Submitted:
09 November 2023
Posted:
09 November 2023
You are already at the latest version
Abstract
Photoelectric smoke detectors are the most cost-effective devices for very early fire alarms. However, due to different light intensity response values for different fire smoke and interference from interferential aerosols, they have a high false alarm rate, which limits their popularity in Chinese homes. To address these issues, an embedded spatial-temporal convolutional neural network (EST-CNN) model is proposed for real fire smokes identification and aerosols (fire smokes and interferential aerosol) classification. EST-CNN consists of three modules including information fusion, scattering feature extraction, and aerosol classification. Moreover, a two dimensional spatial-temporal scattering (2D-TS) matrix is designed to fuse the scattered light intensities in different channels and adjacent time slices, which is the output of the information fusion module and the input of the scattering feature extraction module. EST-CNN is trained and tested with experimental data measured on the established fire test platform using the developed dual-wavelength dual-angle photoelectric smoke detector. The optimal network parameters are selected through extensive experiments resulting in an average classification accuracy of 95.6% for different aerosols with only 66 kB network parameters. The experimental results demonstrate the feasibility of the designed EST-CNN model to be directly installed in existing commercial photoelectric smoke detectors to realize aerosol classification.
Keywords:
Embedded spatial-temporal convolutional neural network (EST-CNN)
; aerosols classification
; fire smokes
; interferential aerosol
1. Introduction
Very early fire detection and alarming is of great importance for disaster risk reduction. It prevents loss of life and reduces the economic and material impact of disasters. Since the release of smoke is the most obvious characteristic of very early fire [1], fire smoke monitoring is considered to be the most effective means of fire warning. Therefore, the most common commercial fire detectors available are mostly based on smoke detection, such as image-based [2,3,4,5] and photoelectric smoke detectors [6,7]. Image-based smoke detection technologies determine the presence of smoke and the occurrence of fire in a target area by analyzing and processing video image information captured by a camera [8,9]. These methods focus on a large target area, and the smoke recognition algorithms are computationally intensive, resulting in a large hardware overhead for the detection system, which are usually used in outdoor areas such as forests [10]. In contrast, photoelectric smoke detectors, which are more sensitive and responsive to smoke, are better suited for indoor fire rapid alarming [11]. At present, they are widely used in households due to the simple detection principle and the small in size and low price of the detection core components. However, existing smoke detection techniques actually monitor all aerosols that include real fire smokes and interferential aerosols and do not have the ability to identify real fire smoke. This leads to a high incidence of detector false alarms [12]. For image-based detector, the images sent to the monitor can be used to identify real and fake fires remotely and manually. Due to the rapid development of computer vision, deep learning-based techniques for detecting and recognizing real fire smoke in images are well established [13]. Even though these techniques are extremely demanding in terms of computing performance. While as for photoelectric detectors, when alarmed by interfering aerosols, the fire cannot be recognized remotely as false in time, leading to a waste of rescue resources.
Photoelectric smoke detection technology is based on the optical scattering theory, in which the scattered light intensity is related to the size, refractive index, shape, and concentration of the particles [14,15,16]. However, to simplify the detection principle, it is often assumed that the intensity of the scattered light obtained by the receiver is approximately proportional to the concentration of aerosol particles entering the measurement area in practical application [14]. Then, a fire is considered to have occurred when the smoke concentration increases to the point where the scattered light intensity reaches the alarm threshold [15]. In fact, non-fire interfering aerosol concentrations can also cause the scattered light intensity to reach the alarm threshold when they are high enough, thereby triggering a false fire alarm [17]. Obviously, recognizing and classifying aerosols for real fire smoke and interfering aerosols is an effective way to reduce detector false alarms. In addition, even for real fire combustion smokes, the intensity of scattered light at the same concentration varies when the smoke type is different [18]. This means that a preset threshold of fixed scattered light intensity is not satisfactory for timely and accurate alarms in all fire situations. Whereas, it is helpful to increase the detector’s alarm accuracy by recognizing the type of smoke and then adaptively adjusting the threshold of scattered light intensity that triggers the alarm for each type of smoke. In conclusion, for reducing the rate of false and missed alarms of fires, photoelectric smoke detectors are required to have the ability of classifying aerosols.
Chaudhry et al. [19] developed a system for obtaining the scattered and transmitted light intensity of fire smoke with five wavelengths in the deep ultraviolet (UV) to near-infrared range to identify urning material based on Random Forest algorithm. This method is impractical for commercial photoelectric detectors due to the large size and complexity of the light intensity information measurement device and the requirement of scattering information in the deep UV for classification. Qu et al. [20] classified four classes of European standard fires and typical interfering aerosols using a combined judgment of multiple parameter information such as temperature, smoke, and CO concentration. Similarly, Yu et al. [21] proposed the multi-detector real-time fire alarm technology to classify oil fume and multiple real fire smoke. These methods require multiple detectors to work simultaneously, which increases the cost of detection. Liu et al. [22] proposed to use the detection information from multiple smoke detectors that are already spatially interconnected to determine whether there is a real fire based on Bayesian estimation. This method also relies on multiple smoke detectors installed in a connected space and cannot classify different fire smoke. Zheng et al. [23] used the parameter of aerosol asymmetry ratio at two wavelengths and two angles to classify black smoke, white smoke and interference aerosols. However, this method can only distinguish dust which has significantly different physical characterization parameters from fire smoke, and cannot identify oil fume. In summary, aerosols (fire smokes and interferential aerosols) recognition and classification methods based on multi-channel and multi-detector using machine learning and deep learning algorithms have attracted extensive attention. However, practical applications require methods that can be directly applied to existing single photoelectric detectors without additional hardware overhead. In detail, a practical approach needs to satisfy the following two requirements. First, the computational complexity of the classification algorithm is so low that it can be used with common commercial detectors. Second, the data samples required for classification do not exceed the actual number of channels in the detector.
To satisfy these demands, an embedded spatial-temporal convolutional neural network (EST-CNN) model for fire smokes recognition and classification is proposed. The EST-CNN model consists of three modules: information fusion of spatial-temporal scattered light intensity, scattering feature extraction and aerosol classification. In information fusion module, the two dimensional spatial-temporal scattering (2D-TS) matrix of the aerosol is obtained based on the scattered light intensities in different channels and adjacent time slices. The 2D-TS matrix is the input to the feature extraction module consisting of multi-layer convolutional neural networks (CNN), and the output features are based on a fully connected network (FCN) for aerosol classification. Moreover, a dual-wavelength dual-angle smoke detector is developed to acquire the aerosol datasets on combustion experimental platform for training and testing the EST-CNN model. The contributions of this study are as follows.
- (1)
- An EST-CNN model that can be directly used in existing commercial photoelectric smoke detectors is established for interferential aerosol recognition and real fire classification.
- (2)
- A 2D-TS matrix is created to describe the smoke scattering distribution information in spatial and temporal to obtain sufficient characterization parameters during aerosol generation.
- (3)
- Methods for constructing and pre-processing the scattered light intensity datasets of real fire smoke and interferential aerosol are provided.
- (4)
- The detector and experimental platform are designed to measure the scattered light intensity information of standard fire smoke and interference oil fume.
The remaining parts of the paper are organized as follows: Section 2 introduces the mechanism of aerosol detection, the datasets used for classification, and EST-CNN model. Section 3 presents the experimental platform for acquiring the datasets and discusses the performance of EST-CNN model. Section 4 is the conclusion of this study.
2. Materials and Methods
2.1 Aerosol optical classification mechanism
Photoelectric smoke detection technology is based on the Mie scattering theory [24], in which the scattered light intensity is related to the incident light intensity , dimensionless particle size (the ratio of the particle size to the incident light wavelength ), and the scattering angle , as shown in Eq. (1).
where is the distance between the receiver to the particle, is the refractive index, represents the amplitude function of the scattered light. It can be seen that among the parameters in Eq. (1), and are determined by the original characteristics of the particles, while , , and are determined by the design of the detector. Generally, is the coefficient of the scattered light intensity, which is taken as a fixed constant.
However, the actual scattered light intensity of real-life aerosol is controlled by multiple variables simultaneously, such as particle size distribution (PSD). The production of fire smoke (or oil fume) is a process of continuous aerosol generation and aggregation. The size of the freshly generated particles is very small and gradually increases with aggregation. Thus, the particle size of aerosol obeys a distribution rather than the monodisperse system with single value. Then, is written as Eq. (2).
where is the total number concentration of real-life aerosol, is the particle size range, denotes the scattered light intensity of a single particle with size . According to Eqs. (1) and (2), the inherent property parameters of different classes of aerosol particles are variable, leading to difference in scattered light intensity . This means that the aerosol class information is involved in the scattered light intensity however it cannot be directly separated. Hence, multi-channel scattered light intensity information feature analysis method is considered for aerosol classification, which is based on the specificity in the scattering features of each class of aerosol under different conditions. To apply this method, receivers of the smoke detector are required to obtain scattered light intensity under different wavelengths of incident light and scattering angles.
2.2. Dataset for classification
The smoke from the real fires used in this study complies with European standard fires, such as beech wood smoldering fire (TF2), cotton smoldering fire (TF3), polyurethane open flame (TF4), n-heptane open flame (TF5) [20,25,26,27,28,29]. Moreover, a survey by the National Fire Protection Association (NFPA) reported that the most likely cause of detector false alarms is oil fume because its particle size as well as its refractive index are very close to that of real fire smoke [30]. As a result, oil fume is used as a typical interferential aerosol. For aerosols, scattered light intensity under different scattering channels constitutes their spatial feature vector data. Considering that the proposed classification method is expected to be directly applicable to existing photodetectors, data from four detection channels with dual wavelengths and dual angles are used. Moreover, as mentioned in previous subsection, aerosols are continuously generated and aggregated during measurement, thus the scattered light intensity under different time constitutes the temporal feature vector data. To ensure that the scattering feature matrix is a square matrix, the temporal feature vector has the same length as the spatial feature vector, i.e., it consists of the scattered light intensity data at the current moment and the three previous moments. The class of aerosols (real fire smoke and interferential aerosol) and each aerosol dataset used for classification is shown in Tables. 1 and 2.

Table 1.
The class of real fire smoke and interferential aerosol.
| Aerosol | Beech smoke (TF2) | Cotton smoke (TF3) | Polyurethane smoke (TF4) | N-Heptane smoke (TF5) | Oil fume (Interferential aerosol) |
| Class (label) | Class 1 | Class 2 | Class 3 | Class 4 | Class 5 |
| Feature dataset |
Table 2.
The dataset of aerosol Class 1 used for classification.
| Class 1 | Channel 1 | Channel 2 | Channel 3 | Channel 4 |
| Time 1 | ||||
| Time 2 | ||||
| Time 3 | ||||
| Time 4 |
2.3. Embedded spatial-temporal convolution neural network
EST-CNN model consists of three modules: data preprocessing, feature analysis and classification. Among them, the data preprocessing and feature analysis modules use CNN and the classification module uses FCN. The overall structural design and network logic schematic of the EST-CNN model are shown in Figs. 1 and 2, respectively. Limited by the processor performance of the photoelectric smoke detector, the overall number of parameters of the model is required to be as few as possible, i.e., the number of layers and nodes of the network are required to be tailored as much as possible. Therefore, in data preprocessing, both the spatial and temporal data of the scattered light intensity are extracted with one layer of CNN to extract the corresponding feature vectors respectively. The scattering feature extraction network is composed of three CNNs with convolutional kernels of size , , . Aerosol classification network is a single full connected layer with Softmax function.
Figure 1.
The overall structural of EST-CNN.
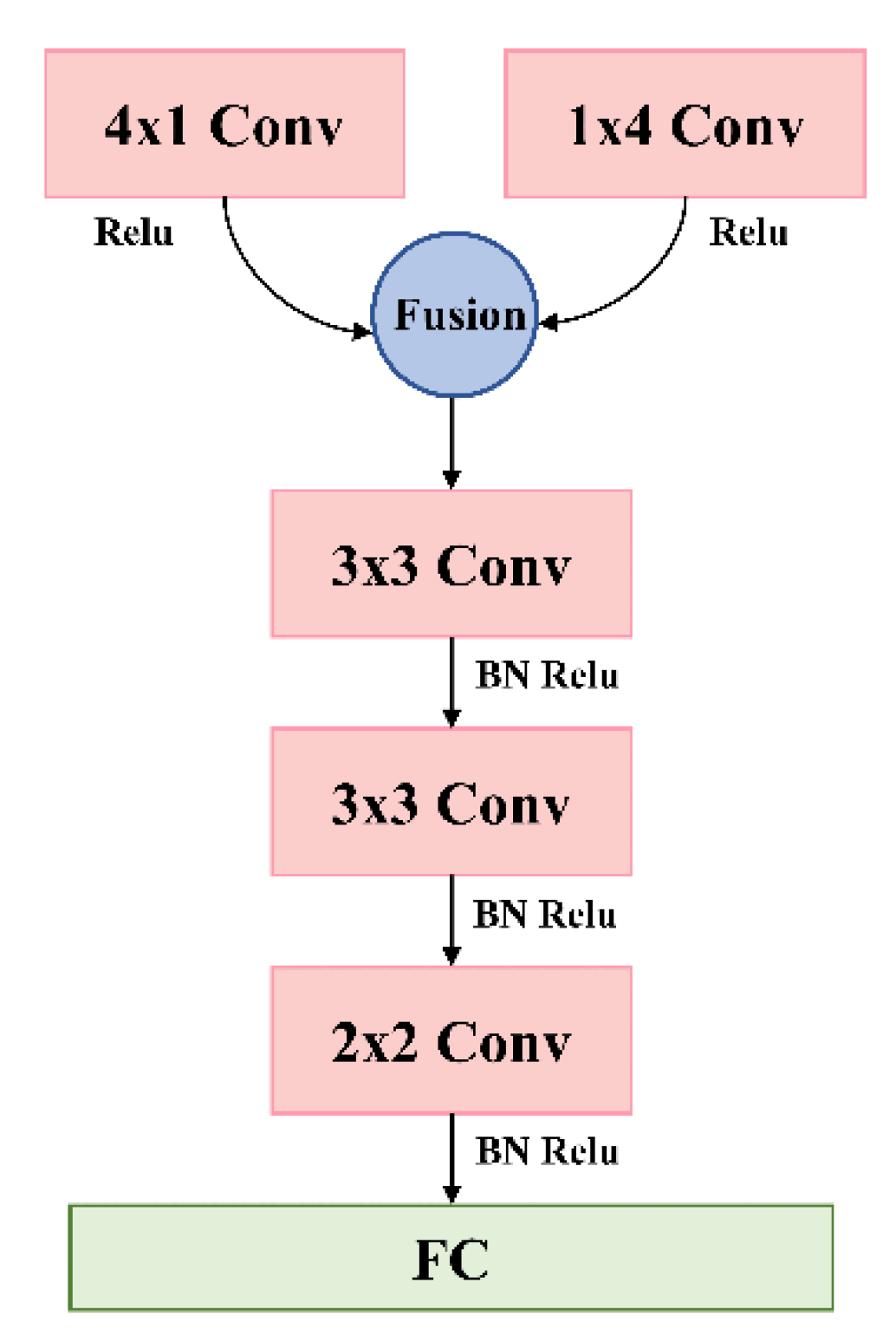
Figure 2.
The logic schematic of EST-CNN.
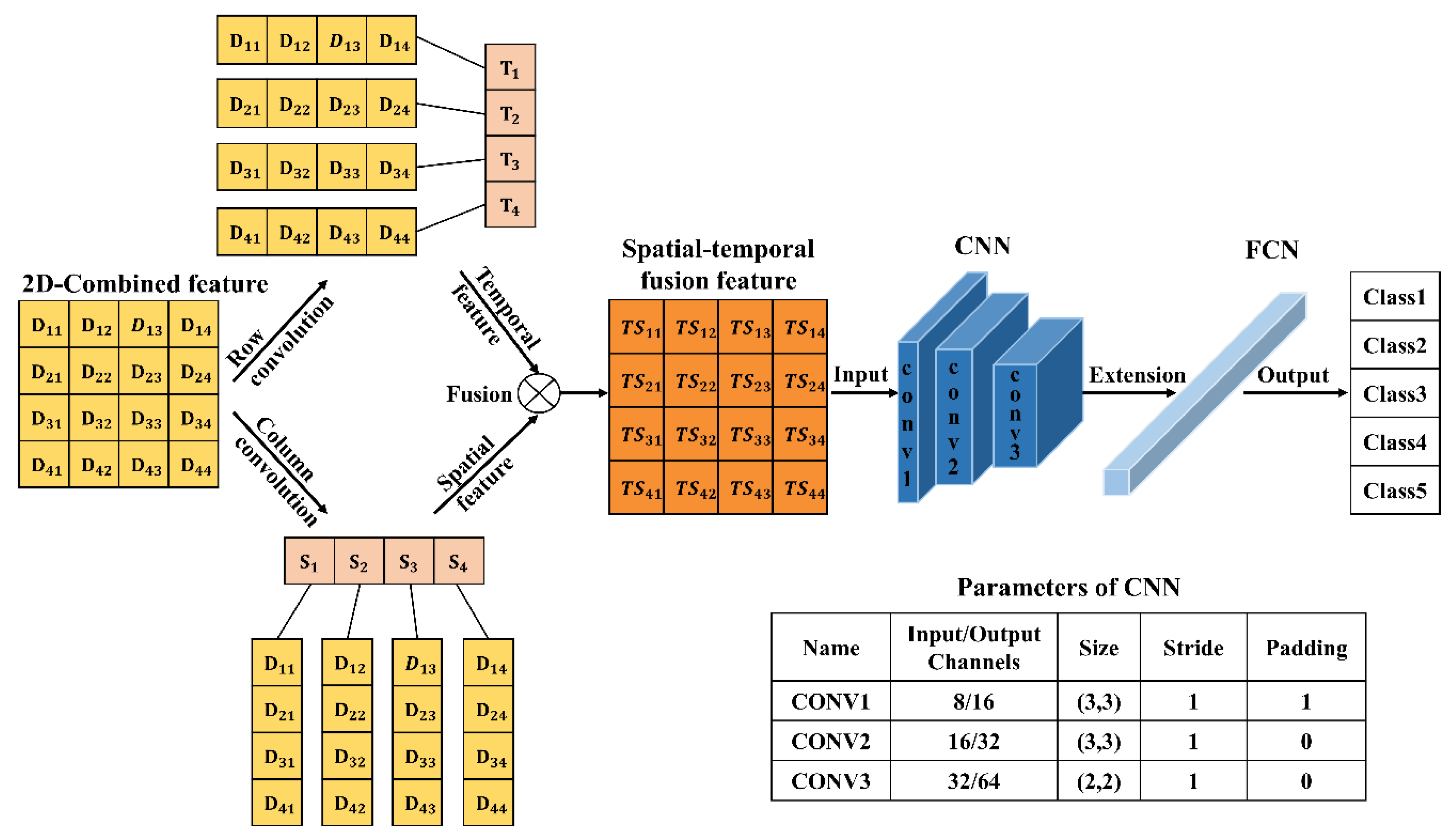
As shown in Figure 2, 2D-Data matrix recodes the original scattered light intensity, whose row and column vectors are convolved to obtain the temporal and spatial features vector of the scattered light intensity. Then, the spatial-temporal fusion scattering feature matrix (2D-TS matrix) is obtained by vector outer product. 2D-TS matrix is the input of the feature extraction network which contains three CNNs, each consisting of a convolutional layer, a normalization layer, and a Rule activation layer. The last level output is extended to 1D vector as the input of FCN. The network model is trained and tested with actual measurements of scattered light intensity from photoelectric smoke detectors. The PR curve is used to evaluate the training performance of the model, and the larger area of the curve and the area enclosed by the coordinate axis indicates the better training performance. Confusion matrix heat map is used to demonstrate the classification accuracy of the trained model for smokes (oil fume). In the PR curve, P and R are the accuracy and recall of the classification prediction results, respectively, which are defined as shown in Eqs. (3) and (4).
where , , and represent true positive, false positive, and false negative, respectively. In fire alarms, they mean true fire, false alarm and missed alarm respectively. A larger area enclosed by the PR curve indicates a better balance between false alarms and missed alarms. The score is employed to quantify the general performance of the PR curve, as shown in Eq. (5).
3. Results and discussion
3.1 Experimental platform and datasets
Experimental platform and the photoelectric detector are shown in Figure 3. Figure 3a shows a complete view of the experimental area, including the experimental platform, the hood, and the photoelectric smoke detector placed on the ceiling. Figure 3b shows the physical appearance of the photoelectric smoke detector and the internal structure of the measurement chamber. Figure 3c shows a scheme of measurement principle of a photoelectric smoke detector. The detector consists of a dual-wavelength emitter LED that can emit 480 nm blue light and 980 nm infrared light and three photoreceivers. LED emits two wavelengths of light in sequence. The photoreceiver at the 40° position receives forward blue and infrared light, the photoreceiver at the 100° position receives infrared light, and the photoreceiver at the 140° position receives blue light. Thus, scattered light intensity data can be obtained for four channels and for each measurement. These channels are selected based on simulation calculations by substituting the typical characteristic parameters of these five classes of aerosols based on Mie scattering theory.
Real fire smokes and oil fume are generated as shown in Figure 4. Beech wood smoke is obtained by heating in a resistance-heated furnace. Cotton smoke is obtained under smouldering conditions. Polyurethane and n-heptane smoke are generated by open flame combustion. Oil fume is generated by frying minced pork. Smoke and fume naturally diffuse into the photoelectric smoke detector during the measurement. After each measurement, the hood is turned on to exhaust the aerosol generated from the experiment. The scattered light intensity value measured by the photoelectric smoke detector when there is no smoke is used as a background. The value of scattered light intensity due to smoke (oil fume) is obtained by subtracting the background value from the scattered light intensity measurement. Experiments show that beech and cotton smoulder slowly and generate a small amount of white smoke. Polyurethane and n-heptane combust rapidly and generate large amount of black smoke with a high carbon content due to insufficient combustion. This means that the trend of the scattered light intensity over time is directly related to the class of smoke (oil fume). Thus, multiple four-channel samples of scattered light intensity are collected in chronological order for each experiment during smoke (oil fume) generation to acquire the temporal scattering feature.
3.2 Classification results
19552 samples of beech, cotton, polyurethane, n-heptane smokes, and oil fume are obtained on the experimental platform for the classification which are divided into training and test sets in a ratio of 7:3. These algorithms run in PyCharm (PyCharm Community Edition 2020.1) using PC of Intel(R) Core(TM) i7-10510U CPU @ 1.80 GHz 2.30 GHz. The EST-CNN model is trained and tested using multiple sets of parameters to find the optimal parameters with low amount of network parameters and high classification accuracy.
CNN for feature learning and extraction typically have more than 3 convolutional layers used to increase and decrease the dimensionality of the data. To realize the model running on low-computing power embedded chips, the number of parameters of the model is required to be as few as possible. Therefore, the EST-CNN model applies only 3 convolutional layers in the feature extraction network, and the input data size of the first layer is 4 (number of channels) × 4 (sampling time points). The previous input and final output channels of the feature extraction network are connected with the 2D-TS matrix and full connected classification layer, respectively, which are set to constant values of 8 and 64. In this way, the main parameters that can be adjusted in the model are the number of input and output channels in the middle layer, stride, and padding. For the channels, the number of output channels in each layer of the network is required to be the same as the number of input channels in the next layer. Stride represents the number of data that the convolution kernel slides over in each slide. Padding is the complementary zeros around the boundaries of the input matrix. The parameters of the partial sets of the feature extraction network are shown in Table. 3, and the corresponding training and testing results are shown in Figs. 5-9. In these figures, Class 1, 2, 3, 4, and 5 represent the beech smoke, cotton smoke, polyurethane smoke, n-heptane smoke, and oil fume, respectively.
Table 3.
The parameters of the feature extraction network.
| Set | Layer number | Layer type | Input channel | Output channel | Convolutional kernel size | Stride | Padding | Parameters |
| 1 | 1 | Conv | 8 | 16 | 3×3 | 1 | 1 | 66 kB |
| 2 | Conv | 16 | 32 | 3×3 | 1 | 0 | ||
| 3 | Conv | 32 | 64 | 2×2 | 1 | 0 | ||
| 2 | 1 | Conv | 8 | 32 | 3×3 | 1 | 1 | 158 kB |
| 2 | Conv | 32 | 64 | 3×3 | 1 | 0 | ||
| 3 | Conv | 64 | 64 | 2×2 | 1 | 0 | ||
| 3 | 1 | Conv | 8 | 32 | 3×3 | 1 | 1 | 295 kB |
| 2 | Conv | 32 | 128 | 3×3 | 1 | 0 | ||
| 3 | Conv | 128 | 64 | 2×2 | 1 | 0 | ||
| 4 | 1 | Conv | 8 | 16 | 3×3 | 1 | 1 | 66 kB |
| 2 | Conv | 16 | 32 | 3×3 | 2 | 1 | ||
| 3 | Conv | 32 | 64 | 2×2 | 1 | 0 | ||
| 5 | 1 | Conv | 8 | 16 | 3×3 | 1 | 1 | 66 kB |
| 2 | Conv | 16 | 32 | 3×3 | 2 | 1 | ||
| 3 | Conv | 32 | 64 | 2×2 | 2 | 0 |
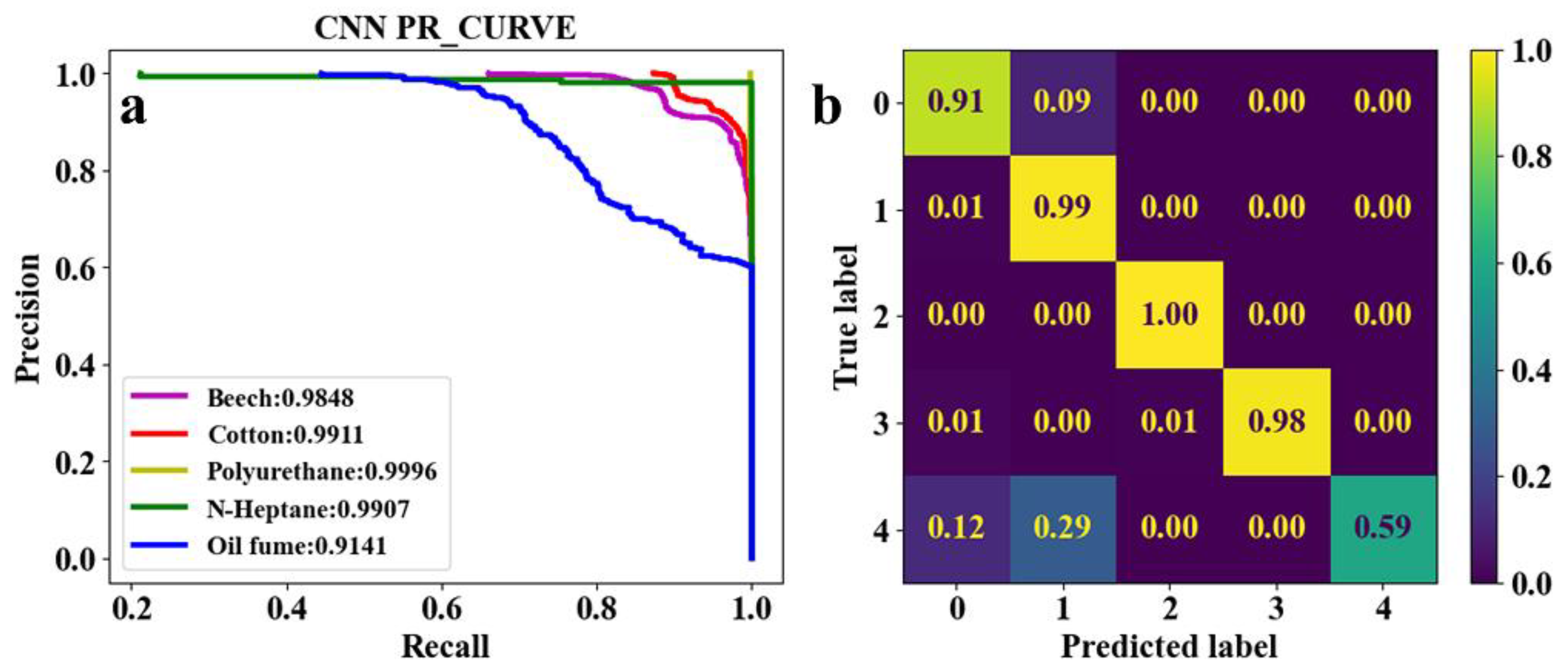
As shown in Table. 3, both the first convolutional layer and the second convolutional layer of Set. 2 have more output channels than those of Set. 1. Similarly, those of Set. 3 have more channels than those of Set. 2. As a result, the number of parameters in Set. 2 and Set. 3 are respectively 2.4 and 4.5 times that of Set. 1. However, it can be seen from Figs. 5a and 6a that the score of Set. 1 and Set. 2 are very close to each other. This demonstrates that trained under both sets of parameters, the network model converges well to reliable classification performance. Meanwhile, as shown in Figs. 5b and 6b, test results indicate that the classification accuracy of beech smoke is higher in Set. 1 than in Set. 2, oil fume is slightly lower than in Set. 2, and the other three classes of smoke have almost the same classification accuracy under Set. 1 and Set. 2. Thus, it is considered that the increased number of parameters in Set. 2 is meaningless. Moreover, as shown in Figure 7a, the score of oil fume PR curve in Set. 3 is only 0.9141, which is lower than that in Set. 1 and Set. 2. Combined with Figure 7b, it can be seen that while the parameters selected in Set. 3 resulted in an increase in the classification accuracy of cotton, polyurethane, and n-heptane smokes, the missed alarm rate for oil fume increased dramatically. Therefore, the number of input and output channels of each layer in Set. 1 is optimal.
Figure 5.
Classification results of five classes of real fire smokes and interferential aerosol (oil fume) under EST-CNN model using Set. 1 network parameters. a Training result, b test result.
Figure 5.
Classification results of five classes of real fire smokes and interferential aerosol (oil fume) under EST-CNN model using Set. 1 network parameters. a Training result, b test result.
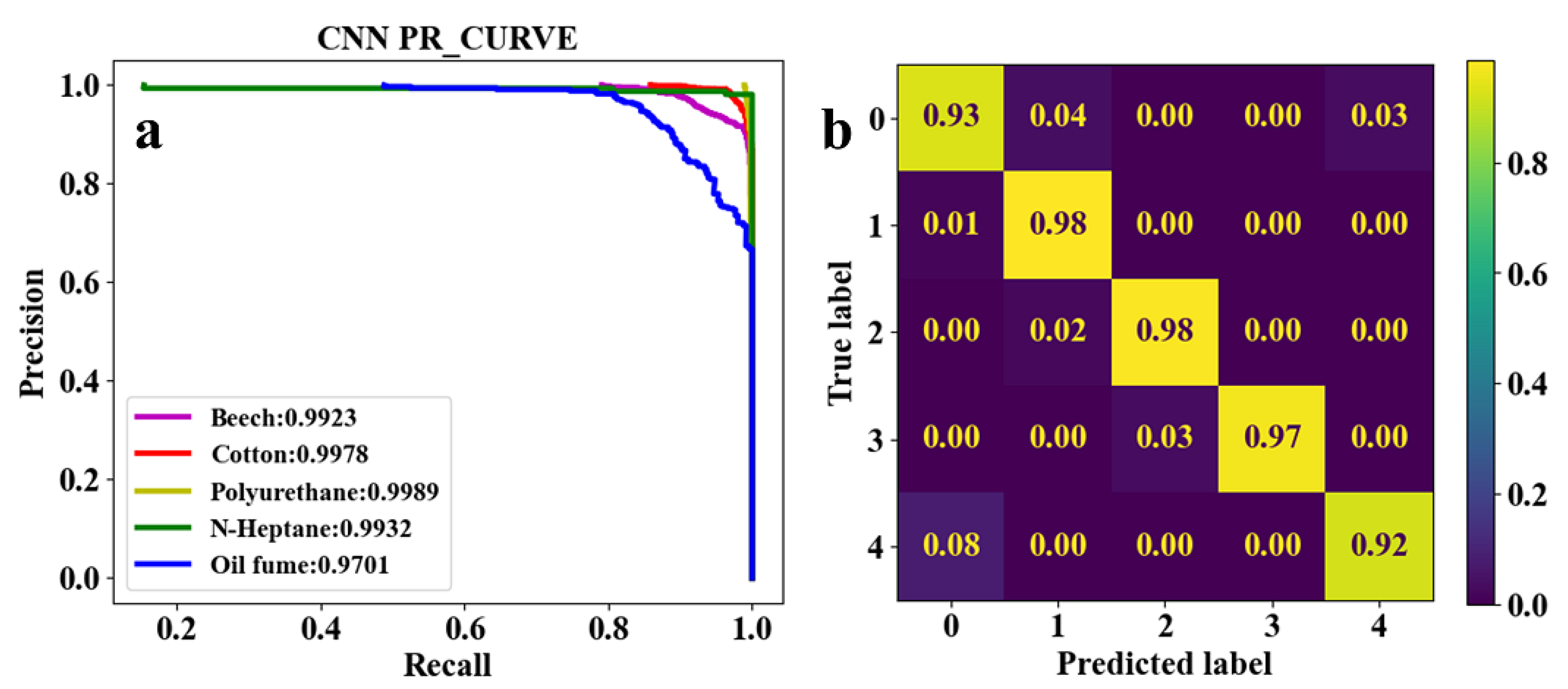
Figure 6.
Classification results of five classes of real fire smokes and interferential aerosol (oil fume) under EST-CNN model using Set. 2 network parameters. a Training result, b test result.
Figure 6.
Classification results of five classes of real fire smokes and interferential aerosol (oil fume) under EST-CNN model using Set. 2 network parameters. a Training result, b test result.
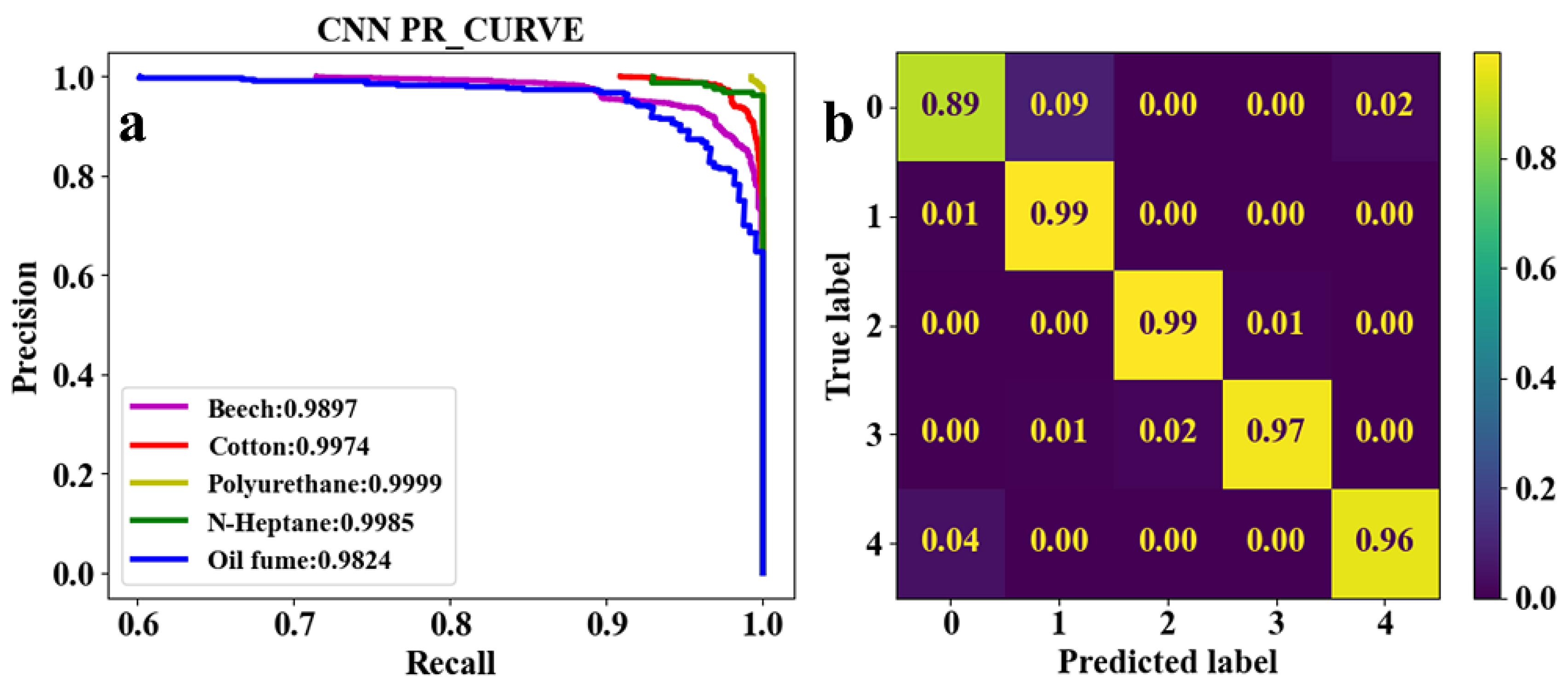
Figure 7.
Classification results of five classes of real fire smokes and interferential aerosol (oil fume) under EST-CNN model using Set. 3 network parameters. a Training result, b test result.
Figure 7.
Classification results of five classes of real fire smokes and interferential aerosol (oil fume) under EST-CNN model using Set. 3 network parameters. a Training result, b test result.
To further reduce the number of parameters, the stride and padding are adjusted, as Set. 4 and 5 in Table. 3. The convolution process is essentially a multiplication of two matrices, after the convolution process, the original input matrix will have a certain degree of shrinkage, when the stride is 1, the matrix length and width will be reduced by 2. When the length and width of the original input matrix are small (e.g., 4 × 4 of the 2D-TS matrix), padding the data with zeros is required before the convolution operation in order to keep the output matrix meaningful after each layer of convolution. As a result, the stride and padding usually are adjusted simultaneously, and the larger the stride the more zeros need to be padded. As shown in Table. 3, Set. 4 increases the stride of only the second convolutional layer, while Set. 5 increases the stride of both the second and third convolutional layers. Nevertheless, the number of parameters in Set. 4 and Set. 5 are not reduced and remain at 66 kB. However, it can be seen in Figs. 8 and 9 that the classification accuracy of oil fume in Set. 4 and n-heptane in Set. 5 is significantly reduced compared to those in Set. 1 as the classification results in Figure 5.
Figure 8.
Classification results of five classes of real fire smokes and interferential aerosol (oil fume) under EST-CNN model using Set. 4 network parameters. a Training result, b test result.
Figure 8.
Classification results of five classes of real fire smokes and interferential aerosol (oil fume) under EST-CNN model using Set. 4 network parameters. a Training result, b test result.
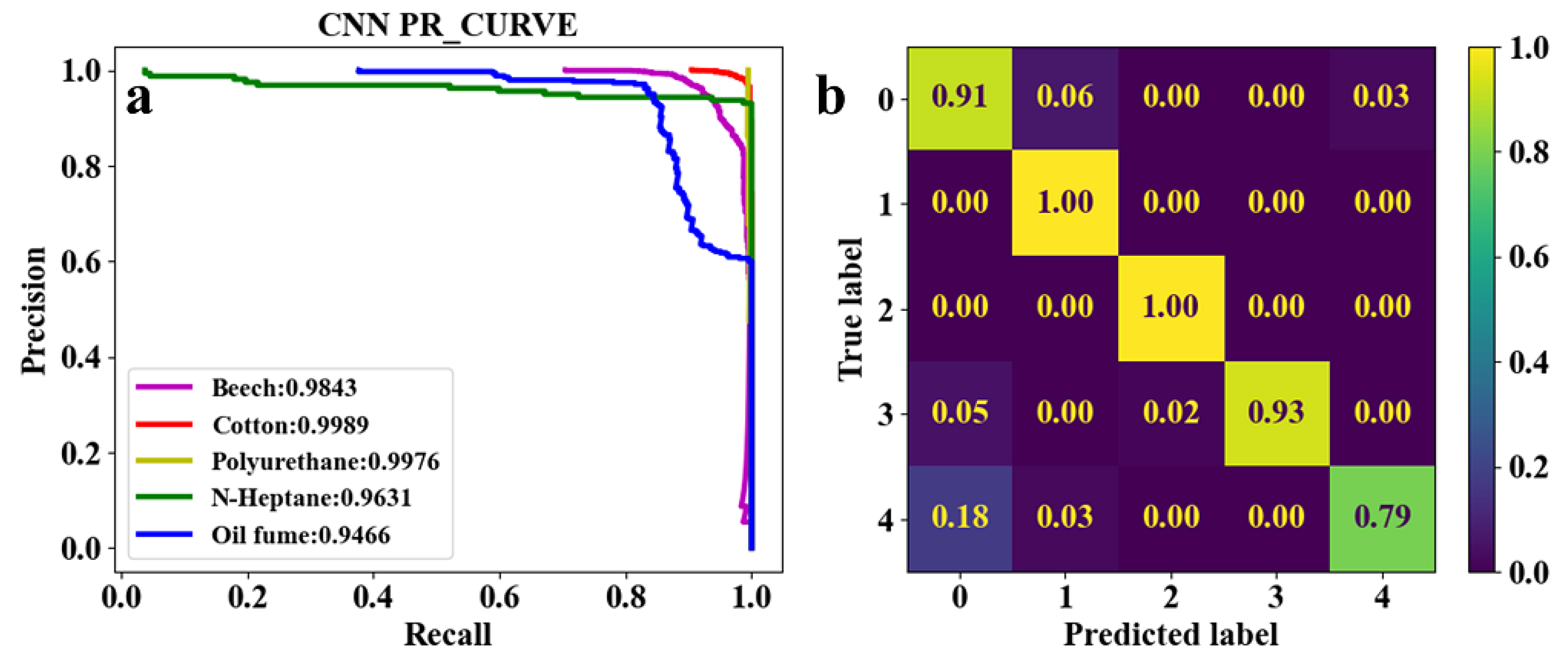
Figure 9.
Classification results of five classes of real fire smokes and interferential aerosol (oil fume) under EST-CNN model using Set. 5 network parameters. a Training result, b test result.
Figure 9.
Classification results of five classes of real fire smokes and interferential aerosol (oil fume) under EST-CNN model using Set. 5 network parameters. a Training result, b test result.
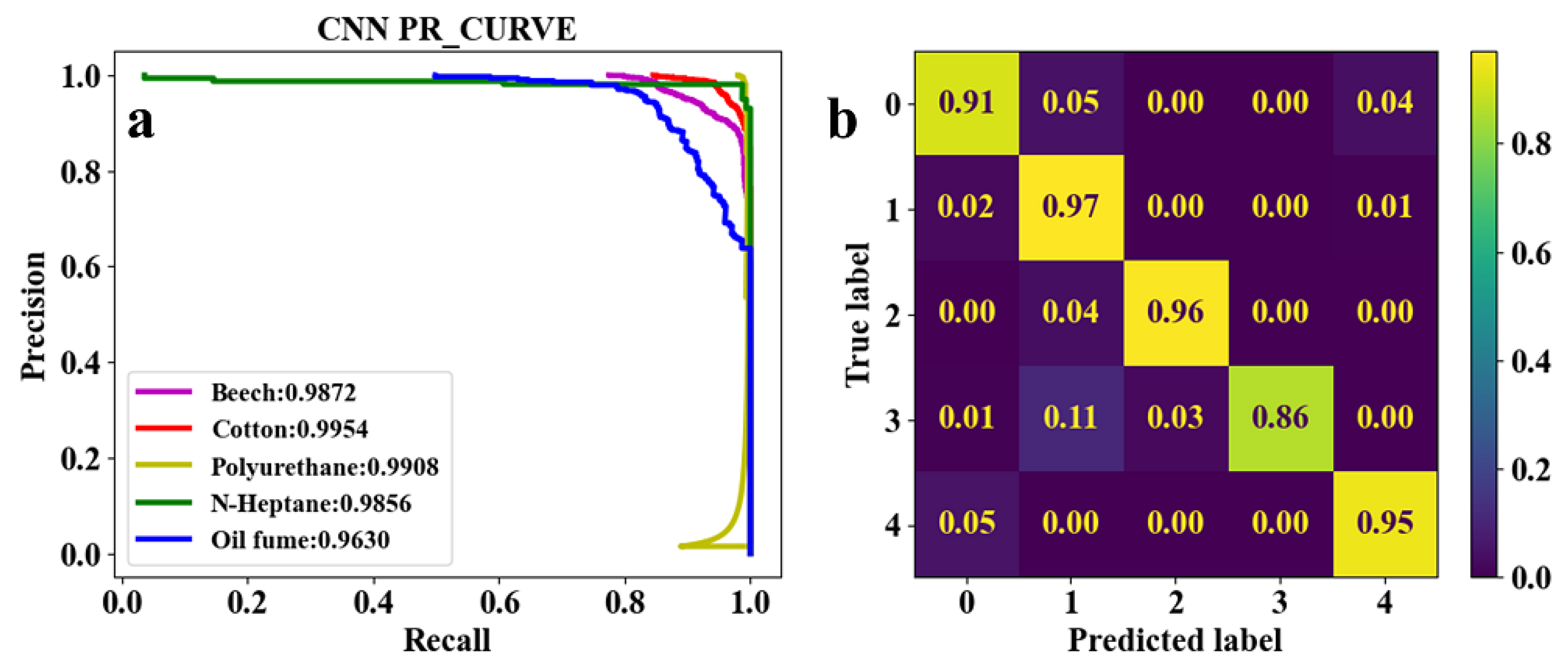
Combining Table 3 and Figs. 5-9, the average classification accuracies of fire smokes and oil fume under the five sets of model parameters are 95.6%, 96.0%, 89.4%, 92.6% and 93.0%, respectively, corresponding to the parametric quantities of 66 kB, 158 kB, 295 kB, 66 kB and 66 kB. In summary, due to the small size of the scattering feature matrix (2D-TS matrix), the parameters that can be adjusted in the convolutional layer are limited. The experimental results show that adjusting the parameters of the convolutional operation (stride and padding) has almost no influence on the number of parameters of the network model while decreasing the classification accuracy, and adjusting the number of input and output channels is an effective method to reduce the number of parameters. Therefore, the Set. 1 parameters, which have the best comprehensive performance, are recognized as the actual parameters chosen for EST-CNN.
4. Conclusions
In this study, an embedded neural network named EST-CNN for multi-class aerosol classification of real fire smokes and interferential aerosol is proposed. In EST-CNN, information fusion module works for fusing the spatial and temporal scattered light intensity information which contain the inherent physical properties such as particle size, shape and refractive index of the aerosol and combustion properties such as generation rate, respectively. To acquire the real aerosol scattered light intensity information, a detector with the same number of channels as the common photoelectric smoke detectors in the market is developed and a real fire test platform is established for experimental measurements. Then, the scattering feature extraction network with three convolutional layers is applied to obtain the most advantageous sample features in preparation for realizing aerosol classification in the last layer of FCN. To minimize the size of the network parameters while ensuring high enough classification accuracy, the performance of multiple sets of network parameters is tested and an optimal set of parameters is selected. The experimental results show that the classification accuracy of beech smoke, cotton smoke, polyurethane smoke, n-heptane smoke, and oil fume can reach 93%, 98%, 98%, 97%, and 92% while the number of parameters is only 66 kB using the network model with the selected optimal parameters.
Although the method proposed in this study has made significant contributions in the area of aerosol classification and accurate identification of smoke from real fires, there are still many problems to be investigated in depth. For instance, how to set reasonable alarm thresholds for each class of smoke after smoke recognition and classification in order to achieve a truly very early and efficient alarm effect. In addition, generally the scattered light reception sensitivity of photoelectric smoke detectors made in different batches by different manufacturers is inconsistent, which leads to differences between scattered light intensity measurements in the same case. In machine learning such a situation is called distributional pair misalignment, which means that each detector requires specific model parameters, which is impractical. Therefore, adapting network models with better generalization ability is our following study.
Author Contributions
Conceptualization, Fang Xu and Maosen Wang; methodology, Mengxue Lin; software, Maosen Wang; validation, Mengxue Lin.; formal analysis, Maosen Wang; investigation, Mengxue Lin and Lei Chen; resources, Ming Zhu; data curation, Maosen Wang and Lei Chen; writing—original draft preparation, Mengxue Lin; writing—review and editing, Fang Xu and Ming Zhu; project administration, Ming Zhu; funding acquisition, Fang Xu and Ming Zhu. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Key Research and Development Program of China (Grant No. 2021YFC3001600), National Natural Science Foundation of China (Grant No. 62071189).
Conflicts of Interest
The authors declare no conflict of interest.
References
- J. Baek, T. J. Alhindi, Y. Jeong, M. K. Jeong, S. Seo, J. Kang, W. Shim, Y. Heo, Real-time fire detection system based on dynamic time warping of multichannel sensor networks, Fire Saf. J., 123(2021), 103364. [CrossRef]
- G. Xu, Y. Zhang, Q. Zhang, G. Lin, J. Wang, Deep domain adaptation based video smoke detection using synthetic smoke images, Fire Saf. J., 93(2017), pp. 53-59. [CrossRef]
- G. Xu, Y. Zhang, Q. Zhang, G. Lin, Z. Wang, Y. Jia, J. Wang, Video smoke detection based on deep saliency network, Fire Saf. J., 105(2019), pp. 277-285. [CrossRef]
- C. Li, B. Yang, H. Ding, H. Shi, X. Jiang, J. Sun, Real-time video-based smoke detection with high accuracy and efficiency, Fire Saf. J., 117(2020), 103184. [CrossRef]
- Y. Huo, Q. Zhang, Y. Zhang, J. Zhu, J. Wang, 3DVSD: An end-to-end 3D convolutional object detection network for video smoke detection, Fire Saf. J., 134(2022), 103690. [CrossRef]
- H. Jang, C. Hwang, Obscuration threshold database construction of smoke detectors for various combustibles, Sensors, 20(2020), 6272. [CrossRef]
- T. Cleary, G. Taylor, Evaluation of empirical evidence against zone models for smoke detector activation prediction, fire technol., 59(2023), pp. 3129-3156. [CrossRef]
- A.S. Pundir, B. Raman, Dual deep learning model for image-based smoke detection, Fire Technol., 55(2019), pp. 2419–2442. [CrossRef]
- T. Liu, J. Cheng, X. Du, X. Luo, L.Zhang, B. Cheng, Y. Wang, Video smoke detection method based on change-cumulative image and fusion deep network, Sensors, 19(2019), 5060. [CrossRef]
- X. Zheng, F. Chen, L. Lou, P. Cheng, Y. Huang, Real-time detection of full-scale forest fire smoke based on deep convolution neural network, Remote Sens., 14(2022), 536. [CrossRef]
- X. Li, J.S.R. Sáez, A. Vázquez-López, X. Ao, R.S. Díaz, D. Wang, Eco-friendly functional cellulose paper as a fire alarming via wireless warning transmission for indoor fireproofing, Ind. Crop. Prod., 200(2023), 116805. [CrossRef]
- S. Festag, False alarm ratio of fire detection and fire alarm systems in Germany-A meta analysis, Fire Saf. J., 79(2016), pp. 119-126. [CrossRef]
- M. Jiang, Y. Zhao, F. Yu, C. Zhou, T. Peng, A self-attention network for smoke detection, Fire Saf. J., 129(2022), 103547. [CrossRef]
- M. Lin, M. Z, X. Xiao, C. Li, J. Wu, Optical sensor for combustion aerosol particle size distribution measurement based on embedded chip with low-complexity Mie scattering algorithm, Opt. Laser Technol., 158(2023), 108791. [CrossRef]
- M. Lin, M. Zhu, C. Li, Aerosol Sauter mean diameter measurement based on the light scattering response of the combined particle volume-surface area, Opt. Express, 31(2023), pp. 3490-3503. [CrossRef]
- M. Lin, M. Zhu, C. Li, Y. Chen, In situ optical sensor for aerosol ovality and size, Sensor. Actuat. A-Phys., 347(2022), 113963. http://doi.10.1016/j.sna.2022.113963.
- M. Loepfe, P. Ryser, C. Tompkin, D. Wieser, Optical properties of fire and non-fire aerosols, Fire Saf. J., 29(1997), pp. 185-194. [CrossRef]
- T. Deng, S. Wang, X. Xiao, M. Zhu, Eliminating the effects of refractive indices for both white smokes and black smokes in optical fire detector, Sensor. Actuat. B-Chem., 253(2017), pp. 187-195. [CrossRef]
- T. Chaudhry, K. Moinuddin, Method of identifying burning material from its smoke using attenuation of light, Fire Saf. J., 93(2017), pp. 84-97. [CrossRef]
- N. Qu, Z. Li, X. Li, S. Zhang, T. Zheng, Multi-parameter fire detection method based on feature depth extraction and stacking ensemble learning model, Fire Saf. J., 128(2022), 103541. [CrossRef]
- M. Yu, H. Yuan, K. Li, J. Wang, Research on multi-detector real-time fire alarm technology based on signal similarity, Fire Saf. J., 136(2023), 103724. [CrossRef]
- G. Liu, H. Yuan, L. Huang, A fire alarm judgment method using multiple smoke alarms based on Bayesian estimation, Fire Saf. J., 136(2023), 103733. [CrossRef]
- R. Zheng, S. Lu, Z. Shi, C. Li, H. Jia, S. Wang, Research on the aerosol identification method for the fire smoke detection in aircraft cargo compartment, Fire Saf. J., 130(2022), 103574. [CrossRef]
- G. Mie, Beiträge zur optik trüber medien, speziell kolloidaler metallösungen, Annn. Phys. 330(1908), pp. 377-445.
- Q. Xie, H. Yuan, H. Guo, Experimental study on false alarms of smoke detectors caused by kitchen oil fume, Fire Sci. Technol., 22(2003), pp. 504-507. [CrossRef]
- M.A. Jackson, I. Robins, Gas sensing for fire detection: Measurements of CO, CO2, H2, O2, and smoke density in European standard fire tests, Fire Saf. J., 22(1994), pp. 181-205. [CrossRef]
- ISO 7240-9, Fire Detection and Alarm Systems--Part 9: Test Fires for Fire Detectors [S], 2012.
- L. Shen, Z. Mei, W. Zheng, Research on multi-information data of cooking fumes in standard combustion room. Fire Safety Science, 2008. DOI:10.3901/JME.2008.05.160.
- E.R. Coffey, D. Pfotenhauer, A. Mukherjee, Kitchen area air quality measurements in northern Ghana: evaluating the performance of a low-cost particulate sensor within a household energy study, Atmosphere, 400(2019), pp. 1–27. [CrossRef]
- W.C. Tam, E.Y.Fu, A. Mensch, A. Hamins, C. You, G. Ngai, H. Leong, Prevention of cooktop ignition using detection and multi-step machine learning algorithms, Fire Saf. J., 120(2021), 103043. [CrossRef]
Figure 3.
Experimental platform and the photoelectric detector.

Figure 4.
Four classes of standard real fire smoke and one class of interferential aerosol oil fume.
Figure 4.
Four classes of standard real fire smoke and one class of interferential aerosol oil fume.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



