
Submitted:
31 October 2023
Posted:
01 November 2023
You are already at the latest version
Abstract
Investigating the network response to node removal and the efficacy of the node removal strategies are related and fundamental questions in network science. Research studies proposed many node centralities based on the network structure ranking node to remove. The random walk (RW) on networks describes a stochastic process in which a walker travels among nodes. RW can be a model of transport, diffusion, and search on networks, and an essential tool for studying the importance of network nodes.
In this manuscript, we propose four new measures of node centrality based on RW. Then, we compare the efficacy of the new RW node removal strategies to network dismantle with effective node removal strategies from the literature, such as betweenness and closeness node removal over synthetic and real-world networks. We evaluate the network dismantle along node removal using the size of the largest connected component (LCC).
We find that, hence the betweenness nodes attack is the best strategy overall, the new node removal strategies based on RW show the highest efficacy in peculiar network topology. Specifically, RW strategies based on covering times emerge as the most effective strategy on a synthetic lattice network and two real-world road networks. Our results may be useful in selecting the best node attack strategies in a specific class of networks and in building more robust network structures.
Keywords:
real-world networks
; node centrality
; random walk processes
; network robustness
; network random walks
1. Introduction
Numerous studies have been conducted in the last years to explore the response of real-world networks to the removal of nodes [1,2,3,4,5,6,7]. These investigations simulate the consequences of node removal (attack) on the network and have applications in diverse scientific fields such as ecology [5], transportation [8], informatics [9], neural [10,11], and social networks [12,13].
The main objectives of these studies have been twofold. Firstly, they aim to assess networks’ robustness, which measures the system’s ability to maintain functionality after link and node removal. Secondly, they seek to identify the link and node removals that cause the most significant damage to the network, thereby uncovering the key players that significantly influence network functioning.
Analyzing attack strategies provides valuable insights into enhancing network resilience by anticipating threats and identifying elements requiring protection [5,6].
An attack strategy refers to the identification and implementation of methods or techniques aiming at disrupting or dismantling a network [5,6,7]. It also plays a crucial role in situations where network disruption is necessary, such as halting the spread of a disease or a computer virus or impeding the growth of a cancer cell [14,15,16]. Many centralities’ measurements have been proposed to select important nodes to remove. See [17] for a summary. Methods to measure node centralities are generally based on the topological structure of the network, such as removing nodes accounting for their degree and betweenness [5,17,18]. The betweenness node removal strategy, which removes nodes according to their recalculated betweenness centrality, yields the best attack in 70-80% of the cases [17].
The random walk (RW) on networks describes a stochastic process in which a walker travels among nodes along network links [19,20]. RW can be a model of transport, diffusion, and search on networks [21,22], a handy tool for studying the structure of networks [19], and the importance of network nodes [23,24,25].
In this manuscript, we join network attack simulation and random walk processes on networks. Here, we propose four new measures of node centrality based on RW. The new removal strategies focus on important notions in RW walks theory, such as the covering time, start, and stop nodes. Then, we test the proposed node centralities as effective strategies to rank nodes to remove to dismantle the network over synthetic and real-world networks. We compare the efficacy of the new node removal strategies based on random walks with effective node removal strategies from the literature, such as betweenness and closeness node removal.
2. Methods
2.1. Basic Notions
In this work, we consider binary and undirected networks where and are the sets of nodes (vertices) and links (edges). indicates the number of nodes. indicates the number of edges. We assume to be undirected. The symbol denotes the adjacency matrix of , having entries , for , such that if , and otherwise (27). A ‘path’ between two nodes and is a sequence of nodes with and , such that , for . The length of the path equals the number of edges it contains. The ‘distance’ is the shortest path length between node and [44]. In this work, all considered networks are connected, i.e., a path exists between each pair of nodes in (28).
2.2. Synthetic Networks
- ER: classical Erdös-Rényi (ER) random graph [26]. In the ER model, each edge has a fixed probability of being present or absent, independently of the other edges. The ER graph is defined by two parameters only, the number of nodes and the probability of drawn links . We indicate of nodes, and probability of link between each pair of vertices. We investigate ER network with and .
- LTC: rectangular (or square) lattice (LTC) complex network. In graph theory, a lattice graph is called a mesh or grid graph. The LTC is a specific lattice graph where nodes form a grid with square meshes. The LTC can be defined with two parameters, , and , indicating the number of nodes along each side. We simulate two networks by choosing and [27].
For statistical relevance of results obtained on random graphs, we performed graph generations.
Figure 1 depicts examples of the synthetic networks used in this research.
2.3. Real-World Complex Networks
- Air Control: This network was constructed from the USA’s FAA (Federal Aviation Administration) National Flight Data Center (NFDC), Preferred Routes Database (Preferred Routes Database: http://www.fly.faa.gov/). Nodes in this network represent airports or service centers, and links are created from strings of preferred routes recommended by the NFDC [32].
- Arenas Email: email communications among people working within a medium-sized university (i.e., Universitat Rovira i Virgily, Spain) with about employees [21]. Nodes are employees, and links describe mailing among them.
- Barcelona Flow: models the traffic flow in Barcelona (Spain). Nodes represent intersections among roads, and links represent roads (Transportation Networks, https://github.com/bstabler/TransportationNetworks).
- Uk Faculty: personal friendship network within a faculty at a university in the UK. This network comprises 81 vertices representing individuals and edges representing their friendship relations [34].
- Netscience: a coauthorship network focusing on scientists involved in network science. The network represents collaborations among these scientists [25]. Nodes are scientists, and links depict the coauthorship in scientific papers.
- represents the second ring road of Beijing city, China’s capital. Nodes and links represent road intersections and roads, respectively [35].
- Beijing : represents the third ring road of Beijing city, China’s capital. Nodes and links represent road intersections and roads, respectively [35].
- Beijing : represents the fourth ring road of Beijing city, China’s capital. Nodes and links represent road intersections and roads, respectively [35].
- Beijing : represents the fifth ring road of Beijing city, China’s capital. Nodes and links represent road intersections and roads, respectively [35].
- Euroroad: a topological representation of international European roads in which nodes represent intersections among roads and links represent roads [36].
- Littlerock food-web: a model of trophic interactions among species of the Little Rock Lake ecosystem in Wisconsin. In this ecological network, nodes represent living species, and links represent the transfer of nutrients between them [37].
- Olocene: the Olocene food web ecological network is the basis of the 48 million years old uppermost early Eocene Messel Shale food web. Nodes are biological species, and links represent trophic relationships among them [38].
- San-Francisco Reduced: represents a reduced version of the San Francisco road network [31] (Real Datasets for Spatial Databases, https://users.cs.utah.edu/~lifeifei/SpatialDataset.htm ), obtained by applying a simple spatial-partitioning algorithm, resulting in a smaller, computationally affordable graph for the scope of this work.
- Road Minnesota: the road map of Minnesota (US) [40]. Nodes represent intersections among roads, and links represent roads.
- San Joaquin County: California (US) city road map [31](Real Datasets for Spatial Databases, https://users.cs.utah.edu/~lifeifei/SpatialDataset.htm). Nodes are the intersections among roads, and links represent roads.
2.4. Network Structural Indicators
In Table 1, we report network structural indicators useful to compare the structure of the networks considered in this work. The network diameter is the maximum length among all shortest paths between each pair of nodes (44); the average node degree is the average number of links to the node [41]; the average clustering coefficient is the number of closed triplets (or triangles) over the total number of triplets (both open and closed) [42,43]; the average node distance is the average length of the shortest path among node pairs (44); and the network density (or connectance) , i.e., the fraction of realized edges among all possible edges that can be drawn in the network [44,45].
2.5. Node Removal Strategies
Node Removal (NR), also called node attack [46,47], refers to the process of selectively removing nodes from a network to study the impact on the structural properties of the network [13]. The removal strategy refers to how nodes are chosen to be removed from the network by assigning a value to each node and then defining an order to perform NR.
We define a series of RW-based node NR strategies and investigate their effectiveness in dismantling the networks. We compare their efficacy against two well-known centrality measures from the literature: closeness and betweenness node removals. We quantify the network dismantling after NR using the largest connected component (LCC) size. Node centrality rank is computed at the beginning of the simulation, i.e., before the first node removal. NR is performed by following the order of node centrality and computing the LCC after each removal. In the case of ties, i.e., nodes with equal centrality values, we randomly sort the nodes. The node centralities and the simulation analyses are performed using the complex network analysis (CNA) library Graph Tool (Tiago P. Peixoto), which consists of Python bindings for C++ and is highly performant as it is based on the Boost Graph Library [49].
In the following, we define the NR strategies used in this work.
2.6. Betweenness Centrality
The betweenness centrality of a node is defined as:
where is the total number of shortest paths from to , and is the number of shortest paths from to that pass through node [50].
2.7. Closeness Centrality
The closeness centrality of a node is defined as
where represents the distance between node and node in the network [51].
2.8. Random Walk Based Strategies
A simple Random Walk (RW) on is a graph traversal in which an agent moves from node to node , such that is chosen with uniform probability among the (first) neighbors of [52]. Formally, the probability of transition from to can be defined as [53]:
where is the neighbor’s node set of , and is the element of the adjacency matrix of . The walk ends when all vertices have been visited at least once. We call the vertex from which the walk starts the ’start node’. For statistical relevance of analysis, we averaged results from RWs for each start node . In the following part of this section, we define four RW-based strategies to perform node removals.
2.9. Recurrence Number
The Recurrence Number (RN) of a node is the number of times a random walker passes through the node during the covering process. Since the random walker covers all graph nodes, the simulation stops with a vector of RNs, one for each node. We call this vector of length , the Recurrence Vector (RV), and each RN is . In this node attack strategy, we remove nodes in decreasing order of RN.
2.10. Stop Node
The Stop Node (SN) is the last node encountered by a RW, or in other terms, the node where the RW stops its travel. We call Stop Vector (SV), the vector of length in which the entry accounts for how many times the node acted as a SN. Since we iterate RW simulations, the sum of the SV entries is . In this node attack strategy, we remove nodes in ascending order of SN.
2.11. Cover Time
Given a vertex , we call the time step the action of passing from to a (randomly chosen) neighbor. The notion of cover time refers to the number of time steps needed to visit all graph nodes [54]. We call Cover Time Vector (CTV), the vector of length in which the entry accounts the CT when is the starting node. The CTV accounts for each source node, the corresponding CT. In this node attack strategy, we remove nodes in decreasing order of CT, i.e., starting nodes producing higher CT are removed first.
2.11. Stop Distance
Given a random walk on , the Stop Distance (SD) is the distance , for , where and are, respectively, the start and the stop node of the random walk. We call Stop Distance Vector (SDV) the vector of length in which the entry accounts for the SD when is the starting node. The SDV stores the corresponding SD for each source node. In this node attack strategy, we remove nodes in ascending order of SD, i.e., starting nodes near the stop node are removed first.
See Algorithm 1 for an explanation of the RW simulation analysis.
| Algorithm 1: Methodology of the RW analysis. |
| RW(G(V,E), start_node): |
| rec |
| rec_number 1 |
| cov_time 1 |
| stop |
| v |
| while ∃ x ∊ V | rec_num[x] == 0 do |
| u randomly chose a neighbor of v |
| rec_num[u] rec_num[u] + 1 |
| stop_node u |
| cov_time cov_time + 1 |
| v u |
| end while |
| stop_distanced(start_node, stop_node) |
2.12. Network Robustness Indicator
2.12.1. Largest Connected Component
The Largest Connected Component (LCC), also called the giant component [29], indicates the connected subgraph of having the largest set of nodes. In literature, it has often been used as a network robustness indicator to evaluate the effectiveness of node or link removal strategies [14,55,56] by observing the decreasing trends of LCC after such removals.
2.12.2. Robustness
The robustness value represents the area under the curve of a decreasing trend of LCC [17,55,57]. The lower , the higher the efficacy of a NR to dismantle the network. On the other hand, the higher , the lower the efficacy of a NR to dismantle the network. For sake of clarity, we also define the inverse of robustness . In this manner, higher values denote more effective NR strategies.
Furthermore, given a fixed network, this value is normalized by the maximum value obtained among all NR strategies. This procedure allows us to compare the different robustness values obtained on a network while varying the different strategies. Additionally, given a fixed strategy, we denote as the average value of obtained across all networks, allowing us to rank the average performance of each NR strategy across all networks.
In Table 2, we furnish a list of abbreviations used in this manuscript.
3. Results and Discussion
In this study, we simulated random walk processes to cover the networks and evaluate node importance. We introduced four node attack strategies based on the simulated random walks process to assign each node a ranking (a value or score). Subsequently, we utilized these scores to define new node centrality measures. The introduced strategies include recurrence number, stop node, stop distance, and covering time. Then, by attacking 19 networks, four of which are synthetic, and the rest are real-world networks, we compared the efficacy of dismantling the network of the new node centralities with two well-known competitors from literature, namely Betweenness (BTW) and Closeness (CLS) node removals.
In Figure 2, we show the LCC decrease as a function of the node removal fraction for real-world networks and in Figure 3 for the synthetic networks. Figure 4 displays the inverse of robustness, , normalized per row (i.e., per network), where each cell in the table is assigned a darker color as the strategy becomes more effective than the others. We report the average inverse robustness value across all networks in the last row.
Moreover, in Figures A1 and A2 in the Appendix, we furnish the scatterplots of the random walk based node centralities vs. the betweenness node centrality for the real-world networks, and in Figures A3 and A4 in the Appendix, we depict the scatterplots of the random walk based node centralities vs. the node degree centrality for the real-world networks.
In the following, we summarize and discuss the outcomes for each NR strategy.
BTW: Our results show that the well-known betweenness nodes attack (BTW) is the best strategy overall as (Figure 4). BTW was the most effective on both food webs, Uk Faculty, Arenas email, and Beijing . It has also achieved good results on synthetic networks, particularly ER networks and BBT. The performance of BTW remains quite good because for all other networks. These results confirm previous studies indicating that betweenness is a very effective strategy for dismantling complex networks [5,17].
CLS: The closeness nodes attack (CLS) performs poorly on most road maps, while it is particularly effective on Uk Faculty, Little Rock Food-web, and Arenas Email regarding real-world networks. Regarding synthetic networks, it exhibits fairly good performance overall, especially on ER, BBT and LTC. CLS ranks fifth among the examined strategies as .
SN: The Stop Node (SN) has notable effectiveness on the ER random graph. Regarding real-world networks, SN is the most effective on Barcelona Flow and the second most effective on UK Faculty. It also demonstrates good effectiveness on Beijing and 4th, as well as on Road Minnesota. SN is the third strategy regarding average effectiveness, with .
We defined a ‘stop node’, the node where the RW stops its travel. For this reason, nodes acting many times as stop nodes are likely to be peripheral nodes, with a very low probability of encountering an RW. On the contrary, nodes that never (or rarely) acted as a stop node are likely to be central in the network and encounter an RW. The SN strategy removes nodes in ascending order of stop node, thus removing first the central nodes.
CT: The cover time (CT) emerges as the most effective strategy on LTC, and two real-world networks, Beijing and 4th. It also exhibits noteworthy effectiveness on Beijing and ER. CT ranks last in terms of average effectiveness, with . The covering time is the number of time steps the RW needs to pass over all nodes in the network [54]. The CT node attack strategy removes nodes in decreasing order of their covering time when they are the start node. This way, start nodes producing higher covering times are removed first. The CT strategy returns peculiar results; on the one hand, CT shows the worst average efficacy (lowest ); on the other hand, it carried out the best performance in dismantling one synthetic and two real-world networks. The synthetic network is the square grid LTC, i.e., the model network with a planar structure and highly homogeneous node degree. In Figure 5 we depict the twenty most central nodes for each node removal strategy for the LTC networks of different size. The twenty most central nodes selected by the CT strategy are distributed over the entire network, whereas for all the other strategies, the most central nodes reside in a central part of the network. Therefore, for example, if we remove the highest BTW nodes from the LTC network, it will survive a large LCC composed by the peripheral nodes of the network (See Figure 5). In other terms, CT selects nodes covering the whole network structure, and for this, removing nodes according to the CT strategy may cause a faster LCC dismantling.
The two real-world networks where CT is highly effective are the road networks of the Beijing ring. Further, CT performs well in dismantling the Minnesota road networks (>0.85, Figure 4). These road networks show a planar-like structure and a narrow range of node degrees (see Figure 6). Therefore, it emerges an interesting ability of the CT node attack strategies to dismantle the networks with the specific characteristics of the planar-like structure and homogeneous node degree. In Figure 7 we depict the fifty most central nodes for each node removal strategy for the Minnesota and the Beijing road networks. Like what was observed for the LTC, the fifty most central nodes, according to the CT strategy, are distributed over the entire network. In contrast, for all the other strategies, most central nodes reside in a part of the network. Therefore, this CT-specific node rank property may result in the effective dismantling of real-world networks with a planar-like structure and homogeneous node degree, such as road networks.
SD: The stop distance (SD) performs well on synthetic graphs, particularly on LTC, proving the most effective strategy. As for real networks, it demonstrates a solid performance on Olocene food-web, UK Faculty, Arenas email, and Beijing . SD is the fourth strategy in terms of average effectiveness, with . We defined the stop distance for a pair of nodes and , the shortest path length between the start node and the stop node of the random walk. SD attack strategy removes nodes in ascending order of SD.
For this reason, the SD remove first the start nodes that are a small distance from the respective stop node. This strategy emerges as particularly effective node removal over the synthetic network square lattice LTC of lower dimension. As we can see in Figure 5, the SD strategy can select nodes whose removals trigger the disruption of the LCC network in two parts. Therefore, removing nodes very near to their stop nodes can be a good method to dismantle this kind of model network and consequently select important nodes for its network robustness.
RN: For a sufficiently large number of iterations, the recurrence number (RN) approximates very well the degree (See Figures A3 and A4 in the Appendix). As easily verified, the degree vector is the eigenvector of the transition matrix corresponding to the eigenvalue 1 (Perron-Frobenius eigenvector)[58]. Given this property, the RN is a degree-like node removal strategy and can be generally effective on most networks. Specifically, RN is the top strategy for San Francisco (reduced), San Joaquin County, and Beijing road networks. Additionally, it maintains an average level of effectiveness greater than 0.75 on all other real networks. As for synthetic networks, it is less effective on lattices (LTC) where and ineffective on BBT. RN is the second most effective strategy among the tested networks with . Remove node based on their degree requires local information only, and for this, the node degree attack is a strategy with a low computational cost. The low computational cost and the good performance confirm this strategy as a good candidate for network dismantling.
4. Conclusions
Finding the best node attack strategy to dismantle the network is a paramount problem in network science [3,5,17,18]. In this manuscript, we proposed four new node removal strategies based on a simulated random walk on the network and compared them with well-known strategies from the literature. The well-known node removal strategy based on the node betweenness resulted in the best strategy, on average, to dismantle the networks, confirming previous research [5]. Nonetheless, the random walk-based node removal proposed here presents peculiar and high effectiveness on specific networks. The CT strategy of removing nodes in decreasing order of the covering time they produce when they start node is highly effective in dismantling network planar-like structures and homogenous node degrees, such as road and square lattice networks. The methodology presented here can open future research. On the one hand, the node removal strategy proposed here can be helpful for another significant network science problem, such as finding the most influential spreader nodes in the network [59]. On the other hand, it will be interesting to investigate the efficacy of the random walk-based node attack strategies proposed here to lower other network robustness indicators, such as network efficiency [51].
A possible shortcoming of the proposed node removal strategies based on a simulated random walk can be the simulation cost. Nonetheless, we can say that dynamic processes based on random walks have become computationally more accessible than two decades ago. It is now possible to establish a series of statistically significant simulations using tools such as [48] that are adequately optimized for conducting small-scale simulations like the ones presented in this study. Our objective in further investigating these topics is to migrate our codes, making them suitable for harnessing parallel hardware in the HPC environment and enabling the simulation of such processes on large-scale graphs. Moreover, we aim to introduce new strategies that facilitate the exploration of novel properties of real networks, which are often challenging to access solely through theoretical analysis.
Acknowledgments
The authors acknowledge the Italian Ministry of Foreign Affairs and International Cooperation. This research is funded by a grant from the Italian Ministry of Foreign Affairs and International Cooperation. This research is funded by Ecosister project, funded under the National Recovery and Resilience Plan (NRRP), Mission 4 Component 2 Investment 1.5 - Call for tender No. 3277 of 30/12/2021 of Italian Ministry of University and Research funded by the European Union – NextGenerationEU Award Number: Project code ECS00000033, Concession Decree No. 1052 of 23/06/2022 adopted by the Italian Ministry. This work is supported by the Vietnam’s Ministry of Science and Technology (MOST) under the Vietnam-Italy scientific and technological cooperation program for the period 2021-2023. This work is supported by the Vietnam National University Ho Chi Minh City (VNU-HCM), Ho Chi Minh city, Vietnam under grant number B2018-42-01. We are greatly thankful to Van Lang University, Vietnam, for providing the budget for this study. This research has benefited from the high-performance computing (HPC) cluster of the Università degli Studi di Parma.
References
- Cohen, R.; Havlin, S. Complex Networks: Structure, Robustness and Function. Cambridge university press, 2010. [Google Scholar]
- Cohen, R.; Erez, K.; Ben-Avraham, D.; Havlin, S. Resilience of the Internet to Random Breakdowns. Phys Rev Lett 2000, 85, 4626. [Google Scholar] [CrossRef] [PubMed]
- Morone, F.; Makse, H.A. Influence Maximization in Complex Networks through Optimal Percolation. Nature 2015, 524, 65–68. [Google Scholar] [CrossRef] [PubMed]
- Callaway, D.S.; Newman, M.E.J.; Strogatz, S.H.; Watts, D.J. Network Robustness and Fragility: Percolation on Random Graphs. Phys Rev Lett 2000, 85, 5468. [Google Scholar] [CrossRef] [PubMed]
- Bellingeri, M.; Cassi, D.; Vincenzi, S. Efficiency of Attack Strategies on Complex Model and Real-World Networks. Physica A: Statistical Mechanics and its Applications 2014, 414, 174–180. [Google Scholar] [CrossRef]
- Huang, X.; Gao, J.; Buldyrev, S.V.; Havlin, S.; Stanley, H.E. Robustness of Interdependent Networks under Targeted Attack. Phys Rev E 2011, 83, 65101. [Google Scholar] [CrossRef] [PubMed]
- Nie, T.; Guo, Z.; Zhao, K.; Lu, Z.-M. New Attack Strategies for Complex Networks. Physica A: Statistical Mechanics and its Applications 2015, 424, 248–253. [Google Scholar] [CrossRef]
- Pagani, A.; Mosquera, G.; Alturki, A.; Johnson, S.; Jarvis, S.; Wilson, A.; Guo, W.; Varga, L. Resilience or Robustness: Identifying Topological Vulnerabilities in Rail Networks. R Soc Open Sci 2019, 6, 181301. [Google Scholar] [CrossRef] [PubMed]
- Cohen, R.; Erez, K.; Ben-Avraham, D.; Havlin, S. Breakdown of the Internet under Intentional Attack. Phys Rev Lett 2001, 86, 3682. [Google Scholar] [CrossRef] [PubMed]
- Bassett, D.S.; Bullmore, E.D. Small-World Brain Networks. The neuroscientist 2006, 12, 512–523. [Google Scholar] [CrossRef]
- Bullmore, E.; Sporns, O. Complex Brain Networks: Graph Theoretical Analysis of Structural and Functional Systems. Nat Rev Neurosci 2009, 10, 186–198. [Google Scholar] [CrossRef]
- Borgatti, S.P.; Mehra, A.; Brass, D.J.; Labianca, G. Network Analysis in the Social Sciences. Science (1979) 2009, 323, 892–895. [Google Scholar] [CrossRef] [PubMed]
- Boldi, P.; Rosa, M.; Vigna, S. Robustness of Social and Web Graphs to Node Removal. Soc Netw Anal Min 2013, 3, 829–842. [Google Scholar] [CrossRef]
- Sartori, F.; Turchetto, M.; Bellingeri, M.; Scotognella, F.; Alfieri, R.; Nguyen, N.-K.-K.; Le, T.-T.; Nguyen, Q.; Cassi, D. A Comparison of Node Vaccination Strategies to Halt SIR Epidemic Spreading in Real-World Complex Networks. Sci Rep 2022, 12, 21355. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, N.-K.-K.; Nguyen, T.-T.; Nguyen, T.-A.; Sartori, F.; Turchetto, M.; Scotognella, F.; Alfieri, R.; Cassi, D.; Nguyen, Q.; Bellingeri, M. Effective Node Vaccination and Containing Strategies to Halt SIR Epidemic Spreading in Real-World Face-to-Face Contact Networks. In Proceedings of the 2022 RIVF International Conference on Computing and Communication Technologies (RIVF); 2022; pp. 1–6. [Google Scholar]
- Michele Bellingeri Massimiliano Turchetto, D.B. Modeling the Consequences of Social Distancing over Epidemics Spreading in Complex Social Networks: From Link Removal Analysis to SARS-CoV-2 Prevention. Front Phys 2021, 9, 681343. [Google Scholar]
- Wandelt, S.; Sun, X.; Feng, D.; Zanin, M.; Havlin, S. A Comparative Analysis of Approaches to Network-Dismantling. Sci Rep 2018, 8, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Iyer, S.; Killingback, T.; Sundaram, B.; Wang, Z. Attack Robustness and Centrality of Complex Networks. PLoS ONE 2013, 8, e59613. [Google Scholar] [CrossRef] [PubMed]
- Burioni, R.; Cassi, D. Random Walks on Graphs: Ideas, Techniques and Results. J Phys A Math Gen 2005, 38, R45. [Google Scholar] [CrossRef]
- Masuda, N.; Porter, M.A.; Lambiotte, R. Random Walks and Diffusion on Networks. Phys Rep 2017, 716, 1–58. [Google Scholar] [CrossRef]
- Guimer, R.; Danon, L.; Diaz-Guilera, A.; Giralt, F.; Arenas, A. Self-Similar Community Structure in a Network of Human Interactions. Phys. Rev. E 2003, 68, 65103. [Google Scholar] [CrossRef] [PubMed]
- Agliari, E. Exact Mean First-Passage Time on the T-Graph. Phys Rev E 2008, 77, 11128. [Google Scholar] [CrossRef]
- Noh, J.D.; Rieger, H. Random Walks on Complex Networks. Phys Rev Lett 2004, 92, 118701. [Google Scholar] [CrossRef] [PubMed]
- Rocha, L.E.C.; Masuda, N. Random Walk Centrality for Temporal Networks. New J Phys 2014, 16, 63023. [Google Scholar] [CrossRef]
- Newman, M.E.J. Analysis of Weighted Networks. Phys Rev E 2004, 70, 56131. [Google Scholar] [CrossRef] [PubMed]
- RENYI, E. On Random Graph. Publicationes Mathematicate 1959, 6, 290–297. [Google Scholar]
- Acharya, B.D.; Gill, M.K. On the Index of Gracefulness of a Graph and the Gracefulness of Two-Dimensional Square Lattice Graphs. Indian J. Math 1981, 23, 14. [Google Scholar]
- Cormen, T.; Leiserson, C.; Rivest, R.; Stein, C. Book: Introduction to Algorithms. 2009. [Google Scholar]
- Van Steen, M. Graph Theory and Complex Networks. An introduction 2010, 144. [Google Scholar]
- Chen, G.; Wang, X.; Li, X. Fundamentals of Complex Networks: Models, Structures and Dynamics. 2014; Volume 96. [Google Scholar]
- Preferred Routes Database.
- Kunegis, J. Konect: The Koblenz Network Collection. In Proceedings of the 22nd international conference on world wide web; 2013; pp. 1343–1350. [Google Scholar]
- Transportation Networks.
- Nepusz, T.; Petróczi, A.; Négyessy, L.; Bazsó, F. Fuzzy Communities and the Concept of Bridgeness in Complex Networks. Phys Rev E 2008, 77, 16107. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.-L.; Lu, Z.-M. Urban Road Network and Taxi Network Modeling Based on Complex Network Theory. J. Inf. Hiding Multim. Signal Process. 2016, 7, 558–568. [Google Scholar]
- Šubelj, L.; Bajec, M. Robust Network Community Detection Using Balanced Propagation. Eur Phys J B 2011, 81, 353–362. [Google Scholar] [CrossRef]
- Martinez, N.D. Artifacts or Attributes? Effects of Resolution on the Little Rock Lake Food Web. Ecol Monogr 1991, 61, 367–392. [Google Scholar] [CrossRef]
- Dunne, J.A.; Labandeira, C.C.; Williams, R.J. Highly Resolved Early Eocene Food Webs Show Development of Modern Trophic Structure after the End-Cretaceous Extinction. Proceedings of the Royal Society B: Biological Sciences 2014, 281, 20133280. [Google Scholar] [CrossRef] [PubMed]
- Real Datasets for Spatial Databases.
- Rossi, R.A.; Ahmed, N.K. The Network Data Repository with Interactive Graph Analytics and Visualization. In Proceedings of the AAAI; 2015. [Google Scholar]
- Bellingeri, M.; Montepietra, D.; Cassi, D.; Scotognella, F. The Robustness of the Photosynthetic System I Energy Transfer Complex Network to Targeted Node Attack and Random Node Failure. J Complex Netw 2021, 10, cnab050. [Google Scholar] [CrossRef]
- Boccaletti, S.; Latora, V.; Moreno, Y.; Chavez, M.; Hwang, D.-U. Complex Networks: Structure and Dynamics. Phys Rep 2006, 424, 175–308. [Google Scholar] [CrossRef]
- Gleeson, J.P.; Melnik, S.; Hackett, A. How Clustering Affects the Bond Percolation Threshold in Complex Networks. Phys Rev E 2010, 81, 66114. [Google Scholar] [CrossRef] [PubMed]
- Dunne, J.A.; Williams, R.J.; Martinez, N.D. Network Structure and Biodiversity Loss in Food Webs: Robustness Increases with Connectance. Ecol Lett 2002, 5, 558–567. [Google Scholar] [CrossRef]
- Bellingeri, M.; Vincenzi, S. Robustness of Empirical Food Webs with Varying Consumer’s Sensitivities to Loss of Resources. J Theor Biol 2013, 333, 18–26. [Google Scholar] [CrossRef]
- Nguyen, Q.; Pham, H.-D.; Cassi, D.; Bellingeri, M. Conditional Attack Strategy for Real-World Complex Networks. Physica A: Statistical Mechanics and its Applications 2019, 530, 121561. [Google Scholar] [CrossRef]
- Albert, R.; Barabási, A.-L. Statistical Mechanics of Complex Networks. Rev Mod Phys 2002, 74, 47. [Google Scholar] [CrossRef]
- Tiago, P. Peixoto Graph-Tool, Efficient Network Analysis. https://Graph-Tool.Skewed.De/.
- Siek, J.G.; Lee, L.-Q.; Lumsdaine, A. The Boost Graph Library: User Guide and Reference Manual, The; Pearson Education, 2001. [Google Scholar]
- Freeman, L.C. A Set of Measures of Centrality Based on Betweenness. Sociometry 1977, 35–41. [Google Scholar] [CrossRef]
- Marchiori, M.; Latora, V. Harmony in the Small-World. Physica A: Statistical Mechanics and its Applications 2000, 285, 539–546. [Google Scholar] [CrossRef]
- Campari, R.; Cassi, D. Random Collisions on Branched Networks: How Simultaneous Diffusion Prevents Encounters in Inhomogeneous Structures. Phys Rev E 2012, 86, 21110. [Google Scholar] [CrossRef] [PubMed]
- Xia, F.; Liu, J.; Nie, H.; Fu, Y.; Wan, L.; Kong, X. Random Walks: A Review of Algorithms and Applications. IEEE Trans Emerg Top Comput Intell 2019, 4, 95–107. [Google Scholar] [CrossRef]
- Lovász, L. Random Walks on Graphs. Combinatorics, Paul erdos is eighty 1993, 2, 4. [Google Scholar]
- Bellingeri, M.; Bevacqua, D.; Scotognella, F.; Cassi, D. The Heterogeneity in Link Weights May Decrease the Robustness of Real-World Complex Weighted Networks. Sci Rep 2019, 9, 10692. [Google Scholar] [CrossRef]
- Zhang, Y.; Ng, S.T. Identification and Quantification of Node Criticality through EWM–TOPSIS: A Study of Hong Kong’s MTR System. Urban Rail Transit 2021, 7, 226–239. [Google Scholar] [CrossRef]
- Schneider, C.M.; Moreira, A.A.; Andrade Jr, J.S.; Havlin, S.; Herrmann, H.J. Mitigation of Malicious Attacks on Networks. Proceedings of the National Academy of Sciences 2011, 108, 3838–3841. [Google Scholar] [CrossRef]
- Levin, D.A.; Peres, Y. Markov Chains and Mixing Times. American Mathematical Soc., 2017; Volume 107. [Google Scholar]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of Influential Spreaders in Complex Networks. Nat Phys 2010, 6, 888–893. [Google Scholar] [CrossRef]
Figure 1.
The picture displays examples of the synthetic networks used in this study. From left to right, the reported networks are: BBT (50 nodes), ER(N=80, p=0.15) and LTC(20,5).
Figure 1.
The picture displays examples of the synthetic networks used in this study. From left to right, the reported networks are: BBT (50 nodes), ER(N=80, p=0.15) and LTC(20,5).
Figure 2.
Impact of NR strategies on real-world networks: LCC (y-axis) as a function of the fraction of removed nodes (x-axis).
Figure 2.
Impact of NR strategies on real-world networks: LCC (y-axis) as a function of the fraction of removed nodes (x-axis).
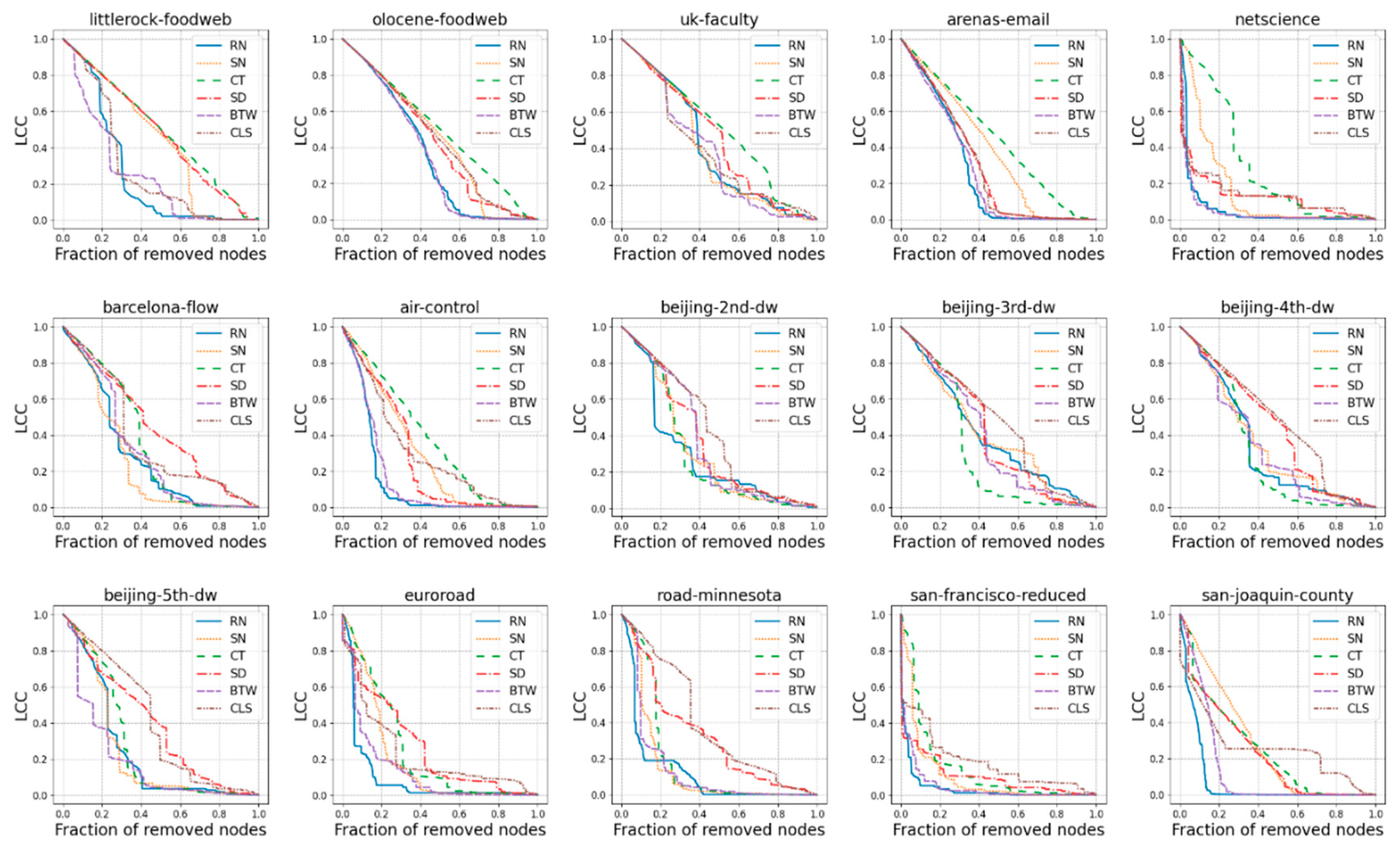
Figure 3.
Impact of NR strategies on synthetic networks: LCC (y-axis) as a function of the fraction of removed nodes (x-axis).
Figure 3.
Impact of NR strategies on synthetic networks: LCC (y-axis) as a function of the fraction of removed nodes (x-axis).
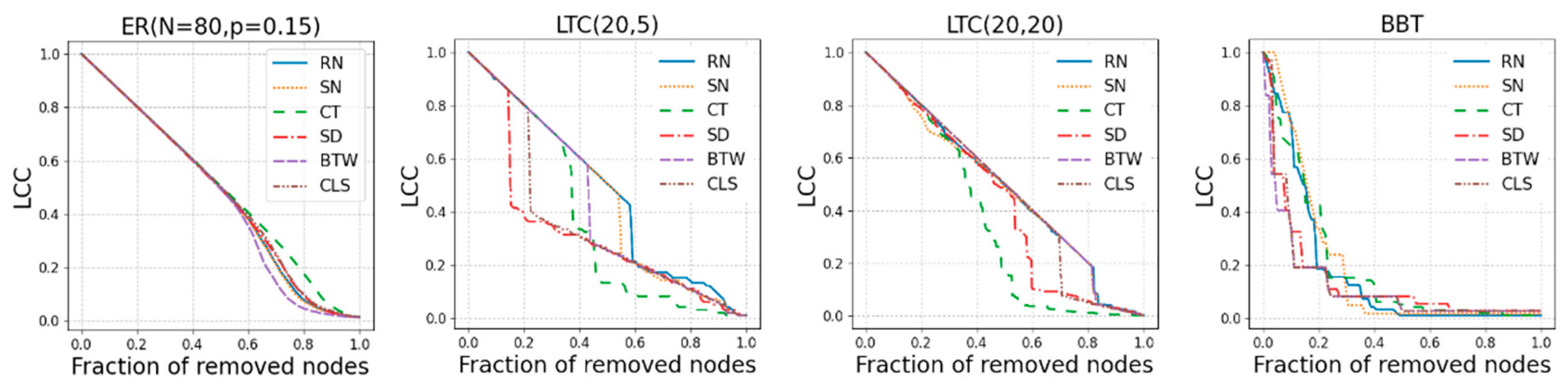
Figure 4.
Inverse network robustness for each network analyzed. To compare the efficacy of the node attack strategies, we normalize with its maximum value for each network. In this way, the maximum for each network equals 1. The higher , the more effective is the attack strategies to dismantle the network. In the last row, we depict the average value for all networks. Darker cell color indicates higher .
Figure 4.
Inverse network robustness for each network analyzed. To compare the efficacy of the node attack strategies, we normalize with its maximum value for each network. In this way, the maximum for each network equals 1. The higher , the more effective is the attack strategies to dismantle the network. In the last row, we depict the average value for all networks. Darker cell color indicates higher .
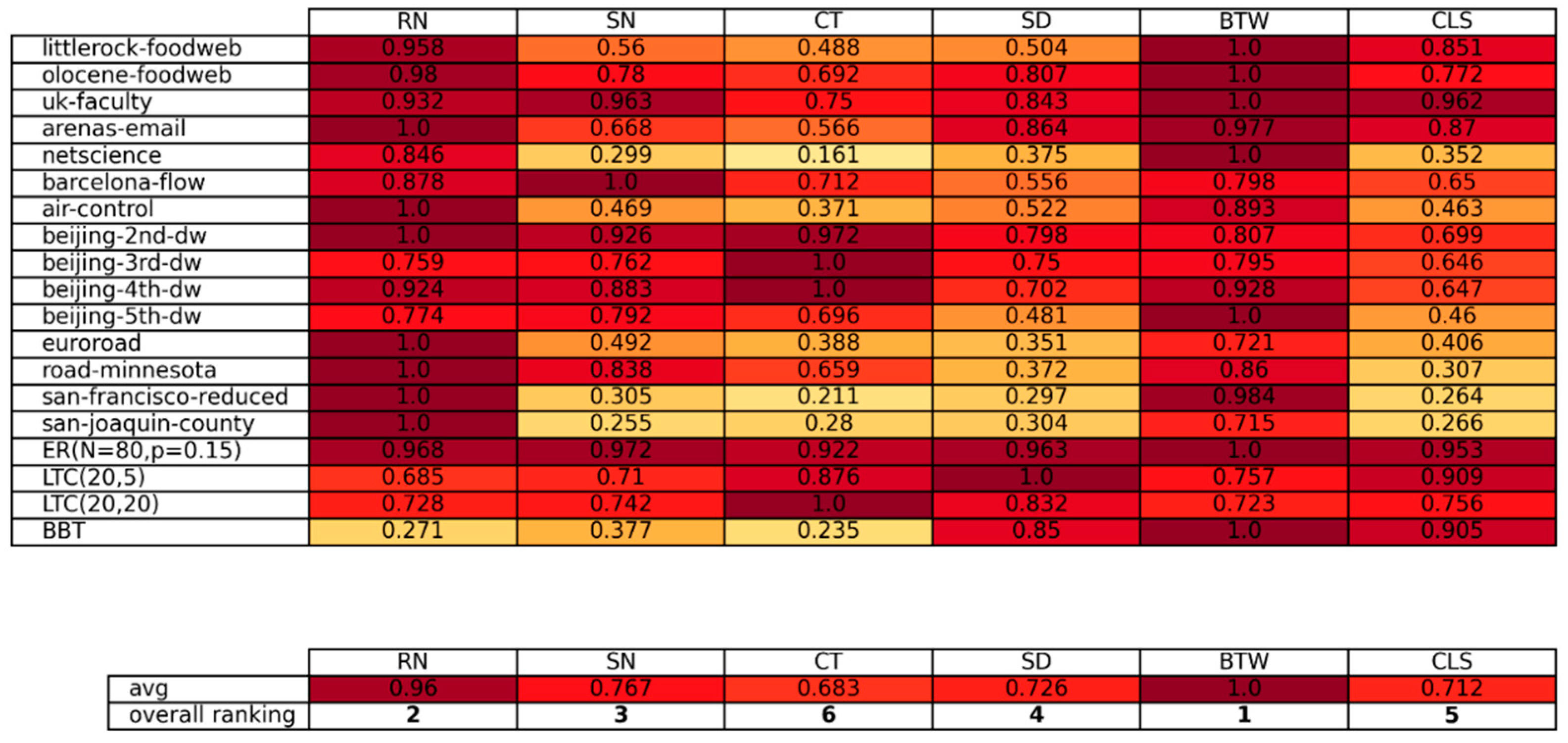
Figure 5.
(Top row) the twenty most central nodes according to each node removal strategy for the LTC. (Bottom row) the twenty most central nodes according to each node removal strategy for the LTC.
Figure 5.
(Top row) the twenty most central nodes according to each node removal strategy for the LTC. (Bottom row) the twenty most central nodes according to each node removal strategy for the LTC.
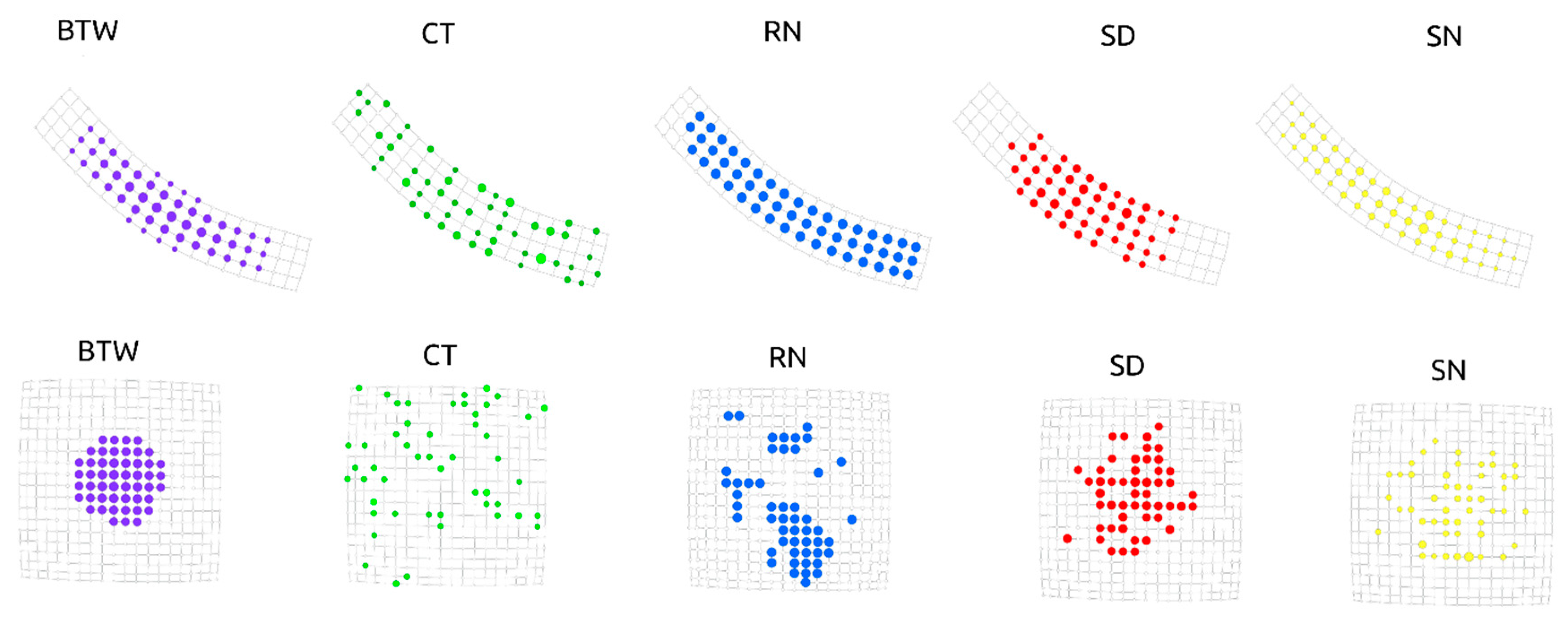
Figure 6.
An illustrative example showcasing the structural approximation of a lattice by specific portions of a road map. The left network is the Beijing ring road network. The right network is the Minnesota road network.
Figure 6.
An illustrative example showcasing the structural approximation of a lattice by specific portions of a road map. The left network is the Beijing ring road network. The right network is the Minnesota road network.
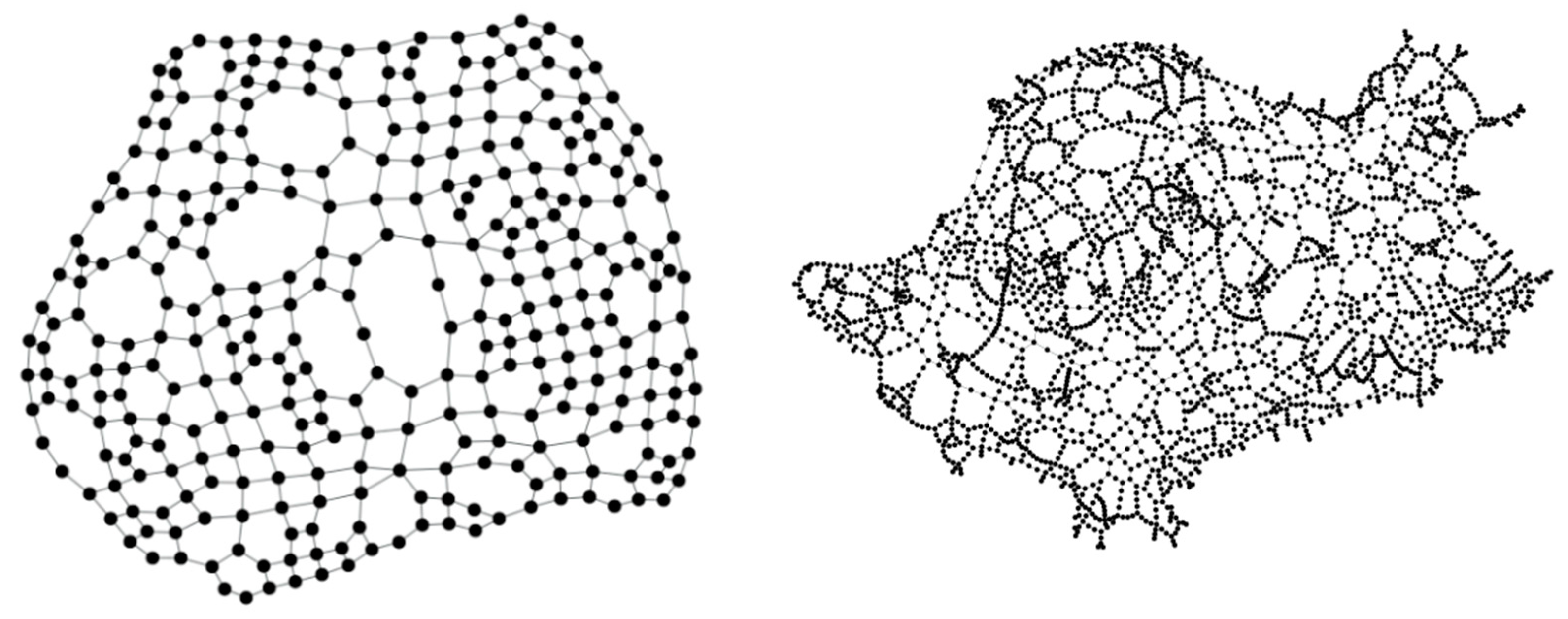
Figure 7.
In this figure, we show the fifty most central nodes according to each node removal strategy. The upper row network is the Minnesota road network. The lower row network is the Beijing ring road network.
Figure 7.
In this figure, we show the fifty most central nodes according to each node removal strategy. The upper row network is the Minnesota road network. The lower row network is the Beijing ring road network.
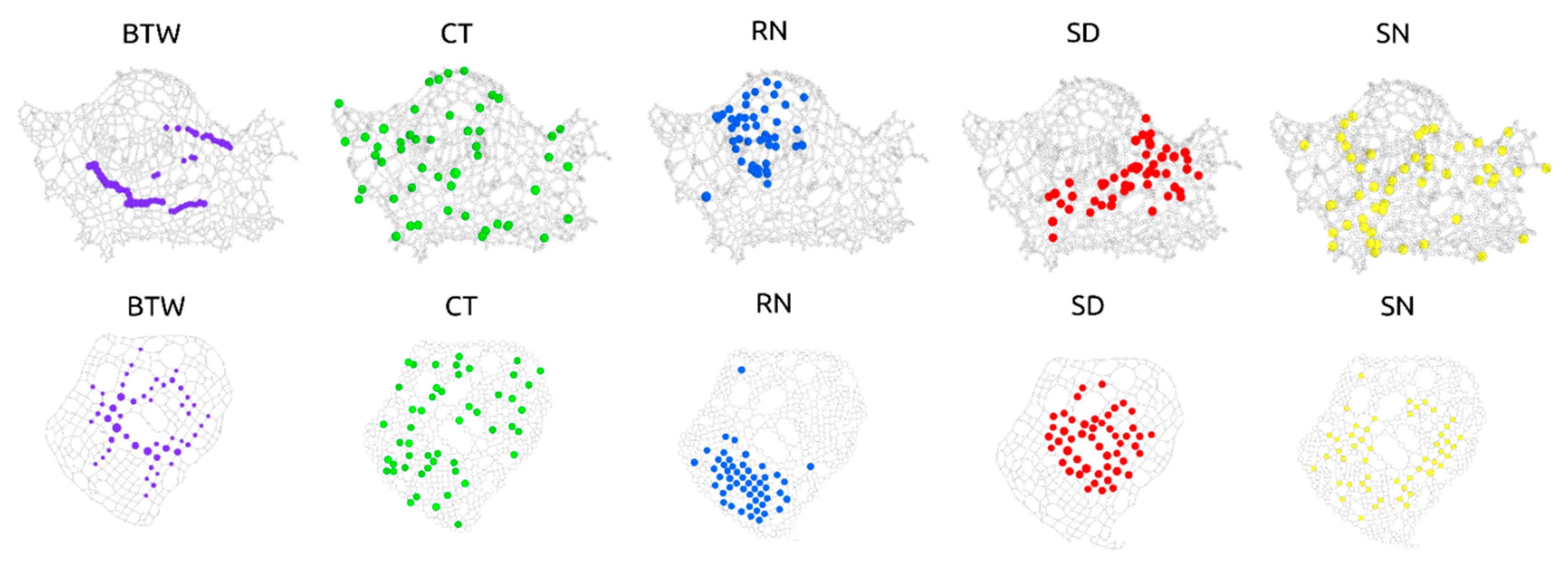

Table 1.
Network structural indicator values for the synthetic and real-world networks analyzed.
| Network | |||||||
|---|---|---|---|---|---|---|---|
| air-control | 1226 | 2410 | 17 | 3.931 | 5.924 | 0.064 | 0.003 |
| arenas-email | 1133 | 5451 | 8 | 9.622 | 3.603 | 0.166 | 0.009 |
| barcelona-flow | 930 | 1798 | 27 | 3.867 | 12.721 | 0.084 | 0.004 |
| beijing-2th | 144 | 233 | 19 | 3.236 | 7.813 | 0.011 | 0.023 |
| beijing-3rd | 322 | 544 | 27 | 3.379 | 11.030 | 0.018 | 0.011 |
| beijing-4th | 547 | 926 | 33 | 3.386 | 13.904 | 0.019 | 0.006 |
| beijing-5th | 815 | 1308 | 48 | 3.210 | 17.246 | 0.024 | 0.004 |
| euroroad | 1039 | 1305 | 62 | 2.512 | 18.377 | 0.035 | 0.002 |
| littlerock-foodweb | 183 | 2452 | 4 | 26.798 | 2.135 | 0.332 | 0.147 |
| netscience | 379 | 914 | 17 | 4.823 | 6.026 | 0.431 | 0.013 |
| olocene-foodweb | 700 | 6425 | 6 | 18.357 | 2.629 | 0.074 | 0.026 |
| road-minnesota | 2641 | 3303 | 100 | 2.501 | 35.349 | 0.028 | 0.001 |
| san-francisco-reduced | 435 | 440 | 41 | 2.023 | 17.461 | 0.000 | 0.005 |
| san-joaquin-county | 7087 | 9793 | 50 | 2.764 | 13.939 | 0.000 | 0.000 |
| uk-faculty | 81 | 577 | 4 | 14.247 | 2.072 | 0.473 | 0.178 |
| LTC(20,5) | 100 | 175 | 23 | 3.500 | 8.250 | 0.000 | 0.035 |
| LTC(20,20) | 400 | 760 | 38 | 3.800 | 13.300 | 0.000 | 0.010 |
| BBT | 100 | 99 | 12 | 1.980 | 7.654 | 0.000 | 0.020 |
| ER(N=80,p=0.15) | 80.0 | 474.52 | 3.1 | 11.863 | 1.969 | 0.148 | 0.150 |
Table 2.
List of the abbreviations used in this manuscript.
| LCC | network largest connected component |
| |𝑽| | number of nodes in the network |
| |𝑬| | Number of links in the network |
| Diam | Diameter of the network |
| Average node degree | |
| Average length of shortest path among all node pairs | |
| 𝑪𝑪 | Clustering coefficient, i.e., number of closed triples |
| 𝝆 | Network density, i.e., fraction of realized links in the network among all possible links |
| R | Robustness of the network |
| Inverse of the network robustness | |
| among all networks | |
| RN | Recurrence Number |
| CT | Covering Time |
| SN | Stop Node |
| SD | Stop Distance |
| BTW | Betweenness Centrality |
| CLS | Closeness Centrality |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



