, each representing a combination of one preprocessing technique with one machine learning algorithm. This systematic exploration aims to identify the most effective pairing for optimal predictive performance. Implementing this structured pipeline approach not only streamlines the process but also effectively mitigates data leakage risks—a prevalent issue in machine learning model development. To ascertain the best configurations for our algorithms, the GridSearchCV method is employed. GridSearchCV stands for "Grid Search and Cross-Validation." This procedure rigorously scans numerous parameter settings while instituting cross-validation, ensuring the identification of the most performative configuration. Through this rigorous approach, we can harness the full predictive capacity of ensembled models and reach optimal accuracy and reliability. Table 2 presents the parameters under consideration for tuning.
2.7. Evaluation Criteria
The performance of the model is assessed using appropriate evaluation metrics. For regression tasks such as production prediction, common metrics, including Standard Deviation (SD), Root Mean Squared Error (RMSE), and R-squared (R²) score are used.
where, is the kth real production, in m3/d; is the kth predicted production, in m3/d; is the mean real production of all wells, in m3/d; is the mean predicted production of all wells, in m3/d; is the standard deviation of real production, in m3/d; is the standard deviation of pipelines predicted production, in m3/d; n is the total count of specimens.
2.8. Optimal pipeline
In this study, we comprehensively evaluated nine distinct processing pipelines. Leveraging a suite of benchmark evaluation metrics, we systematically compared their performance to discern each pipeline's relative strengths and weaknesses. The analysis and empirical comparisons have enabled us to ascertain the most effective pipeline. The results from the comparative study can offer valuable insights into the optimal pipeline configuration for this particular context and contribute to a broader understanding of pipeline performance in the field.
2.9. Generalization Ability Verification
After our preliminary analyses, we dedicated the residual 20% of the dataset to execute production predictions. To depict the precision of our model's forecasting outcomes, we employed Taylor diagrams—an illustrative tool renowned for representing the R2, SD, and RMSE of model predictions. Readers can effortlessly discern the veracity of the model's predictions through this visual representation and assess the degree of uncertainty associated with stochastic forecasting outcomes.
2.10. Result Demonstration
Finally, the findings are elucidated through visual representations. The comparison of predicted outcomes against real results is undertaken for 33 wells, enabling a clear delineation of model accuracy. At the same time, the performance metrics are chosen to provide a granular understanding of the model's predictive capacity. The comprehensive analysis of training results facilitates comprehension of our predictive framework's inherent attributes and highlights potential ways for refinement. The study can provide a complete understanding of the model's utility, illuminating its merits and areas demanding further exploration.
3. Data Preparation and Description
3.1. Production Segmentation
Due to the limited samples provided (only 33 perforated sections) in the study areas, it is difficult to find the relationship between logging data and production and obtain a reliable production prediction model. Therefore, the production segmentation is adopted to enlarge the quantity of samples. The production is divided based on the formation coefficient (the product of permeability, gas saturation, and porosity). The model assumes that the effect of perforation friction at different depths is not considered. The production division is based on the following criteria:
where, Qj represents the gas production of a sampling point after partitioning, in m3/d; Q represents the total gas production of the perforation segment, in m3/d; K is permeability, in md; S is oil saturation, in percentage; represents porosity, in percentage.
As shown in Figure 3, the total production of the perforation section from 1485.40 to1491.40 m is 2800 m3/d. After subdivision, we have determined the production of each sampling point from 1485.40 to1491.40 m with an interval of 0.1 m.
After dividing the production according to the above formula, a total of 2663 samples are obtained from 33 perforation sections, which are used to train the production prediction model.
3.2. Data Description
As shown in Figure 4, when visualizing all data in the form of a histogram, it is evident that the hydraulic fracturing segments of the reservoir predominantly concentrate between 1600 to 1800 m and 2000 to 2300 m. Acoustic travel time predominantly falls within the range of 65 to 70 ft/μs. The density distribution is centered around 2.5 g/cm3. GR values are primarily below 100, and the cncf distribution is mainly between 5-15%, with a substantial proportion of data at 0. For M2RX, the values mostly lie below 100Ω/m, with the vast majority ranging from 0 to 20Ω/m. Porosity generally follows a normal distribution centered around 8%. Notably, about 350 data points display zero porosity, indicating certain reservoir fracturing segments are suboptimal. These 'suboptimal' data points are incorporated into our test set since our goal is to predict gas and oil production capabilities in other regions. To make the database as comprehensive as possible, it is essential to include these points. Water saturation is predominantly around 50%, though nearly 350 formations register as water-bearing layers with a saturation of 100%. After production segmentation, overall changes in output lie between 0 to 500 m3/d.
4. Results and Discussions
4.1. Model Performance Analysis
Optimal model parameters are determined utilizing GridSearchCV. Initially, 80% of the dataset is randomly allocated for training. Within this subset, a comprehensive set of 5,130 sensitivity parameters is established across the nine pipelines. GridSearchCV implicates a five-fold cross-validation strategy. This method entails training the model on 80% of the subset during each iteration (four out of five times) and validating the residual 20% (once). This procedure is iterated five times to include all samples, with the averaged outcome of validations serving as the performance metric. In total, 25,650 models undergo training to ascertain the optimal configuration. Table 3 presents the results of post-parameter optimization corresponding to each pipeline.
Figure 5 shows the prediction results of validation. The horizontal axis represents the real production calculated by Eq.11, and the vertical axis represents the predicted production. If the predicted production of a sample is equal to the real production, the blue dots will fall on the black diagonal line. The overall prediction results of high-productivity data samples are smaller than the real productivity value, but most of the samples are close to the diagonal. It indicates a good correspondence between predicted production and real production. Therefore, the adopted model is considered to have strong predictive ability.
The data normalization is executed within the processing pipeline, while it did not perturb the intrinsic range of our predictive outcomes. Specifically, the production capability in the designated operational zone is expected to span between 0 to 2000 m³/d. The formula delineated in Section 2.7 is employed to compare the actual production capacity against the forecasted values, and the outcomes are illustrated in Figure 6. The analysis reveals that the standard deviation of baseline data stands at 192.2. Notably, every pipeline, post-training, manifests a standard deviation smaller than that of the original dataset. This suggests that the variance within the trained data across all pipelines is less pronounced than that observed in the raw data. Given the significant deviation inherent in the dataset, the RMSE values for all pipelines exceed those from previously reported data; however, they remain substantially below the observed standard deviation. This context suggests that the predictions of the model operate within an acceptable margin. In subsequent sections, the validation against the remaining 20% of the data across 33 Wells will be elucidated. Table 4 shows the evaluation indices for all pipelines.
4.2. Comparative Analysis of PS-XGB vs. PS-RF vs. PS-NN
The remaining 20% of the dataset is used for forecasting, with real and projected productivity values for each well illustrated using well log mapping. The black curve represents the segmented production of the perforation interval, and the red curve represents the predicted production. By fitting the two curves, it can be seen that the model can make a reliable production prediction on many perforation intervals (Wells 2, 5, 14, 17 and 29). These results indicate that the model has good predictive ability.
Notably, significant discrepancies are observed in Wells 3, 6, and 25. Such deviations might be attributed to the insufficient training data of these wells, suggesting the need for refined parameters and enhanced machine learning models. Assuming that the range of parameter optimization is enlarged, the model could move into the overfitting territory, which is detrimental to reservoir productivity forecasting.
Among the three pipelines, PS-XGB exhibits the most severe overfitting, whereas PS-NN demonstrates the least overfitting. This is particularly evident in Well 3, where the predicted curve of PS-XGB displays considerable variability in contrast to the observed smoother curve of the actual data. Although PS-RF exhibits fewer fluctuations compared to PS-XGB, overfitting is still not avoided. When compared with PS-NN, PS-XGB shows superior results.
Figure 7.
Production prediction of the remaining 20% of 33 Wells using PS-XGB.
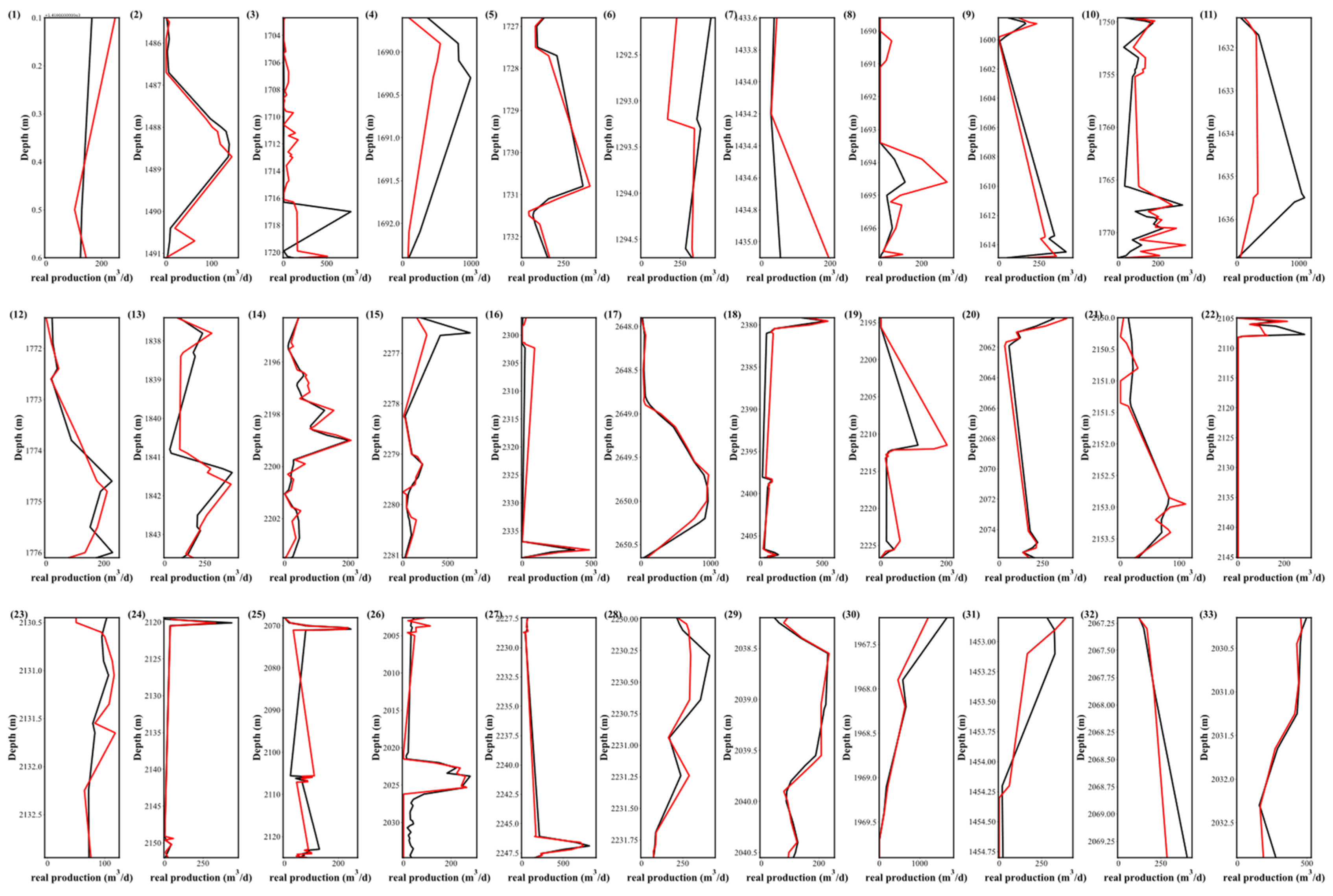
Figure 8.
Production prediction of the remaining 20% of 33 Wells using PS-RF.
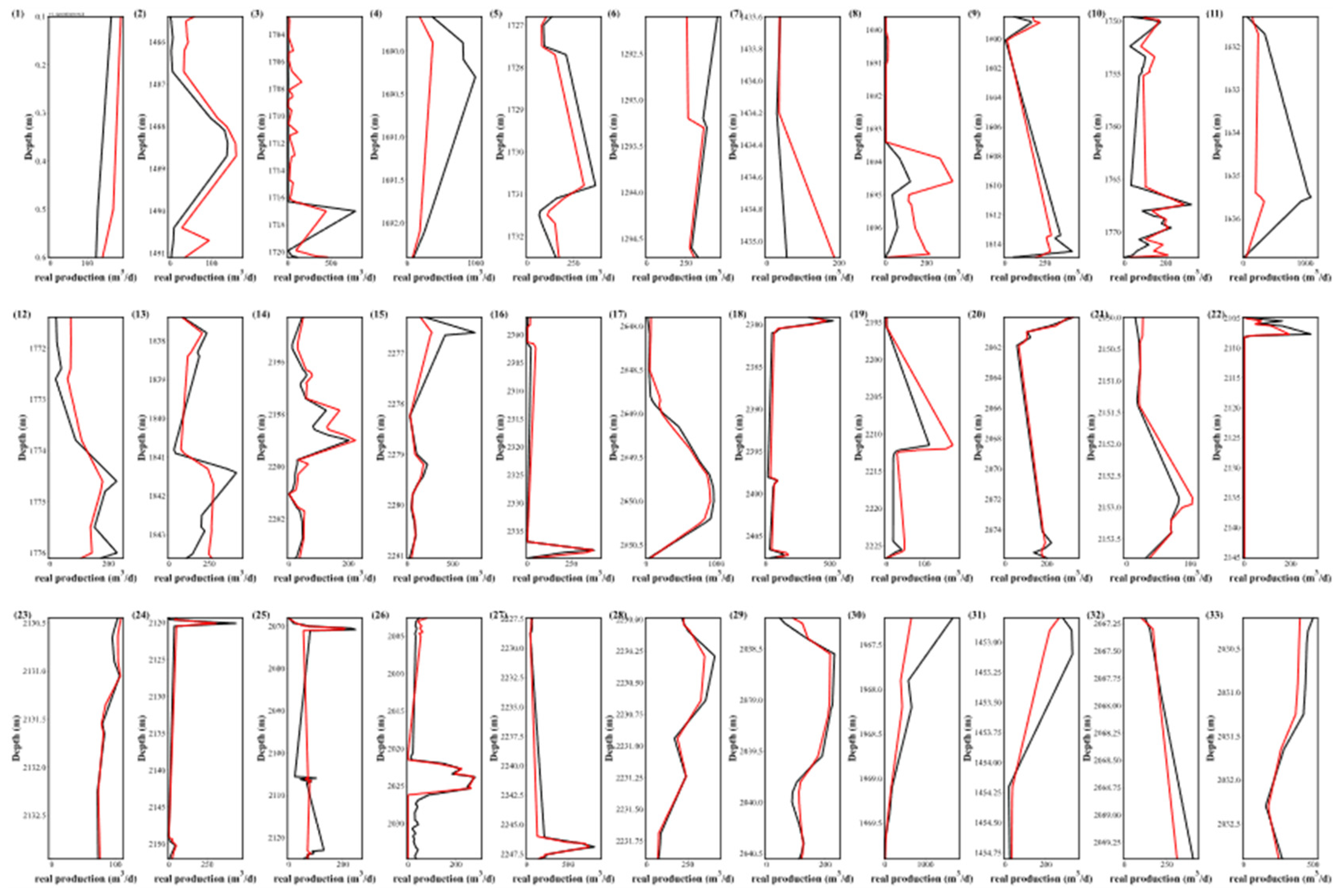
Figure 9.
Production prediction of the remaining 20% of 33 Wells using PS-NN.

4.3. Comparative Analysis of PS-XGB vs. PFS-RF vs. PFS-NN
In general, the fluctuation of the predicted production capacity data of these three pipelines is smaller than that of the three pipelines of PS-XGB, PS-RF, and PS-NN. Simultaneously, the differences in production prediction trends among the three pipelines are minimal, but there is a significant difference in the production prediction of some Wells in the pipeline. For example, between 1717 and 1720 m in well 3, the PFS-XGB and PFS-RF forecasts are good. Still, in the PFS-NN, the productivity forecast surged to 2,000 m3/d, which may be related to the strategic optimization of the neural network parameters. In well 25, an elevated predicted productivity value emerges at shallower depths, yet the predictions from all three pipelines align closely at greater depths. The shallow depth predictions for well 30 significantly deviate from real values. An observable production fluctuation between depths of 1690 and 1692 meters in well 4 eludes the predictive capabilities of all three pipelines. In well 21, the predicted values substantially exceed the real production. Conversely, the trio of pipelines demonstrates commendable accuracy in forecasting the productivity for well 20 and 27. This could be attributed to a more straightforward relationship between logging parameters and productivity for this particular well.
Figure 10.
Production prediction of the remaining 20% of 33 Wells using PFS-XGB.

Figure 11.
Production prediction of the remaining 20% of 33 Wells using PFS-RF.
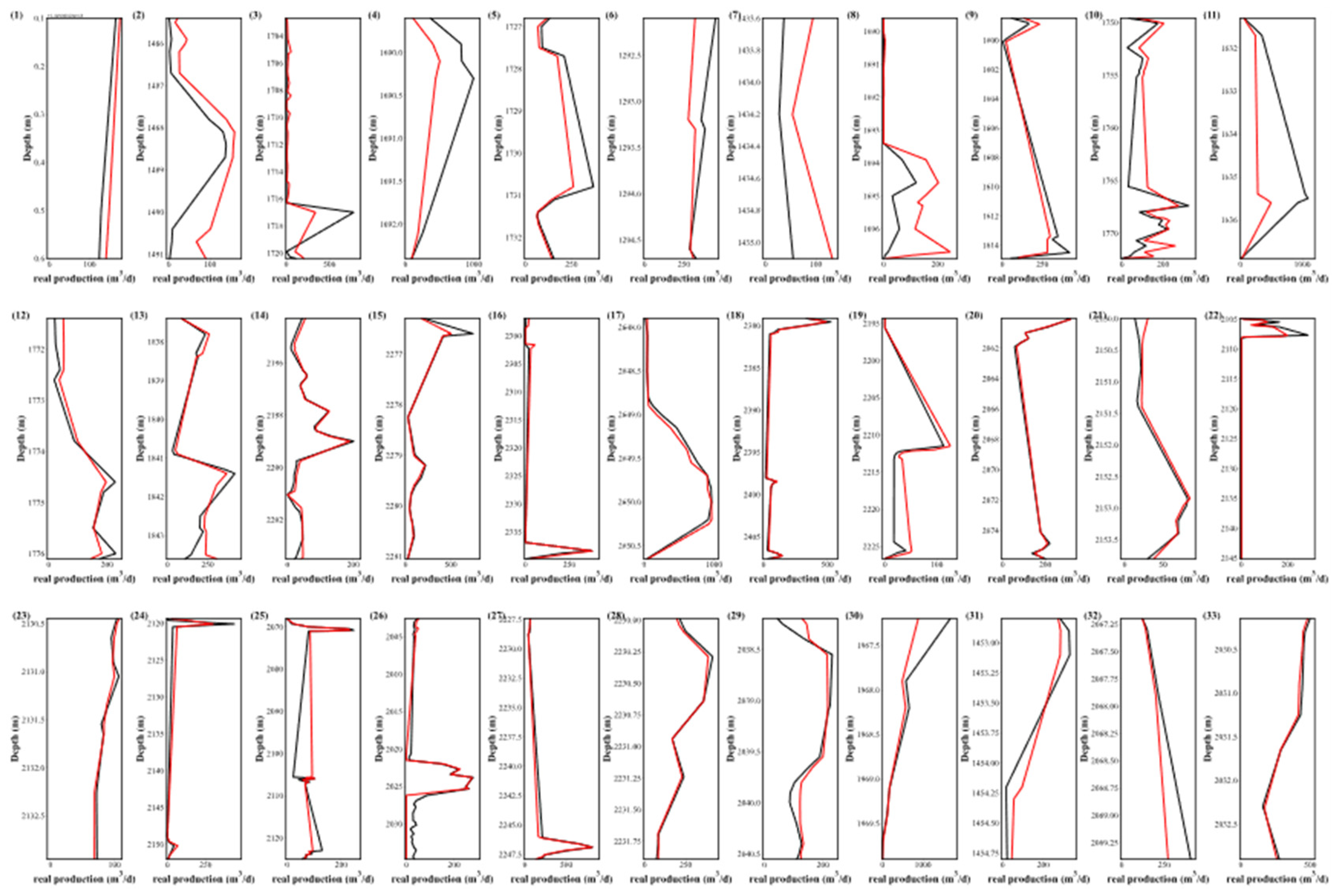
Figure 12.
Production prediction of the remaining 20% of 33 Wells using PFS-NN.

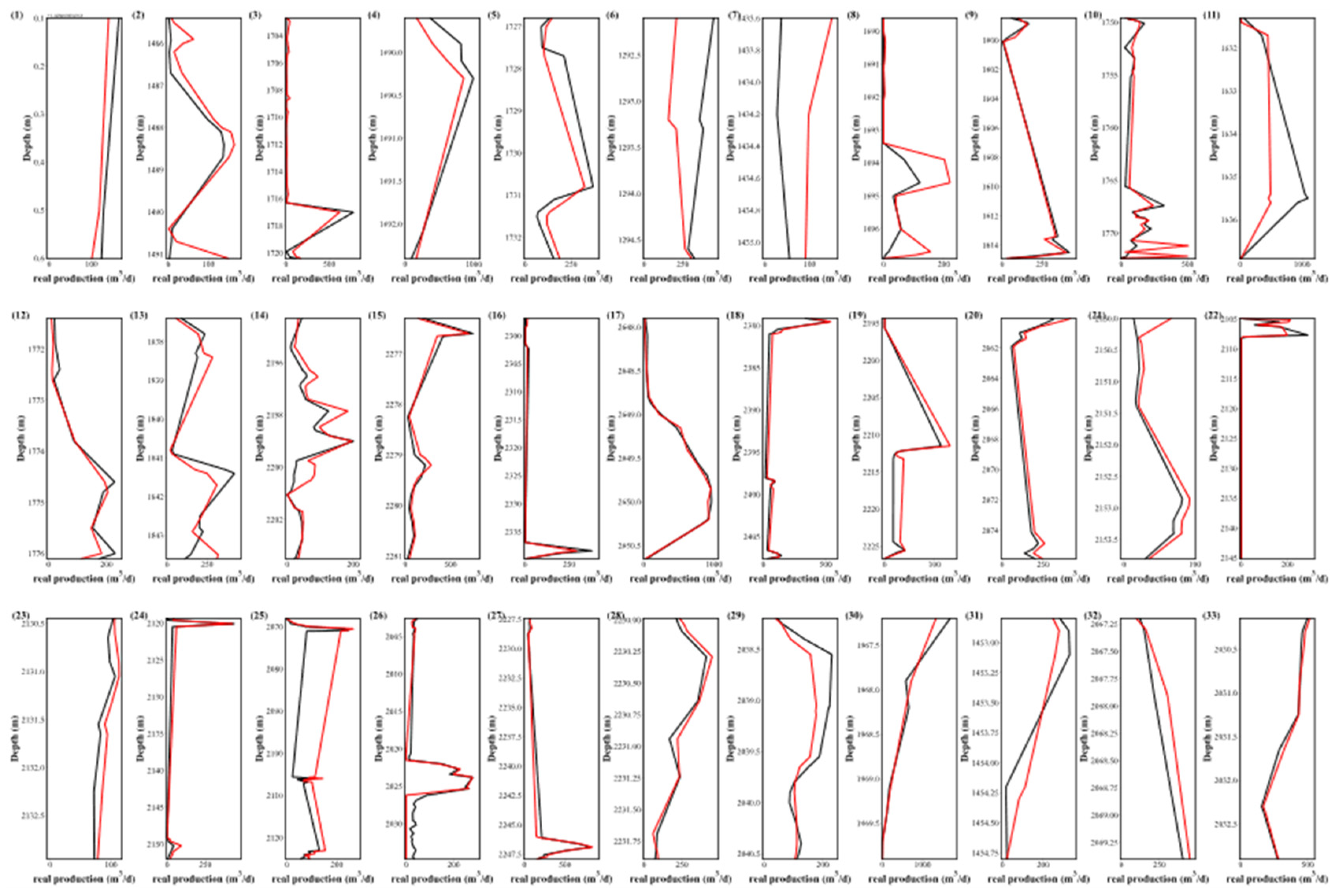
4.4. Comparative Analysis of PR-XGB vs. PR-RF vs. PR-NN
The predictions from the three pipelines showed notable discrepancies from the actual results, particularly in Wells 1 to 11. This deviation might stem from the use of the RobustScaler in data preprocessing. While it adeptly handles outliers through the median and interquartile range, it may not suit near-normal datasets and can miss crucial outlier information due to its non-zero mean. Among the three pipeline configurations, PR-XGB provides a more volatile representation of production. For Wells 6 and 7, the predictions from all three pipelines were off-mark, whereas PR-NN demonstrated notable accuracy. In particular, the production forecast for Well 21 between 2150.5 and 2154 m closely matched the actuals, contrasting with the significant deviations seen in PR-XGB and PR-RF predictions. While PR-RF generally provided the most accurate forecasts, it faltered in certain instances, notably with Well 31.
Figure 13.
Production prediction of the remaining 20% of 33 Wells using PR-XGB.
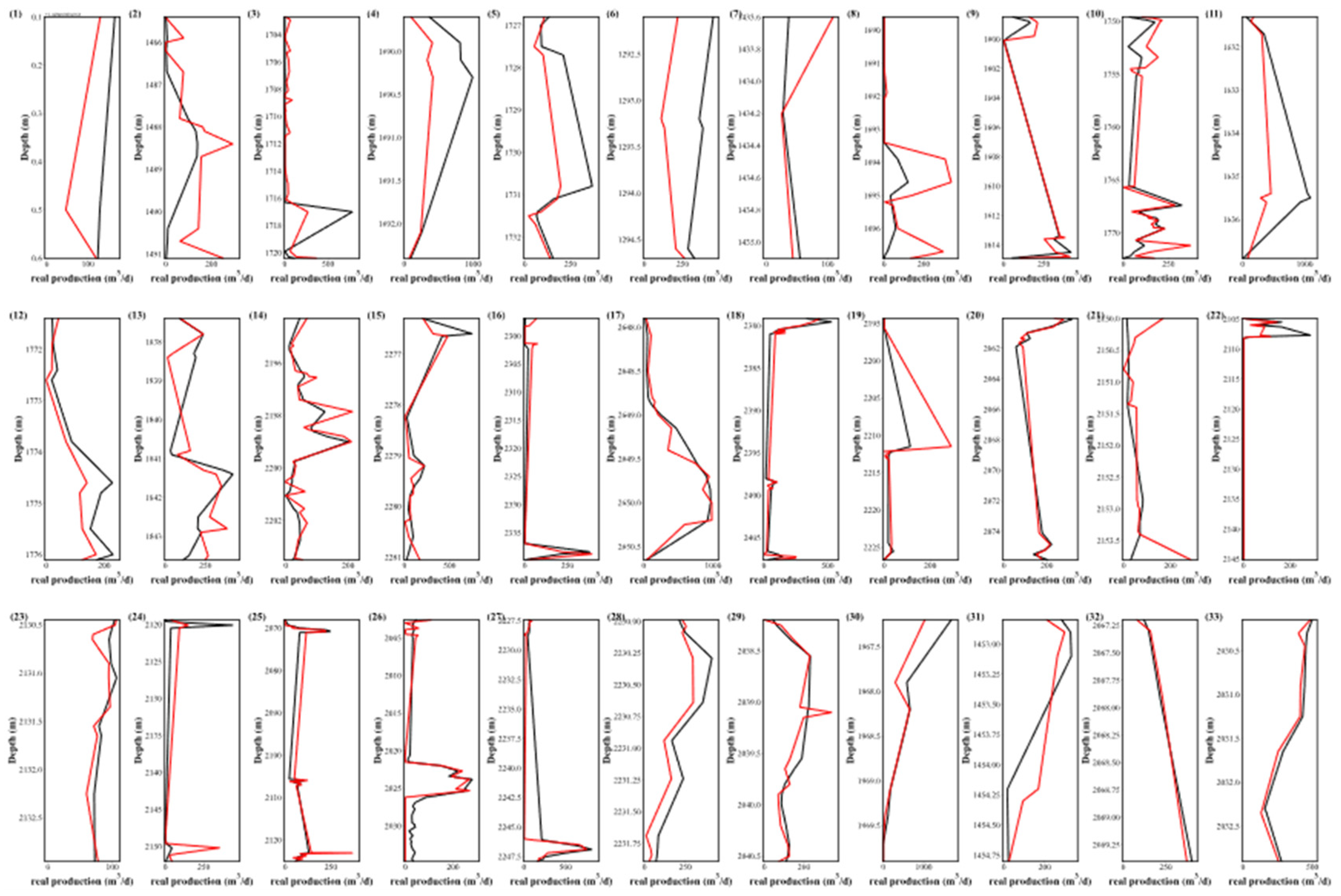
Figure 14.
Production prediction of the remaining 20% of 33 Wells using PR-RF.
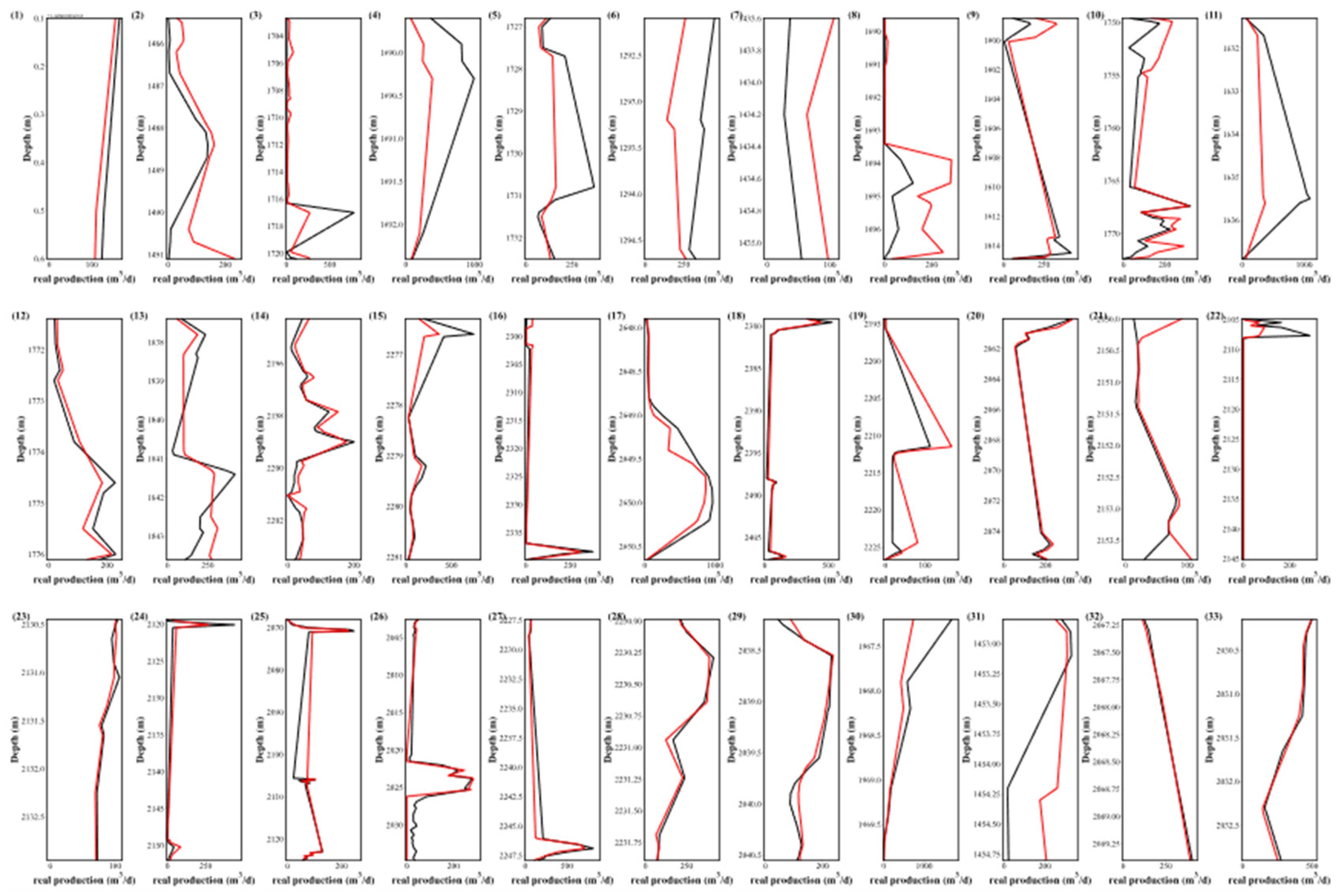
Figure 15.
Production prediction of the remaining 20% of 33 Wells using PR-NN.
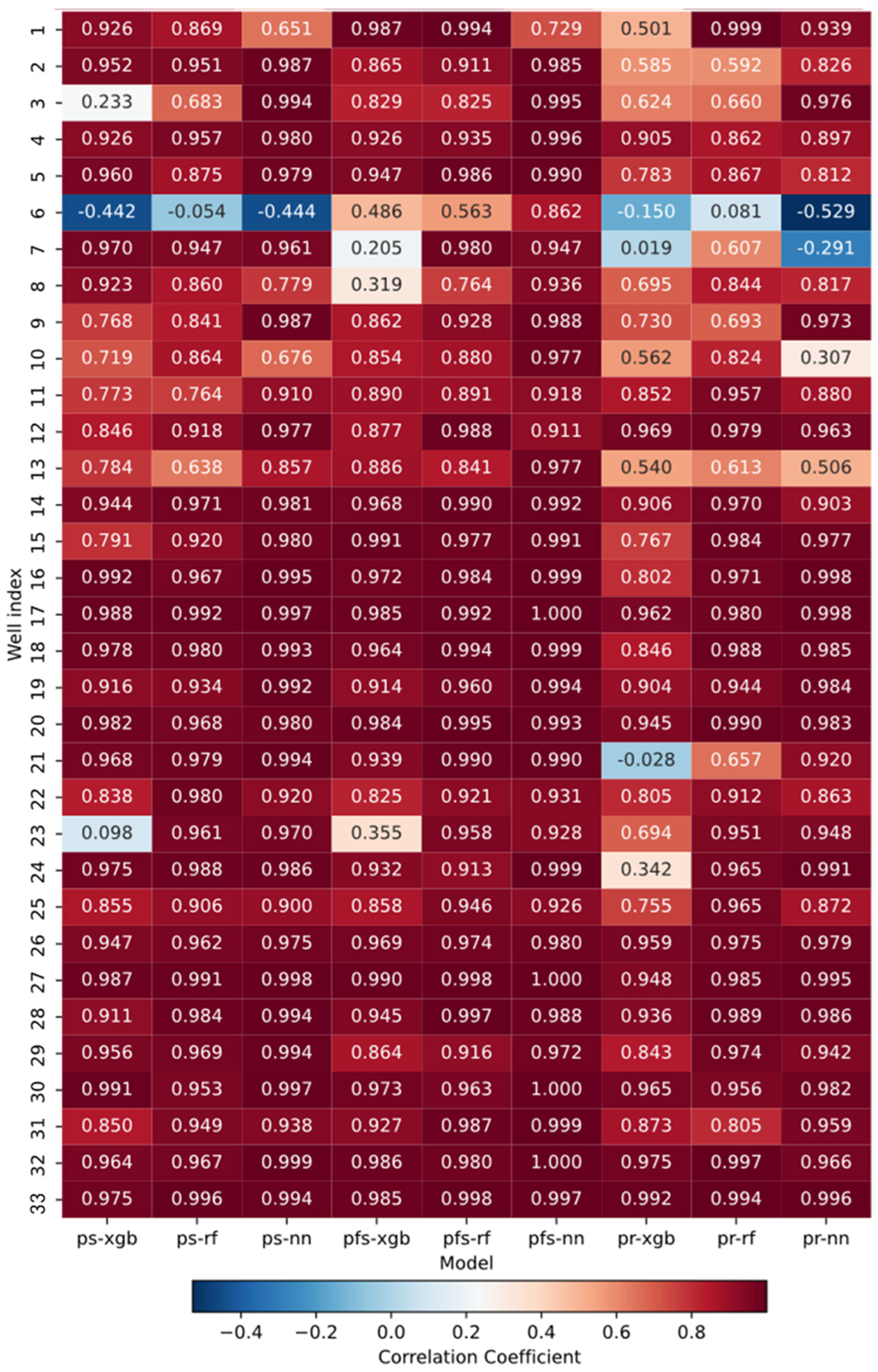
4.5. Correlation coefficient comparison
Pearson correlation coefficients were computed for each well across all pipelines and visualized via heat maps. This linear correlation between actual and predicted yields serves as a measure of prediction accuracy. The findings indicate suboptimal prediction accuracy for Well 6 across all pipelines.
For Well 1, PS-NN exhibited a correlation of 0.651, while PR-XGB registered at 0.501, suggesting room for improvement. In the case of Well 7, PR-NN's predictions negatively correlated with those of Well 33, and PR-XGB's predictions also showed poor alignment with actual results. Notably, PR-XGB consistently underperformed in predictive correlation across all wells, whereas PFS-NN emerged as the top performer in terms of determination coefficient.
Overall, the production predictions across all pipelines exhibit a strong correlation. The trained model demonstrates a reliable performance for production prediction.
Figure 16.
Pearson correlation coefficients of different models on different wells.
5. Conclusion
The post-fracturing production characteristics offer valuable insights for selecting the appropriate fracturing stage. We meticulously segmented the post-pressure productivity of each well based on logging parameters at varying depths. A comprehensive parameter optimization was executed across nine pipelines, employing diverse data preprocessing techniques, feature extraction methods, and machine learning models. This was achieved through the GridSearchCV hyperparameter tuning method, yielding the best-performing model for each pipeline. In conjunction with the optimized pipeline, these logging parameters were then harnessed to forecast post-fracturing production. Subsequently, we conducted a comparative analysis of productivity predictions across different pipelines and evaluated the determination coefficients for all wells under each pipeline.
- After extensive hyperparameter tuning, it became evident that logging parameters can indeed correlate with productivity, and the prediction trends are generally on point. As such, this approach holds promise as a surrogate model for reservoir numerical simulations;
- Segmenting post-fracturing production based on well logging data at different depths is instrumental in maximizing the sample size for data-driven production predicting;
- In the context of oil and gas extraction from low-permeability and low-porosity formations, machine learning models offer an intuitive representation of the productivity distribution in relation to well depth. This is pivotal in guiding the selection of the most suitable fracturing stage during field operations. And this approach provides reservoir engineers an efficient way in reservoir performance oversight.
Nomenclature
| the original dataset | |
| the mean of the dataset | |
| the standard deviation of the dataset | |
| the formation pressure, MPa | |
| the processed value | |
| a value from the original dataset | |
| the median of the dataset | |
| the interquartile range of the dataset | |
| the prediction of the i-th instance at the t-th iteration | |
| the prediction of the k-th tree for instance xi | |
| the leaf weight assigned to the i-th instance when it reaches a leaf in the tree | |
| the function mapping an instance to the corresponding leaf in the tree | |
| the objective is a sum of a loss term (how well the model predicts) and a regularization term (to keep the model simple) | |
| the loss function that measures the difference between the true label and the predicted label for the i-th instance at the t-th iteration | |
| the first order gradient statistics of the loss function with respect to the prediction from the previous iteration | |
| he second order gradient statistics of the loss function with respect to the prediction from the previous iteration | |
| regularization term for the k-th tree | |
| the k-th real production, m3/d | |
| the k-th predicted production, m3/d | |
| the k-th real production, m3/d | |
| the mean predicted production of all wells, m3/d | |
| the standard deviation of pipelines real production, m3/d | |
| the standard deviation of pipelines predicted production, m3/d | |
| the total count of specimens | |
| the gas production of a sampling point after segmenting, m3/d | |
| the total gas production, m3/d | |
| permeability, md | |
| oil saturation, % | |
| porosity, % |
References
- Amineh M P, Yang G. China’s geopolitical economy of energy security: a theoretical and conceptual exploration[J]. African and Asian studies, 2018, 17(1-2): 9-39. [CrossRef]
- Tang, J., Wang, X., Du, X., et al. 2023. Optimization of Integrated Geological-engineering Design of Volume Fracturing with Fan-shaped Well Pattern. Petroleum Exploration and Development. 50(4): 1-8. [CrossRef]
- Tang, J., Wu, K., Zuo, L., et al. 2019. Investigation of Rupture and Slip Mechanisms of Hydraulic Fracture in Multiple-layered Formation. SPE Journal. 24(05): 2292-2307. [CrossRef]
- Huang L, Jiang P, Zhao X, et al. A modeling study of the productivity of horizontal wells in hydrocarbon-bearing reservoirs: effects of fracturing interference[J]. Geofluids, 2021, 2021: 1-13. [CrossRef]
- Zhao, X., Jin, F., Liu, X., et al. 2022. Numerical study of fracture dynamics in different shale fabric facies by integrating machine learning and 3-D lattice method: A case from Cangdong Sag, Bohai Bay basin, China. Journal of Petroleum Science and Engineering. 218: 110861. [CrossRef]
- Li, Y., Li, Z., Shao, L., et al. 2023. A new physics-informed method for the fracability evaluation of shale oil reservoirs. Coal Geology & Exploration. 51(10): 1−15. [CrossRef]
- Yang C, Bu S, Fan Y, et al. Data-driven prediction and evaluation on future impact of energy transition policies in smart regions[J]. Applied Energy, 2023, 332: 120523. [CrossRef]
- Parvizi H, Rezaei-Gomari S, Nabhani F. Robust and flexible hydrocarbon production forecasting considering the heterogeneity impact for hydraulically fractured wells[J]. Energy & Fuels, 2017, 31(8): 8481-8488. [CrossRef]
- Niu W, Lu J, Sun Y. A production prediction method for shale gas wells based on multiple regression[J]. Energies, 2021, 14(5): 1461. [CrossRef]
- Luo S, Ding C, Cheng H, et al. Estimated ultimate recovery prediction of fractured horizontal wells in tight oil reservoirs based on deep neural networks[J]. Advances in Geo-Energy Research, 2022, 6(2): 111-122. [CrossRef]
- Noshi C I, Eissa M R, Abdalla R M. An intelligent data driven approach for production prediction[C]//Offshore Technology Conference. OnePetro, 2019.
- Li X, Ma X, Xiao F, et al. A physics-constrained long-term production prediction method for multiple fractured wells using deep learning[J]. Journal of Petroleum Science and Engineering, 2022, 217: 110844. [CrossRef]
- Hongliang W, Longxin M U, Fugeng S H I, et al. Production prediction at ultra-high water cut stage via Recurrent Neural Network[J]. Petroleum Exploration and Development, 2020, 47(5): 1084-1090. [CrossRef]
- Cheng B, Tianji X U, Shiyi L U O, et al. Method and practice of deep favorable shale reservoirs prediction based on machine learning[J]. Petroleum Exploration and Development, 2022, 49(5): 1056-1068. [CrossRef]
- Hou L, Zou C, Yu Z, et al. Quantitative assessment of the sweet spot in marine shale oil and gas based on geology, engineering, and economics: A case study from the Eagle Ford Shale, USA[J]. Energy Strategy Reviews, 2021, 38: 100713. [CrossRef]
- Tang J, Fan B, Xiao L, et al. A new ensemble machine-learning framework for searching sweet spots in shale reservoirs[J]. SPE Journal, 2021, 26(01): 482-497. [CrossRef]
- Ren L, Su Y, Zhan S, et al. Progress of the research on productivity prediction methods for stimulated reservoir volume (SRV)-fractured horizontal wells in unconventional hydrocarbon reservoirs[J]. Arabian Journal of Geosciences, 2019, 12: 1-15. [CrossRef]
- Wu Y, Tahmasebi P, Lin C, et al. A comprehensive study on geometric, topological and fractal characterizations of pore systems in low-permeability reservoirs based on SEM, MICP, NMR, and X-ray CT experiments[J]. Marine and Petroleum Geology, 2019, 103: 12-28. [CrossRef]
- Huang H, Sun W, Ji W, et al. Effects of pore-throat structure on gas permeability in the tight sandstone reservoirs of the Upper Triassic Yanchang formation in the Western Ordos Basin, China[J]. Journal of Petroleum Science and Engineering, 2018, 162: 602-616. [CrossRef]
- Pimanov V, Lukoshkin V, Toktaliev P, et al. On a workflow for efficient computation of the permeability of tight sandstones[J]. arXiv preprint arXiv:2203.11782, 2022. [CrossRef]
- Ucar E, Berre I, Keilegavlen E. Three-dimensional numerical modeling of shear stimulation of fractured reservoirs[J]. Journal of Geophysical Research: Solid Earth, 2018, 123(5): 3891-3908. [CrossRef]
- Shen L, Cui T, Liu H, et al. Numerical simulation of two-phase flow in naturally fractured reservoirs using dual porosity method on parallel computers: numerical simulation of two-phase flow in naturally fractured reservoirs[C]//Proceedings of the International Conference on High Performance Computing in Asia-Pacific Region. 2019: 91-100.
- Kuhlman K L, Malama B, Heath J E. Multiporosity flow in fractured low-permeability rocks[J]. Water Resources Research, 2015, 51(2): 848-860. [CrossRef]
- van der Linden J H, Jönsthövel T B, Lukyanov A A, et al. The parallel subdomain-levelset deflation method in reservoir simulation[J]. Journal of Computational Physics, 2016, 304: 340-358. [CrossRef]
- Ucar E, Berre I, Keilegavlen E. Three-dimensional numerical modeling of shear stimulation of fractured reservoirs[J]. Journal of Geophysical Research: Solid Earth, 2018, 123(5): 3891-3908.Xin L, CA S M, Liang Z, et al. Microscale crack propagation in shale samples using focused ion beam scanning electron microscopy and three-dimensional numerical modeling. Petroleum Science, 2022.
- Pimanov V, Lukoshkin V, Toktaliev P, et al. On a workflow for efficient computation of the permeability of tight sandstones[J]. arXiv preprint arXiv:2203.11782, 2022. [CrossRef]
- Liu W, Chen Z, Hu Y, et al. A systematic machine learning method for reservoir identification and production prediction[J]. Petroleum Science, 2023, 20(1): 295-308. [CrossRef]
- Li. J., Wang, T., Wang, J., et al. 2023. Machine-Learning Proxy-based Fracture Production Dynamic Inversion with Application to Coal-bed Methane Gas Reservoir Development. Well Logging Technology.
- Ramos-Carreño C, Torrecilla J L, Carbajo-Berrocal M, et al. scikit-fda: a Python package for functional data analysis[J]. arXiv preprint arXiv:2211.02566, 2022. [CrossRef]
- Yang C, Brower-Sinning R A, Lewis G, et al. Data leakage in notebooks: Static detection and better processes[C]//Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 2022: 1-12.
- Schoenfeld B, Giraud-Carrier C, Poggemann M, et al. Preprocessor selection for machine learning pipelines[J]. arXiv preprint arXiv:1810.09942, 2018. [CrossRef]
- Jamieson K, Talwalkar A. Non-stochastic best arm identification and hyperparameter optimization[C]//Artificial intelligence and statistics. PMLR, 2016: 240-248.
- Bergstra J, Bengio Y. Random search for hyper-parameter optimization[J]. Journal of machine learning research, 2012, 13(2).
- Li L, Jamieson K, DeSalvo G, et al. Hyperband: A novel bandit-based approach to hyperparameter optimization[J]. The journal of machine learning research, 2017, 18(1): 6765-6816.
- Huang. L., Qi, Y., Chen, W., et al. 2023. Geomechanical Modeling of Cluster Wells in Shale Oil Reservoirs using GridSearchCV. Well Logging Technology.
- Standardscaler S P. Available online: https://scikit-learn. org/stable/modules/generated/sklearn. preprocessing[J]. StandardScaler. html (accessed on 20 May 2022).
- BUITINCK L, LOUPPE G, BLONDEL M, et al. RobustScaler: Scikit-Learn Documentation[J]. 2018.
- Chen T, Guestrin C. Xgboost: A scalable tree boosting system[C]//Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 2016: 785-794.
- Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5–32. [CrossRef]
- Roubícková, A., MacGregor, L., Brown, N., Brown, O. T., & Stewart, M. (2020). Using machine learning to reduce ensembles of geological models for oil and gas exploration. Retrieved from http://arxiv.org/abs/2010.08775v1.
- Chang P. Multi-Layer Perceptron Neural Network for Improving Detection Performance of Malicious Phishing URLs Without Affecting Other Attack Types Classification[J]. arXiv preprint arXiv:2203.00774, 2022. [CrossRef]
- Liu T. MLPs to Find Extrema of Functionals[J]. arXiv preprint arXiv:2007.00530, 2020. [CrossRef]
- Zhu Z, Zhao J, Mu T, et al. MC-MLP: Multiple Coordinate Frames in all-MLP Architecture for Vision[J]. arXiv preprint arXiv:2304.03917, 2023. [CrossRef]
- Tran D T, Kiranyaz S, Gabbouj M, et al. Heterogeneous multilayer generalized operational perceptron[J]. IEEE transactions on neural networks and learning systems, 2019, 31(3): 710-724. [CrossRef]
- Ravanbakhsh S. Universal equivariant multilayer perceptrons[C]//International Conference on Machine Learning. PMLR, 2020: 7996-8006.
Figure 1.
The technical approach of post-fracturing production prediction.
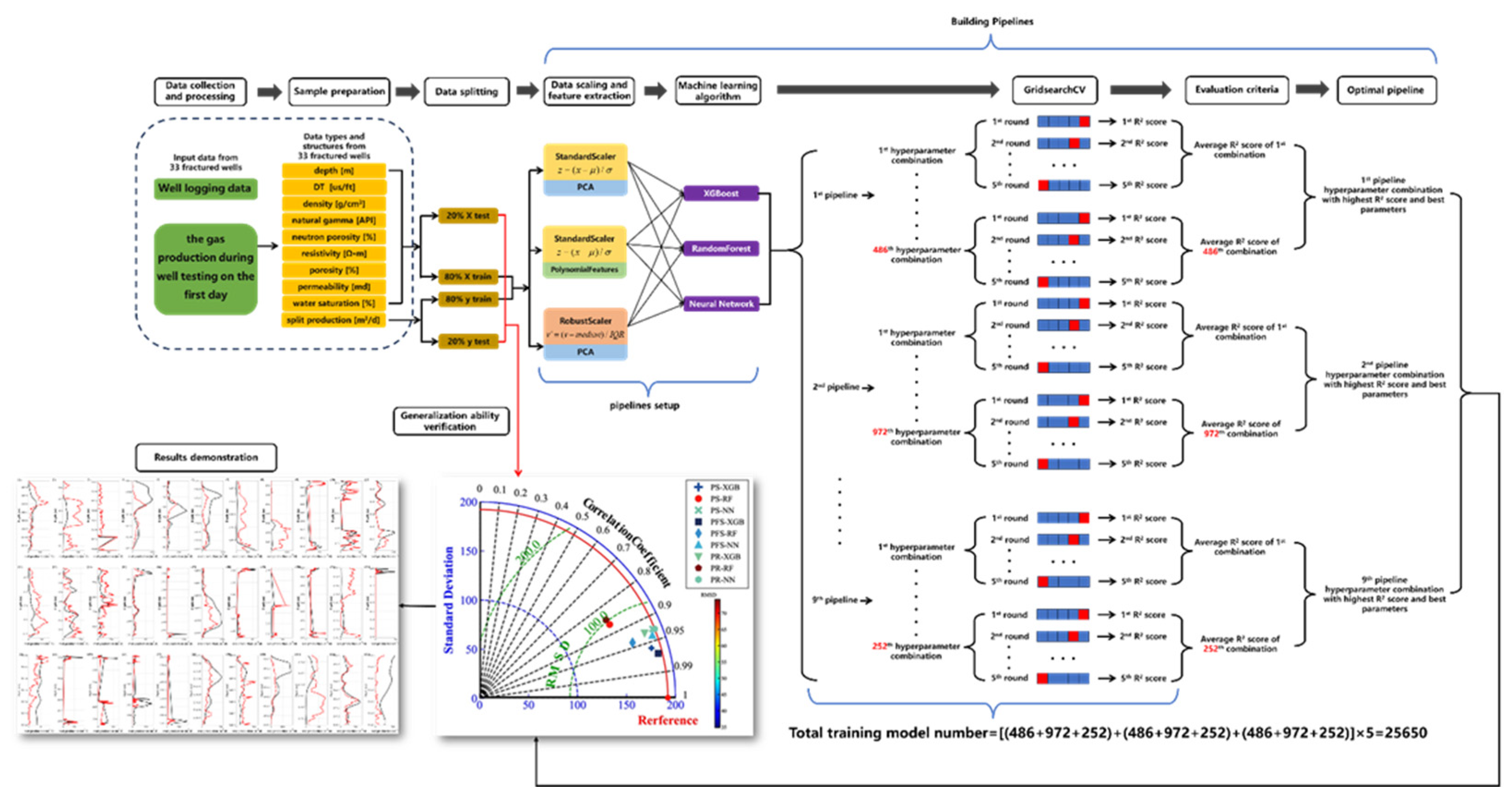
Figure 2.
Flowchart depicting the process, including data collection, sample preparation, and data splitting for well logging data preprocessing.
Figure 2.
Flowchart depicting the process, including data collection, sample preparation, and data splitting for well logging data preprocessing.
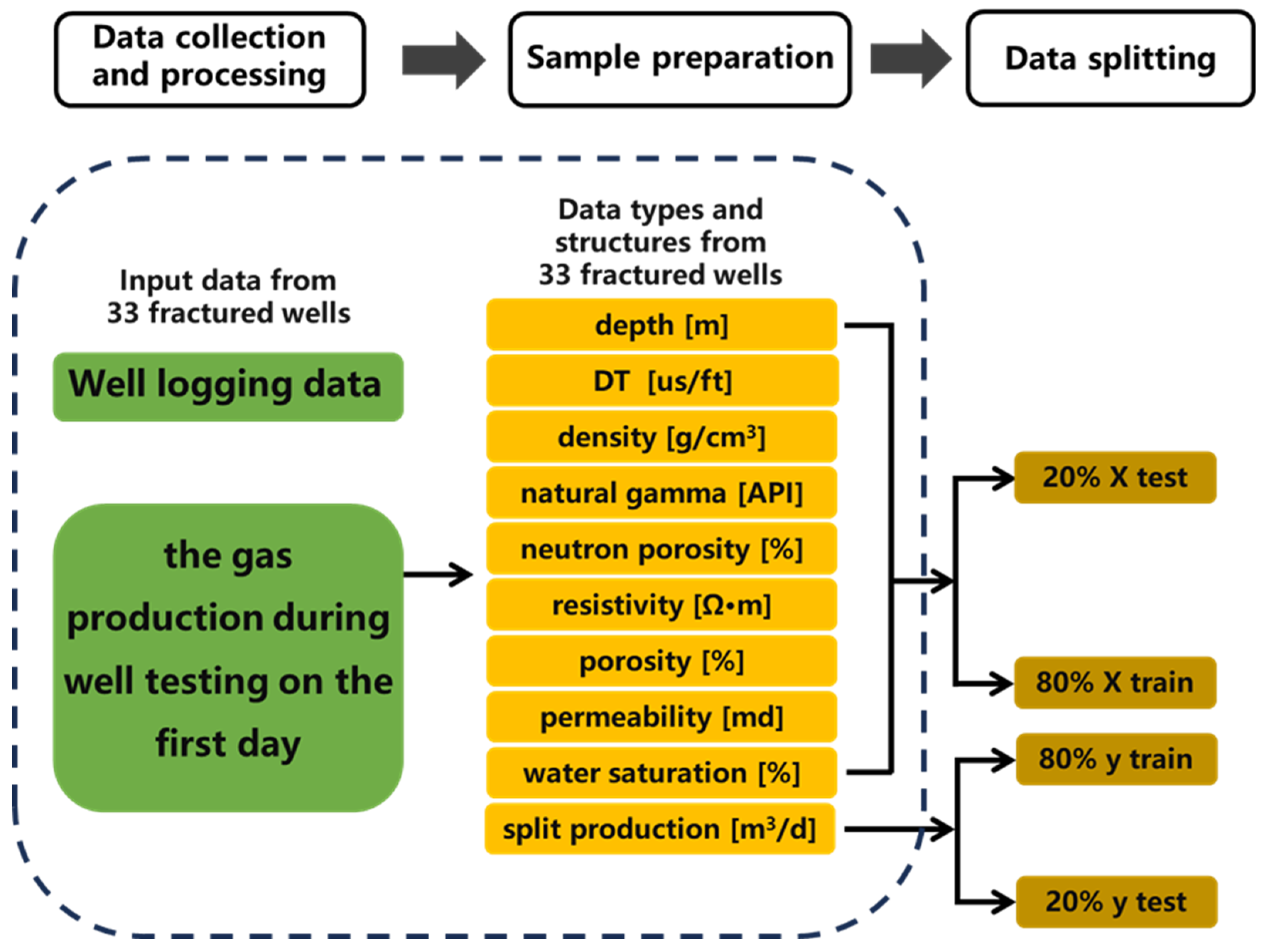
Figure 3.
Schematic diagram of sample collection and preparation process.
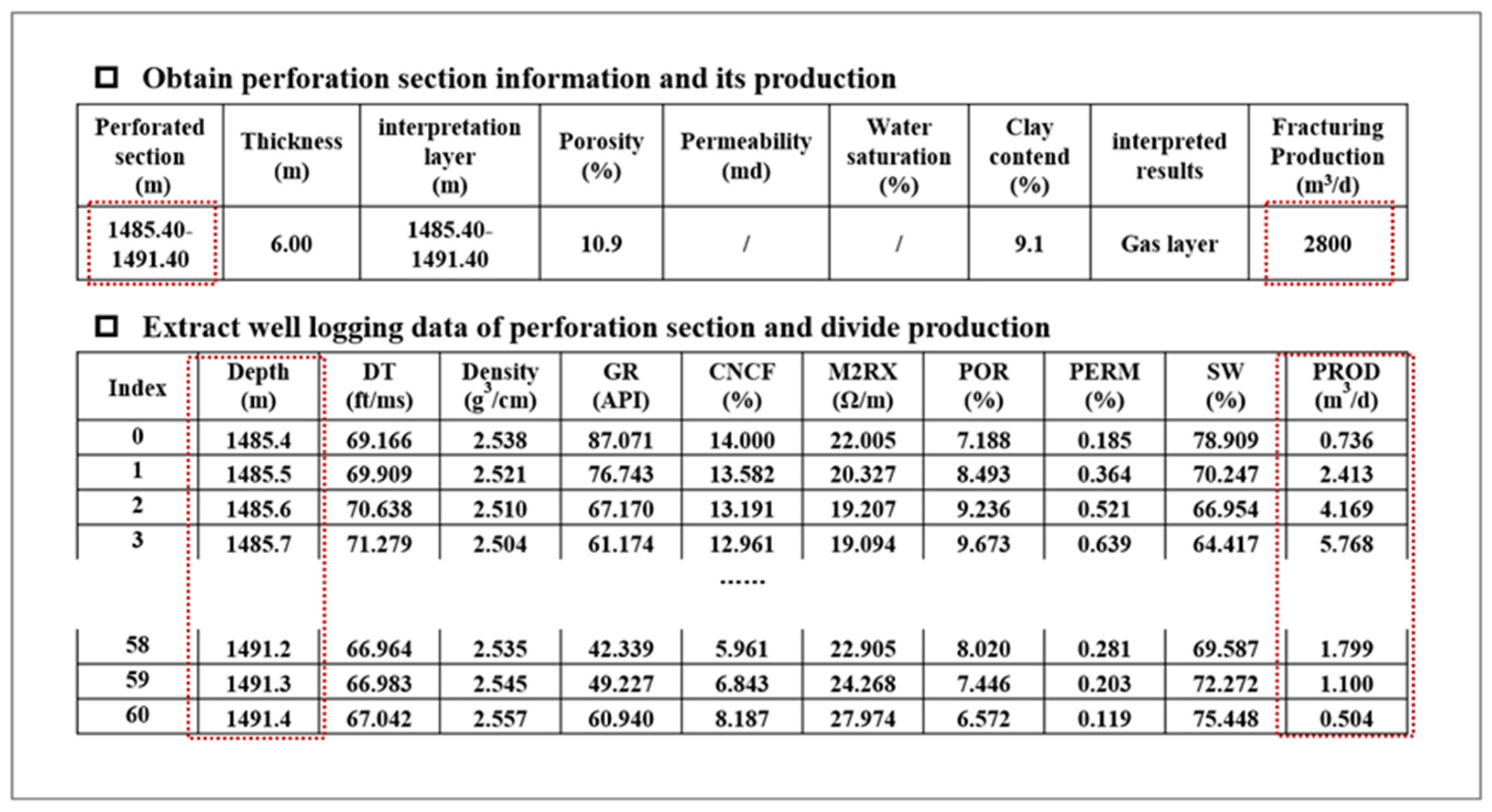
Figure 4.
Histogram of reservoir characteristics and production parameters.
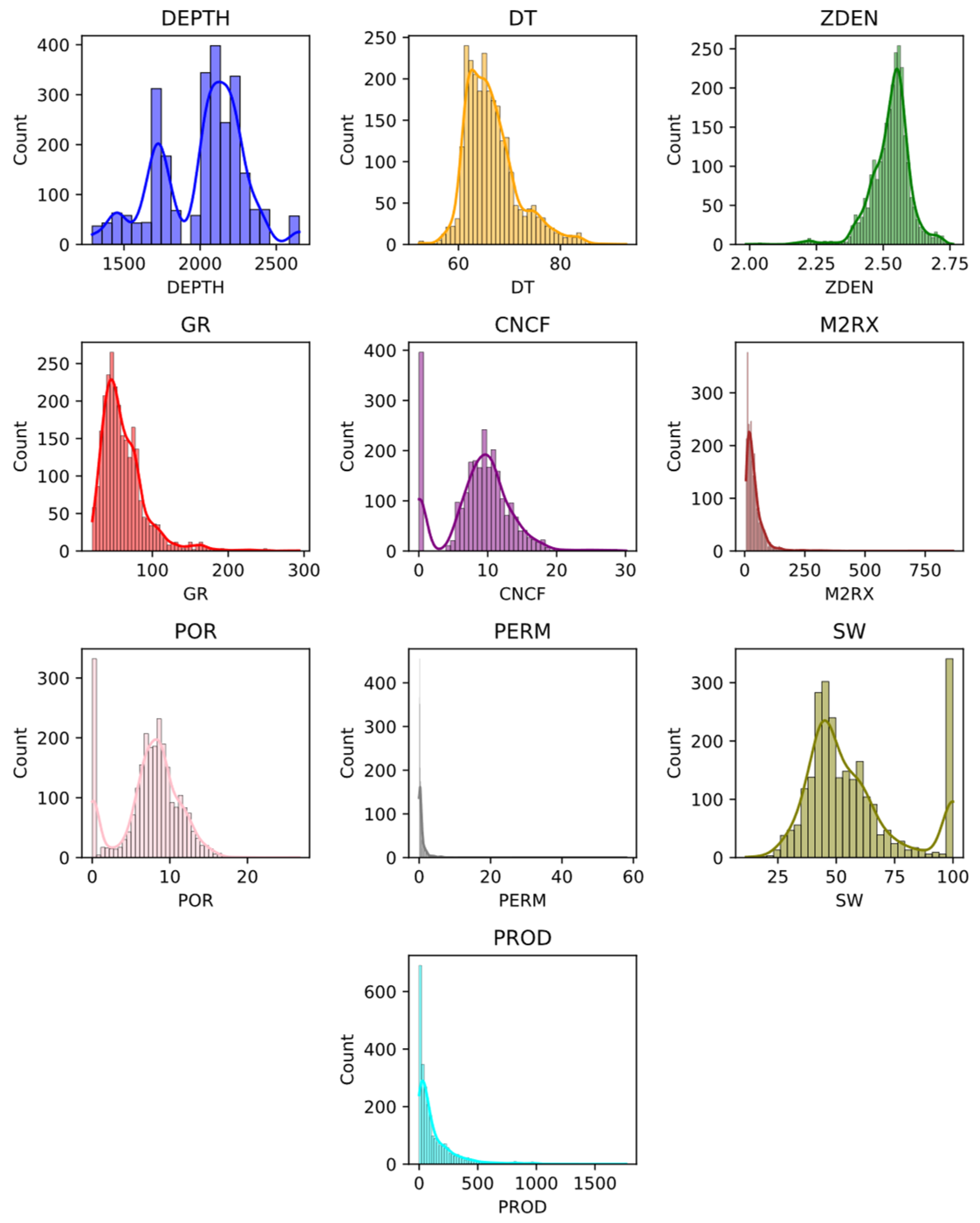
Figure 5.
Comparative analysis of production capacity projections using 20% residual dataset vs. actual predictions.
Figure 5.
Comparative analysis of production capacity projections using 20% residual dataset vs. actual predictions.
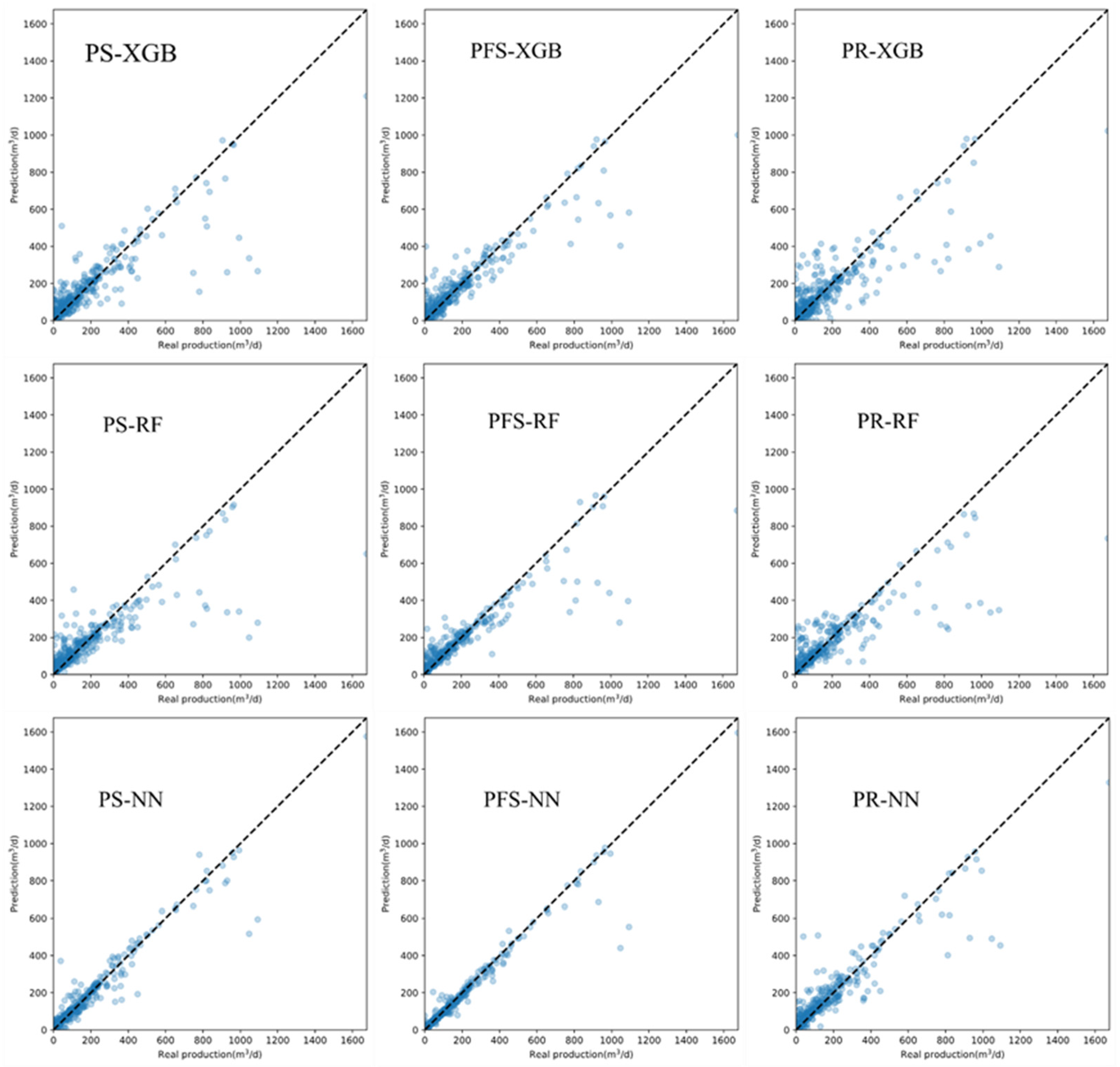
Figure 6.
Taylor diagram representation of model bias and standard deviation in errors. The azimuthal angle represents R2, the radial distance the standard deviation, and the semicircles centered at the “Reference” marker the standard deviation, as 192.2. The color scale shows the value of the root-mean-square error.
Figure 6.
Taylor diagram representation of model bias and standard deviation in errors. The azimuthal angle represents R2, the radial distance the standard deviation, and the semicircles centered at the “Reference” marker the standard deviation, as 192.2. The color scale shows the value of the root-mean-square error.
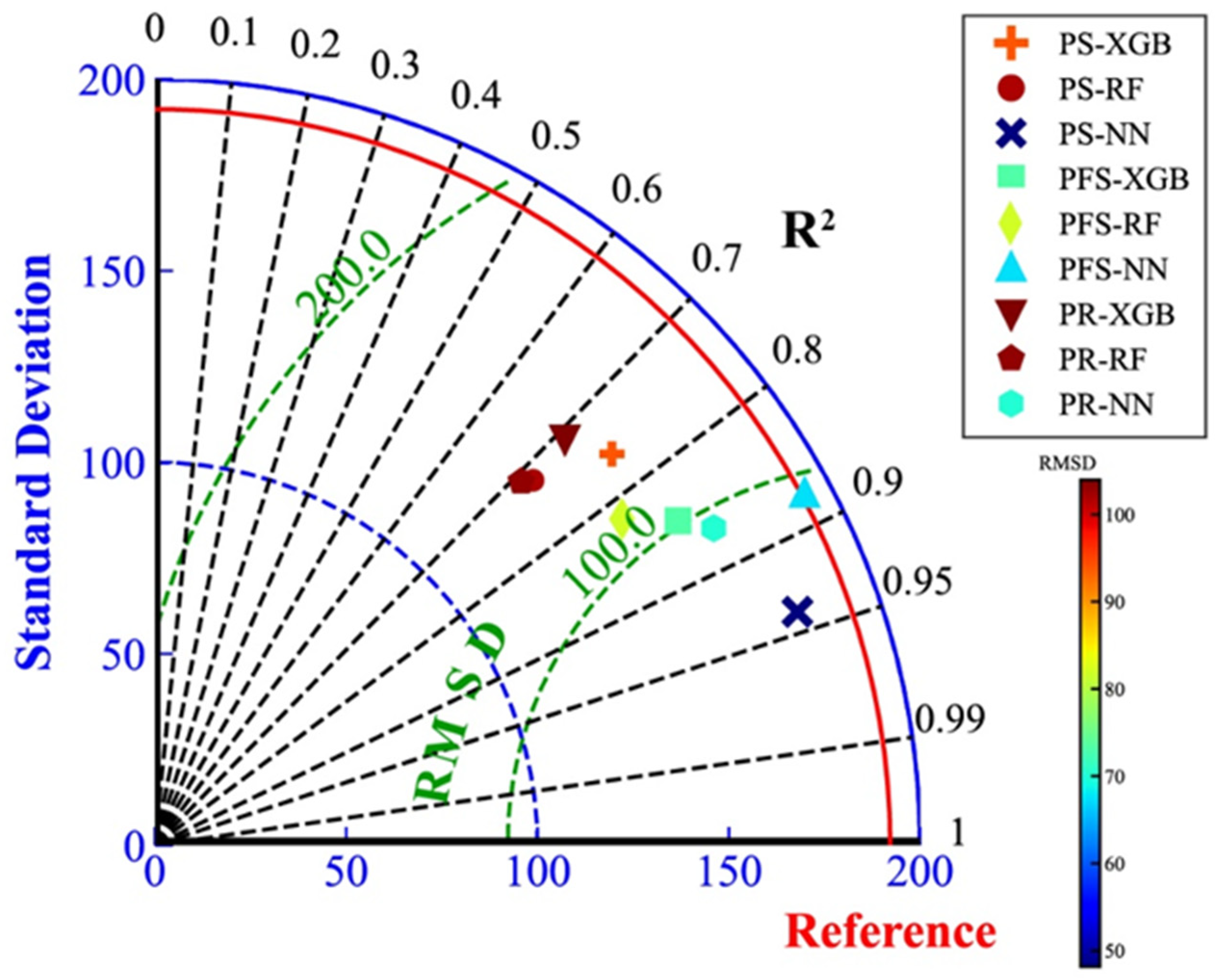

Table 1.
Pipelines setup and abbreviation list.
| Pipelines setup | Pipelines abbreviation |
|---|---|
| Standardscaler + PCA + XGBoost | PS-XGB |
| Standardscaler + PCA + RandomForest | PS-RF |
| Standardscaler + PCA + Neural Network | PS-NN |
| Standardscaler + PolynomialFeatures + XGBoost | PFS-XGB |
| Standardscaler+ PolynomialFeatures + RandomForest | PFS-RF |
| Standardscaler + PolynomialFeatures + Neural Network | PFS-NN |
| Robustscaler + PCA + XGBoost | PR-XGB |
| Robustscaler + PCA + RandomForest | PR-RF |
| Robustscaler + PCA + Neural Network | PR-NN |
Table 2.
Hyperparameter tuning list.
| Pipeline | Method | Hyperparameter | Range of values |
|---|---|---|---|
| PS-XGB | PCA | n_components | 2/4/6 |
| XGBoost | learning_rate | 0.01/0.1/0.5 | |
| n_estimators | 50/100/200 | ||
| max_depth | 1/2/3 | ||
| min_child_weight | 1/3/5 | ||
| booster | 'gbtree'/'gblinear' | ||
| PS-RF | PCA | n_components | 2/4/6 |
| Random Forest | n_estimators | 400/500/600 | |
| max_depth | 2/6/10 | ||
| min_samples_split | 10/15/20 | ||
| min_samples_leaf | 4/6/8 | ||
| max_features | 'auto'/'sqrt' | ||
| bootstrap | True/False | ||
| PS-NN | PCA | n_components | 2/4/6 |
| Neural Network | hidden_layer_sizes | (50,), (100,), (200,), (100, 50), (200, 100), (300, 200, 100), (400, 300, 200, 100) | |
| alpha | 0.0001/0.001/0.01/0.1 | ||
| max_iter | 3000/5000/7000 | ||
| PFS-XGB | Polynomial Features | poly_degree | 2/3/4 |
| XGBoost | learning_rate | 0.01/0.1/0.5 | |
| n_estimators | 50/100/200 | ||
| max_depth | 1/2/3 | ||
| min_child_weight | 1/3/5 | ||
| booster | 'gbtree'/'gblinear' | ||
| PFS-RF | Polynomial Features | poly__degree | 2/3/4 |
| Random Forest | n_estimators | 400/500/600 | |
| max_depth | 2/6/10 | ||
| min_samples_split | 10/15/20 | ||
| min_samples_leaf | 4/6/8 | ||
| max_features | 'auto'/'sqrt' | ||
| bootstrap | True/False | ||
| PFS-NN | Polynomial Features | poly__degree | 2/3/4 |
| Neural Network | hidden_layer_sizes | (50,), (100,), (200,), (100, 50), (200, 100), (300, 200, 100), (400, 300, 200, 100) | |
| alpha | 0.0001/0.001/0.01/0.1 | ||
| max_iter | 3000/5000/7000 | ||
| PR-XGB | PCA | n_components | 2/4/6 |
| XGBoost | learning_rate | 0.01/0.1/0.5 | |
| n_estimators | 50/100/200 | ||
| max_depth | 1/2/3 | ||
| min_child_weight | 1/3/5 | ||
| booster | 'gbtree'/'gblinear' | ||
| PR-RF | PCA | n_components | 2/4/6 |
| Random Forest | n_estimators | 400/500/600 | |
| max_depth | 2/6/10 | ||
| min_samples_split | 10/15/20 | ||
| min_samples_leaf | 4/6/8 | ||
| max_features | 'auto'/'sqrt' | ||
| bootstrap | True/False | ||
| PR-NN | PCA | n_components | 2/4/6 |
| Neural Network | hidden_layer_sizes | (50,), (100,), (200,), (100, 50), (200, 100), (300, 200, 100), (400, 300, 200, 100) | |
| alpha | 0.0001/0.001/0.01/0.1 | ||
| max_iter | 3000/5000/7000 |
Table 3.
Hyperparameter result list.
| Pipeline | Hyperparameter | The best of values |
|---|---|---|
| PS-XGB | n_components | 6 |
| learning_rate | 0.5 | |
| n_estimators | 200 | |
| max_depth | 3 | |
| min_child_weight | 5 | |
| booster | 'gbtree' | |
| PS-RF | n_components | 6 |
| n_estimators | 400 | |
| max_depth | 10 | |
| min_samples_split | 10 | |
| min_samples_leaf | 4 | |
| max_features | 'sqrt' | |
| bootstrap | False | |
| PS-NN | n_components | 6 |
| hidden_layer_sizes | (400, 300, 200, 100) | |
| alpha | 0.01 | |
| max_iter | 7000 | |
| PFS-XGB | poly_degree | 3 |
| learning_rate | 0.1 | |
| n_estimators | 200 | |
| max_depth | 3 | |
| min_child_weight | 5 | |
| booster | 'gbtree' | |
| PFS-RF | poly__degree | 3 |
| n_estimators | 500 | |
| max_depth | 10 | |
| min_samples_split | 10 | |
| min_samples_leaf | 4 | |
| max_features | 'sqrt' | |
| bootstrap | False | |
| PFS-NN | poly__degree | 2 |
| hidden_layer_sizes | (300, 200, 100) | |
| alpha | 0.0001 | |
| max_iter | 3000 | |
| PR-XGB | n_components | 6 |
| learning_rate | 0.5 | |
| n_estimators | 200 | |
| max_depth | 3 | |
| min_child_weight | 1 | |
| booster | 'gbtree' | |
| PR-RF | n_components | 6 |
| n_estimators | 600 | |
| max_depth | 10 | |
| min_samples_split | 10 | |
| min_samples_leaf | 4 | |
| max_features | 'sqrt' | |
| bootstrap | False | |
| PR-NN | n_components | 6 |
| hidden_layer_sizes | (400, 300, 200, 100) | |
| alpha | 0.01 | |
| max_iter | 3000 |
Table 4.
Pipelines evaluation index list.
| Model | R2 | RMSE | SD |
|---|---|---|---|
| Reference | 1 | 0 | 192.2 |
| PS-XGB | 0.76 | 93.79 | 157.19 |
| PS-RF | 0.72 | 101.78 | 137.29 |
| PS-NN | 0.94 | 48.15 | 178.68 |
| PFS-XGB | 0.85 | 73.19 | 160.85 |
| PFS-RF | 0.82 | 81.86 | 148.87 |
| PFS-NN | 0.88 | 67.35 | 192.99 |
| PR-XGB | 0.71 | 103.98 | 150.94 |
| PR-RF | 0.71 | 102.93 | 134.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



