
Submitted:
03 November 2023
Posted:
06 November 2023
You are already at the latest version
Abstract
Applications of gradient method for nonlinear optimization in development of Gradient Neural Network (GNN) and Zhang Neural Network (ZNN) are investigated. Particularly, the solution of the matrix equation AXB=D which changes over time is studied using the novel GNN model, termed as GGNN(A,B,D). The GGNN model is developed applying GNN dynamics on the gradient of the error matrix used in the development of the GNN model. The convergence analysis shows that the neural state matrix of the GGNN(A,B,D) design converges asymptotically to the solution of the matrix equation AXB=D, for any initial state matrix. It is also shown that the convergence result is the least square solution which is defined depending on the selected initial matrix. A hybridization of GGNN with analogous modification GZNN of the ZNN dynamics is considered. The Simulink implementation of presented GGNN models is carried out on the set of real matrices.
Keywords:
gradient neural network
; generalized inverses
; Moore-Penrose inverse
; linear matrix equations
MSC: 68T05; 15A09; 65F20
1. Introduction and background
Recurrent neural networks (RNNs) are important class of algorithms for computing matrix (generalized) inverses. These algorithms are used to find the solutions of the matrix equations or to minimize certain nonlinear matrix functions. RNNs are divided into 2 subgroups: Gradient Neural Networks (GNN) and Zhang Neural Networks (ZNN). The GNN design is explicit and mostly applicable to time-invariant problems, which means that coefficients of the equations which are addressed are constant matrices. ZNN models can be implicit and capable to solve time-varying problems where coefficients of the equations depend on the variable representing the time [31].
GNN neural design models for computing the inverse or the Moore-Penrose inverse and linear matrix equations were proposed in [6,25,26,27]. Further, various dynamical systems aimed to approximating the pseudo-inverse of rank-deficient matrices were originated in [6]. Wei in [28] proposed three RNN models for approximation of the weighted Moore-Penrose inverse. Cichocki in [29] proposed a feed-forward neural network for approximating the Drazin inverse. Online matrix inversion in complex matrix case was considered in [30].
Applications of this type of inverses can be found in important areas such as modeling of electrical circuits [10], estimation of DNA sequences [22,23], balancing chemical equations [11,12] and in other important research domains related to robotics [13] and statistics [14].
In the following sections we will focus on GNN and ZNN dynamic systems based on gradient of the objective function and their implementation. The main goal of this research is the analysis of convergence and the study of analytic solutions. In this study we are concerned with solving the matrix equation [20,21] in real time using the GNN model, denoted by GNN [3,4,5,6,7,8,9], and the novel gradient-based GGNN model, termed as GGNN. The proposed GGNN model is defined evolving the standard GNN dynamics along the gradient of the standard error matrix. The convergence analysis reveals the global asymptotic convergence of GGNN without restrictions, while the output belongs to the set of general solutions to the matrix equation . The implementation is performed in MATLAB Simulink and numerical experiments are developed with simulations of GNN and GGNN models.
The GNN used to solve the general linear matrix equation is defined over the error matrix , where is the time and is an unknown state-variable matrix that approximates the unknown matrix X in . The goal function is and its gradient is equal to
The GNN evolutionary design is defined by the dynamic system
where is real parameter used to speed up the convergence. Thus, the linear GNN aimed at solving is given by the following dynamics:
The dynamical flow (2) is denoted as as GNN. The nonlinear GNN for solving is defined by
The function array is based on appropriate odd and monotonically increasing activation function, which is applicable to elements of a real matrix , i.e. .
Proposition 1 restates restrictions about the solvability of and its general solution.
Proposition 1.
The following results from [15] describe the conditions of convergence and the limit of the unknown matrix from (3) as .
Proposition 2.
The research in [24] investigated various ZNN models based on optimization methods. The goal of current research is to develop the GNN model based on the gradient of instead of the original goal function .
Obtained results are summarized as follows.
- A novel error function is proposed for development of the GNN dynamical evolution.
- GNN design evolved upon the error function is developed and analyzed theoretically and numerically.
- A hybridization of GNN and ZNN dynamical systems based on the error matrix is proposed and investigated.
Global organization of section is as follows. Motivation and derivation of GGNN and GZNN models are presented in Section 2. Section 3 is aimed to convergence analysis of the GGNN dynamics. Numerical comparison on GNN and GGNN dynamics are given in Section 4, in which SubSection 4.1 investigates a practical application of GGNN to electrical networks. Neural dynamics based on the hybridization of GGNN and GZNN model for solving matrix equations are considered in Section 6. Numerical examples on hybrid models model are analysed in Section 6. Finally, the last section presents some concluding remarks and vision of further research.
2. Motivation and derivation of the GGNN and GZNN models
The standard GNN design (2) solves the GLME under the constraint (4). Our goal is to resolve this restriction and propose dynamic evolutions based on the error functions that tend to zero without restrictions.
Our goal is to define the GNN design for solving the GLME based on the error function
The equilibria points of (7) satisfy
We continue investigation from [24]. More precisely, we will develop the GNN model based on the error function instead of the error function . In this way, new neural dynamics is aimed to force the gradient to zero instead of the standard goal function . It is reasonable to call such RNN model as gradient-based GNN (GGNN shortly).
Proposition 3 gives conditions for solvability of the matrix equations and and general solutions to these systems.
Proposition 3.
[24] Consider arbitrary matrices , and . The next statements are true.
(a) The equation is solvable if and only if (4) is satisfied and the general solution to is given by (5).
(b) The equation is always solvable and its general solution coincides with (5).
In this way, the matrix equation is solvable under the condition (4), while the equation is always consistent. In addition, the general solutions to equations and are identical [24].
The next step is to define the GGNN dynamics using the error matrix . Let us define the objective function , whose gradient is equal to
The dynamical system for the GGNN formula is obtained applying the GNN evolution along the gradient of based on , as follows
The nonlinear GGNN dynamics is defined as
in which denotes an odd and monotonically increasing function array, as mentioned in previous section for the GNN model (3). An arbitrary monotonically increasing odd activation function is used for the construction of the GNN neural design. The model (9) is termed as GGNN. Figure 1 represents the Simulink implementation of GGNN dynamics (9).
On the other hand, the GZNN model defined upon the Zhangian matrix is defined in [24] by the general evolution design
3. Convergence analysis of GGNN dynamics
In this section, we will analyze convergence properties of GGNN model given by dynamics (9).
Theorem 1.
Consider matrices and . If an odd and monotonically increasing array activation function based on an elementwise function is used, then the neural state matrix of the model (9) asymptotically converges to the solution of the matrix equation , i.e., , for an arbitrary initial state matrix .
Proof.
From the statement b) of Proposition 3, the solvability of is ensured. The substitution transforms the dynamics (9) into
Lyapunov function candidate which measures the convergence performance is defined by
The conclusion is . According to (12), assuming (11) and using in conjunction with basic properties of the matrix trace function, one can express the time derivative of as in the following
Since the scalar-valued function is an odd and monotonically increasing, it follow for
which implies
Observing the identity
and using the Lyapunov stability theory, globally converges to the zero matrix, from arbitrary initial value . □
Theorem 2.
The activation state variables matrix of the model , defined by (9), is convergent as and its equilibrium state is
for every initial state matrix .
Proof.
From (9), the matrix satisfies
According to the basic properties of the Moore–Penrose inverse [18,19], it follows
which further implies
Consequently, satisfies , which implies
Furthermore, from Theorem 1, and converges to
as . Therefore, converges to the equilibrium state
The proof is finished. □
4. Numerical experiments on GNN and GGNN dynamics
Numerical examples in this section are represented based on the Simulink implementation of GGNN formula in Figure 1. Three activation functions are used in numerical experiments:
1. linear function
2. power-sigmoid activation function
where and is odd integer.
3. smooth power-sigmoid function
where and is odd integer.
The parameter , initial state and parameters and of the nonlinear activation functions (19) and (20), are entered directly in the model, while matrices A, B and D are defined from the workspace. It is assumed in all examples. The ode15s differential equation solver is used in configuration parameters.
The blocks powersig, smoothpowersig and transpmult include the codes described in [15].
Example 4.1.
Let us consider the idempotent matrix A from [32,33]
with the theoretical Moore-Penrose inverse
under the input parameters , , , where and denote the identity and zero matrix, respectively. The Simulink implementation from Figure 1 exports the graphical results in Figure 2 and Figure 3 which display the behavior of and respectively. It is observable that the norms generated by the application of GGNN formula vanish faster to zero against corresponding norms in the GNN model. Graphs in presented figures strengthen the fast convergence of the GGNN dynamical system and the important role which can include the application of this specific model (9) to problems that require the computation of the Moore-Penrose inverse.
Example 4.2.
Let us consider the matrices
Ranks of input matrices are equal to , and . The linear GGNN formula GGNN (9) is applied to solve the matrix equation , which gives in the case
The gain parameter of the model is , and the final time is .
Elementwise trajectories of the variable state matrix with red lines are shown in Figure 4a–c, for linear, power-sigmoid and smooth power-sigmoid activation functions, respectively. It is observable the convergence of elementwise trajectories to the black dashed lines of the theoretical solution X. The trajectories in figures indicate a usual convergence behaviour, so the system is globally asymptotically stable. The norm of the error matrix of both model for linear and non-linear activation function are shown on Figure 5a–c. The nonlinear activation function shows superiority in the convergence speed, comparing with the linear activation function. On each graph, Frobenius norm of the error from GGNN formula vanish faster to zero than GNN model which strengthens the fact that the proposed dynamical system (9) includes accelerated convergence property against (3).
Example 4.3.
Let us explore behavior of GGNN for computing the Moore-Penrose inverse. We consider matrix:
The error matrix initiates the GNN dynamics for computing . Corresponding error matrix for GGNN is
Rank of the input matrix is equal to . The gain parameter of the model is , initial state is with stop time . The Moore–Penrose inverse of A is given by
The error matrix of GNN and GGNN model for both linear and non-linear activation functions are shown on Figure 6a–c, and of both model for linear and non-linear activation function are shown on Figure 7a–c. Like in previously example, we can conclude that GGNN converges faster compared to the GNN model.
Example 4.4.
Consider the matrices
that dissatisfy . Now, we apply GGNN formula to solve the matrix equation . Notice, if we look at GGNN in this example, we actually operate with and . So, we consider GNN. The error matrix for the corresponding GGNN model is
The gain parameter of the model is and the final time is . The zero initial state generates the best approximate solution of the matrix equation , given by
Example 4.5.
Table 2 shows the results obtained during experiments we conducted with nonsquared matrices, where is dimension of matrix. Table 1 is the input data in the Simulink model which are used to perform experiments that generate results in Table 2. Best cases in Table 2 are marked in bold text.
Numerical results arranged in Table 2 are divided into two parts by a horizontal line. The upper part corresponds to test matrices of dimensions while the lower part corresponds to the dimensions . Considering first two columns, it is observable from the upper part that GGNN generates smaller values compared to GGNN. Values in the lower part generated by GNN and GGNN are equal. Considering the third and fourth columns, it is observable from the upper part that GGNN generates smaller values compared to GGNN. On the other hand, values in the lower part, generated by GGNN, are smaller than corresponding values generated by GNN. Last two columns show that the GGNN requires smaller CPU time compared to GNN. General conclusion is that GGNN model is more efficient on rank deficient test matrices of larger order .
4.1. Application of GGNN to electrical networks
It is really interesting to apply the novel GGNN formula (9) for the calculation and study of different parameters related to electrical networks. For this reason the following circuit in Figure 10 from [34] is considered.
Our goal is to estimate the currents in amperes while electrical potential is measured in volts and resistors with resistance is measured in ohms . Applying the current law in the points , relationships and obtained respectively and from the voltage law the relationship which lead to the following system in matrix form
with theoretical solution . For the parameters and the zero initial condition simulink implementation from Figure 1 extracts Figure 11 and Figure 12.
It is observable from Figure 11 that GGNN initiates a faster convergence than GNN formula for the same parameter as error vanishes faster to zero. Figure 12 presents state trajectories of obtained by the exact solution with the trajectories resulting from the GGNN formula for and . These observations indicate that the proposed GGNN formula for solving general linear matrix equations is usable in solving electrical networks, which is an interesting engineering problem.
5. Mixed GGNN-GZNN model for solving matrix equations
Let us define gradient error matrix of the matrix equation by
The GZNN design (10) corresponding to the error matrix , marked with GZNN, is of the form:
Now, the scalar-valued norm-based error function corresponding to is given by
The following dynamic state equation can be derived using the GGNN design formula derived from (9):
Further, it follows
Next step is to define new hybrid model based on the summation of (21) and (23) in the case , as follows:
The model (24) is derived as a combination of the model GGNN and the model GZNN. Hence, it is equally justified to use the term Hybrid GGNN (HGGNN shortly) or Hybrid GZNN (HGZNN shortly) model. But, the model (24) is implicit, so that it is not a kind of GGNN dynamics. On the other hand, it is designed for time-invariant matrices, which is not in accordance with the common nature of GZNN models, because usually GZNN is used for the time-varying case. A formal comparison of (24) and GZNN reveals that both these methods possess identical left hand sides and the right hand side of (24) can be derived multiplying the right hand side of GZNN by the term .
Formally, (24) is closer to the GZNN dynamics, so, we will denote the model (2.4) by HGZNN, considering that this model is not the exact GZNN neural dynamics and it is applicable in time-invariant case. This is the case of constant coefficient matrices A, I, B. Figure 13 represents the Simulink implementation of HGZNN dynamics (24).
Now, we will take into account solving the matrix equation . The error matrix for this equation is defined by
The GZNN design (10) corresponding to the error matrix , marked with GZNN, is of the form:
On the other hand, the GGNN design formula (9) produces the following dynamic state equation:
The GGNN model (26) is denoted by GGNN. It implies
A new hybrid model based on the summation of (25) and (27) in the case can be proposed as follows
The model (28) will be denoted by HGZNN. This is the case of constant coefficient matrices I, C, D.
For the purposes of the proof of the following results, we will denote by the exponential convergence rate of the model . With and , we denote the smallest and largest eigenvalue of a matrix K, respectively. In the continuation of the work we use three types of activation functions : linear, power-sigmoid and smooth power-sigmoid.
Next theorem determines the equilibrium state of HGZNN and defines its global exponential convergence.
Theorem 3.
Let be given and satisfy and be the state matrix of (24), where is defined by , or .
a) Then achieves global convergence and satisfies when , starting from any initial state . The state matrix of HGZNN is stable in the sense of Lyapunov.
b) The exponential convergence rate of the HGZNN model (24) in the linear case is equal to
c) The activation state variables matrix of the model HGZNN is convergent when with the equilibrium state matrix
Proof.
a) With the assumption we have solvability of the matrix equation .
We can define the Lyapunov function as
Hence, from (24) and , it holds that
In the linear case it follows
We also consider next inequality [35], which is valid for a real symmetric matrix K and a real symmetric positive-semidefinite matrix L of the same size:
Now, it can be chosen: and . Let be the minimal eigenvalue of . Then is the minimal nonzero eigenvalue of , which implies
From (31), it can be concluded
According to (32), the Lyapunov stability theory confirms that is a globally asymptotically stable equilibrium point of the HGZNN model (24). So, converges to the zero matrix, i.e. from any initial state .
b) From a) it follows that
This implies
which confirms the convergence rate (29) of HGZNN.
c) This part of the proof can be verified by following an analogous result from [17]. □
Theorem 4.
Let be given and satisfy and be the state matrix of (28), where is defined by , or .
a) Then achieves global convergence when , starting from any initial state . The state matrix of HGZNN is stable in the sense of Lyapunov.
b) The exponential convergence rate of the HGZNN model (28) in the linear case is equal to
c) The activation state variables matrix of the model HGZNN is convergent when with the equilibrium state matrix
Proof.
a) With the assumption we have solvability of the matrix equation .
Lets define the Lyapunov function with
Hence, from (28) and , it holds that
According to similar results from [36], one can verify the following inequality
We also consider next inequality [35], which is valid for a real symmetric matrix K and a real symmetric positive-semidefinite matrix L of the same size:
Now, it can be chosen: and .
Let be the minimal eigenvalue of . Then is the minimal nonzero eigenvalue of . This implies
From (35), it can be concluded
According to (36), the Lyapunov stability theory confirms that is a globally asymptotically stable equilibrium point of the HGZNN model (28). So, converges to the zero matrix, i.e. from any initial state .
b) From a) it follows
This implies
which confirms that the convergence rate of HGZNN is
c) This part of the proof can be verified by following an analogous result from [17]. □
Corollary 5.1.
a) Let the matrices be given and satisfy and be the state matrix of (24), with an arbitrary nonlinear activation . Then .
b) Let the matrices be given and satisfy and be the state matrix of (28) with an arbitrary nonlinear activation . Then .
5.1. Regularized HGZNN model for solving matrix equations
From Theorem 3 and Corollary 5.1 (a), it follows
Similarly, according to Theorem 4 and Corollary 5.1 (b), it can be concluded that
Convergence of HGZNN (resp. HGZNN) can be improved in the case (resp. ). There exist two possible situations when the acceleration terms and improve the convergence. The first case assumes invertibility of A (resp. C), and the second case assumes left invertibility of A (resp. right invertibility of C). Still, in some situations the matrices A and C could be rank deficient. Hence, in the case when A and C are square and singular, it is useful to use the invertible matrices and , instead of A and C, and consider the models HGZNN and HGZNN. In below are presented the convergence results considering nonsingularity of and .
Corollary 5.2.
Let , be given and be the state matrix of (24), where is defined by , or . Let be a selected real number. Then the following statements are valid:
a) The state matrix of the model HGZNN converges globally to
when , starting from any initial state and the solution is stable in the sense of Lyapunov.
b) The minimal exponential convergence rate of HGZNN in the case is equal to
c) Let be the limiting value of when . Then
Proof.
Since is invertible, it follows .
From (30) and invertibility of we can get validity of a). In this case, it follows
Part b) is proved analogously as in Theorem 3. Last part c) follows from a). □
Corollary 5.3.
Let , be given and be the state matrix of (28), where or . Let be a selected real number. Then the following statements are valid:
a) The state matrix of HGZNN converges globally to
when , starting from any initial state and the solution is stable in the sense of Lyapunov.
b) The minimal exponential convergence rate of HGZNN in the case is equal to
c) Let be the limiting value of when . Then
Proof.
It can be proved analogously to Corollary 5.2. □
Remark 1.
The notation and will be used. Main observations about the convergence properties of HGZNN and HGZNN are highlighted as follows.
Hybrid neural dynamics HGZNN (resp. HGZNN ) converge faster than GZNN (resp. GZNN ). The accelerated convergence rate is equal to (resp. ).
Regularized hybrid dynamics HGZNN and HGZNN are applicable even in the case if A and C are singular matrices.
HGZNN (resp. HGZNN ) always faster converge than GZNN (resp. GZNN ). The accelerated convergence rate is (resp. ).
6. Numerical examples on hybrid models model
In this section the numerical examples are represented based on the Simulink implementation of HGZNN formula. The previously mentioned three types of activation functions in (18), (19) and (20) will be used in the following examples. The parameters , initial state and parameters and of the nonlinear activation functions (19) and (20), are entered directly in the model, while matrices A, B, C and D are defined from the workspace. We assume that in all examples. The ordinary differential equation solver in configuration paremeters is the ode15s. The blocks powersig, smoothpowersig and transpmult include the codes described in [16].
We present numerical examples in which we compare Frobenius norms and which are generated by HGZNN, GZNN and GGNN.
Example 6.1.
Consider the matrix
In this example we compare HGZNN model with GZNN and GGNN considering all three types of activation functions. The gain parameter of the model is , initial state and the final time is .
Elementwise trajectories of the state variable with red lines are shown in Figure 14a–c, for linear, power-sigmoid and smooth power-sigmoid activation functions, respectively, and is observable the converge to the black dashed lines of the theoretical solution X. Trajectories indicate a usual convergence behaviour, so the system is globally asymptotically stable. Error matrix of HGZNN, GZNN and GGNN model for both linear and non-linear activation functions are shown on Figure 15a–c, and error matrix of both model for linear and non-linear activation function are shown on Figure 16a–c. On each graph, Frobenius norm of error from HGZNN formula vanish faster to zero than GZNN and GGNN model.
Example 6.2.
Consider the matrices
In this example, we compare HGZNN model with GZNN and GGNN considering all three types of activation functions. The gain parameter of the model is , initial state and the final time is .
Elementwise trajectories of the state variable with red lines are shown in Figure 17a–c, for linear, power-sigmoid and smooth power-sigmoid activation functions, respectively, and is observable the converge to the black dashed lines of the theoretical solution X. We can see that trajectories indicate a usual convergence behaviour, so the system is globally asymptotically stable. The error matrix of HGZNN, GZNN and GGNN model for both linear and non-linear activation functions are shown on Figure 18a–c, and the residual matrix of both models for linear and non-linear activation function are shown on Figure 19a–c. On each graph, for both error cases, the Frobenius norm of error HGZNN formula is similar to the Frobenius norm of error of GZNN model, and they both converges faster to zero than GGNN model.
7. Conclusions
We show that the error function lying in the basement of GNN and ZNN dynamical evolutions can be defined using the gradient of the Frobenius norm of the traditional error function . The result of this intention is usage of an original error function for the basis of GNN dynamics which results in the proposed GGNN model. The results related to the GNN model (called GNN) for solving the general matrix equation are extended on GGNN model (called GGNN) in both theoretical and computational directions. In theoretical sense, the convergence of defined GGNN model is considered. It is shown that the neural state matrix of the GGNN model asymptotically converges to the solution of the matrix equation , for an arbitrary initial state matrix , and coincides with the general solution of the linear matrix equation. A number of applications of GNN(A, B, D) are considered. All applications are globally convergent. Several particular appearances of the general matrix equation are observed and applied in computing various classes of generalized inverses. Illustrative numerical examples and simulation results are obtained using Matlab Simulink implementation and presented to demonstrate validity of the derived theoretical results. The influence of various nonlinear activations on the GNN models is considered in both the theoretical and the computational direction. In the presented examples it can be concluded that GGNN model is faster and has smaller error compared to the GNN model.
Further research can be oriented to definition of finite-time convergent GGNN or GZNN models as well as definition of noise-tolerant GGNN or GZNN design.
Author Contributions
Conceptualization, P.S. and G.V.M.; methodology, P.S., N.T., D.G. and V.S.; software, D.G., V.K. and N.T.; validation, G.V.M., M.P. and P.S.; formal analysis, M.P., N.T. and D.G. ; investigation, M.P., G.V.M. and P.S.; resources, D.G., N.T., V.K., V.S.; data curation, M.P., V.K., V.S., D.G. and N.T.; writing—original draft preparation, P.S., D.G., N.T.; writing—review and editing, M.P. and G.V.M.; visualization, D.G. and N.T.; supervision, G.V.M.; project administration, M.P.; funding acquisition, G.V.M., M.P. and P.S.. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Ministry of Science and Higher Education of the Russian Federation (Grant No. 075-15-2022-1121).
Data Availability Statement
Data results are available on readers request.
Acknowledgments
Predrag Stanimirović is supported by the Science Fund of the Republic of Serbia, (No. 7750185, Quantitative Automata Models: Fundamental Problems and Applications - QUAM). Dimitrios Gerontitis is supported by financial support of the “Savas Parastatidis” named scholarship granted by the Bodossaki Foundation.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| TLA | Three letter acronym |
| LD | Linear dichroism |
References
- Ben-Israel, A.; Greville, T. N. E.Generalized Inverses: Theory and Applications; CMS Books in Mathematics, Springer, New York, NY, second ed., 2003.
- Nocedal, J.; Wright, S. Numerical Optimization; Springer-Verlag New York, Inc., 1999.
- Wang, J. Electronic realisation of recurrent neural network for solving simultaneous linear equations; Electronics Letters, 1992, 28, pp. 493–495.
- Wang, J. A recurrent neural network for real-time matrix inversion. Applied Mathematics and Computation, 1993, 55, pp. 89–100.
- Zhang, Y.; Chen, K.; Tan, H.Z. Performance analysis of gradient neural network exploited for online time-varying matrix inversion. IEEE Transactions on Automatic Control, 54, pp. 1940–1945, 2009.
- Wang, J. Recurrent neural networks for computing pseudoinverses of rank-deficient matrices. SIAM Journal on Scientific Computing, 1997, 18, pp. 1479–1493.
- Wei, Y. Recurrent neural networks for computing weighted Moore–Penrose inverse. Applied Mathematics and Computation, 2000, 116, pp. 279–287.
- Wang, J.; Li,H. Solving simultaneous linear equations using recurrent neural networks. Information Sciences, 1994, 76, pp. 255–277.
- Ding, F.; Chen, T. Gradient based iterative algorithms for solving a class of matrix equations. IEEE Transactions on Automatic Control, 2005, 50, pp. 1216–1221.
- Dash, P.; Zohora, F.T.; Rahaman, M.; Hasan, M.M.; Arifuzzaman, M. Usage of Mathematics Tools with Example in Electrical and Electronic Engineering. American Scientific Research Journal for Engineering, Technology, and Sciences (ASRJETS), 2018, 46, pp. 178–188.
- Soleimani, F.; Stanimirović, P.S.; Soleimani, F. Some matrix iterations for computing generalized inverses and balancing chemical equations. Algorithms, 2015, 8, pp: 982-998.
- Udawat, B.; Begani, J.; Mansinghka, M.; Bhatia, N.; Sharma, H.; Hadap, A. Gauss Jordan method for balancing chemical equation for different materials. Materials Today: Proceedings, 2022, 51 pp: 451-454.
- Doty, K.L.; Melchiorri, C.; Bonivento, C. A theory of generalized inverses applied to robotics. The International Journal of Robotics Research, 1993, 12, pp: 1-19.
- Li, L.; Hu, J. An efficient second-order neural network model for computing the Moore–Penrose inverse of matrices. IET Signal Processing, 2022, 16, pp: 1106-1117.
- Stanimirović, P.S.; Petković, M.D. Gradient neural dynamics for solving matrix equations and their applications. Neurocomputing, 2018, 306, pp. 200–212.
- Stanimirović, P.S.; Petković, M.D.; Gerontitis, D. Gradient neural network with nonlinear activation for computing inner inverses and the Drazin inverse. Neural Processing Letters, 2017, 48, pp: 109-133.
- Stanimirović, P.S.; Cirić, M.; Stojanović, I.; Gerontitis, D. Conditions for existence, representations and computation of matrix generalized inverses. Complexity, Volume 2017, Article ID 6429725, 27 pages. [CrossRef]
- Wang, G.; Wei, Y.; Qiao, S. Generalized Inverses: Theory and Computations. Science Press, 2003.
- Wang, G.; Wei, Y.; Qiao, S., Lin, P.; Chen, Y. Generalized inverses: theory and computations. Singapore: Springer, 2018, 10.
- Zhang, Y.; Chen, K. Comparison on Zhang neural network and gradient neural network for time-varying linear matrix equation AXB = C solving, IEEE International Conference on Industrial Technology, 2008.
- Wang, X.; Tang, B.; Gao, X.G.; Wu, W.H. Finite iterative algorithms for the generalized reflexive and anti-reflexive solutions of the linear matrix equation AXB = C, Filomat 2017, 31, 2151–2162.
- Qin, F.; Lee, J. Dynamic methods for missing value estimation for DNA sequences. In: 2010 International Conference on Computational and Information Sciences. IEEE, 2010.
- Qin, F.; Collins, J.; Lee, J. Robust SVD Method for Missing Value Estimation of DNA Microarrays. In Proceedings of the International Conference on Bioinformatics & Computational Biology (BIOCOMP) (p. 1). The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp), 2011.
- Stanimirović, P.S.; Mourtas, S.D.; Katsikis, V.N.; Kazakovtsev, L.A. Krutikov, V.N. Recurrent neural network models based on optimization methods, Mathematics, 2022, 10.
- Fa-Long, L.; Zheng, B. Neural network approach to computing matrix inversion, Appl. Math. Comput. 1992, 47, 109–120.
- Wang, J. A recurrent neural network for real-time matrix inversion, Appl. Math. Comput., 1993, 55, 89–100.
- Wang, J. Recurrent neural networks for solving linear matrix equations, Comput. Math. Appl., 1993, 26, 23–34.
- Wei, Y. Recurrent neural networks for computing weighted Moore-Penrose inverse, Appl. Math. Comput., 2000, 116, 279–287.
- Cichocki, A.; Kaczorek, T. Stajniak, A. Computation of the Drazin inverse of a singular matrix making use of neural networks, Bulletin of the Polish Academy of Sciences Technical Sciences, 1992, 40, 387–394.
- Xiao, L.; Zhang, Y.; Li, K.; Liao, B.; Tan, Z. FA novel recurrent neural network and its finite-time solution to time-varying complex matrix inversion, Neurocomputing, 2019, 331, 483–492.
- Zhang, Y.; Yi, C.; Guo, D.; Zheng, J. Comparison on Zhang neural dynamics and gradient-based neural dynamics for online solution of nonlinear time-varying equation, Neural Computing and Applications, 2011, 20, 1–7.
- Smoktunowicz, A.; Smoktunowicz, A. Set-theoretic solutions of the Yang–Baxter equation and new classes of R-matrices, Linear Algebra and its Applications, 2018, 546, 86–114.
- Baksalary, O. M.; Trenkler, G. On matrices whose Moore–Penrose inverse is idempotent, Linear and Multilinear Algebra, 2022, 70, 2014–2026.
- Siddiki, A. M. The solution of large system of linear equations by using several methods and its applications, IJISET - International Journal of Innovative Science, Engineering & Technology, 2015, 2, 2.
- Wang, S.D.; Kuo, T.S.; Hsu, C.F. Trace bounds on the solution of the algebraic matrix Riccati and Lyapunov equation, IEEE Transactions on Automatic Control, 1986, 31.
- Wang, X.Z.; Ma, H.; Stanimirović, P.S. Nonlinearly activated recurrent neural network for computing the Drazin inverse, Neural Processing Letters, 2017, 46, pp. 195–217.
Figure 1.
Simulink implementation of GGNN evolution (9).
Figure 1.
Simulink implementation of GGNN evolution (9).
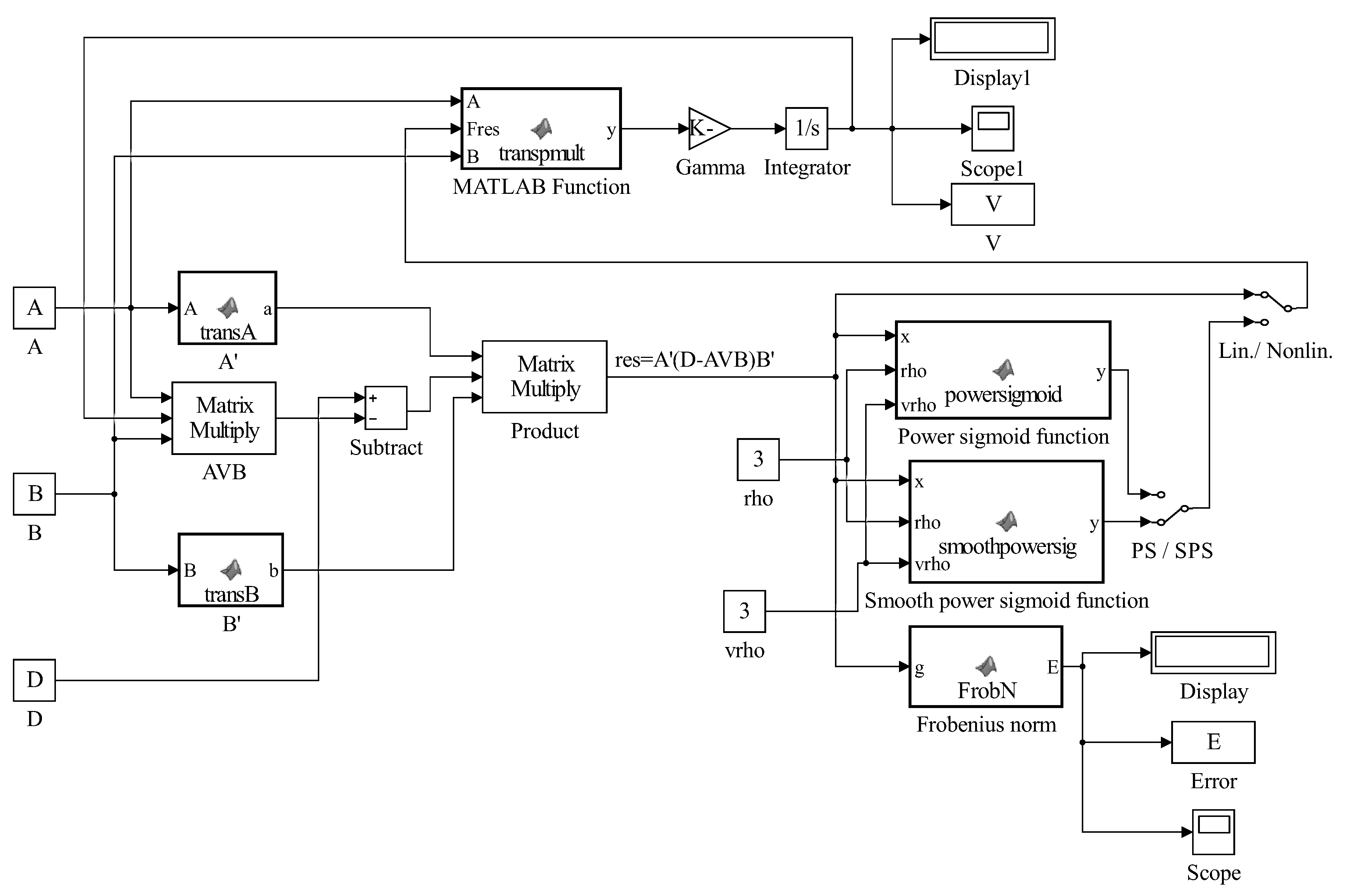
Figure 2.
Frobenius norm of error matrix of GGNN against GNN in Example 4.1.
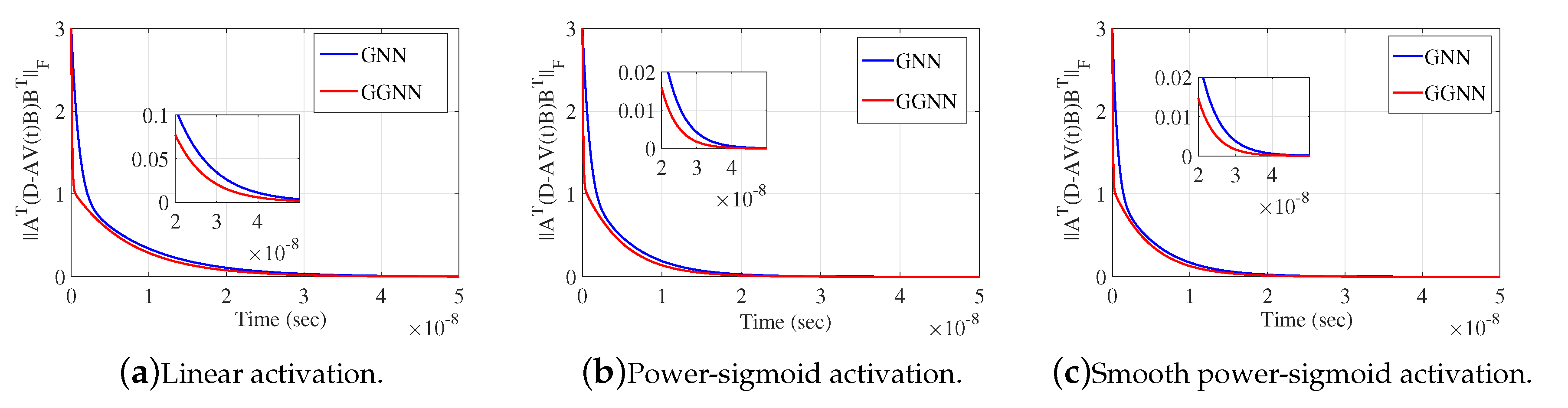
Figure 3.
Frobenius norm of error matrix of GGNN against GNN in Example 4.1.
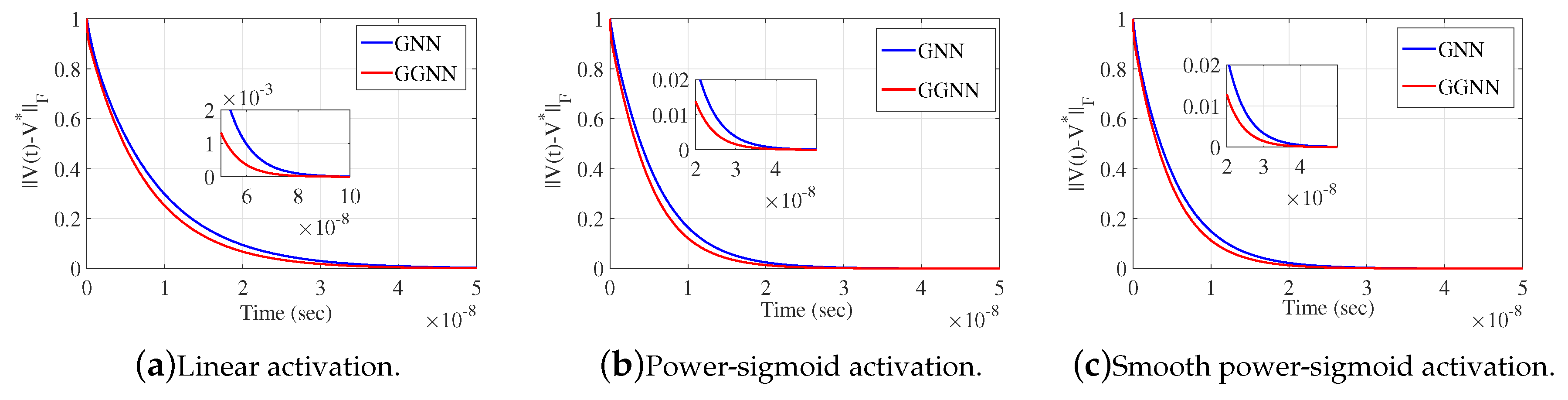
Figure 4.
Elementwise convergence trajectories of the GGNN network in Example 4.2.
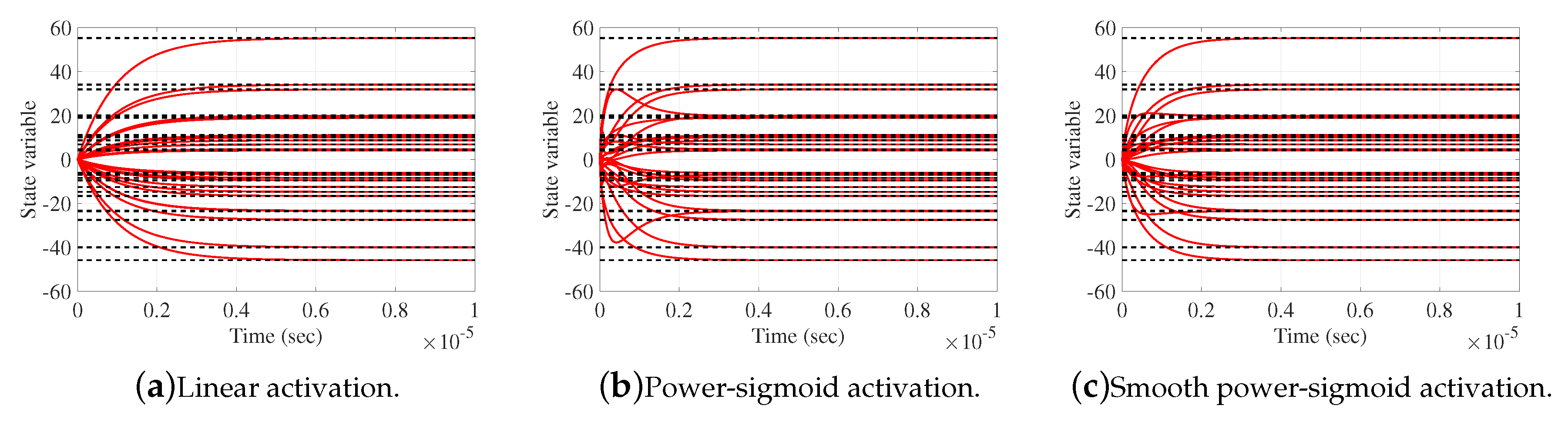
Figure 5.
Frobenius norm of error matrix of GGNN against GNN in Example 4.2.
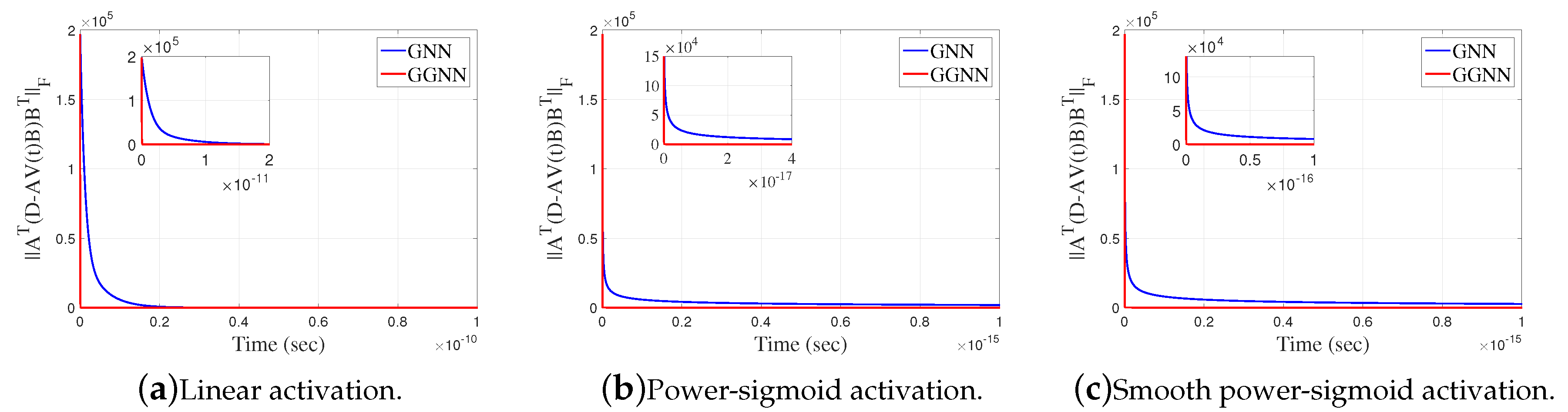
Figure 6.
Frobenius norm of in GGNN against GNN in Example 4.3.
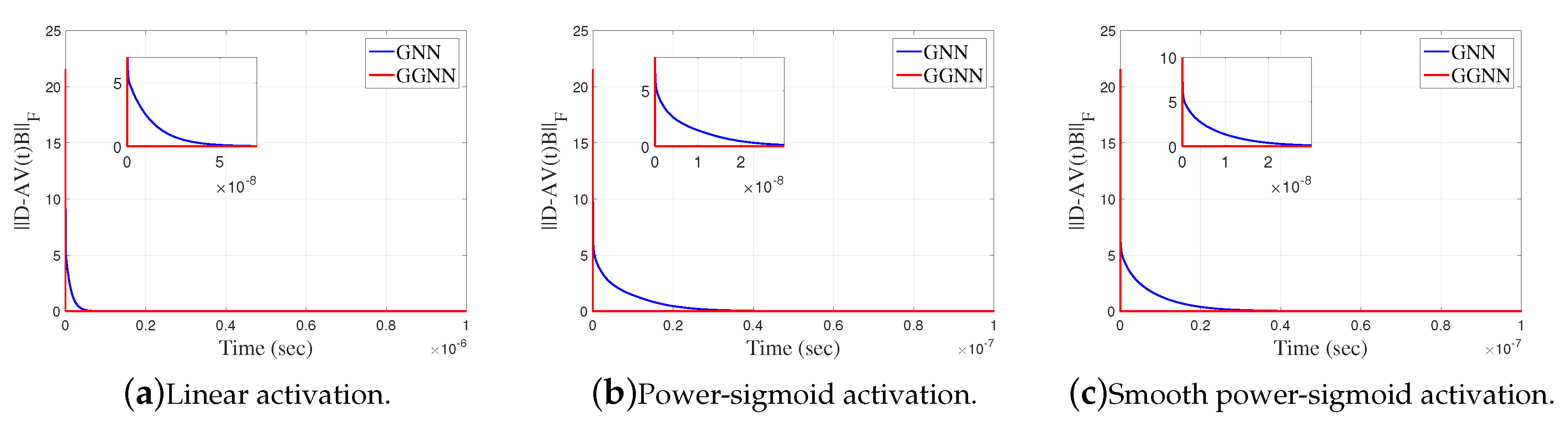
Figure 7.
Frobenius norm of in GGNN against GNN in Example 4.3.
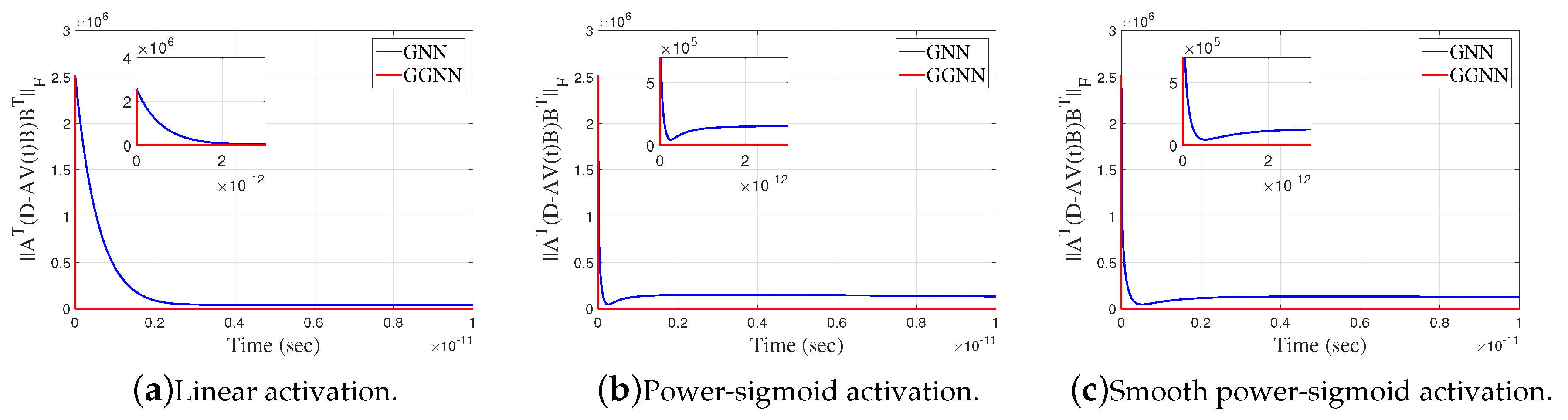
Figure 8.
Frobenius norm of error matrix of GGNN against GNN in Example 4.4.
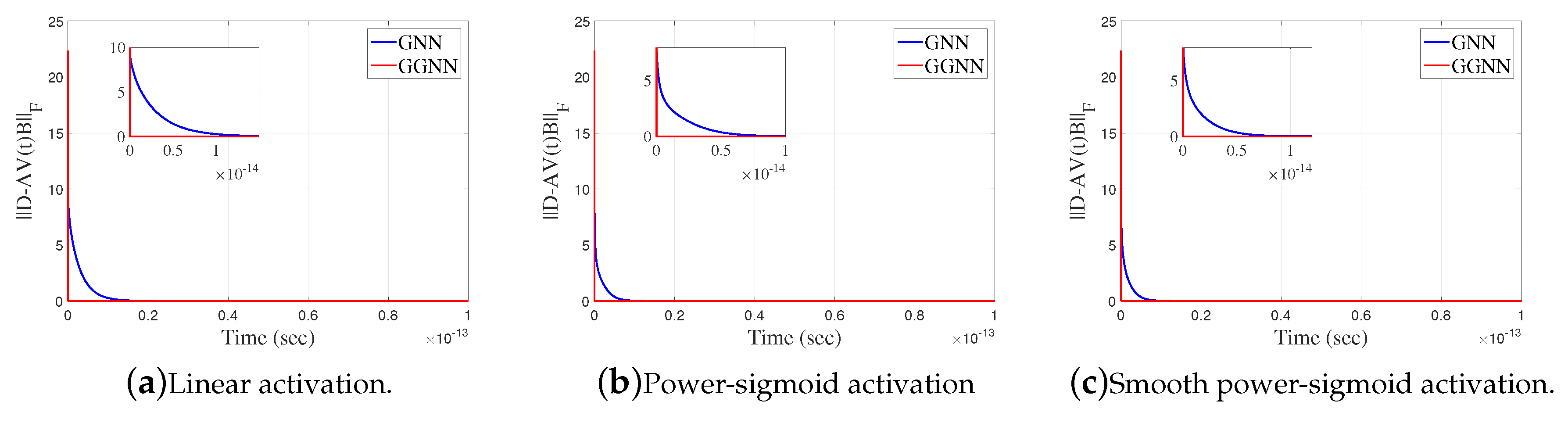
Figure 9.
Frobenius norm of error matrix of GGNN against GNN in Example 4.4.
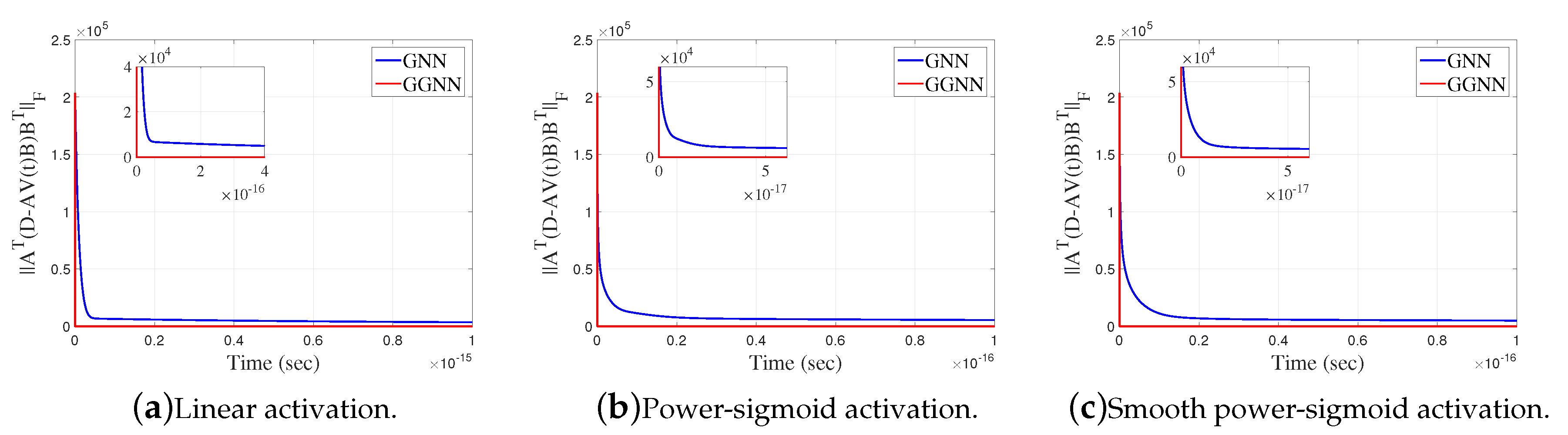
Figure 10.
Electrical Network.
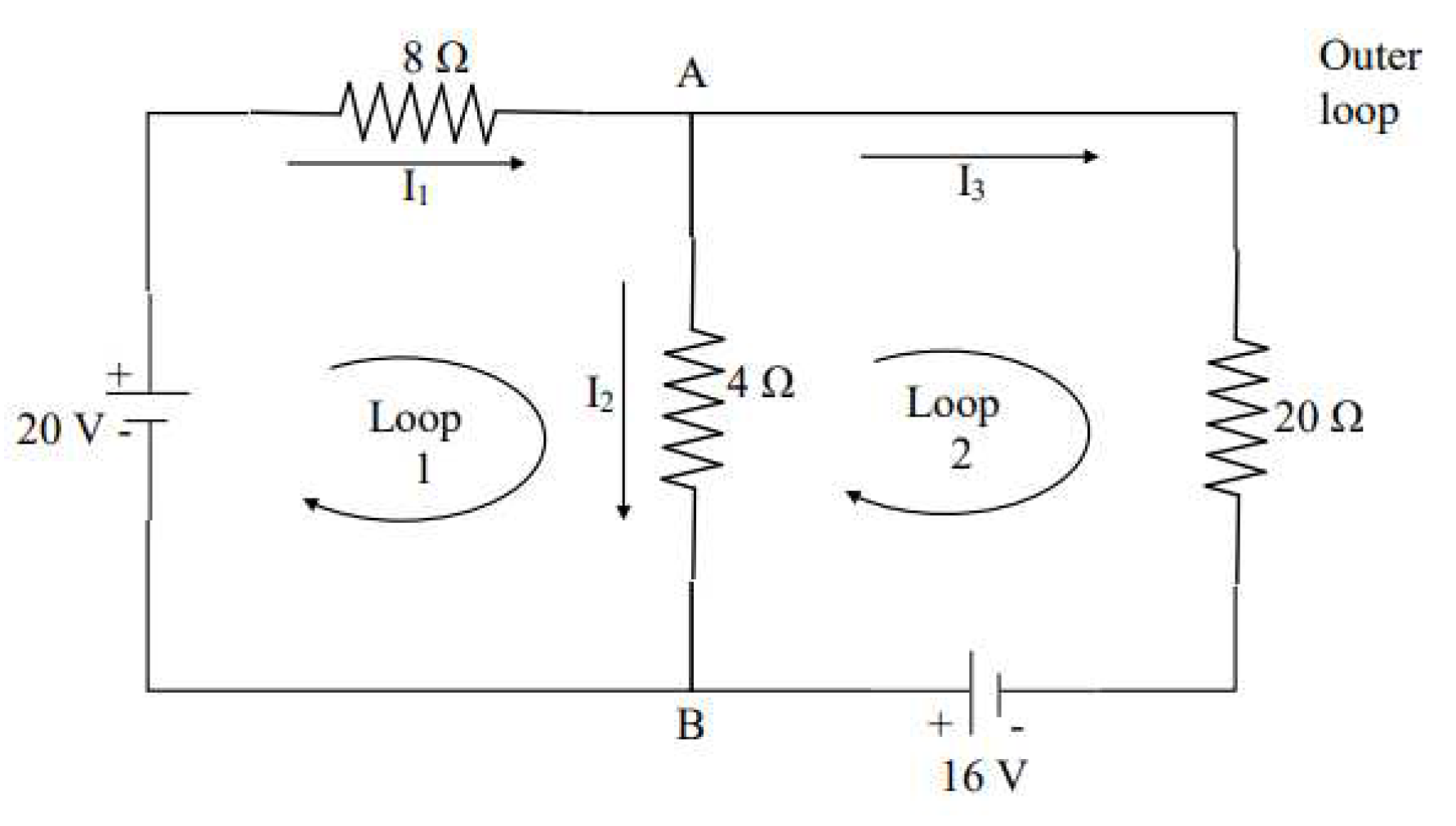
Figure 11.
Frobenius norm of error of GGNN against GNN for the electrical network application.
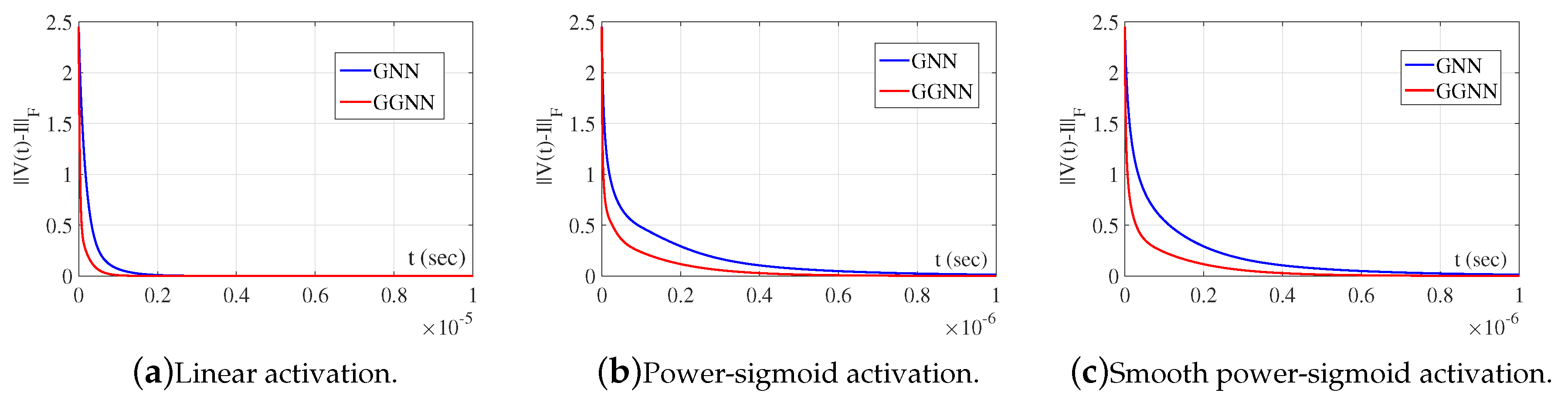
Figure 12.
Elementwise convergence trajectories of the GGNN network in electrical network application.
Figure 12.
Elementwise convergence trajectories of the GGNN network in electrical network application.
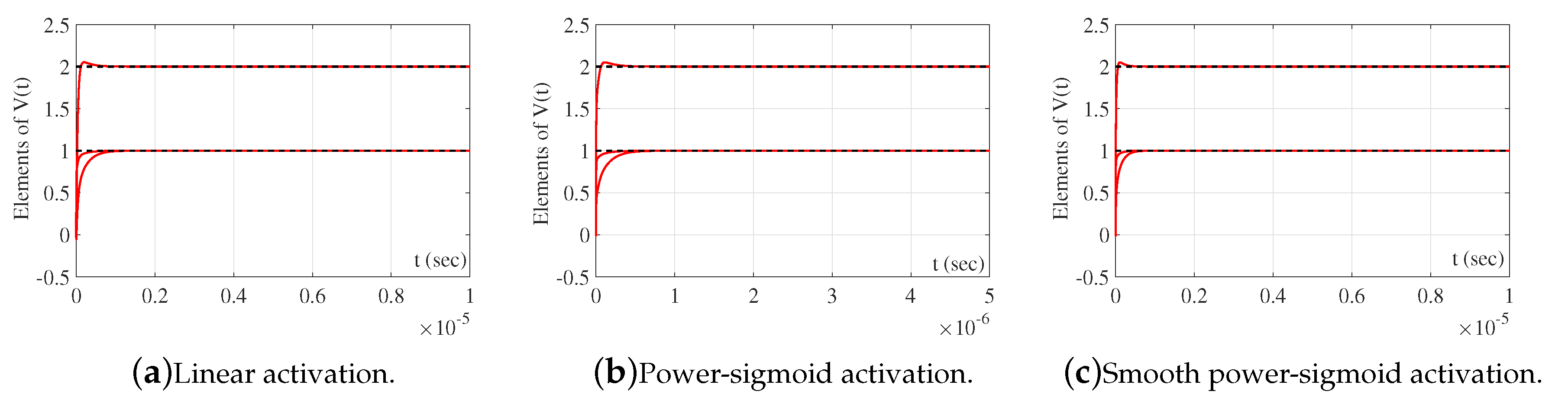
Figure 13.
Simulink implementation of (24).
Figure 13.
Simulink implementation of (24).
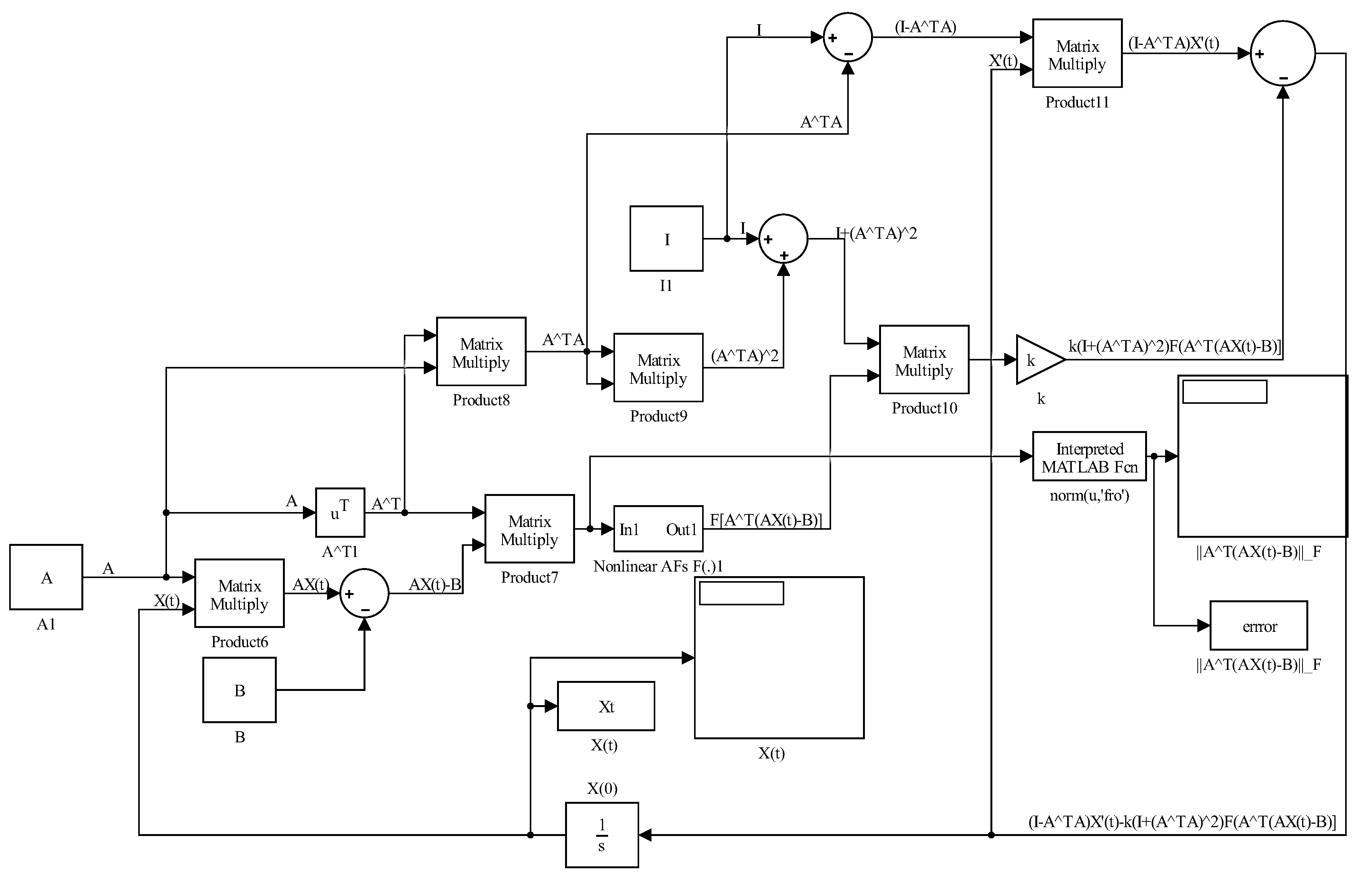
Figure 14.
Elementwise convergence trajectories of the HGZNN network in Example 6.1.
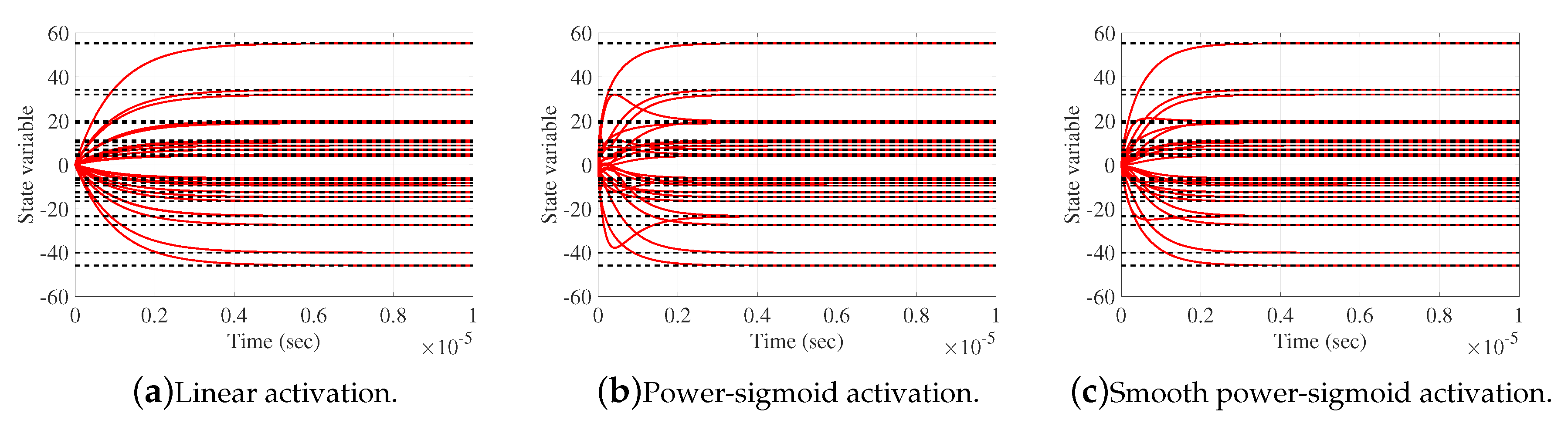
Figure 15.
Frobenius norm of error matrix of HGZNN against GGNN and GZNN in Example 6.1.
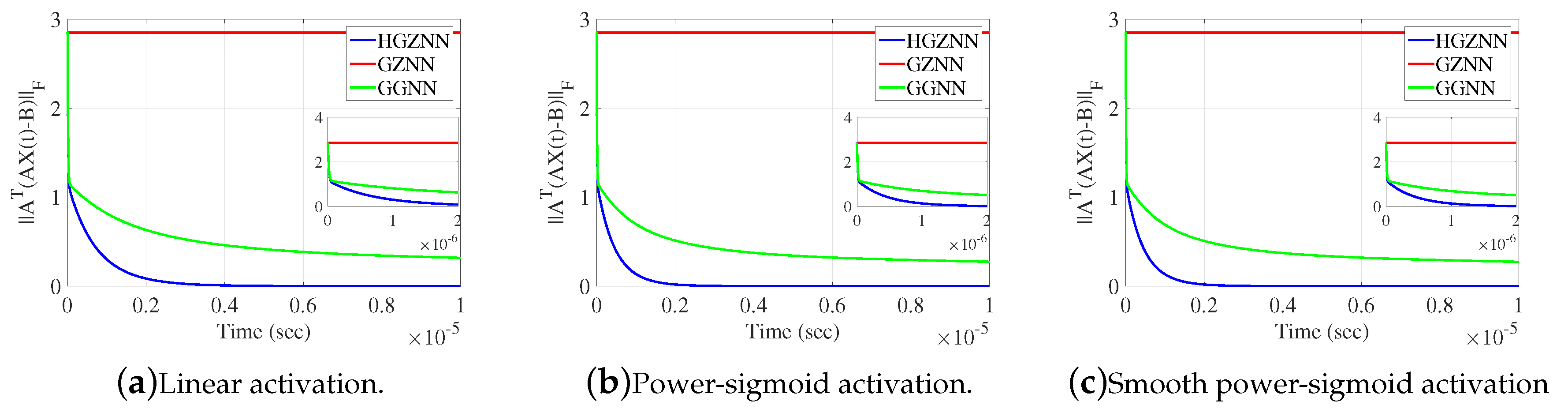
Figure 16.
Frobenius norm of the residual matrix of HGZNN against GGNN and GZNN in Example 6.1.

Figure 17.
Elementwise convergence trajectories of the HGZNN network in Example 6.2.
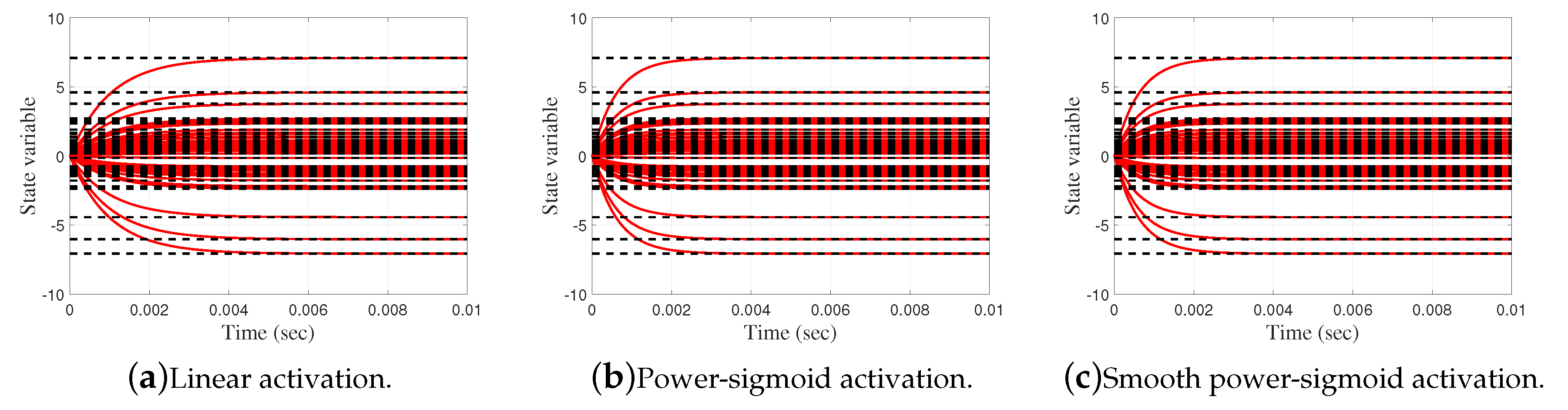
Figure 18.
Frobenius norm of error matrix of HGZNN against GGNN and GZNN in Example 6.2.
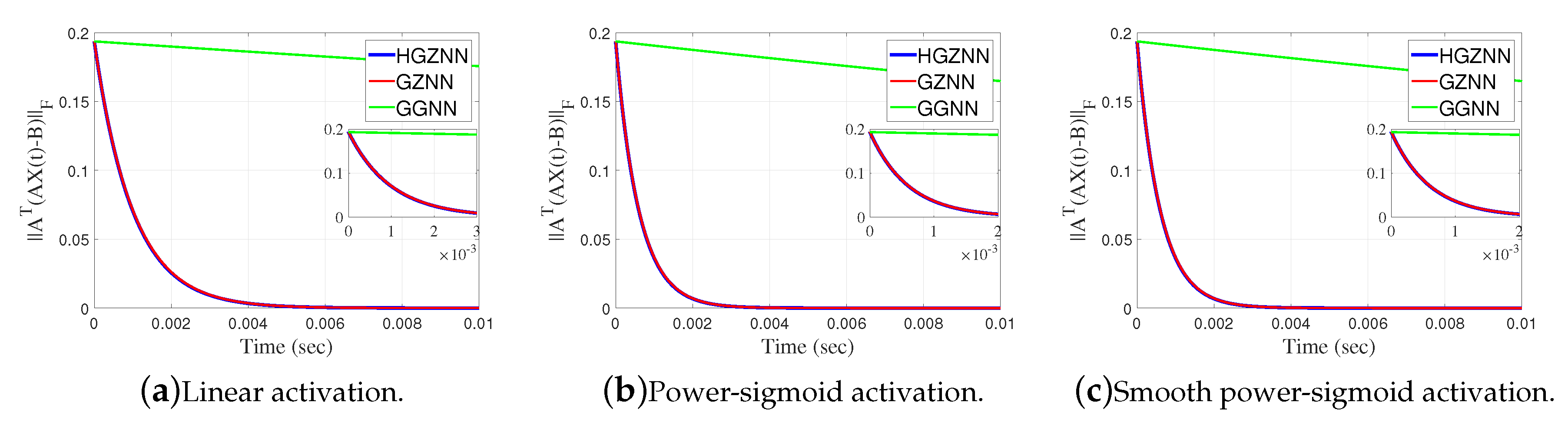
Figure 19.
Frobenius norm of error matrix of HGZNN against GGNN and GZNN in Example 6.2.
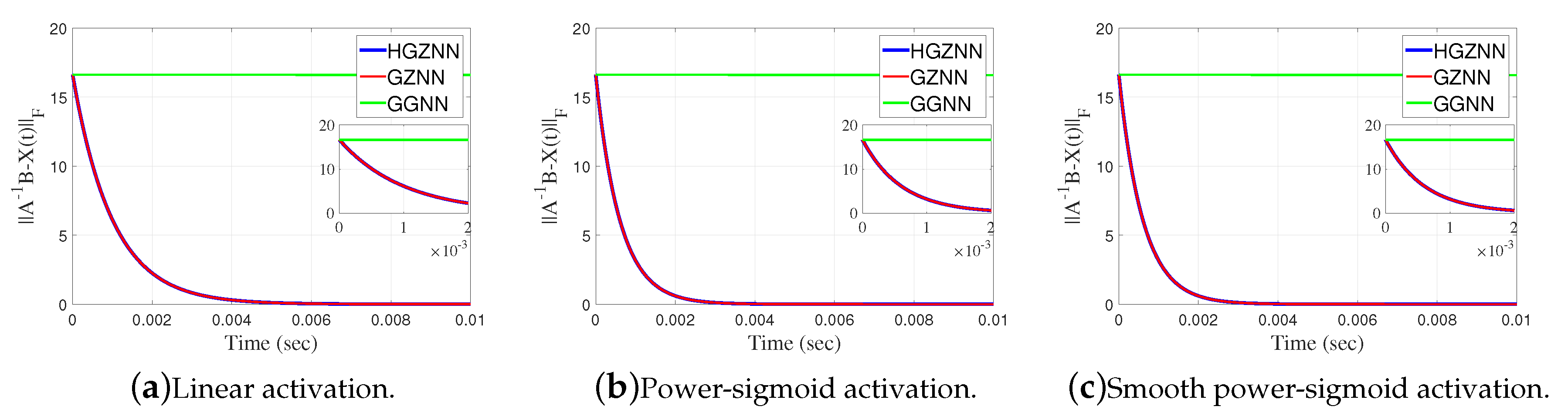

Table 1.
Input data.
| Matrix A | Matrix B | Matrix D | Input and residual norm | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| m | n | p | q | m | q | ||||||
| 10 | 8 | 8 | 9 | 7 | 7 | 10 | 7 | 7 | 0.5 | 1.051 | |
| 10 | 8 | 6 | 9 | 7 | 7 | 10 | 7 | 7 | 0.5 | 1.318 | |
| 10 | 8 | 6 | 9 | 7 | 5 | 10 | 7 | 7 | 0.5 | 1.81 | |
| 10 | 8 | 6 | 9 | 7 | 5 | 10 | 7 | 5 | 5 | 2.048 | |
| 10 | 8 | 1 | 9 | 7 | 2 | 10 | 7 | 1 | 5 | 2.372 | |
| 20 | 10 | 10 | 8 | 5 | 5 | 20 | 5 | 5 | 5 | 1.984 | |
| 20 | 10 | 5 | 8 | 5 | 5 | 20 | 5 | 5 | 5 | 2.455 | |
| 20 | 10 | 5 | 8 | 5 | 2 | 20 | 5 | 5 | 1 | 3.769 | |
| 20 | 10 | 2 | 8 | 5 | 2 | 20 | 5 | 2 | 1 | 2.71 | |
| 20 | 15 | 15 | 5 | 2 | 2 | 20 | 2 | 2 | 1 | 1.1 | |
| 20 | 15 | 10 | 5 | 2 | 2 | 20 | 2 | 2 | 1 | 1.158 | |
| 20 | 15 | 10 | 5 | 2 | 1 | 20 | 2 | 2 | 1 | 2.211 | |
| 20 | 15 | 5 | 5 | 2 | 1 | 20 | 2 | 2 | 1 | 1.726 | |
Table 2.
Experimental results based on data presented in Table 1
Table 2.
Experimental results based on data presented in Table 1
| (GNN) | (GGNN) | (GNN) | (GGNN) | CPU(GNN) | CPU(GGNN) |
|---|---|---|---|---|---|
| 1.393 | 0.03661 | 22.753954 | |||
| 1.899 | 0.03947 | 15.754537 | |||
| 2.082 | 0.00964 | 17.137916 | |||
| 2 | 2.003e-15 | 21.645386 | |||
| 2.288e-14 | 9.978e-15 | 21.645386 | 13.255210 | ||
| 2.455 | 2.455 | 1.657e-11 | 1.693e-14 | 50.846893 | 19.059385 |
| 3.769 | 3.769 | 6.991e-11 | 4.071e-14 | 42.184748 | 13.722390 |
| 2.71 | 2.71 | 1.429e-14 | 1.176e-14 | 148.484258 | 13.527065 |
| 1.1 | 1.1 | 1.766e-13 | 5.949e-15 | 218.169376 | 17.5666568 |
| 1.158 | 1.158 | 2.747e-10 | 2.981e-13 | 45.505618 | 12.441782 |
| 2.211 | 2.211 | 7.942e-12 | 8.963e-14 | 194.605133 | 14.117241 |
| 1.726 | 1.726 | 8.042e-15 | 3.207e-15 | 22.340501 | 11.650829 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



