
Submitted:
25 October 2023
Posted:
26 October 2023
You are already at the latest version
Abstract
Cardiovascular diseases (CVD) are chronic diseases associated with a high risk of mortality
and morbidity. Early detection of CVD is crucial to initiating timely interventions, such as appro-
priate counseling and medication, which can effectively manage the condition and improve patient
outcomes. Preventive measures should be implemented at the general public level, promoting a
healthy lifestyle, and at the individual level, that is, in people with moderate to high risk of CVD
or patients already diagnosed with CVD by addressing an unhealthy lifestyle. Personalized early
diagnostic systems based on artificial intelligence (AI), ontologies, and other medical information
processing systems may prove to be a great preventive measure. In this paper, we focus on the use
of ontology-inspired database models in the diagnosis of cardiovascular disease, as well as their
potential for use in web application development.
Keywords:
n/a
; Ontology
; Database
; Cardiovascular Diseases
; Diagnosis
; Decision Support Systems
1. Introduction
Cardiovascular diseases (CVD) remain the leading cause of death worldwide [1,2]. Approximately 17.9 million people lost their lives due to cardiovascular disease in 2019, representing 32% of total deaths worldwide. Among these deaths, 85% were attributed to heart attacks and strokes. The majority of deaths resulting from cardiovascular diseases, more than 75%, occur in low- and middle-income countries [3]. Of the 17 million premature deaths (accidentally occurring before age 70 years) caused by noncommunicable diseases (NCD) in 2019, 38% were due to cardiovascular disease.
Prevention of cardiovascular disease involves addressing modifiable risk factors, including smoking, unhealthy diet, obesity, physical inactivity, and excessive alcohol consumption. By mitigating these behavioral factors, the incidence of cardiovascular disease can be significantly reduced. Additionally, early detection of cardiovascular disease is crucial for initiating timely interventions, such as appropriate counseling and medication, which can effectively manage the condition and improve patient outcomes.
Prevention should be implemented at the general public level, promoting a healthy lifestyle [4] and at the individual level, that is, in people with moderate to high CVD risk or patients already diagnosed with CVD by addressing an unhealthy lifestyle (e.g., poor quality diet, lack of exercise, smoking tobacco) and optimizing risk factors. Prevention is effective —- Eliminating risk-related activities for health would prevent from CVD cases and even 40% from cancer cases [5,6].
Personalized early diagnostic systems based on artificial intelligence (AI), ontologies, and other medical information processing systems may prove to be a great preventive measure. Ontologies and ontology-database models have also been applied to CVD diagnosis [7] and some other diseases such as pneumonia [8]. Ontologies are formal representations of knowledge that can be used to define the structure and content of a database, allowing the representation of complex and hierarchical relationships between different concepts [9,10].
The ontology-database model combines ontology principles with those of database management systems, allowing the integration of large and complex data sets within a structured and well-defined framework [11,12]. This model has been applied in a variety of fields, including biology, medicine, and healthcare, to facilitate the management and analysis of large and diverse data sets that exemplified the use of ontologies in the diagnosis of CVD using the Human Phenotype Ontology (HPO) to classify and classify phenotypes, including CVD-related phenotypes. HPO is a standardized vocabulary of phenotypic abnormalities that can be used to describe the clinical features of diseases, such as focus diseases. CVDs, which allows for a systematic and comprehensive description of patient phenotypes [13]. This can facilitate the identification of patients with similar clinical characteristics and aid in the diagnosis of CVD.
The use of ontologies for effective knowledge modeling and information retrieval has been explored. In [14], the authors proposed a method to convert an ontology into a database using predefined transformation rules. The utilization of ontologies for representing knowledge within relational databases is discussed, as well as its potential for use in web application development.
In addition to known computational algorithms, there is also an alternative approach to predict CVD risk, which involves the use of risk prediction models. The World Health Organization/International Society of Hypertension (WHO/ISH) risk score charts are a widely used model for predicting CVD risk [15]. These graphs are accompanied by practice notes that provide guidance on interpreting and adjusting scores, as well as on managing risk factors that are not included in the risk score calculations.
A recent study by [16] evaluated the use of WHO/ISH risk prediction charts to assess cardiovascular risk in three low- and middle-income countries in Asia. The study found that these graphs have certain advantages. One limitation is that they may underestimate the risk of CVD if individuals already on treatment are not taken into account. The degree of underestimation varies depending on the extent of coverage and effectiveness of drug treatment.
The Framingham Risk Score (FRS) is another widely used model to calculate the CVD risk. A study by [17] investigated the performance of this model by conducting a validation study on 959 randomly selected individuals aged 30-74 years. The results of the experiment showed that the model tended to overestimate the risk in older women and middle-aged men. Based on these findings, the researchers suggest that the model should be reclassified to account for these slight errors.
The systematic coronary risk evaluation (SCORE) model, which is used to predict the risk of the first fatal atherosclerotic cardiovascular event in 10 years, takes into account factors such as age, gender, smoking, total cholesterol and systolic blood pressure (SBP). In [18], Conroy et al. examined the effectiveness of this model in different regions of Europe with varying levels of CVD risk. The study proposed improvements to the model, but it should be noted that the results may not fully reflect an individual’s typical risk due to the nature of the study being conducted in a single instance.
Selvarajah et al. [19] conducted an evaluation of the FRS, SCORE, and WHO / International Society of Hypertension (WHO/ISH) models. The results showed that the WHO/ISH model was found to be inadequate for stratification of cardiovascular risk.
However, the Framingham and SCORE models effectively identified risk levels in Asian men and women. Specifically, the SCORE-high model accurately predicted the risk for men but not women. On the other hand, the Framingham model performed better in identifying risk levels in women compared to the SCORE models. Overall, the Framingham and SCORE models were found to be more effective in identifying cardiovascular risk in Asian men and women than the WHO/ISH model.
This work evaluates the accuracy of the diagnosis of cardiovascular diseases based on the ontologies of symptoms and guidelines that are implemented in a web application.
2. Material and methods
In the development of a diagnostic tool for diseases, several considerations were taken into account. One of the main decisions that had to be made was the choice between using quantitative or qualitative data. Quantitative data for CVD diagnosis is usually collected through objective measurements, such as electrocardiographic (ECG) signals, and are often used in machine learning algorithms [20,21,22,23,24,25]. However, sensor data are not readily available to patients and can only be accessed by medical personnel. Therefore, we decided to use patient symptoms as the main source of information for the diagnostic tool.
To integrate this information into an existing behavioral risk factor calculator, a non-machine learning-based diagnostic method was sought. After evaluating different options, it was determined that a knowledge base structured following an ontology-inspired approach would be the most suitable. This involved creating a knowledge base/ontology database model by extracting pertinent data from various disease research studies and organizing them into tables (see Table 1).
Each disease was assigned its own table, which includes details on symptoms, duration of symptoms, and the disease itself. Subsequent investigations have revealed instances of misdiagnosis in which certain diseases resemble cardiovascular diseases, as well as associations between specific diseases, such as the correlation between coronary heart disease and panic attacks [42].
2.1. Software
The C# and Microsoft SQL-based application consist of three main components: the database, the application server, and the client user interface. The database is created using Microsoft SQL Server and is designed to ensure data integrity and efficient data retrieval. The application server processes client requests and handles business logic and data processing. The client user interface communicates with the application server and provides a user-friendly way to interact with the application.
3. System Architecture
3.1. Database Architecture
The CVD database is a collection of structured data that is designed to support the management and analysis of CVD-related information. This database is structured so that it consists of two main types of tables: fixed tables and updatable tables.
Fixed tables, also known as the knowledge base, are a set of predetermined tables within the database that contain structured data that are not meant to be modified by users. Instead, these tables serve as a reference source of information for the database or system, providing a reliable and consistent source of information on CVD-related topics. Examples of data that can be stored in fixed tables include information on different types of CVD, risk factors for CVD, and CVD treatments.
Updatable tables, on the other hand, are the tables within the database that are meant to be modified by users. These tables may contain data entered by users, such as personal data, symptoms,or diagnosis generated by the system per session. The data in these tables can be updated, inserted or deleted by users as needed, allowing flexibility in the management and analysis of CVD-related information.
3.2. Applying Inner Join Principle in Diagnosis
Figure 1 shows the use of an inner join in a database to find a match between two tables. The first table, Table A (also represents all disease tables in the database), contains a list of symptoms for each disease that was collected in creating a knowledge base, as illustrated in Figure 2.
The second table, known as Table B, contains the symptoms of a patient, which are input by the user and stored in the database. This database is dynamic and allows the use of SQL commands such as UPDATE and DELETE, meaning that it can change with each user and is reset when the application is closed.
However, during the diagnosis process, Table B is assumed to be static and cannot be changed. This is to ensure that the diagnosis remains accurate and consistent. To find a match between the two tables, the current user’s symptoms in Table B are compared to the symptoms in the disease table (Table A) using an inner join. The inner join function returns only the rows that match the two tables.
To further analyze the match between the two tables, the “count” function is used to count the number of symptoms that match. These values are stored in a table of “disease_count” using the UPDATE command. There is one query for each major CVD and to handle the counting process for each disease (see Figure 3).
To determine the most probable disease, the function “max” is used to find the maximum counted value among all diseases. This maximum value corresponds to the disease with the most number of matching symptoms and is therefore the most likely diagnosis for the patient. This process of inner joining, counting, and finding the maximum value allows an accurate prediction of a disease based on the patient’s symptoms, as shown in Figure 4.
4. Results
In order to evaluate the performance of the application, various scenarios were employed.
4.1. Application Test with Real subjects as Diagnosed by Doctor
The first evaluation method involved seeking feedback from patients who currently have CVD. These patients were asked to document the symptoms they had experienced before receiving a diagnosis, and a physician was also consulted to obtain information on symptoms reported by patients diagnosed with CVDs. Using this approach, three subjects were studied, and the results are summarized below:

Table 2.
Comparison of diagnosis of CVDs conducted by physicians and an app
| Subject | Age [years] | Gender | Reported Symptoms | D.D | A.D |
| 1 | 70 | F | Headache, fatigue, palpitations, blurred vision (which was attributed to headache), edema (which occurred after salt consumption), insomnia (when blood pressure was slightly elevated), dizziness | HTN and DM2 | HTN |
| 2 | 25 | M | Dyspnea (difficulty breathing), cough, edema, elevated blood pressure, abdominal distension, paroxysmal nocturnal dyspnea and chest congestion | CHF | HF |
| 3 | 50 | M | Weakness on the right side, numbness on the arm, a tingling sensation and blurred vision accompanied by flashes of light, a feeling of heaviness and an inability to lift objects | CVA | Early CVA |
Abbreviations: D.D- Doctors Diagnosis,A.D- App Diagnosis,HTN- Hypertension,DM2- Diabetes Mellitus 2,CHF- Congenital Heart Failure,HF- Heart Failure,CVA- Cerebrovascular Accident, is synonymous with stroke.
4.2. Prototype Application versus Existing Application
The second evaluation method involved comparing the performance of the prototype application with that of an existing application, specifically an AI-based Android application named “Symptom Checker.” Seven combinations of random symptoms were entered into both applications and the results were compared (see Table 3).
- Symptom combination 1: Chest Pain, Shortness of Breath, Back Pain, Nausea, Feeling Faint, Cough, Nose bleed
- Symptom combination 2: Chest Pain, Nausea, Dizziness, Cough, Fever
- Symptom combination 3: Shortness of Breath, Body pain, Nausea, Fatigue, Cough, Fever, Headache
- Symptom combination 4: Dizziness, Disorientation, Blurred Vision, Headache
- Symptom combination 5: Chest pain, pain (Jaw / neck / back), disorientation, jaundice, lack of appetite.
- Symptom combination 6: Shortness of breath, body pain, lack of appetite, dry mouth, bleeding gums.
- Symptom combination 7: Chest Pain, Shortness of Breath, Weakness, Headache, Loose Bladder.
4.3. Measuring Diagnostic Accuracy
Measurement of diagnostic accuracy of a new diagnosis application involves comparing its performance with established reference points provided by other applications. By evaluating the diagnostic outcomes produced by the new application and comparing them to the results obtained from established apps, it is possible to assess the application’s ability to correctly identify and classify medical conditions. Key metrics such as sensitivity, specificity, positive predictive value, and negative predictive value can be calculated to quantitatively evaluate the performance of the new application [43].
According to [43], these parameters are ideally used to calculate the accuracy of diagnosis and to elucidate their respective meanings.
- True Positive (TP): This refers to the number of individuals correctly identified as positive by the test. In medical terms, it represents the number of people with the condition being tested who were correctly identified as having the condition.
- True Negative (TN): This represents the number of individuals correctly identified as negative by the test. It refers to individuals without the condition who were correctly identified as not having the condition.
- False Positive (FP): These are the individuals who were incorrectly classified as positive by the test but do not have the condition. In medical terms, it represents the number of people who were mistakenly identified as having the condition when they are actually healthy.
- False Negative (FN): These are the individuals who were incorrectly classified as negative by the test but actually have the condition. It represents the number of individuals who were mistakenly identified as not having the condition when they actually do.
However, the representation is modified for each test to compare the diagnosis of the app with already proven or existing parameters. Test 1 is the comparison of the diagnosis provided by the designed app and a doctor and Test 2 is the comparison of the diagnosis provided by the designed application and an existing AI-based diagnostic Android application (see the confusion matrices in Table 4 and Table 5 respectively).
True Positive (TP): Number of CVD cases correctly identified by the app and that matches the preexisting diagnosis of the doctor (test 1) / AI-diagnosis android app (test 2).
True Negative (TN) Number of CVD cases identified as negative (that is, not identified as CVD) by the app and also by the doctor (Test 1) / AI-diagnosis Android app (Test 2).
False Positive (FP): Number of cases of CVD that were inaccurately identified by the app, despite the absence of the actual condition as proven by a doctor or AI-based diagnosis Android app.
False Negative (FN): Signifies the number of cases of CVD that went undetected by the app, but were actually identified and diagnosed by a doctor or an AI-based diagnosis Android app.
Actual Positive: This refers to a possible diagnosis of CVD that was evaluated by a doctor or an existing application, with supporting evidence or validation.
Actual Negative: This represents a possible diagnosis that was not identified as cardiovascular disease by a doctor or an existing application.
Predicted Positive: This signifies a possible CVD diagnosis made by the app, based on its analysis and algorithm.
Predicted Negative: This denotes other diagnoses that were not detected or identified as cardiovascular diseases by the app. These diagnoses may include conditions or diseases not related to CVD.
4.3.1. Parameters for calculating accuracy
- Positive predictive value (PPV), also known as precision, tells the proportion of correctly predicted positive instances out of all instances predicted as positive by the application.A higher PPV indicates that the application is more reliable in correctly identifying positive instances. It suggests that when the application predicts a positive result, there is a relatively higher chance that it is accurate
- The negative predictive value (NPV) tells us the proportion of correctly predicted negative instances out of all instances predicted as negative by the application.
- Sensitivity, also known as recall or true positive rate, tells us the proportion of correctly predicted positive instances out of all actual positive instances
- Specificity tells us the proportion of correctly predicted negative instances out of all actual negative instances.
- Accuracy is a performance metric that tells us the overall correctness of the predictions made by the application or system being evaluated
Table 6.
Performance indicators of the diagnosis made by the prototype application (App), medical doctor, and an existing application
Table 6.
Performance indicators of the diagnosis made by the prototype application (App), medical doctor, and an existing application
| Parmeters | App V. Doctor diagnosis | App V. Existing Application |
| PPV | 1.000 | 0.714 |
| NPV | Undefined | 1.000 |
| Sensitivity | 1.000 | 1.000 |
| Specificity | Undefined | 0.330 |
| Accuracy | 1.000 | 0.750 |
We observed that the accuracy of the application was 1.0 or 100%. This high accuracy was achieved because the three cases were accurately diagnosed with cardiovascular disease, matching the predictions made by the application. Additionally, the positive predictive value was 100%, indicating that all positive diagnoses made by the application were true positives. However, the negative predictive value is undefined because there were no negative diagnoses; all cases were positively diagnosed as cardiovascular disease, according to the evaluations of the doctors.
4.4. GUI
Figure 5, Figure 6, Figure 7, and Figure 8 show screenshots of the graphical user interface (GUI) of the designed application. Figure 5 presents the selection of symptoms and Figure 6 presents an example of the diagnosis results. An example of the report is shown in Figure 7 and Figure 8 in the application and in the form of a PDF file, respectively.
The screenshots presented in Figure 5, Figure 6, Figure 7 and Figure 8 show the order of the potential diagnosis and show the user a possible diagnosis in a legible and friendly manner. Figure 8 shows that the content of the generated PDF file with a report is consistent with the content shown in Figure 7.
5. Discussion
The use of an ontology-inspired database model and inner join or diagnosis demonstrates a reasonably good level of accuracy. Test 1 achieved a perfect accuracy rate of 100%, while test two yielded an accuracy of 75%. By taking the average of these two tests, we can conclude that the overall accuracy of the diagnosis process is 85%, without considering any bias.
The accuracy various models, such as decision trees, SVM, or ANN models proposed in [44] was 89.6%, 92.1%, and 91.0%, respectively. In our study, we achieved a sensitivity of 1.0 (100%), indicating that it performed excellently in detecting positive cases of cardiovascular disease. Furthermore, the combinations of diseases used to test both the evaluated application and the existing one were similar to those associated with cardiovascular disease.
The reason for testing the application with real subjects diagnosed by physicians was to determine whether the application designed for the diagnosis of CVD can provide accurate diagnoses similar to those of physicians. However, only three patients with preexisting cardiovascular disease were tested, resulting in a small sample size that can introduce bias when evaluating the accuracy of the application.
In addition, when diagnosing cardiovascular disease, doctors can also consider other coexisting conditions, as demonstrated in the first subject where the doctor’s diagnosis included hypertension and diabetes mellitus. This highlights the complexity of the diagnosis of cardiovascular disease and the need to consider potential comorbidities.
The second test aimed to compare the diagnosis provided by the application under evaluation with that of an established and proven application. On the basis of the results of the second test, several observations can be made. Overall, when testing the application against the existing one, it exhibited an accuracy rate of 0.75 (75%) and a positive predictive value (PPV) of 0.714 (71.4%). This indicates that the application is 75% accurate in its diagnoses.
However, the designed application has some limitations. First, the application was tested only against the existing application seven times. This limited sample size suggests a bias in the experiment and also implies that accuracy values could be influenced by further testing.
Secondly, this application concentrates only on the main cardiovascular diseases and diseases that closely resemble cardiovascular disease. As a result, we are working with approximately 14 tables using the ontology-inspired database model. The efficiency of the diagnosis process may vary in terms of speed, but this aspect has not been thoroughly explored due to the limited sample size of the diseases under investigation.
6. Conclusions and Future work
The application has the potential to improve the efficiency and precision of the diagnosis of cardiovascular diseases, particularly in resource-limited settings where access to specialized medical personnel may be limited. By providing users with a tool to identify potential diagnoses and guide further testing, the application can help ensure that patients receive timely and appropriate care. Given that the application is based on novel research, an accurate verification is needed.
There are many directions in which this work could be extended in the future:
- One potential avenue for future work is to improve the symptom checker by adding more detailed and specialized questions to create a more comprehensive and accurate diagnostic tool.
- The evaluation of the processing time and its influence on the accuracy.
- Another potential direction is to expand the range of diseases covered by the application. While the current version focuses on major cardiovascular diseases, there is potential to add support for other types of disease or health conditions.
- Another area of future work is the integration of the application with electronic medical record systems, allowing for the seamless exchange of data and a more efficient diagnosis and treatment.
- Developing a mobile version of the application that allows users to access it from their smartphones or tablets.
- Adding a feature that allows users to track their symptoms over time could aid in the diagnosis and management of chronic diseases. Integrating the application with wearable devices, such as fitness trackers or smartwatches, allows continuous monitoring of vital signs and other health metrics.
Author Contributions
Conceptualization, R.D., E.O.B, and S.S.; methodology, R.D. and E.O.B.; software, E.O.B. and R.D.; validation, R.D. and E.O.B; formal analysis, R.D., E.O.B.; investigation, R.D., E.O.B, and M.T.I.; resources, R.D.; data curation, E.O.B. and R.D.; writing—original draft preparation, R.D., E.O.B., N.P., S.S., and M.T.I.; writing—review and editing, R.D., N.P., S.S., M.T.I., A.P., T.C., A.F., S.G.; visualization, E.O.B., R.D.; supervision, R.D., E.T., M.G., T.C., W.G.; project administration, R.D., E.T., M.G., W.G.; funding acquisition, R.D., E.T, M.G.; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding and The APC was funded by University of Lübeck
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| CVD | Cardiovascular disease |
| ECG | Electrocardiography, electrocardiogram |
| FP | False positive |
| FN | False negative |
| FRS | Framingham Risk Score |
| HPO | Human Phenotype Ontology |
| ISH | International Society of Hypertension |
| NCD | Noncommunicable disease |
| NPV | Negative predictive value |
| PPV | Positive predictive value |
| SCORE | Systematic Coronary Risk Evaluation |
| SBP | Systolic blood pressure |
| TP | True positive |
| TN | True negative |
| V. | Versus |
| WHO | World Health Organization |
References
- WHO. Cardiovascular diseases. Available online at: https://www.who.int/health-topics/cardiovascular-diseases#tab=tab_1, 2013. Accessed 30 May 2023.
- Virani, S.S.; Alonso, A.; Aparicio, H.J.; Benjamin, E.J.; Bittencourt, M.S.; Callaway, C.W.; Carson, A.P.; Chamberlain, A.M.; Cheng, S.; Delling, F.N.; Elkind, M.S.; Evenson, K.R.; Ferguson, J.F.; Gupta, D.K.; Khan, S.S.; Kissela, B.M.; Knutson, K.L.; Lee, C.D.; Lewis, T.T.; Liu, J.; Loop, M.S.; Lutsey, P.L.; Ma, J.; Mackey, J.; Martin, S.S.; Matchar, D.B.; Mussolino, M.E.; Navaneethan, S.D.; Perak, A.M.; Roth, G.A.; Samad, Z.; Satou, G.M.; Schroeder, E.B.; Shah, S.H.; Shay, C.M.; Stokes, A.; VanWagner, L.B.; Wang, N.Y.; Tsao, C.W. Heart Disease and Stroke Statistics—2021 Update. Circulation 2021, 143, e254–e743. [Google Scholar] [CrossRef] [PubMed]
- Ramesh, S.; Kosalram, K. The burden of non-communicable diseases: A scoping review focus on the context of India. Journal of Education and Health Promotion 2023, 12. [Google Scholar]
- Cooney, M.T.; Dudina, A.L.; Graham, I.M. Value and limitations of existing scores for the assessment of cardiovascular risk: a review for clinicians. Journal of the American College of Cardiology 2009, 54, 1209–1227. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Daviglus, M.L.; Loria, C.M.; Colangelo, L.A.; Spring, B.; Moller, A.C.; Lloyd-Jones, D.M. Healthy lifestyle through young adulthood and the presence of low cardiovascular disease risk profile in middle age: the Coronary Artery Risk Development in (Young) Adults (CARDIA) study. Circulation 2012, 125, 996–1004. [Google Scholar] [CrossRef] [PubMed]
- National Institute for Health and Care Excellence. Cardiovascular disease prevention, 2010. Accessed 28 August 2023.
- Al-Hamadani, B.T.; Alwan, R.F. An ontology-based expert system for general practitioners to diagnose cardiovascular diseases. Advances in Computational Sciences and Technology 2015, 8, 53–65. [Google Scholar]
- Azzi, S.; Michalowski, W.; Iglewski, M. Developing a pneumonia diagnosis ontology from multiple knowledge sources. Health Informatics Journal 2022, 28, 14604582221083850. [Google Scholar] [CrossRef]
- Stevens, R.; Rector, A.; Hull, D. What is an ontology? Ontogenesis 2010. [Google Scholar]
- Guarino, N.; Oberle, D.; Staab, S. What Is an Ontology? In Handbook on Ontologies; Springer Berlin Heidelberg, 2009; pp. 1–17. [CrossRef]
- LePendu, P.; Dou, D.; Frishkoff, G.A.; Rong, J. Ontology database: A new method for semantic modeling and an application to brainwave data. International Conference on Scientific and Statistical Database Management. Springer, 2008, pp. 313–330.
- Fareedi, A.A.; Hassan, S. The semantic alignment of H-FOAF, DOMAIN and DBLP ontologies with link open data for a health social network. 2014 14th International Conference on Control, Automation and Systems (ICCAS 2014), 2014, pp. 1508–1513. [CrossRef]
- Robinson, P.; Mundlos, S. The Human Phenotype Ontology. Clinical Genetics 2010, 77, 525–534. [Google Scholar] [CrossRef] [PubMed]
- Mahmudi, K.; Liem, M.I.; Akbar, S. Ontology to relational database transformation for web application development and maintenance. Journal of Physics: Conference Series. IOP Publishing, 2018, Vol. 971, p. 012031.
- Mendis, S.; Lindholm, L.H.; Mancia, G.; Whitworth, J.; Alderman, M.; Lim, S.; Heagerty, T. World Health Organization (WHO) and International Society of Hypertension (ISH)s risk prediction charts: assessment of cardiovascular risk for prevention and control of cardiovascular disease in low and middle-income countries. Journal of hypertension 2007, 25, 1578–1582. [Google Scholar] [CrossRef] [PubMed]
- Otgontuya, D.; Oum, S.; Buckley, B.S.; Bonita, R. Assessment of total cardiovascular risk using WHO/ISH risk prediction charts in three low and middle income countries in Asia. BMC public health 2013, 13, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Artigao-Rodenas, L.M.; Carbayo-Herencia, J.A.; Divison-Garrote, J.A.; Gil-Guillen, V.F.; Masso-Orozco, J.; Simarro-Rueda, M.; Molina-Escribano, F.; Sanchis, C.; Carrion-Valero, L.; Lopez de Coca, E.; others. Framingham risk score for prediction of cardiovascular diseases: a population-based study from southern Europe. PloS one 2013, 8, e73529. [Google Scholar] [CrossRef]
- Conroy, R.M.; Pyörälä, K.; Fitzgerald, A.; Sans, S.; Menotti, A.; De Backer, G.; De Bacquer, D.; Ducimetiere, P.; Jousilahti, P.; Keil, U.; others. Estimation of ten-year risk of fatal cardiovascular disease in Europe: the SCORE project. European heart journal 2003, 24, 987–1003. [Google Scholar] [CrossRef] [PubMed]
- Selvarajah, S.; Kaur, G.; Haniff, J.; Cheong, K.C.; Hiong, T.G.; van der Graaf, Y.; Bots, M.L. Comparison of the Framingham Risk Score, SCORE and WHO/ISH cardiovascular risk prediction models in an Asian population. International Journal of Cardiology 2014, 176, 211–218. [Google Scholar] [CrossRef] [PubMed]
- Irshad, M.T.; Nisar, M.A.; Huang, X.; Hartz, J.; Flak, O.; Li, F.; Gouverneur, P.; Piet, A.; Oltmanns, K.M.; Grzegorzek, M. SenseHunger: Machine Learning Approach to Hunger Detection Using Wearable Sensors. Sensors 2022, 22, 7711. [Google Scholar] [CrossRef] [PubMed]
- Duraj, K.; Piaseczna, N.; Kostka, P.; Tkacz, E. Semantic Segmentation of 12-Lead ECG Using 1D Residual U-Net with Squeeze-Excitation Blocks. Applied Sciences 2022, 12, 3332. [Google Scholar] [CrossRef]
- Duraj, K.M.; Siecinski, S.; Doniec, R.J.; Piaseczna, N.J.; Kostka, P.S.; Tkacz, E.J. Heartbeat Detection in Seismocardiograms with Semantic Segmentation. 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC); IEEE: Glasgow, Scotland, UK, 2022. [CrossRef]
- Huang, X.; Shirahama, K.; Irshad, M.T.; Nisar, M.A.; Piet, A.; Grzegorzek, M. Sleep Stage Classification in Children Using Self-Attention and Gaussian Noise Data Augmentation. Sensors 2023, 23, 3446. [Google Scholar] [CrossRef] [PubMed]
- Doniec, R.; Konior, J.; Sieciński, S.; Piet, A.; Irshad, M.T.; Piaseczna, N.; Hasan, M.A.; Li, F.; Nisar, M.A.; Grzegorzek, M. Sensor-Based Classification of Primary and Secondary Car Driver Activities Using Convolutional Neural Networks. Sensors 2023, 23, 5551. [Google Scholar] [CrossRef] [PubMed]
- Doniec, R.; Sieciński, S.; Piaseczna, N.; Duraj, K.; Chwał, J.; Gawlikowski, M.; Tkacz, E. Classification of Recorded Electrooculographic Signals on Drive Activity for Assessing Four Kind of Driver Inattention by Bagged Trees Algorithm: A Pilot Study. In The Latest Developments and Challenges in Biomedical Engineering; Springer Nature Switzerland, 2023; pp. 225–236. [CrossRef]
- Goff, D.C.; Sellers, D.E.; McGovern, P.G.; Meischke, H.; Goldberg, R.J.; Bittner, V.; Hedges, J.R.; Allender, P.S.; Nichaman, M.Z.; Group, R.S.; others. Knowledge of heart attack symptoms in a population survey in the United States: the REACT trial. Archives of internal medicine 1998, 158, 2329–2338. [Google Scholar] [CrossRef] [PubMed]
- Quah, J.L.J.; Yap, S.; Cheah, S.O.; Ng, Y.Y.; Goh, E.S.; Doctor, N.; Leong, B.S.H.; Tiah, L.; Chia, M.Y.C.; Ong, M.E.H. Knowledge of signs and symptoms of heart attack and stroke among Singapore residents. BioMed research international 2014, 2014. [Google Scholar] [CrossRef] [PubMed]
- Miller, C.L. A review of symptoms of coronary artery disease in women. Journal of advanced nursing 2002, 39, 17–23. [Google Scholar] [CrossRef] [PubMed]
- Nauser, T.D.; Stites, S.W. Diagnosis and treatment of pulmonary hypertension. American family physician 2001, 63, 1789. [Google Scholar] [PubMed]
- Wessely, S.; Nickson, J.; Cox, B. Symptoms of low blood pressure: a population study. British Medical Journal 1990, 301, 362–365. [Google Scholar] [CrossRef]
- Ekman, I.; Cleland, J.G.; Andersson, B.; Swedberg, K. Exploring symptoms in chronic heart failure, 2005.
- Coats, A.J.; Clark, A.L.; Piepoli, M.; Volterrani, M.; Poole-Wilson, P.A. Symptoms and quality of life in heart failure: the muscle hypothesis. British heart journal 1994, 72, S36. [Google Scholar] [CrossRef]
- Albert, N.; Trochelman, K.; Li, J.; Lin, S. Signs and symptoms of heart failure: are you asking the right questions? American Journal of Critical Care 2010, 19, 443–452. [Google Scholar] [CrossRef] [PubMed]
- Sun, R.; Liu, M.; Lu, L.; Zheng, Y.; Zhang, P. Congenital heart disease: causes, diagnosis, symptoms, and treatments. Cell biochemistry and biophysics 2015, 72, 857–860. [Google Scholar] [CrossRef]
- Grimard, B.H.; Larson, J.M. Aortic stenosis: diagnosis and treatment. American family physician 2008, 78, 717–724. [Google Scholar] [PubMed]
- Hansson, A.; Madsen-Härdig, B.; Bertil Olsson, S. Arrhythmia-provoking factors and symptoms at the onset of paroxysmal atrial fibrillation: a study based on interviews with 100 patients seeking hospital assistance. BMC cardiovascular disorders 2004, 4, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Portegies, M.; Koudstaal, P.; Ikram, M. Cerebrovascular disease. Handbook of clinical neurology 2016, 138, 239–261. [Google Scholar] [PubMed]
- Krystal, J.H.; Woods, S.W.; Hill, C.L.; Charney, D.S. Characteristics of panic attack subtypes: Assessment of spontaneous panic, situational panic, sleep panic, and limited symptom attacks. Comprehensive Psychiatry 1991, 32, 474–480. [Google Scholar] [CrossRef] [PubMed]
- Struyf, T.; Deeks, J.J.; Dinnes, J.; Takwoingi, Y.; Davenport, C.; Leeflang, M.M.; Spijker, R.; Hooft, L.; Emperador, D.; Domen, J.; others. Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19. Cochrane Database of Systematic Reviews 2022, 2022, CD013665. [Google Scholar]
- Ludwig, H.; Strasser, K. Symptomatology of anemia. Seminars in oncology. Elsevier, 2001, Vol. 28, pp. 7–14.
- Kim, S.H.; Oh, E.G.; Lee, W.H.; Kim, O.S.; Han, K.H. Symptom experience in Korean patients with liver cirrhosis. Journal of pain and symptom management 2006, 31, 326–334. [Google Scholar] [CrossRef] [PubMed]
- Tully, P.J.; Turnbull, D.A.; Beltrame, J.; Horowitz, J.; Cosh, S.; Baumeister, H.; Wittert, G.A. Panic disorder and incident coronary heart disease: a systematic review and meta-regression in 1 131 612 persons and 58 111 cardiac events. Psychological Medicine 2015, 45, 2909–2920. [Google Scholar] [CrossRef] [PubMed]
- Šimundić, A.M. Measures of diagnostic accuracy: basic definitions. EJIFCC 2009, 19, 203. [Google Scholar] [PubMed]
- Xing, Y.; Wang, J.; Zhao, Z.; Gao, Y. Combination Data Mining Methods with New Medical Data to Predicting Outcome of Coronary Heart Disease. 2007 International Conference on Convergence Information Technology (ICCIT 2007), 2007, pp. 868–872. [CrossRef]
Figure 1.
Diagram of Inner Join
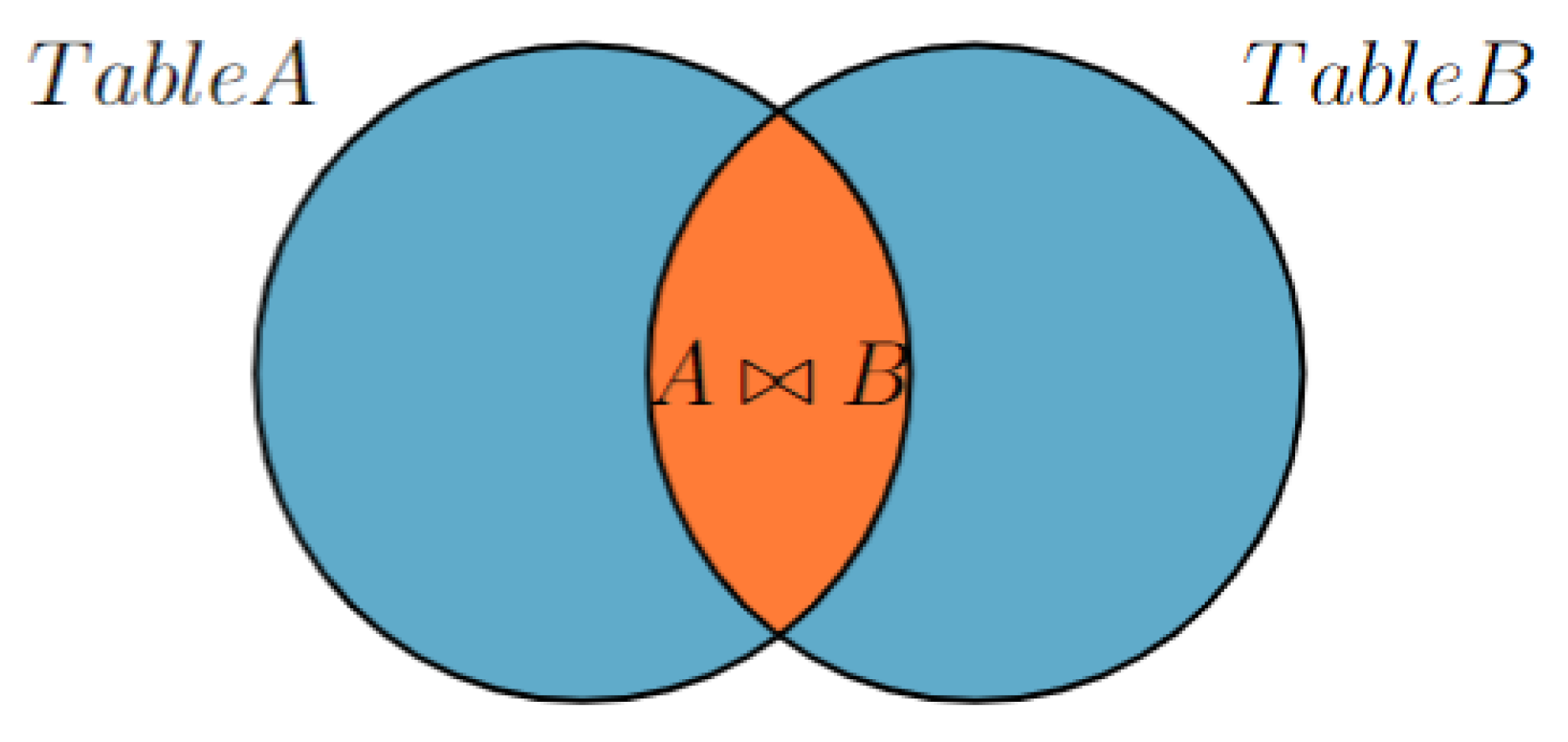
Figure 2.
CVD Database Architecture
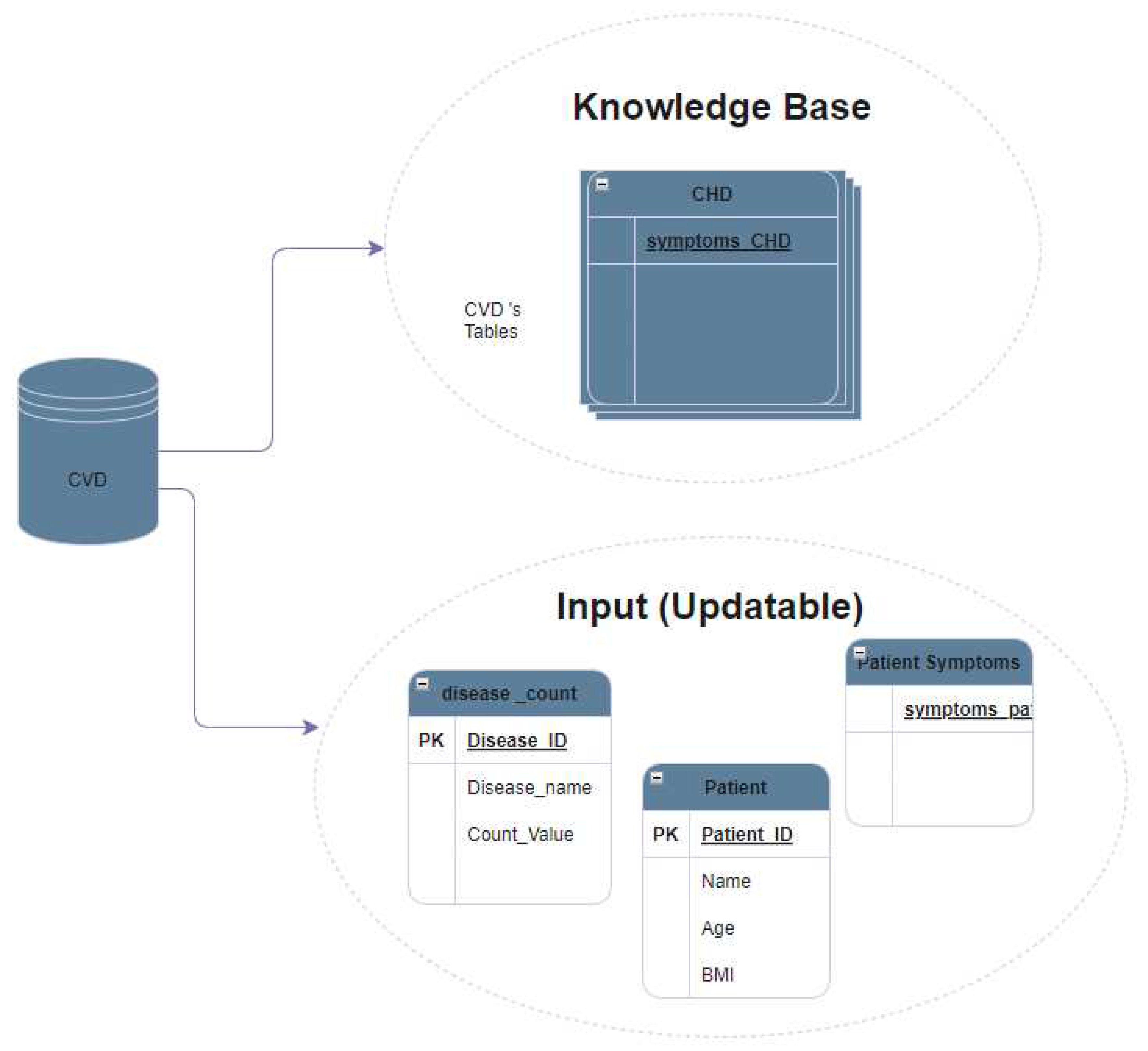
Figure 3.
Inner join principle and count of our proposed approach
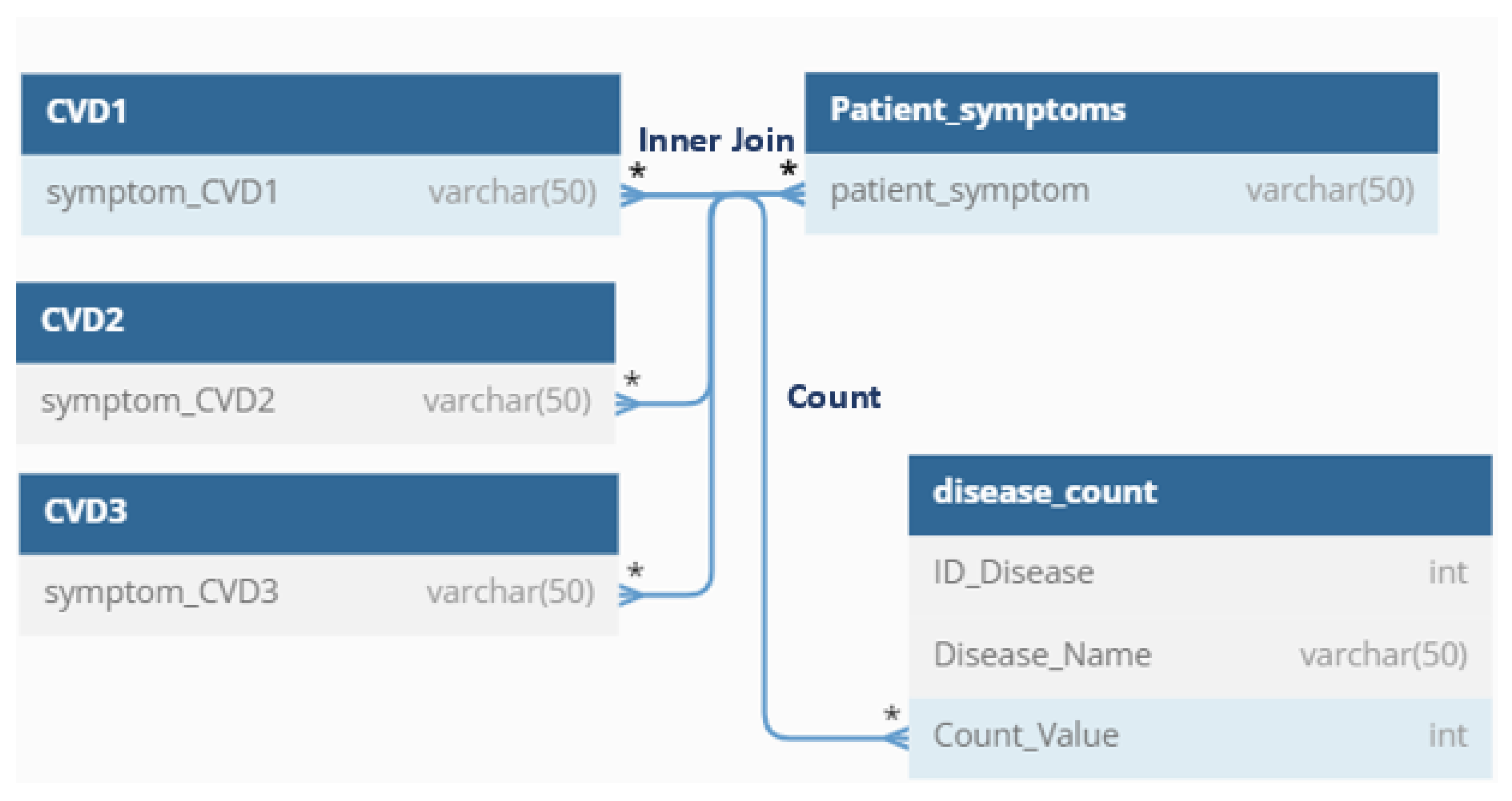
Figure 4.
Max-Plot in diagnosing cardiovascular disease with ontologies
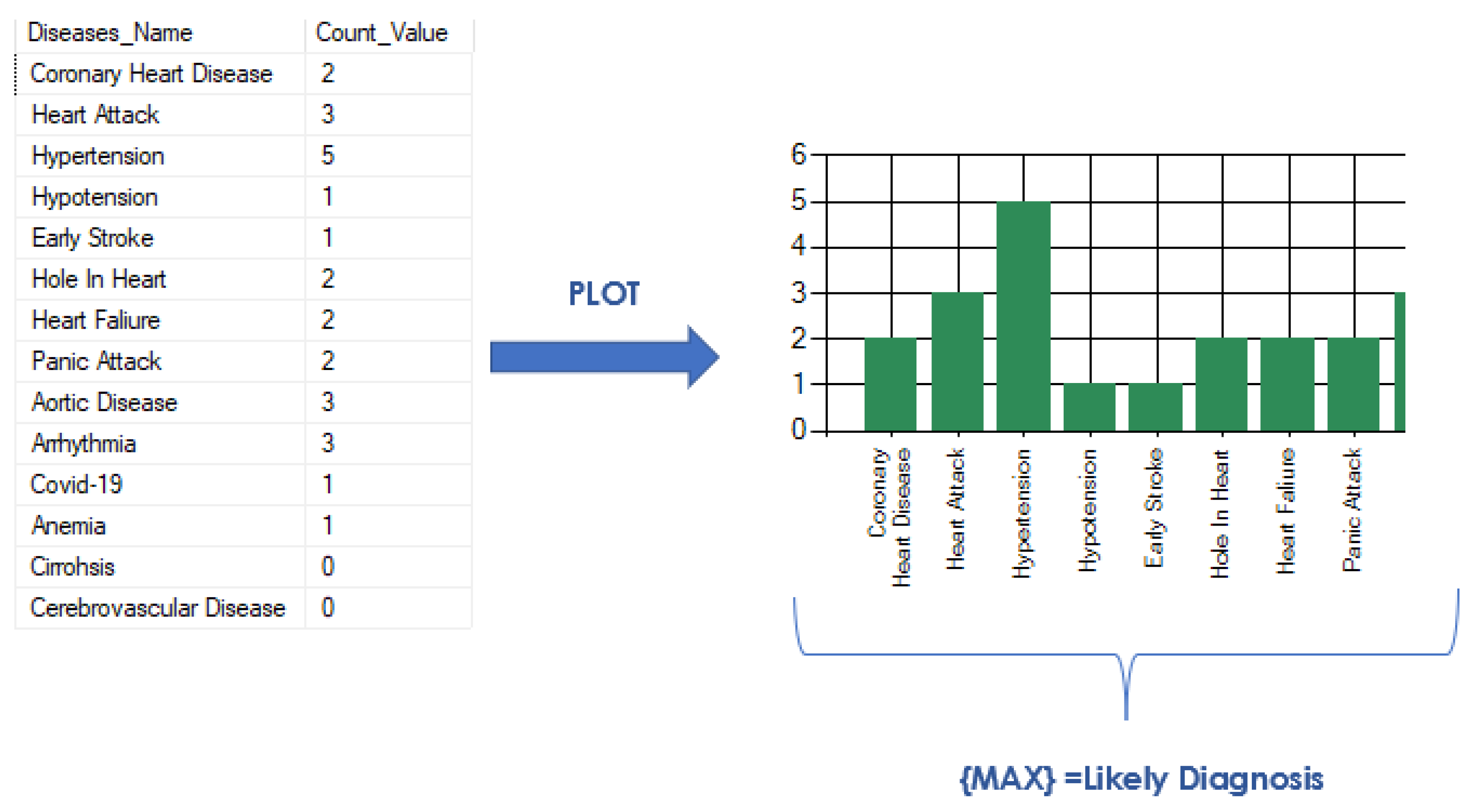
Figure 5.
Symptom-select Panel

Figure 6.
Diagnosis Result Panel
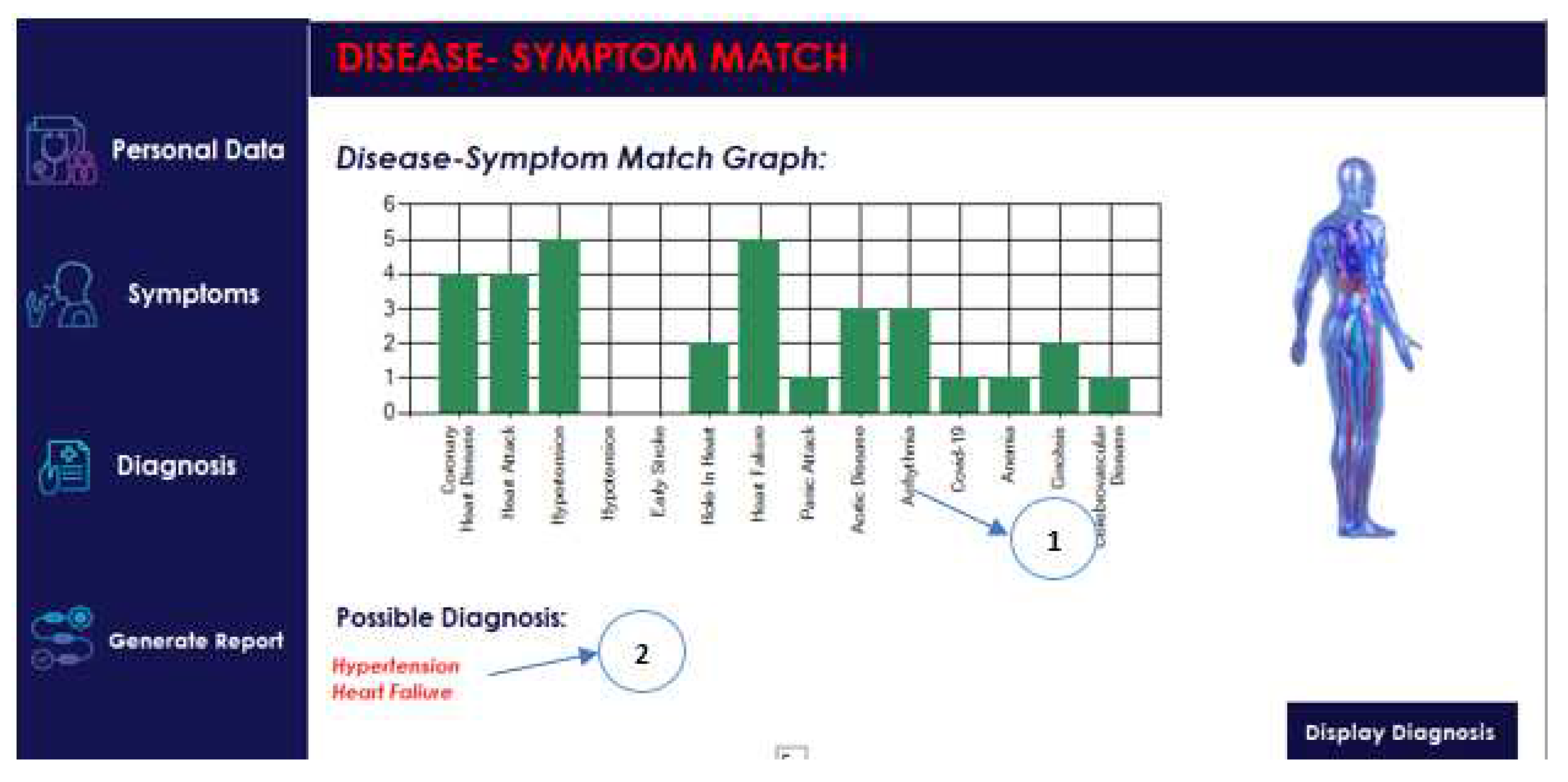
Figure 7.
Auto-generated Report
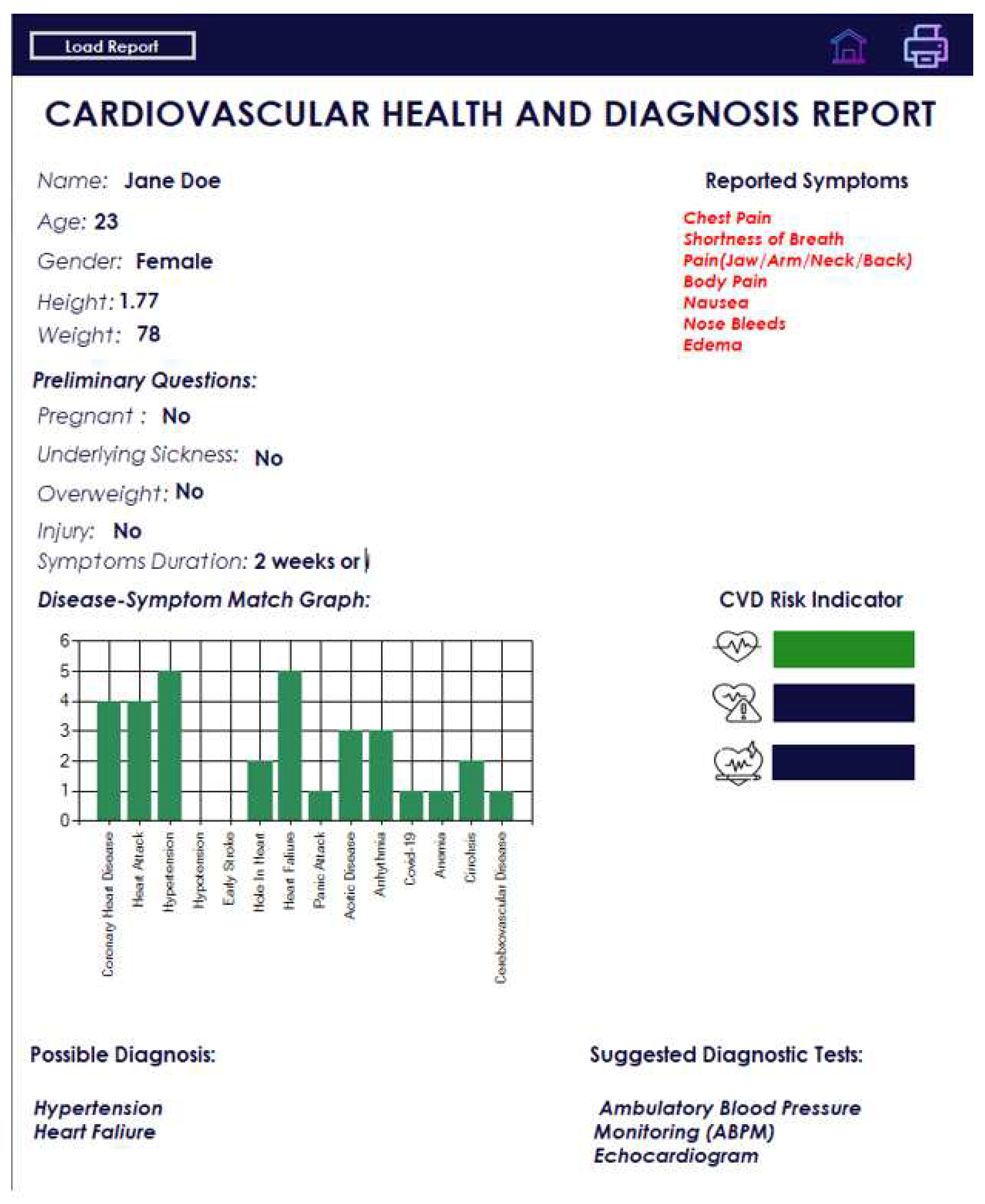
Figure 8.
Diagnosis report in an app and in PDF file

Table 1.
Major CVD Diseases and Research Papers (Citations)
| Major CVD Diseases | References |
|---|---|
| Heart Attack | 26, 27 |
| Early Stroke | 27 |
| Coronary Heart Disease | 28 |
| Hypertension | 29 |
| Hypotension | 30 |
| Heart Failure | 31, 32 ,33 |
| Hole In Heart | 34 |
| Aortic Disease | 35 |
| Arrhythmia | 36 |
| Cerebrovascular Disease | 37 |
| Panic Attack | 38 |
| Covid-19 | 39 |
| Anemia | 40 |
| Cirrhosis | 41 |
Table 3.
Comparison of diagnoses suggested by the prototype application and an existing application
| No. | Prototype Application | Existing Application |
|---|---|---|
| 1 | Hypertension, Heart Failure | Hypertension, Heart failure, Heart Disease |
| 2 | CHD, Heart Attack, Heart Failure | Covid-19, Heart Disease |
| 3 | Covid-19, Heart Failure | Covid-19, Ischemic Heart Disease, Pneumonia |
| 4 | Early Stroke, Hypertension, CBD | Stroke, Pancreatic Neoplasms, Hypertension |
| 5 | Cirrhosis | Aortic Dissection, Anaphylaxis, Pulmonary Hypertension |
| 6 | Cirrhosis | Covid-19, Iron Deficiency |
| 7 | Heart Attack, Hypertension, Heart Failure, Early Stroke | Heart Failure, Lyme Disease, Covid-19, Stoke |
Table 4.
Confusion matrix of the test 1 (comparison of the suggested diagnosis by an app with the diagnosis conducted by the medical doctor)
Table 4.
Confusion matrix of the test 1 (comparison of the suggested diagnosis by an app with the diagnosis conducted by the medical doctor)
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | ||
| Actual Negative |
Table 5.
Confusion matrix of the test 2 (comparison of the suggested diagnosis by an app with the diagnosis suggested by an existing AI-based diagnosis Android app)
Table 5.
Confusion matrix of the test 2 (comparison of the suggested diagnosis by an app with the diagnosis suggested by an existing AI-based diagnosis Android app)
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | ||
| Actual Negative |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



