
Submitted:
10 November 2023
Posted:
13 November 2023
You are already at the latest version
Abstract
In the realm of the five-category classification endeavor, there has been limited exploration into applied techniques for classifying Arabic text. These methods have primarily leaned on singletask learning, incorporating manually crafted features that lack robust sentence representations. Recently, the Transformer paradigm has emerged as a highly promising alternative. However, when these models are trained using single-task learning, they often face challenges in achieving outstanding performance and generating robust latent feature representations, especially when dealing with small datasets. This issue is particularly pronounced in the context of the Arabic dialect, which has a scarcity of available resources. Given these constraints, this study introduces an innovative approach to dissecting sentiment in Arabic text. This approach combines Inductive Transfer (INT) with the Transformer paradigm to augment the adaptability of the model and refine the representation of sentences. By employing self-attention SE-A and feed-forward sub-layers as a shared Transformer encoder for both the five-category and three-category Arabic text classification tasks, this proposed model adeptly discerns sentiment in Arabic dialect sentences. The empirical findings underscore the commendable performance of the proposed model, as demonstrated in assessments of the Hotel Arabic-Reviews Dataset, the Book Reviews Arabic Dataset, and the LARB dataset.
Keywords:
transformer
; inductive transfer
; text classification
; Arabic dialects
; positional encoding
; 5-polarity
MSC: 68T07
1. Introduction
Text classification, a computational technique, involves discerning and comprehending the emotional sentiment conveyed in a text, be it a sentence, document, or social media message. This process proves invaluable for businesses aiming to glean insights into the perceptions surrounding their brands, products, and services, as gleaned from online interactions with customers. Notably, platforms like Twitter experience a substantial daily surge in user-generated content in Arabic, a trend anticipated to persist with an anticipated rise in user-generated content in the years ahead. Opinions expressed in Arabic are estimated to constitute about five percent of the languages represented on the Internet. Furthermore, Arabic has emerged as one of the most influential languages in the online sphere in recent years. Spoken by a global community of over 500 million individuals, Arabic belongs to the Semitic language family. It serves as the official and administrative language in over 21 countries, spanning from the Arabian Gulf to the Atlantic Ocean. In terms of linguistic structure, Arabic possesses a rich and intricate system compared to English, and its distinctive feature lies in the presence of numerous regional variations. The substantial distinctions between Modern Standard Arabic (MSA) and Arabic dialects (ADs) contribute to the heightened complexity of the language. Additionally, within the realm of Arabic, an intriguing linguistic phenomenon known as diglossia arises, where individuals employ Arabic vernaculars in casual settings and turn to Modern Standard Arabic (MSA) for formal contexts. As an illustration, residents of Syria adapt their language choice based on the situation, seamlessly switching between MSA and their local Syrian dialects. The Syrian dialect serves as a reflection, mirroring the intricate tapestry of the nation's history, cultural identity, heritage, and shared life experiences. It's worth noting that Arabic dialects exhibit regional diversity, encompassing the Levantine dialects of Palestine, Jordan, Syria, and Lebanon, the Maghrebi dialects prevalent in Morocco, Algeria, Libya, and Tunisia, as well as the Iraqi and Nile Basin dialects spoken in Egypt and Sudan, alongside the Arabian Gulf dialects used in the UAE, Saudi Arabia, Qatar, Kuwait, Yemen, Bahrain, and Oman. Unraveling the sentiments expressed in these various Arabic variations presents a distinctive challenge due to the complex interplay of morphological features, diverse spellings, and the overall linguistic intricacy. Each Arabic-speaking nation takes pride in its unique vernacular, further contributing to the inherent nuances of the language. This linguistic diversity is exemplified by the fact that Arabic texts encountered on social platforms are composed in both Modern Standard Arabic (MSA) and dialectal Arabic, leading to distinct interpretations for the same word. Furthermore, within Arabic dialects (ADs), a notable syntactic concern lies in the arrangement of words. To delve into this matter, it is imperative to pinpoint the verb, subject, and object within an ADs sentence. As previously elucidated in the literature review, languages fall into distinct categories based on their sentence structures, such as subject-object-verb (as seen in Korean), subject-verb-object (as in English), verb-object-subject (as in Arabic), and others that allow for flexible phrase order, as is the case in ADs. In ADs expressions, this flexible word order imparts crucial information about subjects, objects, and various other elements. Consequently, employing a single-task learning approach and relying solely on manually crafted features proves inadequate for conducting sentiment analysis on Arabic dialects. Furthermore, these disparities in ADs present a formidable challenge for conventional deep learning algorithms and models based on word embeddings. This is because, as phrases in ADs grow lengthier, they amass a greater volume of information pertaining to objects, verbs, subjects, as well as intricate and potentially confounding contextual cues. A drawback of traditional deep learning methods is the loss of input sequence data, leading to a reduction in the performance of the sentiment analysis (SA) model as the length of the input sequence escalates. Furthermore, depending on the context, the root and characters of Arabic words can be in many different forms. In addition, the lack of systematic orthographies is one of the main problems of ADs. This deficiency includes morphological differences between these dialects, which are visible in the use of affixes and suffixes that are not found in MSA.
Furthermore, a multitude of Arabic terms display varying nuances in meaning when employing the same syntax with diacritics. Additionally, the training of sentiment analysis (SA) models rooted in deep learning calls for an extensive corpus of training data, a particularly daunting challenge in the realm of Analytical Dependencies (ADs). ADs, characterized by their lack of structured linguistic elements and resources, pose a significant hurdle for information extraction [1]. As the pool of training data dwindles for ADs, the precision of classification follows suit. Additionally, the majority of tools designed for Modern Standard Arabic (MSA) do not account for the distinctive features of Arabic dialects [2]. Relying on lexical resources, like lexicons, is also considered a less effective approach for Arabic SA due to the vast array of words stemming from various dialects, rendering it improbable to encompass all of them in a lexicon [3]. Moreover, crafting tools and resources tailored specifically for Arabic dialects proves to be a painstaking and time-intensive endeavor [4].
In recent times, there has been a notable upswing in research efforts devoted to sentiment analysis in Arabic vernaculars. These endeavors primarily center around the categorization of reviews and tweets into binary and ternary polarities. The majority of these methodologies [5–10] rely on lexicons, manually crafted attributes, and tweet-specific features, which serve as inputs for Machine Learning (ML) algorithms. Conversely, alternative approaches adopt a rule-based approach, exemplified by the process of lexicalization. This entails formulating and prioritizing a set of heuristic rules used to classify tweets as either negative or positive [11]. Moreover, the realm of Arabic sentiment ontology encompasses sentiments with varying degrees of intensity to discern user sentiments and facilitate tweet classification. Additionally, advanced deep learning techniques for sentiment classification [12-16], including recursive auto-encoders, have garnered considerable attention due to their impressive adaptability and robustness in automated feature extraction. Notably, the recently introduced transformer model [17] has surpassed deep learning models [18] across a range of natural language processing (NLP) tasks, piquing the interest of researchers delving into deep learning. The application of the transformer model, which incorporates self-attention(SE-A) mechanism to analyze the interactions among words in a sentence, has greatly enhanced the effectiveness of various endeavors in Natural Language Processing (NLP). However, strategies to tackle the challenges of Analytical Dependency Sentiment Analysis (ADs SA) are currently under examination and exploration. Up to this point, no prior research has focused on constructing an ADs text classification model based on self-attention (SE-A) within an inductive transfer (INT) framework. Inductive transfer (INT) enhances comprehension abilities, the quality of the encoder, and the proficiency of text classification compared to a traditional single-task classifier by concurrently addressing related tasks through a shared representation of textual sequences [19]. The primary advantage of inductive transfer (INT) lies in its sophisticated approach to utilizing diverse resources for similar tasks. However, the majority of methodologies used in ADs text classification studies lean towards binary and ternary classifications. Hence, our emphasis in this study pertains to the five-polarity AD SA challenge. To the best of our knowledge, no prior investigations have explored the integration of a self-attention (SE-A) approach within an inductive transfer (INT) framework for ADs text. Previous techniques addressing this classification dilemma were rooted in single-task learning (STL). In summary, our contributions can be outlined as follows:
- In this article, we present a cutting-edge Transformer model that incorporates inductive transfer (INT) for the purpose of conducting Analytical Dependencies text classification. We have meticulously designed a specialized INT model that makes use of the self-attention mechanism, aiming to exploit the connections between three to five distinct polarities. To achieve this, we employ a transformer encoder, which integrates both self-attention and Feedforward Layers (FFL), serving as a foundational layer shared across the tasks. We elucidate the process of simultaneously and interchangeably training on two tasks—ternary and five-class classifications—within the inductive transfer (INT) framework. This strategic approach aims to enhance the representation of ADs text for each task, resulting in an expanded spectrum of captured features.
- In this research endeavor, we investigated how altering the number of encoders and utilizing multiple attention heads (AH) within the self-attention (SE-A) sublayer of the encoder influences the performance of the proposed model. The training regimen encompassed a range of dimensions for word embedding and utilized a shared vocabulary that was applied across both tasks.
2. Related Work
The research focused on five-level classification tasks in Arabic text classification has received less attention compared to binary and ternary polarity classification tasks. Moreover, the majority of approaches applied to this task rely on traditional machine learning algorithms. For instance, methods based on corpora and lexicons were evaluated using Bag of Words (BoW) features along with a range of machine learning algorithms including passive-aggressive (PA), support vector machine (SVM), logistic regression (LR), naive Bayes (NB), perceptron, and stochastic gradient descent (SGD) on the Arabic Book Review dataset [20]. In a related study using the same dataset, [21] explored the effects of stemming and balancing the BoW features using various machine learning algorithms. They discovered that stemming led to a decrease in performance. Another strategy presented in [22] proposed a divide-and-conquer approach to tackle ordinal-scale classification tasks. Their model was organized as a hierarchical classifier (HC) in which the five labels were divided into sub-problems. They noted that the HC model outperformed a single classifier. Building on this foundation, several hierarchical classifier configurations were suggested [23]. These configurations were compared with machine learning classifiers such as SVM, KNN, NB, and DT. The experimental outcomes indicated that the hierarchical classifier enhanced performance. Nevertheless, it should be noted that many of these configurations demonstrated reduced performance.
Another investigation [24] delved into various machine learning classifiers, encompassing LR, SVM, and PA, using n-gram characteristics within the Book Reviews in Arabic Dataset (BRAD). The findings demonstrated that SVM and LR achieved the most impressive results. Similarly, [25] assessed a range of sentiment classifiers, including AdaBoost, SVM, PA, random forest, and LR, on the Hotel Arabic-Reviews Dataset (HARD). Their findings highlighted that SVM and LR exhibited superior performance when paired with n-gram features. The previously mentioned methodologies conspicuously overlook the incorporation of deep learning techniques for the five-tier polarity classification tasks in Arabic Sentiment Analysis. Furthermore, the majority of approaches targeted at these five polarity tasks rely on traditional machine learning algorithms that hinge on the feature engineering process, a method deemed time-consuming and laborious. Additionally, these approaches are founded on single-task learning (STL) and lack the capability to discern the interrelationships between various tasks (cross-task transfer) or to model multiple polarities simultaneously, such as both five and three polarities.
Other research endeavors have employed Inductive Transfer (INT) to address the challenge of five-point Sentiment Analysis (SA) classification tasks. For example, in [26], a Inductive Transfer model centered on a Recurrent Neural Network (RNN) was proposed, simultaneously handling five-point and ternary classification tasks. Their model comprised Bidirectional Long Short-Term Memory (Bi-LSTM) and Multilayer Perceptron (MLP) layers. Additionally, they incorporated tweet-specific attributes like punctuation counts, elongated words, emoticons, and sentiment lexicons to augment the feature set. The study concluded that training SA classification tasks collectively heightened the efficacy of the five-polarity task. Similarly, in [27], the interplay between five-polarity and binary sentiment classification tasks was leveraged by concurrently learning them. The suggested model featured an encoder (LSTM) and decoder (variational auto-encoder) as shared layers for both tasks. Empirical results indicated that the INT model bolstered performance in the five-polarity task. The introduction of Adversarial Multitasking Learning (AINT) was first presented in [28]. This model incorporated two LSTM layers as task-specific components and one LSTM layer shared across tasks. Additionally, a Convolutional Neural Network (CNN) was integrated with the LSTM, and the outputs of both networks were merged with the shared layer output to form the ultimate sentence latent representation. The authors determined that the proposed INT model elevated the performance of five-polarity classification tasks and enhanced encoder quality. Although the INT strategies delineated above have been applied in English, a conspicuous dearth exists in the application of Inductive Transfer and deep learning techniques to five-polarity Arabic Sentiment Analysis. Existing studies for this task predominantly rely on single-task learning with machine learning algorithms. Therefore, there remains ample room for improvement in the effectiveness of current Arabic Sentiment Analysis approaches for the five polarities, which still stands at a relatively modest level.
Further investigations have leveraged deep-learning techniques in Sentiment Analysis (SA) across a diverse array of domains, encompassing finance [29,30], evaluations of movies [31-33], Twitter posts related to weather conditions [34], feedback from travel advisors [35], and recommendation systems for cloud services [36]. As highlighted by the authors in [34], text attributes were automatically extracted from diverse data sources. Weather-related knowledge and user information were transformed into word embedding through the application of the word2vec tool. This approach has been adopted in multiple research studies [29,37]. Jeong et al. [48] delineated opportunities for product development by fusing topic modeling with SA insights gleaned from social media content generated by customers. This methodology has served as a real-time monitoring tool for scrutinizing the evolving demands of clients in dynamic product environments. Numerous papers have employed sentiment analysis based on polarity using deep learning techniques applied to Twitter posts [38,39,40,41]. The researchers elucidated how the employment of deep learning methodologies led to an augmentation in the precision of their distinct sentiment analyses. While the majority of these deep learning models have been implemented for English text, there are a few models that handle tweets in other languages, such as Persian [37], Thai [40], and Spanish [42]. The researchers conducted analyses on tweets utilizing various models tailored for polarity-based Sentiment Analysis, including Deep Neural Networks (DNN), Convolutional Neural Networks (CNN), hybrid models [41], and Support Vector Machines (SVM) [43].
Various methods have been suggested to identify fake information, with most of them concentrating solely on linguistic attributes, disregarding the potential of dual emotional characteristics. Luvembe et al. [44] present an efficient strategy for discerning false information by harnessing dual emotional attributes. To accomplish this, the authors employ a stacked bi-GRU layer to extract emotional traits and represent them in a feature vector space. Furthermore, the researchers implement a profound attention mechanism atop the Bi-GRU to enhance the model's ability to grasp vital dual-emotion details. By using the extracted emotional traits as input, the authors apply the Adaptive Genetic Weight Update Random Forest, which repeatedly selects the most pertinent dual characteristics. This iterative procedure significantly boosts the classifier's precision in detection. To assess the proposed technique, the authors conduct extensive trials utilizing three openly accessible datasets. The experimental outcomes illustrate that the suggested model surpasses existing approaches in accurately spotting fabricated information. To summarize, the researchers introduce an innovative approach that incorporates dual emotional features, and the findings indicate its supremacy over conventional methodologies in the domain of fake information detection. Lei et al. [45] present MsEmoTTS, a multi-scale framework for synthesizing emotional speech that aims to model emotions at various tiers. The approach follows a standard attention-based sequence-to-sequence model and integrates three crucial components: the global-level emotion-representation module (GM), the utterance-level emotion-representation module (UM), and the local-level emotion-representation module (LM). Each module is tasked with capturing the overarching emotion category, the variation in emotion at the utterance level, and the strength of emotion at the syllable level, respectively. Moreover, the proposed technique provides flexibility in emotional speech synthesis. It enables the transfer of emotion from a reference audio source, prediction of emotion from the input text, and manual adjustment of emotion intensity during the synthesis process. To evaluate its performance, comprehensive experiments were conducted utilizing a Chinese corpus of emotional speech. The findings demonstrate that MsEmoTTS surpasses existing methods relying on reference audio and text-based approaches for emotional speech synthesis, excelling in both emotions transfer and emotion prediction tasks.
Li et al. [46] introduce a fresh methodology termed "Attributed Influence Maximization based on Crowd Emotion" (AIME). The main goal is to scrutinize the influence of multi-dimensional characteristics on the dissemination of information, by incorporating user emotion and group attributes. To assess the interplay of individual emotions, two metrics are defined: user emotion potency and cluster credibility. Furthermore, a method for discovering potential influential users is proposed, making use of an emotion aggregation mechanism to pinpoint sets of seed candidates. To accommodate the complexities of real-world networks, a two-factor model for information propagation is put forth. This model aims to precisely capture the intricacies involved in the spread of information. Extensive experiments carried out on actual datasets validate the effectiveness of the AIME algorithm. The findings demonstrate that AIME surpasses heuristic approaches and yields results comparable to greedy methods while significantly enhancing time efficiency. The experimental results affirm its superiority over traditional methods, highlighting its potential as an efficient and potent tool for comprehending the dynamics of information dissemination.
A plethora of scholarly articles has increasingly relied on Twitter datasets as a fundamental source for constructing and refining models for sentiment analysis. For example, Vyas et al. [47] introduced an innovative hybrid framework that blends a lexicon-based approach with deep learning techniques to scrutinize and categorize the sentiments conveyed in tweets pertaining to COVID-19. The central aim was to automatically discern the emotions conveyed in tweets about this subject matter. To accomplish this, the authors employed the VADER lexicon method to identify positive, negative, and neutral sentiments, which were then used to tag COVID-19-related tweets accordingly. In the categorization process, a range of machine learning (ML) and deep learning (DL) techniques were utilized. Among these, the LSTM technique exhibited the most superior performance, achieving a classification accuracy of 83%, outperforming the other methods. Additionally, the ML classifier demonstrated a noteworthy speed improvement, approximately ten times faster than the VADER method. These results emphasize the potential of promptly and automatically categorizing societal sentiments related to COVID-19 on the Twitter platform. Such insights could play a pivotal role in steering public health awareness campaigns. Furthermore, Qureshi et al. [48] introduce a model designed to assess the polarity of reviews written in Roman Urdu text. To accomplish this objective, raw data was collected from critiques of 20 songs originating from the Indo-Pak Music Industry. This investigation led to the development of an innovative dataset comprising 24,000 assessments in Roman Urdu. The research employed nine diverse Machine Learning algorithms, including Naïve Bayes, Support Vector Machine, Logistic Regression, K-Nearest Neighbors, Artificial Neural Networks, Convolutional Neural Networks, Recurrent Neural Networks, ID3, and Gradient Boost Tree. Among these algorithms, Logistic Regression showcased the highest efficacy, demonstrating superior performance with testing and cross-validation accuracies of 92.25% and 91.47% respectively. Furthermore, Alali [49] introduced a multitasking approach termed the Multitask learning Hierarchical Attention Network, engineered to enhance sentence representation and enhance generalization. This framework employs a shared word encoder and attention network for both tasks, utilizing a combined and alternating training strategy for the analysis of three-polarity and five-polarity Arabic sentiment. The outcomes of the experiments underscore the outstanding effectiveness of this proposed model. Additionally, the model displayed an exceptionally low macro mean absolute error of 0.632% when applied to the Arabic tweets dataset, effectively rising to the challenge of five-point Arabic sentiment classification.
3. The Proposed Transformer-Based Text Classification Model for Arabic Dialects that Utilizes Inductive Transfer
We designed a text classification model employing self-attention (SE-A) and Inductive Transfer (INT) for classifying text in ADs. The goal of utilizing INT (Inductive Transfer) is to improve the performance of Arabic sentiment analysis, which involves classifying ADs into five-point scales, by leveraging the relationship between the AD sentiment analysis tasks (in both five and ternary polarities). Our approach, the transformer text classification T-TC-INT model that utilize Inductive Transfer (INT), is based on the transformer model recently introduced by Vaswani et al [17]. Inductive Transfer (INT) proves more advantageous than single-task learning (STL), as it employs a shared representation of various loss functions, simultaneously addressing sentiment analysis tasks (with three and five polarities) to enhance the representation of semantic and syntactic features in AD text. Knowledge gained from one task can benefit others in learning more effectively. Additionally, a significant advantage of INT is its ability to tap into resources developed for similar tasks, thereby enhancing the learning process and increasing the amount of useful information available. Sharing layers across associated tasks enhances the model's ability to generalize, learn quickly, and comprehend what it has learned. Furthermore, by leveraging domain expertise observed in the training signals of interconnected tasks as an inductive bias, the INT method facilitates prompt transfers that improve generalization. This inductive transfer aids in increasing the accuracy of generalization, the speed of learning, and the clarity of the learned models. A learner engaged in multiple interconnected tasks simultaneously can use these tasks as an inductive bias for one another, resulting in a better grasp of the domain's regularities. This approach allows for a more effective understanding of sentiment analysis tasks for ADs, even with a small amount of training data. Furthermore, Inductive Transfer can concurrently capture the significant interrelationships between the tasks being learned. As illustrated in Figure 1, our proposed T-TC-INT approach features a unique architecture based on the SE-A, INT, shared vocabulary, and 1D_GlobalAveragepooling layer. The T-TC-INT model we propose is designed to handle diverse classification tasks, encompassing both ternary and five-polarity classification tasks, and it learns them simultaneously. By incorporating a shared transformer block (encoding layer), we enable the transfer of knowledge from the ternary task to the five-point task as part of the learning process. This leads to an enhancement in the learning capabilities of the current task (the five-point task). The encoder within our proposed T-TC-INT model, as depicted in Figure 1, consists of a range of distinct layers. Each layer is further divided into two sublayers: self-attention (SE-A) and position-wise feed-forward (FNN).
In this suggested structure, the encoder employs the SE-A and FNN sublayers to classify ADs of varying lengths without resorting to RNN and CNN algorithms. The model we propose utilizes these sublayers to encode the input phrases from ADs, generating an intermediate representation. The encoder in the suggested model corresponds the input sentence into a vector representation sequence . By considering , the T-TC-INT model generates the sentiment of an AD sentence. Word embeddings, a form of word representation in the realm of natural language processing (NLP), are designed to encapsulate the semantic associations among words. They manifest as numerical vectors that depict words within a continuous, compact space, where words sharing akin meanings or contextual relevance are positioned in closer proximity. Word embeddings have evolved into a cornerstone of numerous NLP applications, including machine translation and sentiment analysis. In contrast, traditional approaches for representing words in NLP, such as one-hot encoding, represent words as sparse binary vectors. In this scheme, each word receives a distinct index and is essentially treated as a standalone entity. This representation falls short in capturing the underlying semantic connections between words, thereby posing challenges for machine learning models in grasping word meanings in context. Word embeddings, conversely, capture these semantic links by adhering to the distributional hypothesis, which posits that words found in similar contexts tend to share similar meanings. By mapping words to dense vectors within a continuous space, word embeddings possess the ability to capture subtleties in meaning, synonymy, analogy, and more. This empowers machine learning models to acquire a deeper comprehension of word semantics and their interrelations. What sets word embeddings apart is their contextual richness. The embedding of a word can adapt to varying contexts, altering based on the surrounding words. This dynamic feature permits the representation to flexibly adjust and align with different contextual scenarios. The embedding layer in the encoder converts the input tokens (source tokens in the encoder) into a vector of dimension . When the information needed for token proximity is interpreted in the SE-A sub-layer, the information for the token’s position is embedded through positional encoding (PE). Particularly, the PE is a matrix that represents the position details of the tokens in the input sentence, and the suggested T-TC-INT system integrates the PE into the embedding matrix of the input tokens. Each part of the PE is determined utilizing sine and cosine function equations with unstable frequencies.
where the indicates the position of each input token, represents the dimension of each element, and represents the embedding dimension of the input tokens. The embedding matrix combined with the PE is fed to the encoder’s first layer. The encoder subnetwork consists of similar layers, where is set to different numbers 12, 8, 2, and 4. Each encoding layer consists of two layers: an SE-A sublayer and a FNN sublayer. A residual connection method and a layer normalization unit (Layer Norm) are utilized on every sublayer to support training and improve performance. The output of every layer is calculated as follows:
where is the output from the SE-A sublayer calculated based on the input sentence representation of the prior encoding layer
3.1. Self- Attention (SE-A)
Self-Attention mechanism (SE-A) is a key component of the seq-2seq design and is utilized to solve an array of sequence-generation problems, such as NMT and document summarization [50]. Figure 2 shows how the T-TC-INT model for ADs accomplishes the scale-dot product attention function. This function uses three vectors as inputs: queries Q, values V, and keys K. It describes the given query and key-value pairs as a weighted sum of values. The weights reveal the relationship between each query and the key. The following is an explanation of the attention method.
where is the key, is the value, and is a query. and are the lengths of the sequences expressed as and , respectively. and are the dimensions of the value and key vectors, respectively. The query dimension is expressed as to perform the dot product calculation. We divided by to measure the output of the product operation, thereby maintaining the calculation of Vaswani et al. [17]. The overall attention weight distribution was obtained by applying the operation to the attention score . For better performance, the transformer architecture uses SE-A, which comprises (number of head attentions) measured dot product attention operations. Provided the , , and , the SE-A computation is as follows:
where , and are the projections of the query, key, and value vectors, respectively, for the head. These projections were made using the metrics , , and . The inputs to the MHA(.) are and . is the output of the measured dot-product calculation for the head. The measured dot product operation was combined using the concatenation function to generate . Eventually, the output is obtained from the projections of using the weight matrix The SE-A contains the same number of parameters as the vanilla attention.
The T-TC-INT model leverages the self-attention (SE-A) mechanism, enabling it to discern the relative importance of each word within a sentence, capturing subtle sentiments and their varying degrees of intensity. Furthermore, the model incorporates a self-attention mechanism (SE-A) that allows it to contextualize words in relation to their neighboring words, leading to more refined sentiment predictions. The T-TC-INT model has undergone meticulous training on a diverse dataset to ensure its efficacy across a spectrum of Arabic text styles and domains. Consequently, the proposed approach for text classification in ADs using Transformer (T) and Inductive Transfer (INT) provides a more precise representation of sentiments, effectively addressing the challenge of varying intensities within the Arabic text classification spectrum.
4. Practical Experiments:
Several practical experiments were performed in order to assess the T-TC-INT model for Arabic dialect ADs. The ADs classification performance of the proposed T-TC-INT model was assessed.
4.1. Data
The proposed model was trained using two prominent benchmark datasets. The initial dataset, HARD [25], consisted of reviews sourced from various reservation websites, which were subsequently categorized into five distinct groups. The second dataset, BRAD [24], and the third dataset, LARB [51], were also utilized. All three datasets (BRAD, HARD, and LARB) employed in this research were analyzed at the review level. BRAD reviews were collected from the Goodreads website and organized into five scales. Detailed class distributions for the HARD, BRAD, and LARB datasets are presented in Table 1, Table 2 and Table 3 respectively. It is worth noting that the datasets used in this research project were left unprocessed, potentially impacting the reliability of the suggested model. Furthermore, all sentences underwent preprocessing. This involved employing sentence breakers to segment reviews into individual sentences. Additionally, any English letters, non-Arabic words and characters, diacritics, hashtags, punctuation, and URLs were completely removed from all ADs texts. Orthographic normalization was applied to all ADs texts. Furthermore, emoticons were replaced with their corresponding explanations, and elongated words were preprocessed. To prevent potential overfitting, an early stopping mechanism with a patience parameter set to three epochs was employed. Additionally, when evaluating the proposed T-TC-INT model for ADs, the model checkpoint mechanism was utilized to save the most optimal weights of the suggested model. In addition to their partitioning for training and testing, the HARD, BRAD and LARB datasets offer valuable insights into the distribution of polarities across their samples. The HARD dataset, comprising a total of 409,562 samples, is divided into 5 polarities, each representing distinct sentiments or attitudes. With 80% of the dataset allocated for training (327,649 samples) and 20% for testing (81,912 samples), these proportions provide a comprehensive representation of the different polarities within both subsets. Similarly, the BRAD dataset, encompassing 510,598 samples, is partitioned with 80% (408,478 samples) for training and 20% (101,019 samples) for testing. Also, LARB dataset encompassing 63,257 samples, is partitioned with 80% (50,606 samples) for training and 20% (12,651 samples) for testing. This partitioning scheme ensures that the 5-polarities are adequately represented in both the training and testing phases, enabling models to grasp the nuances of sentiment variation and effectively generalize their understanding to unseen data.
Biases can have a major influence on sentiment analysis model performance. When biases exist in the data that used to train theses model, they can lead to distorted results. To address the issue of biases and how to select data for the proposed T-TC-INT text classification model for ADs, we considered five steps:
- Ensured that the training data include a variety of sources and cover a wide range of demographics, geographical areas and social circumstances; this will allow to decrease biases and provide a more comprehensive and balanced dataset.
- Ensured that the sentiment labels in the training data are balanced across all demographics groups and opinions; this assists in minimizing overgeneralization and biases caused by imbalance of sentiment examples.
- Established clear labeling guidelines that explicitly instruct human annotators to be impartial and avoid injecting their own biases into the sentiment labels; this can help maintain consistency and minimize biases.
- Performing a detailed analysis of the training data to identify possible biases. This can include checking demographic imbalances, serotype reinforcement or underrepresented groups. Once detected, we took suitable steps to address these biases such as data augmentation, oversampling of underrepresented groups or doing pre-processing technique.
4.2. Settings of the Proposed T-TC-INT Model
The proposed T-TC-INT text classification model was created using Tensor-Flow [52], Keras [53], and scikit-learn [54] frameworks. The experiments for all Arabic dialects (AD) classification tasks, encompassing both three and five polarities, were conducted employing diverse parameter configurations. These included six values for the word-embedding dimension: 512, 300, 256, 128, 64, and 50. Additionally, the attention heads were varied with options of 12, 10, 8, 6, 4, and 2. The position-wise Feedforward Neural Network (FNN) featured filters with dimensions of 512, 300, 256, 128, 64, and 50. The recently devised model incorporates a shared encoder subnetwork with layers, 3, 2, and 1, as well as a one-dimensional average pooling layer tailored for each classification task (ternary and five polarities) on ADs.
4.3. Training Mechanism of the Proposed T-TC-INT Model
Inductive Transfer models employ two primary training methodologies: joint training and alternative training. Joint training entails simultaneously training a model on multiple tasks, allowing for the sharing of information and the acquisition of representations that benefit all tasks. This approach capitalizes on the interdependencies between tasks to enhance overall performance. Conversely, alternative training focuses on training the model on tasks one at a time, cycling through them iteratively. This enables the model to give concentrated attention to each task, potentially leading to improved performance for each task in isolation. Both approaches have their merits and drawbacks. Joint training can lead to superior generalization across tasks, while alternative training may excel in tasks with significant disparities in data distribution or complexity. The selection between these strategies hinges on the specific characteristics of the tasks at hand and the desired trade-offs in performance and efficiency. Ultimately, the choice of training methodology plays a pivotal role in shaping the effectiveness and adaptability of Inductive Transfer models.
The suggested system adeptly manages both three-category and five-category classification tasks. For instance, during the training process on the HARD dataset, the proposed T-TC-INT text classification system seamlessly transitions between instructing the model on the five-category and three-category classification tasks. We examined two different strategies for training the model: alternating [57, 58] and joint learning. In our Inductive Transfer configuration, we apply the loss function and optimizer for each task sequentially. This implies that the training procedure begins with the three-category classification task for a specified number of epochs before shifting to the five-category classification task. The primary goal in training both tasks was to minimize the categorical cross-entropy. The proposed T-TC-INT text classification model underwent training for 12 epochs, implementing an early stopping mechanism set to activate after two epochs, with a batch size of 90. We followed standard protocols for the HARD, BRAD, and LARB datasets, dividing them into an 80% training subset and a 20% testing subset. We opted for the Nadam optimizer to guide each task within the proposed T-TC-INT text classification model. We employed a sentence breaker to segment reviews into sentences, with maximum sentence lengths set at 80 for HARD, 50 for BRAD, and 80 for LARB. The class weights methodology was not integrated into the proposed model [59]. Prior to each epoch, the training data undergoes a random shuffling process. Further details on hyper-parameters can be located in section 4.5.
4.4. State-of-Art Approaches:
Utilizing the BRAD, HARD, and LARB datasets with five-point scales for investigating ADs, we evaluated the T-TC-INT model specifically tailored for this purpose against the most current standard techniques. Initially, Logistic Regression (LR) was introduced in [24] employing unigrams, bi-grams, and TF-IDF, and was subsequently applied to the BRAD dataset. Similarly, Logistic Regression (LR) was initially recommended in [25] using unigrams, bi-grams, and TF-IDF, and was then put into action on the HARD dataset. Our proposed T-TC-INT model has also undergone a comparative assessment utilizing the LABR datasets. These established methods encompass the following: First, the Support Vector Machine (SVM), which employs a support vector machine classifier with n-gram characteristics, as advocated in [58]. Second, the Multinomial Naive Bayes (MNB), which implements a multinomial Naive Bayes approach with bag-of-words attributes, as outlined in [51]. Third, the Hierarchical Classifiers (HC), a model utilizing hierarchical classifiers, is constructed based on the divide-and-conquer technique introduced by [59]. Finally, Enhanced Hierarchical Classifiers (HC(KNN)), which is a refined iteration of the hierarchical classifiers model, still rooted in the divide-and-conquer strategy as elucidated by [60]. In recent developments, tasks in Natural Language Processing (NLP) have achieved remarkable proficiency by harnessing the power of the bi-directional encoder representation from transformers, known as BERT [61]. The AraBERT [62], an Arabic pre-trained BERT model, underwent training on three distinct corpora: OSIAN [63], Arabic Wikipedia, and the MSA corpus, encompassing a staggering 1.5 billion words. We conducted a comparative evaluation between the proposed ST-SA system for ADs and AraBERT [62], which boasts 786 latent dimensions, 12 attention facets, and a composition of 12 encoder layers.
4.5. Results:
Numerous practical trials were conducted using the recommended T-TC-INT text classification (TC) system tailored for Arabic dialects. The T-TC-INT text classification (TC) system was put through training with varying configurations of attention heads (AH) in the self-attention (SE-A) sub-layer, as well as different numbers of encoders, to determine the most effective system structure. Diverse word-embedding dimensions were employed in the training of the proposed T-TC-INT text classification system. This study delved into the repercussions of training the proposed system using two multitasking methodologies - jointly and alternately - to gauge its performance. The efficacy of sentiment analysis in the proposed system was assessed using an automated accuracy metric. This section presents the evaluation of the proposed T-TC-INT text classification system for the task of classifying sentiments into five categories for ADs. The outcomes of the practical experiments on the datasets HARD, BRAD, and LARB are detailed in Table 4, Table 5 and Table 6, respectively. The performance of the suggested T-TC-INT text classification model was summarized when applying both joint and alternate learning methods to the HARD and BRAD datasets in Table 10. As elucidated in Figure 3, along with Table 4 and Table 7, the T-TC-INT text classification system attained an accuracy of 81.83% on the imbalanced HARD dataset. In this setup, the number of attention heads was two, encoding layers numbered two, and the word-embedding dimension stood at 300. This commendable accuracy was achieved due to the positive impact of employing the inductive transfer (INT) framework and the self-attention (SE-A) approach on right-to-left texts, such as ADs. In comparison to the top-performing LR [64] system on the HARD dataset, the results obtained by the proposed T-TC-INT text classification model surpassed it, exhibiting an accuracy difference of 5.79%. Furthermore, the proposed model outperforms AraBERT [62] with a difference in accuracy of 0.98%. Hence, simultaneous learning tasks bolstered the volume of usable data, and the risk of overfitting was mitigated [65]. The suggested system demonstrated proficiency in capturing both syntactic and semantic features, effectively discerning sentiments within ADs sentences.
Furthermore, the proposed T-TC-INT text classification system demonstrated its superior effectiveness on the imbalanced BRAD dataset. As depicted in Figure 4 and outlined in Table 5, the suggested model achieved an accuracy of 61.73%. This was observed when employing six attention heads (AH), two encoding layers, and a word-embedding dimension of 128. As elucidated in Table 8, the recommended T-TC-INT text categorization system surpassed the logistic regression (LR) method put forward by [24] with a notable accuracy margin of 14.03%. It also outperformed the AraBERT model [62] with an accuracy difference of 0.88%. Additionally, the integration of a self-attention-based shared encoder with two distinct global-average pooling one-dimensional layers (one for each classification task) empowers the proposed model to capture a comprehensive representation, encompassing the preceding, subsequent, and local contexts of any position within a sentence.
Moreover, the introduced T-TC-INT model, depicted in Figure 5 and detailed in Table 6, exhibited outstanding performance on the demanding LARB imbalanced dataset. This innovative model attained a commendable accuracy of 78.13%, surpassing alternative AP methodologies. Specifically, employing a defined setup featuring two Attention Heads (AH), two encoding layers, a filter size of 128, and a word-embedding dimension of 200, the proposed system demonstrated its efficacy. This accomplishment highlights the resilience of the INT-MHA SA model in tackling the intricacies of sentiment analysis within the imbalanced dataset scenario. As shown in Table 9, the INT-MHA SA system outperformed various alternative methods, showcasing its superiority by significant margins. For example, it displayed an impressive accuracy difference of 27.83% when compared to the SVM [58] model, a substantial 33.13% accuracy gap over the MNP [51] model, a remarkable 20.33% accuracy lead over the HC(KNN) [59] model, as well as a noteworthy 19.17% accuracy difference compared to AraBERT [62]. Additionally, the proposed model even outperformed HC(KNN) [60] by an accuracy margin of 5.49%.
Joint training in deep learning is a methodology where a single neural network model is trained to tackle multiple interrelated tasks simultaneously. Instead of training distinct models for each task, Joint t training enables the model to exchange and acquire representations that can be advantageous for all tasks. This can result in enhanced adaptability, heightened efficiency, and potentially even elevated performance for each specific task. Imbalanced data denotes a scenario in which the distribution of categories within a dataset is uneven. In certain instances, one or more categories may possess noticeably fewer instances compared to others. Imbalanced data can pose difficulties for deep learning models as they may become skewed towards the predominant category, resulting in subpar performance for the minority categories. The assessment results highlight that the suggested T-TC-INT system, employing both joint and alternate learning, exhibited exceptional efficacy. Alternate training surpassed joint learning, attaining accuracies of 79.07% and 77.59% in the imbalanced HARD dataset, and 61.35% and 60.98% in BRAD, respectively, as outlined in Table 7. A contrast with the benchmark techniques unveiled that alternate training in the five-point classification setting can facilitate the extraction of more comprehensive feature representations within the text sequence compared to the single-task learning approach. These findings underscore that alternate learning proves more apt for addressing intricate SA tasks and has the capacity to comprehend and generate a more robust latent representation in nuanced tasks for ADs SA.
The distinction in effectiveness between the two methodologies lies in how alternate learning is influenced by the volume of data in each task. Tasks with larger datasets lead to richer shared layers. Conversely, joint learning may exhibit bias if one task's dataset significantly outweighs the other. Hence, for tasks in ADs text classification (TC), alternative training methods are recommended. Consider the scenario where we have two distinct datasets for separate tasks, such as machine translation tasks involving translation from AD to MSA and MSA to English [55]. The efficacy of each task can be heightened by constructing a network in an alternate configuration, without the need for additional training data [56]. Additionally, other tasks of relevance can bolster the efficiency of five-point classification. The significance of the enhancements in our proposed model's performance can be attributed to several factors. Surpassing a state-of-the-art model like AraBERT and LR is a notable feat in itself, given AraBERT's widely acknowledged effectiveness in Arabic language processing tasks. By outperforming AraBERT on the same datasets, our proposed model demonstrates its heightened accuracy in handling Arabic dialects. Furthermore, even a slight uptick in accuracy holds significance as it contributes to elevating the overall performance of models for processing Arabic dialects. Even minor improvements can have practical implications, such as refining the accuracy of sentiment analysis, information retrieval, or other NLP applications tailored for Arabic dialects.
4.6. Impact of Attention Head (AH) Number V in self-Attention Sub-Layer:
As depicted in Table 4, Table 5 and Table 6, the efficacy of the proposed T-TC-INT text classification system, derived from varied input representations sourced from the self-attention layer, underscores the significance of this model in the five-polarity classification task. Here, V denotes the number of attention heads (AH) within the encoding layer of the recommended T-TC-INT text classification system. The suggested system underwent training utilizing a range of V values: 2, 4, 6, 8, 10, and 12. As evidenced in Table 4, Table 5 and Table 6, there was a discernible shift in the accuracy metrics for the datasets HARD, BRAD, and LARB.
4.7. Impact of Length of Input Sentence:
Enhancing the classification of lengthy sentences hinges on acquiring comprehensive contextual knowledge and dependencies across tokens in input phrases. To facilitate this, sentences of comparable length (in terms of source tokens) were grouped together, following a methodology similar to that of Luong et al. [66]. Given the extensive nature of the HARD dataset, a five-polarity classification task was undertaken to assess the sentiment analysis (SA) performance specifically for lengthy sentences. The evaluation in this section is based on distinct length categories: <10, 10-20, 20-30, 30-40, 40-50, and >50. An automated accuracy metric was computed for the output generated by the T-TC-INT system. As depicted in Table 11, the effectiveness of the recommended T-TC-INT text classification model saw an improvement as the input sentence length increased, especially for tokens comprising 30 to 40 words and those exceeding 50 words, registering accuracy scores of 79.03 and 81.83, respectively. Leveraging multi-task learning, a self-attention mechanism, and harnessing word units as input features for the (SE-A) sub-layer, the proposed system gains contextually relevant knowledge and dependencies within tokens, regardless of their position within the ADs input phrase. However, shorter sentences containing between 10 and 20 words, as well as those with fewer than 10 words, demonstrated lower efficacy for the proposed model. Additionally, the system's performance was notably lower for sentences with fewer than 10-word tokens, exhibiting an accuracy of 76.88. The noteworthy performance of the suggested T-TC-INT text classification system across different sentence lengths serves as a testament to the effectiveness of employing the self-attention (SE-A) approach and inductive transfer (INT) framework, and employing word units as input features to enhance the encoder’s SE-A sub-layer proficiency in capturing word relationships within ADs input sentences.
4.8. Key Findings:
- T-TC-INT Model for AD Classification: The research introduces Transformer text classification model combined an Inductive Transfer (INT) framework and with a self-Attention (Se-F) approach for the classification of Arabic Dialects (ADs) into five-point categories. This architecture utilizes SE-A to enhance the representation of the global text sequence.
- Selective Term and Word Extraction: The SE-A approach employed in the model demonstrates the capability to select the most meaningful terms and words from the text sequences. This selective attention mechanism enhances the model's ability to capture essential information from the input.
- Quality Enhancement via inductive transfer (INT) and SE-A: Combining the benefits of the INT framework and using word-units as input characteristics to the SE-A sub-layer proves significant, especially for low-resource language text classification tasks, such as Arabic Dialects.
- Experimentation and Configuration Impact: Various experiments were conducted using different configurations, including the use of multiple heads in the SE-A sub-layer and training with multiple encoders. These experiments positively impacted the classification performance of the proposed system.
- Alternate Learning Outperforms Joint Learning: The findings reveal that alternate learning, as opposed to joint learning, yields better efficiency.
- Effect of Input Sentence Length: The effectiveness of the proposed T-TC-INT model increased with longer input sentence lengths, particularly for sentences with 30 to 40-word tokens and larger than 50-word tokens, achieving accuracy scores of 79.03% and 81.83%, respectively.
- State-of-the-Art Enhancement: The proposed model's practical experiment results showcase its superiority over existing approaches, evidenced by total accuracy percentages of 81.83% on HARD dataset ,61.73% on BRAD dataset and 78.13% on LARB dataset. This includes an improvement over well-known models like AraBERT and LR.
5. Conclusion
We introduce a T-TC-INT model tailored for the five-point categorization of ADs. The suggested design incorporates a SE-A methodology and employs the inductive transfer (INT) framework to enhance the comprehensive representation of the global text sequence. Moreover, the SE-A approach effectively identifies the most pertinent terms and phrases from within the text sequences. Through training on SA tasks for ADs, both ternary and five-polarity tasks, the proposed system's effectiveness was notably bolstered. Leveraging the advantages of (SE-A) and inductive transfer (INT) significantly elevates the quality of the recommended text classification system. The outcomes of this study underscore the vital attributes of the T-TC-INT model, which leverages the SE-A approach to enhance accuracy across five-point and three-point classification tasks. The incorporation of the inductive transfer (INT) framework and word-unit characteristics into the SE-A sub-layer indicates their pivotal role in handling low-resource language text classification tasks, such as those in ADs. Similarly, conducting training with diverse configurations, such as employing multiple heads in the SE-A sub-layer and employing multiple encoders, heightened the classification performance of the suggested system. We conducted a series of experiments on two datasets for five-point Arabic SA. The results highlight that alternate learning methodologies yield superior efficacy compared to joint learning, a phenomenon influenced by the dataset sizes of each respective task. Furthermore, the findings demonstrate that the proposed system outperformed other cutting-edge techniques for the HARD, BRAD, and LARB datasets. Our investigation revealed that the performance of five-point classification could be enhanced by alternately approaching the tasks of fine-grained ternary classification within the inductive transfer (INT)-based suggested model. By identifying text as negative in the ternary setup, the distinction between high negative and negative categories in five-point classification can be refined.
The empirical findings from the practical experiments, spanning both five-point and three-point classification tasks, conclusively demonstrated the enhanced accuracy of the suggested system when compared to alternative ADs text classification systems. The proposed T-TC-INT system excels in generating a robust latent feature representation for ADs text sequences. With an overall accuracy of 81.83% on HARD, 61.73% on BRAD, and 78.13% on LARB datasets, the experimental results underscore the superiority of the proposed T-TC-INT model over established state-of-the-art approaches like AraBERT [62], SVM [58], MNP [51], HC(KNN) [59], HC (KNN) [60], and LR [24]. It's worth noting that the proposed T-TC-INT system did not exhibit a significant improvement for the BRAD dataset in comparison to existing models. This discrepancy may be attributed to the fact that the BRAD Arabic dataset encompasses distinct domain-specific nuances, tones, and linguistic styles that are not adequately captured by the proposed T-TC-INT Sentiment Analysis model. The absence of domain adaptation may result in a misalignment between the model's learned features and the unique characteristics of the BRAD dataset. The in-depth investigation of the experimental setup and outcomes revealed that the system's efficiency hinged on the utilization of the SE-A strategy and the dimensionality of word embedding. It was elucidated that incorporating the SE-A technique is advantageous, as it enables the extraction of both global and local semantic knowledge within the context by leveraging the SE-A sub-layer within each encoding layer. Additionally, the proposed T-TC-INT system effectively addresses the challenge of scarce training data in ADs. Furthermore, it successfully tackles the syntactic variability present in ADs phrases. Looking ahead, future endeavors will involve the development of an Inductive Transfer text classification framework incorporating sub-word units as input features to the SE-A sub-layer [67], as well as the implementation of a novel positional encoding mechanism [68] to address the syntactic and semantic intricacies inherent in right-to-left texts like ADs.
Author Contributions
L.H.B., S.K. conceived and designed the methodology and experiments; L.H.B. performed the experiments; L.H.B. analyzed the results; L.H.B., S.K. analyzed the data; L.H.B. wrote the paper. S.K. reviewed the manuscript. All authors have read and agreed to the published version of the manuscript.
Data Availability Statement
The dataset generated during the current study is available in the [T-_TC_INT] repository (https://github.come/laith85).
Acknowledgment
This work was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF), funded by the Ministry of Science and ICT under Grant NRF-2022R1A2C1005316.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Salloum, S.A.; AlHamad, A.Q.; Al-Emran, M.; Shaalan, K. A survey of Arabic text classification. Inter Journal Elctre Comput Engi. 2018, 8, 4352–4355. [Google Scholar]
- Harrat, S.; Meftouh, K.; Smaili, K. Machine translation for Arabic dialects (survey). Inf.Process. Manag . 2019, 56, 262–273. [Google Scholar] [CrossRef]
- El-Masri, M.; Altrabsheh, N.; Mansour, H. Successes and challenges of Arabic sentiment analysis research: A literature review. Soc Netw Anal Min. 2017, 7, 54. [Google Scholar] [CrossRef]
- Elnagar, A.; Yagi, S.M.; Nassif, A.B.; Shahin, I.; Salloum, S.A. Systematic Literature Review of Dialectal Arabic: Identification and Detection. IEEE Access. 2021, 9, 31010–31042. [Google Scholar] [CrossRef]
- Abdul-Mageed, M. Modeling Arabic subjectivity and sentiment in lexical space. info.process.Manag. 2019, 56, 308–319. [Google Scholar] [CrossRef]
- Al-Smadi, M.; Al-Ayyoub, M.; Jararweh, Y.; Qawasmeh, O. Enhancing Aspect-Based Sentiment Analysis of Arabic Hotels’ reviews using morphological, syntactic and semantic features. Info. Process. Manag. 2019, 56, 308–319. [Google Scholar] [CrossRef]
- Baly, R.; Badaro, G.; El-Khoury, G.; Moukalled, R.; Aoun, R.; Hajj, H.; El-Hajj, W.; Habash, N.; Shaban, K.; Diab, M.; et al. A Characterization Study of Arabic Twitter Data with a Benchmarking for State-of-the-Art Opinion Mining Models. In Proceedings of the Third Arabic Natural Language Processing Workshop, Valencia, Spain, 3 April 2017; pp. 110–118.
- El-Beltagy, S.R.; El Kalamawy, M.; Soliman, A.B. NileTMRG at SemEval-2017 Task 4: Arabic Sentiment Analysis. In proceeding of the 11th International Workshop on Semantic Evaluation (semEval-2017), Vancouver, BC, Canada ,3-4 August 2017; pp.790-795.
- Jabreel, M.; Moreno, A. SiTAKA at SemEval-2017 Task 4: Sentiment Analysis in Twitter Based on a Rich set of Features. In proceedings of the 11th International workshops on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada ,3-4 august 2017; pp.692-697.
- Mulki, H.; Haddad, H.; Gridach, M.; Babao ˘glu, I. Tw-StAR at SemEval-2017 Task 4: Sentiment Classification of Arabic Tweets. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 664–669.
- Siddiqui, S.; Monem, A. A.; Shaalan, K. Evaluation and enrichment of Arabic sentiment analysis. Stud.Compu. Intell. 2017, 740, 17–34. [Google Scholar] [CrossRef]
- Al-Azani, S.; El-Alfy, E.S. Using Word Embedding and Ensemble Learning for Highly Imbalanced Data Sentiment analysis in short Arabic text. Pocedia Comput. Sci. 2017, 109, 359–366. [Google Scholar] [CrossRef]
- Alali, M.; Sharef, N.M.; Hamdan, H.; Murad, M.A.A.; Husin, N.A. Multi-layers convolutional neural network for twitter sentiment ordinal scale classification. Adv. Intell. Syst. Comput. 2018, 700, 446–454. [Google Scholar] [CrossRef]
- Alali, M.; Sharef, N.M.; Murad, M.A.A.; Hamdan, H.; Husin, N.A. Narrow Convolutional Neural Network for Arabic Dialects Polarity Classification. IEEE Access 2019, 7, 96272–96283. [Google Scholar] [CrossRef]
- Gridach, M.; Haddad, H.; Mulki, H. Empirical evaluation of word representations on Arabic sentiment analysis. Commun. Comput. Inf. Sci. 2018, 782, 147–158. [Google Scholar] [CrossRef]
- Al Omari, M.; Al-Hajj, M.; Sabra, A.; Hammami, N. Hybrid CNNs-LSTM Deep Analyzer for Arabic Opinion Mining. In Proceedings of the 2019 6th International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; pp. 364–368.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–9008.
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 1243–1252.
- Jin, N.; Wu, J.; Ma, X.; Yan, K.; Mo, Y. Inductive Transfer model based on multi-scale cnn and lstm for sentiment classification. IEEE Access 2020, 8, 77060–77072. [Google Scholar] [CrossRef]
- Aly, M.; Atiya, A. LABR: A large scale Arabic book reviews dataset. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Sofia, Bulgaria, 4–9 August 2013; Volume 2, pp. 494–498.
- Al Shboul, B.; Al-Ayyoub, M.; Jararweh, Y. Multi-way sentiment classification of Arabic reviews. In Proceedings of the 2015 6th International Conference on Information and Communication Systems (ICICS), Amman, Jordan, 7–9 April 2015; pp. 206–211.
- Al-Ayyoub, M.; Nuseir, A.; Kanaan, G.; Al-Shalabi, R. Hierarchical Classifiers for Multi-Way Sentiment Analysis of Arabic Reviews. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 531–539. [Google Scholar] [CrossRef]
- Nuseir, A.; Al-Ayyoub, M.; Al-Kabi, M.; Kanaan, G.; Al-Shalabi, R. Improved hierarchical classifiers for multi-way sentiment analysis. Int. Arab J. Inf. Technol. 2017, 14, 654–661. [Google Scholar]
- Elnagar, A.; Einea, O. BRAD 1.0: Book reviews in Arabic dataset. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November–2 December 2016.
- Elnagar, A.; Khalifa, Y.S.; Einea, A. Hotel Arabic-reviews dataset construction for sentiment analysis applications. Stud. Comput. Intell. 2018, 740, 35–52. [Google Scholar] [CrossRef]
- Balikas, G.; Moura, S.; Amini, M.-R. Inductive Transfer for Fine-Grained Twitter Sentiment Analysis. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Shinjuku, Tokyo, 7–11 August 2017; pp. 1005–1008.
- Lu, G.; Zhao, X.; Yin, J.; Yang, W.; Li, B. Inductive Transfer using variational auto-encoder for sentiment classification. Pattern Recognit. Lett. 2020, 132, 115–122. [Google Scholar] [CrossRef]
- Jin, N.; Wu, J.; Ma, X.; Yan, K.; Mo, Y. Inductive Transfer model based on multi-scale cnn and lstm for sentiment classification. IEEE Access 2020, 8, 77060–77072. [Google Scholar] [CrossRef]
- Sohangir, S.; Wang, D.; Pomeranets, A.; Khoshgoftaar, T.M. Big Data: Deep Learning for financial sentiment analysis. J. Big Data 2018, 5, 3. [Google Scholar] [CrossRef]
- Jangid, H.; Singhal, S.; Shah, R.R.; Zimmermann, R. Aspect-Based Financial Sentiment Analysis using Deep Learning. In Proceedings of the Companion of the The Web Conference 2018 on The Web Conference, Lyon, France, 23–27 April 2018; pp. 1961–1966.
- Ain, Q.T.; Ali, M.; Riaz, A.; Noureen, A.; Kamran, M.; Hayat, B.; Rehman, A. Sentiment analysis using deep learning techniques: A review. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 424. [Google Scholar] [CrossRef]
- Gao, Y.; Rong, W.; Shen, Y.; Xiong, Z. Convolutional neural network based sentiment analysis using Adaboost combination. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1333–1338.
- Hassan, A.; Mahmood, A. Deep learning approach for sentiment analysis of short texts. In Proceedings of the Third International Conference on Control, Automation and Robotics (ICCAR), Nagoya, Japan, 24–26 April 2017; pp. 705–710.
- Qian, J.; Niu, Z.; Shi, C. Sentiment Analysis Model on Weather Related Tweets with Deep Neural Network. In Proceedings of the 2018 10th International Conference on Machine Learning and Computing, Macau, China, 26–28 February 2018; pp. 31–35.
- Pham, D.-H.; Le, A.-C. Learning multiple layers of knowledge representation for aspect based sentiment analysis. Data Knowl. Eng. 2018, 114, 26–39. [Google Scholar] [CrossRef]
- Preethi, G.; Krishna, P.V.; Obaidat, M.S.; Saritha, V.; Yenduri, S. Application of deep learning to sentiment analysis for recommender system on cloud. In Proceedings of the 2017 International Conference on Computer, Information and Telecommunication Systems (CITS), Dalian, China, 21–23 July 2017; pp. 93–97.
- Roshanfekr, B.; Khadivi, S.; Rahmati, M. Sentiment analysis using deep learning on Persian texts. In Proceedings of the 2017 Iranian Conference on Electrical Engineering (ICEE), Tehran, Iran, 2–4 May 2017; pp. 1503–1508.
- Alharbi, A.S.M.; de Doncker, E. Twitter sentiment analysis with a deep neural network: An enhanced approach using user behavioral information. Cogn. Syst. Res. 2019, 54, 50–61. [Google Scholar] [CrossRef]
- Abid, F.; Alam, M.; Yasir, M.; Li, C.J. Sentiment analysis through recurrent variants latterly on convolutional neural network of Twitter. Future Gener. Comput. Syst. 2019, 95, 292–308. [Google Scholar] [CrossRef]
- Vateekul, P.; Koomsubha, T. A study of sentiment analysis using deep learning techniques on Thai Twitter data. In Proceedings of the 2016 13th International Joint Conference on Computer Science and Software Engineering (JCSSE), Khon Kaen, Thailand, 13–15 July 2016; pp. 1–6.
- Pandey, A.C.; Rajpoot, D.S.; Saraswat, M. Twitter sentiment analysis using hybrid cuckoo search method. Inf. Process. Manag. 2017, 53, 764–779. [Google Scholar] [CrossRef]
- Paredes-Valverde, M.A.; Colomo-Palacios, R.; Salas-Zárate, M.D.P.; Valencia-García, R. Sentiment analysis in Spanish for improvement of products and services: A deep learning approach. Sci. Program. 2017, 2017. [Google Scholar] [CrossRef]
- Patil, H.; Sharma, S.; Bhatt, D.P. Hybrid approach to SVM algorithm for sentiment analysis of tweets. In Proceedings pf AIP conference , June 2023; Vol. 2699, No. 1.
- Luvembe, A.M.; Li, W.; Li, S.; Liu, F.; Xu, G. Dual emotion based fake news detection: A deep attention-weight update approach. Inform Proces & Manag 2023, 60, 103354. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, S.; Wang, X.; Xie, L. Msemotts: Multi-scale emotion transfer, prediction, and control for emotional speech synthesis. IEEE/ACM Transac on Audio, Speech, and Langu Process 2022, 30, 853–864. [Google Scholar] [CrossRef]
- Li, W.; Li, Y.; Liu, W.; Wang, C. An influence maximization method based on crowd emotion under an emotion-based attribute social network. Inf. Process. Manag. 2022, 59, 102818. [Google Scholar] [CrossRef]
- Vyas, P.; Reisslein, M.; Rimal, B.P.; Vyas, G.; Basyal, G.P.; Muzumdar, P. Automated classification of societal sentiments on Twitter with machine learning. IEEE Transac Tech Soc. 2022, 3, 100–110. [Google Scholar] [CrossRef]
- Qureshi, M.A.; Asif, M.; Hassan, M.F.; Abid, A.; Kamal, A.; Safdar, S.; Akbar, R. Sentiment analysis of reviews in natural language: Roman Urdu as a case study. IEEE Access 2022, 10, 24945–24954. [Google Scholar] [CrossRef]
- Alali, M.; Mohd Sharef, N.; Azmi Murad, M.A.; Hamdan, H.; Husin, N.A. Multitasking Learning Model Based on Hierarchical Attention Network for Arabic Sentiment Analysis Classification. Electronics 2022, 11, 1193. [Google Scholar] [CrossRef]
- Al-Sabahi, K.; Zuping, Z.; Nadher, M. A hierarchical structured self attentive model for extractive document summarization (HSSAS). IEEE Access 2018, 6, 24205–24212. [Google Scholar] [CrossRef]
- Aly, M.; Atiya, A. LABR: A large scale Arabic book reviews dataset. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Sofia, Bulgaria, 4–9 August 2013; Volume 2, pp. 494–498.
- Dean, Jeff, and Rajat Monga‘TensorFlow. "Large-Scale Machine Learning on Heterogeneous Distributed Systems’." TensorFlow. org (2015).
- Gulli A, Pal S. Deep learning with Keras. Packt Publishing Ltd; 2017 Apr 26.
- Varoquaux, G.; Buitinck, L.; Louppe, G.; Grisel, O.; Pedregosa, F.; Mueller, A. Scikit-learn: Machine Learning in Python. GetMobile Mob. Comput. Commun. 2015, 19, 29–33. [Google Scholar] [CrossRef]
- Baniata, L.H.; Park, S.; Park, S.-B. A multitask-based neural machine translation model with part-of-speech tags integration for Arabic dialects. Appl. Sci. 2018, 8, 2502. [Google Scholar] [CrossRef]
- Baniata, L.H.; Park, S.; Park, S.-B. A Neural Machine Translation Model for Arabic Dialects That Utilizes Inductive Transfer (INT). Comput. Intell. Neurosci. 2018, 2018, 7534712. [Google Scholar] [CrossRef] [PubMed]
- Baziotis, C.; Pelekis, N.; Doulkeridis, C. DataStories at SemEval-2017 Task 4: Deep LSTM with Attention for Message-level and Topic-based Sentiment Analysis. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 747–754.
- Al Shboul, B.; Al-Ayyoub, M.; Jararweh, Y. Multi-way sentiment classification of Arabic reviews. In Proceedings of the 2015 6th International Conference on Information and Communication Systems (ICICS), Amman, Jordan, 7–9 April 2015; pp. 206–211.
- Al-Ayyoub, M.; Nuseir, A.; Kanaan, G.; Al-Shalabi, R. Hierarchical Classifiers for Multi-Way Sentiment Analysis of Arabic Reviews. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 531–539. [Google Scholar] [CrossRef]
- Nuseir, A.; Al-Ayyoub, M.; Al-Kabi, M.; Kanaan, G.; Al-Shalabi, R. Improved hierarchical classifiers for multi-way sentiment analysis. Int. Arab J. Inf. Technol. 2017, 14, 654–661. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186.
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-based Model for Arabic Language Understanding. In Proceedings of the LREC 2020 Workshop Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 9–15.
- Zeroual, I.; Goldhahn, D.; Eckart, T.; Lakhouaja, A. OSIAN: Open Source International Arabic News Corpus—Preparation and Integration into the CLARIN-infrastructure. In Proceedings of the Fourth Arabic Natural Language Processing Workshop, Florence, Italy, 28 July–2 August 2019; pp. 175–182.
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis, Foundations and Trends® in Information Retrieval; Now Publishers: Boston, MA, USA, 2008; pp. 1–135.
- Liu, S.; Johns, E.; Davison, A.J. End-to-end Inductive Transfer with attention. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1871–1880.
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. In Proceedings of the Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421.
- Baniata, L.H.; Ampomah, I.K.E.; Park, S. A Transformer-Based Neural Machine Translation Model for Arabic Dialects that Utilizes Subword Units. Sensors 2021, 21, 6509. [Google Scholar] [CrossRef]
- Baniata, L.H.; Kang, S.; Ampomah, I.K.E. A Reverse Positional Encoding Multi-Head Attention-Based Neural Machine Translation Model for Arabic Dialects. Mathematics 2022, 10, 3666. [Google Scholar] [CrossRef]
Figure 1.
The Architecture of the Suggested T-TC-INT Model for Arabic Dialects.
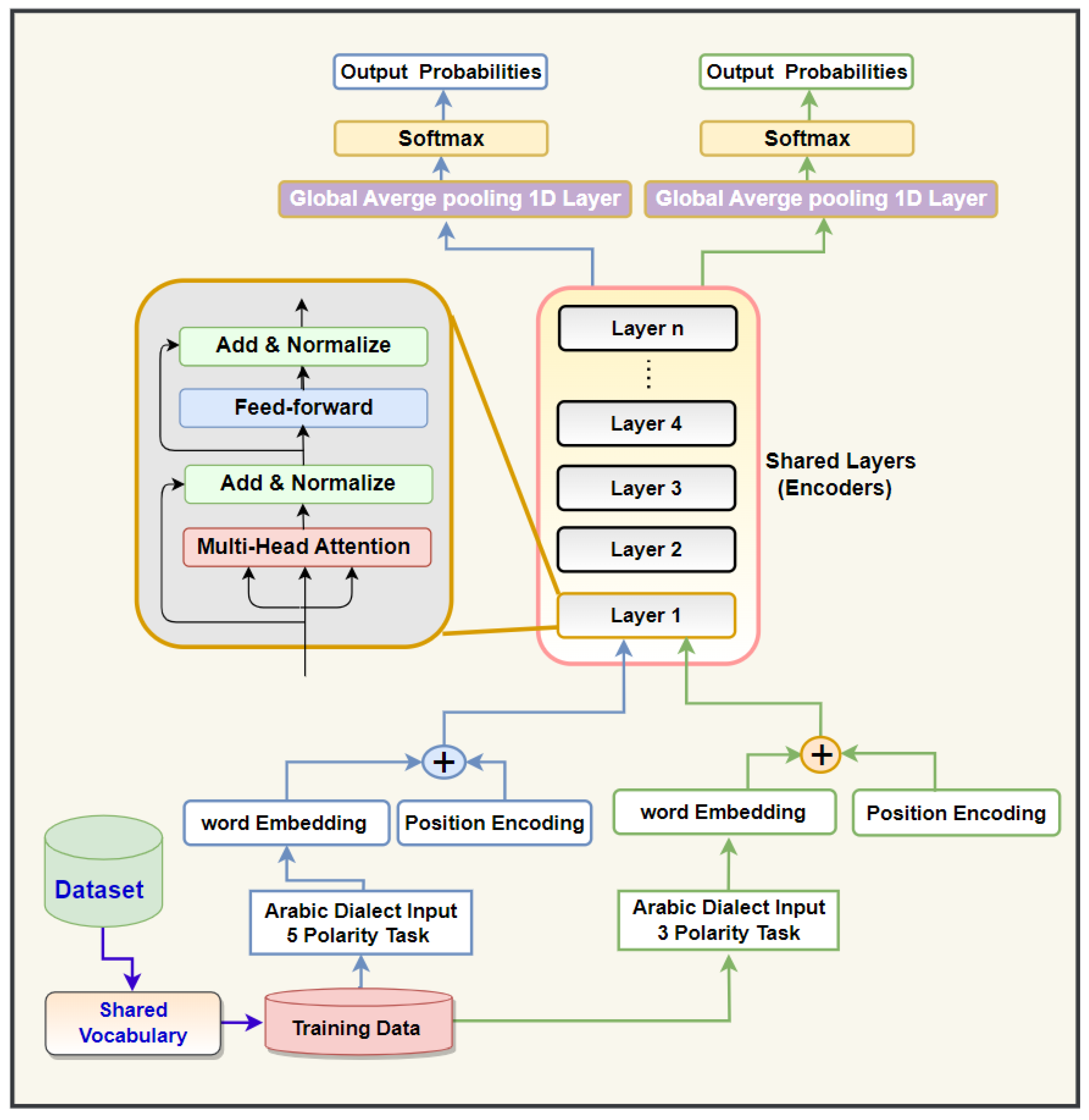
Figure 2.
The Structure of Self-Attention (SE-A) Sub-Layer

Figure 3.
The Evaluation Accuracy of the T-TC-INT Model in Comparison with State-of-Art Approaches on HARD Test set.
Figure 3.
The Evaluation Accuracy of the T-TC-INT Model in Comparison with State-of-Art Approaches on HARD Test set.
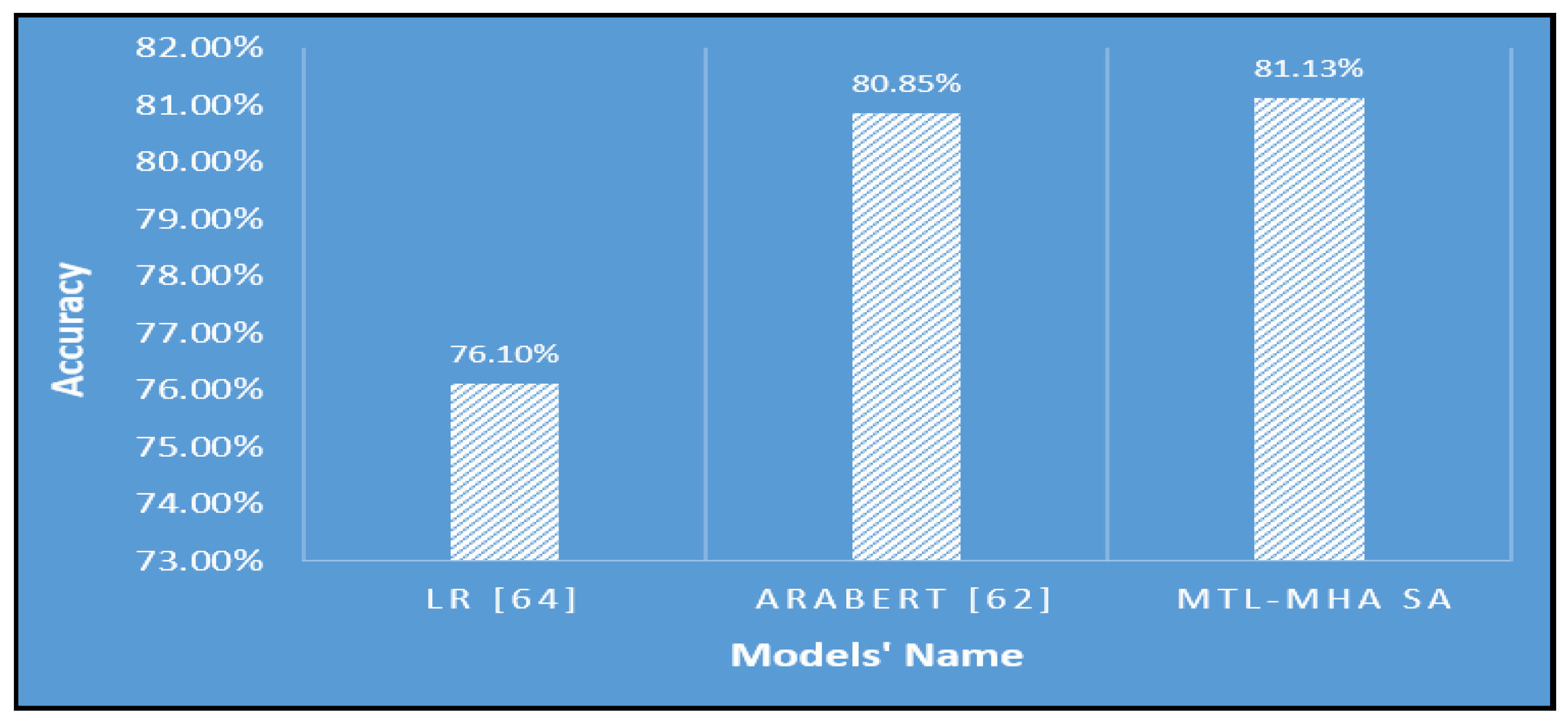
Figure 4.
The Evaluation Accuracy of the T-TC-INT Model in Comparison with State-of-Art Approaches on BRAD Test Set.
Figure 4.
The Evaluation Accuracy of the T-TC-INT Model in Comparison with State-of-Art Approaches on BRAD Test Set.
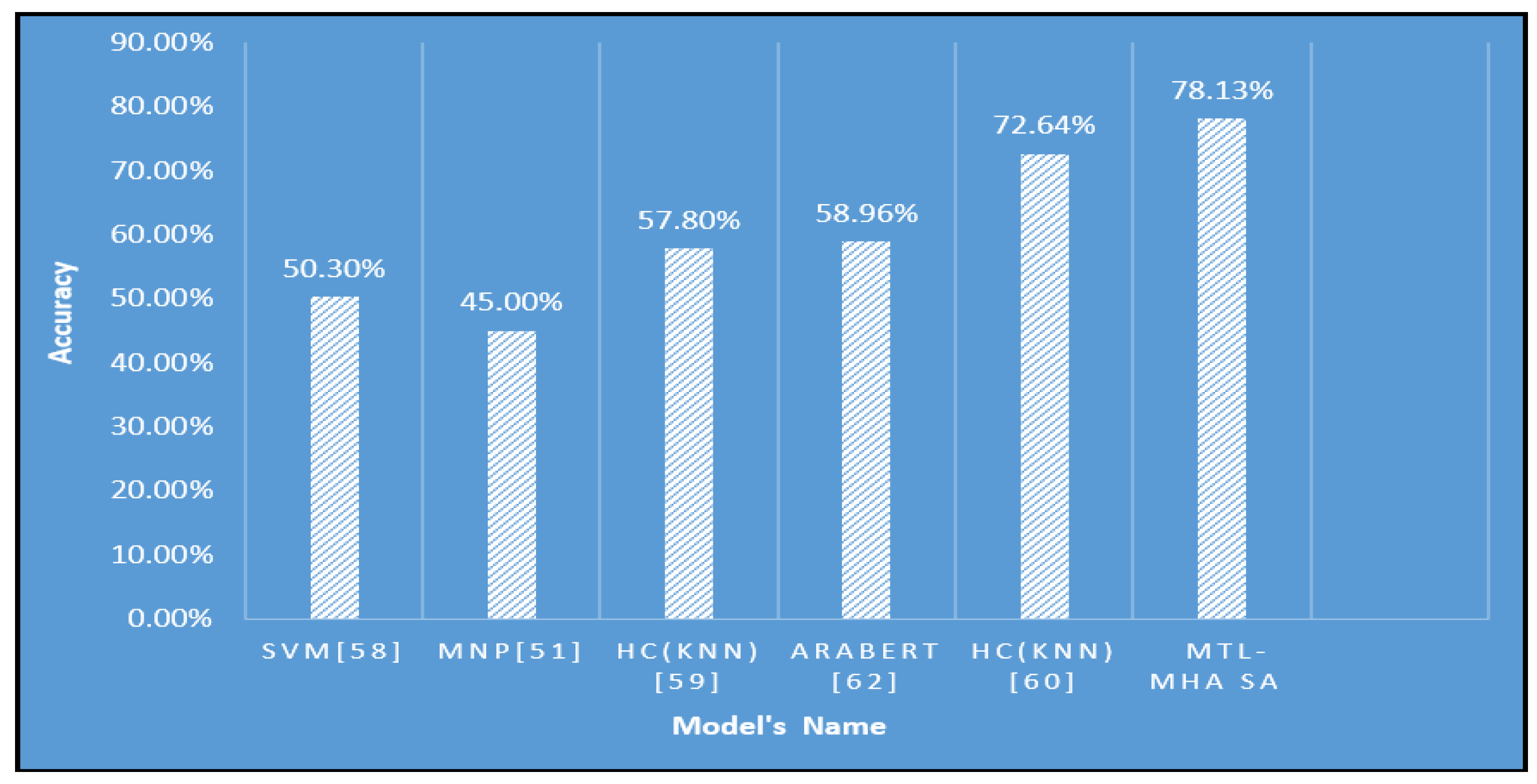
Figure 5.
The Evaluation Accuracy of the T-TC-INT Model in Comparison with State-of-Art Approaches on LARB Test set.
Figure 5.
The Evaluation Accuracy of the T-TC-INT Model in Comparison with State-of-Art Approaches on LARB Test set.
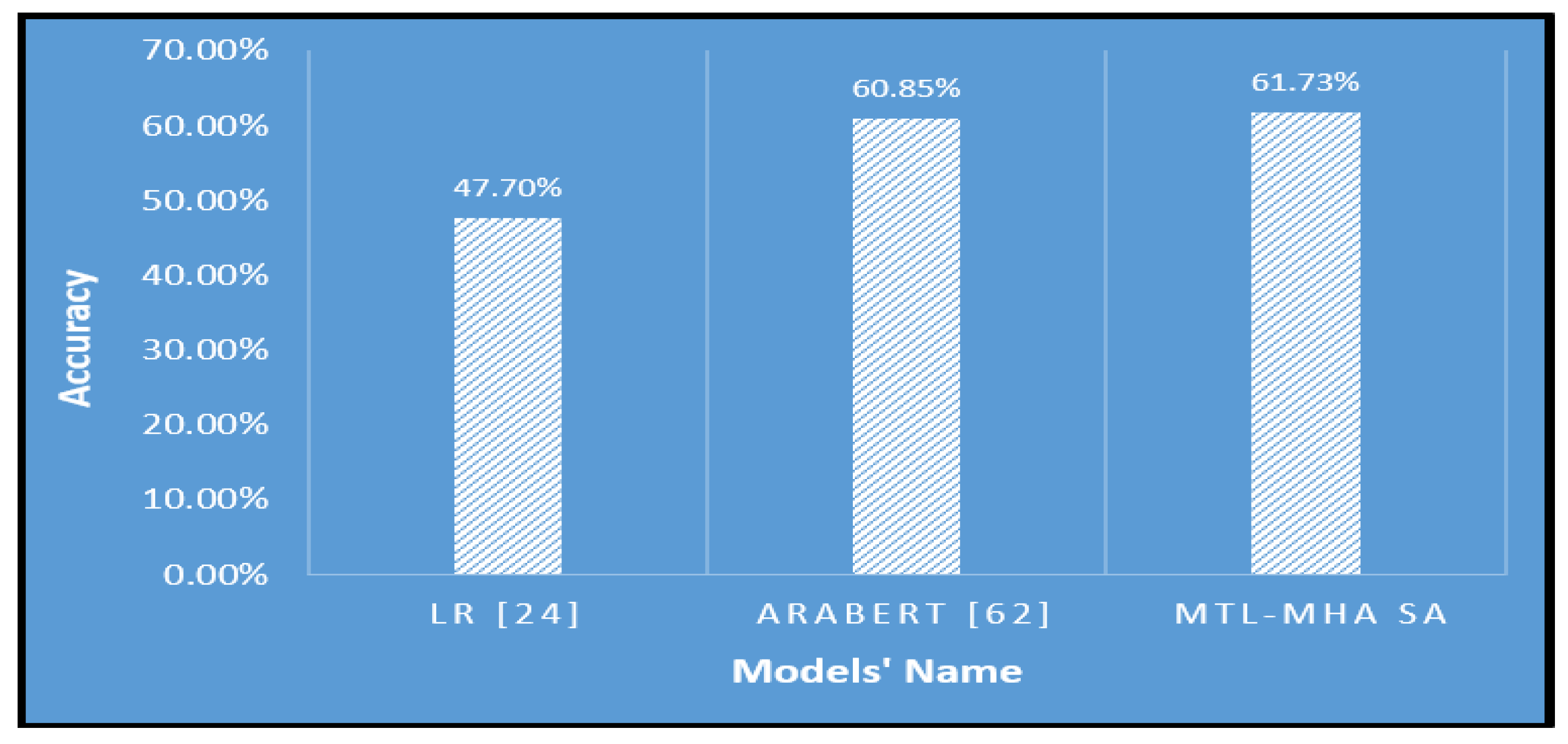

Table 1.
Statistics for HARD imbalanced Dataset.
| Task Type | Highly Positive | Positive | Neutral | Negative | Highly Negative | Total |
|---|---|---|---|---|---|---|
| 3-Polarity | - | 132,208 | 80,326 | 38,467 | - | 251,001 |
| 5-Polarity | 144,179 | 132,208 | 80,326 | 38,467 | 14,382 | 409,562 |
Table 2.
Statistics for BRAD imbalanced Dataset.
| Task Type | Highly Positive | Positive | Neutral | Negative | Highly Negative | Total |
|---|---|---|---|---|---|---|
| 3-Polarity | - | 158,461 | 106,785 | 47,133 | - | 251,001 |
| 5-Polarity | 16,972 | 158,461 | 106,785 | 47,133 | 31,247 | 510,598 |
Table 3.
Statistics for LARB imbalanced Dataset.
| Task Type | Highly Positive | Positive | Neutral | Negative | Highly Negative | Total |
|---|---|---|---|---|---|---|
| 3-Polarity | - | 15,216 | 9841 | 4197 | - | 29,254 |
| 5-Polarity | 19,015 | 15,216 | 9814 | 4197 | 2337 | 50,606 |
Table 4.
Results for the T-TC-INT model on HARD dataset for the five-polarities classification task, where W-E-D is the word embedding dimension, FS is the filter size, EL is the encoding layer, and AH is the number of attention heads.
Table 4.
Results for the T-TC-INT model on HARD dataset for the five-polarities classification task, where W-E-D is the word embedding dimension, FS is the filter size, EL is the encoding layer, and AH is the number of attention heads.
| W-E-D | FS | EL | AH | Accuracy (5-Polarity) |
|---|---|---|---|---|
| 256 | 256 | 2 | 8 | 74.53% |
| 256 | 256 | 2 | 12 | 81.66% |
| 512 | 512 | 1 | 8 | 80.24% |
| 256 | 256 | 1 | 8 | 81.52% |
| 256 | 256 | 2 | 10 | 80.14% |
| 300 | 300 | 2 | 2 | 81.83% |
Table 5.
Results for the proposed T-TC-INT model on BRAD dataset for the five- Polarities classification task.
Table 5.
Results for the proposed T-TC-INT model on BRAD dataset for the five- Polarities classification task.
| W-E-D | FS | EL | AH | Accuracy (5-Polarity) |
|---|---|---|---|---|
| 64 | 164 | 3 | 2 | 61.07% |
| 64 | 164 | 2 | 4 | 61.01% |
| 50 | 128 | 1 | 2 | 56.92% |
| 128 | 128 | 2 | 6 | 61.73% |
| 128 | 128 | 2 | 8 | 61.32% |
| 200 | 200 | 2 | 6 | 51.48% |
Table 6.
Results for the T-TC-INT model on LARB dataset for the five-polarities classification task.
Table 6.
Results for the T-TC-INT model on LARB dataset for the five-polarities classification task.
| W-E-D | FS | EL | AH | Accuracy (5-Polarity) |
|---|---|---|---|---|
| 64 | 164 | 3 | 2 | 63.27% |
| 256 | 164 | 4 | 4 | 72.92% |
| 256 | 128 | 2 | 2 | 70.37% |
| 200 | 128 | 2 | 2 | 78.13% |
| 128 | 128 | 2 | 6 | 67.57 % |
| 200 | 200 | 2 | 6 | 75.68% |
Table 7.
The performance of the proposed T-TC-INT model compared with benchmark approaches on HARD dataset.
Table 7.
The performance of the proposed T-TC-INT model compared with benchmark approaches on HARD dataset.
| Model | Polarity | Accuracy |
|---|---|---|
| LR [64] | 5 | 76.1% |
| AraBERT [62] | 5 | 80.85% |
| Proposed T-TC-INT Model | 5 | 81.83% |
Table 8.
The performance of the proposed T-TC-INT model compared with benchmark approaches on BRAD dataset.
Table 8.
The performance of the proposed T-TC-INT model compared with benchmark approaches on BRAD dataset.
| Model | Polarity | Accuracy |
|---|---|---|
| LR [24] | 5 | 47.7% |
| AraBERT [62] | 5 | 60.85% |
| Proposed T-TC-INT Model | 5 | 61.73.% |
Table 9.
The performance of the proposed T-TC-INT model compared with benchmark approaches on LARB imbalanced dataset.
Table 9.
The performance of the proposed T-TC-INT model compared with benchmark approaches on LARB imbalanced dataset.
| Model | Polarity | Accuracy |
| SVM [58] | 5 | 50.3% |
| MNP [51] HC(KNN) [59] AraBERT [62] HC(KNN) [60] Proposed T-TC-INT Model |
5 5 5 5 5 |
45.0% 57.8% 58.96% 72.64% 78.13% |
Table 10.
Performance of joint and alternate training for five-polarity classification.
| T-TC-INT-Training Method | HARD (imbalance) Accuracy | BRAD (imbalance) Accuracy |
|---|---|---|
| Alternately | 79.07% | 61.35% |
| Jointly | 77.59% | 60.98% |
Table 11.
Accuracy Score on HARD dataset with different sentence lengths.
| Sentence Length | Accuracy |
|---|---|
| <10 | 76.88% |
| (10-20) | 77.02% |
| (20-30) (30-40) (40-50) > 50 |
77.56% 79.03% 78.73% 81.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



