
Submitted:
06 November 2023
Posted:
07 November 2023
You are already at the latest version
Abstract
The accurate classification of landfill waste diversion plays a critical role in efficient waste management practices. Traditional approaches, such as visual inspection, weighing and volume measurement, and manual sorting, have been widely used but suffer from subjectivity, scalability, and labour requirements. In contrast, machine learning approaches, particularly Convolutional Neural Networks (CNN), have emerged as powerful deep learning models for waste detection and classification. This paper analyses VGG-16, InceptionResNetV2, DenseNet121, Inception V3, and MobileNetV2 models to classify real-life waste when trained on pristine and unadulterated materials, versus samples collected at a landfill site. When training on DiversionNet, the unadulterated material dataset with labels required for landfill modelling, classification accuracy was limited to 49.69% in the real environment. Using real-world samples in the newly formed RealWaste dataset showed that practical applications for deep learning in waste classification is possible, with Inception V3 reaching 89.19% classification accuracy on the full spectrum of labels required for accurate modelling.
Keywords:
classification
; machine learning
; deep learning
; convolution neural networks
; dataset
; landfill waste
; waste management
; sustainability
1. Introduction
Solid waste encompasses all materials that are produced as a result of human and societal activities but have lost their utility or desirability [1]. This waste can be the items belonging to three primary groups: i) recyclable inorganics fit for repurposing i.e., plastics, metals; ii) divertible organics from which energy and fertilizer can be derived i.e., food and vegetation; and iii) inorganic materials requiring landfill i.e., ceramics, treated wood. Improper management of the disposal of waste poses significant risks to environmental sustainability and human health, resulting from toxic wastewater byproducts and the global warming potential of methane in landfill gas [2,3,4]. For example, in 2020, 3.48% of global greenhouse gas production was attributed to the waste disposal sector, with the methane component of landfill gas accounting for 20% of worldwide methane emissions in the following year [5,6]. The chemical composition and production of both wastewater and landfill gases are heavily dependent on the organic content within the waste processed, with significant variations arising in the presence of food and vegetation materials [7,8,9,10]. Detection of the waste types under meticulously refined material classes in both an accurate and timely manner is therefore essential in sustainable waste management, by ensuring accountability for both seasonal variations and recycling uptake [11,12,13].
In the literature, various approaches for the detection and classification of solid waste have been explored, including both traditional and machine learning methods. Traditional approaches, such as visual inspection, weighing and volume measurement, and manual sorting, have been widely used for waste detection. Visual inspection relies on the expertise of human operators to visually assess and classify waste based on its appearance. Weighing and volume measurement techniques quantify waste by measuring its weight or volume, providing valuable information for waste estimation and management planning. Manual sorting, commonly employed in recycling facilities, involves the physical separation of different types of waste by workers. While these traditional approaches have their utility, they are limited by subjectivity, scalability, and labor requirements.
Machine learning approaches, on the other hand, have emerged as powerful tools in waste detection and classification. Image processing and computer vision techniques, combined with machine learning algorithms, enable automated waste detection and classification based on visual characteristics. These approaches analyse images or video footage to identify and categorize different types of waste, enhancing waste sorting, recycling efforts, and landfill operations [14,15,16,17,18]. As an alternative to visual analytics, sensor-based systems that are integrated with machine learning algorithms utilize Internet of Things (IoT) devices or embedded sensors in waste bins and collection vehicles to detect abnormalities belonging to material types that are not allowed in the given waste stream [19]. Real-time analytics provided by these systems offer valuable insights for decision-making in waste management.
One prominent deep learning architecture used in waste classification is the Convolutional Neural Network (CNN). CNNs are specifically designed for processing and analyzing visual data, making it an ideal choice for classifying landfill waste diversion. Landfills contain a wide range of waste materials, and accurately categorizing them is essential for effective waste management. By leveraging CNNs, the classification process can be automated, significantly improving the efficiency and accuracy of waste diversion strategies such as recycling, composting, and proper disposal. CNNs excel at image analysis and feature extraction, allowing them to capture intricate details and patterns from waste images. The convolutional layers in CNNs are able to identify edges, textures, and other relevant characteristics, enabling the network to learn and leverage these features for accurate waste classification. Pooling layers nested throughout the architecture down-sample produced feature maps, allowing models to generalize object specific characteristics into differing contexts. The hierarchy of the aforementioned layers enables models to extract low level features early in the architecture and derive semantical information in later layers forming the basis of classifications at the output (Figure 1).
Despite the promising potential of machine learning approaches, they also present challenges. Sensor-based systems may be limited in their ability to detect all material types, providing no information on other items present in the waste stream, which can affect their suitability for comprehensive waste classification. Image processing and computer vision techniques heavily rely on the quality and representativeness of their datasets, and biases in the dataset labels will impact the accuracy of trained models in real-world waste environments. Furthermore, the current state of deep learning models used in waste classification often focuses on a limited number of waste material classes, failing to adequately represent the full range of detectable material types found in real-world waste scenarios. Additionally, these models often rely on object representations that assume the pristine forms of materials, disregarding the diverse and degraded states commonly observed in waste materials. These limitations indicate the need for more diverse and comprehensive datasets that accurately represent the appearance and characteristics of waste materials.
Based on the above limitations, this paper proposes a comprehensive dataset called RealWaste that covers various classes of landfilled waste for sustainable waste management. Furthermore, 5 deep learning models are applied over RealWaste and other existing datasets and we provide a critical analysis over the results to see the impact of quality of the dataset and more detailed classes of the waste. Hence, the main contributions of this paper are as follows:
- We created the first dataset, RealWaste, to comprehensively cover more classes of landfilled waste required for sustainable waste management. It includes three primary material types for divertible organics, recyclable inorganics, and waste, with meticulously refined labels for food, vegetation, metal, glass, plastic, paper, cardboard, textile trash, and miscellaneous trash. There are 4808 samples captured with the resolution of 524×524 from the Whyte’s Gully Waste and Resource Recovery Centre’s landfill site located in Wollongong, New South Wales, Australia, where waste items from municipal waste collection comingle and contaminate one another.
- The evaluation and analysis of five deep learning models over the RealWaste dataset and the datasets existing in the literature. The selection of models used has been intentionally made broad with respect to their design motivations to draw generalised outcomes on the larger input image resolution. Moreover, our objective is to evaluate the performance of the model when type of material over different items is important to be detected. The outcome shows that waste detection is indeed achievable for the meticulously refined classes required in sustainable waste management, with every model reaching above 85% classification accuracy, with the best performer at 89.19%.
2. Related Work
The impact of the training phase of a CNN model on performance is well-recognized. Overfitting occurs when datasets lack diversity in the object features present in labels, causing models to become proficient at classifying training data but lose the ability to generalize label features. Deep learning often faces the challenge of small datasets, which makes it difficult to effectively model the problem domain. To address this, large-scale datasets with thousands of labels and millions of images have been assembled, such as ImageNet by Russakovsky et al. [20]. Training models on such datasets with diverse features has led to the exploration of heterogenous transfer learning in deep learning applications. This supposition has been extensively investigated in the literature. For example, He et al. [21] examined the potential of heterogeneous transfer learning in hyperspectral image classification. Their novel heterogenous approach outperformed four popular classifiers significantly across four datasets, with an improvement of 5.73% in accuracy compared to the closest performer on the Salinas dataset. Heterogenous transfer learning becomes a vital consideration for applications on smaller datasets to ensure success.
The relationship between dataset labels and size, and the depth and width of fully-connected layers has been studied by Basha et al. [22]. Their findings indicate that, regardless of dataset size, fully-connected layers require fewer parameters in deeper networks, while shallower architectures require greater width to achieve the same results.
The connections and organization of hidden layers within networks have also been analyzed by Sharma et al. [23]. They compared three popular architectures: AlexNet, GoogLeNet, and ResNet-50. The performance accuracy on the CFIR-100 dataset revealed significant differences, with AlexNet scoring 13.00%, GoogLeNet scoring 68.95%, and ResNet-50 scoring 52.55%. These results demonstrate that deeper networks are not always the best option, and that connections and network layouts are often more important for the specific task at hand.
Data preprocessing and augmentation play a crucial role in deep learning. Data augmentation, which generates new images from existing samples, is particularly important when training on smaller datasets. It improves a model's generalization capacity and learnable features by increasing the diversity of training data. Shijie et al. [24] evaluated the effectiveness of different data augmentation techniques on the AlexNet model trained on the CFIR-10 and ImageNet datasets. Geometric and photometric transformations were found to boost performance, with geometric transformations performing the best. This result was confirmed by Zhang et al. [25] in their study on leaf species classification. Geometric transformations outperformed photometric transformations across the same model and dataset, indicating their effectiveness in improving performance and generalization.
Data augmentation also helps address the performance degradation caused by imbalanced datasets. Lopez de la Rosa et. al. [26] explored this issue in semiconductor defect classification. By applying geometric augmentations to scale an imbalanced dataset, the study achieved a significant improvement in the mean F1-score, demonstrating the effectiveness of geometric augmentation in handling imbalanced datasets.
Image resolution is another factor that can affect feature extraction. Sabottke and Spieler [27] investigated the impact of resolution on radiography classifications. Higher resolutions provided finer details for feature extraction and led to increased classification accuracy. However, tradeoffs between smaller batch sizes and higher resolutions had to be considered due to hardware memory constraints. The study highlights the importance of choosing the optimal resolution for specific applications.
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC), introduced by Russakovsky et al. [20], has been a driving force in advancing CNNs. Models developed for the ILSVRC have tackled challenges related to dataset size and real-world applicability. For example, the AlexNet model, developed by Krizhevsky et al. [28] to win the ILSVRC in 2012, addressed the computational time requirements by spreading its architecture across two GPUs for training. Subsequent advancements, such as the VGG family of architectures proposed by Simonyan and Zisserman [29], GoogLeNet (Inception V1) developed by Szegedy et al. [30], and ResNet architectures developed by He et al. [31], pushed the depths of networks even further and achieved high object detection and classification accuracies. DenseNet architectures, as described by Huang et al. [32], offered an alternative approach by connecting convolution and pooling layers into dense blocks. InceptionResNet, combining inception blocks with residual connections and developed by Szegedy et al. [33], demonstrated improved convergence and lower error rates compared to the Inception and ResNet families of models from which it was inspired. MobileNetV2, developed by Sandler et al. [34], addressed the computational complexity issue by replacing standard convolution layers with depth wise convolutions, enabling processing on hardware-restricted systems.
In waste classification literature, various models from the aforementioned architectures have been implemented and evaluated on the TrashNet dataset [35]. The combination of a Single Shot Detector (SSD) for object detection and a MobileNetV2 model trained via transfer learning achieved high accuracy, outperforming other models [14]. Moreover, optimization techniques applied to baseline models, such as the Self-Monitoring Module (SMM) for ResNet-18, showed significant improvements in performance [15]. However, studies have shown that under the right conditions, popular baseline models can achieve similar or even better results compared to more complex implementations [16,17]. Nonetheless, the major issue in the literature is the lack of organic labels in the TrashNet dataset, limiting its suitability for waste auditing and landfill modeling.
To address the limitations of the TrashNet dataset, Liang and Gu [18] proposed a multi-task learning (MTL) architecture that localized and classified waste using the WasteRL dataset. Their specialized network achieved high accuracy compared to other architectures. However, the dataset's labeling does not capture the spectrum of waste required for accurate modeling, as the absence of organic breakdown and inorganic recyclable breakdown limits its practical application.
In summary, the related work has investigated various aspects of deep learning, including the impact of dataset size, network architecture, data preprocessing and augmentation, image resolution, and the influence of the ILSVRC on CNN advancements. The studies have provided insights into improving performance, handling imbalanced datasets, and addressing computational constraints. However, the limitations in the datasets and the lack of comprehensive labeling in waste auditing studies remain challenges for practical applications in waste composition data and landfill modeling.
3. Methodology
This section has been structured towards addressing the major gap in the waste classification literature, which pertains to the limitations in datasets and the lack of comprehensive labeling in waste auditing studies [14,15,16,17,18]. To overcome these challenges and improve the accuracy and practicality of waste classification models, we collect and preprocess data to be utilized by different models. Hence, we aim to i) evaluate the effectiveness of pristine, unadulterated material datasets for training models to classify waste in the real-environment; ii) assess the impacts of training on real waste samples to compare the dataset approaches and reveal the suitability of each; and iii) determine the optimal model for waste classification in the live setting.
An experimental study has been conducted to analyse the performance of five popular CNN models, on labelling waste across two datasets. Specifically, VGG-16 has been selected for its shallow design [29], DenseNet121 for pushing layer depth [32], Inception V3 for its grouping of hidden layers [30], InceptionResNet V2 for combining techniques [33], and finally MobileNetV2 for its lightweight design [34].
In terms of dataset, the first dataset is called DiversionNet that has been assembled by combining the TrashNet dataset with elements from several opensource datasets to populate the labels which TrashNet lacks and represent the approach in the literature largely based on pristine and unadulterated objects for model training [14,15,16,17,18]. The second dataset is called RealWaste and we collected the samples during the biannual residential waste audit at the Wollongong Waste and Resource Recovery Centre’s landfill. The samples were taken from bins of municipal, recycling, and organic waste streams. To clearly demonstrate the quality of the two datasets, DiversionNet relies on object samples in their pristine and unadulterated forms, shown in Figure 2a. Conversely, RealWaste is made up of items arriving at landfill, where comingling occurs between material types and objects undergo structural deformation, shown in Figure 2b. The comingling of materials is attributed to the presence of organic waste, where its decomposition and remains in food packaging contaminate other items.
For evaluation purposes, a test dataset has also been assembled from the waste audit samples prior to the curation of RealWaste, with images selected at random. Table 1 provides insights into the distribution of images across different waste categories and highlight potential imbalances or variations within the datasets. For instance, in the DiversionNet dataset, the label with the highest image count is Paper (594 images), followed by Plastic (482 images) and Glass (501 images). On the other hand, the label with the lowest image count in the DiversionNet dataset is Miscellaneous Trash (290 images). These variations in image counts suggest that certain waste categories may be overrepresented or underrepresented in the dataset.
3.1. Data Preprocessing
From the findings of the literature, two strategies have been implemented to treat the datasets before commencing training: relatively large image sizes; and data augmentations.
3.1.1. Image Size
Each dataset has been scaled to 524×524 image resolutions to better distinguish the finer object features and reach better classification accuracies [27]. The selection was made to accommodate several factors present in waste classification: the comingled state of material types; transparent objects in plastic and glass classes; and similarities between specific objects (e.g., glass and plastic bottles). Although the resolution is relatively high, the smaller datasets and mini-batch sizes meet hardware memory requirements, and transfer learning, the process of initializing models with pretrained weights from generalized classification tasks, allows for manageable training times.
3.1.2. Data Augmentation
Data augmentation methods have been applied to the training datasets, using Python and the Augmentor library. Two sets of augmentations outlined in Table 2 have been selected and applied to each image respectively, tripling the total number of images within each training dataset.
Both sets from Table 2 consist of a combination of geometric transformations and are aimed at reducing the effects of overfitting to the training dataset. Geometric transformations have been selected due to their enhancements on deep learning vision-based tasks [14,15,16,25] and effectiveness on imbalanced datasets [26]. Techniques were combined to further increase performance as found in [24].
Each combination contains one transformation on the orientation of the object to provide its features in a different context (horizontal flipping and rotation) and another distorting objects to increase the feature space diversity, to account for the varied structural state of objects received at landfill (elastic distortion and shear). Samples have been included for an original image, elastic distortion and horizontal flipping, and rotation and shearing in Figure 3a,b,c respectively.
4. DiversionNet versus RealWaste
This section details the results achieved by the five models over DiversionNet and RealWaste during training and testing. Further to this, the best performing model and dataset combination has been considered with respect to its confusion matrix to reveal greater insights on deep learning waste classification.
4.1. Model Training
To analyse the learning behaviour of each model, the training and validation accuracies have been plotted against the epoch span in Figure 4, Figure 5, Figure 6, Figure 7 and Figure 8.
The convergence behaviour suggests that the authentic waste materials in RealWaste present a more diverse and complex feature space than their pristine counterparts in DiversionNet, as training and validation accuracies were greater in every model when trained on the latter. Furthermore, the differences between the metrics increased under RealWaste training by 4% for VGG-16 in Figure 4a,b, 3% for DenseNet121 in Figure 5a,b, 4% for Inception V3 in Figure 6a,b, 5% for InceptionResNet V2 in Figure 7a,b, and 3% for MobileNetV2 in Figure 8a,b. Aside from the differences between the training datasets, the individual performance of models exposes insights on deep learning waste classifiers. On both datasets, VGG-16 performed the worst reaching lower training and validation accuracies compared to the deeper models. Although increasing network depth is no sure-fire way to success [23], this outcome suggests that a certain degree is required for accurate waste classification due to complex feature space present in waste material.
4.2. Testing Performance
The performance of the models trained on DiversionNet and RealWaste has been evaluated on the testing dataset with the results presented in Table 3.
The results from Table 3 are very similar to the training performance of the models. Both Inception V3 and DenseNet121 models achieved 89.19% classification accuracy when trained on RealWaste, however the former performed the best by achieving the highest results in the other metrics. Specifically, the 91.34% precision, 87.73% recall, and 90.25% F1-score reached by Inception V3 were more than 0.5% greater than the next closest DenseNet121 model for each metric. With respect to accuracy between RealWaste and DiversionNet training in Table 3, VGG-16 showed a 58.83% improvement, 48.86% in DenseNet121, 31.50% in Inception V3, 42.62% in InceptionResNet V2, and finally, 60.50% in MobileNetV2.
In every single case from Table 3, the RealWaste trained networks greatly outperformed their DiversionNet counterparts. Any model trained on data from a certain sample space has a bias towards classification within said sample space. The significantly greater performance in every metric shows the negative impact from the training samples collected outside the authentic waste environment. The results show that the learning imparted by the pure objects is far too biased for their characteristics to be generalized in the real-life landfill setting, indicating that waste objects possess a much more complex feature space.
In both datasets detailed by Table 3, VGG-16 performed the worst with 26.82% classification accuracy when trained on DiversionNet and 85.65% on RealWaste. Like the training results, this can be attributed to the lack of layer depth within the architecture. MobileNetV2 performed well on RealWaste training with 88.15% accuracy, but like VGG-16, rather poorly on DiversionNet with 27.65%. Interestingly however, the difference in classification accuracy between the worst performing shallow and lightweight designs compared to the best performing Inception V3 model were much larger when trained on DiversionNet, rather than RealWaste; with around 20% difference in the former case, and only 4% in the latter. Even though the results have indicated that the pristine and unadulterated objects within DiversionNet misrepresent real-life waste conditions, the deeper, more complex models are shown to be better at generalizing the available features to the live environment.
With respect to the individual datasets in Table 3, the remaining DenseNet121 and InceptionResNet V2 architectures performed well relative to the others, with classification accuracies of 40.33% and 44.70% on DiversionNet, and 89.19% and 87.32% on RealWaste respectively. These classifications accuracies along with the results of Inception V3 give some credit towards increased layer depth and complexity being required for waste classification in real-life conditions. However, MobileNetV2 outperformed InceptionResNet V2 in the RealWaste experiment group, meaning that network specific classification techniques outweigh this factor, as found in general deep learning applications [23]. Inception V3 outperforming InceptionResNet V2 furthers this finding, where the latter combines the inception block design of the former with residual connections. In the past, the more complex InceptionResNet V2 has been shown as the better out of the two [33], however, the model’s ability for classification within the waste feature space has proven otherwise.
Aside from raw accuracy, the RealWaste trained models performed extremely well for precision, recall, and F1-scores in Table 3. The DiversionNet trained models performed significantly worse, furthering the indication that waste classification requires training samples from the real environment. One generalisation that can be made between both experiment groups, however, is the tendency towards a higher precision then recall. The difference on average for RealWaste was 3.74% and 8.89% for DiversionNet. In practice, this shows that models will tend to minimise the false positives rather than false negatives. In the case of RealWaste, this is less of an issue given the smaller difference and high F1-scores showing a good balance, however, it is still notable. Minimising the number of false negatives to increase recall is the more desirable outcome. Classifiers need to be able to predict the correct label for any object input to the system, given the almost endless diversity in the actual objects belonging to each waste label.
4.3. Analysis
To gain a deeper understanding of its classification performance, a detailed analysis was conducted using the confusion matrix, as shown in Figure 9. The confusion matrix provides insights into the model's performance in correctly classifying different waste categories and reveals the presence of false negatives and false positives.
Out of all the labels in Figure 9, the confusion between classes was most prominent with miscellaneous trash objects. The accuracy for this category was only 74.00%, indicating a significant challenge in correctly identifying these objects. The class encountered 13 false negatives, where actual miscellaneous trash items were mislabelled, and eight false positives, where other waste types were incorrectly classified. The diverse and sparse feature space of miscellaneous trash, characterized by different shapes, textures, and colours, makes it difficult to encode identifiable features into the convolution layers. This issue is somewhat unavoidable due to the label's purpose of containing objects that do not fit into any other material types. However, the poor performance highlights the need for further refinement in labelling objects belonging to the miscellaneous trash category to decrease feature space diversity and improve overall accuracy.
The cardboard label also exhibited relatively poorer performance, with only 80.44% of the total sample size correctly labelled. Analysis of the labels responsible for false negatives and positives revealed confusion with other waste categories. Samples from the metal, paper, and plastic classes, which can possess branding and graphical designs similar to certain cardboard products, caused mislabelling. This confusion is evident in Figure 10, where cardboard was labelled as metal, paper, or plastic. The lower image count of cardboard compared to other labels suggests that increasing the number of samples could help the model learn better representations and prevent misclassifications.
Similar confusion was observed between the metal and plastic labels. The model correctly classified 92.41% of the total metal objects but mislabelled four objects as plastic. The plastic label itself performed slightly poorer, accurately classifying 84.78% of the actual objects in its category. Six items were mislabelled as metal, and one item was mislabelled as cardboard. The similarities between certain objects in the plastic, metal, and cardboard waste categories pose challenges for the model, indicating the need for better differentiation between these materials.
Interestingly, the paper label demonstrated the best performance overall, with 98.18% accuracy in correctly identifying paper objects. Only a single image was mislabelled as cardboard. This superior performance may be attributed to the distinctive structural properties of paper, which can become more deformed compared to other materials, providing distinct features for differentiation.
The plastic class encountered confusion with the glass label, where five plastic objects were mislabelled as glass. This confusion arises from the fact that plastic and glass containers share a similar feature space, particularly with transparent objects, as shown in Figure 11a,b. The glass label achieved 90.48% accuracy, with two false negatives occurring with the metal and plastic classes. The misclassifications with the metal class are interesting as both false negative objects contain a small amount of metal material, causing confusion due to their transparency, as seen in Figure 12a,b. This transparency issue poses a significant challenge for practical applications.
The final inorganic material type, textile trash, achieved an accuracy of 93.75%. Although the model performed well, two false negatives occurred with the miscellaneous trash label. The decision to separate the textile and miscellaneous trash labels was motivated by the uniqueness of the textile feature space compared to miscellaneous trash. However, the limited number of images in the textile trash class may contribute to the false negatives. Increasing the number of samples could improve the model's differentiation between these labels.
Turning to the organic waste types, the food organics label performed second best overall, with 97.56% accuracy. Only a single false negative occurred, where a food organics item was mislabeled as miscellaneous trash, as shown in Figure 13a. The diverse feature space of miscellaneous trash may lead to false negatives for objects at the fringes of the food organics category. Similarly, the vegetation label, which shares similarities with food organics in terms of leafy green objects, achieved 95.45% accuracy. A single false negative occurred with the miscellaneous trash label, as shown in Figure 13b, again indicating the challenge of distinguishing objects at the edges of different waste categories. Figure 13c also shows a false negative, where a vegetation object was mislabelled as food.
Interestingly, no other false negatives or positives were encountered between food organics and vegetation objects with any of the other labels apart from miscellaneous trash. This indicates that the model can handle the compositing issue of organic waste materials when provided with sufficient feature space to learn from.
In summary, the analysis of the confusion matrix for the Inception V3 model trained on the RealWaste dataset reveals important insights into the strengths and weaknesses of waste classification. It highlights the challenges of correctly identifying miscellaneous trash objects due to their diverse feature space, the potential confusion between different waste materials such as cardboard, plastic, metal, and glass, and the superior performance of the model in distinguishing paper and vegetation objects. These findings underscore the need for refined labelling, increased sample sizes, and feature space differentiation to enhance the accuracy and practicality of waste classification models.
5. Conclusions
In this paper, we have shown that machine learning approaches based on CNN deep learning models provide a practical alternative to traditional manual methods for waste classification and are therefore suited towards alleviating the subjectivity, scalability, and labour requirement issues of the latter. The analysis of the VGG-16, InceptionResNet V2, DenseNet121, Inception V3, and MobileNetV2 models has proven deep learning’s capability for waste classification on the full spectrum of labels required for accurate modelling with classification accuracy reaching 89.19% on the Inception V3 architecture. However, these outcomes have revealed the requirement of sampling training data from the real-life environment, exposing the unsuitability of models relying on waste materials represented in their pristine and unadulterated states with classification accuracy being at best limited to 49.69%.
Authors contribution
S.S. contributed to programming, experiments, analysis, and writing. S.I. provided analyses and writing. R.R. conceptualized and supervised the project and reviewed. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The RealWaste dataset introduced by this study is available at https://github.com/sam-single/realwaste [36].
Conflicts of Interest
The authors declare no conflict of interest.
References
- D. Hoornweg and P. Bhada-Tata, "What a waste: a global review of solid waste management," Urban Dev Ser Knowl Pap, vol. 15, pp. 87-88, 01/01 2012.
- C. B. Öman and C. Junestedt, "Chemical characterization of landfill leachates – 400 parameters and compounds," Waste Management, vol. 28, no. 10, pp. 1876-1891, Jan. 2008. [CrossRef]
- N. J. Themelis and P. A. Ulloa, "Methane generation in landfills," Renewable Energy, vol. 32, no. 7, pp. 1243-1257, Jun. 2006. [CrossRef]
- A. Goverment, "National Greenhouse and Energy Reporting Regulations 2008," 2008. [Online]. Available: https://www.legislation.gov.au/Details/F2020C00673.
- Climate Watch Historical GHG Emissions (1990-2020), Washington, DC: World Resources Institute. [Online]. Available: https://www.climatewatchdata.org/ghg-emissions.
- "United Nations Environment Programme and Climate and Clean Air Coalition," Global Methane Assessment: Benefits and Costs of Mitigating Methane Emissions, Nairobi: United Nations Environment Programme, 2021.
- M. El-Fadel, E. Bou-Zeid, W. Chahine, and B. Alayli, "Temporal variation of leachate quality from pre-sorted and baled municipal solid waste with high organic and moisture content," Waste Management, vol. 22, no. 3, pp. 269-282, Jun. 2002. [CrossRef]
- R. V. Karanjekar et al., "Estimating methane emissions from landfills based on rainfall, ambient temperature, and waste composition: The CLEEN model," Waste Management, vol. 46, pp. 389-398, Dec. 2015. [CrossRef]
- F. B. D. l. Cruz and M. A. Barlaz, "Estimation of Waste Component-Specific Landfill Decay Rates Using Laboratory-Scale Decomposition Data," Environmental Science & Technology, vol. 44, no. 12, pp. 4722-4728, Jun. 2016. [CrossRef]
- U. Lee, J. Han, and M. Wang, "Evaluation of landfill gas emissions from municipal solid waste landfills for the life-cycle analysis of waste-to-energy pathways," Journal of Cleaner Production, vol. 166, pp. 335-342, Nov. 2017. [CrossRef]
- A. Kamran, M. N. Chaudhry, and S. A. Batool, "Effects of socio-economic status and seasonal variation on municipal solid waste composition: a baseline study for future planning and development," Environmental Sciences Europe, vol. 27, no. 1, p. 16, Aug. 2015. [CrossRef]
- F. Khan, W. Ahmed, and A. Najmi, "Understanding consumers’ behavior intentions towards dealing with the plastic waste: Perspective of a developing country," Resources, Conservation and Recycling, vol. 142, pp. 49-58, Mar. 2019. [CrossRef]
- K. Parizeau, M. von Massow, and R. Martin, "Household-level dynamics of food waste production and related beliefs, attitudes, and behaviours in Guelph, Ontario," Waste Management, vol. 35, pp. 207-217, Jan. 2015. [CrossRef]
- D. O. Melinte, A.-M. Travediu, and D. N. Dumitriu, "Deep Convolutional Neural Networks Object Detector for Real-Time Waste Identification," Applied Sciences, vol. 10, no. 20, p. 7301, Oct. 2020. [CrossRef]
- Q. Zhang et al., "Recyclable waste image recognition based on deep learning," Resources, Conservation and Recycling, vol. 171, p. 105636, Aug. 2021. [CrossRef]
- W.-L. Mao, W.-C. Chen, C.-T. Wang, and Y.-H. Lin, "Recycling waste classification using optimized convolutional neural network," Resources, Conservation and Recycling, vol. 164, p. 105132, Jan. 2021. [CrossRef]
- R. A. Aral, Ş. R. Keskin, M. Kaya, and M. Hacıömeroğlu, "Classification of TrashNet Dataset Based on Deep Learning Models," in 2018 IEEE International Conference on Big Data (Big Data), Dec. 2018, pp. 2058-2062. [CrossRef]
- S. Liang and Y. Gu, "A deep convolutional neural network to simultaneously localize and recognize waste types in images," Waste Management, vol. 126, pp. 247-257, May. 2021 2021. [CrossRef]
- O. I. Funch, R. Marhaug, S. Kohtala, and M. Steinert, "Detecting glass and metal in consumer trash bags during waste collection using convolutional neural networks," Waste Management, vol. 119, pp. 30-38, 2021/01/01/ 2021. [CrossRef]
- O. Russakovsky et al., "ImageNet Large Scale Visual Recognition Challenge," International Journal of Computer Vision, vol. 115, no. 3, pp. 211-252, Dec. 2015. [CrossRef]
- X. He, Y. Chen, and P. Ghamisi, "Heterogeneous Transfer Learning for Hyperspectral Image Classification Based on Convolutional Neural Network," IEEE Transactions on Geoscience and Remote Sensing, vol. 58, no. 5, pp. 3246-3263, 2020. [CrossRef]
- S. H. S. Basha, S. R. Dubey, V. Pulabaigari, and S. Mukherjee, "Impact of fully connected layers on performance of convolutional neural networks for image classification," Neurocomputing, vol. 378, pp. 112-119, Feb. 2020. [CrossRef]
- N. Sharma, V. Jain, and A. Mishra, "An Analysis Of Convolutional Neural Networks For Image Classification," Procedia Computer Science, vol. 132, pp. 377-384, Jan. 2018 2018. [CrossRef]
- J. Shijie, W. Ping, J. Peiyi, and H. Siping, "Research on data augmentation for image classification based on convolution neural networks," in 2017 Chinese Automation Congress (CAC), Oct. 2017, pp. 4165-4170. [CrossRef]
- C. Zhang, P. Zhou, C. Li, and L. Liu, "A Convolutional Neural Network for Leaves Recognition Using Data Augmentation," in 2015 IEEE International Conference on Computer and Information Technology; Ubiquitous Computing and Communications; Dependable, Autonomic and Secure Computing; Pervasive Intelligence and Computing, Oct. 2015, pp. 2143-2150. [CrossRef]
- F. López de la Rosa, J. L. Gómez-Sirvent, R. Sánchez-Reolid, R. Morales, and A. Fernández-Caballero, "Geometric transformation-based data augmentation on defect classification of segmented images of semiconductor materials using a ResNet50 convolutional neural network," Expert Systems with Applications, vol. 206, p. 117731, 2022/11/15/ 2022. [CrossRef]
- C. F. Sabottke and B. M. Spieler, "The Effect of Image Resolution on Deep Learning in Radiography," Radiology: Artificial Intelligence, vol. 2, no. 1, p. e190015, 2020. [CrossRef]
- A. Krizhevsky, I. Sutskever, and G. E. Hinton, "ImageNet classification with deep convolutional neural networks," Communications of the ACM, vol. 60, pp. 84 - 90, 2012. [CrossRef]
- K. Simonyan and A. Zisserman, "Very Deep Convolutional Networks for Large-Scale Image Recognition," CoRR, Sep. 2014. [CrossRef]
- C. Szegedy et al., "Going deeper with convolutions," in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2015, pp. 1-9. [CrossRef]
- K. He, X. Zhang, S. Ren, and J. Sun, "Deep Residual Learning for Image Recognition," CoRR, vol. abs/1512.03385, pp. 770-778, Dec. 2015. [CrossRef]
- G. Huang, Z. Liu, L. V. D. Maaten, and K. Q. Weinberger, "Densely Connected Convolutional Networks," in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jul. 2017, pp. 2261-2269. [CrossRef]
- C. Szegedy, S. Ioffe, V. Vanhoucke, and A. A. Alemi, "Inception-v4, inception-ResNet and the impact of residual connections on learning," presented at the Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, California, USA, 2017.
- M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L. C. Chen, "MobileNetV2: Inverted Residuals and Linear Bottlenecks," in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun. 2018, pp. 4510-4520. [CrossRef]
- M. Yang and G. Thung. TrashNet, Github, 2016. [Online]. Available: https://github.com/garythung/trashnet.
- S. Single, S. Iranmanesh, R. Raad, RealWaste, electronic dataset, Wollongong City Council, CC BY-NC-SA 4.0 https://github.com/sam-single/realwaste.
Figure 1.
Generic convolution neural network architecture and classification process.
Figure 2.
Training dataset samples from the unadulterated and practical environment approaches: (a) DiversionNet, sourced from [35]. (b) RealWaste (right).
Figure 2.
Training dataset samples from the unadulterated and practical environment approaches: (a) DiversionNet, sourced from [35]. (b) RealWaste (right).

Figure 3.
Data augmentations: (a) Original image. (b) Elastic distortion and horizontal flip. (c) Rotate and shear.
Figure 3.
Data augmentations: (a) Original image. (b) Elastic distortion and horizontal flip. (c) Rotate and shear.

Figure 4.
VGG-16 training performance: (a) DiversionNet dataset. (b) RealWaste dataset.
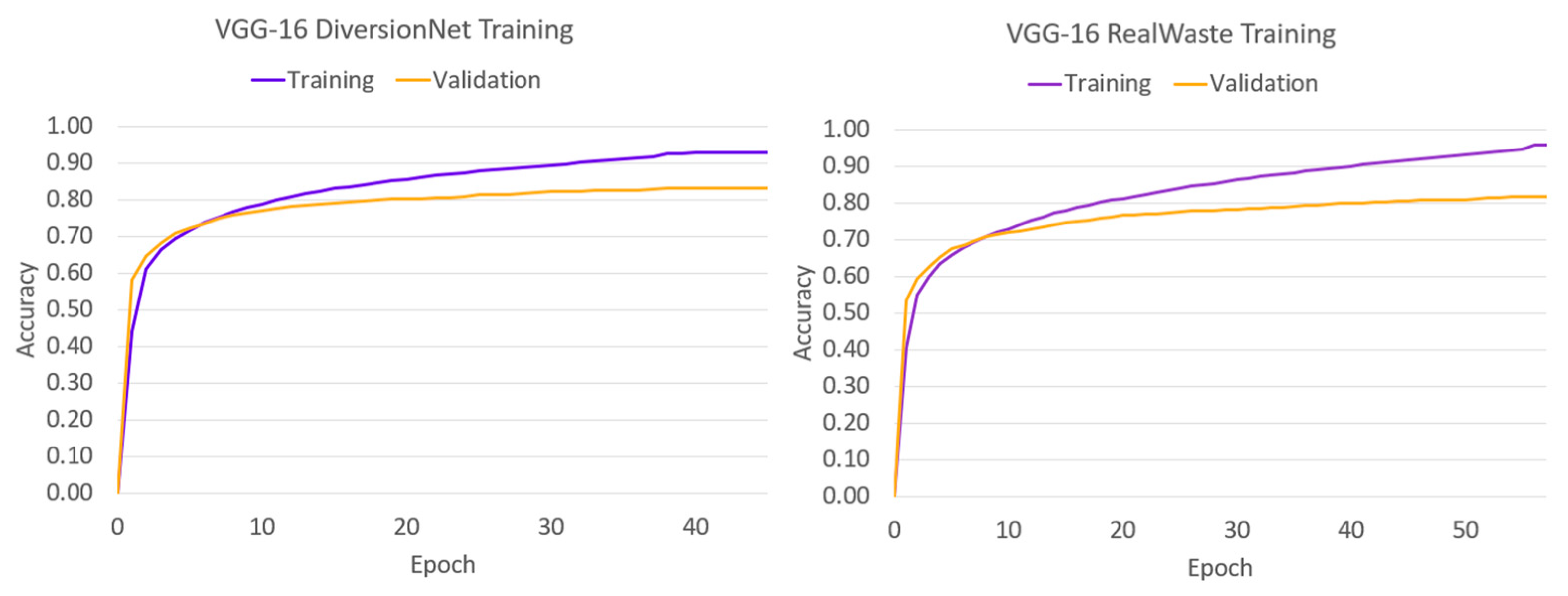
Figure 5.
DenseNet121 training performance: (a) DiversionNet dataset. (b) RealWaste dataset.
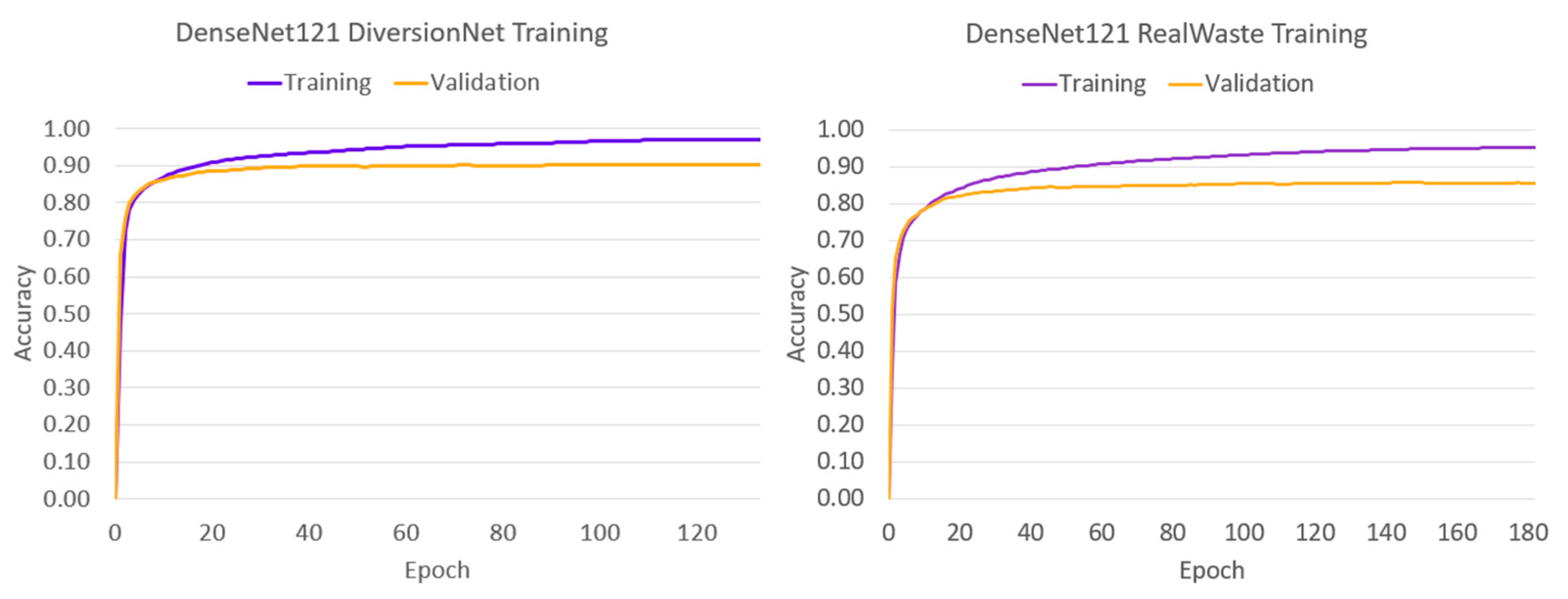
Figure 6.
Inception V3 training performance: (a) DiversionNet dataset. (b) RealWaste dataset.
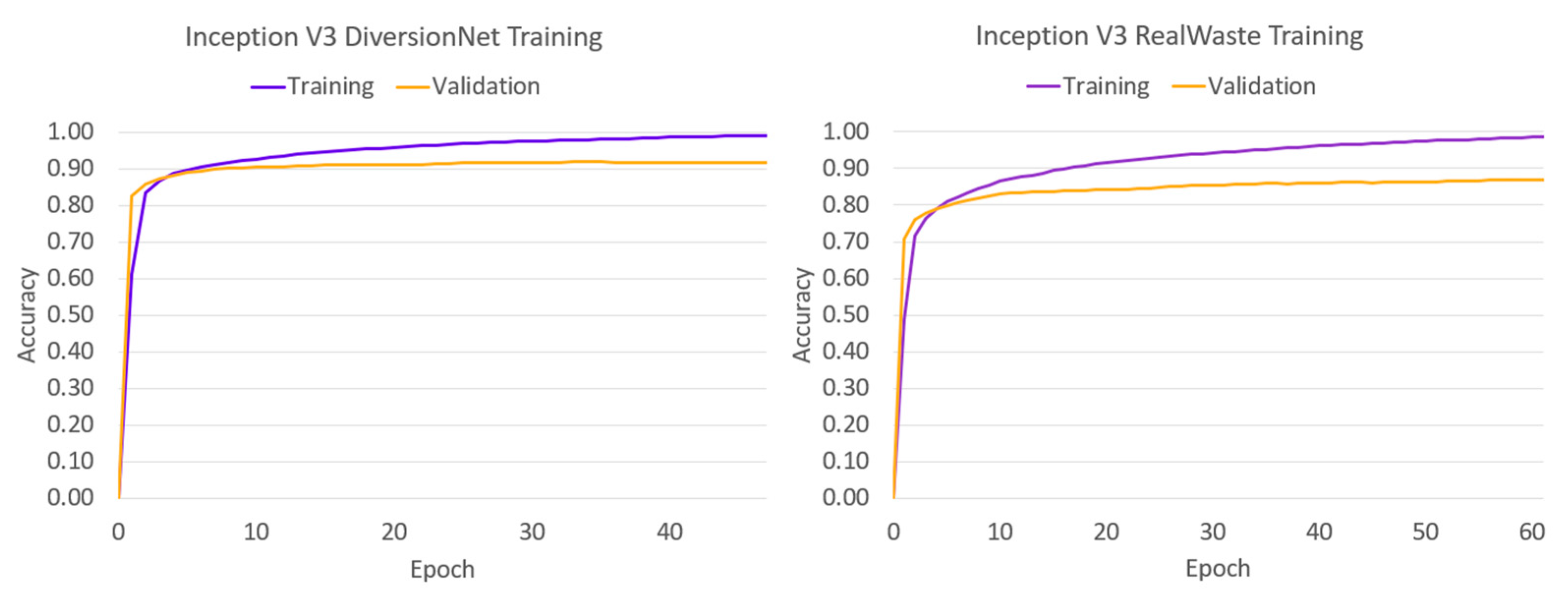
Figure 7.
InceptionResNet V2 training performance: (a) DiversionNet dataset. (b) RealWaste dataset.
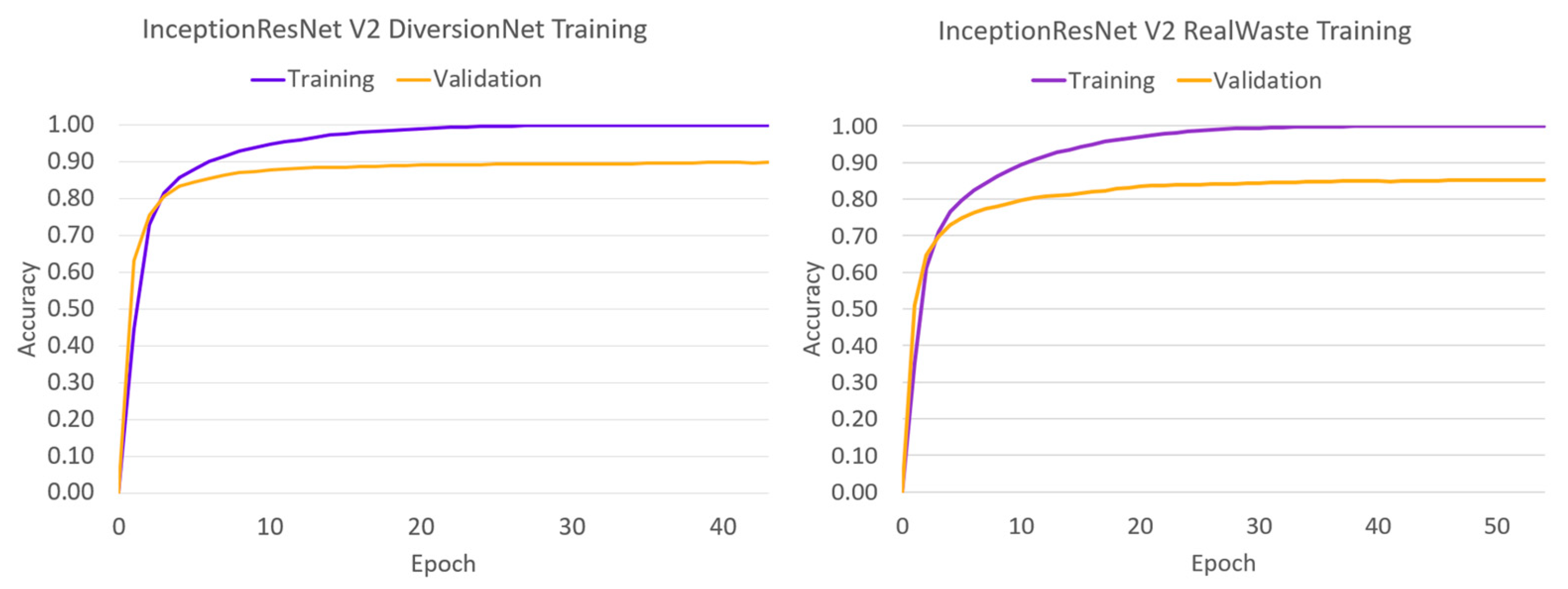
Figure 8.
MobileNetV2 training performance: (a) DiversionNet dataset. (b) RealWaste dataset.
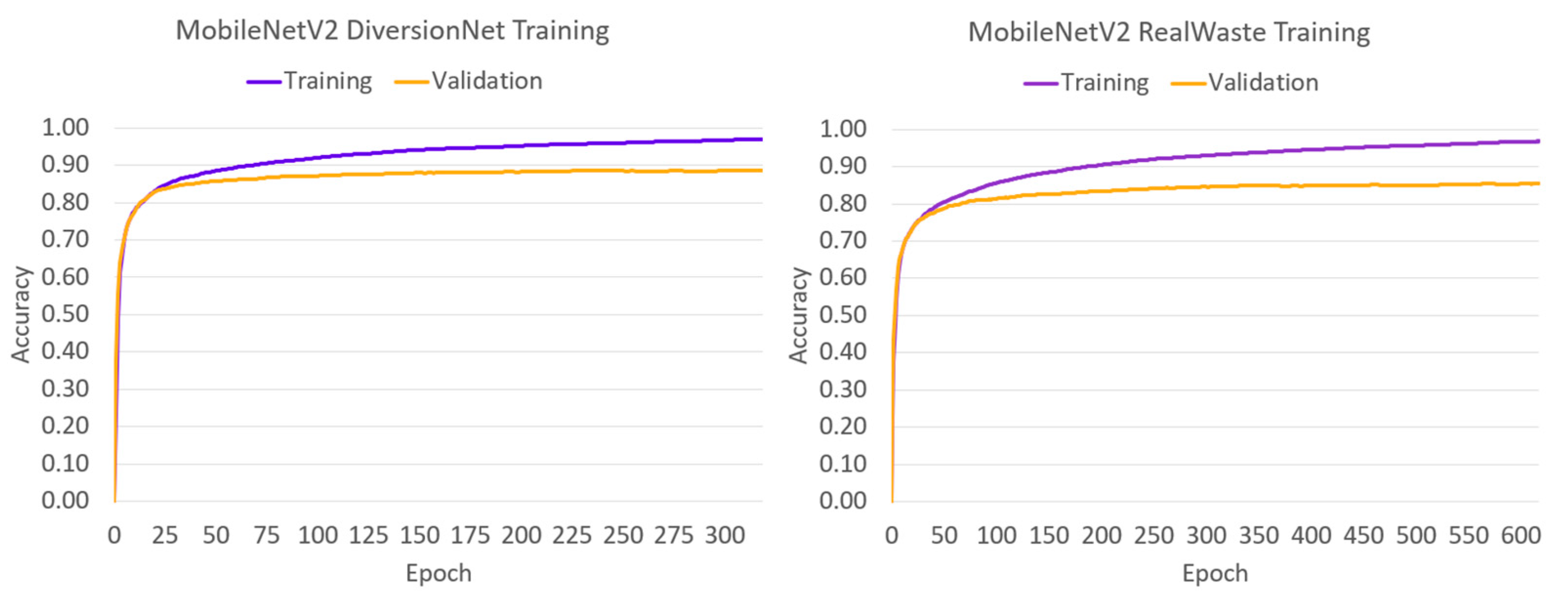
Figure 9.
Confusion matrix for Inception V3 best model testing.
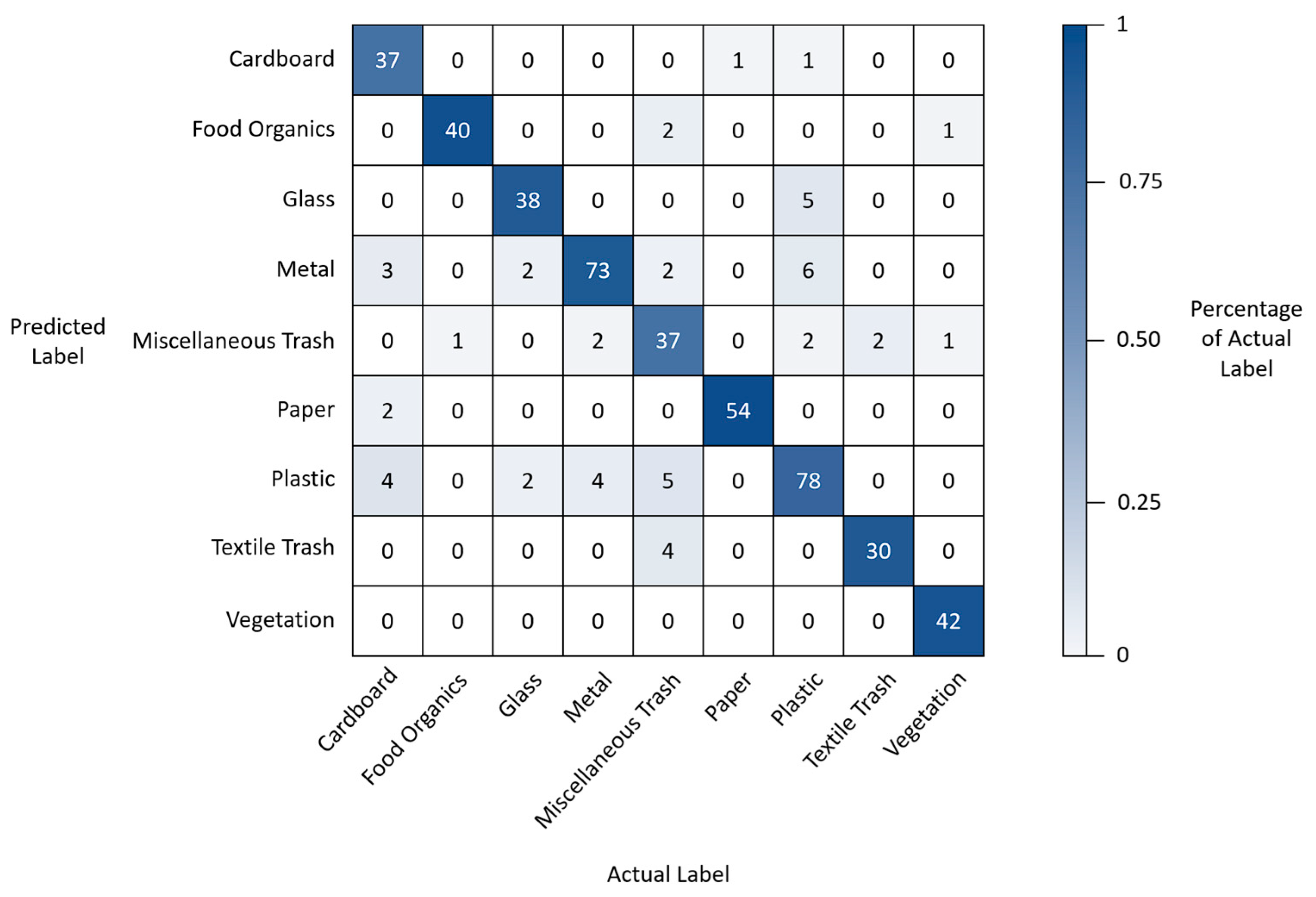
Figure 10.
Confusion between cardboard, metal, paper, and plastic: (a) Cardboard labelled as metal. (b) Cardboard labelled as paper. (c) Cardboard labelled as plastic.
Figure 10.
Confusion between cardboard, metal, paper, and plastic: (a) Cardboard labelled as metal. (b) Cardboard labelled as paper. (c) Cardboard labelled as plastic.
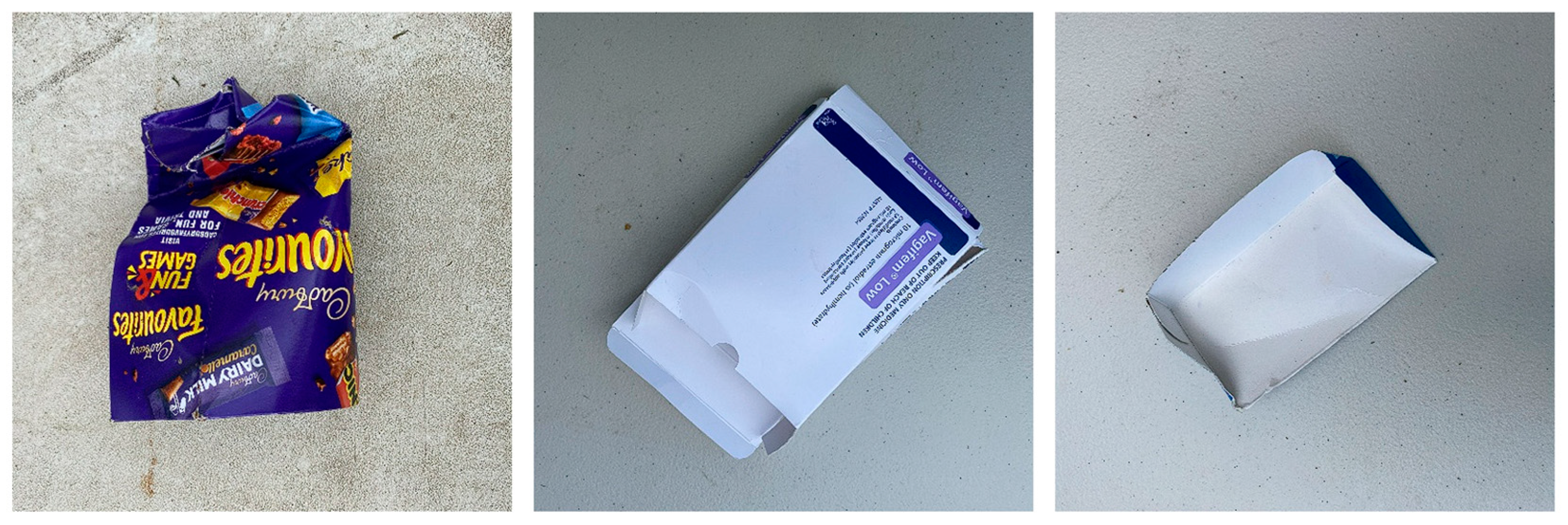
Figure 11.
Confusion between plastic and glass bottles: (a) Plastic labelled as glass. (b) Glass labelled as plastic.
Figure 11.
Confusion between plastic and glass bottles: (a) Plastic labelled as glass. (b) Glass labelled as plastic.

Figure 12.
Confusion between glass and metal: (a) Metal wiring. (b) Metal-appearing bottle top.

Figure 13.
Confusion between organic labels: (a) Food organic labelled as miscellaneous trash. (b) Vegetation labelled as miscellaneous trash. (c) Vegetation labelled as food organic.
Figure 13.
Confusion between organic labels: (a) Food organic labelled as miscellaneous trash. (b) Vegetation labelled as miscellaneous trash. (c) Vegetation labelled as food organic.


Table 1.
Labels and image count of datasets.
| Label | DiversionNet | RealWaste | Test |
|---|---|---|---|
| Cardboard | 403 | 417 | 46 |
| Food Organics | 311 | 370 | 41 |
| Glass | 501 | 378 | 42 |
| Metal | 410 | 711 | 79 |
| Miscellaneous Trash | 290 | 445 | 50 |
| Paper | 594 | 497 | 55 |
| Plastic | 482 | 831 | 92 |
| Textile Trash | 417 | 286 | 32 |
| Vegetation | 519 | 392 | 44 |
Table 2.
Training dataset data augmentation.
| Set No. | Augmentation Techniques |
|---|---|
| 1 | Horizontal flip and elastic distortion |
| 2 | Rotate and shear |
Table 3.
Performance results on testing dataset.
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| DiversionNet Training | ||||
| VGG-16 | 26.82% | 28.80% | 25.99% | 27.32% |
| DenseNet121 | 40.33% | 44.80% | 34.93% | 39.25% |
| Inception V3 | 49.69% | 55.43% | 39.29% | 45.98% |
| InceptionResNet V2 | 44.70% | 52.83% | 40.75% | 46.01% |
| MobileNetV2 | 27.65% | 28.50% | 24.95% | 26.61% |
| RealWaste Training | ||||
| VGG-16 | 85.65% | 87.74% | 84.82% | 86.26% |
| DenseNet121 | 89.19% | 90.06% | 86.69% | 89.62% |
| Inception V3 | 89.19% | 91.34% | 87.73% | 90.25% |
| InceptionResNet V2 | 87.32% | 89.69% | 85.03% | 88.49% |
| MobileNetV2 | 88.15% | 89.98% | 85.86% | 87.87% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



