Submitted:
07 November 2023
Posted:
08 November 2023
You are already at the latest version
Abstract
Handwriting is a form of biometric behavioral characteristic with evident individual distinctiveness. With the surge of the deep learning trend and the demand for forensic identification, handwriting identification has become one of the focal points of research in the field of pattern recognition. The research on handwriting identification in major world languages has reached a mature stage. However, there is still a notable lack of relevant research in the field of Mongolian handwriting identification, despite the fact that Mongolian is used by over 4 million people in China. This paper embarks on an initial exploration of Mongolian handwriting identification by constructing a convolutional neural network named MWInet-12. In this paper, the model evaluation experiments were conducted using a dataset comprising 156,372 samples contributed by 125 authors from the MOLHW dataset. The dataset was divided into training, validation, and test sets in an 8:1:1 ratio. The final results of the experiments reveal impressive accuracy on the test set, achieving a top-1 accuracy of 89.60% and a top-5 accuracy of 97.53%. Furthermore, through comparative experiments involving Resnet, Fragnet, and GRRNN models, this paper establishes that the proposed model yields the most favorable results for Mongolian handwriting identification.
Keywords:
offline handwriting identification
; Mongolian
; CNN
; MOLHW
1. Introduction
Handwriting identification is a technique to determine who the writer of a given sample is by studying the specific characteristics of a person’s handwriting. Handwriting identification technology holds significant research significance in various fields, including the judicial, financial, and forensic sectors. It plays a crucial role in resolving disputes related to handwritten IOUs or wills, conducting forensic analysis, verifying document signatures, and facilitating personal identification through system terminals.
At present, automated handwriting identification work for popular world languages such as Chinese, English, and Arabic has largely matured. However, little attention has been paid to the handwriting identification work of Mongolian, which has more than 4 million speakers. The Mongolian language has very few datasets on Mongolian due to its huge vocabulary, which has led to slow progress in its computerized processing. Despite the lack of strict standards for manual handwriting identification in Mongolian, legal issues arising from handwriting need to be urgently addressed, so this paper conducts exploratory experiments on Mongolian handwriting identification to fill the gap in the field. Handwriting identification can be categorized into online handwriting identification and offline handwriting identification according to the different ways of handwriting information collection, and this paper explores Mongolian handwriting identification in the offline state.
Different languages have their own unique handwriting characteristics and possess different research difficulties [1]. Mongolian writing is characterized by writing vertically from top to bottom and characters are closely connected to each other, sometimes there is an interrupted space between the last character of a word and the previous one. When writing a word, there are different forms of distortion depending on where the characters are located. The order of writing on each page is from top to bottom, left to right. Figure 1 shows a sample of Mongolian writing.
In Mongolian handwriting identification, the model needs to be adapted to the linguistic features of the Mongolian language as well as to its different arrangements. The variations in writing style and the omission of strokes in Mongolian make recognizing and comparing different handwriting more complex than in other languages. The tightly connected nature of the characters makes it challenging to recognize the connections between letters. In addition, the similarity of the shapes of some letters makes it easy to misidentify them.
In response to the aforementioned issue, this paper introduces an exploration of utilizing a convolutional neural network for intelligent Mongolian handwriting identification.
Convolutional neural network has achieved many excellent performances in the field of image classification. The convolutional layer of the convolutional neural network can learn the more detailed features of the image, such as the shape and angle of the strokes, the connection between neighboring strokes, and the lightness and weight changes of the handwriting when performing handwriting identification. With the increase of convolutional layers, the deeper the network becomes, the larger the sensory field it obtains, and then it will be able to obtain richer handwriting style information. The features extracted from the convolutional layer are passed through a maximum pooling layer to retain the key features and reduce the amount of computation. Finally the extracted features are mapped to classification labels through a fully connected layer, which allows the model to synthesize the relationships between different features in order to make a final classification decision.
This paper is organized as follows: section 2 describes the work related to handwriting identification. Section 3 presents the research methodology used in this paper. Section 4 conducts specific experiments and analyzes the results. Finally section 5 summarizes the whole paper and presents the outlook.
2. Related Work
In 2017, Gloria Jennis Tan and colleagues summarized research on handwriting identification in three major languages: English, Arabic, and Chinese [1]. Commonly used datasets for offline handwriting identification research include the CEDAR [2] and IAM datasets for English [3], KHATT [4], AHDB [5], and Al Isra [6] for Arabic, and WDB [7], HCL2000 [8], and the widely used Firemaker dataset [9] for Chinese. Datasets containing a mix of languages include ICDAR2013 [10], CVL [11], QUWI [12], and others. For Mongolian script, there are publicly available handwriting datasets such as the MHW offline handwriting dataset [13], online handwriting datasets like MOLHW [14], and MRG-OHMW [15].
The emergence of deep neural networks has divided the evolution of handwriting identification research into two phases: those relying on manual feature extraction and those harnessing deep learning features. Methods based on manual feature extraction include texture, shape, and contour analysis. In [16], Behzad Helli and colleagues introduced a novel texture-based approach employing XGabor filter feature extraction and the LCS classifier for Persian writer identification. In [17], Djeddi Chawki and team proposed a global texture analysis method, treating each writer’s handwriting as distinct textures, successfully identifying and verifying 130 handwritten images from 650 different Arabic authors. In [18], Fathi H utilized a discrete contour transformation approach with MLP neural network classification to distinguish 50 Arabic authors. In [19], Tayeb Bahram treated contours as textures, computing the joint probability distribution of binary patterns (MLBP) and ink width and shape letter (IWSL) at different pixel locations, achieving excellent results across eight prominent handwriting datasets.
Currently, the most popular approach for handwriting identification is the utilization of deep learning. In 2015, S. Fiel and R. Sablatnig introduced the concept of deep learning into the field by employing an eight-layer convolutional neural network (CNN). They generated a feature vector for each author based on the CNN’s activation features and compared it with precomputed feature vectors stored in a database [20]. Subsequently, deep learning-based methodologies continued to evolve. In 2016, a deep multi-stream CNN was proposed, where handwritten patches were processed and softmax classification was used for author-independent recognition. It was discovered that different languages might share common features and could undergo joint training [21]. In 2016, Youbao Tang and colleagues combined features extracted by CNN with joint Bayesian techniques to achieve handwriting identification. The literature utilized the GMM super-vector encoding method in conjunction with SVM for relatively robust offline author recognition [22]. To fully leverage the deep features learned by the network, Sheng He and others introduced an adaptive convolutional layer, improving the performance of author recognition based on single-character images [23]. In 2020, Parveen Kumar and team presented a segmentation-free and pretrained deep convolutional neural network for offline text-independent handwriting identification, achieving results of 92.79%, 99.35%, and 98.30% on popular datasets like IAM, CVL, IFN/ENIT, respectively [24].
While handwriting data is typically obtained at the page level, author identification processes often involve segmenting it into lines or words. Compared to processing at the line or page level, individual characters, though providing fewer overall stylistic cues, offer finer-grained features. In 2017, the Sheng He team used deep adaptive learning to achieve author identification for single-character images through multi-task learning. They improved the performance of single-character image author recognition on benchmark datasets like CVL and IAM [23]. In 2020, the same team introduced the Fragnet network, which combines features extracted from complete word images and segmented feature maps to extract relevant author-specific information [25]. In 2021, they proposed the Gr-rnn network, which captures complementary information from both global context and local segments for author recognition [26]. In 2022, Vineet Kumar conducted research on offline text-independent author identification at the word level. The SFIT algorithm was used to extract feature points, which were then fed into a convolutional network to generate corresponding feature maps. Weight learning for these feature maps was achieved using an entropy-based method [27].
In 2022, Spurthi Bhat and colleagues conducted exploratory research on handwriting identification in Indian languages. Due to the lack of appropriate databases for Bengali handwriting, they used local binary patterns as texture descriptors and a support vector machine classifier, achieving a result of 93.34% on the Bengali dataset [28]. In 2023, Syed Tufael Nabi and colleagues focused on the less explored Urdu language for offline handwriting identification. They obtained an impressive 99.11% result using an improved VGG16 model on a dataset of 318 Urdu script writers [29]. However, as of now, no relevant research has been discovered for handwriting identification in Mongolian script. Different languages possess their unique handwriting characteristics, leading to distinct research challenges [30]. There is currently no universally applicable model, and the absence of a standardized dataset makes it challenging to evaluate which model yields the best performance, thus lacking comparability. This paper presents an exploratory study that introduces a convolutional neural network for handwriting identification in Mongolian script.
3. Method
The methods for handwriting analysis typically involve three standard steps: preprocessing, feature extraction, and writer identification (classification), as illustrated in Figure 2.
In this chapter, the process of offline Mongolian handwriting identification is introduced. Section 3.1 presents the original dataset and preprocessing techniques. In Section 3.2, the proposed model and its implementation details are discussed, with a focus on handwriting identification. Section 3.3 describes the loss functions utilized in this study.
3.1. Dataset and Preprocessing
The MOLHW dataset is a total of 164631 Mongolian word samples written by 200 authors and saved as a text file. Each line of this dataset is the basic information of a word, including the encoding of the word, the author id, the size of the screen and the coordinate trajectory of each point of the word with [-1, -1] as the breakpoint. Statistically, the number of writing samples of each author is not the same, or even a great disparity, with the most having more than 3,000 samples, and the least having 1, as shown in the Figure 3. In this paper, according to the distribution of the number of samples, we consider deleting the samples with less than 500 authors, and finally 125 authors and 156372 samples remain, which constitute the dataset used in this paper.
Due to the significant variations in the length of Mongolian script characters and the diverse writing habits of individuals, the position of each character can differ when converted into images. Given these considerations, this paper employs bounding box processing to center each character within the image, ensuring that all characters are evenly distributed. This approach maintains the consistency of image dimensions for each word while avoiding distortion, as depicted in Figure 4, which showcases some of the successfully transformed image samples.
3.2. Method
The overall architecture of the model built in this paper is shown in Figure 5. Similar to the network structure of VGG, the MWInet-12 network model in this paper undergoes a total of 12 convolutional operations, four maximal pooling processes, one global average pooling(GAP) process, and one fully connected layer operation. In the model shown in Figure 5. The specific composition of 3Conv is shown in Figure 6. In this part, batch one normalization process and Relu nonlinear activation are carried out in every convolution operation experienced, which improves the stability and nonlinear judgment of the model.
In this network, the convolutional layer is the core component, and a shallow convolutional layer is used to extract low-level features of handwriting, such as the shape, thickness, angle, and curve of the strokes, which are captured by sliding a convolutional kernel over the input image and gradually adjusting the weights based on the training data. As the number of convolutional layers increases, the model gradually learns more abstract features such as shapes, textures and patterns. In this model, all the convolutional operations use a small 3×3 convolutional kernel with a step size of 1 and a padding of 1. Three convolutions yield the same receptive field as a 7×7 convolutional kernel, and compared to the latter, the smaller 3×3 convolutional kernel yields fewer computations and fewer parameters, and at the same time, it can extract finer-grained features, with better training efficiency and better generalization ability. At the network level, the stacking of multiple convolutional layers not only increases the depth, but makes the model more capable of data processing and able to learn more complex features and more abstract representations. All the maximum pooling layers in the model use a convolution kernel size of 2*2 with a step size of 2. The pooling layer can reduce the computational complexity and the number of parameters of the model by reducing the size of the feature map and retaining the handwriting image to express the more prominent features.
After all the convolutional and pooling layers, the model has captured most of the detailed image features. However, for Mongolian handwriting identification, this isn’t sufficient. It’s essential to grasp the overall style features of the characters comprehensively. For instance, some individuals might intentionally imitate the stroke features of another person’s handwriting but often overlook the holistic style. Each person’s handwriting style is challenging to replicate. Adding a global average pooling layer can help capture the global features of the entire image, which aids the model in better interpreting the handwriting information. Furthermore, the global average pooling layer serves to reduce data dimensions and the number of model parameters, thereby mitigating the risk of overfitting and enhancing the model’s robustness. By first focusing on the detailed study of local handwriting features and then integrating the global overall style features, the model’s ability to recognize authors’ handwriting has been significantly improved. Finally, the model utilizes a fully connected classification layer to classify and identify authors, ultimately producing predictions.
3.3. Loss
During training, the model utilizes two loss functions - cross-entropy loss and label smoothing regularization loss.
3.3.1. Cross-Entropy Loss
The Cross-Entropy Loss function is a commonly used loss function in classification tasks. It assesses the model’s performance by calculating the cross-entropy between the predicted probability distribution and the true labels. Mathematically, given a probability distribution of true labels y and a probability distribution of predicted labels ŷ, the Cross-Entropy Loss function can be represented by the following formula:
In some cases, the traditional cross-entropy loss function may have certain drawbacks. For example, in situations where the labels are not entirely reliable or contain noise, the model may make overly confident predictions for a particular class. To address this issue, label smoothing loss can be introduced.
3.3.2. Label Smoothing Loss
Label smoothing loss involves smoothing the true labels, redistributing some of the confidence to other labels, to reduce model overfitting and increase robustness against noise, ultimately enhancing the model’s generalization ability. The calculation of label smoothing loss is as follows:
Where is a smoothing parameter, and we take = 0.1, N represents the number of authors, and is the output of the neural network after softmax. The first term in the formula is similar to the traditional cross-entropy loss and is used to measure the difference between predicted values and true values. The second term introduces a uniform distribution to add some fuzziness to the true labels.
4. Experiment
To validate the Mongolian handwritten text identification model proposed in this paper, we conducted training and testing using the publicly available Mongolian handwritten dataset MOLHW. We evaluated the experimental model using top-k accuracy, specifically, we employed both top-1 and top-5 accuracy as evaluation metrics in our experiments.
4.1. Environment and Hyperparameter
The basic environment and configuration for this experiment are as follows: The runtime platform is a Linux server with a 64GB NVIDIA RTX A6000 GPU. The experimental code is written in Python, with version 3.10.10, and is based on the PyTorch framework, with Torch version 1.12.0.
Regarding the dataset allocation during model training, 80% is used as the training set, 10% as the validation set, and 10% as the test set, ensuring that the training set contains data from all authors. To maximize server memory utilization, the batch size is set to 128, and 8 threads run in parallel. The optimizer used is the commonly used Adam optimizer with a weight decay parameter of 1e-4. The initial learning rate is set to 0.0001, and a fixed interval learning rate adjustment mechanism is applied, with the learning rate reduced to half of the previous learning rate every 10 epochs.
4.2. Image transformation
Prior to inputting the images into the model, they undergo binary thresholding and resizing to a dimension of 128*256. The model is divided into four segments, each consisting of 3 convolutional operations and 1 max-pooling operation. The model has a batch size of 128, and the number of channels in each segment is 64, 128, 256, and 512, respectively. The input images have dimensions of 128*256 with 64 channels. In the first segment, the convolutional operations do not alter the image size or the number of channels; however, after the first max-pooling layer, the image is compressed to 64*128. This process continues, with the second segment producing feature maps of size 32*64, the third segment outputting feature maps of size 16*32, and the fourth segment resulting in an output of 8*16. The specific changes in each segment are outlined in Table 1. In the table, "k" represents the kernel size, "S" represents the stride, and "P" represents padding.
4.3. Experimental Results of Model
During the experimental process, we employed methods such as increasing network depth, changing the loss function, and segmenting image fragments to classify authors of Mongolian text. We compared the results with relevant convolutional models.
4.3.1. Increasing Network Depth
In this subsection, the chosen loss function is the cross-entropy loss function. Since the network model in this paper can be divided into four parts of convolution-pooling, and each part has the same composition, we can customize the network for each layer. In the experiments, we initially selected each part to contain two convolution layers, two batch normalization operations, two ReLU activation functions, and finally, an output pooling layer. The model ultimately comprises 8 convolution operations and 4 max-pooling operations, referred to as MWInet-8. Under this model, the accuracy results were as follows: top-1 accuracy was 83.28%, and top-5 accuracy was 96.56%.
Increasing the network depth can help extract more abstract features. Using the MWInet-12 network proposed in this paper, where each part defines three convolution operations, the accuracy improved compared to MWInet-8. The top-1 accuracy was 88.67%, and the top-5 accuracy was 97.54%, representing a 5.4% improvement in top-1 accuracy and a 1.0% improvement in top-5 accuracy.
However, blindly increasing network depth may not necessarily yield ideal results. Experimental results show that after four rounds of convolution operations, not only did the recognition performance not improve, but stability decreased, and the model’s parameters increased, consuming more GPU memory. Therefore, MWInet-12 represents the optimal network for this model.
4.3.2. Label Smoothing Loss
In this section, as compared to the previous subsection, we only replaced the cross-entropy loss function with the label-smoothed regularization loss. As shown in the figures, accuracy improved for both models. For MWInet-8, the top-1 accuracy was 86.43%, and the top-5 accuracy was 96.66%. For MWInet-12, the top-1 accuracy reached 89.6%, and the top-5 accuracy was 97.53%. It can be observed that after applying label-smoothed regularization, both networks experienced a noticeable increase in top-1 accuracy. Shallow convolution networks showed more substantial improvement compared to deeper networks, while top-5 accuracy remained almost unchanged, indicating that the models have achieved a relatively optimal performance level.
The results are as shown in the Table 2.
4.3.3. Experiments in different models
In order to verify the advantages of this paper’s model in Mongolian handwriting identification, the model proposed in this paper is compared with other models in the field of handwriting identification. Label smoothing regularized loss function is used in all comparison experiments. The experimental results are shown in the Table 3. The test results at resnet50 are 81.44% for top1 and 94.75% for top5. While in Fragnet network experiment top1 only reached 76.5% and top5 91%. Testing on GRRNN model results in 82.71% for top1 and 94.37% for top5. Compared to the above three models, the MWInet-12 proposed in this paper has the highest accuracy for both top1 and top5.
4.4. Discussion
From the perspective of the entire process of handwriting identification for Mongolian text, the research results of this paper can be analyzed as follows. The experimental dataset in this paper consists of images generated directly from online data. Compared to offline images collected directly, the interference of noise is relatively low. This means that the quality of the dataset itself is high. Additionally, during the preprocessing of the images, efforts were made to ensure that the content of the handwriting occupies a reasonable proportion of the entire image, which improved the model’s performance. MWInet-12 utilizes 12 layers of convolution operations, and deeper networks can learn the specific features of Mongolian text more thoroughly. Adding global average pooling to retain crucial global information and performing classification recognition through fully connected layers allows the model to consider the relationships between different features, resulting in better classification capability.
The experiments in this paper began with a shallow model and compared the results after increasing network depth, using label-smoothed regularization loss, and feeding the model with image fragments. In all these cases, the top-1 accuracy improved to varying degrees, while the top-5 accuracy remained relatively stable. MWInet-12 not only achieved a significant increase in accuracy compared to MWInet-8 but also exhibited more stable loss.
However, there are some limitations to this research. The lack of experiments on actual offline Mongolian handwriting due to dataset limitations, the absence of an in-depth exploration of hyperparameter optimization methods, and the relatively simple model structure provide areas for further investigation. The next steps will involve collecting and creating an offline Mongolian text dataset and continuing exploration in this domain.
5. Conclusions
Research in mainstream language handwriting identification is well-established; however, there is still limited attention given to minority languages such as Mongolian script. Despite having over four million users, Mongolian script lacks a comprehensive handwriting identification system. Therefore, this paper conducted an exploratory experiment on Mongolian script handwriting identification.
The paper describes a simple structure convolutional neural network, MWInet-12, for handwriting identification in traditional Mongolian script. Firstly, the MOLHW online Mongolian script dataset was processed into offline images based on its coordinates. Following the distribution of author samples, 125 authors with a total of 156,372 samples were retained. These images were divided into training, validation, and test sets in an 8:1:1 ratio. The images were input into the MWInet-12 network, and after 100 rounds of model training, achieved a single-character recognition accuracy of 89.60%. The study included experiments that involved changing network depth, loss functions. It also compared the results with three other network models, Resnet50, Fragnet, and GRRNN, from recent years. The results indicate that the network presented in this paper has a significantly superior accuracy. While this paper serves as an exploratory experiment in Mongolian script handwriting identification, it falls short of achieving the desired outcomes. To address the handwriting identification challenges in Mongolian script for judicial purposes, further improvements in the model and recognition efficiency are required. Future work will also involve applying the model to offline Mongolian script samples collected by the authors.
Author Contributions
Conceptualization,methodology,software,writing—original draft, Yuxin Sun; software, validation,writing—review, Daoerji Fan; software, writing—review, Huijuan Wu; validation, writing—review and editing, Zhixin Wang; validation, writing—review and editing, Jia Tian. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the National Natural Science Foundation of China (Grant No. 61763034), the National Natural Science Foundation of the Inner Mongolia Autonomous Region (Grant No. 2020MS06005) and the National Natural Science Foundation of behavioral recognition (Grant No. 62261041).
Data Availability Statement
Data was obtained from kaggle and are available kaggle.com /datasets/fandaoerji/molhw-ooo with the permission of kaggle.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Tan G J, Sulong G, Rahim M S M. Writer identification: A comparative study across three world major languages. In: Forensic science international; 2017. 279: 41-52. [CrossRef]
- Hull J J. A database for handwritten text recognition research. In: IEEE Transactions on pattern analysis and machine intelligence; 1994. 16(5): 550-554. [CrossRef]
- Marti U V, Bunke H. A full English sentence database for off-line handwriting recognition. In: Proceedings of the Fifth International Conference on Document Analysis and Recognition; ICDAR’99 (Cat. No. PR00318). 1999. p. 705-708.
- Mahmoud S A, Ahmad I, Al-Khatib W G, et al. KHATT: An open Arabic offline handwritten text database. In: Pattern Recognition; 2014. 47(3): 1096-1112. [CrossRef]
- Al-Ma’adeed S, Elliman D, Higgins C A. A data base for Arabic handwritten text recognition research. In: Proceedings eighth international workshop on frontiers in handwriting recognition; 2002. p. 485-489. [CrossRef]
- Kharma N, Ahmed M, Ward R. A new comprehensive database of handwritten Arabic words, numbers, and signatures used for OCR testing. In: 1999 IEEE Canadian Conference on Electrical and Computer Engineering (Cat. No. 99TH8411); 1999. 2: 766-768. [CrossRef]
- Liu C L, Yin F, Wang D H, et al. CASIA online and offline Chinese handwriting databases. In: 2011 international conference on document analysis and recognition; 2011. p. 37-41. [CrossRef]
- Zhang H, Guo J, Chen G, et al. CL2000-A large-scale handwritten Chinese character database for handwritten character recognition. In: 2009 10th international conference on document analysis and recognition; 2009. p. 286-290. [CrossRef]
- Schomaker L, Vuurpijl L, Schomaker L. Forensic writer identification: A benchmark data set and a comparison of two systems. In: 2000.
- Louloudis G, Gatos B, Stamatopoulos N, et al. ICDAR 2013 competition on writer identification. In: 2013 12th International Conference on Document Analysis and Recognitio; 2013. p. 1397-1401. [CrossRef]
- Kleber F, Fiel S, Diem M, et al. Cvl-database: An off-line database for writer retrieval, writer identification and word spotting. In: 2013 12th international conference on document analysis and recognition; 2013. p. 560-564. [CrossRef]
- Al Maadeed S, Ayouby W, Hassaine A, et al. QUWI: an Arabic and English handwriting dataset for offline writer identification In: 2012 International Conference on Frontiers in Handwriting Recognition; 2012. p. 746-751. [CrossRef]
- Fan D, Gao G, Wu H. MHW Mongolian offline handwritten dataset and its application. In: Journal of Chinese information processing; 2018. 32(1): 89-95.
- Pan Y, Fan D, Wu H, et al. A new dataset for mongolian online handwritten recognition. In: Scientific Reports; 2023. 13(1): 26. [CrossRef]
- Ma L L, Liu J, Wu J. A new database for online handwritten Mongolian word recognition. In: 2016 23rd International Conference on Pattern Recognition (ICPR); 2016. p. 1131-1136. [CrossRef]
- Helli B, Moghaddam M E. A text-independent Persian writer identification system using LCS based classifier In: 2008 IEEE International Symposium on Signal Processing and Information Technology; 2008. p. 203-206. [CrossRef]
- Chawki D, Labiba S M. A texture based approach for Arabic writer identification and verification. In: 2010 International Conference on Machine and Web Intelligence; 2010. p. 115-120. [CrossRef]
- Abdullah H F M R M, Taha R. Writer Identification of Arabic Handwriting Using Contourlet Transform and Neural Network. In: 2020.
- Bahram T. A texture-based approach for offline writer identification. In: Journal of King Saud University-Computer and Information Sciences; 2022. 34(8): 5204-5222. [CrossRef]
- Fiel S, Sablatnig R. Writer identification and retrieval using a convolutional neural network In: International Conference on Computer Analysis of Images and Patterns; 2015. p. 26–37. [CrossRef]
- Xing L, Qiao Y. Deepwriter: A multi-stream deep CNN for text-independent writer identification In: 2016 15th international conference on frontiers in handwriting recognition (ICFHR); 2016. p. 584-589. [CrossRef]
- Tang Y, Wu X. Text-independent writer identification via cnn features and joint bayesian. 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR); 2016. p. 566-571. [CrossRef]
- He S, Schomaker L. Deep adaptive learning for writer identification based on single handwritten word images. Pattern Recognition; 2019. 88: 64-74. [CrossRef]
- Kumar P, Sharma A. Segmentation-free writer identification based on convolutional neural network. In: Computers & Electrical Engineering; 2020. 85: 106707. [CrossRef]
- He S, Schomaker L. Fragnet: Writer identification using deep fragment networks. In: IEEE Transactions on Information Forensics and Security; 2020. p. 15: 3013-3022. [CrossRef]
- He S, Schomaker L. Gr-rnn: Global-context residual recurrent neural networks for writer identification. In: Pattern Recognition, 2021, 117: 107975. [CrossRef]
- Kumar V, Sundaram S. Offline Text-Independent Writer Identification based on word level data. In: arXiv preprint arXiv:2202.10207, 2022. [CrossRef]
- Bhat S, Bhokare V, Bhirud R, et al. Writer Identification using Handwriting Samples. In: 2022 IEEE 4th International Conference on Cybernetics, Cognition and Machine Learning Applications (ICCCMLA). IEEE, 2022: 456-461. [CrossRef]
- Nabi S T, Kumar M, Singh P. DeepNet-WI: a deep-net model for offline Urdu writer identification. In: Evolving Systems, 2023: 1-11. [CrossRef]
- Tan G J, Sulong G, Rahim M S M. Writer identification: A comparative study across three world major languages. In: Forensic science international, 2017, 279: 41-52. [CrossRef]
- Purohit N, Panwar S. State-of-the-Art: offline writer identification methodologies. In: 2021 international conference on computer communication and informatics (ICCCI); IEEE, 2021. p. 1-8. [CrossRef]
Figure 1.
Mongolian handwritten samples.

Figure 2.
The general process of handwriting identification.

Figure 3.
Statistics of sample counts for the 200 authors in the MOLHW dataset.
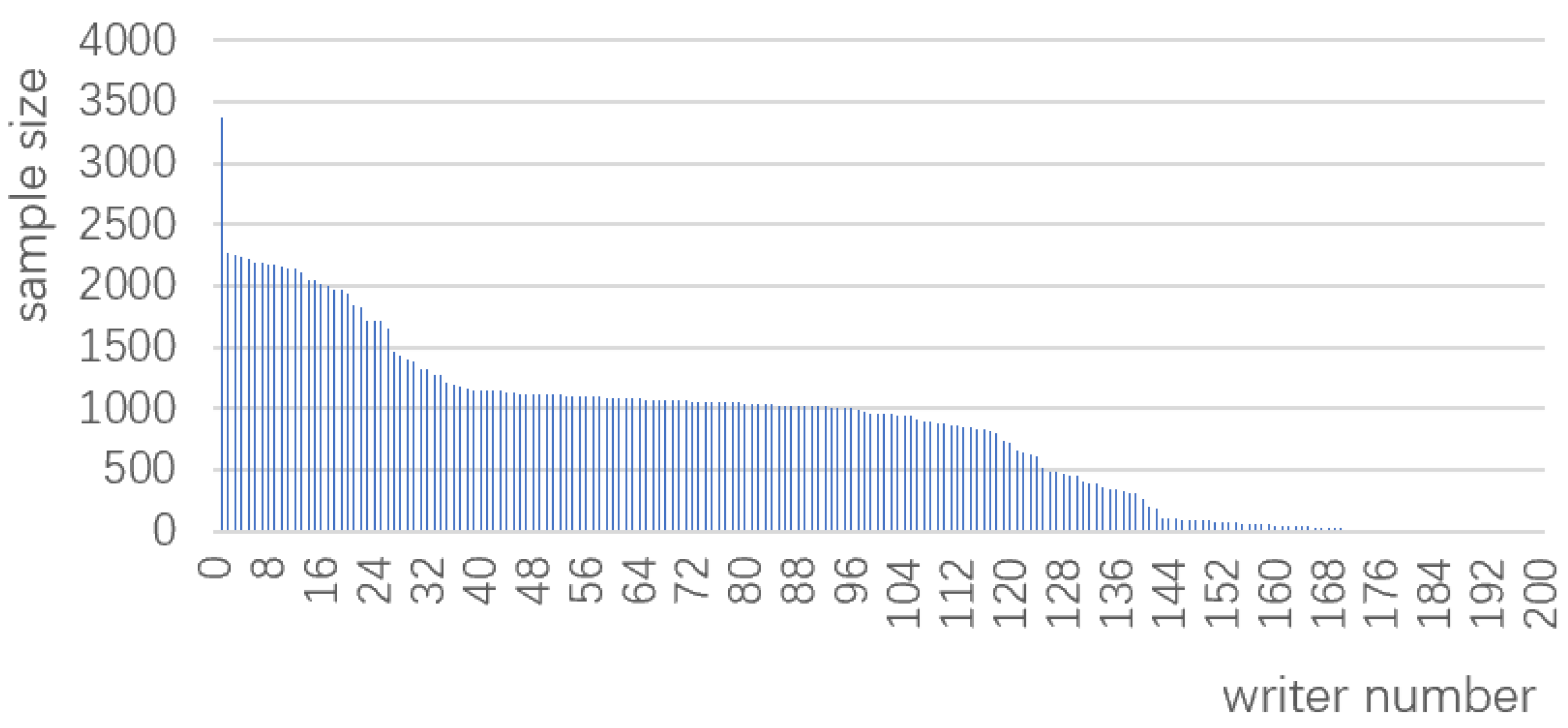
Figure 4.
Offline handwriting images.

Figure 5.
Structure of model.

Figure 6.
3Conv’s structural components.
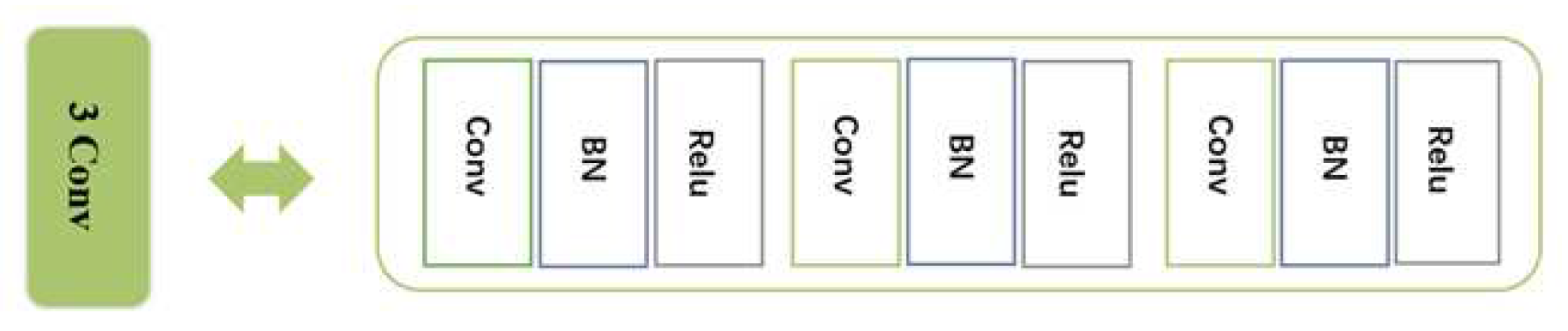

Table 1.
The Outputs of Each Layer in the Model.
| Layers | Specific Configuration | Output shape |
|---|---|---|
| Conv2d-1-1 | k:3*3, S=1, P=1 | (128,64,256,128) |
| Conv2d-1-2 | k:3*3,S=1, P=1 | (128,64,256,128) |
| Conv2d-1-3 | k:3*3, S=1, P=1 | (128,64,256,128) |
| Maxpooling2d-1 | k:3*3, S=2, P=0 | (128,64,128,64) |
| Conv2d-2-1 | k:3*3, S=1, P=1 | (128,128,128,64) |
| Conv2d-2-2 | k:3*3, S=1, P=1 | (128,128,128,64) |
| Conv2d-2-3 | k:3*3, S=1, P=1 | (128,128,128,64) |
| Maxpooling2d-2 | k:2*2, S=2, P=0 | (128,128,64,32) |
| Conv2d-3-1 | k:3*3, S=1, P=1 | (128,256,64,32) |
| Conv2d-3-2 | k:3*3, S=1, P=1 | (128,256,64,32) |
| Conv2d-3-3 | k:3*3, S=1, P=1 | (128,256,64,32) |
| Maxpooling2d-3 | k:2*2, S=2, P=0 | (128,256,32,16) |
| Conv2d-4-1 | k:3*3, S=1, P=1 | (128,512,32,16) |
| Conv2d-4-2 | k:3*3, S=1, P=1 | (128,512,32,16) |
| Conv2d-4-3 | k:3*3, S=1, P=1 | (128,512,32,16) |
| Maxpooling2d-4 | k:2*2, S=2, P=0 | (128,512,16,8) |
Table 2.
Experimental Results Summary.
| Model | Top1(%) | Top5(%) |
|---|---|---|
| MWInet-8 | 83.28 | 96.56 |
| MWInet-12 | 88.67 | 97.54 |
| MWInet-8 (label smooth) | 86.43 | 96.66 |
| MWInet-12(label smooth) | 89.60 | 97.53 |
Table 3.
Experimental Results Summary.
| Model | Top1(%) | Top5(%) |
|---|---|---|
| Resnet50 | 81.44 | 94.75 |
| Fragnet | 72.94 | 89.2 |
| GRRNN | 82.71 | 94.37 |
| MWInet-12(label smooth) | 89.60 | 97.53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



