
Submitted:
24 November 2023
Posted:
24 November 2023
You are already at the latest version
Abstract
The increasing rate of adoption of innovative technological achievements along with the penetration of the Next Generation Internet (NGI) technologies and Artificial Intelligence (AI) in the water sector, are leading to a shift to a Water-Smart Society. New challenges have emerged in terms of data interoperability, sharing, and trustworthiness due to the rapidly increasing volume of heterogeneous data generated by multiple technologies. Hence, there is a need for efficient harmonisation and smart modeling of the data to foster advanced AI analytical processes which will lead to efficient water data management. The main objective of this work is to propose two Smart Data Models focusing on the modeling of the Satellite Imaginary data and the Flood Risk Assessment processes. The utilisation of those models reinforces the fusion and homogenisation of diverse information and data facilitating the adoption of AI technologies for flood mapping and monitoring. Furthermore, a holistic framework has been developed and evaluated via qualitative and quantitative performance indicators revealing the efficacy of the proposed models concerning the usage of the models in real cases. The framework is based on the well-known and compatible technologies on NGSI-LD standards which are customised and applicable easily to support the water data management processes effectively.
Keywords:
Smart Data Models
; Remote sensing
; Satellite Imagery
; Flood Monitoring and Mapping
; Flood Risk Assessment
; Data Sharing
; Interoperability
; Water Data Management
1. Introduction
The water sector is undergoing the so-called fourth revolution, which encounters the Industry 4.0 digital revolution. Hence, the water utilities have started to establish water conservation strategies and transition toward digital transformation [1]. The digital advancements, driven by the Next Generation Internet (NGI) technologies (e.g., Internet of Things (IoT), Blockchain), Artificial Intelligence (AI), Remote Sensing (RS), data modeling and semantic representation and reasoning approaches, etc., are adopted causing the movement from Hydraulic Modeling 1.0 to 2.0 [2]. Recent advances in data management and analysis adopt several state-of-the-art technologies such as efficient and modular Context Brokers, Digital Twins (DT), data integration and creation of appropriate data models. Generally speaking, DT is a digital clone of a real physical system. The vision of DT refers to data-driven software and hardware set that describes a real physical system with all functions and use cases. It also includes all status and information in life-cycle phases ([3,4]). Context brokers allow managing the entire lifecycle of context information including updates, queries, registrations and subscriptions.
The intertwining of AI with affordable sensors, high-resolution remote sensing and communication technologies has contributed to the proliferation of big data in the water sector, emerging the need for effective data-driven discovery, management and processing ([1,5]). Efficient and reliable water management decisions are obtained after the harmonisation and analysis of the massive volumes of data, by utilising innovative prescriptive analytics and AI techniques [5]. Hence, long-term resilience against unexpected disruptive events such as floods, droughts, etc. can be achieved.
Specifically, satellite remote sensing provides significant information for the monitoring of natural disasters [6]. Flood hazards are a constant threat to local communities and infrastructures. The recent increase in the number of natural disasters has become a global issue, because of the damages to the hydrological and ecological environment and human-made infrastructure, and the threats to human lives. Satellite remote sensing techniques provide valuable support for monitoring these disasters and for post-event crisis management [7]. Floods are the most frequent and second-most costliest natural disasters worldwide, making up a share of of the recorded disaster events in 1998–2017 and affecting over 2 billion people, according to the survey of the United Nations Office for Disaster Risk Reduction (UNISDR) ([8,9]). Due to flood hazards’s negative consequences on societies and economic aspects, it is critical to monitor and map those flood risks ([10,11]). Improvements in satellite technology along with an increasingly long historical period of Earth Observation (EO) data available are resulting in the extended use of EO and the assessment and monitoring of flood risk [12]. Especially, in the flood mapping processes the provided solutions vary considerably from region/country to region/country and/or project to project, depending on specific project requirements, available data, resources and country-specific guidelines and regulations [6].
Despite the progress made, the digitalisation of the water sector is yet characterised by certain gaps and challenges including technological, socio-economic, environmental, and regulatory aspects [13]. The lack of industry-wide standardisation and regulatory policies due to the fragmented, tailor-made solutions in the water sector, along with the issues of interoperability, data sharing and trustworthiness are considered the main barriers to the digital transition of the sector [13].
Particularly, data integration is one of the core responsibilities of data management and interoperability [14]. One challenge is the incompatibility of data models, i.e., different software systems use specific or proprietary terminology, data structures, data formats, and semantics. Data need to be interchanged between software systems, and often complex data conversions or transformations are necessary. Data integration involves combining data from several disparate/ heterogeneous sources, which are stored using various technologies and it provides a unified view of the data ([14,15]). The complexity of data integration depends on various factors such as data models, data formats, and data precisions; however, in most cases, it is non-trivial, so a systematic and well-defined approach is necessary. General topics in integration are technologies, architecture, and components of data integration systems, schema and data matching, mappings, mapping languages, constraints, and integrity rules for data integration, query processing for data integration, wrappers, and other aspects such as data warehousing, knowledge representation, and data provenance for data integration ([14,15]).
According to our knowledge, there are no data models relevant to satellite imagery to support flood risk assessment analysis. Thus, in this work, two data models, namely the Satellite Imagery 1 data model and the Risk Management 2 data model, have been designed and implemented adopting the FIWARE NGSI-LD standard. The aim is to empower data sharing and interoperability by harmonising heterogeneous data from multiple sources (i.e., EO data, GIS-based data). The proposed data models facilitate the data exchange, data-sharing trustworthiness and transparency among various legacy systems, and different groups of stakeholders in the water sector. Also, they adopt a coherent terminology and common semantic representation of data combining terms of the fields of remote sensing and risk management. Upon these models, advanced machine learning and AI technologies can be applied easily focusing on various EO and crisis management applications. Particularly, in [16], a methodological framework is proposed that enables flood monitoring and mapping by assessing the flood hazard and risk dynamically fusing optical remote sensing (Sentinel-1) and GIS-based data. The aforementioned data models utilised in order to populate the necessary data into the machine learning models and also to store the results of the analysis.
Beyond these data models, a second aim of this work is to propose a general framework that those models can be applied and interoperable interact with other components. Hence, a multi-layered architecture has been proposed which consists of layers for data collection, data harmonisation, interoperability, and storage as well as a layer for advanced analytical processing of the data in order to visualise the results at the business layer. The proposed framework has been applied and evaluated on real case scenarios in the context of the H2020 aqua3S 3 project.
The core contributions of this work can be summarised as follows:
- Establish two Smart Data Models, the Satellite Imagery and the Risk Management, based on the FIWARE NGSI-LD standard to foster data management processes.
- Assist in the set-up of a unified terminology and semantic representation of data generated by remote sensing and flood risk assessment processes to facilitate interoperability and data sharing.
- Propose and evaluate in real case scenarios a broader framework for seamless interaction with other components, featuring a multi-layered architecture.
- Relying on the proposed SDMs, the integration of advanced Machine Learning and AI technologies for a wide range of EO and flood crisis management applications can be adopted.
2. Background
In [17], a systematic review of data models for the big data problem was presented concluding, among others, that a data model is required to define the data structure and storage as a way to meet the challenges of big data. Also, the article depicts the significance of data models even in databases that lack static data models and flexible schemas. Although there are a variety of data models with various purposes, there must be a logical structure or format for data storage even at the program level. This is evidence of the need for more focus and research on this issue [17]. In [18] the authors cover the evaluation of six open-source and eleven proprietary database modeling tools using a new and tailored approach. Based on [19], a data model is aimed to make data meaningful and data communication possible for information needs while in [20], the data model includes three concepts:
- Data model is a set of data structures that mainly describes data types, properties, and relationships. The data structure is the basic part on which operations and constraints are structured.
- Data model is a set of operators and inference rules that mainly describe types and methods of operation in a particular data structure.
- Data model is a set of comprehensive constraints that can be used to describe syntax, dependencies, and constraints of data to ensure its accuracy, validity, and compatibility
On the other hand, due to the growing awareness of the Internet of Things (IoT), IoT platforms were raised, such as FIWARE4, which is a standard platform for developing Smart applications. It was launched by the European Commission and aims to develop the core future technologies in the IoT paradigm ([21,22]). However, its use seems to be successfully adopted by a variety of other applications. In [23], a data integration, harmonization and provision toolkit for water resource management and prediction support was designed to adopt the FIWARE NGSI-LD standard. NGSI-LD standard is a well-established standard (the first version was created in 2017) and provides a general-purpose API specification. The specification, and some implementations, are open licensed. It is evolved by ETSI, a technical standardization body5. Some features of NGSI-LD like the time series and geo-querying of the information retrieved from heterogeneous sources make it particularly suitable for the aim of this research. Besides this, it also allows the federation between different instances of the servers using the standard (brokers), which empowers the users to use very different configurations and allows horizontal scalability. From the semantic point of view, this standard manages any type of data model structure, which helps to use very different types of data, geographical, environmental, or simply any other type of indicator. In [24], a novel air quality monitoring unit was implemented using clouding and FIWARE technologies while in [25] an industrial data space architecture implementation using FIWARE was carried out. The authors of [26] described a reference implementation for providing data analytic capabilities to context-aware smart environments. Their implementation relied on FIWARE Generic Enablers (GEs) and commonly used open source technologies, a combination that has proven useful for building other types of smart solutions such as digital twins [27], data usage ([28,29]) controlled sharing environments, and enhanced authentication systems [30].
2.1. Smart Data Models by FIWARE
The Smart Data Models6 is a collaborative initiative to compile and curate data models in very different domains. The data models have two major sources. On one hand directly from actual use cases and on the other hand from open and adopted standards or regulations. Four non-profit organizations are the board members and more than 100 organizations are currently collaborating. Although FIWARE Foundation is one of the board members, the data models compiled are independent of the FIWARE platform (which uses NGSI-LD standard) and can be used elsewhere. The models are open-licensed allowing the free use, free modification, or customization to local needs and the free sharing of the modifications only with the credit to the authors. One single source of truth for every data model allows the automatic generation of the documentation (7 languages) and export in several technical formats. The structure is also available in YAML and SQL and the examples are available in json json-ld, csv, geojson features and DTDL. This initiative pioneered the use of the agile standardization paradigm to compile data models (see the Manifesto for agile standardization7). There are more than 1000 data models publicly available in github8 and include domains for environmental information9 and for geographic imaging10 among others.
3. Methodology
3.1. General Considerations
The backbone of a FIWARE-compatible architecture is the NGSI-compatible Broker. An NGSI compatible broker, unlike a messaging broker like RabbitMQ11 or a stateless event streaming service, like Apache Kafka12, is meant to hold the current state of a physical system in the form of digital twins. Instead of handling messages or message stream of information in publication/subscriber context, the NGSI-compatible broker holds an entity corresponding to the physical component which comprises several values. Values can be updated by a client and other clients can actively query the current state of the entity. Clients can also subscribe to notifications generated when specific attributes of one or more entities change.
An entity in this context is an expanded data model, including attributes that are static (e.g., an entity’s id), dynamic (e.g., an entity’s status) as well as timestamped attributes that can be used to generate time series (e.g., measurements produced by a sensor).
In our case of earth observations in the form of satellite imagery, the usual situation is that the observations are available, along with the corresponding metadata in a data hub (e.g., the Sentinel Hub) and they can be ingested, analysed and combined with other data to produce certain analysis results. This process requires the combination and often harmonisation to certain requirements of several heterogeneous types of data for their ingestion by AI models, including static, dynamic and time variable attributes.
These requirements led us to the selection of a digital twin approach, where an earth observation and the accompanying metadata can be modeled as NGSI entities including the earth observation, the instrument involved along with its configuration, the satellite platform that carries it, the corresponding data hub etc. This allows for the easier integration of this information with other types of data (sensor measurements, citizen data, OGS data, etc.) that have been modeled within the same context. Any resulting processing as well as the final analysis results are also represented as entities in the same data model.
In our implementation we opted for a Linked Data approach, using entities encoded in JSON-LD format. In the context of linked data, every entity has a unique ID in the form of a URI. Linked entities have relationship attributes that take the URI ID of other entities as values. This allows for the conceptualization of higher lever interlinked structures. In this way, the entire process is easily integrable, transparent and intuitive as well as easily expandable to new data types.
3.2. Framework
In the figure below (Figure 1), the logical multi-layered architecture of the proposed framework is illustrated. It consists of layers that allow acquiring data and information from various external data sources (Data Collection layer), the transformation of those data into the harmonised FIWARE-compatible data models (Interoperability layer), the storage, processing and forwarding the data (Data layer) into the Business layer. The latter is responsible for the further advanced analytical processing of the data as well as the visualisation of the results to the operators.
Specifically, in this work, the Data collection layer refers to the process of gathering EO (Sentinel) data from the Copernicus API as well as the geospatial data through Legacy systems (GIS layers). The latter is considered as an external resource and it is mentioned as the GIS Data Model (Section 3.5). The Interoperability layer utilizes the Visual Content Acquisition module in order to process the Sentinel and GIS data. The Data Collection and Interoperability layer is part of the Satellite Imagery Data Model described in Section 3.4 below.
Subsequently, in the Data layer, data processed from the Visual Content Acquisition module is been stored using technologies such as OGC Web Services - Geoserver, Orion Context Broker and widespread techniques of Data Repositories. GeoServer is the reference implementation of the Open Geospatial Consortium (OGC) Web Feature Service (WFS) and Web Coverage Service (WCS) standards, as well as a high-performance certified compliant Web Map Service (WMS). GeoServer forms a core component of the Geospatial Web. Orion Context Broker13, which is an NGSI-LD compatible broker, gathers context information from diverse sources and manages the lifecycle of this context information, from registrations, updates, queries, and subscriptions.
Finally, in the Business layer, the Crisis Classification and Decision Support Module is developed and evaluated relying on the analysis of information obtained in the previous layers by employing AI algorithms. The outcome of this process is the assessment of the risk in a potential crisis or extremely hazardous event caused by natural or human-made reasons. This module is based on the deployment of the Risk Management Data Model as will be described in Section 3.6.
3.3. NGSI-LD Context Broker
The role of the context broker is to hold the current state of the system (in contrast with stateless, data streaming applications like Apache Kafka, where the client is responsible for knowing their offset. In the simplified NGSI-LD broker architectural schema (Figure 2), the Clients (Producers or Consumers) can update specific attributes of entities and query the current state of the system or subscribe to notifications. Notifications can be set up to monitor specific attributes on specific entities and contain logical functions (e.g., to only send notifications when a value exceeds a specific threshold).
Entities within the broker need to be identified by a unique ID in the form of a URI (linked entities use this identifier to point to this entity) as well as by the Type attribute that identifies the entity with the corresponding data model (Figure A1). Entities are connected to related “context” that can be accessed online or stored locally and hold the schema of the specific entities. Relationship attributes handle the interconnections between entities, allowing for easier indexing of entities and the mapping of conceptual entity networks.
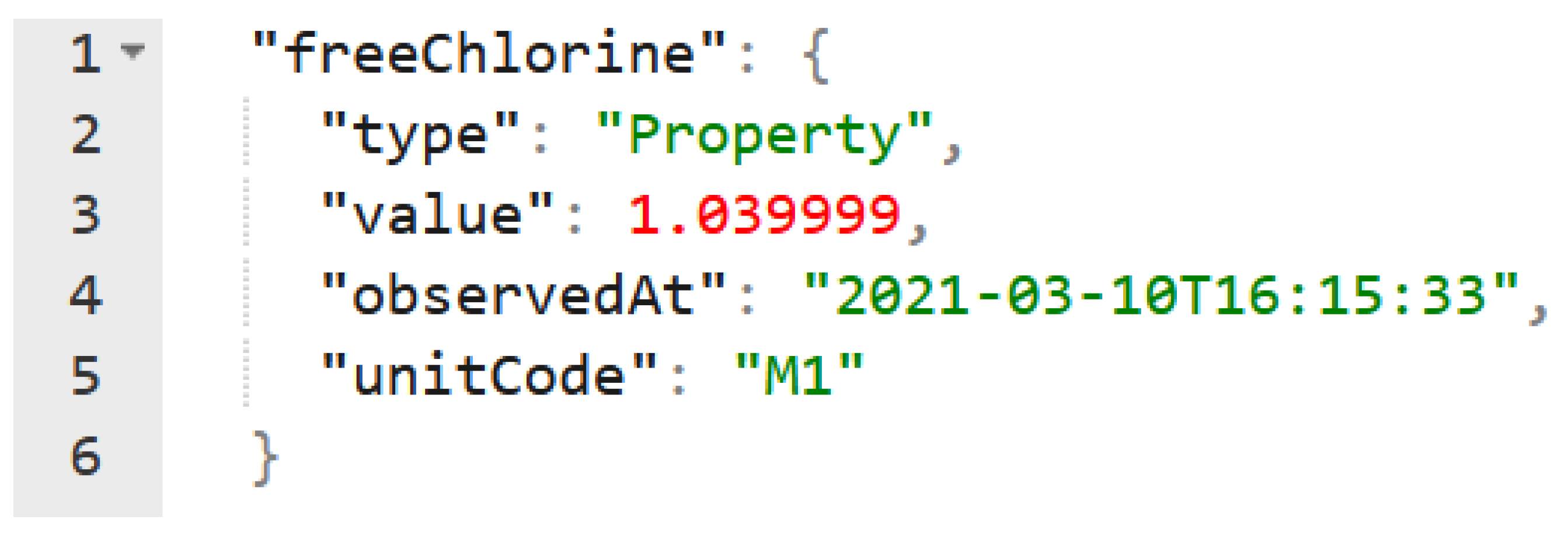
Data that is time critical is marked by a timestamp (Figure A2). A connected historical service that can either be part of the broker or set up to receive notifications is responsible for capturing older values when they are replaced by newer ones in the broker and retaining time-series of past values. Values that are to be monitored need to be marked with a timestamp when created.
NGSI-LD brokers expose a REST API that can be accessed by client applications to create, update and query entities through HTTP(s) requests. Data is stored and exchanged in JSON-LD format.
In the mapping of a physical system in this context, the entities represent digital twins of real system components. In our case of Earth Observations, this is the case for some entities (instruments or satellite platforms) while other entities are conceptual (like analysis results). In some cases the entities correspond to other types of files (such as geo-referenced images) in this case the corresponding entities will hold all relevant data and metadata of the specific file as well as an index of the actual file’s location in a datastore. This simplifies the location and indexing of files, the integration of various heterogeneous data types, but also the better conceptualization of the entire process that processed various data types to produce results in various formats, holding a central mapping of the process and its components and reference data at all stages of the process.
Several NGSI-LD brokers are available as open-source software, offering a robust ecosystem of components that can be used in research or production implementations. Such brokers include the Stellio and Orion NGSI-LD brokers.
3.4. Satellite Imagery Data Model
The FIWARE model for Satellite Data is designed to be adaptable, covering a wide range of use cases and allowing for future expansions. The model facilitates the representation of satellite imagery analysis (Figure 3), supporting vital information about the corresponding instrument and satellite platform, data hub, and the generated image results. The goal is the development of a flexible and well-defined model that could retrieve diverse Earth Observation (EO) analyses products from any satellite data repository and platform. While its main compatibility lies with Copernicus Open Access Hub, the model aims to adapt as much as possible to other satellite data providers, enabling the representation of data from these repositories using the proposed FIWARE model. This extends to alternative Copernicus Data Hubs and Copernicus Data and Information Access Services (DIAS) cloud environments (e.g., ONDA DIAS), which may be utilized by others, including commercial data providers.
3.4.1. Design of the Satellite Imagery Model
The development of the data model was driven by the need to record geo-referenced satellite data, accessible from online data hubs like the Copernicus open source hub. Geo-referenced information from Sentinel satellites is collected from open-source hubs and put through analysis using specialized analytical modules within the FIWARE model. The analysis process relies on the main available Data Hubs such as Copernicus, ONAS DIAS, Sentinel Hub, and Planet. The attributes present in the file metadata are mapped to corresponding attributes within the data model.
3.4.2. Description of the Satellite Imagery Data Model
The Satellite Imagery model encompass six classes: EOAnalysis, EODataHub, EOGeoDataLayer, EOInstrument, EOSatellitePlatform, and EOProduct.
The EOAnalysis entity offers a match description of a generic Analysis performed in the Satellite Imagery domain and its primary focus is on analyzing Earth Observation applications. Key properties of this entity include the location, represented as bounding box coordinates in GeoJSON format, which denotes the analyzed area. Moreover, properties such as analyzedAt indicate the completion time of the analysis, provider identifies the algorithm provider, resultDescription describes the analysis outcome, analysisType specifies the type of analysis applied, and isAnalysisOf refers to the ID of the product used in the analysis.
EODataHub serves as a generic data hub entity within the Satellite Imagery and its primary purpose is to facilitate data hub functionalities related to Earth Observation Analysis applications. EODataHub encompasses two properties, the dataHubName, which declares the name of the utilized data hub, and dataHubURL, which provides the URL of the data hub.
The EOInstrument entity is mainly connected to satellite instruments used in Earth Observation Analysis applications. This entity exploits properties such as instrumentID and instrumentName, which respectively represent the ID and name of the instrument payload. The property operationalMode describes the supported sensor modes, the polarizationMode specifies available polarization modes, and the swathID represents the swath ID. Additionally, the carriedOn property corresponds to the ID of the satellite platform on which the instrument takes place.
EOGeoDataLayer provides a generic description of output data layers associated with Earth Observation Analysis applications. This entity uses properties such as location, which refers to the geographic coordinates, localServerPath that indicates the server path where the output data is being stored, storageFormat stands for the storage format, GeoMetadata specifying the metadata file if available. Furthermore, property contentInformation that describes the type of information for each layer or entity name (e.g., categorical or numerical) and also includes an array containing explanations for depicted values (e.g., [1:oil, 0:no oil]). Finally, the property isOutputOf, which represents the ID of the analysis performed to extract the specific data layer.
The EOProduct entity provides a generic description of Earth Observation products within the Satellite Imagery domain. It primarily focuses on satellite products associated with Earth Observation Analysis applications. This entity encompasses numerous properties essential for its functioning. The entity includes numerous properties such as, productID as a unique identifier, productURL for the download link, productType indicating the product type, productFormat specifying the product format, processingLevel representing the processing level, Timeliness representing the timeliness of the product, hostedOn referring to the ID of the data hub hosting the product, and observedBy indicating the ID of the instrument responsible for observing the product. Another set of properties that refer to the date time includes ingestionDate, representing the time when the data became available in the online archive, sensingDate indicating the time of image capture by the sensor, sensingStartedAt denoting the time of the satellite’s first line acquisition in the product, and sensingStoppedAt representing the time of the satellite’s last line acquisition in the product. Finally, there is the cloudCoverage property, representing the percentage of cloud coverage, and orbitDirection, which refers to the orientation of the satellite’s orbit pass.
EOSatellitePlatform entity pertains to a generic satellite platform within the Satellite Imagery domain and is primarily associated with Earth Observation Analysis applications. The entity includes the properties of platformID, which signifies the unique identifier of the platform, platformName, denoting the name of the platform, and platformNSSDCA, declaring the unique mission ID of the National Space Science Data Center Archive.
3.5. GIS Data Model
The GIS Data model (Figure 4) class provides a complete description of generic GISData formed for the Risk Management domain. This class can be defined by three fundamental properties. Firstly, the location property represents a GeoJSON item in the form of a bounding box polygon, specifying the area where the analysis takes place. Secondly, the analyzedAt property denotes the timestamp when the analysis is completed. Lastly, the provider property is a string that identifies the provider of the harmonized data entity. In addition, the GISData class utilizes two relationships. The identifiesVulnerability relationship, which sends the ID of the Vulnerability Entity that is associated with this data to the Vulnerability class. The isMappedBy relationship that refers to an array of URIs of the GeoDataLayers selected by this GISData Entity.
3.6. Risk Management Data Model
The FIWARE proposed model for Risk Management aims to evaluate risks coming from both cyber attacks (human-made threats) and physical threats caused by natural disasters. It includes entities designed to store data for (a) representing hazard identification through the Hazard entity, (b) fully monitoring natural disasters and their outcome, including the Vulnerability and Exposure entities, along with the Risk entity for risk assessment, and (c) facilitating mitigation and the implementation of necessary countermeasures through the Mitigation and Measure entities.
In this work, we are focusing on the analysis of the Risk Management Data Model that exclusively addresses the risk associated with physical threats, particularly floods. The Flood Risk Management data model focuses on the preparedness (pre-crisis) and response (during crisis) phases within the Crisis Management process for Water Critical Infrastructures. The entities within the Flood Risk Management data model interact with external models such as the GIS data model (Figure 4) and the Satellite Imagery data model (Figure 3). These interactions trigger events and deliver crucial information regarding the risk assessment processes. In the case of natural hazards, the output is stored in GeoData Layers as colored maps, indicating the hazard, vulnerability, exposure, and risk for specific extreme incidents. The main objectives of the Flood Risk Management data model focus on flexibility and compatibility, allowing the representation of various human-made and natural disasters in a well-defined and unambiguous manner.
3.6.1. Design of the Flood Risk Management Data Model
In 2017, the UN Office for Disaster Risk Reduction (UNISDR) proposed an updated definition of disaster risk, incorporating the Sendai Framework for Disaster Risk Reduction 2015-2030 ([31,32]). Therefore, Disaster Risk (R) indicates the potential loss of life, injury, or damage to assets that could affect a system, society, or community in a specific period of time. In order to calculate the Disaster Risk, we must take into account the factors of hazard, exposure, vulnerability, and capacity. Regarding natural hazards, Disaster risk can be calculated and overall assessed by utilizing hazard (H), vulnerability (V), and exposure (E):
Hazard (H) refers to the adverse event responsible for losses. Indicates the probability and intensity within a specific area and time interval of a physical event. Hazard is estimated considering the characteristics of the risk source, the corresponding location, and the intensity of the physical process ([31,32,33]). Exposure (E) encompasses the condition of individuals, livelihoods, housing, infrastructure, production capacities, economic, social, cultural assets, and other substantial human assets that are located in hazard-prone areas and are vulnerable to potential adverse impacts ([31,32,34]). Vulnerability (V) refers to the susceptibility of individuals, communities, assets, or systems when confronted with hazardous physical events. It encompasses the qualities of a person or group and their situation, which influence their ability to anticipate, cope with, resist, respond to, and recover from the impacts of a physical event ([31,32,34]).
Therefore, a data model for Risk Management should consolidate the above notions in classes aiming to facilitate the processes of the assessment of the severity level and the risk of an ongoing crisis resulting from natural and/or human-made threats in general. Upon this data model, advanced analytical processes from the AI field can be applied aiding in the effective response of a crisis event. Thus, the proposed Flood Risk Management data model encompasses various classes designed to store data that are essential to estimate the Hazard, Vulnerability, Exposure, and Risk associated with flood events. This conceptual data model materialises the methodological framework presented in [16] for flood monitoring and mapping. The design and development of flood risk maps play a crucial role since these maps provide an additional level of knowledge as an effective decision-making method [10]. The outcome of the Flood Risk Management data model relies on the fusion of satellite imagery output and GIS data with Explainable Machine Learning techniques to dynamically estimate flood hazard and risk, ultimately generating flood crisis maps. Utilizing Machine learning techniques in flood management is very important since it has the ability to enhance both the accuracy and timeliness of flood predictions [35].
In order to conduct rightful assessments of flood hazard, vulnerability, exposure, and flood risk, it is essential to gather appropriate inputs from various sources exploiting the FIWARE data models. To delve deeper, the Satellite Imagery data model (Section 3.4) provides the satellite image analyses and the GIS data model (Section 3.5) feeds the model with geo-morphological information specific to the Region of Interest for flood hazard estimation. Similarly, to estimate flood vulnerability and exposure the output of GIS data model is required. Lastly, to evaluate the risk level of a flood event, it is necessary to utilize and fuse the data derived from the Hazard, Vulnerability, and Exposure classes. Each of the outcomes of these estimations can be represented as colored map, indicating hazard and severity level, vulnerability, and exposure of the elements which are at risk within the region of interest.
3.6.2. Description of the Flood Risk Management Data Model
As described, the Flood Risk Management data model incorporates four classes: Hazard, Vulnerability, Exposure and Risk. These classes include a range of properties and relationships that define their characteristics, as presented in (Figure 5). Hazard, Vulnerability, and Exposure entities share several common properties as we describe them in this section. A guideline for visualization is contentInformation property, which describes the color assigned to illustrate the severity level of each pixel. To track the timeline of map generation, two properties have been included: analyzedAt gives us the datetime when the map was analysed, and sensingDate indicates the date when satellite images were selected for assessing the area of interest. To get the type of the analysis we use the analysisType property, while the location property represents the delineated area where the analysis took place with the help of a bounding box polygon. Furthermore, the Vulnerability class features a distinctive property called vulnerabilityValues, which is an array describing the color for each severity class.
Hazard, Vulnerability, and Exposure classes communicate with other classes using their respective relationships. For all three classes, the createLayers relationship connects them with the EOGeoDataLayer class in order to share an array of URIs representing the layers created by each class. The communication between the Hazard class and GISData class can be achieved with the isAffectedByGIS relationship and to the EOAnalysis class through the isAffectedByEO relationship; both relationships transfer the corresponding class IDs to identify the hazard. The Exposure class utilizes the createLayers and isAffectedBy relationship to establish a connection with SMAnalysis class.
The Risk class represents the effect of uncertainty on objectives, where an effect denotes a positive or negative deviation from the expected outcome. Objectives can include various features, such as financial, health, safety, and environmental goals, which can be applicable at different levels, including strategic, organization-wide, project, product, and process levels. It should be mentioned, that Risk refers to potential events and consequences, or a combination thereof. It is also very commonly expressed by considering both the potential consequences of an event, including any changes in circumstances, and the likelihood of its occurrence. Uncertainty, on the other hand, refers to a state of deficiency of information, understanding, or knowledge about an event, its consequences, or its likelihood, even if only partially. Technically speaking, the Risk class consists of six properties and is associated with five relationships, as detailed in the next paragraph.
The Risk class incorporates several properties that align with those discussed in the previous paragraph. These properties include the location property, which specifies the area of interest, and the consequence property, which denotes the potential outcome resulting from the materialization of a risk. Moreover, the description property, which provides a textual description of the risk in natural language, the event, which captures the occurrence or alteration of specific circumstances, the threat, which provides additional knowledge about the potential cause of an incident, and the severity, which indicates the severity class of the risk. To forward the output data by the Risk class, various relationships are utilized. The isOutputOf relationship is used for the transfer of an array of URIs representing different Geospatial Data Layers within the GeoDataLayer class. The source relationship indicates the original source of the entity data in the form of a URL, received by the GISData class. Furthermore, the affects relationship refers to an array of URIs linked to the geographic areas that risk could affect. Lastly, the isAssessedBy relationship enables the Risk class to access the Hazard, Vulnerability, and Exposure data, enabling the assessment of the risk severity class for each specific case.
4. Validation of the Smart Data Models
The proposed framework (Figure 1) that integrates those data models in a multi-layered approach for assessment of the flood risk has been evaluated. The assessment of the presented data models is carried out in a user-centered indirect manner, through the verification of user satisfaction with the aqua3S modules that rely on these particular models. It focuses on the user’s needs and revolves around the concept of establishing a practical scenario for the user, referred to as a simulated work task situation. The proposed data models have been evaluated in terms of their ability to adequately represent the necessary information and populate data in a compatible NGSI-LD Context Broker. Unfortunately, since these models were developed recently, there is no other similar system using them and thus we cannot directly compare our results with another platform. In the following subsections, the descriptions of the real case scenarios that took place in the context of the aqua3S project as well as the qualitative results are illustrated.
4.1. Scenaria Description
The scenario takes place in the city of Trieste (Figure 6) including the area nearby (the city of Muggia and part of the Isonzo River Plain). In the region of Friuli Venezia Giulia, the city of Trieste is the most populated one with approximately 410.000 inhabitants in the metropolitan area and it is located near the borders between Italy and Slovenia. The city’s water supply system has always been unique due to the fact that it presents some critical challenges. Since Karst topography does not include any water sources close to the city, the system relies on groundwater near the Isonzo River in San Pier d’Isonzo. To overcome this limitation and connect the water distribution network to the main sources in the Isonzo River Plain, two water mains are established. The first one runs along the coastline for approximately 23 km, and the second one extends 18km under the sea. Water is then pumped through a series of plants all over the city, up to the Karst area.
The study area covers numerous flood risk areas identified with the Flood Risk Management Plan (FRMP) of the Eastern Alps River Basin District (Decree of the Italian President of Ministry of 1st December 2023), redacted by the Water Authority of the Oriental Alps River District (AAWA) in accordance with Directive 2007/60/EU. Because some of the investigated locations (Muggia, harbour area of Trieste) are characterized by low ground elevation above sea level, it makes them vulnerable to flooding due to high tides from the Adriatic Sea, which can be triggered by meteorological factors like rainfall and southern winds. Additionally, Isonzo River Plain including San Pier d’Isonzo, where the main wells of the water supply system are located, is at flood risk caused by the Isonzo River, a significant transboundary water body for the Eastern Alps River Basin District. Considering the flood risk in Trieste’s water distribution and supply system, one specific operational scenario was simulated using satellite data coming from a storm that affected the area in November 2019. This scenario is divided into two sub-scenarios: the first one affects the supply network of Trieste, particularly the wells in the Isonzo River Plain, and the other affects the city’s distribution network in the harbor area. This scenario involves the use of Risk Management, GIS, and Satellite Imagery data models.
SCENARIO A – Blackout in the wells due to the high level of the Isonzo river: The intense rainfall in the region has led to a significant rise of the water level of the Isonzo River in San Pier D’Isonzo. The result is a blackout and disruption in the electrical equipment of the wells responsible for supplying water to the city of Trieste, given their proximity to the river.
Scenario A unfolds as follows: All operators log in to the platform according to their designated roles. Initially, the Water Utility operator receives a warning from the aqua3S platform, and then he/she calls from the call center, confirming the issue. With the collaboration of the Water Authority and Water utility operators, they explore the possibility of the problem being linked to the flood of Isonzo River, because the area falls within the flood risk area as per the FRMP and displayed in the GIS interface of the system. The Water Authority operator checks the platform for available satellite images of the area. Later on, the operator examines the platform analysis output and particularly focuses on the water body mask and the water depth and velocity maps, generated through the GIS and Satellite Imagery data models. Additionally, the operator checks out the flood hazard and flood risk maps produced by the Risk Management data model. From these maps, the operator understands that the level of the Isonzo River is notably high, in particular in the area near the wells. Subsequently, the responsible staff at the Water Utility takes action by utilizing the internal threat management procedure, evaluating potential threat levels, characterize the location, and possible response measures. The operator also checks the Risk Management tool for crisis scenarios related to the current situation. As the crisis is de-escalated, the issue is resolved, and the color of the sensor on the map reverts to green.
SCENARIO B - Damage to the pipes in Trieste due to high tide: during the same storm event responsible of high water level of the Isonzo River and supply network issues in San Pier d’Isonzo, the weather conditions also caused an exceptional tide in the Adriatic Sea. The high tide results in flooding the city area near the harbor and causing damage to the pipes of the water distribution network in that area.
The Scenario B unfolds as follows: Following the resolution of the previous malfunction, the operators continue to monitor the platform for potential anomalies triggered by the meteorological situation. The Water Supply operator identifies the damaged pipe(s) in the static GIS layer of the water distribution network. This situation forces the operator to understand that there is an unavailability issue as the broken pipe does not allow water supply to a specific area of the city, affecting a part of the citizens. The Water Authority Operator examines the satellite data from the last few days to detect any possible flood areas that could be causing the anomaly and the Satellite Imagery data model generates a flood mask for the Trieste and Muggia region. The Water Authority Operator observes that the Risk Management data model algorithm has identified flooded areas in Trieste and Muggia due to the tide. By comparing, the generated FRMP maps of Hazard, Risk, water Velocity, and Water depth, with the static GIS Layer of the Trieste network on the map, the operator confirms that the damaged section of the network matches with the detected hazard and risk map.
An overview of the above Scenarios including information concerning the processes and the data models that were involved as well as the inputs, outcomes, actors (operators) and actions to be taken by them from decision-making perspective, are illustrated in the Table A1 and Table A2 respectively, at the Appendix A.2.
4.2. Quantitative Results
Following the paradigm of [36], who introduced the term “usability” encompassing the concept of user-centered evaluation, this work adopts usability for assessing user satisfaction. The term usability encompasses the examination of user engagement and interaction. Furthermore, as per the ISO 9241-11 standard, usability is defined as the product’s capacity to enable specified users to achieve defined goals with effectiveness (to which level the user is able to achieve his/her goals), efficiency (to which level of effort the user has to invest over the achieved accuracy), and satisfaction within a specific context of use. Thus, effectiveness, efficiency, and satisfaction define usability (the level of comfort and acceptability of use).
The participants involved in the evaluation were 29 professionals with diverse backgrounds and significant work experience (i.e., over 5 years). Specifically, as depicted in Figure 7, the majority of participants (41%) were technical partners from several companies, while a significant proportion of the attendees held positions associated with water quality and served as First Responders (24%).
Regarding the participants’ professional backgrounds, the majority (59%) possessed substantial experience, defined as over 5 years of experience as depicted in Figure 8. It is worth mentioning that there was a good gender balance among the participants, with 59% being male and 41% female.
With respect to the development and the usability of the platform, a questionnaire has been carefully designed that involved a series of questions among which questions concerning the modules related to satellite data usage and risk assessment. Hence, the participants were tasked with assessing their level of usability along the following criteria Effectiveness, Efficiency, and Satisfaction of each module. The responses were assigned weighted values (ranging from 5 to 1, indicating strong agreement to strong disagreement) based on the three aforementioned criteria. It’s important to highlight that the questionnaire underwent validation and approval from every consortium member. Furthermore, particular care was taken to address any ethical concerns associated with the questionnaire’s formulation.
The findings of the research exhibit a positive level of responders’ satisfaction after the usage of both data models. Particularly, approximately 96.5% of participants strongly agree or agree that the Satellite Imagery Data Model is easy to use and useful for storing and exchanging information generated from the analysis of Satellite Imagery (Figure 9). Similarly, 89.3% of the responders consider that the Satellite Imagery Data Model is an efficient tool (agree or strongly agree) in relation to performance and time needed for completing their tasks with adequate accuracy. Significantly higher is the percentage of responders who consider that the particular data model can assist them in completing their task accurately compared with those who are neutral or disagree (85.7% against 14.3%).
Similar findings can be drawn concerning the usability of the Flood Risk Management data model (Figure 10). The 89.3% of responders are satisfied after the usage of the particular model and also they believe that it can effectively aid them in completing their tasks reliably (level of effectiveness is around 89.3%). Slightly different are the results in terms of the efficiency of the Flood Risk Management Data Model, where the percentage of participants who agree that this DM is efficient reaches 82.1% against those who are neutral (17.9%). One potential reason is that the creation of Flood Risk Maps depends on Data Models (i.e., Satellite Imagery), and other processes, that may insert a slight delay in the visualisation of the flood hazard and risk maps. This can be translated as an inefficiency of the DM by a few responders.
5. Conclusions
Water is the lifeblood of many other sectors such as energy, agriculture, industry etc., by supporting their processes. Hence, the digitalisation of the water sector through the deployment of digital solutions fosters the Twin Transition (digital and green transition) as well as water security, sustainability and resilience. The emerging technologies for water data acquisition, smart processing and sharing provide positive reinforcement to the processes of data management in the water sector. Facilitating a faster adoption of the data representations by defining common standard-wise Smart Data Models enhances the data sharing trustworthiness and promotes interoperability.
In this context, this work proposes two Smart Data Models which are FIWARE compatible that enable the modeling processes of the Satellite imaginary as well as the flood risk assessment. Additionally, a general multi-layered architecture has been described in order to adequately incorporate those data models in a workflow, exhibiting their efficiency and applicability. Through the real-case scenarios, the proposed approach has been evaluated using qualitative and quantitative key performance indicators.
In process-oriented organisations, the evaluation of the data models in real-case flooding events can be challenging. The early-stage achievements and progress achieved can be assessed through early-stage validation via pilots and proof-of-concept efforts. Since the assessment of the data models is indirect, there isn’t a direct connection between end-users and SDMs. Thus, the proposed models are part of the general process that has been applied in real scenarios. The end-users evaluate them through surveys using a meticulous questionnaire that was designed and approved by the consortium members, taking into account the ethical considerations and matters. To this extent, comparisons among similar platforms are impossible to occur due to the limitation of data and lack of interoperability of the modules of different systems.
The conclusions from the qualitative research that took place in the content of the aqua3S framework have revealed a high level of participants’ satisfaction regarding the usability of the Satellite Imagery Data Model and the Flood Risk Management Data Model. Users found the Satellite Imagery Data Model easy to use and valuable for storing and exchanging information coming from the satellite imagery analysis. Similarly, the Flood Risk Management Data Model received positive feedback in terms of satisfaction and effectiveness in completing tasks. However, some respondents noted possible weaknesses in the Flood Risk Management Data Model due to dependencies on processes like Satellite Imagery, which could lead to slight delays in visualizing flood hazard and risk maps.
Funding
This research was funded by European Union’s Horizon 2020 Research and Innovation Program aqua3S, under Grant Agreement No 832876, and by Horizon Europe Research and Innovation Program Waterverse, under Grand Agreement No 101070262.
The following abbreviations are used in this manuscript:
| AoI | Area of Interest |
| DEM | Digital Elevation Model |
| DT | Digital Twins |
| DTDL | Digital Twin Definition Language |
| DRR | Disaster Risk Reduction |
| EaR | Elements at Risk |
| Ep | Exposure of people |
| Ee | Exposure of economic activity |
| Ea | Exposure of environment and cultural elements |
| EO | Earth Observation |
| FFPI | Flash-Flood Potential Index |
| FHR | Flood Hazard Rating |
| FRMP | Flood Risk Management Plan |
| GIS | Geographical Information System |
| LIDAR | Laser Imaging, Detection And Ranging |
| LULC | Land Use Land Cover |
| IoT | Internet of Things |
| SAR | Synthetic Aperture Radar |
| SNAP | Sentinel Application Platform |
| TRI | Terrain Ruggedness Index |
| TWI | Topographic Wetness Index |
| Vp | Vulnerability of people |
| Ve | Vulnerability of economic activities |
| Va | Vulnerability of environments and cultural-archaeological assets |
| and protected areas | |
| WAO | Water Authority Operator |
| WUO | Water Utility Operator |
| WSO | Water Supply Operator |
Appendix A
Appendix A.1
Examples of the Entities within the NGSI-LD Context Broker are provided below through the following figures (Figure A1 and Figure A2)
Figure A1.
Sample Entity: the ID in the form of a URI and Type are the only necessary fields to initiate an Entity.
Figure A1.
Sample Entity: the ID in the form of a URI and Type are the only necessary fields to initiate an Entity.
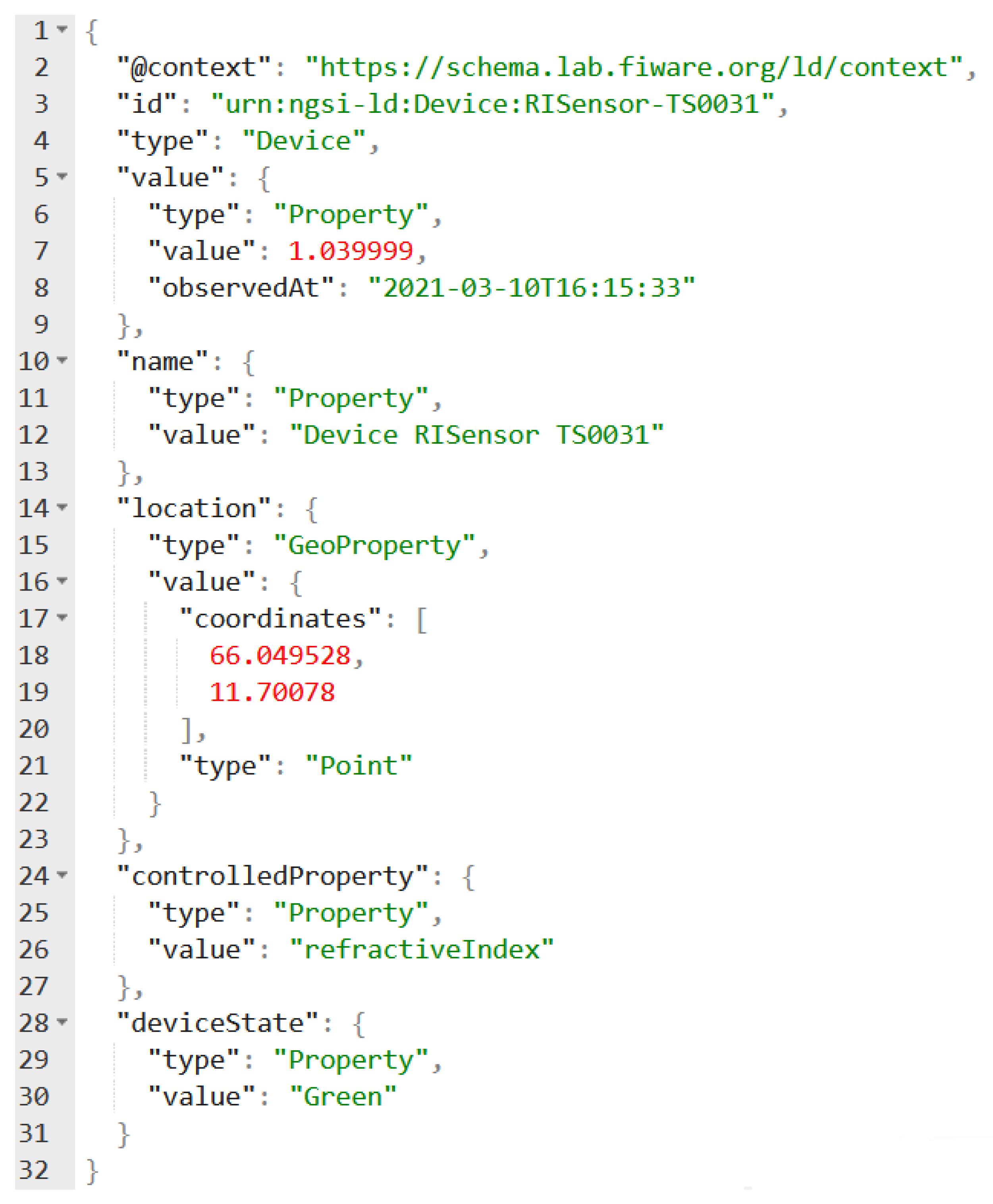
Figure A2.
Sample of a dynamic attribute. The observedAt sub-attribute marks the attribute for the retention of a time-series
Figure A2.
Sample of a dynamic attribute. The observedAt sub-attribute marks the attribute for the retention of a time-series
Appendix A.2

Table A1.
Overview of the SCENARIO A.
| Available information and inputs for the models | Model and process | Actor(s) involved | Result of the process | Action/informed decision taken by the actors |
|---|---|---|---|---|
| Sensor abruptly stopped | Sensor detection:
|
Water Supply Operator (WSO) who is monitoring the sensors’ status. | GIS map interface:
|
WSO:
|
|
GIS interface:
|
Water Authority Operator (WAO) | GIS analysis highlights wells in flood risk area mapped by FRMP. | WAO understands that the issue may be linked to the flood of the Isonzo river. WAO decides to check for satellite data to confirm the result. |
| Satellite data | Flood detection | WAO | Production of the following layers:
|
WAO:
|
| Satellite data | Flood Risk Management Data Model | WAO | Production of the following layers:
|
|
| Ongoing crisis | Flood Risk Management Data Model | WAO | Crisis scenarios:
|
WUO takes action following the internal company procedure to fix the issue. |
| Sensors measures return to normal | Sensor’s status | WSO, WAO | All the sensors on the map show green color. | The issue is resolved and the crisis de-escalted. |
Table A2.
Overview of the SCENARIO B.
| Available information and inputs for the models | Model and process | Actor(s) involved | Result of the process | Action/informed decision taken by the actors |
|---|---|---|---|---|
Receiving information of:
|
Hydraulic model | WUO | Visualisation of:
|
WUO:
|
| Satellite data | Satellite Imagery Data Model | WAO | Production of the following layers:
|
WAO after the estimation of:
|
| Satellite Imagery Data Model output | Flood Risk Management Data Model | WAO | Production of the following layers:
|
|
| Social media posts (Tweets) | Social media posts (TSocial media analysis toolkitweets) | WAO | Social media report on the map regarding the flood in Trieste near the harbor. | |
| GIS static topography layers of the water distribution network. | Layers comparison | WAO | Pipes in the flood report. | WAO communicates the information to the WUO in order to allow the water supply company to take suitable action to repair the pipe. |
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 |
References
- Garrido-Baserba, M.; Corominas, L.; Cortés, U.; Rosso, D.; Poch, M. The Fourth-Revolution in the Water Sector Encounters the Digital Revolution. Environ. Sci. Technol. 2020, 54, 4698–4705. [Google Scholar] [CrossRef]
- Hubert, J.; Wang, Y.; Garcia Alonso, E.; Minguez, R. Using Artificial Intelligence for Smart Water Management Systems. ADB Briefs, 2020. [CrossRef]
- Qian, C.; Liu, X.; Ripley, C.; Qian, M.; Liang, F.; Yu, W. Digital Twin and mdash;Cyber Replica of Physical Things: Architecture, Applications and Future Research Directions. Future Internet 2022, 14. [Google Scholar] [CrossRef]
- Tao, F.; Sui, F.; Liu, A.; Qi, Q.; Zhang, M.; Song, B.; Guo, Z.; Lu, S.; Nee, A. Digital twin-driven product design framework. Int. J. Prod. Res. 2018, 57, 1–19. [Google Scholar] [CrossRef]
- Krishnan, S.R.; Nallakaruppan, M.K.; Chengoden, R.; Koppu, S.; Iyapparaja, M.; Sadhasivam, J.; Sethuraman, S. Smart Water Resource Management Using Artificial Intelligence: A Review. Sustainability 2022, 14. [Google Scholar] [CrossRef]
- Ekeu-wei, I.T.; Blackburn, G.A. Applications of Open-Access Remotely Sensed Data for Flood Modelling and Mapping in Developing Regions. Hydrology 2018, 5. [Google Scholar] [CrossRef]
- Ban, H.J.; Kwon, Y.J.; Shin, H.; Ryu, H.S.; Hong, S. Flood Monitoring Using Satellite-Based RGB Composite Imagery and Refractive Index Retrieval in Visible and Near-Infrared Bands. Remote. Sens. 2017, 9. [Google Scholar] [CrossRef]
- Bauer-Marschallinger, B.; Cao, S.; Tupas, M.E.; Roth, F.; Navacchi, C.; Melzer, T.; Freeman, V.; Wagner, W. Satellite-Based Flood Mapping through Bayesian Inference from a Sentinel-1 SAR Datacube. Remote. Sens. 2022, 14. [Google Scholar] [CrossRef]
- Wallemacq, P.; House, R. Economic losses, poverty and disasters: 1998–2017. UNISDR and CRED. Technical report, Tech. Rep., 2018; 31 pp. Available online: https://reliefweb. int/report/world/economic-losses... (accessed on).
- Sayers, P.; Li, Y.; Galloway, G.; Penning-Rowsell, E.; Shen, F.; Wen, K.; Chen, Y.; Le Quesne, T. Flood Risk Management: A Strategic Approach; UNESCO, 2013.
- Thakuri, S.; Parajuli, B.P.; Shakya, P.; Baskota, P.; Pradhan, D.; Chauhan, R. Open-Source Data Alternatives and Models for Flood Risk Management in Nepal. Remote. Sens. 2022, 14. [Google Scholar] [CrossRef]
- The World Bank. Flood Risk Modeling to Support Risk Transfer: Challenges and Opportunities in Data-Scarce Contexts. 2023. Available online: https://www.insdevforum.org/knowledge/idf-reports-publications/report-flood-risk-modeling-to-support-risk-transfer-challenges-and-opportunities-in-data-scarce-contexts/ (accessed on 6 July 2023).
- Stein, U.; Bueb, B.; Englund, A.; Elelman, R.; Amorsi, N.; Lombardo, F.; Corchero, A.; Brékine, A.; Aquillar, F.; Ferri, M.; Garcia, A.; Manuel, J.; Montenegro, F.; Chen, A.; Moumtzidou, A.; Vries, D.; Caradot, N.; Ugarelli, R.; Vennesland, A.; Vacher, A. Digitalisation in the Water Sector. Recommendations for Policy Developments at EU Level; 2022.
- Petrasch, R.; Petrasch, R. Data Integration and Interoperability: Towards a Model-Driven and Pattern-Oriented Approach. Modelling 2022, 3. [Google Scholar] [CrossRef]
- Halevy, A.; Doan, A.; Ives, Z.G. Principles of data integration; Morgan Kaufmann: Oxford, UK, 2012. [Google Scholar]
- Antzoulatos, G.; Kouloglou, I.O.; Bakratsas, M.; Moumtzidou, A.; Gialampoukidis, I.; Karakostas, A.; Lombardo, F.; Fiorin, R.; Norbiato, D.; Ferri, M.; Symeonidis, A.; Vrochidis, S.; Kompatsiaris, I. Flood Hazard and Risk Mapping by Applying an Explainable Machine Learning Framework Using Satellite Imagery and GIS Data. Sustainability 2022, 14. [Google Scholar] [CrossRef]
- Mostajabi, F.; Safaei, A.; Sahafi, A. A Systematic Review of Data Models for the Big Data Problem. IEEE Access 2021, 1. [Google Scholar] [CrossRef]
- Carvalho, G.; Mykolyshyn, S.; Cabral, B.; Bernardino, J.; Pereira, V. Comparative Analysis of Data Modeling Design Tools. IEEE Access 2021, 10, 1. [Google Scholar] [CrossRef]
- Connolly, T.M.; Begg, C.E. Database Solutions: A Step-by-Step Approach to Building Databases; Addison-Wesley Professional, 1999.
- Zheng, Z.; Du, Z.; Li, L.; Guo, Y. BigData Oriented Open Scalable Relational Data Model. 2014, pp. 398–405. [CrossRef]
- Cirillo, F.; Solmaz, G.; Berz, E.; Bauer, M.; Cheng, B.; Kovacs, E. A Standard-Based Open Source IoT Platform: FIWARE. IEEE Internet Things Mag. 2019, 2, 12–18. [Google Scholar] [CrossRef]
- Ivan, T.; Bogićević, L.; Trikoš, M.; Lalović, K. FIWARE: A web of things development platform. Mil. Tech. Cour. 2018, 66, 880–899. [Google Scholar] [CrossRef]
- Vosinakis, G.; Maltezos, E.; Krommyda, M.; Ouzounoglou, E.; Amditis, A. Data Integration, Harmonization and Provision Toolkit for Water Resource Management and Prediction Support. 2022. [CrossRef]
- Baca Gómez, Y.; Estrada Esquivel, H.; Martínez-Rebollar, A.; Villanueva, D. A Novel Air Quality Monitoring Unit Using Cloudino and FIWARE Technologies. Math. Comput. Appl. 2019, 24. [Google Scholar] [CrossRef]
- Alonso, A.; Pozo Huertas, A.; Cantera, J.; Vega, F.; Hierro, J. Industrial Data Space Architecture Implementation Using FIWARE. Sensors 2018, 18, 2226. [Google Scholar] [CrossRef] [PubMed]
- Muñoz, J.; López-Pernas, S.; Conde, J.; Alonso, A.; Salvachua, J.; Hierro, J. Enabling Context-Aware Data Analytics in Smart Environments: An Open Source Reference Implementation. Sensors 2021, 21, 7095. [Google Scholar] [CrossRef]
- Conde, J.; Muñoz, J.; Alonso, A.; López-Pernas, S.; Salvachua, J. Modeling Digital Twin Data and Architecture: A Building Guide with FIWARE as Enabling Technology. IEEE Internet Comput. 2021, PP, 1–1. [Google Scholar] [CrossRef]
- Muñoz, J.; López-Pernas, S.; Pozo Huertas, A.; Alonso, A.; Salvachua, J.; Huecas, G. Data Usage and Access Control in Industrial Data Spaces: Implementation Using FIWARE. Sustainability 2020, 12, 3885. [Google Scholar] [CrossRef]
- Muñoz, J.; López-Pernas, S.; Pozo Huertas, A.; Alonso, A.; Salvachua, J.; Huecas, G. An Architecture for Providing Data Usage and Access Control in Data Sharing Ecosystems. 2019, 160, 590–597. [CrossRef]
- Alonso, A.; Pozo Huertas, A.; Gordillo, A.; López-Pernas, S.; Muñoz, J.; Marco, L.; Barra, E. Enhancing University Services by Extending the eIDAS European Specification with Academic Attributes. Sustainability 2020, 12, 770. [Google Scholar] [CrossRef]
- Poljansek, K.; Marin Ferrer, M.; De Groeve, T.; Clark, I. Science for Disaster Risk Management 2017: Knowing better and losing less; Number EUR 28034 in JRC102482, Publications Office of the European Union, 2017. [CrossRef]
- UNISDR. Sendai Framework for Disaster Risk Reduction 2015 - 2030. 2015. Available online: https://www.undrr.org/publication/sendai-framework-disaster-risk-reduction-2015-2030 (accessed on).
- EEA. Mapping the Impacts of Natural Hazards and Technological Accidents in Europe, an Overview of the Last Decade. Technical report 13/2010, European Environment Agency, Luxembourg, 2010.
- UNISDR. United Nations International Strategy for Disaster Reduction (UNISDR) Terminology on disaster risk reduction; UNISDR: Geneva, Switzerland, 2009. [Google Scholar]
- Kumar, V.; Azamathulla, H.M.; Sharma, K.V.; Mehta, D.J.; Maharaj, K.T. The State of the Art in Deep Learning Applications, Challenges, and Future Prospects: A Comprehensive Review of Flood Forecasting and Management. Sustainability 2023, 15. [Google Scholar] [CrossRef]
- Barnum, C.M. Usability testing essentials; Elsevier, 2010.
Figure 1.
The logical architecture of the proposed framework.
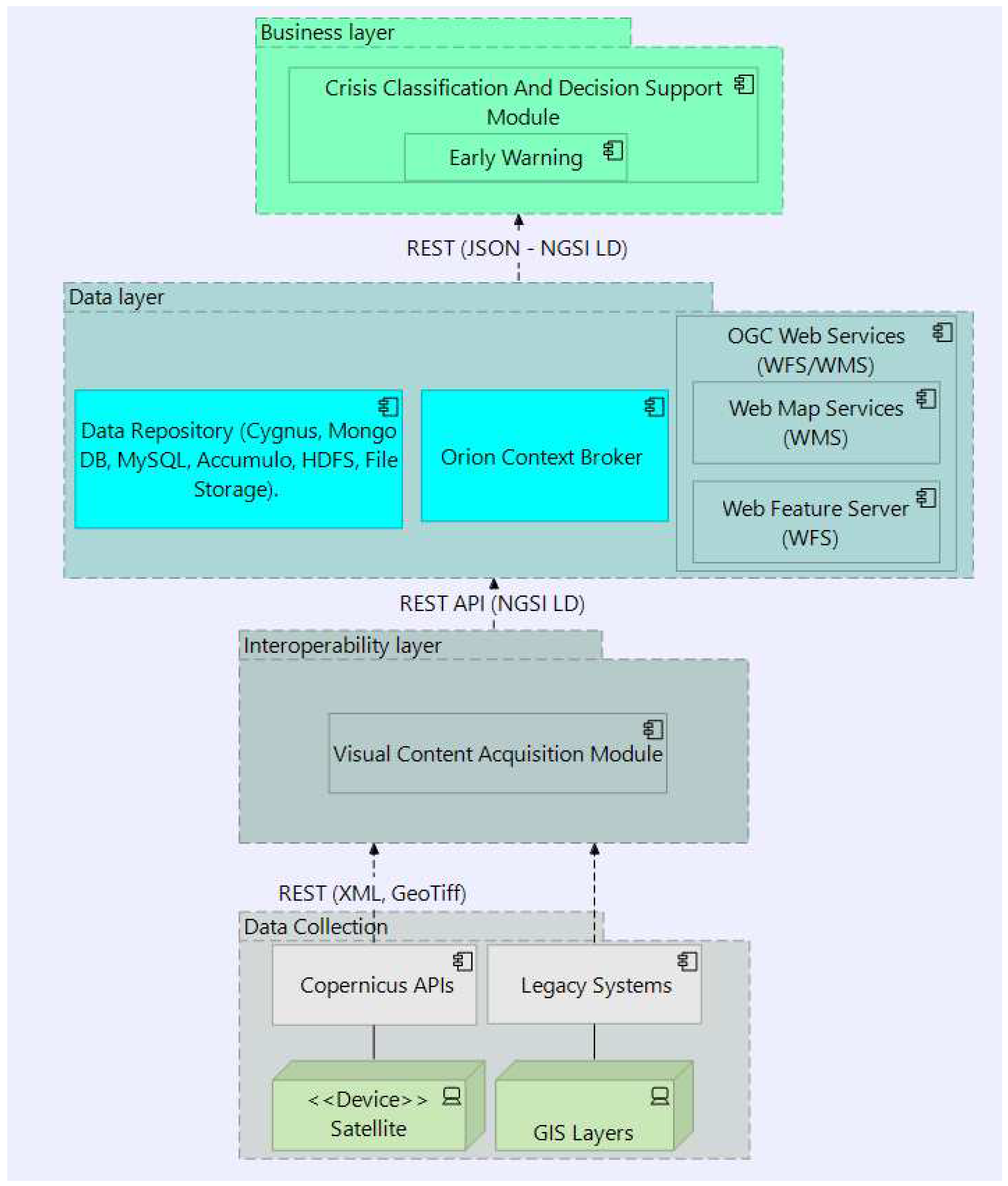
Figure 2.
Simplified architecture around an NGSI-LD broker.
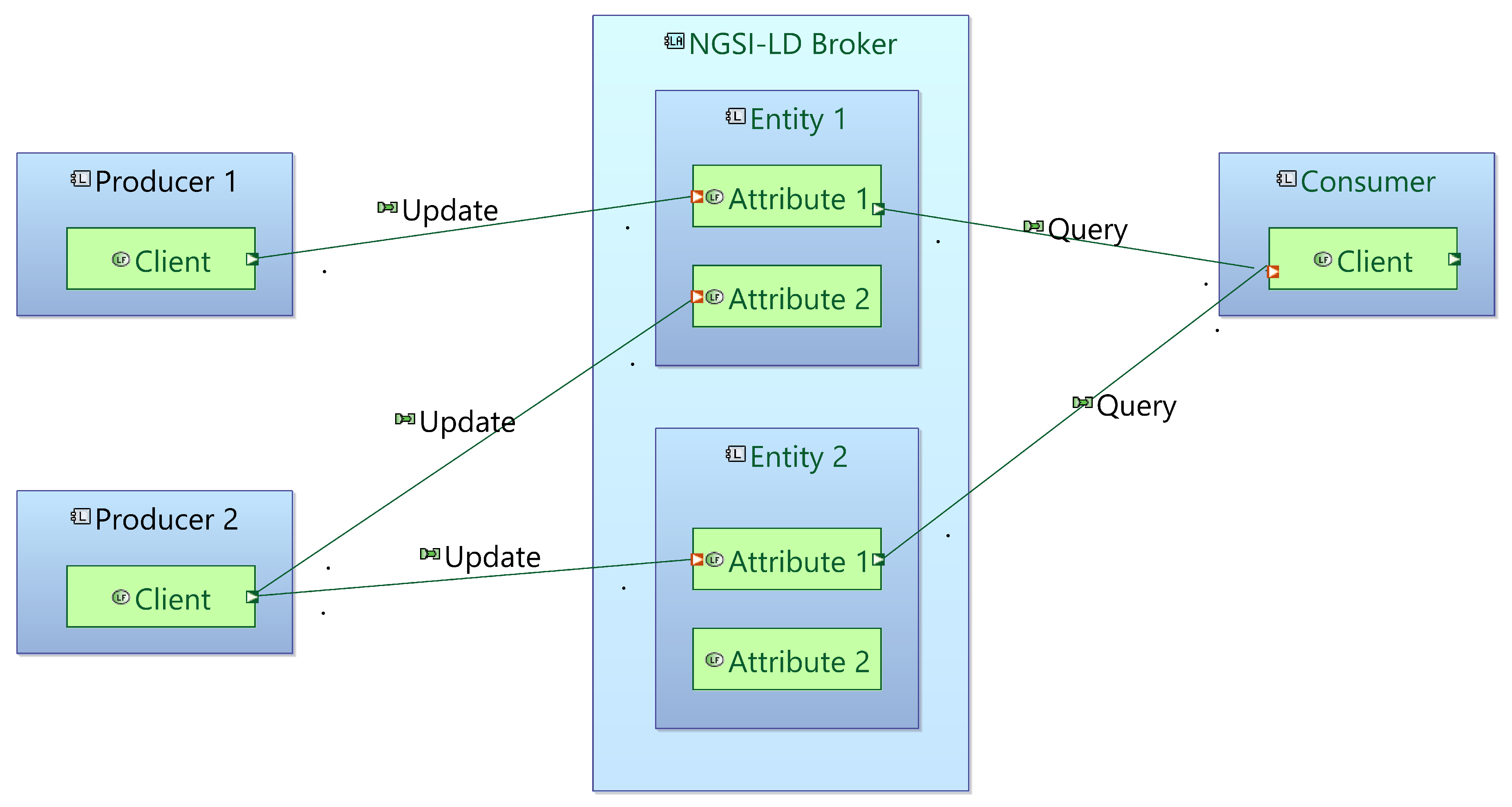
Figure 3.
Visualisation of the Satellite Imagery Data Model schema.
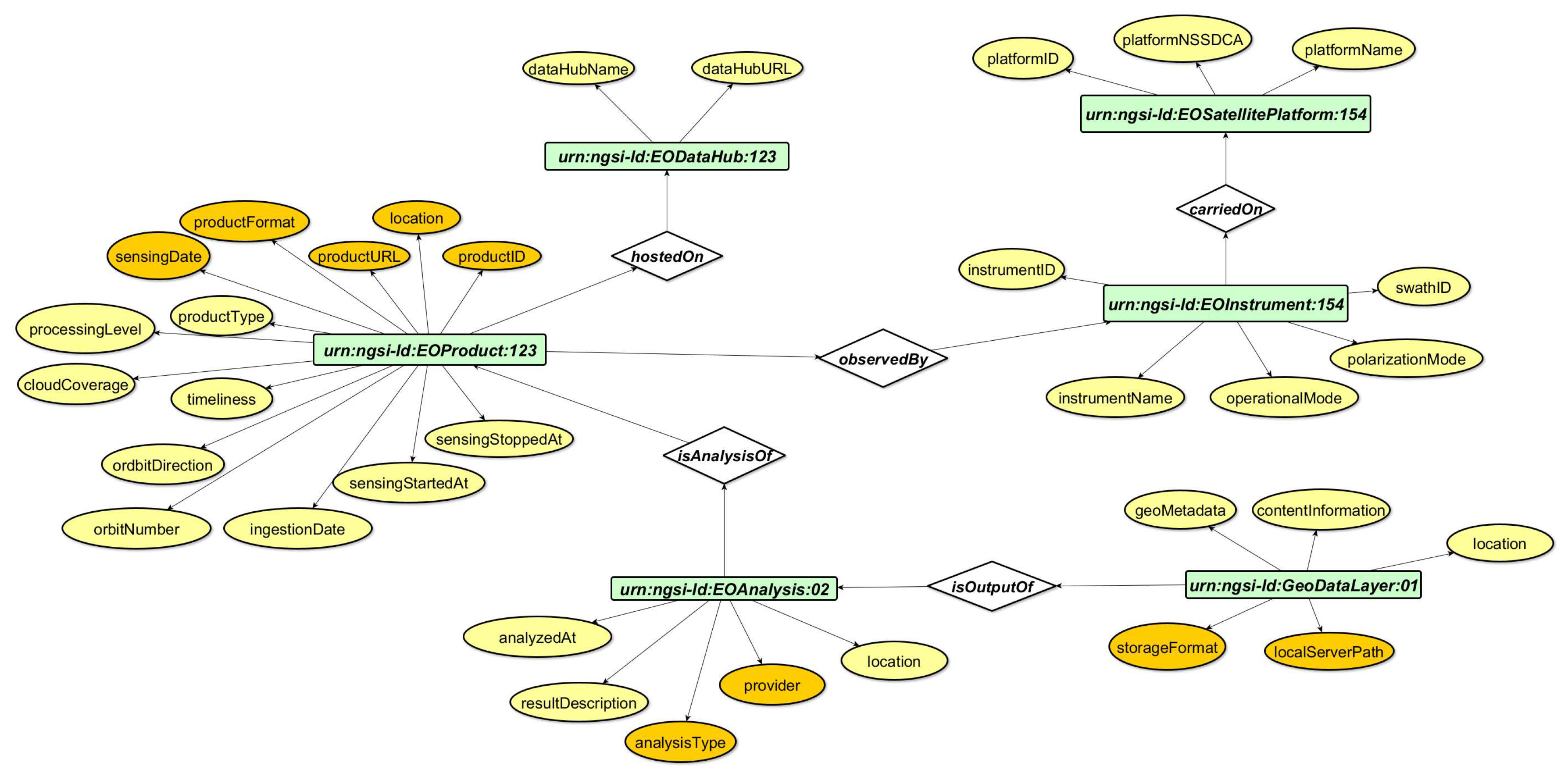
Figure 4.
Visualisation of the GIS Data Model schema.
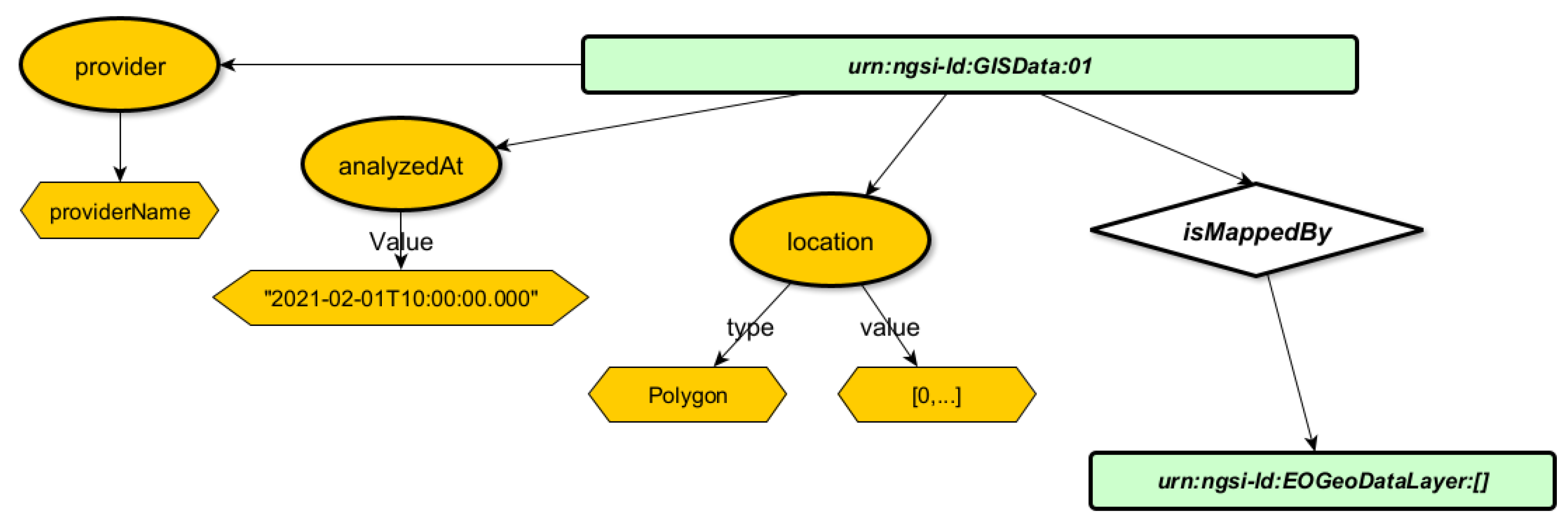
Figure 5.
Visualisation of the Risk Management Data Model schema.

Figure 6.
Region of Interest including the Municipalities of Trieste, Muggia and Monfalcone.
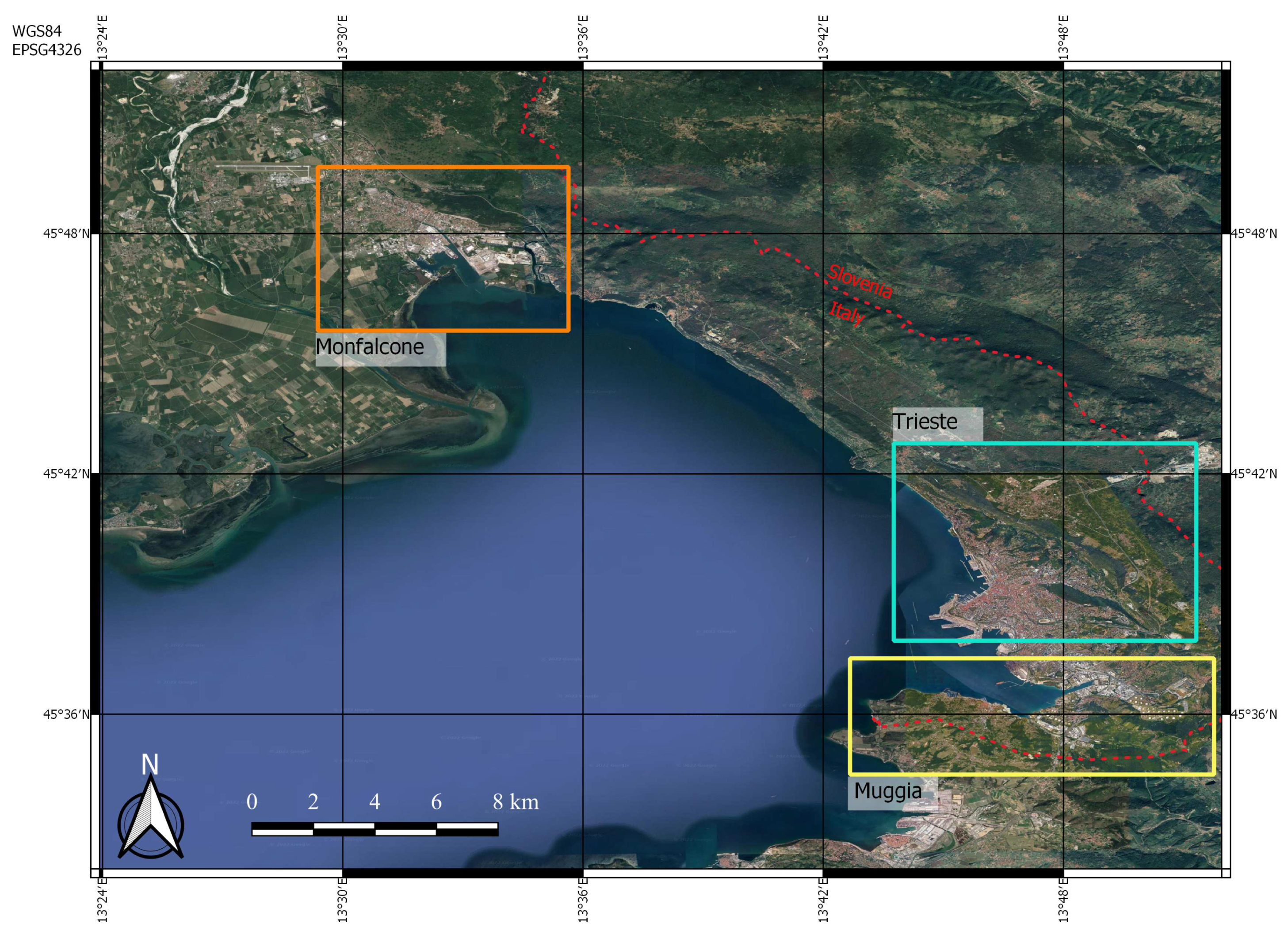
Figure 7.
Professional background statistics.
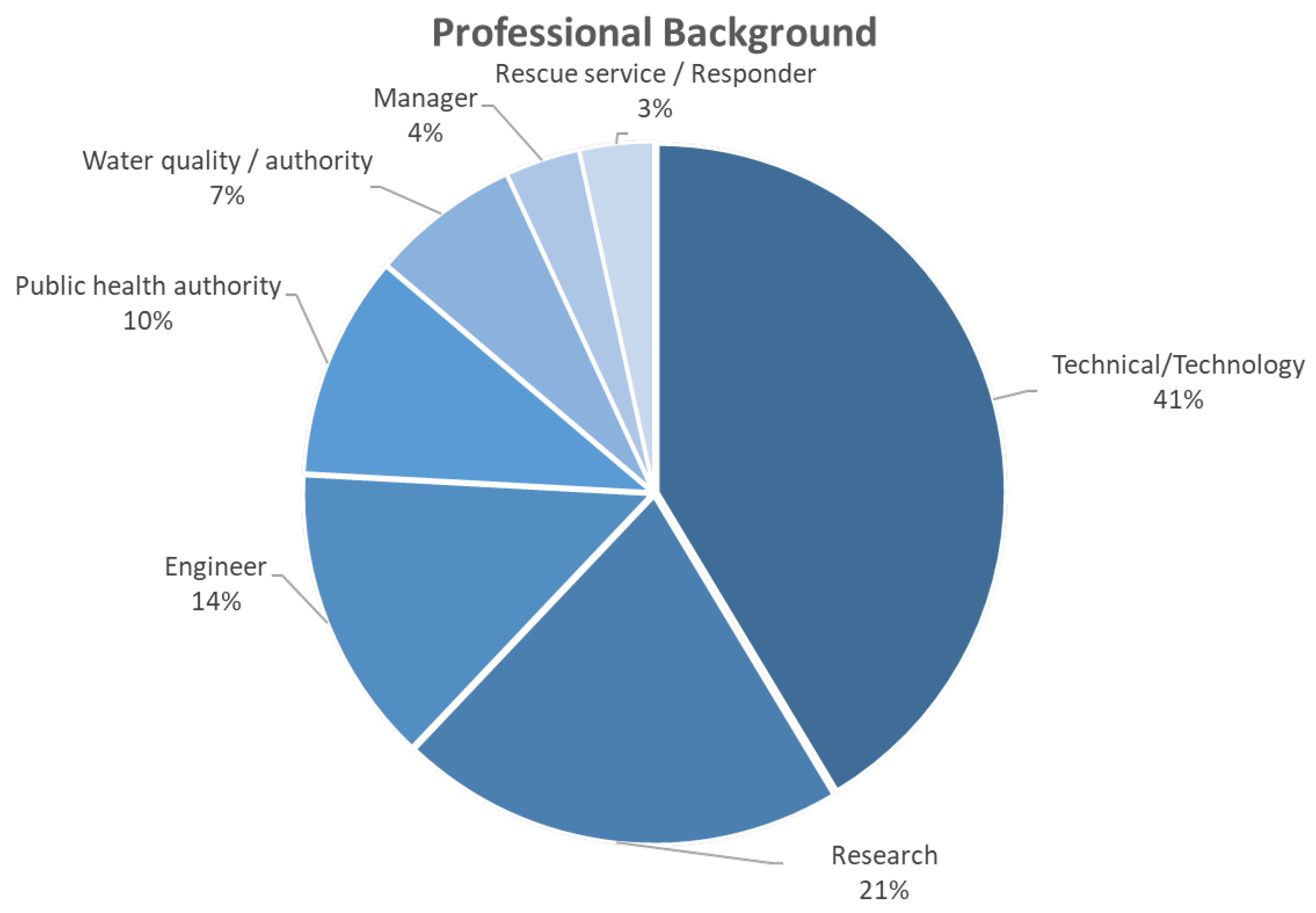
Figure 8.
Professional experience statistics.
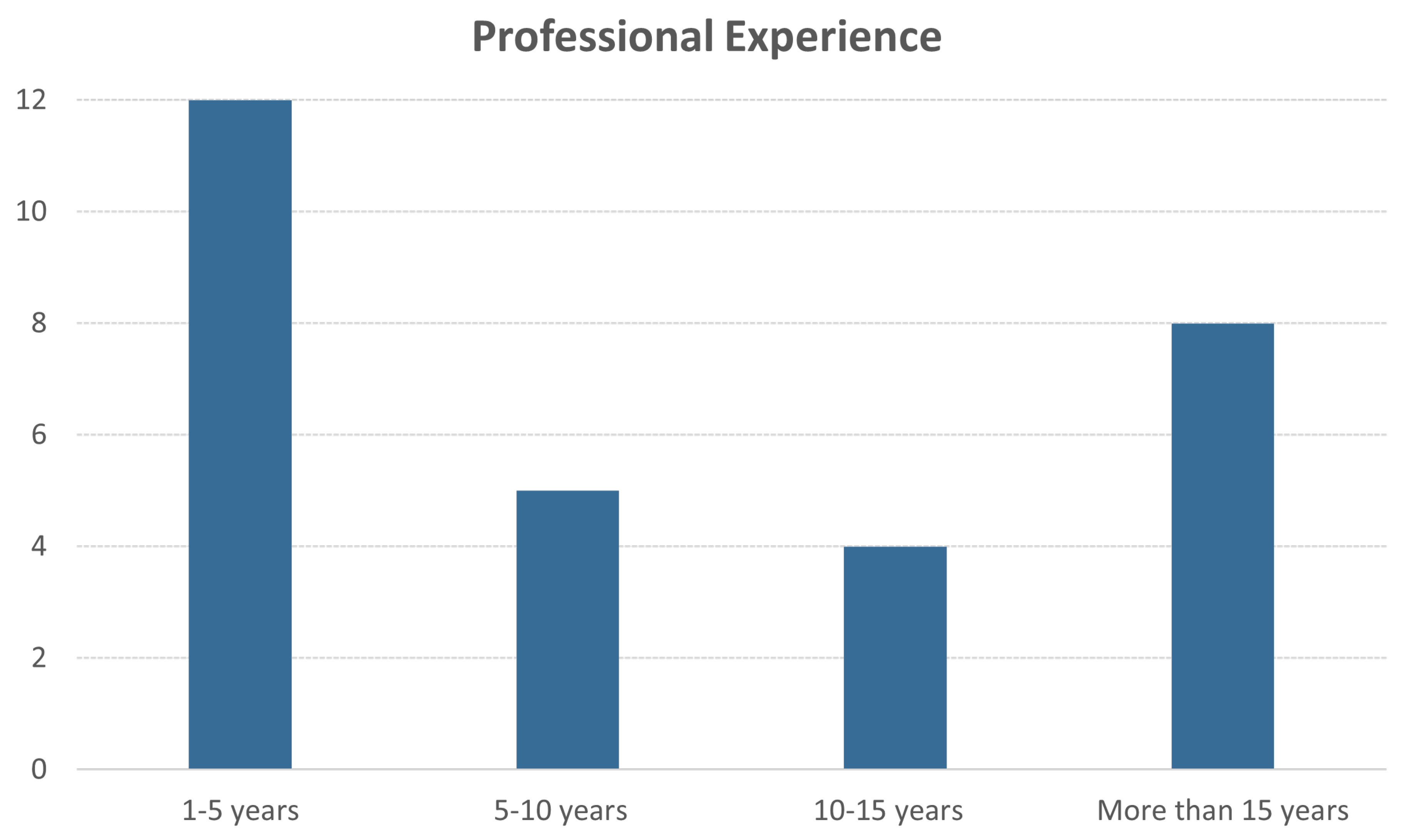
Figure 9.
Satellite Imagery Data Model questionnaire statistics in percentages.

Figure 10.
Flood Risk Management Data Model questionnaire statistics in percentages.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



