
Submitted:
24 May 2024
Posted:
27 May 2024
You are already at the latest version
Abstract
With the rapid growth of large language models (LLMs), there is increasing demand for memory and computation in LLMs. Recent efforts on post-training pruning of LLMs aim to reduce the model size and computation requirements, yet the performance is still sub-optimal. In this paper, we present a plug-and-play solution for post-training pruning of LLMs. The proposed solution has two innovative components: 1) Relative Importance and Activations (RIA), a new pruning metric that jointly considers the weight and activations efficiently on LLMs; and 2) Channel Permutation, a new approach to maximally preserve important weights under N:M sparsity. The two proposed components can be readily combined to further enhance the N:M semi-structured pruning of LLMs. Our empirical experiments show that RIA alone can already surpass all existing post-training pruning methods on prevalent LLMs, e.g., LLaMA ranging from 7B to 65B. Furthermore, N:M semi-structured pruning with channel permutation can even outperform the original LLaMA2-70B on zero-shot tasks, together with practical speed-up on specific hardware. Our code is available at: https://github.com/biomedical-cybernetics/Relative-importance-and-activation-pruning
Keywords:
post-training pruning
; combinatorial optimization
; large language models
; inference acceleration
1. Introduction
Recent research on large language models (LLMs) has attracted significant interest. These LLMs, characterized by their vast number of parameters, have exhibited remarkable proficiency across a wide range of tasks. However, deploying such models poses challenges due to their substantial size, computational demands, and execution time. To address this, several methods for network compression have been explored, such as model quantization [1,2,3,4] and network pruning [5,6,7,8,9].
Unlike quantization techniques, which adjust the precision of weights or activations to compress the network, network sparsity primarily targets the elimination of redundant or useless weights within models. Despite its potential, the exploration of sparsity in LLMs remains limited. Generally, neural networks can achieve sparsity through three primary methods: 1) sparse training [7,10,11,12,13,14,15]; 2) pruning-aware training [16,17]; and 3) post-training pruning (PTP) [6,8,9,18]. However, both sparse training and during-training pruning require multiple rounds of iterative training, which is computationally costly and time-consuming, especially for LLMs. Therefore, PTP on a well-pre-trained model represents a more reasonable approach for LLMs.
The primary challenge associated with post-training pruning lies in the substantial performance degradation compared to dense models. Current methods, like SparseGPT [9] and Wanda [8], exhibit promising results in unstructured pruning. Nonetheless, to achieve practical speed-up, it is favored to conduct N:M semi-structured pruning, which can be supported by specific hardware with sparse matrix multiplications [19]. These prior methods [8,9] under the N:M sparsity suffer from significant performance drops, thereby restricting their applications in practice. Recently, [20] has introduced an input channel permutation method using the greedy search, which can boost the performance under the N:M sparsity. However, the greedy search is time-consuming on LLMs and thus is not feasible.
In this paper, we introduce a plug-and-play post-training pruning method for LLMs. Specifically, the method comprises two key components. First, we introduce Relative Importance and Activation (RIA), a new pruning metric for LLM pruning. We show that prior pruning metrics [8,9] tend to prune away entire channels of network weights, which is undesirable for both unstructured and N:M semi-structured pruning. Instead, RIA jointly considers the input and output channels of weight and the activation information, effectively mitigating such issues. Second, we also consider a better way to convert LLM weight matrices to adhere to N:M sparsity patterns. Unlike existing methods that directly convert the weight matrix to N:M sparsity, we propose channel permutation to properly permute the weight channels so as to maximally preserve the important weights under N:M structures. Finally, the proposed RIA and channel permutation can be readily combined, leading to an efficient and plug-and-play approach for the real-world acceleration of sparse LLMs inference. We name the proposed method “plug-and-play” since 1) it does not need additional fine-tuning or retraining; 2) it can be adopted by any models that have linear layers; 3) it has negligible performance drop when applying channel permutation in the zero-shot experiments.
Extensive evaluation of open-sourced LLMs (e.g., LLaMA [21], LLaMA-2 [22], and OPT [23]) demonstrates that RIA outperforms SOTA one-shot PTP methods in both unstructured sparsity and N:M sparsity scenario. Additionally, channel permutation can be efficiently scaled to LLMs with over 70B parameters within 2 hours, yet recover a lot of the performance drop caused by N:M constraint and surpass the performance of dense models in 3 out of 5 evaluated zero-shot datasets. By employing RIA and channel permutation, LLMs can undergo a smooth transition into N:M constraints. This ensures hardware compatibility while maintaining the intact performance of the pruned model.
2. Related Work
Post-Training Pruning.
Post-training pruning (PTP) methods trace their roots to OBD [5], which employs the hessian matrix for weight pruning. OBS [6] further refines the approach by adjusting remaining weights to minimize loss changes during pruning. The advent of Large Language Models (LLMs) has sparked interest in leveraging the Hessian Matrix for pruning, exemplified by works like AdaPrune [18] and Iterative Adaprune [24] targeting BERT [25]. However, weight reconstruction via Hessian Matrix inverse incurs substantial computational complexity at . SparseGPT [9] reduces this complexity to , while Wanda [8] leverages input activations for efficient one-shot PTP with reduced pruning time and comparable performance to SparseGPT. Our proposed method, Relative Importance and Activations (RIA) inherits the time-saving advantages of Wanda while simultaneously enhancing the performance of the pruned LLMs. Note that the method proposed in this article is designed for model compression without retraining and finetuning, which differentiates it from Dejavu [26], which requires additional training steps. Such post-training methods are also preferred for model quantization as well [3,4,27,28].
N:M Sparsity.
Recently, NVIDIA has introduced the N:M constraint sparsity [19] as a method to compress neural network models while preserving hardware efficiency. This N:M sparsity constraint stipulates that at least N out of every contiguous M element must be set to zero, thereby accelerating matrix-multiply-accumulate instructions. For instance, a 2:4 constraint ratio results in 50% sparsity, effectively doubling the model’s inference speed when utilizing the NVIDIA Ampere GPU architecture. However, directly applying SOTA unstructured pruning methods to meet the N:M sparsity often leads to a noticeable decline in performance, as demonstrated in Table A1. Some approaches [29,30,31] suggest fine-tuning pruned models to recover capacity, but this is prohibitively expensive for Large Language Models (LLMs).
Matrix Permutation.
N:M sparsity primarily targets the application of sparsity in the input channel dimension. [20] presents a permutation method to identify the optimal permutation of input channels through an exhaustive greedy search and an escape phase to navigate local minima. However, this greedy approach becomes impractically time-consuming when applied to LLMs due to their extensive linear layers. In this study, we leverage the specific characteristics of LLMs and propose a Channel Permutation strategy to reduce the computational overhead efficiently.
3. LLM Pruning with Relative Importance and Activations
3.1. Post-Training Pruning: Preliminaries
Post-training pruning (PTP) typically starts from the pre-trained network, removes redundant parameters, and does not need end-to-end fine-tuning. Unlike training-based pruning methods [7,12,15,32,33], PTP is fast, resource-saving, and therefore preferred for compressing LLMs [8,9]. PTP is currently prevalent in unstructured pruning and N:M semi-structured pruning, which is also the main focus of this paper. It is less applied in structured pruning [34] due to a larger performance drop.
A common approach to achieve PTP is layer-wise pruning, e.g., minimizing the discrepancy square error between the dense and pruned model layer-by-layer recursively. Specifically, we denote the input of the l-th linear layer as , and weight , where r and c represent the number of output and input channels respectively. Our primary goal is to find the pruning mask that minimizes the distance error between the original and pruned layer.
Therefore, the objective can be formally expressed as follows:
where k represents the number of remaining weights determined by the pruning ratio, and is the -norm (e.g., the number of non-zero elements). To solve in Equation 1, there are various pruning metrics, e.g., magnitude-based pruning, that mask the weight below a certain threshold. Nonetheless, we show that these prior pruning metrics have intrinsic drawbacks, as discussed in the following section. Optionally, the weight in Equation 1 can also be reconstructed via closed-form updates [9]; see Appendix E for more discussions.
3.2. Relative Importance: A New Pruning Metric
We present the relative importance (dubbed as RI), a new metric for LLM pruning. We find that prevalent PTP methods tend to suffer from channel corruption, i,e., the entire input or output channel is pruned away. This is akin to node removal in network science terms, and it significantly diminishes the performance of Large Language Models (LLMs), in a manner similar to structured pruning. To illustrate this, Figure 1 shows a linear layer with . Magnitude-based pruning with 50% unstructured sparsity will corrupt , i,e, the 4-th output channel. In practice, we find similar issues also exist in other prevalent pruning metrics, e.g., Wanda [8] prunes around 500 channels out of 5120 channels in some layers, with more than 10% channels corrupted. Given that well-trained LLMs contain unique information in the input and output channels, it is critical to avoid channel corruption in post-training pruning. We explain the phenomenon of channel corruption in detail in Appendix F.
To mitigate such issues, the proposed relative importance (RI) aims to re-evaluate the importance of each weight element based on all connections that originate from the input neuron i or lead to the output neuron j. Specifically, the relative importance for can be calculated as:
where sums over the absolute values of the weights in input channel j, and similarly for the sum of the weights in output channels i. The resulting score offers insight into the relative importance of weight in the context of its connections to neurons i and j.
3.3. Incorporating Activations into Relative Importance
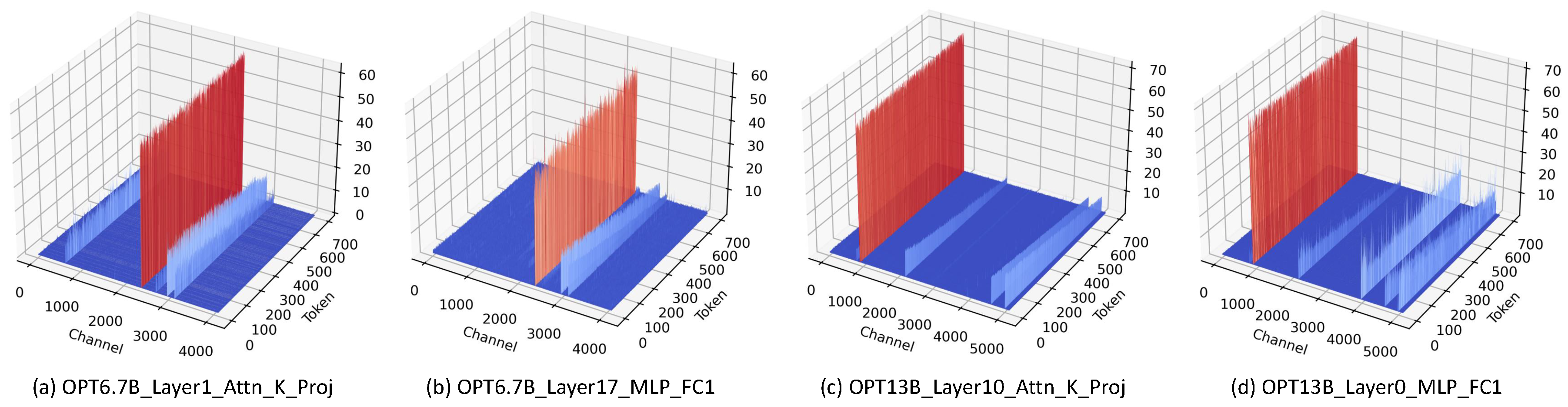
The proposed relative importance can be further combined with activations to assess better the weight significance, dubbed as relative importance and activation (RIA). Recent findings [3] show that the occurrence of activation outliers has become a well-known issue in quantizing LLMs. Our visualizations on LLaMA and OPT also confirm these outliers; see Figure A3 and Figure A4 for details.
Moreover, we find that activation outliers persist regardless of the dataset or parts of the model. To see this, we calculate the Spearman’s Rank Correlation Coefficient of activations between different datasets. From Figure 2, it can be observed that pairwise correlations of activations exhibit positive values and similar trends across different layers and Transformer modules. We offer evidence that the Spearman Rank correlation between pairs of the activations of different datasets is positive. This positivity is a necessary condition to incorporate the activation into our RIA formula. And indeed it is always satisfying.
4. Turning into N:M Sparsity
This section studies how to turn LLMs into N:M sparsity with the pruning metric. N:M sparsity is usually favored by post-training pruning given its practical speed-up on specific hardware. Unlike existing solutions that directly convert to the N:M format, we propose channel permutation, a new approach that better leverages the pruning metrics by efficiently permuting the weight channels. Channel permutation can work seamlessly with the RIA metric in Section 3 and other prevalent methods such as [8,9].
4.1. N:M Semi-Structured Pruning: Formulation
We begin by revisiting unstructured PTP in Equation 1. Without loss of generality, we denote the weight importance score as , which can be either RIA or other pruning metrics. It is an NP-hard problem [9] to find the optimal in Equation 1. A common surrogate is to maximize the sum of retained weight importance scores as follows:
Similarly, for N:M sparsity, every N out of M contiguous elements is zero along each output channel, and the objective is re-formulated as:
A simple solution to Equation 5 in existing works [8,9] is directly setting the mask of top N elements in to 1, and 0 otherwise. Nonetheless, this usually leads to sub-optimal solutions. As illustrated in Figure 3, some input channels with similar scores, either large or small, might get stuck in the same weight block . Consequently, some large weights might be pruned by mistake, while small ones might be preserved.
4.2. Channel Permutation for Improved N:M Sparsity
To address the aforementioned challenge, we present a new channel permutation (CP) approach that yields better N:M structures. Note that permuting the input channels of weight can lead to different importance scores . We thus introduce an additional column permutation matrix for , such that the sum of retained weight importance can be further maximized:
For ease of presentation in what follows, we denote the block of the weight matrix as , where and K is the number of blocks. N:M pruning thus occurs row-wise within each block, e.g., only n values are preserved out of m elements for . Based on the notation, the proposed channel permutation mainly includes the following two steps.
Step 1: Heuristic Channel Allocation.
We first calculate the sum of weight importance for each input channel. These channels are then sorted and allocated into K blocks. To maximally retain the important channels in each block with N:M sparsity, we use a heuristic allocation strategy. Given K blocks, we alternately allocate every top-K input channel into each block, and this process is repeated for m times until all channels are allocated. An example is illustrated in Figure 3. Given 8 input channels and 4 output channels, there are 2 blocks under 2:4 sparsity. The top-1 and top-2 channels are allocated to block 1 and block 2, respectively, and similarly to the remaining input channels. Given such a heuristic channel allocation strategy, it can be found that there is a significant enhancement in the sum of retained weight importance scores compared to direct N:M pruning.
Step 2: Linear Sum Assignment.
Next, we show the heuristic allocation strategy can be further refined. The refining process can be formulated as a linear sum assignment (LSA) problem, which can be efficiently solved by the Hungarian algorithm [35]. To see this, we can take out one allocated channel from each block; thus, there are K channels to be reassigned to K blocks. It is thus a traditional linear sum assignment problem to find a better one-by-one matching between the K channels and K blocks, such that the weight importance sum in Equation 6 can be further improved. From Figure 3, LSA further improves the score sum by , with the top-1 and top-2, top-3 and top-4 channels swapped from the heuristic channel allocation.
Remarks.
Note that the permutation of weight matrices does not affect the output of LLMs. For dense layers, the input activations need to be simultaneously permuted, which can be achieved by permuting the output channels of the previous layer. The exception lies in the residual connection, which can be done with an efficient permutation operator. More details on implementing channel permutation and the Hungarian algorithm are listed in Appendix G.
5. Experiments
5.1. Setup
We evaluate the proposed approach on three popular LLMs: LLaMA 7B-65B [21], LLaMA2 7B-70B [22], and OPT 1.3B [23]. We use the public checkpoints of the involved models in the HuggingFace Transformers library 1. We utilize 3 NVIDIA A100 GPUs, each equipped with 80GB memory. For each model under consideration, we apply uniform pruning to all linear layers, with the exception of embeddings and the head. Specifically, each self-attention module has four linear layers, while each MLP module contains three linear layers for LLaMA model families and two for OPT. All the evaluations are conducted with the same code to make sure the comparison is fair. The detailed settings of tasks, metrics, baseline methods, and calibration data can be found in Appendix C.
5.2. Unstructured Pruning
Main Results.
As highlighted in Table 1, RIA consistently outperforms Wanda and SparseGPT across all scenarios. Notably, our method achieves a 50% improvement in preventing a performance drop of the dense model in comparison to SparseGPT (16% in LLaMA and LLaMA2 model family), and a 17% improvement in preventing a performance drop in comparison to Wanda (13% in LLaMA and LLaMA2 model family). It is essential to note that as the model size increases, the performance gap between models pruned by RIA and the original dense models diminishes significantly.
Ablation Studies.
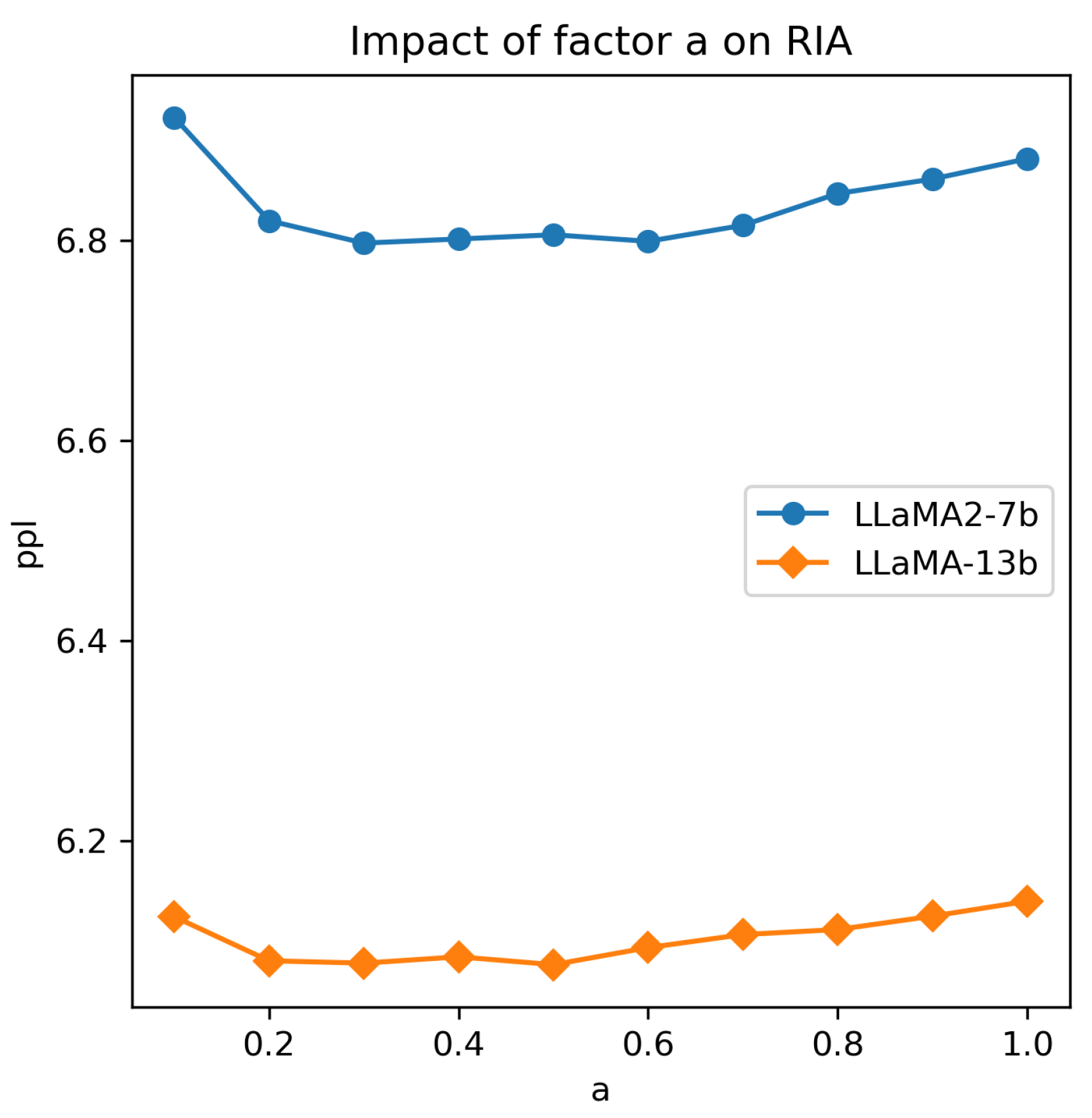
To thoroughly evaluate the influence of each element within our RIA equation, we undertook an ablation test, with the outcomes presented in Table 2. We disassembled our formula into several distinct components for closer scrutiny: : -norm of activations; : weight magnitude; : weight magnitude normalized by the input channels; : weight magnitude normalized by the output channels; RI: stands for relative importance which is the combination of and ; and and combines relative importance with input activations with different values of a. The selection of a is shown in Figure A5.
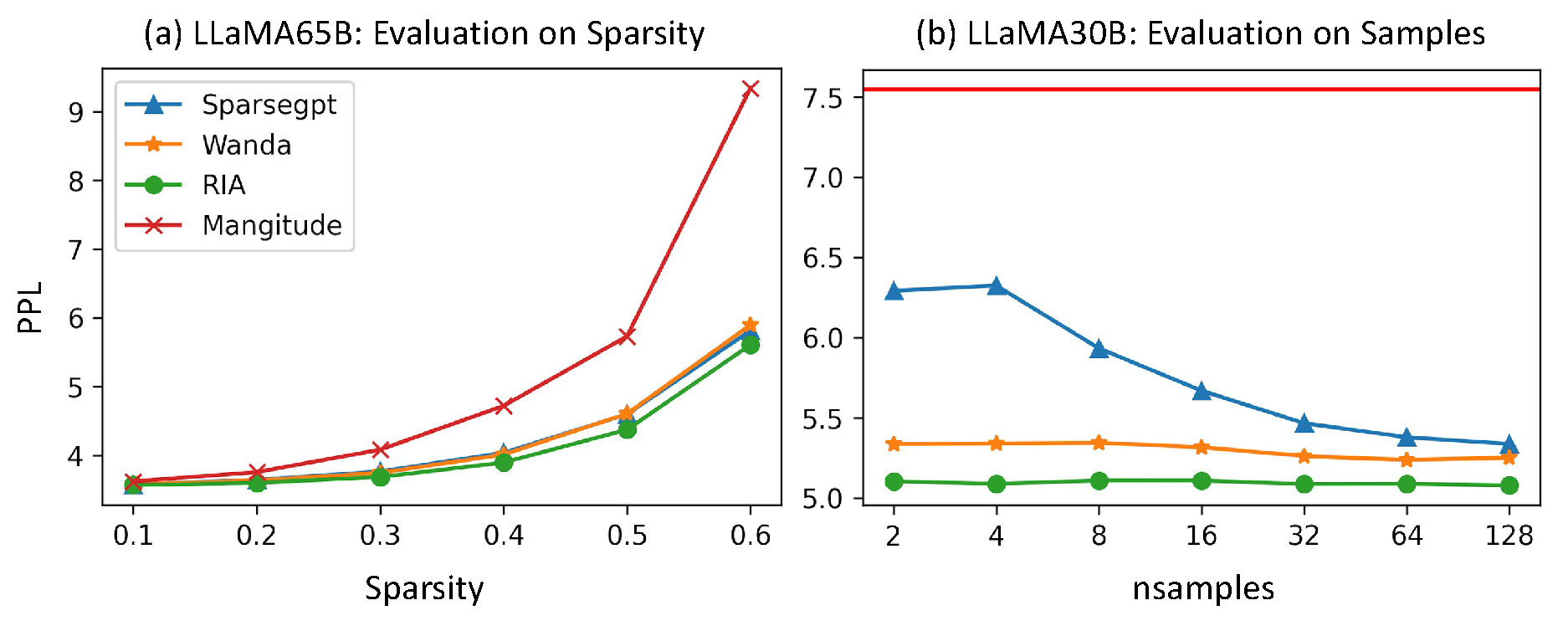
Figure 4.
Sensitivity Evaluation on Sparsity and number of calibration samples (nsamples).
As illustrated in Table 2, normalizing the weight magnitude through either input or output channels offers a substantial performance boost over merely considering weight magnitude. Interestingly, utilizing Relative Importance alone can match or, in instances like LLaMA-30B, even outperform SparseGPT. A distinguishing feature of Relative Importance is its reliance solely on weight information, eliminating the need for calibration data. In contrast, both Wanda and SparseGPT necessitate calibration data to derive input activations or Hessian matrices. The table also showcases enhancements brought about by the other equation components of RIA.
Sparsity.
In Figure 4(a), we examine the effects of varying sparsity levels, ranging from 0.1 to 0.6, on the performance of the LLaMA 65b model. The PPL curves clearly demonstrate that Magnitude pruning is particularly sensitive to increased sparsity levels, with a 60% sparsity level resulting in significant model degradation. In contrast, the SparseGPT, Wanda, and RIA models exhibit more robust performance across all tested sparsity levels, with RIA (green) consistently outperforming the others at every level of sparsity.
Calibration Data.
SparseGPT, Wanda, and RIA all require calibration data for obtaining either input activations or the Hessian matrix. To assess the robustness of our algorithm with respect to the calibration data, we conduct a sensitivity test involving variations in the type of calibration datasets and the number of calibration samples. The influence of calibration datasets is presented in Table A2. Our aim here is to assess the impact of the number of calibration samples.
As illustrated in Figure 4(b), an example of the LLaMA30B model, SparseGPT appears to rely on a larger number of calibration samples, while both Wanda and RIA demonstrate robust performance across varying sample sizes. Notably, RIA consistently outperforms the other methods in all cases.
Zero-Shot Performance.
In Table 3, we present the zero-shot performance of unstructured 50% sparsity of the models pruned with magnitude, Wanda, SparseGPT, and RIA on LLaMA2-70b model. In the last column, we report the average performance across these datasets. As shown in the table, RIA achieves the best performance on 3/5 datasets and also achieves the best average performance across the 5 datasets.
5.3. N:M Semi-Structured Pruning
While RIA aims to explore the upper bounds of performance achievable through one-shot PTP methods, combining it with the N:M constraint seeks to realize the actual inference speed by aligning with the present GPU hardware environment. In this subsection, we assess how Channel Permutation (CP) can enhance the performance of one-shot PTP when incorporated with the N:M constraint.
Main Results.
In this comparison, we assess the performance of unstructured 50% sparsity, 2:4 constraint sparsity, and 4:8 constraint sparsity for Magnitude, Wanda, SparseGPT, and RIA. Additionally, we provide the performance results when applying Channel Permutation (CP) to each of these methods. Directly using step 1 of CP (CP w/o LSA) is also displayed in the table, serving as an ablation test in comparison to the complete one. We present the Perplexity of each pruned model on the Wikitext2 dataset, maintaining the same settings as in Section 5.1.
As presented in Table 4, RIA consistently delivers superior performance across all semi-structured sparsity patterns when employing one-shot PTP. Importantly, when utilizing merely heuristic channel reallocation, every method—with the exception of Magnitude—already exhibits a significant performance improvement. With the incorporation of LSA, the performance is further improved. This highlights our motivation to group the input channels based on their sorted indices, ensuring that similar scaling channels don’t end up in the same block.
Zero-shot Performance. In Table A1, we present the zero-shot performance of the N:M constraint models pruned using RIA and Wanda. The table’s last column also provides the average performance across these datasets. As the table indicates, while there’s a performance decline on the Hellaswag and ARC-C datasets, the case of RIA (2:4+CP) performs even surpasses the dense model on BoolQ, MNLI, and RTE datasets. This highlights the observation that large language models can be prone to overfitting, resulting in an abundance of redundant, unnecessary, or potentially harmful elements. Notably, with the incorporation of CP, there’s a remarkable improvement in performance for both Wanda and RIA.
5.4. Running Time Analysis
Pruning and Permutation Running Time.
We present the actual running time of each algorithm on the largest model involved in this article, LLaMA2-70b. The relative complexity analysis can be found in Appendix H.
- Pruning time. We test each algorithm with 128 calibration data. For SparseGPT, the pruning time amounts to 5756 seconds (approximately 1.5 hours). In contrast, Wanda and RIA demonstrate significantly reduced runtime, with times of approximately 611 seconds (approximately 10 minutes) and 627 seconds (approximately 10 minutes, including the execution of calibration samples).
- Channel permutation time. For a comparative analysis of execution duration, we present the processing time of a single matrix constructed using our algorithm for the N:M sparsity. This is compared against the greedy method and its variants, which employ escaping strategies to circumvent getting trapped in local minima, as discussed in [20]. The results for different dimensions are provided in Table A6.
Inference acceleration. We assess the inference acceleration offered by sparsity in Large Language Models (LLMs). Like SparseGPT [9], we present data for both the unstructured sparsity and 2:4 sparsity acceleration on GPU relative to the dense model across various components. Theoretically, employing an N:M sparsity can yield up to a 2× speedup when contrasted with dense models. We conduct tests on the Nvidia Tesla A100, utilizing the cuTLASS and cuSPARSELt library for Sparse Matrix-Matrix Multiplication (SpMM) [19] with N:M sparse matrices. These two libraries have been incorporated into the latest release of PyTorch. For unstructured sparsity, we treat it as if it is a dense matrix and assess the actual inference speed. Comprehensive acceleration metrics for each module are outlined in Table 5, showing an acceleration of all the linear layers to be about 1.2× for cuTLASS and 1.6× for cuSPARSELT.
6. Conclusion
In this article, we have introduced two novel methods, RIA and Channel Permutation, that together establish an effective plug-and-play pipeline for post-training pruning and inference acceleration of large language models. RIA incorporates relative importance and the feature of input activations that create a criterion for pruning the weights of LLMs. Through extensive experiments on prominent LLMs like LLaMA, LLaMA2, and OPT across varying model sizes, we have demonstrated that RIA consistently outperforms existing SOTA one-shot pruning techniques SparseGPT and Wanda, setting a new benchmark for post-training pruning performance. Furthermore, Channel Permutation successfully reduces the performance drop when adapting the model to the N:M constraint by reframing the input channel permutation problem as a combinatorial optimization task and solving it efficiently with the Hungarian algorithm. RIA and Channel Permutation form a seamless “plug-and-play" method, enabling effective one-shot post-training pruning for all current large language models. Furthermore, this method is hardware-friendly, ensuring enhanced inference acceleration.
Acknowledgments
This work is supported by the Zhou Yahui Chair professorship of Tsinghua University, the starting funding of the Tsinghua Laboratory of Brain and Intelligence, and the National High-level Talent Program of the Ministry of Science and Technology of China.
Appendix A

Table A1.
LLaMA2-70B: Zero-Shot Performance of N:M constraint model comparing to the dense model. Bold values denote the best performance across all N:M constraint models. An asterisk (“*") signifies performance surpassing that of the dense method.
Table A1.
LLaMA2-70B: Zero-Shot Performance of N:M constraint model comparing to the dense model. Bold values denote the best performance across all N:M constraint models. An asterisk (“*") signifies performance surpassing that of the dense method.
| Method | Hellaswag | BoolQ | ARC-C | MNLI | RTE | AVG |
|---|---|---|---|---|---|---|
| Dense | 64.77 | 83.70 | 54.44 | 45.81 | 67.87 | 63.32 |
| Wanda (2:4) | 57.35 | 81.44 | 46.01 | 37.69 | 68.59* | 58.22 |
| Wanda (2:4+CP) | 59.37 | 84.50* | 48.55 | 43.09 | 66.43 | 60.39 |
| Wanda (4:8+CP) | 60.86 | 82.73 | 49.94 | 40.15 | 67.87 | 60.51 |
| RIA (2:4) | 57.13 | 82.78 | 46.76 | 37.39 | 69.31* | 58.68 |
| RIA (2:4+CP) | 58.48 | 85.14* | 49.15 | 49.08* | 68.95* | 62.16 |
| RIA (4:8+CP) | 60.44 | 83.58 | 50.43 | 48.69* | 70.04* | 62.64 |
Appendix B. Motivation of Channel Permutation
Figure A1.
The degree distribution for input channels after pruning.
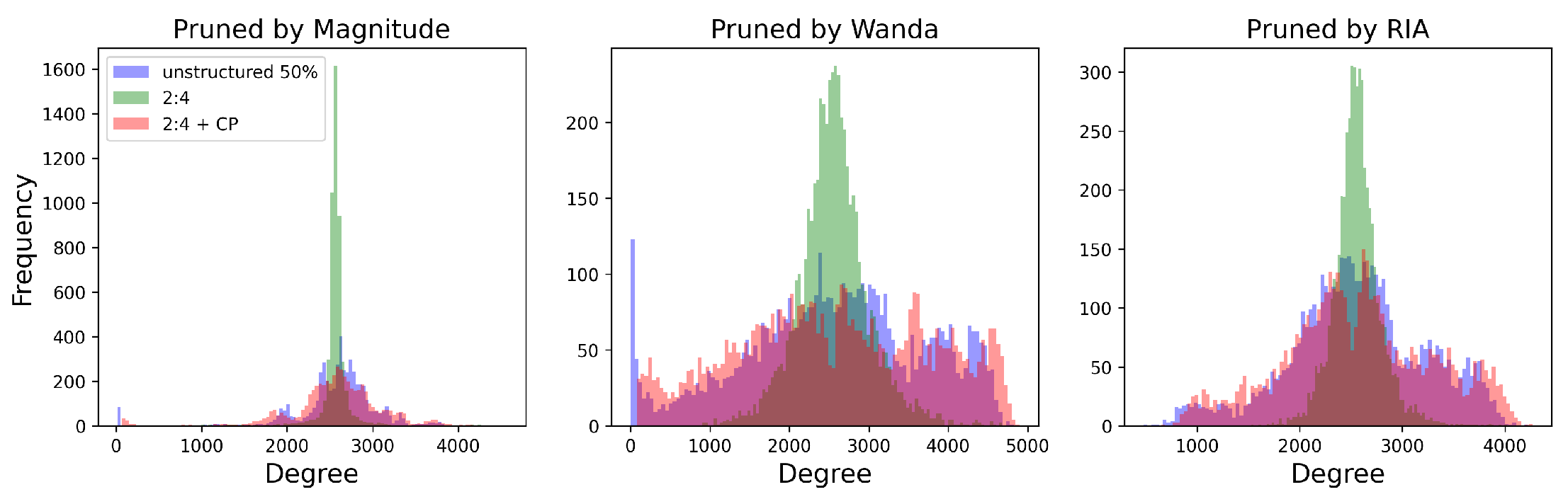
Based on the results presented in Section 5, it is evident that after applying channel permutation, the performance of N:M constraint models significantly improves in comparison to executing N:M sparsity directly. This improvement can be demonstrated through empirical observations made within Large Language Models (LLMs). As shown in Figure A1, pruning with 50% unstructured sparsity versus direct N:M constraint sparsity (2:4 in the figure) produces distinct variances in the distribution of input channels’ retained degree. The N:M constraint, by its nature, results in a more uniform pruning pattern. With an example from the first row of Figure 3, when directly pruning with 2:4 constraint sparsity, if the input channels with universally larger scores get stuck in the same block, some of the weights will be “wrongly" pruned. Conversely, the block with universally smaller scaling scores will “wrongly" preserve some weights. One diminishes while the other grows, resulting in a more uniform pruning, a smaller variance of the retained degree distribution of input channels, and therefore, a lower total sum of scores after pruning. In contrast, unstructured pruning takes on a broader perspective, pruning weights within their global context. This expansive methodology inherently introduces more variability, leading to a larger variance in the retained degree of input channels after pruning. The channel permutation method proposed in this article tackles this challenge smoothly by distributing similar scaling input channels into different blocks, allowing weights that should be retained to be preserved as much as possible. The post-channel-permutation distribution (2:4 + CP) of input channels’ retained degrees can be seen in Figure A1, closely mirroring the results of unstructured pruning.
Appendix C. Detailed Experimental Settings
Tasks and Metrics.
We mainly evaluate language modeling and zero-shot classification. Our initial assessment of language modeling involves a comprehensive evaluation of perplexity (PPL), where lower values indicate better performance. This evaluation is conducted on the test set of Wikitext2 [36]. For further evaluation, we also conduct experiments on zero-shot classification to assess the ability of the sparse model to correctly classify objects or data points into categories it has not seen during training across five common-sense datasets: Hellaswag, BoolQ, ARC-Challenge, MNLI, and RTE, compared to the performance of the dense model. We run the experiments with the public GitHub benchmark EleutherAI/lm-evaluation-harness [37].
Baselines.
For unstructured pruning, we compare with: 1) magnitude pruning [37], the most prevalent pruning approach; and two more recent state-of-the-art works on LLM pruning: 2) SparseGPT [9] and 3) Wanda [8]. These methods can be evaluated both on unstructured pruning and N:M semi-structured pruning in the following sections.
Calibration Data.
We employ 128 samples from the C4 dataset [38] for all models, and each sample contains 2048 tokens. This also aligns with the settings in baseline methods for a fair comparison. Note that we also discuss the choice of calibration data across different datasets, and more details can be found in Appendix D.
Appendix D. Sensitivity Test on Calibration Datasets
Table A2.
Assessing across various calibration and evaluation datasets. (LLaMA2-13B)
| Eval. dataset | PTB | wikitext2 | c4 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Calib. dataset | wikitext2 | c4 | PTB | wikitext2 | c4 | PTB | wikitext2 | c4 | PTB |
| Magnitude | 146.35 | 6.83 | 9.38 | ||||||
| Wanda | 68.49 | 69.70 | 63.58 | 5.85 | 5.97 | 5.89 | 8.43 | 8.30 | 8.25 |
| SparseGPT | 72.94 | 72.31 | 59.10 | 5.69 | 6.03 | 5.90 | 8.50 | 8.22 | 8.30 |
| RIA | 67.58 | 68.69 | 67.88 | 5.75 | 5.83 | 5.83 | 8.07 | 8.03 | 8.08 |
Figure 2 illustrates that different datasets exhibit varying data distributions, which in turn impact the input activations. Consequently, we conduct experiments employing different calibration datasets to evaluate the robustness of the pruned model. Specifically, we utilized three different datasets—Wikitext2, C4, and PTB [39]—with 128 samples, each containing 2048 tokens, for calibration purposes, and evaluated the performance on Wikitext2. RIA is compared with Wanda and SparseGPT, with the results summarized in Table A2. RIA surpasses other algorithms in the majority of scenarios, except when using identical calibration and evaluation datasets for PTB and wikitext2. This exception can be primarily attributed to the weight reconstruction process. A more congruent distribution tends to yield enhanced performance through reconstruction. Therefore, we explore integrating the reconstruction approach with Wanda and RIA in Appendix E. Furthermore, looking at the results across different calibration datasets, the results of RIA are more stable, which indicates that RIA is more robust than the calibration data.
Appendix E. Weight Reconstruction
Following the approach of OBS [6], which replaces the fine-tuning process with weight reconstruction using calibration data, this method has gained traction in LLMs post-pruning as an alternative to fine-tuning and retraining. SparseGPT [9] extends this idea by permitting partial updates, thereby reducing computational complexity. The specific formula for this is detailed in [9]. This weight reconstruction technique is essentially a tool embraced by all PTP methods that revise the objective function of equation 1 to A1.
In this formulation, represents the weight matrix after undergoing the reconstruction process. In this section, we evaluate Wanda and RIA based on their adoption of weight reconstruction and juxtapose their performance with that of SparseGPT. Our findings are presented in Table A3. We omit the results from PTB as their PPLs are excessively high, rendering them of no reference value. It’s evident that RIA+rec outperforms other reconstruction-based algorithms. However, except when Wikitext2 is used both for calibration and evaluation, the reconstruction does not appear to enhance performance. Therefore, we have chosen not to employ this weight reconstruction approach in our main text.
Table A3.
Assessment of Post-Training Pruning Methods Integrating Weight Reconstruction (LLaMA13B).
| wikitext2 | c4 | |||||
|---|---|---|---|---|---|---|
| wikitext2 | c4 | PTB | wikitext2 | c4 | PTB | |
| Magnitude | 6.38 | 9.38 | ||||
| Magnitude + rec | 5.84 | 6.07 | 6.17 | 8.48 | 8.30 | 8.62 |
| Wanda | 5.85 | 5.97 | 5.89 | 8.43 | 8.30 | 8.25 |
| Wanda+rec | 5.70 | 6.00 | 5.91 | 8.57 | 8.29 | 8.35 |
| SparseGPT | 5.69 | 6.03 | 5.90 | 8.50 | 8.22 | 8.30 |
| RIA | 5.75 | 5.83 | 5.83 | 8.07 | 8.03 | 8.08 |
| RIA+rec | 5.57 | 5.86 | 5.83 | 8.20 | 8.03 | 8.21 |
Appendix F. Channel Corruptions and Structured Pruning
Figure A2.
Comparison of Channel Corruption in Wanda and RIA. The plot shows the remaining node degree distribution post-pruning.
Figure A2.
Comparison of Channel Corruption in Wanda and RIA. The plot shows the remaining node degree distribution post-pruning.
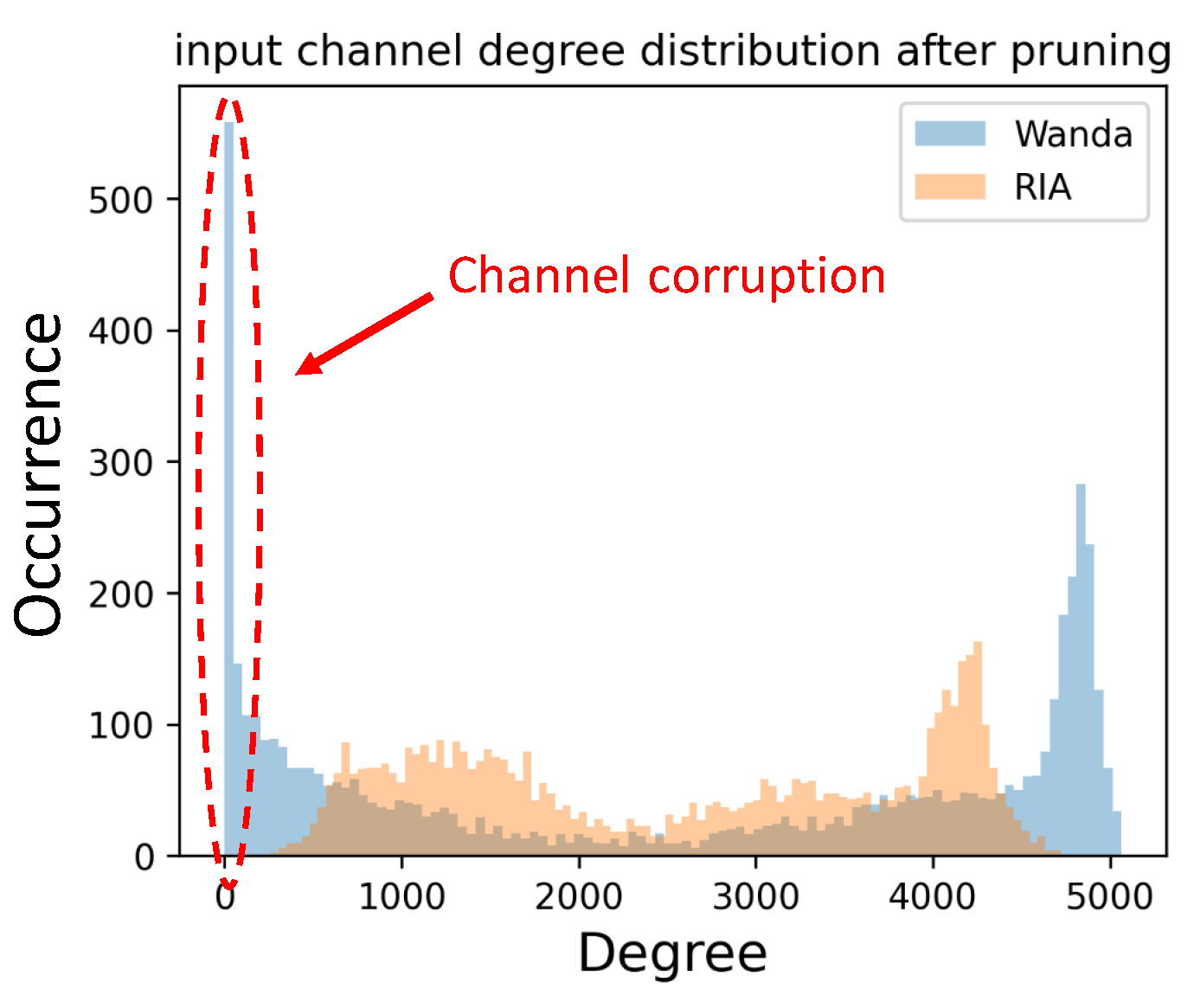
Evidence of Channel Corruption.
In Appendix F, we discussed the occurrence of channel corruption during the application of Wanda for pruning LLMs. Figure A2 illustrates the distribution of connections per input channel in the weight matrix following pruning by both Wanda and RIA, where degree denotes the number of connections a node has. Our findings reveal that in certain layers, Wanda results in roughly 10% of the channels experiencing corruption. Conversely, RIA ensures that no channels undergo corruption.
Detrimental Impact of Channel Corruption on Model Performance.
To assess the effects of full channel pruning on model performance, we utilize LLM-pruner [34], a SOT) method for structured pruning in LLMs. These experiments are designed to demonstrate the influence of channel corruption. Moreover, we adopt a pruning strategy based on activation as a fundamental comparative method, which serves not only as a test of structured pruning but also as an ablation study for our RIA method. We compare the structured pruning methods with Wanda and RIA with both unstructured sparsity results and semi-structured sparsity results. In LLM-pruner [34], they introduce a skip-layer pruning strategy that skips the pruning process for the first several layers and the last few layers. To provide a thorough evaluation, we perform experiments on pruning across all model layers, as elaborated in Table A5.
We have the following observations:
1) The overall performance of different sparsity patterns reveals that structured sparsity is less effective than semi-structured sparsity even at a low sparsity level of 25%, highlighting the detrimental impact of channel corruption on model effectiveness. Across all sparsity degrees and patterns, RIA consistently outperforms Wanda, demonstrating its superior performance.
2) The introduction of channel permutation has been found to boost performance as the model shifts towards semi-structured sparsity. This outcome is consistent with the observations detailed in the main text.
End-to-End Inference Latency of N:M Sparsity and Structured Sparsity.
We offer the LLM inference latency with structured sparsity and 2:4 sparsity. Our experiment is on LLaMA2-7b deployed on 2 NVIDIA A100s with 80 GB memory, where the input context sequence length is 128. We increase the batch size and record the inference latency accordingly. According to Table A4, structured sparsity (50%) marginally outperforms the 2:4 sparsity model as the batch size increases. Importantly, note that with smaller batch sizes, both structured 50% sparsity and 2:4 sparsity models do not significantly boost inference speed. However, as the batch size grows, the acceleration for 2:4 sparsity approximates 1.5x, whereas the structured 50% sparsity tends to reach about 1.7x acceleration.
Table A4.
The inference latency of 2:4 sparsity and structured 50% sparsity with varying batch sizes on LLaMA2-7b model.
Table A4.
The inference latency of 2:4 sparsity and structured 50% sparsity with varying batch sizes on LLaMA2-7b model.
| Batch Size | 1 | 8 | 16 | 64 |
|---|---|---|---|---|
| dense | 281.13 ms | 547.82 ms | 1011.81ms | 3742.76 ms |
| structured sparsity (50%) | 238.92 ms | 326.14 ms | 616.13 ms | 2181.69 ms |
| 2:4 sparsity | 225.60 ms | 357.48 ms | 731.81 ms | 2495.41 ms |
In conclusion, N:M semi-structured sparsity emerges as the optimal compromise between performance and latency. Although structured pruning offers the additional advantage of acceleration at the same sparsity level, the associated performance decrease is significant, even at very low sparsity levels.
Table A5.
Comparative performance of structured and semi-structured pruning at various sparsity levels: experiments on LLaMA2-7B with calibration on C4 with 128 samples and evaluation on Wikitext2 using PPL metrics. The table includes experiments pruning on all layers.
Table A5.
Comparative performance of structured and semi-structured pruning at various sparsity levels: experiments on LLaMA2-7B with calibration on C4 with 128 samples and evaluation on Wikitext2 using PPL metrics. The table includes experiments pruning on all layers.
| 1:4 (25% sparsity) | 2:4 (50% sparsity) | 3:4 (75% sparsity) | |
|---|---|---|---|
| LLM-Pruner (structured) | 28.88 | nan | 13570 |
| Activation-based (structured) | 39.54 | 10467 | nan |
| Wanda (semi-structured) | 5.94 | 12.15 | 2863.3 |
| RIA (semi-structured) | 5.90 | 11.27 | 1891.13 |
| RIA + CP (semi-structured) | 5.81 | 10.12 | 1532.72 |
| Wanda (unstructured) | 5.68 | 6.92 | 1506.13 |
| RIA (unstructured) | 5.56 | 6.81 | 267.61 |
Appendix G. Implementation Details of Channel Permutation
Appendix G.1. Output Channel Reordering
From a computational efficiency perspective, directly implementing permutation on input vectors introduces extra runtime overhead for extracting the permuted index and applying it to the input vectors. However, an alternative approach can be considered. Given that each input serves as the output of the preceding layer, we can permute the output channels of the previous layers’ weights to serve as the permuted index for the next layers’ input channels. This eliminates the need to permute the input index separately, resulting in time savings.
However, two key considerations must be taken into account:
a) The Q, K, and V projection layers within a single module must be treated as a unified matrix, concatenated into a single entity that shares the same input channel indices. This ensures that the input index permutation remains identical across these layers, avoiding the need for additional permutations. In the case of LLaMA, the MLP module presents a similar scenario, as it contains parallel layers, namely, down_proj and gate_proj, which also need to be concatenated into a single matrix.
b) Another important factor to note is that this strategy cannot be applied when dealing with models featuring residual connections. This is because inputs in such modules also originate from the previous module. As a result, permutations must be applied to the input activations at the beginning of each module. However, this process does not significantly impact execution time. We’ve modified the RMS normalization layer — which typically follows the Residual connection — using Triton [40]. This ensures this layer’s output channel indices align with the subsequent layers’ input indices. In our tests, the time taken for this adjustment is negligible.
Appendix G.2. Community-Based Partitioning
In optimizing the process of Channel Permutation, we employ a method that significantly accelerates execution by partitioning the input channels into several communities. This strategic division reduces the runtime of channel permutation to , where n represents the number of communities. The primary source of this reduction in execution time stems from the more efficient computation of the sum of scores following N:M pruning, achieved when input channels are allocated into distinct blocks. The experimental results presented in the main text are grounded on these optimization techniques.
Figure A3.
Outliers in LLaMA-7B and LLaMA-13B.
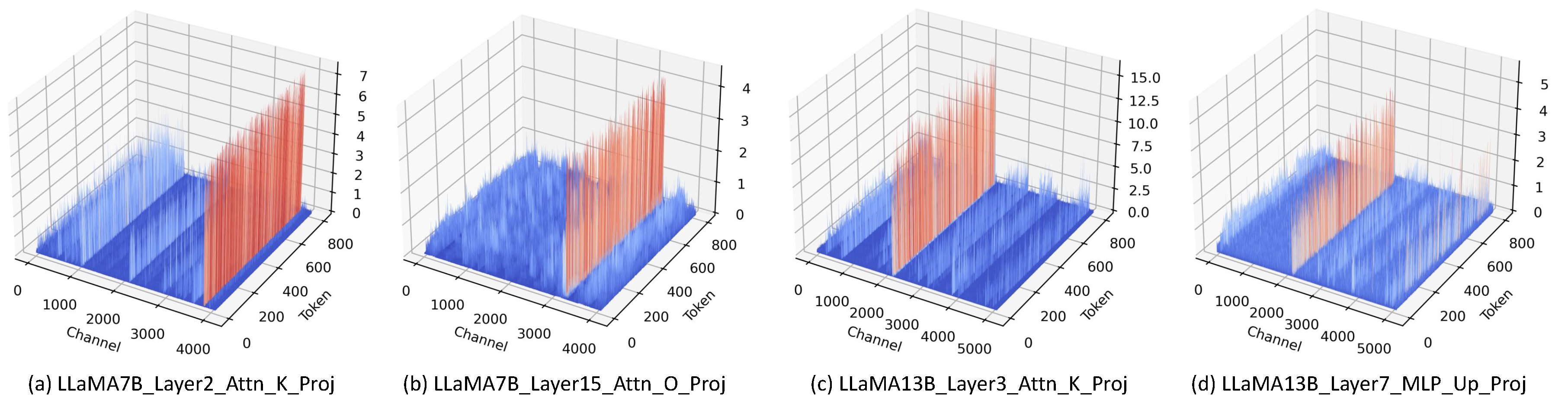
Figure A4.
Outliers in OPT-6.7B and OPT-13B.
Appendix H. Complexity Analysis of RIA and Channel Permutation
RIA. We provide a summary of the computational complexity of various Post-Training Pruning (PTP) algorithms. For SparseGPT, the time complexity is approximately [9], whereas both RIA and Wanda exhibit similar time complexities of approximately [8].
Table A6.
Permutation time (seconds) for Greedy algorithm and Channel Permutation.
| Greedy | 252.1 | 495.4 | 818.7 | 1563.6 |
| Greedy + 100 escapes | 845.3 | 1349.1 | 1896.4 | 3592.3 |
| Channel Permutation | 6.2 | 8.1 | 11.5 | 15.3 |
Channel Permutation.
The process of channel reallocation to obtain the sorted input channel indices is straightforward. Computation of the score matrix S involves determining the outcome of placing each objection into every box and summing the results while processing the 2:4 constraint within each block. Consequently, the time complexity for this computation is , where represents the computational complexity for the N:M constraint within each block. The time complexity of the Hungarian algorithm is .
The greedy method [20] is challenging to implement in LLMs due to its prohibitive running time, as shown in Table A6. We conduct only a single experiment for performance comparison on LLaMA2-13b, which took us 3 days. We tested the greedy method with 100 escape iterations to handle the permutation, the PPL on wikitext2 with a permuted 2:4 constraint is 7.83 which is just comparable to our CP method (7.77). However, the CP’s execution time is just about 1 hour, making it possible to be applied in the LLMs.
Appendix I. Hungarian Algorithm
Given a bipartite graph with N left vertices and N right vertices, depicted by matrix , where represents the weight between the left vertex i and the right vertex j, the algorithm aims to identify the ideal matching that minimizes the aggregate weight. This goal is captured in the subsequent objective function:
In this Equation, is a binary determinant that showcases whether the left vertex i is paired with the right vertex j. In our scenario, the initial first group of input indices is treated as vertex i, with the incomplete boxes acting as vertex j. This transition into an LSA problem is seamlessly facilitated by the Hungarian algorithm, which subsequently derives the optimal permutation. After rearranging the first indices of the blocks, we apply the same procedure to the subsequent groups in sequence.
Appendix J. Integration of Post-Training Pruning with Quantization Methods
Our experiments utilized the LLaMA2-7b model, focusing on two quantization methods: GPTQ [2] and AWQ [4]. The calibration is performed using the C4 dataset, and evaluations are done on Wikitext2. We present our results in Table A7.
Table A7.
Integration of Post-Training Pruning with Quantization Methods.
| Magnitude | SparseGPT | Wanda | RIA | |
|---|---|---|---|---|
| Unstructured (50% sparsity) | 16.02 | 6.99 | 6.92 | 6.81 |
| Unstructured (50% sparsity) With GPTQ | 15.21 | 7.59 | 7.41 | 7.28 |
| Unstructured (50% sparsity) With AWQ | 17.12 | 7.15 | 7.10 | 6.97 |
Our finding suggests that this integration can reduce memory and inference acceleration with a slight detriment to performance.
We have identified two primary strategies for merging post-training pruning with quantization: (a) first pruning, then quantization, and (b) first quantization, then pruning. Our finding indicates a preference for (a) pruning before quantization. This is potentially because for (b), conventional block-wise quantization relies merely on the minimum and maximum weights within a block, and pruning can lead to a reduction in these extremes, thereby potentially aiding quantization. In contrast, (a) quantization before pruning adversely affects the computation of weight importance for pruning, resulting in diminished performance.
Appendix K. The Explanation of Preventing Performance Drop from Dense
The primary goal of post-training pruning methods is to minimize the performance drop compared to the dense model. Therefore, designing metrics that offer a fair evaluation of new methods against this baseline (dense performance) is crucial. Consider two post-training pruning methods, A and B, with perplexities P(A) and P(B), respectively. Let P(D) represent the baseline perplexity of the dense network. The effectiveness of method B in preventing performance degradation compared to method A can be quantified as . This formula allows for a fair assessment of the new method relative to previous approaches, taking into account the performance of the dense model in the post-training pruning context. Using this calculation, the RIA method demonstrates a 17% improvement over Wanda and a 50% improvement over SparseGPT in preventing performance drops from the dense model consistently across all tested models.
Figure A5.
We evaluate how to choose the factor ‘a’ inside the formula of RIA with LLaMA2-7B and LLaMA-13b model. The calibration dataset is C4 with 128 samples, and the evaluation is on wikitext2. The sparsity is fixed at 50%. From the results, there are no significant differences between a=0.2 to a=0.5. For simplicity, we select a=0.5 in the main text to execute all the evaluations.
Figure A5.
We evaluate how to choose the factor ‘a’ inside the formula of RIA with LLaMA2-7B and LLaMA-13b model. The calibration dataset is C4 with 128 samples, and the evaluation is on wikitext2. The sparsity is fixed at 50%. From the results, there are no significant differences between a=0.2 to a=0.5. For simplicity, we select a=0.5 in the main text to execute all the evaluations.
References
- Bai, H.; Zhang, W.; Hou, L.; Shang, L.; Jin, J.; Jiang, X.; Liu, Q.; Lyu, M.; King, I. Binarybert: Pushing the limit of bert quantization. arXiv preprint arXiv:2012.15701 2020.
- Frantar, E.; Ashkboos, S.; Hoefler, T.; Alistarh, D. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323 2022.
- Xiao, G.; Lin, J.; Seznec, M.; Wu, H.; Demouth, J.; Han, S. Smoothquant: Accurate and efficient post-training quantization for large language models. International Conference on Machine Learning. PMLR, 2023, pp. 38087–38099.
- Lin, J.; Tang, J.; Tang, H.; Yang, S.; Dang, X.; Han, S. AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. arXiv preprint arXiv:2306.00978 2023.
- LeCun, Y.; Denker, J.; Solla, S. Optimal brain damage. Advances in neural information processing systems 1989, 2.
- Hassibi, B.; Stork, D.G.; Wolff, G.J. Optimal brain surgeon and general network pruning. IEEE international conference on neural networks. IEEE, 1993, pp. 293–299.
- Mocanu, D.C.; Mocanu, E.; Stone, P.; Nguyen, P.H.; Gibescu, M.; Liotta, A. Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science. Nature communications 2018, 9, 2383.
- Sun, M.; Liu, Z.; Bair, A.; Kolter, J.Z. A Simple and Effective Pruning Approach for Large Language Models. arXiv preprint arXiv:2306.11695 2023.
- Frantar, E.; Alistarh, D. SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot 2023.
- Lee, N.; Ajanthan, T.; Torr, P.H. Snip: Single-shot network pruning based on connection sensitivity. arXiv preprint arXiv:1810.02340 2018.
- Evci, U.; Gale, T.; Menick, J.; Castro, P.S.; Elsen, E. Rigging the lottery: Making all tickets winners. International Conference on Machine Learning. PMLR, 2020, pp. 2943–2952.
- Sanh, V.; Wolf, T.; Rush, A. Movement pruning: Adaptive sparsity by fine-tuning. Advances in Neural Information Processing Systems 2020, 33, 20378–20389.
- Yuan, G.; Ma, X.; Niu, W.; Li, Z.; Kong, Z.; Liu, N.; Gong, Y.; Zhan, Z.; He, C.; Jin, Q.; others. Mest: Accurate and fast memory-economic sparse training framework on the edge. Advances in Neural Information Processing Systems 2021, 34, 20838–20850.
- Hoang, D.N.; Liu, S.; Marculescu, R.; Wang, Z. Revisiting pruning at initialization through the lens of Ramanujan graph. The Eleventh International Conference on Learning Representations, 2022.
- Zhang, Y.; Zhao, J.; Wu, W.; Muscoloni, A.; Cannistraci, C. Epitopological Sparse Ultra-Deep Learning: A Brain-Network Topological Theory Carves Communities in Sparse and Percolated Hyperbolic ANNs 2023.
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. Advances in neural information processing systems 2015, 28.
- Liu, S.; Chen, T.; Chen, X.; Atashgahi, Z.; Yin, L.; Kou, H.; Shen, L.; Pechenizkiy, M.; Wang, Z.; Mocanu, D.C. Sparse training via boosting pruning plasticity with neuroregeneration. Advances in Neural Information Processing Systems 2021, 34, 9908–9922.
- Li, J.; Louri, A. AdaPrune: An accelerator-aware pruning technique for sustainable CNN accelerators. IEEE Transactions on Sustainable Computing 2021, 7, 47–60.
- Mishra, A.; Latorre, J.A.; Pool, J.; Stosic, D.; Stosic, D.; Venkatesh, G.; Yu, C.; Micikevicius, P. Accelerating sparse deep neural networks. arXiv preprint arXiv:2104.08378 2021.
- Pool, J.; Yu, C. Channel permutations for N: M sparsity. Advances in neural information processing systems 2021, 34, 13316–13327.
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; others. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 2023.
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; others. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 2023.
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X.V.; others. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068 2022.
- Frantar, E.; Alistarh, D. SPDY: Accurate pruning with speedup guarantees. International Conference on Machine Learning. PMLR, 2022, pp. 6726–6743.
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 2018.
- Liu, Z.; Wang, J.; Dao, T.; Zhou, T.; Yuan, B.; Song, Z.; Shrivastava, A.; Zhang, C.; Tian, Y.; Re, C.; others. Deja vu: Contextual sparsity for efficient llms at inference time. International Conference on Machine Learning. PMLR, 2023, pp. 22137–22176.
- Bai, H.; Hou, L.; Shang, L.; Jiang, X.; King, I.; Lyu, M.R. Towards efficient post-training quantization of pre-trained language models. Advances in Neural Information Processing Systems 2022, 35, 1405–1418.
- Liu, R.; Bai, H.; Lin, H.; Li, Y.; Gao, H.; Xu, Z.; Hou, L.; Yao, J.; Yuan, C. IntactKV: Improving Large Language Model Quantization by Keeping Pivot Tokens Intact. arXiv preprint arXiv:2403.01241 2024.
- Hubara, I.; Chmiel, B.; Island, M.; Banner, R.; Naor, J.; Soudry, D. Accelerated sparse neural training: A provable and efficient method to find n: m transposable masks. Advances in neural information processing systems 2021, 34, 21099–21111.
- Zhou, A.; Ma, Y.; Zhu, J.; Liu, J.; Zhang, Z.; Yuan, K.; Sun, W.; Li, H. Learning n: m fine-grained structured sparse neural networks from scratch. arXiv preprint arXiv:2102.04010 2021.
- Zhang, Y.; Lin, M.; Lin, Z.; Luo, Y.; Li, K.; Chao, F.; Wu, Y.; Ji, R. Learning best combination for efficient n: M sparsity. Advances in Neural Information Processing Systems 2022, 35, 941–953.
- Tao, C.; Hou, L.; Bai, H.; Wei, J.; Jiang, X.; Liu, Q.; Luo, P.; Wong, N. Structured pruning for efficient generative pre-trained language models. Findings of the Association for Computational Linguistics: ACL 2023, 2023, pp. 10880–10895.
- Lin, H.; Bai, H.; Liu, Z.; Hou, L.; Sun, M.; Song, L.; Wei, Y.; Sun, Z. MoPE-CLIP: Structured Pruning for Efficient Vision-Language Models with Module-wise Pruning Error Metric. arXiv preprint arXiv:2403.07839 2024.
- Ma, X.; Fang, G.; Wang, X. LLM-Pruner: On the Structural Pruning of Large Language Models. arXiv preprint arXiv:2305.11627 2023.
- Kuhn, H.W. The Hungarian method for the assignment problem. Naval Research Logistics Quarterly 1955, 2, 83–97.
- Merity, S.; Xiong, C.; Bradbury, J.; Socher, R. Pointer Sentinel Mixture Models, 2016, [arXiv:cs.CL/1609.07843].
- Zhu, M.; Gupta, S. To prune, or not to prune: exploring the efficacy of pruning for model compression. arXiv preprint arXiv:1710.01878 2017.
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv e-prints 2019, [1910.10683].
- Marcus, M.P.; Santorini, B.; Marcinkiewicz, M.A. Building a Large Annotated Corpus of English: The Penn Treebank. Computational Linguistics 1993, 19, 313–330.
- Tillet, P.; Kung, H.T.; Cox, D. Triton: an intermediate language and compiler for tiled neural network computations. Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, 2019, pp. 10–19.
| 1 |
https://huggingface.co/meta-llama, https://huggingface.co/facebook |
Figure 1.
An example of Relative Importance. The connection at position 44 will be removed based on global network magnitude. However, it is retained when evaluated for its significance within relative connections.
Figure 1.
An example of Relative Importance. The connection at position 44 will be removed based on global network magnitude. However, it is retained when evaluated for its significance within relative connections.
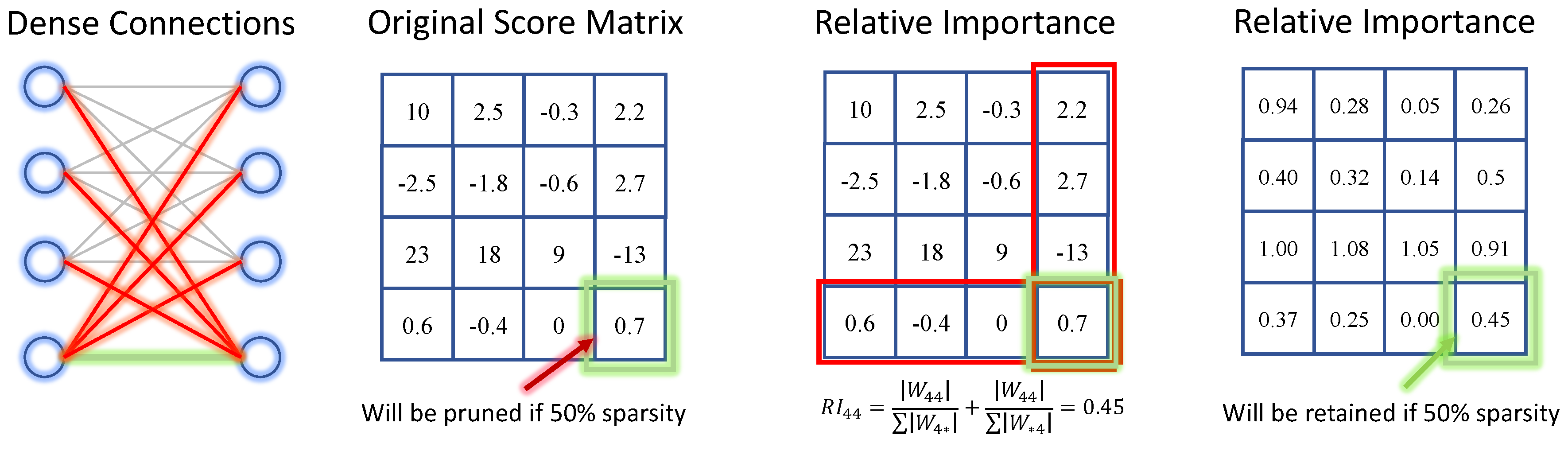
Figure 2.
Spearman’s Rank correlation of LLaMA2-13B activations from Wikitext2, C4, and PTB, each with 128 samples. Note that the Q, K, and V layers all share the same input activations. Similarly, the Up and Gate layers also receive identical input activations.
Figure 2.
Spearman’s Rank correlation of LLaMA2-13B activations from Wikitext2, C4, and PTB, each with 128 samples. Note that the Q, K, and V layers all share the same input activations. Similarly, the Up and Gate layers also receive identical input activations.
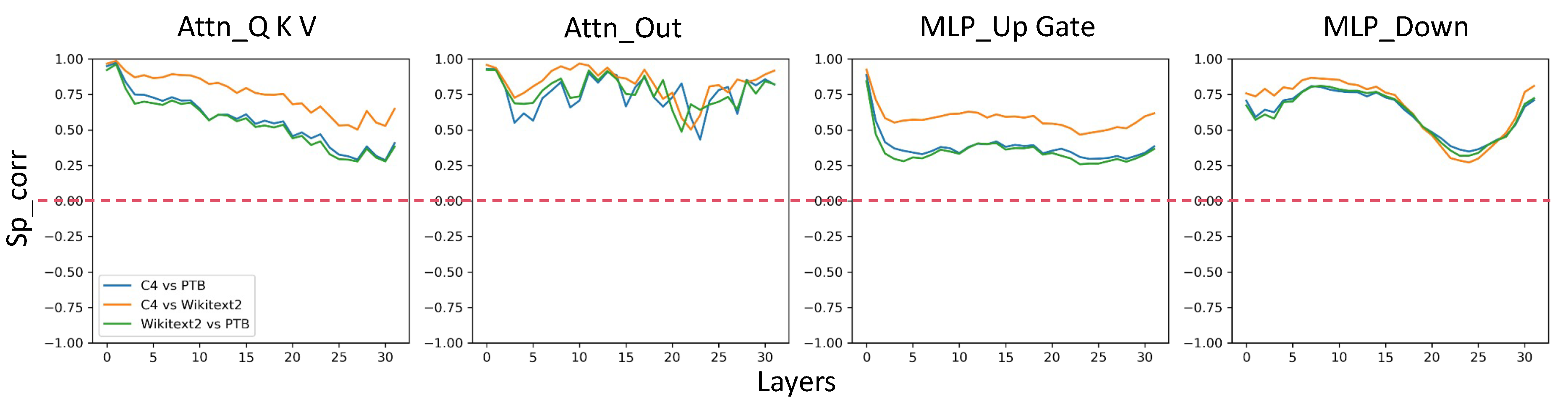
Figure 3.
Illustration of Channel Permutation. Given a score matrix assigned by various criteria, directly processing it with 2:4 sparse results in a total sum of the retained score being 83.7. However, by using channel permutation, we could get a final total sum of score 102.3.
Figure 3.
Illustration of Channel Permutation. Given a score matrix assigned by various criteria, directly processing it with 2:4 sparse results in a total sum of the retained score being 83.7. However, by using channel permutation, we could get a final total sum of score 102.3.
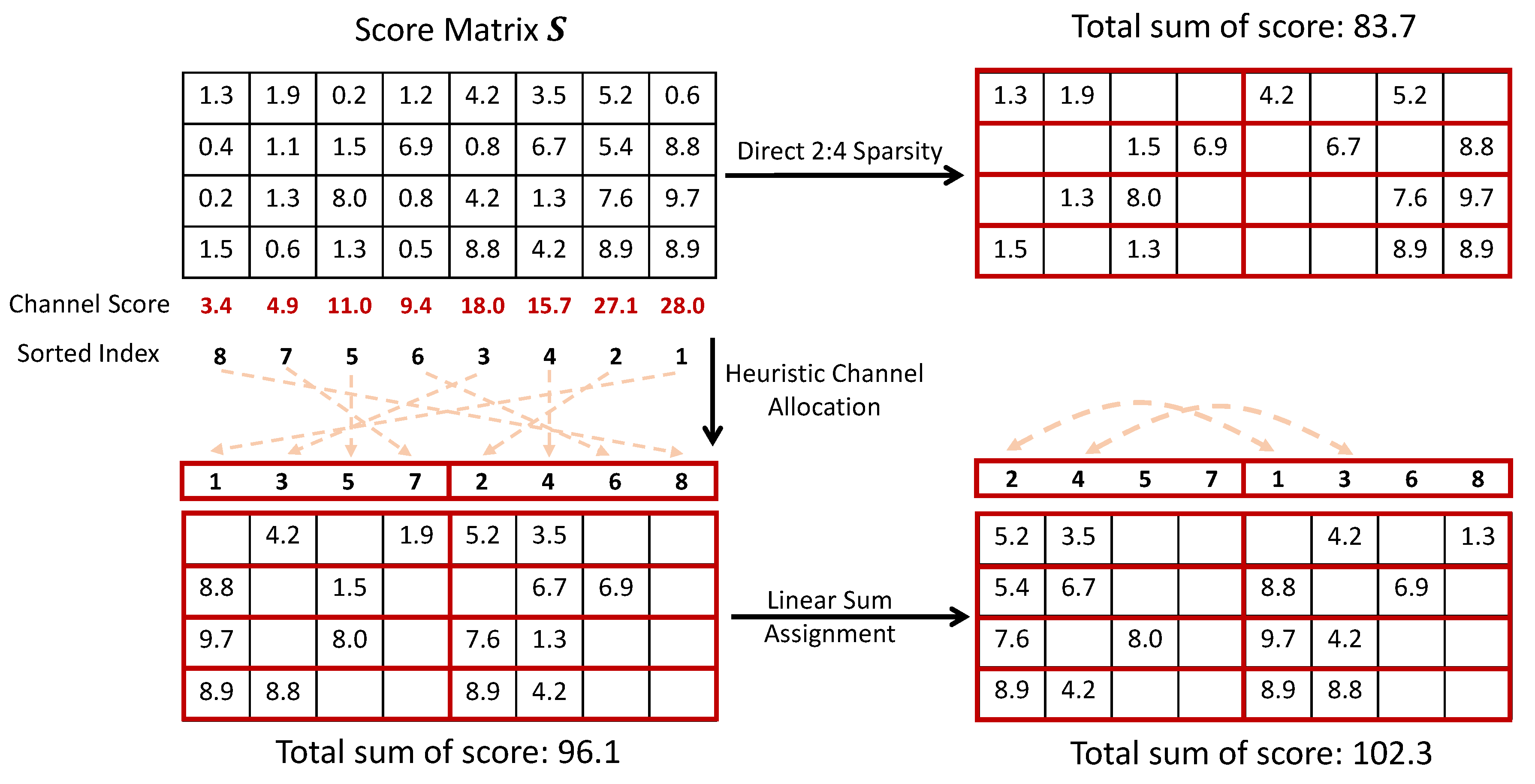
Table 1.
Perplexity results on Wikitext2. We produce the one-shot Post-Training pruning methods with 50% unstructured sparsity on LLaMA, LLaMA2, and OPT models.
Table 1.
Perplexity results on Wikitext2. We produce the one-shot Post-Training pruning methods with 50% unstructured sparsity on LLaMA, LLaMA2, and OPT models.
| Method | LLaMA 7b | LLaMA 13b | LLaMA 30b | LLaMA 65b | LLaMA2 7b | LLaMA2 13b | LLaMA2 70b | OPT 1.3b |
|---|---|---|---|---|---|---|---|---|
| Dense | 5.68 | 5.09 | 4.77 | 3.56 | 5.47 | 4.88 | 3.32 | 14.62 |
| Magnitude | 17.28 | 20.22 | 7.54 | 5.90 | 16.02 | 6.83 | 5.36 | 1712 |
| Wanda | 7.26 | 6.15 | 5.24 | 4.57 | 6.92 | 5.99 | 4.22 | 18.41 |
| SparseGPT | 7.24 | 6.20 | 5.32 | 4.57 | 6.99 | 6.10 | 4.25 | 27.00 |
| RIA (Ours) | 7.12 | 6.08 | 5.08 | 4.38 | 6.81 | 5.83 | 4.11 | 18.08 |
Table 2.
Ablation Studies of RIA on LLaMA-13B and LLaMA-30B models.
| LLaMA-13B | LLaMA-30B | |
|---|---|---|
| 9056 | nan | |
| 20.22 | 7.55 | |
| 11.97 | 6.73 | |
| 7.80 | 5.55 | |
| 6.57 | 5.27 | |
| 6.14 | 5.13 | |
| 6.08 | 5.08 |
Table 3.
LLaMA2-70B: Zero-Shot Performance of the model with unstructured 50% sparsity compared to the dense model. Bold values denote the best performance across all the post-training pruning methods. An asterisk (“*") signifies performance surpassing that of the dense method.
Table 3.
LLaMA2-70B: Zero-Shot Performance of the model with unstructured 50% sparsity compared to the dense model. Bold values denote the best performance across all the post-training pruning methods. An asterisk (“*") signifies performance surpassing that of the dense method.
| Method | Hellaswag | BoolQ | ARC-C | MNLI | RTE | AVG |
|---|---|---|---|---|---|---|
| Dense | 64.77 | 83.70 | 54.44 | 45.81 | 67.87 | 63.32 |
| Magnitude | 60.58 | 71.10 | 49.32 | 32.80 | 60.65 | 54.89 |
| Wanda | 62.70 | 83.27 | 52.50 | 43.19 | 70.84* | 62.50 |
| SparseGPT | 62.36 | 84.26* | 53.07 | 40.29 | 70.76* | 62.15 |
| RIA | 63.22 | 84.77* | 52.56 | 42.80 | 71.48* | 62.97 |
Table 4.
Unstructured sparsity and semi-structured sparsity results on Wikitext2. We highlight the best performance among all methods within the same sparsity pattern in bold.
Table 4.
Unstructured sparsity and semi-structured sparsity results on Wikitext2. We highlight the best performance among all methods within the same sparsity pattern in bold.
| Method | Unstructured 50% | 2:4 | 2:4+CP w/o LSA | 2:4+CP | 4:8 | 4:8+CP | |
|---|---|---|---|---|---|---|---|
| LLaMA2-13b (Dense 4.88) |
Magnitude | 6.83 | 8.74 | 8.89 | 8.87 | 7.32 | 7.16 |
| Wanda | 5.99 | 9.00 | 8.74 | 8.45 | 7.00 | 6.83 | |
| SparseGPT | 6.10 | 8.77 | 8.61 | 8.48 | 7.01 | 6.80 | |
| RIA (Ours) | 5.83 | 8.41 | 8.03 | 7.77 | 6.74 | 6.53 | |
| LLaMA2-70b (Dense 3.32) |
Magnitude | 5.36 | 6.76 | 6.77 | 6.71 | 5.89 | 5.91 |
| Wanda | 4.23 | 5.48 | 5.29 | 5.23 | 4.77 | 4.63 | |
| SparseGPT | 4.25 | 5.68 | 5.37 | 5.31 | 4.91 | 4.79 | |
| RIA (Ours) | 4.11 | 5.36 | 5.18 | 5.11 | 4.68 | 4.54 |
Table 5.
LLaMA2-13B: Inference time of different sparsity patterns. Batch size of input sequences is 8 and the sequence length is 128.
Table 5.
LLaMA2-13B: Inference time of different sparsity patterns. Batch size of input sequences is 8 and the sequence length is 128.
| Method | Q/K/V/Out | Up/Gate | Down | Overall |
|---|---|---|---|---|
| unstructured 50% | 0.98× | 0.98× | 0.97× | 0.98× |
| 2:4 (cuTLASS) | 1.21× | 1.23× | 1.23× | 1.22× |
| 2:4 (cuSPARSELT) | 1.64× | 1.65× | 1.62× | 1.63× |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



