
Submitted:
25 October 2023
Posted:
25 October 2023
You are already at the latest version
Abstract
A digital twin is a virtual representation that serves as the real-time digital counterpart of a physical object or system. Recent advancements have extended the concept of digital twins to humans, incorporating complex biological data such as DNA (Predictiv Care, Inc.) and immune system profiles. These sophisticated models go beyond mere pictorial representations, offering a more holistic digital reflection. However, a significant gap remains. The current human digital twin models are not capable of learning one’s preferences. In this pilot study, we introduce Diginality, a chatbot powered by HyperCLOVA X, a Large Language Model (LLM) developed by NAVER, Inc. Diginality, learns one’s preferences with custom training from data collected by interview-style questions on the user’s topic of interest. Our findings demonstrate that Diginality successfully answers one’s preferences, thereby adding a new dimension to the concept of human digital twins. This work represents a pioneering step towards creating a more comprehensive and psychologically nuanced human digital twin.
Keywords:
AI
; HyperCLOVA X
; Personality
; Digital Twin
; Large Language Model
; Transformer
1. Introduction
The concept of digital twins has gained significant traction in recent years to create real-time, virtual counterparts of physical objects and systems, offering a powerful tool for simulation, analysis, and control [1]. Initially developed for industrial applications, digital twins have found their utility in various sectors, including healthcare, aerospace, and urban planning [2]. The advent of more powerful computational methods and high-throughput data collection techniques has recently extended this concept to encompass biological systems, including humans [3].
The realm of healthcare has seen an influx of digital twin technology, incorporating complex biological data sets such as genomic profiles and immune system characteristics to create virtual representations of individual humans [4]. Companies like Predictiv Care, Inc. have taken strides in using genetic data to create personalized digital twins for healthcare [5]. These models offer more than mere pictorial or structural representations. They aim to provide a holistic, digital reflection of an individual’s biological and physiological state. This has allowed for predictive modeling of disease states, personalization of treatment plans, and even simulations for surgical procedures [6].
Despite these advancements, a considerable gap exists in the current state of human digital twins—the inability to learn one’s preferences. Human communication is not just a function of the words used but also the context, tone, and emotion with which they are delivered as illustrated by one’s character. Current models fall short of capturing these subtle but essential aspects of human interaction.
The field of natural language processing (NLP) has made significant strides in the development of Large Language Models (LLMs) that can understand, generate, and even predict human language with a high degree of accuracy [7]. NAVER, Inc., a leading technology firm, has developed HyperCLOVA X, an advanced LLM that goes beyond basic language understanding and generation to learn and emulate individual preferences in language and emotional tone [8].
This work explores the integration of HyperCLOVA X into the concept of human digital twins. We aim to show that Diginality learns the individual’s language, thereby adding a new layer of complexity and utility to human digital twins. This represents a pioneering step towards creating a more comprehensive and psychologically nuanced model, bridging the gap between existing biological digital twins and the emotional and preferential complexities that make us uniquely human.
In summary, this pilot study aims to expand the boundaries of what is currently possible in the realm of human digital twins by integrating advanced NLP techniques, thereby offering a more faithful model that is both biologically and linguistically reflective of the individual it represents.
2. Methods
Diginality, a contraction between the words Digital and Personality, employs HyperCLOVA X, NAVER, Inc.’s Large Language Model. The base model, LK-0, was used. Diginality was built using Flask version 2.2.2, a Python web framework used for handling web requests and rendering templates. Pandas version 1.5.3, Subprocess, JSON, CSV, String, Chardet version 4.0.0 modules were used for data manipulation. Upon receiving the custom training request from the user, the keyword “wonyoung”, it cleans up the texts by removing punctuations and new line characters followed by string aggregation. The cleaned data were segmented using segmentation module version 1 with API calls. Then, custom tuning is performed with default parameters of learning rate of 10−4. All codes used is available at https://github.com/josephyunpredictiv/Diginality which requires API access to HyperCLOVA X.
3. Results
3.1. Preference Learning Through Interactive Interviewing
We designed to explore the ability of Diginality powered by the HyperCLOVA X, a Large Language Model (LLM), in learning and customizing user preferences through an interactive, interview-style dialog (Figure 1). The conversation starts with a user prompt indicating an area of interest. Diginality then engages the user in a series of questions to refine this subject (Figure 2). The dialogues are categorized into three key components: A) Initial user prompt indicating preferences, B) Diginality’s questions to refine the topic, and C) The user’s responses to these questions.
3.2. Triggering Custom Tuning
When the user input a predefined keyword, “wonyoung,”, Diginality initiates a custom-tuning phase (Figure 3). Upon receiving this keyword, Diginality ceases the interview and commences a custom tuning procedure to adjust its future responses based on the conversational history. The tuning process uses the data gathered in the “Text” and “Completion” columns as shown in the Diginality’s questions and the user’s answers, respectively (Figure 4).
3.3. Case Study—An Interview On The User’s Favorite Sports
To evaluate the efficacy and implication of this custom-tuning mechanism, we conducted pre- and post-tuning tests. One test involved the query “Which teams are the best in college basketball?” (Figure 4). Before tuning, the LK-0 HyperCLOVA X base model provided answers based on general public opinion and statistical achievements such as win/loss records. Post-tuning, Diginality’s answer shifted to reflect the user’s specific preference of evaluating teams based on talent and coaching (Figure 5).
The default HyperCLOVA X LLM model (LK-0) initially interpreted “the best” as the team with the most wins and championships, a common but generalized criterion. However, after custom training, Diginality tailored its answer to align with the user’s unique perspective, citing Duke as the best team due to its talent and coaching quality. The response demonstrates the model’s ability to learn from custom tuning effectively and to answer with personalized nuances.
4. Discussion
Our findings demonstrate that the HyperCLOVA X, a LLM, can effectively learn and adapt to individual user preferences through an interactive, interview-style dialogue followed by a custom-tuning mechanism. This research bridges the gap between generic chatbot interactions and personalized conversational experiences. The shift from a generalized approach to a more nuanced understanding of user preferences post-tuning is particularly noteworthy and inspires for a future where AI can provide meaningful and intuitively personal improvements to our lives.
This development marks an exciting advancement in human-computer interactions, where AI systems can adapt to individual needs, improving productivity, convenience, and overall satisfaction. By exploring user preferences in greater detail and continually refining AI responses, we are paving the way for more empathetic and effective AI companions that can seamlessly integrate into our daily routines, enhancing our interactions with technology.
5. Limitations and Caveats
While the results are promising, it is crucial to acknowledge the limitations of our methodology. Our study did not explore how well the system adapts to changing preferences over time or how it handles contradictory information. The custom-tuning mechanism was tested on a limited set of questions and may not generalize to more complex queries or topics.
A personalized LLM chatbot that knows your preferences and even has your character in the digital world could potentially raise ethical concerns. In our ever-changing world, where most of works can be done online, for example, responding to emails or online bank transactions, we may not have a proper way to distinguish who is the one who did the online work, you or your digital twin. As this technology continues to develop, an equal effort must be put into gaining a deep understanding of how these models work and adopt our technologies to be able to counter concerns of identity theft and plagiarism.
Several avenues for future research are apparent. First, the custom-tuning mechanism could be improved to handle a wider range of queries and preferences. Second, a more comprehensive study could provide insights into the personalized LLM’s ability to adapt to going beyond one’s preferences. Third, the research could be expanded to compare the effectiveness of different machine learning algorithms in custom-tuning such as ChatGPT or Google BARD.
6. Conclusions
In conclusion, our study presents a pioneering approach in the field of AI, showing that a LLM can effectively adapt to individual user preferences through an interview-style dialogue and a real-time, custom-tuning mechanism. While there are limitations and ethical concerns to consider, the method holds significant promise for the development of a more intelligent, personalized digital twin.
Author Contributions
Conceptualization, J.Y. and S.Y.; methodology, J.Y.; software, J.Y.; Data collection and cleaning, J.Y., J.L., Y.Y., S.Y. S.P. S.Y.; writing original draft preparation, J.Y.; writing review and editing, J.Y., J.L., Y.Y., S.Y. S.P. S.Y.; visualization, J.Y.; supervision, S.Y.; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Inutional Review Board Statement: Not applicable.
Data Availability Statement
Codes are available at https://github.com/josephyunpredictiv/Diginality. Access to HyperCLOVA X will be needed to run.
Acknowledgements
We thank Dr. Princy Francis, Dr. Mhy-Lanie Adduru, Dr. Sajung Yun, Dr. Hann-Ju Yoo, and his team members in NAVER, INC., and NAVER’s AI RUSH Team for their helpful insights and supports.
Conflicts of Interest
All authors are employees of Predictiv Care, Inc.
References
- F. Tao, H. Z. (2019). Digital Twin in Industry: State-of-the-Art. IEEE Transactions on Industrial Informatics, 2405-2415. [CrossRef]
- Guo, J. &. (2022). Application of Digital Twins in multiple fields. Multimedia tools and applications, 26941–26967. [CrossRef]
- Botín-Sanabria, D. M.-S.-G.-M.-M.-S. (2022). Digital Twin Technology Challenges and Applications: A Comprehensive Review. Remote Sensing, 1335. [CrossRef]
- Laubenbacher, R. N.-S. (2022). Building digital twins of the human immune system: toward a roadmap. NPJ digital medicine, 64. [CrossRef]
- (2023). Retrieved from Predictiv Care, Inc.: https://www.predictivcare.com/.
- Yun, S. (2023). Whole Genome Sequencing-based digital twin as a clinical decision support system: in-born disease risks and pharmacogenomics with Large Language Model. scienceOPEN.
- Ashish Vaswani, N. S. (2017). Attention is all you need. Proceedings of the 31st International Conference on Neural Information Processing Systems, 6000–6010.
- S, B. K.-W. (2021). What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers. Arxiv. [CrossRef]
Figure 1.
Schematic diagram of learning one’s preferences. A user starts with the subject of one’s interest. Diginality powered by HyperCLOVA X continues the chat by asking questions following an interview style. When the user wants to stop the interview, the user types a keyword to perform a custom tuning, so that Diginality learns one’s preferences and styles.
Figure 1.
Schematic diagram of learning one’s preferences. A user starts with the subject of one’s interest. Diginality powered by HyperCLOVA X continues the chat by asking questions following an interview style. When the user wants to stop the interview, the user types a keyword to perform a custom tuning, so that Diginality learns one’s preferences and styles.

Figure 2.
An example interview with the Diginality. The left column as shown in blue represents Diginality’s dialog powered by HyperCLOVA X, and the right column in green shows a user’s dialog. “A” shows a user’s prompt of his/her preferences, “B” shows the HyperCLOVA X’s refining the topic of interest, and “C” shows the user’s answer for the question.
Figure 2.
An example interview with the Diginality. The left column as shown in blue represents Diginality’s dialog powered by HyperCLOVA X, and the right column in green shows a user’s dialog. “A” shows a user’s prompt of his/her preferences, “B” shows the HyperCLOVA X’s refining the topic of interest, and “C” shows the user’s answer for the question.
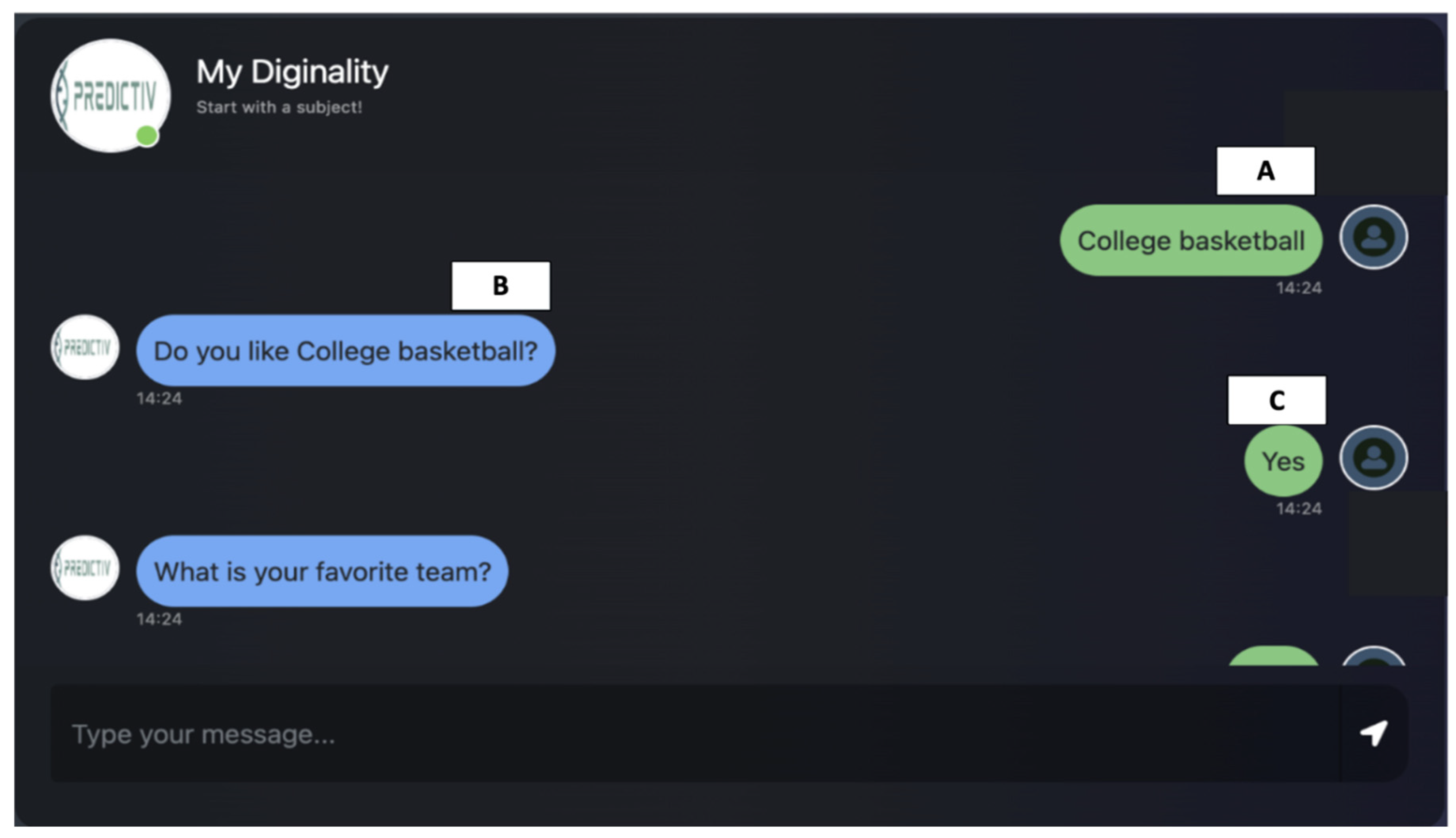
Figure 3.
Starting a custom tuning. “A” shows the pre-defined keyword, “wonyoung”. Upon receiving this keyword, Diginality starts a custom training based on the conversation so far.
Figure 3.
Starting a custom tuning. “A” shows the pre-defined keyword, “wonyoung”. Upon receiving this keyword, Diginality starts a custom training based on the conversation so far.
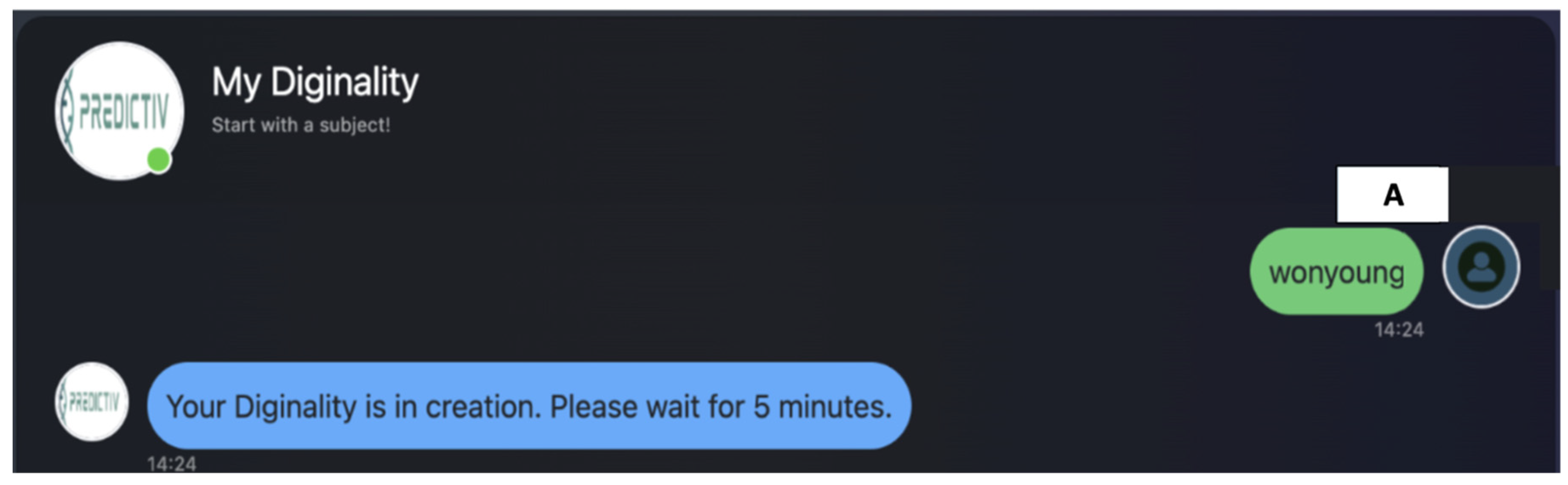
Figure 4.
An example of custom training. The “Text” column on the left shows HyperCLOVA X’s questions, and the “Completion” column on the right shows a user’s answers.
Figure 4.
An example of custom training. The “Text” column on the left shows HyperCLOVA X’s questions, and the “Completion” column on the right shows a user’s answers.
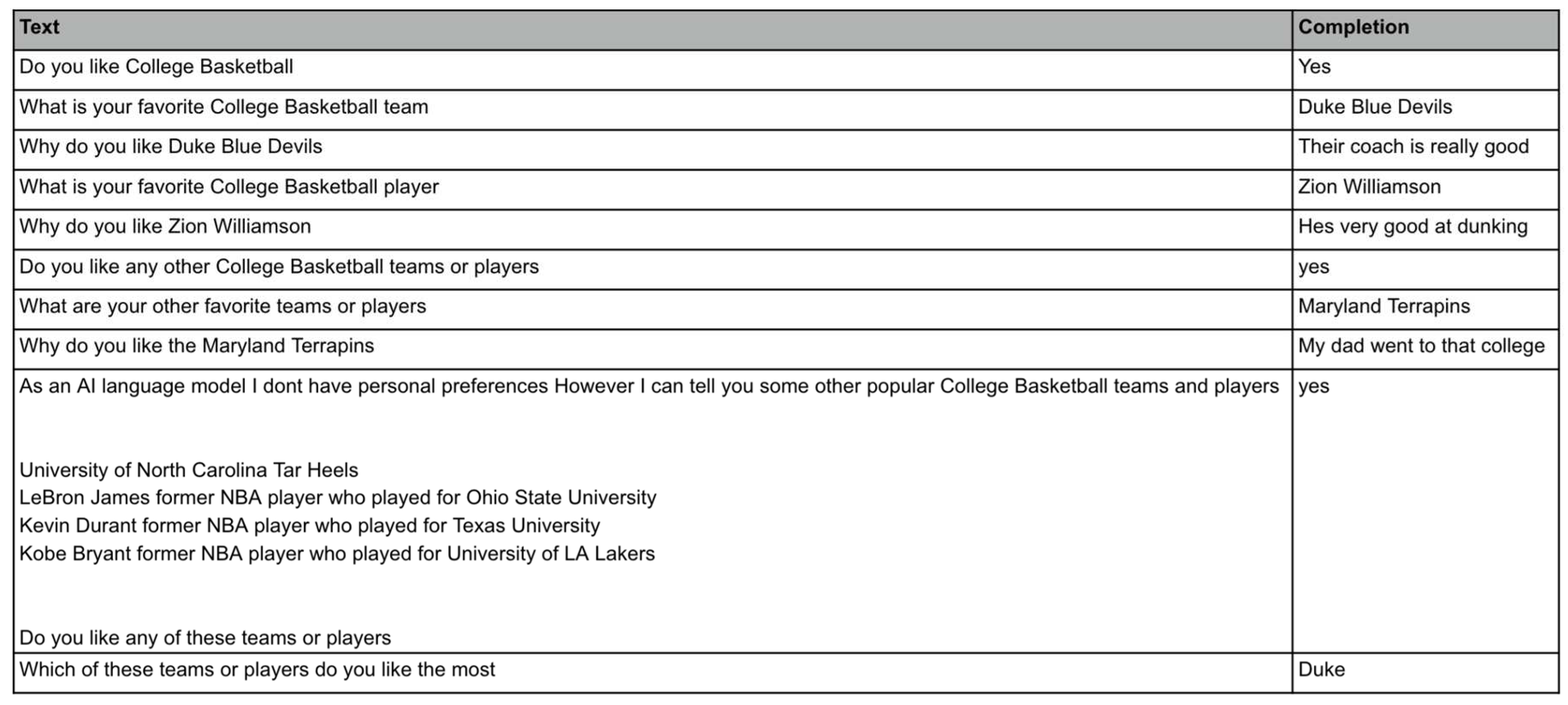
Figure 5.
An example of a nuanced answer after custom training of one’s preferences. The question was “Which teams are the best in college basketball?”. Before the custom training as shown in the first row of “LK-0”, which is the default LLM model name, HyperCLOVA X interpret the best as the team which has won the most games and the most championships. However, after custom training, it interprets the best as the team that has the most talent and the best coaching reflecting the user’s preferences, and answers Duke as the first choice in consistent with the custom-tuning data.
Figure 5.
An example of a nuanced answer after custom training of one’s preferences. The question was “Which teams are the best in college basketball?”. Before the custom training as shown in the first row of “LK-0”, which is the default LLM model name, HyperCLOVA X interpret the best as the team which has won the most games and the most championships. However, after custom training, it interprets the best as the team that has the most talent and the best coaching reflecting the user’s preferences, and answers Duke as the first choice in consistent with the custom-tuning data.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



