
Submitted:
28 November 2023
Posted:
29 November 2023
You are already at the latest version
Abstract
This paper introduces new improvements to the modified version of the BIRECT (BI secting RECTangles) algorithm referred to as BIRECTv. We explore various approaches, by first including a grouping strategy for hyper-rectangles having almost the same sizes by categorizing them into different classes. Therefore constraining them not to exceed a certain pre-defined threshold (a small positive value to define the tolerance level). This approach allows for more efficient computation and can be particularly useful when dealing with a large number of hyper-rectangles with varying sizes. To avoid over-sampling, and preventing redundant or excessive sampling, at some shared vertices in descendant subregions, a particular vertex database is used to limit the number of samples taken within each subregion to two. The experimental investigation shows that these improvements have a positive impact on the performance of the BIRECTv(imp.) algorithm and the proposal is a promising global optimization algorithm compared to the original BIRECTv algorithm and its variants. Additionally, the BIRECTv(imp.) algorithm showed particular efficacy in solving high-dimensional problems.
Keywords:
Global optimization
; Derivative-free global optimization
; Diagonal partitioning scheme
; DIRECT-type algorithms
; Potentially optimal hyper-rectangles
MSC: 90C56; 90C26
1. Introduction
In scientific and engineering domains, optimization problems frequently involve objective functions that can only be obtained through "black-box" methods or simulations, and they often lack explicit derivative information. In black-box optimization cases, the development of derivative-free global optimization methods (DFGO) has been forced by the need to optimize various and often increasingly complex problems in practice because the analytic information about the objective function is unavailable [10,15,33–37]. The absence of derivative information requires the use of derivative-free global optimization (DFGO) methods. DFGO techniques are specifically designed to optimize functions when derivatives are unavailable or unreliable. These methods explore the function’s behavior by sampling it at various points in the input space.
This paper considers a global optimization problem
that require only the availability of objective function values but no derivative information, therefore numerical methods using gradient information can not be used to solve problem (1). The objective function is supposed to be Lipschitz-continuous with some fixed but unknown Lipschitz constant, and the feasible domain is an n-dimensional hyper-rectangle .
Global optimization approaches can be categorized into two main types: deterministic [1,5,6,26,28] and stochastic methods [12,42]. These methods address optimization problem (1) using various domain partition schemes, often involving hyper-rectangles [5,25,42]. While many DIRECT-type techniques employ hyper-rectangular partitions, other alternative approaches use simplicial partitioning [18,19] (as DISIMPL-C [16] and DISIMPL--V [17]) or diagonal sampling schemes (see [22,23,25], as adaptive diagonal curves [24]).
DIRECT-type algorithms, such as the DIRECT (DIvide RECTangles) algorithm [7–9] are the most widely used partitioning-based algorithms for global optimization problems. One of the challenges faced by these algorithms is the selection of potentially optimal rectangles (the most promising), which can lead to inefficiencies and increased computational costs. In this paper, we provide a comprehensive review of techniques and strategies aimed at reducing the set of selected potential optimal hyper-rectangles in DIRECT-type algorithms. We explore various approaches, including a novel grouping strategy which simplify the identification of hyper-rectangles in the selection procedure. This strategy consists in rounding or approximating the measurements (sizes) of hyper-rectangles, that are extremely small in size, by grouping them together into classes. This simplification can help in various computational or analytical tasks, making the problem more manageable without significantly compromising the accuracy of the analysis or optimization process.
Our review highlights the importance of reducing the number of function evaluations while maintaining the algorithm’s convergence properties. The recent papers by [29,38,39] provides a good and a comprehensive overview of techniques aimed at reducing the set of potentially optimal rectangles in DIRECT-type algorithms. It significantly contributes to the field of derivative-free global optimization and serves as a valuable resource for researchers and practitioners seeking to enhance the efficiency and effectiveness of such algorithms. Some suggested methods are summarized in [9,21,29,36,38].
In the context of Optimization Methods in Engineering Mathematics, the size of a hyper-rectangle often incorporate constraints imposed by the engineering problem. These constraints ensure that the optimization process adheres to real-world limitations, such as physical boundaries, safety margins, or resource constraints. For example, in structural engineering, the size of a hyper-rectangle could represent the permissible ranges for material properties, dimensions, or loads. In engineering optimization, reducing the size of a hyper-rectangle can represent the imposition of stricter constraints. This ensures that the optimized solution adheres to more stringent requirements, such as safety limits or design specifications.
We also use an additional assumption to improve this version allowing to evaluate the objective function only once at each vertex of each hyper-rectangle. The objective function values at vertices could be stored in a special vertex database, and then the result is directly retrieved from this database when required. In addition, an update to the modified optimization domain is applied for some test problems as used in the previous version [3].
The original DIRECT algorithm faces challenges when it comes to sampling points at the edges of the feasible region, which can slow down its convergence, particularly in cases where the best solution is located at the boundary. This limitation is especially pronounced in constrained problems. Recent research [13,32,38] has emphasized the importance of addressing this issue, showing that it’s possible to achieve faster convergence by employing strategies that sample points at the vertices of hyper-rectangles, especially when solutions are near the boundary.
Taking these insights into account, we’ve integrated one of the latest versions of DIRECT-type algorithms into our approach, a new diagonal partitioning and sampling scheme called BIRECTv (BIsection of RECTangles with Vertices) based on the BIRECT algorithm. In the BIRECTv framework, the objective function is evaluated at specific points within the initial hyper-rectangle. Instead of evaluating the objective function only at the vertices, as done in most DIRECT-type algorithms, BIRECTv samples two points along the main diagonal of the initial hyper-rectangle, located at and 1 of the way along the diagonal. This approach provides more comprehensive information about the objective function, and helps to improve convergence, particularly near boundaries.
The contributions of the paper can be summarized as follows:
- A review of techniques and strategies aiming to reduce the set of selected potential optimally hyper-rectangles in DIRECT-type algorithms.
- Introduction of a novel grouping strategy which simplify the identification of hyper-rectangles in the selection procedure in DIRECT-type algorithms.
- The new approach incorporates a particular vertex database to avoid more than two samples in descendant subregions.
- The improvements of BIRECTv algorithm positively impacted the performance of the BIRECTv algorithm.
The rest of this paper is organized as follows. In Sect. 2.1, a review of the original BIRECT algorithm is provided, while in Sect. 2.2 a brief description of the new sampling and partitioning scheme called BIRECTv algorithm is also discussed. In Sect. 2.3, we incorporate a novel scheme for grouping and selecting potential optimal hyper-rectangles in BIRECT-type algorithms. Numerical investigation and discussion of the results is given in Sect. 3. Finally, in Sect. 4, we conclude the paper and outline potential directions for future prospects.
2. Materials and Methods
This section provides an overview of the original BIRECT algorithm and its modifications.
2.1. The original BIRECT
The BIRECT (BIsection of RECTangles) algorithm, developed in [20], employs a diagonal space-partitioning approach and involves two primary procedures: sampling on diagonals and bisection of hyper-rectangles.
In the initialization step, the algorithm begins by evaluating the objective function at two initial points, "lower" and "upper" , positioned along the main diagonal of the normalized domain, considered as the first unit hyper-cube, . The hyper-cube representing the search space is then divided into a set of smaller hyper-rectangles obeying a specific sampling and partitioning scheme using the following critera (see Algorithm 1).
2.1.1. Selection criteria
- At each iteration (kth iteration), starting from the current partitionwhere is the index set identifying the current partition, a new partition is created by bisecting a set of potentially optimal hyper-rectangles from the previous partition.
- The identification of a potentially optimal hyper-rectangle is based on lower bound estimates of the objective function over each hyper-rectangle, with a fixed rate of change (analogous to a Lipschitz constant).
- A hyper-rectangle , is considered potentially optimal if specific inequalities involving (a positive constant) and the current best-known function value are satisfied.where the measure (distance, size) of the hyper-rectangle is given by
A hyper-rectangle is potentially optimal if the lower bound for f computed by the left-hand side of (2) is optimal for some fixed rate of change among the hyper-rectangles of the current partition . Inequality (3) helps prevent excessive emphasis on local search [7].
2.1.2. Division and sampling criteria
- After the initial partitioning, BIRECT proceeds to future iterations by partitioning potentially optimal hyper-rectangles and evaluating the objective function at new sampling points.
- New sampling points are generated by adding and subtracting a distance equal to half the side length of the branching coordinate from the previous points. This approach allows for the reuse of old sampled points in descendant subregions.
- An important aspect of the algorithm is how the selected hyper-rectangles are divided. For each potentially optimal hyper-rectangle, the set of maximum coordinates (edges) is computed, and the hyper-rectangle is bisected along the coordinate (branching variable ) with the largest side length. The selection of the coordinate direction is based on the lowest index j, prioritizing directions with more promising function values.
The partitioning process continues until a predefined number of function evaluations has been performed, or a stopping criterion is satisfied. The algorithm keeps track of the best (smallest) objective function value found over all sampled points in the final partition. The corresponding generated point at which this value was achieved provides an approximate solution to the optimization problem. The main steps of the BIRECT algorithm are outlined in Algorithm 1 (see [20] for a detailed pseudo-code).
The BIRECT algorithm is a robust optimization technique that efficiently explores the search space, combines global and local search strategies, and strives to find the optimal or near-optimal solution for multidimensional optimization problems. For a more comprehensive understanding, additional details can be found in the original paper [20].
| Algorithm 1 Main steps of BIRECT algorithm |
 |
2.2. Description of the BIRECTv Algorithm
In this subsection, we return back to one of the most recent versions of DIRECT-type algorithms (called BIRECTv) developed in [3]. One effective strategy is to sample points at the vertices of the hyper-rectangles. This approach ensures that points near the boundaries are explored, increasing the chances of finding solutions located there. Sampling at vertices can significantly improve convergence when the optimal solution is at or near the boundary, see [32]. A description of two different partitioning schemes used in DIRECT-type algorithms is shown in Figure 1. The original DIRECT algorithm primarily focuses on sampling within the interior of the feasible region, which means it may miss exploring points near the boundary. Therefore, it may require a large number of iterations to converge to the optimal solution. This slow convergence is because it relies on subdividing hyper-rectangles within the interior, and it may take many iterations before a hyper-rectangle boundary coincides with the solution. The studies conducted in [33,40] have indeed highlighted the significant impact of the limitation in convergence when the optimal solution lies at the boundary of the feasible region. This issue is particularly prevalent in constrained optimization problems, where solutions often lie at the boundary due to the constraints imposed on the variables.
However, a challenge arises when the newly created sampling points coincide with previously evaluated points at shared vertices. This leads to additional evaluations of the objective function, increasing the number of function evaluations per iteration. To address this issue, the paper suggested modifying the original optimization domain to obtain a good approximation of the global solution.
This approach was presented as an alternative to locate solutions that are situated near the boundary. The results of the experiments demonstrated that the proposed modification to the optimization domain positively impacted the performance of the BIRECTv algorithm. It outperformed the original BIRECT algorithm and the two popular DIRECT-type algorithms on the test problems. Additionally, the BIRECTv algorithm showed particular efficacy in solving high-dimensional problems.
2.3. Integrating Scheme for Identification of Potentially Optimal Hyper-rectangles in DIRECT-based Framework
In this section, we introduce an innovative grouping technique that streamlines the hyper-rectangle identification process during selection. This approach involves the rounding or approximation of measurements (sizes) for hyper-rectangles of exceedingly small dimensions. These are then organized into classes, yielding simplification that enhances the manageability of computational and analytical tasks. Importantly, this simplification doesn’t substantially impact the precision of the analysis or optimization process. The selection of the most promising hyper-rectangles in DIRECT-type algorithms is a crucial aspect of optimization.
Various strategies have been developed to enhance this selection process, resulting in different versions of the algorithm. In the DIRECT-l variant [2,9], the size of a hyper-rectangle is measured by the length of its longest side, which corresponds to the infinity-norm. This approach allows DIRECT-l to group more hyper-rectangles with the same measure, resulting in fewer distinct measures. Moreover, in DIRECT-l, only one hyper-rectangle from each group is selected, even if there are multiple potentially optimal hyper-rectangles in the same group. This reduces the number of divisions within a group. DIRECT-l is found to perform well for lower-dimensional problems that do not have an excessive number of local and global minima.
The aggressive version of DIRECT takes a different approach by selecting and dividing a hyper-rectangle of every measure in each iteration. While this strategy requires more function evaluations compared to other versions of DIRECT, it may be advantageous for solving more complex problems. The PLOR algorithm simplifies the set of potentially optimal hyper-rectangles to just two: the maximal and the minimal Lipschitz constants. This reduction allows the PLOR approach to be independent of user-defined parameters. It strikes a balance between local and global search during the optimization process by considering only these two extreme cases.
In two-phase globally and locally biased algorithms, the selection procedure during one of the phases operates similarly to the original DIRECT algorithm, considering all hyper-rectangles from the current partition. However, in the second phase, the selection of potentially optimal hyper-rectangles is constrained based on their measures. Globally-biased versions [17,24] focus on larger subregions, addressing the algorithm’s first weakness, while locally-biased versions [2,14] concentrate on smaller subregions, addressing the second weakness of DIRECT-type algorithms. These adaptations and strategies aim to improve the efficiency and effectiveness of DIRECT-type algorithms in addressing optimization challenges, particularly in scenarios with complex landscapes and varying dimensions [32,33].
The authors in [29] introduced an improved scheme by extending the set of potentially optimal hyper-rectangles for DIRECT-GL algorithm. These enhanced criteria are designed to reduce the computational cost of the algorithm by focusing on the most promising regions of the search space. By implementing the improved selection criteria, the algorithm becomes more efficient in identifying regions of interest within the optimization landscape. This leads to a reduction in the number of hyper-rectangles that need to be explored, saving computational resources and time. The enhancements introduced in this work are not limited to a specific type of problem or application. They can be applied to a wide range of optimization scenarios where DIRECT-type algorithms are utilized [30,31,34,39].
Let the partition of at iteration k be defined as
Let is the set of indices identifying the subsets defining the current partition . Let a measure of defined by
Let , represents a subset of indices that correspond to elements of with measue having almost the same measure as within a certain tolerance (threshold=), ranging from to , i.e., such that .
The purpose is to identify potentially optimal hyper-rectangles. It looks for hyper-rectangles (indexed by I) where the norm value () is very close (within the defined tolerance) to the normalized norm value ().
The line 11 is used to reduce the set of potentially optimal hyper-rectangles. The code filters the hyper-rectangles and selects only those that meet a specific condition, which is having their norm value () close to the normalized norm value () within a tolerance of .
In summary, this line of code helps to focus on potentially more promising hyper-rectangles, discarding those that are not as close to the desired normalized norm value. It’s a way to efficiently narrow down the search space and improve the efficiency of the algorithm. An illustrative example for two different tolerance levels is given in Figure 2.
The difference between the tolerance and lies in the level of precision used when comparing the and values to filter the potentially optimal hyper-rectangles.
1. Tolerance :
- A tolerance of (0.01) means that the algorithm will consider hyper-rectangles whose and values are within 0.01 of each other.
- It allows for a relatively larger difference between and , meaning the algorithm will be more lenient in selecting potentially optimal hyper-rectangles.
- This might result in a larger set of potentially optimal hyper-rectangles, including some with relatively larger differences in their norm values.
2. Tolerance :
- A tolerance of (0.0000001) means that the algorithm will consider hyper-rectangles whose and values are within of each other.
- It uses a much smaller tolerance, making the algorithm much stricter in selecting potentially optimal hyper-rectangles.
- This will result in a smaller set of potentially optimal hyper-rectangles, only including those with extremely close norm values.
The choice of tolerance depends on the specific problem and the desired level of precision in the algorithm. A larger tolerance may lead to faster execution, but it might also include some hyper-rectangles that are not truly optimal. On the other hand, a smaller tolerance will be more accurate but may require more computational effort to identify the potentially optimal hyper-rectangles. It’s a trade-off between efficiency and precision in the algorithm’s behavior.
Note: The algorithm assumes a zero-based index for the array elements, and the first index found satisfying the condition is returned. If no element satisfies the condition, the algorithm returns -1.
The algorithm essentially performs a linear search through the array and stops as soon as it finds the first element within the specified tolerance level. It’s important to choose an appropriate tolerance level depending on the application and the expected values in the array.
3. Results and Discussion
3.1. Implementation
In this section we provide an overview of the methodology and objectives of our study, which involves benchmarking the new enhanced BIRECTv against the previous version of BIRECTv [3], the original BIRECT [20,21], and other DIRECT-type algorithms on a set of test problems. In our study, the size of the hyper-rectangle in BIRECTv is measured using the same measure as in the original BIRECT algorithm, while in DIRECT-l, it corresponds to the infinity norm, which allows it to collect more hyper-rectangles of the same size. This is in contrast to the Euclidean distance measure used in the original DIRECT algorithm. Our implementation uses the same set of 54 global optimization test problems from [4]. The Hedar test set is a popular benchmark for testing optimization algorithms. These problems are described in Table A1, which includes attributes like problem number, problem name, dimension, feasible domain, number of local minima, and known minimum. Some test problems have multiple variants, and the algorithm is tested for different dimensionalities. In some cases, during the initial steps of the algorithm, sampling is performed near the global minimizer. The feasible domain is modified by increasing the upper bound in these situations. these modified test problems are marked with a star. All computations were performed with MATLAB R2017b on a computer with an Intel Core i5-6300U CPU @ 3.5 GHz Processor, 8GB memory and running on Windows 10 operating system. The output values are rounded up to 10 decimals. All algorithms were tested using a limit of Mmax = function evaluations in each run. For the 54 analytical test cases with a priori known global optima , the used stopping criterion is based on the percent error:
The value of was set to as a default value. This value likely represents a tolerance threshold used during the optimization process such that .
The comparison is based on two primary criteria: the best-found function value and the number of function evaluations (f.eval.). These criteria help evaluate the performance of the algorithms on each test problem. The study provides statistical measures, such as averages and medians, for the number of function evaluations. The average performance provides an overall assessment of each algorithm’s performance across all problems, while the median performance is less influenced by outliers and represents the middle point in the data. In the tables labeled "comparison," the best number of function evaluations is highlighted in bold font to emphasize the most efficient results. Additionally, the study includes information about the number of iterations and the execution time in seconds, these details are specifically reported on GitHub and Zenodo repositories (see Data Availability Statement below). The results of all six algorithms are reported in Table 1, where the same arguments were used: a specific domain modifications, and a grouping scheme from Algorithm 2 with a tolerence level of . Note that,in our results, a correction was made during the current experiments to the minimum value acheived for the Perm test function 27 from [3]. The potentially optimal hyper-rectangles are those that have their norm values close to the normalized norm value, which means they are potentially interesting candidates for further evaluation. By filtering out the hyper-rectangles that don’t satisfy this condition, the set of potentially optimal hyper-rectangles (I) is reduced to a smaller subset. These reduced hyper-rectangles are considered more interesting candidates for further evaluation or processing in the algorithm. Additionally, BIRECTv-l(imp.) and BIRECTv(imp.) are improved versions by using a special vertex database to prevent redundant sampling. Note that this assumption is not applied to the BIRECT algorithm, since the algorithm itself is designed to enable reuse of objective function values in descendant subregions. An illustrative example in Figure 3 demonstrates the corresponding version of the BIRECTv algorithm when the introduced vertex database is applied. The total number of function evaluations is 490 for BIRECTv and 370 for the improved version.
| Algorithm 2 Find First Index within Tolerance |
 |
3.2. Discussion
In this subsection, we discuss the performance evaluation of three optimization algorithms and their variants of the DIRECT-type that are designed for solving global optimization problems using Hedar test set [4]. All six algorithms are variations of the original BIRECT algorithm [20]. The improved versions (with "imp.") are modifications of the original BIRECTv and BIRECTv-l algorithms from [3]. Two new variations of the algorithm, "BIRECT-l (new)" and "BIRECT" (new), are also introduced. The improved version of BIRECTv-l(imp.) consistently outperform their previously published counterparts (BIRECTv-l and BIRECTv, respectively), achieving the lowest average objective function value among all six algorithms. This improvement is evident in terms of both objective function value and the number of function evaluations. This suggests that the algorithm enhancements have been successful in optimizing the problems more efficiently. However, BIRECTv-l(imp.) have the same comparable performance to BIRECTv-l in some cases, indicating that the modification of the optimization domain may not always be necessary. Similar to BIRECTv-l(imp.), the algorithm BIRECTv(imp.) generally performs well on some problems (often requires fewer function evaluations), but may not be as efficient on others as shown for problem 27. For this problem, the algorithm fails to reach a conceivable objective function contrary to BIRECTv and BIRECTv-l algorithms. The versions of BIRECTv-l and BIRECTv are evaluated based on results from [3], but with a tolerance level of . For the first algorithm, both metrics (average-median) show that the algorithm is the second best algorithm. Particularly, it outperforms the BIRECTv(imp.), and dominates across all other problems. The new versions of BIRECT-l(new) and BIRECT(new) introduced in Table 2 show competitive performance compared to their predecessors [20,21], especially in terms of the number of function evaluations required. The average value is smallest using BIRECT-l(new) and BIRECT(new) from Table 2, ( and respectively), compared to the same algorithms from Table 1, ( and respectively). Even more, the average is smaller for BIRECT-l(new) () from Table 3 without the domain modification than from Table 1 with the same tolerance . This means that the modification of the optimization domain is not necessary for the BIRECT algorithm. While they may not always achieve the best objective function value, they often achieve a good balance between solution quality and computational effort. The mention failed in Table 3 means that there no improvement in the objective function value during many succesive iterations, or if an increasing number of evaluations per iteration is observed. In both cases, the number of function evaluations is . The performance of each algorithm varies across different optimization problems. Some algorithms may perform exceptionally well on certain problems but less effectively on others. This demonstrates the importance of algorithm selection based on the specific characteristics of the optimization task.
- The improved versions of BIRECTv-l and BIRECT (imp.) appear to be reliable choices for optimization tasks, as they consistently outperform the previously published versions and demonstrate competitive performance in terms of both objective value and computational effort.
- The new algorithms, BIRECT-l (new) and BIRECT (new), show promise and are particularly efficient in terms of the number of function evaluations. However, their objective function values may vary depending on the problem.
- The choice of algorithm should be problem-dependent. Some algorithms may be more suitable for specific problem characteristics, such as unimodal or multimodal objective functions, and global or local optimization.
- These informations provide a comprehensive assessment of the algorithms’ performance across various aspects, including solution quality and computational efficiency.
4. Conclusions and Future Prospects
The paper introduced a new DIRECT-type algorithm called BIRECTv. The algorithm incorporates the most recent partitioning and selection techniques, which are essential for enhancing its performance in tackling the global optimization problems. The improvements have showed that BIRECTv outperforms existing DIRECT-type algorithms. It is more efficient and performs better in terms of convergence rates and the number of function evaluations required. Existing DIRECT-type algorithms, in contrast, tend to have slower convergence rates and often require a significantly higher number of function evaluations. They face notable difficulties when the optimal solution lies at the boundaries of feasibility. Through experimentation, the results demonstrate the algorithm’s superior performance, particularly in cases where solutions are located at the boundary of feasible regions. This research has opened up new possibilities for addressing global optimization problems, which suggests that BIRECTv has the potential to make significant contributions in this field. The new algorithm is expected to have an important place among all other DIRECT-type algorithms. This implies that it could become a standard choice for solving global optimization problems with the mentioned characteristics. In conclusion, this paper sets the stage for future research by suggesting that this algorithm opens up new possibilities, which could lead to further advancements in the field.
Author Contributions
Conceptualization, L.C.; Data curation, L.C.; Formal analysis, L.C. and M.L.; Funding acquisition, M.L.; Investigation, N.B. and L.C.; Methodology, N.B. and L.C.; Project administration, M.L. and L.C.; Software, N.B. and L.C.; Supervision, L.C. and M.L.; Validation, L.C. and M.L.; Writing—original draft, L.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data underlying this article are available on GitHub repository from BIRECTv v1.1.0 - https://github.com/lchiter/Algorithm-BIRECTv/releases (accessed on 20 September 2023), and used under the MIT license, or at Zenodo: https://zenodo.org/record/7416231 (accessed on 20 July 2023). The first codes for the algorithms BIRECT(new) and BIRECT-l(new) are made available from https://data.mendeley.com/datasets/t6vv9yknbc/1.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A

Table A1.
Key characteristics of the Hedar test problems [4]
| Problem | Problem | Dimension | Feasible region | No. of local | Optimum |
| No. | name | n | minima | ||
| Ackley | 2, 5, 10 | multimodal | 0.0 | ||
| 4 | Beale | 2 | multimodal | 0.0 | |
| Bohachevsky 1 | 2 | multimodal | 0.0 | ||
| Bohachevsky 2 | 2 | multimodal | 0.0 | ||
| Bohachevsky 3 | 2 | multimodal | 0.0 | ||
| 8 | Booth | 2 | unimodal | 0.0 | |
| 9 | Branin | 2 | 3 | ||
| 10 | Colville | 4 | multimodal | 0.0 | |
| Dixon & Price | 2, 5, 10 | unimodal | 0.0 | ||
| 14 | Easom | 2 | multimodal | ||
| 15 | Goldstein & Price | 2 | 4 | 3.0 | |
| Griewank | 2 | multimodal | 0.0 | ||
| 17 | Hartman | 3 | 4 | ||
| 18 | Hartman | 6 | 4 | ||
| 19 | Hump | 2 | 6 | ||
| Levy | 2, 5, 10 | multimodal | 0.0 | ||
| Matyas | 2 | unimodal | 0.0 | ||
| 24 | Michalewics | 2 | 2! | ||
| 25 | Michalewics | 5 | 5! | ||
| 26 | Michalewics | 10 | 10! | ||
| 27 | Perm | 4 | multimodal | ||
| Powell | 4, 8 | multimodal | |||
| 30 | Power Sum | 4 | multimodal | ||
| Rastrigin | 2, 5, 10 | multimodal | |||
| Rosenbrock | 2, 5, 10 | unimodal | |||
| Schwefel | 2, 5, 10 | unimodal | |||
| 40 | Shekel, | 4 | 5 | ||
| 41 | Shekel, | 4 | 7 | ||
| 42 | Shekel, | 4 | 10 | ||
| 43 | Shubert | 2 | 760 | ||
| Sphere | 2, 5, 10 | multimodal | |||
| Sum squares | 2, 5, 10 | unimodal | |||
| 50 | Trid | 6 | multimodal | ||
| 51 | Trid | 10 | multimodal | ||
| Zakharov | 2, 5, 10 | multimodal |
Table A2.
Comparison between BIRECT-(new), BIRECT, DIRECT-l, and DIRECT
| Problem | BIRECT-(new) | BIRECT | DIRECT-l | DIRECT | |||||||
| No. | |||||||||||
| 1 | 202 | 202 | 255 | ||||||||
| 2 | 1268 | 1777 | 8845 | ||||||||
| 3 | 47792 | 80927 | |||||||||
| 4 | 436 | 436 | 655 | ||||||||
| 5 | 468 | 476 | 327 | ||||||||
| 6 | 472 | 478 | 345 | ||||||||
| 7 | 480 | 573 | 693 | ||||||||
| 8 | 194 | 215 | 295 | ||||||||
| 9 | 242 | 242 | 195 | ||||||||
| 10 | 3379 | 6585 | |||||||||
| 11 | 722 | 722 | 513 | ||||||||
| 12 | 54843 | 19661 | |||||||||
| 13 | 164826 | 372619 | |||||||||
| 14 | 16420 | 6851 | 32845 | ||||||||
| 15 | 274 | 274 | 191 | ||||||||
| 16 | 5106 | 8379 | 9215 | ||||||||
| 17 | 352 | 352 | 199 | ||||||||
| 18 | 764 | 764 | 571 | ||||||||
| 19 | 196 | 334 | 321 | ||||||||
| 20 | 152 | 152 | 105 | ||||||||
| 21 | 968 | 1024 | 705 | ||||||||
| 22 | 6402 | 7904 | 5589 | ||||||||
| 23 | 90 | 94 | 107 | ||||||||
| 24 | 126 | 126 | 69 | ||||||||
| 25 | 82562 | 73866 | 26341 | ||||||||
| 26 | |||||||||||
| 27 | |||||||||||
| 28 | 32331 | 14209 | |||||||||
| 29 | 99514 | ||||||||||
| 30 | 10856 | ||||||||||
| 31 | 1727 | 987 | |||||||||
| 32 | 1394 | ||||||||||
| 33 | 40254 | ||||||||||
| 34 | 285 | 1621 | |||||||||
| 35 | 1700 | 2703 | 20025 | ||||||||
| 36 | 10910 | 74071 | 174529 | ||||||||
| 37 | 341 | 255 | |||||||||
| 38 | 7210 | 322039 | 31999 | ||||||||
| 39 | 315960 | ||||||||||
| 40 | 1272 | 1200 | 155 | ||||||||
| 41 | 1204 | 1180 | 145 | ||||||||
| 42 | 1140 | 1140 | 145 | ||||||||
| 43 | 2043 | 2967 | |||||||||
| 44 | 118 | 118 | 209 | ||||||||
| 45 | 602 | 712 | 4653 | ||||||||
| 46 | 8742 | 16974 | 99123 | ||||||||
| 47 | 226 | 244 | 107 | ||||||||
| 48 | 1000 | 1034 | 833 | ||||||||
| 49 | 5538 | 7688 | 8133 | ||||||||
| 50 | 1506 | 8731 | 5693 | ||||||||
| 51 | 32170 | 90375 | |||||||||
| 52 | 338 | 502 | 237 | ||||||||
| 53 | 26088 | 316827 | |||||||||
| 54 | |||||||||||
| Average | |||||||||||
| Median | |||||||||||
References
- Floudas, C.A.: Deterministic Global Optimization: Theory, Methods and Applications. Nonconvex Optimization and Its Applications, vol. 37. Springer, Boston, MA (1999). [CrossRef]
- Gablonsky, J.M., Kelley, C.T.: A locally-biased form of the DIRECT algorithm. J. of Glob. Optim. (2001), 21(1), 27-37. [CrossRef]
- Guessoum, N., Chiter, L.: Diagonal Partitioning Strategy Using Bisection of Rectangles and a Novel Sampling Scheme. MENDEL.(2023), 29, 2 131-146. [CrossRef]
- Hedar, A.: Test functions for unconstrained global optimization. http://www-optima.amp.i.kyotou.ac.jp/member/student/hedar/Hedar_files/TestGO.htm (2005). (accessed on 23 August 2006).
- Horst, R., Pardalos, P.M., Thoai, N.V.: Introduction to Global Optimization. Nonconvex Optimization and Its Application. Kluwer Academic Publishers (1995).
- Horst, R., Tuy, H.: Global Optimization: Deterministic Approaches. Springer, Berlin (1996).
- Jones, D.R., Perttunen, C.D., Stuckman, B.E.: Lipschitzian optimization without the Lipschitz constant. J. of Optim. Theory and Appl. (1993), 79(1), 157-181. [CrossRef]
- Jones, D.R.: The Direct global optimization algorithm. In: C.A. Floudas, P.M. Pardalos (eds.) The Encyclopedia of Optimization, pp. (2001), 431-440. Kluwer Academic Publishers, Dordrect (2001).
- Jones, D.R., Martins, J.R.R.A.: The DIRECT algorithm: 25 years later. J. Glob. Optim. 79, 521–566 (2021). [CrossRef]
- Ma, K., Rios, L. M., Bhosekar, A., Sahinidis, N., V., Rajagopalan, S.: Branch-and-Model: a derivative-free global optimization algorithm. Computational Optimization and Applications. (2023). [CrossRef]
- Kvasov, D.E., Sergeyev, Y.D.: Lipschitz gradients for global optimization in a one-point-based partitioning scheme. Journal of Computational and Applied Mathematics. (2012), 236(16), 4042-4054. [CrossRef]
- Liberti, L., Kucherenko, S.: Comparison of deterministic and stochastic approaches to global optimization. International Transactions in Operational Research 12(3), 263–285 (2005) https:// onlinelibrary.wiley.com/doi/pdf/10.1111/j.1475-3995.2005.00503.x. [CrossRef]
- Liu, H., Xu, S.,Wang, X.,Wu, J., Song, Y.: A global optimization algorithm for simulation-based problems via the extended DIRECT scheme. Eng. Optim. (2015), 47(11), 1441–1458. [CrossRef]
- Liu, Q., Zeng, J., Yang, G.: MrDIRECT: a multilevel robust DIRECT algorithm for global optimization problems. Journal of Global Optimization. (2015), 62(2), 205-227. [CrossRef]
- Liuzzi, G., Lucidi, S., Piccialli, V.: Exploiting derivative-free local searches in direct-type algorithms for global optimization. Computational Optimization and Applications pp. (2014), 1-27. [CrossRef]
- Paulavičius, R., Žilinskas, J., Grothey, A.: Parallel branch and bound for global optimization with combination of Lipschitz bounds. Optimization Methods and Software. (2011), 26(3), 487-498. [CrossRef]
- Paulavičius, R., Žilinskas, J.: Simplicial Global Optimization. SpringerBriefs in Optimization. Springer New York, New York, NY (2014). [CrossRef]
- Paulavičius, R., Sergeyev, Y.D., Kvasov, D.E., Zilinskas, J.: Globally-biased DISIMPL algorithm for expensive global optimization. J. Glob. Optim. (2014) 59, 545–567. [CrossRef]
- Paulavičius, R.; Zilinskas, J. Simplicial Lipschitz optimization without the Lipschitz constant. J. Glob. Optim. 2014, 59, 23–40. [CrossRef]
- Paulavičius, R., Chiter, L., Žilinskas, J.: Global optimization based on bisection of rectangles, function values at diagonals, and a set of Lipschitz constants. J. Glob. Optim. (2018), 71(1), 5–20. [CrossRef]
- Paulavičius, R., Sergeyev, Y.D., Globally-biased BIRECT algorithm with local accelerators for expensive global optimization, Expert Systems with Applications. November 2019.
- Sergeyev, Y.D.: An efficient strategy for adaptive partition of N-dimensional intervals in the framework of diagonal algorithms. Journal of Optimization Theory and Applications. (2000), 107(1), 145-168. [CrossRef]
- Sergeyev, Y.D.: Efficient partition of n-dimensional intervals in the framework of one-point-based algorithms. Journal of optimization theory and applications. (2005), 124(2), 503-510. [CrossRef]
- Sergeyev, Y.D., Kvasov, D.E.: Global search based on diagonal partitions and a set of Lipschitz constants. SIAM Journal on Optimization. (2006), 16(3), 910-937. [CrossRef]
- Sergeyev, Y.D., Kvasov, D.E.: Diagonal Global Optimization Methods. FizMatLit, Moscow (2008). In Russian.
- Sergeyev, Y.D., Kvasov, D.E.: On deterministic diagonal methods for solving global optimization problems with Lipschitz gradients. In: Optimization, Control, and Applications in the Information Age, 130, pp . Springer International Publishing Switzerland. (2015), 315-334. [CrossRef]
- Sergeyev, Y.D., Kvasov, D.E.: Lipschitz global optimization. In: Cochran, J.J., Cox, L.A., Keskinocak, P., Kharoufeh, J.P., Smith, J.C. (eds.) Wiley Encyclopedia of Operations Research and Management Science (in 8 Volumes) vol. 4, pp. 2812–2828. John Wiley and Sons, New York, NY, USA (2011).
- Sergeyev, Y.D.; Kvasov, D.E. Deterministic Global Optimization: An Introduction to the Diagonal Approach; SpringerBriefs in Optimization; Springer: Berlin, Germany, 2017. [CrossRef]
- Stripinis, L., Paulavičius, R., Žilinskas, J.: Improved scheme for selection of potentially optimal hyperrectangles in DIRECT. Optim. Lett. (2018), 12(7), 1699–1712. [CrossRef]
- Stripinis, L., Paulavičius, R.: DIRECTGOLib - DIRECT Global Optimization test problems Library, v1.1. Zenodo (2022). [CrossRef]
- Stripinis, L., Kůdela, J., Paulavičius, R.: Directgolib - direct global optimization test problems library (2023). https://github.com/blockchain-group/DIRECTGOLib. Pre-release v2.0.
- Stripinis, L., Paulavičius, R. Novel Algorithm for Linearly Constrained Derivative Free Global Optimization of Lipschitz Functions; Mathematics, 11(13), (2023), 2920. [CrossRef]
- Stripinis, L., Paulavičius, R. GENDIRECT: a GENeralized DIRECT-type algorithmic framework for derivative-free global optimization. [CrossRef]
- Stripinis, L., Paulavičius, R.: DIRECTGO: A new DIRECT-type MATLAB toolbox for derivative free global optimization. GitHub (2022). https://github.com/blockchain-group/DIRECTGO.
- Stripinis, L., Paulavičiuss, R.: DIRECTGO: A new DIRECT-type MATLAB toolbox for derivative free global optimization. arXiv (2022). https://arxiv.org/abs/2107.0220.
- Stripinis, L., Paulavičius, R.: Lipschitz-inspired HALRECT Algorithm for Derivative-free Global Optimization. [CrossRef]
- Stripinis, L.; Paulavičius, R. An extensive numerical benchmark study of deterministic vs. stochastic derivative-free global optimization algorithms. [CrossRef]
- Stripinis, L.; Paulavičius, R. An empirical study of various candidate selection and partitioning techniques in the DIRECT framework. J. Glob. Optim. 2022, 1–31. [CrossRef]
- Stripinis, L. Improvement, development and implementation of derivative-free global optimization algorithms. DOCTORAL DISSERTATION, VILNIUS UNIVERSITY, 2001. [CrossRef]
- Tsvetkov, E.A., Krymov, R.A. Pure Random Search with Virtual Extension of Feasible Region. J Optim Theory Appl 195, 575–595 (2022). [CrossRef]
- Tuy, H. Convex Analysis and Global Optimization. Springer Science & Business Media (2013).
- Zhigljavsky, A., Žilinskas, A. Stochastic Global Optimization. Springer, New York (2008).
Figure 1.
Description of the initialization and the first two iterations used in two different sampling and partitioning schemes (BIRECT: upper figure), and (BIRECTv: lower figure) on a two-dimensional example.
Figure 1.
Description of the initialization and the first two iterations used in two different sampling and partitioning schemes (BIRECT: upper figure), and (BIRECTv: lower figure) on a two-dimensional example.
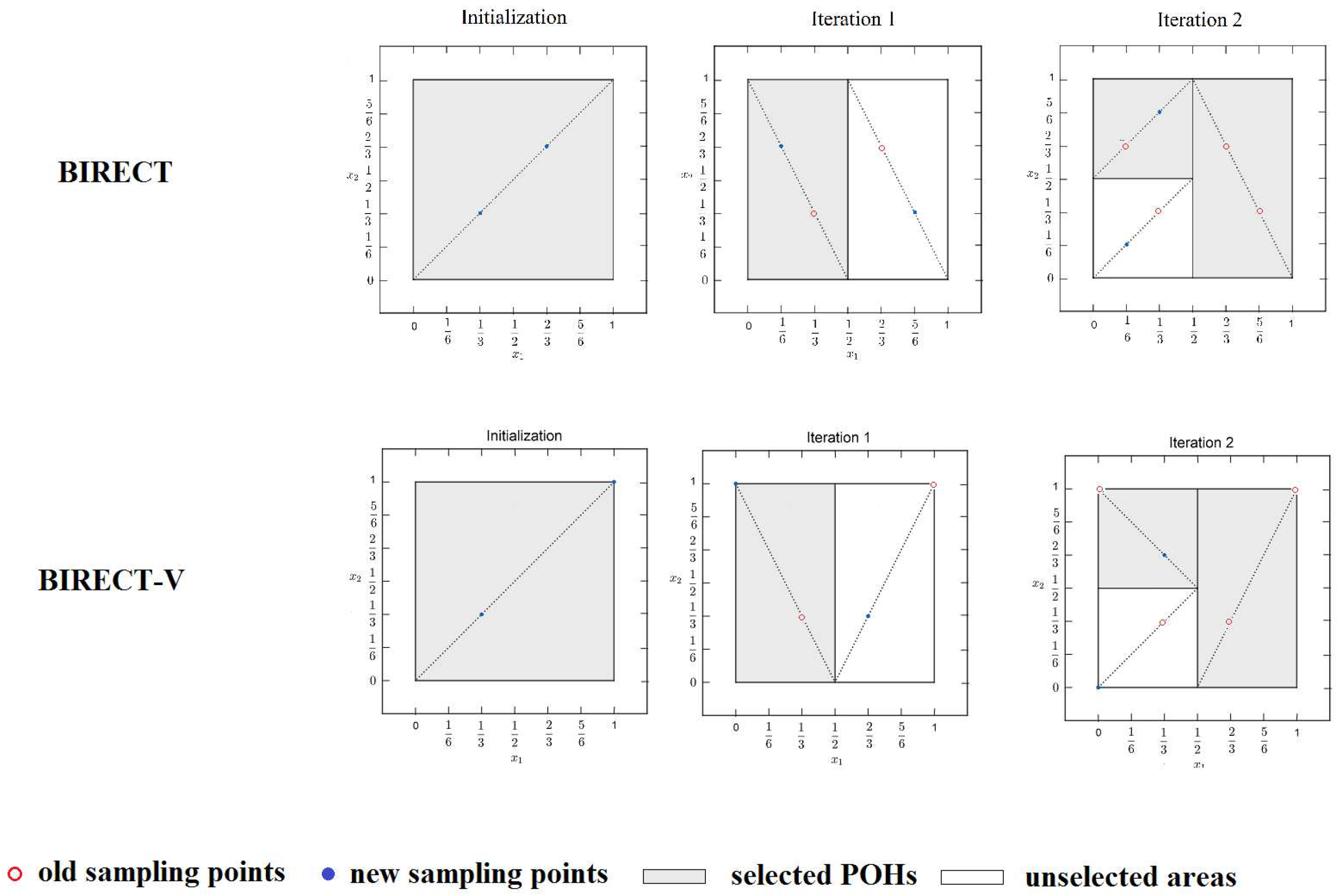
Figure 2.
Grouping strategy using two different tolerance levels in the BIRECT algorithm applied to the Ackley test problem 1 at iteration 36. Small tolerance (left side), large tolerance (right side).
Figure 2.
Grouping strategy using two different tolerance levels in the BIRECT algorithm applied to the Ackley test problem 1 at iteration 36. Small tolerance (left side), large tolerance (right side).
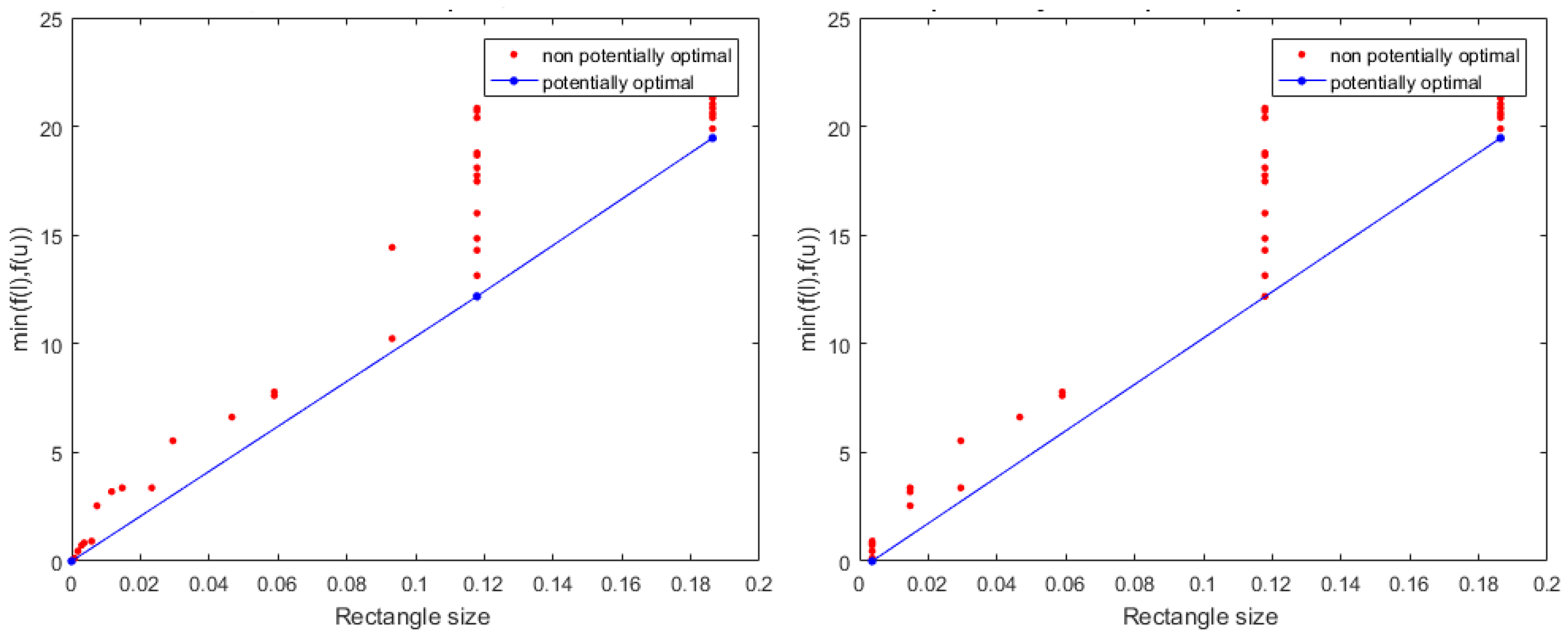
Figure 3.
An example of the iteration progress using the BIRECTv algorithm on the left-hand side from [3], and BIRECTv(imp.) on the right-hand side, while solving Branin test problem (No. 3 from Table 1).
Figure 3.
An example of the iteration progress using the BIRECTv algorithm on the left-hand side from [3], and BIRECTv(imp.) on the right-hand side, while solving Branin test problem (No. 3 from Table 1).
Table 1.
Comparison between BIRECTv-l(imp.), BIRECTv(imp.), BIRECTv-l[3], BIRECTv[3], BIRECT-l(new), and BIRECT(new) algorithms.
Table 1.
Comparison between BIRECTv-l(imp.), BIRECTv(imp.), BIRECTv-l[3], BIRECTv[3], BIRECT-l(new), and BIRECT(new) algorithms.
| Problem | BIRECTv-l (imp.) | BIRECTv (imp.) | BIRECTv-l [3] | BIRECTv [3] | BIRECT-l (new) | BIRECT (new) | ||||||||||||
| No. | f.eval. | f.eval. | f.eval. | f.eval. | f.eval. | f.eval. | ||||||||||||
| 1 | 153 | 156 | 192 | 134 | 158 | |||||||||||||
| 2 | 387 | 1135 | 422 | 1578 | 1062 | |||||||||||||
| 3 | 1000 | 47311 | 1000 | 72804 | 41654 | |||||||||||||
| 4 | 474 | 742 | 638 | 1034 | ||||||||||||||
| 5 | 209 | 254 | 284 | 496 | 496 | |||||||||||||
| 6 | 211 | 252 | 284 | 682 | 682 | |||||||||||||
| 7 | 209 | 248 | 282 | 852 | 849 | |||||||||||||
| 8 | 249 | 300 | 334 | 330 | 330 | |||||||||||||
| 9 | 480 | 370 | 652 | 490 | ||||||||||||||
| 10 | 1614 | 1337 | 2318 | 1868 | ||||||||||||||
| 11 | 263 | 431 | 346 | 578 | ||||||||||||||
| 12 | 2087 | 2652 | 2912 | 6103 | 6125 | |||||||||||||
| 13 | 28871 | 19418 | 38460 | 44114 | ||||||||||||||
| 14 | 138 | 716 | 180 | 1082 | 558 | |||||||||||||
| 15 | 28 | 28 | 274 | 274 | ||||||||||||||
| 16 | 3440 | 4700 | 5192 | 5756 | ||||||||||||||
| 17 | 169 | 200 | 208 | 352 | 352 | |||||||||||||
| 18 | 542 | 542 | 764 | 764 | ||||||||||||||
| 19 | 254 | 202 | 334 | 190 | 196 | |||||||||||||
| 20 | 103 | 116 | 136 | 154 | ||||||||||||||
| 21 | 388 | 459 | 454 | 558 | 354 | |||||||||||||
| 22 | 1133 | 6246 | 1182 | 7440 | 2302 | |||||||||||||
| 23 | 119 | 163 | 148 | 208 | ||||||||||||||
| 24 | 142 | 231 | 184 | 314 | 136 | |||||||||||||
| 25 | 5654 | 8484 | 7526 | 49160 | 47196 | |||||||||||||
| 26 | ||||||||||||||||||
| 27 | 65536 | 48724 | ||||||||||||||||
| 28 | 1837 | 2518 | 1624 | 1814 | 2108 | |||||||||||||
| 29 | 2867 | 3058 | 3400 | 20672 | 21260 | |||||||||||||
| 30 | 204 | 40788 | 4932 | 5623 | ||||||||||||||
| 31 | 523 | 809 | 688 | 820 | 178 | |||||||||||||
| 32 | 6511 | 8512 | 10978 | 66462 | 82546 | |||||||||||||
| 33 | 1439 | 1454 | 1240 | 15544 | ||||||||||||||
| 34 | 540 | 544 | 700 | 716 | ||||||||||||||
| 35 | 1950 | 2231 | 2528 | 3058 | 1692 | |||||||||||||
| 36 | 17176 | 27256 | 18922 | 31756 | 10766 | |||||||||||||
| 37 | 384 | 413 | 486 | 564 | 268 | |||||||||||||
| 38 | 17061 | 10362 | 25904 | 16754 | 3780 | |||||||||||||
| 39 | 55701 | 84784 | 2248 | 265002 | ||||||||||||||
| 40 | 4002 | 3665 | 6146 | 5604 | 1254 | |||||||||||||
| 41 | 1536 | 1655 | 2256 | 2456 | 1186 | |||||||||||||
| 42 | 1740 | 2238 | 2476 | 3332 | 1138 | |||||||||||||
| 43 | 432 | 570 | 226 | 766 | 642 | |||||||||||||
| 44 | 143 | 112 | 190 | 106 | 118 | |||||||||||||
| 45 | 364 | 987 | 392 | 1400 | 602 | |||||||||||||
| 46 | 1043 | 19418 | 1054 | 27566 | 8742 | |||||||||||||
| 47 | 348 | 328 | 494 | 460 | 226 | |||||||||||||
| 48 | 1141 | 1102 | 1484 | 1006 | 1134 | |||||||||||||
| 49 | 5331 | 2452 | 6066 | |||||||||||||||
| 50 | 1414 | 1312 | 1662 | 1322 | 1462 | |||||||||||||
| 51 | 2965 | 10470 | 3114 | 11880 | 3122 | |||||||||||||
| 52 | 122 | 125 | 156 | 162 | 118 | |||||||||||||
| 53 | 2805 | 2948 | 3710 | 3958 | 1858 | |||||||||||||
| 54 | ||||||||||||||||||
| Average | ||||||||||||||||||
| Median | ||||||||||||||||||
Table 2.
Comparison between BIRECT-(new), BIRECT from [20,21], BIRECT-l-(new), and BIRECT-l from [21]
Table 2.
Comparison between BIRECT-(new), BIRECT from [20,21], BIRECT-l-(new), and BIRECT-l from [21]
| Problem | BIRECT-(new) | BIRECT [20,21] | BIRECT-l-(new) | BIRECT-l [21] | |||||||
| No. | |||||||||||
| 1 | 202 | 202 | 176 | 176 | |||||||
| 2 | 1268 | 454 | 454 | ||||||||
| 3 | 47792 | 874 | 874 | ||||||||
| 4 | 436 | 436 | 436 | 436 | |||||||
| 5 | 476 | 468 | 468 | ||||||||
| 6 | 478 | 472 | 472 | ||||||||
| 7 | 480 | 474 | 474 | ||||||||
| 8 | 194 | 188 | 188 | ||||||||
| 9 | 242 | 242 | 242 | 242 | |||||||
| 10 | 794 | 794 | 794 | 794 | |||||||
| 11 | 722 | 722 | 722 | 722 | |||||||
| 12 | 4060 | 4060 | 4060 | 4060 | |||||||
| 13 | 164826 | 1628682 | |||||||||
| 14 | 16420 | 480 | |||||||||
| 15 | 274 | 274 | 274 | 274 | |||||||
| 16 | 5106 | 5106 | |||||||||
| 17 | 352 | 352 | 352 | 352 | |||||||
| 18 | 764 | 764 | 764 | 764 | |||||||
| 19 | 334 | 190 | 190 | ||||||||
| 20 | 152 | 152 | 152 | 152 | |||||||
| 21 | 1024 | 660 | |||||||||
| 22 | 7904 | 1698 | 1698 | ||||||||
| 23 | 94 | 90 | 90 | ||||||||
| 24 | 126 | 126 | 126 | 126 | |||||||
| 25 | 82562 | 101942 | |||||||||
| 26 | |||||||||||
| 27 | |||||||||||
| 28 | 2114 | 2114 | 1832 | ||||||||
| 29 | 99514 | 92884 | |||||||||
| 30 | 10856 | 4994 | |||||||||
| 31 | 180 | 180 | 156 | ||||||||
| 32 | 1394 | 474 | |||||||||
| 33 | 40254 | 1250 | 1250 | ||||||||
| 34 | 242 | 242 | 242 | 242 | |||||||
| 35 | 1700 | 1496 | |||||||||
| 36 | 10910 | 4620 | |||||||||
| 37 | 236 | 236 | 214 | ||||||||
| 38 | 7210 | 1422 | |||||||||
| 39 | 315960 | 58058 | |||||||||
| 40 | 1272 | 1286 | |||||||||
| 41 | 1204 | 1224 | 1224 | ||||||||
| 42 | 1140 | 1140 | 1162 | ||||||||
| 43 | 1780 | 1780 | 2114 | 2114 | |||||||
| 44 | 118 | 118 | 108 | ||||||||
| 45 | 712 | 294 | |||||||||
| 46 | 16974 | 784 | 784 | ||||||||
| 47 | 244 | 226 | 226 | ||||||||
| 48 | 1034 | 836 | 836 | ||||||||
| 49 | 7688 | 3366 | 3366 | ||||||||
| 50 | 1506 | 1138 | |||||||||
| 51 | 32170 | 24716 | |||||||||
| 52 | 502 | 338 | 338 | ||||||||
| 53 | 26088 | 27364 | |||||||||
| 54 | |||||||||||
| Average | |||||||||||
| Median | |||||||||||
Table 3.
Number of function evaluations using BIRECT-l(new) for different values of
| Problem | BIRECT-l | |||||||
| No./ | ||||||||
| 1 | 168 | 182 | 178 | 174 | 176 | |||
| 2 | 530 | 484 | 454 | 454 | ||||
| 3 | 842 | 852 | 874 | 872 | 874 | |||
| 4 | 424 | 434 | 436 | 436 | 436 | |||
| 5 | 424 | 456 | 468 | 468 | 468 | |||
| 6 | 432 | 462 | 472 | 472 | 472 | |||
| 7 | 942 | |||||||
| 8 | 188 | 188 | 188 | 188 | 188 | |||
| 9 | 256 | |||||||
| 10 | 790 | 794 | 790 | 794 | 794 | |||
| 11 | 732 | 722 | 722 | 722 | ||||
| 12 | 5352 | 4060 | 4060 | 4060 | ||||
| 13 | 186694 | 152402 | 156448 | 158880 | ||||
| 14 | ||||||||
| 15 | 272 | 274 | 274 | 274 | 274 | |||
| 16 | 3236 | 3452 | 4148 | 4982 | ||||
| 17 | 354 | 352 | 352 | 352 | 352 | |||
| 18 | 764 | 764 | 764 | 764 | 764 | |||
| 19 | 190 | 190 | 190 | 190 | 190 | |||
| 20 | 152 | 152 | 152 | 152 | 152 | |||
| 21 | 644 | 656 | 656 | 656 | 656 | |||
| 22 | 1698 | 1698 | 1698 | 1698 | 1698 | |||
| 23 | 90 | 90 | 90 | 90 | 90 | |||
| 24 | 126 | 126 | 126 | 126 | 126 | |||
| 25 | 49488 | 90504 | 101900 | 101900 | 101900 | |||
| 26 | ||||||||
| 27 | ||||||||
| 28 | 2440 | 2102 | 1820 | 1820 | 1820 | |||
| 29 | 87502 | 90162 | 92028 | 91954 | ||||
| 30 | 5024 | 5014 | 5002 | 4994 | ||||
| 31 | 152 | 154 | 156 | 156 | 156 | |||
| 32 | 436 | 474 | 474 | 474 | 474 | |||
| 33 | 1166 | 1240 | 1250 | 1250 | 1250 | |||
| 34 | 242 | 242 | 242 | 242 | 242 | |||
| 35 | 1470 | 1498 | 1496 | 1496 | 1496 | |||
| 36 | 4510 | 4612 | 4620 | 4620 | 4620 | |||
| 37 | 204 | 214 | 214 | 214 | 214 | |||
| 38 | 1148 | 1280 | 1400 | 1434 | 1434 | |||
| 39 | 49516 | 57452 | 57994 | 58000 | 58000 | |||
| 40 | 810 | 1254 | 1248 | 1248 | 1248 | |||
| 41 | 818 | 1186 | 1224 | 1224 | 1224 | |||
| 42 | 766 | 1138 | 1162 | 1162 | 1162 | |||
| 43 | 1880 | 2044 | 2086 | 2114 | 2114 | |||
| 44 | 106 | 106 | 106 | 106 | 106 | |||
| 45 | 294 | 294 | 294 | 294 | 294 | |||
| 46 | 786 | |||||||
| 47 | 226 | 226 | 226 | 226 | 226 | |||
| 48 | 826 | 836 | 836 | 836 | 836 | |||
| 49 | 3162 | 3332 | 3366 | 3366 | 3366 | |||
| 50 | 1152 | 992 | 992 | 992 | 992 | |||
| 51 | 28268 | 24704 | 24704 | 24704 | ||||
| 52 | 320 | 338 | 338 | 338 | 338 | |||
| 53 | 27720 | 27286 | 27230 | 27230 | ||||
| 54 | ||||||||
| Average | ||||||||
| Median |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



